
issue
dict | pr
dict | pr_details
dict |
|---|---|---|
{
"body": "<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): windows 10\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): pip\r\n- TensorFlow version (use command below): 2.1.0\r\n- Python version: 3.7\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version: 10.2 & 10.1\r\n- GPU model and memory:\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with:\r\n1. TF 1.0: `python -c \"import tensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"`\r\n2. TF 2.0: `python -c \"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n\r\n**Describe the current behavior**\r\nWhen loading the model with keras.models.load_model the activation functions are not recognized. This happens only when activation functions are not builtin strings\r\n\r\n**Describe the expected behavior**\r\nTo load the model with success\r\n\r\n**Standalone code to reproduce the issue**\r\nProvide a reproducible test case that is the bare minimum necessary to generate\r\nthe problem. If possible, please share a link to Colab/Jupyter/any notebook.\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\nlayer = tf.keras.layers.Dense(1, activation=tf.keras.layers.PReLU(alpha_initializer='random_uniform', alpha_regularizer=None, alpha_constraint=None, shared_axes=None),\\\r\n name='layerX', kernel_initializer=tf.keras.initializers.he_normal())\r\nmodel = tf.keras.Sequential(layer)\r\nmodel.compile(\"adam\", \"binary_crossentropy\", [\"accuracy\"])\r\nmodel.fit([[1]], [1])\r\nmodel.save(\"keras_model.h5\", save_format='h5' \")\r\nmodel = tf.keras.models.load_model(\"keras_model.h5\")\r\n```\r\n**EDIT**: After reading the docs I saved the model with save_format h5, first time I tried without any format (the default is tf for tensorflow 2.0+)\r\nInstead I found a workaround: I can load the model if I save it with (default) save_format='tf'\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\ndiagnose the problem. If including tracebacks, please include the full\r\ntraceback. Large logs and files should be attached.\r\n```Traceback (most recent call last):\r\n File \"C:\\Users\\Teo\\OneDrive\\Licenta\\main.py\", line 138, in <module>\r\n main()\r\n File \"C:\\Users\\Teo\\OneDrive\\Licenta\\main.py\", line 135, in main\r\n model = keras.models.load_model(os.path.join(dataset_path, \"keras_model.h5\"))\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\saving\\save.py\", line 146, in load_model\r\n return hdf5_format.load_model_from_hdf5(filepath, custom_objects, compile)\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\saving\\hdf5_format.py\", line 168, in load_model_from_hdf5\r\n custom_objects=custom_objects)\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\saving\\model_config.py\", line 55, in model_from_config\r\n return deserialize(config, custom_objects=custom_objects)\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\layers\\serialization.py\", line 106, in deserialize\r\n printable_module_name='layer')\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\utils\\generic_utils.py\", line 303, in deserialize_keras_object\r\n list(custom_objects.items())))\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\engine\\sequential.py\", line 377, in from_config\r\n custom_objects=custom_objects)\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\layers\\serialization.py\", line 106, in deserialize\r\n printable_module_name='layer')\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\utils\\generic_utils.py\", line 305, in deserialize_keras_object\r\n return cls.from_config(cls_config)\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\engine\\base_layer.py\", line 519, in from_config\r\n return cls(**config)\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\layers\\core.py\", line 1082, in __init__\r\n self.activation = activations.get(activation)\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\activations.py\", line 450, in get\r\n identifier, printable_module_name='activation')\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\utils\\generic_utils.py\", line 292, in deserialize_keras_object\r\n config, module_objects, custom_objects, printable_module_name)\r\n File \"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\tensorflow_core\\python\\keras\\utils\\generic_utils.py\", line 250, in class_and_config_for_serialized_keras_object\r\n raise ValueError('Unknown ' + printable_module_name + ': ' + class_name)\r\nValueError: Unknown activation: PReLU\r\n```",
"comments": [
{
"body": "@teodor440 \r\n\r\nRequest you to share colab link or simple standalone code to reproduce the issue in our environment.It helps us in localizing the issue faster.Thanks!",
"created_at": "2020-04-29T06:56:00Z"
},
{
"body": "> \r\n> \r\n> @teodor440\r\n> \r\n> Request you to share colab link or simple standalone code to reproduce the issue in our environment.It helps us in localizing the issue faster.Thanks!\r\n\r\nhttps://colab.research.google.com/drive/1qZ8RuI-oNoTsD2uokHZztqeCb20RX3wR\r\nI also updated the code in the issue",
"created_at": "2020-04-29T14:09:43Z"
},
{
"body": "I have tried in colab with TF 2.1.0 , 2.2-rc3 and was able to reproduce the issue. Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/d18890e6d91c6fe62dcff2934500927a/untitled840.ipynb).Thanks!",
"created_at": "2020-04-30T03:55:40Z"
},
{
"body": "@teodor440 I was able to reproduce the issue with `save_format='h5'`. However, when I used `save_format = 'tf'` everything worked as expected. `model.predict` before saving and after loading are exactly same. Please take a look at the [gist here](https://colab.research.google.com/gist/jvishnuvardhan/e753ca365a61c21d77bdd70844156f68/untitled840.ipynb). Thanks!",
"created_at": "2020-04-30T05:19:17Z"
},
{
"body": "I am not familiar with the implementation of tensorflow, but seems like there is a problem with how tf sees keras models\r\nI can recall the same value error when trying to convert the model to an estimator with keras.estimator.model_to_estimator",
"created_at": "2020-05-01T21:59:00Z"
},
{
"body": "Ok so the problem was that I specified the activations in the layers as something different than a string. For some reason or another this confuses the operations made on keras models by tf",
"created_at": "2020-05-03T14:44:09Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38994\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38994\">No</a>\n",
"created_at": "2020-05-03T14:44:11Z"
},
{
"body": "@teodor440 You can use \"tf\" format as it is working well. However, this is still a bug with \"h5\" format. I will reopen the issue. Thanks!",
"created_at": "2020-05-03T15:55:14Z"
},
{
"body": "You can see now at the collab link that the issue with saving h5 model doesn't persist anymore if using separate layers for dense and activation. So basically this is a workaround for the problem",
"created_at": "2020-05-03T16:23:49Z"
},
{
"body": "Closing this issue since the associated PR has been merged and the issue is [fixed](https://colab.research.google.com/gist/ymodak/6217fe6a0850d369c7c8da9107821808/38994.ipynb). Thanks",
"created_at": "2021-04-23T18:10:31Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38994\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38994\">No</a>\n",
"created_at": "2021-04-23T18:10:33Z"
}
],
"number": 38994,
"title": "Can't load saved keras model.h5"
}
|
{
"body": "@k-w-w and @jvishnuvardhan , reference to #38994 \r\n\r\nPlease review changes. Tests: activations_test.py and advanced_activations.py passed.\r\n\r\nWe need to bring in the classes from advanced_activations if there are no custom objects specified. When no custom objects are specified, our module_objects/globals() in activations.deserialize() won't contain any advanced_activations.",
"number": 39252,
"review_comments": [
{
"body": "This if statement can be removed -- [the custom object dict is always checked before the module objects](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/utils/generic_utils.py#L200), so it's safe to add the missing activations here.",
"created_at": "2020-06-03T04:42:18Z"
},
{
"body": "ahh right, removed if statement in 4e74ac602c55a77bd9d238a801df1894297bc464",
"created_at": "2020-06-03T18:16:02Z"
},
{
"body": "Ah, there's a small issue here. Can you swap lines 121 and 122? (deps should appear in alphabetical order)",
"created_at": "2020-10-15T00:44:38Z"
},
{
"body": "ah good to know, sorry about that. Fixed! :)",
"created_at": "2020-10-15T01:55:36Z"
}
],
"title": "Fixed loading saved keras model (h5 files) when using advanced activation functions"
}
|
{
"commits": [
{
"message": "We need to bring in the classes from advanced_activations if there are no custom objects specified. When no custom objects are specified, our module_objects/globals() in activations.deserialize() won't contain any advanced_activations."
},
{
"message": "no need for if statement since custom object dict is checked before module objects"
},
{
"message": "fixing pylint issues"
},
{
"message": "New feature. Use new param log_all in CSVLogger to log all elements in training even if some epochs don't contain the same elements."
},
{
"message": "Revert \"New feature. Use new param log_all in CSVLogger to log all elements in training even if some epochs don't contain the same elements.\"\n\nThis reverts commit 204913109700abfa7fd620bf05c4603dc7795f34."
},
{
"message": "Merge branch 'master' of https://github.com/tensorflow/tensorflow into datapi_tflow"
},
{
"message": "We need to bring in the classes from advanced_activations if there are no custom objects specified. When no custom objects are specified, our module_objects/globals() in activations.deserialize() won't contain any advanced_activations."
},
{
"message": "no need for if statement since custom object dict is checked before module objects"
},
{
"message": "fixing pylint issues"
},
{
"message": "New feature. Use new param log_all in CSVLogger to log all elements in training even if some epochs don't contain the same elements."
},
{
"message": "Revert \"New feature. Use new param log_all in CSVLogger to log all elements in training even if some epochs don't contain the same elements.\"\n\nThis reverts commit 204913109700abfa7fd620bf05c4603dc7795f34."
},
{
"message": "Merge branch 'datapi_tflow' of https://github.com/PiyushDatta/tensorflow into datapi_tflow"
},
{
"message": "added advanced_activations into activation lib dependancies"
},
{
"message": "swap these lines to keep in alphabetical order"
}
],
"files": [
{
"diff": "@@ -118,6 +118,7 @@ py_library(\n srcs_version = \"PY2AND3\",\n deps = [\n \":backend\",\n+ \"//tensorflow/python/keras/layers:advanced_activations\",\n \"//tensorflow/python/keras/utils:engine_utils\",\n ],\n )",
"filename": "tensorflow/python/keras/BUILD",
"status": "modified"
},
{
"diff": "@@ -26,6 +26,7 @@\n from tensorflow.python.ops import nn\n from tensorflow.python.util import dispatch\n from tensorflow.python.util.tf_export import keras_export\n+from tensorflow.python.keras.layers import advanced_activations\n \n # b/123041942\n # In TF 2.x, if the `tf.nn.softmax` is used as an activation function in Keras\n@@ -525,9 +526,17 @@ def deserialize(name, custom_objects=None):\n ValueError: `Unknown activation function` if the input string does not\n denote any defined Tensorflow activation function.\n \"\"\"\n+ globs = globals()\n+\n+ # only replace missing activations\n+ advanced_activations_globs = advanced_activations.get_globals()\n+ for key, val in advanced_activations_globs.items():\n+ if key not in globs:\n+ globs[key] = val\n+\n return deserialize_keras_object(\n name,\n- module_objects=globals(),\n+ module_objects=globs,\n custom_objects=custom_objects,\n printable_module_name='activation function')\n ",
"filename": "tensorflow/python/keras/activations.py",
"status": "modified"
},
{
"diff": "@@ -65,12 +65,19 @@ def test_serialization_with_layers(self):\n activation = advanced_activations.LeakyReLU(alpha=0.1)\n layer = core.Dense(3, activation=activation)\n config = serialization.serialize(layer)\n+ # with custom objects\n deserialized_layer = serialization.deserialize(\n config, custom_objects={'LeakyReLU': activation})\n self.assertEqual(deserialized_layer.__class__.__name__,\n layer.__class__.__name__)\n self.assertEqual(deserialized_layer.activation.__class__.__name__,\n activation.__class__.__name__)\n+ # without custom objects\n+ deserialized_layer = serialization.deserialize(config)\n+ self.assertEqual(deserialized_layer.__class__.__name__,\n+ layer.__class__.__name__)\n+ self.assertEqual(deserialized_layer.activation.__class__.__name__,\n+ activation.__class__.__name__)\n \n def test_softmax(self):\n x = backend.placeholder(ndim=2)",
"filename": "tensorflow/python/keras/activations_test.py",
"status": "modified"
},
{
"diff": "@@ -30,6 +30,10 @@\n from tensorflow.python.util.tf_export import keras_export\n \n \n+def get_globals():\n+ return globals()\n+\n+\n @keras_export('keras.layers.LeakyReLU')\n class LeakyReLU(Layer):\n \"\"\"Leaky version of a Rectified Linear Unit.",
"filename": "tensorflow/python/keras/layers/advanced_activations.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- TensorFlow installed from (source or binary): pip\r\n- TensorFlow version (use command below): v2.2.0-rc4-0-g70087ab4f4\r\n- Python version: 3.6.9\r\n\r\n**Describe the current behavior**\r\nmap_fn doesn't support empty lists\r\n\r\n**Describe the expected behavior**\r\nIt should return an empty list\r\n\r\n**Standalone code to reproduce the issue**\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\nfn = lambda x: x\r\ntf.map_fn(fn, [])\r\n\r\n# additionally, this works:\r\ntf.map_fn(fn, np.array([1.]))\r\n# but not this eventhough [1.] is not a scalar.\r\ntf.map_fn(fn, [1.])\r\n```",
"comments": [
{
"body": "The second and the third examples are expected. In the second example,\r\n```\r\ntf.map_fn(fn, np.array([1.]))\r\n```\r\n`np.array([1.])` is a tensor (converted to tensor by np.array), so it is a **single element of shape `[1]`.**\r\n\r\nThe third example:\r\n```\r\ntf.map_fn(fn, [1.])\r\n```\r\nis a list of one tensor `1.` as map_fn treat it as **a list of one (scalar) element `1.`**, thus you see an error.\r\n\r\nThe first example `tf.map_fn(fn, [])` is not something that has been captured in the implementation of `tf.map_fn`. I think it makes sense to return an explicit error here.\r\n\r\nCreated a PR #39241 for the fix of `tf.map_fn(fn, [])`",
"created_at": "2020-05-06T22:40:33Z"
},
{
"body": "Hi,\r\n\r\nI really don't think you should raise when the list is empty. Every framework out there just returns an empty sequence when using map on an empty sequence.",
"created_at": "2020-05-07T08:50:21Z"
},
{
"body": "Was able to reproduce the issue with TF v2.1, [TF v2.2.0-rc4](https://colab.research.google.com/gist/amahendrakar/c164706bf7bd7f67bf13fe6719e0a489/39229.ipynb) and [TF-nightly](https://colab.research.google.com/gist/amahendrakar/81517ce8a62dd8cc9f121c1956630636/39229-tf-nightly.ipynb). Please find the attached gist. Thanks!",
"created_at": "2020-05-07T11:02:31Z"
},
{
"body": "@AdrienCorenflos If you want to map over a sequence, then you must pass that sequence to `map_fn` as a Tensor. \r\n\r\nIf you pass a non-Tensor sequence to `map_fn`, then it does *not* map over that sequence. Instead, it unstacks each tensor in that sequence, and calls the function with a list constructed from those unstacked slices.\r\n\r\nI.e., `tf.map_fn(func, [a, b, c])` is equivalent to Python's `map(func, a, b, c)`, and *not* to `map(func, [a, b, c])`. So calling `tf.map_fn(func, [])` is equivalent to calling `map(func)` in Python, which does indeed give an error (`\"map() requires at least two args\"`).\r\n\r\nA more complex example might help illustrate what's going on here -- we can pass any nested structure in to `elems`, including e.g. nested dictionaries. So if I call:\r\n\r\n```\r\ntf.map_fn(func, {'a': t1, 'b': [t2, t3]})\r\n```\r\n\r\nThen `func` will be called with:\r\n```\r\nfunc({'a': t1[0], 'b': [t2[0], t3[0]})\r\nfunc({'a': t1[1], 'b': [t2[1], t3[1]})\r\nfunc({'a': t1[2], 'b': [t2[2], t3[2]})\r\n...\r\nfunc({'a': t1[N], 'b': [t2[N], t3[N]})\r\n```\r\n\r\nWhere `N==t1.shape[0]==t2.shape[0]==t3.shape[0]`. By default, each function needs to return a value with the same structure that was passed in. E.g., in the example above, `func` must return a dictionary with keys `a` and `b`, where `a` is a tensor and `b` is a list of two tensors. If you want `func` to return a different structure, then you need to specify that structure with the `fn_output_signature` argument.\r\n",
"created_at": "2020-05-07T16:30:44Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/39229\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/39229\">No</a>\n",
"created_at": "2020-06-30T04:08:04Z"
}
],
"number": 39229,
"title": "map_fn doesn't work with empty lists"
}
|
{
"body": "This PR tries to address the issue raised in #39229 where\r\nempty lists input was not checked and throw out a non-obvious error:\r\n```python\r\n>>> import numpy as np\r\n>>> import tensorflow as tf\r\n>>> fn = lambda x: x\r\n>>> tf.map_fn(fn, [])\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Library/Python/3.7/site-packages/tensorflow/python/util/deprecation.py\", line 574, in new_func\r\n return func(*args, **kwargs)\r\n File \"/Library/Python/3.7/site-packages/tensorflow/python/ops/map_fn.py\", line 425, in map_fn_v2\r\n name=name)\r\n File \"/Library/Python/3.7/site-packages/tensorflow/python/ops/map_fn.py\", line 213, in map_fn\r\n static_shape = elems_flat[0].shape\r\nIndexError: list index out of range\r\n>>>\r\n```\r\n\r\n\r\nThis PR update to perform a check and thrown out\r\n`ValueError(\"elems must not be empty\")` to help clarify.\r\n\r\nThis PR fixes #39229.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 39241,
"review_comments": [
{
"body": "I looks like the common confusion here is that people expect that when `map_fn` is applied to a list, that it will map over that list. To help steer them in the right direction, let's make this message a little more verbose. How about something along the lines of:\r\n\r\n```\r\nraise ValueError(\r\n \"elems must be a Tensor or (possibly nested) sequence of Tensors. \"\r\n \"Got {}, which does not contain any Tensors.\".format(elems))\r\n```",
"created_at": "2020-05-07T13:05:44Z"
},
{
"body": "container -> contain",
"created_at": "2020-05-08T00:54:03Z"
},
{
"body": "@terrytangyuan Updated.",
"created_at": "2020-05-08T01:41:46Z"
},
{
"body": "Consists -> consist",
"created_at": "2020-06-08T17:58:51Z"
}
],
"title": "Return ValueError in case of empty list input for tf.map_fn"
}
|
{
"commits": [
{
"message": "Return ValueError in case of empty list input for tf.map_fn\n\nThis PR tries to address the issue raised in 39229 where\nempty lists input was not checked and throw out a non-obvious error:\n```python\n>>> import numpy as np\n>>> import tensorflow as tf\n>>> fn = lambda x: x\n>>> tf.map_fn(fn, [])\nTraceback (most recent call last):\n File \"<stdin>\", line 1, in <module>\n File \"/Library/Python/3.7/site-packages/tensorflow/python/util/deprecation.py\", line 574, in new_func\n return func(*args, **kwargs)\n File \"/Library/Python/3.7/site-packages/tensorflow/python/ops/map_fn.py\", line 425, in map_fn_v2\n name=name)\n File \"/Library/Python/3.7/site-packages/tensorflow/python/ops/map_fn.py\", line 213, in map_fn\n static_shape = elems_flat[0].shape\nIndexError: list index out of range\n>>>\n```\n\nIn case of empty list the behavior is undefined as we even don't know the output dtype.\n\nThis PR update to perform a check and thrown out\n`ValueError(\"elems must not be empty\")` to help clarify.\n\nThis PR fixes 39229.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update tf.map_fn to specify that at least one tensor must be present\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nTypo fix\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -217,6 +217,12 @@ def testMapEmptyTensor(self):\n self.assertAllEqual([0, 3, 2], map_return.get_shape().dims)\n self.assertAllEqual([0, 3, 2], self.evaluate(map_return).shape)\n \n+ @test_util.run_in_graph_and_eager_modes\n+ def testMapEmptyList(self):\n+ x = []\n+ with self.assertRaisesRegexp(\n+ ValueError, r\"elems must be a Tensor or\"):\n+ _ = map_fn.map_fn(lambda e: e, x)\n \n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/kernel_tests/map_fn_test.py",
"status": "modified"
},
{
"diff": "@@ -267,7 +267,7 @@ def map_fn(fn,\n elems: A tensor or (possibly nested) sequence of tensors, each of which will\n be unstacked along their first dimension. `fn` will be applied to the\n nested sequence of the resulting slices. `elems` may include ragged and\n- sparse tensors.\n+ sparse tensors. `elems` must consist of at least one tensor.\n dtype: Deprecated: Equivalent to `fn_output_signature`.\n parallel_iterations: (optional) The number of iterations allowed to run in\n parallel. When graph building, the default value is 10. While executing\n@@ -296,7 +296,7 @@ def map_fn(fn,\n TypeError: if `fn` is not callable or the structure of the output of\n `fn` and `fn_output_signature` do not match.\n ValueError: if the lengths of the output of `fn` and `fn_output_signature`\n- do not match.\n+ do not match, or if the `elems` does not contain any tensor.\n \n Examples:\n \n@@ -375,6 +375,13 @@ def map_fn(fn,\n \n # Flatten the input tensors, and get the TypeSpec for each one.\n elems_flat = nest.flatten(elems)\n+\n+ # Check in case this is an empty list\n+ if len(elems_flat) == 0:\n+ raise ValueError(\n+ \"elems must be a Tensor or (possibly nested) sequence of Tensors. \"\n+ \"Got {}, which does not contain any Tensors.\".format(elems))\n+\n elems_flat_signature = [type_spec.type_spec_from_value(e) for e in elems_flat]\n elems_unflatten = lambda x: nest.pack_sequence_as(elems, x)\n ",
"filename": "tensorflow/python/ops/map_fn.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Windows 10 x64\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: NA\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): unknown 1.14.0\r\n- Python version: 3.6.8 (Anaconda)\r\n- Bazel version (if compiling from source): NA\r\n- GCC/Compiler version (if compiling from source): NA\r\n- CUDA/cuDNN version: NA\r\n- GPU model and memory: NA\r\n\r\n**Describe the current behavior**\r\n\r\n[`tf.boolean_mask`](https://www.tensorflow.org/api_docs/python/tf/boolean_mask) does not accept a scalar [`tf.Tensor`](https://www.tensorflow.org/api_docs/python/tf/Tensor) object as axis parameter.\r\n\r\n**Describe the expected behavior**\r\n\r\nAs per the docs, [`tf.boolean_mask`](https://www.tensorflow.org/api_docs/python/tf/boolean_mask) should accept a scalar [`tf.Tensor`](https://www.tensorflow.org/api_docs/python/tf/Tensor) object as axis parameter.\r\n\r\n> * `axis`: A 0-D int Tensor representing the axis in `tensor` to mask from. By default, axis is 0 which will mask from the first dimension. Otherwise K + axis <= N.\r\n\r\n**Code to reproduce the issue**\r\n\r\nThe following snippet:\r\n\r\n```py\r\nimport tensorflow as tf\r\ntf.boolean_mask([1, 2, 3], [True, False, True], axis=tf.constant(0, dtype=tf.int32))\r\n```\r\n\r\nCauses the exception:\r\n\r\n```none\r\nTypeError: slice indices must be integers or None or have an __index__ method\r\n```\r\n\r\nFor comparison, the equivalent operation with [`tf.gather`](https://www.tensorflow.org/api_docs/python/tf/gather) works correctly:\r\n\r\n```py\r\nimport tensorflow as tf\r\nwith tf.Session() as sess:\r\n print(sess.run(tf.gather([1, 2, 3], [0, 1], axis=tf.constant(0, dtype=tf.int32))))\r\n # [1 2]\r\n```\r\n\r\n\r\n**Other info / logs**\r\n\r\nFull traceback:\r\n\r\n```none\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-3-4beb5ed72842> in <module>\r\n 1 import tensorflow as tf\r\n----> 2 tf.boolean_mask([1, 2, 3], [True, False, True], axis=tf.constant(0, dtype=tf.int32))\r\n\r\n~\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf_test\\lib\\site-packages\\tensorflow\\python\\ops\\array_ops.py in boolean_mask(tensor, mask, name, axis)\r\n 1369 \" are None. E.g. shape=[None] is ok, but shape=None is not.\")\r\n 1370 axis = 0 if axis is None else axis\r\n-> 1371 shape_tensor[axis:axis + ndims_mask].assert_is_compatible_with(shape_mask)\r\n 1372\r\n 1373 leading_size = gen_math_ops.prod(shape(tensor)[axis:axis + ndims_mask], [0])\r\n\r\n~\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf_test\\lib\\site-packages\\tensorflow\\python\\framework\\tensor_shape.py in __getitem__(self, key)\r\n 861 if self._dims is not None:\r\n 862 if isinstance(key, slice):\r\n--> 863 return TensorShape(self._dims[key])\r\n 864 else:\r\n 865 if self._v2_behavior:\r\n\r\nTypeError: slice indices must be integers or None or have an __index__ method\r\n```",
"comments": [
{
"body": "Issue replicating for the TF version-1.14, kindly find the [gist](https://colab.sandbox.google.com/gist/oanush/8f7790e5d292c7d84482bd3c9629d2e0/32236.ipynb) of colab.Thanks!",
"created_at": "2019-09-06T09:03:42Z"
},
{
"body": "@javidcf I tried with latest TF and the issue should have been fixed. I will close this issue but feel free to reopen if issue persists.",
"created_at": "2020-05-03T18:02:58Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32236\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32236\">No</a>\n",
"created_at": "2020-05-03T18:03:00Z"
},
{
"body": "@yongtang Thanks for having a look. Unfortunately, this still happens in graph mode, e.g. with `tf.function`:\r\n\r\n```python\r\n@tf.function\r\ndef f():\r\n return tf.boolean_mask([1, 2, 3], [True, False, True],\r\n axis=tf.constant(0, dtype=tf.int32))\r\nf()\r\n# TypeError: slice indices must be integers or None or have an __index__ method\r\n```\r\n\r\nTested in TensorFlow 2.2.0-rc4.",
"created_at": "2020-05-04T10:06:28Z"
},
{
"body": "@javidcf Added a PR for the fix.",
"created_at": "2020-05-04T16:14:57Z"
},
{
"body": "@javidcf Update: Added a PR #39159 for the fix.",
"created_at": "2020-05-04T16:15:42Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32236\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32236\">No</a>\n",
"created_at": "2020-05-05T19:17:17Z"
}
],
"number": 32236,
"title": "boolean_mask does not accept a Tensor as axis"
}
|
{
"body": "\r\nThis PR tries to address the issue raised in #32236 where\r\na TypeError was thrown out when axis is passed as a tensor.\r\nIn the docstring axis has been specified as accepting a 1-D tensor.\r\n\r\nThis PR fixes the issue.\r\n\r\nThis PR fixes #32236.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 39159,
"review_comments": [],
"title": "Fix issue in boolean_mask when axis is passed as a tensor"
}
|
{
"commits": [
{
"message": "Fix issue in boolean_mask when axis is passed as a tensor\n\nThis PR tries to address the issue raised in 32236 where\na TypeError was thrown out when axis is passed as a tensor.\nIn the docstring axis has been specified as accepting a 1-D tensor.\n\nThis PR fixes the issue.\n\nThis PR fixes 32236.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for boolean_mask with axis passed as a tensor\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Extend support of non-const axis tensor in boolean_mask\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for non-const axis tensor in boolean_mask\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -281,6 +281,28 @@ def testStringMask(self):\n result = sess.run(masked_tensor, feed_dict={tile_placeholder: [2, 2]})\n self.assertAllEqual([b\"hello\", b\"hello\", b\"hello\", b\"hello\"], result)\n \n+ def testMaskWithAxisTensor(self):\n+ @def_function.function(autograph=False)\n+ def f():\n+ return array_ops.boolean_mask(\n+ [1, 2, 3], [True, False, True],\n+ axis=constant_op.constant(0, dtype=dtypes.int32))\n+\n+ self.assertAllEqual(self.evaluate(f()), [1, 3])\n+\n+ def testMaskWithAxisNonConstTensor(self):\n+ @def_function.function(\n+ autograph=False,\n+ input_signature=[\n+ tensor_spec.TensorSpec(shape=None, dtype=dtypes.int32)])\n+ def f(axis):\n+ return array_ops.boolean_mask(\n+ [1, 2, 3], [True, False, True],\n+ axis=axis)\n+\n+ self.assertAllEqual(\n+ self.evaluate(f(constant_op.constant(0, dtype=dtypes.int32))), [1, 3])\n+\n \n @test_util.run_all_in_graph_and_eager_modes\n class OperatorShapeTest(test_util.TensorFlowTestCase):",
"filename": "tensorflow/python/kernel_tests/array_ops_test.py",
"status": "modified"
},
{
"diff": "@@ -1699,7 +1699,10 @@ def _apply_mask_1d(reshaped_tensor, mask, axis=None):\n \"Number of mask dimensions must be specified, even if some dimensions\"\n \" are None. E.g. shape=[None] is ok, but shape=None is not.\")\n axis = 0 if axis is None else axis\n- shape_tensor[axis:axis + ndims_mask].assert_is_compatible_with(shape_mask)\n+ axis_value = tensor_util.constant_value(axis)\n+ if axis_value is not None:\n+ axis = axis_value\n+ shape_tensor[axis:axis + ndims_mask].assert_is_compatible_with(shape_mask)\n \n leading_size = gen_math_ops.prod(shape(tensor)[axis:axis + ndims_mask], [0])\n tensor = reshape(\n@@ -1708,10 +1711,15 @@ def _apply_mask_1d(reshaped_tensor, mask, axis=None):\n shape(tensor)[:axis], [leading_size],\n shape(tensor)[axis + ndims_mask:]\n ], 0))\n- first_dim = shape_tensor[axis:axis + ndims_mask].num_elements()\n- tensor.set_shape(\n- tensor_shape.as_shape(shape_tensor[:axis]).concatenate(\n- [first_dim]).concatenate(shape_tensor[axis + ndims_mask:]))\n+ # TODO(yongtang): tf.reshape in C++ kernel might have set the shape\n+ # correctly, so the following may not be needed? It still might ben\n+ # possible that there are some edge case where tensor_util.constant_value\n+ # resolves more case than ShapeInference of tf.reshape in C++ kernel.\n+ if axis_value is not None:\n+ first_dim = shape_tensor[axis:axis + ndims_mask].num_elements()\n+ tensor.set_shape(\n+ tensor_shape.as_shape(shape_tensor[:axis]).concatenate(\n+ [first_dim]).concatenate(shape_tensor[axis + ndims_mask:]))\n \n mask = reshape(mask, [-1])\n return _apply_mask_1d(tensor, mask, axis)",
"filename": "tensorflow/python/ops/array_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Windows 10 x64 (1909)\r\n- TensorFlow installed from (source or binary): pip\r\n- TensorFlow version (use command below): v2.1.0-rc2-17-ge5bf8de410 2.1.0\r\n- Python version: 3.7.7\r\n- CUDA/cuDNN version: Using CPU\r\n- GPU model and memory: Using CPU\r\n\r\n**Describe the current behavior**\r\nDoing `Dataset.unbatch()` on dataset with known batch size resets cardinality to -2 (unknown).\r\n\r\n**Describe the expected behavior**\r\nWhen batch size of dataset is known, it should set cardinality to `batch_size * cardinality`.\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nds = tf.data.Dataset.range(10) # shape=()\r\nds = ds.batch(2, drop_remainder=True) # shape=(2,)\r\nprint(tf.data.experimental.cardinality(ds)) # 5\r\nds = ds.unbatch() # shape=()\r\nprint(tf.data.experimental.cardinality(ds)) # Should be 10, but is -2 (unknown)\r\n```\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\ndiagnose the problem. If including tracebacks, please include the full\r\ntraceback. Large logs and files should be attached.\r\nAlthough cardinality is currently experimental, it is used when traning keras model.",
"comments": [
{
"body": "Added a PR #39137 for the fix.",
"created_at": "2020-05-04T03:09:08Z"
},
{
"body": "Was able to reproduce the issue with [TF v2.1](https://colab.research.google.com/gist/amahendrakar/caaefad7a4ba4579d410e203fa20057c/39136-tf-nightly.ipynb), [TF v2.2.0-rc4](https://colab.research.google.com/gist/amahendrakar/b2ef86f09489bdad388f089ab3ba315b/39136-2-2.ipynb#scrollTo=52pV0lOQX93A) and [TF-nightly](https://colab.research.google.com/gist/amahendrakar/b01f15c8b4e12c9e879f62eca2fb8395/39136-tf-nightly.ipynb). Please find the attached gist. Thanks!",
"created_at": "2020-05-04T17:11:34Z"
},
{
"body": "@aaudiber please review the PR from Yong.",
"created_at": "2020-05-04T20:02:43Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/39136\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/39136\">No</a>\n",
"created_at": "2020-05-07T18:26:42Z"
}
],
"number": 39136,
"title": "Dataset.unbatch() sets cardinality to -2 even when batch size is known"
}
|
{
"body": "This PR tries to address the issue raised in #39136 where cardinality\r\nof Dataset.unbatch() was always UNKNOWN, even if it might be known\r\nin certain situations.\r\n\r\nThis PR add the cardinality calculation in case the input cardinality\r\nis known and the leading dim of the output shape is known.\r\n\r\nThis PR fixes #39136.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 39137,
"review_comments": [
{
"body": "combine the two `if` clauses:\r\n```\r\nif (known_batch_size_ < 0 && shape.dim_size(0) >= 0) {\r\n ...\r\n}\r\n```",
"created_at": "2020-05-04T23:08:19Z"
},
{
"body": "can we call this just `batch_size_`? Then add a comment that it may or may not be known, with -1 representing unknown.",
"created_at": "2020-05-04T23:09:33Z"
},
{
"body": "Add test with 2 components, where only the second component's batch size is known:\r\n```\r\nlambda: dataset_ops.Dataset.zip(\r\n dataset_ops.Dataset.range(4).batch(2, drop_remainder=False),\r\n dataset_ops.Dataset.range(5).batch(2, drop_remainder=True))\r\n```",
"created_at": "2020-05-04T23:15:05Z"
},
{
"body": "Thanks @aaudiber, done.",
"created_at": "2020-05-05T16:10:00Z"
},
{
"body": "Thanks @aaudiber, updated.",
"created_at": "2020-05-05T16:10:11Z"
},
{
"body": "Done.",
"created_at": "2020-05-05T16:10:16Z"
}
],
"title": "Add cardinality calculation for Dataset.unbatch() when possible"
}
|
{
"commits": [
{
"message": "Add cardinality calculation for Dataset.unbatch() when possible\n\nThis PR tries to address the issue raised in 39136 where cardinality\nof Dataset.unbatch() was always UNKNOWN, even if it might be known\nin certain situations.\n\nThis PR add the cardinality calculation in case the input cardinality\nis known and the leading dim of the output shape is known.\n\nThis PR fixes 39136.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for cardinality with Dataset.unbatch()\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update based on review feedback.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add additional test case where only the second batch size is known (from the review comment)\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -38,8 +38,12 @@ class UnbatchDatasetOp : public UnaryDatasetOpKernel {\n explicit Dataset(OpKernelContext* ctx, DatasetBase* input)\n : DatasetBase(DatasetContext(ctx)), input_(input) {\n input_->Ref();\n+ batch_size_ = -1;\n for (const PartialTensorShape& shape : input->output_shapes()) {\n if (!shape.unknown_rank()) {\n+ if (batch_size_ < 0 && shape.dim_size(0) >= 0) {\n+ batch_size_ = shape.dim_size(0);\n+ }\n gtl::InlinedVector<int64, 4> partial_dim_sizes;\n for (int i = 1; i < shape.dims(); ++i) {\n partial_dim_sizes.push_back(shape.dim_size(i));\n@@ -69,6 +73,17 @@ class UnbatchDatasetOp : public UnaryDatasetOpKernel {\n \n string DebugString() const override { return \"UnbatchDatasetOp::Dataset\"; }\n \n+ int64 Cardinality() const override {\n+ int64 n = input_->Cardinality();\n+ if (n == kInfiniteCardinality || n == kUnknownCardinality) {\n+ return n;\n+ }\n+ if (batch_size_ > 0) {\n+ return n * batch_size_;\n+ }\n+ return kUnknownCardinality;\n+ }\n+\n Status CheckExternalState() const override {\n return input_->CheckExternalState();\n }\n@@ -222,6 +237,8 @@ class UnbatchDatasetOp : public UnaryDatasetOpKernel {\n \n const DatasetBase* const input_;\n std::vector<PartialTensorShape> shapes_;\n+ // batch_size_ may or may not be known, with -1 as unknown\n+ int64 batch_size_;\n };\n };\n ",
"filename": "tensorflow/core/kernels/data/experimental/unbatch_dataset_op.cc",
"status": "modified"
},
{
"diff": "@@ -134,6 +134,21 @@ def _test_combinations():\n lambda: dataset_ops.Dataset.range(5).filter(lambda _: True).take(2),\n cardinality.UNKNOWN),\n (\"Take4\", lambda: dataset_ops.Dataset.range(5).repeat().take(2), 2),\n+ (\"Unbatch1\",\n+ lambda: dataset_ops.Dataset.range(5).batch(2, drop_remainder=True).unbatch(), 4),\n+ (\"Unbatch2\",\n+ lambda: dataset_ops.Dataset.range(5).batch(2, drop_remainder=False).unbatch(), cardinality.UNKNOWN),\n+ (\"Unbatch3\",\n+ lambda: dataset_ops.Dataset.range(5).batch(2, drop_remainder=True).filter(lambda _: True).unbatch(),\n+ cardinality.UNKNOWN),\n+ (\"Unbatch4\", lambda: dataset_ops.Dataset.range(5).batch(2, drop_remainder=True).repeat().unbatch(),\n+ cardinality.INFINITE),\n+ (\"Unbatch5\",\n+ lambda: dataset_ops.Dataset.zip((\n+ dataset_ops.Dataset.range(4).batch(2, drop_remainder=False),\n+ dataset_ops.Dataset.range(5).batch(2, drop_remainder=True),\n+ )).unbatch(),\n+ 4),\n (\"Window1\", lambda: dataset_ops.Dataset.range(5).window(\n size=2, shift=2, drop_remainder=True), 2),\n (\"Window2\", lambda: dataset_ops.Dataset.range(5).window(",
"filename": "tensorflow/python/data/experimental/kernel_tests/cardinality_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information** - Have I written custom code on **Google Colab**: - \r\n**Code:**\r\n```\r\ntf.keras.backend.set_floatx('float64')\r\n\r\nmodel.compile(optimizer= Adam(learning_rate= 0.001, clipnorm=1.0, clipvalue=0.5),\r\n loss={\r\n 'class_output': BinaryCrossentropy(),\r\n 'decoder_output': BinaryCrossentropy()\r\n },\r\n loss_weights=[0.5, 1.0],\r\n metrics = {\r\n 'class_output':[tf.metrics.Recall(), tf.metrics.Precision()],\r\n 'decoder_output':[tf.metrics.Recall(), tf.metrics.Precision()],\r\n }\r\n ) \r\n```\r\n**Error:**\r\n```\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/ops.py in convert_to_tensor(value, dtype, name, as_ref, preferred_dtype, dtype_hint, ctx, accepted_result_types)\r\n 1288 raise ValueError(\r\n 1289 \"Tensor conversion requested dtype %s for Tensor with dtype %s: %r\" %\r\n-> 1290 (dtype.name, value.dtype.name, value))\r\n 1291 return value\r\n 1292 \r\n\r\nValueError: Tensor conversion requested dtype float64 for Tensor with dtype float32: <tf.Tensor 'metrics_6/class_output_recall_8/Sum:0' shape=(1,) dtype=float32>\r\n```\r\n\r\nOS Platform and Distribution : - \r\n```\r\nos.uname()\r\n>>> posix.uname_result(sysname='Linux', nodename='ed841897617b', release='4.14.137+', version='#1 SMP Thu Aug 8 02:47:02 PDT 2019', machine='x86_64')\r\n```\r\nTensorFlow installed from : - \r\n```!pip install tensorflow==2.10```\r\nTensorFlow version : - \r\n```\r\ntf.__version__\r\n>>> '2.1.0'\r\n```\r\nPython version: - \r\n```\r\n!python -V\r\n>>> Python 3.6.9\r\n```\r\n~~Bazel version :- NA~~\r\n~~GCC/Compiler version : - NA~~ \r\n~~CUDA/cuDNN version: - NA~~\r\n\r\nGPU model and memory:\r\n```\r\nfrom psutil import virtual_memory\r\nmem = virtual_memory()\r\nprint(mem.total / 1024**3, 'GB') # total physical memory available\r\n>>>12.717426300048828 GB\r\n````\r\n~~You can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`~~\r\n\r\n**Describe the current behavior**\r\nWhen using `tf.keras.backend.set_floatx('float64')` , whole tf should be set to float64, right ?\r\nBut the tf.metrics are not getting set as shown in the code above\r\n\r\n**Describe the expected behavior**\r\nAll of tf including tf.metrics should be calculated on the basis of tf.keras.backend.set_floatx('float64')\r\n\r\n**Code to reproduce the issue** \r\n```\r\nimport tensorflow as tf \r\n\r\ntf.keras.backend.set_floatx('float64')\r\n\r\nm = tf.keras.metrics.Recall()\r\nm.update_state([0, 1, 1, 1], [1, 0, 1, 1])\r\nprint('Final result: ', m.result().numpy())\r\n```\r\n\r\n**Other info / logs** ~~Include any logs or source code that would be helpful to\r\ndiagnose the problem. If including tracebacks, please include the full\r\ntraceback. Large logs and files should be attached.~~\r\nStackTrace:\r\n```\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n<ipython-input-30-86f79f751766> in <module>()\r\n 6 loss_weights=[0.5, 1.0],\r\n 7 metrics = {\r\n----> 8 'class_output':[tf.metrics.Recall(), tf.metrics.Precision()],\r\n 9 # 'decoder_output':[tf.metrics.Recall(), tf.metrics.Precision()],\r\n 10 }\r\n\r\n13 frames\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/training/tracking/base.py in _method_wrapper(self, *args, **kwargs)\r\n 455 self._self_setattr_tracking = False # pylint: disable=protected-access\r\n 456 try:\r\n--> 457 result = method(self, *args, **kwargs)\r\n 458 finally:\r\n 459 self._self_setattr_tracking = previous_value # pylint: disable=protected-access\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/training.py in compile(self, optimizer, loss, metrics, loss_weights, sample_weight_mode, weighted_metrics, target_tensors, distribute, **kwargs)\r\n 437 targets=self._targets,\r\n 438 skip_target_masks=self._prepare_skip_target_masks(),\r\n--> 439 masks=self._prepare_output_masks())\r\n 440 \r\n 441 # Prepare sample weight modes. List with the same length as model outputs.\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/training.py in _handle_metrics(self, outputs, targets, skip_target_masks, sample_weights, masks, return_weighted_metrics, return_weighted_and_unweighted_metrics)\r\n 2002 metric_results.extend(\r\n 2003 self._handle_per_output_metrics(self._per_output_metrics[i],\r\n-> 2004 target, output, output_mask))\r\n 2005 if return_weighted_and_unweighted_metrics or return_weighted_metrics:\r\n 2006 metric_results.extend(\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/training.py in _handle_per_output_metrics(self, metrics_dict, y_true, y_pred, mask, weights)\r\n 1953 with K.name_scope(metric_name):\r\n 1954 metric_result = training_utils.call_metric_function(\r\n-> 1955 metric_fn, y_true, y_pred, weights=weights, mask=mask)\r\n 1956 metric_results.append(metric_result)\r\n 1957 return metric_results\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/training_utils.py in call_metric_function(metric_fn, y_true, y_pred, weights, mask)\r\n 1153 \r\n 1154 if y_pred is not None:\r\n-> 1155 return metric_fn(y_true, y_pred, sample_weight=weights)\r\n 1156 # `Mean` metric only takes a single value.\r\n 1157 return metric_fn(y_true, sample_weight=weights)\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/metrics.py in __call__(self, *args, **kwargs)\r\n 194 from tensorflow.python.keras.distribute import distributed_training_utils # pylint:disable=g-import-not-at-top\r\n 195 return distributed_training_utils.call_replica_local_fn(\r\n--> 196 replica_local_fn, *args, **kwargs)\r\n 197 \r\n 198 @property\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/distribute/distributed_training_utils.py in call_replica_local_fn(fn, *args, **kwargs)\r\n 1133 with strategy.scope():\r\n 1134 return strategy.extended.call_for_each_replica(fn, args, kwargs)\r\n-> 1135 return fn(*args, **kwargs)\r\n 1136 \r\n 1137 \r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/metrics.py in replica_local_fn(*args, **kwargs)\r\n 177 def replica_local_fn(*args, **kwargs):\r\n 178 \"\"\"Updates the state of the metric in a replica-local context.\"\"\"\r\n--> 179 update_op = self.update_state(*args, **kwargs) # pylint: disable=not-callable\r\n 180 with ops.control_dependencies([update_op]):\r\n 181 result_t = self.result() # pylint: disable=not-callable\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/utils/metrics_utils.py in decorated(metric_obj, *args, **kwargs)\r\n 74 \r\n 75 with tf_utils.graph_context_for_symbolic_tensors(*args, **kwargs):\r\n---> 76 update_op = update_state_fn(*args, **kwargs)\r\n 77 if update_op is not None: # update_op will be None in eager execution.\r\n 78 metric_obj.add_update(update_op)\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/metrics.py in update_state(self, y_true, y_pred, sample_weight)\r\n 1340 top_k=self.top_k,\r\n 1341 class_id=self.class_id,\r\n-> 1342 sample_weight=sample_weight)\r\n 1343 \r\n 1344 def result(self):\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/utils/metrics_utils.py in update_confusion_matrix_variables(variables_to_update, y_true, y_pred, thresholds, top_k, class_id, sample_weight, multi_label, label_weights)\r\n 438 update_ops.append(\r\n 439 weighted_assign_add(label, pred, weights_tiled,\r\n--> 440 variables_to_update[matrix_cond]))\r\n 441 \r\n 442 return control_flow_ops.group(update_ops)\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/utils/metrics_utils.py in weighted_assign_add(label, pred, weights, var)\r\n 414 if weights is not None:\r\n 415 label_and_pred *= weights\r\n--> 416 return var.assign_add(math_ops.reduce_sum(label_and_pred, 1))\r\n 417 \r\n 418 loop_vars = {\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/ops/resource_variable_ops.py in assign_add(self, delta, use_locking, name, read_value)\r\n 783 with _handle_graph(self.handle), self._assign_dependencies():\r\n 784 assign_add_op = gen_resource_variable_ops.assign_add_variable_op(\r\n--> 785 self.handle, ops.convert_to_tensor(delta, dtype=self.dtype),\r\n 786 name=name)\r\n 787 if read_value:\r\n\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/ops.py in convert_to_tensor(value, dtype, name, as_ref, preferred_dtype, dtype_hint, ctx, accepted_result_types)\r\n 1288 raise ValueError(\r\n 1289 \"Tensor conversion requested dtype %s for Tensor with dtype %s: %r\" %\r\n-> 1290 (dtype.name, value.dtype.name, value))\r\n 1291 return value\r\n 1292 \r\n\r\nValueError: Tensor conversion requested dtype float64 for Tensor with dtype float32: <tf.Tensor 'metrics_6/class_output_recall_8/Sum:0' shape=(1,) dtype=float32>\r\n```\r\n",
"comments": [
{
"body": "@MarkDaoust \r\nTagging you for escalation. Kindly excuse me if this is unprofessional.",
"created_at": "2020-02-16T06:55:40Z"
},
{
"body": "@Hemal-Mamtora Could you please confirm if the issue faced by you is similar to existing [issue](https://github.com/tensorflow/tensorflow/issues/33365)",
"created_at": "2020-02-17T07:07:28Z"
},
{
"body": "Yes, seems like TF 2.0 has issues with float 64\r\n\r\nTill when would this issue be resolved ?",
"created_at": "2020-02-17T12:35:51Z"
},
{
"body": "Hi @Hemal-Mamtora , \r\n\r\nI think you're right.\r\n\r\nIt looks like this is being caused by the mismatch of [metric.py recognizing `floatx`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/metrics.py#L146) but [metric_utils.py casting directly to float32](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/utils/metrics_utils.py#L427) .\r\n\r\n@pavithrasv, what's the right way to fix this?\r\n",
"created_at": "2020-02-18T15:02:52Z"
},
{
"body": "Thank you @MarkDaoust. It should be cast to the predictions' dtype. If anyone would like to work on the fix please feel free to send me a PR.",
"created_at": "2020-02-18T17:52:45Z"
},
{
"body": "Added a fix and test case in PR #39134 that will address this issue.",
"created_at": "2020-05-03T22:43:05Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36790\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36790\">No</a>\n",
"created_at": "2020-05-28T17:07:19Z"
}
],
"number": 36790,
"title": "tf.keras.backend.set_floatx() causing ValueError (dtype conversion error) while computing tf.keras.metrics.*"
}
|
{
"body": "\r\nThis PR fixes the issue raised in #36790 where tf.keras.metrics.Recall\r\ncauses ValueError when the backend of the keras is float64:\r\n\r\nThis PR cast the value to the dtype of var as var.assign_add\r\nis being called.\r\n\r\nThis PR fixes #36790.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\n",
"number": 39134,
"review_comments": [
{
"body": "Could we change other places float32 is used in this function as well?",
"created_at": "2020-05-26T19:31:10Z"
}
],
"title": "Fix ValueError with tf.keras.metrics.Recall and float64 keras backend"
}
|
{
"commits": [
{
"message": "Fix ValueError with tf.keras.metrics.Recall and float64 keras backend\n\nThis PR fixes the issue raised in 36790 where tf.keras.metrics.Recall\ncauses ValueError when the backend of the keras is float64:\n\nThis PR cast the value to the dtype of var as var.assign_add\nis being called.\n\nThis PR fixes 36790.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for tf.keras.metrics.Recall() and float64 keras backend.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update update_confusion_matrix_variables to alwasy cast to variables_to_update dtype (vs. explicit float32)\n\nThis commits updates the function update_confusion_matrix_variables\nto alwasy cast to dtype based on variables_to_update (previously\nthe values are casted to float32 explicitly and that cuases issues\nwhen keras' backend use non-float32).\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -33,6 +33,7 @@\n from tensorflow.python.framework import errors_impl\n from tensorflow.python.framework import ops\n from tensorflow.python.framework import test_util\n+from tensorflow.python.keras import backend\n from tensorflow.python.keras import combinations\n from tensorflow.python.keras import keras_parameterized\n from tensorflow.python.keras import layers\n@@ -2174,6 +2175,23 @@ def test_reset_states_mean_iou(self):\n self.assertArrayNear(self.evaluate(m_obj.total_cm)[0], [1, 0], 1e-1)\n self.assertArrayNear(self.evaluate(m_obj.total_cm)[1], [3, 0], 1e-1)\n \n+ def test_reset_states_recall_float64(self):\n+ # Test case for GitHub issue 36790.\n+ try:\n+ backend.set_floatx('float64')\n+ r_obj = metrics.Recall()\n+ model = _get_model([r_obj])\n+ x = np.concatenate((np.ones((50, 4)), np.zeros((50, 4))))\n+ y = np.concatenate((np.ones((50, 1)), np.ones((50, 1))))\n+ model.evaluate(x, y)\n+ self.assertEqual(self.evaluate(r_obj.true_positives), 50.)\n+ self.assertEqual(self.evaluate(r_obj.false_negatives), 50.)\n+ model.evaluate(x, y)\n+ self.assertEqual(self.evaluate(r_obj.true_positives), 50.)\n+ self.assertEqual(self.evaluate(r_obj.false_negatives), 50.)\n+ finally:\n+ backend.set_floatx('float32')\n+\n \n if __name__ == '__main__':\n test.main()",
"filename": "tensorflow/python/keras/metrics_test.py",
"status": "modified"
},
{
"diff": "@@ -299,9 +299,19 @@ def update_confusion_matrix_variables(variables_to_update,\n '`multi_label` is True.')\n if variables_to_update is None:\n return\n- y_true = math_ops.cast(y_true, dtype=dtypes.float32)\n- y_pred = math_ops.cast(y_pred, dtype=dtypes.float32)\n- thresholds = ops.convert_to_tensor_v2(thresholds, dtype=dtypes.float32)\n+ if not any(\n+ key for key in variables_to_update if key in list(ConfusionMatrix)):\n+ raise ValueError(\n+ 'Please provide at least one valid confusion matrix '\n+ 'variable to update. Valid variable key options are: \"{}\". '\n+ 'Received: \"{}\"'.format(\n+ list(ConfusionMatrix), variables_to_update.keys()))\n+\n+ variable_dtype = list(variables_to_update.values())[0].dtype\n+\n+ y_true = math_ops.cast(y_true, dtype=variable_dtype)\n+ y_pred = math_ops.cast(y_pred, dtype=variable_dtype)\n+ thresholds = ops.convert_to_tensor_v2(thresholds, dtype=variable_dtype)\n num_thresholds = thresholds.shape[0]\n if multi_label:\n one_thresh = math_ops.equal(\n@@ -314,14 +324,6 @@ def update_confusion_matrix_variables(variables_to_update,\n sample_weight)\n one_thresh = math_ops.cast(True, dtype=dtypes.bool)\n \n- if not any(\n- key for key in variables_to_update if key in list(ConfusionMatrix)):\n- raise ValueError(\n- 'Please provide at least one valid confusion matrix '\n- 'variable to update. Valid variable key options are: \"{}\". '\n- 'Received: \"{}\"'.format(\n- list(ConfusionMatrix), variables_to_update.keys()))\n-\n invalid_keys = [\n key for key in variables_to_update if key not in list(ConfusionMatrix)\n ]\n@@ -401,7 +403,7 @@ def update_confusion_matrix_variables(variables_to_update,\n \n if sample_weight is not None:\n sample_weight = weights_broadcast_ops.broadcast_weights(\n- math_ops.cast(sample_weight, dtype=dtypes.float32), y_pred)\n+ math_ops.cast(sample_weight, dtype=variable_dtype), y_pred)\n weights_tiled = array_ops.tile(\n array_ops.reshape(sample_weight, thresh_tiles), data_tiles)\n else:\n@@ -422,9 +424,9 @@ def update_confusion_matrix_variables(variables_to_update,\n \n def weighted_assign_add(label, pred, weights, var):\n label_and_pred = math_ops.cast(\n- math_ops.logical_and(label, pred), dtype=dtypes.float32)\n+ math_ops.logical_and(label, pred), dtype=var.dtype)\n if weights is not None:\n- label_and_pred *= weights\n+ label_and_pred *= math_ops.cast(weights, dtype=var.dtype)\n return var.assign_add(math_ops.reduce_sum(label_and_pred, 1))\n \n loop_vars = {",
"filename": "tensorflow/python/keras/utils/metrics_utils.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): \r\nv2.0.0-beta1-5101-gc75bb66 2.0.0-rc0\r\n- Python version: 3.6.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: CUDA 10.0, cuDNN 7.6.2.24-1\r\n- GPU model and memory: Nvidia RTX 2070 8 GB\r\n\r\n**Describe the current behavior**\r\nA constructor of a tf.keras Model that uses `tf.keras.layers.BatchNormalization` with `virtual_batch_size` set and unspecified input shape dimensions throws an exception.\r\n\r\n**Describe the expected behavior**\r\nSuch a model should be usable.\r\n\r\n**Code to reproduce the issue**\r\n```python\r\nimport tensorflow as tf\r\n\r\ninp = tf.keras.layers.Input(shape=(None, None, 3))\r\nnet = tf.keras.layers.BatchNormalization(virtual_batch_size=8)(inp)\r\n\r\nmodel = tf.keras.Model(inputs=inp, outputs=net)\r\n```\r\n\r\n**Other info / logs**\r\nTraceback of the exception:\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/framework/tensor_util.py\", line 541, in make_tensor_proto\r\n str_values = [compat.as_bytes(x) for x in proto_values]\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/framework/tensor_util.py\", line 541, in <listcomp>\r\n str_values = [compat.as_bytes(x) for x in proto_values]\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/util/compat.py\", line 71, in as_bytes\r\n (bytes_or_text,))\r\nTypeError: Expected binary or unicode string, got 8\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/framework/test_virtual_batch.py\", line 6, in <module>\r\n net = tf.keras.layers.BatchNormalization(virtual_batch_size=8)(inp)\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 802, in __call__\r\n outputs = call_fn(cast_inputs, *args, **kwargs)\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/keras/layers/normalization.py\", line 652, in call\r\n inputs = array_ops.reshape(inputs, expanded_shape)\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/ops/array_ops.py\", line 131, in reshape\r\n result = gen_array_ops.reshape(tensor, shape, name)\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/ops/gen_array_ops.py\", line 8117, in reshape\r\n \"Reshape\", tensor=tensor, shape=shape, name=name)\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/framework/op_def_library.py\", line 530, in _apply_op_helper\r\n raise err\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/framework/op_def_library.py\", line 527, in _apply_op_helper\r\n preferred_dtype=default_dtype)\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/framework/ops.py\", line 1296, in internal_convert_to_tensor\r\n ret = conversion_func(value, dtype=dtype, name=name, as_ref=as_ref)\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/framework/constant_op.py\", line 286, in _constant_tensor_conversion_function\r\n return constant(v, dtype=dtype, name=name)\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/framework/constant_op.py\", line 227, in constant\r\n allow_broadcast=True)\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/framework/constant_op.py\", line 265, in _constant_impl\r\n allow_broadcast=allow_broadcast))\r\n File \"/home/ikrets/tf2/lib/python3.6/site-packages/tensorflow_core/python/framework/tensor_util.py\", line 545, in make_tensor_proto\r\n \"supported type.\" % (type(values), values))\r\nTypeError: Failed to convert object of type <class 'list'> to Tensor. Contents: [8, -1, None, None, 3]. Consider casting elements to a supported type.\r\n```",
"comments": [
{
"body": "I replicate the issue with TF 2.0.0.rc0. Please take a look at [gist here](https://colab.sandbox.google.com/gist/gadagashwini/514760082d2c9017a6a4cd51977e3a51/untitled138.ipynb). Thanks!",
"created_at": "2019-09-11T06:22:55Z"
},
{
"body": "Added a PR #39131 for the fix.",
"created_at": "2020-05-03T20:29:33Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32380\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32380\">No</a>\n",
"created_at": "2020-05-05T19:27:58Z"
}
],
"number": 32380,
"title": "BatchNormalization virtual_batch_size does not work with None in input shape"
}
|
{
"body": "This PR tries to address the issue raised in #32380 where BatchNormalization with virtual_batch_size will throw out error if shape has None:\r\n```\r\nTypeError: Failed to convert object of type <class 'list'> to Tensor. Contents: [8, -1, None, None, 3]. Consider casting elements to a supported type.\r\n```\r\n\r\nThis PR converts None to -1 so that it could be passed as a tensor to `reshape`.\r\n\r\nThis PR fixes #32380.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 39131,
"review_comments": [
{
"body": "This is not super safe as it can generate more than one -1.\r\n\r\nIsn't it better to use tf.shape instead?",
"created_at": "2020-05-04T14:52:04Z"
}
],
"title": "Fix BatchNormalization issue with virtual_batch_size when shape has None"
}
|
{
"commits": [
{
"message": "Fix BatchNormalization issue with virtual_batch_size when shape has None\n\nThis PR tries to address the issue raised in 32380 where\nBatchNormalization with virtual_batch_size will throw out error if\nshape has None:\n```\nTypeError: Failed to convert object of type <class 'list'> to Tensor. Contents: [8, -1, None, None, 3]. Consider casting elements to a supported type.\n```\n\nThis PR converts None to -1 so that it could be passed as a tensor to `reshape`.\n\nThis PR fixes 32380.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for BatchNormalization with virtual_batch_size and shape has None.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update to use tf.shape to get the shape of the tensor, from review comment\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -736,8 +736,13 @@ def call(self, inputs, training=None):\n if self.virtual_batch_size is not None:\n # Virtual batches (aka ghost batches) can be simulated by reshaping the\n # Tensor and reusing the existing batch norm implementation\n- original_shape = [-1] + inputs.shape.as_list()[1:]\n- expanded_shape = [self.virtual_batch_size, -1] + original_shape[1:]\n+ original_shape = array_ops.shape(inputs)\n+ original_shape = array_ops.concat([\n+ constant_op.constant([-1]),\n+ original_shape[1:]], axis=0)\n+ expanded_shape = array_ops.concat([\n+ constant_op.constant([self.virtual_batch_size, -1]),\n+ original_shape[1:]], axis=0)\n \n # Will cause errors if virtual_batch_size does not divide the batch size\n inputs = array_ops.reshape(inputs, expanded_shape)",
"filename": "tensorflow/python/keras/layers/normalization.py",
"status": "modified"
},
{
"diff": "@@ -354,6 +354,13 @@ def my_func():\n # Updates should be tracked in a `wrap_function`.\n self.assertLen(layer.updates, 2)\n \n+ @keras_parameterized.run_all_keras_modes\n+ def test_basic_batchnorm_v2_none_shape_and_virtual_batch_size(self):\n+ # Test case for GitHub issue for 32380\n+ norm = normalization_v2.BatchNormalization(virtual_batch_size=8)\n+ inp = keras.layers.Input(shape=(None, None, 3))\n+ _ = norm(inp)\n+\n \n def _run_batchnorm_correctness_test(layer, dtype='float32', fused=False):\n model = keras.models.Sequential()",
"filename": "tensorflow/python/keras/layers/normalization_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): somewhat custom\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: laptop\r\n- TensorFlow installed from (source or binary):\r\n- TensorFlow version (use command below): \r\n- Python version: 3.6.10\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source): 7.3.0\r\n- CUDA/cuDNN version: None\r\n- GPU model and memory: None\r\n\r\n**Describe the current behavior**\r\nHuber Loss crashes the script with the following error message:\r\n\r\n> TypeError: Input 'y' of 'Mul' Op has type float64 that does not match type float32 of argument 'x'.\r\n\r\nThat happens even though I cast everything to either `tf.float32` or `tf.float64` manually. It **does** work if I put this line \r\n```\r\ntf.keras.backend.set_floatx('float32')\r\n```\r\nOr if I remove the original line with `float64`. Seems to me like setting the global data type fails somewhere. And, I get the following warning that tensors are being re-casted automatically:\r\n>WARNING:tensorflow:Layer dense_8 is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because it's dtype defaults to floatx.\r\n\r\n**Standalone code to reproduce the issue**\r\n```import os\r\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'\r\nfrom sklearn.datasets import load_linnerud\r\nimport tensorflow as tf\r\ntf.keras.backend.set_floatx('float64')\r\nfrom tensorflow.keras.models import Model\r\nfrom tensorflow.keras.layers import Dense, Dropout, LSTM, Concatenate\r\n\r\nX, y = load_linnerud(return_X_y=True)\r\n\r\ndata = tf.data.Dataset.from_tensor_slices((X, y)).\\\r\n map(lambda a, b: (tf.divide(a, tf.reduce_max(X, axis=0, keepdims=True)), b))\r\n\r\ntrain_data = data.take(16).shuffle(16).batch(4)\r\ntest_data = data.skip(16).shuffle(4).batch(4)\r\n\r\n\r\nclass FullyConnectedNetwork(Model):\r\n def __init__(self):\r\n super(FullyConnectedNetwork, self).__init__()\r\n self.layer1 = Dense(9, input_shape=(3,))\r\n self.layer2 = LSTM(8, return_sequences=True)\r\n self.layer3 = Dense(27)\r\n self.layer4 = Dropout(5e-1)\r\n self.layer5 = Dense(27)\r\n self.layer6 = Concatenate()\r\n self.layer7 = Dense(3)\r\n\r\n def __call__(self, x, *args, **kwargs):\r\n x = tf.nn.tanh(self.layer1(x))\r\n y = self.layer2(x)\r\n x = tf.nn.selu(self.layer3(x))\r\n x = self.layer4(x)\r\n x = tf.nn.relu(self.layer5(x))\r\n x = self.layer6([x, y])\r\n x = self.layer7(x)\r\n return x\r\n\r\n\r\nmodel = FullyConnectedNetwork()\r\n\r\nloss_object = tf.keras.losses.Huber()\r\n\r\ntrain_loss = tf.keras.metrics.Mean()\r\ntest_loss = tf.keras.metrics.Mean()\r\n\r\noptimizer = tf.keras.optimizers.Adamax()\r\n\r\n\r\n@tf.function\r\ndef train_step(inputs, targets):\r\n with tf.GradientTape() as tape:\r\n outputs = model(inputs)\r\n loss = loss_object(outputs, targets)\r\n train_loss(loss)\r\n\r\n gradients = tape.gradient(loss, model.trainable_variables)\r\n optimizer.apply_gradients(zip(gradients, model.trainable_variables))\r\n\r\n\r\n@tf.function\r\ndef test_step(inputs, targets):\r\n outputs = model(inputs)\r\n print(outputs.dtype, targets.dtype)\r\n loss = loss_object(outputs, targets)\r\n test_loss(loss)\r\n\r\n\r\ndef main():\r\n train_loss.reset_states()\r\n test_loss.reset_states()\r\n\r\n for epoch in range(1, 10_000 + 1):\r\n for x, y in train_data:\r\n train_step(x, y)\r\n\r\n for x, y in test_data:\r\n test_step(x, y)\r\n\r\n if epoch % 25 == 0:\r\n print(f'Epoch: {epoch:>4} Train Loss: {train_loss.result().numpy():.2f} '\r\n f'Test Loss: {test_loss.result().numpy():.2f}')\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n```\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/IPython/core/interactiveshell.py\", line 3331, in run_code\r\n exec(code_obj, self.user_global_ns, self.user_ns)\r\n File \"<ipython-input-30-b08781047662>\", line 86, in <module>\r\n main()\r\n File \"<ipython-input-30-b08781047662>\", line 75, in main\r\n train_step(x, y)\r\n File \"/home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 568, in __call__\r\n result = self._call(*args, **kwds)\r\n File \"/home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 615, in _call\r\n self._initialize(args, kwds, add_initializers_to=initializers)\r\n File \"/home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 497, in _initialize\r\n *args, **kwds))\r\n File \"/home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 2389, in _get_concrete_function_internal_garbage_collected\r\n graph_function, _, _ = self._maybe_define_function(args, kwargs)\r\n File \"/home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 2703, in _maybe_define_function\r\n graph_function = self._create_graph_function(args, kwargs)\r\n File \"/home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 2593, in _create_graph_function\r\n capture_by_value=self._capture_by_value),\r\n File \"/home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/framework/func_graph.py\", line 978, in func_graph_from_py_func\r\n func_outputs = python_func(*func_args, **func_kwargs)\r\n File \"/home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 439, in wrapped_fn\r\n return weak_wrapped_fn().__wrapped__(*args, **kwds)\r\n File \"/home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/framework/func_graph.py\", line 968, in wrapper\r\n raise e.ag_error_metadata.to_exception(e)\r\nTypeError: in converted code:\r\n <ipython-input-20-f2c31267a363>:54 train_step *\r\n loss = loss_object(outputs, targets)\r\n /home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/keras/losses.py:126 __call__\r\n losses = self.call(y_true, y_pred)\r\n /home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/keras/losses.py:221 call\r\n return self.fn(y_true, y_pred, **self._fn_kwargs)\r\n /home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/keras/losses.py:915 huber_loss\r\n math_ops.multiply(delta, linear))\r\n /home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/util/dispatch.py:180 wrapper\r\n return target(*args, **kwargs)\r\n /home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/ops/math_ops.py:334 multiply\r\n return gen_math_ops.mul(x, y, name)\r\n /home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/ops/gen_math_ops.py:6125 mul\r\n \"Mul\", x=x, y=y, name=name)\r\n /home/nicolas/anaconda3/envs/condaenv/lib/python3.6/site-packages/tensorflow_core/python/framework/op_def_library.py:504 _apply_op_helper\r\n inferred_from[input_arg.type_attr]))\r\n TypeError: Input 'y' of 'Mul' Op has type float64 that does not match type float32 of argument 'x'.\r\n```",
"comments": [
{
"body": "Was able to reproduce the issue with TF v2.1, [TF v2.2.0-rc3](https://colab.research.google.com/gist/amahendrakar/6baa93476d84d2fef692b159e39eaaaa/39004.ipynb) and [TF-nightly](https://colab.research.google.com/gist/amahendrakar/869d37d6c2c3909353ce483f01fa5df0/39004-tf-nightly.ipynb). Please find the attached gist. Thanks!",
"created_at": "2020-04-29T13:56:43Z"
},
{
"body": "Potentially related to #36790",
"created_at": "2020-05-02T22:19:07Z"
},
{
"body": "Added a PR #39123 for the fix of this issue.",
"created_at": "2020-05-03T16:36:19Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/39004\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/39004\">No</a>\n",
"created_at": "2020-05-05T18:16:57Z"
}
],
"number": 39004,
"title": "Huber Loss crashes training loop due to data type mismatch"
}
|
{
"body": "This PR tries to address the issue raised in #39004 where setting keras backend to 'float64' causes Huber Loss crash:\r\n```\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/losses.py:1440 huber\r\n math_ops.multiply(delta, linear)),\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/util/dispatch.py:180 wrapper\r\n return target(*args, **kwargs)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:490 multiply\r\n return gen_math_ops.mul(x, y, name)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/gen_math_ops.py:6153 mul\r\n \"Mul\", x=x, y=y, name=name)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:506 _apply_op_helper\r\n inferred_from[input_arg.type_attr]))\r\n\r\n TypeError: Input 'y' of 'Mul' Op has type float64 that does not match type float32 of argument 'x'.\r\n\r\n```\r\n\r\nThis PR fixes the crash by casting delta the same way as y_pred and y_true accordingly.\r\n\r\nThis PR fixes #39004\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 39123,
"review_comments": [
{
"body": "Let's rename the test name since \"all_correct\" seems to be too generic. How about test_loss_with_non_default_dtype?",
"created_at": "2020-05-04T15:52:18Z"
},
{
"body": "Let's replace this with a URL.",
"created_at": "2020-05-04T15:52:34Z"
},
{
"body": "@qlzh727 Thanks. Updated.",
"created_at": "2020-05-04T16:19:12Z"
},
{
"body": "Thanks, Done.",
"created_at": "2020-05-04T16:19:20Z"
}
],
"title": "Fix Huber Loss crashes due to data type mismatch"
}
|
{
"commits": [
{
"message": "Fix Huber Loss crashes due to data type mismatch\n\nThis PR tries to address the issue raised in 39004 where\nsetting keras backend to 'float64' causes Huber Loss crash:\n```\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/losses.py:1440 huber\n math_ops.multiply(delta, linear)),\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/util/dispatch.py:180 wrapper\n return target(*args, **kwargs)\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:490 multiply\n return gen_math_ops.mul(x, y, name)\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/gen_math_ops.py:6153 mul\n \"Mul\", x=x, y=y, name=name)\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:506 _apply_op_helper\n inferred_from[input_arg.type_attr]))\n\n TypeError: Input 'y' of 'Mul' Op has type float64 that does not match type float32 of argument 'x'.\n\n```\n\nThis PR fixes the crash by casting delta the same way as y_pred and y_true accordingly.\n\nThis PR fixes 39004\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for Huber Loss crashes when data type mismatch\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Address review comment (change test name and add URL)\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -1428,6 +1428,7 @@ def huber(y_true, y_pred, delta=1.0):\n \"\"\"\n y_pred = math_ops.cast(y_pred, dtype=K.floatx())\n y_true = math_ops.cast(y_true, dtype=K.floatx())\n+ delta = math_ops.cast(delta, dtype=K.floatx())\n error = math_ops.subtract(y_pred, y_true)\n abs_error = math_ops.abs(error)\n quadratic = math_ops.minimum(abs_error, delta)",
"filename": "tensorflow/python/keras/losses.py",
"status": "modified"
},
{
"diff": "@@ -1578,6 +1578,19 @@ def test_non_default_delta(self):\n actual_loss = sample_weight * np.sum(self.expected_losses) / self.batch_size\n self.assertAlmostEqual(self.evaluate(loss), actual_loss, 3)\n \n+ def test_loss_with_non_default_dtype(self):\n+ # Test case for GitHub issue:\n+ # https://github.com/tensorflow/tensorflow/issues/39004\n+ self.setup()\n+ h_obj = losses.Huber()\n+ try:\n+ backend.set_floatx('float64')\n+ loss = h_obj(self.y_true, self.y_true)\n+ self.assertAlmostEqual(self.evaluate(loss), 0.0, 3)\n+ finally:\n+ backend.set_floatx('float32')\n+\n+\n \n if __name__ == '__main__':\n test.main()",
"filename": "tensorflow/python/keras/losses_test.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes; minimal working example provided\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux-5.3.0-46-generic-x86_64-with-Ubuntu-18.04-bionic\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.2.0.dev20200501\r\n- Python version: 3.7.5\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with:\r\n1. TF 1.0: `python -c \"import tensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"`\r\n2. TF 2.0: `python -c \"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n\r\n**Describe the current behavior**\r\nIt is not possible to train the \"trainable\" parameters of the RandomFourierFeatures keras layer, when using eager execution.\r\n\r\n**Describe the expected behavior**\r\nIt should be possible to train the \"trainable\" parameters of the RandomFourierFeatures keras layer, even when using eager execution.\r\n\r\n**Standalone code to reproduce the issue**\r\nimport tensorflow as tf\r\nfrom tensorflow_core.python.keras.layers import RandomFourierFeatures\r\n\r\nfourier_features = RandomFourierFeatures(\r\n 1,\r\n kernel_initializer='gaussian',\r\n scale=1.0,\r\n trainable=True,\r\n dtype=tf.float64\r\n)\r\n\r\ninput = tf.keras.Input(shape=(1,), dtype=tf.float64, name='input')\r\noutput = fourier_features(input)\r\nmodel = tf.keras.Model(inputs=input, outputs=output)\r\nmodel.compile(loss='mean_squared_error')\r\n\r\nmodel.fit(tf.constant([[1.0]]), tf.constant([[1.0]]), epochs=1)\r\n\r\n\r\n**Other info / logs**\r\nThe call to fit throws the following error:\r\nValueError: No gradients provided for any variable: ['random_fourier_features/random_features_scale:0'].\r\n1/1 [==============================] - 0s 17ms/sample\r\n",
"comments": [
{
"body": "I have tried in colab with TF 2.1.0, 2.2-rc4 and i am able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/9879324436f65e80eda2cc68cdd1eb15/untitled848.ipynb).Thanks!",
"created_at": "2020-05-04T06:46:41Z"
},
{
"body": "Same here. I only use the `fit()` function, without customization..\r\n\r\nIn previous versions of TF, my projects ran smoothly, but now I'm getting this \"No gradients provided for any variable\" message.",
"created_at": "2020-05-04T20:18:17Z"
},
{
"body": "This appears to have been fixed in the latest nightly build (`2.3.0.dev20200531`). ",
"created_at": "2020-06-01T07:40:55Z"
},
{
"body": "@johnamcleod \r\n\r\nI have tried in latest nightly build (`2.3.0-dev20200531`) and i am not seeing any issue. I have changed small update in code by importing RandomFourierFeatures by (`from tensorflow.python.keras.layers.kernelized import RandomFourierFeatures`).Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/bdf2110e533ab08ae5660620350cdad9/untitled942.ipynb).Please, verify once and close the issue.Thanks!",
"created_at": "2020-06-01T09:57:00Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/39088\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/39088\">No</a>\n",
"created_at": "2020-06-01T10:07:26Z"
}
],
"number": 39088,
"title": "It is not possible to train the trainable parameters of the RandomFourierFeatures keras layer in eager mode"
}
|
{
"body": "fix #39088 \r\n\r\nWhen executing in eager mode, computing the `kernel` value is done at build time, so it is not possible to calculate the gradient of the output with respect to the trainable parameters.",
"number": 39089,
"review_comments": [
{
"body": "You could use layer_test() which will do a bunch of extra verifications for a layer, eg saving/loading etc.\r\n\r\nSee https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/testing_utils.py#L87",
"created_at": "2020-07-14T17:16:50Z"
},
{
"body": "Thanks for your suggestion - this looks really cool and is exactly what I need to use here. Unfortunately I am having some problems using this function with the layer - I am seeing errors that suggest the layer has not been registered. As soon as I can get this cleared up I will update the PR. My apologies for the delay.",
"created_at": "2020-07-20T21:12:00Z"
},
{
"body": "@johnamcleod, Any update on this PR? Please. Thanks!",
"created_at": "2020-08-03T15:04:14Z"
},
{
"body": "I was not able to figure out how to use the `layer_test` function with this layer, so I will close the PR. I apologise for the delay.",
"created_at": "2020-08-03T15:19:42Z"
}
],
"title": "Ensure that the RandomFourierFeatures layer can be trained in eager mode"
}
|
{
"commits": [
{
"message": "Update kernelized.py and kernelized_test.py"
},
{
"message": "Merge remote-tracking branch 'origin/master' into fix-39088\n\n# Conflicts:\n#\ttensorflow/python/keras/layers/kernelized.py"
}
],
"files": [
{
"diff": "@@ -27,6 +27,7 @@\n import numpy as np\n \n from tensorflow.python.eager import context\n+from tensorflow.python import keras\n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n from tensorflow.python.framework import ops\n@@ -47,7 +48,7 @@\n from tensorflow.python.ops import math_ops\n from tensorflow.python.ops import random_ops\n from tensorflow.python.platform import test\n-\n+from tensorflow.python.training import gradient_descent\n \n def _exact_gaussian(stddev):\n return functools.partial(\n@@ -392,6 +393,19 @@ def test_good_kernel_approximation_multiple_inputs(self, initializer, scale,\n exact_kernel_matrix = exact_kernel_fn(x, y)\n self._assert_all_close(approx_kernel_matrix, exact_kernel_matrix, atol=0.05)\n \n+ def testTrainLayer(self):\n+ \"\"\"Ensure the layer may be trained as part of a model.\"\"\"\n+ rff_layer = kernel_layers.RandomFourierFeatures(\n+ output_dim=1,\n+ kernel_initializer='gaussian',\n+ scale=1.0,\n+ trainable=True,\n+ name='random_fourier_features')\n+ model = keras.models.Sequential()\n+ model.add(rff_layer)\n+ model.compile(gradient_descent.GradientDescentOptimizer(0.001), 'mse')\n+ model.train_on_batch(np.array([1.0]), np.array([1.0]))\n+\n \n if __name__ == '__main__':\n test.main()",
"filename": "tensorflow/python/keras/layers/kernelized_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes (code included below in the issue)\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): MacOS 10.14.3\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): pip \r\n- TensorFlow version (use command below): v2.0.0-beta1-5101-gc75bb66a99 2.0.0-rc0\r\n- Python version: Python 3.6.7 :: Anaconda, Inc.\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\nUsing cloudpickle to serialize a Python function that uses `tf.keras.Sequential` fails with a recursion error.\r\n\r\n**Note** that this works with `tensorflow==1.14.0`.\r\n\r\nI imagine it also fails with other things, not just `tf.keras.Sequential`.\r\n\r\n```python\r\nimport cloudpickle # cloudpickle.__version__ == '1.2.1'\r\nimport tensorflow as tf # tf.__version__ == '2.0.0-rc0'\r\n\r\ndef f():\r\n tf.keras.Sequential\r\n\r\ncloudpickle.loads(cloudpickle.dumps(f)) # This fails.\r\n```\r\n\r\nThe last line fails with\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nRecursionError Traceback (most recent call last)\r\n<ipython-input-23-25cc307e6227> in <module>\r\n----> 1 cloudpickle.loads(cloudpickle.dumps(f))\r\n\r\n~/anaconda3/lib/python3.6/site-packages/tensorflow/__init__.py in __getattr__(self, item)\r\n 48 \r\n 49 def __getattr__(self, item):\r\n---> 50 module = self._load()\r\n 51 return getattr(module, item)\r\n 52 \r\n\r\n~/anaconda3/lib/python3.6/site-packages/tensorflow/__init__.py in _load(self)\r\n 42 def _load(self):\r\n 43 \"\"\"Import the target module and insert it into the parent's namespace.\"\"\"\r\n---> 44 module = _importlib.import_module(self.__name__)\r\n 45 self._parent_module_globals[self._local_name] = module\r\n 46 self.__dict__.update(module.__dict__)\r\n\r\n... last 2 frames repeated, from the frame below ...\r\n\r\n~/anaconda3/lib/python3.6/site-packages/tensorflow/__init__.py in __getattr__(self, item)\r\n 48 \r\n 49 def __getattr__(self, item):\r\n---> 50 module = self._load()\r\n 51 return getattr(module, item)\r\n 52 \r\n\r\nRecursionError: maximum recursion depth exceeded while calling a Python object\r\n```\r\n\r\nSee https://stackoverflow.com/questions/57750920/ray-tensorflow-gpu-2-0-recursionerror/57761034#57761034",
"comments": [
{
"body": "I have tried on colab with TF 1.14 and able to execute the code.However i am able to reproduce the issue with TF 2.0.0-rc0 and 2.0 nightly versions.Please, find the [gist ](https://colab.sandbox.google.com/gist/ravikyram/af3b48253cc090e9c2048db71024d890/untitled143.ipynb)here.Thanks!",
"created_at": "2019-09-03T05:46:16Z"
},
{
"body": "What is the goal of serialization here? We have several saving methods that allow you to save and revive a keras model that might be more appropriate here.",
"created_at": "2019-09-03T18:47:16Z"
},
{
"body": "@karmel Note that this issue is not actually about serializing a keras model, but rather about serializing a function that creates a keras model. The APIs you refer to don't help in this case, I think.\r\n\r\nCloudpickle is the standard when it comes to general purpose serialization of arbitrary Python objects (including functions and classes). This is used by many distributed computing frameworks (like Ray, PySpark, Dask, IPython Parallel) that serialize arbitrary user-defined functions and ship them to remote worker processes to be executed.\r\n\r\nAs long as TensorFlow plays nicely with cloudpickle, then cloudpickle will be able to serialize arbitrary functions/classes that use TensorFlow. Serializing arbitrary functions/classes is most likely out of scope for TensorFlow, and so it makes sense to have cloudpickle handle that.",
"created_at": "2019-09-03T19:49:17Z"
},
{
"body": "@yifeif Can you take a look at the cloud pickle issue? It looks like it's getting caught up in an infinite recursion loop in LazyLoader",
"created_at": "2019-09-03T20:36:44Z"
},
{
"body": "Looks like we might need to handle __getstate__, __setstate__ for the LazyLoader at virtual pip level? cc @mihaimaruseac",
"created_at": "2019-09-03T22:03:50Z"
},
{
"body": "Seems that that is the case, `__getstate__`, `__setstate__`, `__getinitargs__` and `__getnewargs__`.\r\n\r\nI will send a fix later today/tomorrow.",
"created_at": "2019-09-03T22:14:41Z"
},
{
"body": "Update: the issue comes from the unpickling part, as shown from the script below:\r\n\r\n```python\r\n_p = print\r\nimport cloudpickle # cloudpickle.__version__ == '1.2.1'\r\nimport tensorflow as tf # tf.__version__ == '2.0.0-rc0'\r\n\r\ndef f():\r\n _p(\"f() called\")\r\n tf.keras.Sequential\r\n _p(\"f() ending\")\r\n\r\n_p(\"Dumping...\")\r\ns = cloudpickle.dumps(f)\r\n_p(\"dumped, loading...\")\r\ncloudpickle.loads(s)\r\n_p(\"done\")\r\n```\r\n\r\nThis outputs:\r\n\r\n```console\r\nDumping...\r\ndumped, loading...\r\nTraceback (most recent call last):\r\n File \"test.py\", line 13, in <module>\r\n cloudpickle.loads(s)\r\n File \"/tmp/gh/1/lib/python3.6/site-packages/tensorflow/__init__.py\", line 51, in __getattr__\r\n _p(\"{}.__getattr__({})\".format(self._local_name, item))\r\n File \"/tmp/gh/1/lib/python3.6/site-packages/tensorflow/__init__.py\", line 51, in __getattr__\r\n _p(\"{}.__getattr__({})\".format(self._local_name, item))\r\n File \"/tmp/gh/1/lib/python3.6/site-packages/tensorflow/__init__.py\", line 51, in __getattr__\r\n _p(\"{}.__getattr__({})\".format(self._local_name, item))\r\n [Previous line repeated 330 more times]\r\nRecursionError: maximum recursion depth exceeded while calling a Python object\r\n```\r\n\r\nFurther investigation reveals that during unpickling `__setattr__` needs to be called (equivalently, `__setstate__` could be called but it needs at least one `__setattr__` to store the new state on the module's `__dict__`). However, the lazy loading approach we're using assumes read only modules, we cannot add new attributes. Even defining an emtpy `__setattr__` results in infinite recursion at the `import tensorflow` line.",
"created_at": "2019-09-04T18:02:42Z"
},
{
"body": "Another update:\r\n\r\n`tf.keras.Sequential`, `tf.keras` and `tf.estimator` all result in the infinite recursion errors.\r\n\r\n`tf.math.sin` doesn't.",
"created_at": "2019-09-04T18:31:03Z"
},
{
"body": "We cannot fix this in time for TF 2.0 final release. In fact, we cannot really fix this unless we give up Python 2 support, so we're looking at a fix that should come up by start of next year or so.\r\n\r\nSorry for the delay, but as we didn't support serialization via pickling we never tested if this functionality would get broken by our changes. We'll fix this in the future",
"created_at": "2019-09-04T19:14:33Z"
},
{
"body": "Thanks for the update @mihaimaruseac. Fixing this in the future would be great. Out of curiosity, why does fixing it mean giving up support for Python 2?",
"created_at": "2019-09-05T17:07:09Z"
},
{
