
repoName
stringlengths 7
77
| tree
stringlengths 0
2.85M
| readme
stringlengths 0
4.9M
|
|---|---|---|
Amarnath-Rao_Polling-Management | .gitpod.yml
README.md
babel.config.js
contract
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
main.spec.ts
as_types.d.ts
index.ts
tsconfig.json
compile.js
package-lock.json
package.json
package.json
src
App.js
Components
Home.js
NewPoll.js
PollingStation.js
__mocks__
fileMock.js
assets
blockvotelogo.svg
loadingcircles.svg
logo-black.svg
logo-white.svg
config.js
global.css
index.html
index.js
jest.init.js
main.test.js
utils.js
wallet
login
index.html
| Polling Management
==================
This [React] app was initialized with [create-near-app]
Use "yarn build && yarn start" to start the page
Images
==========



Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `blockvote.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `blockvote.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account blockvote.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'blockvote.YOUR-NAME.testnet'
blockvote Smart Contract
==================
A [smart contract] written in [AssemblyScript] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install [Node.js] ≥ 12
Exploring The Code
==================
1. The main smart contract code lives in `assembly/index.ts`. You can compile
it with the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard AssemblyScript tests using [as-pect].
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[AssemblyScript]: https://www.assemblyscript.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[as-pect]: https://www.npmjs.com/package/@as-pect/cli
|
n1arash_near-challenge05 | .gitpod.yml
README.md
contract
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
main.spec.ts
as_types.d.ts
index.ts
tsconfig.json
compile.js
package-lock.json
package.json
package.json
src
assets
logo-black.svg
logo-white.svg
config.js
css
global.css
upload.css
index.html
index.js
main.test.js
utils.js
wallet
login
index.html
| challenge05 Smart Contract
==================
A [smart contract] written in [AssemblyScript] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install [Node.js] ≥ 12
Exploring The Code
==================
1. The main smart contract code lives in `assembly/index.ts`. You can compile
it with the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard AssemblyScript tests using [as-pect].
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[AssemblyScript]: https://www.assemblyscript.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[as-pect]: https://www.npmjs.com/package/@as-pect/cli
challenge05
==================
This app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `challenge05.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `challenge05.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account challenge05.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'challenge05.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
|
hack-a-chain-software_near-tipping-bot | .eslintrc.js
.github
ISSUE_TEMPLATE
bug-report.yml
feature-creation.yml
PULL_REQUEST_TEMPLATE.md
workflows
CI.yml
vercel_deploy.yml
.husky
commit-msg.sh
LICENSE.md
commitlint.config.js
cypress.config.ts
cypress
e2e
base.cy.ts
fixtures
example.json
support
commands.ts
e2e.ts
docker-compose.yml
format_rust.sh
package.json
packages
bot
deploy-commands.js
index.js
package.json
src
commands
commands.js
feedback.js
help.js
helpInstall.js
insertServerToken.js
lastServerTips.js
listServerTokens.js
newToken.js
ranking.js
register.js
removeToken.js
send.js
setWallet.js
tutorial.js
verifyWallet.js
viewHistory.js
events
guildCreate.js
interactionCreate.js
modal.js
ready.js
graphql
mutations
deleteServerToken.js
insertServer.js
insertServerToken.js
insertToken.js
insertWallet.js
sendFeedback.js
queries
findCommandHelp.js
findServerById.js
findUserWallet.js
getSendParameters.js
listHelps.js
listServerTokens.js
listTokens.js
handlers
commands.js
events.js
index.js
lib
graphQlClient.js
utils
findDuplicatePkError.js
findServerNotRegisteredError.js
formatDecimals.js
viewFunction.js
contract
Cargo.toml
package.json
readme.md
src
lib.rs
test_token
Cargo.toml
src
errors.rs
lib.rs
tests
Cargo.toml
src
lib
events.rs
mod.rs
main.rs
methods
mod.rs
nep145.rs
tipping_bot.rs
token.rs
tests_launchpad
mod.rs
db
.gmrc.js
README.md
migrations
committed
000001.sql
current
1-current.sql
package.json
src
init.sh
seeds.sql
front
index.html
package.json
postcss.config.js
public
assets
hero-glow.svg
logo.svg
tokens
aurora.svg
logo-black.svg
logo-white.svg
src
components
assets
index.ts
index.ts
loadingtransaction
index.ts
index.css
json
tokens.json
tutorial.json
utils
actions.ts
constants
contracts.ts
index.ts
near.ts
helpers.ts
tailwind.config.js
tsconfig.json
tsconfig.node.json
vercel.json
vite.config.ts
TEST
tsconfig.json
| # Database
This package contains the migrations needed in order to initialize the application's database.
## Migrations
They are located in the `migrations` folder and should be run sequentially in (lexicographical) order to achieve the correct state.
It's assumed they will run against a [Supabase](https://supabase.com/) schema, which already contains some functionality not native to Postgres (e.g. the `storage` schema).
When creating new migrations, keep them named appropriately, that is, with a serial numeric prefix, and underscore-separated (_) words.
|
Learn-NEAR-Hispano_NCD4L1--rust-changeback | README.md
rust-changeback
Cargo.toml
src
lib.rs
main.rs
| # rust-changeback
Contrato inteligente para dar vuelto en comercios. El cliente que pague en efectivo y se transfiere el vuelto por medio de una plataforma de pago. Cuatro funciones básicas. Agregar saldo para tener vuelto disponible, dar cambio, resetear el monto y ver el disponible.
Actualmente sin Parámetros, con 4 funciones básicas:
1. Add, agrega 1000 al contrato disponible para vuelto
2. Change, genera un vuelto de 10 en cada operación e imprime el disponible
3. get_num, indica el monto disponible
4. reset, lleva a cero el contador
|
Gomathi1806_peer-peer-payment-NEAR-pro | README.md
asconfig.json
contract
assembly
as_types.d.ts
index.ts
tsconfig.json
build
babel.config.js
package.json
| # peer-peer-payment-NEAR-pro
git clone
yarn install
create react app
create NEAR account
|
olga24912_bls-signature-example-contract | Cargo.toml
README.md
build.sh
data
light_client_updates_goerli_slots_3885697_3886176.json
next_sync_committee_goerli_period_473.json
next_sync_committee_goerli_period_474.json
src
lib.rs
test-utils
Cargo.toml
src
lib.rs
| # Example contract for bls signature verification
In contract function `verify_bls_signature` takes `LightClientUpdate` and `SyncCommittee` and verify sync committee signature of attested block.
## Dependencies
* https://github.com/olga24912/nearcore/tree/bls-sig
* https://github.com/olga24912/near-sdk-rs/tree/bls-sig-4.0.0
## Test running
1. Clone `nearcore` repository
```bush
$ git clone https://github.com/olga24912/nearcore.git
$ cd nearcore
$ git checkout bls-sig
```
2. Run `make sandbox`
```bush
$ make sandbox
```
3. Save path to sandbox to env var
```bush
$ export NEAR_SANDBOX_BIN_PATH=<PATH_TO_NEARCORE>/target/debug/near-sandbox
```
4. Run tests
```bush
$ cd <PATH_TO_EXAMPLE_CONTRACT>
$ ./build.sh
$ cargo test -- --show-output
```
## Gas Estimation
```bash
$ cd <PATH_TO_NEARCORE>/runtime/runtime-params-estimator/
$ cargo run
```
* `Bls12381VerifyBase = 1_161_108_297_105 gas` - the gas for verifying aggregate signature for a 32-byte message with one public key
* `Bls12381VerifyByte = 123_969_578 gas` - extra gas for each extra byte in a message
* `Bls12381VerifyElements = 58_519_162_009 gas`- extra gas for each extra public key
The `MAX_GAS = 300_000_000_000_000 gas`
|
nearprotocol_Stories | Stories
ARStories
ContentViewController.swift
PreViewController.swift
Utils
ARModel.swift
ARSupport.swift
SegmentedProgressBar.swift
AppDelegate.swift
Assets.xcassets
AppIcon.appiconset
Contents.json
Contents.json
cancel.imageset
Contents.json
flash.imageset
Contents.json
flashOutline.imageset
Contents.json
flashauto.imageset
Contents.json
flipCamera.imageset
Contents.json
focus.imageset
Contents.json
ContainerViewController.swift
SwiftyCam
CameraViewController.swift
PhotoViewController.swift
SwiftyRecordButton.swift
VideoViewController.swift
WebWrapperViewController.swift
web
README.md
bundle.js
index.html
index.js
package-lock.json
package.json
studio-project
README.md
assembly
json
decoder.ts
encoder.ts
main.ts
model.ts
near.ts
tsconfig.json
gulpfile.js
package.json
setup.js
src
loader.html
main.html
main.js
test.html
test.js
| # Using duplex streams to add files to IPFS in the browser
If you have a number of files that you'd like to add to IPFS and end up with a hash representing the directory containing your files, you can invoke [`ipfs.add`](https://github.com/ipfs/interface-ipfs-core/blob/master/SPEC/FILES.md#add) with an array of objects.
But what if you don't know how many there will be in advance? You can add multiple files to a directory in IPFS over time by using [`ipfs.addReadableStream`](https://github.com/ipfs/interface-ipfs-core/blob/master/SPEC/FILES.md#addreadablestream).
See `index.js` for a working example and open `index.html` in your browser to see it run.
# Stories app backend
## Description
TODO
## To Run
*In NEAR Studio (https://studio.nearprotocol.com)*
1. Click the "Run" button on the top of the Studio window
2. You will be redirected to the output for the JavaScript tests described in `src/main.js` to show that the contract is performing properly. This is a fully back-end contract so there is no front end.
## To Explore
See `assembly/main.ts` for the contract code and `src/main.js` for the JavaScript tests which define its usage.
|
lawcia_near-hello-world-smart-contract-rust | Cargo.toml
README.md
docker-compose.yml
src
lib.rs
| # NEAR Hello World Smart Contract
This project consists of two applications
1. A Rust SDK Smart Contract
2. A REACT frontend
## Requirements
1. Docker
2. A testnet account on Near, you can create one [here](https://wallet.testnet.near.org/)
## Commands
Build the contract
```
docker-compose run contract cargo build --target wasm32-unknown-unknown --release
```
Deploy contract
```
docker-compose run contract /bin/bash
```
Then use the terminal to login
```
near login
```
Create a sub account
```
near create-account YOUR_CONTRACT_NAME.YOUR_ACCOUNT.testnet --masterAccount YOUR_ACCOUNT.testnet
```
Then enter this command to deploy your contract
```
near deploy --wasmFile target/wasm32-unknown-unknown/release/YOUR_PROJECT.wasm --accountId YOUR_ACCOUNT_HERE
```
Test
```
docker-compose run contract cargo test -- --nocapture
```
|
OmarRACHIDI_Lightency | lightency
README.md
package.json
public
index.html
manifest.json
robots.txt
src
App.js
components
Backdrop.js
Footer.js
Header.js
Main.js
NavigationBar.js
index.css
index.js
general
Header
Main
footer
nft-frontend-exemple
README.md
contract
Cargo.toml
README.md
build.sh
compile.js
src
approval.rs
enumeration.rs
events.rs
internal.rs
lib.rs
metadata.rs
mint.rs
nft_core.rs
royalty.rs
package.json
src
App.js
Components
InfoBubble.js
MintingTool.js
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
near_icon.svg
near_logo_wht.svg
config.js
global.css
index.html
index.js
jest.init.js
main.test.js
utils.js
wallet
login
index.html
nft-minting
nft-contract
Cargo.toml
README.md
build.sh
src
approval.rs
enumeration.rs
internal.rs
lib.rs
metadata.rs
mint.rs
nft_core.rs
royalty.rs
package.json
| nft-mint-frontend
==================
This [React] app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `nft-mint-frontend.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `nft-mint-frontend.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account nft-mint-frontend.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'nft-mint-frontend.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
# TBD
nft-mint-frontend Smart Contract
==================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
# Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `npm start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in your browser.
The page will reload when you make changes.\
You may also see any lint errors in the console.
### `npm test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `npm run build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `npm run eject`
**Note: this is a one-way operation. Once you `eject`, you can't go back!**
If you aren't satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you're on your own.
You don't have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn't feel obligated to use this feature. However we understand that this tool wouldn't be useful if you couldn't customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `npm run build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
|
NEARBuilders_create | .github
workflows
deploy-prod-mainnet.yml
release-editor-mainnet.yml
README.md
apps
create
bos.config.json
editor
bos.config.json
modules
QoL
Url.js
classNames.js
storage.js
widget.js
everything
sdk.js
utils
UUID.js
debounce.js
package.json
| # Create App
Starter Kit for Builders
## Getting Started
To run locally, first install.
Then, run the command:
```bash
yarn dev
```
This will serve the widgets from `http://127.0.0.1:4040/api/loader`. (or 8080)
Go to [everything.dev/flags](https://everything.dev) and paste this value there.
Once set, see the locally served app at [create.near/widget/app](https://everything.dev/create.near/widget/app).
## How To Contribute
Clone the repository, make some changes, open issues, and submit pull requests.
Updates to this repository's main branch automatically deploy to the create.near workspace.
|
muskbuster_vinyl_record-datalog | README.md
as-pect.config.js
asconfig.json
assembly
__test__
as-pect.d.ts
index.unit.spec.ts
as_types.d.ts
index.ts
models.ts
tsconfig.json
neardev
dev-account.env
package-lock.json
package.json
| # VINYL DATALOG
Vinyl datalog allows user to enter details of viyl records like the name of the album,artist,genre and its price. This contract is made with the idea that it can be used by stores that sell vinyls as collectibles.this contract can be used to log all the vinyls available in a store. There are three functions it can offer right now:
##### (this project is derived from and inspired by https://github.com/Learn-NEAR/NCD.L1.sample--library by Learn-Near I had to add this comment as i had forgotten to fork the repo and cloned it .TO avoid violation of certification rules i have added it here)
1. Vinyls available can be added to the database with the following data:</br>
- Name of the album
- Artist of the album
- the genre
- album's price
2. list of all the vinyls available on the blockchain
3. search a vinyl based on the name of the album
## Installation
To run the CONTRACT locally, follow the below steps:
## Getting started
1. Make sure you have installed Node.js >= 12
2. Make sure you have installed NEAR CLI :<br>
```npm i -g near-cli```
3. Login to your NEAR account.
4. If you don't have a NEAR account , create it at [https://wallet.testnet.near.org/]
5. Configure NEAR CLI to authorize your testnet account:<br>
`near login`
## Running the project
1. Clone this repository
2. In the terminal , navigate to the project folder, to install the dependencies and run `yarn`
## To create a smart contract development and deployment:
1. Run `yarn build` to build the smart contract. Look at package.json folder to see all the command that can be executed with yarn.

3. Run `yarn deploy` to deploy the smart contract to the development server that was built in the previous step. This will return the Txn ID of the deployed contract along with a link to near explorer to see various statistics of the deployed contract.


## Using the methods of the deployed contract
The following commands will allow you to interact with NEAR CLI and the deployed smart contract's methods:
### Command to log a new vinyl data:
`near call $CONTRACT newVinyl '{"songName" : "song", "artist":"artistt", "genre" : "genree","price" : "$"}' --account-id <Enter your account id>`

Insert the data in place of "string" mentioned in the command of the method.<br>
### Command to view all the Vinyls :
`near view $CONTRACT Vinylarsenal '{}'`
### Command to search a vinyl record based on song/album name:
`near call $CONTRACT Vinylavailable '{"songName" : "string"}' --account-id <Enter your account id>`


## USAGE:
this contract can be used to log the details of vinyl records available in a store or a museum.
I am looking forward to add features like being able to pay using near for the records and renting of vinyls with monthly near expenditure. Also auction various rare record by bidding on the near blockchain.
I will soon be working on that.
|
phamminh0811_upgrade_contract | Cargo.toml
src
info.rs
lib.rs
| |
LucasLeandro1204_tonic-indexer-example | Cargo.toml
README.md
diesel.toml
migrations
00000000000000_diesel_initial_setup
down.sql
up.sql
2022-03-22-230442_init_indexer
down.sql
up.sql
2022-04-24-192617_add_fee_and_account_id_fields
down.sql
up.sql
2022-05-02-162037_add_lot_size_fields
down.sql
up.sql
2022-05-04-204517_add_indices_on_fill_and_order_events
down.sql
up.sql
2022-05-04-213658_add_mat_views_for_trade_candles
down.sql
up.sql
2022-05-05-195628_add_unique_symbols_constraint_to_market_table
down.sql
up.sql
2022-05-10-014809_add_fee_and_account_fields
down.sql
up.sql
2022-07-05-203321_add_latest_processed_block
down.sql
up.sql
2022-07-06-004221_add_visible_market_column
down.sql
up.sql
2022-07-10-060747_add_is_swap_column
down.sql
up.sql
src
configs.rs
constants.rs
db.rs
event.rs
main.rs
models.rs
schema.rs
tps_counter.rs
worker.rs
| [tonic-site]: https://tonic.foundation
[diesel-cli]: https://github.com/diesel-rs/diesel/tree/master/diesel_cli
[aws-cli]: https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
[running-a-node]: https://near-nodes.io/validator/compile-and-run-a-node#testnet
[near-lake]: https://github.com/near/near-lake-framework-rs
[tonic-deploy-block]: https://nearblocks.io/txns/3nQNWkwAK4hRydDM9i9AQUEABRgHoXvvczkWbGPiNaCY
# Tonic DEX Indexer
Example indexer using the [NEAR Lake Framework][near-lake] for saving trade data
from [Tonic][tonic-site].
## Developing
**Prerequisites**
- a working [Rust installation](https://rustup.rs/)
- a Postgres instance that you control
- Docker users: a compose file is included in the repo
- the [Diesel CLI][diesel-cli] (`cargo install diesel_cli --no-default-features --features postgres`)
- an AWS account with permission to fetch from the NEAR lake S3 bucket
<details>
<summary>Required IAM permissions</summary>
At a minimum, you need the following permissions
```
GetBucketLocation
ListBucket
GetObject
```
on the following resources
```
arn:aws:s3:::near-lake-data-mainnet
arn:aws:s3:::near-lake-data-mainnet/*
```
A basic policy would be
```terraform
data "aws_iam_policy_document" "near_lake_reader_policy" {
statement {
sid = "AllowReadNearLakeBucket"
actions = [
"s3:GetBucketLocation",
"s3:ListBucket",
"s3:GetObject",
]
resources = [
"arn:aws:s3:::near-lake-data-mainnet",
"arn:aws:s3:::near-lake-data-mainnet/*"
]
}
}
resource "aws_iam_policy" "near_lake_reader_policy" {
name = "near-lake-reader-policy"
description = "Allow access to the NEAR Lake S3 bucket"
policy = data.aws_iam_policy_document.near_lake_reader_policy.json
}
```
</details>
**Set required environment variables**
```bash
export DATABASE_URL=postgres://postgres:test@localhost:5432/postgres
export TONIC_CONTRACT_ID=v1.orderbook.near
```
**(Docker users only): Start dev postgres container**
```
docker compose up -d
```
**Run migrations**
```
diesel migration run
```
**Run indexer**
When the indexer starts, it will check the database for the latest processed
block number. If none is found, it starts from block 0. You can pass the
`--from-blockheight` flag to start at a specific block. The official Tonic
contract was [deployed in block 66,296,455][tonic-deploy-block].
```bash
# if you have Just
just run --from-blockheight 66296455
# or
cargo run --release -- run --contract-ids $TONIC_CONTRACT_ID --from-blockheight 66296455
```
For all future runs, the flag can be omitted
```bash
# if you have Just
just run
# or
cargo run --release -- run --contract-ids $TONIC_CONTRACT_ID
```
|
neoiss_near-api-go-back | .github
workflows
lint.yml
README.md
cmd
block
main.go
edkeypair
main.go
funcall
main.go
genesis
main.go
keys
main.go
transfer
main.go
nearnet
docker-compose.yml
entrypoint.sh
get_creds.sh
tail_logs.sh
pkg
client
access_key.go
access_key_structs.go
account.go
account_structs.go
block.go
block
block.go
block_structs.go
chunk.go
chunk_structs.go
client.go
common.go
context.go
contract.go
contract_structs.go
gas.go
gas_structs.go
genesis.go
light.go
light_structs.go
network.go
network_structs.go
transaction.go
transaction_structs.go
transaction_wrapper.go
utils.go
config
network.go
network_test.go
jsonrpc
client.go
error.go
structs.go
types
action
access_key.go
action.go
balance.go
balance_test.go
basic.go
constants.go
hash
crypto_hash.go
key
aliases.go
base58_public_key.go
common.go
key_pair.go
public_key.go
public_key_test.go
signature
base58_signature.go
common.go
signature.go
signature_test.go
transaction
signed_transaction.go
transaction.go
utils.go
| # near-api-go
[](https://pkg.go.dev/github.com/eteu-technologies/near-api-go)
[](https://github.com/eteu-technologies/near-api-go/actions/workflows/lint.yml)
**WARNING**: This library is still work in progress. While it covers about 90% of the use-cases, it does not have many batteries included.
## Usage
```
go get github.com/eteu-technologies/near-api-go
```
### Notes
What this library does not (and probably won't) provide:
- Access key caching & management
- Retry solution for `TransactionSendAwait`
What this library doesn't have yet:
- Response types for RPC queries marked as experimental by NEAR (prefixed with `EXPERIMENTAL_`)
- Few type definitions (especially complex ones, for example it's not very comfortable to reflect enum types in Go)
## Examples
See [cmd/](cmd/) in this repo for more fully featured CLI examples.
See [NEARKit](https://github.com/eteu-technologies/nearkit) for a project which makes use of this API.
### Query latest block on NEAR testnet
```go
package main
import (
"context"
"fmt"
"github.com/eteu-technologies/near-api-go/pkg/client"
"github.com/eteu-technologies/near-api-go/pkg/client/block"
)
func main() {
rpc, err := client.NewClient("https://rpc.testnet.near.org")
if err != nil {
panic(err)
}
ctx := context.Background()
res, err := rpc.BlockDetails(ctx, block.FinalityFinal())
if err != nil {
panic(err)
}
fmt.Println("latest block: ", res.Header.Hash)
}
```
### Transfer 1 NEAR token between accounts
```go
package main
import (
"context"
"fmt"
"github.com/eteu-technologies/near-api-go/pkg/client"
"github.com/eteu-technologies/near-api-go/pkg/types"
"github.com/eteu-technologies/near-api-go/pkg/types/action"
"github.com/eteu-technologies/near-api-go/pkg/types/key"
)
var (
sender = "mikroskeem.testnet"
recipient = "mikroskeem2.testnet"
senderPrivateKey = `ed25519:...`
)
func main() {
rpc, err := client.NewClient("https://rpc.testnet.near.org")
if err != nil {
panic(err)
}
keyPair, err := key.NewBase58KeyPair(senderPrivateKey)
if err != nil {
panic(err)
}
ctx := client.ContextWithKeyPair(context.Background(), keyPair)
res, err := rpc.TransactionSendAwait(ctx, sender, recipient, []action.Action{
action.NewTransfer(types.NEARToYocto(1)),
})
if err != nil {
panic(err)
}
fmt.Printf("https://rpc.testnet.near.org/transactions/%s\n", res.Transaction.Hash)
}
```
## License
MIT
|
MiguelIslasH_L2.-Company-phone-directory | README.md
package.json
public
index.html
manifest.json
robots.txt
src
App.css
App.js
App.test.js
components
login
description.js
header.js
login-button.js
login.js
login.module.css
main
comapnies-list.js
companies.js
companies.module.css
company-card.js
main.js
navbar.js
navbar.module.css
registerModal.js
index.css
index.js
lib
near.js
logo.svg
reportWebVitals.js
setupTests.js
| # Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `yarn start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in the browser.
The page will reload if you make edits.\
You will also see any lint errors in the console.
### `yarn test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `yarn build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `yarn eject`
**Note: this is a one-way operation. Once you `eject`, you can’t go back!**
If you aren’t satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you’re on your own.
You don’t have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn’t feel obligated to use this feature. However we understand that this tool wouldn’t be useful if you couldn’t customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `yarn build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
|
Pixel8-LLC_near-tooling-frontend | .env
.vscode
settings.json
README.md
config-overrides.js
package.json
postcss.config.js
public
fa
css
all.css
all.min.css
brands.css
brands.min.css
duotone.css
duotone.min.css
fontawesome.css
fontawesome.min.css
light.css
light.min.css
regular.css
regular.min.css
solid.css
solid.min.css
svg-with-js.css
svg-with-js.min.css
thin.css
thin.min.css
v4-font-face.css
v4-font-face.min.css
v4-shims.css
v4-shims.min.css
v5-font-face.css
v5-font-face.min.css
index.html
manifest.json
robots.txt
src
@history.js
ConnectProvider.js
api
Nft.js
UserNft.js
lib
getNTToken.js
ntAxios.js
walletActivity.js
assets
img
NotFound.svg
airdrop.svg
angle-right.svg
bullseye-arrow.svg
eye.svg
file-export.svg
fire-flame-curved.svg
gem.svg
green-check.svg
grey-clock.svg
icicles.svg
near-icon.svg
red-times.svg
search.svg
share-from-square.svg
trophy.svg
user-group.svg
wallet.svg
common
functions
SignWallet.js
components
Layout
index.js
Loading
Loading.css
index.js
constants
actions
topBar.js
artWorks.js
default.js
index.js
contract
config.js
index.css
pages
Airdrop
index.js
steps
Step3.module.css
files.js
SingleNFT.module.css
redux
actions
fans.js
topBar.js
walletActivity.js
reducers
fans.js
index.js
topBar.js
walletActivity.js
store.js
reportWebVitals.js
routes.js
setupTests.js
tailwind.config.js
| 
# NEAR Tooling
The goal for NEAR tooling is to create a suite of open source tools that enables builders and users to streamline their experience on NEAR.
The goal is to create a suite of open source tools that you wish existed when started on NEAR. Currently we have:
- Wallet Activity -- A filterable/searchable wallet explorer
- NFT Explorer -- View the NFTs owner by a particular wallet
- NFT Minters -- Get the minters of a contract
- Airdropper (WIP) -- Easily airdrop tokens and NFTs to an array of wallets
These tools are very early in development and could definitely be expanded upon. If you have any ideas for a tool, even if you're not a dev... please [open an issue](https://github.com/Pixel8-LLC/near-tooling-frontend/issues) so someone can build it for you.
## Getting Started
`yarn install`
`yarn start`
|
mil-lesya_voting-app | .gitpod.yml
README.md
contract
Cargo.toml
README.md
src
lib.rs
frontend
App.js
__mocks__
fileMock.js
assets
constants
colors.js
css
global.css
img
arrow1.svg
arrow2.svg
bg1.svg
bg2.svg
calendar-time.svg
done.svg
endCircle.svg
footer.svg
img1.svg
img2.svg
img3.svg
img4.svg
logo-black.svg
logo-white.svg
startCircle.svg
voted.svg
waitCircle.svg
js
near
config.js
utils.js
components
Button.js
Input.js
Modal.js
Option.js
Poll.js
functions
getPollsWithStatus.js
index.html
index.js
pages
AllPolls.js
CreatePoll.js
Main.js
Modal.js
MyPolls.js
NotFound.js
Poll.js
VotedPolls.js
integration-tests
package.json
src
config.ts
main.ava.ts
package.json
| near-blank-project
==================
This [React] app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `npm install`
3. Run the local development server: `npm run dev` (see `package.json` for a
full list of `scripts` you can run with `npm`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/frontend` folder. `/frontend/index.html` is a great
place to start exploring. Note that it loads in `/frontend/assets/js/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `npm
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `npm run dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `near-blank-project.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `near-blank-project.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account near-blank-project.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'near-blank-project.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
npm run deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
near-blank-project Smart Contract
==================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
|
kuutamolabs_hyper-staticfile | .github
workflows
check.yml
Cargo.toml
README.md
examples
doc_server.rs
rustfmt.toml
src
body.rs
lib.rs
resolve.rs
response_builder.rs
service.rs
util
file_bytes_stream.rs
file_response_builder.rs
mod.rs
requested_path.rs
vfs.rs
tests
hyper.rs
static.rs
| # hyper-staticfile
[](https://docs.rs/hyper-staticfile)
[](https://crates.io/crates/hyper-staticfile)
[](https://travis-ci.org/stephank/hyper-staticfile)
Static file-serving for [Hyper 1.0](https://github.com/hyperium/hyper).
See [`examples/doc_server.rs`](examples/doc_server.rs) for a complete example that you can compile.
## [Documentation](http://docs.rs/hyper-staticfile)
|
everstake_NEAR-Stake-Pool-Smart-Contract | Cargo.toml
README.md
source
account_balance.rs
account_registry.rs
cross_contract_call
classic_validator.rs
mod.rs
data_transfer_object
account_balance.rs
aggregated.rs
base_account_balance.rs
callback_result.rs
delayed_withdrawal_details.rs
epoch_height_registry.rs
fee_registry_light.rs
full.rs
full_for_account.rs
fund.rs
fungible_token_metadata.rs
investment_account_balance.rs
investor_investment.rs
mod.rs
requested_to_withdrawal_fund.rs
storage_staking_price.rs
storage_staking_requested_coverage.rs
validator.rs
delayed_withdrawal.rs
delayed_withdrawn_fund.rs
fee.rs
fee_registry.rs
fund.rs
fungible_token.rs
investment_withdrawal.rs
investor_investment.rs
lib.rs
reward.rs
shared_fee.rs
stake_decreasing_kind.rs
stake_pool.rs
staking_contract_version.rs
storage_key.rs
validating.rs
validator.rs
validator_balance.rs
| # Stake pool contract
This contract provides a way for other users to delegate funds to a pool of validation nodes.
There are some different roles:
- The staking pool contract. An account with the contract that staking pools funds.
- The staking pool is owned by the `owner` and the `owner` is the general manager of the staking pool.
- The pool `manager` manages the pool. The `manager` is assigned by the `owner` of the staking pool and can be changed anytime.
- Delegator accounts - accounts that want to stake their funds with the staking pool.
- Delegator accounts can become an `investor`.
## Reward distribution
The reward is distributed by increasing the exchange rate of the pool's native token at the beginning of each epoch.
Every epoch validators bring rewards to the pool. So, at the beginning of each epoch, the pool synchronizes and updates the information about the native tokens under management from all validators and calculates a new exchange rate for the native token.
## Stake pool contract guarantees and invariants
This staking pool implementation guarantees the required properties of the staking pool standard:
- The contract can't lose or lock tokens of users.
- If a user deposited X, the user should be able to withdraw at least X.
- If a user successfully staked X, the user can unstake at least X.
- The contract should not lock unstaked funds for longer than 8 epochs after delayed withdraw action.
It also has inner invariants:
- The price of staking pool tokens is always at least `1`.
- The price of staking pool tokens never decreases.
- The comission is a fraction be from `0` to `1` inclusive.
- The owner can't withdraw funds from other delegators.
## Implementation details
The owner can set up such contract with different parameters and start receiving users native tokens.
Any other user can send their native tokens to the contract and increase the total stake distributed on validators and receive staking pool fungible tokens.
These users are rewarded by increasing the rate of the staking pool tokens they received, but the contract has the right to charge a commission.
Then users can withdraw their native tokens after some unlocking period by exchanging staking pool tokens.
The price of a staking pool token defined as the total amount of staked native tokens divided by the total amount of staking pool token.
The number of staking pool token is always less than the number of the staked native tokens, so the price of single staking pool token is not less than `1`.
## Existing `call` methods:
- `new`
Available for pool owner.
Initializes staking pool state.
```rust
#[init]
pub fn new(
fungible_token_metadata: FungibleTokenMetadataDto,
manager_id: Option<AccountId>,
self_fee_receiver_account_id: AccountId,
partner_fee_receiver_account_id: AccountId,
reward_fee_self: Option<Fee>,
reward_fee_partner: Option<Fee>,
instant_withdraw_fee_self: Option<Fee>,
instant_withdraw_fee_partner: Option<Fee>
) -> Self
```
near deploy --wasmFile ./target/wasm32-unknown-unknown/release/stake_pool.wasm --accountId=pool.testnet --initDeposit=1 --initArgs='{"fungible_token_metadata": {"name": "NAME", "symbol": "SYMBOL", "icon": "ICON", "reference": null, "reference_hash": null, "decimals": 24}, "manager_id": "account0.testnet", "self_fee_receiver_account_id": "account1.testnet", "partner_fee_receiver_account_id": "account2.testnet", "reward_fee_self": {"numerator": 1, "denominator": 100}, "reward_fee_partner": {"numerator": 1, "denominator": 100}, "instant_withdraw_fee_self": {"numerator": 3, "denominator":1000}, "instant_withdraw_fee_partner": {"numerator": 1, "denominator": 5}}'
- `deposit`
Available for all users.
The delegator makes a deposit of funds, and receiving pool tokens in return.
When a delegator account first deposits funds to the contract, the internal account is created and credited with the
`near_amount` native tokens. The attached deposit must be greater than `near_amount` to hide the storage staking,
with the excess fund being refunded.
```rust
#[payable]
pub fn deposit(&mut self, near_amount: U128) -> PromiseOrValue<()>
```
near call pool.testnet deposit '{"near_amount": "10000000000000000000000000"}' --deposit=2 --accountId=account3.testnet --gas=300000000000000
- `deposit_on_validator`
Available for investors.
The delegator makes a deposit of funds via pool directly to validator, and receiving pool tokens in return.
When a delegator account first deposits funds to the contract, the internal account is created and credited with the
`near_amount` native tokens. The attached deposit must be greater than `near_amount` to hide the storage staking,
with the excess fund being refunded.
```rust
#[payable]
pub fn deposit_on_validator(&mut self, near_amount: U128, validator_account_id: AccountId) -> Promise
```
near call pool.testnet deposit_on_validator '{"near_amount": "1000000000000000000000000", "validator_account_id": "legends.pool.f863973.m0"}' --accountId=account3.testnet --deposit=2 --gas=300000000000000
- `instant_withdraw`
Available for all users.
The delegator makes an instant unstake by exchanging the pool tokens he has for native tokens. Native tokens are returned
to the delegator immediately, so there may be a commission for this action.
```rust
#[payable]
pub fn instant_withdraw(&mut self, token_amount: U128) -> Promise
```
near call pool.testnet instant_withdraw '{"token_amount":"1000000000000000000000000"}' --accountId=account3.testnet --deposit=1 --gas=300000000000000
- `delayed_withdraw`
Available for all users.
The delegator makes an unstake by exchanging the pool tokens he has for native tokens. Native tokens can be returned
to the delegator only after 8 epochs.
```rust
#[payable]
pub fn delayed_withdraw(&mut self, token_amount: U128) -> PromiseOrValue<()>
```
near call pool.testnet delayed_withdraw '{"token_amount": "1000000000000000000000000"}' --accountId=account3.testnet --deposit=1 --gas=300000000000000
- `delayed_withdraw_from_validator`
Available for investors.
The delegator makes an unstake via pool directly from validator by exchanging the pool tokens he has for native tokens. Native tokens can be returned
to the delegator only after 8 epochs.
```rust
#[payable]
pub fn delayed_withdraw_from_validator(&mut self, near_amount: U128, validator_account_id: AccountId) -> PromiseOrValue<()>
```
near call pool.testnet delayed_withdraw_from_validator '{"near_amount": "1000000000000000000000000", "validator_account_id": "legends.pool.f863973.m0"}' --accountId=account3.testnet --deposit=1 --gas=300000000000000
- `take_delayed_withdrawal`
Available for all users.
The delegator takes Native tokens he requested after passing the delayed unstake process.
```rust
#[payable]
pub fn take_delayed_withdrawal(&mut self) -> Promise
```
near call pool.testnet take_delayed_withdrawal --accountId=account3.testnet --deposit=1 --gas=300000000000000
- `increase_validator_stake`
Available for pool manager.
Stakes unstaked funds to the validator.
```rust
pub fn increase_validator_stake(&mut self, validator_account_id: AccountId, near_amount: U128) -> Promise
```
near call pool.testnet increase_validator_stake '{"validator_account_id":"legends.pool.f863973.m0", "near_amount":"1000000000000000000000000"}' --accountId=account0.testnet --gas=300000000000000
- `requested_decrease_validator_stake`
Available for pool manager.
Unstakes staked funds from validator.
```rust
pub fn requested_decrease_validator_stake(
&mut self,
validator_account_id: AccountId,
near_amount: U128,
stake_decreasing_type: StakeDecreasingType
) -> Promise
```
near call pool.testnet requested_decrease_validator_stake '{"validator_account_id":"legends.pool.f863973.m0", "near_amount":"500000000000000000000000", "stake_decreasing_type":"Classic"}' --accountId=account0.testnet --gas=300000000000000
- `take_unstaked_balance`
Available for pool manager.
Takes requested to withdraw balance from validator.
```rust
pub fn take_unstaked_balance(&mut self, validator_account_id: AccountId) -> Promise
```
near call pool.testnet take_unstaked_balance '{"validator_account_id":"legends.pool.f863973.m0"}' --accountId=account0.testnet --gas=300000000000000
- `update_validator`
Available for pool manager.
Updates validator state.
```rust
pub fn update_validator(&mut self, validator_account_id: AccountId) -> Promise
```
near call pool.testnet update_validator '{"validator_account_id":"legends.pool.f863973.m0"}' --accountId=account0.testnet --gas=300000000000000
- `update`
Available for pool manager.
Updates pool state.
```rust
pub fn update(&mut self)
```
near call pool.testnet update --accountId=account0.testnet --gas=300000000000000
- `add_validator`
Available for pool manager.
Adds the validator to the list of validators to which the pool delegates the available native tokens.
```rust
pub fn add_validator(
&mut self,
validator_account_id: AccountId,
staking_contract_version: StakingContractVersion,
is_only_for_investment: bool,
is_preferred: bool
) -> PromiseOrValue<()>
```
near call pool.testnet add_validator '{"validator_account_id":"legends.pool.f863973.m0","staking_contract_version":"Core", "is_only_for_investment": false, "is_preferred": true}' --accountId=account0.testnet --deposit=1 --gas=300000000000000
- `change_validator_investment_context`
Available for pool manager.
Changes validator state in context of investment flow.
```rust
pub fn change_validator_investment_context(&mut self, validator_account_id: AccountId, is_only_for_investment: bool)
```
near call pool.testnet change_validator_investment_context '{"validator_account_id":"legends.pool.f863973.m0", "is_only_for_investment": false}' --accountId=account0.testnet --gas=300000000000000
- `change_preffered_validator`
Available for pool manager.
Changes preffered validator.
```rust
pub fn change_preffered_validator(&mut self, validator_account_id: Option<AccountId>)
```
near call pool.testnet change_preffered_validator '{"validator_account_id":"legends.pool.f863973.m0", "is_only_for_investment": false}' --accountId=account0.testnet --gas=300000000000000
- `remove_validator`
Available for pool manager.
Removes the validator from the list of validators to which the pool delegates the available native tokens.
```rust
pub fn remove_validator(&mut self, validator_account_id: AccountId) -> Promise
```
near call pool.testnet remove_validator '{"validator_account_id":"legends.pool.f863973.m0"}' --accountId=account0.testnet --gas=300000000000000
- `add_investor`
Available for pool manager.
Adds the user to the list of investors.
```rust
#[payable]
pub fn add_investor(&mut self, investor_account_id: AccountId) -> PromiseOrValue<()>
```
near call pool.testnet add_investor '{"investor_account_id":"account4.testnet"}' --accountId=account0.testnet --deposit=1 --gas=300000000000000
- `remove_investor`
Available for pool manager.
Remove the user from the list of investors.
```rust
pub fn remove_investor(&mut self, investor_account_id: AccountId) -> Promise
```
near call pool.testnet remove_investor '{"investor_account_id":"account4.testnet"}' --accountId=account0.testnet --deposit=1 --gas=300000000000000
- `change_manager`
Available for pool owner and manager.
Changes pool manager.
```rust
pub fn change_manager(&mut self, manager_id: AccountId)
```
near call pool.testnet change_manager '{"manager_id":"account5.testnet"}' --accountId=account0.testnet --gas=300000000000000
- `change_reward_fee`
Available for pool manager.
Changes fee for validators rewards.
```rust
pub fn change_reward_fee(&mut self, reward_fee_self: Option<Fee>, reward_fee_partner: Option<Fee>)
```
near call pool.testnet change_reward_fee '{"reward_fee_self": {"numerator": 1, "denominator": 100}, "reward_fee_partner": {"numerator": 1, "denominator": 100}}' --accountId=account0.testnet --gas=300000000000000
- `change_instant_withdraw_fee`
Available for pool manager.
Changes fee for instant unstake process.
```rust
pub fn change_instant_withdraw_fee(&mut self, instant_withdraw_fee_self: Option<Fee>, instant_withdraw_fee_partner: Option<Fee>)
```
near call pool.testnet change_instant_withdraw_fee '{"instant_withdraw_fee_self": {"numerator": 1, "denominator": 100}, "instant_withdraw_fee_partner": {"numerator": 1, "denominator": 100}}' --accountId=account0.testnet --gas=300000000000000
- `confirm_stake_distribution`
Available for pool manager.
Confirms stake distributions.
```rust
pub fn confirm_stake_distribution(&mut self)
```
near call pool.testnet confirm_stake_distribution --accountId=account0.testnet --gas=300000000000000
## Existing `view` methods:
```rust
pub fn get_delayed_withdrawal_details(&self, account_id: AccountId) -> Option<DelayedWithdrawalDetails>
```
near view pool.testnet get_delayed_withdrawal_details '{"account_id": "account6.testnet"}'
```rust
pub fn get_account_balance(&self, account_id: AccountId) -> AccountBalanceDto
```
near view pool.testnet get_account_balance '{"account_id": "account6.testnet"}'
```rust
pub fn get_total_token_supply(&self) -> U128
```
near view pool.testnet get_total_token_supply
```rust
pub fn get_minimum_deposit_amount(&self) -> U128
```
near view pool.testnet get_minimum_deposit_amount
```rust
pub fn get_storage_staking_price(&self) -> StorageStakingPrice
```
near view pool.testnet get_storage_staking_price
```rust
pub fn get_storage_staking_requested_coverage(&self, account_id: AccountId) -> StorageStakingRequestedCoverage
```
near view pool.testnet get_storage_staking_requested_coverage '{"account_id": "account6.testnet"}'
```rust
pub fn get_fund(&self) -> FundDto
```
near view pool.testnet get_fund
```rust
pub fn get_fee_registry(&self) -> FeeRegistry
```
near view pool.testnet get_fee_registry
```rust
pub fn get_fee_registry_light(&self) -> FeeRegistryLight
```
near view pool.testnet get_fee_registry_light
```rust
pub fn get_current_epoch_height(&self) -> EpochHeightRegistry
```
near view pool.testnet get_current_epoch_height
```rust
pub fn is_stake_distributed(&self) -> bool
```
near view pool.testent is_stake_distributed
```rust
pub fn get_investor_investment(&self, account_id: AccountId) -> Option<InvestorInvestmentDto>
```
near view pool.testnet get_investor_investment '{"account_id": "account6.testnet"}'
```rust
pub fn get_validator_registry(&self) -> Vec<ValidatorDto>
```
near view pool.testnet get_validator_registry
```rust
pub fn get_preffered_validator(&self) -> Option<ValidatorDto>
```
near view pool.testnet get_preffered_validator
```rust
pub fn get_aggregated(&self) -> Aggregated
```
near view pool.testnet get_aggregated
```rust
pub fn get_requested_to_withdrawal_fund(&self) -> RequestedToWithdrawalFund
```
near view pool.testnet get_requested_to_withdrawal_fund
```rust
pub fn get_full(&self) -> Full
```
near view pool.testnet get_full
```rust
pub fn get_full_for_account(&self, account_id: AccountId) -> FullForAccount
```
near view pool.testnet get_full for account '{"account_id": "account6.testnet"}'
|
modelomaker812_team-boilerplate | .github
ISSUE_TEMPLATE
01_BUG_REPORT.md
02_FEATURE_REQUEST.md
03_CODEBASE_IMPROVEMENT.md
04_SUPPORT_QUESTION.md
config.yml
PULL_REQUEST_TEMPLATE.md
workflows
build.yml
lock.yml
stale.yml
README.md
contract
README.md
babel.config.json
build.sh
check-deploy.sh
deploy.sh
package-lock.json
package.json
src
contract.ts
tsconfig.json
docs
CODE_OF_CONDUCT.md
CONTRIBUTING.md
SECURITY.md
frontend
.env
.eslintrc.json
.prettierrc.json
contracts
contract.ts
greeting-contract.ts
next-env.d.ts
next.config.js
package-lock.json
package.json
pages
api
hello.ts
postcss.config.js
public
next.svg
thirteen.svg
vercel.svg
styles
globals.css
tailwind.config.js
tsconfig.json
integration-tests
package-lock.json
package.json
src
main.ava.ts
package-lock.json
package.json
| <h1 align="center">
<a href="https://github.com/near/boilerplate-template">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/near/boilerplate-template/main/docs/images/pagoda_logo_light.png">
<source media="(prefers-color-scheme: light)" srcset="https://raw.githubusercontent.com/near/boilerplate-template/main/docs/images/pagoda_logo_dark.png">
<img alt="" src="https://raw.githubusercontent.com/near/boilerplate-template/main/docs/images/pagoda_logo_dark.png">
</picture>
</a>
</h1>
<div align="center">
Boilerplate Template React
<br />
<br />
<a href="https://github.com/near/boilerplate-template/issues/new?assignees=&labels=bug&template=01_BUG_REPORT.md&title=bug%3A+">Report a Bug</a>
·
<a href="https://github.com/near/boilerplate-template/issues/new?assignees=&labels=enhancement&template=02_FEATURE_REQUEST.md&title=feat%3A+">Request a Feature</a>
.
<a href="https://github.com/near/boilerplate-template/issues/new?assignees=&labels=question&template=04_SUPPORT_QUESTION.md&title=support%3A+">Ask a Question</a>
</div>
<div align="center">
<br />
[](https://github.com/near/boilerplate-template/issues?q=is%3Aissue+is%3Aopen+label%3A%22help+wanted%22)
[](https://github.com/near)
</div>
<details open="open">
<summary>Table of Contents</summary>
- [Getting Started](#getting-started)
- [Prerequisites](#prerequisites)
- [Installation](#installation)
- [Usage](#usage)
- [Exploring The Code](#exploring-the-code)
- [Deploy](#deploy)
- [Step 0: Install near-cli (optional)](#step-0-install-near-cli-optional)
- [Step 1: Create an account for the contract](#step-1-create-an-account-for-the-contract)
- [Step 2: deploy the contract](#step-2-deploy-the-contract)
- [Step 3: set contract name in your frontend code](#step-3-set-contract-name-in-your-frontend-code)
- [Troubleshooting](#troubleshooting)
- [Deploy on Vercel](#deploy-on-vercel)
- [Roadmap](#roadmap)
- [Support](#support)
- [Project assistance](#project-assistance)
- [Contributing](#contributing)
- [Authors \& contributors](#authors--contributors)
- [Security](#security)
</details>
---
## About
This is a [Next.js](https://nextjs.org/) project bootstrapped with [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app) and [`tailwindcss`](https://tailwindcss.com/docs/guides/nextjs) created for easy-to-start as a React skeleton template in the Pagoda Gallery. Smart-contract was initialized with [create-near-app]. Use this template and start to build your own gallery project!
### Built With
[`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app), [`tailwindcss`](https://tailwindcss.com/docs/guides/nextjs), [`tailwindui`](https://tailwindui.com/), [`@headlessui/react`](https://headlessui.com/), [`@heroicons/react`](https://heroicons.com/), [create-near-app], [`amazing-github-template`](https://github.com/dec0dOS/amazing-github-template)
Getting Started
==================
### Prerequisites
Make sure you have a [current version of Node.js](https://nodejs.org/en/about/releases/) installed – we are targeting versions `18>`.
Read about other [prerequisites](https://docs.near.org/develop/prerequisites) in our docs.
### Installation
Install all dependencies:
npm install
Build your contract:
npm run build
Deploy your contract to TestNet with a temporary dev account:
npm run deploy
Usage
=====
Start your frontend in development mode:
npm run dev
Start your frontend in production mode:
npm run start
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
Test your contract:
npm run test
Exploring The Code
==================
1. The smart-contract code lives in the `/contract` folder. See the README there for
more info. In blockchain apps the smart contract is the "backend" of your app.
2. The frontend code lives in the `/frontend` folder. You can start editing the page by
modifying `frontend/pages/index.tsx`. The page auto-updates as you edit the file.
This is your entrypoint to learn how the frontend connects to the NEAR blockchain.
3. Test your contract: `npm test`, this will run the tests in `integration-tests` directory.
4. [API routes](https://nextjs.org/docs/api-routes/introduction) can be accessed on [http://localhost:3000/api/hello](http://localhost:3000/api/hello). This endpoint can be edited in `frontend/pages/api/hello.ts`.
5. The `frontend/pages/api` directory is mapped to `/api/*`. Files in this directory are treated as [API routes](https://nextjs.org/docs/api-routes/introduction) instead of React pages.
6. This project uses [`next/font`](https://nextjs.org/docs/basic-features/font-optimization) to automatically optimize and load Inter, a custom Google Font.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts].
When you run `npm run deploy`, your smart contract gets deployed to the live NEAR TestNet with a temporary dev account.
When you're ready to make it permanent, here's how:
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `near-blank-project.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `near-blank-project.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account near-blank-project.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: deploy the contract
---------------------------
Use the CLI to deploy the contract to TestNet with your account ID.
Replace `PATH_TO_WASM_FILE` with the `wasm` that was generated in `contract` build directory.
near deploy --accountId near-blank-project.YOUR-NAME.testnet --wasmFile PATH_TO_WASM_FILE
Step 3: set contract name in your frontend code
-----------------------------------------------
Modify `NEXT_PUBLIC_CONTRACT_NAME` in `frontend/.env.local` that sets the account name of the contract. Set it to the account id you used above.
NEXT_PUBLIC_CONTRACT_NAME=near-blank-project.YOUR-NAME.testnet
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-next-app]: https://github.com/vercel/next.js/tree/canary/packages/create-next-app
[Node.js]: https://nodejs.org/en/download/package-manager
[tailwindcss]: https://tailwindcss.com/docs/guides/nextjs
[create-near-app]: https://github.com/near/create-near-app
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/concepts/basics/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
You can check out [the Next.js GitHub repository](https://github.com/vercel/next.js/) - your feedback and contributions are welcome!
## Deploy on Vercel
The easiest way to deploy your Next.js app is to use the [Vercel Platform](https://vercel.com/new?utm_medium=default-template&filter=next.js&utm_source=create-next-app&utm_campaign=create-next-app-readme) from the creators of Next.js.
Check out our [Next.js deployment documentation](https://nextjs.org/docs/deployment) for more details.
## Roadmap
See the [open issues](https://github.com/near/boilerplate-template/issues) for a list of proposed features (and known issues).
- [Top Feature Requests](https://github.com/near/boilerplate-template/issues?q=label%3Aenhancement+is%3Aopen+sort%3Areactions-%2B1-desc) (Add your votes using the 👍 reaction)
- [Top Bugs](https://github.com/near/boilerplate-template/issues?q=is%3Aissue+is%3Aopen+label%3Abug+sort%3Areactions-%2B1-desc) (Add your votes using the 👍 reaction)
- [Newest Bugs](https://github.com/near/boilerplate-template/issues?q=is%3Aopen+is%3Aissue+label%3Abug)
## Support
Reach out to the maintainer:
- [GitHub issues](https://github.com/near/boilerplate-template/issues/new?assignees=&labels=question&template=04_SUPPORT_QUESTION.md&title=support%3A+)
## Project assistance
If you want to say **thank you** or/and support active development of Boilerplate Template React:
- Add a [GitHub Star](https://github.com/near/boilerplate-template) to the project.
- Tweet about the Boilerplate Template React.
- Write interesting articles about the project on [Dev.to](https://dev.to/), [Medium](https://medium.com/) or your personal blog.
Together, we can make Boilerplate Template React **better**!
## Contributing
First off, thanks for taking the time to contribute! Contributions are what make the open-source community such an amazing place to learn, inspire, and create. Any contributions you make will benefit everybody else and are **greatly appreciated**.
Please read [our contribution guidelines](docs/CONTRIBUTING.md), and thank you for being involved!
## Authors & contributors
The original setup of this repository is by [Dmitriy Sheleg](https://github.com/shelegdmitriy).
For a full list of all authors and contributors, see [the contributors page](https://github.com/near/boilerplate-template/contributors).
## Security
Boilerplate Template React follows good practices of security, but 100% security cannot be assured.
Boilerplate Template React is provided **"as is"** without any **warranty**. Use at your own risk.
_For more information and to report security issues, please refer to our [security documentation](docs/SECURITY.md)._
# Hello NEAR Contract
The smart contract exposes two methods to enable storing and retrieving a greeting in the NEAR network.
```ts
@NearBindgen({})
class HelloNear {
greeting: string = "Hello";
@view // This method is read-only and can be called for free
get_greeting(): string {
return this.greeting;
}
@call // This method changes the state, for which it cost gas
set_greeting({ greeting }: { greeting: string }): void {
// Record a log permanently to the blockchain!
near.log(`Saving greeting ${greeting}`);
this.greeting = greeting;
}
}
```
<br />
# Quickstart
1. Make sure you have installed [node.js](https://nodejs.org/en/download/package-manager/) >= 16.
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
npm run deploy
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Retrieve the Greeting
`get_greeting` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the greeting
near view <dev-account> get_greeting
```
<br />
## 3. Store a New Greeting
`set_greeting` changes the contract's state, for which it is a `call` method.
`Call` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set a new greeting
near call <dev-account> set_greeting '{"greeting":"howdy"}' --accountId <dev-account>
```
**Tip:** If you would like to call `set_greeting` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
|
NEAR-Edu_welcome-track | .env
README.md
babel.config.js
docs
developers
01-react
01-getting-started
01-react-app-quickstart.md
02-react-tutorial.md
_category_.json
02-quick-reference
01-cheatsheet.md
02-cookbook.md
03-useful-links.md
_category_.json
_category_.json
03-theory
01-application-architecture.md
_category_.json
04-protocol
01-accounts.md
02-access-keys.md
03-storage.md
04-smart-contracts.md
05-shards.md
_category_.json
05-contract-patterns
01-storage-keys.md
02-storage-fees.md
03-assert_one_yocto-forced-confirmation.md
04-ownership.md
05-schema-migration.md
_category_.json
06-comparisons-to-other-blockchains
01-ethereum.md
02-algorand.md
_category_.json
intro.md
entrepreneurs
01-find-your-place-in-web3.md
02-get-started-with-your-idea.md
03-launch-your-business-on-near.md
intro.md
|
docusaurus.config.js
package-lock.json
package.json
prettier.config.js
sidebars.js
src
components
HomepageFeatures
styles.module.css
config
footerLinks.ts
routeUpdate.ts
css
custom.css
pages
build-with-react.md
plugins
onRouteUpdate.ts
static
img
logo.svg
nu_logo.svg
nu_logo_white.svg
undraw_docusaurus_mountain.svg
undraw_docusaurus_react.svg
undraw_docusaurus_tree.svg
tsconfig.json
| # Welcome Track - NEAR Education
> _Find your place in the NEAR ecosystem._
The Welcome Track is a website for introducing people to Web3 and NEAR.
This website is built using [Docusaurus 2](https://docusaurus.io/), a modern static website generator.
## Getting started
### Installation
```bash
npm install
npm run prepare
```
### Local Development
```bash
npm run start
```
This command starts a local development server and opens up a browser window. Most changes are reflected live without having to restart the server.
### Build
```bash
npm run build
```
This command generates static content into the `build` directory and can be served using any static contents hosting service.
## Adding documentation
When adding documentation, whether it be a single article or a whole folder (category) of articles, please follow the following guidelines:
- Use article numbering (e.g. `01-ethereum.md`) in filenames and folder names to maintain ordering in the sidebar.
- Use [kebab case](https://www.theserverside.com/definition/Kebab-case) (e.g. lowercase separated by hyphens) filenames and folder names to maintain consistency in URL generation.
- Use the `title` metadata field to set the title of the article for the sidebar and heading of the article. Try to keep it the same as the name of the file but with the actual casing and separators.
- Use the `label` metadata field in the `_category_.json` file of the folder (category) to set the title of the category in the sidebar.
## Editing footer links
When editing footer links, please edit the `src/config/footerLinks.ts` file.
You will see a variable with the name of `FOOTER_LINKS` which holds the links.
Each persona has a different array of columns and links within those columns.
**IMPORTANT**: Make sure that the persona name matches the name of the directory where the persona documentation is located at (e.g. for `developers` write `developers`, don't use abbreviations in this config if they are not used in the file name, like using `devs`).
|
larry-a4_near-token-amm | Cargo.toml
README.md
src
ft.rs
lib.rs
| # A simple AMM contract with the following methods:
## Initialization method
>Input is the address of the contract owner and the addresses of two tokens (token A and token B).
>The method requests and stores the metadata of tokens (name, decimals)
>Creates wallets for tokens А & В.
## View method
>The method for getting information about the contract (ticker, decimals, ratio of tokens A and B)
## Deposit method
>The user can transfer a certain number of tokens A to the contract account and in return must receive a certain number of tokens B (similarly in the other direction). The contract supports a certain ratio of tokens A and B. X * Y = K (K is some constant value, X and Y are the number of tokens A and B respectively.
## Add liquidity method
>The owner of the contract can transfer a certain amount of tokens A or B to the contract account, thereby changing the ratio K.
# Steps Guide
## Setup Token A
```
deposit scheme pulse lucky feed barely weather color velvet bunker trophy virus
```
1. Initialization
```
near call test-token-a.testnet new '{"owner_id": "'test-token-a.testnet'", "total_supply": "1000000000000000", "metadata": { "spec": "ft-1.0.0", "name": "Test Token A", "symbol": "TESTA", "decimals": 8 }}' --accountId test-token-a.testnet
```
2. Transfer
```shell
near call test-token-a.testnet ft_transfer '{"receiver_id": "user.testnet", "amount": "200"}' --accountId test-token-a.testnet --depositYocto 1
```
* If Error reported, then you need to register first
```
Smart contract panicked: The account user.testnet is not registered
```
3. Register
```shell
near call test-token-a.testnet storage_deposit --accountId user.testnet --depositYocto 1
```
## Setup Token B
```
dumb earth inject vendor salad glass near crazy vague connect hood radio
```
1. Initialization
```shell
near call test-token-b.testnet new '{"owner_id": "'test-token-b.testnet'", "total_supply": "1000000000000000", "metadata": { "spec": "ft-1.0.0", "name": "Test Token B", "symbol": "TESTB", "decimals": 8 }}' --accountId test-token-b.testnet
```
## Setup AMM contract:
```
punch rally scrap client dream industry egg unfold cart tilt chaos kite
```
## Setup Test User
```
flavor forget tape sponsor main artefact stamp belt endless best erosion crane
```
* View balance of two tokens
```shell
near view user.testnet get_balance_a
near view user.testnet get_balance_b
```
## Bring everything together
1. Register user with both tokens
```
near call test-token-a.testnet storage_deposit --accountId user.testnet --amount 0.00125
near call test-token-b.testnet storage_deposit --accountId user.testnet --amount 0.00125
```
2. Transfer 2000 Token A to user ,and add liquidity
```
near call test-token-a.testnet ft_transfer '{"receiver_id": "user.testnet", "amount": "200"}' --accountId test-token-a.testnet --depositYocto 1
near call user.testnet add_liquidity '{"token": "test-token-a.testnet", "amount_in": 200}' --accountId owner.testnet
```
3. Transfer 2000 Token B to user ,and add liquidity
```shell
near call test-token-b.testnet ft_transfer '{"receiver_id": "user.testnet", "amount": "2000"}' --accountId test-token-b.testnet --depositYocto 1
near call user.testnet add_liquidity '{"token": "test-token-b.testnet", "amount_in": 2000}' --accountId owner.testnet
```
4. Register another user `user-test-amm-1` with both tokens
```shell
near call test-token-a.testnet storage_deposit --accountId user-test-amm-1.testnet --amount 0.00125
near call test-token-b.testnet storage_deposit --accountId user-test-amm-1.testnet --amount 0.00125
```
5. Transfer 2000 Token B to test user
```shell
near call test-token-b.testnet ft_transfer '{"receiver_id": "user.testnet", "amount": "40"}' --accountId test-token-b.testnet --depositYocto 1
```
6. Execute Swap
```
near call user.testnet swap '{"token_in": "test-token-b.testnet", "amount_in": 40}' --accountId user-test-amm-1.testnet --depositYocto 1
```
|
amel007_near-random-id | Cargo.toml
src
lib.rs
| |
GeFi-Team_MetaBUIDL | gefi_gomoku
.gitpod.yml
.prettierrc.json
README.md
babel.config.js
package.json
src
App.js
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
component
common
modal.js
switch.js
content
game
caro
caro.js
detailmatch.js
main.js
modalcreatematch.js
game.js
home
home.js
main.js
profile
profile.js
register
register.js
trade
exchange.js
liquidity.js
trade.js
navigation
header.js
navigation.js
config.js
global.css
index.html
index.js
jest.init.js
lang
en.json
vi.json
main.test.js
redux
action.js
actions
caro.js
reducer
caroreducer.js
changelangreducer.js
contentnavigationreducer.js
homecontrolnavigationreducer.js
nearwalletreducer.js
pagenavigationreducer.js
playreducer.js
reducer.js
themeselectionreducer.js
userreducer.js
store.js
type.js
theme
default
icon
add.svg
arrowDown.svg
close.svg
dotSildeActive.svg
dotSlideDeactive.svg
game.svg
gameA.svg
home.svg
homeA.svg
loading.svg
logo.svg
logout.svg
menu.svg
recent.svg
right.svg
transfer.svg
transferA.svg
user.svg
userA.svg
x.svg
theme.js
utils.js
wallet
login
index.html
gefi_gomoku_server
.env
.prettierrc.json
README.md
babel.config.js
inversify.config.ts
package.json
src
controller
v1
Match.controller.ts
helper
Logger.helper.ts
Storage.helper.ts
Valid.helper.ts
index.ts
interface
ICRUD.interface.ts
ILogger.interface.ts
IStorage.interface.ts
IValid.interface.ts
model
v1
Match.model.ts
response
Error.response.ts
route
v1
route.v1.ts
valid
v1
Match.valid.ts
tsconfig.json
webpack.config.js
gefi_hub
README.md
asconfig.json
assembly
__test__
as-pect.d.ts
main.spec.ts
as_types.d.ts
controller
product.controller.ts
space.controller.ts
token.controller.ts
user.controller.ts
helper
cross.helper.ts
pagination.helper.ts
response.helper.ts
transform.helper.ts
index.ts
model
cross.model.ts
pool.model.ts
product.model.ts
space.model.ts
token.model.ts
user.model.ts
storage
pool.storage.ts
product.storage.ts
space.storage.ts
token.storage.ts
user.storage.ts
usertoken.storage.ts
tsconfig.json
user.ts
image
gefi_architecture.svg
gefi_bussiness.svg
gefi_bussiness_cf.svg
package-lock.json
package.json
src
config.js
gefi_match
README.md
asconfig.json
assembly
__test__
as-pect.d.ts
main.spec.ts
as_types.d.ts
controller
history.controller.ts
match.controller.ts
swap.controller.ts
user.controller.ts
helper
pagination.helper.ts
response.helper.ts
transform.helper.ts
index.ts
model
fee.model.ts
history.model.ts
match.model.ts
user.model.ts
storage
history.storage.ts
match.storage.ts
user.storage.ts
tsconfig.json
user.ts
package-lock.json
package.json
src
config.js
gomoko_flow.svg
| # How to install
## Install dependencies
========================
```js
yarn install
```
## Deploy
===============
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `amm.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `amm.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account amm.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'amm.YOUR-NAME.testnet'
Step 3: deploy!
---------------
yarn deploy or near deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
## Troubleshooting
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
# Code structure
```js
/**
* Vector chứa các trận đấu đang chờ
* PersistentVector ~ List ~ Danh sách liên kết đơn/đôi
**/
const waitingMatch = new PersistentVector<Match>("w");
```
```js
/**
* Vector chứa các trận đấu đang diễn ra
* Khi 1 trận đấu đang ở waiting mà đủ người chơi, trận đấu sẽ chuyển sang trạng thái running
* Trình tự: Remove match from waitingMatch Vertor -> Insert to RunningMatch Vector
**/
const runningMatch = new PersistentVector<Match>("r");
```
```js
/**
* Vector chứa các trận đấu đã diễn ra
* Khi 1 trận đấu đang ở running mà đã có kết quả, dữ liệu trận đấu sẽ được lưu vào finishedMatch
* Trình tự: Remove match from runningMatch vector -> Insert to FinishedMatch Vector
**/
const finishedMatch = new PersistentVector<Match>("f");
```
```js
/**
* Vector chứa lịch sử thi đấu của người chơi
* Khi runningMatch hoàn thành, trận đấu sẽ kết thúc
* Hệ thống sẽ ghi nhận người thắng/ thua và lưu vào danh sách lịch sử của người chơi
**/
const historyMatch = new PersistentMap<String, PersistentVector<History>>("h")
```
# Welcome to GeFi Gomoku Server
This server only broadcast the message between competitor in match. Using room domain, a feature of socket.io for broadcasting to every one in a room.
<center>

</center>
When a client create match, Server will create a room by using match Id. All of clients join to match also join to room in server.
Thus, Any player will broadcast his actions to all other players via the server.
## Steps to run this project
### Install all prerequisite
#### install node modules
```sh
npm i
npm i -g nodemon typedoc typescript
```
#### install PostgresSQL
* Windows
```url
https://www.postgresql.org/download/windows/
```
* Linux
```url
https://www.postgresql.org/download/
```
* macOSX
```url
https://www.postgresql.org/download/macosx/
```
#### install Visual studio code
```url
https://code.visualstudio.com/download
```
#### Run project
```sh
nodemon
```
By default, server will listen in port ```7000```
amm
==================
This [React] app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `amm.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `amm.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account amm.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'amm.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
# GeFi Hub
Online games are currently the most popular and popular form of entertainment today. We play games after hard working hours, we choose games when we feel bored, and don't know what to do during the days of social distancing or work-from-home due to the Covid epidemic. Not only helps relieve stress, but games are also a means to help people connect and get closer to each other. Therefore, games are an indispensable part of life.
Moreover, games are not only a form of entertainment but also a means of increasing the income of many gamers today. They play games, exchange items, and convert to money. However, all transactions are spontaneous, with no guarantee of authenticity.
Therefore, we introduce a project that is both entertaining and helps gamers easily convert in-game items and money into NEAR tokens.
```At this time```, our platform will help the game publishers implement their games with the blockchain network. Centralized games have billions of players over the world, most of them can not bring their token in-game to reality, to deal with this problem, we provide a platform that helps players can swap their in-game tokens with a cryptocurrency like NEAR, ETH, or other game tokens on our network.
Each user can have their wallet where they can trade, donate, join a bet or get profit with their in-game tokens by swapping with a cryptocurrency and stake them. Moreover, because all transactions are performed on the blockchain network, everything is transparent, private, and has no scam. That's so exciting!
In the future, GeFi will not only support games, but also all products with payment integration.
## System Architechture

In bassically, GeFi hub have 4 block:
1. ```GeFi Space Management```: This block will store all spaces of producer. Each space can be considered as an independent company. The companies are all in different industries and offer distinct products.
2. ```GeFi Token Management```: This block will store all kind of digital token of producer. Token can be use across from all producer space. That mean, Token(1) of producer A can be swapped to Token(2) of Producer B in a liquidity pool. Further, token also can be swapped to NEAR (GeFi NEP-141)
3. ```GeFi Product Management```: All products of producer will be stored in this block. Each product will belong to a certain producer ```space``` and using one ```token``` for make a payments. At the time of create ```token```, producer need to deposit the amount of NEAR and provide a value of token's volume. The rate between NEAR and ```token``` will be caculated, and be modified by time. We plan to make a DAO for voting the rate by governance in the furture.
4. ```GeFi User Management```: We develop a block to centrally manage tokens of all clients participating in GeFi. From there, an application similar to an e-wallet will be created and directly interact with this block in the future.
## GeFi Bussiness model

Our Platform has two types of customers
1. Producers
When producers publishing their product ```(game)``` on GeFi, publishers have to register the token for that game.
Token will be synchronized with their in-game token, they can earn tokens for the player, and on another side, the player can trade their token to play the game or get money through swapping with cryptocurrency like NEAR, ETH, and so on.
Producers can store in-game datas like user tokens, user information, or something else as them want. GeFi will not interfere deeply with the organization of the product.
For some potential provider, Sandbox is our impression feature, where the new game publisher can raise the fund to perform their dream game
2. Clients / Players.
To using any products in GeFi Platform, clients need to deposit the amount of ```NEAR``` then swap them to ```in-game Token``` respectively. A wallet will help the client to store whole their tokens in any product as the deposit before. Thus, It will help players easier to swap with other in-game tokens on the GeFi platform, connect with GeFi Player Services, and some other interesting services.
Additionaly, NFT is a trend right now. So GeFi also has multiple plans to apply it. An ```item Marketplace``` for example, where the player can buy the beautiful avatar or other NFT products from third party. It can become a potential investment channel.
They also can trade their in-game tokens on ```Token Exchange``` or try to become an investor with ```Game Crowdfunding```.
## GeFi Cash Flow

Start with the player, they can be earned tokens from publishers by play games, trade tokens, or NFT on the marketplace and token exchange and get profit from Crowdfunding services.
Publishers can get money by their token value, create and sell the NFT asset or raise the fund from the community through the Sandbox with the startup game studios.
With GEFI, we collect the transaction fee on our system, publish the NEP-141 called GEFI, and the other comes from our services.
## How to install
### Install dependencies
========================
```js
yarn install
```
### Deploy
===============
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `amm.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `amm.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account amm.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'amm.YOUR-NAME.testnet'
Step 3: deploy!
---------------
yarn deploy or near deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
### Troubleshooting
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
## GeFi Interface
### Space Hub
- Each owner can have multiple spaces (company, co.op, ...). Example: You establish a game building company, a logistics company or whatever else you want. Each company will have its own number of products
- Space will be storage in ```PersistentUnorderedMap``` to get the maximum performance during ```get``` and ```set```
```typescript
type space_name = String;
class Space {
public owner: String;
public name: String;
public symbol: String;
public icon: String
}
const gefi_Spaces = PersistentUnorderedMap<space_name, Space>("gSp");
```
- Space public user interface
1. Register new space to system
```typescript
/**
* Each owner can register multiple spaces, but them need to have a unique name
* @param:
* name: Unique of space
* symbol: The symbol of space
* icon: The icon of space in base64
* @return
* a new space or null if it exists
**/
function sp_register(name: String, symbol: String, icon: String): Space | null {}
```
1. Unregister all space of owner
```typescript
/**
* @param:
* @return:
* return all spaces of owner or null if the owner does not have any spaces
**/
function sp_unregisters(): Space[] | null {}
```
1. Unregister a space of owner
```typescript
/**
* @param:
* name: Space name need to be unregister
* @return:
* return a deleted space or null if it is not exist
**/
function sp_unregister(name: String): Space | null {}
```
1. Update space detail
```typescript
/**
* @param:
* name: Name of space need to be updated
* symbol: new symbol of space
* icon: new icon of space
* @return
* true if space updated otherwise false
**/
function sp_update(name: String, symbol: String, icon: String): bool {}
```
### Token Hub
- Each owner can have multiple tokens at multiple rates. Owners can use tokens for multiple products or one token for all products. It depends on the needs of the owner.
- Token will be storage in ```PersistentUnorderedMap``` to get the maximum performance during ```get``` and ```set```
```typescript
type token_name = String;
class Token {
public owner: String;
public name: String;
public symbol: String;
public icon: String
public rate: f64; // rate = token/near
public balance: u128 = u128.Zero;
public near_balance: u128 = u128.Zero; // For MVP product only
private P: u128; // For MVP product only
}
const gefi_Tokens = new PersistentUnorderedMap<token_name, Token>("gtk");
```
1. Register new token to system.
```js
/**
* @param:
* name: Name of token need to be uniqe
* symbol: The symbol of token
* icon: The icon of token
* @return
* return the created token or null if it exists
**/
function tk_register(name: String, symbol: String, icon: String): Token | null {}
```
1. Unregister all token
```js
/**
* @param
* @return
* return all unregistered tokens or null if owner does not have any tokens
**/
export function tk_unregisters(): Token[] | null {}
```
1. Unregister a specific token
```js
/**
* @param
* name: Name of token that need to be unregistered
* @return
* return the unregistered token or null if it is not exists
**/
export function tk_unregister(name: String): Token | null {}
```
1. Update token detail
```js
/**
* @param
* name: Name of the token that need to be updated
* symbol: new symbol of token
* icon: new icon of token
* @return
* return trur if the token updated otherwise false
**/
function tk_update(name: String, symbol: String, icon: String): bool {}
```
1. Get the token rate
```js
/**
* @param
* ownerId: ownerid of the token
* name: name of token
* @return
* return the rate token/near
**/
function get_rate(ownerId: String, name: String): f64 {}
```
1. Swap from ```in-game Token``` to ```NEAR```
```typescript
/**
* @param
* ownerId
**/
export function buy_near(ownerId: String, name: String, amount: u128): ContractPromiseBatch | null {}
```
export function buy_token(ownerId: String, name: String): ContractPromise | null {
return token.buy_token(ownerId, name);
}
### Product Hub
- Each owner can have multiple product as described above. A product can be a game, a music stream or anything else, needs to belong to a certain space and own a token for it.
- Product will be storage in ```PersistentUnorderedMap``` to get the maximum performance during ```get``` and ```set```
```typescript
type product_name = String;
class Token {
public name: String;
public symbol: String;
public icon: String
public space: Space;
public token: Token;
}
const gefi_Products = new PersistentUnorderedMap<product_name, Product>("gGm");
```
1. Register new product to space and assign token
```typescript
/**
* @param
* name: Name of product need to be uniqe
* symbol: symbol of product
* icon: icon of product
* space: space will contain the product
* token: token will be used in the product
* @return
* return the registered product or null if space or token could not be found or product exists
**/
export function gm_register(name: String, symbol: String, icon: String, space: String, token: String): : Product | null {
}
```
1. Unregister all products
```typescript
/**
* @param
* space: Space name need to unregister all product
* @return
* return all unregistered product or null if the space does not have any product
**/
export function gm_unregisters(space: String): Product[] | null {}
```
1. Unregister a certain product
```typescript
/**
* @param
* space: Space of product
* name: Name of product that need to be unregistered
* @return
* the unregisterd product or null if it is not exist
**/
export function gm_unregister(space: String, name: String): Product | null {}
```
1. Update product detail
```typescript
/**
* @param:
* space: Space of product that need to be updated
* name: Name of product that need to be updated
* symbol: new symbol of product
* icon: new icon of product
**/
export function gm_update(space: String, name: String, symbol: String, icon: String): bool {}
```
|
hasanozkul_nearzombies | .vscode
settings.json
README.md
next-env.d.ts
next.config.js
package-lock.json
package.json
postcss.config.js
prettier.config.js
public
images
bg-footer.svg
bg-navbar.svg
near_logo.svg
styles
globals.css
tailwind.config.js
tsconfig.json
| # Next.js + Tailwind CSS Example
This example shows how to use [Tailwind CSS](https://tailwindcss.com/) [(v3.0)](https://tailwindcss.com/blog/tailwindcss-v3) with Next.js. It follows the steps outlined in the official [Tailwind docs](https://tailwindcss.com/docs/guides/nextjs).
## Preview
Preview the example live on [StackBlitz](http://stackblitz.com/):
[](https://stackblitz.com/github/vercel/next.js/tree/canary/examples/with-tailwindcss)
## Deploy your own
Deploy the example using [Vercel](https://vercel.com?utm_source=github&utm_medium=readme&utm_campaign=next-example):
[](https://vercel.com/new/git/external?repository-url=https://github.com/vercel/next.js/tree/canary/examples/with-tailwindcss&project-name=with-tailwindcss&repository-name=with-tailwindcss)
## How to use
Execute [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app) with [npm](https://docs.npmjs.com/cli/init) or [Yarn](https://yarnpkg.com/lang/en/docs/cli/create/) to bootstrap the example:
```bash
npx create-next-app --example with-tailwindcss with-tailwindcss-app
# or
yarn create next-app --example with-tailwindcss with-tailwindcss-app
```
Deploy it to the cloud with [Vercel](https://vercel.com/new?utm_source=github&utm_medium=readme&utm_campaign=next-example) ([Documentation](https://nextjs.org/docs/deployment)).
|
priyankads296_evote | blockvote
.gitpod.yml
README.md
babel.config.js
contract
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
main.spec.ts
as_types.d.ts
index.ts
tsconfig.json
compile.js
node_modules
.bin
acorn.cmd
acorn.ps1
asb.cmd
asb.ps1
asbuild.cmd
asbuild.ps1
asc.cmd
asc.ps1
asinit.cmd
asinit.ps1
asp.cmd
asp.ps1
aspect.cmd
aspect.ps1
assemblyscript-build.cmd
assemblyscript-build.ps1
eslint.cmd
eslint.ps1
esparse.cmd
esparse.ps1
esvalidate.cmd
esvalidate.ps1
js-yaml.cmd
js-yaml.ps1
mkdirp.cmd
mkdirp.ps1
near-vm-as.cmd
near-vm-as.ps1
near-vm.cmd
near-vm.ps1
nearley-railroad.cmd
nearley-railroad.ps1
nearley-test.cmd
nearley-test.ps1
nearley-unparse.cmd
nearley-unparse.ps1
nearleyc.cmd
nearleyc.ps1
node-which.cmd
node-which.ps1
rimraf.cmd
rimraf.ps1
semver.cmd
semver.ps1
shjs.cmd
shjs.ps1
wasm-opt.cmd
wasm-opt.ps1
.package-lock.json
@as-covers
assembly
CONTRIBUTING.md
README.md
index.ts
package.json
tsconfig.json
core
CONTRIBUTING.md
README.md
package.json
glue
README.md
lib
index.d.ts
index.js
package.json
transform
README.md
lib
index.d.ts
index.js
util.d.ts
util.js
node_modules
visitor-as
.github
workflows
test.yml
README.md
as
index.d.ts
index.js
asconfig.json
dist
astBuilder.d.ts
astBuilder.js
base.d.ts
base.js
baseTransform.d.ts
baseTransform.js
decorator.d.ts
decorator.js
examples
capitalize.d.ts
capitalize.js
exportAs.d.ts
exportAs.js
functionCallTransform.d.ts
functionCallTransform.js
includeBytesTransform.d.ts
includeBytesTransform.js
list.d.ts
list.js
toString.d.ts
toString.js
index.d.ts
index.js
path.d.ts
path.js
simpleParser.d.ts
simpleParser.js
transformRange.d.ts
transformRange.js
transformer.d.ts
transformer.js
utils.d.ts
utils.js
visitor.d.ts
visitor.js
package.json
tsconfig.json
package.json
@as-pect
assembly
README.md
assembly
index.ts
internal
Actual.ts
Expectation.ts
Expected.ts
Reflect.ts
ReflectedValueType.ts
Test.ts
assert.ts
call.ts
comparison
toIncludeComparison.ts
toIncludeEqualComparison.ts
log.ts
noOp.ts
package.json
types
as-pect.d.ts
as-pect.portable.d.ts
env.d.ts
cli
README.md
init
as-pect.config.js
env.d.ts
example.spec.ts
init-types.d.ts
portable-types.d.ts
lib
as-pect.cli.amd.d.ts
as-pect.cli.amd.js
help.d.ts
help.js
index.d.ts
index.js
init.d.ts
init.js
portable.d.ts
portable.js
run.d.ts
run.js
test.d.ts
test.js
types.d.ts
types.js
util
CommandLineArg.d.ts
CommandLineArg.js
IConfiguration.d.ts
IConfiguration.js
asciiArt.d.ts
asciiArt.js
collectReporter.d.ts
collectReporter.js
getTestEntryFiles.d.ts
getTestEntryFiles.js
removeFile.d.ts
removeFile.js
strings.d.ts
strings.js
writeFile.d.ts
writeFile.js
worklets
ICommand.d.ts
ICommand.js
compiler.d.ts
compiler.js
package.json
core
README.md
lib
as-pect.core.amd.d.ts
as-pect.core.amd.js
index.d.ts
index.js
reporter
CombinationReporter.d.ts
CombinationReporter.js
EmptyReporter.d.ts
EmptyReporter.js
IReporter.d.ts
IReporter.js
SummaryReporter.d.ts
SummaryReporter.js
VerboseReporter.d.ts
VerboseReporter.js
test
IWarning.d.ts
IWarning.js
TestContext.d.ts
TestContext.js
TestNode.d.ts
TestNode.js
transform
assemblyscript.d.ts
assemblyscript.js
createAddReflectedValueKeyValuePairsMember.d.ts
createAddReflectedValueKeyValuePairsMember.js
createGenericTypeParameter.d.ts
createGenericTypeParameter.js
createStrictEqualsMember.d.ts
createStrictEqualsMember.js
emptyTransformer.d.ts
emptyTransformer.js
hash.d.ts
hash.js
index.d.ts
index.js
util
IAspectExports.d.ts
IAspectExports.js
IWriteable.d.ts
IWriteable.js
ReflectedValue.d.ts
ReflectedValue.js
TestNodeType.d.ts
TestNodeType.js
rTrace.d.ts
rTrace.js
stringifyReflectedValue.d.ts
stringifyReflectedValue.js
timeDifference.d.ts
timeDifference.js
wasmTools.d.ts
wasmTools.js
package.json
csv-reporter
index.ts
lib
as-pect.csv-reporter.amd.d.ts
as-pect.csv-reporter.amd.js
index.d.ts
index.js
package.json
readme.md
tsconfig.json
json-reporter
index.ts
lib
as-pect.json-reporter.amd.d.ts
as-pect.json-reporter.amd.js
index.d.ts
index.js
package.json
readme.md
tsconfig.json
snapshots
__tests__
snapshot.spec.ts
jest.config.js
lib
Snapshot.d.ts
Snapshot.js
SnapshotDiff.d.ts
SnapshotDiff.js
SnapshotDiffResult.d.ts
SnapshotDiffResult.js
as-pect.core.amd.d.ts
as-pect.core.amd.js
index.d.ts
index.js
parser
grammar.d.ts
grammar.js
package.json
src
Snapshot.ts
SnapshotDiff.ts
SnapshotDiffResult.ts
index.ts
parser
grammar.ts
tsconfig.json
@assemblyscript
loader
README.md
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
@babel
code-frame
README.md
lib
index.js
package.json
helper-validator-identifier
README.md
lib
identifier.js
index.js
keyword.js
package.json
scripts
generate-identifier-regex.js
highlight
README.md
lib
index.js
node_modules
ansi-styles
index.js
package.json
readme.md
chalk
index.js
package.json
readme.md
templates.js
types
index.d.ts
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
.eslintrc.json
README.md
index.js
package.json
test.js
escape-string-regexp
index.js
package.json
readme.md
has-flag
index.js
package.json
readme.md
supports-color
browser.js
index.js
package.json
readme.md
package.json
@eslint
eslintrc
CHANGELOG.md
README.md
conf
config-schema.js
environments.js
eslint-all.js
eslint-recommended.js
lib
cascading-config-array-factory.js
config-array-factory.js
config-array
config-array.js
config-dependency.js
extracted-config.js
ignore-pattern.js
index.js
override-tester.js
flat-compat.js
index.js
shared
ajv.js
config-ops.js
config-validator.js
deprecation-warnings.js
naming.js
relative-module-resolver.js
types.js
package.json
@humanwhocodes
config-array
README.md
api.js
package.json
object-schema
.eslintrc.js
.github
workflows
nodejs-test.yml
release-please.yml
CHANGELOG.md
README.md
package.json
src
index.js
merge-strategy.js
object-schema.js
validation-strategy.js
tests
merge-strategy.js
object-schema.js
validation-strategy.js
acorn-jsx
README.md
index.d.ts
index.js
package.json
xhtml.js
acorn
CHANGELOG.md
README.md
dist
acorn.d.ts
acorn.js
acorn.mjs.d.ts
bin.js
package.json
ajv
.tonic_example.js
README.md
dist
ajv.bundle.js
ajv.min.js
lib
ajv.d.ts
ajv.js
cache.js
compile
async.js
equal.js
error_classes.js
formats.js
index.js
resolve.js
rules.js
schema_obj.js
ucs2length.js
util.js
data.js
definition_schema.js
dotjs
README.md
_limit.js
_limitItems.js
_limitLength.js
_limitProperties.js
allOf.js
anyOf.js
comment.js
const.js
contains.js
custom.js
dependencies.js
enum.js
format.js
if.js
index.js
items.js
multipleOf.js
not.js
oneOf.js
pattern.js
properties.js
propertyNames.js
ref.js
required.js
uniqueItems.js
validate.js
keyword.js
refs
data.json
json-schema-draft-04.json
json-schema-draft-06.json
json-schema-draft-07.json
json-schema-secure.json
package.json
scripts
.eslintrc.yml
bundle.js
compile-dots.js
ansi-colors
README.md
index.js
package.json
symbols.js
types
index.d.ts
ansi-regex
index.d.ts
index.js
package.json
readme.md
ansi-styles
index.d.ts
index.js
package.json
readme.md
argparse
CHANGELOG.md
README.md
index.js
lib
action.js
action
append.js
append
constant.js
count.js
help.js
store.js
store
constant.js
false.js
true.js
subparsers.js
version.js
action_container.js
argparse.js
argument
error.js
exclusive.js
group.js
argument_parser.js
const.js
help
added_formatters.js
formatter.js
namespace.js
utils.js
package.json
as-bignum
README.md
assembly
__tests__
as-pect.d.ts
i128.spec.as.ts
safe_u128.spec.as.ts
u128.spec.as.ts
u256.spec.as.ts
utils.ts
fixed
fp128.ts
fp256.ts
index.ts
safe
fp128.ts
fp256.ts
types.ts
globals.ts
index.ts
integer
i128.ts
i256.ts
index.ts
safe
i128.ts
i256.ts
i64.ts
index.ts
u128.ts
u256.ts
u64.ts
u128.ts
u256.ts
tsconfig.json
utils.ts
package.json
asbuild
README.md
dist
cli.d.ts
cli.js
commands
build.d.ts
build.js
fmt.d.ts
fmt.js
index.d.ts
index.js
init
cmd.d.ts
cmd.js
files
asconfigJson.d.ts
asconfigJson.js
aspecConfig.d.ts
aspecConfig.js
assembly_files.d.ts
assembly_files.js
eslintConfig.d.ts
eslintConfig.js
gitignores.d.ts
gitignores.js
index.d.ts
index.js
indexJs.d.ts
indexJs.js
packageJson.d.ts
packageJson.js
test_files.d.ts
test_files.js
index.d.ts
index.js
interfaces.d.ts
interfaces.js
run.d.ts
run.js
test.d.ts
test.js
index.d.ts
index.js
main.d.ts
main.js
utils.d.ts
utils.js
index.js
node_modules
cliui
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
wrap-ansi
index.js
package.json
readme.md
y18n
CHANGELOG.md
README.md
index.js
package.json
yargs-parser
CHANGELOG.md
LICENSE.txt
README.md
index.js
lib
tokenize-arg-string.js
package.json
yargs
CHANGELOG.md
README.md
build
lib
apply-extends.d.ts
apply-extends.js
argsert.d.ts
argsert.js
command.d.ts
command.js
common-types.d.ts
common-types.js
completion-templates.d.ts
completion-templates.js
completion.d.ts
completion.js
is-promise.d.ts
is-promise.js
levenshtein.d.ts
levenshtein.js
middleware.d.ts
middleware.js
obj-filter.d.ts
obj-filter.js
parse-command.d.ts
parse-command.js
process-argv.d.ts
process-argv.js
usage.d.ts
usage.js
validation.d.ts
validation.js
yargs.d.ts
yargs.js
yerror.d.ts
yerror.js
index.js
locales
be.json
de.json
en.json
es.json
fi.json
fr.json
hi.json
hu.json
id.json
it.json
ja.json
ko.json
nb.json
nl.json
nn.json
pirate.json
pl.json
pt.json
pt_BR.json
ru.json
th.json
tr.json
zh_CN.json
zh_TW.json
package.json
yargs.js
package.json
assemblyscript-json
.eslintrc.js
.travis.yml
README.md
assembly
JSON.ts
decoder.ts
encoder.ts
index.ts
tsconfig.json
util
index.ts
index.js
package.json
temp-docs
README.md
classes
decoderstate.md
json.arr.md
json.bool.md
json.float.md
json.integer.md
json.null.md
json.num.md
json.obj.md
json.str.md
json.value.md
jsondecoder.md
jsonencoder.md
jsonhandler.md
throwingjsonhandler.md
modules
json.md
assemblyscript-regex
.eslintrc.js
.github
workflows
benchmark.yml
release.yml
test.yml
README.md
as-pect.config.js
asconfig.empty.json
asconfig.json
assembly
__spec_tests__
generated.spec.ts
__tests__
alterations.spec.ts
as-pect.d.ts
boundary-assertions.spec.ts
capture-group.spec.ts
character-classes.spec.ts
character-sets.spec.ts
characters.ts
empty.ts
quantifiers.spec.ts
range-quantifiers.spec.ts
regex.spec.ts
utils.ts
char.ts
env.ts
index.ts
nfa
matcher.ts
nfa.ts
types.ts
walker.ts
parser
node.ts
parser.ts
string-iterator.ts
walker.ts
regexp.ts
tsconfig.json
util.ts
benchmark
benchmark.js
package.json
spec
test-generator.js
ts
index.ts
tsconfig.json
assemblyscript-temporal
.github
workflows
node.js.yml
release.yml
.vscode
launch.json
README.md
as-pect.config.js
asconfig.empty.json
asconfig.json
assembly
__tests__
README.md
as-pect.d.ts
date.spec.ts
duration.spec.ts
empty.ts
plaindate.spec.ts
plaindatetime.spec.ts
plainmonthday.spec.ts
plaintime.spec.ts
plainyearmonth.spec.ts
timezone.spec.ts
zoneddatetime.spec.ts
constants.ts
date.ts
duration.ts
enums.ts
env.ts
index.ts
instant.ts
now.ts
plaindate.ts
plaindatetime.ts
plainmonthday.ts
plaintime.ts
plainyearmonth.ts
timezone.ts
tsconfig.json
tz
__tests__
index.spec.ts
rule.spec.ts
zone.spec.ts
iana.ts
index.ts
rule.ts
zone.ts
utils.ts
zoneddatetime.ts
development.md
package.json
tzdb
README.md
iana
theory.html
zoneinfo2tdf.pl
assemblyscript
README.md
cli
README.md
asc.d.ts
asc.js
asc.json
shim
README.md
fs.js
path.js
process.js
transform.d.ts
transform.js
util
colors.d.ts
colors.js
find.d.ts
find.js
mkdirp.d.ts
mkdirp.js
options.d.ts
options.js
utf8.d.ts
utf8.js
dist
asc.js
assemblyscript.d.ts
assemblyscript.js
sdk.js
index.d.ts
index.js
lib
loader
README.md
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
rtrace
README.md
bin
rtplot.js
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
package-lock.json
package.json
std
README.md
assembly.json
assembly
array.ts
arraybuffer.ts
atomics.ts
bindings
Date.ts
Math.ts
Reflect.ts
asyncify.ts
console.ts
wasi.ts
wasi_snapshot_preview1.ts
wasi_unstable.ts
builtins.ts
compat.ts
console.ts
crypto.ts
dataview.ts
date.ts
diagnostics.ts
error.ts
function.ts
index.d.ts
iterator.ts
map.ts
math.ts
memory.ts
number.ts
object.ts
polyfills.ts
process.ts
reference.ts
regexp.ts
rt.ts
rt
README.md
common.ts
index-incremental.ts
index-minimal.ts
index-stub.ts
index.d.ts
itcms.ts
rtrace.ts
stub.ts
tcms.ts
tlsf.ts
set.ts
shared
feature.ts
target.ts
tsconfig.json
typeinfo.ts
staticarray.ts
string.ts
symbol.ts
table.ts
tsconfig.json
typedarray.ts
uri.ts
util
casemap.ts
error.ts
hash.ts
math.ts
memory.ts
number.ts
sort.ts
string.ts
uri.ts
vector.ts
wasi
index.ts
portable.json
portable
index.d.ts
index.js
types
assembly
index.d.ts
package.json
portable
index.d.ts
package.json
tsconfig-base.json
astral-regex
index.d.ts
index.js
package.json
readme.md
axios
CHANGELOG.md
README.md
UPGRADE_GUIDE.md
dist
axios.js
axios.min.js
index.d.ts
index.js
lib
adapters
README.md
http.js
xhr.js
axios.js
cancel
Cancel.js
CancelToken.js
isCancel.js
core
Axios.js
InterceptorManager.js
README.md
buildFullPath.js
createError.js
dispatchRequest.js
enhanceError.js
mergeConfig.js
settle.js
transformData.js
defaults.js
helpers
README.md
bind.js
buildURL.js
combineURLs.js
cookies.js
deprecatedMethod.js
isAbsoluteURL.js
isURLSameOrigin.js
normalizeHeaderName.js
parseHeaders.js
spread.js
utils.js
package.json
balanced-match
.github
FUNDING.yml
LICENSE.md
README.md
index.js
package.json
base-x
LICENSE.md
README.md
package.json
src
index.d.ts
index.js
binary-install
README.md
example
binary.js
package.json
run.js
index.js
package.json
src
binary.js
binaryen
README.md
index.d.ts
package-lock.json
package.json
wasm.d.ts
bn.js
CHANGELOG.md
README.md
lib
bn.js
package.json
brace-expansion
README.md
index.js
package.json
bs58
CHANGELOG.md
README.md
index.js
package.json
callsites
index.d.ts
index.js
package.json
readme.md
camelcase
index.d.ts
index.js
package.json
readme.md
chalk
index.d.ts
package.json
readme.md
source
index.js
templates.js
util.js
chownr
README.md
chownr.js
package.json
cliui
CHANGELOG.md
LICENSE.txt
README.md
build
lib
index.js
string-utils.js
package.json
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
README.md
index.js
package.json
commander
CHANGELOG.md
Readme.md
index.js
package.json
typings
index.d.ts
concat-map
.travis.yml
example
map.js
index.js
package.json
test
map.js
cross-spawn
CHANGELOG.md
README.md
index.js
lib
enoent.js
parse.js
util
escape.js
readShebang.js
resolveCommand.js
package.json
csv-stringify
README.md
lib
browser
index.js
sync.js
es5
index.d.ts
index.js
sync.d.ts
sync.js
index.d.ts
index.js
sync.d.ts
sync.js
package.json
debug
README.md
package.json
src
browser.js
common.js
index.js
node.js
decamelize
index.js
package.json
readme.md
deep-is
.travis.yml
example
cmp.js
index.js
package.json
test
NaN.js
cmp.js
neg-vs-pos-0.js
diff
CONTRIBUTING.md
README.md
dist
diff.js
lib
convert
dmp.js
xml.js
diff
array.js
base.js
character.js
css.js
json.js
line.js
sentence.js
word.js
index.es6.js
index.js
patch
apply.js
create.js
merge.js
parse.js
util
array.js
distance-iterator.js
params.js
package.json
release-notes.md
runtime.js
discontinuous-range
.travis.yml
README.md
index.js
package.json
test
main-test.js
doctrine
CHANGELOG.md
README.md
lib
doctrine.js
typed.js
utility.js
package.json
emoji-regex
LICENSE-MIT.txt
README.md
es2015
index.js
text.js
index.d.ts
index.js
package.json
text.js
enquirer
CHANGELOG.md
README.md
index.d.ts
index.js
lib
ansi.js
combos.js
completer.js
interpolate.js
keypress.js
placeholder.js
prompt.js
prompts
autocomplete.js
basicauth.js
confirm.js
editable.js
form.js
index.js
input.js
invisible.js
list.js
multiselect.js
numeral.js
password.js
quiz.js
scale.js
select.js
snippet.js
sort.js
survey.js
text.js
toggle.js
render.js
roles.js
state.js
styles.js
symbols.js
theme.js
timer.js
types
array.js
auth.js
boolean.js
index.js
number.js
string.js
utils.js
package.json
env-paths
index.d.ts
index.js
package.json
readme.md
escalade
dist
index.js
index.d.ts
package.json
readme.md
sync
index.d.ts
index.js
escape-string-regexp
index.d.ts
index.js
package.json
readme.md
eslint-scope
CHANGELOG.md
README.md
lib
definition.js
index.js
pattern-visitor.js
reference.js
referencer.js
scope-manager.js
scope.js
variable.js
package.json
eslint-utils
README.md
index.js
node_modules
eslint-visitor-keys
CHANGELOG.md
README.md
lib
index.js
visitor-keys.json
package.json
package.json
eslint-visitor-keys
CHANGELOG.md
README.md
lib
index.js
visitor-keys.json
package.json
eslint
CHANGELOG.md
README.md
bin
eslint.js
conf
category-list.json
config-schema.js
default-cli-options.js
eslint-all.js
eslint-recommended.js
replacements.json
lib
api.js
cli-engine
cli-engine.js
file-enumerator.js
formatters
checkstyle.js
codeframe.js
compact.js
html.js
jslint-xml.js
json-with-metadata.js
json.js
junit.js
stylish.js
table.js
tap.js
unix.js
visualstudio.js
hash.js
index.js
lint-result-cache.js
load-rules.js
xml-escape.js
cli.js
config
default-config.js
flat-config-array.js
flat-config-schema.js
rule-validator.js
eslint
eslint.js
index.js
init
autoconfig.js
config-file.js
config-initializer.js
config-rule.js
npm-utils.js
source-code-utils.js
linter
apply-disable-directives.js
code-path-analysis
code-path-analyzer.js
code-path-segment.js
code-path-state.js
code-path.js
debug-helpers.js
fork-context.js
id-generator.js
config-comment-parser.js
index.js
interpolate.js
linter.js
node-event-generator.js
report-translator.js
rule-fixer.js
rules.js
safe-emitter.js
source-code-fixer.js
timing.js
options.js
rule-tester
index.js
rule-tester.js
rules
accessor-pairs.js
array-bracket-newline.js
array-bracket-spacing.js
array-callback-return.js
array-element-newline.js
arrow-body-style.js
arrow-parens.js
arrow-spacing.js
block-scoped-var.js
block-spacing.js
brace-style.js
callback-return.js
camelcase.js
capitalized-comments.js
class-methods-use-this.js
comma-dangle.js
comma-spacing.js
comma-style.js
complexity.js
computed-property-spacing.js
consistent-return.js
consistent-this.js
constructor-super.js
curly.js
default-case-last.js
default-case.js
default-param-last.js
dot-location.js
dot-notation.js
eol-last.js
eqeqeq.js
for-direction.js
func-call-spacing.js
func-name-matching.js
func-names.js
func-style.js
function-call-argument-newline.js
function-paren-newline.js
generator-star-spacing.js
getter-return.js
global-require.js
grouped-accessor-pairs.js
guard-for-in.js
handle-callback-err.js
id-blacklist.js
id-denylist.js
id-length.js
id-match.js
implicit-arrow-linebreak.js
indent-legacy.js
indent.js
index.js
init-declarations.js
jsx-quotes.js
key-spacing.js
keyword-spacing.js
line-comment-position.js
linebreak-style.js
lines-around-comment.js
lines-around-directive.js
lines-between-class-members.js
max-classes-per-file.js
max-depth.js
max-len.js
max-lines-per-function.js
max-lines.js
max-nested-callbacks.js
max-params.js
max-statements-per-line.js
max-statements.js
multiline-comment-style.js
multiline-ternary.js
new-cap.js
new-parens.js
newline-after-var.js
newline-before-return.js
newline-per-chained-call.js
no-alert.js
no-array-constructor.js
no-async-promise-executor.js
no-await-in-loop.js
no-bitwise.js
no-buffer-constructor.js
no-caller.js
no-case-declarations.js
no-catch-shadow.js
no-class-assign.js
no-compare-neg-zero.js
no-cond-assign.js
no-confusing-arrow.js
no-console.js
no-const-assign.js
no-constant-condition.js
no-constructor-return.js
no-continue.js
no-control-regex.js
no-debugger.js
no-delete-var.js
no-div-regex.js
no-dupe-args.js
no-dupe-class-members.js
no-dupe-else-if.js
no-dupe-keys.js
no-duplicate-case.js
no-duplicate-imports.js
no-else-return.js
no-empty-character-class.js
no-empty-function.js
no-empty-pattern.js
no-empty.js
no-eq-null.js
no-eval.js
no-ex-assign.js
no-extend-native.js
no-extra-bind.js
no-extra-boolean-cast.js
no-extra-label.js
no-extra-parens.js
no-extra-semi.js
no-fallthrough.js
no-floating-decimal.js
no-func-assign.js
no-global-assign.js
no-implicit-coercion.js
no-implicit-globals.js
no-implied-eval.js
no-import-assign.js
no-inline-comments.js
no-inner-declarations.js
no-invalid-regexp.js
no-invalid-this.js
no-irregular-whitespace.js
no-iterator.js
no-label-var.js
no-labels.js
no-lone-blocks.js
no-lonely-if.js
no-loop-func.js
no-loss-of-precision.js
no-magic-numbers.js
no-misleading-character-class.js
no-mixed-operators.js
no-mixed-requires.js
no-mixed-spaces-and-tabs.js
no-multi-assign.js
no-multi-spaces.js
no-multi-str.js
no-multiple-empty-lines.js
no-native-reassign.js
no-negated-condition.js
no-negated-in-lhs.js
no-nested-ternary.js
no-new-func.js
no-new-object.js
no-new-require.js
no-new-symbol.js
no-new-wrappers.js
no-new.js
no-nonoctal-decimal-escape.js
no-obj-calls.js
no-octal-escape.js
no-octal.js
no-param-reassign.js
no-path-concat.js
no-plusplus.js
no-process-env.js
no-process-exit.js
no-promise-executor-return.js
no-proto.js
no-prototype-builtins.js
no-redeclare.js
no-regex-spaces.js
no-restricted-exports.js
no-restricted-globals.js
no-restricted-imports.js
no-restricted-modules.js
no-restricted-properties.js
no-restricted-syntax.js
no-return-assign.js
no-return-await.js
no-script-url.js
no-self-assign.js
no-self-compare.js
no-sequences.js
no-setter-return.js
no-shadow-restricted-names.js
no-shadow.js
no-spaced-func.js
no-sparse-arrays.js
no-sync.js
no-tabs.js
no-template-curly-in-string.js
no-ternary.js
no-this-before-super.js
no-throw-literal.js
no-trailing-spaces.js
no-undef-init.js
no-undef.js
no-undefined.js
no-underscore-dangle.js
no-unexpected-multiline.js
no-unmodified-loop-condition.js
no-unneeded-ternary.js
no-unreachable-loop.js
no-unreachable.js
no-unsafe-finally.js
no-unsafe-negation.js
no-unsafe-optional-chaining.js
no-unused-expressions.js
no-unused-labels.js
no-unused-vars.js
no-use-before-define.js
no-useless-backreference.js
no-useless-call.js
no-useless-catch.js
no-useless-computed-key.js
no-useless-concat.js
no-useless-constructor.js
no-useless-escape.js
no-useless-rename.js
no-useless-return.js
no-var.js
no-void.js
no-warning-comments.js
no-whitespace-before-property.js
no-with.js
nonblock-statement-body-position.js
object-curly-newline.js
object-curly-spacing.js
object-property-newline.js
object-shorthand.js
one-var-declaration-per-line.js
one-var.js
operator-assignment.js
operator-linebreak.js
padded-blocks.js
padding-line-between-statements.js
prefer-arrow-callback.js
prefer-const.js
prefer-destructuring.js
prefer-exponentiation-operator.js
prefer-named-capture-group.js
prefer-numeric-literals.js
prefer-object-spread.js
prefer-promise-reject-errors.js
prefer-reflect.js
prefer-regex-literals.js
prefer-rest-params.js
prefer-spread.js
prefer-template.js
quote-props.js
quotes.js
radix.js
require-atomic-updates.js
require-await.js
require-jsdoc.js
require-unicode-regexp.js
require-yield.js
rest-spread-spacing.js
semi-spacing.js
semi-style.js
semi.js
sort-imports.js
sort-keys.js
sort-vars.js
space-before-blocks.js
space-before-function-paren.js
space-in-parens.js
space-infix-ops.js
space-unary-ops.js
spaced-comment.js
strict.js
switch-colon-spacing.js
symbol-description.js
template-curly-spacing.js
template-tag-spacing.js
unicode-bom.js
use-isnan.js
utils
ast-utils.js
fix-tracker.js
keywords.js
lazy-loading-rule-map.js
patterns
letters.js
unicode
index.js
is-combining-character.js
is-emoji-modifier.js
is-regional-indicator-symbol.js
is-surrogate-pair.js
valid-jsdoc.js
valid-typeof.js
vars-on-top.js
wrap-iife.js
wrap-regex.js
yield-star-spacing.js
yoda.js
shared
ajv.js
ast-utils.js
config-validator.js
deprecation-warnings.js
logging.js
relative-module-resolver.js
runtime-info.js
string-utils.js
traverser.js
types.js
source-code
index.js
source-code.js
token-store
backward-token-comment-cursor.js
backward-token-cursor.js
cursor.js
cursors.js
decorative-cursor.js
filter-cursor.js
forward-token-comment-cursor.js
forward-token-cursor.js
index.js
limit-cursor.js
padded-token-cursor.js
skip-cursor.js
utils.js
messages
all-files-ignored.js
extend-config-missing.js
failed-to-read-json.js
file-not-found.js
no-config-found.js
plugin-conflict.js
plugin-invalid.js
plugin-missing.js
print-config-with-directory-path.js
whitespace-found.js
package.json
espree
CHANGELOG.md
README.md
espree.js
lib
ast-node-types.js
espree.js
features.js
options.js
token-translator.js
visitor-keys.js
node_modules
eslint-visitor-keys
CHANGELOG.md
README.md
lib
index.js
visitor-keys.json
package.json
package.json
esprima
README.md
bin
esparse.js
esvalidate.js
dist
esprima.js
package.json
esquery
README.md
dist
esquery.esm.js
esquery.esm.min.js
esquery.js
esquery.lite.js
esquery.lite.min.js
esquery.min.js
license.txt
node_modules
estraverse
README.md
estraverse.js
gulpfile.js
package.json
package.json
parser.js
esrecurse
README.md
esrecurse.js
gulpfile.babel.js
node_modules
estraverse
README.md
estraverse.js
gulpfile.js
package.json
package.json
estraverse
README.md
estraverse.js
gulpfile.js
package.json
esutils
README.md
lib
ast.js
code.js
keyword.js
utils.js
package.json
fast-deep-equal
README.md
es6
index.d.ts
index.js
react.d.ts
react.js
index.d.ts
index.js
package.json
react.d.ts
react.js
fast-json-stable-stringify
.eslintrc.yml
.github
FUNDING.yml
.travis.yml
README.md
benchmark
index.js
test.json
example
key_cmp.js
nested.js
str.js
value_cmp.js
index.d.ts
index.js
package.json
test
cmp.js
nested.js
str.js
to-json.js
fast-levenshtein
LICENSE.md
README.md
levenshtein.js
package.json
file-entry-cache
README.md
cache.js
changelog.md
package.json
find-up
index.d.ts
index.js
package.json
readme.md
flat-cache
README.md
changelog.md
package.json
src
cache.js
del.js
utils.js
flatted
.github
FUNDING.yml
workflows
node.js.yml
README.md
SPECS.md
cjs
index.js
package.json
es.js
esm
index.js
index.js
min.js
package.json
php
flatted.php
types.d.ts
follow-redirects
README.md
http.js
https.js
index.js
node_modules
debug
.coveralls.yml
.travis.yml
CHANGELOG.md
README.md
karma.conf.js
node.js
package.json
src
browser.js
debug.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
fs-minipass
README.md
index.js
package.json
fs.realpath
README.md
index.js
old.js
package.json
function-bind
.jscs.json
.travis.yml
README.md
implementation.js
index.js
package.json
test
index.js
functional-red-black-tree
README.md
bench
test.js
package.json
rbtree.js
test
test.js
get-caller-file
LICENSE.md
README.md
index.d.ts
index.js
package.json
glob-parent
CHANGELOG.md
README.md
index.js
package.json
glob
README.md
common.js
glob.js
package.json
sync.js
globals
globals.json
index.d.ts
index.js
package.json
readme.md
has-flag
index.d.ts
index.js
package.json
readme.md
has
README.md
package.json
src
index.js
test
index.js
hasurl
README.md
index.js
package.json
ignore
CHANGELOG.md
README.md
index.d.ts
index.js
legacy.js
package.json
import-fresh
index.d.ts
index.js
package.json
readme.md
imurmurhash
README.md
imurmurhash.js
imurmurhash.min.js
package.json
inflight
README.md
inflight.js
package.json
inherits
README.md
inherits.js
inherits_browser.js
package.json
interpret
README.md
index.js
mjs-stub.js
package.json
is-core-module
CHANGELOG.md
README.md
core.json
index.js
package.json
test
index.js
is-extglob
README.md
index.js
package.json
is-fullwidth-code-point
index.d.ts
index.js
package.json
readme.md
is-glob
README.md
index.js
package.json
isarray
.travis.yml
README.md
component.json
index.js
package.json
test.js
isexe
README.md
index.js
mode.js
package.json
test
basic.js
windows.js
isobject
README.md
index.js
package.json
js-base64
LICENSE.md
README.md
base64.d.ts
base64.js
package.json
js-tokens
CHANGELOG.md
README.md
index.js
package.json
js-yaml
CHANGELOG.md
README.md
bin
js-yaml.js
dist
js-yaml.js
js-yaml.min.js
index.js
lib
js-yaml.js
js-yaml
common.js
dumper.js
exception.js
loader.js
mark.js
schema.js
schema
core.js
default_full.js
default_safe.js
failsafe.js
json.js
type.js
type
binary.js
bool.js
float.js
int.js
js
function.js
regexp.js
undefined.js
map.js
merge.js
null.js
omap.js
pairs.js
seq.js
set.js
str.js
timestamp.js
package.json
json-schema-traverse
.eslintrc.yml
.travis.yml
README.md
index.js
package.json
spec
.eslintrc.yml
fixtures
schema.js
index.spec.js
json-stable-stringify-without-jsonify
.travis.yml
example
key_cmp.js
nested.js
str.js
value_cmp.js
index.js
package.json
test
cmp.js
nested.js
replacer.js
space.js
str.js
to-json.js
levn
README.md
lib
cast.js
index.js
parse-string.js
package.json
line-column
README.md
lib
line-column.js
package.json
locate-path
index.d.ts
index.js
package.json
readme.md
lodash.clonedeep
README.md
index.js
package.json
lodash.merge
README.md
index.js
package.json
lodash.sortby
README.md
index.js
package.json
lodash.truncate
README.md
index.js
package.json
long
README.md
dist
long.js
index.js
package.json
src
long.js
lru-cache
README.md
index.js
package.json
minimatch
README.md
minimatch.js
package.json
minimist
.travis.yml
example
parse.js
index.js
package.json
test
all_bool.js
bool.js
dash.js
default_bool.js
dotted.js
kv_short.js
long.js
num.js
parse.js
parse_modified.js
proto.js
short.js
stop_early.js
unknown.js
whitespace.js
minipass
README.md
index.js
package.json
minizlib
README.md
constants.js
index.js
package.json
mkdirp
bin
cmd.js
usage.txt
index.js
package.json
moo
README.md
moo.js
package.json
ms
index.js
license.md
package.json
readme.md
natural-compare
README.md
index.js
package.json
near-mock-vm
assembly
__tests__
main.ts
context.ts
index.ts
outcome.ts
vm.ts
bin
bin.js
package.json
pkg
near_mock_vm.d.ts
near_mock_vm.js
package.json
vm
dist
cli.d.ts
cli.js
context.d.ts
context.js
index.d.ts
index.js
memory.d.ts
memory.js
runner.d.ts
runner.js
utils.d.ts
utils.js
index.js
near-sdk-as
as-pect.config.js
as_types.d.ts
asconfig.json
asp.asconfig.json
assembly
__tests__
as-pect.d.ts
assert.spec.ts
avl-tree.spec.ts
bignum.spec.ts
contract.spec.ts
contract.ts
data.txt
empty.ts
generic.ts
includeBytes.spec.ts
main.ts
max-heap.spec.ts
model.ts
near.spec.ts
persistent-set.spec.ts
promise.spec.ts
rollback.spec.ts
roundtrip.spec.ts
runtime.spec.ts
unordered-map.spec.ts
util.ts
utils.spec.ts
as_types.d.ts
bindgen.ts
index.ts
json.lib.ts
tsconfig.json
vm
__tests__
vm.include.ts
index.ts
compiler.js
imports.js
package.json
near-sdk-bindgen
README.md
assembly
index.ts
compiler.js
dist
JSONBuilder.d.ts
JSONBuilder.js
classExporter.d.ts
classExporter.js
index.d.ts
index.js
transformer.d.ts
transformer.js
typeChecker.d.ts
typeChecker.js
utils.d.ts
utils.js
index.js
package.json
near-sdk-core
README.md
asconfig.json
assembly
as_types.d.ts
base58.ts
base64.ts
bignum.ts
collections
avlTree.ts
index.ts
maxHeap.ts
persistentDeque.ts
persistentMap.ts
persistentSet.ts
persistentUnorderedMap.ts
persistentVector.ts
util.ts
contract.ts
datetime.ts
env
env.ts
index.ts
runtime_api.ts
index.ts
logging.ts
math.ts
promise.ts
storage.ts
tsconfig.json
util.ts
docs
assets
css
main.css
js
main.js
search.json
classes
_sdk_core_assembly_collections_avltree_.avltree.html
_sdk_core_assembly_collections_avltree_.avltreenode.html
_sdk_core_assembly_collections_avltree_.childparentpair.html
_sdk_core_assembly_collections_avltree_.nullable.html
_sdk_core_assembly_collections_persistentdeque_.persistentdeque.html
_sdk_core_assembly_collections_persistentmap_.persistentmap.html
_sdk_core_assembly_collections_persistentset_.persistentset.html
_sdk_core_assembly_collections_persistentunorderedmap_.persistentunorderedmap.html
_sdk_core_assembly_collections_persistentvector_.persistentvector.html
_sdk_core_assembly_contract_.context-1.html
_sdk_core_assembly_contract_.contractpromise.html
_sdk_core_assembly_contract_.contractpromiseresult.html
_sdk_core_assembly_math_.rng.html
_sdk_core_assembly_promise_.contractpromisebatch.html
_sdk_core_assembly_storage_.storage-1.html
globals.html
index.html
modules
_sdk_core_assembly_base58_.base58.html
_sdk_core_assembly_base58_.html
_sdk_core_assembly_base64_.base64.html
_sdk_core_assembly_base64_.html
_sdk_core_assembly_collections_avltree_.html
_sdk_core_assembly_collections_index_.collections.html
_sdk_core_assembly_collections_index_.html
_sdk_core_assembly_collections_persistentdeque_.html
_sdk_core_assembly_collections_persistentmap_.html
_sdk_core_assembly_collections_persistentset_.html
_sdk_core_assembly_collections_persistentunorderedmap_.html
_sdk_core_assembly_collections_persistentvector_.html
_sdk_core_assembly_collections_util_.html
_sdk_core_assembly_contract_.html
_sdk_core_assembly_env_env_.env.html
_sdk_core_assembly_env_env_.html
_sdk_core_assembly_env_index_.html
_sdk_core_assembly_env_runtime_api_.html
_sdk_core_assembly_index_.html
_sdk_core_assembly_logging_.html
_sdk_core_assembly_logging_.logging.html
_sdk_core_assembly_math_.html
_sdk_core_assembly_math_.math.html
_sdk_core_assembly_promise_.html
_sdk_core_assembly_storage_.html
_sdk_core_assembly_util_.html
_sdk_core_assembly_util_.util.html
package.json
near-sdk-simulator
__tests__
avl-tree-contract.spec.ts
cross.spec.ts
empty.spec.ts
exportAs.spec.ts
singleton-no-constructor.spec.ts
singleton.spec.ts
asconfig.js
asconfig.json
assembly
__tests__
avlTreeContract.ts
empty.ts
exportAs.ts
model.ts
sentences.ts
singleton-fail.ts
singleton-no-constructor.ts
singleton.ts
words.ts
as_types.d.ts
tsconfig.json
dist
bin.d.ts
bin.js
context.d.ts
context.js
index.d.ts
index.js
runtime.d.ts
runtime.js
types.d.ts
types.js
utils.d.ts
utils.js
jest.config.js
out
assembly
__tests__
empty.ts
exportAs.ts
model.ts
sentences.ts
singleton copy.ts
singleton-no-constructor.ts
singleton.ts
package.json
src
context.ts
index.ts
runtime.ts
types.ts
utils.ts
tsconfig.json
near-vm
getBinary.js
install.js
package.json
run.js
uninstall.js
nearley
LICENSE.txt
README.md
bin
nearley-railroad.js
nearley-test.js
nearley-unparse.js
nearleyc.js
lib
compile.js
generate.js
lint.js
nearley-language-bootstrapped.js
nearley.js
stream.js
unparse.js
package.json
once
README.md
once.js
package.json
optionator
CHANGELOG.md
README.md
lib
help.js
index.js
util.js
package.json
p-limit
index.d.ts
index.js
package.json
readme.md
p-locate
index.d.ts
index.js
package.json
readme.md
p-try
index.d.ts
index.js
package.json
readme.md
parent-module
index.js
package.json
readme.md
path-exists
index.d.ts
index.js
package.json
readme.md
path-is-absolute
index.js
package.json
readme.md
path-key
index.d.ts
index.js
package.json
readme.md
path-parse
README.md
index.js
package.json
prelude-ls
CHANGELOG.md
README.md
lib
Func.js
List.js
Num.js
Obj.js
Str.js
index.js
package.json
progress
CHANGELOG.md
Readme.md
index.js
lib
node-progress.js
package.json
punycode
LICENSE-MIT.txt
README.md
package.json
punycode.es6.js
punycode.js
railroad-diagrams
README.md
example.html
generator.html
package.json
railroad-diagrams.css
railroad-diagrams.js
railroad_diagrams.py
randexp
README.md
lib
randexp.js
package.json
rechoir
.travis.yml
README.md
index.js
lib
extension.js
normalize.js
register.js
package.json
regexpp
README.md
index.d.ts
index.js
package.json
require-directory
.travis.yml
index.js
package.json
require-from-string
index.js
package.json
readme.md
require-main-filename
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
resolve-from
index.js
package.json
readme.md
resolve
SECURITY.md
appveyor.yml
example
async.js
sync.js
index.js
lib
async.js
caller.js
core.js
core.json
is-core.js
node-modules-paths.js
normalize-options.js
sync.js
package.json
test
core.js
dotdot.js
dotdot
abc
index.js
index.js
faulty_basedir.js
filter.js
filter_sync.js
mock.js
mock_sync.js
module_dir.js
module_dir
xmodules
aaa
index.js
ymodules
aaa
index.js
zmodules
bbb
main.js
package.json
node-modules-paths.js
node_path.js
node_path
x
aaa
index.js
ccc
index.js
y
bbb
index.js
ccc
index.js
nonstring.js
pathfilter.js
pathfilter
deep_ref
main.js
precedence.js
precedence
aaa.js
aaa
index.js
main.js
bbb.js
bbb
main.js
resolver.js
resolver
baz
doom.js
package.json
quux.js
browser_field
a.js
b.js
package.json
cup.coffee
dot_main
index.js
package.json
dot_slash_main
index.js
package.json
foo.js
incorrect_main
index.js
package.json
invalid_main
package.json
mug.coffee
mug.js
multirepo
lerna.json
package.json
packages
package-a
index.js
package.json
package-b
index.js
package.json
nested_symlinks
mylib
async.js
package.json
sync.js
other_path
lib
other-lib.js
root.js
quux
foo
index.js
same_names
foo.js
foo
index.js
symlinked
_
node_modules
foo.js
package
bar.js
package.json
without_basedir
main.js
resolver_sync.js
shadowed_core.js
shadowed_core
node_modules
util
index.js
subdirs.js
symlinks.js
ret
README.md
lib
index.js
positions.js
sets.js
types.js
util.js
package.json
rimraf
CHANGELOG.md
README.md
bin.js
package.json
rimraf.js
safe-buffer
README.md
index.d.ts
index.js
package.json
semver
CHANGELOG.md
README.md
bin
semver.js
classes
comparator.js
index.js
range.js
semver.js
functions
clean.js
cmp.js
coerce.js
compare-build.js
compare-loose.js
compare.js
diff.js
eq.js
gt.js
gte.js
inc.js
lt.js
lte.js
major.js
minor.js
neq.js
parse.js
patch.js
prerelease.js
rcompare.js
rsort.js
satisfies.js
sort.js
valid.js
index.js
internal
constants.js
debug.js
identifiers.js
parse-options.js
re.js
package.json
preload.js
ranges
gtr.js
intersects.js
ltr.js
max-satisfying.js
min-satisfying.js
min-version.js
outside.js
simplify.js
subset.js
to-comparators.js
valid.js
set-blocking
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
shebang-command
index.js
package.json
readme.md
shebang-regex
index.d.ts
index.js
package.json
readme.md
shelljs
CHANGELOG.md
README.md
commands.js
global.js
make.js
package.json
plugin.js
shell.js
src
cat.js
cd.js
chmod.js
common.js
cp.js
dirs.js
echo.js
error.js
exec-child.js
exec.js
find.js
grep.js
head.js
ln.js
ls.js
mkdir.js
mv.js
popd.js
pushd.js
pwd.js
rm.js
sed.js
set.js
sort.js
tail.js
tempdir.js
test.js
to.js
toEnd.js
touch.js
uniq.js
which.js
slice-ansi
index.js
package.json
readme.md
sprintf-js
README.md
bower.json
demo
angular.html
dist
angular-sprintf.min.js
sprintf.min.js
gruntfile.js
package.json
src
angular-sprintf.js
sprintf.js
test
test.js
string-width
index.d.ts
index.js
package.json
readme.md
strip-ansi
index.d.ts
index.js
package.json
readme.md
strip-json-comments
index.d.ts
index.js
package.json
readme.md
supports-color
browser.js
index.js
package.json
readme.md
table
README.md
dist
src
alignString.d.ts
alignString.js
alignTableData.d.ts
alignTableData.js
calculateCellHeight.d.ts
calculateCellHeight.js
calculateCellWidths.d.ts
calculateCellWidths.js
calculateColumnWidths.d.ts
calculateColumnWidths.js
calculateRowHeights.d.ts
calculateRowHeights.js
createStream.d.ts
createStream.js
drawBorder.d.ts
drawBorder.js
drawContent.d.ts
drawContent.js
drawHeader.d.ts
drawHeader.js
drawRow.d.ts
drawRow.js
drawTable.d.ts
drawTable.js
generated
validators.d.ts
validators.js
getBorderCharacters.d.ts
getBorderCharacters.js
index.d.ts
index.js
makeStreamConfig.d.ts
makeStreamConfig.js
makeTableConfig.d.ts
makeTableConfig.js
mapDataUsingRowHeights.d.ts
mapDataUsingRowHeights.js
padTableData.d.ts
padTableData.js
stringifyTableData.d.ts
stringifyTableData.js
table.d.ts
table.js
truncateTableData.d.ts
truncateTableData.js
types
api.d.ts
api.js
internal.d.ts
internal.js
utils.d.ts
utils.js
validateConfig.d.ts
validateConfig.js
validateTableData.d.ts
validateTableData.js
wrapCell.d.ts
wrapCell.js
wrapString.d.ts
wrapString.js
wrapWord.d.ts
wrapWord.js
node_modules
ajv
.runkit_example.js
README.md
dist
2019.d.ts
2019.js
2020.d.ts
2020.js
ajv.d.ts
ajv.js
compile
codegen
code.d.ts
code.js
index.d.ts
index.js
scope.d.ts
scope.js
errors.d.ts
errors.js
index.d.ts
index.js
jtd
parse.d.ts
parse.js
serialize.d.ts
serialize.js
types.d.ts
types.js
names.d.ts
names.js
ref_error.d.ts
ref_error.js
resolve.d.ts
resolve.js
rules.d.ts
rules.js
util.d.ts
util.js
validate
applicability.d.ts
applicability.js
boolSchema.d.ts
boolSchema.js
dataType.d.ts
dataType.js
defaults.d.ts
defaults.js
index.d.ts
index.js
keyword.d.ts
keyword.js
subschema.d.ts
subschema.js
core.d.ts
core.js
jtd.d.ts
jtd.js
refs
data.json
json-schema-2019-09
index.d.ts
index.js
meta
applicator.json
content.json
core.json
format.json
meta-data.json
validation.json
schema.json
json-schema-2020-12
index.d.ts
index.js
meta
applicator.json
content.json
core.json
format-annotation.json
meta-data.json
unevaluated.json
validation.json
schema.json
json-schema-draft-06.json
json-schema-draft-07.json
json-schema-secure.json
jtd-schema.d.ts
jtd-schema.js
runtime
equal.d.ts
equal.js
parseJson.d.ts
parseJson.js
quote.d.ts
quote.js
re2.d.ts
re2.js
timestamp.d.ts
timestamp.js
ucs2length.d.ts
ucs2length.js
validation_error.d.ts
validation_error.js
standalone
index.d.ts
index.js
instance.d.ts
instance.js
types
index.d.ts
index.js
json-schema.d.ts
json-schema.js
jtd-schema.d.ts
jtd-schema.js
vocabularies
applicator
additionalItems.d.ts
additionalItems.js
additionalProperties.d.ts
additionalProperties.js
allOf.d.ts
allOf.js
anyOf.d.ts
anyOf.js
contains.d.ts
contains.js
dependencies.d.ts
dependencies.js
dependentSchemas.d.ts
dependentSchemas.js
if.d.ts
if.js
index.d.ts
index.js
items.d.ts
items.js
items2020.d.ts
items2020.js
not.d.ts
not.js
oneOf.d.ts
oneOf.js
patternProperties.d.ts
patternProperties.js
prefixItems.d.ts
prefixItems.js
properties.d.ts
properties.js
propertyNames.d.ts
propertyNames.js
thenElse.d.ts
thenElse.js
code.d.ts
code.js
core
id.d.ts
id.js
index.d.ts
index.js
ref.d.ts
ref.js
discriminator
index.d.ts
index.js
types.d.ts
types.js
draft2020.d.ts
draft2020.js
draft7.d.ts
draft7.js
dynamic
dynamicAnchor.d.ts
dynamicAnchor.js
dynamicRef.d.ts
dynamicRef.js
index.d.ts
index.js
recursiveAnchor.d.ts
recursiveAnchor.js
recursiveRef.d.ts
recursiveRef.js
errors.d.ts
errors.js
format
format.d.ts
format.js
index.d.ts
index.js
jtd
discriminator.d.ts
discriminator.js
elements.d.ts
elements.js
enum.d.ts
enum.js
error.d.ts
error.js
index.d.ts
index.js
metadata.d.ts
metadata.js
nullable.d.ts
nullable.js
optionalProperties.d.ts
optionalProperties.js
properties.d.ts
properties.js
ref.d.ts
ref.js
type.d.ts
type.js
union.d.ts
union.js
values.d.ts
values.js
metadata.d.ts
metadata.js
next.d.ts
next.js
unevaluated
index.d.ts
index.js
unevaluatedItems.d.ts
unevaluatedItems.js
unevaluatedProperties.d.ts
unevaluatedProperties.js
validation
const.d.ts
const.js
dependentRequired.d.ts
dependentRequired.js
enum.d.ts
enum.js
index.d.ts
index.js
limitContains.d.ts
limitContains.js
limitItems.d.ts
limitItems.js
limitLength.d.ts
limitLength.js
limitNumber.d.ts
limitNumber.js
limitProperties.d.ts
limitProperties.js
multipleOf.d.ts
multipleOf.js
pattern.d.ts
pattern.js
required.d.ts
required.js
uniqueItems.d.ts
uniqueItems.js
lib
2019.ts
2020.ts
ajv.ts
compile
codegen
code.ts
index.ts
scope.ts
errors.ts
index.ts
jtd
parse.ts
serialize.ts
types.ts
names.ts
ref_error.ts
resolve.ts
rules.ts
util.ts
validate
applicability.ts
boolSchema.ts
dataType.ts
defaults.ts
index.ts
keyword.ts
subschema.ts
core.ts
jtd.ts
refs
data.json
json-schema-2019-09
index.ts
meta
applicator.json
content.json
core.json
format.json
meta-data.json
validation.json
schema.json
json-schema-2020-12
index.ts
meta
applicator.json
content.json
core.json
format-annotation.json
meta-data.json
unevaluated.json
validation.json
schema.json
json-schema-draft-06.json
json-schema-draft-07.json
json-schema-secure.json
jtd-schema.ts
runtime
equal.ts
parseJson.ts
quote.ts
re2.ts
timestamp.ts
ucs2length.ts
validation_error.ts
standalone
index.ts
instance.ts
types
index.ts
json-schema.ts
jtd-schema.ts
vocabularies
applicator
additionalItems.ts
additionalProperties.ts
allOf.ts
anyOf.ts
contains.ts
dependencies.ts
dependentSchemas.ts
if.ts
index.ts
items.ts
items2020.ts
not.ts
oneOf.ts
patternProperties.ts
prefixItems.ts
properties.ts
propertyNames.ts
thenElse.ts
code.ts
core
id.ts
index.ts
ref.ts
discriminator
index.ts
types.ts
draft2020.ts
draft7.ts
dynamic
dynamicAnchor.ts
dynamicRef.ts
index.ts
recursiveAnchor.ts
recursiveRef.ts
errors.ts
format
format.ts
index.ts
jtd
discriminator.ts
elements.ts
enum.ts
error.ts
index.ts
metadata.ts
nullable.ts
optionalProperties.ts
properties.ts
ref.ts
type.ts
union.ts
values.ts
metadata.ts
next.ts
unevaluated
index.ts
unevaluatedItems.ts
unevaluatedProperties.ts
validation
const.ts
dependentRequired.ts
enum.ts
index.ts
limitContains.ts
limitItems.ts
limitLength.ts
limitNumber.ts
limitProperties.ts
multipleOf.ts
pattern.ts
required.ts
uniqueItems.ts
package.json
json-schema-traverse
.eslintrc.yml
.github
FUNDING.yml
workflows
build.yml
publish.yml
README.md
index.d.ts
index.js
package.json
spec
.eslintrc.yml
fixtures
schema.js
index.spec.js
package.json
tar
README.md
index.js
lib
create.js
extract.js
get-write-flag.js
header.js
high-level-opt.js
large-numbers.js
list.js
mkdir.js
mode-fix.js
normalize-windows-path.js
pack.js
parse.js
path-reservations.js
pax.js
read-entry.js
replace.js
strip-absolute-path.js
strip-trailing-slashes.js
types.js
unpack.js
update.js
warn-mixin.js
winchars.js
write-entry.js
package.json
text-table
.travis.yml
example
align.js
center.js
dotalign.js
doubledot.js
table.js
index.js
package.json
test
align.js
ansi-colors.js
center.js
dotalign.js
doubledot.js
table.js
tr46
LICENSE.md
README.md
index.js
lib
mappingTable.json
regexes.js
package.json
ts-mixer
CHANGELOG.md
README.md
dist
cjs
decorator.js
index.js
mixin-tracking.js
mixins.js
proxy.js
settings.js
types.js
util.js
esm
index.js
index.min.js
types
decorator.d.ts
index.d.ts
mixin-tracking.d.ts
mixins.d.ts
proxy.d.ts
settings.d.ts
types.d.ts
util.d.ts
package.json
type-check
README.md
lib
check.js
index.js
parse-type.js
package.json
type-fest
base.d.ts
index.d.ts
package.json
readme.md
source
async-return-type.d.ts
asyncify.d.ts
basic.d.ts
conditional-except.d.ts
conditional-keys.d.ts
conditional-pick.d.ts
entries.d.ts
entry.d.ts
except.d.ts
fixed-length-array.d.ts
iterable-element.d.ts
literal-union.d.ts
merge-exclusive.d.ts
merge.d.ts
mutable.d.ts
opaque.d.ts
package-json.d.ts
partial-deep.d.ts
promisable.d.ts
promise-value.d.ts
readonly-deep.d.ts
require-at-least-one.d.ts
require-exactly-one.d.ts
set-optional.d.ts
set-required.d.ts
set-return-type.d.ts
stringified.d.ts
tsconfig-json.d.ts
union-to-intersection.d.ts
utilities.d.ts
value-of.d.ts
ts41
camel-case.d.ts
delimiter-case.d.ts
index.d.ts
kebab-case.d.ts
pascal-case.d.ts
snake-case.d.ts
universal-url
README.md
browser.js
index.js
package.json
uri-js
README.md
dist
es5
uri.all.d.ts
uri.all.js
uri.all.min.d.ts
uri.all.min.js
esnext
index.d.ts
index.js
regexps-iri.d.ts
regexps-iri.js
regexps-uri.d.ts
regexps-uri.js
schemes
http.d.ts
http.js
https.d.ts
https.js
mailto.d.ts
mailto.js
urn-uuid.d.ts
urn-uuid.js
urn.d.ts
urn.js
ws.d.ts
ws.js
wss.d.ts
wss.js
uri.d.ts
uri.js
util.d.ts
util.js
package.json
v8-compile-cache
CHANGELOG.md
README.md
package.json
v8-compile-cache.js
visitor-as
.github
workflows
test.yml
README.md
as
index.d.ts
index.js
asconfig.json
dist
astBuilder.d.ts
astBuilder.js
base.d.ts
base.js
baseTransform.d.ts
baseTransform.js
decorator.d.ts
decorator.js
examples
capitalize.d.ts
capitalize.js
exportAs.d.ts
exportAs.js
functionCallTransform.d.ts
functionCallTransform.js
includeBytesTransform.d.ts
includeBytesTransform.js
list.d.ts
list.js
index.d.ts
index.js
path.d.ts
path.js
simpleParser.d.ts
simpleParser.js
transformer.d.ts
transformer.js
utils.d.ts
utils.js
visitor.d.ts
visitor.js
package.json
tsconfig.json
webidl-conversions
LICENSE.md
README.md
lib
index.js
package.json
whatwg-url
LICENSE.txt
README.md
lib
URL-impl.js
URL.js
URLSearchParams-impl.js
URLSearchParams.js
infra.js
public-api.js
url-state-machine.js
urlencoded.js
utils.js
package.json
which-module
CHANGELOG.md
README.md
index.js
package.json
which
CHANGELOG.md
README.md
package.json
which.js
word-wrap
README.md
index.d.ts
index.js
package.json
wrap-ansi
index.js
package.json
readme.md
wrappy
README.md
package.json
wrappy.js
y18n
CHANGELOG.md
README.md
build
lib
cjs.js
index.js
platform-shims
node.js
package.json
yallist
README.md
iterator.js
package.json
yallist.js
yargs-parser
CHANGELOG.md
LICENSE.txt
README.md
browser.js
build
lib
index.js
string-utils.js
tokenize-arg-string.js
yargs-parser-types.js
yargs-parser.js
package.json
yargs
CHANGELOG.md
README.md
build
lib
argsert.js
command.js
completion-templates.js
completion.js
middleware.js
parse-command.js
typings
common-types.js
yargs-parser-types.js
usage.js
utils
apply-extends.js
is-promise.js
levenshtein.js
obj-filter.js
process-argv.js
set-blocking.js
which-module.js
validation.js
yargs-factory.js
yerror.js
helpers
index.js
package.json
locales
be.json
de.json
en.json
es.json
fi.json
fr.json
hi.json
hu.json
id.json
it.json
ja.json
ko.json
nb.json
nl.json
nn.json
pirate.json
pl.json
pt.json
pt_BR.json
ru.json
th.json
tr.json
zh_CN.json
zh_TW.json
package.json
package-lock.json
package.json
package.json
src
App.js
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
components
Home.js
NewPoll.js
PollingStation.js
config.js
global.css
index.html
index.js
jest.init.js
main.test.js
utils.js
wallet
login
index.html
|
features not yet implemented
issues with the tests
differences between PCRE and JS regex
|
|
|
| Railroad-diagram Generator
==========================
This is a small js library for generating railroad diagrams
(like what [JSON.org](http://json.org) uses)
using SVG.
Railroad diagrams are a way of visually representing a grammar
in a form that is more readable than using regular expressions or BNF.
I think (though I haven't given it a lot of thought yet) that if it's easy to write a context-free grammar for the language,
the corresponding railroad diagram will be easy as well.
There are several railroad-diagram generators out there, but none of them had the visual appeal I wanted.
[Here's an example of how they look!](http://www.xanthir.com/etc/railroad-diagrams/example.html)
And [here's an online generator for you to play with and get SVG code from!](http://www.xanthir.com/etc/railroad-diagrams/generator.html)
The library now exists in a Python port as well! See the information further down.
Details
-------
To use the library, just include the js and css files, and then call the Diagram() function.
Its arguments are the components of the diagram (Diagram is a special form of Sequence).
An alternative to Diagram() is ComplexDiagram() which is used to describe a complex type diagram.
Components are either leaves or containers.
The leaves:
* Terminal(text) or a bare string - represents literal text
* NonTerminal(text) - represents an instruction or another production
* Comment(text) - a comment
* Skip() - an empty line
The containers:
* Sequence(children) - like simple concatenation in a regex
* Choice(index, children) - like | in a regex. The index argument specifies which child is the "normal" choice and should go in the middle
* Optional(child, skip) - like ? in a regex. A shorthand for `Choice(1, [Skip(), child])`. If the optional `skip` parameter has the value `"skip"`, it instead puts the Skip() in the straight-line path, for when the "normal" behavior is to omit the item.
* OneOrMore(child, repeat) - like + in a regex. The 'repeat' argument is optional, and specifies something that must go between the repetitions.
* ZeroOrMore(child, repeat, skip) - like * in a regex. A shorthand for `Optional(OneOrMore(child, repeat))`. The optional `skip` parameter is identical to Optional().
For convenience, each component can be called with or without `new`.
If called without `new`,
the container components become n-ary;
that is, you can say either `new Sequence([A, B])` or just `Sequence(A,B)`.
After constructing a Diagram, call `.format(...padding)` on it, specifying 0-4 padding values (just like CSS) for some additional "breathing space" around the diagram (the paddings default to 20px).
The result can either be `.toString()`'d for the markup, or `.toSVG()`'d for an `<svg>` element, which can then be immediately inserted to the document. As a convenience, Diagram also has an `.addTo(element)` method, which immediately converts it to SVG and appends it to the referenced element with default paddings. `element` defaults to `document.body`.
Options
-------
There are a few options you can tweak, at the bottom of the file. Just tweak either until the diagram looks like what you want.
You can also change the CSS file - feel free to tweak to your heart's content.
Note, though, that if you change the text sizes in the CSS,
you'll have to go adjust the metrics for the leaf nodes as well.
* VERTICAL_SEPARATION - sets the minimum amount of vertical separation between two items. Note that the stroke width isn't counted when computing the separation; this shouldn't be relevant unless you have a very small separation or very large stroke width.
* ARC_RADIUS - the radius of the arcs used in the branching containers like Choice. This has a relatively large effect on the size of non-trivial diagrams. Both tight and loose values look good, depending on what you're going for.
* DIAGRAM_CLASS - the class set on the root `<svg>` element of each diagram, for use in the CSS stylesheet.
* STROKE_ODD_PIXEL_LENGTH - the default stylesheet uses odd pixel lengths for 'stroke'. Due to rasterization artifacts, they look best when the item has been translated half a pixel in both directions. If you change the styling to use a stroke with even pixel lengths, you'll want to set this variable to `false`.
* INTERNAL_ALIGNMENT - when some branches of a container are narrower than others, this determines how they're aligned in the extra space. Defaults to "center", but can be set to "left" or "right".
Caveats
-------
At this early stage, the generator is feature-complete and works as intended, but still has several TODOs:
* The font-sizes are hard-coded right now, and the font handling in general is very dumb - I'm just guessing at some metrics that are probably "good enough" rather than measuring things properly.
Python Port
-----------
In addition to the canonical JS version, the library now exists as a Python library as well.
Using it is basically identical. The config variables are globals in the file, and so may be adjusted either manually or via tweaking from inside your program.
The main difference from the JS port is how you extract the string from the Diagram. You'll find a `writeSvg(writerFunc)` method on `Diagram`, which takes a callback of one argument and passes it the string form of the diagram. For example, it can be used like `Diagram(...).writeSvg(sys.stdout.write)` to write to stdout. **Note**: the callback will be called multiple times as it builds up the string, not just once with the whole thing. If you need it all at once, consider something like a `StringIO` as an easy way to collect it into a single string.
License
-------
This document and all associated files in the github project are licensed under [CC0](http://creativecommons.org/publicdomain/zero/1.0/) .
This means you can reuse, remix, or otherwise appropriate this project for your own use **without restriction**.
(The actual legal meaning can be found at the above link.)
Don't ask me for permission to use any part of this project, **just use it**.
I would appreciate attribution, but that is not required by the license.
[](https://travis-ci.org/#!/adaltas/node-csv-stringify) [](https://www.npmjs.com/package/csv-stringify) [](https://www.npmjs.com/package/csv-stringify)
This package is a stringifier converting records into a CSV text and
implementing the Node.js [`stream.Transform`
API](https://nodejs.org/api/stream.html). It also provides the easier
synchronous and callback-based APIs for conveniency. It is both extremely easy
to use and powerful. It was first released in 2010 and is tested against big
data sets by a large community.
## Documentation
* [Project homepage](http://csv.js.org/stringify/)
* [API](http://csv.js.org/stringify/api/)
* [Options](http://csv.js.org/stringify/options/)
* [Examples](http://csv.js.org/stringify/examples/)
## Main features
* Follow the Node.js streaming API
* Simplicity with the optional callback API
* Support for custom formatters, delimiters, quotes, escape characters and header
* Support big datasets
* Complete test coverage and samples for inspiration
* Only 1 external dependency
* to be used conjointly with `csv-generate`, `csv-parse` and `stream-transform`
* MIT License
## Usage
The module is built on the Node.js Stream API. For the sake of simplicity, a
simple callback API is also provided. To give you a quick look, here's an
example of the callback API:
```javascript
const stringify = require('csv-stringify')
const assert = require('assert')
// import stringify from 'csv-stringify'
// import assert from 'assert/strict'
const input = [ [ '1', '2', '3', '4' ], [ 'a', 'b', 'c', 'd' ] ]
stringify(input, function(err, output) {
const expected = '1,2,3,4\na,b,c,d\n'
assert.strictEqual(output, expected, `output.should.eql ${expected}`)
console.log("Passed.", output)
})
```
## Development
Tests are executed with mocha. To install it, run `npm install` followed by `npm
test`. It will install mocha and its dependencies in your project "node_modules"
directory and run the test suite. The tests run against the CoffeeScript source
files.
To generate the JavaScript files, run `npm run build`.
The test suite is run online with
[Travis](https://travis-ci.org/#!/adaltas/node-csv-stringify). See the [Travis
definition
file](https://github.com/adaltas/node-csv-stringify/blob/master/.travis.yml) to
view the tested Node.js version.
## Contributors
* David Worms: <https://github.com/wdavidw>
[csv_home]: https://github.com/adaltas/node-csv
[stream_transform]: http://nodejs.org/api/stream.html#stream_class_stream_transform
[examples]: http://csv.js.org/stringify/examples/
[csv]: https://github.com/adaltas/node-csv
### Estraverse [](http://travis-ci.org/estools/estraverse)
Estraverse ([estraverse](http://github.com/estools/estraverse)) is
[ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
traversal functions from [esmangle project](http://github.com/estools/esmangle).
### Documentation
You can find usage docs at [wiki page](https://github.com/estools/estraverse/wiki/Usage).
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
estraverse.traverse(ast, {
enter: function (node, parent) {
if (node.type == 'FunctionExpression' || node.type == 'FunctionDeclaration')
return estraverse.VisitorOption.Skip;
},
leave: function (node, parent) {
if (node.type == 'VariableDeclarator')
console.log(node.id.name);
}
});
```
We can use `this.skip`, `this.remove` and `this.break` functions instead of using Skip, Remove and Break.
```javascript
estraverse.traverse(ast, {
enter: function (node) {
this.break();
}
});
```
And estraverse provides `estraverse.replace` function. When returning node from `enter`/`leave`, current node is replaced with it.
```javascript
result = estraverse.replace(tree, {
enter: function (node) {
// Replace it with replaced.
if (node.type === 'Literal')
return replaced;
}
});
```
By passing `visitor.keys` mapping, we can extend estraverse traversing functionality.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Extending the existing traversing rules.
keys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
});
```
By passing `visitor.fallback` option, we can control the behavior when encountering unknown nodes.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Iterating the child **nodes** of unknown nodes.
fallback: 'iteration'
});
```
When `visitor.fallback` is a function, we can determine which keys to visit on each node.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Skip the `argument` property of each node
fallback: function(node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument';
});
}
});
```
### License
Copyright (C) 2012-2016 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# json-schema-traverse
Traverse JSON Schema passing each schema object to callback
[](https://github.com/epoberezkin/json-schema-traverse/actions?query=workflow%3Abuild)
[](https://www.npmjs.com/package/json-schema-traverse)
[](https://coveralls.io/github/epoberezkin/json-schema-traverse?branch=master)
## Install
```
npm install json-schema-traverse
```
## Usage
```javascript
const traverse = require('json-schema-traverse');
const schema = {
properties: {
foo: {type: 'string'},
bar: {type: 'integer'}
}
};
traverse(schema, {cb});
// cb is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
// Or:
traverse(schema, {cb: {pre, post}});
// pre is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
//
// post is called 3 times with:
// 1. {type: 'string'}
// 2. {type: 'integer'}
// 3. root schema
```
Callback function `cb` is called for each schema object (not including draft-06 boolean schemas), including the root schema, in pre-order traversal. Schema references ($ref) are not resolved, they are passed as is. Alternatively, you can pass a `{pre, post}` object as `cb`, and then `pre` will be called before traversing child elements, and `post` will be called after all child elements have been traversed.
Callback is passed these parameters:
- _schema_: the current schema object
- _JSON pointer_: from the root schema to the current schema object
- _root schema_: the schema passed to `traverse` object
- _parent JSON pointer_: from the root schema to the parent schema object (see below)
- _parent keyword_: the keyword inside which this schema appears (e.g. `properties`, `anyOf`, etc.)
- _parent schema_: not necessarily parent object/array; in the example above the parent schema for `{type: 'string'}` is the root schema
- _index/property_: index or property name in the array/object containing multiple schemas; in the example above for `{type: 'string'}` the property name is `'foo'`
## Traverse objects in all unknown keywords
```javascript
const traverse = require('json-schema-traverse');
const schema = {
mySchema: {
minimum: 1,
maximum: 2
}
};
traverse(schema, {allKeys: true, cb});
// cb is called 2 times with:
// 1. root schema
// 2. mySchema
```
Without option `allKeys: true` callback will be called only with root schema.
## Enterprise support
json-schema-traverse package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-json-schema-traverse?utm_source=npm-json-schema-traverse&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
## License
[MIT](https://github.com/epoberezkin/json-schema-traverse/blob/master/LICENSE)
# fs.realpath
A backwards-compatible fs.realpath for Node v6 and above
In Node v6, the JavaScript implementation of fs.realpath was replaced
with a faster (but less resilient) native implementation. That raises
new and platform-specific errors and cannot handle long or excessively
symlink-looping paths.
This module handles those cases by detecting the new errors and
falling back to the JavaScript implementation. On versions of Node
prior to v6, it has no effect.
## USAGE
```js
var rp = require('fs.realpath')
// async version
rp.realpath(someLongAndLoopingPath, function (er, real) {
// the ELOOP was handled, but it was a bit slower
})
// sync version
var real = rp.realpathSync(someLongAndLoopingPath)
// monkeypatch at your own risk!
// This replaces the fs.realpath/fs.realpathSync builtins
rp.monkeypatch()
// un-do the monkeypatching
rp.unmonkeypatch()
```
ESQuery is a library for querying the AST output by Esprima for patterns of syntax using a CSS style selector system. Check out the demo:
[demo](https://estools.github.io/esquery/)
The following selectors are supported:
* AST node type: `ForStatement`
* [wildcard](http://dev.w3.org/csswg/selectors4/#universal-selector): `*`
* [attribute existence](http://dev.w3.org/csswg/selectors4/#attribute-selectors): `[attr]`
* [attribute value](http://dev.w3.org/csswg/selectors4/#attribute-selectors): `[attr="foo"]` or `[attr=123]`
* attribute regex: `[attr=/foo.*/]` or (with flags) `[attr=/foo.*/is]`
* attribute conditions: `[attr!="foo"]`, `[attr>2]`, `[attr<3]`, `[attr>=2]`, or `[attr<=3]`
* nested attribute: `[attr.level2="foo"]`
* field: `FunctionDeclaration > Identifier.id`
* [First](http://dev.w3.org/csswg/selectors4/#the-first-child-pseudo) or [last](http://dev.w3.org/csswg/selectors4/#the-last-child-pseudo) child: `:first-child` or `:last-child`
* [nth-child](http://dev.w3.org/csswg/selectors4/#the-nth-child-pseudo) (no ax+b support): `:nth-child(2)`
* [nth-last-child](http://dev.w3.org/csswg/selectors4/#the-nth-last-child-pseudo) (no ax+b support): `:nth-last-child(1)`
* [descendant](http://dev.w3.org/csswg/selectors4/#descendant-combinators): `ancestor descendant`
* [child](http://dev.w3.org/csswg/selectors4/#child-combinators): `parent > child`
* [following sibling](http://dev.w3.org/csswg/selectors4/#general-sibling-combinators): `node ~ sibling`
* [adjacent sibling](http://dev.w3.org/csswg/selectors4/#adjacent-sibling-combinators): `node + adjacent`
* [negation](http://dev.w3.org/csswg/selectors4/#negation-pseudo): `:not(ForStatement)`
* [has](https://drafts.csswg.org/selectors-4/#has-pseudo): `:has(ForStatement)`
* [matches-any](http://dev.w3.org/csswg/selectors4/#matches): `:matches([attr] > :first-child, :last-child)`
* [subject indicator](http://dev.w3.org/csswg/selectors4/#subject): `!IfStatement > [name="foo"]`
* class of AST node: `:statement`, `:expression`, `:declaration`, `:function`, or `:pattern`
[](https://travis-ci.org/estools/esquery)
# AssemblyScript Loader
A convenient loader for [AssemblyScript](https://assemblyscript.org) modules. Demangles module exports to a friendly object structure compatible with TypeScript definitions and provides useful utility to read/write data from/to memory.
[Documentation](https://assemblyscript.org/loader.html)
# color-convert
[](https://travis-ci.org/Qix-/color-convert)
Color-convert is a color conversion library for JavaScript and node.
It converts all ways between `rgb`, `hsl`, `hsv`, `hwb`, `cmyk`, `ansi`, `ansi16`, `hex` strings, and CSS `keyword`s (will round to closest):
```js
var convert = require('color-convert');
convert.rgb.hsl(140, 200, 100); // [96, 48, 59]
convert.keyword.rgb('blue'); // [0, 0, 255]
var rgbChannels = convert.rgb.channels; // 3
var cmykChannels = convert.cmyk.channels; // 4
var ansiChannels = convert.ansi16.channels; // 1
```
# Install
```console
$ npm install color-convert
```
# API
Simply get the property of the _from_ and _to_ conversion that you're looking for.
All functions have a rounded and unrounded variant. By default, return values are rounded. To get the unrounded (raw) results, simply tack on `.raw` to the function.
All 'from' functions have a hidden property called `.channels` that indicates the number of channels the function expects (not including alpha).
```js
var convert = require('color-convert');
// Hex to LAB
convert.hex.lab('DEADBF'); // [ 76, 21, -2 ]
convert.hex.lab.raw('DEADBF'); // [ 75.56213190997677, 20.653827952644754, -2.290532499330533 ]
// RGB to CMYK
convert.rgb.cmyk(167, 255, 4); // [ 35, 0, 98, 0 ]
convert.rgb.cmyk.raw(167, 255, 4); // [ 34.509803921568626, 0, 98.43137254901961, 0 ]
```
### Arrays
All functions that accept multiple arguments also support passing an array.
Note that this does **not** apply to functions that convert from a color that only requires one value (e.g. `keyword`, `ansi256`, `hex`, etc.)
```js
var convert = require('color-convert');
convert.rgb.hex(123, 45, 67); // '7B2D43'
convert.rgb.hex([123, 45, 67]); // '7B2D43'
```
## Routing
Conversions that don't have an _explicitly_ defined conversion (in [conversions.js](conversions.js)), but can be converted by means of sub-conversions (e.g. XYZ -> **RGB** -> CMYK), are automatically routed together. This allows just about any color model supported by `color-convert` to be converted to any other model, so long as a sub-conversion path exists. This is also true for conversions requiring more than one step in between (e.g. LCH -> **LAB** -> **XYZ** -> **RGB** -> Hex).
Keep in mind that extensive conversions _may_ result in a loss of precision, and exist only to be complete. For a list of "direct" (single-step) conversions, see [conversions.js](conversions.js).
# Contribute
If there is a new model you would like to support, or want to add a direct conversion between two existing models, please send us a pull request.
# License
Copyright © 2011-2016, Heather Arthur and Josh Junon. Licensed under the [MIT License](LICENSE).
Standard library
================
Standard library components for use with `tsc` (portable) and `asc` (assembly).
Base configurations (.json) and definition files (.d.ts) are relevant to `tsc` only and not used by `asc`.
long.js
=======
A Long class for representing a 64 bit two's-complement integer value derived from the [Closure Library](https://github.com/google/closure-library)
for stand-alone use and extended with unsigned support.
[](https://travis-ci.org/dcodeIO/long.js)
Background
----------
As of [ECMA-262 5th Edition](http://ecma262-5.com/ELS5_HTML.htm#Section_8.5), "all the positive and negative integers
whose magnitude is no greater than 2<sup>53</sup> are representable in the Number type", which is "representing the
doubleprecision 64-bit format IEEE 754 values as specified in the IEEE Standard for Binary Floating-Point Arithmetic".
The [maximum safe integer](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Number/MAX_SAFE_INTEGER)
in JavaScript is 2<sup>53</sup>-1.
Example: 2<sup>64</sup>-1 is 1844674407370955**1615** but in JavaScript it evaluates to 1844674407370955**2000**.
Furthermore, bitwise operators in JavaScript "deal only with integers in the range −2<sup>31</sup> through
2<sup>31</sup>−1, inclusive, or in the range 0 through 2<sup>32</sup>−1, inclusive. These operators accept any value of
the Number type but first convert each such value to one of 2<sup>32</sup> integer values."
In some use cases, however, it is required to be able to reliably work with and perform bitwise operations on the full
64 bits. This is where long.js comes into play.
Usage
-----
The class is compatible with CommonJS and AMD loaders and is exposed globally as `Long` if neither is available.
```javascript
var Long = require("long");
var longVal = new Long(0xFFFFFFFF, 0x7FFFFFFF);
console.log(longVal.toString());
...
```
API
---
### Constructor
* new **Long**(low: `number`, high: `number`, unsigned?: `boolean`)<br />
Constructs a 64 bit two's-complement integer, given its low and high 32 bit values as *signed* integers. See the from* functions below for more convenient ways of constructing Longs.
### Fields
* Long#**low**: `number`<br />
The low 32 bits as a signed value.
* Long#**high**: `number`<br />
The high 32 bits as a signed value.
* Long#**unsigned**: `boolean`<br />
Whether unsigned or not.
### Constants
* Long.**ZERO**: `Long`<br />
Signed zero.
* Long.**ONE**: `Long`<br />
Signed one.
* Long.**NEG_ONE**: `Long`<br />
Signed negative one.
* Long.**UZERO**: `Long`<br />
Unsigned zero.
* Long.**UONE**: `Long`<br />
Unsigned one.
* Long.**MAX_VALUE**: `Long`<br />
Maximum signed value.
* Long.**MIN_VALUE**: `Long`<br />
Minimum signed value.
* Long.**MAX_UNSIGNED_VALUE**: `Long`<br />
Maximum unsigned value.
### Utility
* Long.**isLong**(obj: `*`): `boolean`<br />
Tests if the specified object is a Long.
* Long.**fromBits**(lowBits: `number`, highBits: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the 64 bit integer that comes by concatenating the given low and high bits. Each is assumed to use 32 bits.
* Long.**fromBytes**(bytes: `number[]`, unsigned?: `boolean`, le?: `boolean`): `Long`<br />
Creates a Long from its byte representation.
* Long.**fromBytesLE**(bytes: `number[]`, unsigned?: `boolean`): `Long`<br />
Creates a Long from its little endian byte representation.
* Long.**fromBytesBE**(bytes: `number[]`, unsigned?: `boolean`): `Long`<br />
Creates a Long from its big endian byte representation.
* Long.**fromInt**(value: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the given 32 bit integer value.
* Long.**fromNumber**(value: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the given value, provided that it is a finite number. Otherwise, zero is returned.
* Long.**fromString**(str: `string`, unsigned?: `boolean`, radix?: `number`)<br />
Long.**fromString**(str: `string`, radix: `number`)<br />
Returns a Long representation of the given string, written using the specified radix.
* Long.**fromValue**(val: `*`, unsigned?: `boolean`): `Long`<br />
Converts the specified value to a Long using the appropriate from* function for its type.
### Methods
* Long#**add**(addend: `Long | number | string`): `Long`<br />
Returns the sum of this and the specified Long.
* Long#**and**(other: `Long | number | string`): `Long`<br />
Returns the bitwise AND of this Long and the specified.
* Long#**compare**/**comp**(other: `Long | number | string`): `number`<br />
Compares this Long's value with the specified's. Returns `0` if they are the same, `1` if the this is greater and `-1` if the given one is greater.
* Long#**divide**/**div**(divisor: `Long | number | string`): `Long`<br />
Returns this Long divided by the specified.
* Long#**equals**/**eq**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value equals the specified's.
* Long#**getHighBits**(): `number`<br />
Gets the high 32 bits as a signed integer.
* Long#**getHighBitsUnsigned**(): `number`<br />
Gets the high 32 bits as an unsigned integer.
* Long#**getLowBits**(): `number`<br />
Gets the low 32 bits as a signed integer.
* Long#**getLowBitsUnsigned**(): `number`<br />
Gets the low 32 bits as an unsigned integer.
* Long#**getNumBitsAbs**(): `number`<br />
Gets the number of bits needed to represent the absolute value of this Long.
* Long#**greaterThan**/**gt**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is greater than the specified's.
* Long#**greaterThanOrEqual**/**gte**/**ge**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is greater than or equal the specified's.
* Long#**isEven**(): `boolean`<br />
Tests if this Long's value is even.
* Long#**isNegative**(): `boolean`<br />
Tests if this Long's value is negative.
* Long#**isOdd**(): `boolean`<br />
Tests if this Long's value is odd.
* Long#**isPositive**(): `boolean`<br />
Tests if this Long's value is positive.
* Long#**isZero**/**eqz**(): `boolean`<br />
Tests if this Long's value equals zero.
* Long#**lessThan**/**lt**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is less than the specified's.
* Long#**lessThanOrEqual**/**lte**/**le**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is less than or equal the specified's.
* Long#**modulo**/**mod**/**rem**(divisor: `Long | number | string`): `Long`<br />
Returns this Long modulo the specified.
* Long#**multiply**/**mul**(multiplier: `Long | number | string`): `Long`<br />
Returns the product of this and the specified Long.
* Long#**negate**/**neg**(): `Long`<br />
Negates this Long's value.
* Long#**not**(): `Long`<br />
Returns the bitwise NOT of this Long.
* Long#**notEquals**/**neq**/**ne**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value differs from the specified's.
* Long#**or**(other: `Long | number | string`): `Long`<br />
Returns the bitwise OR of this Long and the specified.
* Long#**shiftLeft**/**shl**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits shifted to the left by the given amount.
* Long#**shiftRight**/**shr**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits arithmetically shifted to the right by the given amount.
* Long#**shiftRightUnsigned**/**shru**/**shr_u**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits logically shifted to the right by the given amount.
* Long#**subtract**/**sub**(subtrahend: `Long | number | string`): `Long`<br />
Returns the difference of this and the specified Long.
* Long#**toBytes**(le?: `boolean`): `number[]`<br />
Converts this Long to its byte representation.
* Long#**toBytesLE**(): `number[]`<br />
Converts this Long to its little endian byte representation.
* Long#**toBytesBE**(): `number[]`<br />
Converts this Long to its big endian byte representation.
* Long#**toInt**(): `number`<br />
Converts the Long to a 32 bit integer, assuming it is a 32 bit integer.
* Long#**toNumber**(): `number`<br />
Converts the Long to a the nearest floating-point representation of this value (double, 53 bit mantissa).
* Long#**toSigned**(): `Long`<br />
Converts this Long to signed.
* Long#**toString**(radix?: `number`): `string`<br />
Converts the Long to a string written in the specified radix.
* Long#**toUnsigned**(): `Long`<br />
Converts this Long to unsigned.
* Long#**xor**(other: `Long | number | string`): `Long`<br />
Returns the bitwise XOR of this Long and the given one.
Building
--------
To build an UMD bundle to `dist/long.js`, run:
```
$> npm install
$> npm run build
```
Running the [tests](./tests):
```
$> npm test
```
iMurmurHash.js
==============
An incremental implementation of the MurmurHash3 (32-bit) hashing algorithm for JavaScript based on [Gary Court's implementation](https://github.com/garycourt/murmurhash-js) with [kazuyukitanimura's modifications](https://github.com/kazuyukitanimura/murmurhash-js).
This version works significantly faster than the non-incremental version if you need to hash many small strings into a single hash, since string concatenation (to build the single string to pass the non-incremental version) is fairly costly. In one case tested, using the incremental version was about 50% faster than concatenating 5-10 strings and then hashing.
Installation
------------
To use iMurmurHash in the browser, [download the latest version](https://raw.github.com/jensyt/imurmurhash-js/master/imurmurhash.min.js) and include it as a script on your site.
```html
<script type="text/javascript" src="/scripts/imurmurhash.min.js"></script>
<script>
// Your code here, access iMurmurHash using the global object MurmurHash3
</script>
```
---
To use iMurmurHash in Node.js, install the module using NPM:
```bash
npm install imurmurhash
```
Then simply include it in your scripts:
```javascript
MurmurHash3 = require('imurmurhash');
```
Quick Example
-------------
```javascript
// Create the initial hash
var hashState = MurmurHash3('string');
// Incrementally add text
hashState.hash('more strings');
hashState.hash('even more strings');
// All calls can be chained if desired
hashState.hash('and').hash('some').hash('more');
// Get a result
hashState.result();
// returns 0xe4ccfe6b
```
Functions
---------
### MurmurHash3 ([string], [seed])
Get a hash state object, optionally initialized with the given _string_ and _seed_. _Seed_ must be a positive integer if provided. Calling this function without the `new` keyword will return a cached state object that has been reset. This is safe to use as long as the object is only used from a single thread and no other hashes are created while operating on this one. If this constraint cannot be met, you can use `new` to create a new state object. For example:
```javascript
// Use the cached object, calling the function again will return the same
// object (but reset, so the current state would be lost)
hashState = MurmurHash3();
...
// Create a new object that can be safely used however you wish. Calling the
// function again will simply return a new state object, and no state loss
// will occur, at the cost of creating more objects.
hashState = new MurmurHash3();
```
Both methods can be mixed however you like if you have different use cases.
---
### MurmurHash3.prototype.hash (string)
Incrementally add _string_ to the hash. This can be called as many times as you want for the hash state object, including after a call to `result()`. Returns `this` so calls can be chained.
---
### MurmurHash3.prototype.result ()
Get the result of the hash as a 32-bit positive integer. This performs the tail and finalizer portions of the algorithm, but does not store the result in the state object. This means that it is perfectly safe to get results and then continue adding strings via `hash`.
```javascript
// Do the whole string at once
MurmurHash3('this is a test string').result();
// 0x70529328
// Do part of the string, get a result, then the other part
var m = MurmurHash3('this is a');
m.result();
// 0xbfc4f834
m.hash(' test string').result();
// 0x70529328 (same as above)
```
---
### MurmurHash3.prototype.reset ([seed])
Reset the state object for reuse, optionally using the given _seed_ (defaults to 0 like the constructor). Returns `this` so calls can be chained.
---
License (MIT)
-------------
Copyright (c) 2013 Gary Court, Jens Taylor
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# levn [](https://travis-ci.org/gkz/levn) <a name="levn" />
__Light ECMAScript (JavaScript) Value Notation__
Levn is a library which allows you to parse a string into a JavaScript value based on an expected type. It is meant for short amounts of human entered data (eg. config files, command line arguments).
Levn aims to concisely describe JavaScript values in text, and allow for the extraction and validation of those values. Levn uses [type-check](https://github.com/gkz/type-check) for its type format, and to validate the results. MIT license. Version 0.4.1.
__How is this different than JSON?__ levn is meant to be written by humans only, is (due to the previous point) much more concise, can be validated against supplied types, has regex and date literals, and can easily be extended with custom types. On the other hand, it is probably slower and thus less efficient at transporting large amounts of data, which is fine since this is not its purpose.
npm install levn
For updates on levn, [follow me on twitter](https://twitter.com/gkzahariev).
## Quick Examples
```js
var parse = require('levn').parse;
parse('Number', '2'); // 2
parse('String', '2'); // '2'
parse('String', 'levn'); // 'levn'
parse('String', 'a b'); // 'a b'
parse('Boolean', 'true'); // true
parse('Date', '#2011-11-11#'); // (Date object)
parse('Date', '2011-11-11'); // (Date object)
parse('RegExp', '/[a-z]/gi'); // /[a-z]/gi
parse('RegExp', 're'); // /re/
parse('Int', '2'); // 2
parse('Number | String', 'str'); // 'str'
parse('Number | String', '2'); // 2
parse('[Number]', '[1,2,3]'); // [1,2,3]
parse('(String, Boolean)', '(hi, false)'); // ['hi', false]
parse('{a: String, b: Number}', '{a: str, b: 2}'); // {a: 'str', b: 2}
// at the top level, you can ommit surrounding delimiters
parse('[Number]', '1,2,3'); // [1,2,3]
parse('(String, Boolean)', 'hi, false'); // ['hi', false]
parse('{a: String, b: Number}', 'a: str, b: 2'); // {a: 'str', b: 2}
// wildcard - auto choose type
parse('*', '[hi,(null,[42]),{k: true}]'); // ['hi', [null, [42]], {k: true}]
```
## Usage
`require('levn');` returns an object that exposes three properties. `VERSION` is the current version of the library as a string. `parse` and `parsedTypeParse` are functions.
```js
// parse(type, input, options);
parse('[Number]', '1,2,3'); // [1, 2, 3]
// parsedTypeParse(parsedType, input, options);
var parsedType = require('type-check').parseType('[Number]');
parsedTypeParse(parsedType, '1,2,3'); // [1, 2, 3]
```
### parse(type, input, options)
`parse` casts the string `input` into a JavaScript value according to the specified `type` in the [type format](https://github.com/gkz/type-check#type-format) (and taking account the optional `options`) and returns the resulting JavaScript value.
##### arguments
* type - `String` - the type written in the [type format](https://github.com/gkz/type-check#type-format) which to check against
* input - `String` - the value written in the [levn format](#levn-format)
* options - `Maybe Object` - an optional parameter specifying additional [options](#options)
##### returns
`*` - the resulting JavaScript value
##### example
```js
parse('[Number]', '1,2,3'); // [1, 2, 3]
```
### parsedTypeParse(parsedType, input, options)
`parsedTypeParse` casts the string `input` into a JavaScript value according to the specified `type` which has already been parsed (and taking account the optional `options`) and returns the resulting JavaScript value. You can parse a type using the [type-check](https://github.com/gkz/type-check) library's `parseType` function.
##### arguments
* type - `Object` - the type in the parsed type format which to check against
* input - `String` - the value written in the [levn format](#levn-format)
* options - `Maybe Object` - an optional parameter specifying additional [options](#options)
##### returns
`*` - the resulting JavaScript value
##### example
```js
var parsedType = require('type-check').parseType('[Number]');
parsedTypeParse(parsedType, '1,2,3'); // [1, 2, 3]
```
## Levn Format
Levn can use the type information you provide to choose the appropriate value to produce from the input. For the same input, it will choose a different output value depending on the type provided. For example, `parse('Number', '2')` will produce the number `2`, but `parse('String', '2')` will produce the string `"2"`.
If you do not provide type information, and simply use `*`, levn will parse the input according the unambiguous "explicit" mode, which we will now detail - you can also set the `explicit` option to true manually in the [options](#options).
* `"string"`, `'string'` are parsed as a String, eg. `"a msg"` is `"a msg"`
* `#date#` is parsed as a Date, eg. `#2011-11-11#` is `new Date('2011-11-11')`
* `/regexp/flags` is parsed as a RegExp, eg. `/re/gi` is `/re/gi`
* `undefined`, `null`, `NaN`, `true`, and `false` are all their JavaScript equivalents
* `[element1, element2, etc]` is an Array, and the casting procedure is recursively applied to each element. Eg. `[1,2,3]` is `[1,2,3]`.
* `(element1, element2, etc)` is an tuple, and the casting procedure is recursively applied to each element. Eg. `(1, a)` is `(1, a)` (is `[1, 'a']`).
* `{key1: val1, key2: val2, ...}` is an Object, and the casting procedure is recursively applied to each property. Eg. `{a: 1, b: 2}` is `{a: 1, b: 2}`.
* Any test which does not fall under the above, and which does not contain special characters (`[``]``(``)``{``}``:``,`) is a string, eg. `$12- blah` is `"$12- blah"`.
If you do provide type information, you can make your input more concise as the program already has some information about what it expects. Please see the [type format](https://github.com/gkz/type-check#type-format) section of [type-check](https://github.com/gkz/type-check) for more information about how to specify types. There are some rules about what levn can do with the information:
* If a String is expected, and only a String, all characters of the input (including any special ones) will become part of the output. Eg. `[({})]` is `"[({})]"`, and `"hi"` is `'"hi"'`.
* If a Date is expected, the surrounding `#` can be omitted from date literals. Eg. `2011-11-11` is `new Date('2011-11-11')`.
* If a RegExp is expected, no flags need to be specified, and the regex is not using any of the special characters,the opening and closing `/` can be omitted - this will have the affect of setting the source of the regex to the input. Eg. `regex` is `/regex/`.
* If an Array is expected, and it is the root node (at the top level), the opening `[` and closing `]` can be omitted. Eg. `1,2,3` is `[1,2,3]`.
* If a tuple is expected, and it is the root node (at the top level), the opening `(` and closing `)` can be omitted. Eg. `1, a` is `(1, a)` (is `[1, 'a']`).
* If an Object is expected, and it is the root node (at the top level), the opening `{` and closing `}` can be omitted. Eg `a: 1, b: 2` is `{a: 1, b: 2}`.
If you list multiple types (eg. `Number | String`), it will first attempt to cast to the first type and then validate - if the validation fails it will move on to the next type and so forth, left to right. You must be careful as some types will succeed with any input, such as String. Thus put String at the end of your list. In non-explicit mode, Date and RegExp will succeed with a large variety of input - also be careful with these and list them near the end if not last in your list.
Whitespace between special characters and elements is inconsequential.
## Options
Options is an object. It is an optional parameter to the `parse` and `parsedTypeParse` functions.
### Explicit
A `Boolean`. By default it is `false`.
__Example:__
```js
parse('RegExp', 're', {explicit: false}); // /re/
parse('RegExp', 're', {explicit: true}); // Error: ... does not type check...
parse('RegExp | String', 're', {explicit: true}); // 're'
```
`explicit` sets whether to be in explicit mode or not. Using `*` automatically activates explicit mode. For more information, read the [levn format](#levn-format) section.
### customTypes
An `Object`. Empty `{}` by default.
__Example:__
```js
var options = {
customTypes: {
Even: {
typeOf: 'Number',
validate: function (x) {
return x % 2 === 0;
},
cast: function (x) {
return {type: 'Just', value: parseInt(x)};
}
}
}
}
parse('Even', '2', options); // 2
parse('Even', '3', options); // Error: Value: "3" does not type check...
```
__Another Example:__
```js
function Person(name, age){
this.name = name;
this.age = age;
}
var options = {
customTypes: {
Person: {
typeOf: 'Object',
validate: function (x) {
x instanceof Person;
},
cast: function (value, options, typesCast) {
var name, age;
if ({}.toString.call(value).slice(8, -1) !== 'Object') {
return {type: 'Nothing'};
}
name = typesCast(value.name, [{type: 'String'}], options);
age = typesCast(value.age, [{type: 'Numger'}], options);
return {type: 'Just', value: new Person(name, age)};
}
}
}
parse('Person', '{name: Laura, age: 25}', options); // Person {name: 'Laura', age: 25}
```
`customTypes` is an object whose keys are the name of the types, and whose values are an object with three properties, `typeOf`, `validate`, and `cast`. For more information about `typeOf` and `validate`, please see the [custom types](https://github.com/gkz/type-check#custom-types) section of type-check.
`cast` is a function which receives three arguments, the value under question, options, and the typesCast function. In `cast`, attempt to cast the value into the specified type. If you are successful, return an object in the format `{type: 'Just', value: CAST-VALUE}`, if you know it won't work, return `{type: 'Nothing'}`. You can use the `typesCast` function to cast any child values. Remember to pass `options` to it. In your function you can also check for `options.explicit` and act accordingly.
## Technical About
`levn` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It uses [type-check](https://github.com/gkz/type-check) to both parse types and validate values. It also uses the [prelude.ls](http://preludels.com/) library.
[](https://www.npmjs.com/package/as-bignum)[](https://travis-ci.com/MaxGraey/as-bignum)[](LICENSE.md)
## WebAssembly fixed length big numbers written on [AssemblyScript](https://github.com/AssemblyScript/assemblyscript)
### Status: Work in progress
Provide wide numeric types such as `u128`, `u256`, `i128`, `i256` and fixed points and also its arithmetic operations.
Namespace `safe` contain equivalents with overflow/underflow traps.
All kind of types pretty useful for economical and cryptographic usages and provide deterministic behavior.
### Install
> yarn add as-bignum
or
> npm i as-bignum
### Usage via AssemblyScript
```ts
import { u128 } from "as-bignum";
declare function logF64(value: f64): void;
declare function logU128(hi: u64, lo: u64): void;
var a = u128.One;
var b = u128.from(-32); // same as u128.from<i32>(-32)
var c = new u128(0x1, -0xF);
var d = u128.from(0x0123456789ABCDEF); // same as u128.from<i64>(0x0123456789ABCDEF)
var e = u128.from('0x0123456789ABCDEF01234567');
var f = u128.fromString('11100010101100101', 2); // same as u128.from('0b11100010101100101')
var r = d / c + (b << 5) + e;
logF64(r.as<f64>());
logU128(r.hi, r.lo);
```
### Usage via JavaScript/Typescript
```ts
TODO
```
### List of types
- [x] [`u128`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/u128.ts) unsigned type (tested)
- [ ] [`u256`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/u256.ts) unsigned type (very basic)
- [ ] `i128` signed type
- [ ] `i256` signed type
---
- [x] [`safe.u128`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/safe/u128.ts) unsigned type (tested)
- [ ] `safe.u256` unsigned type
- [ ] `safe.i128` signed type
- [ ] `safe.i256` signed type
---
- [ ] [`fp128<Q>`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/fixed/fp128.ts) generic fixed point signed type٭ (very basic for now)
- [ ] `fp256<Q>` generic fixed point signed type٭
---
- [ ] `safe.fp128<Q>` generic fixed point signed type٭
- [ ] `safe.fp256<Q>` generic fixed point signed type٭
٭ _typename_ `Q` _is a type representing count of fractional bits_
assemblyscript-json
# assemblyscript-json
## Table of contents
### Namespaces
- [JSON](modules/json.md)
### Classes
- [DecoderState](classes/decoderstate.md)
- [JSONDecoder](classes/jsondecoder.md)
- [JSONEncoder](classes/jsonencoder.md)
- [JSONHandler](classes/jsonhandler.md)
- [ThrowingJSONHandler](classes/throwingjsonhandler.md)
# axios // helpers
The modules found in `helpers/` should be generic modules that are _not_ specific to the domain logic of axios. These modules could theoretically be published to npm on their own and consumed by other modules or apps. Some examples of generic modules are things like:
- Browser polyfills
- Managing cookies
- Parsing HTTP headers
<p align="center">
<img width="250" src="/yargs-logo.png">
</p>
<h1 align="center"> Yargs </h1>
<p align="center">
<b >Yargs be a node.js library fer hearties tryin' ter parse optstrings</b>
</p>
<br>
[![Build Status][travis-image]][travis-url]
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[![Coverage][coverage-image]][coverage-url]
[![Conventional Commits][conventional-commits-image]][conventional-commits-url]
[![Slack][slack-image]][slack-url]
## Description :
Yargs helps you build interactive command line tools, by parsing arguments and generating an elegant user interface.
It gives you:
* commands and (grouped) options (`my-program.js serve --port=5000`).
* a dynamically generated help menu based on your arguments.
> <img width="400" src="/screen.png">
* bash-completion shortcuts for commands and options.
* and [tons more](/docs/api.md).
## Installation
Stable version:
```bash
npm i yargs
```
Bleeding edge version with the most recent features:
```bash
npm i yargs@next
```
## Usage :
### Simple Example
```javascript
#!/usr/bin/env node
const {argv} = require('yargs')
if (argv.ships > 3 && argv.distance < 53.5) {
console.log('Plunder more riffiwobbles!')
} else {
console.log('Retreat from the xupptumblers!')
}
```
```bash
$ ./plunder.js --ships=4 --distance=22
Plunder more riffiwobbles!
$ ./plunder.js --ships 12 --distance 98.7
Retreat from the xupptumblers!
```
### Complex Example
```javascript
#!/usr/bin/env node
require('yargs') // eslint-disable-line
.command('serve [port]', 'start the server', (yargs) => {
yargs
.positional('port', {
describe: 'port to bind on',
default: 5000
})
}, (argv) => {
if (argv.verbose) console.info(`start server on :${argv.port}`)
serve(argv.port)
})
.option('verbose', {
alias: 'v',
type: 'boolean',
description: 'Run with verbose logging'
})
.argv
```
Run the example above with `--help` to see the help for the application.
## TypeScript
yargs has type definitions at [@types/yargs][type-definitions].
```
npm i @types/yargs --save-dev
```
See usage examples in [docs](/docs/typescript.md).
## Webpack
See usage examples of yargs with webpack in [docs](/docs/webpack.md).
## Community :
Having problems? want to contribute? join our [community slack](http://devtoolscommunity.herokuapp.com).
## Documentation :
### Table of Contents
* [Yargs' API](/docs/api.md)
* [Examples](/docs/examples.md)
* [Parsing Tricks](/docs/tricks.md)
* [Stop the Parser](/docs/tricks.md#stop)
* [Negating Boolean Arguments](/docs/tricks.md#negate)
* [Numbers](/docs/tricks.md#numbers)
* [Arrays](/docs/tricks.md#arrays)
* [Objects](/docs/tricks.md#objects)
* [Quotes](/docs/tricks.md#quotes)
* [Advanced Topics](/docs/advanced.md)
* [Composing Your App Using Commands](/docs/advanced.md#commands)
* [Building Configurable CLI Apps](/docs/advanced.md#configuration)
* [Customizing Yargs' Parser](/docs/advanced.md#customizing)
* [Contributing](/contributing.md)
[travis-url]: https://travis-ci.org/yargs/yargs
[travis-image]: https://img.shields.io/travis/yargs/yargs/master.svg
[npm-url]: https://www.npmjs.com/package/yargs
[npm-image]: https://img.shields.io/npm/v/yargs.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: http://standardjs.com/
[conventional-commits-image]: https://img.shields.io/badge/Conventional%20Commits-1.0.0-yellow.svg
[conventional-commits-url]: https://conventionalcommits.org/
[slack-image]: http://devtoolscommunity.herokuapp.com/badge.svg
[slack-url]: http://devtoolscommunity.herokuapp.com
[type-definitions]: https://github.com/DefinitelyTyped/DefinitelyTyped/tree/master/types/yargs
[coverage-image]: https://img.shields.io/nycrc/yargs/yargs
[coverage-url]: https://github.com/yargs/yargs/blob/master/.nycrc
# fast-deep-equal
The fastest deep equal with ES6 Map, Set and Typed arrays support.
[](https://travis-ci.org/epoberezkin/fast-deep-equal)
[](https://www.npmjs.com/package/fast-deep-equal)
[](https://coveralls.io/github/epoberezkin/fast-deep-equal?branch=master)
## Install
```bash
npm install fast-deep-equal
```
## Features
- ES5 compatible
- works in node.js (8+) and browsers (IE9+)
- checks equality of Date and RegExp objects by value.
ES6 equal (`require('fast-deep-equal/es6')`) also supports:
- Maps
- Sets
- Typed arrays
## Usage
```javascript
var equal = require('fast-deep-equal');
console.log(equal({foo: 'bar'}, {foo: 'bar'})); // true
```
To support ES6 Maps, Sets and Typed arrays equality use:
```javascript
var equal = require('fast-deep-equal/es6');
console.log(equal(Int16Array([1, 2]), Int16Array([1, 2]))); // true
```
To use with React (avoiding the traversal of React elements' _owner
property that contains circular references and is not needed when
comparing the elements - borrowed from [react-fast-compare](https://github.com/FormidableLabs/react-fast-compare)):
```javascript
var equal = require('fast-deep-equal/react');
var equal = require('fast-deep-equal/es6/react');
```
## Performance benchmark
Node.js v12.6.0:
```
fast-deep-equal x 261,950 ops/sec ±0.52% (89 runs sampled)
fast-deep-equal/es6 x 212,991 ops/sec ±0.34% (92 runs sampled)
fast-equals x 230,957 ops/sec ±0.83% (85 runs sampled)
nano-equal x 187,995 ops/sec ±0.53% (88 runs sampled)
shallow-equal-fuzzy x 138,302 ops/sec ±0.49% (90 runs sampled)
underscore.isEqual x 74,423 ops/sec ±0.38% (89 runs sampled)
lodash.isEqual x 36,637 ops/sec ±0.72% (90 runs sampled)
deep-equal x 2,310 ops/sec ±0.37% (90 runs sampled)
deep-eql x 35,312 ops/sec ±0.67% (91 runs sampled)
ramda.equals x 12,054 ops/sec ±0.40% (91 runs sampled)
util.isDeepStrictEqual x 46,440 ops/sec ±0.43% (90 runs sampled)
assert.deepStrictEqual x 456 ops/sec ±0.71% (88 runs sampled)
The fastest is fast-deep-equal
```
To run benchmark (requires node.js 6+):
```bash
npm run benchmark
```
__Please note__: this benchmark runs against the available test cases. To choose the most performant library for your application, it is recommended to benchmark against your data and to NOT expect this benchmark to reflect the performance difference in your application.
## Enterprise support
fast-deep-equal package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-fast-deep-equal?utm_source=npm-fast-deep-equal&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
## License
[MIT](https://github.com/epoberezkin/fast-deep-equal/blob/master/LICENSE)
# yargs-parser

[](https://www.npmjs.com/package/yargs-parser)
[](https://conventionalcommits.org)

The mighty option parser used by [yargs](https://github.com/yargs/yargs).
visit the [yargs website](http://yargs.js.org/) for more examples, and thorough usage instructions.
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs-parser/main/yargs-logo.png">
## Example
```sh
npm i yargs-parser --save
```
```js
const argv = require('yargs-parser')(process.argv.slice(2))
console.log(argv)
```
```console
$ node example.js --foo=33 --bar hello
{ _: [], foo: 33, bar: 'hello' }
```
_or parse a string!_
```js
const argv = require('yargs-parser')('--foo=99 --bar=33')
console.log(argv)
```
```console
{ _: [], foo: 99, bar: 33 }
```
Convert an array of mixed types before passing to `yargs-parser`:
```js
const parse = require('yargs-parser')
parse(['-f', 11, '--zoom', 55].join(' ')) // <-- array to string
parse(['-f', 11, '--zoom', 55].map(String)) // <-- array of strings
```
## Deno Example
As of `v19` `yargs-parser` supports [Deno](https://github.com/denoland/deno):
```typescript
import parser from "https://deno.land/x/yargs_parser/deno.ts";
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
```
## ESM Example
As of `v19` `yargs-parser` supports ESM (_both in Node.js and in the browser_):
**Node.js:**
```js
import parser from 'yargs-parser'
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
```
**Browsers:**
```html
<!doctype html>
<body>
<script type="module">
import parser from "https://unpkg.com/yargs-parser@19.0.0/browser.js";
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
</script>
</body>
```
## API
### parser(args, opts={})
Parses command line arguments returning a simple mapping of keys and values.
**expects:**
* `args`: a string or array of strings representing the options to parse.
* `opts`: provide a set of hints indicating how `args` should be parsed:
* `opts.alias`: an object representing the set of aliases for a key: `{alias: {foo: ['f']}}`.
* `opts.array`: indicate that keys should be parsed as an array: `{array: ['foo', 'bar']}`.<br>
Indicate that keys should be parsed as an array and coerced to booleans / numbers:<br>
`{array: [{ key: 'foo', boolean: true }, {key: 'bar', number: true}]}`.
* `opts.boolean`: arguments should be parsed as booleans: `{boolean: ['x', 'y']}`.
* `opts.coerce`: provide a custom synchronous function that returns a coerced value from the argument provided
(or throws an error). For arrays the function is called only once for the entire array:<br>
`{coerce: {foo: function (arg) {return modifiedArg}}}`.
* `opts.config`: indicate a key that represents a path to a configuration file (this file will be loaded and parsed).
* `opts.configObjects`: configuration objects to parse, their properties will be set as arguments:<br>
`{configObjects: [{'x': 5, 'y': 33}, {'z': 44}]}`.
* `opts.configuration`: provide configuration options to the yargs-parser (see: [configuration](#configuration)).
* `opts.count`: indicate a key that should be used as a counter, e.g., `-vvv` = `{v: 3}`.
* `opts.default`: provide default values for keys: `{default: {x: 33, y: 'hello world!'}}`.
* `opts.envPrefix`: environment variables (`process.env`) with the prefix provided should be parsed.
* `opts.narg`: specify that a key requires `n` arguments: `{narg: {x: 2}}`.
* `opts.normalize`: `path.normalize()` will be applied to values set to this key.
* `opts.number`: keys should be treated as numbers.
* `opts.string`: keys should be treated as strings (even if they resemble a number `-x 33`).
**returns:**
* `obj`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
### require('yargs-parser').detailed(args, opts={})
Parses a command line string, returning detailed information required by the
yargs engine.
**expects:**
* `args`: a string or array of strings representing options to parse.
* `opts`: provide a set of hints indicating how `args`, inputs are identical to `require('yargs-parser')(args, opts={})`.
**returns:**
* `argv`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
* `error`: populated with an error object if an exception occurred during parsing.
* `aliases`: the inferred list of aliases built by combining lists in `opts.alias`.
* `newAliases`: any new aliases added via camel-case expansion:
* `boolean`: `{ fooBar: true }`
* `defaulted`: any new argument created by `opts.default`, no aliases included.
* `boolean`: `{ foo: true }`
* `configuration`: given by default settings and `opts.configuration`.
<a name="configuration"></a>
### Configuration
The yargs-parser applies several automated transformations on the keys provided
in `args`. These features can be turned on and off using the `configuration` field
of `opts`.
```js
var parsed = parser(['--no-dice'], {
configuration: {
'boolean-negation': false
}
})
```
### short option groups
* default: `true`.
* key: `short-option-groups`.
Should a group of short-options be treated as boolean flags?
```console
$ node example.js -abc
{ _: [], a: true, b: true, c: true }
```
_if disabled:_
```console
$ node example.js -abc
{ _: [], abc: true }
```
### camel-case expansion
* default: `true`.
* key: `camel-case-expansion`.
Should hyphenated arguments be expanded into camel-case aliases?
```console
$ node example.js --foo-bar
{ _: [], 'foo-bar': true, fooBar: true }
```
_if disabled:_
```console
$ node example.js --foo-bar
{ _: [], 'foo-bar': true }
```
### dot-notation
* default: `true`
* key: `dot-notation`
Should keys that contain `.` be treated as objects?
```console
$ node example.js --foo.bar
{ _: [], foo: { bar: true } }
```
_if disabled:_
```console
$ node example.js --foo.bar
{ _: [], "foo.bar": true }
```
### parse numbers
* default: `true`
* key: `parse-numbers`
Should keys that look like numbers be treated as such?
```console
$ node example.js --foo=99.3
{ _: [], foo: 99.3 }
```
_if disabled:_
```console
$ node example.js --foo=99.3
{ _: [], foo: "99.3" }
```
### parse positional numbers
* default: `true`
* key: `parse-positional-numbers`
Should positional keys that look like numbers be treated as such.
```console
$ node example.js 99.3
{ _: [99.3] }
```
_if disabled:_
```console
$ node example.js 99.3
{ _: ['99.3'] }
```
### boolean negation
* default: `true`
* key: `boolean-negation`
Should variables prefixed with `--no` be treated as negations?
```console
$ node example.js --no-foo
{ _: [], foo: false }
```
_if disabled:_
```console
$ node example.js --no-foo
{ _: [], "no-foo": true }
```
### combine arrays
* default: `false`
* key: `combine-arrays`
Should arrays be combined when provided by both command line arguments and
a configuration file.
### duplicate arguments array
* default: `true`
* key: `duplicate-arguments-array`
Should arguments be coerced into an array when duplicated:
```console
$ node example.js -x 1 -x 2
{ _: [], x: [1, 2] }
```
_if disabled:_
```console
$ node example.js -x 1 -x 2
{ _: [], x: 2 }
```
### flatten duplicate arrays
* default: `true`
* key: `flatten-duplicate-arrays`
Should array arguments be coerced into a single array when duplicated:
```console
$ node example.js -x 1 2 -x 3 4
{ _: [], x: [1, 2, 3, 4] }
```
_if disabled:_
```console
$ node example.js -x 1 2 -x 3 4
{ _: [], x: [[1, 2], [3, 4]] }
```
### greedy arrays
* default: `true`
* key: `greedy-arrays`
Should arrays consume more than one positional argument following their flag.
```console
$ node example --arr 1 2
{ _: [], arr: [1, 2] }
```
_if disabled:_
```console
$ node example --arr 1 2
{ _: [2], arr: [1] }
```
**Note: in `v18.0.0` we are considering defaulting greedy arrays to `false`.**
### nargs eats options
* default: `false`
* key: `nargs-eats-options`
Should nargs consume dash options as well as positional arguments.
### negation prefix
* default: `no-`
* key: `negation-prefix`
The prefix to use for negated boolean variables.
```console
$ node example.js --no-foo
{ _: [], foo: false }
```
_if set to `quux`:_
```console
$ node example.js --quuxfoo
{ _: [], foo: false }
```
### populate --
* default: `false`.
* key: `populate--`
Should unparsed flags be stored in `--` or `_`.
_If disabled:_
```console
$ node example.js a -b -- x y
{ _: [ 'a', 'x', 'y' ], b: true }
```
_If enabled:_
```console
$ node example.js a -b -- x y
{ _: [ 'a' ], '--': [ 'x', 'y' ], b: true }
```
### set placeholder key
* default: `false`.
* key: `set-placeholder-key`.
Should a placeholder be added for keys not set via the corresponding CLI argument?
_If disabled:_
```console
$ node example.js -a 1 -c 2
{ _: [], a: 1, c: 2 }
```
_If enabled:_
```console
$ node example.js -a 1 -c 2
{ _: [], a: 1, b: undefined, c: 2 }
```
### halt at non-option
* default: `false`.
* key: `halt-at-non-option`.
Should parsing stop at the first positional argument? This is similar to how e.g. `ssh` parses its command line.
_If disabled:_
```console
$ node example.js -a run b -x y
{ _: [ 'b' ], a: 'run', x: 'y' }
```
_If enabled:_
```console
$ node example.js -a run b -x y
{ _: [ 'b', '-x', 'y' ], a: 'run' }
```
### strip aliased
* default: `false`
* key: `strip-aliased`
Should aliases be removed before returning results?
_If disabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1, 'test-alias': 1, testAlias: 1 }
```
_If enabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
### strip dashed
* default: `false`
* key: `strip-dashed`
Should dashed keys be removed before returning results? This option has no effect if
`camel-case-expansion` is disabled.
_If disabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
_If enabled:_
```console
$ node example.js --test-field 1
{ _: [], testField: 1 }
```
### unknown options as args
* default: `false`
* key: `unknown-options-as-args`
Should unknown options be treated like regular arguments? An unknown option is one that is not
configured in `opts`.
_If disabled_
```console
$ node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: [], unknownOption: true, knownOption: 2, stringOption: '', unknownOption2: true }
```
_If enabled_
```console
$ node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: ['--unknown-option'], knownOption: 2, stringOption: '--unknown-option2' }
```
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
## Special Thanks
The yargs project evolves from optimist and minimist. It owes its
existence to a lot of James Halliday's hard work. Thanks [substack](https://github.com/substack) **beep** **boop** \o/
## License
ISC
# ansi-colors [](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=W8YFZ425KND68) [](https://www.npmjs.com/package/ansi-colors) [](https://npmjs.org/package/ansi-colors) [](https://npmjs.org/package/ansi-colors) [](https://travis-ci.org/doowb/ansi-colors)
> Easily add ANSI colors to your text and symbols in the terminal. A faster drop-in replacement for chalk, kleur and turbocolor (without the dependencies and rendering bugs).
Please consider following this project's author, [Brian Woodward](https://github.com/doowb), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save ansi-colors
```

## Why use this?
ansi-colors is _the fastest Node.js library for terminal styling_. A more performant drop-in replacement for chalk, with no dependencies.
* _Blazing fast_ - Fastest terminal styling library in node.js, 10-20x faster than chalk!
* _Drop-in replacement_ for [chalk](https://github.com/chalk/chalk).
* _No dependencies_ (Chalk has 7 dependencies in its tree!)
* _Safe_ - Does not modify the `String.prototype` like [colors](https://github.com/Marak/colors.js).
* Supports [nested colors](#nested-colors), **and does not have the [nested styling bug](#nested-styling-bug) that is present in [colorette](https://github.com/jorgebucaran/colorette), [chalk](https://github.com/chalk/chalk), and [kleur](https://github.com/lukeed/kleur)**.
* Supports [chained colors](#chained-colors).
* [Toggle color support](#toggle-color-support) on or off.
## Usage
```js
const c = require('ansi-colors');
console.log(c.red('This is a red string!'));
console.log(c.green('This is a red string!'));
console.log(c.cyan('This is a cyan string!'));
console.log(c.yellow('This is a yellow string!'));
```

## Chained colors
```js
console.log(c.bold.red('this is a bold red message'));
console.log(c.bold.yellow.italic('this is a bold yellow italicized message'));
console.log(c.green.bold.underline('this is a bold green underlined message'));
```

## Nested colors
```js
console.log(c.yellow(`foo ${c.red.bold('red')} bar ${c.cyan('cyan')} baz`));
```

### Nested styling bug
`ansi-colors` does not have the nested styling bug found in [colorette](https://github.com/jorgebucaran/colorette), [chalk](https://github.com/chalk/chalk), and [kleur](https://github.com/lukeed/kleur).
```js
const { bold, red } = require('ansi-styles');
console.log(bold(`foo ${red.dim('bar')} baz`));
const colorette = require('colorette');
console.log(colorette.bold(`foo ${colorette.red(colorette.dim('bar'))} baz`));
const kleur = require('kleur');
console.log(kleur.bold(`foo ${kleur.red.dim('bar')} baz`));
const chalk = require('chalk');
console.log(chalk.bold(`foo ${chalk.red.dim('bar')} baz`));
```
**Results in the following**
(sans icons and labels)

## Toggle color support
Easily enable/disable colors.
```js
const c = require('ansi-colors');
// disable colors manually
c.enabled = false;
// or use a library to automatically detect support
c.enabled = require('color-support').hasBasic;
console.log(c.red('I will only be colored red if the terminal supports colors'));
```
## Strip ANSI codes
Use the `.unstyle` method to strip ANSI codes from a string.
```js
console.log(c.unstyle(c.blue.bold('foo bar baz')));
//=> 'foo bar baz'
```
## Available styles
**Note** that bright and bright-background colors are not always supported.
| Colors | Background Colors | Bright Colors | Bright Background Colors |
| ------- | ----------------- | ------------- | ------------------------ |
| black | bgBlack | blackBright | bgBlackBright |
| red | bgRed | redBright | bgRedBright |
| green | bgGreen | greenBright | bgGreenBright |
| yellow | bgYellow | yellowBright | bgYellowBright |
| blue | bgBlue | blueBright | bgBlueBright |
| magenta | bgMagenta | magentaBright | bgMagentaBright |
| cyan | bgCyan | cyanBright | bgCyanBright |
| white | bgWhite | whiteBright | bgWhiteBright |
| gray | | | |
| grey | | | |
_(`gray` is the U.S. spelling, `grey` is more commonly used in the Canada and U.K.)_
### Style modifiers
* dim
* **bold**
* hidden
* _italic_
* underline
* inverse
* ~~strikethrough~~
* reset
## Aliases
Create custom aliases for styles.
```js
const colors = require('ansi-colors');
colors.alias('primary', colors.yellow);
colors.alias('secondary', colors.bold);
console.log(colors.primary.secondary('Foo'));
```
## Themes
A theme is an object of custom aliases.
```js
const colors = require('ansi-colors');
colors.theme({
danger: colors.red,
dark: colors.dim.gray,
disabled: colors.gray,
em: colors.italic,
heading: colors.bold.underline,
info: colors.cyan,
muted: colors.dim,
primary: colors.blue,
strong: colors.bold,
success: colors.green,
underline: colors.underline,
warning: colors.yellow
});
// Now, we can use our custom styles alongside the built-in styles!
console.log(colors.danger.strong.em('Error!'));
console.log(colors.warning('Heads up!'));
console.log(colors.info('Did you know...'));
console.log(colors.success.bold('It worked!'));
```
## Performance
**Libraries tested**
* ansi-colors v3.0.4
* chalk v2.4.1
### Mac
> MacBook Pro, Intel Core i7, 2.3 GHz, 16 GB.
**Load time**
Time it takes to load the first time `require()` is called:
* ansi-colors - `1.915ms`
* chalk - `12.437ms`
**Benchmarks**
```
# All Colors
ansi-colors x 173,851 ops/sec ±0.42% (91 runs sampled)
chalk x 9,944 ops/sec ±2.53% (81 runs sampled)))
# Chained colors
ansi-colors x 20,791 ops/sec ±0.60% (88 runs sampled)
chalk x 2,111 ops/sec ±2.34% (83 runs sampled)
# Nested colors
ansi-colors x 59,304 ops/sec ±0.98% (92 runs sampled)
chalk x 4,590 ops/sec ±2.08% (82 runs sampled)
```
### Windows
> Windows 10, Intel Core i7-7700k CPU @ 4.2 GHz, 32 GB
**Load time**
Time it takes to load the first time `require()` is called:
* ansi-colors - `1.494ms`
* chalk - `11.523ms`
**Benchmarks**
```
# All Colors
ansi-colors x 193,088 ops/sec ±0.51% (95 runs sampled))
chalk x 9,612 ops/sec ±3.31% (77 runs sampled)))
# Chained colors
ansi-colors x 26,093 ops/sec ±1.13% (94 runs sampled)
chalk x 2,267 ops/sec ±2.88% (80 runs sampled))
# Nested colors
ansi-colors x 67,747 ops/sec ±0.49% (93 runs sampled)
chalk x 4,446 ops/sec ±3.01% (82 runs sampled))
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [ansi-wrap](https://www.npmjs.com/package/ansi-wrap): Create ansi colors by passing the open and close codes. | [homepage](https://github.com/jonschlinkert/ansi-wrap "Create ansi colors by passing the open and close codes.")
* [strip-color](https://www.npmjs.com/package/strip-color): Strip ANSI color codes from a string. No dependencies. | [homepage](https://github.com/jonschlinkert/strip-color "Strip ANSI color codes from a string. No dependencies.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 48 | [jonschlinkert](https://github.com/jonschlinkert) |
| 42 | [doowb](https://github.com/doowb) |
| 6 | [lukeed](https://github.com/lukeed) |
| 2 | [Silic0nS0ldier](https://github.com/Silic0nS0ldier) |
| 1 | [dwieeb](https://github.com/dwieeb) |
| 1 | [jorgebucaran](https://github.com/jorgebucaran) |
| 1 | [madhavarshney](https://github.com/madhavarshney) |
| 1 | [chapterjason](https://github.com/chapterjason) |
### Author
**Brian Woodward**
* [GitHub Profile](https://github.com/doowb)
* [Twitter Profile](https://twitter.com/doowb)
* [LinkedIn Profile](https://linkedin.com/in/woodwardbrian)
### License
Copyright © 2019, [Brian Woodward](https://github.com/doowb).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on July 01, 2019._
# universal-url [![NPM Version][npm-image]][npm-url] [![Build Status][travis-image]][travis-url] [![Dependency Monitor][greenkeeper-image]][greenkeeper-url]
> WHATWG [`URL`](https://developer.mozilla.org/en/docs/Web/API/URL) for Node & Browser.
* For Node.js versions `>= 8`, the native implementation will be used.
* For Node.js versions `< 8`, a [shim](https://npmjs.com/whatwg-url) will be used.
* For web browsers without a native implementation, the same shim will be used.
## Installation
[Node.js](http://nodejs.org/) `>= 6` is required. To install, type this at the command line:
```shell
npm install universal-url
```
## Usage
```js
const {URL, URLSearchParams} = require('universal-url');
const url = new URL('http://domain/');
const params = new URLSearchParams('?param=value');
```
Global shim:
```js
require('universal-url').shim();
const url = new URL('http://domain/');
const params = new URLSearchParams('?param=value');
```
## Browserify/etc
The bundled file size of this library can be large for a web browser. If this is a problem, try using [universal-url-lite](https://npmjs.com/universal-url-lite) in your build as an alias for this module.
[npm-image]: https://img.shields.io/npm/v/universal-url.svg
[npm-url]: https://npmjs.org/package/universal-url
[travis-image]: https://img.shields.io/travis/stevenvachon/universal-url.svg
[travis-url]: https://travis-ci.org/stevenvachon/universal-url
[greenkeeper-image]: https://badges.greenkeeper.io/stevenvachon/universal-url.svg
[greenkeeper-url]: https://greenkeeper.io/
argparse
========
[](http://travis-ci.org/nodeca/argparse)
[](https://www.npmjs.org/package/argparse)
CLI arguments parser for node.js. Javascript port of python's
[argparse](http://docs.python.org/dev/library/argparse.html) module
(original version 3.2). That's a full port, except some very rare options,
recorded in issue tracker.
**NB. Difference with original.**
- Method names changed to camelCase. See [generated docs](http://nodeca.github.com/argparse/).
- Use `defaultValue` instead of `default`.
- Use `argparse.Const.REMAINDER` instead of `argparse.REMAINDER`, and
similarly for constant values `OPTIONAL`, `ZERO_OR_MORE`, and `ONE_OR_MORE`
(aliases for `nargs` values `'?'`, `'*'`, `'+'`, respectively), and
`SUPPRESS`.
Example
=======
test.js file:
```javascript
#!/usr/bin/env node
'use strict';
var ArgumentParser = require('../lib/argparse').ArgumentParser;
var parser = new ArgumentParser({
version: '0.0.1',
addHelp:true,
description: 'Argparse example'
});
parser.addArgument(
[ '-f', '--foo' ],
{
help: 'foo bar'
}
);
parser.addArgument(
[ '-b', '--bar' ],
{
help: 'bar foo'
}
);
parser.addArgument(
'--baz',
{
help: 'baz bar'
}
);
var args = parser.parseArgs();
console.dir(args);
```
Display help:
```
$ ./test.js -h
usage: example.js [-h] [-v] [-f FOO] [-b BAR] [--baz BAZ]
Argparse example
Optional arguments:
-h, --help Show this help message and exit.
-v, --version Show program's version number and exit.
-f FOO, --foo FOO foo bar
-b BAR, --bar BAR bar foo
--baz BAZ baz bar
```
Parse arguments:
```
$ ./test.js -f=3 --bar=4 --baz 5
{ foo: '3', bar: '4', baz: '5' }
```
More [examples](https://github.com/nodeca/argparse/tree/master/examples).
ArgumentParser objects
======================
```
new ArgumentParser({parameters hash});
```
Creates a new ArgumentParser object.
**Supported params:**
- ```description``` - Text to display before the argument help.
- ```epilog``` - Text to display after the argument help.
- ```addHelp``` - Add a -h/–help option to the parser. (default: true)
- ```argumentDefault``` - Set the global default value for arguments. (default: null)
- ```parents``` - A list of ArgumentParser objects whose arguments should also be included.
- ```prefixChars``` - The set of characters that prefix optional arguments. (default: ‘-‘)
- ```formatterClass``` - A class for customizing the help output.
- ```prog``` - The name of the program (default: `path.basename(process.argv[1])`)
- ```usage``` - The string describing the program usage (default: generated)
- ```conflictHandler``` - Usually unnecessary, defines strategy for resolving conflicting optionals.
**Not supported yet**
- ```fromfilePrefixChars``` - The set of characters that prefix files from which additional arguments should be read.
Details in [original ArgumentParser guide](http://docs.python.org/dev/library/argparse.html#argumentparser-objects)
addArgument() method
====================
```
ArgumentParser.addArgument(name or flag or [name] or [flags...], {options})
```
Defines how a single command-line argument should be parsed.
- ```name or flag or [name] or [flags...]``` - Either a positional name
(e.g., `'foo'`), a single option (e.g., `'-f'` or `'--foo'`), an array
of a single positional name (e.g., `['foo']`), or an array of options
(e.g., `['-f', '--foo']`).
Options:
- ```action``` - The basic type of action to be taken when this argument is encountered at the command line.
- ```nargs```- The number of command-line arguments that should be consumed.
- ```constant``` - A constant value required by some action and nargs selections.
- ```defaultValue``` - The value produced if the argument is absent from the command line.
- ```type``` - The type to which the command-line argument should be converted.
- ```choices``` - A container of the allowable values for the argument.
- ```required``` - Whether or not the command-line option may be omitted (optionals only).
- ```help``` - A brief description of what the argument does.
- ```metavar``` - A name for the argument in usage messages.
- ```dest``` - The name of the attribute to be added to the object returned by parseArgs().
Details in [original add_argument guide](http://docs.python.org/dev/library/argparse.html#the-add-argument-method)
Action (some details)
================
ArgumentParser objects associate command-line arguments with actions.
These actions can do just about anything with the command-line arguments associated
with them, though most actions simply add an attribute to the object returned by
parseArgs(). The action keyword argument specifies how the command-line arguments
should be handled. The supported actions are:
- ```store``` - Just stores the argument’s value. This is the default action.
- ```storeConst``` - Stores value, specified by the const keyword argument.
(Note that the const keyword argument defaults to the rather unhelpful None.)
The 'storeConst' action is most commonly used with optional arguments, that
specify some sort of flag.
- ```storeTrue``` and ```storeFalse``` - Stores values True and False
respectively. These are special cases of 'storeConst'.
- ```append``` - Stores a list, and appends each argument value to the list.
This is useful to allow an option to be specified multiple times.
- ```appendConst``` - Stores a list, and appends value, specified by the
const keyword argument to the list. (Note, that the const keyword argument defaults
is None.) The 'appendConst' action is typically used when multiple arguments need
to store constants to the same list.
- ```count``` - Counts the number of times a keyword argument occurs. For example,
used for increasing verbosity levels.
- ```help``` - Prints a complete help message for all the options in the current
parser and then exits. By default a help action is automatically added to the parser.
See ArgumentParser for details of how the output is created.
- ```version``` - Prints version information and exit. Expects a `version=`
keyword argument in the addArgument() call.
Details in [original action guide](http://docs.python.org/dev/library/argparse.html#action)
Sub-commands
============
ArgumentParser.addSubparsers()
Many programs split their functionality into a number of sub-commands, for
example, the svn program can invoke sub-commands like `svn checkout`, `svn update`,
and `svn commit`. Splitting up functionality this way can be a particularly good
idea when a program performs several different functions which require different
kinds of command-line arguments. `ArgumentParser` supports creation of such
sub-commands with `addSubparsers()` method. The `addSubparsers()` method is
normally called with no arguments and returns an special action object.
This object has a single method `addParser()`, which takes a command name and
any `ArgumentParser` constructor arguments, and returns an `ArgumentParser` object
that can be modified as usual.
Example:
sub_commands.js
```javascript
#!/usr/bin/env node
'use strict';
var ArgumentParser = require('../lib/argparse').ArgumentParser;
var parser = new ArgumentParser({
version: '0.0.1',
addHelp:true,
description: 'Argparse examples: sub-commands',
});
var subparsers = parser.addSubparsers({
title:'subcommands',
dest:"subcommand_name"
});
var bar = subparsers.addParser('c1', {addHelp:true});
bar.addArgument(
[ '-f', '--foo' ],
{
action: 'store',
help: 'foo3 bar3'
}
);
var bar = subparsers.addParser(
'c2',
{aliases:['co'], addHelp:true}
);
bar.addArgument(
[ '-b', '--bar' ],
{
action: 'store',
type: 'int',
help: 'foo3 bar3'
}
);
var args = parser.parseArgs();
console.dir(args);
```
Details in [original sub-commands guide](http://docs.python.org/dev/library/argparse.html#sub-commands)
Contributors
============
- [Eugene Shkuropat](https://github.com/shkuropat)
- [Paul Jacobson](https://github.com/hpaulj)
[others](https://github.com/nodeca/argparse/graphs/contributors)
License
=======
Copyright (c) 2012 [Vitaly Puzrin](https://github.com/puzrin).
Released under the MIT license. See
[LICENSE](https://github.com/nodeca/argparse/blob/master/LICENSE) for details.
<h1 align="center">Enquirer</h1>
<p align="center">
<a href="https://npmjs.org/package/enquirer">
<img src="https://img.shields.io/npm/v/enquirer.svg" alt="version">
</a>
<a href="https://travis-ci.org/enquirer/enquirer">
<img src="https://img.shields.io/travis/enquirer/enquirer.svg" alt="travis">
</a>
<a href="https://npmjs.org/package/enquirer">
<img src="https://img.shields.io/npm/dm/enquirer.svg" alt="downloads">
</a>
</p>
<br>
<br>
<p align="center">
<b>Stylish CLI prompts that are user-friendly, intuitive and easy to create.</b><br>
<sub>>_ Prompts should be more like conversations than inquisitions▌</sub>
</p>
<br>
<p align="center">
<sub>(Example shows Enquirer's <a href="#survey-prompt">Survey Prompt</a>)</a></sub>
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/survey-prompt.gif" alt="Enquirer Survey Prompt" width="750"><br>
<sub>The terminal in all examples is <a href="https://hyper.is/">Hyper</a>, theme is <a href="https://github.com/jonschlinkert/hyper-monokai-extended">hyper-monokai-extended</a>.</sub><br><br>
<a href="#built-in-prompts"><strong>See more prompt examples</strong></a>
</p>
<br>
<br>
Created by [jonschlinkert](https://github.com/jonschlinkert) and [doowb](https://github.com/doowb), Enquirer is fast, easy to use, and lightweight enough for small projects, while also being powerful and customizable enough for the most advanced use cases.
* **Fast** - [Loads in ~4ms](#-performance) (that's about _3-4 times faster than a [single frame of a HD movie](http://www.endmemo.com/sconvert/framespersecondframespermillisecond.php) at 60fps_)
* **Lightweight** - Only one dependency, the excellent [ansi-colors](https://github.com/doowb/ansi-colors) by [Brian Woodward](https://github.com/doowb).
* **Easy to implement** - Uses promises and async/await and sensible defaults to make prompts easy to create and implement.
* **Easy to use** - Thrill your users with a better experience! Navigating around input and choices is a breeze. You can even create [quizzes](examples/fun/countdown.js), or [record](examples/fun/record.js) and [playback](examples/fun/play.js) key bindings to aid with tutorials and videos.
* **Intuitive** - Keypress combos are available to simplify usage.
* **Flexible** - All prompts can be used standalone or chained together.
* **Stylish** - Easily override semantic styles and symbols for any part of the prompt.
* **Extensible** - Easily create and use custom prompts by extending Enquirer's built-in [prompts](#-prompts).
* **Pluggable** - Add advanced features to Enquirer using plugins.
* **Validation** - Optionally validate user input with any prompt.
* **Well tested** - All prompts are well-tested, and tests are easy to create without having to use brittle, hacky solutions to spy on prompts or "inject" values.
* **Examples** - There are numerous [examples](examples) available to help you get started.
If you like Enquirer, please consider starring or tweeting about this project to show your support. Thanks!
<br>
<p align="center">
<b>>_ Ready to start making prompts your users will love? ▌</b><br>
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/heartbeat.gif" alt="Enquirer Select Prompt with heartbeat example" width="750">
</p>
<br>
<br>
## ❯ Getting started
Get started with Enquirer, the most powerful and easy-to-use Node.js library for creating interactive CLI prompts.
* [Install](#-install)
* [Usage](#-usage)
* [Enquirer](#-enquirer)
* [Prompts](#-prompts)
- [Built-in Prompts](#-prompts)
- [Custom Prompts](#-custom-prompts)
* [Key Bindings](#-key-bindings)
* [Options](#-options)
* [Release History](#-release-history)
* [Performance](#-performance)
* [About](#-about)
<br>
## ❯ Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install enquirer --save
```
Install with [yarn](https://yarnpkg.com/en/):
```sh
$ yarn add enquirer
```
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/npm-install.gif" alt="Install Enquirer with NPM" width="750">
</p>
_(Requires Node.js 8.6 or higher. Please let us know if you need support for an earlier version by creating an [issue](../../issues/new).)_
<br>
## ❯ Usage
### Single prompt
The easiest way to get started with enquirer is to pass a [question object](#prompt-options) to the `prompt` method.
```js
const { prompt } = require('enquirer');
const response = await prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response); // { username: 'jonschlinkert' }
```
_(Examples with `await` need to be run inside an `async` function)_
### Multiple prompts
Pass an array of ["question" objects](#prompt-options) to run a series of prompts.
```js
const response = await prompt([
{
type: 'input',
name: 'name',
message: 'What is your name?'
},
{
type: 'input',
name: 'username',
message: 'What is your username?'
}
]);
console.log(response); // { name: 'Edward Chan', username: 'edwardmchan' }
```
### Different ways to run enquirer
#### 1. By importing the specific `built-in prompt`
```js
const { Confirm } = require('enquirer');
const prompt = new Confirm({
name: 'question',
message: 'Did you like enquirer?'
});
prompt.run()
.then(answer => console.log('Answer:', answer));
```
#### 2. By passing the options to `prompt`
```js
const { prompt } = require('enquirer');
prompt({
type: 'confirm',
name: 'question',
message: 'Did you like enquirer?'
})
.then(answer => console.log('Answer:', answer));
```
**Jump to**: [Getting Started](#-getting-started) · [Prompts](#-prompts) · [Options](#-options) · [Key Bindings](#-key-bindings)
<br>
## ❯ Enquirer
**Enquirer is a prompt runner**
Add Enquirer to your JavaScript project with following line of code.
```js
const Enquirer = require('enquirer');
```
The main export of this library is the `Enquirer` class, which has methods and features designed to simplify running prompts.
```js
const { prompt } = require('enquirer');
const question = [
{
type: 'input',
name: 'username',
message: 'What is your username?'
},
{
type: 'password',
name: 'password',
message: 'What is your password?'
}
];
let answers = await prompt(question);
console.log(answers);
```
**Prompts control how values are rendered and returned**
Each individual prompt is a class with special features and functionality for rendering the types of values you want to show users in the terminal, and subsequently returning the types of values you need to use in your application.
**How can I customize prompts?**
Below in this guide you will find information about creating [custom prompts](#-custom-prompts). For now, we'll focus on how to customize an existing prompt.
All of the individual [prompt classes](#built-in-prompts) in this library are exposed as static properties on Enquirer. This allows them to be used directly without using `enquirer.prompt()`.
Use this approach if you need to modify a prompt instance, or listen for events on the prompt.
**Example**
```js
const { Input } = require('enquirer');
const prompt = new Input({
name: 'username',
message: 'What is your username?'
});
prompt.run()
.then(answer => console.log('Username:', answer))
.catch(console.error);
```
### [Enquirer](index.js#L20)
Create an instance of `Enquirer`.
**Params**
* `options` **{Object}**: (optional) Options to use with all prompts.
* `answers` **{Object}**: (optional) Answers object to initialize with.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
```
### [register()](index.js#L42)
Register a custom prompt type.
**Params**
* `type` **{String}**
* `fn` **{Function|Prompt}**: `Prompt` class, or a function that returns a `Prompt` class.
* `returns` **{Object}**: Returns the Enquirer instance
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
enquirer.register('customType', require('./custom-prompt'));
```
### [prompt()](index.js#L78)
Prompt function that takes a "question" object or array of question objects, and returns an object with responses from the user.
**Params**
* `questions` **{Array|Object}**: Options objects for one or more prompts to run.
* `returns` **{Promise}**: Promise that returns an "answers" object with the user's responses.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
const response = await enquirer.prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response);
```
### [use()](index.js#L160)
Use an enquirer plugin.
**Params**
* `plugin` **{Function}**: Plugin function that takes an instance of Enquirer.
* `returns` **{Object}**: Returns the Enquirer instance.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
const plugin = enquirer => {
// do stuff to enquire instance
};
enquirer.use(plugin);
```
### [Enquirer#prompt](index.js#L210)
Prompt function that takes a "question" object or array of question objects, and returns an object with responses from the user.
**Params**
* `questions` **{Array|Object}**: Options objects for one or more prompts to run.
* `returns` **{Promise}**: Promise that returns an "answers" object with the user's responses.
**Example**
```js
const { prompt } = require('enquirer');
const response = await prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response);
```
<br>
## ❯ Prompts
This section is about Enquirer's prompts: what they look like, how they work, how to run them, available options, and how to customize the prompts or create your own prompt concept.
**Getting started with Enquirer's prompts**
* [Prompt](#prompt) - The base `Prompt` class used by other prompts
- [Prompt Options](#prompt-options)
* [Built-in prompts](#built-in-prompts)
* [Prompt Types](#prompt-types) - The base `Prompt` class used by other prompts
* [Custom prompts](#%E2%9D%AF-custom-prompts) - Enquirer 2.0 introduced the concept of prompt "types", with the goal of making custom prompts easier than ever to create and use.
### Prompt
The base `Prompt` class is used to create all other prompts.
```js
const { Prompt } = require('enquirer');
class MyCustomPrompt extends Prompt {}
```
See the documentation for [creating custom prompts](#-custom-prompts) to learn more about how this works.
#### Prompt Options
Each prompt takes an options object (aka "question" object), that implements the following interface:
```js
{
// required
type: string | function,
name: string | function,
message: string | function | async function,
// optional
skip: boolean | function | async function,
initial: string | function | async function,
format: function | async function,
result: function | async function,
validate: function | async function,
}
```
Each property of the options object is described below:
| **Property** | **Required?** | **Type** | **Description** |
| ------------ | ------------- | ------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `type` | yes | `string\|function` | Enquirer uses this value to determine the type of prompt to run, but it's optional when prompts are run directly. |
| `name` | yes | `string\|function` | Used as the key for the answer on the returned values (answers) object. |
| `message` | yes | `string\|function` | The message to display when the prompt is rendered in the terminal. |
| `skip` | no | `boolean\|function` | If `true` it will not ask that prompt. |
| `initial` | no | `string\|function` | The default value to return if the user does not supply a value. |
| `format` | no | `function` | Function to format user input in the terminal. |
| `result` | no | `function` | Function to format the final submitted value before it's returned. |
| `validate` | no | `function` | Function to validate the submitted value before it's returned. This function may return a boolean or a string. If a string is returned it will be used as the validation error message. |
**Example usage**
```js
const { prompt } = require('enquirer');
const question = {
type: 'input',
name: 'username',
message: 'What is your username?'
};
prompt(question)
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
<br>
### Built-in prompts
* [AutoComplete Prompt](#autocomplete-prompt)
* [BasicAuth Prompt](#basicauth-prompt)
* [Confirm Prompt](#confirm-prompt)
* [Form Prompt](#form-prompt)
* [Input Prompt](#input-prompt)
* [Invisible Prompt](#invisible-prompt)
* [List Prompt](#list-prompt)
* [MultiSelect Prompt](#multiselect-prompt)
* [Numeral Prompt](#numeral-prompt)
* [Password Prompt](#password-prompt)
* [Quiz Prompt](#quiz-prompt)
* [Survey Prompt](#survey-prompt)
* [Scale Prompt](#scale-prompt)
* [Select Prompt](#select-prompt)
* [Sort Prompt](#sort-prompt)
* [Snippet Prompt](#snippet-prompt)
* [Toggle Prompt](#toggle-prompt)
### AutoComplete Prompt
Prompt that auto-completes as the user types, and returns the selected value as a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/autocomplete-prompt.gif" alt="Enquirer AutoComplete Prompt" width="750">
</p>
**Example Usage**
```js
const { AutoComplete } = require('enquirer');
const prompt = new AutoComplete({
name: 'flavor',
message: 'Pick your favorite flavor',
limit: 10,
initial: 2,
choices: [
'Almond',
'Apple',
'Banana',
'Blackberry',
'Blueberry',
'Cherry',
'Chocolate',
'Cinnamon',
'Coconut',
'Cranberry',
'Grape',
'Nougat',
'Orange',
'Pear',
'Pineapple',
'Raspberry',
'Strawberry',
'Vanilla',
'Watermelon',
'Wintergreen'
]
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**AutoComplete Options**
| Option | Type | Default | Description |
| ----------- | ---------- | ------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------ |
| `highlight` | `function` | `dim` version of primary style | The color to use when "highlighting" characters in the list that match user input. |
| `multiple` | `boolean` | `false` | Allow multiple choices to be selected. |
| `suggest` | `function` | Greedy match, returns true if choice message contains input string. | Function that filters choices. Takes user input and a choices array, and returns a list of matching choices. |
| `initial` | `number` | 0 | Preselected item in the list of choices. |
| `footer` | `function` | None | Function that displays [footer text](https://github.com/enquirer/enquirer/blob/6c2819518a1e2ed284242a99a685655fbaabfa28/examples/autocomplete/option-footer.js#L10) |
**Related prompts**
* [Select](#select-prompt)
* [MultiSelect](#multiselect-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### BasicAuth Prompt
Prompt that asks for username and password to authenticate the user. The default implementation of `authenticate` function in `BasicAuth` prompt is to compare the username and password with the values supplied while running the prompt. The implementer is expected to override the `authenticate` function with a custom logic such as making an API request to a server to authenticate the username and password entered and expect a token back.
<p align="center">
<img src="https://user-images.githubusercontent.com/13731210/61570485-7ffd9c00-aaaa-11e9-857a-d47dc7008284.gif" alt="Enquirer BasicAuth Prompt" width="750">
</p>
**Example Usage**
```js
const { BasicAuth } = require('enquirer');
const prompt = new BasicAuth({
name: 'password',
message: 'Please enter your password',
username: 'rajat-sr',
password: '123',
showPassword: true
});
prompt
.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Confirm Prompt
Prompt that returns `true` or `false`.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/confirm-prompt.gif" alt="Enquirer Confirm Prompt" width="750">
</p>
**Example Usage**
```js
const { Confirm } = require('enquirer');
const prompt = new Confirm({
name: 'question',
message: 'Want to answer?'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Numeral](#numeral-prompt)
* [Password](#password-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Form Prompt
Prompt that allows the user to enter and submit multiple values on a single terminal screen.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/form-prompt.gif" alt="Enquirer Form Prompt" width="750">
</p>
**Example Usage**
```js
const { Form } = require('enquirer');
const prompt = new Form({
name: 'user',
message: 'Please provide the following information:',
choices: [
{ name: 'firstname', message: 'First Name', initial: 'Jon' },
{ name: 'lastname', message: 'Last Name', initial: 'Schlinkert' },
{ name: 'username', message: 'GitHub username', initial: 'jonschlinkert' }
]
});
prompt.run()
.then(value => console.log('Answer:', value))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Input Prompt
Prompt that takes user input and returns a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/input-prompt.gif" alt="Enquirer Input Prompt" width="750">
</p>
**Example Usage**
```js
const { Input } = require('enquirer');
const prompt = new Input({
message: 'What is your username?',
initial: 'jonschlinkert'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.log);
```
You can use [data-store](https://github.com/jonschlinkert/data-store) to store [input history](https://github.com/enquirer/enquirer/blob/master/examples/input/option-history.js) that the user can cycle through (see [source](https://github.com/enquirer/enquirer/blob/8407dc3579123df5e6e20215078e33bb605b0c37/lib/prompts/input.js)).
**Related prompts**
* [Confirm](#confirm-prompt)
* [Numeral](#numeral-prompt)
* [Password](#password-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Invisible Prompt
Prompt that takes user input, hides it from the terminal, and returns a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/invisible-prompt.gif" alt="Enquirer Invisible Prompt" width="750">
</p>
**Example Usage**
```js
const { Invisible } = require('enquirer');
const prompt = new Invisible({
name: 'secret',
message: 'What is your secret?'
});
prompt.run()
.then(answer => console.log('Answer:', { secret: answer }))
.catch(console.error);
```
**Related prompts**
* [Password](#password-prompt)
* [Input](#input-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### List Prompt
Prompt that returns a list of values, created by splitting the user input. The default split character is `,` with optional trailing whitespace.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/list-prompt.gif" alt="Enquirer List Prompt" width="750">
</p>
**Example Usage**
```js
const { List } = require('enquirer');
const prompt = new List({
name: 'keywords',
message: 'Type comma-separated keywords'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Sort](#sort-prompt)
* [Select](#select-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### MultiSelect Prompt
Prompt that allows the user to select multiple items from a list of options.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/multiselect-prompt.gif" alt="Enquirer MultiSelect Prompt" width="750">
</p>
**Example Usage**
```js
const { MultiSelect } = require('enquirer');
const prompt = new MultiSelect({
name: 'value',
message: 'Pick your favorite colors',
limit: 7,
choices: [
{ name: 'aqua', value: '#00ffff' },
{ name: 'black', value: '#000000' },
{ name: 'blue', value: '#0000ff' },
{ name: 'fuchsia', value: '#ff00ff' },
{ name: 'gray', value: '#808080' },
{ name: 'green', value: '#008000' },
{ name: 'lime', value: '#00ff00' },
{ name: 'maroon', value: '#800000' },
{ name: 'navy', value: '#000080' },
{ name: 'olive', value: '#808000' },
{ name: 'purple', value: '#800080' },
{ name: 'red', value: '#ff0000' },
{ name: 'silver', value: '#c0c0c0' },
{ name: 'teal', value: '#008080' },
{ name: 'white', value: '#ffffff' },
{ name: 'yellow', value: '#ffff00' }
]
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
// Answer: ['aqua', 'blue', 'fuchsia']
```
**Example key-value pairs**
Optionally, pass a `result` function and use the `.map` method to return an object of key-value pairs of the selected names and values: [example](./examples/multiselect/option-result.js)
```js
const { MultiSelect } = require('enquirer');
const prompt = new MultiSelect({
name: 'value',
message: 'Pick your favorite colors',
limit: 7,
choices: [
{ name: 'aqua', value: '#00ffff' },
{ name: 'black', value: '#000000' },
{ name: 'blue', value: '#0000ff' },
{ name: 'fuchsia', value: '#ff00ff' },
{ name: 'gray', value: '#808080' },
{ name: 'green', value: '#008000' },
{ name: 'lime', value: '#00ff00' },
{ name: 'maroon', value: '#800000' },
{ name: 'navy', value: '#000080' },
{ name: 'olive', value: '#808000' },
{ name: 'purple', value: '#800080' },
{ name: 'red', value: '#ff0000' },
{ name: 'silver', value: '#c0c0c0' },
{ name: 'teal', value: '#008080' },
{ name: 'white', value: '#ffffff' },
{ name: 'yellow', value: '#ffff00' }
],
result(names) {
return this.map(names);
}
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
// Answer: { aqua: '#00ffff', blue: '#0000ff', fuchsia: '#ff00ff' }
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Numeral Prompt
Prompt that takes a number as input.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/numeral-prompt.gif" alt="Enquirer Numeral Prompt" width="750">
</p>
**Example Usage**
```js
const { NumberPrompt } = require('enquirer');
const prompt = new NumberPrompt({
name: 'number',
message: 'Please enter a number'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Confirm](#confirm-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Password Prompt
Prompt that takes user input and masks it in the terminal. Also see the [invisible prompt](#invisible-prompt)
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/password-prompt.gif" alt="Enquirer Password Prompt" width="750">
</p>
**Example Usage**
```js
const { Password } = require('enquirer');
const prompt = new Password({
name: 'password',
message: 'What is your password?'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Invisible](#invisible-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Quiz Prompt
Prompt that allows the user to play multiple-choice quiz questions.
<p align="center">
<img src="https://user-images.githubusercontent.com/13731210/61567561-891d4780-aa6f-11e9-9b09-3d504abd24ed.gif" alt="Enquirer Quiz Prompt" width="750">
</p>
**Example Usage**
```js
const { Quiz } = require('enquirer');
const prompt = new Quiz({
name: 'countries',
message: 'How many countries are there in the world?',
choices: ['165', '175', '185', '195', '205'],
correctChoice: 3
});
prompt
.run()
.then(answer => {
if (answer.correct) {
console.log('Correct!');
} else {
console.log(`Wrong! Correct answer is ${answer.correctAnswer}`);
}
})
.catch(console.error);
```
**Quiz Options**
| Option | Type | Required | Description |
| ----------- | ---------- | ---------- | ------------------------------------------------------------------------------------------------------------ |
| `choices` | `array` | Yes | The list of possible answers to the quiz question. |
| `correctChoice`| `number` | Yes | Index of the correct choice from the `choices` array. |
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Survey Prompt
Prompt that allows the user to provide feedback for a list of questions.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/survey-prompt.gif" alt="Enquirer Survey Prompt" width="750">
</p>
**Example Usage**
```js
const { Survey } = require('enquirer');
const prompt = new Survey({
name: 'experience',
message: 'Please rate your experience',
scale: [
{ name: '1', message: 'Strongly Disagree' },
{ name: '2', message: 'Disagree' },
{ name: '3', message: 'Neutral' },
{ name: '4', message: 'Agree' },
{ name: '5', message: 'Strongly Agree' }
],
margin: [0, 0, 2, 1],
choices: [
{
name: 'interface',
message: 'The website has a friendly interface.'
},
{
name: 'navigation',
message: 'The website is easy to navigate.'
},
{
name: 'images',
message: 'The website usually has good images.'
},
{
name: 'upload',
message: 'The website makes it easy to upload images.'
},
{
name: 'colors',
message: 'The website has a pleasing color palette.'
}
]
});
prompt.run()
.then(value => console.log('ANSWERS:', value))
.catch(console.error);
```
**Related prompts**
* [Scale](#scale-prompt)
* [Snippet](#snippet-prompt)
* [Select](#select-prompt)
***
### Scale Prompt
A more compact version of the [Survey prompt](#survey-prompt), the Scale prompt allows the user to quickly provide feedback using a [Likert Scale](https://en.wikipedia.org/wiki/Likert_scale).
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/scale-prompt.gif" alt="Enquirer Scale Prompt" width="750">
</p>
**Example Usage**
```js
const { Scale } = require('enquirer');
const prompt = new Scale({
name: 'experience',
message: 'Please rate your experience',
scale: [
{ name: '1', message: 'Strongly Disagree' },
{ name: '2', message: 'Disagree' },
{ name: '3', message: 'Neutral' },
{ name: '4', message: 'Agree' },
{ name: '5', message: 'Strongly Agree' }
],
margin: [0, 0, 2, 1],
choices: [
{
name: 'interface',
message: 'The website has a friendly interface.',
initial: 2
},
{
name: 'navigation',
message: 'The website is easy to navigate.',
initial: 2
},
{
name: 'images',
message: 'The website usually has good images.',
initial: 2
},
{
name: 'upload',
message: 'The website makes it easy to upload images.',
initial: 2
},
{
name: 'colors',
message: 'The website has a pleasing color palette.',
initial: 2
}
]
});
prompt.run()
.then(value => console.log('ANSWERS:', value))
.catch(console.error);
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Select Prompt
Prompt that allows the user to select from a list of options.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/select-prompt.gif" alt="Enquirer Select Prompt" width="750">
</p>
**Example Usage**
```js
const { Select } = require('enquirer');
const prompt = new Select({
name: 'color',
message: 'Pick a flavor',
choices: ['apple', 'grape', 'watermelon', 'cherry', 'orange']
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [MultiSelect](#multiselect-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Sort Prompt
Prompt that allows the user to sort items in a list.
**Example**
In this [example](https://github.com/enquirer/enquirer/raw/master/examples/sort/prompt.js), custom styling is applied to the returned values to make it easier to see what's happening.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/sort-prompt.gif" alt="Enquirer Sort Prompt" width="750">
</p>
**Example Usage**
```js
const colors = require('ansi-colors');
const { Sort } = require('enquirer');
const prompt = new Sort({
name: 'colors',
message: 'Sort the colors in order of preference',
hint: 'Top is best, bottom is worst',
numbered: true,
choices: ['red', 'white', 'green', 'cyan', 'yellow'].map(n => ({
name: n,
message: colors[n](n)
}))
});
prompt.run()
.then(function(answer = []) {
console.log(answer);
console.log('Your preferred order of colors is:');
console.log(answer.map(key => colors[key](key)).join('\n'));
})
.catch(console.error);
```
**Related prompts**
* [List](#list-prompt)
* [Select](#select-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Snippet Prompt
Prompt that allows the user to replace placeholders in a snippet of code or text.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/snippet-prompt.gif" alt="Prompts" width="750">
</p>
**Example Usage**
```js
const semver = require('semver');
const { Snippet } = require('enquirer');
const prompt = new Snippet({
name: 'username',
message: 'Fill out the fields in package.json',
required: true,
fields: [
{
name: 'author_name',
message: 'Author Name'
},
{
name: 'version',
validate(value, state, item, index) {
if (item && item.name === 'version' && !semver.valid(value)) {
return prompt.styles.danger('version should be a valid semver value');
}
return true;
}
}
],
template: `{
"name": "\${name}",
"description": "\${description}",
"version": "\${version}",
"homepage": "https://github.com/\${username}/\${name}",
"author": "\${author_name} (https://github.com/\${username})",
"repository": "\${username}/\${name}",
"license": "\${license:ISC}"
}
`
});
prompt.run()
.then(answer => console.log('Answer:', answer.result))
.catch(console.error);
```
**Related prompts**
* [Survey](#survey-prompt)
* [AutoComplete](#autocomplete-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Toggle Prompt
Prompt that allows the user to toggle between two values then returns `true` or `false`.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/toggle-prompt.gif" alt="Enquirer Toggle Prompt" width="750">
</p>
**Example Usage**
```js
const { Toggle } = require('enquirer');
const prompt = new Toggle({
message: 'Want to answer?',
enabled: 'Yep',
disabled: 'Nope'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Confirm](#confirm-prompt)
* [Input](#input-prompt)
* [Sort](#sort-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Prompt Types
There are 5 (soon to be 6!) type classes:
* [ArrayPrompt](#arrayprompt)
- [Options](#options)
- [Properties](#properties)
- [Methods](#methods)
- [Choices](#choices)
- [Defining choices](#defining-choices)
- [Choice properties](#choice-properties)
- [Related prompts](#related-prompts)
* [AuthPrompt](#authprompt)
* [BooleanPrompt](#booleanprompt)
* DatePrompt (Coming Soon!)
* [NumberPrompt](#numberprompt)
* [StringPrompt](#stringprompt)
Each type is a low-level class that may be used as a starting point for creating higher level prompts. Continue reading to learn how.
### ArrayPrompt
The `ArrayPrompt` class is used for creating prompts that display a list of choices in the terminal. For example, Enquirer uses this class as the basis for the [Select](#select) and [Survey](#survey) prompts.
#### Options
In addition to the [options](#options) available to all prompts, Array prompts also support the following options.
| **Option** | **Required?** | **Type** | **Description** |
| ----------- | ------------- | --------------- | ----------------------------------------------------------------------------------------------------------------------- |
| `autofocus` | `no` | `string\|number` | The index or name of the choice that should have focus when the prompt loads. Only one choice may have focus at a time. | |
| `stdin` | `no` | `stream` | The input stream to use for emitting keypress events. Defaults to `process.stdin`. |
| `stdout` | `no` | `stream` | The output stream to use for writing the prompt to the terminal. Defaults to `process.stdout`. |
| |
#### Properties
Array prompts have the following instance properties and getters.
| **Property name** | **Type** | **Description** |
| ----------------- | --------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `choices` | `array` | Array of choices that have been normalized from choices passed on the prompt options. |
| `cursor` | `number` | Position of the cursor relative to the _user input (string)_. |
| `enabled` | `array` | Returns an array of enabled choices. |
| `focused` | `array` | Returns the currently selected choice in the visible list of choices. This is similar to the concept of focus in HTML and CSS. Focused choices are always visible (on-screen). When a list of choices is longer than the list of visible choices, and an off-screen choice is _focused_, the list will scroll to the focused choice and re-render. |
| `focused` | Gets the currently selected choice. Equivalent to `prompt.choices[prompt.index]`. |
| `index` | `number` | Position of the pointer in the _visible list (array) of choices_. |
| `limit` | `number` | The number of choices to display on-screen. |
| `selected` | `array` | Either a list of enabled choices (when `options.multiple` is true) or the currently focused choice. |
| `visible` | `string` | |
#### Methods
| **Method** | **Description** |
| ------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `pointer()` | Returns the visual symbol to use to identify the choice that currently has focus. The `❯` symbol is often used for this. The pointer is not always visible, as with the `autocomplete` prompt. |
| `indicator()` | Returns the visual symbol that indicates whether or not a choice is checked/enabled. |
| `focus()` | Sets focus on a choice, if it can be focused. |
#### Choices
Array prompts support the `choices` option, which is the array of choices users will be able to select from when rendered in the terminal.
**Type**: `string|object`
**Example**
```js
const { prompt } = require('enquirer');
const questions = [{
type: 'select',
name: 'color',
message: 'Favorite color?',
initial: 1,
choices: [
{ name: 'red', message: 'Red', value: '#ff0000' }, //<= choice object
{ name: 'green', message: 'Green', value: '#00ff00' }, //<= choice object
{ name: 'blue', message: 'Blue', value: '#0000ff' } //<= choice object
]
}];
let answers = await prompt(questions);
console.log('Answer:', answers.color);
```
#### Defining choices
Whether defined as a string or object, choices are normalized to the following interface:
```js
{
name: string;
message: string | undefined;
value: string | undefined;
hint: string | undefined;
disabled: boolean | string | undefined;
}
```
**Example**
```js
const question = {
name: 'fruit',
message: 'Favorite fruit?',
choices: ['Apple', 'Orange', 'Raspberry']
};
```
Normalizes to the following when the prompt is run:
```js
const question = {
name: 'fruit',
message: 'Favorite fruit?',
choices: [
{ name: 'Apple', message: 'Apple', value: 'Apple' },
{ name: 'Orange', message: 'Orange', value: 'Orange' },
{ name: 'Raspberry', message: 'Raspberry', value: 'Raspberry' }
]
};
```
#### Choice properties
The following properties are supported on `choice` objects.
| **Option** | **Type** | **Description** |
| ----------- | ----------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `name` | `string` | The unique key to identify a choice |
| `message` | `string` | The message to display in the terminal. `name` is used when this is undefined. |
| `value` | `string` | Value to associate with the choice. Useful for creating key-value pairs from user choices. `name` is used when this is undefined. |
| `choices` | `array` | Array of "child" choices. |
| `hint` | `string` | Help message to display next to a choice. |
| `role` | `string` | Determines how the choice will be displayed. Currently the only role supported is `separator`. Additional roles may be added in the future (like `heading`, etc). Please create a [feature request] |
| `enabled` | `boolean` | Enabled a choice by default. This is only supported when `options.multiple` is true or on prompts that support multiple choices, like [MultiSelect](#-multiselect). |
| `disabled` | `boolean\|string` | Disable a choice so that it cannot be selected. This value may either be `true`, `false`, or a message to display. |
| `indicator` | `string\|function` | Custom indicator to render for a choice (like a check or radio button). |
#### Related prompts
* [AutoComplete](#autocomplete-prompt)
* [Form](#form-prompt)
* [MultiSelect](#multiselect-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
***
### AuthPrompt
The `AuthPrompt` is used to create prompts to log in user using any authentication method. For example, Enquirer uses this class as the basis for the [BasicAuth Prompt](#basicauth-prompt). You can also find prompt examples in `examples/auth/` folder that utilizes `AuthPrompt` to create OAuth based authentication prompt or a prompt that authenticates using time-based OTP, among others.
`AuthPrompt` has a factory function that creates an instance of `AuthPrompt` class and it expects an `authenticate` function, as an argument, which overrides the `authenticate` function of the `AuthPrompt` class.
#### Methods
| **Method** | **Description** |
| ------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `authenticate()` | Contain all the authentication logic. This function should be overridden to implement custom authentication logic. The default `authenticate` function throws an error if no other function is provided. |
#### Choices
Auth prompt supports the `choices` option, which is the similar to the choices used in [Form Prompt](#form-prompt).
**Example**
```js
const { AuthPrompt } = require('enquirer');
function authenticate(value, state) {
if (value.username === this.options.username && value.password === this.options.password) {
return true;
}
return false;
}
const CustomAuthPrompt = AuthPrompt.create(authenticate);
const prompt = new CustomAuthPrompt({
name: 'password',
message: 'Please enter your password',
username: 'rajat-sr',
password: '1234567',
choices: [
{ name: 'username', message: 'username' },
{ name: 'password', message: 'password' }
]
});
prompt
.run()
.then(answer => console.log('Authenticated?', answer))
.catch(console.error);
```
#### Related prompts
* [BasicAuth Prompt](#basicauth-prompt)
***
### BooleanPrompt
The `BooleanPrompt` class is used for creating prompts that display and return a boolean value.
```js
const { BooleanPrompt } = require('enquirer');
const prompt = new BooleanPrompt({
header: '========================',
message: 'Do you love enquirer?',
footer: '========================',
});
prompt.run()
.then(answer => console.log('Selected:', answer))
.catch(console.error);
```
**Returns**: `boolean`
***
### NumberPrompt
The `NumberPrompt` class is used for creating prompts that display and return a numerical value.
```js
const { NumberPrompt } = require('enquirer');
const prompt = new NumberPrompt({
header: '************************',
message: 'Input the Numbers:',
footer: '************************',
});
prompt.run()
.then(answer => console.log('Numbers are:', answer))
.catch(console.error);
```
**Returns**: `string|number` (number, or number formatted as a string)
***
### StringPrompt
The `StringPrompt` class is used for creating prompts that display and return a string value.
```js
const { StringPrompt } = require('enquirer');
const prompt = new StringPrompt({
header: '************************',
message: 'Input the String:',
footer: '************************'
});
prompt.run()
.then(answer => console.log('String is:', answer))
.catch(console.error);
```
**Returns**: `string`
<br>
## ❯ Custom prompts
With Enquirer 2.0, custom prompts are easier than ever to create and use.
**How do I create a custom prompt?**
Custom prompts are created by extending either:
* Enquirer's `Prompt` class
* one of the built-in [prompts](#-prompts), or
* low-level [types](#-types).
<!-- Example: HaiKarate Custom Prompt -->
```js
const { Prompt } = require('enquirer');
class HaiKarate extends Prompt {
constructor(options = {}) {
super(options);
this.value = options.initial || 0;
this.cursorHide();
}
up() {
this.value++;
this.render();
}
down() {
this.value--;
this.render();
}
render() {
this.clear(); // clear previously rendered prompt from the terminal
this.write(`${this.state.message}: ${this.value}`);
}
}
// Use the prompt by creating an instance of your custom prompt class.
const prompt = new HaiKarate({
message: 'How many sprays do you want?',
initial: 10
});
prompt.run()
.then(answer => console.log('Sprays:', answer))
.catch(console.error);
```
If you want to be able to specify your prompt by `type` so that it may be used alongside other prompts, you will need to first create an instance of `Enquirer`.
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
```
Then use the `.register()` method to add your custom prompt.
```js
enquirer.register('haikarate', HaiKarate);
```
Now you can do the following when defining "questions".
```js
let spritzer = require('cologne-drone');
let answers = await enquirer.prompt([
{
type: 'haikarate',
name: 'cologne',
message: 'How many sprays do you need?',
initial: 10,
async onSubmit(name, value) {
await spritzer.activate(value); //<= activate drone
return value;
}
}
]);
```
<br>
## ❯ Key Bindings
### All prompts
These key combinations may be used with all prompts.
| **command** | **description** |
| -------------------------------- | -------------------------------------- |
| <kbd>ctrl</kbd> + <kbd>c</kbd> | Cancel the prompt. |
| <kbd>ctrl</kbd> + <kbd>g</kbd> | Reset the prompt to its initial state. |
<br>
### Move cursor
These combinations may be used on prompts that support user input (eg. [input prompt](#input-prompt), [password prompt](#password-prompt), and [invisible prompt](#invisible-prompt)).
| **command** | **description** |
| ------------------------------ | ---------------------------------------- |
| <kbd>left</kbd> | Move the cursor back one character. |
| <kbd>right</kbd> | Move the cursor forward one character. |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move cursor to the start of the line |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move cursor to the end of the line |
| <kbd>ctrl</kbd> + <kbd>b</kbd> | Move cursor back one character |
| <kbd>ctrl</kbd> + <kbd>f</kbd> | Move cursor forward one character |
| <kbd>ctrl</kbd> + <kbd>x</kbd> | Toggle between first and cursor position |
<br>
### Edit Input
These key combinations may be used on prompts that support user input (eg. [input prompt](#input-prompt), [password prompt](#password-prompt), and [invisible prompt](#invisible-prompt)).
| **command** | **description** |
| ------------------------------ | ---------------------------------------- |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move cursor to the start of the line |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move cursor to the end of the line |
| <kbd>ctrl</kbd> + <kbd>b</kbd> | Move cursor back one character |
| <kbd>ctrl</kbd> + <kbd>f</kbd> | Move cursor forward one character |
| <kbd>ctrl</kbd> + <kbd>x</kbd> | Toggle between first and cursor position |
<br>
| **command (Mac)** | **command (Windows)** | **description** |
| ----------------------------------- | -------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------- |
| <kbd>delete</kbd> | <kbd>backspace</kbd> | Delete one character to the left. |
| <kbd>fn</kbd> + <kbd>delete</kbd> | <kbd>delete</kbd> | Delete one character to the right. |
| <kbd>option</kbd> + <kbd>up</kbd> | <kbd>alt</kbd> + <kbd>up</kbd> | Scroll to the previous item in history ([Input prompt](#input-prompt) only, when [history is enabled](examples/input/option-history.js)). |
| <kbd>option</kbd> + <kbd>down</kbd> | <kbd>alt</kbd> + <kbd>down</kbd> | Scroll to the next item in history ([Input prompt](#input-prompt) only, when [history is enabled](examples/input/option-history.js)). |
### Select choices
These key combinations may be used on prompts that support _multiple_ choices, such as the [multiselect prompt](#multiselect-prompt), or the [select prompt](#select-prompt) when the `multiple` options is true.
| **command** | **description** |
| ----------------- | -------------------------------------------------------------------------------------------------------------------- |
| <kbd>space</kbd> | Toggle the currently selected choice when `options.multiple` is true. |
| <kbd>number</kbd> | Move the pointer to the choice at the given index. Also toggles the selected choice when `options.multiple` is true. |
| <kbd>a</kbd> | Toggle all choices to be enabled or disabled. |
| <kbd>i</kbd> | Invert the current selection of choices. |
| <kbd>g</kbd> | Toggle the current choice group. |
<br>
### Hide/show choices
| **command** | **description** |
| ------------------------------- | ---------------------------------------------- |
| <kbd>fn</kbd> + <kbd>up</kbd> | Decrease the number of visible choices by one. |
| <kbd>fn</kbd> + <kbd>down</kbd> | Increase the number of visible choices by one. |
<br>
### Move/lock Pointer
| **command** | **description** |
| ---------------------------------- | -------------------------------------------------------------------------------------------------------------------- |
| <kbd>number</kbd> | Move the pointer to the choice at the given index. Also toggles the selected choice when `options.multiple` is true. |
| <kbd>up</kbd> | Move the pointer up. |
| <kbd>down</kbd> | Move the pointer down. |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move the pointer to the first _visible_ choice. |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move the pointer to the last _visible_ choice. |
| <kbd>shift</kbd> + <kbd>up</kbd> | Scroll up one choice without changing pointer position (locks the pointer while scrolling). |
| <kbd>shift</kbd> + <kbd>down</kbd> | Scroll down one choice without changing pointer position (locks the pointer while scrolling). |
<br>
| **command (Mac)** | **command (Windows)** | **description** |
| -------------------------------- | --------------------- | ---------------------------------------------------------- |
| <kbd>fn</kbd> + <kbd>left</kbd> | <kbd>home</kbd> | Move the pointer to the first choice in the choices array. |
| <kbd>fn</kbd> + <kbd>right</kbd> | <kbd>end</kbd> | Move the pointer to the last choice in the choices array. |
<br>
## ❯ Release History
Please see [CHANGELOG.md](CHANGELOG.md).
## ❯ Performance
### System specs
MacBook Pro, Intel Core i7, 2.5 GHz, 16 GB.
### Load time
Time it takes for the module to load the first time (average of 3 runs):
```
enquirer: 4.013ms
inquirer: 286.717ms
```
<br>
## ❯ About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Todo
We're currently working on documentation for the following items. Please star and watch the repository for updates!
* [ ] Customizing symbols
* [ ] Customizing styles (palette)
* [ ] Customizing rendered input
* [ ] Customizing returned values
* [ ] Customizing key bindings
* [ ] Question validation
* [ ] Choice validation
* [ ] Skipping questions
* [ ] Async choices
* [ ] Async timers: loaders, spinners and other animations
* [ ] Links to examples
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
```sh
$ yarn && yarn test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
#### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 283 | [jonschlinkert](https://github.com/jonschlinkert) |
| 82 | [doowb](https://github.com/doowb) |
| 32 | [rajat-sr](https://github.com/rajat-sr) |
| 20 | [318097](https://github.com/318097) |
| 15 | [g-plane](https://github.com/g-plane) |
| 12 | [pixelass](https://github.com/pixelass) |
| 5 | [adityavyas611](https://github.com/adityavyas611) |
| 5 | [satotake](https://github.com/satotake) |
| 3 | [tunnckoCore](https://github.com/tunnckoCore) |
| 3 | [Ovyerus](https://github.com/Ovyerus) |
| 3 | [sw-yx](https://github.com/sw-yx) |
| 2 | [DanielRuf](https://github.com/DanielRuf) |
| 2 | [GabeL7r](https://github.com/GabeL7r) |
| 1 | [AlCalzone](https://github.com/AlCalzone) |
| 1 | [hipstersmoothie](https://github.com/hipstersmoothie) |
| 1 | [danieldelcore](https://github.com/danieldelcore) |
| 1 | [ImgBotApp](https://github.com/ImgBotApp) |
| 1 | [jsonkao](https://github.com/jsonkao) |
| 1 | [knpwrs](https://github.com/knpwrs) |
| 1 | [yeskunall](https://github.com/yeskunall) |
| 1 | [mischah](https://github.com/mischah) |
| 1 | [renarsvilnis](https://github.com/renarsvilnis) |
| 1 | [sbugert](https://github.com/sbugert) |
| 1 | [stephencweiss](https://github.com/stephencweiss) |
| 1 | [skellock](https://github.com/skellock) |
| 1 | [whxaxes](https://github.com/whxaxes) |
#### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
#### Credit
Thanks to [derhuerst](https://github.com/derhuerst), creator of prompt libraries such as [prompt-skeleton](https://github.com/derhuerst/prompt-skeleton), which influenced some of the concepts we used in our prompts.
#### License
Copyright © 2018-present, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
# minizlib
A fast zlib stream built on [minipass](http://npm.im/minipass) and
Node.js's zlib binding.
This module was created to serve the needs of
[node-tar](http://npm.im/tar) and
[minipass-fetch](http://npm.im/minipass-fetch).
Brotli is supported in versions of node with a Brotli binding.
## How does this differ from the streams in `require('zlib')`?
First, there are no convenience methods to compress or decompress a
buffer. If you want those, use the built-in `zlib` module. This is
only streams. That being said, Minipass streams to make it fairly easy to
use as one-liners: `new zlib.Deflate().end(data).read()` will return the
deflate compressed result.
This module compresses and decompresses the data as fast as you feed
it in. It is synchronous, and runs on the main process thread. Zlib
and Brotli operations can be high CPU, but they're very fast, and doing it
this way means much less bookkeeping and artificial deferral.
Node's built in zlib streams are built on top of `stream.Transform`.
They do the maximally safe thing with respect to consistent
asynchrony, buffering, and backpressure.
See [Minipass](http://npm.im/minipass) for more on the differences between
Node.js core streams and Minipass streams, and the convenience methods
provided by that class.
## Classes
- Deflate
- Inflate
- Gzip
- Gunzip
- DeflateRaw
- InflateRaw
- Unzip
- BrotliCompress (Node v10 and higher)
- BrotliDecompress (Node v10 and higher)
## USAGE
```js
const zlib = require('minizlib')
const input = sourceOfCompressedData()
const decode = new zlib.BrotliDecompress()
const output = whereToWriteTheDecodedData()
input.pipe(decode).pipe(output)
```
## REPRODUCIBLE BUILDS
To create reproducible gzip compressed files across different operating
systems, set `portable: true` in the options. This causes minizlib to set
the `OS` indicator in byte 9 of the extended gzip header to `0xFF` for
'unknown'.
Browser-friendly inheritance fully compatible with standard node.js
[inherits](http://nodejs.org/api/util.html#util_util_inherits_constructor_superconstructor).
This package exports standard `inherits` from node.js `util` module in
node environment, but also provides alternative browser-friendly
implementation through [browser
field](https://gist.github.com/shtylman/4339901). Alternative
implementation is a literal copy of standard one located in standalone
module to avoid requiring of `util`. It also has a shim for old
browsers with no `Object.create` support.
While keeping you sure you are using standard `inherits`
implementation in node.js environment, it allows bundlers such as
[browserify](https://github.com/substack/node-browserify) to not
include full `util` package to your client code if all you need is
just `inherits` function. It worth, because browser shim for `util`
package is large and `inherits` is often the single function you need
from it.
It's recommended to use this package instead of
`require('util').inherits` for any code that has chances to be used
not only in node.js but in browser too.
## usage
```js
var inherits = require('inherits');
// then use exactly as the standard one
```
## note on version ~1.0
Version ~1.0 had completely different motivation and is not compatible
neither with 2.0 nor with standard node.js `inherits`.
If you are using version ~1.0 and planning to switch to ~2.0, be
careful:
* new version uses `super_` instead of `super` for referencing
superclass
* new version overwrites current prototype while old one preserves any
existing fields on it
# word-wrap [](https://www.npmjs.com/package/word-wrap) [](https://npmjs.org/package/word-wrap) [](https://npmjs.org/package/word-wrap) [](https://travis-ci.org/jonschlinkert/word-wrap)
> Wrap words to a specified length.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save word-wrap
```
## Usage
```js
var wrap = require('word-wrap');
wrap('Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.');
```
Results in:
```
Lorem ipsum dolor sit amet, consectetur adipiscing
elit, sed do eiusmod tempor incididunt ut labore
et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut
aliquip ex ea commodo consequat.
```
## Options

### options.width
Type: `Number`
Default: `50`
The width of the text before wrapping to a new line.
**Example:**
```js
wrap(str, {width: 60});
```
### options.indent
Type: `String`
Default: `` (two spaces)
The string to use at the beginning of each line.
**Example:**
```js
wrap(str, {indent: ' '});
```
### options.newline
Type: `String`
Default: `\n`
The string to use at the end of each line.
**Example:**
```js
wrap(str, {newline: '\n\n'});
```
### options.escape
Type: `function`
Default: `function(str){return str;}`
An escape function to run on each line after splitting them.
**Example:**
```js
var xmlescape = require('xml-escape');
wrap(str, {
escape: function(string){
return xmlescape(string);
}
});
```
### options.trim
Type: `Boolean`
Default: `false`
Trim trailing whitespace from the returned string. This option is included since `.trim()` would also strip the leading indentation from the first line.
**Example:**
```js
wrap(str, {trim: true});
```
### options.cut
Type: `Boolean`
Default: `false`
Break a word between any two letters when the word is longer than the specified width.
**Example:**
```js
wrap(str, {cut: true});
```
## About
### Related projects
* [common-words](https://www.npmjs.com/package/common-words): Updated list (JSON) of the 100 most common words in the English language. Useful for… [more](https://github.com/jonschlinkert/common-words) | [homepage](https://github.com/jonschlinkert/common-words "Updated list (JSON) of the 100 most common words in the English language. Useful for excluding these words from arrays.")
* [shuffle-words](https://www.npmjs.com/package/shuffle-words): Shuffle the words in a string and optionally the letters in each word using the… [more](https://github.com/jonschlinkert/shuffle-words) | [homepage](https://github.com/jonschlinkert/shuffle-words "Shuffle the words in a string and optionally the letters in each word using the Fisher-Yates algorithm. Useful for creating test fixtures, benchmarking samples, etc.")
* [unique-words](https://www.npmjs.com/package/unique-words): Return the unique words in a string or array. | [homepage](https://github.com/jonschlinkert/unique-words "Return the unique words in a string or array.")
* [wordcount](https://www.npmjs.com/package/wordcount): Count the words in a string. Support for english, CJK and Cyrillic. | [homepage](https://github.com/jonschlinkert/wordcount "Count the words in a string. Support for english, CJK and Cyrillic.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 43 | [jonschlinkert](https://github.com/jonschlinkert) |
| 2 | [lordvlad](https://github.com/lordvlad) |
| 2 | [hildjj](https://github.com/hildjj) |
| 1 | [danilosampaio](https://github.com/danilosampaio) |
| 1 | [2fd](https://github.com/2fd) |
| 1 | [toddself](https://github.com/toddself) |
| 1 | [wolfgang42](https://github.com/wolfgang42) |
| 1 | [zachhale](https://github.com/zachhale) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on June 02, 2017._
# hasurl [![NPM Version][npm-image]][npm-url] [![Build Status][travis-image]][travis-url]
> Determine whether Node.js' native [WHATWG `URL`](https://nodejs.org/api/url.html#url_the_whatwg_url_api) implementation is available.
## Installation
[Node.js](http://nodejs.org/) `>= 4` is required. To install, type this at the command line:
```shell
npm install hasurl
```
## Usage
```js
const hasURL = require('hasurl');
if (hasURL()) {
// supported
} else {
// fallback
}
```
[npm-image]: https://img.shields.io/npm/v/hasurl.svg
[npm-url]: https://npmjs.org/package/hasurl
[travis-image]: https://img.shields.io/travis/stevenvachon/hasurl.svg
[travis-url]: https://travis-ci.org/stevenvachon/hasurl
# rechoir [](http://travis-ci.org/tkellen/js-rechoir)
> Require any supported file as a node module.
[](https://nodei.co/npm/rechoir/)
## What is it?
This module, in conjunction with [interpret]-like objects can register any file type the npm ecosystem has a module loader for. This library is a dependency of [Liftoff].
## API
### prepare(config, filepath, requireFrom)
Look for a module loader associated with the provided file and attempt require it. If necessary, run any setup required to inject it into [require.extensions](http://nodejs.org/api/globals.html#globals_require_extensions).
`config` An [interpret]-like configuration object.
`filepath` A file whose type you'd like to register a module loader for.
`requireFrom` An optional path to start searching for the module required to load the requested file. Defaults to the directory of `filepath`.
If calling this method is successful (aka: it doesn't throw), you can now require files of the type you requested natively.
An error with a `failures` property will be thrown if the module loader(s) configured for a given extension cannot be registered.
If a loader is already registered, this will simply return `true`.
**Note:** While rechoir will automatically load and register transpilers like `coffee-script`, you must provide a local installation. The transpilers are **not** bundled with this module.
#### Usage
```js
const config = require('interpret').extensions;
const rechoir = require('rechoir');
rechoir.prepare(config, './test/fixtures/test.coffee');
rechoir.prepare(config, './test/fixtures/test.csv');
rechoir.prepare(config, './test/fixtures/test.toml');
console.log(require('./test/fixtures/test.coffee'));
console.log(require('./test/fixtures/test.csv'));
console.log(require('./test/fixtures/test.toml'));
```
[interpret]: http://github.com/tkellen/js-interpret
[Liftoff]: http://github.com/tkellen/js-liftoff
# Acorn-JSX
[](https://travis-ci.org/acornjs/acorn-jsx)
[](https://www.npmjs.org/package/acorn-jsx)
This is plugin for [Acorn](http://marijnhaverbeke.nl/acorn/) - a tiny, fast JavaScript parser, written completely in JavaScript.
It was created as an experimental alternative, faster [React.js JSX](http://facebook.github.io/react/docs/jsx-in-depth.html) parser. Later, it replaced the [official parser](https://github.com/facebookarchive/esprima) and these days is used by many prominent development tools.
## Transpiler
Please note that this tool only parses source code to JSX AST, which is useful for various language tools and services. If you want to transpile your code to regular ES5-compliant JavaScript with source map, check out [Babel](https://babeljs.io/) and [Buble](https://buble.surge.sh/) transpilers which use `acorn-jsx` under the hood.
## Usage
Requiring this module provides you with an Acorn plugin that you can use like this:
```javascript
var acorn = require("acorn");
var jsx = require("acorn-jsx");
acorn.Parser.extend(jsx()).parse("my(<jsx/>, 'code');");
```
Note that official spec doesn't support mix of XML namespaces and object-style access in tag names (#27) like in `<namespace:Object.Property />`, so it was deprecated in `acorn-jsx@3.0`. If you still want to opt-in to support of such constructions, you can pass the following option:
```javascript
acorn.Parser.extend(jsx({ allowNamespacedObjects: true }))
```
Also, since most apps use pure React transformer, a new option was introduced that allows to prohibit namespaces completely:
```javascript
acorn.Parser.extend(jsx({ allowNamespaces: false }))
```
Note that by default `allowNamespaces` is enabled for spec compliancy.
## License
This plugin is issued under the [MIT license](./LICENSE).
# tr46.js
> An implementation of the [Unicode TR46 specification](http://unicode.org/reports/tr46/).
## Installation
[Node.js](http://nodejs.org) `>= 6` is required. To install, type this at the command line:
```shell
npm install tr46
```
## API
### `toASCII(domainName[, options])`
Converts a string of Unicode symbols to a case-folded Punycode string of ASCII symbols.
Available options:
* [`checkBidi`](#checkBidi)
* [`checkHyphens`](#checkHyphens)
* [`checkJoiners`](#checkJoiners)
* [`processingOption`](#processingOption)
* [`useSTD3ASCIIRules`](#useSTD3ASCIIRules)
* [`verifyDNSLength`](#verifyDNSLength)
### `toUnicode(domainName[, options])`
Converts a case-folded Punycode string of ASCII symbols to a string of Unicode symbols.
Available options:
* [`checkBidi`](#checkBidi)
* [`checkHyphens`](#checkHyphens)
* [`checkJoiners`](#checkJoiners)
* [`useSTD3ASCIIRules`](#useSTD3ASCIIRules)
## Options
### `checkBidi`
Type: `Boolean`
Default value: `false`
When set to `true`, any bi-directional text within the input will be checked for validation.
### `checkHyphens`
Type: `Boolean`
Default value: `false`
When set to `true`, the positions of any hyphen characters within the input will be checked for validation.
### `checkJoiners`
Type: `Boolean`
Default value: `false`
When set to `true`, any word joiner characters within the input will be checked for validation.
### `processingOption`
Type: `String`
Default value: `"nontransitional"`
When set to `"transitional"`, symbols within the input will be validated according to the older IDNA2003 protocol. When set to `"nontransitional"`, the current IDNA2008 protocol will be used.
### `useSTD3ASCIIRules`
Type: `Boolean`
Default value: `false`
When set to `true`, input will be validated according to [STD3 Rules](http://unicode.org/reports/tr46/#STD3_Rules).
### `verifyDNSLength`
Type: `Boolean`
Default value: `false`
When set to `true`, the length of each DNS label within the input will be checked for validation.
# debug
[](https://travis-ci.org/debug-js/debug) [](https://coveralls.io/github/debug-js/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
`disable()`
Will disable all namespaces. The functions returns the namespaces currently
enabled (and skipped). This can be useful if you want to disable debugging
temporarily without knowing what was enabled to begin with.
For example:
```js
let debug = require('debug');
debug.enable('foo:*,-foo:bar');
let namespaces = debug.disable();
debug.enable(namespaces);
```
Note: There is no guarantee that the string will be identical to the initial
enable string, but semantically they will be identical.
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Usage in child processes
Due to the way `debug` detects if the output is a TTY or not, colors are not shown in child processes when `stderr` is piped. A solution is to pass the `DEBUG_COLORS=1` environment variable to the child process.
For example:
```javascript
worker = fork(WORKER_WRAP_PATH, [workerPath], {
stdio: [
/* stdin: */ 0,
/* stdout: */ 'pipe',
/* stderr: */ 'pipe',
'ipc',
],
env: Object.assign({}, process.env, {
DEBUG_COLORS: 1 // without this settings, colors won't be shown
}),
});
worker.stderr.pipe(process.stderr, { end: false });
```
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
- Josh Junon
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <tj@vision-media.ca>
Copyright (c) 2018-2021 Josh Junon
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# eslint-visitor-keys
[](https://www.npmjs.com/package/eslint-visitor-keys)
[](http://www.npmtrends.com/eslint-visitor-keys)
[](https://travis-ci.org/eslint/eslint-visitor-keys)
[](https://david-dm.org/eslint/eslint-visitor-keys)
Constants and utilities about visitor keys to traverse AST.
## 💿 Installation
Use [npm] to install.
```bash
$ npm install eslint-visitor-keys
```
### Requirements
- [Node.js] 4.0.0 or later.
## 📖 Usage
```js
const evk = require("eslint-visitor-keys")
```
### evk.KEYS
> type: `{ [type: string]: string[] | undefined }`
Visitor keys. This keys are frozen.
This is an object. Keys are the type of [ESTree] nodes. Their values are an array of property names which have child nodes.
For example:
```
console.log(evk.KEYS.AssignmentExpression) // → ["left", "right"]
```
### evk.getKeys(node)
> type: `(node: object) => string[]`
Get the visitor keys of a given AST node.
This is similar to `Object.keys(node)` of ES Standard, but some keys are excluded: `parent`, `leadingComments`, `trailingComments`, and names which start with `_`.
This will be used to traverse unknown nodes.
For example:
```
const node = {
type: "AssignmentExpression",
left: { type: "Identifier", name: "foo" },
right: { type: "Literal", value: 0 }
}
console.log(evk.getKeys(node)) // → ["type", "left", "right"]
```
### evk.unionWith(additionalKeys)
> type: `(additionalKeys: object) => { [type: string]: string[] | undefined }`
Make the union set with `evk.KEYS` and the given keys.
- The order of keys is, `additionalKeys` is at first, then `evk.KEYS` is concatenated after that.
- It removes duplicated keys as keeping the first one.
For example:
```
console.log(evk.unionWith({
MethodDefinition: ["decorators"]
})) // → { ..., MethodDefinition: ["decorators", "key", "value"], ... }
```
## 📰 Change log
See [GitHub releases](https://github.com/eslint/eslint-visitor-keys/releases).
## 🍻 Contributing
Welcome. See [ESLint contribution guidelines](https://eslint.org/docs/developer-guide/contributing/).
### Development commands
- `npm test` runs tests and measures code coverage.
- `npm run lint` checks source codes with ESLint.
- `npm run coverage` opens the code coverage report of the previous test with your default browser.
- `npm run release` publishes this package to [npm] registory.
[npm]: https://www.npmjs.com/
[Node.js]: https://nodejs.org/en/
[ESTree]: https://github.com/estree/estree
### esutils [](http://travis-ci.org/estools/esutils)
esutils ([esutils](http://github.com/estools/esutils)) is
utility box for ECMAScript language tools.
### API
### ast
#### ast.isExpression(node)
Returns true if `node` is an Expression as defined in ECMA262 edition 5.1 section
[11](https://es5.github.io/#x11).
#### ast.isStatement(node)
Returns true if `node` is a Statement as defined in ECMA262 edition 5.1 section
[12](https://es5.github.io/#x12).
#### ast.isIterationStatement(node)
Returns true if `node` is an IterationStatement as defined in ECMA262 edition
5.1 section [12.6](https://es5.github.io/#x12.6).
#### ast.isSourceElement(node)
Returns true if `node` is a SourceElement as defined in ECMA262 edition 5.1
section [14](https://es5.github.io/#x14).
#### ast.trailingStatement(node)
Returns `Statement?` if `node` has trailing `Statement`.
```js
if (cond)
consequent;
```
When taking this `IfStatement`, returns `consequent;` statement.
#### ast.isProblematicIfStatement(node)
Returns true if `node` is a problematic IfStatement. If `node` is a problematic `IfStatement`, `node` cannot be represented as an one on one JavaScript code.
```js
{
type: 'IfStatement',
consequent: {
type: 'WithStatement',
body: {
type: 'IfStatement',
consequent: {type: 'EmptyStatement'}
}
},
alternate: {type: 'EmptyStatement'}
}
```
The above node cannot be represented as a JavaScript code, since the top level `else` alternate belongs to an inner `IfStatement`.
### code
#### code.isDecimalDigit(code)
Return true if provided code is decimal digit.
#### code.isHexDigit(code)
Return true if provided code is hexadecimal digit.
#### code.isOctalDigit(code)
Return true if provided code is octal digit.
#### code.isWhiteSpace(code)
Return true if provided code is white space. White space characters are formally defined in ECMA262.
#### code.isLineTerminator(code)
Return true if provided code is line terminator. Line terminator characters are formally defined in ECMA262.
#### code.isIdentifierStart(code)
Return true if provided code can be the first character of ECMA262 Identifier. They are formally defined in ECMA262.
#### code.isIdentifierPart(code)
Return true if provided code can be the trailing character of ECMA262 Identifier. They are formally defined in ECMA262.
### keyword
#### keyword.isKeywordES5(id, strict)
Returns `true` if provided identifier string is a Keyword or Future Reserved Word
in ECMA262 edition 5.1. They are formally defined in ECMA262 sections
[7.6.1.1](http://es5.github.io/#x7.6.1.1) and [7.6.1.2](http://es5.github.io/#x7.6.1.2),
respectively. If the `strict` flag is truthy, this function additionally checks whether
`id` is a Keyword or Future Reserved Word under strict mode.
#### keyword.isKeywordES6(id, strict)
Returns `true` if provided identifier string is a Keyword or Future Reserved Word
in ECMA262 edition 6. They are formally defined in ECMA262 sections
[11.6.2.1](http://ecma-international.org/ecma-262/6.0/#sec-keywords) and
[11.6.2.2](http://ecma-international.org/ecma-262/6.0/#sec-future-reserved-words),
respectively. If the `strict` flag is truthy, this function additionally checks whether
`id` is a Keyword or Future Reserved Word under strict mode.
#### keyword.isReservedWordES5(id, strict)
Returns `true` if provided identifier string is a Reserved Word in ECMA262 edition 5.1.
They are formally defined in ECMA262 section [7.6.1](http://es5.github.io/#x7.6.1).
If the `strict` flag is truthy, this function additionally checks whether `id`
is a Reserved Word under strict mode.
#### keyword.isReservedWordES6(id, strict)
Returns `true` if provided identifier string is a Reserved Word in ECMA262 edition 6.
They are formally defined in ECMA262 section [11.6.2](http://ecma-international.org/ecma-262/6.0/#sec-reserved-words).
If the `strict` flag is truthy, this function additionally checks whether `id`
is a Reserved Word under strict mode.
#### keyword.isRestrictedWord(id)
Returns `true` if provided identifier string is one of `eval` or `arguments`.
They are restricted in strict mode code throughout ECMA262 edition 5.1 and
in ECMA262 edition 6 section [12.1.1](http://ecma-international.org/ecma-262/6.0/#sec-identifiers-static-semantics-early-errors).
#### keyword.isIdentifierNameES5(id)
Return true if provided identifier string is an IdentifierName as specified in
ECMA262 edition 5.1 section [7.6](https://es5.github.io/#x7.6).
#### keyword.isIdentifierNameES6(id)
Return true if provided identifier string is an IdentifierName as specified in
ECMA262 edition 6 section [11.6](http://ecma-international.org/ecma-262/6.0/#sec-names-and-keywords).
#### keyword.isIdentifierES5(id, strict)
Return true if provided identifier string is an Identifier as specified in
ECMA262 edition 5.1 section [7.6](https://es5.github.io/#x7.6). If the `strict`
flag is truthy, this function additionally checks whether `id` is an Identifier
under strict mode.
#### keyword.isIdentifierES6(id, strict)
Return true if provided identifier string is an Identifier as specified in
ECMA262 edition 6 section [12.1](http://ecma-international.org/ecma-262/6.0/#sec-identifiers).
If the `strict` flag is truthy, this function additionally checks whether `id`
is an Identifier under strict mode.
### License
Copyright (C) 2013 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# brace-expansion
[Brace expansion](https://www.gnu.org/software/bash/manual/html_node/Brace-Expansion.html),
as known from sh/bash, in JavaScript.
[](http://travis-ci.org/juliangruber/brace-expansion)
[](https://www.npmjs.org/package/brace-expansion)
[](https://greenkeeper.io/)
[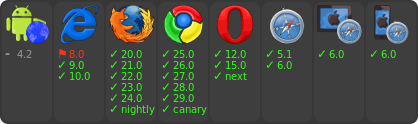](https://ci.testling.com/juliangruber/brace-expansion)
## Example
```js
var expand = require('brace-expansion');
expand('file-{a,b,c}.jpg')
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
expand('-v{,,}')
// => ['-v', '-v', '-v']
expand('file{0..2}.jpg')
// => ['file0.jpg', 'file1.jpg', 'file2.jpg']
expand('file-{a..c}.jpg')
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
expand('file{2..0}.jpg')
// => ['file2.jpg', 'file1.jpg', 'file0.jpg']
expand('file{0..4..2}.jpg')
// => ['file0.jpg', 'file2.jpg', 'file4.jpg']
expand('file-{a..e..2}.jpg')
// => ['file-a.jpg', 'file-c.jpg', 'file-e.jpg']
expand('file{00..10..5}.jpg')
// => ['file00.jpg', 'file05.jpg', 'file10.jpg']
expand('{{A..C},{a..c}}')
// => ['A', 'B', 'C', 'a', 'b', 'c']
expand('ppp{,config,oe{,conf}}')
// => ['ppp', 'pppconfig', 'pppoe', 'pppoeconf']
```
## API
```js
var expand = require('brace-expansion');
```
### var expanded = expand(str)
Return an array of all possible and valid expansions of `str`. If none are
found, `[str]` is returned.
Valid expansions are:
```js
/^(.*,)+(.+)?$/
// {a,b,...}
```
A comma separated list of options, like `{a,b}` or `{a,{b,c}}` or `{,a,}`.
```js
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
// {x..y[..incr]}
```
A numeric sequence from `x` to `y` inclusive, with optional increment.
If `x` or `y` start with a leading `0`, all the numbers will be padded
to have equal length. Negative numbers and backwards iteration work too.
```js
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
// {x..y[..incr]}
```
An alphabetic sequence from `x` to `y` inclusive, with optional increment.
`x` and `y` must be exactly one character, and if given, `incr` must be a
number.
For compatibility reasons, the string `${` is not eligible for brace expansion.
## Installation
With [npm](https://npmjs.org) do:
```bash
npm install brace-expansion
```
## Contributors
- [Julian Gruber](https://github.com/juliangruber)
- [Isaac Z. Schlueter](https://github.com/isaacs)
## Sponsors
This module is proudly supported by my [Sponsors](https://github.com/juliangruber/sponsors)!
Do you want to support modules like this to improve their quality, stability and weigh in on new features? Then please consider donating to my [Patreon](https://www.patreon.com/juliangruber). Not sure how much of my modules you're using? Try [feross/thanks](https://github.com/feross/thanks)!
## License
(MIT)
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
[](https://www.npmjs.com/package/espree)
[](https://travis-ci.org/eslint/espree)
[](https://www.npmjs.com/package/espree)
[](https://www.bountysource.com/trackers/9348450-eslint?utm_source=9348450&utm_medium=shield&utm_campaign=TRACKER_BADGE)
# Espree
Espree started out as a fork of [Esprima](http://esprima.org) v1.2.2, the last stable published released of Esprima before work on ECMAScript 6 began. Espree is now built on top of [Acorn](https://github.com/ternjs/acorn), which has a modular architecture that allows extension of core functionality. The goal of Espree is to produce output that is similar to Esprima with a similar API so that it can be used in place of Esprima.
## Usage
Install:
```
npm i espree
```
And in your Node.js code:
```javascript
const espree = require("espree");
const ast = espree.parse(code);
```
## API
### `parse()`
`parse` parses the given code and returns a abstract syntax tree (AST). It takes two parameters.
- `code` [string]() - the code which needs to be parsed.
- `options (Optional)` [Object]() - read more about this [here](#options).
```javascript
const espree = require("espree");
const ast = espree.parse(code, options);
```
**Example :**
```js
const ast = espree.parse('let foo = "bar"', { ecmaVersion: 6 });
console.log(ast);
```
<details><summary>Output</summary>
<p>
```
Node {
type: 'Program',
start: 0,
end: 15,
body: [
Node {
type: 'VariableDeclaration',
start: 0,
end: 15,
declarations: [Array],
kind: 'let'
}
],
sourceType: 'script'
}
```
</p>
</details>
### `tokenize()`
`tokenize` returns the tokens of a given code. It takes two parameters.
- `code` [string]() - the code which needs to be parsed.
- `options (Optional)` [Object]() - read more about this [here](#options).
Even if `options` is empty or undefined or `options.tokens` is `false`, it assigns it to `true` in order to get the `tokens` array
**Example :**
```js
const tokens = espree.tokenize('let foo = "bar"', { ecmaVersion: 6 });
console.log(tokens);
```
<details><summary>Output</summary>
<p>
```
Token { type: 'Keyword', value: 'let', start: 0, end: 3 },
Token { type: 'Identifier', value: 'foo', start: 4, end: 7 },
Token { type: 'Punctuator', value: '=', start: 8, end: 9 },
Token { type: 'String', value: '"bar"', start: 10, end: 15 }
```
</p>
</details>
### `version`
Returns the current `espree` version
### `VisitorKeys`
Returns all visitor keys for traversing the AST from [eslint-visitor-keys](https://github.com/eslint/eslint-visitor-keys)
### `latestEcmaVersion`
Returns the latest ECMAScript supported by `espree`
### `supportedEcmaVersions`
Returns an array of all supported ECMAScript versions
## Options
```js
const options = {
// attach range information to each node
range: false,
// attach line/column location information to each node
loc: false,
// create a top-level comments array containing all comments
comment: false,
// create a top-level tokens array containing all tokens
tokens: false,
// Set to 3, 5 (default), 6, 7, 8, 9, 10, 11, or 12 to specify the version of ECMAScript syntax you want to use.
// You can also set to 2015 (same as 6), 2016 (same as 7), 2017 (same as 8), 2018 (same as 9), 2019 (same as 10), 2020 (same as 11), or 2021 (same as 12) to use the year-based naming.
ecmaVersion: 5,
// specify which type of script you're parsing ("script" or "module")
sourceType: "script",
// specify additional language features
ecmaFeatures: {
// enable JSX parsing
jsx: false,
// enable return in global scope
globalReturn: false,
// enable implied strict mode (if ecmaVersion >= 5)
impliedStrict: false
}
}
```
## Esprima Compatibility Going Forward
The primary goal is to produce the exact same AST structure and tokens as Esprima, and that takes precedence over anything else. (The AST structure being the [ESTree](https://github.com/estree/estree) API with JSX extensions.) Separate from that, Espree may deviate from what Esprima outputs in terms of where and how comments are attached, as well as what additional information is available on AST nodes. That is to say, Espree may add more things to the AST nodes than Esprima does but the overall AST structure produced will be the same.
Espree may also deviate from Esprima in the interface it exposes.
## Contributing
Issues and pull requests will be triaged and responded to as quickly as possible. We operate under the [ESLint Contributor Guidelines](http://eslint.org/docs/developer-guide/contributing), so please be sure to read them before contributing. If you're not sure where to dig in, check out the [issues](https://github.com/eslint/espree/issues).
Espree is licensed under a permissive BSD 2-clause license.
## Security Policy
We work hard to ensure that Espree is safe for everyone and that security issues are addressed quickly and responsibly. Read the full [security policy](https://github.com/eslint/.github/blob/master/SECURITY.md).
## Build Commands
* `npm test` - run all linting and tests
* `npm run lint` - run all linting
* `npm run browserify` - creates a version of Espree that is usable in a browser
## Differences from Espree 2.x
* The `tokenize()` method does not use `ecmaFeatures`. Any string will be tokenized completely based on ECMAScript 6 semantics.
* Trailing whitespace no longer is counted as part of a node.
* `let` and `const` declarations are no longer parsed by default. You must opt-in by using an `ecmaVersion` newer than `5` or setting `sourceType` to `module`.
* The `esparse` and `esvalidate` binary scripts have been removed.
* There is no `tolerant` option. We will investigate adding this back in the future.
## Known Incompatibilities
In an effort to help those wanting to transition from other parsers to Espree, the following is a list of noteworthy incompatibilities with other parsers. These are known differences that we do not intend to change.
### Esprima 1.2.2
* Esprima counts trailing whitespace as part of each AST node while Espree does not. In Espree, the end of a node is where the last token occurs.
* Espree does not parse `let` and `const` declarations by default.
* Error messages returned for parsing errors are different.
* There are two addition properties on every node and token: `start` and `end`. These represent the same data as `range` and are used internally by Acorn.
### Esprima 2.x
* Esprima 2.x uses a different comment attachment algorithm that results in some comments being added in different places than Espree. The algorithm Espree uses is the same one used in Esprima 1.2.2.
## Frequently Asked Questions
### Why another parser
[ESLint](http://eslint.org) had been relying on Esprima as its parser from the beginning. While that was fine when the JavaScript language was evolving slowly, the pace of development increased dramatically and Esprima had fallen behind. ESLint, like many other tools reliant on Esprima, has been stuck in using new JavaScript language features until Esprima updates, and that caused our users frustration.
We decided the only way for us to move forward was to create our own parser, bringing us inline with JSHint and JSLint, and allowing us to keep implementing new features as we need them. We chose to fork Esprima instead of starting from scratch in order to move as quickly as possible with a compatible API.
With Espree 2.0.0, we are no longer a fork of Esprima but rather a translation layer between Acorn and Esprima syntax. This allows us to put work back into a community-supported parser (Acorn) that is continuing to grow and evolve while maintaining an Esprima-compatible parser for those utilities still built on Esprima.
### Have you tried working with Esprima?
Yes. Since the start of ESLint, we've regularly filed bugs and feature requests with Esprima and will continue to do so. However, there are some different philosophies around how the projects work that need to be worked through. The initial goal was to have Espree track Esprima and eventually merge the two back together, but we ultimately decided that building on top of Acorn was a better choice due to Acorn's plugin support.
### Why don't you just use Acorn?
Acorn is a great JavaScript parser that produces an AST that is compatible with Esprima. Unfortunately, ESLint relies on more than just the AST to do its job. It relies on Esprima's tokens and comment attachment features to get a complete picture of the source code. We investigated switching to Acorn, but the inconsistencies between Esprima and Acorn created too much work for a project like ESLint.
We are building on top of Acorn, however, so that we can contribute back and help make Acorn even better.
### What ECMAScript features do you support?
Espree supports all ECMAScript 2020 features and partially supports ECMAScript 2021 features.
Because ECMAScript 2021 is still under development, we are implementing features as they are finalized. Currently, Espree supports:
* [Logical Assignment Operators](https://github.com/tc39/proposal-logical-assignment)
* [Numeric Separators](https://github.com/tc39/proposal-numeric-separator)
See [finished-proposals.md](https://github.com/tc39/proposals/blob/master/finished-proposals.md) to know what features are finalized.
### How do you determine which experimental features to support?
In general, we do not support experimental JavaScript features. We may make exceptions from time to time depending on the maturity of the features.
[](https://www.npmjs.com/package/eslint)
[](https://www.npmjs.com/package/eslint)
[](https://github.com/eslint/eslint/actions)
[](https://app.fossa.io/projects/git%2Bhttps%3A%2F%2Fgithub.com%2Feslint%2Feslint?ref=badge_shield)
<br />
[](https://opencollective.com/eslint)
[](https://opencollective.com/eslint)
[](https://twitter.com/intent/user?screen_name=geteslint)
# ESLint
[Website](https://eslint.org) |
[Configuring](https://eslint.org/docs/user-guide/configuring) |
[Rules](https://eslint.org/docs/rules/) |
[Contributing](https://eslint.org/docs/developer-guide/contributing) |
[Reporting Bugs](https://eslint.org/docs/developer-guide/contributing/reporting-bugs) |
[Code of Conduct](https://eslint.org/conduct) |
[Twitter](https://twitter.com/geteslint) |
[Mailing List](https://groups.google.com/group/eslint) |
[Chat Room](https://eslint.org/chat)
ESLint is a tool for identifying and reporting on patterns found in ECMAScript/JavaScript code. In many ways, it is similar to JSLint and JSHint with a few exceptions:
* ESLint uses [Espree](https://github.com/eslint/espree) for JavaScript parsing.
* ESLint uses an AST to evaluate patterns in code.
* ESLint is completely pluggable, every single rule is a plugin and you can add more at runtime.
## Table of Contents
1. [Installation and Usage](#installation-and-usage)
2. [Configuration](#configuration)
3. [Code of Conduct](#code-of-conduct)
4. [Filing Issues](#filing-issues)
5. [Frequently Asked Questions](#faq)
6. [Releases](#releases)
7. [Security Policy](#security-policy)
8. [Semantic Versioning Policy](#semantic-versioning-policy)
9. [Stylistic Rule Updates](#stylistic-rule-updates)
10. [License](#license)
11. [Team](#team)
12. [Sponsors](#sponsors)
13. [Technology Sponsors](#technology-sponsors)
## <a name="installation-and-usage"></a>Installation and Usage
Prerequisites: [Node.js](https://nodejs.org/) (`^10.12.0`, or `>=12.0.0`) built with SSL support. (If you are using an official Node.js distribution, SSL is always built in.)
You can install ESLint using npm:
```
$ npm install eslint --save-dev
```
You should then set up a configuration file:
```
$ ./node_modules/.bin/eslint --init
```
After that, you can run ESLint on any file or directory like this:
```
$ ./node_modules/.bin/eslint yourfile.js
```
## <a name="configuration"></a>Configuration
After running `eslint --init`, you'll have a `.eslintrc` file in your directory. In it, you'll see some rules configured like this:
```json
{
"rules": {
"semi": ["error", "always"],
"quotes": ["error", "double"]
}
}
```
The names `"semi"` and `"quotes"` are the names of [rules](https://eslint.org/docs/rules) in ESLint. The first value is the error level of the rule and can be one of these values:
* `"off"` or `0` - turn the rule off
* `"warn"` or `1` - turn the rule on as a warning (doesn't affect exit code)
* `"error"` or `2` - turn the rule on as an error (exit code will be 1)
The three error levels allow you fine-grained control over how ESLint applies rules (for more configuration options and details, see the [configuration docs](https://eslint.org/docs/user-guide/configuring)).
## <a name="code-of-conduct"></a>Code of Conduct
ESLint adheres to the [JS Foundation Code of Conduct](https://eslint.org/conduct).
## <a name="filing-issues"></a>Filing Issues
Before filing an issue, please be sure to read the guidelines for what you're reporting:
* [Bug Report](https://eslint.org/docs/developer-guide/contributing/reporting-bugs)
* [Propose a New Rule](https://eslint.org/docs/developer-guide/contributing/new-rules)
* [Proposing a Rule Change](https://eslint.org/docs/developer-guide/contributing/rule-changes)
* [Request a Change](https://eslint.org/docs/developer-guide/contributing/changes)
## <a name="faq"></a>Frequently Asked Questions
### I'm using JSCS, should I migrate to ESLint?
Yes. [JSCS has reached end of life](https://eslint.org/blog/2016/07/jscs-end-of-life) and is no longer supported.
We have prepared a [migration guide](https://eslint.org/docs/user-guide/migrating-from-jscs) to help you convert your JSCS settings to an ESLint configuration.
We are now at or near 100% compatibility with JSCS. If you try ESLint and believe we are not yet compatible with a JSCS rule/configuration, please create an issue (mentioning that it is a JSCS compatibility issue) and we will evaluate it as per our normal process.
### Does Prettier replace ESLint?
No, ESLint does both traditional linting (looking for problematic patterns) and style checking (enforcement of conventions). You can use ESLint for everything, or you can combine both using Prettier to format your code and ESLint to catch possible errors.
### Why can't ESLint find my plugins?
* Make sure your plugins (and ESLint) are both in your project's `package.json` as devDependencies (or dependencies, if your project uses ESLint at runtime).
* Make sure you have run `npm install` and all your dependencies are installed.
* Make sure your plugins' peerDependencies have been installed as well. You can use `npm view eslint-plugin-myplugin peerDependencies` to see what peer dependencies `eslint-plugin-myplugin` has.
### Does ESLint support JSX?
Yes, ESLint natively supports parsing JSX syntax (this must be enabled in [configuration](https://eslint.org/docs/user-guide/configuring)). Please note that supporting JSX syntax *is not* the same as supporting React. React applies specific semantics to JSX syntax that ESLint doesn't recognize. We recommend using [eslint-plugin-react](https://www.npmjs.com/package/eslint-plugin-react) if you are using React and want React semantics.
### What ECMAScript versions does ESLint support?
ESLint has full support for ECMAScript 3, 5 (default), 2015, 2016, 2017, 2018, 2019, and 2020. You can set your desired ECMAScript syntax (and other settings, like global variables or your target environments) through [configuration](https://eslint.org/docs/user-guide/configuring).
### What about experimental features?
ESLint's parser only officially supports the latest final ECMAScript standard. We will make changes to core rules in order to avoid crashes on stage 3 ECMAScript syntax proposals (as long as they are implemented using the correct experimental ESTree syntax). We may make changes to core rules to better work with language extensions (such as JSX, Flow, and TypeScript) on a case-by-case basis.
In other cases (including if rules need to warn on more or fewer cases due to new syntax, rather than just not crashing), we recommend you use other parsers and/or rule plugins. If you are using Babel, you can use the [babel-eslint](https://github.com/babel/babel-eslint) parser and [eslint-plugin-babel](https://github.com/babel/eslint-plugin-babel) to use any option available in Babel.
Once a language feature has been adopted into the ECMAScript standard (stage 4 according to the [TC39 process](https://tc39.github.io/process-document/)), we will accept issues and pull requests related to the new feature, subject to our [contributing guidelines](https://eslint.org/docs/developer-guide/contributing). Until then, please use the appropriate parser and plugin(s) for your experimental feature.
### Where to ask for help?
Join our [Mailing List](https://groups.google.com/group/eslint) or [Chatroom](https://eslint.org/chat).
### Why doesn't ESLint lock dependency versions?
Lock files like `package-lock.json` are helpful for deployed applications. They ensure that dependencies are consistent between environments and across deployments.
Packages like `eslint` that get published to the npm registry do not include lock files. `npm install eslint` as a user will respect version constraints in ESLint's `package.json`. ESLint and its dependencies will be included in the user's lock file if one exists, but ESLint's own lock file would not be used.
We intentionally don't lock dependency versions so that we have the latest compatible dependency versions in development and CI that our users get when installing ESLint in a project.
The Twilio blog has a [deeper dive](https://www.twilio.com/blog/lockfiles-nodejs) to learn more.
## <a name="releases"></a>Releases
We have scheduled releases every two weeks on Friday or Saturday. You can follow a [release issue](https://github.com/eslint/eslint/issues?q=is%3Aopen+is%3Aissue+label%3Arelease) for updates about the scheduling of any particular release.
## <a name="security-policy"></a>Security Policy
ESLint takes security seriously. We work hard to ensure that ESLint is safe for everyone and that security issues are addressed quickly and responsibly. Read the full [security policy](https://github.com/eslint/.github/blob/master/SECURITY.md).
## <a name="semantic-versioning-policy"></a>Semantic Versioning Policy
ESLint follows [semantic versioning](https://semver.org). However, due to the nature of ESLint as a code quality tool, it's not always clear when a minor or major version bump occurs. To help clarify this for everyone, we've defined the following semantic versioning policy for ESLint:
* Patch release (intended to not break your lint build)
* A bug fix in a rule that results in ESLint reporting fewer linting errors.
* A bug fix to the CLI or core (including formatters).
* Improvements to documentation.
* Non-user-facing changes such as refactoring code, adding, deleting, or modifying tests, and increasing test coverage.
* Re-releasing after a failed release (i.e., publishing a release that doesn't work for anyone).
* Minor release (might break your lint build)
* A bug fix in a rule that results in ESLint reporting more linting errors.
* A new rule is created.
* A new option to an existing rule that does not result in ESLint reporting more linting errors by default.
* A new addition to an existing rule to support a newly-added language feature (within the last 12 months) that will result in ESLint reporting more linting errors by default.
* An existing rule is deprecated.
* A new CLI capability is created.
* New capabilities to the public API are added (new classes, new methods, new arguments to existing methods, etc.).
* A new formatter is created.
* `eslint:recommended` is updated and will result in strictly fewer linting errors (e.g., rule removals).
* Major release (likely to break your lint build)
* `eslint:recommended` is updated and may result in new linting errors (e.g., rule additions, most rule option updates).
* A new option to an existing rule that results in ESLint reporting more linting errors by default.
* An existing formatter is removed.
* Part of the public API is removed or changed in an incompatible way. The public API includes:
* Rule schemas
* Configuration schema
* Command-line options
* Node.js API
* Rule, formatter, parser, plugin APIs
According to our policy, any minor update may report more linting errors than the previous release (ex: from a bug fix). As such, we recommend using the tilde (`~`) in `package.json` e.g. `"eslint": "~3.1.0"` to guarantee the results of your builds.
## <a name="stylistic-rule-updates"></a>Stylistic Rule Updates
Stylistic rules are frozen according to [our policy](https://eslint.org/blog/2020/05/changes-to-rules-policies) on how we evaluate new rules and rule changes.
This means:
* **Bug fixes**: We will still fix bugs in stylistic rules.
* **New ECMAScript features**: We will also make sure stylistic rules are compatible with new ECMAScript features.
* **New options**: We will **not** add any new options to stylistic rules unless an option is the only way to fix a bug or support a newly-added ECMAScript feature.
## <a name="license"></a>License
[](https://app.fossa.io/projects/git%2Bhttps%3A%2F%2Fgithub.com%2Feslint%2Feslint?ref=badge_large)
## <a name="team"></a>Team
These folks keep the project moving and are resources for help.
<!-- NOTE: This section is autogenerated. Do not manually edit.-->
<!--teamstart-->
### Technical Steering Committee (TSC)
The people who manage releases, review feature requests, and meet regularly to ensure ESLint is properly maintained.
<table><tbody><tr><td align="center" valign="top" width="11%">
<a href="https://github.com/nzakas">
<img src="https://github.com/nzakas.png?s=75" width="75" height="75"><br />
Nicholas C. Zakas
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/btmills">
<img src="https://github.com/btmills.png?s=75" width="75" height="75"><br />
Brandon Mills
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/mdjermanovic">
<img src="https://github.com/mdjermanovic.png?s=75" width="75" height="75"><br />
Milos Djermanovic
</a>
</td></tr></tbody></table>
### Reviewers
The people who review and implement new features.
<table><tbody><tr><td align="center" valign="top" width="11%">
<a href="https://github.com/mysticatea">
<img src="https://github.com/mysticatea.png?s=75" width="75" height="75"><br />
Toru Nagashima
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/aladdin-add">
<img src="https://github.com/aladdin-add.png?s=75" width="75" height="75"><br />
薛定谔的猫
</a>
</td></tr></tbody></table>
### Committers
The people who review and fix bugs and help triage issues.
<table><tbody><tr><td align="center" valign="top" width="11%">
<a href="https://github.com/brettz9">
<img src="https://github.com/brettz9.png?s=75" width="75" height="75"><br />
Brett Zamir
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/bmish">
<img src="https://github.com/bmish.png?s=75" width="75" height="75"><br />
Bryan Mishkin
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/g-plane">
<img src="https://github.com/g-plane.png?s=75" width="75" height="75"><br />
Pig Fang
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/anikethsaha">
<img src="https://github.com/anikethsaha.png?s=75" width="75" height="75"><br />
Anix
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/yeonjuan">
<img src="https://github.com/yeonjuan.png?s=75" width="75" height="75"><br />
YeonJuan
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/snitin315">
<img src="https://github.com/snitin315.png?s=75" width="75" height="75"><br />
Nitin Kumar
</a>
</td></tr></tbody></table>
<!--teamend-->
## <a name="sponsors"></a>Sponsors
The following companies, organizations, and individuals support ESLint's ongoing maintenance and development. [Become a Sponsor](https://opencollective.com/eslint) to get your logo on our README and website.
<!-- NOTE: This section is autogenerated. Do not manually edit.-->
<!--sponsorsstart-->
<h3>Platinum Sponsors</h3>
<p><a href="https://automattic.com"><img src="https://images.opencollective.com/photomatt/d0ef3e1/logo.png" alt="Automattic" height="undefined"></a></p><h3>Gold Sponsors</h3>
<p><a href="https://nx.dev"><img src="https://images.opencollective.com/nx/0efbe42/logo.png" alt="Nx (by Nrwl)" height="96"></a> <a href="https://google.com/chrome"><img src="https://images.opencollective.com/chrome/dc55bd4/logo.png" alt="Chrome's Web Framework & Tools Performance Fund" height="96"></a> <a href="https://www.salesforce.com"><img src="https://images.opencollective.com/salesforce/ca8f997/logo.png" alt="Salesforce" height="96"></a> <a href="https://www.airbnb.com/"><img src="https://images.opencollective.com/airbnb/d327d66/logo.png" alt="Airbnb" height="96"></a> <a href="https://coinbase.com"><img src="https://avatars.githubusercontent.com/u/1885080?v=4" alt="Coinbase" height="96"></a> <a href="https://substack.com/"><img src="https://avatars.githubusercontent.com/u/53023767?v=4" alt="Substack" height="96"></a></p><h3>Silver Sponsors</h3>
<p><a href="https://retool.com/"><img src="https://images.opencollective.com/retool/98ea68e/logo.png" alt="Retool" height="64"></a> <a href="https://liftoff.io/"><img src="https://images.opencollective.com/liftoff/5c4fa84/logo.png" alt="Liftoff" height="64"></a></p><h3>Bronze Sponsors</h3>
<p><a href="https://www.crosswordsolver.org/anagram-solver/"><img src="https://images.opencollective.com/anagram-solver/2666271/logo.png" alt="Anagram Solver" height="32"></a> <a href="null"><img src="https://images.opencollective.com/bugsnag-stability-monitoring/c2cef36/logo.png" alt="Bugsnag Stability Monitoring" height="32"></a> <a href="https://mixpanel.com"><img src="https://images.opencollective.com/mixpanel/cd682f7/logo.png" alt="Mixpanel" height="32"></a> <a href="https://www.vpsserver.com"><img src="https://images.opencollective.com/vpsservercom/logo.png" alt="VPS Server" height="32"></a> <a href="https://icons8.com"><img src="https://images.opencollective.com/icons8/7fa1641/logo.png" alt="Icons8: free icons, photos, illustrations, and music" height="32"></a> <a href="https://discord.com"><img src="https://images.opencollective.com/discordapp/f9645d9/logo.png" alt="Discord" height="32"></a> <a href="https://themeisle.com"><img src="https://images.opencollective.com/themeisle/d5592fe/logo.png" alt="ThemeIsle" height="32"></a> <a href="https://www.firesticktricks.com"><img src="https://images.opencollective.com/fire-stick-tricks/b8fbe2c/logo.png" alt="Fire Stick Tricks" height="32"></a> <a href="https://www.practiceignition.com"><img src="https://avatars.githubusercontent.com/u/5753491?v=4" alt="Practice Ignition" height="32"></a></p>
<!--sponsorsend-->
## <a name="technology-sponsors"></a>Technology Sponsors
* Site search ([eslint.org](https://eslint.org)) is sponsored by [Algolia](https://www.algolia.com)
* Hosting for ([eslint.org](https://eslint.org)) is sponsored by [Netlify](https://www.netlify.com)
* Password management is sponsored by [1Password](https://www.1password.com)
blockvote
==================
This [React] app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `blockvote.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `blockvote.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account blockvote.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'blockvote.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
[](https://app.travis-ci.com/github/dankogai/js-base64)
# base64.js
Yet another [Base64] transcoder.
[Base64]: http://en.wikipedia.org/wiki/Base64
## Install
```shell
$ npm install --save js-base64
```
## Usage
### In Browser
Locally…
```html
<script src="base64.js"></script>
```
… or Directly from CDN. In which case you don't even need to install.
```html
<script src="https://cdn.jsdelivr.net/npm/js-base64@3.7.2/base64.min.js"></script>
```
This good old way loads `Base64` in the global context (`window`). Though `Base64.noConflict()` is made available, you should consider using ES6 Module to avoid tainting `window`.
### As an ES6 Module
locally…
```javascript
import { Base64 } from 'js-base64';
```
```javascript
// or if you prefer no Base64 namespace
import { encode, decode } from 'js-base64';
```
or even remotely.
```html
<script type="module">
// note jsdelivr.net does not automatically minify .mjs
import { Base64 } from 'https://cdn.jsdelivr.net/npm/js-base64@3.7.2/base64.mjs';
</script>
```
```html
<script type="module">
// or if you prefer no Base64 namespace
import { encode, decode } from 'https://cdn.jsdelivr.net/npm/js-base64@3.7.2/base64.mjs';
</script>
```
### node.js (commonjs)
```javascript
const {Base64} = require('js-base64');
```
Unlike the case above, the global context is no longer modified.
You can also use [esm] to `import` instead of `require`.
[esm]: https://github.com/standard-things/esm
```javascript
require=require('esm')(module);
import {Base64} from 'js-base64';
```
## SYNOPSIS
```javascript
let latin = 'dankogai';
let utf8 = '小飼弾'
let u8s = new Uint8Array([100,97,110,107,111,103,97,105]);
Base64.encode(latin); // ZGFua29nYWk=
Base64.encode(latin, true)); // ZGFua29nYWk skips padding
Base64.encodeURI(latin)); // ZGFua29nYWk
Base64.btoa(latin); // ZGFua29nYWk=
Base64.btoa(utf8); // raises exception
Base64.fromUint8Array(u8s); // ZGFua29nYWk=
Base64.fromUint8Array(u8s, true); // ZGFua29nYW which is URI safe
Base64.encode(utf8); // 5bCP6aO85by+
Base64.encode(utf8, true) // 5bCP6aO85by-
Base64.encodeURI(utf8); // 5bCP6aO85by-
```
```javascript
Base64.decode( 'ZGFua29nYWk=');// dankogai
Base64.decode( 'ZGFua29nYWk'); // dankogai
Base64.atob( 'ZGFua29nYWk=');// dankogai
Base64.atob( '5bCP6aO85by+');// 'å°é£¼å¼¾' which is nonsense
Base64.toUint8Array('ZGFua29nYWk=');// u8s above
Base64.decode( '5bCP6aO85by+');// 小飼弾
// note .decodeURI() is unnecessary since it accepts both flavors
Base64.decode( '5bCP6aO85by-');// 小飼弾
```
```javascript
Base64.isValid(0); // false: 0 is not string
Base64.isValid(''); // true: a valid Base64-encoded empty byte
Base64.isValid('ZA=='); // true: a valid Base64-encoded 'd'
Base64.isValid('Z A='); // true: whitespaces are okay
Base64.isValid('ZA'); // true: padding ='s can be omitted
Base64.isValid('++'); // true: can be non URL-safe
Base64.isValid('--'); // true: or URL-safe
Base64.isValid('+-'); // false: can't mix both
```
### Built-in Extensions
By default `Base64` leaves built-in prototypes untouched. But you can extend them as below.
```javascript
// you have to explicitly extend String.prototype
Base64.extendString();
// once extended, you can do the following
'dankogai'.toBase64(); // ZGFua29nYWk=
'小飼弾'.toBase64(); // 5bCP6aO85by+
'小飼弾'.toBase64(true); // 5bCP6aO85by-
'小飼弾'.toBase64URI(); // 5bCP6aO85by- ab alias of .toBase64(true)
'小飼弾'.toBase64URL(); // 5bCP6aO85by- an alias of .toBase64URI()
'ZGFua29nYWk='.fromBase64(); // dankogai
'5bCP6aO85by+'.fromBase64(); // 小飼弾
'5bCP6aO85by-'.fromBase64(); // 小飼弾
'5bCP6aO85by-'.toUint8Array();// u8s above
```
```javascript
// you have to explicitly extend Uint8Array.prototype
Base64.extendUint8Array();
// once extended, you can do the following
u8s.toBase64(); // 'ZGFua29nYWk='
u8s.toBase64URI(); // 'ZGFua29nYWk'
u8s.toBase64URL(); // 'ZGFua29nYWk' an alias of .toBase64URI()
```
```javascript
// extend all at once
Base64.extendBuiltins()
```
## `.decode()` vs `.atob` (and `.encode()` vs `btoa()`)
Suppose you have:
```
var pngBase64 =
"iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAQAAAC1HAwCAAAAC0lEQVR42mNkYAAAAAYAAjCB0C8AAAAASUVORK5CYII=";
```
Which is a Base64-encoded 1x1 transparent PNG, **DO NOT USE** `Base64.decode(pngBase64)`. Use `Base64.atob(pngBase64)` instead. `Base64.decode()` decodes to UTF-8 string while `Base64.atob()` decodes to bytes, which is compatible to browser built-in `atob()` (Which is absent in node.js). The same rule applies to the opposite direction.
Or even better, `Base64.toUint8Array(pngBase64)`.
### If you really, really need an ES5 version
You can transpiles to an ES5 that runs on IEs before 11. Do the following in your shell.
```shell
$ make base64.es5.js
```
## Brief History
* Since version 3.3 it is written in TypeScript. Now `base64.mjs` is compiled from `base64.ts` then `base64.js` is generated from `base64.mjs`.
* Since version 3.7 `base64.js` is ES5-compatible again (hence IE11-compabile).
* Since 3.0 `js-base64` switch to ES2015 module so it is no longer compatible with legacy browsers like IE (see above)
# [nearley](http://nearley.js.org) ↗️
[](http://js.org)
[](https://badge.fury.io/js/nearley)
nearley is a simple, fast and powerful parsing toolkit. It consists of:
1. [A powerful, modular DSL for describing
languages](https://nearley.js.org/docs/grammar)
2. [An efficient, lightweight Earley
parser](https://nearley.js.org/docs/parser)
3. [Loads of tools, editor plug-ins, and other
goodies!](https://nearley.js.org/docs/tooling)
nearley is a **streaming** parser with support for catching **errors**
gracefully and providing _all_ parsings for **ambiguous** grammars. It is
compatible with a variety of **lexers** (we recommend
[moo](http://github.com/tjvr/moo)). It comes with tools for creating **tests**,
**railroad diagrams** and **fuzzers** from your grammars, and has support for a
variety of editors and platforms. It works in both node and the browser.
Unlike most other parser generators, nearley can handle *any* grammar you can
define in BNF (and more!). In particular, while most existing JS parsers such
as PEGjs and Jison choke on certain grammars (e.g. [left recursive
ones](http://en.wikipedia.org/wiki/Left_recursion)), nearley handles them
easily and efficiently by using the [Earley parsing
algorithm](https://en.wikipedia.org/wiki/Earley_parser).
nearley is used by a wide variety of projects:
- [artificial
intelligence](https://github.com/ChalmersGU-AI-course/shrdlite-course-project)
and
- [computational
linguistics](https://wiki.eecs.yorku.ca/course_archive/2014-15/W/6339/useful_handouts)
classes at universities;
- [file format parsers](https://github.com/raymond-h/node-dmi);
- [data-driven markup languages](https://github.com/idyll-lang/idyll-compiler);
- [compilers for real-world programming
languages](https://github.com/sizigi/lp5562);
- and nearley itself! The nearley compiler is bootstrapped.
nearley is an npm [staff
pick](https://www.npmjs.com/package/npm-collection-staff-picks).
## Documentation
Please visit our website https://nearley.js.org to get started! You will find a
tutorial, detailed reference documents, and links to several real-world
examples to get inspired.
## Contributing
Please read [this document](.github/CONTRIBUTING.md) *before* working on
nearley. If you are interested in contributing but unsure where to start, take
a look at the issues labeled "up for grabs" on the issue tracker, or message a
maintainer (@kach or @tjvr on Github).
nearley is MIT licensed.
A big thanks to Nathan Dinsmore for teaching me how to Earley, Aria Stewart for
helping structure nearley into a mature module, and Robin Windels for
bootstrapping the grammar. Additionally, Jacob Edelman wrote an experimental
JavaScript parser with nearley and contributed ideas for EBNF support. Joshua
T. Corbin refactored the compiler to be much, much prettier. Bojidar Marinov
implemented postprocessors-in-other-languages. Shachar Itzhaky fixed a subtle
bug with nullables.
## Citing nearley
If you are citing nearley in academic work, please use the following BibTeX
entry.
```bibtex
@misc{nearley,
author = "Kartik Chandra and Tim Radvan",
title = "{nearley}: a parsing toolkit for {JavaScript}",
year = {2014},
doi = {10.5281/zenodo.3897993},
url = {https://github.com/kach/nearley}
}
```
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
* `n` - the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
* `rn` - both argument and return value of the function are plain JavaScript
Numbers. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
* `BN.max(a, b)` - return `a` if `a` bigger than `b`
* `BN.min(a, b)` - return `a` if `a` less than `b`
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divmod(b)` - quotient and modulus obtained by dividing
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b, value)` - set specified bit to `value`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
### Number Size
Optimized for elliptic curves that work with 256-bit numbers.
There is no limitation on the size of the numbers.
## LICENSE
This software is licensed under the MIT License.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# lru cache
A cache object that deletes the least-recently-used items.
[](https://travis-ci.org/isaacs/node-lru-cache) [](https://coveralls.io/github/isaacs/node-lru-cache)
## Installation:
```javascript
npm install lru-cache --save
```
## Usage:
```javascript
var LRU = require("lru-cache")
, options = { max: 500
, length: function (n, key) { return n * 2 + key.length }
, dispose: function (key, n) { n.close() }
, maxAge: 1000 * 60 * 60 }
, cache = new LRU(options)
, otherCache = new LRU(50) // sets just the max size
cache.set("key", "value")
cache.get("key") // "value"
// non-string keys ARE fully supported
// but note that it must be THE SAME object, not
// just a JSON-equivalent object.
var someObject = { a: 1 }
cache.set(someObject, 'a value')
// Object keys are not toString()-ed
cache.set('[object Object]', 'a different value')
assert.equal(cache.get(someObject), 'a value')
// A similar object with same keys/values won't work,
// because it's a different object identity
assert.equal(cache.get({ a: 1 }), undefined)
cache.reset() // empty the cache
```
If you put more stuff in it, then items will fall out.
If you try to put an oversized thing in it, then it'll fall out right
away.
## Options
* `max` The maximum size of the cache, checked by applying the length
function to all values in the cache. Not setting this is kind of
silly, since that's the whole purpose of this lib, but it defaults
to `Infinity`. Setting it to a non-number or negative number will
throw a `TypeError`. Setting it to 0 makes it be `Infinity`.
* `maxAge` Maximum age in ms. Items are not pro-actively pruned out
as they age, but if you try to get an item that is too old, it'll
drop it and return undefined instead of giving it to you.
Setting this to a negative value will make everything seem old!
Setting it to a non-number will throw a `TypeError`.
* `length` Function that is used to calculate the length of stored
items. If you're storing strings or buffers, then you probably want
to do something like `function(n, key){return n.length}`. The default is
`function(){return 1}`, which is fine if you want to store `max`
like-sized things. The item is passed as the first argument, and
the key is passed as the second argumnet.
* `dispose` Function that is called on items when they are dropped
from the cache. This can be handy if you want to close file
descriptors or do other cleanup tasks when items are no longer
accessible. Called with `key, value`. It's called *before*
actually removing the item from the internal cache, so if you want
to immediately put it back in, you'll have to do that in a
`nextTick` or `setTimeout` callback or it won't do anything.
* `stale` By default, if you set a `maxAge`, it'll only actually pull
stale items out of the cache when you `get(key)`. (That is, it's
not pre-emptively doing a `setTimeout` or anything.) If you set
`stale:true`, it'll return the stale value before deleting it. If
you don't set this, then it'll return `undefined` when you try to
get a stale entry, as if it had already been deleted.
* `noDisposeOnSet` By default, if you set a `dispose()` method, then
it'll be called whenever a `set()` operation overwrites an existing
key. If you set this option, `dispose()` will only be called when a
key falls out of the cache, not when it is overwritten.
* `updateAgeOnGet` When using time-expiring entries with `maxAge`,
setting this to `true` will make each item's effective time update
to the current time whenever it is retrieved from cache, causing it
to not expire. (It can still fall out of cache based on recency of
use, of course.)
## API
* `set(key, value, maxAge)`
* `get(key) => value`
Both of these will update the "recently used"-ness of the key.
They do what you think. `maxAge` is optional and overrides the
cache `maxAge` option if provided.
If the key is not found, `get()` will return `undefined`.
The key and val can be any value.
* `peek(key)`
Returns the key value (or `undefined` if not found) without
updating the "recently used"-ness of the key.
(If you find yourself using this a lot, you *might* be using the
wrong sort of data structure, but there are some use cases where
it's handy.)
* `del(key)`
Deletes a key out of the cache.
* `reset()`
Clear the cache entirely, throwing away all values.
* `has(key)`
Check if a key is in the cache, without updating the recent-ness
or deleting it for being stale.
* `forEach(function(value,key,cache), [thisp])`
Just like `Array.prototype.forEach`. Iterates over all the keys
in the cache, in order of recent-ness. (Ie, more recently used
items are iterated over first.)
* `rforEach(function(value,key,cache), [thisp])`
The same as `cache.forEach(...)` but items are iterated over in
reverse order. (ie, less recently used items are iterated over
first.)
* `keys()`
Return an array of the keys in the cache.
* `values()`
Return an array of the values in the cache.
* `length`
Return total length of objects in cache taking into account
`length` options function.
* `itemCount`
Return total quantity of objects currently in cache. Note, that
`stale` (see options) items are returned as part of this item
count.
* `dump()`
Return an array of the cache entries ready for serialization and usage
with 'destinationCache.load(arr)`.
* `load(cacheEntriesArray)`
Loads another cache entries array, obtained with `sourceCache.dump()`,
into the cache. The destination cache is reset before loading new entries
* `prune()`
Manually iterates over the entire cache proactively pruning old entries
# minipass
A _very_ minimal implementation of a [PassThrough
stream](https://nodejs.org/api/stream.html#stream_class_stream_passthrough)
[It's very
fast](https://docs.google.com/spreadsheets/d/1oObKSrVwLX_7Ut4Z6g3fZW-AX1j1-k6w-cDsrkaSbHM/edit#gid=0)
for objects, strings, and buffers.
Supports `pipe()`ing (including multi-`pipe()` and backpressure transmission),
buffering data until either a `data` event handler or `pipe()` is added (so
you don't lose the first chunk), and most other cases where PassThrough is
a good idea.
There is a `read()` method, but it's much more efficient to consume data
from this stream via `'data'` events or by calling `pipe()` into some other
stream. Calling `read()` requires the buffer to be flattened in some
cases, which requires copying memory.
There is also no `unpipe()` method. Once you start piping, there is no
stopping it!
If you set `objectMode: true` in the options, then whatever is written will
be emitted. Otherwise, it'll do a minimal amount of Buffer copying to
ensure proper Streams semantics when `read(n)` is called.
`objectMode` can also be set by doing `stream.objectMode = true`, or by
writing any non-string/non-buffer data. `objectMode` cannot be set to
false once it is set.
This is not a `through` or `through2` stream. It doesn't transform the
data, it just passes it right through. If you want to transform the data,
extend the class, and override the `write()` method. Once you're done
transforming the data however you want, call `super.write()` with the
transform output.
For some examples of streams that extend Minipass in various ways, check
out:
- [minizlib](http://npm.im/minizlib)
- [fs-minipass](http://npm.im/fs-minipass)
- [tar](http://npm.im/tar)
- [minipass-collect](http://npm.im/minipass-collect)
- [minipass-flush](http://npm.im/minipass-flush)
- [minipass-pipeline](http://npm.im/minipass-pipeline)
- [tap](http://npm.im/tap)
- [tap-parser](http://npm.im/tap-parser)
- [treport](http://npm.im/treport)
- [minipass-fetch](http://npm.im/minipass-fetch)
- [pacote](http://npm.im/pacote)
- [make-fetch-happen](http://npm.im/make-fetch-happen)
- [cacache](http://npm.im/cacache)
- [ssri](http://npm.im/ssri)
- [npm-registry-fetch](http://npm.im/npm-registry-fetch)
- [minipass-json-stream](http://npm.im/minipass-json-stream)
- [minipass-sized](http://npm.im/minipass-sized)
## Differences from Node.js Streams
There are several things that make Minipass streams different from (and in
some ways superior to) Node.js core streams.
Please read these caveats if you are familiar with node-core streams and
intend to use Minipass streams in your programs.
### Timing
Minipass streams are designed to support synchronous use-cases. Thus, data
is emitted as soon as it is available, always. It is buffered until read,
but no longer. Another way to look at it is that Minipass streams are
exactly as synchronous as the logic that writes into them.
This can be surprising if your code relies on `PassThrough.write()` always
providing data on the next tick rather than the current one, or being able
to call `resume()` and not have the entire buffer disappear immediately.
However, without this synchronicity guarantee, there would be no way for
Minipass to achieve the speeds it does, or support the synchronous use
cases that it does. Simply put, waiting takes time.
This non-deferring approach makes Minipass streams much easier to reason
about, especially in the context of Promises and other flow-control
mechanisms.
### No High/Low Water Marks
Node.js core streams will optimistically fill up a buffer, returning `true`
on all writes until the limit is hit, even if the data has nowhere to go.
Then, they will not attempt to draw more data in until the buffer size dips
below a minimum value.
Minipass streams are much simpler. The `write()` method will return `true`
if the data has somewhere to go (which is to say, given the timing
guarantees, that the data is already there by the time `write()` returns).
If the data has nowhere to go, then `write()` returns false, and the data
sits in a buffer, to be drained out immediately as soon as anyone consumes
it.
### Hazards of Buffering (or: Why Minipass Is So Fast)
Since data written to a Minipass stream is immediately written all the way
through the pipeline, and `write()` always returns true/false based on
whether the data was fully flushed, backpressure is communicated
immediately to the upstream caller. This minimizes buffering.
Consider this case:
```js
const {PassThrough} = require('stream')
const p1 = new PassThrough({ highWaterMark: 1024 })
const p2 = new PassThrough({ highWaterMark: 1024 })
const p3 = new PassThrough({ highWaterMark: 1024 })
const p4 = new PassThrough({ highWaterMark: 1024 })
p1.pipe(p2).pipe(p3).pipe(p4)
p4.on('data', () => console.log('made it through'))
// this returns false and buffers, then writes to p2 on next tick (1)
// p2 returns false and buffers, pausing p1, then writes to p3 on next tick (2)
// p3 returns false and buffers, pausing p2, then writes to p4 on next tick (3)
// p4 returns false and buffers, pausing p3, then emits 'data' and 'drain'
// on next tick (4)
// p3 sees p4's 'drain' event, and calls resume(), emitting 'resume' and
// 'drain' on next tick (5)
// p2 sees p3's 'drain', calls resume(), emits 'resume' and 'drain' on next tick (6)
// p1 sees p2's 'drain', calls resume(), emits 'resume' and 'drain' on next
// tick (7)
p1.write(Buffer.alloc(2048)) // returns false
```
Along the way, the data was buffered and deferred at each stage, and
multiple event deferrals happened, for an unblocked pipeline where it was
perfectly safe to write all the way through!
Furthermore, setting a `highWaterMark` of `1024` might lead someone reading
the code to think an advisory maximum of 1KiB is being set for the
pipeline. However, the actual advisory buffering level is the _sum_ of
`highWaterMark` values, since each one has its own bucket.
Consider the Minipass case:
```js
const m1 = new Minipass()
const m2 = new Minipass()
const m3 = new Minipass()
const m4 = new Minipass()
m1.pipe(m2).pipe(m3).pipe(m4)
m4.on('data', () => console.log('made it through'))
// m1 is flowing, so it writes the data to m2 immediately
// m2 is flowing, so it writes the data to m3 immediately
// m3 is flowing, so it writes the data to m4 immediately
// m4 is flowing, so it fires the 'data' event immediately, returns true
// m4's write returned true, so m3 is still flowing, returns true
// m3's write returned true, so m2 is still flowing, returns true
// m2's write returned true, so m1 is still flowing, returns true
// No event deferrals or buffering along the way!
m1.write(Buffer.alloc(2048)) // returns true
```
It is extremely unlikely that you _don't_ want to buffer any data written,
or _ever_ buffer data that can be flushed all the way through. Neither
node-core streams nor Minipass ever fail to buffer written data, but
node-core streams do a lot of unnecessary buffering and pausing.
As always, the faster implementation is the one that does less stuff and
waits less time to do it.
### Immediately emit `end` for empty streams (when not paused)
If a stream is not paused, and `end()` is called before writing any data
into it, then it will emit `end` immediately.
If you have logic that occurs on the `end` event which you don't want to
potentially happen immediately (for example, closing file descriptors,
moving on to the next entry in an archive parse stream, etc.) then be sure
to call `stream.pause()` on creation, and then `stream.resume()` once you
are ready to respond to the `end` event.
### Emit `end` When Asked
One hazard of immediately emitting `'end'` is that you may not yet have had
a chance to add a listener. In order to avoid this hazard, Minipass
streams safely re-emit the `'end'` event if a new listener is added after
`'end'` has been emitted.
Ie, if you do `stream.on('end', someFunction)`, and the stream has already
emitted `end`, then it will call the handler right away. (You can think of
this somewhat like attaching a new `.then(fn)` to a previously-resolved
Promise.)
To prevent calling handlers multiple times who would not expect multiple
ends to occur, all listeners are removed from the `'end'` event whenever it
is emitted.
### Impact of "immediate flow" on Tee-streams
A "tee stream" is a stream piping to multiple destinations:
```js
const tee = new Minipass()
t.pipe(dest1)
t.pipe(dest2)
t.write('foo') // goes to both destinations
```
Since Minipass streams _immediately_ process any pending data through the
pipeline when a new pipe destination is added, this can have surprising
effects, especially when a stream comes in from some other function and may
or may not have data in its buffer.
```js
// WARNING! WILL LOSE DATA!
const src = new Minipass()
src.write('foo')
src.pipe(dest1) // 'foo' chunk flows to dest1 immediately, and is gone
src.pipe(dest2) // gets nothing!
```
The solution is to create a dedicated tee-stream junction that pipes to
both locations, and then pipe to _that_ instead.
```js
// Safe example: tee to both places
const src = new Minipass()
src.write('foo')
const tee = new Minipass()
tee.pipe(dest1)
tee.pipe(dest2)
src.pipe(tee) // tee gets 'foo', pipes to both locations
```
The same caveat applies to `on('data')` event listeners. The first one
added will _immediately_ receive all of the data, leaving nothing for the
second:
```js
// WARNING! WILL LOSE DATA!
const src = new Minipass()
src.write('foo')
src.on('data', handler1) // receives 'foo' right away
src.on('data', handler2) // nothing to see here!
```
Using a dedicated tee-stream can be used in this case as well:
```js
// Safe example: tee to both data handlers
const src = new Minipass()
src.write('foo')
const tee = new Minipass()
tee.on('data', handler1)
tee.on('data', handler2)
src.pipe(tee)
```
## USAGE
It's a stream! Use it like a stream and it'll most likely do what you
want.
```js
const Minipass = require('minipass')
const mp = new Minipass(options) // optional: { encoding, objectMode }
mp.write('foo')
mp.pipe(someOtherStream)
mp.end('bar')
```
### OPTIONS
* `encoding` How would you like the data coming _out_ of the stream to be
encoded? Accepts any values that can be passed to `Buffer.toString()`.
* `objectMode` Emit data exactly as it comes in. This will be flipped on
by default if you write() something other than a string or Buffer at any
point. Setting `objectMode: true` will prevent setting any encoding
value.
### API
Implements the user-facing portions of Node.js's `Readable` and `Writable`
streams.
### Methods
* `write(chunk, [encoding], [callback])` - Put data in. (Note that, in the
base Minipass class, the same data will come out.) Returns `false` if
the stream will buffer the next write, or true if it's still in "flowing"
mode.
* `end([chunk, [encoding]], [callback])` - Signal that you have no more
data to write. This will queue an `end` event to be fired when all the
data has been consumed.
* `setEncoding(encoding)` - Set the encoding for data coming of the stream.
This can only be done once.
* `pause()` - No more data for a while, please. This also prevents `end`
from being emitted for empty streams until the stream is resumed.
* `resume()` - Resume the stream. If there's data in the buffer, it is all
discarded. Any buffered events are immediately emitted.
* `pipe(dest)` - Send all output to the stream provided. There is no way
to unpipe. When data is emitted, it is immediately written to any and
all pipe destinations.
* `on(ev, fn)`, `emit(ev, fn)` - Minipass streams are EventEmitters. Some
events are given special treatment, however. (See below under "events".)
* `promise()` - Returns a Promise that resolves when the stream emits
`end`, or rejects if the stream emits `error`.
* `collect()` - Return a Promise that resolves on `end` with an array
containing each chunk of data that was emitted, or rejects if the stream
emits `error`. Note that this consumes the stream data.
* `concat()` - Same as `collect()`, but concatenates the data into a single
Buffer object. Will reject the returned promise if the stream is in
objectMode, or if it goes into objectMode by the end of the data.
* `read(n)` - Consume `n` bytes of data out of the buffer. If `n` is not
provided, then consume all of it. If `n` bytes are not available, then
it returns null. **Note** consuming streams in this way is less
efficient, and can lead to unnecessary Buffer copying.
* `destroy([er])` - Destroy the stream. If an error is provided, then an
`'error'` event is emitted. If the stream has a `close()` method, and
has not emitted a `'close'` event yet, then `stream.close()` will be
called. Any Promises returned by `.promise()`, `.collect()` or
`.concat()` will be rejected. After being destroyed, writing to the
stream will emit an error. No more data will be emitted if the stream is
destroyed, even if it was previously buffered.
### Properties
* `bufferLength` Read-only. Total number of bytes buffered, or in the case
of objectMode, the total number of objects.
* `encoding` The encoding that has been set. (Setting this is equivalent
to calling `setEncoding(enc)` and has the same prohibition against
setting multiple times.)
* `flowing` Read-only. Boolean indicating whether a chunk written to the
stream will be immediately emitted.
* `emittedEnd` Read-only. Boolean indicating whether the end-ish events
(ie, `end`, `prefinish`, `finish`) have been emitted. Note that
listening on any end-ish event will immediateyl re-emit it if it has
already been emitted.
* `writable` Whether the stream is writable. Default `true`. Set to
`false` when `end()`
* `readable` Whether the stream is readable. Default `true`.
* `buffer` A [yallist](http://npm.im/yallist) linked list of chunks written
to the stream that have not yet been emitted. (It's probably a bad idea
to mess with this.)
* `pipes` A [yallist](http://npm.im/yallist) linked list of streams that
this stream is piping into. (It's probably a bad idea to mess with
this.)
* `destroyed` A getter that indicates whether the stream was destroyed.
* `paused` True if the stream has been explicitly paused, otherwise false.
* `objectMode` Indicates whether the stream is in `objectMode`. Once set
to `true`, it cannot be set to `false`.
### Events
* `data` Emitted when there's data to read. Argument is the data to read.
This is never emitted while not flowing. If a listener is attached, that
will resume the stream.
* `end` Emitted when there's no more data to read. This will be emitted
immediately for empty streams when `end()` is called. If a listener is
attached, and `end` was already emitted, then it will be emitted again.
All listeners are removed when `end` is emitted.
* `prefinish` An end-ish event that follows the same logic as `end` and is
emitted in the same conditions where `end` is emitted. Emitted after
`'end'`.
* `finish` An end-ish event that follows the same logic as `end` and is
emitted in the same conditions where `end` is emitted. Emitted after
`'prefinish'`.
* `close` An indication that an underlying resource has been released.
Minipass does not emit this event, but will defer it until after `end`
has been emitted, since it throws off some stream libraries otherwise.
* `drain` Emitted when the internal buffer empties, and it is again
suitable to `write()` into the stream.
* `readable` Emitted when data is buffered and ready to be read by a
consumer.
* `resume` Emitted when stream changes state from buffering to flowing
mode. (Ie, when `resume` is called, `pipe` is called, or a `data` event
listener is added.)
### Static Methods
* `Minipass.isStream(stream)` Returns `true` if the argument is a stream,
and false otherwise. To be considered a stream, the object must be
either an instance of Minipass, or an EventEmitter that has either a
`pipe()` method, or both `write()` and `end()` methods. (Pretty much any
stream in node-land will return `true` for this.)
## EXAMPLES
Here are some examples of things you can do with Minipass streams.
### simple "are you done yet" promise
```js
mp.promise().then(() => {
// stream is finished
}, er => {
// stream emitted an error
})
```
### collecting
```js
mp.collect().then(all => {
// all is an array of all the data emitted
// encoding is supported in this case, so
// so the result will be a collection of strings if
// an encoding is specified, or buffers/objects if not.
//
// In an async function, you may do
// const data = await stream.collect()
})
```
### collecting into a single blob
This is a bit slower because it concatenates the data into one chunk for
you, but if you're going to do it yourself anyway, it's convenient this
way:
```js
mp.concat().then(onebigchunk => {
// onebigchunk is a string if the stream
// had an encoding set, or a buffer otherwise.
})
```
### iteration
You can iterate over streams synchronously or asynchronously in platforms
that support it.
Synchronous iteration will end when the currently available data is
consumed, even if the `end` event has not been reached. In string and
buffer mode, the data is concatenated, so unless multiple writes are
occurring in the same tick as the `read()`, sync iteration loops will
generally only have a single iteration.
To consume chunks in this way exactly as they have been written, with no
flattening, create the stream with the `{ objectMode: true }` option.
```js
const mp = new Minipass({ objectMode: true })
mp.write('a')
mp.write('b')
for (let letter of mp) {
console.log(letter) // a, b
}
mp.write('c')
mp.write('d')
for (let letter of mp) {
console.log(letter) // c, d
}
mp.write('e')
mp.end()
for (let letter of mp) {
console.log(letter) // e
}
for (let letter of mp) {
console.log(letter) // nothing
}
```
Asynchronous iteration will continue until the end event is reached,
consuming all of the data.
```js
const mp = new Minipass({ encoding: 'utf8' })
// some source of some data
let i = 5
const inter = setInterval(() => {
if (i-- > 0)
mp.write(Buffer.from('foo\n', 'utf8'))
else {
mp.end()
clearInterval(inter)
}
}, 100)
// consume the data with asynchronous iteration
async function consume () {
for await (let chunk of mp) {
console.log(chunk)
}
return 'ok'
}
consume().then(res => console.log(res))
// logs `foo\n` 5 times, and then `ok`
```
### subclass that `console.log()`s everything written into it
```js
class Logger extends Minipass {
write (chunk, encoding, callback) {
console.log('WRITE', chunk, encoding)
return super.write(chunk, encoding, callback)
}
end (chunk, encoding, callback) {
console.log('END', chunk, encoding)
return super.end(chunk, encoding, callback)
}
}
someSource.pipe(new Logger()).pipe(someDest)
```
### same thing, but using an inline anonymous class
```js
// js classes are fun
someSource
.pipe(new (class extends Minipass {
emit (ev, ...data) {
// let's also log events, because debugging some weird thing
console.log('EMIT', ev)
return super.emit(ev, ...data)
}
write (chunk, encoding, callback) {
console.log('WRITE', chunk, encoding)
return super.write(chunk, encoding, callback)
}
end (chunk, encoding, callback) {
console.log('END', chunk, encoding)
return super.end(chunk, encoding, callback)
}
}))
.pipe(someDest)
```
### subclass that defers 'end' for some reason
```js
class SlowEnd extends Minipass {
emit (ev, ...args) {
if (ev === 'end') {
console.log('going to end, hold on a sec')
setTimeout(() => {
console.log('ok, ready to end now')
super.emit('end', ...args)
}, 100)
} else {
return super.emit(ev, ...args)
}
}
}
```
### transform that creates newline-delimited JSON
```js
class NDJSONEncode extends Minipass {
write (obj, cb) {
try {
// JSON.stringify can throw, emit an error on that
return super.write(JSON.stringify(obj) + '\n', 'utf8', cb)
} catch (er) {
this.emit('error', er)
}
}
end (obj, cb) {
if (typeof obj === 'function') {
cb = obj
obj = undefined
}
if (obj !== undefined) {
this.write(obj)
}
return super.end(cb)
}
}
```
### transform that parses newline-delimited JSON
```js
class NDJSONDecode extends Minipass {
constructor (options) {
// always be in object mode, as far as Minipass is concerned
super({ objectMode: true })
this._jsonBuffer = ''
}
write (chunk, encoding, cb) {
if (typeof chunk === 'string' &&
typeof encoding === 'string' &&
encoding !== 'utf8') {
chunk = Buffer.from(chunk, encoding).toString()
} else if (Buffer.isBuffer(chunk))
chunk = chunk.toString()
}
if (typeof encoding === 'function') {
cb = encoding
}
const jsonData = (this._jsonBuffer + chunk).split('\n')
this._jsonBuffer = jsonData.pop()
for (let i = 0; i < jsonData.length; i++) {
try {
// JSON.parse can throw, emit an error on that
super.write(JSON.parse(jsonData[i]))
} catch (er) {
this.emit('error', er)
continue
}
}
if (cb)
cb()
}
}
```
## Timezone support
In order to provide support for timezones, without relying on the JavaScript host or any other time-zone aware environment, this library makes use of teh IANA Timezone Database directly:
https://www.iana.org/time-zones
The database files are parsed by the scripts in this folder, which emit AssemblyScript code which is used to process the various rules at runtime.
# json-schema-traverse
Traverse JSON Schema passing each schema object to callback
[](https://travis-ci.org/epoberezkin/json-schema-traverse)
[](https://www.npmjs.com/package/json-schema-traverse)
[](https://coveralls.io/github/epoberezkin/json-schema-traverse?branch=master)
## Install
```
npm install json-schema-traverse
```
## Usage
```javascript
const traverse = require('json-schema-traverse');
const schema = {
properties: {
foo: {type: 'string'},
bar: {type: 'integer'}
}
};
traverse(schema, {cb});
// cb is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
// Or:
traverse(schema, {cb: {pre, post}});
// pre is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
//
// post is called 3 times with:
// 1. {type: 'string'}
// 2. {type: 'integer'}
// 3. root schema
```
Callback function `cb` is called for each schema object (not including draft-06 boolean schemas), including the root schema, in pre-order traversal. Schema references ($ref) are not resolved, they are passed as is. Alternatively, you can pass a `{pre, post}` object as `cb`, and then `pre` will be called before traversing child elements, and `post` will be called after all child elements have been traversed.
Callback is passed these parameters:
- _schema_: the current schema object
- _JSON pointer_: from the root schema to the current schema object
- _root schema_: the schema passed to `traverse` object
- _parent JSON pointer_: from the root schema to the parent schema object (see below)
- _parent keyword_: the keyword inside which this schema appears (e.g. `properties`, `anyOf`, etc.)
- _parent schema_: not necessarily parent object/array; in the example above the parent schema for `{type: 'string'}` is the root schema
- _index/property_: index or property name in the array/object containing multiple schemas; in the example above for `{type: 'string'}` the property name is `'foo'`
## Traverse objects in all unknown keywords
```javascript
const traverse = require('json-schema-traverse');
const schema = {
mySchema: {
minimum: 1,
maximum: 2
}
};
traverse(schema, {allKeys: true, cb});
// cb is called 2 times with:
// 1. root schema
// 2. mySchema
```
Without option `allKeys: true` callback will be called only with root schema.
## License
[MIT](https://github.com/epoberezkin/json-schema-traverse/blob/master/LICENSE)
# set-blocking
[](https://travis-ci.org/yargs/set-blocking)
[](https://www.npmjs.com/package/set-blocking)
[](https://coveralls.io/r/yargs/set-blocking?branch=master)
[](https://github.com/conventional-changelog/standard-version)
set blocking `stdio` and `stderr` ensuring that terminal output does not truncate.
```js
const setBlocking = require('set-blocking')
setBlocking(true)
console.log(someLargeStringToOutput)
```
## Historical Context/Word of Warning
This was created as a shim to address the bug discussed in [node #6456](https://github.com/nodejs/node/issues/6456). This bug crops up on
newer versions of Node.js (`0.12+`), truncating terminal output.
You should be mindful of the side-effects caused by using `set-blocking`:
* if your module sets blocking to `true`, it will effect other modules
consuming your library. In [yargs](https://github.com/yargs/yargs/blob/master/yargs.js#L653) we only call
`setBlocking(true)` once we already know we are about to call `process.exit(code)`.
* this patch will not apply to subprocesses spawned with `isTTY = true`, this is
the [default `spawn()` behavior](https://nodejs.org/api/child_process.html#child_process_child_process_spawn_command_args_options).
## License
ISC
# require-main-filename
[](https://travis-ci.org/yargs/require-main-filename)
[](https://coveralls.io/r/yargs/require-main-filename?branch=master)
[](https://www.npmjs.com/package/require-main-filename)
`require.main.filename` is great for figuring out the entry
point for the current application. This can be combined with a module like
[pkg-conf](https://www.npmjs.com/package/pkg-conf) to, _as if by magic_, load
top-level configuration.
Unfortunately, `require.main.filename` sometimes fails when an application is
executed with an alternative process manager, e.g., [iisnode](https://github.com/tjanczuk/iisnode).
`require-main-filename` is a shim that addresses this problem.
## Usage
```js
var main = require('require-main-filename')()
// use main as an alternative to require.main.filename.
```
## License
ISC
# sprintf.js
**sprintf.js** is a complete open source JavaScript sprintf implementation for the *browser* and *node.js*.
Its prototype is simple:
string sprintf(string format , [mixed arg1 [, mixed arg2 [ ,...]]])
The placeholders in the format string are marked by `%` and are followed by one or more of these elements, in this order:
* An optional number followed by a `$` sign that selects which argument index to use for the value. If not specified, arguments will be placed in the same order as the placeholders in the input string.
* An optional `+` sign that forces to preceed the result with a plus or minus sign on numeric values. By default, only the `-` sign is used on negative numbers.
* An optional padding specifier that says what character to use for padding (if specified). Possible values are `0` or any other character precedeed by a `'` (single quote). The default is to pad with *spaces*.
* An optional `-` sign, that causes sprintf to left-align the result of this placeholder. The default is to right-align the result.
* An optional number, that says how many characters the result should have. If the value to be returned is shorter than this number, the result will be padded. When used with the `j` (JSON) type specifier, the padding length specifies the tab size used for indentation.
* An optional precision modifier, consisting of a `.` (dot) followed by a number, that says how many digits should be displayed for floating point numbers. When used with the `g` type specifier, it specifies the number of significant digits. When used on a string, it causes the result to be truncated.
* A type specifier that can be any of:
* `%` — yields a literal `%` character
* `b` — yields an integer as a binary number
* `c` — yields an integer as the character with that ASCII value
* `d` or `i` — yields an integer as a signed decimal number
* `e` — yields a float using scientific notation
* `u` — yields an integer as an unsigned decimal number
* `f` — yields a float as is; see notes on precision above
* `g` — yields a float as is; see notes on precision above
* `o` — yields an integer as an octal number
* `s` — yields a string as is
* `x` — yields an integer as a hexadecimal number (lower-case)
* `X` — yields an integer as a hexadecimal number (upper-case)
* `j` — yields a JavaScript object or array as a JSON encoded string
## JavaScript `vsprintf`
`vsprintf` is the same as `sprintf` except that it accepts an array of arguments, rather than a variable number of arguments:
vsprintf("The first 4 letters of the english alphabet are: %s, %s, %s and %s", ["a", "b", "c", "d"])
## Argument swapping
You can also swap the arguments. That is, the order of the placeholders doesn't have to match the order of the arguments. You can do that by simply indicating in the format string which arguments the placeholders refer to:
sprintf("%2$s %3$s a %1$s", "cracker", "Polly", "wants")
And, of course, you can repeat the placeholders without having to increase the number of arguments.
## Named arguments
Format strings may contain replacement fields rather than positional placeholders. Instead of referring to a certain argument, you can now refer to a certain key within an object. Replacement fields are surrounded by rounded parentheses - `(` and `)` - and begin with a keyword that refers to a key:
var user = {
name: "Dolly"
}
sprintf("Hello %(name)s", user) // Hello Dolly
Keywords in replacement fields can be optionally followed by any number of keywords or indexes:
var users = [
{name: "Dolly"},
{name: "Molly"},
{name: "Polly"}
]
sprintf("Hello %(users[0].name)s, %(users[1].name)s and %(users[2].name)s", {users: users}) // Hello Dolly, Molly and Polly
Note: mixing positional and named placeholders is not (yet) supported
## Computed values
You can pass in a function as a dynamic value and it will be invoked (with no arguments) in order to compute the value on-the-fly.
sprintf("Current timestamp: %d", Date.now) // Current timestamp: 1398005382890
sprintf("Current date and time: %s", function() { return new Date().toString() })
# AngularJS
You can now use `sprintf` and `vsprintf` (also aliased as `fmt` and `vfmt` respectively) in your AngularJS projects. See `demo/`.
# Installation
## Via Bower
bower install sprintf
## Or as a node.js module
npm install sprintf-js
### Usage
var sprintf = require("sprintf-js").sprintf,
vsprintf = require("sprintf-js").vsprintf
sprintf("%2$s %3$s a %1$s", "cracker", "Polly", "wants")
vsprintf("The first 4 letters of the english alphabet are: %s, %s, %s and %s", ["a", "b", "c", "d"])
# License
**sprintf.js** is licensed under the terms of the 3-clause BSD license.
# minimatch
A minimal matching utility.
[](http://travis-ci.org/isaacs/minimatch)
This is the matching library used internally by npm.
It works by converting glob expressions into JavaScript `RegExp`
objects.
## Usage
```javascript
var minimatch = require("minimatch")
minimatch("bar.foo", "*.foo") // true!
minimatch("bar.foo", "*.bar") // false!
minimatch("bar.foo", "*.+(bar|foo)", { debug: true }) // true, and noisy!
```
## Features
Supports these glob features:
* Brace Expansion
* Extended glob matching
* "Globstar" `**` matching
See:
* `man sh`
* `man bash`
* `man 3 fnmatch`
* `man 5 gitignore`
## Minimatch Class
Create a minimatch object by instantiating the `minimatch.Minimatch` class.
```javascript
var Minimatch = require("minimatch").Minimatch
var mm = new Minimatch(pattern, options)
```
### Properties
* `pattern` The original pattern the minimatch object represents.
* `options` The options supplied to the constructor.
* `set` A 2-dimensional array of regexp or string expressions.
Each row in the
array corresponds to a brace-expanded pattern. Each item in the row
corresponds to a single path-part. For example, the pattern
`{a,b/c}/d` would expand to a set of patterns like:
[ [ a, d ]
, [ b, c, d ] ]
If a portion of the pattern doesn't have any "magic" in it
(that is, it's something like `"foo"` rather than `fo*o?`), then it
will be left as a string rather than converted to a regular
expression.
* `regexp` Created by the `makeRe` method. A single regular expression
expressing the entire pattern. This is useful in cases where you wish
to use the pattern somewhat like `fnmatch(3)` with `FNM_PATH` enabled.
* `negate` True if the pattern is negated.
* `comment` True if the pattern is a comment.
* `empty` True if the pattern is `""`.
### Methods
* `makeRe` Generate the `regexp` member if necessary, and return it.
Will return `false` if the pattern is invalid.
* `match(fname)` Return true if the filename matches the pattern, or
false otherwise.
* `matchOne(fileArray, patternArray, partial)` Take a `/`-split
filename, and match it against a single row in the `regExpSet`. This
method is mainly for internal use, but is exposed so that it can be
used by a glob-walker that needs to avoid excessive filesystem calls.
All other methods are internal, and will be called as necessary.
### minimatch(path, pattern, options)
Main export. Tests a path against the pattern using the options.
```javascript
var isJS = minimatch(file, "*.js", { matchBase: true })
```
### minimatch.filter(pattern, options)
Returns a function that tests its
supplied argument, suitable for use with `Array.filter`. Example:
```javascript
var javascripts = fileList.filter(minimatch.filter("*.js", {matchBase: true}))
```
### minimatch.match(list, pattern, options)
Match against the list of
files, in the style of fnmatch or glob. If nothing is matched, and
options.nonull is set, then return a list containing the pattern itself.
```javascript
var javascripts = minimatch.match(fileList, "*.js", {matchBase: true}))
```
### minimatch.makeRe(pattern, options)
Make a regular expression object from the pattern.
## Options
All options are `false` by default.
### debug
Dump a ton of stuff to stderr.
### nobrace
Do not expand `{a,b}` and `{1..3}` brace sets.
### noglobstar
Disable `**` matching against multiple folder names.
### dot
Allow patterns to match filenames starting with a period, even if
the pattern does not explicitly have a period in that spot.
Note that by default, `a/**/b` will **not** match `a/.d/b`, unless `dot`
is set.
### noext
Disable "extglob" style patterns like `+(a|b)`.
### nocase
Perform a case-insensitive match.
### nonull
When a match is not found by `minimatch.match`, return a list containing
the pattern itself if this option is set. When not set, an empty list
is returned if there are no matches.
### matchBase
If set, then patterns without slashes will be matched
against the basename of the path if it contains slashes. For example,
`a?b` would match the path `/xyz/123/acb`, but not `/xyz/acb/123`.
### nocomment
Suppress the behavior of treating `#` at the start of a pattern as a
comment.
### nonegate
Suppress the behavior of treating a leading `!` character as negation.
### flipNegate
Returns from negate expressions the same as if they were not negated.
(Ie, true on a hit, false on a miss.)
## Comparisons to other fnmatch/glob implementations
While strict compliance with the existing standards is a worthwhile
goal, some discrepancies exist between minimatch and other
implementations, and are intentional.
If the pattern starts with a `!` character, then it is negated. Set the
`nonegate` flag to suppress this behavior, and treat leading `!`
characters normally. This is perhaps relevant if you wish to start the
pattern with a negative extglob pattern like `!(a|B)`. Multiple `!`
characters at the start of a pattern will negate the pattern multiple
times.
If a pattern starts with `#`, then it is treated as a comment, and
will not match anything. Use `\#` to match a literal `#` at the
start of a line, or set the `nocomment` flag to suppress this behavior.
The double-star character `**` is supported by default, unless the
`noglobstar` flag is set. This is supported in the manner of bsdglob
and bash 4.1, where `**` only has special significance if it is the only
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
`a/**b` will not.
If an escaped pattern has no matches, and the `nonull` flag is set,
then minimatch.match returns the pattern as-provided, rather than
interpreting the character escapes. For example,
`minimatch.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
that it does not resolve escaped pattern characters.
If brace expansion is not disabled, then it is performed before any
other interpretation of the glob pattern. Thus, a pattern like
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
checked for validity. Since those two are valid, matching proceeds.
### Estraverse [](http://travis-ci.org/estools/estraverse)
Estraverse ([estraverse](http://github.com/estools/estraverse)) is
[ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
traversal functions from [esmangle project](http://github.com/estools/esmangle).
### Documentation
You can find usage docs at [wiki page](https://github.com/estools/estraverse/wiki/Usage).
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
estraverse.traverse(ast, {
enter: function (node, parent) {
if (node.type == 'FunctionExpression' || node.type == 'FunctionDeclaration')
return estraverse.VisitorOption.Skip;
},
leave: function (node, parent) {
if (node.type == 'VariableDeclarator')
console.log(node.id.name);
}
});
```
We can use `this.skip`, `this.remove` and `this.break` functions instead of using Skip, Remove and Break.
```javascript
estraverse.traverse(ast, {
enter: function (node) {
this.break();
}
});
```
And estraverse provides `estraverse.replace` function. When returning node from `enter`/`leave`, current node is replaced with it.
```javascript
result = estraverse.replace(tree, {
enter: function (node) {
// Replace it with replaced.
if (node.type === 'Literal')
return replaced;
}
});
```
By passing `visitor.keys` mapping, we can extend estraverse traversing functionality.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Extending the existing traversing rules.
keys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
});
```
By passing `visitor.fallback` option, we can control the behavior when encountering unknown nodes.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Iterating the child **nodes** of unknown nodes.
fallback: 'iteration'
});
```
When `visitor.fallback` is a function, we can determine which keys to visit on each node.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Skip the `argument` property of each node
fallback: function(node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument';
});
}
});
```
### License
Copyright (C) 2012-2016 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Like `chown -R`.
Takes the same arguments as `fs.chown()`
# fs-minipass
Filesystem streams based on [minipass](http://npm.im/minipass).
4 classes are exported:
- ReadStream
- ReadStreamSync
- WriteStream
- WriteStreamSync
When using `ReadStreamSync`, all of the data is made available
immediately upon consuming the stream. Nothing is buffered in memory
when the stream is constructed. If the stream is piped to a writer,
then it will synchronously `read()` and emit data into the writer as
fast as the writer can consume it. (That is, it will respect
backpressure.) If you call `stream.read()` then it will read the
entire file and return the contents.
When using `WriteStreamSync`, every write is flushed to the file
synchronously. If your writes all come in a single tick, then it'll
write it all out in a single tick. It's as synchronous as you are.
The async versions work much like their node builtin counterparts,
with the exception of introducing significantly less Stream machinery
overhead.
## USAGE
It's just streams, you pipe them or read() them or write() to them.
```js
const fsm = require('fs-minipass')
const readStream = new fsm.ReadStream('file.txt')
const writeStream = new fsm.WriteStream('output.txt')
writeStream.write('some file header or whatever\n')
readStream.pipe(writeStream)
```
## ReadStream(path, options)
Path string is required, but somewhat irrelevant if an open file
descriptor is passed in as an option.
Options:
- `fd` Pass in a numeric file descriptor, if the file is already open.
- `readSize` The size of reads to do, defaults to 16MB
- `size` The size of the file, if known. Prevents zero-byte read()
call at the end.
- `autoClose` Set to `false` to prevent the file descriptor from being
closed when the file is done being read.
## WriteStream(path, options)
Path string is required, but somewhat irrelevant if an open file
descriptor is passed in as an option.
Options:
- `fd` Pass in a numeric file descriptor, if the file is already open.
- `mode` The mode to create the file with. Defaults to `0o666`.
- `start` The position in the file to start reading. If not
specified, then the file will start writing at position zero, and be
truncated by default.
- `autoClose` Set to `false` to prevent the file descriptor from being
closed when the stream is ended.
- `flags` Flags to use when opening the file. Irrelevant if `fd` is
passed in, since file won't be opened in that case. Defaults to
`'a'` if a `pos` is specified, or `'w'` otherwise.
# cliui
[](https://travis-ci.org/yargs/cliui)
[](https://coveralls.io/r/yargs/cliui?branch=)
[](https://www.npmjs.com/package/cliui)
[](https://github.com/conventional-changelog/standard-version)
easily create complex multi-column command-line-interfaces.
## Example
```js
var ui = require('cliui')()
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 2, 0]
})
ui.div(
{
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
},
{
text: "the file to load." +
chalk.green("(if this description is long it wraps).")
,
width: 20
},
{
text: chalk.red("[required]"),
align: 'right'
}
)
console.log(ui.toString())
```
<img width="500" src="screenshot.png">
## Layout DSL
cliui exposes a simple layout DSL:
If you create a single `ui.div`, passing a string rather than an
object:
* `\n`: characters will be interpreted as new rows.
* `\t`: characters will be interpreted as new columns.
* `\s`: characters will be interpreted as padding.
**as an example...**
```js
var ui = require('./')({
width: 60
})
ui.div(
'Usage: node ./bin/foo.js\n' +
' <regex>\t provide a regex\n' +
' <glob>\t provide a glob\t [required]'
)
console.log(ui.toString())
```
**will output:**
```shell
Usage: node ./bin/foo.js
<regex> provide a regex
<glob> provide a glob [required]
```
## Methods
```js
cliui = require('cliui')
```
### cliui({width: integer})
Specify the maximum width of the UI being generated.
If no width is provided, cliui will try to get the current window's width and use it, and if that doesn't work, width will be set to `80`.
### cliui({wrap: boolean})
Enable or disable the wrapping of text in a column.
### cliui.div(column, column, column)
Create a row with any number of columns, a column
can either be a string, or an object with the following
options:
* **text:** some text to place in the column.
* **width:** the width of a column.
* **align:** alignment, `right` or `center`.
* **padding:** `[top, right, bottom, left]`.
* **border:** should a border be placed around the div?
### cliui.span(column, column, column)
Similar to `div`, except the next row will be appended without
a new line being created.
### cliui.resetOutput()
Resets the UI elements of the current cliui instance, maintaining the values
set for `width` and `wrap`.
# isobject [](https://www.npmjs.com/package/isobject) [](https://npmjs.org/package/isobject) [](https://travis-ci.org/jonschlinkert/isobject)
Returns true if the value is an object and not an array or null.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install isobject --save
```
Use [is-plain-object](https://github.com/jonschlinkert/is-plain-object) if you want only objects that are created by the `Object` constructor.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install isobject
```
Install with [bower](http://bower.io/)
```sh
$ bower install isobject
```
## Usage
```js
var isObject = require('isobject');
```
**True**
All of the following return `true`:
```js
isObject({});
isObject(Object.create({}));
isObject(Object.create(Object.prototype));
isObject(Object.create(null));
isObject({});
isObject(new Foo);
isObject(/foo/);
```
**False**
All of the following return `false`:
```js
isObject();
isObject(function () {});
isObject(1);
isObject([]);
isObject(undefined);
isObject(null);
```
## Related projects
You might also be interested in these projects:
[merge-deep](https://www.npmjs.com/package/merge-deep): Recursively merge values in a javascript object. | [homepage](https://github.com/jonschlinkert/merge-deep)
* [extend-shallow](https://www.npmjs.com/package/extend-shallow): Extend an object with the properties of additional objects. node.js/javascript util. | [homepage](https://github.com/jonschlinkert/extend-shallow)
* [is-plain-object](https://www.npmjs.com/package/is-plain-object): Returns true if an object was created by the `Object` constructor. | [homepage](https://github.com/jonschlinkert/is-plain-object)
* [kind-of](https://www.npmjs.com/package/kind-of): Get the native type of a value. | [homepage](https://github.com/jonschlinkert/kind-of)
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/isobject/issues/new).
## Building docs
Generate readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install verb && npm run docs
```
Or, if [verb](https://github.com/verbose/verb) is installed globally:
```sh
$ verb
```
## Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
## Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/isobject/blob/master/LICENSE).
***
_This file was generated by [verb](https://github.com/verbose/verb), v0.9.0, on April 25, 2016._
# is-glob [](https://www.npmjs.com/package/is-glob) [](https://npmjs.org/package/is-glob) [](https://npmjs.org/package/is-glob) [](https://github.com/micromatch/is-glob/actions)
> Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a better user experience.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-glob
```
You might also be interested in [is-valid-glob](https://github.com/jonschlinkert/is-valid-glob) and [has-glob](https://github.com/jonschlinkert/has-glob).
## Usage
```js
var isGlob = require('is-glob');
```
### Default behavior
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js');
isGlob('*.js');
isGlob('**/abc.js');
isGlob('abc/*.js');
isGlob('abc/(aaa|bbb).js');
isGlob('abc/[a-z].js');
isGlob('abc/{a,b}.js');
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js');
isGlob('abc/!(a).js');
isGlob('abc/+(a).js');
isGlob('abc/*(a).js');
isGlob('abc/?(a).js');
//=> true
```
**False**
Escaped globs or extglobs return `false`:
```js
isGlob('abc/\\@(a).js');
isGlob('abc/\\!(a).js');
isGlob('abc/\\+(a).js');
isGlob('abc/\\*(a).js');
isGlob('abc/\\?(a).js');
isGlob('\\!foo.js');
isGlob('\\*.js');
isGlob('\\*\\*/abc.js');
isGlob('abc/\\*.js');
isGlob('abc/\\(aaa|bbb).js');
isGlob('abc/\\[a-z].js');
isGlob('abc/\\{a,b}.js');
//=> false
```
Patterns that do not have glob patterns return `false`:
```js
isGlob('abc.js');
isGlob('abc/def/ghi.js');
isGlob('foo.js');
isGlob('abc/@.js');
isGlob('abc/+.js');
isGlob('abc/?.js');
isGlob();
isGlob(null);
//=> false
```
Arrays are also `false` (If you want to check if an array has a glob pattern, use [has-glob](https://github.com/jonschlinkert/has-glob)):
```js
isGlob(['**/*.js']);
isGlob(['foo.js']);
//=> false
```
### Option strict
When `options.strict === false` the behavior is less strict in determining if a pattern is a glob. Meaning that
some patterns that would return `false` may return `true`. This is done so that matching libraries like [micromatch](https://github.com/micromatch/micromatch) have a chance at determining if the pattern is a glob or not.
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js', {strict: false});
isGlob('*.js', {strict: false});
isGlob('**/abc.js', {strict: false});
isGlob('abc/*.js', {strict: false});
isGlob('abc/(aaa|bbb).js', {strict: false});
isGlob('abc/[a-z].js', {strict: false});
isGlob('abc/{a,b}.js', {strict: false});
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js', {strict: false});
isGlob('abc/!(a).js', {strict: false});
isGlob('abc/+(a).js', {strict: false});
isGlob('abc/*(a).js', {strict: false});
isGlob('abc/?(a).js', {strict: false});
//=> true
```
**False**
Escaped globs or extglobs return `false`:
```js
isGlob('\\!foo.js', {strict: false});
isGlob('\\*.js', {strict: false});
isGlob('\\*\\*/abc.js', {strict: false});
isGlob('abc/\\*.js', {strict: false});
isGlob('abc/\\(aaa|bbb).js', {strict: false});
isGlob('abc/\\[a-z].js', {strict: false});
isGlob('abc/\\{a,b}.js', {strict: false});
//=> false
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [assemble](https://www.npmjs.com/package/assemble): Get the rocks out of your socks! Assemble makes you fast at creating web projects… [more](https://github.com/assemble/assemble) | [homepage](https://github.com/assemble/assemble "Get the rocks out of your socks! Assemble makes you fast at creating web projects. Assemble is used by thousands of projects for rapid prototyping, creating themes, scaffolds, boilerplates, e-books, UI components, API documentation, blogs, building websit")
* [base](https://www.npmjs.com/package/base): Framework for rapidly creating high quality, server-side node.js applications, using plugins like building blocks | [homepage](https://github.com/node-base/base "Framework for rapidly creating high quality, server-side node.js applications, using plugins like building blocks")
* [update](https://www.npmjs.com/package/update): Be scalable! Update is a new, open source developer framework and CLI for automating updates… [more](https://github.com/update/update) | [homepage](https://github.com/update/update "Be scalable! Update is a new, open source developer framework and CLI for automating updates of any kind in code projects.")
* [verb](https://www.npmjs.com/package/verb): Documentation generator for GitHub projects. Verb is extremely powerful, easy to use, and is used… [more](https://github.com/verbose/verb) | [homepage](https://github.com/verbose/verb "Documentation generator for GitHub projects. Verb is extremely powerful, easy to use, and is used on hundreds of projects of all sizes to generate everything from API docs to readmes.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 47 | [jonschlinkert](https://github.com/jonschlinkert) |
| 5 | [doowb](https://github.com/doowb) |
| 1 | [phated](https://github.com/phated) |
| 1 | [danhper](https://github.com/danhper) |
| 1 | [paulmillr](https://github.com/paulmillr) |
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
### License
Copyright © 2019, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on March 27, 2019._
# is-core-module <sup>[![Version Badge][2]][1]</sup>
[![github actions][actions-image]][actions-url]
[![coverage][codecov-image]][codecov-url]
[![dependency status][5]][6]
[![dev dependency status][7]][8]
[![License][license-image]][license-url]
[![Downloads][downloads-image]][downloads-url]
[![npm badge][11]][1]
Is this specifier a node.js core module? Optionally provide a node version to check; defaults to the current node version.
## Example
```js
var isCore = require('is-core-module');
var assert = require('assert');
assert(isCore('fs'));
assert(!isCore('butts'));
```
## Tests
Clone the repo, `npm install`, and run `npm test`
[1]: https://npmjs.org/package/is-core-module
[2]: https://versionbadg.es/inspect-js/is-core-module.svg
[5]: https://david-dm.org/inspect-js/is-core-module.svg
[6]: https://david-dm.org/inspect-js/is-core-module
[7]: https://david-dm.org/inspect-js/is-core-module/dev-status.svg
[8]: https://david-dm.org/inspect-js/is-core-module#info=devDependencies
[11]: https://nodei.co/npm/is-core-module.png?downloads=true&stars=true
[license-image]: https://img.shields.io/npm/l/is-core-module.svg
[license-url]: LICENSE
[downloads-image]: https://img.shields.io/npm/dm/is-core-module.svg
[downloads-url]: https://npm-stat.com/charts.html?package=is-core-module
[codecov-image]: https://codecov.io/gh/inspect-js/is-core-module/branch/main/graphs/badge.svg
[codecov-url]: https://app.codecov.io/gh/inspect-js/is-core-module/
[actions-image]: https://img.shields.io/endpoint?url=https://github-actions-badge-u3jn4tfpocch.runkit.sh/inspect-js/is-core-module
[actions-url]: https://github.com/inspect-js/is-core-module/actions
Compiler frontend for node.js
=============================
Usage
-----
For an up to date list of available command line options, see:
```
$> asc --help
```
API
---
The API accepts the same options as the CLI but also lets you override stdout and stderr and/or provide a callback. Example:
```js
const asc = require("assemblyscript/cli/asc");
asc.ready.then(() => {
asc.main([
"myModule.ts",
"--binaryFile", "myModule.wasm",
"--optimize",
"--sourceMap",
"--measure"
], {
stdout: process.stdout,
stderr: process.stderr
}, function(err) {
if (err)
throw err;
...
});
});
```
Available command line options can also be obtained programmatically:
```js
const options = require("assemblyscript/cli/asc.json");
...
```
You can also compile a source string directly, for example in a browser environment:
```js
const asc = require("assemblyscript/cli/asc");
asc.ready.then(() => {
const { binary, text, stdout, stderr } = asc.compileString(`...`, { optimize: 2 });
});
...
```
## assemblyscript-temporal
An implementation of temporal within AssemblyScript, with an initial focus on non-timezone-aware classes and functionality.
### Why?
AssemblyScript has minimal `Date` support, however, the JS Date API itself is terrible and people tend not to use it that often. As a result libraries like moment / luxon have become staple replacements. However, there is now a [relatively mature TC39 proposal](https://github.com/tc39/proposal-temporal) that adds greatly improved date support to JS. The goal of this project is to implement Temporal for AssemblyScript.
### Usage
This library currently supports the following types:
#### `PlainDateTime`
A `PlainDateTime` represents a calendar date and wall-clock time that does not carry time zone information, e.g. December 7th, 1995 at 3:00 PM (in the Gregorian calendar). For detailed documentation see the [TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plaindatetime.html), this implementation follows the specification as closely as possible.
You can create a `PlainDateTime` from individual components, a string or an object literal:
```javascript
datetime = new PlainDateTime(1976, 11, 18, 15, 23, 30, 123, 456, 789);
datetime.year; // 2019;
datetime.month; // 11;
// ...
datetime.nanosecond; // 789;
datetime = PlainDateTime.from("1976-11-18T12:34:56");
datetime.toString(); // "1976-11-18T12:34:56"
datetime = PlainDateTime.from({ year: 1966, month: 3, day: 3 });
datetime.toString(); // "1966-03-03T00:00:00"
```
There are various ways you can manipulate a date:
```javascript
// use 'with' to copy a date but with various property values overriden
datetime = new PlainDateTime(1976, 11, 18, 15, 23, 30, 123, 456, 789);
datetime.with({ year: 2019 }).toString(); // "2019-11-18T15:23:30.123456789"
// use 'add' or 'substract' to add / subtract a duration
datetime = PlainDateTime.from("2020-01-12T15:00");
datetime.add({ months: 1 }).toString(); // "2020-02-12T15:00:00");
// add / subtract support Duration objects or object literals
datetime.add(new Duration(1)).toString(); // "2021-01-12T15:00:00");
```
You can compare dates and check for equality
```javascript
dt1 = PlainDateTime.from("1976-11-18");
dt2 = PlainDateTime.from("2019-10-29");
PlainDateTime.compare(dt1, dt1); // 0
PlainDateTime.compare(dt1, dt2); // -1
dt1.equals(dt1); // true
```
Currently `PlainDateTime` only supports the ISO 8601 (Gregorian) calendar.
#### `PlainDate`
A `PlainDate` object represents a calendar date that is not associated with a particular time or time zone, e.g. August 24th, 2006. For detailed documentation see the [TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plaindate.html), this implementation follows the specification as closely as possible.
The `PlainDate` API is almost identical to `PlainDateTime`, so see above for API usage examples.
#### `PlainTime`
A `PlainTime` object represents a wall-clock time that is not associated with a particular date or time zone, e.g. 7:39 PM. For detailed documentation see the [TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plaintime.html), this implementation follows the specification as closely as possible.
The `PlainTime` API is almost identical to `PlainDateTime`, so see above for API usage examples.
#### `PlainMonthDay`
A date without a year component. This is useful to express things like "Bastille Day is on the 14th of July".
For detailed documentation see the
[TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plainmonthday.html)
, this implementation follows the specification as closely as possible.
```javascript
const monthDay = PlainMonthDay.from({ month: 7, day: 14 }); // => 07-14
const date = monthDay.toPlainDate({ year: 2030 }); // => 2030-07-14
date.dayOfWeek; // => 7
```
The `PlainMonthDay` API is almost identical to `PlainDateTime`, so see above for more API usage examples.
#### `PlainYearMonth`
A date without a day component. This is useful to express things like "the October 2020 meeting".
For detailed documentation see the
[TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plainyearmonth.html)
, this implementation follows the specification as closely as possible.
The `PlainYearMonth` API is almost identical to `PlainDateTime`, so see above for API usage examples.
#### `now`
The `now` object has several methods which give information about the current time and date.
```javascript
dateTime = now.plainDateTimeISO();
dateTime.toString(); // 2021-04-01T12:05:47.357
```
## Contributing
This project is open source, MIT licensed and your contributions are very much welcomed.
There is a [brief document that outlines implementation progress and priorities](./development.md).
# file-entry-cache
> Super simple cache for file metadata, useful for process that work o a given series of files
> and that only need to repeat the job on the changed ones since the previous run of the process — Edit
[](https://npmjs.org/package/file-entry-cache)
[](https://travis-ci.org/royriojas/file-entry-cache)
## install
```bash
npm i --save file-entry-cache
```
## Usage
The module exposes two functions `create` and `createFromFile`.
## `create(cacheName, [directory, useCheckSum])`
- **cacheName**: the name of the cache to be created
- **directory**: Optional the directory to load the cache from
- **usecheckSum**: Whether to use md5 checksum to verify if file changed. If false the default will be to use the mtime and size of the file.
## `createFromFile(pathToCache, [useCheckSum])`
- **pathToCache**: the path to the cache file (this combines the cache name and directory)
- **useCheckSum**: Whether to use md5 checksum to verify if file changed. If false the default will be to use the mtime and size of the file.
```js
// loads the cache, if one does not exists for the given
// Id a new one will be prepared to be created
var fileEntryCache = require('file-entry-cache');
var cache = fileEntryCache.create('testCache');
var files = expand('../fixtures/*.txt');
// the first time this method is called, will return all the files
var oFiles = cache.getUpdatedFiles(files);
// this will persist this to disk checking each file stats and
// updating the meta attributes `size` and `mtime`.
// custom fields could also be added to the meta object and will be persisted
// in order to retrieve them later
cache.reconcile();
// use this if you want the non visited file entries to be kept in the cache
// for more than one execution
//
// cache.reconcile( true /* noPrune */)
// on a second run
var cache2 = fileEntryCache.create('testCache');
// will return now only the files that were modified or none
// if no files were modified previous to the execution of this function
var oFiles = cache.getUpdatedFiles(files);
// if you want to prevent a file from being considered non modified
// something useful if a file failed some sort of validation
// you can then remove the entry from the cache doing
cache.removeEntry('path/to/file'); // path to file should be the same path of the file received on `getUpdatedFiles`
// that will effectively make the file to appear again as modified until the validation is passed. In that
// case you should not remove it from the cache
// if you need all the files, so you can determine what to do with the changed ones
// you can call
var oFiles = cache.normalizeEntries(files);
// oFiles will be an array of objects like the following
entry = {
key: 'some/name/file', the path to the file
changed: true, // if the file was changed since previous run
meta: {
size: 3242, // the size of the file
mtime: 231231231, // the modification time of the file
data: {} // some extra field stored for this file (useful to save the result of a transformation on the file
}
}
```
## Motivation for this module
I needed a super simple and dumb **in-memory cache** with optional disk persistence (write-back cache) in order to make
a script that will beautify files with `esformatter` to execute only on the files that were changed since the last run.
In doing so the process of beautifying files was reduced from several seconds to a small fraction of a second.
This module uses [flat-cache](https://www.npmjs.com/package/flat-cache) a super simple `key/value` cache storage with
optional file persistance.
The main idea is to read the files when the task begins, apply the transforms required, and if the process succeed,
then store the new state of the files. The next time this module request for `getChangedFiles` will return only
the files that were modified. Making the process to end faster.
This module could also be used by processes that modify the files applying a transform, in that case the result of the
transform could be stored in the `meta` field, of the entries. Anything added to the meta field will be persisted.
Those processes won't need to call `getChangedFiles` they will instead call `normalizeEntries` that will return the
entries with a `changed` field that can be used to determine if the file was changed or not. If it was not changed
the transformed stored data could be used instead of actually applying the transformation, saving time in case of only
a few files changed.
In the worst case scenario all the files will be processed. In the best case scenario only a few of them will be processed.
## Important notes
- The values set on the meta attribute of the entries should be `stringify-able` ones if possible, flat-cache uses `circular-json` to try to persist circular structures, but this should be considered experimental. The best results are always obtained with non circular values
- All the changes to the cache state are done to memory first and only persisted after reconcile.
## License
MIT
bs58
====
[](https://travis-ci.org/cryptocoinjs/bs58)
JavaScript component to compute base 58 encoding. This encoding is typically used for crypto currencies such as Bitcoin.
**Note:** If you're looking for **base 58 check** encoding, see: [https://github.com/bitcoinjs/bs58check](https://github.com/bitcoinjs/bs58check), which depends upon this library.
Install
-------
npm i --save bs58
API
---
### encode(input)
`input` must be a [Buffer](https://nodejs.org/api/buffer.html) or an `Array`. It returns a `string`.
**example**:
```js
const bs58 = require('bs58')
const bytes = Buffer.from('003c176e659bea0f29a3e9bf7880c112b1b31b4dc826268187', 'hex')
const address = bs58.encode(bytes)
console.log(address)
// => 16UjcYNBG9GTK4uq2f7yYEbuifqCzoLMGS
```
### decode(input)
`input` must be a base 58 encoded string. Returns a [Buffer](https://nodejs.org/api/buffer.html).
**example**:
```js
const bs58 = require('bs58')
const address = '16UjcYNBG9GTK4uq2f7yYEbuifqCzoLMGS'
const bytes = bs58.decode(address)
console.log(out.toString('hex'))
// => 003c176e659bea0f29a3e9bf7880c112b1b31b4dc826268187
```
Hack / Test
-----------
Uses JavaScript standard style. Read more:
[](https://github.com/feross/standard)
Credits
-------
- [Mike Hearn](https://github.com/mikehearn) for original Java implementation
- [Stefan Thomas](https://github.com/justmoon) for porting to JavaScript
- [Stephan Pair](https://github.com/gasteve) for buffer improvements
- [Daniel Cousens](https://github.com/dcousens) for cleanup and merging improvements from bitcoinjs-lib
- [Jared Deckard](https://github.com/deckar01) for killing `bigi` as a dependency
License
-------
MIT
# path-parse [](https://travis-ci.org/jbgutierrez/path-parse)
> Node.js [`path.parse(pathString)`](https://nodejs.org/api/path.html#path_path_parse_pathstring) [ponyfill](https://ponyfill.com).
## Install
```
$ npm install --save path-parse
```
## Usage
```js
var pathParse = require('path-parse');
pathParse('/home/user/dir/file.txt');
//=> {
// root : "/",
// dir : "/home/user/dir",
// base : "file.txt",
// ext : ".txt",
// name : "file"
// }
```
## API
See [`path.parse(pathString)`](https://nodejs.org/api/path.html#path_path_parse_pathstring) docs.
### pathParse(path)
### pathParse.posix(path)
The Posix specific version.
### pathParse.win32(path)
The Windows specific version.
## License
MIT © [Javier Blanco](http://jbgutierrez.info)
# yallist
Yet Another Linked List
There are many doubly-linked list implementations like it, but this
one is mine.
For when an array would be too big, and a Map can't be iterated in
reverse order.
[](https://travis-ci.org/isaacs/yallist) [](https://coveralls.io/github/isaacs/yallist)
## basic usage
```javascript
var yallist = require('yallist')
var myList = yallist.create([1, 2, 3])
myList.push('foo')
myList.unshift('bar')
// of course pop() and shift() are there, too
console.log(myList.toArray()) // ['bar', 1, 2, 3, 'foo']
myList.forEach(function (k) {
// walk the list head to tail
})
myList.forEachReverse(function (k, index, list) {
// walk the list tail to head
})
var myDoubledList = myList.map(function (k) {
return k + k
})
// now myDoubledList contains ['barbar', 2, 4, 6, 'foofoo']
// mapReverse is also a thing
var myDoubledListReverse = myList.mapReverse(function (k) {
return k + k
}) // ['foofoo', 6, 4, 2, 'barbar']
var reduced = myList.reduce(function (set, entry) {
set += entry
return set
}, 'start')
console.log(reduced) // 'startfoo123bar'
```
## api
The whole API is considered "public".
Functions with the same name as an Array method work more or less the
same way.
There's reverse versions of most things because that's the point.
### Yallist
Default export, the class that holds and manages a list.
Call it with either a forEach-able (like an array) or a set of
arguments, to initialize the list.
The Array-ish methods all act like you'd expect. No magic length,
though, so if you change that it won't automatically prune or add
empty spots.
### Yallist.create(..)
Alias for Yallist function. Some people like factories.
#### yallist.head
The first node in the list
#### yallist.tail
The last node in the list
#### yallist.length
The number of nodes in the list. (Change this at your peril. It is
not magic like Array length.)
#### yallist.toArray()
Convert the list to an array.
#### yallist.forEach(fn, [thisp])
Call a function on each item in the list.
#### yallist.forEachReverse(fn, [thisp])
Call a function on each item in the list, in reverse order.
#### yallist.get(n)
Get the data at position `n` in the list. If you use this a lot,
probably better off just using an Array.
#### yallist.getReverse(n)
Get the data at position `n`, counting from the tail.
#### yallist.map(fn, thisp)
Create a new Yallist with the result of calling the function on each
item.
#### yallist.mapReverse(fn, thisp)
Same as `map`, but in reverse.
#### yallist.pop()
Get the data from the list tail, and remove the tail from the list.
#### yallist.push(item, ...)
Insert one or more items to the tail of the list.
#### yallist.reduce(fn, initialValue)
Like Array.reduce.
#### yallist.reduceReverse
Like Array.reduce, but in reverse.
#### yallist.reverse
Reverse the list in place.
#### yallist.shift()
Get the data from the list head, and remove the head from the list.
#### yallist.slice([from], [to])
Just like Array.slice, but returns a new Yallist.
#### yallist.sliceReverse([from], [to])
Just like yallist.slice, but the result is returned in reverse.
#### yallist.toArray()
Create an array representation of the list.
#### yallist.toArrayReverse()
Create a reversed array representation of the list.
#### yallist.unshift(item, ...)
Insert one or more items to the head of the list.
#### yallist.unshiftNode(node)
Move a Node object to the front of the list. (That is, pull it out of
wherever it lives, and make it the new head.)
If the node belongs to a different list, then that list will remove it
first.
#### yallist.pushNode(node)
Move a Node object to the end of the list. (That is, pull it out of
wherever it lives, and make it the new tail.)
If the node belongs to a list already, then that list will remove it
first.
#### yallist.removeNode(node)
Remove a node from the list, preserving referential integrity of head
and tail and other nodes.
Will throw an error if you try to have a list remove a node that
doesn't belong to it.
### Yallist.Node
The class that holds the data and is actually the list.
Call with `var n = new Node(value, previousNode, nextNode)`
Note that if you do direct operations on Nodes themselves, it's very
easy to get into weird states where the list is broken. Be careful :)
#### node.next
The next node in the list.
#### node.prev
The previous node in the list.
#### node.value
The data the node contains.
#### node.list
The list to which this node belongs. (Null if it does not belong to
any list.)
# Near Bindings Generator
Transforms the Assembyscript AST to serialize exported functions and add `encode` and `decode` functions for generating and parsing JSON strings.
## Using via CLI
After installling, `npm install nearprotocol/near-bindgen-as`, it can be added to the cli arguments of the assemblyscript compiler you must add the following:
```bash
asc <file> --transform near-bindgen-as ...
```
This module also adds a binary `near-asc` which adds the default arguments required to build near contracts as well as the transformer.
```bash
near-asc <input file> <output file>
```
## Using a script to compile
Another way is to add a file such as `asconfig.js` such as:
```js
const compile = require("near-bindgen-as/compiler").compile;
compile("assembly/index.ts", // input file
"out/index.wasm", // output file
[
// "-O1", // Optional arguments
"--debug",
"--measure"
],
// Prints out the final cli arguments passed to compiler.
{verbose: true}
);
```
It can then be built with `node asconfig.js`. There is an example of this in the test directory.
JS-YAML - YAML 1.2 parser / writer for JavaScript
=================================================
[](https://travis-ci.org/nodeca/js-yaml)
[](https://www.npmjs.org/package/js-yaml)
__[Online Demo](http://nodeca.github.com/js-yaml/)__
This is an implementation of [YAML](http://yaml.org/), a human-friendly data
serialization language. Started as [PyYAML](http://pyyaml.org/) port, it was
completely rewritten from scratch. Now it's very fast, and supports 1.2 spec.
Installation
------------
### YAML module for node.js
```
npm install js-yaml
```
### CLI executable
If you want to inspect your YAML files from CLI, install js-yaml globally:
```
npm install -g js-yaml
```
#### Usage
```
usage: js-yaml [-h] [-v] [-c] [-t] file
Positional arguments:
file File with YAML document(s)
Optional arguments:
-h, --help Show this help message and exit.
-v, --version Show program's version number and exit.
-c, --compact Display errors in compact mode
-t, --trace Show stack trace on error
```
### Bundled YAML library for browsers
``` html
<!-- esprima required only for !!js/function -->
<script src="esprima.js"></script>
<script src="js-yaml.min.js"></script>
<script type="text/javascript">
var doc = jsyaml.load('greeting: hello\nname: world');
</script>
```
Browser support was done mostly for the online demo. If you find any errors - feel
free to send pull requests with fixes. Also note, that IE and other old browsers
needs [es5-shims](https://github.com/kriskowal/es5-shim) to operate.
Notes:
1. We have no resources to support browserified version. Don't expect it to be
well tested. Don't expect fast fixes if something goes wrong there.
2. `!!js/function` in browser bundle will not work by default. If you really need
it - load `esprima` parser first (via amd or directly).
3. `!!bin` in browser will return `Array`, because browsers do not support
node.js `Buffer` and adding Buffer shims is completely useless on practice.
API
---
Here we cover the most 'useful' methods. If you need advanced details (creating
your own tags), see [wiki](https://github.com/nodeca/js-yaml/wiki) and
[examples](https://github.com/nodeca/js-yaml/tree/master/examples) for more
info.
``` javascript
const yaml = require('js-yaml');
const fs = require('fs');
// Get document, or throw exception on error
try {
const doc = yaml.safeLoad(fs.readFileSync('/home/ixti/example.yml', 'utf8'));
console.log(doc);
} catch (e) {
console.log(e);
}
```
### safeLoad (string [ , options ])
**Recommended loading way.** Parses `string` as single YAML document. Returns either a
plain object, a string or `undefined`, or throws `YAMLException` on error. By default, does
not support regexps, functions and undefined. This method is safe for untrusted data.
options:
- `filename` _(default: null)_ - string to be used as a file path in
error/warning messages.
- `onWarning` _(default: null)_ - function to call on warning messages.
Loader will call this function with an instance of `YAMLException` for each warning.
- `schema` _(default: `DEFAULT_SAFE_SCHEMA`)_ - specifies a schema to use.
- `FAILSAFE_SCHEMA` - only strings, arrays and plain objects:
http://www.yaml.org/spec/1.2/spec.html#id2802346
- `JSON_SCHEMA` - all JSON-supported types:
http://www.yaml.org/spec/1.2/spec.html#id2803231
- `CORE_SCHEMA` - same as `JSON_SCHEMA`:
http://www.yaml.org/spec/1.2/spec.html#id2804923
- `DEFAULT_SAFE_SCHEMA` - all supported YAML types, without unsafe ones
(`!!js/undefined`, `!!js/regexp` and `!!js/function`):
http://yaml.org/type/
- `DEFAULT_FULL_SCHEMA` - all supported YAML types.
- `json` _(default: false)_ - compatibility with JSON.parse behaviour. If true, then duplicate keys in a mapping will override values rather than throwing an error.
NOTE: This function **does not** understand multi-document sources, it throws
exception on those.
NOTE: JS-YAML **does not** support schema-specific tag resolution restrictions.
So, the JSON schema is not as strictly defined in the YAML specification.
It allows numbers in any notation, use `Null` and `NULL` as `null`, etc.
The core schema also has no such restrictions. It allows binary notation for integers.
### load (string [ , options ])
**Use with care with untrusted sources**. The same as `safeLoad()` but uses
`DEFAULT_FULL_SCHEMA` by default - adds some JavaScript-specific types:
`!!js/function`, `!!js/regexp` and `!!js/undefined`. For untrusted sources, you
must additionally validate object structure to avoid injections:
``` javascript
const untrusted_code = '"toString": !<tag:yaml.org,2002:js/function> "function (){very_evil_thing();}"';
// I'm just converting that string, what could possibly go wrong?
require('js-yaml').load(untrusted_code) + ''
```
### safeLoadAll (string [, iterator] [, options ])
Same as `safeLoad()`, but understands multi-document sources. Applies
`iterator` to each document if specified, or returns array of documents.
``` javascript
const yaml = require('js-yaml');
yaml.safeLoadAll(data, function (doc) {
console.log(doc);
});
```
### loadAll (string [, iterator] [ , options ])
Same as `safeLoadAll()` but uses `DEFAULT_FULL_SCHEMA` by default.
### safeDump (object [ , options ])
Serializes `object` as a YAML document. Uses `DEFAULT_SAFE_SCHEMA`, so it will
throw an exception if you try to dump regexps or functions. However, you can
disable exceptions by setting the `skipInvalid` option to `true`.
options:
- `indent` _(default: 2)_ - indentation width to use (in spaces).
- `noArrayIndent` _(default: false)_ - when true, will not add an indentation level to array elements
- `skipInvalid` _(default: false)_ - do not throw on invalid types (like function
in the safe schema) and skip pairs and single values with such types.
- `flowLevel` (default: -1) - specifies level of nesting, when to switch from
block to flow style for collections. -1 means block style everwhere
- `styles` - "tag" => "style" map. Each tag may have own set of styles.
- `schema` _(default: `DEFAULT_SAFE_SCHEMA`)_ specifies a schema to use.
- `sortKeys` _(default: `false`)_ - if `true`, sort keys when dumping YAML. If a
function, use the function to sort the keys.
- `lineWidth` _(default: `80`)_ - set max line width.
- `noRefs` _(default: `false`)_ - if `true`, don't convert duplicate objects into references
- `noCompatMode` _(default: `false`)_ - if `true` don't try to be compatible with older
yaml versions. Currently: don't quote "yes", "no" and so on, as required for YAML 1.1
- `condenseFlow` _(default: `false`)_ - if `true` flow sequences will be condensed, omitting the space between `a, b`. Eg. `'[a,b]'`, and omitting the space between `key: value` and quoting the key. Eg. `'{"a":b}'` Can be useful when using yaml for pretty URL query params as spaces are %-encoded.
The following table show availlable styles (e.g. "canonical",
"binary"...) available for each tag (.e.g. !!null, !!int ...). Yaml
output is shown on the right side after `=>` (default setting) or `->`:
``` none
!!null
"canonical" -> "~"
"lowercase" => "null"
"uppercase" -> "NULL"
"camelcase" -> "Null"
!!int
"binary" -> "0b1", "0b101010", "0b1110001111010"
"octal" -> "01", "052", "016172"
"decimal" => "1", "42", "7290"
"hexadecimal" -> "0x1", "0x2A", "0x1C7A"
!!bool
"lowercase" => "true", "false"
"uppercase" -> "TRUE", "FALSE"
"camelcase" -> "True", "False"
!!float
"lowercase" => ".nan", '.inf'
"uppercase" -> ".NAN", '.INF'
"camelcase" -> ".NaN", '.Inf'
```
Example:
``` javascript
safeDump (object, {
'styles': {
'!!null': 'canonical' // dump null as ~
},
'sortKeys': true // sort object keys
});
```
### dump (object [ , options ])
Same as `safeDump()` but without limits (uses `DEFAULT_FULL_SCHEMA` by default).
Supported YAML types
--------------------
The list of standard YAML tags and corresponding JavaScipt types. See also
[YAML tag discussion](http://pyyaml.org/wiki/YAMLTagDiscussion) and
[YAML types repository](http://yaml.org/type/).
```
!!null '' # null
!!bool 'yes' # bool
!!int '3...' # number
!!float '3.14...' # number
!!binary '...base64...' # buffer
!!timestamp 'YYYY-...' # date
!!omap [ ... ] # array of key-value pairs
!!pairs [ ... ] # array or array pairs
!!set { ... } # array of objects with given keys and null values
!!str '...' # string
!!seq [ ... ] # array
!!map { ... } # object
```
**JavaScript-specific tags**
```
!!js/regexp /pattern/gim # RegExp
!!js/undefined '' # Undefined
!!js/function 'function () {...}' # Function
```
Caveats
-------
Note, that you use arrays or objects as key in JS-YAML. JS does not allow objects
or arrays as keys, and stringifies (by calling `toString()` method) them at the
moment of adding them.
``` yaml
---
? [ foo, bar ]
: - baz
? { foo: bar }
: - baz
- baz
```
``` javascript
{ "foo,bar": ["baz"], "[object Object]": ["baz", "baz"] }
```
Also, reading of properties on implicit block mapping keys is not supported yet.
So, the following YAML document cannot be loaded.
``` yaml
&anchor foo:
foo: bar
*anchor: duplicate key
baz: bat
*anchor: duplicate key
```
js-yaml for enterprise
----------------------
Available as part of the Tidelift Subscription
The maintainers of js-yaml and thousands of other packages are working with Tidelift to deliver commercial support and maintenance for the open source dependencies you use to build your applications. Save time, reduce risk, and improve code health, while paying the maintainers of the exact dependencies you use. [Learn more.](https://tidelift.com/subscription/pkg/npm-js-yaml?utm_source=npm-js-yaml&utm_medium=referral&utm_campaign=enterprise&utm_term=repo)
# eslint-utils
[](https://www.npmjs.com/package/eslint-utils)
[](http://www.npmtrends.com/eslint-utils)
[](https://github.com/mysticatea/eslint-utils/actions)
[](https://codecov.io/gh/mysticatea/eslint-utils)
[](https://david-dm.org/mysticatea/eslint-utils)
## 🏁 Goal
This package provides utility functions and classes for make ESLint custom rules.
For examples:
- [getStaticValue](https://eslint-utils.mysticatea.dev/api/ast-utils.html#getstaticvalue) evaluates static value on AST.
- [ReferenceTracker](https://eslint-utils.mysticatea.dev/api/scope-utils.html#referencetracker-class) checks the members of modules/globals as handling assignments and destructuring.
## 📖 Usage
See [documentation](https://eslint-utils.mysticatea.dev/).
## 📰 Changelog
See [releases](https://github.com/mysticatea/eslint-utils/releases).
## ❤️ Contributing
Welcome contributing!
Please use GitHub's Issues/PRs.
### Development Tools
- `npm test` runs tests and measures coverage.
- `npm run clean` removes the coverage result of `npm test` command.
- `npm run coverage` shows the coverage result of the last `npm test` command.
- `npm run lint` runs ESLint.
- `npm run watch` runs tests on each file change.
# v8-compile-cache
[](https://travis-ci.org/zertosh/v8-compile-cache)
`v8-compile-cache` attaches a `require` hook to use [V8's code cache](https://v8project.blogspot.com/2015/07/code-caching.html) to speed up instantiation time. The "code cache" is the work of parsing and compiling done by V8.
The ability to tap into V8 to produce/consume this cache was introduced in [Node v5.7.0](https://nodejs.org/en/blog/release/v5.7.0/).
## Usage
1. Add the dependency:
```sh
$ npm install --save v8-compile-cache
```
2. Then, in your entry module add:
```js
require('v8-compile-cache');
```
**Requiring `v8-compile-cache` in Node <5.7.0 is a noop – but you need at least Node 4.0.0 to support the ES2015 syntax used by `v8-compile-cache`.**
## Options
Set the environment variable `DISABLE_V8_COMPILE_CACHE=1` to disable the cache.
Cache directory is defined by environment variable `V8_COMPILE_CACHE_CACHE_DIR` or defaults to `<os.tmpdir()>/v8-compile-cache-<V8_VERSION>`.
## Internals
Cache files are suffixed `.BLOB` and `.MAP` corresponding to the entry module that required `v8-compile-cache`. The cache is _entry module specific_ because it is faster to load the entire code cache into memory at once, than it is to read it from disk on a file-by-file basis.
## Benchmarks
See https://github.com/zertosh/v8-compile-cache/tree/master/bench.
**Load Times:**
| Module | Without Cache | With Cache |
| ---------------- | -------------:| ----------:|
| `babel-core` | `218ms` | `185ms` |
| `yarn` | `153ms` | `113ms` |
| `yarn` (bundled) | `228ms` | `105ms` |
_^ Includes the overhead of loading the cache itself._
## Acknowledgements
* `FileSystemBlobStore` and `NativeCompileCache` are based on Atom's implementation of their v8 compile cache:
- https://github.com/atom/atom/blob/b0d7a8a/src/file-system-blob-store.js
- https://github.com/atom/atom/blob/b0d7a8a/src/native-compile-cache.js
* `mkdirpSync` is based on:
- https://github.com/substack/node-mkdirp/blob/f2003bb/index.js#L55-L98
# balanced-match
Match balanced string pairs, like `{` and `}` or `<b>` and `</b>`. Supports regular expressions as well!
[](http://travis-ci.org/juliangruber/balanced-match)
[](https://www.npmjs.org/package/balanced-match)
[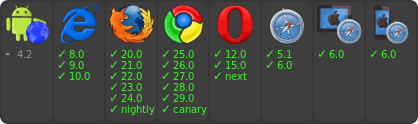](https://ci.testling.com/juliangruber/balanced-match)
## Example
Get the first matching pair of braces:
```js
var balanced = require('balanced-match');
console.log(balanced('{', '}', 'pre{in{nested}}post'));
console.log(balanced('{', '}', 'pre{first}between{second}post'));
console.log(balanced(/\s+\{\s+/, /\s+\}\s+/, 'pre { in{nest} } post'));
```
The matches are:
```bash
$ node example.js
{ start: 3, end: 14, pre: 'pre', body: 'in{nested}', post: 'post' }
{ start: 3,
end: 9,
pre: 'pre',
body: 'first',
post: 'between{second}post' }
{ start: 3, end: 17, pre: 'pre', body: 'in{nest}', post: 'post' }
```
## API
### var m = balanced(a, b, str)
For the first non-nested matching pair of `a` and `b` in `str`, return an
object with those keys:
* **start** the index of the first match of `a`
* **end** the index of the matching `b`
* **pre** the preamble, `a` and `b` not included
* **body** the match, `a` and `b` not included
* **post** the postscript, `a` and `b` not included
If there's no match, `undefined` will be returned.
If the `str` contains more `a` than `b` / there are unmatched pairs, the first match that was closed will be used. For example, `{{a}` will match `['{', 'a', '']` and `{a}}` will match `['', 'a', '}']`.
### var r = balanced.range(a, b, str)
For the first non-nested matching pair of `a` and `b` in `str`, return an
array with indexes: `[ <a index>, <b index> ]`.
If there's no match, `undefined` will be returned.
If the `str` contains more `a` than `b` / there are unmatched pairs, the first match that was closed will be used. For example, `{{a}` will match `[ 1, 3 ]` and `{a}}` will match `[0, 2]`.
## Installation
With [npm](https://npmjs.org) do:
```bash
npm install balanced-match
```
## Security contact information
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure.
## License
(MIT)
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# is-extglob [](https://www.npmjs.com/package/is-extglob) [](https://npmjs.org/package/is-extglob) [](https://travis-ci.org/jonschlinkert/is-extglob)
> Returns true if a string has an extglob.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-extglob
```
## Usage
```js
var isExtglob = require('is-extglob');
```
**True**
```js
isExtglob('?(abc)');
isExtglob('@(abc)');
isExtglob('!(abc)');
isExtglob('*(abc)');
isExtglob('+(abc)');
```
**False**
Escaped extglobs:
```js
isExtglob('\\?(abc)');
isExtglob('\\@(abc)');
isExtglob('\\!(abc)');
isExtglob('\\*(abc)');
isExtglob('\\+(abc)');
```
Everything else...
```js
isExtglob('foo.js');
isExtglob('!foo.js');
isExtglob('*.js');
isExtglob('**/abc.js');
isExtglob('abc/*.js');
isExtglob('abc/(aaa|bbb).js');
isExtglob('abc/[a-z].js');
isExtglob('abc/{a,b}.js');
isExtglob('abc/?.js');
isExtglob('abc.js');
isExtglob('abc/def/ghi.js');
```
## History
**v2.0**
Adds support for escaping. Escaped exglobs no longer return true.
## About
### Related projects
* [has-glob](https://www.npmjs.com/package/has-glob): Returns `true` if an array has a glob pattern. | [homepage](https://github.com/jonschlinkert/has-glob "Returns `true` if an array has a glob pattern.")
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern… [more](https://github.com/jonschlinkert/is-glob) | [homepage](https://github.com/jonschlinkert/is-glob "Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a bet")
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. | [homepage](https://github.com/jonschlinkert/micromatch "Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Building docs
_(This document was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme) (a [verb](https://github.com/verbose/verb) generator), please don't edit the readme directly. Any changes to the readme must be made in [.verb.md](.verb.md).)_
To generate the readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install -g verb verb-generate-readme && verb
```
### Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
### License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/is-extglob/blob/master/LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.1.31, on October 12, 2016._
# type-check [](https://travis-ci.org/gkz/type-check)
<a name="type-check" />
`type-check` is a library which allows you to check the types of JavaScript values at runtime with a Haskell like type syntax. It is great for checking external input, for testing, or even for adding a bit of safety to your internal code. It is a major component of [levn](https://github.com/gkz/levn). MIT license. Version 0.4.0. Check out the [demo](http://gkz.github.io/type-check/).
For updates on `type-check`, [follow me on twitter](https://twitter.com/gkzahariev).
npm install type-check
## Quick Examples
```js
// Basic types:
var typeCheck = require('type-check').typeCheck;
typeCheck('Number', 1); // true
typeCheck('Number', 'str'); // false
typeCheck('Error', new Error); // true
typeCheck('Undefined', undefined); // true
// Comment
typeCheck('count::Number', 1); // true
// One type OR another type:
typeCheck('Number | String', 2); // true
typeCheck('Number | String', 'str'); // true
// Wildcard, matches all types:
typeCheck('*', 2) // true
// Array, all elements of a single type:
typeCheck('[Number]', [1, 2, 3]); // true
typeCheck('[Number]', [1, 'str', 3]); // false
// Tuples, or fixed length arrays with elements of different types:
typeCheck('(String, Number)', ['str', 2]); // true
typeCheck('(String, Number)', ['str']); // false
typeCheck('(String, Number)', ['str', 2, 5]); // false
// Object properties:
typeCheck('{x: Number, y: Boolean}', {x: 2, y: false}); // true
typeCheck('{x: Number, y: Boolean}', {x: 2}); // false
typeCheck('{x: Number, y: Maybe Boolean}', {x: 2}); // true
typeCheck('{x: Number, y: Boolean}', {x: 2, y: false, z: 3}); // false
typeCheck('{x: Number, y: Boolean, ...}', {x: 2, y: false, z: 3}); // true
// A particular type AND object properties:
typeCheck('RegExp{source: String, ...}', /re/i); // true
typeCheck('RegExp{source: String, ...}', {source: 're'}); // false
// Custom types:
var opt = {customTypes:
{Even: { typeOf: 'Number', validate: function(x) { return x % 2 === 0; }}}};
typeCheck('Even', 2, opt); // true
// Nested:
var type = '{a: (String, [Number], {y: Array, ...}), b: Error{message: String, ...}}'
typeCheck(type, {a: ['hi', [1, 2, 3], {y: [1, 'ms']}], b: new Error('oh no')}); // true
```
Check out the [type syntax format](#syntax) and [guide](#guide).
## Usage
`require('type-check');` returns an object that exposes four properties. `VERSION` is the current version of the library as a string. `typeCheck`, `parseType`, and `parsedTypeCheck` are functions.
```js
// typeCheck(type, input, options);
typeCheck('Number', 2); // true
// parseType(type);
var parsedType = parseType('Number'); // object
// parsedTypeCheck(parsedType, input, options);
parsedTypeCheck(parsedType, 2); // true
```
### typeCheck(type, input, options)
`typeCheck` checks a JavaScript value `input` against `type` written in the [type format](#type-format) (and taking account the optional `options`) and returns whether the `input` matches the `type`.
##### arguments
* type - `String` - the type written in the [type format](#type-format) which to check against
* input - `*` - any JavaScript value, which is to be checked against the type
* options - `Maybe Object` - an optional parameter specifying additional options, currently the only available option is specifying [custom types](#custom-types)
##### returns
`Boolean` - whether the input matches the type
##### example
```js
typeCheck('Number', 2); // true
```
### parseType(type)
`parseType` parses string `type` written in the [type format](#type-format) into an object representing the parsed type.
##### arguments
* type - `String` - the type written in the [type format](#type-format) which to parse
##### returns
`Object` - an object in the parsed type format representing the parsed type
##### example
```js
parseType('Number'); // [{type: 'Number'}]
```
### parsedTypeCheck(parsedType, input, options)
`parsedTypeCheck` checks a JavaScript value `input` against parsed `type` in the parsed type format (and taking account the optional `options`) and returns whether the `input` matches the `type`. Use this in conjunction with `parseType` if you are going to use a type more than once.
##### arguments
* type - `Object` - the type in the parsed type format which to check against
* input - `*` - any JavaScript value, which is to be checked against the type
* options - `Maybe Object` - an optional parameter specifying additional options, currently the only available option is specifying [custom types](#custom-types)
##### returns
`Boolean` - whether the input matches the type
##### example
```js
parsedTypeCheck([{type: 'Number'}], 2); // true
var parsedType = parseType('String');
parsedTypeCheck(parsedType, 'str'); // true
```
<a name="type-format" />
## Type Format
### Syntax
White space is ignored. The root node is a __Types__.
* __Identifier__ = `[\$\w]+` - a group of any lower or upper case letters, numbers, underscores, or dollar signs - eg. `String`
* __Type__ = an `Identifier`, an `Identifier` followed by a `Structure`, just a `Structure`, or a wildcard `*` - eg. `String`, `Object{x: Number}`, `{x: Number}`, `Array{0: String, 1: Boolean, length: Number}`, `*`
* __Types__ = optionally a comment (an `Identifier` followed by a `::`), optionally the identifier `Maybe`, one or more `Type`, separated by `|` - eg. `Number`, `String | Date`, `Maybe Number`, `Maybe Boolean | String`
* __Structure__ = `Fields`, or a `Tuple`, or an `Array` - eg. `{x: Number}`, `(String, Number)`, `[Date]`
* __Fields__ = a `{`, followed one or more `Field` separated by a comma `,` (trailing comma `,` is permitted), optionally an `...` (always preceded by a comma `,`), followed by a `}` - eg. `{x: Number, y: String}`, `{k: Function, ...}`
* __Field__ = an `Identifier`, followed by a colon `:`, followed by `Types` - eg. `x: Date | String`, `y: Boolean`
* __Tuple__ = a `(`, followed by one or more `Types` separated by a comma `,` (trailing comma `,` is permitted), followed by a `)` - eg `(Date)`, `(Number, Date)`
* __Array__ = a `[` followed by exactly one `Types` followed by a `]` - eg. `[Boolean]`, `[Boolean | Null]`
### Guide
`type-check` uses `Object.toString` to find out the basic type of a value. Specifically,
```js
{}.toString.call(VALUE).slice(8, -1)
{}.toString.call(true).slice(8, -1) // 'Boolean'
```
A basic type, eg. `Number`, uses this check. This is much more versatile than using `typeof` - for example, with `document`, `typeof` produces `'object'` which isn't that useful, and our technique produces `'HTMLDocument'`.
You may check for multiple types by separating types with a `|`. The checker proceeds from left to right, and passes if the value is any of the types - eg. `String | Boolean` first checks if the value is a string, and then if it is a boolean. If it is none of those, then it returns false.
Adding a `Maybe` in front of a list of multiple types is the same as also checking for `Null` and `Undefined` - eg. `Maybe String` is equivalent to `Undefined | Null | String`.
You may add a comment to remind you of what the type is for by following an identifier with a `::` before a type (or multiple types). The comment is simply thrown out.
The wildcard `*` matches all types.
There are three types of structures for checking the contents of a value: 'fields', 'tuple', and 'array'.
If used by itself, a 'fields' structure will pass with any type of object as long as it is an instance of `Object` and the properties pass - this allows for duck typing - eg. `{x: Boolean}`.
To check if the properties pass, and the value is of a certain type, you can specify the type - eg. `Error{message: String}`.
If you want to make a field optional, you can simply use `Maybe` - eg. `{x: Boolean, y: Maybe String}` will still pass if `y` is undefined (or null).
If you don't care if the value has properties beyond what you have specified, you can use the 'etc' operator `...` - eg. `{x: Boolean, ...}` will match an object with an `x` property that is a boolean, and with zero or more other properties.
For an array, you must specify one or more types (separated by `|`) - it will pass for something of any length as long as each element passes the types provided - eg. `[Number]`, `[Number | String]`.
A tuple checks for a fixed number of elements, each of a potentially different type. Each element is separated by a comma - eg. `(String, Number)`.
An array and tuple structure check that the value is of type `Array` by default, but if another type is specified, they will check for that instead - eg. `Int32Array[Number]`. You can use the wildcard `*` to search for any type at all.
Check out the [type precedence](https://github.com/zaboco/type-precedence) library for type-check.
## Options
Options is an object. It is an optional parameter to the `typeCheck` and `parsedTypeCheck` functions. The only current option is `customTypes`.
<a name="custom-types" />
### Custom Types
__Example:__
```js
var options = {
customTypes: {
Even: {
typeOf: 'Number',
validate: function(x) {
return x % 2 === 0;
}
}
}
};
typeCheck('Even', 2, options); // true
typeCheck('Even', 3, options); // false
```
`customTypes` allows you to set up custom types for validation. The value of this is an object. The keys of the object are the types you will be matching. Each value of the object will be an object having a `typeOf` property - a string, and `validate` property - a function.
The `typeOf` property is the type the value should be (optional - if not set only `validate` will be used), and `validate` is a function which should return true if the value is of that type. `validate` receives one parameter, which is the value that we are checking.
## Technical About
`type-check` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It also uses the [prelude.ls](http://preludels.com/) library.
# ShellJS - Unix shell commands for Node.js
[](https://travis-ci.org/shelljs/shelljs)
[](https://ci.appveyor.com/project/shelljs/shelljs/branch/master)
[](https://codecov.io/gh/shelljs/shelljs)
[](https://www.npmjs.com/package/shelljs)
[](https://www.npmjs.com/package/shelljs)
ShellJS is a portable **(Windows/Linux/OS X)** implementation of Unix shell
commands on top of the Node.js API. You can use it to eliminate your shell
script's dependency on Unix while still keeping its familiar and powerful
commands. You can also install it globally so you can run it from outside Node
projects - say goodbye to those gnarly Bash scripts!
ShellJS is proudly tested on every node release since `v4`!
The project is [unit-tested](http://travis-ci.org/shelljs/shelljs) and battle-tested in projects like:
+ [Firebug](http://getfirebug.com/) - Firefox's infamous debugger
+ [JSHint](http://jshint.com) & [ESLint](http://eslint.org/) - popular JavaScript linters
+ [Zepto](http://zeptojs.com) - jQuery-compatible JavaScript library for modern browsers
+ [Yeoman](http://yeoman.io/) - Web application stack and development tool
+ [Deployd.com](http://deployd.com) - Open source PaaS for quick API backend generation
+ And [many more](https://npmjs.org/browse/depended/shelljs).
If you have feedback, suggestions, or need help, feel free to post in our [issue
tracker](https://github.com/shelljs/shelljs/issues).
Think ShellJS is cool? Check out some related projects in our [Wiki
page](https://github.com/shelljs/shelljs/wiki)!
Upgrading from an older version? Check out our [breaking
changes](https://github.com/shelljs/shelljs/wiki/Breaking-Changes) page to see
what changes to watch out for while upgrading.
## Command line use
If you just want cross platform UNIX commands, checkout our new project
[shelljs/shx](https://github.com/shelljs/shx), a utility to expose `shelljs` to
the command line.
For example:
```
$ shx mkdir -p foo
$ shx touch foo/bar.txt
$ shx rm -rf foo
```
## Plugin API
ShellJS now supports third-party plugins! You can learn more about using plugins
and writing your own ShellJS commands in [the
wiki](https://github.com/shelljs/shelljs/wiki/Using-ShellJS-Plugins).
## A quick note about the docs
For documentation on all the latest features, check out our
[README](https://github.com/shelljs/shelljs). To read docs that are consistent
with the latest release, check out [the npm
page](https://www.npmjs.com/package/shelljs) or
[shelljs.org](http://documentup.com/shelljs/shelljs).
## Installing
Via npm:
```bash
$ npm install [-g] shelljs
```
## Examples
```javascript
var shell = require('shelljs');
if (!shell.which('git')) {
shell.echo('Sorry, this script requires git');
shell.exit(1);
}
// Copy files to release dir
shell.rm('-rf', 'out/Release');
shell.cp('-R', 'stuff/', 'out/Release');
// Replace macros in each .js file
shell.cd('lib');
shell.ls('*.js').forEach(function (file) {
shell.sed('-i', 'BUILD_VERSION', 'v0.1.2', file);
shell.sed('-i', /^.*REMOVE_THIS_LINE.*$/, '', file);
shell.sed('-i', /.*REPLACE_LINE_WITH_MACRO.*\n/, shell.cat('macro.js'), file);
});
shell.cd('..');
// Run external tool synchronously
if (shell.exec('git commit -am "Auto-commit"').code !== 0) {
shell.echo('Error: Git commit failed');
shell.exit(1);
}
```
## Exclude options
If you need to pass a parameter that looks like an option, you can do so like:
```js
shell.grep('--', '-v', 'path/to/file'); // Search for "-v", no grep options
shell.cp('-R', '-dir', 'outdir'); // If already using an option, you're done
```
## Global vs. Local
We no longer recommend using a global-import for ShellJS (i.e.
`require('shelljs/global')`). While still supported for convenience, this
pollutes the global namespace, and should therefore only be used with caution.
Instead, we recommend a local import (standard for npm packages):
```javascript
var shell = require('shelljs');
shell.echo('hello world');
```
<!-- DO NOT MODIFY BEYOND THIS POINT - IT'S AUTOMATICALLY GENERATED -->
## Command reference
All commands run synchronously, unless otherwise stated.
All commands accept standard bash globbing characters (`*`, `?`, etc.),
compatible with the [node `glob` module](https://github.com/isaacs/node-glob).
For less-commonly used commands and features, please check out our [wiki
page](https://github.com/shelljs/shelljs/wiki).
### cat([options,] file [, file ...])
### cat([options,] file_array)
Available options:
+ `-n`: number all output lines
Examples:
```javascript
var str = cat('file*.txt');
var str = cat('file1', 'file2');
var str = cat(['file1', 'file2']); // same as above
```
Returns a string containing the given file, or a concatenated string
containing the files if more than one file is given (a new line character is
introduced between each file).
### cd([dir])
Changes to directory `dir` for the duration of the script. Changes to home
directory if no argument is supplied.
### chmod([options,] octal_mode || octal_string, file)
### chmod([options,] symbolic_mode, file)
Available options:
+ `-v`: output a diagnostic for every file processed
+ `-c`: like verbose, but report only when a change is made
+ `-R`: change files and directories recursively
Examples:
```javascript
chmod(755, '/Users/brandon');
chmod('755', '/Users/brandon'); // same as above
chmod('u+x', '/Users/brandon');
chmod('-R', 'a-w', '/Users/brandon');
```
Alters the permissions of a file or directory by either specifying the
absolute permissions in octal form or expressing the changes in symbols.
This command tries to mimic the POSIX behavior as much as possible.
Notable exceptions:
+ In symbolic modes, `a-r` and `-r` are identical. No consideration is
given to the `umask`.
+ There is no "quiet" option, since default behavior is to run silent.
### cp([options,] source [, source ...], dest)
### cp([options,] source_array, dest)
Available options:
+ `-f`: force (default behavior)
+ `-n`: no-clobber
+ `-u`: only copy if `source` is newer than `dest`
+ `-r`, `-R`: recursive
+ `-L`: follow symlinks
+ `-P`: don't follow symlinks
Examples:
```javascript
cp('file1', 'dir1');
cp('-R', 'path/to/dir/', '~/newCopy/');
cp('-Rf', '/tmp/*', '/usr/local/*', '/home/tmp');
cp('-Rf', ['/tmp/*', '/usr/local/*'], '/home/tmp'); // same as above
```
Copies files.
### pushd([options,] [dir | '-N' | '+N'])
Available options:
+ `-n`: Suppresses the normal change of directory when adding directories to the stack, so that only the stack is manipulated.
+ `-q`: Supresses output to the console.
Arguments:
+ `dir`: Sets the current working directory to the top of the stack, then executes the equivalent of `cd dir`.
+ `+N`: Brings the Nth directory (counting from the left of the list printed by dirs, starting with zero) to the top of the list by rotating the stack.
+ `-N`: Brings the Nth directory (counting from the right of the list printed by dirs, starting with zero) to the top of the list by rotating the stack.
Examples:
```javascript
// process.cwd() === '/usr'
pushd('/etc'); // Returns /etc /usr
pushd('+1'); // Returns /usr /etc
```
Save the current directory on the top of the directory stack and then `cd` to `dir`. With no arguments, `pushd` exchanges the top two directories. Returns an array of paths in the stack.
### popd([options,] ['-N' | '+N'])
Available options:
+ `-n`: Suppress the normal directory change when removing directories from the stack, so that only the stack is manipulated.
+ `-q`: Supresses output to the console.
Arguments:
+ `+N`: Removes the Nth directory (counting from the left of the list printed by dirs), starting with zero.
+ `-N`: Removes the Nth directory (counting from the right of the list printed by dirs), starting with zero.
Examples:
```javascript
echo(process.cwd()); // '/usr'
pushd('/etc'); // '/etc /usr'
echo(process.cwd()); // '/etc'
popd(); // '/usr'
echo(process.cwd()); // '/usr'
```
When no arguments are given, `popd` removes the top directory from the stack and performs a `cd` to the new top directory. The elements are numbered from 0, starting at the first directory listed with dirs (i.e., `popd` is equivalent to `popd +0`). Returns an array of paths in the stack.
### dirs([options | '+N' | '-N'])
Available options:
+ `-c`: Clears the directory stack by deleting all of the elements.
+ `-q`: Supresses output to the console.
Arguments:
+ `+N`: Displays the Nth directory (counting from the left of the list printed by dirs when invoked without options), starting with zero.
+ `-N`: Displays the Nth directory (counting from the right of the list printed by dirs when invoked without options), starting with zero.
Display the list of currently remembered directories. Returns an array of paths in the stack, or a single path if `+N` or `-N` was specified.
See also: `pushd`, `popd`
### echo([options,] string [, string ...])
Available options:
+ `-e`: interpret backslash escapes (default)
+ `-n`: remove trailing newline from output
Examples:
```javascript
echo('hello world');
var str = echo('hello world');
echo('-n', 'no newline at end');
```
Prints `string` to stdout, and returns string with additional utility methods
like `.to()`.
### exec(command [, options] [, callback])
Available options:
+ `async`: Asynchronous execution. If a callback is provided, it will be set to
`true`, regardless of the passed value (default: `false`).
+ `silent`: Do not echo program output to console (default: `false`).
+ `encoding`: Character encoding to use. Affects the values returned to stdout and stderr, and
what is written to stdout and stderr when not in silent mode (default: `'utf8'`).
+ and any option available to Node.js's
[`child_process.exec()`](https://nodejs.org/api/child_process.html#child_process_child_process_exec_command_options_callback)
Examples:
```javascript
var version = exec('node --version', {silent:true}).stdout;
var child = exec('some_long_running_process', {async:true});
child.stdout.on('data', function(data) {
/* ... do something with data ... */
});
exec('some_long_running_process', function(code, stdout, stderr) {
console.log('Exit code:', code);
console.log('Program output:', stdout);
console.log('Program stderr:', stderr);
});
```
Executes the given `command` _synchronously_, unless otherwise specified. When in synchronous
mode, this returns a `ShellString` (compatible with ShellJS v0.6.x, which returns an object
of the form `{ code:..., stdout:... , stderr:... }`). Otherwise, this returns the child process
object, and the `callback` receives the arguments `(code, stdout, stderr)`.
Not seeing the behavior you want? `exec()` runs everything through `sh`
by default (or `cmd.exe` on Windows), which differs from `bash`. If you
need bash-specific behavior, try out the `{shell: 'path/to/bash'}` option.
### find(path [, path ...])
### find(path_array)
Examples:
```javascript
find('src', 'lib');
find(['src', 'lib']); // same as above
find('.').filter(function(file) { return file.match(/\.js$/); });
```
Returns array of all files (however deep) in the given paths.
The main difference from `ls('-R', path)` is that the resulting file names
include the base directories (e.g., `lib/resources/file1` instead of just `file1`).
### grep([options,] regex_filter, file [, file ...])
### grep([options,] regex_filter, file_array)
Available options:
+ `-v`: Invert `regex_filter` (only print non-matching lines).
+ `-l`: Print only filenames of matching files.
+ `-i`: Ignore case.
Examples:
```javascript
grep('-v', 'GLOBAL_VARIABLE', '*.js');
grep('GLOBAL_VARIABLE', '*.js');
```
Reads input string from given files and returns a string containing all lines of the
file that match the given `regex_filter`.
### head([{'-n': \<num\>},] file [, file ...])
### head([{'-n': \<num\>},] file_array)
Available options:
+ `-n <num>`: Show the first `<num>` lines of the files
Examples:
```javascript
var str = head({'-n': 1}, 'file*.txt');
var str = head('file1', 'file2');
var str = head(['file1', 'file2']); // same as above
```
Read the start of a file.
### ln([options,] source, dest)
Available options:
+ `-s`: symlink
+ `-f`: force
Examples:
```javascript
ln('file', 'newlink');
ln('-sf', 'file', 'existing');
```
Links `source` to `dest`. Use `-f` to force the link, should `dest` already exist.
### ls([options,] [path, ...])
### ls([options,] path_array)
Available options:
+ `-R`: recursive
+ `-A`: all files (include files beginning with `.`, except for `.` and `..`)
+ `-L`: follow symlinks
+ `-d`: list directories themselves, not their contents
+ `-l`: list objects representing each file, each with fields containing `ls
-l` output fields. See
[`fs.Stats`](https://nodejs.org/api/fs.html#fs_class_fs_stats)
for more info
Examples:
```javascript
ls('projs/*.js');
ls('-R', '/users/me', '/tmp');
ls('-R', ['/users/me', '/tmp']); // same as above
ls('-l', 'file.txt'); // { name: 'file.txt', mode: 33188, nlink: 1, ...}
```
Returns array of files in the given `path`, or files in
the current directory if no `path` is provided.
### mkdir([options,] dir [, dir ...])
### mkdir([options,] dir_array)
Available options:
+ `-p`: full path (and create intermediate directories, if necessary)
Examples:
```javascript
mkdir('-p', '/tmp/a/b/c/d', '/tmp/e/f/g');
mkdir('-p', ['/tmp/a/b/c/d', '/tmp/e/f/g']); // same as above
```
Creates directories.
### mv([options ,] source [, source ...], dest')
### mv([options ,] source_array, dest')
Available options:
+ `-f`: force (default behavior)
+ `-n`: no-clobber
Examples:
```javascript
mv('-n', 'file', 'dir/');
mv('file1', 'file2', 'dir/');
mv(['file1', 'file2'], 'dir/'); // same as above
```
Moves `source` file(s) to `dest`.
### pwd()
Returns the current directory.
### rm([options,] file [, file ...])
### rm([options,] file_array)
Available options:
+ `-f`: force
+ `-r, -R`: recursive
Examples:
```javascript
rm('-rf', '/tmp/*');
rm('some_file.txt', 'another_file.txt');
rm(['some_file.txt', 'another_file.txt']); // same as above
```
Removes files.
### sed([options,] search_regex, replacement, file [, file ...])
### sed([options,] search_regex, replacement, file_array)
Available options:
+ `-i`: Replace contents of `file` in-place. _Note that no backups will be created!_
Examples:
```javascript
sed('-i', 'PROGRAM_VERSION', 'v0.1.3', 'source.js');
sed(/.*DELETE_THIS_LINE.*\n/, '', 'source.js');
```
Reads an input string from `file`s, and performs a JavaScript `replace()` on the input
using the given `search_regex` and `replacement` string or function. Returns the new string after replacement.
Note:
Like unix `sed`, ShellJS `sed` supports capture groups. Capture groups are specified
using the `$n` syntax:
```javascript
sed(/(\w+)\s(\w+)/, '$2, $1', 'file.txt');
```
### set(options)
Available options:
+ `+/-e`: exit upon error (`config.fatal`)
+ `+/-v`: verbose: show all commands (`config.verbose`)
+ `+/-f`: disable filename expansion (globbing)
Examples:
```javascript
set('-e'); // exit upon first error
set('+e'); // this undoes a "set('-e')"
```
Sets global configuration variables.
### sort([options,] file [, file ...])
### sort([options,] file_array)
Available options:
+ `-r`: Reverse the results
+ `-n`: Compare according to numerical value
Examples:
```javascript
sort('foo.txt', 'bar.txt');
sort('-r', 'foo.txt');
```
Return the contents of the `file`s, sorted line-by-line. Sorting multiple
files mixes their content (just as unix `sort` does).
### tail([{'-n': \<num\>},] file [, file ...])
### tail([{'-n': \<num\>},] file_array)
Available options:
+ `-n <num>`: Show the last `<num>` lines of `file`s
Examples:
```javascript
var str = tail({'-n': 1}, 'file*.txt');
var str = tail('file1', 'file2');
var str = tail(['file1', 'file2']); // same as above
```
Read the end of a `file`.
### tempdir()
Examples:
```javascript
var tmp = tempdir(); // "/tmp" for most *nix platforms
```
Searches and returns string containing a writeable, platform-dependent temporary directory.
Follows Python's [tempfile algorithm](http://docs.python.org/library/tempfile.html#tempfile.tempdir).
### test(expression)
Available expression primaries:
+ `'-b', 'path'`: true if path is a block device
+ `'-c', 'path'`: true if path is a character device
+ `'-d', 'path'`: true if path is a directory
+ `'-e', 'path'`: true if path exists
+ `'-f', 'path'`: true if path is a regular file
+ `'-L', 'path'`: true if path is a symbolic link
+ `'-p', 'path'`: true if path is a pipe (FIFO)
+ `'-S', 'path'`: true if path is a socket
Examples:
```javascript
if (test('-d', path)) { /* do something with dir */ };
if (!test('-f', path)) continue; // skip if it's a regular file
```
Evaluates `expression` using the available primaries and returns corresponding value.
### ShellString.prototype.to(file)
Examples:
```javascript
cat('input.txt').to('output.txt');
```
Analogous to the redirection operator `>` in Unix, but works with
`ShellStrings` (such as those returned by `cat`, `grep`, etc.). _Like Unix
redirections, `to()` will overwrite any existing file!_
### ShellString.prototype.toEnd(file)
Examples:
```javascript
cat('input.txt').toEnd('output.txt');
```
Analogous to the redirect-and-append operator `>>` in Unix, but works with
`ShellStrings` (such as those returned by `cat`, `grep`, etc.).
### touch([options,] file [, file ...])
### touch([options,] file_array)
Available options:
+ `-a`: Change only the access time
+ `-c`: Do not create any files
+ `-m`: Change only the modification time
+ `-d DATE`: Parse `DATE` and use it instead of current time
+ `-r FILE`: Use `FILE`'s times instead of current time
Examples:
```javascript
touch('source.js');
touch('-c', '/path/to/some/dir/source.js');
touch({ '-r': FILE }, '/path/to/some/dir/source.js');
```
Update the access and modification times of each `FILE` to the current time.
A `FILE` argument that does not exist is created empty, unless `-c` is supplied.
This is a partial implementation of [`touch(1)`](http://linux.die.net/man/1/touch).
### uniq([options,] [input, [output]])
Available options:
+ `-i`: Ignore case while comparing
+ `-c`: Prefix lines by the number of occurrences
+ `-d`: Only print duplicate lines, one for each group of identical lines
Examples:
```javascript
uniq('foo.txt');
uniq('-i', 'foo.txt');
uniq('-cd', 'foo.txt', 'bar.txt');
```
Filter adjacent matching lines from `input`.
### which(command)
Examples:
```javascript
var nodeExec = which('node');
```
Searches for `command` in the system's `PATH`. On Windows, this uses the
`PATHEXT` variable to append the extension if it's not already executable.
Returns string containing the absolute path to `command`.
### exit(code)
Exits the current process with the given exit `code`.
### error()
Tests if error occurred in the last command. Returns a truthy value if an
error returned, or a falsy value otherwise.
**Note**: do not rely on the
return value to be an error message. If you need the last error message, use
the `.stderr` attribute from the last command's return value instead.
### ShellString(str)
Examples:
```javascript
var foo = ShellString('hello world');
```
Turns a regular string into a string-like object similar to what each
command returns. This has special methods, like `.to()` and `.toEnd()`.
### env['VAR_NAME']
Object containing environment variables (both getter and setter). Shortcut
to `process.env`.
### Pipes
Examples:
```javascript
grep('foo', 'file1.txt', 'file2.txt').sed(/o/g, 'a').to('output.txt');
echo('files with o\'s in the name:\n' + ls().grep('o'));
cat('test.js').exec('node'); // pipe to exec() call
```
Commands can send their output to another command in a pipe-like fashion.
`sed`, `grep`, `cat`, `exec`, `to`, and `toEnd` can appear on the right-hand
side of a pipe. Pipes can be chained.
## Configuration
### config.silent
Example:
```javascript
var sh = require('shelljs');
var silentState = sh.config.silent; // save old silent state
sh.config.silent = true;
/* ... */
sh.config.silent = silentState; // restore old silent state
```
Suppresses all command output if `true`, except for `echo()` calls.
Default is `false`.
### config.fatal
Example:
```javascript
require('shelljs/global');
config.fatal = true; // or set('-e');
cp('this_file_does_not_exist', '/dev/null'); // throws Error here
/* more commands... */
```
If `true`, the script will throw a Javascript error when any shell.js
command encounters an error. Default is `false`. This is analogous to
Bash's `set -e`.
### config.verbose
Example:
```javascript
config.verbose = true; // or set('-v');
cd('dir/');
rm('-rf', 'foo.txt', 'bar.txt');
exec('echo hello');
```
Will print each command as follows:
```
cd dir/
rm -rf foo.txt bar.txt
exec echo hello
```
### config.globOptions
Example:
```javascript
config.globOptions = {nodir: true};
```
Use this value for calls to `glob.sync()` instead of the default options.
### config.reset()
Example:
```javascript
var shell = require('shelljs');
// Make changes to shell.config, and do stuff...
/* ... */
shell.config.reset(); // reset to original state
// Do more stuff, but with original settings
/* ... */
```
Reset `shell.config` to the defaults:
```javascript
{
fatal: false,
globOptions: {},
maxdepth: 255,
noglob: false,
silent: false,
verbose: false,
}
```
## Team
| [](https://github.com/nfischer) | [](http://github.com/freitagbr) |
|:---:|:---:|
| [Nate Fischer](https://github.com/nfischer) | [Brandon Freitag](http://github.com/freitagbr) |
[](https://www.npmjs.com/package/esprima)
[](https://www.npmjs.com/package/esprima)
[](https://travis-ci.org/jquery/esprima)
[](https://codecov.io/github/jquery/esprima)
**Esprima** ([esprima.org](http://esprima.org), BSD license) is a high performance,
standard-compliant [ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
parser written in ECMAScript (also popularly known as
[JavaScript](https://en.wikipedia.org/wiki/JavaScript)).
Esprima is created and maintained by [Ariya Hidayat](https://twitter.com/ariyahidayat),
with the help of [many contributors](https://github.com/jquery/esprima/contributors).
### Features
- Full support for ECMAScript 2017 ([ECMA-262 8th Edition](http://www.ecma-international.org/publications/standards/Ecma-262.htm))
- Sensible [syntax tree format](https://github.com/estree/estree/blob/master/es5.md) as standardized by [ESTree project](https://github.com/estree/estree)
- Experimental support for [JSX](https://facebook.github.io/jsx/), a syntax extension for [React](https://facebook.github.io/react/)
- Optional tracking of syntax node location (index-based and line-column)
- [Heavily tested](http://esprima.org/test/ci.html) (~1500 [unit tests](https://github.com/jquery/esprima/tree/master/test/fixtures) with [full code coverage](https://codecov.io/github/jquery/esprima))
### API
Esprima can be used to perform [lexical analysis](https://en.wikipedia.org/wiki/Lexical_analysis) (tokenization) or [syntactic analysis](https://en.wikipedia.org/wiki/Parsing) (parsing) of a JavaScript program.
A simple example on Node.js REPL:
```javascript
> var esprima = require('esprima');
> var program = 'const answer = 42';
> esprima.tokenize(program);
[ { type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'answer' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '42' } ]
> esprima.parseScript(program);
{ type: 'Program',
body:
[ { type: 'VariableDeclaration',
declarations: [Object],
kind: 'const' } ],
sourceType: 'script' }
```
For more information, please read the [complete documentation](http://esprima.org/doc).
# which
Like the unix `which` utility.
Finds the first instance of a specified executable in the PATH
environment variable. Does not cache the results, so `hash -r` is not
needed when the PATH changes.
## USAGE
```javascript
var which = require('which')
// async usage
which('node', function (er, resolvedPath) {
// er is returned if no "node" is found on the PATH
// if it is found, then the absolute path to the exec is returned
})
// or promise
which('node').then(resolvedPath => { ... }).catch(er => { ... not found ... })
// sync usage
// throws if not found
var resolved = which.sync('node')
// if nothrow option is used, returns null if not found
resolved = which.sync('node', {nothrow: true})
// Pass options to override the PATH and PATHEXT environment vars.
which('node', { path: someOtherPath }, function (er, resolved) {
if (er)
throw er
console.log('found at %j', resolved)
})
```
## CLI USAGE
Same as the BSD `which(1)` binary.
```
usage: which [-as] program ...
```
## OPTIONS
You may pass an options object as the second argument.
- `path`: Use instead of the `PATH` environment variable.
- `pathExt`: Use instead of the `PATHEXT` environment variable.
- `all`: Return all matches, instead of just the first one. Note that
this means the function returns an array of strings instead of a
single string.
# ts-mixer
[version-badge]: https://badgen.net/npm/v/ts-mixer
[version-link]: https://npmjs.com/package/ts-mixer
[build-badge]: https://img.shields.io/github/workflow/status/tannerntannern/ts-mixer/ts-mixer%20CI
[build-link]: https://github.com/tannerntannern/ts-mixer/actions
[ts-versions]: https://badgen.net/badge/icon/3.8,3.9,4.0,4.1,4.2?icon=typescript&label&list=|
[node-versions]: https://badgen.net/badge/node/10%2C12%2C14/blue/?list=|
[![npm version][version-badge]][version-link]
[![github actions][build-badge]][build-link]
[![TS Versions][ts-versions]][build-link]
[![Node.js Versions][node-versions]][build-link]
[](https://bundlephobia.com/result?p=ts-mixer)
[](https://conventionalcommits.org)
## Overview
`ts-mixer` brings mixins to TypeScript. "Mixins" to `ts-mixer` are just classes, so you already know how to write them, and you can probably mix classes from your favorite library without trouble.
The mixin problem is more nuanced than it appears. I've seen countless code snippets that work for certain situations, but fail in others. `ts-mixer` tries to take the best from all these solutions while accounting for the situations you might not have considered.
[Quick start guide](#quick-start)
### Features
* mixes plain classes
* mixes classes that extend other classes
* mixes classes that were mixed with `ts-mixer`
* supports static properties
* supports protected/private properties (the popular function-that-returns-a-class solution does not)
* mixes abstract classes (with caveats [[1](#caveats)])
* mixes generic classes (with caveats [[2](#caveats)])
* supports class, method, and property decorators (with caveats [[3, 6](#caveats)])
* mostly supports the complexity presented by constructor functions (with caveats [[4](#caveats)])
* comes with an `instanceof`-like replacement (with caveats [[5, 6](#caveats)])
* [multiple mixing strategies](#settings) (ES6 proxies vs hard copy)
### Caveats
1. Mixing abstract classes requires a bit of a hack that may break in future versions of TypeScript. See [mixing abstract classes](#mixing-abstract-classes) below.
2. Mixing generic classes requires a more cumbersome notation, but it's still possible. See [mixing generic classes](#mixing-generic-classes) below.
3. Using decorators in mixed classes also requires a more cumbersome notation. See [mixing with decorators](#mixing-with-decorators) below.
4. ES6 made it impossible to use `.apply(...)` on class constructors (or any means of calling them without `new`), which makes it impossible for `ts-mixer` to pass the proper `this` to your constructors. This may or may not be an issue for your code, but there are options to work around it. See [dealing with constructors](#dealing-with-constructors) below.
5. `ts-mixer` does not support `instanceof` for mixins, but it does offer a replacement. See the [hasMixin function](#hasmixin) for more details.
6. Certain features (specifically, `@decorator` and `hasMixin`) make use of ES6 `Map`s, which means you must either use ES6+ or polyfill `Map` to use them. If you don't need these features, you should be fine without.
## Quick Start
### Installation
```
$ npm install ts-mixer
```
or if you prefer [Yarn](https://yarnpkg.com):
```
$ yarn add ts-mixer
```
### Basic Example
```typescript
import { Mixin } from 'ts-mixer';
class Foo {
protected makeFoo() {
return 'foo';
}
}
class Bar {
protected makeBar() {
return 'bar';
}
}
class FooBar extends Mixin(Foo, Bar) {
public makeFooBar() {
return this.makeFoo() + this.makeBar();
}
}
const fooBar = new FooBar();
console.log(fooBar.makeFooBar()); // "foobar"
```
## Special Cases
### Mixing Abstract Classes
Abstract classes, by definition, cannot be constructed, which means they cannot take on the type, `new(...args) => any`, and by extension, are incompatible with `ts-mixer`. BUT, you can "trick" TypeScript into giving you all the benefits of an abstract class without making it technically abstract. The trick is just some strategic `// @ts-ignore`'s:
```typescript
import { Mixin } from 'ts-mixer';
// note that Foo is not marked as an abstract class
class Foo {
// @ts-ignore: "Abstract methods can only appear within an abstract class"
public abstract makeFoo(): string;
}
class Bar {
public makeBar() {
return 'bar';
}
}
class FooBar extends Mixin(Foo, Bar) {
// we still get all the benefits of abstract classes here, because TypeScript
// will still complain if this method isn't implemented
public makeFoo() {
return 'foo';
}
}
```
Do note that while this does work quite well, it is a bit of a hack and I can't promise that it will continue to work in future TypeScript versions.
### Mixing Generic Classes
Frustratingly, it is _impossible_ for generic parameters to be referenced in base class expressions. No matter what, you will eventually run into `Base class expressions cannot reference class type parameters.`
The way to get around this is to leverage [declaration merging](https://www.typescriptlang.org/docs/handbook/declaration-merging.html), and a slightly different mixing function from ts-mixer: `mix`. It works exactly like `Mixin`, except it's a decorator, which means it doesn't affect the type information of the class being decorated. See it in action below:
```typescript
import { mix } from 'ts-mixer';
class Foo<T> {
public fooMethod(input: T): T {
return input;
}
}
class Bar<T> {
public barMethod(input: T): T {
return input;
}
}
interface FooBar<T1, T2> extends Foo<T1>, Bar<T2> { }
@mix(Foo, Bar)
class FooBar<T1, T2> {
public fooBarMethod(input1: T1, input2: T2) {
return [this.fooMethod(input1), this.barMethod(input2)];
}
}
```
Key takeaways from this example:
* `interface FooBar<T1, T2> extends Foo<T1>, Bar<T2> { }` makes sure `FooBar` has the typing we want, thanks to declaration merging
* `@mix(Foo, Bar)` wires things up "on the JavaScript side", since the interface declaration has nothing to do with runtime behavior.
* The reason we have to use the `mix` decorator is that the typing produced by `Mixin(Foo, Bar)` would conflict with the typing of the interface. `mix` has no effect "on the TypeScript side," thus avoiding type conflicts.
### Mixing with Decorators
Popular libraries such as [class-validator](https://github.com/typestack/class-validator) and [TypeORM](https://github.com/typeorm/typeorm) use decorators to add functionality. Unfortunately, `ts-mixer` has no way of knowing what these libraries do with the decorators behind the scenes. So if you want these decorators to be "inherited" with classes you plan to mix, you first have to wrap them with a special `decorate` function exported by `ts-mixer`. Here's an example using `class-validator`:
```typescript
import { IsBoolean, IsIn, validate } from 'class-validator';
import { Mixin, decorate } from 'ts-mixer';
class Disposable {
@decorate(IsBoolean()) // instead of @IsBoolean()
isDisposed: boolean = false;
}
class Statusable {
@decorate(IsIn(['red', 'green'])) // instead of @IsIn(['red', 'green'])
status: string = 'green';
}
class ExtendedObject extends Mixin(Disposable, Statusable) {}
const extendedObject = new ExtendedObject();
extendedObject.status = 'blue';
validate(extendedObject).then(errors => {
console.log(errors);
});
```
### Dealing with Constructors
As mentioned in the [caveats section](#caveats), ES6 disallowed calling constructor functions without `new`. This means that the only way for `ts-mixer` to mix instance properties is to instantiate each base class separately, then copy the instance properties into a common object. The consequence of this is that constructors mixed by `ts-mixer` will _not_ receive the proper `this`.
**This very well may not be an issue for you!** It only means that your constructors need to be "mostly pure" in terms of how they handle `this`. Specifically, your constructors cannot produce [side effects](https://en.wikipedia.org/wiki/Side_effect_%28computer_science%29) involving `this`, _other than adding properties to `this`_ (the most common side effect in JavaScript constructors).
If you simply cannot eliminate `this` side effects from your constructor, there is a workaround available: `ts-mixer` will automatically forward constructor parameters to a predesignated init function (`settings.initFunction`) if it's present on the class. Unlike constructors, functions can be called with an arbitrary `this`, so this predesignated init function _will_ have the proper `this`. Here's a basic example:
```typescript
import { Mixin, settings } from 'ts-mixer';
settings.initFunction = 'init';
class Person {
public static allPeople: Set<Person> = new Set();
protected init() {
Person.allPeople.add(this);
}
}
type PartyAffiliation = 'democrat' | 'republican';
class PoliticalParticipant {
public static democrats: Set<PoliticalParticipant> = new Set();
public static republicans: Set<PoliticalParticipant> = new Set();
public party: PartyAffiliation;
// note that these same args will also be passed to init function
public constructor(party: PartyAffiliation) {
this.party = party;
}
protected init(party: PartyAffiliation) {
if (party === 'democrat')
PoliticalParticipant.democrats.add(this);
else
PoliticalParticipant.republicans.add(this);
}
}
class Voter extends Mixin(Person, PoliticalParticipant) {}
const v1 = new Voter('democrat');
const v2 = new Voter('democrat');
const v3 = new Voter('republican');
const v4 = new Voter('republican');
```
Note the above `.add(this)` statements. These would not work as expected if they were placed in the constructor instead, since `this` is not the same between the constructor and `init`, as explained above.
## Other Features
### hasMixin
As mentioned above, `ts-mixer` does not support `instanceof` for mixins. While it is possible to implement [custom `instanceof` behavior](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/hasInstance), this library does not do so because it would require modifying the source classes, which is deliberately avoided.
You can fill this missing functionality with `hasMixin(instance, mixinClass)` instead. See the below example:
```typescript
import { Mixin, hasMixin } from 'ts-mixer';
class Foo {}
class Bar {}
class FooBar extends Mixin(Foo, Bar) {}
const instance = new FooBar();
// doesn't work with instanceof...
console.log(instance instanceof FooBar) // true
console.log(instance instanceof Foo) // false
console.log(instance instanceof Bar) // false
// but everything works nicely with hasMixin!
console.log(hasMixin(instance, FooBar)) // true
console.log(hasMixin(instance, Foo)) // true
console.log(hasMixin(instance, Bar)) // true
```
`hasMixin(instance, mixinClass)` will work anywhere that `instance instanceof mixinClass` works. Additionally, like `instanceof`, you get the same [type narrowing benefits](https://www.typescriptlang.org/docs/handbook/advanced-types.html#instanceof-type-guards):
```typescript
if (hasMixin(instance, Foo)) {
// inferred type of instance is "Foo"
}
if (hasMixin(instance, Bar)) {
// inferred type of instance of "Bar"
}
```
## Settings
ts-mixer has multiple strategies for mixing classes which can be configured by modifying `settings` from ts-mixer. For example:
```typescript
import { settings, Mixin } from 'ts-mixer';
settings.prototypeStrategy = 'proxy';
// then use `Mixin` as normal...
```
### `settings.prototypeStrategy`
* Determines how ts-mixer will mix class prototypes together
* Possible values:
- `'copy'` (default) - Copies all methods from the classes being mixed into a new prototype object. (This will include all methods up the prototype chains as well.) This is the default for ES5 compatibility, but it has the downside of stale references. For example, if you mix `Foo` and `Bar` to make `FooBar`, then redefine a method on `Foo`, `FooBar` will not have the latest methods from `Foo`. If this is not a concern for you, `'copy'` is the best value for this setting.
- `'proxy'` - Uses an ES6 Proxy to "soft mix" prototypes. Unlike `'copy'`, updates to the base classes _will_ be reflected in the mixed class, which may be desirable. The downside is that method access is not as performant, nor is it ES5 compatible.
### `settings.staticsStrategy`
* Determines how static properties are inherited
* Possible values:
- `'copy'` (default) - Simply copies all properties (minus `prototype`) from the base classes/constructor functions onto the mixed class. Like `settings.prototypeStrategy = 'copy'`, this strategy also suffers from stale references, but shouldn't be a concern if you don't redefine static methods after mixing.
- `'proxy'` - Similar to `settings.prototypeStrategy`, proxy's static method access to base classes. Has the same benefits/downsides.
### `settings.initFunction`
* If set, `ts-mixer` will automatically call the function with this name upon construction
* Possible values:
- `null` (default) - disables the behavior
- a string - function name to call upon construction
* Read more about why you would want this in [dealing with constructors](#dealing-with-constructors)
### `settings.decoratorInheritance`
* Determines how decorators are inherited from classes passed to `Mixin(...)`
* Possible values:
- `'deep'` (default) - Deeply inherits decorators from all given classes and their ancestors
- `'direct'` - Only inherits decorators defined directly on the given classes
- `'none'` - Skips decorator inheritance
# Author
Tanner Nielsen <tannerntannern@gmail.com>
* Website - [tannernielsen.com](http://tannernielsen.com)
* Github - [tannerntannern](https://github.com/tannerntannern)
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows note
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Note that PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Then, run the program to be debugged as usual.
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <tj@vision-media.ca>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# Optionator
<a name="optionator" />
Optionator is a JavaScript/Node.js option parsing and help generation library used by [eslint](http://eslint.org), [Grasp](http://graspjs.com), [LiveScript](http://livescript.net), [esmangle](https://github.com/estools/esmangle), [escodegen](https://github.com/estools/escodegen), and [many more](https://www.npmjs.com/browse/depended/optionator).
For an online demo, check out the [Grasp online demo](http://www.graspjs.com/#demo).
[About](#about) · [Usage](#usage) · [Settings Format](#settings-format) · [Argument Format](#argument-format)
## Why?
The problem with other option parsers, such as `yargs` or `minimist`, is they just accept all input, valid or not.
With Optionator, if you mistype an option, it will give you an error (with a suggestion for what you meant).
If you give the wrong type of argument for an option, it will give you an error rather than supplying the wrong input to your application.
$ cmd --halp
Invalid option '--halp' - perhaps you meant '--help'?
$ cmd --count str
Invalid value for option 'count' - expected type Int, received value: str.
Other helpful features include reformatting the help text based on the size of the console, so that it fits even if the console is narrow, and accepting not just an array (eg. process.argv), but a string or object as well, making things like testing much easier.
## About
Optionator uses [type-check](https://github.com/gkz/type-check) and [levn](https://github.com/gkz/levn) behind the scenes to cast and verify input according the specified types.
MIT license. Version 0.9.1
npm install optionator
For updates on Optionator, [follow me on twitter](https://twitter.com/gkzahariev).
Optionator is a Node.js module, but can be used in the browser as well if packed with webpack/browserify.
## Usage
`require('optionator');` returns a function. It has one property, `VERSION`, the current version of the library as a string. This function is called with an object specifying your options and other information, see the [settings format section](#settings-format). This in turn returns an object with three properties, `parse`, `parseArgv`, `generateHelp`, and `generateHelpForOption`, which are all functions.
```js
var optionator = require('optionator')({
prepend: 'Usage: cmd [options]',
append: 'Version 1.0.0',
options: [{
option: 'help',
alias: 'h',
type: 'Boolean',
description: 'displays help'
}, {
option: 'count',
alias: 'c',
type: 'Int',
description: 'number of things',
example: 'cmd --count 2'
}]
});
var options = optionator.parseArgv(process.argv);
if (options.help) {
console.log(optionator.generateHelp());
}
...
```
### parse(input, parseOptions)
`parse` processes the `input` according to your settings, and returns an object with the results.
##### arguments
* input - `[String] | Object | String` - the input you wish to parse
* parseOptions - `{slice: Int}` - all options optional
- `slice` specifies how much to slice away from the beginning if the input is an array or string - by default `0` for string, `2` for array (works with `process.argv`)
##### returns
`Object` - the parsed options, each key is a camelCase version of the option name (specified in dash-case), and each value is the processed value for that option. Positional values are in an array under the `_` key.
##### example
```js
parse(['node', 't.js', '--count', '2', 'positional']); // {count: 2, _: ['positional']}
parse('--count 2 positional'); // {count: 2, _: ['positional']}
parse({count: 2, _:['positional']}); // {count: 2, _: ['positional']}
```
### parseArgv(input)
`parseArgv` works exactly like `parse`, but only for array input and it slices off the first two elements.
##### arguments
* input - `[String]` - the input you wish to parse
##### returns
See "returns" section in "parse"
##### example
```js
parseArgv(process.argv);
```
### generateHelp(helpOptions)
`generateHelp` produces help text based on your settings.
##### arguments
* helpOptions - `{showHidden: Boolean, interpolate: Object}` - all options optional
- `showHidden` specifies whether to show options with `hidden: true` specified, by default it is `false`
- `interpolate` specify data to be interpolated in `prepend` and `append` text, `{{key}}` is the format - eg. `generateHelp({interpolate:{version: '0.4.2'}})`, will change this `append` text: `Version {{version}}` to `Version 0.4.2`
##### returns
`String` - the generated help text
##### example
```js
generateHelp(); /*
"Usage: cmd [options] positional
-h, --help displays help
-c, --count Int number of things
Version 1.0.0
"*/
```
### generateHelpForOption(optionName)
`generateHelpForOption` produces expanded help text for the specified with `optionName` option. If an `example` was specified for the option, it will be displayed, and if a `longDescription` was specified, it will display that instead of the `description`.
##### arguments
* optionName - `String` - the name of the option to display
##### returns
`String` - the generated help text for the option
##### example
```js
generateHelpForOption('count'); /*
"-c, --count Int
description: number of things
example: cmd --count 2
"*/
```
## Settings Format
When your `require('optionator')`, you get a function that takes in a settings object. This object has the type:
{
prepend: String,
append: String,
options: [{heading: String} | {
option: String,
alias: [String] | String,
type: String,
enum: [String],
default: String,
restPositional: Boolean,
required: Boolean,
overrideRequired: Boolean,
dependsOn: [String] | String,
concatRepeatedArrays: Boolean | (Boolean, Object),
mergeRepeatedObjects: Boolean,
description: String,
longDescription: String,
example: [String] | String
}],
helpStyle: {
aliasSeparator: String,
typeSeparator: String,
descriptionSeparator: String,
initialIndent: Int,
secondaryIndent: Int,
maxPadFactor: Number
},
mutuallyExclusive: [[String | [String]]],
concatRepeatedArrays: Boolean | (Boolean, Object), // deprecated, set in defaults object
mergeRepeatedObjects: Boolean, // deprecated, set in defaults object
positionalAnywhere: Boolean,
typeAliases: Object,
defaults: Object
}
All of the properties are optional (the `Maybe` has been excluded for brevities sake), except for having either `heading: String` or `option: String` in each object in the `options` array.
### Top Level Properties
* `prepend` is an optional string to be placed before the options in the help text
* `append` is an optional string to be placed after the options in the help text
* `options` is a required array specifying your options and headings, the options and headings will be displayed in the order specified
* `helpStyle` is an optional object which enables you to change the default appearance of some aspects of the help text
* `mutuallyExclusive` is an optional array of arrays of either strings or arrays of strings. The top level array is a list of rules, each rule is a list of elements - each element can be either a string (the name of an option), or a list of strings (a group of option names) - there will be an error if more than one element is present
* `concatRepeatedArrays` see description under the "Option Properties" heading - use at the top level is deprecated, if you want to set this for all options, use the `defaults` property
* `mergeRepeatedObjects` see description under the "Option Properties" heading - use at the top level is deprecated, if you want to set this for all options, use the `defaults` property
* `positionalAnywhere` is an optional boolean (defaults to `true`) - when `true` it allows positional arguments anywhere, when `false`, all arguments after the first positional one are taken to be positional as well, even if they look like a flag. For example, with `positionalAnywhere: false`, the arguments `--flag --boom 12 --crack` would have two positional arguments: `12` and `--crack`
* `typeAliases` is an optional object, it allows you to set aliases for types, eg. `{Path: 'String'}` would allow you to use the type `Path` as an alias for the type `String`
* `defaults` is an optional object following the option properties format, which specifies default values for all options. A default will be overridden if manually set. For example, you can do `default: { type: "String" }` to set the default type of all options to `String`, and then override that default in an individual option by setting the `type` property
#### Heading Properties
* `heading` a required string, the name of the heading
#### Option Properties
* `option` the required name of the option - use dash-case, without the leading dashes
* `alias` is an optional string or array of strings which specify any aliases for the option
* `type` is a required string in the [type check](https://github.com/gkz/type-check) [format](https://github.com/gkz/type-check#type-format), this will be used to cast the inputted value and validate it
* `enum` is an optional array of strings, each string will be parsed by [levn](https://github.com/gkz/levn) - the argument value must be one of the resulting values - each potential value must validate against the specified `type`
* `default` is a optional string, which will be parsed by [levn](https://github.com/gkz/levn) and used as the default value if none is set - the value must validate against the specified `type`
* `restPositional` is an optional boolean - if set to `true`, everything after the option will be taken to be a positional argument, even if it looks like a named argument
* `required` is an optional boolean - if set to `true`, the option parsing will fail if the option is not defined
* `overrideRequired` is a optional boolean - if set to `true` and the option is used, and there is another option which is required but not set, it will override the need for the required option and there will be no error - this is useful if you have required options and want to use `--help` or `--version` flags
* `concatRepeatedArrays` is an optional boolean or tuple with boolean and options object (defaults to `false`) - when set to `true` and an option contains an array value and is repeated, the subsequent values for the flag will be appended rather than overwriting the original value - eg. option `g` of type `[String]`: `-g a -g b -g c,d` will result in `['a','b','c','d']`
You can supply an options object by giving the following value: `[true, options]`. The one currently supported option is `oneValuePerFlag`, this only allows one array value per flag. This is useful if your potential values contain a comma.
* `mergeRepeatedObjects` is an optional boolean (defaults to `false`) - when set to `true` and an option contains an object value and is repeated, the subsequent values for the flag will be merged rather than overwriting the original value - eg. option `g` of type `Object`: `-g a:1 -g b:2 -g c:3,d:4` will result in `{a: 1, b: 2, c: 3, d: 4}`
* `dependsOn` is an optional string or array of strings - if simply a string (the name of another option), it will make sure that that other option is set, if an array of strings, depending on whether `'and'` or `'or'` is first, it will either check whether all (`['and', 'option-a', 'option-b']`), or at least one (`['or', 'option-a', 'option-b']`) other options are set
* `description` is an optional string, which will be displayed next to the option in the help text
* `longDescription` is an optional string, it will be displayed instead of the `description` when `generateHelpForOption` is used
* `example` is an optional string or array of strings with example(s) for the option - these will be displayed when `generateHelpForOption` is used
#### Help Style Properties
* `aliasSeparator` is an optional string, separates multiple names from each other - default: ' ,'
* `typeSeparator` is an optional string, separates the type from the names - default: ' '
* `descriptionSeparator` is an optional string , separates the description from the padded name and type - default: ' '
* `initialIndent` is an optional int - the amount of indent for options - default: 2
* `secondaryIndent` is an optional int - the amount of indent if wrapped fully (in addition to the initial indent) - default: 4
* `maxPadFactor` is an optional number - affects the default level of padding for the names/type, it is multiplied by the average of the length of the names/type - default: 1.5
## Argument Format
At the highest level there are two types of arguments: named, and positional.
Name arguments of any length are prefixed with `--` (eg. `--go`), and those of one character may be prefixed with either `--` or `-` (eg. `-g`).
There are two types of named arguments: boolean flags (eg. `--problemo`, `-p`) which take no value and result in a `true` if they are present, the falsey `undefined` if they are not present, or `false` if present and explicitly prefixed with `no` (eg. `--no-problemo`). Named arguments with values (eg. `--tseries 800`, `-t 800`) are the other type. If the option has a type `Boolean` it will automatically be made into a boolean flag. Any other type results in a named argument that takes a value.
For more information about how to properly set types to get the value you want, take a look at the [type check](https://github.com/gkz/type-check) and [levn](https://github.com/gkz/levn) pages.
You can group single character arguments that use a single `-`, however all except the last must be boolean flags (which take no value). The last may be a boolean flag, or an argument which takes a value - eg. `-ba 2` is equivalent to `-b -a 2`.
Positional arguments are all those values which do not fall under the above - they can be anywhere, not just at the end. For example, in `cmd -b one -a 2 two` where `b` is a boolean flag, and `a` has the type `Number`, there are two positional arguments, `one` and `two`.
Everything after an `--` is positional, even if it looks like a named argument.
You may optionally use `=` to separate option names from values, for example: `--count=2`.
If you specify the option `NUM`, then any argument using a single `-` followed by a number will be valid and will set the value of `NUM`. Eg. `-2` will be parsed into `NUM: 2`.
If duplicate named arguments are present, the last one will be taken.
## Technical About
`optionator` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It uses [levn](https://github.com/gkz/levn) to cast arguments to their specified type, and uses [type-check](https://github.com/gkz/type-check) to validate values. It also uses the [prelude.ls](http://preludels.com/) library.
<p align="center">
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs/master/yargs-logo.png">
</p>
<h1 align="center"> Yargs </h1>
<p align="center">
<b >Yargs be a node.js library fer hearties tryin' ter parse optstrings</b>
</p>
<br>

[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[![Coverage][coverage-image]][coverage-url]
[![Conventional Commits][conventional-commits-image]][conventional-commits-url]
[![Slack][slack-image]][slack-url]
## Description
Yargs helps you build interactive command line tools, by parsing arguments and generating an elegant user interface.
It gives you:
* commands and (grouped) options (`my-program.js serve --port=5000`).
* a dynamically generated help menu based on your arguments:
```
mocha [spec..]
Run tests with Mocha
Commands
mocha inspect [spec..] Run tests with Mocha [default]
mocha init <path> create a client-side Mocha setup at <path>
Rules & Behavior
--allow-uncaught Allow uncaught errors to propagate [boolean]
--async-only, -A Require all tests to use a callback (async) or
return a Promise [boolean]
```
* bash-completion shortcuts for commands and options.
* and [tons more](/docs/api.md).
## Installation
Stable version:
```bash
npm i yargs
```
Bleeding edge version with the most recent features:
```bash
npm i yargs@next
```
## Usage
### Simple Example
```javascript
#!/usr/bin/env node
const yargs = require('yargs/yargs')
const { hideBin } = require('yargs/helpers')
const argv = yargs(hideBin(process.argv)).argv
if (argv.ships > 3 && argv.distance < 53.5) {
console.log('Plunder more riffiwobbles!')
} else {
console.log('Retreat from the xupptumblers!')
}
```
```bash
$ ./plunder.js --ships=4 --distance=22
Plunder more riffiwobbles!
$ ./plunder.js --ships 12 --distance 98.7
Retreat from the xupptumblers!
```
### Complex Example
```javascript
#!/usr/bin/env node
const yargs = require('yargs/yargs')
const { hideBin } = require('yargs/helpers')
yargs(hideBin(process.argv))
.command('serve [port]', 'start the server', (yargs) => {
yargs
.positional('port', {
describe: 'port to bind on',
default: 5000
})
}, (argv) => {
if (argv.verbose) console.info(`start server on :${argv.port}`)
serve(argv.port)
})
.option('verbose', {
alias: 'v',
type: 'boolean',
description: 'Run with verbose logging'
})
.argv
```
Run the example above with `--help` to see the help for the application.
## Supported Platforms
### TypeScript
yargs has type definitions at [@types/yargs][type-definitions].
```
npm i @types/yargs --save-dev
```
See usage examples in [docs](/docs/typescript.md).
### Deno
As of `v16`, `yargs` supports [Deno](https://github.com/denoland/deno):
```typescript
import yargs from 'https://deno.land/x/yargs/deno.ts'
import { Arguments } from 'https://deno.land/x/yargs/deno-types.ts'
yargs(Deno.args)
.command('download <files...>', 'download a list of files', (yargs: any) => {
return yargs.positional('files', {
describe: 'a list of files to do something with'
})
}, (argv: Arguments) => {
console.info(argv)
})
.strictCommands()
.demandCommand(1)
.argv
```
### ESM
As of `v16`,`yargs` supports ESM imports:
```js
import yargs from 'yargs'
import { hideBin } from 'yargs/helpers'
yargs(hideBin(process.argv))
.command('curl <url>', 'fetch the contents of the URL', () => {}, (argv) => {
console.info(argv)
})
.demandCommand(1)
.argv
```
### Usage in Browser
See examples of using yargs in the browser in [docs](/docs/browser.md).
## Community
Having problems? want to contribute? join our [community slack](http://devtoolscommunity.herokuapp.com).
## Documentation
### Table of Contents
* [Yargs' API](/docs/api.md)
* [Examples](/docs/examples.md)
* [Parsing Tricks](/docs/tricks.md)
* [Stop the Parser](/docs/tricks.md#stop)
* [Negating Boolean Arguments](/docs/tricks.md#negate)
* [Numbers](/docs/tricks.md#numbers)
* [Arrays](/docs/tricks.md#arrays)
* [Objects](/docs/tricks.md#objects)
* [Quotes](/docs/tricks.md#quotes)
* [Advanced Topics](/docs/advanced.md)
* [Composing Your App Using Commands](/docs/advanced.md#commands)
* [Building Configurable CLI Apps](/docs/advanced.md#configuration)
* [Customizing Yargs' Parser](/docs/advanced.md#customizing)
* [Bundling yargs](/docs/bundling.md)
* [Contributing](/contributing.md)
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
[npm-url]: https://www.npmjs.com/package/yargs
[npm-image]: https://img.shields.io/npm/v/yargs.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: http://standardjs.com/
[conventional-commits-image]: https://img.shields.io/badge/Conventional%20Commits-1.0.0-yellow.svg
[conventional-commits-url]: https://conventionalcommits.org/
[slack-image]: http://devtoolscommunity.herokuapp.com/badge.svg
[slack-url]: http://devtoolscommunity.herokuapp.com
[type-definitions]: https://github.com/DefinitelyTyped/DefinitelyTyped/tree/master/types/yargs
[coverage-image]: https://img.shields.io/nycrc/yargs/yargs
[coverage-url]: https://github.com/yargs/yargs/blob/master/.nycrc
# axios // adapters
The modules under `adapters/` are modules that handle dispatching a request and settling a returned `Promise` once a response is received.
## Example
```js
var settle = require('./../core/settle');
module.exports = function myAdapter(config) {
// At this point:
// - config has been merged with defaults
// - request transformers have already run
// - request interceptors have already run
// Make the request using config provided
// Upon response settle the Promise
return new Promise(function(resolve, reject) {
var response = {
data: responseData,
status: request.status,
statusText: request.statusText,
headers: responseHeaders,
config: config,
request: request
};
settle(resolve, reject, response);
// From here:
// - response transformers will run
// - response interceptors will run
});
}
```
# assemblyscript-regex
A regex engine for AssemblyScript.
[AssemblyScript](https://www.assemblyscript.org/) is a new language, based on TypeScript, that runs on WebAssembly. AssemblyScript has a lightweight standard library, but lacks support for Regular Expression. The project fills that gap!
This project exposes an API that mirrors the JavaScript [RegExp](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp) class:
```javascript
const regex = new RegExp("fo*", "g");
const str = "table football, foul";
let match: Match | null = regex.exec(str);
while (match != null) {
// first iteration
// match.index = 6
// match.matches[0] = "foo"
// second iteration
// match.index = 16
// match.matches[0] = "fo"
match = regex.exec(str);
}
```
## Project status
The initial focus of this implementation has been feature support and functionality over performance. It currently supports a sufficient number of regex features to be considered useful, including most character classes, common assertions, groups, alternations, capturing groups and quantifiers.
The next phase of development will focussed on more extensive testing and performance. The project currently has reasonable unit test coverage, focussed on positive and negative test cases on a per-feature basis. It also includes a more exhaustive test suite with test cases borrowed from another regex library.
### Feature support
Based on the classfication within the [MDN cheatsheet](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions/Cheatsheet)
**Character sets**
- [x] .
- [x] \d
- [x] \D
- [x] \w
- [x] \W
- [x] \s
- [x] \S
- [x] \t
- [x] \r
- [x] \n
- [x] \v
- [x] \f
- [ ] [\b]
- [ ] \0
- [ ] \cX
- [x] \xhh
- [x] \uhhhh
- [ ] \u{hhhh} or \u{hhhhh}
- [x] \
**Assertions**
- [x] ^
- [x] $
- [ ] \b
- [ ] \B
**Other assertions**
- [ ] x(?=y) Lookahead assertion
- [ ] x(?!y) Negative lookahead assertion
- [ ] (?<=y)x Lookbehind assertion
- [ ] (?<!y)x Negative lookbehind assertion
**Groups and ranges**
- [x] x|y
- [x] [xyz][a-c]
- [x] [^xyz][^a-c]
- [x] (x) capturing group
- [ ] \n back reference
- [ ] (?<Name>x) named capturing group
- [x] (?:x) Non-capturing group
**Quantifiers**
- [x] x\*
- [x] x+
- [x] x?
- [x] x{n}
- [x] x{n,}
- [x] x{n,m}
- [ ] x\*? / x+? / ...
**RegExp**
- [x] global
- [ ] sticky
- [x] case insensitive
- [x] multiline
- [x] dotAll
- [ ] unicode
### Development
This project is open source, MIT licenced and your contributions are very much welcomed.
To get started, check out the repository and install dependencies:
```
$ npm install
```
A few general points about the tools and processes this project uses:
- This project uses prettier for code formatting and eslint to provide additional syntactic checks. These are both run on `npm test` and as part of the CI build.
- The unit tests are executed using [as-pect](https://github.com/jtenner/as-pect) - a native AssemblyScript test runner
- The specification tests are within the `spec` folder. The `npm run test:generate` target transforms these tests into as-pect tests which execute as part of the standard build / test cycle
- In order to support improved debugging you can execute this library as TypeScript (rather than WebAssembly), via the `npm run tsrun` target.
# AssemblyScript Rtrace
A tiny utility to sanitize the AssemblyScript runtime. Records allocations and frees performed by the runtime and emits an error if something is off. Also checks for leaks.
Instructions
------------
Compile your module that uses the full or half runtime with `-use ASC_RTRACE=1 --explicitStart` and include an instance of this module as the import named `rtrace`.
```js
const rtrace = new Rtrace({
onerror(err, info) {
// handle error
},
oninfo(msg) {
// print message, optional
},
getMemory() {
// obtain the module's memory,
// e.g. with --explicitStart:
return instance.exports.memory;
}
});
const { module, instance } = await WebAssembly.instantiate(...,
rtrace.install({
...imports...
})
);
instance.exports._start();
...
if (rtrace.active) {
let leakCount = rtr.check();
if (leakCount) {
// handle error
}
}
```
Note that references in globals which are not cleared before collection is performed appear as leaks, including their inner members. A TypedArray would leak itself and its backing ArrayBuffer in this case for example. This is perfectly normal and clearing all globals avoids this.
# Acorn
A tiny, fast JavaScript parser written in JavaScript.
## Community
Acorn is open source software released under an
[MIT license](https://github.com/acornjs/acorn/blob/master/acorn/LICENSE).
You are welcome to
[report bugs](https://github.com/acornjs/acorn/issues) or create pull
requests on [github](https://github.com/acornjs/acorn). For questions
and discussion, please use the
[Tern discussion forum](https://discuss.ternjs.net).
## Installation
The easiest way to install acorn is from [`npm`](https://www.npmjs.com/):
```sh
npm install acorn
```
Alternately, you can download the source and build acorn yourself:
```sh
git clone https://github.com/acornjs/acorn.git
cd acorn
npm install
```
## Interface
**parse**`(input, options)` is the main interface to the library. The
`input` parameter is a string, `options` can be undefined or an object
setting some of the options listed below. The return value will be an
abstract syntax tree object as specified by the [ESTree
spec](https://github.com/estree/estree).
```javascript
let acorn = require("acorn");
console.log(acorn.parse("1 + 1"));
```
When encountering a syntax error, the parser will raise a
`SyntaxError` object with a meaningful message. The error object will
have a `pos` property that indicates the string offset at which the
error occurred, and a `loc` object that contains a `{line, column}`
object referring to that same position.
Options can be provided by passing a second argument, which should be
an object containing any of these fields:
- **ecmaVersion**: Indicates the ECMAScript version to parse. Must be
either 3, 5, 6 (2015), 7 (2016), 8 (2017), 9 (2018), 10 (2019) or 11
(2020, partial support). This influences support for strict mode,
the set of reserved words, and support for new syntax features.
Default is 10.
**NOTE**: Only 'stage 4' (finalized) ECMAScript features are being
implemented by Acorn. Other proposed new features can be implemented
through plugins.
- **sourceType**: Indicate the mode the code should be parsed in. Can be
either `"script"` or `"module"`. This influences global strict mode
and parsing of `import` and `export` declarations.
**NOTE**: If set to `"module"`, then static `import` / `export` syntax
will be valid, even if `ecmaVersion` is less than 6.
- **onInsertedSemicolon**: If given a callback, that callback will be
called whenever a missing semicolon is inserted by the parser. The
callback will be given the character offset of the point where the
semicolon is inserted as argument, and if `locations` is on, also a
`{line, column}` object representing this position.
- **onTrailingComma**: Like `onInsertedSemicolon`, but for trailing
commas.
- **allowReserved**: If `false`, using a reserved word will generate
an error. Defaults to `true` for `ecmaVersion` 3, `false` for higher
versions. When given the value `"never"`, reserved words and
keywords can also not be used as property names (as in Internet
Explorer's old parser).
- **allowReturnOutsideFunction**: By default, a return statement at
the top level raises an error. Set this to `true` to accept such
code.
- **allowImportExportEverywhere**: By default, `import` and `export`
declarations can only appear at a program's top level. Setting this
option to `true` allows them anywhere where a statement is allowed.
- **allowAwaitOutsideFunction**: By default, `await` expressions can
only appear inside `async` functions. Setting this option to
`true` allows to have top-level `await` expressions. They are
still not allowed in non-`async` functions, though.
- **allowHashBang**: When this is enabled (off by default), if the
code starts with the characters `#!` (as in a shellscript), the
first line will be treated as a comment.
- **locations**: When `true`, each node has a `loc` object attached
with `start` and `end` subobjects, each of which contains the
one-based line and zero-based column numbers in `{line, column}`
form. Default is `false`.
- **onToken**: If a function is passed for this option, each found
token will be passed in same format as tokens returned from
`tokenizer().getToken()`.
If array is passed, each found token is pushed to it.
Note that you are not allowed to call the parser from the
callback—that will corrupt its internal state.
- **onComment**: If a function is passed for this option, whenever a
comment is encountered the function will be called with the
following parameters:
- `block`: `true` if the comment is a block comment, false if it
is a line comment.
- `text`: The content of the comment.
- `start`: Character offset of the start of the comment.
- `end`: Character offset of the end of the comment.
When the `locations` options is on, the `{line, column}` locations
of the comment’s start and end are passed as two additional
parameters.
If array is passed for this option, each found comment is pushed
to it as object in Esprima format:
```javascript
{
"type": "Line" | "Block",
"value": "comment text",
"start": Number,
"end": Number,
// If `locations` option is on:
"loc": {
"start": {line: Number, column: Number}
"end": {line: Number, column: Number}
},
// If `ranges` option is on:
"range": [Number, Number]
}
```
Note that you are not allowed to call the parser from the
callback—that will corrupt its internal state.
- **ranges**: Nodes have their start and end characters offsets
recorded in `start` and `end` properties (directly on the node,
rather than the `loc` object, which holds line/column data. To also
add a
[semi-standardized](https://bugzilla.mozilla.org/show_bug.cgi?id=745678)
`range` property holding a `[start, end]` array with the same
numbers, set the `ranges` option to `true`.
- **program**: It is possible to parse multiple files into a single
AST by passing the tree produced by parsing the first file as the
`program` option in subsequent parses. This will add the toplevel
forms of the parsed file to the "Program" (top) node of an existing
parse tree.
- **sourceFile**: When the `locations` option is `true`, you can pass
this option to add a `source` attribute in every node’s `loc`
object. Note that the contents of this option are not examined or
processed in any way; you are free to use whatever format you
choose.
- **directSourceFile**: Like `sourceFile`, but a `sourceFile` property
will be added (regardless of the `location` option) directly to the
nodes, rather than the `loc` object.
- **preserveParens**: If this option is `true`, parenthesized expressions
are represented by (non-standard) `ParenthesizedExpression` nodes
that have a single `expression` property containing the expression
inside parentheses.
**parseExpressionAt**`(input, offset, options)` will parse a single
expression in a string, and return its AST. It will not complain if
there is more of the string left after the expression.
**tokenizer**`(input, options)` returns an object with a `getToken`
method that can be called repeatedly to get the next token, a `{start,
end, type, value}` object (with added `loc` property when the
`locations` option is enabled and `range` property when the `ranges`
option is enabled). When the token's type is `tokTypes.eof`, you
should stop calling the method, since it will keep returning that same
token forever.
In ES6 environment, returned result can be used as any other
protocol-compliant iterable:
```javascript
for (let token of acorn.tokenizer(str)) {
// iterate over the tokens
}
// transform code to array of tokens:
var tokens = [...acorn.tokenizer(str)];
```
**tokTypes** holds an object mapping names to the token type objects
that end up in the `type` properties of tokens.
**getLineInfo**`(input, offset)` can be used to get a `{line,
column}` object for a given program string and offset.
### The `Parser` class
Instances of the **`Parser`** class contain all the state and logic
that drives a parse. It has static methods `parse`,
`parseExpressionAt`, and `tokenizer` that match the top-level
functions by the same name.
When extending the parser with plugins, you need to call these methods
on the extended version of the class. To extend a parser with plugins,
you can use its static `extend` method.
```javascript
var acorn = require("acorn");
var jsx = require("acorn-jsx");
var JSXParser = acorn.Parser.extend(jsx());
JSXParser.parse("foo(<bar/>)");
```
The `extend` method takes any number of plugin values, and returns a
new `Parser` class that includes the extra parser logic provided by
the plugins.
## Command line interface
The `bin/acorn` utility can be used to parse a file from the command
line. It accepts as arguments its input file and the following
options:
- `--ecma3|--ecma5|--ecma6|--ecma7|--ecma8|--ecma9|--ecma10`: Sets the ECMAScript version
to parse. Default is version 9.
- `--module`: Sets the parsing mode to `"module"`. Is set to `"script"` otherwise.
- `--locations`: Attaches a "loc" object to each node with "start" and
"end" subobjects, each of which contains the one-based line and
zero-based column numbers in `{line, column}` form.
- `--allow-hash-bang`: If the code starts with the characters #! (as
in a shellscript), the first line will be treated as a comment.
- `--compact`: No whitespace is used in the AST output.
- `--silent`: Do not output the AST, just return the exit status.
- `--help`: Print the usage information and quit.
The utility spits out the syntax tree as JSON data.
## Existing plugins
- [`acorn-jsx`](https://github.com/RReverser/acorn-jsx): Parse [Facebook JSX syntax extensions](https://github.com/facebook/jsx)
Plugins for ECMAScript proposals:
- [`acorn-stage3`](https://github.com/acornjs/acorn-stage3): Parse most stage 3 proposals, bundling:
- [`acorn-class-fields`](https://github.com/acornjs/acorn-class-fields): Parse [class fields proposal](https://github.com/tc39/proposal-class-fields)
- [`acorn-import-meta`](https://github.com/acornjs/acorn-import-meta): Parse [import.meta proposal](https://github.com/tc39/proposal-import-meta)
- [`acorn-private-methods`](https://github.com/acornjs/acorn-private-methods): parse [private methods, getters and setters proposal](https://github.com/tc39/proposal-private-methods)n
# node-tar
[](https://travis-ci.org/npm/node-tar)
[Fast](./benchmarks) and full-featured Tar for Node.js
The API is designed to mimic the behavior of `tar(1)` on unix systems.
If you are familiar with how tar works, most of this will hopefully be
straightforward for you. If not, then hopefully this module can teach
you useful unix skills that may come in handy someday :)
## Background
A "tar file" or "tarball" is an archive of file system entries
(directories, files, links, etc.) The name comes from "tape archive".
If you run `man tar` on almost any Unix command line, you'll learn
quite a bit about what it can do, and its history.
Tar has 5 main top-level commands:
* `c` Create an archive
* `r` Replace entries within an archive
* `u` Update entries within an archive (ie, replace if they're newer)
* `t` List out the contents of an archive
* `x` Extract an archive to disk
The other flags and options modify how this top level function works.
## High-Level API
These 5 functions are the high-level API. All of them have a
single-character name (for unix nerds familiar with `tar(1)`) as well
as a long name (for everyone else).
All the high-level functions take the following arguments, all three
of which are optional and may be omitted.
1. `options` - An optional object specifying various options
2. `paths` - An array of paths to add or extract
3. `callback` - Called when the command is completed, if async. (If
sync or no file specified, providing a callback throws a
`TypeError`.)
If the command is sync (ie, if `options.sync=true`), then the
callback is not allowed, since the action will be completed immediately.
If a `file` argument is specified, and the command is async, then a
`Promise` is returned. In this case, if async, a callback may be
provided which is called when the command is completed.
If a `file` option is not specified, then a stream is returned. For
`create`, this is a readable stream of the generated archive. For
`list` and `extract` this is a writable stream that an archive should
be written into. If a file is not specified, then a callback is not
allowed, because you're already getting a stream to work with.
`replace` and `update` only work on existing archives, and so require
a `file` argument.
Sync commands without a file argument return a stream that acts on its
input immediately in the same tick. For readable streams, this means
that all of the data is immediately available by calling
`stream.read()`. For writable streams, it will be acted upon as soon
as it is provided, but this can be at any time.
### Warnings and Errors
Tar emits warnings and errors for recoverable and unrecoverable situations,
respectively. In many cases, a warning only affects a single entry in an
archive, or is simply informing you that it's modifying an entry to comply
with the settings provided.
Unrecoverable warnings will always raise an error (ie, emit `'error'` on
streaming actions, throw for non-streaming sync actions, reject the
returned Promise for non-streaming async operations, or call a provided
callback with an `Error` as the first argument). Recoverable errors will
raise an error only if `strict: true` is set in the options.
Respond to (recoverable) warnings by listening to the `warn` event.
Handlers receive 3 arguments:
- `code` String. One of the error codes below. This may not match
`data.code`, which preserves the original error code from fs and zlib.
- `message` String. More details about the error.
- `data` Metadata about the error. An `Error` object for errors raised by
fs and zlib. All fields are attached to errors raisd by tar. Typically
contains the following fields, as relevant:
- `tarCode` The tar error code.
- `code` Either the tar error code, or the error code set by the
underlying system.
- `file` The archive file being read or written.
- `cwd` Working directory for creation and extraction operations.
- `entry` The entry object (if it could be created) for `TAR_ENTRY_INFO`,
`TAR_ENTRY_INVALID`, and `TAR_ENTRY_ERROR` warnings.
- `header` The header object (if it could be created, and the entry could
not be created) for `TAR_ENTRY_INFO` and `TAR_ENTRY_INVALID` warnings.
- `recoverable` Boolean. If `false`, then the warning will emit an
`error`, even in non-strict mode.
#### Error Codes
* `TAR_ENTRY_INFO` An informative error indicating that an entry is being
modified, but otherwise processed normally. For example, removing `/` or
`C:\` from absolute paths if `preservePaths` is not set.
* `TAR_ENTRY_INVALID` An indication that a given entry is not a valid tar
archive entry, and will be skipped. This occurs when:
- a checksum fails,
- a `linkpath` is missing for a link type, or
- a `linkpath` is provided for a non-link type.
If every entry in a parsed archive raises an `TAR_ENTRY_INVALID` error,
then the archive is presumed to be unrecoverably broken, and
`TAR_BAD_ARCHIVE` will be raised.
* `TAR_ENTRY_ERROR` The entry appears to be a valid tar archive entry, but
encountered an error which prevented it from being unpacked. This occurs
when:
- an unrecoverable fs error happens during unpacking,
- an entry has `..` in the path and `preservePaths` is not set, or
- an entry is extracting through a symbolic link, when `preservePaths` is
not set.
* `TAR_ENTRY_UNSUPPORTED` An indication that a given entry is
a valid archive entry, but of a type that is unsupported, and so will be
skipped in archive creation or extracting.
* `TAR_ABORT` When parsing gzipped-encoded archives, the parser will
abort the parse process raise a warning for any zlib errors encountered.
Aborts are considered unrecoverable for both parsing and unpacking.
* `TAR_BAD_ARCHIVE` The archive file is totally hosed. This can happen for
a number of reasons, and always occurs at the end of a parse or extract:
- An entry body was truncated before seeing the full number of bytes.
- The archive contained only invalid entries, indicating that it is
likely not an archive, or at least, not an archive this library can
parse.
`TAR_BAD_ARCHIVE` is considered informative for parse operations, but
unrecoverable for extraction. Note that, if encountered at the end of an
extraction, tar WILL still have extracted as much it could from the
archive, so there may be some garbage files to clean up.
Errors that occur deeper in the system (ie, either the filesystem or zlib)
will have their error codes left intact, and a `tarCode` matching one of
the above will be added to the warning metadata or the raised error object.
Errors generated by tar will have one of the above codes set as the
`error.code` field as well, but since errors originating in zlib or fs will
have their original codes, it's better to read `error.tarCode` if you wish
to see how tar is handling the issue.
### Examples
The API mimics the `tar(1)` command line functionality, with aliases
for more human-readable option and function names. The goal is that
if you know how to use `tar(1)` in Unix, then you know how to use
`require('tar')` in JavaScript.
To replicate `tar czf my-tarball.tgz files and folders`, you'd do:
```js
tar.c(
{
gzip: <true|gzip options>,
file: 'my-tarball.tgz'
},
['some', 'files', 'and', 'folders']
).then(_ => { .. tarball has been created .. })
```
To replicate `tar cz files and folders > my-tarball.tgz`, you'd do:
```js
tar.c( // or tar.create
{
gzip: <true|gzip options>
},
['some', 'files', 'and', 'folders']
).pipe(fs.createWriteStream('my-tarball.tgz'))
```
To replicate `tar xf my-tarball.tgz` you'd do:
```js
tar.x( // or tar.extract(
{
file: 'my-tarball.tgz'
}
).then(_=> { .. tarball has been dumped in cwd .. })
```
To replicate `cat my-tarball.tgz | tar x -C some-dir --strip=1`:
```js
fs.createReadStream('my-tarball.tgz').pipe(
tar.x({
strip: 1,
C: 'some-dir' // alias for cwd:'some-dir', also ok
})
)
```
To replicate `tar tf my-tarball.tgz`, do this:
```js
tar.t({
file: 'my-tarball.tgz',
onentry: entry => { .. do whatever with it .. }
})
```
To replicate `cat my-tarball.tgz | tar t` do:
```js
fs.createReadStream('my-tarball.tgz')
.pipe(tar.t())
.on('entry', entry => { .. do whatever with it .. })
```
To do anything synchronous, add `sync: true` to the options. Note
that sync functions don't take a callback and don't return a promise.
When the function returns, it's already done. Sync methods without a
file argument return a sync stream, which flushes immediately. But,
of course, it still won't be done until you `.end()` it.
To filter entries, add `filter: <function>` to the options.
Tar-creating methods call the filter with `filter(path, stat)`.
Tar-reading methods (including extraction) call the filter with
`filter(path, entry)`. The filter is called in the `this`-context of
the `Pack` or `Unpack` stream object.
The arguments list to `tar t` and `tar x` specify a list of filenames
to extract or list, so they're equivalent to a filter that tests if
the file is in the list.
For those who _aren't_ fans of tar's single-character command names:
```
tar.c === tar.create
tar.r === tar.replace (appends to archive, file is required)
tar.u === tar.update (appends if newer, file is required)
tar.x === tar.extract
tar.t === tar.list
```
Keep reading for all the command descriptions and options, as well as
the low-level API that they are built on.
### tar.c(options, fileList, callback) [alias: tar.create]
Create a tarball archive.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Write the tarball archive to the specified filename. If this
is specified, then the callback will be fired when the file has been
written, and a promise will be returned that resolves when the file
is written. If a filename is not specified, then a Readable Stream
will be returned which will emit the file data. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`. If this is set,
and a file is not provided, then the resulting stream will already
have the data ready to `read` or `emit('data')` as soon as you
request it.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `mode` The mode to set on the created file archive
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
The following options are mostly internal, but can be modified in some
advanced use cases, such as re-using caches between runs.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `readdirCache` A Map object that caches calls to `readdir`.
- `jobs` A number specifying how many concurrent jobs to run.
Defaults to 4.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
### tar.x(options, fileList, callback) [alias: tar.extract]
Extract a tarball archive.
The `fileList` is an array of paths to extract from the tarball. If
no paths are provided, then all the entries are extracted.
If the archive is gzipped, then tar will detect this and unzip it.
Note that all directories that are created will be forced to be
writable, readable, and listable by their owner, to avoid cases where
a directory prevents extraction of child entries by virtue of its
mode.
Most extraction errors will cause a `warn` event to be emitted. If
the `cwd` is missing, or not a directory, then the extraction will
fail completely.
The following options are supported:
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. If provided, this must exist and must be a
directory. [Alias: `C`]
- `file` The archive file to extract. If not specified, then a
Writable stream is returned where the archive data should be
written. [Alias: `f`]
- `sync` Create files and directories synchronously.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being unpacked. Return `true` to unpack the entry from the
archive, or `false` to skip it.
- `newer` Set to true to keep the existing file on disk if it's newer
than the file in the archive. [Alias: `keep-newer`,
`keep-newer-files`]
- `keep` Do not overwrite existing files. In particular, if a file
appears more than once in an archive, later copies will not
overwrite earlier copies. [Alias: `k`, `keep-existing`]
- `preservePaths` Allow absolute paths, paths containing `..`, and
extracting through symbolic links. By default, `/` is stripped from
absolute paths, `..` paths are not extracted, and any file whose
location would be modified by a symbolic link is not extracted.
[Alias: `P`]
- `unlink` Unlink files before creating them. Without this option,
tar overwrites existing files, which preserves existing hardlinks.
With this option, existing hardlinks will be broken, as will any
symlink that would affect the location of an extracted file. [Alias:
`U`]
- `strip` Remove the specified number of leading path elements.
Pathnames with fewer elements will be silently skipped. Note that
the pathname is edited after applying the filter, but before
security checks. [Alias: `strip-components`, `stripComponents`]
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `preserveOwner` If true, tar will set the `uid` and `gid` of
extracted entries to the `uid` and `gid` fields in the archive.
This defaults to true when run as root, and false otherwise. If
false, then files and directories will be set with the owner and
group of the user running the process. This is similar to `-p` in
`tar(1)`, but ACLs and other system-specific data is never unpacked
in this implementation, and modes are set by default already.
[Alias: `p`]
- `uid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified user id, regardless of the `uid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`gid` option.
- `gid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified group id, regardless of the `gid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`uid` option.
- `noMtime` Set to true to omit writing `mtime` value for extracted
entries. [Alias: `m`, `no-mtime`]
- `transform` Provide a function that takes an `entry` object, and
returns a stream, or any falsey value. If a stream is provided,
then that stream's data will be written instead of the contents of
the archive entry. If a falsey value is provided, then the entry is
written to disk as normal. (To exclude items from extraction, use
the `filter` option described above.)
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
The following options are mostly internal, but can be modified in some
advanced use cases, such as re-using caches between runs.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `umask` Filter the modes of entries like `process.umask()`.
- `dmode` Default mode for directories
- `fmode` Default mode for files
- `dirCache` A Map object of which directories exist.
- `maxMetaEntrySize` The maximum size of meta entries that is
supported. Defaults to 1 MB.
Note that using an asynchronous stream type with the `transform`
option will cause undefined behavior in sync extractions.
[MiniPass](http://npm.im/minipass)-based streams are designed for this
use case.
### tar.t(options, fileList, callback) [alias: tar.list]
List the contents of a tarball archive.
The `fileList` is an array of paths to list from the tarball. If
no paths are provided, then all the entries are listed.
If the archive is gzipped, then tar will detect this and unzip it.
Returns an event emitter that emits `entry` events with
`tar.ReadEntry` objects. However, they don't emit `'data'` or `'end'`
events. (If you want to get actual readable entries, use the
`tar.Parse` class instead.)
The following options are supported:
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. [Alias: `C`]
- `file` The archive file to list. If not specified, then a
Writable stream is returned where the archive data should be
written. [Alias: `f`]
- `sync` Read the specified file synchronously. (This has no effect
when a file option isn't specified, because entries are emitted as
fast as they are parsed from the stream anyway.)
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being listed. Return `true` to emit the entry from the
archive, or `false` to skip it.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter. This is important for when both `file` and
`sync` are set, because it will be called synchronously.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noResume` By default, `entry` streams are resumed immediately after
the call to `onentry`. Set `noResume: true` to suppress this
behavior. Note that by opting into this, the stream will never
complete until the entry data is consumed.
### tar.u(options, fileList, callback) [alias: tar.update]
Add files to an archive if they are newer than the entry already in
the tarball archive.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Required. Write the tarball archive to the specified
filename. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for adding entries to the
archive. Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
### tar.r(options, fileList, callback) [alias: tar.replace]
Add files to an existing archive. Because later entries override
earlier entries, this effectively replaces any existing entries.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Required. Write the tarball archive to the specified
filename. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for adding entries to the
archive. Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
## Low-Level API
### class tar.Pack
A readable tar stream.
Has all the standard readable stream interface stuff. `'data'` and
`'end'` events, `read()` method, `pause()` and `resume()`, etc.
#### constructor(options)
The following options are supported:
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()`
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `readdirCache` A Map object that caches calls to `readdir`.
- `jobs` A number specifying how many concurrent jobs to run.
Defaults to 4.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories.
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such.
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
#### add(path)
Adds an entry to the archive. Returns the Pack stream.
#### write(path)
Adds an entry to the archive. Returns true if flushed.
#### end()
Finishes the archive.
### class tar.Pack.Sync
Synchronous version of `tar.Pack`.
### class tar.Unpack
A writable stream that unpacks a tar archive onto the file system.
All the normal writable stream stuff is supported. `write()` and
`end()` methods, `'drain'` events, etc.
Note that all directories that are created will be forced to be
writable, readable, and listable by their owner, to avoid cases where
a directory prevents extraction of child entries by virtue of its
mode.
`'close'` is emitted when it's done writing stuff to the file system.
Most unpack errors will cause a `warn` event to be emitted. If the
`cwd` is missing, or not a directory, then an error will be emitted.
#### constructor(options)
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. If provided, this must exist and must be a
directory.
- `filter` A function that gets called with `(path, entry)` for each
entry being unpacked. Return `true` to unpack the entry from the
archive, or `false` to skip it.
- `newer` Set to true to keep the existing file on disk if it's newer
than the file in the archive.
- `keep` Do not overwrite existing files. In particular, if a file
appears more than once in an archive, later copies will not
overwrite earlier copies.
- `preservePaths` Allow absolute paths, paths containing `..`, and
extracting through symbolic links. By default, `/` is stripped from
absolute paths, `..` paths are not extracted, and any file whose
location would be modified by a symbolic link is not extracted.
- `unlink` Unlink files before creating them. Without this option,
tar overwrites existing files, which preserves existing hardlinks.
With this option, existing hardlinks will be broken, as will any
symlink that would affect the location of an extracted file.
- `strip` Remove the specified number of leading path elements.
Pathnames with fewer elements will be silently skipped. Note that
the pathname is edited after applying the filter, but before
security checks.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `umask` Filter the modes of entries like `process.umask()`.
- `dmode` Default mode for directories
- `fmode` Default mode for files
- `dirCache` A Map object of which directories exist.
- `maxMetaEntrySize` The maximum size of meta entries that is
supported. Defaults to 1 MB.
- `preserveOwner` If true, tar will set the `uid` and `gid` of
extracted entries to the `uid` and `gid` fields in the archive.
This defaults to true when run as root, and false otherwise. If
false, then files and directories will be set with the owner and
group of the user running the process. This is similar to `-p` in
`tar(1)`, but ACLs and other system-specific data is never unpacked
in this implementation, and modes are set by default already.
- `win32` True if on a windows platform. Causes behavior where
filenames containing `<|>?` chars are converted to
windows-compatible values while being unpacked.
- `uid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified user id, regardless of the `uid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`gid` option.
- `gid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified group id, regardless of the `gid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`uid` option.
- `noMtime` Set to true to omit writing `mtime` value for extracted
entries.
- `transform` Provide a function that takes an `entry` object, and
returns a stream, or any falsey value. If a stream is provided,
then that stream's data will be written instead of the contents of
the archive entry. If a falsey value is provided, then the entry is
written to disk as normal. (To exclude items from extraction, use
the `filter` option described above.)
- `strict` Treat warnings as crash-worthy errors. Default false.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
### class tar.Unpack.Sync
Synchronous version of `tar.Unpack`.
Note that using an asynchronous stream type with the `transform`
option will cause undefined behavior in sync unpack streams.
[MiniPass](http://npm.im/minipass)-based streams are designed for this
use case.
### class tar.Parse
A writable stream that parses a tar archive stream. All the standard
writable stream stuff is supported.
If the archive is gzipped, then tar will detect this and unzip it.
Emits `'entry'` events with `tar.ReadEntry` objects, which are
themselves readable streams that you can pipe wherever.
Each `entry` will not emit until the one before it is flushed through,
so make sure to either consume the data (with `on('data', ...)` or
`.pipe(...)`) or throw it away with `.resume()` to keep the stream
flowing.
#### constructor(options)
Returns an event emitter that emits `entry` events with
`tar.ReadEntry` objects.
The following options are supported:
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being listed. Return `true` to emit the entry from the
archive, or `false` to skip it.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
#### abort(error)
Stop all parsing activities. This is called when there are zlib
errors. It also emits an unrecoverable warning with the error provided.
### class tar.ReadEntry extends [MiniPass](http://npm.im/minipass)
A representation of an entry that is being read out of a tar archive.
It has the following fields:
- `extended` The extended metadata object provided to the constructor.
- `globalExtended` The global extended metadata object provided to the
constructor.
- `remain` The number of bytes remaining to be written into the
stream.
- `blockRemain` The number of 512-byte blocks remaining to be written
into the stream.
- `ignore` Whether this entry should be ignored.
- `meta` True if this represents metadata about the next entry, false
if it represents a filesystem object.
- All the fields from the header, extended header, and global extended
header are added to the ReadEntry object. So it has `path`, `type`,
`size, `mode`, and so on.
#### constructor(header, extended, globalExtended)
Create a new ReadEntry object with the specified header, extended
header, and global extended header values.
### class tar.WriteEntry extends [MiniPass](http://npm.im/minipass)
A representation of an entry that is being written from the file
system into a tar archive.
Emits data for the Header, and for the Pax Extended Header if one is
required, as well as any body data.
Creating a WriteEntry for a directory does not also create
WriteEntry objects for all of the directory contents.
It has the following fields:
- `path` The path field that will be written to the archive. By
default, this is also the path from the cwd to the file system
object.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `myuid` If supported, the uid of the user running the current
process.
- `myuser` The `env.USER` string if set, or `''`. Set as the entry
`uname` field if the file's `uid` matches `this.myuid`.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 1 MB.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `absolute` The absolute path to the entry on the filesystem. By
default, this is `path.resolve(this.cwd, this.path)`, but it can be
overridden explicitly.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `win32` True if on a windows platform. Causes behavior where paths
replace `\` with `/` and filenames containing the windows-compatible
forms of `<|>?:` characters are converted to actual `<|>?:` characters
in the archive.
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
#### constructor(path, options)
`path` is the path of the entry as it is written in the archive.
The following options are supported:
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 1 MB.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `absolute` The absolute path to the entry on the filesystem. By
default, this is `path.resolve(this.cwd, this.path)`, but it can be
overridden explicitly.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `win32` True if on a windows platform. Causes behavior where paths
replace `\` with `/`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
- `umask` Set to restrict the modes on the entries in the archive,
somewhat like how umask works on file creation. Defaults to
`process.umask()` on unix systems, or `0o22` on Windows.
#### warn(message, data)
If strict, emit an error with the provided message.
Othewise, emit a `'warn'` event with the provided message and data.
### class tar.WriteEntry.Sync
Synchronous version of tar.WriteEntry
### class tar.WriteEntry.Tar
A version of tar.WriteEntry that gets its data from a tar.ReadEntry
instead of from the filesystem.
#### constructor(readEntry, options)
`readEntry` is the entry being read out of another archive.
The following options are supported:
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
### class tar.Header
A class for reading and writing header blocks.
It has the following fields:
- `nullBlock` True if decoding a block which is entirely composed of
`0x00` null bytes. (Useful because tar files are terminated by
at least 2 null blocks.)
- `cksumValid` True if the checksum in the header is valid, false
otherwise.
- `needPax` True if the values, as encoded, will require a Pax
extended header.
- `path` The path of the entry.
- `mode` The 4 lowest-order octal digits of the file mode. That is,
read/write/execute permissions for world, group, and owner, and the
setuid, setgid, and sticky bits.
- `uid` Numeric user id of the file owner
- `gid` Numeric group id of the file owner
- `size` Size of the file in bytes
- `mtime` Modified time of the file
- `cksum` The checksum of the header. This is generated by adding all
the bytes of the header block, treating the checksum field itself as
all ascii space characters (that is, `0x20`).
- `type` The human-readable name of the type of entry this represents,
or the alphanumeric key if unknown.
- `typeKey` The alphanumeric key for the type of entry this header
represents.
- `linkpath` The target of Link and SymbolicLink entries.
- `uname` Human-readable user name of the file owner
- `gname` Human-readable group name of the file owner
- `devmaj` The major portion of the device number. Always `0` for
files, directories, and links.
- `devmin` The minor portion of the device number. Always `0` for
files, directories, and links.
- `atime` File access time.
- `ctime` File change time.
#### constructor(data, [offset=0])
`data` is optional. It is either a Buffer that should be interpreted
as a tar Header starting at the specified offset and continuing for
512 bytes, or a data object of keys and values to set on the header
object, and eventually encode as a tar Header.
#### decode(block, offset)
Decode the provided buffer starting at the specified offset.
Buffer length must be greater than 512 bytes.
#### set(data)
Set the fields in the data object.
#### encode(buffer, offset)
Encode the header fields into the buffer at the specified offset.
Returns `this.needPax` to indicate whether a Pax Extended Header is
required to properly encode the specified data.
### class tar.Pax
An object representing a set of key-value pairs in an Pax extended
header entry.
It has the following fields. Where the same name is used, they have
the same semantics as the tar.Header field of the same name.
- `global` True if this represents a global extended header, or false
if it is for a single entry.
- `atime`
- `charset`
- `comment`
- `ctime`
- `gid`
- `gname`
- `linkpath`
- `mtime`
- `path`
- `size`
- `uid`
- `uname`
- `dev`
- `ino`
- `nlink`
#### constructor(object, global)
Set the fields set in the object. `global` is a boolean that defaults
to false.
#### encode()
Return a Buffer containing the header and body for the Pax extended
header entry, or `null` if there is nothing to encode.
#### encodeBody()
Return a string representing the body of the pax extended header
entry.
#### encodeField(fieldName)
Return a string representing the key/value encoding for the specified
fieldName, or `''` if the field is unset.
### tar.Pax.parse(string, extended, global)
Return a new Pax object created by parsing the contents of the string
provided.
If the `extended` object is set, then also add the fields from that
object. (This is necessary because multiple metadata entries can
occur in sequence.)
### tar.types
A translation table for the `type` field in tar headers.
#### tar.types.name.get(code)
Get the human-readable name for a given alphanumeric code.
#### tar.types.code.get(name)
Get the alphanumeric code for a given human-readable name.
# jsdiff
[](http://travis-ci.org/kpdecker/jsdiff)
[](https://saucelabs.com/u/jsdiff)
A javascript text differencing implementation.
Based on the algorithm proposed in
["An O(ND) Difference Algorithm and its Variations" (Myers, 1986)](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.4.6927).
## Installation
```bash
npm install diff --save
```
## API
* `Diff.diffChars(oldStr, newStr[, options])` - diffs two blocks of text, comparing character by character.
Returns a list of change objects (See below).
Options
* `ignoreCase`: `true` to ignore casing difference. Defaults to `false`.
* `Diff.diffWords(oldStr, newStr[, options])` - diffs two blocks of text, comparing word by word, ignoring whitespace.
Returns a list of change objects (See below).
Options
* `ignoreCase`: Same as in `diffChars`.
* `Diff.diffWordsWithSpace(oldStr, newStr[, options])` - diffs two blocks of text, comparing word by word, treating whitespace as significant.
Returns a list of change objects (See below).
* `Diff.diffLines(oldStr, newStr[, options])` - diffs two blocks of text, comparing line by line.
Options
* `ignoreWhitespace`: `true` to ignore leading and trailing whitespace. This is the same as `diffTrimmedLines`
* `newlineIsToken`: `true` to treat newline characters as separate tokens. This allows for changes to the newline structure to occur independently of the line content and to be treated as such. In general this is the more human friendly form of `diffLines` and `diffLines` is better suited for patches and other computer friendly output.
Returns a list of change objects (See below).
* `Diff.diffTrimmedLines(oldStr, newStr[, options])` - diffs two blocks of text, comparing line by line, ignoring leading and trailing whitespace.
Returns a list of change objects (See below).
* `Diff.diffSentences(oldStr, newStr[, options])` - diffs two blocks of text, comparing sentence by sentence.
Returns a list of change objects (See below).
* `Diff.diffCss(oldStr, newStr[, options])` - diffs two blocks of text, comparing CSS tokens.
Returns a list of change objects (See below).
* `Diff.diffJson(oldObj, newObj[, options])` - diffs two JSON objects, comparing the fields defined on each. The order of fields, etc does not matter in this comparison.
Returns a list of change objects (See below).
* `Diff.diffArrays(oldArr, newArr[, options])` - diffs two arrays, comparing each item for strict equality (===).
Options
* `comparator`: `function(left, right)` for custom equality checks
Returns a list of change objects (See below).
* `Diff.createTwoFilesPatch(oldFileName, newFileName, oldStr, newStr, oldHeader, newHeader)` - creates a unified diff patch.
Parameters:
* `oldFileName` : String to be output in the filename section of the patch for the removals
* `newFileName` : String to be output in the filename section of the patch for the additions
* `oldStr` : Original string value
* `newStr` : New string value
* `oldHeader` : Additional information to include in the old file header
* `newHeader` : Additional information to include in the new file header
* `options` : An object with options. Currently, only `context` is supported and describes how many lines of context should be included.
* `Diff.createPatch(fileName, oldStr, newStr, oldHeader, newHeader)` - creates a unified diff patch.
Just like Diff.createTwoFilesPatch, but with oldFileName being equal to newFileName.
* `Diff.structuredPatch(oldFileName, newFileName, oldStr, newStr, oldHeader, newHeader, options)` - returns an object with an array of hunk objects.
This method is similar to createTwoFilesPatch, but returns a data structure
suitable for further processing. Parameters are the same as createTwoFilesPatch. The data structure returned may look like this:
```js
{
oldFileName: 'oldfile', newFileName: 'newfile',
oldHeader: 'header1', newHeader: 'header2',
hunks: [{
oldStart: 1, oldLines: 3, newStart: 1, newLines: 3,
lines: [' line2', ' line3', '-line4', '+line5', '\\ No newline at end of file'],
}]
}
```
* `Diff.applyPatch(source, patch[, options])` - applies a unified diff patch.
Return a string containing new version of provided data. `patch` may be a string diff or the output from the `parsePatch` or `structuredPatch` methods.
The optional `options` object may have the following keys:
- `fuzzFactor`: Number of lines that are allowed to differ before rejecting a patch. Defaults to 0.
- `compareLine(lineNumber, line, operation, patchContent)`: Callback used to compare to given lines to determine if they should be considered equal when patching. Defaults to strict equality but may be overridden to provide fuzzier comparison. Should return false if the lines should be rejected.
* `Diff.applyPatches(patch, options)` - applies one or more patches.
This method will iterate over the contents of the patch and apply to data provided through callbacks. The general flow for each patch index is:
- `options.loadFile(index, callback)` is called. The caller should then load the contents of the file and then pass that to the `callback(err, data)` callback. Passing an `err` will terminate further patch execution.
- `options.patched(index, content, callback)` is called once the patch has been applied. `content` will be the return value from `applyPatch`. When it's ready, the caller should call `callback(err)` callback. Passing an `err` will terminate further patch execution.
Once all patches have been applied or an error occurs, the `options.complete(err)` callback is made.
* `Diff.parsePatch(diffStr)` - Parses a patch into structured data
Return a JSON object representation of the a patch, suitable for use with the `applyPatch` method. This parses to the same structure returned by `Diff.structuredPatch`.
* `convertChangesToXML(changes)` - converts a list of changes to a serialized XML format
All methods above which accept the optional `callback` method will run in sync mode when that parameter is omitted and in async mode when supplied. This allows for larger diffs without blocking the event loop. This may be passed either directly as the final parameter or as the `callback` field in the `options` object.
### Change Objects
Many of the methods above return change objects. These objects consist of the following fields:
* `value`: Text content
* `added`: True if the value was inserted into the new string
* `removed`: True if the value was removed from the old string
Note that some cases may omit a particular flag field. Comparison on the flag fields should always be done in a truthy or falsy manner.
## Examples
Basic example in Node
```js
require('colors');
const Diff = require('diff');
const one = 'beep boop';
const other = 'beep boob blah';
const diff = Diff.diffChars(one, other);
diff.forEach((part) => {
// green for additions, red for deletions
// grey for common parts
const color = part.added ? 'green' :
part.removed ? 'red' : 'grey';
process.stderr.write(part.value[color]);
});
console.log();
```
Running the above program should yield
<img src="images/node_example.png" alt="Node Example">
Basic example in a web page
```html
<pre id="display"></pre>
<script src="diff.js"></script>
<script>
const one = 'beep boop',
other = 'beep boob blah',
color = '';
let span = null;
const diff = Diff.diffChars(one, other),
display = document.getElementById('display'),
fragment = document.createDocumentFragment();
diff.forEach((part) => {
// green for additions, red for deletions
// grey for common parts
const color = part.added ? 'green' :
part.removed ? 'red' : 'grey';
span = document.createElement('span');
span.style.color = color;
span.appendChild(document
.createTextNode(part.value));
fragment.appendChild(span);
});
display.appendChild(fragment);
</script>
```
Open the above .html file in a browser and you should see
<img src="images/web_example.png" alt="Node Example">
**[Full online demo](http://kpdecker.github.com/jsdiff)**
## Compatibility
[](https://saucelabs.com/u/jsdiff)
jsdiff supports all ES3 environments with some known issues on IE8 and below. Under these browsers some diff algorithms such as word diff and others may fail due to lack of support for capturing groups in the `split` operation.
## License
See [LICENSE](https://github.com/kpdecker/jsdiff/blob/master/LICENSE).
# flatted
[](https://www.npmjs.com/package/flatted) [](https://coveralls.io/github/WebReflection/flatted?branch=main) [](https://travis-ci.com/WebReflection/flatted) [](https://opensource.org/licenses/ISC) 