"body": "We are using a custom lazy loader object to mimic functionality that is present only in Python3.5 and later to create some modules on the fly.",
"created_at": "2019-09-05T17:10:15Z"
},
{
"body": "@mihaimaruseac I saw https://github.com/tensorflow/tensorflow/commit/4675891bd3c9e9ee7a57552486ec5bdc40379787 . Is it relevant to this issue?",
"created_at": "2019-10-15T23:29:12Z"
},
{
"body": "I'll have to check this, as it is on a different path.",
"created_at": "2019-10-15T23:59:14Z"
},
{
"body": "Is there any type of workaround for this? Running Ray and TF 2.0 and now facing this issue. Would be great to see a fix for this any time soon, rather than next year.",
"created_at": "2019-10-17T10:42:28Z"
},
{
"body": "If you are just blocked by some framework that ships the serialized function you could bypass the tensorflow serialization by using `importlib.import_module` and then during de-serialization make sure the module you use is shipped/available in the PYTHONPATH.\r\n\r\nSomething like:\r\n```\r\nmymodule.py\r\ndef tf_fn():\r\n tf.keras.Sequential\r\n\r\ndef f():\r\n module = importlib.import_module(\"mymodule\")\r\n return module.tf_fn()\r\n```\r\n\r\nIn our use case to run distributed TensorFlow on Hadoop we provide a [safe_experiment function ](https://github.com/criteo/tf-yarn/blob/master/tf_yarn/__init__.py#L566) function and then we upload the TensorFlow functions inside a module to the cluster. This works as a workaround for the moment with tf2.\r\n\r\n",
"created_at": "2019-10-23T15:07:00Z"
},
{
"body": "@jharaldson the easiest workaround might be the one described in https://github.com/ray-project/ray/issues/5614#issuecomment-527292289.\r\n\r\nAnother workaround is described in https://stackoverflow.com/a/57761034/7858504",
"created_at": "2019-10-23T16:37:42Z"
},
{
"body": "Coming back to the example at https://github.com/tensorflow/tensorflow/issues/32159#issuecomment-528016376\r\n\r\nIn python2 all works\r\n\r\n```console\r\n(py2) mihaimaruseac@ankh:/tmp/pickle/py2$ python test.py\r\nDumping...\r\ndumped, loading...\r\ndone\r\n```\r\n\r\nIn python3.5 the error is from `PyCapsule` objects:\r\n\r\n```console\r\n(py35) mihaimaruseac@ankh:/tmp/pickle/py35$ python test.py\r\nDumping...\r\nTraceback (most recent call last):\r\n File \"test.py\", line 11, in <module>\r\n s = cloudpickle.dumps(f)\r\n File \"/tmp/pickle/py35/lib/python3.5/site-packages/cloudpickle/cloudpickle.py\", line 1125, in dumps\r\n cp.dump(obj)\r\n File \"/tmp/pickle/py35/lib/python3.5/site-packages/cloudpickle/cloudpickle.py\", line 482, in dump\r\n return Pickler.dump(self, obj)\r\n File \"/usr/lib/python3.5/pickle.py\", line 408, in dump\r\n self.save(obj)\r\n File \"/usr/lib/python3.5/pickle.py\", line 475, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/tmp/pickle/py35/lib/python3.5/site-packages/cloudpickle/cloudpickle.py\", line 556, in save_function\r\n return self.save_function_tuple(obj)\r\n File \"/tmp/pickle/py35/lib/python3.5/site-packages/cloudpickle/cloudpickle.py\", line 758, in save_function_tuple\r\n save(state)\r\n File \"/usr/lib/python3.5/pickle.py\", line 475, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/usr/lib/python3.5/pickle.py\", line 814, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/usr/lib/python3.5/pickle.py\", line 840, in _batch_setitems\r\n save(v)\r\n File \"/usr/lib/python3.5/pickle.py\", line 475, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/usr/lib/python3.5/pickle.py\", line 774, in save_list\r\n self._batch_appends(obj)\r\n File \"/usr/lib/python3.5/pickle.py\", line 801, in _batch_appends\r\n save(tmp[0])\r\n File \"/usr/lib/python3.5/pickle.py\", line 520, in save\r\n self.save_reduce(obj=obj, *rv)\r\n File \"/usr/lib/python3.5/pickle.py\", line 627, in save_reduce\r\n save(state)\r\n File \"/usr/lib/python3.5/pickle.py\", line 475, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/usr/lib/python3.5/pickle.py\", line 814, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/usr/lib/python3.5/pickle.py\", line 840, in _batch_setitems\r\n save(v)\r\n File \"/usr/lib/python3.5/pickle.py\", line 475, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/usr/lib/python3.5/pickle.py\", line 814, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/usr/lib/python3.5/pickle.py\", line 840, in _batch_setitems\r\n save(v)\r\n File \"/usr/lib/python3.5/pickle.py\", line 495, in save\r\n rv = reduce(self.proto)\r\nTypeError: can't pickle PyCapsule objects\r\n```\r\n\r\nIn Python3.7 the error is from `_LazyLoader`\r\n\r\n```console\r\n(py37) mihaimaruseac@ankh:/tmp/pickle/py37$ python test.py\r\nDumping...\r\nTraceback (most recent call last):\r\n File \"test.py\", line 11, in <module>\r\n s = cloudpickle.dumps(f)\r\n File \"/tmp/pickle/py37/lib/python3.7/site-packages/cloudpickle/cloudpickle.py\", line 1125, in dumps\r\n cp.dump(obj)\r\n File \"/tmp/pickle/py37/lib/python3.7/site-packages/cloudpickle/cloudpickle.py\", line 482, in dump\r\n return Pickler.dump(self, obj)\r\n File \"/usr/lib/python3.7/pickle.py\", line 437, in dump\r\n self.save(obj)\r\n File \"/usr/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/tmp/pickle/py37/lib/python3.7/site-packages/cloudpickle/cloudpickle.py\", line 556, in save_function\r\n return self.save_function_tuple(obj)\r\n File \"/tmp/pickle/py37/lib/python3.7/site-packages/cloudpickle/cloudpickle.py\", line 758, in save_function_tuple\r\n save(state)\r\n File \"/usr/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/usr/lib/python3.7/pickle.py\", line 856, in save_dict\r\n self._batch_setitems(obj.items())\r\n File \"/usr/lib/python3.7/pickle.py\", line 882, in _batch_setitems\r\n save(v)\r\n File \"/usr/lib/python3.7/pickle.py\", line 504, in save\r\n f(self, obj) # Call unbound method with explicit self\r\n File \"/usr/lib/python3.7/pickle.py\", line 816, in save_list\r\n self._batch_appends(obj)\r\n File \"/usr/lib/python3.7/pickle.py\", line 843, in _batch_appends\r\n save(tmp[0])\r\n File \"/usr/lib/python3.7/pickle.py\", line 524, in save\r\n rv = reduce(self.proto)\r\nTypeError: can't pickle _LazyLoader objects\r\n```\r\n\r\nCan't test python3.6 anymore due to an issue in my system.\r\n\r\nManually applying the fix from 4675891bd3c9e9ee7a57552486ec5bdc40379787 to the other codepath makes that test pass in all 3 instances.\r\n\r\nI'm running the change through more tests and will submit a fix.",
"created_at": "2019-10-23T17:02:46Z"
},
{
"body": "Let's wait for a new tf-nightly and test this again. Or, you can build from source, with 353b8a1",
"created_at": "2019-10-23T17:37:49Z"
},
{
"body": "Seems the fix works with Ray. However if we use custom layers with functions decorated with @tf.function there are still pickling issues. As a workaround for that I figured one could save the model as a \"savedmodel\" on a distributed storage and then have the ray worker load the model from the distributed storage, but this throws an error. \r\n\r\nNote: Removing the LSTM layer does not result in an error, which would suggest that this error is related to the while operation (as the error suggests).\r\n\r\n```\r\nLookupError: No gradient defined for operation 'while' (op type: While)\r\n```\r\n\r\nCode to reproduce\r\n```\r\nimport tensorflow as tf\r\nimport ray \r\nimport numpy as np\r\n\r\nray.init()\r\n\r\ndef build_save_model():\r\n lstm_in = tf.keras.Input(shape=(24,1))\r\n lstm_out = tf.keras.layers.LSTM(6)(lstm_in)\r\n dense_out = tf.keras.layers.Dense(24)(lstm_out)\r\n model = tf.keras.Model([lstm_in], dense_out)\r\n model.save('/path/in/common/storage/lstm_model')\r\n\r\n@ray.remote\r\nclass Worker():\r\n def __init__(self):\r\n self.model = tf.keras.models.load_model('/path/in/common/storage/lstm_model')\r\n self.model.compile(optimizer=tf.keras.optimizers.Adam(1e-1), loss=tf.keras.losses.mse)\r\n self.data = np.arange(24).reshape(1,24,1)\r\n self.label = np.arange(24).reshape(1,24)\r\n \r\n def train(self):\r\n history = self.model.fit(self.data, self.label, epochs=10)\r\n return history.history\r\n \r\nbuild_save_model()\r\nlstm_worker = Worker.remote()\r\nw = ray.get(lstm_worker.train.remote())\r\n```\r\n\r\nError\r\n```\r\n---------------------------------------------------------------------------\r\nRayTaskError Traceback (most recent call last)\r\n<ipython-input-3-a18941ca631a> in <module>\r\n 22 build_save_model()\r\n 23 lstm_worker = Worker.remote()\r\n---> 24 w = ray.get(lstm_worker.train.remote())\r\n\r\n/opt/conda/lib/python3.6/site-packages/ray/worker.py in get(object_ids)\r\n 2245 if isinstance(value, RayError):\r\n 2246 last_task_error_raise_time = time.time()\r\n-> 2247 raise value\r\n 2248 \r\n 2249 # Run post processors.\r\n\r\nRayTaskError: ray_worker (pid=1397, host=thesis-clustering-7dfb7867df-pk5fc)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/framework/ops.py\", line 2326, in get_attr\r\n c_api.TF_OperationGetAttrValueProto(self._c_op, name, buf)\r\ntensorflow.python.framework.errors_impl.InvalidArgumentError: Operation 'StatefulPartitionedCall' has no attr named '_XlaCompile'.\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nray_worker (pid=1397, host=thesis-clustering-7dfb7867df-pk5fc)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/gradients_util.py\", line 331, in _MaybeCompile\r\n xla_compile = op.get_attr(\"_XlaCompile\")\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/framework/ops.py\", line 2330, in get_attr\r\n raise ValueError(str(e))\r\nValueError: Operation 'StatefulPartitionedCall' has no attr named '_XlaCompile'.\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nray_worker (pid=1397, host=thesis-clustering-7dfb7867df-pk5fc)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/framework/ops.py\", line 2326, in get_attr\r\n c_api.TF_OperationGetAttrValueProto(self._c_op, name, buf)\r\ntensorflow.python.framework.errors_impl.InvalidArgumentError: Operation 'StatefulPartitionedCall' has no attr named '_XlaCompile'.\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nray_worker (pid=1397, host=thesis-clustering-7dfb7867df-pk5fc)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/gradients_util.py\", line 331, in _MaybeCompile\r\n xla_compile = op.get_attr(\"_XlaCompile\")\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/framework/ops.py\", line 2330, in get_attr\r\n raise ValueError(str(e))\r\nValueError: Operation 'StatefulPartitionedCall' has no attr named '_XlaCompile'.\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nray_worker (pid=1397, host=thesis-clustering-7dfb7867df-pk5fc)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/gradients_util.py\", line 607, in _GradientsHelper\r\n grad_fn = ops.get_gradient_function(op)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/framework/ops.py\", line 2495, in get_gradient_function\r\n return _gradient_registry.lookup(op_type)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/framework/registry.py\", line 97, in lookup\r\n \"%s registry has no entry for: %s\" % (self._name, name))\r\nLookupError: gradient registry has no entry for: While\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nray_worker (pid=1397, host=thesis-clustering-7dfb7867df-pk5fc)\r\n File \"<ipython-input-3-a18941ca631a>\", line 19, in train\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training.py\", line 785, in fit\r\n use_multiprocessing=use_multiprocessing)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2.py\", line 337, in fit\r\n total_epochs=epochs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2.py\", line 127, in run_one_epoch\r\n batch_outs = execution_function(iterator)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2_utils.py\", line 86, in execution_function\r\n distributed_function(input_fn))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 568, in __call__\r\n result = self._call(*args, **kwds)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 615, in _call\r\n self._initialize(args, kwds, add_initializers_to=initializers)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 497, in _initialize\r\n *args, **kwds))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 2366, in _get_concrete_function_internal_garbage_collected\r\n graph_function, _, _ = self._maybe_define_function(args, kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 2675, in _maybe_define_function\r\n graph_function = self._create_graph_function(args, kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 2565, in _create_graph_function\r\n capture_by_value=self._capture_by_value),\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/framework/func_graph.py\", line 974, in func_graph_from_py_func\r\n func_outputs = python_func(*func_args, **func_kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 439, in wrapped_fn\r\n return weak_wrapped_fn().__wrapped__(*args, **kwds)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2_utils.py\", line 73, in distributed_function\r\n per_replica_function, args=(x, y, sample_weights))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/distribute/distribute_lib.py\", line 763, in experimental_run_v2\r\n return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/distribute/distribute_lib.py\", line 1819, in call_for_each_replica\r\n return self._call_for_each_replica(fn, args, kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/distribute/distribute_lib.py\", line 2164, in _call_for_each_replica\r\n return fn(*args, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/autograph/impl/api.py\", line 292, in wrapper\r\n return func(*args, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_v2_utils.py\", line 264, in train_on_batch\r\n output_loss_metrics=model._output_loss_metrics)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_eager.py\", line 312, in train_on_batch\r\n output_loss_metrics=output_loss_metrics))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/training_eager.py\", line 269, in _process_single_batch\r\n grads = tape.gradient(scaled_total_loss, trainable_weights)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/backprop.py\", line 1029, in gradient\r\n unconnected_gradients=unconnected_gradients)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/imperative_grad.py\", line 77, in imperative_grad\r\n compat.as_str(unconnected_gradients.value))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 766, in _backward_function\r\n return self._rewrite_forward_and_call_backward(call_op, *args)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 685, in _rewrite_forward_and_call_backward\r\n forward_function, backwards_function = self.forward_backward(len(doutputs))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 594, in forward_backward\r\n forward, backward = self._construct_forward_backward(num_doutputs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 642, in _construct_forward_backward\r\n func_graph=backwards_graph)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/framework/func_graph.py\", line 974, in func_graph_from_py_func\r\n func_outputs = python_func(*func_args, **func_kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 632, in _backprop_function\r\n src_graph=self._func_graph)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/gradients_util.py\", line 669, in _GradientsHelper\r\n lambda: grad_fn(op, *out_grads))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/gradients_util.py\", line 336, in _MaybeCompile\r\n return grad_fn() # Exit early\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/gradients_util.py\", line 669, in <lambda>\r\n lambda: grad_fn(op, *out_grads))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 685, in _rewrite_forward_and_call_backward\r\n forward_function, backwards_function = self.forward_backward(len(doutputs))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 594, in forward_backward\r\n forward, backward = self._construct_forward_backward(num_doutputs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 642, in _construct_forward_backward\r\n func_graph=backwards_graph)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/framework/func_graph.py\", line 974, in func_graph_from_py_func\r\n func_outputs = python_func(*func_args, **func_kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 632, in _backprop_function\r\n src_graph=self._func_graph)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/gradients_util.py\", line 669, in _GradientsHelper\r\n lambda: grad_fn(op, *out_grads))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/gradients_util.py\", line 336, in _MaybeCompile\r\n return grad_fn() # Exit early\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/gradients_util.py\", line 669, in <lambda>\r\n lambda: grad_fn(op, *out_grads))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 685, in _rewrite_forward_and_call_backward\r\n forward_function, backwards_function = self.forward_backward(len(doutputs))\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 594, in forward_backward\r\n forward, backward = self._construct_forward_backward(num_doutputs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 642, in _construct_forward_backward\r\n func_graph=backwards_graph)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/framework/func_graph.py\", line 974, in func_graph_from_py_func\r\n func_outputs = python_func(*func_args, **func_kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 632, in _backprop_function\r\n src_graph=self._func_graph)\r\n File \"/opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/gradients_util.py\", line 623, in _GradientsHelper\r\n (op.name, op.type))\r\nLookupError: No gradient defined for operation 'while' (op type: While)\r\n```\r\n\r\n",
"created_at": "2019-11-01T13:44:22Z"
},
{
"body": "Can you run a model with `while` but without pickling/unpickling? Afaik, `while` doesn't have gradients (maybe with gradient tape but then I don't know if those get pickled anyway)",
"created_at": "2019-11-01T15:33:41Z"
},
{
"body": "Two examples that runs without errors:\r\n\r\n1. the above example commenting out the @ray.remote decorator and call the train function without the remote call.\r\n\r\n2. the above example adding a return statement to the build_save_model() to return the built model. We swap out tf.keras.models.load_model() in the Worker to self.model = build_save_model() and call train()\r\n\r\nOne example that runs with error:\r\n1. we build and save the model in the Worker (as part of remote call) and tries to load the saved model in the main python session (not remote)\r\n\r\n",
"created_at": "2019-11-02T12:01:36Z"
},
{
"body": "Any updates on this?",
"created_at": "2020-03-19T22:10:15Z"
},
{
"body": "Are there any updates regarding this issue? Has there been a fix (such as https://github.com/tensorflow/tensorflow/commit/353b8a1adcb471a48ef9b1c5cbfc6097d036473e) applied to tf 1.15?",
"created_at": "2020-04-20T14:38:58Z"
},
{
"body": "No, but if you want to make a cherry-pick we can merge it if and when we do a new patch release on 1.15",
"created_at": "2020-04-20T17:35:30Z"
},
{
"body": "@mihaimaruseac I opened https://github.com/tensorflow/tensorflow/pull/39034 for this.",
"created_at": "2020-04-29T18:22:47Z"
},
{
"body": "I think this can be closed now as it has been solved and backported to 1.15 too.",
"created_at": "2020-06-20T21:56:02Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32159\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32159\">No</a>\n",
"created_at": "2020-06-20T21:56:04Z"
}
],
"number": 32159,
"title": "TF 2.0 regression: cloudpickle cannot serialize tf.keras.Sequential."
}
|
{
"body": "Fixes pickling issue #32159\r\n\r\nTested manually: just applied patch to tensorflow nightly and checked required imports.\r\n\r\nPiperOrigin-RevId: 276301497\r\nChange-Id: I6b3b6ae8b1218b43c31403ea7cc595ed11136ff9\r\n(cherry picked from commit 353b8a1adcb471a48ef9b1c5cbfc6097d036473e)\r\n\r\nIntended for a possible future r1.15 patch.",
"number": 39034,
"review_comments": [],
"title": "[r1.15-CherryPick] Add __reduce__ method in virtual pip root due to lazy loading"
}
|
{
"commits": [
{
"message": "Add __reduce__ method in virtual pip root due to lazy loading\n\nFixes pickling issue #32159\n\nTested manually: just applied patch to tensorflow nightly and checked required imports.\n\nPiperOrigin-RevId: 276301497\nChange-Id: I6b3b6ae8b1218b43c31403ea7cc595ed11136ff9\n(cherry picked from commit 353b8a1adcb471a48ef9b1c5cbfc6097d036473e)"
}
],
"files": [
{
"diff": "@@ -54,6 +54,9 @@ def __dir__(self):\n module = self._load()\n return dir(module)\n \n+ def __reduce__(self):\n+ return __import__, (self.__name__,)\n+\n \n # Forwarding a module is as simple as lazy loading the module from the new path\n # and then registering it to sys.modules using the old path",
"filename": "tensorflow/virtual_root_template_v1.__init__.py",
"status": "modified"
},
{
"diff": "@@ -54,6 +54,9 @@ def __dir__(self):\n module = self._load()\n return dir(module)\n \n+ def __reduce__(self):\n+ return __import__, (self.__name__,)\n+\n \n # Forwarding a module is as simple as lazy loading the module from the new path\n # and then registering it to sys.modules using the old path",
"filename": "tensorflow/virtual_root_template_v2.__init__.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): mac 10.13.5\r\n- TensorFlow version (use command below): 1.11.0\r\n- Python version: 3.6.5\r\n\r\n**Describe the current behavior**\r\nThe `_VALID_SCOPE_NAME_REGEX` and `_VALID_OP_NAME_REGEX` are defined in line 1583 of `tensorflow/python/framework/ops.py`\r\n\r\n```\r\n_VALID_OP_NAME_REGEX = re.compile(\"^[A-Za-z0-9.][A-Za-z0-9_.\\\\-/]*$\")\r\n_VALID_SCOPE_NAME_REGEX = re.compile(\"^[A-Za-z0-9_.\\\\-/]*$\")\r\n```\r\nwhich should recognize the `\\` symbol.\r\n\r\nThe result are: \r\n```\r\n>>> _VALID_SCOPE_NAME_REGEX = re.compile(\"^[A-Za-z0-9_.\\\\-/]*$\")\r\n>>> _VALID_SCOPE_NAME_REGEX.match(\"n_CatCntc_campaign/c_campaign\")\r\n<_sre.SRE_Match object; span=(0, 29), match='n_CatCntc_campaign/c_campaign'>\r\n>>> _VALID_SCOPE_NAME_REGEX.match(\"n_CatCntc_campaign\\c_campaign\")\r\n>>> _VALID_SCOPE_NAME_REGEX.match(\"n_CatCntc_campaign\\\\c_campaign\")\r\n>>> _VALID_SCOPE_NAME_REGEX.match(\"n_CatCntc_campaign\\\\\\c_campaign\")\r\n>>> \r\n```\r\nThe above pattern can't recognize `\\`, but with below pattern, it works.\r\n\r\n```\r\n>>> _VALID_SCOPE_NAME_REGEX = re.compile(r\"^[A-Za-z0-9_.\\\\\\-/]*$\")\r\n>>> _VALID_SCOPE_NAME_REGEX.match(\"n_CatCntc_campaign\\c_campaign\")\r\n<_sre.SRE_Match object; span=(0, 29), match='n_CatCntc_campaign\\\\c_campaign'>\r\n>>> _VALID_SCOPE_NAME_REGEX.match(\"n_CatCntc_campaign\\\\c_campaign\")\r\n<_sre.SRE_Match object; span=(0, 29), match='n_CatCntc_campaign\\\\c_campaign'>\r\n>>> _VALID_SCOPE_NAME_REGEX.match(\"n_CatCntc_campaign/c_campaign\")\r\n<_sre.SRE_Match object; span=(0, 29), match='n_CatCntc_campaign/c_campaign'>\r\n\r\n```\r\n\r\n**Describe the expected behavior**\r\n\r\n\r\n",
"comments": [
{
"body": "The following will work as well (move `-` to end as otherwise it will be considered as range, and prefix with `r` to not escape). This avoid three backslash`\\\\\\` which might be less understandable:\r\n```\r\nVALID_OP_NAME_REGEX = re.compile(r\"^[A-Za-z0-9.][A-Za-z0-9_.\\\\/>-]*$\")\r\n_VALID_SCOPE_NAME_REGEX = re.compile(r\"^[A-Za-z0-9_.\\\\/>-]*$\")\r\n```\r\n\r\nAdded a PR #39029 for the fix.",
"created_at": "2020-04-29T14:57:49Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/39019\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/39019\">No</a>\n",
"created_at": "2020-04-30T17:04:38Z"
}
],
"number": 39019,
"title": "bug with _VALID_SCOPE_NAME_REGEX"
}
|
{
"body": "This PR tries to address the issue raised in #39019 where\r\nregex for scope name does not capture `\\` symbol.\r\n```\r\nVALID_OP_NAME_REGEX = re.compile(\"^[A-Za-z0-9.][A-Za-z0-9_.\\\\-/>]*$\")\r\n_VALID_SCOPE_NAME_REGEX = re.compile(\"^[A-Za-z0-9_.\\\\-/>]*$\")\r\n```\r\nThe reason was:\r\n1. `-` was placed in the middle and was incorrectly considered by python as a range.\r\n2. `\\\\` was considered as escape by python, so only one `\\` when `re` starts processing.\r\n\r\nThis PR moves `-` to the end, and prefix with `r` for the string:\r\n```\r\nVALID_OP_NAME_REGEX = re.compile(r\"^[A-Za-z0-9.][A-Za-z0-9_.\\\\/>-]*$\")\r\n_VALID_SCOPE_NAME_REGEX = re.compile(r\"^[A-Za-z0-9_.\\\\/>-]*$\")\r\n```\r\n\r\nThis PR fixes #39019.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 39029,
"review_comments": [
{
"body": "I think we need to escape this backslash, otherwise Python will complain that \"\\c\" is an invalid escape sequence.",
"created_at": "2020-04-29T19:21:02Z"
},
{
"body": "Please also include a string that contains a dash character (adding it to the tests below is fine).",
"created_at": "2020-04-29T19:22:18Z"
},
{
"body": "Thanks @mdanatg, updated.",
"created_at": "2020-04-29T19:30:34Z"
},
{
"body": "Thanks @mdanatg, added `-` into part of the tested string.",
"created_at": "2020-04-29T19:30:56Z"
}
],
"title": "Fix regex for scope name specification"
}
|
{
"commits": [
{
"message": "Fix regex for scope name specification\n\nThis PR tries to address the issue raised in 39019 where\nregex for scope name does not capture `\\` symbol.\n```\nVALID_OP_NAME_REGEX = re.compile(\"^[A-Za-z0-9.][A-Za-z0-9_.\\\\-/>]*$\")\n_VALID_SCOPE_NAME_REGEX = re.compile(\"^[A-Za-z0-9_.\\\\-/>]*$\")\n```\nThe reason was:\n1. `-` was placed in the middle and was incorrectly considered by python as a range.\n2. `\\\\` was considered as escape by python, so only one `\\` when `re` starts processing.\n\nThis PR moves `-` to the end, and prefix with `r` for the string:\n```\nVALID_OP_NAME_REGEX = re.compile(r\"^[A-Za-z0-9.][A-Za-z0-9_.\\\\/>-]*$\")\n_VALID_SCOPE_NAME_REGEX = re.compile(r\"^[A-Za-z0-9_.\\\\/>-]*$\")\n```\n\nThis PR fixes 39019.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for scope name regex\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update test case to escape correctly, and add dash in part of the example\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -1748,8 +1748,8 @@ def _NodeDef(op_type, name, attrs=None):\n \n # Copied from core/framework/node_def_util.cc\n # TODO(mrry,josh11b): Consolidate this validation in C++ code.\n-_VALID_OP_NAME_REGEX = re.compile(\"^[A-Za-z0-9.][A-Za-z0-9_.\\\\-/>]*$\")\n-_VALID_SCOPE_NAME_REGEX = re.compile(\"^[A-Za-z0-9_.\\\\-/>]*$\")\n+_VALID_OP_NAME_REGEX = re.compile(r\"^[A-Za-z0-9.][A-Za-z0-9_.\\\\/>-]*$\")\n+_VALID_SCOPE_NAME_REGEX = re.compile(r\"^[A-Za-z0-9_.\\\\/>-]*$\")\n \n \n def _create_c_op(graph, node_def, inputs, control_inputs, op_def=None):",
"filename": "tensorflow/python/framework/ops.py",
"status": "modified"
},
{
"diff": "@@ -1308,6 +1308,18 @@ def testBasics(self):\n self.assertEqual(\"bar_2\", g.unique_name(\"bar\", mark_as_used=False))\n self.assertEqual(\"bar_2\", g.unique_name(\"bar\"))\n \n+ def testBackslashAndDashRegex(self):\n+ # GitHub issue 39019, all should pass\n+ g = ops.Graph()\n+ with g.name_scope(\"n_CatCntc-campaign\\\\c_campaign\"):\n+ pass\n+ with g.name_scope(\"foo\"):\n+ with g.name_scope(\"n_CatCntc-campaign\\\\c_campaign\"):\n+ pass\n+ with g.name_scope(\"n_CatCntc-campaign\\\\c_campaign\"):\n+ with g.name_scope(\"foo\"):\n+ pass\n+\n @test_util.run_deprecated_v1\n def testNameAndVariableScope(self):\n with self.cached_session() as sess:",
"filename": "tensorflow/python/framework/ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.0.0-beta0\r\n- Python version: python3 from colab\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version:\r\n- GPU model and memory:\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\nwhen value range for `tf.histogram_fixed_width_bins ` is `[0.0, 0.0], it outputs an index outside `nbins`. See the code below.\r\n\r\n```\r\nnbins = 5\r\nvalue_range = [.0, .0]\r\nnew_values = [-1.0, 0.0, 1.5, 2.0, 5.0, 15]\r\nindices = tf.histogram_fixed_width_bins(new_values, value_range, nbins=5)\r\nprint(indices)\r\n\r\n```\r\nOutput is \r\n```\r\ntf.Tensor([ 0 -2147483648 4 4 4 4], shape=(6,), dtype=int32)\r\n```\r\n\r\n**Describe the expected behavior**\r\nIt should show indices as [0,0,4,4,4,4] and throw a warning saying that the range needs to be updated\r\n\r\n**Code to reproduce the issue**\r\nProvide a reproducible test case that is the bare minimum necessary to generate the problem.\r\nSee above\r\n\r\n**Other info / logs**\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\n",
"comments": [
{
"body": "Tried on Colab with TF version 2.0-beta and was able to replicate the issue.",
"created_at": "2019-06-14T12:02:11Z"
},
{
"body": "Was able to reproduce the issue with [TF v2.1](https://colab.research.google.com/gist/amahendrakar/60c13c6f2c1cc4948add81e210f150c1/2-1-template.ipynb) and [TF-nightly](https://colab.research.google.com/gist/amahendrakar/cf4dab2373adf64de686a77e94cad76c/tf-nightly.ipynb) i.e. 2.2.0-dev20200327. Please find the attached gist. Thanks!",
"created_at": "2020-03-27T19:57:47Z"
},
{
"body": "This is fixed with tf-nightly version '2.2.0-dev20200402'. Thanks!\r\n```python\r\ntf.Tensor([0 4 4 4 4 4], shape=(6,), dtype=int32)\r\n```",
"created_at": "2020-04-02T23:22:01Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/29661\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/29661\">No</a>\n",
"created_at": "2020-04-21T19:27:38Z"
},
{
"body": "It is working as expected in GPU. But, the error still persists with CPU. \r\n[Here](https://colab.research.google.com/gist/jvishnuvardhan/858ba13ef8b77cf63355c84bd398e026/tf-nightly.ipynb) is the gist with GPU and [here](https://colab.research.google.com/gist/jvishnuvardhan/4b80e167f59162e373f0fc5591d9c14d/tf-nightly.ipynb) with CPU. Thanks!",
"created_at": "2020-04-21T22:17:59Z"
},
{
"body": "Added a PR #38899 for the fix. In comparison with `tf.histogram_fixed_width` which throws out InvalidArgument in case value_range is not monotonous increasing (implemented in C++ kernel), I think `tf.histogram_fixed_width_bins` needs to apply the same restriction, as was specified in its docstring.",
"created_at": "2020-04-25T23:10:05Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/29661\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/29661\">No</a>\n",
"created_at": "2020-05-06T15:06:42Z"
}
],
"number": 29661,
"title": "Bug in exception handling of tf.histogram_fixed_width_bins "
}
|
{
"body": "\r\nThis PR tries to address the issue in #29661 where\r\ntf.histogram_fixed_width_bins does not throw out an exception\r\nwhen (value_range[0] < value_range[1]) is not satified.\r\nThis is dfferent from the documentation specified in the docstring.\r\n\r\nThis is different from a similiar API `tf.histogram_fixed_width`\r\nwhere exception is thrown out correctly. The reason is that\r\n`tf.histogram_fixed_width_bins` is handled in python while\r\n`tf.histogram_fixed_width` has a C++ kernel.\r\n\r\nThis PR uses tf.Assert to make sure `(value_range[0] < value_range[1])`\r\nsatisty.\r\n\r\nThis PR fixes #29661.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 38899,
"review_comments": [],
"title": "Fix exception handling of tf.histogram_fixed_width_bins"
}
|
{
"commits": [
{
"message": "Fix exception handling of tf.histogram_fixed_width_bins\n\nThis PR tries to address the issue in 29661 where\ntf.histogram_fixed_width_bins does not throw out an exception\nwhen (value_range[0] < value_range[1]) is not satified.\nThis is dfferent from the documentation specified in the docstring.\n\nThis is different from a similiar API `tf.histogram_fixed_width`\nwhere exception is thrown out correctly. The reason is that\n`tf.histogram_fixed_width_bins` is handled in python while\n`tf.histogram_fixed_width` has a C++ kernel.\n\nThis PR uses tf.Assert to make sure `(value_range[0] < value_range[1])`\nsatisty.\n\nThis PR fixes 29661.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for exception handling in `tf.histogram_fixed_width_bins`\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Pylint fix\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Change to use tensor_util.constant_value if possible and raise ValueError\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Pylint fix to remove unused import\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -22,6 +22,7 @@\n \n from tensorflow.python.framework import dtypes\n from tensorflow.python.framework import ops\n+from tensorflow.python.framework import tensor_util\n from tensorflow.python.ops import array_ops\n from tensorflow.python.ops import clip_ops\n from tensorflow.python.ops import gen_math_ops\n@@ -76,11 +77,20 @@ def histogram_fixed_width_bins(values,\n \"\"\"\n with ops.name_scope(name, 'histogram_fixed_width_bins',\n [values, value_range, nbins]):\n+ value_range_value = tensor_util.constant_value(value_range)\n+ if value_range_value is not None:\n+ if (value_range_value[0] >= value_range_value[1]):\n+ raise ValueError(\n+ \"value_range should satisfy value_range[0] < value_range[1], \",\n+ \"but got '[{}, {}]\".format(\n+ value_range_value[0], value_range_value[1]))\n+\n values = ops.convert_to_tensor(values, name='values')\n shape = array_ops.shape(values)\n \n values = array_ops.reshape(values, [-1])\n value_range = ops.convert_to_tensor(value_range, name='value_range')\n+\n nbins = ops.convert_to_tensor(nbins, dtype=dtypes.int32, name='nbins')\n nbins_float = math_ops.cast(nbins, values.dtype)\n ",
"filename": "tensorflow/python/ops/histogram_ops.py",
"status": "modified"
},
{
"diff": "@@ -79,6 +79,16 @@ def test_2d_values(self):\n self.assertEqual(dtypes.int32, bins.dtype)\n self.assertAllClose(expected_bins, self.evaluate(bins))\n \n+ def test_range_overlap(self):\n+ # GitHub issue 29661\n+ value_range = np.float32([0.0, 0.0])\n+ values = np.float32([-1.0, 0.0, 1.5, 2.0, 5.0, 15])\n+ expected_bins = [0, 0, 4, 4, 4, 4]\n+ with self.assertRaises(ValueError):\n+ with self.cached_session():\n+ _ = histogram_ops.histogram_fixed_width_bins(\n+ values, value_range, nbins=5)\n+\n \n class HistogramFixedWidthTest(test.TestCase):\n ",
"filename": "tensorflow/python/ops/histogram_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.2.0rc3\r\n- Python version: 3.7\r\n- CUDA/cuDNN version: 10.1 / 7.6.5.32\r\n- GPU model and memory: 4 x NVIDIA V100 on GCP\r\n\r\n**Describe the current behavior**\r\n\r\nWhen running the code below with cached training and validations datasets in a multi-GPU environment (I am using a GCP VM with 312GB of memory and 4 NVIDIA V100s) with `tf.distribute.MirroredStrategy()` the validation dataset isn't correctly cached and examples are still read from GCS during validation.\r\n\r\nThe memory usage suggests that the validation dataset is cached, but during the Keras validation loop it looks like that data is still read from GCS instead of from the cache which can be observed by the very high network usage during validation. I would expect no network usage after the first epoch.\r\n\r\nIn the example below I intentionally use an very large validation set to make this issue very obvious and easy to detect through monitoring network usage. This behaviour can also be observed with other datasets, but the unexpected network access will be less noticible on smaller datsets.\r\n\r\n**In which cases can this issue not be observed?**\r\nTo narrow down the possible causes for this I found two cases where this issue doesn't exist:\r\n\r\n1. When running on a single GPU without `MirroredStrategy` the validation data is correctly read from the cache and after the start of the second epoch no additional network traffic reading from GCS can be observed.\r\n\r\n2. When not using a validation dataset at all the network usage is zero after the first epoch so caching of the training set works as expected.\r\n\r\nThis seems to be a complicated interaction between `tf.data`, `tf.keras` and `tf.distribute`, do you have an idea what could cause this behaviour? Please let me know what additional information I could provide.\r\n\r\n**Describe the expected behavior**\r\n\r\nNetwork usage should be zero after the start of the second epoch since both datasets are cached in memory and no additional reads from GCS should be required.\r\n\r\n**Standalone code to reproduce the issue**\r\n```python\r\nimport tensorflow as tf\r\nimport tensorflow_datasets as tfds\r\n\r\n\r\nbatch_size = 1024\r\ndecoders = {\"image\": tfds.decode.SkipDecoding()}\r\n\r\ndataset = tfds.load(\r\n \"imagenet2012:5.0.0\",\r\n decoders=decoders,\r\n split=\"validation\",\r\n data_dir=\"gs://my-data-bucket\",\r\n)\r\n\r\nval_dataset = tfds.load(\r\n \"imagenet2012:5.0.0\",\r\n decoders=decoders,\r\n split=\"train\",\r\n data_dir=\"gs://my-data-bucket\",\r\n)\r\n\r\n\r\ndef _decode_and_center_crop(image_bytes):\r\n \"\"\"Crops to center of image with padding then scales image_size.\"\"\"\r\n shape = tf.image.extract_jpeg_shape(image_bytes)\r\n image_height = shape[0]\r\n image_width = shape[1]\r\n image_size = 224\r\n\r\n padded_center_crop_size = tf.cast(\r\n (\r\n (image_size / (image_size + 32))\r\n * tf.cast(tf.minimum(image_height, image_width), tf.float32)\r\n ),\r\n tf.int32,\r\n )\r\n\r\n offset_height = ((image_height - padded_center_crop_size) + 1) // 2\r\n offset_width = ((image_width - padded_center_crop_size) + 1) // 2\r\n crop_window = tf.stack(\r\n [offset_height, offset_width, padded_center_crop_size, padded_center_crop_size]\r\n )\r\n image = tf.image.decode_and_crop_jpeg(image_bytes, crop_window, channels=3)\r\n return tf.image.resize(image, [image_size, image_size], method=\"bicubic\")\r\n\r\n\r\ndef preprocessing(data):\r\n return tf.cast(_decode_and_center_crop(data[\"image\"]), tf.float32), data[\"label\"]\r\n\r\n\r\ndef apply_preprocessing(dataset):\r\n return (\r\n dataset.cache()\r\n .map(preprocessing, num_parallel_calls=tf.data.experimental.AUTOTUNE)\r\n .batch(batch_size)\r\n .prefetch(1)\r\n )\r\n\r\n\r\ndataset = apply_preprocessing(dataset)\r\nval_dataset = apply_preprocessing(val_dataset)\r\n\r\nwith tf.distribute.MirroredStrategy().scope():\r\n model = tf.keras.models.Sequential(\r\n [\r\n tf.keras.layers.GlobalMaxPool2D(input_shape=(224, 224, 3)),\r\n tf.keras.layers.Dense(1000, activation=\"softmax\",),\r\n ]\r\n )\r\n\r\n model.compile(\r\n optimizer=\"adam\",\r\n loss=\"sparse_categorical_crossentropy\",\r\n metrics=[\"accuracy\", \"sparse_top_k_categorical_accuracy\"],\r\n )\r\n\r\nmodel.fit(\r\n dataset, epochs=5, validation_data=val_dataset,\r\n)\r\n```\r\n\r\n**Other info / logs**\r\n\r\nTo monitor the network usage over time tools like [`ytop`](https://github.com/cjbassi/ytop/) can be used.",
"comments": [
{
"body": "Thank you for filing, it seems like this is known issue and the team is looking into it. I can suggest a workaround with tf-nightly if this is blocking you. ",
"created_at": "2020-04-18T03:20:57Z"
},
{
"body": "@lgeiger \r\nplease update as per above comment ",
"created_at": "2020-04-20T13:41:44Z"
},
{
"body": "> Thank you for filing, it seems like this is known issue and the team is looking into it. I can suggest a workaround with tf-nightly if this is blocking you.\r\n\r\nIt'd be great to have a workaround, in case the fix cannot make into v2.2.",
"created_at": "2020-04-20T14:18:23Z"
},
{
"body": "Actually @jsimsa just submitted a fix for this yesterday (https://github.com/tensorflow/tensorflow/commit/7ebbab819e736319ec35b48e31f4d62fbad6626b). Assuming that has made it to the nightly - could @lgeiger could you try the nightly and see if this has been fixed for your use case? \r\nWe will try to have this fix in 2.2 as well. \r\n\r\n",
"created_at": "2020-04-21T17:28:41Z"
},
{
"body": "@guptapriya @jsimsa Thank you for the fast fix 🎉 \r\n\r\nI can confirm that this issue doesn't exist on the latest nightly.\r\n\r\nShould I open a PR to cherry-pick 7ebbab819e736319ec35b48e31f4d62fbad6626b onto the release branch?\r\n",
"created_at": "2020-04-21T21:34:28Z"
},
{
"body": "Has been cherrypicked as #38807 ",
"created_at": "2020-04-23T16:10:35Z"
},
{
"body": "Thanks for the fast fix 👍 ",
"created_at": "2020-04-23T16:17:21Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38655\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38655\">No</a>\n",
"created_at": "2020-04-23T16:17:23Z"
},
{
"body": "Hi, I was training my model using Multi Workers Mirrored Strategy and still get this issue.\r\nTime by time, the memory usage is still increasing until I got OOM.",
"created_at": "2020-04-28T14:21:02Z"
},
{
"body": "@alimhanif Could you check if your issue is related to #38617?",
"created_at": "2020-04-28T14:25:44Z"
}
],
"number": 38655,
"title": "[2.2rc3] Keras validation data doesn't respect cache in MirroredStrategy"
}
|
{
"body": "…cache.\r\n\r\nPiperOrigin-RevId: 307736215\r\nChange-Id: If10ef65e6706a106e6bb4fc2d6fe4542bbe056cc\r\n\r\nfixes #38655",
"number": 38844,
"review_comments": [],
"title": "[tf.data] Memory-safe implementation of sharing access to the memory …"
}
|
{
"commits": [
{
"message": "[tf.data] Memory-safe implementation of sharing access to the memory cache.\n\nPiperOrigin-RevId: 307736215\nChange-Id: If10ef65e6706a106e6bb4fc2d6fe4542bbe056cc"
}
],
"files": [
{
"diff": "@@ -690,8 +690,10 @@ Status RestoreCache(IteratorContext* ctx, IteratorStateReader* reader, T* cache,\n class CacheDatasetOp::MemoryDatasetBase : public DatasetBase {\n public:\n explicit MemoryDatasetBase(OpKernelContext* ctx, const DatasetBase* input,\n- MemoryCache* cache)\n- : DatasetBase(DatasetContext(ctx)), input_(input), cache_(cache) {\n+ std::shared_ptr<MemoryCache> cache)\n+ : DatasetBase(DatasetContext(ctx)),\n+ input_(input),\n+ cache_(std::move(cache)) {\n input_->Ref();\n }\n \n@@ -704,7 +706,7 @@ class CacheDatasetOp::MemoryDatasetBase : public DatasetBase {\n return absl::make_unique<MemoryIterator>(\n MemoryIterator::Params{\n this, name_utils::IteratorPrefix(kDatasetType, prefix, params)},\n- cache_);\n+ cache_.get());\n }\n \n const DataTypeVector& output_dtypes() const override {\n@@ -942,7 +944,7 @@ class CacheDatasetOp::MemoryDatasetBase : public DatasetBase {\n }; // MemoryIterator\n \n const DatasetBase* const input_;\n- MemoryCache* const cache_;\n+ const std::shared_ptr<MemoryCache> cache_;\n }; // MemoryDatasetBase\n \n // This version of memory dataset has an exclusive ownership of the memory cache\n@@ -951,22 +953,19 @@ class CacheDatasetOp::MemoryDatasetBase : public DatasetBase {\n class CacheDatasetOp::MemoryDataset : public CacheDatasetOp::MemoryDatasetBase {\n public:\n MemoryDataset(OpKernelContext* ctx, const DatasetBase* input,\n- MemoryCache* cache, const ResourceHandle& resource_handle)\n- : MemoryDatasetBase(ctx, input, cache),\n- resource_handle_(resource_handle) {\n- cleanup_ = [this, mgr = ctx->resource_manager()]() {\n- DCHECK(cache_->RefCountIsOne());\n- Status s = mgr->Delete<MemoryCache>(resource_handle_.container(),\n- resource_handle_.name());\n- if (!s.ok()) {\n- LOG(WARNING) << \"Failed to delete cache resource: \" << s.ToString();\n- }\n- };\n- }\n+ MemoryCacheManager* manager, ResourceHandle&& resource_handle)\n+ : MemoryDatasetBase(ctx, input, manager->get()),\n+ manager_(manager),\n+ resource_handle_(std::move(resource_handle)),\n+ resource_mgr_(ctx->resource_manager()) {}\n \n ~MemoryDataset() override {\n- cache_->Unref();\n- cleanup_();\n+ manager_->Unref();\n+ Status s = resource_mgr_->Delete<MemoryCacheManager>(\n+ resource_handle_.container(), resource_handle_.name());\n+ if (!s.ok()) {\n+ LOG(WARNING) << \"Failed to delete cache resource: \" << s.ToString();\n+ }\n }\n \n protected:\n@@ -983,8 +982,9 @@ class CacheDatasetOp::MemoryDataset : public CacheDatasetOp::MemoryDatasetBase {\n }\n \n private:\n- std::function<void()> cleanup_;\n+ MemoryCacheManager* const manager_; // Owned.\n const ResourceHandle resource_handle_;\n+ ResourceMgr* const resource_mgr_; // Not owned.\n };\n \n // This version of memory dataset has a shared ownership of the memory cache\n@@ -994,28 +994,23 @@ class CacheDatasetOp::MemoryDatasetV2\n : public CacheDatasetOp::MemoryDatasetBase {\n public:\n MemoryDatasetV2(OpKernelContext* ctx, const DatasetBase* input,\n- MemoryCache* cache, const ResourceHandle& resource_handle)\n- : MemoryDatasetBase(ctx, input, cache),\n- resource_handle_(std::move(resource_handle)) {\n- cleanup_ = [this, mgr = ctx->resource_manager()]() {\n- if (cache_->RefCountIsOne()) {\n- Status s = mgr->Delete<MemoryCache>(resource_handle_.container(),\n- resource_handle_.name());\n- if (!s.ok()) {\n- if (errors::IsNotFound(s)) {\n- // This is a bening race resulting from concurrent deletion.\n- VLOG(1) << \"Failed to delete cache resource: \" << s.ToString();\n- } else {\n- LOG(WARNING) << \"Failed to delete cache resource: \" << s.ToString();\n- }\n- }\n- }\n- };\n- }\n+ MemoryCacheManager* manager, ResourceHandle&& resource_handle,\n+ bool owns_resource)\n+ : MemoryDatasetBase(ctx, input, manager->get()),\n+ manager_(manager),\n+ owns_resource_(owns_resource),\n+ resource_handle_(std::move(resource_handle)),\n+ resource_mgr_(ctx->resource_manager()) {}\n \n ~MemoryDatasetV2() override {\n- cache_->Unref();\n- cleanup_();\n+ manager_->Unref();\n+ if (owns_resource_) {\n+ Status s = resource_mgr_->Delete<MemoryCacheManager>(\n+ resource_handle_.container(), resource_handle_.name());\n+ if (!s.ok()) {\n+ LOG(WARNING) << \"Failed to delete cache resource: \" << s.ToString();\n+ }\n+ }\n }\n \n protected:\n@@ -1036,8 +1031,10 @@ class CacheDatasetOp::MemoryDatasetV2\n }\n \n private:\n- std::function<void()> cleanup_;\n+ MemoryCacheManager* const manager_; // Owned.\n+ const bool owns_resource_;\n const ResourceHandle resource_handle_;\n+ ResourceMgr* const resource_mgr_; // Not owned.\n };\n \n CacheDatasetOp::CacheDatasetOp(OpKernelConstruction* ctx)\n@@ -1055,33 +1052,39 @@ void CacheDatasetOp::MakeDataset(OpKernelContext* ctx, DatasetBase* input,\n auto name = strings::StrCat(ctx->op_kernel().name(), \"/\", kMemoryCache, \"_\",\n resource_id_counter.fetch_add(1));\n if (op_version_ == 2) {\n- MemoryCache* cache = nullptr;\n+ bool owns_resource = false;\n+ MemoryCacheManager* manager = nullptr;\n auto handle = HandleFromInput(ctx, 2);\n- Status s = ctx->resource_manager()->Lookup<MemoryCache>(\n- handle.container(), handle.name(), &cache);\n+ Status s = ctx->resource_manager()->Lookup<MemoryCacheManager>(\n+ handle.container(), handle.name(), &manager);\n if (errors::IsNotFound(s)) {\n- OP_REQUIRES_OK(ctx,\n- ctx->resource_manager()->LookupOrCreate<MemoryCache>(\n- container, name, &cache, [](MemoryCache** cache) {\n- *cache = new MemoryCache();\n- return Status::OK();\n- }));\n- handle = MakeResourceHandle<MemoryCache>(ctx, container, name);\n+ owns_resource = true;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ctx->resource_manager()->LookupOrCreate<MemoryCacheManager>(\n+ container, name, &manager, [](MemoryCacheManager** manager) {\n+ *manager = new MemoryCacheManager();\n+ return Status::OK();\n+ }));\n+ handle = MakeResourceHandle<MemoryCacheManager>(ctx, container, name);\n } else {\n OP_REQUIRES_OK(ctx, s);\n }\n- // Ownership of cache is transferred onto `MemoryDatasetV2`.\n- *output = new MemoryDatasetV2(ctx, input, cache, std::move(handle));\n+ // Ownership of manager is transferred onto `MemoryDatasetV2`.\n+ *output = new MemoryDatasetV2(ctx, input, manager, std::move(handle),\n+ owns_resource);\n } else {\n- MemoryCache* cache;\n- OP_REQUIRES_OK(ctx, ctx->resource_manager()->LookupOrCreate<MemoryCache>(\n- container, name, &cache, [](MemoryCache** cache) {\n- *cache = new MemoryCache();\n- return Status::OK();\n- }));\n- auto handle = MakeResourceHandle<MemoryCache>(ctx, container, name);\n- // Ownership of cache is transferred onto `MemoryDataset`.\n- *output = new MemoryDataset(ctx, input, cache, handle);\n+ MemoryCacheManager* manager;\n+ OP_REQUIRES_OK(\n+ ctx, ctx->resource_manager()->LookupOrCreate<MemoryCacheManager>(\n+ container, name, &manager, [](MemoryCacheManager** manager) {\n+ *manager = new MemoryCacheManager();\n+ return Status::OK();\n+ }));\n+ auto handle =\n+ MakeResourceHandle<MemoryCacheManager>(ctx, container, name);\n+ // Ownership of manager is transferred onto `MemoryDataset`.\n+ *output = new MemoryDataset(ctx, input, manager, std::move(handle));\n }\n } else {\n if (op_version_ == 2) {",
"filename": "tensorflow/core/kernels/data/cache_dataset_ops.cc",
"status": "modified"
},
{
"diff": "@@ -31,7 +31,7 @@ constexpr char kMemoryCache[] = \"MemoryCache\";\n \n } // namespace\n \n-string MemoryCache::DebugString() const { return kMemoryCache; }\n+string MemoryCacheManager::DebugString() const { return kMemoryCache; }\n \n void MemoryCache::Complete(std::vector<std::vector<Tensor>>&& cache) {\n mutex_lock l(mu_);\n@@ -65,19 +65,15 @@ size_t MemoryCache::size() {\n \n AnonymousMemoryCacheHandleOp::AnonymousMemoryCacheHandleOp(\n OpKernelConstruction* ctx)\n- : AnonymousResourceOp<MemoryCache>(ctx) {}\n-\n-void AnonymousMemoryCacheHandleOp::Compute(OpKernelContext* ctx) {\n- AnonymousResourceOp<MemoryCache>::Compute(ctx);\n-}\n+ : AnonymousResourceOp<MemoryCacheManager>(ctx) {}\n \n string AnonymousMemoryCacheHandleOp::name() { return kMemoryCache; }\n \n Status AnonymousMemoryCacheHandleOp::CreateResource(\n OpKernelContext* ctx, std::unique_ptr<FunctionLibraryDefinition> flib_def,\n std::unique_ptr<ProcessFunctionLibraryRuntime> pflr,\n- FunctionLibraryRuntime* lib, MemoryCache** resource) {\n- *resource = new MemoryCache();\n+ FunctionLibraryRuntime* lib, MemoryCacheManager** manager) {\n+ *manager = new MemoryCacheManager();\n return Status::OK();\n }\n ",
"filename": "tensorflow/core/kernels/data/cache_ops.cc",
"status": "modified"
},
{
"diff": "@@ -27,12 +27,10 @@ namespace data {\n // The expected use is that a single `MemoryWriterIterator` populates the\n // cache with dataset elements. Once all elements are cached, the cache can\n // be used by one or more `MemoryReaderIterator`s.\n-class MemoryCache : public ResourceBase {\n+class MemoryCache {\n public:\n MemoryCache() = default;\n \n- string DebugString() const override;\n-\n // Marks the cache as completed.\n void Complete(std::vector<std::vector<Tensor>>&& cache);\n \n@@ -55,19 +53,32 @@ class MemoryCache : public ResourceBase {\n std::vector<std::vector<Tensor>> cache_ TF_GUARDED_BY(mu_);\n };\n \n+// A resource wrapping a shared instance of a memory cache.\n+class MemoryCacheManager : public ResourceBase {\n+ public:\n+ MemoryCacheManager() : cache_(std::make_shared<MemoryCache>()) {}\n+\n+ string DebugString() const override;\n+\n+ std::shared_ptr<MemoryCache> get() { return cache_; }\n+\n+ private:\n+ std::shared_ptr<MemoryCache> cache_;\n+};\n+\n // Creates an instance of cache resource and transfers ownership to the caller.\n-class AnonymousMemoryCacheHandleOp : public AnonymousResourceOp<MemoryCache> {\n+class AnonymousMemoryCacheHandleOp\n+ : public AnonymousResourceOp<MemoryCacheManager> {\n public:\n explicit AnonymousMemoryCacheHandleOp(OpKernelConstruction* ctx);\n- void Compute(OpKernelContext* ctx) override;\n \n private:\n string name() override;\n Status CreateResource(OpKernelContext* ctx,\n std::unique_ptr<FunctionLibraryDefinition> flib_def,\n std::unique_ptr<ProcessFunctionLibraryRuntime> pflr,\n FunctionLibraryRuntime* lib,\n- MemoryCache** resource) override;\n+ MemoryCacheManager** manager) override;\n };\n \n // Deletes an instance of cache resource.",
"filename": "tensorflow/core/kernels/data/cache_ops.h",
"status": "modified"
}
]
}
|
{
"body": "ksizes should be sizes on:\r\nhttps://github.com/tensorflow/tensorflow/blob/e5bf8de410005de06a7ff5393fafdf832ef1d4ad/tensorflow/python/ops/array_ops.py#L4806\r\n\r\nalso on lines 4805 and 4835 the call needs updating to\r\n\r\n`tf.image.extract_patches`\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/e5bf8de410005de06a7ff5393fafdf832ef1d4ad/tensorflow/python/ops/array_ops.py#L4805\r\n\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/e5bf8de410005de06a7ff5393fafdf832ef1d4ad/tensorflow/python/ops/array_ops.py#L4835\r\n\r\n",
"comments": [
{
"body": "@fbordignon Added a PR #38819 for the fix. Thanks for pointing out!",
"created_at": "2020-04-22T23:17:13Z"
},
{
"body": "Great, thanks!",
"created_at": "2020-04-22T23:59:52Z"
}
],
"number": 38818,
"title": "Documentation updates"
}
|
{
"body": "This PR is from #38818 (Thanks @fbordignon) which updates the\r\ndeprecated tf.extract_image_patches to use tf.image.extract_patches instead.\r\nAlso fix ksizes to sizes in docstring\r\n\r\nThis PR fixes #38818.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 38819,
"review_comments": [],
"title": "Update documentation to switch from deprecated tf.extract_image_patches to tf.image.extract_patches"
}
|
{
"commits": [
{
"message": "Update documentation to switch from deprecated tf.extract_image_patches to tf.image.extract_patches\n\nThis PR is from 38818 (Thanks fbordignon) which updates the\ndeprecated tf.extract_image_patches to use tf.image.extract_patches instead.\nAlso fix ksizes to sizes in docstring\n\nThis PR fixes 38818.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -5259,8 +5259,8 @@ def extract_image_patches_v2(images, sizes, strides, rates, padding, name=None):\n # We generate two outputs as follows:\n # 1. 3x3 patches with stride length 5\n # 2. Same as above, but the rate is increased to 2\n- tf.extract_image_patches(images=images,\n- ksizes=[1, 3, 3, 1],\n+ tf.image.extract_patches(images=images,\n+ sizes=[1, 3, 3, 1],\n strides=[1, 5, 5, 1],\n rates=[1, 1, 1, 1],\n padding='VALID')\n@@ -5289,7 +5289,7 @@ def extract_image_patches_v2(images, sizes, strides, rates, padding, name=None):\n ```\n \n ```\n- tf.extract_image_patches(images=images,\n+ tf.image.extract_patches(images=images,\n sizes=[1, 3, 3, 1],\n strides=[1, 5, 5, 1],\n rates=[1, 2, 2, 1],",
"filename": "tensorflow/python/ops/array_ops.py",
"status": "modified"
}
]
}
|
{
"body": "## System information\r\n- OS Platform and Distribution: Google Colab Notebook\r\n- TensorFlow version (use command below): 2.2.0-rc2\r\n- Python version: 3.6\r\n\r\n## Describe the current behavior\r\n\r\nIn `tf.keras` models, the `model.test_step()` method (which is called by `model.fit()` and `model.evaluate()`) incorrectly computes the mean loss over all batches in an epoch when the dataset size is not evenly divisible by the batch size. This applies for both training and validation loss. This bug affects the reported epoch loss, but NOT the training loss used for computing gradient updates.\r\n\r\nCurrently, TensorFlow-Keras computes the loss for each batch, adds together the losses across batches, then divides by the number of batches. In other words, the reported loss at the end of each epoch is (incorrectly) unweighted with respect to the size of each batch.\r\n\r\nFor example, suppose there are 3 samples in a dataset, and the batch size is 2. Then there are 2 batches of size 2 and 1. If the first batch has mean loss of 10 and the second batch has mean loss of 9, then the mean loss over the entire dataset is currently (incorrectly) computed as `(10 + 9) / 2 = 9.5`.\r\n\r\n## Describe the expected behavior\r\n\r\nContinuing with the example above, the correct mean loss over the dataset should be a weighted mean of the batch losses, where the weights are given by each batch size. Thus, the correct mean loss should be `(10*2 + 9*1) / (2 + 1) = 9.66666`. This is shown in the code below.\r\n\r\n## Standalone code to reproduce the issue\r\n\r\nCode ([gist here](https://colab.research.google.com/gist/bentyeh/9ec7fd68564f411cc4a1f8a7060c9b92/tf_keras_issue38596.ipynb))\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\nX = tf.constant([[1],\r\n [2],\r\n [3]], dtype=tf.float32)\r\ny = tf.constant([[5],\r\n [4],\r\n [6]], dtype=tf.float32)\r\n\r\n# y_pred = a * x + b, where weights are intialized as a = 1, b = 0\r\n# thus, MSE = (x - y)**2 / len(x)\r\nmodel = tf.keras.Sequential([\r\n tf.keras.layers.Dense(1, input_dim=1, kernel_initializer='ones', bias_initializer='zeros')])\r\nmodel.compile(optimizer='sgd', loss='mean_squared_error')\r\n\r\ndef mse(y, y_pred):\r\n assert len(y) == len(y_pred)\r\n return sum((y - y_pred)**2)/len(y)\r\n\r\nprint('model.evaluate():')\r\nprint('- batch_size=1:', model.evaluate(X, y, batch_size=1, verbose=0))\r\nprint('- batch_size=2:', model.evaluate(X, y, batch_size=2, verbose=0))\r\nprint('- batch_size=3:', model.evaluate(X, y, batch_size=3, verbose=0))\r\nprint()\r\n\r\n# incorrect mean of two different-sized batches\r\n# Batch 1 is size 2, but Batch 2 is size 1\r\n# So we should compute a weighted mean, but Tensorflow-Keras fails to do so\r\nprint((mse(X[:-1], y[:-1]) + mse(X[-1], y[-1]))/2)\r\n```\r\n\r\nOutput\r\n```\r\nmodel.evaluate():\r\n- batch_size=1: 9.666666984558105\r\n- batch_size=2: 9.5\r\n- batch_size=3: 9.666666984558105\r\n\r\ntf.Tensor([9.5], shape=(1,), dtype=float32)\r\n```\r\n\r\n## Where this error occurs in TensorFlow source code\r\n\r\nThe following line in the `model.test_step()` method calls the `self.compiled_loss` object.\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/42052dcb8ea0265e9b8b6eafd2ab3dcb4cb1f73c/tensorflow/python/keras/engine/training.py#L971-L972\r\n\r\n`self.compiled_loss` is a `compile_utils.LossesContainer` object whose `__call__()` method seems to be implemented incorrectly. Specifically, the following line is where each batch's total loss is accumulated over an epoch, but the accumulation is done without any record of the batch size.\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/42052dcb8ea0265e9b8b6eafd2ab3dcb4cb1f73c/tensorflow/python/keras/engine/compile_utils.py#L235\r\n\r\nConsequently, the mean epoch loss is calculated (`m.result()` below)\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/42052dcb8ea0265e9b8b6eafd2ab3dcb4cb1f73c/tensorflow/python/keras/engine/training.py#L975\r\n\r\nby dividing the total accumulated loss by the number of batches (`self.count`).\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/a5a8ceea2180665b660862d1efd1de51ea8cb0c2/tensorflow/python/keras/metrics.py#L383\r\n\r\n## Proposed solution\r\n\r\nI don't know what the best way to solve this problem may be, but the accumulation of each batch's loss should clearly track each batch's actual size. One possible solution may be to use the `sample_weight` argument and replace\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/42052dcb8ea0265e9b8b6eafd2ab3dcb4cb1f73c/tensorflow/python/keras/engine/compile_utils.py#L235\r\n\r\nwith\r\n\r\n`self._loss_metric.update_state(total_loss_metric_value, sample_weight=ACTUAL_BATCH_SIZE)`\r\n\r\n## Related Issues\r\n\r\nTo the best of my knowledge, the problem described above is the root problem for a number of other reported issues: #35585 #35533 #38004 #38165",
"comments": [
{
"body": "Experiencing the same bug here. Can confirm and reproduce using the code shared above.",
"created_at": "2020-04-16T08:53:42Z"
},
{
"body": "I agree the loss should weight by batch size, but I don't think the big gaps loss between model.fit with GradientTape is cause by this. you can try with my code in https://github.com/tensorflow/tensorflow/issues/35585#issuecomment-606379061, I discover, if you want to get same metrics between GradientTape with model.fit , you should set GradientTape's epochs bigger than model.fit, like the epochs of model.fit is 10, the epochs of GradientTape is 100.",
"created_at": "2020-04-16T09:31:20Z"
},
{
"body": "I have tried on colab with TF version 2.2.0-rc2 and was able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/ae42f851c0f6ee95183e5998ede1c390/untitled780.ipynb). Thanks!",
"created_at": "2020-04-16T12:12:52Z"
},
{
"body": "@chrisyeh96 This was resolved in recent tf-nightly. It will be available in stable `TF2.2` in near future. [Here](https://colab.research.google.com/gist/jvishnuvardhan/bfd3642c92417f9a260a0e07326ca3ee/untitled780.ipynb) is the gist for your reference. Thanks!\r\n\r\nI am closing this issue as this was resolved. Please feel free to reopen if the issue persists again. Thanks!",
"created_at": "2020-04-28T17:39:01Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38596\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38596\">No</a>\n",
"created_at": "2020-04-28T17:39:03Z"
},
{
"body": "Note to self: Original fix commit to the master branch is https://github.com/tensorflow/tensorflow/commit/4f17f35befc1b2cefd22c404a8ceb7fe849291f7",
"created_at": "2020-04-28T17:43:55Z"
}
],
"number": 38596,
"title": "Keras fails to account for smaller last batch in loss metric calculation"
}
|
{
"body": "PiperOrigin-RevId: 307666011\r\nChange-Id: I4ede295280b78e18b5b8b52f0c211d5c0a7913e2\r\n\r\nFixes issue \r\n#38596\r\n",
"number": 38808,
"review_comments": [],
"title": "[r2.2:Cherrypick] Fix last partial batch loss regression in 2.2"
}
|
{
"commits": [
{
"message": "Fix last partial batch loss regression in 2.2\n\nPiperOrigin-RevId: 307666011\nChange-Id: I4ede295280b78e18b5b8b52f0c211d5c0a7913e2"
}
],
"files": [
{
"diff": "@@ -192,6 +192,7 @@ def __call__(self,\n \n loss_values = [] # Used for gradient calculation.\n loss_metric_values = [] # Used for loss metric calculation.\n+ batch_dim = None\n zip_args = (y_true, y_pred, sample_weight, self._losses, self._loss_weights,\n self._per_output_metrics)\n for y_t, y_p, sw, loss_obj, loss_weight, metric_obj in zip(*zip_args):\n@@ -207,8 +208,11 @@ def __call__(self,\n # Correct for the `Mean` loss metrics counting each replica as a batch.\n if loss_obj.reduction == losses_utils.ReductionV2.SUM:\n loss_metric_value *= ds_context.get_strategy().num_replicas_in_sync\n+\n+ if batch_dim is None:\n+ batch_dim = array_ops.shape(y_t)[0]\n if metric_obj is not None:\n- metric_obj.update_state(loss_metric_value)\n+ metric_obj.update_state(loss_metric_value, sample_weight=batch_dim)\n \n if loss_weight is not None:\n loss_value *= loss_weight\n@@ -232,7 +236,8 @@ def __call__(self,\n loss_metric_values = losses_utils.cast_losses_to_common_dtype(\n loss_metric_values)\n total_loss_metric_value = math_ops.add_n(loss_metric_values)\n- self._loss_metric.update_state(total_loss_metric_value)\n+ self._loss_metric.update_state(\n+ total_loss_metric_value, sample_weight=batch_dim)\n \n loss_values = losses_utils.cast_losses_to_common_dtype(loss_values)\n total_loss = math_ops.add_n(loss_values)",
"filename": "tensorflow/python/keras/engine/compile_utils.py",
"status": "modified"
},
{
"diff": "@@ -47,22 +47,22 @@ def get_multi_io_model():\n \n def custom_generator_multi_io(sample_weights=None):\n batch_size = 2\n- num_samples = 4\n- inputs = np.asarray([[1.], [2.], [3.], [4.]])\n- targets_1 = np.asarray([[2.], [4.], [6.], [8.]])\n- targets_2 = np.asarray([[1.], [2.], [3.], [4.]])\n- i = 0\n+ num_samples = 5\n+ inputs = np.asarray([[1.], [2.], [3.], [4.], [5.]])\n+ targets_1 = np.asarray([[2.], [4.], [6.], [8.], [10.]])\n+ targets_2 = np.asarray([[1.], [2.], [3.], [4.], [5.]])\n+ start = 0\n while True:\n- batch_index = i * batch_size % num_samples\n- i += 1\n- start = batch_index\n+ if start > num_samples:\n+ start = 0\n end = start + batch_size\n x = [inputs[start:end], inputs[start:end]]\n y = [targets_1[start:end], targets_2[start:end]]\n if sample_weights:\n sw = nest.map_structure(lambda w: w[start:end], sample_weights)\n else:\n sw = None\n+ start = end\n yield x, y, sw\n \n \n@@ -84,97 +84,103 @@ def _get_compiled_multi_io_model(self):\n \n def setUp(self):\n super(TestMetricsCorrectnessMultiIO, self).setUp()\n- self.x = np.asarray([[1.], [2.], [3.], [4.]])\n- self.y1 = np.asarray([[2.], [4.], [6.], [8.]])\n- self.y2 = np.asarray([[1.], [2.], [3.], [4.]])\n- self.sample_weight_1 = np.asarray([2., 3., 4., 5.])\n- self.sample_weight_2 = np.asarray([3.5, 2.5, 1.5, 0.5])\n+ self.x = np.asarray([[1.], [2.], [3.], [4.], [5.]])\n+ self.y1 = np.asarray([[2.], [4.], [6.], [8.], [10.]])\n+ self.y2 = np.asarray([[1.], [2.], [3.], [4.], [5.]])\n+ self.sample_weight_1 = np.asarray([2., 3., 4., 5., 6.])\n+ self.sample_weight_2 = np.asarray([3.5, 2.5, 1.5, 0.5, 3.])\n \n- # y_true_1 = [[2.], [4.], [6.], [8.]], y_pred = [[3.], [6.], [9.], [12.]]\n- # y_true_2 = [[1.], [2.], [3.], [4.]], y_pred = [[3.], [6.], [9.], [12.]]\n+ # y_true_1 = [[2.], [4.], [6.], [8.], [10.]]\n+ # y_pred_1 = [[3.], [6.], [9.], [12.], [15.]]\n+ # y_true_2 = [[1.], [2.], [3.], [4.], [5.]]\n+ # y_pred_2 = [[3.], [6.], [9.], [12.], [15.]]\n \n # Weighted metric `output_1`:\n- # Total = ((3 - 2)^2 * 2 + (6 - 4)^2 * 3) +\n- # ((9 - 6)^2 * 4 + (12 - 8)^2 * 5)\n- # = 130\n- # Count = (2 + 3) + (4 + 5)\n- # Result = 9.2857141\n+ # Total = ((3 - 2)^2 * 2 + (6 - 4)^2 * 3) +\n+ # ((9 - 6)^2 * 4 + (12 - 8)^2 * 5) +\n+ # ((15 - 10)^2 * 6)\n+ # = 280\n+ # Count = (2 + 3) + (4 + 5) + 6 = 20\n+ # Result = 14\n \n # Weighted metric `output_2`:\n # Total = ((3 - 1)^2 * 3.5 + (6 - 2)^2 * 2.5) +\n- # ((9 - 3)^2 * 1.5 + (12 - 4)^2 * 0.5)\n- # = 140\n- # Count = (3.5 + 2.5) + (1.5 + 0.5)\n- # Result = 17.5\n+ # ((9 - 3)^2 * 1.5 + (12 - 4)^2 * 0.5) +\n+ # (15 - 5)^2 * 3.0\n+ # = 440\n+ # Count = (3.5 + 2.5) + (1.5 + 0.5) + 3.0 = 11.0\n+ # Result = 40\n \n # Loss `output_1` with weights:\n # Total = ((3 - 2)^2 * 2 + (6 - 4)^2 * 3) +\n- # ((9 - 6)^2 * 4 + (12 - 8)^2 * 5)\n- # = 130\n- # Count = 2 + 2\n- # Result = 32.5\n+ # ((9 - 6)^2 * 4 + (12 - 8)^2 * 5) +\n+ # ((15 - 10)^2 * 6)\n+ # = 280\n+ # Count = 2 + 2 + 1\n+ # Result = 56\n \n # Loss `output_1` without weights/Metric `output_1`:\n- # Total = ((3 - 2)^2 + (6 - 4)^2) + ((9 - 6)^2 + (12 - 8)^2) = 30\n- # Count = 2 + 2\n- # Result = 7.5\n+ # Total = ((3 - 2)^2 + (6 - 4)^2) + ((9 - 6)^2 + (12 - 8)^2) + (15 - 10)^2\n+ # = 55\n+ # Count = 2 + 2 + 1\n+ # Result = 11\n \n # Loss `output_2` with weights:\n # Total = ((3 - 1)^2 * 3.5 + (6 - 2)^2 * 2.5) +\n- # ((9 - 3)^2 * 1.5 + (12 - 4)^2 * 0.5)\n- # = 140\n- # Count = 2 + 2\n- # Result = 35\n+ # ((9 - 3)^2 * 1.5 + (12 - 4)^2 * 0.5) +\n+ # (15 - 5)^2 * 3.0\n+ # = 440\n+ # Count = 2 + 2 + 1\n+ # Result = 88\n \n # Loss `output_2` without weights/Metric `output_2`:\n- # Total = ((3 - 1)^2 + (6 - 2)^2) + ((9 - 3)^2 + (12 - 4)^2) = 120\n- # Count = 2 + 2\n- # Result = 30\n+ # Total = ((3 - 1)^2 + (6 - 2)^2) + ((9 - 3)^2 + (12 - 4)^2) + (15 - 5)^2\n+ # = 220\n+ # Count = 2 + 2 + 1\n+ # Result = 44\n \n- # Total loss with weights = 32.5 + 35 = 67.5\n- # Total loss without weights = 7.5 + 30 = 37.5\n+ # Total loss with weights = 56 + 88 = 144\n+ # Total loss without weights = 11 + 44 = 55\n \n self.wmse = 'mean_squared_error_2'\n self.expected_fit_result_with_weights = {\n- 'output_1_mean_squared_error': [7.5, 7.5],\n- 'output_2_mean_squared_error': [30, 30],\n- 'output_1_' + self.wmse: [9.286, 9.286],\n- 'output_2_' + self.wmse: [17.5, 17.5],\n- 'loss': [67.5, 67.5],\n- 'output_1_loss': [32.5, 32.5],\n- 'output_2_loss': [35, 35],\n+ 'output_1_mean_squared_error': [11, 11],\n+ 'output_2_mean_squared_error': [44, 44],\n+ 'output_1_' + self.wmse: [14, 14],\n+ 'output_2_' + self.wmse: [40, 40],\n+ 'loss': [144, 144],\n+ 'output_1_loss': [56, 56],\n+ 'output_2_loss': [88, 88],\n }\n \n self.expected_fit_result_with_weights_output_2 = {\n- 'output_1_mean_squared_error': [7.5, 7.5],\n- 'output_2_mean_squared_error': [30, 30],\n- 'output_1_' + self.wmse: [7.5, 7.5],\n- 'output_2_' + self.wmse: [17.5, 17.5],\n- 'loss': [42.5, 42.5],\n- 'output_1_loss': [7.5, 7.5],\n- 'output_2_loss': [35, 35],\n+ 'output_1_mean_squared_error': [11, 11],\n+ 'output_2_mean_squared_error': [44, 44],\n+ 'output_1_' + self.wmse: [11, 11],\n+ 'output_2_' + self.wmse: [40, 40],\n+ 'loss': [99, 99],\n+ 'output_1_loss': [11, 11],\n+ 'output_2_loss': [88, 88],\n }\n \n self.expected_fit_result = {\n- 'output_1_mean_squared_error': [7.5, 7.5],\n- 'output_2_mean_squared_error': [30, 30],\n- 'output_1_' + self.wmse: [7.5, 7.5],\n- 'output_2_' + self.wmse: [30, 30],\n- 'loss': [37.5, 37.5],\n- 'output_1_loss': [7.5, 7.5],\n- 'output_2_loss': [30, 30],\n+ 'output_1_mean_squared_error': [11, 11],\n+ 'output_2_mean_squared_error': [44, 44],\n+ 'output_1_' + self.wmse: [11, 11],\n+ 'output_2_' + self.wmse: [44, 44],\n+ 'loss': [55, 55],\n+ 'output_1_loss': [11, 11],\n+ 'output_2_loss': [44, 44],\n }\n \n # In the order: 'loss', 'output_1_loss', 'output_2_loss',\n # 'output_1_mean_squared_error', 'output_1_mean_squared_error_2',\n # 'output_2_mean_squared_error', 'output_2_mean_squared_error_2'\n- self.expected_batch_result_with_weights = [\n- 67.5, 32.5, 35, 7.5, 9.286, 30, 17.5\n- ]\n+ self.expected_batch_result_with_weights = [144, 56, 88, 11, 14, 44, 40]\n self.expected_batch_result_with_weights_output_2 = [\n- 42.5, 7.5, 35, 7.5, 7.5, 30, 17.5\n+ 99, 11, 88, 11, 11, 44, 40\n ]\n- self.expected_batch_result = [37.5, 7.5, 30, 7.5, 7.5, 30, 30]\n+ self.expected_batch_result = [55, 11, 44, 11, 11, 44, 44]\n \n def test_fit(self):\n model = self._get_compiled_multi_io_model()\n@@ -291,7 +297,7 @@ def test_test_on_batch_with_sample_weight(self):\n def test_fit_generator(self):\n model = self._get_compiled_multi_io_model()\n history = model.fit_generator(\n- custom_generator_multi_io(), steps_per_epoch=2, epochs=2)\n+ custom_generator_multi_io(), steps_per_epoch=3, epochs=2)\n for key, value in self.expected_fit_result.items():\n self.assertAllClose(history.history[key], value, 1e-3)\n \n@@ -300,7 +306,7 @@ def test_fit_generator_with_sample_weight(self):\n history = model.fit_generator(\n custom_generator_multi_io(\n sample_weights=[self.sample_weight_1, self.sample_weight_2]),\n- steps_per_epoch=2,\n+ steps_per_epoch=3,\n epochs=2)\n for key, value in self.expected_fit_result_with_weights.items():\n self.assertAllClose(history.history[key], value, 1e-3)\n@@ -309,30 +315,30 @@ def test_fit_generator_with_sample_weight(self):\n history = model.fit_generator(\n custom_generator_multi_io(\n sample_weights={'output_2': self.sample_weight_2}),\n- steps_per_epoch=2,\n+ steps_per_epoch=3,\n epochs=2)\n for key, value in self.expected_fit_result_with_weights_output_2.items():\n self.assertAllClose(history.history[key], value, 1e-3)\n \n def test_eval_generator(self):\n model = self._get_compiled_multi_io_model()\n- eval_result = model.evaluate_generator(custom_generator_multi_io(), steps=2)\n+ eval_result = model.evaluate_generator(custom_generator_multi_io(), steps=3)\n self.assertAllClose(eval_result, self.expected_batch_result, 1e-3)\n \n def test_eval_generator_with_sample_weight(self):\n model = self._get_compiled_multi_io_model()\n eval_result = model.evaluate_generator(\n custom_generator_multi_io(\n sample_weights=[self.sample_weight_1, self.sample_weight_2]),\n- steps=2)\n+ steps=3)\n self.assertAllClose(eval_result, self.expected_batch_result_with_weights,\n 1e-3)\n \n # Set weights for one output.\n eval_result = model.evaluate_generator(\n custom_generator_multi_io(\n sample_weights={'output_2': self.sample_weight_2}),\n- steps=2)\n+ steps=3)\n self.assertAllClose(eval_result,\n self.expected_batch_result_with_weights_output_2, 1e-3)\n \n@@ -549,7 +555,7 @@ def test_eval_generator_with_sample_weight(self):\n \n \n @keras_parameterized.run_with_all_model_types(exclude_models=['sequential'])\n-@keras_parameterized.run_all_keras_modes\n+@keras_parameterized.run_all_keras_modes(always_skip_v1=True)\n @parameterized.parameters([\n loss_reduction.ReductionV2.SUM_OVER_BATCH_SIZE,\n loss_reduction.ReductionV2.AUTO,\n@@ -567,29 +573,34 @@ def _get_compiled_multi_io_model(self, loss):\n \n def setUp(self):\n super(TestOutputLossMetrics, self).setUp()\n- self.x = np.asarray([[1.], [2.], [3.], [4.]])\n- self.y1 = np.asarray([[2.], [4.], [6.], [8.]])\n- self.y2 = np.asarray([[1.], [2.], [3.], [4.]])\n- self.sample_weight_1 = np.asarray([2., 3., 4., 5.])\n- self.sample_weight_2 = np.asarray([3.5, 2.5, 1.5, 0.5])\n+ self.x = np.asarray([[1.], [2.], [3.], [4.], [5.]])\n+ self.y1 = np.asarray([[2.], [4.], [6.], [8.], [10.]])\n+ self.y2 = np.asarray([[1.], [2.], [3.], [4.], [5.]])\n+ self.sample_weight_1 = np.asarray([2., 3., 4., 5., 6.])\n+ self.sample_weight_2 = np.asarray([3.5, 2.5, 1.5, 0.5, 3.])\n \n- # y_true = [[2.], [4.], [6.], [8.]], y_pred = [[3.], [6.], [9.], [12.]]\n+ # y_true_1 = [[2.], [4.], [6.], [8.], [10.]]\n+ # y_pred_1 = [[3.], [6.], [9.], [12.], [15.]]\n+ # y_true_2 = [[1.], [2.], [3.], [4.], [5.]]\n+ # y_pred_2 = [[3.], [6.], [9.], [12.], [15.]]\n \n # Loss `output_1`:\n # Per-sample weighted losses\n # Batch 1 = [(3 - 2)^2 * 2, (6 - 4)^2 * 3)] = [2, 12]\n # Batch 2 = [((9 - 6)^2 * 4, (12 - 8)^2 * 5)] = [36, 80]\n+ # Batch 3 = [(15 - 10)^2 * 6] = [150]\n \n- # Result (reduction=SUM) = ((2 + 12) + (36 + 80))/2 = 65\n- # Result (reduction=SUM_OVER_BATCH_SIZE/AUTO/NONE) = 130 / 4 = 32.5\n+ # Result (reduction=SUM) = ((2 + 12)*2 + (36 + 80)*2 + 150) / 5 = 82\n+ # Result (reduction=SUM_OVER_BATCH_SIZE/AUTO/NONE) = 280 / 5 = 56\n \n # Loss `output_2`:\n # Per-sample weighted losses\n # Batch 1 = [(3 - 1)^2 * 3.5, (6 - 2)^2 * 2.5)] = [14, 40]\n # Batch 2 = [(9 - 3)^2 * 1.5, (12 - 4)^2 * 0.5)] = [54, 32]\n+ # Batch 3 = [(15 - 5)^2 * 3] = [300]\n \n- # Result (reduction=SUM) = ((14 + 40) + (54 + 32))/2 = 70\n- # Result (reduction=SUM_OVER_BATCH_SIZE/AUTO/NONE) = 140 / 4 = 35\n+ # Result (reduction=SUM) = ((14 + 40)*2 + (54 + 32)*2 + 300) / 5 = 116\n+ # Result (reduction=SUM_OVER_BATCH_SIZE/AUTO/NONE) = 440 / 5 = 88\n \n # When reduction is 'NONE' loss value that is passed to the optimizer will\n # be vector loss but what is reported is a scalar, which is an average of\n@@ -598,18 +609,18 @@ def setUp(self):\n # Total loss = Output_loss_1 + Output_loss_2\n \n sum_over_batch_size_fit_result = {\n- 'loss': [67.5, 67.5],\n- 'output_1_loss': [32.5, 32.5],\n- 'output_2_loss': [35, 35],\n+ 'loss': [144, 144],\n+ 'output_1_loss': [56, 56],\n+ 'output_2_loss': [88, 88],\n }\n \n self.expected_fit_result = {\n loss_reduction.ReductionV2.NONE:\n sum_over_batch_size_fit_result,\n loss_reduction.ReductionV2.SUM: {\n- 'loss': [135, 135],\n- 'output_1_loss': [65, 65],\n- 'output_2_loss': [70, 70],\n+ 'loss': [198, 198],\n+ 'output_1_loss': [82, 82],\n+ 'output_2_loss': [116, 116],\n },\n loss_reduction.ReductionV2.AUTO:\n sum_over_batch_size_fit_result,\n@@ -619,12 +630,16 @@ def setUp(self):\n \n # In the order: 'loss', 'output_1_loss', 'output_2_loss',\n self.expected_batch_result = {\n- loss_reduction.ReductionV2.NONE: [67.5, 32.5, 35],\n- loss_reduction.ReductionV2.SUM: [135, 65, 70],\n- loss_reduction.ReductionV2.AUTO: [67.5, 32.5, 35],\n- loss_reduction.ReductionV2.SUM_OVER_BATCH_SIZE: [67.5, 32.5, 35],\n+ loss_reduction.ReductionV2.NONE: [144, 56, 88],\n+ loss_reduction.ReductionV2.SUM: [198, 82, 116],\n+ loss_reduction.ReductionV2.AUTO: [144, 56, 88],\n+ loss_reduction.ReductionV2.SUM_OVER_BATCH_SIZE: [144, 56, 88],\n }\n \n+ # 2 + 12 + 36 + 80 + 150 = 280\n+ # 14 + 40 + 54 + 32 + 300 = 440\n+ self.expected_single_batch_result = [720, 280, 440]\n+\n def test_fit(self, reduction):\n model = self._get_compiled_multi_io_model(\n loss=losses.MeanSquaredError(reduction=reduction))\n@@ -661,8 +676,7 @@ def test_train_on_batch(self, reduction):\n \n expected_values = self.expected_batch_result[reduction]\n if reduction == loss_reduction.ReductionV2.SUM:\n- # We are taking all the data as one batch, so undo the averaging here.\n- expected_values = [x * 2 for x in self.expected_batch_result[reduction]]\n+ expected_values = self.expected_single_batch_result\n self.assertAllClose(result, expected_values)\n \n def test_test_on_batch(self, reduction):\n@@ -675,8 +689,7 @@ def test_test_on_batch(self, reduction):\n })\n expected_values = self.expected_batch_result[reduction]\n if reduction == loss_reduction.ReductionV2.SUM:\n- # We are taking all the data as one batch, so undo the averaging here.\n- expected_values = [x * 2 for x in self.expected_batch_result[reduction]]\n+ expected_values = self.expected_single_batch_result\n self.assertAllClose(result, expected_values)\n \n def test_fit_generator(self, reduction):\n@@ -685,7 +698,7 @@ def test_fit_generator(self, reduction):\n history = model.fit_generator(\n custom_generator_multi_io(\n sample_weights=[self.sample_weight_1, self.sample_weight_2]),\n- steps_per_epoch=2,\n+ steps_per_epoch=3,\n epochs=2)\n for key, value in self.expected_fit_result[reduction].items():\n self.assertAllClose(history.history[key], value)\n@@ -696,7 +709,7 @@ def test_eval_generator(self, reduction):\n eval_result = model.evaluate_generator(\n custom_generator_multi_io(\n sample_weights=[self.sample_weight_1, self.sample_weight_2]),\n- steps=2)\n+ steps=3)\n self.assertAllClose(eval_result, self.expected_batch_result[reduction])\n \n ",
"filename": "tensorflow/python/keras/metrics_correctness_test.py",
"status": "modified"
}
]
}
|
{
"body": "This issue is related to the concat implementation used for TFlite and TFlite micro.\r\nFor uint8 there are no restrictions on having the same scaling/zeropoint in the Input/Output.\r\n\r\nBut the implementation is not quantized\r\nin concatenation.cc:\r\n// TODO(prabhumk): This is the same as the optimized implementation.\r\n// TODO(prabhumk): The quantized implementation of concatentation isn't fully\r\n// quantized as it takes scale as a floating point value. This should be fixed\r\n// when optimizng this routine further.\r\ninline void ConcatenationWithScaling(const ConcatenationParams& params,\r\n const RuntimeShape* const* input_shapes,\r\n const uint8* const* input_data,\r\n const RuntimeShape& output_shape,\r\n uint8* output_data) {\r\n...\r\n if (input_zeropoint[i] == output_zeropoint &&\r\n input_scale[i] == output_scale) {\r\n memcpy(output_ptr, input_ptr, copy_size);\r\n } else {\r\n const float scale = input_scale[i] * inverse_output_scale;\r\n const float bias = -input_zeropoint[i] * scale;\r\n for (int j = 0; j < copy_size; ++j) {\r\n const int32_t value =\r\n static_cast<int32_t>(std::round(input_ptr[j] * scale + bias)) +\r\n output_zeropoint;\r\n output_ptr[j] = static_cast<uint8_t>(\r\n std::max<int32_t>(std::min<int32_t>(255, value), 0));\r\n }\r\n }\r\n\r\n**Standalone code to reproduce the issue** \r\nI have attached a tflite file that includes a concat op with different scaling/zeropoint in the Input/Output.\r\n\r\n[concat_1x1x1x2048_requantize_6.zip](https://github.com/tensorflow/tensorflow/files/4325464/concat_1x1x1x2048_requantize_6.zip)\r\n\r\n\r\n",
"comments": [
{
"body": "This is a known issue with the uint8 kernel. The int8 version of this op (the tflite recommend official quantized kernel) does not have the rescale in the op, and is purely integer. \r\n\r\nWhat is your use case where the rescaling concatenation is causing an issue with the uint8 kernel. (note we are working on making all conversion of quantization-aware-training also output only the int8 kernels, so that may resolve your issue).",
"created_at": "2020-04-02T17:31:01Z"
},
{
"body": "I changed the op spec of concat, so the uint8 scheme doesn't require same input/ouput scales anymore. Please check it again.",
"created_at": "2020-07-15T06:49:13Z"
},
{
"body": "I'm wondering how to keep the same scaling/zeropoint in the Input/Output for int8.",
"created_at": "2021-02-27T10:36:56Z"
},
{
"body": "@ppatrikg It looks like you are using an older Version of Tensorflow. Many bugs have been fixed in the latest version. Could you please execute your code using Latest Version 2.4.1 or 2.5 and let us know if the issue still persists? Thanks!",
"created_at": "2021-08-01T15:20:04Z"
},
{
"body": "I'm still getting the same issue with v2.6.0-rc1.",
"created_at": "2021-08-08T02:41:23Z"
},
{
"body": "I see it, too. On tfnightly==2.8.0-dev20211001\r\n",
"created_at": "2021-10-02T03:54:10Z"
},
{
"body": "@yisongsong \r\n\r\n>I'm wondering how to keep the same scaling/zeropoint in the Input/Output for int8.\r\n\r\nHave you got the solution?",
"created_at": "2021-11-15T04:26:29Z"
},
{
"body": "> @yisongsong\r\n> \r\n> > I'm wondering how to keep the same scaling/zeropoint in the Input/Output for int8.\r\n> \r\n> Have you got the solution?\r\n\r\nYou can refer to this [link](https://github.com/tensorflow/tensorflow/blob/d65ffd105c438ab6693e84243c6ab7b849bb3af8/tensorflow/lite/tools/optimize/quantize_model_test.cc#L425). It will check min/max for all inputs, and insert Quantize node for some inputs or all. \r\n```\r\n// There are two inputs for concat, \"input0\" and \"input1\". \"input0\" has [0, 5]\r\n// as min/max and \"input1\" has [0, 10] as min/max. The output \"output\" for\r\n// concat has [0, 10] as min/max.\r\n// After applyging QuantizeModel(), \"input0\" will have a requant op added, along\r\n// with a tensor \"input0_reqaunt\" that has [0, 10] as min/max. So the topology\r\n// becomes:\r\n// input0 -> requant -> input0_requant \\\r\n// concat - output\r\n// input1 /\r\n```\r\n\r\nAlso, tflite provide `HardcodeMinMaxForConcatenation()` to change min/max.\r\n```\r\n# Usage for this flag is --change_concat_input_ranges=true or\r\n# --change_concat_input_ranges=false in order to make it clear what the flag\r\n# is set to. This keeps the usage consistent with other usages of the flag\r\n# where the default is different. The default value here is False.\r\nparser.add_argument(\r\n\"--change_concat_input_ranges\",\r\ntype=str.upper,\r\nchoices=[\"TRUE\", \"FALSE\"],\r\nhelp=(\"Boolean to change behavior of min/max ranges for inputs and \"\r\n \"outputs of the concat operator for quantized models. Changes the \"\r\n \"ranges of concat operator overlap when true. (default False)\"))\r\n```\r\n",
"created_at": "2021-11-17T07:59:27Z"
},
{
"body": "Hi @ppatrikg! \r\nWe are checking to see whether you still need help in this issue . Did above [comment](https://github.com/tensorflow/tensorflow/issues/37544#issuecomment-971326816) work for you?",
"created_at": "2021-11-23T09:56:39Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2021-11-30T10:30:17Z"
},
{
"body": "Closing as stale. Please reopen if you'd like to work on this further.\n",
"created_at": "2021-12-07T10:51:32Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37544\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37544\">No</a>\n",
"created_at": "2021-12-07T10:51:35Z"
}
],
"number": 37544,
"title": "Concat op not quantized "
}
|
{
"body": "Hi,\r\n\r\nThis PR fixes the issue raised by #37544 and fully quantizes the uint8 concatenation kernel in TFLite and TFLite micro so that it only uses integer operations..\r\n\r\nIt pre-calculates the scaling multiplier and shift with QuantizeMultiplier and then uses MultiplyByQuantizedMultiplier instead of a floating-point multiplication.\r\n\r\nThibaut",
"number": 38704,
"review_comments": [
{
"body": "Is it necessary to add a `fixed_point_scaling` field for the MLIR converter? From what I understand, the `SameOperandsAndResultsScale` trait of `TFL_ConcatenationOp` guarantees that the scaling of the inputs and output will be the same . In this case the concatenation kernel for uint8 only does a memcpy regardless of the value of the `fixed_point_scaling` in the TFLite flatbuffer. ",
"created_at": "2020-05-01T12:08:23Z"
},
{
"body": "Yes, my understanding is that you will not need to add this because of that trait.",
"created_at": "2020-06-02T18:59:47Z"
},
{
"body": "right. the scales will be the same and the kernel will use memory copy. ",
"created_at": "2020-06-03T06:15:51Z"
}
],
"title": "[TFLite] Fully quantize the uint8 concatenation kernel to make it pure integer"
}
|
{
"commits": [
{
"message": "[TFLite] Fully quantize the uint8 concatenation kernel to make it pure integer"
},
{
"message": "Add a fixed_point_scaling parameter with false as default value to the TFLite concatenation operator to keep backward compatibiltiy. This create the version 4 of the operator."