<sup>**Social Media Photo by [Matt Seymour](https://unsplash.com/@mattseymour) on [Unsplash](https://unsplash.com/)**</sup>
## Announcement 📣
There is a standard approach to recursion and more data-types than what JSON allow, and it's part of this [Structured Clone Module](https://github.com/ungap/structured-clone/#readme).
Beside acting as a polyfill, its `@ungap/structured-clone/json` export provides both `stringify` and `parse`, and it's been tested for being faster than *flatted*, but its produced output is also smaller than *flatted*.
The *@ungap/structured-clone* module is, in short, a drop in replacement for *flatted*, but it's not compatible with *flatted* specialized syntax.
However, if recursion, as well as more data-types, are what you are after, or interesting for your projects, consider switching to this new module whenever you can 👍
- - -
A super light (0.5K) and fast circular JSON parser, directly from the creator of [CircularJSON](https://github.com/WebReflection/circular-json/#circularjson).
Now available also for **[PHP](./php/flatted.php)**.
```js
npm i flatted
```
Usable via [CDN](https://unpkg.com/flatted) or as regular module.
```js
// ESM
import {parse, stringify, toJSON, fromJSON} from 'flatted';
// CJS
const {parse, stringify, toJSON, fromJSON} = require('flatted');
const a = [{}];
a[0].a = a;
a.push(a);
stringify(a); // [["1","0"],{"a":"0"}]
```
## toJSON and from JSON
If you'd like to implicitly survive JSON serialization, these two helpers helps:
```js
import {toJSON, fromJSON} from 'flatted';
class RecursiveMap extends Map {
static fromJSON(any) {
return new this(fromJSON(any));
}
toJSON() {
return toJSON([...this.entries()]);
}
}
const recursive = new RecursiveMap;
const same = {};
same.same = same;
recursive.set('same', same);
const asString = JSON.stringify(recursive);
const asMap = RecursiveMap.fromJSON(JSON.parse(asString));
asMap.get('same') === asMap.get('same').same;
// true
```
## Flatted VS JSON
As it is for every other specialized format capable of serializing and deserializing circular data, you should never `JSON.parse(Flatted.stringify(data))`, and you should never `Flatted.parse(JSON.stringify(data))`.
The only way this could work is to `Flatted.parse(Flatted.stringify(data))`, as it is also for _CircularJSON_ or any other, otherwise there's no granted data integrity.
Also please note this project serializes and deserializes only data compatible with JSON, so that sockets, or anything else with internal classes different from those allowed by JSON standard, won't be serialized and unserialized as expected.
### New in V1: Exact same JSON API
* Added a [reviver](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse#Syntax) parameter to `.parse(string, reviver)` and revive your own objects.
* Added a [replacer](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify#Syntax) and a `space` parameter to `.stringify(object, replacer, space)` for feature parity with JSON signature.
### Compatibility
All ECMAScript engines compatible with `Map`, `Set`, `Object.keys`, and `Array.prototype.reduce` will work, even if polyfilled.
### How does it work ?
While stringifying, all Objects, including Arrays, and strings, are flattened out and replaced as unique index. `*`
Once parsed, all indexes will be replaced through the flattened collection.
<sup><sub>`*` represented as string to avoid conflicts with numbers</sub></sup>
```js
// logic example
var a = [{one: 1}, {two: '2'}];
a[0].a = a;
// a is the main object, will be at index '0'
// {one: 1} is the second object, index '1'
// {two: '2'} the third, in '2', and it has a string
// which will be found at index '3'
Flatted.stringify(a);
// [["1","2"],{"one":1,"a":"0"},{"two":"3"},"2"]
// a[one,two] {one: 1, a} {two: '2'} '2'
```
<a name="table"></a>
# Table
> Produces a string that represents array data in a text table.
[](https://travis-ci.org/gajus/table)
[](https://coveralls.io/github/gajus/table)
[](https://www.npmjs.org/package/table)
[](https://github.com/gajus/canonical)
[](https://twitter.com/kuizinas)
* [Table](#table)
* [Features](#table-features)
* [Install](#table-install)
* [Usage](#table-usage)
* [API](#table-api)
* [table](#table-api-table-1)
* [createStream](#table-api-createstream)
* [getBorderCharacters](#table-api-getbordercharacters)

<a name="table-features"></a>
## Features
* Works with strings containing [fullwidth](https://en.wikipedia.org/wiki/Halfwidth_and_fullwidth_forms) characters.
* Works with strings containing [ANSI escape codes](https://en.wikipedia.org/wiki/ANSI_escape_code).
* Configurable border characters.
* Configurable content alignment per column.
* Configurable content padding per column.
* Configurable column width.
* Text wrapping.
<a name="table-install"></a>
## Install
```bash
npm install table
```
[](https://www.buymeacoffee.com/gajus)
[](https://www.patreon.com/gajus)
<a name="table-usage"></a>
## Usage
```js
import { table } from 'table';
// Using commonjs?
// const { table } = require('table');
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
console.log(table(data));
```
```
╔════╤════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────┼────╢
║ 1A │ 1B │ 1C ║
╟────┼────┼────╢
║ 2A │ 2B │ 2C ║
╚════╧════╧════╝
```
<a name="table-api"></a>
## API
<a name="table-api-table-1"></a>
### table
Returns the string in the table format
**Parameters:**
- **_data_:** The data to display
- Type: `any[][]`
- Required: `true`
- **_config_:** Table configuration
- Type: `object`
- Required: `false`
<a name="table-api-table-1-config-border"></a>
##### config.border
Type: `{ [type: string]: string }`\
Default: `honeywell` [template](#getbordercharacters)
Custom borders. The keys are any of:
- `topLeft`, `topRight`, `topBody`,`topJoin`
- `bottomLeft`, `bottomRight`, `bottomBody`, `bottomJoin`
- `joinLeft`, `joinRight`, `joinBody`, `joinJoin`
- `bodyLeft`, `bodyRight`, `bodyJoin`
- `headerJoin`
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
border: {
topBody: `─`,
topJoin: `┬`,
topLeft: `┌`,
topRight: `┐`,
bottomBody: `─`,
bottomJoin: `┴`,
bottomLeft: `└`,
bottomRight: `┘`,
bodyLeft: `│`,
bodyRight: `│`,
bodyJoin: `│`,
joinBody: `─`,
joinLeft: `├`,
joinRight: `┤`,
joinJoin: `┼`
}
};
console.log(table(data, config));
```
```
┌────┬────┬────┐
│ 0A │ 0B │ 0C │
├────┼────┼────┤
│ 1A │ 1B │ 1C │
├────┼────┼────┤
│ 2A │ 2B │ 2C │
└────┴────┴────┘
```
<a name="table-api-table-1-config-drawverticalline"></a>
##### config.drawVerticalLine
Type: `(lineIndex: number, columnCount: number) => boolean`\
Default: `() => true`
It is used to tell whether to draw a vertical line. This callback is called for each vertical border of the table.
If the table has `n` columns, then the `index` parameter is alternatively received all numbers in range `[0, n]` inclusively.
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C'],
['3A', '3B', '3C'],
['4A', '4B', '4C']
];
const config = {
drawVerticalLine: (lineIndex, columnCount) => {
return lineIndex === 0 || lineIndex === columnCount;
}
};
console.log(table(data, config));
```
```
╔════════════╗
║ 0A 0B 0C ║
╟────────────╢
║ 1A 1B 1C ║
╟────────────╢
║ 2A 2B 2C ║
╟────────────╢
║ 3A 3B 3C ║
╟────────────╢
║ 4A 4B 4C ║
╚════════════╝
```
<a name="table-api-table-1-config-drawhorizontalline"></a>
##### config.drawHorizontalLine
Type: `(lineIndex: number, rowCount: number) => boolean`\
Default: `() => true`
It is used to tell whether to draw a horizontal line. This callback is called for each horizontal border of the table.
If the table has `n` rows, then the `index` parameter is alternatively received all numbers in range `[0, n]` inclusively.
If the table has `n` rows and contains the header, then the range will be `[0, n+1]` inclusively.
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C'],
['3A', '3B', '3C'],
['4A', '4B', '4C']
];
const config = {
drawHorizontalLine: (lineIndex, rowCount) => {
return lineIndex === 0 || lineIndex === 1 || lineIndex === rowCount - 1 || lineIndex === rowCount;
}
};
console.log(table(data, config));
```
```
╔════╤════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────┼────╢
║ 1A │ 1B │ 1C ║
║ 2A │ 2B │ 2C ║
║ 3A │ 3B │ 3C ║
╟────┼────┼────╢
║ 4A │ 4B │ 4C ║
╚════╧════╧════╝
```
<a name="table-api-table-1-config-singleline"></a>
##### config.singleLine
Type: `boolean`\
Default: `false`
If `true`, horizontal lines inside the table are not drawn. This option also overrides the `config.drawHorizontalLine` if specified.
```js
const data = [
['-rw-r--r--', '1', 'pandorym', 'staff', '1529', 'May 23 11:25', 'LICENSE'],
['-rw-r--r--', '1', 'pandorym', 'staff', '16327', 'May 23 11:58', 'README.md'],
['drwxr-xr-x', '76', 'pandorym', 'staff', '2432', 'May 23 12:02', 'dist'],
['drwxr-xr-x', '634', 'pandorym', 'staff', '20288', 'May 23 11:54', 'node_modules'],
['-rw-r--r--', '1,', 'pandorym', 'staff', '525688', 'May 23 11:52', 'package-lock.json'],
['-rw-r--r--@', '1', 'pandorym', 'staff', '2440', 'May 23 11:25', 'package.json'],
['drwxr-xr-x', '27', 'pandorym', 'staff', '864', 'May 23 11:25', 'src'],
['drwxr-xr-x', '20', 'pandorym', 'staff', '640', 'May 23 11:25', 'test'],
];
const config = {
singleLine: true
};
console.log(table(data, config));
```
```
╔═════════════╤═════╤══════════╤═══════╤════════╤══════════════╤═══════════════════╗
║ -rw-r--r-- │ 1 │ pandorym │ staff │ 1529 │ May 23 11:25 │ LICENSE ║
║ -rw-r--r-- │ 1 │ pandorym │ staff │ 16327 │ May 23 11:58 │ README.md ║
║ drwxr-xr-x │ 76 │ pandorym │ staff │ 2432 │ May 23 12:02 │ dist ║
║ drwxr-xr-x │ 634 │ pandorym │ staff │ 20288 │ May 23 11:54 │ node_modules ║
║ -rw-r--r-- │ 1, │ pandorym │ staff │ 525688 │ May 23 11:52 │ package-lock.json ║
║ -rw-r--r--@ │ 1 │ pandorym │ staff │ 2440 │ May 23 11:25 │ package.json ║
║ drwxr-xr-x │ 27 │ pandorym │ staff │ 864 │ May 23 11:25 │ src ║
║ drwxr-xr-x │ 20 │ pandorym │ staff │ 640 │ May 23 11:25 │ test ║
╚═════════════╧═════╧══════════╧═══════╧════════╧══════════════╧═══════════════════╝
```
<a name="table-api-table-1-config-columns"></a>
##### config.columns
Type: `Column[] | { [columnIndex: number]: Column }`
Column specific configurations.
<a name="table-api-table-1-config-columns-config-columns-width"></a>
###### config.columns[*].width
Type: `number`\
Default: the maximum cell widths of the column
Column width (excluding the paddings).
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
columns: {
1: { width: 10 }
}
};
console.log(table(data, config));
```
```
╔════╤════════════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────────────┼────╢
║ 1A │ 1B │ 1C ║
╟────┼────────────┼────╢
║ 2A │ 2B │ 2C ║
╚════╧════════════╧════╝
```
<a name="table-api-table-1-config-columns-config-columns-alignment"></a>
###### config.columns[*].alignment
Type: `'center' | 'justify' | 'left' | 'right'`\
Default: `'left'`
Cell content horizontal alignment
```js
const data = [
['0A', '0B', '0C', '0D 0E 0F'],
['1A', '1B', '1C', '1D 1E 1F'],
['2A', '2B', '2C', '2D 2E 2F'],
];
const config = {
columnDefault: {
width: 10,
},
columns: [
{ alignment: 'left' },
{ alignment: 'center' },
{ alignment: 'right' },
{ alignment: 'justify' }
],
};
console.log(table(data, config));
```
```
╔════════════╤════════════╤════════════╤════════════╗
║ 0A │ 0B │ 0C │ 0D 0E 0F ║
╟────────────┼────────────┼────────────┼────────────╢
║ 1A │ 1B │ 1C │ 1D 1E 1F ║
╟────────────┼────────────┼────────────┼────────────╢
║ 2A │ 2B │ 2C │ 2D 2E 2F ║
╚════════════╧════════════╧════════════╧════════════╝
```
<a name="table-api-table-1-config-columns-config-columns-verticalalignment"></a>
###### config.columns[*].verticalAlignment
Type: `'top' | 'middle' | 'bottom'`\
Default: `'top'`
Cell content vertical alignment
```js
const data = [
['A', 'B', 'C', 'DEF'],
];
const config = {
columnDefault: {
width: 1,
},
columns: [
{ verticalAlignment: 'top' },
{ verticalAlignment: 'middle' },
{ verticalAlignment: 'bottom' },
],
};
console.log(table(data, config));
```
```
╔═══╤═══╤═══╤═══╗
║ A │ │ │ D ║
║ │ B │ │ E ║
║ │ │ C │ F ║
╚═══╧═══╧═══╧═══╝
```
<a name="table-api-table-1-config-columns-config-columns-paddingleft"></a>
###### config.columns[*].paddingLeft
Type: `number`\
Default: `1`
The number of whitespaces used to pad the content on the left.
<a name="table-api-table-1-config-columns-config-columns-paddingright"></a>
###### config.columns[*].paddingRight
Type: `number`\
Default: `1`
The number of whitespaces used to pad the content on the right.
The `paddingLeft` and `paddingRight` options do not count on the column width. So the column has `width = 5`, `paddingLeft = 2` and `paddingRight = 2` will have the total width is `9`.
```js
const data = [
['0A', 'AABBCC', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
columns: [
{
paddingLeft: 3
},
{
width: 2,
paddingRight: 3
}
]
};
console.log(table(data, config));
```
```
╔══════╤══════╤════╗
║ 0A │ AA │ 0C ║
║ │ BB │ ║
║ │ CC │ ║
╟──────┼──────┼────╢
║ 1A │ 1B │ 1C ║
╟──────┼──────┼────╢
║ 2A │ 2B │ 2C ║
╚══════╧══════╧════╝
```
<a name="table-api-table-1-config-columns-config-columns-truncate"></a>
###### config.columns[*].truncate
Type: `number`\
Default: `Infinity`
The number of characters is which the content will be truncated.
To handle a content that overflows the container width, `table` package implements [text wrapping](#config.columns[*].wrapWord). However, sometimes you may want to truncate content that is too long to be displayed in the table.
```js
const data = [
['Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus pulvinar nibh sed mauris convallis dapibus. Nunc venenatis tempus nulla sit amet viverra.']
];
const config = {
columns: [
{
width: 20,
truncate: 100
}
]
};
console.log(table(data, config));
```
```
╔══════════════════════╗
║ Lorem ipsum dolor si ║
║ t amet, consectetur ║
║ adipiscing elit. Pha ║
║ sellus pulvinar nibh ║
║ sed mauris convall… ║
╚══════════════════════╝
```
<a name="table-api-table-1-config-columns-config-columns-wrapword"></a>
###### config.columns[*].wrapWord
Type: `boolean`\
Default: `false`
The `table` package implements auto text wrapping, i.e., text that has the width greater than the container width will be separated into multiple lines at the nearest space or one of the special characters: `\|/_.,;-`.
When `wrapWord` is `false`:
```js
const data = [
['Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus pulvinar nibh sed mauris convallis dapibus. Nunc venenatis tempus nulla sit amet viverra.']
];
const config = {
columns: [ { width: 20 } ]
};
console.log(table(data, config));
```
```
╔══════════════════════╗
║ Lorem ipsum dolor si ║
║ t amet, consectetur ║
║ adipiscing elit. Pha ║
║ sellus pulvinar nibh ║
║ sed mauris convallis ║
║ dapibus. Nunc venena ║
║ tis tempus nulla sit ║
║ amet viverra. ║
╚══════════════════════╝
```
When `wrapWord` is `true`:
```
╔══════════════════════╗
║ Lorem ipsum dolor ║
║ sit amet, ║
║ consectetur ║
║ adipiscing elit. ║
║ Phasellus pulvinar ║
║ nibh sed mauris ║
║ convallis dapibus. ║
║ Nunc venenatis ║
║ tempus nulla sit ║
║ amet viverra. ║
╚══════════════════════╝
```
<a name="table-api-table-1-config-columndefault"></a>
##### config.columnDefault
Type: `Column`\
Default: `{}`
The default configuration for all columns. Column-specific settings will overwrite the default values.
<a name="table-api-table-1-config-header"></a>
##### config.header
Type: `object`
Header configuration.
The header configuration inherits the most of the column's, except:
- `content` **{string}**: the header content.
- `width:` calculate based on the content width automatically.
- `alignment:` `center` be default.
- `verticalAlignment:` is not supported.
- `config.border.topJoin` will be `config.border.topBody` for prettier.
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C'],
];
const config = {
columnDefault: {
width: 10,
},
header: {
alignment: 'center',
content: 'THE HEADER\nThis is the table about something',
},
}
console.log(table(data, config));
```
```
╔══════════════════════════════════════╗
║ THE HEADER ║
║ This is the table about something ║
╟────────────┬────────────┬────────────╢
║ 0A │ 0B │ 0C ║
╟────────────┼────────────┼────────────╢
║ 1A │ 1B │ 1C ║
╟────────────┼────────────┼────────────╢
║ 2A │ 2B │ 2C ║
╚════════════╧════════════╧════════════╝
```
<a name="table-api-createstream"></a>
### createStream
`table` package exports `createStream` function used to draw a table and append rows.
**Parameter:**
- _**config:**_ the same as `table`'s, except `config.columnDefault.width` and `config.columnCount` must be provided.
```js
import { createStream } from 'table';
const config = {
columnDefault: {
width: 50
},
columnCount: 1
};
const stream = createStream(config);
setInterval(() => {
stream.write([new Date()]);
}, 500);
```

`table` package uses ANSI escape codes to overwrite the output of the last line when a new row is printed.
The underlying implementation is explained in this [Stack Overflow answer](http://stackoverflow.com/a/32938658/368691).
Streaming supports all of the configuration properties and functionality of a static table (such as auto text wrapping, alignment and padding), e.g.
```js
import { createStream } from 'table';
import _ from 'lodash';
const config = {
columnDefault: {
width: 50
},
columnCount: 3,
columns: [
{
width: 10,
alignment: 'right'
},
{ alignment: 'center' },
{ width: 10 }
]
};
const stream = createStream(config);
let i = 0;
setInterval(() => {
let random;
random = _.sample('abcdefghijklmnopqrstuvwxyz', _.random(1, 30)).join('');
stream.write([i++, new Date(), random]);
}, 500);
```

<a name="table-api-getbordercharacters"></a>
### getBorderCharacters
**Parameter:**
- **_template_**
- Type: `'honeywell' | 'norc' | 'ramac' | 'void'`
- Required: `true`
You can load one of the predefined border templates using `getBorderCharacters` function.
```js
import { table, getBorderCharacters } from 'table';
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
border: getBorderCharacters(`name of the template`)
};
console.log(table(data, config));
```
```
# honeywell
╔════╤════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────┼────╢
║ 1A │ 1B │ 1C ║
╟────┼────┼────╢
║ 2A │ 2B │ 2C ║
╚════╧════╧════╝
# norc
┌────┬────┬────┐
│ 0A │ 0B │ 0C │
├────┼────┼────┤
│ 1A │ 1B │ 1C │
├────┼────┼────┤
│ 2A │ 2B │ 2C │
└────┴────┴────┘
# ramac (ASCII; for use in terminals that do not support Unicode characters)
+----+----+----+
| 0A | 0B | 0C |
|----|----|----|
| 1A | 1B | 1C |
|----|----|----|
| 2A | 2B | 2C |
+----+----+----+
# void (no borders; see "borderless table" section of the documentation)
0A 0B 0C
1A 1B 1C
2A 2B 2C
```
Raise [an issue](https://github.com/gajus/table/issues) if you'd like to contribute a new border template.
<a name="table-api-getbordercharacters-borderless-table"></a>
#### Borderless Table
Simply using `void` border character template creates a table with a lot of unnecessary spacing.
To create a more pleasant to the eye table, reset the padding and remove the joining rows, e.g.
```js
const output = table(data, {
border: getBorderCharacters('void'),
columnDefault: {
paddingLeft: 0,
paddingRight: 1
},
drawHorizontalLine: () => false
}
);
console.log(output);
```
```
0A 0B 0C
1A 1B 1C
2A 2B 2C
```
Overview [](https://travis-ci.org/lydell/js-tokens)
========
A regex that tokenizes JavaScript.
```js
var jsTokens = require("js-tokens").default
var jsString = "var foo=opts.foo;\n..."
jsString.match(jsTokens)
// ["var", " ", "foo", "=", "opts", ".", "foo", ";", "\n", ...]
```
Installation
============
`npm install js-tokens`
```js
import jsTokens from "js-tokens"
// or:
var jsTokens = require("js-tokens").default
```
Usage
=====
### `jsTokens` ###
A regex with the `g` flag that matches JavaScript tokens.
The regex _always_ matches, even invalid JavaScript and the empty string.
The next match is always directly after the previous.
### `var token = matchToToken(match)` ###
```js
import {matchToToken} from "js-tokens"
// or:
var matchToToken = require("js-tokens").matchToToken
```
Takes a `match` returned by `jsTokens.exec(string)`, and returns a `{type:
String, value: String}` object. The following types are available:
- string
- comment
- regex
- number
- name
- punctuator
- whitespace
- invalid
Multi-line comments and strings also have a `closed` property indicating if the
token was closed or not (see below).
Comments and strings both come in several flavors. To distinguish them, check if
the token starts with `//`, `/*`, `'`, `"` or `` ` ``.
Names are ECMAScript IdentifierNames, that is, including both identifiers and
keywords. You may use [is-keyword-js] to tell them apart.
Whitespace includes both line terminators and other whitespace.
[is-keyword-js]: https://github.com/crissdev/is-keyword-js
ECMAScript support
==================
The intention is to always support the latest ECMAScript version whose feature
set has been finalized.
If adding support for a newer version requires changes, a new version with a
major verion bump will be released.
Currently, ECMAScript 2018 is supported.
Invalid code handling
=====================
Unterminated strings are still matched as strings. JavaScript strings cannot
contain (unescaped) newlines, so unterminated strings simply end at the end of
the line. Unterminated template strings can contain unescaped newlines, though,
so they go on to the end of input.
Unterminated multi-line comments are also still matched as comments. They
simply go on to the end of the input.
Unterminated regex literals are likely matched as division and whatever is
inside the regex.
Invalid ASCII characters have their own capturing group.
Invalid non-ASCII characters are treated as names, to simplify the matching of
names (except unicode spaces which are treated as whitespace). Note: See also
the [ES2018](#es2018) section.
Regex literals may contain invalid regex syntax. They are still matched as
regex literals. They may also contain repeated regex flags, to keep the regex
simple.
Strings may contain invalid escape sequences.
Limitations
===========
Tokenizing JavaScript using regexes—in fact, _one single regex_—won’t be
perfect. But that’s not the point either.
You may compare jsTokens with [esprima] by using `esprima-compare.js`.
See `npm run esprima-compare`!
[esprima]: http://esprima.org/
### Template string interpolation ###
Template strings are matched as single tokens, from the starting `` ` `` to the
ending `` ` ``, including interpolations (whose tokens are not matched
individually).
Matching template string interpolations requires recursive balancing of `{` and
`}`—something that JavaScript regexes cannot do. Only one level of nesting is
supported.
### Division and regex literals collision ###
Consider this example:
```js
var g = 9.82
var number = bar / 2/g
var regex = / 2/g
```
A human can easily understand that in the `number` line we’re dealing with
division, and in the `regex` line we’re dealing with a regex literal. How come?
Because humans can look at the whole code to put the `/` characters in context.
A JavaScript regex cannot. It only sees forwards. (Well, ES2018 regexes can also
look backwards. See the [ES2018](#es2018) section).
When the `jsTokens` regex scans throught the above, it will see the following
at the end of both the `number` and `regex` rows:
```js
/ 2/g
```
It is then impossible to know if that is a regex literal, or part of an
expression dealing with division.
Here is a similar case:
```js
foo /= 2/g
foo(/= 2/g)
```
The first line divides the `foo` variable with `2/g`. The second line calls the
`foo` function with the regex literal `/= 2/g`. Again, since `jsTokens` only
sees forwards, it cannot tell the two cases apart.
There are some cases where we _can_ tell division and regex literals apart,
though.
First off, we have the simple cases where there’s only one slash in the line:
```js
var foo = 2/g
foo /= 2
```
Regex literals cannot contain newlines, so the above cases are correctly
identified as division. Things are only problematic when there are more than
one non-comment slash in a single line.
Secondly, not every character is a valid regex flag.
```js
var number = bar / 2/e
```
The above example is also correctly identified as division, because `e` is not a
valid regex flag. I initially wanted to future-proof by allowing `[a-zA-Z]*`
(any letter) as flags, but it is not worth it since it increases the amount of
ambigous cases. So only the standard `g`, `m`, `i`, `y` and `u` flags are
allowed. This means that the above example will be identified as division as
long as you don’t rename the `e` variable to some permutation of `gmiyus` 1 to 6
characters long.
Lastly, we can look _forward_ for information.
- If the token following what looks like a regex literal is not valid after a
regex literal, but is valid in a division expression, then the regex literal
is treated as division instead. For example, a flagless regex cannot be
followed by a string, number or name, but all of those three can be the
denominator of a division.
- Generally, if what looks like a regex literal is followed by an operator, the
regex literal is treated as division instead. This is because regexes are
seldomly used with operators (such as `+`, `*`, `&&` and `==`), but division
could likely be part of such an expression.
Please consult the regex source and the test cases for precise information on
when regex or division is matched (should you need to know). In short, you
could sum it up as:
If the end of a statement looks like a regex literal (even if it isn’t), it
will be treated as one. Otherwise it should work as expected (if you write sane
code).
### ES2018 ###
ES2018 added some nice regex improvements to the language.
- [Unicode property escapes] should allow telling names and invalid non-ASCII
characters apart without blowing up the regex size.
- [Lookbehind assertions] should allow matching telling division and regex
literals apart in more cases.
- [Named capture groups] might simplify some things.
These things would be nice to do, but are not critical. They probably have to
wait until the oldest maintained Node.js LTS release supports those features.
[Unicode property escapes]: http://2ality.com/2017/07/regexp-unicode-property-escapes.html
[Lookbehind assertions]: http://2ality.com/2017/05/regexp-lookbehind-assertions.html
[Named capture groups]: http://2ality.com/2017/05/regexp-named-capture-groups.html
License
=======
[MIT](LICENSE).
Shims used when bundling asc for browser usage.
# isexe
Minimal module to check if a file is executable, and a normal file.
Uses `fs.stat` and tests against the `PATHEXT` environment variable on
Windows.
## USAGE
```javascript
var isexe = require('isexe')
isexe('some-file-name', function (err, isExe) {
if (err) {
console.error('probably file does not exist or something', err)
} else if (isExe) {
console.error('this thing can be run')
} else {
console.error('cannot be run')
}
})
// same thing but synchronous, throws errors
var isExe = isexe.sync('some-file-name')
// treat errors as just "not executable"
isexe('maybe-missing-file', { ignoreErrors: true }, callback)
var isExe = isexe.sync('maybe-missing-file', { ignoreErrors: true })
```
## API
### `isexe(path, [options], [callback])`
Check if the path is executable. If no callback provided, and a
global `Promise` object is available, then a Promise will be returned.
Will raise whatever errors may be raised by `fs.stat`, unless
`options.ignoreErrors` is set to true.
### `isexe.sync(path, [options])`
Same as `isexe` but returns the value and throws any errors raised.
### Options
* `ignoreErrors` Treat all errors as "no, this is not executable", but
don't raise them.
* `uid` Number to use as the user id
* `gid` Number to use as the group id
* `pathExt` List of path extensions to use instead of `PATHEXT`
environment variable on Windows.
<img align="right" alt="Ajv logo" width="160" src="https://ajv.js.org/images/ajv_logo.png">
# Ajv: Another JSON Schema Validator
The fastest JSON Schema validator for Node.js and browser. Supports draft-04/06/07.
[](https://travis-ci.org/ajv-validator/ajv)
[](https://www.npmjs.com/package/ajv)
[](https://www.npmjs.com/package/ajv/v/7.0.0-beta.0)
[](https://www.npmjs.com/package/ajv)
[](https://coveralls.io/github/ajv-validator/ajv?branch=master)
[](https://gitter.im/ajv-validator/ajv)
[](https://github.com/sponsors/epoberezkin)
## Ajv v7 beta is released
[Ajv version 7.0.0-beta.0](https://github.com/ajv-validator/ajv/tree/v7-beta) is released with these changes:
- to reduce the mistakes in JSON schemas and unexpected validation results, [strict mode](./docs/strict-mode.md) is added - it prohibits ignored or ambiguous JSON Schema elements.
- to make code injection from untrusted schemas impossible, [code generation](./docs/codegen.md) is fully re-written to be safe.
- to simplify Ajv extensions, the new keyword API that is used by pre-defined keywords is available to user-defined keywords - it is much easier to define any keywords now, especially with subschemas.
- schemas are compiled to ES6 code (ES5 code generation is supported with an option).
- to improve reliability and maintainability the code is migrated to TypeScript.
**Please note**:
- the support for JSON-Schema draft-04 is removed - if you have schemas using "id" attributes you have to replace them with "\$id" (or continue using version 6 that will be supported until 02/28/2021).
- all formats are separated to ajv-formats package - they have to be explicitely added if you use them.
See [release notes](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0-beta.0) for the details.
To install the new version:
```bash
npm install ajv@beta
```
See [Getting started with v7](https://github.com/ajv-validator/ajv/tree/v7-beta#usage) for code example.
## Mozilla MOSS grant and OpenJS Foundation
[<img src="https://www.poberezkin.com/images/mozilla.png" width="240" height="68">](https://www.mozilla.org/en-US/moss/) [<img src="https://www.poberezkin.com/images/openjs.png" width="220" height="68">](https://openjsf.org/blog/2020/08/14/ajv-joins-openjs-foundation-as-an-incubation-project/)
Ajv has been awarded a grant from Mozilla’s [Open Source Support (MOSS) program](https://www.mozilla.org/en-US/moss/) in the “Foundational Technology” track! It will sponsor the development of Ajv support of [JSON Schema version 2019-09](https://tools.ietf.org/html/draft-handrews-json-schema-02) and of [JSON Type Definition](https://tools.ietf.org/html/draft-ucarion-json-type-definition-04).
Ajv also joined [OpenJS Foundation](https://openjsf.org/) – having this support will help ensure the longevity and stability of Ajv for all its users.
This [blog post](https://www.poberezkin.com/posts/2020-08-14-ajv-json-validator-mozilla-open-source-grant-openjs-foundation.html) has more details.
I am looking for the long term maintainers of Ajv – working with [ReadySet](https://www.thereadyset.co/), also sponsored by Mozilla, to establish clear guidelines for the role of a "maintainer" and the contribution standards, and to encourage a wider, more inclusive, contribution from the community.
## Please [sponsor Ajv development](https://github.com/sponsors/epoberezkin)
Since I asked to support Ajv development 40 people and 6 organizations contributed via GitHub and OpenCollective - this support helped receiving the MOSS grant!
Your continuing support is very important - the funds will be used to develop and maintain Ajv once the next major version is released.
Please sponsor Ajv via:
- [GitHub sponsors page](https://github.com/sponsors/epoberezkin) (GitHub will match it)
- [Ajv Open Collective️](https://opencollective.com/ajv)
Thank you.
#### Open Collective sponsors
<a href="https://opencollective.com/ajv"><img src="https://opencollective.com/ajv/individuals.svg?width=890"></a>
<a href="https://opencollective.com/ajv/organization/0/website"><img src="https://opencollective.com/ajv/organization/0/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/1/website"><img src="https://opencollective.com/ajv/organization/1/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/2/website"><img src="https://opencollective.com/ajv/organization/2/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/3/website"><img src="https://opencollective.com/ajv/organization/3/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/4/website"><img src="https://opencollective.com/ajv/organization/4/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/5/website"><img src="https://opencollective.com/ajv/organization/5/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/6/website"><img src="https://opencollective.com/ajv/organization/6/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/7/website"><img src="https://opencollective.com/ajv/organization/7/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/8/website"><img src="https://opencollective.com/ajv/organization/8/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/9/website"><img src="https://opencollective.com/ajv/organization/9/avatar.svg"></a>
## Using version 6
[JSON Schema draft-07](http://json-schema.org/latest/json-schema-validation.html) is published.
[Ajv version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0) that supports draft-07 is released. It may require either migrating your schemas or updating your code (to continue using draft-04 and v5 schemas, draft-06 schemas will be supported without changes).
__Please note__: To use Ajv with draft-06 schemas you need to explicitly add the meta-schema to the validator instance:
```javascript
ajv.addMetaSchema(require('ajv/lib/refs/json-schema-draft-06.json'));
```
To use Ajv with draft-04 schemas in addition to explicitly adding meta-schema you also need to use option schemaId:
```javascript
var ajv = new Ajv({schemaId: 'id'});
// If you want to use both draft-04 and draft-06/07 schemas:
// var ajv = new Ajv({schemaId: 'auto'});
ajv.addMetaSchema(require('ajv/lib/refs/json-schema-draft-04.json'));
```
## Contents
- [Performance](#performance)
- [Features](#features)
- [Getting started](#getting-started)
- [Frequently Asked Questions](https://github.com/ajv-validator/ajv/blob/master/FAQ.md)
- [Using in browser](#using-in-browser)
- [Ajv and Content Security Policies (CSP)](#ajv-and-content-security-policies-csp)
- [Command line interface](#command-line-interface)
- Validation
- [Keywords](#validation-keywords)
- [Annotation keywords](#annotation-keywords)
- [Formats](#formats)
- [Combining schemas with $ref](#ref)
- [$data reference](#data-reference)
- NEW: [$merge and $patch keywords](#merge-and-patch-keywords)
- [Defining custom keywords](#defining-custom-keywords)
- [Asynchronous schema compilation](#asynchronous-schema-compilation)
- [Asynchronous validation](#asynchronous-validation)
- [Security considerations](#security-considerations)
- [Security contact](#security-contact)
- [Untrusted schemas](#untrusted-schemas)
- [Circular references in objects](#circular-references-in-javascript-objects)
- [Trusted schemas](#security-risks-of-trusted-schemas)
- [ReDoS attack](#redos-attack)
- Modifying data during validation
- [Filtering data](#filtering-data)
- [Assigning defaults](#assigning-defaults)
- [Coercing data types](#coercing-data-types)
- API
- [Methods](#api)
- [Options](#options)
- [Validation errors](#validation-errors)
- [Plugins](#plugins)
- [Related packages](#related-packages)
- [Some packages using Ajv](#some-packages-using-ajv)
- [Tests, Contributing, Changes history](#tests)
- [Support, Code of conduct, License](#open-source-software-support)
## Performance
Ajv generates code using [doT templates](https://github.com/olado/doT) to turn JSON Schemas into super-fast validation functions that are efficient for v8 optimization.
Currently Ajv is the fastest and the most standard compliant validator according to these benchmarks:
- [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark) - 50% faster than the second place
- [jsck benchmark](https://github.com/pandastrike/jsck#benchmarks) - 20-190% faster
- [z-schema benchmark](https://rawgit.com/zaggino/z-schema/master/benchmark/results.html)
- [themis benchmark](https://cdn.rawgit.com/playlyfe/themis/master/benchmark/results.html)
Performance of different validators by [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark):
[](https://github.com/ebdrup/json-schema-benchmark/blob/master/README.md#performance)
## Features
- Ajv implements full JSON Schema [draft-06/07](http://json-schema.org/) and draft-04 standards:
- all validation keywords (see [JSON Schema validation keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md))
- full support of remote refs (remote schemas have to be added with `addSchema` or compiled to be available)
- support of circular references between schemas
- correct string lengths for strings with unicode pairs (can be turned off)
- [formats](#formats) defined by JSON Schema draft-07 standard and custom formats (can be turned off)
- [validates schemas against meta-schema](#api-validateschema)
- supports [browsers](#using-in-browser) and Node.js 0.10-14.x
- [asynchronous loading](#asynchronous-schema-compilation) of referenced schemas during compilation
- "All errors" validation mode with [option allErrors](#options)
- [error messages with parameters](#validation-errors) describing error reasons to allow creating custom error messages
- i18n error messages support with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package
- [filtering data](#filtering-data) from additional properties
- [assigning defaults](#assigning-defaults) to missing properties and items
- [coercing data](#coercing-data-types) to the types specified in `type` keywords
- [custom keywords](#defining-custom-keywords)
- draft-06/07 keywords `const`, `contains`, `propertyNames` and `if/then/else`
- draft-06 boolean schemas (`true`/`false` as a schema to always pass/fail).
- keywords `switch`, `patternRequired`, `formatMaximum` / `formatMinimum` and `formatExclusiveMaximum` / `formatExclusiveMinimum` from [JSON Schema extension proposals](https://github.com/json-schema/json-schema/wiki/v5-Proposals) with [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package
- [$data reference](#data-reference) to use values from the validated data as values for the schema keywords
- [asynchronous validation](#asynchronous-validation) of custom formats and keywords
## Install
```
npm install ajv
```
## <a name="usage"></a>Getting started
Try it in the Node.js REPL: https://tonicdev.com/npm/ajv
The fastest validation call:
```javascript
// Node.js require:
var Ajv = require('ajv');
// or ESM/TypeScript import
import Ajv from 'ajv';
var ajv = new Ajv(); // options can be passed, e.g. {allErrors: true}
var validate = ajv.compile(schema);
var valid = validate(data);
if (!valid) console.log(validate.errors);
```
or with less code
```javascript
// ...
var valid = ajv.validate(schema, data);
if (!valid) console.log(ajv.errors);
// ...
```
or
```javascript
// ...
var valid = ajv.addSchema(schema, 'mySchema')
.validate('mySchema', data);
if (!valid) console.log(ajv.errorsText());
// ...
```
See [API](#api) and [Options](#options) for more details.
Ajv compiles schemas to functions and caches them in all cases (using schema serialized with [fast-json-stable-stringify](https://github.com/epoberezkin/fast-json-stable-stringify) or a custom function as a key), so that the next time the same schema is used (not necessarily the same object instance) it won't be compiled again.
The best performance is achieved when using compiled functions returned by `compile` or `getSchema` methods (there is no additional function call).
__Please note__: every time a validation function or `ajv.validate` are called `errors` property is overwritten. You need to copy `errors` array reference to another variable if you want to use it later (e.g., in the callback). See [Validation errors](#validation-errors)
__Note for TypeScript users__: `ajv` provides its own TypeScript declarations
out of the box, so you don't need to install the deprecated `@types/ajv`
module.
## Using in browser
You can require Ajv directly from the code you browserify - in this case Ajv will be a part of your bundle.
If you need to use Ajv in several bundles you can create a separate UMD bundle using `npm run bundle` script (thanks to [siddo420](https://github.com/siddo420)).
Then you need to load Ajv in the browser:
```html
<script src="ajv.min.js"></script>
```
This bundle can be used with different module systems; it creates global `Ajv` if no module system is found.
The browser bundle is available on [cdnjs](https://cdnjs.com/libraries/ajv).
Ajv is tested with these browsers:
[](https://saucelabs.com/u/epoberezkin)
__Please note__: some frameworks, e.g. Dojo, may redefine global require in such way that is not compatible with CommonJS module format. In such case Ajv bundle has to be loaded before the framework and then you can use global Ajv (see issue [#234](https://github.com/ajv-validator/ajv/issues/234)).
### Ajv and Content Security Policies (CSP)
If you're using Ajv to compile a schema (the typical use) in a browser document that is loaded with a Content Security Policy (CSP), that policy will require a `script-src` directive that includes the value `'unsafe-eval'`.
:warning: NOTE, however, that `unsafe-eval` is NOT recommended in a secure CSP[[1]](https://developer.chrome.com/extensions/contentSecurityPolicy#relaxing-eval), as it has the potential to open the document to cross-site scripting (XSS) attacks.
In order to make use of Ajv without easing your CSP, you can [pre-compile a schema using the CLI](https://github.com/ajv-validator/ajv-cli#compile-schemas). This will transpile the schema JSON into a JavaScript file that exports a `validate` function that works simlarly to a schema compiled at runtime.
Note that pre-compilation of schemas is performed using [ajv-pack](https://github.com/ajv-validator/ajv-pack) and there are [some limitations to the schema features it can compile](https://github.com/ajv-validator/ajv-pack#limitations). A successfully pre-compiled schema is equivalent to the same schema compiled at runtime.
## Command line interface
CLI is available as a separate npm package [ajv-cli](https://github.com/ajv-validator/ajv-cli). It supports:
- compiling JSON Schemas to test their validity
- BETA: generating standalone module exporting a validation function to be used without Ajv (using [ajv-pack](https://github.com/ajv-validator/ajv-pack))
- migrate schemas to draft-07 (using [json-schema-migrate](https://github.com/epoberezkin/json-schema-migrate))
- validating data file(s) against JSON Schema
- testing expected validity of data against JSON Schema
- referenced schemas
- custom meta-schemas
- files in JSON, JSON5, YAML, and JavaScript format
- all Ajv options
- reporting changes in data after validation in [JSON-patch](https://tools.ietf.org/html/rfc6902) format
## Validation keywords
Ajv supports all validation keywords from draft-07 of JSON Schema standard:
- [type](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#type)
- [for numbers](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-numbers) - maximum, minimum, exclusiveMaximum, exclusiveMinimum, multipleOf
- [for strings](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-strings) - maxLength, minLength, pattern, format
- [for arrays](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-arrays) - maxItems, minItems, uniqueItems, items, additionalItems, [contains](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#contains)
- [for objects](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-objects) - maxProperties, minProperties, required, properties, patternProperties, additionalProperties, dependencies, [propertyNames](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#propertynames)
- [for all types](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-all-types) - enum, [const](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#const)
- [compound keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#compound-keywords) - not, oneOf, anyOf, allOf, [if/then/else](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#ifthenelse)
With [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package Ajv also supports validation keywords from [JSON Schema extension proposals](https://github.com/json-schema/json-schema/wiki/v5-Proposals) for JSON Schema standard:
- [patternRequired](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#patternrequired-proposed) - like `required` but with patterns that some property should match.
- [formatMaximum, formatMinimum, formatExclusiveMaximum, formatExclusiveMinimum](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#formatmaximum--formatminimum-and-exclusiveformatmaximum--exclusiveformatminimum-proposed) - setting limits for date, time, etc.
See [JSON Schema validation keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md) for more details.
## Annotation keywords
JSON Schema specification defines several annotation keywords that describe schema itself but do not perform any validation.
- `title` and `description`: information about the data represented by that schema
- `$comment` (NEW in draft-07): information for developers. With option `$comment` Ajv logs or passes the comment string to the user-supplied function. See [Options](#options).
- `default`: a default value of the data instance, see [Assigning defaults](#assigning-defaults).
- `examples` (NEW in draft-06): an array of data instances. Ajv does not check the validity of these instances against the schema.
- `readOnly` and `writeOnly` (NEW in draft-07): marks data-instance as read-only or write-only in relation to the source of the data (database, api, etc.).
- `contentEncoding`: [RFC 2045](https://tools.ietf.org/html/rfc2045#section-6.1 ), e.g., "base64".
- `contentMediaType`: [RFC 2046](https://tools.ietf.org/html/rfc2046), e.g., "image/png".
__Please note__: Ajv does not implement validation of the keywords `examples`, `contentEncoding` and `contentMediaType` but it reserves them. If you want to create a plugin that implements some of them, it should remove these keywords from the instance.
## Formats
Ajv implements formats defined by JSON Schema specification and several other formats. It is recommended NOT to use "format" keyword implementations with untrusted data, as they use potentially unsafe regular expressions - see [ReDoS attack](#redos-attack).
__Please note__: if you need to use "format" keyword to validate untrusted data, you MUST assess their suitability and safety for your validation scenarios.
The following formats are implemented for string validation with "format" keyword:
- _date_: full-date according to [RFC3339](http://tools.ietf.org/html/rfc3339#section-5.6).
- _time_: time with optional time-zone.
- _date-time_: date-time from the same source (time-zone is mandatory). `date`, `time` and `date-time` validate ranges in `full` mode and only regexp in `fast` mode (see [options](#options)).
- _uri_: full URI.
- _uri-reference_: URI reference, including full and relative URIs.
- _uri-template_: URI template according to [RFC6570](https://tools.ietf.org/html/rfc6570)
- _url_ (deprecated): [URL record](https://url.spec.whatwg.org/#concept-url).
- _email_: email address.
- _hostname_: host name according to [RFC1034](http://tools.ietf.org/html/rfc1034#section-3.5).
- _ipv4_: IP address v4.
- _ipv6_: IP address v6.
- _regex_: tests whether a string is a valid regular expression by passing it to RegExp constructor.
- _uuid_: Universally Unique IDentifier according to [RFC4122](http://tools.ietf.org/html/rfc4122).
- _json-pointer_: JSON-pointer according to [RFC6901](https://tools.ietf.org/html/rfc6901).
- _relative-json-pointer_: relative JSON-pointer according to [this draft](http://tools.ietf.org/html/draft-luff-relative-json-pointer-00).
__Please note__: JSON Schema draft-07 also defines formats `iri`, `iri-reference`, `idn-hostname` and `idn-email` for URLs, hostnames and emails with international characters. Ajv does not implement these formats. If you create Ajv plugin that implements them please make a PR to mention this plugin here.
There are two modes of format validation: `fast` and `full`. This mode affects formats `date`, `time`, `date-time`, `uri`, `uri-reference`, and `email`. See [Options](#options) for details.
You can add additional formats and replace any of the formats above using [addFormat](#api-addformat) method.
The option `unknownFormats` allows changing the default behaviour when an unknown format is encountered. In this case Ajv can either fail schema compilation (default) or ignore it (default in versions before 5.0.0). You also can allow specific format(s) that will be ignored. See [Options](#options) for details.
You can find regular expressions used for format validation and the sources that were used in [formats.js](https://github.com/ajv-validator/ajv/blob/master/lib/compile/formats.js).
## <a name="ref"></a>Combining schemas with $ref
You can structure your validation logic across multiple schema files and have schemas reference each other using `$ref` keyword.
Example:
```javascript
var schema = {
"$id": "http://example.com/schemas/schema.json",
"type": "object",
"properties": {
"foo": { "$ref": "defs.json#/definitions/int" },
"bar": { "$ref": "defs.json#/definitions/str" }
}
};
var defsSchema = {
"$id": "http://example.com/schemas/defs.json",
"definitions": {
"int": { "type": "integer" },
"str": { "type": "string" }
}
};
```
Now to compile your schema you can either pass all schemas to Ajv instance:
```javascript
var ajv = new Ajv({schemas: [schema, defsSchema]});
var validate = ajv.getSchema('http://example.com/schemas/schema.json');
```
or use `addSchema` method:
```javascript
var ajv = new Ajv;
var validate = ajv.addSchema(defsSchema)
.compile(schema);
```
See [Options](#options) and [addSchema](#api) method.
__Please note__:
- `$ref` is resolved as the uri-reference using schema $id as the base URI (see the example).
- References can be recursive (and mutually recursive) to implement the schemas for different data structures (such as linked lists, trees, graphs, etc.).
- You don't have to host your schema files at the URIs that you use as schema $id. These URIs are only used to identify the schemas, and according to JSON Schema specification validators should not expect to be able to download the schemas from these URIs.
- The actual location of the schema file in the file system is not used.
- You can pass the identifier of the schema as the second parameter of `addSchema` method or as a property name in `schemas` option. This identifier can be used instead of (or in addition to) schema $id.
- You cannot have the same $id (or the schema identifier) used for more than one schema - the exception will be thrown.
- You can implement dynamic resolution of the referenced schemas using `compileAsync` method. In this way you can store schemas in any system (files, web, database, etc.) and reference them without explicitly adding to Ajv instance. See [Asynchronous schema compilation](#asynchronous-schema-compilation).
## $data reference
With `$data` option you can use values from the validated data as the values for the schema keywords. See [proposal](https://github.com/json-schema-org/json-schema-spec/issues/51) for more information about how it works.
`$data` reference is supported in the keywords: const, enum, format, maximum/minimum, exclusiveMaximum / exclusiveMinimum, maxLength / minLength, maxItems / minItems, maxProperties / minProperties, formatMaximum / formatMinimum, formatExclusiveMaximum / formatExclusiveMinimum, multipleOf, pattern, required, uniqueItems.
The value of "$data" should be a [JSON-pointer](https://tools.ietf.org/html/rfc6901) to the data (the root is always the top level data object, even if the $data reference is inside a referenced subschema) or a [relative JSON-pointer](http://tools.ietf.org/html/draft-luff-relative-json-pointer-00) (it is relative to the current point in data; if the $data reference is inside a referenced subschema it cannot point to the data outside of the root level for this subschema).
Examples.
This schema requires that the value in property `smaller` is less or equal than the value in the property larger:
```javascript
var ajv = new Ajv({$data: true});
var schema = {
"properties": {
"smaller": {
"type": "number",
"maximum": { "$data": "1/larger" }
},
"larger": { "type": "number" }
}
};
var validData = {
smaller: 5,
larger: 7
};
ajv.validate(schema, validData); // true
```
This schema requires that the properties have the same format as their field names:
```javascript
var schema = {
"additionalProperties": {
"type": "string",
"format": { "$data": "0#" }
}
};
var validData = {
'date-time': '1963-06-19T08:30:06.283185Z',
email: 'joe.bloggs@example.com'
}
```
`$data` reference is resolved safely - it won't throw even if some property is undefined. If `$data` resolves to `undefined` the validation succeeds (with the exclusion of `const` keyword). If `$data` resolves to incorrect type (e.g. not "number" for maximum keyword) the validation fails.
## $merge and $patch keywords
With the package [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) you can use the keywords `$merge` and `$patch` that allow extending JSON Schemas with patches using formats [JSON Merge Patch (RFC 7396)](https://tools.ietf.org/html/rfc7396) and [JSON Patch (RFC 6902)](https://tools.ietf.org/html/rfc6902).
To add keywords `$merge` and `$patch` to Ajv instance use this code:
```javascript
require('ajv-merge-patch')(ajv);
```
Examples.
Using `$merge`:
```json
{
"$merge": {
"source": {
"type": "object",
"properties": { "p": { "type": "string" } },
"additionalProperties": false
},
"with": {
"properties": { "q": { "type": "number" } }
}
}
}
```
Using `$patch`:
```json
{
"$patch": {
"source": {
"type": "object",
"properties": { "p": { "type": "string" } },
"additionalProperties": false
},
"with": [
{ "op": "add", "path": "/properties/q", "value": { "type": "number" } }
]
}
}
```
The schemas above are equivalent to this schema:
```json
{
"type": "object",
"properties": {
"p": { "type": "string" },
"q": { "type": "number" }
},
"additionalProperties": false
}
```
The properties `source` and `with` in the keywords `$merge` and `$patch` can use absolute or relative `$ref` to point to other schemas previously added to the Ajv instance or to the fragments of the current schema.
See the package [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) for more information.
## Defining custom keywords
The advantages of using custom keywords are:
- allow creating validation scenarios that cannot be expressed using JSON Schema
- simplify your schemas
- help bringing a bigger part of the validation logic to your schemas
- make your schemas more expressive, less verbose and closer to your application domain
- implement custom data processors that modify your data (`modifying` option MUST be used in keyword definition) and/or create side effects while the data is being validated
If a keyword is used only for side-effects and its validation result is pre-defined, use option `valid: true/false` in keyword definition to simplify both generated code (no error handling in case of `valid: true`) and your keyword functions (no need to return any validation result).
The concerns you have to be aware of when extending JSON Schema standard with custom keywords are the portability and understanding of your schemas. You will have to support these custom keywords on other platforms and to properly document these keywords so that everybody can understand them in your schemas.
You can define custom keywords with [addKeyword](#api-addkeyword) method. Keywords are defined on the `ajv` instance level - new instances will not have previously defined keywords.
Ajv allows defining keywords with:
- validation function
- compilation function
- macro function
- inline compilation function that should return code (as string) that will be inlined in the currently compiled schema.
Example. `range` and `exclusiveRange` keywords using compiled schema:
```javascript
ajv.addKeyword('range', {
type: 'number',
compile: function (sch, parentSchema) {
var min = sch[0];
var max = sch[1];
return parentSchema.exclusiveRange === true
? function (data) { return data > min && data < max; }
: function (data) { return data >= min && data <= max; }
}
});
var schema = { "range": [2, 4], "exclusiveRange": true };
var validate = ajv.compile(schema);
console.log(validate(2.01)); // true
console.log(validate(3.99)); // true
console.log(validate(2)); // false
console.log(validate(4)); // false
```
Several custom keywords (typeof, instanceof, range and propertyNames) are defined in [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package - they can be used for your schemas and as a starting point for your own custom keywords.
See [Defining custom keywords](https://github.com/ajv-validator/ajv/blob/master/CUSTOM.md) for more details.
## Asynchronous schema compilation
During asynchronous compilation remote references are loaded using supplied function. See `compileAsync` [method](#api-compileAsync) and `loadSchema` [option](#options).
Example:
```javascript
var ajv = new Ajv({ loadSchema: loadSchema });
ajv.compileAsync(schema).then(function (validate) {
var valid = validate(data);
// ...
});
function loadSchema(uri) {
return request.json(uri).then(function (res) {
if (res.statusCode >= 400)
throw new Error('Loading error: ' + res.statusCode);
return res.body;
});
}
```
__Please note__: [Option](#options) `missingRefs` should NOT be set to `"ignore"` or `"fail"` for asynchronous compilation to work.
## Asynchronous validation
Example in Node.js REPL: https://tonicdev.com/esp/ajv-asynchronous-validation
You can define custom formats and keywords that perform validation asynchronously by accessing database or some other service. You should add `async: true` in the keyword or format definition (see [addFormat](#api-addformat), [addKeyword](#api-addkeyword) and [Defining custom keywords](#defining-custom-keywords)).
If your schema uses asynchronous formats/keywords or refers to some schema that contains them it should have `"$async": true` keyword so that Ajv can compile it correctly. If asynchronous format/keyword or reference to asynchronous schema is used in the schema without `$async` keyword Ajv will throw an exception during schema compilation.
__Please note__: all asynchronous subschemas that are referenced from the current or other schemas should have `"$async": true` keyword as well, otherwise the schema compilation will fail.
Validation function for an asynchronous custom format/keyword should return a promise that resolves with `true` or `false` (or rejects with `new Ajv.ValidationError(errors)` if you want to return custom errors from the keyword function).
Ajv compiles asynchronous schemas to [es7 async functions](http://tc39.github.io/ecmascript-asyncawait/) that can optionally be transpiled with [nodent](https://github.com/MatAtBread/nodent). Async functions are supported in Node.js 7+ and all modern browsers. You can also supply any other transpiler as a function via `processCode` option. See [Options](#options).
The compiled validation function has `$async: true` property (if the schema is asynchronous), so you can differentiate these functions if you are using both synchronous and asynchronous schemas.
Validation result will be a promise that resolves with validated data or rejects with an exception `Ajv.ValidationError` that contains the array of validation errors in `errors` property.
Example:
```javascript
var ajv = new Ajv;
// require('ajv-async')(ajv);
ajv.addKeyword('idExists', {
async: true,
type: 'number',
validate: checkIdExists
});
function checkIdExists(schema, data) {
return knex(schema.table)
.select('id')
.where('id', data)
.then(function (rows) {
return !!rows.length; // true if record is found
});
}
var schema = {
"$async": true,
"properties": {
"userId": {
"type": "integer",
"idExists": { "table": "users" }
},
"postId": {
"type": "integer",
"idExists": { "table": "posts" }
}
}
};
var validate = ajv.compile(schema);
validate({ userId: 1, postId: 19 })
.then(function (data) {
console.log('Data is valid', data); // { userId: 1, postId: 19 }
})
.catch(function (err) {
if (!(err instanceof Ajv.ValidationError)) throw err;
// data is invalid
console.log('Validation errors:', err.errors);
});
```
### Using transpilers with asynchronous validation functions.
[ajv-async](https://github.com/ajv-validator/ajv-async) uses [nodent](https://github.com/MatAtBread/nodent) to transpile async functions. To use another transpiler you should separately install it (or load its bundle in the browser).
#### Using nodent
```javascript
var ajv = new Ajv;
require('ajv-async')(ajv);
// in the browser if you want to load ajv-async bundle separately you can:
// window.ajvAsync(ajv);
var validate = ajv.compile(schema); // transpiled es7 async function
validate(data).then(successFunc).catch(errorFunc);
```
#### Using other transpilers
```javascript
var ajv = new Ajv({ processCode: transpileFunc });
var validate = ajv.compile(schema); // transpiled es7 async function
validate(data).then(successFunc).catch(errorFunc);
```
See [Options](#options).
## Security considerations
JSON Schema, if properly used, can replace data sanitisation. It doesn't replace other API security considerations. It also introduces additional security aspects to consider.
##### Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerabilities via GitHub issues.
##### Untrusted schemas
Ajv treats JSON schemas as trusted as your application code. This security model is based on the most common use case, when the schemas are static and bundled together with the application.
If your schemas are received from untrusted sources (or generated from untrusted data) there are several scenarios you need to prevent:
- compiling schemas can cause stack overflow (if they are too deep)
- compiling schemas can be slow (e.g. [#557](https://github.com/ajv-validator/ajv/issues/557))
- validating certain data can be slow
It is difficult to predict all the scenarios, but at the very least it may help to limit the size of untrusted schemas (e.g. limit JSON string length) and also the maximum schema object depth (that can be high for relatively small JSON strings). You also may want to mitigate slow regular expressions in `pattern` and `patternProperties` keywords.
Regardless the measures you take, using untrusted schemas increases security risks.
##### Circular references in JavaScript objects
Ajv does not support schemas and validated data that have circular references in objects. See [issue #802](https://github.com/ajv-validator/ajv/issues/802).
An attempt to compile such schemas or validate such data would cause stack overflow (or will not complete in case of asynchronous validation). Depending on the parser you use, untrusted data can lead to circular references.
##### Security risks of trusted schemas
Some keywords in JSON Schemas can lead to very slow validation for certain data. These keywords include (but may be not limited to):
- `pattern` and `format` for large strings - in some cases using `maxLength` can help mitigate it, but certain regular expressions can lead to exponential validation time even with relatively short strings (see [ReDoS attack](#redos-attack)).
- `patternProperties` for large property names - use `propertyNames` to mitigate, but some regular expressions can have exponential evaluation time as well.
- `uniqueItems` for large non-scalar arrays - use `maxItems` to mitigate
__Please note__: The suggestions above to prevent slow validation would only work if you do NOT use `allErrors: true` in production code (using it would continue validation after validation errors).
You can validate your JSON schemas against [this meta-schema](https://github.com/ajv-validator/ajv/blob/master/lib/refs/json-schema-secure.json) to check that these recommendations are followed:
```javascript
const isSchemaSecure = ajv.compile(require('ajv/lib/refs/json-schema-secure.json'));
const schema1 = {format: 'email'};
isSchemaSecure(schema1); // false
const schema2 = {format: 'email', maxLength: MAX_LENGTH};
isSchemaSecure(schema2); // true
```
__Please note__: following all these recommendation is not a guarantee that validation of untrusted data is safe - it can still lead to some undesirable results.
##### Content Security Policies (CSP)
See [Ajv and Content Security Policies (CSP)](#ajv-and-content-security-policies-csp)
## ReDoS attack
Certain regular expressions can lead to the exponential evaluation time even with relatively short strings.
Please assess the regular expressions you use in the schemas on their vulnerability to this attack - see [safe-regex](https://github.com/substack/safe-regex), for example.
__Please note__: some formats that Ajv implements use [regular expressions](https://github.com/ajv-validator/ajv/blob/master/lib/compile/formats.js) that can be vulnerable to ReDoS attack, so if you use Ajv to validate data from untrusted sources __it is strongly recommended__ to consider the following:
- making assessment of "format" implementations in Ajv.
- using `format: 'fast'` option that simplifies some of the regular expressions (although it does not guarantee that they are safe).
- replacing format implementations provided by Ajv with your own implementations of "format" keyword that either uses different regular expressions or another approach to format validation. Please see [addFormat](#api-addformat) method.
- disabling format validation by ignoring "format" keyword with option `format: false`
Whatever mitigation you choose, please assume all formats provided by Ajv as potentially unsafe and make your own assessment of their suitability for your validation scenarios.
## Filtering data
With [option `removeAdditional`](#options) (added by [andyscott](https://github.com/andyscott)) you can filter data during the validation.
This option modifies original data.
Example:
```javascript
var ajv = new Ajv({ removeAdditional: true });
var schema = {
"additionalProperties": false,
"properties": {
"foo": { "type": "number" },
"bar": {
"additionalProperties": { "type": "number" },
"properties": {
"baz": { "type": "string" }
}
}
}
}
var data = {
"foo": 0,
"additional1": 1, // will be removed; `additionalProperties` == false
"bar": {
"baz": "abc",
"additional2": 2 // will NOT be removed; `additionalProperties` != false
},
}
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 0, "bar": { "baz": "abc", "additional2": 2 }
```
If `removeAdditional` option in the example above were `"all"` then both `additional1` and `additional2` properties would have been removed.
If the option were `"failing"` then property `additional1` would have been removed regardless of its value and property `additional2` would have been removed only if its value were failing the schema in the inner `additionalProperties` (so in the example above it would have stayed because it passes the schema, but any non-number would have been removed).
__Please note__: If you use `removeAdditional` option with `additionalProperties` keyword inside `anyOf`/`oneOf` keywords your validation can fail with this schema, for example:
```json
{
"type": "object",
"oneOf": [
{
"properties": {
"foo": { "type": "string" }
},
"required": [ "foo" ],
"additionalProperties": false
},
{
"properties": {
"bar": { "type": "integer" }
},
"required": [ "bar" ],
"additionalProperties": false
}
]
}
```
The intention of the schema above is to allow objects with either the string property "foo" or the integer property "bar", but not with both and not with any other properties.
With the option `removeAdditional: true` the validation will pass for the object `{ "foo": "abc"}` but will fail for the object `{"bar": 1}`. It happens because while the first subschema in `oneOf` is validated, the property `bar` is removed because it is an additional property according to the standard (because it is not included in `properties` keyword in the same schema).
While this behaviour is unexpected (issues [#129](https://github.com/ajv-validator/ajv/issues/129), [#134](https://github.com/ajv-validator/ajv/issues/134)), it is correct. To have the expected behaviour (both objects are allowed and additional properties are removed) the schema has to be refactored in this way:
```json
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "integer" }
},
"additionalProperties": false,
"oneOf": [
{ "required": [ "foo" ] },
{ "required": [ "bar" ] }
]
}
```
The schema above is also more efficient - it will compile into a faster function.
## Assigning defaults
With [option `useDefaults`](#options) Ajv will assign values from `default` keyword in the schemas of `properties` and `items` (when it is the array of schemas) to the missing properties and items.
With the option value `"empty"` properties and items equal to `null` or `""` (empty string) will be considered missing and assigned defaults.
This option modifies original data.
__Please note__: the default value is inserted in the generated validation code as a literal, so the value inserted in the data will be the deep clone of the default in the schema.
Example 1 (`default` in `properties`):
```javascript
var ajv = new Ajv({ useDefaults: true });
var schema = {
"type": "object",
"properties": {
"foo": { "type": "number" },
"bar": { "type": "string", "default": "baz" }
},
"required": [ "foo", "bar" ]
};
var data = { "foo": 1 };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 1, "bar": "baz" }
```
Example 2 (`default` in `items`):
```javascript
var schema = {
"type": "array",
"items": [
{ "type": "number" },
{ "type": "string", "default": "foo" }
]
}
var data = [ 1 ];
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // [ 1, "foo" ]
```
`default` keywords in other cases are ignored:
- not in `properties` or `items` subschemas
- in schemas inside `anyOf`, `oneOf` and `not` (see [#42](https://github.com/ajv-validator/ajv/issues/42))
- in `if` subschema of `switch` keyword
- in schemas generated by custom macro keywords
The [`strictDefaults` option](#options) customizes Ajv's behavior for the defaults that Ajv ignores (`true` raises an error, and `"log"` outputs a warning).
## Coercing data types
When you are validating user inputs all your data properties are usually strings. The option `coerceTypes` allows you to have your data types coerced to the types specified in your schema `type` keywords, both to pass the validation and to use the correctly typed data afterwards.
This option modifies original data.
__Please note__: if you pass a scalar value to the validating function its type will be coerced and it will pass the validation, but the value of the variable you pass won't be updated because scalars are passed by value.
Example 1:
```javascript
var ajv = new Ajv({ coerceTypes: true });
var schema = {
"type": "object",
"properties": {
"foo": { "type": "number" },
"bar": { "type": "boolean" }
},
"required": [ "foo", "bar" ]
};
var data = { "foo": "1", "bar": "false" };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 1, "bar": false }
```
Example 2 (array coercions):
```javascript
var ajv = new Ajv({ coerceTypes: 'array' });
var schema = {
"properties": {
"foo": { "type": "array", "items": { "type": "number" } },
"bar": { "type": "boolean" }
}
};
var data = { "foo": "1", "bar": ["false"] };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": [1], "bar": false }
```
The coercion rules, as you can see from the example, are different from JavaScript both to validate user input as expected and to have the coercion reversible (to correctly validate cases where different types are defined in subschemas of "anyOf" and other compound keywords).
See [Coercion rules](https://github.com/ajv-validator/ajv/blob/master/COERCION.md) for details.
## API
##### new Ajv(Object options) -> Object
Create Ajv instance.
##### .compile(Object schema) -> Function<Object data>
Generate validating function and cache the compiled schema for future use.
Validating function returns a boolean value. This function has properties `errors` and `schema`. Errors encountered during the last validation are assigned to `errors` property (it is assigned `null` if there was no errors). `schema` property contains the reference to the original schema.
The schema passed to this method will be validated against meta-schema unless `validateSchema` option is false. If schema is invalid, an error will be thrown. See [options](#options).
##### <a name="api-compileAsync"></a>.compileAsync(Object schema [, Boolean meta] [, Function callback]) -> Promise
Asynchronous version of `compile` method that loads missing remote schemas using asynchronous function in `options.loadSchema`. This function returns a Promise that resolves to a validation function. An optional callback passed to `compileAsync` will be called with 2 parameters: error (or null) and validating function. The returned promise will reject (and the callback will be called with an error) when:
- missing schema can't be loaded (`loadSchema` returns a Promise that rejects).
- a schema containing a missing reference is loaded, but the reference cannot be resolved.
- schema (or some loaded/referenced schema) is invalid.
The function compiles schema and loads the first missing schema (or meta-schema) until all missing schemas are loaded.
You can asynchronously compile meta-schema by passing `true` as the second parameter.
See example in [Asynchronous compilation](#asynchronous-schema-compilation).
##### .validate(Object schema|String key|String ref, data) -> Boolean
Validate data using passed schema (it will be compiled and cached).
Instead of the schema you can use the key that was previously passed to `addSchema`, the schema id if it was present in the schema or any previously resolved reference.
Validation errors will be available in the `errors` property of Ajv instance (`null` if there were no errors).
__Please note__: every time this method is called the errors are overwritten so you need to copy them to another variable if you want to use them later.
If the schema is asynchronous (has `$async` keyword on the top level) this method returns a Promise. See [Asynchronous validation](#asynchronous-validation).
##### .addSchema(Array<Object>|Object schema [, String key]) -> Ajv
Add schema(s) to validator instance. This method does not compile schemas (but it still validates them). Because of that dependencies can be added in any order and circular dependencies are supported. It also prevents unnecessary compilation of schemas that are containers for other schemas but not used as a whole.
Array of schemas can be passed (schemas should have ids), the second parameter will be ignored.
Key can be passed that can be used to reference the schema and will be used as the schema id if there is no id inside the schema. If the key is not passed, the schema id will be used as the key.
Once the schema is added, it (and all the references inside it) can be referenced in other schemas and used to validate data.
Although `addSchema` does not compile schemas, explicit compilation is not required - the schema will be compiled when it is used first time.
By default the schema is validated against meta-schema before it is added, and if the schema does not pass validation the exception is thrown. This behaviour is controlled by `validateSchema` option.
__Please note__: Ajv uses the [method chaining syntax](https://en.wikipedia.org/wiki/Method_chaining) for all methods with the prefix `add*` and `remove*`.
This allows you to do nice things like the following.
```javascript
var validate = new Ajv().addSchema(schema).addFormat(name, regex).getSchema(uri);
```
##### .addMetaSchema(Array<Object>|Object schema [, String key]) -> Ajv
Adds meta schema(s) that can be used to validate other schemas. That function should be used instead of `addSchema` because there may be instance options that would compile a meta schema incorrectly (at the moment it is `removeAdditional` option).
There is no need to explicitly add draft-07 meta schema (http://json-schema.org/draft-07/schema) - it is added by default, unless option `meta` is set to `false`. You only need to use it if you have a changed meta-schema that you want to use to validate your schemas. See `validateSchema`.
##### <a name="api-validateschema"></a>.validateSchema(Object schema) -> Boolean
Validates schema. This method should be used to validate schemas rather than `validate` due to the inconsistency of `uri` format in JSON Schema standard.
By default this method is called automatically when the schema is added, so you rarely need to use it directly.
If schema doesn't have `$schema` property, it is validated against draft 6 meta-schema (option `meta` should not be false).
If schema has `$schema` property, then the schema with this id (that should be previously added) is used to validate passed schema.
Errors will be available at `ajv.errors`.
##### .getSchema(String key) -> Function<Object data>
Retrieve compiled schema previously added with `addSchema` by the key passed to `addSchema` or by its full reference (id). The returned validating function has `schema` property with the reference to the original schema.
##### .removeSchema([Object schema|String key|String ref|RegExp pattern]) -> Ajv
Remove added/cached schema. Even if schema is referenced by other schemas it can be safely removed as dependent schemas have local references.
Schema can be removed using:
- key passed to `addSchema`
- it's full reference (id)
- RegExp that should match schema id or key (meta-schemas won't be removed)
- actual schema object that will be stable-stringified to remove schema from cache
If no parameter is passed all schemas but meta-schemas will be removed and the cache will be cleared.
##### <a name="api-addformat"></a>.addFormat(String name, String|RegExp|Function|Object format) -> Ajv
Add custom format to validate strings or numbers. It can also be used to replace pre-defined formats for Ajv instance.
Strings are converted to RegExp.
Function should return validation result as `true` or `false`.
If object is passed it should have properties `validate`, `compare` and `async`:
- _validate_: a string, RegExp or a function as described above.
- _compare_: an optional comparison function that accepts two strings and compares them according to the format meaning. This function is used with keywords `formatMaximum`/`formatMinimum` (defined in [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package). It should return `1` if the first value is bigger than the second value, `-1` if it is smaller and `0` if it is equal.
- _async_: an optional `true` value if `validate` is an asynchronous function; in this case it should return a promise that resolves with a value `true` or `false`.
- _type_: an optional type of data that the format applies to. It can be `"string"` (default) or `"number"` (see https://github.com/ajv-validator/ajv/issues/291#issuecomment-259923858). If the type of data is different, the validation will pass.
Custom formats can be also added via `formats` option.
##### <a name="api-addkeyword"></a>.addKeyword(String keyword, Object definition) -> Ajv
Add custom validation keyword to Ajv instance.
Keyword should be different from all standard JSON Schema keywords and different from previously defined keywords. There is no way to redefine keywords or to remove keyword definition from the instance.
Keyword must start with a letter, `_` or `$`, and may continue with letters, numbers, `_`, `$`, or `-`.
It is recommended to use an application-specific prefix for keywords to avoid current and future name collisions.
Example Keywords:
- `"xyz-example"`: valid, and uses prefix for the xyz project to avoid name collisions.
- `"example"`: valid, but not recommended as it could collide with future versions of JSON Schema etc.
- `"3-example"`: invalid as numbers are not allowed to be the first character in a keyword
Keyword definition is an object with the following properties:
- _type_: optional string or array of strings with data type(s) that the keyword applies to. If not present, the keyword will apply to all types.
- _validate_: validating function
- _compile_: compiling function
- _macro_: macro function
- _inline_: compiling function that returns code (as string)
- _schema_: an optional `false` value used with "validate" keyword to not pass schema
- _metaSchema_: an optional meta-schema for keyword schema
- _dependencies_: an optional list of properties that must be present in the parent schema - it will be checked during schema compilation
- _modifying_: `true` MUST be passed if keyword modifies data
- _statements_: `true` can be passed in case inline keyword generates statements (as opposed to expression)
- _valid_: pass `true`/`false` to pre-define validation result, the result returned from validation function will be ignored. This option cannot be used with macro keywords.
- _$data_: an optional `true` value to support [$data reference](#data-reference) as the value of custom keyword. The reference will be resolved at validation time. If the keyword has meta-schema it would be extended to allow $data and it will be used to validate the resolved value. Supporting $data reference requires that keyword has validating function (as the only option or in addition to compile, macro or inline function).
- _async_: an optional `true` value if the validation function is asynchronous (whether it is compiled or passed in _validate_ property); in this case it should return a promise that resolves with a value `true` or `false`. This option is ignored in case of "macro" and "inline" keywords.
- _errors_: an optional boolean or string `"full"` indicating whether keyword returns errors. If this property is not set Ajv will determine if the errors were set in case of failed validation.
_compile_, _macro_ and _inline_ are mutually exclusive, only one should be used at a time. _validate_ can be used separately or in addition to them to support $data reference.
__Please note__: If the keyword is validating data type that is different from the type(s) in its definition, the validation function will not be called (and expanded macro will not be used), so there is no need to check for data type inside validation function or inside schema returned by macro function (unless you want to enforce a specific type and for some reason do not want to use a separate `type` keyword for that). In the same way as standard keywords work, if the keyword does not apply to the data type being validated, the validation of this keyword will succeed.
See [Defining custom keywords](#defining-custom-keywords) for more details.
##### .getKeyword(String keyword) -> Object|Boolean
Returns custom keyword definition, `true` for pre-defined keywords and `false` if the keyword is unknown.
##### .removeKeyword(String keyword) -> Ajv
Removes custom or pre-defined keyword so you can redefine them.
While this method can be used to extend pre-defined keywords, it can also be used to completely change their meaning - it may lead to unexpected results.
__Please note__: schemas compiled before the keyword is removed will continue to work without changes. To recompile schemas use `removeSchema` method and compile them again.
##### .errorsText([Array<Object> errors [, Object options]]) -> String
Returns the text with all errors in a String.
Options can have properties `separator` (string used to separate errors, ", " by default) and `dataVar` (the variable name that dataPaths are prefixed with, "data" by default).
## Options
Defaults:
```javascript
{
// validation and reporting options:
$data: false,
allErrors: false,
verbose: false,
$comment: false, // NEW in Ajv version 6.0
jsonPointers: false,
uniqueItems: true,
unicode: true,
nullable: false,
format: 'fast',
formats: {},
unknownFormats: true,
schemas: {},
logger: undefined,
// referenced schema options:
schemaId: '$id',
missingRefs: true,
extendRefs: 'ignore', // recommended 'fail'
loadSchema: undefined, // function(uri: string): Promise {}
// options to modify validated data:
removeAdditional: false,
useDefaults: false,
coerceTypes: false,
// strict mode options
strictDefaults: false,
strictKeywords: false,
strictNumbers: false,
// asynchronous validation options:
transpile: undefined, // requires ajv-async package
// advanced options:
meta: true,
validateSchema: true,
addUsedSchema: true,
inlineRefs: true,
passContext: false,
loopRequired: Infinity,
ownProperties: false,
multipleOfPrecision: false,
errorDataPath: 'object', // deprecated
messages: true,
sourceCode: false,
processCode: undefined, // function (str: string, schema: object): string {}
cache: new Cache,
serialize: undefined
}
```
##### Validation and reporting options
- _$data_: support [$data references](#data-reference). Draft 6 meta-schema that is added by default will be extended to allow them. If you want to use another meta-schema you need to use $dataMetaSchema method to add support for $data reference. See [API](#api).
- _allErrors_: check all rules collecting all errors. Default is to return after the first error.
- _verbose_: include the reference to the part of the schema (`schema` and `parentSchema`) and validated data in errors (false by default).
- _$comment_ (NEW in Ajv version 6.0): log or pass the value of `$comment` keyword to a function. Option values:
- `false` (default): ignore $comment keyword.
- `true`: log the keyword value to console.
- function: pass the keyword value, its schema path and root schema to the specified function
- _jsonPointers_: set `dataPath` property of errors using [JSON Pointers](https://tools.ietf.org/html/rfc6901) instead of JavaScript property access notation.
- _uniqueItems_: validate `uniqueItems` keyword (true by default).
- _unicode_: calculate correct length of strings with unicode pairs (true by default). Pass `false` to use `.length` of strings that is faster, but gives "incorrect" lengths of strings with unicode pairs - each unicode pair is counted as two characters.
- _nullable_: support keyword "nullable" from [Open API 3 specification](https://swagger.io/docs/specification/data-models/data-types/).
- _format_: formats validation mode. Option values:
- `"fast"` (default) - simplified and fast validation (see [Formats](#formats) for details of which formats are available and affected by this option).
- `"full"` - more restrictive and slow validation. E.g., 25:00:00 and 2015/14/33 will be invalid time and date in 'full' mode but it will be valid in 'fast' mode.
- `false` - ignore all format keywords.
- _formats_: an object with custom formats. Keys and values will be passed to `addFormat` method.
- _keywords_: an object with custom keywords. Keys and values will be passed to `addKeyword` method.
- _unknownFormats_: handling of unknown formats. Option values:
- `true` (default) - if an unknown format is encountered the exception is thrown during schema compilation. If `format` keyword value is [$data reference](#data-reference) and it is unknown the validation will fail.
- `[String]` - an array of unknown format names that will be ignored. This option can be used to allow usage of third party schemas with format(s) for which you don't have definitions, but still fail if another unknown format is used. If `format` keyword value is [$data reference](#data-reference) and it is not in this array the validation will fail.
- `"ignore"` - to log warning during schema compilation and always pass validation (the default behaviour in versions before 5.0.0). This option is not recommended, as it allows to mistype format name and it won't be validated without any error message. This behaviour is required by JSON Schema specification.
- _schemas_: an array or object of schemas that will be added to the instance. In case you pass the array the schemas must have IDs in them. When the object is passed the method `addSchema(value, key)` will be called for each schema in this object.
- _logger_: sets the logging method. Default is the global `console` object that should have methods `log`, `warn` and `error`. See [Error logging](#error-logging). Option values:
- custom logger - it should have methods `log`, `warn` and `error`. If any of these methods is missing an exception will be thrown.
- `false` - logging is disabled.
##### Referenced schema options
- _schemaId_: this option defines which keywords are used as schema URI. Option value:
- `"$id"` (default) - only use `$id` keyword as schema URI (as specified in JSON Schema draft-06/07), ignore `id` keyword (if it is present a warning will be logged).
- `"id"` - only use `id` keyword as schema URI (as specified in JSON Schema draft-04), ignore `$id` keyword (if it is present a warning will be logged).
- `"auto"` - use both `$id` and `id` keywords as schema URI. If both are present (in the same schema object) and different the exception will be thrown during schema compilation.
- _missingRefs_: handling of missing referenced schemas. Option values:
- `true` (default) - if the reference cannot be resolved during compilation the exception is thrown. The thrown error has properties `missingRef` (with hash fragment) and `missingSchema` (without it). Both properties are resolved relative to the current base id (usually schema id, unless it was substituted).
- `"ignore"` - to log error during compilation and always pass validation.
- `"fail"` - to log error and successfully compile schema but fail validation if this rule is checked.
- _extendRefs_: validation of other keywords when `$ref` is present in the schema. Option values:
- `"ignore"` (default) - when `$ref` is used other keywords are ignored (as per [JSON Reference](https://tools.ietf.org/html/draft-pbryan-zyp-json-ref-03#section-3) standard). A warning will be logged during the schema compilation.
- `"fail"` (recommended) - if other validation keywords are used together with `$ref` the exception will be thrown when the schema is compiled. This option is recommended to make sure schema has no keywords that are ignored, which can be confusing.
- `true` - validate all keywords in the schemas with `$ref` (the default behaviour in versions before 5.0.0).
- _loadSchema_: asynchronous function that will be used to load remote schemas when `compileAsync` [method](#api-compileAsync) is used and some reference is missing (option `missingRefs` should NOT be 'fail' or 'ignore'). This function should accept remote schema uri as a parameter and return a Promise that resolves to a schema. See example in [Asynchronous compilation](#asynchronous-schema-compilation).
##### Options to modify validated data
- _removeAdditional_: remove additional properties - see example in [Filtering data](#filtering-data). This option is not used if schema is added with `addMetaSchema` method. Option values:
- `false` (default) - not to remove additional properties
- `"all"` - all additional properties are removed, regardless of `additionalProperties` keyword in schema (and no validation is made for them).
- `true` - only additional properties with `additionalProperties` keyword equal to `false` are removed.
- `"failing"` - additional properties that fail schema validation will be removed (where `additionalProperties` keyword is `false` or schema).
- _useDefaults_: replace missing or undefined properties and items with the values from corresponding `default` keywords. Default behaviour is to ignore `default` keywords. This option is not used if schema is added with `addMetaSchema` method. See examples in [Assigning defaults](#assigning-defaults). Option values:
- `false` (default) - do not use defaults
- `true` - insert defaults by value (object literal is used).
- `"empty"` - in addition to missing or undefined, use defaults for properties and items that are equal to `null` or `""` (an empty string).
- `"shared"` (deprecated) - insert defaults by reference. If the default is an object, it will be shared by all instances of validated data. If you modify the inserted default in the validated data, it will be modified in the schema as well.
- _coerceTypes_: change data type of data to match `type` keyword. See the example in [Coercing data types](#coercing-data-types) and [coercion rules](https://github.com/ajv-validator/ajv/blob/master/COERCION.md). Option values:
- `false` (default) - no type coercion.
- `true` - coerce scalar data types.
- `"array"` - in addition to coercions between scalar types, coerce scalar data to an array with one element and vice versa (as required by the schema).
##### Strict mode options
- _strictDefaults_: report ignored `default` keywords in schemas. Option values:
- `false` (default) - ignored defaults are not reported
- `true` - if an ignored default is present, throw an error
- `"log"` - if an ignored default is present, log warning
- _strictKeywords_: report unknown keywords in schemas. Option values:
- `false` (default) - unknown keywords are not reported
- `true` - if an unknown keyword is present, throw an error
- `"log"` - if an unknown keyword is present, log warning
- _strictNumbers_: validate numbers strictly, failing validation for NaN and Infinity. Option values:
- `false` (default) - NaN or Infinity will pass validation for numeric types
- `true` - NaN or Infinity will not pass validation for numeric types
##### Asynchronous validation options
- _transpile_: Requires [ajv-async](https://github.com/ajv-validator/ajv-async) package. It determines whether Ajv transpiles compiled asynchronous validation function. Option values:
- `undefined` (default) - transpile with [nodent](https://github.com/MatAtBread/nodent) if async functions are not supported.
- `true` - always transpile with nodent.
- `false` - do not transpile; if async functions are not supported an exception will be thrown.
##### Advanced options
- _meta_: add [meta-schema](http://json-schema.org/documentation.html) so it can be used by other schemas (true by default). If an object is passed, it will be used as the default meta-schema for schemas that have no `$schema` keyword. This default meta-schema MUST have `$schema` keyword.
- _validateSchema_: validate added/compiled schemas against meta-schema (true by default). `$schema` property in the schema can be http://json-schema.org/draft-07/schema or absent (draft-07 meta-schema will be used) or can be a reference to the schema previously added with `addMetaSchema` method. Option values:
- `true` (default) - if the validation fails, throw the exception.
- `"log"` - if the validation fails, log error.
- `false` - skip schema validation.
- _addUsedSchema_: by default methods `compile` and `validate` add schemas to the instance if they have `$id` (or `id`) property that doesn't start with "#". If `$id` is present and it is not unique the exception will be thrown. Set this option to `false` to skip adding schemas to the instance and the `$id` uniqueness check when these methods are used. This option does not affect `addSchema` method.
- _inlineRefs_: Affects compilation of referenced schemas. Option values:
- `true` (default) - the referenced schemas that don't have refs in them are inlined, regardless of their size - that substantially improves performance at the cost of the bigger size of compiled schema functions.
- `false` - to not inline referenced schemas (they will be compiled as separate functions).
- integer number - to limit the maximum number of keywords of the schema that will be inlined.
- _passContext_: pass validation context to custom keyword functions. If this option is `true` and you pass some context to the compiled validation function with `validate.call(context, data)`, the `context` will be available as `this` in your custom keywords. By default `this` is Ajv instance.
- _loopRequired_: by default `required` keyword is compiled into a single expression (or a sequence of statements in `allErrors` mode). In case of a very large number of properties in this keyword it may result in a very big validation function. Pass integer to set the number of properties above which `required` keyword will be validated in a loop - smaller validation function size but also worse performance.
- _ownProperties_: by default Ajv iterates over all enumerable object properties; when this option is `true` only own enumerable object properties (i.e. found directly on the object rather than on its prototype) are iterated. Contributed by @mbroadst.
- _multipleOfPrecision_: by default `multipleOf` keyword is validated by comparing the result of division with parseInt() of that result. It works for dividers that are bigger than 1. For small dividers such as 0.01 the result of the division is usually not integer (even when it should be integer, see issue [#84](https://github.com/ajv-validator/ajv/issues/84)). If you need to use fractional dividers set this option to some positive integer N to have `multipleOf` validated using this formula: `Math.abs(Math.round(division) - division) < 1e-N` (it is slower but allows for float arithmetics deviations).
- _errorDataPath_ (deprecated): set `dataPath` to point to 'object' (default) or to 'property' when validating keywords `required`, `additionalProperties` and `dependencies`.
- _messages_: Include human-readable messages in errors. `true` by default. `false` can be passed when custom messages are used (e.g. with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n)).
- _sourceCode_: add `sourceCode` property to validating function (for debugging; this code can be different from the result of toString call).
- _processCode_: an optional function to process generated code before it is passed to Function constructor. It can be used to either beautify (the validating function is generated without line-breaks) or to transpile code. Starting from version 5.0.0 this option replaced options:
- `beautify` that formatted the generated function using [js-beautify](https://github.com/beautify-web/js-beautify). If you want to beautify the generated code pass a function calling `require('js-beautify').js_beautify` as `processCode: code => js_beautify(code)`.
- `transpile` that transpiled asynchronous validation function. You can still use `transpile` option with [ajv-async](https://github.com/ajv-validator/ajv-async) package. See [Asynchronous validation](#asynchronous-validation) for more information.
- _cache_: an optional instance of cache to store compiled schemas using stable-stringified schema as a key. For example, set-associative cache [sacjs](https://github.com/epoberezkin/sacjs) can be used. If not passed then a simple hash is used which is good enough for the common use case (a limited number of statically defined schemas). Cache should have methods `put(key, value)`, `get(key)`, `del(key)` and `clear()`.
- _serialize_: an optional function to serialize schema to cache key. Pass `false` to use schema itself as a key (e.g., if WeakMap used as a cache). By default [fast-json-stable-stringify](https://github.com/epoberezkin/fast-json-stable-stringify) is used.
## Validation errors
In case of validation failure, Ajv assigns the array of errors to `errors` property of validation function (or to `errors` property of Ajv instance when `validate` or `validateSchema` methods were called). In case of [asynchronous validation](#asynchronous-validation), the returned promise is rejected with exception `Ajv.ValidationError` that has `errors` property.
### Error objects
Each error is an object with the following properties:
- _keyword_: validation keyword.
- _dataPath_: the path to the part of the data that was validated. By default `dataPath` uses JavaScript property access notation (e.g., `".prop[1].subProp"`). When the option `jsonPointers` is true (see [Options](#options)) `dataPath` will be set using JSON pointer standard (e.g., `"/prop/1/subProp"`).
- _schemaPath_: the path (JSON-pointer as a URI fragment) to the schema of the keyword that failed validation.
- _params_: the object with the additional information about error that can be used to create custom error messages (e.g., using [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package). See below for parameters set by all keywords.
- _message_: the standard error message (can be excluded with option `messages` set to false).
- _schema_: the schema of the keyword (added with `verbose` option).
- _parentSchema_: the schema containing the keyword (added with `verbose` option)
- _data_: the data validated by the keyword (added with `verbose` option).
__Please note__: `propertyNames` keyword schema validation errors have an additional property `propertyName`, `dataPath` points to the object. After schema validation for each property name, if it is invalid an additional error is added with the property `keyword` equal to `"propertyNames"`.
### Error parameters
Properties of `params` object in errors depend on the keyword that failed validation.
- `maxItems`, `minItems`, `maxLength`, `minLength`, `maxProperties`, `minProperties` - property `limit` (number, the schema of the keyword).
- `additionalItems` - property `limit` (the maximum number of allowed items in case when `items` keyword is an array of schemas and `additionalItems` is false).
- `additionalProperties` - property `additionalProperty` (the property not used in `properties` and `patternProperties` keywords).
- `dependencies` - properties:
- `property` (dependent property),
- `missingProperty` (required missing dependency - only the first one is reported currently)
- `deps` (required dependencies, comma separated list as a string),
- `depsCount` (the number of required dependencies).
- `format` - property `format` (the schema of the keyword).
- `maximum`, `minimum` - properties:
- `limit` (number, the schema of the keyword),
- `exclusive` (boolean, the schema of `exclusiveMaximum` or `exclusiveMinimum`),
- `comparison` (string, comparison operation to compare the data to the limit, with the data on the left and the limit on the right; can be "<", "<=", ">", ">=")
- `multipleOf` - property `multipleOf` (the schema of the keyword)
- `pattern` - property `pattern` (the schema of the keyword)
- `required` - property `missingProperty` (required property that is missing).
- `propertyNames` - property `propertyName` (an invalid property name).
- `patternRequired` (in ajv-keywords) - property `missingPattern` (required pattern that did not match any property).
- `type` - property `type` (required type(s), a string, can be a comma-separated list)
- `uniqueItems` - properties `i` and `j` (indices of duplicate items).
- `const` - property `allowedValue` pointing to the value (the schema of the keyword).
- `enum` - property `allowedValues` pointing to the array of values (the schema of the keyword).
- `$ref` - property `ref` with the referenced schema URI.
- `oneOf` - property `passingSchemas` (array of indices of passing schemas, null if no schema passes).
- custom keywords (in case keyword definition doesn't create errors) - property `keyword` (the keyword name).
### Error logging
Using the `logger` option when initiallizing Ajv will allow you to define custom logging. Here you can build upon the exisiting logging. The use of other logging packages is supported as long as the package or its associated wrapper exposes the required methods. If any of the required methods are missing an exception will be thrown.
- **Required Methods**: `log`, `warn`, `error`
```javascript
var otherLogger = new OtherLogger();
var ajv = new Ajv({
logger: {
log: console.log.bind(console),
warn: function warn() {
otherLogger.logWarn.apply(otherLogger, arguments);
},
error: function error() {
otherLogger.logError.apply(otherLogger, arguments);
console.error.apply(console, arguments);
}
}
});
```
## Plugins
Ajv can be extended with plugins that add custom keywords, formats or functions to process generated code. When such plugin is published as npm package it is recommended that it follows these conventions:
- it exports a function
- this function accepts ajv instance as the first parameter and returns the same instance to allow chaining
- this function can accept an optional configuration as the second parameter
If you have published a useful plugin please submit a PR to add it to the next section.
## Related packages
- [ajv-async](https://github.com/ajv-validator/ajv-async) - plugin to configure async validation mode
- [ajv-bsontype](https://github.com/BoLaMN/ajv-bsontype) - plugin to validate mongodb's bsonType formats
- [ajv-cli](https://github.com/jessedc/ajv-cli) - command line interface
- [ajv-errors](https://github.com/ajv-validator/ajv-errors) - plugin for custom error messages
- [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) - internationalised error messages
- [ajv-istanbul](https://github.com/ajv-validator/ajv-istanbul) - plugin to instrument generated validation code to measure test coverage of your schemas
- [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) - plugin with custom validation keywords (select, typeof, etc.)
- [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) - plugin with keywords $merge and $patch
- [ajv-pack](https://github.com/ajv-validator/ajv-pack) - produces a compact module exporting validation functions
- [ajv-formats-draft2019](https://github.com/luzlab/ajv-formats-draft2019) - format validators for draft2019 that aren't already included in ajv (ie. `idn-hostname`, `idn-email`, `iri`, `iri-reference` and `duration`).
## Some packages using Ajv
- [webpack](https://github.com/webpack/webpack) - a module bundler. Its main purpose is to bundle JavaScript files for usage in a browser
- [jsonscript-js](https://github.com/JSONScript/jsonscript-js) - the interpreter for [JSONScript](http://www.jsonscript.org) - scripted processing of existing endpoints and services
- [osprey-method-handler](https://github.com/mulesoft-labs/osprey-method-handler) - Express middleware for validating requests and responses based on a RAML method object, used in [osprey](https://github.com/mulesoft/osprey) - validating API proxy generated from a RAML definition
- [har-validator](https://github.com/ahmadnassri/har-validator) - HTTP Archive (HAR) validator
- [jsoneditor](https://github.com/josdejong/jsoneditor) - a web-based tool to view, edit, format, and validate JSON http://jsoneditoronline.org
- [JSON Schema Lint](https://github.com/nickcmaynard/jsonschemalint) - a web tool to validate JSON/YAML document against a single JSON Schema http://jsonschemalint.com
- [objection](https://github.com/vincit/objection.js) - SQL-friendly ORM for Node.js
- [table](https://github.com/gajus/table) - formats data into a string table
- [ripple-lib](https://github.com/ripple/ripple-lib) - a JavaScript API for interacting with [Ripple](https://ripple.com) in Node.js and the browser
- [restbase](https://github.com/wikimedia/restbase) - distributed storage with REST API & dispatcher for backend services built to provide a low-latency & high-throughput API for Wikipedia / Wikimedia content
- [hippie-swagger](https://github.com/CacheControl/hippie-swagger) - [Hippie](https://github.com/vesln/hippie) wrapper that provides end to end API testing with swagger validation
- [react-form-controlled](https://github.com/seeden/react-form-controlled) - React controlled form components with validation
- [rabbitmq-schema](https://github.com/tjmehta/rabbitmq-schema) - a schema definition module for RabbitMQ graphs and messages
- [@query/schema](https://www.npmjs.com/package/@query/schema) - stream filtering with a URI-safe query syntax parsing to JSON Schema
- [chai-ajv-json-schema](https://github.com/peon374/chai-ajv-json-schema) - chai plugin to us JSON Schema with expect in mocha tests
- [grunt-jsonschema-ajv](https://github.com/SignpostMarv/grunt-jsonschema-ajv) - Grunt plugin for validating files against JSON Schema
- [extract-text-webpack-plugin](https://github.com/webpack-contrib/extract-text-webpack-plugin) - extract text from bundle into a file
- [electron-builder](https://github.com/electron-userland/electron-builder) - a solution to package and build a ready for distribution Electron app
- [addons-linter](https://github.com/mozilla/addons-linter) - Mozilla Add-ons Linter
- [gh-pages-generator](https://github.com/epoberezkin/gh-pages-generator) - multi-page site generator converting markdown files to GitHub pages
- [ESLint](https://github.com/eslint/eslint) - the pluggable linting utility for JavaScript and JSX
## Tests
```
npm install
git submodule update --init
npm test
```
## Contributing
All validation functions are generated using doT templates in [dot](https://github.com/ajv-validator/ajv/tree/master/lib/dot) folder. Templates are precompiled so doT is not a run-time dependency.
`npm run build` - compiles templates to [dotjs](https://github.com/ajv-validator/ajv/tree/master/lib/dotjs) folder.
`npm run watch` - automatically compiles templates when files in dot folder change
Please see [Contributing guidelines](https://github.com/ajv-validator/ajv/blob/master/CONTRIBUTING.md)
## Changes history
See https://github.com/ajv-validator/ajv/releases
__Please note__: [Changes in version 7.0.0-beta](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0-beta.0)
[Version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0).
## Code of conduct
Please review and follow the [Code of conduct](https://github.com/ajv-validator/ajv/blob/master/CODE_OF_CONDUCT.md).
Please report any unacceptable behaviour to ajv.validator@gmail.com - it will be reviewed by the project team.
## Open-source software support
Ajv is a part of [Tidelift subscription](https://tidelift.com/subscription/pkg/npm-ajv?utm_source=npm-ajv&utm_medium=referral&utm_campaign=readme) - it provides a centralised support to open-source software users, in addition to the support provided by software maintainers.
## License
[MIT](https://github.com/ajv-validator/ajv/blob/master/LICENSE)
# randexp.js
randexp will generate a random string that matches a given RegExp Javascript object.
[](http://travis-ci.org/fent/randexp.js)
[](https://david-dm.org/fent/randexp.js)
[](https://codecov.io/gh/fent/randexp.js)
# Usage
```js
var RandExp = require('randexp');
// supports grouping and piping
new RandExp(/hello+ (world|to you)/).gen();
// => hellooooooooooooooooooo world
// sets and ranges and references
new RandExp(/<([a-z]\w{0,20})>foo<\1>/).gen();
// => <m5xhdg>foo<m5xhdg>
// wildcard
new RandExp(/random stuff: .+/).gen();
// => random stuff: l3m;Hf9XYbI [YPaxV>U*4-_F!WXQh9>;rH3i l!8.zoh?[utt1OWFQrE ^~8zEQm]~tK
// ignore case
new RandExp(/xxx xtreme dragon warrior xxx/i).gen();
// => xxx xtReME dRAGON warRiOR xXX
// dynamic regexp shortcut
new RandExp('(sun|mon|tue|wednes|thurs|fri|satur)day', 'i');
// is the same as
new RandExp(new RegExp('(sun|mon|tue|wednes|thurs|fri|satur)day', 'i'));
```
If you're only going to use `gen()` once with a regexp and want slightly shorter syntax for it
```js
var randexp = require('randexp').randexp;
randexp(/[1-6]/); // 4
randexp('great|good( job)?|excellent'); // great
```
If you miss the old syntax
```js
require('randexp').sugar();
/yes|no|maybe|i don't know/.gen(); // maybe
```
# Motivation
Regular expressions are used in every language, every programmer is familiar with them. Regex can be used to easily express complex strings. What better way to generate a random string than with a language you can use to express the string you want?
Thanks to [String-Random](http://search.cpan.org/~steve/String-Random-0.22/lib/String/Random.pm) for giving me the idea to make this in the first place and [randexp](https://github.com/benburkert/randexp) for the sweet `.gen()` syntax.
# Default Range
The default generated character range includes printable ASCII. In order to add or remove characters,
a `defaultRange` attribute is exposed. you can `subtract(from, to)` and `add(from, to)`
```js
var randexp = new RandExp(/random stuff: .+/);
randexp.defaultRange.subtract(32, 126);
randexp.defaultRange.add(0, 65535);
randexp.gen();
// => random stuff: 湐箻ໜ䫴㳸長���邓蕲뤀쑡篷皇硬剈궦佔칗븛뀃匫鴔事좍ﯣ⭼ꝏ䭍詳蒂䥂뽭
```
# Custom PRNG
The default randomness is provided by `Math.random()`. If you need to use a seedable or cryptographic PRNG, you
can override `RandExp.prototype.randInt` or `randexp.randInt` (where `randexp` is an instance of `RandExp`). `randInt(from, to)` accepts an inclusive range and returns a randomly selected
number within that range.
# Infinite Repetitionals
Repetitional tokens such as `*`, `+`, and `{3,}` have an infinite max range. In this case, randexp looks at its min and adds 100 to it to get a useable max value. If you want to use another int other than 100 you can change the `max` property in `RandExp.prototype` or the RandExp instance.
```js
var randexp = new RandExp(/no{1,}/);
randexp.max = 1000000;
```
With `RandExp.sugar()`
```js
var regexp = /(hi)*/;
regexp.max = 1000000;
```
# Bad Regular Expressions
There are some regular expressions which can never match any string.
* Ones with badly placed positionals such as `/a^/` and `/$c/m`. Randexp will ignore positional tokens.
* Back references to non-existing groups like `/(a)\1\2/`. Randexp will ignore those references, returning an empty string for them. If the group exists only after the reference is used such as in `/\1 (hey)/`, it will too be ignored.
* Custom negated character sets with two sets inside that cancel each other out. Example: `/[^\w\W]/`. If you give this to randexp, it will return an empty string for this set since it can't match anything.
# Projects based on randexp.js
## JSON-Schema Faker
Use generators to populate JSON Schema samples. See: [jsf on github](https://github.com/json-schema-faker/json-schema-faker/) and [jsf demo page](http://json-schema-faker.js.org/).
# Install
### Node.js
npm install randexp
### Browser
Download the [minified version](https://github.com/fent/randexp.js/releases) from the latest release.
# Tests
Tests are written with [mocha](https://mochajs.org)
```bash
npm test
```
# License
MIT
[Build]: http://img.shields.io/travis/litejs/natural-compare-lite.png
[Coverage]: http://img.shields.io/coveralls/litejs/natural-compare-lite.png
[1]: https://travis-ci.org/litejs/natural-compare-lite
[2]: https://coveralls.io/r/litejs/natural-compare-lite
[npm package]: https://npmjs.org/package/natural-compare-lite
[GitHub repo]: https://github.com/litejs/natural-compare-lite
@version 1.4.0
@date 2015-10-26
@stability 3 - Stable
Natural Compare – [![Build][]][1] [![Coverage][]][2]
===============
Compare strings containing a mix of letters and numbers
in the way a human being would in sort order.
This is described as a "natural ordering".
```text
Standard sorting: Natural order sorting:
img1.png img1.png
img10.png img2.png
img12.png img10.png
img2.png img12.png
```
String.naturalCompare returns a number indicating
whether a reference string comes before or after or is the same
as the given string in sort order.
Use it with builtin sort() function.
### Installation
- In browser
```html
<script src=min.natural-compare.js></script>
```
- In node.js: `npm install natural-compare-lite`
```javascript
require("natural-compare-lite")
```
### Usage
```javascript
// Simple case sensitive example
var a = ["z1.doc", "z10.doc", "z17.doc", "z2.doc", "z23.doc", "z3.doc"];
a.sort(String.naturalCompare);
// ["z1.doc", "z2.doc", "z3.doc", "z10.doc", "z17.doc", "z23.doc"]
// Use wrapper function for case insensitivity
a.sort(function(a, b){
return String.naturalCompare(a.toLowerCase(), b.toLowerCase());
})
// In most cases we want to sort an array of objects
var a = [ {"street":"350 5th Ave", "room":"A-1021"}
, {"street":"350 5th Ave", "room":"A-21046-b"} ];
// sort by street, then by room
a.sort(function(a, b){
return String.naturalCompare(a.street, b.street) || String.naturalCompare(a.room, b.room);
})
// When text transformation is needed (eg toLowerCase()),
// it is best for performance to keep
// transformed key in that object.
// There are no need to do text transformation
// on each comparision when sorting.
var a = [ {"make":"Audi", "model":"A6"}
, {"make":"Kia", "model":"Rio"} ];
// sort by make, then by model
a.map(function(car){
car.sort_key = (car.make + " " + car.model).toLowerCase();
})
a.sort(function(a, b){
return String.naturalCompare(a.sort_key, b.sort_key);
})
```
- Works well with dates in ISO format eg "Rev 2012-07-26.doc".
### Custom alphabet
It is possible to configure a custom alphabet
to achieve a desired order.
```javascript
// Estonian alphabet
String.alphabet = "ABDEFGHIJKLMNOPRSŠZŽTUVÕÄÖÜXYabdefghijklmnoprsšzžtuvõäöüxy"
["t", "z", "x", "õ"].sort(String.naturalCompare)
// ["z", "t", "õ", "x"]
// Russian alphabet
String.alphabet = "АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдеёжзийклмнопрстуфхцчшщъыьэюя"
["Ё", "А", "Б"].sort(String.naturalCompare)
// ["А", "Б", "Ё"]
```
External links
--------------
- [GitHub repo][https://github.com/litejs/natural-compare-lite]
- [jsperf test](http://jsperf.com/natural-sort-2/12)
Licence
-------
Copyright (c) 2012-2015 Lauri Rooden <lauri@rooden.ee>
[The MIT License](http://lauri.rooden.ee/mit-license.txt)
# y18n
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[](https://conventionalcommits.org)
The bare-bones internationalization library used by yargs.
Inspired by [i18n](https://www.npmjs.com/package/i18n).
## Examples
_simple string translation:_
```js
const __ = require('y18n')().__;
console.log(__('my awesome string %s', 'foo'));
```
output:
`my awesome string foo`
_using tagged template literals_
```js
const __ = require('y18n')().__;
const str = 'foo';
console.log(__`my awesome string ${str}`);
```
output:
`my awesome string foo`
_pluralization support:_
```js
const __n = require('y18n')().__n;
console.log(__n('one fish %s', '%d fishes %s', 2, 'foo'));
```
output:
`2 fishes foo`
## Deno Example
As of `v5` `y18n` supports [Deno](https://github.com/denoland/deno):
```typescript
import y18n from "https://deno.land/x/y18n/deno.ts";
const __ = y18n({
locale: 'pirate',
directory: './test/locales'
}).__
console.info(__`Hi, ${'Ben'} ${'Coe'}!`)
```
You will need to run with `--allow-read` to load alternative locales.
## JSON Language Files
The JSON language files should be stored in a `./locales` folder.
File names correspond to locales, e.g., `en.json`, `pirate.json`.
When strings are observed for the first time they will be
added to the JSON file corresponding to the current locale.
## Methods
### require('y18n')(config)
Create an instance of y18n with the config provided, options include:
* `directory`: the locale directory, default `./locales`.
* `updateFiles`: should newly observed strings be updated in file, default `true`.
* `locale`: what locale should be used.
* `fallbackToLanguage`: should fallback to a language-only file (e.g. `en.json`)
be allowed if a file matching the locale does not exist (e.g. `en_US.json`),
default `true`.
### y18n.\_\_(str, arg, arg, arg)
Print a localized string, `%s` will be replaced with `arg`s.
This function can also be used as a tag for a template literal. You can use it
like this: <code>__`hello ${'world'}`</code>. This will be equivalent to
`__('hello %s', 'world')`.
### y18n.\_\_n(singularString, pluralString, count, arg, arg, arg)
Print a localized string with appropriate pluralization. If `%d` is provided
in the string, the `count` will replace this placeholder.
### y18n.setLocale(str)
Set the current locale being used.
### y18n.getLocale()
What locale is currently being used?
### y18n.updateLocale(obj)
Update the current locale with the key value pairs in `obj`.
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
## License
ISC
[npm-url]: https://npmjs.org/package/y18n
[npm-image]: https://img.shields.io/npm/v/y18n.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: https://github.com/feross/standard
[![NPM version][npm-image]][npm-url]
[![build status][travis-image]][travis-url]
[![Test coverage][coveralls-image]][coveralls-url]
[![Downloads][downloads-image]][downloads-url]
[](https://gitter.im/eslint/doctrine?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
# Doctrine
Doctrine is a [JSDoc](http://usejsdoc.org) parser that parses documentation comments from JavaScript (you need to pass in the comment, not a whole JavaScript file).
## Installation
You can install Doctrine using [npm](https://npmjs.com):
```
$ npm install doctrine --save-dev
```
Doctrine can also be used in web browsers using [Browserify](http://browserify.org).
## Usage
Require doctrine inside of your JavaScript:
```js
var doctrine = require("doctrine");
```
### parse()
The primary method is `parse()`, which accepts two arguments: the JSDoc comment to parse and an optional options object. The available options are:
* `unwrap` - set to `true` to delete the leading `/**`, any `*` that begins a line, and the trailing `*/` from the source text. Default: `false`.
* `tags` - an array of tags to return. When specified, Doctrine returns only tags in this array. For example, if `tags` is `["param"]`, then only `@param` tags will be returned. Default: `null`.
* `recoverable` - set to `true` to keep parsing even when syntax errors occur. Default: `false`.
* `sloppy` - set to `true` to allow optional parameters to be specified in brackets (`@param {string} [foo]`). Default: `false`.
* `lineNumbers` - set to `true` to add `lineNumber` to each node, specifying the line on which the node is found in the source. Default: `false`.
* `range` - set to `true` to add `range` to each node, specifying the start and end index of the node in the original comment. Default: `false`.
Here's a simple example:
```js
var ast = doctrine.parse(
[
"/**",
" * This function comment is parsed by doctrine",
" * @param {{ok:String}} userName",
"*/"
].join('\n'), { unwrap: true });
```
This example returns the following AST:
{
"description": "This function comment is parsed by doctrine",
"tags": [
{
"title": "param",
"description": null,
"type": {
"type": "RecordType",
"fields": [
{
"type": "FieldType",
"key": "ok",
"value": {
"type": "NameExpression",
"name": "String"
}
}
]
},
"name": "userName"
}
]
}
See the [demo page](http://eslint.org/doctrine/demo/) more detail.
## Team
These folks keep the project moving and are resources for help:
* Nicholas C. Zakas ([@nzakas](https://github.com/nzakas)) - project lead
* Yusuke Suzuki ([@constellation](https://github.com/constellation)) - reviewer
## Contributing
Issues and pull requests will be triaged and responded to as quickly as possible. We operate under the [ESLint Contributor Guidelines](http://eslint.org/docs/developer-guide/contributing), so please be sure to read them before contributing. If you're not sure where to dig in, check out the [issues](https://github.com/eslint/doctrine/issues).
## Frequently Asked Questions
### Can I pass a whole JavaScript file to Doctrine?
No. Doctrine can only parse JSDoc comments, so you'll need to pass just the JSDoc comment to Doctrine in order to work.
### License
#### doctrine
Copyright JS Foundation and other contributors, https://js.foundation
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
#### esprima
some of functions is derived from esprima
Copyright (C) 2012, 2011 [Ariya Hidayat](http://ariya.ofilabs.com/about)
(twitter: [@ariyahidayat](http://twitter.com/ariyahidayat)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
#### closure-compiler
some of extensions is derived from closure-compiler
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
### Where to ask for help?
Join our [Chatroom](https://gitter.im/eslint/doctrine)
[npm-image]: https://img.shields.io/npm/v/doctrine.svg?style=flat-square
[npm-url]: https://www.npmjs.com/package/doctrine
[travis-image]: https://img.shields.io/travis/eslint/doctrine/master.svg?style=flat-square
[travis-url]: https://travis-ci.org/eslint/doctrine
[coveralls-image]: https://img.shields.io/coveralls/eslint/doctrine/master.svg?style=flat-square
[coveralls-url]: https://coveralls.io/r/eslint/doctrine?branch=master
[downloads-image]: http://img.shields.io/npm/dm/doctrine.svg?style=flat-square
[downloads-url]: https://www.npmjs.com/package/doctrine
<p align="center">
<a href="https://assemblyscript.org" target="_blank" rel="noopener"><img width="100" src="https://avatars1.githubusercontent.com/u/28916798?s=200&v=4" alt="AssemblyScript logo"></a>
</p>
<p align="center">
<a href="https://github.com/AssemblyScript/assemblyscript/actions?query=workflow%3ATest"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/assemblyscript/Test/master?label=test&logo=github" alt="Test status" /></a>
<a href="https://github.com/AssemblyScript/assemblyscript/actions?query=workflow%3APublish"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/assemblyscript/Publish/master?label=publish&logo=github" alt="Publish status" /></a>
<a href="https://www.npmjs.com/package/assemblyscript"><img src="https://img.shields.io/npm/v/assemblyscript.svg?label=compiler&color=007acc&logo=npm" alt="npm compiler version" /></a>
<a href="https://www.npmjs.com/package/@assemblyscript/loader"><img src="https://img.shields.io/npm/v/@assemblyscript/loader.svg?label=loader&color=007acc&logo=npm" alt="npm loader version" /></a>
<a href="https://discord.gg/assemblyscript"><img src="https://img.shields.io/discord/721472913886281818.svg?label=&logo=discord&logoColor=ffffff&color=7389D8&labelColor=6A7EC2" alt="Discord online" /></a>
</p>
<p align="justify"><strong>AssemblyScript</strong> compiles a strict variant of <a href="http://www.typescriptlang.org">TypeScript</a> (basically JavaScript with types) to <a href="http://webassembly.org">WebAssembly</a> using <a href="https://github.com/WebAssembly/binaryen">Binaryen</a>. It generates lean and mean WebAssembly modules while being just an <code>npm install</code> away.</p>
<h3 align="center">
<a href="https://assemblyscript.org">About</a> ·
<a href="https://assemblyscript.org/introduction.html">Introduction</a> ·
<a href="https://assemblyscript.org/quick-start.html">Quick start</a> ·
<a href="https://assemblyscript.org/examples.html">Examples</a> ·
<a href="https://assemblyscript.org/development.html">Development instructions</a>
</h3>
<br>
<h2 align="center">Contributors</h2>
<p align="center">
<a href="https://assemblyscript.org/#contributors"><img src="https://assemblyscript.org/contributors.svg" alt="Contributor logos" width="720" /></a>
</p>
<h2 align="center">Thanks to our sponsors!</h2>
<p align="justify">Most of the core team members and most contributors do this open source work in their free time. If you use AssemblyScript for a serious task or plan to do so, and you'd like us to invest more time on it, <a href="https://opencollective.com/assemblyscript/donate" target="_blank" rel="noopener">please donate</a> to our <a href="https://opencollective.com/assemblyscript" target="_blank" rel="noopener">OpenCollective</a>. By sponsoring this project, your logo will show up below. Thank you so much for your support!</p>
<p align="center">
<a href="https://assemblyscript.org/#sponsors"><img src="https://assemblyscript.org/sponsors.svg" alt="Sponsor logos" width="720" /></a>
</p>
<table><thead>
<tr>
<th>Linux</th>
<th>OS X</th>
<th>Windows</th>
<th>Coverage</th>
<th>Downloads</th>
</tr>
</thead><tbody><tr>
<td colspan="2" align="center">
<a href="https://travis-ci.org/kaelzhang/node-ignore">
<img
src="https://travis-ci.org/kaelzhang/node-ignore.svg?branch=master"
alt="Build Status" /></a>
</td>
<td align="center">
<a href="https://ci.appveyor.com/project/kaelzhang/node-ignore">
<img
src="https://ci.appveyor.com/api/projects/status/github/kaelzhang/node-ignore?branch=master&svg=true"
alt="Windows Build Status" /></a>
</td>
<td align="center">
<a href="https://codecov.io/gh/kaelzhang/node-ignore">
<img
src="https://codecov.io/gh/kaelzhang/node-ignore/branch/master/graph/badge.svg"
alt="Coverage Status" /></a>
</td>
<td align="center">
<a href="https://www.npmjs.org/package/ignore">
<img
src="http://img.shields.io/npm/dm/ignore.svg"
alt="npm module downloads per month" /></a>
</td>
</tr></tbody></table>
# ignore
`ignore` is a manager, filter and parser which implemented in pure JavaScript according to the .gitignore [spec](http://git-scm.com/docs/gitignore).
Pay attention that [`minimatch`](https://www.npmjs.org/package/minimatch) does not work in the gitignore way. To filter filenames according to .gitignore file, I recommend this module.
##### Tested on
- Linux + Node: `0.8` - `7.x`
- Windows + Node: `0.10` - `7.x`, node < `0.10` is not tested due to the lack of support of appveyor.
Actually, `ignore` does not rely on any versions of node specially.
Since `4.0.0`, ignore will no longer support `node < 6` by default, to use in node < 6, `require('ignore/legacy')`. For details, see [CHANGELOG](https://github.com/kaelzhang/node-ignore/blob/master/CHANGELOG.md).
## Table Of Main Contents
- [Usage](#usage)
- [`Pathname` Conventions](#pathname-conventions)
- [Guide for 2.x -> 3.x](#upgrade-2x---3x)
- [Guide for 3.x -> 4.x](#upgrade-3x---4x)
- See Also:
- [`glob-gitignore`](https://www.npmjs.com/package/glob-gitignore) matches files using patterns and filters them according to gitignore rules.
## Usage
```js
import ignore from 'ignore'
const ig = ignore().add(['.abc/*', '!.abc/d/'])
```
### Filter the given paths
```js
const paths = [
'.abc/a.js', // filtered out
'.abc/d/e.js' // included
]
ig.filter(paths) // ['.abc/d/e.js']
ig.ignores('.abc/a.js') // true
```
### As the filter function
```js
paths.filter(ig.createFilter()); // ['.abc/d/e.js']
```
### Win32 paths will be handled
```js
ig.filter(['.abc\\a.js', '.abc\\d\\e.js'])
// if the code above runs on windows, the result will be
// ['.abc\\d\\e.js']
```
## Why another ignore?
- `ignore` is a standalone module, and is much simpler so that it could easy work with other programs, unlike [isaacs](https://npmjs.org/~isaacs)'s [fstream-ignore](https://npmjs.org/package/fstream-ignore) which must work with the modules of the fstream family.
- `ignore` only contains utility methods to filter paths according to the specified ignore rules, so
- `ignore` never try to find out ignore rules by traversing directories or fetching from git configurations.
- `ignore` don't cares about sub-modules of git projects.
- Exactly according to [gitignore man page](http://git-scm.com/docs/gitignore), fixes some known matching issues of fstream-ignore, such as:
- '`/*.js`' should only match '`a.js`', but not '`abc/a.js`'.
- '`**/foo`' should match '`foo`' anywhere.
- Prevent re-including a file if a parent directory of that file is excluded.
- Handle trailing whitespaces:
- `'a '`(one space) should not match `'a '`(two spaces).
- `'a \ '` matches `'a '`
- All test cases are verified with the result of `git check-ignore`.
# Methods
## .add(pattern: string | Ignore): this
## .add(patterns: Array<string | Ignore>): this
- **pattern** `String | Ignore` An ignore pattern string, or the `Ignore` instance
- **patterns** `Array<String | Ignore>` Array of ignore patterns.
Adds a rule or several rules to the current manager.
Returns `this`
Notice that a line starting with `'#'`(hash) is treated as a comment. Put a backslash (`'\'`) in front of the first hash for patterns that begin with a hash, if you want to ignore a file with a hash at the beginning of the filename.
```js
ignore().add('#abc').ignores('#abc') // false
ignore().add('\#abc').ignores('#abc') // true
```
`pattern` could either be a line of ignore pattern or a string of multiple ignore patterns, which means we could just `ignore().add()` the content of a ignore file:
```js
ignore()
.add(fs.readFileSync(filenameOfGitignore).toString())
.filter(filenames)
```
`pattern` could also be an `ignore` instance, so that we could easily inherit the rules of another `Ignore` instance.
## <strike>.addIgnoreFile(path)</strike>
REMOVED in `3.x` for now.
To upgrade `ignore@2.x` up to `3.x`, use
```js
import fs from 'fs'
if (fs.existsSync(filename)) {
ignore().add(fs.readFileSync(filename).toString())
}
```
instead.
## .filter(paths: Array<Pathname>): Array<Pathname>
```ts
type Pathname = string
```
Filters the given array of pathnames, and returns the filtered array.
- **paths** `Array.<Pathname>` The array of `pathname`s to be filtered.
### `Pathname` Conventions:
#### 1. `Pathname` should be a `path.relative()`d pathname
`Pathname` should be a string that have been `path.join()`ed, or the return value of `path.relative()` to the current directory.
```js
// WRONG
ig.ignores('./abc')
// WRONG, for it will never happen.
// If the gitignore rule locates at the root directory,
// `'/abc'` should be changed to `'abc'`.
// ```
// path.relative('/', '/abc') -> 'abc'
// ```
ig.ignores('/abc')
// Right
ig.ignores('abc')
// Right
ig.ignores(path.join('./abc')) // path.join('./abc') -> 'abc'
```
In other words, each `Pathname` here should be a relative path to the directory of the gitignore rules.
Suppose the dir structure is:
```
/path/to/your/repo
|-- a
| |-- a.js
|
|-- .b
|
|-- .c
|-- .DS_store
```
Then the `paths` might be like this:
```js
[
'a/a.js'
'.b',
'.c/.DS_store'
]
```
Usually, you could use [`glob`](http://npmjs.org/package/glob) with `option.mark = true` to fetch the structure of the current directory:
```js
import glob from 'glob'
glob('**', {
// Adds a / character to directory matches.
mark: true
}, (err, files) => {
if (err) {
return console.error(err)
}
let filtered = ignore().add(patterns).filter(files)
console.log(filtered)
})
```
#### 2. filenames and dirnames
`node-ignore` does NO `fs.stat` during path matching, so for the example below:
```js
ig.add('config/')
// `ig` does NOT know if 'config' is a normal file, directory or something
ig.ignores('config') // And it returns `false`
ig.ignores('config/') // returns `true`
```
Specially for people who develop some library based on `node-ignore`, it is important to understand that.
## .ignores(pathname: Pathname): boolean
> new in 3.2.0
Returns `Boolean` whether `pathname` should be ignored.
```js
ig.ignores('.abc/a.js') // true
```
## .createFilter()
Creates a filter function which could filter an array of paths with `Array.prototype.filter`.
Returns `function(path)` the filter function.
## `options.ignorecase` since 4.0.0
Similar as the `core.ignorecase` option of [git-config](https://git-scm.com/docs/git-config), `node-ignore` will be case insensitive if `options.ignorecase` is set to `true` (default value), otherwise case sensitive.
```js
const ig = ignore({
ignorecase: false
})
ig.add('*.png')
ig.ignores('*.PNG') // false
```
****
# Upgrade Guide
## Upgrade 2.x -> 3.x
- All `options` of 2.x are unnecessary and removed, so just remove them.
- `ignore()` instance is no longer an [`EventEmitter`](nodejs.org/api/events.html), and all events are unnecessary and removed.
- `.addIgnoreFile()` is removed, see the [.addIgnoreFile](#addignorefilepath) section for details.
## Upgrade 3.x -> 4.x
Since `4.0.0`, `ignore` will no longer support node < 6, to use `ignore` in node < 6:
```js
var ignore = require('ignore/legacy')
```
****
# Collaborators
- [@whitecolor](https://github.com/whitecolor) *Alex*
- [@SamyPesse](https://github.com/SamyPesse) *Samy Pessé*
- [@azproduction](https://github.com/azproduction) *Mikhail Davydov*
- [@TrySound](https://github.com/TrySound) *Bogdan Chadkin*
- [@JanMattner](https://github.com/JanMattner) *Jan Mattner*
- [@ntwb](https://github.com/ntwb) *Stephen Edgar*
- [@kasperisager](https://github.com/kasperisager) *Kasper Isager*
- [@sandersn](https://github.com/sandersn) *Nathan Shively-Sanders*
These files are compiled dot templates from dot folder.
Do NOT edit them directly, edit the templates and run `npm run build` from main ajv folder.
# y18n
[![Build Status][travis-image]][travis-url]
[![Coverage Status][coveralls-image]][coveralls-url]
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[](https://conventionalcommits.org)
The bare-bones internationalization library used by yargs.
Inspired by [i18n](https://www.npmjs.com/package/i18n).
## Examples
_simple string translation:_
```js
var __ = require('y18n').__
console.log(__('my awesome string %s', 'foo'))
```
output:
`my awesome string foo`
_using tagged template literals_
```js
var __ = require('y18n').__
var str = 'foo'
console.log(__`my awesome string ${str}`)
```
output:
`my awesome string foo`
_pluralization support:_
```js
var __n = require('y18n').__n
console.log(__n('one fish %s', '%d fishes %s', 2, 'foo'))
```
output:
`2 fishes foo`
## JSON Language Files
The JSON language files should be stored in a `./locales` folder.
File names correspond to locales, e.g., `en.json`, `pirate.json`.
When strings are observed for the first time they will be
added to the JSON file corresponding to the current locale.
## Methods
### require('y18n')(config)
Create an instance of y18n with the config provided, options include:
* `directory`: the locale directory, default `./locales`.
* `updateFiles`: should newly observed strings be updated in file, default `true`.
* `locale`: what locale should be used.
* `fallbackToLanguage`: should fallback to a language-only file (e.g. `en.json`)
be allowed if a file matching the locale does not exist (e.g. `en_US.json`),
default `true`.
### y18n.\_\_(str, arg, arg, arg)
Print a localized string, `%s` will be replaced with `arg`s.
This function can also be used as a tag for a template literal. You can use it
like this: <code>__`hello ${'world'}`</code>. This will be equivalent to
`__('hello %s', 'world')`.
### y18n.\_\_n(singularString, pluralString, count, arg, arg, arg)
Print a localized string with appropriate pluralization. If `%d` is provided
in the string, the `count` will replace this placeholder.
### y18n.setLocale(str)
Set the current locale being used.
### y18n.getLocale()
What locale is currently being used?
### y18n.updateLocale(obj)
Update the current locale with the key value pairs in `obj`.
## License
ISC
[travis-url]: https://travis-ci.org/yargs/y18n
[travis-image]: https://img.shields.io/travis/yargs/y18n.svg
[coveralls-url]: https://coveralls.io/github/yargs/y18n
[coveralls-image]: https://img.shields.io/coveralls/yargs/y18n.svg
[npm-url]: https://npmjs.org/package/y18n
[npm-image]: https://img.shields.io/npm/v/y18n.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: https://github.com/feross/standard

Moo!
====
Moo is a highly-optimised tokenizer/lexer generator. Use it to tokenize your strings, before parsing 'em with a parser like [nearley](https://github.com/hardmath123/nearley) or whatever else you're into.
* [Fast](#is-it-fast)
* [Convenient](#usage)
* uses [Regular Expressions](#on-regular-expressions)
* tracks [Line Numbers](#line-numbers)
* handles [Keywords](#keywords)
* supports [States](#states)
* custom [Errors](#errors)
* is even [Iterable](#iteration)
* has no dependencies
* 4KB minified + gzipped
* Moo!
Is it fast?
-----------
Yup! Flying-cows-and-singed-steak fast.
Moo is the fastest JS tokenizer around. It's **~2–10x** faster than most other tokenizers; it's a **couple orders of magnitude** faster than some of the slower ones.
Define your tokens **using regular expressions**. Moo will compile 'em down to a **single RegExp for performance**. It uses the new ES6 **sticky flag** where possible to make things faster; otherwise it falls back to an almost-as-efficient workaround. (For more than you ever wanted to know about this, read [adventures in the land of substrings and RegExps](http://mrale.ph/blog/2016/11/23/making-less-dart-faster.html).)
You _might_ be able to go faster still by writing your lexer by hand rather than using RegExps, but that's icky.
Oh, and it [avoids parsing RegExps by itself](https://hackernoon.com/the-madness-of-parsing-real-world-javascript-regexps-d9ee336df983#.2l8qu3l76). Because that would be horrible.
Usage
-----
First, you need to do the needful: `$ npm install moo`, or whatever will ship this code to your computer. Alternatively, grab the `moo.js` file by itself and slap it into your web page via a `<script>` tag; moo is completely standalone.
Then you can start roasting your very own lexer/tokenizer:
```js
const moo = require('moo')
let lexer = moo.compile({
WS: /[ \t]+/,
comment: /\/\/.*?$/,
number: /0|[1-9][0-9]*/,
string: /"(?:\\["\\]|[^\n"\\])*"/,
lparen: '(',
rparen: ')',
keyword: ['while', 'if', 'else', 'moo', 'cows'],
NL: { match: /\n/, lineBreaks: true },
})
```
And now throw some text at it:
```js
lexer.reset('while (10) cows\nmoo')
lexer.next() // -> { type: 'keyword', value: 'while' }
lexer.next() // -> { type: 'WS', value: ' ' }
lexer.next() // -> { type: 'lparen', value: '(' }
lexer.next() // -> { type: 'number', value: '10' }
// ...
```
When you reach the end of Moo's internal buffer, next() will return `undefined`. You can always `reset()` it and feed it more data when that happens.
On Regular Expressions
----------------------
RegExps are nifty for making tokenizers, but they can be a bit of a pain. Here are some things to be aware of:
* You often want to use **non-greedy quantifiers**: e.g. `*?` instead of `*`. Otherwise your tokens will be longer than you expect:
```js
let lexer = moo.compile({
string: /".*"/, // greedy quantifier *
// ...
})
lexer.reset('"foo" "bar"')
lexer.next() // -> { type: 'string', value: 'foo" "bar' }
```
Better:
```js
let lexer = moo.compile({
string: /".*?"/, // non-greedy quantifier *?
// ...
})
lexer.reset('"foo" "bar"')
lexer.next() // -> { type: 'string', value: 'foo' }
lexer.next() // -> { type: 'space', value: ' ' }
lexer.next() // -> { type: 'string', value: 'bar' }
```
* The **order of your rules** matters. Earlier ones will take precedence.
```js
moo.compile({
identifier: /[a-z0-9]+/,
number: /[0-9]+/,
}).reset('42').next() // -> { type: 'identifier', value: '42' }
moo.compile({
number: /[0-9]+/,
identifier: /[a-z0-9]+/,
}).reset('42').next() // -> { type: 'number', value: '42' }
```
* Moo uses **multiline RegExps**. This has a few quirks: for example, the **dot `/./` doesn't include newlines**. Use `[^]` instead if you want to match newlines too.
* Since an excluding character ranges like `/[^ ]/` (which matches anything but a space) _will_ include newlines, you have to be careful not to include them by accident! In particular, the whitespace metacharacter `\s` includes newlines.
Line Numbers
------------
Moo tracks detailed information about the input for you.
It will track line numbers, as long as you **apply the `lineBreaks: true` option to any rules which might contain newlines**. Moo will try to warn you if you forget to do this.
Note that this is `false` by default, for performance reasons: counting the number of lines in a matched token has a small cost. For optimal performance, only match newlines inside a dedicated token:
```js
newline: {match: '\n', lineBreaks: true},
```
### Token Info ###
Token objects (returned from `next()`) have the following attributes:
* **`type`**: the name of the group, as passed to compile.
* **`text`**: the string that was matched.
* **`value`**: the string that was matched, transformed by your `value` function (if any).
* **`offset`**: the number of bytes from the start of the buffer where the match starts.
* **`lineBreaks`**: the number of line breaks found in the match. (Always zero if this rule has `lineBreaks: false`.)
* **`line`**: the line number of the beginning of the match, starting from 1.
* **`col`**: the column where the match begins, starting from 1.
### Value vs. Text ###
The `value` is the same as the `text`, unless you provide a [value transform](#transform).
```js
const moo = require('moo')
const lexer = moo.compile({
ws: /[ \t]+/,
string: {match: /"(?:\\["\\]|[^\n"\\])*"/, value: s => s.slice(1, -1)},
})
lexer.reset('"test"')
lexer.next() /* { value: 'test', text: '"test"', ... } */
```
### Reset ###
Calling `reset()` on your lexer will empty its internal buffer, and set the line, column, and offset counts back to their initial value.
If you don't want this, you can `save()` the state, and later pass it as the second argument to `reset()` to explicitly control the internal state of the lexer.
```js
lexer.reset('some line\n')
let info = lexer.save() // -> { line: 10 }
lexer.next() // -> { line: 10 }
lexer.next() // -> { line: 11 }
// ...
lexer.reset('a different line\n', info)
lexer.next() // -> { line: 10 }
```
Keywords
--------
Moo makes it convenient to define literals.
```js
moo.compile({
lparen: '(',
rparen: ')',
keyword: ['while', 'if', 'else', 'moo', 'cows'],
})
```
It'll automatically compile them into regular expressions, escaping them where necessary.
**Keywords** should be written using the `keywords` transform.
```js
moo.compile({
IDEN: {match: /[a-zA-Z]+/, type: moo.keywords({
KW: ['while', 'if', 'else', 'moo', 'cows'],
})},
SPACE: {match: /\s+/, lineBreaks: true},
})
```
### Why? ###
You need to do this to ensure the **longest match** principle applies, even in edge cases.
Imagine trying to parse the input `className` with the following rules:
```js
keyword: ['class'],
identifier: /[a-zA-Z]+/,
```
You'll get _two_ tokens — `['class', 'Name']` -- which is _not_ what you want! If you swap the order of the rules, you'll fix this example; but now you'll lex `class` wrong (as an `identifier`).
The keywords helper checks matches against the list of keywords; if any of them match, it uses the type `'keyword'` instead of `'identifier'` (for this example).
### Keyword Types ###
Keywords can also have **individual types**.
```js
let lexer = moo.compile({
name: {match: /[a-zA-Z]+/, type: moo.keywords({
'kw-class': 'class',
'kw-def': 'def',
'kw-if': 'if',
})},
// ...
})
lexer.reset('def foo')
lexer.next() // -> { type: 'kw-def', value: 'def' }
lexer.next() // space
lexer.next() // -> { type: 'name', value: 'foo' }
```
You can use [itt](https://github.com/nathan/itt)'s iterator adapters to make constructing keyword objects easier:
```js
itt(['class', 'def', 'if'])
.map(k => ['kw-' + k, k])
.toObject()
```
States
------
Moo allows you to define multiple lexer **states**. Each state defines its own separate set of token rules. Your lexer will start off in the first state given to `moo.states({})`.
Rules can be annotated with `next`, `push`, and `pop`, to change the current state after that token is matched. A "stack" of past states is kept, which is used by `push` and `pop`.
* **`next: 'bar'`** moves to the state named `bar`. (The stack is not changed.)
* **`push: 'bar'`** moves to the state named `bar`, and pushes the old state onto the stack.
* **`pop: 1`** removes one state from the top of the stack, and moves to that state. (Only `1` is supported.)
Only rules from the current state can be matched. You need to copy your rule into all the states you want it to be matched in.
For example, to tokenize JS-style string interpolation such as `a${{c: d}}e`, you might use:
```js
let lexer = moo.states({
main: {
strstart: {match: '`', push: 'lit'},
ident: /\w+/,
lbrace: {match: '{', push: 'main'},
rbrace: {match: '}', pop: true},
colon: ':',
space: {match: /\s+/, lineBreaks: true},
},
lit: {
interp: {match: '${', push: 'main'},
escape: /\\./,
strend: {match: '`', pop: true},
const: {match: /(?:[^$`]|\$(?!\{))+/, lineBreaks: true},
},
})
// <= `a${{c: d}}e`
// => strstart const interp lbrace ident colon space ident rbrace rbrace const strend
```
The `rbrace` rule is annotated with `pop`, so it moves from the `main` state into either `lit` or `main`, depending on the stack.
Errors
------
If none of your rules match, Moo will throw an Error; since it doesn't know what else to do.
If you prefer, you can have moo return an error token instead of throwing an exception. The error token will contain the whole of the rest of the buffer.
```js
moo.compile({
// ...
myError: moo.error,
})
moo.reset('invalid')
moo.next() // -> { type: 'myError', value: 'invalid', text: 'invalid', offset: 0, lineBreaks: 0, line: 1, col: 1 }
moo.next() // -> undefined
```
You can have a token type that both matches tokens _and_ contains error values.
```js
moo.compile({
// ...
myError: {match: /[\$?`]/, error: true},
})
```
### Formatting errors ###
If you want to throw an error from your parser, you might find `formatError` helpful. Call it with the offending token:
```js
throw new Error(lexer.formatError(token, "invalid syntax"))
```
It returns a string with a pretty error message.
```
Error: invalid syntax at line 2 col 15:
totally valid `syntax`
^
```
Iteration
---------
Iterators: we got 'em.
```js
for (let here of lexer) {
// here = { type: 'number', value: '123', ... }
}
```
Create an array of tokens.
```js
let tokens = Array.from(lexer);
```
Use [itt](https://github.com/nathan/itt)'s iteration tools with Moo.
```js
for (let [here, next] = itt(lexer).lookahead()) { // pass a number if you need more tokens
// enjoy!
}
```
Transform
---------
Moo doesn't allow capturing groups, but you can supply a transform function, `value()`, which will be called on the value before storing it in the Token object.
```js
moo.compile({
STRING: [
{match: /"""[^]*?"""/, lineBreaks: true, value: x => x.slice(3, -3)},
{match: /"(?:\\["\\rn]|[^"\\])*?"/, lineBreaks: true, value: x => x.slice(1, -1)},
{match: /'(?:\\['\\rn]|[^'\\])*?'/, lineBreaks: true, value: x => x.slice(1, -1)},
],
// ...
})
```
Contributing
------------
Do check the [FAQ](https://github.com/tjvr/moo/issues?q=label%3Aquestion).
Before submitting an issue, [remember...](https://github.com/tjvr/moo/blob/master/.github/CONTRIBUTING.md)
A JSON with color names and its values. Based on http://dev.w3.org/csswg/css-color/#named-colors.
[](https://nodei.co/npm/color-name/)
```js
var colors = require('color-name');
colors.red //[255,0,0]
```
<a href="LICENSE"><img src="https://upload.wikimedia.org/wikipedia/commons/0/0c/MIT_logo.svg" width="120"/></a>
# Visitor utilities for AssemblyScript Compiler transformers
## Example
### List Fields
The transformer:
```ts
import {
ClassDeclaration,
FieldDeclaration,
MethodDeclaration,
} from "../../as";
import { ClassDecorator, registerDecorator } from "../decorator";
import { toString } from "../utils";
class ListMembers extends ClassDecorator {
visitFieldDeclaration(node: FieldDeclaration): void {
if (!node.name) console.log(toString(node) + "\n");
const name = toString(node.name);
const _type = toString(node.type!);
this.stdout.write(name + ": " + _type + "\n");
}
visitMethodDeclaration(node: MethodDeclaration): void {
const name = toString(node.name);
if (name == "constructor") {
return;
}
const sig = toString(node.signature);
this.stdout.write(name + ": " + sig + "\n");
}
visitClassDeclaration(node: ClassDeclaration): void {
this.visit(node.members);
}
get name(): string {
return "list";
}
}
export = registerDecorator(new ListMembers());
```
assembly/foo.ts:
```ts
@list
class Foo {
a: u8;
b: bool;
i: i32;
}
```
And then compile with `--transform` flag:
```
asc assembly/foo.ts --transform ./dist/examples/list --noEmit
```
Which prints the following to the console:
```
a: u8
b: bool
i: i32
```
<p align="center">
<a href="https://gulpjs.com">
<img height="257" width="114" src="https://raw.githubusercontent.com/gulpjs/artwork/master/gulp-2x.png">
</a>
</p>
# glob-parent
[![NPM version][npm-image]][npm-url] [![Downloads][downloads-image]][npm-url] [![Azure Pipelines Build Status][azure-pipelines-image]][azure-pipelines-url] [![Travis Build Status][travis-image]][travis-url] [![AppVeyor Build Status][appveyor-image]][appveyor-url] [![Coveralls Status][coveralls-image]][coveralls-url] [![Gitter chat][gitter-image]][gitter-url]
Extract the non-magic parent path from a glob string.
## Usage
```js
var globParent = require('glob-parent');
globParent('path/to/*.js'); // 'path/to'
globParent('/root/path/to/*.js'); // '/root/path/to'
globParent('/*.js'); // '/'
globParent('*.js'); // '.'
globParent('**/*.js'); // '.'
globParent('path/{to,from}'); // 'path'
globParent('path/!(to|from)'); // 'path'
globParent('path/?(to|from)'); // 'path'
globParent('path/+(to|from)'); // 'path'
globParent('path/*(to|from)'); // 'path'
globParent('path/@(to|from)'); // 'path'
globParent('path/**/*'); // 'path'
// if provided a non-glob path, returns the nearest dir
globParent('path/foo/bar.js'); // 'path/foo'
globParent('path/foo/'); // 'path/foo'
globParent('path/foo'); // 'path' (see issue #3 for details)
```
## API
### `globParent(maybeGlobString, [options])`
Takes a string and returns the part of the path before the glob begins. Be aware of Escaping rules and Limitations below.
#### options
```js
{
// Disables the automatic conversion of slashes for Windows
flipBackslashes: true
}
```
## Escaping
The following characters have special significance in glob patterns and must be escaped if you want them to be treated as regular path characters:
- `?` (question mark) unless used as a path segment alone
- `*` (asterisk)
- `|` (pipe)
- `(` (opening parenthesis)
- `)` (closing parenthesis)
- `{` (opening curly brace)
- `}` (closing curly brace)
- `[` (opening bracket)
- `]` (closing bracket)
**Example**
```js
globParent('foo/[bar]/') // 'foo'
globParent('foo/\\[bar]/') // 'foo/[bar]'
```
## Limitations
### Braces & Brackets
This library attempts a quick and imperfect method of determining which path
parts have glob magic without fully parsing/lexing the pattern. There are some
advanced use cases that can trip it up, such as nested braces where the outer
pair is escaped and the inner one contains a path separator. If you find
yourself in the unlikely circumstance of being affected by this or need to
ensure higher-fidelity glob handling in your library, it is recommended that you
pre-process your input with [expand-braces] and/or [expand-brackets].
### Windows
Backslashes are not valid path separators for globs. If a path with backslashes
is provided anyway, for simple cases, glob-parent will replace the path
separator for you and return the non-glob parent path (now with
forward-slashes, which are still valid as Windows path separators).
This cannot be used in conjunction with escape characters.
```js
// BAD
globParent('C:\\Program Files \\(x86\\)\\*.ext') // 'C:/Program Files /(x86/)'
// GOOD
globParent('C:/Program Files\\(x86\\)/*.ext') // 'C:/Program Files (x86)'
```
If you are using escape characters for a pattern without path parts (i.e.
relative to `cwd`), prefix with `./` to avoid confusing glob-parent.
```js
// BAD
globParent('foo \\[bar]') // 'foo '
globParent('foo \\[bar]*') // 'foo '
// GOOD
globParent('./foo \\[bar]') // 'foo [bar]'
globParent('./foo \\[bar]*') // '.'
```
## License
ISC
[expand-braces]: https://github.com/jonschlinkert/expand-braces
[expand-brackets]: https://github.com/jonschlinkert/expand-brackets
[downloads-image]: https://img.shields.io/npm/dm/glob-parent.svg
[npm-url]: https://www.npmjs.com/package/glob-parent
[npm-image]: https://img.shields.io/npm/v/glob-parent.svg
[azure-pipelines-url]: https://dev.azure.com/gulpjs/gulp/_build/latest?definitionId=2&branchName=master
[azure-pipelines-image]: https://dev.azure.com/gulpjs/gulp/_apis/build/status/glob-parent?branchName=master
[travis-url]: https://travis-ci.org/gulpjs/glob-parent
[travis-image]: https://img.shields.io/travis/gulpjs/glob-parent.svg?label=travis-ci
[appveyor-url]: https://ci.appveyor.com/project/gulpjs/glob-parent
[appveyor-image]: https://img.shields.io/appveyor/ci/gulpjs/glob-parent.svg?label=appveyor
[coveralls-url]: https://coveralls.io/r/gulpjs/glob-parent
[coveralls-image]: https://img.shields.io/coveralls/gulpjs/glob-parent/master.svg
[gitter-url]: https://gitter.im/gulpjs/gulp
[gitter-image]: https://badges.gitter.im/gulpjs/gulp.svg
# prelude.ls [](https://travis-ci.org/gkz/prelude-ls)
is a functionally oriented utility library. It is powerful and flexible. Almost all of its functions are curried. It is written in, and is the recommended base library for, <a href="http://livescript.net">LiveScript</a>.
See **[the prelude.ls site](http://preludels.com)** for examples, a reference, and more.
You can install via npm `npm install prelude-ls`
### Development
`make test` to test
`make build` to build `lib` from `src`
`make build-browser` to build browser versions
## Test Strategy
- tests are copied from the [polyfill implementation](https://github.com/tc39/proposal-temporal/tree/main/polyfill/test)
- tests should be removed if they relate to features that do not make sense for TS/AS, i.e. tests that validate the shape of an object do not make sense in a language with compile-time type checking
- tests that fail because a feature has not been implemented yet should be left as failures.
# regexpp
[](https://www.npmjs.com/package/regexpp)
[](http://www.npmtrends.com/regexpp)
[](https://github.com/mysticatea/regexpp/actions)
[](https://codecov.io/gh/mysticatea/regexpp)
[](https://david-dm.org/mysticatea/regexpp)
A regular expression parser for ECMAScript.
## 💿 Installation
```bash
$ npm install regexpp
```
- require Node.js 8 or newer.
## 📖 Usage
```ts
import {
AST,
RegExpParser,
RegExpValidator,
RegExpVisitor,
parseRegExpLiteral,
validateRegExpLiteral,
visitRegExpAST
} from "regexpp"
```
### parseRegExpLiteral(source, options?)
Parse a given regular expression literal then make AST object.
This is equivalent to `new RegExpParser(options).parseLiteral(source)`.
- **Parameters:**
- `source` (`string | RegExp`) The source code to parse.
- `options?` ([`RegExpParser.Options`]) The options to parse.
- **Return:**
- The AST of the regular expression.
### validateRegExpLiteral(source, options?)
Validate a given regular expression literal.
This is equivalent to `new RegExpValidator(options).validateLiteral(source)`.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `options?` ([`RegExpValidator.Options`]) The options to validate.
### visitRegExpAST(ast, handlers)
Visit each node of a given AST.
This is equivalent to `new RegExpVisitor(handlers).visit(ast)`.
- **Parameters:**
- `ast` ([`AST.Node`]) The AST to visit.
- `handlers` ([`RegExpVisitor.Handlers`]) The callbacks.
### RegExpParser
#### new RegExpParser(options?)
- **Parameters:**
- `options?` ([`RegExpParser.Options`]) The options to parse.
#### parser.parseLiteral(source, start?, end?)
Parse a regular expression literal.
- **Parameters:**
- `source` (`string`) The source code to parse. E.g. `"/abc/g"`.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- **Return:**
- The AST of the regular expression.
#### parser.parsePattern(source, start?, end?, uFlag?)
Parse a regular expression pattern.
- **Parameters:**
- `source` (`string`) The source code to parse. E.g. `"abc"`.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- `uFlag?` (`boolean`) The flag to enable Unicode mode.
- **Return:**
- The AST of the regular expression pattern.
#### parser.parseFlags(source, start?, end?)
Parse a regular expression flags.
- **Parameters:**
- `source` (`string`) The source code to parse. E.g. `"gim"`.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- **Return:**
- The AST of the regular expression flags.
### RegExpValidator
#### new RegExpValidator(options)
- **Parameters:**
- `options` ([`RegExpValidator.Options`]) The options to validate.
#### validator.validateLiteral(source, start, end)
Validate a regular expression literal.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
#### validator.validatePattern(source, start, end, uFlag)
Validate a regular expression pattern.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- `uFlag?` (`boolean`) The flag to enable Unicode mode.
#### validator.validateFlags(source, start, end)
Validate a regular expression flags.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
### RegExpVisitor
#### new RegExpVisitor(handlers)
- **Parameters:**
- `handlers` ([`RegExpVisitor.Handlers`]) The callbacks.
#### visitor.visit(ast)
Validate a regular expression literal.
- **Parameters:**
- `ast` ([`AST.Node`]) The AST to visit.
## 📰 Changelog
- [GitHub Releases](https://github.com/mysticatea/regexpp/releases)
## 🍻 Contributing
Welcome contributing!
Please use GitHub's Issues/PRs.
### Development Tools
- `npm test` runs tests and measures coverage.
- `npm run build` compiles TypeScript source code to `index.js`, `index.js.map`, and `index.d.ts`.
- `npm run clean` removes the temporary files which are created by `npm test` and `npm run build`.
- `npm run lint` runs ESLint.
- `npm run update:test` updates test fixtures.
- `npm run update:ids` updates `src/unicode/ids.ts`.
- `npm run watch` runs tests with `--watch` option.
[`AST.Node`]: src/ast.ts#L4
[`RegExpParser.Options`]: src/parser.ts#L539
[`RegExpValidator.Options`]: src/validator.ts#L127
[`RegExpVisitor.Handlers`]: src/visitor.ts#L204
# axios // core
The modules found in `core/` should be modules that are specific to the domain logic of axios. These modules would most likely not make sense to be consumed outside of the axios module, as their logic is too specific. Some examples of core modules are:
- Dispatching requests
- Managing interceptors
- Handling config
# inflight
Add callbacks to requests in flight to avoid async duplication
## USAGE
```javascript
var inflight = require('inflight')
// some request that does some stuff
function req(key, callback) {
// key is any random string. like a url or filename or whatever.
//
// will return either a falsey value, indicating that the
// request for this key is already in flight, or a new callback
// which when called will call all callbacks passed to inflightk
// with the same key
callback = inflight(key, callback)
// If we got a falsey value back, then there's already a req going
if (!callback) return
// this is where you'd fetch the url or whatever
// callback is also once()-ified, so it can safely be assigned
// to multiple events etc. First call wins.
setTimeout(function() {
callback(null, key)
}, 100)
}
// only assigns a single setTimeout
// when it dings, all cbs get called
req('foo', cb1)
req('foo', cb2)
req('foo', cb3)
req('foo', cb4)
```
## Follow Redirects
Drop-in replacement for Nodes `http` and `https` that automatically follows redirects.
[](https://www.npmjs.com/package/follow-redirects)
[](https://travis-ci.org/follow-redirects/follow-redirects)
[](https://coveralls.io/r/follow-redirects/follow-redirects?branch=master)
[](https://david-dm.org/follow-redirects/follow-redirects)
[](https://www.npmjs.com/package/follow-redirects)
`follow-redirects` provides [request](https://nodejs.org/api/http.html#http_http_request_options_callback) and [get](https://nodejs.org/api/http.html#http_http_get_options_callback)
methods that behave identically to those found on the native [http](https://nodejs.org/api/http.html#http_http_request_options_callback) and [https](https://nodejs.org/api/https.html#https_https_request_options_callback)
modules, with the exception that they will seamlessly follow redirects.
```javascript
var http = require('follow-redirects').http;
var https = require('follow-redirects').https;
http.get('http://bit.ly/900913', function (response) {
response.on('data', function (chunk) {
console.log(chunk);
});
}).on('error', function (err) {
console.error(err);
});
```
You can inspect the final redirected URL through the `responseUrl` property on the `response`.
If no redirection happened, `responseUrl` is the original request URL.
```javascript
https.request({
host: 'bitly.com',
path: '/UHfDGO',
}, function (response) {
console.log(response.responseUrl);
// 'http://duckduckgo.com/robots.txt'
});
```
## Options
### Global options
Global options are set directly on the `follow-redirects` module:
```javascript
var followRedirects = require('follow-redirects');
followRedirects.maxRedirects = 10;
followRedirects.maxBodyLength = 20 * 1024 * 1024; // 20 MB
```
The following global options are supported:
- `maxRedirects` (default: `21`) – sets the maximum number of allowed redirects; if exceeded, an error will be emitted.
- `maxBodyLength` (default: 10MB) – sets the maximum size of the request body; if exceeded, an error will be emitted.
### Per-request options
Per-request options are set by passing an `options` object:
```javascript
var url = require('url');
var followRedirects = require('follow-redirects');
var options = url.parse('http://bit.ly/900913');
options.maxRedirects = 10;
http.request(options);
```
In addition to the [standard HTTP](https://nodejs.org/api/http.html#http_http_request_options_callback) and [HTTPS options](https://nodejs.org/api/https.html#https_https_request_options_callback),
the following per-request options are supported:
- `followRedirects` (default: `true`) – whether redirects should be followed.
- `maxRedirects` (default: `21`) – sets the maximum number of allowed redirects; if exceeded, an error will be emitted.
- `maxBodyLength` (default: 10MB) – sets the maximum size of the request body; if exceeded, an error will be emitted.
- `agents` (default: `undefined`) – sets the `agent` option per protocol, since HTTP and HTTPS use different agents. Example value: `{ http: new http.Agent(), https: new https.Agent() }`
- `trackRedirects` (default: `false`) – whether to store the redirected response details into the `redirects` array on the response object.
### Advanced usage
By default, `follow-redirects` will use the Node.js default implementations
of [`http`](https://nodejs.org/api/http.html)
and [`https`](https://nodejs.org/api/https.html).
To enable features such as caching and/or intermediate request tracking,
you might instead want to wrap `follow-redirects` around custom protocol implementations:
```javascript
var followRedirects = require('follow-redirects').wrap({
http: require('your-custom-http'),
https: require('your-custom-https'),
});
```
Such custom protocols only need an implementation of the `request` method.
## Browserify Usage
Due to the way `XMLHttpRequest` works, the `browserify` versions of `http` and `https` already follow redirects.
If you are *only* targeting the browser, then this library has little value for you. If you want to write cross
platform code for node and the browser, `follow-redirects` provides a great solution for making the native node
modules behave the same as they do in browserified builds in the browser. To avoid bundling unnecessary code
you should tell browserify to swap out `follow-redirects` with the standard modules when bundling.
To make this easier, you need to change how you require the modules:
```javascript
var http = require('follow-redirects/http');
var https = require('follow-redirects/https');
```
You can then replace `follow-redirects` in your browserify configuration like so:
```javascript
"browser": {
"follow-redirects/http" : "http",
"follow-redirects/https" : "https"
}
```
The `browserify-http` module has not kept pace with node development, and no long behaves identically to the native
module when running in the browser. If you are experiencing problems, you may want to check out
[browserify-http-2](https://www.npmjs.com/package/http-browserify-2). It is more actively maintained and
attempts to address a few of the shortcomings of `browserify-http`. In that case, your browserify config should
look something like this:
```javascript
"browser": {
"follow-redirects/http" : "browserify-http-2/http",
"follow-redirects/https" : "browserify-http-2/https"
}
```
## Contributing
Pull Requests are always welcome. Please [file an issue](https://github.com/follow-redirects/follow-redirects/issues)
detailing your proposal before you invest your valuable time. Additional features and bug fixes should be accompanied
by tests. You can run the test suite locally with a simple `npm test` command.
## Debug Logging
`follow-redirects` uses the excellent [debug](https://www.npmjs.com/package/debug) for logging. To turn on logging
set the environment variable `DEBUG=follow-redirects` for debug output from just this module. When running the test
suite it is sometimes advantageous to set `DEBUG=*` to see output from the express server as well.
## Authors
- Olivier Lalonde (olalonde@gmail.com)
- James Talmage (james@talmage.io)
- [Ruben Verborgh](https://ruben.verborgh.org/)
## License
[https://github.com/follow-redirects/follow-redirects/blob/master/LICENSE](MIT License)
# eslint-visitor-keys
[](https://www.npmjs.com/package/eslint-visitor-keys)
[](http://www.npmtrends.com/eslint-visitor-keys)
[](https://travis-ci.org/eslint/eslint-visitor-keys)
[](https://david-dm.org/eslint/eslint-visitor-keys)
Constants and utilities about visitor keys to traverse AST.
## 💿 Installation
Use [npm] to install.
```bash
$ npm install eslint-visitor-keys
```
### Requirements
- [Node.js] 4.0.0 or later.
## 📖 Usage
```js
const evk = require("eslint-visitor-keys")
```
### evk.KEYS
> type: `{ [type: string]: string[] | undefined }`
Visitor keys. This keys are frozen.
This is an object. Keys are the type of [ESTree] nodes. Their values are an array of property names which have child nodes.
For example:
```
console.log(evk.KEYS.AssignmentExpression) // → ["left", "right"]
```
### evk.getKeys(node)
> type: `(node: object) => string[]`
Get the visitor keys of a given AST node.
This is similar to `Object.keys(node)` of ES Standard, but some keys are excluded: `parent`, `leadingComments`, `trailingComments`, and names which start with `_`.
This will be used to traverse unknown nodes.
For example:
```
const node = {
type: "AssignmentExpression",
left: { type: "Identifier", name: "foo" },
right: { type: "Literal", value: 0 }
}
console.log(evk.getKeys(node)) // → ["type", "left", "right"]
```
### evk.unionWith(additionalKeys)
> type: `(additionalKeys: object) => { [type: string]: string[] | undefined }`
Make the union set with `evk.KEYS` and the given keys.
- The order of keys is, `additionalKeys` is at first, then `evk.KEYS` is concatenated after that.
- It removes duplicated keys as keeping the first one.
For example:
```
console.log(evk.unionWith({
MethodDefinition: ["decorators"]
})) // → { ..., MethodDefinition: ["decorators", "key", "value"], ... }
```
## 📰 Change log
See [GitHub releases](https://github.com/eslint/eslint-visitor-keys/releases).
## 🍻 Contributing
Welcome. See [ESLint contribution guidelines](https://eslint.org/docs/developer-guide/contributing/).
### Development commands
- `npm test` runs tests and measures code coverage.
- `npm run lint` checks source codes with ESLint.
- `npm run coverage` opens the code coverage report of the previous test with your default browser.
- `npm run release` publishes this package to [npm] registory.
[npm]: https://www.npmjs.com/
[Node.js]: https://nodejs.org/en/
[ESTree]: https://github.com/estree/estree
# lodash.sortby v4.7.0
The [lodash](https://lodash.com/) method `_.sortBy` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.sortby
```
In Node.js:
```js
var sortBy = require('lodash.sortby');
```
See the [documentation](https://lodash.com/docs#sortBy) or [package source](https://github.com/lodash/lodash/blob/4.7.0-npm-packages/lodash.sortby) for more details.
# Punycode.js [](https://travis-ci.org/bestiejs/punycode.js) [](https://codecov.io/gh/bestiejs/punycode.js) [](https://gemnasium.com/bestiejs/punycode.js)
Punycode.js is a robust Punycode converter that fully complies to [RFC 3492](https://tools.ietf.org/html/rfc3492) and [RFC 5891](https://tools.ietf.org/html/rfc5891).
This JavaScript library is the result of comparing, optimizing and documenting different open-source implementations of the Punycode algorithm:
* [The C example code from RFC 3492](https://tools.ietf.org/html/rfc3492#appendix-C)
* [`punycode.c` by _Markus W. Scherer_ (IBM)](http://opensource.apple.com/source/ICU/ICU-400.42/icuSources/common/punycode.c)
* [`punycode.c` by _Ben Noordhuis_](https://github.com/bnoordhuis/punycode/blob/master/punycode.c)
* [JavaScript implementation by _some_](http://stackoverflow.com/questions/183485/can-anyone-recommend-a-good-free-javascript-for-punycode-to-unicode-conversion/301287#301287)
* [`punycode.js` by _Ben Noordhuis_](https://github.com/joyent/node/blob/426298c8c1c0d5b5224ac3658c41e7c2a3fe9377/lib/punycode.js) (note: [not fully compliant](https://github.com/joyent/node/issues/2072))
This project was [bundled](https://github.com/joyent/node/blob/master/lib/punycode.js) with Node.js from [v0.6.2+](https://github.com/joyent/node/compare/975f1930b1...61e796decc) until [v7](https://github.com/nodejs/node/pull/7941) (soft-deprecated).
The current version supports recent versions of Node.js only. It provides a CommonJS module and an ES6 module. For the old version that offers the same functionality with broader support, including Rhino, Ringo, Narwhal, and web browsers, see [v1.4.1](https://github.com/bestiejs/punycode.js/releases/tag/v1.4.1).
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install punycode --save
```
In [Node.js](https://nodejs.org/):
```js
const punycode = require('punycode');
```
## API
### `punycode.decode(string)`
Converts a Punycode string of ASCII symbols to a string of Unicode symbols.
```js
// decode domain name parts
punycode.decode('maana-pta'); // 'mañana'
punycode.decode('--dqo34k'); // '☃-⌘'
```
### `punycode.encode(string)`
Converts a string of Unicode symbols to a Punycode string of ASCII symbols.
```js
// encode domain name parts
punycode.encode('mañana'); // 'maana-pta'
punycode.encode('☃-⌘'); // '--dqo34k'
```
### `punycode.toUnicode(input)`
Converts a Punycode string representing a domain name or an email address to Unicode. Only the Punycoded parts of the input will be converted, i.e. it doesn’t matter if you call it on a string that has already been converted to Unicode.
```js
// decode domain names
punycode.toUnicode('xn--maana-pta.com');
// → 'mañana.com'
punycode.toUnicode('xn----dqo34k.com');
// → '☃-⌘.com'
// decode email addresses
punycode.toUnicode('джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq');
// → 'джумла@джpумлатест.bрфa'
```
### `punycode.toASCII(input)`
Converts a lowercased Unicode string representing a domain name or an email address to Punycode. Only the non-ASCII parts of the input will be converted, i.e. it doesn’t matter if you call it with a domain that’s already in ASCII.
```js
// encode domain names
punycode.toASCII('mañana.com');
// → 'xn--maana-pta.com'
punycode.toASCII('☃-⌘.com');
// → 'xn----dqo34k.com'
// encode email addresses
punycode.toASCII('джумла@джpумлатест.bрфa');
// → 'джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq'
```
### `punycode.ucs2`
#### `punycode.ucs2.decode(string)`
Creates an array containing the numeric code point values of each Unicode symbol in the string. While [JavaScript uses UCS-2 internally](https://mathiasbynens.be/notes/javascript-encoding), this function will convert a pair of surrogate halves (each of which UCS-2 exposes as separate characters) into a single code point, matching UTF-16.
```js
punycode.ucs2.decode('abc');
// → [0x61, 0x62, 0x63]
// surrogate pair for U+1D306 TETRAGRAM FOR CENTRE:
punycode.ucs2.decode('\uD834\uDF06');
// → [0x1D306]
```
#### `punycode.ucs2.encode(codePoints)`
Creates a string based on an array of numeric code point values.
```js
punycode.ucs2.encode([0x61, 0x62, 0x63]);
// → 'abc'
punycode.ucs2.encode([0x1D306]);
// → '\uD834\uDF06'
```
### `punycode.version`
A string representing the current Punycode.js version number.
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
Punycode.js is available under the [MIT](https://mths.be/mit) license.
# cliui

[](https://www.npmjs.com/package/cliui)
[](https://conventionalcommits.org)

easily create complex multi-column command-line-interfaces.
## Example
```js
const ui = require('cliui')()
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 1, 0]
})
ui.div(
{
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
},
{
text: "the file to load." +
chalk.green("(if this description is long it wraps).")
,
width: 20
},
{
text: chalk.red("[required]"),
align: 'right'
}
)
console.log(ui.toString())
```
## Deno/ESM Support
As of `v7` `cliui` supports [Deno](https://github.com/denoland/deno) and
[ESM](https://nodejs.org/api/esm.html#esm_ecmascript_modules):
```typescript
import cliui from "https://deno.land/x/cliui/deno.ts";
const ui = cliui({})
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 1, 0]
})
ui.div({
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
})
console.log(ui.toString())
```
<img width="500" src="screenshot.png">
## Layout DSL
cliui exposes a simple layout DSL:
If you create a single `ui.div`, passing a string rather than an
object:
* `\n`: characters will be interpreted as new rows.
* `\t`: characters will be interpreted as new columns.
* `\s`: characters will be interpreted as padding.
**as an example...**
```js
var ui = require('./')({
width: 60
})
ui.div(
'Usage: node ./bin/foo.js\n' +
' <regex>\t provide a regex\n' +
' <glob>\t provide a glob\t [required]'
)
console.log(ui.toString())
```
**will output:**
```shell
Usage: node ./bin/foo.js
<regex> provide a regex
<glob> provide a glob [required]
```
## Methods
```js
cliui = require('cliui')
```
### cliui({width: integer})
Specify the maximum width of the UI being generated.
If no width is provided, cliui will try to get the current window's width and use it, and if that doesn't work, width will be set to `80`.
### cliui({wrap: boolean})
Enable or disable the wrapping of text in a column.
### cliui.div(column, column, column)
Create a row with any number of columns, a column
can either be a string, or an object with the following
options:
* **text:** some text to place in the column.
* **width:** the width of a column.
* **align:** alignment, `right` or `center`.
* **padding:** `[top, right, bottom, left]`.
* **border:** should a border be placed around the div?
### cliui.span(column, column, column)
Similar to `div`, except the next row will be appended without
a new line being created.
### cliui.resetOutput()
Resets the UI elements of the current cliui instance, maintaining the values
set for `width` and `wrap`.
# isarray
`Array#isArray` for older browsers.
[](http://travis-ci.org/juliangruber/isarray)
[](https://www.npmjs.org/package/isarray)
[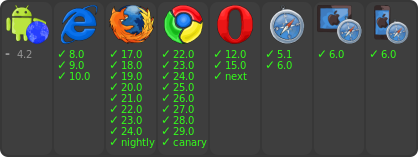
](https://ci.testling.com/juliangruber/isarray)
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# lodash.truncate v4.4.2
The [lodash](https://lodash.com/) method `_.truncate` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.truncate
```
In Node.js:
```js
var truncate = require('lodash.truncate');
```
See the [documentation](https://lodash.com/docs#truncate) or [package source](https://github.com/lodash/lodash/blob/4.4.2-npm-packages/lodash.truncate) for more details.
# Glob
Match files using the patterns the shell uses, like stars and stuff.
[](https://travis-ci.org/isaacs/node-glob/) [](https://ci.appveyor.com/project/isaacs/node-glob) [](https://coveralls.io/github/isaacs/node-glob?branch=master)
This is a glob implementation in JavaScript. It uses the `minimatch`
library to do its matching.

## Usage
Install with npm
```
npm i glob
```
```javascript
var glob = require("glob")
// options is optional
glob("**/*.js", options, function (er, files) {
// files is an array of filenames.
// If the `nonull` option is set, and nothing
// was found, then files is ["**/*.js"]
// er is an error object or null.
})
```
## Glob Primer
"Globs" are the patterns you type when you do stuff like `ls *.js` on
the command line, or put `build/*` in a `.gitignore` file.
Before parsing the path part patterns, braced sections are expanded
into a set. Braced sections start with `{` and end with `}`, with any
number of comma-delimited sections within. Braced sections may contain
slash characters, so `a{/b/c,bcd}` would expand into `a/b/c` and `abcd`.
The following characters have special magic meaning when used in a
path portion:
* `*` Matches 0 or more characters in a single path portion
* `?` Matches 1 character
* `[...]` Matches a range of characters, similar to a RegExp range.
If the first character of the range is `!` or `^` then it matches
any character not in the range.
* `!(pattern|pattern|pattern)` Matches anything that does not match
any of the patterns provided.
* `?(pattern|pattern|pattern)` Matches zero or one occurrence of the
patterns provided.
* `+(pattern|pattern|pattern)` Matches one or more occurrences of the
patterns provided.
* `*(a|b|c)` Matches zero or more occurrences of the patterns provided
* `@(pattern|pat*|pat?erN)` Matches exactly one of the patterns
provided
* `**` If a "globstar" is alone in a path portion, then it matches
zero or more directories and subdirectories searching for matches.
It does not crawl symlinked directories.
### Dots
If a file or directory path portion has a `.` as the first character,
then it will not match any glob pattern unless that pattern's
corresponding path part also has a `.` as its first character.
For example, the pattern `a/.*/c` would match the file at `a/.b/c`.
However the pattern `a/*/c` would not, because `*` does not start with
a dot character.
You can make glob treat dots as normal characters by setting
`dot:true` in the options.
### Basename Matching
If you set `matchBase:true` in the options, and the pattern has no
slashes in it, then it will seek for any file anywhere in the tree
with a matching basename. For example, `*.js` would match
`test/simple/basic.js`.
### Empty Sets
If no matching files are found, then an empty array is returned. This
differs from the shell, where the pattern itself is returned. For
example:
$ echo a*s*d*f
a*s*d*f
To get the bash-style behavior, set the `nonull:true` in the options.
### See Also:
* `man sh`
* `man bash` (Search for "Pattern Matching")
* `man 3 fnmatch`
* `man 5 gitignore`
* [minimatch documentation](https://github.com/isaacs/minimatch)
## glob.hasMagic(pattern, [options])
Returns `true` if there are any special characters in the pattern, and
`false` otherwise.
Note that the options affect the results. If `noext:true` is set in
the options object, then `+(a|b)` will not be considered a magic
pattern. If the pattern has a brace expansion, like `a/{b/c,x/y}`
then that is considered magical, unless `nobrace:true` is set in the
options.
## glob(pattern, [options], cb)
* `pattern` `{String}` Pattern to be matched
* `options` `{Object}`
* `cb` `{Function}`
* `err` `{Error | null}`
* `matches` `{Array<String>}` filenames found matching the pattern
Perform an asynchronous glob search.
## glob.sync(pattern, [options])
* `pattern` `{String}` Pattern to be matched
* `options` `{Object}`
* return: `{Array<String>}` filenames found matching the pattern
Perform a synchronous glob search.
## Class: glob.Glob
Create a Glob object by instantiating the `glob.Glob` class.
```javascript
var Glob = require("glob").Glob
var mg = new Glob(pattern, options, cb)
```
It's an EventEmitter, and starts walking the filesystem to find matches
immediately.
### new glob.Glob(pattern, [options], [cb])
* `pattern` `{String}` pattern to search for
* `options` `{Object}`
* `cb` `{Function}` Called when an error occurs, or matches are found
* `err` `{Error | null}`
* `matches` `{Array<String>}` filenames found matching the pattern
Note that if the `sync` flag is set in the options, then matches will
be immediately available on the `g.found` member.
### Properties
* `minimatch` The minimatch object that the glob uses.
* `options` The options object passed in.
* `aborted` Boolean which is set to true when calling `abort()`. There
is no way at this time to continue a glob search after aborting, but
you can re-use the statCache to avoid having to duplicate syscalls.
* `cache` Convenience object. Each field has the following possible
values:
* `false` - Path does not exist
* `true` - Path exists
* `'FILE'` - Path exists, and is not a directory
* `'DIR'` - Path exists, and is a directory
* `[file, entries, ...]` - Path exists, is a directory, and the
array value is the results of `fs.readdir`
* `statCache` Cache of `fs.stat` results, to prevent statting the same
path multiple times.
* `symlinks` A record of which paths are symbolic links, which is
relevant in resolving `**` patterns.
* `realpathCache` An optional object which is passed to `fs.realpath`
to minimize unnecessary syscalls. It is stored on the instantiated
Glob object, and may be re-used.
### Events
* `end` When the matching is finished, this is emitted with all the
matches found. If the `nonull` option is set, and no match was found,
then the `matches` list contains the original pattern. The matches
are sorted, unless the `nosort` flag is set.
* `match` Every time a match is found, this is emitted with the specific
thing that matched. It is not deduplicated or resolved to a realpath.
* `error` Emitted when an unexpected error is encountered, or whenever
any fs error occurs if `options.strict` is set.
* `abort` When `abort()` is called, this event is raised.
### Methods
* `pause` Temporarily stop the search
* `resume` Resume the search
* `abort` Stop the search forever
### Options
All the options that can be passed to Minimatch can also be passed to
Glob to change pattern matching behavior. Also, some have been added,
or have glob-specific ramifications.
All options are false by default, unless otherwise noted.
All options are added to the Glob object, as well.
If you are running many `glob` operations, you can pass a Glob object
as the `options` argument to a subsequent operation to shortcut some
`stat` and `readdir` calls. At the very least, you may pass in shared
`symlinks`, `statCache`, `realpathCache`, and `cache` options, so that
parallel glob operations will be sped up by sharing information about
the filesystem.
* `cwd` The current working directory in which to search. Defaults
to `process.cwd()`.
* `root` The place where patterns starting with `/` will be mounted
onto. Defaults to `path.resolve(options.cwd, "/")` (`/` on Unix
systems, and `C:\` or some such on Windows.)
* `dot` Include `.dot` files in normal matches and `globstar` matches.
Note that an explicit dot in a portion of the pattern will always
match dot files.
* `nomount` By default, a pattern starting with a forward-slash will be
"mounted" onto the root setting, so that a valid filesystem path is
returned. Set this flag to disable that behavior.
* `mark` Add a `/` character to directory matches. Note that this
requires additional stat calls.
* `nosort` Don't sort the results.
* `stat` Set to true to stat *all* results. This reduces performance
somewhat, and is completely unnecessary, unless `readdir` is presumed
to be an untrustworthy indicator of file existence.
* `silent` When an unusual error is encountered when attempting to
read a directory, a warning will be printed to stderr. Set the
`silent` option to true to suppress these warnings.
* `strict` When an unusual error is encountered when attempting to
read a directory, the process will just continue on in search of
other matches. Set the `strict` option to raise an error in these
cases.
* `cache` See `cache` property above. Pass in a previously generated
cache object to save some fs calls.
* `statCache` A cache of results of filesystem information, to prevent
unnecessary stat calls. While it should not normally be necessary
to set this, you may pass the statCache from one glob() call to the
options object of another, if you know that the filesystem will not
change between calls. (See "Race Conditions" below.)
* `symlinks` A cache of known symbolic links. You may pass in a
previously generated `symlinks` object to save `lstat` calls when
resolving `**` matches.
* `sync` DEPRECATED: use `glob.sync(pattern, opts)` instead.
* `nounique` In some cases, brace-expanded patterns can result in the
same file showing up multiple times in the result set. By default,
this implementation prevents duplicates in the result set. Set this
flag to disable that behavior.
* `nonull` Set to never return an empty set, instead returning a set
containing the pattern itself. This is the default in glob(3).
* `debug` Set to enable debug logging in minimatch and glob.
* `nobrace` Do not expand `{a,b}` and `{1..3}` brace sets.
* `noglobstar` Do not match `**` against multiple filenames. (Ie,
treat it as a normal `*` instead.)
* `noext` Do not match `+(a|b)` "extglob" patterns.
* `nocase` Perform a case-insensitive match. Note: on
case-insensitive filesystems, non-magic patterns will match by
default, since `stat` and `readdir` will not raise errors.
* `matchBase` Perform a basename-only match if the pattern does not
contain any slash characters. That is, `*.js` would be treated as
equivalent to `**/*.js`, matching all js files in all directories.
* `nodir` Do not match directories, only files. (Note: to match
*only* directories, simply put a `/` at the end of the pattern.)
* `ignore` Add a pattern or an array of glob patterns to exclude matches.
Note: `ignore` patterns are *always* in `dot:true` mode, regardless
of any other settings.
* `follow` Follow symlinked directories when expanding `**` patterns.
Note that this can result in a lot of duplicate references in the
presence of cyclic links.
* `realpath` Set to true to call `fs.realpath` on all of the results.
In the case of a symlink that cannot be resolved, the full absolute
path to the matched entry is returned (though it will usually be a
broken symlink)
* `absolute` Set to true to always receive absolute paths for matched
files. Unlike `realpath`, this also affects the values returned in
the `match` event.
* `fs` File-system object with Node's `fs` API. By default, the built-in
`fs` module will be used. Set to a volume provided by a library like
`memfs` to avoid using the "real" file-system.
## Comparisons to other fnmatch/glob implementations
While strict compliance with the existing standards is a worthwhile
goal, some discrepancies exist between node-glob and other
implementations, and are intentional.
The double-star character `**` is supported by default, unless the
`noglobstar` flag is set. This is supported in the manner of bsdglob
and bash 4.3, where `**` only has special significance if it is the only
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
`a/**b` will not.
Note that symlinked directories are not crawled as part of a `**`,
though their contents may match against subsequent portions of the
pattern. This prevents infinite loops and duplicates and the like.
If an escaped pattern has no matches, and the `nonull` flag is set,
then glob returns the pattern as-provided, rather than
interpreting the character escapes. For example,
`glob.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
that it does not resolve escaped pattern characters.
If brace expansion is not disabled, then it is performed before any
other interpretation of the glob pattern. Thus, a pattern like
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
checked for validity. Since those two are valid, matching proceeds.
### Comments and Negation
Previously, this module let you mark a pattern as a "comment" if it
started with a `#` character, or a "negated" pattern if it started
with a `!` character.
These options were deprecated in version 5, and removed in version 6.
To specify things that should not match, use the `ignore` option.
## Windows
**Please only use forward-slashes in glob expressions.**
Though windows uses either `/` or `\` as its path separator, only `/`
characters are used by this glob implementation. You must use
forward-slashes **only** in glob expressions. Back-slashes will always
be interpreted as escape characters, not path separators.
Results from absolute patterns such as `/foo/*` are mounted onto the
root setting using `path.join`. On windows, this will by default result
in `/foo/*` matching `C:\foo\bar.txt`.
## Race Conditions
Glob searching, by its very nature, is susceptible to race conditions,
since it relies on directory walking and such.
As a result, it is possible that a file that exists when glob looks for
it may have been deleted or modified by the time it returns the result.
As part of its internal implementation, this program caches all stat
and readdir calls that it makes, in order to cut down on system
overhead. However, this also makes it even more susceptible to races,
especially if the cache or statCache objects are reused between glob
calls.
Users are thus advised not to use a glob result as a guarantee of
filesystem state in the face of rapid changes. For the vast majority
of operations, this is never a problem.
## Glob Logo
Glob's logo was created by [Tanya Brassie](http://tanyabrassie.com/). Logo files can be found [here](https://github.com/isaacs/node-glob/tree/master/logo).
The logo is licensed under a [Creative Commons Attribution-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-sa/4.0/).
## Contributing
Any change to behavior (including bugfixes) must come with a test.
Patches that fail tests or reduce performance will be rejected.
```
# to run tests
npm test
# to re-generate test fixtures
npm run test-regen
# to benchmark against bash/zsh
npm run bench
# to profile javascript
npm run prof
```

# lodash.clonedeep v4.5.0
The [lodash](https://lodash.com/) method `_.cloneDeep` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.clonedeep
```
In Node.js:
```js
var cloneDeep = require('lodash.clonedeep');
```
See the [documentation](https://lodash.com/docs#cloneDeep) or [package source](https://github.com/lodash/lodash/blob/4.5.0-npm-packages/lodash.clonedeep) for more details.
The AssemblyScript Runtime
==========================
The runtime provides the functionality necessary to dynamically allocate and deallocate memory of objects, arrays and buffers, as well as collect garbage that is no longer used. The current implementation is either a Two-Color Mark & Sweep (TCMS) garbage collector that must be called manually when the execution stack is unwound or an Incremental Tri-Color Mark & Sweep (ITCMS) garbage collector that is fully automated with a shadow stack, implemented on top of a Two-Level Segregate Fit (TLSF) memory manager. It's not designed to be the fastest of its kind, but intentionally focuses on simplicity and ease of integration until we can replace it with the real deal, i.e. Wasm GC.
Interface
---------
### Garbage collector / `--exportRuntime`
* **__new**(size: `usize`, id: `u32` = 0): `usize`<br />
Dynamically allocates a GC object of at least the specified size and returns its address.
Alignment is guaranteed to be 16 bytes to fit up to v128 values naturally.
GC-allocated objects cannot be used with `__realloc` and `__free`.
* **__pin**(ptr: `usize`): `usize`<br />
Pins the object pointed to by `ptr` externally so it and its directly reachable members and indirectly reachable objects do not become garbage collected.
* **__unpin**(ptr: `usize`): `void`<br />
Unpins the object pointed to by `ptr` externally so it can become garbage collected.
* **__collect**(): `void`<br />
Performs a full garbage collection.
### Internals
* **__alloc**(size: `usize`): `usize`<br />
Dynamically allocates a chunk of memory of at least the specified size and returns its address.
Alignment is guaranteed to be 16 bytes to fit up to v128 values naturally.
* **__realloc**(ptr: `usize`, size: `usize`): `usize`<br />
Dynamically changes the size of a chunk of memory, possibly moving it to a new address.
* **__free**(ptr: `usize`): `void`<br />
Frees a dynamically allocated chunk of memory by its address.
* **__renew**(ptr: `usize`, size: `usize`): `usize`<br />
Like `__realloc`, but for `__new`ed GC objects.
* **__link**(parentPtr: `usize`, childPtr: `usize`, expectMultiple: `bool`): `void`<br />
Introduces a link from a parent object to a child object, i.e. upon `parent.field = child`.
* **__visit**(ptr: `usize`, cookie: `u32`): `void`<br />
Concrete visitor implementation called during traversal. Cookie can be used to indicate one of multiple operations.
* **__visit_globals**(cookie: `u32`): `void`<br />
Calls `__visit` on each global that is of a managed type.
* **__visit_members**(ptr: `usize`, cookie: `u32`): `void`<br />
Calls `__visit` on each member of the object pointed to by `ptr`.
* **__typeinfo**(id: `u32`): `RTTIFlags`<br />
Obtains the runtime type information for objects with the specified runtime id. Runtime type information is a set of flags indicating whether a type is managed, an array or similar, and what the relevant alignments when creating an instance externally are etc.
* **__instanceof**(ptr: `usize`, classId: `u32`): `bool`<br />
Tests if the object pointed to by `ptr` is an instance of the specified class id.
ITCMS / `--runtime incremental`
-----
The Incremental Tri-Color Mark & Sweep garbage collector maintains a separate shadow stack of managed values in the background to achieve full automation. Maintaining another stack introduces some overhead compared to the simpler Two-Color Mark & Sweep garbage collector, but makes it independent of whether the execution stack is unwound or not when it is invoked, so the garbage collector can run interleaved with the program.
There are several constants one can experiment with to tweak ITCMS's automation:
* `--use ASC_GC_GRANULARITY=1024`<br />
How often to interrupt. The default of 1024 means "interrupt each 1024 bytes allocated".
* `--use ASC_GC_STEPFACTOR=200`<br />
How long to interrupt. The default of 200% means "run at double the speed of allocations".
* `--use ASC_GC_IDLEFACTOR=200`<br />
How long to idle. The default of 200% means "wait for memory to double before kicking in again".
* `--use ASC_GC_MARKCOST=1`<br />
How costly it is to mark one object. Budget per interrupt is `GRANULARITY * STEPFACTOR / 100`.
* `--use ASC_GC_SWEEPCOST=10`<br />
How costly it is to sweep one object. Budget per interrupt is `GRANULARITY * STEPFACTOR / 100`.
TCMS / `--runtime minimal`
----
If automation and low pause times aren't strictly necessary, using the Two-Color Mark & Sweep garbage collector instead by invoking collection manually at appropriate times when the execution stack is unwound may be more performant as it simpler and has less overhead. The execution stack is typically unwound when invoking the collector externally, at a place that is not indirectly called from Wasm.
STUB / `--runtime stub`
----
The stub is a maximally minimal runtime substitute, consisting of a simple and fast bump allocator with no means of freeing up memory again, except when freeing the respective most recently allocated object on top of the bump. Useful where memory is not a concern, and/or where it is sufficient to destroy the whole module including any potential garbage after execution.
See also: [Garbage collection](https://www.assemblyscript.org/garbage-collection.html)
# cross-spawn
[![NPM version][npm-image]][npm-url] [![Downloads][downloads-image]][npm-url] [![Build Status][travis-image]][travis-url] [![Build status][appveyor-image]][appveyor-url] [![Coverage Status][codecov-image]][codecov-url] [![Dependency status][david-dm-image]][david-dm-url] [![Dev Dependency status][david-dm-dev-image]][david-dm-dev-url]
[npm-url]:https://npmjs.org/package/cross-spawn
[downloads-image]:https://img.shields.io/npm/dm/cross-spawn.svg
[npm-image]:https://img.shields.io/npm/v/cross-spawn.svg
[travis-url]:https://travis-ci.org/moxystudio/node-cross-spawn
[travis-image]:https://img.shields.io/travis/moxystudio/node-cross-spawn/master.svg
[appveyor-url]:https://ci.appveyor.com/project/satazor/node-cross-spawn
[appveyor-image]:https://img.shields.io/appveyor/ci/satazor/node-cross-spawn/master.svg
[codecov-url]:https://codecov.io/gh/moxystudio/node-cross-spawn
[codecov-image]:https://img.shields.io/codecov/c/github/moxystudio/node-cross-spawn/master.svg
[david-dm-url]:https://david-dm.org/moxystudio/node-cross-spawn
[david-dm-image]:https://img.shields.io/david/moxystudio/node-cross-spawn.svg
[david-dm-dev-url]:https://david-dm.org/moxystudio/node-cross-spawn?type=dev
[david-dm-dev-image]:https://img.shields.io/david/dev/moxystudio/node-cross-spawn.svg
A cross platform solution to node's spawn and spawnSync.
## Installation
Node.js version 8 and up:
`$ npm install cross-spawn`
Node.js version 7 and under:
`$ npm install cross-spawn@6`
## Why
Node has issues when using spawn on Windows:
- It ignores [PATHEXT](https://github.com/joyent/node/issues/2318)
- It does not support [shebangs](https://en.wikipedia.org/wiki/Shebang_(Unix))
- Has problems running commands with [spaces](https://github.com/nodejs/node/issues/7367)
- Has problems running commands with posix relative paths (e.g.: `./my-folder/my-executable`)
- Has an [issue](https://github.com/moxystudio/node-cross-spawn/issues/82) with command shims (files in `node_modules/.bin/`), where arguments with quotes and parenthesis would result in [invalid syntax error](https://github.com/moxystudio/node-cross-spawn/blob/e77b8f22a416db46b6196767bcd35601d7e11d54/test/index.test.js#L149)
- No `options.shell` support on node `<v4.8`
All these issues are handled correctly by `cross-spawn`.
There are some known modules, such as [win-spawn](https://github.com/ForbesLindesay/win-spawn), that try to solve this but they are either broken or provide faulty escaping of shell arguments.
## Usage
Exactly the same way as node's [`spawn`](https://nodejs.org/api/child_process.html#child_process_child_process_spawn_command_args_options) or [`spawnSync`](https://nodejs.org/api/child_process.html#child_process_child_process_spawnsync_command_args_options), so it's a drop in replacement.
```js
const spawn = require('cross-spawn');
// Spawn NPM asynchronously
const child = spawn('npm', ['list', '-g', '-depth', '0'], { stdio: 'inherit' });
// Spawn NPM synchronously
const result = spawn.sync('npm', ['list', '-g', '-depth', '0'], { stdio: 'inherit' });
```
## Caveats
### Using `options.shell` as an alternative to `cross-spawn`
Starting from node `v4.8`, `spawn` has a `shell` option that allows you run commands from within a shell. This new option solves
the [PATHEXT](https://github.com/joyent/node/issues/2318) issue but:
- It's not supported in node `<v4.8`
- You must manually escape the command and arguments which is very error prone, specially when passing user input
- There are a lot of other unresolved issues from the [Why](#why) section that you must take into account
If you are using the `shell` option to spawn a command in a cross platform way, consider using `cross-spawn` instead. You have been warned.
### `options.shell` support
While `cross-spawn` adds support for `options.shell` in node `<v4.8`, all of its enhancements are disabled.
This mimics the Node.js behavior. More specifically, the command and its arguments will not be automatically escaped nor shebang support will be offered. This is by design because if you are using `options.shell` you are probably targeting a specific platform anyway and you don't want things to get into your way.
### Shebangs support
While `cross-spawn` handles shebangs on Windows, its support is limited. More specifically, it just supports `#!/usr/bin/env <program>` where `<program>` must not contain any arguments.
If you would like to have the shebang support improved, feel free to contribute via a pull-request.
Remember to always test your code on Windows!
## Tests
`$ npm test`
`$ npm test -- --watch` during development
## License
Released under the [MIT License](https://www.opensource.org/licenses/mit-license.php).
# yargs-parser
[](https://travis-ci.org/yargs/yargs-parser)
[](https://www.npmjs.com/package/yargs-parser)
[](https://github.com/conventional-changelog/standard-version)
The mighty option parser used by [yargs](https://github.com/yargs/yargs).
visit the [yargs website](http://yargs.js.org/) for more examples, and thorough usage instructions.
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs-parser/master/yargs-logo.png">
## Example
```sh
npm i yargs-parser --save
```
```js
var argv = require('yargs-parser')(process.argv.slice(2))
console.log(argv)
```
```sh
node example.js --foo=33 --bar hello
{ _: [], foo: 33, bar: 'hello' }
```
_or parse a string!_
```js
var argv = require('yargs-parser')('--foo=99 --bar=33')
console.log(argv)
```
```sh
{ _: [], foo: 99, bar: 33 }
```
Convert an array of mixed types before passing to `yargs-parser`:
```js
var parse = require('yargs-parser')
parse(['-f', 11, '--zoom', 55].join(' ')) // <-- array to string
parse(['-f', 11, '--zoom', 55].map(String)) // <-- array of strings
```
## API
### require('yargs-parser')(args, opts={})
Parses command line arguments returning a simple mapping of keys and values.
**expects:**
* `args`: a string or array of strings representing the options to parse.
* `opts`: provide a set of hints indicating how `args` should be parsed:
* `opts.alias`: an object representing the set of aliases for a key: `{alias: {foo: ['f']}}`.
* `opts.array`: indicate that keys should be parsed as an array: `{array: ['foo', 'bar']}`.<br>
Indicate that keys should be parsed as an array and coerced to booleans / numbers:<br>
`{array: [{ key: 'foo', boolean: true }, {key: 'bar', number: true}]}`.
* `opts.boolean`: arguments should be parsed as booleans: `{boolean: ['x', 'y']}`.
* `opts.coerce`: provide a custom synchronous function that returns a coerced value from the argument provided
(or throws an error). For arrays the function is called only once for the entire array:<br>
`{coerce: {foo: function (arg) {return modifiedArg}}}`.
* `opts.config`: indicate a key that represents a path to a configuration file (this file will be loaded and parsed).
* `opts.configObjects`: configuration objects to parse, their properties will be set as arguments:<br>
`{configObjects: [{'x': 5, 'y': 33}, {'z': 44}]}`.
* `opts.configuration`: provide configuration options to the yargs-parser (see: [configuration](#configuration)).
* `opts.count`: indicate a key that should be used as a counter, e.g., `-vvv` = `{v: 3}`.
* `opts.default`: provide default values for keys: `{default: {x: 33, y: 'hello world!'}}`.
* `opts.envPrefix`: environment variables (`process.env`) with the prefix provided should be parsed.
* `opts.narg`: specify that a key requires `n` arguments: `{narg: {x: 2}}`.
* `opts.normalize`: `path.normalize()` will be applied to values set to this key.
* `opts.number`: keys should be treated as numbers.
* `opts.string`: keys should be treated as strings (even if they resemble a number `-x 33`).
**returns:**
* `obj`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
### require('yargs-parser').detailed(args, opts={})
Parses a command line string, returning detailed information required by the
yargs engine.
**expects:**
* `args`: a string or array of strings representing options to parse.
* `opts`: provide a set of hints indicating how `args`, inputs are identical to `require('yargs-parser')(args, opts={})`.
**returns:**
* `argv`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
* `error`: populated with an error object if an exception occurred during parsing.
* `aliases`: the inferred list of aliases built by combining lists in `opts.alias`.
* `newAliases`: any new aliases added via camel-case expansion:
* `boolean`: `{ fooBar: true }`
* `defaulted`: any new argument created by `opts.default`, no aliases included.
* `boolean`: `{ foo: true }`
* `configuration`: given by default settings and `opts.configuration`.
<a name="configuration"></a>
### Configuration
The yargs-parser applies several automated transformations on the keys provided
in `args`. These features can be turned on and off using the `configuration` field
of `opts`.
```js
var parsed = parser(['--no-dice'], {
configuration: {
'boolean-negation': false
}
})
```
### short option groups
* default: `true`.
* key: `short-option-groups`.
Should a group of short-options be treated as boolean flags?
```sh
node example.js -abc
{ _: [], a: true, b: true, c: true }
```
_if disabled:_
```sh
node example.js -abc
{ _: [], abc: true }
```
### camel-case expansion
* default: `true`.
* key: `camel-case-expansion`.
Should hyphenated arguments be expanded into camel-case aliases?
```sh
node example.js --foo-bar
{ _: [], 'foo-bar': true, fooBar: true }
```
_if disabled:_
```sh
node example.js --foo-bar
{ _: [], 'foo-bar': true }
```
### dot-notation
* default: `true`
* key: `dot-notation`
Should keys that contain `.` be treated as objects?
```sh
node example.js --foo.bar
{ _: [], foo: { bar: true } }
```
_if disabled:_
```sh
node example.js --foo.bar
{ _: [], "foo.bar": true }
```
### parse numbers
* default: `true`
* key: `parse-numbers`
Should keys that look like numbers be treated as such?
```sh
node example.js --foo=99.3
{ _: [], foo: 99.3 }
```
_if disabled:_
```sh
node example.js --foo=99.3
{ _: [], foo: "99.3" }
```
### boolean negation
* default: `true`
* key: `boolean-negation`
Should variables prefixed with `--no` be treated as negations?
```sh
node example.js --no-foo
{ _: [], foo: false }
```
_if disabled:_
```sh
node example.js --no-foo
{ _: [], "no-foo": true }
```
### combine arrays
* default: `false`
* key: `combine-arrays`
Should arrays be combined when provided by both command line arguments and
a configuration file.
### duplicate arguments array
* default: `true`
* key: `duplicate-arguments-array`
Should arguments be coerced into an array when duplicated:
```sh
node example.js -x 1 -x 2
{ _: [], x: [1, 2] }
```
_if disabled:_
```sh
node example.js -x 1 -x 2
{ _: [], x: 2 }
```
### flatten duplicate arrays
* default: `true`
* key: `flatten-duplicate-arrays`
Should array arguments be coerced into a single array when duplicated:
```sh
node example.js -x 1 2 -x 3 4
{ _: [], x: [1, 2, 3, 4] }
```
_if disabled:_
```sh
node example.js -x 1 2 -x 3 4
{ _: [], x: [[1, 2], [3, 4]] }
```
### greedy arrays
* default: `true`
* key: `greedy-arrays`
Should arrays consume more than one positional argument following their flag.
```sh
node example --arr 1 2
{ _[], arr: [1, 2] }
```
_if disabled:_
```sh
node example --arr 1 2
{ _[2], arr: [1] }
```
**Note: in `v18.0.0` we are considering defaulting greedy arrays to `false`.**
### nargs eats options
* default: `false`
* key: `nargs-eats-options`
Should nargs consume dash options as well as positional arguments.
### negation prefix
* default: `no-`
* key: `negation-prefix`
The prefix to use for negated boolean variables.
```sh
node example.js --no-foo
{ _: [], foo: false }
```
_if set to `quux`:_
```sh
node example.js --quuxfoo
{ _: [], foo: false }
```
### populate --
* default: `false`.
* key: `populate--`
Should unparsed flags be stored in `--` or `_`.
_If disabled:_
```sh
node example.js a -b -- x y
{ _: [ 'a', 'x', 'y' ], b: true }
```
_If enabled:_
```sh
node example.js a -b -- x y
{ _: [ 'a' ], '--': [ 'x', 'y' ], b: true }
```
### set placeholder key
* default: `false`.
* key: `set-placeholder-key`.
Should a placeholder be added for keys not set via the corresponding CLI argument?
_If disabled:_
```sh
node example.js -a 1 -c 2
{ _: [], a: 1, c: 2 }
```
_If enabled:_
```sh
node example.js -a 1 -c 2
{ _: [], a: 1, b: undefined, c: 2 }
```
### halt at non-option
* default: `false`.
* key: `halt-at-non-option`.
Should parsing stop at the first positional argument? This is similar to how e.g. `ssh` parses its command line.
_If disabled:_
```sh
node example.js -a run b -x y
{ _: [ 'b' ], a: 'run', x: 'y' }
```
_If enabled:_
```sh
node example.js -a run b -x y
{ _: [ 'b', '-x', 'y' ], a: 'run' }
```
### strip aliased
* default: `false`
* key: `strip-aliased`
Should aliases be removed before returning results?
_If disabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1, 'test-alias': 1, testAlias: 1 }
```
_If enabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
### strip dashed
* default: `false`
* key: `strip-dashed`
Should dashed keys be removed before returning results? This option has no effect if
`camel-case-expansion` is disabled.
_If disabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
_If enabled:_
```sh
node example.js --test-field 1
{ _: [], testField: 1 }
```
### unknown options as args
* default: `false`
* key: `unknown-options-as-args`
Should unknown options be treated like regular arguments? An unknown option is one that is not
configured in `opts`.
_If disabled_
```sh
node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: [], unknownOption: true, knownOption: 2, stringOption: '', unknownOption2: true }
```
_If enabled_
```sh
node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: ['--unknown-option'], knownOption: 2, stringOption: '--unknown-option2' }
```
## Special Thanks
The yargs project evolves from optimist and minimist. It owes its
existence to a lot of James Halliday's hard work. Thanks [substack](https://github.com/substack) **beep** **boop** \o/
## License
ISC
blockvote Smart Contract
==================
A [smart contract] written in [AssemblyScript] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install [Node.js] ≥ 12
Exploring The Code
==================
1. The main smart contract code lives in `assembly/index.ts`. You can compile
it with the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard AssemblyScript tests using [as-pect].
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[AssemblyScript]: https://www.assemblyscript.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[as-pect]: https://www.npmjs.com/package/@as-pect/cli
# `asbuild` [](https://github.com/AssemblyScript/asbuild/stargazers)
*A simple build tool for [AssemblyScript](https://assemblyscript.org) projects, similar to `cargo`, etc.*
## 🚩 Table of Contents
- [Installing](#-installing)
- [Usage](#-usage)
- [`asb init`](#asb-init---create-an-empty-project)
- [`asb test`](#asb-test---run-as-pect-tests)
- [`asb fmt`](#asb-fmt---format-as-files-using-eslint)
- [`asb run`](#asb-run---run-a-wasi-binary)
- [`asb build`](#asb-build---compile-the-project-using-asc)
- [Background](#-background)
## 🔧 Installing
Install it globally
```
npm install -g asbuild
```
Or, locally as dev dependencies
```
npm install --save-dev asbuild
```
## 💡 Usage
```
Build tool for AssemblyScript projects.
Usage:
asb [command] [options]
Commands:
asb Alias of build command, to maintain back-ward
compatibility [default]
asb build Compile a local package and all of its dependencies
[aliases: compile, make]
asb init [baseDir] Create a new AS package in an given directory
asb test Run as-pect tests
asb fmt [paths..] This utility formats current module using eslint.
[aliases: format, lint]
Options:
--version Show version number [boolean]
--help Show help [boolean]
```
### `asb init` - Create an empty project
```
asb init [baseDir]
Create a new AS package in an given directory
Positionals:
baseDir Create a sample AS project in this directory [string] [default: "."]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--yes Skip the interactive prompt [boolean] [default: false]
```
### `asb test` - Run as-pect tests
```
asb test
Run as-pect tests
USAGE:
asb test [options] -- [aspect_options]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--verbose, --vv Print out arguments passed to as-pect
[boolean] [default: false]
```
### `asb fmt` - Format AS files using ESlint
```
asb fmt [paths..]
This utility formats current module using eslint.
Positionals:
paths Paths to format [array] [default: ["."]]
Initialisation:
--init Generates recommended eslint config for AS Projects [boolean]
Miscellaneous
--lint, --dry-run Tries to fix problems without saving the changes to the
file system [boolean] [default: false]
Options:
--version Show version number [boolean]
--help Show help
```
### `asb run` - Run a WASI binary
```
asb run
Run a WASI binary
USAGE:
asb run [options] [binary path] -- [binary options]
Positionals:
binary path to Wasm binary [string] [required]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--preopen, -p comma separated list of directories to open.
[default: "."]
```
### `asb build` - Compile the project using asc
```
asb build
Compile a local package and all of its dependencies
USAGE:
asb build [entry_file] [options] -- [asc_options]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--baseDir, -d Base directory of project. [string] [default: "."]
--config, -c Path to asconfig file [string] [default: "./asconfig.json"]
--wat Output wat file to outDir [boolean] [default: false]
--outDir Directory to place built binaries. Default "./build/<target>/"
[string]
--target Target for compilation [string] [default: "release"]
--verbose Print out arguments passed to asc [boolean] [default: false]
Examples:
asb build Build release of 'assembly/index.ts to
build/release/packageName.wasm
asb build --target release Build a release binary
asb build -- --measure Pass argument to 'asc'
```
#### Defaults
##### Project structure
```
project/
package.json
asconfig.json
assembly/
index.ts
build/
release/
project.wasm
debug/
project.wasm
```
- If no entry file passed and no `entry` field is in `asconfig.json`, `project/assembly/index.ts` is assumed.
- `asconfig.json` allows for options for different compile targets, e.g. release, debug, etc. `asc` defaults to the release target.
- The default build directory is `./build`, and artifacts are placed at `./build/<target>/packageName.wasm`.
##### Workspaces
If a `workspace` field is added to a top level `asconfig.json` file, then each path in the array is built and placed into the top level `outDir`.
For example,
`asconfig.json`:
```json
{
"workspaces": ["a", "b"]
}
```
Running `asb` in the directory below will use the top level build directory to place all the binaries.
```
project/
package.json
asconfig.json
a/
asconfig.json
assembly/
index.ts
b/
asconfig.json
assembly/
index.ts
build/
release/
a.wasm
b.wasm
debug/
a.wasm
b.wasm
```
To see an example in action check out the [test workspace](./tests/build_test)
## 📖 Background
Asbuild started as wrapper around `asc` to provide an easier CLI interface and now has been extened to support other commands
like `init`, `test` and `fmt` just like `cargo` to become a one stop build tool for AS Projects.
## 📜 License
This library is provided under the open-source
[MIT license](https://choosealicense.com/licenses/mit/).
# base-x
[](https://www.npmjs.org/package/base-x)
[](https://travis-ci.org/cryptocoinjs/base-x)
[](https://github.com/feross/standard)
Fast base encoding / decoding of any given alphabet using bitcoin style leading
zero compression.
**WARNING:** This module is **NOT RFC3548** compliant, it cannot be used for base16 (hex), base32, or base64 encoding in a standards compliant manner.
## Example
Base58
``` javascript
var BASE58 = '123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz'
var bs58 = require('base-x')(BASE58)
var decoded = bs58.decode('5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr')
console.log(decoded)
// => <Buffer 80 ed db dc 11 68 f1 da ea db d3 e4 4c 1e 3f 8f 5a 28 4c 20 29 f7 8a d2 6a f9 85 83 a4 99 de 5b 19>
console.log(bs58.encode(decoded))
// => 5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr
```
### Alphabets
See below for a list of commonly recognized alphabets, and their respective base.
Base | Alphabet
------------- | -------------
2 | `01`
8 | `01234567`
11 | `0123456789a`
16 | `0123456789abcdef`
32 | `0123456789ABCDEFGHJKMNPQRSTVWXYZ`
32 | `ybndrfg8ejkmcpqxot1uwisza345h769` (z-base-32)
36 | `0123456789abcdefghijklmnopqrstuvwxyz`
58 | `123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz`
62 | `0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ`
64 | `ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/`
67 | `ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_.!~`
## How it works
It encodes octet arrays by doing long divisions on all significant digits in the
array, creating a representation of that number in the new base. Then for every
leading zero in the input (not significant as a number) it will encode as a
single leader character. This is the first in the alphabet and will decode as 8
bits. The other characters depend upon the base. For example, a base58 alphabet
packs roughly 5.858 bits per character.
This means the encoded string 000f (using a base16, 0-f alphabet) will actually decode
to 4 bytes unlike a canonical hex encoding which uniformly packs 4 bits into each
character.
While unusual, this does mean that no padding is required and it works for bases
like 43.
## LICENSE [MIT](LICENSE)
A direct derivation of the base58 implementation from [`bitcoin/bitcoin`](https://github.com/bitcoin/bitcoin/blob/f1e2f2a85962c1664e4e55471061af0eaa798d40/src/base58.cpp), generalized for variable length alphabets.
# eslint-visitor-keys
[](https://www.npmjs.com/package/eslint-visitor-keys)
[](http://www.npmtrends.com/eslint-visitor-keys)
[](https://travis-ci.org/eslint/eslint-visitor-keys)
[](https://david-dm.org/eslint/eslint-visitor-keys)
Constants and utilities about visitor keys to traverse AST.
## 💿 Installation
Use [npm] to install.
```bash
$ npm install eslint-visitor-keys
```
### Requirements
- [Node.js] 10.0.0 or later.
## 📖 Usage
```js
const evk = require("eslint-visitor-keys")
```
### evk.KEYS
> type: `{ [type: string]: string[] | undefined }`
Visitor keys. This keys are frozen.
This is an object. Keys are the type of [ESTree] nodes. Their values are an array of property names which have child nodes.
For example:
```
console.log(evk.KEYS.AssignmentExpression) // → ["left", "right"]
```
### evk.getKeys(node)
> type: `(node: object) => string[]`
Get the visitor keys of a given AST node.
This is similar to `Object.keys(node)` of ES Standard, but some keys are excluded: `parent`, `leadingComments`, `trailingComments`, and names which start with `_`.
This will be used to traverse unknown nodes.
For example:
```
const node = {
type: "AssignmentExpression",
left: { type: "Identifier", name: "foo" },
right: { type: "Literal", value: 0 }
}
console.log(evk.getKeys(node)) // → ["type", "left", "right"]
```
### evk.unionWith(additionalKeys)
> type: `(additionalKeys: object) => { [type: string]: string[] | undefined }`
Make the union set with `evk.KEYS` and the given keys.
- The order of keys is, `additionalKeys` is at first, then `evk.KEYS` is concatenated after that.
- It removes duplicated keys as keeping the first one.
For example:
```
console.log(evk.unionWith({
MethodDefinition: ["decorators"]
})) // → { ..., MethodDefinition: ["decorators", "key", "value"], ... }
```
## 📰 Change log
See [GitHub releases](https://github.com/eslint/eslint-visitor-keys/releases).
## 🍻 Contributing
Welcome. See [ESLint contribution guidelines](https://eslint.org/docs/developer-guide/contributing/).
### Development commands
- `npm test` runs tests and measures code coverage.
- `npm run lint` checks source codes with ESLint.
- `npm run coverage` opens the code coverage report of the previous test with your default browser.
- `npm run release` publishes this package to [npm] registory.
[npm]: https://www.npmjs.com/
[Node.js]: https://nodejs.org/en/
[ESTree]: https://github.com/estree/estree
# URI.js
URI.js is an [RFC 3986](http://www.ietf.org/rfc/rfc3986.txt) compliant, scheme extendable URI parsing/validating/resolving library for all JavaScript environments (browsers, Node.js, etc).
It is also compliant with the IRI ([RFC 3987](http://www.ietf.org/rfc/rfc3987.txt)), IDNA ([RFC 5890](http://www.ietf.org/rfc/rfc5890.txt)), IPv6 Address ([RFC 5952](http://www.ietf.org/rfc/rfc5952.txt)), IPv6 Zone Identifier ([RFC 6874](http://www.ietf.org/rfc/rfc6874.txt)) specifications.
URI.js has an extensive test suite, and works in all (Node.js, web) environments. It weighs in at 6.4kb (gzipped, 17kb deflated).
## API
### Parsing
URI.parse("uri://user:pass@example.com:123/one/two.three?q1=a1&q2=a2#body");
//returns:
//{
// scheme : "uri",
// userinfo : "user:pass",
// host : "example.com",
// port : 123,
// path : "/one/two.three",
// query : "q1=a1&q2=a2",
// fragment : "body"
//}
### Serializing
URI.serialize({scheme : "http", host : "example.com", fragment : "footer"}) === "http://example.com/#footer"
### Resolving
URI.resolve("uri://a/b/c/d?q", "../../g") === "uri://a/g"
### Normalizing
URI.normalize("HTTP://ABC.com:80/%7Esmith/home.html") === "http://abc.com/~smith/home.html"
### Comparison
URI.equal("example://a/b/c/%7Bfoo%7D", "eXAMPLE://a/./b/../b/%63/%7bfoo%7d") === true
### IP Support
//IPv4 normalization
URI.normalize("//192.068.001.000") === "//192.68.1.0"
//IPv6 normalization
URI.normalize("//[2001:0:0DB8::0:0001]") === "//[2001:0:db8::1]"
//IPv6 zone identifier support
URI.parse("//[2001:db8::7%25en1]");
//returns:
//{
// host : "2001:db8::7%en1"
//}
### IRI Support
//convert IRI to URI
URI.serialize(URI.parse("http://examplé.org/rosé")) === "http://xn--exampl-gva.org/ros%C3%A9"
//convert URI to IRI
URI.serialize(URI.parse("http://xn--exampl-gva.org/ros%C3%A9"), {iri:true}) === "http://examplé.org/rosé"
### Options
All of the above functions can accept an additional options argument that is an object that can contain one or more of the following properties:
* `scheme` (string)
Indicates the scheme that the URI should be treated as, overriding the URI's normal scheme parsing behavior.
* `reference` (string)
If set to `"suffix"`, it indicates that the URI is in the suffix format, and the validator will use the option's `scheme` property to determine the URI's scheme.
* `tolerant` (boolean, false)
If set to `true`, the parser will relax URI resolving rules.
* `absolutePath` (boolean, false)
If set to `true`, the serializer will not resolve a relative `path` component.
* `iri` (boolean, false)
If set to `true`, the serializer will unescape non-ASCII characters as per [RFC 3987](http://www.ietf.org/rfc/rfc3987.txt).
* `unicodeSupport` (boolean, false)
If set to `true`, the parser will unescape non-ASCII characters in the parsed output as per [RFC 3987](http://www.ietf.org/rfc/rfc3987.txt).
* `domainHost` (boolean, false)
If set to `true`, the library will treat the `host` component as a domain name, and convert IDNs (International Domain Names) as per [RFC 5891](http://www.ietf.org/rfc/rfc5891.txt).
## Scheme Extendable
URI.js supports inserting custom [scheme](http://en.wikipedia.org/wiki/URI_scheme) dependent processing rules. Currently, URI.js has built in support for the following schemes:
* http \[[RFC 2616](http://www.ietf.org/rfc/rfc2616.txt)\]
* https \[[RFC 2818](http://www.ietf.org/rfc/rfc2818.txt)\]
* ws \[[RFC 6455](http://www.ietf.org/rfc/rfc6455.txt)\]
* wss \[[RFC 6455](http://www.ietf.org/rfc/rfc6455.txt)\]
* mailto \[[RFC 6068](http://www.ietf.org/rfc/rfc6068.txt)\]
* urn \[[RFC 2141](http://www.ietf.org/rfc/rfc2141.txt)\]
* urn:uuid \[[RFC 4122](http://www.ietf.org/rfc/rfc4122.txt)\]
### HTTP/HTTPS Support
URI.equal("HTTP://ABC.COM:80", "http://abc.com/") === true
URI.equal("https://abc.com", "HTTPS://ABC.COM:443/") === true
### WS/WSS Support
URI.parse("wss://example.com/foo?bar=baz");
//returns:
//{
// scheme : "wss",
// host: "example.com",
// resourceName: "/foo?bar=baz",
// secure: true,
//}
URI.equal("WS://ABC.COM:80/chat#one", "ws://abc.com/chat") === true
### Mailto Support
URI.parse("mailto:alpha@example.com,bravo@example.com?subject=SUBSCRIBE&body=Sign%20me%20up!");
//returns:
//{
// scheme : "mailto",
// to : ["alpha@example.com", "bravo@example.com"],
// subject : "SUBSCRIBE",
// body : "Sign me up!"
//}
URI.serialize({
scheme : "mailto",
to : ["alpha@example.com"],
subject : "REMOVE",
body : "Please remove me",
headers : {
cc : "charlie@example.com"
}
}) === "mailto:alpha@example.com?cc=charlie@example.com&subject=REMOVE&body=Please%20remove%20me"
### URN Support
URI.parse("urn:example:foo");
//returns:
//{
// scheme : "urn",
// nid : "example",
// nss : "foo",
//}
#### URN UUID Support
URI.parse("urn:uuid:f81d4fae-7dec-11d0-a765-00a0c91e6bf6");
//returns:
//{
// scheme : "urn",
// nid : "uuid",
// uuid : "f81d4fae-7dec-11d0-a765-00a0c91e6bf6",
//}
## Usage
To load in a browser, use the following tag:
<script type="text/javascript" src="uri-js/dist/es5/uri.all.min.js"></script>
To load in a CommonJS/Module environment, first install with npm/yarn by running on the command line:
npm install uri-js
# OR
yarn add uri-js
Then, in your code, load it using:
const URI = require("uri-js");
If you are writing your code in ES6+ (ESNEXT) or TypeScript, you would load it using:
import * as URI from "uri-js";
Or you can load just what you need using named exports:
import { parse, serialize, resolve, resolveComponents, normalize, equal, removeDotSegments, pctEncChar, pctDecChars, escapeComponent, unescapeComponent } from "uri-js";
## Breaking changes
### Breaking changes from 3.x
URN parsing has been completely changed to better align with the specification. Scheme is now always `urn`, but has two new properties: `nid` which contains the Namspace Identifier, and `nss` which contains the Namespace Specific String. The `nss` property will be removed by higher order scheme handlers, such as the UUID URN scheme handler.
The UUID of a URN can now be found in the `uuid` property.
### Breaking changes from 2.x
URI validation has been removed as it was slow, exposed a vulnerabilty, and was generally not useful.
### Breaking changes from 1.x
The `errors` array on parsed components is now an `error` string.
# near-sdk-core
This package contain a convenient interface for interacting with NEAR's host runtime. To see the functions that are provided by the host node see [`env.ts`](./assembly/env/env.ts).
<img align="right" alt="Ajv logo" width="160" src="https://ajv.js.org/img/ajv.svg">
# Ajv JSON schema validator
The fastest JSON validator for Node.js and browser.
Supports JSON Schema draft-04/06/07/2019-09/2020-12 ([draft-04 support](https://ajv.js.org/json-schema.html#draft-04) requires ajv-draft-04 package) and JSON Type Definition [RFC8927](https://datatracker.ietf.org/doc/rfc8927/).
[](https://github.com/ajv-validator/ajv/actions?query=workflow%3Abuild)
[](https://www.npmjs.com/package/ajv)
[](https://www.npmjs.com/package/ajv)
[](https://coveralls.io/github/ajv-validator/ajv?branch=master)
[](https://gitter.im/ajv-validator/ajv)
[](https://github.com/sponsors/epoberezkin)
## Ajv sponsors
[<img src="https://ajv.js.org/img/mozilla.svg" width="45%" alt="Mozilla">](https://www.mozilla.org)<img src="https://ajv.js.org/img/gap.svg" width="9%">[<img src="https://ajv.js.org/img/reserved.svg" width="45%">](https://opencollective.com/ajv)
[<img src="https://ajv.js.org/img/microsoft.png" width="31%" alt="Microsoft">](https://opensource.microsoft.com)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/reserved.svg" width="31%">](https://opencollective.com/ajv)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/reserved.svg" width="31%">](https://opencollective.com/ajv)
[<img src="https://ajv.js.org/img/retool.svg" width="22.5%" alt="Retool">](https://retool.com/?utm_source=sponsor&utm_campaign=ajv)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/tidelift.svg" width="22.5%" alt="Tidelift">](https://tidelift.com/subscription/pkg/npm-ajv?utm_source=npm-ajv&utm_medium=referral&utm_campaign=enterprise)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/reserved.svg" width="22.5%">](https://opencollective.com/ajv)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/reserved.svg" width="22.5%">](https://opencollective.com/ajv)
## Contributing
More than 100 people contributed to Ajv, and we would love to have you join the development. We welcome implementing new features that will benefit many users and ideas to improve our documentation.
Please review [Contributing guidelines](./CONTRIBUTING.md) and [Code components](https://ajv.js.org/components.html).
## Documentation
All documentation is available on the [Ajv website](https://ajv.js.org).
Some useful site links:
- [Getting started](https://ajv.js.org/guide/getting-started.html)
- [JSON Schema vs JSON Type Definition](https://ajv.js.org/guide/schema-language.html)
- [API reference](https://ajv.js.org/api.html)
- [Strict mode](https://ajv.js.org/strict-mode.html)
- [Standalone validation code](https://ajv.js.org/standalone.html)
- [Security considerations](https://ajv.js.org/security.html)
- [Command line interface](https://ajv.js.org/packages/ajv-cli.html)
- [Frequently Asked Questions](https://ajv.js.org/faq.html)
## <a name="sponsors"></a>Please [sponsor Ajv development](https://github.com/sponsors/epoberezkin)
Since I asked to support Ajv development 40 people and 6 organizations contributed via GitHub and OpenCollective - this support helped receiving the MOSS grant!
Your continuing support is very important - the funds will be used to develop and maintain Ajv once the next major version is released.
Please sponsor Ajv via:
- [GitHub sponsors page](https://github.com/sponsors/epoberezkin) (GitHub will match it)
- [Ajv Open Collective️](https://opencollective.com/ajv)
Thank you.
#### Open Collective sponsors
<a href="https://opencollective.com/ajv"><img src="https://opencollective.com/ajv/individuals.svg?width=890"></a>
<a href="https://opencollective.com/ajv/organization/0/website"><img src="https://opencollective.com/ajv/organization/0/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/1/website"><img src="https://opencollective.com/ajv/organization/1/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/2/website"><img src="https://opencollective.com/ajv/organization/2/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/3/website"><img src="https://opencollective.com/ajv/organization/3/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/4/website"><img src="https://opencollective.com/ajv/organization/4/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/5/website"><img src="https://opencollective.com/ajv/organization/5/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/6/website"><img src="https://opencollective.com/ajv/organization/6/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/7/website"><img src="https://opencollective.com/ajv/organization/7/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/8/website"><img src="https://opencollective.com/ajv/organization/8/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/9/website"><img src="https://opencollective.com/ajv/organization/9/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/10/website"><img src="https://opencollective.com/ajv/organization/10/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/11/website"><img src="https://opencollective.com/ajv/organization/11/avatar.svg"></a>
## Performance
Ajv generates code to turn JSON Schemas into super-fast validation functions that are efficient for v8 optimization.
Currently Ajv is the fastest and the most standard compliant validator according to these benchmarks:
- [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark) - 50% faster than the second place
- [jsck benchmark](https://github.com/pandastrike/jsck#benchmarks) - 20-190% faster
- [z-schema benchmark](https://rawgit.com/zaggino/z-schema/master/benchmark/results.html)
- [themis benchmark](https://cdn.rawgit.com/playlyfe/themis/master/benchmark/results.html)
Performance of different validators by [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark):
[](https://github.com/ebdrup/json-schema-benchmark/blob/master/README.md#performance)
## Features
- Ajv implements JSON Schema [draft-06/07/2019-09/2020-12](http://json-schema.org/) standards (draft-04 is supported in v6):
- all validation keywords (see [JSON Schema validation keywords](https://ajv.js.org/json-schema.html))
- [OpenAPI](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.3.md) extensions:
- NEW: keyword [discriminator](https://ajv.js.org/json-schema.html#discriminator).
- keyword [nullable](https://ajv.js.org/json-schema.html#nullable).
- full support of remote references (remote schemas have to be added with `addSchema` or compiled to be available)
- support of recursive references between schemas
- correct string lengths for strings with unicode pairs
- JSON Schema [formats](https://ajv.js.org/guide/formats.html) (with [ajv-formats](https://github.com/ajv-validator/ajv-formats) plugin).
- [validates schemas against meta-schema](https://ajv.js.org/api.html#api-validateschema)
- NEW: supports [JSON Type Definition](https://datatracker.ietf.org/doc/rfc8927/):
- all keywords (see [JSON Type Definition schema forms](https://ajv.js.org/json-type-definition.html))
- meta-schema for JTD schemas
- "union" keyword and user-defined keywords (can be used inside "metadata" member of the schema)
- supports [browsers](https://ajv.js.org/guide/environments.html#browsers) and Node.js 10.x - current
- [asynchronous loading](https://ajv.js.org/guide/managing-schemas.html#asynchronous-schema-loading) of referenced schemas during compilation
- "All errors" validation mode with [option allErrors](https://ajv.js.org/options.html#allerrors)
- [error messages with parameters](https://ajv.js.org/api.html#validation-errors) describing error reasons to allow error message generation
- i18n error messages support with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package
- [removing-additional-properties](https://ajv.js.org/guide/modifying-data.html#removing-additional-properties)
- [assigning defaults](https://ajv.js.org/guide/modifying-data.html#assigning-defaults) to missing properties and items
- [coercing data](https://ajv.js.org/guide/modifying-data.html#coercing-data-types) to the types specified in `type` keywords
- [user-defined keywords](https://ajv.js.org/guide/user-keywords.html)
- additional extension keywords with [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package
- [\$data reference](https://ajv.js.org/guide/combining-schemas.html#data-reference) to use values from the validated data as values for the schema keywords
- [asynchronous validation](https://ajv.js.org/guide/async-validation.html) of user-defined formats and keywords
## Install
To install version 8:
```
npm install ajv
```
## <a name="usage"></a>Getting started
Try it in the Node.js REPL: https://runkit.com/npm/ajv
In JavaScript:
```javascript
// or ESM/TypeScript import
import Ajv from "ajv"
// Node.js require:
const Ajv = require("ajv")
const ajv = new Ajv() // options can be passed, e.g. {allErrors: true}
const schema = {
type: "object",
properties: {
foo: {type: "integer"},
bar: {type: "string"}
},
required: ["foo"],
additionalProperties: false,
}
const data = {
foo: 1,
bar: "abc"
}
const validate = ajv.compile(schema)
const valid = validate(data)
if (!valid) console.log(validate.errors)
```
Learn how to use Ajv and see more examples in the [Guide: getting started](https://ajv.js.org/guide/getting-started.html)
## Changes history
See [https://github.com/ajv-validator/ajv/releases](https://github.com/ajv-validator/ajv/releases)
**Please note**: [Changes in version 8.0.0](https://github.com/ajv-validator/ajv/releases/tag/v8.0.0)
[Version 7.0.0](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0)
[Version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0).
## Code of conduct
Please review and follow the [Code of conduct](./CODE_OF_CONDUCT.md).
Please report any unacceptable behaviour to ajv.validator@gmail.com - it will be reviewed by the project team.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerabilities via GitHub issues.
## Open-source software support
Ajv is a part of [Tidelift subscription](https://tidelift.com/subscription/pkg/npm-ajv?utm_source=npm-ajv&utm_medium=referral&utm_campaign=readme) - it provides a centralised support to open-source software users, in addition to the support provided by software maintainers.
## License
[MIT](./LICENSE)
# whatwg-url
whatwg-url is a full implementation of the WHATWG [URL Standard](https://url.spec.whatwg.org/). It can be used standalone, but it also exposes a lot of the internal algorithms that are useful for integrating a URL parser into a project like [jsdom](https://github.com/tmpvar/jsdom).
## Specification conformance
whatwg-url is currently up to date with the URL spec up to commit [7ae1c69](https://github.com/whatwg/url/commit/7ae1c691c96f0d82fafa24c33aa1e8df9ffbf2bc).
For `file:` URLs, whose [origin is left unspecified](https://url.spec.whatwg.org/#concept-url-origin), whatwg-url chooses to use a new opaque origin (which serializes to `"null"`).
## API
### The `URL` and `URLSearchParams` classes
The main API is provided by the [`URL`](https://url.spec.whatwg.org/#url-class) and [`URLSearchParams`](https://url.spec.whatwg.org/#interface-urlsearchparams) exports, which follows the spec's behavior in all ways (including e.g. `USVString` conversion). Most consumers of this library will want to use these.
### Low-level URL Standard API
The following methods are exported for use by places like jsdom that need to implement things like [`HTMLHyperlinkElementUtils`](https://html.spec.whatwg.org/#htmlhyperlinkelementutils). They mostly operate on or return an "internal URL" or ["URL record"](https://url.spec.whatwg.org/#concept-url) type.
- [URL parser](https://url.spec.whatwg.org/#concept-url-parser): `parseURL(input, { baseURL, encodingOverride })`
- [Basic URL parser](https://url.spec.whatwg.org/#concept-basic-url-parser): `basicURLParse(input, { baseURL, encodingOverride, url, stateOverride })`
- [URL serializer](https://url.spec.whatwg.org/#concept-url-serializer): `serializeURL(urlRecord, excludeFragment)`
- [Host serializer](https://url.spec.whatwg.org/#concept-host-serializer): `serializeHost(hostFromURLRecord)`
- [Serialize an integer](https://url.spec.whatwg.org/#serialize-an-integer): `serializeInteger(number)`
- [Origin](https://url.spec.whatwg.org/#concept-url-origin) [serializer](https://html.spec.whatwg.org/multipage/origin.html#ascii-serialisation-of-an-origin): `serializeURLOrigin(urlRecord)`
- [Set the username](https://url.spec.whatwg.org/#set-the-username): `setTheUsername(urlRecord, usernameString)`
- [Set the password](https://url.spec.whatwg.org/#set-the-password): `setThePassword(urlRecord, passwordString)`
- [Cannot have a username/password/port](https://url.spec.whatwg.org/#cannot-have-a-username-password-port): `cannotHaveAUsernamePasswordPort(urlRecord)`
- [Percent decode](https://url.spec.whatwg.org/#percent-decode): `percentDecode(buffer)`
The `stateOverride` parameter is one of the following strings:
- [`"scheme start"`](https://url.spec.whatwg.org/#scheme-start-state)
- [`"scheme"`](https://url.spec.whatwg.org/#scheme-state)
- [`"no scheme"`](https://url.spec.whatwg.org/#no-scheme-state)
- [`"special relative or authority"`](https://url.spec.whatwg.org/#special-relative-or-authority-state)
- [`"path or authority"`](https://url.spec.whatwg.org/#path-or-authority-state)
- [`"relative"`](https://url.spec.whatwg.org/#relative-state)
- [`"relative slash"`](https://url.spec.whatwg.org/#relative-slash-state)
- [`"special authority slashes"`](https://url.spec.whatwg.org/#special-authority-slashes-state)
- [`"special authority ignore slashes"`](https://url.spec.whatwg.org/#special-authority-ignore-slashes-state)
- [`"authority"`](https://url.spec.whatwg.org/#authority-state)
- [`"host"`](https://url.spec.whatwg.org/#host-state)
- [`"hostname"`](https://url.spec.whatwg.org/#hostname-state)
- [`"port"`](https://url.spec.whatwg.org/#port-state)
- [`"file"`](https://url.spec.whatwg.org/#file-state)
- [`"file slash"`](https://url.spec.whatwg.org/#file-slash-state)
- [`"file host"`](https://url.spec.whatwg.org/#file-host-state)
- [`"path start"`](https://url.spec.whatwg.org/#path-start-state)
- [`"path"`](https://url.spec.whatwg.org/#path-state)
- [`"cannot-be-a-base-URL path"`](https://url.spec.whatwg.org/#cannot-be-a-base-url-path-state)
- [`"query"`](https://url.spec.whatwg.org/#query-state)
- [`"fragment"`](https://url.spec.whatwg.org/#fragment-state)
The URL record type has the following API:
- [`scheme`](https://url.spec.whatwg.org/#concept-url-scheme)
- [`username`](https://url.spec.whatwg.org/#concept-url-username)
- [`password`](https://url.spec.whatwg.org/#concept-url-password)
- [`host`](https://url.spec.whatwg.org/#concept-url-host)
- [`port`](https://url.spec.whatwg.org/#concept-url-port)
- [`path`](https://url.spec.whatwg.org/#concept-url-path) (as an array)
- [`query`](https://url.spec.whatwg.org/#concept-url-query)
- [`fragment`](https://url.spec.whatwg.org/#concept-url-fragment)
- [`cannotBeABaseURL`](https://url.spec.whatwg.org/#url-cannot-be-a-base-url-flag) (as a boolean)
These properties should be treated with care, as in general changing them will cause the URL record to be in an inconsistent state until the appropriate invocation of `basicURLParse` is used to fix it up. You can see examples of this in the URL Standard, where there are many step sequences like "4. Set context object’s url’s fragment to the empty string. 5. Basic URL parse _input_ with context object’s url as _url_ and fragment state as _state override_." In between those two steps, a URL record is in an unusable state.
The return value of "failure" in the spec is represented by `null`. That is, functions like `parseURL` and `basicURLParse` can return _either_ a URL record _or_ `null`.
## Development instructions
First, install [Node.js](https://nodejs.org/). Then, fetch the dependencies of whatwg-url, by running from this directory:
npm install
To run tests:
npm test
To generate a coverage report:
npm run coverage
To build and run the live viewer:
npm run build
npm run build-live-viewer
Serve the contents of the `live-viewer` directory using any web server.
## Supporting whatwg-url
The jsdom project (including whatwg-url) is a community-driven project maintained by a team of [volunteers](https://github.com/orgs/jsdom/people). You could support us by:
- [Getting professional support for whatwg-url](https://tidelift.com/subscription/pkg/npm-whatwg-url?utm_source=npm-whatwg-url&utm_medium=referral&utm_campaign=readme) as part of a Tidelift subscription. Tidelift helps making open source sustainable for us while giving teams assurances for maintenance, licensing, and security.
- Contributing directly to the project.
### Estraverse [](http://travis-ci.org/estools/estraverse)
Estraverse ([estraverse](http://github.com/estools/estraverse)) is
[ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
traversal functions from [esmangle project](http://github.com/estools/esmangle).
### Documentation
You can find usage docs at [wiki page](https://github.com/estools/estraverse/wiki/Usage).
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
estraverse.traverse(ast, {
enter: function (node, parent) {
if (node.type == 'FunctionExpression' || node.type == 'FunctionDeclaration')
return estraverse.VisitorOption.Skip;
},
leave: function (node, parent) {
if (node.type == 'VariableDeclarator')
console.log(node.id.name);
}
});
```
We can use `this.skip`, `this.remove` and `this.break` functions instead of using Skip, Remove and Break.
```javascript
estraverse.traverse(ast, {
enter: function (node) {
this.break();
}
});
```
And estraverse provides `estraverse.replace` function. When returning node from `enter`/`leave`, current node is replaced with it.
```javascript
result = estraverse.replace(tree, {
enter: function (node) {
// Replace it with replaced.
if (node.type === 'Literal')
return replaced;
}
});
```
By passing `visitor.keys` mapping, we can extend estraverse traversing functionality.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Extending the existing traversing rules.
keys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
});
```
By passing `visitor.fallback` option, we can control the behavior when encountering unknown nodes.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Iterating the child **nodes** of unknown nodes.
fallback: 'iteration'
});
```
When `visitor.fallback` is a function, we can determine which keys to visit on each node.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Skip the `argument` property of each node
fallback: function(node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument';
});
}
});
```
### License
Copyright (C) 2012-2016 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# assemblyscript-json
 
JSON encoder / decoder for AssemblyScript.
Special thanks to https://github.com/MaxGraey/bignum.wasm for basic unit testing infra for AssemblyScript.
## Installation
`assemblyscript-json` is available as a [npm package](https://www.npmjs.com/package/assemblyscript-json). You can install `assemblyscript-json` in your AssemblyScript project by running:
`npm install --save assemblyscript-json`
## Usage
### Parsing JSON
```typescript
import { JSON } from "assemblyscript-json";
// Parse an object using the JSON object
let jsonObj: JSON.Obj = <JSON.Obj>(JSON.parse('{"hello": "world", "value": 24}'));
// We can then use the .getX functions to read from the object if you know it's type
// This will return the appropriate JSON.X value if the key exists, or null if the key does not exist
let worldOrNull: JSON.Str | null = jsonObj.getString("hello"); // This will return a JSON.Str or null
if (worldOrNull != null) {
// use .valueOf() to turn the high level JSON.Str type into a string
let world: string = worldOrNull.valueOf();
}
let numOrNull: JSON.Num | null = jsonObj.getNum("value");
if (numOrNull != null) {
// use .valueOf() to turn the high level JSON.Num type into a f64
let value: f64 = numOrNull.valueOf();
}
// If you don't know the value type, get the parent JSON.Value
let valueOrNull: JSON.Value | null = jsonObj.getValue("hello");
if (valueOrNull != null) {
let value = <JSON.Value>valueOrNull;
// Next we could figure out what type we are
if(value.isString) {
// value.isString would be true, so we can cast to a string
let innerString = (<JSON.Str>value).valueOf();
let jsonString = (<JSON.Str>value).stringify();
// Do something with string value
}
}
```
### Encoding JSON
```typescript
import { JSONEncoder } from "assemblyscript-json";
// Create encoder
let encoder = new JSONEncoder();
// Construct necessary object
encoder.pushObject("obj");
encoder.setInteger("int", 10);
encoder.setString("str", "");
encoder.popObject();
// Get serialized data
let json: Uint8Array = encoder.serialize();
// Or get serialized data as string
let jsonString: string = encoder.stringify();
assert(jsonString, '"obj": {"int": 10, "str": ""}'); // True!
```
### Custom JSON Deserializers
```typescript
import { JSONDecoder, JSONHandler } from "assemblyscript-json";
// Events need to be received by custom object extending JSONHandler.
// NOTE: All methods are optional to implement.
class MyJSONEventsHandler extends JSONHandler {
setString(name: string, value: string): void {
// Handle field
}
setBoolean(name: string, value: bool): void {
// Handle field
}
setNull(name: string): void {
// Handle field
}
setInteger(name: string, value: i64): void {
// Handle field
}
setFloat(name: string, value: f64): void {
// Handle field
}
pushArray(name: string): bool {
// Handle array start
// true means that nested object needs to be traversed, false otherwise
// Note that returning false means JSONDecoder.startIndex need to be updated by handler
return true;
}
popArray(): void {
// Handle array end
}
pushObject(name: string): bool {
// Handle object start
// true means that nested object needs to be traversed, false otherwise
// Note that returning false means JSONDecoder.startIndex need to be updated by handler
return true;
}
popObject(): void {
// Handle object end
}
}
// Create decoder
let decoder = new JSONDecoder<MyJSONEventsHandler>(new MyJSONEventsHandler());
// Create a byte buffer of our JSON. NOTE: Deserializers work on UTF8 string buffers.
let jsonString = '{"hello": "world"}';
let jsonBuffer = Uint8Array.wrap(String.UTF8.encode(jsonString));
// Parse JSON
decoder.deserialize(jsonBuffer); // This will send events to MyJSONEventsHandler
```
Feel free to look through the [tests](https://github.com/nearprotocol/assemblyscript-json/tree/master/assembly/__tests__) for more usage examples.
## Reference Documentation
Reference API Documentation can be found in the [docs directory](./docs).
## License
[MIT](./LICENSE)
# emoji-regex [](https://travis-ci.org/mathiasbynens/emoji-regex)
_emoji-regex_ offers a regular expression to match all emoji symbols (including textual representations of emoji) as per the Unicode Standard.
This repository contains a script that generates this regular expression based on [the data from Unicode v12](https://github.com/mathiasbynens/unicode-12.0.0). Because of this, the regular expression can easily be updated whenever new emoji are added to the Unicode standard.
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install emoji-regex
```
In [Node.js](https://nodejs.org/):
```js
const emojiRegex = require('emoji-regex');
// Note: because the regular expression has the global flag set, this module
// exports a function that returns the regex rather than exporting the regular
// expression itself, to make it impossible to (accidentally) mutate the
// original regular expression.
const text = `
\u{231A}: ⌚ default emoji presentation character (Emoji_Presentation)
\u{2194}\u{FE0F}: ↔️ default text presentation character rendered as emoji
\u{1F469}: 👩 emoji modifier base (Emoji_Modifier_Base)
\u{1F469}\u{1F3FF}: 👩🏿 emoji modifier base followed by a modifier
`;
const regex = emojiRegex();
let match;
while (match = regex.exec(text)) {
const emoji = match[0];
console.log(`Matched sequence ${ emoji } — code points: ${ [...emoji].length }`);
}
```
Console output:
```
Matched sequence ⌚ — code points: 1
Matched sequence ⌚ — code points: 1
Matched sequence ↔️ — code points: 2
Matched sequence ↔️ — code points: 2
Matched sequence 👩 — code points: 1
Matched sequence 👩 — code points: 1
Matched sequence 👩🏿 — code points: 2
Matched sequence 👩🏿 — code points: 2
```
To match emoji in their textual representation as well (i.e. emoji that are not `Emoji_Presentation` symbols and that aren’t forced to render as emoji by a variation selector), `require` the other regex:
```js
const emojiRegex = require('emoji-regex/text.js');
```
Additionally, in environments which support ES2015 Unicode escapes, you may `require` ES2015-style versions of the regexes:
```js
const emojiRegex = require('emoji-regex/es2015/index.js');
const emojiRegexText = require('emoji-regex/es2015/text.js');
```
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
_emoji-regex_ is available under the [MIT](https://mths.be/mit) license.
# fast-levenshtein - Levenshtein algorithm in Javascript
[](http://travis-ci.org/hiddentao/fast-levenshtein)
[](https://badge.fury.io/js/fast-levenshtein)
[](https://www.npmjs.com/package/fast-levenshtein)
[](https://twitter.com/hiddentao)
An efficient Javascript implementation of the [Levenshtein algorithm](http://en.wikipedia.org/wiki/Levenshtein_distance) with locale-specific collator support.
## Features
* Works in node.js and in the browser.
* Better performance than other implementations by not needing to store the whole matrix ([more info](http://www.codeproject.com/Articles/13525/Fast-memory-efficient-Levenshtein-algorithm)).
* Locale-sensitive string comparisions if needed.
* Comprehensive test suite and performance benchmark.
* Small: <1 KB minified and gzipped
## Installation
### node.js
Install using [npm](http://npmjs.org/):
```bash
$ npm install fast-levenshtein
```
### Browser
Using bower:
```bash
$ bower install fast-levenshtein
```
If you are not using any module loader system then the API will then be accessible via the `window.Levenshtein` object.
## Examples
**Default usage**
```javascript
var levenshtein = require('fast-levenshtein');
var distance = levenshtein.get('back', 'book'); // 2
var distance = levenshtein.get('我愛你', '我叫你'); // 1
```
**Locale-sensitive string comparisons**
It supports using [Intl.Collator](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Collator) for locale-sensitive string comparisons:
```javascript
var levenshtein = require('fast-levenshtein');
levenshtein.get('mikailovitch', 'Mikhaïlovitch', { useCollator: true});
// 1
```
## Building and Testing
To build the code and run the tests:
```bash
$ npm install -g grunt-cli
$ npm install
$ npm run build
```
## Performance
_Thanks to [Titus Wormer](https://github.com/wooorm) for [encouraging me](https://github.com/hiddentao/fast-levenshtein/issues/1) to do this._
Benchmarked against other node.js levenshtein distance modules (on Macbook Air 2012, Core i7, 8GB RAM):
```bash
Running suite Implementation comparison [benchmark/speed.js]...
>> levenshtein-edit-distance x 234 ops/sec ±3.02% (73 runs sampled)
>> levenshtein-component x 422 ops/sec ±4.38% (83 runs sampled)
>> levenshtein-deltas x 283 ops/sec ±3.83% (78 runs sampled)
>> natural x 255 ops/sec ±0.76% (88 runs sampled)
>> levenshtein x 180 ops/sec ±3.55% (86 runs sampled)
>> fast-levenshtein x 1,792 ops/sec ±2.72% (95 runs sampled)
Benchmark done.
Fastest test is fast-levenshtein at 4.2x faster than levenshtein-component
```
You can run this benchmark yourself by doing:
```bash
$ npm install
$ npm run build
$ npm run benchmark
```
## Contributing
If you wish to submit a pull request please update and/or create new tests for any changes you make and ensure the grunt build passes.
See [CONTRIBUTING.md](https://github.com/hiddentao/fast-levenshtein/blob/master/CONTRIBUTING.md) for details.
## License
MIT - see [LICENSE.md](https://github.com/hiddentao/fast-levenshtein/blob/master/LICENSE.md)
# once
Only call a function once.
## usage
```javascript
var once = require('once')
function load (file, cb) {
cb = once(cb)
loader.load('file')
loader.once('load', cb)
loader.once('error', cb)
}
```
Or add to the Function.prototype in a responsible way:
```javascript
// only has to be done once
require('once').proto()
function load (file, cb) {
cb = cb.once()
loader.load('file')
loader.once('load', cb)
loader.once('error', cb)
}
```
Ironically, the prototype feature makes this module twice as
complicated as necessary.
To check whether you function has been called, use `fn.called`. Once the
function is called for the first time the return value of the original
function is saved in `fn.value` and subsequent calls will continue to
return this value.
```javascript
var once = require('once')
function load (cb) {
cb = once(cb)
var stream = createStream()
stream.once('data', cb)
stream.once('end', function () {
if (!cb.called) cb(new Error('not found'))
})
}
```
## `once.strict(func)`
Throw an error if the function is called twice.
Some functions are expected to be called only once. Using `once` for them would
potentially hide logical errors.
In the example below, the `greet` function has to call the callback only once:
```javascript
function greet (name, cb) {
// return is missing from the if statement
// when no name is passed, the callback is called twice
if (!name) cb('Hello anonymous')
cb('Hello ' + name)
}
function log (msg) {
console.log(msg)
}
// this will print 'Hello anonymous' but the logical error will be missed
greet(null, once(msg))
// once.strict will print 'Hello anonymous' and throw an error when the callback will be called the second time
greet(null, once.strict(msg))
```
# binary-install
Install .tar.gz binary applications via npm
## Usage
This library provides a single class `Binary` that takes a download url and some optional arguments. You **must** provide either `name` or `installDirectory` when creating your `Binary`.
| option | decription |
| ---------------- | --------------------------------------------- |
| name | The name of your binary |
| installDirectory | A path to the directory to install the binary |
If an `installDirectory` is not provided, the binary will be installed at your OS specific config directory. On MacOS it defaults to `~/Library/Preferences/${name}-nodejs`
After your `Binary` has been created, you can run `.install()` to install the binary, and `.run()` to run it.
### Example
This is meant to be used as a library - create your `Binary` with your desired options, then call `.install()` in the `postinstall` of your `package.json`, `.run()` in the `bin` section of your `package.json`, and `.uninstall()` in the `preuninstall` section of your `package.json`. See [this example project](/example) to see how to create an npm package that installs and runs a binary using the Github releases API.
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# Web IDL Type Conversions on JavaScript Values
This package implements, in JavaScript, the algorithms to convert a given JavaScript value according to a given [Web IDL](http://heycam.github.io/webidl/) [type](http://heycam.github.io/webidl/#idl-types).
The goal is that you should be able to write code like
```js
"use strict";
const conversions = require("webidl-conversions");
function doStuff(x, y) {
x = conversions["boolean"](x);
y = conversions["unsigned long"](y);
// actual algorithm code here
}
```
and your function `doStuff` will behave the same as a Web IDL operation declared as
```webidl
void doStuff(boolean x, unsigned long y);
```
## API
This package's main module's default export is an object with a variety of methods, each corresponding to a different Web IDL type. Each method, when invoked on a JavaScript value, will give back the new JavaScript value that results after passing through the Web IDL conversion rules. (See below for more details on what that means.) Alternately, the method could throw an error, if the Web IDL algorithm is specified to do so: for example `conversions["float"](NaN)` [will throw a `TypeError`](http://heycam.github.io/webidl/#es-float).
Each method also accepts a second, optional, parameter for miscellaneous options. For conversion methods that throw errors, a string option `{ context }` may be provided to provide more information in the error message. (For example, `conversions["float"](NaN, { context: "Argument 1 of Interface's operation" })` will throw an error with message `"Argument 1 of Interface's operation is not a finite floating-point value."`) Specific conversions may also accept other options, the details of which can be found below.
## Conversions implemented
Conversions for all of the basic types from the Web IDL specification are implemented:
- [`any`](https://heycam.github.io/webidl/#es-any)
- [`void`](https://heycam.github.io/webidl/#es-void)
- [`boolean`](https://heycam.github.io/webidl/#es-boolean)
- [Integer types](https://heycam.github.io/webidl/#es-integer-types), which can additionally be provided the boolean options `{ clamp, enforceRange }` as a second parameter
- [`float`](https://heycam.github.io/webidl/#es-float), [`unrestricted float`](https://heycam.github.io/webidl/#es-unrestricted-float)
- [`double`](https://heycam.github.io/webidl/#es-double), [`unrestricted double`](https://heycam.github.io/webidl/#es-unrestricted-double)
- [`DOMString`](https://heycam.github.io/webidl/#es-DOMString), which can additionally be provided the boolean option `{ treatNullAsEmptyString }` as a second parameter
- [`ByteString`](https://heycam.github.io/webidl/#es-ByteString), [`USVString`](https://heycam.github.io/webidl/#es-USVString)
- [`object`](https://heycam.github.io/webidl/#es-object)
- [`Error`](https://heycam.github.io/webidl/#es-Error)
- [Buffer source types](https://heycam.github.io/webidl/#es-buffer-source-types)
Additionally, for convenience, the following derived type definitions are implemented:
- [`ArrayBufferView`](https://heycam.github.io/webidl/#ArrayBufferView)
- [`BufferSource`](https://heycam.github.io/webidl/#BufferSource)
- [`DOMTimeStamp`](https://heycam.github.io/webidl/#DOMTimeStamp)
- [`Function`](https://heycam.github.io/webidl/#Function)
- [`VoidFunction`](https://heycam.github.io/webidl/#VoidFunction) (although it will not censor the return type)
Derived types, such as nullable types, promise types, sequences, records, etc. are not handled by this library. You may wish to investigate the [webidl2js](https://github.com/jsdom/webidl2js) project.
### A note on the `long long` types
The `long long` and `unsigned long long` Web IDL types can hold values that cannot be stored in JavaScript numbers, so the conversion is imperfect. For example, converting the JavaScript number `18446744073709552000` to a Web IDL `long long` is supposed to produce the Web IDL value `-18446744073709551232`. Since we are representing our Web IDL values in JavaScript, we can't represent `-18446744073709551232`, so we instead the best we could do is `-18446744073709552000` as the output.
This library actually doesn't even get that far. Producing those results would require doing accurate modular arithmetic on 64-bit intermediate values, but JavaScript does not make this easy. We could pull in a big-integer library as a dependency, but in lieu of that, we for now have decided to just produce inaccurate results if you pass in numbers that are not strictly between `Number.MIN_SAFE_INTEGER` and `Number.MAX_SAFE_INTEGER`.
## Background
What's actually going on here, conceptually, is pretty weird. Let's try to explain.
Web IDL, as part of its madness-inducing design, has its own type system. When people write algorithms in web platform specs, they usually operate on Web IDL values, i.e. instances of Web IDL types. For example, if they were specifying the algorithm for our `doStuff` operation above, they would treat `x` as a Web IDL value of [Web IDL type `boolean`](http://heycam.github.io/webidl/#idl-boolean). Crucially, they would _not_ treat `x` as a JavaScript variable whose value is either the JavaScript `true` or `false`. They're instead working in a different type system altogether, with its own rules.
Separately from its type system, Web IDL defines a ["binding"](http://heycam.github.io/webidl/#ecmascript-binding) of the type system into JavaScript. This contains rules like: when you pass a JavaScript value to the JavaScript method that manifests a given Web IDL operation, how does that get converted into a Web IDL value? For example, a JavaScript `true` passed in the position of a Web IDL `boolean` argument becomes a Web IDL `true`. But, a JavaScript `true` passed in the position of a [Web IDL `unsigned long`](http://heycam.github.io/webidl/#idl-unsigned-long) becomes a Web IDL `1`. And so on.
Finally, we have the actual implementation code. This is usually C++, although these days [some smart people are using Rust](https://github.com/servo/servo). The implementation, of course, has its own type system. So when they implement the Web IDL algorithms, they don't actually use Web IDL values, since those aren't "real" outside of specs. Instead, implementations apply the Web IDL binding rules in such a way as to convert incoming JavaScript values into C++ values. For example, if code in the browser called `doStuff(true, true)`, then the implementation code would eventually receive a C++ `bool` containing `true` and a C++ `uint32_t` containing `1`.
The upside of all this is that implementations can abstract all the conversion logic away, letting Web IDL handle it, and focus on implementing the relevant methods in C++ with values of the correct type already provided. That is payoff of Web IDL, in a nutshell.
And getting to that payoff is the goal of _this_ project—but for JavaScript implementations, instead of C++ ones. That is, this library is designed to make it easier for JavaScript developers to write functions that behave like a given Web IDL operation. So conceptually, the conversion pipeline, which in its general form is JavaScript values ↦ Web IDL values ↦ implementation-language values, in this case becomes JavaScript values ↦ Web IDL values ↦ JavaScript values. And that intermediate step is where all the logic is performed: a JavaScript `true` becomes a Web IDL `1` in an unsigned long context, which then becomes a JavaScript `1`.
## Don't use this
Seriously, why would you ever use this? You really shouldn't. Web IDL is … strange, and you shouldn't be emulating its semantics. If you're looking for a generic argument-processing library, you should find one with better rules than those from Web IDL. In general, your JavaScript should not be trying to become more like Web IDL; if anything, we should fix Web IDL to make it more like JavaScript.
The _only_ people who should use this are those trying to create faithful implementations (or polyfills) of web platform interfaces defined in Web IDL. Its main consumer is the [jsdom](https://github.com/tmpvar/jsdom) project.
# ESLint Scope
ESLint Scope is the [ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm) scope analyzer used in ESLint. It is a fork of [escope](http://github.com/estools/escope).
## Usage
Install:
```
npm i eslint-scope --save
```
Example:
```js
var eslintScope = require('eslint-scope');
var espree = require('espree');
var estraverse = require('estraverse');
var ast = espree.parse(code);
var scopeManager = eslintScope.analyze(ast);
var currentScope = scopeManager.acquire(ast); // global scope
estraverse.traverse(ast, {
enter: function(node, parent) {
// do stuff
if (/Function/.test(node.type)) {
currentScope = scopeManager.acquire(node); // get current function scope
}
},
leave: function(node, parent) {
if (/Function/.test(node.type)) {
currentScope = currentScope.upper; // set to parent scope
}
// do stuff
}
});
```
## Contributing
Issues and pull requests will be triaged and responded to as quickly as possible. We operate under the [ESLint Contributor Guidelines](http://eslint.org/docs/developer-guide/contributing), so please be sure to read them before contributing. If you're not sure where to dig in, check out the [issues](https://github.com/eslint/eslint-scope/issues).
## Build Commands
* `npm test` - run all linting and tests
* `npm run lint` - run all linting
## License
ESLint Scope is licensed under a permissive BSD 2-clause license.
# axios
[](https://www.npmjs.org/package/axios)
[](https://travis-ci.org/axios/axios)
[](https://coveralls.io/r/mzabriskie/axios)
[](https://packagephobia.now.sh/result?p=axios)
[](http://npm-stat.com/charts.html?package=axios)
[](https://gitter.im/mzabriskie/axios)
[](https://www.codetriage.com/axios/axios)
Promise based HTTP client for the browser and node.js
## Features
- Make [XMLHttpRequests](https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest) from the browser
- Make [http](http://nodejs.org/api/http.html) requests from node.js
- Supports the [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) API
- Intercept request and response
- Transform request and response data
- Cancel requests
- Automatic transforms for JSON data
- Client side support for protecting against [XSRF](http://en.wikipedia.org/wiki/Cross-site_request_forgery)
## Browser Support
 |  |  |  |  |  |
--- | --- | --- | --- | --- | --- |
Latest ✔ | Latest ✔ | Latest ✔ | Latest ✔ | Latest ✔ | 11 ✔ |
[](https://saucelabs.com/u/axios)
## Installing
Using npm:
```bash
$ npm install axios
```
Using bower:
```bash
$ bower install axios
```
Using yarn:
```bash
$ yarn add axios
```
Using cdn:
```html
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
```
## Example
### note: CommonJS usage
In order to gain the TypeScript typings (for intellisense / autocomplete) while using CommonJS imports with `require()` use the following approach:
```js
const axios = require('axios').default;
// axios.<method> will now provide autocomplete and parameter typings
```
Performing a `GET` request
```js
const axios = require('axios');
// Make a request for a user with a given ID
axios.get('/user?ID=12345')
.then(function (response) {
// handle success
console.log(response);
})
.catch(function (error) {
// handle error
console.log(error);
})
.finally(function () {
// always executed
});
// Optionally the request above could also be done as
axios.get('/user', {
params: {
ID: 12345
}
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
})
.finally(function () {
// always executed
});
// Want to use async/await? Add the `async` keyword to your outer function/method.
async function getUser() {
try {
const response = await axios.get('/user?ID=12345');
console.log(response);
} catch (error) {
console.error(error);
}
}
```
> **NOTE:** `async/await` is part of ECMAScript 2017 and is not supported in Internet
> Explorer and older browsers, so use with caution.
Performing a `POST` request
```js
axios.post('/user', {
firstName: 'Fred',
lastName: 'Flintstone'
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
```
Performing multiple concurrent requests
```js
function getUserAccount() {
return axios.get('/user/12345');
}
function getUserPermissions() {
return axios.get('/user/12345/permissions');
}
axios.all([getUserAccount(), getUserPermissions()])
.then(axios.spread(function (acct, perms) {
// Both requests are now complete
}));
```
## axios API
Requests can be made by passing the relevant config to `axios`.
##### axios(config)
```js
// Send a POST request
axios({
method: 'post',
url: '/user/12345',
data: {
firstName: 'Fred',
lastName: 'Flintstone'
}
});
```
```js
// GET request for remote image
axios({
method: 'get',
url: 'http://bit.ly/2mTM3nY',
responseType: 'stream'
})
.then(function (response) {
response.data.pipe(fs.createWriteStream('ada_lovelace.jpg'))
});
```
##### axios(url[, config])
```js
// Send a GET request (default method)
axios('/user/12345');
```
### Request method aliases
For convenience aliases have been provided for all supported request methods.
##### axios.request(config)
##### axios.get(url[, config])
##### axios.delete(url[, config])
##### axios.head(url[, config])
##### axios.options(url[, config])
##### axios.post(url[, data[, config]])
##### axios.put(url[, data[, config]])
##### axios.patch(url[, data[, config]])
###### NOTE
When using the alias methods `url`, `method`, and `data` properties don't need to be specified in config.
### Concurrency
Helper functions for dealing with concurrent requests.
##### axios.all(iterable)
##### axios.spread(callback)
### Creating an instance
You can create a new instance of axios with a custom config.
##### axios.create([config])
```js
const instance = axios.create({
baseURL: 'https://some-domain.com/api/',
timeout: 1000,
headers: {'X-Custom-Header': 'foobar'}
});
```
### Instance methods
The available instance methods are listed below. The specified config will be merged with the instance config.
##### axios#request(config)
##### axios#get(url[, config])
##### axios#delete(url[, config])
##### axios#head(url[, config])
##### axios#options(url[, config])
##### axios#post(url[, data[, config]])
##### axios#put(url[, data[, config]])
##### axios#patch(url[, data[, config]])
##### axios#getUri([config])
## Request Config
These are the available config options for making requests. Only the `url` is required. Requests will default to `GET` if `method` is not specified.
```js
{
// `url` is the server URL that will be used for the request
url: '/user',
// `method` is the request method to be used when making the request
method: 'get', // default
// `baseURL` will be prepended to `url` unless `url` is absolute.
// It can be convenient to set `baseURL` for an instance of axios to pass relative URLs
// to methods of that instance.
baseURL: 'https://some-domain.com/api/',
// `transformRequest` allows changes to the request data before it is sent to the server
// This is only applicable for request methods 'PUT', 'POST', 'PATCH' and 'DELETE'
// The last function in the array must return a string or an instance of Buffer, ArrayBuffer,
// FormData or Stream
// You may modify the headers object.
transformRequest: [function (data, headers) {
// Do whatever you want to transform the data
return data;
}],
// `transformResponse` allows changes to the response data to be made before
// it is passed to then/catch
transformResponse: [function (data) {
// Do whatever you want to transform the data
return data;
}],
// `headers` are custom headers to be sent
headers: {'X-Requested-With': 'XMLHttpRequest'},
// `params` are the URL parameters to be sent with the request
// Must be a plain object or a URLSearchParams object
params: {
ID: 12345
},
// `paramsSerializer` is an optional function in charge of serializing `params`
// (e.g. https://www.npmjs.com/package/qs, http://api.jquery.com/jquery.param/)
paramsSerializer: function (params) {
return Qs.stringify(params, {arrayFormat: 'brackets'})
},
// `data` is the data to be sent as the request body
// Only applicable for request methods 'PUT', 'POST', and 'PATCH'
// When no `transformRequest` is set, must be of one of the following types:
// - string, plain object, ArrayBuffer, ArrayBufferView, URLSearchParams
// - Browser only: FormData, File, Blob
// - Node only: Stream, Buffer
data: {
firstName: 'Fred'
},
// syntax alternative to send data into the body
// method post
// only the value is sent, not the key
data: 'Country=Brasil&City=Belo Horizonte',
// `timeout` specifies the number of milliseconds before the request times out.
// If the request takes longer than `timeout`, the request will be aborted.
timeout: 1000, // default is `0` (no timeout)
// `withCredentials` indicates whether or not cross-site Access-Control requests
// should be made using credentials
withCredentials: false, // default
// `adapter` allows custom handling of requests which makes testing easier.
// Return a promise and supply a valid response (see lib/adapters/README.md).
adapter: function (config) {
/* ... */
},
// `auth` indicates that HTTP Basic auth should be used, and supplies credentials.
// This will set an `Authorization` header, overwriting any existing
// `Authorization` custom headers you have set using `headers`.
// Please note that only HTTP Basic auth is configurable through this parameter.
// For Bearer tokens and such, use `Authorization` custom headers instead.
auth: {
username: 'janedoe',
password: 's00pers3cret'
},
// `responseType` indicates the type of data that the server will respond with
// options are: 'arraybuffer', 'document', 'json', 'text', 'stream'
// browser only: 'blob'
responseType: 'json', // default
// `responseEncoding` indicates encoding to use for decoding responses
// Note: Ignored for `responseType` of 'stream' or client-side requests
responseEncoding: 'utf8', // default
// `xsrfCookieName` is the name of the cookie to use as a value for xsrf token
xsrfCookieName: 'XSRF-TOKEN', // default
// `xsrfHeaderName` is the name of the http header that carries the xsrf token value
xsrfHeaderName: 'X-XSRF-TOKEN', // default
// `onUploadProgress` allows handling of progress events for uploads
onUploadProgress: function (progressEvent) {
// Do whatever you want with the native progress event
},
// `onDownloadProgress` allows handling of progress events for downloads
onDownloadProgress: function (progressEvent) {
// Do whatever you want with the native progress event
},
// `maxContentLength` defines the max size of the http response content in bytes allowed
maxContentLength: 2000,
// `validateStatus` defines whether to resolve or reject the promise for a given
// HTTP response status code. If `validateStatus` returns `true` (or is set to `null`
// or `undefined`), the promise will be resolved; otherwise, the promise will be
// rejected.
validateStatus: function (status) {
return status >= 200 && status < 300; // default
},
// `maxRedirects` defines the maximum number of redirects to follow in node.js.
// If set to 0, no redirects will be followed.
maxRedirects: 5, // default
// `socketPath` defines a UNIX Socket to be used in node.js.
// e.g. '/var/run/docker.sock' to send requests to the docker daemon.
// Only either `socketPath` or `proxy` can be specified.
// If both are specified, `socketPath` is used.
socketPath: null, // default
// `httpAgent` and `httpsAgent` define a custom agent to be used when performing http
// and https requests, respectively, in node.js. This allows options to be added like
// `keepAlive` that are not enabled by default.
httpAgent: new http.Agent({ keepAlive: true }),
httpsAgent: new https.Agent({ keepAlive: true }),
// 'proxy' defines the hostname and port of the proxy server.
// You can also define your proxy using the conventional `http_proxy` and
// `https_proxy` environment variables. If you are using environment variables
// for your proxy configuration, you can also define a `no_proxy` environment
// variable as a comma-separated list of domains that should not be proxied.
// Use `false` to disable proxies, ignoring environment variables.
// `auth` indicates that HTTP Basic auth should be used to connect to the proxy, and
// supplies credentials.
// This will set an `Proxy-Authorization` header, overwriting any existing
// `Proxy-Authorization` custom headers you have set using `headers`.
proxy: {
host: '127.0.0.1',
port: 9000,
auth: {
username: 'mikeymike',
password: 'rapunz3l'
}
},
// `cancelToken` specifies a cancel token that can be used to cancel the request
// (see Cancellation section below for details)
cancelToken: new CancelToken(function (cancel) {
})
}
```
## Response Schema
The response for a request contains the following information.
```js
{
// `data` is the response that was provided by the server
data: {},
// `status` is the HTTP status code from the server response
status: 200,
// `statusText` is the HTTP status message from the server response
statusText: 'OK',
// `headers` the headers that the server responded with
// All header names are lower cased
headers: {},
// `config` is the config that was provided to `axios` for the request
config: {},
// `request` is the request that generated this response
// It is the last ClientRequest instance in node.js (in redirects)
// and an XMLHttpRequest instance in the browser
request: {}
}
```
When using `then`, you will receive the response as follows:
```js
axios.get('/user/12345')
.then(function (response) {
console.log(response.data);
console.log(response.status);
console.log(response.statusText);
console.log(response.headers);
console.log(response.config);
});
```
When using `catch`, or passing a [rejection callback](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise/then) as second parameter of `then`, the response will be available through the `error` object as explained in the [Handling Errors](#handling-errors) section.
## Config Defaults
You can specify config defaults that will be applied to every request.
### Global axios defaults
```js
axios.defaults.baseURL = 'https://api.example.com';
axios.defaults.headers.common['Authorization'] = AUTH_TOKEN;
axios.defaults.headers.post['Content-Type'] = 'application/x-www-form-urlencoded';
```
### Custom instance defaults
```js
// Set config defaults when creating the instance
const instance = axios.create({
baseURL: 'https://api.example.com'
});
// Alter defaults after instance has been created
instance.defaults.headers.common['Authorization'] = AUTH_TOKEN;
```
### Config order of precedence
Config will be merged with an order of precedence. The order is library defaults found in [lib/defaults.js](https://github.com/axios/axios/blob/master/lib/defaults.js#L28), then `defaults` property of the instance, and finally `config` argument for the request. The latter will take precedence over the former. Here's an example.
```js
// Create an instance using the config defaults provided by the library
// At this point the timeout config value is `0` as is the default for the library
const instance = axios.create();
// Override timeout default for the library
// Now all requests using this instance will wait 2.5 seconds before timing out
instance.defaults.timeout = 2500;
// Override timeout for this request as it's known to take a long time
instance.get('/longRequest', {
timeout: 5000
});
```
## Interceptors
You can intercept requests or responses before they are handled by `then` or `catch`.
```js
// Add a request interceptor
axios.interceptors.request.use(function (config) {
// Do something before request is sent
return config;
}, function (error) {
// Do something with request error
return Promise.reject(error);
});
// Add a response interceptor
axios.interceptors.response.use(function (response) {
// Any status code that lie within the range of 2xx cause this function to trigger
// Do something with response data
return response;
}, function (error) {
// Any status codes that falls outside the range of 2xx cause this function to trigger
// Do something with response error
return Promise.reject(error);
});
```
If you need to remove an interceptor later you can.
```js
const myInterceptor = axios.interceptors.request.use(function () {/*...*/});
axios.interceptors.request.eject(myInterceptor);
```
You can add interceptors to a custom instance of axios.
```js
const instance = axios.create();
instance.interceptors.request.use(function () {/*...*/});
```
## Handling Errors
```js
axios.get('/user/12345')
.catch(function (error) {
if (error.response) {
// The request was made and the server responded with a status code
// that falls out of the range of 2xx
console.log(error.response.data);
console.log(error.response.status);
console.log(error.response.headers);
} else if (error.request) {
// The request was made but no response was received
// `error.request` is an instance of XMLHttpRequest in the browser and an instance of
// http.ClientRequest in node.js
console.log(error.request);
} else {
// Something happened in setting up the request that triggered an Error
console.log('Error', error.message);
}
console.log(error.config);
});
```
Using the `validateStatus` config option, you can define HTTP code(s) that should throw an error.
```js
axios.get('/user/12345', {
validateStatus: function (status) {
return status < 500; // Reject only if the status code is greater than or equal to 500
}
})
```
Using `toJSON` you get an object with more information about the HTTP error.
```js
axios.get('/user/12345')
.catch(function (error) {
console.log(error.toJSON());
});
```
## Cancellation
You can cancel a request using a *cancel token*.
> The axios cancel token API is based on the withdrawn [cancelable promises proposal](https://github.com/tc39/proposal-cancelable-promises).
You can create a cancel token using the `CancelToken.source` factory as shown below:
```js
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.get('/user/12345', {
cancelToken: source.token
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// handle error
}
});
axios.post('/user/12345', {
name: 'new name'
}, {
cancelToken: source.token
})
// cancel the request (the message parameter is optional)
source.cancel('Operation canceled by the user.');
```
You can also create a cancel token by passing an executor function to the `CancelToken` constructor:
```js
const CancelToken = axios.CancelToken;
let cancel;
axios.get('/user/12345', {
cancelToken: new CancelToken(function executor(c) {
// An executor function receives a cancel function as a parameter
cancel = c;
})
});
// cancel the request
cancel();
```
> Note: you can cancel several requests with the same cancel token.
## Using application/x-www-form-urlencoded format
By default, axios serializes JavaScript objects to `JSON`. To send data in the `application/x-www-form-urlencoded` format instead, you can use one of the following options.
### Browser
In a browser, you can use the [`URLSearchParams`](https://developer.mozilla.org/en-US/docs/Web/API/URLSearchParams) API as follows:
```js
const params = new URLSearchParams();
params.append('param1', 'value1');
params.append('param2', 'value2');
axios.post('/foo', params);
```
> Note that `URLSearchParams` is not supported by all browsers (see [caniuse.com](http://www.caniuse.com/#feat=urlsearchparams)), but there is a [polyfill](https://github.com/WebReflection/url-search-params) available (make sure to polyfill the global environment).
Alternatively, you can encode data using the [`qs`](https://github.com/ljharb/qs) library:
```js
const qs = require('qs');
axios.post('/foo', qs.stringify({ 'bar': 123 }));
```
Or in another way (ES6),
```js
import qs from 'qs';
const data = { 'bar': 123 };
const options = {
method: 'POST',
headers: { 'content-type': 'application/x-www-form-urlencoded' },
data: qs.stringify(data),
url,
};
axios(options);
```
### Node.js
In node.js, you can use the [`querystring`](https://nodejs.org/api/querystring.html) module as follows:
```js
const querystring = require('querystring');
axios.post('http://something.com/', querystring.stringify({ foo: 'bar' }));
```
You can also use the [`qs`](https://github.com/ljharb/qs) library.
###### NOTE
The `qs` library is preferable if you need to stringify nested objects, as the `querystring` method has known issues with that use case (https://github.com/nodejs/node-v0.x-archive/issues/1665).
## Semver
Until axios reaches a `1.0` release, breaking changes will be released with a new minor version. For example `0.5.1`, and `0.5.4` will have the same API, but `0.6.0` will have breaking changes.
## Promises
axios depends on a native ES6 Promise implementation to be [supported](http://caniuse.com/promises).
If your environment doesn't support ES6 Promises, you can [polyfill](https://github.com/jakearchibald/es6-promise).
## TypeScript
axios includes [TypeScript](http://typescriptlang.org) definitions.
```typescript
import axios from 'axios';
axios.get('/user?ID=12345');
```
## Resources
* [Changelog](https://github.com/axios/axios/blob/master/CHANGELOG.md)
* [Upgrade Guide](https://github.com/axios/axios/blob/master/UPGRADE_GUIDE.md)
* [Ecosystem](https://github.com/axios/axios/blob/master/ECOSYSTEM.md)
* [Contributing Guide](https://github.com/axios/axios/blob/master/CONTRIBUTING.md)
* [Code of Conduct](https://github.com/axios/axios/blob/master/CODE_OF_CONDUCT.md)
## Credits
axios is heavily inspired by the [$http service](https://docs.angularjs.org/api/ng/service/$http) provided in [Angular](https://angularjs.org/). Ultimately axios is an effort to provide a standalone `$http`-like service for use outside of Angular.
## License
[MIT](LICENSE)
functional-red-black-tree
=========================
A [fully persistent](http://en.wikipedia.org/wiki/Persistent_data_structure) [red-black tree](http://en.wikipedia.org/wiki/Red%E2%80%93black_tree) written 100% in JavaScript. Works both in node.js and in the browser via [browserify](http://browserify.org/).
Functional (or fully presistent) data structures allow for non-destructive updates. So if you insert an element into the tree, it returns a new tree with the inserted element rather than destructively updating the existing tree in place. Doing this requires using extra memory, and if one were naive it could cost as much as reallocating the entire tree. Instead, this data structure saves some memory by recycling references to previously allocated subtrees. This requires using only O(log(n)) additional memory per update instead of a full O(n) copy.
Some advantages of this is that it is possible to apply insertions and removals to the tree while still iterating over previous versions of the tree. Functional and persistent data structures can also be useful in many geometric algorithms like point location within triangulations or ray queries, and can be used to analyze the history of executing various algorithms. This added power though comes at a cost, since it is generally a bit slower to use a functional data structure than an imperative version. However, if your application needs this behavior then you may consider using this module.
# Install
npm install functional-red-black-tree
# Example
Here is an example of some basic usage:
```javascript
//Load the library
var createTree = require("functional-red-black-tree")
//Create a tree
var t1 = createTree()
//Insert some items into the tree
var t2 = t1.insert(1, "foo")
var t3 = t2.insert(2, "bar")
//Remove something
var t4 = t3.remove(1)
```
# API
```javascript
var createTree = require("functional-red-black-tree")
```
## Overview
- [Tree methods](#tree-methods)
- [`var tree = createTree([compare])`](#var-tree-=-createtreecompare)
- [`tree.keys`](#treekeys)
- [`tree.values`](#treevalues)
- [`tree.length`](#treelength)
- [`tree.get(key)`](#treegetkey)
- [`tree.insert(key, value)`](#treeinsertkey-value)
- [`tree.remove(key)`](#treeremovekey)
- [`tree.find(key)`](#treefindkey)
- [`tree.ge(key)`](#treegekey)
- [`tree.gt(key)`](#treegtkey)
- [`tree.lt(key)`](#treeltkey)
- [`tree.le(key)`](#treelekey)
- [`tree.at(position)`](#treeatposition)
- [`tree.begin`](#treebegin)
- [`tree.end`](#treeend)
- [`tree.forEach(visitor(key,value)[, lo[, hi]])`](#treeforEachvisitorkeyvalue-lo-hi)
- [`tree.root`](#treeroot)
- [Node properties](#node-properties)
- [`node.key`](#nodekey)
- [`node.value`](#nodevalue)
- [`node.left`](#nodeleft)
- [`node.right`](#noderight)
- [Iterator methods](#iterator-methods)
- [`iter.key`](#iterkey)
- [`iter.value`](#itervalue)
- [`iter.node`](#iternode)
- [`iter.tree`](#itertree)
- [`iter.index`](#iterindex)
- [`iter.valid`](#itervalid)
- [`iter.clone()`](#iterclone)
- [`iter.remove()`](#iterremove)
- [`iter.update(value)`](#iterupdatevalue)
- [`iter.next()`](#iternext)
- [`iter.prev()`](#iterprev)
- [`iter.hasNext`](#iterhasnext)
- [`iter.hasPrev`](#iterhasprev)
## Tree methods
### `var tree = createTree([compare])`
Creates an empty functional tree
* `compare` is an optional comparison function, same semantics as array.sort()
**Returns** An empty tree ordered by `compare`
### `tree.keys`
A sorted array of all the keys in the tree
### `tree.values`
An array array of all the values in the tree
### `tree.length`
The number of items in the tree
### `tree.get(key)`
Retrieves the value associated to the given key
* `key` is the key of the item to look up
**Returns** The value of the first node associated to `key`
### `tree.insert(key, value)`
Creates a new tree with the new pair inserted.
* `key` is the key of the item to insert
* `value` is the value of the item to insert
**Returns** A new tree with `key` and `value` inserted
### `tree.remove(key)`
Removes the first item with `key` in the tree
* `key` is the key of the item to remove
**Returns** A new tree with the given item removed if it exists
### `tree.find(key)`
Returns an iterator pointing to the first item in the tree with `key`, otherwise `null`.
### `tree.ge(key)`
Find the first item in the tree whose key is `>= key`
* `key` is the key to search for
**Returns** An iterator at the given element.
### `tree.gt(key)`
Finds the first item in the tree whose key is `> key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.lt(key)`
Finds the last item in the tree whose key is `< key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.le(key)`
Finds the last item in the tree whose key is `<= key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.at(position)`
Finds an iterator starting at the given element
* `position` is the index at which the iterator gets created
**Returns** An iterator starting at position
### `tree.begin`
An iterator pointing to the first element in the tree
### `tree.end`
An iterator pointing to the last element in the tree
### `tree.forEach(visitor(key,value)[, lo[, hi]])`
Walks a visitor function over the nodes of the tree in order.
* `visitor(key,value)` is a callback that gets executed on each node. If a truthy value is returned from the visitor, then iteration is stopped.
* `lo` is an optional start of the range to visit (inclusive)
* `hi` is an optional end of the range to visit (non-inclusive)
**Returns** The last value returned by the callback
### `tree.root`
Returns the root node of the tree
## Node properties
Each node of the tree has the following properties:
### `node.key`
The key associated to the node
### `node.value`
The value associated to the node
### `node.left`
The left subtree of the node
### `node.right`
The right subtree of the node
## Iterator methods
### `iter.key`
The key of the item referenced by the iterator
### `iter.value`
The value of the item referenced by the iterator
### `iter.node`
The value of the node at the iterator's current position. `null` is iterator is node valid.
### `iter.tree`
The tree associated to the iterator
### `iter.index`
Returns the position of this iterator in the sequence.
### `iter.valid`
Checks if the iterator is valid
### `iter.clone()`
Makes a copy of the iterator
### `iter.remove()`
Removes the item at the position of the iterator
**Returns** A new binary search tree with `iter`'s item removed
### `iter.update(value)`
Updates the value of the node in the tree at this iterator
**Returns** A new binary search tree with the corresponding node updated
### `iter.next()`
Advances the iterator to the next position
### `iter.prev()`
Moves the iterator backward one element
### `iter.hasNext`
If true, then the iterator is not at the end of the sequence
### `iter.hasPrev`
If true, then the iterator is not at the beginning of the sequence
# Credits
(c) 2013 Mikola Lysenko. MIT License
discontinuous-range
===================
```
DiscontinuousRange(1, 10).subtract(4, 6); // [ 1-3, 7-10 ]
```
[](https://travis-ci.org/dtudury/discontinuous-range)
this is a pretty simple module, but it exists to service another project
so this'll be pretty lacking documentation.
reading the test to see how this works may help. otherwise, here's an example
that I think pretty much sums it up
###Example
```
var all_numbers = new DiscontinuousRange(1, 100);
var bad_numbers = DiscontinuousRange(13).add(8).add(60,80);
var good_numbers = all_numbers.clone().subtract(bad_numbers);
console.log(good_numbers.toString()); //[ 1-7, 9-12, 14-59, 81-100 ]
var random_good_number = good_numbers.index(Math.floor(Math.random() * good_numbers.length));
```
semver(1) -- The semantic versioner for npm
===========================================
## Install
```bash
npm install semver
````
## Usage
As a node module:
```js
const semver = require('semver')
semver.valid('1.2.3') // '1.2.3'
semver.valid('a.b.c') // null
semver.clean(' =v1.2.3 ') // '1.2.3'
semver.satisfies('1.2.3', '1.x || >=2.5.0 || 5.0.0 - 7.2.3') // true
semver.gt('1.2.3', '9.8.7') // false
semver.lt('1.2.3', '9.8.7') // true
semver.minVersion('>=1.0.0') // '1.0.0'
semver.valid(semver.coerce('v2')) // '2.0.0'
semver.valid(semver.coerce('42.6.7.9.3-alpha')) // '42.6.7'
```
You can also just load the module for the function that you care about, if
you'd like to minimize your footprint.
```js
// load the whole API at once in a single object
const semver = require('semver')
// or just load the bits you need
// all of them listed here, just pick and choose what you want
// classes
const SemVer = require('semver/classes/semver')
const Comparator = require('semver/classes/comparator')
const Range = require('semver/classes/range')
// functions for working with versions
const semverParse = require('semver/functions/parse')
const semverValid = require('semver/functions/valid')
const semverClean = require('semver/functions/clean')
const semverInc = require('semver/functions/inc')
const semverDiff = require('semver/functions/diff')
const semverMajor = require('semver/functions/major')
const semverMinor = require('semver/functions/minor')
const semverPatch = require('semver/functions/patch')
const semverPrerelease = require('semver/functions/prerelease')
const semverCompare = require('semver/functions/compare')
const semverRcompare = require('semver/functions/rcompare')
const semverCompareLoose = require('semver/functions/compare-loose')
const semverCompareBuild = require('semver/functions/compare-build')
const semverSort = require('semver/functions/sort')
const semverRsort = require('semver/functions/rsort')
// low-level comparators between versions
const semverGt = require('semver/functions/gt')
const semverLt = require('semver/functions/lt')
const semverEq = require('semver/functions/eq')
const semverNeq = require('semver/functions/neq')
const semverGte = require('semver/functions/gte')
const semverLte = require('semver/functions/lte')
const semverCmp = require('semver/functions/cmp')
const semverCoerce = require('semver/functions/coerce')
// working with ranges
const semverSatisfies = require('semver/functions/satisfies')
const semverMaxSatisfying = require('semver/ranges/max-satisfying')
const semverMinSatisfying = require('semver/ranges/min-satisfying')
const semverToComparators = require('semver/ranges/to-comparators')
const semverMinVersion = require('semver/ranges/min-version')
const semverValidRange = require('semver/ranges/valid')
const semverOutside = require('semver/ranges/outside')
const semverGtr = require('semver/ranges/gtr')
const semverLtr = require('semver/ranges/ltr')
const semverIntersects = require('semver/ranges/intersects')
const simplifyRange = require('semver/ranges/simplify')
const rangeSubset = require('semver/ranges/subset')
```
As a command-line utility:
```
$ semver -h
A JavaScript implementation of the https://semver.org/ specification
Copyright Isaac Z. Schlueter
Usage: semver [options] <version> [<version> [...]]
Prints valid versions sorted by SemVer precedence
Options:
-r --range <range>
Print versions that match the specified range.
-i --increment [<level>]
Increment a version by the specified level. Level can
be one of: major, minor, patch, premajor, preminor,
prepatch, or prerelease. Default level is 'patch'.
Only one version may be specified.
--preid <identifier>
Identifier to be used to prefix premajor, preminor,
prepatch or prerelease version increments.
-l --loose
Interpret versions and ranges loosely
-p --include-prerelease
Always include prerelease versions in range matching
-c --coerce
Coerce a string into SemVer if possible
(does not imply --loose)
--rtl
Coerce version strings right to left
--ltr
Coerce version strings left to right (default)
Program exits successfully if any valid version satisfies
all supplied ranges, and prints all satisfying versions.
If no satisfying versions are found, then exits failure.
Versions are printed in ascending order, so supplying
multiple versions to the utility will just sort them.
```
## Versions
A "version" is described by the `v2.0.0` specification found at
<https://semver.org/>.
A leading `"="` or `"v"` character is stripped off and ignored.
## Ranges
A `version range` is a set of `comparators` which specify versions
that satisfy the range.
A `comparator` is composed of an `operator` and a `version`. The set
of primitive `operators` is:
* `<` Less than
* `<=` Less than or equal to
* `>` Greater than
* `>=` Greater than or equal to
* `=` Equal. If no operator is specified, then equality is assumed,
so this operator is optional, but MAY be included.
For example, the comparator `>=1.2.7` would match the versions
`1.2.7`, `1.2.8`, `2.5.3`, and `1.3.9`, but not the versions `1.2.6`
or `1.1.0`.
Comparators can be joined by whitespace to form a `comparator set`,
which is satisfied by the **intersection** of all of the comparators
it includes.
A range is composed of one or more comparator sets, joined by `||`. A
version matches a range if and only if every comparator in at least
one of the `||`-separated comparator sets is satisfied by the version.
For example, the range `>=1.2.7 <1.3.0` would match the versions
`1.2.7`, `1.2.8`, and `1.2.99`, but not the versions `1.2.6`, `1.3.0`,
or `1.1.0`.
The range `1.2.7 || >=1.2.9 <2.0.0` would match the versions `1.2.7`,
`1.2.9`, and `1.4.6`, but not the versions `1.2.8` or `2.0.0`.
### Prerelease Tags
If a version has a prerelease tag (for example, `1.2.3-alpha.3`) then
it will only be allowed to satisfy comparator sets if at least one
comparator with the same `[major, minor, patch]` tuple also has a
prerelease tag.
For example, the range `>1.2.3-alpha.3` would be allowed to match the
version `1.2.3-alpha.7`, but it would *not* be satisfied by
`3.4.5-alpha.9`, even though `3.4.5-alpha.9` is technically "greater
than" `1.2.3-alpha.3` according to the SemVer sort rules. The version
range only accepts prerelease tags on the `1.2.3` version. The
version `3.4.5` *would* satisfy the range, because it does not have a
prerelease flag, and `3.4.5` is greater than `1.2.3-alpha.7`.
The purpose for this behavior is twofold. First, prerelease versions
frequently are updated very quickly, and contain many breaking changes
that are (by the author's design) not yet fit for public consumption.
Therefore, by default, they are excluded from range matching
semantics.
Second, a user who has opted into using a prerelease version has
clearly indicated the intent to use *that specific* set of
alpha/beta/rc versions. By including a prerelease tag in the range,
the user is indicating that they are aware of the risk. However, it
is still not appropriate to assume that they have opted into taking a
similar risk on the *next* set of prerelease versions.
Note that this behavior can be suppressed (treating all prerelease
versions as if they were normal versions, for the purpose of range
matching) by setting the `includePrerelease` flag on the options
object to any
[functions](https://github.com/npm/node-semver#functions) that do
range matching.
#### Prerelease Identifiers
The method `.inc` takes an additional `identifier` string argument that
will append the value of the string as a prerelease identifier:
```javascript
semver.inc('1.2.3', 'prerelease', 'beta')
// '1.2.4-beta.0'
```
command-line example:
```bash
$ semver 1.2.3 -i prerelease --preid beta
1.2.4-beta.0
```
Which then can be used to increment further:
```bash
$ semver 1.2.4-beta.0 -i prerelease
1.2.4-beta.1
```
### Advanced Range Syntax
Advanced range syntax desugars to primitive comparators in
deterministic ways.
Advanced ranges may be combined in the same way as primitive
comparators using white space or `||`.
#### Hyphen Ranges `X.Y.Z - A.B.C`
Specifies an inclusive set.
* `1.2.3 - 2.3.4` := `>=1.2.3 <=2.3.4`
If a partial version is provided as the first version in the inclusive
range, then the missing pieces are replaced with zeroes.
* `1.2 - 2.3.4` := `>=1.2.0 <=2.3.4`
If a partial version is provided as the second version in the
inclusive range, then all versions that start with the supplied parts
of the tuple are accepted, but nothing that would be greater than the
provided tuple parts.
* `1.2.3 - 2.3` := `>=1.2.3 <2.4.0-0`
* `1.2.3 - 2` := `>=1.2.3 <3.0.0-0`
#### X-Ranges `1.2.x` `1.X` `1.2.*` `*`
Any of `X`, `x`, or `*` may be used to "stand in" for one of the
numeric values in the `[major, minor, patch]` tuple.
* `*` := `>=0.0.0` (Any version satisfies)
* `1.x` := `>=1.0.0 <2.0.0-0` (Matching major version)
* `1.2.x` := `>=1.2.0 <1.3.0-0` (Matching major and minor versions)
A partial version range is treated as an X-Range, so the special
character is in fact optional.
* `""` (empty string) := `*` := `>=0.0.0`
* `1` := `1.x.x` := `>=1.0.0 <2.0.0-0`
* `1.2` := `1.2.x` := `>=1.2.0 <1.3.0-0`
#### Tilde Ranges `~1.2.3` `~1.2` `~1`
Allows patch-level changes if a minor version is specified on the
comparator. Allows minor-level changes if not.
* `~1.2.3` := `>=1.2.3 <1.(2+1).0` := `>=1.2.3 <1.3.0-0`
* `~1.2` := `>=1.2.0 <1.(2+1).0` := `>=1.2.0 <1.3.0-0` (Same as `1.2.x`)
* `~1` := `>=1.0.0 <(1+1).0.0` := `>=1.0.0 <2.0.0-0` (Same as `1.x`)
* `~0.2.3` := `>=0.2.3 <0.(2+1).0` := `>=0.2.3 <0.3.0-0`
* `~0.2` := `>=0.2.0 <0.(2+1).0` := `>=0.2.0 <0.3.0-0` (Same as `0.2.x`)
* `~0` := `>=0.0.0 <(0+1).0.0` := `>=0.0.0 <1.0.0-0` (Same as `0.x`)
* `~1.2.3-beta.2` := `>=1.2.3-beta.2 <1.3.0-0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
#### Caret Ranges `^1.2.3` `^0.2.5` `^0.0.4`
Allows changes that do not modify the left-most non-zero element in the
`[major, minor, patch]` tuple. In other words, this allows patch and
minor updates for versions `1.0.0` and above, patch updates for
versions `0.X >=0.1.0`, and *no* updates for versions `0.0.X`.
Many authors treat a `0.x` version as if the `x` were the major
"breaking-change" indicator.
Caret ranges are ideal when an author may make breaking changes
between `0.2.4` and `0.3.0` releases, which is a common practice.
However, it presumes that there will *not* be breaking changes between
`0.2.4` and `0.2.5`. It allows for changes that are presumed to be
additive (but non-breaking), according to commonly observed practices.
* `^1.2.3` := `>=1.2.3 <2.0.0-0`
* `^0.2.3` := `>=0.2.3 <0.3.0-0`
* `^0.0.3` := `>=0.0.3 <0.0.4-0`
* `^1.2.3-beta.2` := `>=1.2.3-beta.2 <2.0.0-0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
* `^0.0.3-beta` := `>=0.0.3-beta <0.0.4-0` Note that prereleases in the
`0.0.3` version *only* will be allowed, if they are greater than or
equal to `beta`. So, `0.0.3-pr.2` would be allowed.
When parsing caret ranges, a missing `patch` value desugars to the
number `0`, but will allow flexibility within that value, even if the
major and minor versions are both `0`.
* `^1.2.x` := `>=1.2.0 <2.0.0-0`
* `^0.0.x` := `>=0.0.0 <0.1.0-0`
* `^0.0` := `>=0.0.0 <0.1.0-0`
A missing `minor` and `patch` values will desugar to zero, but also
allow flexibility within those values, even if the major version is
zero.
* `^1.x` := `>=1.0.0 <2.0.0-0`
* `^0.x` := `>=0.0.0 <1.0.0-0`
### Range Grammar
Putting all this together, here is a Backus-Naur grammar for ranges,
for the benefit of parser authors:
```bnf
range-set ::= range ( logical-or range ) *
logical-or ::= ( ' ' ) * '||' ( ' ' ) *
range ::= hyphen | simple ( ' ' simple ) * | ''
hyphen ::= partial ' - ' partial
simple ::= primitive | partial | tilde | caret
primitive ::= ( '<' | '>' | '>=' | '<=' | '=' ) partial
partial ::= xr ( '.' xr ( '.' xr qualifier ? )? )?
xr ::= 'x' | 'X' | '*' | nr
nr ::= '0' | ['1'-'9'] ( ['0'-'9'] ) *
tilde ::= '~' partial
caret ::= '^' partial
qualifier ::= ( '-' pre )? ( '+' build )?
pre ::= parts
build ::= parts
parts ::= part ( '.' part ) *
part ::= nr | [-0-9A-Za-z]+
```
## Functions
All methods and classes take a final `options` object argument. All
options in this object are `false` by default. The options supported
are:
- `loose` Be more forgiving about not-quite-valid semver strings.
(Any resulting output will always be 100% strict compliant, of
course.) For backwards compatibility reasons, if the `options`
argument is a boolean value instead of an object, it is interpreted
to be the `loose` param.
- `includePrerelease` Set to suppress the [default
behavior](https://github.com/npm/node-semver#prerelease-tags) of
excluding prerelease tagged versions from ranges unless they are
explicitly opted into.
Strict-mode Comparators and Ranges will be strict about the SemVer
strings that they parse.
* `valid(v)`: Return the parsed version, or null if it's not valid.
* `inc(v, release)`: Return the version incremented by the release
type (`major`, `premajor`, `minor`, `preminor`, `patch`,
`prepatch`, or `prerelease`), or null if it's not valid
* `premajor` in one call will bump the version up to the next major
version and down to a prerelease of that major version.
`preminor`, and `prepatch` work the same way.
* If called from a non-prerelease version, the `prerelease` will work the
same as `prepatch`. It increments the patch version, then makes a
prerelease. If the input version is already a prerelease it simply
increments it.
* `prerelease(v)`: Returns an array of prerelease components, or null
if none exist. Example: `prerelease('1.2.3-alpha.1') -> ['alpha', 1]`
* `major(v)`: Return the major version number.
* `minor(v)`: Return the minor version number.
* `patch(v)`: Return the patch version number.
* `intersects(r1, r2, loose)`: Return true if the two supplied ranges
or comparators intersect.
* `parse(v)`: Attempt to parse a string as a semantic version, returning either
a `SemVer` object or `null`.
### Comparison
* `gt(v1, v2)`: `v1 > v2`
* `gte(v1, v2)`: `v1 >= v2`
* `lt(v1, v2)`: `v1 < v2`
* `lte(v1, v2)`: `v1 <= v2`
* `eq(v1, v2)`: `v1 == v2` This is true if they're logically equivalent,
even if they're not the exact same string. You already know how to
compare strings.
* `neq(v1, v2)`: `v1 != v2` The opposite of `eq`.
* `cmp(v1, comparator, v2)`: Pass in a comparison string, and it'll call
the corresponding function above. `"==="` and `"!=="` do simple
string comparison, but are included for completeness. Throws if an
invalid comparison string is provided.
* `compare(v1, v2)`: Return `0` if `v1 == v2`, or `1` if `v1` is greater, or `-1` if
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `rcompare(v1, v2)`: The reverse of compare. Sorts an array of versions
in descending order when passed to `Array.sort()`.
* `compareBuild(v1, v2)`: The same as `compare` but considers `build` when two versions
are equal. Sorts in ascending order if passed to `Array.sort()`.
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `diff(v1, v2)`: Returns difference between two versions by the release type
(`major`, `premajor`, `minor`, `preminor`, `patch`, `prepatch`, or `prerelease`),
or null if the versions are the same.
### Comparators
* `intersects(comparator)`: Return true if the comparators intersect
### Ranges
* `validRange(range)`: Return the valid range or null if it's not valid
* `satisfies(version, range)`: Return true if the version satisfies the
range.
* `maxSatisfying(versions, range)`: Return the highest version in the list
that satisfies the range, or `null` if none of them do.
* `minSatisfying(versions, range)`: Return the lowest version in the list
that satisfies the range, or `null` if none of them do.
* `minVersion(range)`: Return the lowest version that can possibly match
the given range.
* `gtr(version, range)`: Return `true` if version is greater than all the
versions possible in the range.
* `ltr(version, range)`: Return `true` if version is less than all the
versions possible in the range.
* `outside(version, range, hilo)`: Return true if the version is outside
the bounds of the range in either the high or low direction. The
`hilo` argument must be either the string `'>'` or `'<'`. (This is
the function called by `gtr` and `ltr`.)
* `intersects(range)`: Return true if any of the ranges comparators intersect
* `simplifyRange(versions, range)`: Return a "simplified" range that
matches the same items in `versions` list as the range specified. Note
that it does *not* guarantee that it would match the same versions in all
cases, only for the set of versions provided. This is useful when
generating ranges by joining together multiple versions with `||`
programmatically, to provide the user with something a bit more
ergonomic. If the provided range is shorter in string-length than the
generated range, then that is returned.
* `subset(subRange, superRange)`: Return `true` if the `subRange` range is
entirely contained by the `superRange` range.
Note that, since ranges may be non-contiguous, a version might not be
greater than a range, less than a range, *or* satisfy a range! For
example, the range `1.2 <1.2.9 || >2.0.0` would have a hole from `1.2.9`
until `2.0.0`, so the version `1.2.10` would not be greater than the
range (because `2.0.1` satisfies, which is higher), nor less than the
range (since `1.2.8` satisfies, which is lower), and it also does not
satisfy the range.
If you want to know if a version satisfies or does not satisfy a
range, use the `satisfies(version, range)` function.
### Coercion
* `coerce(version, options)`: Coerces a string to semver if possible
This aims to provide a very forgiving translation of a non-semver string to
semver. It looks for the first digit in a string, and consumes all
remaining characters which satisfy at least a partial semver (e.g., `1`,
`1.2`, `1.2.3`) up to the max permitted length (256 characters). Longer
versions are simply truncated (`4.6.3.9.2-alpha2` becomes `4.6.3`). All
surrounding text is simply ignored (`v3.4 replaces v3.3.1` becomes
`3.4.0`). Only text which lacks digits will fail coercion (`version one`
is not valid). The maximum length for any semver component considered for
coercion is 16 characters; longer components will be ignored
(`10000000000000000.4.7.4` becomes `4.7.4`). The maximum value for any
semver component is `Number.MAX_SAFE_INTEGER || (2**53 - 1)`; higher value
components are invalid (`9999999999999999.4.7.4` is likely invalid).
If the `options.rtl` flag is set, then `coerce` will return the right-most
coercible tuple that does not share an ending index with a longer coercible
tuple. For example, `1.2.3.4` will return `2.3.4` in rtl mode, not
`4.0.0`. `1.2.3/4` will return `4.0.0`, because the `4` is not a part of
any other overlapping SemVer tuple.
### Clean
* `clean(version)`: Clean a string to be a valid semver if possible
This will return a cleaned and trimmed semver version. If the provided
version is not valid a null will be returned. This does not work for
ranges.
ex.
* `s.clean(' = v 2.1.5foo')`: `null`
* `s.clean(' = v 2.1.5foo', { loose: true })`: `'2.1.5-foo'`
* `s.clean(' = v 2.1.5-foo')`: `null`
* `s.clean(' = v 2.1.5-foo', { loose: true })`: `'2.1.5-foo'`
* `s.clean('=v2.1.5')`: `'2.1.5'`
* `s.clean(' =v2.1.5')`: `2.1.5`
* `s.clean(' 2.1.5 ')`: `'2.1.5'`
* `s.clean('~1.0.0')`: `null`
## Exported Modules
<!--
TODO: Make sure that all of these items are documented (classes aren't,
eg), and then pull the module name into the documentation for that specific
thing.
-->
You may pull in just the part of this semver utility that you need, if you
are sensitive to packing and tree-shaking concerns. The main
`require('semver')` export uses getter functions to lazily load the parts
of the API that are used.
The following modules are available:
* `require('semver')`
* `require('semver/classes')`
* `require('semver/classes/comparator')`
* `require('semver/classes/range')`
* `require('semver/classes/semver')`
* `require('semver/functions/clean')`
* `require('semver/functions/cmp')`
* `require('semver/functions/coerce')`
* `require('semver/functions/compare')`
* `require('semver/functions/compare-build')`
* `require('semver/functions/compare-loose')`
* `require('semver/functions/diff')`
* `require('semver/functions/eq')`
* `require('semver/functions/gt')`
* `require('semver/functions/gte')`
* `require('semver/functions/inc')`
* `require('semver/functions/lt')`
* `require('semver/functions/lte')`
* `require('semver/functions/major')`
* `require('semver/functions/minor')`
* `require('semver/functions/neq')`
* `require('semver/functions/parse')`
* `require('semver/functions/patch')`
* `require('semver/functions/prerelease')`
* `require('semver/functions/rcompare')`
* `require('semver/functions/rsort')`
* `require('semver/functions/satisfies')`
* `require('semver/functions/sort')`
* `require('semver/functions/valid')`
* `require('semver/ranges/gtr')`
* `require('semver/ranges/intersects')`
* `require('semver/ranges/ltr')`
* `require('semver/ranges/max-satisfying')`
* `require('semver/ranges/min-satisfying')`
* `require('semver/ranges/min-version')`
* `require('semver/ranges/outside')`
* `require('semver/ranges/to-comparators')`
* `require('semver/ranges/valid')`
# wrappy
Callback wrapping utility
## USAGE
```javascript
var wrappy = require("wrappy")
// var wrapper = wrappy(wrapperFunction)
// make sure a cb is called only once
// See also: http://npm.im/once for this specific use case
var once = wrappy(function (cb) {
var called = false
return function () {
if (called) return
called = true
return cb.apply(this, arguments)
}
})
function printBoo () {
console.log('boo')
}
// has some rando property
printBoo.iAmBooPrinter = true
var onlyPrintOnce = once(printBoo)
onlyPrintOnce() // prints 'boo'
onlyPrintOnce() // does nothing
// random property is retained!
assert.equal(onlyPrintOnce.iAmBooPrinter, true)
```
### Esrecurse [](https://travis-ci.org/estools/esrecurse)
Esrecurse ([esrecurse](https://github.com/estools/esrecurse)) is
[ECMAScript](https://www.ecma-international.org/publications/standards/Ecma-262.htm)
recursive traversing functionality.
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
esrecurse.visit(ast, {
XXXStatement: function (node) {
this.visit(node.left);
// do something...
this.visit(node.right);
}
});
```
We can use `Visitor` instance.
```javascript
var visitor = new esrecurse.Visitor({
XXXStatement: function (node) {
this.visit(node.left);
// do something...
this.visit(node.right);
}
});
visitor.visit(ast);
```
We can inherit `Visitor` instance easily.
```javascript
class Derived extends esrecurse.Visitor {
constructor()
{
super(null);
}
XXXStatement(node) {
}
}
```
```javascript
function DerivedVisitor() {
esrecurse.Visitor.call(/* this for constructor */ this /* visitor object automatically becomes this. */);
}
util.inherits(DerivedVisitor, esrecurse.Visitor);
DerivedVisitor.prototype.XXXStatement = function (node) {
this.visit(node.left);
// do something...
this.visit(node.right);
};
```
And you can invoke default visiting operation inside custom visit operation.
```javascript
function DerivedVisitor() {
esrecurse.Visitor.call(/* this for constructor */ this /* visitor object automatically becomes this. */);
}
util.inherits(DerivedVisitor, esrecurse.Visitor);
DerivedVisitor.prototype.XXXStatement = function (node) {
// do something...
this.visitChildren(node);
};
```
The `childVisitorKeys` option does customize the behaviour of `this.visitChildren(node)`.
We can use user-defined node types.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
esrecurse.visit(
ast,
{
Literal: function (node) {
// do something...
}
},
{
// Extending the existing traversing rules.
childVisitorKeys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
}
);
```
We can use the `fallback` option as well.
If the `fallback` option is `"iteration"`, `esrecurse` would visit all enumerable properties of unknown nodes.
Please note circular references cause the stack overflow. AST might have circular references in additional properties for some purpose (e.g. `node.parent`).
```javascript
esrecurse.visit(
ast,
{
Literal: function (node) {
// do something...
}
},
{
fallback: 'iteration'
}
);
```
If the `fallback` option is a function, `esrecurse` calls this function to determine the enumerable properties of unknown nodes.
Please note circular references cause the stack overflow. AST might have circular references in additional properties for some purpose (e.g. `node.parent`).
```javascript
esrecurse.visit(
ast,
{
Literal: function (node) {
// do something...
}
},
{
fallback: function (node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument'
});
}
}
);
```
### License
Copyright (C) 2014 [Yusuke Suzuki](https://github.com/Constellation)
(twitter: [@Constellation](https://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# lodash.merge v4.6.2
The [Lodash](https://lodash.com/) method `_.merge` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.merge
```
In Node.js:
```js
var merge = require('lodash.merge');
```
See the [documentation](https://lodash.com/docs#merge) or [package source](https://github.com/lodash/lodash/blob/4.6.2-npm-packages/lodash.merge) for more details.
# function-bind
<!--
[![build status][travis-svg]][travis-url]
[![NPM version][npm-badge-svg]][npm-url]
[![Coverage Status][5]][6]
[![gemnasium Dependency Status][7]][8]
[![Dependency status][deps-svg]][deps-url]
[![Dev Dependency status][dev-deps-svg]][dev-deps-url]
-->
<!-- [![browser support][11]][12] -->
Implementation of function.prototype.bind
## Example
I mainly do this for unit tests I run on phantomjs.
PhantomJS does not have Function.prototype.bind :(
```js
Function.prototype.bind = require("function-bind")
```
## Installation
`npm install function-bind`
## Contributors
- Raynos
## MIT Licenced
[travis-svg]: https://travis-ci.org/Raynos/function-bind.svg
[travis-url]: https://travis-ci.org/Raynos/function-bind
[npm-badge-svg]: https://badge.fury.io/js/function-bind.svg
[npm-url]: https://npmjs.org/package/function-bind
[5]: https://coveralls.io/repos/Raynos/function-bind/badge.png
[6]: https://coveralls.io/r/Raynos/function-bind
[7]: https://gemnasium.com/Raynos/function-bind.png
[8]: https://gemnasium.com/Raynos/function-bind
[deps-svg]: https://david-dm.org/Raynos/function-bind.svg
[deps-url]: https://david-dm.org/Raynos/function-bind
[dev-deps-svg]: https://david-dm.org/Raynos/function-bind/dev-status.svg
[dev-deps-url]: https://david-dm.org/Raynos/function-bind#info=devDependencies
[11]: https://ci.testling.com/Raynos/function-bind.png
[12]: https://ci.testling.com/Raynos/function-bind
# flat-cache
> A stupidly simple key/value storage using files to persist the data
[](https://npmjs.org/package/flat-cache)
[](https://travis-ci.org/royriojas/flat-cache)
## install
```bash
npm i --save flat-cache
```
## Usage
```js
var flatCache = require('flat-cache')
// loads the cache, if one does not exists for the given
// Id a new one will be prepared to be created
var cache = flatCache.load('cacheId');
// sets a key on the cache
cache.setKey('key', { foo: 'var' });
// get a key from the cache
cache.getKey('key') // { foo: 'var' }
// fetch the entire persisted object
cache.all() // { 'key': { foo: 'var' } }
// remove a key
cache.removeKey('key'); // removes a key from the cache
// save it to disk
cache.save(); // very important, if you don't save no changes will be persisted.
// cache.save( true /* noPrune */) // can be used to prevent the removal of non visited keys
// loads the cache from a given directory, if one does
// not exists for the given Id a new one will be prepared to be created
var cache = flatCache.load('cacheId', path.resolve('./path/to/folder'));
// The following methods are useful to clear the cache
// delete a given cache
flatCache.clearCacheById('cacheId') // removes the cacheId document if one exists.
// delete all cache
flatCache.clearAll(); // remove the cache directory
```
## Motivation for this module
I needed a super simple and dumb **in-memory cache** with optional disk persistance in order to make
a script that will beutify files with `esformatter` only execute on the files that were changed since the last run.
To make that possible we need to store the `fileSize` and `modificationTime` of the files. So a simple `key/value`
storage was needed and Bam! this module was born.
## Important notes
- If no directory is especified when the `load` method is called, a folder named `.cache` will be created
inside the module directory when `cache.save` is called. If you're committing your `node_modules` to any vcs, you
might want to ignore the default `.cache` folder, or specify a custom directory.
- The values set on the keys of the cache should be `stringify-able` ones, meaning no circular references
- All the changes to the cache state are done to memory
- I could have used a timer or `Object.observe` to deliver the changes to disk, but I wanted to keep this module
intentionally dumb and simple
- Non visited keys are removed when `cache.save()` is called. If this is not desired, you can pass `true` to the save call
like: `cache.save( true /* noPrune */ )`.
## License
MIT
## Changelog
[changelog](./changelog.md)
# get-caller-file
[](https://travis-ci.org/stefanpenner/get-caller-file)
[](https://ci.appveyor.com/project/embercli/get-caller-file/branch/master)
This is a utility, which allows a function to figure out from which file it was invoked. It does so by inspecting v8's stack trace at the time it is invoked.
Inspired by http://stackoverflow.com/questions/13227489
*note: this relies on Node/V8 specific APIs, as such other runtimes may not work*
## Installation
```bash
yarn add get-caller-file
```
## Usage
Given:
```js
// ./foo.js
const getCallerFile = require('get-caller-file');
module.exports = function() {
return getCallerFile(); // figures out who called it
};
```
```js
// index.js
const foo = require('./foo');
foo() // => /full/path/to/this/file/index.js
```
## Options:
* `getCallerFile(position = 2)`: where position is stack frame whos fileName we want.
# Regular Expression Tokenizer
Tokenizes strings that represent a regular expressions.
[](http://travis-ci.org/fent/ret.js)
[](https://david-dm.org/fent/ret.js)
[](https://codecov.io/gh/fent/ret.js)
# Usage
```js
var ret = require('ret');
var tokens = ret(/foo|bar/.source);
```
`tokens` will contain the following object
```js
{
"type": ret.types.ROOT
"options": [
[ { "type": ret.types.CHAR, "value", 102 },
{ "type": ret.types.CHAR, "value", 111 },
{ "type": ret.types.CHAR, "value", 111 } ],
[ { "type": ret.types.CHAR, "value", 98 },
{ "type": ret.types.CHAR, "value", 97 },
{ "type": ret.types.CHAR, "value", 114 } ]
]
}
```
# Token Types
`ret.types` is a collection of the various token types exported by ret.
### ROOT
Only used in the root of the regexp. This is needed due to the posibility of the root containing a pipe `|` character. In that case, the token will have an `options` key that will be an array of arrays of tokens. If not, it will contain a `stack` key that is an array of tokens.
```js
{
"type": ret.types.ROOT,
"stack": [token1, token2...],
}
```
```js
{
"type": ret.types.ROOT,
"options" [
[token1, token2...],
[othertoken1, othertoken2...]
...
],
}
```
### GROUP
Groups contain tokens that are inside of a parenthesis. If the group begins with `?` followed by another character, it's a special type of group. A ':' tells the group not to be remembered when `exec` is used. '=' means the previous token matches only if followed by this group, and '!' means the previous token matches only if NOT followed.
Like root, it can contain an `options` key instead of `stack` if there is a pipe.
```js
{
"type": ret.types.GROUP,
"remember" true,
"followedBy": false,
"notFollowedBy": false,
"stack": [token1, token2...],
}
```
```js
{
"type": ret.types.GROUP,
"remember" true,
"followedBy": false,
"notFollowedBy": false,
"options" [
[token1, token2...],
[othertoken1, othertoken2...]
...
],
}
```
### POSITION
`\b`, `\B`, `^`, and `$` specify positions in the regexp.
```js
{
"type": ret.types.POSITION,
"value": "^",
}
```
### SET
Contains a key `set` specifying what tokens are allowed and a key `not` specifying if the set should be negated. A set can contain other sets, ranges, and characters.
```js
{
"type": ret.types.SET,
"set": [token1, token2...],
"not": false,
}
```
### RANGE
Used in set tokens to specify a character range. `from` and `to` are character codes.
```js
{
"type": ret.types.RANGE,
"from": 97,
"to": 122,
}
```
### REPETITION
```js
{
"type": ret.types.REPETITION,
"min": 0,
"max": Infinity,
"value": token,
}
```
### REFERENCE
References a group token. `value` is 1-9.
```js
{
"type": ret.types.REFERENCE,
"value": 1,
}
```
### CHAR
Represents a single character token. `value` is the character code. This might seem a bit cluttering instead of concatenating characters together. But since repetition tokens only repeat the last token and not the last clause like the pipe, it's simpler to do it this way.
```js
{
"type": ret.types.CHAR,
"value": 123,
}
```
## Errors
ret.js will throw errors if given a string with an invalid regular expression. All possible errors are
* Invalid group. When a group with an immediate `?` character is followed by an invalid character. It can only be followed by `!`, `=`, or `:`. Example: `/(?_abc)/`
* Nothing to repeat. Thrown when a repetitional token is used as the first token in the current clause, as in right in the beginning of the regexp or group, or right after a pipe. Example: `/foo|?bar/`, `/{1,3}foo|bar/`, `/foo(+bar)/`
* Unmatched ). A group was not opened, but was closed. Example: `/hello)2u/`
* Unterminated group. A group was not closed. Example: `/(1(23)4/`
* Unterminated character class. A custom character set was not closed. Example: `/[abc/`
# Install
npm install ret
# Tests
Tests are written with [vows](http://vowsjs.org/)
```bash
npm test
```
# License
MIT
# fast-json-stable-stringify
Deterministic `JSON.stringify()` - a faster version of [@substack](https://github.com/substack)'s json-stable-strigify without [jsonify](https://github.com/substack/jsonify).
You can also pass in a custom comparison function.
[](https://travis-ci.org/epoberezkin/fast-json-stable-stringify)
[](https://coveralls.io/github/epoberezkin/fast-json-stable-stringify?branch=master)
# example
``` js
var stringify = require('fast-json-stable-stringify');
var obj = { c: 8, b: [{z:6,y:5,x:4},7], a: 3 };
console.log(stringify(obj));
```
output:
```
{"a":3,"b":[{"x":4,"y":5,"z":6},7],"c":8}
```
# methods
``` js
var stringify = require('fast-json-stable-stringify')
```
## var str = stringify(obj, opts)
Return a deterministic stringified string `str` from the object `obj`.
## options
### cmp
If `opts` is given, you can supply an `opts.cmp` to have a custom comparison
function for object keys. Your function `opts.cmp` is called with these
parameters:
``` js
opts.cmp({ key: akey, value: avalue }, { key: bkey, value: bvalue })
```
For example, to sort on the object key names in reverse order you could write:
``` js
var stringify = require('fast-json-stable-stringify');
var obj = { c: 8, b: [{z:6,y:5,x:4},7], a: 3 };
var s = stringify(obj, function (a, b) {
return a.key < b.key ? 1 : -1;
});
console.log(s);
```
which results in the output string:
```
{"c":8,"b":[{"z":6,"y":5,"x":4},7],"a":3}
```
Or if you wanted to sort on the object values in reverse order, you could write:
```
var stringify = require('fast-json-stable-stringify');
var obj = { d: 6, c: 5, b: [{z:3,y:2,x:1},9], a: 10 };
var s = stringify(obj, function (a, b) {
return a.value < b.value ? 1 : -1;
});
console.log(s);
```
which outputs:
```
{"d":6,"c":5,"b":[{"z":3,"y":2,"x":1},9],"a":10}
```
### cycles
Pass `true` in `opts.cycles` to stringify circular property as `__cycle__` - the result will not be a valid JSON string in this case.
TypeError will be thrown in case of circular object without this option.
# install
With [npm](https://npmjs.org) do:
```
npm install fast-json-stable-stringify
```
# benchmark
To run benchmark (requires Node.js 6+):
```
node benchmark
```
Results:
```
fast-json-stable-stringify x 17,189 ops/sec ±1.43% (83 runs sampled)
json-stable-stringify x 13,634 ops/sec ±1.39% (85 runs sampled)
fast-stable-stringify x 20,212 ops/sec ±1.20% (84 runs sampled)
faster-stable-stringify x 15,549 ops/sec ±1.12% (84 runs sampled)
The fastest is fast-stable-stringify
```
## Enterprise support
fast-json-stable-stringify package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-fast-json-stable-stringify?utm_source=npm-fast-json-stable-stringify&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
# license
[MIT](https://github.com/epoberezkin/fast-json-stable-stringify/blob/master/LICENSE)
# has
> Object.prototype.hasOwnProperty.call shortcut
## Installation
```sh
npm install --save has
```
## Usage
```js
var has = require('has');
has({}, 'hasOwnProperty'); // false
has(Object.prototype, 'hasOwnProperty'); // true
```
# which-module
> Find the module object for something that was require()d
[](https://travis-ci.org/nexdrew/which-module)
[](https://coveralls.io/github/nexdrew/which-module?branch=master)
[](https://github.com/conventional-changelog/standard-version)
Find the `module` object in `require.cache` for something that was `require()`d
or `import`ed - essentially a reverse `require()` lookup.
Useful for libs that want to e.g. lookup a filename for a module or submodule
that it did not `require()` itself.
## Install and Usage
```
npm install --save which-module
```
```js
const whichModule = require('which-module')
console.log(whichModule(require('something')))
// Module {
// id: '/path/to/project/node_modules/something/index.js',
// exports: [Function],
// parent: ...,
// filename: '/path/to/project/node_modules/something/index.js',
// loaded: true,
// children: [],
// paths: [ '/path/to/project/node_modules/something/node_modules',
// '/path/to/project/node_modules',
// '/path/to/node_modules',
// '/path/node_modules',
// '/node_modules' ] }
```
## API
### `whichModule(exported)`
Return the [`module` object](https://nodejs.org/api/modules.html#modules_the_module_object),
if any, that represents the given argument in the `require.cache`.
`exported` can be anything that was previously `require()`d or `import`ed as a
module, submodule, or dependency - which means `exported` is identical to the
`module.exports` returned by this method.
If `exported` did not come from the `exports` of a `module` in `require.cache`,
then this method returns `null`.
## License
ISC © Contributors
binaryen.js
===========
**binaryen.js** is a port of [Binaryen](https://github.com/WebAssembly/binaryen) to the Web, allowing you to generate [WebAssembly](https://webassembly.org) using a JavaScript API.
<a href="https://github.com/AssemblyScript/binaryen.js/actions?query=workflow%3ABuild"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/binaryen.js/Build/master?label=build&logo=github" alt="Build status" /></a>
<a href="https://www.npmjs.com/package/binaryen"><img src="https://img.shields.io/npm/v/binaryen.svg?label=latest&color=007acc&logo=npm" alt="npm version" /></a>
<a href="https://www.npmjs.com/package/binaryen"><img src="https://img.shields.io/npm/v/binaryen/nightly.svg?label=nightly&color=007acc&logo=npm" alt="npm nightly version" /></a>
Usage
-----
```
$> npm install binaryen
```
```js
var binaryen = require("binaryen");
// Create a module with a single function
var myModule = new binaryen.Module();
myModule.addFunction("add", binaryen.createType([ binaryen.i32, binaryen.i32 ]), binaryen.i32, [ binaryen.i32 ],
myModule.block(null, [
myModule.local.set(2,
myModule.i32.add(
myModule.local.get(0, binaryen.i32),
myModule.local.get(1, binaryen.i32)
)
),
myModule.return(
myModule.local.get(2, binaryen.i32)
)
])
);
myModule.addFunctionExport("add", "add");
// Optimize the module using default passes and levels
myModule.optimize();
// Validate the module
if (!myModule.validate())
throw new Error("validation error");
// Generate text format and binary
var textData = myModule.emitText();
var wasmData = myModule.emitBinary();
// Example usage with the WebAssembly API
var compiled = new WebAssembly.Module(wasmData);
var instance = new WebAssembly.Instance(compiled, {});
console.log(instance.exports.add(41, 1));
```
The buildbot also publishes nightly versions once a day if there have been changes. The latest nightly can be installed through
```
$> npm install binaryen@nightly
```
or you can use one of the [previous versions](https://github.com/AssemblyScript/binaryen.js/tags) instead if necessary.
### Usage with a CDN
* From GitHub via [jsDelivr](https://www.jsdelivr.com):<br />
`https://cdn.jsdelivr.net/gh/AssemblyScript/binaryen.js@VERSION/index.js`
* From npm via [jsDelivr](https://www.jsdelivr.com):<br />
`https://cdn.jsdelivr.net/npm/binaryen@VERSION/index.js`
* From npm via [unpkg](https://unpkg.com):<br />
`https://unpkg.com/binaryen@VERSION/index.js`
Replace `VERSION` with a [specific version](https://github.com/AssemblyScript/binaryen.js/releases) or omit it (not recommended in production) to use master/latest.
API
---
**Please note** that the Binaryen API is evolving fast and that definitions and documentation provided by the package tend to get out of sync despite our best efforts. It's a bot after all. If you rely on binaryen.js and spot an issue, please consider sending a PR our way by updating [index.d.ts](./index.d.ts) and [README.md](./README.md) to reflect the [current API](https://github.com/WebAssembly/binaryen/blob/master/src/js/binaryen.js-post.js).
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
### Contents
- [Types](#types)
- [Module construction](#module-construction)
- [Module manipulation](#module-manipulation)
- [Module validation](#module-validation)
- [Module optimization](#module-optimization)
- [Module creation](#module-creation)
- [Expression construction](#expression-construction)
- [Control flow](#control-flow)
- [Variable accesses](#variable-accesses)
- [Integer operations](#integer-operations)
- [Floating point operations](#floating-point-operations)
- [Datatype conversions](#datatype-conversions)
- [Function calls](#function-calls)
- [Linear memory accesses](#linear-memory-accesses)
- [Host operations](#host-operations)
- [Vector operations 🦄](#vector-operations-)
- [Atomic memory accesses 🦄](#atomic-memory-accesses-)
- [Atomic read-modify-write operations 🦄](#atomic-read-modify-write-operations-)
- [Atomic wait and notify operations 🦄](#atomic-wait-and-notify-operations-)
- [Sign extension operations 🦄](#sign-extension-operations-)
- [Multi-value operations 🦄](#multi-value-operations-)
- [Exception handling operations 🦄](#exception-handling-operations-)
- [Reference types operations 🦄](#reference-types-operations-)
- [Expression manipulation](#expression-manipulation)
- [Relooper](#relooper)
- [Source maps](#source-maps)
- [Debugging](#debugging)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
[Future features](http://webassembly.org/docs/future-features/) 🦄 might not be supported by all runtimes.
### Types
* **none**: `Type`<br />
The none type, e.g., `void`.
* **i32**: `Type`<br />
32-bit integer type.
* **i64**: `Type`<br />
64-bit integer type.
* **f32**: `Type`<br />
32-bit float type.
* **f64**: `Type`<br />
64-bit float (double) type.
* **v128**: `Type`<br />
128-bit vector type. 🦄
* **funcref**: `Type`<br />
A function reference. 🦄
* **anyref**: `Type`<br />
Any host reference. 🦄
* **nullref**: `Type`<br />
A null reference. 🦄
* **exnref**: `Type`<br />
An exception reference. 🦄
* **unreachable**: `Type`<br />
Special type indicating unreachable code when obtaining information about an expression.
* **auto**: `Type`<br />
Special type used in **Module#block** exclusively. Lets the API figure out a block's result type automatically.
* **createType**(types: `Type[]`): `Type`<br />
Creates a multi-value type from an array of types.
* **expandType**(type: `Type`): `Type[]`<br />
Expands a multi-value type to an array of types.
### Module construction
* new **Module**()<br />
Constructs a new module.
* **parseText**(text: `string`): `Module`<br />
Creates a module from Binaryen's s-expression text format (not official stack-style text format).
* **readBinary**(data: `Uint8Array`): `Module`<br />
Creates a module from binary data.
### Module manipulation
* Module#**addFunction**(name: `string`, params: `Type`, results: `Type`, vars: `Type[]`, body: `ExpressionRef`): `FunctionRef`<br />
Adds a function. `vars` indicate additional locals, in the given order.
* Module#**getFunction**(name: `string`): `FunctionRef`<br />
Gets a function, by name,
* Module#**removeFunction**(name: `string`): `void`<br />
Removes a function, by name.
* Module#**getNumFunctions**(): `number`<br />
Gets the number of functions within the module.
* Module#**getFunctionByIndex**(index: `number`): `FunctionRef`<br />
Gets the function at the specified index.
* Module#**addFunctionImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, params: `Type`, results: `Type`): `void`<br />
Adds a function import.
* Module#**addTableImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`): `void`<br />
Adds a table import. There's just one table for now, using name `"0"`.
* Module#**addMemoryImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`): `void`<br />
Adds a memory import. There's just one memory for now, using name `"0"`.
* Module#**addGlobalImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, globalType: `Type`): `void`<br />
Adds a global variable import. Imported globals must be immutable.
* Module#**addFunctionExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a function export.
* Module#**addTableExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a table export. There's just one table for now, using name `"0"`.
* Module#**addMemoryExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a memory export. There's just one memory for now, using name `"0"`.
* Module#**addGlobalExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a global variable export. Exported globals must be immutable.
* Module#**getNumExports**(): `number`<br />
Gets the number of exports witin the module.
* Module#**getExportByIndex**(index: `number`): `ExportRef`<br />
Gets the export at the specified index.
* Module#**removeExport**(externalName: `string`): `void`<br />
Removes an export, by external name.
* Module#**addGlobal**(name: `string`, type: `Type`, mutable: `number`, value: `ExpressionRef`): `GlobalRef`<br />
Adds a global instance variable.
* Module#**getGlobal**(name: `string`): `GlobalRef`<br />
Gets a global, by name,
* Module#**removeGlobal**(name: `string`): `void`<br />
Removes a global, by name.
* Module#**setFunctionTable**(initial: `number`, maximum: `number`, funcs: `string[]`, offset?: `ExpressionRef`): `void`<br />
Sets the contents of the function table. There's just one table for now, using name `"0"`.
* Module#**getFunctionTable**(): `{ imported: boolean, segments: TableElement[] }`<br />
Gets the contents of the function table.
* TableElement#**offset**: `ExpressionRef`
* TableElement#**names**: `string[]`
* Module#**setMemory**(initial: `number`, maximum: `number`, exportName: `string | null`, segments: `MemorySegment[]`, flags?: `number[]`, shared?: `boolean`): `void`<br />
Sets the memory. There's just one memory for now, using name `"0"`. Providing `exportName` also creates a memory export.
* MemorySegment#**offset**: `ExpressionRef`
* MemorySegment#**data**: `Uint8Array`
* MemorySegment#**passive**: `boolean`
* Module#**getNumMemorySegments**(): `number`<br />
Gets the number of memory segments within the module.
* Module#**getMemorySegmentInfoByIndex**(index: `number`): `MemorySegmentInfo`<br />
Gets information about the memory segment at the specified index.
* MemorySegmentInfo#**offset**: `number`
* MemorySegmentInfo#**data**: `Uint8Array`
* MemorySegmentInfo#**passive**: `boolean`
* Module#**setStart**(start: `FunctionRef`): `void`<br />
Sets the start function.
* Module#**getFeatures**(): `Features`<br />
Gets the WebAssembly features enabled for this module.
Note that the return value may be a bitmask indicating multiple features. Possible feature flags are:
* Features.**MVP**: `Features`
* Features.**Atomics**: `Features`
* Features.**BulkMemory**: `Features`
* Features.**MutableGlobals**: `Features`
* Features.**NontrappingFPToInt**: `Features`
* Features.**SignExt**: `Features`
* Features.**SIMD128**: `Features`
* Features.**ExceptionHandling**: `Features`
* Features.**TailCall**: `Features`
* Features.**ReferenceTypes**: `Features`
* Features.**Multivalue**: `Features`
* Features.**All**: `Features`
* Module#**setFeatures**(features: `Features`): `void`<br />
Sets the WebAssembly features enabled for this module.
* Module#**addCustomSection**(name: `string`, contents: `Uint8Array`): `void`<br />
Adds a custom section to the binary.
* Module#**autoDrop**(): `void`<br />
Enables automatic insertion of `drop` operations where needed. Lets you not worry about dropping when creating your code.
* **getFunctionInfo**(ftype: `FunctionRef`: `FunctionInfo`<br />
Obtains information about a function.
* FunctionInfo#**name**: `string`
* FunctionInfo#**module**: `string | null` (if imported)
* FunctionInfo#**base**: `string | null` (if imported)
* FunctionInfo#**params**: `Type`
* FunctionInfo#**results**: `Type`
* FunctionInfo#**vars**: `Type`
* FunctionInfo#**body**: `ExpressionRef`
* **getGlobalInfo**(global: `GlobalRef`): `GlobalInfo`<br />
Obtains information about a global.
* GlobalInfo#**name**: `string`
* GlobalInfo#**module**: `string | null` (if imported)
* GlobalInfo#**base**: `string | null` (if imported)
* GlobalInfo#**type**: `Type`
* GlobalInfo#**mutable**: `boolean`
* GlobalInfo#**init**: `ExpressionRef`
* **getExportInfo**(export_: `ExportRef`): `ExportInfo`<br />
Obtains information about an export.
* ExportInfo#**kind**: `ExternalKind`
* ExportInfo#**name**: `string`
* ExportInfo#**value**: `string`
Possible `ExternalKind` values are:
* **ExternalFunction**: `ExternalKind`
* **ExternalTable**: `ExternalKind`
* **ExternalMemory**: `ExternalKind`
* **ExternalGlobal**: `ExternalKind`
* **ExternalEvent**: `ExternalKind`
* **getEventInfo**(event: `EventRef`): `EventInfo`<br />
Obtains information about an event.
* EventInfo#**name**: `string`
* EventInfo#**module**: `string | null` (if imported)
* EventInfo#**base**: `string | null` (if imported)
* EventInfo#**attribute**: `number`
* EventInfo#**params**: `Type`
* EventInfo#**results**: `Type`
* **getSideEffects**(expr: `ExpressionRef`, features: `FeatureFlags`): `SideEffects`<br />
Gets the side effects of the specified expression.
* SideEffects.**None**: `SideEffects`
* SideEffects.**Branches**: `SideEffects`
* SideEffects.**Calls**: `SideEffects`
* SideEffects.**ReadsLocal**: `SideEffects`
* SideEffects.**WritesLocal**: `SideEffects`
* SideEffects.**ReadsGlobal**: `SideEffects`
* SideEffects.**WritesGlobal**: `SideEffects`
* SideEffects.**ReadsMemory**: `SideEffects`
* SideEffects.**WritesMemory**: `SideEffects`
* SideEffects.**ImplicitTrap**: `SideEffects`
* SideEffects.**IsAtomic**: `SideEffects`
* SideEffects.**Throws**: `SideEffects`
* SideEffects.**Any**: `SideEffects`
### Module validation
* Module#**validate**(): `boolean`<br />
Validates the module. Returns `true` if valid, otherwise prints validation errors and returns `false`.
### Module optimization
* Module#**optimize**(): `void`<br />
Optimizes the module using the default optimization passes.
* Module#**optimizeFunction**(func: `FunctionRef | string`): `void`<br />
Optimizes a single function using the default optimization passes.
* Module#**runPasses**(passes: `string[]`): `void`<br />
Runs the specified passes on the module.
* Module#**runPassesOnFunction**(func: `FunctionRef | string`, passes: `string[]`): `void`<br />
Runs the specified passes on a single function.
* **getOptimizeLevel**(): `number`<br />
Gets the currently set optimize level. `0`, `1`, `2` correspond to `-O0`, `-O1`, `-O2` (default), etc.
* **setOptimizeLevel**(level: `number`): `void`<br />
Sets the optimization level to use. `0`, `1`, `2` correspond to `-O0`, `-O1`, `-O2` (default), etc.
* **getShrinkLevel**(): `number`<br />
Gets the currently set shrink level. `0`, `1`, `2` correspond to `-O0`, `-Os` (default), `-Oz`.
* **setShrinkLevel**(level: `number`): `void`<br />
Sets the shrink level to use. `0`, `1`, `2` correspond to `-O0`, `-Os` (default), `-Oz`.
* **getDebugInfo**(): `boolean`<br />
Gets whether generating debug information is currently enabled or not.
* **setDebugInfo**(on: `boolean`): `void`<br />
Enables or disables debug information in emitted binaries.
* **getLowMemoryUnused**(): `boolean`<br />
Gets whether the low 1K of memory can be considered unused when optimizing.
* **setLowMemoryUnused**(on: `boolean`): `void`<br />
Enables or disables whether the low 1K of memory can be considered unused when optimizing.
* **getPassArgument**(key: `string`): `string | null`<br />
Gets the value of the specified arbitrary pass argument.
* **setPassArgument**(key: `string`, value: `string | null`): `void`<br />
Sets the value of the specified arbitrary pass argument. Removes the respective argument if `value` is `null`.
* **clearPassArguments**(): `void`<br />
Clears all arbitrary pass arguments.
* **getAlwaysInlineMaxSize**(): `number`<br />
Gets the function size at which we always inline.
* **setAlwaysInlineMaxSize**(size: `number`): `void`<br />
Sets the function size at which we always inline.
* **getFlexibleInlineMaxSize**(): `number`<br />
Gets the function size which we inline when functions are lightweight.
* **setFlexibleInlineMaxSize**(size: `number`): `void`<br />
Sets the function size which we inline when functions are lightweight.
* **getOneCallerInlineMaxSize**(): `number`<br />
Gets the function size which we inline when there is only one caller.
* **setOneCallerInlineMaxSize**(size: `number`): `void`<br />
Sets the function size which we inline when there is only one caller.
### Module creation
* Module#**emitBinary**(): `Uint8Array`<br />
Returns the module in binary format.
* Module#**emitBinary**(sourceMapUrl: `string | null`): `BinaryWithSourceMap`<br />
Returns the module in binary format with its source map. If `sourceMapUrl` is `null`, source map generation is skipped.
* BinaryWithSourceMap#**binary**: `Uint8Array`
* BinaryWithSourceMap#**sourceMap**: `string | null`
* Module#**emitText**(): `string`<br />
Returns the module in Binaryen's s-expression text format (not official stack-style text format).
* Module#**emitAsmjs**(): `string`<br />
Returns the [asm.js](http://asmjs.org/) representation of the module.
* Module#**dispose**(): `void`<br />
Releases the resources held by the module once it isn't needed anymore.
### Expression construction
#### [Control flow](http://webassembly.org/docs/semantics/#control-constructs-and-instructions)
* Module#**block**(label: `string | null`, children: `ExpressionRef[]`, resultType?: `Type`): `ExpressionRef`<br />
Creates a block. `resultType` defaults to `none`.
* Module#**if**(condition: `ExpressionRef`, ifTrue: `ExpressionRef`, ifFalse?: `ExpressionRef`): `ExpressionRef`<br />
Creates an if or if/else combination.
* Module#**loop**(label: `string | null`, body: `ExpressionRef`): `ExpressionRef`<br />
Creates a loop.
* Module#**br**(label: `string`, condition?: `ExpressionRef`, value?: `ExpressionRef`): `ExpressionRef`<br />
Creates a branch (br) to a label.
* Module#**switch**(labels: `string[]`, defaultLabel: `string`, condition: `ExpressionRef`, value?: `ExpressionRef`): `ExpressionRef`<br />
Creates a switch (br_table).
* Module#**nop**(): `ExpressionRef`<br />
Creates a no-operation (nop) instruction.
* Module#**return**(value?: `ExpressionRef`): `ExpressionRef`
Creates a return.
* Module#**unreachable**(): `ExpressionRef`<br />
Creates an [unreachable](http://webassembly.org/docs/semantics/#unreachable) instruction that will always trap.
* Module#**drop**(value: `ExpressionRef`): `ExpressionRef`<br />
Creates a [drop](http://webassembly.org/docs/semantics/#type-parametric-operators) of a value.
* Module#**select**(condition: `ExpressionRef`, ifTrue: `ExpressionRef`, ifFalse: `ExpressionRef`, type?: `Type`): `ExpressionRef`<br />
Creates a [select](http://webassembly.org/docs/semantics/#type-parametric-operators) of one of two values.
#### [Variable accesses](http://webassembly.org/docs/semantics/#local-variables)
* Module#**local.get**(index: `number`, type: `Type`): `ExpressionRef`<br />
Creates a local.get for the local at the specified index. Note that we must specify the type here as we may not have created the local being accessed yet.
* Module#**local.set**(index: `number`, value: `ExpressionRef`): `ExpressionRef`<br />
Creates a local.set for the local at the specified index.
* Module#**local.tee**(index: `number`, value: `ExpressionRef`, type: `Type`): `ExpressionRef`<br />
Creates a local.tee for the local at the specified index. A tee differs from a set in that the value remains on the stack. Note that we must specify the type here as we may not have created the local being accessed yet.
* Module#**global.get**(name: `string`, type: `Type`): `ExpressionRef`<br />
Creates a global.get for the global with the specified name. Note that we must specify the type here as we may not have created the global being accessed yet.
* Module#**global.set**(name: `string`, value: `ExpressionRef`): `ExpressionRef`<br />
Creates a global.set for the global with the specified name.
#### [Integer operations](http://webassembly.org/docs/semantics/#32-bit-integer-operators)
* Module#i32.**const**(value: `number`): `ExpressionRef`
* Module#i32.**clz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ctz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**popcnt**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**eqz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**div_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**div_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rem_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rem_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shr_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rotl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rotr**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**le_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**const**(low: `number`, high: `number`): `ExpressionRef`
* Module#i64.**clz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ctz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**popcnt**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**eqz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**div_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**div_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rem_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rem_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shr_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rotl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rotr**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**le_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
#### [Floating point operations](http://webassembly.org/docs/semantics/#floating-point-operators)
* Module#f32.**const**(value: `number`): `ExpressionRef`
* Module#f32.**const_bits**(value: `number`): `ExpressionRef`
* Module#f32.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ceil**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**floor**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**trunc**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**nearest**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**copysign**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**const**(value: `number`): `ExpressionRef`
* Module#f64.**const_bits**(value: `number`): `ExpressionRef`
* Module#f64.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ceil**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**floor**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**trunc**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**nearest**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**copysign**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
#### [Datatype conversions](http://webassembly.org/docs/semantics/#datatype-conversions-truncations-reinterpretations-promotions-and-demotions)
* Module#i32.**trunc_s.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_s.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_u.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_u.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**wrap**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**trunc_s.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_s.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_u.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_u.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f32.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_s.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_s.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_u.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_u.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**demote**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_s.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_s.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_u.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_u.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**promote**(value: `ExpressionRef`): `ExpressionRef`
#### [Function calls](http://webassembly.org/docs/semantics/#calls)
* Module#**call**(name: `string`, operands: `ExpressionRef[]`, returnType: `Type`): `ExpressionRef`
Creates a call to a function. Note that we must specify the return type here as we may not have created the function being called yet.
* Module#**return_call**(name: `string`, operands: `ExpressionRef[]`, returnType: `Type`): `ExpressionRef`<br />
Like **call**, but creates a tail-call. 🦄
* Module#**call_indirect**(target: `ExpressionRef`, operands: `ExpressionRef[]`, params: `Type`, results: `Type`): `ExpressionRef`<br />
Similar to **call**, but calls indirectly, i.e., via a function pointer, so an expression replaces the name as the called value.
* Module#**return_call_indirect**(target: `ExpressionRef`, operands: `ExpressionRef[]`, params: `Type`, results: `Type`): `ExpressionRef`<br />
Like **call_indirect**, but creates a tail-call. 🦄
#### [Linear memory accesses](http://webassembly.org/docs/semantics/#linear-memory-accesses)
* Module#i32.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load16_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load16_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store8**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store16**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
>
* Module#i64.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load16_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load16_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load32_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load32_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store8**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store16**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store32**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#f32.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#f32.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#f64.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
#### [Host operations](http://webassembly.org/docs/semantics/#resizing)
* Module#**memory.size**(): `ExpressionRef`
* Module#**memory.grow**(value: `number`): `ExpressionRef`
#### [Vector operations](https://github.com/WebAssembly/simd/blob/master/proposals/simd/SIMD.md) 🦄
* Module#v128.**const**(bytes: `Uint8Array`): `ExpressionRef`
* Module#v128.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#v128.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#v128.**not**(value: `ExpressionRef`): `ExpressionRef`
* Module#v128.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**andnot**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**bitselect**(left: `ExpressionRef`, right: `ExpressionRef`, cond: `ExpressionRef`): `ExpressionRef`
>
* Module#i8x16.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i8x16.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i8x16.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**avgr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**narrow_i16x8_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**narrow_i16x8_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#i16x8.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i16x8.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i16x8.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**avgr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**narrow_i32x4_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**narrow_i32x4_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_low_i8x16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_high_i8x16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_low_i8x16_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_high_i8x16_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**load8x8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**load8x8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#i32x4.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i32x4.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i32x4.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**dot_i16x8_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**trunc_sat_f32x4_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**trunc_sat_f32x4_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_low_i16x8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_high_i16x8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_low_i16x8_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_high_i16x8_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**load16x4_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**load16x4_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#i64x2.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i64x2.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i64x2.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**trunc_sat_f64x2_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**trunc_sat_f64x2_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**load32x2_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**load32x2_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#f32x4.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**extract_lane**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#f32x4.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**qfma**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**qfms**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**convert_i32x4_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**convert_i32x4_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64x2.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**extract_lane**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#f64x2.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**qfma**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**qfms**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**convert_i64x2_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**convert_i64x2_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#v8x16.**shuffle**(left: `ExpressionRef`, right: `ExpressionRef`, mask: `Uint8Array`): `ExpressionRef`
* Module#v8x16.**swizzle**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v8x16.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v16x8.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v32x4.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v64x2.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
#### [Atomic memory accesses](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#atomic-memory-accesses) 🦄
* Module#i32.**atomic.load**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.load8_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.load16_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store8**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store16**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**atomic.load**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load8_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load16_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load32_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store8**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store16**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store32**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
#### [Atomic read-modify-write operations](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#read-modify-write) 🦄
* Module#i32.**atomic.rmw.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**atomic.rmw.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
#### [Atomic wait and notify operations](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#wait-and-notify-operators) 🦄
* Module#i32.**atomic.wait**(ptr: `ExpressionRef`, expected: `ExpressionRef`, timeout: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.wait**(ptr: `ExpressionRef`, expected: `ExpressionRef`, timeout: `ExpressionRef`): `ExpressionRef`
* Module#**atomic.notify**(ptr: `ExpressionRef`, notifyCount: `ExpressionRef`): `ExpressionRef`
* Module#**atomic.fence**(): `ExpressionRef`
#### [Sign extension operations](https://github.com/WebAssembly/sign-extension-ops/blob/master/proposals/sign-extension-ops/Overview.md) 🦄
* Module#i32.**extend8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**extend16_s**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**extend8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend32_s**(value: `ExpressionRef`): `ExpressionRef`
#### [Multi-value operations](https://github.com/WebAssembly/multi-value/blob/master/proposals/multi-value/Overview.md) 🦄
Note that these are pseudo instructions enabling Binaryen to reason about multiple values on the stack.
* Module#**push**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**pop**(): `ExpressionRef`
* Module#i64.**pop**(): `ExpressionRef`
* Module#f32.**pop**(): `ExpressionRef`
* Module#f64.**pop**(): `ExpressionRef`
* Module#v128.**pop**(): `ExpressionRef`
* Module#funcref.**pop**(): `ExpressionRef`
* Module#anyref.**pop**(): `ExpressionRef`
* Module#nullref.**pop**(): `ExpressionRef`
* Module#exnref.**pop**(): `ExpressionRef`
* Module#tuple.**make**(elements: `ExpressionRef[]`): `ExpressionRef`
* Module#tuple.**extract**(tuple: `ExpressionRef`, index: `number`): `ExpressionRef`
#### [Exception handling operations](https://github.com/WebAssembly/exception-handling/blob/master/proposals/Exceptions.md) 🦄
* Module#**try**(body: `ExpressionRef`, catchBody: `ExpressionRef`): `ExpressionRef`
* Module#**throw**(event: `string`, operands: `ExpressionRef[]`): `ExpressionRef`
* Module#**rethrow**(exnref: `ExpressionRef`): `ExpressionRef`
* Module#**br_on_exn**(label: `string`, event: `string`, exnref: `ExpressionRef`): `ExpressionRef`
>
* Module#**addEvent**(name: `string`, attribute: `number`, params: `Type`, results: `Type`): `Event`
* Module#**getEvent**(name: `string`): `Event`
* Module#**removeEvent**(name: `stirng`): `void`
* Module#**addEventImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, attribute: `number`, params: `Type`, results: `Type`): `void`
* Module#**addEventExport**(internalName: `string`, externalName: `string`): `ExportRef`
#### [Reference types operations](https://github.com/WebAssembly/reference-types/blob/master/proposals/reference-types/Overview.md) 🦄
* Module#ref.**null**(): `ExpressionRef`
* Module#ref.**is_null**(value: `ExpressionRef`): `ExpressionRef`
* Module#ref.**func**(name: `string`): `ExpressionRef`
### Expression manipulation
* **getExpressionId**(expr: `ExpressionRef`): `ExpressionId`<br />
Gets the id (kind) of the specified expression. Possible values are:
* **InvalidId**: `ExpressionId`
* **BlockId**: `ExpressionId`
* **IfId**: `ExpressionId`
* **LoopId**: `ExpressionId`
* **BreakId**: `ExpressionId`
* **SwitchId**: `ExpressionId`
* **CallId**: `ExpressionId`
* **CallIndirectId**: `ExpressionId`
* **LocalGetId**: `ExpressionId`
* **LocalSetId**: `ExpressionId`
* **GlobalGetId**: `ExpressionId`
* **GlobalSetId**: `ExpressionId`
* **LoadId**: `ExpressionId`
* **StoreId**: `ExpressionId`
* **ConstId**: `ExpressionId`
* **UnaryId**: `ExpressionId`
* **BinaryId**: `ExpressionId`
* **SelectId**: `ExpressionId`
* **DropId**: `ExpressionId`
* **ReturnId**: `ExpressionId`
* **HostId**: `ExpressionId`
* **NopId**: `ExpressionId`
* **UnreachableId**: `ExpressionId`
* **AtomicCmpxchgId**: `ExpressionId`
* **AtomicRMWId**: `ExpressionId`
* **AtomicWaitId**: `ExpressionId`
* **AtomicNotifyId**: `ExpressionId`
* **AtomicFenceId**: `ExpressionId`
* **SIMDExtractId**: `ExpressionId`
* **SIMDReplaceId**: `ExpressionId`
* **SIMDShuffleId**: `ExpressionId`
* **SIMDTernaryId**: `ExpressionId`
* **SIMDShiftId**: `ExpressionId`
* **SIMDLoadId**: `ExpressionId`
* **MemoryInitId**: `ExpressionId`
* **DataDropId**: `ExpressionId`
* **MemoryCopyId**: `ExpressionId`
* **MemoryFillId**: `ExpressionId`
* **RefNullId**: `ExpressionId`
* **RefIsNullId**: `ExpressionId`
* **RefFuncId**: `ExpressionId`
* **TryId**: `ExpressionId`
* **ThrowId**: `ExpressionId`
* **RethrowId**: `ExpressionId`
* **BrOnExnId**: `ExpressionId`
* **PushId**: `ExpressionId`
* **PopId**: `ExpressionId`
* **getExpressionType**(expr: `ExpressionRef`): `Type`<br />
Gets the type of the specified expression.
* **getExpressionInfo**(expr: `ExpressionRef`): `ExpressionInfo`<br />
Obtains information about an expression, always including:
* Info#**id**: `ExpressionId`
* Info#**type**: `Type`
Additional properties depend on the expression's `id` and are usually equivalent to the respective parameters when creating such an expression:
* BlockInfo#**name**: `string`
* BlockInfo#**children**: `ExpressionRef[]`
>
* IfInfo#**condition**: `ExpressionRef`
* IfInfo#**ifTrue**: `ExpressionRef`
* IfInfo#**ifFalse**: `ExpressionRef | null`
>
* LoopInfo#**name**: `string`
* LoopInfo#**body**: `ExpressionRef`
>
* BreakInfo#**name**: `string`
* BreakInfo#**condition**: `ExpressionRef | null`
* BreakInfo#**value**: `ExpressionRef | null`
>
* SwitchInfo#**names**: `string[]`
* SwitchInfo#**defaultName**: `string | null`
* SwitchInfo#**condition**: `ExpressionRef`
* SwitchInfo#**value**: `ExpressionRef | null`
>
* CallInfo#**target**: `string`
* CallInfo#**operands**: `ExpressionRef[]`
>
* CallImportInfo#**target**: `string`
* CallImportInfo#**operands**: `ExpressionRef[]`
>
* CallIndirectInfo#**target**: `ExpressionRef`
* CallIndirectInfo#**operands**: `ExpressionRef[]`
>
* LocalGetInfo#**index**: `number`
>
* LocalSetInfo#**isTee**: `boolean`
* LocalSetInfo#**index**: `number`
* LocalSetInfo#**value**: `ExpressionRef`
>
* GlobalGetInfo#**name**: `string`
>
* GlobalSetInfo#**name**: `string`
* GlobalSetInfo#**value**: `ExpressionRef`
>
* LoadInfo#**isAtomic**: `boolean`
* LoadInfo#**isSigned**: `boolean`
* LoadInfo#**offset**: `number`
* LoadInfo#**bytes**: `number`
* LoadInfo#**align**: `number`
* LoadInfo#**ptr**: `ExpressionRef`
>
* StoreInfo#**isAtomic**: `boolean`
* StoreInfo#**offset**: `number`
* StoreInfo#**bytes**: `number`
* StoreInfo#**align**: `number`
* StoreInfo#**ptr**: `ExpressionRef`
* StoreInfo#**value**: `ExpressionRef`
>
* ConstInfo#**value**: `number | { low: number, high: number }`
>
* UnaryInfo#**op**: `number`
* UnaryInfo#**value**: `ExpressionRef`
>
* BinaryInfo#**op**: `number`
* BinaryInfo#**left**: `ExpressionRef`
* BinaryInfo#**right**: `ExpressionRef`
>
* SelectInfo#**ifTrue**: `ExpressionRef`
* SelectInfo#**ifFalse**: `ExpressionRef`
* SelectInfo#**condition**: `ExpressionRef`
>
* DropInfo#**value**: `ExpressionRef`
>
* ReturnInfo#**value**: `ExpressionRef | null`
>
* NopInfo
>
* UnreachableInfo
>
* HostInfo#**op**: `number`
* HostInfo#**nameOperand**: `string | null`
* HostInfo#**operands**: `ExpressionRef[]`
>
* AtomicRMWInfo#**op**: `number`
* AtomicRMWInfo#**bytes**: `number`
* AtomicRMWInfo#**offset**: `number`
* AtomicRMWInfo#**ptr**: `ExpressionRef`
* AtomicRMWInfo#**value**: `ExpressionRef`
>
* AtomicCmpxchgInfo#**bytes**: `number`
* AtomicCmpxchgInfo#**offset**: `number`
* AtomicCmpxchgInfo#**ptr**: `ExpressionRef`
* AtomicCmpxchgInfo#**expected**: `ExpressionRef`
* AtomicCmpxchgInfo#**replacement**: `ExpressionRef`
>
* AtomicWaitInfo#**ptr**: `ExpressionRef`
* AtomicWaitInfo#**expected**: `ExpressionRef`
* AtomicWaitInfo#**timeout**: `ExpressionRef`
* AtomicWaitInfo#**expectedType**: `Type`
>
* AtomicNotifyInfo#**ptr**: `ExpressionRef`
* AtomicNotifyInfo#**notifyCount**: `ExpressionRef`
>
* AtomicFenceInfo
>
* SIMDExtractInfo#**op**: `Op`
* SIMDExtractInfo#**vec**: `ExpressionRef`
* SIMDExtractInfo#**index**: `ExpressionRef`
>
* SIMDReplaceInfo#**op**: `Op`
* SIMDReplaceInfo#**vec**: `ExpressionRef`
* SIMDReplaceInfo#**index**: `ExpressionRef`
* SIMDReplaceInfo#**value**: `ExpressionRef`
>
* SIMDShuffleInfo#**left**: `ExpressionRef`
* SIMDShuffleInfo#**right**: `ExpressionRef`
* SIMDShuffleInfo#**mask**: `Uint8Array`
>
* SIMDTernaryInfo#**op**: `Op`
* SIMDTernaryInfo#**a**: `ExpressionRef`
* SIMDTernaryInfo#**b**: `ExpressionRef`
* SIMDTernaryInfo#**c**: `ExpressionRef`
>
* SIMDShiftInfo#**op**: `Op`
* SIMDShiftInfo#**vec**: `ExpressionRef`
* SIMDShiftInfo#**shift**: `ExpressionRef`
>
* SIMDLoadInfo#**op**: `Op`
* SIMDLoadInfo#**offset**: `number`
* SIMDLoadInfo#**align**: `number`
* SIMDLoadInfo#**ptr**: `ExpressionRef`
>
* MemoryInitInfo#**segment**: `number`
* MemoryInitInfo#**dest**: `ExpressionRef`
* MemoryInitInfo#**offset**: `ExpressionRef`
* MemoryInitInfo#**size**: `ExpressionRef`
>
* MemoryDropInfo#**segment**: `number`
>
* MemoryCopyInfo#**dest**: `ExpressionRef`
* MemoryCopyInfo#**source**: `ExpressionRef`
* MemoryCopyInfo#**size**: `ExpressionRef`
>
* MemoryFillInfo#**dest**: `ExpressionRef`
* MemoryFillInfo#**value**: `ExpressionRef`
* MemoryFillInfo#**size**: `ExpressionRef`
>
* TryInfo#**body**: `ExpressionRef`
* TryInfo#**catchBody**: `ExpressionRef`
>
* RefNullInfo
>
* RefIsNullInfo#**value**: `ExpressionRef`
>
* RefFuncInfo#**func**: `string`
>
* ThrowInfo#**event**: `string`
* ThrowInfo#**operands**: `ExpressionRef[]`
>
* RethrowInfo#**exnref**: `ExpressionRef`
>
* BrOnExnInfo#**name**: `string`
* BrOnExnInfo#**event**: `string`
* BrOnExnInfo#**exnref**: `ExpressionRef`
>
* PopInfo
>
* PushInfo#**value**: `ExpressionRef`
* **emitText**(expression: `ExpressionRef`): `string`<br />
Emits the expression in Binaryen's s-expression text format (not official stack-style text format).
* **copyExpression**(expression: `ExpressionRef`): `ExpressionRef`<br />
Creates a deep copy of an expression.
### Relooper
* new **Relooper**()<br />
Constructs a relooper instance. This lets you provide an arbitrary CFG, and the relooper will structure it for WebAssembly.
* Relooper#**addBlock**(code: `ExpressionRef`): `RelooperBlockRef`<br />
Adds a new block to the CFG, containing the provided code as its body.
* Relooper#**addBranch**(from: `RelooperBlockRef`, to: `RelooperBlockRef`, condition: `ExpressionRef`, code: `ExpressionRef`): `void`<br />
Adds a branch from a block to another block, with a condition (or nothing, if this is the default branch to take from the origin - each block must have one such branch), and optional code to execute on the branch (useful for phis).
* Relooper#**addBlockWithSwitch**(code: `ExpressionRef`, condition: `ExpressionRef`): `RelooperBlockRef`<br />
Adds a new block, which ends with a switch/br_table, with provided code and condition (that determines where we go in the switch).
* Relooper#**addBranchForSwitch**(from: `RelooperBlockRef`, to: `RelooperBlockRef`, indexes: `number[]`, code: `ExpressionRef`): `void`<br />
Adds a branch from a block ending in a switch, to another block, using an array of indexes that determine where to go, and optional code to execute on the branch.
* Relooper#**renderAndDispose**(entry: `RelooperBlockRef`, labelHelper: `number`, module: `Module`): `ExpressionRef`<br />
Renders and cleans up the Relooper instance. Call this after you have created all the blocks and branches, giving it the entry block (where control flow begins), a label helper variable (an index of a local we can use, necessary for irreducible control flow), and the module. This returns an expression - normal WebAssembly code - that you can use normally anywhere.
### Source maps
* Module#**addDebugInfoFileName**(filename: `string`): `number`<br />
Adds a debug info file name to the module and returns its index.
* Module#**getDebugInfoFileName**(index: `number`): `string | null` <br />
Gets the name of the debug info file at the specified index.
* Module#**setDebugLocation**(func: `FunctionRef`, expr: `ExpressionRef`, fileIndex: `number`, lineNumber: `number`, columnNumber: `number`): `void`<br />
Sets the debug location of the specified `ExpressionRef` within the specified `FunctionRef`.
### Debugging
* Module#**interpret**(): `void`<br />
Runs the module in the interpreter, calling the start function.
<p align="center">
<a href="http://gulpjs.com">
<img height="257" width="114" src="https://raw.githubusercontent.com/gulpjs/artwork/master/gulp-2x.png">
</a>
</p>
# interpret
[![NPM version][npm-image]][npm-url] [![Downloads][downloads-image]][npm-url] [![Travis Build Status][travis-image]][travis-url] [![AppVeyor Build Status][appveyor-image]][appveyor-url] [![Coveralls Status][coveralls-image]][coveralls-url] [![Gitter chat][gitter-image]][gitter-url]
A dictionary of file extensions and associated module loaders.
## What is it
This is used by [Liftoff](http://github.com/tkellen/node-liftoff) to automatically require dependencies for configuration files, and by [rechoir](http://github.com/tkellen/node-rechoir) for registering module loaders.
## API
### extensions
Map file types to modules which provide a [require.extensions] loader.
```js
{
'.babel.js': [
{
module: '@babel/register',
register: function(hook) {
// register on .js extension due to https://github.com/joyent/node/blob/v0.12.0/lib/module.js#L353
// which only captures the final extension (.babel.js -> .js)
hook({ extensions: '.js' });
},
},
{
module: 'babel-register',
register: function(hook) {
hook({ extensions: '.js' });
},
},
{
module: 'babel-core/register',
register: function(hook) {
hook({ extensions: '.js' });
},
},
{
module: 'babel/register',
register: function(hook) {
hook({ extensions: '.js' });
},
},
],
'.babel.ts': [
{
module: '@babel/register',
register: function(hook) {
hook({ extensions: '.ts' });
},
},
],
'.buble.js': 'buble/register',
'.cirru': 'cirru-script/lib/register',
'.cjsx': 'node-cjsx/register',
'.co': 'coco',
'.coffee': ['coffeescript/register', 'coffee-script/register', 'coffeescript', 'coffee-script'],
'.coffee.md': ['coffeescript/register', 'coffee-script/register', 'coffeescript', 'coffee-script'],
'.csv': 'require-csv',
'.eg': 'earlgrey/register',
'.esm.js': {
module: 'esm',
register: function(hook) {
// register on .js extension due to https://github.com/joyent/node/blob/v0.12.0/lib/module.js#L353
// which only captures the final extension (.babel.js -> .js)
var esmLoader = hook(module);
require.extensions['.js'] = esmLoader('module')._extensions['.js'];
},
},
'.iced': ['iced-coffee-script/register', 'iced-coffee-script'],
'.iced.md': 'iced-coffee-script/register',
'.ini': 'require-ini',
'.js': null,
'.json': null,
'.json5': 'json5/lib/require',
'.jsx': [
{
module: '@babel/register',
register: function(hook) {
hook({ extensions: '.jsx' });
},
},
{
module: 'babel-register',
register: function(hook) {
hook({ extensions: '.jsx' });
},
},
{
module: 'babel-core/register',
register: function(hook) {
hook({ extensions: '.jsx' });
},
},
{
module: 'babel/register',
register: function(hook) {
hook({ extensions: '.jsx' });
},
},
{
module: 'node-jsx',
register: function(hook) {
hook.install({ extension: '.jsx', harmony: true });
},
},
],
'.litcoffee': ['coffeescript/register', 'coffee-script/register', 'coffeescript', 'coffee-script'],
'.liticed': 'iced-coffee-script/register',
'.ls': ['livescript', 'LiveScript'],
'.mjs': '/absolute/path/to/interpret/mjs-stub.js',
'.node': null,
'.toml': {
module: 'toml-require',
register: function(hook) {
hook.install();
},
},
'.ts': [
'ts-node/register',
'typescript-node/register',
'typescript-register',
'typescript-require',
'sucrase/register/ts',
{
module: '@babel/register',
register: function(hook) {
hook({ extensions: '.ts' });
},
},
],
'.tsx': [
'ts-node/register',
'typescript-node/register',
'sucrase/register',
{
module: '@babel/register',
register: function(hook) {
hook({ extensions: '.tsx' });
},
},
],
'.wisp': 'wisp/engine/node',
'.xml': 'require-xml',
'.yaml': 'require-yaml',
'.yml': 'require-yaml',
}
```
### jsVariants
Same as above, but only include the extensions which are javascript variants.
## How to use it
Consumers should use the exported `extensions` or `jsVariants` object to determine which module should be loaded for a given extension. If a matching extension is found, consumers should do the following:
1. If the value is null, do nothing.
2. If the value is a string, try to require it.
3. If the value is an object, try to require the `module` property. If successful, the `register` property (a function) should be called with the module passed as the first argument.
4. If the value is an array, iterate over it, attempting step #2 or #3 until one of the attempts does not throw.
[require.extensions]: http://nodejs.org/api/globals.html#globals_require_extensions
[downloads-image]: http://img.shields.io/npm/dm/interpret.svg
[npm-url]: https://www.npmjs.com/package/interpret
[npm-image]: http://img.shields.io/npm/v/interpret.svg
[travis-url]: https://travis-ci.org/gulpjs/interpret
[travis-image]: http://img.shields.io/travis/gulpjs/interpret.svg?label=travis-ci
[appveyor-url]: https://ci.appveyor.com/project/gulpjs/interpret
[appveyor-image]: https://img.shields.io/appveyor/ci/gulpjs/interpret.svg?label=appveyor
[coveralls-url]: https://coveralls.io/r/gulpjs/interpret
[coveralls-image]: http://img.shields.io/coveralls/gulpjs/interpret/master.svg
[gitter-url]: https://gitter.im/gulpjs/gulp
[gitter-image]: https://badges.gitter.im/gulpjs/gulp.svg
[](https://travis-ci.org/isaacs/rimraf) [](https://david-dm.org/isaacs/rimraf) [](https://david-dm.org/isaacs/rimraf#info=devDependencies)
The [UNIX command](http://en.wikipedia.org/wiki/Rm_(Unix)) `rm -rf` for node.
Install with `npm install rimraf`, or just drop rimraf.js somewhere.
## API
`rimraf(f, [opts], callback)`
The first parameter will be interpreted as a globbing pattern for files. If you
want to disable globbing you can do so with `opts.disableGlob` (defaults to
`false`). This might be handy, for instance, if you have filenames that contain
globbing wildcard characters.
The callback will be called with an error if there is one. Certain
errors are handled for you:
* Windows: `EBUSY` and `ENOTEMPTY` - rimraf will back off a maximum of
`opts.maxBusyTries` times before giving up, adding 100ms of wait
between each attempt. The default `maxBusyTries` is 3.
* `ENOENT` - If the file doesn't exist, rimraf will return
successfully, since your desired outcome is already the case.
* `EMFILE` - Since `readdir` requires opening a file descriptor, it's
possible to hit `EMFILE` if too many file descriptors are in use.
In the sync case, there's nothing to be done for this. But in the
async case, rimraf will gradually back off with timeouts up to
`opts.emfileWait` ms, which defaults to 1000.
## options
* unlink, chmod, stat, lstat, rmdir, readdir,
unlinkSync, chmodSync, statSync, lstatSync, rmdirSync, readdirSync
In order to use a custom file system library, you can override
specific fs functions on the options object.
If any of these functions are present on the options object, then
the supplied function will be used instead of the default fs
method.
Sync methods are only relevant for `rimraf.sync()`, of course.
For example:
```javascript
var myCustomFS = require('some-custom-fs')
rimraf('some-thing', myCustomFS, callback)
```
* maxBusyTries
If an `EBUSY`, `ENOTEMPTY`, or `EPERM` error code is encountered
on Windows systems, then rimraf will retry with a linear backoff
wait of 100ms longer on each try. The default maxBusyTries is 3.
Only relevant for async usage.
* emfileWait
If an `EMFILE` error is encountered, then rimraf will retry
repeatedly with a linear backoff of 1ms longer on each try, until
the timeout counter hits this max. The default limit is 1000.
If you repeatedly encounter `EMFILE` errors, then consider using
[graceful-fs](http://npm.im/graceful-fs) in your program.
Only relevant for async usage.
* glob
Set to `false` to disable [glob](http://npm.im/glob) pattern
matching.
Set to an object to pass options to the glob module. The default
glob options are `{ nosort: true, silent: true }`.
Glob version 6 is used in this module.
Relevant for both sync and async usage.
* disableGlob
Set to any non-falsey value to disable globbing entirely.
(Equivalent to setting `glob: false`.)
## rimraf.sync
It can remove stuff synchronously, too. But that's not so good. Use
the async API. It's better.
## CLI
If installed with `npm install rimraf -g` it can be used as a global
command `rimraf <path> [<path> ...]` which is useful for cross platform support.
## mkdirp
If you need to create a directory recursively, check out
[mkdirp](https://github.com/substack/node-mkdirp).
# line-column
[](https://travis-ci.org/io-monad/line-column) [](https://coveralls.io/github/io-monad/line-column?branch=master) [](https://badge.fury.io/js/line-column)
Node module to convert efficiently index to/from line-column in a string.
## Install
npm install line-column
## Usage
### lineColumn(str, options = {})
Returns a `LineColumnFinder` instance for given string `str`.
#### Options
| Key | Description | Default |
| ------- | ----------- | ------- |
| `origin` | The origin value of line number and column number | `1` |
### lineColumn(str, index)
This is just a shorthand for `lineColumn(str).fromIndex(index)`.
### LineColumnFinder#fromIndex(index)
Find line and column from index in the string.
Parameters:
- `index` - `number` Index in the string. (0-origin)
Returns:
- `{ line: x, col: y }` Found line number and column number.
- `null` if the given index is out of range.
### LineColumnFinder#toIndex(line, column)
Find index from line and column in the string.
Parameters:
- `line` - `number` Line number in the string.
- `column` - `number` Column number in the string.
or
- `{ line: x, col: y }` - `Object` line and column numbers in the string.<br>A key name `column` can be used instead of `col`.
or
- `[ line, col ]` - `Array` line and column numbers in the string.
Returns:
- `number` Found index in the string.
- `-1` if the given line or column is out of range.
## Example
```js
var lineColumn = require("line-column");
var testString = [
"ABCDEFG\n", // line:0, index:0
"HIJKLMNOPQRSTU\n", // line:1, index:8
"VWXYZ\n", // line:2, index:23
"日本語の文字\n", // line:3, index:29
"English words" // line:4, index:36
].join(""); // length:49
lineColumn(testString).fromIndex(3) // { line: 1, col: 4 }
lineColumn(testString).fromIndex(33) // { line: 4, col: 5 }
lineColumn(testString).toIndex(1, 4) // 3
lineColumn(testString).toIndex(4, 5) // 33
// Shorthand of .fromIndex (compatible with find-line-column)
lineColumn(testString, 33) // { line:4, col: 5 }
// Object or Array is also acceptable
lineColumn(testString).toIndex({ line: 4, col: 5 }) // 33
lineColumn(testString).toIndex({ line: 4, column: 5 }) // 33
lineColumn(testString).toIndex([4, 5]) // 33
// You can cache it for the same string. It is so efficient. (See benchmark)
var finder = lineColumn(testString);
finder.fromIndex(33) // { line: 4, column: 5 }
finder.toIndex(4, 5) // 33
// For 0-origin line and column numbers
var oneOrigin = lineColumn(testString, { origin: 0 });
oneOrigin.fromIndex(33) // { line: 3, column: 4 }
oneOrigin.toIndex(3, 4) // 33
```
## Testing
npm test
## Benchmark
The popular package [find-line-column](https://www.npmjs.com/package/find-line-column) provides the same "index to line-column" feature.
Here is some benchmarking on `line-column` vs `find-line-column`. You can run this benchmark by `npm run benchmark`. See [benchmark/](benchmark/) for the source code.
```
long text + line-column (not cached) x 72,989 ops/sec ±0.83% (89 runs sampled)
long text + line-column (cached) x 13,074,242 ops/sec ±0.32% (89 runs sampled)
long text + find-line-column x 33,887 ops/sec ±0.54% (84 runs sampled)
short text + line-column (not cached) x 1,636,766 ops/sec ±0.77% (82 runs sampled)
short text + line-column (cached) x 21,699,686 ops/sec ±1.04% (82 runs sampled)
short text + find-line-column x 382,145 ops/sec ±1.04% (85 runs sampled)
```
As you might have noticed, even not cached version of `line-column` is 2x - 4x faster than `find-line-column`, and cached version of `line-column` is remarkable 50x - 380x faster.
## Contributing
1. Fork it!
2. Create your feature branch: `git checkout -b my-new-feature`
3. Commit your changes: `git commit -am 'Add some feature'`
4. Push to the branch: `git push origin my-new-feature`
5. Submit a pull request :D
## License
MIT (See LICENSE)
|
kaanarslan1990_ptk-starter-near-sdk-as | README.md
aasignment.md
as-pect.config.js
asconfig.json
package-lock.json
package.json
scripts
1.dev-deploy.sh
2.use-contract.sh
3.cleanup.sh
README.md
src
as_types.d.ts
simple
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
singleton
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
| ## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
# `near-sdk-as` Starter Kit
This is a good project to use as a starting point for your AssemblyScript project.
## Samples
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
There are 2 AssemblyScript contracts in this project, each in their own folder:
- **simple** in the `src/simple` folder
- **singleton** in the `src/singleton` folder
### Simple
We say that an AssemblyScript contract is written in the "simple style" when the `index.ts` file (the contract entry point) includes a series of exported functions.
In this case, all exported functions become public contract methods.
```ts
// return the string 'hello world'
export function helloWorld(): string {}
// read the given key from account (contract) storage
export function read(key: string): string {}
// write the given value at the given key to account (contract) storage
export function write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
```
### Singleton
We say that an AssemblyScript contract is written in the "singleton style" when the `index.ts` file (the contract entry point) has a single exported class (the name of the class doesn't matter) that is decorated with `@nearBindgen`.
In this case, all methods on the class become public contract methods unless marked `private`. Also, all instance variables are stored as a serialized instance of the class under a special storage key named `STATE`. AssemblyScript uses JSON for storage serialization (as opposed to Rust contracts which use a custom binary serialization format called borsh).
```ts
@nearBindgen
export class Contract {
// return the string 'hello world'
helloWorld(): string {}
// read the given key from account (contract) storage
read(key: string): string {}
// write the given value at the given key to account (contract) storage
@mutateState()
write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
}
```
## Usage
### Getting started
(see below for video recordings of each of the following steps)
INSTALL `NEAR CLI` first like this: `npm i -g near-cli`
1. clone this repo to a local folder
2. run `yarn`
3. run `./scripts/1.dev-deploy.sh`
3. run `./scripts/2.use-contract.sh`
4. run `./scripts/2.use-contract.sh` (yes, run it to see changes)
5. run `./scripts/3.cleanup.sh`
### Videos
**`1.dev-deploy.sh`**
This video shows the build and deployment of the contract.
[](https://asciinema.org/a/409575)
**`2.use-contract.sh`**
This video shows contract methods being called. You should run the script twice to see the effect it has on contract state.
[](https://asciinema.org/a/409577)
**`3.cleanup.sh`**
This video shows the cleanup script running. Make sure you add the `BENEFICIARY` environment variable. The script will remind you if you forget.
```sh
export BENEFICIARY=<your-account-here> # this account receives contract account balance
```
[](https://asciinema.org/a/409580)
### Other documentation
- See `./scripts/README.md` for documentation about the scripts
- Watch this video where Willem Wyndham walks us through refactoring a simple example of a NEAR smart contract written in AssemblyScript
https://youtu.be/QP7aveSqRPo
```
There are 2 "styles" of implementing AssemblyScript NEAR contracts:
- the contract interface can either be a collection of exported functions
- or the contract interface can be the methods of a an exported class
We call the second style "Singleton" because there is only one instance of the class which is serialized to the blockchain storage. Rust contracts written for NEAR do this by default with the contract struct.
0:00 noise (to cut)
0:10 Welcome
0:59 Create project starting with "npm init"
2:20 Customize the project for AssemblyScript development
9:25 Import the Counter example and get unit tests passing
18:30 Adapt the Counter example to a Singleton style contract
21:49 Refactoring unit tests to access the new methods
24:45 Review and summary
```
## The file system
```sh
├── README.md # this file
├── as-pect.config.js # configuration for as-pect (AssemblyScript unit testing)
├── asconfig.json # configuration for AssemblyScript compiler (supports multiple contracts)
├── package.json # NodeJS project manifest
├── scripts
│ ├── 1.dev-deploy.sh # helper: build and deploy contracts
│ ├── 2.use-contract.sh # helper: call methods on ContractPromise
│ ├── 3.cleanup.sh # helper: delete build and deploy artifacts
│ └── README.md # documentation for helper scripts
├── src
│ ├── as_types.d.ts # AssemblyScript headers for type hints
│ ├── simple # Contract 1: "Simple example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 1
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 1
│ ├── singleton # Contract 2: "Singleton-style example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 2
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 2
│ ├── tsconfig.json # Typescript configuration
│ └── utils.ts # common contract utility functions
└── yarn.lock # project manifest version lock
```
You may clone this repo to get started OR create everything from scratch.
Please note that, in order to create the AssemblyScript and tests folder structure, you may use the command `asp --init` which will create the following folders and files:
```
./assembly/
./assembly/tests/
./assembly/tests/example.spec.ts
./assembly/tests/as-pect.d.ts
```
|
popudev_hackathon-near-contract | Cargo.toml
Makefile.toml
rust-toolchain.toml
rustfmt.toml
src
application
mod.rs
repository
internal_major.rs
internal_score.rs
internal_subject.rs
internal_user.rs
mod.rs
services
impl_degree.rs
impl_major.rs
impl_score.rs
impl_subject.rs
impl_user.rs
mod.rs
lib.rs
models
contract.rs
degree.rs
major.rs
mod.rs
score.rs
subject.rs
user.rs
| |
Kiews-OU_NEAR-Bildr-Contract | asconfig.json
assembly
as_type.d.ts
index.ts
model.ts
tsconfig.json
package-lock.json
package.json
| |
kiskesis_pay-on-use | README.md
craco.config.js
package.json
pay-on-use-contract
.github
dependabot.yml
workflows
tests.yml
.gitpod.yml
.travis.yml
Cargo.toml
README-Gitpod.md
README-Windows.md
README.md
borsh.js
integration-tests
rs
Cargo.toml
src
tests.rs
ts
main.ava.ts
package.json
src
lib.rs
public
index.html
manifest.json
robots.txt
src
assets
logo-black.svg
logo-white.svg
components
ActionPage
index.css
index.js
Loading
assets
CarLoader.svg
index.css
index.js
Login
index.css
index.js
MainPage
index.css
index.js
PageWrapper
index.css
index.js
index.css
index.js
near-connection
config.js
utils.js
service-worker.js
serviceWorkerRegistration.js
utils
hooks.js
| # Pay on use
<p>
An application contains that parts:
</p>
<ol>
<li>Login</li>
<li>Wrap Near</li>
<li>Add minutes</li>
<li>Start stream</li>
<li>Dont want to pay? Pause stream</li>
</ol>
<p>
But the idea is deeper, so:
<ol>
<li>
Create NPM module for React for pay on use, with connection to rocketo
</li>
<li>
NPM module that will automatically handle when you on use page and when not and pause stream when you off and start when you want
</li>
<li>
It will open to us new world of pay on use schema
</li>
</ol>
</p>
Status Message
==============
[](https://gitpod.io/#https://github.com/near-examples/rust-status-message)
<!-- MAGIC COMMENT: DO NOT DELETE! Everything above this line is hidden on NEAR Examples page -->
This smart contract saves and records the status messages of NEAR accounts that call it.
Windows users: please visit the [Windows-specific README file](README-Windows.md).
## Prerequisites
Ensure `near-cli` is installed by running:
```
near --version
```
If needed, install `near-cli`:
```
npm install near-cli -g
```
Ensure `Rust` is installed by running:
```
rustc --version
```
If needed, install `Rust`:
```
curl https://sh.rustup.rs -sSf | sh
```
Install dependencies
```
npm install
```
## Quick Start
To run this project locally:
1. Prerequisites: Make sure you have Node.js ≥ 12 installed (https://nodejs.org), then use it to install yarn: `npm install --global yarn` (or just `npm i -g yarn`)
2. Run the local development server: `yarn && yarn dev` (see package.json for a full list of scripts you can run with yarn)
Now you'll have a local development environment backed by the NEAR TestNet! Running yarn dev will tell you the URL you can visit in your browser to see the app.
## Building this contract
To make the build process compatible with multiple operating systems, the build process exists as a script in `package.json`.
There are a number of special flags used to compile the smart contract into the wasm file.
Run this command to build and place the wasm file in the `res` directory:
```bash
npm run build
```
**Note**: Instead of `npm`, users of [yarn](https://yarnpkg.com) may run:
```bash
yarn build
```
### Important
If you encounter an error similar to:
>note: the `wasm32-unknown-unknown` target may not be installed
Then run:
```bash
rustup target add wasm32-unknown-unknown
```
## Using this contract
### Web app
Deploy the smart contract to a specific account created with the NEAR Wallet. Then interact with the smart contract using near-api-js on the frontend.
If you do not have a NEAR account, please create one with [NEAR Wallet](https://wallet.testnet.near.org).
Make sure you have credentials saved locally for the account you want to deploy the contract to. To perform this run the following `near-cli` command:
```
near login
```
Deploy the contract to your NEAR account:
```bash
near deploy --wasmFile res/status_message.wasm --accountId YOUR_ACCOUNT_NAME
```
Build the frontend:
```bash
npm start
```
If all is successful the app should be live at `localhost:1234`!
### Quickest deploy
Build and deploy this smart contract to an development account. This development account will be created automatically and is not intended to be permanent. Please see the "Standard deploy" section for creating a more personalized account to deploy to.
```bash
near dev-deploy --wasmFile res/status_message.wasm --helperUrl https://near-contract-helper.onrender.com
```
Behind the scenes, this is creating an account and deploying a contract to it. On the console, notice a message like:
>Done deploying to dev-1234567890123
In this instance, the account is `dev-1234567890123`. A file has been created containing the key to the account, located at `neardev/dev-account`. To make the next few steps easier, we're going to set an environment variable containing this development account id and use that when copy/pasting commands.
Run this command to the environment variable:
```bash
source neardev/dev-account.env
```
You can tell if the environment variable is set correctly if your command line prints the account name after this command:
```bash
echo $CONTRACT_NAME
```
The next command will call the contract's `set_status` method:
```bash
near call $CONTRACT_NAME set_status '{"message": "aloha!"}' --accountId $CONTRACT_NAME
```
To retrieve the message from the contract, call `get_status` with the following:
```bash
near view $CONTRACT_NAME get_status '{"account_id": "'$CONTRACT_NAME'"}'
```
### Standard deploy
In this option, the smart contract will get deployed to a specific account created with the NEAR Wallet.
If you do not have a NEAR account, please create one with [NEAR Wallet](https://wallet.testnet.near.org).
Make sure you have credentials saved locally for the account you want to deploy the contract to. To perform this run the following `near-cli` command:
```
near login
```
Deploy the contract:
```bash
near deploy --wasmFile res/status_message.wasm --accountId YOUR_ACCOUNT_NAME
```
Set a status for your account:
```bash
near call YOUR_ACCOUNT_NAME set_status '{"message": "aloha friend"}' --accountId YOUR_ACCOUNT_NAME
```
Get the status:
```bash
near view YOUR_ACCOUNT_NAME get_status '{"account_id": "YOUR_ACCOUNT_NAME"}'
```
Note that these status messages are stored per account in a `HashMap`. See `src/lib.rs` for the code. We can try the same steps with another account to verify.
**Note**: we're adding `NEW_ACCOUNT_NAME` for the next couple steps.
There are two ways to create a new account:
- the NEAR Wallet (as we did before)
- `near create_account NEW_ACCOUNT_NAME --masterAccount YOUR_ACCOUNT_NAME`
Now call the contract on the first account (where it's deployed):
```bash
near call YOUR_ACCOUNT_NAME set_status '{"message": "bonjour"}' --accountId NEW_ACCOUNT_NAME
```
```bash
near view YOUR_ACCOUNT_NAME get_status '{"account_id": "NEW_ACCOUNT_NAME"}'
```
Returns `bonjour`.
Make sure the original status remains:
```bash
near view YOUR_ACCOUNT_NAME get_status '{"account_id": "YOUR_ACCOUNT_NAME"}'
```
## Testing
To test run:
```bash
cargo test --package status-message -- --nocapture
```
|
nearlog_nearlog-fe | .eslintrc.json
README.md
components
style.ts
next.config.js
package-lock.json
package.json
pages
api
hello.ts
public
checked.svg
close.svg
discord.svg
medium.svg
mobileMenu.svg
nearLogo.svg
plus.svg
telegram.svg
twiter.svg
vercel.svg
styles
Common.module.css
Home.module.css
Portfolio.module.css
globals.css
tsconfig.json
utils
connect
contract.js
constant.ts
index.ts
useWindow.ts
| This is a [Next.js](https://nextjs.org/) project bootstrapped with [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app).
## Getting Started
First, run the development server:
```bash
npm run dev
# or
yarn dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
You can start editing the page by modifying `pages/index.tsx`. The page auto-updates as you edit the file.
[API routes](https://nextjs.org/docs/api-routes/introduction) can be accessed on [http://localhost:3000/api/hello](http://localhost:3000/api/hello). This endpoint can be edited in `pages/api/hello.ts`.
The `pages/api` directory is mapped to `/api/*`. Files in this directory are treated as [API routes](https://nextjs.org/docs/api-routes/introduction) instead of React pages.
## Learn More
To learn more about Next.js, take a look at the following resources:
- [Next.js Documentation](https://nextjs.org/docs) - learn about Next.js features and API.
- [Learn Next.js](https://nextjs.org/learn) - an interactive Next.js tutorial.
You can check out [the Next.js GitHub repository](https://github.com/vercel/next.js/) - your feedback and contributions are welcome!
## Deploy on Vercel
The easiest way to deploy your Next.js app is to use the [Vercel Platform](https://vercel.com/new?utm_medium=default-template&filter=next.js&utm_source=create-next-app&utm_campaign=create-next-app-readme) from the creators of Next.js.
Check out our [Next.js deployment documentation](https://nextjs.org/docs/deployment) for more details.
|
keypom_keypom-app | README.md
package.json
src
App.js
components
Account.js
Blank.js
Claim.js
Contracts.js
Create.js
Deploy.js
Distro.js
Drops.js
Form.js
Header.js
Home.js
Loading.js
Message.js
Scanner.js
Sidebar.js
SidebarLinks.js
Ticket.js
css
modal-ui.css
theme.css
data
nft-series.js
nft-simple.js
img
my-near-wallet-icon.svg
near-icon.svg
sender-icon.svg
index.html
index.js
qr-worker.js
state
app.js
contracts.js
deploy.js
drops.js
near.js
utils
crypto.js
mobile.js
state.js
store.js
wallet-selector-compat.ts
utils
config.js
near-utils.js
patch-config.js
| # React 17, Parcel with useContext and useReducer
- Bundled with Parcel 2.0.1
- *Minimal all-in-one state management with async/await support*
## Getting Started: State Store & useContext
>The following steps are already done, but describe how to use `src/utils/state` to create and use your own `store` and `StateProvider`.
1. Create a file e.g. `/state/app.js` and add the following code
```js
import { State } from '../utils/state';
// example
const initialState = {
app: {
mounted: false
}
};
export const { store, Provider } = State(initialState);
```
2. Now in your `index.js` wrap your `App` component with the `StateProvider`
```js
import { Provider } from './state/app';
ReactDOM.render(
<Provider>
<App />
</Provider>,
document.getElementById('root')
);
```
3. Finally in `App.js` you can `useContext(store)`
```js
const { state, dispatch, update } = useContext(store);
```
## Usage in Components
### Print out state values
```js
<p>Hello {state.foo && state.foo.bar.hello}</p>
```
### Update state directly in component functions
```js
const handleClick = () => {
update('clicked', !state.clicked);
};
```
### Dispatch a state update function (action listener)
```js
const onMount = () => {
dispatch(onAppMount('world'));
};
useEffect(onMount, []);
```
## Dispatched Functions with context (update, getState, dispatch)
When a function is called using dispatch, it expects arguments passed in to the outer function and the inner function returned to be async with the following json args: `{ update, getState, dispatch }`
Example of a call:
```js
dispatch(onAppMount('world'));
```
All dispatched methods **and** update calls are async and can be awaited. It also doesn't matter what file/module the functions are in, since the json args provide all the context needed for updates to state.
For example:
```js
import { helloWorld } from './hello';
export const onAppMount = (message) => async ({ update, getState, dispatch }) => {
update('app', { mounted: true });
update('clicked', false);
update('data', { mounted: true });
await update('', { data: { mounted: false } });
console.log('getState', getState());
update('foo.bar', { hello: true });
update('foo.bar', { hello: false, goodbye: true });
update('foo', { bar: { hello: true, goodbye: false } });
update('foo.bar.goodbye', true);
await new Promise((resolve) => setTimeout(() => {
console.log('getState', getState());
resolve();
}, 2000));
dispatch(helloWorld(message));
};
```
## Prefixing store and Provider
The default names the `State` factory method returns are `store` and `Provider`. However, if you want multiple stores and provider contexts you can pass an additional `prefix` argument to disambiguate.
```js
export const { appStore, AppProvider } = State(initialState, 'app');
```
## Performance and memo
The updating of a single store, even several levels down, is quite quick. If you're worried about components re-rendering, use `memo`:
```js
import React, { memo } from 'react';
const HelloMessage = memo(({ message }) => {
console.log('rendered message');
return <p>Hello { message }</p>;
});
export default HelloMessage;
```
Higher up the component hierarchy you might have:
```js
const App = () => {
const { state, dispatch, update } = useContext(appStore);
...
const handleClick = () => {
update('clicked', !state.clicked);
};
return (
<div className="root">
<HelloMessage message={state.foo && state.foo.bar.hello} />
<p>clicked: {JSON.stringify(state.clicked)}</p>
<button className="outline" onClick={handleClick}>Click Me</button>
</div>
);
};
```
When the button is clicked, the component HelloMessage will not re-render, it's value has been memoized (cached). Using this method you can easily prevent performance intensive state updates in further down components until they are neccessary.
Reference:
- https://reactjs.org/docs/context.html
- https://dmitripavlutin.com/use-react-memo-wisely/
|
keypom_keypom-docs-examples | README.md
advanced-tutorials
dao-onboarding-skeleton
configurations.js
createDaoDrop.js
package.json
view-roles.js
dao-onboarding
configurations.js
createDaoDrop-mainnet.js
createDaoDrop.js
package.json
pre-security
createDaoDrop.js
test.js
test
dao.test.js
view-roles.js
ticket-app-mainnet
App.css
components
qrcode.js
scanner.js
css
global.css
index.css
index.html
index.js
near-apac-ticket-checker.js
package.json
state
App.js
keyInfo.js
styles.css
utils
allowEntry.js
createTickDrop.js
temp.js
testTickDrop.js
ticket-app-skeleton
App.css
components
qrcode.js
scanner.js
css
global.css
index.css
index.html
index.js
package.json
state
App.js
keyInfo.js
styles.css
utils
allowEntry.js
createTickDrop.js
testTickDrop.js
ticket-app
App.css
components
qrcode.js
scanner.js
css
global.css
index.css
index.html
index.js
package.json
state
App.js
keyInfo.js
styles.css
utils
allowEntry.js
createTickDrop.js
temp.js
testTickDrop.js
trial-accounts
create-trial-drop-mainnet.js
create-trial-drop.js
guest-book
App.js
contract.env
index.html
index.js
keypom-data.js
near-interface.js
near-wallet.js
package.json
start.sh
basic-tutorials
function-call-drop
fc-example.js
fc-near-example.js
fungible-token-drop
ft-example.js
ft-near-example.js
non-fungible-token-drop
nft-example.js
nft-near-example.js
package.json
simple-drop
simple-example.js
simple-near-example.js
utils
general.js
cookbook
drops.js
keys.js
password.js
saleConfig.js
timeConfig.js
usageConfig.js
package.json
| # keypom-docs-examples
Scripts referenced in the documentation tutorials
https://docs.keypom.xyz/
|
near_near-sdk-js-template-project | __tests__
test-template.ava.js
src
index.js
| |
hoangtrung18_zk-blue-tick | .gitpod.yml
README.md
contract
README.md
babel.config.json
build.sh
deploy.sh
package-lock.json
package.json
src
contract.ts
tsconfig.json
integration-tests
package-lock.json
package.json
src
main.ava.ts
package-lock.json
package.json
| # Zk Blue Tick NEAR Contract
<br />
# Quickstart
1. Make sure you have installed [node.js](https://nodejs.org/en/download/package-manager/) >= 16.
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
npm run deploy
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Retrieve the Greeting
`get_greeting` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the greeting
near view <dev-account> get_greeting
```
<br />
## 3. Store a New Greeting
`set_greeting` changes the contract's state, for which it is a `call` method.
`Call` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set a new greeting
near call <dev-account> set_greeting '{"greeting":"howdy"}' --accountId <dev-account>
```
**Tip:** If you would like to call `set_greeting` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
```bash
# Init:
near call zk-blue-tick.YOUR-NAME.testnet init '{"owner_id": "YOUR-NAME.testnet"}' --accountId zk-blue-tick.YOUR-NAME.testnet
```
```bash
# Set operator
near call zk-blue-tick.YOUR-NAME.testnet set_operator '{"operator_address": "YOUR-ACCOUNT-2.testnet", "value": true}' --accountId YOUR-NAME.testnet
```
```bash
# Approval kyc
near call zk-blue-tick.YOUR-NAME.testnet approved_kyc '{"address": "YOUR-ACCOUNT-test.testnet", "identifyId":"12384517623" }' --accountId YOUR-ACCOUNT-2.testnet
```
```bash
# Check my Kyc
near call zk-blue-tick.tny.testnet get_my_kyc --accountId dark2.testnet --depositYocto 1
```
```bash
# Set fee 0.25 near
near call zk-blue-tick.YOUR-NAME.testnet set_fee '{"new_fee": 0.25}' --accountId YOUR-NAME.testnet
```
```bash
# Set receiver fee
near call zk-blue-tick.YOUR-NAME.testnet set_receiver_fee '{"address": "test_account.testnet"}' --accountId YOUR-NAME.testnet
```
```bash
# get fee
near view zk-blue-tick.YOUR-NAME.testnet get_fee
```
```bash
# Add wallet to kyc
near call zk-blue-tick.YOUR-NAME.testnet add_wallet_to_kyc '{"address": "test_account.testnet"}' --accountId YOUR-NAME.testnet --deposit 0.25
```
```bash
# Check kyc
near view zk-blue-tick.YOUR-NAME.testnet check_kyc '{"address": "test_account.testnet" }'
```
zk-blue-tick
==================
This app was initialized with [create-near-app]
Quick Start
===========
If you haven't installed dependencies during setup:
npm install
Build and deploy your contract to TestNet with a temporary dev account:
npm run deploy
Test your contract:
npm test
If you have a frontend, run `npm start`. This will run a dev server.
Exploring The Code
==================
1. The smart-contract code lives in the `/contract` folder. See the README there for
more info. In blockchain apps the smart contract is the "backend" of your app.
2. The frontend code lives in the `/frontend` folder. `/frontend/index.html` is a great
place to start exploring. Note that it loads in `/frontend/index.js`,
this is your entrypoint to learn how the frontend connects to the NEAR blockchain.
3. Test your contract: `npm test`, this will run the tests in `integration-tests` directory.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts].
When you run `npm run deploy`, your smart contract gets deployed to the live NEAR TestNet with a temporary dev account.
When you're ready to make it permanent, here's how:
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `zk-blue-tick.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `zk-blue-tick.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account zk-blue-tick.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet --initialBalance 10
Step 2: deploy the contract
---------------------------
Use the CLI to deploy the contract to TestNet with your account ID.
Replace `PATH_TO_WASM_FILE` with the `wasm` that was generated in `contract` build directory.
near deploy --accountId zk-blue-tick.YOUR-NAME.testnet --wasmFile contract/build/zk_blue_tick.wasm
Step 3: set contract name in your frontend code
-----------------------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'zk-blue-tick.YOUR-NAME.testnet'
|
near_near-drop-demo | .github
ISSUE_TEMPLATE
BOUNTY.yml
.travis.yml
README.md
babel.config.js
gulpfile.js
package.json
src
App.css
App.js
App.test.js
Drops.js
__mocks__
fileMock.js
assets
gray_near_logo.svg
logo.svg
near.svg
config.js
index.html
index.js
jest.init.js
main.test.js
util
near-util.js
util.js
wallet
login
index.html
| <br />
<br />
<p>
<img src="https://nearprotocol.com/wp-content/themes/near-19/assets/img/logo.svg?t=1553011311" width="240">
</p>
## Linkdrop example with contract account deployment
## About the app
The app allows you to send funds to the Linkdrop contract which will create "Drops". You will have a list of these in local storage and you can remove them at any time. This claims the funds back to your current account.
**NOTE:** If you follow the wallet link of a drop, be warned it will not create accounts because your contract is not eligible to create the `.testnet` domain accounts.
Instead, click "Share Drop Link" and visit your own drop.
You will now see a *URL Drop* heading with some information about the drop. This is what another user would see if they used your URL.
You can either:
1. claim the funds
2. create an account
3. create a contract account (deploys a locked multisig account)
## Contract
For more details on the linkdrop contract:
https://github.com/near/near-linkdrop
## Quickstart
```
yarn && yarn dev
```
## Deploying your own contract
It's recommended you create a sub account to handle your contract deployments:
```
near login
near create_account [account_id] --masterAccount [your_account_id] --initialBalance [1-5 N]
```
Now update config.js and set:
```
const CONTRACT_NAME = [account_id]
```
## The Linkdrop contract and calling it from JS
All calls to the contract can be found in `src/Drops.js`.
The original linkdrop contract is here:
https://github.com/nearprotocol/near-linkdrop
An additional function is added to the regular linkdrop contract:
```
pub fn create_limited_contract_account
```
This takes 3 additional arguments over the existing `pub fn create_account_and_claim` function.
In order to successfully invoke from JS you must pass in the following:
```
new_account_id: string,
new_public_key: string,
allowance: string,
contract_bytes: [...new Uint8Array(contract_bytes)],
method_names: [...new Uint8Array(new TextEncoder().encode(`
methods,account,is_limited_too_call
`))]
```
##### IMPORTANT: Make sure you have the latest version of NEAR Shell and Node Version > 10.x
1. [Node.js](https://nodejs.org/en/download/package-manager/)
2. near-shell
```
npm i -g near-shell
```
### To run on NEAR testnet
```bash
yarn && yarn dev
```
|
hdriqi_paras-sdk | README.md
examples
acceptBid.js
addBid.js
burnToken.js
buy.js
deleteBid.js
deleteMarketData.js
getActivity.js
getBid.js
getToken.js
mintAndList.js
mintAndSell.js
mintOnly.js
sell.js
transfer.js
index.js
package.json
| # Intro to Paras
Paras is an NFT marketplace that focuses on digital card collectibles. We thrive upon bringing conventional collectibles to crypto space. Trading cards have been bulletproof and forever lasting since they were introduced back in the 80s. We believe that every single physical art form needs to be stored and digitized to keep it future-proof. Paras, an all-in-one Digital Art Card marketplace, is eager to diversify the assets to digital art cards. By applying a 64x89 ratio, we want to make it as faithful to the original.
By building the platform under NEAR and IPFS/Filecoin, we want to track the ownership of every single collectible in our platform. Through these solutions, Paras validates ownership and gives access to every purchase and mint to the public. Running on top of NEAR, a scalable blockchain, Paras offers very cheap and fast transactions for users.
Paras offers an easy way for creators and developers to build their crypto-native application on top of the Paras marketplace. There are 2 ways to interact with Paras Marketplace:
## Paras SDK
Paras offers a software development kit (SDK) in Javascript/NodeJS. This SDK can be used in browser and server.
## Paras API
Paras also offer API for everyone that uses language outside Javascript/NodeJS. This enables more flexibility for developers to integrate Paras with their current system.
## Documentation
Visit https://parasdev.gitbook.io/paras-documentation/ to view the full documentation.
|
paul-cruz_ConnectIoT-API | README.md
|
api.js
app.js
blockchain.js
near-api-server.config.json
package-lock.json
package.json
| # NEAR REST API SERVER FOR Connect IoT
> ### This repository is a specific implementation for the Connect IoT project based on the official [NEAR REST API SERVER repository](https://github.com/near-examples/near-api-rest-server) following its license, so if you use this code, keep in mind to check its protection.
---
## Overview
_Click on a route for more information and examples_
| Route | Method | Description |
| ------------------------------------------ | ------ | --------------------------------------------------------------------------------------------------------------------------- |
| **CONNECT IOT CONTRACT** | | |
| [`/call`](#call) | POST | Performs a call to the smart contract, validating the method |
---
## Requirements
- [NEAR Account](https://docs.near.org/concepts/basics/account) _(with access to private key or seed phrase)_
- [Node.js](https://nodejs.org/en/download/package-manager/)
- [npm](https://www.npmjs.com/get-npm) or [Yarn](https://yarnpkg.com/getting-started/install)
- API request tool such as [Postman](https://www.postman.com/downloads/)
- Crear archivo .env conteniendo el id del contrato:
```
NEAR_CONTRACT_ID=dev-1659666583036-94152895119798
```
---
## Setup
1. Clone repository
```bash
https://github.com/paul-cruz/Connect-IoT-API.git
```
2. Install dependencies
```bash
npm install
```
3. Configure `near-api-server.config.json`
Default settings:
```json
{
"server_host": "0.0.0.0",
"server_port": 5000,
"rpc_node": "https://rpc.testnet.near.org",
"init_disabled": true
}
```
4. Start server
```bash
node app
```
---
# Contract
## `/call`
> _Performs a call to the smart contract, validating the method._
**Method:** **`POST`**
**Valid methods:**
- **`create_registry`**
- **`delete_registry`**
- **`add_device_to_registry`**
- **`delete_device_from_registry`**
- **`set_device_data`**
- **`get_device_data`**
- **`set_device_data_param`**
- **`get_device_data_param`**
- **`set_device_metadata`**
- **`get_device_metadata`**
- **`set_device_metadata_param`**
- **`get_device_metadata_param`**
| Param | Description |
| -------------------------------- | --------------------------------------------------------------------------------------------------------------------- |
| `account_id` | _Account id that will be performing the call and will be charged for gas and attached tokens / deposit._ |
| `seed_phrase` _OR_ `private_key` | _Seed phrase OR private key of the account id above._ |
| `method` | _A valid method for the ConnectIoT method._ |
| `params` | _Arguments the method of the contract takes._ |
_**Note:** Use [`near login`](https://docs.near.org/docs/tools/near-cli#near-login) to save your key pair to your local machine._
Example:
```json
{
"account_id": "paulcruz.testnet",
"private_key": "5a92dJw8NtnwPZmHAuCt3M123pE1aD2wM5z7BkTasdnCxbEHX22Gei2jnoWjaGcZUk2ZZtPriMa25CLpcp96s7Mw",
"method": "get_device_metadata_param",
"params": {"registry_name": "my_registry", "device_name": "my_device", "param": "timestamp"}
}
```
<details>
<summary><strong>Example Response:</strong> </summary>
<p>
```json
{
"data": "1659740812726"
}
```
</p>
</details>
Example:
```json
{
"account_id": "paulcruz.testnet",
"private_key": "5a92dJw8NtnwPZmHAuCt3M123pE1aD2wM5z7BkTasdnCxbEHX22Gei2jnoWjaGcZUk2ZZtPriMa25CLpcp96s7Mw",
"method": "get_device_metadata",
"params": {"registry_name": "my_registry", "device_name": "my_device", "param": "timestamp"}
}
```
<details>
<summary><strong>Example Response:</strong> </summary>
<p>
```json
{
"read_type": "streaming",
"timestamp": "1659740812726",
"area": "west"
}
```
</p>
</details>
---
|
ManuelenRed_NearOrbit-Airdrop | .gitpod.yml
README.md
contract
Cargo.toml
README.md
build.sh
deploy.sh
neardev
dev-account.env
src
lib.rs
target
.rustc_info.json
debug
.fingerprint
Inflector-d4369701b6f44cbc
lib-inflector.json
ahash-2620b3b090912135
run-build-script-build-script-build.json
ahash-4666b6b9e1f1171b
build-script-build-script-build.json
ahash-5c1bc3dc6f9d99af
lib-ahash.json
arrayref-544c63f210a6854b
lib-arrayref.json
arrayvec-47f87771b3cb6c5c
lib-arrayvec.json
arrayvec-b95a0daaf93df46c
lib-arrayvec.json
autocfg-38ce632ae4947f24
lib-autocfg.json
base64-2d9f3cfdc61f715a
lib-base64.json
base64-73b57833ce07c506
lib-base64.json
bitvec-2061b8483e73da4d
lib-bitvec.json
blake2-2ddfc5d28a7291ed
lib-blake2.json
block-buffer-4e6f0fb50db32de1
lib-block-buffer.json
block-buffer-b324b9cc94c025ac
lib-block-buffer.json
borsh-dcbc5d2cd9c81b40
lib-borsh.json
borsh-derive-7dd74d8637c81da9
lib-borsh-derive.json
borsh-derive-internal-35b907dd1183b09d
lib-borsh-derive-internal.json
borsh-schema-derive-internal-270d96330ccf97da
lib-borsh-schema-derive-internal.json
bs58-01eedf7f7f3fc989
lib-bs58.json
byte-slice-cast-cf8c27a850fd1281
lib-byte-slice-cast.json
byteorder-009986822af81557
lib-byteorder.json
bytesize-8e56d4e8600e334e
lib-bytesize.json
c2-chacha-2358461583ac40e2
lib-c2-chacha.json
cc-0aa93f22f7e3f7c9
lib-cc.json
cfg-if-535db3d3fe0297ba
lib-cfg-if.json
cfg-if-decebf5e5dc1aac8
lib-cfg-if.json
cfg-if-edad02de537eeacf
lib-cfg-if.json
chrono-3179c6f695431971
lib-chrono.json
cipher-23c7c16beebf9bdd
lib-cipher.json
convert_case-9981ae9ddcf2b2ef
lib-convert_case.json
cpufeatures-cd3ece85741fbe4f
lib-cpufeatures.json
crunchy-17d778c4290d7b36
build-script-build-script-build.json
crunchy-43dababa46599c35
lib-crunchy.json
crunchy-e712411e4c80baa2
run-build-script-build-script-build.json
crypto-common-16be71f4799cff9e
lib-crypto-common.json
crypto-mac-39c5b335973c5012
lib-crypto-mac.json
curve25519-dalek-77b817bde4613b2c
lib-curve25519-dalek.json
derive_more-594be4dd3a7ee10c
lib-derive_more.json
digest-76ef22e44d825ee1
lib-digest.json
digest-7faf7ba077f0a1f5
lib-digest.json
easy-ext-8e0b538b9739d90b
lib-easy-ext.json
ed25519-aa0f1526bec9e271
lib-ed25519.json
ed25519-dalek-97fc6586a739b1ff
lib-ed25519-dalek.json
fixed-hash-c3186744bb3a5cad
lib-fixed-hash.json
funty-91e03354d352e5c6
lib-funty.json
generic-array-17f01b88efe75163
lib-generic_array.json
generic-array-241441b7829a5932
build-script-build-script-build.json
generic-array-4109f8629e1ff131
run-build-script-build-script-build.json
getrandom-2e23330c20c376db
build-script-build-script-build.json
getrandom-5f1bfe31473350e5
run-build-script-build-script-build.json
getrandom-71e60a35b4c5634d
lib-getrandom.json
getrandom-be964fa37503f1e4
lib-getrandom.json
hashbrown-73d6d1d2db780c0b
lib-hashbrown.json
heck-662642063d61ece9
lib-heck.json
hello_near-65e162cfd94c6835
test-lib-hello_near.json
hello_near-7b4766aff1d8caa6
lib-hello_near.json
hex-37bf29a6196037c6
lib-hex.json
iana-time-zone-8836deac6be3617e
lib-iana-time-zone.json
impl-codec-be8201d05d71ecb2
lib-impl-codec.json
impl-trait-for-tuples-b76ab75e70b6c05d
lib-impl-trait-for-tuples.json
itoa-ffc83d8229b8b401
lib-itoa.json
keccak-c3b9e854f93e7c0d
lib-keccak.json
libc-564927e086a3a70a
build-script-build-script-build.json
libc-bb7efdd7dae38758
run-build-script-build-script-build.json
libc-ce6144570b13485f
lib-libc.json
memory_units-82792013c6524aca
lib-memory_units.json
near-account-id-ca9cc30861c22655
lib-near-account-id.json
near-crypto-705361916be31ab0
lib-near-crypto.json
near-primitives-7e068bb5e9e8e94a
lib-near-primitives.json
near-primitives-core-44f2e24128c5a8aa
lib-near-primitives-core.json
near-rpc-error-core-1455156b6f26b186
lib-near-rpc-error-core.json
near-rpc-error-macro-ef37b46ca60a5dd2
lib-near-rpc-error-macro.json
near-sdk-8d2d5fa194f00b65
lib-near-sdk.json
near-sdk-macros-aba2c81a403afc1b
lib-near-sdk-macros.json
near-sys-f27f1ab4ae5e284c
lib-near-sys.json
near-vm-errors-d130f9ed6cc14087
lib-near-vm-errors.json
near-vm-logic-be17868fd7eea83a
lib-near-vm-logic.json
num-bigint-7b5a46c7ff3aea97
build-script-build-script-build.json
num-bigint-81cde4f58b1d0c55
run-build-script-build-script-build.json
num-bigint-d11c591298cc3d2e
lib-num-bigint.json
num-integer-280c5596c5aa1455
lib-num-integer.json
num-integer-57f09cf366311f34
build-script-build-script-build.json
num-integer-bf3a8bad6671d6da
run-build-script-build-script-build.json
num-rational-672bdba1e844c68c
run-build-script-build-script-build.json
num-rational-8767960bebfdb602
build-script-build-script-build.json
num-rational-b0d027defa43aaad
lib-num-rational.json
num-traits-0ab924901b158460
build-script-build-script-build.json
num-traits-4697555d791ead6c
run-build-script-build-script-build.json
num-traits-de7b6c3b5d30fac2
lib-num-traits.json
once_cell-84b880e04a3232e2
lib-once_cell.json
once_cell-c4d57e5041e1b607
lib-once_cell.json
opaque-debug-ed756e5879a54799
lib-opaque-debug.json
parity-scale-codec-deedfef743947f7e
lib-parity-scale-codec.json
parity-scale-codec-derive-a74649e06f446667
lib-parity-scale-codec-derive.json
parity-secp256k1-ab5c37ac64071ff3
lib-secp256k1.json
parity-secp256k1-e72839f63da20383
build-script-build-script-build.json
parity-secp256k1-f6e8ec58caac2f55
run-build-script-build-script-build.json
ppv-lite86-21aa8af17a544621
lib-ppv-lite86.json
primitive-types-2d562ca53c39121a
lib-primitive-types.json
proc-macro-crate-2bb4ca0eb7f68853
lib-proc-macro-crate.json
proc-macro-crate-d6817614d630b2b0
lib-proc-macro-crate.json
proc-macro2-82334ae4e4c75248
lib-proc-macro2.json
proc-macro2-b2d75d8ffb426a15
run-build-script-build-script-build.json
proc-macro2-fd9ab3c032c832d9
build-script-build-script-build.json
quote-6b15d0cb383ab226
build-script-build-script-build.json
quote-6ca35ba55317bb56
run-build-script-build-script-build.json
quote-759a13b20512cb50
lib-quote.json
radium-2e2e3df4d4ad1238
run-build-script-build-script-build.json
radium-54ada634c0de4d67
build-script-build-script-build.json
radium-9e7dbcda942b7c8a
lib-radium.json
rand-42a04b0afe55aa2c
lib-rand.json
rand-7dcfe632a75adf25
lib-rand.json
rand_chacha-a1e8ca1a2054adbf
lib-rand_chacha.json
rand_chacha-e4bf0b5dfb47a32d
lib-rand_chacha.json
rand_core-0aba1ffab34e6040
lib-rand_core.json
rand_core-7710ca4872d5bb25
lib-rand_core.json
reed-solomon-erasure-30091da4d9fc4c2f
build-script-build-script-build.json
reed-solomon-erasure-3218ba8df723f8f3
lib-reed-solomon-erasure.json
reed-solomon-erasure-aeb9e85b3a37e2c6
run-build-script-build-script-build.json
ripemd-b3e7b21c73fe444d
lib-ripemd.json
rustc-hex-bd428ed43a5472e2
lib-rustc-hex.json
rustversion-5d1ea9af322437b9
build-script-build-script-build.json
rustversion-b05e1d228e778dc2
lib-rustversion.json
rustversion-c0537fb703928163
run-build-script-build-script-build.json
ryu-323428e5cd6e37a6
lib-ryu.json
serde-096da7ee29d45fa4
lib-serde.json
serde-1b39428c83f9a8e3
build-script-build-script-build.json
serde-25630a761c27e7e8
lib-serde.json
serde-25721f7f07013377
run-build-script-build-script-build.json
serde-49b57df6c20044a8
build-script-build-script-build.json
serde-7496eb5514c973d7
run-build-script-build-script-build.json
serde_derive-134546bdb1f14179
build-script-build-script-build.json
serde_derive-82d48547c4891331
run-build-script-build-script-build.json
serde_derive-c9e493900b2fc6ad
lib-serde_derive.json
serde_json-31007affb7ff5fda
lib-serde_json.json
serde_json-6f2800ef8dd0b292
build-script-build-script-build.json
serde_json-a7761de8d93c9d3f
run-build-script-build-script-build.json
sha2-4188222edceb3995
lib-sha2.json
sha2-6ea6112c944dda74
lib-sha2.json
sha3-df273542c8e19da3
lib-sha3.json
signature-b59fe0a5bff15200
lib-signature.json
smallvec-f593ba25aeac9cc2
lib-smallvec.json
smart-default-6e196f4fc070cbdc
lib-smart-default.json
static_assertions-546de2735ce13872
lib-static_assertions.json
strum-e7b0e97063aca35b
lib-strum.json
strum_macros-cba1ca04cf7f9e61
lib-strum_macros.json
subtle-3991c01dd6e71d5e
lib-subtle.json
syn-2e4f42d01984553e
build-script-build-script-build.json
syn-75215d3ae1e0321e
lib-syn.json
syn-db5ffd3633253fcf
run-build-script-build-script-build.json
synstructure-0544b2d395585b47
lib-synstructure.json
tap-add61e1d980eb649
lib-tap.json
thiserror-391b17a97942dfb2
lib-thiserror.json
thiserror-3c2d872cc4a5c098
build-script-build-script-build.json
thiserror-d7fac104ff623417
run-build-script-build-script-build.json
thiserror-dd725296b86fad9e
lib-thiserror.json
thiserror-impl-2a796757d383daa9
lib-thiserror-impl.json
time-ae624a5ca302da31
lib-time.json
toml-f1a738928a3247d6
lib-toml.json
typenum-1a918de526f7ca40
lib-typenum.json
typenum-cc474ada7a1acd83
build-script-build-script-main.json
typenum-d95e4fbba31c1498
run-build-script-build-script-main.json
uint-d7a3dfd9bebd926d
lib-uint.json
unicode-ident-4381bf832c3024f9
lib-unicode-ident.json
unicode-xid-5c47a351cf3b9ad7
lib-unicode-xid.json
version_check-90fb829ed00cd8d6
lib-version_check.json
wee_alloc-2a8b4446ff56f761
build-script-build-script-build.json
wee_alloc-69e1cf817d782ffe
run-build-script-build-script-build.json
wee_alloc-f6f01b470097191e
lib-wee_alloc.json
winapi-083ad57c97d542f3
run-build-script-build-script-build.json
winapi-8885311489c062e1
build-script-build-script-build.json
winapi-a677e55ffe7362d8
lib-winapi.json
wyz-2ba3e705031de871
lib-wyz.json
zeroize-ebe62f1703fd9a90
lib-zeroize.json
zeroize_derive-bc25ab72bffc3c89
lib-zeroize_derive.json
build
crunchy-e712411e4c80baa2
out
lib.rs
num-bigint-81cde4f58b1d0c55
out
radix_bases.rs
parity-secp256k1-f6e8ec58caac2f55
out
flag_check.c
reed-solomon-erasure-aeb9e85b3a37e2c6
out
table.rs
thiserror-d7fac104ff623417
out
probe.rs
typenum-d95e4fbba31c1498
out
consts.rs
op.rs
tests.rs
wee_alloc-69e1cf817d782ffe
out
wee_alloc_static_array_backend_size_bytes.txt
release
.fingerprint
Inflector-f13c978d1aadb31b
lib-inflector.json
ahash-585ee5915143711e
build-script-build-script-build.json
borsh-derive-5d8e3e690a704c58
lib-borsh-derive.json
borsh-derive-internal-987b0e15713ff7dd
lib-borsh-derive-internal.json
borsh-schema-derive-internal-7ac9b6b06730187f
lib-borsh-schema-derive-internal.json
crunchy-4aea0594f90fa7a8
build-script-build-script-build.json
near-sdk-macros-2bfb8d3334c793ed
lib-near-sdk-macros.json
proc-macro-crate-59ce7cc3c633390f
lib-proc-macro-crate.json
proc-macro2-4285eee214e776e7
lib-proc-macro2.json
proc-macro2-6afb81fa8313a0a6
run-build-script-build-script-build.json
proc-macro2-b0db05a18fdd060a
build-script-build-script-build.json
quote-13a8d32fe124988e
lib-quote.json
quote-4f109f35fffae2b0
run-build-script-build-script-build.json
quote-bf57674ebeff5b89
build-script-build-script-build.json
serde-281b7b3b763a261a
build-script-build-script-build.json
serde-3aca90b5d66dafa1
build-script-build-script-build.json
serde-50b4abda624d35e9
run-build-script-build-script-build.json
serde-f7502c286aad6aef
lib-serde.json
serde_derive-4ec12993f787c226
run-build-script-build-script-build.json
serde_derive-6d1508c655af3cba
lib-serde_derive.json
serde_derive-742b90324875daaf
build-script-build-script-build.json
serde_json-940f6ffaf8245ede
build-script-build-script-build.json
syn-1b53236001990edb
run-build-script-build-script-build.json
syn-4af4bd0bc918a78a
build-script-build-script-build.json
syn-64799755ebe285c6
lib-syn.json
toml-e804673d3f048140
lib-toml.json
unicode-ident-51be5dfdc102386a
lib-unicode-ident.json
version_check-28922478539c9cad
lib-version_check.json
wee_alloc-10c79473ba7c8522
build-script-build-script-build.json
wasm32-unknown-unknown
release
.fingerprint
ahash-c1dbdff08e52ddac
lib-ahash.json
ahash-e9c8d9fc5a0f9a13
run-build-script-build-script-build.json
base64-d9edbd2f2dc2d956
lib-base64.json
borsh-8f50812eaa3ca040
lib-borsh.json
bs58-9f10c4b1b3984643
lib-bs58.json
byteorder-9bfc0a7b6bd12f32
lib-byteorder.json
cfg-if-051471ea479febcb
lib-cfg-if.json
crunchy-5f68feb4877f62f7
run-build-script-build-script-build.json
crunchy-e2de7fd44095dfb1
lib-crunchy.json
hashbrown-c765772b21efb6c4
lib-hashbrown.json
hello_near-00ca379cccdf6430
lib-hello_near.json
hex-5d60733e3d120d80
lib-hex.json
itoa-462fd4b8d8e08994
lib-itoa.json
memory_units-16900eb0f3221f3f
lib-memory_units.json
near-sdk-ca957f3e6a945172
lib-near-sdk.json
near-sys-8155e02f70b6f85e
lib-near-sys.json
once_cell-8137368909678986
lib-once_cell.json
ryu-2864b9f286b1e2ac
lib-ryu.json
serde-135657c210b7d506
lib-serde.json
serde-1794fd4a728aa6bf
run-build-script-build-script-build.json
serde_json-ad10cac7e8bc659e
lib-serde_json.json
serde_json-c6878b0a3b5e59b2
run-build-script-build-script-build.json
static_assertions-d95c8c5a77238f05
lib-static_assertions.json
uint-2a4f9a92f50eacb4
lib-uint.json
wee_alloc-019678edf7d788ed
run-build-script-build-script-build.json
wee_alloc-c5fdfac1f46cc75c
lib-wee_alloc.json
build
crunchy-5f68feb4877f62f7
out
lib.rs
wee_alloc-019678edf7d788ed
out
wee_alloc_static_array_backend_size_bytes.txt
frontend
assets
global.css
logo-black.svg
logo-white.svg
dist
index.066e5f91.css
index.bc0daea6.css
index.html
logo-black.4514ed42.svg
logo-black.54439fde.svg
logo-white.605d2742.svg
logo-white.a7716062.svg
index.html
index.js
near-interface.js
near-wallet.js
package-lock.json
package.json
start.sh
integration-tests
Cargo.toml
src
tests.rs
target
.rustc_info.json
debug
.fingerprint
addr2line-24e8bb0da86b2598
lib-addr2line.json
addr2line-814d77a6d2163b4a
lib-addr2line.json
adler-0f4acef8c1fd1b07
lib-adler.json
adler-1359fa384ba1709e
lib-adler.json
ahash-2620b3b090912135
run-build-script-build-script-build.json
ahash-4666b6b9e1f1171b
build-script-build-script-build.json
ahash-5c1bc3dc6f9d99af
lib-ahash.json
aho-corasick-61993e4e9c5cf945
lib-aho_corasick.json
aho-corasick-e91e834716e32e74
lib-aho_corasick.json
anyhow-09015523be1b8116
lib-anyhow.json
anyhow-123b54cbe52f8c43
lib-anyhow.json
anyhow-b5b943b5d1767b51
build-script-build-script-build.json
anyhow-c568b442755d27a1
run-build-script-build-script-build.json
arrayref-544c63f210a6854b
lib-arrayref.json
arrayvec-f355034c76e6831f
lib-arrayvec.json
arrayvec-f5247086d498e41f
lib-arrayvec.json
async-channel-989656f0f4617b4f
lib-async-channel.json
async-channel-9c1f12a43a14ac6a
lib-async-channel.json
async-process-73d5140fa5f628ec
lib-async-process.json
async-process-c4b873bf8853b7e7
build-script-build-script-build.json
async-process-d600011eed72fb4e
lib-async-process.json
async-process-de80cbbab0731457
run-build-script-build-script-build.json
async-task-0740986b4b827f54
lib-async-task.json
async-task-c7259cf23f75fd09
lib-async-task.json
async-trait-76474667864e2632
build-script-build-script-build.json
async-trait-a2852cdec2200ffa
lib-async-trait.json
async-trait-e6368f192161f2b7
run-build-script-build-script-build.json
atomic-waker-4beca85212b0a9e1
lib-atomic-waker.json
atomic-waker-78966391bdd12733
lib-atomic-waker.json
autocfg-38ce632ae4947f24
lib-autocfg.json
backtrace-89a8e0a25a538d1d
run-build-script-build-script-build.json
backtrace-a016c9dc5dda20bb
lib-backtrace.json
backtrace-d0946e44e009fe24
lib-backtrace.json
backtrace-e163f6d34ff7e439
build-script-build-script-build.json
base64-2d9f3cfdc61f715a
lib-base64.json
binary-install-552d5a3fe60891eb
lib-binary-install.json
binary-install-ec6ef89a1fa83775
lib-binary-install.json
blake2-2ddfc5d28a7291ed
lib-blake2.json
block-buffer-4e6f0fb50db32de1
lib-block-buffer.json
block-buffer-b324b9cc94c025ac
lib-block-buffer.json
blocking-1250719e8442e7ca
lib-blocking.json
blocking-4335695faed14255
lib-blocking.json
borsh-4607691d43e3955f
lib-borsh.json
borsh-derive-e882a6a59e2ee5dd
lib-borsh-derive.json
borsh-derive-internal-ce5ca718b7356d61
lib-borsh-derive-internal.json
borsh-schema-derive-internal-3b6788dd56a2bcef
lib-borsh-schema-derive-internal.json
bs58-01eedf7f7f3fc989
lib-bs58.json
byteorder-009986822af81557
lib-byteorder.json
byteorder-adc9d466c1738094
lib-byteorder.json
bytes-ca22e9352815a40d
lib-bytes.json
bytesize-8e56d4e8600e334e
lib-bytesize.json
bzip2-aedb147bf7c0a340
lib-bzip2.json
bzip2-fb47a4a507f29c16
lib-bzip2.json
bzip2-sys-05325ea3491e4197
build-script-build-script-build.json
bzip2-sys-1a6f831f5850d7f5
run-build-script-build-script-build.json
bzip2-sys-3842a20ac36c818a
lib-bzip2_sys.json
bzip2-sys-67920493fab8a9e5
lib-bzip2_sys.json
c2-chacha-2358461583ac40e2
lib-c2-chacha.json
cache-padded-a89a2146c542b5fc
lib-cache-padded.json
cache-padded-f1e980f934c91f77
lib-cache-padded.json
cc-0aa93f22f7e3f7c9
lib-cc.json
cfg-if-e7691989c03c3175
lib-cfg-if.json
cfg-if-edad02de537eeacf
lib-cfg-if.json
chrono-777c9285cf90f366
lib-chrono.json
chrono-d0cff1efc06398d9
lib-chrono.json
cipher-23c7c16beebf9bdd
lib-cipher.json
concurrent-queue-57b660d3e65a61c7
lib-concurrent-queue.json
concurrent-queue-c72ebe6dc4b41f66
lib-concurrent-queue.json
convert_case-9981ae9ddcf2b2ef
lib-convert_case.json
cpufeatures-cd3ece85741fbe4f
lib-cpufeatures.json
crc32fast-09a1cf278b5bd859
lib-crc32fast.json
crc32fast-89e41a336b47d4e4
lib-crc32fast.json
crc32fast-8dfdeabc22498dee
build-script-build-script-build.json
crc32fast-8ef794d2392d4d8c
run-build-script-build-script-build.json
crunchy-15dee71b4068d7be
build-script-build-script-build.json
crunchy-701a9814e7d1c766
run-build-script-build-script-build.json
crunchy-98908c682787752d
lib-crunchy.json
crypto-common-16be71f4799cff9e
lib-crypto-common.json
crypto-mac-39c5b335973c5012
lib-crypto-mac.json
curl-0c67e2e0a4be8886
lib-curl.json
curl-aa720332e089e19d
build-script-build-script-build.json
curl-b6fef109c50dcd58
run-build-script-build-script-build.json
curl-ef248d948d1de3e5
lib-curl.json
curl-sys-235be09f2b43415f
build-script-build-script-build.json
curl-sys-4fbf8972659bb759
lib-curl_sys.json
curl-sys-682fe463df39dc51
run-build-script-build-script-build.json
curl-sys-ebf0f74dde495ca4
lib-curl_sys.json
curve25519-dalek-f4c5d6ffe312cdb2
lib-curve25519-dalek.json
derive_more-295489a2b7219a1e
lib-derive_more.json
digest-76ef22e44d825ee1
lib-digest.json
digest-7faf7ba077f0a1f5
lib-digest.json
dirs-2841acdead4c95b3
lib-dirs.json
dirs-35fd5446d2e30f3d
lib-dirs.json
dirs-986963f52b39028d
lib-dirs.json
dirs-sys-9b463e29cb48ba6e
lib-dirs-sys.json
easy-ext-8e0b538b9739d90b
lib-easy-ext.json
ed25519-aa0f1526bec9e271
lib-ed25519.json
ed25519-dalek-8c60056a6b6141bc
lib-ed25519-dalek.json
encoding_rs-13af6a7aec8882ee
run-build-script-build-script-build.json
encoding_rs-15854a37ab2309c9
lib-encoding_rs.json
encoding_rs-2ffb01cf887e2ccf
build-script-build-script-build.json
event-listener-09c3df79754f21c2
lib-event-listener.json
event-listener-a20895c2c3ff1294
lib-event-listener.json
failure-5802e24fd8f6a699
lib-failure.json
failure-a9611bd066f99cc8
lib-failure.json
failure_derive-b974f8575f45f6ed
lib-failure_derive.json
failure_derive-dd14ffd158bcb99a
run-build-script-build-script-build.json
failure_derive-f436c050819c3613
build-script-build-script-build.json
fastrand-998edfb41fb78e2e
lib-fastrand.json
fastrand-ca9c85c3080e9ec1
lib-fastrand.json
filetime-d80dd4b7f50f1033
lib-filetime.json
filetime-e192c1f4d1e19ad2
lib-filetime.json
fixed-hash-c38b6dec877f86bf
lib-fixed-hash.json
flate2-26e0b970bc4b887e
lib-flate2.json
flate2-5fcfe1753c53c262
lib-flate2.json
fnv-079e4f74820c4a9d
lib-fnv.json
form_urlencoded-b4d84818b8b56146
lib-form_urlencoded.json
fs2-b3a2a9759da17676
lib-fs2.json
fs2-f4c996fad3ae06f0
lib-fs2.json
futures-channel-487b5feee098e095
lib-futures-channel.json
futures-channel-622cb18d4604210f
build-script-build-script-build.json
futures-channel-b3a5cfe7b0c3c599
run-build-script-build-script-build.json
futures-core-265d8f5ce595b54e
lib-futures-core.json
futures-core-b7ddd405aaf345fb
run-build-script-build-script-build.json
futures-core-ccc602b9e1995a11
lib-futures-core.json
futures-core-e7702125ae7e59bc
build-script-build-script-build.json
futures-io-2cb7e2a5e9d9954d
lib-futures-io.json
futures-io-2d5af907dbdf3f03
lib-futures-io.json
futures-lite-a92c27a7f54fc1bb
lib-futures-lite.json
futures-lite-ae52d5c10748147a
lib-futures-lite.json
futures-sink-bbb0abad2c849115
lib-futures-sink.json
futures-task-258c77059edc23ac
build-script-build-script-build.json
futures-task-ad42719ff55cea75
lib-futures-task.json
futures-task-eeca04f7d75c97a9
run-build-script-build-script-build.json
futures-util-2441567d7e96beef
build-script-build-script-build.json
futures-util-7ac36c6982787011
run-build-script-build-script-build.json
futures-util-922e4559a091e56c
lib-futures-util.json
generic-array-17f01b88efe75163
lib-generic_array.json
generic-array-241441b7829a5932
build-script-build-script-build.json
generic-array-4109f8629e1ff131
run-build-script-build-script-build.json
getrandom-2e23330c20c376db
build-script-build-script-build.json
getrandom-5f1bfe31473350e5
run-build-script-build-script-build.json
getrandom-71e60a35b4c5634d
lib-getrandom.json
getrandom-be964fa37503f1e4
lib-getrandom.json
gimli-276ed97f7252b9e3
lib-gimli.json
gimli-89e96f2cd9aeeda1
lib-gimli.json
h2-fd3a3879afc17e4d
lib-h2.json
hashbrown-73d6d1d2db780c0b
lib-hashbrown.json
hashbrown-e301d5b2ba76233b
lib-hashbrown.json
heck-662642063d61ece9
lib-heck.json
hex-37bf29a6196037c6
lib-hex.json
hex-c670a1b517d90f97
lib-hex.json
hex-d8fa9b521c0168f7
lib-hex.json
home-321debf2043145ff
lib-home.json
home-fc78e68a208e3394
lib-home.json
http-a977026150a92e9c
lib-http.json
http-body-e8b42fc0bcca850d
lib-http-body.json
httparse-0dcfc9bae5b6762a
run-build-script-build-script-build.json
httparse-ba131b792200b112
lib-httparse.json
httparse-f8dff50fb2996fc0
build-script-build-script-build.json
httpdate-170e665920b39c94
lib-httpdate.json
hyper-73f002921ab9de32
lib-hyper.json
hyper-tls-af5df7955bcf078f
lib-hyper-tls.json
iana-time-zone-1c8ec1495424cc66
lib-iana-time-zone.json
iana-time-zone-f2916ae9e6c17e7a
lib-iana-time-zone.json
idna-42ab6ac8bdf92041
lib-idna.json
indexmap-23c56916b50fedb3
run-build-script-build-script-build.json
indexmap-b1fff96857bcae7a
lib-indexmap.json
indexmap-c0504761562d671e
build-script-build-script-build.json
ipnet-a0304e3f63f7a12b
lib-ipnet.json
is_executable-0b23b46f310ea39b
lib-is_executable.json
is_executable-db1a10f1905836c3
lib-is_executable.json
itoa-e2fe36c950ce16b4
lib-itoa.json
itoa-ffc83d8229b8b401
lib-itoa.json
lazy_static-94032fc67d169ba0
lib-lazy_static.json
lazy_static-cc9cce119807ba20
lib-lazy_static.json
libc-33d50219ec2d56d1
lib-libc.json
libc-564927e086a3a70a
build-script-build-script-build.json
libc-bb7efdd7dae38758
run-build-script-build-script-build.json
libc-ce6144570b13485f
lib-libc.json
libz-sys-62d6114f7c1c495f
build-script-build-script-build.json
libz-sys-6b284bbb57c9f654
lib-libz-sys.json
libz-sys-bcde504bf4cff0d8
run-build-script-build-script-build.json
libz-sys-fd55fc2bd3731b3a
lib-libz-sys.json
lock_api-295d3a1260b55f97
lib-lock_api.json
lock_api-9920d2d2bb65b9a8
run-build-script-build-script-build.json
lock_api-aa0cc521522b3cb9
build-script-build-script-build.json
log-2ef5da4050e16f84
build-script-build-script-build.json
log-649cb5bb83cbd854
run-build-script-build-script-build.json
log-f74e62458e04194f
lib-log.json
maplit-c4b52478fce5f84a
lib-maplit.json
matchers-84ae08e4e8cb8ba8
lib-matchers.json
memchr-647f69dd5dc2e380
lib-memchr.json
memchr-694a19fe9a6aee3f
lib-memchr.json
memchr-b9b5d146c8cf2394
build-script-build-script-build.json
memchr-fbf1b158e7ab6b04
run-build-script-build-script-build.json
mime-74c0fb90eadf7630
lib-mime.json
miniz_oxide-81d467e980bee551
lib-miniz_oxide.json
miniz_oxide-c16472ad055a2a05
lib-miniz_oxide.json
mio-6e5a3d4d7d77e204
lib-mio.json
native-tls-7961ce60f7730995
lib-native-tls.json
native-tls-7b89033b999e6e5b
build-script-build-script-build.json
native-tls-8e4373d66bad71ba
run-build-script-build-script-build.json
near-account-id-df0a15daabf57575
lib-near-account-id.json
near-chain-configs-dc4af0bfdb670199
lib-near-chain-configs.json
near-crypto-9b7fda794a2d769d
lib-near-crypto.json
near-jsonrpc-client-6caba88c639dc871
lib-near-jsonrpc-client.json
near-jsonrpc-primitives-7b58ca3e8434705e
lib-near-jsonrpc-primitives.json
near-primitives-6695bd63d1d6a279
lib-near-primitives.json
near-primitives-core-65653068118df66d
lib-near-primitives-core.json
near-rpc-error-core-abb17f5bf4d0c670
lib-near-rpc-error-core.json
near-rpc-error-macro-e888dbdc53a30052
lib-near-rpc-error-macro.json
near-sandbox-utils-02ba451e7f25ad70
lib-near-sandbox-utils.json
near-sandbox-utils-5fc09e6fb2b10349
lib-near-sandbox-utils.json
near-sandbox-utils-bba3cc861c2b9839
build-script-build-script-build.json
near-sandbox-utils-f0fae7677681d621
run-build-script-build-script-build.json
near-units-core-4a43ea182185e2c7
lib-near-units-core.json
near-units-core-79584c970418a644
lib-near-units-core.json
near-units-efda6a1ea794e246
lib-near-units.json
near-units-macro-3b10e21c70d01978
lib-near-units-macro.json
near-vm-errors-df4b74fa843d4567
lib-near-vm-errors.json
nu-ansi-term-846de61dfe0da57c
lib-nu-ansi-term.json
num-bigint-7b5a46c7ff3aea97
build-script-build-script-build.json
num-bigint-81cde4f58b1d0c55
run-build-script-build-script-build.json
num-bigint-d11c591298cc3d2e
lib-num-bigint.json
num-format-343d5c02c28acf3a
lib-num-format.json
num-format-3a48001a3b6ae13f
lib-num-format.json
num-integer-280c5596c5aa1455
lib-num-integer.json
num-integer-43d765ade26501d1
lib-num-integer.json
num-integer-57f09cf366311f34
build-script-build-script-build.json
num-integer-bf3a8bad6671d6da
run-build-script-build-script-build.json
num-rational-672bdba1e844c68c
run-build-script-build-script-build.json
num-rational-8767960bebfdb602
build-script-build-script-build.json
num-rational-c5b6f3d5b2eecdf6
lib-num-rational.json
num-traits-0ab924901b158460
build-script-build-script-build.json
num-traits-4697555d791ead6c
run-build-script-build-script-build.json
num-traits-b16d30f8f94cb5a9
lib-num-traits.json
num-traits-de7b6c3b5d30fac2
lib-num-traits.json
num_cpus-d9e81c1d585bdb6e
lib-num_cpus.json
object-016f899e559ed4cd
lib-object.json
object-1ab3ba550f6695de
lib-object.json
once_cell-84b880e04a3232e2
lib-once_cell.json
once_cell-c4d57e5041e1b607
lib-once_cell.json
opaque-debug-ed756e5879a54799
lib-opaque-debug.json
overload-f7d966b74c8fdf26
lib-overload.json
parking-2035fb06085276d3
lib-parking.json
parking-6119ccf19c3a6fe0
lib-parking.json
parking_lot-ed90fe57b199027f
lib-parking_lot.json
parking_lot_core-1da11f1ef81cc14d
lib-parking_lot_core.json
parking_lot_core-5b3f592385c1a774
build-script-build-script-build.json
parking_lot_core-8f034dc255a2932e
run-build-script-build-script-build.json
percent-encoding-56f3fb4075d52e15
lib-percent-encoding.json
pin-project-7dcc3dabe54c457d
lib-pin-project.json
pin-project-internal-6024b1d46b06d985
lib-pin-project-internal.json
pin-project-lite-232ef7cd835419c5
lib-pin-project-lite.json
pin-project-lite-bdf9675ce26166ac
lib-pin-project-lite.json
pin-utils-4140e432be261ac5
lib-pin-utils.json
pkg-config-4a7a0d55eca11cdc
lib-pkg-config.json
pkg-config-6247f0910c7db9dc
lib-pkg-config.json
portpicker-82d01a1b43a41024
lib-portpicker.json
ppv-lite86-21aa8af17a544621
lib-ppv-lite86.json
primitive-types-fdd68ea58397fa79
lib-primitive-types.json
proc-macro-crate-0a6a04d685c49064
lib-proc-macro-crate.json
proc-macro2-36adc7ba93b4319e
run-build-script-build-script-build.json
proc-macro2-7ddbd4e6c6a784e6
build-script-build-script-build.json
proc-macro2-b2b2b20392fbd469
lib-proc-macro2.json
quote-6b15d0cb383ab226
build-script-build-script-build.json
quote-6ca35ba55317bb56
run-build-script-build-script-build.json
quote-9787329a6a689f1b
lib-quote.json
rand-7dcfe632a75adf25
lib-rand.json
rand-95189ceda7883ae0
lib-rand.json
rand_chacha-a1e8ca1a2054adbf
lib-rand_chacha.json
rand_chacha-e4bf0b5dfb47a32d
lib-rand_chacha.json
rand_core-0aba1ffab34e6040
lib-rand_core.json
rand_core-7710ca4872d5bb25
lib-rand_core.json
reed-solomon-erasure-30091da4d9fc4c2f
build-script-build-script-build.json
reed-solomon-erasure-3218ba8df723f8f3
lib-reed-solomon-erasure.json
reed-solomon-erasure-aeb9e85b3a37e2c6
run-build-script-build-script-build.json
regex-86ca3704651fd0f9
lib-regex.json
regex-9a9783e24e7c12fc
lib-regex.json
regex-automata-705009f0beb780c5
lib-regex-automata.json
regex-syntax-aec0807e4da08791
lib-regex-syntax.json
regex-syntax-dfd2fa47063489a5
lib-regex-syntax.json
reqwest-92e7c617bf7503be
lib-reqwest.json
rustc-demangle-9e7ccc60fa23440d
lib-rustc-demangle.json
rustc-demangle-d46798f35480bc9e
lib-rustc-demangle.json
rustversion-5d1ea9af322437b9
build-script-build-script-build.json
rustversion-b05e1d228e778dc2
lib-rustversion.json
rustversion-c0537fb703928163
run-build-script-build-script-build.json
ryu-323428e5cd6e37a6
lib-ryu.json
schannel-8d9032a333293080
lib-schannel.json
schannel-f0f17d6de18af893
lib-schannel.json
scopeguard-5889818c91a55aa3
lib-scopeguard.json
secp256k1-d47cc54cea91ea50
lib-secp256k1.json
secp256k1-sys-34df52cf7b1fe809
run-build-script-build-script-build.json
secp256k1-sys-c3b327b1c2efe45b
lib-secp256k1-sys.json
secp256k1-sys-cd7f3d76ac391680
build-script-build-script-build.json
serde-1b39428c83f9a8e3
build-script-build-script-build.json
serde-3989e9dcf3c46d8a
lib-serde.json
serde-7496eb5514c973d7
run-build-script-build-script-build.json
serde-7c02d3b26dc04bde
lib-serde.json
serde_derive-134546bdb1f14179
build-script-build-script-build.json
serde_derive-82d48547c4891331
run-build-script-build-script-build.json
serde_derive-a5d9aa27cb01866a
lib-serde_derive.json
serde_json-3471805a96755e44
run-build-script-build-script-build.json
serde_json-9136ad2dbf71e974
lib-serde_json.json
serde_json-da7f68f427a832a0
build-script-build-script-build.json
serde_repr-47e059e6057a1097
lib-serde_repr.json
serde_urlencoded-9aece3a5f9b516f6
lib-serde_urlencoded.json
sha2-4188222edceb3995
lib-sha2.json
sha2-6ea6112c944dda74
lib-sha2.json
sharded-slab-6d62979c2ab22a53
lib-sharded-slab.json
signature-b59fe0a5bff15200
lib-signature.json
siphasher-108a83d813223dea
lib-siphasher.json
siphasher-c9db22b810e8d618
lib-siphasher.json
slab-0933bee86453a523
build-script-build-script-build.json
slab-6c9a04cca5fab5bc
lib-slab.json
slab-cc0153cd1954c07e
run-build-script-build-script-build.json
smallvec-f593ba25aeac9cc2
lib-smallvec.json
smart-default-cf00c5d9ec5eb549
lib-smart-default.json
socket2-7f53eb278f82aa25
lib-socket2.json
socket2-d9565ad93b0b078f
lib-socket2.json
static_assertions-546de2735ce13872
lib-static_assertions.json
strum-36380ff1a9ccd629
lib-strum.json
strum_macros-67155d1e4048a6d5
lib-strum_macros.json
subtle-3991c01dd6e71d5e
lib-subtle.json
syn-57e7f0b75e84423e
run-build-script-build-script-build.json
syn-8198faf5e6a9be79
build-script-build-script-build.json
syn-af94e9d7c2fe24c1
lib-syn.json
synstructure-b9075f42912e0219
lib-synstructure.json
tar-587a78234c7d9051
lib-tar.json
tar-61d1e293d5d198ab
lib-tar.json
thiserror-3c2d872cc4a5c098
build-script-build-script-build.json
thiserror-4aaf3b77eab6c881
lib-thiserror.json
thiserror-6a3ade530318678d
lib-thiserror.json
thiserror-d7fac104ff623417
run-build-script-build-script-build.json
thiserror-impl-dde04ad043f76c4b
lib-thiserror-impl.json
thread_local-dacda164c6327c2e
lib-thread_local.json
time-6f08f88d2e4935b1
lib-time.json
time-7f0e4f32e8acdacc
lib-time.json
tinyvec-1a9613fdc194326f
lib-tinyvec.json
tinyvec_macros-5f08f6db3c162e82
lib-tinyvec_macros.json
tokio-4d3a5468b3279239
run-build-script-build-script-build.json
tokio-90fd3e0b1f78ae5b
build-script-build-script-build.json
tokio-e3dc5b8cc8557273
lib-tokio.json
tokio-macros-766f174690621202
lib-tokio-macros.json
tokio-native-tls-bb781b328d1a7510
lib-tokio-native-tls.json
tokio-retry-af25c916542326b2
lib-tokio-retry.json
tokio-util-303e43df04954a44
lib-tokio-util.json
toml-3e274cff57c2681a
lib-toml.json
tower-service-e7895c61b148f597
lib-tower-service.json
tracing-7163cbf29e763982
lib-tracing.json
tracing-attributes-a5a1314372fe597f
lib-tracing-attributes.json
tracing-core-2963afe0bae956e6
lib-tracing-core.json
tracing-log-a9158f7225b536eb
lib-tracing-log.json
tracing-subscriber-f0a9afe0a62c409f
lib-tracing-subscriber.json
try-lock-5da2815a8a281f66
lib-try-lock.json
typenum-1a918de526f7ca40
lib-typenum.json
typenum-cc474ada7a1acd83
build-script-build-script-main.json
typenum-d95e4fbba31c1498
run-build-script-build-script-main.json
uint-7b631df1c48e8bbd
lib-uint.json
unicode-bidi-f819bcd6b730e0f0
lib-unicode_bidi.json
unicode-ident-4381bf832c3024f9
lib-unicode-ident.json
unicode-normalization-b9b1675b392ca4ad
lib-unicode-normalization.json
unicode-xid-5c47a351cf3b9ad7
lib-unicode-xid.json
url-477c3ed59acd32b2
lib-url.json
uuid-508b0e8efbf6304a
lib-uuid.json
vcpkg-3370ccbec1bd601a
lib-vcpkg.json
version_check-90fb829ed00cd8d6
lib-version_check.json
waker-fn-483c0ae2c47ef42f
lib-waker-fn.json
waker-fn-f088b6715d55d13c
lib-waker-fn.json
want-560343b5fc05cef7
lib-want.json
winapi-37cedc96519812d2
lib-winapi.json
winapi-5340b4400adcd989
run-build-script-build-script-build.json
winapi-5f745db124ba6c61
lib-winapi.json
winapi-6168b021ce04354b
build-script-build-script-build.json
windows-sys-54da191a59ef4e79
lib-windows-sys.json
windows-sys-5dd7d3864865d813
lib-windows-sys.json
windows-sys-ce73d5b46fa45b0e
lib-windows-sys.json
windows-sys-e61aad7ea8e3f675
lib-windows-sys.json
windows_x86_64_msvc-3e75d7c354041063
lib-windows_x86_64_msvc.json
windows_x86_64_msvc-4531f093ea343415
lib-windows_x86_64_msvc.json
windows_x86_64_msvc-7deb386342b216b3
run-build-script-build-script-build.json
windows_x86_64_msvc-936b0e19aa3978c0
build-script-build-script-build.json
windows_x86_64_msvc-963916c5dbf01d1d
build-script-build-script-build.json
windows_x86_64_msvc-a01cda6f7c24d189
lib-windows_x86_64_msvc.json
windows_x86_64_msvc-c7eb5039cf3b047f
run-build-script-build-script-build.json
windows_x86_64_msvc-f337ad3e1a2e61f5
lib-windows_x86_64_msvc.json
winreg-5f384a706e63435c
lib-winreg.json
winreg-80563b99989d65a0
run-build-script-build-script-build.json
winreg-d4ed7697970fb468
build-script-build-script-build.json
workspaces-fdd2928b23e6d9d8
build-script-build-script-build.json
zeroize-e57d754ec71de9b2
lib-zeroize.json
zeroize_derive-6d7c8c34bdd11d76
lib-zeroize_derive.json
zip-7c832bb175c008e7
lib-zip.json
zip-bfba8e7ec63b7635
lib-zip.json
build
anyhow-c568b442755d27a1
out
probe.rs
bzip2-sys-1a6f831f5850d7f5
out
include
bzlib.h
crunchy-701a9814e7d1c766
out
lib.rs
curl-sys-682fe463df39dc51
out
include
curl
curl.h
curlver.h
easy.h
header.h
mprintf.h
multi.h
options.h
stdcheaders.h
system.h
typecheck-gcc.h
urlapi.h
websockets.h
libz-sys-bcde504bf4cff0d8
out
include
zconf.h
zlib.h
num-bigint-81cde4f58b1d0c55
out
radix_bases.rs
reed-solomon-erasure-aeb9e85b3a37e2c6
out
table.rs
secp256k1-sys-34df52cf7b1fe809
out
flag_check.c
thiserror-d7fac104ff623417
out
probe.rs
typenum-d95e4fbba31c1498
out
consts.rs
op.rs
tests.rs
Public header file for the library.
bzlib.h
end bzlib.h
package-lock.json
package.json
| NEAR Orbit
Comunidad startup con capacidad de accion colectiva mediante el uso de
smart contracts en el protocolo de NEAR.
INTRO:
Nuestra vision es bridar valor al protocolo de NEAR, dando poder a las comunidades o (DAOs),
mediante la creacion de smart contracts que faciliten conectar a los usuarios con metas u objetivos similares.
Para motivos del NCD nuestro equipo desarrollara un smart contract donde un Manager (Admin)
¨community manager, CFO, influencer, Marketing head¨; recompensa a sus seguidores o usuarios mas leales mediante un airdrop.
//Continuamos trabajando en desarrollar integracion con discord y twitter para verificar mas requisitos.
# Hello NEAR Contract
The smart contract exposes two methods to enable storing and retrieving a greeting in the NEAR network.
```rust
const DEFAULT_GREETING: &str = "Hello";
#[near_bindgen]
#[derive(BorshDeserialize, BorshSerialize)]
pub struct Contract {
greeting: String,
}
impl Default for Contract {
fn default() -> Self {
Self{greeting: DEFAULT_GREETING.to_string()}
}
}
#[near_bindgen]
impl Contract {
// Public: Returns the stored greeting, defaulting to 'Hello'
pub fn get_greeting(&self) -> String {
return self.greeting.clone();
}
// Public: Takes a greeting, such as 'howdy', and records it
pub fn set_greeting(&mut self, greeting: String) {
// Record a log permanently to the blockchain!
log!("Saving greeting {}", greeting);
self.greeting = greeting;
}
}
```
<br />
# Quickstart
1. Make sure you have installed [rust](https://rust.org/).
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
./deploy.sh
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Retrieve the Greeting
`get_greeting` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the greeting
near view <dev-account> get_greeting
```
<br />
## 3. Store a New Greeting
`set_greeting` changes the contract's state, for which it is a `change` method.
`Change` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set a new greeting
near call <dev-account> set_greeting '{"message":"howdy"}' --accountId <dev-account>
```
**Tip:** If you would like to call `set_greeting` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
|
leonsting_ta-book | .eslintrc.yml
.github
dependabot.yml
workflows
deploy.yml
tests.yml
.gitpod.yml
.travis.yml
README-Gitpod.md
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
guestbook.spec.ts
as_types.d.ts
main.ts
model.ts
tsconfig.json
babel.config.js
neardev
shared-test-staging
test.near.json
shared-test
test.near.json
package.json
src
App.js
config.js
index.html
index.js
tests
integration
App-integration.test.js
ui
App-ui.test.js
| Guest Book
==========
[](https://travis-ci.com/near-examples/guest-book)
[](https://gitpod.io/#https://github.com/near-examples/guest-book)
<!-- MAGIC COMMENT: DO NOT DELETE! Everything above this line is hidden on NEAR Examples page -->
Sign in with [NEAR] and add a message to the guest book! A starter app built with an [AssemblyScript] backend and a [React] frontend.
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you have Node.js ≥ 12 installed (https://nodejs.org), then use it to install [yarn]: `npm install --global yarn` (or just `npm i -g yarn`)
2. Run the local development server: `yarn && yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet! Running `yarn dev` will tell you the URL you can visit in your browser to see the app.
Exploring The Code
==================
1. The backend code lives in the `/assembly` folder. This code gets deployed to
the NEAR blockchain when you run `yarn deploy:contract`. This sort of
code-that-runs-on-a-blockchain is called a "smart contract" – [learn more
about NEAR smart contracts][smart contract docs].
2. The frontend code lives in the `/src` folder.
[/src/index.html](/src/index.html) is a great place to start exploring. Note
that it loads in `/src/index.js`, where you can learn how the frontend
connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and backend. The
backend code gets tested with the [asp] command for running the backend
AssemblyScript tests, and [jest] for running frontend tests. You can run
both of these at once with `yarn test`.
Both contract and client-side code will auto-reload as you change source files.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contracts get deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli
--------------------------
You need near-cli installed globally. Here's how:
npm install --global near-cli
This will give you the `near` [CLI] tool. Ensure that it's installed with:
near --version
Step 1: Create an account for the contract
------------------------------------------
Visit [NEAR Wallet] and make a new account. You'll be deploying these smart contracts to this new account.
Now authorize NEAR CLI for this new account, and follow the instructions it gives you:
near login
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'your-account-here!'
Step 3: change remote URL if you cloned this repo
-------------------------
Unless you forked this repository you will need to change the remote URL to a repo that you have commit access to. This will allow auto deployment to Github Pages from the command line.
1) go to GitHub and create a new repository for this project
2) open your terminal and in the root of this project enter the following:
$ `git remote set-url origin https://github.com/YOUR_USERNAME/YOUR_REPOSITORY.git`
Step 4: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contracts to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
[NEAR]: https://nearprotocol.com/
[yarn]: https://yarnpkg.com/
[AssemblyScript]: https://docs.assemblyscript.org/
[React]: https://reactjs.org
[smart contract docs]: https://docs.nearprotocol.com/docs/roles/developer/contracts/assemblyscript
[asp]: https://www.npmjs.com/package/@as-pect/cli
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.nearprotocol.com/docs/concepts/account
[NEAR Wallet]: https://wallet.nearprotocol.com
[near-cli]: https://github.com/nearprotocol/near-cli
[CLI]: https://www.w3schools.com/whatis/whatis_cli.asp
[create-near-app]: https://github.com/nearprotocol/create-near-app
[gh-pages]: https://github.com/tschaub/gh-pages
|
khanetor_blockipedia-near | .cargo
config.toml
.github
workflows
frontend-check.yml
github-pages.yml
rust-lint.yml
.gitpod.yml
.vscode
settings.json
Cargo.toml
README.md
frontend
README.md
gatsby-browser.js
gatsby-config.ts
package.json
postcss.config.js
src
assets
svg.type.ts
svg
arrow-down.svg
arrow-up.svg
components
landing
style.module.css
style.module.css.d.ts
markdown
index.module.css
index.module.css.d.ts
nearAuth
extendedContract.ts
css
index.css
layouts
index.module.css
index.module.css.d.ts
near-wallet
contract.ts
index.ts
pages
index.module.css
index.module.css.d.ts
read
[id].module.css
[id].module.css.d.ts
write
index.module.css
index.module.css.d.ts
tailwind.config.js
tsconfig.json
src
constants.rs
lib.rs
models.rs
utils.rs
| # Blockipedia-NEAR
A wikipedia on NEAR Protocol
[](https://gitpod.io/#https://github.com/nlhkh/blockipedia-near)
## Visit the Blockipedia page
https://nlhkh.github.io/blockipedia-near/
# How to develop locally
## Backend (smart contract on NEAR rust sdk)
Prerequisites:
- [near-cli](https://www.npmjs.com/package/near-cli)
- [rustc](https://www.rust-lang.org/tools/install)
```
make build
make dev-deploy
```
## Frontend (Gatsby React app)
Prerequisites:
- [Node.js](https://nodejs.dev/learn/how-to-install-nodejs)
- [yarn](https://classic.yarnpkg.com/lang/en/docs/install/#mac-stable)
All frontend resources are under `./frontend` directory
For local development, Gatsby expects env vars from the `.env.development` file
Feel free to copy from `.env.development.sample` and make any change you need
```bash
make dev-frontend
```
# How to run tests
## Run tests against the entire suite
```bash
make test
```
## Run test for a single unit test
```bash
make test TEST_TARGET=test_name
# where `test_name` is the name of the specific test function
# e.g. "create_article_with_insufficient_fund"
```
## Run tests while allowing console log messages (e.g. from `println!` or `dbg!`) to show up
```bash
# run all tests
make test-verbose
# run a specific test
make test-verbose TEST_TARGET=test_name
```
<p align="center">
<a href="https://www.gatsbyjs.com/?utm_source=starter&utm_medium=readme&utm_campaign=minimal-starter-ts">
<img alt="Gatsby" src="https://www.gatsbyjs.com/Gatsby-Monogram.svg" width="60" />
</a>
</p>
<h1 align="center">
Gatsby minimal TypeScript starter
</h1>
## 🚀 Quick start
1. **Create a Gatsby site.**
Use the Gatsby CLI to create a new site, specifying the minimal TypeScript starter.
```shell
# create a new Gatsby site using the minimal TypeScript starter
npm init gatsby
```
2. **Start developing.**
Navigate into your new site’s directory and start it up.
```shell
cd my-gatsby-site/
npm run develop
```
3. **Open the code and start customizing!**
Your site is now running at http://localhost:8000!
Edit `src/pages/index.tsx` to see your site update in real-time!
4. **Learn more**
- [Documentation](https://www.gatsbyjs.com/docs/?utm_source=starter&utm_medium=readme&utm_campaign=minimal-starter-ts)
- [Tutorials](https://www.gatsbyjs.com/tutorial/?utm_source=starter&utm_medium=readme&utm_campaign=minimal-starter-ts)
- [Guides](https://www.gatsbyjs.com/tutorial/?utm_source=starter&utm_medium=readme&utm_campaign=minimal-starter-ts)
- [API Reference](https://www.gatsbyjs.com/docs/api-reference/?utm_source=starter&utm_medium=readme&utm_campaign=minimal-starter-ts)
- [Plugin Library](https://www.gatsbyjs.com/plugins?utm_source=starter&utm_medium=readme&utm_campaign=minimal-starter-ts)
- [Cheat Sheet](https://www.gatsbyjs.com/docs/cheat-sheet/?utm_source=starter&utm_medium=readme&utm_campaign=minimal-starter-ts)
## 🚀 Quick start (Gatsby Cloud)
Deploy this starter with one click on [Gatsby Cloud](https://www.gatsbyjs.com/cloud/):
[<img src="https://www.gatsbyjs.com/deploynow.svg" alt="Deploy to Gatsby Cloud">](https://www.gatsbyjs.com/dashboard/deploynow?url=https://github.com/gatsbyjs/gatsby-starter-minimal-ts)
|
narawitPtm_yeji-contract | README.md
token-contract-as
.dependabot
config.yml
.gitpod.yml
.travis.yml
LICENSE-APACHE.txt
LICENSE-MIT.txt
README-Gitpod.md
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
example.spec.ts
token.spec.ts
as_types.d.ts
index.ts
tsconfig.json
dist
index.html
index.js
main.1f19ae8e.js
neardev
shared-test-staging
test.near.json
shared-test
test.near.json
package-lock.json
package.json
src
config.js
index.html
loader.html
main.js
test.js
| Token Contract in AssemblyScript
================================
[](https://gitpod.io/#https://github.com/near-examples/token-contract-as)
<!-- MAGIC COMMENT: DO NOT DELETE! Everything above this line is hidden on NEAR Examples page -->
This project contains an implementation of a token contract similar to [ERC20](https://theethereum.wiki/w/index.php/ERC20_Token_Standard) but simpler. We'll visit a page, sign in and use your browser's console to run commands to initialize, send, and get the balance of a custom token.
**Note**: this example uses a basic version of a token. It is not the supported token contract laid out in the [NEAR Enhancement Proposal for non-fungible tokens](https://github.com/nearprotocol/NEPs/pull/4).
Visit [this example](https://github.com/near-examples/NFT) illustrating implementations of the non-fungible token in Rust and AssemblyScript. It is not recommended to deploy non-fungible tokens written in AssemblyScript for financial use cases.
Getting started
===============
There's a button at the top of this file that says "Open in Gitpod." If you want to try out this project as fast as possible, that's what you want. It will open the project in your browser with a complete integrated development environment configured for you. If you want to run the project yourself locally, read on.
There are two ways to run this project locally. The first is quick, and a good way to instantly become familiar with this example. Once familiar, the next step is to create your own NEAR account and deploy the contract to testnet.
Quick option
---------------
1. Install dependencies:
yarn
2. Build and deploy this smart contract to a development account. This development account will be created automatically and is not intended for reuse:
yarn dev
Standard deploy option
----------------------
In this second option, the smart contract will get deployed to a specific account created with the NEAR Wallet.
1. Ensure `near-cli` is installed by running:
near --version
If needed, install `near-cli`:
npm install near-cli -g
2. If you do not have a NEAR account, please create one with [NEAR Wallet](https://wallet.nearprotocol.com). Then, in the project root, login with `near-cli` by following the instructions after this command:
near login
3. Modify the top of `src/config.js`, changing the `CONTRACT_NAME` to be the NEAR account that you just used to log in.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'YOUR_ACCOUNT_NAME_HERE'; /* TODO: fill this in! */
4. Start the example!
yarn start
Exploring The Code
==================
1. The backend code lives in the `/assembly` folder. This code gets deployed to
the NEAR blockchain when you run `yarn deploy:contract`. This sort of
code-that-runs-on-a-blockchain is called a "smart contract" – [learn more
about NEAR smart contracts][smart contract docs].
2. The frontend code lives in the `/src` folder.
[/src/index.html](/src/index.html) is a great place to start exploring. Note
that it loads in `/src/main.js`, where you can learn how the frontend
connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and backend. The
backend code gets tested with the [asp] command for running the backend
AssemblyScript tests, and [jest] for running frontend tests. You can run
both of these at once with `yarn test`.
Both contract and client-side code will auto-reload as you change source files.
[smart contract docs]: https://docs.nearprotocol.com/docs/roles/developer/contracts/assemblyscript
[asp]: https://www.npmjs.com/package/@as-pect/cli
[jest]: https://jestjs.io/
# yeji-contract
smart contract for yeji swap
|
LasloMagnusen_minternear | IDEAS.md
NOTES.md
README.md
simple-gallery
.eslintrc.json
README.md
config
constants.ts
hooks
useStoreNfts.ts
next-env.d.ts
next.config.js
package-lock.json
package.json
postcss.config.js
queries
queries.ts
services
providers
apollo.ts
constants.ts
styles
globals.css
tailwind.config.js
tsconfig.json
types
types.ts
wallet.types.ts
simple-login
.eslintrc.json
README.md
next-env.d.ts
next.config.js
package-lock.json
package.json
postcss.config.js
services
providers
constants.ts
styles
globals.css
tailwind.config.js
tsconfig.json
simple-marketplace
.eslintrc.json
README.md
config
constants.ts
global.d.ts
hooks
useNearPrice.ts
useStoreNfts.ts
useStores.ts
useTokenListData.ts
lib
numbers.ts
next-env.d.ts
next.config.js
package-lock.json
package.json
postcss.config.js
queries
fragments.ts
marketplace.queries.ts
services
providers
apollo.ts
styles
globals.css
tailwind.config.js
tsconfig.json
types
types.ts
wallet.types.ts
utils
BuyModal.utils.ts
index.ts
simple-minter
.eslintrc.json
README.md
config
constants.ts
next-env.d.ts
next.config.js
package-lock.json
package.json
postcss.config.js
services
providers
apollo.ts
constants.ts
styles
globals.css
tailwind.config.js
tsconfig.json
types
types.ts
| <p align="center">
<a href="https://mintbase.io">
<img src="./assets/mb-logo.png" style="object-fit: cover">
<h3 align="center">Examples</h3>
</a>
</p>
## Index
- [Simple Login](./simple-login)
- [Simple Gallery](./simple-gallery)
- [Simple Marketplace](./simple-marketplace)
- [Simple Minter](./simple-minter)
---
name: Simple Login
slug: simple-login
description: Simple NEAR wallet login
framework: Next.js
css: Tailwind
deployUrl: https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2FMintbase%2Fexamples%2Ftree%2Fmain%2Fsimple-login
demoUrl: https://examples-simple-login.vercel.app/
---
# Simple Login
This examples shows a simple login with NEAR example.
## Demo
https://examples-simple-login.vercel.app/
## Try on CodeSandbox
[](https://codesandbox.io/s/github/Mintbase/examples/tree/main/simple-login)
### One-Click Deploy
Deploy the example using [Vercel](https://vercel.com?utm_source=github&utm_medium=readme):
[](https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2FMintbase%2Fexamples%2Ftree%2Fmain%2Fsimple-login)
## Getting Started
Execute [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app) with [npm](https://docs.npmjs.com/cli/init) or [Yarn](https://yarnpkg.com/lang/en/docs/cli/create/) to bootstrap the example:
```bash
npx create-next-app --example https://github.com/Mintbase/examples/tree/main/simple-login
# or
yarn create next-app --example https://github.com/Mintbase/examples/tree/main/simple-login
```
Run Next.js in development mode:
```bash
npm install
npm run dev
# or
yarn
yarn dev
```
Once that's done, copy the `.env.example` file in this directory to `.env.local` (which will be ignored by Git):
```bash
cp .env.example .env.local
```
Then open `.env.local` and set the environment variables to match the ones for your Google Optimize account.
## Set ENV variables
Once that's done, copy the `.env.example` file in this directory to `.env.local` (which will be ignored by Git):
```bash
cp .env.example .env.local
```
if you use windows without powershell or cygwin:
```bash
copy .env.example .env.local
```
Then open `.env.local` and set the environment variables to match the ones for your Google Optimize account.
`NEXT_PUBLIC_NETWORK` could be `testnet` or `mainnet`
```
NEXT_PUBLIC_NETWORK=testnet
```
`NEXT_PUBLIC_USER_ID` its your near wallet user id
```
NEXT_PUBLIC_USER_ID=mintbase_user_on_near
```
## Extending
This project is setup using Next.js + MintBase UI + Tailwind.
You can use this project as a reference to build your own, and use or remove any library you think it would suit your needs.
## 🙋♀️ Need extra help?
[Ask on our Telegram Channel](https://t.me/mintdev) <br/>
[Create an Issue](https://github.com/Mintbase/examples/issues)
---
name: Simple Marketplace
slug: simple-marketplace
description: Simple Marketplace on MintBase
framework: Next.js
css: Tailwind
deployUrl: https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2FMintbase%2Fexamples%2Ftree%2Fmain%2Fsimple-marketplace
demoUrl: https://examples-simple-marketplace.vercel.app/
---
# Simple Marketplace
This examples shows a simple marketplace.
## Demo
https://examples-simple-marketplace.vercel.app/
## Requirements
- [Setup a Near Wallet](https://wallet.testnet.near.org/)
- [Setup a Mintbase store aka Smart Contract](https://www.youtube.com/watch?v=Ck2EPrtuxa8) and [Mint NFTS](https://www.youtube.com/watch?v=6L_aAnJc3hM):
- [Get a Developer Key](https://testnet.mintbase.io/developer)
## Try on CodeSandbox
[](https://codesandbox.io/s/github/Mintbase/examples/tree/main/simple-marketplace)
## One-Click Deploy
Deploy the example using [Vercel](https://vercel.com?utm_source=github&utm_medium=readme):
[](https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2FMintbase%2Fexamples%2Ftree%2Fmain%2Fsimple-marketplace)
## Getting Started
Execute [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app) with [npm](https://docs.npmjs.com/cli/init) or [Yarn](https://yarnpkg.com/lang/en/docs/cli/create/) to bootstrap the example:
```bash
npx create-next-app --example https://github.com/Mintbase/examples/tree/main/simple-marketplace
# or
yarn create next-app --example https://github.com/Mintbase/examples/tree/main/simple-marketplace
```
Run Next.js in development mode:
```bash
npm install
npm run dev
# or
yarn
yarn dev
```
## Set ENV variables
Once that's done, copy the `.env.example` file in this directory to `.env.local` (which will be ignored by Git):
```bash
cp .env.example .env.local
```
if you use windows without powershell or cygwin:
```bash
copy .env.example .env.local
```
To get your `api key` visit :
[Mintbase Developers Page for Mainnet](https://www.mintbase.io/developer):
[Mintbase Developers Page for testnet](https://testnet.mintbase.io/developer):
```
NEXT_PUBLIC_DEVELOPER_KEY=your_mintbase_api_key
```
`NEXT_PUBLIC_NETWORK` could be `testnet` or `mainnet`
```
NEXT_PUBLIC_NETWORK=testnet
```
`NEXT_PUBLIC_STORES` its your stores ids
```
NEXT_PUBLIC_STORES=latium.mintspace2.testnet,mufasa.mintspace2.testnet
```
## Extending
This project is setup using Next.js + MintBase UI + Tailwind + Apollo.
You can use this project as a reference to build your own, and use or remove any library you think it would suit your needs.
## 🙋♀️ Need extra help?
[Ask on our Telegram Channel](https://t.me/mintdev) <br/>
[Create an Issue](https://github.com/Mintbase/examples/issues)
---
name: Simple Gallery
slug: simple-gallery
description: Simple Mintbase Gallery
framework: Next.js
css: Tailwind
deployUrl: https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2FMintbase%2Fexamples%2Ftree%2Fmain%2Fsimple-gallery
demoUrl: https://examples-simple-gallery.vercel.app/
---
# Simple Gallery
This examples shows a simple gallery.
## Demo
https://examples-simple-gallery.vercel.app/
## Try on CodeSandbox
[](https://codesandbox.io/s/github/Mintbase/examples/tree/main/simple-gallery)
### One-Click Deploy
Deploy the example using [Vercel](https://vercel.com?utm_source=github&utm_medium=readme):
[](https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2FMintbase%2Fexamples%2Ftree%2Fmain%2Fsimple-gallery)
## Getting Started
Execute [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app) with [npm](https://docs.npmjs.com/cli/init) or [Yarn](https://yarnpkg.com/lang/en/docs/cli/create/) to bootstrap the example:
```bash
npx create-next-app --example https://github.com/Mintbase/examples/tree/main/simple-gallery
# or
yarn create next-app --example https://github.com/Mintbase/examples/tree/main/simple-gallery
```
Run Next.js in development mode:
```bash
npm install
npm run dev
# or
yarn
yarn dev
```
Once that's done, copy the `.env.example` file in this directory to `.env.local` (which will be ignored by Git):
```bash
cp .env.example .env.local
```
## Set ENV variables
Once that's done, copy the `.env.example` file in this directory to `.env.local` (which will be ignored by Git):
```bash
cp .env.example .env.local
```
if you use windows without powershell or cygwin:
```bash
copy .env.example .env.local
```
To get your `api key` visit :
[Mintbase Developers Page for Mainnet](https://www.mintbase.io/developer):
[Mintbase Developers Page for testnet](https://testnet.mintbase.io/developer):
```
NEXT_PUBLIC_DEVELOPER_KEY=your_mintbase_api_key
`NEXT_PUBLIC_NETWORK` could be `testnet` or `mainnet`
```
NEXT_PUBLIC_NETWORK=testnet
```
`NEXT_PUBLIC_STORE_ID` its your store id
```
NEXT_PUBLIC_STORE_ID=hellovirtualworld.mintspace2.testnet
```
## Extending
This project is setup using Next.js + MintBase UI + Tailwind + Apollo.
You can use this project as a reference to build your own, and use or remove any library you think it would suit your needs.
## 🙋♀️ Need extra help?
[Ask on our Telegram Channel](https://t.me/mintdev) <br/>
[Create an Issue](https://github.com/Mintbase/examples/issues)
---
name: Simple Minter
slug: simple-minter
description: Simple Minter on Mintbase
framework: Next.js
css: Tailwind
deployUrl: https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2FMintbase%2Fexamples%2Ftree%2Fmain%2Fsimple-minter
demoUrl: https://examples-simple-minter.vercel.app/
---
# Simple Minter
This examples shows a simple minter on Mintbase.
## Demo
https://examples-simple-minter.vercel.app/
## Try on CodeSandbox
[](https://codesandbox.io/s/github/Mintbase/examples/tree/main/simple-minter)
## 🚀 One-Click Deploy
Deploy the example using [Vercel](https://vercel.com?utm_source=github&utm_medium=readme):
[](https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2FMintbase%2Fexamples%2Ftree%2Fmain%2Fsimple-minter)
## Getting Started
Execute [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app) with [npm](https://docs.npmjs.com/cli/init) or [Yarn](https://yarnpkg.com/lang/en/docs/cli/create/) to bootstrap the example:
```bash
npx create-next-app --example https://github.com/Mintbase/examples/tree/main/simple-minter
# or
yarn create next-app --example https://github.com/Mintbase/examples/tree/main/simple-minter
```
Run Next.js in development mode:
```bash
npm install
npm run dev
# or
yarn
yarn dev
```
## Set ENV variables
Once that's done, copy the `.env.example` file in this directory to `.env.local` (which will be ignored by Git):
```bash
cp .env.example .env.local
```
if you use windows without powershell or cygwin:
```bash
copy .env.example .env.local
```
Then open `.env.local` and set the environment variables to match the ones for your Google Optimize account.
To get your `api key` visit :
[Mintbase Developers Page for Mainnet](https://www.mintbase.io/developer):
[Mintbase Developers Page for testnet](https://testnet.mintbase.io/developer):
```
NEXT_PUBLIC_DEVELOPER_KEY=your_mintbase_api_key
```
`NEXT_PUBLIC_NETWORK` could be `testnet` or `mainnet`
```
NEXT_PUBLIC_NETWORK=testnet
```
`NEXT_PUBLIC_STORE_ID` its your store id
```
NEXT_PUBLIC_STORE_ID=hellovirtualworld.mintspace2.testnet
```
## Extending
This project is setup using Next.js + MintBase UI + Tailwind + Apollo + React Hook Form.
You can use this project as a reference to build your own, and use or remove any library you think it would suit your needs.
## 🙋♀️ Need extra help?
[Ask on our Telegram Channel](https://t.me/mintdev) <br/>
[Create an Issue](https://github.com/Mintbase/examples/issues)
|
Gungz_flux-bot | README.md
config
default.js
index.js
package-lock.json
package.json
scripts
check-markets.js
remove-webhook.js
| # Flux Bot
A Twitter bot that creates market when it is tagged in the tweet.
This is created to fulfill use-case mentioned in [Gitcoin Hackathon](https://gitcoin.co/issue/nearprotocol/ready-layer-one-hackathon/8/4311)
A Twitter bot that allows people to create a market by tagging a bot. E.g.: @flux_bot "Will Donald Trump be re-elected in 2020?" 31-12-2020 11:59pm
## Prerequisite (has been tested with version mentioned below)
1. Node v10.15.x
2. [NearShell](https://docs.near.org/docs/development/near-clitool) v0.23.2
3. A [Near Account](https://docs.near.org/docs/local-setup/create-account) in TestNet
4. A [Twitter Developer Account](https://developer.twitter.com/en)
### Twitter Application Creation
1. Login to your [Twitter Developer Account](https://developer.twitter.com/en)
2. Create [new apps](https://developer.twitter.com/en/apps) by filling in all necessary information
3. Go to the App Details
4. Click Permissions
5. Ensure to give Read, write, and Direct Messages Access permission
6. Click Keys and Tokens
7. Note down API key and API Secret key (those are APPLICATION_CONSUMER_KEY and APPLICATION_CONSUMER_SECRET env variables that you will need to set in below section)
8. Generate Access Token and Access Token Secret
9. Note them down (those are ACCESS_TOKEN and ACCESS_TOKEN_SECRET env variables that you will need to set in below section)
10. Go to [environments](https://developer.twitter.com/en/account/environments)
11. In Account Activity API / Sandbox, click Set up dev environment, choose your own label but make sure App is assigned to the app you created earlier (the label will be ENVIRONMENT env variable that you will need to set in below section)
12. Find the user ID of your Twitter account (you can use this [site](https://codeofaninja.com/tools/find-twitter-id), enter your Twitter username and you get your ID) - the ID is TWITTER_USER_ID env variable you will need to set in below section
### Setup Near Account to be used by Flux SDK
1. Create folder `neardev/default`
2. Put your Near Account json file to folder `neardev/default`
3. You can find your Near Account json file by following this [guide](https://docs.near.org/docs/roles/developer/examples/near-api-js/guides#authenticating-with-near-shell)
The json file should contain information like below
```
{
"account_id": "YOUR_DEVELOPER_ACCOUNT",
"private_key": "ed25519:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
}
3. The account_id is NEAR_ACCOUNT_ID env variable that you will need to set in below section
```
### Setup Environment Variables
Open `config/default.js` to see what environment variables need to be setup, you can use export command in your terminal to set the environment variables
```
WEBHOOK_SERVER_URL --> this is URL of your deployed webhook (see Deploy section below how to get it)
WEBHOOK_ROUTE --> this is the route of your webhook (you can choose any route e.g. /webhook/twitter)
APPLICATION_CONSUMER_KEY --> this is your Twitter Application Consumer Key
APPLICATION_CONSUMER_SECRET --> this is your Twitter Application Consumer Secret
ACCESS_TOKEN --> this is your Twitter Application Access Token
ACCESS_TOKEN_SECRET --> this is your Twitter Application Access Token Secret
ENVIRONMENT --> this is your Twitter Application Environment
TWITTER_USER_ID --> this is Twitter User ID that you want to subscribe
NEAR_ACCOUNT_ID --> this is Near Account ID used to interact with Flux Protocol
```
### Install Dependencies
1. Run `npm i`
### Do Modification on flux-sdk
1. On this date (19 May 2020), I need to modify `node_modules/flux-sdk/src/FluxProvider.js` by changing `async connect` method to below code
```
async connect(contractId, keyStore, accountId) {
this.near = await connect({...helpers.getConfig(contractId), deps: { keyStore: keyStore ? keyStore : new keyStores.BrowserLocalStorageKeyStore() } });
if (typeof window !== 'undefined') {
this.walletConnection = new WalletConnection(this.near, contractId);
this.account = this.walletConnection.account();
this.contract = new Contract(this.account, contractId, {
viewMethods,
changeMethods,
sender: this.walletConnection.getAccountId(),
});
} else {
this.account = await this.near.account(accountId);
this.contract = new Contract(this.account, contractId, {
viewMethods,
changeMethods,
sender: accountId,
});
}
this.connected = true;
}
```
This is required because `flux-sdk` seems to work only from javascript in browser that supports `window` variable and doesn't have support yet for server-side Near Account that is normally used for server-side only application
## Deploy locally (using ngrok)
1. Download and install [ngrok](https://ngrok.com/download)
2. In separate terminal, run `ngrok http -bind-tls=true 3000`, this command will create ngrok tunnel to your machine port 3000 - Twitter will require the webhook to use https, hence why `-bind-tls` is required
3. Set environment variable WEBHOOK_SERVER_URL with value ngrok URL you obtained (e.g. https://16c1fc4a.ngrok.io)
4. Run the application by executing `npm start` - this will start webhook in localhost port 3000
P.S.: When you run `npm start` for the second time, third time, etc., your console may output error like "Error when creating subscription, Error when register", do not worry, this error happens because actually you only need to register your webhook and add your subscription to Twitter once but the current codebase keeps executing the registration and subscription request whenever the application is started
## Demo Video
See the demo [here](https://drive.google.com/file/d/1d5BuZ-YFvxjBZ_vczTKXZ2HVJo4tn_J4/view?usp=sharing)
You can run `npm run check-markets` and check that the market with ID mentioned in twitter bot reply is indeed there on the Blockchain
P.S.: Error handling has not been done properly, so when you test it, kindly ensure you always use same format of tweet, e.g. `@BotHackathon "<description inside double-quotes>" <end time in format like 31-12-2020 11:59pm>`
## TODO
1. Request pull / merge of my fix on `FluxProvider.js` to `flux-sdk` team
2. Proper error handling for flux timeout and invalid input in Twitter
3. Add linter to the codebase
4. Create scripts to add / remove Twitter webhook, add / remove user subscription independently and not put it in the `index.js`
5. Make the codebase more modular and add unit test
6. Deployment to public server (e.g. Heroku)
7. Handle MainNet - need to check if this requires `flux-sdk` change to support MainNet or not
8. Enhance the bot to do categorical market creation
9. Etc.
|
near_wasmtime | .github
ISSUE_TEMPLATE
blank-issue.md
clif-bug-report.md
fuzzbug.md
improvement.md
wasmtime-bug-report.md
actions
binary-compatible-builds
README.md
action.yml
main.js
github-release
README.md
action.yml
main.js
package-lock.json
package.json
install-cargo-vet
action.yml
install-rust
README.md
action.yml
label-messager.json
label-messager
wasmtime-config.md
labeler.yml
pull_request_template.md
subscribe-to-label.json
workflows
cargo-audit.yml
main.yml
performance.yml
publish-artifacts.yml
publish-to-cratesio.yml
release-process.yml
triage.yml
ADOPTERS.md
CODE_OF_CONDUCT.md
CONTRIBUTING.md
Cargo.toml
ORG_CODE_OF_CONDUCT.md
README.md
RELEASES.md
SECURITY.md
benches
call.rs
instantiation.rs
thread_eager_init.rs
trap.rs
wasi.rs
build.rs
ci
RELEASES-template.md
build-build-matrix.js
build-release-artifacts.sh
build-src-tarball.sh
build-tarballs.sh
build-test-matrix.js
build-wasi-preview1-component-adapter.sh
ensure_deterministic_build.sh
find-latest-release.rs
merge-artifacts.sh
print-current-version.sh
run-tests.sh
test-all-zkasm.sh
test-zkasm.sh
update-release-date.rs
zkasm-result.py
cranelift
Cargo.toml
README.md
bforest
Cargo.toml
README.md
src
lib.rs
map.rs
node.rs
path.rs
pool.rs
set.rs
codegen
Cargo.toml
README.md
benches
x64-evex-encoding.rs
build.rs
meta
Cargo.toml
README.md
src
cdsl
formats.rs
instructions.rs
isa.rs
mod.rs
operands.rs
settings.rs
types.rs
typevar.rs
constant_hash.rs
error.rs
gen_inst.rs
gen_settings.rs
gen_types.rs
isa
arm64.rs
mod.rs
riscv64.rs
s390x.rs
x86.rs
zkasm.rs
lib.rs
shared
entities.rs
formats.rs
immediates.rs
instructions.rs
mod.rs
settings.rs
types.rs
srcgen.rs
unique_table.rs
shared
Cargo.toml
README.md
src
constant_hash.rs
constants.rs
lib.rs
src
alias_analysis.rs
binemit
mod.rs
stack_map.rs
bitset.rs
cfg_printer.rs
constant_hash.rs
context.rs
ctxhash.rs
cursor.rs
data_value.rs
dbg.rs
dce.rs
dominator_tree.rs
egraph.rs
egraph
cost.rs
domtree.rs
elaborate.rs
flowgraph.rs
fx.rs
incremental_cache.rs
inst_predicates.rs
ir
atomic_rmw_op.rs
builder.rs
condcodes.rs
constant.rs
dfg.rs
dynamic_type.rs
entities.rs
extfunc.rs
extname.rs
function.rs
globalvalue.rs
immediates.rs
instructions.rs
jumptable.rs
known_symbol.rs
layout.rs
libcall.rs
memflags.rs
memtype.rs
mod.rs
pcc.rs
progpoint.rs
sourceloc.rs
stackslot.rs
table.rs
trapcode.rs
types.rs
isa
aarch64
abi.rs
inst
args.rs
emit.rs
emit_tests.rs
imms.rs
mod.rs
regs.rs
unwind.rs
unwind
systemv.rs
lower.rs
lower
isle.rs
isle
generated_code.rs
mod.rs
pcc.rs
settings.rs
call_conv.rs
mod.rs
riscv64
abi.rs
inst
args.rs
emit.rs
emit_tests.rs
encode.rs
imms.rs
mod.rs
regs.rs
unwind.rs
unwind
systemv.rs
vector.rs
lower.rs
lower
isle.rs
isle
generated_code.rs
mod.rs
settings.rs
s390x
abi.rs
inst
args.rs
emit.rs
emit_tests.rs
imms.rs
mod.rs
regs.rs
unwind.rs
unwind
systemv.rs
lower.rs
lower
isle.rs
isle
generated_code.rs
mod.rs
settings.rs
unwind.rs
unwind
systemv.rs
winx64.rs
x64
abi.rs
encoding
evex.rs
mod.rs
rex.rs
vex.rs
inst
args.rs
emit.rs
emit_state.rs
emit_tests.rs
mod.rs
regs.rs
unwind.rs
unwind
systemv.rs
winx64.rs
lower.rs
lower
isle.rs
isle
generated_code.rs
mod.rs
pcc.rs
settings.rs
zkasm
abi.rs
inst
args.rs
emit.rs
emit_tests.rs
encode.rs
imms.rs
mod.rs
regs.rs
lower.rs
lower
isle.rs
isle
generated_code.rs
mod.rs
settings.rs
isle_prelude.rs
iterators.rs
legalizer
globalvalue.rs
mod.rs
table.rs
lib.rs
loop_analysis.rs
machinst
abi.rs
blockorder.rs
buffer.rs
compile.rs
helpers.rs
inst_common.rs
isle.rs
lower.rs
mod.rs
pcc.rs
reg.rs
valueregs.rs
vcode.rs
nan_canonicalization.rs
opts.rs
opts
README.md
generated_code.rs
print_errors.rs
remove_constant_phis.rs
result.rs
scoped_hash_map.rs
settings.rs
souper_harvest.rs
timing.rs
unionfind.rs
unreachable_code.rs
value_label.rs
verifier
mod.rs
write.rs
control
Cargo.toml
README.md
src
chaos.rs
lib.rs
zero_sized.rs
docs
compare-llvm.md
index.md
ir.md
isle-integration.md
testing.md
entity
Cargo.toml
README.md
src
boxed_slice.rs
iter.rs
keys.rs
lib.rs
list.rs
map.rs
packed_option.rs
primary.rs
set.rs
sparse.rs
unsigned.rs
filetests
Cargo.toml
README.md
filetests
egraph
make-icmp-parameterized-tests.sh
wasm
load-store
make-load-store-tests.sh
src
concurrent.rs
function_runner.rs
lib.rs
match_directive.rs
runner.rs
runone.rs
subtest.rs
test_alias_analysis.rs
test_cat.rs
test_compile.rs
test_dce.rs
test_domtree.rs
test_interpret.rs
test_legalizer.rs
test_optimize.rs
test_print_cfg.rs
test_run.rs
test_run_zkasm.rs
test_safepoint.rs
test_unwind.rs
test_verifier.rs
test_wasm.rs
test_wasm
config.rs
env.rs
test_zkasm.rs
zkasm_codegen.rs
zkasm_runner.rs
frontend
Cargo.toml
README.md
src
frontend.rs
lib.rs
ssa.rs
switch.rs
variable.rs
fuzzgen
Cargo.toml
README.md
src
config.rs
cranelift_arbitrary.rs
function_generator.rs
lib.rs
passes
fcvt.rs
int_divz.rs
mod.rs
print.rs
target_isa_extras.rs
interpreter
Cargo.toml
README.md
src
address.rs
environment.rs
frame.rs
instruction.rs
interpreter.rs
lib.rs
state.rs
step.rs
value.rs
isle
README.md
docs
language-reference.md
fuzz
Cargo.toml
README.md
fuzz_targets
compile.rs
isle
Cargo.toml
README.md
build.rs
isle_examples
link
borrows_main.rs
iflets_main.rs
multi_constructor_main.rs
multi_extractor_main.rs
test_main.rs
run
iconst_main.rs
let_shadowing_main.rs
src
ast.rs
codegen.rs
compile.rs
error.rs
lexer.rs
lib.rs
log.rs
overlap.rs
parser.rs
sema.rs
serialize.rs
trie_again.rs
tests
run_tests.rs
islec
Cargo.toml
src
main.rs
jit
Cargo.toml
README.md
examples
jit-minimal.rs
src
backend.rs
compiled_blob.rs
lib.rs
memory.rs
tests
basic.rs
media
crane-ferris.svg
module
Cargo.toml
README.md
src
data_context.rs
lib.rs
module.rs
traps.rs
native
Cargo.toml
README.md
src
lib.rs
riscv.rs
object
Cargo.toml
README.md
src
backend.rs
lib.rs
tests
basic.rs
reader
Cargo.toml
README.md
src
error.rs
isaspec.rs
lexer.rs
lib.rs
parser.rs
run_command.rs
sourcemap.rs
testcommand.rs
testfile.rs
run-souper.sh
rustc.md
serde
Cargo.toml
README.md
src
clif-json.rs
src
bugpoint.rs
cat.rs
clif-util.rs
compile.rs
disasm.rs
interpret.rs
print_cfg.rs
run.rs
souper_harvest.rs
utils.rs
wasm.rs
tests
filetests.rs
umbrella
Cargo.toml
README.md
src
lib.rs
wasm
Cargo.toml
README.md
src
code_translator.rs
code_translator
bounds_checks.rs
environ
dummy.rs
mod.rs
spec.rs
zkasm.rs
func_translator.rs
heap.rs
lib.rs
module_translator.rs
sections_translator.rs
state.rs
translation_utils.rs
tests
wasm_testsuite.rs
zkasm_data
analyze-zkasm
Cargo.toml
src
main.rs
testfiles
README.md
--------
|
crates
asm-macros
Cargo.toml
src
lib.rs
bench-api
Cargo.toml
src
lib.rs
unsafe_send_sync.rs
c-api-macros
Cargo.toml
src
lib.rs
c-api
CMakeLists.txt
Cargo.toml
README.md
artifact
Cargo.toml
src
lib.rs
build.rs
include
doc-wasm.h
wasi.h
wasmtime.h
wasmtime
async.h
config.h
engine.h
error.h
extern.h
func.h
global.h
instance.h
linker.h
memory.h
module.h
profiling.h
store.h
table.h
trap.h
val.h
src
async.rs
config.rs
engine.rs
error.rs
extern.rs
func.rs
global.rs
instance.rs
lib.rs
linker.rs
memory.rs
module.rs
profiling.rs
ref.rs
store.rs
table.rs
trap.rs
types.rs
types
export.rs
extern.rs
func.rs
global.rs
import.rs
memory.rs
table.rs
val.rs
val.rs
vec.rs
wasi.rs
wat2wasm.rs
cache
Cargo.toml
build.rs
src
config.rs
config
tests.rs
lib.rs
tests.rs
worker.rs
worker
tests.rs
tests
system_time_stub.rs
tests
cache_write_default_config.rs
cli-flags
Cargo.toml
src
lib.rs
opt.rs
component-macro
Cargo.toml
build.rs
src
bindgen.rs
component.rs
lib.rs
test-helpers
Cargo.toml
src
lib.rs
tests
codegen.rs
component-util
Cargo.toml
src
lib.rs
cranelift-shared
Cargo.toml
src
compiled_function.rs
isa_builder.rs
lib.rs
obj.rs
cranelift
Cargo.toml
SECURITY.md
src
builder.rs
compiler.rs
compiler
component.rs
debug.rs
debug
gc.rs
transform
address_transform.rs
attr.rs
expression.rs
line_program.rs
mod.rs
range_info_builder.rs
refs.rs
simulate.rs
unit.rs
utils.rs
write_debuginfo.rs
func_environ.rs
lib.rs
environ
Cargo.toml
examples
factc.rs
fuzz
Cargo.toml
fuzz_targets
fact-valid-module.rs
src
address_map.rs
builtin.rs
compilation.rs
component.rs
component
artifacts.rs
compiler.rs
dfg.rs
info.rs
translate.rs
translate
adapt.rs
inline.rs
types.rs
types
resources.rs
vmcomponent_offsets.rs
demangling.rs
fact.rs
fact
core_types.rs
signature.rs
trampoline.rs
transcode.rs
traps.rs
lib.rs
module.rs
module_artifacts.rs
module_environ.rs
module_types.rs
obj.rs
ref_bits.rs
scopevec.rs
stack_map.rs
trap_encoding.rs
tunables.rs
vmoffsets.rs
explorer
Cargo.toml
src
.eslintrc.yml
index.css
index.js
lib.rs
fiber
Cargo.toml
build.rs
src
lib.rs
unix.rs
unix
aarch64.rs
arm.rs
riscv64.rs
x86.rs
x86_64.rs
windows.c
windows.rs
fuzzing
Cargo.toml
README.md
build.rs
src
generators.rs
generators
api.rs
codegen_settings.rs
component_types.rs
config.rs
instance_allocation_strategy.rs
memory.rs
module.rs
pooling_config.rs
single_inst_module.rs
spec_test.rs
stacks.rs
table_ops.rs
value.rs
lib.rs
mutators.rs
oracles.rs
oracles
diff_spec.rs
diff_v8.rs
diff_wasmi.rs
diff_wasmtime.rs
dummy.rs
engine.rs
stacks.rs
single_module_fuzzer.rs
wasm-spec-interpreter
Cargo.toml
README.md
build.rs
ocaml
README.md
src
lib.rs
with_library.rs
without_library.rs
jit-debug
Cargo.toml
README.md
src
gdb_jit_int.rs
lib.rs
perf_jitdump.rs
jit-icache-coherence
Cargo.toml
src
lib.rs
libc.rs
miri.rs
win.rs
misc
component-fuzz-util
Cargo.toml
src
lib.rs
component-macro-test
Cargo.toml
src
lib.rs
component-test-util
Cargo.toml
src
lib.rs
runtime
Cargo.toml
build.rs
proptest-regressions
instance
allocator
pooling
memory_pool.txt
src
arch
aarch64.rs
mod.rs
riscv64.rs
s390x.rs
x86_64.rs
component.rs
component
libcalls.rs
resources.rs
cow.rs
debug_builtins.rs
export.rs
externref.rs
helpers.c
imports.rs
instance.rs
instance
allocator.rs
allocator
on_demand.rs
pooling.rs
pooling
index_allocator.rs
memory_pool.rs
stack_pool.rs
table_pool.rs
lib.rs
libcalls.rs
memory.rs
mmap.rs
mmap_vec.rs
module_id.rs
mpk
disabled.rs
enabled.rs
mod.rs
pkru.rs
sys.rs
parking_spot.rs
send_sync_ptr.rs
store_box.rs
sys
miri
mmap.rs
mod.rs
traphandlers.rs
unwind.rs
vm.rs
mod.rs
unix
machports.rs
macos_traphandlers.rs
mmap.rs
mod.rs
signals.rs
unwind.rs
vm.rs
windows
mmap.rs
mod.rs
traphandlers.rs
unwind.rs
vm.rs
table.rs
traphandlers.rs
traphandlers
backtrace.rs
coredump.rs
vmcontext.rs
vmcontext
vm_host_func_context.rs
test-programs
Cargo.toml
artifacts
Cargo.toml
build.rs
src
lib.rs
src
bin
api_proxy.rs
api_proxy_streaming.rs
api_reactor.rs
api_read_only.rs
api_time.rs
cli_args.rs
cli_default_clocks.rs
cli_directory_list.rs
cli_env.rs
cli_exit_default.rs
cli_exit_failure.rs
cli_exit_panic.rs
cli_exit_success.rs
cli_export_cabi_realloc.rs
cli_file_append.rs
cli_file_dir_sync.rs
cli_file_read.rs
cli_hello_stdout.rs
cli_no_ip_name_lookup.rs
cli_no_tcp.rs
cli_no_udp.rs
cli_splice_stdin.rs
cli_stdin.rs
cli_stdio_write_flushes.rs
http_outbound_request_content_length.rs
http_outbound_request_get.rs
http_outbound_request_invalid_dnsname.rs
http_outbound_request_invalid_header.rs
http_outbound_request_invalid_port.rs
http_outbound_request_invalid_version.rs
http_outbound_request_large_post.rs
http_outbound_request_post.rs
http_outbound_request_put.rs
http_outbound_request_response_build.rs
http_outbound_request_unknown_method.rs
http_outbound_request_unsupported_scheme.rs
nn_image_classification.rs
nn_image_classification_named.rs
piped_multiple.rs
piped_polling.rs
piped_simple.rs
preview1_big_random_buf.rs
preview1_clock_time_get.rs
preview1_close_preopen.rs
preview1_dangling_fd.rs
preview1_dangling_symlink.rs
preview1_dir_fd_op_failures.rs
preview1_directory_seek.rs
preview1_fd_advise.rs
preview1_fd_filestat_get.rs
preview1_fd_filestat_set.rs
preview1_fd_flags_set.rs
preview1_fd_readdir.rs
preview1_file_allocate.rs
preview1_file_pread_pwrite.rs
preview1_file_seek_tell.rs
preview1_file_truncation.rs
preview1_file_unbuffered_write.rs
preview1_file_write.rs
preview1_interesting_paths.rs
preview1_nofollow_errors.rs
preview1_overwrite_preopen.rs
preview1_path_exists.rs
preview1_path_filestat.rs
preview1_path_link.rs
preview1_path_open_create_existing.rs
preview1_path_open_dirfd_not_dir.rs
preview1_path_open_lots.rs
preview1_path_open_missing.rs
preview1_path_open_nonblock.rs
preview1_path_open_preopen.rs
preview1_path_open_read_write.rs
preview1_path_rename.rs
preview1_path_rename_dir_trailing_slashes.rs
preview1_path_symlink_trailing_slashes.rs
preview1_poll_oneoff_files.rs
preview1_poll_oneoff_stdio.rs
preview1_readlink.rs
preview1_regular_file_isatty.rs
preview1_remove_directory.rs
preview1_remove_nonempty_directory.rs
preview1_renumber.rs
preview1_sched_yield.rs
preview1_stdio.rs
preview1_stdio_isatty.rs
preview1_stdio_not_isatty.rs
preview1_symlink_create.rs
preview1_symlink_filestat.rs
preview1_symlink_loop.rs
preview1_unicode_output.rs
preview1_unlink_file_trailing_slashes.rs
preview2_adapter_badfd.rs
preview2_ip_name_lookup.rs
preview2_random.rs
preview2_sleep.rs
preview2_stream_pollable_correct.rs
preview2_stream_pollable_traps.rs
preview2_tcp_bind.rs
preview2_tcp_connect.rs
preview2_tcp_sample_application.rs
preview2_tcp_sockopts.rs
preview2_tcp_states.rs
preview2_udp_bind.rs
preview2_udp_connect.rs
preview2_udp_sample_application.rs
preview2_udp_sockopts.rs
preview2_udp_states.rs
http.rs
lib.rs
preview1.rs
sockets.rs
types
Cargo.toml
src
error.rs
lib.rs
versioned-export-macros
Cargo.toml
src
lib.rs
wasi-common
Cargo.toml
README.md
build.rs
src
clocks.rs
ctx.rs
dir.rs
error.rs
file.rs
lib.rs
pipe.rs
random.rs
sched.rs
sched
subscription.rs
snapshots
mod.rs
preview_0.rs
preview_1.rs
preview_1
error.rs
string_array.rs
sync
clocks.rs
dir.rs
file.rs
mod.rs
net.rs
sched.rs
sched
unix.rs
windows.rs
stdio.rs
table.rs
tokio
dir.rs
file.rs
mod.rs
net.rs
sched.rs
sched
unix.rs
windows.rs
stdio.rs
tests
all
async_.rs
main.rs
sync.rs
wasi-http
Cargo.toml
src
body.rs
http_impl.rs
io.rs
lib.rs
proxy.rs
types.rs
types_impl.rs
tests
all
async_.rs
http_server.rs
main.rs
sync.rs
wasi-nn
Cargo.toml
README.md
build.rs
examples
README.md
classification-example-named
Cargo.toml
README.md
src
main.rs
classification-example
Cargo.toml
README.md
src
main.rs
src
backend
mod.rs
openvino.rs
ctx.rs
lib.rs
registry
in_memory.rs
mod.rs
testing.rs
wit.rs
witx.rs
tests
all.rs
wasi-preview1-component-adapter
Cargo.toml
README.md
build.rs
byte-array-literals
Cargo.toml
README.md
src
lib.rs
src
descriptors.rs
lib.rs
macros.rs
verify
Cargo.toml
README.md
src
main.rs
wasi-threads
Cargo.toml
README.md
src
lib.rs
wasi
Cargo.toml
README.md
src
lib.rs
preview2
clocks.rs
clocks
host.rs
command.rs
ctx.rs
error.rs
filesystem.rs
host
clocks.rs
env.rs
exit.rs
filesystem.rs
filesystem
sync.rs
instance_network.rs
io.rs
mod.rs
network.rs
random.rs
tcp.rs
tcp_create_socket.rs
udp.rs
udp_create_socket.rs
ip_name_lookup.rs
mod.rs
network.rs
pipe.rs
poll.rs
preview0.rs
preview1.rs
random.rs
stdio.rs
stdio
worker_thread_stdin.rs
stream.rs
tcp.rs
udp.rs
write_stream.rs
tests
all
api.rs
async_.rs
main.rs
preview1.rs
sync.rs
process_stdin.rs
wasmtime
Cargo.toml
README.md
src
compile.rs
config.rs
engine.rs
engine
serialization.rs
lib.rs
profiling_agent.rs
profiling_agent
jitdump.rs
perfmap.rs
vtune.rs
runtime.rs
runtime
code.rs
code_memory.rs
component
component.rs
func.rs
func
host.rs
options.rs
typed.rs
instance.rs
linker.rs
matching.rs
mod.rs
resource_table.rs
resources.rs
storage.rs
store.rs
types.rs
values.rs
coredump.rs
debug.rs
externals.rs
externals
global.rs
table.rs
func.rs
func
typed.rs
instance.rs
instantiate.rs
limits.rs
linker.rs
memory.rs
module.rs
module
registry.rs
profiling.rs
ref.rs
resources.rs
signatures.rs
stack.rs
store.rs
store
context.rs
data.rs
func_refs.rs
trampoline.rs
trampoline
func.rs
global.rs
memory.rs
table.rs
trap.rs
type_registry.rs
types.rs
types
matching.rs
unix.rs
v128.rs
values.rs
windows.rs
wast
Cargo.toml
src
component.rs
core.rs
lib.rs
spectest.rs
wast.rs
wiggle
Cargo.toml
README.md
generate
Cargo.toml
README.md
src
codegen_settings.rs
config.rs
funcs.rs
lib.rs
lifetimes.rs
module_trait.rs
names.rs
types
error.rs
flags.rs
handle.rs
mod.rs
record.rs
variant.rs
wasmtime.rs
macro
Cargo.toml
src
lib.rs
src
borrow.rs
error.rs
guest_type.rs
lib.rs
region.rs
wasmtime.rs
test-helpers
Cargo.toml
examples
tracing.rs
src
lib.rs
tests
atoms.rs
atoms_async.rs
errors.rs
flags.rs
handles.rs
ints.rs
keywords.rs
lists.rs
pointers.rs
records.rs
strings.rs
tracing.rs
variant.rs
wasi.rs
wasmtime_async.rs
wasmtime_integration.rs
wasmtime_sync.rs
winch
Cargo.toml
src
builder.rs
compiler.rs
lib.rs
wit-bindgen
Cargo.toml
src
lib.rs
rust.rs
source.rs
types.rs
wmemcheck
Cargo.toml
src
lib.rs
Tracing through one Wasm frame
deny.toml
docs
SUMMARY.md
WASI-api.md
WASI-background.md
WASI-capabilities.md
WASI-documents.md
WASI-intro.md
WASI-overview.md
WASI-possible-future-features.md
WASI-rationale.md
WASI-some-possible-changes.md
WASI-tutorial.md
assemblyscript-hello-world
README.md
asconfig.json
package.json
tsconfig.json
wasi-hello.ts
assemblyscript_demo
README.md
asconfig.json
package.json
tsconfig.json
wasi-demo.ts
book.toml
cli-cache.md
cli-install.md
cli-logging.md
cli-options.md
cli.md
contributing-architecture.md
contributing-building.md
contributing-ci.md
contributing-coc.md
contributing-code-review.md
contributing-coding-guidelines.md
contributing-cross-compiling.md
contributing-development-process.md
contributing-fuzzing.md
contributing-governance.md
contributing-implementing-wasm-proposals.md
contributing-maintainer-guidelines.md
contributing-reducing-test-cases.md
contributing-release-process.md
contributing-testing.md
contributing.md
examples-c-debugging.md
examples-c-embed.md
examples-c-gcd.md
examples-c-hello-world.md
examples-c-linking.md
examples-c-memory.md
examples-c-multi-value.md
examples-c-wasi.md
examples-coredump.md
examples-debugging-core-dumps.md
examples-debugging-native-debugger.md
examples-debugging.md
examples-minimal.md
examples-profiling-guest.md
examples-profiling-perf.md
examples-profiling-samply.md
examples-profiling-vtune.md
examples-profiling.md
examples-rust-core-dumps.md
examples-rust-debugging.md
examples-rust-embed.md
examples-rust-gcd.md
examples-rust-hello-world.md
examples-rust-linking.md
examples-rust-memory.md
examples-rust-multi-value.md
examples-rust-wasi.md
examples.md
introduction.md
lang-bash.md
lang-c.md
lang-dotnet.md
lang-elixir.md
lang-go.md
lang-python.md
lang-ruby.md
lang-rust.md
lang.md
rust_wasi_markdown_parser
Cargo.toml
example_markdown.md
src
main.rs
security-disclosure.md
security.md
stability-platform-support.md
stability-release.md
stability-tiers.md
stability.md
wmemcheck.md
zkasm
README.md
api.md
architecture.md
roadmap.md
test-infra.md
usage.md
--------------
examples
CMakeLists.txt
README.md
async.cpp
component
main.rs
wasm
Cargo.toml
guest.rs
coredump.rs
epochs.rs
externref.c
externref.rs
fib-debug
main.c
main.rs
wasm
Cargo.toml
fib.rs
fuel.c
fuel.rs
gcd.c
gcd.rs
hello.c
hello.rs
interrupt.c
interrupt.rs
linking.c
linking.rs
memory.c
memory.rs
mpk-available.rs
mpk.rs
multi.c
multi.rs
multimemory.c
multimemory.rs
serialize.c
serialize.rs
threads.c
threads.rs
tokio
main.rs
wasm
Cargo.toml
tokio-wasi.rs
wasi-async
main.rs
wasi
main.c
main.rs
wasm
Cargo.toml
wasi.rs
fuzz
Cargo.toml
README.md
build.rs
fuzz_targets
api_calls.rs
compile.rs
component_api.rs
cranelift-fuzzgen.rs
cranelift-icache.rs
differential.rs
instantiate-many.rs
instantiate.rs
spectests.rs
stacks.rs
table_ops.rs
pyproject.toml
scripts
format-all.sh
publish.rs
src
bin
wasmtime.rs
commands.rs
commands
compile.rs
config.rs
explore.rs
run.rs
serve.rs
settings.rs
wast.rs
common.rs
lib.rs
old_cli.rs
supply-chain
README.md
audits.toml
config.toml
tests
all
async_functions.rs
call_hook.rs
cli_tests.rs
code_too_large.rs
component_model.rs
component_model
aot.rs
async.rs
bindgen.rs
bindgen
ownership.rs
results.rs
dynamic.rs
func.rs
import.rs
instance.rs
macros.rs
nested.rs
post_return.rs
resources.rs
strings.rs
coredump.rs
debug
dump.rs
gdb.rs
lldb.rs
mod.rs
obj.rs
simulate.rs
testsuite
dead_code.c
fib-wasm.c
reverse-str.c
spilled_frame_base.c
translate.rs
epoch_interruption.rs
externals.rs
fuel.rs
func.rs
funcref.rs
gc.rs
globals.rs
host_funcs.rs
iloop.rs
import_calling_export.rs
import_indexes.rs
instance.rs
invoke_func_via_table.rs
limits.rs
linker.rs
main.rs
memory.rs
memory_creator.rs
module.rs
module_serialize.rs
name.rs
piped_tests.rs
pooling_allocator.rs
relocs.rs
stack_creator.rs
stack_overflow.rs
store.rs
table.rs
threads.rs
traps.rs
wait_notify.rs
wasi_testsuite.rs
wast.rs
winch.rs
custom_signal_handler.rs
host_segfault.rs
pcc_memory.rs
rlimited-memory.rs
zkasm
assert_helper.js
helpers
InstructionTracer.js
data-dump.js
package-lock.json
package.json
run-tests-zkasm.js
winch
Cargo.toml
codegen
Cargo.toml
build.rs
src
abi
local.rs
mod.rs
codegen
bounds.rs
builtin.rs
call.rs
context.rs
control.rs
env.rs
mod.rs
frame
mod.rs
isa
aarch64
abi.rs
address.rs
asm.rs
masm.rs
mod.rs
regs.rs
mod.rs
reg.rs
x64
abi.rs
address.rs
asm.rs
masm.rs
mod.rs
regs.rs
lib.rs
masm.rs
regalloc.rs
regset.rs
stack.rs
trampoline.rs
visitor.rs
docs
testing.md
filetests
Cargo.toml
build.rs
src
disasm.rs
lib.rs
src
compile.rs
filetests.rs
main.rs
test-macros
Cargo.toml
src
lib.rs
| # wasmtime-wasi-threads
Implement the `wasi-threads` [specification] in Wasmtime.
[specification]: https://github.com/WebAssembly/wasi-threads
> Note: this crate is experimental and not yet suitable for use in multi-tenant
> embeddings. As specified, a trap or WASI exit in one thread must end execution
> for all threads. Due to the complexity of stopping threads, however, this
> implementation currently exits the process entirely. This will work for some
> use cases (e.g., CLI usage) but not for embedders. This warning can be removed
> once a suitable mechanism is implemented that avoids exiting the process.
# `cranelift-fuzzgen`
This crate implements a generator to create random Cranelift modules.
<div align="center">
<h1><code>wasmtime</code></h1>
<p>
<strong>A standalone runtime for
<a href="https://webassembly.org/">WebAssembly</a></strong>
</p>
<strong>A <a href="https://bytecodealliance.org/">Bytecode Alliance</a> project</strong>
<p>
<a href="https://github.com/bytecodealliance/wasmtime/actions?query=workflow%3ACI"><img src="https://github.com/bytecodealliance/wasmtime/workflows/CI/badge.svg" alt="build status" /></a>
<a href="https://bytecodealliance.zulipchat.com/#narrow/stream/217126-wasmtime"><img src="https://img.shields.io/badge/zulip-join_chat-brightgreen.svg" alt="zulip chat" /></a>
<img src="https://img.shields.io/badge/rustc-stable+-green.svg" alt="supported rustc stable" />
<a href="https://docs.rs/wasmtime"><img src="https://docs.rs/wasmtime/badge.svg" alt="Documentation Status" /></a>
</p>
<h3>
<a href="https://bytecodealliance.github.io/wasmtime/">Guide</a>
<span> | </span>
<a href="https://bytecodealliance.github.io/wasmtime/contributing.html">Contributing</a>
<span> | </span>
<a href="https://wasmtime.dev/">Website</a>
<span> | </span>
<a href="https://bytecodealliance.zulipchat.com/#narrow/stream/217126-wasmtime">Chat</a>
</h3>
</div>
## Installation
The Wasmtime CLI can be installed on Linux and macOS (locally) with a small install
script:
```sh
curl https://wasmtime.dev/install.sh -sSf | bash
```
Windows or otherwise interested users can download installers and
binaries directly from the [GitHub
Releases](https://github.com/bytecodealliance/wasmtime/releases) page.
## Example
If you've got the [Rust compiler
installed](https://www.rust-lang.org/tools/install) then you can take some Rust
source code:
```rust
fn main() {
println!("Hello, world!");
}
```
and compile/run it with:
```sh
$ rustup target add wasm32-wasi
$ rustc hello.rs --target wasm32-wasi
$ wasmtime hello.wasm
Hello, world!
```
(Note: make sure you installed Rust using the `rustup` method in the official
instructions above, and do not have a copy of the Rust toolchain installed on
your system in some other way as well (e.g. the system package manager). Otherwise, the `rustup target add...`
command may not install the target for the correct copy of Rust.)
## Features
* **Fast**. Wasmtime is built on the optimizing [Cranelift] code generator to
quickly generate high-quality machine code either at runtime or
ahead-of-time. Wasmtime is optimized for efficient instantiation, low-overhead
calls between the embedder and wasm, and scalability of concurrent instances.
* **[Secure]**. Wasmtime's development is strongly focused on correctness and
security. Building on top of Rust's runtime safety guarantees, each Wasmtime
feature goes through careful review and consideration via an [RFC
process]. Once features are designed and implemented, they undergo 24/7
fuzzing donated by [Google's OSS Fuzz]. As features stabilize they become part
of a [release][release policy], and when things go wrong we have a
well-defined [security policy] in place to quickly mitigate and patch any
issues. We follow best practices for defense-in-depth and integrate
protections and mitigations for issues like Spectre. Finally, we're working to
push the state-of-the-art by collaborating with academic researchers to
formally verify critical parts of Wasmtime and Cranelift.
* **[Configurable]**. Wasmtime uses sensible defaults, but can also be
configured to provide more fine-grained control over things like CPU and
memory consumption. Whether you want to run Wasmtime in a tiny environment or
on massive servers with many concurrent instances, we've got you covered.
* **[WASI]**. Wasmtime supports a rich set of APIs for interacting with the host
environment through the [WASI standard](https://wasi.dev).
* **[Standards Compliant]**. Wasmtime passes the [official WebAssembly test
suite](https://github.com/WebAssembly/testsuite), implements the [official C
API of wasm](https://github.com/WebAssembly/wasm-c-api), and implements
[future proposals to WebAssembly](https://github.com/WebAssembly/proposals) as
well. Wasmtime developers are intimately engaged with the WebAssembly
standards process all along the way too.
[Wasmtime]: https://github.com/bytecodealliance/wasmtime
[Cranelift]: https://cranelift.dev/
[Google's OSS Fuzz]: https://google.github.io/oss-fuzz/
[security policy]: https://bytecodealliance.org/security
[RFC process]: https://github.com/bytecodealliance/rfcs
[release policy]: https://docs.wasmtime.dev/stability-release.html
[Secure]: https://docs.wasmtime.dev/security.html
[Configurable]: https://docs.rs/wasmtime/latest/wasmtime/struct.Config.html
[WASI]: https://docs.rs/wasmtime-wasi/latest/wasmtime_wasi/
[Standards Compliant]: https://docs.wasmtime.dev/stability-wasm-proposals-support.html
## Language Support
You can use Wasmtime from a variety of different languages through embeddings of
the implementation.
Languages supported by the Bytecode Alliance:
* **[Rust]** - the [`wasmtime` crate]
* **[C]** - the [`wasm.h`, `wasi.h`, and `wasmtime.h` headers][c-headers], [CMake](crates/c-api/CMakeLists.txt) or [`wasmtime` Conan package]
* **C++** - the [`wasmtime-cpp` repository][wasmtime-cpp] or use [`wasmtime-cpp` Conan package]
* **[Python]** - the [`wasmtime` PyPI package]
* **[.NET]** - the [`Wasmtime` NuGet package]
* **[Go]** - the [`wasmtime-go` repository]
* **[Ruby]** - the [`wasmtime` gem]
Languages supported by the community:
* **[Elixir]** - the [`wasmex` hex package]
* **Perl** - the [`Wasm` Perl package's `Wasm::Wasmtime`]
[Rust]: https://bytecodealliance.github.io/wasmtime/lang-rust.html
[C]: https://bytecodealliance.github.io/wasmtime/examples-c-embed.html
[`wasmtime` crate]: https://crates.io/crates/wasmtime
[c-headers]: https://bytecodealliance.github.io/wasmtime/c-api/
[Python]: https://bytecodealliance.github.io/wasmtime/lang-python.html
[`wasmtime` PyPI package]: https://pypi.org/project/wasmtime/
[.NET]: https://bytecodealliance.github.io/wasmtime/lang-dotnet.html
[`Wasmtime` NuGet package]: https://www.nuget.org/packages/Wasmtime
[Go]: https://bytecodealliance.github.io/wasmtime/lang-go.html
[`wasmtime-go` repository]: https://pkg.go.dev/github.com/bytecodealliance/wasmtime-go
[wasmtime-cpp]: https://github.com/bytecodealliance/wasmtime-cpp
[`wasmtime` Conan package]: https://conan.io/center/wasmtime
[`wasmtime-cpp` Conan package]: https://conan.io/center/wasmtime-cpp
[Ruby]: https://bytecodealliance.github.io/wasmtime/lang-ruby.html
[`wasmtime` gem]: https://rubygems.org/gems/wasmtime
[Elixir]: https://docs.wasmtime.dev/lang-elixir.html
[`wasmex` hex package]: https://hex.pm/packages/wasmex
[`Wasm` Perl package's `Wasm::Wasmtime`]: https://metacpan.org/pod/Wasm::Wasmtime
## Documentation
[📚 Read the Wasmtime guide here! 📚][guide]
The [wasmtime guide][guide] is the best starting point to learn about what
Wasmtime can do for you or help answer your questions about Wasmtime. If you're
curious in contributing to Wasmtime, [it can also help you do
that][contributing]!
[contributing]: https://bytecodealliance.github.io/wasmtime/contributing.html
[guide]: https://bytecodealliance.github.io/wasmtime
---
It's Wasmtime.
# AssemblyScript WASI Demo
This demo shows some WASI features off such as System Time, User Input, Writing to the Console, and Random Numbers.
The module `@assemblyscript/wasi-shim` as well as a wasi-enabled runtime are required.
## Setup
Navigate to `./docs/assemblyscript_demo` and run
```
npm install
```
Build the AssemblyScript demo file
```
npm run build
```
Run the WASI Demo
```
npm run demo
```
# byte-array-literals
This crate exists to solve a very peculiar problem for the
`wasi-preview1-component-adapter`: we want to use string literals in our
source code, but the resulting binary (when compiled for
wasm32-unknown-unknown) cannot contain any data sections.
The answer that @sunfishcode discovered is that these string literals, if
represented as an array of u8 literals, these will somehow not end up in the
data section, at least when compiled with opt-level='s' on today's rustc
(1.69.0). So, this crate exists to transform these literals using a proc
macro.
It is very possible this cheat code will abruptly stop working in some future
compiler, but we'll cross that bridge when we get to it.
# ISLE Fuzz Targets
These are separate from the top-level `wasmtime/fuzz` fuzz targets because we
don't intend to run them on OSS-Fuzz. They are just for local ISLE hacking.
This crate provides module-level functionality, which allow multiple
functions and data to be emitted with
[Cranelift](https://crates.io/crates/cranelift) and then linked together.
This crate is structured as an optional layer on top of cranelift-codegen.
It provides additional functionality, such as linking, however users that
require greater flexibility don't need to use it.
A module is a collection of functions and data objects that are linked
together. The `Module` trait that defines a common interface for various kinds
of modules. Most users will use one of the following `Module` implementations:
- `JITModule`, provided by [cranelift-jit], which JITs code to memory for direct execution.
- `ObjectModule`, provided by [cranelift-object], which emits native object files.
[cranelift-jit]: https://crates.io/crates/cranelift-jit
[cranelift-object]: https://crates.io/crates/cranelift-object
# ISLE: Instruction Selection / Lowering Expressions
ISLE is a domain specific language (DSL) for instruction selection and lowering
clif instructions to vcode's `MachInst`s in Cranelift.
ISLE is a statically-typed term-rewriting language. You define rewriting rules
that map input terms (clif instructions) into output terms (`MachInst`s). These
rules get compiled down into Rust source test that uses a tree of `match`
expressions that is as good or better than what you would have written by hand.
# github-release
An action used to publish GitHub releases for `wasmtime`.
As of the time of this writing there's a few actions floating around which
perform github releases but they all tend to have their set of drawbacks.
Additionally nothing handles deleting releases which we need for our rolling
`dev` release.
To handle all this this action rolls-its-own implementation using the
actions/toolkit repository and packages published there. These run in a Docker
container and take various inputs to orchestrate the release from the build.
More comments can be found in `main.js`.
Testing this is really hard. If you want to try though run `npm install` and
then `node main.js`. You'll have to configure a bunch of env vars though to get
anything reasonably working.
This is the `wasmtime-jit-debug` crate, which contains JIT debug interfaces support for Wasmtime.
This crate contains the metaprogram used by cranelift-codegen. It's not
useful on its own.
# wiggle
Wiggle is a code generator for the host side of a `witx` interface. It is
invoked as a Rust procedural macro.
Wiggle is not specialized to any particular WebAssembly runtime. It is usable
in at least Wasmtime and Lucet.
## Learning more
Read the docs on [docs.rs](https://docs.rs/wiggle/).
There are child crates for [integrating with Wasmtime](https://github.com/bytecodealliance/wasmtime/tree/main/crates/wiggle) (this crate), and [Lucet](https://github.com/bytecodealliance/lucet/tree/main/lucet-wiggle).
The [wasi-common crate](https://github.com/bytecodealliance/wasmtime/tree/main/crates/wasi-common) is implemented using Wiggle and the [wasmtime-wasi
crate](https://github.com/bytecodealliance/wasmtime/tree/main/crates/wasi) integrates wasi-common with the Wasmtime engine.
Andrew Brown wrote a great [blog post](https://bytecodealliance.org/articles/implementing-wasi-nn-in-wasmtime) on using Wiggle with Wasmtime.
Cranelift Code Generator
========================
**A [Bytecode Alliance][BA] project**
[Website](https://cranelift.dev/)
Cranelift is a low-level retargetable code generator. It translates a
[target-independent intermediate representation](docs/ir.md)
into executable machine code.
[BA]: https://bytecodealliance.org/
[](https://github.com/bytecodealliance/wasmtime/actions)
[](https://bytecodealliance.zulipchat.com/#narrow/stream/217117-cranelift/topic/general)