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Use BoolAttr instead of auto."
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Adapt new test to the new fixed_point_scaling field."
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Remove unnecessary fixed_point_scaling field in the MLIR concatenation operator."
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Fix merge, rename concatenation_params to schema_params."
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Don't use fixed point scaling for Concatenation legacy op."
},
{
"message": "Add new Concatenation op runtime version."
},
{
"message": "Merge remote-tracking branch 'upstream/master' into toupstream/quantized-uint8-concat"
},
{
"message": "Merge remote-tracking branch 'upstream/master' into toupstream/quantized-uint8-concat"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Adapt TFL and TFLµ concatenation tests to the changes from the master branch"
},
{
"message": "Fix missing initializer member warning in TFLµ concatenation test"
},
{
"message": "Avoid implicit conversion from float to double in TFLµ concatenation prepare"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Set concatenation fixed_point_scaling parameter to true by default for new MLIR-converted models"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
},
{
"message": "Merge branch 'master' into toupstream/quantized-uint8-concat"
}
],
"files": [
{
"diff": "@@ -729,7 +729,8 @@ OpFoldResult ConcatenationOp::fold(ArrayRef<Attribute> operands) {\n auto new_concat = builder.create<TFL::ConcatenationOp>(\n getLoc(), getType(), non_empty_values,\n builder.getIntegerAttr(builder.getIntegerType(32), axis()),\n- builder.getStringAttr(fused_activation_function()));\n+ builder.getStringAttr(fused_activation_function()),\n+ builder.getBoolAttr(fixed_point_scaling()));\n return new_concat.getResult();\n }\n ",
"filename": "tensorflow/compiler/mlir/lite/ir/tfl_ops.cc",
"status": "modified"
},
{
"diff": "@@ -785,7 +785,8 @@ def TFL_ConcatenationOp : TFL_Op<\"concatenation\",\n ins TFL_VariadicTensorOf<\n [F32, I64, I32, I16, I8, QI8, QUI8, UI8, I1]>:$values,\n I32Attr:$axis,\n- TFL_AFAttr:$fused_activation_function\n+ TFL_AFAttr:$fused_activation_function,\n+ DefaultValuedAttr<BoolAttr, \"true\">:$fixed_point_scaling\n );\n \n let results = (outs",
"filename": "tensorflow/compiler/mlir/lite/ir/tfl_ops.td",
"status": "modified"
},
{
"diff": "@@ -551,7 +551,7 @@ func @concat_3_tensors_1_empty() -> tensor<?xi32> {\n %3 = \"tfl.concatenation\"(%0, %1, %2) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<2xi32>, tensor<2xi32>, tensor<0xi32>) -> tensor<?xi32>\n return %3 : tensor<?xi32>\n \n- // CHECK: %0 = \"tfl.concatenation\"(%[[CST]], %[[CST]]) {axis = 0 : i32, fused_activation_function = \"NONE\"}\n+ // CHECK: %0 = \"tfl.concatenation\"(%[[CST]], %[[CST]]) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"}\n // CHECK: return %0 : tensor<?xi32>\n }\n ",
"filename": "tensorflow/compiler/mlir/lite/tests/const-fold.mlir",
"status": "modified"
},
{
"diff": "@@ -29,7 +29,7 @@ func @quantized_constant(%arg0: tensor<1x2xf32>) -> tensor<2x2xf32> {\n \n // CHECK-NEXT: %[[Q:.*]] = \"tfl.quantize\"(%arg0) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e+00>>} : (tensor<1x2xf32>) -> tensor<1x2x!quant.uniform<u8:f32, 1.000000e+00>>\n // CHECK-NEXT: %[[CST:.*]] = \"tfl.pseudo_qconst\"() {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e+00>>, value = dense<-76> : tensor<1x2xi8>} : () -> tensor<1x2x!quant.uniform<u8:f32, 1.000000e+00>>\n-// CHECK-NEXT: %[[CONCAT:.*]] = \"tfl.concatenation\"(%[[Q]], %[[CST]]) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e+00>>, tensor<1x2x!quant.uniform<u8:f32, 1.000000e+00>>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e+00>>\n+// CHECK-NEXT: %[[CONCAT:.*]] = \"tfl.concatenation\"(%[[Q]], %[[CST]]) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e+00>>, tensor<1x2x!quant.uniform<u8:f32, 1.000000e+00>>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e+00>>\n // CHECK-NEXT: %[[DQ:.*]] = \"tfl.dequantize\"(%[[CONCAT]]) : (tensor<2x2x!quant.uniform<u8:f32, 1.000000e+00>>) -> tensor<2x2xf32>\n // CHECK-NEXT: return %[[DQ]] : tensor<2x2xf32>\n }",
"filename": "tensorflow/compiler/mlir/lite/tests/flatbuffer2mlir/quantization.mlir",
"status": "modified"
},
{
"diff": "@@ -1168,7 +1168,7 @@ func @concat_v2_with_3_tensors(%arg0: tensor<2x1xi32>, %arg1: tensor<2x1xi32>, %\n return %1 : tensor<2x3xi32>\n \n // CHECK-LABEL: concat_v2_with_3_tensors\n-// CHECK: \"tfl.concatenation\"(%arg0, %arg1, %arg2) {axis = -1 : i32, fused_activation_function = \"NONE\"} : (tensor<2x1xi32>, tensor<2x1xi32>, tensor<2x1xi32>) -> tensor<2x3xi32>\n+// CHECK: \"tfl.concatenation\"(%arg0, %arg1, %arg2) {axis = -1 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<2x1xi32>, tensor<2x1xi32>, tensor<2x1xi32>) -> tensor<2x3xi32>\n }\n \n func @concat_v2_i64_axis(%arg0: tensor<2x1xi32>, %arg1: tensor<2x1xi32>, %arg2: tensor<2x1xi32>) -> tensor<2x3xi32> {\n@@ -1177,7 +1177,7 @@ func @concat_v2_i64_axis(%arg0: tensor<2x1xi32>, %arg1: tensor<2x1xi32>, %arg2:\n return %1 : tensor<2x3xi32>\n \n // CHECK-LABEL: concat_v2_i64_axis\n-// CHECK: \"tfl.concatenation\"(%arg0, %arg1, %arg2) {axis = -1 : i32, fused_activation_function = \"NONE\"} : (tensor<2x1xi32>, tensor<2x1xi32>, tensor<2x1xi32>) -> tensor<2x3xi32>\n+// CHECK: \"tfl.concatenation\"(%arg0, %arg1, %arg2) {axis = -1 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<2x1xi32>, tensor<2x1xi32>, tensor<2x1xi32>) -> tensor<2x3xi32>\n }\n \n func @concat_v2_with_bool_type(%arg0: tensor<?x1xi1>, %arg1: tensor<?x1xi1>) -> tensor<?x2xi1> {\n@@ -1186,7 +1186,7 @@ func @concat_v2_with_bool_type(%arg0: tensor<?x1xi1>, %arg1: tensor<?x1xi1>) ->\n return %1 : tensor<?x2xi1>\n \n // CHECK-LABEL: concat_v2_with_bool_type\n-// CHECK: \"tfl.concatenation\"(%arg0, %arg1) {axis = -1 : i32, fused_activation_function = \"NONE\"} : (tensor<?x1xi1>, tensor<?x1xi1>) -> tensor<?x2xi1>\n+// CHECK: \"tfl.concatenation\"(%arg0, %arg1) {axis = -1 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<?x1xi1>, tensor<?x1xi1>) -> tensor<?x2xi1>\n }\n \n func @resize_with_bilinear(%arg0: tensor<1x100x100x3xf32>, %arg1: tensor<4xi32>) -> tensor<?xf32> {",
"filename": "tensorflow/compiler/mlir/lite/tests/legalize-tf.mlir",
"status": "modified"
},
{
"diff": "@@ -1390,16 +1390,16 @@ func @testBatchMatmulQuant(%arg0 : tensor<1x4x384x32x!quant.uniform<i8:f32, 0.06\n // -----\n \n func @testConcat(%arg0: tensor<1x2xi32>, %arg1: tensor<1x2xi32>) -> tensor<2x2xi32> {\n- // CHECK: \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"}\n- %0 = \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xi32>, tensor<1x2xi32>) -> tensor<2x2xi32>\n+ // CHECK: \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"}\n+ %0 = \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xi32>, tensor<1x2xi32>) -> tensor<2x2xi32>\n return %0 : tensor<2x2xi32>\n }\n \n // -----\n \n func @testConcatQuantized(%arg0: tensor<1x2x!quant.uniform<i8:f32, 0.1:128>>, %arg1: tensor<1x2x!quant.uniform<i8:f32, 0.1:128>>) -> tensor<2x2x!quant.uniform<i8:f32, 0.1:128>> {\n- // CHECK: \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"}\n- %0 = \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2x!quant.uniform<i8:f32, 0.1:128>>, tensor<1x2x!quant.uniform<i8:f32, 0.1:128>>) -> tensor<2x2x!quant.uniform<i8:f32, 0.1:128>>\n+ // CHECK: \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"}\n+ %0 = \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2x!quant.uniform<i8:f32, 0.1:128>>, tensor<1x2x!quant.uniform<i8:f32, 0.1:128>>) -> tensor<2x2x!quant.uniform<i8:f32, 0.1:128>>\n return %0 : tensor<2x2x!quant.uniform<i8:f32, 0.1:128>>\n }\n ",
"filename": "tensorflow/compiler/mlir/lite/tests/ops.mlir",
"status": "modified"
},
{
"diff": "@@ -347,13 +347,13 @@ func @NotQuantizeConcatConstantOperand(%arg0: tensor<1x2xf32>) -> tensor<2x2xf32\n func @QuantizeConcatOperand0ToAll(tensor<1x2x!quant.uniform<u8:f32, 0.1:128>>, tensor<1x2xf32>) -> tensor<2x2xf32> {\n ^bb0(%arg0: tensor<1x2x!quant.uniform<u8:f32, 0.1:128>>, %arg1: tensor<1x2xf32>):\n %0 = \"tfl.dequantize\"(%arg0) : (tensor<1x2x!quant.uniform<u8:f32, 0.1:128>>) -> tensor<1x2xf32>\n- %1 = \"tfl.concatenation\"(%0, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+ %1 = \"tfl.concatenation\"(%0, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n return %1 : tensor<2x2xf32>\n \n // CHECK: %0 = \"tfl.quantize\"(%arg1) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n // CHECK: %1 = \"tfl.dequantize\"(%0) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n // CHECK: %2 = \"tfl.dequantize\"(%arg0) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n-// CHECK: %3 = \"tfl.concatenation\"(%2, %1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+// CHECK: %3 = \"tfl.concatenation\"(%2, %1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n // CHECK: %4 = \"tfl.quantize\"(%3) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n // CHECK: %5 = \"tfl.dequantize\"(%4) : (tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<2x2xf32>\n // CHECK: return %5 : tensor<2x2xf32>\n@@ -363,13 +363,13 @@ func @QuantizeConcatOperand0ToAll(tensor<1x2x!quant.uniform<u8:f32, 0.1:128>>, t\n func @QuantizeConcatOperand1ToAll(tensor<1x2xf32>, tensor<1x2x!quant.uniform<u8:f32, 0.1:128>>) -> tensor<2x2xf32> {\n ^bb0(%arg0: tensor<1x2xf32>, %arg1: tensor<1x2x!quant.uniform<u8:f32, 0.1:128>>):\n %0 = \"tfl.dequantize\"(%arg1) : (tensor<1x2x!quant.uniform<u8:f32, 0.1:128>>) -> tensor<1x2xf32>\n- %1 = \"tfl.concatenation\"(%arg0, %0) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+ %1 = \"tfl.concatenation\"(%arg0, %0) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n return %1 : tensor<2x2xf32>\n \n // CHECK: %0 = \"tfl.quantize\"(%arg0) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n // CHECK: %1 = \"tfl.dequantize\"(%0) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n // CHECK: %2 = \"tfl.dequantize\"(%arg1) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n-// CHECK: %3 = \"tfl.concatenation\"(%1, %2) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+// CHECK: %3 = \"tfl.concatenation\"(%1, %2) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n // CHECK: %4 = \"tfl.quantize\"(%3) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n // CHECK: %5 = \"tfl.dequantize\"(%4) : (tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<2x2xf32>\n // CHECK: return %5 : tensor<2x2xf32>\n@@ -378,15 +378,15 @@ func @QuantizeConcatOperand1ToAll(tensor<1x2xf32>, tensor<1x2x!quant.uniform<u8:\n // CHECK-LABEL: QuantizeConcatResToAll\n func @QuantizeConcatResToAll(tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 0.1:128>> {\n ^bb0(%arg0: tensor<1x2xf32>, %arg1: tensor<1x2xf32>):\n- %0 = \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+ %0 = \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n %1 = \"tfl.quantize\"(%0) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<2x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n return %1 : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n \n // CHECK: %0 = \"tfl.quantize\"(%arg1) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n // CHECK: %1 = \"tfl.dequantize\"(%0) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n // CHECK: %2 = \"tfl.quantize\"(%arg0) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n // CHECK: %3 = \"tfl.dequantize\"(%2) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n-// CHECK: %4 = \"tfl.concatenation\"(%3, %1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+// CHECK: %4 = \"tfl.concatenation\"(%3, %1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n // CHECK: %5 = \"tfl.quantize\"(%4) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<2x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n // CHECK: return %5 : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n }\n@@ -395,14 +395,14 @@ func @QuantizeConcatResToAll(tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2x!qu\n func @QuantizeConcatResToAllNoRequantize(tensor<1x2x!quant.uniform<u8:f32, 0.1:128>>, tensor<1x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 0.1:128>> {\n ^bb0(%arg0: tensor<1x2x!quant.uniform<u8:f32, 0.1:128>>, %arg1: tensor<1x2xf32>):\n %0 = \"tfl.dequantize\"(%arg0) : (tensor<1x2x!quant.uniform<u8:f32, 0.1:128>>) -> tensor<1x2xf32>\n- %1 = \"tfl.concatenation\"(%0, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+ %1 = \"tfl.concatenation\"(%0, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n %2 = \"tfl.quantize\"(%1) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<2x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n return %2 : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n \n // CHECK: %0 = \"tfl.quantize\"(%arg1) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n // CHECK: %1 = \"tfl.dequantize\"(%0) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n // CHECK: %2 = \"tfl.dequantize\"(%arg0) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n-// CHECK: %3 = \"tfl.concatenation\"(%2, %1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+// CHECK: %3 = \"tfl.concatenation\"(%2, %1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n // CHECK: %4 = \"tfl.quantize\"(%3) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<2x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n // CHECK: return %4 : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n }\n@@ -412,7 +412,7 @@ func @QuantizeConcatResToAllRequantize(tensor<1x2xf32>, tensor<1x2xf32>) -> tens\n ^bb0(%arg0: tensor<1x2xf32>, %arg1: tensor<1x2xf32>):\n %0 = \"tfl.quantize\"(%arg0) {qtype = tensor<1x2x!quant.uniform<u8:f32, 2.0:128>>} : (tensor<1x2xf32>) -> tensor<1x2x!quant.uniform<u8:f32, 2.0:128>>\n %1 = \"tfl.dequantize\"(%0) : (tensor<1x2x!quant.uniform<u8:f32, 2.0:128>>) -> tensor<1x2xf32>\n- %2 = \"tfl.concatenation\"(%1, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+ %2 = \"tfl.concatenation\"(%1, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n %3 = \"tfl.quantize\"(%2) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<2x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n return %3 : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n \n@@ -421,7 +421,7 @@ func @QuantizeConcatResToAllRequantize(tensor<1x2xf32>, tensor<1x2xf32>) -> tens\n // CHECK: %[[Q0:.*]] = \"tfl.quantize\"(%arg0) {qtype = tensor<1x2x!quant.uniform<u8:f32, 2.000000e+00:128>>} : (tensor<1x2xf32>) -> tensor<1x2x!quant.uniform<u8:f32, 2.000000e+00:128>>\n // CHECK: %[[RQ0:.*]] = \"tfl.quantize\"(%[[Q0]]) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<1x2x!quant.uniform<u8:f32, 2.000000e+00:128>>) -> tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n // CHECK: %[[DQ0:.*]] = \"tfl.dequantize\"(%[[RQ0]]) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n-// CHECK: %[[CONC:.*]] = \"tfl.concatenation\"(%[[DQ0]], %[[DQ1]]) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+// CHECK: %[[CONC:.*]] = \"tfl.concatenation\"(%[[DQ0]], %[[DQ1]]) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n // CHECK: %[[Q:.*]] = \"tfl.quantize\"(%[[CONC]]) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<2x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n // CHECK: return %[[Q]] : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n }\n@@ -430,27 +430,27 @@ func @QuantizeConcatResToAllRequantize(tensor<1x2xf32>, tensor<1x2xf32>) -> tens\n func @QuantizeConcatResToAllRequantizeArg(tensor<1x2x!quant.uniform<u8:f32, 2.0:128>>, tensor<1x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 0.1:128>> {\n ^bb0(%arg0: tensor<1x2x!quant.uniform<u8:f32, 2.0:128>>, %arg1: tensor<1x2xf32>):\n %1 = \"tfl.dequantize\"(%arg0) : (tensor<1x2x!quant.uniform<u8:f32, 2.0:128>>) -> tensor<1x2xf32>\n- %2 = \"tfl.concatenation\"(%1, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+ %2 = \"tfl.concatenation\"(%1, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n %3 = \"tfl.quantize\"(%2) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<2x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n return %3 : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n \n // CHECK: %[[Q1:.*]] = \"tfl.quantize\"(%arg1) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n // CHECK: %[[DQ1:.*]] = \"tfl.dequantize\"(%[[Q1]]) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n // CHECK: %[[RQ0:.*]] = \"tfl.quantize\"(%arg0) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<1x2x!quant.uniform<u8:f32, 2.000000e+00:128>>) -> tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n // CHECK: %[[DQ0:.*]] = \"tfl.dequantize\"(%[[RQ0]]) : (tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>) -> tensor<1x2xf32>\n-// CHECK: %[[CONC:.*]] = \"tfl.concatenation\"(%[[DQ0]], %[[DQ1]]) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+// CHECK: %[[CONC:.*]] = \"tfl.concatenation\"(%[[DQ0]], %[[DQ1]]) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n // CHECK: %[[Q:.*]] = \"tfl.quantize\"(%[[CONC]]) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<2x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n // CHECK: return %[[Q]] : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n }\n \n // CHECK-LABEL: NotRequantizeAlreadyQuantizedModel\n func @NotRequantizeAlreadyQuantizedModel(%arg0: tensor<1x73x73x64x!quant.uniform<u8:f32, 1.0>>, %arg1: tensor<1x147x147x96x!quant.uniform<u8:f32, 2.0>>) -> tensor<1x73x73x160x!quant.uniform<u8:f32, 1.0>> {\n %9 = \"tfl.max_pool_2d\"(%arg1) {filter_height = 3 : i32, filter_width = 3 : i32, fused_activation_function = \"NONE\", padding = \"VALID\", stride_h = 2 : i32, stride_w = 2 : i32} : (tensor<1x147x147x96x!quant.uniform<u8:f32, 2.0>>) -> tensor<1x73x73x96x!quant.uniform<u8:f32, 2.0>>\n- %10 = \"tfl.concatenation\"(%arg0, %9) {axis = 3 : i32, fused_activation_function = \"NONE\"} : (tensor<1x73x73x64x!quant.uniform<u8:f32, 1.0>>, tensor<1x73x73x96x!quant.uniform<u8:f32, 2.0>>) -> tensor<1x73x73x160x!quant.uniform<u8:f32, 1.0>>\n+ %10 = \"tfl.concatenation\"(%arg0, %9) {axis = 3 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x73x73x64x!quant.uniform<u8:f32, 1.0>>, tensor<1x73x73x96x!quant.uniform<u8:f32, 2.0>>) -> tensor<1x73x73x160x!quant.uniform<u8:f32, 1.0>>\n return %10 : tensor<1x73x73x160x!quant.uniform<u8:f32, 1.0>>\n \n // CHECK: %[[max:.*]] = \"tfl.max_pool_2d\"(%arg1) {filter_height = 3 : i32, filter_width = 3 : i32, fused_activation_function = \"NONE\", padding = \"VALID\", stride_h = 2 : i32, stride_w = 2 : i32} : (tensor<1x147x147x96x!quant.uniform<u8:f32, 2.000000e+00>>) -> tensor<1x73x73x96x!quant.uniform<u8:f32, 2.000000e+00>>\n-// CHECK: %[[cat:.*]] = \"tfl.concatenation\"(%arg0, %[[max]]) {axis = 3 : i32, fused_activation_function = \"NONE\"} : (tensor<1x73x73x64x!quant.uniform<u8:f32, 1.000000e+00>>, tensor<1x73x73x96x!quant.uniform<u8:f32, 2.000000e+00>>) -> tensor<1x73x73x160x!quant.uniform<u8:f32, 1.000000e+00>>\n+// CHECK: %[[cat:.*]] = \"tfl.concatenation\"(%arg0, %[[max]]) {axis = 3 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x73x73x64x!quant.uniform<u8:f32, 1.000000e+00>>, tensor<1x73x73x96x!quant.uniform<u8:f32, 2.000000e+00>>) -> tensor<1x73x73x160x!quant.uniform<u8:f32, 1.000000e+00>>\n // CHECK: return %[[cat]] : tensor<1x73x73x160x!quant.uniform<u8:f32, 1.000000e+00>>\n }\n ",
"filename": "tensorflow/compiler/mlir/lite/tests/prepare-quantize.mlir",
"status": "modified"
},
{
"diff": "@@ -191,27 +191,27 @@ func @QuantizeAdd(tensor<1x56x56x24x!quant.uniform<u8:f32, 0.27583434161017922:1\n // CHECK-LABEL: QuantizeConcat\n func @QuantizeConcat(tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>> {\n ^bb0(%arg0: tensor<1x2xf32>, %arg1: tensor<1x2xf32>):\n- %0 = \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+ %0 = \"tfl.concatenation\"(%arg0, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n %1 = \"tfl.quantize\"(%0) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<2x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n return %1 : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n \n // CHECK: %[[q0:.*]] = \"tfl.quantize\"(%arg1) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n // CHECK: %[[q1:.*]] = \"tfl.quantize\"(%arg0) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n-// CHECK: %[[cc:.*]] = \"tfl.concatenation\"(%[[q1]], %[[q0]]) {axis = 0 : i32, fused_activation_function = \"NONE\"}\n+// CHECK: %[[cc:.*]] = \"tfl.concatenation\"(%[[q1]], %[[q0]]) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"}\n // CHECK: return %[[cc]] : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n }\n \n // CHECK-LABEL: QuantizeConcatRequantize\n func @QuantizeConcatRequantize(tensor<1x2x!quant.uniform<u8:f32, 2.0:128>>, tensor<1x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 0.1:128>> {\n ^bb0(%arg0: tensor<1x2x!quant.uniform<u8:f32, 2.0:128>>, %arg1: tensor<1x2xf32>):\n %1 = \"tfl.dequantize\"(%arg0) : (tensor<1x2x!quant.uniform<u8:f32, 2.0:128>>) -> tensor<1x2xf32>\n- %2 = \"tfl.concatenation\"(%1, %arg1) {axis = 0 : i32, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n+ %2 = \"tfl.concatenation\"(%1, %arg1) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"} : (tensor<1x2xf32>, tensor<1x2xf32>) -> tensor<2x2xf32>\n %3 = \"tfl.quantize\"(%2) {qtype = tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>} : (tensor<2x2xf32>) -> tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n return %3 : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n \n // CHECK: %[[q1:.*]] = \"tfl.quantize\"(%arg1) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>, volatile}\n // CHECK: %[[q0:.*]] = \"tfl.quantize\"(%arg0) {qtype = tensor<1x2x!quant.uniform<u8:f32, 1.000000e-01:128>>}\n-// CHECK: %[[cc:.*]] = \"tfl.concatenation\"(%[[q0]], %[[q1]]) {axis = 0 : i32, fused_activation_function = \"NONE\"}\n+// CHECK: %[[cc:.*]] = \"tfl.concatenation\"(%[[q0]], %[[q1]]) {axis = 0 : i32, fixed_point_scaling = true, fused_activation_function = \"NONE\"}\n // CHECK: return %[[cc]] : tensor<2x2x!quant.uniform<u8:f32, 1.000000e-01:128>>\n }\n ",
"filename": "tensorflow/compiler/mlir/lite/tests/quantize.mlir",
"status": "modified"
},
{
"diff": "@@ -234,8 +234,10 @@ LogicalResult ConvertTFConcatV2Op::matchAndRewrite(\n \n StringAttr fused_activation_function =\n StringAttr::get(rewriter.getContext(), \"NONE\");\n+ BoolAttr fixed_point_scaling = rewriter.getBoolAttr(true);\n rewriter.replaceOpWithNewOp<ConcatenationOp>(\n- op, output_type, values, axis_i32, fused_activation_function);\n+ op, output_type, values, axis_i32, fused_activation_function,\n+ fixed_point_scaling);\n return success();\n }\n ",
"filename": "tensorflow/compiler/mlir/lite/transforms/legalize_tf.cc",
"status": "modified"
},
{
"diff": "@@ -203,8 +203,14 @@ typedef struct {\n } TfLiteSoftmaxParams;\n \n typedef struct {\n+ // Parameters for Concatenation version 1 or above.\n int axis;\n TfLiteFusedActivation activation;\n+\n+ // Parameters for Concatenation version 4 or above.\n+ // If set to true, then fixed-point arithmetic is used for the rescaling of\n+ // the output. Otherwise floating-point arithmetic is used.\n+ bool fixed_point_scaling;\n } TfLiteConcatenationParams;\n \n typedef struct {",
"filename": "tensorflow/lite/c/builtin_op_data.h",
"status": "modified"
},
{
"diff": "@@ -1054,6 +1054,7 @@ TfLiteStatus ParseConcatenation(const Operator* op,\n params->activation =\n ConvertActivation(schema_params->fused_activation_function());\n params->axis = schema_params->axis();\n+ params->fixed_point_scaling = schema_params->fixed_point_scaling();\n } else {\n // TODO(b/157480169): We should either return kTfLiteError or fill in some\n // reasonable defaults in the params struct. We are not doing so until we",
"filename": "tensorflow/lite/core/api/flatbuffer_conversions.cc",
"status": "modified"
},
{
"diff": "@@ -15,11 +15,13 @@ limitations under the License.\n #include \"tensorflow/lite/kernels/internal/reference/concatenation.h\"\n \n #include <stdint.h>\n+#include <vector>\n \n #include \"tensorflow/lite/c/builtin_op_data.h\"\n #include \"tensorflow/lite/c/common.h\"\n #include \"tensorflow/lite/kernels/internal/compatibility.h\"\n #include \"tensorflow/lite/kernels/internal/optimized/optimized_ops.h\"\n+#include \"tensorflow/lite/kernels/internal/quantization_util.h\"\n #include \"tensorflow/lite/kernels/internal/reference/reference_ops.h\"\n #include \"tensorflow/lite/kernels/internal/tensor.h\"\n #include \"tensorflow/lite/kernels/internal/tensor_ctypes.h\"\n@@ -140,25 +142,40 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {\n } \\\n }\n \n-#define TF_LITE_CONCATENATION_QUANTIZED() \\\n- { \\\n- VectorOfQuantizedTensors all_inputs(*context, *node->inputs); \\\n- tflite::ConcatenationParams op_params; \\\n- op_params.axis = axis; \\\n- op_params.input_zeropoint = all_inputs.zero_point(); \\\n- op_params.input_scale = all_inputs.scale(); \\\n- op_params.inputs_count = node->inputs->size; \\\n- op_params.output_zeropoint = output->params.zero_point; \\\n- op_params.output_scale = output->params.scale; \\\n- if (kernel_type == kReference) { \\\n- reference_ops::ConcatenationWithScaling( \\\n- op_params, all_inputs.shapes(), all_inputs.data(), \\\n- GetTensorShape(output), GetTensorData<uint8>(output)); \\\n- } else { \\\n- optimized_ops::ConcatenationWithScaling( \\\n- op_params, all_inputs.shapes(), all_inputs.data(), \\\n- GetTensorShape(output), GetTensorData<uint8>(output)); \\\n- } \\\n+#define TF_LITE_CONCATENATION_QUANTIZED() \\\n+ { \\\n+ VectorOfQuantizedTensors all_inputs(*context, *node->inputs); \\\n+ std::vector<int32_t> effective_scale_multiplier; \\\n+ std::vector<int> effective_scale_shift; \\\n+ if (params->fixed_point_scaling) { \\\n+ effective_scale_multiplier.resize(node->inputs->size); \\\n+ effective_scale_shift.resize(node->inputs->size); \\\n+ const double inverse_output_scale = 1.0 / output->params.scale; \\\n+ for (int i = 0; i < node->inputs->size; i++) { \\\n+ QuantizeMultiplier(all_inputs.scale()[i] * inverse_output_scale, \\\n+ &effective_scale_multiplier[i], \\\n+ &effective_scale_shift[i]); \\\n+ } \\\n+ } \\\n+ tflite::ConcatenationParams op_params; \\\n+ op_params.axis = axis; \\\n+ op_params.input_zeropoint = all_inputs.zero_point(); \\\n+ op_params.input_scale = all_inputs.scale(); \\\n+ op_params.inputs_count = node->inputs->size; \\\n+ op_params.output_zeropoint = output->params.zero_point; \\\n+ op_params.output_scale = output->params.scale; \\\n+ op_params.fixed_point_scaling = params->fixed_point_scaling; \\\n+ op_params.effective_scale_multiplier = effective_scale_multiplier.data(); \\\n+ op_params.effective_scale_shift = effective_scale_shift.data(); \\\n+ if (kernel_type == kReference) { \\\n+ reference_ops::ConcatenationWithScaling( \\\n+ op_params, all_inputs.shapes(), all_inputs.data(), \\\n+ GetTensorShape(output), GetTensorData<uint8>(output)); \\\n+ } else { \\\n+ optimized_ops::ConcatenationWithScaling( \\\n+ op_params, all_inputs.shapes(), all_inputs.data(), \\\n+ GetTensorShape(output), GetTensorData<uint8>(output)); \\\n+ } \\\n }\n \n switch (output->type) { // Already know in/outtypes are same.",
"filename": "tensorflow/lite/kernels/concatenation.cc",
"status": "modified"
},
{
"diff": "@@ -31,12 +31,11 @@ namespace {\n using ::testing::ElementsAreArray;\n \n class BaseConcatenationOpModel : public SingleOpModel {\n- public:\n+ protected:\n // TODO(ahentz): Also test different activation types, axis, input\n // dimensions.\n- BaseConcatenationOpModel() {}\n BaseConcatenationOpModel(const std::vector<TensorData>& input_template,\n- int axis, int num_inputs,\n+ int axis, bool fixed_point_scaling, int num_inputs,\n const TensorData& output_template) {\n std::vector<std::vector<int>> all_input_shapes;\n CHECK_EQ(input_template.size(), num_inputs);\n@@ -48,23 +47,28 @@ class BaseConcatenationOpModel : public SingleOpModel {\n output_template.min, output_template.max});\n SetBuiltinOp(\n BuiltinOperator_CONCATENATION, BuiltinOptions_ConcatenationOptions,\n- CreateConcatenationOptions(builder_, axis, ActivationFunctionType_NONE)\n+ CreateConcatenationOptions(builder_, axis, ActivationFunctionType_NONE,\n+ fixed_point_scaling)\n .Union());\n BuildInterpreter(all_input_shapes);\n }\n- BaseConcatenationOpModel(const TensorData& input_template, int axis,\n- int num_inputs)\n- : BaseConcatenationOpModel(\n- std::vector<TensorData>(num_inputs, input_template), axis,\n- num_inputs, input_template) {}\n \n protected:\n int output_;\n };\n \n class ConcatenationOpModel : public BaseConcatenationOpModel {\n public:\n- using BaseConcatenationOpModel::BaseConcatenationOpModel;\n+ ConcatenationOpModel(const std::vector<TensorData>& input_template, int axis,\n+ int num_inputs, const TensorData& output_template)\n+ : BaseConcatenationOpModel(input_template, axis,\n+ /*fixed_point_scaling=*/false, num_inputs,\n+ output_template) {}\n+ ConcatenationOpModel(const TensorData& input_template, int axis,\n+ int num_inputs)\n+ : ConcatenationOpModel(\n+ std::vector<TensorData>(num_inputs, input_template), axis,\n+ num_inputs, input_template) {}\n void SetInput(int index, std::initializer_list<float> data) {\n PopulateTensor(index, data);\n }\n@@ -73,8 +77,17 @@ class ConcatenationOpModel : public BaseConcatenationOpModel {\n \n class QuantizedConcatenationOpModel : public BaseConcatenationOpModel {\n public:\n- using BaseConcatenationOpModel::BaseConcatenationOpModel;\n-\n+ QuantizedConcatenationOpModel(const std::vector<TensorData>& input_template,\n+ int axis, bool fixed_point_scaling,\n+ int num_inputs,\n+ const TensorData& output_template)\n+ : BaseConcatenationOpModel(input_template, axis, fixed_point_scaling,\n+ num_inputs, output_template) {}\n+ QuantizedConcatenationOpModel(const TensorData& input_template, int axis,\n+ bool fixed_point_scaling, int num_inputs)\n+ : QuantizedConcatenationOpModel(\n+ std::vector<TensorData>(num_inputs, input_template), axis,\n+ fixed_point_scaling, num_inputs, input_template) {}\n template <typename T>\n void SetInput(int index, std::initializer_list<float> data) {\n QuantizeAndPopulate<T>(index, data);\n@@ -92,7 +105,17 @@ class QuantizedConcatenationOpModel : public BaseConcatenationOpModel {\n \n class BoolConcatenationOpModel : public BaseConcatenationOpModel {\n public:\n- using BaseConcatenationOpModel::BaseConcatenationOpModel;\n+ BoolConcatenationOpModel(const std::vector<TensorData>& input_template,\n+ int axis, int num_inputs,\n+ const TensorData& output_template)\n+ : BaseConcatenationOpModel(input_template, axis,\n+ /*fixed_point_scaling=*/false, num_inputs,\n+ output_template) {}\n+ BoolConcatenationOpModel(const TensorData& input_template, int axis,\n+ int num_inputs)\n+ : BoolConcatenationOpModel(\n+ std::vector<TensorData>(num_inputs, input_template), axis,\n+ num_inputs, input_template) {}\n void SetInput(int index, std::initializer_list<bool> data) {\n PopulateTensor(index, data);\n }\n@@ -148,6 +171,7 @@ TEST(ConcatenationOpTest, FiveDimensionalTwoInputQuantizedUint8) {\n QuantizedConcatenationOpModel m0(\n {TensorType_UINT8, {2, 1, 2, 1, 3}, -12.7, 12.8},\n /*axis=*/0,\n+ /*fixed_point=*/false,\n /*num_inputs=*/2);\n \n m0.SetInput<uint8_t>(0, {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f, 9.0f,\n@@ -263,6 +287,7 @@ TEST(ConcatenationOpTest, FourInputs) {\n TEST(ConcatenationOpTest, FourInputsQuantizedUint8) {\n QuantizedConcatenationOpModel m0({TensorType_UINT8, {2, 1, 2}, -12.7, 12.8},\n /*axis=*/2,\n+ /*fixed_point=*/false,\n /*num_inputs=*/4);\n \n m0.SetInput<uint8_t>(0, {1.0f, 3.0f, 4.0f, 7.0f});\n@@ -304,6 +329,7 @@ TYPED_TEST(ConcatenationOpTestTyped, FourInputsQuantizedInt8) {\n QuantizedConcatenationOpModel m0(\n {TestFixture::tensor_type, {2, 1, 2}, 12.8f * kMin, 12.8f * kMax},\n /*axis=*/2,\n+ /*fixed_point=*/false,\n /*num_inputs=*/4);\n \n m0.SetInput<TestType>(0, {1.0f, 3.0f, 4.0f, 7.0f});\n@@ -318,12 +344,16 @@ TYPED_TEST(ConcatenationOpTestTyped, FourInputsQuantizedInt8) {\n })));\n }\n \n-TEST(ConcatenationOpTest, FourInputsQuantizedMixedRange) {\n+class ConcatenationOpTestFPScParametrized\n+ : public ::testing::TestWithParam<bool> {};\n+TEST_P(ConcatenationOpTestFPScParametrized, FourInputsQuantizedMixedRange) {\n+ const bool fixed_point_scaling = GetParam();\n QuantizedConcatenationOpModel m0({{TensorType_UINT8, {2, 1, 2}, -10.7, 10.8},\n {TensorType_UINT8, {2, 1, 2}, 0, 12.8},\n {TensorType_UINT8, {2, 1, 2}, -11, 11.8},\n {TensorType_UINT8, {2, 1, 2}, 0, 7.4}},\n- /*axis=*/2, /*num_inputs=*/4,\n+ /*axis=*/2, fixed_point_scaling,\n+ /*num_inputs=*/4,\n {TensorType_UINT8, {2, 1, 2}, -12.7, 12.8});\n \n m0.SetInput<uint8_t>(0, {1.0f, 3.0f, 4.0f, 7.0f});\n@@ -343,12 +373,15 @@ TEST(ConcatenationOpTest, FourInputsQuantizedMixedRange) {\n }));\n }\n \n-TEST(ConcatenationOpTest, FourInputsQuantizedMixedRangeClampingLogic) {\n+TEST_P(ConcatenationOpTestFPScParametrized,\n+ FourInputsQuantizedMixedRangeClampingLogic) {\n+ const bool fixed_point_scaling = GetParam();\n QuantizedConcatenationOpModel m0({{TensorType_UINT8, {2, 1, 2}, -10.7, 10.8},\n {TensorType_UINT8, {2, 1, 2}, 0, 12.8},\n {TensorType_UINT8, {2, 1, 2}, -11, 11.8},\n {TensorType_UINT8, {2, 1, 2}, 0, 7.4}},\n- /*axis=*/2, /*num_inputs=*/4,\n+ /*axis=*/2, fixed_point_scaling,\n+ /*num_inputs=*/4,\n {TensorType_UINT8, {2, 1, 2}, -1., 1.});\n \n m0.SetInput<uint8_t>(0, {1.0f, -3.0f, -4.0f, -7.0f});\n@@ -369,11 +402,15 @@ TEST(ConcatenationOpTest, FourInputsQuantizedMixedRangeClampingLogic) {\n 0, 0, 255, 255, 0, 255, 255, 255, //\n }));\n }\n+INSTANTIATE_TEST_CASE_P(ConcatenationOpTestFPScParametrized,\n+ ConcatenationOpTestFPScParametrized,\n+ ::testing::Values(true, false));\n \n TEST(ConcatenationOpTest, ThreeDimensionalNonQuantizedOneInput) {\n QuantizedConcatenationOpModel m0(\n {TensorType_UINT8, {2, 1, 2}, 0, std::numeric_limits<uint8_t>::max()},\n /*axis=*/1,\n+ /*fixed_point=*/false,\n /*num_inputs=*/1);\n m0.SetInput<uint8_t>(0, {1.0f, 3.0f, 4.0f, 7.0f});\n m0.Invoke();\n@@ -385,6 +422,7 @@ TEST(ConcatenationOpTest, OneTrivialNonQuantizedInput) {\n QuantizedConcatenationOpModel m0(\n {TensorType_UINT8, {1}, 0, std::numeric_limits<uint8_t>::max()},\n /*axis=*/0,\n+ /*fixed_point=*/false,\n /*num_inputs=*/1);\n m0.SetInput<uint8_t>(0, {5.0f});\n m0.Invoke();\n@@ -395,6 +433,7 @@ TEST(ConcatenationOpTest, TwoDimensionalNonQuantizedOneInput) {\n QuantizedConcatenationOpModel m0(\n {TensorType_UINT8, {2, 3}, 0, std::numeric_limits<uint8_t>::max()},\n /*axis=*/0,\n+ /*fixed_point=*/false,\n /*num_inputs=*/1);\n m0.SetInput<uint8_t>(0, {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f});\n m0.Invoke();\n@@ -409,6 +448,7 @@ TEST(ConcatenationOpTest, TwoInputsTwoAxesNegativeAxesNonQuantized) {\n QuantizedConcatenationOpModel m0(\n {TensorType_UINT8, {2, 3}, 0, std::numeric_limits<uint8_t>::max()},\n /*axis=*/0,\n+ /*fixed_point=*/false,\n /*num_inputs=*/2);\n m0.SetInput<uint8_t>(0, tensor0);\n m0.SetInput<uint8_t>(1, tensor1);\n@@ -419,6 +459,7 @@ TEST(ConcatenationOpTest, TwoInputsTwoAxesNegativeAxesNonQuantized) {\n QuantizedConcatenationOpModel m0_negative(\n {TensorType_UINT8, {2, 3}, 0, std::numeric_limits<uint8_t>::max()},\n /*axis=*/-2,\n+ /*fixed_point=*/false,\n /*num_inputs=*/2);\n m0_negative.SetInput<uint8_t>(0, tensor0);\n m0_negative.SetInput<uint8_t>(1, tensor1);\n@@ -429,6 +470,7 @@ TEST(ConcatenationOpTest, TwoInputsTwoAxesNegativeAxesNonQuantized) {\n QuantizedConcatenationOpModel m1(\n {TensorType_UINT8, {2, 3}, 0, std::numeric_limits<uint8_t>::max()},\n /*axis=*/1,\n+ /*fixed_point=*/false,\n /*num_inputs=*/2);\n m1.SetInput<uint8_t>(0, tensor0);\n m1.SetInput<uint8_t>(1, tensor1);\n@@ -439,6 +481,7 @@ TEST(ConcatenationOpTest, TwoInputsTwoAxesNegativeAxesNonQuantized) {\n QuantizedConcatenationOpModel m1_negative(\n {TensorType_UINT8, {2, 3}, 0, std::numeric_limits<uint8_t>::max()},\n /*axis=*/-1,\n+ /*fixed_point=*/false,\n /*num_inputs=*/2);\n m1_negative.SetInput<uint8_t>(0, tensor0);\n m1_negative.SetInput<uint8_t>(1, tensor1);",
"filename": "tensorflow/lite/kernels/concatenation_test.cc",
"status": "modified"
},
{
"diff": "@@ -19,6 +19,7 @@ limitations under the License.\n #include \"tensorflow/lite/kernels/internal/common.h\"\n #include \"tensorflow/lite/kernels/internal/compatibility.h\"\n #include \"tensorflow/lite/kernels/internal/cppmath.h\"\n+#include \"tensorflow/lite/kernels/internal/quantization_util.h\"\n #include \"tensorflow/lite/kernels/internal/types.h\"\n \n namespace tflite {\n@@ -68,9 +69,6 @@ inline void Concatenation(const ConcatenationParams& params,\n }\n }\n \n-// TODO(b/174275780): The quantized implementation of concatentation isn't fully\n-// quantized as it takes scale as a floating point value. This should be fixed\n-// when optimizng this routine further.\n inline void ConcatenationWithScaling(const ConcatenationParams& params,\n const RuntimeShape* const* input_shapes,\n const uint8_t* const* input_data,\n@@ -82,6 +80,9 @@ inline void ConcatenationWithScaling(const ConcatenationParams& params,\n int inputs_count = params.inputs_count;\n const int32_t output_zeropoint = params.output_zeropoint;\n const float output_scale = params.output_scale;\n+ const bool fixed_point_scaling = params.fixed_point_scaling;\n+ const int32_t* effective_scale_multiplier = params.effective_scale_multiplier;\n+ const int* effective_scale_shift = params.effective_scale_shift;\n \n const int concat_dimensions = output_shape.DimensionsCount();\n TFLITE_DCHECK_LT(axis, concat_dimensions);\n@@ -108,7 +109,10 @@ inline void ConcatenationWithScaling(const ConcatenationParams& params,\n base_inner_size *= output_shape.Dims(i);\n }\n \n- const float inverse_output_scale = 1.f / output_scale;\n+ // Not used when using fixed point scaling, set it to 0.f to avoid a\n+ // calculation\n+ const float inverse_output_scale =\n+ fixed_point_scaling ? 0.f : 1.f / output_scale;\n uint8_t* output_ptr = output_data;\n for (int k = 0; k < outer_size; k++) {\n for (int i = 0; i < inputs_count; ++i) {\n@@ -117,6 +121,16 @@ inline void ConcatenationWithScaling(const ConcatenationParams& params,\n if (input_zeropoint[i] == output_zeropoint &&\n input_scale[i] == output_scale) {\n memcpy(output_ptr, input_ptr, copy_size);\n+ } else if (fixed_point_scaling) {\n+ for (int j = 0; j < copy_size; ++j) {\n+ const int32_t value =\n+ MultiplyByQuantizedMultiplier(input_ptr[j] - input_zeropoint[i],\n+ effective_scale_multiplier[i],\n+ effective_scale_shift[i]) +\n+ output_zeropoint;\n+ output_ptr[j] = static_cast<uint8_t>(\n+ std::max<int32_t>(std::min<int32_t>(255, value), 0));\n+ }\n } else {\n const float scale = input_scale[i] * inverse_output_scale;\n const float bias = -input_zeropoint[i] * scale;",
"filename": "tensorflow/lite/kernels/internal/reference/concatenation.h",
"status": "modified"
},
{
"diff": "@@ -685,6 +685,7 @@ inline void Concatenation(int concat_dim, const uint8* const* input_data,\n op_params.inputs_count = inputs_count;\n op_params.output_zeropoint = output_zeropoint;\n op_params.output_scale = output_scale;\n+ op_params.fixed_point_scaling = false;\n \n ConcatenationWithScaling(op_params, input_shapes_indirect.data(), input_data,\n DimsToShape(output_dims), output_data);",
"filename": "tensorflow/lite/kernels/internal/reference/legacy_reference_ops.h",
"status": "modified"
},
{
"diff": "@@ -834,6 +834,9 @@ struct ConcatenationParams {\n uint16_t inputs_count;\n int32_t output_zeropoint;\n float output_scale;\n+ bool fixed_point_scaling;\n+ const int32_t* effective_scale_multiplier;\n+ const int* effective_scale_shift;\n };\n \n struct ComparisonParams {",
"filename": "tensorflow/lite/kernels/internal/types.h",
"status": "modified"
},
{
"diff": "@@ -89,7 +89,7 @@ BuiltinOpResolver::BuiltinOpResolver() {\n /* max_version = */ 3);\n AddBuiltin(BuiltinOperator_CONCATENATION, Register_CONCATENATION(),\n /* min_version = */ 1,\n- /* max_version = */ 3);\n+ /* max_version = */ 4);\n AddBuiltin(BuiltinOperator_ADD, Register_ADD(),\n /* min_version */ 1,\n /* max_version */ 3);",
"filename": "tensorflow/lite/kernels/register.cc",
"status": "modified"
},
{
"diff": "@@ -19,6 +19,7 @@ limitations under the License.\n #include \"tensorflow/lite/c/builtin_op_data.h\"\n #include \"tensorflow/lite/c/common.h\"\n #include \"tensorflow/lite/kernels/internal/portable_tensor.h\"\n+#include \"tensorflow/lite/kernels/internal/quantization_util.h\"\n #include \"tensorflow/lite/kernels/internal/tensor_ctypes.h\"\n #include \"tensorflow/lite/kernels/internal/types.h\"\n #include \"tensorflow/lite/kernels/kernel_util.h\"\n@@ -182,14 +183,14 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {\n \n switch (output_type) { // Already know in/outtypes are same.\n case kTfLiteFloat32:\n+ case kTfLiteInt8:\n case kTfLiteInt32:\n case kTfLiteInt64: {\n data->params.axis = CalculatePositiveAxis(params->axis, output);\n data->params.inputs_count = node->inputs->size;\n break;\n }\n- case kTfLiteUInt8:\n- case kTfLiteInt8: {\n+ case kTfLiteUInt8: {\n data->params.axis = CalculatePositiveAxis(params->axis, output);\n data->params.inputs_count = node->inputs->size;\n \n@@ -210,10 +211,33 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {\n input_zero_points[i] = t->params.zero_point;\n }\n \n+ int32_t* effective_scale_multiplier = nullptr;\n+ int* effective_scale_shift = nullptr;\n+ if (params->fixed_point_scaling) {\n+ effective_scale_multiplier =\n+ reinterpret_cast<int32_t*>(context->AllocatePersistentBuffer(\n+ context, node->inputs->size * sizeof(int32_t)));\n+\n+ effective_scale_shift =\n+ reinterpret_cast<int*>(context->AllocatePersistentBuffer(\n+ context, node->inputs->size * sizeof(int)));\n+\n+ const double inverse_output_scale =\n+ 1.0 / static_cast<double>(output->params.scale);\n+ for (int i = 0; i < node->inputs->size; i++) {\n+ QuantizeMultiplier(\n+ static_cast<double>(input_scales[i]) * inverse_output_scale,\n+ &effective_scale_multiplier[i], &effective_scale_shift[i]);\n+ }\n+ }\n+\n data->params.input_scale = input_scales;\n data->params.input_zeropoint = input_zero_points;\n data->params.output_zeropoint = output->params.zero_point;\n data->params.output_scale = output->params.scale;\n+ data->params.fixed_point_scaling = params->fixed_point_scaling;\n+ data->params.effective_scale_multiplier = effective_scale_multiplier;\n+ data->params.effective_scale_shift = effective_scale_shift;\n break;\n }\n default:",
"filename": "tensorflow/lite/micro/kernels/concatenation.cc",
"status": "modified"
},
{
"diff": "@@ -49,8 +49,8 @@ void TestConcatenateTwoInputs(const int* input1_dims_data,\n \n TfLiteConcatenationParams builtin_data = {\n .axis = axis,\n- .activation = kTfLiteActNone // Only activation supported in this impl\n- };\n+ .activation = kTfLiteActNone, // Only activation supported in this impl\n+ .fixed_point_scaling = false};\n \n const TfLiteRegistration registration =\n tflite::ops::micro::Register_CONCATENATION();\n@@ -68,12 +68,12 @@ void TestConcatenateTwoInputs(const int* input1_dims_data,\n }\n \n void TestConcatenateQuantizedTwoInputs(\n- const int* input1_dims_data, const uint8_t* input1_data,\n- const int* input2_dims_data, const uint8_t* input2_data,\n- const float input_scale, const int input_zero_point, int axis,\n- const int* output_dims_data, const uint8_t* expected_output_data,\n- const float output_scale, const int output_zero_point,\n- uint8_t* output_data) {\n+ const int* input1_dims_data, const uint8_t* input1_data, float input1_scale,\n+ int input1_zero_point, const int* input2_dims_data,\n+ const uint8_t* input2_data, float input2_scale, int input2_zero_point,\n+ int axis, bool fixed_point_scaling, const int* output_dims_data,\n+ const uint8_t* expected_output_data, float output_scale,\n+ int output_zero_point, uint8_t* output_data) {\n TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);\n TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);\n TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);\n@@ -82,10 +82,10 @@ void TestConcatenateQuantizedTwoInputs(\n constexpr int output_size = 1;\n constexpr int tensors_size = input_size + output_size;\n TfLiteTensor tensors[tensors_size] = {\n- CreateQuantizedTensor(input1_data, input1_dims, input_scale,\n- input_zero_point),\n- CreateQuantizedTensor(input2_data, input2_dims, input_scale,\n- input_zero_point),\n+ CreateQuantizedTensor(input1_data, input1_dims, input1_scale,\n+ input1_zero_point),\n+ CreateQuantizedTensor(input2_data, input2_dims, input2_scale,\n+ input2_zero_point),\n CreateQuantizedTensor(output_data, output_dims, output_scale,\n output_zero_point)};\n \n@@ -96,8 +96,8 @@ void TestConcatenateQuantizedTwoInputs(\n \n TfLiteConcatenationParams builtin_data = {\n .axis = axis,\n- .activation = kTfLiteActNone // Only activation supported in this impl\n- };\n+ .activation = kTfLiteActNone, // Only activation supported in this impl\n+ .fixed_point_scaling = fixed_point_scaling};\n \n const TfLiteRegistration registration =\n tflite::ops::micro::Register_CONCATENATION();\n@@ -162,11 +162,14 @@ TF_LITE_MICRO_TEST(TwoInputsAllAxesCombinations) {\n \n TF_LITE_MICRO_TEST(TwoInputsQuantizedUint8) {\n const int axis = 2;\n+ const bool fixed_point_scaling = false;\n const int input_shape[] = {3, 2, 1, 2};\n const int output_shape[] = {3, 2, 1, 4};\n \n- const float input_scale = 0.1f;\n- const int input_zero_point = 127;\n+ const float input1_scale = 0.1f;\n+ const int input1_zero_point = 127;\n+ const float input2_scale = 0.1f;\n+ const int input2_zero_point = 127;\n const float output_scale = 0.1f;\n const int output_zero_point = 127;\n \n@@ -180,8 +183,44 @@ TF_LITE_MICRO_TEST(TwoInputsQuantizedUint8) {\n \n uint8_t output_data[8];\n tflite::testing::TestConcatenateQuantizedTwoInputs(\n- input_shape, input1_values, input_shape, input2_values, input_scale,\n- input_zero_point, axis, output_shape, output_value, output_scale,\n+ input_shape, input1_values, input1_scale, input1_zero_point, input_shape,\n+ input2_values, input2_scale, input2_zero_point, axis, fixed_point_scaling,\n+ output_shape, output_value, output_scale, output_zero_point, output_data);\n+}\n+\n+TF_LITE_MICRO_TEST(TwoInputsQuantizedUint8MixedScale) {\n+ const int axis = 2;\n+ const int input_shape[] = {3, 2, 1, 2};\n+ const int output_shape[] = {3, 2, 1, 4};\n+\n+ const float input1_scale = 0.1f;\n+ const int input1_zero_point = 127;\n+ const float input2_scale = 0.2f;\n+ const int input2_zero_point = 1;\n+ const float output_scale = 0.1f;\n+ const int output_zero_point = 127;\n+\n+ const uint8_t input1_values[] = {137, 157, 167, 197};\n+\n+ const uint8_t input2_values[] = {10, 15, 27, 31};\n+\n+ // Concatenated intput2 are calculated as\n+ // (input2 - input2_zero_point) * (input2_scale / output_scale) +\n+ // output_zero_point\n+ const uint8_t output_value[] = {\n+ 137, 157, 9 * 2 + 127, 14 * 2 + 127, 167, 197, 26 * 2 + 127, 30 * 2 + 127,\n+ };\n+\n+ uint8_t output_data[8];\n+ tflite::testing::TestConcatenateQuantizedTwoInputs(\n+ input_shape, input1_values, input1_scale, input1_zero_point, input_shape,\n+ input2_values, input2_scale, input2_zero_point, axis,\n+ false /* fixed_point_scaling */, output_shape, output_value, output_scale,\n+ output_zero_point, output_data);\n+ tflite::testing::TestConcatenateQuantizedTwoInputs(\n+ input_shape, input1_values, input1_scale, input1_zero_point, input_shape,\n+ input2_values, input2_scale, input2_zero_point, axis,\n+ true /* fixed_point_scaling */, output_shape, output_value, output_scale,\n output_zero_point, output_data);\n }\n ",
"filename": "tensorflow/lite/micro/kernels/concatenation_test.cc",
"status": "modified"
},
{
"diff": "@@ -606,8 +606,14 @@ table SoftmaxOptions {\n \n // An implementation of TensorFlow concat.\n table ConcatenationOptions {\n+ // Parameters for Concatenation version 1 or above.\n axis:int;\n fused_activation_function:ActivationFunctionType;\n+\n+ // Parameters for Concatenation version 4 or above.\n+ // If set to true, then fixed-point arithmetic is used for the rescaling of\n+ // the output. Otherwise floating-point arithmetic is used.\n+ fixed_point_scaling:bool = false;\n }\n \n table AddOptions {",
"filename": "tensorflow/lite/schema/schema.fbs",
"status": "modified"
},
{
"diff": "@@ -4948,28 +4948,35 @@ struct ConcatenationOptionsT : public flatbuffers::NativeTable {\n typedef ConcatenationOptions TableType;\n int32_t axis;\n tflite::ActivationFunctionType fused_activation_function;\n+ bool fixed_point_scaling;\n ConcatenationOptionsT()\n : axis(0),\n- fused_activation_function(tflite::ActivationFunctionType_NONE) {\n+ fused_activation_function(tflite::ActivationFunctionType_NONE),\n+ fixed_point_scaling(false) {\n }\n };\n \n struct ConcatenationOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {\n typedef ConcatenationOptionsT NativeTableType;\n enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {\n VT_AXIS = 4,\n- VT_FUSED_ACTIVATION_FUNCTION = 6\n+ VT_FUSED_ACTIVATION_FUNCTION = 6,\n+ VT_FIXED_POINT_SCALING = 8\n };\n int32_t axis() const {\n return GetField<int32_t>(VT_AXIS, 0);\n }\n tflite::ActivationFunctionType fused_activation_function() const {\n return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));\n }\n+ bool fixed_point_scaling() const {\n+ return GetField<uint8_t>(VT_FIXED_POINT_SCALING, 0) != 0;\n+ }\n bool Verify(flatbuffers::Verifier &verifier) const {\n return VerifyTableStart(verifier) &&\n VerifyField<int32_t>(verifier, VT_AXIS) &&\n VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&\n+ VerifyField<uint8_t>(verifier, VT_FIXED_POINT_SCALING) &&\n verifier.EndTable();\n }\n ConcatenationOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;\n@@ -4986,6 +4993,9 @@ struct ConcatenationOptionsBuilder {\n void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {\n fbb_.AddElement<int8_t>(ConcatenationOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);\n }\n+ void add_fixed_point_scaling(bool fixed_point_scaling) {\n+ fbb_.AddElement<uint8_t>(ConcatenationOptions::VT_FIXED_POINT_SCALING, static_cast<uint8_t>(fixed_point_scaling), 0);\n+ }\n explicit ConcatenationOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)\n : fbb_(_fbb) {\n start_ = fbb_.StartTable();\n@@ -5001,10 +5011,12 @@ struct ConcatenationOptionsBuilder {\n inline flatbuffers::Offset<ConcatenationOptions> CreateConcatenationOptions(\n flatbuffers::FlatBufferBuilder &_fbb,\n int32_t axis = 0,\n- tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE) {\n+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,\n+ bool fixed_point_scaling = false) {\n ConcatenationOptionsBuilder builder_(_fbb);\n builder_.add_axis(axis);\n builder_.add_fused_activation_function(fused_activation_function);\n+ builder_.add_fixed_point_scaling(fixed_point_scaling);\n return builder_.Finish();\n }\n \n@@ -12168,6 +12180,7 @@ inline void ConcatenationOptions::UnPackTo(ConcatenationOptionsT *_o, const flat\n (void)_resolver;\n { auto _e = axis(); _o->axis = _e; }\n { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }\n+ { auto _e = fixed_point_scaling(); _o->fixed_point_scaling = _e; }\n }\n \n inline flatbuffers::Offset<ConcatenationOptions> ConcatenationOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ConcatenationOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {\n@@ -12180,10 +12193,12 @@ inline flatbuffers::Offset<ConcatenationOptions> CreateConcatenationOptions(flat\n struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ConcatenationOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;\n auto _axis = _o->axis;\n auto _fused_activation_function = _o->fused_activation_function;\n+ auto _fixed_point_scaling = _o->fixed_point_scaling;\n return tflite::CreateConcatenationOptions(\n _fbb,\n _axis,\n- _fused_activation_function);\n+ _fused_activation_function,\n+ _fixed_point_scaling);\n }\n \n inline AddOptionsT *AddOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {",
"filename": "tensorflow/lite/schema/schema_generated.h",
"status": "modified"
},
{
"diff": "@@ -884,6 +884,7 @@ struct AddNOperator : Operator {\n struct ConcatenationOperator : Operator {\n ConcatenationOperator() : Operator(OperatorType::kConcatenation) {}\n int axis = 0;\n+ bool fixed_point_scaling = true;\n };\n \n // Reordering dimensions. Used only during tooling to transform graphs from",
"filename": "tensorflow/lite/toco/model.h",
"status": "modified"
},
{
"diff": "@@ -70,6 +70,7 @@ std::string GetMinimumRuntimeVersionForModel(const Model& model) {\n {{OperatorType::kConcatenation, 1}, \"1.5.0\"},\n {{OperatorType::kConcatenation, 2}, \"1.14.0\"},\n {{OperatorType::kConcatenation, 3}, kPendingReleaseOpVersion},\n+ {{OperatorType::kConcatenation, 4}, kPendingReleaseOpVersion},\n {{OperatorType::kDepthToSpace, 1}, \"2.1.0\"},\n {{OperatorType::kFakeQuant, 1}, \"1.5.0\"},\n {{OperatorType::kFakeQuant, 2}, \"1.10.0\"},",
"filename": "tensorflow/lite/toco/tflite/op_version.cc",
"status": "modified"
},
{
"diff": "@@ -379,12 +379,15 @@ class Concatenation\n flatbuffers::Offset<TfLiteOptions> WriteOptions(\n const TocoOperator& op,\n flatbuffers::FlatBufferBuilder* builder) const override {\n- return ::tflite::CreateConcatenationOptions(*builder, op.axis);\n+ return ::tflite::CreateConcatenationOptions(\n+ *builder, op.axis, ::tflite::ActivationFunctionType_NONE,\n+ op.fixed_point_scaling);\n }\n \n void ReadOptions(const TfLiteOptions& options,\n TocoOperator* op) const override {\n op->axis = options.axis();\n+ op->fixed_point_scaling = options.fixed_point_scaling();\n }\n };\n ",
"filename": "tensorflow/lite/toco/tflite/operator.cc",
"status": "modified"
},
{
"diff": "@@ -571,6 +571,18 @@ int GetBuiltinOperatorVersion(const OpSignature& op_sig) {\n }\n return 1;\n \n+ case BuiltinOperator_CONCATENATION:\n+ if (op_sig.options.concatenation.fixed_point_scaling) {\n+ return 4;\n+ }\n+ if (op_sig.input_types.at(0) == TensorType_INT16) {\n+ return 3;\n+ }\n+ if (op_sig.input_types.at(0) == TensorType_INT8) {\n+ return 2;\n+ }\n+ return 1;\n+\n case BuiltinOperator_BATCH_MATMUL:\n // In case of int16 inputs, the version is 3.\n if (op_sig.input_types.at(0) == TensorType_INT16) {\n@@ -589,7 +601,6 @@ int GetBuiltinOperatorVersion(const OpSignature& op_sig) {\n }\n return 1;\n \n- case BuiltinOperator_CONCATENATION:\n case BuiltinOperator_SOFTMAX:\n case BuiltinOperator_MEAN:\n case BuiltinOperator_PAD:\n@@ -828,6 +839,14 @@ OpSignature GetOpSignature(const OperatorCode* op_code, const Operator* op,\n std::max(GetNumDims(subgraph, op, 0), GetNumDims(subgraph, op, 1));\n } break;\n \n+ case BuiltinOperator_CONCATENATION: {\n+ auto concatenation_option = op->builtin_options_as_ConcatenationOptions();\n+ if (concatenation_option) {\n+ op_sig.options.concatenation.fixed_point_scaling =\n+ concatenation_option->fixed_point_scaling();\n+ }\n+ } break;\n+\n case BuiltinOperator_BATCH_MATMUL: {\n auto batch_matmul_option = op->builtin_options_as_BatchMatMulOptions();\n op_sig.options.input_quantization.asymmetric_quantize_inputs =",
"filename": "tensorflow/lite/tools/versioning/op_version.cc",
"status": "modified"
},
{
"diff": "@@ -74,6 +74,9 @@ typedef struct {\n struct {\n bool asymmetric_quantize_inputs;\n } input_quantization;\n+ struct {\n+ bool fixed_point_scaling;\n+ } concatenation;\n } options;\n } OpSignature;\n ",
"filename": "tensorflow/lite/tools/versioning/op_version.h",
"status": "modified"
},
{
"diff": "@@ -398,6 +398,12 @@ TEST(OpVersionTest, VersioningPadV2Test) {\n \n TEST(OpVersionTest, VersioningConcatenationTest) {\n SimpleVersioningTest(BuiltinOperator_CONCATENATION);\n+ OpSignature fake_op_sig = {\n+ .op = BuiltinOperator_CONCATENATION,\n+ .input_types = std::vector<TensorType>{TensorType_UINT8},\n+ };\n+ fake_op_sig.options.concatenation.fixed_point_scaling = true;\n+ EXPECT_EQ(GetBuiltinOperatorVersion(fake_op_sig), 4);\n }\n \n TEST(OpVersionTest, VersioningSelectTest) {",
"filename": "tensorflow/lite/tools/versioning/op_version_test.cc",
"status": "modified"
},
{
"diff": "@@ -101,6 +101,7 @@ std::string FindMinimumRuntimeVersionForOp(tflite::BuiltinOperator op_code,\n {{BuiltinOperator_CONCATENATION, 1}, \"1.5.0\"},\n {{BuiltinOperator_CONCATENATION, 2}, \"1.14.0\"},\n {{BuiltinOperator_CONCATENATION, 3}, \"2.3.0\"},\n+ {{BuiltinOperator_CONCATENATION, 4}, kPendingReleaseVersion},\n {{BuiltinOperator_DEPTH_TO_SPACE, 1}, \"2.1.0\"},\n {{BuiltinOperator_DEPTH_TO_SPACE, 2}, kPendingReleaseVersion},\n {{BuiltinOperator_EMBEDDING_LOOKUP, 1}, \"1.13.0\"},",
"filename": "tensorflow/lite/tools/versioning/runtime_version.cc",
"status": "modified"
}
]
}
|
{
"body": "In `ModelCheckpoint` callback, there is a parameter given named `save_freq` to save model. If `save_freq` is set to `epoch`, it will save model at the end of every epoch. (This works perfectly fine). But when `save_freq` is set to an integer let's say `N`, then the callback should save the model after `N` batches in every epoch. But the problem here is the callback doesn't accept the filepath as `file.batch{batch:02d}epoch{epoch:02d}.h5` and raises error as `batch` is invalid key. \r\nThe problem in the code that I have noticed is that the `_save_model` function has access to `epoch` but it doesn't have access to `batch`. And that's why `_get_file_path()` has access to `epoch` but not `batch`. The functionality should be changed little bit. I am raising PR to add access to `batch` param in both `_save_model` and `_get_file_path` variable.\r\nI noticed this error in tf code during the work on my PR [#1702](https://github.com/tensorflow/addons/pull/1702) in tensorflow/addons. \r\n\r\ncc @gabrieldemarmiesse.\r\n",
"comments": [
{
"body": "@ashutosh1919 would be willing to send a PR for this issue ?",
"created_at": "2020-10-09T04:37:45Z"
},
{
"body": "same problem here. It should support batch number formatting, especially when save_freq is not epoch but batch, only have epoch number would make previous weights files of same epoch been override.",
"created_at": "2020-10-28T16:58:17Z"
},
{
"body": "Same issue here. Is there actually no support for this yet?",
"created_at": "2021-06-09T06:26:30Z"
},
{
"body": "@aningineer , I have raised PR #49376 to fix this issue and you can see that it is approved as well. Let it get merged and you will be able to use this fix in `tf-nightly`",
"created_at": "2021-06-09T07:49:37Z"
},
{
"body": "The PR that fix this issue is merged to keras-team/keras as keras-team/keras@c567184. Closing this now.",
"created_at": "2021-06-17T22:20:09Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38668\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38668\">No</a>\n",
"created_at": "2021-06-17T22:20:13Z"
},
{
"body": "next PR",
"created_at": "2022-07-22T03:57:03Z"
}
],
"number": 38668,
"title": "In ModelCheckpoint, filepath is not accepting batch as formatting parameter."
}
|
{
"body": "Fixes #38668 . \r\n@mihaimaruseac - Please review.",
"number": 38669,
"review_comments": [
{
"body": "We shouldn't need this if-else anymore since distributed_file_utils.write_filepath would take care of that writing path. Can you fix this?",
"created_at": "2020-04-22T20:55:41Z"
},
{
"body": "Done",
"created_at": "2020-04-23T11:15:55Z"
},
{
"body": "Can this fit in one line?",
"created_at": "2020-04-23T21:21:50Z"
},
{
"body": "Can this fit in the previous line?",
"created_at": "2020-04-23T21:22:03Z"
},
{
"body": "No, will give pylint error. But I have changed it to resolve error.",
"created_at": "2020-04-24T04:18:22Z"
},
{
"body": "No, will give pylint error. But I have changed it to resolve error.",
"created_at": "2020-04-24T04:18:33Z"
}
],
"title": "Fixed _save_model not working for batches in ModelCheckpoint Callback"
}
|
{
"commits": [
{
"message": "Fixed _save_model not working for batches in ModelCheckpoint Callback"
},
{
"message": "remove 1 space after comma and made it 1"
},
{
"message": "Merge remote-tracking branch 'upstream/master' into save_freq_mdckpt"
},
{
"message": "resolved merge conflict"
},
{
"message": "Merge remote-tracking branch 'upstream/master' into save_freq_mdckpt"
},
{
"message": "Refactored code"
},
{
"message": "Refactored code"
},
{
"message": "Resolved sanity errors"
},
{
"message": "Merge remote-tracking branch 'upstream/master' into save_freq_mdckpt"
},
{
"message": "Rebasing"
}
],
"files": [
{
"diff": "@@ -1247,7 +1247,7 @@ def on_train_begin(self, logs=None):\n \n def on_train_batch_end(self, batch, logs=None):\n if self._should_save_on_batch(batch):\n- self._save_model(epoch=self._current_epoch, logs=logs)\n+ self._save_model(epoch=self._current_epoch, batch=batch, logs=logs)\n \n def on_epoch_begin(self, epoch, logs=None):\n self._current_epoch = epoch\n@@ -1256,7 +1256,7 @@ def on_epoch_end(self, epoch, logs=None):\n self.epochs_since_last_save += 1\n # pylint: disable=protected-access\n if self.save_freq == 'epoch':\n- self._save_model(epoch=epoch, logs=logs)\n+ self._save_model(epoch=epoch, batch=None, logs=logs)\n \n def _should_save_on_batch(self, batch):\n \"\"\"Handles batch-level saving logic, supports steps_per_execution.\"\"\"\n@@ -1275,11 +1275,13 @@ def _should_save_on_batch(self, batch):\n return True\n return False\n \n- def _save_model(self, epoch, logs):\n+ def _save_model(self, epoch, batch, logs):\n \"\"\"Saves the model.\n \n Arguments:\n epoch: the epoch this iteration is in.\n+ batch: the batch this iteration is in. `None` if the `save_freq`\n+ is set to `epoch`.\n logs: the `logs` dict passed in to `on_batch_end` or `on_epoch_end`.\n \"\"\"\n logs = logs or {}\n@@ -1289,7 +1291,7 @@ def _save_model(self, epoch, logs):\n # Block only when saving interval is reached.\n logs = tf_utils.to_numpy_or_python_type(logs)\n self.epochs_since_last_save = 0\n- filepath = self._get_file_path(epoch, logs)\n+ filepath = self._get_file_path(epoch, batch, logs)\n \n try:\n if self.save_best_only:\n@@ -1330,14 +1332,20 @@ def _save_model(self, epoch, logs):\n 'ModelCheckpoint. Filepath used is an existing '\n 'directory: {}'.format(filepath))\n \n- def _get_file_path(self, epoch, logs):\n+ def _get_file_path(self, epoch, batch, logs):\n \"\"\"Returns the file path for checkpoint.\"\"\"\n # pylint: disable=protected-access\n try:\n # `filepath` may contain placeholders such as `{epoch:02d}` and\n- # `{mape:.2f}`. A mismatch between logged metrics and the path's\n+ # `{batch:02d}`. A mismatch between logged metrics and the path's\n # placeholders can cause formatting to fail.\n- file_path = self.filepath.format(epoch=epoch + 1, **logs)\n+ if not batch:\n+ file_path = self.filepath.format(epoch=epoch + 1, **logs)\n+ else:\n+ file_path = self.filepath.format(\n+ epoch=epoch + 1,\n+ batch=batch + 1,\n+ **logs)\n except KeyError as e:\n raise KeyError('Failed to format this callback filepath: \"{}\". '\n 'Reason: {}'.format(self.filepath, e))",
"filename": "tensorflow/python/keras/callbacks.py",
"status": "modified"
}
]
}
|
{
"body": "**System information** \r\n- Have I written custom code (as opposed to using a stock\r\nexample script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g.,\r\nLinux Ubuntu 16.04): CentOS\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if\r\nthe issue happens on mobile device: \r\n- TensorFlow installed from (source orbinary): source\r\n- TensorFlow version (use command below): latest master\r\n- Python version: python3.6\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source): gcc8\r\n- CUDA/cuDNN version: - GPU model and memory:\r\n\r\nTensorFlow propagates \"localhost\" instead of real ip address to remote.\r\n\r\nDemo code:\r\none is ps\r\n```python\r\nimport tensorflow.compat.v1 as tf \r\ntf.disable_v2_behavior()\r\nserver = tf.distribute.Server(tf.train.ClusterSpec({\"ps\" : [\"ps_ip_address:5333\"]}), job_name=\"ps\", task_index=0, protocol='grpc') \r\nprint(\"start ps\")\r\nserver.join() \r\n```\r\n\r\none worker\r\n```python\r\nimport tensorflow.compat.v1 as tf\r\nfrom tensorflow.core.protobuf import config_pb2\r\nfrom tensorflow.python.training import server_lib\r\nfrom tensorflow.core.protobuf import cluster_pb2\r\nimport time\r\ntf.disable_v2_behavior()\r\n\r\nwith tf.device(\"/job:ps/replica:0/task:0\"):\r\n a = tf.get_variable(\"param\", [10], tf.float32, initializer=tf.zeros_initializer)\r\n\r\nwith tf.device(\"/job:worker/replica:0/task:0\"):\r\n update = tf.get_variable(\"update\", [10], tf.float32, initializer=tf.ones_initializer)\r\n add_op = a.assign_add(update)\r\n\r\ninit_op = tf.initialize_all_variables()\r\n\r\nserver = tf.distribute.Server({\"localhost\": [\"worker_ip_address:0\"]}, protocol=\"grpc\")\r\ncluster_def = cluster_pb2.ClusterDef()\r\nworker_job = cluster_def.job.add()\r\nworker_job.name = 'worker'\r\nworker_job.tasks[0] = server.target[len('grpc://'):]\r\nps_job = cluster_def.job.add()\r\nps_job.name = \"ps\"\r\nps_job.tasks[0] = \"ps_ip_address:5333\"\r\nconfig = config_pb2.ConfigProto(cluster_def=cluster_def, \r\n experimental=config_pb2.ConfigProto.Experimental(share_session_state_in_clusterspec_propagation=True))\r\n\r\nwith tf.Session(server.target, config=config) as sess:\r\n sess.run(init_op)\r\n print(sess.run(add_op))\r\n\r\n```\r\nps and server starts on different machines. The ps starts without worker device information and relies cluster spec propagation to propagates worker device information to ps.\r\nHowever, from ps log, worker device is propagated as \"localhost\" to ps.\r\n```console\r\n2020-04-14 13:30:21.673766: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:300] Initialize GrpcChannelCache for job ps -> {0 -> localhost:5333}\r\n2020-04-14 13:30:21.676047: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:390] Started server with target: grpc://localhost:5333\r\nstart ps\r\n2020-04-14 13:36:33.582439: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:300] Initialize GrpcChannelCache for job worker -> {0 -> localhost:51798}\r\n2020-04-14 13:36:33.582471: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:300] Initialize GrpcChannelCache for job ps -> {0 -> localhost:5333}\r\n```\r\nSo ps server tries to create grpc channel to the wrong worker device `localhost:51798` and the session run hangs forever.\r\n\r\nI tried to replace `worker_job.tasks[0] = server.target[len('grpc://'):]` with `worker_job.tasks[0] = server.target[len('grpc://'):].replace(\"localhost\", \"worker_ip_address\")`, but TF failed to create session with following error:\r\n```console\r\ntensorflow.python.framework.errors_impl.InvalidArgumentError: The master (current machine) is not included in the provided cluster_def. job {\r\n name: \"worker\"\r\n tasks {\r\n key: 0\r\n value: \"worker_ip_address:43479\"\r\n }\r\n}\r\njob {\r\n name: \"ps\"\r\n tasks {\r\n key: 0\r\n value: \"ps_ip_address:5333\"\r\n } \r\n}\r\n```\r\n\r\nI changed the code of https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/distributed_runtime/master_session.cc#L1355 and replaced all localhost with real ip address, it works. I'm not sure if this change will cause other issues.\r\n\r\nAny idea how to fix this generally?\r\n\r\n",
"comments": [
{
"body": "Gently ping @guptapriya; Priya, mind to take a look here?",
"created_at": "2020-04-26T12:40:29Z"
},
{
"body": "cc @saeta who seems to implemented this feature in the first place.",
"created_at": "2020-04-26T13:41:37Z"
},
{
"body": "Close this as the PR has been merged.",
"created_at": "2020-05-19T02:10:55Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38519\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38519\">No</a>\n",
"created_at": "2020-05-19T02:10:56Z"
}
],
"number": 38519,
"title": "ClusterSpec propagation propagates \"localhost\" to remote"
}
|
{
"body": "Now grpc server ignores use provided host name/ip and always return \"localhost\" as server target. This makes cluster spec propagation propagates \"localhost\" to remote. See #38519 ",
"number": 38600,
"review_comments": [
{
"body": "Please limit the line width within 80 characters.\r\n```suggestion\r\n virtual Status GetHostAndPort(\r\n const ServerDef& server_def, string* host_name, int* port) const;\r\n```",
"created_at": "2020-04-16T16:42:52Z"
},
{
"body": "Please limit the line width within 80 characters.",
"created_at": "2020-04-28T16:54:35Z"
},
{
"body": "Why creating a temporary `host_name` instead of directly using `host_name_`?",
"created_at": "2020-04-28T16:55:06Z"
},
{
"body": "To align requested_port, and it's const function. I will use host_name_ directly if you'd prefer. ",
"created_at": "2020-04-29T02:23:10Z"
}
],
"title": "Grpc server uses provided host name/ip instead of localhost if possible"
}
|
{
"commits": [
{
"message": "Use provided host name/ip instead of localhost if possible"
},
{
"message": "Edit according to PR comments"
}
],
"files": [
{
"diff": "@@ -132,8 +132,11 @@ GrpcServer::~GrpcServer() {\n void GrpcServer::MaybeMutateBuilder(::grpc::ServerBuilder* builder) {}\n \n // Look up the port that has been requested for this task in `server_def`.\n-Status GrpcServer::GetPort(const ServerDef& server_def, int* port) const {\n+Status GrpcServer::GetHostAndPort(const ServerDef& server_def,\n+ string* host_name,\n+ int* port) const {\n *port = -1;\n+ *host_name = \"localhost\";\n for (const auto& job : server_def.cluster().job()) {\n if (job.name() == server_def.job_name()) {\n auto iter = job.tasks().find(server_def.task_index());\n@@ -153,6 +156,10 @@ Status GrpcServer::GetPort(const ServerDef& server_def, int* port) const {\n \"Could not parse port for local server from \\\"\", iter->second,\n \"\\\".\");\n }\n+\n+ if (colon_index != string::npos && !iter->second.substr(0, colon_index).empty()) {\n+ *host_name = iter->second.substr(0, colon_index);\n+ }\n }\n break;\n }\n@@ -175,7 +182,7 @@ Status GrpcServer::Init(const GrpcServerOptions& opts) {\n // otherwise if 'task_index=-1' the program will abort.\n \n int requested_port;\n- TF_RETURN_IF_ERROR(GetPort(server_def_, &requested_port));\n+ TF_RETURN_IF_ERROR(GetHostAndPort(server_def_, &host_name_, &requested_port));\n \n SessionOptions sess_opts;\n ConfigProto config = server_def_.default_session_config();\n@@ -325,7 +332,7 @@ Status GrpcServer::ParseChannelSpec(const WorkerCacheFactoryOptions& options,\n task.second);\n }\n if (job.name() == *options.job_name && task.first == options.task_index) {\n- host_port = strings::StrCat(\"localhost:\", bound_port_);\n+ host_port = strings::StrCat(host_name_, \":\", bound_port_);\n } else {\n host_port = task.second;\n }\n@@ -478,7 +485,7 @@ Status GrpcServer::Join() {\n }\n \n const string GrpcServer::target() const {\n- return strings::StrCat(\"grpc://localhost:\", bound_port_);\n+ return strings::StrCat(\"grpc://\", host_name_, \":\", bound_port_);\n }\n \n std::shared_ptr<::grpc::ServerCredentials> GrpcServer::GetServerCredentials(",
"filename": "tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc",
"status": "modified"
},
{
"diff": "@@ -104,7 +104,9 @@ class GrpcServer : public ServerInterface {\n Status UpdateServerDef(const ServerDef& server_def);\n \n protected:\n- virtual Status GetPort(const ServerDef& server_def, int* port) const;\n+ virtual Status GetHostAndPort(const ServerDef& server_def,\n+ string* host_name,\n+ int* port) const;\n Status Init(const GrpcServerOptions& opts = GrpcServerOptions());\n \n // A subclass can override this method to support secure credentials.\n@@ -136,6 +138,9 @@ class GrpcServer : public ServerInterface {\n // The port to which this server is bound.\n int bound_port_ = 0;\n \n+ // The host name of this server\n+ string host_name_;\n+\n // Guards server configuration, server, and state.\n mutex mu_;\n ",
"filename": "tensorflow/core/distributed_runtime/rpc/grpc_server_lib.h",
"status": "modified"
}
]
}
|
{
"body": "```\r\n>>> import tensorflow as tf\r\n>>> scalar = tf.zeros(shape=())\r\n>>> array = tf.zeros(shape=(1,))\r\n\r\n>>> tf.random.uniform(shape=(),minval = scalar)\r\n<tf.Tensor: id=25, shape=(), dtype=float32, numpy=0.021499991>\r\n\r\n>>> tf.random.uniform(shape=(),minval = array)\r\n<tf.Tensor: id=31, shape=(1,), dtype=float32, numpy=array([0.9388697], dtype=float32)>\r\n```\r\nExpected behavior is to either trow an error or treat single element tensor as scalar and return a scalar.\r\n\r\n-win10, tf2, cuda",
"comments": [
{
"body": "@Pixel-Therapy,\r\nCorrect me if I am wrong but, From this [TF Link](https://www.tensorflow.org/api_docs/python/tf/random/uniform) and [The Source Code](https://github.com/tensorflow/tensorflow/blob/r2.0/tensorflow/python/ops/random_ops.py#L186-L252), it is mentioned that `random.uniform()` returns a Tensor but it is not mentioned that it will be a Scalar Tensor.\r\n\r\nCan you please provide the reference where it mentions `random.uniform` returns a Scalar Tensor. Thanks!",
"created_at": "2019-11-18T08:21:38Z"
},
{
"body": "> @Pixel-Therapy,\r\n> Correct me if I am wrong but, From this [TF Link](https://www.tensorflow.org/api_docs/python/tf/random/uniform) and [The Source Code](https://github.com/tensorflow/tensorflow/blob/r2.0/tensorflow/python/ops/random_ops.py#L186-L252), it is mentioned that `random.uniform()` returns a Tensor but it is not mentioned that it will be a Scalar Tensor.\r\n> \r\n> Can you please provide the reference where it mentions `random.uniform` returns a Scalar Tensor. Thanks!\r\n\r\nThe first argument in random.uniform asks for shape, ill edit my example as shape = ().\r\nIt seems that random.uniform always follows this shape except in the above case.",
"created_at": "2019-11-18T11:50:06Z"
},
{
"body": "The issue is that in one code path, math_ops.add was called which implicitly broadcast.\r\n\r\nCreated a PR #34399 for the fix.",
"created_at": "2019-11-19T02:10:01Z"
},
{
"body": "This issue is still being worked on. PR #34399 depends on PR #38544. Once PR #38544 is merged, PR #34399 will be reopened and this issue will be fixed by then.",
"created_at": "2020-04-14T16:59:55Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">No</a>\n",
"created_at": "2020-04-15T16:06:14Z"
},
{
"body": "PR #38544 has been merged. However, the issue is not fixed yet. Will re-submit the PR of PR #34399 to eventually fix this issue.",
"created_at": "2020-04-15T16:12:14Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">No</a>\n",
"created_at": "2020-05-27T20:04:13Z"
}
],
"number": 34363,
"title": "random.uniform((),minval,maxval) returns array instead of scalar tensor when min or maxval is not a scalar tensor"
}
|
{
"body": "Note: This PR is a resubmission from #34399\r\n\r\nThis PR tries to address the issue raised in #34363 where\r\ninvalid shape passed to minval/maxval (expected to be 0-D)\r\ndoes not raise an error.\r\n\r\nThe issue was that in most of the scenarios the shape was\r\nchecked inside the C++ kernel ops.\r\n\r\nHowever, in one condition math_ops.add was used which will\r\nimplicitly do broadcast when necessarily.\r\nThis results in maxval/minval's shape getting carried.\r\n\r\nThis PR adds the shape check before math_ops.add, to make\r\nsure the shape is guaranteed.\r\n\r\nThis PR fixes #34363.\r\n\r\nSigned-off-by: Yong Tang yong.tang.github@outlook.com",
"number": 38585,
"review_comments": [
{
"body": "Doesn't this prevent us from making broadcast-correct randomuniform? As in, if I'm asking for a random uniform with shape [a, b] I should be able to have maxval/minval with any shape which broadcasts to [a, b] as we can broadcast the elementwise operations",
"created_at": "2020-04-16T15:24:43Z"
},
{
"body": "`tensorflow/python/framework/ops.py\", line 1820, in _create_c_op\r\n c_op = pywrap_tf_session.TF_FinishOperation(op_desc)\r\ngoogle3.third_party.tensorflow.python.framework.errors_impl.InvalidArgumentError: Shape must be at most rank 0 but is rank 1 for '{{node random_uniform/BroadcastTo_1}} = BroadcastTo[T=DT_FLOAT, Tidx=DT_INT32](zeros, random_uniform/shape)' with input shapes: [1], [0].\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"<embedded stdlib>/unittest/case.py\", line 59, in testPartExecutor\r\n yield\r\n File \"<embedded stdlib>/unittest/case.py\", line 605, in run\r\n testMethod()\r\n File \"tensorflow/python/framework/test_util.py\", line 1785, in decorated\r\n return func(self, *args, **kwargs)\r\n File \"/tensorflow/python/kernel_tests/random/random_ops_test.py\", line 425, in testUniformWithInvalidMaxMindShape\r\n random_ops.random_uniform(shape=(), minval=array)\r\n File \"//tensorflow/python/util/dispatch.py\", line 201, in wrapper\r\n return target(*args, **kwargs)\r\n File \"tensorflow/python/ops/random_ops.py\", line 312, in random_uniform\r\n minval = array_ops.broadcast_to(minval, shape)\r\n File \"/tensorflow/python/ops/gen_array_ops.py\", line 854, in broadcast_to\r\n \"BroadcastTo\", input=input, shape=shape, name=name)\r\n File \"/tensorflow/python/framework/op_def_library.py\", line 744, in _apply_op_helper\r\n attrs=attr_protos, op_def=op_def)\r\n File \"//tensorflow/python/framework/ops.py\", line 3493, in _create_op_internal\r\n op_def=op_def)\r\n File \"/tensorflow/python/framework/ops.py\", line 1983, in __init__\r\n control_input_ops, op_def)\r\n File \"//tensorflow/python/framework/ops.py\", line 1823, in _create_c_op\r\n raise ValueError(str(e))\r\nValueError: Shape must be at most rank 0 but is rank 1 for '{{node random_uniform/BroadcastTo_1}} = BroadcastTo[T=DT_FLOAT, Tidx=DT_INT32](zeros, random_uniform/shape)' with input shapes: [1], [0].`",
"created_at": "2020-05-26T22:08:47Z"
}
],
"title": "Fix invalid shape issue in random.uniform"
}
|
{
"commits": [
{
"message": "Fix invalid shape issue in random.uniform\n\nThis PR tries to address the issue raised in 34363 where\ninvalid shape passed to minval/maxval (expected to be 0-D)\ndoes not raise an error.\n\nThe issue was that in most of the scenarios the shape was\nchecked inside the C++ kernel ops.\n\nHowever, in one condition math_ops.add was used which will\nimplicitly do broadcast when necessarily.\nThis results in maxval/minval's shape getting carried.\n\nThis PR adds the shape check before math_ops.add, to make\nsure the shape is guaranteed.\n\nThis PR fixes 34363.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for invalid shape issue in random.uniform\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Use explicit broadcast_to to prevent shape overflow\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Relax the Error type for assertRaises(), as differnet types could be thrown out in eager vs. graph mode\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -23,6 +23,7 @@\n \n from tensorflow.python.eager import context\n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors\n from tensorflow.python.framework import ops\n from tensorflow.python.framework import random_seed\n from tensorflow.python.framework import test_util\n@@ -413,6 +414,13 @@ def testSingleSessionGraphSeedNotConstant(self):\n use_gpu=use_gpu,\n graph_seed=965)\n \n+ def testUniformWithInvalidMaxMindShape(self):\n+ # Test case for GitHub issue 34363.\n+ with self.assertRaises(\n+ (errors.InvalidArgumentError, errors.UnknownError, ValueError)):\n+ array = array_ops.zeros(shape=(1,))\n+ random_ops.random_uniform(shape=(), minval=array)\n+\n \n class RandomShapeTest(test.TestCase):\n ",
"filename": "tensorflow/python/kernel_tests/random/random_ops_test.py",
"status": "modified"
},
{
"diff": "@@ -300,6 +300,12 @@ def random_uniform(shape,\n if not maxval_is_one:\n result = math_ops.multiply(result, maxval)\n else:\n+ # Use explicit \"broadcast_to\" so that any shape incompatibility\n+ # are returned with InvalidArgument error.\n+ # This prevent \"slient broadcast\" that may cause the shape of\n+ # result \"overflow\" when minval or maxval is larger than expected shape\n+ maxval = array_ops.broadcast_to(maxval, shape)\n+ minval = array_ops.broadcast_to(minval, shape)\n result = math_ops.add(result * (maxval - minval), minval, name=name)\n # TODO(b/132092188): C++ shape inference inside functional ops does not\n # cross FuncGraph boundaries since that information is only available in",
"filename": "tensorflow/python/ops/random_ops.py",
"status": "modified"
}
]
}
|
{
"body": "```\r\n>>> import tensorflow as tf\r\n>>> scalar = tf.zeros(shape=())\r\n>>> array = tf.zeros(shape=(1,))\r\n\r\n>>> tf.random.uniform(shape=(),minval = scalar)\r\n<tf.Tensor: id=25, shape=(), dtype=float32, numpy=0.021499991>\r\n\r\n>>> tf.random.uniform(shape=(),minval = array)\r\n<tf.Tensor: id=31, shape=(1,), dtype=float32, numpy=array([0.9388697], dtype=float32)>\r\n```\r\nExpected behavior is to either trow an error or treat single element tensor as scalar and return a scalar.\r\n\r\n-win10, tf2, cuda",
"comments": [
{
"body": "@Pixel-Therapy,\r\nCorrect me if I am wrong but, From this [TF Link](https://www.tensorflow.org/api_docs/python/tf/random/uniform) and [The Source Code](https://github.com/tensorflow/tensorflow/blob/r2.0/tensorflow/python/ops/random_ops.py#L186-L252), it is mentioned that `random.uniform()` returns a Tensor but it is not mentioned that it will be a Scalar Tensor.\r\n\r\nCan you please provide the reference where it mentions `random.uniform` returns a Scalar Tensor. Thanks!",
"created_at": "2019-11-18T08:21:38Z"
},
{
"body": "> @Pixel-Therapy,\r\n> Correct me if I am wrong but, From this [TF Link](https://www.tensorflow.org/api_docs/python/tf/random/uniform) and [The Source Code](https://github.com/tensorflow/tensorflow/blob/r2.0/tensorflow/python/ops/random_ops.py#L186-L252), it is mentioned that `random.uniform()` returns a Tensor but it is not mentioned that it will be a Scalar Tensor.\r\n> \r\n> Can you please provide the reference where it mentions `random.uniform` returns a Scalar Tensor. Thanks!\r\n\r\nThe first argument in random.uniform asks for shape, ill edit my example as shape = ().\r\nIt seems that random.uniform always follows this shape except in the above case.",
"created_at": "2019-11-18T11:50:06Z"
},
{
"body": "The issue is that in one code path, math_ops.add was called which implicitly broadcast.\r\n\r\nCreated a PR #34399 for the fix.",
"created_at": "2019-11-19T02:10:01Z"
},
{
"body": "This issue is still being worked on. PR #34399 depends on PR #38544. Once PR #38544 is merged, PR #34399 will be reopened and this issue will be fixed by then.",
"created_at": "2020-04-14T16:59:55Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">No</a>\n",
"created_at": "2020-04-15T16:06:14Z"
},
{
"body": "PR #38544 has been merged. However, the issue is not fixed yet. Will re-submit the PR of PR #34399 to eventually fix this issue.",
"created_at": "2020-04-15T16:12:14Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">No</a>\n",
"created_at": "2020-05-27T20:04:13Z"
}
],
"number": 34363,
"title": "random.uniform((),minval,maxval) returns array instead of scalar tensor when min or maxval is not a scalar tensor"
}
|
{
"body": "This PR is part of the effort to address #34363 and a prerequisite for PR #34399 which will resolve #34363. \r\n\r\nIn order for the PR #34399 to pass all tests, an XLA kernel for tf.ensure_shape need\r\nto be added. See https://github.com/tensorflow/tensorflow/pull/34399#issuecomment-563283239 for more details.\r\n\r\nOnce this PR is merged, PR #34399 will be re-opened to address #34363.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 38544,
"review_comments": [],
"title": "Add XLA kernel for tf.ensure_shape"
}
|
{
"commits": [
{
"message": "Add XLA kernel for tf.ensure_shape\n\nThis PR is part of the effort to fix 34363 and a prerequisite for PR 34399 which will resolve 34363.\n\nIn order for the PR 34399 to pass all tests, an XLA kernel for tf.ensure_shape need\nto be added.\n\nOnce this PR is merged, PR 34399 will be re-opened to address 34363.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Sanitize with clang-format\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for XLA kernel of EnsureShape\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Pylint and bazel buildifier fix to pass Ubuntu Sanity CI test\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Remove unused math_ops import to pass CI test\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add EnsureShape to XLALiteWhitelist to pass the CI test\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -1891,6 +1891,7 @@ absl::flat_hash_set<string> GetKnownXLAWhitelistOp() {\n \"DynamicStitch\",\n \"Einsum\",\n \"EmptyTensorList\",\n+ \"EnsureShape\",\n \"ExtractImagePatches\",\n \"Igamma\",\n \"IgammaGradA\",",
"filename": "tensorflow/compiler/jit/mark_for_compilation_pass.cc",
"status": "modified"
},
{
"diff": "@@ -1865,3 +1865,20 @@ tf_xla_py_test(\n \"@absl_py//absl/testing:parameterized\",\n ],\n )\n+\n+tf_xla_py_test(\n+ name = \"ensure_shape_op_test\",\n+ size = \"medium\",\n+ srcs = [\"ensure_shape_op_test.py\"],\n+ python_version = \"PY3\",\n+ tags = [\n+ \"no_pip\", # TODO(b/149738646): fix pip install so these tests run on kokoro pip\n+ \"optonly\",\n+ ],\n+ deps = [\n+ \":xla_test\",\n+ \"//tensorflow/python:array_ops\",\n+ \"//tensorflow/python:framework\",\n+ \"//tensorflow/python:platform_test\",\n+ ],\n+)",
"filename": "tensorflow/compiler/tests/BUILD",
"status": "modified"
},
{
"diff": "@@ -0,0 +1,51 @@\n+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n+#\n+# Licensed under the Apache License, Version 2.0 (the \"License\");\n+# you may not use this file except in compliance with the License.\n+# You may obtain a copy of the License at\n+#\n+# http://www.apache.org/licenses/LICENSE-2.0\n+#\n+# Unless required by applicable law or agreed to in writing, software\n+# distributed under the License is distributed on an \"AS IS\" BASIS,\n+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n+# See the License for the specific language governing permissions and\n+# limitations under the License.\n+# ==============================================================================\n+\"\"\"Tests for ensure_shape_op.\"\"\"\n+\n+from __future__ import absolute_import\n+from __future__ import division\n+from __future__ import print_function\n+\n+from tensorflow.compiler.tests import xla_test\n+from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors_impl\n+from tensorflow.python.ops import array_ops\n+from tensorflow.python.ops import check_ops\n+from tensorflow.python.platform import test\n+\n+\n+class EnsureShapeOpTest(xla_test.XLATestCase):\n+\n+ def testEnsureShape(self):\n+ with self.session() as sess:\n+ p = array_ops.placeholder(dtypes.int32)\n+ with self.test_scope():\n+ op = check_ops.ensure_shape(p, (None, 3))\n+ expected_out = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]\n+ self.assertAllEqual(\n+ expected_out, sess.run(op, {p: [[0, 1, 2], [3, 4, 5], [6, 7, 8]]}))\n+\n+ def testInvalidEnsureShape(self):\n+ with self.session() as sess:\n+ p = array_ops.placeholder(dtypes.int32)\n+ with self.test_scope():\n+ op = check_ops.ensure_shape(p, (None, 3, 3))\n+ with self.assertRaisesRegexp(errors_impl.InvalidArgumentError,\n+ \"is not compatible with expected shape\"):\n+ sess.run(op, {p: [[0, 1, 2], [3, 4, 5], [6, 7, 8]]})\n+\n+\n+if __name__ == \"__main__\":\n+ test.main()",
"filename": "tensorflow/compiler/tests/ensure_shape_op_test.py",
"status": "added"
},
{
"diff": "@@ -39,6 +39,7 @@ tf_kernel_library(\n \"elu_op.cc\",\n \"elu_op.h\",\n \"empty_op.cc\",\n+ \"ensure_shape_op.cc\",\n \"extract_image_patches_op.cc\",\n \"fake_param_op.cc\",\n \"fake_quantize_ops.cc\",",
"filename": "tensorflow/compiler/tf2xla/kernels/BUILD",
"status": "modified"
},
{
"diff": "@@ -0,0 +1,59 @@\n+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.\n+\n+Licensed under the Apache License, Version 2.0 (the \"License\");\n+you may not use this file except in compliance with the License.\n+You may obtain a copy of the License at\n+\n+ http://www.apache.org/licenses/LICENSE-2.0\n+\n+Unless required by applicable law or agreed to in writing, software\n+distributed under the License is distributed on an \"AS IS\" BASIS,\n+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n+See the License for the specific language governing permissions and\n+limitations under the License.\n+==============================================================================*/\n+\n+// XLA-specific ensure_shape Op.\n+\n+#include \"tensorflow/compiler/tf2xla/type_util.h\"\n+#include \"tensorflow/compiler/tf2xla/xla_helpers.h\"\n+#include \"tensorflow/compiler/tf2xla/xla_op_kernel.h\"\n+#include \"tensorflow/compiler/tf2xla/xla_op_registry.h\"\n+#include \"tensorflow/compiler/xla/client/xla_builder.h\"\n+#include \"tensorflow/compiler/xla/literal.h\"\n+#include \"tensorflow/core/framework/op_kernel.h\"\n+#include \"tensorflow/core/framework/register_types.h\"\n+#include \"tensorflow/core/framework/tensor.h\"\n+\n+namespace tensorflow {\n+namespace {\n+\n+class EnsureShapeOp : public XlaOpKernel {\n+ public:\n+ explicit EnsureShapeOp(OpKernelConstruction* ctx) : XlaOpKernel(ctx) {\n+ OP_REQUIRES_OK(ctx, ctx->GetAttr(\"shape\", &expected_shape_));\n+ }\n+\n+ void Compile(XlaOpKernelContext* ctx) override {\n+ const TensorShape shape = ctx->InputShape(0);\n+\n+ // valiate shape\n+ OP_REQUIRES(\n+ ctx, expected_shape_.IsCompatibleWith(shape),\n+ errors::InvalidArgument(\"Shape of tensor \", this->def().input(0), \" \",\n+ shape.DebugString(),\n+ \" is not compatible with expected shape \",\n+ expected_shape_.DebugString(), \".\"));\n+\n+ // If shape matches, outputs the tensor.\n+ ctx->SetOutput(0, ctx->Input(0));\n+ }\n+\n+ private:\n+ PartialTensorShape expected_shape_;\n+};\n+\n+REGISTER_XLA_OP(Name(\"EnsureShape\"), EnsureShapeOp);\n+\n+} // namespace\n+} // namespace tensorflow",
"filename": "tensorflow/compiler/tf2xla/kernels/ensure_shape_op.cc",
"status": "added"
}
]
}
|
{
"body": "You can see the current implementation of `fit()` ([here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/engine/training.py#L950)) and `evaluate()` ([here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/engine/training.py#L1180)) methods that the logs passed to the methods `on_train_end()` and `on_test_end()` are None which is as per the documentation can be changed in future. \r\nIn tensorflow/addons, There is addition of `TQDMProgressBar()` callback. And recently I have raised PR [#1649](https://github.com/tensorflow/addons/pull/1649) to add code to make progress bar work in case of `evaluate()` too. \r\nHere, we came across the problem that there are `logs` passed to `on_test_batch_end()` method to update the progress bar. But after the epoch is complete and when `on_test_end()` method is called, there are no `logs` passed to that. Because of this, there is no metrics results passed to the method. But in my opinion and also from @shun-lin's [#1649 (comment)](https://github.com/tensorflow/addons/pull/1649#issuecomment-612785521), it is good to pass logs which are output from the last call to `on_test_batch_end()` method. Currenly in tqdm callback, we are storing the `on_test_batch_end()` logs in class variable and using them in `on_test_end()`, which we think is temporary fix. \r\n\r\ncc @shun-lin, @gabrieldemarmiesse.",
"comments": [
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38498\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38498\">No</a>\n",
"created_at": "2020-04-17T18:43:11Z"
}
],
"number": 38498,
"title": "Currently logs param is None for on_train_end() and on_test_end()"
}
|
{
"body": "fixes #38498 . \r\n@mihaimaruseac , please review.",
"number": 38499,
"review_comments": [
{
"body": "```suggestion\r\n callbacks.on_train_end(logs=training_logs)\r\n```\r\n\r\nThis way even reordering the arguments will keep the semantics",
"created_at": "2020-04-14T16:51:12Z"
},
{
"body": "```suggestion\r\n callbacks.on_test_end(logs=logs)\r\n```",
"created_at": "2020-04-14T16:51:28Z"
}
],
"title": "Added code to pass appropriate logs to on_test|train_end() methods"
}
|
{
"commits": [
{
"message": "Added code to pass appropriate logs to on_test|train_end() methods"
},
{
"message": "Update tensorflow/python/keras/engine/training.py\n\nCo-Authored-By: Mihai Maruseac <mihai.maruseac@gmail.com>"
},
{
"message": "Update tensorflow/python/keras/engine/training.py\n\nCo-Authored-By: Mihai Maruseac <mihai.maruseac@gmail.com>"
}
],
"files": [
{
"diff": "@@ -715,8 +715,9 @@ def on_train_end(self, logs=None):\n Subclasses should override for any actions to run.\n \n Arguments:\n- logs: Dict. Currently no data is passed to this argument for this method\n- but that may change in the future.\n+ logs: Dict. Currently the output of the last call to `on_epoch_end()`\n+ is passed to this argument for this method but that may change in\n+ the future.\n \"\"\"\n \n @doc_controls.for_subclass_implementers\n@@ -737,7 +738,8 @@ def on_test_end(self, logs=None):\n Subclasses should override for any actions to run.\n \n Arguments:\n- logs: Dict. Currently no data is passed to this argument for this method\n+ logs: Dict. Currently the output of the last call to\n+ `on_test_batch_end()` is passed to this argument for this method\n but that may change in the future.\n \"\"\"\n ",
"filename": "tensorflow/python/keras/callbacks.py",
"status": "modified"
},
{
"diff": "@@ -900,6 +900,7 @@ def fit(self,\n train_function = self.make_train_function()\n self._train_counter.assign(0)\n callbacks.on_train_begin()\n+ training_logs = None\n # Handle fault-tolerance for multi-worker.\n # TODO(omalleyt): Fix the ordering issues that mean this has to\n # happen after `callbacks.on_train_begin`.\n@@ -944,10 +945,11 @@ def fit(self,\n epoch_logs.update(val_logs)\n \n callbacks.on_epoch_end(epoch, epoch_logs)\n+ training_logs = epoch_logs\n if self.stop_training:\n break\n \n- callbacks.on_train_end()\n+ callbacks.on_train_end(logs=training_logs)\n return self.history\n \n def test_step(self, data):\n@@ -1177,9 +1179,9 @@ def evaluate(self,\n logs = tmp_logs # No error, now safe to assign to logs.\n end_step = step + data_handler.step_increment\n callbacks.on_test_batch_end(end_step, logs)\n- callbacks.on_test_end()\n-\n logs = tf_utils.to_numpy_or_python_type(logs)\n+ callbacks.on_test_end(logs=logs)\n+ \n if return_dict:\n return logs\n else:",
"filename": "tensorflow/python/keras/engine/training.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information** \r\n- Have I written custom code (as opposed to using a stock\r\nexample script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g.,\r\nLinux Ubuntu 16.04): Debian GNU/Linux 10 (buster)\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if\r\nthe issue happens on mobile device: \r\n- TensorFlow installed from (source or\r\nbinary): binary\r\n- TensorFlow version (use command below): v2.1.0-rc2-17-ge5bf8de 2.1.0 / v1.12.1-29016-g38797a1c8b 2.2.0-dev20200407\r\n- Python version: 3.7.7\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source): \r\n- CUDA/cuDNN version: - GPU model and memory:\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\nWell-defined function with `tf.where` has `nan` gradients at points where `tf.where` inactive branch is undefined.\r\n\r\n**Describe the expected behavior**\r\nInactive branch should be ignored in gradients calculations.\r\n\r\n**Standalone code to reproduce the issue** \r\nProvide a reproducible test case that is the bare minimum necessary to generate\r\nthe problem. If possible, please share a link to Colab/Jupyter/any notebook.\r\n```\r\nimport tensorflow as tf\r\n\r\nfor ex in range(-3, 3):\r\n x = tf.convert_to_tensor(10.**ex)\r\n with tf.GradientTape() as g:\r\n g.watch(x)\r\n y = tf.where(x >= -1., x, tf.math.log1p(-x))\r\n# y = tf.where(x >= -1., x, tf.math.log(1.-x))\r\n# y = tf.where(x >= -1., x, 1./(1.-x))\r\n dy_dx = g.gradient(y, x)\r\n print(f'y({x})={y}, dy/dx({x})={dy_dx}')\r\n```\r\n\r\nAll 3 functions above are well defined for positive values used for testing. Still they show no gradient at point `1.`. while it has to be equal to `1.`\r\n\r\n```\r\ny(0.0010000000474974513)=0.0010000000474974513, dy/dx(0.0010000000474974513)=1.0\r\ny(0.009999999776482582)=0.009999999776482582, dy/dx(0.009999999776482582)=1.0\r\ny(0.10000000149011612)=0.10000000149011612, dy/dx(0.10000000149011612)=1.0\r\ny(1.0)=1.0, dy/dx(1.0)=nan\r\ny(10.0)=10.0, dy/dx(10.0)=1.0\r\ny(100.0)=100.0, dy/dx(100.0)=1.0\r\n```\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\ndiagnose the problem. If including tracebacks, please include the full\r\ntraceback. Large logs and files should be attached.\r\n",
"comments": [
{
"body": "I have tried on colab with TF version 2.1.0 , 2.2.0-rc2 and was able to reproduce the issue.Please, find the gist [here](https://colab.research.google.com/gist/ravikyram/806f63f2cf04070a4601289d7003cf0a/untitled24.ipynb). Thanks!",
"created_at": "2020-04-08T16:16:55Z"
},
{
"body": "This is due to a limitation limitation in how gradients are calculated. Unfortunately, it is unlikely to be fixed in the foreseable future.\r\n\r\nYou can find more detail here, along with a recipe for how to avoid it: https://stackoverflow.com/questions/33712178/tensorflow-nan-bug/42497444#42497444\r\n\r\nIn short, if the input to a tf.where contains NaNs, the gradient will always be NaN, regardless whether the input is actually used or not, and the workaround is to prevent the inputs from ever containing NaNs.",
"created_at": "2020-04-08T21:21:52Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38349\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38349\">No</a>\n",
"created_at": "2020-04-08T21:21:54Z"
},
{
"body": "Shouldn't this be documented with big warning in `tf.where` docs in this case?",
"created_at": "2020-04-08T21:27:19Z"
},
{
"body": "Indeed it should.",
"created_at": "2020-04-08T22:25:09Z"
},
{
"body": "@mdanatg Hello, this is my first time contributing to TensofFlow lib. From the thread I gather you would require the `tf.where` be updated. If it is so can I work on this?",
"created_at": "2020-04-09T02:42:48Z"
},
{
"body": "Hello @0x0badc0de , @mdanatg \r\nShould the updated doc contain a something like a warning? or will a small note at the end, about the input not being Nan will do? Also should the workaround for avoiding it also be added to the doc?",
"created_at": "2020-04-11T18:53:42Z"
},
{
"body": "@joemaren @anorak-k \r\n\r\nSorry for the delay. Feel free to send a PR - it's only a matter of adding a paragraph to the docstring.\r\n\r\nThe text should be more in the lines of a warning. Something like: **Important: if any of the inputs contain NaN values, etc.**. And yes, it should include the workaround as well, which is something in the lines of: instead of `tf.where(x, ops_that_can_nan(z), ...)`, write `tf.where(x, ops_that_can_nan(tf.where(x, z, safe_value)), ...)`.",
"created_at": "2020-04-11T19:16:08Z"
},
{
"body": "@mdanatg I have added the change and raised a PR #38467 ",
"created_at": "2020-04-13T10:02:31Z"
},
{
"body": "@mdanatg Thanks for your reply. However, I would like to mention that this behavior also happens when the generated value in the inactive branch **is not finite** (i.e. `inf` or `-inf`). Here is a minimal reproducible example:\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\na = tf.Variable(10.)\r\nwith tf.GradientTape() as tape:\r\n out = tf.where(a < 15., a, tf.math.pow(10.0, tf.math.exp(a)))\r\n grads = tape.gradient(out, a)\r\n\r\nprint(grads)\r\n# tf.Tensor(nan, shape=(), dtype=float32)\r\n```\r\n\r\nAnd also if we reverse the condition such that the branch with infinite value is selected, the gradient would be infinite (which is a bit surprising that it does not generate `nan` instead, like above):\r\n```python\r\nwith tf.GradientTape() as tape:\r\n out = tf.where(a > 15., a, tf.math.pow(10.0, tf.math.exp(a)))\r\n grads = tape.gradient(out, a)\r\n\r\nprint(grads)\r\n# tf.Tensor(inf, shape=(), dtype=float32)\r\n```\r\nSo this behavior happens for both `nan` and **infinite values** in inactive branch. I wish it wasn't like this, because it's a bit unreasonable and makes it impossible to use user-defined ops/functions which generate extremely large values for some input values; hence, that inner `tf.where` workaround may not be practical always (unfortunately, even gradient clipping does not help with this, because clipping a `nan` value produces `nan` in TF).\r\n\r\nCC: @anorak-k for potential consideration in your PR after @mdanatg confirms this.",
"created_at": "2020-04-18T22:25:55Z"
},
{
"body": "@mkaze that's true - nan, inf and any other special FP value will disrupt the gradient calculation.\r\n\r\nWhat happens internally is that the gradients are aggregated in this fashion: `1 * <grad of branch taken> + 0 * <grad of branch not taken>`. In the former case, you have `0 * inf = nan`. In the latter case, you have `1 * inf = inf`. I agree it's very confusing, unfortunately a naive fix would add significant overhead to gradient calculations.\r\n\r\nMoreover, the forward calculation doesn't need to result in a nan or inf. You can also get weird results if the gradient alone is nan or inf. For example, the cube root function is defined and well-behaved everywhere, but its derivative at zero is infinite. So this will give you a nan gradient too:\r\n\r\n```\r\na = tf.Variable(0.0)\r\nwith tf.GradientTape() as tape:\r\n out = tf.where(a < 1, a, tf.pow(a, 1.0/3.0))\r\n grads = tape.gradient(out, a)\r\nprint(grads)\r\n```\r\n\r\nI think the tf.where workaround is useful with infinite values as well, so long as the branch not taken is forced to take a gradient that can be safely multiplied by 0. For your example, it would be something like this:\r\n\r\n```\r\ndummy_safe_value = 0\r\nsafe_a = tf.where(a > 15., dummy_safe_value, a)\r\nout = tf.where(a > 15., a, tf.math.pow(10.0, tf.math.exp(safe_a)))\r\n```\r\n\r\nI agree that it sometimes can be impractical to do, but in principle it should always be possible as long as you control the inputs to the sensitive functions - all they have to do is force finite values in all the elements that are dropped.",
"created_at": "2020-04-19T02:27:57Z"
},
{
"body": "I want to fix the issue [#38349](https://github.com/tensorflow/tensorflow/issues/38349)",
"created_at": "2020-05-07T14:42:20Z"
},
{
"body": "> This is due to a limitation limitation in how gradients are calculated. Unfortunately, it is unlikely to be fixed in the foreseable future.\r\n> \r\n> You can find more detail here, along with a recipe for how to avoid it: https://stackoverflow.com/questions/33712178/tensorflow-nan-bug/42497444#42497444\r\n> \r\n> In short, if the input to a tf.where contains NaNs, the gradient will always be NaN, regardless whether the input is actually used or not, and the workaround is to prevent the inputs from ever containing NaNs.\r\n\r\nYou can simply have it raise a value error if its getting Nan inputs. Or does it not work like that?",
"created_at": "2020-05-14T15:47:54Z"
},
{
"body": "Can I work on this issue if someone isn't now?",
"created_at": "2020-05-29T11:17:54Z"
},
{
"body": "@tushar-dalal The challenge is that verifying for such NaN inputs can be taking on performance. When debugging, `tf.debugging.check_numerics` can indeed help with that.\r\n\r\n@unicorn-io Feel free to tackle it, but note that it's extremely challenging to solve. That said, there was a PR (#38467) to add a warning message to the docs of tf.where, it would be useful to revive it.",
"created_at": "2020-05-29T14:36:50Z"
},
{
"body": "I am motivated to do this can you give me some tips to start with I will try my best to understand and resolve this issue.",
"created_at": "2020-05-29T16:19:20Z"
},
{
"body": "> I am motivated to do this can you give me some tips to start with I will try my best to understand and resolve this issue. @mdanatg \r\n\r\n",
"created_at": "2020-06-02T01:38:13Z"
},
{
"body": "@unicorn-io You can start by looking at the [gradient code](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/c/eager/tape.h#L149) and understanding how it works. Then you can reproduce when happens in the case of a where with bad gradients.",
"created_at": "2020-06-02T12:11:03Z"
},
{
"body": "Cool I'll get to it",
"created_at": "2020-06-02T15:26:53Z"
},
{
"body": "Hey i would like to work on it. can also help please ",
"created_at": "2020-06-08T09:39:52Z"
},
{
"body": "> \r\n> \r\n> Cool I'll get to it\r\n\r\nThis bug cannot be fixed as of now it seems.",
"created_at": "2020-06-17T11:34:28Z"
},
{
"body": "It's indeed very challenging to fix. However, the documentation of affected ops, like `tf.where` can still be updated to alert the users about it.",
"created_at": "2020-06-17T11:51:13Z"
},
{
"body": "@mdanatg isn't #38497 addressing this and is closed?",
"created_at": "2020-06-18T05:00:16Z"
},
{
"body": "You mean #38467? It's closed due to staleness, and it would be useful to revive. By the looks of it it's safe to assume noone else is working on it.",
"created_at": "2020-06-18T11:40:47Z"
},
{
"body": "Seems like its a long time since the last activity. Is this issue still open to be worked on?",
"created_at": "2020-07-01T16:44:28Z"
},
{
"body": "I think so. There are two parts to it: (1) updating the docs of tf.where, which is fairly straightforward, and (2) actually trying to address the issue, which is a significant undertaking because it involves a rather fundamental issue.",
"created_at": "2020-07-01T16:47:47Z"
},
{
"body": "Is this issue still addressable ?",
"created_at": "2020-07-08T11:41:29Z"
},
{
"body": "Nice to be part of the group.\r\nPlease, have a look to my pull request for the workaround: #41721 \r\nI'm going to work on the main issue too.\r\nI'll be happy to cooperate with anybody else interested.",
"created_at": "2020-07-25T07:42:20Z"
},
{
"body": "@codeadmin-peritiae The PR appears to be empty. Perhaps there's an issue with the git client?",
"created_at": "2020-07-27T13:18:53Z"
},
{
"body": "Just to follow up on the events. It looks like codeadmin-peritiae had an issue with his original PR #41721 where he had trouble with his SSH certificate. He then opened up another PR #41775 which is currently blocked since some of the checks haven't completed. By the looks of it, the documentation update part of this problem is almost completed.",
"created_at": "2020-08-14T14:30:40Z"
}
],
"number": 38349,
"title": "`nan` gradient when `tf.where` is used"
}
|
{
"body": "This is to solve the issue `nan` gradient when `tf.where` is used #38349",
"number": 38467,
"review_comments": [
{
"body": "That's not true.\r\n\r\nThe issue is more like \r\n\r\nPlease note that if the gradient of either branch of the `tf.where` generates a NaN then the gradient of the entire `tf.where` will be NaN. For example, `tf.where(y > 0, tf.sqrt(y), y)` has a NaN gradient if `y` has any negative numbers in it. To avoid the NaN you need to avoid computing any operation which might have a NaN gradient, so instead do `tf.where(y > 0, tf.sqrt(tf.where(y > 0, y, 1)), y)` (essentially using `tf.where` again to avoid computing a value whose gradient is NaN by replacing dangerous inputs with safe inputs).\r\n\r\n",
"created_at": "2020-04-13T15:40:15Z"
}
],
"title": "Added a warning note in tf.where documentation for 'NaN' gradient issue with workaround"
}
|
{
"commits": [
{
"message": "Added a warning note in tf.where documentation for 'NaN' gradient issue"
},
{
"message": "Added a warning note in tf.where documentation for 'NaN' gradient issue with workaround"
},
{
"message": "Added new changes to the note"
},
{
"message": "Added a fix to failing Ubuntu CPU and Ubuntu Sanity"
},
{
"message": "Fixed pylint error"
},
{
"message": "Added intendation fix to the Ubuntu CPU CI build"
}
],
"files": [
{
"diff": "@@ -552,7 +552,7 @@ def broadcast_static_shape(shape_x, shape_y):\n def shape_v2(input, out_type=dtypes.int32, name=None):\n # pylint: disable=redefined-builtin\n \"\"\"Returns the shape of a tensor.\n- \n+\n See also `tf.size`, `tf.rank`.\n \n This operation returns a 1-D integer tensor representing the shape of `input`.\n@@ -672,7 +672,7 @@ def shape_n(input, out_type=dtypes.int32, name=None):\n def size_v2(input, out_type=dtypes.int32, name=None):\n # pylint: disable=redefined-builtin\n \"\"\"Returns the size of a tensor.\n- \n+\n See also `tf.shape`.\n \n Returns a 0-D `Tensor` representing the number of elements in `input`\n@@ -4352,6 +4352,21 @@ def where_v2(condition, x=None, y=None, name=None):\n <tf.Tensor: shape=(4,), dtype=int32, numpy=array([100, 100, 100, 100],\n dtype=int32)>\n \n+ Note that if the gradient of either branch of the tf.where generates\n+ a NaN then the gradient of the entire tf.where will be NaN. The\n+ workaround will be to use an inner tf.where to ensure the function has\n+ no asymptote and to avoid computing a value whose gradient is NaN by\n+ replacing dangerous inputs with safe inputs.\n+\n+ Instead of this\n+\n+ >>> y = -1\n+ >>> tf.where(y > 0, tf.sqrt(y), y)\n+\n+ Use this\n+\n+ >>> tf.where(y > 0, tf.sqrt(tf.where(y > 0, y, 1)), y)\n+\n Args:\n condition: A `tf.Tensor` of type `bool`\n x: If provided, a Tensor which is of the same type as `y`, and has a shape\n@@ -5638,7 +5653,7 @@ def _with_nonzero_rank(data):\n @tf_export(\"repeat\")\n def repeat(input, repeats, axis=None, name=None): # pylint: disable=redefined-builtin\n \"\"\"Repeat elements of `input`.\n- \n+\n See also `tf.concat`, `tf.stack`, `tf.tile`.\n \n Args:",
"filename": "tensorflow/python/ops/array_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n\r\nHave I written custom code (as opposed to using a stock example script provided in TensorFlow):\r\nNo\r\nOS Platform and Distribution (e.g., Linux Ubuntu 16.04): ProductName:\tMac OS X, ProductVersion:\t10.15.2, BuildVersion:\t19C57\r\nTensorFlow installed from (source or binary): pip\r\nTensorFlow version (use command below): 2.1.0\r\nPython version: 3.6.8\r\nCUDA/cuDNN version: None\r\nGPU model and memory: None\r\n\r\n**Describe the current behavior**\r\n\r\nWhen trying to load one of my models using tf.keras.models.load_model an error is thrown at the following location:\r\n\r\n```\r\ntensorflow_core\\python\\keras\\utils\\generic_utils.py\", line 254, in class_and_config_for_serialized_keras_object\r\nfor key, item in cls_config.items():\r\n**AttributeError: 'list' object has no attribute 'items'**\r\n```\r\nThis code expects cls_config to be a dictionary, while for this model it is a list of dictionaries.\r\n\r\nI can successfully load and run this model using TensorFlow versions 2.0.0, 1.15.0 and 1.14.0.\r\n\r\nThis section of code was introduced when adding support for passive serialization in Keras\r\n\r\n**Describe the expected behavior**\r\n\r\nCan successfully load a model from a hdf5 file.\r\n\r\n**Code to reproduce the issue:**\r\n\r\n```\r\nimport tensorflow as tf\r\n\r\nmodel = tf.keras.models.load_model('cnn_multichannel_dense_f0_b0.h5', compile=False)\r\n```\r\n\r\n**Other info / logs:**\r\n\r\n**_I am also attaching a dummy hdf5 model below which can be used to test._**\r\n\r\n\r\n\r\nComplete Stacktrace of the error:\r\n\r\n```\r\n File \"/lib/python3.6/site-packages/tensorflow_core/python/keras/saving/save.py\", line 146, in load_model\r\n return hdf5_format.load_model_from_hdf5(filepath, custom_objects, compile)\r\n File \"lib/python3.6/site-packages/tensorflow_core/python/keras/saving/hdf5_format.py\", line 168, in load_model_from_hdf5\r\n custom_objects=custom_objects)\r\n File \"lib/python3.6/site-packages/tensorflow_core/python/keras/saving/model_config.py\", line 55, in model_from_config\r\n return deserialize(config, custom_objects=custom_objects)\r\n File \"lib/python3.6/site-packages/tensorflow_core/python/keras/layers/serialization.py\", line 106, in deserialize\r\n printable_module_name='layer')\r\n File \"lib/python3.6/site-packages/tensorflow_core/python/keras/utils/generic_utils.py\", line 292, in deserialize_keras_object\r\n config, module_objects, custom_objects, printable_module_name)\r\n File \"lib/python3.6/site-packages/tensorflow_core/python/keras/utils/generic_utils.py\", line 254, in class_and_config_for_serialized_keras_object\r\n for key, item in cls_config.items():\r\nAttributeError: 'list' object has no attribute 'items'\r\n\r\n```\r\n\r\n\r\n\r\nWhen loaded with tf.keras in v2.0.0 the layers, model config, inputs, outputs, summary etc. are all parsed correctly, as well as being able to run data through the model.",
"comments": [
{
"body": "\r\n[cnn_multichannel_dense_f0_b0.h5.zip](https://github.com/tensorflow/tensorflow/files/4416739/cnn_multichannel_dense_f0_b0.h5.zip)\r\n",
"created_at": "2020-04-01T17:40:42Z"
},
{
"body": "Was able to reproduce the issue with [TF v2.1](https://colab.research.google.com/gist/amahendrakar/8ffb93fe9c91670fb8e3e6d21038bbcd/38135-2-1.ipynb), [TF v2.2.0-rc2](https://colab.research.google.com/gist/amahendrakar/78f9cc5cc4fdcebbe9e8e62745af53aa/38135-2-2.ipynb) and [TF-nightly](https://colab.research.google.com/gist/amahendrakar/3f7747e2187f252273d49872d4615c48/38135-tf-nightly.ipynb). Works fine on [TF v2.0](https://colab.research.google.com/gist/amahendrakar/e1c64f58d7da6e77b9a5dae802664dea/38135-2-0.ipynb). Please find the attached gist. Thanks!",
"created_at": "2020-04-02T11:27:51Z"
},
{
"body": "@tripathysa Can you please share simple standalone code to reproduce the issue? The provided `*.h5` file is not sufficient to find root-cause of the issue. If your code is proprietary code then please try to use public data to create a standalone code. Thanks!",
"created_at": "2020-04-02T15:03:28Z"
},
{
"body": "@jvishnuvardhan : Do you mean sharing train code? Yes its proprietary. If some change is needed in the train code, then it will be a problem since the trained models are being supported by all TF versions except 2.1 and we don’t want to retrain them again.\r\n\r\n@amahendrakar was already able to reproduce the issue with:\r\n`import tensorflow as tf\r\n\r\nmodel = tf.keras.models.load_model('cnn_multichannel_dense_f0_b0.h5', compile=False)’",
"created_at": "2020-04-02T16:23:03Z"
},
{
"body": "It looks like `config['config']` is expected to be a dictionary here in 2.1 while its a list(https://github.com/tensorflow/tensorflow/blob/r2.1/tensorflow/python/keras/utils/generic_utils.py#L252) but in 2.0. no such assumed deserialization happens as I see it.",
"created_at": "2020-04-02T16:56:33Z"
},
{
"body": "@jvishnuvardhan @k-w-w @tripathysa #38339 has been submitted to fix this issue.",
"created_at": "2020-04-08T03:13:20Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38135\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38135\">No</a>\n",
"created_at": "2020-06-03T20:16:26Z"
}
],
"number": 38135,
"title": "Keras Model Errors on Loading - 'list' object has no attribute 'items' with TF 2.1"
}
|
{
"body": "This PR makes `tf.keras.models.load_model(...)` compatible with the old versions of keras models (e.g. `tf-1.2.1`). More details about this issue can be found [here](https://github.com/tensorflow/tensorflow/issues/38135). Note that `tf-2.0` supports the models generated by `tf-1.2.1` but [recent changes](https://github.com/tensorflow/tensorflow/commit/c71c58beb262152d4b486eb92ff29b917584c201#diff-ca2f2579ed6d04b0be9c2bacfa1a4d38L224) in `tf-2.1` break it.\r\n\r\nFix #38135 ",
"number": 38339,
"review_comments": [],
"title": "Make keras model load compatible with old version of models"
}
|
{
"commits": [
{
"message": "Make keras model load compatible with old version of models"
},
{
"message": "Add the test case"
}
],
"files": [
{
"diff": "@@ -296,6 +296,15 @@ def class_and_config_for_serialized_keras_object(\n raise ValueError('Unknown ' + printable_module_name + ': ' + class_name)\n \n cls_config = config['config']\n+ # Check if `cls_config` is a list. If it is a list, return the class and the\n+ # associated class configs for recursively deserialization. This case will\n+ # happen on the old version of sequential model (e.g. `keras_version` ==\n+ # \"2.0.6\"), which is serialized in a different structure, for example \n+ # \"{'class_name': 'Sequential',\n+ # 'config': [{'class_name': 'Embedding', 'config': ...}, {}, ...]}\".\n+ if isinstance(cls_config, list):\n+ return (cls, cls_config)\n+\n deserialized_objects = {}\n for key, item in cls_config.items():\n if isinstance(item, dict) and '__passive_serialization__' in item:",
"filename": "tensorflow/python/keras/utils/generic_utils.py",
"status": "modified"
},
{
"diff": "@@ -18,6 +18,8 @@\n from __future__ import division\n from __future__ import print_function\n \n+import numpy as np\n+\n from tensorflow.python import keras\n from tensorflow.python.platform import test\n \n@@ -298,6 +300,53 @@ def from_config(cls, config):\n self.assertEqual(new_layer.units, 3)\n self.assertIs(new_layer.units.fn, serializable_fn)\n \n+ def test_serializable_with_old_config(self):\n+ # model config generated by tf-1.2.1\n+ old_model_config = {\n+ 'class_name': 'Sequential',\n+ 'config': [\n+ {\n+ 'class_name': 'Dense',\n+ 'config': {\n+ 'name': 'dense_1',\n+ 'trainable': True,\n+ 'batch_input_shape': [\n+ None,\n+ 784\n+ ],\n+ 'dtype': 'float32',\n+ 'units': 32,\n+ 'activation': 'linear',\n+ 'use_bias': True,\n+ 'kernel_initializer': {\n+ 'class_name': 'Ones',\n+ 'config': {\n+ 'dtype': 'float32'\n+ }\n+ },\n+ 'bias_initializer': {\n+ 'class_name': 'Zeros',\n+ 'config': {\n+ 'dtype': 'float32'\n+ }\n+ },\n+ 'kernel_regularizer': None,\n+ 'bias_regularizer': None,\n+ 'activity_regularizer': None,\n+ 'kernel_constraint': None,\n+ 'bias_constraint': None\n+ }\n+ }\n+ ]\n+ }\n+ old_model = keras.utils.generic_utils.deserialize_keras_object(\n+ old_model_config, module_objects={'Sequential': keras.Sequential})\n+ new_model = keras.Sequential(\n+ [keras.layers.Dense(32, input_dim=784, kernel_initializer='Ones'),])\n+ input_data = np.random.normal(2, 1, (5, 784))\n+ output = old_model.predict(input_data)\n+ expected_output = new_model.predict(input_data)\n+ self.assertAllEqual(output, expected_output)\n \n class SliceArraysTest(test.TestCase):\n ",
"filename": "tensorflow/python/keras/utils/generic_utils_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information** \r\n- Have I written custom code (as opposed to using a stock\r\nexample script provided in TensorFlow): yes\r\n- OS Platform and Distribution (e.g.,\r\nLinux Ubuntu 16.04): Linux Ubuntu 16.04\r\n- TensorFlow installed from (source or binary): pip\r\n- TensorFlow version (use command below): 2.1.0\r\n- Python version: 3.6.8\r\n\r\n**Describe the current behavior**\r\nWhen using the `fftshift` op, I would like to specify the shift axes using negative indexes. Right now, the op fails if I specify negative axes.\r\n\r\n**Describe the expected behavior**\r\nI would like the op not to fail.\r\n\r\n**Standalone code to reproduce the issue** \r\n```python\r\nimport tensorflow as tf \r\ntf.signal.fftshift(tf.ones([1, 32, 32]), axes=[-2, -1])\r\n```\r\n\r\n**Other info / logs** \r\n```\r\n---------------------------------------------------------------------------\r\nInvalidArgumentError Traceback (most recent call last)\r\n<ipython-input-3-11929d1809ec> in <module>\r\n----> 1 tf.signal.fftshift(tf.ones([1, 32, 32]), axes=[-2, -1])\r\n\r\n~/workspace/fastmri-reproducible-benchmark/venv/lib/python3.6/site-packages/tensorflow_core/python/ops/signal/fft_ops.py in fftshift(x, axes, name)\r\n 389 shift = _array_ops.shape(x)[axes] // 2\r\n 390 else:\r\n--> 391 shift = _array_ops.gather(_array_ops.shape(x), axes) // 2\r\n 392 \r\n 393 return manip_ops.roll(x, shift, axes, name)\r\n\r\n~/workspace/fastmri-reproducible-benchmark/venv/lib/python3.6/site-packages/tensorflow_core/python/util/dispatch.py in wrapper(*args, **kwargs)\r\n 178 \"\"\"Call target, and fall back on dispatchers if there is a TypeError.\"\"\"\r\n 179 try:\r\n--> 180 return target(*args, **kwargs)\r\n 181 except (TypeError, ValueError):\r\n 182 # Note: convert_to_eager_tensor currently raises a ValueError, not a\r\n\r\n~/workspace/fastmri-reproducible-benchmark/venv/lib/python3.6/site-packages/tensorflow_core/python/ops/array_ops.py in gather(***failed resolving arguments***)\r\n 4106 return params.sparse_read(indices, name=name)\r\n 4107 except AttributeError:\r\n-> 4108 return gen_array_ops.gather_v2(params, indices, axis, name=name)\r\n 4109 \r\n 4110 \r\n\r\n~/workspace/fastmri-reproducible-benchmark/venv/lib/python3.6/site-packages/tensorflow_core/python/ops/gen_array_ops.py in gather_v2(params, indices, axis, batch_dims, name)\r\n 3677 try:\r\n 3678 return gather_v2_eager_fallback(\r\n-> 3679 params, indices, axis, batch_dims=batch_dims, name=name, ctx=_ctx)\r\n 3680 except _core._SymbolicException:\r\n 3681 pass # Add nodes to the TensorFlow graph.\r\n\r\n~/workspace/fastmri-reproducible-benchmark/venv/lib/python3.6/site-packages/tensorflow_core/python/ops/gen_array_ops.py in gather_v2_eager_fallback(params, indices, axis, batch_dims, name, ctx)\r\n 3715 _attr_Tindices, \"Taxis\", _attr_Taxis)\r\n 3716 _result = _execute.execute(b\"GatherV2\", 1, inputs=_inputs_flat,\r\n-> 3717 attrs=_attrs, ctx=ctx, name=name)\r\n 3718 if _execute.must_record_gradient():\r\n 3719 _execute.record_gradient(\r\n\r\n~/workspace/fastmri-reproducible-benchmark/venv/lib/python3.6/site-packages/tensorflow_core/python/eager/execute.py in quick_execute(op_name, num_outputs, inputs, attrs, ctx, name)\r\n 65 else:\r\n 66 message = e.message\r\n---> 67 six.raise_from(core._status_to_exception(e.code, message), None)\r\n 68 except TypeError as e:\r\n 69 keras_symbolic_tensors = [\r\n\r\n~/workspace/fastmri-reproducible-benchmark/venv/lib/python3.6/site-packages/six.py in raise_from(value, from_value)\r\n\r\nInvalidArgumentError: indices[0] = -2 is not in [0, 3) [Op:GatherV2]\r\n```\r\n",
"comments": [
{
"body": "I could replicate the issue with Tf 2.1.\r\nPlease find the gist [here](https://colab.sandbox.google.com/gist/gadagashwini/e8c8b2522f2b3c5839880fdf65247537/38172.ipynb). Thanks!",
"created_at": "2020-04-03T06:26:34Z"
},
{
"body": "I tested above case on my Windows system Python 3.7.7. I did not see any error as shown in below image. I will check on Ubuntu and get back.\r\n\r\n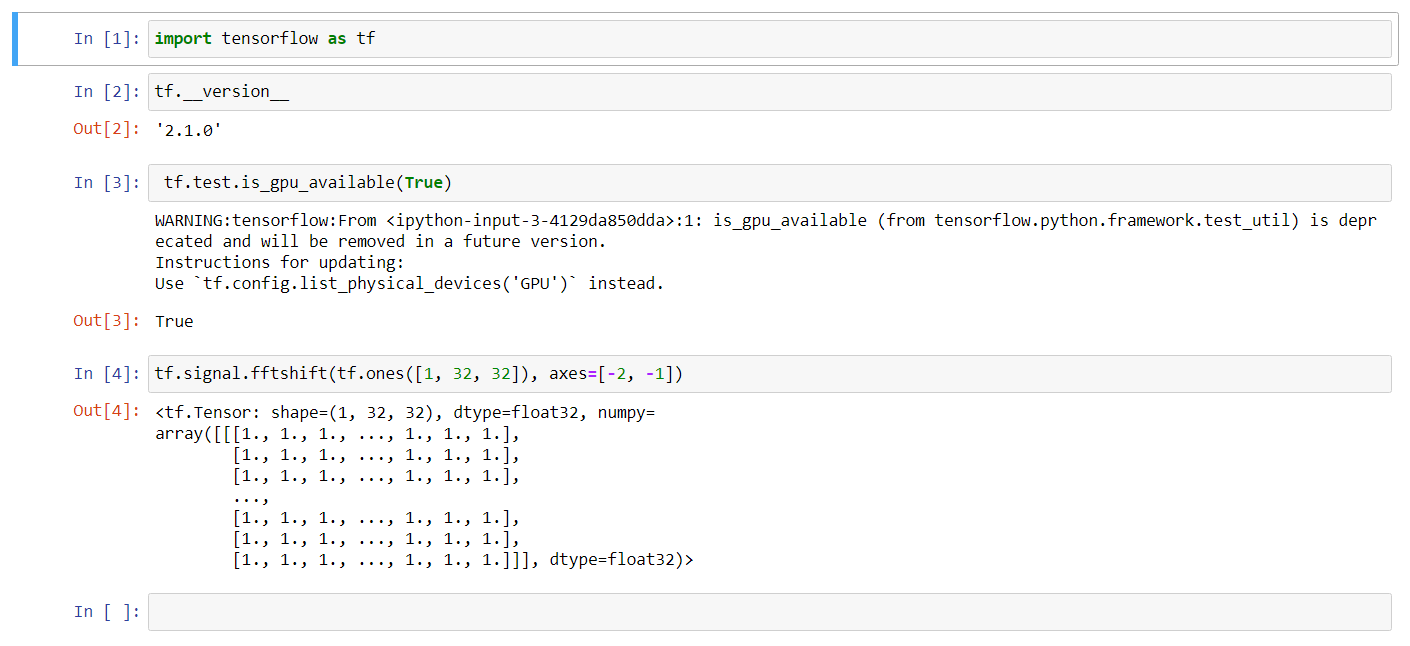\r\n",
"created_at": "2020-04-03T18:04:36Z"
},
{
"body": "Added a PR #38209 for the fix.",
"created_at": "2020-04-03T20:45:51Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38172\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/38172\">No</a>\n",
"created_at": "2020-04-07T15:46:35Z"
}
],
"number": 38172,
"title": "fftshift is failing for negative axes"
}
|
{
"body": "\r\nThis PR tries to address the issue raised in #38172 where\r\nnegative axis is not supported for tf.signal.fftshift\r\n\r\nThis PR use tf.where to adjust the axis when it is less than zero.\r\n\r\nThis PR fixes #38172.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 38209,
"review_comments": [
{
"body": "Can you test for negative scalar axes too (like axes=-1)?",
"created_at": "2020-04-06T16:06:26Z"
},
{
"body": "@alextp Thanks. The PR has been updated with additional test cases added.",
"created_at": "2020-04-06T16:26:01Z"
}
],
"title": "Support negative axis for tf.signal.fftshift"
}
|
{
"commits": [
{
"message": "Support negative axis for tf.signal.fftshift\n\nThis PR tries to address the issue raised in 38172 where\nnegative axis is not supported for tf.signal.fftshift\n\nThis PR use tf.where to adjust the axis when it is less than zero.\n\nThis PR fixes 38172.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add negative axis support for tf.signal.ifftshift and add test case\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add additional test case of scalar (e.g., axis=-1) negative axis support for tf.signal.ifftshift\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -662,6 +662,19 @@ def test_placeholder(self, axes):\n self.assertAllClose(y_fftshift_res, np.fft.fftshift(x_np, axes=axes))\n self.assertAllClose(y_ifftshift_res, np.fft.ifftshift(x_np, axes=axes))\n \n+ def test_negative_axes(self):\n+ with self.session():\n+ freqs = [[0, 1, 2], [3, 4, -4], [-3, -2, -1]]\n+ shifted = [[-1, -3, -2], [2, 0, 1], [-4, 3, 4]]\n+ self.assertAllEqual(fft_ops.fftshift(freqs, axes=(0, -1)), shifted)\n+ self.assertAllEqual(fft_ops.ifftshift(shifted, axes=(0, -1)), freqs)\n+ self.assertAllEqual(\n+ fft_ops.fftshift(freqs, axes=-1),\n+ fft_ops.fftshift(freqs, axes=(1,)))\n+ self.assertAllEqual(\n+ fft_ops.ifftshift(shifted, axes=-1),\n+ fft_ops.ifftshift(shifted, axes=(1,)))\n+\n \n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/kernel_tests/signal/fft_ops_test.py",
"status": "modified"
},
{
"diff": "@@ -398,6 +398,9 @@ def fftshift(x, axes=None, name=None):\n elif isinstance(axes, int):\n shift = _array_ops.shape(x)[axes] // 2\n else:\n+ rank = _array_ops.rank(x)\n+ # allows negative axis\n+ axes = _array_ops.where(_math_ops.less(axes, 0), axes + rank, axes)\n shift = _array_ops.gather(_array_ops.shape(x), axes) // 2\n \n return manip_ops.roll(x, shift, axes, name)\n@@ -439,6 +442,9 @@ def ifftshift(x, axes=None, name=None):\n elif isinstance(axes, int):\n shift = -(_array_ops.shape(x)[axes] // 2)\n else:\n+ rank = _array_ops.rank(x)\n+ # allows negative axis\n+ axes = _array_ops.where(_math_ops.less(axes, 0), axes + rank, axes)\n shift = -(_array_ops.gather(_array_ops.shape(x), axes) // 2)\n \n return manip_ops.roll(x, shift, axes, name)",
"filename": "tensorflow/python/ops/signal/fft_ops.py",
"status": "modified"
}
]
}
|
{
"body": "With tf.function, if an argument `x` of a function is a 2-d `tf.SparseTensor`, its shape is `(None, None)`. However, after some operations such as `tf.sparse.transpose` and `tf.sparse.reduce_sum`, the shapes of the resulting tensors become `<unknown>`.\r\n\r\nPlease refer to this [script](https://colab.research.google.com/drive/17DqrrFVZePJlJsfymrRCXNGBMNPNKeqd) for reproduction.\r\n",
"comments": [
{
"body": "@llan-ml \r\ncould you please share the tensorflow version and simple stand alone code for us to replicate the issue faced.",
"created_at": "2020-03-17T11:24:40Z"
},
{
"body": "@Saduf2019 I tested on `2.1` and `nightly`. The code is as follows:\r\n```python\r\nimport tensorflow as tf\r\n\r\ndef foo(t):\r\n print(t.shape)\r\n print(tf.shape(t))\r\n print(\"=====\")\r\n t1 = tf.sparse.transpose(t)\r\n print(t1.shape)\r\n print(tf.shape(t1))\r\n print(\"=====\")\r\n t2 = tf.sparse.reduce_sum(t, axis=1)\r\n print(t2.shape)\r\n print(tf.shape(t2))\r\n print(\"=====\")\r\n\r\nt = tf.sparse.SparseTensor(indices=[[0, 0], [1, 2]], values=[1., 2], dense_shape=[3, 4])\r\ntf.function(foo)(t)\r\n```\r\n\r\nBTW, can't you access the colab link in my original post? ",
"created_at": "2020-03-17T13:00:15Z"
},
{
"body": "i am able to replicate this issue, please find gist [here](https://colab.sandbox.google.com/gist/Saduf2019/06ff7c15f1bd9b04f65bbb140019224c/untitled96.ipynb)",
"created_at": "2020-03-18T10:00:07Z"
},
{
"body": "It looks like [sparse_transpose](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/sparse_ops.py#L2597) defaults to an unknown rank for all but the fully-defined shapes, which is too strict.\r\n\r\nSo a workaround would be this:\r\n```\r\ndef foo(t):\r\n print(t.shape)\r\n print(tf.shape(t))\r\n t = tf.SparseTensor(values=t.values, indices=t.indices, dense_shape=[3, 4])\r\n ...\r\n```\r\n\r\nIt should be straightforward to add an extra check so that a known rank is preserved.",
"created_at": "2020-03-18T15:44:14Z"
},
{
"body": "@mdanatg @llan-ml I added a PR #38142 to address the `sparse.transpose` issue. For the other issue `sparse.reduce_sum`, it is inference from the C++ `SparseReduceSumSparse` ops which\r\nwill output unknown shape anyway. So it may not be easily fixable. I leave the `sparse.reduce_sum`.\r\n\r\nPlease take a look at PR #38142 for shape of `sparse.transpose`",
"created_at": "2020-04-01T20:08:26Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37638\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37638\">No</a>\n",
"created_at": "2020-04-03T13:40:39Z"
}
],
"number": 37638,
"title": "[2.x] SparseTensor shape becomes <unknown> after some operations if using tf.function"
}
|
{
"body": "This PR tries to address the issue raised in #37638 where\r\nthe shape after sparse.transpose is <unknown> even though\r\nthe input shape's rank is known. This PR relexed the shape\r\nto only use rank (vs. is_fully_defined) to populate the shape.\r\n\r\nThe other issue raised about `sparse.reduce_sum` is a little challanging\r\nas the shape is inference from C++ `SparseReduceSumSparse` ops which\r\nwill output unknown shape anyway. For that reason this PR does not\r\naddress the `sparse.reduce_sum` issue.\r\n\r\nThis PR fixes #37638.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 38142,
"review_comments": [
{
"body": "I think this decorator was meant to annotate whole classes - I'm not sure it will work. Anyway, if it doesn't, it's always an option to actually create a tf.function and call that instead, something like this:\r\n\r\ndef testShape(self):\r\n @def_function.function\r\n def test_fn():\r\n tensor = ...\r\n tensor = ...\r\n self.assertEqual(tensor.shape.rank, 2)\r\n test_fn()",
"created_at": "2020-04-01T21:05:44Z"
},
{
"body": "Please use self.assertEqual here.",
"created_at": "2020-04-01T21:05:59Z"
},
{
"body": "Ah that works. Thanks!\r\n",
"created_at": "2020-04-01T21:23:45Z"
},
{
"body": "Updated. Thanks!",
"created_at": "2020-04-01T21:23:53Z"
}
],
"title": "Fix <unknown> shape issue for sparse.transpose"
}
|
{
"commits": [
{
"message": "Fix <unknown> shape issue for sparse.transpose\n\nThis PR tries to address the issue raised in 37638 where\nthe shape after sparse.transpose is <unknown> even though\nthe input shape's rank is known. This PR relexed the shape\nto only use rank (vs. is_fully_defined) to populate the shape.\n\nThe other issue raised about `sparse.reduce_sum` is a little challanging\nas the shape is inference from C++ `SparseReduceSumSparse` ops which\nwill output unknown shape anyway. For that reason this PR does not\naddress the `sparse.reduce_sum` issue.\n\nThis PR fixes 37638.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for <unknown> shape issue for sparse.transpose issue\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix test case based on review\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -22,6 +22,7 @@\n import numpy as np\n \n from tensorflow.python.eager import context\n+from tensorflow.python.eager import def_function\n from tensorflow.python.framework import dtypes\n from tensorflow.python.framework import ops\n from tensorflow.python.framework import sparse_tensor\n@@ -59,6 +60,16 @@ def testPythonConstruction(self):\n self.assertAllEqual(sess_run_value.values, value.values)\n self.assertAllEqual(sess_run_value.dense_shape, value.dense_shape)\n \n+ def testShape(self):\n+ @def_function.function\n+ def test_fn(tensor):\n+ tensor = sparse_ops.sparse_transpose(tensor)\n+ self.assertEqual(tensor.shape.rank, 2)\n+ return tensor\n+ tensor = sparse_tensor.SparseTensor(\n+ indices=[[0, 0], [1, 2]], values=[1., 2], dense_shape=[3, 4])\n+ test_fn(tensor)\n+\n def testIsSparse(self):\n self.assertFalse(sparse_tensor.is_sparse(3))\n self.assertFalse(sparse_tensor.is_sparse(\"foo\"))",
"filename": "tensorflow/python/framework/sparse_tensor_test.py",
"status": "modified"
},
{
"diff": "@@ -2594,8 +2594,8 @@ def sparse_transpose(sp_input, perm=None, name=None):\n \"\"\"\n with ops.name_scope(name, \"SparseTranspose\", [sp_input]) as name:\n if perm is None:\n- if sp_input.shape.is_fully_defined():\n- rank = len(sp_input.shape)\n+ if sp_input.shape.rank is not None:\n+ rank = sp_input.shape.rank\n perm = (rank - 1) - np.arange(0, rank, 1)\n else:\n rank = array_ops.rank(sp_input)",
"filename": "tensorflow/python/ops/sparse_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information** \r\n- OS Platform and Distribution (e.g.,\r\nLinux Ubuntu 16.04): Linux centos 7\r\n- TensorFlow installed from (source or\r\nbinary): - find in tf_1.10, and recurrent in master.\r\n- Python version: find in python2.7, recurrent in python3.6.5 \r\n- Bazel version :find in 0.15.2, recurrent:2.0.0,\r\n- GCC/Compiler version find in 4.8.5, recurrent:7.3.0\r\n\r\nI meet a problem with HDFSWritableFile::Append\r\nBackground 1: I save model and checkpoint in HDFS.\r\nBackground 2: \tMy users want to add a big dict(30millon data, above 3GB) to graph.\r\nThe Problem:\t\tHDFS abort quit when TF saves graph.txt to HDFS.\r\nPart of logs:\r\n```\r\nFile \"/usr/lib/python2.7/site-packages/tensorflow/python/training/basic_session_run_hooks.py\", line 450, in after_create_session\r\n \"graph.pbtxt\")\r\n File \"/usr/lib/python2.7/site-packages/tensorflow/python/framework/graph_io.py\", line 71, in write_graph\r\n text_format.MessageToString(graph_def))\r\n File \"/usr/lib/python2.7/site-packages/tensorflow/python/lib/io/file_io.py\", line 434, in atomic_write_string_to_file\r\n write_string_to_file(temp_pathname, contents)\r\n File \"/usr/lib/python2.7/site-packages/tensorflow/python/lib/io/file_io.py\", line 314, in write_string_to_file\r\n f.write(file_content)\r\n File \"/usr/lib/python2.7/site-packages/tensorflow/python/lib/io/file_io.py\", line 111, in write\r\n compat.as_bytes(file_content), self._writable_file, status)\r\n File \"/usr/lib/python2.7/site-packages/tensorflow/python/framework/errors_impl.py\", line 519, in __exit__\r\n c_api.TF_GetCode(self.status.status))\r\nInvalidArgumentError: viewfs://hadoop-meituan/xxxx01/user/hadoop-waimai/xxxx/model/model//date/graph.pbtxt.tmp04d0a32366f548ec9f3aa629600fa19f; Invalid argument\r\n```\r\n\r\nI deal with this question by logs, then I get a result that the graph is too big to save. \r\nproblem code:\r\n```\r\nStatus HDFSWritableFile::Append(StringPiece data) {\r\n if (libhdfs()->hdfsWrite(fs_, file_, data.data(),\r\n static_cast<tSize>(data.size())) == -1) {\r\n return IOError(filename_, errno);\r\n}\r\n```\r\ndata.size() return uint64_t, but hdfsWrite only accept int, so there are some questions when append a big string(len > INT_MAX)\r\n\r\nSo I change HDFSWritableFile::Append function to solve my question, and successfully solve it.\r\nso I want to make a pull request .",
"comments": [
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37961\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37961\">No</a>\n",
"created_at": "2020-03-31T18:17:10Z"
},
{
"body": "@zhaozheng09 good",
"created_at": "2023-03-16T08:30:55Z"
}
],
"number": 37961,
"title": "I meet a problem with HDFSWritableFile::Append"
}
|
{
"body": "change append function to while loop .\r\nFixes #37961",
"number": 37962,
"review_comments": [],
"title": "Add support for large writes to Hadoop Filesystem"
}
|
{
"commits": [
{
"message": "Change append function to while loop ."