[](https://docs.rs/cranelift)
For more information, see [the documentation](docs/index.md).
For an example of how to use the JIT, see the [JIT Demo], which
implements a toy language.
[JIT Demo]: https://github.com/bytecodealliance/cranelift-jit-demo
For an example of how to use Cranelift to run WebAssembly code, see
[Wasmtime], which implements a standalone, embeddable, VM using Cranelift.
[Wasmtime]: https://github.com/bytecodealliance/wasmtime
Status
------
Cranelift currently supports enough functionality to run a wide variety
of programs, including all the functionality needed to execute
WebAssembly (MVP and various extensions like SIMD), although it needs to be
used within an external WebAssembly embedding such as Wasmtime to be part of a
complete WebAssembly implementation. It is also usable as a backend for
non-WebAssembly use cases: for example, there is an effort to build a [Rust
compiler backend] using Cranelift.
Cranelift is production-ready, and is used in production in several places, all
within the context of Wasmtime. It is carefully fuzzed as part of Wasmtime with
differential comparison against V8 and the executable Wasm spec, and the
register allocator is separately fuzzed with symbolic verification. There is an
active effort to formally verify Cranelift's instruction-selection backends. We
take security seriously and have a [security policy] as a part of Bytecode
Alliance.
Cranelift has four backends: x86-64, aarch64 (aka ARM64), s390x (aka IBM
Z) and riscv64. All backends fully support enough functionality for Wasm MVP, and
x86-64 and aarch64 fully support SIMD as well. On x86-64, Cranelift supports
both the System V AMD64 ABI calling convention used on many platforms and the
Windows x64 calling convention. On aarch64, Cranelift supports the standard
Linux calling convention and also has specific support for macOS (i.e., M1 /
Apple Silicon).
Cranelift's code quality is within range of competitiveness to browser JIT
engines' optimizing tiers. A [recent paper] includes third-party benchmarks of
Cranelift, driven by Wasmtime, against V8 and an LLVM-based Wasm engine, WAVM
(Fig 22). The speed of Cranelift's generated code is ~2% slower than that of
V8 (TurboFan), and ~14% slower than WAVM (LLVM). Its compilation speed, in the
same paper, is measured as approximately an order of magnitude faster than WAVM
(LLVM). We continue to work to improve both measures.
[Rust compiler backend]: https://github.com/bjorn3/rustc_codegen_cranelift
[security policy]: https://bytecodealliance.org/security
[recent paper]: https://arxiv.org/abs/2011.13127
The core codegen crates have minimal dependencies and are carefully written to
handle malicious or arbitrary compiler input: in particular, they do not use
callstack recursion.
Cranelift performs some basic mitigations for Spectre attacks on heap bounds
checks, table bounds checks, and indirect branch bounds checks; see
[#1032] for more.
[#1032]: https://github.com/bytecodealliance/wasmtime/issues/1032
Cranelift's APIs are not yet considered stable, though we do follow
semantic-versioning (semver) with minor-version patch releases.
Cranelift generally requires the latest stable Rust to build as a policy, and
is tested as such, but we can incorporate fixes for compilation with older Rust
versions on a best-effort basis.
Contributing
------------
If you're interested in contributing to Cranelift: thank you! We have a
[contributing guide] which will help you getting involved in the Cranelift
project.
[contributing guide]: https://bytecodealliance.github.io/wasmtime/contributing.html
Planned uses
------------
Cranelift is designed to be a code generator for WebAssembly, but it is
general enough to be useful elsewhere too. The initial planned uses that
affected its design were:
- [Wasmtime non-Web wasm engine](https://github.com/bytecodealliance/wasmtime).
- [Debug build backend for the Rust compiler](rustc.md).
- WebAssembly compiler for the SpiderMonkey engine in Firefox
(currently not planned anymore; SpiderMonkey team may re-assess in
the future).
- Backend for the IonMonkey JavaScript JIT compiler in Firefox
(currently not planned anymore; SpiderMonkey team may re-assess in
the future).
Building Cranelift
------------------
Cranelift uses a [conventional Cargo build
process](https://doc.rust-lang.org/cargo/guide/working-on-an-existing-project.html).
Cranelift consists of a collection of crates, and uses a [Cargo
Workspace](https://doc.rust-lang.org/book/ch14-03-cargo-workspaces.html),
so for some cargo commands, such as `cargo test`, the `--all` is needed
to tell cargo to visit all of the crates.
`test-all.sh` at the top level is a script which runs all the cargo
tests and also performs code format, lint, and documentation checks.
<details>
<summary>Log configuration</summary>
Cranelift uses the `log` crate to log messages at various levels. It doesn't
specify any maximal logging level, so embedders can choose what it should be;
however, this can have an impact of Cranelift's code size. You can use `log`
features to reduce the maximum logging level. For instance if you want to limit
the level of logging to `warn` messages and above in release mode:
```
[dependency.log]
...
features = ["release_max_level_warn"]
```
</details>
Editor Support
--------------
Editor support for working with Cranelift IR (clif) files:
- Vim: https://github.com/bytecodealliance/cranelift.vim
<div align="center">
<h1><code>wasmtime</code></h1>
<p>
<strong>A standalone runtime for
<a href="https://webassembly.org/">WebAssembly</a></strong>
</p>
<strong>A <a href="https://bytecodealliance.org/">Bytecode Alliance</a> project</strong>
</div>
## About
This crate is the Rust embedding API for the [Wasmtime] project: a
cross-platform engine for running WebAssembly programs. Notable features of
Wasmtime are:
* **Fast**. Wasmtime is built on the optimizing [Cranelift] code generator to
quickly generate high-quality machine code either at runtime or
ahead-of-time. Wasmtime's runtime is also optimized for cases such as
efficient instantiation, low-overhead transitions between the embedder and
wasm, and scalability of concurrent instances.
* **[Secure]**. Wasmtime's development is strongly focused on the correctness of
its implementation with 24/7 fuzzing donated by [Google's OSS Fuzz],
leveraging Rust's API and runtime safety guarantees, careful design of
features and APIs through an [RFC process], a [security policy] in place
for when things go wrong, and a [release policy] for patching older versions
as well. We follow best practices for defense-in-depth and known
protections and mitigations for issues like Spectre. Finally, we're working
to push the state-of-the-art by collaborating with academic
researchers to formally verify critical parts of Wasmtime and Cranelift.
* **[Configurable]**. Wastime supports a rich set of APIs and build time
configuration to provide many options such as further means of restricting
WebAssembly beyond its basic guarantees such as its CPU and Memory
consumption. Wasmtime also runs in tiny environments all the way up to massive
servers with many concurrent instances.
* **[WASI]**. Wasmtime supports a rich set of APIs for interacting with the host
environment through the [WASI standard](https://wasi.dev).
* **[Standards Compliant]**. Wasmtime passes the [official WebAssembly test
suite](https://github.com/WebAssembly/testsuite), implements the [official C
API of wasm](https://github.com/WebAssembly/wasm-c-api), and implements
[future proposals to WebAssembly](https://github.com/WebAssembly/proposals) as
well. Wasmtime developers are intimately engaged with the WebAssembly
standards process all along the way too.
[Wasmtime]: https://github.com/bytecodealliance/wasmtime
[Cranelift]: https://github.com/bytecodealliance/wasmtime/blob/main/cranelift/README.md
[Google's OSS Fuzz]: https://google.github.io/oss-fuzz/
[security policy]: https://bytecodealliance.org/security
[RFC process]: https://github.com/bytecodealliance/rfcs
[release policy]: https://docs.wasmtime.dev/stability-release.html
[Secure]: https://docs.wasmtime.dev/security.html
[Configurable]: https://docs.rs/wasmtime/latest/wasmtime/struct.Config.html
[WASI]: https://docs.rs/wasmtime-wasi/latest/wasmtime_wasi/
[Standards Compliant]: https://docs.wasmtime.dev/stability-wasm-proposals-support.html
## Example
An example of using the Wasmtime embedding API for running a small WebAssembly
module might look like:
```rust
use anyhow::Result;
use wasmtime::*;
fn main() -> Result<()> {
// Modules can be compiled through either the text or binary format
let engine = Engine::default();
let wat = r#"
(module
(import "host" "host_func" (func $host_hello (param i32)))
(func (export "hello")
i32.const 3
call $host_hello)
)
"#;
let module = Module::new(&engine, wat)?;
// Create a `Linker` which will be later used to instantiate this module.
// Host functionality is defined by name within the `Linker`.
let mut linker = Linker::new(&engine);
linker.func_wrap("host", "host_func", |caller: Caller<'_, u32>, param: i32| {
println!("Got {} from WebAssembly", param);
println!("my host state is: {}", caller.data());
})?;
// All wasm objects operate within the context of a "store". Each
// `Store` has a type parameter to store host-specific data, which in
// this case we're using `4` for.
let mut store = Store::new(&engine, 4);
let instance = linker.instantiate(&mut store, &module)?;
let hello = instance.get_typed_func::<(), ()>(&mut store, "hello")?;
// And finally we can call the wasm!
hello.call(&mut store, ())?;
Ok(())
}
```
More examples and information can be found in the `wasmtime` crate's [online
documentation](https://docs.rs/wasmtime) as well.
## Documentation
[📚 Read the Wasmtime guide here! 📚][guide]
The [wasmtime guide][guide] is the best starting point to learn about what
Wasmtime can do for you or help answer your questions about Wasmtime. If you're
curious in contributing to Wasmtime, [it can also help you do
that][contributing]!
[contributing]: https://bytecodealliance.github.io/wasmtime/contributing.html
[guide]: https://bytecodealliance.github.io/wasmtime
This is an umbrella crate which contains no code of its own, but pulls in
other cranelift library crates to provide a convenient one-line dependency,
and a prelude, for common use cases.
This crate contains a library that enables
[Cranelift](https://crates.io/crates/cranelift)
to emit native object (".o") files, using the
[object](https://crates.io/crates/object) library.
# AssemblyScript Hello World (WASI)
This example implements the typical "Hello, World!" application in AssemblyScript, utilizing WASI.
## Setup
Navigate to `./docs/assemblyscript-hello-world` and run
```
npm install
```
Build the AssemblyScript example
```
npm run build
```
Run the example
```
npm run start
```
This crate library supports reading .clif files. This functionality is needed
for testing [Cranelift](https://crates.io/crates/cranelift), but is not essential
for a JIT compiler.
This crate contains array-based data structures used by the core Cranelift code
generator which represent a set of small ordered sets or maps.
**These are not general purpose data structures that are somehow magically faster that the
standard library's `BTreeSet` and `BTreeMap` types.**
The tradeoffs are different:
- Keys and values are expected to be small and copyable. We optimize for 32-bit types.
- A comparator object is used to compare keys, allowing smaller "context free" keys.
- Empty trees have a very small 32-bit footprint.
- All the trees in a forest can be cleared in constant time.
This directory contains the necessary parts for building a library with FFI
access to the Wasm spec interpreter. Its major parts:
- `spec`: the Wasm spec code as a Git submodule (you may need to retrieve it:
`git clone -b wasmtime_fuzzing https://github.com/conrad-watt/spec`).
- `interpret.ml`: a shim layer for calling the Wasm spec code and exposing it
for FFI access
- `Makefile`: the steps for gluing these pieces together into a static library
Note: the `Makefile` must be configured with the path to `libgmp.a`; see
`LIBGMP_PATHS` in the `Makefile` (Ubuntu: `libgmp-dev`, Fedora: `gmp-static`).
# Wasmtime's C API
For more information you can find the documentation for this library
[online](https://bytecodealliance.github.io/wasmtime/c-api/).
## Using in a C Project
To use Wasmtime from a C or C++ project, you can use Cargo to build the Wasmtime C bindings. From the root of the Wasmtime repository, run the following command:
```
cargo build --release wasmtime-c-api
```
This will create static and dynamic libraries called `libwasmtime` in the `target/release` directory.
## Using in a Rust Project
If you have a Rust crate that contains bindings to a C or C++ library that uses Wasmtime, you can link the Wasmtime C API using Cargo.
1. Add a dependency on the `wasmtime-c-api-impl` crate to your `Cargo.toml`. Note that package name differs from the library name.
```toml
[dependencies]
wasmtime-c-api = { version = "16.0.0", package = "wasmtime-c-api-impl" }
```
2. In your `build.rs` file, when compiling your C/C++ source code, add the C `wasmtime-c-api` headers to the include path:
```rust
fn main() {
let mut cfg = cc::Build::new();
// Add to the include path the wasmtime headers and the standard
// Wasm C API headers.
cfg
.include(std::env::var("DEP_WASMTIME_C_API_INCLUDE").unwrap());
.include(std::env::var("DEP_WASMTIME_C_API_WASM_INCLUDE").unwrap());
// Compile your C code.
cfg
.file("src/your_c_code.c")
.compile("your_library");
}
```
This example project demonstrates using the `wasi-nn` API to perform ML inference. It consists of Rust code that is
built using the `wasm32-wasi` target. See `ci/run-wasi-nn-example.sh` for how this is used.
# ISLE: Instruction Selection/Lowering Expressions DSL
See also: [Language Reference](./docs/language-reference.md)
## Table of Contents
* [Introduction](#introduction)
* [Example Usage](#example-usage)
* [Tutorial](#tutorial)
* [Implementation](#implementation)
## Introduction
ISLE is a DSL that allows one to write instruction-lowering rules for a
compiler backend. It is based on a "term-rewriting" paradigm in which the input
-- some sort of compiler IR -- is, conceptually, a tree of terms, and we have a
set of rewrite rules that turn this into another tree of terms.
This repository contains a prototype meta-compiler that compiles ISLE rules
down to an instruction selector implementation in generated Rust code. The
generated code operates efficiently in a single pass over the input, and merges
all rules into a decision tree, sharing work where possible, while respecting
user-configurable priorities on each rule.
The ISLE language is designed so that the rules can both be compiled into an
efficient compiler backend and can be used in formal reasoning about the
compiler. The compiler in this repository implements the former. The latter
use-case is future work and outside the scope of this prototype, but at a high
level, the rules can be seen as simple equivalences between values in two
languages, and so should be translatable to formal constraints or other logical
specification languages.
Some more details and motivation are in [BA RFC #15](https://github.com/bytecodealliance/rfcs/pull/15).
Reference documentation can be found [here](docs/language-reference.md).
Details on ISLE's integration into Cranelift can be found
[here](../docs/isle-integration.md).
## Example Usage
Build `islec`, the ISLE compiler:
```shell
$ cargo build --release
```
Compile a `.isle` source file into Rust code:
```shell
$ target/release/islec -i isle_examples/test.isle -o isle_examples/test.rs
```
Include that Rust code in your crate and compile it:
```shell
$ rustc isle_examples/test_main.rs
```
## Tutorial
This tutorial walks through defining an instruction selection and lowering pass
for a simple, RISC-y, high-level IR down to low-level, CISC-y machine
instructions. It is intentionally somewhat similar to CLIF to MachInst lowering,
although it restricts the input and output languages to only adds, loads, and
constants so that we can focus on ISLE itself.
> The full ISLE source code for this tutorial is available at
> `isle_examples/tutorial.isle`.
The ISLE language is based around rules for translating a term (i.e. expression)
into another term. Terms are typed, so before we can write rules for translating
some type of term into another type of term, we have to define those types:
```lisp
;; Declare that we are using the `i32` primitive type from Rust.
(type i32 (primitive i32))
;; Our high-level, RISC-y input IR.
(type HighLevelInst
(enum (Add (a Value) (b Value))
(Load (addr Value))
(Const (c i32))))
;; A value in our high-level IR is a Rust `Copy` type. Values are either defined
;; by an instruction, or are a basic block argument.
(type Value (primitive Value))
;; Our low-level, CISC-y machine instructions.
(type LowLevelInst
(enum (Add (mode AddrMode))
(Load (offset i32) (addr Reg))
(Const (c i32))))
;; Different kinds of addressing modes for operands to our low-level machine
;; instructions.
(type AddrMode
(enum
;; Both operands in registers.
(RegReg (a Reg) (b Reg))
;; The destination/first operand is a register; the second operand is in
;; memory at `[b + offset]`.
(RegMem (a Reg) (b Reg) (offset i32))
;; The destination/first operand is a register, second operand is an
;; immediate.
(RegImm (a Reg) (imm i32))))
;; The register type is a Rust `Copy` type.
(type Reg (primitive Reg))
```
Now we can start writing some basic lowering rules! We declare the top-level
lowering function (a "constructor term" in ISLE terminology) and attach rules to
it. The simplest case is matching a high-level `Const` instruction and lowering
that to a low-level `Const` instruction, since there isn't any translation we
really have to do.
```lisp
;; Declare our top-level lowering function. We will attach rules to this
;; declaration for lowering various patterns of `HighLevelInst` inputs.
(decl lower (HighLevelInst) LowLevelInst)
;; Simple rule for lowering constants.
(rule (lower (HighLevelInst.Const c))
(LowLevelInst.Const c))
```
Each rule has the form `(rule <left-hand side> <right-hand-side>)`. The
left-hand side (LHS) is a *pattern* and the right-hand side (RHS) is an
*expression*. When the LHS pattern matches the input, then we evaluate the RHS
expression. The LHS pattern can bind variables from the input that are then
available in the right-hand side. For example, in our `Const`-lowering rule, the
variable `c` is bound from the LHS and then reused in the RHS.
Now we can compile this code by running
```shell
$ islec isle_examples/tutorial.isle
```
and we'll get the following output <sup>(ignoring any minor code generation
changes in the future)</sup>:
```rust
// GENERATED BY ISLE. DO NOT EDIT!
//
// Generated automatically from the instruction-selection DSL code in:
// - isle_examples/tutorial.isle
// [Type and `Context` definitions removed for brevity...]
// Generated as internal constructor for term lower.
pub fn constructor_lower<C: Context>(ctx: &mut C, arg0: &HighLevelInst) -> Option<LowLevelInst> {
let pattern0_0 = arg0;
if let &HighLevelInst::Const { c: pattern1_0 } = pattern0_0 {
// Rule at isle_examples/tutorial.isle line 45.
let expr0_0 = LowLevelInst::Const {
c: pattern1_0,
};
return Some(expr0_0);
}
return None;
}
```
There are a few things to notice about this generated Rust code:
* The `lower` constructor term becomes the `constructor_lower` function in the
generated code.
* The function returns a value of type `Option<LowLevelInst>` and returns `None`
when it doesn't know how to lower an input `HighLevelInst`. This is useful for
incrementally porting hand-written lowering code to ISLE.
* There is a helpful comment documenting where in the ISLE source code a rule
was defined. The goal is to make ISLE more transparent and less magical.
* The code is parameterized by a type that implements a `Context`
trait. Implementing this trait is how you glue the generated code into your
compiler. Right now this is an empty trait; more on `Context` later.
* Lastly, and most importantly, this generated Rust code is basically what we
would have written by hand to do the same thing, other than things like
variable names. It checks if the input is a `Const`, and if so, translates it
into a `LowLevelInst::Const`.
Okay, one rule isn't very impressive, but in order to start writing more rules
we need to be able to put the result of a lowered instruction into a `Reg`. This
might internally have to do arbitrary things like update use counts or anything
else that Cranelift's existing `LowerCtx::put_input_in_reg` does for different
target architectures. To allow for plugging in this kind of arbitrary logic,
ISLE supports *external constructors*. These end up as methods of the `Context`
trait in the generated Rust code, and you can implement them however you want
with custom Rust code.
Here is how we declare an external helper to put a value into a register:
```lisp
;; Declare an external constructor that puts a high-level `Value` into a
;; low-level `Reg`.
(decl put_in_reg (Value) Reg)
(extern constructor put_in_reg put_in_reg)
```
If we rerun `islec` on our ISLE source, instead of an empty `Context` trait, now
we will get this trait definition:
```rust
pub trait Context {
fn put_in_reg(&mut self, arg0: Value) -> (Reg,);
}
```
With the `put_in_reg` helper available, we can define rules for lowering loads
and adds:
```lisp
;; Simple rule for lowering adds.
(rule (lower (HighLevelInst.Add a b))
(LowLevelInst.Add
(AddrMode.RegReg (put_in_reg a) (put_in_reg b))))
;; Simple rule for lowering loads.
(rule (lower (HighLevelInst.Load addr))
(LowLevelInst.Load 0 (put_in_reg addr)))
```
If we compile our ISLE source into Rust code once again, the generated code for
`lower` now looks like this:
```rust
// Generated as internal constructor for term lower.
pub fn constructor_lower<C: Context>(ctx: &mut C, arg0: &HighLevelInst) -> Option<LowLevelInst> {
let pattern0_0 = arg0;
match pattern0_0 {
&HighLevelInst::Const { c: pattern1_0 } => {
// Rule at isle_examples/tutorial.isle line 45.
let expr0_0 = LowLevelInst::Const {
c: pattern1_0,
};
return Some(expr0_0);
}
&HighLevelInst::Load { addr: pattern1_0 } => {
// Rule at isle_examples/tutorial.isle line 59.
let expr0_0: i32 = 0;
let expr1_0 = C::put_in_reg(ctx, pattern1_0);
let expr2_0 = LowLevelInst::Load {
offset: expr0_0,
addr: expr1_0,
};
return Some(expr2_0);
}
&HighLevelInst::Add { a: pattern1_0, b: pattern1_1 } => {
// Rule at isle_examples/tutorial.isle line 54.
let expr0_0 = C::put_in_reg(ctx, pattern1_0);
let expr1_0 = C::put_in_reg(ctx, pattern1_1);
let expr2_0 = AddrMode::RegReg {
a: expr0_0,
b: expr1_0,
};
let expr3_0 = LowLevelInst::Add {
mode: expr2_0,
};
return Some(expr3_0);
}
_ => {}
}
return None;
}
```
As you can see, each of our rules was collapsed into a single, efficient `match`
expression. Just like we would have otherwise written by hand. And wherever we
need to get a high-level operand as a low-level register, there is a call to the
`Context::put_in_reg` trait method, allowing us to hook whatever arbitrary logic
we need to when putting a value into a register when we implement the `Context`
trait.
Things start to get more interesting when we want to do things like sink a load
into the add's addressing mode. This is only desirable when our add is the only
use of the loaded value. Furthermore, it is only valid to do when there isn't
any store that might write to the same address we are loading from in between
the load and the add. Otherwise, moving the load across the store could result
in a miscompilation where we load the wrong value to add:
```text
x = load addr
store 42 -> addr
y = add x, 1
==/==>
store 42 -> addr
x = load addr
y = add x, 1
```
We can encode these kinds of preconditions in an *external extractor*. An
extractor is like our regular constructor functions, but it is used inside LHS
patterns, rather than RHS expressions, and its arguments and results flipped
around: instead of taking arguments and producing results, it takes a result and
(fallibly) produces the arguments. This allows us to write custom preconditions
for matching code.
Let's make this more clear with a concrete example. Here is the declaration of
an external extractor to match on the high-level instruction that defined a
given operand `Value`, along with a new rule to sink loads into adds:
```lisp
;; Declare an external extractor for extracting the instruction that defined a
;; given operand value.
(decl inst_result (HighLevelInst) Value)
(extern extractor inst_result inst_result)
;; Rule to sink loads into adds.
(rule (lower (HighLevelInst.Add a (inst_result (HighLevelInst.Load addr))))
(LowLevelInst.Add
(AddrMode.RegMem (put_in_reg a)
(put_in_reg addr)
0)))
```
Note that the operand `Value` passed into this extractor might be a basic block
parameter, in which case there is no such instruction. Or there might be a store
or function call instruction in between the current instruction and the
instruction that defines the given operand value, in which case we want to
"hide" the instruction so that we don't illegally sink loads into adds they
shouldn't be sunk into. So this extractor might fail to return an instruction
for a given operand `Value`.
If we recompile our ISLE source into Rust code once again, we see a new
`inst_result` method defined on our `Context` trait, we notice that its
arguments and returns are flipped around from the `decl` in the ISLE source
because it is an extractor, and finally that it returns an `Option` because it
isn't guaranteed that we can extract a defining instruction for the given
operand `Value`:
```rust
pub trait Context {
fn put_in_reg(&mut self, arg0: Value) -> (Reg,);
fn inst_result(&mut self, arg0: Value) -> Option<(HighLevelInst,)>;
}
```
And if we look at the generated code for our `lower` function, there is a new,
nested case for sinking loads into adds that uses the `Context::inst_result`
trait method to see if our new rule can be applied:
```rust
// Generated as internal constructor for term lower.
pub fn constructor_lower<C: Context>(ctx: &mut C, arg0: &HighLevelInst) -> Option<LowLevelInst> {
let pattern0_0 = arg0;
match pattern0_0 {
&HighLevelInst::Const { c: pattern1_0 } => {
// [...]
}
&HighLevelInst::Load { addr: pattern1_0 } => {
// [...]
}
&HighLevelInst::Add { a: pattern1_0, b: pattern1_1 } => {
if let Some((pattern2_0,)) = C::inst_result(ctx, pattern1_1) {
if let &HighLevelInst::Load { addr: pattern3_0 } = &pattern2_0 {
// Rule at isle_examples/tutorial.isle line 68.
let expr0_0 = C::put_in_reg(ctx, pattern1_0);
let expr1_0 = C::put_in_reg(ctx, pattern3_0);
let expr2_0: i32 = 0;
let expr3_0 = AddrMode::RegMem {
a: expr0_0,
b: expr1_0,
offset: expr2_0,
};
let expr4_0 = LowLevelInst::Add {
mode: expr3_0,
};
return Some(expr4_0);
}
}
// Rule at isle_examples/tutorial.isle line 54.
let expr0_0 = C::put_in_reg(ctx, pattern1_0);
let expr1_0 = C::put_in_reg(ctx, pattern1_1);
let expr2_0 = AddrMode::RegReg {
a: expr0_0,
b: expr1_0,
};
let expr3_0 = LowLevelInst::Add {
mode: expr2_0,
};
return Some(expr3_0);
}
_ => {}
}
return None;
}
```
Once again, this is pretty much the code you would have otherwise written by
hand to sink the load into the add.
At this point we can start defining a whole bunch of even-more-complicated
lowering rules that do things like take advantage of folding static offsets into
loads into adds:
```lisp
;; Rule to sink a load of a base address with a static offset into a single add.
(rule (lower (HighLevelInst.Add
a
(inst_result (HighLevelInst.Load
(inst_result (HighLevelInst.Add
base
(inst_result (HighLevelInst.Const offset))))))))
(LowLevelInst.Add
(AddrMode.RegMem (put_in_reg a)
(put_in_reg base)
offset)))
;; Rule for sinking an immediate into an add.
(rule (lower (HighLevelInst.Add a (inst_result (HighLevelInst.Const c))))
(LowLevelInst.Add
(AddrMode.RegImm (put_in_reg a) c)))
;; Rule for lowering loads of a base address with a static offset.
(rule (lower (HighLevelInst.Load
(inst_result (HighLevelInst.Add
base
(inst_result (HighLevelInst.Const offset))))))
(LowLevelInst.Load offset (put_in_reg base)))
```
I'm not going to show the generated Rust code for these new rules here because
it is starting to get a bit too big. But you can compile
`isle_examples/tutorial.isle` and verify yourself that it generates the code you
expect it to.
In conclusion, adding new lowering rules is easy with ISLE. And you still get
that efficient, compact tree of `match` expressions in the generated Rust code
that you would otherwise write by hand.
## Implementation
This is an overview of `islec`'s passes and data structures:
```text
+------------------+
| ISLE Source Text |
+------------------+
|
| Lex
V
+--------+
| Tokens |
+--------+
|
| Parse
V
+----------------------+
| Abstract Syntax Tree |
+----------------------+
|
| Semantic Analysis
V
+----------------------------+
| Term and Type Environments |
+----------------------------+
|
| Trie Construction
V
+-----------+
| Term Trie |
+-----------+
|
| Code Generation
V
+------------------+
| Rust Source Code |
+------------------+
```
### Lexing
Lexing breaks up the input ISLE source text into a stream of tokens. Our lexer
is pull-based, meaning that we don't eagerly construct the full stream of
tokens. Instead, we wait until the next token is requested, at which point we
lazily lex it.
Relevant source files:
* `isle/src/lexer.rs`
### Parsing
Parsing translates the stream of tokens into an abstract syntax tree (AST). Our
parser is a simple, hand-written, recursive-descent parser.
Relevant source files:
* `isle/src/ast.rs`
* `isle/src/parser.rs`
### Semantic Analysis
Semantic analysis performs type checking, figures out which rules apply to which
terms, etc. It creates a type environment and a term environment that we can use
to get information about our terms throughout the rest of the pipeline.
Relevant source files:
* `isle/src/sema.rs`
### Trie Construction
The trie construction phase linearizes each rule's LHS pattern and inserts them
into a trie that maps LHS patterns to RHS expressions. This trie is the skeleton
of the decision tree that will be emitted during code generation.
Relevant source files:
* `isle/src/ir.rs`
* `isle/src/trie.rs`
### Code Generation
Code generation takes in the term trie and emits Rust source code that
implements it.
Relevant source files:
* `isle/src/codegen.rs`
<div align="center">
<h1><code>wasi-common</code></h1>
<strong>A <a href="https://bytecodealliance.org/">Bytecode Alliance</a> project</strong>
<p>
<strong>A library providing a common implementation of WASI hostcalls for re-use in any WASI-enabled runtime.</strong>
</p>
<p>
<a href="https://crates.io/crates/wasi-common"><img src="https://img.shields.io/crates/v/wasi-common.svg?style=flat-square" alt="Crates.io version" /></a>
<a href="https://crates.io/crates/wasi-common"><img src="https://img.shields.io/crates/d/wasi-common.svg?style=flat-square" alt="Download" /></a>
<a href="https://docs.rs/wasi-common/"><img src="https://img.shields.io/badge/docs-latest-blue.svg?style=flat-square" alt="docs.rs docs" /></a>
</p>
</div>
The `wasi-common` crate will ultimately serve as a library providing a common implementation of
WASI hostcalls for re-use in any WASI (and potentially non-WASI) runtimes
such as [Wasmtime] and [Lucet].
The library is an adaption of [lucet-wasi] crate from the [Lucet] project, and it is
currently based on [40ae1df][lucet-wasi-tracker] git revision.
Please note that the library requires Rust compiler version at least 1.37.0.
[Wasmtime]: https://github.com/bytecodealliance/wasmtime
[Lucet]: https://github.com/fastly/lucet
[lucet-wasi]: https://github.com/fastly/lucet/tree/master/lucet-wasi
[lucet-wasi-tracker]: https://github.com/fastly/lucet/commit/40ae1df64536250a2b6ab67e7f167d22f4aa7f94
## Supported syscalls
### *nix
In our *nix implementation, we currently support the entire [WASI API]
with the exception of the `proc_raise` hostcall, as it is expected to
be dropped entirely from WASI.
[WASI API]: https://github.com/WebAssembly/WASI/blob/master/phases/snapshot/docs.md
### Windows
In our Windows implementation, we currently support the minimal subset of [WASI API]
which allows for running the very basic "Hello world!" style WASM apps. More coming shortly,
so stay tuned!
## Development hints
When testing the crate, you may want to enable and run full wasm32 integration testsuite. This
requires `wasm32-wasi` target installed which can be done as follows using [rustup]
```
rustup target add wasm32-wasi
```
[rustup]: https://rustup.rs
Now, you should be able to run the integration testsuite by running `cargo test` on the
`test-programs` package with `test-programs/test_programs` feature enabled:
```
cargo test --features test-programs/test_programs --package test-programs
```
wasm-spec-interpreter
=====================
This project shows how to use `ocaml-interop` to call into the Wasm spec
interpreter. There are several steps to making this work:
- building the OCaml Wasm spec interpreter as a static library
- building a Rust-to-OCaml FFI bridge using `ocaml-interop` and a custom OCaml
wrapper
- linking both things into a Rust crate
### Dependencies
This crate only builds in an environment with:
- `make` (the Wasm spec interpreter uses a `Makefile`)
- `ocamlopt`, `ocamlbuild` (available with, e.g., `dnf install ocaml`)
- Linux tools (e.g. `ar`); currently it is easiest to build the static
libraries in a single environment but this could be fixed in the future (TODO)
- `libgmp`, for the OCaml `zarith` package
- `git` is used by `build.rs` to retrieve the repository containing the Wasm
spec interpreter; it is safe to completely remove `ocaml/spec` to get a new
copy
### Build
```
cargo build --features build-libinterpret
```
Use `FFI_LIB_DIR=path/to/lib/...` to specify a different location for the static
library (this is mainly for debugging). If the `build-libinterpret` feature is
not provided, this crate will build successfully but fail at runtime.
### Test
```
cargo test --features build-libinterpret
```
This crate contains the core Cranelift code generator. It translates code from an
intermediate representation into executable machine code.
# Rules for Writing Optimization Rules
For both correctness and compile speed, we must be careful with our rules. A lot
of it boils down to the fact that, unlike traditional e-graphs, our rules are
*directional*.
1. Rules should not rewrite to worse code: the right-hand side should be at
least as good as the left-hand side or better.
For example, the rule
x => (add x 0)
is disallowed, but swapping its left- and right-hand sides produces a rule
that is allowed.
Any kind of canonicalizing rule that intends to help subsequent rules match
and unlock further optimizations (e.g. floating constants to the right side
for our constant-propagation rules to match) must produce canonicalized
output that is no worse than its noncanonical input.
We assume this invariant as a heuristic to break ties between two
otherwise-equal-cost expressions in various places, making up for some
limitations of our explicit cost function.
2. Any rule that removes value-uses in its right-hand side that previously
existed in its left-hand side MUST use `subsume`.
For example, the rule
(select 1 x y) => x
MUST use `subsume`.
This is required for correctness because, once a value-use is removed, some
e-nodes in the e-class are more equal than others. There might be uses of `x`
in a scope where `y` is not available, and so emitting `(select 1 x y)` in
place of `x` in such cases would introduce uses of `y` where it is not
defined.
An exception to this rule is discarding constants, as they can be
rematerialized anywhere without introducing correctness issues. For example,
the (admittedly silly) rule `(select 1 x (iconst_u _)) => x` would be a good
candidate for not using `subsume`, as it does not discard any non-constant
values introduced in its LHS.
3. Avoid overly general rewrites like commutativity and associativity. Instead,
prefer targeted instances of the rewrite (for example, canonicalizing adds
where one operand is a constant such that the constant is always the add's
second operand, rather than general commutativity for adds) or even writing
the "same" optimization rule multiple times.
For example, the commutativity in the first rule in the following snippet is
bad because it will match even when the first operand is not an add:
;; Commute to allow `(foo (add ...) x)`, when we see it, to match.
(foo x y) => (foo y x)
;; Optimize.
(foo x (add ...)) => (bar x)
Better is to commute only when we know that canonicalizing in this way will
all definitely allow the subsequent optimization rule to match:
;; Canonicalize all adds to `foo`'s second operand.
(foo (add ...) x) => (foo x (add ...))
;; Optimize.
(foo x (add ...)) => (bar x)
But even better in this case is to write the "same" optimization multiple
times:
(foo (add ...) x) => (bar x)
(foo x (add ...)) => (bar x)
The cost of rule-matching is amortized by the ISLE compiler, where as the
intermediate result of each rewrite allocates new e-nodes and requires
storage in the dataflow graph. Therefore, additional rules are cheaper than
additional e-nodes.
Commutativity and associativity in particular can cause huge amounts of
e-graph bloat.
One day we intend to extend ISLE with built-in support for commutativity, so
we don't need to author the redundant commutations ourselves:
https://github.com/bytecodealliance/wasmtime/issues/6128
# Fuzzing Infrastructure for Wasmtime
This crate provides test case generators and oracles for use with fuzzing.
These generators and oracles are generally independent of the fuzzing engine
that might be using them and driving the whole fuzzing process (e.g. libFuzzer
or AFL). As such, this crate does *not* contain any actual fuzz targets
itself. Those are generally just a couple lines of glue code that plug raw input
from (for example) `libFuzzer` into a generator, and then run one or more
oracles on the generated test case.
If you're looking for the actual fuzz target definitions we currently have, they
live in `wasmtime/fuzz/fuzz_targets/*` and are driven by `cargo fuzz` and
`libFuzzer`.
This crate performs autodetection of the host architecture, which can be used to
configure [Cranelift](https://crates.io/crates/cranelift) to generate code
specialized for the machine it's running on.
# Wasmtime's Configuration of `cargo vet`
This directory contains the state for [`cargo vet`], a tool to help projects
ensure that third-party Rust dependencies have been audited by a trusted entity.
For more information about Wasmtime's usage of `cargo vet` see our
[documentation](https://docs.wasmtime.dev/contributing-coding-guidelines.html#dependencies-of-wasmtime).
[`cargo vet`]: https://mozilla.github.io/cargo-vet/
# `wasi_snapshot_preview1.wasm`
> **Note**: This repository is a work in progress. This is intended to be an
> internal tool which not everyone has to look at but many might rely on. You
> may need to reach out via issues or
> [Zulip](https://bytecodealliance.zulipchat.com/) to learn more about this
> repository.
This repository currently contains an implementation of a WebAssembly module:
`wasi_snapshot_preview1.wasm`. This module bridges the `wasi_snapshot_preview1`
ABI to the preview2 ABI of the component model. At this time the preview2 APIs
themselves are not done being specified so a local copy of `wit/*.wit` is used
instead.
## Building
This adapter can be built with:
```sh
$ cargo build -p wasi-preview1-component-adapter --target wasm32-unknown-unknown --release
```
And the artifact will be located at
`target/wasm32-unknown-unknown/release/wasi_snapshot_preview1.wasm`.
This by default builds a "reactor" adapter which means that it only provides
adaptation from preview1 to preview2. Alternatively you can also build a
"command" adapter by passing `--features command --no-default-features` which
will additionally export a `run` function entrypoint. This is suitable for use
with preview1 binaries that export a `_start` function.
Alternatively the latest copy of the command and reactor adapters can be
[downloaded from the `dev` tag assets][dev-tag]
[dev-tag]: https://github.com/bytecodealliance/wasmtime/releases/tag/dev
## Using
With a `wasi_snapshot_preview1.wasm` file on-hand you can create a component
from a module that imports WASI functions using the [`wasm-tools`
CLI](https://github.com/bytecodealliance/wasm-tools)
```sh
$ cat foo.rs
fn main() {
println!("Hello, world!");
}
$ rustc foo.rs --target wasm32-wasi
$ wasm-tools print foo.wasm | grep '(import'
(import "wasi_snapshot_preview1" "fd_write" (func ...
(import "wasi_snapshot_preview1" "environ_get" (func ...
(import "wasi_snapshot_preview1" "environ_sizes_get" ...
(import "wasi_snapshot_preview1" "proc_exit" (func ...
$ wasm-tools component new foo.wasm --adapt wasi_snapshot_preview1.wasm -o component.wasm
# Inspect the generated `component.wasm`
$ wasm-tools validate component.wasm --features component-model
$ wasm-tools component wit component.wasm
```
Here the `component.wasm` that's generated is a ready-to-run component which
imports wasi preview2 functions and is compatible with the wasi-preview1-using
module internally.
# filetests
Filetests is a crate that contains multiple test suites for testing
various parts of cranelift. Each folder under `cranelift/filetests/filetests` is a different
test suite that tests different parts.
## Adding a runtest
One of the available testsuites is the "runtest" testsuite. Its goal is to compile some piece
of clif code, run it and ensure that what comes out is what we expect.
To build a run test you can add the following to a file:
```
test interpret
test run
target x86_64
target aarch64
target s390x
function %band_f32(f32, f32) -> f32 {
block0(v0: f32, v1: f32):
v2 = band v0, v1
return v2
}
; run: %band_f32(0x0.5, 0x1.0) == 0x1.5
```
Since this is a run test for `band` we can put it in: `runtests/band.clif`.
Once we have the file in the test suite we can run it by invoking: `cargo run -- test filetests/filetests/runtests/band.clif` from the cranelift directory.
The first lines tell `clif-util` what kind of tests we want to run on this file.
`test interpret` invokes the interpreter and checks if the conditions in the `; run` comments pass. `test run` does the same, but compiles the file and runs it as a native binary.
For more information about testing see [testing.md](../docs/testing.md).
This crate provides a straightforward way to create a
[Cranelift](https://crates.io/crates/cranelift) IR function and fill it with
instructions translated from another language. It contains an SSA construction
module that provides convenient methods for translating non-SSA variables into
SSA Cranelift IR values via `use_var` and `def_var` calls.
This crate contains array-based data structures used by the core Cranelift code
generator which use densely numbered entity references as mapping keys.
One major difference between this crate and crates like [slotmap], [slab],
and [generational-arena] is that this crate currently provides no way to delete
entities. This limits its use to situations where deleting isn't important,
however this also makes it more efficient, because it doesn't need extra
bookkeeping state to reuse the storage for deleted objects, or to ensure that
new objects always have unique keys (eg. slotmap's and generational-arena's
versioning).
Another major difference is that this crate protects against using a key from
one map to access an element in another. Where `SlotMap`, `Slab`, and `Arena`
have a value type parameter, `PrimaryMap` has a key type parameter and a value
type parameter. The crate also provides the `entity_impl` macro which makes it
easy to declare new unique types for use as keys. Any attempt to use a key in
a map it's not intended for is diagnosed with a type error.
Another is that this crate has two core map types, `PrimaryMap` and
`SecondaryMap`, which serve complementary purposes. A `PrimaryMap` creates its
own keys when elements are inserted, while an `SecondaryMap` reuses the keys
values of a `PrimaryMap`, conceptually storing additional data in the same
index space. `SecondaryMap`'s values must implement `Default` and all elements
in an `SecondaryMap` initially have the value of `default()`.
A common way to implement `Default` is to wrap a type in `Option`, however
this crate also provides the `PackedOption` utility which can use less memory
in some cases.
Additional utilities provided by this crate include:
- `EntityList`, for allocating many small arrays (such as instruction operand
lists in a compiler code generator).
- `SparseMap`: an alternative to `SecondaryMap` which can use less memory
in some situations.
- `EntitySet`: a specialized form of `SecondaryMap` using a bitvector to
record which entities are members of the set.
[slotmap]: https://crates.io/crates/slotmap
[slab]: https://crates.io/crates/slab
[generational-arena]: https://crates.io/crates/generational-arena
This crate contains the control plane for "chaos mode". It can be used to
inject pseudo-random perturbations into specific sections in the code while
fuzzing. Its compilation is feature-gated to prevent any performance
impact on release builds.
See `ci/run-wasi-nn-example.sh` for how the classification example is tested during CI.
# zkASM Cranelift Backend
This is an experimental backend from Cranelift IR to [Polygon zkASM](https://wiki.polygon.technology/docs/zkevm/zkProver/the-processor/) virtual machine aimed to enable Zero-Knowledge proofs about execution of general programs.
## Index
- [Project Architecture](./architecture.md)
- [Project Roadmap](./roadmap.md)
# wiggle-generate
This is a library crate that implements all of the component parts of
the `wiggle` proc-macro crate.
Code lives in a separate non-proc-macro crate so that it can be reused in
other settings, e.g. the `lucet-wiggle` crate.
Code generated by this crate should not have any references to a particular
WebAssembly runtime or engine. It should instead expose traits that may be
implemented by an engine. Today, it is consumed by both Lucet and Wasmtime.
This crate performs the translation from a wasm module in binary format to the
in-memory form of the [Cranelift IR].
If you're looking for a complete WebAssembly implementation that uses this
library, see [Wasmtime].
[Wasmtime]: https://github.com/bytecodealliance/wasmtime
[Cranelift IR]: https://github.com/bytecodealliance/wasmtime/blob/main/cranelift/docs/ir.md
# install-rust
A small github action to install `rustup` and a Rust toolchain. This is
generally expressed inline, but it was repeated enough in this repository it
seemed worthwhile to extract.
Some gotchas:
* Can't `--self-update` on Windows due to permission errors (a bug in Github
Actions)
* `rustup` isn't installed on macOS (a bug in Github Actions)
When the above are fixed we should delete this action and just use this inline:
```yml
- run: rustup update $toolchain && rustup default $toolchain
shell: bash
```
# binary-compatible-builds
A small (ish) action which is intended to be used and will configure builds of
Rust projects to be "more binary compatible". On Windows and macOS this
involves setting a few env vars, and on Linux this involves spinning up a CentOS
6 container which is running in the background.
All subsequent build commands need to be wrapped in `$CENTOS` to optionally run
on `$CENTOS` on Linux to ensure builds happen inside the container.
# verify-component-adapter
The `wasi-preview1-component-adapter` crate must compile to a wasm binary that
meets a challenging set of constraints, in order to be used as an adapter by
the `wasm-tools component new` tool.
There are a limited set of wasm sections allowed in the binary, and a limited
set of wasm modules we allow imports from.
This crate is a bin target which parses a wasm file and reports an error if it
does not fit in those constraints.
# Examples of the `wasmtime` API
This directory contains a number of examples of using the `wasmtime` API from
different languages. Currently examples are all in Rust and C using the
`wasmtime` crate or the wasmtime embedding API.
Each example is available in both C and in Rust. Examples are accompanied with a
`*.wat` file which is the wasm input, or a Rust project in a `wasm` folder which
is the source code for the original wasm file.
Rust examples can be executed with `cargo run --example $name`. C examples can
be built with `mkdir build && cd build && cmake ..`. You can run
`cmake --build .` to build all examples or
`cmake --build . --target wasmtime-$name`, replacing the name as you wish. They
can also be [built manually](https://docs.wasmtime.dev/c-api/).
For more information see the examples themselves!
# About
Contains files used in tests.
# Updating files containing expected zkASM
Use the CLI, for instance:
```
# In the analyze-zkasm directory run
cargo run -- instrument-inst ./testfiles/simple.wat ./testfiles/simple_instrumented.zkasm
```
This crate contains shared definitions for use in both `cranelift-codegen-meta` and `cranelift
-codegen`.
# wasmtime-wasi-nn
This crate enables support for the [wasi-nn] API in Wasmtime. Currently it
contains an implementation of [wasi-nn] using OpenVINO™ but in the future it
could support multiple machine learning backends. Since the [wasi-nn] API is
expected to be an optional feature of WASI, this crate is currently separate
from the [wasi-common] crate. This crate is experimental and its API,
functionality, and location could quickly change.
[examples]: examples
[openvino]: https://crates.io/crates/openvino
[wasi-nn]: https://github.com/WebAssembly/wasi-nn
[wasi-common]: ../wasi-common
[bindings]: https://crates.io/crates/wasi-nn
### Use
Use the Wasmtime APIs to instantiate a Wasm module and link in the `wasi-nn`
implementation as follows:
```rust
let wasi_nn = WasiNnCtx::new()?;
wasmtime_wasi_nn::witx::add_to_linker(...);
```
### Build
```sh
$ cargo build
```
To use the WIT-based ABI, compile with `--features component-model` and use `wasmtime_wasi_nn::wit::add_to_linker`.
### Example
An end-to-end example demonstrating ML classification is included in [examples]:
`examples/classification-example` contains a standalone Rust project that uses
the [wasi-nn] APIs and is compiled to the `wasm32-wasi` target using the
high-level `wasi-nn` [bindings].
Crate defining the `Wasi` type for Wasmtime, which represents a WASI
instance which may be added to a linker.
This example project demonstrates using the `wasi-nn` API to perform ML inference. It consists of Rust code that is
built using the `wasm32-wasi` target. See `ci/run-wasi-nn-example.sh` for how this is used.
This crate provides a JIT library that uses
[Cranelift](https://crates.io/crates/cranelift).
This crate is extremely experimental.
See the [example program] for a brief overview of how to use this.
[example program]: https://github.com/bytecodealliance/wasmtime/blob/main/cranelift/jit/examples/jit-minimal.rs
This crate provides an interpreter for Cranelift IR. It is still a work in progress, as many
instructions are unimplemented and various implementation gaps exist. Use at your own risk.
# `cargo fuzz` Targets for Wasmtime
This crate defines various [libFuzzer](https://www.llvm.org/docs/LibFuzzer.html)
fuzzing targets for Wasmtime, which can be run via [`cargo
fuzz`](https://rust-fuzz.github.io/book/cargo-fuzz.html).
These fuzz targets just glue together pre-defined test case generators with
oracles and pass libFuzzer-provided inputs to them. The test case generators and
oracles themselves are independent from the fuzzing engine that is driving the
fuzzing process and are defined in `wasmtime/crates/fuzzing`.
## Example
To start fuzzing run the following command, where `$MY_FUZZ_TARGET` is one of
the [available fuzz targets](#available-fuzz-targets):
```shell
cargo fuzz run $MY_FUZZ_TARGET
```
## Available Fuzz Targets
At the time of writing, we have the following fuzz targets:
* `api_calls`: stress the Wasmtime API by executing sequences of API calls; only
the subset of the API is currently supported.
* `compile`: Attempt to compile libFuzzer's raw input bytes with Wasmtime.
* `compile-maybe-invalid`: Attempt to compile a wasm-smith-generated Wasm module
with code sequences that may be invalid.
* `cranelift-fuzzgen`: Generate a Cranelift function and check that it returns
the same results when compiled to the host and when using the Cranelift
interpreter; only a subset of Cranelift IR is currently supported.
* `cranelift-icache`: Generate a Cranelift function A, applies a small mutation
to its source, yielding a function A', and checks that A compiled +
incremental compilation generates the same machine code as if A' was compiled
from scratch.
* `differential`: Generate a Wasm module, evaluate each exported function
with random inputs, and check that Wasmtime returns the same results as a
choice of another engine: the Wasm spec interpreter (see the
`wasm-spec-interpreter` crate), the `wasmi` interpreter, V8 (through the `v8`
crate), or Wasmtime itself run with a different configuration.
* `instantiate`: Generate a Wasm module and Wasmtime configuration and attempt
to compile and instantiate with them.
* `instantiate-many`: Generate many Wasm modules and attempt to compile and
instantiate them concurrently.
* `spectests`: Pick a random spec test and run it with a generated
configuration.
* `table_ops`: Generate a sequence of `externref` table operations and run them
in a GC environment.
The canonical list of fuzz targets is the `.rs` files in the `fuzz_targets`
directory:
```shell
ls wasmtime/fuzz/fuzz_targets/
```
## Corpora
While you *can* start from scratch, libFuzzer will work better if it is given a
[corpus](https://www.llvm.org/docs/LibFuzzer.html#corpus) of seed inputs to kick
start the fuzzing process. We maintain a corpus for each of these fuzz targets
in [a dedicated repo on
github](https://github.com/bytecodealliance/wasmtime-libfuzzer-corpus).
You can use our corpora by cloning it and placing it at `wasmtime/fuzz/corpus`:
```shell
git clone \
https://github.com/bytecodealliance/wasmtime-libfuzzer-corpus.git \
wasmtime/fuzz/corpus
```
## Reproducing a Fuzz Bug
When investigating a fuzz bug (especially one found by OSS-Fuzz), use the
following steps to reproduce it locally:
1. Download the test case (either the "Minimized Testcase" or "Unminimized
Testcase" from OSS-Fuzz will do).
2. Run the test case in the correct fuzz target:
```shell
cargo +nightly fuzz run <target> <test case>
```
If all goes well, the bug should reproduce and libFuzzer will dump the
failure stack trace to stdout
3. For more debugging information, run the command above with `RUST_LOG=debug`
to print the configuration and WebAssembly input used by the test case (see
uses of `log_wasm` in the `wasmtime-fuzzing` crate).
## Target specific options
### `cranelift-fuzzgen`
Fuzzgen supports passing the `FUZZGEN_ALLOWED_OPS` environment variable, which when available restricts the instructions that it will generate.
Running `FUZZGEN_ALLOWED_OPS=ineg,ishl cargo fuzz run cranelift-fuzzgen` will run fuzzgen but only generate `ineg` or `ishl` opcodes.
### `cranelift-icache`
The icache target also uses the fuzzgen library, thus also supports the `FUZZGEN_ALLOWED_OPS` enviornment variable as described in the `cranelift-fuzzgen` section above.
This crate performs serialization of the [Cranelift](https://crates.io/crates/cranelift) IR.
This crate is structured as an optional ability to serialize and deserialize cranelift IR into JSON
format.
Status
------
Cranelift IR can be serialized into JSON.
Deserialize is a work in progress, as it currently deserializes into the serializable data structure
that can be utilized by serde instead of the actual Cranelift IR data structure.
Building and Using Cranelift Serde
----------------------------------
clif-json usage:
clif-json serialize [-p] <file>
clif-json deserialize <file>
Where the -p flag outputs Cranelift IR as pretty JSON.
For example to build and use clif-json:
``` {.sourceCode .sh}
cd cranelift-serde
cargo build
clif-json serialize -p test.clif
```
|
amiyatulu_avrit_uniswap | README.md
contract
Cargo.toml
build.js
src
lib.rs
package.json
public
index.html
manifest.json
robots.txt
src
App.css
App.js
App.test.js
index.css
index.js
logo.svg
reportWebVitals.js
setupTests.js
| # Uniswap Avrit
# Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `yarn start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in the browser.
The page will reload if you make edits.\
You will also see any lint errors in the console.
### `yarn test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `yarn build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `yarn eject`
**Note: this is a one-way operation. Once you `eject`, you can’t go back!**
If you aren’t satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you’re on your own.
You don’t have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn’t feel obligated to use this feature. However we understand that this tool wouldn’t be useful if you couldn’t customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `yarn build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
|
lemonDAO_artist-dao | README.md
craco.config.js
package-lock.json
package.json
public
index.html
manifest.json
robots.txt
src
App.css
App.test.js
index.css
index.js
logo.svg
reportWebVitals.js
services
index.js
setupTests.js
tailwind.config.js
| lemonDAO rethinks commissioned work. Artists visit lemonDAO to create a sub-DAO called an artistDAO. Everyone can join these artistDAOs and propose a task via a bounty. Artists can accept the task and create the requested artwork. Once done, the artist posts completed artwork and claims the bounty. The lemonDAO community acts as a governance body to help decide cases where the artist and artistDAO community disagree on the delivery.
In addition, the lemonDAO community acts as a curator community. artistDAOs issue curator tokens, which can be used to stake on the different artworks.
## lemonDAO Plattform
Preview: https://deploy-preview-5--lemondao.netlify.app/
This is still early alpha. You can create an artistDAO and propose. Posting the created artifacts and claiming the reward is not supported yet.
Learn more about lemonDAO in 28 seconds: https://www.youtube.com/watch?v=oW-kWW5JNQ0
## How to Contribute
Create an issue, add a feature or comment your ideas on our vision document https://docs.google.com/document/d/1puDxPpuj5XRRw4zgKVIwko9aIS7Aq-51VMhVgEZ4Gqg/edit?usp=sharing
# Getting Started with Development
```
npm start
# Runs the app in the development mode.
# Open http://localhost:3000 to view it in the browser.
# The page will reload if you make edits.
npm run build
# Builds the app for production to the `build` folder.
# It correctly bundles React in production mode
# and optimizes the build for the best performance.
```
|
Grants-Projects_distancia-contract | README.md
contract
Cargo.toml
src
distancia.rs
lib.rs
token.rs
| # Distancia Smart Contract
Smart Contract Implementation for Diatancia
|
legendaryangelist_near-zoo-memory-game | .env
README.md
package.json
public
browserconfig.xml
index.html
manifest.json
robots.txt
src
App.js
components
game-card
game-card.module.css
game-info
game-info.module.css
game-points
game-points.module.css
game-wins
game-wins.module.css
points-counter
points-counter.module.css
hooks
use-interval.js
use-theme.js
use-update-effect.js
index.js
pages
game-page
game-page.module.css
store
account.store.js
index.js
utils
config.js
date-time.js
game-rules.js
game.js
near.js
| # Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `npm start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in your browser.
The page will reload when you make changes.\
You may also see any lint errors in the console.
### `npm test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `npm run build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `npm run eject`
**Note: this is a one-way operation. Once you `eject`, you can't go back!**
If you aren't satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you're on your own.
You don't have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn't feel obligated to use this feature. However we understand that this tool wouldn't be useful if you couldn't customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `npm run build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
|
HongThaiPham_near-todos-crud-app | as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
index.spec.ts
as_types.d.ts
index.ts
tsconfig.json
index.html
package.json
tests
index.js
todos-crud-web
README.md
package-lock.json
package.json
public
index.html
manifest.json
robots.txt
src
App.css
App.js
App.test.js
config.js
index.css
index.js
logo.svg
reportWebVitals.js
setupTests.js
| # Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `npm start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in your browser.
The page will reload when you make changes.\
You may also see any lint errors in the console.
### `npm test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `npm run build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `npm run eject`
**Note: this is a one-way operation. Once you `eject`, you can't go back!**
If you aren't satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you're on your own.
You don't have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn't feel obligated to use this feature. However we understand that this tool wouldn't be useful if you couldn't customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `npm run build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
|
iraritchiemeek_learn_polygon | README.md
components
protocols
near
components
Steps
index.ts
context
index.ts
hooks
index.ts
lib
index.ts
types
index.ts
solana
utils.js
contracts
near
Cargo.toml
README.md
compile.js
src
lib.rs
polygon
SimpleStorage
README.md
build
contracts
Migrations.json
SimpleStorage.json
migrations
1_initial_migration.js
2_deploy_contracts.js
package-lock.json
package.json
truffle-config.js
solana
program
Cargo.toml
Xargo.toml
src
lib.rs
tests
lib.rs
hooks
steps-hooks.ts
lib
constants.ts
next-env.d.ts
next.config.js
package-lock.json
package.json
pages
api
avalanche
account.ts
connect.ts
query.ts
transfer.ts
near
balance.ts
callFunction.ts
callView.ts
checkAccountId.ts
connect.ts
createAccountId.ts
deploy.ts
transfer.ts
polkadot
account.ts
connect.ts
query.ts
polygon
query.ts
solana
balance.ts
connect.ts
fund.ts
public
figment-learn-compact.svg
vercel.svg
tsconfig.json
types
avalanche-types.ts
polkadot-types.ts
polygon-types.ts
solana-types.ts
types.ts
utils
avalanche-utils.ts
colors-utils.ts
datahub-utils.ts
polygon-utils.ts
| # Pathway Smart Contract
A [smart contract] written in [Rust] for [figment pathway]
# Quick Start
Before you compile this code, you will need to install Rust with [correct target]
# Exploring The Code
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[rust]: https://www.rust-lang.org/
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
Based on:
MetaCoin tutorial from Truffle docs https://www.trufflesuite.com/docs/truffle/quickstart
SimpleStorage example contract from Solidity docs https://docs.soliditylang.org/en/v0.4.24/introduction-to-smart-contracts.html#storage
1. Install truffle (https://www.trufflesuite.com/docs/truffle/getting-started/installation)
`npm install -g truffle`
2. Navigate to this directory (/contracts/polygon/SimpleStorage)
3. Install dependencies
`yarn`
4. Test contract
`truffle test ./test/TestSimpleStorage.sol`
**Possible issue:** "Something went wrong while attempting to connect to the network. Check your network configuration. Could not connect to your Ethereum client with the following parameters:"
**Solution:** run `truffle develop` and make sure port matches the one in truffle-config.js under development and test networks
5. Run locally via `truffle develop`
$ truffle develop
```
migrate
let instance = await SimpleStorage.deployed();
let storedDataBefore = await instance.get();
storedDataBefore.toNumber() // Should print 0
instance.set(50);
let storedDataAfter = await instance.get();
storedDataAfter.toNumber() // Should print 50
```
6. Create Polygon testnet account
* Install MetaMask (https://chrome.google.com/webstore/detail/metamask/nkbihfbeogaeaoehlefnkodbefgpgknn?hl=en)
* Add a custom network with the following params:
Network Name: "Polygon Mumbai"
RPC URL: https://rpc-mumbai.maticvigil.com/
Chain ID: 80001
Currency Symbol: MATIC
Block Explorer URL: https://mumbai.polygonscan.com
7. Fund your account from the Matic Faucet
https://faucet.matic.network
Select MATIC Token, Mumbai Network
Enter your account address from MetaMask
Wait until time limit is up, requests tokens 3-4 times so you have enough to deploy your contract
8. Add a `.secret` file in this directory with your account's seed phrase or mnemonic (you should be required to write this down or store it securely when creating your account in MetaMask). In `truffle-config.js`, uncomment the three constant declarations at the top, along with the matic section of the networks section of the configuration object.
9. Deploy contract
`truffle migrate --network matic`
8. Interact via web3.js
```js
const { ethers } = require('ethers')
const fs = require('fs');
const mnemonic = fs.readFileSync(".secret").toString().trim();
const signer = new ethers.Wallet.fromMnemonic(mnemonic)
const provider = new ethers.providers.JsonRpcProvider('https://matic-mumbai.chainstacklabs.com')
const json = JSON.parse(fs.readFileSync('build/contracts/SimpleStorage.json').toString())
const contract = new ethers.Contract(json.networks['80001'].address, json.abi, signer.connect(provider))
contract.get().then(val => console.log(val.toNumber()))
// should log 0
contract.set(50).then(receipt => console.log(receipt))
contract.get().then(val => console.log(val.toNumber()))
// should log 50
```
# Figment Learn - Solana Pathway
We made this app to help developers learn about Solana.
You will build a simple web client using Solana's JS SDK to interact with a Solana program (aka smart contract) that you will deploy using the Solana CLI.
Read the instructions on how to get setup over at [Figment Learn](https://learn.figment.io/network-documentation/solana/solana-pathway).
Learn more about [Figment](https://figment.io/)
<img width="1526" alt="Screen Shot 2021-06-29 at 11 35 16 PM" src="https://user-images.githubusercontent.com/206753/123898137-c6b0cd80-d932-11eb-9db7-4972b8d43df4.png">
<img width="1544" alt="Screen Shot 2021-07-02 at 12 32 50 PM" src="https://user-images.githubusercontent.com/206753/124304397-a0a54c00-db31-11eb-91bd-30df8b63d6b2.png">
|
marco-sundsk_near_laboratory | README.md
cross-contracts
AcallBcallC
Cargo.toml
README.md
build.sh
src
lib.rs
| Smart Contract
==================
init contracts
```shell
near deploy nl_abc_a.testnet res/nl_abc.wasm --account_id=nl_abc_a.testnet
near deploy nl_abc_b.testnet res/nl_abc.wasm --account_id=nl_abc_b.testnet
near deploy nl_abc_c.testnet res/nl_abc.wasm --account_id=nl_abc_c.testnet
near call nl_abc_a.testnet new '{"contract_next": "nl_abc_b.testnet", "status": 1}' --account_id=nl_abc_a.testnet
near call nl_abc_b.testnet new '{"contract_next": "nl_abc_c.testnet", "status": 2}' --account_id=nl_abc_b.testnet
near call nl_abc_c.testnet new '{"contract_next": "", "status": 3}' --account_id=nl_abc_c.testnet
```
show status of each contracts
```shell
near view nl_abc_a.testnet get_status ''
near view nl_abc_b.testnet get_status ''
near view nl_abc_c.testnet get_status ''
```
reset status of each contracts
```shell
near call nl_abc_a.testnet set_status '{"status": 1}' --account_id=humeng.testnet
near call nl_abc_b.testnet set_status '{"status": 2}' --account_id=humeng.testnet
near call nl_abc_c.testnet set_status '{"status": 3}' --account_id=humeng.testnet
```
```shell
near call nl_abc_a.testnet call_has_promise '' --gas 60000000000000 --amount=20 --account_id=humeng.testnet
```
# panic at the third contract
---------
caller: humeng.testnet
formattedAmount: '484.592298222830042580637283'
called: nl_abc_a/b/c
formattedAmount: '204.9990073731614979'
formattedAmount: '204.9985917401582891'
formattedAmount: '209.99874930775771809999999'
```shell
near call nl_abc_a.testnet call_has_promise '' --gas 60000000000000 --amount=12 --account_id=humeng.testnet
near view nl_abc_a.testnet get_status
near view nl_abc_b.testnet get_status
near view nl_abc_c.testnet get_status
```
# near_laboratory
|
MusicFeast_graph | generated
schema copy.ts
schema.ts
package-lock.json
package.json
src
backend.ts
market.ts
tsconfig.json
| |
ItsRisingTide_test_near | README.md
package-lock.json
package.json
public
index.html
manifest.json
robots.txt
src
App.css
App.js
App.test.js
Components
Wallet.js
marketplace
AddProduct.js
Product.js
Products.js
utils
Cover.js
Loader.js
Notifications.js
index.css
index.js
logo.svg
reportWebVitals.js
setupTests.js
utils
config.js
marketplace.js
near.js
| # Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `npm start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in your browser.
The page will reload when you make changes.\
You may also see any lint errors in the console.
### `npm test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `npm run build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `npm run eject`
**Note: this is a one-way operation. Once you `eject`, you can't go back!**
If you aren't satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you're on your own.
You don't have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn't feel obligated to use this feature. However we understand that this tool wouldn't be useful if you couldn't customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `npm run build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
|
Peersyst_frontend-technical-challenge | README.md
craco.config.ts
package-lock.json
package.json
public
index.html
manifest.json
robots.txt
src
assets
search-icon.svg
xrpl-logo.svg
components
Navbar
Navbar.css
Searchbar
Searchbar.css
Searchbar.types.ts
hooks
useLoad.ts
index.css
react-app-env.d.ts
service
XrplService.ts
tsconfig.json
| # 🖥 Peersyst Frontend Technical Challenge
This is the challenge that frontend engineer applicants will have to face as a part of the hiring process at Peersyst. The idea is to make as much progress as possible under a given time constraint (4 hours).
## Summary
You will have to implement a simplified version of the account page found in the official [XRPL explorer](https://livenet.xrpl.org/accounts/rSCXRaUyg9CkzHMidE7oYETB4W2bM2se7) **using React**.
We'll also add some tweaks to it, just to make it a bit fancier.
We provide you with a very simple craco based project with the essential tools to get you started. Notice that everything is done with vanilla React and CSS. This way, you will not be influenced by our code. We want you to be proactive and take decisions, so feel free to change everything you need!
## Clarifications
First of all, for the header part, you should include the address and XRP balance. You don't have to implement the "ACCOUNT INFO" section, as it includes more especific concepts of XRPL, such as the "reserve" or "current sequence".
Secondly, we'll put the focus on the tabs. As you can see on the [transactions tab](https://livenet.xrpl.org/accounts/rSCXRaUyg9CkzHMidE7oYETB4W2bM2se7/transactions), there are a lot of transaction types.
For this challenge, we will ask you to show **payments only**.
This list does not have to be paginated, but you will get extra points if you do it.
Each payment in the list will have to show the following fields:
- Account
- Transaction type
- Status
- Date/Time
- Amount
- Currency
- Receiver
Nevertheless, we encourage you to create an extendable _Transaction_ component, as we might want to introduce other transaction types in the future. The way we prefer it, is by building a _Transaction_ component that accepts different props depending on the type of the transaction.
For example, a transaction of type "Payment" will require an _Amount_ field, while a transaction of type "NFTokenMint" will not. On the other hand, you won't be asked to implement the [assets tab](https://livenet.xrpl.org/accounts/r3RaNVLvWjqqtFAawC6jbRhgKyFH7HvRS8/assets/issued). Nonetheless, you will have to include it on the tabs next to transactions, but you can leave that tab empty. Keep in mind that there might be more scenarios where we want to use tabs, thus it is quite important to make them reusable.
To make it more interesting, we will ask you to include a search bar that allows the user to navigate to other account pages. We already did some work building the bases of the search bar, so you can focus on adding the search functionality.
Finally, you will have to add a caching system that saves the state of the last account page visited.
You can use the local storage of the browser for that.
This way, it won't be necessary to refetch all the information when the browser is reopened.
If there is no cached value you can load the account page of the following address by default _rSCXRaUyg9CkzHMidE7oYETB4W2bM2se7_.
## Requirements
- Typescript is mandatory
- Use the xrpl library to fetch all the necessary data from the XRPL blockchain. You can find its documentation [here](https://js.xrpl.org/index.html) and [here](https://xrpl.org/concepts.html). Notice that we give you an initial implementation of an `XrplService` so you don't have to work out how its initialization works.
- You are allowed to use any library, apart from React
- You have to implement the Tabs component by yourself
- The UI has to have a certain level of responsiveness
## Extras
Do not tackle this unless you have time left.
- Paginated transactions list (load more button, infinite scroll, etc)
- Loading behaviours (skeletons, spinners, etc)
- Empty states
- Not found page
- Some unit testing (up to you)
- Search bar validation (xrpl address validation)
## Work environment
To start working with the project we provide you can follow the following instructions:
- Install the depencendies with `npm i`
- Start the project in development mode with `npm run start`
## Evaluation
- Try to respect the time limit
- **Quality over quantity:** better half of the features 100% done than all of the features 50% done
|
near_cargo-near-new-project-template | .devcontainer
devcontainer.json
.github
workflows
deploy-production.yml
deploy-staging.yml
test.yml
undeploy-staging.yml
Cargo.toml
README.md
rust-toolchain.toml
src
lib.rs
tests
test_basics.rs
| # cargo-near-new-project-name
cargo-near-new-project-description
## Quickstart Guide
You can start coding on the NEAR Rust stack in less than a minute, thanks to [NEAR Devcontainers](https://github.com/near/near-devcontainers). How?
1. Click **Use this template** > **Create a new repository**
<img width="750" alt="Create a new repository" src="https://github.com/njelich/cargo-near-new-project-template/assets/12912633/d59d89f1-8bc4-42f1-8e0d-842521d87768">
2. In your newly created repo, click **Code** > **Codespaces** > **Create codespace on main**
<img width="750" alt="Create Codespace" src="https://github.com/njelich/cargo-near-new-project-template/assets/12912633/352566cf-2eca-4d42-8232-6136ea8ec9d3">
## Where to Get Started?
Start writing your contract logic in [src/lib.rs](src/lib.rs) and integration tests in [tests/test_basics.rs](tests/test_basics.rs).
## How to Build Locally?
Install [`cargo-near`](https://github.com/near/cargo-near) and run:
```bash
cargo near build
```
## How to Test Locally?
```bash
cargo test
```
## How to Deploy?
Deployment is automated with GitHub Actions CI/CD pipeline.
To deploy manually, install [`cargo-near`](https://github.com/near/cargo-near) and run:
```bash
cargo near deploy <account-id>
```
## Useful Links
- [cargo-near](https://github.com/near/cargo-near) - NEAR smart contract development toolkit for Rust
- [near CLI](https://near.cli.rs) - Iteract with NEAR blockchain from command line
- [NEAR Rust SDK Documentation](https://docs.near.org/sdk/rust/introduction)
- [NEAR Documentation](https://docs.near.org)
- [NEAR StackOverflow](https://stackoverflow.com/questions/tagged/nearprotocol)
- [NEAR Discord](https://near.chat)
- [NEAR Telegram Developers Community Group](https://t.me/neardev)
- NEAR DevHub: [Telegram](https://t.me/neardevhub), [Twitter](https://twitter.com/neardevhub)
|
quantox-dejan_near-shop-contract | docs
wallet.txt
src
.gitpod.yml
.idea
modules.xml
vcs.xml
README.md
contract
.env
Cargo.toml
README.md
diesel.toml
migrations
2022-08-22-143738_create_initial_tables
down.sql
up.sql
neardev
dev-account.env
src
contract
mod.rs
near_shop.rs
dto
coupon.rs
mod.rs
product.rs
return_value.rs
user_shop.rs
lib.rs
model
coupon.rs
mod.rs
product.rs
storage_keys.rs
user_shop.rs
non_blockchain_model
favorite_product.rs
favorite_shop.rs
mod.rs
purchase.rs
wishlisted_product.rs
schema.rs
utils
mod.rs
random_utils.rs
vector_utils.rs
integration-tests
Cargo.toml
src
tests.rs
neardev
dev-account.env
package.json
| near-blank-project
==================
This app was initialized with [create-near-app]
Quick Start
===========
If you haven't installed dependencies during setup:
npm run deps-install
Build and deploy your contract to TestNet with a temporary dev account:
npm run deploy
Test your contract:
npm test
If you have a frontend, run `npm start`. This will run a dev server.
Exploring The Code
==================
1. The smart-contract code lives in the `/contract` folder. See the README there for
more info. In blockchain apps the smart contract is the "backend" of your app.
2. The frontend code lives in the `/frontend` folder. `/frontend/index.html` is a great
place to start exploring. Note that it loads in `/frontend/index.js`,
this is your entrypoint to learn how the frontend connects to the NEAR blockchain.
3. Test your contract: `npm test`, this will run the tests in `integration-tests` directory.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts].
When you run `npm run deploy`, your smart contract gets deployed to the live NEAR TestNet with a temporary dev account.
When you're ready to make it permanent, here's how:
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `near-blank-project.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `near-blank-project.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account near-blank-project.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: deploy the contract
---------------------------
Use the CLI to deploy the contract to TestNet with your account ID.
Replace `PATH_TO_WASM_FILE` with the `wasm` that was generated in `contract` build directory.
near deploy --accountId near-blank-project.YOUR-NAME.testnet --wasmFile PATH_TO_WASM_FILE
Step 3: set contract name in your frontend code
-----------------------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'near-blank-project.YOUR-NAME.testnet'
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/concepts/basics/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
Hello NEAR!
=================================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`.
2. There are two functions to the smart contract: `get_greeting` and `set_greeting`.
3. Tests: You can run smart contract tests with the `cargo test`.
[smart contract]: https://docs.near.org/develop/welcome
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://docs.near.org/develop/prerequisites#rust-and-wasm
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
|
frdomovic_near-login | README.md
next.config.js
package-lock.json
package.json
pages
api
hello.ts
postcss.config.js
public
next.svg
vercel.svg
styles
globals.css
tailwind.config.js
tsconfig.json
| This is a [Next.js](https://nextjs.org/) project bootstrapped with [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app).
## Getting Started
First, run the development server:
```bash
npm run dev
# or
yarn dev
# or
pnpm dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
You can start editing the page by modifying `pages/index.tsx`. The page auto-updates as you edit the file.
[API routes](https://nextjs.org/docs/api-routes/introduction) can be accessed on [http://localhost:3000/api/hello](http://localhost:3000/api/hello). This endpoint can be edited in `pages/api/hello.ts`.
The `pages/api` directory is mapped to `/api/*`. Files in this directory are treated as [API routes](https://nextjs.org/docs/api-routes/introduction) instead of React pages.
This project uses [`next/font`](https://nextjs.org/docs/basic-features/font-optimization) to automatically optimize and load Inter, a custom Google Font.
## Learn More
To learn more about Next.js, take a look at the following resources:
- [Next.js Documentation](https://nextjs.org/docs) - learn about Next.js features and API.
- [Learn Next.js](https://nextjs.org/learn) - an interactive Next.js tutorial.
You can check out [the Next.js GitHub repository](https://github.com/vercel/next.js/) - your feedback and contributions are welcome!
## Deploy on Vercel
The easiest way to deploy your Next.js app is to use the [Vercel Platform](https://vercel.com/new?utm_medium=default-template&filter=next.js&utm_source=create-next-app&utm_campaign=create-next-app-readme) from the creators of Next.js.
Check out our [Next.js deployment documentation](https://nextjs.org/docs/deployment) for more details.
|
mtoan2111_Gefi-Match | .vscode
settings.json
README.md
asconfig.json
assembly
__test__
as-pect.d.ts
main.spec.ts
as_types.d.ts
controller
history.controller.ts
match.controller.ts
swap.controller.ts
user.controller.ts
helper
pagination.helper.ts
response.helper.ts
transform.helper.ts
index.ts
model
fee.model.ts
history.model.ts
match.model.ts
user.model.ts
storage
history.storage.ts
match.storage.ts
user.storage.ts
tsconfig.json
user.ts
cmds_test.txt
package-lock.json
package.json
src
config.js
| # How to install
## Install dependencies
========================
```js
yarn install
```
## Deploy
===============
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `amm.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `amm.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account amm.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'amm.YOUR-NAME.testnet'
Step 3: deploy!
---------------
yarn deploy or near deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
## Troubleshooting
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
# Code structure
```js
/**
* Vector chứa các trận đấu đang chờ
* PersistentVector ~ List ~ Danh sách liên kết đơn/đôi
**/
const waitingMatch = new PersistentVector<Match>("w");
```
```js
/**
* Vector chứa các trận đấu đang diễn ra
* Khi 1 trận đấu đang ở waiting mà đủ người chơi, trận đấu sẽ chuyển sang trạng thái running
* Trình tự: Remove match from waitingMatch Vertor -> Insert to RunningMatch Vector
**/
const runningMatch = new PersistentVector<Match>("r");
```
```js
/**
* Vector chứa các trận đấu đã diễn ra
* Khi 1 trận đấu đang ở running mà đã có kết quả, dữ liệu trận đấu sẽ được lưu vào finishedMatch
* Trình tự: Remove match from runningMatch vector -> Insert to FinishedMatch Vector
**/
const finishedMatch = new PersistentVector<Match>("f");
```
```js
/**
* Vector chứa lịch sử thi đấu của người chơi
* Khi runningMatch hoàn thành, trận đấu sẽ kết thúc
* Hệ thống sẽ ghi nhận người thắng/ thua và lưu vào danh sách lịch sử của người chơi
**/
const historyMatch = new PersistentMap<String, PersistentVector<History>>("h")
```
|
My-GatewayApp_Gateway-Smart-Contracts | .gitpod.yml
README.md
commands.sh
contract
Cargo.toml
README.md
build.sh
deploy.sh
neardev
dev-account.env
src
approval.rs
burn.rs
enumeration.rs
events.rs
internal.rs
lib.rs
metadata.rs
nft_core.rs
owner.rs
royalty.rs
series.rs
tests.rs
integration-tests
package-lock.json
package.json
src
sandbox.ava.ts
utils.ts
package.json
scripts
build
burnNFTInBatch.js
config.js
contract-ts
GatewayNFTMarketPlaceContract.js
contracts
GatewayNFTMarketplace.js
createCollection.js
deploy.js
main.js
mintAndTransferNFT.js
mintNFT.js
mintNFTInBatch.js
transferNFT.js
utils.js
withdrawNFT.js
src
burnNFTInBatch.ts
config.ts
contracts
GatewayNFTMarketplace.ts
createCollection.ts
deploy.ts
main.ts
mintNFT.ts
mintNFTInBatch.ts
utils.ts
withdrawNFT.ts
types.d.ts
tsconfig.json
| # Hello NEAR Contract
The smart contract exposes two methods to enable storing and retrieving a greeting in the NEAR network.
```rust
const DEFAULT_GREETING: &str = "Hello";
#[near_bindgen]
#[derive(BorshDeserialize, BorshSerialize)]
pub struct Contract {
greeting: String,
}
impl Default for Contract {
fn default() -> Self {
Self{greeting: DEFAULT_GREETING.to_string()}
}
}
#[near_bindgen]
impl Contract {
// Public: Returns the stored greeting, defaulting to 'Hello'
pub fn get_greeting(&self) -> String {
return self.greeting.clone();
}
// Public: Takes a greeting, such as 'howdy', and records it
pub fn set_greeting(&mut self, greeting: String) {
// Record a log permanently to the blockchain!
log!("Saving greeting {}", greeting);
self.greeting = greeting;
}
}
```
<br />
# Quickstart
1. Make sure you have installed [rust](https://rust.org/).
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
./deploy.sh
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Retrieve the Greeting
`get_greeting` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the greeting
near view <dev-account> get_greeting
```
<br />
## 3. Store a New Greeting
`set_greeting` changes the contract's state, for which it is a `change` method.
`Change` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set a new greeting
near call <dev-account> set_greeting '{"message":"howdy"}' --accountId <dev-account>
```
**Tip:** If you would like to call `set_greeting` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
near-blank-project
==================
This app was initialized with [create-near-app]
Quick Start
===========
If you haven't installed dependencies during setup:
npm install
Build and deploy your contract to TestNet with a temporary dev account:
npm run deploy
Test your contract:
npm test
If you have a frontend, run `npm start`. This will run a dev server.
Exploring The Code
==================
1. The smart-contract code lives in the `/contract` folder. See the README there for
more info. In blockchain apps the smart contract is the "backend" of your app.
2. The frontend code lives in the `/frontend` folder. `/frontend/index.html` is a great
place to start exploring. Note that it loads in `/frontend/index.js`,
this is your entrypoint to learn how the frontend connects to the NEAR blockchain.
3. Test your contract: `npm test`, this will run the tests in `integration-tests` directory.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts].
When you run `npm run deploy`, your smart contract gets deployed to the live NEAR TestNet with a temporary dev account.
When you're ready to make it permanent, here's how:
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `near-blank-project.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `near-blank-project.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account near-blank-project.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: deploy the contract
---------------------------
Use the CLI to deploy the contract to TestNet with your account ID.
Replace `PATH_TO_WASM_FILE` with the `wasm` that was generated in `contract` build directory.
near deploy --accountId near-blank-project.YOUR-NAME.testnet --wasmFile PATH_TO_WASM_FILE
Step 3: set contract name in your frontend code
-----------------------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'near-blank-project.YOUR-NAME.testnet'
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/concepts/basics/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
|
phongnguyen2012_create-token | Cargo.toml
README.md
build.sh
src
lib.rs
| ## Create-token
Fungible Token
Example implementation of a Fungible Token contract which uses near-contract-standards and simulation tests. This is a contract-only example.
<sup>
### 1. Prerequisites Install Rust
Building ./build.sh
### 2. Using this contract : Deloy contract
near deploy --wasmFile out/create-token.wasm --accountId $ID
Fungiable Token contract should be initialized before usage. You can read more about metadata at 'nomicon.io'. Modify the parameters and create a token:
near call $ID new '{"owner_id": "'$ID'", "total_supply": "1000000000000000", "metadata": { "spec": "ft-1.0.0", "name": "Example Token Name", "symbol":
"EXLT", "decimals": 8 }}' --accountId $ID
Get metadata: near view $ID ft_metadata
#### 3. Transfer Example
near create-account teo.$ID --masterAccount $ID --initialBalance 5
Add storage deposit for teo's account:
near call $ID storage_deposit '' --accountId teo.$ID --amount 0.2
Check balance of teo's account
near view $ID ft_balance_of '{"account_id": "'teo.$ID'"}'
Transfer tokens to teo from the contract that minted these fungible tokens, exactly 1 yoctoNEAR of deposit should be attached:
near call $ID ft_transfer '{"receiver_id": "'teo.$ID'", "amount": "1"}' --accountId $ID --amount 0.000000000000000000000001
#### 4. Test
cargo test
</sup>
|
near-examples_counter-rust | .devcontainer
devcontainer.json
.github
workflows
tests-rs.yml
tests-ts.yml
README.md
contract-rs
Cargo.toml
README.md
rust-toolchain.toml
src
lib.rs
tests
sandbox.rs
contract-ts
README.md
package.json
sandbox-ts
main.ava.ts
src
contract.ts
tsconfig.json
frontend
assets
global.css
index.html
index.js
near-wallet.js
package.json
| # Count on NEAR Contract Example
The smart contract exposes methods to interact with a counter stored in the NEAR
network.
## How to Build Locally?
Install [`cargo-near`](https://github.com/near/cargo-near) and run:
```bash
cargo near build
```
## How to Test Locally?
```bash
cargo test
```
## How to Deploy?
Deployment is automated with GitHub Actions CI/CD pipeline. To deploy manually,
install [`cargo-near`](https://github.com/near/cargo-near) and run:
```bash
cargo near deploy <account-id>
```
## How to Interact?
_In this example we will be using [NEAR CLI](https://github.com/near/near-cli)
to intract with the NEAR blockchain and the smart contract_
_If you want full control over of your interactions we recommend using the
[near-cli-rs](https://near.cli.rs)._
### Get the Counter
`get_num` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a
NEAR account**!
```bash
# Use near-cli to get the counter value
near view <contract-account-id> get_num
```
### Modify the Counter
`increment`, `decrement` and `reset` change the contract's state, for which they
are `call` methods.
`Call` methods can only be invoked using a NEAR account, since the account needs
to pay GAS for the transaction.
```bash
# Use near-cli to set increment the counter
near call <contract-account-id> increment --accountId --accountId <your-account>
```
## Useful Links
- [cargo-near](https://github.com/near/cargo-near) - NEAR smart contract
development toolkit for Rust
- [near CLI-rs](https://near.cli.rs) - Iteract with NEAR blockchain from command
line
- [NEAR Rust SDK Documentation](https://docs.near.org/sdk/rust/introduction)
- [NEAR Documentation](https://docs.near.org)
- [NEAR StackOverflow](https://stackoverflow.com/questions/tagged/nearprotocol)
- [NEAR Discord](https://near.chat)
- [NEAR Telegram Developers Community Group](https://t.me/neardev)
- NEAR DevHub: [Telegram](https://t.me/neardevhub),
[Twitter](https://twitter.com/neardevhub)
# Counter Examples
This repository contains examples for a simple counter in both Rust and JavaScript, and an examples of a frontend interacting with a Counter smart contract.
## Repositories
- [Counter TS Examples](contract-ts)
- [Counter RS Example](contract-rs)
- [Counter Frontend Example](frontend)
# Count on NEAR Contract
The smart contract exposes methods to interact with a counter stored in the NEAR network.
```ts
val: number = 0;
@view
// Public read-only method: Returns the counter value.
get_num(): number {
return this.val
}
@call
// Public method: Increment the counter.
increment() {
this.val += 1;
near.log(`Increased number to ${this.val}`)
}
@call
// Public method: Decrement the counter.
decrement() {
this.val -= 1;
near.log(`Decreased number to ${this.val}`)
}
@call
// Public method - Reset to zero.
reset() {
this.val = 0;
near.log(`Reset counter to zero`)
}
```
<br />
# Quickstart
1. Make sure you have installed [node.js](https://nodejs.org/en/download/package-manager/) >= 16.
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
npm run deploy
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Get the Counter
`get_num` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the counter value
near view <dev-account> get_num
```
<br />
## 3. Modify the Counter
`increment`, `decrement` and `reset` change the contract's state, for which they are `call` methods.
`Call` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set increment the counter
near call <dev-account> increment --accountId <dev-account>
```
**Tip:** If you would like to call `increment` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
|
proyecto26_NeaRent | .gitpod.yml
README.md
contract
README.md
babel.config.json
build.sh
deploy.sh
package-lock.json
package.json
src
contract.ts
tsconfig.json
frontend
assets
global.css
logo-black.svg
logo-white.svg
index.html
index.js
near-wallet.js
package-lock.json
package.json
start.sh
integration-tests
package-lock.json
package.json
src
main.ava.ts
package-lock.json
package.json
| # Hello NEAR Contract
The smart contract exposes two methods to enable storing and retrieving a greeting in the NEAR network.
```ts
@NearBindgen({})
class HelloNear {
greeting: string = "Hello";
@view // This method is read-only and can be called for free
get_greeting(): string {
return this.greeting;
}
@call // This method changes the state, for which it cost gas
set_greeting({ greeting }: { greeting: string }): void {
// Record a log permanently to the blockchain!
near.log(`Saving greeting ${greeting}`);
this.greeting = greeting;
}
}
```
<br />
# Quickstart
1. Make sure you have installed [node.js](https://nodejs.org/en/download/package-manager/) >= 16.
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
npm run deploy
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Retrieve the Greeting
`get_greeting` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the greeting
near view <dev-account> get_greeting
```
<br />
## 3. Store a New Greeting
`set_greeting` changes the contract's state, for which it is a `call` method.
`Call` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set a new greeting
near call <dev-account> set_greeting '{"greeting":"howdy"}' --accountId <dev-account>
```
**Tip:** If you would like to call `set_greeting` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
# NeaRent
Smart Rent powered by NEAR Protocol
## Smart Contract
### Objetos/Structs
#### Real estate
Metadatos de una propiedad:
- Valor por día
- Dirección
### Storage
- LookupMap de Propiedad x Arrendatarios - ID de la propiedad y el valor es la wallet del arrendatario.
### Metodos
- Crear una nueva propiedad - Owner
- Agregar propietarios (porcentaje de participación) - Owner
- Asignar arrendatario - Owner
- Validar que no tenga arrendatario asignado (No esté en el LookupMap de arrendatarios)
- Agregar un arrendatario al LookupMap de arrendatarios
- Desasignar arrendatario - Owner
### TODO Terminal
Acciones desde la Terminal:
- Crear cuentas de propietarios
- Crear cuentas de arrendatarios
### TODO UI
Acciones desde la Terminal:
- Listar propiedades
- Filtrar propiedades con rangos de fecha
- Seleccionar propiedad para ver el detalle
Quick Start
===========
If you haven't installed dependencies during setup:
npm install
Build and deploy your contract to TestNet with a temporary dev account:
npm run deploy
Test your contract:
npm test
If you have a frontend, run `npm start`. This will run a dev server.
Exploring The Code
==================
1. The smart-contract code lives in the `/contract` folder. See the README there for
more info. In blockchain apps the smart contract is the "backend" of your app.
2. The frontend code lives in the `/frontend` folder. `/frontend/index.html` is a great
place to start exploring. Note that it loads in `/frontend/index.js`,
this is your entrypoint to learn how the frontend connects to the NEAR blockchain.
3. Test your contract: `npm test`, this will run the tests in `integration-tests` directory.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts].
When you run `npm run deploy`, your smart contract gets deployed to the live NEAR TestNet with a temporary dev account.
When you're ready to make it permanent, here's how:
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `near-blank-project.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `near-blank-project.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account near-blank-project.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: deploy the contract
---------------------------
Use the CLI to deploy the contract to TestNet with your account ID.
Replace `PATH_TO_WASM_FILE` with the `wasm` that was generated in `contract` build directory.
near deploy --accountId near-blank-project.YOUR-NAME.testnet --wasmFile PATH_TO_WASM_FILE
Step 3: set contract name in your frontend code
-----------------------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'near-blank-project.YOUR-NAME.testnet'
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/concepts/basics/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
|
metanear_chatbot-contract-rs | Cargo.toml
README.md
build.sh
src
lib.rs
| # Chat Bot Meta NEAR contract for mail app
Contract implements `mail` app messaging interface to receive and randomly send messages.
It's deployed on `chatbot` account on NEAR testnet. Try use [Meta NEAR](https://metanear.com) to send a mail to `chatbot`.
## Testing
To test run:
```bash
cargo test --package metanear-chatbot -- --nocapture
```
|
imdivyanshusingh_CrowdFund-Near | README.md
contract
README.md
build.sh
deploy.sh
package-lock.json
package.json
src
contract.ts
model.ts
utils.ts
tsconfig.json
frontend
App.js
assets
global.css
index.html
index.js
near-interface.js
near-wallet.js
package-lock.json
package.json
start.sh
ui-components.js
package-lock.json
package.json
rust-toolchain.toml
| # Hello NEAR Contract
The smart contract exposes two methods to enable storing and retrieving a greeting in the NEAR network.
```ts
@NearBindgen({})
class HelloNear {
greeting: string = "Hello";
@view // This method is read-only and can be called for free
get_greeting(): string {
return this.greeting;
}
@call // This method changes the state, for which it cost gas
set_greeting({ greeting }: { greeting: string }): void {
// Record a log permanently to the blockchain!
near.log(`Saving greeting ${greeting}`);
this.greeting = greeting;
}
}
```
<br />
# Quickstart
1. Make sure you have installed [node.js](https://nodejs.org/en/download/package-manager/) >= 16.
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
npm run deploy
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Retrieve the Greeting
`get_greeting` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the greeting
near view <dev-account> get_greeting
```
<br />
## 3. Store a New Greeting
`set_greeting` changes the contract's state, for which it is a `call` method.
`Call` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set a new greeting
near call <dev-account> set_greeting '{"greeting":"howdy"}' --accountId <dev-account>
```
**Tip:** If you would like to call `set_greeting` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
# Project Name - Crowd Near
# ENCODE x NEAR 2023
# Description
Near Crowd is a blockchain-based crowdfunding platform designed to support and empower creators, artists, and entrepreneurs. By harnessing the near blockchain's scalability and low transaction fees, Near Crowd enables individuals from all over the world to showcase their projects and receive funding from a global community of supporters. With its user-friendly interface and integrated smart contracts, Near Crowd ensures that funds are securely managed and distributed to project creators upon successful completion.
# Inspiration
One of the primary inspirations is to democratize access to funding and provide equal opportunities for creators and entrepreneurs worldwide. By leveraging blockchain technology, the platform can eliminate barriers such as geographic limitations, stringent financial requirements, and traditional gatekeepers.
secondly, Traditional funding models often involve numerous intermediaries, high fees, and lengthy processes. By harnessing the near blockchain's scalability and low transaction costs, the platform can streamline the fundraising process, reduce overhead expenses, and provide cost-effective solutions for both project creators and contributors.
and lastly, the inspiration behind the platform lies in supporting and empowering innovative projects across various domains. By providing a platform that connects creative individuals and forward-thinking entrepreneurs with a global community.
|
near-guildnet_autodelegation | Readme.md
auto-delegate-with-seat
Readme.md
key
shardnet
autodelegate.shardnet.near.json
log.txt
package.json
pool_delegate.js
pull_id.txt
near-delegation
Readme.md
collect.js
delegate.js
key
shardnet
autodelegate.shardnet.near.json
package.json
scoreboard.js
unstake.js
| |
NEAR-P2P_p2p-subaccount | Cargo.toml
README.md
lib_old.rs
src
lib.rs
main.rs
| # p2p-subaccount
Smart Contract
This smart contract will be deployed on subaccounts of NEARP2P for each transactions
|
meinharrd_stellar-helpers | README.md
lib
stellar.js
package.json
stellar-create-account.js
stellar-keypair.js
stellar-payment.js
| # Stellar Helpers
A collection of scripts for managing Stellar accounts.
## Install
```bash
$ npm install
```
## Usage
**Generate a key pair:**
```bash
$ node stellar-keypair.js
```
Outputs a secret key followed by the corresponding public account ID, for example:
`SBXXXXXXXXXXXXYJWRXEER7W7ZVTFZBF3S3GJKXQ5PJNEARYS677QWVJ GAXXXXXXXXXXXXIUUI5OMTULLU5SYB3EDTDLJB54LGVHRW3QEPAYDS5B`
The key pair can be used for all Stellar networks (public, testnet, others).
**Activate an account by adding a starting balance from a funded account (testnet):**
```bash
$ node stellar-create-account.js --secret=SECRET_KEY_OF_FUNDING_ACCOUNT --starting_balance=1.1 --destination=ACCOUNT_ID_OF_RECIPIENT --memo="Creating account" --testnet
```
Outputs a transaction ID on success, for example:
`4a261121cca088f40e503de4a19ba10f216bdf083149fcc21e8934705b98b8ac`
**Make a payment of 10 XLM to an account (testnet):**
```bash
$ node stellar-payment.js --secret=SECRET_KEY_OF_SENDER --amount=10 --destination=ACCOUNT_ID_OF_RECIPIENT --testnet
```
Outputs a transaction ID on success.
**Make a payment of 4.50 EURT to an account:**
```bash
$ node stellar-payment.js --secret=SECRET_KEY_OF_SENDER --amount=4.5 --destination=ACCOUNT_ID_OF_RECIPIENT --asset_code=EURT --asset_issuer=GAP5LETOV6YIE62YAM56STDANPRDO7ZFDBGSNHJQIYGGKSMOZAHOOS2S --memo="4.50 EUR for coffee"
```
Outputs a transaction ID on success.
|
PhantomOz_pixicle | .eslintrc.json
README.md
next.config.js
package-lock.json
package.json
public
images
group-2.svg
next.svg
vercel.svg
src
app
globals.css
page.module.css
utils
Data.ts
Wallet.ts
types.ts
upload.ts
tsconfig.json
| # Pixicle - NFT Marketplace Frontend
## Description
This is a frontend project for the Pixicle NFT Marketplace smart contract. It is built with Next.js, a React framework that enables server-side rendering and static site generation. It uses the NEAR-API-JS to interact with the smart contract on the Near blockchain.
## Features
- Connect a NEAR wallet to the frontend project
- Read data from the smart contract using the NEAR-API-JS
- Sign NEAR transactions using your NEAR wallet
- Mint, buy, and sell NFTs using the frontend interface
- Browse and search NFTs by collection or owner
## Live Demo
You can find the live demo on [Pixicle Marketplace](https://pixicle.vercel.app/) - **Note you should turn on Dark Mode when using the site to get the best experience.**
Made with &love; by [Favour Aniogor](https://github.com/PhantomOz).
|
Mangoboxlabs_picasarts.io---Aurora | README.md
build
contracts
Address.json
CollectionFactory.json
Context.json
Counters.json
ERC165.json
ERC165Checker.json
ERC721Enumerable.json
ERC721URIStorage.json
IERC165.json
IERC2981.json
IERC721.json
IERC721Enumerable.json
IERC721Metadata.json
IERC721Receiver.json
Migrations.json
Ownable.json
ReefRoyalty.json
ReentrancyGuard.json
Strings.json
changelog.md
jsconfig.json
migrations
1_initial_migration.js
2_deploy_contracts.js
next.config.js
package.json
src
abi
ABI.json
CollectionFactoryABI.json
MarketPlaceABI.json
NftABI.json
config
contractAddress.js
createEmotionCache.js
lib
gtag.js
public
static
css
style.css
img
near-logo.svg
logo_white.svg
theme.js
truffle-config.js
| # WARNING
This repository is a sample source code for NFT marketplace on [AURORA](https://aurora.dev/). It's not ready and need improvements for production.
# NFT Market Reference Implementation
A PoC backbone for NFT Marketplaces on Aurora.
- [ERC 171](https://eips.ethereum.org/EIPS/eip-721)
- [REEF NFT Marketplace](https://github.com/Vikings-Tech/reef-nft-marketplace)
- [CryptoBoys NFT Marketplace](https://github.com/devpavan04/cryptoboys-nft-marketplace)
# Changelog
[Changelog](changelog.md)
## Progress:
- [x] NFT & Market smart contracts following REC-171
- [x] Mint NFT
- [x] Add a NFT to market
- [x] integrate with Crust dStorage Solution
- [x] integrate with DiaData - CoinMarketCap endpoint to convert ETH to USD
- [x] frontend with MUI (Material Design - React UI components )
- [x] test and determine standards for markets (best practice?) to buy/sell NFTs (finish standard) with FTs (already standard)
- [x] first pass / internal audit
- [ ] demo some basic auction types, secondary markets and
- [ ] integrate with Google Analytic to count page views for each NFT item.
- [ ] show collections on home page
- [ ] show related NFTs item on NFT detailed page.
- [ ] switch between chains (NEAR, Aurora, XRP, Ethereum...)
- [ ] connect with bridged tokens e.g. buy and sell with wETH/nDAI (or whatever we call these)
## Tech Stack
- [NextJS 11](https://nextjs.org/)
- [Mongo Atlas](https://www.mongodb.com/atlas/database)
- [MUI](https://mui.com/)
- Smart Contracts use [Solidity](https://docs.soliditylang.org/en/v0.8.12/) with Aurora EVM
- IPFS uses [Crust](https://crust.network/)
- Web3 & Ethers.js
## Install development environment
As dApp development on Ethereum. We can use Truffle and Ganache. Detailed document at [here](https://doc.aurora.dev/interact/truffle)
## Working
**Build Smart Contract**:
Go to truffle-config.js to change your settings. Adding aurora testnet to MetaMask at [here](https://doc.aurora.dev/interact/metamask)
- `npm run deploy:aurora`
**Run Dev Mode for frontend**
- `npm run dev`
**Run Production Mode for frontend**
- `npm run build`
- `npm run start`
**App can be started by [PM2](https://pm2.keymetrics.io/)**
- `pm2 start npm --name "Your app name" -- run start`
|
mel1huc4r_first-smart-contract-practice | README.md
as-pect.config.js
asconfig.json
package.json
scripts
1.dev-deploy.sh
2.use-contract.sh
3.cleanup.sh
README.md
src
as_types.d.ts
simple
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
singleton
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
| ## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
# `near-sdk-as` Starter Kit
This is a good project to use as a starting point for your AssemblyScript project.
## Samples
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
There are 2 AssemblyScript contracts in this project, each in their own folder:
- **simple** in the `src/simple` folder
- **singleton** in the `src/singleton` folder
### Simple
We say that an AssemblyScript contract is written in the "simple style" when the `index.ts` file (the contract entry point) includes a series of exported functions.
In this case, all exported functions become public contract methods.
```ts
// return the string 'hello world'
export function helloWorld(): string {}
// read the given key from account (contract) storage
export function read(key: string): string {}
// write the given value at the given key to account (contract) storage
export function write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
```
### Singleton
We say that an AssemblyScript contract is written in the "singleton style" when the `index.ts` file (the contract entry point) has a single exported class (the name of the class doesn't matter) that is decorated with `@nearBindgen`.
In this case, all methods on the class become public contract methods unless marked `private`. Also, all instance variables are stored as a serialized instance of the class under a special storage key named `STATE`. AssemblyScript uses JSON for storage serialization (as opposed to Rust contracts which use a custom binary serialization format called borsh).
```ts
@nearBindgen
export class Contract {
// return the string 'hello world'
helloWorld(): string {}
// read the given key from account (contract) storage
read(key: string): string {}
// write the given value at the given key to account (contract) storage
@mutateState()
write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
}
```
## Usage
### Getting started
(see below for video recordings of each of the following steps)
INSTALL `NEAR CLI` first like this: `npm i -g near-cli`
1. clone this repo to a local folder
2. run `yarn`
3. run `./scripts/1.dev-deploy.sh`
3. run `./scripts/2.use-contract.sh`
4. run `./scripts/2.use-contract.sh` (yes, run it to see changes)
5. run `./scripts/3.cleanup.sh`
### Videos
**`1.dev-deploy.sh`**
This video shows the build and deployment of the contract.
[](https://asciinema.org/a/409575)
**`2.use-contract.sh`**
This video shows contract methods being called. You should run the script twice to see the effect it has on contract state.
[](https://asciinema.org/a/409577)
**`3.cleanup.sh`**
This video shows the cleanup script running. Make sure you add the `BENEFICIARY` environment variable. The script will remind you if you forget.
```sh
export BENEFICIARY=<your-account-here> # this account receives contract account balance
```
[](https://asciinema.org/a/409580)
### Other documentation
- See `./scripts/README.md` for documentation about the scripts
- Watch this video where Willem Wyndham walks us through refactoring a simple example of a NEAR smart contract written in AssemblyScript
https://youtu.be/QP7aveSqRPo
```
There are 2 "styles" of implementing AssemblyScript NEAR contracts:
- the contract interface can either be a collection of exported functions
- or the contract interface can be the methods of a an exported class
We call the second style "Singleton" because there is only one instance of the class which is serialized to the blockchain storage. Rust contracts written for NEAR do this by default with the contract struct.
0:00 noise (to cut)
0:10 Welcome
0:59 Create project starting with "npm init"
2:20 Customize the project for AssemblyScript development
9:25 Import the Counter example and get unit tests passing
18:30 Adapt the Counter example to a Singleton style contract
21:49 Refactoring unit tests to access the new methods
24:45 Review and summary
```
## The file system
```sh
├── README.md # this file
├── as-pect.config.js # configuration for as-pect (AssemblyScript unit testing)
├── asconfig.json # configuration for AssemblyScript compiler (supports multiple contracts)
├── package.json # NodeJS project manifest
├── scripts
│ ├── 1.dev-deploy.sh # helper: build and deploy contracts
│ ├── 2.use-contract.sh # helper: call methods on ContractPromise
│ ├── 3.cleanup.sh # helper: delete build and deploy artifacts
│ └── README.md # documentation for helper scripts
├── src
│ ├── as_types.d.ts # AssemblyScript headers for type hints
│ ├── simple # Contract 1: "Simple example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 1
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 1
│ ├── singleton # Contract 2: "Singleton-style example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 2
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 2
│ ├── tsconfig.json # Typescript configuration
│ └── utils.ts # common contract utility functions
└── yarn.lock # project manifest version lock
```
You may clone this repo to get started OR create everything from scratch.
Please note that, in order to create the AssemblyScript and tests folder structure, you may use the command `asp --init` which will create the following folders and files:
```
./assembly/
./assembly/tests/
./assembly/tests/example.spec.ts
./assembly/tests/as-pect.d.ts
```
www.patika.dev
|
jdnichollsc_my-first-near-nft | .gitpod.yml
README.md
babel.config.js
contract
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
main.spec.ts
as_types.d.ts
index.ts
tsconfig.json
compile.js
package-lock.json
package.json
package.json
src
App.js
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
config.js
global.css
index.html
index.js
jest.init.js
main.test.js
utils.js
wallet
login
index.html
| my-first-near-nft Smart Contract
==================
A [smart contract] written in [AssemblyScript] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install [Node.js] ≥ 12
Exploring The Code
==================
1. The main smart contract code lives in `assembly/index.ts`. You can compile
it with the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard AssemblyScript tests using [as-pect].
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[AssemblyScript]: https://www.assemblyscript.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[as-pect]: https://www.npmjs.com/package/@as-pect/cli
my-first-near-nft
==================
This [React] app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `my-first-near-nft.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `my-first-near-nft.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account my-first-near-nft.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'my-first-near-nft.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
|
Kariimayman_VerifiedProfileV2 | contract
__tests__
as-pect.d.ts
index.unit.spec.ts
as-pect.config.js
asconfig.json
assembly
as_types.d.ts
index.ts
tsconfig.json
package.json
package.json
public
index.html
manifest.json
robots.txt
src
App.css
App.js
App.test.js
components
AccountExists.js
CreateAccount.js
Direct.js
Splitusers.js
Wallet.js
admin.js
form.js
storageconfig.js
utils
Cover.js
config.js
functions.js
loader.js
near.js
index.css
index.js
logo.svg
reportWebVitals.js
setupTests.js
| |
jelilat_kickstarterDapp | .gitpod.yml
README.md
babel.config.js
contract
Cargo.toml
README.md
build.sh
compile.js
neardev
dev-account.env
src
lib.rs
models.rs
utils.rs
target
.rustc_info.json
debug
.fingerprint
Inflector-e85997604b197eb8
lib-inflector.json
autocfg-3b46087fcc03a313
lib-autocfg.json
borsh-derive-ced236a1a2f528bf
lib-borsh-derive.json
borsh-derive-internal-69f5a2866d969f01
lib-borsh-derive-internal.json
borsh-schema-derive-internal-688955fed824c439
lib-borsh-schema-derive-internal.json
byteorder-a347edd1c8213cb2
build-script-build-script-build.json
convert_case-5373dc264603673f
lib-convert_case.json
derive_more-818a63533b5fa684
lib-derive_more.json
generic-array-a2766f61c40e699e
build-script-build-script-build.json
hashbrown-334be713dc6d1730
build-script-build-script-build.json
hashbrown-c318c6ad5598b603
run-build-script-build-script-build.json
hashbrown-faf269d72c9b5688
lib-hashbrown.json
indexmap-42c41fb0dcb4f9d0
build-script-build-script-build.json
indexmap-6d35a1089d38ef9a
run-build-script-build-script-build.json
indexmap-7d1cf213db2d48e6
lib-indexmap.json
itoa-aaabd564ee228685
lib-itoa.json
memchr-4280c75f2d93519f
build-script-build-script-build.json
near-rpc-error-core-6da8a7067365558f
lib-near-rpc-error-core.json
near-rpc-error-macro-4f519d1e58221e78
lib-near-rpc-error-macro.json
near-sdk-core-56df58cb8631868b
lib-near-sdk-core.json
near-sdk-macros-f2fb4d55052f6854
lib-near-sdk-macros.json
num-bigint-7641482363eb2f1a
build-script-build-script-build.json
num-integer-da4d34de8a587eda
build-script-build-script-build.json
num-rational-60f63fbc3925e74d
build-script-build-script-build.json
num-traits-5c680b5d9fbec50f
build-script-build-script-build.json
proc-macro-crate-bd023abd7fbf7c95
lib-proc-macro-crate.json
proc-macro2-4b2f368060df7759
build-script-build-script-build.json
proc-macro2-5f174c960d10b8bd
run-build-script-build-script-build.json
proc-macro2-ac9ad377c3628ae6
lib-proc-macro2.json
quote-8288eff28a84ac26
lib-quote.json
ryu-245f6b9a7d182ea7
build-script-build-script-build.json
ryu-5fde18e73251d600
run-build-script-build-script-build.json
ryu-7ac3a0adc59041c4
lib-ryu.json
serde-c80c1aeb51872e6e
run-build-script-build-script-build.json
serde-cea453f905716d7f
lib-serde.json
serde-ef963256674464ab
build-script-build-script-build.json
serde_derive-3f2fceae7309615d
lib-serde_derive.json
serde_derive-60e576deaddd4f04
build-script-build-script-build.json
serde_derive-a0e8959f62e9cbf2
run-build-script-build-script-build.json
serde_json-0a4921c9161f38a3
run-build-script-build-script-build.json
serde_json-0fab69a98fe408c8
lib-serde_json.json
serde_json-45790d96787ac1bd
build-script-build-script-build.json
syn-1bdbb534c19c8546
run-build-script-build-script-build.json
syn-94635965b00b8c2d
build-script-build-script-build.json
syn-f38f0b34099bb685
lib-syn.json
toml-6298ae64fcba578c
lib-toml.json
typenum-bf0b9e8f59c97b28
build-script-build-script-main.json
unicode-xid-b21a415b7c3e8cae
lib-unicode-xid.json
version_check-98696068c27b5d28
lib-version_check.json
wee_alloc-9d57a7994eff615a
build-script-build-script-build.json
release
.fingerprint
Inflector-2e01ad059b2075e3
lib-inflector.json
autocfg-64de2423c6cd8f34
lib-autocfg.json
borsh-derive-a05e0d8b7f903878
lib-borsh-derive.json
borsh-derive-internal-941a69ae440661e9
lib-borsh-derive-internal.json
borsh-schema-derive-internal-a156d7f01a16035f
lib-borsh-schema-derive-internal.json
byteorder-974ab065a9c4bf30
build-script-build-script-build.json
convert_case-1db220996bc027e7
lib-convert_case.json
derive_more-65585474528922dd
lib-derive_more.json
generic-array-58893d39e622717a
build-script-build-script-build.json
hashbrown-0e4c1d9077b16eed
lib-hashbrown.json
hashbrown-304656f2f51aa1cd
run-build-script-build-script-build.json
hashbrown-675fd93a5f0b5846
build-script-build-script-build.json
indexmap-b106f068506ddda9
lib-indexmap.json
indexmap-be28cfa96fb6c8f9
run-build-script-build-script-build.json
indexmap-cd7a765da61e3db3
build-script-build-script-build.json
itoa-cafce133f26882fe
lib-itoa.json
memchr-1688c9bbc8748067
build-script-build-script-build.json
near-rpc-error-core-d6874f931733e5e0
lib-near-rpc-error-core.json
near-rpc-error-macro-4eefcba5fe248a1e
lib-near-rpc-error-macro.json
near-sdk-core-36b21d2529b03e3d
lib-near-sdk-core.json
near-sdk-macros-3c97cb03dd6e99dc
lib-near-sdk-macros.json
num-bigint-d7249ad70b3ecf6c
build-script-build-script-build.json
num-integer-8c4c5ec189a5945b
build-script-build-script-build.json
num-rational-7e373b74e3a4f82e
build-script-build-script-build.json
num-traits-38f523628369cd40
build-script-build-script-build.json
proc-macro-crate-223707aa9493e36b
lib-proc-macro-crate.json
proc-macro2-2fa67cc17ad82ae9
build-script-build-script-build.json
proc-macro2-b23b97f7c6ec114c
run-build-script-build-script-build.json
proc-macro2-ee60f1cd1115c9c9
lib-proc-macro2.json
quote-5433f863ffc4f2b1
lib-quote.json
ryu-08aea7202e711c1c
build-script-build-script-build.json
ryu-56ef55fed5198fa3
lib-ryu.json
ryu-f3b6978e65e7fadb
run-build-script-build-script-build.json
serde-4d5dd2a2f097c037
lib-serde.json
serde-7d5062f1313e1070
run-build-script-build-script-build.json
serde-edcec945c21a492c
build-script-build-script-build.json
serde_derive-5f563ad2f96c71aa
lib-serde_derive.json
serde_derive-7088addaa69d35ed
run-build-script-build-script-build.json
serde_derive-8490118848ce1736
build-script-build-script-build.json
serde_json-6467b3ef52b24cb2
build-script-build-script-build.json
serde_json-ab94fd1dac9650f8
run-build-script-build-script-build.json
serde_json-d734691f7a3e7f19
lib-serde_json.json
syn-59aa77fbb56f3faf
lib-syn.json
syn-bf4b7d0e22b05479
build-script-build-script-build.json
syn-fa26437ec92c9dc1
run-build-script-build-script-build.json
toml-39a0a124e078b083
lib-toml.json
typenum-d32257c70b7894fd
build-script-build-script-main.json
unicode-xid-e26a2b157d3caa41
lib-unicode-xid.json
version_check-e2c518a70d645c57
lib-version_check.json
wee_alloc-d2114529c70f2f49
build-script-build-script-build.json
wasm32-unknown-unknown
debug
.fingerprint
ahash-de4940e468f9bc74
lib-ahash.json
aho-corasick-1b5c4ccf7965e0de
lib-aho_corasick.json
base64-4fec4efa5a48813b
lib-base64.json
block-buffer-237f068f07bae217
lib-block-buffer.json
block-buffer-abaf19e47fbaad38
lib-block-buffer.json
block-padding-1ab66b0a12349683
lib-block-padding.json
borsh-caa35a036df3ae17
lib-borsh.json
bs58-7eece13532a00edd
lib-bs58.json
byte-tools-3466ed5b646045ad
lib-byte-tools.json
byteorder-2fe1ca057f2319fd
lib-byteorder.json
byteorder-70d3fc17a12bce22
run-build-script-build-script-build.json
cfg-if-45937cc7211576d5
lib-cfg-if.json
cfg-if-686dc58943ddc805
lib-cfg-if.json
digest-25e9c6d6c470788f
lib-digest.json
digest-2a3b414446a15990
lib-digest.json
generic-array-12f462597599c32c
lib-generic_array.json
generic-array-1585bc0290365eea
run-build-script-build-script-build.json
generic-array-2201726c90948480
lib-generic_array.json
greeter-98ace302c5fafa12
lib-greeter.json
hashbrown-7d9cb16af349de65
run-build-script-build-script-build.json
hashbrown-8ab779d7ca37cdb3
lib-hashbrown.json
hashbrown-bff21bba13d30b13
lib-hashbrown.json
hex-56182cc95fc90567
lib-hex.json
indexmap-3da2b57fafe8a922
lib-indexmap.json
indexmap-6430bcc6d9b6b022
run-build-script-build-script-build.json
itoa-38ca23f3b5cc1084
lib-itoa.json
keccak-c30f5e3f08dc6c11
lib-keccak.json
kickstarter-8be96a7c496feca5
lib-kickstarter.json
lazy_static-562387b3080fbc51
lib-lazy_static.json
memchr-9491eacefe0ad0dc
lib-memchr.json
memchr-e1c82dfc39c96ef7
run-build-script-build-script-build.json
memory_units-84a27755269c7ea0
lib-memory_units.json
near-primitives-core-cd02cb3ef378e353
lib-near-primitives-core.json
near-runtime-utils-f9ea6bdbe1bd12f7
lib-near-runtime-utils.json
near-sdk-5b2ab2955f2d6a75
lib-near-sdk.json
near-vm-errors-ad70bc8683aa8245
lib-near-vm-errors.json
near-vm-logic-0eb78ca9f125780b
lib-near-vm-logic.json
num-bigint-3977628d9dfbc775
lib-num-bigint.json
num-bigint-dbf9b0071d97cd3a
run-build-script-build-script-build.json
num-integer-5342594a6a02ebb8
run-build-script-build-script-build.json
num-integer-de11449a2e8df9d2
lib-num-integer.json
num-rational-1ee1b52ec200339e
run-build-script-build-script-build.json
num-rational-9e965740b1f1abcc
lib-num-rational.json
num-traits-129223ec70e4a8fe
lib-num-traits.json
num-traits-de57e672bda80ad4
run-build-script-build-script-build.json
opaque-debug-b6512314fc4b03ad
lib-opaque-debug.json
opaque-debug-c93c59623386fe78
lib-opaque-debug.json
regex-5887df20ed30600f
lib-regex.json
regex-syntax-9513715ec2d372d3
lib-regex-syntax.json
ryu-0e2a6d63b01d628c
lib-ryu.json
ryu-bb294c8eae7cfa08
run-build-script-build-script-build.json
serde-913016233980cf22
run-build-script-build-script-build.json
serde-dc4dd176c77499d9
lib-serde.json
serde_json-745422327ab7f238
lib-serde_json.json
serde_json-a376a6c6a0ea0dab
run-build-script-build-script-build.json
sha2-15b8663b2afd96e1
lib-sha2.json
sha3-1f1d5e5bb5884235
lib-sha3.json
typenum-06c51cf13ce231ef
run-build-script-build-script-main.json
typenum-2423079fbeb1a893
lib-typenum.json
wee_alloc-73630bc798d4f91c
lib-wee_alloc.json
wee_alloc-c7ef28050c3faa0b
run-build-script-build-script-build.json
build
num-bigint-dbf9b0071d97cd3a
out
radix_bases.rs
typenum-06c51cf13ce231ef
out
consts.rs
op.rs
tests.rs
wee_alloc-c7ef28050c3faa0b
out
wee_alloc_static_array_backend_size_bytes.txt
release
.fingerprint
ahash-5815f64aabde95f9
lib-ahash.json
aho-corasick-d04910c8b9149a85
lib-aho_corasick.json
base64-1f2951f76e992c63
lib-base64.json
block-buffer-15e5aa3d04d85d23
lib-block-buffer.json
block-buffer-a2380fc66e3ea82a
lib-block-buffer.json
block-padding-b4e583795d825d18
lib-block-padding.json
borsh-3dfbc529d4664b81
lib-borsh.json
bs58-68513a901160cb3e
lib-bs58.json
byte-tools-46b14d6e8e2f9a01
lib-byte-tools.json
byteorder-4557c722f37dace2
run-build-script-build-script-build.json
byteorder-8e3d32f690a120d5
lib-byteorder.json
cfg-if-86d9006dfb3e5fdf
lib-cfg-if.json
cfg-if-a275be0f72367260
lib-cfg-if.json
digest-2e8782c96b33e448
lib-digest.json
digest-f0aa4396e061e507
lib-digest.json
generic-array-05af4b32a0e3acd9
run-build-script-build-script-build.json
generic-array-346f70a73b21002f
lib-generic_array.json
generic-array-3fe6f2b3e1a083eb
lib-generic_array.json
greeter-98ace302c5fafa12
lib-greeter.json
hashbrown-01f48a4e19c2889d
lib-hashbrown.json
hashbrown-584611e9a36290b6
lib-hashbrown.json
hashbrown-cb7616551ab7d7e4
run-build-script-build-script-build.json
hex-98a3b9206e7c4e36
lib-hex.json
indexmap-877508f4d36dfe1d
lib-indexmap.json
indexmap-9f6cbf867726efc2
run-build-script-build-script-build.json
itoa-eb97f2ec576dea37
lib-itoa.json
keccak-9274143908b1239e
lib-keccak.json
kickstarter-8be96a7c496feca5
lib-kickstarter.json
lazy_static-4c067f64a4120a4b
lib-lazy_static.json
memchr-8fc76c8e2d003af8
run-build-script-build-script-build.json
memchr-bee7d9fc9cd9852c
lib-memchr.json
memory_units-3c482ee33b18f213
lib-memory_units.json
near-primitives-core-e88eaebb79a25a6d
lib-near-primitives-core.json
near-runtime-utils-03e7cd74f9d5cb14
lib-near-runtime-utils.json
near-sdk-ad3e7d59b4dbce6f
lib-near-sdk.json
near-vm-errors-84859b8189eb79ca
lib-near-vm-errors.json
near-vm-logic-4e42a100747c73cf
lib-near-vm-logic.json
num-bigint-4bb5ef0e7243d65f
run-build-script-build-script-build.json
num-bigint-6718f830f7d04205
lib-num-bigint.json
num-integer-6a3415c8d47c93be
run-build-script-build-script-build.json
num-integer-d128ea9eb47f115c
lib-num-integer.json
num-rational-99fa9fbfddeb01e1
lib-num-rational.json
num-rational-fa63d29ccc1c4434
run-build-script-build-script-build.json
num-traits-5160e3ab608b94b7
run-build-script-build-script-build.json
num-traits-747401cdf8a6dd69
lib-num-traits.json
opaque-debug-c0922baedcec4b33
lib-opaque-debug.json
opaque-debug-c4a89a0e1f9aef91
lib-opaque-debug.json
regex-95f2dd2a4ffa40ae
lib-regex.json
regex-syntax-f066ee2d69d9704b
lib-regex-syntax.json
ryu-a3c590b722eafbc2
lib-ryu.json
ryu-d4f751c424fd487e
run-build-script-build-script-build.json
serde-01bedb55801ea5e3
run-build-script-build-script-build.json
serde-123b4b086de59a25
lib-serde.json
serde_json-8c8c25ca536b524a
lib-serde_json.json
serde_json-ea70985868cc1b6d
run-build-script-build-script-build.json
sha2-29d4607209cb6d31
lib-sha2.json
sha3-d029838bb3a0720b
lib-sha3.json
typenum-1c1d8719c1f9d001
lib-typenum.json
typenum-5ebcd42d6340e668
run-build-script-build-script-main.json
wee_alloc-31f6879f0be31dfe
lib-wee_alloc.json
wee_alloc-79381b86304a059d
run-build-script-build-script-build.json
build
num-bigint-4bb5ef0e7243d65f
out
radix_bases.rs
typenum-5ebcd42d6340e668
out
consts.rs
op.rs
tests.rs
wee_alloc-79381b86304a059d
out
wee_alloc_static_array_backend_size_bytes.txt
package.json
src
App.js
Components
Campaign.css
Header.css
Projects.css
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
config.js
global.css
index.html
index.js
jest.init.js
main.test.js
utils.js
wallet
login
index.html
| kickstarterDapp
==================
This [React] app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `kickstarterDapp.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `kickstarterDapp.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account kickstarterDapp.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'kickstarterDapp.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
kickstarterDapp Smart Contract
==================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
|
novilusio_dacade-near-dapp | near-marketplace-contract
asconfig.json
assembly
as_types.d.ts
index.ts
model.ts
tsconfig.json
node_modules
@as-covers
assembly
CONTRIBUTING.md
README.md
index.ts
package.json
tsconfig.json
core
CONTRIBUTING.md
README.md
package.json
glue
README.md
lib
index.d.ts
index.js
package.json
transform
README.md
lib
index.d.ts
index.js
util.d.ts
util.js
node_modules
visitor-as
.github
workflows
test.yml
README.md
as
index.d.ts
index.js
asconfig.json
dist
astBuilder.d.ts
astBuilder.js
base.d.ts
base.js
baseTransform.d.ts
baseTransform.js
decorator.d.ts
decorator.js
examples
capitalize.d.ts
capitalize.js
exportAs.d.ts
exportAs.js
functionCallTransform.d.ts
functionCallTransform.js
includeBytesTransform.d.ts
includeBytesTransform.js
list.d.ts
list.js
toString.d.ts
toString.js
index.d.ts
index.js
path.d.ts
path.js
simpleParser.d.ts
simpleParser.js
transformRange.d.ts
transformRange.js
transformer.d.ts
transformer.js
utils.d.ts
utils.js
visitor.d.ts
visitor.js
package.json
tsconfig.json
package.json
@as-pect
assembly
README.md
assembly
index.ts
internal
Actual.ts
Expectation.ts
Expected.ts
Reflect.ts
ReflectedValueType.ts
Test.ts
assert.ts
call.ts
comparison
toIncludeComparison.ts
toIncludeEqualComparison.ts
log.ts
noOp.ts
package.json
types
as-pect.d.ts
as-pect.portable.d.ts
env.d.ts
cli
README.md
init
as-pect.config.js
env.d.ts
example.spec.ts
init-types.d.ts
portable-types.d.ts
lib
as-pect.cli.amd.d.ts
as-pect.cli.amd.js
help.d.ts
help.js
index.d.ts
index.js
init.d.ts
init.js
portable.d.ts
portable.js
run.d.ts
run.js
test.d.ts
test.js
types.d.ts
types.js
util
CommandLineArg.d.ts
CommandLineArg.js
IConfiguration.d.ts
IConfiguration.js
asciiArt.d.ts
asciiArt.js
collectReporter.d.ts
collectReporter.js
getTestEntryFiles.d.ts
getTestEntryFiles.js
removeFile.d.ts
removeFile.js
strings.d.ts
strings.js
writeFile.d.ts
writeFile.js
worklets
ICommand.d.ts
ICommand.js
compiler.d.ts
compiler.js
package.json
core
README.md
lib
as-pect.core.amd.d.ts
as-pect.core.amd.js
index.d.ts
index.js
reporter
CombinationReporter.d.ts
CombinationReporter.js
EmptyReporter.d.ts
EmptyReporter.js
IReporter.d.ts
IReporter.js
SummaryReporter.d.ts
SummaryReporter.js
VerboseReporter.d.ts
VerboseReporter.js
test
IWarning.d.ts
IWarning.js
TestContext.d.ts
TestContext.js
TestNode.d.ts
TestNode.js
transform
assemblyscript.d.ts
assemblyscript.js
createAddReflectedValueKeyValuePairsMember.d.ts
createAddReflectedValueKeyValuePairsMember.js
createGenericTypeParameter.d.ts
createGenericTypeParameter.js
createStrictEqualsMember.d.ts
createStrictEqualsMember.js
emptyTransformer.d.ts
emptyTransformer.js
hash.d.ts
hash.js
index.d.ts
index.js
util
IAspectExports.d.ts
IAspectExports.js
IWriteable.d.ts
IWriteable.js
ReflectedValue.d.ts
ReflectedValue.js
TestNodeType.d.ts
TestNodeType.js
rTrace.d.ts
rTrace.js
stringifyReflectedValue.d.ts
stringifyReflectedValue.js
timeDifference.d.ts
timeDifference.js
wasmTools.d.ts
wasmTools.js
package.json
csv-reporter
index.ts
lib
as-pect.csv-reporter.amd.d.ts
as-pect.csv-reporter.amd.js
index.d.ts
index.js
package.json
readme.md
tsconfig.json
json-reporter
index.ts
lib
as-pect.json-reporter.amd.d.ts
as-pect.json-reporter.amd.js
index.d.ts
index.js
package.json
readme.md
tsconfig.json
snapshots
__tests__
snapshot.spec.ts
jest.config.js
lib
Snapshot.d.ts
Snapshot.js
SnapshotDiff.d.ts
SnapshotDiff.js
SnapshotDiffResult.d.ts
SnapshotDiffResult.js
as-pect.core.amd.d.ts
as-pect.core.amd.js
index.d.ts
index.js
parser
grammar.d.ts
grammar.js
package.json
src
Snapshot.ts
SnapshotDiff.ts
SnapshotDiffResult.ts
index.ts
parser
grammar.ts
tsconfig.json
@assemblyscript
loader
README.md
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
@babel
code-frame
README.md
lib
index.js
package.json
helper-validator-identifier
README.md
lib
identifier.js
index.js
keyword.js
package.json
scripts
generate-identifier-regex.js
highlight
README.md
lib
index.js
node_modules
ansi-styles
index.js
package.json
readme.md
chalk
index.js
package.json
readme.md
templates.js
types
index.d.ts
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
.eslintrc.json
README.md
index.js
package.json
test.js
escape-string-regexp
index.js
package.json
readme.md
has-flag
index.js
package.json
readme.md
supports-color
browser.js
index.js
package.json
readme.md
package.json
@eslint
eslintrc
CHANGELOG.md
README.md
conf
config-schema.js
environments.js
eslint-all.js
eslint-recommended.js
lib
cascading-config-array-factory.js
config-array-factory.js
config-array
config-array.js
config-dependency.js
extracted-config.js
ignore-pattern.js
index.js
override-tester.js
flat-compat.js
index.js
shared
ajv.js
config-ops.js
config-validator.js
deprecation-warnings.js
naming.js
relative-module-resolver.js
types.js
package.json
@humanwhocodes
config-array
README.md
api.js
package.json
object-schema
.eslintrc.js
.github
workflows
nodejs-test.yml
release-please.yml
CHANGELOG.md
README.md
package.json
src
index.js
merge-strategy.js
object-schema.js
validation-strategy.js
tests
merge-strategy.js
object-schema.js
validation-strategy.js
acorn-jsx
README.md
index.d.ts
index.js
package.json
xhtml.js
acorn
CHANGELOG.md
README.md
dist
acorn.d.ts
acorn.js
acorn.mjs.d.ts
bin.js
package.json
ajv
.tonic_example.js
README.md
dist
ajv.bundle.js
ajv.min.js
lib
ajv.d.ts
ajv.js
cache.js
compile
async.js
equal.js
error_classes.js
formats.js
index.js
resolve.js
rules.js
schema_obj.js
ucs2length.js
util.js
data.js
definition_schema.js
dotjs
README.md
_limit.js
_limitItems.js
_limitLength.js
_limitProperties.js
allOf.js
anyOf.js
comment.js
const.js
contains.js
custom.js
dependencies.js
enum.js
format.js
if.js
index.js
items.js
multipleOf.js
not.js
oneOf.js
pattern.js
properties.js
propertyNames.js
ref.js
required.js
uniqueItems.js
validate.js
keyword.js
refs
data.json
json-schema-draft-04.json
json-schema-draft-06.json
json-schema-draft-07.json
json-schema-secure.json
package.json
scripts
.eslintrc.yml
bundle.js
compile-dots.js
ansi-colors
README.md
index.js
package.json
symbols.js
types
index.d.ts
ansi-regex
index.d.ts
index.js
package.json
readme.md
ansi-styles
index.d.ts
index.js
package.json
readme.md
argparse
CHANGELOG.md
README.md
index.js
lib
action.js
action
append.js
append
constant.js
count.js
help.js
store.js
store
constant.js
false.js
true.js
subparsers.js
version.js
action_container.js
argparse.js
argument
error.js
exclusive.js
group.js
argument_parser.js
const.js
help
added_formatters.js
formatter.js
namespace.js
utils.js
package.json
as-bignum
README.md
assembly
__tests__
as-pect.d.ts
i128.spec.as.ts
safe_u128.spec.as.ts
u128.spec.as.ts
u256.spec.as.ts
utils.ts
fixed
fp128.ts
fp256.ts
index.ts
safe
fp128.ts
fp256.ts
types.ts
globals.ts
index.ts
integer
i128.ts
i256.ts
index.ts
safe
i128.ts
i256.ts
i64.ts
index.ts
u128.ts
u256.ts
u64.ts
u128.ts
u256.ts
tsconfig.json
utils.ts
package.json
asbuild
README.md
dist
cli.d.ts
cli.js
commands
build.d.ts
build.js
fmt.d.ts
fmt.js
index.d.ts
index.js
init
cmd.d.ts
cmd.js
files
asconfigJson.d.ts
asconfigJson.js
aspecConfig.d.ts
aspecConfig.js
assembly_files.d.ts
assembly_files.js
eslintConfig.d.ts
eslintConfig.js
gitignores.d.ts
gitignores.js
index.d.ts
index.js
indexJs.d.ts
indexJs.js
packageJson.d.ts
packageJson.js
test_files.d.ts
test_files.js
index.d.ts
index.js
interfaces.d.ts
interfaces.js
run.d.ts
run.js
test.d.ts
test.js
index.d.ts
index.js
main.d.ts
main.js
utils.d.ts
utils.js
index.js
node_modules
cliui
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
wrap-ansi
index.js
package.json
readme.md
y18n
CHANGELOG.md
README.md
index.js
package.json
yargs-parser
CHANGELOG.md
LICENSE.txt
README.md
index.js
lib
tokenize-arg-string.js
package.json
yargs
CHANGELOG.md
README.md
build
lib
apply-extends.d.ts
apply-extends.js
argsert.d.ts
argsert.js
command.d.ts
command.js
common-types.d.ts
common-types.js
completion-templates.d.ts
completion-templates.js
completion.d.ts
completion.js
is-promise.d.ts
is-promise.js
levenshtein.d.ts
levenshtein.js
middleware.d.ts
middleware.js
obj-filter.d.ts
obj-filter.js
parse-command.d.ts
parse-command.js
process-argv.d.ts
process-argv.js
usage.d.ts
usage.js
validation.d.ts
validation.js
yargs.d.ts
yargs.js
yerror.d.ts
yerror.js
index.js
locales
be.json
de.json
en.json
es.json
fi.json
fr.json
hi.json
hu.json
id.json
it.json
ja.json
ko.json
nb.json
nl.json
nn.json
pirate.json
pl.json
pt.json
pt_BR.json
ru.json
th.json
tr.json
zh_CN.json
zh_TW.json
package.json
yargs.js
package.json
assemblyscript-json
.eslintrc.js
.travis.yml
README.md
assembly
JSON.ts
decoder.ts
encoder.ts
index.ts
tsconfig.json
util
index.ts
index.js
package.json
temp-docs
README.md
classes
decoderstate.md
json.arr.md
json.bool.md
json.float.md
json.integer.md
json.null.md
json.num.md
json.obj.md
json.str.md
json.value.md
jsondecoder.md
jsonencoder.md
jsonhandler.md
throwingjsonhandler.md
modules
json.md
assemblyscript-regex
.eslintrc.js
.github
workflows
benchmark.yml
release.yml
test.yml
README.md
as-pect.config.js
asconfig.empty.json
asconfig.json
assembly
__spec_tests__
generated.spec.ts
__tests__
alterations.spec.ts
as-pect.d.ts
boundary-assertions.spec.ts
capture-group.spec.ts
character-classes.spec.ts
character-sets.spec.ts
characters.ts
empty.ts
quantifiers.spec.ts
range-quantifiers.spec.ts
regex.spec.ts
utils.ts
char.ts
env.ts
index.ts
nfa
matcher.ts
nfa.ts
types.ts
walker.ts
parser
node.ts
parser.ts
string-iterator.ts
walker.ts
regexp.ts
tsconfig.json
util.ts
benchmark
benchmark.js
package.json
spec
test-generator.js
ts
index.ts
tsconfig.json
assemblyscript-temporal
.github
workflows
node.js.yml
release.yml
.vscode
launch.json
README.md
as-pect.config.js
asconfig.empty.json
asconfig.json
assembly
__tests__
README.md
as-pect.d.ts
date.spec.ts
duration.spec.ts
empty.ts
plaindate.spec.ts
plaindatetime.spec.ts
plainmonthday.spec.ts
plaintime.spec.ts
plainyearmonth.spec.ts
timezone.spec.ts
zoneddatetime.spec.ts
constants.ts
date.ts
duration.ts
enums.ts
env.ts
index.ts
instant.ts
now.ts
plaindate.ts
plaindatetime.ts
plainmonthday.ts
plaintime.ts
plainyearmonth.ts
timezone.ts
tsconfig.json
tz
__tests__
index.spec.ts
rule.spec.ts
zone.spec.ts
iana.ts
index.ts
rule.ts
zone.ts
utils.ts
zoneddatetime.ts
development.md
package.json
tzdb
README.md
iana
theory.html
zoneinfo2tdf.pl
assemblyscript
README.md
cli
README.md
asc.d.ts
asc.js
asc.json
shim
README.md
fs.js
path.js
process.js
transform.d.ts
transform.js
util
colors.d.ts
colors.js
find.d.ts
find.js
mkdirp.d.ts
mkdirp.js
options.d.ts
options.js
utf8.d.ts
utf8.js
dist
asc.js
assemblyscript.d.ts
assemblyscript.js
sdk.js
index.d.ts
index.js
lib
loader
README.md
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
rtrace
README.md
bin
rtplot.js
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
package-lock.json
package.json
std
README.md
assembly.json
assembly
array.ts
arraybuffer.ts
atomics.ts
bindings
Date.ts
Math.ts
Reflect.ts
asyncify.ts
console.ts
wasi.ts
wasi_snapshot_preview1.ts
wasi_unstable.ts
builtins.ts
compat.ts
console.ts
crypto.ts
dataview.ts
date.ts
diagnostics.ts
error.ts
function.ts
index.d.ts
iterator.ts
map.ts
math.ts
memory.ts
number.ts
object.ts
polyfills.ts
process.ts
reference.ts
regexp.ts
rt.ts
rt
README.md
common.ts
index-incremental.ts
index-minimal.ts
index-stub.ts
index.d.ts
itcms.ts
rtrace.ts
stub.ts
tcms.ts
tlsf.ts
set.ts
shared
feature.ts
target.ts
tsconfig.json
typeinfo.ts
staticarray.ts
string.ts
symbol.ts
table.ts
tsconfig.json
typedarray.ts
uri.ts
util
casemap.ts
error.ts
hash.ts
math.ts
memory.ts
number.ts
sort.ts
string.ts
uri.ts
vector.ts
wasi
index.ts
portable.json
portable
index.d.ts
index.js
types
assembly
index.d.ts
package.json
portable
index.d.ts
package.json
tsconfig-base.json
astral-regex
index.d.ts
index.js
package.json
readme.md
axios
CHANGELOG.md
README.md
UPGRADE_GUIDE.md
dist
axios.js
axios.min.js
index.d.ts
index.js
lib
adapters
README.md
http.js
xhr.js
axios.js
cancel
Cancel.js
CancelToken.js
isCancel.js
core
Axios.js
InterceptorManager.js
README.md
buildFullPath.js
createError.js
dispatchRequest.js
enhanceError.js
mergeConfig.js
settle.js
transformData.js
defaults.js
helpers
README.md
bind.js
buildURL.js
combineURLs.js
cookies.js
deprecatedMethod.js
isAbsoluteURL.js
isURLSameOrigin.js
normalizeHeaderName.js
parseHeaders.js
spread.js
utils.js
package.json
balanced-match
.github
FUNDING.yml
LICENSE.md
README.md
index.js
package.json
base-x
LICENSE.md
README.md
package.json
src
index.d.ts
index.js
binary-install
README.md
example
binary.js
package.json
run.js
index.js
package.json
src
binary.js
binaryen
README.md
index.d.ts
package-lock.json
package.json
wasm.d.ts
bn.js
CHANGELOG.md
README.md
lib
bn.js
package.json
brace-expansion
README.md
index.js
package.json
bs58
CHANGELOG.md
README.md
index.js
package.json
callsites
index.d.ts
index.js
package.json
readme.md
camelcase
index.d.ts
index.js
package.json
readme.md
chalk
index.d.ts
package.json
readme.md
source
index.js
templates.js
util.js
chownr
README.md
chownr.js
package.json
cliui
CHANGELOG.md
LICENSE.txt
README.md
build
lib
index.js
string-utils.js
package.json
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
README.md
index.js
package.json
commander
CHANGELOG.md
Readme.md
index.js
package.json
typings
index.d.ts
concat-map
.travis.yml
example
map.js
index.js
package.json
test
map.js
cross-spawn
CHANGELOG.md
README.md
index.js
lib
enoent.js
parse.js
util
escape.js
readShebang.js
resolveCommand.js
package.json
csv-stringify
README.md
lib
browser
index.js
sync.js
es5
index.d.ts
index.js
sync.d.ts
sync.js
index.d.ts
index.js
sync.d.ts
sync.js
package.json
debug
README.md
package.json
src
browser.js
common.js
index.js
node.js
decamelize
index.js
package.json
readme.md
deep-is
.travis.yml
example
cmp.js
index.js
package.json
test
NaN.js
cmp.js
neg-vs-pos-0.js
diff
CONTRIBUTING.md
README.md
dist
diff.js
lib
convert
dmp.js
xml.js
diff
array.js
base.js
character.js
css.js
json.js
line.js
sentence.js
word.js
index.es6.js
index.js
patch
apply.js
create.js
merge.js
parse.js
util
array.js
distance-iterator.js
params.js
package.json
release-notes.md
runtime.js
discontinuous-range
.travis.yml
README.md
index.js
package.json
test
main-test.js
doctrine
CHANGELOG.md
README.md
lib
doctrine.js
typed.js
utility.js
package.json
emoji-regex
LICENSE-MIT.txt
README.md
es2015
index.js
text.js
index.d.ts
index.js
package.json
text.js
enquirer
CHANGELOG.md
README.md
index.d.ts
index.js
lib
ansi.js
combos.js
completer.js
interpolate.js
keypress.js
placeholder.js
prompt.js
prompts
autocomplete.js
basicauth.js
confirm.js
editable.js
form.js
index.js
input.js
invisible.js
list.js
multiselect.js
numeral.js
password.js
quiz.js
scale.js
select.js
snippet.js
sort.js
survey.js
text.js
toggle.js
render.js
roles.js
state.js
styles.js
symbols.js
theme.js
timer.js
types
array.js
auth.js
boolean.js
index.js
number.js
string.js
utils.js
package.json
env-paths
index.d.ts
index.js
package.json
readme.md
escalade
dist
index.js
index.d.ts
package.json
readme.md
sync
index.d.ts
index.js
escape-string-regexp
index.d.ts
index.js
package.json
readme.md
eslint-scope
CHANGELOG.md
README.md
lib
definition.js
index.js
pattern-visitor.js
reference.js
referencer.js
scope-manager.js
scope.js
variable.js
node_modules
estraverse
README.md
estraverse.js
gulpfile.js
package.json
package.json
eslint-utils
README.md
index.js
package.json
eslint-visitor-keys
CHANGELOG.md
README.md
lib
index.js
visitor-keys.json
package.json
eslint
CHANGELOG.md
README.md
bin
eslint.js
conf
category-list.json
config-schema.js
default-cli-options.js
eslint-all.js
eslint-recommended.js
replacements.json
lib
api.js
cli-engine
cli-engine.js
file-enumerator.js
formatters
checkstyle.js
codeframe.js
compact.js
html.js
jslint-xml.js
json-with-metadata.js
json.js
junit.js
stylish.js
table.js
tap.js
unix.js
visualstudio.js
hash.js
index.js
lint-result-cache.js
load-rules.js
xml-escape.js
cli.js
config
default-config.js
flat-config-array.js
flat-config-schema.js
rule-validator.js
eslint
eslint.js
index.js
init
autoconfig.js
config-file.js
config-initializer.js
config-rule.js
npm-utils.js
source-code-utils.js
linter
apply-disable-directives.js
code-path-analysis
code-path-analyzer.js
code-path-segment.js
code-path-state.js
code-path.js
debug-helpers.js
fork-context.js
id-generator.js
config-comment-parser.js
index.js
interpolate.js
linter.js
node-event-generator.js
report-translator.js
rule-fixer.js
rules.js
safe-emitter.js
source-code-fixer.js
timing.js
options.js
rule-tester
index.js
rule-tester.js
rules
accessor-pairs.js
array-bracket-newline.js
array-bracket-spacing.js
array-callback-return.js
array-element-newline.js
arrow-body-style.js
arrow-parens.js
arrow-spacing.js
block-scoped-var.js
block-spacing.js
brace-style.js
callback-return.js
camelcase.js
capitalized-comments.js
class-methods-use-this.js
comma-dangle.js
comma-spacing.js
comma-style.js
complexity.js
computed-property-spacing.js
consistent-return.js
consistent-this.js
constructor-super.js
curly.js
default-case-last.js
default-case.js
default-param-last.js
dot-location.js
dot-notation.js
eol-last.js
eqeqeq.js
for-direction.js
func-call-spacing.js
func-name-matching.js
func-names.js
func-style.js
function-call-argument-newline.js
function-paren-newline.js
generator-star-spacing.js
getter-return.js
global-require.js
grouped-accessor-pairs.js
guard-for-in.js
handle-callback-err.js
id-blacklist.js
id-denylist.js
id-length.js
id-match.js
implicit-arrow-linebreak.js
indent-legacy.js
indent.js
index.js
init-declarations.js
jsx-quotes.js
key-spacing.js
keyword-spacing.js
line-comment-position.js
linebreak-style.js
lines-around-comment.js
lines-around-directive.js
lines-between-class-members.js
max-classes-per-file.js
max-depth.js
max-len.js
max-lines-per-function.js
max-lines.js
max-nested-callbacks.js
max-params.js
max-statements-per-line.js
max-statements.js
multiline-comment-style.js
multiline-ternary.js
new-cap.js
new-parens.js
newline-after-var.js
newline-before-return.js
newline-per-chained-call.js
no-alert.js
no-array-constructor.js
no-async-promise-executor.js
no-await-in-loop.js
no-bitwise.js
no-buffer-constructor.js
no-caller.js
no-case-declarations.js
no-catch-shadow.js
no-class-assign.js
no-compare-neg-zero.js
no-cond-assign.js
no-confusing-arrow.js
no-console.js
no-const-assign.js
no-constant-condition.js
no-constructor-return.js
no-continue.js
no-control-regex.js
no-debugger.js
no-delete-var.js
no-div-regex.js
no-dupe-args.js
no-dupe-class-members.js
no-dupe-else-if.js
no-dupe-keys.js
no-duplicate-case.js
no-duplicate-imports.js
no-else-return.js
no-empty-character-class.js
no-empty-function.js
no-empty-pattern.js
no-empty.js
no-eq-null.js
no-eval.js
no-ex-assign.js
no-extend-native.js
no-extra-bind.js
no-extra-boolean-cast.js
no-extra-label.js
no-extra-parens.js
no-extra-semi.js
no-fallthrough.js
no-floating-decimal.js
no-func-assign.js
no-global-assign.js
no-implicit-coercion.js
no-implicit-globals.js
no-implied-eval.js
no-import-assign.js
no-inline-comments.js
no-inner-declarations.js
no-invalid-regexp.js
no-invalid-this.js
no-irregular-whitespace.js
no-iterator.js
no-label-var.js
no-labels.js
no-lone-blocks.js
no-lonely-if.js
no-loop-func.js
no-loss-of-precision.js
no-magic-numbers.js
no-misleading-character-class.js
no-mixed-operators.js
no-mixed-requires.js
no-mixed-spaces-and-tabs.js
no-multi-assign.js
no-multi-spaces.js
no-multi-str.js
no-multiple-empty-lines.js
no-native-reassign.js
no-negated-condition.js
no-negated-in-lhs.js
no-nested-ternary.js
no-new-func.js
no-new-object.js
no-new-require.js
no-new-symbol.js
no-new-wrappers.js
no-new.js
no-nonoctal-decimal-escape.js
no-obj-calls.js
no-octal-escape.js
no-octal.js
no-param-reassign.js
no-path-concat.js
no-plusplus.js
no-process-env.js
no-process-exit.js
no-promise-executor-return.js
no-proto.js
no-prototype-builtins.js
no-redeclare.js
no-regex-spaces.js
no-restricted-exports.js
no-restricted-globals.js
no-restricted-imports.js
no-restricted-modules.js
no-restricted-properties.js
no-restricted-syntax.js
no-return-assign.js
no-return-await.js
no-script-url.js
no-self-assign.js
no-self-compare.js
no-sequences.js
no-setter-return.js
no-shadow-restricted-names.js
no-shadow.js
no-spaced-func.js
no-sparse-arrays.js
no-sync.js
no-tabs.js
no-template-curly-in-string.js
no-ternary.js
no-this-before-super.js
no-throw-literal.js
no-trailing-spaces.js
no-undef-init.js
no-undef.js
no-undefined.js
no-underscore-dangle.js
no-unexpected-multiline.js
no-unmodified-loop-condition.js
no-unneeded-ternary.js
no-unreachable-loop.js
no-unreachable.js
no-unsafe-finally.js
no-unsafe-negation.js
no-unsafe-optional-chaining.js
no-unused-expressions.js
no-unused-labels.js
no-unused-vars.js
no-use-before-define.js
no-useless-backreference.js
no-useless-call.js
no-useless-catch.js
no-useless-computed-key.js
no-useless-concat.js
no-useless-constructor.js
no-useless-escape.js
no-useless-rename.js
no-useless-return.js
no-var.js
no-void.js
no-warning-comments.js
no-whitespace-before-property.js
no-with.js
nonblock-statement-body-position.js
object-curly-newline.js
object-curly-spacing.js
object-property-newline.js
object-shorthand.js
one-var-declaration-per-line.js
one-var.js
operator-assignment.js
operator-linebreak.js
padded-blocks.js
padding-line-between-statements.js
prefer-arrow-callback.js
prefer-const.js
prefer-destructuring.js
prefer-exponentiation-operator.js
prefer-named-capture-group.js
prefer-numeric-literals.js
prefer-object-spread.js
prefer-promise-reject-errors.js
prefer-reflect.js
prefer-regex-literals.js
prefer-rest-params.js
prefer-spread.js
prefer-template.js
quote-props.js
quotes.js
radix.js
require-atomic-updates.js
require-await.js
require-jsdoc.js
require-unicode-regexp.js
require-yield.js
rest-spread-spacing.js
semi-spacing.js
semi-style.js
semi.js
sort-imports.js
sort-keys.js
sort-vars.js
space-before-blocks.js
space-before-function-paren.js
space-in-parens.js
space-infix-ops.js
space-unary-ops.js
spaced-comment.js
strict.js
switch-colon-spacing.js
symbol-description.js
template-curly-spacing.js
template-tag-spacing.js
unicode-bom.js
use-isnan.js
utils
ast-utils.js
fix-tracker.js
keywords.js
lazy-loading-rule-map.js
patterns
letters.js
unicode
index.js
is-combining-character.js
is-emoji-modifier.js
is-regional-indicator-symbol.js
is-surrogate-pair.js
valid-jsdoc.js
valid-typeof.js
vars-on-top.js
wrap-iife.js
wrap-regex.js
yield-star-spacing.js
yoda.js
shared
ajv.js
ast-utils.js
config-validator.js
deprecation-warnings.js
logging.js
relative-module-resolver.js
runtime-info.js
string-utils.js
traverser.js
types.js
source-code
index.js
source-code.js
token-store
backward-token-comment-cursor.js
backward-token-cursor.js
cursor.js
cursors.js
decorative-cursor.js
filter-cursor.js
forward-token-comment-cursor.js
forward-token-cursor.js
index.js
limit-cursor.js
padded-token-cursor.js
skip-cursor.js
utils.js
messages
all-files-ignored.js
extend-config-missing.js
failed-to-read-json.js
file-not-found.js
no-config-found.js
plugin-conflict.js
plugin-invalid.js
plugin-missing.js
print-config-with-directory-path.js
whitespace-found.js
node_modules
eslint-visitor-keys
CHANGELOG.md
README.md
lib
index.js
visitor-keys.json
package.json
package.json
espree
CHANGELOG.md
README.md
espree.js
lib
ast-node-types.js
espree.js
features.js
options.js
token-translator.js
visitor-keys.js
package.json
esprima
README.md
bin
esparse.js
esvalidate.js
dist
esprima.js
package.json
esquery
README.md
dist
esquery.esm.js
esquery.esm.min.js
esquery.js
esquery.lite.js
esquery.lite.min.js
esquery.min.js
license.txt
package.json
parser.js
esrecurse
README.md
esrecurse.js
gulpfile.babel.js
package.json
estraverse
README.md
estraverse.js
gulpfile.js
package.json
esutils
README.md
lib
ast.js
code.js
keyword.js
utils.js
package.json
fast-deep-equal
README.md
es6
index.d.ts
index.js
react.d.ts
react.js
index.d.ts
index.js
package.json
react.d.ts
react.js
fast-json-stable-stringify
.eslintrc.yml
.github
FUNDING.yml
.travis.yml
README.md
benchmark
index.js
test.json
example
key_cmp.js
nested.js
str.js
value_cmp.js
index.d.ts
index.js
package.json
test
cmp.js
nested.js
str.js
to-json.js
fast-levenshtein
LICENSE.md
README.md
levenshtein.js
package.json
file-entry-cache
README.md
cache.js
changelog.md
package.json
find-up
index.d.ts
index.js
package.json
readme.md
flat-cache
README.md
changelog.md
package.json
src
cache.js
del.js
utils.js
flatted
.github
FUNDING.yml
workflows
node.js.yml
README.md
SPECS.md
cjs
index.js
package.json
es.js
esm
index.js
index.js
min.js
package.json
php
flatted.php
types.d.ts
follow-redirects
README.md
http.js
https.js
index.js
node_modules
debug
.coveralls.yml
.travis.yml
CHANGELOG.md
README.md
karma.conf.js
node.js
package.json
src
browser.js
debug.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
fs-minipass
README.md
index.js
package.json
fs.realpath
README.md
index.js
old.js
package.json
functional-red-black-tree
README.md
bench
test.js
package.json
rbtree.js
test
test.js
get-caller-file
LICENSE.md
README.md
index.d.ts
index.js
package.json
glob-parent
CHANGELOG.md
README.md
index.js
package.json
glob
README.md
common.js
glob.js
package.json
sync.js
globals
globals.json
index.d.ts
index.js
package.json
readme.md
has-flag
index.d.ts
index.js
package.json
readme.md
hasurl
README.md
index.js
package.json
ignore
CHANGELOG.md
README.md
index.d.ts
index.js
legacy.js
package.json
import-fresh
index.d.ts
index.js
package.json
readme.md
imurmurhash
README.md
imurmurhash.js
imurmurhash.min.js
package.json
inflight
README.md
inflight.js
package.json
inherits
README.md
inherits.js
inherits_browser.js
package.json
is-extglob
README.md
index.js
package.json
is-fullwidth-code-point
index.d.ts
index.js
package.json
readme.md
is-glob
README.md
index.js
package.json
isarray
.travis.yml
README.md
component.json
index.js
package.json
test.js
isexe
README.md
index.js
mode.js
package.json
test
basic.js
windows.js
isobject
README.md
index.js
package.json
js-base64
LICENSE.md
README.md
base64.d.ts
base64.js
package.json
js-tokens
CHANGELOG.md
README.md
index.js
package.json
js-yaml
CHANGELOG.md
README.md
bin
js-yaml.js
dist
js-yaml.js
js-yaml.min.js
index.js
lib
js-yaml.js
js-yaml
common.js
dumper.js
exception.js
loader.js
mark.js
schema.js
schema
core.js
default_full.js
default_safe.js
failsafe.js
json.js
type.js
type
binary.js
bool.js
float.js
int.js
js
function.js
regexp.js
undefined.js
map.js
merge.js
null.js
omap.js
pairs.js
seq.js
set.js
str.js
timestamp.js
package.json
json-schema-traverse
.eslintrc.yml
.travis.yml
README.md
index.js
package.json
spec
.eslintrc.yml
fixtures
schema.js
index.spec.js
json-stable-stringify-without-jsonify
.travis.yml
example
key_cmp.js
nested.js
str.js
value_cmp.js
index.js
package.json
test
cmp.js
nested.js
replacer.js
space.js
str.js
to-json.js
levn
README.md
lib
cast.js
index.js
parse-string.js
package.json
line-column
README.md
lib
line-column.js
package.json
locate-path
index.d.ts
index.js
package.json
readme.md
lodash.clonedeep
README.md
index.js
package.json
lodash.merge
README.md
index.js
package.json
lodash.sortby
README.md
index.js
package.json
lodash.truncate
README.md
index.js
package.json
long
README.md
dist
long.js
index.js
package.json
src
long.js
lru-cache
README.md
index.js
package.json
minimatch
README.md
minimatch.js
package.json
minimist
.travis.yml
example
parse.js
index.js
package.json
test
all_bool.js
bool.js
dash.js
default_bool.js
dotted.js
kv_short.js
long.js
num.js
parse.js
parse_modified.js
proto.js
short.js
stop_early.js
unknown.js
whitespace.js
minipass
README.md
index.js
package.json
minizlib
README.md
constants.js
index.js
package.json
mkdirp
bin
cmd.js
usage.txt
index.js
package.json
moo
README.md
moo.js
package.json
ms
index.js
license.md
package.json
readme.md
natural-compare
README.md
index.js
package.json
near-mock-vm
assembly
__tests__
main.ts
context.ts
index.ts
outcome.ts
vm.ts
bin
bin.js
package.json
pkg
near_mock_vm.d.ts
near_mock_vm.js
package.json
vm
dist
cli.d.ts
cli.js
context.d.ts
context.js
index.d.ts
index.js
memory.d.ts
memory.js
runner.d.ts
runner.js
utils.d.ts
utils.js
index.js
near-sdk-as
README.md
as-pect.config.js
as_types.d.ts
asconfig.json
asp.asconfig.json
assembly
__tests__
as-pect.d.ts
assert.spec.ts
avl-tree.spec.ts
bignum.spec.ts
contract.spec.ts
contract.ts
data.txt
datetime.spec.ts
empty.ts
generic.ts
includeBytes.spec.ts
main.ts
max-heap.spec.ts
model.ts
near.spec.ts
persistent-set.spec.ts
promise.spec.ts
rollback.spec.ts
roundtrip.spec.ts
runtime.spec.ts
unordered-map.spec.ts
util.ts
utils.spec.ts
as_types.d.ts
bindgen.ts
index.ts
json.lib.ts
tsconfig.json
vm
__tests__
vm.include.ts
index.ts
compiler.js
imports.js
out
assembly
__tests__
ason.ts
model.ts
~lib
as-bignum
integer
safe
u128.ts
package.json
near-sdk-bindgen
README.md
assembly
index.ts
compiler.js
dist
JSONBuilder.d.ts
JSONBuilder.js
classExporter.d.ts
classExporter.js
index.d.ts
index.js
transformer.d.ts
transformer.js
typeChecker.d.ts
typeChecker.js
utils.d.ts
utils.js
index.js
package.json
near-sdk-core
README.md
asconfig.json
assembly
as_types.d.ts
base58.ts
base64.ts
bignum.ts
collections
avlTree.ts
index.ts
maxHeap.ts
persistentDeque.ts
persistentMap.ts
persistentSet.ts
persistentUnorderedMap.ts
persistentVector.ts
util.ts
contract.ts
datetime.ts
env
env.ts
index.ts
runtime_api.ts
index.ts
logging.ts
math.ts
promise.ts
storage.ts
tsconfig.json
util.ts
docs
assets
css
main.css
js
main.js
search.json
classes
_sdk_core_assembly_collections_avltree_.avltree.html
_sdk_core_assembly_collections_avltree_.avltreenode.html
_sdk_core_assembly_collections_avltree_.childparentpair.html
_sdk_core_assembly_collections_avltree_.nullable.html
_sdk_core_assembly_collections_persistentdeque_.persistentdeque.html
_sdk_core_assembly_collections_persistentmap_.persistentmap.html
_sdk_core_assembly_collections_persistentset_.persistentset.html
_sdk_core_assembly_collections_persistentunorderedmap_.persistentunorderedmap.html
_sdk_core_assembly_collections_persistentvector_.persistentvector.html
_sdk_core_assembly_contract_.context-1.html
_sdk_core_assembly_contract_.contractpromise.html
_sdk_core_assembly_contract_.contractpromiseresult.html
_sdk_core_assembly_math_.rng.html
_sdk_core_assembly_promise_.contractpromisebatch.html
_sdk_core_assembly_storage_.storage-1.html
globals.html
index.html
modules
_sdk_core_assembly_base58_.base58.html
_sdk_core_assembly_base58_.html
_sdk_core_assembly_base64_.base64.html
_sdk_core_assembly_base64_.html
_sdk_core_assembly_collections_avltree_.html
_sdk_core_assembly_collections_index_.collections.html
_sdk_core_assembly_collections_index_.html
_sdk_core_assembly_collections_persistentdeque_.html
_sdk_core_assembly_collections_persistentmap_.html
_sdk_core_assembly_collections_persistentset_.html
_sdk_core_assembly_collections_persistentunorderedmap_.html
_sdk_core_assembly_collections_persistentvector_.html
_sdk_core_assembly_collections_util_.html
_sdk_core_assembly_contract_.html
_sdk_core_assembly_env_env_.env.html
_sdk_core_assembly_env_env_.html
_sdk_core_assembly_env_index_.html
_sdk_core_assembly_env_runtime_api_.html
_sdk_core_assembly_index_.html
_sdk_core_assembly_logging_.html
_sdk_core_assembly_logging_.logging.html
_sdk_core_assembly_math_.html
_sdk_core_assembly_math_.math.html
_sdk_core_assembly_promise_.html
_sdk_core_assembly_storage_.html
_sdk_core_assembly_util_.html
_sdk_core_assembly_util_.util.html
package.json
near-sdk-simulator
__tests__
avl-tree-contract.spec.ts
cross.spec.ts
empty.spec.ts
exportAs.spec.ts
singleton-no-constructor.spec.ts
singleton.spec.ts
asconfig.js
asconfig.json
assembly
__tests__
avlTreeContract.ts
empty.ts
exportAs.ts
model.ts
sentences.ts
singleton-fail.ts
singleton-no-constructor.ts
singleton.ts
words.ts
as_types.d.ts
tsconfig.json
dist
bin.d.ts
bin.js
context.d.ts
context.js
index.d.ts
index.js
runtime.d.ts
runtime.js
types.d.ts
types.js
utils.d.ts
utils.js
jest.config.js
out
assembly
__tests__
empty.ts
exportAs.ts
model.ts
sentences.ts
singleton copy.ts
singleton-no-constructor.ts
singleton.ts
package.json
src
context.ts
index.ts
runtime.ts
types.ts
utils.ts
tsconfig.json
near-vm
getBinary.js
install.js
package.json
run.js
uninstall.js
nearley
LICENSE.txt
README.md
bin
nearley-railroad.js
nearley-test.js
nearley-unparse.js
nearleyc.js
lib
compile.js
generate.js
lint.js
nearley-language-bootstrapped.js
nearley.js
stream.js
unparse.js
package.json
once
README.md
once.js
package.json
optionator
CHANGELOG.md
README.md
lib
help.js
index.js
util.js
package.json
p-limit
index.d.ts
index.js
package.json
readme.md
p-locate
index.d.ts
index.js
package.json
readme.md
p-try
index.d.ts
index.js
package.json
readme.md
parent-module
index.js
package.json
readme.md
path-exists
index.d.ts
index.js
package.json
readme.md
path-is-absolute
index.js
package.json
readme.md
path-key
index.d.ts
index.js
package.json
readme.md
prelude-ls
CHANGELOG.md
README.md
lib
Func.js
List.js
Num.js
Obj.js
Str.js
index.js
package.json
progress
CHANGELOG.md
Readme.md
index.js
lib
node-progress.js
package.json
punycode
LICENSE-MIT.txt
README.md
package.json
punycode.es6.js
punycode.js
railroad-diagrams
README.md
example.html
generator.html
package.json
railroad-diagrams.css
railroad-diagrams.js
railroad_diagrams.py
randexp
README.md
lib
randexp.js
package.json
regexpp
README.md
index.d.ts
index.js
package.json
require-directory
.travis.yml
index.js
package.json
require-from-string
index.js
package.json
readme.md
require-main-filename
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
resolve-from
index.js
package.json
readme.md
ret
README.md
lib
index.js
positions.js
sets.js
types.js
util.js
package.json
rimraf
CHANGELOG.md
README.md
bin.js
package.json
rimraf.js
safe-buffer
README.md
index.d.ts
index.js
package.json
semver
README.md
bin
semver.js
classes
comparator.js
index.js
range.js
semver.js
functions
clean.js
cmp.js
coerce.js
compare-build.js
compare-loose.js
compare.js
diff.js
eq.js
gt.js
gte.js
inc.js
lt.js
lte.js
major.js
minor.js
neq.js
parse.js
patch.js
prerelease.js
rcompare.js
rsort.js
satisfies.js
sort.js
valid.js
index.js
internal
constants.js
debug.js
identifiers.js
parse-options.js
re.js
package.json
preload.js
ranges
gtr.js
intersects.js
ltr.js
max-satisfying.js
min-satisfying.js
min-version.js
outside.js
simplify.js
subset.js
to-comparators.js
valid.js
set-blocking
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
shebang-command
index.js
package.json
readme.md
shebang-regex
index.d.ts
index.js
package.json
readme.md
slice-ansi
index.js
package.json
readme.md
sprintf-js
README.md
bower.json
demo
angular.html
dist
angular-sprintf.min.js
sprintf.min.js
gruntfile.js
package.json
src
angular-sprintf.js
sprintf.js
test
test.js
string-width
index.d.ts
index.js
package.json
readme.md
strip-ansi
index.d.ts
index.js
package.json
readme.md
strip-json-comments
index.d.ts
index.js
package.json
readme.md
supports-color
browser.js
index.js
package.json
readme.md
table
README.md
dist
src
alignSpanningCell.d.ts
alignSpanningCell.js
alignString.d.ts
alignString.js
alignTableData.d.ts
alignTableData.js
calculateCellHeight.d.ts
calculateCellHeight.js
calculateMaximumColumnWidths.d.ts
calculateMaximumColumnWidths.js
calculateOutputColumnWidths.d.ts
calculateOutputColumnWidths.js
calculateRowHeights.d.ts
calculateRowHeights.js
calculateSpanningCellWidth.d.ts
calculateSpanningCellWidth.js
createStream.d.ts
createStream.js
drawBorder.d.ts
drawBorder.js
drawContent.d.ts
drawContent.js
drawRow.d.ts
drawRow.js
drawTable.d.ts
drawTable.js
generated
validators.d.ts
validators.js
getBorderCharacters.d.ts
getBorderCharacters.js
index.d.ts
index.js
injectHeaderConfig.d.ts
injectHeaderConfig.js
makeRangeConfig.d.ts
makeRangeConfig.js
makeStreamConfig.d.ts
makeStreamConfig.js
makeTableConfig.d.ts
makeTableConfig.js
mapDataUsingRowHeights.d.ts
mapDataUsingRowHeights.js
padTableData.d.ts
padTableData.js
schemas
config.json
shared.json
streamConfig.json
spanningCellManager.d.ts
spanningCellManager.js
stringifyTableData.d.ts
stringifyTableData.js
table.d.ts
table.js
truncateTableData.d.ts
truncateTableData.js
types
api.d.ts
api.js
internal.d.ts
internal.js
utils.d.ts
utils.js
validateConfig.d.ts
validateConfig.js
validateSpanningCellConfig.d.ts
validateSpanningCellConfig.js
validateTableData.d.ts
validateTableData.js
wrapCell.d.ts
wrapCell.js
wrapString.d.ts
wrapString.js
wrapWord.d.ts
wrapWord.js
node_modules
ajv
.runkit_example.js
README.md
dist
2019.d.ts
2019.js
2020.d.ts
2020.js
ajv.d.ts
ajv.js
compile
codegen
code.d.ts
code.js
index.d.ts
index.js
scope.d.ts
scope.js
errors.d.ts
errors.js
index.d.ts
index.js
jtd
parse.d.ts
parse.js
serialize.d.ts
serialize.js
types.d.ts
types.js
names.d.ts
names.js
ref_error.d.ts
ref_error.js
resolve.d.ts
resolve.js
rules.d.ts
rules.js
util.d.ts
util.js
validate
applicability.d.ts
applicability.js
boolSchema.d.ts
boolSchema.js
dataType.d.ts
dataType.js
defaults.d.ts
defaults.js
index.d.ts
index.js
keyword.d.ts
keyword.js
subschema.d.ts
subschema.js
core.d.ts
core.js
jtd.d.ts
jtd.js
refs
data.json
json-schema-2019-09
index.d.ts
index.js
meta
applicator.json
content.json
core.json
format.json
meta-data.json
validation.json
schema.json
json-schema-2020-12
index.d.ts
index.js
meta
applicator.json
content.json
core.json
format-annotation.json
meta-data.json
unevaluated.json
validation.json
schema.json
json-schema-draft-06.json
json-schema-draft-07.json
json-schema-secure.json
jtd-schema.d.ts
jtd-schema.js
runtime
equal.d.ts
equal.js
parseJson.d.ts
parseJson.js
quote.d.ts
quote.js
re2.d.ts
re2.js
timestamp.d.ts
timestamp.js
ucs2length.d.ts
ucs2length.js
uri.d.ts
uri.js
validation_error.d.ts
validation_error.js
standalone
index.d.ts
index.js
instance.d.ts
instance.js
types
index.d.ts
index.js
json-schema.d.ts
json-schema.js
jtd-schema.d.ts
jtd-schema.js
vocabularies
applicator
additionalItems.d.ts
additionalItems.js
additionalProperties.d.ts
additionalProperties.js
allOf.d.ts
allOf.js
anyOf.d.ts
anyOf.js
contains.d.ts
contains.js
dependencies.d.ts
dependencies.js
dependentSchemas.d.ts
dependentSchemas.js
if.d.ts
if.js
index.d.ts
index.js
items.d.ts
items.js
items2020.d.ts
items2020.js
not.d.ts
not.js
oneOf.d.ts
oneOf.js
patternProperties.d.ts
patternProperties.js
prefixItems.d.ts
prefixItems.js
properties.d.ts
properties.js
propertyNames.d.ts
propertyNames.js
thenElse.d.ts
thenElse.js
code.d.ts
code.js
core
id.d.ts
id.js
index.d.ts
index.js
ref.d.ts
ref.js
discriminator
index.d.ts
index.js
types.d.ts
types.js
draft2020.d.ts
draft2020.js
draft7.d.ts
draft7.js
dynamic
dynamicAnchor.d.ts
dynamicAnchor.js
dynamicRef.d.ts
dynamicRef.js
index.d.ts
index.js
recursiveAnchor.d.ts
recursiveAnchor.js
recursiveRef.d.ts
recursiveRef.js
errors.d.ts
errors.js
format
format.d.ts
format.js
index.d.ts
index.js
jtd
discriminator.d.ts
discriminator.js
elements.d.ts
elements.js
enum.d.ts
enum.js
error.d.ts
error.js
index.d.ts
index.js
metadata.d.ts
metadata.js
nullable.d.ts
nullable.js
optionalProperties.d.ts
optionalProperties.js
properties.d.ts
properties.js
ref.d.ts
ref.js
type.d.ts
type.js
union.d.ts
union.js
values.d.ts
values.js
metadata.d.ts
metadata.js
next.d.ts
next.js
unevaluated
index.d.ts
index.js
unevaluatedItems.d.ts
unevaluatedItems.js
unevaluatedProperties.d.ts
unevaluatedProperties.js
validation
const.d.ts
const.js
dependentRequired.d.ts
dependentRequired.js
enum.d.ts
enum.js
index.d.ts
index.js
limitContains.d.ts
limitContains.js
limitItems.d.ts
limitItems.js
limitLength.d.ts
limitLength.js
limitNumber.d.ts
limitNumber.js
limitProperties.d.ts
limitProperties.js
multipleOf.d.ts
multipleOf.js
pattern.d.ts
pattern.js
required.d.ts
required.js
uniqueItems.d.ts
uniqueItems.js
lib
2019.ts
2020.ts
ajv.ts
compile
codegen
code.ts
index.ts
scope.ts
errors.ts
index.ts
jtd
parse.ts
serialize.ts
types.ts
names.ts
ref_error.ts
resolve.ts
rules.ts
util.ts
validate
applicability.ts
boolSchema.ts
dataType.ts
defaults.ts
index.ts
keyword.ts
subschema.ts
core.ts
jtd.ts
refs
data.json
json-schema-2019-09
index.ts
meta
applicator.json
content.json
core.json
format.json
meta-data.json
validation.json
schema.json
json-schema-2020-12
index.ts
meta
applicator.json
content.json
core.json
format-annotation.json
meta-data.json
unevaluated.json
validation.json
schema.json
json-schema-draft-06.json
json-schema-draft-07.json
json-schema-secure.json
jtd-schema.ts
runtime
equal.ts
parseJson.ts
quote.ts
re2.ts
timestamp.ts
ucs2length.ts
uri.ts
validation_error.ts
standalone
index.ts
instance.ts
types
index.ts
json-schema.ts
jtd-schema.ts
vocabularies
applicator
additionalItems.ts
additionalProperties.ts
allOf.ts
anyOf.ts
contains.ts
dependencies.ts
dependentSchemas.ts
if.ts
index.ts
items.ts
items2020.ts
not.ts
oneOf.ts
patternProperties.ts
prefixItems.ts
properties.ts
propertyNames.ts
thenElse.ts
code.ts
core
id.ts
index.ts
ref.ts
discriminator
index.ts
types.ts
draft2020.ts
draft7.ts
dynamic
dynamicAnchor.ts
dynamicRef.ts
index.ts
recursiveAnchor.ts
recursiveRef.ts
errors.ts
format
format.ts
index.ts
jtd
discriminator.ts
elements.ts
enum.ts
error.ts
index.ts
metadata.ts
nullable.ts
optionalProperties.ts
properties.ts
ref.ts
type.ts
union.ts
values.ts
metadata.ts
next.ts
unevaluated
index.ts
unevaluatedItems.ts
unevaluatedProperties.ts
validation
const.ts
dependentRequired.ts
enum.ts
index.ts
limitContains.ts
limitItems.ts
limitLength.ts
limitNumber.ts
limitProperties.ts
multipleOf.ts
pattern.ts
required.ts
uniqueItems.ts
package.json
json-schema-traverse
.eslintrc.yml
.github
FUNDING.yml
workflows
build.yml
publish.yml
README.md
index.d.ts
index.js
package.json
spec
.eslintrc.yml
fixtures
schema.js
index.spec.js
package.json
tar
README.md
index.js
lib
create.js
extract.js
get-write-flag.js
header.js
high-level-opt.js
large-numbers.js
list.js
mkdir.js
mode-fix.js
normalize-windows-path.js
pack.js
parse.js
path-reservations.js
pax.js
read-entry.js
replace.js
strip-absolute-path.js
strip-trailing-slashes.js
types.js
unpack.js
update.js
warn-mixin.js
winchars.js
write-entry.js
package.json
text-table
.travis.yml
example
align.js
center.js
dotalign.js
doubledot.js
table.js
index.js
package.json
test
align.js
ansi-colors.js
center.js
dotalign.js
doubledot.js
table.js
tr46
LICENSE.md
README.md
index.js
lib
mappingTable.json
regexes.js
package.json
ts-mixer
CHANGELOG.md
README.md
dist
cjs
decorator.js
index.js
mixin-tracking.js
mixins.js
proxy.js
settings.js
types.js
util.js
esm
index.js
index.min.js
types
decorator.d.ts
index.d.ts
mixin-tracking.d.ts
mixins.d.ts
proxy.d.ts
settings.d.ts
types.d.ts
util.d.ts
package.json
type-check
README.md
lib
check.js
index.js
parse-type.js
package.json
type-fest
base.d.ts
index.d.ts
package.json
readme.md
source
async-return-type.d.ts
asyncify.d.ts
basic.d.ts
conditional-except.d.ts
conditional-keys.d.ts
conditional-pick.d.ts
entries.d.ts
entry.d.ts
except.d.ts
fixed-length-array.d.ts
iterable-element.d.ts
literal-union.d.ts
merge-exclusive.d.ts
merge.d.ts
mutable.d.ts
opaque.d.ts
package-json.d.ts
partial-deep.d.ts
promisable.d.ts
promise-value.d.ts
readonly-deep.d.ts
require-at-least-one.d.ts
require-exactly-one.d.ts
set-optional.d.ts
set-required.d.ts
set-return-type.d.ts
stringified.d.ts
tsconfig-json.d.ts
union-to-intersection.d.ts
utilities.d.ts
value-of.d.ts
ts41
camel-case.d.ts
delimiter-case.d.ts
index.d.ts
kebab-case.d.ts
pascal-case.d.ts
snake-case.d.ts
universal-url
README.md
browser.js
index.js
package.json
uri-js
README.md
dist
es5
uri.all.d.ts
uri.all.js
uri.all.min.d.ts
uri.all.min.js
esnext
index.d.ts
index.js
regexps-iri.d.ts
regexps-iri.js
regexps-uri.d.ts
regexps-uri.js
schemes
http.d.ts
http.js
https.d.ts
https.js
mailto.d.ts
mailto.js
urn-uuid.d.ts
urn-uuid.js
urn.d.ts
urn.js
ws.d.ts
ws.js
wss.d.ts
wss.js
uri.d.ts
uri.js
util.d.ts
util.js
package.json
v8-compile-cache
CHANGELOG.md
README.md
package.json
v8-compile-cache.js
visitor-as
.github
workflows
test.yml
README.md
as
index.d.ts
index.js
asconfig.json
dist
astBuilder.d.ts
astBuilder.js
base.d.ts
base.js
baseTransform.d.ts
baseTransform.js
decorator.d.ts
decorator.js
examples
capitalize.d.ts
capitalize.js
exportAs.d.ts
exportAs.js
functionCallTransform.d.ts
functionCallTransform.js
includeBytesTransform.d.ts
includeBytesTransform.js
list.d.ts
list.js
index.d.ts
index.js
path.d.ts
path.js
simpleParser.d.ts
simpleParser.js
transformer.d.ts
transformer.js
utils.d.ts
utils.js
visitor.d.ts
visitor.js
package.json
tsconfig.json
webidl-conversions
LICENSE.md
README.md
lib
index.js
package.json
whatwg-url
LICENSE.txt
README.md
lib
URL-impl.js
URL.js
URLSearchParams-impl.js
URLSearchParams.js
infra.js
public-api.js
url-state-machine.js
urlencoded.js
utils.js
package.json
which-module
CHANGELOG.md
README.md
index.js
package.json
which
CHANGELOG.md
README.md
package.json
which.js
word-wrap
README.md
index.d.ts
index.js
package.json
wrap-ansi
index.js
package.json
readme.md
wrappy
README.md
package.json
wrappy.js
y18n
CHANGELOG.md
README.md
build
lib
cjs.js
index.js
platform-shims
node.js
package.json
yallist
README.md
iterator.js
package.json
yallist.js
yargs-parser
CHANGELOG.md
LICENSE.txt
README.md
browser.js
build
lib
index.js
string-utils.js
tokenize-arg-string.js
yargs-parser-types.js
yargs-parser.js
package.json
yargs
CHANGELOG.md
README.md
build
lib
argsert.js
command.js
completion-templates.js
completion.js
middleware.js
parse-command.js
typings
common-types.js
yargs-parser-types.js
usage.js
utils
apply-extends.js
is-promise.js
levenshtein.js
obj-filter.js
process-argv.js
set-blocking.js
which-module.js
validation.js
yargs-factory.js
yerror.js
helpers
index.js
package.json
locales
be.json
de.json
en.json
es.json
fi.json
fr.json
hi.json
hu.json
id.json
it.json
ja.json
ko.json
nb.json
nl.json
nn.json
pirate.json
pl.json
pt.json
pt_BR.json
ru.json
th.json
tr.json
zh_CN.json
zh_TW.json
package.json
package.json
|
features not yet implemented
issues with the tests
differences between PCRE and JS regex
|
|
|
| # color-convert
[](https://travis-ci.org/Qix-/color-convert)
Color-convert is a color conversion library for JavaScript and node.
It converts all ways between `rgb`, `hsl`, `hsv`, `hwb`, `cmyk`, `ansi`, `ansi16`, `hex` strings, and CSS `keyword`s (will round to closest):
```js
var convert = require('color-convert');
convert.rgb.hsl(140, 200, 100); // [96, 48, 59]
convert.keyword.rgb('blue'); // [0, 0, 255]
var rgbChannels = convert.rgb.channels; // 3
var cmykChannels = convert.cmyk.channels; // 4
var ansiChannels = convert.ansi16.channels; // 1
```
# Install
```console
$ npm install color-convert
```
# API
Simply get the property of the _from_ and _to_ conversion that you're looking for.
All functions have a rounded and unrounded variant. By default, return values are rounded. To get the unrounded (raw) results, simply tack on `.raw` to the function.
All 'from' functions have a hidden property called `.channels` that indicates the number of channels the function expects (not including alpha).
```js
var convert = require('color-convert');
// Hex to LAB
convert.hex.lab('DEADBF'); // [ 76, 21, -2 ]
convert.hex.lab.raw('DEADBF'); // [ 75.56213190997677, 20.653827952644754, -2.290532499330533 ]
// RGB to CMYK
convert.rgb.cmyk(167, 255, 4); // [ 35, 0, 98, 0 ]
convert.rgb.cmyk.raw(167, 255, 4); // [ 34.509803921568626, 0, 98.43137254901961, 0 ]
```
### Arrays
All functions that accept multiple arguments also support passing an array.
Note that this does **not** apply to functions that convert from a color that only requires one value (e.g. `keyword`, `ansi256`, `hex`, etc.)
```js
var convert = require('color-convert');
convert.rgb.hex(123, 45, 67); // '7B2D43'
convert.rgb.hex([123, 45, 67]); // '7B2D43'
```
## Routing
Conversions that don't have an _explicitly_ defined conversion (in [conversions.js](conversions.js)), but can be converted by means of sub-conversions (e.g. XYZ -> **RGB** -> CMYK), are automatically routed together. This allows just about any color model supported by `color-convert` to be converted to any other model, so long as a sub-conversion path exists. This is also true for conversions requiring more than one step in between (e.g. LCH -> **LAB** -> **XYZ** -> **RGB** -> Hex).
Keep in mind that extensive conversions _may_ result in a loss of precision, and exist only to be complete. For a list of "direct" (single-step) conversions, see [conversions.js](conversions.js).
# Contribute
If there is a new model you would like to support, or want to add a direct conversion between two existing models, please send us a pull request.
# License
Copyright © 2011-2016, Heather Arthur and Josh Junon. Licensed under the [MIT License](LICENSE).
# isobject [](https://www.npmjs.com/package/isobject) [](https://npmjs.org/package/isobject) [](https://travis-ci.org/jonschlinkert/isobject)
Returns true if the value is an object and not an array or null.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install isobject --save
```
Use [is-plain-object](https://github.com/jonschlinkert/is-plain-object) if you want only objects that are created by the `Object` constructor.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install isobject
```
Install with [bower](http://bower.io/)
```sh
$ bower install isobject
```
## Usage
```js
var isObject = require('isobject');
```
**True**
All of the following return `true`:
```js
isObject({});
isObject(Object.create({}));
isObject(Object.create(Object.prototype));
isObject(Object.create(null));
isObject({});
isObject(new Foo);
isObject(/foo/);
```
**False**
All of the following return `false`:
```js
isObject();
isObject(function () {});
isObject(1);
isObject([]);
isObject(undefined);
isObject(null);
```
## Related projects
You might also be interested in these projects:
[merge-deep](https://www.npmjs.com/package/merge-deep): Recursively merge values in a javascript object. | [homepage](https://github.com/jonschlinkert/merge-deep)
* [extend-shallow](https://www.npmjs.com/package/extend-shallow): Extend an object with the properties of additional objects. node.js/javascript util. | [homepage](https://github.com/jonschlinkert/extend-shallow)
* [is-plain-object](https://www.npmjs.com/package/is-plain-object): Returns true if an object was created by the `Object` constructor. | [homepage](https://github.com/jonschlinkert/is-plain-object)
* [kind-of](https://www.npmjs.com/package/kind-of): Get the native type of a value. | [homepage](https://github.com/jonschlinkert/kind-of)
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/isobject/issues/new).
## Building docs
Generate readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install verb && npm run docs
```
Or, if [verb](https://github.com/verbose/verb) is installed globally:
```sh
$ verb
```
## Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
## Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/isobject/blob/master/LICENSE).
***
_This file was generated by [verb](https://github.com/verbose/verb), v0.9.0, on April 25, 2016._
Standard library
================
Standard library components for use with `tsc` (portable) and `asc` (assembly).
Base configurations (.json) and definition files (.d.ts) are relevant to `tsc` only and not used by `asc`.
# whatwg-url
whatwg-url is a full implementation of the WHATWG [URL Standard](https://url.spec.whatwg.org/). It can be used standalone, but it also exposes a lot of the internal algorithms that are useful for integrating a URL parser into a project like [jsdom](https://github.com/tmpvar/jsdom).
## Specification conformance
whatwg-url is currently up to date with the URL spec up to commit [7ae1c69](https://github.com/whatwg/url/commit/7ae1c691c96f0d82fafa24c33aa1e8df9ffbf2bc).
For `file:` URLs, whose [origin is left unspecified](https://url.spec.whatwg.org/#concept-url-origin), whatwg-url chooses to use a new opaque origin (which serializes to `"null"`).
## API
### The `URL` and `URLSearchParams` classes
The main API is provided by the [`URL`](https://url.spec.whatwg.org/#url-class) and [`URLSearchParams`](https://url.spec.whatwg.org/#interface-urlsearchparams) exports, which follows the spec's behavior in all ways (including e.g. `USVString` conversion). Most consumers of this library will want to use these.
### Low-level URL Standard API
The following methods are exported for use by places like jsdom that need to implement things like [`HTMLHyperlinkElementUtils`](https://html.spec.whatwg.org/#htmlhyperlinkelementutils). They mostly operate on or return an "internal URL" or ["URL record"](https://url.spec.whatwg.org/#concept-url) type.
- [URL parser](https://url.spec.whatwg.org/#concept-url-parser): `parseURL(input, { baseURL, encodingOverride })`
- [Basic URL parser](https://url.spec.whatwg.org/#concept-basic-url-parser): `basicURLParse(input, { baseURL, encodingOverride, url, stateOverride })`
- [URL serializer](https://url.spec.whatwg.org/#concept-url-serializer): `serializeURL(urlRecord, excludeFragment)`
- [Host serializer](https://url.spec.whatwg.org/#concept-host-serializer): `serializeHost(hostFromURLRecord)`
- [Serialize an integer](https://url.spec.whatwg.org/#serialize-an-integer): `serializeInteger(number)`
- [Origin](https://url.spec.whatwg.org/#concept-url-origin) [serializer](https://html.spec.whatwg.org/multipage/origin.html#ascii-serialisation-of-an-origin): `serializeURLOrigin(urlRecord)`
- [Set the username](https://url.spec.whatwg.org/#set-the-username): `setTheUsername(urlRecord, usernameString)`
- [Set the password](https://url.spec.whatwg.org/#set-the-password): `setThePassword(urlRecord, passwordString)`
- [Cannot have a username/password/port](https://url.spec.whatwg.org/#cannot-have-a-username-password-port): `cannotHaveAUsernamePasswordPort(urlRecord)`
- [Percent decode](https://url.spec.whatwg.org/#percent-decode): `percentDecode(buffer)`
The `stateOverride` parameter is one of the following strings:
- [`"scheme start"`](https://url.spec.whatwg.org/#scheme-start-state)
- [`"scheme"`](https://url.spec.whatwg.org/#scheme-state)
- [`"no scheme"`](https://url.spec.whatwg.org/#no-scheme-state)
- [`"special relative or authority"`](https://url.spec.whatwg.org/#special-relative-or-authority-state)
- [`"path or authority"`](https://url.spec.whatwg.org/#path-or-authority-state)
- [`"relative"`](https://url.spec.whatwg.org/#relative-state)
- [`"relative slash"`](https://url.spec.whatwg.org/#relative-slash-state)
- [`"special authority slashes"`](https://url.spec.whatwg.org/#special-authority-slashes-state)
- [`"special authority ignore slashes"`](https://url.spec.whatwg.org/#special-authority-ignore-slashes-state)
- [`"authority"`](https://url.spec.whatwg.org/#authority-state)
- [`"host"`](https://url.spec.whatwg.org/#host-state)
- [`"hostname"`](https://url.spec.whatwg.org/#hostname-state)
- [`"port"`](https://url.spec.whatwg.org/#port-state)
- [`"file"`](https://url.spec.whatwg.org/#file-state)
- [`"file slash"`](https://url.spec.whatwg.org/#file-slash-state)
- [`"file host"`](https://url.spec.whatwg.org/#file-host-state)
- [`"path start"`](https://url.spec.whatwg.org/#path-start-state)
- [`"path"`](https://url.spec.whatwg.org/#path-state)
- [`"cannot-be-a-base-URL path"`](https://url.spec.whatwg.org/#cannot-be-a-base-url-path-state)
- [`"query"`](https://url.spec.whatwg.org/#query-state)
- [`"fragment"`](https://url.spec.whatwg.org/#fragment-state)
The URL record type has the following API:
- [`scheme`](https://url.spec.whatwg.org/#concept-url-scheme)
- [`username`](https://url.spec.whatwg.org/#concept-url-username)
- [`password`](https://url.spec.whatwg.org/#concept-url-password)
- [`host`](https://url.spec.whatwg.org/#concept-url-host)
- [`port`](https://url.spec.whatwg.org/#concept-url-port)
- [`path`](https://url.spec.whatwg.org/#concept-url-path) (as an array)
- [`query`](https://url.spec.whatwg.org/#concept-url-query)
- [`fragment`](https://url.spec.whatwg.org/#concept-url-fragment)
- [`cannotBeABaseURL`](https://url.spec.whatwg.org/#url-cannot-be-a-base-url-flag) (as a boolean)
These properties should be treated with care, as in general changing them will cause the URL record to be in an inconsistent state until the appropriate invocation of `basicURLParse` is used to fix it up. You can see examples of this in the URL Standard, where there are many step sequences like "4. Set context object’s url’s fragment to the empty string. 5. Basic URL parse _input_ with context object’s url as _url_ and fragment state as _state override_." In between those two steps, a URL record is in an unusable state.
The return value of "failure" in the spec is represented by `null`. That is, functions like `parseURL` and `basicURLParse` can return _either_ a URL record _or_ `null`.
## Development instructions
First, install [Node.js](https://nodejs.org/). Then, fetch the dependencies of whatwg-url, by running from this directory:
npm install
To run tests:
npm test
To generate a coverage report:
npm run coverage
To build and run the live viewer:
npm run build
npm run build-live-viewer
Serve the contents of the `live-viewer` directory using any web server.
## Supporting whatwg-url
The jsdom project (including whatwg-url) is a community-driven project maintained by a team of [volunteers](https://github.com/orgs/jsdom/people). You could support us by:
- [Getting professional support for whatwg-url](https://tidelift.com/subscription/pkg/npm-whatwg-url?utm_source=npm-whatwg-url&utm_medium=referral&utm_campaign=readme) as part of a Tidelift subscription. Tidelift helps making open source sustainable for us while giving teams assurances for maintenance, licensing, and security.
- Contributing directly to the project.
# `asbuild` [](https://github.com/AssemblyScript/asbuild/stargazers)
*A simple build tool for [AssemblyScript](https://assemblyscript.org) projects, similar to `cargo`, etc.*
## 🚩 Table of Contents
- [Installing](#-installing)
- [Usage](#-usage)
- [`asb init`](#asb-init---create-an-empty-project)
- [`asb test`](#asb-test---run-as-pect-tests)
- [`asb fmt`](#asb-fmt---format-as-files-using-eslint)
- [`asb run`](#asb-run---run-a-wasi-binary)
- [`asb build`](#asb-build---compile-the-project-using-asc)
- [Background](#-background)
## 🔧 Installing
Install it globally
```
npm install -g asbuild
```
Or, locally as dev dependencies
```
npm install --save-dev asbuild
```
## 💡 Usage
```
Build tool for AssemblyScript projects.
Usage:
asb [command] [options]
Commands:
asb Alias of build command, to maintain back-ward
compatibility [default]
asb build Compile a local package and all of its dependencies
[aliases: compile, make]
asb init [baseDir] Create a new AS package in an given directory
asb test Run as-pect tests
asb fmt [paths..] This utility formats current module using eslint.
[aliases: format, lint]
Options:
--version Show version number [boolean]
--help Show help [boolean]
```
### `asb init` - Create an empty project
```
asb init [baseDir]
Create a new AS package in an given directory
Positionals:
baseDir Create a sample AS project in this directory [string] [default: "."]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--yes Skip the interactive prompt [boolean] [default: false]
```
### `asb test` - Run as-pect tests
```
asb test
Run as-pect tests
USAGE:
asb test [options] -- [aspect_options]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--verbose, --vv Print out arguments passed to as-pect
[boolean] [default: false]
```
### `asb fmt` - Format AS files using ESlint
```
asb fmt [paths..]
This utility formats current module using eslint.
Positionals:
paths Paths to format [array] [default: ["."]]
Initialisation:
--init Generates recommended eslint config for AS Projects [boolean]
Miscellaneous
--lint, --dry-run Tries to fix problems without saving the changes to the
file system [boolean] [default: false]
Options:
--version Show version number [boolean]
--help Show help
```
### `asb run` - Run a WASI binary
```
asb run
Run a WASI binary
USAGE:
asb run [options] [binary path] -- [binary options]
Positionals:
binary path to Wasm binary [string] [required]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--preopen, -p comma separated list of directories to open.
[default: "."]
```
### `asb build` - Compile the project using asc
```
asb build
Compile a local package and all of its dependencies
USAGE:
asb build [entry_file] [options] -- [asc_options]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--baseDir, -d Base directory of project. [string] [default: "."]
--config, -c Path to asconfig file [string] [default: "./asconfig.json"]
--wat Output wat file to outDir [boolean] [default: false]
--outDir Directory to place built binaries. Default "./build/<target>/"
[string]
--target Target for compilation [string] [default: "release"]
--verbose Print out arguments passed to asc [boolean] [default: false]
Examples:
asb build Build release of 'assembly/index.ts to
build/release/packageName.wasm
asb build --target release Build a release binary
asb build -- --measure Pass argument to 'asc'
```
#### Defaults
##### Project structure
```
project/
package.json
asconfig.json
assembly/
index.ts
build/
release/
project.wasm
debug/
project.wasm
```
- If no entry file passed and no `entry` field is in `asconfig.json`, `project/assembly/index.ts` is assumed.
- `asconfig.json` allows for options for different compile targets, e.g. release, debug, etc. `asc` defaults to the release target.
- The default build directory is `./build`, and artifacts are placed at `./build/<target>/packageName.wasm`.
##### Workspaces
If a `workspace` field is added to a top level `asconfig.json` file, then each path in the array is built and placed into the top level `outDir`.
For example,
`asconfig.json`:
```json
{
"workspaces": ["a", "b"]
}
```
Running `asb` in the directory below will use the top level build directory to place all the binaries.
```
project/
package.json
asconfig.json
a/
asconfig.json
assembly/
index.ts
b/
asconfig.json
assembly/
index.ts
build/
release/
a.wasm
b.wasm
debug/
a.wasm
b.wasm
```
To see an example in action check out the [test workspace](./tests/build_test)
## 📖 Background
Asbuild started as wrapper around `asc` to provide an easier CLI interface and now has been extened to support other commands
like `init`, `test` and `fmt` just like `cargo` to become a one stop build tool for AS Projects.
## 📜 License
This library is provided under the open-source
[MIT license](https://choosealicense.com/licenses/mit/).
[](https://app.travis-ci.com/github/dankogai/js-base64)
# base64.js
Yet another [Base64] transcoder.
[Base64]: http://en.wikipedia.org/wiki/Base64
## Install
```shell
$ npm install --save js-base64
```
## Usage
### In Browser
Locally…
```html
<script src="base64.js"></script>
```
… or Directly from CDN. In which case you don't even need to install.
```html
<script src="https://cdn.jsdelivr.net/npm/js-base64@3.7.2/base64.min.js"></script>
```
This good old way loads `Base64` in the global context (`window`). Though `Base64.noConflict()` is made available, you should consider using ES6 Module to avoid tainting `window`.
### As an ES6 Module
locally…
```javascript
import { Base64 } from 'js-base64';
```
```javascript
// or if you prefer no Base64 namespace
import { encode, decode } from 'js-base64';
```
or even remotely.
```html
<script type="module">
// note jsdelivr.net does not automatically minify .mjs
import { Base64 } from 'https://cdn.jsdelivr.net/npm/js-base64@3.7.2/base64.mjs';
</script>
```
```html
<script type="module">
// or if you prefer no Base64 namespace
import { encode, decode } from 'https://cdn.jsdelivr.net/npm/js-base64@3.7.2/base64.mjs';
</script>
```
### node.js (commonjs)
```javascript
const {Base64} = require('js-base64');
```
Unlike the case above, the global context is no longer modified.
You can also use [esm] to `import` instead of `require`.
[esm]: https://github.com/standard-things/esm
```javascript
require=require('esm')(module);
import {Base64} from 'js-base64';
```
## SYNOPSIS
```javascript
let latin = 'dankogai';
let utf8 = '小飼弾'
let u8s = new Uint8Array([100,97,110,107,111,103,97,105]);
Base64.encode(latin); // ZGFua29nYWk=
Base64.encode(latin, true)); // ZGFua29nYWk skips padding
Base64.encodeURI(latin)); // ZGFua29nYWk
Base64.btoa(latin); // ZGFua29nYWk=
Base64.btoa(utf8); // raises exception
Base64.fromUint8Array(u8s); // ZGFua29nYWk=
Base64.fromUint8Array(u8s, true); // ZGFua29nYW which is URI safe
Base64.encode(utf8); // 5bCP6aO85by+
Base64.encode(utf8, true) // 5bCP6aO85by-
Base64.encodeURI(utf8); // 5bCP6aO85by-
```
```javascript
Base64.decode( 'ZGFua29nYWk=');// dankogai
Base64.decode( 'ZGFua29nYWk'); // dankogai
Base64.atob( 'ZGFua29nYWk=');// dankogai
Base64.atob( '5bCP6aO85by+');// 'å°é£¼å¼¾' which is nonsense
Base64.toUint8Array('ZGFua29nYWk=');// u8s above
Base64.decode( '5bCP6aO85by+');// 小飼弾
// note .decodeURI() is unnecessary since it accepts both flavors
Base64.decode( '5bCP6aO85by-');// 小飼弾
```
```javascript
Base64.isValid(0); // false: 0 is not string
Base64.isValid(''); // true: a valid Base64-encoded empty byte
Base64.isValid('ZA=='); // true: a valid Base64-encoded 'd'
Base64.isValid('Z A='); // true: whitespaces are okay
Base64.isValid('ZA'); // true: padding ='s can be omitted
Base64.isValid('++'); // true: can be non URL-safe
Base64.isValid('--'); // true: or URL-safe
Base64.isValid('+-'); // false: can't mix both
```
### Built-in Extensions
By default `Base64` leaves built-in prototypes untouched. But you can extend them as below.
```javascript
// you have to explicitly extend String.prototype
Base64.extendString();
// once extended, you can do the following
'dankogai'.toBase64(); // ZGFua29nYWk=
'小飼弾'.toBase64(); // 5bCP6aO85by+
'小飼弾'.toBase64(true); // 5bCP6aO85by-
'小飼弾'.toBase64URI(); // 5bCP6aO85by- ab alias of .toBase64(true)
'小飼弾'.toBase64URL(); // 5bCP6aO85by- an alias of .toBase64URI()
'ZGFua29nYWk='.fromBase64(); // dankogai
'5bCP6aO85by+'.fromBase64(); // 小飼弾
'5bCP6aO85by-'.fromBase64(); // 小飼弾
'5bCP6aO85by-'.toUint8Array();// u8s above
```
```javascript
// you have to explicitly extend Uint8Array.prototype
Base64.extendUint8Array();
// once extended, you can do the following
u8s.toBase64(); // 'ZGFua29nYWk='
u8s.toBase64URI(); // 'ZGFua29nYWk'
u8s.toBase64URL(); // 'ZGFua29nYWk' an alias of .toBase64URI()
```
```javascript
// extend all at once
Base64.extendBuiltins()
```
## `.decode()` vs `.atob` (and `.encode()` vs `btoa()`)
Suppose you have:
```
var pngBase64 =
"iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAQAAAC1HAwCAAAAC0lEQVR42mNkYAAAAAYAAjCB0C8AAAAASUVORK5CYII=";
```
Which is a Base64-encoded 1x1 transparent PNG, **DO NOT USE** `Base64.decode(pngBase64)`. Use `Base64.atob(pngBase64)` instead. `Base64.decode()` decodes to UTF-8 string while `Base64.atob()` decodes to bytes, which is compatible to browser built-in `atob()` (Which is absent in node.js). The same rule applies to the opposite direction.
Or even better, `Base64.toUint8Array(pngBase64)`.
### If you really, really need an ES5 version
You can transpiles to an ES5 that runs on IEs before 11. Do the following in your shell.
```shell
$ make base64.es5.js
```
## Brief History
* Since version 3.3 it is written in TypeScript. Now `base64.mjs` is compiled from `base64.ts` then `base64.js` is generated from `base64.mjs`.
* Since version 3.7 `base64.js` is ES5-compatible again (hence IE11-compabile).
* Since 3.0 `js-base64` switch to ES2015 module so it is no longer compatible with legacy browsers like IE (see above)
<a name="table"></a>
# Table
> Produces a string that represents array data in a text table.
[](https://github.com/gajus/table/actions)
[](https://coveralls.io/github/gajus/table)
[](https://www.npmjs.org/package/table)
[](https://github.com/gajus/canonical)
[](https://twitter.com/kuizinas)
* [Table](#table)
* [Features](#table-features)
* [Install](#table-install)
* [Usage](#table-usage)
* [API](#table-api)
* [table](#table-api-table-1)
* [createStream](#table-api-createstream)
* [getBorderCharacters](#table-api-getbordercharacters)