}
],
"files": [
{
"diff": "@@ -306,9 +306,24 @@ class HDFSWritableFile : public WritableFile {\n }\n \n Status Append(StringPiece data) override {\n- if (libhdfs()->hdfsWrite(fs_, file_, data.data(),\n- static_cast<tSize>(data.size())) == -1) {\n- return IOError(filename_, errno);\n+ size_t cur_pos = 0, write_len = 0;\n+ bool retry = false;\n+ // max() - 2 can avoid OutOfMemoryError in JVM .\n+ static const size_t max_len_once =\n+ static_cast<size_t>(std::numeric_limits<tSize>::max() - 2);\n+ while (cur_pos < data.size()) {\n+ write_len = std::min(data.size() - cur_pos, max_len_once);\n+ tSize w = libhdfs()->hdfsWrite(fs_, file_, data.data() + cur_pos,\n+ static_cast<tSize>(write_len));\n+ if (w == -1) {\n+ if (!retry && (errno == EINTR || errno == EAGAIN)) {\n+ retry = true;\n+ } else {\n+ return IOError(filename_, errno);\n+ }\n+ } else {\n+ cur_pos += w;\n+ }\n }\n return Status::OK();\n }",
"filename": "tensorflow/core/platform/hadoop/hadoop_file_system.cc",
"status": "modified"
},
{
"diff": "@@ -20,6 +20,7 @@ limitations under the License.\n #include \"tensorflow/core/platform/path.h\"\n #include \"tensorflow/core/platform/str_util.h\"\n #include \"tensorflow/core/platform/test.h\"\n+#include \"third_party/hadoop/hdfs.h\"\n \n namespace tensorflow {\n namespace {\n@@ -273,6 +274,23 @@ TEST_F(HadoopFileSystemTest, HarRootPath) {\n EXPECT_EQ(\"har://hdfs-root/user/j.doe/my_archive.har\", nn);\n EXPECT_EQ(\"/\", path);\n }\n+\n+TEST_F(HadoopFileSystemTest, WriteBigFile) {\n+ const string fname = TmpDir(\"BigFile\");\n+ const size_t file_len =\n+ static_cast<size_t>(std::numeric_limits<tSize>::max()) + 1024;\n+ // Fake a test string .\n+ char* p = new char[file_len];\n+ for (size_t i = 0; i < file_len; ++i) {\n+ *(p + i) = (i % 128);\n+ }\n+ string file_write_content(p, file_len);\n+ TF_ASSERT_OK(WriteString(fname, file_write_content));\n+ string file_read_content;\n+ TF_EXPECT_OK(ReadAll(fname, &file_read_content));\n+ EXPECT_EQ(file_write_content, file_read_content);\n+ delete p;\n+}\n // NewAppendableFile() is not testable. Local filesystem maps to\n // ChecksumFileSystem in Hadoop, where appending is an unsupported operation.\n ",
"filename": "tensorflow/core/platform/hadoop/hadoop_file_system_test.cc",
"status": "modified"
}
]
}
|
{
"body": "**System information** \r\n- Have I written custom code (as opposed to using a stock\r\nexample script provided in TensorFlow): \r\n- OS Platform and Distribution (e.g.,\r\nLinux Ubuntu 16.04): Windows 10\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if\r\nthe issue happens on mobile device: \r\n- TensorFlow installed from (source or\r\nbinary): - TensorFlow version (use command below): tf-nightly\r\n- Python version: - Bazel\r\nversion (if compiling from source):\r\n- GCC/Compiler version (if compiling from\r\nsource): \r\n- CUDA/cuDNN version: - GPU model and memory:\r\n\r\n\r\n**Describe the current behavior**\r\ncc @Conchylicultor,\r\nPlease have a look on issue from `TFDS` tensorflow/datasets#1670, tests are failing for `PlantVillage `and `The300wLp` datasets because in `_generate_example ` function of both [`plant_village.py`](https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/image/plant_village.py#L142) and [the300w_lp.py](https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/image/the300w_lp.py#L116) `tf.io.gfile.glob()` does not correctly matches all examples patterns. However python [`glob`](https://docs.python.org/3/library/glob.html) solves issue see PR tensorflow/datasets#1684\r\n**Describe the expected behavior**\r\ntf.io.gfile.glob() must matches all patterns provided so that all required examples are generated.\r\n\r\n**Standalone code to reproduce the issue** \r\nPlease have a look on this [`colab`](https://colab.research.google.com/drive/1tfLOQubRWd6Dc9mPTtAwca-eAzctGLId) notebook, it contains all tracebacks as well as problem with ` tf.io.gfile.glob()` and how python `glob `solves this issue.\r\n\r\n**As glob fix this issue but we have to use `tf.io.gfile` because we need to support GCS and other distributed files systems.**\r\n",
"comments": [
{
"body": "Yes, TFDS tests have started failing for patterns like: `tf.io.gfile.glob('/path/to/file/[!Code]*[!_Flip]/[!_]*.jpg')` or `tf.io.gfile.glob('/path/to/*.[jJ][pP][gG]')`.\r\n\r\n@Eshan-Agarwal Could you provide a small self-contained code snippet to reproduce the issue ?\r\n\r\nSomething like:\r\n```\r\nimport glob\r\nimport tensorflow as tf\r\n\r\nwith tf.io.gfile.GFile('/tmp/file') as f:\r\n pass\r\n\r\nprint(list(tf.io.gfile('/tmp/some_pattern')))\r\nprint(list(glob.glob('/tmp/some_pattern'))) # Should show different result\r\n```",
"created_at": "2020-03-20T21:41:51Z"
},
{
"body": "+1 on providing simple patterns.\r\n\r\nI can look into this in about a month or two, once modular filesystems (tensorflow/community#101) are implemented",
"created_at": "2020-03-21T00:01:57Z"
},
{
"body": "@Conchylicultor @mihaimaruseac please look on this [colab](https://colab.research.google.com/drive/1rXrpPVhiDfUH4DBT3Og65yx61R5MleHr) notebook",
"created_at": "2020-03-21T00:18:19Z"
},
{
"body": "@Eshan-Agarwal I get `NotFoundError: /content/temp/plant_village/Grape___Leaf_blight_(Isariopsis_Leaf_Spot); No such file or directory` when executing your colab.",
"created_at": "2020-03-21T00:44:52Z"
},
{
"body": "@Eshan-Agarwal the difference between the colab and the example template suggested is that we need to have the exact same setup for the colab, whereas the suggested template creates the files (with zero bytes) so it can be easily converted into a test case that now fails and after fixing will succeed.\r\n\r\nBut it's ok, I'll take care of this issue.",
"created_at": "2020-03-21T00:58:41Z"
},
{
"body": "@Eshan-Agarwal For the future, here is what a minimum reproductible example looks like:\r\n\r\n```python\r\nimport os\r\nimport glob\r\nimport tensorflow.compat.v2 as tf\r\n\r\n# Write a dummy file\r\nroot_dir = '/tmp/dir_with_(brace)/'\r\ntf.io.gfile.makedirs(root_dir)\r\nwith tf.io.gfile.GFile(os.path.join(root_dir, 'some_file.txt'), 'w') as f:\r\n f.write('')\r\n\r\n# Search the file\r\nglob_path = os.path.join(root_dir, \"*\")\r\nprint(list(glob.iglob(glob_path))) # ['/tmp/dir_with_(brace)/some_file.txt']\r\nprint(list(tf.io.gfile.glob(glob_path))) # [] << Bug: File not found\r\n```\r\n\r\nThis allow the team to easily understand what the issue is. They can just copy past the code and experiment with it. This save many hours, as all people working on the issue can get started immediately without having to go through the 10000+ lines of codes of TFDS.\r\n\r\n@mihaimaruseac The bug is that `tf.io.gfile.glob` fails when `(` are present in the path. This is a regression as it only appear in TF nightly. Not TF 2.1.\r\nThis make some TFDS tests fails as some datasets rely on this global pattern to generate the dataset.\r\n",
"created_at": "2020-03-21T01:00:00Z"
},
{
"body": "I think I have an idea where that might come from.",
"created_at": "2020-03-21T01:01:32Z"
},
{
"body": "@Conchylicultor @mihaimaruseac thanks for your quick responses, Actually I upload temp folder containing some example you can download folder from [here](https://drive.google.com/drive/folders/1DyMHIXSUue10k1a9pDbwgHK0Lng9VxuM?usp=sharing).\r\nbut it is good to use code provided by @Conchylicultor without any external uploading.\r\n",
"created_at": "2020-03-21T01:09:11Z"
},
{
"body": "@mihaimaruseac, do you know if this will this be fixed before the 2.2 release ? Otherwise, it will break some of our TFDS users using those datasets.\r\nWorse, as no error is raised with `tf.io.gfile.glob`, it will silently generate bad datasets where some examples are missing.\r\n\r\n@gadagashwini I'm not sure why you added the `TF 2.1` label. `TF 2.1` works fine, but `tf-nightly` is broken.",
"created_at": "2020-03-23T17:33:58Z"
},
{
"body": "We haven't prioritized this for 2.2 release, unfortunately. Can you verify that installing 2.2.-rc1 breaks you? Let me know if that is the case and I'll see if we can prioritize it.",
"created_at": "2020-03-23T23:21:53Z"
},
{
"body": "@Eshan-Agarwal, could you check if the issue occurs with `2.2.-rc1` ?",
"created_at": "2020-03-23T23:44:36Z"
},
{
"body": "@Conchylicultor sure, I will",
"created_at": "2020-03-24T02:09:44Z"
},
{
"body": "@Conchylicultor @mihaimaruseac Yes same problem occurs with `2.2.-rc1`, `tf.io.gfile.glob()` not matches patterns. \r\nPlease see this [colab ](https://colab.research.google.com/drive/1SAXEnHx0fXdnRjKYRdk3g0BzCoCgitKL)notebook, it shows both original tests as well as test with minimal reproductible code. ",
"created_at": "2020-03-24T02:34:45Z"
},
{
"body": "@Eshan-Agarwal thank you for confirming.\r\n\r\n@mihaimaruseac I believe this should be prioritised. This not only impact TFDS but potentially every users using `tf.io.gfile.glob`. As the issue is silent, users may not even notice there is a bug.\r\nIn our case we got lucky to have good unit-tests.\r\nNote: The issue only happened externally. Internally, our tests works fine.\r\n",
"created_at": "2020-03-24T15:49:30Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37758\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37758\">No</a>\n",
"created_at": "2020-03-26T00:58:23Z"
},
{
"body": "Reopening to close once the fix lands on `r2.2` branch (and then will be picked up by the next RC).\r\n\r\nSee #37915",
"created_at": "2020-03-26T01:05:20Z"
},
{
"body": "@mihaimaruseac Thank you for the fix.\r\nI'll update here when [our tests](https://storage.googleapis.com/tfds-kokoro-public/kokoro-build.html) are back to green.",
"created_at": "2020-03-26T01:17:11Z"
},
{
"body": "the cherrypick has been merged into the r2.2 branch",
"created_at": "2020-03-26T17:51:03Z"
},
{
"body": "TF 2.2.0-rc2 has been released and this issue should be fixed now.",
"created_at": "2020-03-28T02:22:50Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37758\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37758\">No</a>\n",
"created_at": "2020-03-28T02:22:52Z"
},
{
"body": "I confirm this fixed our tests. Thank you very much!",
"created_at": "2020-03-28T05:43:44Z"
}
],
"number": 37758,
"title": "tf.io.gfile.glob missing some patterns. Using tf-nightly"
}
|
{
"body": "After 5659465166daa218168c1f50f1d63c30f9f2bbd9, `GetMatchingPaths` was converted to use RE2 instead of `fnmatch` as that allows non-local filesystems (e.g., GCS, Hadoop, S3) to also be used from Windows. However, this breaks compatibility between `tf.io.gfile.glob` and Python `glob` and that results in tests silently failing or examples being silently skipped during training.\r\n\r\nThe fix is two-pronged. First, to fix #37758 only, we add regexp replacements for `(` and `)` in the pattern, escaping them before matching. After testing and seeing that this works, we then re-enable `fnmatch` on POSIX environments to reduce binary size, just like we did for mobile platforms.\r\n\r\nFixes #37758 (everywhere) and tensorflow/tensorboard#3260 (on posix platforms).\r\n\r\nTested via `bazel run //tensorflow/python:file_io_test` after adding a test for the pattern in #37758.\r\n\r\nWill need to be cherry-picked onto `r2.2` branch.\r\n\r\nPiperOrigin-RevId: 303009914\r\nChange-Id: Ieab047f63e9ba6bb0ec0499e0fa864f6ca6090ff",
"number": 37915,
"review_comments": [],
"title": "Fix `GetMatchingPaths` with special chars bug."
}
|
{
"commits": [
{
"message": "Fix `GetMatchingPaths` with special chars bug.\n\nAfter 5659465166daa218168c1f50f1d63c30f9f2bbd9, `GetMatchingPaths` was converted to use RE2 instead of `fnmatch` as that allows non-local filesystems (e.g., GCS, Hadoop, S3) to also be used from Windows. However, this breaks compatibility between `tf.io.gfile.glob` and Python `glob` and that results in tests silently failing or examples being silently skipped during training.\n\nThe fix is two-pronged. First, to fix #37758 only, we add regexp replacements for `(` and `)` in the pattern, escaping them before matching. After testing and seeing that this works, we then re-enable `fnmatch` on POSIX environments to reduce binary size, just like we did for mobile platforms.\n\nFixes #37758 (everywhere) and tensorflow/tensorboard#3260 (on posix platforms).\n\nTested via `bazel run //tensorflow/python:file_io_test` after adding a test for the pattern in #37758.\n\nWill need to be cherry-picked onto `r2.2` branch.\n\nPiperOrigin-RevId: 303009914\nChange-Id: Ieab047f63e9ba6bb0ec0499e0fa864f6ca6090ff"
}
],
"files": [
{
"diff": "@@ -16,39 +16,43 @@ limitations under the License.\n #include \"tensorflow/core/platform/file_system.h\"\n \n #include <sys/stat.h>\n-#if defined(IS_MOBILE_PLATFORM)\n-#include <fnmatch.h>\n-#endif\n \n #include <algorithm>\n #include <deque>\n #include <string>\n #include <utility>\n #include <vector>\n \n+#if defined(PLATFORM_POSIX) || defined(IS_MOBILE_PLATFORM)\n+#include <fnmatch.h>\n+#else\n+#include \"tensorflow/core/platform/regexp.h\"\n+#endif // defined(PLATFORM_POSIX) || defined(IS_MOBILE_PLATFORM)\n+\n #include \"tensorflow/core/platform/env.h\"\n #include \"tensorflow/core/platform/errors.h\"\n #include \"tensorflow/core/platform/platform.h\"\n-#if !defined(IS_MOBILE_PLATFORM)\n-#include \"tensorflow/core/platform/regexp.h\"\n-#endif\n #include \"tensorflow/core/platform/scanner.h\"\n #include \"tensorflow/core/platform/str_util.h\"\n #include \"tensorflow/core/platform/strcat.h\"\n \n namespace tensorflow {\n \n bool FileSystem::Match(const string& filename, const string& pattern) {\n-#if defined(IS_MOBILE_PLATFORM)\n+#if defined(PLATFORM_POSIX) || defined(IS_MOBILE_PLATFORM)\n // We avoid relying on RE2 on mobile platforms, because it incurs a\n // significant binary size increase.\n+ // For POSIX platforms, there is no need to depend on RE2 if `fnmatch` can be\n+ // used safely.\n return fnmatch(pattern.c_str(), filename.c_str(), FNM_PATHNAME) == 0;\n #else\n string regexp(pattern);\n- RE2::GlobalReplace(®exp, \"\\\\*\", \"[^/]*\");\n- RE2::GlobalReplace(®exp, \"\\\\?\", \".\");\n+ regexp = str_util::StringReplace(regexp, \"*\", \"[^/]*\", true);\n+ regexp = str_util::StringReplace(regexp, \"?\", \".\", true);\n+ regexp = str_util::StringReplace(regexp, \"(\", \"\\\\(\", true);\n+ regexp = str_util::StringReplace(regexp, \")\", \"\\\\)\", true);\n return RE2::FullMatch(filename, regexp);\n-#endif\n+#endif // defined(PLATFORM_POSIX) || defined(IS_MOBILE_PLATFORM)\n }\n \n string FileSystem::TranslateName(const string& name) const {",
"filename": "tensorflow/core/platform/file_system.cc",
"status": "modified"
},
{
"diff": "@@ -159,6 +159,18 @@ def testGetMatchingFiles(self):\n file_io.delete_recursively(dir_path)\n self.assertFalse(file_io.file_exists(os.path.join(dir_path, \"file3.txt\")))\n \n+ def testGetMatchingFilesWhenParentDirContainsParantheses(self):\n+ dir_path = os.path.join(self._base_dir, \"dir_(special)\")\n+ file_io.create_dir(dir_path)\n+ files = [\"file1.txt\", \"file(2).txt\"]\n+ for name in files:\n+ file_path = os.path.join(dir_path, name)\n+ file_io.FileIO(file_path, mode=\"w\").write(\"testing\")\n+ expected_match = [os.path.join(dir_path, name) for name in files]\n+ glob_pattern = os.path.join(dir_path, \"*\")\n+ self.assertItemsEqual(\n+ file_io.get_matching_files(glob_pattern), expected_match)\n+\n def testCreateRecursiveDir(self):\n dir_path = os.path.join(self._base_dir, \"temp_dir/temp_dir1/temp_dir2\")\n file_io.recursive_create_dir(dir_path)",
"filename": "tensorflow/python/lib/io/file_io_test.py",
"status": "modified"
}
]
}
|
{
"body": "With the recent changes in the Tensorflow Keras Optimizer API and Horovod. We did some testing and found that the following configuration was now broken:\r\n- Tensorflow 2.2.0rc0\r\n- Horovod 0.19.1\r\n- AMP + Keras Model Compile & Fit \r\n\r\n@sanjoy @pkanwar23 could we make sure to fix this one before TF 2.2.0 gets officially published ? It's still an RC release for now :)\r\n\r\nIf needed you can use this docker container which contains the right set of dependency and based on the public TF2.2.0rc0 container:\r\n```bash\r\ndocker pull born2data/tensorflow:hvd-0.19.1_tf_2.2.0rc0\r\n```\r\n\r\n**Code to reproduce:**\r\n```bash\r\nmpirun \\\r\n -np 2 \\\r\n -H localhost:2 \\\r\n -bind-to none \\\r\n -map-by slot \\\r\n -x NCCL_DEBUG=VERSION \\\r\n -x LD_LIBRARY_PATH \\\r\n -x PATH \\\r\n -mca pml ob1 -mca btl ^openib \\\r\n --allow-run-as-root \\\r\n python main.py\r\n```\r\n\r\n```python\r\nimport tensorflow as tf\r\nimport horovod.tensorflow.keras as hvd\r\n\r\n# Horovod: initialize Horovod.\r\nhvd.init()\r\n\r\n# Horovod: pin GPU to be used to process local rank (one GPU per process)\r\ngpus = tf.config.experimental.list_physical_devices('GPU')\r\nfor gpu in gpus:\r\n tf.config.experimental.set_memory_growth(gpu, True)\r\nif gpus:\r\n tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')\r\n\r\n(mnist_images, mnist_labels), _ = \\\r\n tf.keras.datasets.mnist.load_data(path='mnist-%d.npz' % hvd.rank())\r\n\r\ndataset = tf.data.Dataset.from_tensor_slices(\r\n (tf.cast(mnist_images[..., tf.newaxis] / 255.0, tf.float32),\r\n tf.cast(mnist_labels, tf.int64))\r\n)\r\ndataset = dataset.repeat().shuffle(10000).batch(128)\r\n\r\npolicy = tf.keras.mixed_precision.experimental.Policy('mixed_float16', 128)\r\ntf.keras.mixed_precision.experimental.set_policy(policy)\r\n\r\nmnist_model = tf.keras.Sequential([\r\n tf.keras.layers.Conv2D(32, [3, 3], activation='relu'),\r\n tf.keras.layers.Conv2D(64, [3, 3], activation='relu'),\r\n tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),\r\n tf.keras.layers.Dropout(0.25),\r\n tf.keras.layers.Flatten(),\r\n tf.keras.layers.Dense(128, activation='relu'),\r\n tf.keras.layers.Dropout(0.5),\r\n tf.keras.layers.Dense(10, activation='softmax')\r\n])\r\n\r\n# Horovod: adjust learning rate based on number of GPUs.\r\nopt = tf.optimizers.Adam(0.001)\r\n\r\n# Horovod: add Horovod DistributedOptimizer.\r\nopt = hvd.DistributedOptimizer(opt)\r\n\r\n# Horovod: Specify `experimental_run_tf_function=False` to ensure TensorFlow\r\n# uses hvd.DistributedOptimizer() to compute gradients.\r\nmnist_model.compile(loss=tf.losses.SparseCategoricalCrossentropy(),\r\n optimizer=opt,\r\n metrics=['accuracy'],\r\n experimental_run_tf_function=False)\r\n\r\ncallbacks = [\r\n # Horovod: broadcast initial variable states from rank 0 to all other processes.\r\n # This is necessary to ensure consistent initialization of all workers when\r\n # training is started with random weights or restored from a checkpoint.\r\n hvd.callbacks.BroadcastGlobalVariablesCallback(0),\r\n]\r\n\r\n# Train the model.\r\n# Horovod: adjust number of steps based on number of GPUs.\r\nmnist_model.fit(\r\n dataset,\r\n steps_per_epoch=500 // hvd.size(),\r\n callbacks=callbacks,\r\n epochs=24,\r\n verbose=1 if hvd.rank() == 0 else 0\r\n)\r\n```\r\n\r\n**Error:**\r\n```python\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py:503 train_function *\r\n outputs = self.distribute_strategy.run(\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/distribute/distribute_lib.py:951 run **\r\n return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/distribute/distribute_lib.py:2290 call_for_each_replica\r\n return self._call_for_each_replica(fn, args, kwargs)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/distribute/distribute_lib.py:2649 _call_for_each_replica\r\n return fn(*args, **kwargs)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py:473 train_step **\r\n _minimize(tape, self.optimizer, loss, self.trainable_variables)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py:1739 _minimize\r\n optimizer.apply_gradients(zip(gradients, trainable_variables))\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/mixed_precision/experimental/loss_scale_optimizer.py:232 apply_gradients\r\n args=(grads_and_vars, name, all_reduce_sum_gradients))\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/distribute/distribute_lib.py:2420 merge_call\r\n return self._merge_call(merge_fn, args, kwargs)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/distribute/distribute_lib.py:2427 _merge_call\r\n return merge_fn(self._strategy, *args, **kwargs)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/mixed_precision/experimental/loss_scale_optimizer.py:256 _apply_gradients_cross_replica **\r\n control_flow_ops.no_op)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/smart_cond.py:54 smart_cond\r\n return true_fn()\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/mixed_precision/experimental/loss_scale_optimizer.py:248 apply_fn\r\n all_reduce_sum_gradients))\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/distribute/distribute_lib.py:2290 call_for_each_replica\r\n return self._call_for_each_replica(fn, args, kwargs)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/distribute/distribute_lib.py:2649 _call_for_each_replica\r\n return fn(*args, **kwargs)\r\n /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/mixed_precision/experimental/loss_scale_optimizer.py:262 _apply_gradients\r\n name, all_reduce_sum_gradients)\r\n /usr/local/lib/python3.6/dist-packages/horovod/_keras/__init__.py:73 apply_gradients\r\n raise Exception('`apply_gradients()` was called without a call to '\r\n\r\n Exception: `apply_gradients()` was called without a call to `get_gradients()` or `_aggregate_gradients`. If you're using TensorFlow 2.0, please specify `experimental_run_tf_function=False` in `compile()`.\r\n```\r\n\r\nPlease let me know how I can help\r\n\r\nCC: @nluehr @reedwm @tgaddair @cliffwoolley @omalleyt12 @houtoms",
"comments": [
{
"body": "Hmmm this is probably because LossScaleOptimizer doesn't define _HAS_ALL_REDUCE_SUM_GRAD. We should set _HAS_ALL_REDUCE_SUM_GRAD to True if the inner optimizer has set it to true.",
"created_at": "2020-03-21T00:05:14Z"
},
{
"body": "JFYI. @reedwm By changing the loss_scale_optimizer.py as the following can solve the problem. But we are not sure if this is just a WAR.\r\n```python\r\nclass LossScaleOptimizer(optimizer_v2.OptimizerV2):\r\n ...\r\n _HAS_ALL_REDUCE_SUM_GRAD = True\r\n def _aggregate_gradients(self, grads_and_vars):\r\n return self._optimizer._aggregate_gradients(grads_and_vars)\r\n ...\r\n```",
"created_at": "2020-03-21T00:05:19Z"
},
{
"body": "@reedwm any chance we can get this small fix inside 2.2.0 ?",
"created_at": "2020-03-21T00:06:41Z"
},
{
"body": "Ah we commented at the same time. Yeah that would fix it but it should be set to True only if the inner optimizer defined it.\r\n\r\nI will fix.",
"created_at": "2020-03-21T00:06:44Z"
},
{
"body": "I will try very hard to cherrypick but I cannot promise anything",
"created_at": "2020-03-21T00:06:56Z"
},
{
"body": "Awesome, thanks a lot. Let us know if we can do anything to help ya",
"created_at": "2020-03-21T00:07:24Z"
},
{
"body": "@reedwm Any good news ?",
"created_at": "2020-03-24T20:19:43Z"
},
{
"body": "In trying to fix this by adding `_HAS_ALL_REDUCE_SUM_GRAD = True`, the mixed precision CentralStorageStrategy tests broke. We realized the `all_reduce_sum_gradients` parameter has issues with CentralStorageStrategy. As a result, the the parameter was renamed to `experimental_aggregate_gradients` in 75ae7742abc027b001a5f3d7c020bb4504cc0f78. The attribute has also been renamed to `_HAS_AGGREGATE_GRAD`. You will have to make these changes in the Horovod optimizer.\r\n\r\nI'll disable the central storage tests, then add the `_HAS_AGGREGATE_GRAD` attribute, which should fix this.",
"created_at": "2020-03-24T20:47:58Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37765\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37765\">No</a>\n",
"created_at": "2020-03-25T20:05:46Z"
},
{
"body": "This is not closed until bcfc1ba6798ced6889f579644c2c79515832d098 is cherrypicked into 2.2",
"created_at": "2020-03-25T20:57:24Z"
},
{
"body": "Thanks @reedwm for your quick help. **Much** appreciated ;) ",
"created_at": "2020-03-25T21:03:43Z"
},
{
"body": "@reedwm It seems we still get ```Exception: `apply_gradients()` was called without a call to `get_gradients()` or `_aggregate_gradients`. If you're using TensorFlow 2.0, please specify `experimental_run_tf_function=False` in `compile()`.``` error.\r\n\r\nDon't we need \r\n```python\r\ndef _aggregate_gradients(self, grads_and_vars):\r\n return self._optimizer._aggregate_gradients(grads_and_vars)\r\n```\r\nin class LossScaleOptimizer to pass the gradients aggregation to the wrapped optimizer? After I add these two lines, the problem is gone.",
"created_at": "2020-03-27T22:53:39Z"
},
{
"body": "Good point, we need to define `_aggregate_gradients` if the LossScaleOptimizer wraps the DistributedOptimizer, as is done in the example. If the LossScaleOptimizer wraps the DistributedOptimizer, everything should work fine.\r\n\r\nI'll try to cherry-pick the fix in, but 2.2rc2 is already released so there's a good chance I won't be able to. Also try testing with that fix in and let me know if there are any other fixes that are needed.",
"created_at": "2020-03-28T01:35:08Z"
},
{
"body": "[2.2.0-rc3](https://pypi.org/project/tensorflow/2.2.0rc3/#files) is now released, @houtoms can you please check ?",
"created_at": "2020-04-14T21:04:42Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37765\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37765\">No</a>\n",
"created_at": "2020-12-03T01:51:08Z"
}
],
"number": 37765,
"title": "[Bug] TF 2.2.0rc0 fails with AMP and Horovod 0.19.1 in Keras compile & fit"
}
|
{
"body": "all_reduce_sum_gradients can be misleading since for certain distributed strategy we don't do all reduce.\r\n\r\nThis PR also disables experimental_aggregate_gradients=False for CentralStroage and ParameterServer. They're not supported at this moment.\r\n\r\nFixes #37765\r\n\r\n<!-- Reviewable:start -->\r\n---\r\nThis change is [<img src=\"https://reviewable.io/review_button.svg\" height=\"34\" align=\"absmiddle\" alt=\"Reviewable\"/>](https://reviewable.io/reviews/tensorflow/tensorflow/37908)\r\n<!-- Reviewable:end -->\r\n",
"number": 37908,
"review_comments": [],
"title": "Rename all_reduce_sum_gradients to experimental_aggregate_gradients "
}
|
{
"commits": [
{
"message": "Add _HAS_ALL_REDUCE_SUM_GRAD to SGD\n\nPiperOrigin-RevId: 302150669\nChange-Id: I9c48c608ab6930da77a2800e00418c2ff559f111"
},
{
"message": "Rename all_reduce_sum_gradients to experimental_aggregate_gradients\n\nFor some strategies we don't do all reduce, so all_reduce_sum_gradients can be\nmisleading. The parameter is also changed to experimental because of issues with\nCentralStorageStrategy.\n\nPiperOrigin-RevId: 302734837\nChange-Id: Ic30e2f81ab61eef568ee68e5752015f950117d47"
},
{
"message": "Disallow mixed precision from being used with certain strategies.\n\nSince CentralStorageStrategy is no longer supported, its mixed precision tests were removed.\n\nThis will allow certain improvements to be made to LossScaleOptimizer.\n\nPiperOrigin-RevId: 302762675\nChange-Id: I90cfcd6f72a2fb1b25fc5eedcde328a25f9049cf"
},
{
"message": "Error when experimental_aggregate_gradients=False is used with\nCentralStorageStrategy\n\nPiperOrigin-RevId: 302804311\nChange-Id: Ibb27c529251390f40338cd296537cd98f8940b56"
},
{
"message": "Set _HAS_AGGREGATE_GRAD in LossScaleOptimizer.\n\nThis will fix https://github.com/tensorflow/tensorflow/issues/37765 once cherrypicked into 2.2.\n\nPiperOrigin-RevId: 302949295\nChange-Id: I9f4370f6c3cb49431ec946cd956de78bc9df3e64"
}
],
"files": [
{
"diff": "@@ -41,7 +41,8 @@ class Hints(object):\n bytes_per_pack=50 * 1024 * 1024)\n grads = tf.distribute.get_replica_context().all_reduce(\n 'sum', grads, experimental_hints=hints)\n- optimizer.apply_gradients(zip(grads, vars), all_reduce_sum_gradients=False)\n+ optimizer.apply_gradients(zip(grads, vars),\n+ experimental_aggregate_gradients=False)\n ```\n \n \"\"\"",
"filename": "tensorflow/python/distribute/collective_util.py",
"status": "modified"
},
{
"diff": "@@ -40,14 +40,14 @@ class OptimizerTest(test.TestCase, parameterized.TestCase):\n ),\n combinations.concat(\n combinations.combine(\n- all_reduce_sum_gradients=True,\n+ experimental_aggregate_gradients=True,\n expected=[[[-0.3, -0.3], [-0.3, -0.3]]]),\n combinations.combine(\n- all_reduce_sum_gradients=False,\n+ experimental_aggregate_gradients=False,\n expected=[[[-0.1, -0.1], [-0.2, -0.2]]]),\n )))\n- def test_custom_aggregation(self, distribution, all_reduce_sum_gradients,\n- expected):\n+ def test_custom_aggregation(self, distribution,\n+ experimental_aggregate_gradients, expected):\n \n with distribution.scope():\n v = variables.Variable([0., 0.])\n@@ -62,7 +62,8 @@ def optimize():\n \n def step_fn(grads):\n optimizer.apply_gradients(\n- [(grads, v)], all_reduce_sum_gradients=all_reduce_sum_gradients)\n+ [(grads, v)],\n+ experimental_aggregate_gradients=experimental_aggregate_gradients)\n return v.read_value()\n \n return distribution.experimental_local_results(\n@@ -74,9 +75,9 @@ def step_fn(grads):\n combinations.combine(\n distribution=strategy_combinations.one_device_strategy,\n mode=[\"eager\"],\n- all_reduce_sum_gradients=[True, False]))\n+ experimental_aggregate_gradients=[True, False]))\n def test_custom_aggregation_one_device(self, distribution,\n- all_reduce_sum_gradients):\n+ experimental_aggregate_gradients):\n \n with distribution.scope():\n v = variables.Variable([0., 0.])\n@@ -88,14 +89,33 @@ def optimize():\n \n def step_fn(grads):\n optimizer.apply_gradients(\n- [(grads, v)], all_reduce_sum_gradients=all_reduce_sum_gradients)\n+ [(grads, v)],\n+ experimental_aggregate_gradients=experimental_aggregate_gradients)\n return v.read_value()\n \n return distribution.experimental_local_results(\n distribution.run(step_fn, args=(grads,)))\n \n self.assertAllClose(optimize(), [[-0.1, -0.1]])\n \n+ @combinations.generate(\n+ combinations.combine(distribution=[\n+ strategy_combinations.central_storage_strategy_with_gpu_and_cpu\n+ ]))\n+ def test_custom_aggregation_central_storage(self, distribution):\n+ with distribution.scope():\n+ v = variables.Variable([0., 0.])\n+ optimizer = keras.optimizer_v2.gradient_descent.SGD(0.1)\n+\n+ grads = ops.convert_to_tensor([1., 1.])\n+\n+ def step_fn(grads):\n+ with self.assertRaises(NotImplementedError):\n+ optimizer.apply_gradients([(grads, v)],\n+ experimental_aggregate_gradients=False)\n+\n+ return distribution.run(step_fn, args=(grads,))\n+\n \n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/distribute/custom_training_loop_optimizer_test.py",
"status": "modified"
},
{
"diff": "@@ -86,6 +86,7 @@ py_library(\n \"//tensorflow/python/distribute:combinations\",\n \"//tensorflow/python/distribute:distribute_lib\",\n \"//tensorflow/python/distribute:mirrored_strategy\",\n+ \"//tensorflow/python/distribute:parameter_server_strategy\",\n \"//tensorflow/python/distribute:strategy_combinations\",\n \"//tensorflow/python/distribute:tpu_strategy\",\n \"//tensorflow/python/eager:context\",\n@@ -117,7 +118,7 @@ distribute_py_test(\n srcs = [\"distribute_strategy_test.py\"],\n full_precision = True,\n main = \"distribute_strategy_test.py\",\n- shard_count = 8,\n+ shard_count = 10,\n tags = [\n \"multi_and_single_gpu\",\n \"no_rocm\", # times out on ROCm\n@@ -278,6 +279,7 @@ distribute_py_test(\n ],\n deps = [\n \":keras_test_lib\",\n+ \"//tensorflow/python/distribute:parameter_server_strategy\",\n \"//tensorflow/python/keras/distribute:distribute_strategy_test_lib\",\n ],\n )",
"filename": "tensorflow/python/keras/distribute/BUILD",
"status": "modified"
},
{
"diff": "@@ -25,6 +25,7 @@\n from tensorflow.python.distribute import combinations\n from tensorflow.python.distribute import distribution_strategy_context\n from tensorflow.python.distribute import mirrored_strategy\n+from tensorflow.python.distribute import parameter_server_strategy\n from tensorflow.python.distribute import reduce_util\n from tensorflow.python.distribute import strategy_combinations\n from tensorflow.python.distribute import tpu_strategy\n@@ -216,15 +217,17 @@ def multi_input_output_model():\n strategy_combinations.one_device_strategy,\n strategy_combinations.one_device_strategy_gpu,\n strategy_combinations.mirrored_strategy_with_gpu_and_cpu,\n- strategy_combinations.mirrored_strategy_with_two_gpus\n+ strategy_combinations.mirrored_strategy_with_two_gpus,\n+ strategy_combinations.central_storage_strategy_with_gpu_and_cpu\n ]\n \n strategies_minus_tpu = [\n strategy_combinations.default_strategy,\n strategy_combinations.one_device_strategy,\n strategy_combinations.one_device_strategy_gpu,\n strategy_combinations.mirrored_strategy_with_gpu_and_cpu,\n- strategy_combinations.mirrored_strategy_with_two_gpus\n+ strategy_combinations.mirrored_strategy_with_two_gpus,\n+ strategy_combinations.central_storage_strategy_with_gpu_and_cpu\n ]\n \n tpu_strategies = [\n@@ -458,6 +461,9 @@ def test_calling_model_with_numpy_arrays(self, distribution):\n \n @combinations.generate(all_strategy_combinations_plus_run_distributed())\n def test_calling_model_with_mixed_precision(self, distribution):\n+ if isinstance(distribution.extended,\n+ parameter_server_strategy.ParameterServerStrategyExtended):\n+ self.skipTest('b/152097775')\n if isinstance(distribution,\n (tpu_strategy.TPUStrategy, tpu_strategy.TPUStrategyV1)):\n policy_name = 'mixed_bfloat16'\n@@ -505,6 +511,10 @@ def test_operator_overload_mixed_precision(self, distribution):\n # AutoCastVariable to a tensor on a TPU, where the variable was the LHS of\n # the '+' operator, used to cause the gradient w.r.t. the variable to be\n # None.\n+ if isinstance(distribution.extended,\n+ parameter_server_strategy.ParameterServerStrategyExtended):\n+ self.skipTest('b/152097775')\n+\n if isinstance(distribution,\n (tpu_strategy.TPUStrategy, tpu_strategy.TPUStrategyV1)):\n policy_name = 'mixed_bfloat16'",
"filename": "tensorflow/python/keras/distribute/distribute_strategy_test.py",
"status": "modified"
},
{
"diff": "@@ -26,6 +26,7 @@\n from tensorflow.python import keras\n from tensorflow.python.data.ops import dataset_ops\n from tensorflow.python.distribute import combinations\n+from tensorflow.python.distribute import parameter_server_strategy\n from tensorflow.python.distribute import strategy_combinations\n from tensorflow.python.distribute import tpu_strategy\n from tensorflow.python.distribute import values\n@@ -397,6 +398,9 @@ class TestDistributionStrategyWithNormalizationLayer(test.TestCase,\n optimizer=strategy_combinations\n .gradient_descent_optimizer_keras_v2_fn)))\n def test_batchnorm_correctness(self, distribution, fused, optimizer):\n+ if isinstance(distribution.extended,\n+ parameter_server_strategy.ParameterServerStrategyExtended):\n+ self.skipTest('b/152353796')\n with self.cached_session():\n with distribution.scope():\n model = keras.models.Sequential()",
"filename": "tensorflow/python/keras/distribute/keras_utils_test.py",
"status": "modified"
},
{
"diff": "@@ -42,6 +42,7 @@ py_library(\n \"//tensorflow/python/distribute:distribute_coordinator\",\n \"//tensorflow/python/distribute:distribute_lib\",\n \"//tensorflow/python/distribute:input_lib\",\n+ \"//tensorflow/python/distribute:parameter_server_strategy\",\n \"//tensorflow/python/distribute:reduce_util\",\n \"//tensorflow/python/eager:monitoring\",\n \"//tensorflow/python/keras:activations\",",
"filename": "tensorflow/python/keras/engine/BUILD",
"status": "modified"
},
{
"diff": "@@ -54,6 +54,7 @@\n from tensorflow.python.keras.engine import input_spec\n from tensorflow.python.keras.engine import node as node_module\n from tensorflow.python.keras.mixed_precision.experimental import autocast_variable\n+from tensorflow.python.keras.mixed_precision.experimental import loss_scale_optimizer\n from tensorflow.python.keras.mixed_precision.experimental import policy\n from tensorflow.python.keras.saving.saved_model import layer_serialization\n from tensorflow.python.keras.utils import generic_utils\n@@ -1989,6 +1990,18 @@ def _set_dtype_policy(self, dtype):\n self._dtype_policy = policy.Policy(dtypes.as_dtype(dtype).name)\n else:\n self._dtype_policy = policy.global_policy()\n+ if (self._dtype_policy.name == 'mixed_float16' and\n+ not loss_scale_optimizer.strategy_supports_loss_scaling()):\n+ # Although only loss scaling doesn't support certain strategies, to avoid\n+ # confusion, we disallow the 'mixed_float16' policy with unsupported\n+ # strategies. This is because 'mixed_float16' requires loss scaling for\n+ # numeric stability.\n+ strategy = ds_context.get_strategy()\n+ raise ValueError('Mixed precision is not supported with the '\n+ 'tf.distribute.Strategy: %s. Either stop using mixed '\n+ 'precision by removing the use of the \"%s\" policy or '\n+ 'use a different Strategy, e.g. a MirroredStrategy.' %\n+ (strategy.__class__.__name__, self._dtype_policy.name))\n \n # This has no impact on the layer behavior, and is only used for printing\n # warnings.",
"filename": "tensorflow/python/keras/engine/base_layer.py",
"status": "modified"
},
{
"diff": "@@ -47,6 +47,7 @@\n from tensorflow.python.keras.engine import input_spec\n from tensorflow.python.keras.engine import node as node_module\n from tensorflow.python.keras.mixed_precision.experimental import autocast_variable\n+from tensorflow.python.keras.mixed_precision.experimental import loss_scale_optimizer\n from tensorflow.python.keras.mixed_precision.experimental import policy\n from tensorflow.python.keras.saving.saved_model import layer_serialization\n from tensorflow.python.keras.utils import generic_utils\n@@ -1733,6 +1734,18 @@ def _set_dtype_policy(self, dtype):\n self._dtype_policy = policy.Policy(dtypes.as_dtype(dtype).name)\n else:\n self._dtype_policy = policy.global_policy()\n+ if (self._dtype_policy.name == 'mixed_float16' and\n+ not loss_scale_optimizer.strategy_supports_loss_scaling()):\n+ # Although only loss scaling doesn't support certain strategies, to avoid\n+ # confusion, we disallow the 'mixed_float16' policy with unsupported\n+ # strategies. This is because 'mixed_float16' requires loss scaling for\n+ # numeric stability.\n+ strategy = ds_context.get_strategy()\n+ raise ValueError('Mixed precision is not supported with the '\n+ 'tf.distribute.Strategy: %s. Either stop using mixed '\n+ 'precision by removing the use of the \"%s\" policy or '\n+ 'use a different Strategy, e.g. a MirroredStrategy.' %\n+ (strategy.__class__.__name__, self._dtype_policy.name))\n \n # This has no impact on the layer behavior, and is only used for printing\n # warnings.",
"filename": "tensorflow/python/keras/engine/base_layer_v1.py",
"status": "modified"
},
{
"diff": "@@ -23,6 +23,7 @@\n from tensorflow.python.distribute import distribute_coordinator as dc\n from tensorflow.python.distribute import distribute_coordinator_context as dc_context\n from tensorflow.python.distribute import distribution_strategy_context as ds_context\n+from tensorflow.python.distribute import parameter_server_strategy\n from tensorflow.python.distribute import values as ds_values\n from tensorflow.python.eager import backprop\n from tensorflow.python.eager import context\n@@ -470,7 +471,8 @@ def train_step(self, data):\n # self.optimizer.apply_gradients(zip(gradients, trainable_variables))\n # The _minimize call does a few extra steps unnecessary in most cases,\n # such as loss scaling and gradient clipping.\n- _minimize(tape, self.optimizer, loss, self.trainable_variables)\n+ _minimize(self.distribute_strategy, tape, self.optimizer, loss,\n+ self.trainable_variables)\n \n self.compiled_metrics.update_state(y, y_pred, sample_weight)\n return {m.name: m.result() for m in self.metrics}\n@@ -1695,7 +1697,7 @@ def _tpu_multi_host_concat(v, strategy):\n return concat(ordered_replicas)\n \n \n-def _minimize(tape, optimizer, loss, trainable_variables):\n+def _minimize(strategy, tape, optimizer, loss, trainable_variables):\n \"\"\"Minimizes loss for one step by updating `trainable_variables`.\n \n This is roughly equivalent to\n@@ -1709,6 +1711,7 @@ def _minimize(tape, optimizer, loss, trainable_variables):\n optimizer is a LossScaleOptimizer.\n \n Args:\n+ strategy: `tf.distribute.Strategy`.\n tape: A gradient tape. The loss must have been computed under this tape.\n optimizer: The optimizer used to minimize the loss.\n loss: The loss tensor.\n@@ -1722,7 +1725,15 @@ def _minimize(tape, optimizer, loss, trainable_variables):\n \n gradients = tape.gradient(loss, trainable_variables)\n \n- if optimizer._HAS_ALL_REDUCE_SUM_GRAD: # pylint: disable=protected-access\n+ # Whether to aggregate gradients outside of optimizer. This requires support\n+ # of the optimizer and doesn't work with ParameterServerStrategy and\n+ # CentralStroageStrategy.\n+ aggregate_grads_outside_optimizer = (\n+ optimizer._HAS_AGGREGATE_GRAD and # pylint: disable=protected-access\n+ not isinstance(strategy.extended,\n+ parameter_server_strategy.ParameterServerStrategyExtended))\n+\n+ if aggregate_grads_outside_optimizer:\n # We aggregate gradients before unscaling them, in case a subclass of\n # LossScaleOptimizer all-reduces in fp16. All-reducing in fp16 can only be\n # done on scaled gradients, not unscaled gradients, for numeric stability.\n@@ -1732,8 +1743,9 @@ def _minimize(tape, optimizer, loss, trainable_variables):\n gradients = optimizer.get_unscaled_gradients(gradients)\n gradients = optimizer._clip_gradients(gradients) # pylint: disable=protected-access\n if trainable_variables:\n- if optimizer._HAS_ALL_REDUCE_SUM_GRAD: # pylint: disable=protected-access\n- optimizer.apply_gradients(zip(gradients, trainable_variables),\n- all_reduce_sum_gradients=False)\n+ if aggregate_grads_outside_optimizer:\n+ optimizer.apply_gradients(\n+ zip(gradients, trainable_variables),\n+ experimental_aggregate_gradients=False)\n else:\n optimizer.apply_gradients(zip(gradients, trainable_variables))",
"filename": "tensorflow/python/keras/engine/training.py",
"status": "modified"
},
{
"diff": "@@ -1323,7 +1323,7 @@ def test_calling_aggregate_gradient(self):\n class _Optimizer(gradient_descent.SGD):\n \"\"\"Mock optimizer to check if _aggregate_gradient is called.\"\"\"\n \n- _HAS_ALL_REDUCE_SUM_GRAD = True\n+ _HAS_AGGREGATE_GRAD = True\n \n def __init__(self):\n self.aggregate_gradients_called = False\n@@ -1348,10 +1348,10 @@ class _OptimizerOverrideApplyGradients(_Optimizer):\n \"\"\"Override apply_gradients.\n \n To test the case where the optimizer does not define the\n- all_reduce_sum_gradients parameter.\n+ experimental_aggregate_gradients parameter.\n \"\"\"\n \n- _HAS_ALL_REDUCE_SUM_GRAD = False\n+ _HAS_AGGREGATE_GRAD = False\n \n def apply_gradients(self, grads_and_vars, name=None): # pylint: disable=useless-super-delegation\n return super(_OptimizerOverrideApplyGradients,",
"filename": "tensorflow/python/keras/engine/training_test.py",
"status": "modified"
},
{
"diff": "@@ -159,6 +159,10 @@ py_library(\n deps = [\n \":loss_scale\",\n \"//tensorflow/python:loss_scale\",\n+ \"//tensorflow/python/distribute:collective_all_reduce_strategy\",\n+ \"//tensorflow/python/distribute:distribute_lib\",\n+ \"//tensorflow/python/distribute:mirrored_strategy\",\n+ \"//tensorflow/python/distribute:one_device_strategy\",\n \"//tensorflow/python/keras/optimizer_v2\",\n \"@absl_py//absl/testing:parameterized\",\n ],\n@@ -174,8 +178,7 @@ cuda_py_test(\n \":test_util\",\n \"//tensorflow/python:client_testlib\",\n \"//tensorflow/python:control_flow_v2_toggles\",\n- \"//tensorflow/python/distribute:mirrored_strategy\",\n- \"//tensorflow/python/distribute:one_device_strategy\",\n+ \"//tensorflow/python/distribute:central_storage_strategy\",\n \"//tensorflow/python/keras\",\n ],\n )",
"filename": "tensorflow/python/keras/mixed_precision/experimental/BUILD",
"status": "modified"
},
{
"diff": "@@ -417,6 +417,18 @@ def f():\n self.assertEqual(layer.v.dtype, 'float32')\n self.assertEqual(self.evaluate(y), 1.)\n \n+ def test_unsupported_strategy(self):\n+ strategy = create_central_storage_strategy()\n+ with strategy.scope(), self.assertRaisesRegexp(\n+ ValueError, 'Mixed precision is not supported with the '\n+ 'tf.distribute.Strategy: CentralStorageStrategy. Either '\n+ 'stop using mixed precision by removing the use of the '\n+ '\"mixed_float16\" policy or use a different Strategy, e.g. '\n+ 'a MirroredStrategy.'):\n+ mp_test_util.MultiplyLayer(dtype=policy.Policy('mixed_float16'))\n+ # Non-mixed policies are fine\n+ mp_test_util.MultiplyLayer(dtype=policy.Policy('float64'))\n+\n \n class KerasModelTest(keras_parameterized.TestCase):\n \"\"\"Test mixed precision with Keras models.\"\"\"\n@@ -491,11 +503,6 @@ def _skip_if_save_format_unsupported(self, save_format):\n 'strategy_fn': create_mirrored_strategy,\n 'save_format': 'h5',\n 'use_regularizer': True,\n- }, {\n- 'testcase_name': 'central_storage',\n- 'strategy_fn': create_central_storage_strategy,\n- 'use_regularizer': True,\n- 'save_format': 'tf'\n })\n def test_model(self,\n strategy_fn,\n@@ -743,10 +750,6 @@ def loss_fn(y_true, y_pred):\n 'strategy_fn': create_mirrored_strategy,\n 'get_config': True,\n 'pass_loss_scale_to_policy': True,\n- }, {\n- 'testcase_name': 'central_storage',\n- 'strategy_fn': create_central_storage_strategy,\n- 'get_config': True,\n })\n def test_dynamic_loss_scaling(self,\n strategy_fn,",
"filename": "tensorflow/python/keras/mixed_precision/experimental/keras_test.py",
"status": "modified"
},
{
"diff": "@@ -17,7 +17,10 @@\n from __future__ import division\n from __future__ import print_function\n \n+from tensorflow.python.distribute import collective_all_reduce_strategy\n from tensorflow.python.distribute import distribution_strategy_context\n+from tensorflow.python.distribute import mirrored_strategy\n+from tensorflow.python.distribute import one_device_strategy\n from tensorflow.python.framework import smart_cond\n from tensorflow.python.keras import backend\n from tensorflow.python.keras import optimizers\n@@ -103,6 +106,8 @@ class LossScaleOptimizer(optimizer_v2.OptimizerV2):\n 0.25\n \"\"\"\n \n+ _HAS_AGGREGATE_GRAD = True\n+\n def __init__(self, optimizer, loss_scale):\n \"\"\"Initializes this loss scale optimizer.\n \n@@ -127,6 +132,7 @@ def __init__(self, optimizer, loss_scale):\n raise ValueError('LossScaleOptimizer does not support wrapping '\n 'optimizers with a clipvalue. Optimizer %s has '\n 'clipvalue %s' % (optimizer, optimizer.clipvalue))\n+ self._raise_if_strategy_unsupported()\n \n self.clipnorm = None\n self.clipvalue = None\n@@ -222,17 +228,23 @@ def get_gradients(self, loss, params):\n grads = self._optimizer.get_gradients(loss, params)\n return self.get_unscaled_gradients(grads)\n \n- def apply_gradients(self, grads_and_vars, name=None,\n- all_reduce_sum_gradients=True):\n+ def apply_gradients(self,\n+ grads_and_vars,\n+ name=None,\n+ experimental_aggregate_gradients=True):\n if distribution_strategy_context.in_cross_replica_context():\n raise ValueError('apply_gradients() must be called in a replica context.')\n+ # We check for the strategy here despite already checking in the constructor\n+ # as frequently the optimizer is created outside the strategy's scope.\n+ self._raise_if_strategy_unsupported()\n+\n grads_and_vars = tuple(grads_and_vars)\n return distribution_strategy_context.get_replica_context().merge_call(\n self._apply_gradients_cross_replica,\n- args=(grads_and_vars, name, all_reduce_sum_gradients))\n+ args=(grads_and_vars, name, experimental_aggregate_gradients))\n \n def _apply_gradients_cross_replica(self, distribution, grads_and_vars, name,\n- all_reduce_sum_gradients):\n+ experimental_aggregate_gradients):\n grads = [g for g, _ in grads_and_vars]\n loss_scale_update_op, should_apply_grads = self._loss_scale.update(grads)\n \n@@ -244,8 +256,8 @@ def apply_fn():\n # MirroredVariables.\n wrapped_vars = _UnwrapPreventer([v for _, v in grads_and_vars])\n return distribution.extended.call_for_each_replica(\n- self._apply_gradients, args=(grads, wrapped_vars, name,\n- all_reduce_sum_gradients))\n+ self._apply_gradients,\n+ args=(grads, wrapped_vars, name, experimental_aggregate_gradients))\n \n # Note: We must call this cond() in a cross-replica context.\n # DistributionStrategy does not support having a cond in a replica context\n@@ -257,9 +269,13 @@ def apply_fn():\n return control_flow_ops.group(maybe_apply_op, loss_scale_update_op)\n \n def _apply_gradients(self, grads, wrapped_vars, name,\n- all_reduce_sum_gradients):\n- return self._optimizer.apply_gradients(list(zip(grads, wrapped_vars.value)),\n- name, all_reduce_sum_gradients)\n+ experimental_aggregate_gradients):\n+ # TODO(reedwm): This will raise a fairly cryptic error message if\n+ # self._optimizer.apply_gradients does not take\n+ # experimental_aggregate_gradients.\n+ return self._optimizer.apply_gradients(\n+ list(zip(grads, wrapped_vars.value)), name,\n+ experimental_aggregate_gradients=experimental_aggregate_gradients)\n \n def get_config(self):\n serialized_optimizer = optimizers.serialize(self._optimizer)\n@@ -278,6 +294,14 @@ def from_config(cls, config, custom_objects=None):\n config['loss_scale'], custom_objects=custom_objects)\n return cls(**config)\n \n+ def _raise_if_strategy_unsupported(self):\n+ if not strategy_supports_loss_scaling():\n+ strategy = distribution_strategy_context.get_strategy()\n+ raise ValueError('Loss scaling is not supported with the '\n+ 'tf.distribute.Strategy: %s. Try using a different '\n+ 'Strategy, e.g. a MirroredStrategy' %\n+ strategy.__class__.__name__)\n+\n # Delegations: We delegate most OptimizerV2 methods to the wrapped optimizer\n # below.\n \n@@ -358,3 +382,25 @@ def add_slot(self, var, slot_name, initializer='zeros'):\n \n # TODO(reedwm): Maybe throw an error if mixed precision is used without this\n # optimizer being used.\n+\n+\n+def strategy_supports_loss_scaling():\n+ \"\"\"Returns True if the current Strategy supports loss scaling.\"\"\"\n+ if not distribution_strategy_context.has_strategy():\n+ return True\n+ strategy = distribution_strategy_context.get_strategy()\n+ # Strategies are supported if either there is only one replica or if variables\n+ # are replicated per device. Otherwise, the current model.fit() implementation\n+ # and most custom training loops incorrectly unscale the gradients. Currently,\n+ # gradients are unscaled once per compute replica, but they should be unscaled\n+ # once per variable replica. When there is one variable replica for each\n+ # compute replica, this works fine, but otherwise issues will occur.\n+ # TODO(reedwm): Support all strategies.\n+ return isinstance(strategy, (\n+ collective_all_reduce_strategy.CollectiveAllReduceStrategy,\n+ collective_all_reduce_strategy.CollectiveAllReduceStrategyV1,\n+ one_device_strategy.OneDeviceStrategy,\n+ one_device_strategy.OneDeviceStrategyV1,\n+ mirrored_strategy.MirroredStrategy,\n+ mirrored_strategy.MirroredStrategyV1,\n+ ))",
"filename": "tensorflow/python/keras/mixed_precision/experimental/loss_scale_optimizer.py",
"status": "modified"
},
{
"diff": "@@ -23,6 +23,7 @@\n from absl.testing import parameterized\n import numpy as np\n \n+from tensorflow.python.distribute import central_storage_strategy\n from tensorflow.python.distribute import distribution_strategy_context\n from tensorflow.python.distribute import mirrored_strategy\n from tensorflow.python.eager import context\n@@ -373,13 +374,15 @@ def testApplyGradientsGetsUnwrappedTensors(self):\n \n class MyOptimizer(gradient_descent.SGD):\n \n- def apply_gradients(self, grads_and_vars, name=None,\n- all_reduce_sum_gradients=True):\n+ def apply_gradients(self,\n+ grads_and_vars,\n+ name=None,\n+ experimental_aggregate_gradients=True):\n for grad, _ in grads_and_vars:\n outer_self.assertIsInstance(grad, ops.Tensor)\n return super(MyOptimizer,\n self).apply_gradients(grads_and_vars, name,\n- all_reduce_sum_gradients)\n+ experimental_aggregate_gradients)\n \n with create_mirrored_strategy().scope() as strategy:\n var = variables.Variable([5.0])\n@@ -499,6 +502,22 @@ def __init__(self, *args, **kwargs):\n self.assertEqual(opt.loss_scale.multiplier, 4.)\n self.assertEqual(opt._optimizer.my_attribute, 123)\n \n+ def testUnsupportedStrategy(self):\n+ strategy = central_storage_strategy.CentralStorageStrategy()\n+ expected_error = (\n+ 'Loss scaling is not supported with the tf.distribute.Strategy: '\n+ 'CentralStorageStrategy. Try using a different Strategy, e.g. a '\n+ 'MirroredStrategy')\n+ with strategy.scope(), self.assertRaisesRegexp(ValueError, expected_error):\n+ loss_scale_optimizer.LossScaleOptimizer(gradient_descent.SGD(), 1.)\n+ opt = loss_scale_optimizer.LossScaleOptimizer(gradient_descent.SGD(), 1.)\n+ with strategy.scope():\n+ var = variables.Variable(1.0)\n+ loss = lambda: var * 2.0\n+ run_fn = lambda: opt.minimize(loss, [var])\n+ with self.assertRaisesRegexp(ValueError, expected_error):\n+ strategy.experimental_run(run_fn)\n+\n \n if __name__ == '__main__':\n test.main()",
"filename": "tensorflow/python/keras/mixed_precision/experimental/loss_scale_optimizer_test.py",
"status": "modified"
},
{
"diff": "@@ -34,6 +34,7 @@ py_library(\n \"//tensorflow/python:variable_scope\",\n \"//tensorflow/python:variables\",\n \"//tensorflow/python/distribute:distribute_lib\",\n+ \"//tensorflow/python/distribute:parameter_server_strategy\",\n \"//tensorflow/python/distribute:reduce_util\",\n \"//tensorflow/python/distribute:values\",\n \"//tensorflow/python/keras:backend\",",
"filename": "tensorflow/python/keras/optimizer_v2/BUILD",
"status": "modified"
},
{
"diff": "@@ -58,7 +58,7 @@ class Adadelta(optimizer_v2.OptimizerV2):\n \n \"\"\"\n \n- _HAS_ALL_REDUCE_SUM_GRAD = True\n+ _HAS_AGGREGATE_GRAD = True\n \n def __init__(self,\n learning_rate=0.001,",
"filename": "tensorflow/python/keras/optimizer_v2/adadelta.py",
"status": "modified"
},
{
"diff": "@@ -54,7 +54,7 @@ class Adagrad(optimizer_v2.OptimizerV2):\n (https://ppasupat.github.io/a9online/uploads/proximal_notes.pdf).\n \"\"\"\n \n- _HAS_ALL_REDUCE_SUM_GRAD = True\n+ _HAS_AGGREGATE_GRAD = True\n \n def __init__(self,\n learning_rate=0.001,",
"filename": "tensorflow/python/keras/optimizer_v2/adagrad.py",
"status": "modified"
},
{
"diff": "@@ -45,7 +45,7 @@ class Adam(optimizer_v2.OptimizerV2):\n Reddi et al., 5-8](https://openreview.net/pdf?id=ryQu7f-RZ).\n \"\"\"\n \n- _HAS_ALL_REDUCE_SUM_GRAD = True\n+ _HAS_AGGREGATE_GRAD = True\n \n def __init__(self,\n learning_rate=0.001,",
"filename": "tensorflow/python/keras/optimizer_v2/adam.py",
"status": "modified"
},
{
"diff": "@@ -42,7 +42,7 @@ class Adamax(optimizer_v2.OptimizerV2):\n ([pdf](http://arxiv.org/pdf/1412.6980.pdf)).\n \"\"\"\n \n- _HAS_ALL_REDUCE_SUM_GRAD = True\n+ _HAS_AGGREGATE_GRAD = True\n \n def __init__(self,\n learning_rate=0.001,",
"filename": "tensorflow/python/keras/optimizer_v2/adamax.py",
"status": "modified"
},
{
"diff": "@@ -74,6 +74,8 @@ class SGD(optimizer_v2.OptimizerV2):\n http://jmlr.org/proceedings/papers/v28/sutskever13.pdf).\n \"\"\"\n \n+ _HAS_AGGREGATE_GRAD = True\n+\n def __init__(self,\n learning_rate=0.01,\n momentum=0.0,",
"filename": "tensorflow/python/keras/optimizer_v2/gradient_descent.py",
"status": "modified"
},
{
"diff": "@@ -61,7 +61,7 @@ class Nadam(optimizer_v2.OptimizerV2):\n See [Dozat, T., 2015](http://cs229.stanford.edu/proj2015/054_report.pdf).\n \"\"\"\n \n- _HAS_ALL_REDUCE_SUM_GRAD = True\n+ _HAS_AGGREGATE_GRAD = True\n \n def __init__(self,\n learning_rate=0.001,",
"filename": "tensorflow/python/keras/optimizer_v2/nadam.py",
"status": "modified"
},
{
"diff": "@@ -26,6 +26,7 @@\n import six\n \n from tensorflow.python.distribute import distribution_strategy_context as distribute_ctx\n+from tensorflow.python.distribute import parameter_server_strategy\n from tensorflow.python.distribute import reduce_util as ds_reduce_util\n from tensorflow.python.distribute import values as ds_values\n from tensorflow.python.eager import backprop\n@@ -160,8 +161,8 @@ class directly, but instead instantiate one of its subclasses such as\n `tf.keras.losses.Reduction.SUM` for not.\n \n To aggregate gradients yourself, call `apply_gradients` with\n- `all_reduce_sum_gradients` set to False. This is useful if you need to process\n- aggregated gradients.\n+ `experimental_aggregate_gradients` set to False. This is useful if you need to\n+ process aggregated gradients.\n \n If you are not using these and you want to average gradients, you should use\n `tf.math.reduce_sum` to add up your per-example losses and then divide by the\n@@ -230,13 +231,13 @@ class directly, but instead instantiate one of its subclasses such as\n \"\"\"\n \n # Subclasses should set this to True unless they override `apply_gradients`\n- # with a version that does not have the `all_reduce_sum_gradients` argument.\n- # Older versions of Keras did not have this argument so custom optimizers may\n- # have overridden `apply_gradients` without the `all_reduce_sum_gradients`\n- # argument. Keras only passes `all_reduce_sum_gradients` if this attribute is\n- # True.\n+ # with a version that does not have the `experimental_aggregate_gradients`\n+ # argument. Older versions of Keras did not have this argument so custom\n+ # optimizers may have overridden `apply_gradients` without the\n+ # `experimental_aggregate_gradients` argument. Keras only passes\n+ # `experimental_aggregate_gradients` if this attribute is True.\n # Note: This attribute will likely be removed in an upcoming release.\n- _HAS_ALL_REDUCE_SUM_GRAD = False\n+ _HAS_AGGREGATE_GRAD = False\n \n def __init__(self, name, **kwargs):\n \"\"\"Create a new Optimizer.\n@@ -432,31 +433,32 @@ def get_gradients(self, loss, params):\n def apply_gradients(self,\n grads_and_vars,\n name=None,\n- all_reduce_sum_gradients=True):\n+ experimental_aggregate_gradients=True):\n \"\"\"Apply gradients to variables.\n \n This is the second part of `minimize()`. It returns an `Operation` that\n applies gradients.\n \n The method sums gradients from all replicas in the presence of\n `tf.distribute.Strategy` by default. You can aggregate gradients yourself by\n- passing `all_reduce_sum_gradients=False`.\n+ passing `experimental_aggregate_gradients=False`.\n \n Example:\n \n ```python\n grads = tape.gradient(loss, vars)\n grads = tf.distribute.get_replica_context().all_reduce('sum', grads)\n # Processing aggregated gradients.\n- optimizer.apply_gradients(zip(grads, vars), all_reduce_sum_gradients=False)\n+ optimizer.apply_gradients(zip(grads, vars),\n+ experimental_aggregate_gradients=False)\n \n ```\n \n Args:\n grads_and_vars: List of (gradient, variable) pairs.\n name: Optional name for the returned operation. Default to the name passed\n to the `Optimizer` constructor.\n- all_reduce_sum_gradients: Whether to sum gradients from different\n+ experimental_aggregate_gradients: Whether to sum gradients from different\n replicas in the presense of `tf.distribute.Strategy`. If False, it's\n user responsibility to aggregate the gradients. Default to True.\n \n@@ -489,8 +491,16 @@ def apply_gradients(self,\n \"Use `tf.distribute.Strategy.experimental_run_v2` to enter replica \"\n \"context.\")\n \n+ strategy = distribute_ctx.get_strategy()\n+ if (not experimental_aggregate_gradients and strategy and isinstance(\n+ strategy.extended,\n+ parameter_server_strategy.ParameterServerStrategyExtended)):\n+ raise NotImplementedError(\n+ \"`experimental_aggregate_gradients=False is not supported for \"\n+ \"ParameterServerStrategy and CentralStorageStrategy\")\n+\n apply_state = self._prepare(var_list)\n- if all_reduce_sum_gradients:\n+ if experimental_aggregate_gradients:\n reduced_grads = self._aggregate_gradients(grads_and_vars)\n var_list = [v for _, v in grads_and_vars]\n grads_and_vars = list(zip(reduced_grads, var_list))",
"filename": "tensorflow/python/keras/optimizer_v2/optimizer_v2.py",
"status": "modified"
},
{
"diff": "@@ -623,30 +623,30 @@ def testEmptyVarList(self):\n \n @test_util.run_in_graph_and_eager_modes\n def testAggregationTrue(self):\n- # Test that all_reduce_sum_gradients=True works without distributed\n+ # Test that experimental_aggregate_gradients=True works without distributed\n # strategy.\n var = resource_variable_ops.ResourceVariable([1., 2.])\n opt = gradient_descent.SGD(3.0)\n \n self.evaluate(variables.global_variables_initializer())\n self.assertAllClose([1., 2.], self.evaluate(var))\n opt_op = opt.apply_gradients([([0.1, 0.1], var)],\n- all_reduce_sum_gradients=True)\n+ experimental_aggregate_gradients=True)\n self.evaluate(variables.global_variables_initializer())\n self.evaluate(opt_op)\n self.assertAllClose([0.7, 1.7], self.evaluate(var))\n \n @test_util.run_in_graph_and_eager_modes\n def testAggregationFalse(self):\n- # Test that all_reduce_sum_gradients=False works without distributed\n+ # Test that experimental_aggregate_gradients=False works without distributed\n # strategy.\n var = resource_variable_ops.ResourceVariable([1., 2.])\n opt = gradient_descent.SGD(3.0)\n \n self.evaluate(variables.global_variables_initializer())\n self.assertAllClose([1., 2.], self.evaluate(var))\n opt_op = opt.apply_gradients([([0.1, 0.1], var)],\n- all_reduce_sum_gradients=False)\n+ experimental_aggregate_gradients=False)\n self.evaluate(variables.global_variables_initializer())\n self.evaluate(opt_op)\n self.assertAllClose([0.7, 1.7], self.evaluate(var))",
"filename": "tensorflow/python/keras/optimizer_v2/optimizer_v2_test.py",
"status": "modified"
},
{
"diff": "@@ -79,7 +79,7 @@ class RMSprop(optimizer_v2.OptimizerV2):\n http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf).\n \"\"\"\n \n- _HAS_ALL_REDUCE_SUM_GRAD = True\n+ _HAS_AGGREGATE_GRAD = True\n \n def __init__(self,\n learning_rate=0.001,",
"filename": "tensorflow/python/keras/optimizer_v2/rmsprop.py",
"status": "modified"
},
{
"diff": "@@ -72,8 +72,8 @@ def __init__(self, **kwargs):\n self.weights = []\n \n # Set this to False, indicating `apply_gradients` does not take the\n- # `all_reduce_sum_gradients` argument.\n- _HAS_ALL_REDUCE_SUM_GRAD = False\n+ # `experimental_aggregate_gradients` argument.\n+ _HAS_AGGREGATE_GRAD = False\n \n def get_updates(self, loss, params):\n raise NotImplementedError",
"filename": "tensorflow/python/keras/optimizers.py",
"status": "modified"
},
{
"diff": "@@ -38,7 +38,7 @@ tf_class {\n }\n member_method {\n name: \"apply_gradients\"\n- argspec: \"args=[\\'self\\', \\'grads_and_vars\\', \\'name\\', \\'all_reduce_sum_gradients\\'], varargs=None, keywords=None, defaults=[\\'None\\', \\'True\\'], \"\n+ argspec: \"args=[\\'self\\', \\'grads_and_vars\\', \\'name\\', \\'experimental_aggregate_gradients\\'], varargs=None, keywords=None, defaults=[\\'None\\', \\'True\\'], \"\n }\n member_method {\n name: \"from_config\"",
"filename": "tensorflow/tools/api/golden/v1/tensorflow.keras.mixed_precision.experimental.-loss-scale-optimizer.pbtxt",
"status": "modified"
},
{
"diff": "@@ -26,7 +26,7 @@ tf_class {\n }\n member_method {\n name: \"apply_gradients\"\n- argspec: \"args=[\\'self\\', \\'grads_and_vars\\', \\'name\\', \\'all_reduce_sum_gradients\\'], varargs=None, keywords=None, defaults=[\\'None\\', \\'True\\'], \"\n+ argspec: \"args=[\\'self\\', \\'grads_and_vars\\', \\'name\\', \\'experimental_aggregate_gradients\\'], varargs=None, keywords=None, defaults=[\\'None\\', \\'True\\'], \"\n }\n member_method {\n name: \"from_config\"",
"filename": "tensorflow/tools/api/golden/v1/tensorflow.keras.optimizers.-adadelta.pbtxt",
"status": "modified"
},
{
"diff": "@@ -26,7 +26,7 @@ tf_class {\n }\n member_method {\n name: \"apply_gradients\"\n- argspec: \"args=[\\'self\\', \\'grads_and_vars\\', \\'name\\', \\'all_reduce_sum_gradients\\'], varargs=None, keywords=None, defaults=[\\'None\\', \\'True\\'], \"\n+ argspec: \"args=[\\'self\\', \\'grads_and_vars\\', \\'name\\', \\'experimental_aggregate_gradients\\'], varargs=None, keywords=None, defaults=[\\'None\\', \\'True\\'], \"\n }\n member_method {\n name: \"from_config\"",
"filename": "tensorflow/tools/api/golden/v1/tensorflow.keras.optimizers.-adagrad.pbtxt",
"status": "modified"
},
{
"diff": "@@ -26,7 +26,7 @@ tf_class {\n }\n member_method {\n name: \"apply_gradients\"\n- argspec: \"args=[\\'self\\', \\'grads_and_vars\\', \\'name\\', \\'all_reduce_sum_gradients\\'], varargs=None, keywords=None, defaults=[\\'None\\', \\'True\\'], \"\n+ argspec: \"args=[\\'self\\', \\'grads_and_vars\\', \\'name\\', \\'experimental_aggregate_gradients\\'], varargs=None, keywords=None, defaults=[\\'None\\', \\'True\\'], \"\n }\n member_method {\n name: \"from_config\"",
"filename": "tensorflow/tools/api/golden/v1/tensorflow.keras.optimizers.-adam.pbtxt",
"status": "modified"
},
{
"diff": "@@ -26,7 +26,7 @@ tf_class {\n }\n member_method {\n name: \"apply_gradients\"\n- argspec: \"args=[\\'self\\', \\'grads_and_vars\\', \\'name\\', \\'all_reduce_sum_gradients\\'], varargs=None, keywords=None, defaults=[\\'None\\', \\'True\\'], \"\n+ argspec: \"args=[\\'self\\', \\'grads_and_vars\\', \\'name\\', \\'experimental_aggregate_gradients\\'], varargs=None, keywords=None, defaults=[\\'None\\', \\'True\\'], \"\n }\n member_method {\n name: \"from_config\"",
"filename": "tensorflow/tools/api/golden/v1/tensorflow.keras.optimizers.-adamax.pbtxt",
"status": "modified"
}
]
}
|
{
"body": "**System information** \r\n- Have I written custom code (as opposed to using a stock\r\nexample script provided in TensorFlow): `No`\r\n- OS Platform and Distribution (e.g.,\r\nLinux Ubuntu 16.04): `Linux Debian GNU/Linux 9`\r\n- TensorFlow installed from (source or\r\nbinary): `binary`\r\n- TensorFlow version (use command below): `v1.15.2-1-g61ff2cb 1.15.2`\r\n- Python version: `3.7.6`\r\n- CUDA/cuDNN version: `CUDA 10, cuDNN 7.6.5`\r\n- GPU model and memory: `2x Tesla K80`\r\n\r\n**Describe the current behavior**\r\n\r\n`tf.metrics.mean_cosine_distance` fails at the end of distributed evaluation with `MirroredStrategy`:\r\n\r\n```\r\nTypeError: Fetch argument PerReplica:{\r\n 0 /replica:0/task:0/device:GPU:0: <tf.Tensor 'Sub:0' shape=() dtype=float32>,\r\n 1 /replica:0/task:0/device:GPU:1: <tf.Tensor 'replica_1/Sub:0' shape=() dtype=float32>\r\n} has invalid type <class 'tensorflow.python.distribute.values.PerReplica'>, must be a string or Tensor. (Can not convert a PerReplica into a Tensor or Operation.)\r\n```\r\n\r\nNon-distributed evaluation (that is, with `RunConfig.eval_distribute=None` or with a single GPU only) finishes without errors.\r\n\r\n**Standalone code to reproduce the issue** \r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\n\r\ndef model_fn(features, labels, mode):\r\n predictions = tf.layers.dense(features, 2)\r\n metrics = {'cos': tf.metrics.mean_cosine_distance(labels, predictions, 1)}\r\n return tf.estimator.EstimatorSpec(\r\n mode=mode,\r\n predictions=predictions,\r\n loss=tf.constant(0.1),\r\n train_op=None,\r\n eval_metric_ops=metrics)\r\n\r\n\r\ndef input_fn():\r\n dataset = tf.data.Dataset.from_tensor_slices(\r\n (np.array([[1., 1.]]), np.array([[2., 2.]])))\r\n dataset = dataset.repeat()\r\n dataset = dataset.batch(1, drop_remainder=True)\r\n return dataset\r\n\r\n\r\nif __name__ == '__main__':\r\n gpus = tf.config.experimental.list_physical_devices('GPU')\r\n assert len(gpus) > 1, 'Need >1 GPUs to run'\r\n strategy = tf.distribute.MirroredStrategy()\r\n run_config = tf.estimator.RunConfig(train_distribute=strategy,\r\n eval_distribute=strategy)\r\n\r\n estimator = tf.estimator.Estimator(model_fn=model_fn, config=run_config)\r\n print(estimator.evaluate(input_fn, steps=5))\r\n```\r\n\r\n**Other info / logs**: \r\n[logs_1_15.txt](https://github.com/tensorflow/tensorflow/files/4368761/logs_1_15.txt)\r\n",
"comments": [
{
"body": "@master \r\nAs we see there is a pr related to this issue, can we move this to closed status, as this will be monitored in pr #37828",
"created_at": "2020-03-23T11:02:22Z"
},
{
"body": "Sounds good, closing.",
"created_at": "2020-03-23T15:20:17Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37827\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37827\">No</a>\n",
"created_at": "2020-03-23T15:20:19Z"
}
],
"number": 37827,
"title": "tf.metrics.mean_cosine_distance fails during distributed evaluation"
}
|
{
"body": "Fix #37827",
"number": 37828,
"review_comments": [],
"title": "Fix metrics.mean_cosine_distance"
}
|
{
"commits": [
{
"message": "Fix metrics.mean_cosine_distance"
}
],
"files": [
{
"diff": "@@ -980,18 +980,9 @@ def mean_cosine_distance(labels,\n radial_diffs, axis=[\n dim,\n ], keepdims=True)\n- mean_distance, update_op = mean(radial_diffs, weights, None, None, name or\n- 'mean_cosine_distance')\n- mean_distance = math_ops.subtract(1.0, mean_distance)\n- update_op = math_ops.subtract(1.0, update_op)\n-\n- if metrics_collections:\n- ops.add_to_collections(metrics_collections, mean_distance)\n-\n- if updates_collections:\n- ops.add_to_collections(updates_collections, update_op)\n-\n- return mean_distance, update_op\n+ radial_diffs = math_ops.subtract(1.0, radial_diffs)\n+ return mean(radial_diffs, weights, metrics_collections, updates_collections,\n+ name or 'mean_cosine_distance')\n \n \n @tf_export(v1=['metrics.mean_per_class_accuracy'])",
"filename": "tensorflow/python/ops/metrics_impl.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 18.04):\r\n- TensorFlow installed from source:\r\n- TensorFlow version 2.1.0:\r\n\r\n\r\n**Command used to run the converter or code if you’re using the Python API**\r\nIf possible, please share a link to Colab/Jupyter/any notebook.\r\n\r\n```\r\nconverter = tf.lite.TFLiteConverter.from_saved_model(model_path)\r\ntflite_model = converter.convert()\r\n```\r\n\r\n**The output from the converter invocation**\r\n\r\n```\r\nValueError: This converter can only convert a single ConcreteFunction. Converting multiple functions is under development.\r\n```\r\n\r\n**Failure details**\r\nWhen attempting to convert a model in which no ConcreteFunctions have been defined, the error message implies that there are multiple.\r\n\r\nAs someone new coming to TF and TFLite, I found this very confusing as to where my concrete functions were being defined. \r\n\r\nInspecting the code from https://github.com/tensorflow/tensorflow/blob/v2.1.0/tensorflow/lite/python/lite.py in the ```convert``` method at line 417 the Value Error is thrown when anything but 1 concrete function is defined in the model (rightly so) but the error message implies that more than one have been defined.\r\n\r\n```\r\nif len(self._funcs) != 1:\r\n raise ValueError(\"This converter can only convert a single \"\r\n \"ConcreteFunction. Converting multiple functions is \"\r\n \"under development.\")\r\n```",
"comments": [
{
"body": "@PRDrum5 \r\n\r\nCan you please share the simple standalone code to reproduce the issue in our environment. It helps us in localizing the issue faster. Thanks!",
"created_at": "2020-02-27T06:35:10Z"
},
{
"body": "Sure\r\n\r\nHere I've made a simple model but not defined the input_signature for the tf.function for the `__call__` of the model. In doing so there is **no** concrete functions at all. But the error message which is returned implies that there are multiple and that this is the issue.\r\n\r\nMy suggestion is that the error thrown should be clear that in this scinario the user has not defined any concrete functions rather that suggesting that there exists more than one which is not the case.\r\n\r\n```\r\nimport tensorflow as tf\r\nfrom tensorflow.keras.layers import Dense\r\n\r\n\r\n# Define very simple classification model\r\nclass Model(tf.Module):\r\n def __init__(self):\r\n super(Model, self).__init__()\r\n\r\n self.d1 = Dense(2, activation='relu')\r\n self.d2 = Dense(2, activation='softmax')\r\n \r\n @tf.function\r\n def __call__(self, x):\r\n print(\"Tracing the model\")\r\n x = self.d1(x)\r\n return self.d2(x)\r\n\r\nmodel = Model()\r\n\r\nexample_data = tf.constant([[1.0, 2.0]])\r\npreds = model(example_data)\r\ntf.print(preds)\r\n\r\n# Save the model\r\ntf.saved_model.save(model, './model_example')\r\n\r\n\r\n# Load the saved model and convert to TFLite\r\nconverter = tf.lite.TFLiteConverter.from_saved_model('./model_example')\r\ntflite_model = converter.convert()\r\nopen(\"converted_model.tflite\", \"wb\").write(tflite_model)\r\n\r\n\r\n```",
"created_at": "2020-02-27T09:19:45Z"
},
{
"body": "I have tried on colab with TF version 2.1.0,2.2.0-dev20200227 and was able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/39a05cacd98c1c561c6c2b94f986db69/untitled683.ipynb). Thanks!",
"created_at": "2020-02-28T08:03:40Z"
},
{
"body": "@gargn for this case is it possible to provide the signature w/ the `from_saved_model` method? Or do they have to load the model and then explicitly call `from_concrete_functions`?",
"created_at": "2020-03-04T22:16:18Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37086\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37086\">No</a>\n",
"created_at": "2020-04-24T01:41:24Z"
}
],
"number": 37086,
"title": "Misleading convert error when no concrete functions are given"
}
|
{
"body": "resolves #37086 ",
"number": 37798,
"review_comments": [
{
"body": "I would also suggest to add descriptions here about when it will raise `No concrete func` and when it will raise `multiple concrete func`.",
"created_at": "2020-03-23T06:05:06Z"
},
{
"body": "nit:\r\n1) Can you remove the dashes (\"-\")\r\n2) Can you change the text to be simpler (you don't need to specify the text of the error in the docstring, just when the error can occur since the text can change over time):\r\n```\r\nNo concrete functions is specified.\r\nMultiple concrete functions are specified.\r\nInput shape is not specified.\r\nInvalid quantization parameters.\r\n```",
"created_at": "2020-04-22T16:17:30Z"
},
{
"body": "I have made that change.",
"created_at": "2020-04-22T16:35:56Z"
}
],
"title": "Fix: Misleading convert error when no concrete functions are given"
}
|
{
"commits": [
{
"message": "add check for 0 funcs and raise error"
},
{
"message": "fix typo"
},
{
"message": "add test and fix docstring"
},
{
"message": "update docstring"
}
],
"files": [
{
"diff": "@@ -516,12 +516,17 @@ def convert(self):\n \n Raises:\n ValueError:\n+ No concrete functions is specified.\n Multiple concrete functions are specified.\n Input shape is not specified.\n Invalid quantization parameters.\n \"\"\"\n # TODO(b/130297984): Add support for converting multiple function.\n- if len(self._funcs) != 1:\n+\n+ if len(self._funcs) == 0:\n+ raise ValueError(\"No ConcreteFunction is specified.\")\n+\n+ if len(self._funcs) > 1:\n raise ValueError(\"This converter can only convert a single \"\n \"ConcreteFunction. Converting multiple functions is \"\n \"under development.\")",
"filename": "tensorflow/lite/python/lite.py",
"status": "modified"
},
{
"diff": "@@ -468,6 +468,22 @@ def testMultipleFunctionModel(self):\n self.assertIn('This converter can only convert a single ConcreteFunction',\n str(error.exception))\n \n+ @test_util.run_v2_only\n+ def testNoConcreteFunctionModel(self):\n+ root = self._getMultiFunctionModel()\n+ input_data = tf.constant(1., shape=[1])\n+\n+ save_dir = os.path.join(self.get_temp_dir(), 'saved_model')\n+ save(root, save_dir)\n+\n+ converter = lite.TFLiteConverterV2.from_saved_model(save_dir)\n+ self.assertLen(converter._funcs, 0)\n+\n+ with self.assertRaises(ValueError) as error:\n+ _ = converter.convert()\n+ self.assertIn('No ConcreteFunction is specified.',\n+ str(error.exception))\n+\n @test_util.run_v2_only\n def testKerasSequentialModel(self):\n \"\"\"Test a simple sequential tf.Keras model.\"\"\"",
"filename": "tensorflow/lite/python/lite_v2_test.py",
"status": "modified"
}
]
}
|
{
"body": "System information\r\n\r\n Have I written custom code (as opposed to using a stock\r\n example script provided in TensorFlow): No\r\n OS Platform and Distribution (e.g.,\r\n Linux Ubuntu 16.04): Linux Mint 19.3 (ubuntu)\r\n TensorFlow installed from (source or\r\n binary): binatry\r\n TensorFlow version (use command below): both tf-nightly and tf-2.1\r\n Python version: 3.8 and 3.6\r\n\r\n**Describe the current behavior**\r\nwhen passing an int32 tensor to Sparce Tensor\r\nlast Error displayed is:\r\n```\r\nValueError: Unable to create eager SparseTensor. Check that your shape is correctly defined. Eager SparseTensors don't support unknown dimesions.\r\ngot shape:\r\n [4 4 4 4]\r\n```\r\nwhen looking back in stack trace, the right error is raced:\r\n\r\n`ValueError: Tensor conversion requested dtype int64 for Tensor with dtype int32: <tf.Tensor: shape=(4,), dtype=int32, numpy=array([4, 4, 4, 4], dtype=int32)>`\r\n\r\n\r\n**Describe the expected behavior**\r\none of the following:\r\n1) conversion should not fail\r\n2) last Error should be:\r\nexpected int64 tensor for shape argument got int32 tensor\r\n\r\n**Standalone code to reproduce the issue** \r\n```\r\nimport tensorflow as tf\r\n\r\nindices = tf.cast([[1,1,1,1],[1,3,1,1]],dtype=tf.int64)\r\nshape = tf.cast([4,4,4,4],dtype=tf.int64)\r\n\r\nheat_map = tf.SparseTensor(indices = indices, values = tf.ones(tf.shape(indices)[0]), dense_shape = shape)\r\n\r\nindices = tf.cast([[1,1,1,1],[1,3,1,1]],dtype=tf.int64)\r\nshape = tf.cast([4,4,4,4],dtype=tf.int32)\r\n\r\nheat_map = tf.SparseTensor(indices = indices, values = tf.ones(tf.shape(indices)[0]), dense_shape = shape)\r\n```\r\n\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\ndiagnose the problem. If including tracebacks, please include the full\r\ntraceback. Large logs and files should be attached.\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow/python/framework/sparse_tensor.py\", line 142, in __init__\r\n dense_shape, name=\"dense_shape\", dtype=dtypes.int64)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow/python/framework/ops.py\", line 1317, in convert_to_tensor\r\n (dtype.name, value.dtype.name, value))\r\nValueError: Tensor conversion requested dtype int64 for Tensor with dtype int32: <tf.Tensor: shape=(4,), dtype=int32, numpy=array([4, 4, 4, 4], dtype=int32)>\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/bhb/.vscode/extensions/ms-python.python-2020.2.64397/pythonFiles/ptvsd_launcher.py\", line 48, in <module>\r\n main(ptvsdArgs)\r\n File \"/home/bhb/.vscode/extensions/ms-python.python-2020.2.64397/pythonFiles/lib/python/old_ptvsd/ptvsd/__main__.py\", line 432, in main\r\n run()\r\n File \"/home/bhb/.vscode/extensions/ms-python.python-2020.2.64397/pythonFiles/lib/python/old_ptvsd/ptvsd/__main__.py\", line 316, in run_file\r\n runpy.run_path(target, run_name='__main__')\r\n File \"/usr/lib/python3.6/runpy.py\", line 263, in run_path\r\n pkg_name=pkg_name, script_name=fname)\r\n File \"/usr/lib/python3.6/runpy.py\", line 96, in _run_module_code\r\n mod_name, mod_spec, pkg_name, script_name)\r\n File \"/usr/lib/python3.6/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/test_sparce_tensor.py\", line 11, in <module>\r\n heat_map = tf.SparseTensor(indices = indices, values = tf.ones(tf.shape(indices)[0]), dense_shape = shape)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow/python/framework/sparse_tensor.py\", line 148, in __init__\r\n \"got shape:\\n {}\".format(dense_shape))\r\nValueError: Unable to create eager SparseTensor. Check that your shape is correctly defined. Eager SparseTensors don't support unknown dimesions.\r\ngot shape:\r\n [4 4 4 4]\r\nBeendet\r\n```\r\n",
"comments": [
{
"body": "@bela127,\r\nOn running the above code with [TF-nightly](https://colab.research.google.com/gist/amahendrakar/d1fd04827fc673713a0b728c20bc15a1/37640-tf-nightly.ipynb), I got an error stating\r\n`ValueError: Unable to create eager SparseTensor. Check that your shape is correctly defined. Eager SparseTensors don't support unknown dimesions.\r\ngot shape:\r\n [4 4 4 4]`\r\n\r\nHowever, with [TF2.1](https://colab.research.google.com/gist/amahendrakar/6bde0978e3a5a9ace8b36a36c40d4432/37640.ipynb), the error states \r\n`ValueError: Tensor conversion requested dtype int64 for Tensor with dtype int32: <tf.Tensor: shape=(4,), dtype=int32, numpy=array([4, 4, 4, 4], dtype=int32)>`\r\n\r\nIs the behavior for 2.1 as expected? Please find the attached gist. Thanks!",
"created_at": "2020-03-17T12:42:50Z"
},
{
"body": "2.1 behavior seems to be as expected.\r\nSo it seems only nightly has the miss leading Message.",
"created_at": "2020-03-17T18:54:44Z"
},
{
"body": "Was able to reproduce the issue with TF-2.2-rc0. Please find the gist [here](https://colab.research.google.com/gist/amahendrakar/1161b25237908e9a7d95aec53b2a0eb6/37640-2-2.ipynb). Thanks!",
"created_at": "2020-03-18T10:20:05Z"
},
{
"body": "I would like to fix this.\r\nwill be opening a PR soon.",
"created_at": "2020-03-19T14:51:01Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37640\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37640\">No</a>\n",
"created_at": "2020-04-22T15:26:03Z"
}
],
"number": 37640,
"title": "Sparce Tensor wrong exeption Message when passing argument with wrong Type"
}
|
{
"body": "resolves #37640 ",
"number": 37722,
"review_comments": [
{
"body": "I really don't like this type of error message parsing. This is super fragile.",
"created_at": "2020-03-23T15:37:46Z"
}
],
"title": "Fix: Sparce Tensor wrong exeption Message when passing argument with wrong Type"
}
|
{
"commits": [
{
"message": "raise error"
},
{
"message": "try fixingthe conflicts"
}
],
"files": [
{
"diff": "@@ -141,8 +141,11 @@ def __init__(self, indices, values, dense_shape):\n dense_shape = ops.convert_to_tensor(\n dense_shape, name=\"dense_shape\", dtype=dtypes.int64)\n dense_shape_default = tensor_shape.TensorShape(dense_shape)\n- except ValueError:\n- raise ValueError(\"Unable to create eager SparseTensor. Check that \"\n+ except ValueError as e:\n+ if \"Tensor conversion requested dtype int64\" in str(e):\n+ raise ValueError(e)\n+ else:\n+ raise ValueError(\"Unable to create eager SparseTensor. Check that \"\n \"your shape is correctly defined. Eager \"\n \"SparseTensors don't support unknown dimesions.\\n\"\n \"got shape:\\n {}\".format(dense_shape))",
"filename": "tensorflow/python/framework/sparse_tensor.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information** \r\n- Have I written custom code (as opposed to using a stock\r\nexample script provided in TensorFlow): Yes \r\n- OS Platform and Distribution: CentOS Linux 7.4\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if\r\nthe issue happens on mobile device: Unknown\r\n- TensorFlow installed from (source or binary):source \r\n- TensorFlow version (use command below): TF 2.0\r\n- Python version:3.7 \r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from\r\nsource): 8.3\r\n- CUDA/cuDNN version: None\r\n- GPU model and memory: None\r\n\r\n**Describe the current behavior**\r\nI build a graph, then call `AddSymbolicGradients` to generate gradients, but I found the order of generated gradients does not match inputs. My inputs are `[a,b]`, but the generated gradients are `[b_grad, a_grad]`\r\n**Describe the expected behavior**\r\ngradients order match inputs. Gradients of inputs `[a,b]` should be `[a_grad, b_grad]`\r\n\r\n**My work to solve the problem** \r\nI checked the code in tensorflow/cc/framework/gradients.cc [L532](https://github.com/tensorflow/tensorflow/blob/07112a5c7e233989652ecac3184f0dd640e1462b/tensorflow/cc/framework/gradients.cc#L532) \r\n```c++\r\n size_t dx_index = 0;\r\n for (const Edge* e : n->in_edges()) {\r\n if (e->IsControlEdge()) continue;\r\n if (dx_index == dx.size()) {\r\n return errors::Internal(\r\n \"Invalid gradient output index: \", dx_index, \" size: \", dx.size());\r\n }\r\n TF_RETURN_IF_ERROR(\r\n BackpropAlongEdge(dx[dx_index++], {e->src(), e->src_output()}));\r\n }\r\n```\r\nI think `dx_index` in code should be `e->dst_input()`, because `in_edges() `returns a `unordered_set` which order is not match `dx`, the input index of edge is `dst_input()`.The right code may be:\r\n```c++\r\nfor (const Edge* e : n->in_edges()) {\r\n if (e->IsControlEdge()) continue;\r\n int dx_index = e->dst_input();\r\n if (dx_index >= dx.size()) {\r\n return errors::Internal(\"Invalid gradient output index: \", dx_index, \" size: \", dx.size());\r\n }\r\n TF_RETURN_IF_ERROR(BackpropAlongEdge(dx[dx_index], {e->src(), e->src_output()}));\r\n }\r\n```\r\n\r\nAfter I modified the code, my program seems works fine.\r\n",
"comments": [
{
"body": "@buaasun \r\ncould you please provide us with simple stand alone code for us to replicate the issue faced by you.",
"created_at": "2020-03-16T07:19:39Z"
},
{
"body": "@Saduf2019 @gowthamkpr \r\nThis error occurs with a low probability. `n->in_edges()` returns EdgeSet which contains `std::set<Edge*>`, so `in_edges` are ordered by the pointer of Edge. In most cases, pointers are allocated sequentially, so it works. But when executed many times, the error occurs randomly.\r\n\r\nI write a simple unit test as below.\r\n```c++\r\n\r\n#include \"tensorflow/cc/client/client_session.h\"\r\n#include \"tensorflow/cc/framework/grad_op_registry.h\"\r\n#include \"tensorflow/cc/framework/gradients.h\"\r\n#include \"tensorflow/cc/framework/testutil.h\"\r\n#include \"tensorflow/cc/ops/standard_ops.h\"\r\n#include \"tensorflow/core/framework/graph.pb.h\"\r\n#include \"tensorflow/core/framework/node_def_util.h\"\r\n#include \"tensorflow/core/framework/tensor_testutil.h\"\r\n#include \"tensorflow/core/lib/core/status_test_util.h\"\r\n#include \"tensorflow/core/platform/test.h\"\r\n\r\nnamespace tensorflow {\r\nnamespace {\r\nusing namespace ops;\r\n\r\nclass GradientsTest : public ::testing::Test {\r\n protected:\r\n GradientsTest() {}\r\n\r\n void TestSingle(const Scope& scope) {\r\n int N = 5 + rand() % 10;\r\n // Construct forward graph.\r\n OutputList inputs;\r\n for (int i = 0; i < N; ++i) {\r\n auto a = Const(scope, i, {1});\r\n inputs.push_back(a);\r\n }\r\n\r\n auto pack = Stack(scope, inputs);\r\n TF_ASSERT_OK(scope.status());\r\n\r\n // Construct grad inputs.\r\n OutputList output_grads;\r\n Tensor ts(DT_INT32, {N, 1});\r\n auto v = ts.matrix<int32>();\r\n for (int i = 0; i < N; ++i) {\r\n v(i, 0) = i;\r\n }\r\n auto dy = Const(scope, ts);\r\n output_grads.push_back(dy);\r\n // Call AddSymbolicGradients.\r\n std::vector<Output> grad_outputs;\r\n TF_ASSERT_OK(AddSymbolicGradients(scope, {pack.output}, inputs, output_grads, &grad_outputs));\r\n ClientSession session((scope));\r\n std::vector<Tensor> in_grad;\r\n TF_ASSERT_OK(session.Run(grad_outputs, &in_grad));\r\n for (int i = 0; i < N; ++i) {\r\n test::ExpectTensorEqual<int>(in_grad[i], test::AsTensor<int>({i}, {1}));\r\n }\r\n }\r\n};\r\nTEST_F(GradientsTest, SubScopeTest) {\r\n Scope scope = Scope::NewRootScope();\r\n for (int cnt = 0; cnt < 1000; ++cnt) {\r\n LOG(INFO) << cnt;\r\n TestSingle(scope.NewSubScope(std::to_string(cnt)));\r\n }\r\n}\r\n\r\n} // namespace\r\n} // namespace tensorflow\r\n```\r\nAs in code, the test run 1000 cnts, about 5 of them failed.\r\n\r\n\r\n\r\n",
"created_at": "2020-03-17T05:54:39Z"
},
{
"body": "I don't work on TF anymore, sorry!",
"created_at": "2020-03-17T18:06:35Z"
},
{
"body": "Thanks for debugging this! Your proposal looks good. Would you like to send a PR for the fix?",
"created_at": "2020-03-17T23:32:14Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37593\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37593\">No</a>\n",
"created_at": "2020-03-20T21:00:33Z"
}
],
"number": 37593,
"title": "bug in C++ API \"AddSymbolicGradients\""
}
|
{
"body": "Fixes #37593 ",
"number": 37684,
"review_comments": [],
"title": "fix a bug in AddSymbolicGradients"
}
|
{
"commits": [
{
"message": "fix a bug in AddSymbolicGradients"
},
{
"message": "add unit test for bugfix"
}
],
"files": [
{
"diff": "@@ -521,15 +521,15 @@ Status SymbolicGradientBuilder::AddGradients() {\n // gradient function to the src node/output to which it should be\n // backpropped. Maybe grad functions can return a vector of Output pairs to\n // make this association explicit.\n- size_t dx_index = 0;\n for (const Edge* e : n->in_edges()) {\n if (e->IsControlEdge()) continue;\n- if (dx_index == dx.size()) {\n+ int dx_index = e->dst_input();\n+ if (dx_index >= dx.size()) {\n return errors::Internal(\n \"Invalid gradient output index: \", dx_index, \" size: \", dx.size());\n }\n TF_RETURN_IF_ERROR(\n- BackpropAlongEdge(dx[dx_index++], {e->src(), e->src_output()}));\n+ BackpropAlongEdge(dx[dx_index], {e->src(), e->src_output()}));\n }\n }\n ",
"filename": "tensorflow/cc/framework/gradients.cc",
"status": "modified"
},
{
"diff": "@@ -503,6 +503,42 @@ TEST_F(GradientsTest, MultiOutputNodeDependentOutputs) {\n EXPECT_EQ(grad_result[0].flat<float>()(0), 17610.0f);\n }\n \n+TEST_F(GradientsTest, AddSymbolicGradientsTest) {\n+ Scope scope = Scope::NewRootScope();\n+ for (int cnt = 0; cnt < 100; ++cnt) {\n+ int N = 5 + rand() % 10;\n+ // Construct forward graph.\n+ OutputList inputs;\n+ for (int i = 0; i < N; ++i) {\n+ auto a = Const(scope, i, {1});\n+ inputs.push_back(a);\n+ }\n+\n+ auto pack = Stack(scope, inputs);\n+ TF_ASSERT_OK(scope.status());\n+\n+ // Construct grad inputs.\n+ OutputList output_grads;\n+ Tensor ts(DT_INT32, {N, 1});\n+ auto v = ts.matrix<int32>();\n+ for (int i = 0; i < N; ++i) {\n+ v(i, 0) = i;\n+ }\n+ auto dy = Const(scope, ts);\n+ output_grads.push_back(dy);\n+ // Call AddSymbolicGradients.\n+ std::vector<Output> grad_outputs;\n+ TF_ASSERT_OK(AddSymbolicGradients(scope, {pack.output}, inputs,\n+ output_grads, &grad_outputs));\n+ ClientSession session((scope));\n+ std::vector<Tensor> in_grad;\n+ TF_ASSERT_OK(session.Run(grad_outputs, &in_grad));\n+ for (int i = 0; i < N; ++i) {\n+ test::ExpectTensorEqual<int>(in_grad[i], test::AsTensor<int>({i}, {1}));\n+ }\n+ }\n+}\n+\n // StopGradientSingleOutputMultiEdgeTest tests combinations of valid and\n // 'NoGradient' (induced by StopGradient op) returned along multiple edges from\n // a single nodes output.",
"filename": "tensorflow/cc/framework/gradients_test.cc",
"status": "modified"
}
]
}
|
{
"body": "- OS Platform and Distribution Macbook\r\n- TensorFlow installed from (source or binary): github latest bf282dece59bdf88f7a58bcf1064723cb3eea51e \r\n- TensorFlow version:trunk\r\n- Bazel version (if compiling from source): 1.0.0-homebrew\r\n- GCC/Compiler version (if compiling from source): Apple clang version 11.0.0 (clang-1100.0.33.8)\r\n\r\nRun ./tensorflow/lite/tools/make/build_lib.sh or ./tensorflow/lite/tools/make/build_ios_universal_lib.sh\r\nSame build problem:\r\n\r\ng++ -O3 -DNDEBUG -fPIC --std=c++11 -I. -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/../../../../../ -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/../../../../../../ -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/ -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/eigen -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/absl -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/gemmlowp -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/neon_2_sse -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/farmhash/src -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/flatbuffers/include -I -I/usr/local/include -c tensorflow/lite/experimental/ruy/block_map.cc -o /Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/gen/osx_x86_64/obj/tensorflow/lite/experimental/ruy/block_map.o\r\nIn file included from tensorflow/lite/core/api/op_resolver.cc:16:\r\nIn file included from ./tensorflow/lite/core/api/op_resolver.h:20:\r\n**./tensorflow/lite/schema/schema_generated.h:2660:8: error: ISO C++ forbids forward references to 'enum' types**\r\nIn file included from tensorflow/lite/core/api/flatbuffer_conversions.cc: enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {\r\n16:\r\n ^In file included from \r\n./tensorflow/lite/core/api/flatbuffer_conversions.h:24:\r\nIn file included from ./tensorflow/lite/core/api/op_resolver.h:20:\r\n**./tensorflow/lite/schema/schema_generated.h:2660:8: error: ISO C++ forbids forward references to 'enum' types**\r\n**./tensorflow/lite/schema/schema_generated.h:2660:32: error: field has incomplete type 'enum FlatBuffersVTableOffset'**\r\n enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {\r\n ^\r\n enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {\r\n",
"comments": [
{
"body": "Run ./tensorflow/lite/tools/make/download_dependencies.sh\r\n before build_lib.sh fixes the issue above, but still encounter error:\r\n\r\ng++ -O3 -DNDEBUG -fPIC --std=c++11 -I. -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/../../../../../ -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/../../../../../../ -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/ -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/eigen -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/absl -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/gemmlowp -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/neon_2_sse -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/farmhash/src -I/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/flatbuffers/include -I -I/usr/local/include -c tensorflow/lite/tools/make/downloads/absl/absl//types/optional.cc -o /Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/gen/osx_x86_64/obj/tensorflow/lite/tools/make/downloads/absl/absl//types/optional.o\r\ntensorflow/lite/tools/make/downloads/absl/absl//types/optional.cc:20:1: error: no type named 'init_t' in 'absl::nullopt_t'; did you mean\r\n 'optional_internal::init_t'?\r\nnullopt_t::init_t nullopt_t::init;\r\n^~~~~~~~~~~~~~~~~\r\noptional_internal::init_t\r\n/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/absl/absl/types/internal/optional.h:65:8: note: 'optional_internal::init_t' declared\r\n here\r\nstruct init_t {\r\n ^\r\ntensorflow/lite/tools/make/downloads/absl/absl//types/optional.cc:20:30: error: no member named 'init' in 'absl::nullopt_t'\r\nnullopt_t::init_t nullopt_t::init;\r\n ~~~~~~~~~~~^\r\ntensorflow/lite/tools/make/downloads/absl/absl//types/optional.cc:21:24: error: redeclaration of 'nullopt' with a different type: 'const absl::nullopt_t' vs\r\n 'const ::absl::internal::identity_t<nullopt_t> &' (aka 'const absl::nullopt_t &')\r\nextern const nullopt_t nullopt{nullopt_t::init};\r\n ^\r\n/Users/kmok/workspaces/tensorflow/tensorflow/lite/tools/make/downloads/absl/absl/types/optional.h:82:43: note: previous definition is here\r\nABSL_INTERNAL_INLINE_CONSTEXPR(nullopt_t, nullopt,\r\n ^\r\n3 errors generated.\r\n",
"created_at": "2019-11-04T19:28:55Z"
},
{
"body": "I have the same question at 'flatbuffer' and 'enum'. Please make sure that U **use the latest FLATTERBUFFER** so that _flatbuffers/flatbuffers.h has type 'FlatBuffersVTableOffset'._ I solve the problem with it. U can try it. Good Luck.",
"created_at": "2019-11-07T02:40:50Z"
},
{
"body": "It had nothing related to flatbuffer from the log , also the flatbuffer is downloaded by download_dependencies.sh, not using system one.",
"created_at": "2019-11-08T00:14:37Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33983\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33983\">No</a>\n",
"created_at": "2020-03-21T07:28:04Z"
}
],
"number": 33983,
"title": "Build error in Macbook (tensorflow lite)"
}
|
{
"body": "It takes me a lot time to fix this issue:\r\n\r\n```\r\n./tensorflow/lite/schema/schema_generated.h:21:37: fatal error: flatbuffers/flatbuffers.h: No such file or directory\r\n```\r\nAnd finally, I found this: https://www.tensorflow.org/lite/guide/build_rpi\r\nSo there is a missing command to download dependencies before build in the README file.\r\n\r\nBy the way, this pr should close #33983 and close #34423",
"number": 37677,
"review_comments": [],
"title": "Add missing dependencies download command"
}
|
{
"commits": [
{
"message": "Add missing dependencies download command"
}
],
"files": [
{
"diff": "@@ -8,6 +8,7 @@ Python without requiring the rest of TensorFlow.\n To build a binary wheel run this script:\n ```\n sudo apt install swig libjpeg-dev zlib1g-dev python3-dev python3-numpy\n+sh tensorflow/lite/tools/make/download_dependencies.sh\n sh tensorflow/lite/tools/pip_package/build_pip_package.sh\n ```\n That will print out some output and a .whl file. You can then install that",
"filename": "tensorflow/lite/tools/pip_package/README.md",
"status": "modified"
}
]
}
|
{
"body": "**Describe the current behavior**\r\n\r\nJSON saved by Keras contains `NaN` which is invalid according to [RFC 7159](https://tools.ietf.org/html/rfc7159):\r\n\r\n> \"Numeric values that cannot be represented in the grammar below (such as Infinity and NaN) are not permitted.\"\r\n\r\n**Describe the expected behavior**\r\n\r\nKeras saves correct JSON format.\r\n\r\n**Standalone code to reproduce the issue** \r\n\r\n```\r\nimport tensorflow as tf\r\ni = tf.keras.layers.Input((600,600,3))\r\no = tf.keras.layers.Conv2D(16, (3, 3), padding='same', name='conv0',\r\n kernel_regularizer=tf.keras.regularizers.l2(1e-2),\r\n bias_regularizer=tf.keras.regularizers.l2(None),\r\n kernel_initializer=tf.keras.initializers.RandomNormal(stddev=0.01),\r\n bias_initializer=tf.keras.initializers.constant(0.0))(i)\r\nmodel = tf.keras.models.Model(i, o)\r\nwith open('repro.json', 'w') as json_file:\r\n json_file.write(model.to_json())\r\n```\r\n\r\n```\r\n~ node\r\n> JSON.parse(require('fs').readFileSync('repro.json', 'utf-8'))\r\nUncaught SyntaxError: Unexpected token N in JSON at position 861 \r\n```\r\n\r\n[repro.zip](https://github.com/tensorflow/tensorflow/files/4270871/repro.zip)\r\n\r\nlutzroeder/netron#435\r\n",
"comments": [
{
"body": "I was able to replicate the issue Tf 2.1.\r\nPlease find the gist [here](https://colab.sandbox.google.com/gist/gadagashwini/d029a1da140e81b7b510335a0acf23db/untitled.ipynb). Thanks!",
"created_at": "2020-03-04T09:00:51Z"
},
{
"body": "@lutzroeder @gadagashwini I am willing to take a closer look, fix it and send a PR.",
"created_at": "2020-03-13T02:34:58Z"
},
{
"body": "@lutzroeder @gadagashwini \r\n\r\nThis bug is caused by `tf.keras.regularizers.l2` which will convert `None` to JSON string when `model.to_json` is called. \r\n`None` will convert to NumPy float first, it will be a `np.nan`. \r\nThen `np.nan` will be converted to Python float, it will be `float('nan')`. \r\nFinally, `float('nan')` will be converted to a JSON string, python's built-in JSON library allow dump `float('nan')` to string as `NaN` (https://docs.python.org/3.6/library/json.html#infinite-and-nan-number-values). \r\n\r\nA gist for this can be found [here](https://colab.research.google.com/drive/1bOOODHoS9T1_gvFNA8PhqsSQigsj35__).\r\n\r\n@lutzroeder Use `tf.keras.regularizers.l2(0)` instead of `tf.keras.regularizers.l2(None)` can fix you problem. \r\n\r\nI will submit a PR later to make sure `tf.keras.regularizers.l2` don't accept None.\r\n",
"created_at": "2020-03-16T06:57:27Z"
},
{
"body": "Does this same issue apply to `tf.keras.layers.BatchNormalization()`?\r\nI'm using the Pix2Pix example code and having a similar problem with NaN values in my one set of weights and in my model.json when created with tfjs.",
"created_at": "2020-04-19T05:50:15Z"
},
{
"body": "Hi @clkruse, If your arguments contain None which not supposed to be. It's likely to be the same issue. ",
"created_at": "2020-04-19T07:45:43Z"
},
{
"body": "@clkruse Can you submit an issue for your problem, so I can check and fix it.",
"created_at": "2020-06-02T07:57:12Z"
},
{
"body": "@howl-anderson I have an issue out for my version of the problem in #38698. \r\n\r\nNote: the error only seems to occur when batchnorm is used with a batch size of 1. ",
"created_at": "2020-06-03T05:34:36Z"
},
{
"body": "@clkruse I will take a close look to see if I can fix it.",
"created_at": "2020-06-03T05:48:19Z"
},
{
"body": "@lutzroeder can you confirm if your issue is fixed with the above commit by @howl-anderson , if so please close the issue.",
"created_at": "2020-07-13T20:50:02Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37196\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37196\">No</a>\n",
"created_at": "2020-07-13T23:04:35Z"
}
],
"number": 37196,
"title": "Keras saves invalid JSON files containing NaN"
}
|
{
"body": "Use `numpy.asarray_chkfinite` instead of `numpy.asarray` in `tf.keras.backend.cast_to_floatx`.\r\n\r\nIt can help prevent user pass value which contains None, `inf`, `np.nan` or `np.inf` as input.\r\n\r\nrelated to issue #37196\r\nfixes #37627",
"number": 37634,
"review_comments": [],
"title": "[Feature] use np.asarray_chkfinite in tf.keras.backend.cast_to_floatx"
}
|
{
"commits": [
{
"message": "feat: use np.asarray_chkfinite in tf.keras.backend.cast_to_floatx"
}
],
"files": [
{
"diff": "@@ -196,7 +196,7 @@ def cast_to_floatx(x):\n variables_module.Variable,\n sparse_tensor.SparseTensor)):\n return math_ops.cast(x, dtype=floatx())\n- return np.asarray(x, dtype=floatx())\n+ return np.asarray_chkfinite(x, dtype=floatx())\n \n \n # A global dictionary mapping graph objects to an index of counters used",
"filename": "tensorflow/python/keras/backend.py",
"status": "modified"
}
]
}
|
{
"body": "**System information** \r\n- Have I written custom code \r\n- OS Platform and Distribution: *Google Colab*\r\n- TensorFlow version: *2.1.0*\r\n- Keras: *2.2.4-tf*\r\n- Python version: *3* \r\n- CUDA/cuDNN version: No GPU but happens also with it\r\n\r\n**Describe the current behavior**\r\nWhen a CustomCallback uses `model.predict` or `model.evaluate` as part of `on_epoch_end`, to for example, track a custom evaluation metric on an test dataset, `model.stop_training` is reset to False even if it was previously set to True by Early Stopping. Training does not stop. Current workaround is putting EarlyStopping as the last callback of the list.\r\n\r\n**Describe the expected behavior**\r\nRegardless the order in which callbacks are called, if one of the sets the model to stop training it should stop even if a later callback resets the stop flag.\r\n\r\n**Standalone code to reproduce the issue** \r\nCheck this colab with the full example: https://colab.research.google.com/drive/1lw943Ggwkp_wvGxVX-5XqaEJ5qXmrHlA\r\n\r\nIn short:\r\n```\r\nclass MyCallback(keras.callbacks.Callback):\r\n def __init__(self, test_data):\r\n super(MyCallback, self).__init__()\r\n self.test_data = test_data\r\n\r\n def on_epoch_end(self, epoch, logs=None):\r\n print(f\"\\n--------- pre-predict stop_training={self.model.stop_training}\\n\")\r\n #The problem is in the prediction: if commented ES works fine\r\n predictions = self.model.predict(self.test_data.batch(512))\r\n print(f\"\\n--------- post-predict stop_training={self.model.stop_training}\\n\")\r\n```\r\n```\r\nes = keras.callbacks.EarlyStopping(patience=2)\r\nmyc = MyCallback(test_data)\r\n\r\n#This causes EarlyStop not to stop\r\nmy_callbacks = [es, myc]\r\n#Either of these works fine\r\n#my_callbacks = [myc, es]\r\n#my_callbacks = [es]\r\n...\r\nmodel.fit(train_data.batch(512),\r\n validation_data=validation_data.batch(512),\r\n epochs=100,\r\n callbacks=my_callbacks,\r\n verbose=1)\r\n```\r\n\r\nThis issue is refered also in the keras repository: https://github.com/keras-team/keras/issues/13381\r\n\r\nSome thoughts: I'm not sure if the correct solution would be to discourage the use of predict or evaluate inside a training loop since there may be some other side effects of running one of those to the model.\r\n\r\nAnyway, I'm opening the issue and submitting a pull request to fix this.\r\n",
"comments": [
{
"body": "I am able to reproduce the issue with Tf 2.1.\r\nPlease find the gist [here](https://colab.sandbox.google.com/gist/gadagashwini/756228eeeca347ffa8f4a40cd662d7f1/untitled457.ipynb). Thanks!",
"created_at": "2020-03-16T07:30:41Z"
},
{
"body": "As suggested on the [pull request](https://github.com/tensorflow/tensorflow/pull/37588) it's now fixed on v2.2rc0 and current master. Closing the issue. Thanks! ",
"created_at": "2020-03-17T01:13:11Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37587\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37587\">No</a>\n",
"created_at": "2020-03-17T01:13:12Z"
}
],
"number": 37587,
"title": "EarlyStopping Callback not working with Multiple Callbacks"
}
|
{
"body": "When a CustomCallback uses internally model.predict or model.evaluate as part of on_epoch_end, for instance, to track a custom evaluation on an test dataset, model.stop_training is reset to False even if it was previously set to True by Early Stopping. And then the training does not stop. Current workaround is putting EarlyStopping as the last callback of the list.\r\n\r\nCheck this colab with the full example: https://colab.research.google.com/drive/1lw943Ggwkp_wvGxVX-5XqaEJ5qXmrHlA\r\n\r\nThis patch fixes this by checking first if stop_training exists, and only if it doesn't, it initializes it to False. \r\nFixes #37587",
"number": 37588,
"review_comments": [],
"title": "Fixing issue with EarlyStopping not working after CustomCallback"
}
|
{
"commits": [
{
"message": "Fixing CustomCallback that uses model.predict or model.evaluate resets stop_training so EarlyStopping does not works"
}
],
"files": [
{
"diff": "@@ -117,7 +117,9 @@ def configure_callbacks(callbacks,\n verbose=verbose,\n mode=mode)\n \n- callback_list.model.stop_training = False\n+ if not hasattr(callback_list.model, 'stop_training'):\n+ callback_list.model.stop_training = False\n+\n return callback_list\n \n ",
"filename": "tensorflow/python/keras/callbacks.py",
"status": "modified"
},
{
"diff": "@@ -741,7 +741,8 @@ def on_start(self, model, callbacks=None, use_samples=False, verbose=0,\n model, 'samples' if use_samples else 'steps')\n progbar.params = callbacks.params\n progbar.params['verbose'] = verbose\n- callbacks.model.stop_training = False\n+ if not hasattr(callbacks.model, 'stop_training'):\n+ callbacks.model.stop_training = False\n callbacks._call_begin_hook(mode)\n progbar.on_train_begin()\n ",
"filename": "tensorflow/python/keras/engine/training_v2.py",
"status": "modified"
}
]
}
|
{
"body": "**System information** \r\n- Have I written custom code (as opposed to using example directory): \r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Win 10 & Linux Ubuntu18.04\r\n- Tensorflow backend (yes/no): yes\r\n- TensorFlow version:1.15.0(CPU)\r\n- Python version: 3.6.9\r\n- CUDA/cuDNN version: -\r\n- GPU model and memory: -\r\n\r\n**Describe the current behavior** \r\nWhen I build a model with unreasonable parameters `Conv2D(kernel_size=0)` on TensorFlow, **it can run normally and even generate/save an model** . When I use this model to predict, Tensorflow spend about 5 minutes and still can't return an output.\r\n`Conv2D(kernel_size=0)` seems like a corner case because **in the convolution operation, it is impossible to calculate with `kernel_size=0`**\r\n\r\nDoes `kernel_size=0` have some special meaning in Tensorflow? I have not found any description about this case in documents. If no special meaning, **Should Tensorflow set a check for such unreasonable parameters to avoid the risks and incorrect usages in the model?** \r\n\r\n**Code to reproduce the issue** \r\n\r\n```\r\nimport os\r\nimport numpy as np\r\nimport keras.layers as L\r\nfrom keras.models import load_model\r\nfrom keras.engine import Model, Input\r\n\r\nkwargs = {'filters': 19, 'kernel_size': 0, 'padding': 'valid', 'strides': (2, 4), 'dilation_rate': 1, 'data_format': 'channels_first'}\r\ninput = (10 * np.random.random((1,32,32,16)))\r\nlayer = L.convolutional.Conv2D(**kwargs)\r\nx = Input(batch_shape=input.shape)\r\ny = layer(x)\r\nbk_model = Model(x, y)\r\nmodel_path = os.path.join('./', 'model.h5')\r\nbk_model.save(model_path, bk_model)\r\nmodel = load_model(model_path)\r\noutput = model.predict(input)\r\nprint('finish')\r\n```",
"comments": [
{
"body": "@shiningrain \r\nI have run the code shared by you and it executes as expected, please find[ gist here](https://colab.sandbox.google.com/gist/Saduf2019/002a441ed92036884b41ae5a9f104210/37334.ipynb)\r\nFor kernel_size related information please refer to [this link](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2D#arguments_2), also please refer to this link if it [helps](https://github.com/cwehmeyer/pydpc/issues/2#issuecomment-510912684)",
"created_at": "2020-03-05T07:58:25Z"
},
{
"body": "> @shiningrain\r\n> I have run the code shared by you and it executes as expected, please find[ gist here](https://colab.sandbox.google.com/gist/Saduf2019/002a441ed92036884b41ae5a9f104210/37334.ipynb)\r\n> For kernel_size related information please refer to [this link](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2D#arguments_2), also please refer to this link if it [helps](https://github.com/cwehmeyer/pydpc/issues/2#issuecomment-510912684)\r\n\r\nHi! @Saduf2019 \r\nThanks for your help!\r\nHowever, I still have some problems with your reply.\r\n1. I have read your reproduced code, but the `kernel_size` in it is set to 1, which is not the problem I want to explain. I have also tested with `kernel_size = 1` and it did work properly. Here I want to focusing on illogical inputs such as `kernel_size = 0.`\r\n2. The description of `kernel_size` in the TensorFlow document you gave just said that **the value can be an integer or an integer tuple**. **The value of 0 does conform to what the document says**, so at least the document is not precise.\r\n3. The [last link](https://github.com/cwehmeyer/pydpc/issues/2) you gave seems to have nothing to do with the convolution operation and does not reflect how TensorFlow handle with the illogical operation such as `kenel_size = 0`.\r\n\r\nTo sum up, I mean that TensorFlow can still generate models and make predictions with illogical parameters such as `kenel_size = 0`. This should be an implementation issue. Developers should consider this situation to check its value or at least set a default value to avoid such problems.\r\n\r\n**Hope to receive your response and thank you very much for your help**",
"created_at": "2020-03-05T09:03:21Z"
},
{
"body": "please find the [gist](https://colab.sandbox.google.com/gist/Saduf2019/04e40b481d05e6a0c2e36ef9c0887ae6/37334.ipynb) for kernel_size=0",
"created_at": "2020-03-05T09:25:56Z"
},
{
"body": "This has been fixed with tf-nightly version.\r\nhttps://github.com/tensorflow/tensorflow/blob/84eb083bb5328912dde064b8b0f61d28c6edbe43/tensorflow/python/keras/layers/convolutional.py#L132\r\ncommit 1e102f63964365d82d7f22402b7ba21e0e0e64fe",
"created_at": "2020-03-16T23:25:39Z"
},
{
"body": "The problem still exists if I use nn module or other tensorflow clients. e.g node.js,Java, CPP",
"created_at": "2020-03-19T14:17:37Z"
},
{
"body": "@fsx950223 Can you please create a new issue and provide your repro example? Also refer this issue on the new thread. Thanks!",
"created_at": "2020-03-20T23:21:43Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37334\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37334\">No</a>\n",
"created_at": "2020-03-23T19:51:46Z"
}
],
"number": 37334,
"title": "Tensorflow can build and even run a model with `Conv2D('Kernel_size=0' )`"
}
|
{
"body": "fixes issue #37334",
"number": 37395,
"review_comments": [
{
"body": "share this with other conv layers?",
"created_at": "2020-03-17T03:58:09Z"
},
{
"body": "remove",
"created_at": "2020-03-18T08:48:06Z"
},
{
"body": "try with assertRaisesException",
"created_at": "2020-03-18T08:48:50Z"
},
{
"body": "why do we need this file here?",
"created_at": "2020-03-18T08:49:01Z"
},
{
"body": "this is a very weird return value....the previous implementation looks mostly good, simply just check without returning anything",
"created_at": "2020-03-19T13:50:48Z"
},
{
"body": "Can I use some other return value like(\"True\") as some kind of check needs to be performed before super(Conv1D) is called? Else the super() function will be called at any cost and the problem addressed in #37334 will still exist.",
"created_at": "2020-03-19T14:10:25Z"
},
{
"body": "why not use that in some base layer, or a regular function?",
"created_at": "2020-03-20T00:43:48Z"
},
{
"body": "this indent doesn't seem correct.",
"created_at": "2020-03-20T00:43:53Z"
},
{
"body": "I had implemented the function in base class Conv.",
"created_at": "2020-03-20T04:03:26Z"
}
],
"title": "Puts a ckeck on kernel_size=0 and raises an error if kernel_size=0 in conv2D"
}
|
{
"commits": [
{
"message": "Create pythonpackage.yml"
},
{
"message": "fixes zero kernel size"
},
{
"message": "Puts check on kernel_size=0"
},
{
"message": "raise valueerror when kernel_size=0"
},
{
"message": "fixes indentation bug"
},
{
"message": "adds check on all the conv1d, conv2d and conv3d"
},
{
"message": "unitTest.py"
},
{
"message": "All convolution classes kernel_size=0 check"
},
{
"message": "unit test"
},
{
"message": "Delete pythonpackage.yml"
},
{
"message": "remove return"
},
{
"message": "Merge branch 'master' of https://github.com/ghosalsattam/tensorflow"
},
{
"message": "implemented check in the base class"
}
],
"files": [
{
"diff": "@@ -147,6 +147,20 @@ def __init__(self, rank,\n self.kernel_constraint = constraints.get(kernel_constraint)\n self.bias_constraint = constraints.get(bias_constraint)\n self.input_spec = InputSpec(ndim=self.rank + 2)\n+ \n+ \n+ \n+ def checkProperKernel(self,kernel_size):\n+ \n+ if(isinstance(kernel_size,tuple)):\n+ \t for i in kernel_size:\n+ \t\t if(i==0):\n+ \t\t\t raise ValueError(\"Kernel dimension cannot be zero\")\n+ else:\n+ \t if(kernel_size==0):\n+ \n+ raise ValueError(\"Kernel size cannot be zero\")\n+ return \n \n def build(self, input_shape):\n input_shape = tensor_shape.TensorShape(input_shape)\n@@ -426,24 +440,35 @@ def __init__(self,\n kernel_constraint=None,\n bias_constraint=None,\n **kwargs):\n+ self.checkProperKernel(kernel_size)\n+ #if(rv==0):\n super(Conv1D, self).__init__(\n- rank=1,\n- filters=filters,\n- kernel_size=kernel_size,\n- strides=strides,\n- padding=padding,\n- data_format=data_format,\n- dilation_rate=dilation_rate,\n- activation=activations.get(activation),\n- use_bias=use_bias,\n- kernel_initializer=initializers.get(kernel_initializer),\n- bias_initializer=initializers.get(bias_initializer),\n- kernel_regularizer=regularizers.get(kernel_regularizer),\n- bias_regularizer=regularizers.get(bias_regularizer),\n- activity_regularizer=regularizers.get(activity_regularizer),\n- kernel_constraint=constraints.get(kernel_constraint),\n- bias_constraint=constraints.get(bias_constraint),\n- **kwargs)\n+ rank=1,\n+ filters=filters,\n+ kernel_size=kernel_size,\n+ strides=strides,\n+ padding=padding,\n+ data_format=data_format,\n+ dilation_rate=dilation_rate,\n+ activation=activations.get(activation),\n+ use_bias=use_bias,\n+ kernel_initializer=initializers.get(kernel_initializer),\n+ bias_initializer=initializers.get(bias_initializer),\n+ kernel_regularizer=regularizers.get(kernel_regularizer),\n+ bias_regularizer=regularizers.get(bias_regularizer),\n+ activity_regularizer=regularizers.get(activity_regularizer),\n+ kernel_constraint=constraints.get(kernel_constraint),\n+ bias_constraint=constraints.get(bias_constraint),\n+ **kwargs)\n+ \n+ \n+ \n+ \n+\n+\n+ \n+ \n+ \n \n \n @keras_export('keras.layers.Conv2D', 'keras.layers.Convolution2D')\n@@ -561,7 +586,7 @@ class Conv2D(Conv):\n ValueError: if `padding` is \"causal\".\n ValueError: when both `strides` > 1 and `dilation_rate` > 1.\n \"\"\"\n-\n+ \n def __init__(self,\n filters,\n kernel_size,\n@@ -579,24 +604,32 @@ def __init__(self,\n kernel_constraint=None,\n bias_constraint=None,\n **kwargs):\n+ self.checkProperKernel(kernel_size)\n+ #if(rv==0):\n+ \n super(Conv2D, self).__init__(\n- rank=2,\n- filters=filters,\n- kernel_size=kernel_size,\n- strides=strides,\n- padding=padding,\n- data_format=data_format,\n- dilation_rate=dilation_rate,\n- activation=activations.get(activation),\n- use_bias=use_bias,\n- kernel_initializer=initializers.get(kernel_initializer),\n- bias_initializer=initializers.get(bias_initializer),\n- kernel_regularizer=regularizers.get(kernel_regularizer),\n- bias_regularizer=regularizers.get(bias_regularizer),\n- activity_regularizer=regularizers.get(activity_regularizer),\n- kernel_constraint=constraints.get(kernel_constraint),\n- bias_constraint=constraints.get(bias_constraint),\n- **kwargs)\n+ rank=2,\n+ filters=filters,\n+ kernel_size=kernel_size,\n+ strides=strides,\n+ padding=padding,\n+ data_format=data_format,\n+ dilation_rate=dilation_rate,\n+ activation=activations.get(activation),\n+ use_bias=use_bias,\n+ kernel_initializer=initializers.get(kernel_initializer),\n+ bias_initializer=initializers.get(bias_initializer),\n+ kernel_regularizer=regularizers.get(kernel_regularizer),\n+ bias_regularizer=regularizers.get(bias_regularizer),\n+ activity_regularizer=regularizers.get(activity_regularizer),\n+ kernel_constraint=constraints.get(kernel_constraint),\n+ bias_constraint=constraints.get(bias_constraint),\n+ **kwargs)\n+ \n+ \n+ \n+ \n+ \n \n \n @keras_export('keras.layers.Conv3D', 'keras.layers.Convolution3D')\n@@ -723,24 +756,34 @@ def __init__(self,\n kernel_constraint=None,\n bias_constraint=None,\n **kwargs):\n+ self.checkProperKernel(kernel_size)\n+ #if(rv==0):\n super(Conv3D, self).__init__(\n- rank=3,\n- filters=filters,\n- kernel_size=kernel_size,\n- strides=strides,\n- padding=padding,\n- data_format=data_format,\n- dilation_rate=dilation_rate,\n- activation=activations.get(activation),\n- use_bias=use_bias,\n- kernel_initializer=initializers.get(kernel_initializer),\n- bias_initializer=initializers.get(bias_initializer),\n- kernel_regularizer=regularizers.get(kernel_regularizer),\n- bias_regularizer=regularizers.get(bias_regularizer),\n- activity_regularizer=regularizers.get(activity_regularizer),\n- kernel_constraint=constraints.get(kernel_constraint),\n- bias_constraint=constraints.get(bias_constraint),\n- **kwargs)\n+ rank=3,\n+ filters=filters,\n+ kernel_size=kernel_size,\n+ strides=strides,\n+ padding=padding,\n+ data_format=data_format,\n+ dilation_rate=dilation_rate,\n+ activation=activations.get(activation),\n+ use_bias=use_bias,\n+ kernel_initializer=initializers.get(kernel_initializer),\n+ bias_initializer=initializers.get(bias_initializer),\n+ kernel_regularizer=regularizers.get(kernel_regularizer),\n+ bias_regularizer=regularizers.get(bias_regularizer),\n+ activity_regularizer=regularizers.get(activity_regularizer),\n+ kernel_constraint=constraints.get(kernel_constraint),\n+ bias_constraint=constraints.get(bias_constraint),\n+ **kwargs)\n+ \n+ \n+ \n+ \n+ \n+\n+ \n+\n \n \n @keras_export('keras.layers.Conv2DTranspose',\n@@ -871,23 +914,25 @@ def __init__(self,\n kernel_constraint=None,\n bias_constraint=None,\n **kwargs):\n+ self.checkProperKernel(kernel_size)\n+ #if(rv==0):\n super(Conv2DTranspose, self).__init__(\n- filters=filters,\n- kernel_size=kernel_size,\n- strides=strides,\n- padding=padding,\n- data_format=data_format,\n- dilation_rate=dilation_rate,\n- activation=activations.get(activation),\n- use_bias=use_bias,\n- kernel_initializer=initializers.get(kernel_initializer),\n- bias_initializer=initializers.get(bias_initializer),\n- kernel_regularizer=regularizers.get(kernel_regularizer),\n- bias_regularizer=regularizers.get(bias_regularizer),\n- activity_regularizer=regularizers.get(activity_regularizer),\n- kernel_constraint=constraints.get(kernel_constraint),\n- bias_constraint=constraints.get(bias_constraint),\n- **kwargs)\n+ filters=filters,\n+ kernel_size=kernel_size,\n+ strides=strides,\n+ padding=padding,\n+ data_format=data_format,\n+ dilation_rate=dilation_rate,\n+ activation=activations.get(activation),\n+ use_bias=use_bias,\n+ kernel_initializer=initializers.get(kernel_initializer),\n+ bias_initializer=initializers.get(bias_initializer),\n+ kernel_regularizer=regularizers.get(kernel_regularizer),\n+ bias_regularizer=regularizers.get(bias_regularizer),\n+ activity_regularizer=regularizers.get(activity_regularizer),\n+ kernel_constraint=constraints.get(kernel_constraint),\n+ bias_constraint=constraints.get(bias_constraint),\n+ **kwargs)\n \n self.output_padding = output_padding\n if self.output_padding is not None:\n@@ -898,6 +943,17 @@ def __init__(self,\n raise ValueError('Stride ' + str(self.strides) + ' must be '\n 'greater than output padding ' +\n str(self.output_padding))\n+ \n+ \n+ \n+ \n+ \n+ \n+\n+\n+ \n+ \n+ \n \n def build(self, input_shape):\n input_shape = tensor_shape.TensorShape(input_shape)\n@@ -1164,22 +1220,24 @@ def __init__(self,\n kernel_constraint=None,\n bias_constraint=None,\n **kwargs):\n+ self.checkProperKernel(kernel_size)\n+ #if(rv==0):\n super(Conv3DTranspose, self).__init__(\n- filters=filters,\n- kernel_size=kernel_size,\n- strides=strides,\n- padding=padding,\n- data_format=data_format,\n- activation=activations.get(activation),\n- use_bias=use_bias,\n- kernel_initializer=initializers.get(kernel_initializer),\n- bias_initializer=initializers.get(bias_initializer),\n- kernel_regularizer=regularizers.get(kernel_regularizer),\n- bias_regularizer=regularizers.get(bias_regularizer),\n- activity_regularizer=regularizers.get(activity_regularizer),\n- kernel_constraint=constraints.get(kernel_constraint),\n- bias_constraint=constraints.get(bias_constraint),\n- **kwargs)\n+ filters=filters,\n+ kernel_size=kernel_size,\n+ strides=strides,\n+ padding=padding,\n+ data_format=data_format,\n+ activation=activations.get(activation),\n+ use_bias=use_bias,\n+ kernel_initializer=initializers.get(kernel_initializer),\n+ bias_initializer=initializers.get(bias_initializer),\n+ kernel_regularizer=regularizers.get(kernel_regularizer),\n+ bias_regularizer=regularizers.get(bias_regularizer),\n+ activity_regularizer=regularizers.get(activity_regularizer),\n+ kernel_constraint=constraints.get(kernel_constraint),\n+ bias_constraint=constraints.get(bias_constraint),\n+ **kwargs)\n \n self.output_padding = output_padding\n if self.output_padding is not None:\n@@ -1190,6 +1248,13 @@ def __init__(self,\n raise ValueError('Stride ' + str(self.strides) + ' must be '\n 'greater than output padding ' +\n str(self.output_padding))\n+ \n+ \n+ \n+ \n+ \n+\n+\n \n def build(self, input_shape):\n input_shape = tensor_shape.TensorShape(input_shape)\n@@ -1427,6 +1492,8 @@ def __init__(self,\n trainable=True,\n name=None,\n **kwargs):\n+ self.checkProperKernel(kernel_size)\n+ #if(rv==0):\n super(SeparableConv, self).__init__(\n rank=rank,\n filters=filters,\n@@ -1451,6 +1518,10 @@ def __init__(self,\n self.pointwise_regularizer = regularizers.get(pointwise_regularizer)\n self.depthwise_constraint = constraints.get(depthwise_constraint)\n self.pointwise_constraint = constraints.get(pointwise_constraint)\n+ \n+ \n+ \n+ \n \n def build(self, input_shape):\n input_shape = tensor_shape.TensorShape(input_shape)\n@@ -1653,6 +1724,8 @@ def __init__(self,\n pointwise_constraint=None,\n bias_constraint=None,\n **kwargs):\n+ self.checkProperKernel(kernel_size)\n+ #if(rv==0):\n super(SeparableConv1D, self).__init__(\n rank=1,\n filters=filters,\n@@ -1675,6 +1748,9 @@ def __init__(self,\n pointwise_constraint=constraints.get(pointwise_constraint),\n bias_constraint=constraints.get(bias_constraint),\n **kwargs)\n+ \n+ \n+ \n \n def call(self, inputs):\n if self.padding == 'causal':\n@@ -1838,6 +1914,7 @@ def __init__(self,\n pointwise_constraint=None,\n bias_constraint=None,\n **kwargs):\n+ self.checkProperKernel(kernel_size)\n super(SeparableConv2D, self).__init__(\n rank=2,\n filters=filters,\n@@ -1860,6 +1937,9 @@ def __init__(self,\n pointwise_constraint=constraints.get(pointwise_constraint),\n bias_constraint=constraints.get(bias_constraint),\n **kwargs)\n+ \n+ \n+ \n \n def call(self, inputs):\n # Apply the actual ops.\n@@ -1982,6 +2062,8 @@ def __init__(self,\n depthwise_constraint=None,\n bias_constraint=None,\n **kwargs):\n+ self.checkProperKernel(kernel_size)\n+ #if(rv==0):\n super(DepthwiseConv2D, self).__init__(\n filters=None,\n kernel_size=kernel_size,\n@@ -1999,6 +2081,10 @@ def __init__(self,\n self.depthwise_regularizer = regularizers.get(depthwise_regularizer)\n self.depthwise_constraint = constraints.get(depthwise_constraint)\n self.bias_initializer = initializers.get(bias_initializer)\n+ \n+ \n+ \n+ \n \n def build(self, input_shape):\n if len(input_shape) < 4:",
"filename": "tensorflow/python/keras/layers/convolutional.py",
"status": "modified"
},
{
"diff": "@@ -0,0 +1,20 @@\n+from tensorflow.keras.models import Sequential\n+from tensorflow.keras.layers import Conv2D\n+from tensorflow.keras.layers import MaxPooling2D\n+from tensorflow.keras.layers import Flatten\n+from tensorflow.keras.layers import Dense\n+import tensorflow as tf\n+class Test(tf.test.TestCase):\n+ def setUp(self):\n+ super(Test, self).setUp()\n+ self.classifier=tf.keras.Sequential()\n+ \n+\n+ def testOutput(self):\n+ try:\n+ \tself.classifier.add(Convolution2D(64,0,padding=\"same\",input_shape=(32,32,1),activation='relu'))\n+ except:\n+ \tprint(\"Cant do\") \n+\n+\n+tf.test.main()",
"filename": "tensorflow/python/keras/layers/unitTest.py",
"status": "added"
},
{
"diff": "@@ -0,0 +1,41 @@\n+#from tensorflow.keras.models import Sequential\n+from tensorflow.keras.layers import Convolution2D,Convolution1D,Convolution3D,Conv2DTranspose,Conv3DTranspose,SeparableConv1D,SeparableConv2D,DepthwiseConv2D\n+#from tensorflow.keras.layers import MaxPooling2D\n+#from tensorflow.keras.layers import Flatten\n+#from tensorflow.keras.layers import Dense\n+import tensorflow as tf\n+class Test(tf.test.TestCase):\n+ def setUp(self):\n+ super(Test, self).setUp()\n+ self.classifier=tf.keras.Sequential()\n+ \n+\n+ def testOutput(self):\n+ with self.assertRaises(ValueError) as cm:\n+ \tself.classifier.add(Convolution1D(64,0,padding=\"same\",input_shape=(32,32,1),activation='relu'))\n+ print(cm.expected)\n+ with self.assertRaises(ValueError) as cm:\n+ \tself.classifier.add(Convolution2D(64,0,padding=\"same\",input_shape=(32,32,1),activation='relu'))\n+ print(cm.expected)\n+ with self.assertRaises(ValueError) as cm:\n+ \tself.classifier.add(Convolution3D(64,0,padding=\"same\",input_shape=(32,32,1),activation='relu'))\n+ print(cm.expected)\n+ with self.assertRaises(ValueError) as cm:\n+ \tself.classifier.add(Conv2DTranspose(64,0,padding=\"same\",input_shape=(32,32,1),activation='relu'))\n+ print(cm.expected)\n+ with self.assertRaises(ValueError) as cm:\n+ \tself.classifier.add(Conv3DTranspose(64,0,padding=\"same\",input_shape=(32,32,1),activation='relu'))\n+ print(cm.expected)\n+ with self.assertRaises(ValueError) as cm:\n+ \tself.classifier.add(SeparableConv1D(64,0,padding=\"same\",input_shape=(32,32,1),activation='relu'))\n+ print(cm.expected)\n+ with self.assertRaises(ValueError) as cm:\n+ \tself.classifier.add(SeparableConv2D(64,0,padding=\"same\",input_shape=(32,32,1),activation='relu'))\n+ print(cm.expected)\n+ with self.assertRaises(ValueError) as cm:\n+ \tself.classifier.add(DepthwiseConv2D(0,padding=\"same\",input_shape=(32,32,1),activation='relu'))\n+ print(cm.expected)\n+ \n+\n+\n+tf.test.main()",
"filename": "unitTest.py",
"status": "added"
}
]
}
|
{
"body": "## Description of issue (what needs changing):\r\n\r\ndocument for tensorflow.keras.losses.categorical_hinge is wrong\r\n\r\n### Clear description\r\n\r\n```python\r\n@keras_export('keras.losses.categorical_hinge')\r\ndef categorical_hinge(y_true, y_pred):\r\n \"\"\"Computes the categorical hinge loss between `y_true` and `y_pred`.\r\n `loss = maximum(neg - pos + 1, 0)`\r\n where `neg = sum(y_true * y_pred)` and `pos = maximum(1 - y_true)`\r\n Args:\r\n y_true: The ground truth values. `y_true` values are expected to be -1 or 1.\r\n If binary (0 or 1) labels are provided they will be converted to -1 or 1.\r\n y_pred: The predicted values.\r\n Returns:\r\n Categorical hinge loss values.\r\n \"\"\"\r\n y_pred = ops.convert_to_tensor_v2(y_pred)\r\n y_true = math_ops.cast(y_true, y_pred.dtype)\r\n pos = math_ops.reduce_sum(y_true * y_pred, axis=-1)\r\n neg = math_ops.reduce_max((1. - y_true) * y_pred, axis=-1)\r\n return math_ops.maximum(0., neg - pos + 1.)\r\n```\r\n\r\nShould be: `neg=maximum((1-y_true)*y_pred)` and `pos=sum(y_true*y_pred)`\r\n",