<a name="table-features"></a>
## Features
* Works with strings containing [fullwidth](https://en.wikipedia.org/wiki/Halfwidth_and_fullwidth_forms) characters.
* Works with strings containing [ANSI escape codes](https://en.wikipedia.org/wiki/ANSI_escape_code).
* Configurable border characters.
* Configurable content alignment per column.
* Configurable content padding per column.
* Configurable column width.
* Text wrapping.
<a name="table-install"></a>
## Install
```bash
npm install table
```
[](https://www.buymeacoffee.com/gajus)
[](https://www.patreon.com/gajus)
<a name="table-usage"></a>
## Usage
```js
import { table } from 'table';
// Using commonjs?
// const { table } = require('table');
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
console.log(table(data));
```
```
╔════╤════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────┼────╢
║ 1A │ 1B │ 1C ║
╟────┼────┼────╢
║ 2A │ 2B │ 2C ║
╚════╧════╧════╝
```
<a name="table-api"></a>
## API
<a name="table-api-table-1"></a>
### table
Returns the string in the table format
**Parameters:**
- **_data_:** The data to display
- Type: `any[][]`
- Required: `true`
- **_config_:** Table configuration
- Type: `object`
- Required: `false`
<a name="table-api-table-1-config-border"></a>
##### config.border
Type: `{ [type: string]: string }`\
Default: `honeywell` [template](#getbordercharacters)
Custom borders. The keys are any of:
- `topLeft`, `topRight`, `topBody`,`topJoin`
- `bottomLeft`, `bottomRight`, `bottomBody`, `bottomJoin`
- `joinLeft`, `joinRight`, `joinBody`, `joinJoin`
- `bodyLeft`, `bodyRight`, `bodyJoin`
- `headerJoin`
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
border: {
topBody: `─`,
topJoin: `┬`,
topLeft: `┌`,
topRight: `┐`,
bottomBody: `─`,
bottomJoin: `┴`,
bottomLeft: `└`,
bottomRight: `┘`,
bodyLeft: `│`,
bodyRight: `│`,
bodyJoin: `│`,
joinBody: `─`,
joinLeft: `├`,
joinRight: `┤`,
joinJoin: `┼`
}
};
console.log(table(data, config));
```
```
┌────┬────┬────┐
│ 0A │ 0B │ 0C │
├────┼────┼────┤
│ 1A │ 1B │ 1C │
├────┼────┼────┤
│ 2A │ 2B │ 2C │
└────┴────┴────┘
```
<a name="table-api-table-1-config-drawverticalline"></a>
##### config.drawVerticalLine
Type: `(lineIndex: number, columnCount: number) => boolean`\
Default: `() => true`
It is used to tell whether to draw a vertical line. This callback is called for each vertical border of the table.
If the table has `n` columns, then the `index` parameter is alternatively received all numbers in range `[0, n]` inclusively.
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C'],
['3A', '3B', '3C'],
['4A', '4B', '4C']
];
const config = {
drawVerticalLine: (lineIndex, columnCount) => {
return lineIndex === 0 || lineIndex === columnCount;
}
};
console.log(table(data, config));
```
```
╔════════════╗
║ 0A 0B 0C ║
╟────────────╢
║ 1A 1B 1C ║
╟────────────╢
║ 2A 2B 2C ║
╟────────────╢
║ 3A 3B 3C ║
╟────────────╢
║ 4A 4B 4C ║
╚════════════╝
```
<a name="table-api-table-1-config-drawhorizontalline"></a>
##### config.drawHorizontalLine
Type: `(lineIndex: number, rowCount: number) => boolean`\
Default: `() => true`
It is used to tell whether to draw a horizontal line. This callback is called for each horizontal border of the table.
If the table has `n` rows, then the `index` parameter is alternatively received all numbers in range `[0, n]` inclusively.
If the table has `n` rows and contains the header, then the range will be `[0, n+1]` inclusively.
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C'],
['3A', '3B', '3C'],
['4A', '4B', '4C']
];
const config = {
drawHorizontalLine: (lineIndex, rowCount) => {
return lineIndex === 0 || lineIndex === 1 || lineIndex === rowCount - 1 || lineIndex === rowCount;
}
};
console.log(table(data, config));
```
```
╔════╤════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────┼────╢
║ 1A │ 1B │ 1C ║
║ 2A │ 2B │ 2C ║
║ 3A │ 3B │ 3C ║
╟────┼────┼────╢
║ 4A │ 4B │ 4C ║
╚════╧════╧════╝
```
<a name="table-api-table-1-config-singleline"></a>
##### config.singleLine
Type: `boolean`\
Default: `false`
If `true`, horizontal lines inside the table are not drawn. This option also overrides the `config.drawHorizontalLine` if specified.
```js
const data = [
['-rw-r--r--', '1', 'pandorym', 'staff', '1529', 'May 23 11:25', 'LICENSE'],
['-rw-r--r--', '1', 'pandorym', 'staff', '16327', 'May 23 11:58', 'README.md'],
['drwxr-xr-x', '76', 'pandorym', 'staff', '2432', 'May 23 12:02', 'dist'],
['drwxr-xr-x', '634', 'pandorym', 'staff', '20288', 'May 23 11:54', 'node_modules'],
['-rw-r--r--', '1,', 'pandorym', 'staff', '525688', 'May 23 11:52', 'package-lock.json'],
['-rw-r--r--@', '1', 'pandorym', 'staff', '2440', 'May 23 11:25', 'package.json'],
['drwxr-xr-x', '27', 'pandorym', 'staff', '864', 'May 23 11:25', 'src'],
['drwxr-xr-x', '20', 'pandorym', 'staff', '640', 'May 23 11:25', 'test'],
];
const config = {
singleLine: true
};
console.log(table(data, config));
```
```
╔═════════════╤═════╤══════════╤═══════╤════════╤══════════════╤═══════════════════╗
║ -rw-r--r-- │ 1 │ pandorym │ staff │ 1529 │ May 23 11:25 │ LICENSE ║
║ -rw-r--r-- │ 1 │ pandorym │ staff │ 16327 │ May 23 11:58 │ README.md ║
║ drwxr-xr-x │ 76 │ pandorym │ staff │ 2432 │ May 23 12:02 │ dist ║
║ drwxr-xr-x │ 634 │ pandorym │ staff │ 20288 │ May 23 11:54 │ node_modules ║
║ -rw-r--r-- │ 1, │ pandorym │ staff │ 525688 │ May 23 11:52 │ package-lock.json ║
║ -rw-r--r--@ │ 1 │ pandorym │ staff │ 2440 │ May 23 11:25 │ package.json ║
║ drwxr-xr-x │ 27 │ pandorym │ staff │ 864 │ May 23 11:25 │ src ║
║ drwxr-xr-x │ 20 │ pandorym │ staff │ 640 │ May 23 11:25 │ test ║
╚═════════════╧═════╧══════════╧═══════╧════════╧══════════════╧═══════════════════╝
```
<a name="table-api-table-1-config-columns"></a>
##### config.columns
Type: `Column[] | { [columnIndex: number]: Column }`
Column specific configurations.
<a name="table-api-table-1-config-columns-config-columns-width"></a>
###### config.columns[*].width
Type: `number`\
Default: the maximum cell widths of the column
Column width (excluding the paddings).
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
columns: {
1: { width: 10 }
}
};
console.log(table(data, config));
```
```
╔════╤════════════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────────────┼────╢
║ 1A │ 1B │ 1C ║
╟────┼────────────┼────╢
║ 2A │ 2B │ 2C ║
╚════╧════════════╧════╝
```
<a name="table-api-table-1-config-columns-config-columns-alignment"></a>
###### config.columns[*].alignment
Type: `'center' | 'justify' | 'left' | 'right'`\
Default: `'left'`
Cell content horizontal alignment
```js
const data = [
['0A', '0B', '0C', '0D 0E 0F'],
['1A', '1B', '1C', '1D 1E 1F'],
['2A', '2B', '2C', '2D 2E 2F'],
];
const config = {
columnDefault: {
width: 10,
},
columns: [
{ alignment: 'left' },
{ alignment: 'center' },
{ alignment: 'right' },
{ alignment: 'justify' }
],
};
console.log(table(data, config));
```
```
╔════════════╤════════════╤════════════╤════════════╗
║ 0A │ 0B │ 0C │ 0D 0E 0F ║
╟────────────┼────────────┼────────────┼────────────╢
║ 1A │ 1B │ 1C │ 1D 1E 1F ║
╟────────────┼────────────┼────────────┼────────────╢
║ 2A │ 2B │ 2C │ 2D 2E 2F ║
╚════════════╧════════════╧════════════╧════════════╝
```
<a name="table-api-table-1-config-columns-config-columns-verticalalignment"></a>
###### config.columns[*].verticalAlignment
Type: `'top' | 'middle' | 'bottom'`\
Default: `'top'`
Cell content vertical alignment
```js
const data = [
['A', 'B', 'C', 'DEF'],
];
const config = {
columnDefault: {
width: 1,
},
columns: [
{ verticalAlignment: 'top' },
{ verticalAlignment: 'middle' },
{ verticalAlignment: 'bottom' },
],
};
console.log(table(data, config));
```
```
╔═══╤═══╤═══╤═══╗
║ A │ │ │ D ║
║ │ B │ │ E ║
║ │ │ C │ F ║
╚═══╧═══╧═══╧═══╝
```
<a name="table-api-table-1-config-columns-config-columns-paddingleft"></a>
###### config.columns[*].paddingLeft
Type: `number`\
Default: `1`
The number of whitespaces used to pad the content on the left.
<a name="table-api-table-1-config-columns-config-columns-paddingright"></a>
###### config.columns[*].paddingRight
Type: `number`\
Default: `1`
The number of whitespaces used to pad the content on the right.
The `paddingLeft` and `paddingRight` options do not count on the column width. So the column has `width = 5`, `paddingLeft = 2` and `paddingRight = 2` will have the total width is `9`.
```js
const data = [
['0A', 'AABBCC', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
columns: [
{
paddingLeft: 3
},
{
width: 2,
paddingRight: 3
}
]
};
console.log(table(data, config));
```
```
╔══════╤══════╤════╗
║ 0A │ AA │ 0C ║
║ │ BB │ ║
║ │ CC │ ║
╟──────┼──────┼────╢
║ 1A │ 1B │ 1C ║
╟──────┼──────┼────╢
║ 2A │ 2B │ 2C ║
╚══════╧══════╧════╝
```
<a name="table-api-table-1-config-columns-config-columns-truncate"></a>
###### config.columns[*].truncate
Type: `number`\
Default: `Infinity`
The number of characters is which the content will be truncated.
To handle a content that overflows the container width, `table` package implements [text wrapping](#config.columns[*].wrapWord). However, sometimes you may want to truncate content that is too long to be displayed in the table.
```js
const data = [
['Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus pulvinar nibh sed mauris convallis dapibus. Nunc venenatis tempus nulla sit amet viverra.']
];
const config = {
columns: [
{
width: 20,
truncate: 100
}
]
};
console.log(table(data, config));
```
```
╔══════════════════════╗
║ Lorem ipsum dolor si ║
║ t amet, consectetur ║
║ adipiscing elit. Pha ║
║ sellus pulvinar nibh ║
║ sed mauris convall… ║
╚══════════════════════╝
```
<a name="table-api-table-1-config-columns-config-columns-wrapword"></a>
###### config.columns[*].wrapWord
Type: `boolean`\
Default: `false`
The `table` package implements auto text wrapping, i.e., text that has the width greater than the container width will be separated into multiple lines at the nearest space or one of the special characters: `\|/_.,;-`.
When `wrapWord` is `false`:
```js
const data = [
['Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus pulvinar nibh sed mauris convallis dapibus. Nunc venenatis tempus nulla sit amet viverra.']
];
const config = {
columns: [ { width: 20 } ]
};
console.log(table(data, config));
```
```
╔══════════════════════╗
║ Lorem ipsum dolor si ║
║ t amet, consectetur ║
║ adipiscing elit. Pha ║
║ sellus pulvinar nibh ║
║ sed mauris convallis ║
║ dapibus. Nunc venena ║
║ tis tempus nulla sit ║
║ amet viverra. ║
╚══════════════════════╝
```
When `wrapWord` is `true`:
```
╔══════════════════════╗
║ Lorem ipsum dolor ║
║ sit amet, ║
║ consectetur ║
║ adipiscing elit. ║
║ Phasellus pulvinar ║
║ nibh sed mauris ║
║ convallis dapibus. ║
║ Nunc venenatis ║
║ tempus nulla sit ║
║ amet viverra. ║
╚══════════════════════╝
```
<a name="table-api-table-1-config-columndefault"></a>
##### config.columnDefault
Type: `Column`\
Default: `{}`
The default configuration for all columns. Column-specific settings will overwrite the default values.
<a name="table-api-table-1-config-header"></a>
##### config.header
Type: `object`
Header configuration.
*Deprecated in favor of the new spanning cells API.*
The header configuration inherits the most of the column's, except:
- `content` **{string}**: the header content.
- `width:` calculate based on the content width automatically.
- `alignment:` `center` be default.
- `verticalAlignment:` is not supported.
- `config.border.topJoin` will be `config.border.topBody` for prettier.
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C'],
];
const config = {
columnDefault: {
width: 10,
},
header: {
alignment: 'center',
content: 'THE HEADER\nThis is the table about something',
},
}
console.log(table(data, config));
```
```
╔══════════════════════════════════════╗
║ THE HEADER ║
║ This is the table about something ║
╟────────────┬────────────┬────────────╢
║ 0A │ 0B │ 0C ║
╟────────────┼────────────┼────────────╢
║ 1A │ 1B │ 1C ║
╟────────────┼────────────┼────────────╢
║ 2A │ 2B │ 2C ║
╚════════════╧════════════╧════════════╝
```
<a name="table-api-table-1-config-spanningcells"></a>
##### config.spanningCells
Type: `SpanningCellConfig[]`
Spanning cells configuration.
The configuration should be straightforward: just specify an array of minimal cell configurations including the position of top-left cell
and the number of columns and/or rows will be expanded from it.
The content of overlap cells will be ignored to make the `data` shape be consistent.
By default, the configuration of column that the top-left cell belongs to will be applied to the whole spanning cell, except:
* The `width` will be summed up of all spanning columns.
* The `paddingRight` will be received from the right-most column intentionally.
Advances customized column-like styles can be configurable to each spanning cell to overwrite the default behavior.
```js
const data = [
['Test Coverage Report', '', '', '', '', ''],
['Module', 'Component', 'Test Cases', 'Failures', 'Durations', 'Success Rate'],
['Services', 'User', '50', '30', '3m 7s', '60.0%'],
['', 'Payment', '100', '80', '7m 15s', '80.0%'],
['Subtotal', '', '150', '110', '10m 22s', '73.3%'],
['Controllers', 'User', '24', '18', '1m 30s', '75.0%'],
['', 'Payment', '30', '24', '50s', '80.0%'],
['Subtotal', '', '54', '42', '2m 20s', '77.8%'],
['Total', '', '204', '152', '12m 42s', '74.5%'],
];
const config = {
columns: [
{ alignment: 'center', width: 12 },
{ alignment: 'center', width: 10 },
{ alignment: 'right' },
{ alignment: 'right' },
{ alignment: 'right' },
{ alignment: 'right' }
],
spanningCells: [
{ col: 0, row: 0, colSpan: 6 },
{ col: 0, row: 2, rowSpan: 2, verticalAlignment: 'middle'},
{ col: 0, row: 4, colSpan: 2, alignment: 'right'},
{ col: 0, row: 5, rowSpan: 2, verticalAlignment: 'middle'},
{ col: 0, row: 7, colSpan: 2, alignment: 'right' },
{ col: 0, row: 8, colSpan: 2, alignment: 'right' }
],
};
console.log(table(data, config));
```
```
╔══════════════════════════════════════════════════════════════════════════════╗
║ Test Coverage Report ║
╟──────────────┬────────────┬────────────┬──────────┬───────────┬──────────────╢
║ Module │ Component │ Test Cases │ Failures │ Durations │ Success Rate ║
╟──────────────┼────────────┼────────────┼──────────┼───────────┼──────────────╢
║ │ User │ 50 │ 30 │ 3m 7s │ 60.0% ║
║ Services ├────────────┼────────────┼──────────┼───────────┼──────────────╢
║ │ Payment │ 100 │ 80 │ 7m 15s │ 80.0% ║
╟──────────────┴────────────┼────────────┼──────────┼───────────┼──────────────╢
║ Subtotal │ 150 │ 110 │ 10m 22s │ 73.3% ║
╟──────────────┬────────────┼────────────┼──────────┼───────────┼──────────────╢
║ │ User │ 24 │ 18 │ 1m 30s │ 75.0% ║
║ Controllers ├────────────┼────────────┼──────────┼───────────┼──────────────╢
║ │ Payment │ 30 │ 24 │ 50s │ 80.0% ║
╟──────────────┴────────────┼────────────┼──────────┼───────────┼──────────────╢
║ Subtotal │ 54 │ 42 │ 2m 20s │ 77.8% ║
╟───────────────────────────┼────────────┼──────────┼───────────┼──────────────╢
║ Total │ 204 │ 152 │ 12m 42s │ 74.5% ║
╚═══════════════════════════╧════════════╧══════════╧═══════════╧══════════════╝
```
<a name="table-api-createstream"></a>
### createStream
`table` package exports `createStream` function used to draw a table and append rows.
**Parameter:**
- _**config:**_ the same as `table`'s, except `config.columnDefault.width` and `config.columnCount` must be provided.
```js
import { createStream } from 'table';
const config = {
columnDefault: {
width: 50
},
columnCount: 1
};
const stream = createStream(config);
setInterval(() => {
stream.write([new Date()]);
}, 500);
```

`table` package uses ANSI escape codes to overwrite the output of the last line when a new row is printed.
The underlying implementation is explained in this [Stack Overflow answer](http://stackoverflow.com/a/32938658/368691).
Streaming supports all of the configuration properties and functionality of a static table (such as auto text wrapping, alignment and padding), e.g.
```js
import { createStream } from 'table';
import _ from 'lodash';
const config = {
columnDefault: {
width: 50
},
columnCount: 3,
columns: [
{
width: 10,
alignment: 'right'
},
{ alignment: 'center' },
{ width: 10 }
]
};
const stream = createStream(config);
let i = 0;
setInterval(() => {
let random;
random = _.sample('abcdefghijklmnopqrstuvwxyz', _.random(1, 30)).join('');
stream.write([i++, new Date(), random]);
}, 500);
```

<a name="table-api-getbordercharacters"></a>
### getBorderCharacters
**Parameter:**
- **_template_**
- Type: `'honeywell' | 'norc' | 'ramac' | 'void'`
- Required: `true`
You can load one of the predefined border templates using `getBorderCharacters` function.
```js
import { table, getBorderCharacters } from 'table';
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
border: getBorderCharacters(`name of the template`)
};
console.log(table(data, config));
```
```
# honeywell
╔════╤════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────┼────╢
║ 1A │ 1B │ 1C ║
╟────┼────┼────╢
║ 2A │ 2B │ 2C ║
╚════╧════╧════╝
# norc
┌────┬────┬────┐
│ 0A │ 0B │ 0C │
├────┼────┼────┤
│ 1A │ 1B │ 1C │
├────┼────┼────┤
│ 2A │ 2B │ 2C │
└────┴────┴────┘
# ramac (ASCII; for use in terminals that do not support Unicode characters)
+----+----+----+
| 0A | 0B | 0C |
|----|----|----|
| 1A | 1B | 1C |
|----|----|----|
| 2A | 2B | 2C |
+----+----+----+
# void (no borders; see "borderless table" section of the documentation)
0A 0B 0C
1A 1B 1C
2A 2B 2C
```
Raise [an issue](https://github.com/gajus/table/issues) if you'd like to contribute a new border template.
<a name="table-api-getbordercharacters-borderless-table"></a>
#### Borderless Table
Simply using `void` border character template creates a table with a lot of unnecessary spacing.
To create a more pleasant to the eye table, reset the padding and remove the joining rows, e.g.
```js
const output = table(data, {
border: getBorderCharacters('void'),
columnDefault: {
paddingLeft: 0,
paddingRight: 1
},
drawHorizontalLine: () => false
}
);
console.log(output);
```
```
0A 0B 0C
1A 1B 1C
2A 2B 2C
```
### Estraverse [](http://travis-ci.org/estools/estraverse)
Estraverse ([estraverse](http://github.com/estools/estraverse)) is
[ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
traversal functions from [esmangle project](http://github.com/estools/esmangle).
### Documentation
You can find usage docs at [wiki page](https://github.com/estools/estraverse/wiki/Usage).
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
estraverse.traverse(ast, {
enter: function (node, parent) {
if (node.type == 'FunctionExpression' || node.type == 'FunctionDeclaration')
return estraverse.VisitorOption.Skip;
},
leave: function (node, parent) {
if (node.type == 'VariableDeclarator')
console.log(node.id.name);
}
});
```
We can use `this.skip`, `this.remove` and `this.break` functions instead of using Skip, Remove and Break.
```javascript
estraverse.traverse(ast, {
enter: function (node) {
this.break();
}
});
```
And estraverse provides `estraverse.replace` function. When returning node from `enter`/`leave`, current node is replaced with it.
```javascript
result = estraverse.replace(tree, {
enter: function (node) {
// Replace it with replaced.
if (node.type === 'Literal')
return replaced;
}
});
```
By passing `visitor.keys` mapping, we can extend estraverse traversing functionality.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Extending the existing traversing rules.
keys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
});
```
By passing `visitor.fallback` option, we can control the behavior when encountering unknown nodes.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Iterating the child **nodes** of unknown nodes.
fallback: 'iteration'
});
```
When `visitor.fallback` is a function, we can determine which keys to visit on each node.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Skip the `argument` property of each node
fallback: function(node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument';
});
}
});
```
### License
Copyright (C) 2012-2016 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
<img align="right" alt="Ajv logo" width="160" src="https://ajv.js.org/images/ajv_logo.png">
# Ajv: Another JSON Schema Validator
The fastest JSON Schema validator for Node.js and browser. Supports draft-04/06/07.
[](https://travis-ci.org/ajv-validator/ajv)
[](https://www.npmjs.com/package/ajv)
[](https://www.npmjs.com/package/ajv/v/7.0.0-beta.0)
[](https://www.npmjs.com/package/ajv)
[](https://coveralls.io/github/ajv-validator/ajv?branch=master)
[](https://gitter.im/ajv-validator/ajv)
[](https://github.com/sponsors/epoberezkin)
## Ajv v7 beta is released
[Ajv version 7.0.0-beta.0](https://github.com/ajv-validator/ajv/tree/v7-beta) is released with these changes:
- to reduce the mistakes in JSON schemas and unexpected validation results, [strict mode](./docs/strict-mode.md) is added - it prohibits ignored or ambiguous JSON Schema elements.
- to make code injection from untrusted schemas impossible, [code generation](./docs/codegen.md) is fully re-written to be safe.
- to simplify Ajv extensions, the new keyword API that is used by pre-defined keywords is available to user-defined keywords - it is much easier to define any keywords now, especially with subschemas.
- schemas are compiled to ES6 code (ES5 code generation is supported with an option).
- to improve reliability and maintainability the code is migrated to TypeScript.
**Please note**:
- the support for JSON-Schema draft-04 is removed - if you have schemas using "id" attributes you have to replace them with "\$id" (or continue using version 6 that will be supported until 02/28/2021).
- all formats are separated to ajv-formats package - they have to be explicitely added if you use them.
See [release notes](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0-beta.0) for the details.
To install the new version:
```bash
npm install ajv@beta
```
See [Getting started with v7](https://github.com/ajv-validator/ajv/tree/v7-beta#usage) for code example.
## Mozilla MOSS grant and OpenJS Foundation
[<img src="https://www.poberezkin.com/images/mozilla.png" width="240" height="68">](https://www.mozilla.org/en-US/moss/) [<img src="https://www.poberezkin.com/images/openjs.png" width="220" height="68">](https://openjsf.org/blog/2020/08/14/ajv-joins-openjs-foundation-as-an-incubation-project/)
Ajv has been awarded a grant from Mozilla’s [Open Source Support (MOSS) program](https://www.mozilla.org/en-US/moss/) in the “Foundational Technology” track! It will sponsor the development of Ajv support of [JSON Schema version 2019-09](https://tools.ietf.org/html/draft-handrews-json-schema-02) and of [JSON Type Definition](https://tools.ietf.org/html/draft-ucarion-json-type-definition-04).
Ajv also joined [OpenJS Foundation](https://openjsf.org/) – having this support will help ensure the longevity and stability of Ajv for all its users.
This [blog post](https://www.poberezkin.com/posts/2020-08-14-ajv-json-validator-mozilla-open-source-grant-openjs-foundation.html) has more details.
I am looking for the long term maintainers of Ajv – working with [ReadySet](https://www.thereadyset.co/), also sponsored by Mozilla, to establish clear guidelines for the role of a "maintainer" and the contribution standards, and to encourage a wider, more inclusive, contribution from the community.
## Please [sponsor Ajv development](https://github.com/sponsors/epoberezkin)
Since I asked to support Ajv development 40 people and 6 organizations contributed via GitHub and OpenCollective - this support helped receiving the MOSS grant!
Your continuing support is very important - the funds will be used to develop and maintain Ajv once the next major version is released.
Please sponsor Ajv via:
- [GitHub sponsors page](https://github.com/sponsors/epoberezkin) (GitHub will match it)
- [Ajv Open Collective️](https://opencollective.com/ajv)
Thank you.
#### Open Collective sponsors
<a href="https://opencollective.com/ajv"><img src="https://opencollective.com/ajv/individuals.svg?width=890"></a>
<a href="https://opencollective.com/ajv/organization/0/website"><img src="https://opencollective.com/ajv/organization/0/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/1/website"><img src="https://opencollective.com/ajv/organization/1/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/2/website"><img src="https://opencollective.com/ajv/organization/2/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/3/website"><img src="https://opencollective.com/ajv/organization/3/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/4/website"><img src="https://opencollective.com/ajv/organization/4/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/5/website"><img src="https://opencollective.com/ajv/organization/5/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/6/website"><img src="https://opencollective.com/ajv/organization/6/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/7/website"><img src="https://opencollective.com/ajv/organization/7/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/8/website"><img src="https://opencollective.com/ajv/organization/8/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/9/website"><img src="https://opencollective.com/ajv/organization/9/avatar.svg"></a>
## Using version 6
[JSON Schema draft-07](http://json-schema.org/latest/json-schema-validation.html) is published.
[Ajv version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0) that supports draft-07 is released. It may require either migrating your schemas or updating your code (to continue using draft-04 and v5 schemas, draft-06 schemas will be supported without changes).
__Please note__: To use Ajv with draft-06 schemas you need to explicitly add the meta-schema to the validator instance:
```javascript
ajv.addMetaSchema(require('ajv/lib/refs/json-schema-draft-06.json'));
```
To use Ajv with draft-04 schemas in addition to explicitly adding meta-schema you also need to use option schemaId:
```javascript
var ajv = new Ajv({schemaId: 'id'});
// If you want to use both draft-04 and draft-06/07 schemas:
// var ajv = new Ajv({schemaId: 'auto'});
ajv.addMetaSchema(require('ajv/lib/refs/json-schema-draft-04.json'));
```
## Contents
- [Performance](#performance)
- [Features](#features)
- [Getting started](#getting-started)
- [Frequently Asked Questions](https://github.com/ajv-validator/ajv/blob/master/FAQ.md)
- [Using in browser](#using-in-browser)
- [Ajv and Content Security Policies (CSP)](#ajv-and-content-security-policies-csp)
- [Command line interface](#command-line-interface)
- Validation
- [Keywords](#validation-keywords)
- [Annotation keywords](#annotation-keywords)
- [Formats](#formats)
- [Combining schemas with $ref](#ref)
- [$data reference](#data-reference)
- NEW: [$merge and $patch keywords](#merge-and-patch-keywords)
- [Defining custom keywords](#defining-custom-keywords)
- [Asynchronous schema compilation](#asynchronous-schema-compilation)
- [Asynchronous validation](#asynchronous-validation)
- [Security considerations](#security-considerations)
- [Security contact](#security-contact)
- [Untrusted schemas](#untrusted-schemas)
- [Circular references in objects](#circular-references-in-javascript-objects)
- [Trusted schemas](#security-risks-of-trusted-schemas)
- [ReDoS attack](#redos-attack)
- Modifying data during validation
- [Filtering data](#filtering-data)
- [Assigning defaults](#assigning-defaults)
- [Coercing data types](#coercing-data-types)
- API
- [Methods](#api)
- [Options](#options)
- [Validation errors](#validation-errors)
- [Plugins](#plugins)
- [Related packages](#related-packages)
- [Some packages using Ajv](#some-packages-using-ajv)
- [Tests, Contributing, Changes history](#tests)
- [Support, Code of conduct, License](#open-source-software-support)
## Performance
Ajv generates code using [doT templates](https://github.com/olado/doT) to turn JSON Schemas into super-fast validation functions that are efficient for v8 optimization.
Currently Ajv is the fastest and the most standard compliant validator according to these benchmarks:
- [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark) - 50% faster than the second place
- [jsck benchmark](https://github.com/pandastrike/jsck#benchmarks) - 20-190% faster
- [z-schema benchmark](https://rawgit.com/zaggino/z-schema/master/benchmark/results.html)
- [themis benchmark](https://cdn.rawgit.com/playlyfe/themis/master/benchmark/results.html)
Performance of different validators by [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark):
[](https://github.com/ebdrup/json-schema-benchmark/blob/master/README.md#performance)
## Features
- Ajv implements full JSON Schema [draft-06/07](http://json-schema.org/) and draft-04 standards:
- all validation keywords (see [JSON Schema validation keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md))
- full support of remote refs (remote schemas have to be added with `addSchema` or compiled to be available)
- support of circular references between schemas
- correct string lengths for strings with unicode pairs (can be turned off)
- [formats](#formats) defined by JSON Schema draft-07 standard and custom formats (can be turned off)
- [validates schemas against meta-schema](#api-validateschema)
- supports [browsers](#using-in-browser) and Node.js 0.10-14.x
- [asynchronous loading](#asynchronous-schema-compilation) of referenced schemas during compilation
- "All errors" validation mode with [option allErrors](#options)
- [error messages with parameters](#validation-errors) describing error reasons to allow creating custom error messages
- i18n error messages support with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package
- [filtering data](#filtering-data) from additional properties
- [assigning defaults](#assigning-defaults) to missing properties and items
- [coercing data](#coercing-data-types) to the types specified in `type` keywords
- [custom keywords](#defining-custom-keywords)
- draft-06/07 keywords `const`, `contains`, `propertyNames` and `if/then/else`
- draft-06 boolean schemas (`true`/`false` as a schema to always pass/fail).
- keywords `switch`, `patternRequired`, `formatMaximum` / `formatMinimum` and `formatExclusiveMaximum` / `formatExclusiveMinimum` from [JSON Schema extension proposals](https://github.com/json-schema/json-schema/wiki/v5-Proposals) with [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package
- [$data reference](#data-reference) to use values from the validated data as values for the schema keywords
- [asynchronous validation](#asynchronous-validation) of custom formats and keywords
## Install
```
npm install ajv
```
## <a name="usage"></a>Getting started
Try it in the Node.js REPL: https://tonicdev.com/npm/ajv
The fastest validation call:
```javascript
// Node.js require:
var Ajv = require('ajv');
// or ESM/TypeScript import
import Ajv from 'ajv';
var ajv = new Ajv(); // options can be passed, e.g. {allErrors: true}
var validate = ajv.compile(schema);
var valid = validate(data);
if (!valid) console.log(validate.errors);
```
or with less code
```javascript
// ...
var valid = ajv.validate(schema, data);
if (!valid) console.log(ajv.errors);
// ...
```
or
```javascript
// ...
var valid = ajv.addSchema(schema, 'mySchema')
.validate('mySchema', data);
if (!valid) console.log(ajv.errorsText());
// ...
```
See [API](#api) and [Options](#options) for more details.
Ajv compiles schemas to functions and caches them in all cases (using schema serialized with [fast-json-stable-stringify](https://github.com/epoberezkin/fast-json-stable-stringify) or a custom function as a key), so that the next time the same schema is used (not necessarily the same object instance) it won't be compiled again.
The best performance is achieved when using compiled functions returned by `compile` or `getSchema` methods (there is no additional function call).
__Please note__: every time a validation function or `ajv.validate` are called `errors` property is overwritten. You need to copy `errors` array reference to another variable if you want to use it later (e.g., in the callback). See [Validation errors](#validation-errors)
__Note for TypeScript users__: `ajv` provides its own TypeScript declarations
out of the box, so you don't need to install the deprecated `@types/ajv`
module.
## Using in browser
You can require Ajv directly from the code you browserify - in this case Ajv will be a part of your bundle.
If you need to use Ajv in several bundles you can create a separate UMD bundle using `npm run bundle` script (thanks to [siddo420](https://github.com/siddo420)).
Then you need to load Ajv in the browser:
```html
<script src="ajv.min.js"></script>
```
This bundle can be used with different module systems; it creates global `Ajv` if no module system is found.
The browser bundle is available on [cdnjs](https://cdnjs.com/libraries/ajv).
Ajv is tested with these browsers:
[](https://saucelabs.com/u/epoberezkin)
__Please note__: some frameworks, e.g. Dojo, may redefine global require in such way that is not compatible with CommonJS module format. In such case Ajv bundle has to be loaded before the framework and then you can use global Ajv (see issue [#234](https://github.com/ajv-validator/ajv/issues/234)).
### Ajv and Content Security Policies (CSP)
If you're using Ajv to compile a schema (the typical use) in a browser document that is loaded with a Content Security Policy (CSP), that policy will require a `script-src` directive that includes the value `'unsafe-eval'`.
:warning: NOTE, however, that `unsafe-eval` is NOT recommended in a secure CSP[[1]](https://developer.chrome.com/extensions/contentSecurityPolicy#relaxing-eval), as it has the potential to open the document to cross-site scripting (XSS) attacks.
In order to make use of Ajv without easing your CSP, you can [pre-compile a schema using the CLI](https://github.com/ajv-validator/ajv-cli#compile-schemas). This will transpile the schema JSON into a JavaScript file that exports a `validate` function that works simlarly to a schema compiled at runtime.
Note that pre-compilation of schemas is performed using [ajv-pack](https://github.com/ajv-validator/ajv-pack) and there are [some limitations to the schema features it can compile](https://github.com/ajv-validator/ajv-pack#limitations). A successfully pre-compiled schema is equivalent to the same schema compiled at runtime.
## Command line interface
CLI is available as a separate npm package [ajv-cli](https://github.com/ajv-validator/ajv-cli). It supports:
- compiling JSON Schemas to test their validity
- BETA: generating standalone module exporting a validation function to be used without Ajv (using [ajv-pack](https://github.com/ajv-validator/ajv-pack))
- migrate schemas to draft-07 (using [json-schema-migrate](https://github.com/epoberezkin/json-schema-migrate))
- validating data file(s) against JSON Schema
- testing expected validity of data against JSON Schema
- referenced schemas
- custom meta-schemas
- files in JSON, JSON5, YAML, and JavaScript format
- all Ajv options
- reporting changes in data after validation in [JSON-patch](https://tools.ietf.org/html/rfc6902) format
## Validation keywords
Ajv supports all validation keywords from draft-07 of JSON Schema standard:
- [type](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#type)
- [for numbers](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-numbers) - maximum, minimum, exclusiveMaximum, exclusiveMinimum, multipleOf
- [for strings](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-strings) - maxLength, minLength, pattern, format
- [for arrays](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-arrays) - maxItems, minItems, uniqueItems, items, additionalItems, [contains](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#contains)
- [for objects](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-objects) - maxProperties, minProperties, required, properties, patternProperties, additionalProperties, dependencies, [propertyNames](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#propertynames)
- [for all types](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-all-types) - enum, [const](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#const)
- [compound keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#compound-keywords) - not, oneOf, anyOf, allOf, [if/then/else](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#ifthenelse)
With [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package Ajv also supports validation keywords from [JSON Schema extension proposals](https://github.com/json-schema/json-schema/wiki/v5-Proposals) for JSON Schema standard:
- [patternRequired](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#patternrequired-proposed) - like `required` but with patterns that some property should match.
- [formatMaximum, formatMinimum, formatExclusiveMaximum, formatExclusiveMinimum](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#formatmaximum--formatminimum-and-exclusiveformatmaximum--exclusiveformatminimum-proposed) - setting limits for date, time, etc.
See [JSON Schema validation keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md) for more details.
## Annotation keywords
JSON Schema specification defines several annotation keywords that describe schema itself but do not perform any validation.
- `title` and `description`: information about the data represented by that schema
- `$comment` (NEW in draft-07): information for developers. With option `$comment` Ajv logs or passes the comment string to the user-supplied function. See [Options](#options).
- `default`: a default value of the data instance, see [Assigning defaults](#assigning-defaults).
- `examples` (NEW in draft-06): an array of data instances. Ajv does not check the validity of these instances against the schema.
- `readOnly` and `writeOnly` (NEW in draft-07): marks data-instance as read-only or write-only in relation to the source of the data (database, api, etc.).
- `contentEncoding`: [RFC 2045](https://tools.ietf.org/html/rfc2045#section-6.1 ), e.g., "base64".
- `contentMediaType`: [RFC 2046](https://tools.ietf.org/html/rfc2046), e.g., "image/png".
__Please note__: Ajv does not implement validation of the keywords `examples`, `contentEncoding` and `contentMediaType` but it reserves them. If you want to create a plugin that implements some of them, it should remove these keywords from the instance.
## Formats
Ajv implements formats defined by JSON Schema specification and several other formats. It is recommended NOT to use "format" keyword implementations with untrusted data, as they use potentially unsafe regular expressions - see [ReDoS attack](#redos-attack).
__Please note__: if you need to use "format" keyword to validate untrusted data, you MUST assess their suitability and safety for your validation scenarios.
The following formats are implemented for string validation with "format" keyword:
- _date_: full-date according to [RFC3339](http://tools.ietf.org/html/rfc3339#section-5.6).
- _time_: time with optional time-zone.
- _date-time_: date-time from the same source (time-zone is mandatory). `date`, `time` and `date-time` validate ranges in `full` mode and only regexp in `fast` mode (see [options](#options)).
- _uri_: full URI.
- _uri-reference_: URI reference, including full and relative URIs.
- _uri-template_: URI template according to [RFC6570](https://tools.ietf.org/html/rfc6570)
- _url_ (deprecated): [URL record](https://url.spec.whatwg.org/#concept-url).
- _email_: email address.
- _hostname_: host name according to [RFC1034](http://tools.ietf.org/html/rfc1034#section-3.5).
- _ipv4_: IP address v4.
- _ipv6_: IP address v6.
- _regex_: tests whether a string is a valid regular expression by passing it to RegExp constructor.
- _uuid_: Universally Unique IDentifier according to [RFC4122](http://tools.ietf.org/html/rfc4122).
- _json-pointer_: JSON-pointer according to [RFC6901](https://tools.ietf.org/html/rfc6901).
- _relative-json-pointer_: relative JSON-pointer according to [this draft](http://tools.ietf.org/html/draft-luff-relative-json-pointer-00).
__Please note__: JSON Schema draft-07 also defines formats `iri`, `iri-reference`, `idn-hostname` and `idn-email` for URLs, hostnames and emails with international characters. Ajv does not implement these formats. If you create Ajv plugin that implements them please make a PR to mention this plugin here.
There are two modes of format validation: `fast` and `full`. This mode affects formats `date`, `time`, `date-time`, `uri`, `uri-reference`, and `email`. See [Options](#options) for details.
You can add additional formats and replace any of the formats above using [addFormat](#api-addformat) method.
The option `unknownFormats` allows changing the default behaviour when an unknown format is encountered. In this case Ajv can either fail schema compilation (default) or ignore it (default in versions before 5.0.0). You also can allow specific format(s) that will be ignored. See [Options](#options) for details.
You can find regular expressions used for format validation and the sources that were used in [formats.js](https://github.com/ajv-validator/ajv/blob/master/lib/compile/formats.js).
## <a name="ref"></a>Combining schemas with $ref
You can structure your validation logic across multiple schema files and have schemas reference each other using `$ref` keyword.
Example:
```javascript
var schema = {
"$id": "http://example.com/schemas/schema.json",
"type": "object",
"properties": {
"foo": { "$ref": "defs.json#/definitions/int" },
"bar": { "$ref": "defs.json#/definitions/str" }
}
};
var defsSchema = {
"$id": "http://example.com/schemas/defs.json",
"definitions": {
"int": { "type": "integer" },
"str": { "type": "string" }
}
};
```
Now to compile your schema you can either pass all schemas to Ajv instance:
```javascript
var ajv = new Ajv({schemas: [schema, defsSchema]});
var validate = ajv.getSchema('http://example.com/schemas/schema.json');
```
or use `addSchema` method:
```javascript
var ajv = new Ajv;
var validate = ajv.addSchema(defsSchema)
.compile(schema);
```
See [Options](#options) and [addSchema](#api) method.
__Please note__:
- `$ref` is resolved as the uri-reference using schema $id as the base URI (see the example).
- References can be recursive (and mutually recursive) to implement the schemas for different data structures (such as linked lists, trees, graphs, etc.).
- You don't have to host your schema files at the URIs that you use as schema $id. These URIs are only used to identify the schemas, and according to JSON Schema specification validators should not expect to be able to download the schemas from these URIs.
- The actual location of the schema file in the file system is not used.
- You can pass the identifier of the schema as the second parameter of `addSchema` method or as a property name in `schemas` option. This identifier can be used instead of (or in addition to) schema $id.
- You cannot have the same $id (or the schema identifier) used for more than one schema - the exception will be thrown.
- You can implement dynamic resolution of the referenced schemas using `compileAsync` method. In this way you can store schemas in any system (files, web, database, etc.) and reference them without explicitly adding to Ajv instance. See [Asynchronous schema compilation](#asynchronous-schema-compilation).
## $data reference
With `$data` option you can use values from the validated data as the values for the schema keywords. See [proposal](https://github.com/json-schema-org/json-schema-spec/issues/51) for more information about how it works.
`$data` reference is supported in the keywords: const, enum, format, maximum/minimum, exclusiveMaximum / exclusiveMinimum, maxLength / minLength, maxItems / minItems, maxProperties / minProperties, formatMaximum / formatMinimum, formatExclusiveMaximum / formatExclusiveMinimum, multipleOf, pattern, required, uniqueItems.
The value of "$data" should be a [JSON-pointer](https://tools.ietf.org/html/rfc6901) to the data (the root is always the top level data object, even if the $data reference is inside a referenced subschema) or a [relative JSON-pointer](http://tools.ietf.org/html/draft-luff-relative-json-pointer-00) (it is relative to the current point in data; if the $data reference is inside a referenced subschema it cannot point to the data outside of the root level for this subschema).
Examples.
This schema requires that the value in property `smaller` is less or equal than the value in the property larger:
```javascript
var ajv = new Ajv({$data: true});
var schema = {
"properties": {
"smaller": {
"type": "number",
"maximum": { "$data": "1/larger" }
},
"larger": { "type": "number" }
}
};
var validData = {
smaller: 5,
larger: 7
};
ajv.validate(schema, validData); // true
```
This schema requires that the properties have the same format as their field names:
```javascript
var schema = {
"additionalProperties": {
"type": "string",
"format": { "$data": "0#" }
}
};
var validData = {
'date-time': '1963-06-19T08:30:06.283185Z',
email: 'joe.bloggs@example.com'
}
```
`$data` reference is resolved safely - it won't throw even if some property is undefined. If `$data` resolves to `undefined` the validation succeeds (with the exclusion of `const` keyword). If `$data` resolves to incorrect type (e.g. not "number" for maximum keyword) the validation fails.
## $merge and $patch keywords
With the package [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) you can use the keywords `$merge` and `$patch` that allow extending JSON Schemas with patches using formats [JSON Merge Patch (RFC 7396)](https://tools.ietf.org/html/rfc7396) and [JSON Patch (RFC 6902)](https://tools.ietf.org/html/rfc6902).
To add keywords `$merge` and `$patch` to Ajv instance use this code:
```javascript
require('ajv-merge-patch')(ajv);
```
Examples.
Using `$merge`:
```json
{
"$merge": {
"source": {
"type": "object",
"properties": { "p": { "type": "string" } },
"additionalProperties": false
},
"with": {
"properties": { "q": { "type": "number" } }
}
}
}
```
Using `$patch`:
```json
{
"$patch": {
"source": {
"type": "object",
"properties": { "p": { "type": "string" } },
"additionalProperties": false
},
"with": [
{ "op": "add", "path": "/properties/q", "value": { "type": "number" } }
]
}
}
```
The schemas above are equivalent to this schema:
```json
{
"type": "object",
"properties": {
"p": { "type": "string" },
"q": { "type": "number" }
},
"additionalProperties": false
}
```
The properties `source` and `with` in the keywords `$merge` and `$patch` can use absolute or relative `$ref` to point to other schemas previously added to the Ajv instance or to the fragments of the current schema.
See the package [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) for more information.
## Defining custom keywords
The advantages of using custom keywords are:
- allow creating validation scenarios that cannot be expressed using JSON Schema
- simplify your schemas
- help bringing a bigger part of the validation logic to your schemas
- make your schemas more expressive, less verbose and closer to your application domain
- implement custom data processors that modify your data (`modifying` option MUST be used in keyword definition) and/or create side effects while the data is being validated
If a keyword is used only for side-effects and its validation result is pre-defined, use option `valid: true/false` in keyword definition to simplify both generated code (no error handling in case of `valid: true`) and your keyword functions (no need to return any validation result).
The concerns you have to be aware of when extending JSON Schema standard with custom keywords are the portability and understanding of your schemas. You will have to support these custom keywords on other platforms and to properly document these keywords so that everybody can understand them in your schemas.
You can define custom keywords with [addKeyword](#api-addkeyword) method. Keywords are defined on the `ajv` instance level - new instances will not have previously defined keywords.
Ajv allows defining keywords with:
- validation function
- compilation function
- macro function
- inline compilation function that should return code (as string) that will be inlined in the currently compiled schema.
Example. `range` and `exclusiveRange` keywords using compiled schema:
```javascript
ajv.addKeyword('range', {
type: 'number',
compile: function (sch, parentSchema) {
var min = sch[0];
var max = sch[1];
return parentSchema.exclusiveRange === true
? function (data) { return data > min && data < max; }
: function (data) { return data >= min && data <= max; }
}
});
var schema = { "range": [2, 4], "exclusiveRange": true };
var validate = ajv.compile(schema);
console.log(validate(2.01)); // true
console.log(validate(3.99)); // true
console.log(validate(2)); // false
console.log(validate(4)); // false
```
Several custom keywords (typeof, instanceof, range and propertyNames) are defined in [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package - they can be used for your schemas and as a starting point for your own custom keywords.
See [Defining custom keywords](https://github.com/ajv-validator/ajv/blob/master/CUSTOM.md) for more details.
## Asynchronous schema compilation
During asynchronous compilation remote references are loaded using supplied function. See `compileAsync` [method](#api-compileAsync) and `loadSchema` [option](#options).
Example:
```javascript
var ajv = new Ajv({ loadSchema: loadSchema });
ajv.compileAsync(schema).then(function (validate) {
var valid = validate(data);
// ...
});
function loadSchema(uri) {
return request.json(uri).then(function (res) {
if (res.statusCode >= 400)
throw new Error('Loading error: ' + res.statusCode);
return res.body;
});
}
```
__Please note__: [Option](#options) `missingRefs` should NOT be set to `"ignore"` or `"fail"` for asynchronous compilation to work.
## Asynchronous validation
Example in Node.js REPL: https://tonicdev.com/esp/ajv-asynchronous-validation
You can define custom formats and keywords that perform validation asynchronously by accessing database or some other service. You should add `async: true` in the keyword or format definition (see [addFormat](#api-addformat), [addKeyword](#api-addkeyword) and [Defining custom keywords](#defining-custom-keywords)).
If your schema uses asynchronous formats/keywords or refers to some schema that contains them it should have `"$async": true` keyword so that Ajv can compile it correctly. If asynchronous format/keyword or reference to asynchronous schema is used in the schema without `$async` keyword Ajv will throw an exception during schema compilation.
__Please note__: all asynchronous subschemas that are referenced from the current or other schemas should have `"$async": true` keyword as well, otherwise the schema compilation will fail.
Validation function for an asynchronous custom format/keyword should return a promise that resolves with `true` or `false` (or rejects with `new Ajv.ValidationError(errors)` if you want to return custom errors from the keyword function).
Ajv compiles asynchronous schemas to [es7 async functions](http://tc39.github.io/ecmascript-asyncawait/) that can optionally be transpiled with [nodent](https://github.com/MatAtBread/nodent). Async functions are supported in Node.js 7+ and all modern browsers. You can also supply any other transpiler as a function via `processCode` option. See [Options](#options).
The compiled validation function has `$async: true` property (if the schema is asynchronous), so you can differentiate these functions if you are using both synchronous and asynchronous schemas.
Validation result will be a promise that resolves with validated data or rejects with an exception `Ajv.ValidationError` that contains the array of validation errors in `errors` property.
Example:
```javascript
var ajv = new Ajv;
// require('ajv-async')(ajv);
ajv.addKeyword('idExists', {
async: true,
type: 'number',
validate: checkIdExists
});
function checkIdExists(schema, data) {
return knex(schema.table)
.select('id')
.where('id', data)
.then(function (rows) {
return !!rows.length; // true if record is found
});
}
var schema = {
"$async": true,
"properties": {
"userId": {
"type": "integer",
"idExists": { "table": "users" }
},
"postId": {
"type": "integer",
"idExists": { "table": "posts" }
}
}
};
var validate = ajv.compile(schema);
validate({ userId: 1, postId: 19 })
.then(function (data) {
console.log('Data is valid', data); // { userId: 1, postId: 19 }
})
.catch(function (err) {
if (!(err instanceof Ajv.ValidationError)) throw err;
// data is invalid
console.log('Validation errors:', err.errors);
});
```
### Using transpilers with asynchronous validation functions.
[ajv-async](https://github.com/ajv-validator/ajv-async) uses [nodent](https://github.com/MatAtBread/nodent) to transpile async functions. To use another transpiler you should separately install it (or load its bundle in the browser).
#### Using nodent
```javascript
var ajv = new Ajv;
require('ajv-async')(ajv);
// in the browser if you want to load ajv-async bundle separately you can:
// window.ajvAsync(ajv);
var validate = ajv.compile(schema); // transpiled es7 async function
validate(data).then(successFunc).catch(errorFunc);
```
#### Using other transpilers
```javascript
var ajv = new Ajv({ processCode: transpileFunc });
var validate = ajv.compile(schema); // transpiled es7 async function
validate(data).then(successFunc).catch(errorFunc);
```
See [Options](#options).
## Security considerations
JSON Schema, if properly used, can replace data sanitisation. It doesn't replace other API security considerations. It also introduces additional security aspects to consider.
##### Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerabilities via GitHub issues.
##### Untrusted schemas
Ajv treats JSON schemas as trusted as your application code. This security model is based on the most common use case, when the schemas are static and bundled together with the application.
If your schemas are received from untrusted sources (or generated from untrusted data) there are several scenarios you need to prevent:
- compiling schemas can cause stack overflow (if they are too deep)
- compiling schemas can be slow (e.g. [#557](https://github.com/ajv-validator/ajv/issues/557))
- validating certain data can be slow
It is difficult to predict all the scenarios, but at the very least it may help to limit the size of untrusted schemas (e.g. limit JSON string length) and also the maximum schema object depth (that can be high for relatively small JSON strings). You also may want to mitigate slow regular expressions in `pattern` and `patternProperties` keywords.
Regardless the measures you take, using untrusted schemas increases security risks.
##### Circular references in JavaScript objects
Ajv does not support schemas and validated data that have circular references in objects. See [issue #802](https://github.com/ajv-validator/ajv/issues/802).
An attempt to compile such schemas or validate such data would cause stack overflow (or will not complete in case of asynchronous validation). Depending on the parser you use, untrusted data can lead to circular references.
##### Security risks of trusted schemas
Some keywords in JSON Schemas can lead to very slow validation for certain data. These keywords include (but may be not limited to):
- `pattern` and `format` for large strings - in some cases using `maxLength` can help mitigate it, but certain regular expressions can lead to exponential validation time even with relatively short strings (see [ReDoS attack](#redos-attack)).
- `patternProperties` for large property names - use `propertyNames` to mitigate, but some regular expressions can have exponential evaluation time as well.
- `uniqueItems` for large non-scalar arrays - use `maxItems` to mitigate
__Please note__: The suggestions above to prevent slow validation would only work if you do NOT use `allErrors: true` in production code (using it would continue validation after validation errors).
You can validate your JSON schemas against [this meta-schema](https://github.com/ajv-validator/ajv/blob/master/lib/refs/json-schema-secure.json) to check that these recommendations are followed:
```javascript
const isSchemaSecure = ajv.compile(require('ajv/lib/refs/json-schema-secure.json'));
const schema1 = {format: 'email'};
isSchemaSecure(schema1); // false
const schema2 = {format: 'email', maxLength: MAX_LENGTH};
isSchemaSecure(schema2); // true
```
__Please note__: following all these recommendation is not a guarantee that validation of untrusted data is safe - it can still lead to some undesirable results.
##### Content Security Policies (CSP)
See [Ajv and Content Security Policies (CSP)](#ajv-and-content-security-policies-csp)
## ReDoS attack
Certain regular expressions can lead to the exponential evaluation time even with relatively short strings.
Please assess the regular expressions you use in the schemas on their vulnerability to this attack - see [safe-regex](https://github.com/substack/safe-regex), for example.
__Please note__: some formats that Ajv implements use [regular expressions](https://github.com/ajv-validator/ajv/blob/master/lib/compile/formats.js) that can be vulnerable to ReDoS attack, so if you use Ajv to validate data from untrusted sources __it is strongly recommended__ to consider the following:
- making assessment of "format" implementations in Ajv.
- using `format: 'fast'` option that simplifies some of the regular expressions (although it does not guarantee that they are safe).
- replacing format implementations provided by Ajv with your own implementations of "format" keyword that either uses different regular expressions or another approach to format validation. Please see [addFormat](#api-addformat) method.
- disabling format validation by ignoring "format" keyword with option `format: false`
Whatever mitigation you choose, please assume all formats provided by Ajv as potentially unsafe and make your own assessment of their suitability for your validation scenarios.
## Filtering data
With [option `removeAdditional`](#options) (added by [andyscott](https://github.com/andyscott)) you can filter data during the validation.
This option modifies original data.
Example:
```javascript
var ajv = new Ajv({ removeAdditional: true });
var schema = {
"additionalProperties": false,
"properties": {
"foo": { "type": "number" },
"bar": {
"additionalProperties": { "type": "number" },
"properties": {
"baz": { "type": "string" }
}
}
}
}
var data = {
"foo": 0,
"additional1": 1, // will be removed; `additionalProperties` == false
"bar": {
"baz": "abc",
"additional2": 2 // will NOT be removed; `additionalProperties` != false
},
}
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 0, "bar": { "baz": "abc", "additional2": 2 }
```
If `removeAdditional` option in the example above were `"all"` then both `additional1` and `additional2` properties would have been removed.
If the option were `"failing"` then property `additional1` would have been removed regardless of its value and property `additional2` would have been removed only if its value were failing the schema in the inner `additionalProperties` (so in the example above it would have stayed because it passes the schema, but any non-number would have been removed).
__Please note__: If you use `removeAdditional` option with `additionalProperties` keyword inside `anyOf`/`oneOf` keywords your validation can fail with this schema, for example:
```json
{
"type": "object",
"oneOf": [
{
"properties": {
"foo": { "type": "string" }
},
"required": [ "foo" ],
"additionalProperties": false
},
{
"properties": {
"bar": { "type": "integer" }
},
"required": [ "bar" ],
"additionalProperties": false
}
]
}
```
The intention of the schema above is to allow objects with either the string property "foo" or the integer property "bar", but not with both and not with any other properties.
With the option `removeAdditional: true` the validation will pass for the object `{ "foo": "abc"}` but will fail for the object `{"bar": 1}`. It happens because while the first subschema in `oneOf` is validated, the property `bar` is removed because it is an additional property according to the standard (because it is not included in `properties` keyword in the same schema).
While this behaviour is unexpected (issues [#129](https://github.com/ajv-validator/ajv/issues/129), [#134](https://github.com/ajv-validator/ajv/issues/134)), it is correct. To have the expected behaviour (both objects are allowed and additional properties are removed) the schema has to be refactored in this way:
```json
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "integer" }
},
"additionalProperties": false,
"oneOf": [
{ "required": [ "foo" ] },
{ "required": [ "bar" ] }
]
}
```
The schema above is also more efficient - it will compile into a faster function.
## Assigning defaults
With [option `useDefaults`](#options) Ajv will assign values from `default` keyword in the schemas of `properties` and `items` (when it is the array of schemas) to the missing properties and items.
With the option value `"empty"` properties and items equal to `null` or `""` (empty string) will be considered missing and assigned defaults.
This option modifies original data.
__Please note__: the default value is inserted in the generated validation code as a literal, so the value inserted in the data will be the deep clone of the default in the schema.
Example 1 (`default` in `properties`):
```javascript
var ajv = new Ajv({ useDefaults: true });
var schema = {
"type": "object",
"properties": {
"foo": { "type": "number" },
"bar": { "type": "string", "default": "baz" }
},
"required": [ "foo", "bar" ]
};
var data = { "foo": 1 };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 1, "bar": "baz" }
```
Example 2 (`default` in `items`):
```javascript
var schema = {
"type": "array",
"items": [
{ "type": "number" },
{ "type": "string", "default": "foo" }
]
}
var data = [ 1 ];
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // [ 1, "foo" ]
```
`default` keywords in other cases are ignored:
- not in `properties` or `items` subschemas
- in schemas inside `anyOf`, `oneOf` and `not` (see [#42](https://github.com/ajv-validator/ajv/issues/42))
- in `if` subschema of `switch` keyword
- in schemas generated by custom macro keywords
The [`strictDefaults` option](#options) customizes Ajv's behavior for the defaults that Ajv ignores (`true` raises an error, and `"log"` outputs a warning).
## Coercing data types
When you are validating user inputs all your data properties are usually strings. The option `coerceTypes` allows you to have your data types coerced to the types specified in your schema `type` keywords, both to pass the validation and to use the correctly typed data afterwards.
This option modifies original data.
__Please note__: if you pass a scalar value to the validating function its type will be coerced and it will pass the validation, but the value of the variable you pass won't be updated because scalars are passed by value.
Example 1:
```javascript
var ajv = new Ajv({ coerceTypes: true });
var schema = {
"type": "object",
"properties": {
"foo": { "type": "number" },
"bar": { "type": "boolean" }
},
"required": [ "foo", "bar" ]
};
var data = { "foo": "1", "bar": "false" };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 1, "bar": false }
```
Example 2 (array coercions):
```javascript
var ajv = new Ajv({ coerceTypes: 'array' });
var schema = {
"properties": {
"foo": { "type": "array", "items": { "type": "number" } },
"bar": { "type": "boolean" }
}
};
var data = { "foo": "1", "bar": ["false"] };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": [1], "bar": false }
```
The coercion rules, as you can see from the example, are different from JavaScript both to validate user input as expected and to have the coercion reversible (to correctly validate cases where different types are defined in subschemas of "anyOf" and other compound keywords).
See [Coercion rules](https://github.com/ajv-validator/ajv/blob/master/COERCION.md) for details.
## API
##### new Ajv(Object options) -> Object
Create Ajv instance.
##### .compile(Object schema) -> Function<Object data>
Generate validating function and cache the compiled schema for future use.
Validating function returns a boolean value. This function has properties `errors` and `schema`. Errors encountered during the last validation are assigned to `errors` property (it is assigned `null` if there was no errors). `schema` property contains the reference to the original schema.
The schema passed to this method will be validated against meta-schema unless `validateSchema` option is false. If schema is invalid, an error will be thrown. See [options](#options).
##### <a name="api-compileAsync"></a>.compileAsync(Object schema [, Boolean meta] [, Function callback]) -> Promise
Asynchronous version of `compile` method that loads missing remote schemas using asynchronous function in `options.loadSchema`. This function returns a Promise that resolves to a validation function. An optional callback passed to `compileAsync` will be called with 2 parameters: error (or null) and validating function. The returned promise will reject (and the callback will be called with an error) when:
- missing schema can't be loaded (`loadSchema` returns a Promise that rejects).
- a schema containing a missing reference is loaded, but the reference cannot be resolved.
- schema (or some loaded/referenced schema) is invalid.
The function compiles schema and loads the first missing schema (or meta-schema) until all missing schemas are loaded.
You can asynchronously compile meta-schema by passing `true` as the second parameter.
See example in [Asynchronous compilation](#asynchronous-schema-compilation).
##### .validate(Object schema|String key|String ref, data) -> Boolean
Validate data using passed schema (it will be compiled and cached).
Instead of the schema you can use the key that was previously passed to `addSchema`, the schema id if it was present in the schema or any previously resolved reference.
Validation errors will be available in the `errors` property of Ajv instance (`null` if there were no errors).
__Please note__: every time this method is called the errors are overwritten so you need to copy them to another variable if you want to use them later.
If the schema is asynchronous (has `$async` keyword on the top level) this method returns a Promise. See [Asynchronous validation](#asynchronous-validation).
##### .addSchema(Array<Object>|Object schema [, String key]) -> Ajv
Add schema(s) to validator instance. This method does not compile schemas (but it still validates them). Because of that dependencies can be added in any order and circular dependencies are supported. It also prevents unnecessary compilation of schemas that are containers for other schemas but not used as a whole.
Array of schemas can be passed (schemas should have ids), the second parameter will be ignored.
Key can be passed that can be used to reference the schema and will be used as the schema id if there is no id inside the schema. If the key is not passed, the schema id will be used as the key.
Once the schema is added, it (and all the references inside it) can be referenced in other schemas and used to validate data.
Although `addSchema` does not compile schemas, explicit compilation is not required - the schema will be compiled when it is used first time.
By default the schema is validated against meta-schema before it is added, and if the schema does not pass validation the exception is thrown. This behaviour is controlled by `validateSchema` option.
__Please note__: Ajv uses the [method chaining syntax](https://en.wikipedia.org/wiki/Method_chaining) for all methods with the prefix `add*` and `remove*`.
This allows you to do nice things like the following.
```javascript
var validate = new Ajv().addSchema(schema).addFormat(name, regex).getSchema(uri);
```
##### .addMetaSchema(Array<Object>|Object schema [, String key]) -> Ajv
Adds meta schema(s) that can be used to validate other schemas. That function should be used instead of `addSchema` because there may be instance options that would compile a meta schema incorrectly (at the moment it is `removeAdditional` option).
There is no need to explicitly add draft-07 meta schema (http://json-schema.org/draft-07/schema) - it is added by default, unless option `meta` is set to `false`. You only need to use it if you have a changed meta-schema that you want to use to validate your schemas. See `validateSchema`.
##### <a name="api-validateschema"></a>.validateSchema(Object schema) -> Boolean
Validates schema. This method should be used to validate schemas rather than `validate` due to the inconsistency of `uri` format in JSON Schema standard.
By default this method is called automatically when the schema is added, so you rarely need to use it directly.
If schema doesn't have `$schema` property, it is validated against draft 6 meta-schema (option `meta` should not be false).
If schema has `$schema` property, then the schema with this id (that should be previously added) is used to validate passed schema.
Errors will be available at `ajv.errors`.
##### .getSchema(String key) -> Function<Object data>
Retrieve compiled schema previously added with `addSchema` by the key passed to `addSchema` or by its full reference (id). The returned validating function has `schema` property with the reference to the original schema.
##### .removeSchema([Object schema|String key|String ref|RegExp pattern]) -> Ajv
Remove added/cached schema. Even if schema is referenced by other schemas it can be safely removed as dependent schemas have local references.
Schema can be removed using:
- key passed to `addSchema`
- it's full reference (id)
- RegExp that should match schema id or key (meta-schemas won't be removed)
- actual schema object that will be stable-stringified to remove schema from cache
If no parameter is passed all schemas but meta-schemas will be removed and the cache will be cleared.
##### <a name="api-addformat"></a>.addFormat(String name, String|RegExp|Function|Object format) -> Ajv
Add custom format to validate strings or numbers. It can also be used to replace pre-defined formats for Ajv instance.
Strings are converted to RegExp.
Function should return validation result as `true` or `false`.
If object is passed it should have properties `validate`, `compare` and `async`:
- _validate_: a string, RegExp or a function as described above.
- _compare_: an optional comparison function that accepts two strings and compares them according to the format meaning. This function is used with keywords `formatMaximum`/`formatMinimum` (defined in [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package). It should return `1` if the first value is bigger than the second value, `-1` if it is smaller and `0` if it is equal.
- _async_: an optional `true` value if `validate` is an asynchronous function; in this case it should return a promise that resolves with a value `true` or `false`.
- _type_: an optional type of data that the format applies to. It can be `"string"` (default) or `"number"` (see https://github.com/ajv-validator/ajv/issues/291#issuecomment-259923858). If the type of data is different, the validation will pass.
Custom formats can be also added via `formats` option.
##### <a name="api-addkeyword"></a>.addKeyword(String keyword, Object definition) -> Ajv
Add custom validation keyword to Ajv instance.
Keyword should be different from all standard JSON Schema keywords and different from previously defined keywords. There is no way to redefine keywords or to remove keyword definition from the instance.
Keyword must start with a letter, `_` or `$`, and may continue with letters, numbers, `_`, `$`, or `-`.
It is recommended to use an application-specific prefix for keywords to avoid current and future name collisions.
Example Keywords:
- `"xyz-example"`: valid, and uses prefix for the xyz project to avoid name collisions.
- `"example"`: valid, but not recommended as it could collide with future versions of JSON Schema etc.
- `"3-example"`: invalid as numbers are not allowed to be the first character in a keyword
Keyword definition is an object with the following properties:
- _type_: optional string or array of strings with data type(s) that the keyword applies to. If not present, the keyword will apply to all types.
- _validate_: validating function
- _compile_: compiling function
- _macro_: macro function
- _inline_: compiling function that returns code (as string)
- _schema_: an optional `false` value used with "validate" keyword to not pass schema
- _metaSchema_: an optional meta-schema for keyword schema
- _dependencies_: an optional list of properties that must be present in the parent schema - it will be checked during schema compilation
- _modifying_: `true` MUST be passed if keyword modifies data
- _statements_: `true` can be passed in case inline keyword generates statements (as opposed to expression)
- _valid_: pass `true`/`false` to pre-define validation result, the result returned from validation function will be ignored. This option cannot be used with macro keywords.
- _$data_: an optional `true` value to support [$data reference](#data-reference) as the value of custom keyword. The reference will be resolved at validation time. If the keyword has meta-schema it would be extended to allow $data and it will be used to validate the resolved value. Supporting $data reference requires that keyword has validating function (as the only option or in addition to compile, macro or inline function).
- _async_: an optional `true` value if the validation function is asynchronous (whether it is compiled or passed in _validate_ property); in this case it should return a promise that resolves with a value `true` or `false`. This option is ignored in case of "macro" and "inline" keywords.
- _errors_: an optional boolean or string `"full"` indicating whether keyword returns errors. If this property is not set Ajv will determine if the errors were set in case of failed validation.
_compile_, _macro_ and _inline_ are mutually exclusive, only one should be used at a time. _validate_ can be used separately or in addition to them to support $data reference.
__Please note__: If the keyword is validating data type that is different from the type(s) in its definition, the validation function will not be called (and expanded macro will not be used), so there is no need to check for data type inside validation function or inside schema returned by macro function (unless you want to enforce a specific type and for some reason do not want to use a separate `type` keyword for that). In the same way as standard keywords work, if the keyword does not apply to the data type being validated, the validation of this keyword will succeed.
See [Defining custom keywords](#defining-custom-keywords) for more details.
##### .getKeyword(String keyword) -> Object|Boolean
Returns custom keyword definition, `true` for pre-defined keywords and `false` if the keyword is unknown.
##### .removeKeyword(String keyword) -> Ajv
Removes custom or pre-defined keyword so you can redefine them.
While this method can be used to extend pre-defined keywords, it can also be used to completely change their meaning - it may lead to unexpected results.
__Please note__: schemas compiled before the keyword is removed will continue to work without changes. To recompile schemas use `removeSchema` method and compile them again.
##### .errorsText([Array<Object> errors [, Object options]]) -> String
Returns the text with all errors in a String.
Options can have properties `separator` (string used to separate errors, ", " by default) and `dataVar` (the variable name that dataPaths are prefixed with, "data" by default).
## Options
Defaults:
```javascript
{
// validation and reporting options:
$data: false,
allErrors: false,
verbose: false,
$comment: false, // NEW in Ajv version 6.0
jsonPointers: false,
uniqueItems: true,
unicode: true,
nullable: false,
format: 'fast',
formats: {},
unknownFormats: true,
schemas: {},
logger: undefined,
// referenced schema options:
schemaId: '$id',
missingRefs: true,
extendRefs: 'ignore', // recommended 'fail'
loadSchema: undefined, // function(uri: string): Promise {}
// options to modify validated data:
removeAdditional: false,
useDefaults: false,
coerceTypes: false,
// strict mode options
strictDefaults: false,
strictKeywords: false,
strictNumbers: false,
// asynchronous validation options:
transpile: undefined, // requires ajv-async package
// advanced options:
meta: true,
validateSchema: true,
addUsedSchema: true,
inlineRefs: true,
passContext: false,
loopRequired: Infinity,
ownProperties: false,
multipleOfPrecision: false,
errorDataPath: 'object', // deprecated
messages: true,
sourceCode: false,
processCode: undefined, // function (str: string, schema: object): string {}
cache: new Cache,
serialize: undefined
}
```
##### Validation and reporting options
- _$data_: support [$data references](#data-reference). Draft 6 meta-schema that is added by default will be extended to allow them. If you want to use another meta-schema you need to use $dataMetaSchema method to add support for $data reference. See [API](#api).
- _allErrors_: check all rules collecting all errors. Default is to return after the first error.
- _verbose_: include the reference to the part of the schema (`schema` and `parentSchema`) and validated data in errors (false by default).
- _$comment_ (NEW in Ajv version 6.0): log or pass the value of `$comment` keyword to a function. Option values:
- `false` (default): ignore $comment keyword.
- `true`: log the keyword value to console.
- function: pass the keyword value, its schema path and root schema to the specified function
- _jsonPointers_: set `dataPath` property of errors using [JSON Pointers](https://tools.ietf.org/html/rfc6901) instead of JavaScript property access notation.
- _uniqueItems_: validate `uniqueItems` keyword (true by default).
- _unicode_: calculate correct length of strings with unicode pairs (true by default). Pass `false` to use `.length` of strings that is faster, but gives "incorrect" lengths of strings with unicode pairs - each unicode pair is counted as two characters.
- _nullable_: support keyword "nullable" from [Open API 3 specification](https://swagger.io/docs/specification/data-models/data-types/).
- _format_: formats validation mode. Option values:
- `"fast"` (default) - simplified and fast validation (see [Formats](#formats) for details of which formats are available and affected by this option).
- `"full"` - more restrictive and slow validation. E.g., 25:00:00 and 2015/14/33 will be invalid time and date in 'full' mode but it will be valid in 'fast' mode.
- `false` - ignore all format keywords.
- _formats_: an object with custom formats. Keys and values will be passed to `addFormat` method.
- _keywords_: an object with custom keywords. Keys and values will be passed to `addKeyword` method.
- _unknownFormats_: handling of unknown formats. Option values:
- `true` (default) - if an unknown format is encountered the exception is thrown during schema compilation. If `format` keyword value is [$data reference](#data-reference) and it is unknown the validation will fail.
- `[String]` - an array of unknown format names that will be ignored. This option can be used to allow usage of third party schemas with format(s) for which you don't have definitions, but still fail if another unknown format is used. If `format` keyword value is [$data reference](#data-reference) and it is not in this array the validation will fail.
- `"ignore"` - to log warning during schema compilation and always pass validation (the default behaviour in versions before 5.0.0). This option is not recommended, as it allows to mistype format name and it won't be validated without any error message. This behaviour is required by JSON Schema specification.
- _schemas_: an array or object of schemas that will be added to the instance. In case you pass the array the schemas must have IDs in them. When the object is passed the method `addSchema(value, key)` will be called for each schema in this object.
- _logger_: sets the logging method. Default is the global `console` object that should have methods `log`, `warn` and `error`. See [Error logging](#error-logging). Option values:
- custom logger - it should have methods `log`, `warn` and `error`. If any of these methods is missing an exception will be thrown.
- `false` - logging is disabled.
##### Referenced schema options
- _schemaId_: this option defines which keywords are used as schema URI. Option value:
- `"$id"` (default) - only use `$id` keyword as schema URI (as specified in JSON Schema draft-06/07), ignore `id` keyword (if it is present a warning will be logged).
- `"id"` - only use `id` keyword as schema URI (as specified in JSON Schema draft-04), ignore `$id` keyword (if it is present a warning will be logged).
- `"auto"` - use both `$id` and `id` keywords as schema URI. If both are present (in the same schema object) and different the exception will be thrown during schema compilation.
- _missingRefs_: handling of missing referenced schemas. Option values:
- `true` (default) - if the reference cannot be resolved during compilation the exception is thrown. The thrown error has properties `missingRef` (with hash fragment) and `missingSchema` (without it). Both properties are resolved relative to the current base id (usually schema id, unless it was substituted).
- `"ignore"` - to log error during compilation and always pass validation.
- `"fail"` - to log error and successfully compile schema but fail validation if this rule is checked.
- _extendRefs_: validation of other keywords when `$ref` is present in the schema. Option values:
- `"ignore"` (default) - when `$ref` is used other keywords are ignored (as per [JSON Reference](https://tools.ietf.org/html/draft-pbryan-zyp-json-ref-03#section-3) standard). A warning will be logged during the schema compilation.
- `"fail"` (recommended) - if other validation keywords are used together with `$ref` the exception will be thrown when the schema is compiled. This option is recommended to make sure schema has no keywords that are ignored, which can be confusing.
- `true` - validate all keywords in the schemas with `$ref` (the default behaviour in versions before 5.0.0).
- _loadSchema_: asynchronous function that will be used to load remote schemas when `compileAsync` [method](#api-compileAsync) is used and some reference is missing (option `missingRefs` should NOT be 'fail' or 'ignore'). This function should accept remote schema uri as a parameter and return a Promise that resolves to a schema. See example in [Asynchronous compilation](#asynchronous-schema-compilation).
##### Options to modify validated data
- _removeAdditional_: remove additional properties - see example in [Filtering data](#filtering-data). This option is not used if schema is added with `addMetaSchema` method. Option values:
- `false` (default) - not to remove additional properties
- `"all"` - all additional properties are removed, regardless of `additionalProperties` keyword in schema (and no validation is made for them).
- `true` - only additional properties with `additionalProperties` keyword equal to `false` are removed.
- `"failing"` - additional properties that fail schema validation will be removed (where `additionalProperties` keyword is `false` or schema).
- _useDefaults_: replace missing or undefined properties and items with the values from corresponding `default` keywords. Default behaviour is to ignore `default` keywords. This option is not used if schema is added with `addMetaSchema` method. See examples in [Assigning defaults](#assigning-defaults). Option values:
- `false` (default) - do not use defaults
- `true` - insert defaults by value (object literal is used).
- `"empty"` - in addition to missing or undefined, use defaults for properties and items that are equal to `null` or `""` (an empty string).
- `"shared"` (deprecated) - insert defaults by reference. If the default is an object, it will be shared by all instances of validated data. If you modify the inserted default in the validated data, it will be modified in the schema as well.
- _coerceTypes_: change data type of data to match `type` keyword. See the example in [Coercing data types](#coercing-data-types) and [coercion rules](https://github.com/ajv-validator/ajv/blob/master/COERCION.md). Option values:
- `false` (default) - no type coercion.
- `true` - coerce scalar data types.
- `"array"` - in addition to coercions between scalar types, coerce scalar data to an array with one element and vice versa (as required by the schema).
##### Strict mode options
- _strictDefaults_: report ignored `default` keywords in schemas. Option values:
- `false` (default) - ignored defaults are not reported
- `true` - if an ignored default is present, throw an error
- `"log"` - if an ignored default is present, log warning
- _strictKeywords_: report unknown keywords in schemas. Option values:
- `false` (default) - unknown keywords are not reported
- `true` - if an unknown keyword is present, throw an error
- `"log"` - if an unknown keyword is present, log warning
- _strictNumbers_: validate numbers strictly, failing validation for NaN and Infinity. Option values:
- `false` (default) - NaN or Infinity will pass validation for numeric types
- `true` - NaN or Infinity will not pass validation for numeric types
##### Asynchronous validation options
- _transpile_: Requires [ajv-async](https://github.com/ajv-validator/ajv-async) package. It determines whether Ajv transpiles compiled asynchronous validation function. Option values:
- `undefined` (default) - transpile with [nodent](https://github.com/MatAtBread/nodent) if async functions are not supported.
- `true` - always transpile with nodent.
- `false` - do not transpile; if async functions are not supported an exception will be thrown.
##### Advanced options
- _meta_: add [meta-schema](http://json-schema.org/documentation.html) so it can be used by other schemas (true by default). If an object is passed, it will be used as the default meta-schema for schemas that have no `$schema` keyword. This default meta-schema MUST have `$schema` keyword.
- _validateSchema_: validate added/compiled schemas against meta-schema (true by default). `$schema` property in the schema can be http://json-schema.org/draft-07/schema or absent (draft-07 meta-schema will be used) or can be a reference to the schema previously added with `addMetaSchema` method. Option values:
- `true` (default) - if the validation fails, throw the exception.
- `"log"` - if the validation fails, log error.
- `false` - skip schema validation.
- _addUsedSchema_: by default methods `compile` and `validate` add schemas to the instance if they have `$id` (or `id`) property that doesn't start with "#". If `$id` is present and it is not unique the exception will be thrown. Set this option to `false` to skip adding schemas to the instance and the `$id` uniqueness check when these methods are used. This option does not affect `addSchema` method.
- _inlineRefs_: Affects compilation of referenced schemas. Option values:
- `true` (default) - the referenced schemas that don't have refs in them are inlined, regardless of their size - that substantially improves performance at the cost of the bigger size of compiled schema functions.
- `false` - to not inline referenced schemas (they will be compiled as separate functions).
- integer number - to limit the maximum number of keywords of the schema that will be inlined.
- _passContext_: pass validation context to custom keyword functions. If this option is `true` and you pass some context to the compiled validation function with `validate.call(context, data)`, the `context` will be available as `this` in your custom keywords. By default `this` is Ajv instance.
- _loopRequired_: by default `required` keyword is compiled into a single expression (or a sequence of statements in `allErrors` mode). In case of a very large number of properties in this keyword it may result in a very big validation function. Pass integer to set the number of properties above which `required` keyword will be validated in a loop - smaller validation function size but also worse performance.
- _ownProperties_: by default Ajv iterates over all enumerable object properties; when this option is `true` only own enumerable object properties (i.e. found directly on the object rather than on its prototype) are iterated. Contributed by @mbroadst.
- _multipleOfPrecision_: by default `multipleOf` keyword is validated by comparing the result of division with parseInt() of that result. It works for dividers that are bigger than 1. For small dividers such as 0.01 the result of the division is usually not integer (even when it should be integer, see issue [#84](https://github.com/ajv-validator/ajv/issues/84)). If you need to use fractional dividers set this option to some positive integer N to have `multipleOf` validated using this formula: `Math.abs(Math.round(division) - division) < 1e-N` (it is slower but allows for float arithmetics deviations).
- _errorDataPath_ (deprecated): set `dataPath` to point to 'object' (default) or to 'property' when validating keywords `required`, `additionalProperties` and `dependencies`.
- _messages_: Include human-readable messages in errors. `true` by default. `false` can be passed when custom messages are used (e.g. with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n)).
- _sourceCode_: add `sourceCode` property to validating function (for debugging; this code can be different from the result of toString call).
- _processCode_: an optional function to process generated code before it is passed to Function constructor. It can be used to either beautify (the validating function is generated without line-breaks) or to transpile code. Starting from version 5.0.0 this option replaced options:
- `beautify` that formatted the generated function using [js-beautify](https://github.com/beautify-web/js-beautify). If you want to beautify the generated code pass a function calling `require('js-beautify').js_beautify` as `processCode: code => js_beautify(code)`.
- `transpile` that transpiled asynchronous validation function. You can still use `transpile` option with [ajv-async](https://github.com/ajv-validator/ajv-async) package. See [Asynchronous validation](#asynchronous-validation) for more information.
- _cache_: an optional instance of cache to store compiled schemas using stable-stringified schema as a key. For example, set-associative cache [sacjs](https://github.com/epoberezkin/sacjs) can be used. If not passed then a simple hash is used which is good enough for the common use case (a limited number of statically defined schemas). Cache should have methods `put(key, value)`, `get(key)`, `del(key)` and `clear()`.
- _serialize_: an optional function to serialize schema to cache key. Pass `false` to use schema itself as a key (e.g., if WeakMap used as a cache). By default [fast-json-stable-stringify](https://github.com/epoberezkin/fast-json-stable-stringify) is used.
## Validation errors
In case of validation failure, Ajv assigns the array of errors to `errors` property of validation function (or to `errors` property of Ajv instance when `validate` or `validateSchema` methods were called). In case of [asynchronous validation](#asynchronous-validation), the returned promise is rejected with exception `Ajv.ValidationError` that has `errors` property.
### Error objects
Each error is an object with the following properties:
- _keyword_: validation keyword.
- _dataPath_: the path to the part of the data that was validated. By default `dataPath` uses JavaScript property access notation (e.g., `".prop[1].subProp"`). When the option `jsonPointers` is true (see [Options](#options)) `dataPath` will be set using JSON pointer standard (e.g., `"/prop/1/subProp"`).
- _schemaPath_: the path (JSON-pointer as a URI fragment) to the schema of the keyword that failed validation.
- _params_: the object with the additional information about error that can be used to create custom error messages (e.g., using [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package). See below for parameters set by all keywords.
- _message_: the standard error message (can be excluded with option `messages` set to false).
- _schema_: the schema of the keyword (added with `verbose` option).
- _parentSchema_: the schema containing the keyword (added with `verbose` option)
- _data_: the data validated by the keyword (added with `verbose` option).
__Please note__: `propertyNames` keyword schema validation errors have an additional property `propertyName`, `dataPath` points to the object. After schema validation for each property name, if it is invalid an additional error is added with the property `keyword` equal to `"propertyNames"`.
### Error parameters
Properties of `params` object in errors depend on the keyword that failed validation.
- `maxItems`, `minItems`, `maxLength`, `minLength`, `maxProperties`, `minProperties` - property `limit` (number, the schema of the keyword).
- `additionalItems` - property `limit` (the maximum number of allowed items in case when `items` keyword is an array of schemas and `additionalItems` is false).
- `additionalProperties` - property `additionalProperty` (the property not used in `properties` and `patternProperties` keywords).
- `dependencies` - properties:
- `property` (dependent property),
- `missingProperty` (required missing dependency - only the first one is reported currently)
- `deps` (required dependencies, comma separated list as a string),
- `depsCount` (the number of required dependencies).
- `format` - property `format` (the schema of the keyword).
- `maximum`, `minimum` - properties:
- `limit` (number, the schema of the keyword),
- `exclusive` (boolean, the schema of `exclusiveMaximum` or `exclusiveMinimum`),
- `comparison` (string, comparison operation to compare the data to the limit, with the data on the left and the limit on the right; can be "<", "<=", ">", ">=")
- `multipleOf` - property `multipleOf` (the schema of the keyword)
- `pattern` - property `pattern` (the schema of the keyword)
- `required` - property `missingProperty` (required property that is missing).
- `propertyNames` - property `propertyName` (an invalid property name).
- `patternRequired` (in ajv-keywords) - property `missingPattern` (required pattern that did not match any property).
- `type` - property `type` (required type(s), a string, can be a comma-separated list)
- `uniqueItems` - properties `i` and `j` (indices of duplicate items).
- `const` - property `allowedValue` pointing to the value (the schema of the keyword).
- `enum` - property `allowedValues` pointing to the array of values (the schema of the keyword).
- `$ref` - property `ref` with the referenced schema URI.
- `oneOf` - property `passingSchemas` (array of indices of passing schemas, null if no schema passes).
- custom keywords (in case keyword definition doesn't create errors) - property `keyword` (the keyword name).
### Error logging
Using the `logger` option when initiallizing Ajv will allow you to define custom logging. Here you can build upon the exisiting logging. The use of other logging packages is supported as long as the package or its associated wrapper exposes the required methods. If any of the required methods are missing an exception will be thrown.
- **Required Methods**: `log`, `warn`, `error`
```javascript
var otherLogger = new OtherLogger();
var ajv = new Ajv({
logger: {
log: console.log.bind(console),
warn: function warn() {
otherLogger.logWarn.apply(otherLogger, arguments);
},
error: function error() {
otherLogger.logError.apply(otherLogger, arguments);
console.error.apply(console, arguments);
}
}
});
```
## Plugins
Ajv can be extended with plugins that add custom keywords, formats or functions to process generated code. When such plugin is published as npm package it is recommended that it follows these conventions:
- it exports a function
- this function accepts ajv instance as the first parameter and returns the same instance to allow chaining
- this function can accept an optional configuration as the second parameter
If you have published a useful plugin please submit a PR to add it to the next section.
## Related packages
- [ajv-async](https://github.com/ajv-validator/ajv-async) - plugin to configure async validation mode
- [ajv-bsontype](https://github.com/BoLaMN/ajv-bsontype) - plugin to validate mongodb's bsonType formats
- [ajv-cli](https://github.com/jessedc/ajv-cli) - command line interface
- [ajv-errors](https://github.com/ajv-validator/ajv-errors) - plugin for custom error messages
- [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) - internationalised error messages
- [ajv-istanbul](https://github.com/ajv-validator/ajv-istanbul) - plugin to instrument generated validation code to measure test coverage of your schemas
- [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) - plugin with custom validation keywords (select, typeof, etc.)
- [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) - plugin with keywords $merge and $patch
- [ajv-pack](https://github.com/ajv-validator/ajv-pack) - produces a compact module exporting validation functions
- [ajv-formats-draft2019](https://github.com/luzlab/ajv-formats-draft2019) - format validators for draft2019 that aren't already included in ajv (ie. `idn-hostname`, `idn-email`, `iri`, `iri-reference` and `duration`).
## Some packages using Ajv
- [webpack](https://github.com/webpack/webpack) - a module bundler. Its main purpose is to bundle JavaScript files for usage in a browser
- [jsonscript-js](https://github.com/JSONScript/jsonscript-js) - the interpreter for [JSONScript](http://www.jsonscript.org) - scripted processing of existing endpoints and services
- [osprey-method-handler](https://github.com/mulesoft-labs/osprey-method-handler) - Express middleware for validating requests and responses based on a RAML method object, used in [osprey](https://github.com/mulesoft/osprey) - validating API proxy generated from a RAML definition
- [har-validator](https://github.com/ahmadnassri/har-validator) - HTTP Archive (HAR) validator
- [jsoneditor](https://github.com/josdejong/jsoneditor) - a web-based tool to view, edit, format, and validate JSON http://jsoneditoronline.org
- [JSON Schema Lint](https://github.com/nickcmaynard/jsonschemalint) - a web tool to validate JSON/YAML document against a single JSON Schema http://jsonschemalint.com
- [objection](https://github.com/vincit/objection.js) - SQL-friendly ORM for Node.js
- [table](https://github.com/gajus/table) - formats data into a string table
- [ripple-lib](https://github.com/ripple/ripple-lib) - a JavaScript API for interacting with [Ripple](https://ripple.com) in Node.js and the browser
- [restbase](https://github.com/wikimedia/restbase) - distributed storage with REST API & dispatcher for backend services built to provide a low-latency & high-throughput API for Wikipedia / Wikimedia content
- [hippie-swagger](https://github.com/CacheControl/hippie-swagger) - [Hippie](https://github.com/vesln/hippie) wrapper that provides end to end API testing with swagger validation
- [react-form-controlled](https://github.com/seeden/react-form-controlled) - React controlled form components with validation
- [rabbitmq-schema](https://github.com/tjmehta/rabbitmq-schema) - a schema definition module for RabbitMQ graphs and messages
- [@query/schema](https://www.npmjs.com/package/@query/schema) - stream filtering with a URI-safe query syntax parsing to JSON Schema
- [chai-ajv-json-schema](https://github.com/peon374/chai-ajv-json-schema) - chai plugin to us JSON Schema with expect in mocha tests
- [grunt-jsonschema-ajv](https://github.com/SignpostMarv/grunt-jsonschema-ajv) - Grunt plugin for validating files against JSON Schema
- [extract-text-webpack-plugin](https://github.com/webpack-contrib/extract-text-webpack-plugin) - extract text from bundle into a file
- [electron-builder](https://github.com/electron-userland/electron-builder) - a solution to package and build a ready for distribution Electron app
- [addons-linter](https://github.com/mozilla/addons-linter) - Mozilla Add-ons Linter
- [gh-pages-generator](https://github.com/epoberezkin/gh-pages-generator) - multi-page site generator converting markdown files to GitHub pages
- [ESLint](https://github.com/eslint/eslint) - the pluggable linting utility for JavaScript and JSX
## Tests
```
npm install
git submodule update --init
npm test
```
## Contributing
All validation functions are generated using doT templates in [dot](https://github.com/ajv-validator/ajv/tree/master/lib/dot) folder. Templates are precompiled so doT is not a run-time dependency.
`npm run build` - compiles templates to [dotjs](https://github.com/ajv-validator/ajv/tree/master/lib/dotjs) folder.
`npm run watch` - automatically compiles templates when files in dot folder change
Please see [Contributing guidelines](https://github.com/ajv-validator/ajv/blob/master/CONTRIBUTING.md)
## Changes history
See https://github.com/ajv-validator/ajv/releases
__Please note__: [Changes in version 7.0.0-beta](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0-beta.0)
[Version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0).
## Code of conduct
Please review and follow the [Code of conduct](https://github.com/ajv-validator/ajv/blob/master/CODE_OF_CONDUCT.md).
Please report any unacceptable behaviour to ajv.validator@gmail.com - it will be reviewed by the project team.
## Open-source software support
Ajv is a part of [Tidelift subscription](https://tidelift.com/subscription/pkg/npm-ajv?utm_source=npm-ajv&utm_medium=referral&utm_campaign=readme) - it provides a centralised support to open-source software users, in addition to the support provided by software maintainers.
## License
[MIT](https://github.com/ajv-validator/ajv/blob/master/LICENSE)
[](https://travis-ci.org/#!/adaltas/node-csv-stringify) [](https://www.npmjs.com/package/csv-stringify) [](https://www.npmjs.com/package/csv-stringify)
This package is a stringifier converting records into a CSV text and
implementing the Node.js [`stream.Transform`
API](https://nodejs.org/api/stream.html). It also provides the easier
synchronous and callback-based APIs for conveniency. It is both extremely easy
to use and powerful. It was first released in 2010 and is tested against big
data sets by a large community.
## Documentation
* [Project homepage](http://csv.js.org/stringify/)
* [API](http://csv.js.org/stringify/api/)
* [Options](http://csv.js.org/stringify/options/)
* [Examples](http://csv.js.org/stringify/examples/)
## Main features
* Follow the Node.js streaming API
* Simplicity with the optional callback API
* Support for custom formatters, delimiters, quotes, escape characters and header
* Support big datasets
* Complete test coverage and samples for inspiration
* Only 1 external dependency
* to be used conjointly with `csv-generate`, `csv-parse` and `stream-transform`
* MIT License
## Usage
The module is built on the Node.js Stream API. For the sake of simplicity, a
simple callback API is also provided. To give you a quick look, here's an
example of the callback API:
```javascript
const stringify = require('csv-stringify')
const assert = require('assert')
// import stringify from 'csv-stringify'
// import assert from 'assert/strict'
const input = [ [ '1', '2', '3', '4' ], [ 'a', 'b', 'c', 'd' ] ]
stringify(input, function(err, output) {
const expected = '1,2,3,4\na,b,c,d\n'
assert.strictEqual(output, expected, `output.should.eql ${expected}`)
console.log("Passed.", output)
})
```
## Development
Tests are executed with mocha. To install it, run `npm install` followed by `npm
test`. It will install mocha and its dependencies in your project "node_modules"
directory and run the test suite. The tests run against the CoffeeScript source
files.
To generate the JavaScript files, run `npm run build`.
The test suite is run online with
[Travis](https://travis-ci.org/#!/adaltas/node-csv-stringify). See the [Travis
definition
file](https://github.com/adaltas/node-csv-stringify/blob/master/.travis.yml) to
view the tested Node.js version.
## Contributors
* David Worms: <https://github.com/wdavidw>
[csv_home]: https://github.com/adaltas/node-csv
[stream_transform]: http://nodejs.org/api/stream.html#stream_class_stream_transform
[examples]: http://csv.js.org/stringify/examples/
[csv]: https://github.com/adaltas/node-csv
<p align="center">
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs/master/yargs-logo.png">
</p>
<h1 align="center"> Yargs </h1>
<p align="center">
<b >Yargs be a node.js library fer hearties tryin' ter parse optstrings</b>
</p>
<br>

[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[![Coverage][coverage-image]][coverage-url]
[![Conventional Commits][conventional-commits-image]][conventional-commits-url]
[![Slack][slack-image]][slack-url]
## Description
Yargs helps you build interactive command line tools, by parsing arguments and generating an elegant user interface.
It gives you:
* commands and (grouped) options (`my-program.js serve --port=5000`).
* a dynamically generated help menu based on your arguments:
```
mocha [spec..]
Run tests with Mocha
Commands
mocha inspect [spec..] Run tests with Mocha [default]
mocha init <path> create a client-side Mocha setup at <path>
Rules & Behavior
--allow-uncaught Allow uncaught errors to propagate [boolean]
--async-only, -A Require all tests to use a callback (async) or
return a Promise [boolean]
```
* bash-completion shortcuts for commands and options.
* and [tons more](/docs/api.md).
## Installation
Stable version:
```bash
npm i yargs
```
Bleeding edge version with the most recent features:
```bash
npm i yargs@next
```
## Usage
### Simple Example
```javascript
#!/usr/bin/env node
const yargs = require('yargs/yargs')
const { hideBin } = require('yargs/helpers')
const argv = yargs(hideBin(process.argv)).argv
if (argv.ships > 3 && argv.distance < 53.5) {
console.log('Plunder more riffiwobbles!')
} else {
console.log('Retreat from the xupptumblers!')
}
```
```bash
$ ./plunder.js --ships=4 --distance=22
Plunder more riffiwobbles!
$ ./plunder.js --ships 12 --distance 98.7
Retreat from the xupptumblers!
```
### Complex Example
```javascript
#!/usr/bin/env node
const yargs = require('yargs/yargs')
const { hideBin } = require('yargs/helpers')
yargs(hideBin(process.argv))
.command('serve [port]', 'start the server', (yargs) => {
yargs
.positional('port', {
describe: 'port to bind on',
default: 5000
})
}, (argv) => {
if (argv.verbose) console.info(`start server on :${argv.port}`)
serve(argv.port)
})
.option('verbose', {
alias: 'v',
type: 'boolean',
description: 'Run with verbose logging'
})
.argv
```
Run the example above with `--help` to see the help for the application.
## Supported Platforms
### TypeScript
yargs has type definitions at [@types/yargs][type-definitions].
```
npm i @types/yargs --save-dev
```
See usage examples in [docs](/docs/typescript.md).
### Deno
As of `v16`, `yargs` supports [Deno](https://github.com/denoland/deno):
```typescript
import yargs from 'https://deno.land/x/yargs/deno.ts'
import { Arguments } from 'https://deno.land/x/yargs/deno-types.ts'
yargs(Deno.args)
.command('download <files...>', 'download a list of files', (yargs: any) => {
return yargs.positional('files', {
describe: 'a list of files to do something with'
})
}, (argv: Arguments) => {
console.info(argv)
})
.strictCommands()
.demandCommand(1)
.argv
```
### ESM
As of `v16`,`yargs` supports ESM imports:
```js
import yargs from 'yargs'
import { hideBin } from 'yargs/helpers'
yargs(hideBin(process.argv))
.command('curl <url>', 'fetch the contents of the URL', () => {}, (argv) => {
console.info(argv)
})
.demandCommand(1)
.argv
```
### Usage in Browser
See examples of using yargs in the browser in [docs](/docs/browser.md).
## Community
Having problems? want to contribute? join our [community slack](http://devtoolscommunity.herokuapp.com).
## Documentation
### Table of Contents
* [Yargs' API](/docs/api.md)
* [Examples](/docs/examples.md)
* [Parsing Tricks](/docs/tricks.md)
* [Stop the Parser](/docs/tricks.md#stop)
* [Negating Boolean Arguments](/docs/tricks.md#negate)
* [Numbers](/docs/tricks.md#numbers)
* [Arrays](/docs/tricks.md#arrays)
* [Objects](/docs/tricks.md#objects)
* [Quotes](/docs/tricks.md#quotes)
* [Advanced Topics](/docs/advanced.md)
* [Composing Your App Using Commands](/docs/advanced.md#commands)
* [Building Configurable CLI Apps](/docs/advanced.md#configuration)
* [Customizing Yargs' Parser](/docs/advanced.md#customizing)
* [Bundling yargs](/docs/bundling.md)
* [Contributing](/contributing.md)
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
[npm-url]: https://www.npmjs.com/package/yargs
[npm-image]: https://img.shields.io/npm/v/yargs.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: http://standardjs.com/
[conventional-commits-image]: https://img.shields.io/badge/Conventional%20Commits-1.0.0-yellow.svg
[conventional-commits-url]: https://conventionalcommits.org/
[slack-image]: http://devtoolscommunity.herokuapp.com/badge.svg
[slack-url]: http://devtoolscommunity.herokuapp.com
[type-definitions]: https://github.com/DefinitelyTyped/DefinitelyTyped/tree/master/types/yargs
[coverage-image]: https://img.shields.io/nycrc/yargs/yargs
[coverage-url]: https://github.com/yargs/yargs/blob/master/.nycrc
# minipass
A _very_ minimal implementation of a [PassThrough
stream](https://nodejs.org/api/stream.html#stream_class_stream_passthrough)
[It's very
fast](https://docs.google.com/spreadsheets/d/1oObKSrVwLX_7Ut4Z6g3fZW-AX1j1-k6w-cDsrkaSbHM/edit#gid=0)
for objects, strings, and buffers.
Supports `pipe()`ing (including multi-`pipe()` and backpressure transmission),
buffering data until either a `data` event handler or `pipe()` is added (so
you don't lose the first chunk), and most other cases where PassThrough is
a good idea.
There is a `read()` method, but it's much more efficient to consume data
from this stream via `'data'` events or by calling `pipe()` into some other
stream. Calling `read()` requires the buffer to be flattened in some
cases, which requires copying memory.
There is also no `unpipe()` method. Once you start piping, there is no
stopping it!
If you set `objectMode: true` in the options, then whatever is written will
be emitted. Otherwise, it'll do a minimal amount of Buffer copying to
ensure proper Streams semantics when `read(n)` is called.
`objectMode` can also be set by doing `stream.objectMode = true`, or by
writing any non-string/non-buffer data. `objectMode` cannot be set to
false once it is set.
This is not a `through` or `through2` stream. It doesn't transform the
data, it just passes it right through. If you want to transform the data,
extend the class, and override the `write()` method. Once you're done
transforming the data however you want, call `super.write()` with the
transform output.
For some examples of streams that extend Minipass in various ways, check
out:
- [minizlib](http://npm.im/minizlib)
- [fs-minipass](http://npm.im/fs-minipass)
- [tar](http://npm.im/tar)
- [minipass-collect](http://npm.im/minipass-collect)
- [minipass-flush](http://npm.im/minipass-flush)
- [minipass-pipeline](http://npm.im/minipass-pipeline)
- [tap](http://npm.im/tap)
- [tap-parser](http://npm.im/tap-parser)
- [treport](http://npm.im/treport)
- [minipass-fetch](http://npm.im/minipass-fetch)
- [pacote](http://npm.im/pacote)
- [make-fetch-happen](http://npm.im/make-fetch-happen)
- [cacache](http://npm.im/cacache)
- [ssri](http://npm.im/ssri)
- [npm-registry-fetch](http://npm.im/npm-registry-fetch)
- [minipass-json-stream](http://npm.im/minipass-json-stream)
- [minipass-sized](http://npm.im/minipass-sized)
## Differences from Node.js Streams
There are several things that make Minipass streams different from (and in
some ways superior to) Node.js core streams.
Please read these caveats if you are familiar with node-core streams and
intend to use Minipass streams in your programs.
### Timing
Minipass streams are designed to support synchronous use-cases. Thus, data
is emitted as soon as it is available, always. It is buffered until read,
but no longer. Another way to look at it is that Minipass streams are
exactly as synchronous as the logic that writes into them.
This can be surprising if your code relies on `PassThrough.write()` always
providing data on the next tick rather than the current one, or being able
to call `resume()` and not have the entire buffer disappear immediately.
However, without this synchronicity guarantee, there would be no way for
Minipass to achieve the speeds it does, or support the synchronous use
cases that it does. Simply put, waiting takes time.
This non-deferring approach makes Minipass streams much easier to reason
about, especially in the context of Promises and other flow-control
mechanisms.
### No High/Low Water Marks
Node.js core streams will optimistically fill up a buffer, returning `true`
on all writes until the limit is hit, even if the data has nowhere to go.
Then, they will not attempt to draw more data in until the buffer size dips
below a minimum value.
Minipass streams are much simpler. The `write()` method will return `true`
if the data has somewhere to go (which is to say, given the timing
guarantees, that the data is already there by the time `write()` returns).
If the data has nowhere to go, then `write()` returns false, and the data
sits in a buffer, to be drained out immediately as soon as anyone consumes
it.
### Hazards of Buffering (or: Why Minipass Is So Fast)
Since data written to a Minipass stream is immediately written all the way
through the pipeline, and `write()` always returns true/false based on
whether the data was fully flushed, backpressure is communicated
immediately to the upstream caller. This minimizes buffering.
Consider this case:
```js
const {PassThrough} = require('stream')
const p1 = new PassThrough({ highWaterMark: 1024 })
const p2 = new PassThrough({ highWaterMark: 1024 })
const p3 = new PassThrough({ highWaterMark: 1024 })
const p4 = new PassThrough({ highWaterMark: 1024 })
p1.pipe(p2).pipe(p3).pipe(p4)
p4.on('data', () => console.log('made it through'))
// this returns false and buffers, then writes to p2 on next tick (1)
// p2 returns false and buffers, pausing p1, then writes to p3 on next tick (2)
// p3 returns false and buffers, pausing p2, then writes to p4 on next tick (3)
// p4 returns false and buffers, pausing p3, then emits 'data' and 'drain'
// on next tick (4)
// p3 sees p4's 'drain' event, and calls resume(), emitting 'resume' and
// 'drain' on next tick (5)
// p2 sees p3's 'drain', calls resume(), emits 'resume' and 'drain' on next tick (6)
// p1 sees p2's 'drain', calls resume(), emits 'resume' and 'drain' on next
// tick (7)
p1.write(Buffer.alloc(2048)) // returns false
```
Along the way, the data was buffered and deferred at each stage, and
multiple event deferrals happened, for an unblocked pipeline where it was
perfectly safe to write all the way through!
Furthermore, setting a `highWaterMark` of `1024` might lead someone reading
the code to think an advisory maximum of 1KiB is being set for the
pipeline. However, the actual advisory buffering level is the _sum_ of
`highWaterMark` values, since each one has its own bucket.
Consider the Minipass case:
```js
const m1 = new Minipass()
const m2 = new Minipass()
const m3 = new Minipass()
const m4 = new Minipass()
m1.pipe(m2).pipe(m3).pipe(m4)
m4.on('data', () => console.log('made it through'))
// m1 is flowing, so it writes the data to m2 immediately
// m2 is flowing, so it writes the data to m3 immediately
// m3 is flowing, so it writes the data to m4 immediately
// m4 is flowing, so it fires the 'data' event immediately, returns true
// m4's write returned true, so m3 is still flowing, returns true
// m3's write returned true, so m2 is still flowing, returns true
// m2's write returned true, so m1 is still flowing, returns true
// No event deferrals or buffering along the way!
m1.write(Buffer.alloc(2048)) // returns true
```
It is extremely unlikely that you _don't_ want to buffer any data written,
or _ever_ buffer data that can be flushed all the way through. Neither
node-core streams nor Minipass ever fail to buffer written data, but
node-core streams do a lot of unnecessary buffering and pausing.
As always, the faster implementation is the one that does less stuff and
waits less time to do it.
### Immediately emit `end` for empty streams (when not paused)
If a stream is not paused, and `end()` is called before writing any data
into it, then it will emit `end` immediately.
If you have logic that occurs on the `end` event which you don't want to
potentially happen immediately (for example, closing file descriptors,
moving on to the next entry in an archive parse stream, etc.) then be sure
to call `stream.pause()` on creation, and then `stream.resume()` once you
are ready to respond to the `end` event.
### Emit `end` When Asked
One hazard of immediately emitting `'end'` is that you may not yet have had
a chance to add a listener. In order to avoid this hazard, Minipass
streams safely re-emit the `'end'` event if a new listener is added after
`'end'` has been emitted.
Ie, if you do `stream.on('end', someFunction)`, and the stream has already
emitted `end`, then it will call the handler right away. (You can think of
this somewhat like attaching a new `.then(fn)` to a previously-resolved
Promise.)
To prevent calling handlers multiple times who would not expect multiple
ends to occur, all listeners are removed from the `'end'` event whenever it
is emitted.
### Impact of "immediate flow" on Tee-streams
A "tee stream" is a stream piping to multiple destinations:
```js
const tee = new Minipass()
t.pipe(dest1)
t.pipe(dest2)
t.write('foo') // goes to both destinations
```
Since Minipass streams _immediately_ process any pending data through the
pipeline when a new pipe destination is added, this can have surprising
effects, especially when a stream comes in from some other function and may
or may not have data in its buffer.
```js
// WARNING! WILL LOSE DATA!
const src = new Minipass()
src.write('foo')
src.pipe(dest1) // 'foo' chunk flows to dest1 immediately, and is gone
src.pipe(dest2) // gets nothing!
```
The solution is to create a dedicated tee-stream junction that pipes to
both locations, and then pipe to _that_ instead.
```js
// Safe example: tee to both places
const src = new Minipass()
src.write('foo')
const tee = new Minipass()
tee.pipe(dest1)
tee.pipe(dest2)
src.pipe(tee) // tee gets 'foo', pipes to both locations
```
The same caveat applies to `on('data')` event listeners. The first one
added will _immediately_ receive all of the data, leaving nothing for the
second:
```js
// WARNING! WILL LOSE DATA!
const src = new Minipass()
src.write('foo')
src.on('data', handler1) // receives 'foo' right away
src.on('data', handler2) // nothing to see here!
```
Using a dedicated tee-stream can be used in this case as well:
```js
// Safe example: tee to both data handlers
const src = new Minipass()
src.write('foo')
const tee = new Minipass()
tee.on('data', handler1)
tee.on('data', handler2)
src.pipe(tee)
```
## USAGE
It's a stream! Use it like a stream and it'll most likely do what you
want.
```js
const Minipass = require('minipass')
const mp = new Minipass(options) // optional: { encoding, objectMode }
mp.write('foo')
mp.pipe(someOtherStream)
mp.end('bar')
```
### OPTIONS
* `encoding` How would you like the data coming _out_ of the stream to be
encoded? Accepts any values that can be passed to `Buffer.toString()`.
* `objectMode` Emit data exactly as it comes in. This will be flipped on
by default if you write() something other than a string or Buffer at any
point. Setting `objectMode: true` will prevent setting any encoding
value.
### API
Implements the user-facing portions of Node.js's `Readable` and `Writable`
streams.
### Methods
* `write(chunk, [encoding], [callback])` - Put data in. (Note that, in the
base Minipass class, the same data will come out.) Returns `false` if
the stream will buffer the next write, or true if it's still in "flowing"
mode.
* `end([chunk, [encoding]], [callback])` - Signal that you have no more
data to write. This will queue an `end` event to be fired when all the
data has been consumed.
* `setEncoding(encoding)` - Set the encoding for data coming of the stream.
This can only be done once.
* `pause()` - No more data for a while, please. This also prevents `end`
from being emitted for empty streams until the stream is resumed.
* `resume()` - Resume the stream. If there's data in the buffer, it is all
discarded. Any buffered events are immediately emitted.
* `pipe(dest)` - Send all output to the stream provided. There is no way
to unpipe. When data is emitted, it is immediately written to any and
all pipe destinations.
* `on(ev, fn)`, `emit(ev, fn)` - Minipass streams are EventEmitters. Some
events are given special treatment, however. (See below under "events".)
* `promise()` - Returns a Promise that resolves when the stream emits
`end`, or rejects if the stream emits `error`.
* `collect()` - Return a Promise that resolves on `end` with an array
containing each chunk of data that was emitted, or rejects if the stream
emits `error`. Note that this consumes the stream data.
* `concat()` - Same as `collect()`, but concatenates the data into a single
Buffer object. Will reject the returned promise if the stream is in
objectMode, or if it goes into objectMode by the end of the data.
* `read(n)` - Consume `n` bytes of data out of the buffer. If `n` is not
provided, then consume all of it. If `n` bytes are not available, then
it returns null. **Note** consuming streams in this way is less
efficient, and can lead to unnecessary Buffer copying.
* `destroy([er])` - Destroy the stream. If an error is provided, then an
`'error'` event is emitted. If the stream has a `close()` method, and
has not emitted a `'close'` event yet, then `stream.close()` will be
called. Any Promises returned by `.promise()`, `.collect()` or
`.concat()` will be rejected. After being destroyed, writing to the
stream will emit an error. No more data will be emitted if the stream is
destroyed, even if it was previously buffered.
### Properties
* `bufferLength` Read-only. Total number of bytes buffered, or in the case
of objectMode, the total number of objects.
* `encoding` The encoding that has been set. (Setting this is equivalent
to calling `setEncoding(enc)` and has the same prohibition against
setting multiple times.)
* `flowing` Read-only. Boolean indicating whether a chunk written to the
stream will be immediately emitted.
* `emittedEnd` Read-only. Boolean indicating whether the end-ish events
(ie, `end`, `prefinish`, `finish`) have been emitted. Note that
listening on any end-ish event will immediateyl re-emit it if it has
already been emitted.
* `writable` Whether the stream is writable. Default `true`. Set to
`false` when `end()`
* `readable` Whether the stream is readable. Default `true`.
* `buffer` A [yallist](http://npm.im/yallist) linked list of chunks written
to the stream that have not yet been emitted. (It's probably a bad idea
to mess with this.)
* `pipes` A [yallist](http://npm.im/yallist) linked list of streams that
this stream is piping into. (It's probably a bad idea to mess with
this.)
* `destroyed` A getter that indicates whether the stream was destroyed.
* `paused` True if the stream has been explicitly paused, otherwise false.
* `objectMode` Indicates whether the stream is in `objectMode`. Once set
to `true`, it cannot be set to `false`.
### Events
* `data` Emitted when there's data to read. Argument is the data to read.
This is never emitted while not flowing. If a listener is attached, that
will resume the stream.
* `end` Emitted when there's no more data to read. This will be emitted
immediately for empty streams when `end()` is called. If a listener is
attached, and `end` was already emitted, then it will be emitted again.
All listeners are removed when `end` is emitted.
* `prefinish` An end-ish event that follows the same logic as `end` and is
emitted in the same conditions where `end` is emitted. Emitted after
`'end'`.
* `finish` An end-ish event that follows the same logic as `end` and is
emitted in the same conditions where `end` is emitted. Emitted after
`'prefinish'`.
* `close` An indication that an underlying resource has been released.
Minipass does not emit this event, but will defer it until after `end`
has been emitted, since it throws off some stream libraries otherwise.
* `drain` Emitted when the internal buffer empties, and it is again
suitable to `write()` into the stream.
* `readable` Emitted when data is buffered and ready to be read by a
consumer.
* `resume` Emitted when stream changes state from buffering to flowing
mode. (Ie, when `resume` is called, `pipe` is called, or a `data` event
listener is added.)
### Static Methods
* `Minipass.isStream(stream)` Returns `true` if the argument is a stream,
and false otherwise. To be considered a stream, the object must be
either an instance of Minipass, or an EventEmitter that has either a
`pipe()` method, or both `write()` and `end()` methods. (Pretty much any
stream in node-land will return `true` for this.)
## EXAMPLES
Here are some examples of things you can do with Minipass streams.
### simple "are you done yet" promise
```js
mp.promise().then(() => {
// stream is finished
}, er => {
// stream emitted an error
})
```
### collecting
```js
mp.collect().then(all => {
// all is an array of all the data emitted
// encoding is supported in this case, so
// so the result will be a collection of strings if
// an encoding is specified, or buffers/objects if not.
//
// In an async function, you may do
// const data = await stream.collect()
})
```
### collecting into a single blob
This is a bit slower because it concatenates the data into one chunk for
you, but if you're going to do it yourself anyway, it's convenient this
way:
```js
mp.concat().then(onebigchunk => {
// onebigchunk is a string if the stream
// had an encoding set, or a buffer otherwise.
})
```
### iteration
You can iterate over streams synchronously or asynchronously in platforms
that support it.
Synchronous iteration will end when the currently available data is
consumed, even if the `end` event has not been reached. In string and
buffer mode, the data is concatenated, so unless multiple writes are
occurring in the same tick as the `read()`, sync iteration loops will
generally only have a single iteration.
To consume chunks in this way exactly as they have been written, with no
flattening, create the stream with the `{ objectMode: true }` option.
```js
const mp = new Minipass({ objectMode: true })
mp.write('a')
mp.write('b')
for (let letter of mp) {
console.log(letter) // a, b
}
mp.write('c')
mp.write('d')
for (let letter of mp) {
console.log(letter) // c, d
}
mp.write('e')
mp.end()
for (let letter of mp) {
console.log(letter) // e
}
for (let letter of mp) {
console.log(letter) // nothing
}
```
Asynchronous iteration will continue until the end event is reached,
consuming all of the data.
```js
const mp = new Minipass({ encoding: 'utf8' })
// some source of some data
let i = 5
const inter = setInterval(() => {
if (i-- > 0)
mp.write(Buffer.from('foo\n', 'utf8'))
else {
mp.end()
clearInterval(inter)
}
}, 100)
// consume the data with asynchronous iteration
async function consume () {
for await (let chunk of mp) {
console.log(chunk)
}
return 'ok'
}
consume().then(res => console.log(res))
// logs `foo\n` 5 times, and then `ok`
```
### subclass that `console.log()`s everything written into it
```js
class Logger extends Minipass {
write (chunk, encoding, callback) {
console.log('WRITE', chunk, encoding)
return super.write(chunk, encoding, callback)
}
end (chunk, encoding, callback) {
console.log('END', chunk, encoding)
return super.end(chunk, encoding, callback)
}
}
someSource.pipe(new Logger()).pipe(someDest)
```
### same thing, but using an inline anonymous class
```js
// js classes are fun
someSource
.pipe(new (class extends Minipass {
emit (ev, ...data) {
// let's also log events, because debugging some weird thing
console.log('EMIT', ev)
return super.emit(ev, ...data)
}
write (chunk, encoding, callback) {
console.log('WRITE', chunk, encoding)
return super.write(chunk, encoding, callback)
}
end (chunk, encoding, callback) {
console.log('END', chunk, encoding)
return super.end(chunk, encoding, callback)
}
}))
.pipe(someDest)
```
### subclass that defers 'end' for some reason
```js
class SlowEnd extends Minipass {
emit (ev, ...args) {
if (ev === 'end') {
console.log('going to end, hold on a sec')
setTimeout(() => {
console.log('ok, ready to end now')
super.emit('end', ...args)
}, 100)
} else {
return super.emit(ev, ...args)
}
}
}
```
### transform that creates newline-delimited JSON
```js
class NDJSONEncode extends Minipass {
write (obj, cb) {
try {
// JSON.stringify can throw, emit an error on that
return super.write(JSON.stringify(obj) + '\n', 'utf8', cb)
} catch (er) {
this.emit('error', er)
}
}
end (obj, cb) {
if (typeof obj === 'function') {
cb = obj
obj = undefined
}
if (obj !== undefined) {
this.write(obj)
}
return super.end(cb)
}
}
```
### transform that parses newline-delimited JSON
```js
class NDJSONDecode extends Minipass {
constructor (options) {
// always be in object mode, as far as Minipass is concerned
super({ objectMode: true })
this._jsonBuffer = ''
}
write (chunk, encoding, cb) {
if (typeof chunk === 'string' &&
typeof encoding === 'string' &&
encoding !== 'utf8') {
chunk = Buffer.from(chunk, encoding).toString()
} else if (Buffer.isBuffer(chunk))
chunk = chunk.toString()
}
if (typeof encoding === 'function') {
cb = encoding
}
const jsonData = (this._jsonBuffer + chunk).split('\n')
this._jsonBuffer = jsonData.pop()
for (let i = 0; i < jsonData.length; i++) {
try {
// JSON.parse can throw, emit an error on that
super.write(JSON.parse(jsonData[i]))
} catch (er) {
this.emit('error', er)
continue
}
}
if (cb)
cb()
}
}
```
# which
Like the unix `which` utility.
Finds the first instance of a specified executable in the PATH
environment variable. Does not cache the results, so `hash -r` is not
needed when the PATH changes.
## USAGE
```javascript
var which = require('which')
// async usage
which('node', function (er, resolvedPath) {
// er is returned if no "node" is found on the PATH
// if it is found, then the absolute path to the exec is returned
})
// or promise
which('node').then(resolvedPath => { ... }).catch(er => { ... not found ... })
// sync usage
// throws if not found
var resolved = which.sync('node')
// if nothrow option is used, returns null if not found
resolved = which.sync('node', {nothrow: true})
// Pass options to override the PATH and PATHEXT environment vars.
which('node', { path: someOtherPath }, function (er, resolved) {
if (er)
throw er
console.log('found at %j', resolved)
})
```
## CLI USAGE
Same as the BSD `which(1)` binary.
```
usage: which [-as] program ...
```
## OPTIONS
You may pass an options object as the second argument.
- `path`: Use instead of the `PATH` environment variable.
- `pathExt`: Use instead of the `PATHEXT` environment variable.
- `all`: Return all matches, instead of just the first one. Note that
this means the function returns an array of strings instead of a
single string.
# levn [](https://travis-ci.org/gkz/levn) <a name="levn" />
__Light ECMAScript (JavaScript) Value Notation__
Levn is a library which allows you to parse a string into a JavaScript value based on an expected type. It is meant for short amounts of human entered data (eg. config files, command line arguments).
Levn aims to concisely describe JavaScript values in text, and allow for the extraction and validation of those values. Levn uses [type-check](https://github.com/gkz/type-check) for its type format, and to validate the results. MIT license. Version 0.4.1.
__How is this different than JSON?__ levn is meant to be written by humans only, is (due to the previous point) much more concise, can be validated against supplied types, has regex and date literals, and can easily be extended with custom types. On the other hand, it is probably slower and thus less efficient at transporting large amounts of data, which is fine since this is not its purpose.
npm install levn
For updates on levn, [follow me on twitter](https://twitter.com/gkzahariev).
## Quick Examples
```js
var parse = require('levn').parse;
parse('Number', '2'); // 2
parse('String', '2'); // '2'
parse('String', 'levn'); // 'levn'
parse('String', 'a b'); // 'a b'
parse('Boolean', 'true'); // true
parse('Date', '#2011-11-11#'); // (Date object)
parse('Date', '2011-11-11'); // (Date object)
parse('RegExp', '/[a-z]/gi'); // /[a-z]/gi
parse('RegExp', 're'); // /re/
parse('Int', '2'); // 2
parse('Number | String', 'str'); // 'str'
parse('Number | String', '2'); // 2
parse('[Number]', '[1,2,3]'); // [1,2,3]
parse('(String, Boolean)', '(hi, false)'); // ['hi', false]
parse('{a: String, b: Number}', '{a: str, b: 2}'); // {a: 'str', b: 2}
// at the top level, you can ommit surrounding delimiters
parse('[Number]', '1,2,3'); // [1,2,3]
parse('(String, Boolean)', 'hi, false'); // ['hi', false]
parse('{a: String, b: Number}', 'a: str, b: 2'); // {a: 'str', b: 2}
// wildcard - auto choose type
parse('*', '[hi,(null,[42]),{k: true}]'); // ['hi', [null, [42]], {k: true}]
```
## Usage
`require('levn');` returns an object that exposes three properties. `VERSION` is the current version of the library as a string. `parse` and `parsedTypeParse` are functions.
```js
// parse(type, input, options);
parse('[Number]', '1,2,3'); // [1, 2, 3]
// parsedTypeParse(parsedType, input, options);
var parsedType = require('type-check').parseType('[Number]');
parsedTypeParse(parsedType, '1,2,3'); // [1, 2, 3]
```
### parse(type, input, options)
`parse` casts the string `input` into a JavaScript value according to the specified `type` in the [type format](https://github.com/gkz/type-check#type-format) (and taking account the optional `options`) and returns the resulting JavaScript value.
##### arguments
* type - `String` - the type written in the [type format](https://github.com/gkz/type-check#type-format) which to check against
* input - `String` - the value written in the [levn format](#levn-format)
* options - `Maybe Object` - an optional parameter specifying additional [options](#options)
##### returns
`*` - the resulting JavaScript value
##### example
```js
parse('[Number]', '1,2,3'); // [1, 2, 3]
```
### parsedTypeParse(parsedType, input, options)
`parsedTypeParse` casts the string `input` into a JavaScript value according to the specified `type` which has already been parsed (and taking account the optional `options`) and returns the resulting JavaScript value. You can parse a type using the [type-check](https://github.com/gkz/type-check) library's `parseType` function.
##### arguments
* type - `Object` - the type in the parsed type format which to check against
* input - `String` - the value written in the [levn format](#levn-format)
* options - `Maybe Object` - an optional parameter specifying additional [options](#options)
##### returns
`*` - the resulting JavaScript value
##### example
```js
var parsedType = require('type-check').parseType('[Number]');
parsedTypeParse(parsedType, '1,2,3'); // [1, 2, 3]
```
## Levn Format
Levn can use the type information you provide to choose the appropriate value to produce from the input. For the same input, it will choose a different output value depending on the type provided. For example, `parse('Number', '2')` will produce the number `2`, but `parse('String', '2')` will produce the string `"2"`.
If you do not provide type information, and simply use `*`, levn will parse the input according the unambiguous "explicit" mode, which we will now detail - you can also set the `explicit` option to true manually in the [options](#options).
* `"string"`, `'string'` are parsed as a String, eg. `"a msg"` is `"a msg"`
* `#date#` is parsed as a Date, eg. `#2011-11-11#` is `new Date('2011-11-11')`
* `/regexp/flags` is parsed as a RegExp, eg. `/re/gi` is `/re/gi`
* `undefined`, `null`, `NaN`, `true`, and `false` are all their JavaScript equivalents
* `[element1, element2, etc]` is an Array, and the casting procedure is recursively applied to each element. Eg. `[1,2,3]` is `[1,2,3]`.
* `(element1, element2, etc)` is an tuple, and the casting procedure is recursively applied to each element. Eg. `(1, a)` is `(1, a)` (is `[1, 'a']`).
* `{key1: val1, key2: val2, ...}` is an Object, and the casting procedure is recursively applied to each property. Eg. `{a: 1, b: 2}` is `{a: 1, b: 2}`.
* Any test which does not fall under the above, and which does not contain special characters (`[``]``(``)``{``}``:``,`) is a string, eg. `$12- blah` is `"$12- blah"`.
If you do provide type information, you can make your input more concise as the program already has some information about what it expects. Please see the [type format](https://github.com/gkz/type-check#type-format) section of [type-check](https://github.com/gkz/type-check) for more information about how to specify types. There are some rules about what levn can do with the information:
* If a String is expected, and only a String, all characters of the input (including any special ones) will become part of the output. Eg. `[({})]` is `"[({})]"`, and `"hi"` is `'"hi"'`.
* If a Date is expected, the surrounding `#` can be omitted from date literals. Eg. `2011-11-11` is `new Date('2011-11-11')`.
* If a RegExp is expected, no flags need to be specified, and the regex is not using any of the special characters,the opening and closing `/` can be omitted - this will have the affect of setting the source of the regex to the input. Eg. `regex` is `/regex/`.
* If an Array is expected, and it is the root node (at the top level), the opening `[` and closing `]` can be omitted. Eg. `1,2,3` is `[1,2,3]`.
* If a tuple is expected, and it is the root node (at the top level), the opening `(` and closing `)` can be omitted. Eg. `1, a` is `(1, a)` (is `[1, 'a']`).
* If an Object is expected, and it is the root node (at the top level), the opening `{` and closing `}` can be omitted. Eg `a: 1, b: 2` is `{a: 1, b: 2}`.
If you list multiple types (eg. `Number | String`), it will first attempt to cast to the first type and then validate - if the validation fails it will move on to the next type and so forth, left to right. You must be careful as some types will succeed with any input, such as String. Thus put String at the end of your list. In non-explicit mode, Date and RegExp will succeed with a large variety of input - also be careful with these and list them near the end if not last in your list.
Whitespace between special characters and elements is inconsequential.
## Options
Options is an object. It is an optional parameter to the `parse` and `parsedTypeParse` functions.
### Explicit
A `Boolean`. By default it is `false`.
__Example:__
```js
parse('RegExp', 're', {explicit: false}); // /re/
parse('RegExp', 're', {explicit: true}); // Error: ... does not type check...
parse('RegExp | String', 're', {explicit: true}); // 're'
```
`explicit` sets whether to be in explicit mode or not. Using `*` automatically activates explicit mode. For more information, read the [levn format](#levn-format) section.
### customTypes
An `Object`. Empty `{}` by default.
__Example:__
```js
var options = {
customTypes: {
Even: {
typeOf: 'Number',
validate: function (x) {
return x % 2 === 0;
},
cast: function (x) {
return {type: 'Just', value: parseInt(x)};
}
}
}
}
parse('Even', '2', options); // 2
parse('Even', '3', options); // Error: Value: "3" does not type check...
```
__Another Example:__
```js
function Person(name, age){
this.name = name;
this.age = age;
}
var options = {
customTypes: {
Person: {
typeOf: 'Object',
validate: function (x) {
x instanceof Person;
},
cast: function (value, options, typesCast) {
var name, age;
if ({}.toString.call(value).slice(8, -1) !== 'Object') {
return {type: 'Nothing'};
}
name = typesCast(value.name, [{type: 'String'}], options);
age = typesCast(value.age, [{type: 'Numger'}], options);
return {type: 'Just', value: new Person(name, age)};
}
}
}
parse('Person', '{name: Laura, age: 25}', options); // Person {name: 'Laura', age: 25}
```
`customTypes` is an object whose keys are the name of the types, and whose values are an object with three properties, `typeOf`, `validate`, and `cast`. For more information about `typeOf` and `validate`, please see the [custom types](https://github.com/gkz/type-check#custom-types) section of type-check.
`cast` is a function which receives three arguments, the value under question, options, and the typesCast function. In `cast`, attempt to cast the value into the specified type. If you are successful, return an object in the format `{type: 'Just', value: CAST-VALUE}`, if you know it won't work, return `{type: 'Nothing'}`. You can use the `typesCast` function to cast any child values. Remember to pass `options` to it. In your function you can also check for `options.explicit` and act accordingly.
## Technical About
`levn` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It uses [type-check](https://github.com/gkz/type-check) to both parse types and validate values. It also uses the [prelude.ls](http://preludels.com/) library.
assemblyscript-json
# assemblyscript-json
## Table of contents
### Namespaces
- [JSON](modules/json.md)
### Classes
- [DecoderState](classes/decoderstate.md)
- [JSONDecoder](classes/jsondecoder.md)
- [JSONEncoder](classes/jsonencoder.md)
- [JSONHandler](classes/jsonhandler.md)
- [ThrowingJSONHandler](classes/throwingjsonhandler.md)
long.js
=======
A Long class for representing a 64 bit two's-complement integer value derived from the [Closure Library](https://github.com/google/closure-library)
for stand-alone use and extended with unsigned support.
[](https://travis-ci.org/dcodeIO/long.js)
Background
----------
As of [ECMA-262 5th Edition](http://ecma262-5.com/ELS5_HTML.htm#Section_8.5), "all the positive and negative integers
whose magnitude is no greater than 2<sup>53</sup> are representable in the Number type", which is "representing the
doubleprecision 64-bit format IEEE 754 values as specified in the IEEE Standard for Binary Floating-Point Arithmetic".
The [maximum safe integer](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Number/MAX_SAFE_INTEGER)
in JavaScript is 2<sup>53</sup>-1.
Example: 2<sup>64</sup>-1 is 1844674407370955**1615** but in JavaScript it evaluates to 1844674407370955**2000**.
Furthermore, bitwise operators in JavaScript "deal only with integers in the range −2<sup>31</sup> through
2<sup>31</sup>−1, inclusive, or in the range 0 through 2<sup>32</sup>−1, inclusive. These operators accept any value of
the Number type but first convert each such value to one of 2<sup>32</sup> integer values."
In some use cases, however, it is required to be able to reliably work with and perform bitwise operations on the full
64 bits. This is where long.js comes into play.
Usage
-----
The class is compatible with CommonJS and AMD loaders and is exposed globally as `Long` if neither is available.
```javascript
var Long = require("long");
var longVal = new Long(0xFFFFFFFF, 0x7FFFFFFF);
console.log(longVal.toString());
...
```
API
---
### Constructor
* new **Long**(low: `number`, high: `number`, unsigned?: `boolean`)<br />
Constructs a 64 bit two's-complement integer, given its low and high 32 bit values as *signed* integers. See the from* functions below for more convenient ways of constructing Longs.
### Fields
* Long#**low**: `number`<br />
The low 32 bits as a signed value.
* Long#**high**: `number`<br />
The high 32 bits as a signed value.
* Long#**unsigned**: `boolean`<br />
Whether unsigned or not.
### Constants
* Long.**ZERO**: `Long`<br />
Signed zero.
* Long.**ONE**: `Long`<br />
Signed one.
* Long.**NEG_ONE**: `Long`<br />
Signed negative one.
* Long.**UZERO**: `Long`<br />
Unsigned zero.
* Long.**UONE**: `Long`<br />
Unsigned one.
* Long.**MAX_VALUE**: `Long`<br />
Maximum signed value.
* Long.**MIN_VALUE**: `Long`<br />
Minimum signed value.
* Long.**MAX_UNSIGNED_VALUE**: `Long`<br />
Maximum unsigned value.
### Utility
* Long.**isLong**(obj: `*`): `boolean`<br />
Tests if the specified object is a Long.
* Long.**fromBits**(lowBits: `number`, highBits: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the 64 bit integer that comes by concatenating the given low and high bits. Each is assumed to use 32 bits.
* Long.**fromBytes**(bytes: `number[]`, unsigned?: `boolean`, le?: `boolean`): `Long`<br />
Creates a Long from its byte representation.
* Long.**fromBytesLE**(bytes: `number[]`, unsigned?: `boolean`): `Long`<br />
Creates a Long from its little endian byte representation.
* Long.**fromBytesBE**(bytes: `number[]`, unsigned?: `boolean`): `Long`<br />
Creates a Long from its big endian byte representation.
* Long.**fromInt**(value: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the given 32 bit integer value.
* Long.**fromNumber**(value: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the given value, provided that it is a finite number. Otherwise, zero is returned.
* Long.**fromString**(str: `string`, unsigned?: `boolean`, radix?: `number`)<br />
Long.**fromString**(str: `string`, radix: `number`)<br />
Returns a Long representation of the given string, written using the specified radix.
* Long.**fromValue**(val: `*`, unsigned?: `boolean`): `Long`<br />
Converts the specified value to a Long using the appropriate from* function for its type.
### Methods
* Long#**add**(addend: `Long | number | string`): `Long`<br />
Returns the sum of this and the specified Long.
* Long#**and**(other: `Long | number | string`): `Long`<br />
Returns the bitwise AND of this Long and the specified.
* Long#**compare**/**comp**(other: `Long | number | string`): `number`<br />
Compares this Long's value with the specified's. Returns `0` if they are the same, `1` if the this is greater and `-1` if the given one is greater.
* Long#**divide**/**div**(divisor: `Long | number | string`): `Long`<br />
Returns this Long divided by the specified.
* Long#**equals**/**eq**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value equals the specified's.
* Long#**getHighBits**(): `number`<br />
Gets the high 32 bits as a signed integer.
* Long#**getHighBitsUnsigned**(): `number`<br />
Gets the high 32 bits as an unsigned integer.
* Long#**getLowBits**(): `number`<br />
Gets the low 32 bits as a signed integer.
* Long#**getLowBitsUnsigned**(): `number`<br />
Gets the low 32 bits as an unsigned integer.
* Long#**getNumBitsAbs**(): `number`<br />
Gets the number of bits needed to represent the absolute value of this Long.
* Long#**greaterThan**/**gt**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is greater than the specified's.
* Long#**greaterThanOrEqual**/**gte**/**ge**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is greater than or equal the specified's.
* Long#**isEven**(): `boolean`<br />
Tests if this Long's value is even.
* Long#**isNegative**(): `boolean`<br />
Tests if this Long's value is negative.
* Long#**isOdd**(): `boolean`<br />
Tests if this Long's value is odd.
* Long#**isPositive**(): `boolean`<br />
Tests if this Long's value is positive.
* Long#**isZero**/**eqz**(): `boolean`<br />
Tests if this Long's value equals zero.
* Long#**lessThan**/**lt**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is less than the specified's.
* Long#**lessThanOrEqual**/**lte**/**le**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is less than or equal the specified's.
* Long#**modulo**/**mod**/**rem**(divisor: `Long | number | string`): `Long`<br />
Returns this Long modulo the specified.
* Long#**multiply**/**mul**(multiplier: `Long | number | string`): `Long`<br />
Returns the product of this and the specified Long.
* Long#**negate**/**neg**(): `Long`<br />
Negates this Long's value.
* Long#**not**(): `Long`<br />
Returns the bitwise NOT of this Long.
* Long#**notEquals**/**neq**/**ne**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value differs from the specified's.
* Long#**or**(other: `Long | number | string`): `Long`<br />
Returns the bitwise OR of this Long and the specified.
* Long#**shiftLeft**/**shl**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits shifted to the left by the given amount.
* Long#**shiftRight**/**shr**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits arithmetically shifted to the right by the given amount.
* Long#**shiftRightUnsigned**/**shru**/**shr_u**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits logically shifted to the right by the given amount.
* Long#**subtract**/**sub**(subtrahend: `Long | number | string`): `Long`<br />
Returns the difference of this and the specified Long.
* Long#**toBytes**(le?: `boolean`): `number[]`<br />
Converts this Long to its byte representation.
* Long#**toBytesLE**(): `number[]`<br />
Converts this Long to its little endian byte representation.
* Long#**toBytesBE**(): `number[]`<br />
Converts this Long to its big endian byte representation.
* Long#**toInt**(): `number`<br />
Converts the Long to a 32 bit integer, assuming it is a 32 bit integer.
* Long#**toNumber**(): `number`<br />
Converts the Long to a the nearest floating-point representation of this value (double, 53 bit mantissa).
* Long#**toSigned**(): `Long`<br />
Converts this Long to signed.
* Long#**toString**(radix?: `number`): `string`<br />
Converts the Long to a string written in the specified radix.
* Long#**toUnsigned**(): `Long`<br />
Converts this Long to unsigned.
* Long#**xor**(other: `Long | number | string`): `Long`<br />
Returns the bitwise XOR of this Long and the given one.
Building
--------
To build an UMD bundle to `dist/long.js`, run:
```
$> npm install
$> npm run build
```
Running the [tests](./tests):
```
$> npm test
```

Moo!
====
Moo is a highly-optimised tokenizer/lexer generator. Use it to tokenize your strings, before parsing 'em with a parser like [nearley](https://github.com/hardmath123/nearley) or whatever else you're into.
* [Fast](#is-it-fast)
* [Convenient](#usage)
* uses [Regular Expressions](#on-regular-expressions)
* tracks [Line Numbers](#line-numbers)
* handles [Keywords](#keywords)
* supports [States](#states)
* custom [Errors](#errors)
* is even [Iterable](#iteration)
* has no dependencies
* 4KB minified + gzipped
* Moo!
Is it fast?
-----------
Yup! Flying-cows-and-singed-steak fast.
Moo is the fastest JS tokenizer around. It's **~2–10x** faster than most other tokenizers; it's a **couple orders of magnitude** faster than some of the slower ones.
Define your tokens **using regular expressions**. Moo will compile 'em down to a **single RegExp for performance**. It uses the new ES6 **sticky flag** where possible to make things faster; otherwise it falls back to an almost-as-efficient workaround. (For more than you ever wanted to know about this, read [adventures in the land of substrings and RegExps](http://mrale.ph/blog/2016/11/23/making-less-dart-faster.html).)
You _might_ be able to go faster still by writing your lexer by hand rather than using RegExps, but that's icky.
Oh, and it [avoids parsing RegExps by itself](https://hackernoon.com/the-madness-of-parsing-real-world-javascript-regexps-d9ee336df983#.2l8qu3l76). Because that would be horrible.
Usage
-----
First, you need to do the needful: `$ npm install moo`, or whatever will ship this code to your computer. Alternatively, grab the `moo.js` file by itself and slap it into your web page via a `<script>` tag; moo is completely standalone.
Then you can start roasting your very own lexer/tokenizer:
```js
const moo = require('moo')
let lexer = moo.compile({
WS: /[ \t]+/,
comment: /\/\/.*?$/,
number: /0|[1-9][0-9]*/,
string: /"(?:\\["\\]|[^\n"\\])*"/,
lparen: '(',
rparen: ')',
keyword: ['while', 'if', 'else', 'moo', 'cows'],
NL: { match: /\n/, lineBreaks: true },
})
```
And now throw some text at it:
```js
lexer.reset('while (10) cows\nmoo')
lexer.next() // -> { type: 'keyword', value: 'while' }
lexer.next() // -> { type: 'WS', value: ' ' }
lexer.next() // -> { type: 'lparen', value: '(' }
lexer.next() // -> { type: 'number', value: '10' }
// ...
```
When you reach the end of Moo's internal buffer, next() will return `undefined`. You can always `reset()` it and feed it more data when that happens.
On Regular Expressions
----------------------
RegExps are nifty for making tokenizers, but they can be a bit of a pain. Here are some things to be aware of:
* You often want to use **non-greedy quantifiers**: e.g. `*?` instead of `*`. Otherwise your tokens will be longer than you expect:
```js
let lexer = moo.compile({
string: /".*"/, // greedy quantifier *
// ...
})
lexer.reset('"foo" "bar"')
lexer.next() // -> { type: 'string', value: 'foo" "bar' }
```
Better:
```js
let lexer = moo.compile({
string: /".*?"/, // non-greedy quantifier *?
// ...
})
lexer.reset('"foo" "bar"')
lexer.next() // -> { type: 'string', value: 'foo' }
lexer.next() // -> { type: 'space', value: ' ' }
lexer.next() // -> { type: 'string', value: 'bar' }
```
* The **order of your rules** matters. Earlier ones will take precedence.
```js
moo.compile({
identifier: /[a-z0-9]+/,
number: /[0-9]+/,
}).reset('42').next() // -> { type: 'identifier', value: '42' }
moo.compile({
number: /[0-9]+/,
identifier: /[a-z0-9]+/,
}).reset('42').next() // -> { type: 'number', value: '42' }
```
* Moo uses **multiline RegExps**. This has a few quirks: for example, the **dot `/./` doesn't include newlines**. Use `[^]` instead if you want to match newlines too.
* Since an excluding character ranges like `/[^ ]/` (which matches anything but a space) _will_ include newlines, you have to be careful not to include them by accident! In particular, the whitespace metacharacter `\s` includes newlines.
Line Numbers
------------
Moo tracks detailed information about the input for you.
It will track line numbers, as long as you **apply the `lineBreaks: true` option to any rules which might contain newlines**. Moo will try to warn you if you forget to do this.
Note that this is `false` by default, for performance reasons: counting the number of lines in a matched token has a small cost. For optimal performance, only match newlines inside a dedicated token:
```js
newline: {match: '\n', lineBreaks: true},
```
### Token Info ###
Token objects (returned from `next()`) have the following attributes:
* **`type`**: the name of the group, as passed to compile.
* **`text`**: the string that was matched.
* **`value`**: the string that was matched, transformed by your `value` function (if any).
* **`offset`**: the number of bytes from the start of the buffer where the match starts.
* **`lineBreaks`**: the number of line breaks found in the match. (Always zero if this rule has `lineBreaks: false`.)
* **`line`**: the line number of the beginning of the match, starting from 1.
* **`col`**: the column where the match begins, starting from 1.
### Value vs. Text ###
The `value` is the same as the `text`, unless you provide a [value transform](#transform).
```js
const moo = require('moo')
const lexer = moo.compile({
ws: /[ \t]+/,
string: {match: /"(?:\\["\\]|[^\n"\\])*"/, value: s => s.slice(1, -1)},
})
lexer.reset('"test"')
lexer.next() /* { value: 'test', text: '"test"', ... } */
```
### Reset ###
Calling `reset()` on your lexer will empty its internal buffer, and set the line, column, and offset counts back to their initial value.
If you don't want this, you can `save()` the state, and later pass it as the second argument to `reset()` to explicitly control the internal state of the lexer.
```js
lexer.reset('some line\n')
let info = lexer.save() // -> { line: 10 }
lexer.next() // -> { line: 10 }
lexer.next() // -> { line: 11 }
// ...
lexer.reset('a different line\n', info)
lexer.next() // -> { line: 10 }
```
Keywords
--------
Moo makes it convenient to define literals.
```js
moo.compile({
lparen: '(',
rparen: ')',
keyword: ['while', 'if', 'else', 'moo', 'cows'],
})
```
It'll automatically compile them into regular expressions, escaping them where necessary.
**Keywords** should be written using the `keywords` transform.
```js
moo.compile({
IDEN: {match: /[a-zA-Z]+/, type: moo.keywords({
KW: ['while', 'if', 'else', 'moo', 'cows'],
})},
SPACE: {match: /\s+/, lineBreaks: true},
})
```
### Why? ###
You need to do this to ensure the **longest match** principle applies, even in edge cases.
Imagine trying to parse the input `className` with the following rules:
```js
keyword: ['class'],
identifier: /[a-zA-Z]+/,
```
You'll get _two_ tokens — `['class', 'Name']` -- which is _not_ what you want! If you swap the order of the rules, you'll fix this example; but now you'll lex `class` wrong (as an `identifier`).
The keywords helper checks matches against the list of keywords; if any of them match, it uses the type `'keyword'` instead of `'identifier'` (for this example).
### Keyword Types ###
Keywords can also have **individual types**.
```js
let lexer = moo.compile({
name: {match: /[a-zA-Z]+/, type: moo.keywords({
'kw-class': 'class',
'kw-def': 'def',
'kw-if': 'if',
})},
// ...
})
lexer.reset('def foo')
lexer.next() // -> { type: 'kw-def', value: 'def' }
lexer.next() // space
lexer.next() // -> { type: 'name', value: 'foo' }
```
You can use [itt](https://github.com/nathan/itt)'s iterator adapters to make constructing keyword objects easier:
```js
itt(['class', 'def', 'if'])
.map(k => ['kw-' + k, k])
.toObject()
```
States
------
Moo allows you to define multiple lexer **states**. Each state defines its own separate set of token rules. Your lexer will start off in the first state given to `moo.states({})`.
Rules can be annotated with `next`, `push`, and `pop`, to change the current state after that token is matched. A "stack" of past states is kept, which is used by `push` and `pop`.
* **`next: 'bar'`** moves to the state named `bar`. (The stack is not changed.)
* **`push: 'bar'`** moves to the state named `bar`, and pushes the old state onto the stack.
* **`pop: 1`** removes one state from the top of the stack, and moves to that state. (Only `1` is supported.)
Only rules from the current state can be matched. You need to copy your rule into all the states you want it to be matched in.
For example, to tokenize JS-style string interpolation such as `a${{c: d}}e`, you might use:
```js
let lexer = moo.states({
main: {
strstart: {match: '`', push: 'lit'},
ident: /\w+/,
lbrace: {match: '{', push: 'main'},
rbrace: {match: '}', pop: true},
colon: ':',
space: {match: /\s+/, lineBreaks: true},
},
lit: {
interp: {match: '${', push: 'main'},
escape: /\\./,
strend: {match: '`', pop: true},
const: {match: /(?:[^$`]|\$(?!\{))+/, lineBreaks: true},
},
})
// <= `a${{c: d}}e`
// => strstart const interp lbrace ident colon space ident rbrace rbrace const strend
```
The `rbrace` rule is annotated with `pop`, so it moves from the `main` state into either `lit` or `main`, depending on the stack.
Errors
------
If none of your rules match, Moo will throw an Error; since it doesn't know what else to do.
If you prefer, you can have moo return an error token instead of throwing an exception. The error token will contain the whole of the rest of the buffer.
```js
moo.compile({
// ...
myError: moo.error,
})
moo.reset('invalid')
moo.next() // -> { type: 'myError', value: 'invalid', text: 'invalid', offset: 0, lineBreaks: 0, line: 1, col: 1 }
moo.next() // -> undefined
```
You can have a token type that both matches tokens _and_ contains error values.
```js
moo.compile({
// ...
myError: {match: /[\$?`]/, error: true},
})
```
### Formatting errors ###
If you want to throw an error from your parser, you might find `formatError` helpful. Call it with the offending token:
```js
throw new Error(lexer.formatError(token, "invalid syntax"))
```
It returns a string with a pretty error message.
```
Error: invalid syntax at line 2 col 15:
totally valid `syntax`
^
```
Iteration
---------
Iterators: we got 'em.
```js
for (let here of lexer) {
// here = { type: 'number', value: '123', ... }
}
```
Create an array of tokens.
```js
let tokens = Array.from(lexer);
```
Use [itt](https://github.com/nathan/itt)'s iteration tools with Moo.
```js
for (let [here, next] = itt(lexer).lookahead()) { // pass a number if you need more tokens
// enjoy!
}
```
Transform
---------
Moo doesn't allow capturing groups, but you can supply a transform function, `value()`, which will be called on the value before storing it in the Token object.
```js
moo.compile({
STRING: [
{match: /"""[^]*?"""/, lineBreaks: true, value: x => x.slice(3, -3)},
{match: /"(?:\\["\\rn]|[^"\\])*?"/, lineBreaks: true, value: x => x.slice(1, -1)},
{match: /'(?:\\['\\rn]|[^'\\])*?'/, lineBreaks: true, value: x => x.slice(1, -1)},
],
// ...
})
```
Contributing
------------
Do check the [FAQ](https://github.com/tjvr/moo/issues?q=label%3Aquestion).
Before submitting an issue, [remember...](https://github.com/tjvr/moo/blob/master/.github/CONTRIBUTING.md)
# Acorn-JSX
[](https://travis-ci.org/acornjs/acorn-jsx)
[](https://www.npmjs.org/package/acorn-jsx)
This is plugin for [Acorn](http://marijnhaverbeke.nl/acorn/) - a tiny, fast JavaScript parser, written completely in JavaScript.
It was created as an experimental alternative, faster [React.js JSX](http://facebook.github.io/react/docs/jsx-in-depth.html) parser. Later, it replaced the [official parser](https://github.com/facebookarchive/esprima) and these days is used by many prominent development tools.
## Transpiler
Please note that this tool only parses source code to JSX AST, which is useful for various language tools and services. If you want to transpile your code to regular ES5-compliant JavaScript with source map, check out [Babel](https://babeljs.io/) and [Buble](https://buble.surge.sh/) transpilers which use `acorn-jsx` under the hood.
## Usage
Requiring this module provides you with an Acorn plugin that you can use like this:
```javascript
var acorn = require("acorn");
var jsx = require("acorn-jsx");
acorn.Parser.extend(jsx()).parse("my(<jsx/>, 'code');");
```
Note that official spec doesn't support mix of XML namespaces and object-style access in tag names (#27) like in `<namespace:Object.Property />`, so it was deprecated in `acorn-jsx@3.0`. If you still want to opt-in to support of such constructions, you can pass the following option:
```javascript
acorn.Parser.extend(jsx({ allowNamespacedObjects: true }))
```
Also, since most apps use pure React transformer, a new option was introduced that allows to prohibit namespaces completely:
```javascript
acorn.Parser.extend(jsx({ allowNamespaces: false }))
```
Note that by default `allowNamespaces` is enabled for spec compliancy.
## License
This plugin is issued under the [MIT license](./LICENSE).
# Acorn
A tiny, fast JavaScript parser written in JavaScript.
## Community
Acorn is open source software released under an
[MIT license](https://github.com/acornjs/acorn/blob/master/acorn/LICENSE).
You are welcome to
[report bugs](https://github.com/acornjs/acorn/issues) or create pull
requests on [github](https://github.com/acornjs/acorn). For questions
and discussion, please use the
[Tern discussion forum](https://discuss.ternjs.net).
## Installation
The easiest way to install acorn is from [`npm`](https://www.npmjs.com/):
```sh
npm install acorn
```
Alternately, you can download the source and build acorn yourself:
```sh
git clone https://github.com/acornjs/acorn.git
cd acorn
npm install
```
## Interface
**parse**`(input, options)` is the main interface to the library. The
`input` parameter is a string, `options` can be undefined or an object
setting some of the options listed below. The return value will be an
abstract syntax tree object as specified by the [ESTree
spec](https://github.com/estree/estree).
```javascript
let acorn = require("acorn");
console.log(acorn.parse("1 + 1"));
```
When encountering a syntax error, the parser will raise a
`SyntaxError` object with a meaningful message. The error object will
have a `pos` property that indicates the string offset at which the
error occurred, and a `loc` object that contains a `{line, column}`
object referring to that same position.
Options can be provided by passing a second argument, which should be
an object containing any of these fields:
- **ecmaVersion**: Indicates the ECMAScript version to parse. Must be
either 3, 5, 6 (2015), 7 (2016), 8 (2017), 9 (2018), 10 (2019) or 11
(2020, partial support). This influences support for strict mode,
the set of reserved words, and support for new syntax features.
Default is 10.
**NOTE**: Only 'stage 4' (finalized) ECMAScript features are being
implemented by Acorn. Other proposed new features can be implemented
through plugins.
- **sourceType**: Indicate the mode the code should be parsed in. Can be
either `"script"` or `"module"`. This influences global strict mode
and parsing of `import` and `export` declarations.
**NOTE**: If set to `"module"`, then static `import` / `export` syntax
will be valid, even if `ecmaVersion` is less than 6.
- **onInsertedSemicolon**: If given a callback, that callback will be
called whenever a missing semicolon is inserted by the parser. The
callback will be given the character offset of the point where the
semicolon is inserted as argument, and if `locations` is on, also a
`{line, column}` object representing this position.
- **onTrailingComma**: Like `onInsertedSemicolon`, but for trailing
commas.
- **allowReserved**: If `false`, using a reserved word will generate
an error. Defaults to `true` for `ecmaVersion` 3, `false` for higher
versions. When given the value `"never"`, reserved words and
keywords can also not be used as property names (as in Internet
Explorer's old parser).
- **allowReturnOutsideFunction**: By default, a return statement at
the top level raises an error. Set this to `true` to accept such
code.
- **allowImportExportEverywhere**: By default, `import` and `export`
declarations can only appear at a program's top level. Setting this
option to `true` allows them anywhere where a statement is allowed.
- **allowAwaitOutsideFunction**: By default, `await` expressions can
only appear inside `async` functions. Setting this option to
`true` allows to have top-level `await` expressions. They are
still not allowed in non-`async` functions, though.
- **allowHashBang**: When this is enabled (off by default), if the
code starts with the characters `#!` (as in a shellscript), the
first line will be treated as a comment.
- **locations**: When `true`, each node has a `loc` object attached
with `start` and `end` subobjects, each of which contains the
one-based line and zero-based column numbers in `{line, column}`
form. Default is `false`.
- **onToken**: If a function is passed for this option, each found
token will be passed in same format as tokens returned from
`tokenizer().getToken()`.
If array is passed, each found token is pushed to it.
Note that you are not allowed to call the parser from the
callback—that will corrupt its internal state.
- **onComment**: If a function is passed for this option, whenever a
comment is encountered the function will be called with the
following parameters:
- `block`: `true` if the comment is a block comment, false if it
is a line comment.
- `text`: The content of the comment.
- `start`: Character offset of the start of the comment.
- `end`: Character offset of the end of the comment.
When the `locations` options is on, the `{line, column}` locations
of the comment’s start and end are passed as two additional
parameters.
If array is passed for this option, each found comment is pushed
to it as object in Esprima format:
```javascript
{
"type": "Line" | "Block",
"value": "comment text",
"start": Number,
"end": Number,
// If `locations` option is on:
"loc": {
"start": {line: Number, column: Number}
"end": {line: Number, column: Number}
},
// If `ranges` option is on:
"range": [Number, Number]
}
```
Note that you are not allowed to call the parser from the
callback—that will corrupt its internal state.
- **ranges**: Nodes have their start and end characters offsets
recorded in `start` and `end` properties (directly on the node,
rather than the `loc` object, which holds line/column data. To also
add a
[semi-standardized](https://bugzilla.mozilla.org/show_bug.cgi?id=745678)
`range` property holding a `[start, end]` array with the same
numbers, set the `ranges` option to `true`.
- **program**: It is possible to parse multiple files into a single
AST by passing the tree produced by parsing the first file as the
`program` option in subsequent parses. This will add the toplevel
forms of the parsed file to the "Program" (top) node of an existing
parse tree.
- **sourceFile**: When the `locations` option is `true`, you can pass
this option to add a `source` attribute in every node’s `loc`
object. Note that the contents of this option are not examined or
processed in any way; you are free to use whatever format you
choose.
- **directSourceFile**: Like `sourceFile`, but a `sourceFile` property
will be added (regardless of the `location` option) directly to the
nodes, rather than the `loc` object.
- **preserveParens**: If this option is `true`, parenthesized expressions
are represented by (non-standard) `ParenthesizedExpression` nodes
that have a single `expression` property containing the expression
inside parentheses.
**parseExpressionAt**`(input, offset, options)` will parse a single
expression in a string, and return its AST. It will not complain if
there is more of the string left after the expression.
**tokenizer**`(input, options)` returns an object with a `getToken`
method that can be called repeatedly to get the next token, a `{start,
end, type, value}` object (with added `loc` property when the
`locations` option is enabled and `range` property when the `ranges`
option is enabled). When the token's type is `tokTypes.eof`, you
should stop calling the method, since it will keep returning that same
token forever.
In ES6 environment, returned result can be used as any other
protocol-compliant iterable:
```javascript
for (let token of acorn.tokenizer(str)) {
// iterate over the tokens
}
// transform code to array of tokens:
var tokens = [...acorn.tokenizer(str)];
```
**tokTypes** holds an object mapping names to the token type objects
that end up in the `type` properties of tokens.
**getLineInfo**`(input, offset)` can be used to get a `{line,
column}` object for a given program string and offset.
### The `Parser` class
Instances of the **`Parser`** class contain all the state and logic
that drives a parse. It has static methods `parse`,
`parseExpressionAt`, and `tokenizer` that match the top-level
functions by the same name.
When extending the parser with plugins, you need to call these methods
on the extended version of the class. To extend a parser with plugins,
you can use its static `extend` method.
```javascript
var acorn = require("acorn");
var jsx = require("acorn-jsx");
var JSXParser = acorn.Parser.extend(jsx());
JSXParser.parse("foo(<bar/>)");
```
The `extend` method takes any number of plugin values, and returns a
new `Parser` class that includes the extra parser logic provided by
the plugins.
## Command line interface
The `bin/acorn` utility can be used to parse a file from the command
line. It accepts as arguments its input file and the following
options:
- `--ecma3|--ecma5|--ecma6|--ecma7|--ecma8|--ecma9|--ecma10`: Sets the ECMAScript version
to parse. Default is version 9.
- `--module`: Sets the parsing mode to `"module"`. Is set to `"script"` otherwise.
- `--locations`: Attaches a "loc" object to each node with "start" and
"end" subobjects, each of which contains the one-based line and
zero-based column numbers in `{line, column}` form.
- `--allow-hash-bang`: If the code starts with the characters #! (as
in a shellscript), the first line will be treated as a comment.
- `--compact`: No whitespace is used in the AST output.
- `--silent`: Do not output the AST, just return the exit status.
- `--help`: Print the usage information and quit.
The utility spits out the syntax tree as JSON data.
## Existing plugins
- [`acorn-jsx`](https://github.com/RReverser/acorn-jsx): Parse [Facebook JSX syntax extensions](https://github.com/facebook/jsx)
Plugins for ECMAScript proposals:
- [`acorn-stage3`](https://github.com/acornjs/acorn-stage3): Parse most stage 3 proposals, bundling:
- [`acorn-class-fields`](https://github.com/acornjs/acorn-class-fields): Parse [class fields proposal](https://github.com/tc39/proposal-class-fields)
- [`acorn-import-meta`](https://github.com/acornjs/acorn-import-meta): Parse [import.meta proposal](https://github.com/tc39/proposal-import-meta)
- [`acorn-private-methods`](https://github.com/acornjs/acorn-private-methods): parse [private methods, getters and setters proposal](https://github.com/tc39/proposal-private-methods)n
# isarray
`Array#isArray` for older browsers.
[](http://travis-ci.org/juliangruber/isarray)
[](https://www.npmjs.org/package/isarray)
[
](https://ci.testling.com/juliangruber/isarray)
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# word-wrap [](https://www.npmjs.com/package/word-wrap) [](https://npmjs.org/package/word-wrap) [](https://npmjs.org/package/word-wrap) [](https://travis-ci.org/jonschlinkert/word-wrap)
> Wrap words to a specified length.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save word-wrap
```
## Usage
```js
var wrap = require('word-wrap');
wrap('Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.');
```
Results in:
```
Lorem ipsum dolor sit amet, consectetur adipiscing
elit, sed do eiusmod tempor incididunt ut labore
et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut
aliquip ex ea commodo consequat.
```
## Options

### options.width
Type: `Number`
Default: `50`
The width of the text before wrapping to a new line.
**Example:**
```js
wrap(str, {width: 60});
```
### options.indent
Type: `String`
Default: `` (two spaces)
The string to use at the beginning of each line.
**Example:**
```js
wrap(str, {indent: ' '});
```
### options.newline
Type: `String`
Default: `\n`
The string to use at the end of each line.
**Example:**
```js
wrap(str, {newline: '\n\n'});
```
### options.escape
Type: `function`
Default: `function(str){return str;}`
An escape function to run on each line after splitting them.
**Example:**
```js
var xmlescape = require('xml-escape');
wrap(str, {
escape: function(string){
return xmlescape(string);
}
});
```
### options.trim
Type: `Boolean`
Default: `false`
Trim trailing whitespace from the returned string. This option is included since `.trim()` would also strip the leading indentation from the first line.
**Example:**
```js
wrap(str, {trim: true});
```
### options.cut
Type: `Boolean`
Default: `false`
Break a word between any two letters when the word is longer than the specified width.
**Example:**
```js
wrap(str, {cut: true});
```
## About
### Related projects
* [common-words](https://www.npmjs.com/package/common-words): Updated list (JSON) of the 100 most common words in the English language. Useful for… [more](https://github.com/jonschlinkert/common-words) | [homepage](https://github.com/jonschlinkert/common-words "Updated list (JSON) of the 100 most common words in the English language. Useful for excluding these words from arrays.")
* [shuffle-words](https://www.npmjs.com/package/shuffle-words): Shuffle the words in a string and optionally the letters in each word using the… [more](https://github.com/jonschlinkert/shuffle-words) | [homepage](https://github.com/jonschlinkert/shuffle-words "Shuffle the words in a string and optionally the letters in each word using the Fisher-Yates algorithm. Useful for creating test fixtures, benchmarking samples, etc.")
* [unique-words](https://www.npmjs.com/package/unique-words): Return the unique words in a string or array. | [homepage](https://github.com/jonschlinkert/unique-words "Return the unique words in a string or array.")
* [wordcount](https://www.npmjs.com/package/wordcount): Count the words in a string. Support for english, CJK and Cyrillic. | [homepage](https://github.com/jonschlinkert/wordcount "Count the words in a string. Support for english, CJK and Cyrillic.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 43 | [jonschlinkert](https://github.com/jonschlinkert) |
| 2 | [lordvlad](https://github.com/lordvlad) |
| 2 | [hildjj](https://github.com/hildjj) |
| 1 | [danilosampaio](https://github.com/danilosampaio) |
| 1 | [2fd](https://github.com/2fd) |
| 1 | [toddself](https://github.com/toddself) |
| 1 | [wolfgang42](https://github.com/wolfgang42) |
| 1 | [zachhale](https://github.com/zachhale) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on June 02, 2017._
# lodash.merge v4.6.2
The [Lodash](https://lodash.com/) method `_.merge` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.merge
```
In Node.js:
```js
var merge = require('lodash.merge');
```
See the [documentation](https://lodash.com/docs#merge) or [package source](https://github.com/lodash/lodash/blob/4.6.2-npm-packages/lodash.merge) for more details.
# lodash.clonedeep v4.5.0
The [lodash](https://lodash.com/) method `_.cloneDeep` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.clonedeep
```
In Node.js:
```js
var cloneDeep = require('lodash.clonedeep');
```
See the [documentation](https://lodash.com/docs#cloneDeep) or [package source](https://github.com/lodash/lodash/blob/4.5.0-npm-packages/lodash.clonedeep) for more details.
[](https://www.npmjs.com/package/as-bignum)[](https://travis-ci.com/MaxGraey/as-bignum)[](LICENSE.md)
## WebAssembly fixed length big numbers written on [AssemblyScript](https://github.com/AssemblyScript/assemblyscript)
### Status: Work in progress
Provide wide numeric types such as `u128`, `u256`, `i128`, `i256` and fixed points and also its arithmetic operations.
Namespace `safe` contain equivalents with overflow/underflow traps.
All kind of types pretty useful for economical and cryptographic usages and provide deterministic behavior.
### Install
> yarn add as-bignum
or
> npm i as-bignum
### Usage via AssemblyScript
```ts
import { u128 } from "as-bignum";
declare function logF64(value: f64): void;
declare function logU128(hi: u64, lo: u64): void;
var a = u128.One;
var b = u128.from(-32); // same as u128.from<i32>(-32)
var c = new u128(0x1, -0xF);
var d = u128.from(0x0123456789ABCDEF); // same as u128.from<i64>(0x0123456789ABCDEF)
var e = u128.from('0x0123456789ABCDEF01234567');
var f = u128.fromString('11100010101100101', 2); // same as u128.from('0b11100010101100101')
var r = d / c + (b << 5) + e;
logF64(r.as<f64>());
logU128(r.hi, r.lo);
```
### Usage via JavaScript/Typescript
```ts
TODO
```
### List of types
- [x] [`u128`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/u128.ts) unsigned type (tested)
- [ ] [`u256`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/u256.ts) unsigned type (very basic)
- [ ] `i128` signed type
- [ ] `i256` signed type
---
- [x] [`safe.u128`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/safe/u128.ts) unsigned type (tested)
- [ ] `safe.u256` unsigned type
- [ ] `safe.i128` signed type
- [ ] `safe.i256` signed type
---
- [ ] [`fp128<Q>`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/fixed/fp128.ts) generic fixed point signed type٭ (very basic for now)
- [ ] `fp256<Q>` generic fixed point signed type٭
---
- [ ] `safe.fp128<Q>` generic fixed point signed type٭
- [ ] `safe.fp256<Q>` generic fixed point signed type٭
٭ _typename_ `Q` _is a type representing count of fractional bits_
# flat-cache
> A stupidly simple key/value storage using files to persist the data
[](https://npmjs.org/package/flat-cache)
[](https://travis-ci.org/royriojas/flat-cache)
## install
```bash
npm i --save flat-cache
```
## Usage
```js
var flatCache = require('flat-cache')
// loads the cache, if one does not exists for the given
// Id a new one will be prepared to be created
var cache = flatCache.load('cacheId');
// sets a key on the cache
cache.setKey('key', { foo: 'var' });
// get a key from the cache
cache.getKey('key') // { foo: 'var' }
// fetch the entire persisted object
cache.all() // { 'key': { foo: 'var' } }
// remove a key
cache.removeKey('key'); // removes a key from the cache
// save it to disk
cache.save(); // very important, if you don't save no changes will be persisted.
// cache.save( true /* noPrune */) // can be used to prevent the removal of non visited keys
// loads the cache from a given directory, if one does
// not exists for the given Id a new one will be prepared to be created
var cache = flatCache.load('cacheId', path.resolve('./path/to/folder'));
// The following methods are useful to clear the cache
// delete a given cache
flatCache.clearCacheById('cacheId') // removes the cacheId document if one exists.
// delete all cache
flatCache.clearAll(); // remove the cache directory
```
## Motivation for this module
I needed a super simple and dumb **in-memory cache** with optional disk persistance in order to make
a script that will beutify files with `esformatter` only execute on the files that were changed since the last run.
To make that possible we need to store the `fileSize` and `modificationTime` of the files. So a simple `key/value`
storage was needed and Bam! this module was born.
## Important notes
- If no directory is especified when the `load` method is called, a folder named `.cache` will be created
inside the module directory when `cache.save` is called. If you're committing your `node_modules` to any vcs, you
might want to ignore the default `.cache` folder, or specify a custom directory.
- The values set on the keys of the cache should be `stringify-able` ones, meaning no circular references
- All the changes to the cache state are done to memory
- I could have used a timer or `Object.observe` to deliver the changes to disk, but I wanted to keep this module
intentionally dumb and simple
- Non visited keys are removed when `cache.save()` is called. If this is not desired, you can pass `true` to the save call
like: `cache.save( true /* noPrune */ )`.
## License
MIT
## Changelog
[changelog](./changelog.md)
# node-tar
[](https://travis-ci.org/npm/node-tar)
[Fast](./benchmarks) and full-featured Tar for Node.js
The API is designed to mimic the behavior of `tar(1)` on unix systems.
If you are familiar with how tar works, most of this will hopefully be
straightforward for you. If not, then hopefully this module can teach
you useful unix skills that may come in handy someday :)
## Background
A "tar file" or "tarball" is an archive of file system entries
(directories, files, links, etc.) The name comes from "tape archive".
If you run `man tar` on almost any Unix command line, you'll learn
quite a bit about what it can do, and its history.
Tar has 5 main top-level commands:
* `c` Create an archive
* `r` Replace entries within an archive
* `u` Update entries within an archive (ie, replace if they're newer)
* `t` List out the contents of an archive
* `x` Extract an archive to disk
The other flags and options modify how this top level function works.
## High-Level API
These 5 functions are the high-level API. All of them have a
single-character name (for unix nerds familiar with `tar(1)`) as well
as a long name (for everyone else).
All the high-level functions take the following arguments, all three
of which are optional and may be omitted.
1. `options` - An optional object specifying various options
2. `paths` - An array of paths to add or extract
3. `callback` - Called when the command is completed, if async. (If
sync or no file specified, providing a callback throws a
`TypeError`.)
If the command is sync (ie, if `options.sync=true`), then the
callback is not allowed, since the action will be completed immediately.
If a `file` argument is specified, and the command is async, then a
`Promise` is returned. In this case, if async, a callback may be
provided which is called when the command is completed.
If a `file` option is not specified, then a stream is returned. For
`create`, this is a readable stream of the generated archive. For
`list` and `extract` this is a writable stream that an archive should
be written into. If a file is not specified, then a callback is not
allowed, because you're already getting a stream to work with.
`replace` and `update` only work on existing archives, and so require
a `file` argument.
Sync commands without a file argument return a stream that acts on its
input immediately in the same tick. For readable streams, this means
that all of the data is immediately available by calling
`stream.read()`. For writable streams, it will be acted upon as soon
as it is provided, but this can be at any time.
### Warnings and Errors
Tar emits warnings and errors for recoverable and unrecoverable situations,
respectively. In many cases, a warning only affects a single entry in an
archive, or is simply informing you that it's modifying an entry to comply
with the settings provided.
Unrecoverable warnings will always raise an error (ie, emit `'error'` on
streaming actions, throw for non-streaming sync actions, reject the
returned Promise for non-streaming async operations, or call a provided
callback with an `Error` as the first argument). Recoverable errors will
raise an error only if `strict: true` is set in the options.
Respond to (recoverable) warnings by listening to the `warn` event.
Handlers receive 3 arguments:
- `code` String. One of the error codes below. This may not match
`data.code`, which preserves the original error code from fs and zlib.
- `message` String. More details about the error.
- `data` Metadata about the error. An `Error` object for errors raised by
fs and zlib. All fields are attached to errors raisd by tar. Typically
contains the following fields, as relevant:
- `tarCode` The tar error code.
- `code` Either the tar error code, or the error code set by the
underlying system.
- `file` The archive file being read or written.
- `cwd` Working directory for creation and extraction operations.
- `entry` The entry object (if it could be created) for `TAR_ENTRY_INFO`,
`TAR_ENTRY_INVALID`, and `TAR_ENTRY_ERROR` warnings.
- `header` The header object (if it could be created, and the entry could
not be created) for `TAR_ENTRY_INFO` and `TAR_ENTRY_INVALID` warnings.
- `recoverable` Boolean. If `false`, then the warning will emit an
`error`, even in non-strict mode.
#### Error Codes
* `TAR_ENTRY_INFO` An informative error indicating that an entry is being
modified, but otherwise processed normally. For example, removing `/` or
`C:\` from absolute paths if `preservePaths` is not set.
* `TAR_ENTRY_INVALID` An indication that a given entry is not a valid tar
archive entry, and will be skipped. This occurs when:
- a checksum fails,
- a `linkpath` is missing for a link type, or
- a `linkpath` is provided for a non-link type.
If every entry in a parsed archive raises an `TAR_ENTRY_INVALID` error,
then the archive is presumed to be unrecoverably broken, and
`TAR_BAD_ARCHIVE` will be raised.
* `TAR_ENTRY_ERROR` The entry appears to be a valid tar archive entry, but
encountered an error which prevented it from being unpacked. This occurs
when:
- an unrecoverable fs error happens during unpacking,
- an entry has `..` in the path and `preservePaths` is not set, or
- an entry is extracting through a symbolic link, when `preservePaths` is
not set.
* `TAR_ENTRY_UNSUPPORTED` An indication that a given entry is
a valid archive entry, but of a type that is unsupported, and so will be
skipped in archive creation or extracting.
* `TAR_ABORT` When parsing gzipped-encoded archives, the parser will
abort the parse process raise a warning for any zlib errors encountered.
Aborts are considered unrecoverable for both parsing and unpacking.
* `TAR_BAD_ARCHIVE` The archive file is totally hosed. This can happen for
a number of reasons, and always occurs at the end of a parse or extract:
- An entry body was truncated before seeing the full number of bytes.
- The archive contained only invalid entries, indicating that it is
likely not an archive, or at least, not an archive this library can
parse.
`TAR_BAD_ARCHIVE` is considered informative for parse operations, but
unrecoverable for extraction. Note that, if encountered at the end of an
extraction, tar WILL still have extracted as much it could from the
archive, so there may be some garbage files to clean up.
Errors that occur deeper in the system (ie, either the filesystem or zlib)
will have their error codes left intact, and a `tarCode` matching one of
the above will be added to the warning metadata or the raised error object.
Errors generated by tar will have one of the above codes set as the
`error.code` field as well, but since errors originating in zlib or fs will
have their original codes, it's better to read `error.tarCode` if you wish
to see how tar is handling the issue.
### Examples
The API mimics the `tar(1)` command line functionality, with aliases
for more human-readable option and function names. The goal is that
if you know how to use `tar(1)` in Unix, then you know how to use
`require('tar')` in JavaScript.
To replicate `tar czf my-tarball.tgz files and folders`, you'd do:
```js
tar.c(
{
gzip: <true|gzip options>,
file: 'my-tarball.tgz'
},
['some', 'files', 'and', 'folders']
).then(_ => { .. tarball has been created .. })
```
To replicate `tar cz files and folders > my-tarball.tgz`, you'd do:
```js
tar.c( // or tar.create
{
gzip: <true|gzip options>
},
['some', 'files', 'and', 'folders']
).pipe(fs.createWriteStream('my-tarball.tgz'))
```
To replicate `tar xf my-tarball.tgz` you'd do:
```js
tar.x( // or tar.extract(
{
file: 'my-tarball.tgz'
}
).then(_=> { .. tarball has been dumped in cwd .. })
```
To replicate `cat my-tarball.tgz | tar x -C some-dir --strip=1`:
```js
fs.createReadStream('my-tarball.tgz').pipe(
tar.x({
strip: 1,
C: 'some-dir' // alias for cwd:'some-dir', also ok
})
)
```
To replicate `tar tf my-tarball.tgz`, do this:
```js
tar.t({
file: 'my-tarball.tgz',
onentry: entry => { .. do whatever with it .. }
})
```
To replicate `cat my-tarball.tgz | tar t` do:
```js
fs.createReadStream('my-tarball.tgz')
.pipe(tar.t())
.on('entry', entry => { .. do whatever with it .. })
```
To do anything synchronous, add `sync: true` to the options. Note
that sync functions don't take a callback and don't return a promise.
When the function returns, it's already done. Sync methods without a
file argument return a sync stream, which flushes immediately. But,
of course, it still won't be done until you `.end()` it.
To filter entries, add `filter: <function>` to the options.
Tar-creating methods call the filter with `filter(path, stat)`.
Tar-reading methods (including extraction) call the filter with
`filter(path, entry)`. The filter is called in the `this`-context of
the `Pack` or `Unpack` stream object.
The arguments list to `tar t` and `tar x` specify a list of filenames
to extract or list, so they're equivalent to a filter that tests if
the file is in the list.
For those who _aren't_ fans of tar's single-character command names:
```
tar.c === tar.create
tar.r === tar.replace (appends to archive, file is required)
tar.u === tar.update (appends if newer, file is required)
tar.x === tar.extract
tar.t === tar.list
```
Keep reading for all the command descriptions and options, as well as
the low-level API that they are built on.
### tar.c(options, fileList, callback) [alias: tar.create]
Create a tarball archive.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Write the tarball archive to the specified filename. If this
is specified, then the callback will be fired when the file has been
written, and a promise will be returned that resolves when the file
is written. If a filename is not specified, then a Readable Stream
will be returned which will emit the file data. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`. If this is set,
and a file is not provided, then the resulting stream will already
have the data ready to `read` or `emit('data')` as soon as you
request it.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `mode` The mode to set on the created file archive
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
The following options are mostly internal, but can be modified in some
advanced use cases, such as re-using caches between runs.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `readdirCache` A Map object that caches calls to `readdir`.
- `jobs` A number specifying how many concurrent jobs to run.
Defaults to 4.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
### tar.x(options, fileList, callback) [alias: tar.extract]
Extract a tarball archive.
The `fileList` is an array of paths to extract from the tarball. If
no paths are provided, then all the entries are extracted.
If the archive is gzipped, then tar will detect this and unzip it.
Note that all directories that are created will be forced to be
writable, readable, and listable by their owner, to avoid cases where
a directory prevents extraction of child entries by virtue of its
mode.
Most extraction errors will cause a `warn` event to be emitted. If
the `cwd` is missing, or not a directory, then the extraction will
fail completely.
The following options are supported:
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. If provided, this must exist and must be a
directory. [Alias: `C`]
- `file` The archive file to extract. If not specified, then a
Writable stream is returned where the archive data should be
written. [Alias: `f`]
- `sync` Create files and directories synchronously.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being unpacked. Return `true` to unpack the entry from the
archive, or `false` to skip it.
- `newer` Set to true to keep the existing file on disk if it's newer
than the file in the archive. [Alias: `keep-newer`,
`keep-newer-files`]
- `keep` Do not overwrite existing files. In particular, if a file
appears more than once in an archive, later copies will not
overwrite earlier copies. [Alias: `k`, `keep-existing`]
- `preservePaths` Allow absolute paths, paths containing `..`, and
extracting through symbolic links. By default, `/` is stripped from
absolute paths, `..` paths are not extracted, and any file whose
location would be modified by a symbolic link is not extracted.
[Alias: `P`]
- `unlink` Unlink files before creating them. Without this option,
tar overwrites existing files, which preserves existing hardlinks.
With this option, existing hardlinks will be broken, as will any
symlink that would affect the location of an extracted file. [Alias:
`U`]
- `strip` Remove the specified number of leading path elements.
Pathnames with fewer elements will be silently skipped. Note that
the pathname is edited after applying the filter, but before
security checks. [Alias: `strip-components`, `stripComponents`]
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `preserveOwner` If true, tar will set the `uid` and `gid` of
extracted entries to the `uid` and `gid` fields in the archive.
This defaults to true when run as root, and false otherwise. If
false, then files and directories will be set with the owner and
group of the user running the process. This is similar to `-p` in
`tar(1)`, but ACLs and other system-specific data is never unpacked
in this implementation, and modes are set by default already.
[Alias: `p`]
- `uid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified user id, regardless of the `uid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`gid` option.
- `gid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified group id, regardless of the `gid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`uid` option.
- `noMtime` Set to true to omit writing `mtime` value for extracted
entries. [Alias: `m`, `no-mtime`]
- `transform` Provide a function that takes an `entry` object, and
returns a stream, or any falsey value. If a stream is provided,
then that stream's data will be written instead of the contents of
the archive entry. If a falsey value is provided, then the entry is
written to disk as normal. (To exclude items from extraction, use
the `filter` option described above.)
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
The following options are mostly internal, but can be modified in some
advanced use cases, such as re-using caches between runs.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `umask` Filter the modes of entries like `process.umask()`.
- `dmode` Default mode for directories
- `fmode` Default mode for files
- `dirCache` A Map object of which directories exist.
- `maxMetaEntrySize` The maximum size of meta entries that is
supported. Defaults to 1 MB.
Note that using an asynchronous stream type with the `transform`
option will cause undefined behavior in sync extractions.
[MiniPass](http://npm.im/minipass)-based streams are designed for this
use case.
### tar.t(options, fileList, callback) [alias: tar.list]
List the contents of a tarball archive.
The `fileList` is an array of paths to list from the tarball. If
no paths are provided, then all the entries are listed.
If the archive is gzipped, then tar will detect this and unzip it.
Returns an event emitter that emits `entry` events with
`tar.ReadEntry` objects. However, they don't emit `'data'` or `'end'`
events. (If you want to get actual readable entries, use the
`tar.Parse` class instead.)
The following options are supported:
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. [Alias: `C`]
- `file` The archive file to list. If not specified, then a
Writable stream is returned where the archive data should be
written. [Alias: `f`]
- `sync` Read the specified file synchronously. (This has no effect
when a file option isn't specified, because entries are emitted as
fast as they are parsed from the stream anyway.)
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being listed. Return `true` to emit the entry from the
archive, or `false` to skip it.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter. This is important for when both `file` and
`sync` are set, because it will be called synchronously.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noResume` By default, `entry` streams are resumed immediately after
the call to `onentry`. Set `noResume: true` to suppress this
behavior. Note that by opting into this, the stream will never
complete until the entry data is consumed.
### tar.u(options, fileList, callback) [alias: tar.update]
Add files to an archive if they are newer than the entry already in
the tarball archive.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Required. Write the tarball archive to the specified
filename. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for adding entries to the
archive. Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
### tar.r(options, fileList, callback) [alias: tar.replace]
Add files to an existing archive. Because later entries override
earlier entries, this effectively replaces any existing entries.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Required. Write the tarball archive to the specified
filename. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for adding entries to the
archive. Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
## Low-Level API
### class tar.Pack
A readable tar stream.
Has all the standard readable stream interface stuff. `'data'` and
`'end'` events, `read()` method, `pause()` and `resume()`, etc.
#### constructor(options)
The following options are supported:
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()`
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `readdirCache` A Map object that caches calls to `readdir`.
- `jobs` A number specifying how many concurrent jobs to run.
Defaults to 4.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories.
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such.
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
#### add(path)
Adds an entry to the archive. Returns the Pack stream.
#### write(path)
Adds an entry to the archive. Returns true if flushed.
#### end()
Finishes the archive.
### class tar.Pack.Sync
Synchronous version of `tar.Pack`.
### class tar.Unpack
A writable stream that unpacks a tar archive onto the file system.
All the normal writable stream stuff is supported. `write()` and
`end()` methods, `'drain'` events, etc.
Note that all directories that are created will be forced to be
writable, readable, and listable by their owner, to avoid cases where
a directory prevents extraction of child entries by virtue of its
mode.
`'close'` is emitted when it's done writing stuff to the file system.
Most unpack errors will cause a `warn` event to be emitted. If the
`cwd` is missing, or not a directory, then an error will be emitted.
#### constructor(options)
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. If provided, this must exist and must be a
directory.
- `filter` A function that gets called with `(path, entry)` for each
entry being unpacked. Return `true` to unpack the entry from the
archive, or `false` to skip it.
- `newer` Set to true to keep the existing file on disk if it's newer
than the file in the archive.
- `keep` Do not overwrite existing files. In particular, if a file
appears more than once in an archive, later copies will not
overwrite earlier copies.
- `preservePaths` Allow absolute paths, paths containing `..`, and
extracting through symbolic links. By default, `/` is stripped from
absolute paths, `..` paths are not extracted, and any file whose
location would be modified by a symbolic link is not extracted.
- `unlink` Unlink files before creating them. Without this option,
tar overwrites existing files, which preserves existing hardlinks.
With this option, existing hardlinks will be broken, as will any
symlink that would affect the location of an extracted file.
- `strip` Remove the specified number of leading path elements.
Pathnames with fewer elements will be silently skipped. Note that
the pathname is edited after applying the filter, but before
security checks.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `umask` Filter the modes of entries like `process.umask()`.
- `dmode` Default mode for directories
- `fmode` Default mode for files
- `dirCache` A Map object of which directories exist.
- `maxMetaEntrySize` The maximum size of meta entries that is
supported. Defaults to 1 MB.
- `preserveOwner` If true, tar will set the `uid` and `gid` of
extracted entries to the `uid` and `gid` fields in the archive.
This defaults to true when run as root, and false otherwise. If
false, then files and directories will be set with the owner and
group of the user running the process. This is similar to `-p` in
`tar(1)`, but ACLs and other system-specific data is never unpacked
in this implementation, and modes are set by default already.
- `win32` True if on a windows platform. Causes behavior where
filenames containing `<|>?` chars are converted to
windows-compatible values while being unpacked.
- `uid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified user id, regardless of the `uid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`gid` option.
- `gid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified group id, regardless of the `gid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`uid` option.
- `noMtime` Set to true to omit writing `mtime` value for extracted
entries.
- `transform` Provide a function that takes an `entry` object, and
returns a stream, or any falsey value. If a stream is provided,
then that stream's data will be written instead of the contents of
the archive entry. If a falsey value is provided, then the entry is
written to disk as normal. (To exclude items from extraction, use
the `filter` option described above.)
- `strict` Treat warnings as crash-worthy errors. Default false.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
### class tar.Unpack.Sync
Synchronous version of `tar.Unpack`.
Note that using an asynchronous stream type with the `transform`
option will cause undefined behavior in sync unpack streams.
[MiniPass](http://npm.im/minipass)-based streams are designed for this
use case.
### class tar.Parse
A writable stream that parses a tar archive stream. All the standard
writable stream stuff is supported.
If the archive is gzipped, then tar will detect this and unzip it.
Emits `'entry'` events with `tar.ReadEntry` objects, which are
themselves readable streams that you can pipe wherever.
Each `entry` will not emit until the one before it is flushed through,
so make sure to either consume the data (with `on('data', ...)` or
`.pipe(...)`) or throw it away with `.resume()` to keep the stream
flowing.
#### constructor(options)
Returns an event emitter that emits `entry` events with
`tar.ReadEntry` objects.
The following options are supported:
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being listed. Return `true` to emit the entry from the
archive, or `false` to skip it.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
#### abort(error)
Stop all parsing activities. This is called when there are zlib
errors. It also emits an unrecoverable warning with the error provided.
### class tar.ReadEntry extends [MiniPass](http://npm.im/minipass)
A representation of an entry that is being read out of a tar archive.
It has the following fields:
- `extended` The extended metadata object provided to the constructor.
- `globalExtended` The global extended metadata object provided to the
constructor.
- `remain` The number of bytes remaining to be written into the
stream.
- `blockRemain` The number of 512-byte blocks remaining to be written
into the stream.
- `ignore` Whether this entry should be ignored.
- `meta` True if this represents metadata about the next entry, false
if it represents a filesystem object.
- All the fields from the header, extended header, and global extended
header are added to the ReadEntry object. So it has `path`, `type`,
`size, `mode`, and so on.
#### constructor(header, extended, globalExtended)
Create a new ReadEntry object with the specified header, extended
header, and global extended header values.
### class tar.WriteEntry extends [MiniPass](http://npm.im/minipass)
A representation of an entry that is being written from the file
system into a tar archive.
Emits data for the Header, and for the Pax Extended Header if one is
required, as well as any body data.
Creating a WriteEntry for a directory does not also create
WriteEntry objects for all of the directory contents.
It has the following fields:
- `path` The path field that will be written to the archive. By
default, this is also the path from the cwd to the file system
object.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `myuid` If supported, the uid of the user running the current
process.
- `myuser` The `env.USER` string if set, or `''`. Set as the entry
`uname` field if the file's `uid` matches `this.myuid`.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 1 MB.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `absolute` The absolute path to the entry on the filesystem. By
default, this is `path.resolve(this.cwd, this.path)`, but it can be
overridden explicitly.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `win32` True if on a windows platform. Causes behavior where paths
replace `\` with `/` and filenames containing the windows-compatible
forms of `<|>?:` characters are converted to actual `<|>?:` characters
in the archive.
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
#### constructor(path, options)
`path` is the path of the entry as it is written in the archive.
The following options are supported:
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 1 MB.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `absolute` The absolute path to the entry on the filesystem. By
default, this is `path.resolve(this.cwd, this.path)`, but it can be
overridden explicitly.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `win32` True if on a windows platform. Causes behavior where paths
replace `\` with `/`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
- `umask` Set to restrict the modes on the entries in the archive,
somewhat like how umask works on file creation. Defaults to
`process.umask()` on unix systems, or `0o22` on Windows.
#### warn(message, data)
If strict, emit an error with the provided message.
Othewise, emit a `'warn'` event with the provided message and data.
### class tar.WriteEntry.Sync
Synchronous version of tar.WriteEntry
### class tar.WriteEntry.Tar
A version of tar.WriteEntry that gets its data from a tar.ReadEntry
instead of from the filesystem.
#### constructor(readEntry, options)
`readEntry` is the entry being read out of another archive.
The following options are supported:
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
### class tar.Header
A class for reading and writing header blocks.
It has the following fields:
- `nullBlock` True if decoding a block which is entirely composed of
`0x00` null bytes. (Useful because tar files are terminated by
at least 2 null blocks.)
- `cksumValid` True if the checksum in the header is valid, false
otherwise.
- `needPax` True if the values, as encoded, will require a Pax
extended header.
- `path` The path of the entry.
- `mode` The 4 lowest-order octal digits of the file mode. That is,
read/write/execute permissions for world, group, and owner, and the
setuid, setgid, and sticky bits.
- `uid` Numeric user id of the file owner
- `gid` Numeric group id of the file owner
- `size` Size of the file in bytes
- `mtime` Modified time of the file
- `cksum` The checksum of the header. This is generated by adding all
the bytes of the header block, treating the checksum field itself as
all ascii space characters (that is, `0x20`).
- `type` The human-readable name of the type of entry this represents,
or the alphanumeric key if unknown.
- `typeKey` The alphanumeric key for the type of entry this header
represents.
- `linkpath` The target of Link and SymbolicLink entries.
- `uname` Human-readable user name of the file owner
- `gname` Human-readable group name of the file owner
- `devmaj` The major portion of the device number. Always `0` for
files, directories, and links.
- `devmin` The minor portion of the device number. Always `0` for
files, directories, and links.
- `atime` File access time.
- `ctime` File change time.
#### constructor(data, [offset=0])
`data` is optional. It is either a Buffer that should be interpreted
as a tar Header starting at the specified offset and continuing for
512 bytes, or a data object of keys and values to set on the header
object, and eventually encode as a tar Header.
#### decode(block, offset)
Decode the provided buffer starting at the specified offset.
Buffer length must be greater than 512 bytes.
#### set(data)
Set the fields in the data object.
#### encode(buffer, offset)
Encode the header fields into the buffer at the specified offset.
Returns `this.needPax` to indicate whether a Pax Extended Header is
required to properly encode the specified data.
### class tar.Pax
An object representing a set of key-value pairs in an Pax extended
header entry.
It has the following fields. Where the same name is used, they have
the same semantics as the tar.Header field of the same name.
- `global` True if this represents a global extended header, or false
if it is for a single entry.
- `atime`
- `charset`
- `comment`
- `ctime`
- `gid`
- `gname`
- `linkpath`
- `mtime`
- `path`
- `size`
- `uid`
- `uname`
- `dev`
- `ino`
- `nlink`
#### constructor(object, global)
Set the fields set in the object. `global` is a boolean that defaults
to false.
#### encode()
Return a Buffer containing the header and body for the Pax extended
header entry, or `null` if there is nothing to encode.
#### encodeBody()
Return a string representing the body of the pax extended header
entry.
#### encodeField(fieldName)
Return a string representing the key/value encoding for the specified
fieldName, or `''` if the field is unset.
### tar.Pax.parse(string, extended, global)
Return a new Pax object created by parsing the contents of the string
provided.
If the `extended` object is set, then also add the fields from that
object. (This is necessary because multiple metadata entries can
occur in sequence.)
### tar.types
A translation table for the `type` field in tar headers.
#### tar.types.name.get(code)
Get the human-readable name for a given alphanumeric code.
#### tar.types.code.get(name)
Get the alphanumeric code for a given human-readable name.
# cliui
[](https://travis-ci.org/yargs/cliui)
[](https://coveralls.io/r/yargs/cliui?branch=)
[](https://www.npmjs.com/package/cliui)
[](https://github.com/conventional-changelog/standard-version)
easily create complex multi-column command-line-interfaces.
## Example
```js
var ui = require('cliui')()
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 2, 0]
})
ui.div(
{
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
},
{
text: "the file to load." +
chalk.green("(if this description is long it wraps).")
,
width: 20
},
{
text: chalk.red("[required]"),
align: 'right'
}
)
console.log(ui.toString())
```
<img width="500" src="screenshot.png">
## Layout DSL
cliui exposes a simple layout DSL:
If you create a single `ui.div`, passing a string rather than an
object:
* `\n`: characters will be interpreted as new rows.
* `\t`: characters will be interpreted as new columns.
* `\s`: characters will be interpreted as padding.
**as an example...**
```js
var ui = require('./')({
width: 60
})
ui.div(
'Usage: node ./bin/foo.js\n' +
' <regex>\t provide a regex\n' +
' <glob>\t provide a glob\t [required]'
)
console.log(ui.toString())
```
**will output:**
```shell
Usage: node ./bin/foo.js
<regex> provide a regex
<glob> provide a glob [required]
```
## Methods
```js
cliui = require('cliui')
```
### cliui({width: integer})
Specify the maximum width of the UI being generated.
If no width is provided, cliui will try to get the current window's width and use it, and if that doesn't work, width will be set to `80`.
### cliui({wrap: boolean})
Enable or disable the wrapping of text in a column.
### cliui.div(column, column, column)
Create a row with any number of columns, a column
can either be a string, or an object with the following
options:
* **text:** some text to place in the column.
* **width:** the width of a column.
* **align:** alignment, `right` or `center`.
* **padding:** `[top, right, bottom, left]`.
* **border:** should a border be placed around the div?
### cliui.span(column, column, column)
Similar to `div`, except the next row will be appended without
a new line being created.
### cliui.resetOutput()
Resets the UI elements of the current cliui instance, maintaining the values
set for `width` and `wrap`.
# universal-url [![NPM Version][npm-image]][npm-url] [![Build Status][travis-image]][travis-url] [![Dependency Monitor][greenkeeper-image]][greenkeeper-url]
> WHATWG [`URL`](https://developer.mozilla.org/en/docs/Web/API/URL) for Node & Browser.
* For Node.js versions `>= 8`, the native implementation will be used.
* For Node.js versions `< 8`, a [shim](https://npmjs.com/whatwg-url) will be used.
* For web browsers without a native implementation, the same shim will be used.
## Installation
[Node.js](http://nodejs.org/) `>= 6` is required. To install, type this at the command line:
```shell
npm install universal-url
```
## Usage
```js
const {URL, URLSearchParams} = require('universal-url');
const url = new URL('http://domain/');
const params = new URLSearchParams('?param=value');
```
Global shim:
```js
require('universal-url').shim();
const url = new URL('http://domain/');
const params = new URLSearchParams('?param=value');
```
## Browserify/etc
The bundled file size of this library can be large for a web browser. If this is a problem, try using [universal-url-lite](https://npmjs.com/universal-url-lite) in your build as an alias for this module.
[npm-image]: https://img.shields.io/npm/v/universal-url.svg
[npm-url]: https://npmjs.org/package/universal-url
[travis-image]: https://img.shields.io/travis/stevenvachon/universal-url.svg
[travis-url]: https://travis-ci.org/stevenvachon/universal-url
[greenkeeper-image]: https://badges.greenkeeper.io/stevenvachon/universal-url.svg
[greenkeeper-url]: https://greenkeeper.io/
# tr46.js
> An implementation of the [Unicode TR46 specification](http://unicode.org/reports/tr46/).
## Installation
[Node.js](http://nodejs.org) `>= 6` is required. To install, type this at the command line:
```shell
npm install tr46
```
## API
### `toASCII(domainName[, options])`
Converts a string of Unicode symbols to a case-folded Punycode string of ASCII symbols.
Available options:
* [`checkBidi`](#checkBidi)
* [`checkHyphens`](#checkHyphens)
* [`checkJoiners`](#checkJoiners)
* [`processingOption`](#processingOption)
* [`useSTD3ASCIIRules`](#useSTD3ASCIIRules)
* [`verifyDNSLength`](#verifyDNSLength)
### `toUnicode(domainName[, options])`
Converts a case-folded Punycode string of ASCII symbols to a string of Unicode symbols.
Available options:
* [`checkBidi`](#checkBidi)
* [`checkHyphens`](#checkHyphens)
* [`checkJoiners`](#checkJoiners)
* [`useSTD3ASCIIRules`](#useSTD3ASCIIRules)
## Options
### `checkBidi`
Type: `Boolean`
Default value: `false`
When set to `true`, any bi-directional text within the input will be checked for validation.
### `checkHyphens`
Type: `Boolean`
Default value: `false`
When set to `true`, the positions of any hyphen characters within the input will be checked for validation.
### `checkJoiners`
Type: `Boolean`
Default value: `false`
When set to `true`, any word joiner characters within the input will be checked for validation.
### `processingOption`
Type: `String`
Default value: `"nontransitional"`
When set to `"transitional"`, symbols within the input will be validated according to the older IDNA2003 protocol. When set to `"nontransitional"`, the current IDNA2008 protocol will be used.
### `useSTD3ASCIIRules`
Type: `Boolean`
Default value: `false`
When set to `true`, input will be validated according to [STD3 Rules](http://unicode.org/reports/tr46/#STD3_Rules).
### `verifyDNSLength`
Type: `Boolean`
Default value: `false`
When set to `true`, the length of each DNS label within the input will be checked for validation.
[Build]: http://img.shields.io/travis/litejs/natural-compare-lite.png
[Coverage]: http://img.shields.io/coveralls/litejs/natural-compare-lite.png
[1]: https://travis-ci.org/litejs/natural-compare-lite
[2]: https://coveralls.io/r/litejs/natural-compare-lite
[npm package]: https://npmjs.org/package/natural-compare-lite
[GitHub repo]: https://github.com/litejs/natural-compare-lite
@version 1.4.0
@date 2015-10-26
@stability 3 - Stable
Natural Compare – [![Build][]][1] [![Coverage][]][2]
===============
Compare strings containing a mix of letters and numbers
in the way a human being would in sort order.
This is described as a "natural ordering".
```text
Standard sorting: Natural order sorting:
img1.png img1.png
img10.png img2.png
img12.png img10.png
img2.png img12.png
```
String.naturalCompare returns a number indicating
whether a reference string comes before or after or is the same
as the given string in sort order.
Use it with builtin sort() function.
### Installation
- In browser
```html
<script src=min.natural-compare.js></script>
```
- In node.js: `npm install natural-compare-lite`
```javascript
require("natural-compare-lite")
```
### Usage
```javascript
// Simple case sensitive example
var a = ["z1.doc", "z10.doc", "z17.doc", "z2.doc", "z23.doc", "z3.doc"];
a.sort(String.naturalCompare);
// ["z1.doc", "z2.doc", "z3.doc", "z10.doc", "z17.doc", "z23.doc"]
// Use wrapper function for case insensitivity
a.sort(function(a, b){
return String.naturalCompare(a.toLowerCase(), b.toLowerCase());
})
// In most cases we want to sort an array of objects
var a = [ {"street":"350 5th Ave", "room":"A-1021"}
, {"street":"350 5th Ave", "room":"A-21046-b"} ];
// sort by street, then by room
a.sort(function(a, b){
return String.naturalCompare(a.street, b.street) || String.naturalCompare(a.room, b.room);
})
// When text transformation is needed (eg toLowerCase()),
// it is best for performance to keep
// transformed key in that object.
// There are no need to do text transformation
// on each comparision when sorting.
var a = [ {"make":"Audi", "model":"A6"}
, {"make":"Kia", "model":"Rio"} ];
// sort by make, then by model
a.map(function(car){
car.sort_key = (car.make + " " + car.model).toLowerCase();
})
a.sort(function(a, b){
return String.naturalCompare(a.sort_key, b.sort_key);
})
```
- Works well with dates in ISO format eg "Rev 2012-07-26.doc".
### Custom alphabet
It is possible to configure a custom alphabet
to achieve a desired order.
```javascript
// Estonian alphabet
String.alphabet = "ABDEFGHIJKLMNOPRSŠZŽTUVÕÄÖÜXYabdefghijklmnoprsšzžtuvõäöüxy"
["t", "z", "x", "õ"].sort(String.naturalCompare)
// ["z", "t", "õ", "x"]
// Russian alphabet
String.alphabet = "АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдеёжзийклмнопрстуфхцчшщъыьэюя"
["Ё", "А", "Б"].sort(String.naturalCompare)
// ["А", "Б", "Ё"]
```
External links
--------------
- [GitHub repo][https://github.com/litejs/natural-compare-lite]
- [jsperf test](http://jsperf.com/natural-sort-2/12)
Licence
-------
Copyright (c) 2012-2015 Lauri Rooden <lauri@rooden.ee>
[The MIT License](http://lauri.rooden.ee/mit-license.txt)
# near-sdk-as
Collection of packages used in developing NEAR smart contracts in AssemblyScript including:
- [`runtime library`](https://github.com/near/near-sdk-as/tree/master/sdk-core) - AssemblyScript near runtime library
- [`bindgen`](https://github.com/near/near-sdk-as/tree/master/bindgen) - AssemblyScript transformer that adds the bindings needed to (de)serialize input and outputs.
- [`near-mock-vm`](https://github.com/near/near-sdk-as/tree/master/near-mock-vm) - Core of the NEAR VM compiled to WebAssembly used for running unit tests.
- [`@as-pect/cli`](https://github.com/jtenner/as-pect) - AssemblyScript testing framework similar to jest.
## To Install
```sh
yarn add -D near-sdk-as
```
## Project Setup
To set up a AS project to compile with the sdk add the following `asconfig.json` file to the root:
```json
{
"extends": "near-sdk-as/asconfig.json"
}
```
Then if your main file is `assembly/index.ts`, then the project can be build with [`asbuild`](https://github.com/willemneal/asbuild):
```sh
yarn asb
```
will create a release build and place it `./build/release/<name-in-package.json>.wasm`
```sh
yarn asb --target debug
```
will create a debug build and place it in `./build/debug/..`
## Testing
### Unit Testing
See the [sdk's as-pect tests for an example](./sdk/assembly/__tests__) of creating unit tests. Must be ending in `.spec.ts` in a `assembly/__tests__`.
## License
`near-sdk-as` is distributed under the terms of both the MIT license and the Apache License (Version 2.0).
See [LICENSE-MIT](LICENSE-MIT) and [LICENSE-APACHE](LICENSE-APACHE) for details.
<img align="right" alt="Ajv logo" width="160" src="https://ajv.js.org/img/ajv.svg">
# Ajv JSON schema validator
The fastest JSON validator for Node.js and browser.
Supports JSON Schema draft-04/06/07/2019-09/2020-12 ([draft-04 support](https://ajv.js.org/json-schema.html#draft-04) requires ajv-draft-04 package) and JSON Type Definition [RFC8927](https://datatracker.ietf.org/doc/rfc8927/).
[](https://github.com/ajv-validator/ajv/actions?query=workflow%3Abuild)
[](https://www.npmjs.com/package/ajv)
[](https://www.npmjs.com/package/ajv)
[](https://coveralls.io/github/ajv-validator/ajv?branch=master)
[](https://simplex.chat/contact#/?v=1&smp=smp%3A%2F%2Fu2dS9sG8nMNURyZwqASV4yROM28Er0luVTx5X1CsMrU%3D%40smp4.simplex.im%2Fap4lMFzfXF8Hzmh-Vz0WNxp_1jKiOa-h%23MCowBQYDK2VuAyEAcdefddRvDfI8iAuBpztm_J3qFucj8MDZoVs_2EcMTzU%3D)
[](https://gitter.im/ajv-validator/ajv)
[](https://github.com/sponsors/epoberezkin)
## Ajv sponsors
[<img src="https://ajv.js.org/img/mozilla.svg" width="45%" alt="Mozilla">](https://www.mozilla.org)<img src="https://ajv.js.org/img/gap.svg" width="9%">[<img src="https://ajv.js.org/img/reserved.svg" width="45%">](https://opencollective.com/ajv)
[<img src="https://ajv.js.org/img/microsoft.png" width="31%" alt="Microsoft">](https://opensource.microsoft.com)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/reserved.svg" width="31%">](https://opencollective.com/ajv)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/reserved.svg" width="31%">](https://opencollective.com/ajv)
[<img src="https://ajv.js.org/img/retool.svg" width="22.5%" alt="Retool">](https://retool.com/?utm_source=sponsor&utm_campaign=ajv)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/tidelift.svg" width="22.5%" alt="Tidelift">](https://tidelift.com/subscription/pkg/npm-ajv?utm_source=npm-ajv&utm_medium=referral&utm_campaign=enterprise)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/simplex.svg" width="22.5%" alt="SimpleX">](https://github.com/simplex-chat/simplex-chat)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/reserved.svg" width="22.5%">](https://opencollective.com/ajv)
## Contributing
More than 100 people contributed to Ajv, and we would love to have you join the development. We welcome implementing new features that will benefit many users and ideas to improve our documentation.
Please review [Contributing guidelines](./CONTRIBUTING.md) and [Code components](https://ajv.js.org/components.html).
## Documentation
All documentation is available on the [Ajv website](https://ajv.js.org).
Some useful site links:
- [Getting started](https://ajv.js.org/guide/getting-started.html)
- [JSON Schema vs JSON Type Definition](https://ajv.js.org/guide/schema-language.html)
- [API reference](https://ajv.js.org/api.html)
- [Strict mode](https://ajv.js.org/strict-mode.html)
- [Standalone validation code](https://ajv.js.org/standalone.html)
- [Security considerations](https://ajv.js.org/security.html)
- [Command line interface](https://ajv.js.org/packages/ajv-cli.html)
- [Frequently Asked Questions](https://ajv.js.org/faq.html)
## <a name="sponsors"></a>Please [sponsor Ajv development](https://github.com/sponsors/epoberezkin)
Since I asked to support Ajv development 40 people and 6 organizations contributed via GitHub and OpenCollective - this support helped receiving the MOSS grant!
Your continuing support is very important - the funds will be used to develop and maintain Ajv once the next major version is released.
Please sponsor Ajv via:
- [GitHub sponsors page](https://github.com/sponsors/epoberezkin) (GitHub will match it)
- [Ajv Open Collective️](https://opencollective.com/ajv)
Thank you.
#### Open Collective sponsors
<a href="https://opencollective.com/ajv"><img src="https://opencollective.com/ajv/individuals.svg?width=890"></a>
<a href="https://opencollective.com/ajv/organization/0/website"><img src="https://opencollective.com/ajv/organization/0/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/1/website"><img src="https://opencollective.com/ajv/organization/1/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/2/website"><img src="https://opencollective.com/ajv/organization/2/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/3/website"><img src="https://opencollective.com/ajv/organization/3/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/4/website"><img src="https://opencollective.com/ajv/organization/4/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/5/website"><img src="https://opencollective.com/ajv/organization/5/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/6/website"><img src="https://opencollective.com/ajv/organization/6/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/7/website"><img src="https://opencollective.com/ajv/organization/7/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/8/website"><img src="https://opencollective.com/ajv/organization/8/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/9/website"><img src="https://opencollective.com/ajv/organization/9/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/10/website"><img src="https://opencollective.com/ajv/organization/10/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/11/website"><img src="https://opencollective.com/ajv/organization/11/avatar.svg"></a>
## Performance
Ajv generates code to turn JSON Schemas into super-fast validation functions that are efficient for v8 optimization.
Currently Ajv is the fastest and the most standard compliant validator according to these benchmarks:
- [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark) - 50% faster than the second place
- [jsck benchmark](https://github.com/pandastrike/jsck#benchmarks) - 20-190% faster
- [z-schema benchmark](https://rawgit.com/zaggino/z-schema/master/benchmark/results.html)
- [themis benchmark](https://cdn.rawgit.com/playlyfe/themis/master/benchmark/results.html)
Performance of different validators by [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark):
[](https://github.com/ebdrup/json-schema-benchmark/blob/master/README.md#performance)
## Features
- Ajv implements JSON Schema [draft-06/07/2019-09/2020-12](http://json-schema.org/) standards (draft-04 is supported in v6):
- all validation keywords (see [JSON Schema validation keywords](https://ajv.js.org/json-schema.html))
- [OpenAPI](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.3.md) extensions:
- NEW: keyword [discriminator](https://ajv.js.org/json-schema.html#discriminator).
- keyword [nullable](https://ajv.js.org/json-schema.html#nullable).
- full support of remote references (remote schemas have to be added with `addSchema` or compiled to be available)
- support of recursive references between schemas
- correct string lengths for strings with unicode pairs
- JSON Schema [formats](https://ajv.js.org/guide/formats.html) (with [ajv-formats](https://github.com/ajv-validator/ajv-formats) plugin).
- [validates schemas against meta-schema](https://ajv.js.org/api.html#api-validateschema)
- NEW: supports [JSON Type Definition](https://datatracker.ietf.org/doc/rfc8927/):
- all keywords (see [JSON Type Definition schema forms](https://ajv.js.org/json-type-definition.html))
- meta-schema for JTD schemas
- "union" keyword and user-defined keywords (can be used inside "metadata" member of the schema)
- supports [browsers](https://ajv.js.org/guide/environments.html#browsers) and Node.js 10.x - current
- [asynchronous loading](https://ajv.js.org/guide/managing-schemas.html#asynchronous-schema-loading) of referenced schemas during compilation
- "All errors" validation mode with [option allErrors](https://ajv.js.org/options.html#allerrors)
- [error messages with parameters](https://ajv.js.org/api.html#validation-errors) describing error reasons to allow error message generation
- i18n error messages support with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package
- [removing-additional-properties](https://ajv.js.org/guide/modifying-data.html#removing-additional-properties)
- [assigning defaults](https://ajv.js.org/guide/modifying-data.html#assigning-defaults) to missing properties and items
- [coercing data](https://ajv.js.org/guide/modifying-data.html#coercing-data-types) to the types specified in `type` keywords
- [user-defined keywords](https://ajv.js.org/guide/user-keywords.html)
- additional extension keywords with [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package
- [\$data reference](https://ajv.js.org/guide/combining-schemas.html#data-reference) to use values from the validated data as values for the schema keywords
- [asynchronous validation](https://ajv.js.org/guide/async-validation.html) of user-defined formats and keywords
## Install
To install version 8:
```
npm install ajv
```
## <a name="usage"></a>Getting started
Try it in the Node.js REPL: https://runkit.com/npm/ajv
In JavaScript:
```javascript
// or ESM/TypeScript import
import Ajv from "ajv"
// Node.js require:
const Ajv = require("ajv")
const ajv = new Ajv() // options can be passed, e.g. {allErrors: true}
const schema = {
type: "object",
properties: {
foo: {type: "integer"},
bar: {type: "string"}
},
required: ["foo"],
additionalProperties: false,
}
const data = {
foo: 1,
bar: "abc"
}
const validate = ajv.compile(schema)
const valid = validate(data)
if (!valid) console.log(validate.errors)
```
Learn how to use Ajv and see more examples in the [Guide: getting started](https://ajv.js.org/guide/getting-started.html)
## Changes history
See [https://github.com/ajv-validator/ajv/releases](https://github.com/ajv-validator/ajv/releases)
**Please note**: [Changes in version 8.0.0](https://github.com/ajv-validator/ajv/releases/tag/v8.0.0)
[Version 7.0.0](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0)
[Version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0).
## Code of conduct
Please review and follow the [Code of conduct](./CODE_OF_CONDUCT.md).
Please report any unacceptable behaviour to ajv.validator@gmail.com - it will be reviewed by the project team.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerabilities via GitHub issues.
## Open-source software support
Ajv is a part of [Tidelift subscription](https://tidelift.com/subscription/pkg/npm-ajv?utm_source=npm-ajv&utm_medium=referral&utm_campaign=readme) - it provides a centralised support to open-source software users, in addition to the support provided by software maintainers.
## License
[MIT](./LICENSE)
# binary-install
Install .tar.gz binary applications via npm
## Usage
This library provides a single class `Binary` that takes a download url and some optional arguments. You **must** provide either `name` or `installDirectory` when creating your `Binary`.
| option | decription |
| ---------------- | --------------------------------------------- |
| name | The name of your binary |
| installDirectory | A path to the directory to install the binary |
If an `installDirectory` is not provided, the binary will be installed at your OS specific config directory. On MacOS it defaults to `~/Library/Preferences/${name}-nodejs`
After your `Binary` has been created, you can run `.install()` to install the binary, and `.run()` to run it.
### Example
This is meant to be used as a library - create your `Binary` with your desired options, then call `.install()` in the `postinstall` of your `package.json`, `.run()` in the `bin` section of your `package.json`, and `.uninstall()` in the `preuninstall` section of your `package.json`. See [this example project](/example) to see how to create an npm package that installs and runs a binary using the Github releases API.
# ESLint Scope
ESLint Scope is the [ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm) scope analyzer used in ESLint. It is a fork of [escope](http://github.com/estools/escope).
## Usage
Install:
```
npm i eslint-scope --save
```
Example:
```js
var eslintScope = require('eslint-scope');
var espree = require('espree');
var estraverse = require('estraverse');
var ast = espree.parse(code);
var scopeManager = eslintScope.analyze(ast);
var currentScope = scopeManager.acquire(ast); // global scope
estraverse.traverse(ast, {
enter: function(node, parent) {
// do stuff
if (/Function/.test(node.type)) {
currentScope = scopeManager.acquire(node); // get current function scope
}
},
leave: function(node, parent) {
if (/Function/.test(node.type)) {
currentScope = currentScope.upper; // set to parent scope
}
// do stuff
}
});
```
## Contributing
Issues and pull requests will be triaged and responded to as quickly as possible. We operate under the [ESLint Contributor Guidelines](http://eslint.org/docs/developer-guide/contributing), so please be sure to read them before contributing. If you're not sure where to dig in, check out the [issues](https://github.com/eslint/eslint-scope/issues).
## Build Commands
* `npm test` - run all linting and tests
* `npm run lint` - run all linting
## License
ESLint Scope is licensed under a permissive BSD 2-clause license.
# isexe
Minimal module to check if a file is executable, and a normal file.
Uses `fs.stat` and tests against the `PATHEXT` environment variable on
Windows.
## USAGE
```javascript
var isexe = require('isexe')
isexe('some-file-name', function (err, isExe) {
if (err) {
console.error('probably file does not exist or something', err)
} else if (isExe) {
console.error('this thing can be run')
} else {
console.error('cannot be run')
}
})
// same thing but synchronous, throws errors
var isExe = isexe.sync('some-file-name')
// treat errors as just "not executable"
isexe('maybe-missing-file', { ignoreErrors: true }, callback)
var isExe = isexe.sync('maybe-missing-file', { ignoreErrors: true })
```
## API
### `isexe(path, [options], [callback])`
Check if the path is executable. If no callback provided, and a
global `Promise` object is available, then a Promise will be returned.
Will raise whatever errors may be raised by `fs.stat`, unless
`options.ignoreErrors` is set to true.
### `isexe.sync(path, [options])`
Same as `isexe` but returns the value and throws any errors raised.
### Options
* `ignoreErrors` Treat all errors as "no, this is not executable", but
don't raise them.
* `uid` Number to use as the user id
* `gid` Number to use as the group id
* `pathExt` List of path extensions to use instead of `PATHEXT`
environment variable on Windows.
# json-schema-traverse
Traverse JSON Schema passing each schema object to callback
[](https://travis-ci.org/epoberezkin/json-schema-traverse)
[](https://www.npmjs.com/package/json-schema-traverse)
[](https://coveralls.io/github/epoberezkin/json-schema-traverse?branch=master)
## Install
```
npm install json-schema-traverse
```
## Usage
```javascript
const traverse = require('json-schema-traverse');
const schema = {
properties: {
foo: {type: 'string'},
bar: {type: 'integer'}
}
};
traverse(schema, {cb});
// cb is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
// Or:
traverse(schema, {cb: {pre, post}});
// pre is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
//
// post is called 3 times with:
// 1. {type: 'string'}
// 2. {type: 'integer'}
// 3. root schema
```
Callback function `cb` is called for each schema object (not including draft-06 boolean schemas), including the root schema, in pre-order traversal. Schema references ($ref) are not resolved, they are passed as is. Alternatively, you can pass a `{pre, post}` object as `cb`, and then `pre` will be called before traversing child elements, and `post` will be called after all child elements have been traversed.
Callback is passed these parameters:
- _schema_: the current schema object
- _JSON pointer_: from the root schema to the current schema object
- _root schema_: the schema passed to `traverse` object
- _parent JSON pointer_: from the root schema to the parent schema object (see below)
- _parent keyword_: the keyword inside which this schema appears (e.g. `properties`, `anyOf`, etc.)
- _parent schema_: not necessarily parent object/array; in the example above the parent schema for `{type: 'string'}` is the root schema
- _index/property_: index or property name in the array/object containing multiple schemas; in the example above for `{type: 'string'}` the property name is `'foo'`
## Traverse objects in all unknown keywords
```javascript
const traverse = require('json-schema-traverse');
const schema = {
mySchema: {
minimum: 1,
maximum: 2
}
};
traverse(schema, {allKeys: true, cb});
// cb is called 2 times with:
// 1. root schema
// 2. mySchema
```
Without option `allKeys: true` callback will be called only with root schema.
## License
[MIT](https://github.com/epoberezkin/json-schema-traverse/blob/master/LICENSE)
<p align="center">
<a href="https://gulpjs.com">
<img height="257" width="114" src="https://raw.githubusercontent.com/gulpjs/artwork/master/gulp-2x.png">
</a>
</p>
# glob-parent
[![NPM version][npm-image]][npm-url] [![Downloads][downloads-image]][npm-url] [![Azure Pipelines Build Status][azure-pipelines-image]][azure-pipelines-url] [![Travis Build Status][travis-image]][travis-url] [![AppVeyor Build Status][appveyor-image]][appveyor-url] [![Coveralls Status][coveralls-image]][coveralls-url] [![Gitter chat][gitter-image]][gitter-url]
Extract the non-magic parent path from a glob string.
## Usage
```js
var globParent = require('glob-parent');
globParent('path/to/*.js'); // 'path/to'
globParent('/root/path/to/*.js'); // '/root/path/to'
globParent('/*.js'); // '/'
globParent('*.js'); // '.'
globParent('**/*.js'); // '.'
globParent('path/{to,from}'); // 'path'
globParent('path/!(to|from)'); // 'path'
globParent('path/?(to|from)'); // 'path'
globParent('path/+(to|from)'); // 'path'
globParent('path/*(to|from)'); // 'path'
globParent('path/@(to|from)'); // 'path'
globParent('path/**/*'); // 'path'
// if provided a non-glob path, returns the nearest dir
globParent('path/foo/bar.js'); // 'path/foo'
globParent('path/foo/'); // 'path/foo'
globParent('path/foo'); // 'path' (see issue #3 for details)
```
## API
### `globParent(maybeGlobString, [options])`
Takes a string and returns the part of the path before the glob begins. Be aware of Escaping rules and Limitations below.
#### options
```js
{
// Disables the automatic conversion of slashes for Windows
flipBackslashes: true
}
```
## Escaping
The following characters have special significance in glob patterns and must be escaped if you want them to be treated as regular path characters:
- `?` (question mark) unless used as a path segment alone
- `*` (asterisk)
- `|` (pipe)
- `(` (opening parenthesis)
- `)` (closing parenthesis)
- `{` (opening curly brace)
- `}` (closing curly brace)
- `[` (opening bracket)
- `]` (closing bracket)
**Example**
```js
globParent('foo/[bar]/') // 'foo'
globParent('foo/\\[bar]/') // 'foo/[bar]'
```
## Limitations
### Braces & Brackets
This library attempts a quick and imperfect method of determining which path
parts have glob magic without fully parsing/lexing the pattern. There are some
advanced use cases that can trip it up, such as nested braces where the outer
pair is escaped and the inner one contains a path separator. If you find
yourself in the unlikely circumstance of being affected by this or need to
ensure higher-fidelity glob handling in your library, it is recommended that you
pre-process your input with [expand-braces] and/or [expand-brackets].
### Windows
Backslashes are not valid path separators for globs. If a path with backslashes
is provided anyway, for simple cases, glob-parent will replace the path
separator for you and return the non-glob parent path (now with
forward-slashes, which are still valid as Windows path separators).
This cannot be used in conjunction with escape characters.
```js
// BAD
globParent('C:\\Program Files \\(x86\\)\\*.ext') // 'C:/Program Files /(x86/)'
// GOOD
globParent('C:/Program Files\\(x86\\)/*.ext') // 'C:/Program Files (x86)'
```
If you are using escape characters for a pattern without path parts (i.e.
relative to `cwd`), prefix with `./` to avoid confusing glob-parent.
```js
// BAD
globParent('foo \\[bar]') // 'foo '
globParent('foo \\[bar]*') // 'foo '
// GOOD
globParent('./foo \\[bar]') // 'foo [bar]'
globParent('./foo \\[bar]*') // '.'
```
## License
ISC
[expand-braces]: https://github.com/jonschlinkert/expand-braces
[expand-brackets]: https://github.com/jonschlinkert/expand-brackets
[downloads-image]: https://img.shields.io/npm/dm/glob-parent.svg
[npm-url]: https://www.npmjs.com/package/glob-parent
[npm-image]: https://img.shields.io/npm/v/glob-parent.svg
[azure-pipelines-url]: https://dev.azure.com/gulpjs/gulp/_build/latest?definitionId=2&branchName=master
[azure-pipelines-image]: https://dev.azure.com/gulpjs/gulp/_apis/build/status/glob-parent?branchName=master
[travis-url]: https://travis-ci.org/gulpjs/glob-parent
[travis-image]: https://img.shields.io/travis/gulpjs/glob-parent.svg?label=travis-ci
[appveyor-url]: https://ci.appveyor.com/project/gulpjs/glob-parent
[appveyor-image]: https://img.shields.io/appveyor/ci/gulpjs/glob-parent.svg?label=appveyor
[coveralls-url]: https://coveralls.io/r/gulpjs/glob-parent
[coveralls-image]: https://img.shields.io/coveralls/gulpjs/glob-parent/master.svg
[gitter-url]: https://gitter.im/gulpjs/gulp
[gitter-image]: https://badges.gitter.im/gulpjs/gulp.svg
<table><thead>
<tr>
<th>Linux</th>
<th>OS X</th>
<th>Windows</th>
<th>Coverage</th>
<th>Downloads</th>
</tr>
</thead><tbody><tr>
<td colspan="2" align="center">
<a href="https://travis-ci.org/kaelzhang/node-ignore">
<img
src="https://travis-ci.org/kaelzhang/node-ignore.svg?branch=master"
alt="Build Status" /></a>
</td>
<td align="center">
<a href="https://ci.appveyor.com/project/kaelzhang/node-ignore">
<img
src="https://ci.appveyor.com/api/projects/status/github/kaelzhang/node-ignore?branch=master&svg=true"
alt="Windows Build Status" /></a>
</td>
<td align="center">
<a href="https://codecov.io/gh/kaelzhang/node-ignore">
<img
src="https://codecov.io/gh/kaelzhang/node-ignore/branch/master/graph/badge.svg"
alt="Coverage Status" /></a>
</td>
<td align="center">
<a href="https://www.npmjs.org/package/ignore">
<img
src="http://img.shields.io/npm/dm/ignore.svg"
alt="npm module downloads per month" /></a>
</td>
</tr></tbody></table>
# ignore
`ignore` is a manager, filter and parser which implemented in pure JavaScript according to the .gitignore [spec](http://git-scm.com/docs/gitignore).
Pay attention that [`minimatch`](https://www.npmjs.org/package/minimatch) does not work in the gitignore way. To filter filenames according to .gitignore file, I recommend this module.
##### Tested on
- Linux + Node: `0.8` - `7.x`
- Windows + Node: `0.10` - `7.x`, node < `0.10` is not tested due to the lack of support of appveyor.
Actually, `ignore` does not rely on any versions of node specially.
Since `4.0.0`, ignore will no longer support `node < 6` by default, to use in node < 6, `require('ignore/legacy')`. For details, see [CHANGELOG](https://github.com/kaelzhang/node-ignore/blob/master/CHANGELOG.md).
## Table Of Main Contents
- [Usage](#usage)
- [`Pathname` Conventions](#pathname-conventions)
- [Guide for 2.x -> 3.x](#upgrade-2x---3x)
- [Guide for 3.x -> 4.x](#upgrade-3x---4x)
- See Also:
- [`glob-gitignore`](https://www.npmjs.com/package/glob-gitignore) matches files using patterns and filters them according to gitignore rules.
## Usage
```js
import ignore from 'ignore'
const ig = ignore().add(['.abc/*', '!.abc/d/'])
```
### Filter the given paths
```js
const paths = [
'.abc/a.js', // filtered out
'.abc/d/e.js' // included
]
ig.filter(paths) // ['.abc/d/e.js']
ig.ignores('.abc/a.js') // true
```
### As the filter function
```js
paths.filter(ig.createFilter()); // ['.abc/d/e.js']
```
### Win32 paths will be handled
```js
ig.filter(['.abc\\a.js', '.abc\\d\\e.js'])
// if the code above runs on windows, the result will be
// ['.abc\\d\\e.js']
```
## Why another ignore?
- `ignore` is a standalone module, and is much simpler so that it could easy work with other programs, unlike [isaacs](https://npmjs.org/~isaacs)'s [fstream-ignore](https://npmjs.org/package/fstream-ignore) which must work with the modules of the fstream family.
- `ignore` only contains utility methods to filter paths according to the specified ignore rules, so
- `ignore` never try to find out ignore rules by traversing directories or fetching from git configurations.
- `ignore` don't cares about sub-modules of git projects.
- Exactly according to [gitignore man page](http://git-scm.com/docs/gitignore), fixes some known matching issues of fstream-ignore, such as:
- '`/*.js`' should only match '`a.js`', but not '`abc/a.js`'.
- '`**/foo`' should match '`foo`' anywhere.
- Prevent re-including a file if a parent directory of that file is excluded.
- Handle trailing whitespaces:
- `'a '`(one space) should not match `'a '`(two spaces).
- `'a \ '` matches `'a '`
- All test cases are verified with the result of `git check-ignore`.
# Methods
## .add(pattern: string | Ignore): this
## .add(patterns: Array<string | Ignore>): this
- **pattern** `String | Ignore` An ignore pattern string, or the `Ignore` instance
- **patterns** `Array<String | Ignore>` Array of ignore patterns.
Adds a rule or several rules to the current manager.
Returns `this`
Notice that a line starting with `'#'`(hash) is treated as a comment. Put a backslash (`'\'`) in front of the first hash for patterns that begin with a hash, if you want to ignore a file with a hash at the beginning of the filename.
```js
ignore().add('#abc').ignores('#abc') // false
ignore().add('\#abc').ignores('#abc') // true
```
`pattern` could either be a line of ignore pattern or a string of multiple ignore patterns, which means we could just `ignore().add()` the content of a ignore file:
```js
ignore()
.add(fs.readFileSync(filenameOfGitignore).toString())
.filter(filenames)
```
`pattern` could also be an `ignore` instance, so that we could easily inherit the rules of another `Ignore` instance.
## <strike>.addIgnoreFile(path)</strike>
REMOVED in `3.x` for now.
To upgrade `ignore@2.x` up to `3.x`, use
```js
import fs from 'fs'
if (fs.existsSync(filename)) {
ignore().add(fs.readFileSync(filename).toString())
}
```
instead.
## .filter(paths: Array<Pathname>): Array<Pathname>
```ts
type Pathname = string
```
Filters the given array of pathnames, and returns the filtered array.
- **paths** `Array.<Pathname>` The array of `pathname`s to be filtered.
### `Pathname` Conventions:
#### 1. `Pathname` should be a `path.relative()`d pathname
`Pathname` should be a string that have been `path.join()`ed, or the return value of `path.relative()` to the current directory.
```js
// WRONG
ig.ignores('./abc')
// WRONG, for it will never happen.
// If the gitignore rule locates at the root directory,
// `'/abc'` should be changed to `'abc'`.
// ```
// path.relative('/', '/abc') -> 'abc'
// ```
ig.ignores('/abc')
// Right
ig.ignores('abc')
// Right
ig.ignores(path.join('./abc')) // path.join('./abc') -> 'abc'
```
In other words, each `Pathname` here should be a relative path to the directory of the gitignore rules.
Suppose the dir structure is:
```
/path/to/your/repo
|-- a
| |-- a.js
|
|-- .b
|
|-- .c
|-- .DS_store
```
Then the `paths` might be like this:
```js
[
'a/a.js'
'.b',
'.c/.DS_store'
]
```
Usually, you could use [`glob`](http://npmjs.org/package/glob) with `option.mark = true` to fetch the structure of the current directory:
```js
import glob from 'glob'
glob('**', {
// Adds a / character to directory matches.
mark: true
}, (err, files) => {
if (err) {
return console.error(err)
}
let filtered = ignore().add(patterns).filter(files)
console.log(filtered)
})
```
#### 2. filenames and dirnames
`node-ignore` does NO `fs.stat` during path matching, so for the example below:
```js
ig.add('config/')
// `ig` does NOT know if 'config' is a normal file, directory or something
ig.ignores('config') // And it returns `false`
ig.ignores('config/') // returns `true`
```
Specially for people who develop some library based on `node-ignore`, it is important to understand that.
## .ignores(pathname: Pathname): boolean
> new in 3.2.0
Returns `Boolean` whether `pathname` should be ignored.
```js
ig.ignores('.abc/a.js') // true
```
## .createFilter()
Creates a filter function which could filter an array of paths with `Array.prototype.filter`.
Returns `function(path)` the filter function.
## `options.ignorecase` since 4.0.0
Similar as the `core.ignorecase` option of [git-config](https://git-scm.com/docs/git-config), `node-ignore` will be case insensitive if `options.ignorecase` is set to `true` (default value), otherwise case sensitive.
```js
const ig = ignore({
ignorecase: false
})
ig.add('*.png')
ig.ignores('*.PNG') // false
```
****
# Upgrade Guide
## Upgrade 2.x -> 3.x
- All `options` of 2.x are unnecessary and removed, so just remove them.
- `ignore()` instance is no longer an [`EventEmitter`](nodejs.org/api/events.html), and all events are unnecessary and removed.
- `.addIgnoreFile()` is removed, see the [.addIgnoreFile](#addignorefilepath) section for details.
## Upgrade 3.x -> 4.x
Since `4.0.0`, `ignore` will no longer support node < 6, to use `ignore` in node < 6:
```js
var ignore = require('ignore/legacy')
```
****
# Collaborators
- [@whitecolor](https://github.com/whitecolor) *Alex*
- [@SamyPesse](https://github.com/SamyPesse) *Samy Pessé*
- [@azproduction](https://github.com/azproduction) *Mikhail Davydov*
- [@TrySound](https://github.com/TrySound) *Bogdan Chadkin*
- [@JanMattner](https://github.com/JanMattner) *Jan Mattner*
- [@ntwb](https://github.com/ntwb) *Stephen Edgar*
- [@kasperisager](https://github.com/kasperisager) *Kasper Isager*
- [@sandersn](https://github.com/sandersn) *Nathan Shively-Sanders*
# fast-levenshtein - Levenshtein algorithm in Javascript
[](http://travis-ci.org/hiddentao/fast-levenshtein)
[](https://badge.fury.io/js/fast-levenshtein)
[](https://www.npmjs.com/package/fast-levenshtein)
[](https://twitter.com/hiddentao)
An efficient Javascript implementation of the [Levenshtein algorithm](http://en.wikipedia.org/wiki/Levenshtein_distance) with locale-specific collator support.
## Features
* Works in node.js and in the browser.
* Better performance than other implementations by not needing to store the whole matrix ([more info](http://www.codeproject.com/Articles/13525/Fast-memory-efficient-Levenshtein-algorithm)).
* Locale-sensitive string comparisions if needed.
* Comprehensive test suite and performance benchmark.
* Small: <1 KB minified and gzipped
## Installation
### node.js
Install using [npm](http://npmjs.org/):
```bash
$ npm install fast-levenshtein
```
### Browser
Using bower:
```bash
$ bower install fast-levenshtein
```
If you are not using any module loader system then the API will then be accessible via the `window.Levenshtein` object.
## Examples
**Default usage**
```javascript
var levenshtein = require('fast-levenshtein');
var distance = levenshtein.get('back', 'book'); // 2
var distance = levenshtein.get('我愛你', '我叫你'); // 1
```
**Locale-sensitive string comparisons**
It supports using [Intl.Collator](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Collator) for locale-sensitive string comparisons:
```javascript
var levenshtein = require('fast-levenshtein');
levenshtein.get('mikailovitch', 'Mikhaïlovitch', { useCollator: true});
// 1
```
## Building and Testing
To build the code and run the tests:
```bash
$ npm install -g grunt-cli
$ npm install
$ npm run build
```
## Performance
_Thanks to [Titus Wormer](https://github.com/wooorm) for [encouraging me](https://github.com/hiddentao/fast-levenshtein/issues/1) to do this._
Benchmarked against other node.js levenshtein distance modules (on Macbook Air 2012, Core i7, 8GB RAM):
```bash
Running suite Implementation comparison [benchmark/speed.js]...
>> levenshtein-edit-distance x 234 ops/sec ±3.02% (73 runs sampled)
>> levenshtein-component x 422 ops/sec ±4.38% (83 runs sampled)
>> levenshtein-deltas x 283 ops/sec ±3.83% (78 runs sampled)
>> natural x 255 ops/sec ±0.76% (88 runs sampled)
>> levenshtein x 180 ops/sec ±3.55% (86 runs sampled)
>> fast-levenshtein x 1,792 ops/sec ±2.72% (95 runs sampled)
Benchmark done.
Fastest test is fast-levenshtein at 4.2x faster than levenshtein-component
```
You can run this benchmark yourself by doing:
```bash
$ npm install
$ npm run build
$ npm run benchmark
```
## Contributing
If you wish to submit a pull request please update and/or create new tests for any changes you make and ensure the grunt build passes.
See [CONTRIBUTING.md](https://github.com/hiddentao/fast-levenshtein/blob/master/CONTRIBUTING.md) for details.
## License
MIT - see [LICENSE.md](https://github.com/hiddentao/fast-levenshtein/blob/master/LICENSE.md)
# which-module
> Find the module object for something that was require()d
[](https://travis-ci.org/nexdrew/which-module)
[](https://coveralls.io/github/nexdrew/which-module?branch=master)
[](https://github.com/conventional-changelog/standard-version)
Find the `module` object in `require.cache` for something that was `require()`d
or `import`ed - essentially a reverse `require()` lookup.
Useful for libs that want to e.g. lookup a filename for a module or submodule
that it did not `require()` itself.
## Install and Usage
```
npm install --save which-module
```
```js
const whichModule = require('which-module')
console.log(whichModule(require('something')))
// Module {
// id: '/path/to/project/node_modules/something/index.js',
// exports: [Function],
// parent: ...,
// filename: '/path/to/project/node_modules/something/index.js',
// loaded: true,
// children: [],
// paths: [ '/path/to/project/node_modules/something/node_modules',
// '/path/to/project/node_modules',
// '/path/to/node_modules',
// '/path/node_modules',
// '/node_modules' ] }
```
## API
### `whichModule(exported)`
Return the [`module` object](https://nodejs.org/api/modules.html#modules_the_module_object),
if any, that represents the given argument in the `require.cache`.
`exported` can be anything that was previously `require()`d or `import`ed as a
module, submodule, or dependency - which means `exported` is identical to the
`module.exports` returned by this method.
If `exported` did not come from the `exports` of a `module` in `require.cache`,
then this method returns `null`.
## License
ISC © Contributors
# flatted
[](https://www.npmjs.com/package/flatted) [](https://coveralls.io/github/WebReflection/flatted?branch=main) [](https://travis-ci.com/WebReflection/flatted) [](https://opensource.org/licenses/ISC) 