"comments": [
{
"body": "Can i be assigned to this issue?\r\n",
"created_at": "2020-02-17T10:27:51Z"
},
{
"body": "@ayushmankumar7 feel free to send me a PR.",
"created_at": "2020-03-04T23:20:35Z"
},
{
"body": "Sure. Thanks",
"created_at": "2020-03-05T03:34:48Z"
},
{
"body": "Closing this issue since the associated PR has been merged. Thanks!",
"created_at": "2020-03-19T20:01:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36807\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36807\">No</a>\n",
"created_at": "2020-03-19T20:01:51Z"
}
],
"number": 36807,
"title": "wrong doc for categorical_hinge loss "
}
|
{
"body": "Issue : #36807 @pavithrasv Check this",
"number": 37329,
"review_comments": [
{
"body": "Thank you, can you make the same change in the `categorical_hinge` function below?",
"created_at": "2020-03-05T18:10:47Z"
},
{
"body": "Sure",
"created_at": "2020-03-06T02:29:48Z"
},
{
"body": "Done.",
"created_at": "2020-03-06T02:56:00Z"
}
],
"title": "Categorical Hinge Loss Doc Updated"
}
|
{
"commits": [
{
"message": "module_test error solved"
},
{
"message": "module_test error solved"
},
{
"message": "Merge pull request #1 from tensorflow/master\n\nUpdated"
},
{
"message": "Merge branch 'master' of https://github.com/ayushmankumar7/tensorflow"
},
{
"message": "Categorical Hinge Losses Doc corrected"
},
{
"message": "documentation in categorical_hinge also corrected"
}
],
"files": [
{
"diff": "@@ -861,7 +861,7 @@ class CategoricalHinge(LossFunctionWrapper):\n \"\"\"Computes the categorical hinge loss between `y_true` and `y_pred`.\n \n `loss = maximum(neg - pos + 1, 0)`\n- where `neg = sum(y_true * y_pred)` and `pos = maximum(1 - y_true)`\n+ where `neg=maximum((1-y_true)*y_pred) and pos=sum(y_true*y_pred)`\n \n Usage:\n \n@@ -1387,7 +1387,7 @@ def categorical_hinge(y_true, y_pred):\n \"\"\"Computes the categorical hinge loss between `y_true` and `y_pred`.\n \n `loss = maximum(neg - pos + 1, 0)`\n- where `neg = sum(y_true * y_pred)` and `pos = maximum(1 - y_true)`\n+ where `neg=maximum((1-y_true)*y_pred) and pos=sum(y_true*y_pred)`\n \n Usage:\n ",
"filename": "tensorflow/python/keras/losses.py",
"status": "modified"
}
]
}
|
{
"body": "## Description of issue (what needs changing):\r\n\r\ndocument for tensorflow.keras.losses.categorical_hinge is wrong\r\n\r\n### Clear description\r\n\r\n```python\r\n@keras_export('keras.losses.categorical_hinge')\r\ndef categorical_hinge(y_true, y_pred):\r\n \"\"\"Computes the categorical hinge loss between `y_true` and `y_pred`.\r\n `loss = maximum(neg - pos + 1, 0)`\r\n where `neg = sum(y_true * y_pred)` and `pos = maximum(1 - y_true)`\r\n Args:\r\n y_true: The ground truth values. `y_true` values are expected to be -1 or 1.\r\n If binary (0 or 1) labels are provided they will be converted to -1 or 1.\r\n y_pred: The predicted values.\r\n Returns:\r\n Categorical hinge loss values.\r\n \"\"\"\r\n y_pred = ops.convert_to_tensor_v2(y_pred)\r\n y_true = math_ops.cast(y_true, y_pred.dtype)\r\n pos = math_ops.reduce_sum(y_true * y_pred, axis=-1)\r\n neg = math_ops.reduce_max((1. - y_true) * y_pred, axis=-1)\r\n return math_ops.maximum(0., neg - pos + 1.)\r\n```\r\n\r\nShould be: `neg=maximum((1-y_true)*y_pred)` and `pos=sum(y_true*y_pred)`\r\n",
"comments": [
{
"body": "Can i be assigned to this issue?\r\n",
"created_at": "2020-02-17T10:27:51Z"
},
{
"body": "@ayushmankumar7 feel free to send me a PR.",
"created_at": "2020-03-04T23:20:35Z"
},
{
"body": "Sure. Thanks",
"created_at": "2020-03-05T03:34:48Z"
},
{
"body": "Closing this issue since the associated PR has been merged. Thanks!",
"created_at": "2020-03-19T20:01:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36807\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36807\">No</a>\n",
"created_at": "2020-03-19T20:01:51Z"
}
],
"number": 36807,
"title": "wrong doc for categorical_hinge loss "
}
|
{
"body": "Issue: #36807 \r\n\r\n@pavithrasv Check this.",
"number": 37328,
"review_comments": [],
"title": "Categorical Hinge loss doc updated"
}
|
{
"commits": [
{
"message": "module_test error solved"
},
{
"message": "module_test error solved"
},
{
"message": "Merge pull request #1 from tensorflow/master\n\nUpdated"
},
{
"message": "Merge branch 'master' of https://github.com/ayushmankumar7/tensorflow"
},
{
"message": "Categorical Hinge Losses Doc corrected"
}
],
"files": [
{
"diff": "@@ -861,7 +861,7 @@ class CategoricalHinge(LossFunctionWrapper):\n \"\"\"Computes the categorical hinge loss between `y_true` and `y_pred`.\n \n `loss = maximum(neg - pos + 1, 0)`\n- where `neg = sum(y_true * y_pred)` and `pos = maximum(1 - y_true)`\n+ where `neg=maximum((1-y_true)*y_pred) and pos=sum(y_true*y_pred)`\n \n Usage:\n ",
"filename": "tensorflow/python/keras/losses.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information** \r\n- Have I written custom code (as opposed to using a stock\r\nexample script provided in TensorFlow): \r\n- OS Platform and Distribution (e.g.,\r\nLinux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if\r\nthe issue happens on mobile device: \r\n- TensorFlow installed from (source or\r\nbinary): pip3\r\n - TensorFlow version (use command below): 2.1.0 \r\n- Python version: - Bazel\r\nversion (if compiling from source):\r\n- GCC/Compiler version (if compiling from\r\nsource): \r\n- CUDA/cuDNN version: - GPU model and memory:\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\n\r\n**Describe the expected behavior**\r\n\r\n**Standalone code to reproduce the issue** \r\nProvide a reproducible test case that is the bare minimum necessary to generate\r\nthe problem. If possible, please share a link to Colab/Jupyter/any notebook.\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\ndiagnose the problem. If including tracebacks, please include the full\r\ntraceback. Large logs and files should be attached.\r\n2020-02-27 10:37:08.494214: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\n[ OK ] ModuleTest.testBuiltInName\r\n[ RUN ] ModuleTest.testCanLoadWithPkgutil\r\n[ OK ] ModuleTest.testCanLoadWithPkgutil\r\n[ RUN ] ModuleTest.testCompatV2HasCompatV1\r\n[ OK ] ModuleTest.testCompatV2HasCompatV1\r\n[ RUN ] ModuleTest.testDict\r\n[ OK ] ModuleTest.testDict\r\n[ RUN ] ModuleTest.testDocString\r\n[ OK ] ModuleTest.testDocString\r\n[ RUN ] ModuleTest.testName\r\n[ OK ] ModuleTest.testName\r\n[ RUN ] ModuleTest.testSummaryMerged\r\n[ FAILED ] ModuleTest.testSummaryMerged\r\n[ RUN ] ModuleTest.test_session\r\n[ SKIPPED ] ModuleTest.test_session\r\n======================================================================\r\nERROR: testSummaryMerged (__main__.ModuleTest)\r\ntestSummaryMerged (__main__.ModuleTest)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"module_test.py\", line 79, in testSummaryMerged\r\n tf.summary.FileWriter\r\nAttributeError: module 'tensorboard.summary._tf.summary' has no attribute 'FileWriter'\r\n\r\n----------------------------------------------------------------------\r\nRan 8 tests in 0.035s\r\n",
"comments": [
{
"body": "@Saduf2019 Please check the changes i made.",
"created_at": "2020-02-27T05:22:48Z"
},
{
"body": "@ayushmankumar7 \r\nIn order to expedite the trouble-shooting process, please provide a code snippet to reproduce the issue reported here. Thanks!\r\n\r\nCould you try \"changing tf.summary.FileWriter() to tf.train.SummaryWriter()\"\r\nAlso you may check #412 [link](https://github.com/eriklindernoren/PyTorch-YOLOv3/issues/327)\r\n\r\n",
"created_at": "2020-02-27T05:48:04Z"
},
{
"body": "https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/api/tests/module_test.py\r\nThis is the link to the code snippet to reproduce the issue. \r\n\r\n\r\n",
"created_at": "2020-02-27T06:53:15Z"
},
{
"body": "@Saduf2019 \r\nChanging tf.summar.FileWrite() to tf.train.SummaryWriter() gives the following error: \r\n\r\nTraceback (most recent call last):\r\n File \"module_test.py\", line 79, in testSummaryMerged\r\n tf.train.SummaryWriter()\r\nAttributeError: module 'tensorflow_core._api.v2.train' has no attribute 'SummaryWriter'",
"created_at": "2020-02-27T06:55:02Z"
},
{
"body": "@ayushmankumar7 \r\nplease let us know if we could move this to closed status as it is monitored in #37223 ",
"created_at": "2020-03-06T08:50:20Z"
},
{
"body": "Yeah. It's not a problem. ",
"created_at": "2020-03-06T08:53:09Z"
},
{
"body": "Moving this issue to closed status with confirmation that it will be monitored in #37233 ",
"created_at": "2020-03-06T11:57:58Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37113\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37113\">No</a>\n",
"created_at": "2020-03-06T11:57:59Z"
},
{
"body": "In Google Colab, you can use the magic word ```%tensorflow_version 1.x``` to select tensorflow version 1.",
"created_at": "2020-05-12T12:42:58Z"
}
],
"number": 37113,
"title": "AttributeError: module 'tensorboard.summary._tf.summary' has no attribute 'FileWriter'"
}
|
{
"body": "@mihaimaruseac Here is the new Pull Request. \r\n\r\nIssue: #37113 ",
"number": 37223,
"review_comments": [],
"title": "Use `tf.compat.v1.summary.FileWriter` under TF v1"
}
|
{
"commits": [
{
"message": "module_test error solved"
},
{
"message": "module_test error solved"
},
{
"message": "module_test solved"
}
],
"files": [
{
"diff": "@@ -76,7 +76,7 @@ def testSummaryMerged(self):\n if hasattr(tf, '_major_api_version') and tf._major_api_version == 2:\n tf.summary.create_file_writer\n else:\n- tf.summary.FileWriter\n+ tf.compat.v1.summary.FileWriter\n # pylint: enable=pointless-statement\n \n ",
"filename": "tensorflow/tools/api/tests/module_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information** \r\n- Have I written custom code (as opposed to using a stock\r\nexample script provided in TensorFlow): custom Layer, using tf.image.resize\r\n- OS Platform and Distribution (e.g.,\r\nLinux Ubuntu 16.04): Linux Mint 19.3 Cinnamon (Ubuntu based)\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if\r\nthe issue happens on mobile device: No\r\n- TensorFlow installed from (source or\r\nbinary): pip install\r\n - TensorFlow version (use command below): v2.1.0-rc2-17-ge5bf8de 2.1.0\r\n- Python version: 3.6.9\r\n\r\n**Describe the current behavior**\r\nimage.resize is working in eager(standard) mode, with tensor as size argument\r\nstops working if warped in tf.function\r\n\r\n**Describe the expected behavior**\r\nshould work like in eager\r\n\r\npossible reason:\r\nlive tf.function tensor is in the implementation of image.resize not evaluated.\r\nso the cast to a appropriate value fails and None is returned\r\n\r\nError (full):\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/bhb/.vscode/extensions/ms-python.python-2020.2.63990/pythonFiles/ptvsd_launcher.py\", line 48, in <module>\r\n main(ptvsdArgs)\r\n File \"/home/bhb/.vscode/extensions/ms-python.python-2020.2.63990/pythonFiles/lib/python/old_ptvsd/ptvsd/__main__.py\", line 432, in main\r\n run()\r\n File \"/home/bhb/.vscode/extensions/ms-python.python-2020.2.63990/pythonFiles/lib/python/old_ptvsd/ptvsd/__main__.py\", line 316, in run_file\r\n runpy.run_path(target, run_name='__main__')\r\n File \"/usr/lib/python3.6/runpy.py\", line 263, in run_path\r\n pkg_name=pkg_name, script_name=fname)\r\n File \"/usr/lib/python3.6/runpy.py\", line 96, in _run_module_code\r\n mod_name, mod_spec, pkg_name, script_name)\r\n File \"/usr/lib/python3.6/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/ShAReD_Net/model/modules/base.py\", line 204, in <module>\r\n main()\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/ShAReD_Net/model/modules/base.py\", line 191, in main\r\n out = test_multiscale(inputs)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/ShAReD_Net/model/modules/base.py\", line 175, in run\r\n outputs = op(inputs, **kwargs)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 822, in __call__\r\n outputs = self.call(cast_inputs, *args, **kwargs)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/ShAReD_Net/model/modules/base.py\", line 126, in call\r\n outs.append(self.hour_glass(ins))\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 822, in __call__\r\n outputs = self.call(cast_inputs, *args, **kwargs)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/ShAReD_Net/model/modules/base.py\", line 62, in call\r\n big_normal = self.big_normal(big_shared2_shc, scale_2)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 822, in __call__\r\n outputs = self.call(cast_inputs, *args, **kwargs)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 568, in __call__\r\n result = self._call(*args, **kwds)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 615, in _call\r\n self._initialize(args, kwds, add_initializers_to=initializers)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 497, in _initialize\r\n *args, **kwds))\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 2389, in _get_concrete_function_internal_garbage_collected\r\n graph_function, _, _ = self._maybe_define_function(args, kwargs)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 2703, in _maybe_define_function\r\n graph_function = self._create_graph_function(args, kwargs)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 2593, in _create_graph_function\r\n capture_by_value=self._capture_by_value),\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/framework/func_graph.py\", line 978, in func_graph_from_py_func\r\n func_outputs = python_func(*func_args, **func_kwargs)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/eager/def_function.py\", line 439, in wrapped_fn\r\n return weak_wrapped_fn().__wrapped__(*args, **kwds)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/eager/function.py\", line 3211, in bound_method_wrapper\r\n return wrapped_fn(*args, **kwargs)\r\n File \"/home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/framework/func_graph.py\", line 968, in wrapper\r\n raise e.ag_error_metadata.to_exception(e)\r\nValueError: in converted code:\r\n\r\n /mnt/7f43981f-bc0a-4b76-a721-46c0159f0cf5/cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/ShAReD_Net/model/layer/base.py:228 call *\r\n scaled_conv = tf.image.resize(conv, destination_size, preserve_aspect_ratio=True, antialias=True)\r\n /home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/ops/image_ops_impl.py:1357 resize_images_v2\r\n skip_resize_if_same=False)\r\n /home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/ops/image_ops_impl.py:1100 _resize_images_common\r\n math_ops.cast(new_height_const, dtypes.float32) /\r\n /home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/util/dispatch.py:180 wrapper\r\n return target(*args, **kwargs)\r\n /home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/ops/math_ops.py:705 cast\r\n x = ops.convert_to_tensor(x, name=\"x\")\r\n /home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/framework/ops.py:1314 convert_to_tensor\r\n ret = conversion_func(value, dtype=dtype, name=name, as_ref=as_ref)\r\n /home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/framework/constant_op.py:317 _constant_tensor_conversion_function\r\n return constant(v, dtype=dtype, name=name)\r\n /home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/framework/constant_op.py:258 constant\r\n allow_broadcast=True)\r\n /home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/framework/constant_op.py:296 _constant_impl\r\n allow_broadcast=allow_broadcast))\r\n /home/bhb/Cloud/Code/Git/3D_Person_Pose_Estimation_from_2D_Singelview_Image_Data/src/venv/lib/python3.6/site-packages/tensorflow_core/python/framework/tensor_util.py:439 make_tensor_proto\r\n raise ValueError(\"None values not supported.\")\r\n\r\n ValueError: None values not supported.\r\n```\r\n\r\n**Standalone code to reproduce the issue** \r\nSorry not yet the time, but relevant code is:\r\n\r\ncustom Layer for scaling features to variable (depended on other feature size) size :+1: \r\n```\r\nclass Scale(keras.layers.Layer):\r\n def __init__(self, destination_channel = None, name = \"Scale\", **kwargs):\r\n super().__init__(name = name, **kwargs)\r\n self.destination_channel = destination_channel\r\n \r\n def build(self, input_shape):\r\n if self.destination_channel is None:\r\n self.destination_channel = input_shape[-1]\r\n self.compress_input = keras.layers.Convolution2D(int(input_shape[-1]/2), kernel_size=1, padding='SAME', activation=tf.nn.leaky_relu, kernel_initializer=tf.initializers.he_normal(), bias_initializer=tf.initializers.he_uniform())\r\n self.conv = keras.layers.Convolution2D(input_shape[-1], kernel_size=3, padding='SAME', activation=tf.nn.leaky_relu, kernel_initializer=tf.initializers.he_normal(), bias_initializer=tf.initializers.he_uniform())\r\n self.pool = keras.layers.MaxPool2D(pool_size=3,strides=1,padding=\"SAME\")\r\n self.compress_output = keras.layers.Convolution2D(self.destination_channel, kernel_size=1, padding='SAME', activation=tf.nn.leaky_relu, kernel_initializer=tf.initializers.he_normal(), bias_initializer=tf.initializers.he_uniform())\r\n super().build(input_shape)\r\n\r\n def call(self, inputs, destination_size):\r\n \r\n compressed_input = self.compress_input(inputs)\r\n conv = self.conv(compressed_input)\r\n pool = self.pool(inputs)\r\n \r\n scaled_conv = tf.image.resize(conv, destination_size, preserve_aspect_ratio=True, antialias=True)\r\n scaled_pool = tf.image.resize(pool, destination_size, preserve_aspect_ratio=True, antialias=True)\r\n \r\n concat = keras.layers.concatenate([scaled_pool, scaled_conv])\r\n compressed_output = self.compress_output(concat)\r\n return compressed_output\r\n```\r\nworks if like shown, stops working if @tf.function is added to \r\n`def call(self, inputs, destination_size):`\r\n\r\nCalling code:\r\n```\r\ndef call(self, inputs):\r\n input_res, input_shc = inputs\r\n \r\n scale = tf.cast(input_shc.shape[1:3], dtype=tf.int32)\r\n scale_2 = tf.cast(scale/2, dtype=tf.int32)\r\n scale_4 = tf.cast(scale/4, dtype=tf.int32)\r\n scale_8 = tf.cast(scale/8, dtype=tf.int32)\r\n \r\n big_normal = self.big_normal(big_shared2_shc, scale_2)\r\n return big_normal\r\n```\r\n`big_normal` is a instance of `class Scale`\r\n\r\nthanks in advance",
"comments": [
{
"body": "@bela127, Thanks for reporting this issue. \r\nCan you provide the complete code snippet to reproduce the reported issue. Thanks!",
"created_at": "2020-02-24T11:53:58Z"
},
{
"body": "Thanks for replying so fast,\r\nI will build a minimum test script today and provide it as soon as possible.",
"created_at": "2020-02-24T12:24:46Z"
},
{
"body": "here you go:\r\nfull test script with 3 test cases\r\n\r\n```\r\nimport tensorflow as tf\r\nkeras = tf.keras\r\n\r\n\r\ndef main():\r\n eager = True ### please change to FALSE in eager mode all 3 tests are fine\r\n test_nr = 1 # 1 or 2 or 3 ### please test 1 and 2 and 3 -> diffrent errors\r\n ### error 3 ist clear, TensorShape is not tf.function compatible\r\n ### error 1,2 has somthing todo with the image.resize implementation\r\n ### runtime tensor is not evaluated and so the value is None\r\n \r\n tf.config.experimental_run_functions_eagerly(eager)\r\n optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)\r\n \r\n inputs = tf.constant(100.,shape=[1,100,100,20])\r\n inputs_small = tf.constant(100.,shape=[1,80,80,20])\r\n \r\n if eager or test_nr == 1:\r\n print(\"Scaled1\")\r\n scaled_shared = Scaled1()\r\n test_scaled_shared = test(scaled_shared, optimizer, training = True)\r\n out = test_scaled_shared([inputs,inputs_small])\r\n print(\"Scaled1\")\r\n \r\n if eager or test_nr == 2:\r\n print(\"Scaled2\")\r\n scaled_shared = Scaled2()\r\n test_scaled_shared = test(scaled_shared, optimizer, training = True)\r\n out = test_scaled_shared([inputs,inputs_small])\r\n print(\"Scaled2\")\r\n \r\n if eager or test_nr == 3:\r\n print(\"Scaled3\")\r\n scaled_shared = Scaled3()\r\n test_scaled_shared = test(scaled_shared, optimizer, training = True)\r\n out = test_scaled_shared([inputs,inputs_small])\r\n print(\"Scaled3\")\r\n\r\ndef test(op, optimizer, **kwargs):\r\n def run(inputs):\r\n with tf.GradientTape() as tape:\r\n tape.watch(op.trainable_variables)\r\n outputs = op(inputs, **kwargs)\r\n g = tape.gradient(outputs, op.trainable_variables)\r\n optimizer.apply_gradients(zip(g, op.trainable_variables))\r\n return outputs, g\r\n return run\r\n \r\nclass Scale(keras.layers.Layer):\r\n def __init__(self, destination_channel = None, name = \"Scale\", **kwargs):\r\n super().__init__(name = name, **kwargs)\r\n self.destination_channel = destination_channel\r\n \r\n def build(self, input_shape):\r\n if self.destination_channel is None:\r\n self.destination_channel = input_shape[-1]\r\n self.compress_input = keras.layers.Convolution2D(int(input_shape[-1]/2), kernel_size=1, padding='SAME', activation=tf.nn.leaky_relu, kernel_initializer=tf.initializers.he_normal(), bias_initializer=tf.initializers.he_uniform())\r\n self.conv = keras.layers.Convolution2D(input_shape[-1], kernel_size=3, padding='SAME', activation=tf.nn.leaky_relu, kernel_initializer=tf.initializers.he_normal(), bias_initializer=tf.initializers.he_uniform())\r\n self.pool = keras.layers.MaxPool2D(pool_size=3,strides=1,padding=\"SAME\")\r\n self.compress_output = keras.layers.Convolution2D(self.destination_channel, kernel_size=1, padding='SAME', activation=tf.nn.leaky_relu, kernel_initializer=tf.initializers.he_normal(), bias_initializer=tf.initializers.he_uniform())\r\n super().build(input_shape)\r\n\r\n @tf.function\r\n def call(self, inputs, destination_size):\r\n \r\n compressed_input = self.compress_input(inputs)\r\n conv = self.conv(compressed_input)\r\n pool = self.pool(inputs)\r\n \r\n scaled_conv = tf.image.resize(conv, destination_size, preserve_aspect_ratio=True, antialias=True)\r\n scaled_pool = tf.image.resize(pool, destination_size, preserve_aspect_ratio=True, antialias=True)\r\n \r\n concat = keras.layers.concatenate([scaled_pool, scaled_conv])\r\n compressed_output = self.compress_output(concat)\r\n return compressed_output\r\n \r\n def get_config(self):\r\n config = super().get_config()\r\n config.update({'destination_channel': self.destination_channel,\r\n })\r\n return config\r\n\r\n\r\nclass Scaled1(keras.layers.Layer):\r\n def __init__(self, name = \"Scaled1\", **kwargs):\r\n super().__init__(name = name, **kwargs)\r\n\r\n \r\n def build(self, input_shape):\r\n res_shape, shc_shape = input_shape\r\n self.scale_up = Scale(destination_channel = res_shape[-1])\r\n self.scale_down = Scale()\r\n super().build(input_shape)\r\n \r\n def call(self, inputs):\r\n inputs_res, inputs_shc = inputs\r\n shape1 = tf.shape(inputs_shc)[1:3]\r\n shape2 = tf.shape(inputs_shc)[1:3]\r\n \r\n scaled_res = self.scale_down(inputs_res, shape1)\r\n scaled_dense = self.scale_up(scaled_res, shape2)\r\n return scaled_dense \r\n \r\nclass Scaled2(keras.layers.Layer):\r\n def __init__(self, name = \"Scaled2\", **kwargs):\r\n super().__init__(name = name, **kwargs)\r\n\r\n \r\n def build(self, input_shape):\r\n res_shape, shc_shape = input_shape\r\n self.scale_up = Scale(destination_channel = res_shape[-1])\r\n self.scale_down = Scale()\r\n super().build(input_shape)\r\n \r\n def call(self, inputs):\r\n inputs_res, inputs_shc = inputs\r\n \r\n shape1 = tf.cast(tf.shape(inputs_shc)[1:3], dtype = tf.int32)\r\n shape2 = tf.cast(tf.shape(inputs_shc)[1:3], dtype = tf.int32)\r\n \r\n scaled_res = self.scale_down(inputs_res, shape1)\r\n scaled_dense = self.scale_up(scaled_res, shape2)\r\n return scaled_dense\r\n \r\nclass Scaled3(keras.layers.Layer):\r\n def __init__(self, name = \"Scaled2\", **kwargs):\r\n super().__init__(name = name, **kwargs)\r\n\r\n \r\n def build(self, input_shape):\r\n res_shape, shc_shape = input_shape\r\n self.scale_up = Scale(destination_channel = res_shape[-1])\r\n self.scale_down = Scale()\r\n super().build(input_shape)\r\n \r\n def call(self, inputs):\r\n inputs_res, inputs_shc = inputs\r\n \r\n shape1 = inputs_shc.shape[1:3]\r\n shape2 = inputs_shc.shape[1:3]\r\n \r\n scaled_res = self.scale_down(inputs_res, shape1)\r\n scaled_dense = self.scale_up(scaled_res, shape2)\r\n return scaled_dense\r\n\r\n \r\nif __name__ == '__main__':\r\n main()\r\n \r\n```",
"created_at": "2020-02-24T13:03:41Z"
},
{
"body": "Could able to replicate the reported issue with TF 2.1 and TF-nightly.\r\nPlease find the gist [here](https://colab.sandbox.google.com/gist/gadagashwini/b758c604ee2b51b63905bf69fd10b57f/untitled401.ipynb). Thanks",
"created_at": "2020-02-25T06:04:13Z"
},
{
"body": "I have similar problems when adding signatures function for an existing model. But if I remove the `preserve_aspect_ratio=True`, everything works well.\r\n\r\n",
"created_at": "2020-02-26T04:48:19Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36963\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36963\">No</a>\n",
"created_at": "2020-03-05T17:12:40Z"
},
{
"body": "thanks, changed to nightly and the fix is working",
"created_at": "2020-03-09T13:08:12Z"
}
],
"number": 36963,
"title": "image.resize tensor as size argumentnot working in tf.function"
}
|
{
"body": "fix #36963",
"number": 37115,
"review_comments": [],
"title": "fix resize image bug"
}
|
{
"commits": [
{
"message": "fix resize image bug"
},
{
"message": "add test case"
},
{
"message": "fix test"
},
{
"message": "refact test case"
},
{
"message": "convert sixe to tensor"
}
],
"files": [
{
"diff": "@@ -1201,20 +1201,17 @@ def _resize_images_common(images, resizer_fn, size, preserve_aspect_ratio, name,\n if not size.get_shape().is_compatible_with([2]):\n raise ValueError('\\'size\\' must be a 1-D Tensor of 2 elements: '\n 'new_height, new_width')\n- size_const_as_shape = tensor_util.constant_value_as_shape(size)\n- new_height_const = size_const_as_shape.dims[0].value\n- new_width_const = size_const_as_shape.dims[1].value\n \n if preserve_aspect_ratio:\n # Get the current shapes of the image, even if dynamic.\n _, current_height, current_width, _ = _ImageDimensions(images, rank=4)\n \n # do the computation to find the right scale and height/width.\n scale_factor_height = (\n- math_ops.cast(new_height_const, dtypes.float32) /\n+ math_ops.cast(size[0], dtypes.float32) /\n math_ops.cast(current_height, dtypes.float32))\n scale_factor_width = (\n- math_ops.cast(new_width_const, dtypes.float32) /\n+ math_ops.cast(size[1], dtypes.float32) /\n math_ops.cast(current_width, dtypes.float32))\n scale_factor = math_ops.minimum(scale_factor_height, scale_factor_width)\n scaled_height_const = math_ops.cast(\n@@ -1230,9 +1227,10 @@ def _resize_images_common(images, resizer_fn, size, preserve_aspect_ratio, name,\n size = ops.convert_to_tensor([scaled_height_const, scaled_width_const],\n dtypes.int32,\n name='size')\n- size_const_as_shape = tensor_util.constant_value_as_shape(size)\n- new_height_const = size_const_as_shape.dims[0].value\n- new_width_const = size_const_as_shape.dims[1].value\n+\n+ size_const_as_shape = tensor_util.constant_value_as_shape(size)\n+ new_height_const = size_const_as_shape.dims[0].value\n+ new_width_const = size_const_as_shape.dims[1].value\n \n # If we can determine that the height and width will be unmodified by this\n # transformation, we avoid performing the resize.",
"filename": "tensorflow/python/ops/image_ops_impl.py",
"status": "modified"
},
{
"diff": "@@ -2712,7 +2712,8 @@ def _ResizeImageCall(self, x, max_h, max_w, preserve_aspect_ratio,\n feed_dict = {}\n \n y = image_ops.resize_images(\n- x_tensor, target_max, preserve_aspect_ratio=preserve_aspect_ratio)\n+ x_tensor, ops.convert_to_tensor(target_max),\n+ preserve_aspect_ratio=preserve_aspect_ratio)\n \n with self.cached_session(use_gpu=True):\n return y.eval(feed_dict=feed_dict)\n@@ -2753,11 +2754,15 @@ def _assertResizeCheckShape(self,\n \n @test_util.run_deprecated_v1\n def testPreserveAspectRatioMultipleImages(self):\n- x_shape = [10, 100, 100, 10]\n+ x_shape = [10, 100, 80, 10]\n x = np.random.uniform(size=x_shape)\n-\n- self._assertResizeCheckShape(\n- x, x_shape, [250, 250], [10, 250, 250, 10], preserve_aspect_ratio=False)\n+ for preserve_aspect_ratio in [True, False]:\n+ with self.subTest(preserve_aspect_ratio=preserve_aspect_ratio):\n+ expect_shape = [10, 250, 200, 10] if preserve_aspect_ratio \\\n+ else [10, 250, 250, 10]\n+ self._assertResizeCheckShape(\n+ x, x_shape, [250, 250], expect_shape,\n+ preserve_aspect_ratio=preserve_aspect_ratio)\n \n @test_util.run_deprecated_v1\n def testPreserveAspectRatioNoOp(self):",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information** \r\n- Have I written custom code (as opposed to using a stock\r\nexample script provided in TensorFlow): \r\n- OS Platform and Distribution (e.g.,\r\nLinux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if\r\nthe issue happens on mobile device: \r\n- TensorFlow installed from (source or\r\nbinary): pip3\r\n - TensorFlow version (use command below): 2.1.0 \r\n- Python version: - Bazel\r\nversion (if compiling from source):\r\n- GCC/Compiler version (if compiling from\r\nsource): \r\n- CUDA/cuDNN version: - GPU model and memory:\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\n\r\n**Describe the expected behavior**\r\n\r\n**Standalone code to reproduce the issue** \r\nProvide a reproducible test case that is the bare minimum necessary to generate\r\nthe problem. If possible, please share a link to Colab/Jupyter/any notebook.\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\ndiagnose the problem. If including tracebacks, please include the full\r\ntraceback. Large logs and files should be attached.\r\n2020-02-27 10:37:08.494214: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\n[ OK ] ModuleTest.testBuiltInName\r\n[ RUN ] ModuleTest.testCanLoadWithPkgutil\r\n[ OK ] ModuleTest.testCanLoadWithPkgutil\r\n[ RUN ] ModuleTest.testCompatV2HasCompatV1\r\n[ OK ] ModuleTest.testCompatV2HasCompatV1\r\n[ RUN ] ModuleTest.testDict\r\n[ OK ] ModuleTest.testDict\r\n[ RUN ] ModuleTest.testDocString\r\n[ OK ] ModuleTest.testDocString\r\n[ RUN ] ModuleTest.testName\r\n[ OK ] ModuleTest.testName\r\n[ RUN ] ModuleTest.testSummaryMerged\r\n[ FAILED ] ModuleTest.testSummaryMerged\r\n[ RUN ] ModuleTest.test_session\r\n[ SKIPPED ] ModuleTest.test_session\r\n======================================================================\r\nERROR: testSummaryMerged (__main__.ModuleTest)\r\ntestSummaryMerged (__main__.ModuleTest)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"module_test.py\", line 79, in testSummaryMerged\r\n tf.summary.FileWriter\r\nAttributeError: module 'tensorboard.summary._tf.summary' has no attribute 'FileWriter'\r\n\r\n----------------------------------------------------------------------\r\nRan 8 tests in 0.035s\r\n",
"comments": [
{
"body": "@Saduf2019 Please check the changes i made.",
"created_at": "2020-02-27T05:22:48Z"
},
{
"body": "@ayushmankumar7 \r\nIn order to expedite the trouble-shooting process, please provide a code snippet to reproduce the issue reported here. Thanks!\r\n\r\nCould you try \"changing tf.summary.FileWriter() to tf.train.SummaryWriter()\"\r\nAlso you may check #412 [link](https://github.com/eriklindernoren/PyTorch-YOLOv3/issues/327)\r\n\r\n",
"created_at": "2020-02-27T05:48:04Z"
},
{
"body": "https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/api/tests/module_test.py\r\nThis is the link to the code snippet to reproduce the issue. \r\n\r\n\r\n",
"created_at": "2020-02-27T06:53:15Z"
},
{
"body": "@Saduf2019 \r\nChanging tf.summar.FileWrite() to tf.train.SummaryWriter() gives the following error: \r\n\r\nTraceback (most recent call last):\r\n File \"module_test.py\", line 79, in testSummaryMerged\r\n tf.train.SummaryWriter()\r\nAttributeError: module 'tensorflow_core._api.v2.train' has no attribute 'SummaryWriter'",
"created_at": "2020-02-27T06:55:02Z"
},
{
"body": "@ayushmankumar7 \r\nplease let us know if we could move this to closed status as it is monitored in #37223 ",
"created_at": "2020-03-06T08:50:20Z"
},
{
"body": "Yeah. It's not a problem. ",
"created_at": "2020-03-06T08:53:09Z"
},
{
"body": "Moving this issue to closed status with confirmation that it will be monitored in #37233 ",
"created_at": "2020-03-06T11:57:58Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37113\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37113\">No</a>\n",
"created_at": "2020-03-06T11:57:59Z"
},
{
"body": "In Google Colab, you can use the magic word ```%tensorflow_version 1.x``` to select tensorflow version 1.",
"created_at": "2020-05-12T12:42:58Z"
}
],
"number": 37113,
"title": "AttributeError: module 'tensorboard.summary._tf.summary' has no attribute 'FileWriter'"
}
|
{
"body": "Issue: #37113 ",
"number": 37114,
"review_comments": [
{
"body": "Let's not change this file. In several usecases `pip` is `pip3` already.",
"created_at": "2020-02-28T18:12:13Z"
},
{
"body": "This is unrelated change. Please don't include unrelated changes.",
"created_at": "2020-02-28T18:12:37Z"
},
{
"body": "Unrelated change",
"created_at": "2020-02-28T18:12:49Z"
},
{
"body": "We should prefer V2 symbols.",
"created_at": "2020-02-28T18:14:00Z"
},
{
"body": "Sure. Then let me revert the changes\r\n",
"created_at": "2020-02-29T01:10:50Z"
},
{
"body": "Okay \r\n",
"created_at": "2020-02-29T01:12:34Z"
},
{
"body": "Sure. Changed\r\n",
"created_at": "2020-02-29T01:20:02Z"
},
{
"body": "This one should also be reverted",
"created_at": "2020-02-29T17:15:44Z"
},
{
"body": "This change should not be in this PR",
"created_at": "2020-02-29T17:16:21Z"
},
{
"body": "`tf.compat.v2` is TF 2.x but then `tf.` is the same API. Do we really need to change this line?",
"created_at": "2020-02-29T17:17:11Z"
},
{
"body": "Required changes made. ",
"created_at": "2020-03-01T18:16:18Z"
},
{
"body": "Reverted.",
"created_at": "2020-03-01T18:16:30Z"
},
{
"body": "I am sorry. I am unable to remove this commit as this was in the same branch. ",
"created_at": "2020-03-01T18:32:25Z"
},
{
"body": "I am Closing this PR and creating a fresh PR",
"created_at": "2020-03-02T06:58:23Z"
}
],
"title": "FileWriter in tf.summary solved"
}
|
{
"commits": [
{
"message": "Merge pull request #1 from tensorflow/master\n\nUpdate from Original"
},
{
"message": "Merge pull request #2 from tensorflow/master\n\nUpdating"
},
{
"message": "wrong doc for categorical_hinge loss"
},
{
"message": "Merge pull request #3 from tensorflow/master\n\nupdated"
},
{
"message": "Merge pull request #4 from tensorflow/master\n\nupdated"
},
{
"message": "Merge pull request #5 from tensorflow/master\n\nUpgraded"
},
{
"message": "Update README.md"
},
{
"message": "Merge pull request #6 from tensorflow/master\n\nUpdated"
},
{
"message": "FileWriter Error solved"
},
{
"message": "changed"
},
{
"message": "reverted some changes"
},
{
"message": "reverted Hinge Loss change"
},
{
"message": "reverted some code"
},
{
"message": "converted v1 to v2"
},
{
"message": "compat removed"
},
{
"message": "change reverted"
}
],
"files": [
{
"diff": "@@ -646,8 +646,7 @@ class CategoricalHinge(LossFunctionWrapper):\n \"\"\"Computes the categorical hinge loss between `y_true` and `y_pred`.\n \n `loss = maximum(neg - pos + 1, 0)`\n- where `neg = sum(y_true * y_pred)` and `pos = maximum(1 - y_true)`\n-\n+ where `neg = sum(y_true * y_pred)` and `pos = maximum(1 - y_true)`\t\n Usage:\n \n >>> h = tf.keras.losses.CategoricalHinge()",
"filename": "tensorflow/python/keras/losses.py",
"status": "modified"
},
{
"diff": "@@ -76,9 +76,8 @@ def testSummaryMerged(self):\n if hasattr(tf, '_major_api_version') and tf._major_api_version == 2:\n tf.summary.create_file_writer\n else:\n- tf.summary.FileWriter\n+ tf.compat.v1.summary.FileWriter\n # pylint: enable=pointless-statement\n \n-\n if __name__ == '__main__':\n test.main()",
"filename": "tensorflow/tools/api/tests/module_test.py",
"status": "modified"
}
]
}
|
{
"body": "I'm trying to use `model.fit()` on a `Sequential` model consisting of custom layers subclassing `tf.keras.layers.Layer`. Using `GradientTape` where I feed every batch in explicitly works fine (including in graph mode with `tf.function`). Trying to use the high-level Keras API for training,\r\n\r\n```py\r\nmodel.compile(loss=loss_fn, optimizer=\"adam\")\r\nmodel.fit(X_train, y_train)\r\n```\r\n\r\nI get a bunch of `ValueError: None values not supported.` for things like\r\n\r\n```py\r\ndef call(self, x):\r\n ...\r\n epsilon = tf.random.normal(x.shape) # reparametrization trick\r\n ...\r\n```\r\n\r\nsince `x.shape[0]` is `None`. So the question is, how do I get an integer batch size when using `model.fit()`? I tried\r\n\r\n```py\r\nmodel.compile(loss=loss_fn, optimizer=\"adam\")\r\nmodel.fit(\r\n X_train, y_train, batch_size=64, steps_per_epoch=X_train.shape[0] // 64,\r\n)\r\n```\r\n\r\nbut that makes no difference. `x.shape[0]` remains `None` during graph creation.",
"comments": [
{
"body": "Can you please try numpy.shape(X_train)[0]//64",
"created_at": "2020-02-23T15:41:59Z"
},
{
"body": "Please let me know if it works.",
"created_at": "2020-02-23T15:51:58Z"
},
{
"body": "@ghosalsattam Makes no difference.",
"created_at": "2020-02-23T17:39:50Z"
},
{
"body": "Can you provide me the full code?",
"created_at": "2020-02-23T18:02:27Z"
},
{
"body": "@ghosalsattam Sorry, the code should remain private for now. But the following stripped down example already exhibits the problem:\r\n\r\n```py\r\nimport tensorflow as tf\r\n\r\nclass Foo(tf.keras.layers.Layer):\r\n def __init__(self):\r\n super().__init__()\r\n\r\n def call(self, x):\r\n return tf.random.normal(x.shape)\r\n\r\nmodel = tf.keras.Sequential([Foo()])\r\n\r\nmodel.compile()\r\n\r\nmodel.fit(tf.random.normal([10,5]), tf.random.normal([10]))\r\n```",
"created_at": "2020-02-23T20:00:07Z"
},
{
"body": "It is difficult to say something if I don't have any information of x. But from the error it seems that in the function, the value of x passed does not match the x you intend to pass. May be it is an array of None.",
"created_at": "2020-02-24T04:42:15Z"
},
{
"body": "@janosh,\r\nI tried to run the above code snippet and am facing an error stating ` ValueError: Cannot convert a partially known TensorShape to a Tensor: (None, 5)`. You can find the gist of it [here](https://colab.sandbox.google.com/gist/saikumarchalla/641b725d245017106586ab46c03acdea/36991.ipynb).\r\n\r\nCould you please confirm if you are facing the same error? Thanks!",
"created_at": "2020-02-24T14:11:06Z"
},
{
"body": "@amahendrakar Yes, that's the error I'm getting as well.",
"created_at": "2020-02-24T14:12:28Z"
},
{
"body": "@janosh \r\nThen you can try using batch size =1\r\nI used the approach for a slightly different case and it worked there.\r\nYou can use the format of batch size used in predict().\r\nfor i in range(30,70):\r\n print(i)\r\n Pixels,img=detectCorner(path,i)\r\n if(len(Pixels)==0):\r\n continue\r\n Roi=findClusters(Pixels,img)\r\n print(Roi)\r\n crop = np.empty((40,32,32,1),dtype=int)\r\n for roi in range(len(Roi)):\r\n for j in range(30,70):\r\n ll=Roi[roi][0]\r\n ur=Roi[roi][1]\r\n print(ll,ur)\r\n img1=pronounce(data[:,:,j].T)\r\n #print(ll[0],ur[0])\r\n crop1=img1[ur[0]:ll[0],ll[1]:ur[1]]\r\n plt.imshow(crop1,'gray')\r\n #plt.show()\r\n crop1=cv2.resize(crop1,interpolation=cv2.INTER_CUBIC,dsize=(32,32))\r\n crop[j-30,]=np.expand_dims(crop1,axis=2)\r\n #print(np.shape(crop[roi]))\r\n #crop[roi]=np.expand_dims(crop[roi],axis=2)\r\n a=classifier.predict_classes(crop)#batch size=1\r\n\r\n\r\nFor details:\r\nhttps://stackoverflow.com/questions/35289773/cannot-convert-a-partially-converted-tensor-in-tensorflow",
"created_at": "2020-02-24T15:10:50Z"
},
{
"body": "Hope this helps.",
"created_at": "2020-02-24T15:11:11Z"
},
{
"body": "Use tf.shape(x) instead of x.shape. \r\n\r\nx.shape is the static shape of x and evaluates to (None,5).\r\n\r\ntf.shape(x) on the other hand is the dynamic shape of x and is evaluated as the actual shape of x when training/predicting.",
"created_at": "2020-02-24T17:23:07Z"
},
{
"body": "@sixChar Thanks, I tried that as well but it's not really a solution. The errors in my case are thrown by some nested functions that really only need to know the size of the first dimension of `x`. If I pass in `tf.shape(x)[0]` instead of `x.shape[0]`, nothing changes. I get the same errors saying `None values not supported.` for things like `tf.zeros(batch_size)` where `batch_size` was passed in as `tf.shape(x)[0]`. I suspect that it might work if I pass in the whole tensor and only call tf.shape in the nested functions themselves. But I'd prefer not to do that since those functions don't need to know anything except `tf.shape(x)[0]`.",
"created_at": "2020-02-24T17:36:15Z"
},
{
"body": "Could you give an example of the kind of code that still causes the same error when using tf.shape(x)[0]?",
"created_at": "2020-02-24T20:22:43Z"
},
{
"body": "@sixChar Oops, I take it all back. I tried producing a minimal example that errors with `tf.shape(x)`. Didn't manage though. So I went back to my actual code and tried to find out why I was still getting the error there. Turns out there was one place I had overlooked converting from `x.shape` to `tf.shape(x)`. To be fair, the graph code you get when debugging `model.fit(...)` is pretty near unreadable which is why I'd missed it. Sorry about the noise.",
"created_at": "2020-02-25T11:58:20Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36991\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36991\">No</a>\n",
"created_at": "2020-02-25T11:58:23Z"
},
{
"body": "One final suggestion though: I think it would help if the [docs on `tf.shape`](https://www.tensorflow.org/api_docs/python/tf/shape?version=nightly) as well as the [Writing custom layers and models with Keras](https://www.tensorflow.org/guide/keras/custom_layers_and_models) guide had a note on this, i.e. that `tf.shape` should be used instead of `x.shape` when defining custom layers and models to avoid `None` errors.",
"created_at": "2020-02-25T15:56:55Z"
},
{
"body": "@janosh Would you like to update docs through PR? Thanks!",
"created_at": "2020-02-25T20:27:55Z"
},
{
"body": "@jvishnuvardhan PR submitted. Suggestions for improvement welcome.",
"created_at": "2020-02-26T10:40:52Z"
},
{
"body": "@Al-Badri179 Can you please open a new issue with a simple standalone code to reproduce the issue? Thanks!",
"created_at": "2020-08-17T16:53:10Z"
},
{
"body": "@jvishnuvardhan ok, sorry for inconvenience",
"created_at": "2020-08-17T19:13:17Z"
}
],
"number": 36991,
"title": "How to get integer batch size in Keras model.fit()"
}
|
{
"body": "See #36991 for details.",
"number": 37087,
"review_comments": [
{
"body": "The example above this says exactly this. Note the difference between `tf.shape(a)` and `a.shape` above.",
"created_at": "2020-05-19T15:44:58Z"
},
{
"body": "I find the information above inactionable. Even reading it now already knowing what it's trying to tell me, I have a hard time connecting the difference in behavior between `tf.shape(x)` and `x.shape` to the decision when to use which. The docs could be clearer on that point in my opinion. Hence the hint to prefer `tf.shape(x)` over `x.shape` when running in graph mode. Maybe we can shorten it?",
"created_at": "2020-05-19T15:58:07Z"
},
{
"body": "Agree with shortening.",
"created_at": "2020-05-19T16:01:10Z"
},
{
"body": "Do you have something in mind or should I have a go?",
"created_at": "2020-05-19T16:02:37Z"
},
{
"body": "Better you have a go. The relevant parts that should be included are that `tf.shape(x)` computes the dynamic shape whereas `x.shape` is the static shape known at the attribute access location. Then maybe one short phrase of where this would be different, but not too long",
"created_at": "2020-05-19T16:29:48Z"
},
{
"body": "Gave it a shot.",
"created_at": "2020-05-20T04:57:06Z"
},
{
"body": "Thanks Janosh. I read one SO answer where a googler working in TF Team answered it with great clarity. May be it will help you update and bring out the difference between tf.shape(x) and x.shape. [Here](https://stackoverflow.com/questions/37096225/how-to-understand-static-shape-and-dynamic-shape-in-tensorflow) is the link to that SO answer.",
"created_at": "2020-05-20T14:26:23Z"
},
{
"body": "I would keep this line about the minimal information",
"created_at": "2020-05-20T16:27:50Z"
},
{
"body": "Sure. I was going to do a second revision with the link provided by @jvishnuvardhan. Surprised this was merged already.",
"created_at": "2020-05-21T04:10:33Z"
}
],
"title": "docs: add tip to prefer tf.shape(x) over x.shape in custom layers/models"
}
|
{
"commits": [
{
"message": "docs: add tip to prefer tf.shape(x) over x.shape when writing custom layers/models\n\nSee #36991 for details."
},
{
"message": "shorten tf.shape docstring\n\nclarify when it's different from `x.shape`"
}
],
"files": [
{
"diff": "@@ -535,19 +535,16 @@ def shape_v2(input, out_type=dtypes.int32, name=None):\n # pylint: disable=redefined-builtin\n \"\"\"Returns the shape of a tensor.\n \n- This operation returns a 1-D integer tensor representing the shape of `input`.\n- This represents the minimal set of known information at definition time.\n+ `tf.shape` returns a 1-D integer tensor representing the shape of `input`.\n \n For example:\n \n >>> t = tf.constant([[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]])\n >>> tf.shape(t)\n <tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 2, 3], dtype=int32)>\n- >>> tf.shape(t).numpy()\n- array([2, 2, 3], dtype=int32)\n \n- Note: When using symbolic tensors, such as when using the Keras functional\n- API, tf.shape() will return the shape of the symbolic tensor.\n+ Note: When using symbolic tensors, such as when using the Keras API,\n+ tf.shape() will return the shape of the symbolic tensor.\n \n >>> a = tf.keras.layers.Input((None, 10))\n >>> tf.shape(a)\n@@ -557,10 +554,13 @@ def shape_v2(input, out_type=dtypes.int32, name=None):\n \n >>> a.shape\n TensorShape([None, None, 10])\n+ \n+ (The first `None` represents the as yet unknown batch size.)\n \n `tf.shape` and `Tensor.shape` should be identical in eager mode. Within\n `tf.function` or within a `compat.v1` context, not all dimensions may be\n- known until execution time.\n+ known until execution time. Hence when defining custom layers and models\n+ for graph mode, prefer the dynamic `tf.shape(x)` over the static `x.shape`.\n \n Args:\n input: A `Tensor` or `SparseTensor`.",
"filename": "tensorflow/python/ops/array_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code): yes\r\n- TensorFlow installed from: binary\r\n- TensorFlow version: 2.1\r\n- Python version: 3.7\r\n\r\n**Describe the current behavior**\r\n\r\nUsing the `tf.keras.utils.register_keras_serializable` decorator does not allow correct serialization/restoration of a custom `tf.keras.losses.Loss` subclass without using a `custom_objects` argument.\r\n\r\n**Describe the expected behavior**\r\n\r\nUsing `tf.keras.utils.register_keras_serializable` allows serialization/restoration of custom losses without using a `custom_objects` argument.\r\n\r\n**Code to reproduce the issue**\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\n\r\n@tf.keras.utils.register_keras_serializable()\r\nclass CustomLoss(tf.keras.losses.MeanSquaredError):\r\n pass\r\n\r\n\r\nmodel = tf.keras.Sequential([tf.keras.layers.Dense(units=1, input_shape=(1,))])\r\nmodel.compile(optimizer='sgd', loss=CustomLoss())\r\nmodel.save('model')\r\n\r\n# ValueError: Unknown loss function: CustomLoss\r\ntf.keras.models.load_model('model', compile=True)\r\n```\r\n\r\n**Other info / logs**\r\nRelevant traceback:\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/fd242bad45bd9778d61ad116001fd4b191e51c30/tensorflow/python/keras/saving/save.py#L190\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/fd242bad45bd9778d61ad116001fd4b191e51c30/tensorflow/python/keras/saving/saved_model/load.py#L114-L115\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/fd242bad45bd9778d61ad116001fd4b191e51c30/tensorflow/python/keras/saving/saving_utils.py#L259\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/fd242bad45bd9778d61ad116001fd4b191e51c30/tensorflow/python/keras/losses.py#L1301-L1305\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/fd242bad45bd9778d61ad116001fd4b191e51c30/tensorflow/python/keras/utils/generic_utils.py#L361-L362\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/fd242bad45bd9778d61ad116001fd4b191e51c30/tensorflow/python/keras/utils/generic_utils.py#L321",
"comments": [
{
"body": "I have tried on colab with TF version 2.1.0-rc2, 2.2.0-dev20200128 and was able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/55d11b811078c362ff6e49379da72353/untitled597.ipynb).Thanks!",
"created_at": "2020-01-29T09:35:07Z"
},
{
"body": "I found this bug too and fixed in #37018",
"created_at": "2020-02-26T13:21:06Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36259\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36259\">No</a>\n",
"created_at": "2020-03-02T17:37:25Z"
}
],
"number": 36259,
"title": "Error registering Keras serializable loss"
}
|
{
"body": "fix the issue that Keras cannot correctly serialize custom train config (loss, metrics) for Model.\r\n\r\nFixes #36259",
"number": 37018,
"review_comments": [],
"title": "Bugfix: keras custom train config serialize"
}
|
{
"commits": [
{
"message": "fix(keras): unable serialize custom train config"
},
{
"message": "fix: TF API changes"
},
{
"message": "fix: code style"
},
{
"message": "Merge branch 'master' into bugfix/keras_custom_train_config_serialize"
},
{
"message": "style: fix pylint error"
}
],
"files": [
{
"diff": "@@ -23,6 +23,7 @@\n \n from tensorflow.python.framework import tensor_shape\n from tensorflow.python.util.compat import collections_abc\n+from tensorflow.python.keras.utils import generic_utils\n \n \n def get_json_type(obj):\n@@ -40,7 +41,10 @@ def get_json_type(obj):\n # if obj is a serializable Keras class instance\n # e.g. optimizer, layer\n if hasattr(obj, 'get_config'):\n- return {'class_name': obj.__class__.__name__, 'config': obj.get_config()}\n+ return {\n+ 'class_name': generic_utils.get_registered_name(obj.__class__),\n+ 'config': obj.get_config()\n+ }\n \n # if obj is any numpy type\n if type(obj).__module__ == np.__name__:",
"filename": "tensorflow/python/util/serialization.py",
"status": "modified"
},
{
"diff": "@@ -23,10 +23,12 @@\n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import tensor_shape\n from tensorflow.python.framework import test_util\n+from tensorflow.python.keras import losses\n from tensorflow.python.keras.engine import input_layer\n from tensorflow.python.keras.engine import sequential\n from tensorflow.python.keras.engine import training\n from tensorflow.python.keras.layers import core\n+from tensorflow.python.keras.utils import losses_utils, generic_utils\n from tensorflow.python.platform import test\n from tensorflow.python.util import serialization\n \n@@ -69,5 +71,47 @@ def test_serialize_model(self):\n self.assertEqual(\n 10, model_round_trip[\"config\"][\"layers\"][1][\"config\"][\"units\"])\n \n+ @test_util.run_in_graph_and_eager_modes\n+ def test_serialize_custom_model_compile(self):\n+ with generic_utils.custom_object_scope():\n+ @generic_utils.register_keras_serializable(package='dummy-package')\n+ class DummySparseCategoricalCrossentropyLoss(losses.LossFunctionWrapper):\n+ # This loss is identical equal to tf.keras.losses.SparseCategoricalCrossentropy\n+ def __init__(\n+ self,\n+ from_logits=False,\n+ reduction=losses_utils.ReductionV2.AUTO,\n+ name=\"dummy_sparse_categorical_crossentropy_loss\",\n+ ):\n+ super(DummySparseCategoricalCrossentropyLoss, self).__init__(\n+ losses.sparse_categorical_crossentropy,\n+ name=name,\n+ reduction=reduction,\n+ from_logits=from_logits,\n+ )\n+\n+ x = input_layer.Input(shape=[3])\n+ y = core.Dense(10)(x)\n+ model = training.Model(x, y)\n+ model.compile(\n+ loss=DummySparseCategoricalCrossentropyLoss(from_logits=True)\n+ )\n+ model_round_trip = json.loads(\n+ json.dumps(model.loss, default=serialization.get_json_type)\n+ )\n+\n+ # check if class name with package scope\n+ self.assertEqual(\n+ \"dummy-package>DummySparseCategoricalCrossentropyLoss\",\n+ model_round_trip[\"class_name\"]\n+ )\n+\n+ # check if configure is correctly\n+ self.assertEqual(\n+ True,\n+ model_round_trip[\"config\"][\"from_logits\"]\n+ )\n+\n+\n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/util/serialization_test.py",
"status": "modified"
}
]
}
|
{
"body": "Hi @tanzhenyu @lamberta @dynamicwebpaige There are two param default values for AdaDelta that look different from the original implementation. It is probably explained in past discussions (and if it is the case pls let me know where I can find it so we can close this issue.) Cheers.\r\n\r\nSimilar issues: https://github.com/tensorflow/tensorflow/issues/31024 and https://github.com/tensorflow/tensorflow/pull/31025.\r\n\r\nTF 2.1 [API docs for the Adadelta optimizer](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adadelta) come from [`/optimizer-v2/`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/optimizer_v2/adadelta.py), where: \r\n- The learning rate is set to 0.001:\r\n - Keras' implementation states that learning rate is 1.\r\n - [`optimizer.py`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/optimizers.py) (v1) sets it to 1 (synced with Keras, I suppose).\r\n - There's a Keras PR - https://github.com/keras-team/keras/pull/12841 - that proposed to change the LR from 1 to 0.001. It may have been reverted back to 1 (see commit https://github.com/keras-team/keras/pull/12888/commits/2009cab5217a57bfbb4dae88371640ce1bb4a0e9).\r\n- The default epsilon does not match the one in the original AdaDelta [paper](https://arxiv.org/pdf/1212.5701.pdf) as well as Keras' implementation:\r\n - They use `1e-6` instead of `1e-7` (`\"Setting the hyperparameters to ε = 1e − 6 and ρ = 0.95...\"`).\r\n\r\nSources: \r\n\r\n- [TF 2.1 /optimizer_v2/](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/optimizer_v2/adadelta.py):\r\n\r\n```python\r\n@keras_export('keras.optimizers.Adadelta')\r\nclass Adadelta(optimizer_v2.OptimizerV2):\r\n ...\r\n def __init__(self,\r\n learning_rate=0.001,\r\n rho=0.95,\r\n epsilon=1e-7,\r\n name='Adadelta',\r\n **kwargs):\r\n```\r\n\r\n- [TF 2.1 optimizers.py - version 1](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/optimizers.py):\r\n\r\n```python\r\nclass Adadelta(Optimizer):\r\n...\r\n def __init__(self, lr=1.0, rho=0.95, epsilon=None, decay=0., **kwargs):\r\n...\r\n```\r\n\r\n- [Keras optimizers.py](https://github.com/keras-team/keras/blob/master/keras/optimizers.py):\r\n```python\r\nclass Adadelta(Optimizer):\r\n...\r\n def __init__(self, learning_rate=1.0, rho=0.95, **kwargs):\r\n...\r\n```\r\n\r\nThanks for taking your time to look at this potential issue.",
"comments": [
{
"body": "Hi @8bitmp3 , I also had a similar doubt when I came across the paper and the API documentation. I think according to the paper,the step size converges to 1 at end of training and the convergence occurs when the gradients and parameters updates are smaller. However there is a mismatch in the documentation which suggests that lr=0.001 whereas in the paper it is lr=1.0 and epsilon=1e-6. The less the LR I think it would be locally stuck in minima and not contribute significantly .",
"created_at": "2020-02-16T19:28:38Z"
},
{
"body": "Hi @8bitmp3 ,@gadagashwini, Have made a comment in the https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/optimizer_v2/adadelta.py \r\nThe comment states the original details as mentioned in the paper with LR 1 and epsilon 1e-6.\r\n PR #36832 ",
"created_at": "2020-02-17T18:36:41Z"
},
{
"body": "@8bitmp3 I checked that @abhilash1910 PR https://github.com/tensorflow/tensorflow/pull/36849 got merged and I also reviewed that `AddaDelta` in `keras-team/keras` and `tf.keras` are in sync.\r\n\r\n[Here](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adadelta?version=nightly) is the TF page on `AdaDelta` with the update.\r\n\r\n[Here](https://github.com/keras-team/keras/blob/master/keras/optimizer_v2/adadelta.py) is the link to `AddaDelta` in `keras-team/keras`.\r\n```\r\n def __init__(self,\r\n learning_rate=0.001,\r\n rho=0.95,\r\n epsilon=1e-7,\r\n name='Adadelta',\r\n **kwargs):\r\n```\r\nPlease verify once and close the issue if this was resolved for you. Thanks!",
"created_at": "2021-05-06T20:24:22Z"
},
{
"body": "Thank you @jvishnuvardhan @lamberta \r\n\r\n`learning_rate=0.001`, `epsilon=1e-7`\r\n\r\n👍 Closing the issue",
"created_at": "2021-05-08T17:30:02Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36785\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36785\">No</a>\n",
"created_at": "2021-05-08T17:30:05Z"
}
],
"number": 36785,
"title": "TF 2.1/tf.keras AdaDelta optimizer: default epsilon and learning rate values"
}
|
{
"body": "The original implementation of Adadelta by M.D Zeiler (https://arxiv.org/pdf/1212.5701.pdf) had a eta of 1.0 and epsilon of 1e-6 which is not matching with the function mentioned here. Hence commented the original implementation according to paper. Reference Issue #36785",
"number": 36832,
"review_comments": [
{
"body": "No need for this.",
"created_at": "2020-02-18T04:01:10Z"
},
{
"body": "Please put this at top of docstring.\r\nAlso please put description, i.e., which section in this paper that a recommended learning rate is proposed so users are well aware of it.",
"created_at": "2020-02-18T04:02:13Z"
},
{
"body": "Hi @tanzhenyu, sure I will put it at the top of the docstring. ",
"created_at": "2020-02-18T05:16:13Z"
}
],
"title": "Comments for alternate implementation in Adadelta Paper #36785"
}
|
{
"commits": [
{
"message": "Comments for alternate implementation in Adadelta Paper #36785\n\nThe original implementation of Adadelta by M.D Zeiler (https://arxiv.org/pdf/1212.5701.pdf) had a eta of 1.0 and epsilon of 1e-6 which is not matching with the function mentioned here. Hence commented the original implementation according to paper. Reference Issue #36785"
}
],
"files": [
{
"diff": "@@ -57,7 +57,8 @@ class Adadelta(optimizer_v2.OptimizerV2):\n ([pdf](http://arxiv.org/pdf/1212.5701v1.pdf))\n \n \"\"\"\n-\n+ #def __init__(self, lr=1.0, rho=0.95, epsilon=None, decay=0., **kwargs):\n+ #Adadelta function definition as per paper by M.D. Zeiler (https://arxiv.org/pdf/1212.5701.pdf) where epsilon=1e-6and learning rate=1.0\n def __init__(self,\n learning_rate=0.001,\n rho=0.95,",
"filename": "tensorflow/python/keras/optimizer_v2/adadelta.py",
"status": "modified"
}
]
}
|
{
"body": "## Description of issue (what needs changing):\r\n\r\ndocument for tensorflow.keras.losses.categorical_hinge is wrong\r\n\r\n### Clear description\r\n\r\n```python\r\n@keras_export('keras.losses.categorical_hinge')\r\ndef categorical_hinge(y_true, y_pred):\r\n \"\"\"Computes the categorical hinge loss between `y_true` and `y_pred`.\r\n `loss = maximum(neg - pos + 1, 0)`\r\n where `neg = sum(y_true * y_pred)` and `pos = maximum(1 - y_true)`\r\n Args:\r\n y_true: The ground truth values. `y_true` values are expected to be -1 or 1.\r\n If binary (0 or 1) labels are provided they will be converted to -1 or 1.\r\n y_pred: The predicted values.\r\n Returns:\r\n Categorical hinge loss values.\r\n \"\"\"\r\n y_pred = ops.convert_to_tensor_v2(y_pred)\r\n y_true = math_ops.cast(y_true, y_pred.dtype)\r\n pos = math_ops.reduce_sum(y_true * y_pred, axis=-1)\r\n neg = math_ops.reduce_max((1. - y_true) * y_pred, axis=-1)\r\n return math_ops.maximum(0., neg - pos + 1.)\r\n```\r\n\r\nShould be: `neg=maximum((1-y_true)*y_pred)` and `pos=sum(y_true*y_pred)`\r\n",
"comments": [
{
"body": "Can i be assigned to this issue?\r\n",
"created_at": "2020-02-17T10:27:51Z"
},
{
"body": "@ayushmankumar7 feel free to send me a PR.",
"created_at": "2020-03-04T23:20:35Z"
},
{
"body": "Sure. Thanks",
"created_at": "2020-03-05T03:34:48Z"
},
{
"body": "Closing this issue since the associated PR has been merged. Thanks!",
"created_at": "2020-03-19T20:01:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36807\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36807\">No</a>\n",
"created_at": "2020-03-19T20:01:51Z"
}
],
"number": 36807,
"title": "wrong doc for categorical_hinge loss "
}
|
{
"body": "Issue : #36807\r\nIssue : #37075\r\nRequired changes made.",
"number": 36817,
"review_comments": [],
"title": "#37075 Readme Updated for Python3."
}
|
{
"commits": [
{
"message": "Merge pull request #1 from tensorflow/master\n\nUpdate from Original"
},
{
"message": "Merge pull request #2 from tensorflow/master\n\nUpdating"
},
{
"message": "wrong doc for categorical_hinge loss"
},
{
"message": "Merge pull request #3 from tensorflow/master\n\nupdated"
},
{
"message": "Merge pull request #4 from tensorflow/master\n\nupdated"
},
{
"message": "Merge pull request #5 from tensorflow/master\n\nUpgraded"
},
{
"message": "Update README.md"
},
{
"message": "Merge pull request #6 from tensorflow/master\n\nUpdated"
},
{
"message": "FileWriter Error solved"
},
{
"message": "Merge pull request #7 from tensorflow/master\n\nUpdated Repo"
}
],
"files": [
{
"diff": "@@ -42,13 +42,13 @@ To install the current release, which includes support for\n Windows)*:\n \n ```\n-$ pip install tensorflow\n+$ pip3 install tensorflow\n ```\n \n A smaller CPU-only package is also available:\n \n ```\n-$ pip install tensorflow-cpu\n+$ pip3 install tensorflow-cpu\n ```\n \n To update TensorFlow to the latest version, add `--upgrade` flag to the above\n@@ -61,7 +61,7 @@ commands.\n #### *Try your first TensorFlow program*\n \n ```shell\n-$ python\n+$ python3\n ```\n \n ```python",
"filename": "README.md",
"status": "modified"
},
{
"diff": "@@ -861,7 +861,7 @@ class CategoricalHinge(LossFunctionWrapper):\n \"\"\"Computes the categorical hinge loss between `y_true` and `y_pred`.\n \n `loss = maximum(neg - pos + 1, 0)`\n- where `neg = sum(y_true * y_pred)` and `pos = maximum(1 - y_true)`\n+ where `neg = maximum((1 - y_true)*y_pred)` and `pos = sum(y_true * y_pred)`\n \n Usage:\n ",
"filename": "tensorflow/python/keras/losses.py",
"status": "modified"
},
{
"diff": "@@ -70,13 +70,13 @@ def testCompatV2HasCompatV1(self):\n \n def testSummaryMerged(self):\n # pylint: disable=pointless-statement\n- tf.summary.image\n+ tf.compat.v1.summary.image\n # If we use v2 API, check for create_file_writer,\n # otherwise check for FileWriter.\n if hasattr(tf, '_major_api_version') and tf._major_api_version == 2:\n- tf.summary.create_file_writer\n+ tf.compat.v1.summary.create_file_writer\n else:\n- tf.summary.FileWriter\n+ tf.compat.v1.summary.FileWriter\n # pylint: enable=pointless-statement\n \n ",
"filename": "tensorflow/tools/api/tests/module_test.py",
"status": "modified"
}
]
}
|
{
"body": "Note that the option for bug reports is missing.\r\n\r\n\r\n\r\nI suspect this is related to #36636 which was recently merged.\r\n\r\nWhen I look at the [`00-bug-issue.md` file](https://raw.githubusercontent.com/tensorflow/tensorflow/master/.github/ISSUE_TEMPLATE/00-bug-issue.md), there is a space instead of a newline before `about:`. Don't know if this would cause it to go missing, but definitely seems not right.\r\n\r\n\r\nOthers appear missing as well, such as the build/installation issue, & performance issue.\r\n",
"comments": [
{
"body": "Working on a fix",
"created_at": "2020-02-13T17:04:53Z"
}
],
"number": 36721,
"title": "Github issue creation for bugs missing"
}
|
{
"body": "Fixes #36721 and also makes sure style is consistent in all headers.",
"number": 36732,
"review_comments": [],
"title": "Fix issue templates"
}
|
{
"commits": [
{
"message": "Fix issue templates\n\nFixes #36721 and also makes sure style is consistent in all headers."