<sup>**Social Media Photo by [Matt Seymour](https://unsplash.com/@mattseymour) on [Unsplash](https://unsplash.com/)**</sup>
## Announcement 📣
There is a standard approach to recursion and more data-types than what JSON allows, and it's part of the [Structured Clone polyfill](https://github.com/ungap/structured-clone/#readme).
Beside acting as a polyfill, its `@ungap/structured-clone/json` export provides both `stringify` and `parse`, and it's been tested for being faster than *flatted*, but its produced output is also smaller than *flatted* in general.
The *@ungap/structured-clone* module is, in short, a drop in replacement for *flatted*, but it's not compatible with *flatted* specialized syntax.
However, if recursion, as well as more data-types, are what you are after, or interesting for your projects/use cases, consider switching to this new module whenever you can 👍
- - -
A super light (0.5K) and fast circular JSON parser, directly from the creator of [CircularJSON](https://github.com/WebReflection/circular-json/#circularjson).
Now available also for **[PHP](./php/flatted.php)**.
```js
npm i flatted
```
Usable via [CDN](https://unpkg.com/flatted) or as regular module.
```js
// ESM
import {parse, stringify, toJSON, fromJSON} from 'flatted';
// CJS
const {parse, stringify, toJSON, fromJSON} = require('flatted');
const a = [{}];
a[0].a = a;
a.push(a);
stringify(a); // [["1","0"],{"a":"0"}]
```
## toJSON and fromJSON
If you'd like to implicitly survive JSON serialization, these two helpers helps:
```js
import {toJSON, fromJSON} from 'flatted';
class RecursiveMap extends Map {
static fromJSON(any) {
return new this(fromJSON(any));
}
toJSON() {
return toJSON([...this.entries()]);
}
}
const recursive = new RecursiveMap;
const same = {};
same.same = same;
recursive.set('same', same);
const asString = JSON.stringify(recursive);
const asMap = RecursiveMap.fromJSON(JSON.parse(asString));
asMap.get('same') === asMap.get('same').same;
// true
```
## Flatted VS JSON
As it is for every other specialized format capable of serializing and deserializing circular data, you should never `JSON.parse(Flatted.stringify(data))`, and you should never `Flatted.parse(JSON.stringify(data))`.
The only way this could work is to `Flatted.parse(Flatted.stringify(data))`, as it is also for _CircularJSON_ or any other, otherwise there's no granted data integrity.
Also please note this project serializes and deserializes only data compatible with JSON, so that sockets, or anything else with internal classes different from those allowed by JSON standard, won't be serialized and unserialized as expected.
### New in V1: Exact same JSON API
* Added a [reviver](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse#Syntax) parameter to `.parse(string, reviver)` and revive your own objects.
* Added a [replacer](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify#Syntax) and a `space` parameter to `.stringify(object, replacer, space)` for feature parity with JSON signature.
### Compatibility
All ECMAScript engines compatible with `Map`, `Set`, `Object.keys`, and `Array.prototype.reduce` will work, even if polyfilled.
### How does it work ?
While stringifying, all Objects, including Arrays, and strings, are flattened out and replaced as unique index. `*`
Once parsed, all indexes will be replaced through the flattened collection.
<sup><sub>`*` represented as string to avoid conflicts with numbers</sub></sup>
```js
// logic example
var a = [{one: 1}, {two: '2'}];
a[0].a = a;
// a is the main object, will be at index '0'
// {one: 1} is the second object, index '1'
// {two: '2'} the third, in '2', and it has a string
// which will be found at index '3'
Flatted.stringify(a);
// [["1","2"],{"one":1,"a":"0"},{"two":"3"},"2"]
// a[one,two] {one: 1, a} {two: '2'} '2'
```
# lodash.truncate v4.4.2
The [lodash](https://lodash.com/) method `_.truncate` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.truncate
```
In Node.js:
```js
var truncate = require('lodash.truncate');
```
See the [documentation](https://lodash.com/docs#truncate) or [package source](https://github.com/lodash/lodash/blob/4.4.2-npm-packages/lodash.truncate) for more details.
# axios // core
The modules found in `core/` should be modules that are specific to the domain logic of axios. These modules would most likely not make sense to be consumed outside of the axios module, as their logic is too specific. Some examples of core modules are:
- Dispatching requests
- Managing interceptors
- Handling config
# URI.js
URI.js is an [RFC 3986](http://www.ietf.org/rfc/rfc3986.txt) compliant, scheme extendable URI parsing/validating/resolving library for all JavaScript environments (browsers, Node.js, etc).
It is also compliant with the IRI ([RFC 3987](http://www.ietf.org/rfc/rfc3987.txt)), IDNA ([RFC 5890](http://www.ietf.org/rfc/rfc5890.txt)), IPv6 Address ([RFC 5952](http://www.ietf.org/rfc/rfc5952.txt)), IPv6 Zone Identifier ([RFC 6874](http://www.ietf.org/rfc/rfc6874.txt)) specifications.
URI.js has an extensive test suite, and works in all (Node.js, web) environments. It weighs in at 6.4kb (gzipped, 17kb deflated).
## API
### Parsing
URI.parse("uri://user:pass@example.com:123/one/two.three?q1=a1&q2=a2#body");
//returns:
//{
// scheme : "uri",
// userinfo : "user:pass",
// host : "example.com",
// port : 123,
// path : "/one/two.three",
// query : "q1=a1&q2=a2",
// fragment : "body"
//}
### Serializing
URI.serialize({scheme : "http", host : "example.com", fragment : "footer"}) === "http://example.com/#footer"
### Resolving
URI.resolve("uri://a/b/c/d?q", "../../g") === "uri://a/g"
### Normalizing
URI.normalize("HTTP://ABC.com:80/%7Esmith/home.html") === "http://abc.com/~smith/home.html"
### Comparison
URI.equal("example://a/b/c/%7Bfoo%7D", "eXAMPLE://a/./b/../b/%63/%7bfoo%7d") === true
### IP Support
//IPv4 normalization
URI.normalize("//192.068.001.000") === "//192.68.1.0"
//IPv6 normalization
URI.normalize("//[2001:0:0DB8::0:0001]") === "//[2001:0:db8::1]"
//IPv6 zone identifier support
URI.parse("//[2001:db8::7%25en1]");
//returns:
//{
// host : "2001:db8::7%en1"
//}
### IRI Support
//convert IRI to URI
URI.serialize(URI.parse("http://examplé.org/rosé")) === "http://xn--exampl-gva.org/ros%C3%A9"
//convert URI to IRI
URI.serialize(URI.parse("http://xn--exampl-gva.org/ros%C3%A9"), {iri:true}) === "http://examplé.org/rosé"
### Options
All of the above functions can accept an additional options argument that is an object that can contain one or more of the following properties:
* `scheme` (string)
Indicates the scheme that the URI should be treated as, overriding the URI's normal scheme parsing behavior.
* `reference` (string)
If set to `"suffix"`, it indicates that the URI is in the suffix format, and the validator will use the option's `scheme` property to determine the URI's scheme.
* `tolerant` (boolean, false)
If set to `true`, the parser will relax URI resolving rules.
* `absolutePath` (boolean, false)
If set to `true`, the serializer will not resolve a relative `path` component.
* `iri` (boolean, false)
If set to `true`, the serializer will unescape non-ASCII characters as per [RFC 3987](http://www.ietf.org/rfc/rfc3987.txt).
* `unicodeSupport` (boolean, false)
If set to `true`, the parser will unescape non-ASCII characters in the parsed output as per [RFC 3987](http://www.ietf.org/rfc/rfc3987.txt).
* `domainHost` (boolean, false)
If set to `true`, the library will treat the `host` component as a domain name, and convert IDNs (International Domain Names) as per [RFC 5891](http://www.ietf.org/rfc/rfc5891.txt).
## Scheme Extendable
URI.js supports inserting custom [scheme](http://en.wikipedia.org/wiki/URI_scheme) dependent processing rules. Currently, URI.js has built in support for the following schemes:
* http \[[RFC 2616](http://www.ietf.org/rfc/rfc2616.txt)\]
* https \[[RFC 2818](http://www.ietf.org/rfc/rfc2818.txt)\]
* ws \[[RFC 6455](http://www.ietf.org/rfc/rfc6455.txt)\]
* wss \[[RFC 6455](http://www.ietf.org/rfc/rfc6455.txt)\]
* mailto \[[RFC 6068](http://www.ietf.org/rfc/rfc6068.txt)\]
* urn \[[RFC 2141](http://www.ietf.org/rfc/rfc2141.txt)\]
* urn:uuid \[[RFC 4122](http://www.ietf.org/rfc/rfc4122.txt)\]
### HTTP/HTTPS Support
URI.equal("HTTP://ABC.COM:80", "http://abc.com/") === true
URI.equal("https://abc.com", "HTTPS://ABC.COM:443/") === true
### WS/WSS Support
URI.parse("wss://example.com/foo?bar=baz");
//returns:
//{
// scheme : "wss",
// host: "example.com",
// resourceName: "/foo?bar=baz",
// secure: true,
//}
URI.equal("WS://ABC.COM:80/chat#one", "ws://abc.com/chat") === true
### Mailto Support
URI.parse("mailto:alpha@example.com,bravo@example.com?subject=SUBSCRIBE&body=Sign%20me%20up!");
//returns:
//{
// scheme : "mailto",
// to : ["alpha@example.com", "bravo@example.com"],
// subject : "SUBSCRIBE",
// body : "Sign me up!"
//}
URI.serialize({
scheme : "mailto",
to : ["alpha@example.com"],
subject : "REMOVE",
body : "Please remove me",
headers : {
cc : "charlie@example.com"
}
}) === "mailto:alpha@example.com?cc=charlie@example.com&subject=REMOVE&body=Please%20remove%20me"
### URN Support
URI.parse("urn:example:foo");
//returns:
//{
// scheme : "urn",
// nid : "example",
// nss : "foo",
//}
#### URN UUID Support
URI.parse("urn:uuid:f81d4fae-7dec-11d0-a765-00a0c91e6bf6");
//returns:
//{
// scheme : "urn",
// nid : "uuid",
// uuid : "f81d4fae-7dec-11d0-a765-00a0c91e6bf6",
//}
## Usage
To load in a browser, use the following tag:
<script type="text/javascript" src="uri-js/dist/es5/uri.all.min.js"></script>
To load in a CommonJS/Module environment, first install with npm/yarn by running on the command line:
npm install uri-js
# OR
yarn add uri-js
Then, in your code, load it using:
const URI = require("uri-js");
If you are writing your code in ES6+ (ESNEXT) or TypeScript, you would load it using:
import * as URI from "uri-js";
Or you can load just what you need using named exports:
import { parse, serialize, resolve, resolveComponents, normalize, equal, removeDotSegments, pctEncChar, pctDecChars, escapeComponent, unescapeComponent } from "uri-js";
## Breaking changes
### Breaking changes from 3.x
URN parsing has been completely changed to better align with the specification. Scheme is now always `urn`, but has two new properties: `nid` which contains the Namspace Identifier, and `nss` which contains the Namespace Specific String. The `nss` property will be removed by higher order scheme handlers, such as the UUID URN scheme handler.
The UUID of a URN can now be found in the `uuid` property.
### Breaking changes from 2.x
URI validation has been removed as it was slow, exposed a vulnerabilty, and was generally not useful.
### Breaking changes from 1.x
The `errors` array on parsed components is now an `error` string.
# base-x
[](https://www.npmjs.org/package/base-x)
[](https://travis-ci.org/cryptocoinjs/base-x)
[](https://github.com/feross/standard)
Fast base encoding / decoding of any given alphabet using bitcoin style leading
zero compression.
**WARNING:** This module is **NOT RFC3548** compliant, it cannot be used for base16 (hex), base32, or base64 encoding in a standards compliant manner.
## Example
Base58
``` javascript
var BASE58 = '123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz'
var bs58 = require('base-x')(BASE58)
var decoded = bs58.decode('5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr')
console.log(decoded)
// => <Buffer 80 ed db dc 11 68 f1 da ea db d3 e4 4c 1e 3f 8f 5a 28 4c 20 29 f7 8a d2 6a f9 85 83 a4 99 de 5b 19>
console.log(bs58.encode(decoded))
// => 5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr
```
### Alphabets
See below for a list of commonly recognized alphabets, and their respective base.
Base | Alphabet
------------- | -------------
2 | `01`
8 | `01234567`
11 | `0123456789a`
16 | `0123456789abcdef`
32 | `0123456789ABCDEFGHJKMNPQRSTVWXYZ`
32 | `ybndrfg8ejkmcpqxot1uwisza345h769` (z-base-32)
36 | `0123456789abcdefghijklmnopqrstuvwxyz`
58 | `123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz`
62 | `0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ`
64 | `ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/`
67 | `ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_.!~`
## How it works
It encodes octet arrays by doing long divisions on all significant digits in the
array, creating a representation of that number in the new base. Then for every
leading zero in the input (not significant as a number) it will encode as a
single leader character. This is the first in the alphabet and will decode as 8
bits. The other characters depend upon the base. For example, a base58 alphabet
packs roughly 5.858 bits per character.
This means the encoded string 000f (using a base16, 0-f alphabet) will actually decode
to 4 bytes unlike a canonical hex encoding which uniformly packs 4 bits into each
character.
While unusual, this does mean that no padding is required and it works for bases
like 43.
## LICENSE [MIT](LICENSE)
A direct derivation of the base58 implementation from [`bitcoin/bitcoin`](https://github.com/bitcoin/bitcoin/blob/f1e2f2a85962c1664e4e55471061af0eaa798d40/src/base58.cpp), generalized for variable length alphabets.
# cross-spawn
[![NPM version][npm-image]][npm-url] [![Downloads][downloads-image]][npm-url] [![Build Status][travis-image]][travis-url] [![Build status][appveyor-image]][appveyor-url] [![Coverage Status][codecov-image]][codecov-url] [![Dependency status][david-dm-image]][david-dm-url] [![Dev Dependency status][david-dm-dev-image]][david-dm-dev-url]
[npm-url]:https://npmjs.org/package/cross-spawn
[downloads-image]:https://img.shields.io/npm/dm/cross-spawn.svg
[npm-image]:https://img.shields.io/npm/v/cross-spawn.svg
[travis-url]:https://travis-ci.org/moxystudio/node-cross-spawn
[travis-image]:https://img.shields.io/travis/moxystudio/node-cross-spawn/master.svg
[appveyor-url]:https://ci.appveyor.com/project/satazor/node-cross-spawn
[appveyor-image]:https://img.shields.io/appveyor/ci/satazor/node-cross-spawn/master.svg
[codecov-url]:https://codecov.io/gh/moxystudio/node-cross-spawn
[codecov-image]:https://img.shields.io/codecov/c/github/moxystudio/node-cross-spawn/master.svg
[david-dm-url]:https://david-dm.org/moxystudio/node-cross-spawn
[david-dm-image]:https://img.shields.io/david/moxystudio/node-cross-spawn.svg
[david-dm-dev-url]:https://david-dm.org/moxystudio/node-cross-spawn?type=dev
[david-dm-dev-image]:https://img.shields.io/david/dev/moxystudio/node-cross-spawn.svg
A cross platform solution to node's spawn and spawnSync.
## Installation
Node.js version 8 and up:
`$ npm install cross-spawn`
Node.js version 7 and under:
`$ npm install cross-spawn@6`
## Why
Node has issues when using spawn on Windows:
- It ignores [PATHEXT](https://github.com/joyent/node/issues/2318)
- It does not support [shebangs](https://en.wikipedia.org/wiki/Shebang_(Unix))
- Has problems running commands with [spaces](https://github.com/nodejs/node/issues/7367)
- Has problems running commands with posix relative paths (e.g.: `./my-folder/my-executable`)
- Has an [issue](https://github.com/moxystudio/node-cross-spawn/issues/82) with command shims (files in `node_modules/.bin/`), where arguments with quotes and parenthesis would result in [invalid syntax error](https://github.com/moxystudio/node-cross-spawn/blob/e77b8f22a416db46b6196767bcd35601d7e11d54/test/index.test.js#L149)
- No `options.shell` support on node `<v4.8`
All these issues are handled correctly by `cross-spawn`.
There are some known modules, such as [win-spawn](https://github.com/ForbesLindesay/win-spawn), that try to solve this but they are either broken or provide faulty escaping of shell arguments.
## Usage
Exactly the same way as node's [`spawn`](https://nodejs.org/api/child_process.html#child_process_child_process_spawn_command_args_options) or [`spawnSync`](https://nodejs.org/api/child_process.html#child_process_child_process_spawnsync_command_args_options), so it's a drop in replacement.
```js
const spawn = require('cross-spawn');
// Spawn NPM asynchronously
const child = spawn('npm', ['list', '-g', '-depth', '0'], { stdio: 'inherit' });
// Spawn NPM synchronously
const result = spawn.sync('npm', ['list', '-g', '-depth', '0'], { stdio: 'inherit' });
```
## Caveats
### Using `options.shell` as an alternative to `cross-spawn`
Starting from node `v4.8`, `spawn` has a `shell` option that allows you run commands from within a shell. This new option solves
the [PATHEXT](https://github.com/joyent/node/issues/2318) issue but:
- It's not supported in node `<v4.8`
- You must manually escape the command and arguments which is very error prone, specially when passing user input
- There are a lot of other unresolved issues from the [Why](#why) section that you must take into account
If you are using the `shell` option to spawn a command in a cross platform way, consider using `cross-spawn` instead. You have been warned.
### `options.shell` support
While `cross-spawn` adds support for `options.shell` in node `<v4.8`, all of its enhancements are disabled.
This mimics the Node.js behavior. More specifically, the command and its arguments will not be automatically escaped nor shebang support will be offered. This is by design because if you are using `options.shell` you are probably targeting a specific platform anyway and you don't want things to get into your way.
### Shebangs support
While `cross-spawn` handles shebangs on Windows, its support is limited. More specifically, it just supports `#!/usr/bin/env <program>` where `<program>` must not contain any arguments.
If you would like to have the shebang support improved, feel free to contribute via a pull-request.
Remember to always test your code on Windows!
## Tests
`$ npm test`
`$ npm test -- --watch` during development
## License
Released under the [MIT License](https://www.opensource.org/licenses/mit-license.php).
## Follow Redirects
Drop-in replacement for Nodes `http` and `https` that automatically follows redirects.
[](https://www.npmjs.com/package/follow-redirects)
[](https://travis-ci.org/follow-redirects/follow-redirects)
[](https://coveralls.io/r/follow-redirects/follow-redirects?branch=master)
[](https://david-dm.org/follow-redirects/follow-redirects)
[](https://www.npmjs.com/package/follow-redirects)
`follow-redirects` provides [request](https://nodejs.org/api/http.html#http_http_request_options_callback) and [get](https://nodejs.org/api/http.html#http_http_get_options_callback)
methods that behave identically to those found on the native [http](https://nodejs.org/api/http.html#http_http_request_options_callback) and [https](https://nodejs.org/api/https.html#https_https_request_options_callback)
modules, with the exception that they will seamlessly follow redirects.
```javascript
var http = require('follow-redirects').http;
var https = require('follow-redirects').https;
http.get('http://bit.ly/900913', function (response) {
response.on('data', function (chunk) {
console.log(chunk);
});
}).on('error', function (err) {
console.error(err);
});
```
You can inspect the final redirected URL through the `responseUrl` property on the `response`.
If no redirection happened, `responseUrl` is the original request URL.
```javascript
https.request({
host: 'bitly.com',
path: '/UHfDGO',
}, function (response) {
console.log(response.responseUrl);
// 'http://duckduckgo.com/robots.txt'
});
```
## Options
### Global options
Global options are set directly on the `follow-redirects` module:
```javascript
var followRedirects = require('follow-redirects');
followRedirects.maxRedirects = 10;
followRedirects.maxBodyLength = 20 * 1024 * 1024; // 20 MB
```
The following global options are supported:
- `maxRedirects` (default: `21`) – sets the maximum number of allowed redirects; if exceeded, an error will be emitted.
- `maxBodyLength` (default: 10MB) – sets the maximum size of the request body; if exceeded, an error will be emitted.
### Per-request options
Per-request options are set by passing an `options` object:
```javascript
var url = require('url');
var followRedirects = require('follow-redirects');
var options = url.parse('http://bit.ly/900913');
options.maxRedirects = 10;
http.request(options);
```
In addition to the [standard HTTP](https://nodejs.org/api/http.html#http_http_request_options_callback) and [HTTPS options](https://nodejs.org/api/https.html#https_https_request_options_callback),
the following per-request options are supported:
- `followRedirects` (default: `true`) – whether redirects should be followed.
- `maxRedirects` (default: `21`) – sets the maximum number of allowed redirects; if exceeded, an error will be emitted.
- `maxBodyLength` (default: 10MB) – sets the maximum size of the request body; if exceeded, an error will be emitted.
- `agents` (default: `undefined`) – sets the `agent` option per protocol, since HTTP and HTTPS use different agents. Example value: `{ http: new http.Agent(), https: new https.Agent() }`
- `trackRedirects` (default: `false`) – whether to store the redirected response details into the `redirects` array on the response object.
### Advanced usage
By default, `follow-redirects` will use the Node.js default implementations
of [`http`](https://nodejs.org/api/http.html)
and [`https`](https://nodejs.org/api/https.html).
To enable features such as caching and/or intermediate request tracking,
you might instead want to wrap `follow-redirects` around custom protocol implementations:
```javascript
var followRedirects = require('follow-redirects').wrap({
http: require('your-custom-http'),
https: require('your-custom-https'),
});
```
Such custom protocols only need an implementation of the `request` method.
## Browserify Usage
Due to the way `XMLHttpRequest` works, the `browserify` versions of `http` and `https` already follow redirects.
If you are *only* targeting the browser, then this library has little value for you. If you want to write cross
platform code for node and the browser, `follow-redirects` provides a great solution for making the native node
modules behave the same as they do in browserified builds in the browser. To avoid bundling unnecessary code
you should tell browserify to swap out `follow-redirects` with the standard modules when bundling.
To make this easier, you need to change how you require the modules:
```javascript
var http = require('follow-redirects/http');
var https = require('follow-redirects/https');
```
You can then replace `follow-redirects` in your browserify configuration like so:
```javascript
"browser": {
"follow-redirects/http" : "http",
"follow-redirects/https" : "https"
}
```
The `browserify-http` module has not kept pace with node development, and no long behaves identically to the native
module when running in the browser. If you are experiencing problems, you may want to check out
[browserify-http-2](https://www.npmjs.com/package/http-browserify-2). It is more actively maintained and
attempts to address a few of the shortcomings of `browserify-http`. In that case, your browserify config should
look something like this:
```javascript
"browser": {
"follow-redirects/http" : "browserify-http-2/http",
"follow-redirects/https" : "browserify-http-2/https"
}
```
## Contributing
Pull Requests are always welcome. Please [file an issue](https://github.com/follow-redirects/follow-redirects/issues)
detailing your proposal before you invest your valuable time. Additional features and bug fixes should be accompanied
by tests. You can run the test suite locally with a simple `npm test` command.
## Debug Logging
`follow-redirects` uses the excellent [debug](https://www.npmjs.com/package/debug) for logging. To turn on logging
set the environment variable `DEBUG=follow-redirects` for debug output from just this module. When running the test
suite it is sometimes advantageous to set `DEBUG=*` to see output from the express server as well.
## Authors
- Olivier Lalonde (olalonde@gmail.com)
- James Talmage (james@talmage.io)
- [Ruben Verborgh](https://ruben.verborgh.org/)
## License
[https://github.com/follow-redirects/follow-redirects/blob/master/LICENSE](MIT License)
# type-check [](https://travis-ci.org/gkz/type-check)
<a name="type-check" />
`type-check` is a library which allows you to check the types of JavaScript values at runtime with a Haskell like type syntax. It is great for checking external input, for testing, or even for adding a bit of safety to your internal code. It is a major component of [levn](https://github.com/gkz/levn). MIT license. Version 0.4.0. Check out the [demo](http://gkz.github.io/type-check/).
For updates on `type-check`, [follow me on twitter](https://twitter.com/gkzahariev).
npm install type-check
## Quick Examples
```js
// Basic types:
var typeCheck = require('type-check').typeCheck;
typeCheck('Number', 1); // true
typeCheck('Number', 'str'); // false
typeCheck('Error', new Error); // true
typeCheck('Undefined', undefined); // true
// Comment
typeCheck('count::Number', 1); // true
// One type OR another type:
typeCheck('Number | String', 2); // true
typeCheck('Number | String', 'str'); // true
// Wildcard, matches all types:
typeCheck('*', 2) // true
// Array, all elements of a single type:
typeCheck('[Number]', [1, 2, 3]); // true
typeCheck('[Number]', [1, 'str', 3]); // false
// Tuples, or fixed length arrays with elements of different types:
typeCheck('(String, Number)', ['str', 2]); // true
typeCheck('(String, Number)', ['str']); // false
typeCheck('(String, Number)', ['str', 2, 5]); // false
// Object properties:
typeCheck('{x: Number, y: Boolean}', {x: 2, y: false}); // true
typeCheck('{x: Number, y: Boolean}', {x: 2}); // false
typeCheck('{x: Number, y: Maybe Boolean}', {x: 2}); // true
typeCheck('{x: Number, y: Boolean}', {x: 2, y: false, z: 3}); // false
typeCheck('{x: Number, y: Boolean, ...}', {x: 2, y: false, z: 3}); // true
// A particular type AND object properties:
typeCheck('RegExp{source: String, ...}', /re/i); // true
typeCheck('RegExp{source: String, ...}', {source: 're'}); // false
// Custom types:
var opt = {customTypes:
{Even: { typeOf: 'Number', validate: function(x) { return x % 2 === 0; }}}};
typeCheck('Even', 2, opt); // true
// Nested:
var type = '{a: (String, [Number], {y: Array, ...}), b: Error{message: String, ...}}'
typeCheck(type, {a: ['hi', [1, 2, 3], {y: [1, 'ms']}], b: new Error('oh no')}); // true
```
Check out the [type syntax format](#syntax) and [guide](#guide).
## Usage
`require('type-check');` returns an object that exposes four properties. `VERSION` is the current version of the library as a string. `typeCheck`, `parseType`, and `parsedTypeCheck` are functions.
```js
// typeCheck(type, input, options);
typeCheck('Number', 2); // true
// parseType(type);
var parsedType = parseType('Number'); // object
// parsedTypeCheck(parsedType, input, options);
parsedTypeCheck(parsedType, 2); // true
```
### typeCheck(type, input, options)
`typeCheck` checks a JavaScript value `input` against `type` written in the [type format](#type-format) (and taking account the optional `options`) and returns whether the `input` matches the `type`.
##### arguments
* type - `String` - the type written in the [type format](#type-format) which to check against
* input - `*` - any JavaScript value, which is to be checked against the type
* options - `Maybe Object` - an optional parameter specifying additional options, currently the only available option is specifying [custom types](#custom-types)
##### returns
`Boolean` - whether the input matches the type
##### example
```js
typeCheck('Number', 2); // true
```
### parseType(type)
`parseType` parses string `type` written in the [type format](#type-format) into an object representing the parsed type.
##### arguments
* type - `String` - the type written in the [type format](#type-format) which to parse
##### returns
`Object` - an object in the parsed type format representing the parsed type
##### example
```js
parseType('Number'); // [{type: 'Number'}]
```
### parsedTypeCheck(parsedType, input, options)
`parsedTypeCheck` checks a JavaScript value `input` against parsed `type` in the parsed type format (and taking account the optional `options`) and returns whether the `input` matches the `type`. Use this in conjunction with `parseType` if you are going to use a type more than once.
##### arguments
* type - `Object` - the type in the parsed type format which to check against
* input - `*` - any JavaScript value, which is to be checked against the type
* options - `Maybe Object` - an optional parameter specifying additional options, currently the only available option is specifying [custom types](#custom-types)
##### returns
`Boolean` - whether the input matches the type
##### example
```js
parsedTypeCheck([{type: 'Number'}], 2); // true
var parsedType = parseType('String');
parsedTypeCheck(parsedType, 'str'); // true
```
<a name="type-format" />
## Type Format
### Syntax
White space is ignored. The root node is a __Types__.
* __Identifier__ = `[\$\w]+` - a group of any lower or upper case letters, numbers, underscores, or dollar signs - eg. `String`
* __Type__ = an `Identifier`, an `Identifier` followed by a `Structure`, just a `Structure`, or a wildcard `*` - eg. `String`, `Object{x: Number}`, `{x: Number}`, `Array{0: String, 1: Boolean, length: Number}`, `*`
* __Types__ = optionally a comment (an `Identifier` followed by a `::`), optionally the identifier `Maybe`, one or more `Type`, separated by `|` - eg. `Number`, `String | Date`, `Maybe Number`, `Maybe Boolean | String`
* __Structure__ = `Fields`, or a `Tuple`, or an `Array` - eg. `{x: Number}`, `(String, Number)`, `[Date]`
* __Fields__ = a `{`, followed one or more `Field` separated by a comma `,` (trailing comma `,` is permitted), optionally an `...` (always preceded by a comma `,`), followed by a `}` - eg. `{x: Number, y: String}`, `{k: Function, ...}`
* __Field__ = an `Identifier`, followed by a colon `:`, followed by `Types` - eg. `x: Date | String`, `y: Boolean`
* __Tuple__ = a `(`, followed by one or more `Types` separated by a comma `,` (trailing comma `,` is permitted), followed by a `)` - eg `(Date)`, `(Number, Date)`
* __Array__ = a `[` followed by exactly one `Types` followed by a `]` - eg. `[Boolean]`, `[Boolean | Null]`
### Guide
`type-check` uses `Object.toString` to find out the basic type of a value. Specifically,
```js
{}.toString.call(VALUE).slice(8, -1)
{}.toString.call(true).slice(8, -1) // 'Boolean'
```
A basic type, eg. `Number`, uses this check. This is much more versatile than using `typeof` - for example, with `document`, `typeof` produces `'object'` which isn't that useful, and our technique produces `'HTMLDocument'`.
You may check for multiple types by separating types with a `|`. The checker proceeds from left to right, and passes if the value is any of the types - eg. `String | Boolean` first checks if the value is a string, and then if it is a boolean. If it is none of those, then it returns false.
Adding a `Maybe` in front of a list of multiple types is the same as also checking for `Null` and `Undefined` - eg. `Maybe String` is equivalent to `Undefined | Null | String`.
You may add a comment to remind you of what the type is for by following an identifier with a `::` before a type (or multiple types). The comment is simply thrown out.
The wildcard `*` matches all types.
There are three types of structures for checking the contents of a value: 'fields', 'tuple', and 'array'.
If used by itself, a 'fields' structure will pass with any type of object as long as it is an instance of `Object` and the properties pass - this allows for duck typing - eg. `{x: Boolean}`.
To check if the properties pass, and the value is of a certain type, you can specify the type - eg. `Error{message: String}`.
If you want to make a field optional, you can simply use `Maybe` - eg. `{x: Boolean, y: Maybe String}` will still pass if `y` is undefined (or null).
If you don't care if the value has properties beyond what you have specified, you can use the 'etc' operator `...` - eg. `{x: Boolean, ...}` will match an object with an `x` property that is a boolean, and with zero or more other properties.
For an array, you must specify one or more types (separated by `|`) - it will pass for something of any length as long as each element passes the types provided - eg. `[Number]`, `[Number | String]`.
A tuple checks for a fixed number of elements, each of a potentially different type. Each element is separated by a comma - eg. `(String, Number)`.
An array and tuple structure check that the value is of type `Array` by default, but if another type is specified, they will check for that instead - eg. `Int32Array[Number]`. You can use the wildcard `*` to search for any type at all.
Check out the [type precedence](https://github.com/zaboco/type-precedence) library for type-check.
## Options
Options is an object. It is an optional parameter to the `typeCheck` and `parsedTypeCheck` functions. The only current option is `customTypes`.
<a name="custom-types" />
### Custom Types
__Example:__
```js
var options = {
customTypes: {
Even: {
typeOf: 'Number',
validate: function(x) {
return x % 2 === 0;
}
}
}
};
typeCheck('Even', 2, options); // true
typeCheck('Even', 3, options); // false
```
`customTypes` allows you to set up custom types for validation. The value of this is an object. The keys of the object are the types you will be matching. Each value of the object will be an object having a `typeOf` property - a string, and `validate` property - a function.
The `typeOf` property is the type the value should be (optional - if not set only `validate` will be used), and `validate` is a function which should return true if the value is of that type. `validate` receives one parameter, which is the value that we are checking.
## Technical About
`type-check` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It also uses the [prelude.ls](http://preludels.com/) library.
# json-schema-traverse
Traverse JSON Schema passing each schema object to callback
[](https://github.com/epoberezkin/json-schema-traverse/actions?query=workflow%3Abuild)
[](https://www.npmjs.com/package/json-schema-traverse)
[](https://coveralls.io/github/epoberezkin/json-schema-traverse?branch=master)
## Install
```
npm install json-schema-traverse
```
## Usage
```javascript
const traverse = require('json-schema-traverse');
const schema = {
properties: {
foo: {type: 'string'},
bar: {type: 'integer'}
}
};
traverse(schema, {cb});
// cb is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
// Or:
traverse(schema, {cb: {pre, post}});
// pre is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
//
// post is called 3 times with:
// 1. {type: 'string'}
// 2. {type: 'integer'}
// 3. root schema
```
Callback function `cb` is called for each schema object (not including draft-06 boolean schemas), including the root schema, in pre-order traversal. Schema references ($ref) are not resolved, they are passed as is. Alternatively, you can pass a `{pre, post}` object as `cb`, and then `pre` will be called before traversing child elements, and `post` will be called after all child elements have been traversed.
Callback is passed these parameters:
- _schema_: the current schema object
- _JSON pointer_: from the root schema to the current schema object
- _root schema_: the schema passed to `traverse` object
- _parent JSON pointer_: from the root schema to the parent schema object (see below)
- _parent keyword_: the keyword inside which this schema appears (e.g. `properties`, `anyOf`, etc.)
- _parent schema_: not necessarily parent object/array; in the example above the parent schema for `{type: 'string'}` is the root schema
- _index/property_: index or property name in the array/object containing multiple schemas; in the example above for `{type: 'string'}` the property name is `'foo'`
## Traverse objects in all unknown keywords
```javascript
const traverse = require('json-schema-traverse');
const schema = {
mySchema: {
minimum: 1,
maximum: 2
}
};
traverse(schema, {allKeys: true, cb});
// cb is called 2 times with:
// 1. root schema
// 2. mySchema
```
Without option `allKeys: true` callback will be called only with root schema.
## Enterprise support
json-schema-traverse package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-json-schema-traverse?utm_source=npm-json-schema-traverse&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
## License
[MIT](https://github.com/epoberezkin/json-schema-traverse/blob/master/LICENSE)
# Optionator
<a name="optionator" />
Optionator is a JavaScript/Node.js option parsing and help generation library used by [eslint](http://eslint.org), [Grasp](http://graspjs.com), [LiveScript](http://livescript.net), [esmangle](https://github.com/estools/esmangle), [escodegen](https://github.com/estools/escodegen), and [many more](https://www.npmjs.com/browse/depended/optionator).
For an online demo, check out the [Grasp online demo](http://www.graspjs.com/#demo).
[About](#about) · [Usage](#usage) · [Settings Format](#settings-format) · [Argument Format](#argument-format)
## Why?
The problem with other option parsers, such as `yargs` or `minimist`, is they just accept all input, valid or not.
With Optionator, if you mistype an option, it will give you an error (with a suggestion for what you meant).
If you give the wrong type of argument for an option, it will give you an error rather than supplying the wrong input to your application.
$ cmd --halp
Invalid option '--halp' - perhaps you meant '--help'?
$ cmd --count str
Invalid value for option 'count' - expected type Int, received value: str.
Other helpful features include reformatting the help text based on the size of the console, so that it fits even if the console is narrow, and accepting not just an array (eg. process.argv), but a string or object as well, making things like testing much easier.
## About
Optionator uses [type-check](https://github.com/gkz/type-check) and [levn](https://github.com/gkz/levn) behind the scenes to cast and verify input according the specified types.
MIT license. Version 0.9.1
npm install optionator
For updates on Optionator, [follow me on twitter](https://twitter.com/gkzahariev).
Optionator is a Node.js module, but can be used in the browser as well if packed with webpack/browserify.
## Usage
`require('optionator');` returns a function. It has one property, `VERSION`, the current version of the library as a string. This function is called with an object specifying your options and other information, see the [settings format section](#settings-format). This in turn returns an object with three properties, `parse`, `parseArgv`, `generateHelp`, and `generateHelpForOption`, which are all functions.
```js
var optionator = require('optionator')({
prepend: 'Usage: cmd [options]',
append: 'Version 1.0.0',
options: [{
option: 'help',
alias: 'h',
type: 'Boolean',
description: 'displays help'
}, {
option: 'count',
alias: 'c',
type: 'Int',
description: 'number of things',
example: 'cmd --count 2'
}]
});
var options = optionator.parseArgv(process.argv);
if (options.help) {
console.log(optionator.generateHelp());
}
...
```
### parse(input, parseOptions)
`parse` processes the `input` according to your settings, and returns an object with the results.
##### arguments
* input - `[String] | Object | String` - the input you wish to parse
* parseOptions - `{slice: Int}` - all options optional
- `slice` specifies how much to slice away from the beginning if the input is an array or string - by default `0` for string, `2` for array (works with `process.argv`)
##### returns
`Object` - the parsed options, each key is a camelCase version of the option name (specified in dash-case), and each value is the processed value for that option. Positional values are in an array under the `_` key.
##### example
```js
parse(['node', 't.js', '--count', '2', 'positional']); // {count: 2, _: ['positional']}
parse('--count 2 positional'); // {count: 2, _: ['positional']}
parse({count: 2, _:['positional']}); // {count: 2, _: ['positional']}
```
### parseArgv(input)
`parseArgv` works exactly like `parse`, but only for array input and it slices off the first two elements.
##### arguments
* input - `[String]` - the input you wish to parse
##### returns
See "returns" section in "parse"
##### example
```js
parseArgv(process.argv);
```
### generateHelp(helpOptions)
`generateHelp` produces help text based on your settings.
##### arguments
* helpOptions - `{showHidden: Boolean, interpolate: Object}` - all options optional
- `showHidden` specifies whether to show options with `hidden: true` specified, by default it is `false`
- `interpolate` specify data to be interpolated in `prepend` and `append` text, `{{key}}` is the format - eg. `generateHelp({interpolate:{version: '0.4.2'}})`, will change this `append` text: `Version {{version}}` to `Version 0.4.2`
##### returns
`String` - the generated help text
##### example
```js
generateHelp(); /*
"Usage: cmd [options] positional
-h, --help displays help
-c, --count Int number of things
Version 1.0.0
"*/
```
### generateHelpForOption(optionName)
`generateHelpForOption` produces expanded help text for the specified with `optionName` option. If an `example` was specified for the option, it will be displayed, and if a `longDescription` was specified, it will display that instead of the `description`.
##### arguments
* optionName - `String` - the name of the option to display
##### returns
`String` - the generated help text for the option
##### example
```js
generateHelpForOption('count'); /*
"-c, --count Int
description: number of things
example: cmd --count 2
"*/
```
## Settings Format
When your `require('optionator')`, you get a function that takes in a settings object. This object has the type:
{
prepend: String,
append: String,
options: [{heading: String} | {
option: String,
alias: [String] | String,
type: String,
enum: [String],
default: String,
restPositional: Boolean,
required: Boolean,
overrideRequired: Boolean,
dependsOn: [String] | String,
concatRepeatedArrays: Boolean | (Boolean, Object),
mergeRepeatedObjects: Boolean,
description: String,
longDescription: String,
example: [String] | String
}],
helpStyle: {
aliasSeparator: String,
typeSeparator: String,
descriptionSeparator: String,
initialIndent: Int,
secondaryIndent: Int,
maxPadFactor: Number
},
mutuallyExclusive: [[String | [String]]],
concatRepeatedArrays: Boolean | (Boolean, Object), // deprecated, set in defaults object
mergeRepeatedObjects: Boolean, // deprecated, set in defaults object
positionalAnywhere: Boolean,
typeAliases: Object,
defaults: Object
}
All of the properties are optional (the `Maybe` has been excluded for brevities sake), except for having either `heading: String` or `option: String` in each object in the `options` array.
### Top Level Properties
* `prepend` is an optional string to be placed before the options in the help text
* `append` is an optional string to be placed after the options in the help text
* `options` is a required array specifying your options and headings, the options and headings will be displayed in the order specified
* `helpStyle` is an optional object which enables you to change the default appearance of some aspects of the help text
* `mutuallyExclusive` is an optional array of arrays of either strings or arrays of strings. The top level array is a list of rules, each rule is a list of elements - each element can be either a string (the name of an option), or a list of strings (a group of option names) - there will be an error if more than one element is present
* `concatRepeatedArrays` see description under the "Option Properties" heading - use at the top level is deprecated, if you want to set this for all options, use the `defaults` property
* `mergeRepeatedObjects` see description under the "Option Properties" heading - use at the top level is deprecated, if you want to set this for all options, use the `defaults` property
* `positionalAnywhere` is an optional boolean (defaults to `true`) - when `true` it allows positional arguments anywhere, when `false`, all arguments after the first positional one are taken to be positional as well, even if they look like a flag. For example, with `positionalAnywhere: false`, the arguments `--flag --boom 12 --crack` would have two positional arguments: `12` and `--crack`
* `typeAliases` is an optional object, it allows you to set aliases for types, eg. `{Path: 'String'}` would allow you to use the type `Path` as an alias for the type `String`
* `defaults` is an optional object following the option properties format, which specifies default values for all options. A default will be overridden if manually set. For example, you can do `default: { type: "String" }` to set the default type of all options to `String`, and then override that default in an individual option by setting the `type` property
#### Heading Properties
* `heading` a required string, the name of the heading
#### Option Properties
* `option` the required name of the option - use dash-case, without the leading dashes
* `alias` is an optional string or array of strings which specify any aliases for the option
* `type` is a required string in the [type check](https://github.com/gkz/type-check) [format](https://github.com/gkz/type-check#type-format), this will be used to cast the inputted value and validate it
* `enum` is an optional array of strings, each string will be parsed by [levn](https://github.com/gkz/levn) - the argument value must be one of the resulting values - each potential value must validate against the specified `type`
* `default` is a optional string, which will be parsed by [levn](https://github.com/gkz/levn) and used as the default value if none is set - the value must validate against the specified `type`
* `restPositional` is an optional boolean - if set to `true`, everything after the option will be taken to be a positional argument, even if it looks like a named argument
* `required` is an optional boolean - if set to `true`, the option parsing will fail if the option is not defined
* `overrideRequired` is a optional boolean - if set to `true` and the option is used, and there is another option which is required but not set, it will override the need for the required option and there will be no error - this is useful if you have required options and want to use `--help` or `--version` flags
* `concatRepeatedArrays` is an optional boolean or tuple with boolean and options object (defaults to `false`) - when set to `true` and an option contains an array value and is repeated, the subsequent values for the flag will be appended rather than overwriting the original value - eg. option `g` of type `[String]`: `-g a -g b -g c,d` will result in `['a','b','c','d']`
You can supply an options object by giving the following value: `[true, options]`. The one currently supported option is `oneValuePerFlag`, this only allows one array value per flag. This is useful if your potential values contain a comma.
* `mergeRepeatedObjects` is an optional boolean (defaults to `false`) - when set to `true` and an option contains an object value and is repeated, the subsequent values for the flag will be merged rather than overwriting the original value - eg. option `g` of type `Object`: `-g a:1 -g b:2 -g c:3,d:4` will result in `{a: 1, b: 2, c: 3, d: 4}`
* `dependsOn` is an optional string or array of strings - if simply a string (the name of another option), it will make sure that that other option is set, if an array of strings, depending on whether `'and'` or `'or'` is first, it will either check whether all (`['and', 'option-a', 'option-b']`), or at least one (`['or', 'option-a', 'option-b']`) other options are set
* `description` is an optional string, which will be displayed next to the option in the help text
* `longDescription` is an optional string, it will be displayed instead of the `description` when `generateHelpForOption` is used
* `example` is an optional string or array of strings with example(s) for the option - these will be displayed when `generateHelpForOption` is used
#### Help Style Properties
* `aliasSeparator` is an optional string, separates multiple names from each other - default: ' ,'
* `typeSeparator` is an optional string, separates the type from the names - default: ' '
* `descriptionSeparator` is an optional string , separates the description from the padded name and type - default: ' '
* `initialIndent` is an optional int - the amount of indent for options - default: 2
* `secondaryIndent` is an optional int - the amount of indent if wrapped fully (in addition to the initial indent) - default: 4
* `maxPadFactor` is an optional number - affects the default level of padding for the names/type, it is multiplied by the average of the length of the names/type - default: 1.5
## Argument Format
At the highest level there are two types of arguments: named, and positional.
Name arguments of any length are prefixed with `--` (eg. `--go`), and those of one character may be prefixed with either `--` or `-` (eg. `-g`).
There are two types of named arguments: boolean flags (eg. `--problemo`, `-p`) which take no value and result in a `true` if they are present, the falsey `undefined` if they are not present, or `false` if present and explicitly prefixed with `no` (eg. `--no-problemo`). Named arguments with values (eg. `--tseries 800`, `-t 800`) are the other type. If the option has a type `Boolean` it will automatically be made into a boolean flag. Any other type results in a named argument that takes a value.
For more information about how to properly set types to get the value you want, take a look at the [type check](https://github.com/gkz/type-check) and [levn](https://github.com/gkz/levn) pages.
You can group single character arguments that use a single `-`, however all except the last must be boolean flags (which take no value). The last may be a boolean flag, or an argument which takes a value - eg. `-ba 2` is equivalent to `-b -a 2`.
Positional arguments are all those values which do not fall under the above - they can be anywhere, not just at the end. For example, in `cmd -b one -a 2 two` where `b` is a boolean flag, and `a` has the type `Number`, there are two positional arguments, `one` and `two`.
Everything after an `--` is positional, even if it looks like a named argument.
You may optionally use `=` to separate option names from values, for example: `--count=2`.
If you specify the option `NUM`, then any argument using a single `-` followed by a number will be valid and will set the value of `NUM`. Eg. `-2` will be parsed into `NUM: 2`.
If duplicate named arguments are present, the last one will be taken.
## Technical About
`optionator` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It uses [levn](https://github.com/gkz/levn) to cast arguments to their specified type, and uses [type-check](https://github.com/gkz/type-check) to validate values. It also uses the [prelude.ls](http://preludels.com/) library.
# cliui

[](https://www.npmjs.com/package/cliui)
[](https://conventionalcommits.org)

easily create complex multi-column command-line-interfaces.
## Example
```js
const ui = require('cliui')()
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 1, 0]
})
ui.div(
{
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
},
{
text: "the file to load." +
chalk.green("(if this description is long it wraps).")
,
width: 20
},
{
text: chalk.red("[required]"),
align: 'right'
}
)
console.log(ui.toString())
```
## Deno/ESM Support
As of `v7` `cliui` supports [Deno](https://github.com/denoland/deno) and
[ESM](https://nodejs.org/api/esm.html#esm_ecmascript_modules):
```typescript
import cliui from "https://deno.land/x/cliui/deno.ts";
const ui = cliui({})
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 1, 0]
})
ui.div({
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
})
console.log(ui.toString())
```
<img width="500" src="screenshot.png">
## Layout DSL
cliui exposes a simple layout DSL:
If you create a single `ui.div`, passing a string rather than an
object:
* `\n`: characters will be interpreted as new rows.
* `\t`: characters will be interpreted as new columns.
* `\s`: characters will be interpreted as padding.
**as an example...**
```js
var ui = require('./')({
width: 60
})
ui.div(
'Usage: node ./bin/foo.js\n' +
' <regex>\t provide a regex\n' +
' <glob>\t provide a glob\t [required]'
)
console.log(ui.toString())
```
**will output:**
```shell
Usage: node ./bin/foo.js
<regex> provide a regex
<glob> provide a glob [required]
```
## Methods
```js
cliui = require('cliui')
```
### cliui({width: integer})
Specify the maximum width of the UI being generated.
If no width is provided, cliui will try to get the current window's width and use it, and if that doesn't work, width will be set to `80`.
### cliui({wrap: boolean})
Enable or disable the wrapping of text in a column.
### cliui.div(column, column, column)
Create a row with any number of columns, a column
can either be a string, or an object with the following
options:
* **text:** some text to place in the column.
* **width:** the width of a column.
* **align:** alignment, `right` or `center`.
* **padding:** `[top, right, bottom, left]`.
* **border:** should a border be placed around the div?
### cliui.span(column, column, column)
Similar to `div`, except the next row will be appended without
a new line being created.
### cliui.resetOutput()
Resets the UI elements of the current cliui instance, maintaining the values
set for `width` and `wrap`.
# emoji-regex [](https://travis-ci.org/mathiasbynens/emoji-regex)
_emoji-regex_ offers a regular expression to match all emoji symbols (including textual representations of emoji) as per the Unicode Standard.
This repository contains a script that generates this regular expression based on [the data from Unicode v12](https://github.com/mathiasbynens/unicode-12.0.0). Because of this, the regular expression can easily be updated whenever new emoji are added to the Unicode standard.
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install emoji-regex
```
In [Node.js](https://nodejs.org/):
```js
const emojiRegex = require('emoji-regex');
// Note: because the regular expression has the global flag set, this module
// exports a function that returns the regex rather than exporting the regular
// expression itself, to make it impossible to (accidentally) mutate the
// original regular expression.
const text = `
\u{231A}: ⌚ default emoji presentation character (Emoji_Presentation)
\u{2194}\u{FE0F}: ↔️ default text presentation character rendered as emoji
\u{1F469}: 👩 emoji modifier base (Emoji_Modifier_Base)
\u{1F469}\u{1F3FF}: 👩🏿 emoji modifier base followed by a modifier
`;
const regex = emojiRegex();
let match;
while (match = regex.exec(text)) {
const emoji = match[0];
console.log(`Matched sequence ${ emoji } — code points: ${ [...emoji].length }`);
}
```
Console output:
```
Matched sequence ⌚ — code points: 1
Matched sequence ⌚ — code points: 1
Matched sequence ↔️ — code points: 2
Matched sequence ↔️ — code points: 2
Matched sequence 👩 — code points: 1
Matched sequence 👩 — code points: 1
Matched sequence 👩🏿 — code points: 2
Matched sequence 👩🏿 — code points: 2
```
To match emoji in their textual representation as well (i.e. emoji that are not `Emoji_Presentation` symbols and that aren’t forced to render as emoji by a variation selector), `require` the other regex:
```js
const emojiRegex = require('emoji-regex/text.js');
```
Additionally, in environments which support ES2015 Unicode escapes, you may `require` ES2015-style versions of the regexes:
```js
const emojiRegex = require('emoji-regex/es2015/index.js');
const emojiRegexText = require('emoji-regex/es2015/text.js');
```
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
_emoji-regex_ is available under the [MIT](https://mths.be/mit) license.
# Regular Expression Tokenizer
Tokenizes strings that represent a regular expressions.
[](http://travis-ci.org/fent/ret.js)
[](https://david-dm.org/fent/ret.js)
[](https://codecov.io/gh/fent/ret.js)
# Usage
```js
var ret = require('ret');
var tokens = ret(/foo|bar/.source);
```
`tokens` will contain the following object
```js
{
"type": ret.types.ROOT
"options": [
[ { "type": ret.types.CHAR, "value", 102 },
{ "type": ret.types.CHAR, "value", 111 },
{ "type": ret.types.CHAR, "value", 111 } ],
[ { "type": ret.types.CHAR, "value", 98 },
{ "type": ret.types.CHAR, "value", 97 },
{ "type": ret.types.CHAR, "value", 114 } ]
]
}
```
# Token Types
`ret.types` is a collection of the various token types exported by ret.
### ROOT
Only used in the root of the regexp. This is needed due to the posibility of the root containing a pipe `|` character. In that case, the token will have an `options` key that will be an array of arrays of tokens. If not, it will contain a `stack` key that is an array of tokens.
```js
{
"type": ret.types.ROOT,
"stack": [token1, token2...],
}
```
```js
{
"type": ret.types.ROOT,
"options" [
[token1, token2...],
[othertoken1, othertoken2...]
...
],
}
```
### GROUP
Groups contain tokens that are inside of a parenthesis. If the group begins with `?` followed by another character, it's a special type of group. A ':' tells the group not to be remembered when `exec` is used. '=' means the previous token matches only if followed by this group, and '!' means the previous token matches only if NOT followed.
Like root, it can contain an `options` key instead of `stack` if there is a pipe.
```js
{
"type": ret.types.GROUP,
"remember" true,
"followedBy": false,
"notFollowedBy": false,
"stack": [token1, token2...],
}
```
```js
{
"type": ret.types.GROUP,
"remember" true,
"followedBy": false,
"notFollowedBy": false,
"options" [
[token1, token2...],
[othertoken1, othertoken2...]
...
],
}
```
### POSITION
`\b`, `\B`, `^`, and `$` specify positions in the regexp.
```js
{
"type": ret.types.POSITION,
"value": "^",
}
```
### SET
Contains a key `set` specifying what tokens are allowed and a key `not` specifying if the set should be negated. A set can contain other sets, ranges, and characters.
```js
{
"type": ret.types.SET,
"set": [token1, token2...],
"not": false,
}
```
### RANGE
Used in set tokens to specify a character range. `from` and `to` are character codes.
```js
{
"type": ret.types.RANGE,
"from": 97,
"to": 122,
}
```
### REPETITION
```js
{
"type": ret.types.REPETITION,
"min": 0,
"max": Infinity,
"value": token,
}
```
### REFERENCE
References a group token. `value` is 1-9.
```js
{
"type": ret.types.REFERENCE,
"value": 1,
}
```
### CHAR
Represents a single character token. `value` is the character code. This might seem a bit cluttering instead of concatenating characters together. But since repetition tokens only repeat the last token and not the last clause like the pipe, it's simpler to do it this way.
```js
{
"type": ret.types.CHAR,
"value": 123,
}
```
## Errors
ret.js will throw errors if given a string with an invalid regular expression. All possible errors are
* Invalid group. When a group with an immediate `?` character is followed by an invalid character. It can only be followed by `!`, `=`, or `:`. Example: `/(?_abc)/`
* Nothing to repeat. Thrown when a repetitional token is used as the first token in the current clause, as in right in the beginning of the regexp or group, or right after a pipe. Example: `/foo|?bar/`, `/{1,3}foo|bar/`, `/foo(+bar)/`
* Unmatched ). A group was not opened, but was closed. Example: `/hello)2u/`
* Unterminated group. A group was not closed. Example: `/(1(23)4/`
* Unterminated character class. A custom character set was not closed. Example: `/[abc/`
# Install
npm install ret
# Tests
Tests are written with [vows](http://vowsjs.org/)
```bash
npm test
```
# License
MIT
<p align="center">
<a href="https://assemblyscript.org" target="_blank" rel="noopener"><img width="100" src="https://avatars1.githubusercontent.com/u/28916798?s=200&v=4" alt="AssemblyScript logo"></a>
</p>
<p align="center">
<a href="https://github.com/AssemblyScript/assemblyscript/actions?query=workflow%3ATest"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/assemblyscript/Test/master?label=test&logo=github" alt="Test status" /></a>
<a href="https://github.com/AssemblyScript/assemblyscript/actions?query=workflow%3APublish"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/assemblyscript/Publish/master?label=publish&logo=github" alt="Publish status" /></a>
<a href="https://www.npmjs.com/package/assemblyscript"><img src="https://img.shields.io/npm/v/assemblyscript.svg?label=compiler&color=007acc&logo=npm" alt="npm compiler version" /></a>
<a href="https://www.npmjs.com/package/@assemblyscript/loader"><img src="https://img.shields.io/npm/v/@assemblyscript/loader.svg?label=loader&color=007acc&logo=npm" alt="npm loader version" /></a>
<a href="https://discord.gg/assemblyscript"><img src="https://img.shields.io/discord/721472913886281818.svg?label=&logo=discord&logoColor=ffffff&color=7389D8&labelColor=6A7EC2" alt="Discord online" /></a>
</p>
<p align="justify"><strong>AssemblyScript</strong> compiles a strict variant of <a href="http://www.typescriptlang.org">TypeScript</a> (basically JavaScript with types) to <a href="http://webassembly.org">WebAssembly</a> using <a href="https://github.com/WebAssembly/binaryen">Binaryen</a>. It generates lean and mean WebAssembly modules while being just an <code>npm install</code> away.</p>
<h3 align="center">
<a href="https://assemblyscript.org">About</a> ·
<a href="https://assemblyscript.org/introduction.html">Introduction</a> ·
<a href="https://assemblyscript.org/quick-start.html">Quick start</a> ·
<a href="https://assemblyscript.org/examples.html">Examples</a> ·
<a href="https://assemblyscript.org/development.html">Development instructions</a>
</h3>
<br>
<h2 align="center">Contributors</h2>
<p align="center">
<a href="https://assemblyscript.org/#contributors"><img src="https://assemblyscript.org/contributors.svg" alt="Contributor logos" width="720" /></a>
</p>
<h2 align="center">Thanks to our sponsors!</h2>
<p align="justify">Most of the core team members and most contributors do this open source work in their free time. If you use AssemblyScript for a serious task or plan to do so, and you'd like us to invest more time on it, <a href="https://opencollective.com/assemblyscript/donate" target="_blank" rel="noopener">please donate</a> to our <a href="https://opencollective.com/assemblyscript" target="_blank" rel="noopener">OpenCollective</a>. By sponsoring this project, your logo will show up below. Thank you so much for your support!</p>
<p align="center">
<a href="https://assemblyscript.org/#sponsors"><img src="https://assemblyscript.org/sponsors.svg" alt="Sponsor logos" width="720" /></a>
</p>
[](https://www.npmjs.com/package/esprima)
[](https://www.npmjs.com/package/esprima)
[](https://travis-ci.org/jquery/esprima)
[](https://codecov.io/github/jquery/esprima)
**Esprima** ([esprima.org](http://esprima.org), BSD license) is a high performance,
standard-compliant [ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
parser written in ECMAScript (also popularly known as
[JavaScript](https://en.wikipedia.org/wiki/JavaScript)).
Esprima is created and maintained by [Ariya Hidayat](https://twitter.com/ariyahidayat),
with the help of [many contributors](https://github.com/jquery/esprima/contributors).
### Features
- Full support for ECMAScript 2017 ([ECMA-262 8th Edition](http://www.ecma-international.org/publications/standards/Ecma-262.htm))
- Sensible [syntax tree format](https://github.com/estree/estree/blob/master/es5.md) as standardized by [ESTree project](https://github.com/estree/estree)
- Experimental support for [JSX](https://facebook.github.io/jsx/), a syntax extension for [React](https://facebook.github.io/react/)
- Optional tracking of syntax node location (index-based and line-column)
- [Heavily tested](http://esprima.org/test/ci.html) (~1500 [unit tests](https://github.com/jquery/esprima/tree/master/test/fixtures) with [full code coverage](https://codecov.io/github/jquery/esprima))
### API
Esprima can be used to perform [lexical analysis](https://en.wikipedia.org/wiki/Lexical_analysis) (tokenization) or [syntactic analysis](https://en.wikipedia.org/wiki/Parsing) (parsing) of a JavaScript program.
A simple example on Node.js REPL:
```javascript
> var esprima = require('esprima');
> var program = 'const answer = 42';
> esprima.tokenize(program);
[ { type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'answer' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '42' } ]
> esprima.parseScript(program);
{ type: 'Program',
body:
[ { type: 'VariableDeclaration',
declarations: [Object],
kind: 'const' } ],
sourceType: 'script' }
```
For more information, please read the [complete documentation](http://esprima.org/doc).
Compiler frontend for node.js
=============================
Usage
-----
For an up to date list of available command line options, see:
```
$> asc --help
```
API
---
The API accepts the same options as the CLI but also lets you override stdout and stderr and/or provide a callback. Example:
```js
const asc = require("assemblyscript/cli/asc");
asc.ready.then(() => {
asc.main([
"myModule.ts",
"--binaryFile", "myModule.wasm",
"--optimize",
"--sourceMap",
"--measure"
], {
stdout: process.stdout,
stderr: process.stderr
}, function(err) {
if (err)
throw err;
...
});
});
```
Available command line options can also be obtained programmatically:
```js
const options = require("assemblyscript/cli/asc.json");
...
```
You can also compile a source string directly, for example in a browser environment:
```js
const asc = require("assemblyscript/cli/asc");
asc.ready.then(() => {
const { binary, text, stdout, stderr } = asc.compileString(`...`, { optimize: 2 });
});
...
```
<p align="center">
<img width="250" src="/yargs-logo.png">
</p>
<h1 align="center"> Yargs </h1>
<p align="center">
<b >Yargs be a node.js library fer hearties tryin' ter parse optstrings</b>
</p>
<br>
[![Build Status][travis-image]][travis-url]
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[![Coverage][coverage-image]][coverage-url]
[![Conventional Commits][conventional-commits-image]][conventional-commits-url]
[![Slack][slack-image]][slack-url]
## Description :
Yargs helps you build interactive command line tools, by parsing arguments and generating an elegant user interface.
It gives you:
* commands and (grouped) options (`my-program.js serve --port=5000`).
* a dynamically generated help menu based on your arguments.
> <img width="400" src="/screen.png">
* bash-completion shortcuts for commands and options.
* and [tons more](/docs/api.md).
## Installation
Stable version:
```bash
npm i yargs
```
Bleeding edge version with the most recent features:
```bash
npm i yargs@next
```
## Usage :
### Simple Example
```javascript
#!/usr/bin/env node
const {argv} = require('yargs')
if (argv.ships > 3 && argv.distance < 53.5) {
console.log('Plunder more riffiwobbles!')
} else {
console.log('Retreat from the xupptumblers!')
}
```
```bash
$ ./plunder.js --ships=4 --distance=22
Plunder more riffiwobbles!
$ ./plunder.js --ships 12 --distance 98.7
Retreat from the xupptumblers!
```
### Complex Example
```javascript
#!/usr/bin/env node
require('yargs') // eslint-disable-line
.command('serve [port]', 'start the server', (yargs) => {
yargs
.positional('port', {
describe: 'port to bind on',
default: 5000
})
}, (argv) => {
if (argv.verbose) console.info(`start server on :${argv.port}`)
serve(argv.port)
})
.option('verbose', {
alias: 'v',
type: 'boolean',
description: 'Run with verbose logging'
})
.argv
```
Run the example above with `--help` to see the help for the application.
## TypeScript
yargs has type definitions at [@types/yargs][type-definitions].
```
npm i @types/yargs --save-dev
```
See usage examples in [docs](/docs/typescript.md).
## Webpack
See usage examples of yargs with webpack in [docs](/docs/webpack.md).
## Community :
Having problems? want to contribute? join our [community slack](http://devtoolscommunity.herokuapp.com).
## Documentation :
### Table of Contents
* [Yargs' API](/docs/api.md)
* [Examples](/docs/examples.md)
* [Parsing Tricks](/docs/tricks.md)
* [Stop the Parser](/docs/tricks.md#stop)
* [Negating Boolean Arguments](/docs/tricks.md#negate)
* [Numbers](/docs/tricks.md#numbers)
* [Arrays](/docs/tricks.md#arrays)
* [Objects](/docs/tricks.md#objects)
* [Quotes](/docs/tricks.md#quotes)
* [Advanced Topics](/docs/advanced.md)
* [Composing Your App Using Commands](/docs/advanced.md#commands)
* [Building Configurable CLI Apps](/docs/advanced.md#configuration)
* [Customizing Yargs' Parser](/docs/advanced.md#customizing)
* [Contributing](/contributing.md)
[travis-url]: https://travis-ci.org/yargs/yargs
[travis-image]: https://img.shields.io/travis/yargs/yargs/master.svg
[npm-url]: https://www.npmjs.com/package/yargs
[npm-image]: https://img.shields.io/npm/v/yargs.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: http://standardjs.com/
[conventional-commits-image]: https://img.shields.io/badge/Conventional%20Commits-1.0.0-yellow.svg
[conventional-commits-url]: https://conventionalcommits.org/
[slack-image]: http://devtoolscommunity.herokuapp.com/badge.svg
[slack-url]: http://devtoolscommunity.herokuapp.com
[type-definitions]: https://github.com/DefinitelyTyped/DefinitelyTyped/tree/master/types/yargs
[coverage-image]: https://img.shields.io/nycrc/yargs/yargs
[coverage-url]: https://github.com/yargs/yargs/blob/master/.nycrc
# minimatch
A minimal matching utility.
[](http://travis-ci.org/isaacs/minimatch)
This is the matching library used internally by npm.
It works by converting glob expressions into JavaScript `RegExp`
objects.
## Usage
```javascript
var minimatch = require("minimatch")
minimatch("bar.foo", "*.foo") // true!
minimatch("bar.foo", "*.bar") // false!
minimatch("bar.foo", "*.+(bar|foo)", { debug: true }) // true, and noisy!
```
## Features
Supports these glob features:
* Brace Expansion
* Extended glob matching
* "Globstar" `**` matching
See:
* `man sh`
* `man bash`
* `man 3 fnmatch`
* `man 5 gitignore`
## Minimatch Class
Create a minimatch object by instantiating the `minimatch.Minimatch` class.
```javascript
var Minimatch = require("minimatch").Minimatch
var mm = new Minimatch(pattern, options)
```
### Properties
* `pattern` The original pattern the minimatch object represents.
* `options` The options supplied to the constructor.
* `set` A 2-dimensional array of regexp or string expressions.
Each row in the
array corresponds to a brace-expanded pattern. Each item in the row
corresponds to a single path-part. For example, the pattern
`{a,b/c}/d` would expand to a set of patterns like:
[ [ a, d ]
, [ b, c, d ] ]
If a portion of the pattern doesn't have any "magic" in it
(that is, it's something like `"foo"` rather than `fo*o?`), then it
will be left as a string rather than converted to a regular
expression.
* `regexp` Created by the `makeRe` method. A single regular expression
expressing the entire pattern. This is useful in cases where you wish
to use the pattern somewhat like `fnmatch(3)` with `FNM_PATH` enabled.
* `negate` True if the pattern is negated.
* `comment` True if the pattern is a comment.
* `empty` True if the pattern is `""`.
### Methods
* `makeRe` Generate the `regexp` member if necessary, and return it.
Will return `false` if the pattern is invalid.
* `match(fname)` Return true if the filename matches the pattern, or
false otherwise.
* `matchOne(fileArray, patternArray, partial)` Take a `/`-split
filename, and match it against a single row in the `regExpSet`. This
method is mainly for internal use, but is exposed so that it can be
used by a glob-walker that needs to avoid excessive filesystem calls.
All other methods are internal, and will be called as necessary.
### minimatch(path, pattern, options)
Main export. Tests a path against the pattern using the options.
```javascript
var isJS = minimatch(file, "*.js", { matchBase: true })
```
### minimatch.filter(pattern, options)
Returns a function that tests its
supplied argument, suitable for use with `Array.filter`. Example:
```javascript
var javascripts = fileList.filter(minimatch.filter("*.js", {matchBase: true}))
```
### minimatch.match(list, pattern, options)
Match against the list of
files, in the style of fnmatch or glob. If nothing is matched, and
options.nonull is set, then return a list containing the pattern itself.
```javascript
var javascripts = minimatch.match(fileList, "*.js", {matchBase: true}))
```
### minimatch.makeRe(pattern, options)
Make a regular expression object from the pattern.
## Options
All options are `false` by default.
### debug
Dump a ton of stuff to stderr.
### nobrace
Do not expand `{a,b}` and `{1..3}` brace sets.
### noglobstar
Disable `**` matching against multiple folder names.
### dot
Allow patterns to match filenames starting with a period, even if
the pattern does not explicitly have a period in that spot.
Note that by default, `a/**/b` will **not** match `a/.d/b`, unless `dot`
is set.
### noext
Disable "extglob" style patterns like `+(a|b)`.
### nocase
Perform a case-insensitive match.
### nonull
When a match is not found by `minimatch.match`, return a list containing
the pattern itself if this option is set. When not set, an empty list
is returned if there are no matches.
### matchBase
If set, then patterns without slashes will be matched
against the basename of the path if it contains slashes. For example,
`a?b` would match the path `/xyz/123/acb`, but not `/xyz/acb/123`.
### nocomment
Suppress the behavior of treating `#` at the start of a pattern as a
comment.
### nonegate
Suppress the behavior of treating a leading `!` character as negation.
### flipNegate
Returns from negate expressions the same as if they were not negated.
(Ie, true on a hit, false on a miss.)
### partial
Compare a partial path to a pattern. As long as the parts of the path that
are present are not contradicted by the pattern, it will be treated as a
match. This is useful in applications where you're walking through a
folder structure, and don't yet have the full path, but want to ensure that
you do not walk down paths that can never be a match.
For example,
```js
minimatch('/a/b', '/a/*/c/d', { partial: true }) // true, might be /a/b/c/d
minimatch('/a/b', '/**/d', { partial: true }) // true, might be /a/b/.../d
minimatch('/x/y/z', '/a/**/z', { partial: true }) // false, because x !== a
```
### allowWindowsEscape
Windows path separator `\` is by default converted to `/`, which
prohibits the usage of `\` as a escape character. This flag skips that
behavior and allows using the escape character.
## Comparisons to other fnmatch/glob implementations
While strict compliance with the existing standards is a worthwhile
goal, some discrepancies exist between minimatch and other
implementations, and are intentional.
If the pattern starts with a `!` character, then it is negated. Set the
`nonegate` flag to suppress this behavior, and treat leading `!`
characters normally. This is perhaps relevant if you wish to start the
pattern with a negative extglob pattern like `!(a|B)`. Multiple `!`
characters at the start of a pattern will negate the pattern multiple
times.
If a pattern starts with `#`, then it is treated as a comment, and
will not match anything. Use `\#` to match a literal `#` at the
start of a line, or set the `nocomment` flag to suppress this behavior.
The double-star character `**` is supported by default, unless the
`noglobstar` flag is set. This is supported in the manner of bsdglob
and bash 4.1, where `**` only has special significance if it is the only
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
`a/**b` will not.
If an escaped pattern has no matches, and the `nonull` flag is set,
then minimatch.match returns the pattern as-provided, rather than
interpreting the character escapes. For example,
`minimatch.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
that it does not resolve escaped pattern characters.
If brace expansion is not disabled, then it is performed before any
other interpretation of the glob pattern. Thus, a pattern like
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
checked for validity. Since those two are valid, matching proceeds.
# Visitor utilities for AssemblyScript Compiler transformers
## Example
### List Fields
The transformer:
```ts
import {
ClassDeclaration,
FieldDeclaration,
MethodDeclaration,
} from "../../as";
import { ClassDecorator, registerDecorator } from "../decorator";
import { toString } from "../utils";
class ListMembers extends ClassDecorator {
visitFieldDeclaration(node: FieldDeclaration): void {
if (!node.name) console.log(toString(node) + "\n");
const name = toString(node.name);
const _type = toString(node.type!);
this.stdout.write(name + ": " + _type + "\n");
}
visitMethodDeclaration(node: MethodDeclaration): void {
const name = toString(node.name);
if (name == "constructor") {
return;
}
const sig = toString(node.signature);
this.stdout.write(name + ": " + sig + "\n");
}
visitClassDeclaration(node: ClassDeclaration): void {
this.visit(node.members);
}
get name(): string {
return "list";
}
}
export = registerDecorator(new ListMembers());
```
assembly/foo.ts:
```ts
@list
class Foo {
a: u8;
b: bool;
i: i32;
}
```
And then compile with `--transform` flag:
```
asc assembly/foo.ts --transform ./dist/examples/list --noEmit
```
Which prints the following to the console:
```
a: u8
b: bool
i: i32
```
[](https://travis-ci.org/isaacs/rimraf) [](https://david-dm.org/isaacs/rimraf) [](https://david-dm.org/isaacs/rimraf#info=devDependencies)
The [UNIX command](http://en.wikipedia.org/wiki/Rm_(Unix)) `rm -rf` for node.
Install with `npm install rimraf`, or just drop rimraf.js somewhere.
## API
`rimraf(f, [opts], callback)`
The first parameter will be interpreted as a globbing pattern for files. If you
want to disable globbing you can do so with `opts.disableGlob` (defaults to
`false`). This might be handy, for instance, if you have filenames that contain
globbing wildcard characters.
The callback will be called with an error if there is one. Certain
errors are handled for you:
* Windows: `EBUSY` and `ENOTEMPTY` - rimraf will back off a maximum of
`opts.maxBusyTries` times before giving up, adding 100ms of wait
between each attempt. The default `maxBusyTries` is 3.
* `ENOENT` - If the file doesn't exist, rimraf will return
successfully, since your desired outcome is already the case.
* `EMFILE` - Since `readdir` requires opening a file descriptor, it's
possible to hit `EMFILE` if too many file descriptors are in use.
In the sync case, there's nothing to be done for this. But in the
async case, rimraf will gradually back off with timeouts up to
`opts.emfileWait` ms, which defaults to 1000.
## options
* unlink, chmod, stat, lstat, rmdir, readdir,
unlinkSync, chmodSync, statSync, lstatSync, rmdirSync, readdirSync
In order to use a custom file system library, you can override
specific fs functions on the options object.
If any of these functions are present on the options object, then
the supplied function will be used instead of the default fs
method.
Sync methods are only relevant for `rimraf.sync()`, of course.
For example:
```javascript
var myCustomFS = require('some-custom-fs')
rimraf('some-thing', myCustomFS, callback)
```
* maxBusyTries
If an `EBUSY`, `ENOTEMPTY`, or `EPERM` error code is encountered
on Windows systems, then rimraf will retry with a linear backoff
wait of 100ms longer on each try. The default maxBusyTries is 3.
Only relevant for async usage.
* emfileWait
If an `EMFILE` error is encountered, then rimraf will retry
repeatedly with a linear backoff of 1ms longer on each try, until
the timeout counter hits this max. The default limit is 1000.
If you repeatedly encounter `EMFILE` errors, then consider using
[graceful-fs](http://npm.im/graceful-fs) in your program.
Only relevant for async usage.
* glob
Set to `false` to disable [glob](http://npm.im/glob) pattern
matching.
Set to an object to pass options to the glob module. The default
glob options are `{ nosort: true, silent: true }`.
Glob version 6 is used in this module.
Relevant for both sync and async usage.
* disableGlob
Set to any non-falsey value to disable globbing entirely.
(Equivalent to setting `glob: false`.)
## rimraf.sync
It can remove stuff synchronously, too. But that's not so good. Use
the async API. It's better.
## CLI
If installed with `npm install rimraf -g` it can be used as a global
command `rimraf <path> [<path> ...]` which is useful for cross platform support.
## mkdirp
If you need to create a directory recursively, check out
[mkdirp](https://github.com/substack/node-mkdirp).
A JSON with color names and its values. Based on http://dev.w3.org/csswg/css-color/#named-colors.
[](https://nodei.co/npm/color-name/)
```js
var colors = require('color-name');
colors.red //[255,0,0]
```
<a href="LICENSE"><img src="https://upload.wikimedia.org/wikipedia/commons/0/0c/MIT_logo.svg" width="120"/></a>
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# prelude.ls [](https://travis-ci.org/gkz/prelude-ls)
is a functionally oriented utility library. It is powerful and flexible. Almost all of its functions are curried. It is written in, and is the recommended base library for, <a href="http://livescript.net">LiveScript</a>.
See **[the prelude.ls site](http://preludels.com)** for examples, a reference, and more.
You can install via npm `npm install prelude-ls`
### Development
`make test` to test
`make build` to build `lib` from `src`
`make build-browser` to build browser versions
bs58
====
[](https://travis-ci.org/cryptocoinjs/bs58)
JavaScript component to compute base 58 encoding. This encoding is typically used for crypto currencies such as Bitcoin.
**Note:** If you're looking for **base 58 check** encoding, see: [https://github.com/bitcoinjs/bs58check](https://github.com/bitcoinjs/bs58check), which depends upon this library.
Install
-------
npm i --save bs58
API
---
### encode(input)
`input` must be a [Buffer](https://nodejs.org/api/buffer.html) or an `Array`. It returns a `string`.
**example**:
```js
const bs58 = require('bs58')
const bytes = Buffer.from('003c176e659bea0f29a3e9bf7880c112b1b31b4dc826268187', 'hex')
const address = bs58.encode(bytes)
console.log(address)
// => 16UjcYNBG9GTK4uq2f7yYEbuifqCzoLMGS
```
### decode(input)
`input` must be a base 58 encoded string. Returns a [Buffer](https://nodejs.org/api/buffer.html).
**example**:
```js
const bs58 = require('bs58')
const address = '16UjcYNBG9GTK4uq2f7yYEbuifqCzoLMGS'
const bytes = bs58.decode(address)
console.log(out.toString('hex'))
// => 003c176e659bea0f29a3e9bf7880c112b1b31b4dc826268187
```
Hack / Test
-----------
Uses JavaScript standard style. Read more:
[](https://github.com/feross/standard)
Credits
-------
- [Mike Hearn](https://github.com/mikehearn) for original Java implementation
- [Stefan Thomas](https://github.com/justmoon) for porting to JavaScript
- [Stephan Pair](https://github.com/gasteve) for buffer improvements
- [Daniel Cousens](https://github.com/dcousens) for cleanup and merging improvements from bitcoinjs-lib
- [Jared Deckard](https://github.com/deckar01) for killing `bigi` as a dependency
License
-------
MIT
# regexpp
[](https://www.npmjs.com/package/regexpp)
[](http://www.npmtrends.com/regexpp)
[](https://github.com/mysticatea/regexpp/actions)
[](https://codecov.io/gh/mysticatea/regexpp)
[](https://david-dm.org/mysticatea/regexpp)
A regular expression parser for ECMAScript.
## 💿 Installation
```bash
$ npm install regexpp
```
- require Node.js 8 or newer.
## 📖 Usage
```ts
import {
AST,
RegExpParser,
RegExpValidator,
RegExpVisitor,
parseRegExpLiteral,
validateRegExpLiteral,
visitRegExpAST
} from "regexpp"
```
### parseRegExpLiteral(source, options?)
Parse a given regular expression literal then make AST object.
This is equivalent to `new RegExpParser(options).parseLiteral(source)`.
- **Parameters:**
- `source` (`string | RegExp`) The source code to parse.
- `options?` ([`RegExpParser.Options`]) The options to parse.
- **Return:**
- The AST of the regular expression.
### validateRegExpLiteral(source, options?)
Validate a given regular expression literal.
This is equivalent to `new RegExpValidator(options).validateLiteral(source)`.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `options?` ([`RegExpValidator.Options`]) The options to validate.
### visitRegExpAST(ast, handlers)
Visit each node of a given AST.
This is equivalent to `new RegExpVisitor(handlers).visit(ast)`.
- **Parameters:**
- `ast` ([`AST.Node`]) The AST to visit.
- `handlers` ([`RegExpVisitor.Handlers`]) The callbacks.
### RegExpParser
#### new RegExpParser(options?)
- **Parameters:**
- `options?` ([`RegExpParser.Options`]) The options to parse.
#### parser.parseLiteral(source, start?, end?)
Parse a regular expression literal.
- **Parameters:**
- `source` (`string`) The source code to parse. E.g. `"/abc/g"`.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- **Return:**
- The AST of the regular expression.
#### parser.parsePattern(source, start?, end?, uFlag?)
Parse a regular expression pattern.
- **Parameters:**
- `source` (`string`) The source code to parse. E.g. `"abc"`.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- `uFlag?` (`boolean`) The flag to enable Unicode mode.
- **Return:**
- The AST of the regular expression pattern.
#### parser.parseFlags(source, start?, end?)
Parse a regular expression flags.
- **Parameters:**
- `source` (`string`) The source code to parse. E.g. `"gim"`.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- **Return:**
- The AST of the regular expression flags.
### RegExpValidator
#### new RegExpValidator(options)
- **Parameters:**
- `options` ([`RegExpValidator.Options`]) The options to validate.
#### validator.validateLiteral(source, start, end)
Validate a regular expression literal.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
#### validator.validatePattern(source, start, end, uFlag)
Validate a regular expression pattern.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- `uFlag?` (`boolean`) The flag to enable Unicode mode.
#### validator.validateFlags(source, start, end)
Validate a regular expression flags.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
### RegExpVisitor
#### new RegExpVisitor(handlers)
- **Parameters:**
- `handlers` ([`RegExpVisitor.Handlers`]) The callbacks.
#### visitor.visit(ast)
Validate a regular expression literal.
- **Parameters:**
- `ast` ([`AST.Node`]) The AST to visit.
## 📰 Changelog
- [GitHub Releases](https://github.com/mysticatea/regexpp/releases)
## 🍻 Contributing
Welcome contributing!
Please use GitHub's Issues/PRs.
### Development Tools
- `npm test` runs tests and measures coverage.
- `npm run build` compiles TypeScript source code to `index.js`, `index.js.map`, and `index.d.ts`.
- `npm run clean` removes the temporary files which are created by `npm test` and `npm run build`.
- `npm run lint` runs ESLint.
- `npm run update:test` updates test fixtures.
- `npm run update:ids` updates `src/unicode/ids.ts`.
- `npm run watch` runs tests with `--watch` option.
[`AST.Node`]: src/ast.ts#L4
[`RegExpParser.Options`]: src/parser.ts#L539
[`RegExpValidator.Options`]: src/validator.ts#L127
[`RegExpVisitor.Handlers`]: src/visitor.ts#L204
# lru cache
A cache object that deletes the least-recently-used items.
[](https://travis-ci.org/isaacs/node-lru-cache) [](https://coveralls.io/github/isaacs/node-lru-cache)
## Installation:
```javascript
npm install lru-cache --save
```
## Usage:
```javascript
var LRU = require("lru-cache")
, options = { max: 500
, length: function (n, key) { return n * 2 + key.length }
, dispose: function (key, n) { n.close() }
, maxAge: 1000 * 60 * 60 }
, cache = new LRU(options)
, otherCache = new LRU(50) // sets just the max size
cache.set("key", "value")
cache.get("key") // "value"
// non-string keys ARE fully supported
// but note that it must be THE SAME object, not
// just a JSON-equivalent object.
var someObject = { a: 1 }
cache.set(someObject, 'a value')
// Object keys are not toString()-ed
cache.set('[object Object]', 'a different value')
assert.equal(cache.get(someObject), 'a value')
// A similar object with same keys/values won't work,
// because it's a different object identity
assert.equal(cache.get({ a: 1 }), undefined)
cache.reset() // empty the cache
```
If you put more stuff in it, then items will fall out.
If you try to put an oversized thing in it, then it'll fall out right
away.
## Options
* `max` The maximum size of the cache, checked by applying the length
function to all values in the cache. Not setting this is kind of
silly, since that's the whole purpose of this lib, but it defaults
to `Infinity`. Setting it to a non-number or negative number will
throw a `TypeError`. Setting it to 0 makes it be `Infinity`.
* `maxAge` Maximum age in ms. Items are not pro-actively pruned out
as they age, but if you try to get an item that is too old, it'll
drop it and return undefined instead of giving it to you.
Setting this to a negative value will make everything seem old!
Setting it to a non-number will throw a `TypeError`.
* `length` Function that is used to calculate the length of stored
items. If you're storing strings or buffers, then you probably want
to do something like `function(n, key){return n.length}`. The default is
`function(){return 1}`, which is fine if you want to store `max`
like-sized things. The item is passed as the first argument, and
the key is passed as the second argumnet.
* `dispose` Function that is called on items when they are dropped
from the cache. This can be handy if you want to close file
descriptors or do other cleanup tasks when items are no longer
accessible. Called with `key, value`. It's called *before*
actually removing the item from the internal cache, so if you want
to immediately put it back in, you'll have to do that in a
`nextTick` or `setTimeout` callback or it won't do anything.
* `stale` By default, if you set a `maxAge`, it'll only actually pull
stale items out of the cache when you `get(key)`. (That is, it's
not pre-emptively doing a `setTimeout` or anything.) If you set
`stale:true`, it'll return the stale value before deleting it. If
you don't set this, then it'll return `undefined` when you try to
get a stale entry, as if it had already been deleted.
* `noDisposeOnSet` By default, if you set a `dispose()` method, then
it'll be called whenever a `set()` operation overwrites an existing
key. If you set this option, `dispose()` will only be called when a
key falls out of the cache, not when it is overwritten.
* `updateAgeOnGet` When using time-expiring entries with `maxAge`,
setting this to `true` will make each item's effective time update
to the current time whenever it is retrieved from cache, causing it
to not expire. (It can still fall out of cache based on recency of
use, of course.)
## API
* `set(key, value, maxAge)`
* `get(key) => value`
Both of these will update the "recently used"-ness of the key.
They do what you think. `maxAge` is optional and overrides the
cache `maxAge` option if provided.
If the key is not found, `get()` will return `undefined`.
The key and val can be any value.
* `peek(key)`
Returns the key value (or `undefined` if not found) without
updating the "recently used"-ness of the key.
(If you find yourself using this a lot, you *might* be using the
wrong sort of data structure, but there are some use cases where
it's handy.)
* `del(key)`
Deletes a key out of the cache.
* `reset()`
Clear the cache entirely, throwing away all values.
* `has(key)`
Check if a key is in the cache, without updating the recent-ness
or deleting it for being stale.
* `forEach(function(value,key,cache), [thisp])`
Just like `Array.prototype.forEach`. Iterates over all the keys
in the cache, in order of recent-ness. (Ie, more recently used
items are iterated over first.)
* `rforEach(function(value,key,cache), [thisp])`
The same as `cache.forEach(...)` but items are iterated over in
reverse order. (ie, less recently used items are iterated over
first.)
* `keys()`
Return an array of the keys in the cache.
* `values()`
Return an array of the values in the cache.
* `length`
Return total length of objects in cache taking into account
`length` options function.
* `itemCount`
Return total quantity of objects currently in cache. Note, that
`stale` (see options) items are returned as part of this item
count.
* `dump()`
Return an array of the cache entries ready for serialization and usage
with 'destinationCache.load(arr)`.
* `load(cacheEntriesArray)`
Loads another cache entries array, obtained with `sourceCache.dump()`,
into the cache. The destination cache is reset before loading new entries
* `prune()`
Manually iterates over the entire cache proactively pruning old entries
# get-caller-file
[](https://travis-ci.org/stefanpenner/get-caller-file)
[](https://ci.appveyor.com/project/embercli/get-caller-file/branch/master)
This is a utility, which allows a function to figure out from which file it was invoked. It does so by inspecting v8's stack trace at the time it is invoked.
Inspired by http://stackoverflow.com/questions/13227489
*note: this relies on Node/V8 specific APIs, as such other runtimes may not work*
## Installation
```bash
yarn add get-caller-file
```
## Usage
Given:
```js
// ./foo.js
const getCallerFile = require('get-caller-file');
module.exports = function() {
return getCallerFile(); // figures out who called it
};
```
```js
// index.js
const foo = require('./foo');
foo() // => /full/path/to/this/file/index.js
```
## Options:
* `getCallerFile(position = 2)`: where position is stack frame whos fileName we want.
Browser-friendly inheritance fully compatible with standard node.js
[inherits](http://nodejs.org/api/util.html#util_util_inherits_constructor_superconstructor).
This package exports standard `inherits` from node.js `util` module in
node environment, but also provides alternative browser-friendly
implementation through [browser
field](https://gist.github.com/shtylman/4339901). Alternative
implementation is a literal copy of standard one located in standalone
module to avoid requiring of `util`. It also has a shim for old
browsers with no `Object.create` support.
While keeping you sure you are using standard `inherits`
implementation in node.js environment, it allows bundlers such as
[browserify](https://github.com/substack/node-browserify) to not
include full `util` package to your client code if all you need is
just `inherits` function. It worth, because browser shim for `util`
package is large and `inherits` is often the single function you need
from it.
It's recommended to use this package instead of
`require('util').inherits` for any code that has chances to be used
not only in node.js but in browser too.
## usage
```js
var inherits = require('inherits');
// then use exactly as the standard one
```
## note on version ~1.0
Version ~1.0 had completely different motivation and is not compatible
neither with 2.0 nor with standard node.js `inherits`.
If you are using version ~1.0 and planning to switch to ~2.0, be
careful:
* new version uses `super_` instead of `super` for referencing
superclass
* new version overwrites current prototype while old one preserves any
existing fields on it
# wrappy
Callback wrapping utility
## USAGE
```javascript
var wrappy = require("wrappy")
// var wrapper = wrappy(wrapperFunction)
// make sure a cb is called only once
// See also: http://npm.im/once for this specific use case
var once = wrappy(function (cb) {
var called = false
return function () {
if (called) return
called = true
return cb.apply(this, arguments)
}
})
function printBoo () {
console.log('boo')
}
// has some rando property
printBoo.iAmBooPrinter = true
var onlyPrintOnce = once(printBoo)
onlyPrintOnce() // prints 'boo'
onlyPrintOnce() // does nothing
// random property is retained!
assert.equal(onlyPrintOnce.iAmBooPrinter, true)
```
semver(1) -- The semantic versioner for npm
===========================================
## Install
```bash
npm install semver
````
## Usage
As a node module:
```js
const semver = require('semver')
semver.valid('1.2.3') // '1.2.3'
semver.valid('a.b.c') // null
semver.clean(' =v1.2.3 ') // '1.2.3'
semver.satisfies('1.2.3', '1.x || >=2.5.0 || 5.0.0 - 7.2.3') // true
semver.gt('1.2.3', '9.8.7') // false
semver.lt('1.2.3', '9.8.7') // true
semver.minVersion('>=1.0.0') // '1.0.0'
semver.valid(semver.coerce('v2')) // '2.0.0'
semver.valid(semver.coerce('42.6.7.9.3-alpha')) // '42.6.7'
```
You can also just load the module for the function that you care about, if
you'd like to minimize your footprint.
```js
// load the whole API at once in a single object
const semver = require('semver')
// or just load the bits you need
// all of them listed here, just pick and choose what you want
// classes
const SemVer = require('semver/classes/semver')
const Comparator = require('semver/classes/comparator')
const Range = require('semver/classes/range')
// functions for working with versions
const semverParse = require('semver/functions/parse')
const semverValid = require('semver/functions/valid')
const semverClean = require('semver/functions/clean')
const semverInc = require('semver/functions/inc')
const semverDiff = require('semver/functions/diff')
const semverMajor = require('semver/functions/major')
const semverMinor = require('semver/functions/minor')
const semverPatch = require('semver/functions/patch')
const semverPrerelease = require('semver/functions/prerelease')
const semverCompare = require('semver/functions/compare')
const semverRcompare = require('semver/functions/rcompare')
const semverCompareLoose = require('semver/functions/compare-loose')
const semverCompareBuild = require('semver/functions/compare-build')
const semverSort = require('semver/functions/sort')
const semverRsort = require('semver/functions/rsort')
// low-level comparators between versions
const semverGt = require('semver/functions/gt')
const semverLt = require('semver/functions/lt')
const semverEq = require('semver/functions/eq')
const semverNeq = require('semver/functions/neq')
const semverGte = require('semver/functions/gte')
const semverLte = require('semver/functions/lte')
const semverCmp = require('semver/functions/cmp')
const semverCoerce = require('semver/functions/coerce')
// working with ranges
const semverSatisfies = require('semver/functions/satisfies')
const semverMaxSatisfying = require('semver/ranges/max-satisfying')
const semverMinSatisfying = require('semver/ranges/min-satisfying')
const semverToComparators = require('semver/ranges/to-comparators')
const semverMinVersion = require('semver/ranges/min-version')
const semverValidRange = require('semver/ranges/valid')
const semverOutside = require('semver/ranges/outside')
const semverGtr = require('semver/ranges/gtr')
const semverLtr = require('semver/ranges/ltr')
const semverIntersects = require('semver/ranges/intersects')
const simplifyRange = require('semver/ranges/simplify')
const rangeSubset = require('semver/ranges/subset')
```
As a command-line utility:
```
$ semver -h
A JavaScript implementation of the https://semver.org/ specification
Copyright Isaac Z. Schlueter
Usage: semver [options] <version> [<version> [...]]
Prints valid versions sorted by SemVer precedence
Options:
-r --range <range>
Print versions that match the specified range.
-i --increment [<level>]
Increment a version by the specified level. Level can
be one of: major, minor, patch, premajor, preminor,
prepatch, or prerelease. Default level is 'patch'.
Only one version may be specified.
--preid <identifier>
Identifier to be used to prefix premajor, preminor,
prepatch or prerelease version increments.
-l --loose
Interpret versions and ranges loosely
-p --include-prerelease
Always include prerelease versions in range matching
-c --coerce
Coerce a string into SemVer if possible
(does not imply --loose)
--rtl
Coerce version strings right to left
--ltr
Coerce version strings left to right (default)
Program exits successfully if any valid version satisfies
all supplied ranges, and prints all satisfying versions.
If no satisfying versions are found, then exits failure.
Versions are printed in ascending order, so supplying
multiple versions to the utility will just sort them.
```
## Versions
A "version" is described by the `v2.0.0` specification found at
<https://semver.org/>.
A leading `"="` or `"v"` character is stripped off and ignored.
## Ranges
A `version range` is a set of `comparators` which specify versions
that satisfy the range.
A `comparator` is composed of an `operator` and a `version`. The set
of primitive `operators` is:
* `<` Less than
* `<=` Less than or equal to
* `>` Greater than
* `>=` Greater than or equal to
* `=` Equal. If no operator is specified, then equality is assumed,
so this operator is optional, but MAY be included.
For example, the comparator `>=1.2.7` would match the versions
`1.2.7`, `1.2.8`, `2.5.3`, and `1.3.9`, but not the versions `1.2.6`
or `1.1.0`.
Comparators can be joined by whitespace to form a `comparator set`,
which is satisfied by the **intersection** of all of the comparators
it includes.
A range is composed of one or more comparator sets, joined by `||`. A
version matches a range if and only if every comparator in at least
one of the `||`-separated comparator sets is satisfied by the version.
For example, the range `>=1.2.7 <1.3.0` would match the versions
`1.2.7`, `1.2.8`, and `1.2.99`, but not the versions `1.2.6`, `1.3.0`,
or `1.1.0`.
The range `1.2.7 || >=1.2.9 <2.0.0` would match the versions `1.2.7`,
`1.2.9`, and `1.4.6`, but not the versions `1.2.8` or `2.0.0`.
### Prerelease Tags
If a version has a prerelease tag (for example, `1.2.3-alpha.3`) then
it will only be allowed to satisfy comparator sets if at least one
comparator with the same `[major, minor, patch]` tuple also has a
prerelease tag.
For example, the range `>1.2.3-alpha.3` would be allowed to match the
version `1.2.3-alpha.7`, but it would *not* be satisfied by
`3.4.5-alpha.9`, even though `3.4.5-alpha.9` is technically "greater
than" `1.2.3-alpha.3` according to the SemVer sort rules. The version
range only accepts prerelease tags on the `1.2.3` version. The
version `3.4.5` *would* satisfy the range, because it does not have a
prerelease flag, and `3.4.5` is greater than `1.2.3-alpha.7`.
The purpose for this behavior is twofold. First, prerelease versions
frequently are updated very quickly, and contain many breaking changes
that are (by the author's design) not yet fit for public consumption.
Therefore, by default, they are excluded from range matching
semantics.
Second, a user who has opted into using a prerelease version has
clearly indicated the intent to use *that specific* set of
alpha/beta/rc versions. By including a prerelease tag in the range,
the user is indicating that they are aware of the risk. However, it
is still not appropriate to assume that they have opted into taking a
similar risk on the *next* set of prerelease versions.
Note that this behavior can be suppressed (treating all prerelease
versions as if they were normal versions, for the purpose of range
matching) by setting the `includePrerelease` flag on the options
object to any
[functions](https://github.com/npm/node-semver#functions) that do
range matching.
#### Prerelease Identifiers
The method `.inc` takes an additional `identifier` string argument that
will append the value of the string as a prerelease identifier:
```javascript
semver.inc('1.2.3', 'prerelease', 'beta')
// '1.2.4-beta.0'
```
command-line example:
```bash
$ semver 1.2.3 -i prerelease --preid beta
1.2.4-beta.0
```
Which then can be used to increment further:
```bash
$ semver 1.2.4-beta.0 -i prerelease
1.2.4-beta.1
```
### Advanced Range Syntax
Advanced range syntax desugars to primitive comparators in
deterministic ways.
Advanced ranges may be combined in the same way as primitive
comparators using white space or `||`.
#### Hyphen Ranges `X.Y.Z - A.B.C`
Specifies an inclusive set.
* `1.2.3 - 2.3.4` := `>=1.2.3 <=2.3.4`
If a partial version is provided as the first version in the inclusive
range, then the missing pieces are replaced with zeroes.
* `1.2 - 2.3.4` := `>=1.2.0 <=2.3.4`
If a partial version is provided as the second version in the
inclusive range, then all versions that start with the supplied parts
of the tuple are accepted, but nothing that would be greater than the
provided tuple parts.
* `1.2.3 - 2.3` := `>=1.2.3 <2.4.0-0`
* `1.2.3 - 2` := `>=1.2.3 <3.0.0-0`
#### X-Ranges `1.2.x` `1.X` `1.2.*` `*`
Any of `X`, `x`, or `*` may be used to "stand in" for one of the
numeric values in the `[major, minor, patch]` tuple.
* `*` := `>=0.0.0` (Any non-prerelease version satisfies, unless
`includePrerelease` is specified, in which case any version at all
satisfies)
* `1.x` := `>=1.0.0 <2.0.0-0` (Matching major version)
* `1.2.x` := `>=1.2.0 <1.3.0-0` (Matching major and minor versions)
A partial version range is treated as an X-Range, so the special
character is in fact optional.
* `""` (empty string) := `*` := `>=0.0.0`
* `1` := `1.x.x` := `>=1.0.0 <2.0.0-0`
* `1.2` := `1.2.x` := `>=1.2.0 <1.3.0-0`
#### Tilde Ranges `~1.2.3` `~1.2` `~1`
Allows patch-level changes if a minor version is specified on the
comparator. Allows minor-level changes if not.
* `~1.2.3` := `>=1.2.3 <1.(2+1).0` := `>=1.2.3 <1.3.0-0`
* `~1.2` := `>=1.2.0 <1.(2+1).0` := `>=1.2.0 <1.3.0-0` (Same as `1.2.x`)
* `~1` := `>=1.0.0 <(1+1).0.0` := `>=1.0.0 <2.0.0-0` (Same as `1.x`)
* `~0.2.3` := `>=0.2.3 <0.(2+1).0` := `>=0.2.3 <0.3.0-0`
* `~0.2` := `>=0.2.0 <0.(2+1).0` := `>=0.2.0 <0.3.0-0` (Same as `0.2.x`)
* `~0` := `>=0.0.0 <(0+1).0.0` := `>=0.0.0 <1.0.0-0` (Same as `0.x`)
* `~1.2.3-beta.2` := `>=1.2.3-beta.2 <1.3.0-0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
#### Caret Ranges `^1.2.3` `^0.2.5` `^0.0.4`
Allows changes that do not modify the left-most non-zero element in the
`[major, minor, patch]` tuple. In other words, this allows patch and
minor updates for versions `1.0.0` and above, patch updates for
versions `0.X >=0.1.0`, and *no* updates for versions `0.0.X`.
Many authors treat a `0.x` version as if the `x` were the major
"breaking-change" indicator.
Caret ranges are ideal when an author may make breaking changes
between `0.2.4` and `0.3.0` releases, which is a common practice.
However, it presumes that there will *not* be breaking changes between
`0.2.4` and `0.2.5`. It allows for changes that are presumed to be
additive (but non-breaking), according to commonly observed practices.
* `^1.2.3` := `>=1.2.3 <2.0.0-0`
* `^0.2.3` := `>=0.2.3 <0.3.0-0`
* `^0.0.3` := `>=0.0.3 <0.0.4-0`
* `^1.2.3-beta.2` := `>=1.2.3-beta.2 <2.0.0-0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
* `^0.0.3-beta` := `>=0.0.3-beta <0.0.4-0` Note that prereleases in the
`0.0.3` version *only* will be allowed, if they are greater than or
equal to `beta`. So, `0.0.3-pr.2` would be allowed.
When parsing caret ranges, a missing `patch` value desugars to the
number `0`, but will allow flexibility within that value, even if the
major and minor versions are both `0`.
* `^1.2.x` := `>=1.2.0 <2.0.0-0`
* `^0.0.x` := `>=0.0.0 <0.1.0-0`
* `^0.0` := `>=0.0.0 <0.1.0-0`
A missing `minor` and `patch` values will desugar to zero, but also
allow flexibility within those values, even if the major version is
zero.
* `^1.x` := `>=1.0.0 <2.0.0-0`
* `^0.x` := `>=0.0.0 <1.0.0-0`
### Range Grammar
Putting all this together, here is a Backus-Naur grammar for ranges,
for the benefit of parser authors:
```bnf
range-set ::= range ( logical-or range ) *
logical-or ::= ( ' ' ) * '||' ( ' ' ) *
range ::= hyphen | simple ( ' ' simple ) * | ''
hyphen ::= partial ' - ' partial
simple ::= primitive | partial | tilde | caret
primitive ::= ( '<' | '>' | '>=' | '<=' | '=' ) partial
partial ::= xr ( '.' xr ( '.' xr qualifier ? )? )?
xr ::= 'x' | 'X' | '*' | nr
nr ::= '0' | ['1'-'9'] ( ['0'-'9'] ) *
tilde ::= '~' partial
caret ::= '^' partial
qualifier ::= ( '-' pre )? ( '+' build )?
pre ::= parts
build ::= parts
parts ::= part ( '.' part ) *
part ::= nr | [-0-9A-Za-z]+
```
## Functions
All methods and classes take a final `options` object argument. All
options in this object are `false` by default. The options supported
are:
- `loose` Be more forgiving about not-quite-valid semver strings.
(Any resulting output will always be 100% strict compliant, of
course.) For backwards compatibility reasons, if the `options`
argument is a boolean value instead of an object, it is interpreted
to be the `loose` param.
- `includePrerelease` Set to suppress the [default
behavior](https://github.com/npm/node-semver#prerelease-tags) of
excluding prerelease tagged versions from ranges unless they are
explicitly opted into.
Strict-mode Comparators and Ranges will be strict about the SemVer
strings that they parse.
* `valid(v)`: Return the parsed version, or null if it's not valid.
* `inc(v, release)`: Return the version incremented by the release
type (`major`, `premajor`, `minor`, `preminor`, `patch`,
`prepatch`, or `prerelease`), or null if it's not valid
* `premajor` in one call will bump the version up to the next major
version and down to a prerelease of that major version.
`preminor`, and `prepatch` work the same way.
* If called from a non-prerelease version, the `prerelease` will work the
same as `prepatch`. It increments the patch version, then makes a
prerelease. If the input version is already a prerelease it simply
increments it.
* `prerelease(v)`: Returns an array of prerelease components, or null
if none exist. Example: `prerelease('1.2.3-alpha.1') -> ['alpha', 1]`
* `major(v)`: Return the major version number.
* `minor(v)`: Return the minor version number.
* `patch(v)`: Return the patch version number.
* `intersects(r1, r2, loose)`: Return true if the two supplied ranges
or comparators intersect.
* `parse(v)`: Attempt to parse a string as a semantic version, returning either
a `SemVer` object or `null`.
### Comparison
* `gt(v1, v2)`: `v1 > v2`
* `gte(v1, v2)`: `v1 >= v2`
* `lt(v1, v2)`: `v1 < v2`
* `lte(v1, v2)`: `v1 <= v2`
* `eq(v1, v2)`: `v1 == v2` This is true if they're logically equivalent,
even if they're not the exact same string. You already know how to
compare strings.
* `neq(v1, v2)`: `v1 != v2` The opposite of `eq`.
* `cmp(v1, comparator, v2)`: Pass in a comparison string, and it'll call
the corresponding function above. `"==="` and `"!=="` do simple
string comparison, but are included for completeness. Throws if an
invalid comparison string is provided.
* `compare(v1, v2)`: Return `0` if `v1 == v2`, or `1` if `v1` is greater, or `-1` if
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `rcompare(v1, v2)`: The reverse of compare. Sorts an array of versions
in descending order when passed to `Array.sort()`.
* `compareBuild(v1, v2)`: The same as `compare` but considers `build` when two versions
are equal. Sorts in ascending order if passed to `Array.sort()`.
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `diff(v1, v2)`: Returns difference between two versions by the release type
(`major`, `premajor`, `minor`, `preminor`, `patch`, `prepatch`, or `prerelease`),
or null if the versions are the same.
### Comparators
* `intersects(comparator)`: Return true if the comparators intersect
### Ranges
* `validRange(range)`: Return the valid range or null if it's not valid
* `satisfies(version, range)`: Return true if the version satisfies the
range.
* `maxSatisfying(versions, range)`: Return the highest version in the list
that satisfies the range, or `null` if none of them do.
* `minSatisfying(versions, range)`: Return the lowest version in the list
that satisfies the range, or `null` if none of them do.
* `minVersion(range)`: Return the lowest version that can possibly match
the given range.
* `gtr(version, range)`: Return `true` if version is greater than all the
versions possible in the range.
* `ltr(version, range)`: Return `true` if version is less than all the
versions possible in the range.
* `outside(version, range, hilo)`: Return true if the version is outside
the bounds of the range in either the high or low direction. The
`hilo` argument must be either the string `'>'` or `'<'`. (This is
the function called by `gtr` and `ltr`.)
* `intersects(range)`: Return true if any of the ranges comparators intersect
* `simplifyRange(versions, range)`: Return a "simplified" range that
matches the same items in `versions` list as the range specified. Note
that it does *not* guarantee that it would match the same versions in all
cases, only for the set of versions provided. This is useful when
generating ranges by joining together multiple versions with `||`
programmatically, to provide the user with something a bit more
ergonomic. If the provided range is shorter in string-length than the
generated range, then that is returned.
* `subset(subRange, superRange)`: Return `true` if the `subRange` range is
entirely contained by the `superRange` range.
Note that, since ranges may be non-contiguous, a version might not be
greater than a range, less than a range, *or* satisfy a range! For
example, the range `1.2 <1.2.9 || >2.0.0` would have a hole from `1.2.9`
until `2.0.0`, so the version `1.2.10` would not be greater than the
range (because `2.0.1` satisfies, which is higher), nor less than the
range (since `1.2.8` satisfies, which is lower), and it also does not
satisfy the range.
If you want to know if a version satisfies or does not satisfy a
range, use the `satisfies(version, range)` function.
### Coercion
* `coerce(version, options)`: Coerces a string to semver if possible
This aims to provide a very forgiving translation of a non-semver string to
semver. It looks for the first digit in a string, and consumes all
remaining characters which satisfy at least a partial semver (e.g., `1`,
`1.2`, `1.2.3`) up to the max permitted length (256 characters). Longer
versions are simply truncated (`4.6.3.9.2-alpha2` becomes `4.6.3`). All
surrounding text is simply ignored (`v3.4 replaces v3.3.1` becomes
`3.4.0`). Only text which lacks digits will fail coercion (`version one`
is not valid). The maximum length for any semver component considered for
coercion is 16 characters; longer components will be ignored
(`10000000000000000.4.7.4` becomes `4.7.4`). The maximum value for any
semver component is `Number.MAX_SAFE_INTEGER || (2**53 - 1)`; higher value
components are invalid (`9999999999999999.4.7.4` is likely invalid).
If the `options.rtl` flag is set, then `coerce` will return the right-most
coercible tuple that does not share an ending index with a longer coercible
tuple. For example, `1.2.3.4` will return `2.3.4` in rtl mode, not
`4.0.0`. `1.2.3/4` will return `4.0.0`, because the `4` is not a part of
any other overlapping SemVer tuple.
### Clean
* `clean(version)`: Clean a string to be a valid semver if possible
This will return a cleaned and trimmed semver version. If the provided
version is not valid a null will be returned. This does not work for
ranges.
ex.
* `s.clean(' = v 2.1.5foo')`: `null`
* `s.clean(' = v 2.1.5foo', { loose: true })`: `'2.1.5-foo'`
* `s.clean(' = v 2.1.5-foo')`: `null`
* `s.clean(' = v 2.1.5-foo', { loose: true })`: `'2.1.5-foo'`
* `s.clean('=v2.1.5')`: `'2.1.5'`
* `s.clean(' =v2.1.5')`: `2.1.5`
* `s.clean(' 2.1.5 ')`: `'2.1.5'`
* `s.clean('~1.0.0')`: `null`
## Exported Modules
<!--
TODO: Make sure that all of these items are documented (classes aren't,
eg), and then pull the module name into the documentation for that specific
thing.
-->
You may pull in just the part of this semver utility that you need, if you
are sensitive to packing and tree-shaking concerns. The main
`require('semver')` export uses getter functions to lazily load the parts
of the API that are used.
The following modules are available:
* `require('semver')`
* `require('semver/classes')`
* `require('semver/classes/comparator')`
* `require('semver/classes/range')`
* `require('semver/classes/semver')`
* `require('semver/functions/clean')`
* `require('semver/functions/cmp')`
* `require('semver/functions/coerce')`
* `require('semver/functions/compare')`
* `require('semver/functions/compare-build')`
* `require('semver/functions/compare-loose')`
* `require('semver/functions/diff')`
* `require('semver/functions/eq')`
* `require('semver/functions/gt')`
* `require('semver/functions/gte')`
* `require('semver/functions/inc')`
* `require('semver/functions/lt')`
* `require('semver/functions/lte')`
* `require('semver/functions/major')`
* `require('semver/functions/minor')`
* `require('semver/functions/neq')`
* `require('semver/functions/parse')`
* `require('semver/functions/patch')`
* `require('semver/functions/prerelease')`
* `require('semver/functions/rcompare')`
* `require('semver/functions/rsort')`
* `require('semver/functions/satisfies')`
* `require('semver/functions/sort')`
* `require('semver/functions/valid')`
* `require('semver/ranges/gtr')`
* `require('semver/ranges/intersects')`
* `require('semver/ranges/ltr')`
* `require('semver/ranges/max-satisfying')`
* `require('semver/ranges/min-satisfying')`
* `require('semver/ranges/min-version')`
* `require('semver/ranges/outside')`
* `require('semver/ranges/to-comparators')`
* `require('semver/ranges/valid')`
# AssemblyScript Loader
A convenient loader for [AssemblyScript](https://assemblyscript.org) modules. Demangles module exports to a friendly object structure compatible with TypeScript definitions and provides useful utility to read/write data from/to memory.
[Documentation](https://assemblyscript.org/loader.html)
# axios
[](https://www.npmjs.org/package/axios)
[](https://travis-ci.org/axios/axios)
[](https://coveralls.io/r/mzabriskie/axios)
[](https://packagephobia.now.sh/result?p=axios)
[](http://npm-stat.com/charts.html?package=axios)
[](https://gitter.im/mzabriskie/axios)
[](https://www.codetriage.com/axios/axios)
Promise based HTTP client for the browser and node.js
## Features
- Make [XMLHttpRequests](https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest) from the browser
- Make [http](http://nodejs.org/api/http.html) requests from node.js
- Supports the [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) API
- Intercept request and response
- Transform request and response data
- Cancel requests
- Automatic transforms for JSON data
- Client side support for protecting against [XSRF](http://en.wikipedia.org/wiki/Cross-site_request_forgery)
## Browser Support
 |  |  |  |  |  |
--- | --- | --- | --- | --- | --- |
Latest ✔ | Latest ✔ | Latest ✔ | Latest ✔ | Latest ✔ | 11 ✔ |
[](https://saucelabs.com/u/axios)
## Installing
Using npm:
```bash
$ npm install axios
```
Using bower:
```bash
$ bower install axios
```
Using yarn:
```bash
$ yarn add axios
```
Using cdn:
```html
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
```
## Example
### note: CommonJS usage
In order to gain the TypeScript typings (for intellisense / autocomplete) while using CommonJS imports with `require()` use the following approach:
```js
const axios = require('axios').default;
// axios.<method> will now provide autocomplete and parameter typings
```
Performing a `GET` request
```js
const axios = require('axios');
// Make a request for a user with a given ID
axios.get('/user?ID=12345')
.then(function (response) {
// handle success
console.log(response);
})
.catch(function (error) {
// handle error
console.log(error);
})
.finally(function () {
// always executed
});
// Optionally the request above could also be done as
axios.get('/user', {
params: {
ID: 12345
}
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
})
.finally(function () {
// always executed
});
// Want to use async/await? Add the `async` keyword to your outer function/method.
async function getUser() {
try {
const response = await axios.get('/user?ID=12345');
console.log(response);
} catch (error) {
console.error(error);
}
}
```
> **NOTE:** `async/await` is part of ECMAScript 2017 and is not supported in Internet
> Explorer and older browsers, so use with caution.
Performing a `POST` request
```js
axios.post('/user', {
firstName: 'Fred',
lastName: 'Flintstone'
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
```
Performing multiple concurrent requests
```js
function getUserAccount() {
return axios.get('/user/12345');
}
function getUserPermissions() {
return axios.get('/user/12345/permissions');
}
axios.all([getUserAccount(), getUserPermissions()])
.then(axios.spread(function (acct, perms) {
// Both requests are now complete
}));
```
## axios API
Requests can be made by passing the relevant config to `axios`.
##### axios(config)
```js
// Send a POST request
axios({
method: 'post',
url: '/user/12345',
data: {
firstName: 'Fred',
lastName: 'Flintstone'
}
});
```
```js
// GET request for remote image
axios({
method: 'get',
url: 'http://bit.ly/2mTM3nY',
responseType: 'stream'
})
.then(function (response) {
response.data.pipe(fs.createWriteStream('ada_lovelace.jpg'))
});
```
##### axios(url[, config])
```js
// Send a GET request (default method)
axios('/user/12345');
```
### Request method aliases
For convenience aliases have been provided for all supported request methods.
##### axios.request(config)
##### axios.get(url[, config])
##### axios.delete(url[, config])
##### axios.head(url[, config])
##### axios.options(url[, config])
##### axios.post(url[, data[, config]])
##### axios.put(url[, data[, config]])
##### axios.patch(url[, data[, config]])
###### NOTE
When using the alias methods `url`, `method`, and `data` properties don't need to be specified in config.
### Concurrency
Helper functions for dealing with concurrent requests.
##### axios.all(iterable)
##### axios.spread(callback)
### Creating an instance
You can create a new instance of axios with a custom config.
##### axios.create([config])
```js
const instance = axios.create({
baseURL: 'https://some-domain.com/api/',
timeout: 1000,
headers: {'X-Custom-Header': 'foobar'}
});
```
### Instance methods
The available instance methods are listed below. The specified config will be merged with the instance config.
##### axios#request(config)
##### axios#get(url[, config])
##### axios#delete(url[, config])
##### axios#head(url[, config])
##### axios#options(url[, config])
##### axios#post(url[, data[, config]])
##### axios#put(url[, data[, config]])
##### axios#patch(url[, data[, config]])
##### axios#getUri([config])
## Request Config
These are the available config options for making requests. Only the `url` is required. Requests will default to `GET` if `method` is not specified.
```js
{
// `url` is the server URL that will be used for the request
url: '/user',
// `method` is the request method to be used when making the request
method: 'get', // default
// `baseURL` will be prepended to `url` unless `url` is absolute.
// It can be convenient to set `baseURL` for an instance of axios to pass relative URLs
// to methods of that instance.
baseURL: 'https://some-domain.com/api/',
// `transformRequest` allows changes to the request data before it is sent to the server
// This is only applicable for request methods 'PUT', 'POST', 'PATCH' and 'DELETE'
// The last function in the array must return a string or an instance of Buffer, ArrayBuffer,
// FormData or Stream
// You may modify the headers object.
transformRequest: [function (data, headers) {
// Do whatever you want to transform the data
return data;
}],
// `transformResponse` allows changes to the response data to be made before
// it is passed to then/catch
transformResponse: [function (data) {
// Do whatever you want to transform the data
return data;
}],
// `headers` are custom headers to be sent
headers: {'X-Requested-With': 'XMLHttpRequest'},
// `params` are the URL parameters to be sent with the request
// Must be a plain object or a URLSearchParams object
params: {
ID: 12345
},
// `paramsSerializer` is an optional function in charge of serializing `params`
// (e.g. https://www.npmjs.com/package/qs, http://api.jquery.com/jquery.param/)
paramsSerializer: function (params) {
return Qs.stringify(params, {arrayFormat: 'brackets'})
},
// `data` is the data to be sent as the request body
// Only applicable for request methods 'PUT', 'POST', and 'PATCH'
// When no `transformRequest` is set, must be of one of the following types:
// - string, plain object, ArrayBuffer, ArrayBufferView, URLSearchParams
// - Browser only: FormData, File, Blob
// - Node only: Stream, Buffer
data: {
firstName: 'Fred'
},
// syntax alternative to send data into the body
// method post
// only the value is sent, not the key
data: 'Country=Brasil&City=Belo Horizonte',
// `timeout` specifies the number of milliseconds before the request times out.
// If the request takes longer than `timeout`, the request will be aborted.
timeout: 1000, // default is `0` (no timeout)
// `withCredentials` indicates whether or not cross-site Access-Control requests
// should be made using credentials
withCredentials: false, // default
// `adapter` allows custom handling of requests which makes testing easier.
// Return a promise and supply a valid response (see lib/adapters/README.md).
adapter: function (config) {
/* ... */
},
// `auth` indicates that HTTP Basic auth should be used, and supplies credentials.
// This will set an `Authorization` header, overwriting any existing
// `Authorization` custom headers you have set using `headers`.
// Please note that only HTTP Basic auth is configurable through this parameter.
// For Bearer tokens and such, use `Authorization` custom headers instead.
auth: {
username: 'janedoe',
password: 's00pers3cret'
},
// `responseType` indicates the type of data that the server will respond with
// options are: 'arraybuffer', 'document', 'json', 'text', 'stream'
// browser only: 'blob'
responseType: 'json', // default
// `responseEncoding` indicates encoding to use for decoding responses
// Note: Ignored for `responseType` of 'stream' or client-side requests
responseEncoding: 'utf8', // default
// `xsrfCookieName` is the name of the cookie to use as a value for xsrf token
xsrfCookieName: 'XSRF-TOKEN', // default
// `xsrfHeaderName` is the name of the http header that carries the xsrf token value
xsrfHeaderName: 'X-XSRF-TOKEN', // default
// `onUploadProgress` allows handling of progress events for uploads
onUploadProgress: function (progressEvent) {
// Do whatever you want with the native progress event
},
// `onDownloadProgress` allows handling of progress events for downloads
onDownloadProgress: function (progressEvent) {
// Do whatever you want with the native progress event
},
// `maxContentLength` defines the max size of the http response content in bytes allowed
maxContentLength: 2000,
// `validateStatus` defines whether to resolve or reject the promise for a given
// HTTP response status code. If `validateStatus` returns `true` (or is set to `null`
// or `undefined`), the promise will be resolved; otherwise, the promise will be
// rejected.
validateStatus: function (status) {
return status >= 200 && status < 300; // default
},
// `maxRedirects` defines the maximum number of redirects to follow in node.js.
// If set to 0, no redirects will be followed.
maxRedirects: 5, // default
// `socketPath` defines a UNIX Socket to be used in node.js.
// e.g. '/var/run/docker.sock' to send requests to the docker daemon.
// Only either `socketPath` or `proxy` can be specified.
// If both are specified, `socketPath` is used.
socketPath: null, // default
// `httpAgent` and `httpsAgent` define a custom agent to be used when performing http
// and https requests, respectively, in node.js. This allows options to be added like
// `keepAlive` that are not enabled by default.
httpAgent: new http.Agent({ keepAlive: true }),
httpsAgent: new https.Agent({ keepAlive: true }),
// 'proxy' defines the hostname and port of the proxy server.
// You can also define your proxy using the conventional `http_proxy` and
// `https_proxy` environment variables. If you are using environment variables
// for your proxy configuration, you can also define a `no_proxy` environment
// variable as a comma-separated list of domains that should not be proxied.
// Use `false` to disable proxies, ignoring environment variables.
// `auth` indicates that HTTP Basic auth should be used to connect to the proxy, and
// supplies credentials.
// This will set an `Proxy-Authorization` header, overwriting any existing
// `Proxy-Authorization` custom headers you have set using `headers`.
proxy: {
host: '127.0.0.1',
port: 9000,
auth: {
username: 'mikeymike',
password: 'rapunz3l'
}
},
// `cancelToken` specifies a cancel token that can be used to cancel the request
// (see Cancellation section below for details)
cancelToken: new CancelToken(function (cancel) {
})
}
```
## Response Schema
The response for a request contains the following information.
```js
{
// `data` is the response that was provided by the server
data: {},
// `status` is the HTTP status code from the server response
status: 200,
// `statusText` is the HTTP status message from the server response
statusText: 'OK',
// `headers` the headers that the server responded with
// All header names are lower cased
headers: {},
// `config` is the config that was provided to `axios` for the request
config: {},
// `request` is the request that generated this response
// It is the last ClientRequest instance in node.js (in redirects)
// and an XMLHttpRequest instance in the browser
request: {}
}
```
When using `then`, you will receive the response as follows:
```js
axios.get('/user/12345')
.then(function (response) {
console.log(response.data);
console.log(response.status);
console.log(response.statusText);
console.log(response.headers);
console.log(response.config);
});
```
When using `catch`, or passing a [rejection callback](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise/then) as second parameter of `then`, the response will be available through the `error` object as explained in the [Handling Errors](#handling-errors) section.
## Config Defaults
You can specify config defaults that will be applied to every request.
### Global axios defaults
```js
axios.defaults.baseURL = 'https://api.example.com';
axios.defaults.headers.common['Authorization'] = AUTH_TOKEN;
axios.defaults.headers.post['Content-Type'] = 'application/x-www-form-urlencoded';
```
### Custom instance defaults
```js
// Set config defaults when creating the instance
const instance = axios.create({
baseURL: 'https://api.example.com'
});
// Alter defaults after instance has been created
instance.defaults.headers.common['Authorization'] = AUTH_TOKEN;
```
### Config order of precedence
Config will be merged with an order of precedence. The order is library defaults found in [lib/defaults.js](https://github.com/axios/axios/blob/master/lib/defaults.js#L28), then `defaults` property of the instance, and finally `config` argument for the request. The latter will take precedence over the former. Here's an example.
```js
// Create an instance using the config defaults provided by the library
// At this point the timeout config value is `0` as is the default for the library
const instance = axios.create();
// Override timeout default for the library
// Now all requests using this instance will wait 2.5 seconds before timing out
instance.defaults.timeout = 2500;
// Override timeout for this request as it's known to take a long time
instance.get('/longRequest', {
timeout: 5000
});
```
## Interceptors
You can intercept requests or responses before they are handled by `then` or `catch`.
```js
// Add a request interceptor
axios.interceptors.request.use(function (config) {
// Do something before request is sent
return config;
}, function (error) {
// Do something with request error
return Promise.reject(error);
});
// Add a response interceptor
axios.interceptors.response.use(function (response) {
// Any status code that lie within the range of 2xx cause this function to trigger
// Do something with response data
return response;
}, function (error) {
// Any status codes that falls outside the range of 2xx cause this function to trigger
// Do something with response error
return Promise.reject(error);
});
```
If you need to remove an interceptor later you can.
```js
const myInterceptor = axios.interceptors.request.use(function () {/*...*/});
axios.interceptors.request.eject(myInterceptor);
```
You can add interceptors to a custom instance of axios.
```js
const instance = axios.create();
instance.interceptors.request.use(function () {/*...*/});
```
## Handling Errors
```js
axios.get('/user/12345')
.catch(function (error) {
if (error.response) {
// The request was made and the server responded with a status code
// that falls out of the range of 2xx
console.log(error.response.data);
console.log(error.response.status);
console.log(error.response.headers);
} else if (error.request) {
// The request was made but no response was received
// `error.request` is an instance of XMLHttpRequest in the browser and an instance of
// http.ClientRequest in node.js
console.log(error.request);
} else {
// Something happened in setting up the request that triggered an Error
console.log('Error', error.message);
}
console.log(error.config);
});
```
Using the `validateStatus` config option, you can define HTTP code(s) that should throw an error.
```js
axios.get('/user/12345', {
validateStatus: function (status) {
return status < 500; // Reject only if the status code is greater than or equal to 500
}
})
```
Using `toJSON` you get an object with more information about the HTTP error.
```js
axios.get('/user/12345')
.catch(function (error) {
console.log(error.toJSON());
});
```
## Cancellation
You can cancel a request using a *cancel token*.
> The axios cancel token API is based on the withdrawn [cancelable promises proposal](https://github.com/tc39/proposal-cancelable-promises).
You can create a cancel token using the `CancelToken.source` factory as shown below:
```js
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.get('/user/12345', {
cancelToken: source.token
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// handle error
}
});
axios.post('/user/12345', {
name: 'new name'
}, {
cancelToken: source.token
})
// cancel the request (the message parameter is optional)
source.cancel('Operation canceled by the user.');
```
You can also create a cancel token by passing an executor function to the `CancelToken` constructor:
```js
const CancelToken = axios.CancelToken;
let cancel;
axios.get('/user/12345', {
cancelToken: new CancelToken(function executor(c) {
// An executor function receives a cancel function as a parameter
cancel = c;
})
});
// cancel the request
cancel();
```
> Note: you can cancel several requests with the same cancel token.
## Using application/x-www-form-urlencoded format
By default, axios serializes JavaScript objects to `JSON`. To send data in the `application/x-www-form-urlencoded` format instead, you can use one of the following options.
### Browser
In a browser, you can use the [`URLSearchParams`](https://developer.mozilla.org/en-US/docs/Web/API/URLSearchParams) API as follows:
```js
const params = new URLSearchParams();
params.append('param1', 'value1');
params.append('param2', 'value2');
axios.post('/foo', params);
```
> Note that `URLSearchParams` is not supported by all browsers (see [caniuse.com](http://www.caniuse.com/#feat=urlsearchparams)), but there is a [polyfill](https://github.com/WebReflection/url-search-params) available (make sure to polyfill the global environment).
Alternatively, you can encode data using the [`qs`](https://github.com/ljharb/qs) library:
```js
const qs = require('qs');
axios.post('/foo', qs.stringify({ 'bar': 123 }));
```
Or in another way (ES6),
```js
import qs from 'qs';
const data = { 'bar': 123 };
const options = {
method: 'POST',
headers: { 'content-type': 'application/x-www-form-urlencoded' },
data: qs.stringify(data),
url,
};
axios(options);
```
### Node.js
In node.js, you can use the [`querystring`](https://nodejs.org/api/querystring.html) module as follows:
```js
const querystring = require('querystring');
axios.post('http://something.com/', querystring.stringify({ foo: 'bar' }));
```
You can also use the [`qs`](https://github.com/ljharb/qs) library.
###### NOTE
The `qs` library is preferable if you need to stringify nested objects, as the `querystring` method has known issues with that use case (https://github.com/nodejs/node-v0.x-archive/issues/1665).
## Semver
Until axios reaches a `1.0` release, breaking changes will be released with a new minor version. For example `0.5.1`, and `0.5.4` will have the same API, but `0.6.0` will have breaking changes.
## Promises
axios depends on a native ES6 Promise implementation to be [supported](http://caniuse.com/promises).
If your environment doesn't support ES6 Promises, you can [polyfill](https://github.com/jakearchibald/es6-promise).
## TypeScript
axios includes [TypeScript](http://typescriptlang.org) definitions.
```typescript
import axios from 'axios';
axios.get('/user?ID=12345');
```
## Resources
* [Changelog](https://github.com/axios/axios/blob/master/CHANGELOG.md)
* [Upgrade Guide](https://github.com/axios/axios/blob/master/UPGRADE_GUIDE.md)
* [Ecosystem](https://github.com/axios/axios/blob/master/ECOSYSTEM.md)
* [Contributing Guide](https://github.com/axios/axios/blob/master/CONTRIBUTING.md)
* [Code of Conduct](https://github.com/axios/axios/blob/master/CODE_OF_CONDUCT.md)
## Credits
axios is heavily inspired by the [$http service](https://docs.angularjs.org/api/ng/service/$http) provided in [Angular](https://angularjs.org/). Ultimately axios is an effort to provide a standalone `$http`-like service for use outside of Angular.
## License
[MIT](LICENSE)
Shims used when bundling asc for browser usage.
# line-column
[](https://travis-ci.org/io-monad/line-column) [](https://coveralls.io/github/io-monad/line-column?branch=master) [](https://badge.fury.io/js/line-column)
Node module to convert efficiently index to/from line-column in a string.
## Install
npm install line-column
## Usage
### lineColumn(str, options = {})
Returns a `LineColumnFinder` instance for given string `str`.
#### Options
| Key | Description | Default |
| ------- | ----------- | ------- |
| `origin` | The origin value of line number and column number | `1` |
### lineColumn(str, index)
This is just a shorthand for `lineColumn(str).fromIndex(index)`.
### LineColumnFinder#fromIndex(index)
Find line and column from index in the string.
Parameters:
- `index` - `number` Index in the string. (0-origin)
Returns:
- `{ line: x, col: y }` Found line number and column number.
- `null` if the given index is out of range.
### LineColumnFinder#toIndex(line, column)
Find index from line and column in the string.
Parameters:
- `line` - `number` Line number in the string.
- `column` - `number` Column number in the string.
or
- `{ line: x, col: y }` - `Object` line and column numbers in the string.<br>A key name `column` can be used instead of `col`.
or
- `[ line, col ]` - `Array` line and column numbers in the string.
Returns:
- `number` Found index in the string.
- `-1` if the given line or column is out of range.
## Example
```js
var lineColumn = require("line-column");
var testString = [
"ABCDEFG\n", // line:0, index:0
"HIJKLMNOPQRSTU\n", // line:1, index:8
"VWXYZ\n", // line:2, index:23
"日本語の文字\n", // line:3, index:29
"English words" // line:4, index:36
].join(""); // length:49
lineColumn(testString).fromIndex(3) // { line: 1, col: 4 }
lineColumn(testString).fromIndex(33) // { line: 4, col: 5 }
lineColumn(testString).toIndex(1, 4) // 3
lineColumn(testString).toIndex(4, 5) // 33
// Shorthand of .fromIndex (compatible with find-line-column)
lineColumn(testString, 33) // { line:4, col: 5 }
// Object or Array is also acceptable
lineColumn(testString).toIndex({ line: 4, col: 5 }) // 33
lineColumn(testString).toIndex({ line: 4, column: 5 }) // 33
lineColumn(testString).toIndex([4, 5]) // 33
// You can cache it for the same string. It is so efficient. (See benchmark)
var finder = lineColumn(testString);
finder.fromIndex(33) // { line: 4, column: 5 }
finder.toIndex(4, 5) // 33
// For 0-origin line and column numbers
var oneOrigin = lineColumn(testString, { origin: 0 });
oneOrigin.fromIndex(33) // { line: 3, column: 4 }
oneOrigin.toIndex(3, 4) // 33
```
## Testing
npm test
## Benchmark
The popular package [find-line-column](https://www.npmjs.com/package/find-line-column) provides the same "index to line-column" feature.
Here is some benchmarking on `line-column` vs `find-line-column`. You can run this benchmark by `npm run benchmark`. See [benchmark/](benchmark/) for the source code.
```
long text + line-column (not cached) x 72,989 ops/sec ±0.83% (89 runs sampled)
long text + line-column (cached) x 13,074,242 ops/sec ±0.32% (89 runs sampled)
long text + find-line-column x 33,887 ops/sec ±0.54% (84 runs sampled)
short text + line-column (not cached) x 1,636,766 ops/sec ±0.77% (82 runs sampled)
short text + line-column (cached) x 21,699,686 ops/sec ±1.04% (82 runs sampled)
short text + find-line-column x 382,145 ops/sec ±1.04% (85 runs sampled)
```
As you might have noticed, even not cached version of `line-column` is 2x - 4x faster than `find-line-column`, and cached version of `line-column` is remarkable 50x - 380x faster.
## Contributing
1. Fork it!
2. Create your feature branch: `git checkout -b my-new-feature`
3. Commit your changes: `git commit -am 'Add some feature'`
4. Push to the branch: `git push origin my-new-feature`
5. Submit a pull request :D
## License
MIT (See LICENSE)
# eslint-visitor-keys
[](https://www.npmjs.com/package/eslint-visitor-keys)
[](http://www.npmtrends.com/eslint-visitor-keys)
[](https://travis-ci.org/eslint/eslint-visitor-keys)
[](https://david-dm.org/eslint/eslint-visitor-keys)
Constants and utilities about visitor keys to traverse AST.
## 💿 Installation
Use [npm] to install.
```bash
$ npm install eslint-visitor-keys
```
### Requirements
- [Node.js] 10.0.0 or later.
## 📖 Usage
```js
const evk = require("eslint-visitor-keys")
```
### evk.KEYS
> type: `{ [type: string]: string[] | undefined }`
Visitor keys. This keys are frozen.
This is an object. Keys are the type of [ESTree] nodes. Their values are an array of property names which have child nodes.
For example:
```
console.log(evk.KEYS.AssignmentExpression) // → ["left", "right"]
```
### evk.getKeys(node)
> type: `(node: object) => string[]`
Get the visitor keys of a given AST node.
This is similar to `Object.keys(node)` of ES Standard, but some keys are excluded: `parent`, `leadingComments`, `trailingComments`, and names which start with `_`.
This will be used to traverse unknown nodes.
For example:
```
const node = {
type: "AssignmentExpression",
left: { type: "Identifier", name: "foo" },
right: { type: "Literal", value: 0 }
}
console.log(evk.getKeys(node)) // → ["type", "left", "right"]
```
### evk.unionWith(additionalKeys)
> type: `(additionalKeys: object) => { [type: string]: string[] | undefined }`
Make the union set with `evk.KEYS` and the given keys.
- The order of keys is, `additionalKeys` is at first, then `evk.KEYS` is concatenated after that.
- It removes duplicated keys as keeping the first one.
For example:
```
console.log(evk.unionWith({
MethodDefinition: ["decorators"]
})) // → { ..., MethodDefinition: ["decorators", "key", "value"], ... }
```
## 📰 Change log
See [GitHub releases](https://github.com/eslint/eslint-visitor-keys/releases).
## 🍻 Contributing
Welcome. See [ESLint contribution guidelines](https://eslint.org/docs/developer-guide/contributing/).
### Development commands
- `npm test` runs tests and measures code coverage.
- `npm run lint` checks source codes with ESLint.
- `npm run coverage` opens the code coverage report of the previous test with your default browser.
- `npm run release` publishes this package to [npm] registory.
[npm]: https://www.npmjs.com/
[Node.js]: https://nodejs.org/en/
[ESTree]: https://github.com/estree/estree
argparse
========
[](http://travis-ci.org/nodeca/argparse)
[](https://www.npmjs.org/package/argparse)
CLI arguments parser for node.js. Javascript port of python's
[argparse](http://docs.python.org/dev/library/argparse.html) module
(original version 3.2). That's a full port, except some very rare options,
recorded in issue tracker.
**NB. Difference with original.**
- Method names changed to camelCase. See [generated docs](http://nodeca.github.com/argparse/).
- Use `defaultValue` instead of `default`.
- Use `argparse.Const.REMAINDER` instead of `argparse.REMAINDER`, and
similarly for constant values `OPTIONAL`, `ZERO_OR_MORE`, and `ONE_OR_MORE`
(aliases for `nargs` values `'?'`, `'*'`, `'+'`, respectively), and
`SUPPRESS`.
Example
=======
test.js file:
```javascript
#!/usr/bin/env node
'use strict';
var ArgumentParser = require('../lib/argparse').ArgumentParser;
var parser = new ArgumentParser({
version: '0.0.1',
addHelp:true,
description: 'Argparse example'
});
parser.addArgument(
[ '-f', '--foo' ],
{
help: 'foo bar'
}
);
parser.addArgument(
[ '-b', '--bar' ],
{
help: 'bar foo'
}
);
parser.addArgument(
'--baz',
{
help: 'baz bar'
}
);
var args = parser.parseArgs();
console.dir(args);
```
Display help:
```
$ ./test.js -h
usage: example.js [-h] [-v] [-f FOO] [-b BAR] [--baz BAZ]
Argparse example
Optional arguments:
-h, --help Show this help message and exit.
-v, --version Show program's version number and exit.
-f FOO, --foo FOO foo bar
-b BAR, --bar BAR bar foo
--baz BAZ baz bar
```
Parse arguments:
```
$ ./test.js -f=3 --bar=4 --baz 5
{ foo: '3', bar: '4', baz: '5' }
```
More [examples](https://github.com/nodeca/argparse/tree/master/examples).
ArgumentParser objects
======================
```
new ArgumentParser({parameters hash});
```
Creates a new ArgumentParser object.
**Supported params:**
- ```description``` - Text to display before the argument help.
- ```epilog``` - Text to display after the argument help.
- ```addHelp``` - Add a -h/–help option to the parser. (default: true)
- ```argumentDefault``` - Set the global default value for arguments. (default: null)
- ```parents``` - A list of ArgumentParser objects whose arguments should also be included.
- ```prefixChars``` - The set of characters that prefix optional arguments. (default: ‘-‘)
- ```formatterClass``` - A class for customizing the help output.
- ```prog``` - The name of the program (default: `path.basename(process.argv[1])`)
- ```usage``` - The string describing the program usage (default: generated)
- ```conflictHandler``` - Usually unnecessary, defines strategy for resolving conflicting optionals.
**Not supported yet**
- ```fromfilePrefixChars``` - The set of characters that prefix files from which additional arguments should be read.
Details in [original ArgumentParser guide](http://docs.python.org/dev/library/argparse.html#argumentparser-objects)
addArgument() method
====================
```
ArgumentParser.addArgument(name or flag or [name] or [flags...], {options})
```
Defines how a single command-line argument should be parsed.
- ```name or flag or [name] or [flags...]``` - Either a positional name
(e.g., `'foo'`), a single option (e.g., `'-f'` or `'--foo'`), an array
of a single positional name (e.g., `['foo']`), or an array of options
(e.g., `['-f', '--foo']`).
Options:
- ```action``` - The basic type of action to be taken when this argument is encountered at the command line.
- ```nargs```- The number of command-line arguments that should be consumed.
- ```constant``` - A constant value required by some action and nargs selections.
- ```defaultValue``` - The value produced if the argument is absent from the command line.
- ```type``` - The type to which the command-line argument should be converted.
- ```choices``` - A container of the allowable values for the argument.
- ```required``` - Whether or not the command-line option may be omitted (optionals only).
- ```help``` - A brief description of what the argument does.
- ```metavar``` - A name for the argument in usage messages.
- ```dest``` - The name of the attribute to be added to the object returned by parseArgs().
Details in [original add_argument guide](http://docs.python.org/dev/library/argparse.html#the-add-argument-method)
Action (some details)
================
ArgumentParser objects associate command-line arguments with actions.
These actions can do just about anything with the command-line arguments associated
with them, though most actions simply add an attribute to the object returned by
parseArgs(). The action keyword argument specifies how the command-line arguments
should be handled. The supported actions are:
- ```store``` - Just stores the argument’s value. This is the default action.
- ```storeConst``` - Stores value, specified by the const keyword argument.
(Note that the const keyword argument defaults to the rather unhelpful None.)
The 'storeConst' action is most commonly used with optional arguments, that
specify some sort of flag.
- ```storeTrue``` and ```storeFalse``` - Stores values True and False
respectively. These are special cases of 'storeConst'.
- ```append``` - Stores a list, and appends each argument value to the list.
This is useful to allow an option to be specified multiple times.
- ```appendConst``` - Stores a list, and appends value, specified by the
const keyword argument to the list. (Note, that the const keyword argument defaults
is None.) The 'appendConst' action is typically used when multiple arguments need
to store constants to the same list.
- ```count``` - Counts the number of times a keyword argument occurs. For example,
used for increasing verbosity levels.
- ```help``` - Prints a complete help message for all the options in the current
parser and then exits. By default a help action is automatically added to the parser.
See ArgumentParser for details of how the output is created.
- ```version``` - Prints version information and exit. Expects a `version=`
keyword argument in the addArgument() call.
Details in [original action guide](http://docs.python.org/dev/library/argparse.html#action)
Sub-commands
============
ArgumentParser.addSubparsers()
Many programs split their functionality into a number of sub-commands, for
example, the svn program can invoke sub-commands like `svn checkout`, `svn update`,
and `svn commit`. Splitting up functionality this way can be a particularly good
idea when a program performs several different functions which require different
kinds of command-line arguments. `ArgumentParser` supports creation of such
sub-commands with `addSubparsers()` method. The `addSubparsers()` method is
normally called with no arguments and returns an special action object.
This object has a single method `addParser()`, which takes a command name and
any `ArgumentParser` constructor arguments, and returns an `ArgumentParser` object
that can be modified as usual.
Example:
sub_commands.js
```javascript
#!/usr/bin/env node
'use strict';
var ArgumentParser = require('../lib/argparse').ArgumentParser;
var parser = new ArgumentParser({
version: '0.0.1',
addHelp:true,
description: 'Argparse examples: sub-commands',
});
var subparsers = parser.addSubparsers({
title:'subcommands',
dest:"subcommand_name"
});
var bar = subparsers.addParser('c1', {addHelp:true});
bar.addArgument(
[ '-f', '--foo' ],
{
action: 'store',
help: 'foo3 bar3'
}
);
var bar = subparsers.addParser(
'c2',
{aliases:['co'], addHelp:true}
);
bar.addArgument(
[ '-b', '--bar' ],
{
action: 'store',
type: 'int',
help: 'foo3 bar3'
}
);
var args = parser.parseArgs();
console.dir(args);
```
Details in [original sub-commands guide](http://docs.python.org/dev/library/argparse.html#sub-commands)
Contributors
============
- [Eugene Shkuropat](https://github.com/shkuropat)
- [Paul Jacobson](https://github.com/hpaulj)
[others](https://github.com/nodeca/argparse/graphs/contributors)
License
=======
Copyright (c) 2012 [Vitaly Puzrin](https://github.com/puzrin).
Released under the MIT license. See
[LICENSE](https://github.com/nodeca/argparse/blob/master/LICENSE) for details.
# randexp.js
randexp will generate a random string that matches a given RegExp Javascript object.
[](http://travis-ci.org/fent/randexp.js)
[](https://david-dm.org/fent/randexp.js)
[](https://codecov.io/gh/fent/randexp.js)
# Usage
```js
var RandExp = require('randexp');
// supports grouping and piping
new RandExp(/hello+ (world|to you)/).gen();
// => hellooooooooooooooooooo world
// sets and ranges and references
new RandExp(/<([a-z]\w{0,20})>foo<\1>/).gen();
// => <m5xhdg>foo<m5xhdg>
// wildcard
new RandExp(/random stuff: .+/).gen();
// => random stuff: l3m;Hf9XYbI [YPaxV>U*4-_F!WXQh9>;rH3i l!8.zoh?[utt1OWFQrE ^~8zEQm]~tK
// ignore case
new RandExp(/xxx xtreme dragon warrior xxx/i).gen();
// => xxx xtReME dRAGON warRiOR xXX
// dynamic regexp shortcut
new RandExp('(sun|mon|tue|wednes|thurs|fri|satur)day', 'i');
// is the same as
new RandExp(new RegExp('(sun|mon|tue|wednes|thurs|fri|satur)day', 'i'));
```
If you're only going to use `gen()` once with a regexp and want slightly shorter syntax for it
```js
var randexp = require('randexp').randexp;
randexp(/[1-6]/); // 4
randexp('great|good( job)?|excellent'); // great
```
If you miss the old syntax
```js
require('randexp').sugar();
/yes|no|maybe|i don't know/.gen(); // maybe
```
# Motivation
Regular expressions are used in every language, every programmer is familiar with them. Regex can be used to easily express complex strings. What better way to generate a random string than with a language you can use to express the string you want?
Thanks to [String-Random](http://search.cpan.org/~steve/String-Random-0.22/lib/String/Random.pm) for giving me the idea to make this in the first place and [randexp](https://github.com/benburkert/randexp) for the sweet `.gen()` syntax.
# Default Range
The default generated character range includes printable ASCII. In order to add or remove characters,
a `defaultRange` attribute is exposed. you can `subtract(from, to)` and `add(from, to)`
```js
var randexp = new RandExp(/random stuff: .+/);
randexp.defaultRange.subtract(32, 126);
randexp.defaultRange.add(0, 65535);
randexp.gen();
// => random stuff: 湐箻ໜ䫴㳸長���邓蕲뤀쑡篷皇硬剈궦佔칗븛뀃匫鴔事좍ﯣ⭼ꝏ䭍詳蒂䥂뽭
```
# Custom PRNG
The default randomness is provided by `Math.random()`. If you need to use a seedable or cryptographic PRNG, you
can override `RandExp.prototype.randInt` or `randexp.randInt` (where `randexp` is an instance of `RandExp`). `randInt(from, to)` accepts an inclusive range and returns a randomly selected
number within that range.
# Infinite Repetitionals
Repetitional tokens such as `*`, `+`, and `{3,}` have an infinite max range. In this case, randexp looks at its min and adds 100 to it to get a useable max value. If you want to use another int other than 100 you can change the `max` property in `RandExp.prototype` or the RandExp instance.
```js
var randexp = new RandExp(/no{1,}/);
randexp.max = 1000000;
```
With `RandExp.sugar()`
```js
var regexp = /(hi)*/;
regexp.max = 1000000;
```
# Bad Regular Expressions
There are some regular expressions which can never match any string.
* Ones with badly placed positionals such as `/a^/` and `/$c/m`. Randexp will ignore positional tokens.
* Back references to non-existing groups like `/(a)\1\2/`. Randexp will ignore those references, returning an empty string for them. If the group exists only after the reference is used such as in `/\1 (hey)/`, it will too be ignored.
* Custom negated character sets with two sets inside that cancel each other out. Example: `/[^\w\W]/`. If you give this to randexp, it will return an empty string for this set since it can't match anything.
# Projects based on randexp.js
## JSON-Schema Faker
Use generators to populate JSON Schema samples. See: [jsf on github](https://github.com/json-schema-faker/json-schema-faker/) and [jsf demo page](http://json-schema-faker.js.org/).
# Install
### Node.js
npm install randexp
### Browser
Download the [minified version](https://github.com/fent/randexp.js/releases) from the latest release.
# Tests
Tests are written with [mocha](https://mochajs.org)
```bash
npm test
```
# License
MIT
## Timezone support
In order to provide support for timezones, without relying on the JavaScript host or any other time-zone aware environment, this library makes use of teh IANA Timezone Database directly:
https://www.iana.org/time-zones
The database files are parsed by the scripts in this folder, which emit AssemblyScript code which is used to process the various rules at runtime.
# minizlib
A fast zlib stream built on [minipass](http://npm.im/minipass) and
Node.js's zlib binding.
This module was created to serve the needs of
[node-tar](http://npm.im/tar) and
[minipass-fetch](http://npm.im/minipass-fetch).
Brotli is supported in versions of node with a Brotli binding.
## How does this differ from the streams in `require('zlib')`?
First, there are no convenience methods to compress or decompress a
buffer. If you want those, use the built-in `zlib` module. This is
only streams. That being said, Minipass streams to make it fairly easy to
use as one-liners: `new zlib.Deflate().end(data).read()` will return the
deflate compressed result.
This module compresses and decompresses the data as fast as you feed
it in. It is synchronous, and runs on the main process thread. Zlib
and Brotli operations can be high CPU, but they're very fast, and doing it
this way means much less bookkeeping and artificial deferral.
Node's built in zlib streams are built on top of `stream.Transform`.
They do the maximally safe thing with respect to consistent
asynchrony, buffering, and backpressure.
See [Minipass](http://npm.im/minipass) for more on the differences between
Node.js core streams and Minipass streams, and the convenience methods
provided by that class.
## Classes
- Deflate
- Inflate
- Gzip
- Gunzip
- DeflateRaw
- InflateRaw
- Unzip
- BrotliCompress (Node v10 and higher)
- BrotliDecompress (Node v10 and higher)
## USAGE
```js
const zlib = require('minizlib')
const input = sourceOfCompressedData()
const decode = new zlib.BrotliDecompress()
const output = whereToWriteTheDecodedData()
input.pipe(decode).pipe(output)
```
## REPRODUCIBLE BUILDS
To create reproducible gzip compressed files across different operating
systems, set `portable: true` in the options. This causes minizlib to set
the `OS` indicator in byte 9 of the extended gzip header to `0xFF` for
'unknown'.
<h1 align="center">Enquirer</h1>
<p align="center">
<a href="https://npmjs.org/package/enquirer">
<img src="https://img.shields.io/npm/v/enquirer.svg" alt="version">
</a>
<a href="https://travis-ci.org/enquirer/enquirer">
<img src="https://img.shields.io/travis/enquirer/enquirer.svg" alt="travis">
</a>
<a href="https://npmjs.org/package/enquirer">
<img src="https://img.shields.io/npm/dm/enquirer.svg" alt="downloads">
</a>
</p>
<br>
<br>
<p align="center">
<b>Stylish CLI prompts that are user-friendly, intuitive and easy to create.</b><br>
<sub>>_ Prompts should be more like conversations than inquisitions▌</sub>
</p>
<br>
<p align="center">
<sub>(Example shows Enquirer's <a href="#survey-prompt">Survey Prompt</a>)</a></sub>
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/survey-prompt.gif" alt="Enquirer Survey Prompt" width="750"><br>
<sub>The terminal in all examples is <a href="https://hyper.is/">Hyper</a>, theme is <a href="https://github.com/jonschlinkert/hyper-monokai-extended">hyper-monokai-extended</a>.</sub><br><br>
<a href="#built-in-prompts"><strong>See more prompt examples</strong></a>
</p>
<br>
<br>
Created by [jonschlinkert](https://github.com/jonschlinkert) and [doowb](https://github.com/doowb), Enquirer is fast, easy to use, and lightweight enough for small projects, while also being powerful and customizable enough for the most advanced use cases.
* **Fast** - [Loads in ~4ms](#-performance) (that's about _3-4 times faster than a [single frame of a HD movie](http://www.endmemo.com/sconvert/framespersecondframespermillisecond.php) at 60fps_)
* **Lightweight** - Only one dependency, the excellent [ansi-colors](https://github.com/doowb/ansi-colors) by [Brian Woodward](https://github.com/doowb).
* **Easy to implement** - Uses promises and async/await and sensible defaults to make prompts easy to create and implement.
* **Easy to use** - Thrill your users with a better experience! Navigating around input and choices is a breeze. You can even create [quizzes](examples/fun/countdown.js), or [record](examples/fun/record.js) and [playback](examples/fun/play.js) key bindings to aid with tutorials and videos.
* **Intuitive** - Keypress combos are available to simplify usage.
* **Flexible** - All prompts can be used standalone or chained together.
* **Stylish** - Easily override semantic styles and symbols for any part of the prompt.
* **Extensible** - Easily create and use custom prompts by extending Enquirer's built-in [prompts](#-prompts).
* **Pluggable** - Add advanced features to Enquirer using plugins.
* **Validation** - Optionally validate user input with any prompt.
* **Well tested** - All prompts are well-tested, and tests are easy to create without having to use brittle, hacky solutions to spy on prompts or "inject" values.
* **Examples** - There are numerous [examples](examples) available to help you get started.
If you like Enquirer, please consider starring or tweeting about this project to show your support. Thanks!
<br>
<p align="center">
<b>>_ Ready to start making prompts your users will love? ▌</b><br>
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/heartbeat.gif" alt="Enquirer Select Prompt with heartbeat example" width="750">
</p>
<br>
<br>
## ❯ Getting started
Get started with Enquirer, the most powerful and easy-to-use Node.js library for creating interactive CLI prompts.
* [Install](#-install)
* [Usage](#-usage)
* [Enquirer](#-enquirer)
* [Prompts](#-prompts)
- [Built-in Prompts](#-prompts)
- [Custom Prompts](#-custom-prompts)
* [Key Bindings](#-key-bindings)
* [Options](#-options)
* [Release History](#-release-history)
* [Performance](#-performance)
* [About](#-about)
<br>
## ❯ Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install enquirer --save
```
Install with [yarn](https://yarnpkg.com/en/):
```sh
$ yarn add enquirer
```
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/npm-install.gif" alt="Install Enquirer with NPM" width="750">
</p>
_(Requires Node.js 8.6 or higher. Please let us know if you need support for an earlier version by creating an [issue](../../issues/new).)_
<br>
## ❯ Usage
### Single prompt
The easiest way to get started with enquirer is to pass a [question object](#prompt-options) to the `prompt` method.
```js
const { prompt } = require('enquirer');
const response = await prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response); // { username: 'jonschlinkert' }
```
_(Examples with `await` need to be run inside an `async` function)_
### Multiple prompts
Pass an array of ["question" objects](#prompt-options) to run a series of prompts.
```js
const response = await prompt([
{
type: 'input',
name: 'name',
message: 'What is your name?'
},
{
type: 'input',
name: 'username',
message: 'What is your username?'
}
]);
console.log(response); // { name: 'Edward Chan', username: 'edwardmchan' }
```
### Different ways to run enquirer
#### 1. By importing the specific `built-in prompt`
```js
const { Confirm } = require('enquirer');
const prompt = new Confirm({
name: 'question',
message: 'Did you like enquirer?'
});
prompt.run()
.then(answer => console.log('Answer:', answer));
```
#### 2. By passing the options to `prompt`
```js
const { prompt } = require('enquirer');
prompt({
type: 'confirm',
name: 'question',
message: 'Did you like enquirer?'
})
.then(answer => console.log('Answer:', answer));
```
**Jump to**: [Getting Started](#-getting-started) · [Prompts](#-prompts) · [Options](#-options) · [Key Bindings](#-key-bindings)
<br>
## ❯ Enquirer
**Enquirer is a prompt runner**
Add Enquirer to your JavaScript project with following line of code.
```js
const Enquirer = require('enquirer');
```
The main export of this library is the `Enquirer` class, which has methods and features designed to simplify running prompts.
```js
const { prompt } = require('enquirer');
const question = [
{
type: 'input',
name: 'username',
message: 'What is your username?'
},
{
type: 'password',
name: 'password',
message: 'What is your password?'
}
];
let answers = await prompt(question);
console.log(answers);
```
**Prompts control how values are rendered and returned**
Each individual prompt is a class with special features and functionality for rendering the types of values you want to show users in the terminal, and subsequently returning the types of values you need to use in your application.
**How can I customize prompts?**
Below in this guide you will find information about creating [custom prompts](#-custom-prompts). For now, we'll focus on how to customize an existing prompt.
All of the individual [prompt classes](#built-in-prompts) in this library are exposed as static properties on Enquirer. This allows them to be used directly without using `enquirer.prompt()`.
Use this approach if you need to modify a prompt instance, or listen for events on the prompt.
**Example**
```js
const { Input } = require('enquirer');
const prompt = new Input({
name: 'username',
message: 'What is your username?'
});
prompt.run()
.then(answer => console.log('Username:', answer))
.catch(console.error);
```
### [Enquirer](index.js#L20)
Create an instance of `Enquirer`.
**Params**
* `options` **{Object}**: (optional) Options to use with all prompts.
* `answers` **{Object}**: (optional) Answers object to initialize with.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
```
### [register()](index.js#L42)
Register a custom prompt type.
**Params**
* `type` **{String}**
* `fn` **{Function|Prompt}**: `Prompt` class, or a function that returns a `Prompt` class.
* `returns` **{Object}**: Returns the Enquirer instance
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
enquirer.register('customType', require('./custom-prompt'));
```
### [prompt()](index.js#L78)
Prompt function that takes a "question" object or array of question objects, and returns an object with responses from the user.
**Params**
* `questions` **{Array|Object}**: Options objects for one or more prompts to run.
* `returns` **{Promise}**: Promise that returns an "answers" object with the user's responses.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
const response = await enquirer.prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response);
```
### [use()](index.js#L160)
Use an enquirer plugin.
**Params**
* `plugin` **{Function}**: Plugin function that takes an instance of Enquirer.
* `returns` **{Object}**: Returns the Enquirer instance.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
const plugin = enquirer => {
// do stuff to enquire instance
};
enquirer.use(plugin);
```
### [Enquirer#prompt](index.js#L210)
Prompt function that takes a "question" object or array of question objects, and returns an object with responses from the user.
**Params**
* `questions` **{Array|Object}**: Options objects for one or more prompts to run.
* `returns` **{Promise}**: Promise that returns an "answers" object with the user's responses.
**Example**
```js
const { prompt } = require('enquirer');
const response = await prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response);
```
<br>
## ❯ Prompts
This section is about Enquirer's prompts: what they look like, how they work, how to run them, available options, and how to customize the prompts or create your own prompt concept.
**Getting started with Enquirer's prompts**
* [Prompt](#prompt) - The base `Prompt` class used by other prompts
- [Prompt Options](#prompt-options)
* [Built-in prompts](#built-in-prompts)
* [Prompt Types](#prompt-types) - The base `Prompt` class used by other prompts
* [Custom prompts](#%E2%9D%AF-custom-prompts) - Enquirer 2.0 introduced the concept of prompt "types", with the goal of making custom prompts easier than ever to create and use.
### Prompt
The base `Prompt` class is used to create all other prompts.
```js
const { Prompt } = require('enquirer');
class MyCustomPrompt extends Prompt {}
```
See the documentation for [creating custom prompts](#-custom-prompts) to learn more about how this works.
#### Prompt Options
Each prompt takes an options object (aka "question" object), that implements the following interface:
```js
{
// required
type: string | function,
name: string | function,
message: string | function | async function,
// optional
skip: boolean | function | async function,
initial: string | function | async function,
format: function | async function,
result: function | async function,
validate: function | async function,
}
```
Each property of the options object is described below:
| **Property** | **Required?** | **Type** | **Description** |
| ------------ | ------------- | ------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `type` | yes | `string\|function` | Enquirer uses this value to determine the type of prompt to run, but it's optional when prompts are run directly. |
| `name` | yes | `string\|function` | Used as the key for the answer on the returned values (answers) object. |
| `message` | yes | `string\|function` | The message to display when the prompt is rendered in the terminal. |
| `skip` | no | `boolean\|function` | If `true` it will not ask that prompt. |
| `initial` | no | `string\|function` | The default value to return if the user does not supply a value. |
| `format` | no | `function` | Function to format user input in the terminal. |
| `result` | no | `function` | Function to format the final submitted value before it's returned. |
| `validate` | no | `function` | Function to validate the submitted value before it's returned. This function may return a boolean or a string. If a string is returned it will be used as the validation error message. |
**Example usage**
```js
const { prompt } = require('enquirer');
const question = {
type: 'input',
name: 'username',
message: 'What is your username?'
};
prompt(question)
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
<br>
### Built-in prompts
* [AutoComplete Prompt](#autocomplete-prompt)
* [BasicAuth Prompt](#basicauth-prompt)
* [Confirm Prompt](#confirm-prompt)
* [Form Prompt](#form-prompt)
* [Input Prompt](#input-prompt)
* [Invisible Prompt](#invisible-prompt)
* [List Prompt](#list-prompt)
* [MultiSelect Prompt](#multiselect-prompt)
* [Numeral Prompt](#numeral-prompt)
* [Password Prompt](#password-prompt)
* [Quiz Prompt](#quiz-prompt)
* [Survey Prompt](#survey-prompt)
* [Scale Prompt](#scale-prompt)
* [Select Prompt](#select-prompt)
* [Sort Prompt](#sort-prompt)
* [Snippet Prompt](#snippet-prompt)
* [Toggle Prompt](#toggle-prompt)
### AutoComplete Prompt
Prompt that auto-completes as the user types, and returns the selected value as a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/autocomplete-prompt.gif" alt="Enquirer AutoComplete Prompt" width="750">
</p>
**Example Usage**
```js
const { AutoComplete } = require('enquirer');
const prompt = new AutoComplete({
name: 'flavor',
message: 'Pick your favorite flavor',
limit: 10,
initial: 2,
choices: [
'Almond',
'Apple',
'Banana',
'Blackberry',
'Blueberry',
'Cherry',
'Chocolate',
'Cinnamon',
'Coconut',
'Cranberry',
'Grape',
'Nougat',
'Orange',
'Pear',
'Pineapple',
'Raspberry',
'Strawberry',
'Vanilla',
'Watermelon',
'Wintergreen'
]
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**AutoComplete Options**
| Option | Type | Default | Description |
| ----------- | ---------- | ------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------ |
| `highlight` | `function` | `dim` version of primary style | The color to use when "highlighting" characters in the list that match user input. |
| `multiple` | `boolean` | `false` | Allow multiple choices to be selected. |
| `suggest` | `function` | Greedy match, returns true if choice message contains input string. | Function that filters choices. Takes user input and a choices array, and returns a list of matching choices. |
| `initial` | `number` | 0 | Preselected item in the list of choices. |
| `footer` | `function` | None | Function that displays [footer text](https://github.com/enquirer/enquirer/blob/6c2819518a1e2ed284242a99a685655fbaabfa28/examples/autocomplete/option-footer.js#L10) |
**Related prompts**
* [Select](#select-prompt)
* [MultiSelect](#multiselect-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### BasicAuth Prompt
Prompt that asks for username and password to authenticate the user. The default implementation of `authenticate` function in `BasicAuth` prompt is to compare the username and password with the values supplied while running the prompt. The implementer is expected to override the `authenticate` function with a custom logic such as making an API request to a server to authenticate the username and password entered and expect a token back.
<p align="center">
<img src="https://user-images.githubusercontent.com/13731210/61570485-7ffd9c00-aaaa-11e9-857a-d47dc7008284.gif" alt="Enquirer BasicAuth Prompt" width="750">
</p>
**Example Usage**
```js
const { BasicAuth } = require('enquirer');
const prompt = new BasicAuth({
name: 'password',
message: 'Please enter your password',
username: 'rajat-sr',
password: '123',
showPassword: true
});
prompt
.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Confirm Prompt
Prompt that returns `true` or `false`.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/confirm-prompt.gif" alt="Enquirer Confirm Prompt" width="750">
</p>
**Example Usage**
```js
const { Confirm } = require('enquirer');
const prompt = new Confirm({
name: 'question',
message: 'Want to answer?'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Numeral](#numeral-prompt)
* [Password](#password-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Form Prompt
Prompt that allows the user to enter and submit multiple values on a single terminal screen.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/form-prompt.gif" alt="Enquirer Form Prompt" width="750">
</p>
**Example Usage**
```js
const { Form } = require('enquirer');
const prompt = new Form({
name: 'user',
message: 'Please provide the following information:',
choices: [
{ name: 'firstname', message: 'First Name', initial: 'Jon' },
{ name: 'lastname', message: 'Last Name', initial: 'Schlinkert' },
{ name: 'username', message: 'GitHub username', initial: 'jonschlinkert' }
]
});
prompt.run()
.then(value => console.log('Answer:', value))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Input Prompt
Prompt that takes user input and returns a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/input-prompt.gif" alt="Enquirer Input Prompt" width="750">
</p>
**Example Usage**
```js
const { Input } = require('enquirer');
const prompt = new Input({
message: 'What is your username?',
initial: 'jonschlinkert'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.log);
```
You can use [data-store](https://github.com/jonschlinkert/data-store) to store [input history](https://github.com/enquirer/enquirer/blob/master/examples/input/option-history.js) that the user can cycle through (see [source](https://github.com/enquirer/enquirer/blob/8407dc3579123df5e6e20215078e33bb605b0c37/lib/prompts/input.js)).
**Related prompts**
* [Confirm](#confirm-prompt)
* [Numeral](#numeral-prompt)
* [Password](#password-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Invisible Prompt
Prompt that takes user input, hides it from the terminal, and returns a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/invisible-prompt.gif" alt="Enquirer Invisible Prompt" width="750">
</p>
**Example Usage**
```js
const { Invisible } = require('enquirer');
const prompt = new Invisible({
name: 'secret',
message: 'What is your secret?'
});
prompt.run()
.then(answer => console.log('Answer:', { secret: answer }))
.catch(console.error);
```
**Related prompts**
* [Password](#password-prompt)
* [Input](#input-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### List Prompt
Prompt that returns a list of values, created by splitting the user input. The default split character is `,` with optional trailing whitespace.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/list-prompt.gif" alt="Enquirer List Prompt" width="750">
</p>
**Example Usage**
```js
const { List } = require('enquirer');
const prompt = new List({
name: 'keywords',
message: 'Type comma-separated keywords'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Sort](#sort-prompt)
* [Select](#select-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### MultiSelect Prompt
Prompt that allows the user to select multiple items from a list of options.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/multiselect-prompt.gif" alt="Enquirer MultiSelect Prompt" width="750">
</p>
**Example Usage**
```js
const { MultiSelect } = require('enquirer');
const prompt = new MultiSelect({
name: 'value',
message: 'Pick your favorite colors',
limit: 7,
choices: [
{ name: 'aqua', value: '#00ffff' },
{ name: 'black', value: '#000000' },
{ name: 'blue', value: '#0000ff' },
{ name: 'fuchsia', value: '#ff00ff' },
{ name: 'gray', value: '#808080' },
{ name: 'green', value: '#008000' },
{ name: 'lime', value: '#00ff00' },
{ name: 'maroon', value: '#800000' },
{ name: 'navy', value: '#000080' },
{ name: 'olive', value: '#808000' },
{ name: 'purple', value: '#800080' },
{ name: 'red', value: '#ff0000' },
{ name: 'silver', value: '#c0c0c0' },
{ name: 'teal', value: '#008080' },
{ name: 'white', value: '#ffffff' },
{ name: 'yellow', value: '#ffff00' }
]
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
// Answer: ['aqua', 'blue', 'fuchsia']
```
**Example key-value pairs**
Optionally, pass a `result` function and use the `.map` method to return an object of key-value pairs of the selected names and values: [example](./examples/multiselect/option-result.js)
```js
const { MultiSelect } = require('enquirer');
const prompt = new MultiSelect({
name: 'value',
message: 'Pick your favorite colors',
limit: 7,
choices: [
{ name: 'aqua', value: '#00ffff' },
{ name: 'black', value: '#000000' },
{ name: 'blue', value: '#0000ff' },
{ name: 'fuchsia', value: '#ff00ff' },
{ name: 'gray', value: '#808080' },
{ name: 'green', value: '#008000' },
{ name: 'lime', value: '#00ff00' },
{ name: 'maroon', value: '#800000' },
{ name: 'navy', value: '#000080' },
{ name: 'olive', value: '#808000' },
{ name: 'purple', value: '#800080' },
{ name: 'red', value: '#ff0000' },
{ name: 'silver', value: '#c0c0c0' },
{ name: 'teal', value: '#008080' },
{ name: 'white', value: '#ffffff' },
{ name: 'yellow', value: '#ffff00' }
],
result(names) {
return this.map(names);
}
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
// Answer: { aqua: '#00ffff', blue: '#0000ff', fuchsia: '#ff00ff' }
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Numeral Prompt
Prompt that takes a number as input.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/numeral-prompt.gif" alt="Enquirer Numeral Prompt" width="750">
</p>
**Example Usage**
```js
const { NumberPrompt } = require('enquirer');
const prompt = new NumberPrompt({
name: 'number',
message: 'Please enter a number'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Confirm](#confirm-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Password Prompt
Prompt that takes user input and masks it in the terminal. Also see the [invisible prompt](#invisible-prompt)
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/password-prompt.gif" alt="Enquirer Password Prompt" width="750">
</p>
**Example Usage**
```js
const { Password } = require('enquirer');
const prompt = new Password({
name: 'password',
message: 'What is your password?'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Invisible](#invisible-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Quiz Prompt
Prompt that allows the user to play multiple-choice quiz questions.
<p align="center">
<img src="https://user-images.githubusercontent.com/13731210/61567561-891d4780-aa6f-11e9-9b09-3d504abd24ed.gif" alt="Enquirer Quiz Prompt" width="750">
</p>
**Example Usage**
```js
const { Quiz } = require('enquirer');
const prompt = new Quiz({
name: 'countries',
message: 'How many countries are there in the world?',
choices: ['165', '175', '185', '195', '205'],
correctChoice: 3
});
prompt
.run()
.then(answer => {
if (answer.correct) {
console.log('Correct!');
} else {
console.log(`Wrong! Correct answer is ${answer.correctAnswer}`);
}
})
.catch(console.error);
```
**Quiz Options**
| Option | Type | Required | Description |
| ----------- | ---------- | ---------- | ------------------------------------------------------------------------------------------------------------ |
| `choices` | `array` | Yes | The list of possible answers to the quiz question. |
| `correctChoice`| `number` | Yes | Index of the correct choice from the `choices` array. |
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Survey Prompt
Prompt that allows the user to provide feedback for a list of questions.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/survey-prompt.gif" alt="Enquirer Survey Prompt" width="750">
</p>
**Example Usage**
```js
const { Survey } = require('enquirer');
const prompt = new Survey({
name: 'experience',
message: 'Please rate your experience',
scale: [
{ name: '1', message: 'Strongly Disagree' },
{ name: '2', message: 'Disagree' },
{ name: '3', message: 'Neutral' },
{ name: '4', message: 'Agree' },
{ name: '5', message: 'Strongly Agree' }
],
margin: [0, 0, 2, 1],
choices: [
{
name: 'interface',
message: 'The website has a friendly interface.'
},
{
name: 'navigation',
message: 'The website is easy to navigate.'
},
{
name: 'images',
message: 'The website usually has good images.'
},
{
name: 'upload',
message: 'The website makes it easy to upload images.'
},
{
name: 'colors',
message: 'The website has a pleasing color palette.'
}
]
});
prompt.run()
.then(value => console.log('ANSWERS:', value))
.catch(console.error);
```
**Related prompts**
* [Scale](#scale-prompt)
* [Snippet](#snippet-prompt)
* [Select](#select-prompt)
***
### Scale Prompt
A more compact version of the [Survey prompt](#survey-prompt), the Scale prompt allows the user to quickly provide feedback using a [Likert Scale](https://en.wikipedia.org/wiki/Likert_scale).
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/scale-prompt.gif" alt="Enquirer Scale Prompt" width="750">
</p>
**Example Usage**
```js
const { Scale } = require('enquirer');
const prompt = new Scale({
name: 'experience',
message: 'Please rate your experience',
scale: [
{ name: '1', message: 'Strongly Disagree' },
{ name: '2', message: 'Disagree' },
{ name: '3', message: 'Neutral' },
{ name: '4', message: 'Agree' },
{ name: '5', message: 'Strongly Agree' }
],
margin: [0, 0, 2, 1],
choices: [
{
name: 'interface',
message: 'The website has a friendly interface.',
initial: 2
},
{
name: 'navigation',
message: 'The website is easy to navigate.',
initial: 2
},
{
name: 'images',
message: 'The website usually has good images.',
initial: 2
},
{
name: 'upload',
message: 'The website makes it easy to upload images.',
initial: 2
},
{
name: 'colors',
message: 'The website has a pleasing color palette.',
initial: 2
}
]
});
prompt.run()
.then(value => console.log('ANSWERS:', value))
.catch(console.error);
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Select Prompt
Prompt that allows the user to select from a list of options.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/select-prompt.gif" alt="Enquirer Select Prompt" width="750">
</p>
**Example Usage**
```js
const { Select } = require('enquirer');
const prompt = new Select({
name: 'color',
message: 'Pick a flavor',
choices: ['apple', 'grape', 'watermelon', 'cherry', 'orange']
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [MultiSelect](#multiselect-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Sort Prompt
Prompt that allows the user to sort items in a list.
**Example**
In this [example](https://github.com/enquirer/enquirer/raw/master/examples/sort/prompt.js), custom styling is applied to the returned values to make it easier to see what's happening.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/sort-prompt.gif" alt="Enquirer Sort Prompt" width="750">
</p>
**Example Usage**
```js
const colors = require('ansi-colors');
const { Sort } = require('enquirer');
const prompt = new Sort({
name: 'colors',
message: 'Sort the colors in order of preference',
hint: 'Top is best, bottom is worst',
numbered: true,
choices: ['red', 'white', 'green', 'cyan', 'yellow'].map(n => ({
name: n,
message: colors[n](n)
}))
});
prompt.run()
.then(function(answer = []) {
console.log(answer);
console.log('Your preferred order of colors is:');
console.log(answer.map(key => colors[key](key)).join('\n'));
})
.catch(console.error);
```
**Related prompts**
* [List](#list-prompt)
* [Select](#select-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Snippet Prompt
Prompt that allows the user to replace placeholders in a snippet of code or text.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/snippet-prompt.gif" alt="Prompts" width="750">
</p>
**Example Usage**
```js
const semver = require('semver');
const { Snippet } = require('enquirer');
const prompt = new Snippet({
name: 'username',
message: 'Fill out the fields in package.json',
required: true,
fields: [
{
name: 'author_name',
message: 'Author Name'
},
{
name: 'version',
validate(value, state, item, index) {
if (item && item.name === 'version' && !semver.valid(value)) {
return prompt.styles.danger('version should be a valid semver value');
}
return true;
}
}
],
template: `{
"name": "\${name}",
"description": "\${description}",
"version": "\${version}",
"homepage": "https://github.com/\${username}/\${name}",
"author": "\${author_name} (https://github.com/\${username})",
"repository": "\${username}/\${name}",
"license": "\${license:ISC}"
}
`
});
prompt.run()
.then(answer => console.log('Answer:', answer.result))
.catch(console.error);
```
**Related prompts**
* [Survey](#survey-prompt)
* [AutoComplete](#autocomplete-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Toggle Prompt
Prompt that allows the user to toggle between two values then returns `true` or `false`.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/toggle-prompt.gif" alt="Enquirer Toggle Prompt" width="750">
</p>
**Example Usage**
```js
const { Toggle } = require('enquirer');
const prompt = new Toggle({
message: 'Want to answer?',
enabled: 'Yep',
disabled: 'Nope'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Confirm](#confirm-prompt)
* [Input](#input-prompt)
* [Sort](#sort-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Prompt Types
There are 5 (soon to be 6!) type classes:
* [ArrayPrompt](#arrayprompt)
- [Options](#options)
- [Properties](#properties)
- [Methods](#methods)
- [Choices](#choices)
- [Defining choices](#defining-choices)
- [Choice properties](#choice-properties)
- [Related prompts](#related-prompts)
* [AuthPrompt](#authprompt)
* [BooleanPrompt](#booleanprompt)
* DatePrompt (Coming Soon!)
* [NumberPrompt](#numberprompt)
* [StringPrompt](#stringprompt)
Each type is a low-level class that may be used as a starting point for creating higher level prompts. Continue reading to learn how.
### ArrayPrompt
The `ArrayPrompt` class is used for creating prompts that display a list of choices in the terminal. For example, Enquirer uses this class as the basis for the [Select](#select) and [Survey](#survey) prompts.
#### Options
In addition to the [options](#options) available to all prompts, Array prompts also support the following options.
| **Option** | **Required?** | **Type** | **Description** |
| ----------- | ------------- | --------------- | ----------------------------------------------------------------------------------------------------------------------- |
| `autofocus` | `no` | `string\|number` | The index or name of the choice that should have focus when the prompt loads. Only one choice may have focus at a time. | |
| `stdin` | `no` | `stream` | The input stream to use for emitting keypress events. Defaults to `process.stdin`. |
| `stdout` | `no` | `stream` | The output stream to use for writing the prompt to the terminal. Defaults to `process.stdout`. |
| |
#### Properties
Array prompts have the following instance properties and getters.
| **Property name** | **Type** | **Description** |
| ----------------- | --------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `choices` | `array` | Array of choices that have been normalized from choices passed on the prompt options. |
| `cursor` | `number` | Position of the cursor relative to the _user input (string)_. |
| `enabled` | `array` | Returns an array of enabled choices. |
| `focused` | `array` | Returns the currently selected choice in the visible list of choices. This is similar to the concept of focus in HTML and CSS. Focused choices are always visible (on-screen). When a list of choices is longer than the list of visible choices, and an off-screen choice is _focused_, the list will scroll to the focused choice and re-render. |
| `focused` | Gets the currently selected choice. Equivalent to `prompt.choices[prompt.index]`. |
| `index` | `number` | Position of the pointer in the _visible list (array) of choices_. |
| `limit` | `number` | The number of choices to display on-screen. |
| `selected` | `array` | Either a list of enabled choices (when `options.multiple` is true) or the currently focused choice. |
| `visible` | `string` | |
#### Methods
| **Method** | **Description** |
| ------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `pointer()` | Returns the visual symbol to use to identify the choice that currently has focus. The `❯` symbol is often used for this. The pointer is not always visible, as with the `autocomplete` prompt. |
| `indicator()` | Returns the visual symbol that indicates whether or not a choice is checked/enabled. |
| `focus()` | Sets focus on a choice, if it can be focused. |
#### Choices
Array prompts support the `choices` option, which is the array of choices users will be able to select from when rendered in the terminal.
**Type**: `string|object`
**Example**
```js
const { prompt } = require('enquirer');
const questions = [{
type: 'select',
name: 'color',
message: 'Favorite color?',
initial: 1,
choices: [
{ name: 'red', message: 'Red', value: '#ff0000' }, //<= choice object
{ name: 'green', message: 'Green', value: '#00ff00' }, //<= choice object
{ name: 'blue', message: 'Blue', value: '#0000ff' } //<= choice object
]
}];
let answers = await prompt(questions);
console.log('Answer:', answers.color);
```
#### Defining choices
Whether defined as a string or object, choices are normalized to the following interface:
```js
{
name: string;
message: string | undefined;
value: string | undefined;
hint: string | undefined;
disabled: boolean | string | undefined;
}
```
**Example**
```js
const question = {
name: 'fruit',
message: 'Favorite fruit?',
choices: ['Apple', 'Orange', 'Raspberry']
};
```
Normalizes to the following when the prompt is run:
```js
const question = {
name: 'fruit',
message: 'Favorite fruit?',
choices: [
{ name: 'Apple', message: 'Apple', value: 'Apple' },
{ name: 'Orange', message: 'Orange', value: 'Orange' },
{ name: 'Raspberry', message: 'Raspberry', value: 'Raspberry' }
]
};
```
#### Choice properties
The following properties are supported on `choice` objects.
| **Option** | **Type** | **Description** |
| ----------- | ----------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `name` | `string` | The unique key to identify a choice |
| `message` | `string` | The message to display in the terminal. `name` is used when this is undefined. |
| `value` | `string` | Value to associate with the choice. Useful for creating key-value pairs from user choices. `name` is used when this is undefined. |
| `choices` | `array` | Array of "child" choices. |
| `hint` | `string` | Help message to display next to a choice. |
| `role` | `string` | Determines how the choice will be displayed. Currently the only role supported is `separator`. Additional roles may be added in the future (like `heading`, etc). Please create a [feature request] |
| `enabled` | `boolean` | Enabled a choice by default. This is only supported when `options.multiple` is true or on prompts that support multiple choices, like [MultiSelect](#-multiselect). |
| `disabled` | `boolean\|string` | Disable a choice so that it cannot be selected. This value may either be `true`, `false`, or a message to display. |
| `indicator` | `string\|function` | Custom indicator to render for a choice (like a check or radio button). |
#### Related prompts
* [AutoComplete](#autocomplete-prompt)
* [Form](#form-prompt)
* [MultiSelect](#multiselect-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
***
### AuthPrompt
The `AuthPrompt` is used to create prompts to log in user using any authentication method. For example, Enquirer uses this class as the basis for the [BasicAuth Prompt](#basicauth-prompt). You can also find prompt examples in `examples/auth/` folder that utilizes `AuthPrompt` to create OAuth based authentication prompt or a prompt that authenticates using time-based OTP, among others.
`AuthPrompt` has a factory function that creates an instance of `AuthPrompt` class and it expects an `authenticate` function, as an argument, which overrides the `authenticate` function of the `AuthPrompt` class.
#### Methods
| **Method** | **Description** |
| ------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `authenticate()` | Contain all the authentication logic. This function should be overridden to implement custom authentication logic. The default `authenticate` function throws an error if no other function is provided. |
#### Choices
Auth prompt supports the `choices` option, which is the similar to the choices used in [Form Prompt](#form-prompt).
**Example**
```js
const { AuthPrompt } = require('enquirer');
function authenticate(value, state) {
if (value.username === this.options.username && value.password === this.options.password) {
return true;
}
return false;
}
const CustomAuthPrompt = AuthPrompt.create(authenticate);
const prompt = new CustomAuthPrompt({
name: 'password',
message: 'Please enter your password',
username: 'rajat-sr',
password: '1234567',
choices: [
{ name: 'username', message: 'username' },
{ name: 'password', message: 'password' }
]
});
prompt
.run()
.then(answer => console.log('Authenticated?', answer))
.catch(console.error);
```
#### Related prompts
* [BasicAuth Prompt](#basicauth-prompt)
***
### BooleanPrompt
The `BooleanPrompt` class is used for creating prompts that display and return a boolean value.
```js
const { BooleanPrompt } = require('enquirer');
const prompt = new BooleanPrompt({
header: '========================',
message: 'Do you love enquirer?',
footer: '========================',
});
prompt.run()
.then(answer => console.log('Selected:', answer))
.catch(console.error);
```
**Returns**: `boolean`
***
### NumberPrompt
The `NumberPrompt` class is used for creating prompts that display and return a numerical value.
```js
const { NumberPrompt } = require('enquirer');
const prompt = new NumberPrompt({
header: '************************',
message: 'Input the Numbers:',
footer: '************************',
});
prompt.run()
.then(answer => console.log('Numbers are:', answer))
.catch(console.error);
```
**Returns**: `string|number` (number, or number formatted as a string)
***
### StringPrompt
The `StringPrompt` class is used for creating prompts that display and return a string value.
```js
const { StringPrompt } = require('enquirer');
const prompt = new StringPrompt({
header: '************************',
message: 'Input the String:',
footer: '************************'
});
prompt.run()
.then(answer => console.log('String is:', answer))
.catch(console.error);
```
**Returns**: `string`
<br>
## ❯ Custom prompts
With Enquirer 2.0, custom prompts are easier than ever to create and use.
**How do I create a custom prompt?**
Custom prompts are created by extending either:
* Enquirer's `Prompt` class
* one of the built-in [prompts](#-prompts), or
* low-level [types](#-types).
<!-- Example: HaiKarate Custom Prompt -->
```js
const { Prompt } = require('enquirer');
class HaiKarate extends Prompt {
constructor(options = {}) {
super(options);
this.value = options.initial || 0;
this.cursorHide();
}
up() {
this.value++;
this.render();
}
down() {
this.value--;
this.render();
}
render() {
this.clear(); // clear previously rendered prompt from the terminal
this.write(`${this.state.message}: ${this.value}`);
}
}
// Use the prompt by creating an instance of your custom prompt class.
const prompt = new HaiKarate({
message: 'How many sprays do you want?',
initial: 10
});
prompt.run()
.then(answer => console.log('Sprays:', answer))
.catch(console.error);
```
If you want to be able to specify your prompt by `type` so that it may be used alongside other prompts, you will need to first create an instance of `Enquirer`.
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
```
Then use the `.register()` method to add your custom prompt.
```js
enquirer.register('haikarate', HaiKarate);
```
Now you can do the following when defining "questions".
```js
let spritzer = require('cologne-drone');
let answers = await enquirer.prompt([
{
type: 'haikarate',
name: 'cologne',
message: 'How many sprays do you need?',
initial: 10,
async onSubmit(name, value) {
await spritzer.activate(value); //<= activate drone
return value;
}
}
]);
```
<br>
## ❯ Key Bindings
### All prompts
These key combinations may be used with all prompts.
| **command** | **description** |
| -------------------------------- | -------------------------------------- |
| <kbd>ctrl</kbd> + <kbd>c</kbd> | Cancel the prompt. |
| <kbd>ctrl</kbd> + <kbd>g</kbd> | Reset the prompt to its initial state. |
<br>
### Move cursor
These combinations may be used on prompts that support user input (eg. [input prompt](#input-prompt), [password prompt](#password-prompt), and [invisible prompt](#invisible-prompt)).
| **command** | **description** |
| ------------------------------ | ---------------------------------------- |
| <kbd>left</kbd> | Move the cursor back one character. |
| <kbd>right</kbd> | Move the cursor forward one character. |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move cursor to the start of the line |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move cursor to the end of the line |
| <kbd>ctrl</kbd> + <kbd>b</kbd> | Move cursor back one character |
| <kbd>ctrl</kbd> + <kbd>f</kbd> | Move cursor forward one character |
| <kbd>ctrl</kbd> + <kbd>x</kbd> | Toggle between first and cursor position |
<br>
### Edit Input
These key combinations may be used on prompts that support user input (eg. [input prompt](#input-prompt), [password prompt](#password-prompt), and [invisible prompt](#invisible-prompt)).
| **command** | **description** |
| ------------------------------ | ---------------------------------------- |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move cursor to the start of the line |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move cursor to the end of the line |
| <kbd>ctrl</kbd> + <kbd>b</kbd> | Move cursor back one character |
| <kbd>ctrl</kbd> + <kbd>f</kbd> | Move cursor forward one character |
| <kbd>ctrl</kbd> + <kbd>x</kbd> | Toggle between first and cursor position |
<br>
| **command (Mac)** | **command (Windows)** | **description** |
| ----------------------------------- | -------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------- |
| <kbd>delete</kbd> | <kbd>backspace</kbd> | Delete one character to the left. |
| <kbd>fn</kbd> + <kbd>delete</kbd> | <kbd>delete</kbd> | Delete one character to the right. |
| <kbd>option</kbd> + <kbd>up</kbd> | <kbd>alt</kbd> + <kbd>up</kbd> | Scroll to the previous item in history ([Input prompt](#input-prompt) only, when [history is enabled](examples/input/option-history.js)). |
| <kbd>option</kbd> + <kbd>down</kbd> | <kbd>alt</kbd> + <kbd>down</kbd> | Scroll to the next item in history ([Input prompt](#input-prompt) only, when [history is enabled](examples/input/option-history.js)). |
### Select choices
These key combinations may be used on prompts that support _multiple_ choices, such as the [multiselect prompt](#multiselect-prompt), or the [select prompt](#select-prompt) when the `multiple` options is true.
| **command** | **description** |
| ----------------- | -------------------------------------------------------------------------------------------------------------------- |
| <kbd>space</kbd> | Toggle the currently selected choice when `options.multiple` is true. |
| <kbd>number</kbd> | Move the pointer to the choice at the given index. Also toggles the selected choice when `options.multiple` is true. |
| <kbd>a</kbd> | Toggle all choices to be enabled or disabled. |
| <kbd>i</kbd> | Invert the current selection of choices. |
| <kbd>g</kbd> | Toggle the current choice group. |
<br>
### Hide/show choices
| **command** | **description** |
| ------------------------------- | ---------------------------------------------- |
| <kbd>fn</kbd> + <kbd>up</kbd> | Decrease the number of visible choices by one. |
| <kbd>fn</kbd> + <kbd>down</kbd> | Increase the number of visible choices by one. |
<br>
### Move/lock Pointer
| **command** | **description** |
| ---------------------------------- | -------------------------------------------------------------------------------------------------------------------- |
| <kbd>number</kbd> | Move the pointer to the choice at the given index. Also toggles the selected choice when `options.multiple` is true. |
| <kbd>up</kbd> | Move the pointer up. |
| <kbd>down</kbd> | Move the pointer down. |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move the pointer to the first _visible_ choice. |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move the pointer to the last _visible_ choice. |
| <kbd>shift</kbd> + <kbd>up</kbd> | Scroll up one choice without changing pointer position (locks the pointer while scrolling). |
| <kbd>shift</kbd> + <kbd>down</kbd> | Scroll down one choice without changing pointer position (locks the pointer while scrolling). |
<br>
| **command (Mac)** | **command (Windows)** | **description** |
| -------------------------------- | --------------------- | ---------------------------------------------------------- |
| <kbd>fn</kbd> + <kbd>left</kbd> | <kbd>home</kbd> | Move the pointer to the first choice in the choices array. |
| <kbd>fn</kbd> + <kbd>right</kbd> | <kbd>end</kbd> | Move the pointer to the last choice in the choices array. |
<br>
## ❯ Release History
Please see [CHANGELOG.md](CHANGELOG.md).
## ❯ Performance
### System specs
MacBook Pro, Intel Core i7, 2.5 GHz, 16 GB.
### Load time
Time it takes for the module to load the first time (average of 3 runs):
```
enquirer: 4.013ms
inquirer: 286.717ms
```
<br>
## ❯ About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Todo
We're currently working on documentation for the following items. Please star and watch the repository for updates!
* [ ] Customizing symbols
* [ ] Customizing styles (palette)
* [ ] Customizing rendered input
* [ ] Customizing returned values
* [ ] Customizing key bindings
* [ ] Question validation
* [ ] Choice validation
* [ ] Skipping questions
* [ ] Async choices
* [ ] Async timers: loaders, spinners and other animations
* [ ] Links to examples
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
```sh
$ yarn && yarn test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
#### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 283 | [jonschlinkert](https://github.com/jonschlinkert) |
| 82 | [doowb](https://github.com/doowb) |
| 32 | [rajat-sr](https://github.com/rajat-sr) |
| 20 | [318097](https://github.com/318097) |
| 15 | [g-plane](https://github.com/g-plane) |
| 12 | [pixelass](https://github.com/pixelass) |
| 5 | [adityavyas611](https://github.com/adityavyas611) |
| 5 | [satotake](https://github.com/satotake) |
| 3 | [tunnckoCore](https://github.com/tunnckoCore) |
| 3 | [Ovyerus](https://github.com/Ovyerus) |
| 3 | [sw-yx](https://github.com/sw-yx) |
| 2 | [DanielRuf](https://github.com/DanielRuf) |
| 2 | [GabeL7r](https://github.com/GabeL7r) |
| 1 | [AlCalzone](https://github.com/AlCalzone) |
| 1 | [hipstersmoothie](https://github.com/hipstersmoothie) |
| 1 | [danieldelcore](https://github.com/danieldelcore) |
| 1 | [ImgBotApp](https://github.com/ImgBotApp) |
| 1 | [jsonkao](https://github.com/jsonkao) |
| 1 | [knpwrs](https://github.com/knpwrs) |
| 1 | [yeskunall](https://github.com/yeskunall) |
| 1 | [mischah](https://github.com/mischah) |
| 1 | [renarsvilnis](https://github.com/renarsvilnis) |
| 1 | [sbugert](https://github.com/sbugert) |
| 1 | [stephencweiss](https://github.com/stephencweiss) |
| 1 | [skellock](https://github.com/skellock) |
| 1 | [whxaxes](https://github.com/whxaxes) |
#### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
#### Credit
Thanks to [derhuerst](https://github.com/derhuerst), creator of prompt libraries such as [prompt-skeleton](https://github.com/derhuerst/prompt-skeleton), which influenced some of the concepts we used in our prompts.
#### License
Copyright © 2018-present, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
# axios // adapters
The modules under `adapters/` are modules that handle dispatching a request and settling a returned `Promise` once a response is received.
## Example
```js
var settle = require('./../core/settle');
module.exports = function myAdapter(config) {
// At this point:
// - config has been merged with defaults
// - request transformers have already run
// - request interceptors have already run
// Make the request using config provided
// Upon response settle the Promise
return new Promise(function(resolve, reject) {
var response = {
data: responseData,
status: request.status,
statusText: request.statusText,
headers: responseHeaders,
config: config,
request: request
};
settle(resolve, reject, response);
// From here:
// - response transformers will run
// - response interceptors will run
});
}
```
# set-blocking
[](https://travis-ci.org/yargs/set-blocking)
[](https://www.npmjs.com/package/set-blocking)
[](https://coveralls.io/r/yargs/set-blocking?branch=master)
[](https://github.com/conventional-changelog/standard-version)
set blocking `stdio` and `stderr` ensuring that terminal output does not truncate.
```js
const setBlocking = require('set-blocking')
setBlocking(true)
console.log(someLargeStringToOutput)
```
## Historical Context/Word of Warning
This was created as a shim to address the bug discussed in [node #6456](https://github.com/nodejs/node/issues/6456). This bug crops up on
newer versions of Node.js (`0.12+`), truncating terminal output.
You should be mindful of the side-effects caused by using `set-blocking`:
* if your module sets blocking to `true`, it will effect other modules
consuming your library. In [yargs](https://github.com/yargs/yargs/blob/master/yargs.js#L653) we only call
`setBlocking(true)` once we already know we are about to call `process.exit(code)`.
* this patch will not apply to subprocesses spawned with `isTTY = true`, this is
the [default `spawn()` behavior](https://nodejs.org/api/child_process.html#child_process_child_process_spawn_command_args_options).
## License
ISC
# sprintf.js
**sprintf.js** is a complete open source JavaScript sprintf implementation for the *browser* and *node.js*.
Its prototype is simple:
string sprintf(string format , [mixed arg1 [, mixed arg2 [ ,...]]])
The placeholders in the format string are marked by `%` and are followed by one or more of these elements, in this order:
* An optional number followed by a `$` sign that selects which argument index to use for the value. If not specified, arguments will be placed in the same order as the placeholders in the input string.
* An optional `+` sign that forces to preceed the result with a plus or minus sign on numeric values. By default, only the `-` sign is used on negative numbers.
* An optional padding specifier that says what character to use for padding (if specified). Possible values are `0` or any other character precedeed by a `'` (single quote). The default is to pad with *spaces*.
* An optional `-` sign, that causes sprintf to left-align the result of this placeholder. The default is to right-align the result.
* An optional number, that says how many characters the result should have. If the value to be returned is shorter than this number, the result will be padded. When used with the `j` (JSON) type specifier, the padding length specifies the tab size used for indentation.
* An optional precision modifier, consisting of a `.` (dot) followed by a number, that says how many digits should be displayed for floating point numbers. When used with the `g` type specifier, it specifies the number of significant digits. When used on a string, it causes the result to be truncated.
* A type specifier that can be any of:
* `%` — yields a literal `%` character
* `b` — yields an integer as a binary number
* `c` — yields an integer as the character with that ASCII value
* `d` or `i` — yields an integer as a signed decimal number
* `e` — yields a float using scientific notation
* `u` — yields an integer as an unsigned decimal number
* `f` — yields a float as is; see notes on precision above
* `g` — yields a float as is; see notes on precision above
* `o` — yields an integer as an octal number
* `s` — yields a string as is
* `x` — yields an integer as a hexadecimal number (lower-case)
* `X` — yields an integer as a hexadecimal number (upper-case)
* `j` — yields a JavaScript object or array as a JSON encoded string
## JavaScript `vsprintf`
`vsprintf` is the same as `sprintf` except that it accepts an array of arguments, rather than a variable number of arguments:
vsprintf("The first 4 letters of the english alphabet are: %s, %s, %s and %s", ["a", "b", "c", "d"])
## Argument swapping
You can also swap the arguments. That is, the order of the placeholders doesn't have to match the order of the arguments. You can do that by simply indicating in the format string which arguments the placeholders refer to:
sprintf("%2$s %3$s a %1$s", "cracker", "Polly", "wants")
And, of course, you can repeat the placeholders without having to increase the number of arguments.
## Named arguments
Format strings may contain replacement fields rather than positional placeholders. Instead of referring to a certain argument, you can now refer to a certain key within an object. Replacement fields are surrounded by rounded parentheses - `(` and `)` - and begin with a keyword that refers to a key:
var user = {
name: "Dolly"
}
sprintf("Hello %(name)s", user) // Hello Dolly
Keywords in replacement fields can be optionally followed by any number of keywords or indexes:
var users = [
{name: "Dolly"},
{name: "Molly"},
{name: "Polly"}
]
sprintf("Hello %(users[0].name)s, %(users[1].name)s and %(users[2].name)s", {users: users}) // Hello Dolly, Molly and Polly
Note: mixing positional and named placeholders is not (yet) supported
## Computed values
You can pass in a function as a dynamic value and it will be invoked (with no arguments) in order to compute the value on-the-fly.
sprintf("Current timestamp: %d", Date.now) // Current timestamp: 1398005382890
sprintf("Current date and time: %s", function() { return new Date().toString() })
# AngularJS
You can now use `sprintf` and `vsprintf` (also aliased as `fmt` and `vfmt` respectively) in your AngularJS projects. See `demo/`.
# Installation
## Via Bower
bower install sprintf
## Or as a node.js module
npm install sprintf-js
### Usage
var sprintf = require("sprintf-js").sprintf,
vsprintf = require("sprintf-js").vsprintf
sprintf("%2$s %3$s a %1$s", "cracker", "Polly", "wants")
vsprintf("The first 4 letters of the english alphabet are: %s, %s, %s and %s", ["a", "b", "c", "d"])
# License
**sprintf.js** is licensed under the terms of the 3-clause BSD license.
## Test Strategy
- tests are copied from the [polyfill implementation](https://github.com/tc39/proposal-temporal/tree/main/polyfill/test)
- tests should be removed if they relate to features that do not make sense for TS/AS, i.e. tests that validate the shape of an object do not make sense in a language with compile-time type checking
- tests that fail because a feature has not been implemented yet should be left as failures.
# fs.realpath
A backwards-compatible fs.realpath for Node v6 and above
In Node v6, the JavaScript implementation of fs.realpath was replaced
with a faster (but less resilient) native implementation. That raises
new and platform-specific errors and cannot handle long or excessively
symlink-looping paths.
This module handles those cases by detecting the new errors and
falling back to the JavaScript implementation. On versions of Node
prior to v6, it has no effect.
## USAGE
```js
var rp = require('fs.realpath')
// async version
rp.realpath(someLongAndLoopingPath, function (er, real) {
// the ELOOP was handled, but it was a bit slower
})
// sync version
var real = rp.realpathSync(someLongAndLoopingPath)
// monkeypatch at your own risk!
// This replaces the fs.realpath/fs.realpathSync builtins
rp.monkeypatch()
// un-do the monkeypatching
rp.unmonkeypatch()
```
# file-entry-cache
> Super simple cache for file metadata, useful for process that work o a given series of files
> and that only need to repeat the job on the changed ones since the previous run of the process — Edit
[](https://npmjs.org/package/file-entry-cache)
[](https://travis-ci.org/royriojas/file-entry-cache)
## install
```bash
npm i --save file-entry-cache
```
## Usage
The module exposes two functions `create` and `createFromFile`.
## `create(cacheName, [directory, useCheckSum])`
- **cacheName**: the name of the cache to be created
- **directory**: Optional the directory to load the cache from
- **usecheckSum**: Whether to use md5 checksum to verify if file changed. If false the default will be to use the mtime and size of the file.
## `createFromFile(pathToCache, [useCheckSum])`
- **pathToCache**: the path to the cache file (this combines the cache name and directory)
- **useCheckSum**: Whether to use md5 checksum to verify if file changed. If false the default will be to use the mtime and size of the file.
```js
// loads the cache, if one does not exists for the given
// Id a new one will be prepared to be created
var fileEntryCache = require('file-entry-cache');
var cache = fileEntryCache.create('testCache');
var files = expand('../fixtures/*.txt');
// the first time this method is called, will return all the files
var oFiles = cache.getUpdatedFiles(files);
// this will persist this to disk checking each file stats and
// updating the meta attributes `size` and `mtime`.
// custom fields could also be added to the meta object and will be persisted
// in order to retrieve them later
cache.reconcile();
// use this if you want the non visited file entries to be kept in the cache
// for more than one execution
//
// cache.reconcile( true /* noPrune */)
// on a second run
var cache2 = fileEntryCache.create('testCache');
// will return now only the files that were modified or none
// if no files were modified previous to the execution of this function
var oFiles = cache.getUpdatedFiles(files);
// if you want to prevent a file from being considered non modified
// something useful if a file failed some sort of validation
// you can then remove the entry from the cache doing
cache.removeEntry('path/to/file'); // path to file should be the same path of the file received on `getUpdatedFiles`
// that will effectively make the file to appear again as modified until the validation is passed. In that
// case you should not remove it from the cache
// if you need all the files, so you can determine what to do with the changed ones
// you can call
var oFiles = cache.normalizeEntries(files);
// oFiles will be an array of objects like the following
entry = {
key: 'some/name/file', the path to the file
changed: true, // if the file was changed since previous run
meta: {
size: 3242, // the size of the file
mtime: 231231231, // the modification time of the file
data: {} // some extra field stored for this file (useful to save the result of a transformation on the file
}
}
```
## Motivation for this module
I needed a super simple and dumb **in-memory cache** with optional disk persistence (write-back cache) in order to make
a script that will beautify files with `esformatter` to execute only on the files that were changed since the last run.
In doing so the process of beautifying files was reduced from several seconds to a small fraction of a second.
This module uses [flat-cache](https://www.npmjs.com/package/flat-cache) a super simple `key/value` cache storage with
optional file persistance.
The main idea is to read the files when the task begins, apply the transforms required, and if the process succeed,
then store the new state of the files. The next time this module request for `getChangedFiles` will return only
the files that were modified. Making the process to end faster.
This module could also be used by processes that modify the files applying a transform, in that case the result of the
transform could be stored in the `meta` field, of the entries. Anything added to the meta field will be persisted.
Those processes won't need to call `getChangedFiles` they will instead call `normalizeEntries` that will return the
entries with a `changed` field that can be used to determine if the file was changed or not. If it was not changed
the transformed stored data could be used instead of actually applying the transformation, saving time in case of only
a few files changed.
In the worst case scenario all the files will be processed. In the best case scenario only a few of them will be processed.
## Important notes
- The values set on the meta attribute of the entries should be `stringify-able` ones if possible, flat-cache uses `circular-json` to try to persist circular structures, but this should be considered experimental. The best results are always obtained with non circular values
- All the changes to the cache state are done to memory first and only persisted after reconcile.
## License
MIT
# fast-json-stable-stringify
Deterministic `JSON.stringify()` - a faster version of [@substack](https://github.com/substack)'s json-stable-strigify without [jsonify](https://github.com/substack/jsonify).
You can also pass in a custom comparison function.
[](https://travis-ci.org/epoberezkin/fast-json-stable-stringify)
[](https://coveralls.io/github/epoberezkin/fast-json-stable-stringify?branch=master)
# example
``` js
var stringify = require('fast-json-stable-stringify');
var obj = { c: 8, b: [{z:6,y:5,x:4},7], a: 3 };
console.log(stringify(obj));
```
output:
```
{"a":3,"b":[{"x":4,"y":5,"z":6},7],"c":8}
```
# methods
``` js
var stringify = require('fast-json-stable-stringify')
```
## var str = stringify(obj, opts)
Return a deterministic stringified string `str` from the object `obj`.
## options
### cmp
If `opts` is given, you can supply an `opts.cmp` to have a custom comparison
function for object keys. Your function `opts.cmp` is called with these
parameters:
``` js
opts.cmp({ key: akey, value: avalue }, { key: bkey, value: bvalue })
```
For example, to sort on the object key names in reverse order you could write:
``` js
var stringify = require('fast-json-stable-stringify');
var obj = { c: 8, b: [{z:6,y:5,x:4},7], a: 3 };
var s = stringify(obj, function (a, b) {
return a.key < b.key ? 1 : -1;
});
console.log(s);
```
which results in the output string:
```
{"c":8,"b":[{"z":6,"y":5,"x":4},7],"a":3}
```
Or if you wanted to sort on the object values in reverse order, you could write:
```
var stringify = require('fast-json-stable-stringify');
var obj = { d: 6, c: 5, b: [{z:3,y:2,x:1},9], a: 10 };
var s = stringify(obj, function (a, b) {
return a.value < b.value ? 1 : -1;
});
console.log(s);
```
which outputs:
```
{"d":6,"c":5,"b":[{"z":3,"y":2,"x":1},9],"a":10}
```
### cycles
Pass `true` in `opts.cycles` to stringify circular property as `__cycle__` - the result will not be a valid JSON string in this case.
TypeError will be thrown in case of circular object without this option.
# install
With [npm](https://npmjs.org) do:
```
npm install fast-json-stable-stringify
```
# benchmark
To run benchmark (requires Node.js 6+):
```
node benchmark
```
Results:
```
fast-json-stable-stringify x 17,189 ops/sec ±1.43% (83 runs sampled)
json-stable-stringify x 13,634 ops/sec ±1.39% (85 runs sampled)
fast-stable-stringify x 20,212 ops/sec ±1.20% (84 runs sampled)
faster-stable-stringify x 15,549 ops/sec ±1.12% (84 runs sampled)
The fastest is fast-stable-stringify
```
## Enterprise support
fast-json-stable-stringify package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-fast-json-stable-stringify?utm_source=npm-fast-json-stable-stringify&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
# license
[MIT](https://github.com/epoberezkin/fast-json-stable-stringify/blob/master/LICENSE)
# balanced-match
Match balanced string pairs, like `{` and `}` or `<b>` and `</b>`. Supports regular expressions as well!
[](http://travis-ci.org/juliangruber/balanced-match)
[](https://www.npmjs.org/package/balanced-match)
[](https://ci.testling.com/juliangruber/balanced-match)
## Example
Get the first matching pair of braces:
```js
var balanced = require('balanced-match');
console.log(balanced('{', '}', 'pre{in{nested}}post'));
console.log(balanced('{', '}', 'pre{first}between{second}post'));
console.log(balanced(/\s+\{\s+/, /\s+\}\s+/, 'pre { in{nest} } post'));
```
The matches are:
```bash
$ node example.js
{ start: 3, end: 14, pre: 'pre', body: 'in{nested}', post: 'post' }
{ start: 3,
end: 9,
pre: 'pre',
body: 'first',
post: 'between{second}post' }
{ start: 3, end: 17, pre: 'pre', body: 'in{nest}', post: 'post' }
```
## API
### var m = balanced(a, b, str)
For the first non-nested matching pair of `a` and `b` in `str`, return an
object with those keys:
* **start** the index of the first match of `a`
* **end** the index of the matching `b`
* **pre** the preamble, `a` and `b` not included
* **body** the match, `a` and `b` not included
* **post** the postscript, `a` and `b` not included
If there's no match, `undefined` will be returned.
If the `str` contains more `a` than `b` / there are unmatched pairs, the first match that was closed will be used. For example, `{{a}` will match `['{', 'a', '']` and `{a}}` will match `['', 'a', '}']`.
### var r = balanced.range(a, b, str)
For the first non-nested matching pair of `a` and `b` in `str`, return an
array with indexes: `[ <a index>, <b index> ]`.
If there's no match, `undefined` will be returned.
If the `str` contains more `a` than `b` / there are unmatched pairs, the first match that was closed will be used. For example, `{{a}` will match `[ 1, 3 ]` and `{a}}` will match `[0, 2]`.
## Installation
With [npm](https://npmjs.org) do:
```bash
npm install balanced-match
```
## Security contact information
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure.
## License
(MIT)
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# assemblyscript-json
 
JSON encoder / decoder for AssemblyScript.
Special thanks to https://github.com/MaxGraey/bignum.wasm for basic unit testing infra for AssemblyScript.
## Installation
`assemblyscript-json` is available as a [npm package](https://www.npmjs.com/package/assemblyscript-json). You can install `assemblyscript-json` in your AssemblyScript project by running:
`npm install --save assemblyscript-json`
## Usage
### Parsing JSON
```typescript
import { JSON } from "assemblyscript-json";
// Parse an object using the JSON object
let jsonObj: JSON.Obj = <JSON.Obj>(JSON.parse('{"hello": "world", "value": 24}'));
// We can then use the .getX functions to read from the object if you know it's type
// This will return the appropriate JSON.X value if the key exists, or null if the key does not exist
let worldOrNull: JSON.Str | null = jsonObj.getString("hello"); // This will return a JSON.Str or null
if (worldOrNull != null) {
// use .valueOf() to turn the high level JSON.Str type into a string
let world: string = worldOrNull.valueOf();
}
let numOrNull: JSON.Num | null = jsonObj.getNum("value");
if (numOrNull != null) {
// use .valueOf() to turn the high level JSON.Num type into a f64
let value: f64 = numOrNull.valueOf();
}
// If you don't know the value type, get the parent JSON.Value
let valueOrNull: JSON.Value | null = jsonObj.getValue("hello");
if (valueOrNull != null) {
let value = <JSON.Value>valueOrNull;
// Next we could figure out what type we are
if(value.isString) {
// value.isString would be true, so we can cast to a string
let innerString = (<JSON.Str>value).valueOf();
let jsonString = (<JSON.Str>value).stringify();
// Do something with string value
}
}
```
### Encoding JSON
```typescript
import { JSONEncoder } from "assemblyscript-json";
// Create encoder
let encoder = new JSONEncoder();
// Construct necessary object
encoder.pushObject("obj");
encoder.setInteger("int", 10);
encoder.setString("str", "");
encoder.popObject();
// Get serialized data
let json: Uint8Array = encoder.serialize();
// Or get serialized data as string
let jsonString: string = encoder.stringify();
assert(jsonString, '"obj": {"int": 10, "str": ""}'); // True!
```
### Custom JSON Deserializers
```typescript
import { JSONDecoder, JSONHandler } from "assemblyscript-json";
// Events need to be received by custom object extending JSONHandler.
// NOTE: All methods are optional to implement.
class MyJSONEventsHandler extends JSONHandler {
setString(name: string, value: string): void {
// Handle field
}
setBoolean(name: string, value: bool): void {
// Handle field
}
setNull(name: string): void {
// Handle field
}
setInteger(name: string, value: i64): void {
// Handle field
}
setFloat(name: string, value: f64): void {
// Handle field
}
pushArray(name: string): bool {
// Handle array start
// true means that nested object needs to be traversed, false otherwise
// Note that returning false means JSONDecoder.startIndex need to be updated by handler
return true;
}
popArray(): void {
// Handle array end
}
pushObject(name: string): bool {
// Handle object start
// true means that nested object needs to be traversed, false otherwise
// Note that returning false means JSONDecoder.startIndex need to be updated by handler
return true;
}
popObject(): void {
// Handle object end
}
}
// Create decoder
let decoder = new JSONDecoder<MyJSONEventsHandler>(new MyJSONEventsHandler());
// Create a byte buffer of our JSON. NOTE: Deserializers work on UTF8 string buffers.
let jsonString = '{"hello": "world"}';
let jsonBuffer = Uint8Array.wrap(String.UTF8.encode(jsonString));
// Parse JSON
decoder.deserialize(jsonBuffer); // This will send events to MyJSONEventsHandler
```
Feel free to look through the [tests](https://github.com/nearprotocol/assemblyscript-json/tree/master/assembly/__tests__) for more usage examples.
## Reference Documentation
Reference API Documentation can be found in the [docs directory](./docs).
## License
[MIT](./LICENSE)
# require-main-filename
[](https://travis-ci.org/yargs/require-main-filename)
[](https://coveralls.io/r/yargs/require-main-filename?branch=master)
[](https://www.npmjs.com/package/require-main-filename)
`require.main.filename` is great for figuring out the entry
point for the current application. This can be combined with a module like
[pkg-conf](https://www.npmjs.com/package/pkg-conf) to, _as if by magic_, load
top-level configuration.
Unfortunately, `require.main.filename` sometimes fails when an application is
executed with an alternative process manager, e.g., [iisnode](https://github.com/tjanczuk/iisnode).
`require-main-filename` is a shim that addresses this problem.
## Usage
```js
var main = require('require-main-filename')()
// use main as an alternative to require.main.filename.
```
## License
ISC
# jsdiff
[](http://travis-ci.org/kpdecker/jsdiff)
[](https://saucelabs.com/u/jsdiff)
A javascript text differencing implementation.
Based on the algorithm proposed in
["An O(ND) Difference Algorithm and its Variations" (Myers, 1986)](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.4.6927).
## Installation
```bash
npm install diff --save
```
## API
* `Diff.diffChars(oldStr, newStr[, options])` - diffs two blocks of text, comparing character by character.
Returns a list of change objects (See below).
Options
* `ignoreCase`: `true` to ignore casing difference. Defaults to `false`.
* `Diff.diffWords(oldStr, newStr[, options])` - diffs two blocks of text, comparing word by word, ignoring whitespace.
Returns a list of change objects (See below).
Options
* `ignoreCase`: Same as in `diffChars`.
* `Diff.diffWordsWithSpace(oldStr, newStr[, options])` - diffs two blocks of text, comparing word by word, treating whitespace as significant.
Returns a list of change objects (See below).
* `Diff.diffLines(oldStr, newStr[, options])` - diffs two blocks of text, comparing line by line.
Options
* `ignoreWhitespace`: `true` to ignore leading and trailing whitespace. This is the same as `diffTrimmedLines`
* `newlineIsToken`: `true` to treat newline characters as separate tokens. This allows for changes to the newline structure to occur independently of the line content and to be treated as such. In general this is the more human friendly form of `diffLines` and `diffLines` is better suited for patches and other computer friendly output.
Returns a list of change objects (See below).
* `Diff.diffTrimmedLines(oldStr, newStr[, options])` - diffs two blocks of text, comparing line by line, ignoring leading and trailing whitespace.
Returns a list of change objects (See below).
* `Diff.diffSentences(oldStr, newStr[, options])` - diffs two blocks of text, comparing sentence by sentence.
Returns a list of change objects (See below).
* `Diff.diffCss(oldStr, newStr[, options])` - diffs two blocks of text, comparing CSS tokens.
Returns a list of change objects (See below).
* `Diff.diffJson(oldObj, newObj[, options])` - diffs two JSON objects, comparing the fields defined on each. The order of fields, etc does not matter in this comparison.
Returns a list of change objects (See below).
* `Diff.diffArrays(oldArr, newArr[, options])` - diffs two arrays, comparing each item for strict equality (===).
Options
* `comparator`: `function(left, right)` for custom equality checks
Returns a list of change objects (See below).
* `Diff.createTwoFilesPatch(oldFileName, newFileName, oldStr, newStr, oldHeader, newHeader)` - creates a unified diff patch.
Parameters:
* `oldFileName` : String to be output in the filename section of the patch for the removals
* `newFileName` : String to be output in the filename section of the patch for the additions
* `oldStr` : Original string value
* `newStr` : New string value
* `oldHeader` : Additional information to include in the old file header
* `newHeader` : Additional information to include in the new file header
* `options` : An object with options. Currently, only `context` is supported and describes how many lines of context should be included.
* `Diff.createPatch(fileName, oldStr, newStr, oldHeader, newHeader)` - creates a unified diff patch.
Just like Diff.createTwoFilesPatch, but with oldFileName being equal to newFileName.
* `Diff.structuredPatch(oldFileName, newFileName, oldStr, newStr, oldHeader, newHeader, options)` - returns an object with an array of hunk objects.
This method is similar to createTwoFilesPatch, but returns a data structure
suitable for further processing. Parameters are the same as createTwoFilesPatch. The data structure returned may look like this:
```js
{
oldFileName: 'oldfile', newFileName: 'newfile',
oldHeader: 'header1', newHeader: 'header2',
hunks: [{
oldStart: 1, oldLines: 3, newStart: 1, newLines: 3,
lines: [' line2', ' line3', '-line4', '+line5', '\\ No newline at end of file'],
}]
}
```
* `Diff.applyPatch(source, patch[, options])` - applies a unified diff patch.
Return a string containing new version of provided data. `patch` may be a string diff or the output from the `parsePatch` or `structuredPatch` methods.
The optional `options` object may have the following keys:
- `fuzzFactor`: Number of lines that are allowed to differ before rejecting a patch. Defaults to 0.
- `compareLine(lineNumber, line, operation, patchContent)`: Callback used to compare to given lines to determine if they should be considered equal when patching. Defaults to strict equality but may be overridden to provide fuzzier comparison. Should return false if the lines should be rejected.
* `Diff.applyPatches(patch, options)` - applies one or more patches.
This method will iterate over the contents of the patch and apply to data provided through callbacks. The general flow for each patch index is:
- `options.loadFile(index, callback)` is called. The caller should then load the contents of the file and then pass that to the `callback(err, data)` callback. Passing an `err` will terminate further patch execution.
- `options.patched(index, content, callback)` is called once the patch has been applied. `content` will be the return value from `applyPatch`. When it's ready, the caller should call `callback(err)` callback. Passing an `err` will terminate further patch execution.
Once all patches have been applied or an error occurs, the `options.complete(err)` callback is made.
* `Diff.parsePatch(diffStr)` - Parses a patch into structured data
Return a JSON object representation of the a patch, suitable for use with the `applyPatch` method. This parses to the same structure returned by `Diff.structuredPatch`.
* `convertChangesToXML(changes)` - converts a list of changes to a serialized XML format
All methods above which accept the optional `callback` method will run in sync mode when that parameter is omitted and in async mode when supplied. This allows for larger diffs without blocking the event loop. This may be passed either directly as the final parameter or as the `callback` field in the `options` object.
### Change Objects
Many of the methods above return change objects. These objects consist of the following fields:
* `value`: Text content
* `added`: True if the value was inserted into the new string
* `removed`: True if the value was removed from the old string
Note that some cases may omit a particular flag field. Comparison on the flag fields should always be done in a truthy or falsy manner.
## Examples
Basic example in Node
```js
require('colors');
const Diff = require('diff');
const one = 'beep boop';
const other = 'beep boob blah';
const diff = Diff.diffChars(one, other);
diff.forEach((part) => {
// green for additions, red for deletions
// grey for common parts
const color = part.added ? 'green' :
part.removed ? 'red' : 'grey';
process.stderr.write(part.value[color]);
});
console.log();
```
Running the above program should yield
<img src="images/node_example.png" alt="Node Example">
Basic example in a web page
```html
<pre id="display"></pre>
<script src="diff.js"></script>
<script>
const one = 'beep boop',
other = 'beep boob blah',
color = '';
let span = null;
const diff = Diff.diffChars(one, other),
display = document.getElementById('display'),
fragment = document.createDocumentFragment();
diff.forEach((part) => {
// green for additions, red for deletions
// grey for common parts
const color = part.added ? 'green' :
part.removed ? 'red' : 'grey';
span = document.createElement('span');
span.style.color = color;
span.appendChild(document
.createTextNode(part.value));
fragment.appendChild(span);
});
display.appendChild(fragment);
</script>
```
Open the above .html file in a browser and you should see
<img src="images/web_example.png" alt="Node Example">
**[Full online demo](http://kpdecker.github.com/jsdiff)**
## Compatibility
[](https://saucelabs.com/u/jsdiff)
jsdiff supports all ES3 environments with some known issues on IE8 and below. Under these browsers some diff algorithms such as word diff and others may fail due to lack of support for capturing groups in the `split` operation.
## License
See [LICENSE](https://github.com/kpdecker/jsdiff/blob/master/LICENSE).
iMurmurHash.js
==============
An incremental implementation of the MurmurHash3 (32-bit) hashing algorithm for JavaScript based on [Gary Court's implementation](https://github.com/garycourt/murmurhash-js) with [kazuyukitanimura's modifications](https://github.com/kazuyukitanimura/murmurhash-js).
This version works significantly faster than the non-incremental version if you need to hash many small strings into a single hash, since string concatenation (to build the single string to pass the non-incremental version) is fairly costly. In one case tested, using the incremental version was about 50% faster than concatenating 5-10 strings and then hashing.
Installation
------------
To use iMurmurHash in the browser, [download the latest version](https://raw.github.com/jensyt/imurmurhash-js/master/imurmurhash.min.js) and include it as a script on your site.
```html
<script type="text/javascript" src="/scripts/imurmurhash.min.js"></script>
<script>
// Your code here, access iMurmurHash using the global object MurmurHash3
</script>
```
---
To use iMurmurHash in Node.js, install the module using NPM:
```bash
npm install imurmurhash
```
Then simply include it in your scripts:
```javascript
MurmurHash3 = require('imurmurhash');
```
Quick Example
-------------
```javascript
// Create the initial hash
var hashState = MurmurHash3('string');
// Incrementally add text
hashState.hash('more strings');
hashState.hash('even more strings');
// All calls can be chained if desired
hashState.hash('and').hash('some').hash('more');
// Get a result
hashState.result();
// returns 0xe4ccfe6b
```
Functions
---------
### MurmurHash3 ([string], [seed])
Get a hash state object, optionally initialized with the given _string_ and _seed_. _Seed_ must be a positive integer if provided. Calling this function without the `new` keyword will return a cached state object that has been reset. This is safe to use as long as the object is only used from a single thread and no other hashes are created while operating on this one. If this constraint cannot be met, you can use `new` to create a new state object. For example:
```javascript
// Use the cached object, calling the function again will return the same
// object (but reset, so the current state would be lost)
hashState = MurmurHash3();
...
// Create a new object that can be safely used however you wish. Calling the
// function again will simply return a new state object, and no state loss
// will occur, at the cost of creating more objects.
hashState = new MurmurHash3();
```
Both methods can be mixed however you like if you have different use cases.
---
### MurmurHash3.prototype.hash (string)
Incrementally add _string_ to the hash. This can be called as many times as you want for the hash state object, including after a call to `result()`. Returns `this` so calls can be chained.
---
### MurmurHash3.prototype.result ()
Get the result of the hash as a 32-bit positive integer. This performs the tail and finalizer portions of the algorithm, but does not store the result in the state object. This means that it is perfectly safe to get results and then continue adding strings via `hash`.
```javascript
// Do the whole string at once
MurmurHash3('this is a test string').result();
// 0x70529328
// Do part of the string, get a result, then the other part
var m = MurmurHash3('this is a');
m.result();
// 0xbfc4f834
m.hash(' test string').result();
// 0x70529328 (same as above)
```
---
### MurmurHash3.prototype.reset ([seed])
Reset the state object for reuse, optionally using the given _seed_ (defaults to 0 like the constructor). Returns `this` so calls can be chained.
---
License (MIT)
-------------
Copyright (c) 2013 Gary Court, Jens Taylor
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# v8-compile-cache
[](https://travis-ci.org/zertosh/v8-compile-cache)
`v8-compile-cache` attaches a `require` hook to use [V8's code cache](https://v8project.blogspot.com/2015/07/code-caching.html) to speed up instantiation time. The "code cache" is the work of parsing and compiling done by V8.
The ability to tap into V8 to produce/consume this cache was introduced in [Node v5.7.0](https://nodejs.org/en/blog/release/v5.7.0/).
## Usage
1. Add the dependency:
```sh
$ npm install --save v8-compile-cache
```
2. Then, in your entry module add:
```js
require('v8-compile-cache');
```
**Requiring `v8-compile-cache` in Node <5.7.0 is a noop – but you need at least Node 4.0.0 to support the ES2015 syntax used by `v8-compile-cache`.**
## Options
Set the environment variable `DISABLE_V8_COMPILE_CACHE=1` to disable the cache.
Cache directory is defined by environment variable `V8_COMPILE_CACHE_CACHE_DIR` or defaults to `<os.tmpdir()>/v8-compile-cache-<V8_VERSION>`.
## Internals
Cache files are suffixed `.BLOB` and `.MAP` corresponding to the entry module that required `v8-compile-cache`. The cache is _entry module specific_ because it is faster to load the entire code cache into memory at once, than it is to read it from disk on a file-by-file basis.
## Benchmarks
See https://github.com/zertosh/v8-compile-cache/tree/master/bench.
**Load Times:**
| Module | Without Cache | With Cache |
| ---------------- | -------------:| ----------:|
| `babel-core` | `218ms` | `185ms` |
| `yarn` | `153ms` | `113ms` |
| `yarn` (bundled) | `228ms` | `105ms` |
_^ Includes the overhead of loading the cache itself._
## Acknowledgements
* `FileSystemBlobStore` and `NativeCompileCache` are based on Atom's implementation of their v8 compile cache:
- https://github.com/atom/atom/blob/b0d7a8a/src/file-system-blob-store.js
- https://github.com/atom/atom/blob/b0d7a8a/src/native-compile-cache.js
* `mkdirpSync` is based on:
- https://github.com/substack/node-mkdirp/blob/f2003bb/index.js#L55-L98
# eslint-visitor-keys
[](https://www.npmjs.com/package/eslint-visitor-keys)
[](http://www.npmtrends.com/eslint-visitor-keys)
[](https://travis-ci.org/eslint/eslint-visitor-keys)
[](https://david-dm.org/eslint/eslint-visitor-keys)
Constants and utilities about visitor keys to traverse AST.
## 💿 Installation
Use [npm] to install.
```bash
$ npm install eslint-visitor-keys
```
### Requirements
- [Node.js] 4.0.0 or later.
## 📖 Usage
```js
const evk = require("eslint-visitor-keys")
```
### evk.KEYS
> type: `{ [type: string]: string[] | undefined }`
Visitor keys. This keys are frozen.
This is an object. Keys are the type of [ESTree] nodes. Their values are an array of property names which have child nodes.
For example:
```
console.log(evk.KEYS.AssignmentExpression) // → ["left", "right"]
```
### evk.getKeys(node)
> type: `(node: object) => string[]`
Get the visitor keys of a given AST node.
This is similar to `Object.keys(node)` of ES Standard, but some keys are excluded: `parent`, `leadingComments`, `trailingComments`, and names which start with `_`.
This will be used to traverse unknown nodes.
For example:
```
const node = {
type: "AssignmentExpression",
left: { type: "Identifier", name: "foo" },
right: { type: "Literal", value: 0 }
}
console.log(evk.getKeys(node)) // → ["type", "left", "right"]
```
### evk.unionWith(additionalKeys)
> type: `(additionalKeys: object) => { [type: string]: string[] | undefined }`
Make the union set with `evk.KEYS` and the given keys.
- The order of keys is, `additionalKeys` is at first, then `evk.KEYS` is concatenated after that.
- It removes duplicated keys as keeping the first one.
For example:
```
console.log(evk.unionWith({
MethodDefinition: ["decorators"]
})) // → { ..., MethodDefinition: ["decorators", "key", "value"], ... }
```
## 📰 Change log
See [GitHub releases](https://github.com/eslint/eslint-visitor-keys/releases).
## 🍻 Contributing
Welcome. See [ESLint contribution guidelines](https://eslint.org/docs/developer-guide/contributing/).
### Development commands
- `npm test` runs tests and measures code coverage.
- `npm run lint` checks source codes with ESLint.
- `npm run coverage` opens the code coverage report of the previous test with your default browser.
- `npm run release` publishes this package to [npm] registory.
[npm]: https://www.npmjs.com/
[Node.js]: https://nodejs.org/en/
[ESTree]: https://github.com/estree/estree
# ansi-colors [](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=W8YFZ425KND68) [](https://www.npmjs.com/package/ansi-colors) [](https://npmjs.org/package/ansi-colors) [](https://npmjs.org/package/ansi-colors) [](https://travis-ci.org/doowb/ansi-colors)
> Easily add ANSI colors to your text and symbols in the terminal. A faster drop-in replacement for chalk, kleur and turbocolor (without the dependencies and rendering bugs).
Please consider following this project's author, [Brian Woodward](https://github.com/doowb), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save ansi-colors
```

## Why use this?
ansi-colors is _the fastest Node.js library for terminal styling_. A more performant drop-in replacement for chalk, with no dependencies.
* _Blazing fast_ - Fastest terminal styling library in node.js, 10-20x faster than chalk!
* _Drop-in replacement_ for [chalk](https://github.com/chalk/chalk).
* _No dependencies_ (Chalk has 7 dependencies in its tree!)
* _Safe_ - Does not modify the `String.prototype` like [colors](https://github.com/Marak/colors.js).
* Supports [nested colors](#nested-colors), **and does not have the [nested styling bug](#nested-styling-bug) that is present in [colorette](https://github.com/jorgebucaran/colorette), [chalk](https://github.com/chalk/chalk), and [kleur](https://github.com/lukeed/kleur)**.
* Supports [chained colors](#chained-colors).
* [Toggle color support](#toggle-color-support) on or off.
## Usage
```js
const c = require('ansi-colors');
console.log(c.red('This is a red string!'));
console.log(c.green('This is a red string!'));
console.log(c.cyan('This is a cyan string!'));
console.log(c.yellow('This is a yellow string!'));
```

## Chained colors
```js
console.log(c.bold.red('this is a bold red message'));
console.log(c.bold.yellow.italic('this is a bold yellow italicized message'));
console.log(c.green.bold.underline('this is a bold green underlined message'));
```

## Nested colors
```js
console.log(c.yellow(`foo ${c.red.bold('red')} bar ${c.cyan('cyan')} baz`));
```

### Nested styling bug
`ansi-colors` does not have the nested styling bug found in [colorette](https://github.com/jorgebucaran/colorette), [chalk](https://github.com/chalk/chalk), and [kleur](https://github.com/lukeed/kleur).
```js
const { bold, red } = require('ansi-styles');
console.log(bold(`foo ${red.dim('bar')} baz`));
const colorette = require('colorette');
console.log(colorette.bold(`foo ${colorette.red(colorette.dim('bar'))} baz`));
const kleur = require('kleur');
console.log(kleur.bold(`foo ${kleur.red.dim('bar')} baz`));
const chalk = require('chalk');
console.log(chalk.bold(`foo ${chalk.red.dim('bar')} baz`));
```
**Results in the following**
(sans icons and labels)

## Toggle color support
Easily enable/disable colors.
```js
const c = require('ansi-colors');
// disable colors manually
c.enabled = false;
// or use a library to automatically detect support
c.enabled = require('color-support').hasBasic;
console.log(c.red('I will only be colored red if the terminal supports colors'));
```
## Strip ANSI codes
Use the `.unstyle` method to strip ANSI codes from a string.
```js
console.log(c.unstyle(c.blue.bold('foo bar baz')));
//=> 'foo bar baz'
```
## Available styles
**Note** that bright and bright-background colors are not always supported.
| Colors | Background Colors | Bright Colors | Bright Background Colors |
| ------- | ----------------- | ------------- | ------------------------ |
| black | bgBlack | blackBright | bgBlackBright |
| red | bgRed | redBright | bgRedBright |
| green | bgGreen | greenBright | bgGreenBright |
| yellow | bgYellow | yellowBright | bgYellowBright |
| blue | bgBlue | blueBright | bgBlueBright |
| magenta | bgMagenta | magentaBright | bgMagentaBright |
| cyan | bgCyan | cyanBright | bgCyanBright |
| white | bgWhite | whiteBright | bgWhiteBright |
| gray | | | |
| grey | | | |
_(`gray` is the U.S. spelling, `grey` is more commonly used in the Canada and U.K.)_
### Style modifiers
* dim
* **bold**
* hidden
* _italic_
* underline
* inverse
* ~~strikethrough~~
* reset
## Aliases
Create custom aliases for styles.
```js
const colors = require('ansi-colors');
colors.alias('primary', colors.yellow);
colors.alias('secondary', colors.bold);
console.log(colors.primary.secondary('Foo'));
```
## Themes
A theme is an object of custom aliases.
```js
const colors = require('ansi-colors');
colors.theme({
danger: colors.red,
dark: colors.dim.gray,
disabled: colors.gray,
em: colors.italic,
heading: colors.bold.underline,
info: colors.cyan,
muted: colors.dim,
primary: colors.blue,
strong: colors.bold,
success: colors.green,
underline: colors.underline,
warning: colors.yellow
});
// Now, we can use our custom styles alongside the built-in styles!
console.log(colors.danger.strong.em('Error!'));
console.log(colors.warning('Heads up!'));
console.log(colors.info('Did you know...'));
console.log(colors.success.bold('It worked!'));
```
## Performance
**Libraries tested**
* ansi-colors v3.0.4
* chalk v2.4.1
### Mac
> MacBook Pro, Intel Core i7, 2.3 GHz, 16 GB.
**Load time**
Time it takes to load the first time `require()` is called:
* ansi-colors - `1.915ms`
* chalk - `12.437ms`
**Benchmarks**
```
# All Colors
ansi-colors x 173,851 ops/sec ±0.42% (91 runs sampled)
chalk x 9,944 ops/sec ±2.53% (81 runs sampled)))
# Chained colors
ansi-colors x 20,791 ops/sec ±0.60% (88 runs sampled)
chalk x 2,111 ops/sec ±2.34% (83 runs sampled)
# Nested colors
ansi-colors x 59,304 ops/sec ±0.98% (92 runs sampled)
chalk x 4,590 ops/sec ±2.08% (82 runs sampled)
```
### Windows
> Windows 10, Intel Core i7-7700k CPU @ 4.2 GHz, 32 GB
**Load time**
Time it takes to load the first time `require()` is called:
* ansi-colors - `1.494ms`
* chalk - `11.523ms`
**Benchmarks**
```
# All Colors
ansi-colors x 193,088 ops/sec ±0.51% (95 runs sampled))
chalk x 9,612 ops/sec ±3.31% (77 runs sampled)))
# Chained colors
ansi-colors x 26,093 ops/sec ±1.13% (94 runs sampled)
chalk x 2,267 ops/sec ±2.88% (80 runs sampled))
# Nested colors
ansi-colors x 67,747 ops/sec ±0.49% (93 runs sampled)
chalk x 4,446 ops/sec ±3.01% (82 runs sampled))
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [ansi-wrap](https://www.npmjs.com/package/ansi-wrap): Create ansi colors by passing the open and close codes. | [homepage](https://github.com/jonschlinkert/ansi-wrap "Create ansi colors by passing the open and close codes.")
* [strip-color](https://www.npmjs.com/package/strip-color): Strip ANSI color codes from a string. No dependencies. | [homepage](https://github.com/jonschlinkert/strip-color "Strip ANSI color codes from a string. No dependencies.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 48 | [jonschlinkert](https://github.com/jonschlinkert) |
| 42 | [doowb](https://github.com/doowb) |
| 6 | [lukeed](https://github.com/lukeed) |
| 2 | [Silic0nS0ldier](https://github.com/Silic0nS0ldier) |
| 1 | [dwieeb](https://github.com/dwieeb) |
| 1 | [jorgebucaran](https://github.com/jorgebucaran) |
| 1 | [madhavarshney](https://github.com/madhavarshney) |
| 1 | [chapterjason](https://github.com/chapterjason) |
### Author
**Brian Woodward**
* [GitHub Profile](https://github.com/doowb)
* [Twitter Profile](https://twitter.com/doowb)
* [LinkedIn Profile](https://linkedin.com/in/woodwardbrian)
### License
Copyright © 2019, [Brian Woodward](https://github.com/doowb).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on July 01, 2019._
functional-red-black-tree
=========================
A [fully persistent](http://en.wikipedia.org/wiki/Persistent_data_structure) [red-black tree](http://en.wikipedia.org/wiki/Red%E2%80%93black_tree) written 100% in JavaScript. Works both in node.js and in the browser via [browserify](http://browserify.org/).
Functional (or fully presistent) data structures allow for non-destructive updates. So if you insert an element into the tree, it returns a new tree with the inserted element rather than destructively updating the existing tree in place. Doing this requires using extra memory, and if one were naive it could cost as much as reallocating the entire tree. Instead, this data structure saves some memory by recycling references to previously allocated subtrees. This requires using only O(log(n)) additional memory per update instead of a full O(n) copy.
Some advantages of this is that it is possible to apply insertions and removals to the tree while still iterating over previous versions of the tree. Functional and persistent data structures can also be useful in many geometric algorithms like point location within triangulations or ray queries, and can be used to analyze the history of executing various algorithms. This added power though comes at a cost, since it is generally a bit slower to use a functional data structure than an imperative version. However, if your application needs this behavior then you may consider using this module.
# Install
npm install functional-red-black-tree
# Example
Here is an example of some basic usage:
```javascript
//Load the library
var createTree = require("functional-red-black-tree")
//Create a tree
var t1 = createTree()
//Insert some items into the tree
var t2 = t1.insert(1, "foo")
var t3 = t2.insert(2, "bar")
//Remove something
var t4 = t3.remove(1)
```
# API
```javascript
var createTree = require("functional-red-black-tree")
```
## Overview
- [Tree methods](#tree-methods)
- [`var tree = createTree([compare])`](#var-tree-=-createtreecompare)
- [`tree.keys`](#treekeys)
- [`tree.values`](#treevalues)
- [`tree.length`](#treelength)
- [`tree.get(key)`](#treegetkey)
- [`tree.insert(key, value)`](#treeinsertkey-value)
- [`tree.remove(key)`](#treeremovekey)
- [`tree.find(key)`](#treefindkey)
- [`tree.ge(key)`](#treegekey)
- [`tree.gt(key)`](#treegtkey)
- [`tree.lt(key)`](#treeltkey)
- [`tree.le(key)`](#treelekey)
- [`tree.at(position)`](#treeatposition)
- [`tree.begin`](#treebegin)
- [`tree.end`](#treeend)
- [`tree.forEach(visitor(key,value)[, lo[, hi]])`](#treeforEachvisitorkeyvalue-lo-hi)
- [`tree.root`](#treeroot)
- [Node properties](#node-properties)
- [`node.key`](#nodekey)
- [`node.value`](#nodevalue)
- [`node.left`](#nodeleft)
- [`node.right`](#noderight)
- [Iterator methods](#iterator-methods)
- [`iter.key`](#iterkey)
- [`iter.value`](#itervalue)
- [`iter.node`](#iternode)
- [`iter.tree`](#itertree)
- [`iter.index`](#iterindex)
- [`iter.valid`](#itervalid)
- [`iter.clone()`](#iterclone)
- [`iter.remove()`](#iterremove)
- [`iter.update(value)`](#iterupdatevalue)
- [`iter.next()`](#iternext)
- [`iter.prev()`](#iterprev)
- [`iter.hasNext`](#iterhasnext)
- [`iter.hasPrev`](#iterhasprev)
## Tree methods
### `var tree = createTree([compare])`
Creates an empty functional tree
* `compare` is an optional comparison function, same semantics as array.sort()
**Returns** An empty tree ordered by `compare`
### `tree.keys`
A sorted array of all the keys in the tree
### `tree.values`
An array array of all the values in the tree
### `tree.length`
The number of items in the tree
### `tree.get(key)`
Retrieves the value associated to the given key
* `key` is the key of the item to look up
**Returns** The value of the first node associated to `key`
### `tree.insert(key, value)`
Creates a new tree with the new pair inserted.
* `key` is the key of the item to insert
* `value` is the value of the item to insert
**Returns** A new tree with `key` and `value` inserted
### `tree.remove(key)`
Removes the first item with `key` in the tree
* `key` is the key of the item to remove
**Returns** A new tree with the given item removed if it exists
### `tree.find(key)`
Returns an iterator pointing to the first item in the tree with `key`, otherwise `null`.
### `tree.ge(key)`
Find the first item in the tree whose key is `>= key`
* `key` is the key to search for
**Returns** An iterator at the given element.
### `tree.gt(key)`
Finds the first item in the tree whose key is `> key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.lt(key)`
Finds the last item in the tree whose key is `< key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.le(key)`
Finds the last item in the tree whose key is `<= key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.at(position)`
Finds an iterator starting at the given element
* `position` is the index at which the iterator gets created
**Returns** An iterator starting at position
### `tree.begin`
An iterator pointing to the first element in the tree
### `tree.end`
An iterator pointing to the last element in the tree
### `tree.forEach(visitor(key,value)[, lo[, hi]])`
Walks a visitor function over the nodes of the tree in order.
* `visitor(key,value)` is a callback that gets executed on each node. If a truthy value is returned from the visitor, then iteration is stopped.
* `lo` is an optional start of the range to visit (inclusive)
* `hi` is an optional end of the range to visit (non-inclusive)
**Returns** The last value returned by the callback
### `tree.root`
Returns the root node of the tree
## Node properties
Each node of the tree has the following properties:
### `node.key`
The key associated to the node
### `node.value`
The value associated to the node
### `node.left`
The left subtree of the node
### `node.right`
The right subtree of the node
## Iterator methods
### `iter.key`
The key of the item referenced by the iterator
### `iter.value`
The value of the item referenced by the iterator
### `iter.node`
The value of the node at the iterator's current position. `null` is iterator is node valid.
### `iter.tree`
The tree associated to the iterator
### `iter.index`
Returns the position of this iterator in the sequence.
### `iter.valid`
Checks if the iterator is valid
### `iter.clone()`
Makes a copy of the iterator
### `iter.remove()`
Removes the item at the position of the iterator
**Returns** A new binary search tree with `iter`'s item removed
### `iter.update(value)`
Updates the value of the node in the tree at this iterator
**Returns** A new binary search tree with the corresponding node updated
### `iter.next()`
Advances the iterator to the next position
### `iter.prev()`
Moves the iterator backward one element
### `iter.hasNext`
If true, then the iterator is not at the end of the sequence
### `iter.hasPrev`
If true, then the iterator is not at the beginning of the sequence
# Credits
(c) 2013 Mikola Lysenko. MIT License
# fast-deep-equal
The fastest deep equal with ES6 Map, Set and Typed arrays support.
[](https://travis-ci.org/epoberezkin/fast-deep-equal)
[](https://www.npmjs.com/package/fast-deep-equal)
[](https://coveralls.io/github/epoberezkin/fast-deep-equal?branch=master)
## Install
```bash
npm install fast-deep-equal
```
## Features
- ES5 compatible
- works in node.js (8+) and browsers (IE9+)
- checks equality of Date and RegExp objects by value.
ES6 equal (`require('fast-deep-equal/es6')`) also supports:
- Maps
- Sets
- Typed arrays
## Usage
```javascript
var equal = require('fast-deep-equal');
console.log(equal({foo: 'bar'}, {foo: 'bar'})); // true
```
To support ES6 Maps, Sets and Typed arrays equality use:
```javascript
var equal = require('fast-deep-equal/es6');
console.log(equal(Int16Array([1, 2]), Int16Array([1, 2]))); // true
```
To use with React (avoiding the traversal of React elements' _owner
property that contains circular references and is not needed when
comparing the elements - borrowed from [react-fast-compare](https://github.com/FormidableLabs/react-fast-compare)):
```javascript
var equal = require('fast-deep-equal/react');
var equal = require('fast-deep-equal/es6/react');
```
## Performance benchmark
Node.js v12.6.0:
```
fast-deep-equal x 261,950 ops/sec ±0.52% (89 runs sampled)
fast-deep-equal/es6 x 212,991 ops/sec ±0.34% (92 runs sampled)
fast-equals x 230,957 ops/sec ±0.83% (85 runs sampled)
nano-equal x 187,995 ops/sec ±0.53% (88 runs sampled)
shallow-equal-fuzzy x 138,302 ops/sec ±0.49% (90 runs sampled)
underscore.isEqual x 74,423 ops/sec ±0.38% (89 runs sampled)
lodash.isEqual x 36,637 ops/sec ±0.72% (90 runs sampled)
deep-equal x 2,310 ops/sec ±0.37% (90 runs sampled)
deep-eql x 35,312 ops/sec ±0.67% (91 runs sampled)
ramda.equals x 12,054 ops/sec ±0.40% (91 runs sampled)
util.isDeepStrictEqual x 46,440 ops/sec ±0.43% (90 runs sampled)
assert.deepStrictEqual x 456 ops/sec ±0.71% (88 runs sampled)
The fastest is fast-deep-equal
```
To run benchmark (requires node.js 6+):
```bash
npm run benchmark
```
__Please note__: this benchmark runs against the available test cases. To choose the most performant library for your application, it is recommended to benchmark against your data and to NOT expect this benchmark to reflect the performance difference in your application.
## Enterprise support
fast-deep-equal package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-fast-deep-equal?utm_source=npm-fast-deep-equal&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
## License
[MIT](https://github.com/epoberezkin/fast-deep-equal/blob/master/LICENSE)
# Near Bindings Generator
Transforms the Assembyscript AST to serialize exported functions and add `encode` and `decode` functions for generating and parsing JSON strings.
## Using via CLI
After installling, `npm install nearprotocol/near-bindgen-as`, it can be added to the cli arguments of the assemblyscript compiler you must add the following:
```bash
asc <file> --transform near-bindgen-as ...
```
This module also adds a binary `near-asc` which adds the default arguments required to build near contracts as well as the transformer.
```bash
near-asc <input file> <output file>
```
## Using a script to compile
Another way is to add a file such as `asconfig.js` such as:
```js
const compile = require("near-bindgen-as/compiler").compile;
compile("assembly/index.ts", // input file
"out/index.wasm", // output file
[
// "-O1", // Optional arguments
"--debug",
"--measure"
],
// Prints out the final cli arguments passed to compiler.
{verbose: true}
);
```
It can then be built with `node asconfig.js`. There is an example of this in the test directory.
The AssemblyScript Runtime
==========================
The runtime provides the functionality necessary to dynamically allocate and deallocate memory of objects, arrays and buffers, as well as collect garbage that is no longer used. The current implementation is either a Two-Color Mark & Sweep (TCMS) garbage collector that must be called manually when the execution stack is unwound or an Incremental Tri-Color Mark & Sweep (ITCMS) garbage collector that is fully automated with a shadow stack, implemented on top of a Two-Level Segregate Fit (TLSF) memory manager. It's not designed to be the fastest of its kind, but intentionally focuses on simplicity and ease of integration until we can replace it with the real deal, i.e. Wasm GC.
Interface
---------
### Garbage collector / `--exportRuntime`
* **__new**(size: `usize`, id: `u32` = 0): `usize`<br />
Dynamically allocates a GC object of at least the specified size and returns its address.
Alignment is guaranteed to be 16 bytes to fit up to v128 values naturally.
GC-allocated objects cannot be used with `__realloc` and `__free`.
* **__pin**(ptr: `usize`): `usize`<br />
Pins the object pointed to by `ptr` externally so it and its directly reachable members and indirectly reachable objects do not become garbage collected.
* **__unpin**(ptr: `usize`): `void`<br />
Unpins the object pointed to by `ptr` externally so it can become garbage collected.
* **__collect**(): `void`<br />
Performs a full garbage collection.
### Internals
* **__alloc**(size: `usize`): `usize`<br />
Dynamically allocates a chunk of memory of at least the specified size and returns its address.
Alignment is guaranteed to be 16 bytes to fit up to v128 values naturally.
* **__realloc**(ptr: `usize`, size: `usize`): `usize`<br />
Dynamically changes the size of a chunk of memory, possibly moving it to a new address.
* **__free**(ptr: `usize`): `void`<br />
Frees a dynamically allocated chunk of memory by its address.
* **__renew**(ptr: `usize`, size: `usize`): `usize`<br />
Like `__realloc`, but for `__new`ed GC objects.
* **__link**(parentPtr: `usize`, childPtr: `usize`, expectMultiple: `bool`): `void`<br />
Introduces a link from a parent object to a child object, i.e. upon `parent.field = child`.
* **__visit**(ptr: `usize`, cookie: `u32`): `void`<br />
Concrete visitor implementation called during traversal. Cookie can be used to indicate one of multiple operations.
* **__visit_globals**(cookie: `u32`): `void`<br />
Calls `__visit` on each global that is of a managed type.
* **__visit_members**(ptr: `usize`, cookie: `u32`): `void`<br />
Calls `__visit` on each member of the object pointed to by `ptr`.
* **__typeinfo**(id: `u32`): `RTTIFlags`<br />
Obtains the runtime type information for objects with the specified runtime id. Runtime type information is a set of flags indicating whether a type is managed, an array or similar, and what the relevant alignments when creating an instance externally are etc.
* **__instanceof**(ptr: `usize`, classId: `u32`): `bool`<br />
Tests if the object pointed to by `ptr` is an instance of the specified class id.
ITCMS / `--runtime incremental`
-----
The Incremental Tri-Color Mark & Sweep garbage collector maintains a separate shadow stack of managed values in the background to achieve full automation. Maintaining another stack introduces some overhead compared to the simpler Two-Color Mark & Sweep garbage collector, but makes it independent of whether the execution stack is unwound or not when it is invoked, so the garbage collector can run interleaved with the program.
There are several constants one can experiment with to tweak ITCMS's automation:
* `--use ASC_GC_GRANULARITY=1024`<br />
How often to interrupt. The default of 1024 means "interrupt each 1024 bytes allocated".
* `--use ASC_GC_STEPFACTOR=200`<br />
How long to interrupt. The default of 200% means "run at double the speed of allocations".
* `--use ASC_GC_IDLEFACTOR=200`<br />
How long to idle. The default of 200% means "wait for memory to double before kicking in again".
* `--use ASC_GC_MARKCOST=1`<br />
How costly it is to mark one object. Budget per interrupt is `GRANULARITY * STEPFACTOR / 100`.
* `--use ASC_GC_SWEEPCOST=10`<br />
How costly it is to sweep one object. Budget per interrupt is `GRANULARITY * STEPFACTOR / 100`.
TCMS / `--runtime minimal`
----
If automation and low pause times aren't strictly necessary, using the Two-Color Mark & Sweep garbage collector instead by invoking collection manually at appropriate times when the execution stack is unwound may be more performant as it simpler and has less overhead. The execution stack is typically unwound when invoking the collector externally, at a place that is not indirectly called from Wasm.
STUB / `--runtime stub`
----
The stub is a maximally minimal runtime substitute, consisting of a simple and fast bump allocator with no means of freeing up memory again, except when freeing the respective most recently allocated object on top of the bump. Useful where memory is not a concern, and/or where it is sufficient to destroy the whole module including any potential garbage after execution.
See also: [Garbage collection](https://www.assemblyscript.org/garbage-collection.html)
[](https://www.npmjs.com/package/eslint)
[](https://www.npmjs.com/package/eslint)
[](https://github.com/eslint/eslint/actions)
[](https://app.fossa.io/projects/git%2Bhttps%3A%2F%2Fgithub.com%2Feslint%2Feslint?ref=badge_shield)
<br />
[](https://opencollective.com/eslint)
[](https://opencollective.com/eslint)
[](https://twitter.com/intent/user?screen_name=geteslint)
# ESLint
[Website](https://eslint.org) |
[Configuring](https://eslint.org/docs/user-guide/configuring) |
[Rules](https://eslint.org/docs/rules/) |
[Contributing](https://eslint.org/docs/developer-guide/contributing) |
[Reporting Bugs](https://eslint.org/docs/developer-guide/contributing/reporting-bugs) |
[Code of Conduct](https://eslint.org/conduct) |
[Twitter](https://twitter.com/geteslint) |
[Mailing List](https://groups.google.com/group/eslint) |
[Chat Room](https://eslint.org/chat)
ESLint is a tool for identifying and reporting on patterns found in ECMAScript/JavaScript code. In many ways, it is similar to JSLint and JSHint with a few exceptions:
* ESLint uses [Espree](https://github.com/eslint/espree) for JavaScript parsing.
* ESLint uses an AST to evaluate patterns in code.
* ESLint is completely pluggable, every single rule is a plugin and you can add more at runtime.
## Table of Contents
1. [Installation and Usage](#installation-and-usage)
2. [Configuration](#configuration)
3. [Code of Conduct](#code-of-conduct)
4. [Filing Issues](#filing-issues)
5. [Frequently Asked Questions](#faq)
6. [Releases](#releases)
7. [Security Policy](#security-policy)
8. [Semantic Versioning Policy](#semantic-versioning-policy)
9. [Stylistic Rule Updates](#stylistic-rule-updates)
10. [License](#license)
11. [Team](#team)
12. [Sponsors](#sponsors)
13. [Technology Sponsors](#technology-sponsors)
## <a name="installation-and-usage"></a>Installation and Usage
Prerequisites: [Node.js](https://nodejs.org/) (`^10.12.0`, or `>=12.0.0`) built with SSL support. (If you are using an official Node.js distribution, SSL is always built in.)
You can install ESLint using npm:
```
$ npm install eslint --save-dev
```
You should then set up a configuration file:
```
$ ./node_modules/.bin/eslint --init
```
After that, you can run ESLint on any file or directory like this:
```
$ ./node_modules/.bin/eslint yourfile.js
```
## <a name="configuration"></a>Configuration
After running `eslint --init`, you'll have a `.eslintrc` file in your directory. In it, you'll see some rules configured like this:
```json
{
"rules": {
"semi": ["error", "always"],
"quotes": ["error", "double"]
}
}
```
The names `"semi"` and `"quotes"` are the names of [rules](https://eslint.org/docs/rules) in ESLint. The first value is the error level of the rule and can be one of these values:
* `"off"` or `0` - turn the rule off
* `"warn"` or `1` - turn the rule on as a warning (doesn't affect exit code)
* `"error"` or `2` - turn the rule on as an error (exit code will be 1)
The three error levels allow you fine-grained control over how ESLint applies rules (for more configuration options and details, see the [configuration docs](https://eslint.org/docs/user-guide/configuring)).
## <a name="code-of-conduct"></a>Code of Conduct
ESLint adheres to the [JS Foundation Code of Conduct](https://eslint.org/conduct).
## <a name="filing-issues"></a>Filing Issues
Before filing an issue, please be sure to read the guidelines for what you're reporting:
* [Bug Report](https://eslint.org/docs/developer-guide/contributing/reporting-bugs)
* [Propose a New Rule](https://eslint.org/docs/developer-guide/contributing/new-rules)
* [Proposing a Rule Change](https://eslint.org/docs/developer-guide/contributing/rule-changes)
* [Request a Change](https://eslint.org/docs/developer-guide/contributing/changes)
## <a name="faq"></a>Frequently Asked Questions
### I'm using JSCS, should I migrate to ESLint?
Yes. [JSCS has reached end of life](https://eslint.org/blog/2016/07/jscs-end-of-life) and is no longer supported.
We have prepared a [migration guide](https://eslint.org/docs/user-guide/migrating-from-jscs) to help you convert your JSCS settings to an ESLint configuration.
We are now at or near 100% compatibility with JSCS. If you try ESLint and believe we are not yet compatible with a JSCS rule/configuration, please create an issue (mentioning that it is a JSCS compatibility issue) and we will evaluate it as per our normal process.
### Does Prettier replace ESLint?
No, ESLint does both traditional linting (looking for problematic patterns) and style checking (enforcement of conventions). You can use ESLint for everything, or you can combine both using Prettier to format your code and ESLint to catch possible errors.
### Why can't ESLint find my plugins?
* Make sure your plugins (and ESLint) are both in your project's `package.json` as devDependencies (or dependencies, if your project uses ESLint at runtime).
* Make sure you have run `npm install` and all your dependencies are installed.
* Make sure your plugins' peerDependencies have been installed as well. You can use `npm view eslint-plugin-myplugin peerDependencies` to see what peer dependencies `eslint-plugin-myplugin` has.
### Does ESLint support JSX?
Yes, ESLint natively supports parsing JSX syntax (this must be enabled in [configuration](https://eslint.org/docs/user-guide/configuring)). Please note that supporting JSX syntax *is not* the same as supporting React. React applies specific semantics to JSX syntax that ESLint doesn't recognize. We recommend using [eslint-plugin-react](https://www.npmjs.com/package/eslint-plugin-react) if you are using React and want React semantics.
### What ECMAScript versions does ESLint support?
ESLint has full support for ECMAScript 3, 5 (default), 2015, 2016, 2017, 2018, 2019, and 2020. You can set your desired ECMAScript syntax (and other settings, like global variables or your target environments) through [configuration](https://eslint.org/docs/user-guide/configuring).
### What about experimental features?
ESLint's parser only officially supports the latest final ECMAScript standard. We will make changes to core rules in order to avoid crashes on stage 3 ECMAScript syntax proposals (as long as they are implemented using the correct experimental ESTree syntax). We may make changes to core rules to better work with language extensions (such as JSX, Flow, and TypeScript) on a case-by-case basis.
In other cases (including if rules need to warn on more or fewer cases due to new syntax, rather than just not crashing), we recommend you use other parsers and/or rule plugins. If you are using Babel, you can use the [babel-eslint](https://github.com/babel/babel-eslint) parser and [eslint-plugin-babel](https://github.com/babel/eslint-plugin-babel) to use any option available in Babel.
Once a language feature has been adopted into the ECMAScript standard (stage 4 according to the [TC39 process](https://tc39.github.io/process-document/)), we will accept issues and pull requests related to the new feature, subject to our [contributing guidelines](https://eslint.org/docs/developer-guide/contributing). Until then, please use the appropriate parser and plugin(s) for your experimental feature.
### Where to ask for help?
Join our [Mailing List](https://groups.google.com/group/eslint) or [Chatroom](https://eslint.org/chat).
### Why doesn't ESLint lock dependency versions?
Lock files like `package-lock.json` are helpful for deployed applications. They ensure that dependencies are consistent between environments and across deployments.
Packages like `eslint` that get published to the npm registry do not include lock files. `npm install eslint` as a user will respect version constraints in ESLint's `package.json`. ESLint and its dependencies will be included in the user's lock file if one exists, but ESLint's own lock file would not be used.
We intentionally don't lock dependency versions so that we have the latest compatible dependency versions in development and CI that our users get when installing ESLint in a project.
The Twilio blog has a [deeper dive](https://www.twilio.com/blog/lockfiles-nodejs) to learn more.
## <a name="releases"></a>Releases
We have scheduled releases every two weeks on Friday or Saturday. You can follow a [release issue](https://github.com/eslint/eslint/issues?q=is%3Aopen+is%3Aissue+label%3Arelease) for updates about the scheduling of any particular release.
## <a name="security-policy"></a>Security Policy
ESLint takes security seriously. We work hard to ensure that ESLint is safe for everyone and that security issues are addressed quickly and responsibly. Read the full [security policy](https://github.com/eslint/.github/blob/master/SECURITY.md).
## <a name="semantic-versioning-policy"></a>Semantic Versioning Policy
ESLint follows [semantic versioning](https://semver.org). However, due to the nature of ESLint as a code quality tool, it's not always clear when a minor or major version bump occurs. To help clarify this for everyone, we've defined the following semantic versioning policy for ESLint:
* Patch release (intended to not break your lint build)
* A bug fix in a rule that results in ESLint reporting fewer linting errors.
* A bug fix to the CLI or core (including formatters).
* Improvements to documentation.
* Non-user-facing changes such as refactoring code, adding, deleting, or modifying tests, and increasing test coverage.
* Re-releasing after a failed release (i.e., publishing a release that doesn't work for anyone).
* Minor release (might break your lint build)
* A bug fix in a rule that results in ESLint reporting more linting errors.
* A new rule is created.
* A new option to an existing rule that does not result in ESLint reporting more linting errors by default.
* A new addition to an existing rule to support a newly-added language feature (within the last 12 months) that will result in ESLint reporting more linting errors by default.
* An existing rule is deprecated.
* A new CLI capability is created.
* New capabilities to the public API are added (new classes, new methods, new arguments to existing methods, etc.).
* A new formatter is created.
* `eslint:recommended` is updated and will result in strictly fewer linting errors (e.g., rule removals).
* Major release (likely to break your lint build)
* `eslint:recommended` is updated and may result in new linting errors (e.g., rule additions, most rule option updates).
* A new option to an existing rule that results in ESLint reporting more linting errors by default.
* An existing formatter is removed.
* Part of the public API is removed or changed in an incompatible way. The public API includes:
* Rule schemas
* Configuration schema
* Command-line options
* Node.js API
* Rule, formatter, parser, plugin APIs
According to our policy, any minor update may report more linting errors than the previous release (ex: from a bug fix). As such, we recommend using the tilde (`~`) in `package.json` e.g. `"eslint": "~3.1.0"` to guarantee the results of your builds.
## <a name="stylistic-rule-updates"></a>Stylistic Rule Updates
Stylistic rules are frozen according to [our policy](https://eslint.org/blog/2020/05/changes-to-rules-policies) on how we evaluate new rules and rule changes.
This means:
* **Bug fixes**: We will still fix bugs in stylistic rules.
* **New ECMAScript features**: We will also make sure stylistic rules are compatible with new ECMAScript features.
* **New options**: We will **not** add any new options to stylistic rules unless an option is the only way to fix a bug or support a newly-added ECMAScript feature.
## <a name="license"></a>License
[](https://app.fossa.io/projects/git%2Bhttps%3A%2F%2Fgithub.com%2Feslint%2Feslint?ref=badge_large)
## <a name="team"></a>Team
These folks keep the project moving and are resources for help.
<!-- NOTE: This section is autogenerated. Do not manually edit.-->
<!--teamstart-->
### Technical Steering Committee (TSC)
The people who manage releases, review feature requests, and meet regularly to ensure ESLint is properly maintained.
<table><tbody><tr><td align="center" valign="top" width="11%">
<a href="https://github.com/nzakas">
<img src="https://github.com/nzakas.png?s=75" width="75" height="75"><br />
Nicholas C. Zakas
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/btmills">
<img src="https://github.com/btmills.png?s=75" width="75" height="75"><br />
Brandon Mills
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/mdjermanovic">
<img src="https://github.com/mdjermanovic.png?s=75" width="75" height="75"><br />
Milos Djermanovic
</a>
</td></tr></tbody></table>
### Reviewers
The people who review and implement new features.
<table><tbody><tr><td align="center" valign="top" width="11%">
<a href="https://github.com/mysticatea">
<img src="https://github.com/mysticatea.png?s=75" width="75" height="75"><br />
Toru Nagashima
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/aladdin-add">
<img src="https://github.com/aladdin-add.png?s=75" width="75" height="75"><br />
薛定谔的猫
</a>
</td></tr></tbody></table>
### Committers
The people who review and fix bugs and help triage issues.
<table><tbody><tr><td align="center" valign="top" width="11%">
<a href="https://github.com/brettz9">
<img src="https://github.com/brettz9.png?s=75" width="75" height="75"><br />
Brett Zamir
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/bmish">
<img src="https://github.com/bmish.png?s=75" width="75" height="75"><br />
Bryan Mishkin
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/g-plane">
<img src="https://github.com/g-plane.png?s=75" width="75" height="75"><br />
Pig Fang
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/anikethsaha">
<img src="https://github.com/anikethsaha.png?s=75" width="75" height="75"><br />
Anix
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/yeonjuan">
<img src="https://github.com/yeonjuan.png?s=75" width="75" height="75"><br />
YeonJuan
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/snitin315">
<img src="https://github.com/snitin315.png?s=75" width="75" height="75"><br />
Nitin Kumar
</a>
</td></tr></tbody></table>
<!--teamend-->
## <a name="sponsors"></a>Sponsors
The following companies, organizations, and individuals support ESLint's ongoing maintenance and development. [Become a Sponsor](https://opencollective.com/eslint) to get your logo on our README and website.
<!-- NOTE: This section is autogenerated. Do not manually edit.-->
<!--sponsorsstart-->
<h3>Platinum Sponsors</h3>
<p><a href="https://automattic.com"><img src="https://images.opencollective.com/photomatt/d0ef3e1/logo.png" alt="Automattic" height="undefined"></a></p><h3>Gold Sponsors</h3>
<p><a href="https://nx.dev"><img src="https://images.opencollective.com/nx/0efbe42/logo.png" alt="Nx (by Nrwl)" height="96"></a> <a href="https://google.com/chrome"><img src="https://images.opencollective.com/chrome/dc55bd4/logo.png" alt="Chrome's Web Framework & Tools Performance Fund" height="96"></a> <a href="https://www.salesforce.com"><img src="https://images.opencollective.com/salesforce/ca8f997/logo.png" alt="Salesforce" height="96"></a> <a href="https://www.airbnb.com/"><img src="https://images.opencollective.com/airbnb/d327d66/logo.png" alt="Airbnb" height="96"></a> <a href="https://coinbase.com"><img src="https://avatars.githubusercontent.com/u/1885080?v=4" alt="Coinbase" height="96"></a> <a href="https://substack.com/"><img src="https://avatars.githubusercontent.com/u/53023767?v=4" alt="Substack" height="96"></a></p><h3>Silver Sponsors</h3>
<p><a href="https://retool.com/"><img src="https://images.opencollective.com/retool/98ea68e/logo.png" alt="Retool" height="64"></a> <a href="https://liftoff.io/"><img src="https://images.opencollective.com/liftoff/5c4fa84/logo.png" alt="Liftoff" height="64"></a></p><h3>Bronze Sponsors</h3>
<p><a href="https://www.crosswordsolver.org/anagram-solver/"><img src="https://images.opencollective.com/anagram-solver/2666271/logo.png" alt="Anagram Solver" height="32"></a> <a href="null"><img src="https://images.opencollective.com/bugsnag-stability-monitoring/c2cef36/logo.png" alt="Bugsnag Stability Monitoring" height="32"></a> <a href="https://mixpanel.com"><img src="https://images.opencollective.com/mixpanel/cd682f7/logo.png" alt="Mixpanel" height="32"></a> <a href="https://www.vpsserver.com"><img src="https://images.opencollective.com/vpsservercom/logo.png" alt="VPS Server" height="32"></a> <a href="https://icons8.com"><img src="https://images.opencollective.com/icons8/7fa1641/logo.png" alt="Icons8: free icons, photos, illustrations, and music" height="32"></a> <a href="https://discord.com"><img src="https://images.opencollective.com/discordapp/f9645d9/logo.png" alt="Discord" height="32"></a> <a href="https://themeisle.com"><img src="https://images.opencollective.com/themeisle/d5592fe/logo.png" alt="ThemeIsle" height="32"></a> <a href="https://www.firesticktricks.com"><img src="https://images.opencollective.com/fire-stick-tricks/b8fbe2c/logo.png" alt="Fire Stick Tricks" height="32"></a> <a href="https://www.practiceignition.com"><img src="https://avatars.githubusercontent.com/u/5753491?v=4" alt="Practice Ignition" height="32"></a></p>
<!--sponsorsend-->
## <a name="technology-sponsors"></a>Technology Sponsors
* Site search ([eslint.org](https://eslint.org)) is sponsored by [Algolia](https://www.algolia.com)
* Hosting for ([eslint.org](https://eslint.org)) is sponsored by [Netlify](https://www.netlify.com)
* Password management is sponsored by [1Password](https://www.1password.com)
These files are compiled dot templates from dot folder.
Do NOT edit them directly, edit the templates and run `npm run build` from main ajv folder.
JS-YAML - YAML 1.2 parser / writer for JavaScript
=================================================
[](https://travis-ci.org/nodeca/js-yaml)
[](https://www.npmjs.org/package/js-yaml)
__[Online Demo](http://nodeca.github.com/js-yaml/)__
This is an implementation of [YAML](http://yaml.org/), a human-friendly data
serialization language. Started as [PyYAML](http://pyyaml.org/) port, it was
completely rewritten from scratch. Now it's very fast, and supports 1.2 spec.
Installation
------------
### YAML module for node.js
```
npm install js-yaml
```
### CLI executable
If you want to inspect your YAML files from CLI, install js-yaml globally:
```
npm install -g js-yaml
```
#### Usage
```
usage: js-yaml [-h] [-v] [-c] [-t] file
Positional arguments:
file File with YAML document(s)
Optional arguments:
-h, --help Show this help message and exit.
-v, --version Show program's version number and exit.
-c, --compact Display errors in compact mode
-t, --trace Show stack trace on error
```
### Bundled YAML library for browsers
``` html
<!-- esprima required only for !!js/function -->
<script src="esprima.js"></script>
<script src="js-yaml.min.js"></script>
<script type="text/javascript">
var doc = jsyaml.load('greeting: hello\nname: world');
</script>
```
Browser support was done mostly for the online demo. If you find any errors - feel
free to send pull requests with fixes. Also note, that IE and other old browsers
needs [es5-shims](https://github.com/kriskowal/es5-shim) to operate.
Notes:
1. We have no resources to support browserified version. Don't expect it to be
well tested. Don't expect fast fixes if something goes wrong there.
2. `!!js/function` in browser bundle will not work by default. If you really need
it - load `esprima` parser first (via amd or directly).
3. `!!bin` in browser will return `Array`, because browsers do not support
node.js `Buffer` and adding Buffer shims is completely useless on practice.
API
---
Here we cover the most 'useful' methods. If you need advanced details (creating
your own tags), see [wiki](https://github.com/nodeca/js-yaml/wiki) and
[examples](https://github.com/nodeca/js-yaml/tree/master/examples) for more
info.
``` javascript
const yaml = require('js-yaml');
const fs = require('fs');
// Get document, or throw exception on error
try {
const doc = yaml.safeLoad(fs.readFileSync('/home/ixti/example.yml', 'utf8'));
console.log(doc);
} catch (e) {
console.log(e);
}
```
### safeLoad (string [ , options ])
**Recommended loading way.** Parses `string` as single YAML document. Returns either a
plain object, a string or `undefined`, or throws `YAMLException` on error. By default, does
not support regexps, functions and undefined. This method is safe for untrusted data.
options:
- `filename` _(default: null)_ - string to be used as a file path in
error/warning messages.
- `onWarning` _(default: null)_ - function to call on warning messages.
Loader will call this function with an instance of `YAMLException` for each warning.
- `schema` _(default: `DEFAULT_SAFE_SCHEMA`)_ - specifies a schema to use.
- `FAILSAFE_SCHEMA` - only strings, arrays and plain objects:
http://www.yaml.org/spec/1.2/spec.html#id2802346
- `JSON_SCHEMA` - all JSON-supported types:
http://www.yaml.org/spec/1.2/spec.html#id2803231
- `CORE_SCHEMA` - same as `JSON_SCHEMA`:
http://www.yaml.org/spec/1.2/spec.html#id2804923
- `DEFAULT_SAFE_SCHEMA` - all supported YAML types, without unsafe ones
(`!!js/undefined`, `!!js/regexp` and `!!js/function`):
http://yaml.org/type/
- `DEFAULT_FULL_SCHEMA` - all supported YAML types.
- `json` _(default: false)_ - compatibility with JSON.parse behaviour. If true, then duplicate keys in a mapping will override values rather than throwing an error.
NOTE: This function **does not** understand multi-document sources, it throws
exception on those.
NOTE: JS-YAML **does not** support schema-specific tag resolution restrictions.
So, the JSON schema is not as strictly defined in the YAML specification.
It allows numbers in any notation, use `Null` and `NULL` as `null`, etc.
The core schema also has no such restrictions. It allows binary notation for integers.
### load (string [ , options ])
**Use with care with untrusted sources**. The same as `safeLoad()` but uses
`DEFAULT_FULL_SCHEMA` by default - adds some JavaScript-specific types:
`!!js/function`, `!!js/regexp` and `!!js/undefined`. For untrusted sources, you
must additionally validate object structure to avoid injections:
``` javascript
const untrusted_code = '"toString": !<tag:yaml.org,2002:js/function> "function (){very_evil_thing();}"';
// I'm just converting that string, what could possibly go wrong?
require('js-yaml').load(untrusted_code) + ''
```
### safeLoadAll (string [, iterator] [, options ])
Same as `safeLoad()`, but understands multi-document sources. Applies
`iterator` to each document if specified, or returns array of documents.
``` javascript
const yaml = require('js-yaml');
yaml.safeLoadAll(data, function (doc) {
console.log(doc);
});
```
### loadAll (string [, iterator] [ , options ])
Same as `safeLoadAll()` but uses `DEFAULT_FULL_SCHEMA` by default.
### safeDump (object [ , options ])
Serializes `object` as a YAML document. Uses `DEFAULT_SAFE_SCHEMA`, so it will
throw an exception if you try to dump regexps or functions. However, you can
disable exceptions by setting the `skipInvalid` option to `true`.
options:
- `indent` _(default: 2)_ - indentation width to use (in spaces).
- `noArrayIndent` _(default: false)_ - when true, will not add an indentation level to array elements
- `skipInvalid` _(default: false)_ - do not throw on invalid types (like function
in the safe schema) and skip pairs and single values with such types.
- `flowLevel` (default: -1) - specifies level of nesting, when to switch from
block to flow style for collections. -1 means block style everwhere
- `styles` - "tag" => "style" map. Each tag may have own set of styles.
- `schema` _(default: `DEFAULT_SAFE_SCHEMA`)_ specifies a schema to use.
- `sortKeys` _(default: `false`)_ - if `true`, sort keys when dumping YAML. If a
function, use the function to sort the keys.
- `lineWidth` _(default: `80`)_ - set max line width.
- `noRefs` _(default: `false`)_ - if `true`, don't convert duplicate objects into references
- `noCompatMode` _(default: `false`)_ - if `true` don't try to be compatible with older
yaml versions. Currently: don't quote "yes", "no" and so on, as required for YAML 1.1
- `condenseFlow` _(default: `false`)_ - if `true` flow sequences will be condensed, omitting the space between `a, b`. Eg. `'[a,b]'`, and omitting the space between `key: value` and quoting the key. Eg. `'{"a":b}'` Can be useful when using yaml for pretty URL query params as spaces are %-encoded.
The following table show availlable styles (e.g. "canonical",
"binary"...) available for each tag (.e.g. !!null, !!int ...). Yaml
output is shown on the right side after `=>` (default setting) or `->`:
``` none
!!null
"canonical" -> "~"
"lowercase" => "null"
"uppercase" -> "NULL"
"camelcase" -> "Null"
!!int
"binary" -> "0b1", "0b101010", "0b1110001111010"
"octal" -> "01", "052", "016172"
"decimal" => "1", "42", "7290"
"hexadecimal" -> "0x1", "0x2A", "0x1C7A"
!!bool
"lowercase" => "true", "false"
"uppercase" -> "TRUE", "FALSE"
"camelcase" -> "True", "False"
!!float
"lowercase" => ".nan", '.inf'
"uppercase" -> ".NAN", '.INF'
"camelcase" -> ".NaN", '.Inf'
```
Example:
``` javascript
safeDump (object, {
'styles': {
'!!null': 'canonical' // dump null as ~
},
'sortKeys': true // sort object keys
});
```
### dump (object [ , options ])
Same as `safeDump()` but without limits (uses `DEFAULT_FULL_SCHEMA` by default).
Supported YAML types
--------------------
The list of standard YAML tags and corresponding JavaScipt types. See also
[YAML tag discussion](http://pyyaml.org/wiki/YAMLTagDiscussion) and
[YAML types repository](http://yaml.org/type/).
```
!!null '' # null
!!bool 'yes' # bool
!!int '3...' # number
!!float '3.14...' # number
!!binary '...base64...' # buffer
!!timestamp 'YYYY-...' # date
!!omap [ ... ] # array of key-value pairs
!!pairs [ ... ] # array or array pairs
!!set { ... } # array of objects with given keys and null values
!!str '...' # string
!!seq [ ... ] # array
!!map { ... } # object
```
**JavaScript-specific tags**
```
!!js/regexp /pattern/gim # RegExp
!!js/undefined '' # Undefined
!!js/function 'function () {...}' # Function
```
Caveats
-------
Note, that you use arrays or objects as key in JS-YAML. JS does not allow objects
or arrays as keys, and stringifies (by calling `toString()` method) them at the
moment of adding them.
``` yaml
---
? [ foo, bar ]
: - baz
? { foo: bar }
: - baz
- baz
```
``` javascript
{ "foo,bar": ["baz"], "[object Object]": ["baz", "baz"] }
```
Also, reading of properties on implicit block mapping keys is not supported yet.
So, the following YAML document cannot be loaded.
``` yaml
&anchor foo:
foo: bar
*anchor: duplicate key
baz: bat
*anchor: duplicate key
```
js-yaml for enterprise
----------------------
Available as part of the Tidelift Subscription
The maintainers of js-yaml and thousands of other packages are working with Tidelift to deliver commercial support and maintenance for the open source dependencies you use to build your applications. Save time, reduce risk, and improve code health, while paying the maintainers of the exact dependencies you use. [Learn more.](https://tidelift.com/subscription/pkg/npm-js-yaml?utm_source=npm-js-yaml&utm_medium=referral&utm_campaign=enterprise&utm_term=repo)
# debug
[](https://travis-ci.org/debug-js/debug) [](https://coveralls.io/github/debug-js/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
In Chromium-based web browsers (e.g. Brave, Chrome, and Electron), the JavaScript console will—by default—only show messages logged by `debug` if the "Verbose" log level is _enabled_.
<img width="647" src="https://user-images.githubusercontent.com/7143133/152083257-29034707-c42c-4959-8add-3cee850e6fcf.png">
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
`disable()`
Will disable all namespaces. The functions returns the namespaces currently
enabled (and skipped). This can be useful if you want to disable debugging
temporarily without knowing what was enabled to begin with.
For example:
```js
let debug = require('debug');
debug.enable('foo:*,-foo:bar');
let namespaces = debug.disable();
debug.enable(namespaces);
```
Note: There is no guarantee that the string will be identical to the initial
enable string, but semantically they will be identical.
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Usage in child processes
Due to the way `debug` detects if the output is a TTY or not, colors are not shown in child processes when `stderr` is piped. A solution is to pass the `DEBUG_COLORS=1` environment variable to the child process.
For example:
```javascript
worker = fork(WORKER_WRAP_PATH, [workerPath], {
stdio: [
/* stdin: */ 0,
/* stdout: */ 'pipe',
/* stderr: */ 'pipe',
'ipc',
],
env: Object.assign({}, process.env, {
DEBUG_COLORS: 1 // without this settings, colors won't be shown
}),
});
worker.stderr.pipe(process.stderr, { end: false });
```
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
- Josh Junon
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <tj@vision-media.ca>
Copyright (c) 2018-2021 Josh Junon
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Overview [](https://travis-ci.org/lydell/js-tokens)
========
A regex that tokenizes JavaScript.
```js
var jsTokens = require("js-tokens").default
var jsString = "var foo=opts.foo;\n..."
jsString.match(jsTokens)
// ["var", " ", "foo", "=", "opts", ".", "foo", ";", "\n", ...]
```
Installation
============
`npm install js-tokens`
```js
import jsTokens from "js-tokens"
// or:
var jsTokens = require("js-tokens").default
```
Usage
=====
### `jsTokens` ###
A regex with the `g` flag that matches JavaScript tokens.
The regex _always_ matches, even invalid JavaScript and the empty string.
The next match is always directly after the previous.
### `var token = matchToToken(match)` ###
```js
import {matchToToken} from "js-tokens"
// or:
var matchToToken = require("js-tokens").matchToToken
```
Takes a `match` returned by `jsTokens.exec(string)`, and returns a `{type:
String, value: String}` object. The following types are available:
- string
- comment
- regex
- number
- name
- punctuator
- whitespace
- invalid
Multi-line comments and strings also have a `closed` property indicating if the
token was closed or not (see below).
Comments and strings both come in several flavors. To distinguish them, check if
the token starts with `//`, `/*`, `'`, `"` or `` ` ``.
Names are ECMAScript IdentifierNames, that is, including both identifiers and
keywords. You may use [is-keyword-js] to tell them apart.
Whitespace includes both line terminators and other whitespace.
[is-keyword-js]: https://github.com/crissdev/is-keyword-js
ECMAScript support
==================
The intention is to always support the latest ECMAScript version whose feature
set has been finalized.
If adding support for a newer version requires changes, a new version with a
major verion bump will be released.
Currently, ECMAScript 2018 is supported.
Invalid code handling
=====================
Unterminated strings are still matched as strings. JavaScript strings cannot
contain (unescaped) newlines, so unterminated strings simply end at the end of
the line. Unterminated template strings can contain unescaped newlines, though,
so they go on to the end of input.
Unterminated multi-line comments are also still matched as comments. They
simply go on to the end of the input.
Unterminated regex literals are likely matched as division and whatever is
inside the regex.
Invalid ASCII characters have their own capturing group.
Invalid non-ASCII characters are treated as names, to simplify the matching of
names (except unicode spaces which are treated as whitespace). Note: See also
the [ES2018](#es2018) section.
Regex literals may contain invalid regex syntax. They are still matched as
regex literals. They may also contain repeated regex flags, to keep the regex
simple.
Strings may contain invalid escape sequences.
Limitations
===========
Tokenizing JavaScript using regexes—in fact, _one single regex_—won’t be
perfect. But that’s not the point either.
You may compare jsTokens with [esprima] by using `esprima-compare.js`.
See `npm run esprima-compare`!
[esprima]: http://esprima.org/
### Template string interpolation ###
Template strings are matched as single tokens, from the starting `` ` `` to the
ending `` ` ``, including interpolations (whose tokens are not matched
individually).
Matching template string interpolations requires recursive balancing of `{` and
`}`—something that JavaScript regexes cannot do. Only one level of nesting is
supported.
### Division and regex literals collision ###
Consider this example:
```js
var g = 9.82
var number = bar / 2/g
var regex = / 2/g
```
A human can easily understand that in the `number` line we’re dealing with
division, and in the `regex` line we’re dealing with a regex literal. How come?
Because humans can look at the whole code to put the `/` characters in context.
A JavaScript regex cannot. It only sees forwards. (Well, ES2018 regexes can also
look backwards. See the [ES2018](#es2018) section).
When the `jsTokens` regex scans throught the above, it will see the following
at the end of both the `number` and `regex` rows:
```js
/ 2/g
```
It is then impossible to know if that is a regex literal, or part of an
expression dealing with division.
Here is a similar case:
```js
foo /= 2/g
foo(/= 2/g)
```
The first line divides the `foo` variable with `2/g`. The second line calls the
`foo` function with the regex literal `/= 2/g`. Again, since `jsTokens` only
sees forwards, it cannot tell the two cases apart.
There are some cases where we _can_ tell division and regex literals apart,
though.
First off, we have the simple cases where there’s only one slash in the line:
```js
var foo = 2/g
foo /= 2
```
Regex literals cannot contain newlines, so the above cases are correctly
identified as division. Things are only problematic when there are more than
one non-comment slash in a single line.
Secondly, not every character is a valid regex flag.
```js
var number = bar / 2/e
```
The above example is also correctly identified as division, because `e` is not a
valid regex flag. I initially wanted to future-proof by allowing `[a-zA-Z]*`
(any letter) as flags, but it is not worth it since it increases the amount of
ambigous cases. So only the standard `g`, `m`, `i`, `y` and `u` flags are
allowed. This means that the above example will be identified as division as
long as you don’t rename the `e` variable to some permutation of `gmiyus` 1 to 6
characters long.
Lastly, we can look _forward_ for information.
- If the token following what looks like a regex literal is not valid after a
regex literal, but is valid in a division expression, then the regex literal
is treated as division instead. For example, a flagless regex cannot be
followed by a string, number or name, but all of those three can be the
denominator of a division.
- Generally, if what looks like a regex literal is followed by an operator, the
regex literal is treated as division instead. This is because regexes are
seldomly used with operators (such as `+`, `*`, `&&` and `==`), but division
could likely be part of such an expression.
Please consult the regex source and the test cases for precise information on
when regex or division is matched (should you need to know). In short, you
could sum it up as:
If the end of a statement looks like a regex literal (even if it isn’t), it
will be treated as one. Otherwise it should work as expected (if you write sane
code).
### ES2018 ###
ES2018 added some nice regex improvements to the language.
- [Unicode property escapes] should allow telling names and invalid non-ASCII
characters apart without blowing up the regex size.
- [Lookbehind assertions] should allow matching telling division and regex
literals apart in more cases.
- [Named capture groups] might simplify some things.
These things would be nice to do, but are not critical. They probably have to
wait until the oldest maintained Node.js LTS release supports those features.
[Unicode property escapes]: http://2ality.com/2017/07/regexp-unicode-property-escapes.html
[Lookbehind assertions]: http://2ality.com/2017/05/regexp-lookbehind-assertions.html
[Named capture groups]: http://2ality.com/2017/05/regexp-named-capture-groups.html
License
=======
[MIT](LICENSE).
binaryen.js
===========
**binaryen.js** is a port of [Binaryen](https://github.com/WebAssembly/binaryen) to the Web, allowing you to generate [WebAssembly](https://webassembly.org) using a JavaScript API.
<a href="https://github.com/AssemblyScript/binaryen.js/actions?query=workflow%3ABuild"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/binaryen.js/Build/master?label=build&logo=github" alt="Build status" /></a>
<a href="https://www.npmjs.com/package/binaryen"><img src="https://img.shields.io/npm/v/binaryen.svg?label=latest&color=007acc&logo=npm" alt="npm version" /></a>
<a href="https://www.npmjs.com/package/binaryen"><img src="https://img.shields.io/npm/v/binaryen/nightly.svg?label=nightly&color=007acc&logo=npm" alt="npm nightly version" /></a>
Usage
-----
```
$> npm install binaryen
```
```js
var binaryen = require("binaryen");
// Create a module with a single function
var myModule = new binaryen.Module();
myModule.addFunction("add", binaryen.createType([ binaryen.i32, binaryen.i32 ]), binaryen.i32, [ binaryen.i32 ],
myModule.block(null, [
myModule.local.set(2,
myModule.i32.add(
myModule.local.get(0, binaryen.i32),
myModule.local.get(1, binaryen.i32)
)
),
myModule.return(
myModule.local.get(2, binaryen.i32)
)
])
);
myModule.addFunctionExport("add", "add");
// Optimize the module using default passes and levels
myModule.optimize();
// Validate the module
if (!myModule.validate())
throw new Error("validation error");
// Generate text format and binary
var textData = myModule.emitText();
var wasmData = myModule.emitBinary();
// Example usage with the WebAssembly API
var compiled = new WebAssembly.Module(wasmData);
var instance = new WebAssembly.Instance(compiled, {});
console.log(instance.exports.add(41, 1));
```
The buildbot also publishes nightly versions once a day if there have been changes. The latest nightly can be installed through
```
$> npm install binaryen@nightly
```
or you can use one of the [previous versions](https://github.com/AssemblyScript/binaryen.js/tags) instead if necessary.
### Usage with a CDN
* From GitHub via [jsDelivr](https://www.jsdelivr.com):<br />
`https://cdn.jsdelivr.net/gh/AssemblyScript/binaryen.js@VERSION/index.js`
* From npm via [jsDelivr](https://www.jsdelivr.com):<br />
`https://cdn.jsdelivr.net/npm/binaryen@VERSION/index.js`
* From npm via [unpkg](https://unpkg.com):<br />
`https://unpkg.com/binaryen@VERSION/index.js`
Replace `VERSION` with a [specific version](https://github.com/AssemblyScript/binaryen.js/releases) or omit it (not recommended in production) to use master/latest.
API
---
**Please note** that the Binaryen API is evolving fast and that definitions and documentation provided by the package tend to get out of sync despite our best efforts. It's a bot after all. If you rely on binaryen.js and spot an issue, please consider sending a PR our way by updating [index.d.ts](./index.d.ts) and [README.md](./README.md) to reflect the [current API](https://github.com/WebAssembly/binaryen/blob/master/src/js/binaryen.js-post.js).
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
### Contents
- [Types](#types)
- [Module construction](#module-construction)
- [Module manipulation](#module-manipulation)
- [Module validation](#module-validation)
- [Module optimization](#module-optimization)
- [Module creation](#module-creation)
- [Expression construction](#expression-construction)
- [Control flow](#control-flow)
- [Variable accesses](#variable-accesses)
- [Integer operations](#integer-operations)
- [Floating point operations](#floating-point-operations)
- [Datatype conversions](#datatype-conversions)
- [Function calls](#function-calls)
- [Linear memory accesses](#linear-memory-accesses)
- [Host operations](#host-operations)
- [Vector operations 🦄](#vector-operations-)
- [Atomic memory accesses 🦄](#atomic-memory-accesses-)
- [Atomic read-modify-write operations 🦄](#atomic-read-modify-write-operations-)
- [Atomic wait and notify operations 🦄](#atomic-wait-and-notify-operations-)
- [Sign extension operations 🦄](#sign-extension-operations-)
- [Multi-value operations 🦄](#multi-value-operations-)
- [Exception handling operations 🦄](#exception-handling-operations-)
- [Reference types operations 🦄](#reference-types-operations-)
- [Expression manipulation](#expression-manipulation)
- [Relooper](#relooper)
- [Source maps](#source-maps)
- [Debugging](#debugging)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
[Future features](http://webassembly.org/docs/future-features/) 🦄 might not be supported by all runtimes.
### Types
* **none**: `Type`<br />
The none type, e.g., `void`.
* **i32**: `Type`<br />
32-bit integer type.
* **i64**: `Type`<br />
64-bit integer type.
* **f32**: `Type`<br />
32-bit float type.
* **f64**: `Type`<br />
64-bit float (double) type.
* **v128**: `Type`<br />
128-bit vector type. 🦄
* **funcref**: `Type`<br />
A function reference. 🦄
* **anyref**: `Type`<br />
Any host reference. 🦄
* **nullref**: `Type`<br />
A null reference. 🦄
* **exnref**: `Type`<br />
An exception reference. 🦄
* **unreachable**: `Type`<br />
Special type indicating unreachable code when obtaining information about an expression.
* **auto**: `Type`<br />
Special type used in **Module#block** exclusively. Lets the API figure out a block's result type automatically.
* **createType**(types: `Type[]`): `Type`<br />
Creates a multi-value type from an array of types.
* **expandType**(type: `Type`): `Type[]`<br />
Expands a multi-value type to an array of types.
### Module construction
* new **Module**()<br />
Constructs a new module.
* **parseText**(text: `string`): `Module`<br />
Creates a module from Binaryen's s-expression text format (not official stack-style text format).
* **readBinary**(data: `Uint8Array`): `Module`<br />
Creates a module from binary data.
### Module manipulation
* Module#**addFunction**(name: `string`, params: `Type`, results: `Type`, vars: `Type[]`, body: `ExpressionRef`): `FunctionRef`<br />
Adds a function. `vars` indicate additional locals, in the given order.
* Module#**getFunction**(name: `string`): `FunctionRef`<br />
Gets a function, by name,
* Module#**removeFunction**(name: `string`): `void`<br />
Removes a function, by name.
* Module#**getNumFunctions**(): `number`<br />
Gets the number of functions within the module.
* Module#**getFunctionByIndex**(index: `number`): `FunctionRef`<br />
Gets the function at the specified index.
* Module#**addFunctionImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, params: `Type`, results: `Type`): `void`<br />
Adds a function import.
* Module#**addTableImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`): `void`<br />
Adds a table import. There's just one table for now, using name `"0"`.
* Module#**addMemoryImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`): `void`<br />
Adds a memory import. There's just one memory for now, using name `"0"`.
* Module#**addGlobalImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, globalType: `Type`): `void`<br />
Adds a global variable import. Imported globals must be immutable.
* Module#**addFunctionExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a function export.
* Module#**addTableExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a table export. There's just one table for now, using name `"0"`.
* Module#**addMemoryExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a memory export. There's just one memory for now, using name `"0"`.
* Module#**addGlobalExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a global variable export. Exported globals must be immutable.
* Module#**getNumExports**(): `number`<br />
Gets the number of exports witin the module.
* Module#**getExportByIndex**(index: `number`): `ExportRef`<br />
Gets the export at the specified index.
* Module#**removeExport**(externalName: `string`): `void`<br />
Removes an export, by external name.
* Module#**addGlobal**(name: `string`, type: `Type`, mutable: `number`, value: `ExpressionRef`): `GlobalRef`<br />
Adds a global instance variable.
* Module#**getGlobal**(name: `string`): `GlobalRef`<br />
Gets a global, by name,
* Module#**removeGlobal**(name: `string`): `void`<br />
Removes a global, by name.
* Module#**setFunctionTable**(initial: `number`, maximum: `number`, funcs: `string[]`, offset?: `ExpressionRef`): `void`<br />
Sets the contents of the function table. There's just one table for now, using name `"0"`.
* Module#**getFunctionTable**(): `{ imported: boolean, segments: TableElement[] }`<br />
Gets the contents of the function table.
* TableElement#**offset**: `ExpressionRef`
* TableElement#**names**: `string[]`
* Module#**setMemory**(initial: `number`, maximum: `number`, exportName: `string | null`, segments: `MemorySegment[]`, flags?: `number[]`, shared?: `boolean`): `void`<br />
Sets the memory. There's just one memory for now, using name `"0"`. Providing `exportName` also creates a memory export.
* MemorySegment#**offset**: `ExpressionRef`
* MemorySegment#**data**: `Uint8Array`
* MemorySegment#**passive**: `boolean`
* Module#**getNumMemorySegments**(): `number`<br />
Gets the number of memory segments within the module.
* Module#**getMemorySegmentInfoByIndex**(index: `number`): `MemorySegmentInfo`<br />
Gets information about the memory segment at the specified index.
* MemorySegmentInfo#**offset**: `number`
* MemorySegmentInfo#**data**: `Uint8Array`
* MemorySegmentInfo#**passive**: `boolean`
* Module#**setStart**(start: `FunctionRef`): `void`<br />
Sets the start function.
* Module#**getFeatures**(): `Features`<br />
Gets the WebAssembly features enabled for this module.
Note that the return value may be a bitmask indicating multiple features. Possible feature flags are:
* Features.**MVP**: `Features`
* Features.**Atomics**: `Features`
* Features.**BulkMemory**: `Features`
* Features.**MutableGlobals**: `Features`
* Features.**NontrappingFPToInt**: `Features`
* Features.**SignExt**: `Features`
* Features.**SIMD128**: `Features`
* Features.**ExceptionHandling**: `Features`
* Features.**TailCall**: `Features`
* Features.**ReferenceTypes**: `Features`
* Features.**Multivalue**: `Features`
* Features.**All**: `Features`
* Module#**setFeatures**(features: `Features`): `void`<br />
Sets the WebAssembly features enabled for this module.
* Module#**addCustomSection**(name: `string`, contents: `Uint8Array`): `void`<br />
Adds a custom section to the binary.
* Module#**autoDrop**(): `void`<br />
Enables automatic insertion of `drop` operations where needed. Lets you not worry about dropping when creating your code.
* **getFunctionInfo**(ftype: `FunctionRef`: `FunctionInfo`<br />
Obtains information about a function.
* FunctionInfo#**name**: `string`
* FunctionInfo#**module**: `string | null` (if imported)
* FunctionInfo#**base**: `string | null` (if imported)
* FunctionInfo#**params**: `Type`
* FunctionInfo#**results**: `Type`
* FunctionInfo#**vars**: `Type`
* FunctionInfo#**body**: `ExpressionRef`
* **getGlobalInfo**(global: `GlobalRef`): `GlobalInfo`<br />
Obtains information about a global.
* GlobalInfo#**name**: `string`
* GlobalInfo#**module**: `string | null` (if imported)
* GlobalInfo#**base**: `string | null` (if imported)
* GlobalInfo#**type**: `Type`
* GlobalInfo#**mutable**: `boolean`
* GlobalInfo#**init**: `ExpressionRef`
* **getExportInfo**(export_: `ExportRef`): `ExportInfo`<br />
Obtains information about an export.
* ExportInfo#**kind**: `ExternalKind`
* ExportInfo#**name**: `string`
* ExportInfo#**value**: `string`
Possible `ExternalKind` values are:
* **ExternalFunction**: `ExternalKind`
* **ExternalTable**: `ExternalKind`
* **ExternalMemory**: `ExternalKind`
* **ExternalGlobal**: `ExternalKind`
* **ExternalEvent**: `ExternalKind`
* **getEventInfo**(event: `EventRef`): `EventInfo`<br />
Obtains information about an event.
* EventInfo#**name**: `string`
* EventInfo#**module**: `string | null` (if imported)
* EventInfo#**base**: `string | null` (if imported)
* EventInfo#**attribute**: `number`
* EventInfo#**params**: `Type`
* EventInfo#**results**: `Type`
* **getSideEffects**(expr: `ExpressionRef`, features: `FeatureFlags`): `SideEffects`<br />
Gets the side effects of the specified expression.
* SideEffects.**None**: `SideEffects`
* SideEffects.**Branches**: `SideEffects`
* SideEffects.**Calls**: `SideEffects`
* SideEffects.**ReadsLocal**: `SideEffects`
* SideEffects.**WritesLocal**: `SideEffects`
* SideEffects.**ReadsGlobal**: `SideEffects`
* SideEffects.**WritesGlobal**: `SideEffects`
* SideEffects.**ReadsMemory**: `SideEffects`
* SideEffects.**WritesMemory**: `SideEffects`
* SideEffects.**ImplicitTrap**: `SideEffects`
* SideEffects.**IsAtomic**: `SideEffects`
* SideEffects.**Throws**: `SideEffects`
* SideEffects.**Any**: `SideEffects`
### Module validation
* Module#**validate**(): `boolean`<br />
Validates the module. Returns `true` if valid, otherwise prints validation errors and returns `false`.
### Module optimization
* Module#**optimize**(): `void`<br />
Optimizes the module using the default optimization passes.
* Module#**optimizeFunction**(func: `FunctionRef | string`): `void`<br />
Optimizes a single function using the default optimization passes.
* Module#**runPasses**(passes: `string[]`): `void`<br />
Runs the specified passes on the module.
* Module#**runPassesOnFunction**(func: `FunctionRef | string`, passes: `string[]`): `void`<br />
Runs the specified passes on a single function.
* **getOptimizeLevel**(): `number`<br />
Gets the currently set optimize level. `0`, `1`, `2` correspond to `-O0`, `-O1`, `-O2` (default), etc.
* **setOptimizeLevel**(level: `number`): `void`<br />
Sets the optimization level to use. `0`, `1`, `2` correspond to `-O0`, `-O1`, `-O2` (default), etc.
* **getShrinkLevel**(): `number`<br />
Gets the currently set shrink level. `0`, `1`, `2` correspond to `-O0`, `-Os` (default), `-Oz`.
* **setShrinkLevel**(level: `number`): `void`<br />
Sets the shrink level to use. `0`, `1`, `2` correspond to `-O0`, `-Os` (default), `-Oz`.
* **getDebugInfo**(): `boolean`<br />
Gets whether generating debug information is currently enabled or not.
* **setDebugInfo**(on: `boolean`): `void`<br />
Enables or disables debug information in emitted binaries.
* **getLowMemoryUnused**(): `boolean`<br />
Gets whether the low 1K of memory can be considered unused when optimizing.
* **setLowMemoryUnused**(on: `boolean`): `void`<br />
Enables or disables whether the low 1K of memory can be considered unused when optimizing.
* **getPassArgument**(key: `string`): `string | null`<br />
Gets the value of the specified arbitrary pass argument.
* **setPassArgument**(key: `string`, value: `string | null`): `void`<br />
Sets the value of the specified arbitrary pass argument. Removes the respective argument if `value` is `null`.
* **clearPassArguments**(): `void`<br />
Clears all arbitrary pass arguments.
* **getAlwaysInlineMaxSize**(): `number`<br />
Gets the function size at which we always inline.
* **setAlwaysInlineMaxSize**(size: `number`): `void`<br />
Sets the function size at which we always inline.
* **getFlexibleInlineMaxSize**(): `number`<br />
Gets the function size which we inline when functions are lightweight.
* **setFlexibleInlineMaxSize**(size: `number`): `void`<br />
Sets the function size which we inline when functions are lightweight.
* **getOneCallerInlineMaxSize**(): `number`<br />
Gets the function size which we inline when there is only one caller.
* **setOneCallerInlineMaxSize**(size: `number`): `void`<br />
Sets the function size which we inline when there is only one caller.
### Module creation
* Module#**emitBinary**(): `Uint8Array`<br />
Returns the module in binary format.
* Module#**emitBinary**(sourceMapUrl: `string | null`): `BinaryWithSourceMap`<br />
Returns the module in binary format with its source map. If `sourceMapUrl` is `null`, source map generation is skipped.
* BinaryWithSourceMap#**binary**: `Uint8Array`
* BinaryWithSourceMap#**sourceMap**: `string | null`
* Module#**emitText**(): `string`<br />
Returns the module in Binaryen's s-expression text format (not official stack-style text format).
* Module#**emitAsmjs**(): `string`<br />
Returns the [asm.js](http://asmjs.org/) representation of the module.
* Module#**dispose**(): `void`<br />
Releases the resources held by the module once it isn't needed anymore.
### Expression construction
#### [Control flow](http://webassembly.org/docs/semantics/#control-constructs-and-instructions)
* Module#**block**(label: `string | null`, children: `ExpressionRef[]`, resultType?: `Type`): `ExpressionRef`<br />
Creates a block. `resultType` defaults to `none`.
* Module#**if**(condition: `ExpressionRef`, ifTrue: `ExpressionRef`, ifFalse?: `ExpressionRef`): `ExpressionRef`<br />
Creates an if or if/else combination.
* Module#**loop**(label: `string | null`, body: `ExpressionRef`): `ExpressionRef`<br />
Creates a loop.
* Module#**br**(label: `string`, condition?: `ExpressionRef`, value?: `ExpressionRef`): `ExpressionRef`<br />
Creates a branch (br) to a label.
* Module#**switch**(labels: `string[]`, defaultLabel: `string`, condition: `ExpressionRef`, value?: `ExpressionRef`): `ExpressionRef`<br />
Creates a switch (br_table).
* Module#**nop**(): `ExpressionRef`<br />
Creates a no-operation (nop) instruction.
* Module#**return**(value?: `ExpressionRef`): `ExpressionRef`
Creates a return.
* Module#**unreachable**(): `ExpressionRef`<br />
Creates an [unreachable](http://webassembly.org/docs/semantics/#unreachable) instruction that will always trap.
* Module#**drop**(value: `ExpressionRef`): `ExpressionRef`<br />
Creates a [drop](http://webassembly.org/docs/semantics/#type-parametric-operators) of a value.
* Module#**select**(condition: `ExpressionRef`, ifTrue: `ExpressionRef`, ifFalse: `ExpressionRef`, type?: `Type`): `ExpressionRef`<br />
Creates a [select](http://webassembly.org/docs/semantics/#type-parametric-operators) of one of two values.
#### [Variable accesses](http://webassembly.org/docs/semantics/#local-variables)
* Module#**local.get**(index: `number`, type: `Type`): `ExpressionRef`<br />
Creates a local.get for the local at the specified index. Note that we must specify the type here as we may not have created the local being accessed yet.
* Module#**local.set**(index: `number`, value: `ExpressionRef`): `ExpressionRef`<br />
Creates a local.set for the local at the specified index.
* Module#**local.tee**(index: `number`, value: `ExpressionRef`, type: `Type`): `ExpressionRef`<br />
Creates a local.tee for the local at the specified index. A tee differs from a set in that the value remains on the stack. Note that we must specify the type here as we may not have created the local being accessed yet.
* Module#**global.get**(name: `string`, type: `Type`): `ExpressionRef`<br />
Creates a global.get for the global with the specified name. Note that we must specify the type here as we may not have created the global being accessed yet.
* Module#**global.set**(name: `string`, value: `ExpressionRef`): `ExpressionRef`<br />
Creates a global.set for the global with the specified name.
#### [Integer operations](http://webassembly.org/docs/semantics/#32-bit-integer-operators)
* Module#i32.**const**(value: `number`): `ExpressionRef`
* Module#i32.**clz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ctz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**popcnt**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**eqz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**div_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**div_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rem_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rem_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shr_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rotl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rotr**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**le_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**const**(low: `number`, high: `number`): `ExpressionRef`
* Module#i64.**clz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ctz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**popcnt**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**eqz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**div_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**div_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rem_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rem_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shr_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rotl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rotr**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**le_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
#### [Floating point operations](http://webassembly.org/docs/semantics/#floating-point-operators)
* Module#f32.**const**(value: `number`): `ExpressionRef`
* Module#f32.**const_bits**(value: `number`): `ExpressionRef`
* Module#f32.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ceil**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**floor**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**trunc**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**nearest**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**copysign**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**const**(value: `number`): `ExpressionRef`
* Module#f64.**const_bits**(value: `number`): `ExpressionRef`
* Module#f64.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ceil**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**floor**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**trunc**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**nearest**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**copysign**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
#### [Datatype conversions](http://webassembly.org/docs/semantics/#datatype-conversions-truncations-reinterpretations-promotions-and-demotions)
* Module#i32.**trunc_s.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_s.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_u.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_u.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**wrap**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**trunc_s.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_s.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_u.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_u.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f32.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_s.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_s.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_u.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_u.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**demote**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_s.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_s.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_u.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_u.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**promote**(value: `ExpressionRef`): `ExpressionRef`
#### [Function calls](http://webassembly.org/docs/semantics/#calls)
* Module#**call**(name: `string`, operands: `ExpressionRef[]`, returnType: `Type`): `ExpressionRef`
Creates a call to a function. Note that we must specify the return type here as we may not have created the function being called yet.
* Module#**return_call**(name: `string`, operands: `ExpressionRef[]`, returnType: `Type`): `ExpressionRef`<br />
Like **call**, but creates a tail-call. 🦄
* Module#**call_indirect**(target: `ExpressionRef`, operands: `ExpressionRef[]`, params: `Type`, results: `Type`): `ExpressionRef`<br />
Similar to **call**, but calls indirectly, i.e., via a function pointer, so an expression replaces the name as the called value.
* Module#**return_call_indirect**(target: `ExpressionRef`, operands: `ExpressionRef[]`, params: `Type`, results: `Type`): `ExpressionRef`<br />
Like **call_indirect**, but creates a tail-call. 🦄
#### [Linear memory accesses](http://webassembly.org/docs/semantics/#linear-memory-accesses)
* Module#i32.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load16_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load16_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store8**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store16**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
>
* Module#i64.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load16_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load16_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load32_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load32_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store8**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store16**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store32**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#f32.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#f32.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#f64.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
#### [Host operations](http://webassembly.org/docs/semantics/#resizing)
* Module#**memory.size**(): `ExpressionRef`
* Module#**memory.grow**(value: `number`): `ExpressionRef`
#### [Vector operations](https://github.com/WebAssembly/simd/blob/master/proposals/simd/SIMD.md) 🦄
* Module#v128.**const**(bytes: `Uint8Array`): `ExpressionRef`
* Module#v128.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#v128.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#v128.**not**(value: `ExpressionRef`): `ExpressionRef`
* Module#v128.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**andnot**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**bitselect**(left: `ExpressionRef`, right: `ExpressionRef`, cond: `ExpressionRef`): `ExpressionRef`
>
* Module#i8x16.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i8x16.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i8x16.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**avgr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**narrow_i16x8_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**narrow_i16x8_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#i16x8.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i16x8.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i16x8.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**avgr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**narrow_i32x4_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**narrow_i32x4_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_low_i8x16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_high_i8x16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_low_i8x16_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_high_i8x16_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**load8x8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**load8x8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#i32x4.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i32x4.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i32x4.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**dot_i16x8_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**trunc_sat_f32x4_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**trunc_sat_f32x4_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_low_i16x8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_high_i16x8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_low_i16x8_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_high_i16x8_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**load16x4_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**load16x4_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#i64x2.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i64x2.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i64x2.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**trunc_sat_f64x2_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**trunc_sat_f64x2_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**load32x2_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**load32x2_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#f32x4.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**extract_lane**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#f32x4.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**qfma**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**qfms**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**convert_i32x4_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**convert_i32x4_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64x2.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**extract_lane**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#f64x2.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**qfma**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**qfms**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**convert_i64x2_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**convert_i64x2_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#v8x16.**shuffle**(left: `ExpressionRef`, right: `ExpressionRef`, mask: `Uint8Array`): `ExpressionRef`
* Module#v8x16.**swizzle**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v8x16.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v16x8.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v32x4.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v64x2.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
#### [Atomic memory accesses](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#atomic-memory-accesses) 🦄
* Module#i32.**atomic.load**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.load8_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.load16_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store8**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store16**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**atomic.load**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load8_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load16_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load32_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store8**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store16**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store32**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
#### [Atomic read-modify-write operations](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#read-modify-write) 🦄
* Module#i32.**atomic.rmw.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**atomic.rmw.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
#### [Atomic wait and notify operations](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#wait-and-notify-operators) 🦄
* Module#i32.**atomic.wait**(ptr: `ExpressionRef`, expected: `ExpressionRef`, timeout: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.wait**(ptr: `ExpressionRef`, expected: `ExpressionRef`, timeout: `ExpressionRef`): `ExpressionRef`
* Module#**atomic.notify**(ptr: `ExpressionRef`, notifyCount: `ExpressionRef`): `ExpressionRef`
* Module#**atomic.fence**(): `ExpressionRef`
#### [Sign extension operations](https://github.com/WebAssembly/sign-extension-ops/blob/master/proposals/sign-extension-ops/Overview.md) 🦄
* Module#i32.**extend8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**extend16_s**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**extend8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend32_s**(value: `ExpressionRef`): `ExpressionRef`
#### [Multi-value operations](https://github.com/WebAssembly/multi-value/blob/master/proposals/multi-value/Overview.md) 🦄
Note that these are pseudo instructions enabling Binaryen to reason about multiple values on the stack.
* Module#**push**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**pop**(): `ExpressionRef`
* Module#i64.**pop**(): `ExpressionRef`
* Module#f32.**pop**(): `ExpressionRef`
* Module#f64.**pop**(): `ExpressionRef`
* Module#v128.**pop**(): `ExpressionRef`
* Module#funcref.**pop**(): `ExpressionRef`
* Module#anyref.**pop**(): `ExpressionRef`
* Module#nullref.**pop**(): `ExpressionRef`
* Module#exnref.**pop**(): `ExpressionRef`
* Module#tuple.**make**(elements: `ExpressionRef[]`): `ExpressionRef`
* Module#tuple.**extract**(tuple: `ExpressionRef`, index: `number`): `ExpressionRef`
#### [Exception handling operations](https://github.com/WebAssembly/exception-handling/blob/master/proposals/Exceptions.md) 🦄
* Module#**try**(body: `ExpressionRef`, catchBody: `ExpressionRef`): `ExpressionRef`
* Module#**throw**(event: `string`, operands: `ExpressionRef[]`): `ExpressionRef`
* Module#**rethrow**(exnref: `ExpressionRef`): `ExpressionRef`
* Module#**br_on_exn**(label: `string`, event: `string`, exnref: `ExpressionRef`): `ExpressionRef`
>
* Module#**addEvent**(name: `string`, attribute: `number`, params: `Type`, results: `Type`): `Event`
* Module#**getEvent**(name: `string`): `Event`
* Module#**removeEvent**(name: `stirng`): `void`
* Module#**addEventImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, attribute: `number`, params: `Type`, results: `Type`): `void`
* Module#**addEventExport**(internalName: `string`, externalName: `string`): `ExportRef`
#### [Reference types operations](https://github.com/WebAssembly/reference-types/blob/master/proposals/reference-types/Overview.md) 🦄
* Module#ref.**null**(): `ExpressionRef`
* Module#ref.**is_null**(value: `ExpressionRef`): `ExpressionRef`
* Module#ref.**func**(name: `string`): `ExpressionRef`
### Expression manipulation
* **getExpressionId**(expr: `ExpressionRef`): `ExpressionId`<br />
Gets the id (kind) of the specified expression. Possible values are:
* **InvalidId**: `ExpressionId`
* **BlockId**: `ExpressionId`
* **IfId**: `ExpressionId`
* **LoopId**: `ExpressionId`
* **BreakId**: `ExpressionId`
* **SwitchId**: `ExpressionId`
* **CallId**: `ExpressionId`
* **CallIndirectId**: `ExpressionId`
* **LocalGetId**: `ExpressionId`
* **LocalSetId**: `ExpressionId`
* **GlobalGetId**: `ExpressionId`
* **GlobalSetId**: `ExpressionId`
* **LoadId**: `ExpressionId`
* **StoreId**: `ExpressionId`
* **ConstId**: `ExpressionId`
* **UnaryId**: `ExpressionId`
* **BinaryId**: `ExpressionId`
* **SelectId**: `ExpressionId`
* **DropId**: `ExpressionId`
* **ReturnId**: `ExpressionId`
* **HostId**: `ExpressionId`
* **NopId**: `ExpressionId`
* **UnreachableId**: `ExpressionId`
* **AtomicCmpxchgId**: `ExpressionId`
* **AtomicRMWId**: `ExpressionId`
* **AtomicWaitId**: `ExpressionId`
* **AtomicNotifyId**: `ExpressionId`
* **AtomicFenceId**: `ExpressionId`
* **SIMDExtractId**: `ExpressionId`
* **SIMDReplaceId**: `ExpressionId`
* **SIMDShuffleId**: `ExpressionId`
* **SIMDTernaryId**: `ExpressionId`
* **SIMDShiftId**: `ExpressionId`
* **SIMDLoadId**: `ExpressionId`
* **MemoryInitId**: `ExpressionId`
* **DataDropId**: `ExpressionId`
* **MemoryCopyId**: `ExpressionId`
* **MemoryFillId**: `ExpressionId`
* **RefNullId**: `ExpressionId`
* **RefIsNullId**: `ExpressionId`
* **RefFuncId**: `ExpressionId`
* **TryId**: `ExpressionId`
* **ThrowId**: `ExpressionId`
* **RethrowId**: `ExpressionId`
* **BrOnExnId**: `ExpressionId`
* **PushId**: `ExpressionId`
* **PopId**: `ExpressionId`
* **getExpressionType**(expr: `ExpressionRef`): `Type`<br />
Gets the type of the specified expression.
* **getExpressionInfo**(expr: `ExpressionRef`): `ExpressionInfo`<br />
Obtains information about an expression, always including:
* Info#**id**: `ExpressionId`
* Info#**type**: `Type`
Additional properties depend on the expression's `id` and are usually equivalent to the respective parameters when creating such an expression:
* BlockInfo#**name**: `string`
* BlockInfo#**children**: `ExpressionRef[]`
>
* IfInfo#**condition**: `ExpressionRef`
* IfInfo#**ifTrue**: `ExpressionRef`
* IfInfo#**ifFalse**: `ExpressionRef | null`
>
* LoopInfo#**name**: `string`
* LoopInfo#**body**: `ExpressionRef`
>
* BreakInfo#**name**: `string`
* BreakInfo#**condition**: `ExpressionRef | null`
* BreakInfo#**value**: `ExpressionRef | null`
>
* SwitchInfo#**names**: `string[]`
* SwitchInfo#**defaultName**: `string | null`
* SwitchInfo#**condition**: `ExpressionRef`
* SwitchInfo#**value**: `ExpressionRef | null`
>
* CallInfo#**target**: `string`
* CallInfo#**operands**: `ExpressionRef[]`
>
* CallImportInfo#**target**: `string`
* CallImportInfo#**operands**: `ExpressionRef[]`
>
* CallIndirectInfo#**target**: `ExpressionRef`
* CallIndirectInfo#**operands**: `ExpressionRef[]`
>
* LocalGetInfo#**index**: `number`
>
* LocalSetInfo#**isTee**: `boolean`
* LocalSetInfo#**index**: `number`
* LocalSetInfo#**value**: `ExpressionRef`
>
* GlobalGetInfo#**name**: `string`
>
* GlobalSetInfo#**name**: `string`
* GlobalSetInfo#**value**: `ExpressionRef`
>
* LoadInfo#**isAtomic**: `boolean`
* LoadInfo#**isSigned**: `boolean`
* LoadInfo#**offset**: `number`
* LoadInfo#**bytes**: `number`
* LoadInfo#**align**: `number`
* LoadInfo#**ptr**: `ExpressionRef`
>
* StoreInfo#**isAtomic**: `boolean`
* StoreInfo#**offset**: `number`
* StoreInfo#**bytes**: `number`
* StoreInfo#**align**: `number`
* StoreInfo#**ptr**: `ExpressionRef`
* StoreInfo#**value**: `ExpressionRef`
>
* ConstInfo#**value**: `number | { low: number, high: number }`
>
* UnaryInfo#**op**: `number`
* UnaryInfo#**value**: `ExpressionRef`
>
* BinaryInfo#**op**: `number`
* BinaryInfo#**left**: `ExpressionRef`
* BinaryInfo#**right**: `ExpressionRef`
>
* SelectInfo#**ifTrue**: `ExpressionRef`
* SelectInfo#**ifFalse**: `ExpressionRef`
* SelectInfo#**condition**: `ExpressionRef`
>
* DropInfo#**value**: `ExpressionRef`
>
* ReturnInfo#**value**: `ExpressionRef | null`
>
* NopInfo
>
* UnreachableInfo
>
* HostInfo#**op**: `number`
* HostInfo#**nameOperand**: `string | null`
* HostInfo#**operands**: `ExpressionRef[]`
>
* AtomicRMWInfo#**op**: `number`
* AtomicRMWInfo#**bytes**: `number`
* AtomicRMWInfo#**offset**: `number`
* AtomicRMWInfo#**ptr**: `ExpressionRef`
* AtomicRMWInfo#**value**: `ExpressionRef`
>
* AtomicCmpxchgInfo#**bytes**: `number`
* AtomicCmpxchgInfo#**offset**: `number`
* AtomicCmpxchgInfo#**ptr**: `ExpressionRef`
* AtomicCmpxchgInfo#**expected**: `ExpressionRef`
* AtomicCmpxchgInfo#**replacement**: `ExpressionRef`
>
* AtomicWaitInfo#**ptr**: `ExpressionRef`
* AtomicWaitInfo#**expected**: `ExpressionRef`
* AtomicWaitInfo#**timeout**: `ExpressionRef`
* AtomicWaitInfo#**expectedType**: `Type`
>
* AtomicNotifyInfo#**ptr**: `ExpressionRef`
* AtomicNotifyInfo#**notifyCount**: `ExpressionRef`
>
* AtomicFenceInfo
>
* SIMDExtractInfo#**op**: `Op`
* SIMDExtractInfo#**vec**: `ExpressionRef`
* SIMDExtractInfo#**index**: `ExpressionRef`
>
* SIMDReplaceInfo#**op**: `Op`
* SIMDReplaceInfo#**vec**: `ExpressionRef`
* SIMDReplaceInfo#**index**: `ExpressionRef`
* SIMDReplaceInfo#**value**: `ExpressionRef`
>
* SIMDShuffleInfo#**left**: `ExpressionRef`
* SIMDShuffleInfo#**right**: `ExpressionRef`
* SIMDShuffleInfo#**mask**: `Uint8Array`
>
* SIMDTernaryInfo#**op**: `Op`
* SIMDTernaryInfo#**a**: `ExpressionRef`
* SIMDTernaryInfo#**b**: `ExpressionRef`
* SIMDTernaryInfo#**c**: `ExpressionRef`
>
* SIMDShiftInfo#**op**: `Op`
* SIMDShiftInfo#**vec**: `ExpressionRef`
* SIMDShiftInfo#**shift**: `ExpressionRef`
>
* SIMDLoadInfo#**op**: `Op`
* SIMDLoadInfo#**offset**: `number`
* SIMDLoadInfo#**align**: `number`
* SIMDLoadInfo#**ptr**: `ExpressionRef`
>
* MemoryInitInfo#**segment**: `number`
* MemoryInitInfo#**dest**: `ExpressionRef`
* MemoryInitInfo#**offset**: `ExpressionRef`
* MemoryInitInfo#**size**: `ExpressionRef`
>
* MemoryDropInfo#**segment**: `number`
>
* MemoryCopyInfo#**dest**: `ExpressionRef`
* MemoryCopyInfo#**source**: `ExpressionRef`
* MemoryCopyInfo#**size**: `ExpressionRef`
>
* MemoryFillInfo#**dest**: `ExpressionRef`
* MemoryFillInfo#**value**: `ExpressionRef`
* MemoryFillInfo#**size**: `ExpressionRef`
>
* TryInfo#**body**: `ExpressionRef`
* TryInfo#**catchBody**: `ExpressionRef`
>
* RefNullInfo
>
* RefIsNullInfo#**value**: `ExpressionRef`
>
* RefFuncInfo#**func**: `string`
>
* ThrowInfo#**event**: `string`
* ThrowInfo#**operands**: `ExpressionRef[]`
>
* RethrowInfo#**exnref**: `ExpressionRef`
>
* BrOnExnInfo#**name**: `string`
* BrOnExnInfo#**event**: `string`
* BrOnExnInfo#**exnref**: `ExpressionRef`
>
* PopInfo
>
* PushInfo#**value**: `ExpressionRef`
* **emitText**(expression: `ExpressionRef`): `string`<br />
Emits the expression in Binaryen's s-expression text format (not official stack-style text format).
* **copyExpression**(expression: `ExpressionRef`): `ExpressionRef`<br />
Creates a deep copy of an expression.
### Relooper
* new **Relooper**()<br />
Constructs a relooper instance. This lets you provide an arbitrary CFG, and the relooper will structure it for WebAssembly.
* Relooper#**addBlock**(code: `ExpressionRef`): `RelooperBlockRef`<br />
Adds a new block to the CFG, containing the provided code as its body.
* Relooper#**addBranch**(from: `RelooperBlockRef`, to: `RelooperBlockRef`, condition: `ExpressionRef`, code: `ExpressionRef`): `void`<br />
Adds a branch from a block to another block, with a condition (or nothing, if this is the default branch to take from the origin - each block must have one such branch), and optional code to execute on the branch (useful for phis).
* Relooper#**addBlockWithSwitch**(code: `ExpressionRef`, condition: `ExpressionRef`): `RelooperBlockRef`<br />
Adds a new block, which ends with a switch/br_table, with provided code and condition (that determines where we go in the switch).
* Relooper#**addBranchForSwitch**(from: `RelooperBlockRef`, to: `RelooperBlockRef`, indexes: `number[]`, code: `ExpressionRef`): `void`<br />
Adds a branch from a block ending in a switch, to another block, using an array of indexes that determine where to go, and optional code to execute on the branch.
* Relooper#**renderAndDispose**(entry: `RelooperBlockRef`, labelHelper: `number`, module: `Module`): `ExpressionRef`<br />
Renders and cleans up the Relooper instance. Call this after you have created all the blocks and branches, giving it the entry block (where control flow begins), a label helper variable (an index of a local we can use, necessary for irreducible control flow), and the module. This returns an expression - normal WebAssembly code - that you can use normally anywhere.
### Source maps
* Module#**addDebugInfoFileName**(filename: `string`): `number`<br />
Adds a debug info file name to the module and returns its index.
* Module#**getDebugInfoFileName**(index: `number`): `string | null` <br />
Gets the name of the debug info file at the specified index.
* Module#**setDebugLocation**(func: `FunctionRef`, expr: `ExpressionRef`, fileIndex: `number`, lineNumber: `number`, columnNumber: `number`): `void`<br />
Sets the debug location of the specified `ExpressionRef` within the specified `FunctionRef`.
### Debugging
* Module#**interpret**(): `void`<br />
Runs the module in the interpreter, calling the start function.
[](https://www.npmjs.com/package/espree)
[](https://travis-ci.org/eslint/espree)
[](https://www.npmjs.com/package/espree)
[](https://www.bountysource.com/trackers/9348450-eslint?utm_source=9348450&utm_medium=shield&utm_campaign=TRACKER_BADGE)
# Espree
Espree started out as a fork of [Esprima](http://esprima.org) v1.2.2, the last stable published released of Esprima before work on ECMAScript 6 began. Espree is now built on top of [Acorn](https://github.com/ternjs/acorn), which has a modular architecture that allows extension of core functionality. The goal of Espree is to produce output that is similar to Esprima with a similar API so that it can be used in place of Esprima.
## Usage
Install:
```
npm i espree
```
And in your Node.js code:
```javascript
const espree = require("espree");
const ast = espree.parse(code);
```
## API
### `parse()`
`parse` parses the given code and returns a abstract syntax tree (AST). It takes two parameters.
- `code` [string]() - the code which needs to be parsed.
- `options (Optional)` [Object]() - read more about this [here](#options).
```javascript
const espree = require("espree");
const ast = espree.parse(code, options);
```
**Example :**
```js
const ast = espree.parse('let foo = "bar"', { ecmaVersion: 6 });
console.log(ast);
```
<details><summary>Output</summary>
<p>
```
Node {
type: 'Program',
start: 0,
end: 15,
body: [
Node {
type: 'VariableDeclaration',
start: 0,
end: 15,
declarations: [Array],
kind: 'let'
}
],
sourceType: 'script'
}
```
</p>
</details>
### `tokenize()`
`tokenize` returns the tokens of a given code. It takes two parameters.
- `code` [string]() - the code which needs to be parsed.
- `options (Optional)` [Object]() - read more about this [here](#options).
Even if `options` is empty or undefined or `options.tokens` is `false`, it assigns it to `true` in order to get the `tokens` array
**Example :**
```js
const tokens = espree.tokenize('let foo = "bar"', { ecmaVersion: 6 });
console.log(tokens);
```
<details><summary>Output</summary>
<p>
```
Token { type: 'Keyword', value: 'let', start: 0, end: 3 },
Token { type: 'Identifier', value: 'foo', start: 4, end: 7 },
Token { type: 'Punctuator', value: '=', start: 8, end: 9 },
Token { type: 'String', value: '"bar"', start: 10, end: 15 }
```
</p>
</details>
### `version`
Returns the current `espree` version
### `VisitorKeys`
Returns all visitor keys for traversing the AST from [eslint-visitor-keys](https://github.com/eslint/eslint-visitor-keys)
### `latestEcmaVersion`
Returns the latest ECMAScript supported by `espree`
### `supportedEcmaVersions`
Returns an array of all supported ECMAScript versions
## Options
```js
const options = {
// attach range information to each node
range: false,
// attach line/column location information to each node
loc: false,
// create a top-level comments array containing all comments
comment: false,
// create a top-level tokens array containing all tokens
tokens: false,
// Set to 3, 5 (default), 6, 7, 8, 9, 10, 11, or 12 to specify the version of ECMAScript syntax you want to use.
// You can also set to 2015 (same as 6), 2016 (same as 7), 2017 (same as 8), 2018 (same as 9), 2019 (same as 10), 2020 (same as 11), or 2021 (same as 12) to use the year-based naming.
ecmaVersion: 5,
// specify which type of script you're parsing ("script" or "module")
sourceType: "script",
// specify additional language features
ecmaFeatures: {
// enable JSX parsing
jsx: false,
// enable return in global scope
globalReturn: false,
// enable implied strict mode (if ecmaVersion >= 5)
impliedStrict: false
}
}
```
## Esprima Compatibility Going Forward
The primary goal is to produce the exact same AST structure and tokens as Esprima, and that takes precedence over anything else. (The AST structure being the [ESTree](https://github.com/estree/estree) API with JSX extensions.) Separate from that, Espree may deviate from what Esprima outputs in terms of where and how comments are attached, as well as what additional information is available on AST nodes. That is to say, Espree may add more things to the AST nodes than Esprima does but the overall AST structure produced will be the same.
Espree may also deviate from Esprima in the interface it exposes.
## Contributing
Issues and pull requests will be triaged and responded to as quickly as possible. We operate under the [ESLint Contributor Guidelines](http://eslint.org/docs/developer-guide/contributing), so please be sure to read them before contributing. If you're not sure where to dig in, check out the [issues](https://github.com/eslint/espree/issues).
Espree is licensed under a permissive BSD 2-clause license.
## Security Policy
We work hard to ensure that Espree is safe for everyone and that security issues are addressed quickly and responsibly. Read the full [security policy](https://github.com/eslint/.github/blob/master/SECURITY.md).
## Build Commands
* `npm test` - run all linting and tests
* `npm run lint` - run all linting
* `npm run browserify` - creates a version of Espree that is usable in a browser
## Differences from Espree 2.x
* The `tokenize()` method does not use `ecmaFeatures`. Any string will be tokenized completely based on ECMAScript 6 semantics.
* Trailing whitespace no longer is counted as part of a node.
* `let` and `const` declarations are no longer parsed by default. You must opt-in by using an `ecmaVersion` newer than `5` or setting `sourceType` to `module`.
* The `esparse` and `esvalidate` binary scripts have been removed.
* There is no `tolerant` option. We will investigate adding this back in the future.
## Known Incompatibilities
In an effort to help those wanting to transition from other parsers to Espree, the following is a list of noteworthy incompatibilities with other parsers. These are known differences that we do not intend to change.
### Esprima 1.2.2
* Esprima counts trailing whitespace as part of each AST node while Espree does not. In Espree, the end of a node is where the last token occurs.
* Espree does not parse `let` and `const` declarations by default.
* Error messages returned for parsing errors are different.
* There are two addition properties on every node and token: `start` and `end`. These represent the same data as `range` and are used internally by Acorn.
### Esprima 2.x
* Esprima 2.x uses a different comment attachment algorithm that results in some comments being added in different places than Espree. The algorithm Espree uses is the same one used in Esprima 1.2.2.
## Frequently Asked Questions
### Why another parser
[ESLint](http://eslint.org) had been relying on Esprima as its parser from the beginning. While that was fine when the JavaScript language was evolving slowly, the pace of development increased dramatically and Esprima had fallen behind. ESLint, like many other tools reliant on Esprima, has been stuck in using new JavaScript language features until Esprima updates, and that caused our users frustration.
We decided the only way for us to move forward was to create our own parser, bringing us inline with JSHint and JSLint, and allowing us to keep implementing new features as we need them. We chose to fork Esprima instead of starting from scratch in order to move as quickly as possible with a compatible API.
With Espree 2.0.0, we are no longer a fork of Esprima but rather a translation layer between Acorn and Esprima syntax. This allows us to put work back into a community-supported parser (Acorn) that is continuing to grow and evolve while maintaining an Esprima-compatible parser for those utilities still built on Esprima.
### Have you tried working with Esprima?
Yes. Since the start of ESLint, we've regularly filed bugs and feature requests with Esprima and will continue to do so. However, there are some different philosophies around how the projects work that need to be worked through. The initial goal was to have Espree track Esprima and eventually merge the two back together, but we ultimately decided that building on top of Acorn was a better choice due to Acorn's plugin support.
### Why don't you just use Acorn?
Acorn is a great JavaScript parser that produces an AST that is compatible with Esprima. Unfortunately, ESLint relies on more than just the AST to do its job. It relies on Esprima's tokens and comment attachment features to get a complete picture of the source code. We investigated switching to Acorn, but the inconsistencies between Esprima and Acorn created too much work for a project like ESLint.
We are building on top of Acorn, however, so that we can contribute back and help make Acorn even better.
### What ECMAScript features do you support?
Espree supports all ECMAScript 2020 features and partially supports ECMAScript 2021 features.
Because ECMAScript 2021 is still under development, we are implementing features as they are finalized. Currently, Espree supports:
* [Logical Assignment Operators](https://github.com/tc39/proposal-logical-assignment)
* [Numeric Separators](https://github.com/tc39/proposal-numeric-separator)
See [finished-proposals.md](https://github.com/tc39/proposals/blob/master/finished-proposals.md) to know what features are finalized.
### How do you determine which experimental features to support?
In general, we do not support experimental JavaScript features. We may make exceptions from time to time depending on the maturity of the features.
# is-extglob [](https://www.npmjs.com/package/is-extglob) [](https://npmjs.org/package/is-extglob) [](https://travis-ci.org/jonschlinkert/is-extglob)
> Returns true if a string has an extglob.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-extglob
```
## Usage
```js
var isExtglob = require('is-extglob');
```
**True**
```js
isExtglob('?(abc)');
isExtglob('@(abc)');
isExtglob('!(abc)');
isExtglob('*(abc)');
isExtglob('+(abc)');
```
**False**
Escaped extglobs:
```js
isExtglob('\\?(abc)');
isExtglob('\\@(abc)');
isExtglob('\\!(abc)');
isExtglob('\\*(abc)');
isExtglob('\\+(abc)');
```
Everything else...
```js
isExtglob('foo.js');
isExtglob('!foo.js');
isExtglob('*.js');
isExtglob('**/abc.js');
isExtglob('abc/*.js');
isExtglob('abc/(aaa|bbb).js');
isExtglob('abc/[a-z].js');
isExtglob('abc/{a,b}.js');
isExtglob('abc/?.js');
isExtglob('abc.js');
isExtglob('abc/def/ghi.js');
```
## History
**v2.0**
Adds support for escaping. Escaped exglobs no longer return true.
## About
### Related projects
* [has-glob](https://www.npmjs.com/package/has-glob): Returns `true` if an array has a glob pattern. | [homepage](https://github.com/jonschlinkert/has-glob "Returns `true` if an array has a glob pattern.")
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern… [more](https://github.com/jonschlinkert/is-glob) | [homepage](https://github.com/jonschlinkert/is-glob "Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a bet")
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. | [homepage](https://github.com/jonschlinkert/micromatch "Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Building docs
_(This document was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme) (a [verb](https://github.com/verbose/verb) generator), please don't edit the readme directly. Any changes to the readme must be made in [.verb.md](.verb.md).)_
To generate the readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install -g verb verb-generate-readme && verb
```
### Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
### License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/is-extglob/blob/master/LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.1.31, on October 12, 2016._
discontinuous-range
===================
```
DiscontinuousRange(1, 10).subtract(4, 6); // [ 1-3, 7-10 ]
```
[](https://travis-ci.org/dtudury/discontinuous-range)
this is a pretty simple module, but it exists to service another project
so this'll be pretty lacking documentation.
reading the test to see how this works may help. otherwise, here's an example
that I think pretty much sums it up
###Example
```
var all_numbers = new DiscontinuousRange(1, 100);
var bad_numbers = DiscontinuousRange(13).add(8).add(60,80);
var good_numbers = all_numbers.clone().subtract(bad_numbers);
console.log(good_numbers.toString()); //[ 1-7, 9-12, 14-59, 81-100 ]
var random_good_number = good_numbers.index(Math.floor(Math.random() * good_numbers.length));
```
# yallist
Yet Another Linked List
There are many doubly-linked list implementations like it, but this
one is mine.
For when an array would be too big, and a Map can't be iterated in
reverse order.
[](https://travis-ci.org/isaacs/yallist) [](https://coveralls.io/github/isaacs/yallist)
## basic usage
```javascript
var yallist = require('yallist')
var myList = yallist.create([1, 2, 3])
myList.push('foo')
myList.unshift('bar')
// of course pop() and shift() are there, too
console.log(myList.toArray()) // ['bar', 1, 2, 3, 'foo']
myList.forEach(function (k) {
// walk the list head to tail
})
myList.forEachReverse(function (k, index, list) {
// walk the list tail to head
})
var myDoubledList = myList.map(function (k) {
return k + k
})
// now myDoubledList contains ['barbar', 2, 4, 6, 'foofoo']
// mapReverse is also a thing
var myDoubledListReverse = myList.mapReverse(function (k) {
return k + k
}) // ['foofoo', 6, 4, 2, 'barbar']
var reduced = myList.reduce(function (set, entry) {
set += entry
return set
}, 'start')
console.log(reduced) // 'startfoo123bar'
```
## api
The whole API is considered "public".
Functions with the same name as an Array method work more or less the
same way.
There's reverse versions of most things because that's the point.
### Yallist
Default export, the class that holds and manages a list.
Call it with either a forEach-able (like an array) or a set of
arguments, to initialize the list.
The Array-ish methods all act like you'd expect. No magic length,
though, so if you change that it won't automatically prune or add
empty spots.
### Yallist.create(..)
Alias for Yallist function. Some people like factories.
#### yallist.head
The first node in the list
#### yallist.tail
The last node in the list
#### yallist.length
The number of nodes in the list. (Change this at your peril. It is
not magic like Array length.)
#### yallist.toArray()
Convert the list to an array.
#### yallist.forEach(fn, [thisp])
Call a function on each item in the list.
#### yallist.forEachReverse(fn, [thisp])
Call a function on each item in the list, in reverse order.
#### yallist.get(n)
Get the data at position `n` in the list. If you use this a lot,
probably better off just using an Array.
#### yallist.getReverse(n)
Get the data at position `n`, counting from the tail.
#### yallist.map(fn, thisp)
Create a new Yallist with the result of calling the function on each
item.
#### yallist.mapReverse(fn, thisp)
Same as `map`, but in reverse.
#### yallist.pop()
Get the data from the list tail, and remove the tail from the list.
#### yallist.push(item, ...)
Insert one or more items to the tail of the list.
#### yallist.reduce(fn, initialValue)
Like Array.reduce.
#### yallist.reduceReverse
Like Array.reduce, but in reverse.
#### yallist.reverse
Reverse the list in place.
#### yallist.shift()
Get the data from the list head, and remove the head from the list.
#### yallist.slice([from], [to])
Just like Array.slice, but returns a new Yallist.
#### yallist.sliceReverse([from], [to])
Just like yallist.slice, but the result is returned in reverse.
#### yallist.toArray()
Create an array representation of the list.
#### yallist.toArrayReverse()
Create a reversed array representation of the list.
#### yallist.unshift(item, ...)
Insert one or more items to the head of the list.
#### yallist.unshiftNode(node)
Move a Node object to the front of the list. (That is, pull it out of
wherever it lives, and make it the new head.)
If the node belongs to a different list, then that list will remove it
first.
#### yallist.pushNode(node)
Move a Node object to the end of the list. (That is, pull it out of
wherever it lives, and make it the new tail.)
If the node belongs to a list already, then that list will remove it
first.
#### yallist.removeNode(node)
Remove a node from the list, preserving referential integrity of head
and tail and other nodes.
Will throw an error if you try to have a list remove a node that
doesn't belong to it.
### Yallist.Node
The class that holds the data and is actually the list.
Call with `var n = new Node(value, previousNode, nextNode)`
Note that if you do direct operations on Nodes themselves, it's very
easy to get into weird states where the list is broken. Be careful :)
#### node.next
The next node in the list.
#### node.prev
The previous node in the list.
#### node.value
The data the node contains.
#### node.list
The list to which this node belongs. (Null if it does not belong to
any list.)
# y18n
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[](https://conventionalcommits.org)
The bare-bones internationalization library used by yargs.
Inspired by [i18n](https://www.npmjs.com/package/i18n).
## Examples
_simple string translation:_
```js
const __ = require('y18n')().__;
console.log(__('my awesome string %s', 'foo'));
```
output:
`my awesome string foo`
_using tagged template literals_
```js
const __ = require('y18n')().__;
const str = 'foo';
console.log(__`my awesome string ${str}`);
```
output:
`my awesome string foo`
_pluralization support:_
```js
const __n = require('y18n')().__n;
console.log(__n('one fish %s', '%d fishes %s', 2, 'foo'));
```
output:
`2 fishes foo`
## Deno Example
As of `v5` `y18n` supports [Deno](https://github.com/denoland/deno):
```typescript
import y18n from "https://deno.land/x/y18n/deno.ts";
const __ = y18n({
locale: 'pirate',
directory: './test/locales'
}).__
console.info(__`Hi, ${'Ben'} ${'Coe'}!`)
```
You will need to run with `--allow-read` to load alternative locales.
## JSON Language Files
The JSON language files should be stored in a `./locales` folder.
File names correspond to locales, e.g., `en.json`, `pirate.json`.
When strings are observed for the first time they will be
added to the JSON file corresponding to the current locale.
## Methods
### require('y18n')(config)
Create an instance of y18n with the config provided, options include:
* `directory`: the locale directory, default `./locales`.
* `updateFiles`: should newly observed strings be updated in file, default `true`.
* `locale`: what locale should be used.
* `fallbackToLanguage`: should fallback to a language-only file (e.g. `en.json`)
be allowed if a file matching the locale does not exist (e.g. `en_US.json`),
default `true`.
### y18n.\_\_(str, arg, arg, arg)
Print a localized string, `%s` will be replaced with `arg`s.
This function can also be used as a tag for a template literal. You can use it
like this: <code>__`hello ${'world'}`</code>. This will be equivalent to
`__('hello %s', 'world')`.
### y18n.\_\_n(singularString, pluralString, count, arg, arg, arg)
Print a localized string with appropriate pluralization. If `%d` is provided
in the string, the `count` will replace this placeholder.
### y18n.setLocale(str)
Set the current locale being used.
### y18n.getLocale()
What locale is currently being used?
### y18n.updateLocale(obj)
Update the current locale with the key value pairs in `obj`.
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
## License
ISC
[npm-url]: https://npmjs.org/package/y18n
[npm-image]: https://img.shields.io/npm/v/y18n.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: https://github.com/feross/standard
# hasurl [![NPM Version][npm-image]][npm-url] [![Build Status][travis-image]][travis-url]
> Determine whether Node.js' native [WHATWG `URL`](https://nodejs.org/api/url.html#url_the_whatwg_url_api) implementation is available.
## Installation
[Node.js](http://nodejs.org/) `>= 4` is required. To install, type this at the command line:
```shell
npm install hasurl
```
## Usage
```js
const hasURL = require('hasurl');
if (hasURL()) {
// supported
} else {
// fallback
}
```
[npm-image]: https://img.shields.io/npm/v/hasurl.svg
[npm-url]: https://npmjs.org/package/hasurl
[travis-image]: https://img.shields.io/travis/stevenvachon/hasurl.svg
[travis-url]: https://travis-ci.org/stevenvachon/hasurl
# lodash.sortby v4.7.0
The [lodash](https://lodash.com/) method `_.sortBy` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.sortby
```
In Node.js:
```js
var sortBy = require('lodash.sortby');
```
See the [documentation](https://lodash.com/docs#sortBy) or [package source](https://github.com/lodash/lodash/blob/4.7.0-npm-packages/lodash.sortby) for more details.
# eslint-utils
[](https://www.npmjs.com/package/eslint-utils)
[](http://www.npmtrends.com/eslint-utils)
[](https://github.com/mysticatea/eslint-utils/actions)
[](https://codecov.io/gh/mysticatea/eslint-utils)
[](https://david-dm.org/mysticatea/eslint-utils)
## 🏁 Goal
This package provides utility functions and classes for make ESLint custom rules.
For examples:
- [getStaticValue](https://eslint-utils.mysticatea.dev/api/ast-utils.html#getstaticvalue) evaluates static value on AST.
- [ReferenceTracker](https://eslint-utils.mysticatea.dev/api/scope-utils.html#referencetracker-class) checks the members of modules/globals as handling assignments and destructuring.
## 📖 Usage
See [documentation](https://eslint-utils.mysticatea.dev/).
## 📰 Changelog
See [releases](https://github.com/mysticatea/eslint-utils/releases).
## ❤️ Contributing
Welcome contributing!
Please use GitHub's Issues/PRs.
### Development Tools
- `npm test` runs tests and measures coverage.
- `npm run clean` removes the coverage result of `npm test` command.
- `npm run coverage` shows the coverage result of the last `npm test` command.
- `npm run lint` runs ESLint.
- `npm run watch` runs tests on each file change.
## assemblyscript-temporal
An implementation of temporal within AssemblyScript, with an initial focus on non-timezone-aware classes and functionality.
### Why?
AssemblyScript has minimal `Date` support, however, the JS Date API itself is terrible and people tend not to use it that often. As a result libraries like moment / luxon have become staple replacements. However, there is now a [relatively mature TC39 proposal](https://github.com/tc39/proposal-temporal) that adds greatly improved date support to JS. The goal of this project is to implement Temporal for AssemblyScript.
### Usage
This library currently supports the following types:
#### `PlainDateTime`
A `PlainDateTime` represents a calendar date and wall-clock time that does not carry time zone information, e.g. December 7th, 1995 at 3:00 PM (in the Gregorian calendar). For detailed documentation see the [TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plaindatetime.html), this implementation follows the specification as closely as possible.
You can create a `PlainDateTime` from individual components, a string or an object literal:
```javascript
datetime = new PlainDateTime(1976, 11, 18, 15, 23, 30, 123, 456, 789);
datetime.year; // 2019;
datetime.month; // 11;
// ...
datetime.nanosecond; // 789;
datetime = PlainDateTime.from("1976-11-18T12:34:56");
datetime.toString(); // "1976-11-18T12:34:56"
datetime = PlainDateTime.from({ year: 1966, month: 3, day: 3 });
datetime.toString(); // "1966-03-03T00:00:00"
```
There are various ways you can manipulate a date:
```javascript
// use 'with' to copy a date but with various property values overriden
datetime = new PlainDateTime(1976, 11, 18, 15, 23, 30, 123, 456, 789);
datetime.with({ year: 2019 }).toString(); // "2019-11-18T15:23:30.123456789"
// use 'add' or 'substract' to add / subtract a duration
datetime = PlainDateTime.from("2020-01-12T15:00");
datetime.add({ months: 1 }).toString(); // "2020-02-12T15:00:00");
// add / subtract support Duration objects or object literals
datetime.add(new Duration(1)).toString(); // "2021-01-12T15:00:00");
```
You can compare dates and check for equality
```javascript
dt1 = PlainDateTime.from("1976-11-18");
dt2 = PlainDateTime.from("2019-10-29");
PlainDateTime.compare(dt1, dt1); // 0
PlainDateTime.compare(dt1, dt2); // -1
dt1.equals(dt1); // true
```
Currently `PlainDateTime` only supports the ISO 8601 (Gregorian) calendar.
#### `PlainDate`
A `PlainDate` object represents a calendar date that is not associated with a particular time or time zone, e.g. August 24th, 2006. For detailed documentation see the [TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plaindate.html), this implementation follows the specification as closely as possible.
The `PlainDate` API is almost identical to `PlainDateTime`, so see above for API usage examples.
#### `PlainTime`
A `PlainTime` object represents a wall-clock time that is not associated with a particular date or time zone, e.g. 7:39 PM. For detailed documentation see the [TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plaintime.html), this implementation follows the specification as closely as possible.
The `PlainTime` API is almost identical to `PlainDateTime`, so see above for API usage examples.
#### `PlainMonthDay`
A date without a year component. This is useful to express things like "Bastille Day is on the 14th of July".
For detailed documentation see the
[TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plainmonthday.html)
, this implementation follows the specification as closely as possible.
```javascript
const monthDay = PlainMonthDay.from({ month: 7, day: 14 }); // => 07-14
const date = monthDay.toPlainDate({ year: 2030 }); // => 2030-07-14
date.dayOfWeek; // => 7
```
The `PlainMonthDay` API is almost identical to `PlainDateTime`, so see above for more API usage examples.
#### `PlainYearMonth`
A date without a day component. This is useful to express things like "the October 2020 meeting".
For detailed documentation see the
[TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plainyearmonth.html)
, this implementation follows the specification as closely as possible.
The `PlainYearMonth` API is almost identical to `PlainDateTime`, so see above for API usage examples.
#### `now`
The `now` object has several methods which give information about the current time and date.
```javascript
dateTime = now.plainDateTimeISO();
dateTime.toString(); // 2021-04-01T12:05:47.357
```
## Contributing
This project is open source, MIT licensed and your contributions are very much welcomed.
There is a [brief document that outlines implementation progress and priorities](./development.md).
# brace-expansion
[Brace expansion](https://www.gnu.org/software/bash/manual/html_node/Brace-Expansion.html),
as known from sh/bash, in JavaScript.
[](http://travis-ci.org/juliangruber/brace-expansion)
[](https://www.npmjs.org/package/brace-expansion)
[](https://greenkeeper.io/)
[](https://ci.testling.com/juliangruber/brace-expansion)
## Example
```js
var expand = require('brace-expansion');
expand('file-{a,b,c}.jpg')
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
expand('-v{,,}')
// => ['-v', '-v', '-v']
expand('file{0..2}.jpg')
// => ['file0.jpg', 'file1.jpg', 'file2.jpg']
expand('file-{a..c}.jpg')
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
expand('file{2..0}.jpg')
// => ['file2.jpg', 'file1.jpg', 'file0.jpg']
expand('file{0..4..2}.jpg')
// => ['file0.jpg', 'file2.jpg', 'file4.jpg']
expand('file-{a..e..2}.jpg')
// => ['file-a.jpg', 'file-c.jpg', 'file-e.jpg']
expand('file{00..10..5}.jpg')
// => ['file00.jpg', 'file05.jpg', 'file10.jpg']
expand('{{A..C},{a..c}}')
// => ['A', 'B', 'C', 'a', 'b', 'c']
expand('ppp{,config,oe{,conf}}')
// => ['ppp', 'pppconfig', 'pppoe', 'pppoeconf']
```
## API
```js
var expand = require('brace-expansion');
```
### var expanded = expand(str)
Return an array of all possible and valid expansions of `str`. If none are
found, `[str]` is returned.
Valid expansions are:
```js
/^(.*,)+(.+)?$/
// {a,b,...}
```
A comma separated list of options, like `{a,b}` or `{a,{b,c}}` or `{,a,}`.
```js
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
// {x..y[..incr]}
```
A numeric sequence from `x` to `y` inclusive, with optional increment.
If `x` or `y` start with a leading `0`, all the numbers will be padded
to have equal length. Negative numbers and backwards iteration work too.
```js
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
// {x..y[..incr]}
```
An alphabetic sequence from `x` to `y` inclusive, with optional increment.
`x` and `y` must be exactly one character, and if given, `incr` must be a
number.
For compatibility reasons, the string `${` is not eligible for brace expansion.
## Installation
With [npm](https://npmjs.org) do:
```bash
npm install brace-expansion
```
## Contributors
- [Julian Gruber](https://github.com/juliangruber)
- [Isaac Z. Schlueter](https://github.com/isaacs)
## Sponsors
This module is proudly supported by my [Sponsors](https://github.com/juliangruber/sponsors)!
Do you want to support modules like this to improve their quality, stability and weigh in on new features? Then please consider donating to my [Patreon](https://www.patreon.com/juliangruber). Not sure how much of my modules you're using? Try [feross/thanks](https://github.com/feross/thanks)!
## License
(MIT)
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# is-glob [](https://www.npmjs.com/package/is-glob) [](https://npmjs.org/package/is-glob) [](https://npmjs.org/package/is-glob) [](https://github.com/micromatch/is-glob/actions)
> Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a better user experience.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-glob
```
You might also be interested in [is-valid-glob](https://github.com/jonschlinkert/is-valid-glob) and [has-glob](https://github.com/jonschlinkert/has-glob).
## Usage
```js
var isGlob = require('is-glob');
```
### Default behavior
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js');
isGlob('*.js');
isGlob('**/abc.js');
isGlob('abc/*.js');
isGlob('abc/(aaa|bbb).js');
isGlob('abc/[a-z].js');
isGlob('abc/{a,b}.js');
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js');
isGlob('abc/!(a).js');
isGlob('abc/+(a).js');
isGlob('abc/*(a).js');
isGlob('abc/?(a).js');
//=> true
```
**False**
Escaped globs or extglobs return `false`:
```js
isGlob('abc/\\@(a).js');
isGlob('abc/\\!(a).js');
isGlob('abc/\\+(a).js');
isGlob('abc/\\*(a).js');
isGlob('abc/\\?(a).js');
isGlob('\\!foo.js');
isGlob('\\*.js');
isGlob('\\*\\*/abc.js');
isGlob('abc/\\*.js');
isGlob('abc/\\(aaa|bbb).js');
isGlob('abc/\\[a-z].js');
isGlob('abc/\\{a,b}.js');
//=> false
```
Patterns that do not have glob patterns return `false`:
```js
isGlob('abc.js');
isGlob('abc/def/ghi.js');
isGlob('foo.js');
isGlob('abc/@.js');
isGlob('abc/+.js');
isGlob('abc/?.js');
isGlob();
isGlob(null);
//=> false
```
Arrays are also `false` (If you want to check if an array has a glob pattern, use [has-glob](https://github.com/jonschlinkert/has-glob)):
```js
isGlob(['**/*.js']);
isGlob(['foo.js']);
//=> false
```
### Option strict
When `options.strict === false` the behavior is less strict in determining if a pattern is a glob. Meaning that
some patterns that would return `false` may return `true`. This is done so that matching libraries like [micromatch](https://github.com/micromatch/micromatch) have a chance at determining if the pattern is a glob or not.
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js', {strict: false});
isGlob('*.js', {strict: false});
isGlob('**/abc.js', {strict: false});
isGlob('abc/*.js', {strict: false});
isGlob('abc/(aaa|bbb).js', {strict: false});
isGlob('abc/[a-z].js', {strict: false});
isGlob('abc/{a,b}.js', {strict: false});
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js', {strict: false});
isGlob('abc/!(a).js', {strict: false});
isGlob('abc/+(a).js', {strict: false});
isGlob('abc/*(a).js', {strict: false});
isGlob('abc/?(a).js', {strict: false});
//=> true
```
**False**
Escaped globs or extglobs return `false`:
```js
isGlob('\\!foo.js', {strict: false});
isGlob('\\*.js', {strict: false});
isGlob('\\*\\*/abc.js', {strict: false});
isGlob('abc/\\*.js', {strict: false});
isGlob('abc/\\(aaa|bbb).js', {strict: false});
isGlob('abc/\\[a-z].js', {strict: false});
isGlob('abc/\\{a,b}.js', {strict: false});
//=> false
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [assemble](https://www.npmjs.com/package/assemble): Get the rocks out of your socks! Assemble makes you fast at creating web projects… [more](https://github.com/assemble/assemble) | [homepage](https://github.com/assemble/assemble "Get the rocks out of your socks! Assemble makes you fast at creating web projects. Assemble is used by thousands of projects for rapid prototyping, creating themes, scaffolds, boilerplates, e-books, UI components, API documentation, blogs, building websit")
* [base](https://www.npmjs.com/package/base): Framework for rapidly creating high quality, server-side node.js applications, using plugins like building blocks | [homepage](https://github.com/node-base/base "Framework for rapidly creating high quality, server-side node.js applications, using plugins like building blocks")
* [update](https://www.npmjs.com/package/update): Be scalable! Update is a new, open source developer framework and CLI for automating updates… [more](https://github.com/update/update) | [homepage](https://github.com/update/update "Be scalable! Update is a new, open source developer framework and CLI for automating updates of any kind in code projects.")
* [verb](https://www.npmjs.com/package/verb): Documentation generator for GitHub projects. Verb is extremely powerful, easy to use, and is used… [more](https://github.com/verbose/verb) | [homepage](https://github.com/verbose/verb "Documentation generator for GitHub projects. Verb is extremely powerful, easy to use, and is used on hundreds of projects of all sizes to generate everything from API docs to readmes.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 47 | [jonschlinkert](https://github.com/jonschlinkert) |
| 5 | [doowb](https://github.com/doowb) |
| 1 | [phated](https://github.com/phated) |
| 1 | [danhper](https://github.com/danhper) |
| 1 | [paulmillr](https://github.com/paulmillr) |
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
### License
Copyright © 2019, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on March 27, 2019._
# Glob
Match files using the patterns the shell uses, like stars and stuff.
[](https://travis-ci.org/isaacs/node-glob/) [](https://ci.appveyor.com/project/isaacs/node-glob) [](https://coveralls.io/github/isaacs/node-glob?branch=master)
This is a glob implementation in JavaScript. It uses the `minimatch`
library to do its matching.

## Usage
Install with npm
```
npm i glob
```
```javascript
var glob = require("glob")
// options is optional
glob("**/*.js", options, function (er, files) {
// files is an array of filenames.
// If the `nonull` option is set, and nothing
// was found, then files is ["**/*.js"]
// er is an error object or null.
})
```
## Glob Primer
"Globs" are the patterns you type when you do stuff like `ls *.js` on
the command line, or put `build/*` in a `.gitignore` file.
Before parsing the path part patterns, braced sections are expanded
into a set. Braced sections start with `{` and end with `}`, with any
number of comma-delimited sections within. Braced sections may contain
slash characters, so `a{/b/c,bcd}` would expand into `a/b/c` and `abcd`.
The following characters have special magic meaning when used in a
path portion:
* `*` Matches 0 or more characters in a single path portion
* `?` Matches 1 character
* `[...]` Matches a range of characters, similar to a RegExp range.
If the first character of the range is `!` or `^` then it matches
any character not in the range.
* `!(pattern|pattern|pattern)` Matches anything that does not match
any of the patterns provided.
* `?(pattern|pattern|pattern)` Matches zero or one occurrence of the
patterns provided.
* `+(pattern|pattern|pattern)` Matches one or more occurrences of the
patterns provided.
* `*(a|b|c)` Matches zero or more occurrences of the patterns provided
* `@(pattern|pat*|pat?erN)` Matches exactly one of the patterns
provided
* `**` If a "globstar" is alone in a path portion, then it matches
zero or more directories and subdirectories searching for matches.
It does not crawl symlinked directories.
### Dots
If a file or directory path portion has a `.` as the first character,
then it will not match any glob pattern unless that pattern's
corresponding path part also has a `.` as its first character.
For example, the pattern `a/.*/c` would match the file at `a/.b/c`.
However the pattern `a/*/c` would not, because `*` does not start with
a dot character.
You can make glob treat dots as normal characters by setting
`dot:true` in the options.
### Basename Matching
If you set `matchBase:true` in the options, and the pattern has no
slashes in it, then it will seek for any file anywhere in the tree
with a matching basename. For example, `*.js` would match
`test/simple/basic.js`.
### Empty Sets
If no matching files are found, then an empty array is returned. This
differs from the shell, where the pattern itself is returned. For
example:
$ echo a*s*d*f
a*s*d*f
To get the bash-style behavior, set the `nonull:true` in the options.
### See Also:
* `man sh`
* `man bash` (Search for "Pattern Matching")
* `man 3 fnmatch`
* `man 5 gitignore`
* [minimatch documentation](https://github.com/isaacs/minimatch)
## glob.hasMagic(pattern, [options])
Returns `true` if there are any special characters in the pattern, and
`false` otherwise.
Note that the options affect the results. If `noext:true` is set in
the options object, then `+(a|b)` will not be considered a magic
pattern. If the pattern has a brace expansion, like `a/{b/c,x/y}`
then that is considered magical, unless `nobrace:true` is set in the
options.
## glob(pattern, [options], cb)
* `pattern` `{String}` Pattern to be matched
* `options` `{Object}`
* `cb` `{Function}`
* `err` `{Error | null}`
* `matches` `{Array<String>}` filenames found matching the pattern
Perform an asynchronous glob search.
## glob.sync(pattern, [options])
* `pattern` `{String}` Pattern to be matched
* `options` `{Object}`
* return: `{Array<String>}` filenames found matching the pattern
Perform a synchronous glob search.
## Class: glob.Glob
Create a Glob object by instantiating the `glob.Glob` class.
```javascript
var Glob = require("glob").Glob
var mg = new Glob(pattern, options, cb)
```
It's an EventEmitter, and starts walking the filesystem to find matches
immediately.
### new glob.Glob(pattern, [options], [cb])
* `pattern` `{String}` pattern to search for
* `options` `{Object}`
* `cb` `{Function}` Called when an error occurs, or matches are found
* `err` `{Error | null}`
* `matches` `{Array<String>}` filenames found matching the pattern
Note that if the `sync` flag is set in the options, then matches will
be immediately available on the `g.found` member.
### Properties
* `minimatch` The minimatch object that the glob uses.
* `options` The options object passed in.
* `aborted` Boolean which is set to true when calling `abort()`. There
is no way at this time to continue a glob search after aborting, but
you can re-use the statCache to avoid having to duplicate syscalls.
* `cache` Convenience object. Each field has the following possible
values:
* `false` - Path does not exist
* `true` - Path exists
* `'FILE'` - Path exists, and is not a directory
* `'DIR'` - Path exists, and is a directory
* `[file, entries, ...]` - Path exists, is a directory, and the
array value is the results of `fs.readdir`
* `statCache` Cache of `fs.stat` results, to prevent statting the same
path multiple times.
* `symlinks` A record of which paths are symbolic links, which is
relevant in resolving `**` patterns.
* `realpathCache` An optional object which is passed to `fs.realpath`
to minimize unnecessary syscalls. It is stored on the instantiated
Glob object, and may be re-used.
### Events
* `end` When the matching is finished, this is emitted with all the
matches found. If the `nonull` option is set, and no match was found,
then the `matches` list contains the original pattern. The matches
are sorted, unless the `nosort` flag is set.
* `match` Every time a match is found, this is emitted with the specific
thing that matched. It is not deduplicated or resolved to a realpath.
* `error` Emitted when an unexpected error is encountered, or whenever
any fs error occurs if `options.strict` is set.
* `abort` When `abort()` is called, this event is raised.
### Methods
* `pause` Temporarily stop the search
* `resume` Resume the search
* `abort` Stop the search forever
### Options
All the options that can be passed to Minimatch can also be passed to
Glob to change pattern matching behavior. Also, some have been added,
or have glob-specific ramifications.
All options are false by default, unless otherwise noted.
All options are added to the Glob object, as well.
If you are running many `glob` operations, you can pass a Glob object
as the `options` argument to a subsequent operation to shortcut some
`stat` and `readdir` calls. At the very least, you may pass in shared
`symlinks`, `statCache`, `realpathCache`, and `cache` options, so that
parallel glob operations will be sped up by sharing information about
the filesystem.
* `cwd` The current working directory in which to search. Defaults
to `process.cwd()`.
* `root` The place where patterns starting with `/` will be mounted
onto. Defaults to `path.resolve(options.cwd, "/")` (`/` on Unix
systems, and `C:\` or some such on Windows.)
* `dot` Include `.dot` files in normal matches and `globstar` matches.
Note that an explicit dot in a portion of the pattern will always
match dot files.
* `nomount` By default, a pattern starting with a forward-slash will be
"mounted" onto the root setting, so that a valid filesystem path is
returned. Set this flag to disable that behavior.
* `mark` Add a `/` character to directory matches. Note that this
requires additional stat calls.
* `nosort` Don't sort the results.
* `stat` Set to true to stat *all* results. This reduces performance
somewhat, and is completely unnecessary, unless `readdir` is presumed
to be an untrustworthy indicator of file existence.
* `silent` When an unusual error is encountered when attempting to
read a directory, a warning will be printed to stderr. Set the
`silent` option to true to suppress these warnings.
* `strict` When an unusual error is encountered when attempting to
read a directory, the process will just continue on in search of
other matches. Set the `strict` option to raise an error in these
cases.
* `cache` See `cache` property above. Pass in a previously generated
cache object to save some fs calls.
* `statCache` A cache of results of filesystem information, to prevent
unnecessary stat calls. While it should not normally be necessary
to set this, you may pass the statCache from one glob() call to the
options object of another, if you know that the filesystem will not
change between calls. (See "Race Conditions" below.)
* `symlinks` A cache of known symbolic links. You may pass in a
previously generated `symlinks` object to save `lstat` calls when
resolving `**` matches.
* `sync` DEPRECATED: use `glob.sync(pattern, opts)` instead.
* `nounique` In some cases, brace-expanded patterns can result in the
same file showing up multiple times in the result set. By default,
this implementation prevents duplicates in the result set. Set this
flag to disable that behavior.
* `nonull` Set to never return an empty set, instead returning a set
containing the pattern itself. This is the default in glob(3).
* `debug` Set to enable debug logging in minimatch and glob.
* `nobrace` Do not expand `{a,b}` and `{1..3}` brace sets.
* `noglobstar` Do not match `**` against multiple filenames. (Ie,
treat it as a normal `*` instead.)
* `noext` Do not match `+(a|b)` "extglob" patterns.
* `nocase` Perform a case-insensitive match. Note: on
case-insensitive filesystems, non-magic patterns will match by
default, since `stat` and `readdir` will not raise errors.
* `matchBase` Perform a basename-only match if the pattern does not
contain any slash characters. That is, `*.js` would be treated as
equivalent to `**/*.js`, matching all js files in all directories.
* `nodir` Do not match directories, only files. (Note: to match
*only* directories, simply put a `/` at the end of the pattern.)
* `ignore` Add a pattern or an array of glob patterns to exclude matches.
Note: `ignore` patterns are *always* in `dot:true` mode, regardless
of any other settings.
* `follow` Follow symlinked directories when expanding `**` patterns.
Note that this can result in a lot of duplicate references in the
presence of cyclic links.
* `realpath` Set to true to call `fs.realpath` on all of the results.
In the case of a symlink that cannot be resolved, the full absolute
path to the matched entry is returned (though it will usually be a
broken symlink)
* `absolute` Set to true to always receive absolute paths for matched
files. Unlike `realpath`, this also affects the values returned in
the `match` event.
* `fs` File-system object with Node's `fs` API. By default, the built-in
`fs` module will be used. Set to a volume provided by a library like
`memfs` to avoid using the "real" file-system.
## Comparisons to other fnmatch/glob implementations
While strict compliance with the existing standards is a worthwhile
goal, some discrepancies exist between node-glob and other
implementations, and are intentional.
The double-star character `**` is supported by default, unless the
`noglobstar` flag is set. This is supported in the manner of bsdglob
and bash 4.3, where `**` only has special significance if it is the only
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
`a/**b` will not.
Note that symlinked directories are not crawled as part of a `**`,
though their contents may match against subsequent portions of the
pattern. This prevents infinite loops and duplicates and the like.
If an escaped pattern has no matches, and the `nonull` flag is set,
then glob returns the pattern as-provided, rather than
interpreting the character escapes. For example,
`glob.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
that it does not resolve escaped pattern characters.
If brace expansion is not disabled, then it is performed before any
other interpretation of the glob pattern. Thus, a pattern like
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
checked for validity. Since those two are valid, matching proceeds.
### Comments and Negation
Previously, this module let you mark a pattern as a "comment" if it
started with a `#` character, or a "negated" pattern if it started
with a `!` character.
These options were deprecated in version 5, and removed in version 6.
To specify things that should not match, use the `ignore` option.
## Windows
**Please only use forward-slashes in glob expressions.**
Though windows uses either `/` or `\` as its path separator, only `/`
characters are used by this glob implementation. You must use
forward-slashes **only** in glob expressions. Back-slashes will always
be interpreted as escape characters, not path separators.
Results from absolute patterns such as `/foo/*` are mounted onto the
root setting using `path.join`. On windows, this will by default result
in `/foo/*` matching `C:\foo\bar.txt`.
## Race Conditions
Glob searching, by its very nature, is susceptible to race conditions,
since it relies on directory walking and such.
As a result, it is possible that a file that exists when glob looks for
it may have been deleted or modified by the time it returns the result.
As part of its internal implementation, this program caches all stat
and readdir calls that it makes, in order to cut down on system
overhead. However, this also makes it even more susceptible to races,
especially if the cache or statCache objects are reused between glob
calls.
Users are thus advised not to use a glob result as a guarantee of
filesystem state in the face of rapid changes. For the vast majority
of operations, this is never a problem.
## Glob Logo
Glob's logo was created by [Tanya Brassie](http://tanyabrassie.com/). Logo files can be found [here](https://github.com/isaacs/node-glob/tree/master/logo).
The logo is licensed under a [Creative Commons Attribution-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-sa/4.0/).
## Contributing
Any change to behavior (including bugfixes) must come with a test.
Patches that fail tests or reduce performance will be rejected.
```
# to run tests
npm test
# to re-generate test fixtures
npm run test-regen
# to benchmark against bash/zsh
npm run bench
# to profile javascript
npm run prof
```

Like `chown -R`.
Takes the same arguments as `fs.chown()`
ESQuery is a library for querying the AST output by Esprima for patterns of syntax using a CSS style selector system. Check out the demo:
[demo](https://estools.github.io/esquery/)
The following selectors are supported:
* AST node type: `ForStatement`
* [wildcard](http://dev.w3.org/csswg/selectors4/#universal-selector): `*`
* [attribute existence](http://dev.w3.org/csswg/selectors4/#attribute-selectors): `[attr]`
* [attribute value](http://dev.w3.org/csswg/selectors4/#attribute-selectors): `[attr="foo"]` or `[attr=123]`
* attribute regex: `[attr=/foo.*/]` or (with flags) `[attr=/foo.*/is]`
* attribute conditions: `[attr!="foo"]`, `[attr>2]`, `[attr<3]`, `[attr>=2]`, or `[attr<=3]`
* nested attribute: `[attr.level2="foo"]`
* field: `FunctionDeclaration > Identifier.id`
* [First](http://dev.w3.org/csswg/selectors4/#the-first-child-pseudo) or [last](http://dev.w3.org/csswg/selectors4/#the-last-child-pseudo) child: `:first-child` or `:last-child`
* [nth-child](http://dev.w3.org/csswg/selectors4/#the-nth-child-pseudo) (no ax+b support): `:nth-child(2)`
* [nth-last-child](http://dev.w3.org/csswg/selectors4/#the-nth-last-child-pseudo) (no ax+b support): `:nth-last-child(1)`
* [descendant](http://dev.w3.org/csswg/selectors4/#descendant-combinators): `ancestor descendant`
* [child](http://dev.w3.org/csswg/selectors4/#child-combinators): `parent > child`
* [following sibling](http://dev.w3.org/csswg/selectors4/#general-sibling-combinators): `node ~ sibling`
* [adjacent sibling](http://dev.w3.org/csswg/selectors4/#adjacent-sibling-combinators): `node + adjacent`
* [negation](http://dev.w3.org/csswg/selectors4/#negation-pseudo): `:not(ForStatement)`
* [has](https://drafts.csswg.org/selectors-4/#has-pseudo): `:has(ForStatement)`
* [matches-any](http://dev.w3.org/csswg/selectors4/#matches): `:matches([attr] > :first-child, :last-child)`
* [subject indicator](http://dev.w3.org/csswg/selectors4/#subject): `!IfStatement > [name="foo"]`
* class of AST node: `:statement`, `:expression`, `:declaration`, `:function`, or `:pattern`
[](https://travis-ci.org/estools/esquery)
# y18n
[![Build Status][travis-image]][travis-url]
[![Coverage Status][coveralls-image]][coveralls-url]
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[](https://conventionalcommits.org)
The bare-bones internationalization library used by yargs.
Inspired by [i18n](https://www.npmjs.com/package/i18n).
## Examples
_simple string translation:_
```js
var __ = require('y18n').__
console.log(__('my awesome string %s', 'foo'))
```
output:
`my awesome string foo`
_using tagged template literals_
```js
var __ = require('y18n').__
var str = 'foo'
console.log(__`my awesome string ${str}`)
```
output:
`my awesome string foo`
_pluralization support:_
```js
var __n = require('y18n').__n
console.log(__n('one fish %s', '%d fishes %s', 2, 'foo'))
```
output:
`2 fishes foo`
## JSON Language Files
The JSON language files should be stored in a `./locales` folder.
File names correspond to locales, e.g., `en.json`, `pirate.json`.
When strings are observed for the first time they will be
added to the JSON file corresponding to the current locale.
## Methods
### require('y18n')(config)
Create an instance of y18n with the config provided, options include:
* `directory`: the locale directory, default `./locales`.
* `updateFiles`: should newly observed strings be updated in file, default `true`.
* `locale`: what locale should be used.
* `fallbackToLanguage`: should fallback to a language-only file (e.g. `en.json`)
be allowed if a file matching the locale does not exist (e.g. `en_US.json`),
default `true`.
### y18n.\_\_(str, arg, arg, arg)
Print a localized string, `%s` will be replaced with `arg`s.
This function can also be used as a tag for a template literal. You can use it
like this: <code>__`hello ${'world'}`</code>. This will be equivalent to
`__('hello %s', 'world')`.
### y18n.\_\_n(singularString, pluralString, count, arg, arg, arg)
Print a localized string with appropriate pluralization. If `%d` is provided
in the string, the `count` will replace this placeholder.
### y18n.setLocale(str)
Set the current locale being used.
### y18n.getLocale()
What locale is currently being used?
### y18n.updateLocale(obj)
Update the current locale with the key value pairs in `obj`.
## License
ISC
[travis-url]: https://travis-ci.org/yargs/y18n
[travis-image]: https://img.shields.io/travis/yargs/y18n.svg
[coveralls-url]: https://coveralls.io/github/yargs/y18n
[coveralls-image]: https://img.shields.io/coveralls/yargs/y18n.svg
[npm-url]: https://npmjs.org/package/y18n
[npm-image]: https://img.shields.io/npm/v/y18n.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: https://github.com/feross/standard
# yargs-parser

[](https://www.npmjs.com/package/yargs-parser)
[](https://conventionalcommits.org)

The mighty option parser used by [yargs](https://github.com/yargs/yargs).
visit the [yargs website](http://yargs.js.org/) for more examples, and thorough usage instructions.
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs-parser/main/yargs-logo.png">
## Example
```sh
npm i yargs-parser --save
```
```js
const argv = require('yargs-parser')(process.argv.slice(2))
console.log(argv)
```
```console
$ node example.js --foo=33 --bar hello
{ _: [], foo: 33, bar: 'hello' }
```
_or parse a string!_
```js
const argv = require('yargs-parser')('--foo=99 --bar=33')
console.log(argv)
```
```console
{ _: [], foo: 99, bar: 33 }
```
Convert an array of mixed types before passing to `yargs-parser`:
```js
const parse = require('yargs-parser')
parse(['-f', 11, '--zoom', 55].join(' ')) // <-- array to string
parse(['-f', 11, '--zoom', 55].map(String)) // <-- array of strings
```
## Deno Example
As of `v19` `yargs-parser` supports [Deno](https://github.com/denoland/deno):
```typescript
import parser from "https://deno.land/x/yargs_parser/deno.ts";
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
```
## ESM Example
As of `v19` `yargs-parser` supports ESM (_both in Node.js and in the browser_):
**Node.js:**
```js
import parser from 'yargs-parser'
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
```
**Browsers:**
```html
<!doctype html>
<body>
<script type="module">
import parser from "https://unpkg.com/yargs-parser@19.0.0/browser.js";
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
</script>
</body>
```
## API
### parser(args, opts={})
Parses command line arguments returning a simple mapping of keys and values.
**expects:**
* `args`: a string or array of strings representing the options to parse.
* `opts`: provide a set of hints indicating how `args` should be parsed:
* `opts.alias`: an object representing the set of aliases for a key: `{alias: {foo: ['f']}}`.
* `opts.array`: indicate that keys should be parsed as an array: `{array: ['foo', 'bar']}`.<br>
Indicate that keys should be parsed as an array and coerced to booleans / numbers:<br>
`{array: [{ key: 'foo', boolean: true }, {key: 'bar', number: true}]}`.
* `opts.boolean`: arguments should be parsed as booleans: `{boolean: ['x', 'y']}`.
* `opts.coerce`: provide a custom synchronous function that returns a coerced value from the argument provided
(or throws an error). For arrays the function is called only once for the entire array:<br>
`{coerce: {foo: function (arg) {return modifiedArg}}}`.
* `opts.config`: indicate a key that represents a path to a configuration file (this file will be loaded and parsed).
* `opts.configObjects`: configuration objects to parse, their properties will be set as arguments:<br>
`{configObjects: [{'x': 5, 'y': 33}, {'z': 44}]}`.
* `opts.configuration`: provide configuration options to the yargs-parser (see: [configuration](#configuration)).
* `opts.count`: indicate a key that should be used as a counter, e.g., `-vvv` = `{v: 3}`.
* `opts.default`: provide default values for keys: `{default: {x: 33, y: 'hello world!'}}`.
* `opts.envPrefix`: environment variables (`process.env`) with the prefix provided should be parsed.
* `opts.narg`: specify that a key requires `n` arguments: `{narg: {x: 2}}`.
* `opts.normalize`: `path.normalize()` will be applied to values set to this key.
* `opts.number`: keys should be treated as numbers.
* `opts.string`: keys should be treated as strings (even if they resemble a number `-x 33`).
**returns:**
* `obj`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
### require('yargs-parser').detailed(args, opts={})
Parses a command line string, returning detailed information required by the
yargs engine.
**expects:**
* `args`: a string or array of strings representing options to parse.
* `opts`: provide a set of hints indicating how `args`, inputs are identical to `require('yargs-parser')(args, opts={})`.
**returns:**
* `argv`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
* `error`: populated with an error object if an exception occurred during parsing.
* `aliases`: the inferred list of aliases built by combining lists in `opts.alias`.
* `newAliases`: any new aliases added via camel-case expansion:
* `boolean`: `{ fooBar: true }`
* `defaulted`: any new argument created by `opts.default`, no aliases included.
* `boolean`: `{ foo: true }`
* `configuration`: given by default settings and `opts.configuration`.
<a name="configuration"></a>
### Configuration
The yargs-parser applies several automated transformations on the keys provided
in `args`. These features can be turned on and off using the `configuration` field
of `opts`.
```js
var parsed = parser(['--no-dice'], {
configuration: {
'boolean-negation': false
}
})
```
### short option groups
* default: `true`.
* key: `short-option-groups`.
Should a group of short-options be treated as boolean flags?
```console
$ node example.js -abc
{ _: [], a: true, b: true, c: true }
```
_if disabled:_
```console
$ node example.js -abc
{ _: [], abc: true }
```
### camel-case expansion
* default: `true`.
* key: `camel-case-expansion`.
Should hyphenated arguments be expanded into camel-case aliases?
```console
$ node example.js --foo-bar
{ _: [], 'foo-bar': true, fooBar: true }
```
_if disabled:_
```console
$ node example.js --foo-bar
{ _: [], 'foo-bar': true }
```
### dot-notation
* default: `true`
* key: `dot-notation`
Should keys that contain `.` be treated as objects?
```console
$ node example.js --foo.bar
{ _: [], foo: { bar: true } }
```
_if disabled:_
```console
$ node example.js --foo.bar
{ _: [], "foo.bar": true }
```
### parse numbers
* default: `true`
* key: `parse-numbers`
Should keys that look like numbers be treated as such?
```console
$ node example.js --foo=99.3
{ _: [], foo: 99.3 }
```
_if disabled:_
```console
$ node example.js --foo=99.3
{ _: [], foo: "99.3" }
```
### parse positional numbers
* default: `true`
* key: `parse-positional-numbers`
Should positional keys that look like numbers be treated as such.
```console
$ node example.js 99.3
{ _: [99.3] }
```
_if disabled:_
```console
$ node example.js 99.3
{ _: ['99.3'] }
```
### boolean negation
* default: `true`
* key: `boolean-negation`
Should variables prefixed with `--no` be treated as negations?
```console
$ node example.js --no-foo
{ _: [], foo: false }
```
_if disabled:_
```console
$ node example.js --no-foo
{ _: [], "no-foo": true }
```
### combine arrays
* default: `false`
* key: `combine-arrays`
Should arrays be combined when provided by both command line arguments and
a configuration file.
### duplicate arguments array
* default: `true`
* key: `duplicate-arguments-array`
Should arguments be coerced into an array when duplicated:
```console
$ node example.js -x 1 -x 2
{ _: [], x: [1, 2] }
```
_if disabled:_
```console
$ node example.js -x 1 -x 2
{ _: [], x: 2 }
```
### flatten duplicate arrays
* default: `true`
* key: `flatten-duplicate-arrays`
Should array arguments be coerced into a single array when duplicated:
```console
$ node example.js -x 1 2 -x 3 4
{ _: [], x: [1, 2, 3, 4] }
```
_if disabled:_
```console
$ node example.js -x 1 2 -x 3 4
{ _: [], x: [[1, 2], [3, 4]] }
```
### greedy arrays
* default: `true`
* key: `greedy-arrays`
Should arrays consume more than one positional argument following their flag.
```console
$ node example --arr 1 2
{ _: [], arr: [1, 2] }
```
_if disabled:_
```console
$ node example --arr 1 2
{ _: [2], arr: [1] }
```
**Note: in `v18.0.0` we are considering defaulting greedy arrays to `false`.**
### nargs eats options
* default: `false`
* key: `nargs-eats-options`
Should nargs consume dash options as well as positional arguments.
### negation prefix
* default: `no-`
* key: `negation-prefix`
The prefix to use for negated boolean variables.
```console
$ node example.js --no-foo
{ _: [], foo: false }
```
_if set to `quux`:_
```console
$ node example.js --quuxfoo
{ _: [], foo: false }
```
### populate --
* default: `false`.
* key: `populate--`
Should unparsed flags be stored in `--` or `_`.
_If disabled:_
```console
$ node example.js a -b -- x y
{ _: [ 'a', 'x', 'y' ], b: true }
```
_If enabled:_
```console
$ node example.js a -b -- x y
{ _: [ 'a' ], '--': [ 'x', 'y' ], b: true }
```
### set placeholder key
* default: `false`.
* key: `set-placeholder-key`.
Should a placeholder be added for keys not set via the corresponding CLI argument?
_If disabled:_
```console
$ node example.js -a 1 -c 2
{ _: [], a: 1, c: 2 }
```
_If enabled:_
```console
$ node example.js -a 1 -c 2
{ _: [], a: 1, b: undefined, c: 2 }
```
### halt at non-option
* default: `false`.
* key: `halt-at-non-option`.
Should parsing stop at the first positional argument? This is similar to how e.g. `ssh` parses its command line.
_If disabled:_
```console
$ node example.js -a run b -x y
{ _: [ 'b' ], a: 'run', x: 'y' }
```
_If enabled:_
```console
$ node example.js -a run b -x y
{ _: [ 'b', '-x', 'y' ], a: 'run' }
```
### strip aliased
* default: `false`
* key: `strip-aliased`
Should aliases be removed before returning results?
_If disabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1, 'test-alias': 1, testAlias: 1 }
```
_If enabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
### strip dashed
* default: `false`
* key: `strip-dashed`
Should dashed keys be removed before returning results? This option has no effect if
`camel-case-expansion` is disabled.
_If disabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
_If enabled:_
```console
$ node example.js --test-field 1
{ _: [], testField: 1 }
```
### unknown options as args
* default: `false`
* key: `unknown-options-as-args`
Should unknown options be treated like regular arguments? An unknown option is one that is not
configured in `opts`.
_If disabled_
```console
$ node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: [], unknownOption: true, knownOption: 2, stringOption: '', unknownOption2: true }
```
_If enabled_
```console
$ node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: ['--unknown-option'], knownOption: 2, stringOption: '--unknown-option2' }
```
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
## Special Thanks
The yargs project evolves from optimist and minimist. It owes its
existence to a lot of James Halliday's hard work. Thanks [substack](https://github.com/substack) **beep** **boop** \o/
## License
ISC
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
* `n` - the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
* `rn` - both argument and return value of the function are plain JavaScript
Numbers. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
* `BN.max(a, b)` - return `a` if `a` bigger than `b`
* `BN.min(a, b)` - return `a` if `a` less than `b`
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divmod(b)` - quotient and modulus obtained by dividing
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b, value)` - set specified bit to `value`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
### Number Size
Optimized for elliptic curves that work with 256-bit numbers.
There is no limitation on the size of the numbers.
## LICENSE
This software is licensed under the MIT License.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# near-sdk-core
This package contain a convenient interface for interacting with NEAR's host runtime. To see the functions that are provided by the host node see [`env.ts`](./assembly/env/env.ts).
### Esrecurse [](https://travis-ci.org/estools/esrecurse)
Esrecurse ([esrecurse](https://github.com/estools/esrecurse)) is
[ECMAScript](https://www.ecma-international.org/publications/standards/Ecma-262.htm)
recursive traversing functionality.
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
esrecurse.visit(ast, {
XXXStatement: function (node) {
this.visit(node.left);
// do something...
this.visit(node.right);
}
});
```
We can use `Visitor` instance.
```javascript
var visitor = new esrecurse.Visitor({
XXXStatement: function (node) {
this.visit(node.left);
// do something...
this.visit(node.right);
}
});
visitor.visit(ast);
```
We can inherit `Visitor` instance easily.
```javascript
class Derived extends esrecurse.Visitor {
constructor()
{
super(null);
}
XXXStatement(node) {
}
}
```
```javascript
function DerivedVisitor() {
esrecurse.Visitor.call(/* this for constructor */ this /* visitor object automatically becomes this. */);
}
util.inherits(DerivedVisitor, esrecurse.Visitor);
DerivedVisitor.prototype.XXXStatement = function (node) {
this.visit(node.left);
// do something...
this.visit(node.right);
};
```
And you can invoke default visiting operation inside custom visit operation.
```javascript
function DerivedVisitor() {
esrecurse.Visitor.call(/* this for constructor */ this /* visitor object automatically becomes this. */);
}
util.inherits(DerivedVisitor, esrecurse.Visitor);
DerivedVisitor.prototype.XXXStatement = function (node) {
// do something...
this.visitChildren(node);
};
```
The `childVisitorKeys` option does customize the behaviour of `this.visitChildren(node)`.
We can use user-defined node types.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
esrecurse.visit(
ast,
{
Literal: function (node) {
// do something...
}
},
{
// Extending the existing traversing rules.
childVisitorKeys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
}
);
```
We can use the `fallback` option as well.
If the `fallback` option is `"iteration"`, `esrecurse` would visit all enumerable properties of unknown nodes.
Please note circular references cause the stack overflow. AST might have circular references in additional properties for some purpose (e.g. `node.parent`).
```javascript
esrecurse.visit(
ast,
{
Literal: function (node) {
// do something...
}
},
{
fallback: 'iteration'
}
);
```
If the `fallback` option is a function, `esrecurse` calls this function to determine the enumerable properties of unknown nodes.
Please note circular references cause the stack overflow. AST might have circular references in additional properties for some purpose (e.g. `node.parent`).
```javascript
esrecurse.visit(
ast,
{
Literal: function (node) {
// do something...
}
},
{
fallback: function (node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument'
});
}
}
);
```
### License
Copyright (C) 2014 [Yusuke Suzuki](https://github.com/Constellation)
(twitter: [@Constellation](https://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# once
Only call a function once.
## usage
```javascript
var once = require('once')
function load (file, cb) {
cb = once(cb)
loader.load('file')
loader.once('load', cb)
loader.once('error', cb)
}
```
Or add to the Function.prototype in a responsible way:
```javascript
// only has to be done once
require('once').proto()
function load (file, cb) {
cb = cb.once()
loader.load('file')
loader.once('load', cb)
loader.once('error', cb)
}
```
Ironically, the prototype feature makes this module twice as
complicated as necessary.
To check whether you function has been called, use `fn.called`. Once the
function is called for the first time the return value of the original
function is saved in `fn.value` and subsequent calls will continue to
return this value.
```javascript
var once = require('once')
function load (cb) {
cb = once(cb)
var stream = createStream()
stream.once('data', cb)
stream.once('end', function () {
if (!cb.called) cb(new Error('not found'))
})
}
```
## `once.strict(func)`
Throw an error if the function is called twice.
Some functions are expected to be called only once. Using `once` for them would
potentially hide logical errors.
In the example below, the `greet` function has to call the callback only once:
```javascript
function greet (name, cb) {
// return is missing from the if statement
// when no name is passed, the callback is called twice
if (!name) cb('Hello anonymous')
cb('Hello ' + name)
}
function log (msg) {
console.log(msg)
}
// this will print 'Hello anonymous' but the logical error will be missed
greet(null, once(msg))
// once.strict will print 'Hello anonymous' and throw an error when the callback will be called the second time
greet(null, once.strict(msg))
```
### Estraverse [](http://travis-ci.org/estools/estraverse)
Estraverse ([estraverse](http://github.com/estools/estraverse)) is
[ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
traversal functions from [esmangle project](http://github.com/estools/esmangle).
### Documentation
You can find usage docs at [wiki page](https://github.com/estools/estraverse/wiki/Usage).
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
estraverse.traverse(ast, {
enter: function (node, parent) {
if (node.type == 'FunctionExpression' || node.type == 'FunctionDeclaration')
return estraverse.VisitorOption.Skip;
},
leave: function (node, parent) {
if (node.type == 'VariableDeclarator')
console.log(node.id.name);
}
});
```
We can use `this.skip`, `this.remove` and `this.break` functions instead of using Skip, Remove and Break.
```javascript
estraverse.traverse(ast, {
enter: function (node) {
this.break();
}
});
```
And estraverse provides `estraverse.replace` function. When returning node from `enter`/`leave`, current node is replaced with it.
```javascript
result = estraverse.replace(tree, {
enter: function (node) {
// Replace it with replaced.
if (node.type === 'Literal')
return replaced;
}
});
```
By passing `visitor.keys` mapping, we can extend estraverse traversing functionality.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Extending the existing traversing rules.
keys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
});
```
By passing `visitor.fallback` option, we can control the behavior when encountering unknown nodes.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Iterating the child **nodes** of unknown nodes.
fallback: 'iteration'
});
```
When `visitor.fallback` is a function, we can determine which keys to visit on each node.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Skip the `argument` property of each node
fallback: function(node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument';
});
}
});
```
### License
Copyright (C) 2012-2016 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# ts-mixer
[version-badge]: https://badgen.net/npm/v/ts-mixer
[version-link]: https://npmjs.com/package/ts-mixer
[build-badge]: https://img.shields.io/github/workflow/status/tannerntannern/ts-mixer/ts-mixer%20CI
[build-link]: https://github.com/tannerntannern/ts-mixer/actions
[ts-versions]: https://badgen.net/badge/icon/3.8,3.9,4.0,4.1,4.2?icon=typescript&label&list=|
[node-versions]: https://badgen.net/badge/node/10%2C12%2C14/blue/?list=|
[![npm version][version-badge]][version-link]
[![github actions][build-badge]][build-link]
[![TS Versions][ts-versions]][build-link]
[![Node.js Versions][node-versions]][build-link]
[](https://bundlephobia.com/result?p=ts-mixer)
[](https://conventionalcommits.org)
## Overview
`ts-mixer` brings mixins to TypeScript. "Mixins" to `ts-mixer` are just classes, so you already know how to write them, and you can probably mix classes from your favorite library without trouble.
The mixin problem is more nuanced than it appears. I've seen countless code snippets that work for certain situations, but fail in others. `ts-mixer` tries to take the best from all these solutions while accounting for the situations you might not have considered.
[Quick start guide](#quick-start)
### Features
* mixes plain classes
* mixes classes that extend other classes
* mixes classes that were mixed with `ts-mixer`
* supports static properties
* supports protected/private properties (the popular function-that-returns-a-class solution does not)
* mixes abstract classes (with caveats [[1](#caveats)])
* mixes generic classes (with caveats [[2](#caveats)])
* supports class, method, and property decorators (with caveats [[3, 6](#caveats)])
* mostly supports the complexity presented by constructor functions (with caveats [[4](#caveats)])
* comes with an `instanceof`-like replacement (with caveats [[5, 6](#caveats)])
* [multiple mixing strategies](#settings) (ES6 proxies vs hard copy)
### Caveats
1. Mixing abstract classes requires a bit of a hack that may break in future versions of TypeScript. See [mixing abstract classes](#mixing-abstract-classes) below.
2. Mixing generic classes requires a more cumbersome notation, but it's still possible. See [mixing generic classes](#mixing-generic-classes) below.
3. Using decorators in mixed classes also requires a more cumbersome notation. See [mixing with decorators](#mixing-with-decorators) below.
4. ES6 made it impossible to use `.apply(...)` on class constructors (or any means of calling them without `new`), which makes it impossible for `ts-mixer` to pass the proper `this` to your constructors. This may or may not be an issue for your code, but there are options to work around it. See [dealing with constructors](#dealing-with-constructors) below.
5. `ts-mixer` does not support `instanceof` for mixins, but it does offer a replacement. See the [hasMixin function](#hasmixin) for more details.
6. Certain features (specifically, `@decorator` and `hasMixin`) make use of ES6 `Map`s, which means you must either use ES6+ or polyfill `Map` to use them. If you don't need these features, you should be fine without.
## Quick Start
### Installation
```
$ npm install ts-mixer
```
or if you prefer [Yarn](https://yarnpkg.com):
```
$ yarn add ts-mixer
```
### Basic Example
```typescript
import { Mixin } from 'ts-mixer';
class Foo {
protected makeFoo() {
return 'foo';
}
}
class Bar {
protected makeBar() {
return 'bar';
}
}
class FooBar extends Mixin(Foo, Bar) {
public makeFooBar() {
return this.makeFoo() + this.makeBar();
}
}
const fooBar = new FooBar();
console.log(fooBar.makeFooBar()); // "foobar"
```
## Special Cases
### Mixing Abstract Classes
Abstract classes, by definition, cannot be constructed, which means they cannot take on the type, `new(...args) => any`, and by extension, are incompatible with `ts-mixer`. BUT, you can "trick" TypeScript into giving you all the benefits of an abstract class without making it technically abstract. The trick is just some strategic `// @ts-ignore`'s:
```typescript
import { Mixin } from 'ts-mixer';
// note that Foo is not marked as an abstract class
class Foo {
// @ts-ignore: "Abstract methods can only appear within an abstract class"
public abstract makeFoo(): string;
}
class Bar {
public makeBar() {
return 'bar';
}
}
class FooBar extends Mixin(Foo, Bar) {
// we still get all the benefits of abstract classes here, because TypeScript
// will still complain if this method isn't implemented
public makeFoo() {
return 'foo';
}
}
```
Do note that while this does work quite well, it is a bit of a hack and I can't promise that it will continue to work in future TypeScript versions.
### Mixing Generic Classes
Frustratingly, it is _impossible_ for generic parameters to be referenced in base class expressions. No matter what, you will eventually run into `Base class expressions cannot reference class type parameters.`
The way to get around this is to leverage [declaration merging](https://www.typescriptlang.org/docs/handbook/declaration-merging.html), and a slightly different mixing function from ts-mixer: `mix`. It works exactly like `Mixin`, except it's a decorator, which means it doesn't affect the type information of the class being decorated. See it in action below:
```typescript
import { mix } from 'ts-mixer';
class Foo<T> {
public fooMethod(input: T): T {
return input;
}
}
class Bar<T> {
public barMethod(input: T): T {
return input;
}
}
interface FooBar<T1, T2> extends Foo<T1>, Bar<T2> { }
@mix(Foo, Bar)
class FooBar<T1, T2> {
public fooBarMethod(input1: T1, input2: T2) {
return [this.fooMethod(input1), this.barMethod(input2)];
}
}
```
Key takeaways from this example:
* `interface FooBar<T1, T2> extends Foo<T1>, Bar<T2> { }` makes sure `FooBar` has the typing we want, thanks to declaration merging
* `@mix(Foo, Bar)` wires things up "on the JavaScript side", since the interface declaration has nothing to do with runtime behavior.
* The reason we have to use the `mix` decorator is that the typing produced by `Mixin(Foo, Bar)` would conflict with the typing of the interface. `mix` has no effect "on the TypeScript side," thus avoiding type conflicts.
### Mixing with Decorators
Popular libraries such as [class-validator](https://github.com/typestack/class-validator) and [TypeORM](https://github.com/typeorm/typeorm) use decorators to add functionality. Unfortunately, `ts-mixer` has no way of knowing what these libraries do with the decorators behind the scenes. So if you want these decorators to be "inherited" with classes you plan to mix, you first have to wrap them with a special `decorate` function exported by `ts-mixer`. Here's an example using `class-validator`:
```typescript
import { IsBoolean, IsIn, validate } from 'class-validator';
import { Mixin, decorate } from 'ts-mixer';
class Disposable {
@decorate(IsBoolean()) // instead of @IsBoolean()
isDisposed: boolean = false;
}
class Statusable {
@decorate(IsIn(['red', 'green'])) // instead of @IsIn(['red', 'green'])
status: string = 'green';
}
class ExtendedObject extends Mixin(Disposable, Statusable) {}
const extendedObject = new ExtendedObject();
extendedObject.status = 'blue';
validate(extendedObject).then(errors => {
console.log(errors);
});
```
### Dealing with Constructors
As mentioned in the [caveats section](#caveats), ES6 disallowed calling constructor functions without `new`. This means that the only way for `ts-mixer` to mix instance properties is to instantiate each base class separately, then copy the instance properties into a common object. The consequence of this is that constructors mixed by `ts-mixer` will _not_ receive the proper `this`.
**This very well may not be an issue for you!** It only means that your constructors need to be "mostly pure" in terms of how they handle `this`. Specifically, your constructors cannot produce [side effects](https://en.wikipedia.org/wiki/Side_effect_%28computer_science%29) involving `this`, _other than adding properties to `this`_ (the most common side effect in JavaScript constructors).
If you simply cannot eliminate `this` side effects from your constructor, there is a workaround available: `ts-mixer` will automatically forward constructor parameters to a predesignated init function (`settings.initFunction`) if it's present on the class. Unlike constructors, functions can be called with an arbitrary `this`, so this predesignated init function _will_ have the proper `this`. Here's a basic example:
```typescript
import { Mixin, settings } from 'ts-mixer';
settings.initFunction = 'init';
class Person {
public static allPeople: Set<Person> = new Set();
protected init() {
Person.allPeople.add(this);
}
}
type PartyAffiliation = 'democrat' | 'republican';
class PoliticalParticipant {
public static democrats: Set<PoliticalParticipant> = new Set();
public static republicans: Set<PoliticalParticipant> = new Set();
public party: PartyAffiliation;
// note that these same args will also be passed to init function
public constructor(party: PartyAffiliation) {
this.party = party;
}
protected init(party: PartyAffiliation) {
if (party === 'democrat')
PoliticalParticipant.democrats.add(this);
else
PoliticalParticipant.republicans.add(this);
}
}
class Voter extends Mixin(Person, PoliticalParticipant) {}
const v1 = new Voter('democrat');
const v2 = new Voter('democrat');
const v3 = new Voter('republican');
const v4 = new Voter('republican');
```
Note the above `.add(this)` statements. These would not work as expected if they were placed in the constructor instead, since `this` is not the same between the constructor and `init`, as explained above.
## Other Features
### hasMixin
As mentioned above, `ts-mixer` does not support `instanceof` for mixins. While it is possible to implement [custom `instanceof` behavior](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/hasInstance), this library does not do so because it would require modifying the source classes, which is deliberately avoided.
You can fill this missing functionality with `hasMixin(instance, mixinClass)` instead. See the below example:
```typescript
import { Mixin, hasMixin } from 'ts-mixer';
class Foo {}
class Bar {}
class FooBar extends Mixin(Foo, Bar) {}
const instance = new FooBar();
// doesn't work with instanceof...
console.log(instance instanceof FooBar) // true
console.log(instance instanceof Foo) // false
console.log(instance instanceof Bar) // false
// but everything works nicely with hasMixin!
console.log(hasMixin(instance, FooBar)) // true
console.log(hasMixin(instance, Foo)) // true
console.log(hasMixin(instance, Bar)) // true
```
`hasMixin(instance, mixinClass)` will work anywhere that `instance instanceof mixinClass` works. Additionally, like `instanceof`, you get the same [type narrowing benefits](https://www.typescriptlang.org/docs/handbook/advanced-types.html#instanceof-type-guards):
```typescript
if (hasMixin(instance, Foo)) {
// inferred type of instance is "Foo"
}
if (hasMixin(instance, Bar)) {
// inferred type of instance of "Bar"
}
```
## Settings
ts-mixer has multiple strategies for mixing classes which can be configured by modifying `settings` from ts-mixer. For example:
```typescript
import { settings, Mixin } from 'ts-mixer';
settings.prototypeStrategy = 'proxy';
// then use `Mixin` as normal...
```
### `settings.prototypeStrategy`
* Determines how ts-mixer will mix class prototypes together
* Possible values:
- `'copy'` (default) - Copies all methods from the classes being mixed into a new prototype object. (This will include all methods up the prototype chains as well.) This is the default for ES5 compatibility, but it has the downside of stale references. For example, if you mix `Foo` and `Bar` to make `FooBar`, then redefine a method on `Foo`, `FooBar` will not have the latest methods from `Foo`. If this is not a concern for you, `'copy'` is the best value for this setting.
- `'proxy'` - Uses an ES6 Proxy to "soft mix" prototypes. Unlike `'copy'`, updates to the base classes _will_ be reflected in the mixed class, which may be desirable. The downside is that method access is not as performant, nor is it ES5 compatible.
### `settings.staticsStrategy`
* Determines how static properties are inherited
* Possible values:
- `'copy'` (default) - Simply copies all properties (minus `prototype`) from the base classes/constructor functions onto the mixed class. Like `settings.prototypeStrategy = 'copy'`, this strategy also suffers from stale references, but shouldn't be a concern if you don't redefine static methods after mixing.
- `'proxy'` - Similar to `settings.prototypeStrategy`, proxy's static method access to base classes. Has the same benefits/downsides.
### `settings.initFunction`
* If set, `ts-mixer` will automatically call the function with this name upon construction
* Possible values:
- `null` (default) - disables the behavior
- a string - function name to call upon construction
* Read more about why you would want this in [dealing with constructors](#dealing-with-constructors)
### `settings.decoratorInheritance`
* Determines how decorators are inherited from classes passed to `Mixin(...)`
* Possible values:
- `'deep'` (default) - Deeply inherits decorators from all given classes and their ancestors
- `'direct'` - Only inherits decorators defined directly on the given classes
- `'none'` - Skips decorator inheritance
# Author
Tanner Nielsen <tannerntannern@gmail.com>
* Website - [tannernielsen.com](http://tannernielsen.com)
* Github - [tannerntannern](https://github.com/tannerntannern)
# fs-minipass
Filesystem streams based on [minipass](http://npm.im/minipass).
4 classes are exported:
- ReadStream
- ReadStreamSync
- WriteStream
- WriteStreamSync
When using `ReadStreamSync`, all of the data is made available
immediately upon consuming the stream. Nothing is buffered in memory
when the stream is constructed. If the stream is piped to a writer,
then it will synchronously `read()` and emit data into the writer as
fast as the writer can consume it. (That is, it will respect
backpressure.) If you call `stream.read()` then it will read the
entire file and return the contents.
When using `WriteStreamSync`, every write is flushed to the file
synchronously. If your writes all come in a single tick, then it'll
write it all out in a single tick. It's as synchronous as you are.
The async versions work much like their node builtin counterparts,
with the exception of introducing significantly less Stream machinery
overhead.
## USAGE
It's just streams, you pipe them or read() them or write() to them.
```js
const fsm = require('fs-minipass')
const readStream = new fsm.ReadStream('file.txt')
const writeStream = new fsm.WriteStream('output.txt')
writeStream.write('some file header or whatever\n')
readStream.pipe(writeStream)
```
## ReadStream(path, options)
Path string is required, but somewhat irrelevant if an open file
descriptor is passed in as an option.
Options:
- `fd` Pass in a numeric file descriptor, if the file is already open.
- `readSize` The size of reads to do, defaults to 16MB
- `size` The size of the file, if known. Prevents zero-byte read()
call at the end.
- `autoClose` Set to `false` to prevent the file descriptor from being
closed when the file is done being read.
## WriteStream(path, options)
Path string is required, but somewhat irrelevant if an open file
descriptor is passed in as an option.
Options:
- `fd` Pass in a numeric file descriptor, if the file is already open.
- `mode` The mode to create the file with. Defaults to `0o666`.
- `start` The position in the file to start reading. If not
specified, then the file will start writing at position zero, and be
truncated by default.
- `autoClose` Set to `false` to prevent the file descriptor from being
closed when the stream is ended.
- `flags` Flags to use when opening the file. Irrelevant if `fd` is
passed in, since file won't be opened in that case. Defaults to
`'a'` if a `pos` is specified, or `'w'` otherwise.
# Punycode.js [](https://travis-ci.org/bestiejs/punycode.js) [](https://codecov.io/gh/bestiejs/punycode.js) [](https://gemnasium.com/bestiejs/punycode.js)
Punycode.js is a robust Punycode converter that fully complies to [RFC 3492](https://tools.ietf.org/html/rfc3492) and [RFC 5891](https://tools.ietf.org/html/rfc5891).
This JavaScript library is the result of comparing, optimizing and documenting different open-source implementations of the Punycode algorithm:
* [The C example code from RFC 3492](https://tools.ietf.org/html/rfc3492#appendix-C)
* [`punycode.c` by _Markus W. Scherer_ (IBM)](http://opensource.apple.com/source/ICU/ICU-400.42/icuSources/common/punycode.c)
* [`punycode.c` by _Ben Noordhuis_](https://github.com/bnoordhuis/punycode/blob/master/punycode.c)
* [JavaScript implementation by _some_](http://stackoverflow.com/questions/183485/can-anyone-recommend-a-good-free-javascript-for-punycode-to-unicode-conversion/301287#301287)
* [`punycode.js` by _Ben Noordhuis_](https://github.com/joyent/node/blob/426298c8c1c0d5b5224ac3658c41e7c2a3fe9377/lib/punycode.js) (note: [not fully compliant](https://github.com/joyent/node/issues/2072))
This project was [bundled](https://github.com/joyent/node/blob/master/lib/punycode.js) with Node.js from [v0.6.2+](https://github.com/joyent/node/compare/975f1930b1...61e796decc) until [v7](https://github.com/nodejs/node/pull/7941) (soft-deprecated).
The current version supports recent versions of Node.js only. It provides a CommonJS module and an ES6 module. For the old version that offers the same functionality with broader support, including Rhino, Ringo, Narwhal, and web browsers, see [v1.4.1](https://github.com/bestiejs/punycode.js/releases/tag/v1.4.1).
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install punycode --save
```
In [Node.js](https://nodejs.org/):
```js
const punycode = require('punycode');
```
## API
### `punycode.decode(string)`
Converts a Punycode string of ASCII symbols to a string of Unicode symbols.
```js
// decode domain name parts
punycode.decode('maana-pta'); // 'mañana'
punycode.decode('--dqo34k'); // '☃-⌘'
```
### `punycode.encode(string)`
Converts a string of Unicode symbols to a Punycode string of ASCII symbols.
```js
// encode domain name parts
punycode.encode('mañana'); // 'maana-pta'
punycode.encode('☃-⌘'); // '--dqo34k'
```
### `punycode.toUnicode(input)`
Converts a Punycode string representing a domain name or an email address to Unicode. Only the Punycoded parts of the input will be converted, i.e. it doesn’t matter if you call it on a string that has already been converted to Unicode.
```js
// decode domain names
punycode.toUnicode('xn--maana-pta.com');
// → 'mañana.com'
punycode.toUnicode('xn----dqo34k.com');
// → '☃-⌘.com'
// decode email addresses
punycode.toUnicode('джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq');
// → 'джумла@джpумлатест.bрфa'
```
### `punycode.toASCII(input)`
Converts a lowercased Unicode string representing a domain name or an email address to Punycode. Only the non-ASCII parts of the input will be converted, i.e. it doesn’t matter if you call it with a domain that’s already in ASCII.
```js
// encode domain names
punycode.toASCII('mañana.com');
// → 'xn--maana-pta.com'
punycode.toASCII('☃-⌘.com');
// → 'xn----dqo34k.com'
// encode email addresses
punycode.toASCII('джумла@джpумлатест.bрфa');
// → 'джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq'
```
### `punycode.ucs2`
#### `punycode.ucs2.decode(string)`
Creates an array containing the numeric code point values of each Unicode symbol in the string. While [JavaScript uses UCS-2 internally](https://mathiasbynens.be/notes/javascript-encoding), this function will convert a pair of surrogate halves (each of which UCS-2 exposes as separate characters) into a single code point, matching UTF-16.
```js
punycode.ucs2.decode('abc');
// → [0x61, 0x62, 0x63]
// surrogate pair for U+1D306 TETRAGRAM FOR CENTRE:
punycode.ucs2.decode('\uD834\uDF06');
// → [0x1D306]
```
#### `punycode.ucs2.encode(codePoints)`
Creates a string based on an array of numeric code point values.
```js
punycode.ucs2.encode([0x61, 0x62, 0x63]);
// → 'abc'
punycode.ucs2.encode([0x1D306]);
// → '\uD834\uDF06'
```
### `punycode.version`
A string representing the current Punycode.js version number.
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
Punycode.js is available under the [MIT](https://mths.be/mit) license.
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows note
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Note that PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Then, run the program to be debugged as usual.
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <tj@vision-media.ca>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# [nearley](http://nearley.js.org) ↗️
[](http://js.org)
[](https://badge.fury.io/js/nearley)
nearley is a simple, fast and powerful parsing toolkit. It consists of:
1. [A powerful, modular DSL for describing
languages](https://nearley.js.org/docs/grammar)
2. [An efficient, lightweight Earley
parser](https://nearley.js.org/docs/parser)
3. [Loads of tools, editor plug-ins, and other
goodies!](https://nearley.js.org/docs/tooling)
nearley is a **streaming** parser with support for catching **errors**
gracefully and providing _all_ parsings for **ambiguous** grammars. It is
compatible with a variety of **lexers** (we recommend
[moo](http://github.com/tjvr/moo)). It comes with tools for creating **tests**,
**railroad diagrams** and **fuzzers** from your grammars, and has support for a
variety of editors and platforms. It works in both node and the browser.
Unlike most other parser generators, nearley can handle *any* grammar you can
define in BNF (and more!). In particular, while most existing JS parsers such
as PEGjs and Jison choke on certain grammars (e.g. [left recursive
ones](http://en.wikipedia.org/wiki/Left_recursion)), nearley handles them
easily and efficiently by using the [Earley parsing
algorithm](https://en.wikipedia.org/wiki/Earley_parser).
nearley is used by a wide variety of projects:
- [artificial
intelligence](https://github.com/ChalmersGU-AI-course/shrdlite-course-project)
and
- [computational
linguistics](https://wiki.eecs.yorku.ca/course_archive/2014-15/W/6339/useful_handouts)
classes at universities;
- [file format parsers](https://github.com/raymond-h/node-dmi);
- [data-driven markup languages](https://github.com/idyll-lang/idyll-compiler);
- [compilers for real-world programming
languages](https://github.com/sizigi/lp5562);
- and nearley itself! The nearley compiler is bootstrapped.
nearley is an npm [staff
pick](https://www.npmjs.com/package/npm-collection-staff-picks).
## Documentation
Please visit our website https://nearley.js.org to get started! You will find a
tutorial, detailed reference documents, and links to several real-world
examples to get inspired.
## Contributing
Please read [this document](.github/CONTRIBUTING.md) *before* working on
nearley. If you are interested in contributing but unsure where to start, take
a look at the issues labeled "up for grabs" on the issue tracker, or message a
maintainer (@kach or @tjvr on Github).
nearley is MIT licensed.
A big thanks to Nathan Dinsmore for teaching me how to Earley, Aria Stewart for
helping structure nearley into a mature module, and Robin Windels for
bootstrapping the grammar. Additionally, Jacob Edelman wrote an experimental
JavaScript parser with nearley and contributed ideas for EBNF support. Joshua
T. Corbin refactored the compiler to be much, much prettier. Bojidar Marinov
implemented postprocessors-in-other-languages. Shachar Itzhaky fixed a subtle
bug with nullables.
## Citing nearley
If you are citing nearley in academic work, please use the following BibTeX
entry.
```bibtex
@misc{nearley,
author = "Kartik Chandra and Tim Radvan",
title = "{nearley}: a parsing toolkit for {JavaScript}",
year = {2014},
doi = {10.5281/zenodo.3897993},
url = {https://github.com/kach/nearley}
}
```
# Web IDL Type Conversions on JavaScript Values
This package implements, in JavaScript, the algorithms to convert a given JavaScript value according to a given [Web IDL](http://heycam.github.io/webidl/) [type](http://heycam.github.io/webidl/#idl-types).
The goal is that you should be able to write code like
```js
"use strict";
const conversions = require("webidl-conversions");
function doStuff(x, y) {
x = conversions["boolean"](x);
y = conversions["unsigned long"](y);
// actual algorithm code here
}
```
and your function `doStuff` will behave the same as a Web IDL operation declared as
```webidl
void doStuff(boolean x, unsigned long y);
```
## API
This package's main module's default export is an object with a variety of methods, each corresponding to a different Web IDL type. Each method, when invoked on a JavaScript value, will give back the new JavaScript value that results after passing through the Web IDL conversion rules. (See below for more details on what that means.) Alternately, the method could throw an error, if the Web IDL algorithm is specified to do so: for example `conversions["float"](NaN)` [will throw a `TypeError`](http://heycam.github.io/webidl/#es-float).
Each method also accepts a second, optional, parameter for miscellaneous options. For conversion methods that throw errors, a string option `{ context }` may be provided to provide more information in the error message. (For example, `conversions["float"](NaN, { context: "Argument 1 of Interface's operation" })` will throw an error with message `"Argument 1 of Interface's operation is not a finite floating-point value."`) Specific conversions may also accept other options, the details of which can be found below.
## Conversions implemented
Conversions for all of the basic types from the Web IDL specification are implemented:
- [`any`](https://heycam.github.io/webidl/#es-any)
- [`void`](https://heycam.github.io/webidl/#es-void)
- [`boolean`](https://heycam.github.io/webidl/#es-boolean)
- [Integer types](https://heycam.github.io/webidl/#es-integer-types), which can additionally be provided the boolean options `{ clamp, enforceRange }` as a second parameter
- [`float`](https://heycam.github.io/webidl/#es-float), [`unrestricted float`](https://heycam.github.io/webidl/#es-unrestricted-float)
- [`double`](https://heycam.github.io/webidl/#es-double), [`unrestricted double`](https://heycam.github.io/webidl/#es-unrestricted-double)
- [`DOMString`](https://heycam.github.io/webidl/#es-DOMString), which can additionally be provided the boolean option `{ treatNullAsEmptyString }` as a second parameter
- [`ByteString`](https://heycam.github.io/webidl/#es-ByteString), [`USVString`](https://heycam.github.io/webidl/#es-USVString)
- [`object`](https://heycam.github.io/webidl/#es-object)
- [`Error`](https://heycam.github.io/webidl/#es-Error)
- [Buffer source types](https://heycam.github.io/webidl/#es-buffer-source-types)
Additionally, for convenience, the following derived type definitions are implemented:
- [`ArrayBufferView`](https://heycam.github.io/webidl/#ArrayBufferView)
- [`BufferSource`](https://heycam.github.io/webidl/#BufferSource)
- [`DOMTimeStamp`](https://heycam.github.io/webidl/#DOMTimeStamp)
- [`Function`](https://heycam.github.io/webidl/#Function)
- [`VoidFunction`](https://heycam.github.io/webidl/#VoidFunction) (although it will not censor the return type)
Derived types, such as nullable types, promise types, sequences, records, etc. are not handled by this library. You may wish to investigate the [webidl2js](https://github.com/jsdom/webidl2js) project.
### A note on the `long long` types
The `long long` and `unsigned long long` Web IDL types can hold values that cannot be stored in JavaScript numbers, so the conversion is imperfect. For example, converting the JavaScript number `18446744073709552000` to a Web IDL `long long` is supposed to produce the Web IDL value `-18446744073709551232`. Since we are representing our Web IDL values in JavaScript, we can't represent `-18446744073709551232`, so we instead the best we could do is `-18446744073709552000` as the output.
This library actually doesn't even get that far. Producing those results would require doing accurate modular arithmetic on 64-bit intermediate values, but JavaScript does not make this easy. We could pull in a big-integer library as a dependency, but in lieu of that, we for now have decided to just produce inaccurate results if you pass in numbers that are not strictly between `Number.MIN_SAFE_INTEGER` and `Number.MAX_SAFE_INTEGER`.
## Background
What's actually going on here, conceptually, is pretty weird. Let's try to explain.
Web IDL, as part of its madness-inducing design, has its own type system. When people write algorithms in web platform specs, they usually operate on Web IDL values, i.e. instances of Web IDL types. For example, if they were specifying the algorithm for our `doStuff` operation above, they would treat `x` as a Web IDL value of [Web IDL type `boolean`](http://heycam.github.io/webidl/#idl-boolean). Crucially, they would _not_ treat `x` as a JavaScript variable whose value is either the JavaScript `true` or `false`. They're instead working in a different type system altogether, with its own rules.
Separately from its type system, Web IDL defines a ["binding"](http://heycam.github.io/webidl/#ecmascript-binding) of the type system into JavaScript. This contains rules like: when you pass a JavaScript value to the JavaScript method that manifests a given Web IDL operation, how does that get converted into a Web IDL value? For example, a JavaScript `true` passed in the position of a Web IDL `boolean` argument becomes a Web IDL `true`. But, a JavaScript `true` passed in the position of a [Web IDL `unsigned long`](http://heycam.github.io/webidl/#idl-unsigned-long) becomes a Web IDL `1`. And so on.
Finally, we have the actual implementation code. This is usually C++, although these days [some smart people are using Rust](https://github.com/servo/servo). The implementation, of course, has its own type system. So when they implement the Web IDL algorithms, they don't actually use Web IDL values, since those aren't "real" outside of specs. Instead, implementations apply the Web IDL binding rules in such a way as to convert incoming JavaScript values into C++ values. For example, if code in the browser called `doStuff(true, true)`, then the implementation code would eventually receive a C++ `bool` containing `true` and a C++ `uint32_t` containing `1`.
The upside of all this is that implementations can abstract all the conversion logic away, letting Web IDL handle it, and focus on implementing the relevant methods in C++ with values of the correct type already provided. That is payoff of Web IDL, in a nutshell.
And getting to that payoff is the goal of _this_ project—but for JavaScript implementations, instead of C++ ones. That is, this library is designed to make it easier for JavaScript developers to write functions that behave like a given Web IDL operation. So conceptually, the conversion pipeline, which in its general form is JavaScript values ↦ Web IDL values ↦ implementation-language values, in this case becomes JavaScript values ↦ Web IDL values ↦ JavaScript values. And that intermediate step is where all the logic is performed: a JavaScript `true` becomes a Web IDL `1` in an unsigned long context, which then becomes a JavaScript `1`.
## Don't use this
Seriously, why would you ever use this? You really shouldn't. Web IDL is … strange, and you shouldn't be emulating its semantics. If you're looking for a generic argument-processing library, you should find one with better rules than those from Web IDL. In general, your JavaScript should not be trying to become more like Web IDL; if anything, we should fix Web IDL to make it more like JavaScript.
The _only_ people who should use this are those trying to create faithful implementations (or polyfills) of web platform interfaces defined in Web IDL. Its main consumer is the [jsdom](https://github.com/tmpvar/jsdom) project.
# axios // helpers
The modules found in `helpers/` should be generic modules that are _not_ specific to the domain logic of axios. These modules could theoretically be published to npm on their own and consumed by other modules or apps. Some examples of generic modules are things like:
- Browser polyfills
- Managing cookies
- Parsing HTTP headers
### esutils [](http://travis-ci.org/estools/esutils)
esutils ([esutils](http://github.com/estools/esutils)) is
utility box for ECMAScript language tools.
### API
### ast
#### ast.isExpression(node)
Returns true if `node` is an Expression as defined in ECMA262 edition 5.1 section
[11](https://es5.github.io/#x11).
#### ast.isStatement(node)
Returns true if `node` is a Statement as defined in ECMA262 edition 5.1 section
[12](https://es5.github.io/#x12).
#### ast.isIterationStatement(node)
Returns true if `node` is an IterationStatement as defined in ECMA262 edition
5.1 section [12.6](https://es5.github.io/#x12.6).
#### ast.isSourceElement(node)
Returns true if `node` is a SourceElement as defined in ECMA262 edition 5.1
section [14](https://es5.github.io/#x14).
#### ast.trailingStatement(node)
Returns `Statement?` if `node` has trailing `Statement`.
```js
if (cond)
consequent;
```
When taking this `IfStatement`, returns `consequent;` statement.
#### ast.isProblematicIfStatement(node)
Returns true if `node` is a problematic IfStatement. If `node` is a problematic `IfStatement`, `node` cannot be represented as an one on one JavaScript code.
```js
{
type: 'IfStatement',
consequent: {
type: 'WithStatement',
body: {
type: 'IfStatement',
consequent: {type: 'EmptyStatement'}
}
},
alternate: {type: 'EmptyStatement'}
}
```
The above node cannot be represented as a JavaScript code, since the top level `else` alternate belongs to an inner `IfStatement`.
### code
#### code.isDecimalDigit(code)
Return true if provided code is decimal digit.
#### code.isHexDigit(code)
Return true if provided code is hexadecimal digit.
#### code.isOctalDigit(code)
Return true if provided code is octal digit.
#### code.isWhiteSpace(code)
Return true if provided code is white space. White space characters are formally defined in ECMA262.
#### code.isLineTerminator(code)
Return true if provided code is line terminator. Line terminator characters are formally defined in ECMA262.
#### code.isIdentifierStart(code)
Return true if provided code can be the first character of ECMA262 Identifier. They are formally defined in ECMA262.
#### code.isIdentifierPart(code)
Return true if provided code can be the trailing character of ECMA262 Identifier. They are formally defined in ECMA262.
### keyword
#### keyword.isKeywordES5(id, strict)
Returns `true` if provided identifier string is a Keyword or Future Reserved Word
in ECMA262 edition 5.1. They are formally defined in ECMA262 sections
[7.6.1.1](http://es5.github.io/#x7.6.1.1) and [7.6.1.2](http://es5.github.io/#x7.6.1.2),
respectively. If the `strict` flag is truthy, this function additionally checks whether
`id` is a Keyword or Future Reserved Word under strict mode.
#### keyword.isKeywordES6(id, strict)
Returns `true` if provided identifier string is a Keyword or Future Reserved Word
in ECMA262 edition 6. They are formally defined in ECMA262 sections
[11.6.2.1](http://ecma-international.org/ecma-262/6.0/#sec-keywords) and
[11.6.2.2](http://ecma-international.org/ecma-262/6.0/#sec-future-reserved-words),
respectively. If the `strict` flag is truthy, this function additionally checks whether
`id` is a Keyword or Future Reserved Word under strict mode.
#### keyword.isReservedWordES5(id, strict)
Returns `true` if provided identifier string is a Reserved Word in ECMA262 edition 5.1.
They are formally defined in ECMA262 section [7.6.1](http://es5.github.io/#x7.6.1).
If the `strict` flag is truthy, this function additionally checks whether `id`
is a Reserved Word under strict mode.
#### keyword.isReservedWordES6(id, strict)
Returns `true` if provided identifier string is a Reserved Word in ECMA262 edition 6.
They are formally defined in ECMA262 section [11.6.2](http://ecma-international.org/ecma-262/6.0/#sec-reserved-words).
If the `strict` flag is truthy, this function additionally checks whether `id`
is a Reserved Word under strict mode.
#### keyword.isRestrictedWord(id)
Returns `true` if provided identifier string is one of `eval` or `arguments`.
They are restricted in strict mode code throughout ECMA262 edition 5.1 and
in ECMA262 edition 6 section [12.1.1](http://ecma-international.org/ecma-262/6.0/#sec-identifiers-static-semantics-early-errors).
#### keyword.isIdentifierNameES5(id)
Return true if provided identifier string is an IdentifierName as specified in
ECMA262 edition 5.1 section [7.6](https://es5.github.io/#x7.6).
#### keyword.isIdentifierNameES6(id)
Return true if provided identifier string is an IdentifierName as specified in
ECMA262 edition 6 section [11.6](http://ecma-international.org/ecma-262/6.0/#sec-names-and-keywords).
#### keyword.isIdentifierES5(id, strict)
Return true if provided identifier string is an Identifier as specified in
ECMA262 edition 5.1 section [7.6](https://es5.github.io/#x7.6). If the `strict`
flag is truthy, this function additionally checks whether `id` is an Identifier
under strict mode.
#### keyword.isIdentifierES6(id, strict)
Return true if provided identifier string is an Identifier as specified in
ECMA262 edition 6 section [12.1](http://ecma-international.org/ecma-262/6.0/#sec-identifiers).
If the `strict` flag is truthy, this function additionally checks whether `id`
is an Identifier under strict mode.
### License
Copyright (C) 2013 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# inflight
Add callbacks to requests in flight to avoid async duplication
## USAGE
```javascript
var inflight = require('inflight')
// some request that does some stuff
function req(key, callback) {
// key is any random string. like a url or filename or whatever.
//
// will return either a falsey value, indicating that the
// request for this key is already in flight, or a new callback
// which when called will call all callbacks passed to inflightk
// with the same key
callback = inflight(key, callback)
// If we got a falsey value back, then there's already a req going
if (!callback) return
// this is where you'd fetch the url or whatever
// callback is also once()-ified, so it can safely be assigned
// to multiple events etc. First call wins.
setTimeout(function() {
callback(null, key)
}, 100)
}
// only assigns a single setTimeout
// when it dings, all cbs get called
req('foo', cb1)
req('foo', cb2)
req('foo', cb3)
req('foo', cb4)
```
# yargs-parser
[](https://travis-ci.org/yargs/yargs-parser)
[](https://www.npmjs.com/package/yargs-parser)
[](https://github.com/conventional-changelog/standard-version)
The mighty option parser used by [yargs](https://github.com/yargs/yargs).
visit the [yargs website](http://yargs.js.org/) for more examples, and thorough usage instructions.
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs-parser/master/yargs-logo.png">
## Example
```sh
npm i yargs-parser --save
```
```js
var argv = require('yargs-parser')(process.argv.slice(2))
console.log(argv)
```
```sh
node example.js --foo=33 --bar hello
{ _: [], foo: 33, bar: 'hello' }
```
_or parse a string!_
```js
var argv = require('yargs-parser')('--foo=99 --bar=33')
console.log(argv)
```
```sh
{ _: [], foo: 99, bar: 33 }
```
Convert an array of mixed types before passing to `yargs-parser`:
```js
var parse = require('yargs-parser')
parse(['-f', 11, '--zoom', 55].join(' ')) // <-- array to string
parse(['-f', 11, '--zoom', 55].map(String)) // <-- array of strings
```
## API
### require('yargs-parser')(args, opts={})
Parses command line arguments returning a simple mapping of keys and values.
**expects:**
* `args`: a string or array of strings representing the options to parse.
* `opts`: provide a set of hints indicating how `args` should be parsed:
* `opts.alias`: an object representing the set of aliases for a key: `{alias: {foo: ['f']}}`.
* `opts.array`: indicate that keys should be parsed as an array: `{array: ['foo', 'bar']}`.<br>
Indicate that keys should be parsed as an array and coerced to booleans / numbers:<br>
`{array: [{ key: 'foo', boolean: true }, {key: 'bar', number: true}]}`.
* `opts.boolean`: arguments should be parsed as booleans: `{boolean: ['x', 'y']}`.
* `opts.coerce`: provide a custom synchronous function that returns a coerced value from the argument provided
(or throws an error). For arrays the function is called only once for the entire array:<br>
`{coerce: {foo: function (arg) {return modifiedArg}}}`.
* `opts.config`: indicate a key that represents a path to a configuration file (this file will be loaded and parsed).
* `opts.configObjects`: configuration objects to parse, their properties will be set as arguments:<br>
`{configObjects: [{'x': 5, 'y': 33}, {'z': 44}]}`.
* `opts.configuration`: provide configuration options to the yargs-parser (see: [configuration](#configuration)).
* `opts.count`: indicate a key that should be used as a counter, e.g., `-vvv` = `{v: 3}`.
* `opts.default`: provide default values for keys: `{default: {x: 33, y: 'hello world!'}}`.
* `opts.envPrefix`: environment variables (`process.env`) with the prefix provided should be parsed.
* `opts.narg`: specify that a key requires `n` arguments: `{narg: {x: 2}}`.
* `opts.normalize`: `path.normalize()` will be applied to values set to this key.
* `opts.number`: keys should be treated as numbers.
* `opts.string`: keys should be treated as strings (even if they resemble a number `-x 33`).
**returns:**
* `obj`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
### require('yargs-parser').detailed(args, opts={})
Parses a command line string, returning detailed information required by the
yargs engine.
**expects:**
* `args`: a string or array of strings representing options to parse.
* `opts`: provide a set of hints indicating how `args`, inputs are identical to `require('yargs-parser')(args, opts={})`.
**returns:**
* `argv`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
* `error`: populated with an error object if an exception occurred during parsing.
* `aliases`: the inferred list of aliases built by combining lists in `opts.alias`.
* `newAliases`: any new aliases added via camel-case expansion:
* `boolean`: `{ fooBar: true }`
* `defaulted`: any new argument created by `opts.default`, no aliases included.
* `boolean`: `{ foo: true }`
* `configuration`: given by default settings and `opts.configuration`.
<a name="configuration"></a>
### Configuration
The yargs-parser applies several automated transformations on the keys provided
in `args`. These features can be turned on and off using the `configuration` field
of `opts`.
```js
var parsed = parser(['--no-dice'], {
configuration: {
'boolean-negation': false
}
})
```
### short option groups
* default: `true`.
* key: `short-option-groups`.
Should a group of short-options be treated as boolean flags?
```sh
node example.js -abc
{ _: [], a: true, b: true, c: true }
```
_if disabled:_
```sh
node example.js -abc
{ _: [], abc: true }
```
### camel-case expansion
* default: `true`.
* key: `camel-case-expansion`.
Should hyphenated arguments be expanded into camel-case aliases?
```sh
node example.js --foo-bar
{ _: [], 'foo-bar': true, fooBar: true }
```
_if disabled:_
```sh
node example.js --foo-bar
{ _: [], 'foo-bar': true }
```
### dot-notation
* default: `true`
* key: `dot-notation`
Should keys that contain `.` be treated as objects?
```sh
node example.js --foo.bar
{ _: [], foo: { bar: true } }
```
_if disabled:_
```sh
node example.js --foo.bar
{ _: [], "foo.bar": true }
```
### parse numbers
* default: `true`
* key: `parse-numbers`
Should keys that look like numbers be treated as such?
```sh
node example.js --foo=99.3
{ _: [], foo: 99.3 }
```
_if disabled:_
```sh
node example.js --foo=99.3
{ _: [], foo: "99.3" }
```
### boolean negation
* default: `true`
* key: `boolean-negation`
Should variables prefixed with `--no` be treated as negations?
```sh
node example.js --no-foo
{ _: [], foo: false }
```
_if disabled:_
```sh
node example.js --no-foo
{ _: [], "no-foo": true }
```
### combine arrays
* default: `false`
* key: `combine-arrays`
Should arrays be combined when provided by both command line arguments and
a configuration file.
### duplicate arguments array
* default: `true`
* key: `duplicate-arguments-array`
Should arguments be coerced into an array when duplicated:
```sh
node example.js -x 1 -x 2
{ _: [], x: [1, 2] }
```
_if disabled:_
```sh
node example.js -x 1 -x 2
{ _: [], x: 2 }
```
### flatten duplicate arrays
* default: `true`
* key: `flatten-duplicate-arrays`
Should array arguments be coerced into a single array when duplicated:
```sh
node example.js -x 1 2 -x 3 4
{ _: [], x: [1, 2, 3, 4] }
```
_if disabled:_
```sh
node example.js -x 1 2 -x 3 4
{ _: [], x: [[1, 2], [3, 4]] }
```
### greedy arrays
* default: `true`
* key: `greedy-arrays`
Should arrays consume more than one positional argument following their flag.
```sh
node example --arr 1 2
{ _[], arr: [1, 2] }
```
_if disabled:_
```sh
node example --arr 1 2
{ _[2], arr: [1] }
```
**Note: in `v18.0.0` we are considering defaulting greedy arrays to `false`.**
### nargs eats options
* default: `false`
* key: `nargs-eats-options`
Should nargs consume dash options as well as positional arguments.
### negation prefix
* default: `no-`
* key: `negation-prefix`
The prefix to use for negated boolean variables.
```sh
node example.js --no-foo
{ _: [], foo: false }
```
_if set to `quux`:_
```sh
node example.js --quuxfoo
{ _: [], foo: false }
```
### populate --
* default: `false`.
* key: `populate--`
Should unparsed flags be stored in `--` or `_`.
_If disabled:_
```sh
node example.js a -b -- x y
{ _: [ 'a', 'x', 'y' ], b: true }
```
_If enabled:_
```sh
node example.js a -b -- x y
{ _: [ 'a' ], '--': [ 'x', 'y' ], b: true }
```
### set placeholder key
* default: `false`.
* key: `set-placeholder-key`.
Should a placeholder be added for keys not set via the corresponding CLI argument?
_If disabled:_
```sh
node example.js -a 1 -c 2
{ _: [], a: 1, c: 2 }
```
_If enabled:_
```sh
node example.js -a 1 -c 2
{ _: [], a: 1, b: undefined, c: 2 }
```
### halt at non-option
* default: `false`.
* key: `halt-at-non-option`.
Should parsing stop at the first positional argument? This is similar to how e.g. `ssh` parses its command line.
_If disabled:_
```sh
node example.js -a run b -x y
{ _: [ 'b' ], a: 'run', x: 'y' }
```
_If enabled:_
```sh
node example.js -a run b -x y
{ _: [ 'b', '-x', 'y' ], a: 'run' }
```
### strip aliased
* default: `false`
* key: `strip-aliased`
Should aliases be removed before returning results?
_If disabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1, 'test-alias': 1, testAlias: 1 }
```
_If enabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
### strip dashed
* default: `false`
* key: `strip-dashed`
Should dashed keys be removed before returning results? This option has no effect if
`camel-case-expansion` is disabled.
_If disabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
_If enabled:_
```sh
node example.js --test-field 1
{ _: [], testField: 1 }
```
### unknown options as args
* default: `false`
* key: `unknown-options-as-args`
Should unknown options be treated like regular arguments? An unknown option is one that is not
configured in `opts`.
_If disabled_
```sh
node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: [], unknownOption: true, knownOption: 2, stringOption: '', unknownOption2: true }
```
_If enabled_
```sh
node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: ['--unknown-option'], knownOption: 2, stringOption: '--unknown-option2' }
```
## Special Thanks
The yargs project evolves from optimist and minimist. It owes its
existence to a lot of James Halliday's hard work. Thanks [substack](https://github.com/substack) **beep** **boop** \o/
## License
ISC
# AssemblyScript Rtrace
A tiny utility to sanitize the AssemblyScript runtime. Records allocations and frees performed by the runtime and emits an error if something is off. Also checks for leaks.
Instructions
------------
Compile your module that uses the full or half runtime with `-use ASC_RTRACE=1 --explicitStart` and include an instance of this module as the import named `rtrace`.
```js
const rtrace = new Rtrace({
onerror(err, info) {
// handle error
},
oninfo(msg) {
// print message, optional
},
getMemory() {
// obtain the module's memory,
// e.g. with --explicitStart:
return instance.exports.memory;
}
});
const { module, instance } = await WebAssembly.instantiate(...,
rtrace.install({
...imports...
})
);
instance.exports._start();
...
if (rtrace.active) {
let leakCount = rtr.check();
if (leakCount) {
// handle error
}
}
```
Note that references in globals which are not cleared before collection is performed appear as leaks, including their inner members. A TypedArray would leak itself and its backing ArrayBuffer in this case for example. This is perfectly normal and clearing all globals avoids this.
# assemblyscript-regex
A regex engine for AssemblyScript.
[AssemblyScript](https://www.assemblyscript.org/) is a new language, based on TypeScript, that runs on WebAssembly. AssemblyScript has a lightweight standard library, but lacks support for Regular Expression. The project fills that gap!
This project exposes an API that mirrors the JavaScript [RegExp](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp) class:
```javascript
const regex = new RegExp("fo*", "g");
const str = "table football, foul";
let match: Match | null = regex.exec(str);
while (match != null) {
// first iteration
// match.index = 6
// match.matches[0] = "foo"
// second iteration
// match.index = 16
// match.matches[0] = "fo"
match = regex.exec(str);
}
```
## Project status
The initial focus of this implementation has been feature support and functionality over performance. It currently supports a sufficient number of regex features to be considered useful, including most character classes, common assertions, groups, alternations, capturing groups and quantifiers.
The next phase of development will focussed on more extensive testing and performance. The project currently has reasonable unit test coverage, focussed on positive and negative test cases on a per-feature basis. It also includes a more exhaustive test suite with test cases borrowed from another regex library.
### Feature support
Based on the classfication within the [MDN cheatsheet](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions/Cheatsheet)
**Character sets**
- [x] .
- [x] \d
- [x] \D
- [x] \w
- [x] \W
- [x] \s
- [x] \S
- [x] \t
- [x] \r
- [x] \n
- [x] \v
- [x] \f
- [ ] [\b]
- [ ] \0
- [ ] \cX
- [x] \xhh
- [x] \uhhhh
- [ ] \u{hhhh} or \u{hhhhh}
- [x] \
**Assertions**
- [x] ^
- [x] $
- [ ] \b
- [ ] \B
**Other assertions**
- [ ] x(?=y) Lookahead assertion
- [ ] x(?!y) Negative lookahead assertion
- [ ] (?<=y)x Lookbehind assertion
- [ ] (?<!y)x Negative lookbehind assertion
**Groups and ranges**
- [x] x|y
- [x] [xyz][a-c]
- [x] [^xyz][^a-c]
- [x] (x) capturing group
- [ ] \n back reference
- [ ] (?<Name>x) named capturing group
- [x] (?:x) Non-capturing group
**Quantifiers**
- [x] x\*
- [x] x+
- [x] x?
- [x] x{n}
- [x] x{n,}
- [x] x{n,m}
- [ ] x\*? / x+? / ...
**RegExp**
- [x] global
- [ ] sticky
- [x] case insensitive
- [x] multiline
- [x] dotAll
- [ ] unicode
### Development
This project is open source, MIT licenced and your contributions are very much welcomed.
To get started, check out the repository and install dependencies:
```
$ npm install
```
A few general points about the tools and processes this project uses:
- This project uses prettier for code formatting and eslint to provide additional syntactic checks. These are both run on `npm test` and as part of the CI build.
- The unit tests are executed using [as-pect](https://github.com/jtenner/as-pect) - a native AssemblyScript test runner
- The specification tests are within the `spec` folder. The `npm run test:generate` target transforms these tests into as-pect tests which execute as part of the standard build / test cycle
- In order to support improved debugging you can execute this library as TypeScript (rather than WebAssembly), via the `npm run tsrun` target.
[![NPM version][npm-image]][npm-url]
[![build status][travis-image]][travis-url]
[![Test coverage][coveralls-image]][coveralls-url]
[![Downloads][downloads-image]][downloads-url]
[](https://gitter.im/eslint/doctrine?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
# Doctrine
Doctrine is a [JSDoc](http://usejsdoc.org) parser that parses documentation comments from JavaScript (you need to pass in the comment, not a whole JavaScript file).
## Installation
You can install Doctrine using [npm](https://npmjs.com):
```
$ npm install doctrine --save-dev
```
Doctrine can also be used in web browsers using [Browserify](http://browserify.org).
## Usage
Require doctrine inside of your JavaScript:
```js
var doctrine = require("doctrine");
```
### parse()
The primary method is `parse()`, which accepts two arguments: the JSDoc comment to parse and an optional options object. The available options are:
* `unwrap` - set to `true` to delete the leading `/**`, any `*` that begins a line, and the trailing `*/` from the source text. Default: `false`.
* `tags` - an array of tags to return. When specified, Doctrine returns only tags in this array. For example, if `tags` is `["param"]`, then only `@param` tags will be returned. Default: `null`.
* `recoverable` - set to `true` to keep parsing even when syntax errors occur. Default: `false`.
* `sloppy` - set to `true` to allow optional parameters to be specified in brackets (`@param {string} [foo]`). Default: `false`.
* `lineNumbers` - set to `true` to add `lineNumber` to each node, specifying the line on which the node is found in the source. Default: `false`.
* `range` - set to `true` to add `range` to each node, specifying the start and end index of the node in the original comment. Default: `false`.
Here's a simple example:
```js
var ast = doctrine.parse(
[
"/**",
" * This function comment is parsed by doctrine",
" * @param {{ok:String}} userName",
"*/"
].join('\n'), { unwrap: true });
```
This example returns the following AST:
{
"description": "This function comment is parsed by doctrine",
"tags": [
{
"title": "param",
"description": null,
"type": {
"type": "RecordType",
"fields": [
{
"type": "FieldType",
"key": "ok",
"value": {
"type": "NameExpression",
"name": "String"
}
}
]
},
"name": "userName"
}
]
}
See the [demo page](http://eslint.org/doctrine/demo/) more detail.
## Team
These folks keep the project moving and are resources for help:
* Nicholas C. Zakas ([@nzakas](https://github.com/nzakas)) - project lead
* Yusuke Suzuki ([@constellation](https://github.com/constellation)) - reviewer
## Contributing
Issues and pull requests will be triaged and responded to as quickly as possible. We operate under the [ESLint Contributor Guidelines](http://eslint.org/docs/developer-guide/contributing), so please be sure to read them before contributing. If you're not sure where to dig in, check out the [issues](https://github.com/eslint/doctrine/issues).
## Frequently Asked Questions
### Can I pass a whole JavaScript file to Doctrine?
No. Doctrine can only parse JSDoc comments, so you'll need to pass just the JSDoc comment to Doctrine in order to work.
### License
#### doctrine
Copyright JS Foundation and other contributors, https://js.foundation
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
#### esprima
some of functions is derived from esprima
Copyright (C) 2012, 2011 [Ariya Hidayat](http://ariya.ofilabs.com/about)
(twitter: [@ariyahidayat](http://twitter.com/ariyahidayat)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
#### closure-compiler
some of extensions is derived from closure-compiler
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
### Where to ask for help?
Join our [Chatroom](https://gitter.im/eslint/doctrine)
[npm-image]: https://img.shields.io/npm/v/doctrine.svg?style=flat-square
[npm-url]: https://www.npmjs.com/package/doctrine
[travis-image]: https://img.shields.io/travis/eslint/doctrine/master.svg?style=flat-square
[travis-url]: https://travis-ci.org/eslint/doctrine
[coveralls-image]: https://img.shields.io/coveralls/eslint/doctrine/master.svg?style=flat-square
[coveralls-url]: https://coveralls.io/r/eslint/doctrine?branch=master
[downloads-image]: http://img.shields.io/npm/dm/doctrine.svg?style=flat-square
[downloads-url]: https://www.npmjs.com/package/doctrine
Railroad-diagram Generator
==========================
This is a small js library for generating railroad diagrams
(like what [JSON.org](http://json.org) uses)
using SVG.
Railroad diagrams are a way of visually representing a grammar
in a form that is more readable than using regular expressions or BNF.
I think (though I haven't given it a lot of thought yet) that if it's easy to write a context-free grammar for the language,
the corresponding railroad diagram will be easy as well.
There are several railroad-diagram generators out there, but none of them had the visual appeal I wanted.
[Here's an example of how they look!](http://www.xanthir.com/etc/railroad-diagrams/example.html)
And [here's an online generator for you to play with and get SVG code from!](http://www.xanthir.com/etc/railroad-diagrams/generator.html)
The library now exists in a Python port as well! See the information further down.
Details
-------
To use the library, just include the js and css files, and then call the Diagram() function.
Its arguments are the components of the diagram (Diagram is a special form of Sequence).
An alternative to Diagram() is ComplexDiagram() which is used to describe a complex type diagram.
Components are either leaves or containers.
The leaves:
* Terminal(text) or a bare string - represents literal text
* NonTerminal(text) - represents an instruction or another production
* Comment(text) - a comment
* Skip() - an empty line
The containers:
* Sequence(children) - like simple concatenation in a regex
* Choice(index, children) - like | in a regex. The index argument specifies which child is the "normal" choice and should go in the middle
* Optional(child, skip) - like ? in a regex. A shorthand for `Choice(1, [Skip(), child])`. If the optional `skip` parameter has the value `"skip"`, it instead puts the Skip() in the straight-line path, for when the "normal" behavior is to omit the item.
* OneOrMore(child, repeat) - like + in a regex. The 'repeat' argument is optional, and specifies something that must go between the repetitions.
* ZeroOrMore(child, repeat, skip) - like * in a regex. A shorthand for `Optional(OneOrMore(child, repeat))`. The optional `skip` parameter is identical to Optional().
For convenience, each component can be called with or without `new`.
If called without `new`,
the container components become n-ary;
that is, you can say either `new Sequence([A, B])` or just `Sequence(A,B)`.
After constructing a Diagram, call `.format(...padding)` on it, specifying 0-4 padding values (just like CSS) for some additional "breathing space" around the diagram (the paddings default to 20px).
The result can either be `.toString()`'d for the markup, or `.toSVG()`'d for an `<svg>` element, which can then be immediately inserted to the document. As a convenience, Diagram also has an `.addTo(element)` method, which immediately converts it to SVG and appends it to the referenced element with default paddings. `element` defaults to `document.body`.
Options
-------
There are a few options you can tweak, at the bottom of the file. Just tweak either until the diagram looks like what you want.
You can also change the CSS file - feel free to tweak to your heart's content.
Note, though, that if you change the text sizes in the CSS,
you'll have to go adjust the metrics for the leaf nodes as well.
* VERTICAL_SEPARATION - sets the minimum amount of vertical separation between two items. Note that the stroke width isn't counted when computing the separation; this shouldn't be relevant unless you have a very small separation or very large stroke width.
* ARC_RADIUS - the radius of the arcs used in the branching containers like Choice. This has a relatively large effect on the size of non-trivial diagrams. Both tight and loose values look good, depending on what you're going for.
* DIAGRAM_CLASS - the class set on the root `<svg>` element of each diagram, for use in the CSS stylesheet.
* STROKE_ODD_PIXEL_LENGTH - the default stylesheet uses odd pixel lengths for 'stroke'. Due to rasterization artifacts, they look best when the item has been translated half a pixel in both directions. If you change the styling to use a stroke with even pixel lengths, you'll want to set this variable to `false`.
* INTERNAL_ALIGNMENT - when some branches of a container are narrower than others, this determines how they're aligned in the extra space. Defaults to "center", but can be set to "left" or "right".
Caveats
-------
At this early stage, the generator is feature-complete and works as intended, but still has several TODOs:
* The font-sizes are hard-coded right now, and the font handling in general is very dumb - I'm just guessing at some metrics that are probably "good enough" rather than measuring things properly.
Python Port
-----------
In addition to the canonical JS version, the library now exists as a Python library as well.
Using it is basically identical. The config variables are globals in the file, and so may be adjusted either manually or via tweaking from inside your program.
The main difference from the JS port is how you extract the string from the Diagram. You'll find a `writeSvg(writerFunc)` method on `Diagram`, which takes a callback of one argument and passes it the string form of the diagram. For example, it can be used like `Diagram(...).writeSvg(sys.stdout.write)` to write to stdout. **Note**: the callback will be called multiple times as it builds up the string, not just once with the whole thing. If you need it all at once, consider something like a `StringIO` as an easy way to collect it into a single string.
License
-------
This document and all associated files in the github project are licensed under [CC0](http://creativecommons.org/publicdomain/zero/1.0/) .
This means you can reuse, remix, or otherwise appropriate this project for your own use **without restriction**.
(The actual legal meaning can be found at the above link.)
Don't ask me for permission to use any part of this project, **just use it**.
I would appreciate attribution, but that is not required by the license.
|
Kishoraditya_near_hack2 | .env
.gitpod.yml
README.md
contract
Cargo.toml
README.md
build.sh
deploy.sh
src
JobsMarket.rs
ProfileNFT.rs
Revenue.rs
UserProfie.rs
UserRegistry.rs
lib.rs
target
.rustc_info.json
release
.fingerprint
Inflector-e6c94e9a894426cc
lib-inflector.json
ahash-be7d3dcadc11df0f
build-script-build-script-build.json
borsh-derive-c607c75a349505c9
lib-borsh-derive.json
borsh-derive-internal-015e30a79e0ff5aa
lib-borsh-derive-internal.json
borsh-schema-derive-internal-8db1d31d2cd3c965
lib-borsh-schema-derive-internal.json
crunchy-86ab52436e71cfbe
build-script-build-script-build.json
near-sdk-macros-64b9527309daf330
lib-near-sdk-macros.json
proc-macro-crate-d7058ae77274a354
lib-proc-macro-crate.json
proc-macro2-2af6e608c487cf29
lib-proc-macro2.json
proc-macro2-6942a756ff2fa902
build-script-build-script-build.json
proc-macro2-a971207d3747d958
run-build-script-build-script-build.json
quote-e340e0d1efec2237
lib-quote.json
schemars-98d9b5767950cecd
build-script-build-script-build.json
schemars_derive-757991f73d634616
lib-schemars_derive.json
semver-617c56d76ac1397c
build-script-build-script-build.json
serde-4c176785e9ef6d4f
build-script-build-script-build.json
serde-641a08077b53646a
lib-serde.json
serde-d2260979d22d8d99
run-build-script-build-script-build.json
serde-d72f5e8a71844ee9
build-script-build-script-build.json
serde_derive-257ae34c7db8221a
lib-serde_derive.json
serde_derive_internals-7df0758ca55b7ccf
lib-serde_derive_internals.json
serde_json-8d54e293787ed74c
build-script-build-script-build.json
syn-110d42369912b06e
lib-syn.json
syn-52595f17440013b6
run-build-script-build-script-build.json
syn-93d2f34fdd6f7aaf
lib-syn.json
syn-dee6a7e28f7dcfa7
build-script-build-script-build.json
toml-c1b578df944de9bb
lib-toml.json
unicode-ident-a2435905867009fc
lib-unicode-ident.json
version_check-c2908a003991f88b
lib-version_check.json
wee_alloc-aa531acaf38f55ef
build-script-build-script-build.json
wasm32-unknown-unknown
release
.fingerprint
ahash-8120dd8f398c456e
lib-ahash.json
ahash-badad04baac78cee
run-build-script-build-script-build.json
base64-5f88084a906491af
lib-base64.json
borsh-6e41ed85f2a8d354
lib-borsh.json
bs58-fdcd9e4386053a8a
lib-bs58.json
byteorder-6ee1062ac42e19fd
lib-byteorder.json
cfg-if-ed6319254f2ac6c9
lib-cfg-if.json
crunchy-48bfaffbfe599ad8
run-build-script-build-script-build.json
crunchy-dc25377e27ce5ed5
lib-crunchy.json
dyn-clone-1f893cf1bb88f239
lib-dyn-clone.json
hashbrown-20b8244bf32cf285
lib-hashbrown.json
hex-5848bfa5e5d6fb7b
lib-hex.json
itoa-61bbcca3c98f0b46
lib-itoa.json
memory_units-30fbdd35bce85c99
lib-memory_units.json
near-abi-0a851324b3caf7f3
lib-near-abi.json
near-sdk-9f14c418a42f5edb
lib-near-sdk.json
near-sys-2df7bc89594ec1d0
lib-near-sys.json
once_cell-a84088dd32f6a49d
lib-once_cell.json
ryu-467680a73147b083
lib-ryu.json
schemars-0c2c37b3ddc55fd4
lib-schemars.json
schemars-b0af12db8e031f91
run-build-script-build-script-build.json
semver-2f8830f9c44d3001
lib-semver.json
semver-908f87917051027a
run-build-script-build-script-build.json
serde-827ddacfff8ec951
lib-serde.json
serde-86a35cc7d40f65de
run-build-script-build-script-build.json
serde_json-da6cb2af43ac77ce
lib-serde_json.json
serde_json-dc9ac22e2bf19aa9
run-build-script-build-script-build.json
static_assertions-7fb90f37b417cd40
lib-static_assertions.json
uint-ceb2d198cf8b5dc8
lib-uint.json
wee_alloc-8768961fc67f6cab
lib-wee_alloc.json
wee_alloc-f825098e48d8671d
run-build-script-build-script-build.json
build
crunchy-48bfaffbfe599ad8
out
lib.rs
wee_alloc-f825098e48d8671d
out
wee_alloc_static_array_backend_size_bytes.txt
deps
my_dapp.long-type-8887005322580719149.txt
contracts.txt
frontend
index.html
package-lock.json
package.json
src
App.js
assets
global.css
logo-black.svg
logo-white.svg
components
JobAppForm.js
JobList.js
Navigation.js
ProfileNFT.js
Wallet.js
ui-components.js
contracts
jobsMarket.js
profileNFT.js
userProfile.js
userRegistry.js
index.js
pages
CreateProfile.js
Home.js
JobDetails.js
Jobs.js
Profile.js
SignUp.js
styles
stylesheet.css
utils
ceramic.js
near-wallet.js
near.js
start.sh
integration-tests
Cargo.toml
src
tests.rs
package-lock.json
package.json
rust-toolchain.toml
target
npmlist.json
| #ProfNet: Apply, Employ or Own
Traditional platforms like LinkedIn have amassed massive profits by capitalizing on your professional data, all while leaving you with limited control and compensation. Additionally, existing networks often perpetuate identity biases and nepotism, creating an uneven playing field in the job market. This disparity raises concerns about data ownership, fairness, and transparency. Even if we consider these in marginal aspects, there is no way in this economy to enforce employers with the practice to vet thousands of applications they receive for a single job opening, which as much is frustrating to the employer, is equally if not less frustrating for the applicant to not hear back or not receive the feedback to improve.
ProfNet empowers you with true data ownership. You decide who accesses your encrypted contact information, and you are fairly compensated whenever the contact or any personal information is accessed. When someone purchases your encrypted data, you receive the transaction proceeds, putting you in control of your worth. Best part of all, you dont even need to trust us to have that data control, we would store your data with you and only be accessed the payer party once requested. Our innovative system guarantees a transparent, merit-based process for job applications, eliminating favoritism and promoting equal opportunities for all.
ProfNet stands as more than just another network; it's a paradigm shift towards data empowerment, a fair landscape, and a level playing field within the professional realm. If you share the vision and wish to contribute in any capacity, don't hesitate to reach out. Join us on this transformative journey as we redefine the way professionals connect, apply, and flourish in an environment founded on genuine equity.
# Hello NEAR Contract
The smart contract exposes two methods to enable storing and retrieving a greeting in the NEAR network.
```rust
const DEFAULT_GREETING: &str = "Hello";
#[near_bindgen]
#[derive(BorshDeserialize, BorshSerialize)]
pub struct Contract {
greeting: String,
}
impl Default for Contract {
fn default() -> Self {
Self{greeting: DEFAULT_GREETING.to_string()}
}
}
#[near_bindgen]
impl Contract {
// Public: Returns the stored greeting, defaulting to 'Hello'
pub fn get_greeting(&self) -> String {
return self.greeting.clone();
}
// Public: Takes a greeting, such as 'howdy', and records it
pub fn set_greeting(&mut self, greeting: String) {
// Record a log permanently to the blockchain!
log!("Saving greeting {}", greeting);
self.greeting = greeting;
}
}
```
<br />
# Quickstart
1. Make sure you have installed [rust](https://rust.org/).
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
./deploy.sh
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Retrieve the Greeting
`get_greeting` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the greeting
near view <dev-account> get_greeting
```
<br />
## 3. Store a New Greeting
`set_greeting` changes the contract's state, for which it is a `change` method.
`Change` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set a new greeting
near call <dev-account> set_greeting '{"message":"howdy"}' --accountId <dev-account>
```
**Tip:** If you would like to call `set_greeting` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
|
pichtranst123_telegram-bot-near | README.md
bot.ts
package-lock.json
package.json
util.js
| # telegram-bot-near
Get api from contract
According to command:
cd to-your-mdir
npm start
|
jairerazodev_donation-jair_erazo_devops.testnet | .github
workflows
tests.yml
.gitpod.yml
README.md
contract
README.md
babel.config.json
build.sh
deploy.sh
package-lock.json
package.json
src
contract.ts
model.ts
utils.ts
tsconfig.json
frontend
assets
global.css
logo-black.svg
logo-white.svg
index.html
index.js
near-interface.js
near-wallet.js
package-lock.json
package.json
start.sh
integration-tests
package-lock.json
package.json
src
main.ava.ts
package-lock.json
package.json
| # Donation 💸
[](https://docs.near.org/tutorials/welcome)
[](https://gitpod.io/#/https://github.com/near-examples/donation-js)
[](https://docs.near.org/develop/contracts/anatomy)
[](https://docs.near.org/develop/integrate/frontend)
[](https://docs.near.org/develop/integrate/frontend)
Our Donation example enables to forward money to an account while keeping track of it. It is one of the simplest examples on making a contract receive and send money.

# What This Example Shows
1. How to receive and transfer $NEAR on a contract.
2. How to divide a project into multiple modules.
3. How to handle the storage costs.
4. How to handle transaction results.
5. How to use a `Map`.
<br />
# Quickstart
Clone this repository locally or [**open it in gitpod**](https://gitpod.io/#/github.com/near-examples/donation-js). Then follow these steps:
### 1. Install Dependencies
```bash
npm install
```
### 2. Test the Contract
Deploy your contract in a sandbox and simulate interactions from users.
```bash
npm test
```
### 3. Deploy the Contract
Build the contract and deploy it in a testnet account
```bash
npm run deploy
```
### 4. Start the Frontend
Start the web application to interact with your smart contract
```bash
npm start
```
---
# Learn More
1. Learn more about the contract through its [README](./contract/README.md).
2. Check [**our documentation**](https://docs.near.org/develop/welcome).
# Donation Contract
The smart contract exposes methods to handle donating $NEAR to a `beneficiary`.
```ts
@call
donate() {
// Get who is calling the method and how much $NEAR they attached
let donor = near.predecessorAccountId();
let donationAmount: bigint = near.attachedDeposit() as bigint;
let donatedSoFar = this.donations.get(donor) === null? BigInt(0) : BigInt(this.donations.get(donor) as string)
let toTransfer = donationAmount;
// This is the user's first donation, lets register it, which increases storage
if(donatedSoFar == BigInt(0)) {
assert(donationAmount > STORAGE_COST, `Attach at least ${STORAGE_COST} yoctoNEAR`);
// Subtract the storage cost to the amount to transfer
toTransfer -= STORAGE_COST
}
// Persist in storage the amount donated so far
donatedSoFar += donationAmount
this.donations.set(donor, donatedSoFar.toString())
// Send the money to the beneficiary
const promise = near.promiseBatchCreate(this.beneficiary)
near.promiseBatchActionTransfer(promise, toTransfer)
// Return the total amount donated so far
return donatedSoFar.toString()
}
```
<br />
# Quickstart
1. Make sure you have installed [node.js](https://nodejs.org/en/download/package-manager/) >= 16.
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
npm run deploy
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
The contract will be automatically initialized with a default `beneficiary`.
To initialize the contract yourself do:
```bash
# Use near-cli to initialize contract (optional)
near call <dev-account> init '{"beneficiary":"<account>"}' --accountId <dev-account>
```
<br />
## 2. Get Beneficiary
`beneficiary` is a read-only method (`view` method) that returns the beneficiary of the donations.
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
near view <dev-account> beneficiary
```
<br />
## 3. Get Number of Donations
`donate` forwards any attached money to the `beneficiary` while keeping track of it.
`donate` is a payable method for which can only be invoked using a NEAR account. The account needs to attach money and pay GAS for the transaction.
```bash
# Use near-cli to donate 1 NEAR
near call <dev-account> donate --amount 1 --accountId <account>
```
**Tip:** If you would like to `donate` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
|
near_near-enhanced-api-server | Cargo.toml
DB_DESIGN.md
README.md
src
config.rs
db_helpers.rs
errors.rs
main.rs
modules
ft
data_provider
balance.rs
history.rs
metadata.rs
mod.rs
models.rs
mod.rs
resources.rs
schemas.rs
mod.rs
native
data_provider
balance.rs
history.rs
metadata.rs
mod.rs
models.rs
mod.rs
resources.rs
schemas.rs
nft
data_provider
history.rs
metadata.rs
mod.rs
models.rs
nft_info.rs
mod.rs
resources.rs
schemas.rs
rpc_helpers.rs
types
account_id.rs
mod.rs
numeric.rs
pagoda_api_key.rs
query_params.rs
| # NEAR Enhanced API
API for providing useful information about NEAR blockchain.
Still under heavy development.
### Supported features
- Provide NEAR balances information, history
- Provide FT balances information, FT history (*)
- Provide NFT information and recent history for the contracts implementing Events NEP
- Provide corresponding Metadata for FT, NFT contracts, NFT items
(*) We support all the FT contracts implementing Events NEP and some popular legacy contracts such as `aurora`, `wrap.near` and few others.
If your contract is not supported, please update with our new [SDK](https://github.com/near/near-sdk-rs).
If it's important for you to collect all the previous history as well, you need to make the contribution and implement your own legacy handler.
You can use [existing handlers](https://github.com/near/near-microindexers/tree/main/indexer-events/src/db_adapters/coin/legacy) as the example.
|
jgmercedes_GrantaNear | README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
main.spec.ts
as_types.d.ts
index.ts
models
Proyecto.ts
tsconfig.json
neardev
dev-account.env
package.json
| # GrantaNear :handshake:
GrantaNear es un smart contract de Near protocol, el cual permite que los developers de el ecosistema Near puedan dar a conocer sus proyectos a fin de estar entre los mas votados para que lleguen a ser fondeados para el desarollo de estos. Este smart contract permite:
- Añadir un proyecto usando el metodo crearProyecto.
- Chequear la lista de proyectos con el metodo listarProyectos.
- Verificar informacion de un proyecto con el metodo obtenerProyecto.
- Votar a favor de un proyecto con el metodo votarProyecto.
- Eliminar un proyecto creado con el metodo eliminarProyecto.
# Instalación :mechanic:
Para la instalación local de este projecto:
## Pre - requisitos
- Asegúrese de haber instalado Node.js ≥ 12 (recomendamos usar nvm).
- Asegúrese de haber instalado yarn: npm install -g yarn.
- Instalar dependencias: yarn install.
- Crear un test near account NEAR test account.
- Instalar el NEAR CLI globally: near-cli es una interfaz de linea de comando (CLI) para interacturar con NEAR blockchain.
# Configurar NEAR CLI :technologist:
Configura tu near-cli para autorizar tu cuenta de prueba creada recientemente:
```html
near login
```
# Clonar el repositorio :palms_up_together:
```html
git clone https://github.com/jgmercedes/GrantaNear.git
```
```html
cd GrantaNear
```
# Build del proyecto y despliegue en development mode. :rocket:
Instalar las dependencias necesarias con npm.
```html
npm install
```
Hacer el build y deployment en development mode.
```html
yarn devdeploy
```
# Comandos :construction:
## Comando para crear un proyecto:
```html
near call
<tu contrato desplegado>
crearProyecto "{ \"titulo\": \"string\", \"descripcion\": \"string\", \"fondos\": number }" --account-id <tu cuenta testnet>
```
## Comando para conseguir informacion de un proyecto:
```html
near call
<tu contrato desplegado>
obtenerProyecto "{\"id\": number}" --account-id <tu cuenta testnet>
```
## Comando para conseguir la lista de proyectos:
```html
near view
<tu contrato desplegado>
listarProyectos "{}"
```
## Comando para votar por un proyecto:
```html
near call
<tu contrato desplegado>
votarProyecto "{\"id\": number}" --account-id
<tu cuenta testnet>
```
## Comando para eliminar un proyecto:
```html
near call
<tu contrato desplegado>
eliminarProyecto "{\"id\": number}" --account-id <tu cuenta testnet>
```
# Video en loom:
```html
https://www.loom.com/share/f602dbfb6b4048e5aeb143e546dc3194
```
# :framed_picture: Explora el codigo:
GrantaNear smart contract file system.
```bash
├── assembly
│ ├── __tests__
│ │ ├── as-pect.d.ts # As-pect unidad de pruebas - headers for type hints
│ │ └── main.spec.ts # Test para el contrato
│ ├── as_types.d.ts # AssemblyScript - headers for type hint
│ ├── index.ts # Contains the smart contract code
│ ├── models.ts # Contiene modelos accesibles al contrato
│ │ └── Proyecto.ts # Contiene el modelo Proyecto.
│ └── tsconfig.json # Archivo de configuracion de Typescript
├── neardev
│ ├── dev-account # En este archivo se guarda la cuenta de contrato inteligente de implementación provisional
│ └── dev-account.env # En este archivo, la cuenta se guarda como una variable de entorno
├── out
│ └── main.wasm # Código de contrato inteligente compilado que se usa para el deploy
├── as-pect.config.js # Configuracion de as-pect (AssemblyScript unit testing)
├── asconfig.json # Configuracion del Assemblyscript compiler
├── package-lock.json # Manifesto lock version del proyecto
├── package.json # Manifesto de Node.js (scripts and dependencies)
├── README.md # Este archivo
└── yarn.lock # Manifesto yarn lock version
```
# Gracias por visitar nuestro proyecto. :clap:
Aqui les dejamos nuestro diseño - [UI/UX](https://www.canva.com/design/DAEri4aolfc/qkat_oy0bIIARVNcpDhthg/view?website#1).
## License
MIT License
Copyright (c) [2021]
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
|
Murat-Selim_Practice-Part | README.md
as-pect.config.js
asconfig.json
package.json
scripts
1.dev-deploy.sh
2.use-contract.sh
3.cleanup.sh
README.md
src
as_types.d.ts
simple
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
singleton
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
| ## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
# `near-sdk-as` Starter Kit
This is a good project to use as a starting point for your AssemblyScript project.
## Samples
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
There are 2 AssemblyScript contracts in this project, each in their own folder:
- **simple** in the `src/simple` folder
- **singleton** in the `src/singleton` folder
### Simple
We say that an AssemblyScript contract is written in the "simple style" when the `index.ts` file (the contract entry point) includes a series of exported functions.
In this case, all exported functions become public contract methods.
```ts
// return the string 'hello world'
export function helloWorld(): string {}
// read the given key from account (contract) storage
export function read(key: string): string {}
// write the given value at the given key to account (contract) storage
export function write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
```
### Singleton
We say that an AssemblyScript contract is written in the "singleton style" when the `index.ts` file (the contract entry point) has a single exported class (the name of the class doesn't matter) that is decorated with `@nearBindgen`.
In this case, all methods on the class become public contract methods unless marked `private`. Also, all instance variables are stored as a serialized instance of the class under a special storage key named `STATE`. AssemblyScript uses JSON for storage serialization (as opposed to Rust contracts which use a custom binary serialization format called borsh).
```ts
@nearBindgen
export class Contract {
// return the string 'hello world'
helloWorld(): string {}
// read the given key from account (contract) storage
read(key: string): string {}
// write the given value at the given key to account (contract) storage
@mutateState()
write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
}
```
## Usage
### Getting started
(see below for video recordings of each of the following steps)
INSTALL `NEAR CLI` first like this: `npm i -g near-cli`
1. clone this repo to a local folder
2. run `yarn`
3. run `./scripts/1.dev-deploy.sh`
3. run `./scripts/2.use-contract.sh`
4. run `./scripts/2.use-contract.sh` (yes, run it to see changes)
5. run `./scripts/3.cleanup.sh`
### Videos
**`1.dev-deploy.sh`**
This video shows the build and deployment of the contract.
[](https://asciinema.org/a/409575)
**`2.use-contract.sh`**
This video shows contract methods being called. You should run the script twice to see the effect it has on contract state.
[](https://asciinema.org/a/409577)
**`3.cleanup.sh`**
This video shows the cleanup script running. Make sure you add the `BENEFICIARY` environment variable. The script will remind you if you forget.
```sh
export BENEFICIARY=<your-account-here> # this account receives contract account balance
```
[](https://asciinema.org/a/409580)
### Other documentation
- See `./scripts/README.md` for documentation about the scripts
- Watch this video where Willem Wyndham walks us through refactoring a simple example of a NEAR smart contract written in AssemblyScript
https://youtu.be/QP7aveSqRPo
```
There are 2 "styles" of implementing AssemblyScript NEAR contracts:
- the contract interface can either be a collection of exported functions
- or the contract interface can be the methods of a an exported class
We call the second style "Singleton" because there is only one instance of the class which is serialized to the blockchain storage. Rust contracts written for NEAR do this by default with the contract struct.
0:00 noise (to cut)
0:10 Welcome
0:59 Create project starting with "npm init"
2:20 Customize the project for AssemblyScript development
9:25 Import the Counter example and get unit tests passing
18:30 Adapt the Counter example to a Singleton style contract
21:49 Refactoring unit tests to access the new methods
24:45 Review and summary
```
## The file system
```sh
├── README.md # this file
├── as-pect.config.js # configuration for as-pect (AssemblyScript unit testing)
├── asconfig.json # configuration for AssemblyScript compiler (supports multiple contracts)
├── package.json # NodeJS project manifest
├── scripts
│ ├── 1.dev-deploy.sh # helper: build and deploy contracts
│ ├── 2.use-contract.sh # helper: call methods on ContractPromise
│ ├── 3.cleanup.sh # helper: delete build and deploy artifacts
│ └── README.md # documentation for helper scripts
├── src
│ ├── as_types.d.ts # AssemblyScript headers for type hints
│ ├── simple # Contract 1: "Simple example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 1
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 1
│ ├── singleton # Contract 2: "Singleton-style example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 2
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 2
│ ├── tsconfig.json # Typescript configuration
│ └── utils.ts # common contract utility functions
└── yarn.lock # project manifest version lock
```
You may clone this repo to get started OR create everything from scratch.
Please note that, in order to create the AssemblyScript and tests folder structure, you may use the command `asp --init` which will create the following folders and files:
```
./assembly/
./assembly/tests/
./assembly/tests/example.spec.ts
./assembly/tests/as-pect.d.ts
```
|
lhtdeepak_near-hotelroom | .gitpod.yml
README.md
contract
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
main.spec.ts
as_types.d.ts
index.ts
tsconfig.json
package-lock.json
package.json
frontend
App.js
Components
addRoom.js
roomList.js
__mocks__
fileMock.js
assets
css
global.css
img
logo-black.svg
logo-white.svg
js
near
config.js
utils.js
index.html
index.js
integration-tests
rs
Cargo.toml
src
tests.rs
ts
package.json
src
main.ava.ts
package-lock.json
package.json
| # Near Hotel Room #
- This Near Hotel Room consists of a Smart Contract and it is witten in assembly script.
- Ultimately, the purpose of this project was to build a simple contract to explore how persistent storage, unit tests, and contract calls interact when building on the NEAR ecosystem.
### Features ###
This project includes following features :
- Receptionist login using Near Wallet
- Receptionist allocated rooms for customers
- Receptionist check the booked rooms list
- Customers will get the room allocated messages in their Near Wallet
### Methods of Smart Contracts Used In Project
#### Change Method
`addDetails` `ConfirmRoomNumber`
#### View Method
`getDetails`
### Quick Start ###
To run this project locally:
- Prerequisites: Make sure you've installed [Node.js] ≥ 12 and `yarn latest version`
- Clone the repository - `https://github.com/lhtdeepak/near-hotelroom.git`
- Install dependencies: `yarn install`
- Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
### File Structure ###
- The "backend" code lives in the `/contract` folder. See the README there for
more info.
- The frontend code lives in the `/frontend` folder. `/frontend/index.html` is a great
place to start exploring. Note that it loads in `/frontend/assets/js/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
### Deploy ###
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `leeway.testnet.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `leeway.testnet.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account leeway.testnet.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'leeway.testnet.YOUR-NAME.testnet'
near-HotelRoom Smart Contract
==================
A [smart contract] written in [AssemblyScript] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install [Node.js] ≥ 12
Exploring The Code
==================
1. The main smart contract code lives in `assembly/index.ts`.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard AssemblyScript tests using [as-pect].
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[AssemblyScript]: https://www.assemblyscript.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[as-pect]: https://www.npmjs.com/package/@as-pect/cli
|
near-x_near-localize-dapp | README.md
| # near-localize-dapp
Localize your DApps on NEAR
|
oleksanderkorn_nearvember-challenge-9 | README.md
as-pect.config.js
asconfig.json
package.json
scripts
1.dev-deploy.sh
2.use-contract.sh
3.cleanup.sh
README.md
src
as_types.d.ts
etherium
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
near
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
near_vs_eth
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
| ## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
# `near-sdk-as` Starter Kit
This is a good project to use as a starting point for your AssemblyScript project.
## Samples
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
There are 2 AssemblyScript contracts in this project, each in their own folder:
- **simple** in the `src/simple` folder
- **singleton** in the `src/singleton` folder
### Simple
We say that an AssemblyScript contract is written in the "simple style" when the `index.ts` file (the contract entry point) includes a series of exported functions.
In this case, all exported functions become public contract methods.
```ts
// return the string 'hello world'
export function helloWorld(): string {}
// read the given key from account (contract) storage
export function read(key: string): string {}
// write the given value at the given key to account (contract) storage
export function write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
```
### Singleton
We say that an AssemblyScript contract is written in the "singleton style" when the `index.ts` file (the contract entry point) has a single exported class (the name of the class doesn't matter) that is decorated with `@nearBindgen`.
In this case, all methods on the class become public contract methods unless marked `private`. Also, all instance variables are stored as a serialized instance of the class under a special storage key named `STATE`. AssemblyScript uses JSON for storage serialization (as opposed to Rust contracts which use a custom binary serialization format called borsh).
```ts
@nearBindgen
export class Contract {
// return the string 'hello world'
helloWorld(): string {}
// read the given key from account (contract) storage
read(key: string): string {}
// write the given value at the given key to account (contract) storage
@mutateState()
write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
}
```
## Usage
### Getting started
(see below for video recordings of each of the following steps)
1. clone this repo to a local folder
2. run `yarn`
3. run `./scripts/1.dev-deploy.sh`
3. run `./scripts/2.use-contract.sh`
4. run `./scripts/2.use-contract.sh` (yes, run it to see changes)
5. run `./scripts/3.cleanup.sh`
### Videos
**`1.dev-deploy.sh`**
This video shows the build and deployment of the contract.
[](https://asciinema.org/a/409575)
**`2.use-contract.sh`**
This video shows contract methods being called. You should run the script twice to see the effect it has on contract state.
[](https://asciinema.org/a/409577)
**`3.cleanup.sh`**
This video shows the cleanup script running. Make sure you add the `BENEFICIARY` environment variable. The script will remind you if you forget.
```sh
export BENEFICIARY=<your-account-here> # this account receives contract account balance
```
[](https://asciinema.org/a/409580)
### Other documentation
- See `./scripts/README.md` for documentation about the scripts
- Watch this video where Willem Wyndham walks us through refactoring a simple example of a NEAR smart contract written in AssemblyScript
https://youtu.be/QP7aveSqRPo
```
There are 2 "styles" of implementing AssemblyScript NEAR contracts:
- the contract interface can either be a collection of exported functions
- or the contract interface can be the methods of a an exported class
We call the second style "Singleton" because there is only one instance of the class which is serialized to the blockchain storage. Rust contracts written for NEAR do this by default with the contract struct.
0:00 noise (to cut)
0:10 Welcome
0:59 Create project starting with "npm init"
2:20 Customize the project for AssemblyScript development
9:25 Import the Counter example and get unit tests passing
18:30 Adapt the Counter example to a Singleton style contract
21:49 Refactoring unit tests to access the new methods
24:45 Review and summary
```
## The file system
```sh
├── README.md # this file
├── as-pect.config.js # configuration for as-pect (AssemblyScript unit testing)
├── asconfig.json # configuration for AssemblyScript compiler (supports multiple contracts)
├── package.json # NodeJS project manifest
├── scripts
│ ├── 1.dev-deploy.sh # helper: build and deploy contracts
│ ├── 2.use-contract.sh # helper: call methods on ContractPromise
│ ├── 3.cleanup.sh # helper: delete build and deploy artifacts
│ └── README.md # documentation for helper scripts
├── src
│ ├── as_types.d.ts # AssemblyScript headers for type hints
│ ├── simple # Contract 1: "Simple example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 1
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 1
│ ├── singleton # Contract 2: "Singleton-style example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 2
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 2
│ ├── tsconfig.json # Typescript configuration
│ └── utils.ts # common contract utility functions
└── yarn.lock # project manifest version lock
```
You may clone this repo to get started OR create everything from scratch.
Please note that, in order to create the AssemblyScript and tests folder structure, you may use the command `asp --init` which will create the following folders and files:
```
./assembly/
./assembly/tests/
./assembly/tests/example.spec.ts
./assembly/tests/as-pect.d.ts
```
|
noemk2_uberdao | README.md
asconfig.json
package-lock.json
package.json
src
as-pect.d.ts
as_types.d.ts
dao
__tests__
README.md
index.unit.spec.ts
asconfig.json
assembly
index.ts
models.ts
tsconfig.json
utils.ts
viajes
__tests__
as-pect.d.ts
example.spec.ts
asconfig.json
assembly
index.ts
models.ts
| 🚕 Introducción a uberDao 🚕
==================
[Video Demo]
🚕 🚙Introducción a uberdao 🚗
==================
uberdao es un smart contract escrito bajo el protocolo NEAR que permite:
1. Crear solicitud de viaje.
2. Obtener una lista de las solicitudes de viajes que se han creado.
3. Votar por una propuesta.
4. Cambiar el status de un proyecto.
5. Eliminar de la lista las solicitudes de viaje.
👨💻 Instalación en local
===========
Para correr este proyecto en local debes seguir los siguientes pasos:
Paso 1: Pre - Requisitos
------------------------------
1. Asegúrese de haber instalado [Node.js] ≥ 12 ((recomendamos usar [nvm])
2. Asegúrese de haber instalado yarn: `npm install -g yarn`
3. Instalar dependencias: `yarn install`
4. Crear un test near account [NEAR test account]
5. Instalar el NEAR CLI globally: [near-cli] es una interfaz de linea de comando (CLI) para interacturar con NEAR blockchain
yarn install --global near-cli
Step 2: Configura tu NEAR CLI
-------------------------------
Configura tu near-cli para autorizar su cuenta de prueba creada recientemente:
near login
Step 3: Clonar Repositorio
-------------------------------
Este comando nos permite clonar el repositorio de nuestro proyecto
```bash
git clone https://github.com/noemk2/uberdao.git
```
Una vez que hayas descargado el repositorio, asegurate de ejecutar los comandos dentro del repositorio descargado. Puedes hacerlo con
```bash
cd uberdao/
```
Step 4: Realiza el BUILD para implementación de desarrollo de contrato inteligente
------------------------------------------------------------------------------------
Instale el gestor de dependencia de Node.js dentro del repositorio
```bash
npm install
```
Cree el código de contrato inteligente e implemente el servidor de desarrollo local:
```bash
yarn deploy:dev
```
Consulte` package.json` para obtener una lista completa de `scripts` que puede ejecutar con` yarn`). Este script le devuelve un contrato inteligente provisional
implementado (guárdelo para
usarlo más tarde)
¡Felicitaciones, ahora tendrá un entorno de desarrollo local ejecutándose en NEAR TestNet!
✏️ Comando para CREAR unn Solicitud de Viaje
-----------------------------------------------
Permite crear un proyecto que ha sido revisado para entrar a la red de proyectos colaborativos para ser avalados de manera distribuida.
Permite crear una solicitud de viaje para el usuario
Para Linux:
```bash
near call <your deployed contract> createTravel '{"traveler":"string","route":"string"}' --account-id <username>.testnet
```
Para windows:
```bash
near call <your deployed contract> createTravel "{\"traveler\": \"string\",\"route\":\"string\"}" --account-id <username>.testnet
```
✏️ Comando que LISTAR todas las solicitudes de viaje
--------------------------------------------
Permite listar las solicitudes de viaje que existen en nuestro contrato inteligente.
Antes de ejecutar el comando brindado:
- modifica <your deployed contract> por el número de contrato generado. Por ejemplo: 'dev-1630622185346-59088620194720'.
- modifica <username> por tu nombre de usuario en testnet. Por ejemplo: 'aval1'
Para Linux y Windows:
```bash
near view <your deployed contract> getTravelRequest --account-id <username>.testnet
```
✏️ Comando para ELIMINAR una solicitud de viaje
--------------------------------------------
Permite eliminar una solicitud que ya no pertenece a la red y se da de baja.
Para Linux:
```bash
near call <your deployed contract> eliminateTravelRequest '{"id":1}' --account-id <username>.testnet
```
Para Windows:
```bash
near call <your deployed contract> eliminateTravelRequest "{\"id\":<id de proyecto>}" --account-id <username>.testnet
```
## Para poder votar
✏️ desplegar contrato /build/release/dao.wasm previamente compilado
```bash
near dev-deploy --wasmFile ./build/release/dao.wasm
```
✏️ recuerda
Antes de ejecutar el comando brindado:
- modifica <your deployed contract> por el número de contrato generado. Por ejemplo: 'dev-1630622185346-59088620194720'.
- modifica <username> por tu nombre de usuario en testnet. Por ejemplo: 'aval1'
✏️ Inicializamos y creamos una propuesta
--------------------------------------------
`init(title: string, data: string): void`
```sh
# anyone can initialize meme (so this must be done by the museum at deploy-time)
near call dev-1614603380541-7288163 init '{"title": "hello world", "propose": "I want ..."}' --account_id dev-1614603380541-7288163 --amount 3
```
✏️ Ver la propuesta
--------------------------------------------
`get_proposal(): Proposal`
```sh
# anyone can read proposal metadata
near view dev-1614603380541-7288163 get_proposal
```
```js
{
creator: 'dev-1614603380541-7288163',
created_at: '1614603702927464728',
vote_score: 4,
total_donations: '0',
title: 'hello world',
propose: 'I want ...',
}
```
✏️ Comando para ver votos recientes
--------------------------------------------
```sh
near view dev-1614603380541-7288163 get_recent_votes
```
```js
[
{
created_at: '1614603886399296553',
value: 1,
voter: 'dev-1614603380541-7288163'
},
{
created_at: '1614603988616406809',
value: 1,
voter: 'sherif.testnet'
},
{
created_at: '1614604214413823755',
value: 2,
voter: 'batch-dev-1614603380541-7288163'
},
[length]: 3
]
```
✏️ Ver la calificacion de la propuesta
--------------------------------------------
`get_vote_score(): i32`
```sh
near view dev-1614603380541-7288163 get_vote_score
```
```js
4
```
✏️ Comando para votar un propuesta
--------------------------------------------
`vote(value: i8): void`
```sh
# user votes for meme
near call dev-1614603380541-7288163 vote '{"value": 1}' --account_id sherif.testnet
```
✏️ Comando para votar en lotes un propuesta
--------------------------------------------
`batch_vote(value: i8, is_batch: bool = true): void`
```sh
# only the meme contract can call this method
near call dev-1614603380541-7288163 batch_vote '{"value": 2}' --account_id dev-1614603380541-7288163
```
✏️ Comando para agregar un comentario a un propuesta
--------------------------------------------
`add_comment(text: string): void`
```sh
near call dev-1614603380541-7288163 add_comment '{"text":"i love this meme"}' --account_id sherif.testnet
```
✏️ Comando para ver los comentarios recientes
--------------------------------------------
`get_recent_comments(): Array<Comment>`
```sh
near view dev-1614603380541-7288163 get_recent_comments
```
```js
[
{
created_at: '1614604543670811624',
author: 'sherif.testnet',
text: 'i love this meme'
},
[length]: 1
]
```
🤖 Test
==================
Las pruebas son parte del desarrollo, luego, para ejecutar las pruebas en el contrato inteligente , debe ejecutar el siguiente comando:
yarn test
Esto ejecutará los métodos de prueba en el `assembly/__tests__/example.spec.js` archivo
```bash
near call <your deployed contract> hello --account-id <username>.testnet
```
📂🗃️ Exploring and Explaining The Code
====================================
This is a explanation of the smart contract file system
```bash
├── README.md # this file
├── as-pect.config.js # configuration for as-pect (AssemblyScript unit testing)
├── asconfig.json # configuration file for Assemblyscript compiler
├── src
│ ├── viajes <-- viajes contract
│ │ ├── README.md
│ │ ├── __tests__
│ │ │ ├── README.md
│ │ │ └── index.unit.spec.ts
│ │ └── assembly
│ │ ├── index.ts
│ │ └── models.ts
│ ├── dao <-- dao contract
│ │ ├── README.md
│ │ ├── __tests__
│ │ │ ├── README.md
│ │ │ └── index.unit.spec.ts
│ │ └── assembly
│ │ ├── index.ts
│ │ └── models.ts
│ └── utils.ts <-- shared contract code
│
├── neardev
│ ├── dev-account #in this file the provisional deploy smart contract account is saved
│ └── dev-account.env #in this file the provisional deploy smart contract account is saved like a environment variable
│
├── build
│ └── release
│ ├── dao.wasm # compiled smart contract code using to deploy
│ └── viajes.wasm # compiled smart contract code using to deploy
│
├── package-lock.json # project manifest lock version
├── package.json # Node.js project manifest (scripts and dependencies)
└── yarn.lock # project manifest lock version
```
1. El código de los contrato inteligentes vive en la carpeta `/src` folder.
2. Para realizar una implementación de prueba, use los scripts en el `/package.json` file.
🙏 Gracias por su tiempo
==============================================
Aquí dejamos una propuesta de diseño [UX/UI] para desarrollar la parte frontend del proyecto comunitario.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[NEAR test account]: https://docs.near.org/docs/develop/basics/create-account#creating-a-testnet-account
[nvm]: https://github.com/nvm-sh/nvm
[UX/UI]: https://www.figma.com/proto/GqP5EF5zRZRvAv3HoaSsuN/uniwap?node-id=39%3A2300&scaling=min-zoom&page-id=0%3A1&starting-point-node-id=39%3A2300&hide-ui=1
[UX/UI]: https://www.figma.com/proto/0dZLC0WI1eVsfjeKu3T8J8/Garant%C3%ADzame?node-id=2%3A8&scaling=scale-down-width&page-id=0%3A1&starting-point-node-id=2%3A8
[Video Demo]: https://www.loom.com/share/c3b906012b7e4c32a2250929caab64ec?sharedAppSource=personal_library
# Unit Tests for `Meme` Contract
## Usage
```sh
yarn test:unit -f meme
```
## Output
*Note: the tests marked with `Todo` must be verified using simulation tests because they involve cross-contract calls (which can not be verified using unit tests).*
```txt
[Describe]: meme initialization
[Success]: ✔ creates a new meme with proper metadata
[Success]: ✔ prevents double initialization
[Success]: ✔ requires title not to be blank
[Success]: ✔ requires a minimum balance
[Describe]: meme voting
[Success]: ✔ allows individuals to vote
[Success]: ✔ prevents vote automation for individuals
[Success]: ✔ prevents any user from voting more than once
[Describe]: meme captures votes
[Success]: ✔ captures all votes
[Success]: ✔ calculates a running vote score
[Success]: ✔ returns a list of recent votes
[Success]: ✔ allows groups to vote
[Describe]: meme comments
[Success]: ✔ captures comments
[Success]: ✔ rejects comments that are too long
[Success]: ✔ captures multiple comments
[Describe]: meme donations
[Success]: ✔ captures donations
[Describe]: captures donations
[Success]: ✔ captures all donations
[Success]: ✔ calculates a running donations total
[Success]: ✔ returns a list of recent donations
[Todo]: releases donations
[File]: src/meme/__tests__/index.unit.spec.ts
[Groups]: 7 pass, 7 total
[Result]: ✔ PASS
[Snapshot]: 0 total, 0 added, 0 removed, 0 different
[Summary]: 18 pass, 0 fail, 18 total
[Time]: 46.469ms
```
|
GregTrifan_NEAR-Counter | Cargo.toml
src
lib.rs
| |
near_twiggy | .github
ISSUE_TEMPLATE
BOUNTY.yml
bug_report.md
feature_request.md
.rustfmt.toml
.travis.yml
CHANGELOG.md
CONTRIBUTING.md
Cargo.toml
README.md
analyze
Cargo.toml
analyses
diff.rs
dominators
emit.rs
mod.rs
garbage.rs
mod.rs
monos
emit.rs
entry.rs
mod.rs
paths
mod.rs
paths_emit.rs
paths_entry.rs
top.rs
analyze.rs
formats
json.rs
mod.rs
table.rs
ci
script.sh
guide
book.toml
src
SUMMARY.md
chapter_1.md
concepts
call-graph.md
call-graph.svg
dominator-tree.svg
dominators-and-retained-size.md
generic-functions-and-monomorphization.md
index.md
paths.md
contributing.md
contributing
building.md
code-formatting.md
code-of-conduct.md
index.md
pull-requests.md
team.md
testing.md
index.md
install.md
supported-binary-formats.md
theme
book.js
css
chrome.css
general.css
print.css
variables.css
highlight.css
highlight.js
twiggy.svg
usage
as-a-crate.md
command-line-interface
diff.md
dominators.md
garbage.md
index.md
monos.md
paths.md
top.md
index.md
on-the-web-with-webassembly.md
ir
Cargo.toml
graph_impl.rs
ir.rs
opt
Cargo.toml
build.rs
definitions.rs
opt.rs
parser
Cargo.toml
object_parse
compilation_unit_parse
mod.rs
die_parse
item_name.rs
location_attrs.rs
mod.rs
mod.rs
parser.rs
wasm_parse
mod.rs
publish.sh
releases
friends.sh
release-announcement-template.md
traits
Cargo.toml
traits.rs
twiggy
Cargo.toml
tests
all
diff_tests.rs
dominators_tests.rs
elf_format_tests.rs
fixtures
cpp-monos.cpp
hello_world.rs
monos.rs
garbage_tests.rs
main.rs
monos_tests.rs
paths_tests.rs
top_tests.rs
twiggy.rs
wasm-api
Cargo.toml
wasm-api.rs
| <div align="center">
<h1>Twiggy🌱</h1>
<strong>A code size profiler for Wasm</strong>
<p>
<a href="https://docs.rs/twiggy/"><img src="https://docs.rs/twiggy/badge.svg"/></a>
<a href="https://crates.io/crates/twiggy"><img src="https://img.shields.io/crates/v/twiggy.svg"/></a>
<a href="https://crates.io/crates/twiggy"><img src="https://img.shields.io/crates/d/twiggy.svg"/></a>
<a href="https://travis-ci.org/rustwasm/twiggy"><img src="https://travis-ci.org/rustwasm/twiggy.svg?branch=master"/></a>
</p>
<h3>
<a href="https://rustwasm.github.io/twiggy">Guide</a>
<span> | </span>
<a href="https://rustwasm.github.io/twiggy/contributing/index.html">Contributing</a>
<span> | </span>
<a href="https://discordapp.com/channels/442252698964721669/443151097398296587">Chat</a>
</h3>
<sub>Built with 🦀🕸 by <a href="https://rustwasm.github.io/">The Rust and WebAssembly Working Group</a></sub>
</div>
## About
Twiggy is a code size profiler for Wasm. It analyzes a binary's call graph to
answer questions like:
* Why was this function included in the binary in the first place? Who calls it?
* What is the *retained size* of this function? I.e. how much space would be
saved if I removed it and all the functions that become dead code after its
removal.
Use Twiggy to make your binaries slim!
## Install Twiggy
Ensure that you have [the Rust toolchain installed](https://www.rust-lang.org/),
then run:
```
cargo install twiggy
```
## Learn More!
[**Read the Twiggy guide!**](https://rustwasm.github.io/twiggy)
<div align="center">
<img src="./guide/src/twiggy.png"/>
</div>
|
kng14_NEAR_kng.testnet | README.md
as-pect.config.js
asconfig.json
package.json
| This project is about web3 and NEAR. I tried to practice at the same time as the Patika web3 course.

|
littlelittlebook_rust-helloworld | Cargo.toml
README.md
challenge_helloworld.txt
src
lib.rs
| #
The contract code and the build setup are derived from:
https://docs.near.org/docs/develop/contracts/rust/intro
#### contract code:
src/lib.rs
#### build setup
see cargo.toml
#### run test:
`cargo test -- --nocapture`
#### build release:
`cargo build --target wasm32-unknown-unknown --release`
#### deploy
```
export ID=example-helloworld.littlebook.testnet
near deploy --wasmFile target/wasm32-unknown-unknown/release/rust_helloworld.wasm --accountId $ID
```
#### call helloworld()
`near call $ID helloworld "{\"name\":\"bob\"}" --accountId $ID`
example output
```
$ near call $ID helloworld "{\"name\":\"bob\"}" --accountId $ID
Scheduling a call: example-helloworld.littlebook.testnet.helloworld({"name":"bob"})
Doing account.functionCall()
Transaction Id CL3bT6LqaHP49rXCXCaqyp8SUDr8N4giEjeEysmYRVJf
To see the transaction in the transaction explorer, please open this url in your browser
https://explorer.testnet.near.org/transactions/CL3bT6LqaHP49rXCXCaqyp8SUDr8N4giEjeEysmYRVJf
'hello world! bob'
```
|
near-mezze_boilerplate | README.md
as-pect.config.js
asconfig.json
package.json
scripts
1.dev-deploy.sh
2.call-a-function.sh
README.md
o-transfer.sh
x-deploy.sh
x-remove.sh
src
as-pect.d.ts
as_types.d.ts
contract_name
__tests__
README.md
index.unit.spec.ts
asconfig.json
assembly
index.ts
models.ts
tsconfig.json
utils.ts
| ## Setting up your terminal
The scripts in this folder support a simple demonstration of the contract.
It uses the following setup:
```txt
┌───────────────────────────────────────┬───────────────────────────────────────┐
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
└───────────────────────────────────────┴───────────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_Owner scripts_
```sh
1.dev-deploy.sh # cleanup, compile and deploy contract
o-report.sh # generate a summary report of the contract state
o-transfer.sh # transfer received funds to the owner account
```
_Public scripts_
```sh
2.say-thanks.sh # post a message saying thank you, optionally attaching NEAR tokens
2.say-anon-thanks.sh # post an anonymous message (otherwise same as above)
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
## Unit tests
Unit tests can be run from the top level folder using the following command:
```
yarn test:unit
```
THIS IS A BOILERPLATE REPO TO BE USED AS A REFERENCE WHEN BUILDING YOUR OWN NEAR-MEZZE CONTRIBUTION.
Feel free to fork this repo, but some contributors may find it easier to create their own repos and branches from scratch rather than merging and stashing and all the other parts that go into filtering content by branch.
# Name Of Contract
Brief description of your contract. This is NOT the MezzeTech Tutorial. That will live in its own branch called `mezzetech` in its own folder specific to the `mezzetech` branch:
<!-- mezzetech branch of your contract repo -->
contract_root/ // ie. "thanks"
┣ src/
┃ ┣ mezzetech/
┃ ┃ ┣ README.MD // <===== PUT YOUR MEZZETECH TUTORIAL HERE!
READ THROUGH EVERY FILE IN THIS BOILERPLATE REPO, AND UPDATE VALUES WHERE NECESSARY, LIKE "CONTRACT_NAME"!!!
## ⚠️ Warning
Any content produced by NEAR, or developer resources that NEAR provides, are for educational and inspiration purposes only. NEAR does not encourage, induce or sanction the deployment of any such applications in violation of applicable laws or regulations.
## Contract
```ts
// perhaps relevant code here
```
## Usage
### Development
To deploy the contract for development, follow these steps:
1. clone this repo locally
2. run `./scripts/1.dev-deploy.sh` to deploy the contract (this uses `near dev-deploy`)
**Your contract is now ready to use.**
To use the contract you can do any of the following:
_Public scripts_
```sh
# script.sh files used to run public scripts
```
_Owner scripts_
```sh
# script.sh files that only the contract owner can run
```
### Production
It is recommended that you deploy the contract to a subaccount under your MainNet account to make it easier to identify you as the owner
1. clone this repo locally
2. run `./scripts/x-deploy.sh` to rebuild, deploy and initialize the contract to a target account
requires the following environment variables
- `NEAR_ENV`: Either `testnet` or `mainnet`
- `OWNER`: The owner of the contract and the parent account. The contract will be deployed to `contract_name.$OWNER`
3. run `./scripts/x-remove.sh` to delete the account
requires the following environment variables
- `NEAR_ENV`: Either `testnet` or `mainnet`
- `OWNER`: The owner of the contract and the parent account. The contract will be deployed to `contract_name.$OWNER`
|
nikoturin_etc-stack | README.md
bc
gtw
add.py
create.py
dhl.py
hyper
dhl
dhl-abc.py
dhl.py
network.json
near
NEAR.txt
README.txt
launch-local-near-cluster.sh
sc
Cargo.toml
alias-lnear.sh
lib
near-api-py
.travis.yml
README.md
near_api
__init__.py
account.py
providers.py
serializer.py
signer.py
transactions.py
near_api_py.egg-info
SOURCES.txt
dependency_links.txt
requires.txt
top_level.txt
setup.py
test
config.py
test_account.py
test_provider.py
utils.py
neartosis
validator-key.json
src
lib-counter.rs
lib-message.rs
lib.rs
target
.rustc_info.json
debug
.fingerprint
Inflector-9e3c62115074b9cf
lib-inflector.json
ahash-a39e2761a9b318be
lib-ahash.json
aho-corasick-88c550ce13039f0f
lib-aho_corasick.json
autocfg-b903f59dba3dcf2d
lib-autocfg.json
base64-4c997255cfee02b8
lib-base64.json
block-buffer-5d684c35deec4618
lib-block-buffer.json
block-padding-a8b77e74e5466e61
lib-block-padding.json
borsh-b9535a95bcd5f972
lib-borsh.json
borsh-derive-8c0cc7e2fc4e2878
lib-borsh-derive.json
borsh-derive-internal-2d98830a168db5c4
lib-borsh-derive-internal.json
borsh-schema-derive-internal-75906ce780764124
lib-borsh-schema-derive-internal.json
bs58-892d5bec26868e29
lib-bs58.json
byteorder-0a75c9c26dc9dc2c
lib-byteorder.json
cfg-if-56df745b5175507b
lib-cfg-if.json
cfg-if-77abc38cc38d84d4
lib-cfg-if.json
convert_case-95e284bc56c12eb5
lib-convert_case.json
cpufeatures-25ba4d886967ba8f
lib-cpufeatures.json
derive_more-75a2119f3265b7a4
lib-derive_more.json
digest-0f0918edbd5ce8e3
lib-digest.json
generic-array-2c7057e7269c8b9e
build-script-build-script-build.json
generic-array-48cb1672c59ee265
lib-generic_array.json
generic-array-d477dcc9c8ee7aac
run-build-script-build-script-build.json
hashbrown-4591b767b86fd320
lib-hashbrown.json
hashbrown-8ce5fddf7b71f952
lib-hashbrown.json
hex-916c50638fc1506d
lib-hex.json
indexmap-57a3089c4a03a431
lib-indexmap.json
indexmap-b758339a3de0f6f7
run-build-script-build-script-build.json
indexmap-df2b98be58009378
build-script-build-script-build.json
itoa-eb0b0da4f5c7fd02
lib-itoa.json
keccak-d871074cf8c1da3a
lib-keccak.json
lazy_static-b341606102c7008f
lib-lazy_static.json
libc-4287820d4658b87a
run-build-script-build-script-build.json
libc-65cddf312bcc17ff
lib-libc.json
libc-abbfc0da5b62aaa0
build-script-build-script-build.json
memchr-54fcbe308a18ec4d
build-script-build-script-build.json
memchr-687f6d68fd7a9ecf
run-build-script-build-script-build.json
memchr-bf8567f0069c3773
lib-memchr.json
memory_units-07096131d9263fe1
lib-memory_units.json
near-primitives-core-079066072c89327a
lib-near-primitives-core.json
near-rpc-error-core-cb3040ce35c83754
lib-near-rpc-error-core.json
near-rpc-error-macro-b56d1f15dd4c7116
lib-near-rpc-error-macro.json
near-runtime-utils-0f5442c125b4585a
lib-near-runtime-utils.json
near-sdk-core-eff9c8ab67d12673
lib-near-sdk-core.json
near-sdk-e344bca66ba89d3d
lib-near-sdk.json
near-sdk-macros-b1b3ed2a794facd5
lib-near-sdk-macros.json
near-vm-errors-0aa1d86e36229db1
lib-near-vm-errors.json
near-vm-logic-a65643c174040ddc
lib-near-vm-logic.json
num-bigint-130a7c042f278233
build-script-build-script-build.json
num-bigint-1b8342f3ba35e78c
lib-num-bigint.json
num-bigint-76595dddeb373384
run-build-script-build-script-build.json
num-integer-3cba3983bdbb26c8
lib-num-integer.json
num-integer-5a49193564154244
build-script-build-script-build.json
num-integer-cb4064ece5d2fa7b
run-build-script-build-script-build.json
num-rational-99298ec9c9ebe05d
lib-num-rational.json
num-rational-c6a677e968f18e06
build-script-build-script-build.json
num-rational-d2de59629608c452
run-build-script-build-script-build.json
num-traits-6363ea0c218b155c
build-script-build-script-build.json
num-traits-9404b175556ec8aa
lib-num-traits.json
num-traits-9680194b3bdfe878
run-build-script-build-script-build.json
opaque-debug-fc668c1c55fec23c
lib-opaque-debug.json
proc-macro-crate-9f29659481be9f0a
lib-proc-macro-crate.json
proc-macro2-047710df662d1176
lib-proc-macro2.json
proc-macro2-a618f101f74bf3f5
build-script-build-script-build.json
proc-macro2-d088cc6af031f773
run-build-script-build-script-build.json
quote-43c5dd00f7967594
lib-quote.json
regex-bc3b154a33e8c456
lib-regex.json
regex-syntax-71dab053db1b6952
lib-regex-syntax.json
ryu-53580c25f32ff188
lib-ryu.json
sc-0ea7b8184157949b
test-lib-sc.json
sc-1e696bd03d8525ad
lib-sc.json
serde-461f95a1548349ce
build-script-build-script-build.json
serde-625dbf5e28f5944e
run-build-script-build-script-build.json
serde-954a23121a187aeb
lib-serde.json
serde_derive-0bfa20a1dfc51384
run-build-script-build-script-build.json
serde_derive-c45cada09a671438
lib-serde_derive.json
serde_derive-eef97a6e7660fcc5
build-script-build-script-build.json
serde_json-05fc6194f57eebaf
build-script-build-script-build.json
serde_json-402063a290e5e920
run-build-script-build-script-build.json
serde_json-8224d4b5b41c83a9
build-script-build-script-build.json
serde_json-9033037179275ec0
lib-serde_json.json
serde_json-bc414f14b66e0d36
run-build-script-build-script-build.json
serde_json-f2ec87627f645e22
lib-serde_json.json
sha2-03c9a37c4bd229e6
lib-sha2.json
sha3-4048f4766c44e760
lib-sha3.json
syn-0359a400ed92222f
build-script-build-script-build.json
syn-7193c8fa3691c8e6
lib-syn.json
syn-84879f3141fd595e
run-build-script-build-script-build.json
toml-0b8678bbdc16e0f5
lib-toml.json
typenum-0d421246c9930e76
build-script-build-script-main.json
typenum-71af7066909fd979
run-build-script-build-script-main.json
typenum-7cce747769eb0ca2
lib-typenum.json
unicode-xid-5409942a6294a17e
lib-unicode-xid.json
version_check-f31620567ddfcb83
lib-version_check.json
wee_alloc-4c1d5fc69208e232
build-script-build-script-build.json
wee_alloc-a848f7517e730942
run-build-script-build-script-build.json
wee_alloc-b262fe6bb57af0cd
lib-wee_alloc.json
release
.fingerprint
Inflector-eefff05c7d46c877
lib-inflector.json
autocfg-e11764aaa15da0f2
lib-autocfg.json
borsh-derive-586c662bf17bd4c8
lib-borsh-derive.json
borsh-derive-internal-9aa9ca2626a1faa9
lib-borsh-derive-internal.json
borsh-schema-derive-internal-5b2f325753df5c39
lib-borsh-schema-derive-internal.json
convert_case-309159d13aa0180b
lib-convert_case.json
derive_more-397b2b25c9df9e54
lib-derive_more.json
generic-array-42eb8446d92f987c
build-script-build-script-build.json
hashbrown-dcc999bfdbf49990
lib-hashbrown.json
indexmap-9f7bbb57511db119
run-build-script-build-script-build.json
indexmap-d4bb932b356520d8
build-script-build-script-build.json
indexmap-e57bfc87bfe42bf9
lib-indexmap.json
itoa-41916f16883dab3c
lib-itoa.json
memchr-31abe38597d7b823
build-script-build-script-build.json
near-rpc-error-core-2f14ab5cef8a7d1b
lib-near-rpc-error-core.json
near-rpc-error-macro-0ef6774bf1e32e36
lib-near-rpc-error-macro.json
near-sdk-core-f4205868c163413e
lib-near-sdk-core.json
near-sdk-macros-3185e7dc79c8ae46
lib-near-sdk-macros.json
num-bigint-82d5e7b0fb0cd638
build-script-build-script-build.json
num-integer-8e4760f913b9d2b0
build-script-build-script-build.json
num-rational-46f4e4b7872f2ec9
build-script-build-script-build.json
num-traits-bda8170b699ff08c
build-script-build-script-build.json
proc-macro-crate-85d7050b4130128e
lib-proc-macro-crate.json
proc-macro2-163e23eed4381642
build-script-build-script-build.json
proc-macro2-2979ae51568041fb
run-build-script-build-script-build.json
proc-macro2-7a94e06a9cd88ff8
lib-proc-macro2.json
quote-4d572bb0b998a285
lib-quote.json
ryu-c3a68d6e75e02b00
lib-ryu.json
serde-69aa6b3d77f8bfb6
build-script-build-script-build.json
serde-b2ee758c4b0aa07b
run-build-script-build-script-build.json
serde-ccbd213f144ff48d
lib-serde.json
serde_derive-4b0bf73efd96d202
build-script-build-script-build.json
serde_derive-c79fb7883a53f40b
run-build-script-build-script-build.json
serde_derive-cf11cd19fc59654b
lib-serde_derive.json
serde_json-4e2b506cbd08a729
build-script-build-script-build.json
serde_json-9803a5643ae775bf
build-script-build-script-build.json
serde_json-9c68e9e1c1d4eb2f
run-build-script-build-script-build.json
serde_json-cf1e7a6cba0d50f4
lib-serde_json.json
syn-2584b402440daf00
build-script-build-script-build.json
syn-34d0cd23b80b7deb
run-build-script-build-script-build.json
syn-c783db0ec588505b
lib-syn.json
toml-f73fdef50ce0e08d
lib-toml.json
typenum-76b33697fce6242c
build-script-build-script-main.json
unicode-xid-ca0bb3bdb9d52718
lib-unicode-xid.json
version_check-481946e0a774cb9c
lib-version_check.json
wee_alloc-56f41bf66950ca1a
build-script-build-script-build.json
wasm32-unknown-unknown
release
.fingerprint
ahash-3f602f2bb35305d5
lib-ahash.json
aho-corasick-ab2d41586334adf6
lib-aho_corasick.json
base64-0266aaf2a36d6a95
lib-base64.json
block-buffer-87c4d494b40e7c29
lib-block-buffer.json
block-padding-d82d63ae3d05a6fc
lib-block-padding.json
borsh-485b599027886d68
lib-borsh.json
bs58-f4b2e40280ca61bd
lib-bs58.json
byteorder-f068b63568bb2dc2
lib-byteorder.json
cfg-if-4b6f1020c71c4854
lib-cfg-if.json
cfg-if-996161407648b543
lib-cfg-if.json
digest-9a57f5c8feeca87a
lib-digest.json
generic-array-5e99ac64510a72ef
run-build-script-build-script-build.json
generic-array-c2570338da65f164
lib-generic_array.json
hashbrown-452902ff07dbf6b7
lib-hashbrown.json
hex-cdfd77af73369eda
lib-hex.json
itoa-0feab52b9d88a70f
lib-itoa.json
keccak-f86991b32285e158
lib-keccak.json
lazy_static-f4536af75ba8e49f
lib-lazy_static.json
memchr-af250e1e42bf7a0e
lib-memchr.json
memchr-c0a563a4a38f5852
run-build-script-build-script-build.json
memory_units-a3e83b33528dff62
lib-memory_units.json
near-primitives-core-6b77fc9e72001900
lib-near-primitives-core.json
near-runtime-utils-62b51ce89603707f
lib-near-runtime-utils.json
near-sdk-8818369262d63ff8
lib-near-sdk.json
near-vm-errors-84cca9cd9aef7192
lib-near-vm-errors.json
near-vm-logic-77275e1f5d85ddf9
lib-near-vm-logic.json
num-bigint-18eaa3b21004fa35
run-build-script-build-script-build.json
num-bigint-5dee533122ba1dd3
lib-num-bigint.json
num-integer-6d3a3708adaaaa31
lib-num-integer.json
num-integer-dd8804c6ce0d5b4d
run-build-script-build-script-build.json
num-rational-14dc096e81ae3921
lib-num-rational.json
num-rational-a816356f190add59
run-build-script-build-script-build.json
num-traits-cb1446d6fda4722b
lib-num-traits.json
num-traits-d8996ad2bde53ad7
run-build-script-build-script-build.json
opaque-debug-1b7ea0b07f1afb39
lib-opaque-debug.json
regex-7db1a79e560c4b39
lib-regex.json
regex-syntax-a274abc2f467a00c
lib-regex-syntax.json
ryu-6ffc5441d4711478
lib-ryu.json
sc-1e696bd03d8525ad
lib-sc.json
serde-8ec7d3fc7bfab743
run-build-script-build-script-build.json
serde-bd43b52e7873ec25
lib-serde.json
serde_json-5db171fd9615cdf5
lib-serde_json.json
serde_json-d1d022b10699633b
run-build-script-build-script-build.json
sha2-162997a251efd63a
lib-sha2.json
sha3-d85e5c6232ec6a50
lib-sha3.json
typenum-be4578f4a50040a8
run-build-script-build-script-main.json
typenum-f18ab010645daf28
lib-typenum.json
wee_alloc-034861dc56ef4c30
run-build-script-build-script-build.json
wee_alloc-deb6b3e0ff371f74
lib-wee_alloc.json
build
num-bigint-18eaa3b21004fa35
out
radix_bases.rs
typenum-be4578f4a50040a8
out
consts.rs
op.rs
tests.rs
wee_alloc-034861dc56ef4c30
out
wee_alloc_static_array_backend_size_bytes.txt
MODULE LOGS
END MODULE LOGS
db
README.txt
cruces.sql
operN.sql
gtw
README.md
mq
rabbitmq
script
README.txt
queue.sh
src
README.txt
config.py
network.json
oper2Receive.py
oper3Receive.py
receive.py
send.py
tools
NEAR.txt
README.txt
paramsChange.sh
| Problem
In order for a TAG device to be accepted on a highway, tunnel or bridge affiliated with interoperability, the operators have the task of exchanging data among themselves of any transaction registered in their Electronic Toll infrastructure, with the primary purpose of having an updated global pattern of TAGs.
The current interoperability process is carried out through the use of SFTP servers, in which each Electronic Toll operator deposits the tolls associated with any TAG, with XML being the standard format for exchanging information used between them.
It has been observed that the Electronic Toll operators have manual and, in the best of cases, semi-automated mechanisms to exchange transaction data from both their own and third-party TAGs. The current solution has drawbacks in the data collection and delivery processes, the following being the most relevant:
1.- Loss of communication when exchanging obtaining the XML file, that is, the information may not be completely obtained, since there may be data losses during the transmission of the file.
2.- Review the SFTP server from time to time, it can generate that the allowed number of asynchronous sockets can remain in "TIME WAIT" status, adding said status to the number of sockets allowed by server and user with "ESTABLISHED" status, said behaviors without importing the operating system, Windows or Llinux, which are governed by POSIX, can lead to loss of access to SFTP servers, putting at risk the integrity of the TAGs in terms of their status and/or available balance.
3.- The information could be modified directly in the SFTP servers, by both internal and external attacks, this being a problem when carrying out the toll reconciliation processes, with totally incongruous figures, generating a waste of time and money when generating the tolls. collection invoices for both operators and end customers
The current scenario, in which consumers are increasingly demanding about the quality of the services they demand, forces us to implement alternatives different from how the data is processed. An ideal mechanism is the use of disruptive technologies that can put the Electronic Toll sector in ideal circumstances of connectivity and avant-garde competitiveness.
Solution
Derived from the current technical situation, the development of an interface capable of being able to insert each of the crossings made at the toll booths through electronic tolls in a private blockchain network is proposed, where in the same way it can send data of control figures to a network. public; Once the previous steps have been carried out, you can immediately filter and determine which operator the toll belongs to, complying with the interoperability process, leaving SFTP servers out, and adapting a queuing system that can comply with fault tolerance.
In order to comply with transparency in the transactions carried out and if it is necessary to request information directly from the private network to reconcile information that the regulatory entity may question, where the private blockchain will be its main source of information, NEAR blockchain will be used. public for the issuance of delivery document receipt of requested information, generating document as NFT, and can be used as unique proof, using IPFS as a file storage system, where in the same way the integrity of the generated document can be counted on.
With the foregoing, the acquisition of the NEAR Token by the client is determined to carry out requests to extract information directly from the private blockchain, said fee will be to meet transaction expenses for the creation of receipt delivery receipt; a web portal will be created where the transfer of funds can be made, which will be able to interact with the smart contract developed in NEAR.
Once the transfer of funds for the acquisition of information from the company/operator, a temporary channel will be created that will expose the corresponding information of the applicant, said information extracted from the private blockchain network.
Continuing with the flow of information transparency, said funds transferred through the NEAR token will continue to be transparent for the client, since they will be in a public network, said protocol was selected, since the cost of transactions is lower. to others such as ETHEREUM, in addition to the use of the Proof Of Stake (PoS) protocol, making transactions per second (TPS) more agile and faster.
The cost in the transactions of transparency of control figures, may be assumed by the company that will regulate the electronic toll booths, these figures being uploaded in accordance with what is proposed by it, that is, on a weekly or monthly basis, for validation by the the managing companies.
The infrastructure of the private network will be carried out through the use of AWS, assembling HyperLedger BAF as a framework, making use of Fabric, BAF is contemplated derived from the entire automation environment created.

# near-api-py
*Status: super rough, APIs are subject to change*
A Python library for development of applications that are using NEAR platform.
# Contribution
First, install the package in development mode:
```bash
python setup.py develop
```
To run tests, use nose (`pip install nose`):
```bash
nosetests
```
# License
This repository is distributed under the terms of both the MIT license and the Apache License (Version 2.0). See LICENSE and LICENSE-APACHE for details.
Steps to create Virtual SSL with DNS validated.
ROOT SSL: This files necesary to validate local URL.
1.- openssl genrsa -des3 -out rootCA.key 2048
- This commands will be used to create rootSSL.
2.- openssl req -x509 -new -nodes -key rootCA.key -sha256 -days 1024 -out rootCA.pem
- This parameters will be used to create rootSSL.
MaC -- TRUST root SSL
- Open KeyChain Access on Mac and go to Certificates category on system.
- Import rootCA.pem Files>importa items.
- Double click on rootCA.pem importated, and accept trust.
DOMAIN SSL Certificate:
1.- Create next file server.csr.cnf
[req]
- default_bits = 2048
- prompt = no
- default_md = sha256
- distinguished_name = dn
[dn]
- C=US
- ST=RandomState
- L=RandomCity
- O=RandomOrganization
- OU=RandomOrganizationUnit
- emailAddress=hello@example.com
- CN = localhost
2.- Create file called v3.ext to create a X509 V3 certificate.
- authorityKeyIdentifier=keyid,issuer
- basicConstraints=CA:FALSE
- keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
- subjectAltName = @alt_names
[alt_names]
- DNS.1 = localhost
3.- Execute next line commands and parameters:
openssl req -new -sha256 -nodes -out server.csr -newkey rsa:2048 -keyout server.key -config <( cat server.csr.cnf )
4.- Will create the certifcate necesary to validate Local DNS
openssl x509 -req -in server.csr -CA rootCA.pem -CAkey rootCA.key -CAcreateserial -out server.crt -days 500 -sha256 -extfile v3.ext
EDIT /ETC/HOSTS
1.- Will be necesary to edit /etc/hosts of windows + mac o linux with DNS selected
Note:
This steps using command openssl can be used to windows and linux version, and rootCA.pem on this way:
Windows:
1.- Microsoft Management Console MMC.EXE
2.- Add/Remove Snap In
2.1 - Certificates for the Computer Account and in the next screen for the Local Computer
3.- Import root into Trusted Root Certification Authorities
3.1 - The Import Wizard starts, now. Use "Local Machine" and Next
3.2 - * Browse for file rootCA.crt instead rootCA.pem
3.3 - Browse for the correct Certificate Location for root (Trusted Root Certification Authorities)
3.4 - Finish the import of root
3.5 - And be sure you trust it. Rightclick root as CA cert Signing Authority and select Properties
Note: Command to change pem to crt file, used at windows Certification Authorities (openssl x509 -outform der -in rootCA.pem -out rootCA.crt)
4.- Import "class3" into "Intermediate Certification Authorities"
4.1 The Import Wizard starts, now. Use "Local Machine" and "Next".
4.2 Browse for file "server.crt"
4.3 Browse for the correct Certificate Location for "root" (Trusted Root Certification Authorities)
4.4 Finish the import of "root"
4.5 And be sure you trust it. Rightclick "root" as "CA cert Signing Authority" and select Properties.
|
near_near-api-kotlin | .github
ISSUE_TEMPLATE
BOUNTY.yml
README.md
app
src
main
AndroidManifest.xml
res
drawable-v24
ic_launcher_foreground.xml
drawable
ic_launcher_background.xml
layout
activity_near_demo_main.xml
fragment_login.xml
fragment_transaction.xml
mipmap-anydpi-v26
ic_launcher.xml
ic_launcher_round.xml
values-night
themes.xml
values
colors.xml
strings.xml
themes.xml
gradlew.bat
jitpack.yml
knear-sdk
src
main
AndroidManifest.xml
| # Kotlin SDK
This is a open source project on kotlin for NEAR protocol.
# Description
Near Android SDK implemented in Kotlin to interact with the NEAR blockchain.
# Features
* Includes Login into Near wallet
* Send transactions
* Retrieve information about accounts and contracts
* Sign and send transactions
* View access keys and more.
# Requirements
• Minimum android version API 26+
• Minimum Java 8 version
# RPC Calls
We support [THIS](https://docs.near.org/api/rpc/introduction) rpc calls.
## Configuration
First add dependency to your app build.gradle
```
implementation 'com.github.near:near-api-kotlin:1.0.14`
```
then, add the next resource in your settings.gradle
```
maven { url "https://jitpack.io" }
```
## Usage
In your manifest add the next permissions
```
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<uses-permission android:name="android.permission.INTERNET" />
```
you should have an activity and inside you have to add an intent filter
```
<activity
android:name=".DemoActivity"
android:exported="true">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
<intent-filter>
<action android:name="android.intent.action.VIEW" />
<category android:name="android.intent.category.DEFAULT" />
<category android:name="android.intent.category.BROWSABLE" />
<data
android:host="success-auth"
android:scheme="near" />
</intent-filter>
</activity>
```
this will help your activity catch the data we need after login into your Near wallet account in your browser.
# First
## Login into your account
The first thing you should do before accessing all the other functions in the Near SDK library is logging into yout Near wallet account.
In your activity you should create an instance of ``` NearMainService ```
```
private var nearMainService: NearMainService = NearMainService(this)
```
then, call login() method. This will call an Intent to open browser and login into your Near wallet account.
```
nearMainService.login("yourusername.testnet")
```
Finally, override the onResume() method and check if login was successfull.
```
override fun onResume() {
super.onResume()
val uri = intent.data
if (nearMainService.attemptLogin(uri)){
// Do anything after logging in
}
}
```
Once you are logged in you can use any method inside ``` NearMainService ``` class.
## Make a Transaction
After user is logged in, call ``` sendTransaction() ``` method with the receiver user name and Near amount inside a ``` Coroutine ``` to wait for the response
```
CoroutineScope(Dispatchers.IO).launch {
val sendMoney = withContext(Dispatchers.IO) {
nearMainService.sendTransaction("receiverusername.testnet", "1")
}
}
```
and thats it, that's how you make a transaction.
In this repository we have an example of how to make a transaction and also how to call a [contract method as view function][1].
[1]: https://google.com
## Demo and Screenshots


After building the demo project in you local, you will be able to see the first screen where you have to type your user name and continue to login in the browser.
By clicking on the "Transaction" button 1 Near is send to "android-test-23.testnet" default account ([Transaction docs][2]) and finally prints the response in the logs and displays it on the screen.
[2]: https://docs.near.org/api/rpc/transactions#send-transaction-async
If you click "Call function" button, contract methods are going to be called as [view functions][3].
[3]: https://docs.near.org/api/rpc/contracts#call-a-contract-function
In this case we have a call for 3 different contracts that receives some parameters and returns a call back and finally it prints the response in the logs and displays it on the screen.
```
private fun callFunction() {
var balanceOfArgs = "{ \"tokenOwner\": \"android-test-22.testnet\" }"
val contractName = "android-test-22.testnet"
val balanceOfResponse = this.nearMainService.callViewFunction(contractName, "balanceOf", balanceOfArgs)
if(balanceOfResponse.error == null) {
val functionResult = balanceOfResponse.result.result!!.getDecodedAsciiValue()
}
val totalSupplyArgs = "{}"
val totalSupplyResponse = this.nearMainService.callViewFunction(contractName, "totalSupply", totalSupplyArgs)
if(totalSupplyResponse.error == null) {
val functionResult = totalSupplyResponse.result.result!!.getDecodedAsciiValue()
}
val transferFromArgs = "{ \"from\": \"android-test-22.testnet\", \"to\": \"android-test-23.testnet\", \"tokens\": \"1\" }"
val transferFromResponse = this.nearMainService.callViewFunction(contractName, "transferFrom", transferFromArgs)
if(transferFromResponse.error == null) {
val functionResult = totalSupplyResponse.result.result!!.getDecodedAsciiValue()
}
balanceOfArgs = "{ \"tokenOwner\": \"android-test-22.testnet\" }"
val callViewFunctionTransactionResponse = this.nearMainService.callViewFunctionTransaction(contractName, "balanceOf", balanceOfArgs)
if(callViewFunctionTransactionResponse.result.status.Failure == null) {
callViewFunctionTransactionResponse.result.status.SuccessValue?.let {
val decodedValue = String(Base64.getDecoder().decode(it))
}
}
val invalidBalanceOfArgs = "{ tokenOwner: android-test-22.testnet }"
val errorResponse = this.nearMainService.callViewFunctionTransaction(contractName, "balanceOf", invalidBalanceOfArgs)
}
```
In this block of code we make the calls by using ``` nearMainService.callViewFunction() ``` and ``` nearMainService.callViewFunctionTransaction() ```
|
markeymark32_ragingRhinoCoinFlip | .gitpod.yml
README.md
babel.config.js
contract
Cargo.toml
README.md
compile.js
src
lib.rs
target
.rustc_info.json
debug
.fingerprint
Inflector-a8f4e37dd556cf0f
lib-inflector.json
autocfg-e8d96e7f2b762b9c
lib-autocfg.json
borsh-derive-a078a7b9a2a03464
lib-borsh-derive.json
borsh-derive-internal-103dbffa76195871
lib-borsh-derive-internal.json
borsh-schema-derive-internal-62d34519e20996ba
lib-borsh-schema-derive-internal.json
byteorder-7e9eedb750cb0c68
build-script-build-script-build.json
convert_case-a25c4144c68d7d73
lib-convert_case.json
derive_more-c3d2ec1b6c44a8b4
lib-derive_more.json
generic-array-b3a15bae3bd7dcb8
build-script-build-script-build.json
hashbrown-29e2d33e445a3fe8
build-script-build-script-build.json
hashbrown-3b862f5ff2ac6f18
run-build-script-build-script-build.json
hashbrown-8a0eae45c5c8fe28
lib-hashbrown.json
indexmap-3fe13978a1dc9b3f
run-build-script-build-script-build.json
indexmap-7dfb354d589d374d
build-script-build-script-build.json
indexmap-df8cb351f7c33f76
lib-indexmap.json
itoa-331611d2ec6ae993
lib-itoa.json
memchr-a50d6597a861a8f7
build-script-build-script-build.json
near-rpc-error-core-5b3cc03d1710d7ab
lib-near-rpc-error-core.json
near-rpc-error-macro-6a35fc896e2df83b
lib-near-rpc-error-macro.json
near-sdk-core-eb94d12de2525c81
lib-near-sdk-core.json
near-sdk-macros-b1b8ee25c116c852
lib-near-sdk-macros.json
num-bigint-80833f2f9084448e
build-script-build-script-build.json
num-integer-7cbcc6a07cabe7e8
build-script-build-script-build.json
num-rational-56b5aa6f0fda1b90
build-script-build-script-build.json
num-traits-6b11e7e494784fe9
build-script-build-script-build.json
proc-macro-crate-b1854959dfbabb13
lib-proc-macro-crate.json
proc-macro2-49dd073150bc1e8a
build-script-build-script-build.json
proc-macro2-4e8d526cdba69d52
run-build-script-build-script-build.json
proc-macro2-755220030b6adeba
lib-proc-macro2.json
quote-7404cf61f39c038f
lib-quote.json
ryu-1b2f9606b802eb11
lib-ryu.json
ryu-779cb093985a02e5
build-script-build-script-build.json
ryu-8773db53b69c0f30
run-build-script-build-script-build.json
serde-092aa86710bd1b86
lib-serde.json
serde-73a504bdb0181fd5
run-build-script-build-script-build.json
serde-75e29c70260d7122
build-script-build-script-build.json
serde_derive-6a1ba2f754e150b4
lib-serde_derive.json
serde_derive-d7f1afee7646f1c5
build-script-build-script-build.json
serde_derive-ed6268f28ec92d28
run-build-script-build-script-build.json
serde_json-185ddd35f392fdc6
run-build-script-build-script-build.json
serde_json-5333a6b33ccbec13
lib-serde_json.json
serde_json-a9fb65022ffa8dcc
build-script-build-script-build.json
syn-20c381101c96c377
lib-syn.json
syn-7ed442754f82fc5a
run-build-script-build-script-build.json
syn-e70214b5c99efffe
build-script-build-script-build.json
toml-d7bd9648c130bc79
lib-toml.json
typenum-e70c9dd60c60cb4a
build-script-build-script-main.json
unicode-xid-745589536fdb3b82
lib-unicode-xid.json
version_check-0e39a7d855ce105c
lib-version_check.json
wee_alloc-f4e7c3437706fb20
build-script-build-script-build.json
wasm32-unknown-unknown
debug
.fingerprint
ahash-4151b74ccb9ac658
lib-ahash.json
aho-corasick-30830de0121e7d41
lib-aho_corasick.json
base64-723a5f30cf4b1d9f
lib-base64.json
block-buffer-64d4c090b8fdc4c8
lib-block-buffer.json
block-buffer-800520124a516413
lib-block-buffer.json
block-padding-d35c6e4cb39777ca
lib-block-padding.json
borsh-bb26836f50a7ab69
lib-borsh.json
bs58-2bb05e0df8f22591
lib-bs58.json
byte-tools-c940c9fd834d33ec
lib-byte-tools.json
byteorder-37c174d09247e297
lib-byteorder.json
byteorder-81667a7785ba03f3
run-build-script-build-script-build.json
cfg-if-29986574b9e347b3
lib-cfg-if.json
cfg-if-f98e23c88f079db2
lib-cfg-if.json
digest-8d87f2f9892bbc2b
lib-digest.json
digest-ec0e1f6337796fb7
lib-digest.json
generic-array-3f329714b61c8874
lib-generic_array.json
generic-array-83b306600592ba91
lib-generic_array.json
generic-array-c3aeadd2240ce532
run-build-script-build-script-build.json
greeter-98ace302c5fafa12
lib-greeter.json
hashbrown-263146f50e5146bb
run-build-script-build-script-build.json
hashbrown-27083db2368b3a92
lib-hashbrown.json
hashbrown-49542153239af762
lib-hashbrown.json
hex-b86070c12ddfcacb
lib-hex.json
indexmap-92571100829cca1e
lib-indexmap.json
indexmap-e35bb55c8d49c201
run-build-script-build-script-build.json
itoa-a83116eed5dc3ffc
lib-itoa.json
keccak-5f54c096210a08d4
lib-keccak.json
lazy_static-4c7a6f01f2cc8579
lib-lazy_static.json
memchr-09962c3247d74f55
run-build-script-build-script-build.json
memchr-dc50ab763d846fe1
lib-memchr.json
memory_units-a2806337a5fb87f2
lib-memory_units.json
near-primitives-core-fa72cdc07d790415
lib-near-primitives-core.json
near-runtime-utils-7dd36f383ebef113
lib-near-runtime-utils.json
near-sdk-a8053627dfc276b9
lib-near-sdk.json
near-vm-errors-1f0a53a97416dfd7
lib-near-vm-errors.json
near-vm-logic-6edb9c8bf645b3dc
lib-near-vm-logic.json
num-bigint-47ea9e975d2103d5
run-build-script-build-script-build.json
num-bigint-c65a33bbf00d578e
lib-num-bigint.json
num-integer-b23b5377badfc3a9
run-build-script-build-script-build.json
num-integer-e1e6a00b34df36f3
lib-num-integer.json
num-rational-2ef6957bbbc0c991
lib-num-rational.json
num-rational-5da62b0359936a51
run-build-script-build-script-build.json
num-traits-428db73f2cfdc5e3
lib-num-traits.json
num-traits-47d313abec9f8e0d
run-build-script-build-script-build.json
opaque-debug-288ede7c213d70ab
lib-opaque-debug.json
opaque-debug-be28852925d7b070
lib-opaque-debug.json
regex-431b4d8006fc2546
lib-regex.json
regex-syntax-d56f0695f9bcd6ca
lib-regex-syntax.json
ryu-afb7a552e02812a9
run-build-script-build-script-build.json
ryu-c4ab5e492da7b9f0
lib-ryu.json
serde-15fd5d4f8d2b3d98
lib-serde.json
serde-87d9dc5efef0814e
run-build-script-build-script-build.json
serde_json-a7c20cd9171941d7
lib-serde_json.json
serde_json-e49471fbd0d48f00
run-build-script-build-script-build.json
sha2-7ab0f3bdebe05454
lib-sha2.json
sha3-fc7db6df80412acb
lib-sha3.json
typenum-ee8cab77d406d3c5
lib-typenum.json
typenum-f286b84b88677e26
run-build-script-build-script-main.json
wee_alloc-10300a9e987d1da4
lib-wee_alloc.json
wee_alloc-efe42a590f64ca87
run-build-script-build-script-build.json
build
num-bigint-47ea9e975d2103d5
out
radix_bases.rs
typenum-f286b84b88677e26
out
consts.rs
op.rs
tests.rs
wee_alloc-efe42a590f64ca87
out
wee_alloc_static_array_backend_size_bytes.txt
package.json
src
App.css
App.js
Coinflip.css
GamePlay.js
PixeloidSans-Bold.svg
PixeloidSans.svg
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
components
Coinflip.js
Histroy.js
config.js
css
fonts
PixeloidSans-Bold.svg
PixeloidSans.svg
info.txt
global.css
globals.css
index.html
index.js
info.txt
jest.init.js
main.test.js
styleguide.css
styles.css
utils.js
wallet
login
index.html
| ragingRhinosCoinFlip Smart Contract
==================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
ragingRhinosCoinFlip
==================
This [React] app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `ragingRhinosCoinFlip.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `ragingRhinosCoinFlip.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account ragingRhinosCoinFlip.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'ragingRhinosCoinFlip.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
|
ngocducedu_guest-book-nearspring-hack | .eslintrc.yml
.github
dependabot.yml
workflows
deploy.yml
tests.yml
.gitpod.yml
.travis.yml
README-Gitpod.md
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
guestbook.spec.ts
as_types.d.ts
main.ts
model.ts
tsconfig.json
babel.config.js
neardev
shared-test-staging
test.near.json
shared-test
test.near.json
package.json
src
App.js
config.js
index.html
index.js
tests
integration
App-integration.test.js
ui
App-ui.test.js
| Guest Book
==========
[](https://travis-ci.com/near-examples/guest-book)
[](https://gitpod.io/#https://github.com/near-examples/guest-book)
<!-- MAGIC COMMENT: DO NOT DELETE! Everything above this line is hidden on NEAR Examples page -->
Sign in with [NEAR] and add a message to the guest book! A starter app built with an [AssemblyScript] backend and a [React] frontend.
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you have Node.js ≥ 12 installed (https://nodejs.org), then use it to install [yarn]: `npm install --global yarn` (or just `npm i -g yarn`)
2. Run the local development server: `yarn && yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet! Running `yarn dev` will tell you the URL you can visit in your browser to see the app.
Exploring The Code
==================
1. The backend code lives in the `/assembly` folder. This code gets deployed to
the NEAR blockchain when you run `yarn deploy:contract`. This sort of
code-that-runs-on-a-blockchain is called a "smart contract" – [learn more
about NEAR smart contracts][smart contract docs].
2. The frontend code lives in the `/src` folder.
[/src/index.html](/src/index.html) is a great place to start exploring. Note
that it loads in `/src/index.js`, where you can learn how the frontend
connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and backend. The
backend code gets tested with the [asp] command for running the backend
AssemblyScript tests, and [jest] for running frontend tests. You can run
both of these at once with `yarn test`.
Both contract and client-side code will auto-reload as you change source files.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contracts get deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli
--------------------------
You need near-cli installed globally. Here's how:
npm install --global near-cli
This will give you the `near` [CLI] tool. Ensure that it's installed with:
near --version
Step 1: Create an account for the contract
------------------------------------------
Visit [NEAR Wallet] and make a new account. You'll be deploying these smart contracts to this new account.
Now authorize NEAR CLI for this new account, and follow the instructions it gives you:
near login
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'your-account-here!'
Step 3: change remote URL if you cloned this repo
-------------------------
Unless you forked this repository you will need to change the remote URL to a repo that you have commit access to. This will allow auto deployment to GitHub Pages from the command line.
1) go to GitHub and create a new repository for this project
2) open your terminal and in the root of this project enter the following:
$ `git remote set-url origin https://github.com/YOUR_USERNAME/YOUR_REPOSITORY.git`
Step 4: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contracts to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
[NEAR]: https://near.org/
[yarn]: https://yarnpkg.com/
[AssemblyScript]: https://www.assemblyscript.org/introduction.html
[React]: https://reactjs.org
[smart contract docs]: https://docs.near.org/docs/develop/contracts/overview
[asp]: https://www.npmjs.com/package/@as-pect/cli
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.near.org
[near-cli]: https://github.com/near/near-cli
[CLI]: https://www.w3schools.com/whatis/whatis_cli.asp
[create-near-app]: https://github.com/near/create-near-app
[gh-pages]: https://github.com/tschaub/gh-pages
|
near_bwe-demos | .bos-loader.toml
.github
workflows
deploy-mainnet.yml
README.md
globals.d.ts
package.json
| # bwe-demos
Demo components for BOS Web Engine
|
futurewitness_demon | .cache
05
324700d83f88b5efa82f1412b0179f.json
08
69bfb60e28d45c16c8cd070de514f0.json
09
d7e6b3d84fbc192033b044b3af760b.json
0b
ea080f2bb5b009d976518806fe9903.json
15
247a58d4891dfbecdfb90cacc60130.json
1a
8d2e00b77f1d6ebf9a568d3bc76abe.json
1c
dedd7562cb9def6bd0f5b76e4bdbf1.json
1e
2e869beeb05607e294c9e273c17340.json
1f
3679899d3534873c42ca9a7c1fbdc4.json
21
d7f6c9154fbd6f3984056e5c442db7.json
2a
30ee5dd5bd8e3d5433d63f85e00c1a.json
2d
d0c510b112fb6215d49d6d900061ff.json
2e
a2f8da487376396f278baace6a7c09.json
32
71146d9318e22afe8e817909a451f8.json
3d
cfc2c3bb051164b33745bb54cc7042.json
41
e827a36baec7e13e698e3522c77d96.json
44
e0ef85b2c53c84b92c64a4789974fa.json
fc222299bc2db500749fe401d71584.json
45
9a35efe97c44352059c4ad2709da2a.json
46
642de55ca2824a252652606ddce48d.json
49
94cbbdef861f4dbd6dbcef820abfec.json
4d
3ebf114a6bf2c9a95f9256b6adffc4.json
f4233360367100a78a9b11be26f98c.json
55
9fbbf7863b4e9eead65dae3f8b0605.json
59
d95c9c19ac8875e99c4bfda5deee5b.json
5b
5fd0c1958e0e624302744b96531886.json
a523bb0ea20f0081927ac0d7a016bb.json
5f
f8cc387e19cfca3a865e6874ba7b70.json
60
9728e10af2c016cdefa450f8cfe247.json
a9e72f8c3da094abdc0be9fb3e196f.json
c5e1cf36a2245635a684116be66dae.json
66
403a0d087753094cd71a42b52787b4.json
67
9e91ccaa1356dfeb55a7911a55df6a.json
69
2ab715533176071c1fabf97ebb1380.json
eae2186f6ececf7211349f9b6e9430.json
6a
b298d9808df6bb0f6b5e1e552bd145.json
b8ac050a9249b0a9602560b278dbaf.json
6e
bb291cc32fc4522d2809a771449b6b.json
6f
eefe3b08282b228ed25da404e6cb3a.json
71
90c8399b2e989ad738c915de47a88c.json
72
57aea2fb59bf9b79b81de8ead958aa.json
74
a7f7f2e10975ee6b87433ab93c249e.json
76
b108d5b65f6d985227d795a16caba4.json
7d
9f08e227d0435768c90c4edf5a4f75.json
7f
8ba996fe8fa3a39c7c1291ddd48b83.json
81
6da17a44ddc9a270197b0938627776.json
82
0e330f5e4de3ae45843cb4b6c684d1.json
32b97e7c838b32be569fa64a713586.json
c3889cbfe430dbcabd6a390209b97a.json
84
46dcbfc044ca61a517b8eeee3d4438.json
73a136ef551131dbfd8598771ae4d3.json
7ac98d067ae8b2740c1b65b4992d61.json
8a
4801a92b870b0b3b9155a0b8033e25.json
8b
52b97c8e8524c57e9c1cad6d755ece.json
91
ade14d917d1e0701ac94905cbf51b6.json
93
eda5c181715698494880dd7b351395.json
95
a5f5ab6e8c3c038590f52267dba27d.json
9a
d3785a6ec69b325ae46244873c98f0.json
9e
67234e317926127891fabba4781331.json
7dde2f3cfc84ade0927dc13e46c402.json
d4ae694e1eaf34c627cbbad7416111.json
9f
72a5c81377f951e6081be8298eda50.json
a0
385521e77ec2ab529d2d15d058e234.json
a1
351f5cf54b1fc80a09c761d8ee1c97.json
a9
143d786614727c53913807565b2c73.json
aa
e45198036f9ddc64b6e81e9a671bc9.json
ae
1d5a8a42927583081b123ea29c7133.json
af
d0b224f9e4e197f99772f8d18bf205.json
b2
41e196d2f34b8e32783b85bc5128d6.json
eddd0c69e976f31c3b925c8677492d.json
b5
bc381a413025b2c3d8087418b0daf6.json
b7
7f30f0d0288b74722146d288e3da14.json
ba
72cd50b4c644c0417298081819ee1f.json
bb
f13c387e6ad8e69a9500d9157a2371.json
c1
192322a6b685aea51a0012e6cc4741.json
c2
8586c22f10ea6be31ffdc5336b7829.json
c4
2c9adc726414eba5d711ae33a49f51.json
b2f3be410e5c9217dab550491c0878.json
c8
bf9b82c817665593d9c60dcbeb7c77.json
cc
c031c79e68961509e5e30b507dd9a8.json
cf
2a114479772288872998a909a382fa.json
d0
0d9d632e4981e972d6a93a8e958d6d.json
d7
10f6de133c1978876694fd7d6ae4ba.json
d8
11c8dc912b9f0eeb861ce03eb8be08.json
43299c3aed2de920db671cf1254586.json
db
1e44e04fa67cd405e33f2afa5b9917.json
dc
dc5658674bbfcc8bfb8eaebfef1c2c.json
ed0bedfac8491177e9ea78a7de05e1.json
dd
b169ca4cd7188d09d97528ccde2d2a.json
de
87a04746fa663028245b4f52c02c0b.json
df
1c420fac07b838b4542481cab0ab80.json
84965ec13cfb604da8e5139206e16b.json
e3
cc67b9ab0bbb9d20b3ad7ee3e38c35.json
e5
3e2af582707ef7cc5f47bc4020881e.json
e9
eaf40bea9e785ab386d799ce2b3255.json
ea
92f050c7954431587af0fa96baaae6.json
af7fcb4912250decac1a0e04b63572.json
ec
9239ab7bb9d0bbee7a62f5f61a0621.json
ed
9c802c5b201cb14114d01765de5c58.json
f2
ed29c32cf000517d0f91cde8e467ca.json
f3
db25d6750c52d06030450f7b258ba5.json
f4
bb9a8c41f55ffc6a4253fcf1aeca31.json
f5
de5ff59539fd3e46f64b41777cac58.json
f6
b4d9bf170b0773a87ab13e9ae12a17.json
f8
6566c1f357f85f0a4fdf606b1397dc.json
fc
86e0067e38d4cb4a168a0f4f412832.json
.gitpod.yml
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
main.spec.ts
as_types.d.ts
main.ts
tsconfig.json
dist
global.e50bbfba.css
global.e50bbfba.js
index.html
index.js
logo-black.eab7a939.svg
src.e31bb0bc.js
package.json
src
assets
logo-black.svg
logo-white.svg
config.js
global.css
index.html
index.js
main.test.js
utils.js
wallet
login
index.html
| hack-rainbow
==================
This app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `npm install`
3. Run the local development server: `npm run dev` (see `package.json` for a
full list of `scripts` you can run with `npm`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/assembly` folder. This code gets deployed to
the NEAR blockchain when you run `npm run deploy:contract`. This sort of
code-that-runs-on-a-blockchain is called a "smart contract" – [learn more
about NEAR smart contracts][smart contract docs].
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. The smart contract code gets tested with [asp], and the frontend
code gets tested with [jest]. You can run both of these at once with `npm
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `npm run dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `hack-rainbow.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `hack-rainbow.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account hack-rainbow.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'hack-rainbow.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
npm run deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[React]: https://reactjs.org
[smart contract docs]: https://docs.near.org/docs/roles/developer/contracts/intro
[asp]: https://www.npmjs.com/package/@as-pect/cli
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
|
gaziz86_near-prj1 | .gitpod.yml
README.md
babel.config.js
contract
Cargo.toml
README.md
compile.js
src
lib.rs
target
.rustc_info.json
debug
.fingerprint
Inflector-9e3c62115074b9cf
lib-inflector.json
autocfg-cd255646c4ed3339
lib-autocfg.json
borsh-derive-5ae16aa117c7f399
lib-borsh-derive.json
borsh-derive-internal-d0a21fc13ecc1b98
lib-borsh-derive-internal.json
borsh-schema-derive-internal-ab395ab8b11e5be3
lib-borsh-schema-derive-internal.json
byteorder-f262064c186a8c75
build-script-build-script-build.json
convert_case-95e284bc56c12eb5
lib-convert_case.json
derive_more-69cde6e327ff0a85
lib-derive_more.json
generic-array-092d57466d24febe
build-script-build-script-build.json
hashbrown-23b6f330e2a36dbb
run-build-script-build-script-build.json
hashbrown-cdcf863ec2cdd3e4
build-script-build-script-build.json
hashbrown-d487e72206b07264
lib-hashbrown.json
indexmap-1e685d288818a816
lib-indexmap.json
indexmap-8c9f9453652d0887
run-build-script-build-script-build.json
indexmap-c3ac49ead90ef7d0
build-script-build-script-build.json
itoa-b06d4cff304254a3
lib-itoa.json
memchr-035c4269a6233099
build-script-build-script-build.json
near-rpc-error-core-b63ef2006bff2a54
lib-near-rpc-error-core.json
near-rpc-error-macro-379a6a754086af95
lib-near-rpc-error-macro.json
near-sdk-core-f46d7222a619c60b
lib-near-sdk-core.json
near-sdk-macros-67a465e716adb526
lib-near-sdk-macros.json
num-bigint-d69df36f763339d9
build-script-build-script-build.json
num-integer-733a54d88eb397d7
build-script-build-script-build.json
num-rational-ae7f1682837cfa6a
build-script-build-script-build.json
num-traits-4b4399d154f5b10c
build-script-build-script-build.json
proc-macro-crate-12334d71f27edc5f
lib-proc-macro-crate.json
proc-macro2-3fad645d9b421e8e
run-build-script-build-script-build.json
proc-macro2-5fcfb2a46c5df79c
build-script-build-script-build.json
proc-macro2-c9e8a8bd316f311f
lib-proc-macro2.json
quote-577c40b40ecd60bd
lib-quote.json
ryu-218129458e3751da
run-build-script-build-script-build.json
ryu-a617547c15767d1a
build-script-build-script-build.json
ryu-b54e014f019506d7
lib-ryu.json
serde-283b18786897374f
lib-serde.json
serde-552ea552149e1a4d
build-script-build-script-build.json
serde-b99429f97a9b8ecc
run-build-script-build-script-build.json
serde_derive-4f31ad7a0e5ec105
build-script-build-script-build.json
serde_derive-9dbff8f6028e8a2c
run-build-script-build-script-build.json
serde_derive-ea52ca527bcbc75e
lib-serde_derive.json
serde_json-bf5b0064d1b45776
run-build-script-build-script-build.json
serde_json-c83f8bc67b0f9037
lib-serde_json.json
serde_json-e9017e2e6ab453c7
build-script-build-script-build.json
syn-0359a400ed92222f
build-script-build-script-build.json
syn-60a21e1eff858db6
lib-syn.json
syn-84879f3141fd595e
run-build-script-build-script-build.json
toml-dc98d37f2aab96c5
lib-toml.json
typenum-b487004bf7bc9a32
build-script-build-script-main.json
unicode-xid-1ccf9a8622388d0a
lib-unicode-xid.json
version_check-c02be86861b3fab0
lib-version_check.json
wee_alloc-4c1d5fc69208e232
build-script-build-script-build.json
wasm32-unknown-unknown
debug
.fingerprint
ahash-31500eed5b448aad
lib-ahash.json
aho-corasick-b89132b0381c749e
lib-aho_corasick.json
base64-646109cef868d84f
lib-base64.json
block-buffer-5f9d9d8b55f1d3b1
lib-block-buffer.json
block-buffer-bc99728b4d693dcc
lib-block-buffer.json
block-padding-13821e343f46f753
lib-block-padding.json
borsh-6fb510f42155d666
lib-borsh.json
bs58-7212f4faed67cdbf
lib-bs58.json
byte-tools-a6cd60c7ea46575a
lib-byte-tools.json
byteorder-425eab9cce122222
lib-byteorder.json
byteorder-b1278529b57a037f
run-build-script-build-script-build.json
cfg-if-53998aee5392ec20
lib-cfg-if.json
cfg-if-f1de31271fe8376a
lib-cfg-if.json
digest-02b66ce3a4c78c1c
lib-digest.json
digest-5bb936ed42c05efb
lib-digest.json
generic-array-30cd0a03156a9b87
lib-generic_array.json
generic-array-6802468a8a36c271
run-build-script-build-script-build.json
generic-array-845551d223c666ba
lib-generic_array.json
hashbrown-483ac2a52167ff2a
lib-hashbrown.json
hashbrown-51d3921aceef5ebb
run-build-script-build-script-build.json
hashbrown-9e21cf3d1d28819b
lib-hashbrown.json
hex-261cfc3fcecaa4ef
lib-hex.json
indexmap-33441b070f70d190
run-build-script-build-script-build.json
indexmap-549d81fd1b4aaa1a
lib-indexmap.json
itoa-4c06a779eef25af4
lib-itoa.json
keccak-b0c9ccd044944503
lib-keccak.json
lazy_static-b79bf709c5f09987
lib-lazy_static.json
memchr-8974d6d0eea4ab03
lib-memchr.json
memchr-f922bd3de584c24c
run-build-script-build-script-build.json
memory_units-3804df6a88cda429
lib-memory_units.json
near-primitives-core-22512a59771af8d0
lib-near-primitives-core.json
near-runtime-utils-3357838d53825c1b
lib-near-runtime-utils.json
near-sdk-b965d2f0da3bed34
lib-near-sdk.json
near-vm-errors-20e6f8caa2eb3f21
lib-near-vm-errors.json
near-vm-logic-afd430776e895057
lib-near-vm-logic.json
num-bigint-7e7d1d90c83f30cc
lib-num-bigint.json
num-bigint-a699a4a251dccc5e
run-build-script-build-script-build.json
num-integer-8d01ee791cd20c62
lib-num-integer.json
num-integer-e00df3a90a9271c0
run-build-script-build-script-build.json
num-rational-abf9bfbe7cbd8dd6
lib-num-rational.json
num-rational-e5b980680ebaaecb
run-build-script-build-script-build.json
num-traits-c1660e0226ce670c
run-build-script-build-script-build.json
num-traits-e0f409119940623e
lib-num-traits.json
opaque-debug-20397d3162c70a7a
lib-opaque-debug.json
opaque-debug-67e11037907b0a62
lib-opaque-debug.json
portal-f64da15e081556ac
lib-portal.json
regex-e489d254d1e7e12d
lib-regex.json
regex-syntax-bcaa825332c5ba50
lib-regex-syntax.json
ryu-52a388757c15c1a6
run-build-script-build-script-build.json
ryu-a7a81e23b9bcb06b
lib-ryu.json
serde-6d59abfee35ae43b
run-build-script-build-script-build.json
serde-ebe94b1241f5047e
lib-serde.json
serde_json-1da7a0c73c632567
lib-serde_json.json
serde_json-c3b71e6248b2b8a1
run-build-script-build-script-build.json
sha2-bdebeba22d9faa70
lib-sha2.json
sha3-4cf15448deb657a1
lib-sha3.json
typenum-4976863587ad7c9e
run-build-script-build-script-main.json
typenum-eee99a2ed0f1494e
lib-typenum.json
wee_alloc-1aec1ccd611d0139
run-build-script-build-script-build.json
wee_alloc-6b415af9b59e77f3
lib-wee_alloc.json
build
num-bigint-a699a4a251dccc5e
out
radix_bases.rs
typenum-4976863587ad7c9e
out
consts.rs
op.rs
tests.rs
wee_alloc-1aec1ccd611d0139
out
wee_alloc_static_array_backend_size_bytes.txt
package.json
src
App.js
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
config.js
global.css
index.html
index.js
jest.init.js
main.test.js
utils.js
wallet
login
index.html
| prj-1
==================
This [React] app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `prj-1.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `prj-1.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account prj-1.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'prj-1.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
prj-1 Smart Contract
==================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
|
kiskesis_nftzoo | .idea
modules.xml
README.md
craco.config.js
nft-zoo-contract
README.md
market-contract
Cargo.toml
README.md
build.sh
src
external.rs
internal.rs
lib.rs
nft_callbacks.rs
sale.rs
sale_views.rs
nft-contract
Cargo.toml
README.md
build.sh
src
approval.rs
enumeration.rs
events.rs
game.rs
internal.rs
lib.rs
metadata.rs
mint.rs
nft_core.rs
royalty.rs
package.json
|
|
package.json
public
index.html
manifest.json
robots.txt
src
assets
LoadingZone (1).svg
logo-black.svg
logo-white.svg
components
NFT
index.css
index.js
loading
index.css
index.js
pageWrapper
index.css
index.js
config.js
global.css
index.html
index.js
pages
gamePage
assets
Fifth.svg
First.svg
Food.svg
Fourth.svg
LoadingBorders (1).svg
LoadingBorders.svg
LoadingZone.svg
Second.svg
Third.svg
components
animalCharacter
index.css
index.js
experience
index.css
index.js
food
index.css
index.js
mintModal
index.css
index.js
index.css
index.js
home
index.css
index.js
login
index.css
index.js
mint
index.css
index.js
selectAnimalPage
components
AnimalCard
index.css
index.js
index.css
index.js
utils
hooks.js
utils.js
| # TBD
# Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `yarn start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in the browser.
The page will reload if you make edits.\
You will also see any lint errors in the console.
### `yarn test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `yarn build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `yarn eject`
**Note: this is a one-way operation. Once you `eject`, you can’t go back!**
If you aren’t satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you’re on your own.
You don’t have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn’t feel obligated to use this feature. However we understand that this tool wouldn’t be useful if you couldn’t customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `yarn build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
# TBD
# NEAR NFT-Tutorial
Welcome to NEAR's NFT tutorial, where we will help you parse the details around NEAR's [NEP-171 standard](https://nomicon.io/Standards/NonFungibleToken/Core.html) (Non-Fungible Token Standard), and show you how to build your own NFT smart contract from the ground up, improving your understanding about the NFT standard along the way.
## Prerequisites
* [NEAR Wallet Account](wallet.testnet.near.org)
* [Rust Toolchain](https://docs.near.org/docs/develop/contracts/rust/intro#installing-the-rust-toolchain)
* [NEAR-CLI](https://docs.near.org/docs/tools/near-cli#setup)
* [yarn](https://classic.yarnpkg.com/en/docs/install#mac-stable)
## Tutorial Stages
Each branch you will find in this repo corresponds to various stages of this tutorial with a partially completed contract at each stage. You are welcome to start from any stage you want to learn the most about.
| Branch | Docs Tutorial | Description |
| ------------- | ------------------------------------------------------------------------------------------------ | ----------- |
| 1.skeleton | [Contract Architecture](https://docs.near.org/docs/tutorials/contracts/nfts/skeleton) | You'll learn the basic architecture of the NFT smart contract, and you'll compile this skeleton code with the Rust toolchain. |
| 2.minting | [Minting](https://docs.near.org/docs/tutorials/contracts/nfts/minting) |Here you'll flesh out the skeleton so the smart contract can mint a non-fungible token |
| 3.enumeration | [Enumeration](https://docs.near.org/docs/tutorials/contracts/nfts/enumeration) | Here you'll find different enumeration methods that can be used to return the smart contract's states. |
| 4.core | [Core](https://docs.near.org/docs/tutorials/contracts/nfts/core) | In this tutorial you'll extend the NFT contract using the core standard, which will allow you to transfer non-fungible tokens. |
| 5.approval | [Approval](https://docs.near.org/docs/tutorials/contracts/nfts/approvals) | Here you'll expand the contract allowing other accounts to transfer NFTs on your behalf. |
| 6.royalty | [Royalty](https://docs.near.org/docs/tutorials/contracts/nfts/royalty) |Here you'll add the ability for non-fungible tokens to have royalties. This will allow people to get a percentage of the purchase price when an NFT is purchased. |
| 7.events | ----------- | This allows indexers to know what functions are being called and make it easier and more reliable to keep track of information that can be used to populate the collectibles tab in the wallet for example. (tutorial docs have yet to be implemented ) |
| 8.marketplace | ----------- | ----------- |
The tutorial series also contains a very helpful section on [**Upgrading Smart Contracts**](https://docs.near.org/docs/tutorials/contracts/nfts/upgrade-contract). Definitely go and check it out as this is a common pain point.
# Quick-Start
If you want to see the full completed contract go ahead and clone and build this repo using
```=bash
git clone https://github.com/near-examples/nft-tutorial.git
cd nft-tutorial
git switch 6.royalty
yarn build
```
Now that you've cloned and built the contract we can try a few things.
## Mint An NFT
Once you've created your near wallet go ahead and login to your wallet with your cli and follow the on-screen prompts
```=bash
near login
```
Once your logged in you have to deploy the contract. Make a subaccount with the name of your choosing
```=bash
near create-account nft-example.your-account.testnet --masterAccount your-account.testnet --initialBalance 10
```
After you've created your sub account deploy the contract to that sub account, set this variable to your sub account name
```=bash
NFT_CONTRACT_ID=nft-example.your-account.testnet
MAIN_ACCOUNT=your-account.testnet
```
Verify your new variable has the correct value
```=bash
echo $NFT_CONTRACT_ID
echo $MAIN_ACCOUNT
```
### Deploy Your Contract
```=bash
near deploy --accountId $NFT_CONTRACT_ID --wasmFile out/main.wasm
```
### Initialize Your Contract
```=bash
near call $NFT_CONTRACT_ID new_default_meta '{"owner_id": "'$NFT_CONTRACT_ID'"}' --accountId $NFT_CONTRACT_ID
```
### View Contracts Meta Data
```=bash
near view $NFT_CONTRACT_ID nft_metadata
```
### Minting Token
```bash=
near call $NFT_CONTRACT_ID nft_mint '{"token_id": "token-1", "metadata": {"title": "My Non Fungible Team Token", "description": "The Team Most Certainly Goes :)", "media": "https://bafybeiftczwrtyr3k7a2k4vutd3amkwsmaqyhrdzlhvpt33dyjivufqusq.ipfs.dweb.link/goteam-gif.gif"}, "receiver_id": "'$MAIN_ACCOUNT'"}' --accountId $MAIN_ACCOUNT --amount 0.1
```
After you've minted the token go to wallet.testnet.near.org to `your-account.testnet` and look in the collections tab and check out your new sample NFT!
## View NFT Information
After you've minted your NFT you can make a view call to get a response containing the `token_id` `owner_id` and the `metadata`
```bash=
near view $NFT_CONTRACT_ID nft_token '{"token_id": "token-1"}'
```
## Transfering NFTs
To transfer an NFT go ahead and make another [testnet wallet account](https://wallet.testnet.near.org).
Then run the following
```bash=
MAIN_ACCOUNT_2=your-second-wallet-account.testnet
```
Verify the correct variable names with this
```=bash
echo $NFT_CONTRACT_ID
echo $MAIN_ACCOUNT
echo $MAIN_ACCOUNT_2
```
To initiate the transfer..
```bash=
near call $NFT_CONTRACT_ID nft_transfer '{"receiver_id": "$MAIN_ACCOUNT_2", "token_id": "token-1", "memo": "Go Team :)"}' --accountId $MAIN_ACCOUNT --depositYocto 1
```
In this call you are depositing 1 yoctoNEAR for security and so that the user will be redirected to the NEAR wallet.
## Errata
Large Changes:
* **2022-02-12**: updated the enumeration methods `nft_tokens` and `nft_tokens_for_owner` to no longer use any `to_vector` operations to save GAS. In addition, the default limit was changed from 0 to 50. PR found [here](https://github.com/near-examples/nft-tutorial/pull/17).
Small Changes:
* **2022-02-22**: changed `token_id` parameter type in nft_payout from `String` to `TokenId` for consistency as per pythonicode's suggestion
|
NEARWEEK_NEARWEEK-COMMUNITY-CONTENT | .github
ISSUE_TEMPLATE
BOUNTY.yml
bi-weekly-video-snippets.md
blogpost.md
bounty-idea-.md
bounty-template-for-external-production.md
marketing-request.md
newsletter.md
twitter-content--no-bounty-.md
twitter-contest--bounty-payout-.md
twitter-long-form-post.md
twitterspace.md
README.md
| # NEARWEEK-COMMUNITY-CONTENT
A list of tings produced by NEAR contributors to be edited, curated and distributed by NEARWEEK.
|
johnedvard_js13kgames2021 | CHANGELOG.md
README.md
contract
as-pect.config.js
asconfig.json
assembly
as_types.d.ts
index.ts
tsconfig.json
compile.js
package-lock.json
package.json
entry
bundle.js
index.html
style.css
neardev
dev-account.env
package-lock.json
package.json
src
BulletState.ts
bullet.ts
deadFeedback.ts
engineParticleEffect.ts
game.ts
gameEvent.ts
gameUtils.ts
iGameobject.ts
index.html
index.ts
key.ts
loop.ts
menu.ts
modules.d.ts
monetizeEvent.ts
near
config.js
nearConnection.ts
nearLogin.ts
player.ts
playerState.ts
sound.ts
spaceShip.ts
spaceShipRenderers.ts
style.css
trails.ts
zzfx.js
tsconfig.json
webpack.config.js
| ## Description
This game is inspired by Achtung, die Kurve!
It's a 4 player local multiplayer game. You control a spaceship and need to stay alive as long as possible before there's no space to navigate. You die if you hit a player's trail or any of the walls. Each player has one bullet they can fire to clear some space.
### Controls
Click "space" to start the round. When a round is over, click "space" to play again.
player controls:
- p1: left arrow, right arrow, up arrow (shoot)
- p2: q, w, e
- p3: v, b, n
- p4: i, o, p
- mute sound: m
### Monetization
You can select additional space ship skins for your ship.
### NEAR
You can write your name, and it will be stored on the smart contract. The name also determines the color of p1's space ship when you are logged in to NEAR.
### Protocol labs
The three other ships' color are chosen based on Drand.
|
Subsets and Splits