}
],
"files": [
{
"diff": "@@ -1,9 +1,9 @@\n---------------------------------------------------------------------------------\n-\n-name: Bug Issue about: Use this template for reporting an issue related to bug.\n+---\n+name: Bug Issue\n+about: Use this template for reporting a bug\n labels: 'type:bug'\n \n---------------------------------------------------------------------------------\n+---\n \n <em>Please make sure that this is a bug. As per our\n [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),",
"filename": ".github/ISSUE_TEMPLATE/00-bug-issue.md",
"status": "modified"
},
{
"diff": "@@ -1,7 +1,7 @@\n---------------------------------------------------------------------------------\n-\n-name: Build/Installation Issue about: Use this template for build/installation\n-issues labels: 'type:build/install'\n+---\n+name: Build/Installation Issue\n+about: Use this template for build/installation issues\n+labels: 'type:build/install'\n \n ---\n ",
"filename": ".github/ISSUE_TEMPLATE/10-build-installation-issue.md",
"status": "modified"
},
{
"diff": "@@ -1,6 +1,6 @@\n ---\n name: Documentation Issue\n-about: Use this template for documentation related\n+about: Use this template for documentation related issues\n labels: 'type:docs'\n \n ---",
"filename": ".github/ISSUE_TEMPLATE/20-documentation-issue.md",
"status": "modified"
},
{
"diff": "@@ -1,10 +1,9 @@\n---------------------------------------------------------------------------------\n-\n-name: TensorFlow Lite Op Request about: Use this template for reporting ops you\n-are using or missing. labels: 'comp:lite'\n-\n ---\n+name: TensorFlow Lite Op Request\n+about: Use this template for reporting Lite ops you are using or missing\n+labels: 'comp:lite'\n \n+---\n \n **System information**\n - OS Platform and Distribution (e.g., Linux Ubuntu 16.04):",
"filename": ".github/ISSUE_TEMPLATE/40-tflite-op-request.md",
"status": "modified"
},
{
"diff": "@@ -1,7 +1,7 @@\n---------------------------------------------------------------------------------\n-\n-name: Other Issues about: Use this template for any other non-support related\n-issues labels: 'type:others'\n+---\n+name: Other Issues\n+about: Use this template for any other non-support related issues\n+labels: 'type:others'\n \n ---\n ",
"filename": ".github/ISSUE_TEMPLATE/50-other-issues.md",
"status": "modified"
},
{
"diff": "@@ -1,6 +1,6 @@\n ---\n name: TensorFlow Lite New Converter Issue\n-about: Use this template for reporting issues during model conversion to TFLite.\n+about: Use this template for reporting issues during model conversion to TFLite\n \n ---\n ",
"filename": ".github/ISSUE_TEMPLATE/60-tflite-converter-issue.md",
"status": "modified"
},
{
"diff": "@@ -1,9 +1,9 @@\n---------------------------------------------------------------------------------\n+---\n+name: Performance Issue\n+about: Use this template for reporting a performance issue\n+labels: 'type:performance'\n \n-name: Performance Issue about: Use this template for reporting a performance\n-issue. labels: 'type:performance'\n-\n---------------------------------------------------------------------------------\n+---\n \n <em>Please make sure that this is an issue related to performance of TensorFlow.\n As per our",
"filename": ".github/ISSUE_TEMPLATE/80-performance-issue.md",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Google colab\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): Google colab\r\n- TensorFlow version (use command below): 1.15.0\r\n- Python version: 3.6.9\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: 10.1.243\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\nreduce_euclidean_norm might return false results?\r\nFor example, the following three snippets are all using reduce_euclidean_norm, but all return wrong results (return 4; should return sqrt(17)).\r\n\r\nx = tf.constant([[1, 2, 3], [1, 1, 1]])\r\ny = tf.math.reduce_euclidean_norm(x)\r\nwith tf.Session() as sess: print(y.eval()) \r\nreturns 4, should return numerical value of sqrt(17)\r\n\r\nx = tf.constant([[1, 2, 3], [1, 1, 1]])\r\ny = tf.compat.v1.math.reduce_euclidean_norm(x)\r\nwith tf.Session() as sess: print(y.eval()) \r\nreturns 4, should return numerical value of sqrt(17)\r\n\r\nx = tf.constant([[1, 2, 3], [1, 1, 1]])\r\ny = tf.compat.v2.math.reduce_euclidean_norm(x)\r\nwith tf.Session() as sess: print(y.eval()) \r\nreturns 4, should return numerical value of sqrt(17)\r\n\r\n\r\n**Describe the expected behavior**\r\n\r\nfrom tensorflow docs\r\nhttps://www.tensorflow.org/api_docs/python/tf/math/reduce_euclidean_norm\r\nx = tf.constant([[1, 2, 3], [1, 1, 1]])\r\ntf.reduce_euclidean_norm(x) # sqrt(17)\r\n\r\n**Code to reproduce the issue**\r\nAttached above. \r\n\r\n**Other info / logs**\r\nN/A\r\n\r\nThank you so much!",
"comments": [
{
"body": "Update: When the input is in the form\r\n`x = tf.constant([[1.0, 2.0, 3.0], [1.0, 1.0, 1.0]])`\r\nthe reduce_euclidean_norm returns the correct result.",
"created_at": "2020-02-07T19:26:25Z"
},
{
"body": "Credit: @merterm ",
"created_at": "2020-02-07T19:27:25Z"
},
{
"body": "I have tried on colab with TF version 1.15, Nightly versions and was able to reproduce the issue.Please, find the gist [here.](https://colab.research.google.com/gist/ravikyram/4dc242a7a9391723df71d17e0bf68aa0/untitled630.ipynb) Thanks!",
"created_at": "2020-02-10T09:38:57Z"
},
{
"body": "Thank you so much!",
"created_at": "2020-02-10T15:28:24Z"
},
{
"body": "@martinmamql All those examples are correctly returning 4 instead of sqrt(17). The reason is `x.dtype is tf.int32` and the doc clearly says `Returns : The reduced tensor, of the same dtype as the input_tensor.`. However, the document has typo (sqrt(17)) which needs to be corrected. I raised a PR to correct it in `master` and will be updated in the docs after merging the PR. Thanks!\r\n\r\nAlternatively, you can add dtype to the end of `x` as follows. Please check the [gist here](https://colab.sandbox.google.com/gist/jvishnuvardhan/dd17894e65c1d74841c197750734633a/36615.ipynb).\r\n`x = tf.constant([[1, 2, 3], [1, 1, 1]], dtype = tf.float32)`",
"created_at": "2020-02-10T17:59:58Z"
},
{
"body": "It has been 14 days with no activity and the `awaiting response` label was assigned. Is this still an issue?",
"created_at": "2020-02-27T01:02:25Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36554\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36554\">No</a>\n",
"created_at": "2020-02-27T01:22:56Z"
}
],
"number": 36554,
"title": "reduce_euclidean_norm false results"
}
|
{
"body": "Updated an incorrect example as reported in #36554",
"number": 36670,
"review_comments": [],
"title": "Updated an example for reduce_euclidean_norm"
}
|
{
"commits": [
{
"message": "Updated an example for reduce_euclidean_norm\n\nUpdated an incorrect example as reported in #36554"
}
],
"files": [
{
"diff": "@@ -1768,12 +1768,14 @@ def reduce_euclidean_norm(input_tensor, axis=None, keepdims=False, name=None):\n For example:\n \n ```python\n- x = tf.constant([[1, 2, 3], [1, 1, 1]])\n- tf.reduce_euclidean_norm(x) # sqrt(17)\n- tf.reduce_euclidean_norm(x, 0) # [sqrt(2), sqrt(5), sqrt(10)]\n- tf.reduce_euclidean_norm(x, 1) # [sqrt(14), sqrt(3)]\n- tf.reduce_euclidean_norm(x, 1, keepdims=True) # [[sqrt(14)], [sqrt(3)]]\n- tf.reduce_euclidean_norm(x, [0, 1]) # sqrt(17)\n+ x = tf.constant([[1, 2, 3], [1, 1, 1]]) # x.dtype is tf.int32\n+ tf.math.reduce_euclidean_norm(x) # returns 4 as dtype is tf.int32\n+ y = tf.constant([[1, 2, 3], [1, 1, 1]], dtype = tf.float32)\n+ tf.math.reduce_euclidean_norm(y) # returns 4.1231055 which is sqrt(17)\n+ tf.math.reduce_euclidean_norm(y, 0) # [sqrt(2), sqrt(5), sqrt(10)]\n+ tf.math.reduce_euclidean_norm(y, 1) # [sqrt(14), sqrt(3)]\n+ tf.math.reduce_euclidean_norm(y, 1, keepdims=True) # [[sqrt(14)], [sqrt(3)]]\n+ tf.math.reduce_euclidean_norm(y, [0, 1]) # sqrt(17)\n ```\n \n Args:",
"filename": "tensorflow/python/ops/math_ops.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a build/installation issue. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:build_template</em>\r\n\r\n**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): linux raspbian\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:na\r\n- TensorFlow installed from (source or binary): source\r\n- TensorFlow version: r2.1\r\n- Python version: na\r\n- Installed using virtualenv? pip? conda?: na\r\n- Bazel version (if compiling from source): na\r\n- GCC/Compiler version (if compiling from source):na\r\n- CUDA/cuDNN version: na\r\n- GPU model and memory: na\r\n\r\n\r\n\r\n**Describe the problem**\r\nThe update 3rd party repository script craps out because it can't find the EIGEN url. \r\n\r\n**Provide the exact sequence of commands / steps that you executed before running into the problem**\r\n\r\n./tensorflow/lite/tools/make/download_dependencies.sh\r\n\r\n**Any other info / logs** \r\nIt is fixed in HEAD but wasn't backported to the release branch. \r\n\r\npatch: \r\n[TF-lite-url-patch.txt](https://github.com/tensorflow/tensorflow/files/4145276/TF-lite-url-patch.txt)\r\n",
"comments": [
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36425\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36425\">No</a>\n",
"created_at": "2020-02-10T05:11:41Z"
}
],
"number": 36425,
"title": "tf-lite update 3rd party repo script r2.1 branch "
}
|
{
"body": "This PR fixes issue #36425",
"number": 36608,
"review_comments": [],
"title": "Update eigen archive download path of TFLite r2.1 branch"
}
|
{
"commits": [
{
"message": "Fix the eigen archive download path\n\nPiperOrigin-RevId: 283899224\nChange-Id: Ibd2ca25f9339de143e17569d9296c7f23ae4135c"
},
{
"message": "Fix the eigen archive download path\n\nPiperOrigin-RevId: 284086540\nChange-Id: Id0b6a9d71119fc6487bc94defbf4e8f4ccbda94b"
}
],
"files": [
{
"diff": "@@ -29,7 +29,7 @@ if [ ! -f $BZL_FILE_PATH ]; then\n exit 1;\n fi\n \n-EIGEN_URL=\"$(grep -o 'http.*bitbucket.org/eigen/eigen/get/.*tar\\.gz' \"${BZL_FILE_PATH}\" | grep -v mirror.tensorflow | head -n1)\"\n+EIGEN_URL=\"$(grep -o 'https.*gitlab.com/libeigen/eigen/-/archive/.*tar\\.gz' \"${BZL_FILE_PATH}\" | grep -v mirror.tensorflow | head -n1)\"\n GEMMLOWP_URL=\"$(grep -o 'https://storage.googleapis.com/mirror.tensorflow.org/github.com/google/gemmlowp/.*zip' \"${BZL_FILE_PATH}\" | head -n1)\"\n GOOGLETEST_URL=\"https://github.com/google/googletest/archive/release-1.8.0.tar.gz\"\n ABSL_URL=\"$(grep -o 'https://github.com/abseil/abseil-cpp/.*tar.gz' \"${BZL_FILE_PATH}\" | head -n1)\"",
"filename": "tensorflow/lite/tools/make/download_dependencies.sh",
"status": "modified"
}
]
}
|
{
"body": "This is my first issue, so let me know if it is reported in the wrong place. Thanks! \r\n\r\n**System information**\r\n- Have I written custom code: Example Python code to reproduce provided below\r\n- OS Platform and Distribution: Windows 10 Pro 1903\r\n- TensorFlow installed from binary with pip\r\n- TensorFlow version: 'v2.0.0-rc2-26-g64c3d382ca'; '2.0.0'\r\n- Python version: 3.7.4\r\n\r\n**Describe the current behavior**\r\ntf.math.polyval works correctly when executing eagerly, but when it is called from within a function that has the @tf.function decorator then a TypeError is raised:\r\n\r\n> TypeError: len is not well defined for symbolic Tensors. (eye/diag:0) Please call `x.shape` rather than `len(x)` for shape information.\r\n\r\n**Describe the expected behavior**\r\nThe output of this example should be the same regardless of eager execution or tf.function decoration:\r\n```\r\n[1 1 5]\r\n[[-2 1 10]]\r\n[[8 2 20]]\r\n[[-18 6 30]]\r\n[[24 24 24]]\r\n```\r\n\r\n**Code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\n\r\nx = tf.Variable([[-1.0], [0.0], [1.0]])\r\n\r\n@tf.function\r\ndef func():\r\n with tf.GradientTape(persistent=True) as t:\r\n t.watch(x)\r\n coeffs = tf.eye(5)\r\n pv = tf.math.polyval(coeffs, x)\r\n y = tf.reduce_sum(pv, axis=1)\r\n dy_dx = t.gradient(y, x)\r\n d2y_dx2 = t.gradient(dy_dx, x)\r\n d3y_dx3 = t.gradient(d2y_dx2, x)\r\n d4y_dx4 = t.gradient(d3y_dx3, x)\r\n del t\r\n\r\n tf.print(y)\r\n tf.print(tf.transpose(dy_dx))\r\n tf.print(tf.transpose(d2y_dx2))\r\n tf.print(tf.transpose(d3y_dx3))\r\n tf.print(tf.transpose(d4y_dx4))\r\n\r\nfunc()\r\n```\r\n\r\n",
"comments": [
{
"body": "For whatever it's worth, if you use polyval inside a custom Keras layer then eager execution of polyval doesn't work either due to an OperatorNotAllowedInGraphError. I can also provide a simple example of this, but I'm not sure whether it merits a new issue.",
"created_at": "2019-12-08T21:21:33Z"
},
{
"body": "I have tried on colab with TF version 2.0,2.1.0-dev20191013,2.1.0-rc0 and was able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/4a1b6e066c3e50b9011e86cc0213475d/untitled455.ipynb). Thanks!",
"created_at": "2019-12-10T06:22:55Z"
},
{
"body": "I've been getting this too using custom_gradients. Would love to know a solution",
"created_at": "2020-01-11T03:33:22Z"
},
{
"body": "`tf.math.polyval` only works with lists of tensors, but it doesn't verify its arguments before starting the work and it errors out internally. The fact that it works in eager mode is incidental.\r\n\r\nSo you'll need to split `coeffs`:\r\n\r\n```\r\n coeffs = tf.eye(5)\r\n coeffs = tf.split(coeffs, 5) # Convert coeffs to a list of tensors.\r\n pv = tf.math.polyval(coeffs, x)\r\n```\r\n\r\nThe op implementation could be improved in a couple of ways:\r\n * it should ensure coeffs is a list and raise an appropriate error message\r\n * it may be made to work with tensor coeffs, which should be fairly straightforward",
"created_at": "2020-02-08T14:53:08Z"
},
{
"body": "Hello! I would love to work on this. Could you guide me?",
"created_at": "2020-02-12T05:46:55Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34947\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34947\">No</a>\n",
"created_at": "2020-02-12T07:02:19Z"
},
{
"body": "@Joey155 it might be interesting to see if polyval can be made to work with tensor inputs by taking its source code and putting it in a `tf.function`. That said, there are a couple of bugs and `GradientTape` doesn't give high-order gradients for `tf.while_loop`, which would need to be fixed first.",
"created_at": "2020-02-12T15:14:59Z"
},
{
"body": "@mdanatg the issue is closed now. But i will check out your directions all the same.",
"created_at": "2020-02-13T04:16:36Z"
}
],
"number": 34947,
"title": "polyval gives TypeError when run inside tf.function with Tensor coeffs, but not when run eagerly"
}
|
{
"body": "resolves #34947 ",
"number": 36597,
"review_comments": [
{
"body": "Before you were also checking the error message. I would recommend checking that here too, using method of `tf.TestCase`",
"created_at": "2020-02-11T17:00:30Z"
},
{
"body": "I have added that. Can you review it again, please?",
"created_at": "2020-02-11T18:44:43Z"
}
],
"title": "raise error in tf.math.polyval for non-list coeffs"
}
|
{
"commits": [
{
"message": "add error msg and test"
},
{
"message": "use self.assertRaises"
},
{
"message": "add msg check"
}
],
"files": [
{
"diff": "@@ -1228,6 +1228,12 @@ def testEmpty(self):\n tf_val = math_ops.polyval(coeffs, x)\n self.assertAllClose(np_val, self.evaluate(tf_val))\n \n+ def test_coeffs_raise(self):\n+ x = np.random.rand(2, 2).astype(np.float32)\n+ coeffs = {}\n+ with self.assertRaisesRegexp(ValueError, \"Argument coeffs must be list\"):\n+ math_ops.polyval(coeffs, x)\n+\n \n class SingularGradientOpTest(test.TestCase):\n ",
"filename": "tensorflow/python/kernel_tests/cwise_ops_test.py",
"status": "modified"
},
{
"diff": "@@ -4290,6 +4290,9 @@ def polyval(coeffs, x, name=None):\n Equivalent to numpy.polyval.\n @end_compatibility\n \"\"\"\n+ if not isinstance(coeffs, list):\n+ raise ValueError(\"Argument coeffs must be list type \"\n+ \"found {}.\".format(type(coeffs)))\n \n with ops.name_scope(name, \"polyval\", nest.flatten(coeffs) + [x]) as name:\n x = ops.convert_to_tensor(x, name=\"x\")",
"filename": "tensorflow/python/ops/math_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code: yes\r\n- OS Platform and Distribution: macOS 10\r\n- TensorFlow installed from: binary\r\n- TensorFlow version: 2.1\r\n- Python version: 3.7.2\r\n\r\n**Describe the current behavior**\r\n\r\n[`BinaryElementWiseOp`](https://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/framework/numeric_op.h#L67-L109) expects child classes to define an `Operate()` method, which is used in the `Compute()` method to perform the class's operation. This `Operate()` method has an `int` template parameter `NDIMS` which represents the dimension of the inputs and output.\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/framework/numeric_op.h#L84-L107\r\n\r\nHowever, this template parameter is not used by any `BinaryElementWiseOp` subclass; all subclasses currently call an `OperateNoTemplate()` method from inside `Operate()`. For example, ReLU:\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/kernels/relu_op.h#L66-L79\r\n\r\nThis leads to seemingly unnecessary errors like in the following Python code:\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\nx = tf.reshape(0.0, [1] * 9) # Too many dimensions for ReluGradOp\r\nx = tf.Variable(x)\r\nwith tf.GradientTape() as tape:\r\n tape.watch(x)\r\n y = tf.nn.relu(x)\r\n\r\ntape.gradient(y, x) # tensorflow.python.framework.errors_impl.InvalidArgumentError: We only handle up to Tensor::dims() up to 8, not 9 [Op:ReluGrad]\r\n```\r\n\r\nThe full list of `BinaryElementWiseOp` subclasses I was able to find is\r\n\r\n* [`ReluGradOp`](https://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/kernels/relu_op.h#L61-L80)\r\n* [`Relu6GradOp`](https://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/kernels/relu_op.h#L104-L122)\r\n* [`LeakyReluGradOp`](https://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/kernels/relu_op.h#L154-L182)\r\n* [`EluGradOp`](https://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/kernels/relu_op.h#L207-L225)\r\n* [`SeluGradOp`](https://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/kernels/relu_op.h#L249-L267)\r\n* [`SoftsignGradOp`](https://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/kernels/softsign_op.cc#L46-L66)\r\n* [`SoftplusGradOp`](https://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/kernels/softplus_op.cc#L46-L66)\r\n* [`FakeQuantWithMinMaxArgsGradientOp`](https://github.com/tensorflow/tensorflow/blob/c7a0fc02f6d1211b7c1c34061fd1b821029e089a/tensorflow/core/kernels/fake_quant_ops.cc#L102-L148)\r\n\r\nAll of them follow the `Operate()` calling `OperateNoTemplate()` pattern. It seems like `BinaryElementWiseOp` and its subclasses can be refactored by removing the `NDIMS` template argument from `Operate()` and moving the contents of each subclass's `OperateNoTemplate()` method into the corresponding `Operate()` method.\r\n",
"comments": [
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36525\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36525\">No</a>\n",
"created_at": "2020-02-27T01:19:52Z"
}
],
"number": 36525,
"title": "BinaryElementWiseOp::Operate template argument not used and can cause unnecessary errors"
}
|
{
"body": "Fixes #36525 ",
"number": 36526,
"review_comments": [],
"title": "Removed NDIMS template arg from BinaryElementWiseOp::Operate"
}
|
{
"commits": [
{
"message": "Removed NDIMS template arg from BinaryElementWiseOp::Operate"
},
{
"message": "Fixed undeclared identifier 'alpha'"
}
],
"files": [
{
"diff": "@@ -82,29 +82,7 @@ class BinaryElementWiseOp : public BinaryOp<T> {\n {0, 1}, 0, a.shape(), &output));\n \n // Dispatch to the descendant's Operate() function.\n- switch (a.dims()) {\n-#define NDIM_CASE(NDIMS) \\\n- case NDIMS: { \\\n- static_cast<CHILD*>(this)->template Operate<NDIMS>(context, a, b, output); \\\n- break; \\\n- }\n-\n- NDIM_CASE(0);\n- NDIM_CASE(1);\n- NDIM_CASE(2);\n- NDIM_CASE(3);\n- NDIM_CASE(4);\n- NDIM_CASE(5);\n- NDIM_CASE(6);\n- NDIM_CASE(7);\n- NDIM_CASE(8);\n-#undef NDIM_CASE\n-\n- default:\n- context->SetStatus(errors::InvalidArgument(\n- \"We only handle up to Tensor::dims() up to 8, not \", a.dims()));\n- break;\n- }\n+ static_cast<CHILD*>(this)->Operate(context, a, b, output);\n }\n };\n ",
"filename": "tensorflow/core/framework/numeric_op.h",
"status": "modified"
},
{
"diff": "@@ -124,14 +124,8 @@ class FakeQuantWithMinMaxArgsGradientOp\n quant_max_ = (1 << num_bits) - 1;\n }\n \n- template <int NDIMS>\n void Operate(OpKernelContext* context, const Tensor& gradient,\n const Tensor& input, Tensor* output) {\n- OperateNoTemplate(context, gradient, input, output);\n- }\n-\n- void OperateNoTemplate(OpKernelContext* context, const Tensor& gradient,\n- const Tensor& input, Tensor* output) {\n OP_REQUIRES(context, input.IsSameSize(gradient),\n InvalidArgument(\"gradient and input must be the same size\"));\n FakeQuantWithMinMaxArgsGradientFunctor<Device> functor;",
"filename": "tensorflow/core/kernels/fake_quant_ops.cc",
"status": "modified"
},
{
"diff": "@@ -63,32 +63,21 @@ class ReluGradOp : public BinaryElementWiseOp<T, ReluGradOp<Device, T>> {\n public:\n using BinaryElementWiseOp<T, ReluGradOp<Device, T>>::BinaryElementWiseOp;\n \n- void OperateNoTemplate(OpKernelContext* context, const Tensor& g,\n- const Tensor& a, Tensor* output);\n-\n // INPUTS:\n // g (gradients): backpropagated gradients\n // a (inputs): either the inputs that were passed to ReluOp(), or its\n // outputs (using either one yields the same result here).\n // OUTPUT:\n // gradients to backprop\n- template <int NDIMS>\n void Operate(OpKernelContext* context, const Tensor& g, const Tensor& a,\n Tensor* output) {\n- OperateNoTemplate(context, g, a, output);\n+ if (!ReluHelpers::ValidateSameSize(context, g, a)) return;\n+ functor::ReluGrad<Device, T> functor;\n+ functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n+ output->flat<T>());\n }\n };\n \n-template <typename Device, typename T>\n-void ReluGradOp<Device, T>::OperateNoTemplate(OpKernelContext* context,\n- const Tensor& g, const Tensor& a,\n- Tensor* output) {\n- if (!ReluHelpers::ValidateSameSize(context, g, a)) return;\n- functor::ReluGrad<Device, T> functor;\n- functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n- output->flat<T>());\n-}\n-\n template <typename Device, typename T>\n class Relu6Op : public UnaryElementWiseOp<T, Relu6Op<Device, T>> {\n public:\n@@ -106,31 +95,20 @@ class Relu6GradOp : public BinaryElementWiseOp<T, Relu6GradOp<Device, T>> {\n public:\n using BinaryElementWiseOp<T, Relu6GradOp<Device, T>>::BinaryElementWiseOp;\n \n- void OperateNoTemplate(OpKernelContext* context, const Tensor& g,\n- const Tensor& a, Tensor* output);\n-\n // INPUTS:\n // g (gradients): backpropagated gradients\n // a (inputs): inputs that were passed to Relu6Op()\n // OUTPUT:\n // gradients to backprop\n- template <int NDIMS>\n void Operate(OpKernelContext* context, const Tensor& g, const Tensor& a,\n Tensor* output) {\n- OperateNoTemplate(context, g, a, output);\n+ if (!ReluHelpers::ValidateSameSize(context, g, a)) return;\n+ functor::Relu6Grad<Device, T> functor;\n+ functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n+ output->flat<T>());\n }\n };\n \n-template <typename Device, typename T>\n-void Relu6GradOp<Device, T>::OperateNoTemplate(OpKernelContext* context,\n- const Tensor& g, const Tensor& a,\n- Tensor* output) {\n- if (!ReluHelpers::ValidateSameSize(context, g, a)) return;\n- functor::Relu6Grad<Device, T> functor;\n- functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n- output->flat<T>());\n-}\n-\n template <typename Device, typename T>\n class LeakyReluOp : public UnaryElementWiseOp<T, LeakyReluOp<Device, T>> {\n public:\n@@ -162,36 +140,24 @@ class LeakyReluGradOp\n alpha_ = T(alpha_tmp);\n }\n \n- void OperateNoTemplate(OpKernelContext* context, const Tensor& g,\n- const Tensor& a, T alpha, Tensor* output);\n-\n // INPUTS:\n // g (gradients): backpropagated gradients\n // a (inputs): either the inputs that were passed to LeakyReluOp(), or its\n // outputs (using either one yields the same result here).\n // OUTPUT:\n // gradients to backprop\n- template <int NDIMS>\n void Operate(OpKernelContext* context, const Tensor& g, const Tensor& a,\n Tensor* output) {\n- OperateNoTemplate(context, g, a, alpha_, output);\n+ if (!ReluHelpers::ValidateSameSize(context, g, a)) return;\n+ functor::LeakyReluGrad<Device, T> functor;\n+ functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(), alpha_,\n+ output->flat<T>());\n }\n \n private:\n T alpha_;\n };\n \n-template <typename Device, typename T>\n-void LeakyReluGradOp<Device, T>::OperateNoTemplate(OpKernelContext* context,\n- const Tensor& g,\n- const Tensor& a, T alpha,\n- Tensor* output) {\n- if (!ReluHelpers::ValidateSameSize(context, g, a)) return;\n- functor::LeakyReluGrad<Device, T> functor;\n- functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(), alpha,\n- output->flat<T>());\n-};\n-\n template <typename Device, typename T>\n class EluOp : public UnaryElementWiseOp<T, EluOp<Device, T>> {\n public:\n@@ -209,31 +175,20 @@ class EluGradOp : public BinaryElementWiseOp<T, EluGradOp<Device, T>> {\n public:\n using BinaryElementWiseOp<T, EluGradOp<Device, T>>::BinaryElementWiseOp;\n \n- void OperateNoTemplate(OpKernelContext* context, const Tensor& g,\n- const Tensor& a, Tensor* output);\n-\n // INPUTS:\n // g (gradients): backpropagated gradients\n // a (outputs): outputs of the EluOp()\n // OUTPUT:\n // gradients to backprop\n- template <int NDIMS>\n void Operate(OpKernelContext* context, const Tensor& g, const Tensor& a,\n Tensor* output) {\n- OperateNoTemplate(context, g, a, output);\n+ if (!ReluHelpers::ValidateSameSize(context, g, a)) return;\n+ functor::EluGrad<Device, T> functor;\n+ functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n+ output->flat<T>());\n }\n };\n \n-template <typename Device, typename T>\n-void EluGradOp<Device, T>::OperateNoTemplate(OpKernelContext* context,\n- const Tensor& g, const Tensor& a,\n- Tensor* output) {\n- if (!ReluHelpers::ValidateSameSize(context, g, a)) return;\n- functor::EluGrad<Device, T> functor;\n- functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n- output->flat<T>());\n-}\n-\n template <typename Device, typename T>\n class SeluOp : public UnaryElementWiseOp<T, SeluOp<Device, T>> {\n public:\n@@ -251,31 +206,20 @@ class SeluGradOp : public BinaryElementWiseOp<T, SeluGradOp<Device, T>> {\n public:\n using BinaryElementWiseOp<T, SeluGradOp<Device, T>>::BinaryElementWiseOp;\n \n- void OperateNoTemplate(OpKernelContext* context, const Tensor& g,\n- const Tensor& a, Tensor* output);\n-\n // INPUTS:\n // g (gradients): backpropagated gradients\n // a (outputs): outputs of the SeluOp()\n // OUTPUT:\n // gradients to backprop\n- template <int NDIMS>\n void Operate(OpKernelContext* context, const Tensor& g, const Tensor& a,\n Tensor* output) {\n- OperateNoTemplate(context, g, a, output);\n+ if (!ReluHelpers::ValidateSameSize(context, g, a)) return;\n+ functor::SeluGrad<Device, T> functor;\n+ functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n+ output->flat<T>());\n }\n };\n \n-template <typename Device, typename T>\n-void SeluGradOp<Device, T>::OperateNoTemplate(OpKernelContext* context,\n- const Tensor& g, const Tensor& a,\n- Tensor* output) {\n- if (!ReluHelpers::ValidateSameSize(context, g, a)) return;\n- functor::SeluGrad<Device, T> functor;\n- functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n- output->flat<T>());\n-}\n-\n } // namespace tensorflow\n \n #undef EIGEN_USE_THREADS",
"filename": "tensorflow/core/kernels/relu_op.h",
"status": "modified"
},
{
"diff": "@@ -50,31 +50,20 @@ class SoftplusGradOp\n explicit SoftplusGradOp(OpKernelConstruction* context)\n : BinaryElementWiseOp<T, SoftplusGradOp<Device, T>>(context) {}\n \n- void OperateNoTemplate(OpKernelContext* context, const Tensor& g,\n- const Tensor& a, Tensor* output);\n-\n // INPUTS:\n // g (gradients): backpropagated gradients\n // a (inputs): inputs that were passed to SoftplusOp()\n // OUTPUT:\n // gradients to backprop\n- template <int NDIMS>\n void Operate(OpKernelContext* context, const Tensor& g, const Tensor& a,\n Tensor* output) {\n- OperateNoTemplate(context, g, a, output);\n+ OP_REQUIRES(context, a.IsSameSize(g),\n+ errors::InvalidArgument(\"g and a must be the same size\"));\n+ functor::SoftplusGrad<Device, T> functor;\n+ functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n+ output->flat<T>());\n }\n };\n-template <typename Device, typename T>\n-void SoftplusGradOp<Device, T>::OperateNoTemplate(OpKernelContext* context,\n- const Tensor& g,\n- const Tensor& a,\n- Tensor* output) {\n- OP_REQUIRES(context, a.IsSameSize(g),\n- errors::InvalidArgument(\"g and a must be the same size\"));\n- functor::SoftplusGrad<Device, T> functor;\n- functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n- output->flat<T>());\n-}\n \n #define REGISTER_KERNELS(type) \\\n REGISTER_KERNEL_BUILDER( \\",
"filename": "tensorflow/core/kernels/softplus_op.cc",
"status": "modified"
},
{
"diff": "@@ -50,33 +50,21 @@ class SoftsignGradOp\n explicit SoftsignGradOp(OpKernelConstruction* context)\n : BinaryElementWiseOp<T, SoftsignGradOp<Device, T>>(context) {}\n \n- void OperateNoTemplate(OpKernelContext* context, const Tensor& g,\n- const Tensor& a, Tensor* output);\n-\n // INPUTS:\n // g (gradients): backpropagated gradients\n // a (inputs): inputs that were passed to SoftsignOp()\n // OUTPUT:\n // gradients to backprop\n- template <int NDIMS>\n void Operate(OpKernelContext* context, const Tensor& g, const Tensor& a,\n Tensor* output) {\n- OperateNoTemplate(context, g, a, output);\n+ OP_REQUIRES(context, a.IsSameSize(g),\n+ errors::InvalidArgument(\"g and a must be the same size\"));\n+ functor::SoftsignGrad<Device, T> functor;\n+ functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n+ output->flat<T>());\n }\n };\n \n-template <typename Device, typename T>\n-void SoftsignGradOp<Device, T>::OperateNoTemplate(OpKernelContext* context,\n- const Tensor& g,\n- const Tensor& a,\n- Tensor* output) {\n- OP_REQUIRES(context, a.IsSameSize(g),\n- errors::InvalidArgument(\"g and a must be the same size\"));\n- functor::SoftsignGrad<Device, T> functor;\n- functor(context->eigen_device<Device>(), g.flat<T>(), a.flat<T>(),\n- output->flat<T>());\n-}\n-\n #define REGISTER_KERNELS(type) \\\n REGISTER_KERNEL_BUILDER( \\\n Name(\"Softsign\").Device(DEVICE_CPU).TypeConstraint<type>(\"T\"), \\",
"filename": "tensorflow/core/kernels/softsign_op.cc",
"status": "modified"
}
]
}
|
{
"body": "Various sklearn functions validate _estimator_type. This in the respective constructors fixes that:\r\n\r\nKerasRegressor:\r\n`self._estimator_type = 'regressor'`\r\n\r\nKerasClassifier:\r\n`self._estimator_type = 'classifier'`\r\n",
"comments": [
{
"body": "@oxqfsyef, \r\ncan you elaborate the issue with the code snippet and error log. \r\nAlso provide the tensorflow version. Thanks!",
"created_at": "2020-01-21T11:29:40Z"
},
{
"body": "Tensorflow version is 1.14.0\r\n`from tensorflow.keras.wrappers.scikit_learn import KerasRegressor`\r\n`from sklearn.ensemble import VotingRegressor`\r\n`a = VotingRegressor([('x', KerasRegressor(lambda: None))])`\r\n`a.fit([[1,2]], [3])`\r\nTraceback (most recent call last): \r\n File \"<stdin>\", line 1, in <module> \r\n File \".../.conda/envs/tensorflow-gpu_1.14.0/lib/python3.7/site-packages/sklearn/ensemble/_voting.py\", line 406, in fit \r\n return super().fit(X, y, sample_weight) \r\n File \".../.conda/envs/tensorflow-gpu_1.14.0/lib/python3.7/site-packages/sklearn/ensemble/_voting.py\", line 57, in fit \r\n names, clfs = self._validate_estimators() \r\n File \".../.conda/envs/tensorflow-gpu_1.14.0/lib/python3.7/site-packages/sklearn/ensemble/_base.py\", line 251, in _validate_estimators \r\n est.__class__.__name__, is_estimator_type.__name__[3:] \r\nValueError: The estimator KerasRegressor should be a regressor. ",
"created_at": "2020-01-21T12:52:03Z"
},
{
"body": "Was able to reproduce the issue with Tf 1.14. and Tf 2.1 on colab.\r\nPlease find the gist [here](https://colab.research.google.com/gist/gadagashwini/1d556dddd9622aaa29c829bbf4b09ae0/untitled353.ipynb). Tha",
"created_at": "2020-01-22T07:48:31Z"
},
{
"body": "The `build_fn` in `tf.keras.wrappers.scikit_learn.KerasRegressor` should return a `keras model` which can be used on `fit/predict` method downstream.\r\nSee https://github.com/tensorflow/tensorflow/blob/00fad90125b18b80fe054de1055770cfb8fe4ba3/tensorflow/python/keras/wrappers/scikit_learn.py#L43",
"created_at": "2020-01-30T01:02:27Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36074\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36074\">No</a>\n",
"created_at": "2020-02-03T22:36:50Z"
},
{
"body": "@oxqfsyef Please check out this wrapper package, I think it should fix your issue: https://pypi.org/project/scikeras/\r\nhttps://github.com/adriangb/scikeras",
"created_at": "2020-05-19T23:33:11Z"
}
],
"number": 36074,
"title": "sklearn requires KerasRegressor/KerasClassifier to have _estimator_type set"
}
|
{
"body": "resolves: #36074 ",
"number": 36137,
"review_comments": [],
"title": "add attribute '_estimator_type' to KerasRegressor and KerasClassifier"
}
|
{
"commits": [
{
"message": "add attr '_estimator_type'"
}
],
"files": [
{
"diff": "@@ -191,6 +191,7 @@ def filter_sk_params(self, fn, override=None):\n class KerasClassifier(BaseWrapper):\n \"\"\"Implementation of the scikit-learn classifier API for Keras.\n \"\"\"\n+ _estimator_type = 'classifier'\n \n def fit(self, x, y, **kwargs):\n \"\"\"Constructs a new model with `build_fn` & fit the model to `(x, y)`.\n@@ -314,6 +315,7 @@ def score(self, x, y, **kwargs):\n class KerasRegressor(BaseWrapper):\n \"\"\"Implementation of the scikit-learn regressor API for Keras.\n \"\"\"\n+ _estimator_type = 'regressor'\n \n def predict(self, x, **kwargs):\n \"\"\"Returns predictions for the given test data.",
"filename": "tensorflow/python/keras/wrappers/scikit_learn.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): `no`\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): `Ubuntu 18.04`\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: `no`\r\n- TensorFlow installed from (source or binary): `no`\r\n- TensorFlow version (use command below): `2.0.0`\r\n- Python version: `3.7.3`\r\n- Bazel version (if compiling from source): `-`\r\n- GCC/Compiler version (if compiling from source): `-`\r\n- CUDA/cuDNN version: `-`\r\n- GPU model and memory: `-`\r\n\r\n**Describe the current behavior**\r\nThe TextVectorization layer `split` parameter expects `None` as a possible value but can't handle it.\r\n\r\n**Describe the expected behavior**\r\nThe layer should work properly when `None` is passed as a `split` parameter, or documentation should be updated.\r\n\r\n**Code to reproduce the issue**\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\nfrom tensorflow.keras.layers.experimental.preprocessing import TextVectorization\r\nfrom pprint import pprint\r\nassert tf.__version__ == '2.1.0-rc1'\r\n\r\ndummy_data = [\"Foo\", \"bar\", \"foo foo\", \"foo bar\", \"foobar.\"]\r\npredict_data = [\"foo\", \"bar\", \"foobar\", \"foo foo\", \"OOV\"]\r\ninputs = tf.keras.layers.Input(shape=(1, ), dtype=tf.string, name=\"text\")\r\nvectorize_layer = TextVectorization(output_mode=\"binary\", max_tokens=5, split=None)\r\nvectorize_layer.adapt(np.asarray(dummy_data))\r\nprint(f\"Vocabulary:\\t\\t{vectorize_layer.get_vocabulary()}\")\r\noutputs = vectorize_layer(inputs)\r\nmodel = tf.keras.Model(inputs, outputs)\r\nprint(f\"Prediction data:\\t{predict_data}\")\r\npredictions = model.predict(predict_data)\r\nprint(f\"Predictions:\")\r\npprint(predictions)\r\n\r\nAttributeError Traceback (most recent call last)\r\n<ipython-input-3-f1a03cb1e414> in <module>()\r\n 9 inputs = tf.keras.layers.Input(shape=(1, ), dtype=tf.string, name=\"text\")\r\n 10 vectorize_layer = TextVectorization(output_mode=\"binary\", max_tokens=5, split=None)\r\n---> 11 vectorize_layer.adapt(np.asarray(dummy_data))\r\n 12 print(f\"Vocabulary:\\t\\t{vectorize_layer.get_vocabulary()}\")\r\n 13 outputs = vectorize_layer(inputs)\r\n\r\n/tensorflow-2.1.0/python3.6/tensorflow_core/python/keras/layers/preprocessing/text_vectorization.py in _to_numpy(self, preprocessed_data)\r\n 334 if isinstance(preprocessed_data, np.ndarray):\r\n 335 return preprocessed_data\r\n 336 return np.array(preprocessed_data.to_list())\r\nAttributeError: 'tensorflow.python.framework.ops.EagerTensor' object has no attribute 'to_list'\r\n```",
"comments": [
{
"body": "I have tried on colab with TF version 2.1.0-rc2, 2.2.0-dev20200121 and was able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/c006c43d35583da0a38f75fce1062854/untitled577.ipynb). Thanks!",
"created_at": "2020-01-21T10:53:13Z"
},
{
"body": "HI @stefanondisponibile and @ravikyram: we have fixed this at HEAD internally (we changed how the layer performs adapt() by deferring to internal sublayers) and I have verified your code snippet functions as expected. I believe these changes should be in the nightly, if not now then very shortly.",
"created_at": "2020-05-21T04:37:56Z"
},
{
"body": "@stefanondisponibile This was resolved in recent `tf-nightly`. PTAL at the [gist here](https://colab.research.google.com/gist/jvishnuvardhan/444f44c8ce3d736ae470d994626ce1e5/untitled577.ipynb).\r\n\r\nPlease verify once and close the issue if this was resolved for you. Thanks!",
"created_at": "2020-06-06T00:08:16Z"
},
{
"body": "Thank you @jvishnuvardhan, looks good to me!",
"created_at": "2020-06-06T08:01:23Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36071\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/36071\">No</a>\n",
"created_at": "2020-06-06T08:03:07Z"
}
],
"number": 36071,
"title": "Can't set None on TextVectorization layer's split parameter."
}
|
{
"body": "resolves: #36071 ",
"number": 36103,
"review_comments": [],
"title": "Fix: Can't set None on TextVectorization layer's split parameter problem"
}
|
{
"commits": [
{
"message": "add an extra condition for EagerTensor instance in _to_numpy"
},
{
"message": "add test"
},
{
"message": "add self arg"
},
{
"message": "add tf"
},
{
"message": "fix dtype"
},
{
"message": "fix pylint"
},
{
"message": "Merge branch 'master' into master"
}
],
"files": [
{
"diff": "@@ -310,6 +310,37 @@ def __init__(self,\n def _get_vectorization_class(self):\n return category_encoding.CategoryEncoding\n \n+ def _clear_table(self):\n+ if (self._output_mode in [BINARY, COUNT, TFIDF] and self._called and\n+ not self._pad_to_max):\n+ raise RuntimeError((\"When using TextVectorization in {mode} mode, the \"\n+ \"vocabulary cannot be changed after the layer is \"\n+ \"called.\").format(mode=self._output_mode))\n+ keys, _ = self._table.export()\n+ self._table.remove(keys)\n+ self._vocab_size = 0\n+\n+ def _insert_table_data(self, keys, values):\n+ if (self._output_mode in [BINARY, COUNT, TFIDF] and self._called and\n+ not self._pad_to_max):\n+ raise RuntimeError((\"When using TextVectorization in {mode} mode, the \"\n+ \"vocabulary cannot be changed after the layer is \"\n+ \"called.\").format(mode=self._output_mode))\n+ if len(values) != len(keys):\n+ raise RuntimeError(\"Size mismatch between values and key arrays. \"\n+ \"Keys had size %s, values had size %s.\" %\n+ (len(keys), len(values)))\n+ self._table.insert(keys, values)\n+ self._vocab_size += len(keys)\n+\n+ def _to_numpy(self, preprocessed_data):\n+ \"\"\"Converts preprocessed inputs into numpy arrays.\"\"\"\n+ if isinstance(preprocessed_data, np.ndarray):\n+ return preprocessed_data\n+ elif isinstance(preprocessed_data, ops.EagerTensor):\n+ return preprocessed_data.numpy() \n+ return np.array(preprocessed_data.to_list())\n+\n def _get_index_lookup_class(self):\n return string_lookup.StringLookup\n # End of V1/V2 shim points.",
"filename": "tensorflow/python/keras/layers/preprocessing/text_vectorization.py",
"status": "modified"
},
{
"diff": "@@ -1200,6 +1200,26 @@ def test_accept_1D_input(self):\n layer.adapt(input_array)\n _ = layer(input_array)\n \n+ def test_split_equals_zero_on_adapt(self):\n+ dummy_data = [\"Foo\", \"bar\", \"foo foo\", \"foo bar\", \"foobar.\"]\n+ predict_data = [\"foo\", \"bar\", \"foobar\", \"foo foo\", \"OOV\"]\n+ expected_output = [[0, 0, 0, 0, 1],\n+ [1, 0, 0, 0, 0],\n+ [0, 1, 0, 0, 0],\n+ [0, 0, 1, 0, 0],\n+ [1, 0, 0, 0, 0]]\n+\n+ inputs = keras.Input(shape=(1,), dtype=dtypes.string, name=\"text\")\n+ layers = get_layer_class()(\n+ max_tokens=5,\n+ split=None,\n+ output_mode=\"binary\")\n+ layers.adapt(np.asarray(dummy_data))\n+ outputs = layers(inputs)\n+ model = keras.Model(inputs, outputs)\n+ predictions = model.predict(predict_data)\n+ self.assertAllEqual(expected_output, predictions)\n+\n \n @keras_parameterized.run_all_keras_modes\n class TextVectorizationModelBuildingTest(",
"filename": "tensorflow/python/keras/layers/preprocessing/text_vectorization_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution: Linux Ubuntu 18.04.2\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version: 2.0.0\r\n- Python version: 3.7.3\r\n- CUDA/cuDNN version: CUDA 10.1 cuDNN 7.5.1\r\n- GPU model and memory: TITAN X\r\n\r\n**Describe the current behavior**\r\n\r\nI get a `ValueError` when trying to save a `tf.keras.Model` with a `tf.keras.layers.TimeDistributed` layer wrapping another `tf.keras.Model` that has convolutional layers. I am using `tf.keras.Model.save` with the default `save_format` (SavedModel). See below for examples.\r\n\r\nThere is no error when saving with `save_format='h5'`.\r\n\r\n**Describe the expected behavior**\r\n\r\nSuccessfully saving a SavedModel with the `tf.keras.layers.TimeDistributed` layer.\r\n\r\n**Code to reproduce the issue**\r\n\r\n1. Wrapping a 1-layer convolutional NN with `tf.keras.layers.TimeDistributed`:\r\n\r\n ```python\r\n import tensorflow as tf\r\n\r\n input_shape = (100, 100, 3)\r\n\r\n embedding_model = tf.keras.Sequential([\r\n tf.keras.layers.Input(input_shape),\r\n tf.keras.layers.Conv2D(filters=32, kernel_size=3, strides=1),\r\n ])\r\n\r\n input_sequence = tf.keras.layers.Input((None,) + input_shape)\r\n sequence_embedding = tf.keras.layers.TimeDistributed(embedding_model)\r\n outputs = sequence_embedding(input_sequence)\r\n\r\n model = tf.keras.Model(inputs=input_sequence, outputs=outputs)\r\n\r\n model.save('model1')\r\n ```\r\n\r\n Error:\r\n\r\n ```\r\n ValueError: Input 0 of layer conv2d is incompatible with the layer: expected ndim=4, found ndim=5. Full shape received: [None, None, 100, 100, 3]\r\n ```\r\n\r\n2. Wrapping a pre-trained `tf.keras.applications` model (closer to my actual use case):\r\n\r\n ```python\r\n import tensorflow as tf\r\n\r\n input_shape = (224, 224, 3)\r\n\r\n mobilenet = tf.keras.applications.MobileNet(\r\n input_shape=input_shape,\r\n include_top=False,\r\n weights='imagenet',\r\n pooling='avg',\r\n )\r\n\r\n input_sequence = tf.keras.layers.Input((None,) + input_shape)\r\n sequence_embedding = tf.keras.layers.TimeDistributed(mobilenet)\r\n outputs = sequence_embedding(input_sequence)\r\n\r\n model = tf.keras.Model(inputs=input_sequence, outputs=outputs)\r\n\r\n model.save('model2')\r\n ```\r\n\r\n Error:\r\n\r\n ```\r\n ValueError: Input 0 of layer conv1_pad is incompatible with the layer: expected ndim=4, found ndim=5. Full shape received: [None, None, 224, 224, 3]\r\n ```\r\n\r\n3. Saving as an HDF5 file instead:\r\n\r\n ```python\r\n import tensorflow as tf\r\n\r\n input_shape = (224, 224, 3)\r\n\r\n mobilenet = tf.keras.applications.MobileNet(\r\n input_shape=input_shape,\r\n include_top=False,\r\n weights='imagenet',\r\n pooling='avg',\r\n )\r\n\r\n input_sequence = tf.keras.layers.Input((None,) + input_shape)\r\n sequence_embedding = tf.keras.layers.TimeDistributed(mobilenet)\r\n outputs = sequence_embedding(input_sequence)\r\n\r\n model = tf.keras.Model(inputs=input_sequence, outputs=outputs)\r\n\r\n model.save('model3.h5', save_format='h5')\r\n ```\r\n\r\n This works without errors.\r\n\r\n4. Saving to the SavedModel format works with just dense layers:\r\n\r\n ```python\r\n import tensorflow as tf\r\n\r\n input_shape = (100,)\r\n\r\n embedding_model = tf.keras.Sequential([\r\n tf.keras.layers.Input(input_shape),\r\n tf.keras.layers.Dense(units=10)\r\n ])\r\n\r\n input_sequence = tf.keras.layers.Input((None,) + input_shape)\r\n sequence_embedding = tf.keras.layers.TimeDistributed(embedding_model)\r\n outputs = sequence_embedding(input_sequence)\r\n\r\n model = tf.keras.Model(inputs=input_sequence, outputs=outputs)\r\n\r\n model.save('model4')\r\n ```\r\n\r\n This works without errors.\r\n",
"comments": [
{
"body": "I have tried on colab with TF version 2.0 and was able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/00b7541a4eb2b6492c984d4201acce7f/untitled265.ipynb).Thanks!",
"created_at": "2019-10-14T10:29:41Z"
},
{
"body": "Is there any update? I noticed in #33094 that there was a fix for saving `TimeDistributed` layers in the nightly release. I tried with `tf-nightly==2.1.0-dev20191113`, but I'm getting the same error.",
"created_at": "2019-11-15T19:03:07Z"
},
{
"body": "Any update? ",
"created_at": "2019-11-20T04:24:34Z"
},
{
"body": "Same errors with `tensorflow==2.1.0-rc0`.\r\n\r\n---\r\n\r\nBy the way, there seems to be no problem saving a `TimeDistributed` layer wrapping a convolutional layer instead of a `Model` which has a convolutional layer in it.\r\n\r\nFor example, this works:\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\ntime_distributed_layer = tf.keras.layers.TimeDistributed(\r\n layer=tf.keras.layers.Conv2D(filters=16, kernel_size=3),\r\n input_shape=(None, 100, 100, 3),\r\n)\r\nmodel = tf.keras.Sequential([time_distributed_layer])\r\nmodel.save('model') # Works\r\n\r\n# Check correct restoration\r\nrestored_model = tf.keras.models.load_model('model')\r\nfor weight, restored_weight in zip(model.weights, restored_model.weights):\r\n assert weight.name == restored_weight.name\r\n tf.debugging.assert_equal(weight, restored_weight)\r\n```\r\n\r\nWhereas this doesn't:\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\ntime_distributed_layer = tf.keras.layers.TimeDistributed(\r\n layer=tf.keras.Sequential(\r\n layers=[tf.keras.layers.Conv2D(filters=16, kernel_size=3)],\r\n ),\r\n input_shape=(None, 100, 100, 3),\r\n)\r\nmodel = tf.keras.Sequential([time_distributed_layer])\r\nmodel.save('model') # Same error as before\r\n```",
"created_at": "2019-12-03T01:42:33Z"
},
{
"body": "I also encountered this bug , how can I solve it ",
"created_at": "2019-12-03T03:29:16Z"
},
{
"body": "+1, Also running into this",
"created_at": "2019-12-03T03:34:35Z"
},
{
"body": "@k-w-w this is a pretty major limitation at the moment. Any idea on what needs to be changed to fix it?",
"created_at": "2019-12-04T18:13:32Z"
},
{
"body": "There appears to be a problem with saving layer masks using SavedModel. looking into this",
"created_at": "2019-12-09T19:00:19Z"
},
{
"body": "@k-w-w any update on this issue?",
"created_at": "2019-12-26T03:54:43Z"
},
{
"body": "Bump",
"created_at": "2020-01-15T02:09:09Z"
},
{
"body": "Appears to be fixed by 9f2aa61811b29e700b8325bb57b1f4b0093c1d4d",
"created_at": "2020-01-21T22:06:43Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33261\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33261\">No</a>\n",
"created_at": "2020-01-21T22:06:45Z"
},
{
"body": "Hi there, \r\nI am using time distributed layer to apply another model on each frame and processing the final features by conv 3D. the model is trained properly. but when I want to load the model and use it for test, I face different issues:\r\n- first, the model cant be loaded because of the nested model\r\n- second, the model acc on the same val dataset is not reproducible\r\n ",
"created_at": "2020-11-09T11:04:12Z"
},
{
"body": "@marziehoghbaie Please create a new issue with a simple standalone code to reproduce the error. Thanks!",
"created_at": "2020-11-09T16:27:56Z"
}
],
"number": 33261,
"title": "Can't save a Model with a TimeDistributed layer wrapping another Model"
}
|
{
"body": "Fixes #33261\r\n\r\nWhen `input_uid` isn't a key in `self._input_map`, the wrong `inner_inputs` tensor is passed to `self.layer.compute_mask` (it still has the sequence dimension).",
"number": 36079,
"review_comments": [],
"title": "TimeDistributed compute_mask: Handling case when input uid isn't in _input_map"
}
|
{
"commits": [
{
"message": "Handling case when input uid isn't in _input_map\n\nFixes #33261"
},
{
"message": "Removed redundant assignment"
}
],
"files": [
{
"diff": "@@ -322,7 +322,15 @@ def compute_mask(self, inputs, mask=None):\n inner_mask_shape = self._get_shape_tuple((-1,), mask, 2)\n inner_mask = K.reshape(inner_mask, inner_mask_shape)\n input_uid = generic_utils.object_list_uid(inputs)\n- inner_inputs = self._input_map.get(input_uid, inputs)\n+ if input_uid in self._input_map:\n+ inner_inputs = self._input_map[input_uid]\n+ else:\n+ if isinstance(inputs, ragged_tensor.RaggedTensor):\n+ inner_inputs = inputs.values\n+ else:\n+ inner_input_shape = self._get_shape_tuple((-1,), inputs, 2)\n+ inner_inputs = array_ops.reshape(inputs, inner_input_shape)\n+ self._input_map[input_uid] = inner_inputs\n output_mask = self.layer.compute_mask(inner_inputs, inner_mask)\n if output_mask is None:\n if mask is None:",
"filename": "tensorflow/python/keras/layers/wrappers.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Debian GNU/Linux 10 (buster)\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): v2.1.0-rc0-47-g064e153 2.1.0-rc1\r\n- Python version: 3.7.6\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version: None\r\n- GPU model and memory: NA\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\nAn exception during `tf.keras.layers.ReLU` construction with integer dtype and `max_value`\r\n\r\n**Describe the expected behavior**\r\nA layer is properly constructed and functional\r\n\r\n**Code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\ninput = tf.keras.layers.Input(shape=(), name='x', dtype='int64')\r\ny = tf.keras.layers.ReLU(max_value=100, dtype='int64')(input)\r\n```\r\n\r\n**Other info / logs**\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/framework/tensor_util.py in _AssertCompatible(values, dtype)\r\n 323 try:\r\n--> 324 fn(values)\r\n 325 except ValueError as e:\r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/framework/tensor_util.py in inner(values)\r\n 262 def inner(values):\r\n--> 263 _ = [_check_failed(v) for v in nest.flatten(values)\r\n 264 if not isinstance(v, expected_types)]\r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/framework/tensor_util.py in <listcomp>(.0)\r\n 263 _ = [_check_failed(v) for v in nest.flatten(values)\r\n--> 264 if not isinstance(v, expected_types)]\r\n 265 return inner\r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/framework/tensor_util.py in _check_failed(v)\r\n 247 # it is safe to use here.\r\n--> 248 raise ValueError(v)\r\n 249 \r\n\r\nValueError: 0.0\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-16-2baabe6a9f04> in <module>\r\n 1 input = tf.keras.layers.Input(shape=(), name='x', dtype='int64')\r\n----> 2 y = tf.keras.layers.ReLU(max_value=100, dtype='int64')(input)\r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/base_layer.py in __call__(self, inputs, *args, **kwargs)\r\n 771 not base_layer_utils.is_in_eager_or_tf_function()):\r\n 772 with auto_control_deps.AutomaticControlDependencies() as acd:\r\n--> 773 outputs = call_fn(cast_inputs, *args, **kwargs)\r\n 774 # Wrap Tensors in `outputs` in `tf.identity` to avoid\r\n 775 # circular dependencies.\r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/keras/layers/advanced_activations.py in call(self, inputs)\r\n 317 alpha=self.negative_slope,\r\n 318 max_value=self.max_value,\r\n--> 319 threshold=self.threshold)\r\n 320 \r\n 321 def get_config(self):\r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/keras/backend.py in relu(x, alpha, max_value, threshold)\r\n 4373 if clip_max:\r\n 4374 max_value = _constant_to_tensor(max_value, x.dtype.base_dtype)\r\n-> 4375 zero = _constant_to_tensor(0., x.dtype.base_dtype)\r\n 4376 x = clip_ops.clip_by_value(x, zero, max_value)\r\n 4377 \r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/keras/backend.py in _constant_to_tensor(x, dtype)\r\n 676 A tensor.\r\n 677 \"\"\"\r\n--> 678 return constant_op.constant(x, dtype=dtype)\r\n 679 \r\n 680 \r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/framework/constant_op.py in constant(value, dtype, shape, name)\r\n 256 \"\"\"\r\n 257 return _constant_impl(value, dtype, shape, name, verify_shape=False,\r\n--> 258 allow_broadcast=True)\r\n 259 \r\n 260 \r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/framework/constant_op.py in _constant_impl(value, dtype, shape, name, verify_shape, allow_broadcast)\r\n 294 tensor_util.make_tensor_proto(\r\n 295 value, dtype=dtype, shape=shape, verify_shape=verify_shape,\r\n--> 296 allow_broadcast=allow_broadcast))\r\n 297 dtype_value = attr_value_pb2.AttrValue(type=tensor_value.tensor.dtype)\r\n 298 const_tensor = g._create_op_internal( # pylint: disable=protected-access\r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/framework/tensor_util.py in make_tensor_proto(values, dtype, shape, verify_shape, allow_broadcast)\r\n 449 nparray = np.empty(shape, dtype=np_dt)\r\n 450 else:\r\n--> 451 _AssertCompatible(values, dtype)\r\n 452 nparray = np.array(values, dtype=np_dt)\r\n 453 # check to them.\r\n\r\n/usr/local/lib/python3.7/site-packages/tensorflow_core/python/framework/tensor_util.py in _AssertCompatible(values, dtype)\r\n 329 else:\r\n 330 raise TypeError(\"Expected %s, got %s of type '%s' instead.\" %\r\n--> 331 (dtype.name, repr(mismatch), type(mismatch).__name__))\r\n 332 \r\n 333 \r\n\r\nTypeError: Expected int64, got 0.0 of type 'float' instead.\r\n```\r\n\r\n\r\n```\r\ntf.constant(0., dtype='int64')\r\n```\r\nfails as well but with different backtrace.\r\n\r\ntf_nightly-2.1.0.dev20191226 is affected too.",
"comments": [
{
"body": "@0x0badc0de ,\r\nI was able to replicate the issue for `dtype='int'` , works fine for` 'float'`, [gist](https://colab.sandbox.google.com/gist/oanush/2ae5d64fed93e8376bc70c37dea8e35f/35430.ipynb) of colab replicating the issue.",
"created_at": "2019-12-27T03:50:13Z"
},
{
"body": "Added PR #36037 for the fix.",
"created_at": "2020-01-19T15:08:34Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35430\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35430\">No</a>\n",
"created_at": "2020-01-23T17:59:35Z"
}
],
"number": 35430,
"title": "ReLU layer doesn't handle integer dtype"
}
|
{
"body": "\r\nThis fix tries to address the issue raised in #35430 where\r\nReLU layer + integer dtype causes conversion error.\r\nThis PR fixes the isse by replacing float `0.` with `0`.\r\n\r\nThis fix fixes #35430.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 36037,
"review_comments": [
{
"body": "Thanks for the change, can you move this to the backend_test.py under test_relu()",
"created_at": "2020-01-21T23:08:26Z"
}
],
"title": "Fix issue with ReLU layer and integer dtype"
}
|
{
"commits": [
{
"message": "Fix issue with ReLU layer and integer dtype\n\nThis fix tries to address the issue raised in 35430 where\nReLU layer + integer dtype causes conversion error.\nThis PR fixes the isse by replacing float `0.` with `0`.\n\nThis fix fixes 35430.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub issue 35430.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Move test case to backend_test.py (based on review feedback)\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -4425,7 +4425,7 @@ def relu(x, alpha=0., max_value=None, threshold=0):\n \n if clip_max:\n max_value = _constant_to_tensor(max_value, x.dtype.base_dtype)\n- zero = _constant_to_tensor(0., x.dtype.base_dtype)\n+ zero = _constant_to_tensor(0, x.dtype.base_dtype)\n x = clip_ops.clip_by_value(x, zero, max_value)\n \n if alpha != 0.:",
"filename": "tensorflow/python/keras/backend.py",
"status": "modified"
},
{
"diff": "@@ -544,6 +544,10 @@ def test_relu(self):\n relu_op = keras.backend.relu(x, alpha=0.25, threshold=4, max_value=5)\n self.assertAllClose(keras.backend.eval(relu_op), [[-2, -1], [-0.5, 5]])\n \n+ # Test case for GitHub issue 35430, with integer dtype\n+ x = keras.Input(shape=(), name='x', dtype='int64')\n+ y = keras.layers.ReLU(max_value=100, dtype='int64')(x)\n+\n \n @test_util.run_all_in_graph_and_eager_modes\n class BackendShapeOpsTest(test.TestCase):",
"filename": "tensorflow/python/keras/backend_test.py",
"status": "modified"
}
]
}
|
{
"body": "It would be nice if `tf.image.extract_image_patches` were extended to work with complex numbers as well.\r\n\r\nI work extensively with audio data and after applying an STFT, I get a tensor of complex numbers. As I perform my training on patches from this tensor, it would be great if these patches could be extracted using `tf.image.extract_image_patches`.\r\n\r\nI think this is something that would be valuable to many people working in the audio space.\r\n",
"comments": [
{
"body": "`tf.image.extract_image_patches` is quite useful and I used it before to create a sliding window effect. It makes sense to add full support for all common types.\r\n\r\nAdded a PR #35962 for complex number support.",
"created_at": "2020-01-17T02:50:16Z"
},
{
"body": "Wow. That was fast!",
"created_at": "2020-01-17T04:03:55Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35955\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35955\">No</a>\n",
"created_at": "2020-01-22T18:31:43Z"
}
],
"number": 35955,
"title": "Allow tf.image.extract_image_patches to work with complex numbers"
}
|
{
"body": "\r\nThis PR tries to address the issue raised in #35955 where\r\nthere was no complex number support for tf.extract_image_patches.\r\nThe op `tf.extract_image_patches` itself could be used in many\r\nways than just image so it makes sense to add complex support.\r\n\r\nThis fix fixes #35955.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 35962,
"review_comments": [
{
"body": "I believe this would also include quantized types but that is not included in TF_CALL_GPU_ALL_TYPES",
"created_at": "2020-01-17T17:09:32Z"
},
{
"body": "Please set a non-zero imaginary part for complex data.",
"created_at": "2020-01-21T17:20:19Z"
},
{
"body": "Thanks @rmlarsen. The PR has been updated.",
"created_at": "2020-01-21T22:01:54Z"
}
],
"title": "Add complex number support for tf.extract_image_patches"
}
|
{
"commits": [
{
"message": "Add complex number support for tf.extract_image_patches\n\nThis PR tries to address the issue raised in 35955 where\nthere was no complex number support for tf.extract_image_patches.\nThe op `tf.extract_image_patches` itself could be used in many\nways than just image so it makes sense to add complex support.\n\nThis fix fixes 35955.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nRegister GPU types for tf.extract_image_patches\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nFix build failure with GPU\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nUpdate array_ops.cc to only include TF_CALL_NUMBER_TYPES\n\nThis fix updates array_ops.cc to only include TF_CALL_NUMBER_TYPES\nfor extract_image_patches (realnumbertypes + complex64 + complex128).\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for complex number support for tf.extract_image_patches\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update test case and set non-zero imag part of the complex number\n\nfrom review comment feedback\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -126,7 +126,7 @@ class ExtractImagePatchesOp : public UnaryOp<T> {\n Name(\"ExtractImagePatches\").Device(DEVICE_CPU).TypeConstraint<T>(\"T\"), \\\n ExtractImagePatchesOp<CPUDevice, T>);\n \n-TF_CALL_REAL_NUMBER_TYPES(REGISTER);\n+TF_CALL_NUMBER_TYPES(REGISTER);\n \n #undef REGISTER\n \n@@ -145,7 +145,7 @@ namespace functor {\n typename TTypes<T, 4>::Tensor output); \\\n extern template struct ExtractImagePatchesForward<GPUDevice, T>;\n \n-TF_CALL_GPU_NUMBER_TYPES(DECLARE_GPU_SPEC);\n+TF_CALL_GPU_ALL_TYPES(DECLARE_GPU_SPEC);\n \n #undef DECLARE_GPU_SPEC\n \n@@ -157,7 +157,7 @@ TF_CALL_GPU_NUMBER_TYPES(DECLARE_GPU_SPEC);\n Name(\"ExtractImagePatches\").Device(DEVICE_GPU).TypeConstraint<T>(\"T\"), \\\n ExtractImagePatchesOp<GPUDevice, T>);\n \n-TF_CALL_GPU_NUMBER_TYPES(REGISTER);\n+TF_CALL_GPU_ALL_TYPES(REGISTER);\n \n #undef REGISTER\n ",
"filename": "tensorflow/core/kernels/extract_image_patches_op.cc",
"status": "modified"
},
{
"diff": "@@ -29,7 +29,7 @@ namespace functor {\n \n #define REGISTER(T) template struct ExtractImagePatchesForward<GPUDevice, T>;\n \n-TF_CALL_GPU_NUMBER_TYPES(REGISTER);\n+TF_CALL_GPU_ALL_TYPES(REGISTER);\n \n #undef REGISTER\n ",
"filename": "tensorflow/core/kernels/extract_image_patches_op_gpu.cu.cc",
"status": "modified"
},
{
"diff": "@@ -2525,7 +2525,9 @@ REGISTER_OP(\"ExtractImagePatches\")\n .Attr(\"ksizes: list(int) >= 4\")\n .Attr(\"strides: list(int) >= 4\")\n .Attr(\"rates: list(int) >= 4\")\n- .Attr(\"T: realnumbertype\")\n+ .Attr(\n+ \"T: {bfloat16, half, float, double, int8, int16, int32, int64, \"\n+ \"uint8, uint16, uint32, uint64, complex64, complex128, bool}\")\n .Attr(GetPaddingAttrString())\n .SetShapeFn([](InferenceContext* c) {\n ShapeHandle input_shape;",
"filename": "tensorflow/core/ops/array_ops.cc",
"status": "modified"
},
{
"diff": "@@ -125,5 +125,24 @@ def testKsize2x2Stride1x1Rate2x2Valid(self):\n padding=\"VALID\",\n patches=patches)\n \n+ def testComplexDataTypes(self):\n+ \"\"\"Test for complex data types\"\"\"\n+ for dtype in [np.complex64, np.complex128]:\n+ image = (\n+ np.reshape(range(120), [2, 3, 4, 5]).astype(dtype) +\n+ np.reshape(range(120, 240), [2, 3, 4, 5]).astype(dtype) * 1j)\n+ patches = (\n+ np.reshape(range(120), [2, 3, 4, 5]).astype(dtype) +\n+ np.reshape(range(120, 240), [2, 3, 4, 5]).astype(dtype) * 1j)\n+ for padding in [\"VALID\", \"SAME\"]:\n+ self._VerifyValues(\n+ image,\n+ ksizes=[1, 1],\n+ strides=[1, 1],\n+ rates=[1, 1],\n+ padding=padding,\n+ patches=patches)\n+\n+\n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/kernel_tests/extract_image_patches_op_test.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): I used code in [MultiWorkerMirroredStrategy tutorial](https://www.tensorflow.org/tutorials/distribute/multi_worker_with_keras). And i only changed MultiWorkerMirroredStrategy to ParameterServerStrategy and turned off the eager mode.\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04.2 LTS\r\n- TensorFlow installed from (source or binary): pip3\r\n- TensorFlow version (use command below): tensorflow 2.0.0 / tensorflow-gpu 2.0.0\r\n- Python version: python 3.6.8\r\n- CUDA/cuDNN version: CUDA 10.0\r\n- GPU model and memory: TITAN Xp\r\n\r\n**Code to reproduce the issue**\r\n```\r\nfrom __future__ import absolute_import, division, print_function, unicode_literals\r\nimport tensorflow_datasets as tfds\r\nimport tensorflow as tf\r\n\r\ntf.compat.v1.disable_eager_execution()\r\nstrategy = tf.distribute.experimental.ParameterServerStrategy()\r\n\r\nBUFFER_SIZE = 10000\r\nBATCH_SIZE = 64\r\nNUM_WORKERS = 2\r\n\r\nGLOBAL_BATCH_SIZE = BATCH_SIZE * NUM_WORKERS\r\n\r\ndef scale(image, label):\r\n image = tf.cast(image, tf.float32)\r\n image /= 255\r\n return image, label\r\n\r\ndatasets, info = tfds.load(name='mnist',\r\n with_info=True,\r\n as_supervised=True)\r\n\r\ntrain_datasets_unbatched = datasets['train'].map(scale).cache().shuffle(BUFFER_SIZE)\r\ntrain_datasets = train_datasets_unbatched.batch(GLOBAL_BATCH_SIZE).repeat()\r\n\r\ndef build_and_compile_cnn_model():\r\n model = tf.keras.Sequential([\r\n tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),\r\n tf.keras.layers.MaxPooling2D(),\r\n tf.keras.layers.Flatten(),\r\n tf.keras.layers.Dense(64, activation='relu'),\r\n tf.keras.layers.Dense(10, activation='softmax')\r\n ])\r\n model.compile(\r\n loss=tf.keras.losses.sparse_categorical_crossentropy,\r\n optimizer=tf.keras.optimizers.SGD(learning_rate=0.001),\r\n metrics=['accuracy'])\r\n return model\r\n\r\nwith strategy.scope():\r\n multi_worker_model = build_and_compile_cnn_model()\r\nmulti_worker_model.fit(x=train_datasets, epochs=3, steps_per_epoch=938)\r\n```\r\n**Describe the current behavior**\r\nAbove code works well with CPU. But when using GPU it produces errors like below. \r\nMy TF_CONFIG variable was like this ( TF_CONFIG='{\"cluster\": {\"worker\": [\"localhost:7779\"], \"ps\": [\"localhost:7777\"]}, \"task\": {\"index\": 0, \"type\": \"ps\"}}' ).\r\nAnd it also produces same errors when I tried to apply CentralStorageStrategy.\r\n```\r\nTraceback (most recent call last):\r\n File \"temp.py\", line 48, in <module>\r\n multi_worker_model = build_and_compile_cnn_model()\r\n File \"temp.py\", line 35, in build_and_compile_cnn_model\r\n tf.keras.layers.Dense(10, activation='softmax')\r\n File \"/home/elzino/tf2/lib/python3.6/site-packages/tensorflow_core/python/training/tracking/base.py\", line 457, in _method_wrapper\r\n result = method(self, *args, **kwargs)\r\n File \"/home/elzino/tf2/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/sequential.py\", line 114, in __init__\r\n self.add(layer)\r\n File \"/home/elzino/tf2/lib/python3.6/site-packages/tensorflow_core/python/training/tracking/base.py\", line 457, in _method_wrapper\r\n result = method(self, *args, **kwargs)\r\n File \"/home/elzino/tf2/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/sequential.py\", line 178, in add\r\n layer(x)\r\n File \"/home/elzino/tf2/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 817, in __call__\r\n self._maybe_build(inputs)\r\n File \"/home/elzino/tf2/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 2141, in _maybe_build\r\n self.build(input_shapes)\r\n File \"/home/elzino/tf2/lib/python3.6/site-packages/tensorflow_core/python/keras/layers/convolutional.py\", line 165, in build\r\n dtype=self.dtype)\r\n File \"/home/elzino/tf2/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 2311, in __setattr__\r\n if val.trainable:\r\n File \"/home/elzino/tf2/lib/python3.6/site-packages/tensorflow_core/python/ops/variables.py\", line 477, in trainable\r\n raise NotImplementedError\r\nNotImplementedError\r\n```\r\n\r\n**Describe the expected behavior**\r\nI should work well like when using CPU.\r\n\r\n**Other info / logs**\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\n",
"comments": [
{
"body": "Could you provide more details on how you run with CPU and GPU? ParameterServerStrategy is only supported with Estimator API, not Keras.",
"created_at": "2020-01-15T00:33:14Z"
},
{
"body": "I used environment variable CUDA_VISIBLE_DEVICES to switch between CPU and GPU. Like ```CUDA_VISIBLE_DEVICES= python above_code.py``` or ```CUDA_VISIBLE_DEVICES=0,1,2,3,4 python above_code.py```.\r\nIs there any plan about when to support Keras? I think it will be easily done because it already works well with CPU. Recently i'm digging into tf distribute codes. Can i contribute to this part if there is any chance?",
"created_at": "2020-01-15T01:34:19Z"
},
{
"body": "I found out the reason. When using ParameterServerStrategy, it wraps the value with AggregatingVariable but AggregatingVariable doesn't have the trainable property. I fixed this issue in above PR. Please check that.\r\n\r\n\r\n### More detail:\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/distribute/parameter_server_strategy.py#L392\r\n\r\nWhen using CPU, self._num_replicas_in_sync was not more than one. So it just created value without the AggregatingVariable wrapper. But when using GPU, It wrapped the value with AggregatingVariable class, and the errors came up.",
"created_at": "2020-01-15T04:35:39Z"
},
{
"body": "also related to https://github.com/tensorflow/tensorflow/issues/35017",
"created_at": "2020-01-15T04:54:38Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35442\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35442\">No</a>\n",
"created_at": "2020-01-16T23:06:40Z"
},
{
"body": "Thanks for triage the issue. We're actively working on PS strategy and there're still some design discussion happening. Before that, you can use CentralStorageStrategy if you only have one worker.",
"created_at": "2020-01-17T00:20:19Z"
},
{
"body": "Thank you for letting me know. Actually, I'm working to make [parallax](https://github.com/snuspl/parallax) compatible with tf 2.0. So i need to use more than one worker. But still thanks for your comment and hope your work goes well!",
"created_at": "2020-01-17T01:31:47Z"
}
],
"number": 35442,
"title": "[TF 2.0]ParameterServerStrategy and CentralStorageStrategy doesn't work with Keras when using GPU, even though it works well with CPU."
}
|
{
"body": "#35442 #35017\r\nWhen i tried to train a keras model using ParameterServerStrategy, i found the error message described in above issue. It says that 'trainable' property is not implemented.\r\nAnd i found AggregatingVariable which is a wrapper class used in ParameterServerStrategy doesn't override 'trainable' property. It should be fixed by overriding 'trainable' property.\r\nSo i simply fixed it by using unwrapped value's 'trainable' property.",
"number": 35886,
"review_comments": [],
"title": "add trainable property to AggregatingVariable"
}
|
{
"commits": [
{
"message": "add trainable property to AggregatingVariable"
}
],
"files": [
{
"diff": "@@ -1421,6 +1421,10 @@ def aggregation(self):\n def name(self):\n return self._v.name\n \n+ @property\n+ def trainable(self):\n+ return self._v.trainable\n+\n @property\n def dtype(self):\n return self._v.dtype",
"filename": "tensorflow/python/distribute/values.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n\r\n* **use tensorflow docker hub images: tensorflow / tensorflow : 2.0.0-gpu**\r\n\r\n**Describe the current behavior**\r\n* when i use tf2.0 distributed training with ParameterServerStrategy, the error occurred follow:\r\n```\r\n2019-12-11 14:53:27.569524: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1\r\n2019-12-11 14:53:27.619245: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties:\r\nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\r\npciBusID: 0000:2f:00.0\r\n2019-12-11 14:53:27.621064: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 1 with properties:\r\nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\r\npciBusID: 0000:86:00.0\r\n2019-12-11 14:53:27.622349: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0\r\n2019-12-11 14:53:27.627608: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10.0\r\n2019-12-11 14:53:27.632513: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10.0\r\n2019-12-11 14:53:27.634123: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10.0\r\n2019-12-11 14:53:27.640466: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10.0\r\n2019-12-11 14:53:27.643992: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10.0\r\n2019-12-11 14:53:27.656264: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\r\n2019-12-11 14:53:27.660960: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1746] Adding visible gpu devices: 0, 1\r\n2019-12-11 14:53:27.661734: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 AVX512F FMA\r\n2019-12-11 14:53:27.676662: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2600000000 Hz\r\n2019-12-11 14:53:27.684246: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x565309993340 executing computations on platform Host. Devices:\r\n2019-12-11 14:53:27.684288: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Host, Default Version\r\n2019-12-11 14:53:27.955807: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x5653099f5a60 executing computations on platform CUDA. Devices:\r\n2019-12-11 14:53:27.955947: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Tesla P100-PCIE-16GB, Compute Capability 6.0\r\n2019-12-11 14:53:27.955978: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (1): Tesla P100-PCIE-16GB, Compute Capability 6.0\r\n2019-12-11 14:53:27.958412: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties:\r\nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\r\npciBusID: 0000:2f:00.0\r\n2019-12-11 14:53:27.959282: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 1 with properties:\r\nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\r\npciBusID: 0000:86:00.0\r\n2019-12-11 14:53:27.959338: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0\r\n2019-12-11 14:53:27.959361: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10.0\r\n2019-12-11 14:53:27.959381: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10.0\r\n2019-12-11 14:53:27.959391: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10.0\r\n2019-12-11 14:53:27.959413: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10.0\r\n2019-12-11 14:53:27.959423: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10.0\r\n2019-12-11 14:53:27.959434: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\r\n2019-12-11 14:53:27.962606: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1746] Adding visible gpu devices: 0, 1\r\n2019-12-11 14:53:27.962639: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0\r\n2019-12-11 14:53:27.964634: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1159] Device interconnect StreamExecutor with strength 1 edge matrix:\r\n2019-12-11 14:53:27.964653: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1165] 0 1\r\n2019-12-11 14:53:27.964663: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1178] 0: N Y\r\n2019-12-11 14:53:27.964679: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1178] 1: Y N\r\n2019-12-11 14:53:27.967224: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1304] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15216 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:2f:00.0, compute capability: 6.0)\r\n2019-12-11 14:53:27.968872: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1304] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:1 with 15216 MB memory) -> physical GPU (device: 1, name: Tesla P100-PCIE-16GB, pci bus id: 0000:86:00.0, compute capability: 6.0)\r\nWARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow_core/python/ops/resource_variable_ops.py:1630: calling __init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.\r\nInstructions for updating:\r\nIf using Keras pass *_constraint arguments to layers.\r\nTraceback (most recent call last):\r\n File \"tf_mnist_ps_worker.py\", line 136, in <module>\r\n main()\r\n File \"tf_mnist_ps_worker.py\", line 132, in main\r\n app.train(args)\r\n File \"tf_mnist_ps_worker.py\", line 85, in train\r\n model = Net().model\r\n File \"tf_mnist_ps_worker.py\", line 32, in __init__\r\n tf.keras.layers.Dense(10, activation='softmax')\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_core/python/training/tracking/base.py\", line 457, in _method_wrapper\r\n result = method(self, *args, **kwargs)\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_core/python/keras/engine/sequential.py\", line 114, in __init__\r\n self.add(layer)\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_core/python/training/tracking/base.py\", line 457, in _method_wrapper\r\n result = method(self, *args, **kwargs)\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_core/python/keras/engine/sequential.py\", line 196, in add\r\n output_tensor = layer(self.outputs[0])\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 817, in __call__\r\n self._maybe_build(inputs)\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 2141, in _maybe_build\r\n self.build(input_shapes)\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_core/python/keras/layers/core.py\", line 1027, in build\r\n trainable=True)\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_core/python/keras/engine/base_layer.py\", line 2311, in __setattr__\r\n if val.trainable:\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_core/python/ops/variables.py\", line 477, in trainable\r\n raise NotImplementedError\r\nNotImplementedError\r\n```\r\n\r\n**Code to reproduce the issue**\r\n* my demo code:\r\n```\r\nimport os\r\nimport json\r\nimport argparse\r\n\r\nimport tensorflow as tf\r\nfrom tensorflow.keras import datasets\r\nfrom tensorflow.keras import layers, models\r\nfrom tensorflow.keras import optimizers\r\n\r\nclass Net(object):\r\n def __init__(self):\r\n model = models.Sequential()\r\n model.add(layers.Conv2D(\r\n 32, (3, 3), activation='relu', input_shape=(28, 28, 1)))\r\n model.add(layers.MaxPooling2D((2, 2)))\r\n model.add(layers.Conv2D(64, (3, 3), activation='relu'))\r\n model.add(layers.MaxPooling2D((2, 2)))\r\n model.add(layers.Conv2D(64, (3, 3), activation='relu'))\r\n\r\n model.add(layers.Flatten())\r\n model.add(layers.Dense(64, activation='relu'))\r\n model.add(layers.Dense(10, activation='softmax'))\r\n\r\n model.summary()\r\n\r\n self.model = model\r\n\r\n\r\n# inital dateset\r\nclass DataSet(object):\r\n def __init__(self):\r\n data_path = os.path.dirname(os.path.realpath(__file__)) \\\r\n + '/../../datasets/mnist/mnist.npz'\r\n (train_images, train_labels), (test_images, test_labels) = \\\r\n datasets.mnist.load_data(path=data_path)\r\n train_images = train_images.reshape((60000, 28, 28, 1))\r\n test_images = test_images.reshape((10000, 28, 28, 1))\r\n\r\n train_images, test_images = train_images / 255.0, test_images / 255.0\r\n\r\n self.train_images, self.train_labels = train_images, train_labels\r\n self.test_images, self.test_labels = test_images, test_labels\r\n\r\n\r\n# train and val\r\nclass Train:\r\n def __init__(self):\r\n self.data = DataSet()\r\n\r\n def train(self, args):\r\n # Define the checkpoint directory to store the checkpoints\r\n checkpoint_dir = args.train_dir\r\n # Name of the checkpoint files\r\n checkpoint_path = os.path.join(checkpoint_dir, \"ckpt_{epoch}\")\r\n\r\n callbacks = [\r\n tf.keras.callbacks.TensorBoard(log_dir='./logs'),\r\n tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,\r\n save_weights_only=True),\r\n ]\r\n\r\n with strategy.scope():\r\n model = Net().model\r\n\r\n model.compile(optimizer=optimizers.Adam(),\r\n loss='sparse_categorical_crossentropy',\r\n metrics=['accuracy'])\r\n\r\n model.fit(self.data.train_images, self.data.train_labels,\r\n batch_size=args.batch_size,\r\n epochs=args.epochs,\r\n callbacks=callbacks,\r\n validation_data=(self.data.test_images, self.data.test_labels))\r\n\r\n # EVAL\r\n model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))\r\n eval_loss, eval_acc = model.evaluate(\r\n self.data.test_images, self.data.test_labels, verbose=2)\r\n print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))\r\n\r\n\r\ndef main():\r\n # training params settings\r\n parser = argparse.ArgumentParser(description='Tensorflow 2.0 MNIST Example,'\r\n ' use Mirrorstrategy')\r\n parser.add_argument('--batch_size', '-b', type=int, default=64,\r\n help='input batch size for training (default: 64)')\r\n parser.add_argument('--test_batchsize', '-tb', type=int, default=1000,\r\n help='input batch size for testing (default: 1000)')\r\n parser.add_argument('--epochs', '-e', type=int, default=10,\r\n help='number of epochs to train (default: 10)')\r\n parser.add_argument('--learning_rate', '-lr', type=float, default=0.01,\r\n help='learning rate (default: 0.01)')\r\n parser.add_argument('--momentum', type=float, default=0.5,\r\n help='SGD momentum (default: 0.5)')\r\n parser.add_argument('--log_interval', type=int, default=10,\r\n help='how many batches to wait before logging training status')\r\n parser.add_argument('--save_model', '-sm', action='store_true', default=False,\r\n help='For Saving the current Model')\r\n\r\n args = parser.parse_args()\r\n\r\n app = Train()\r\n app.train(args)\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n```\r\n\r\n* and my cmd line:\r\n\r\n```\r\nTF_CONFIG='{\"cluster\": {\"worker\": [\"10.240.208.106:12345\", \"10.240.208.108:12345\"], \"ps\": [\"10.240.208.106:12346\", \"10.240.208.108:12346\"]}, \"task\": {\"index\": 1, \"type\": \"worker\"}}' python tf_mnist_ps_worker.py\r\n```\r\n\r\n",
"comments": [
{
"body": "This should be fixed now that the associated PR has been merged. Thanks!",
"created_at": "2020-03-18T21:28:58Z"
},
{
"body": "thanks for you comment. Please allow me to ask whether the above PR is merged by the current master branch? Should i use the master branch code to verify my issue?",
"created_at": "2020-03-26T15:40:59Z"
},
{
"body": "Hi @Crisescode, it looks like you are trying to use Keras with ParameterServerStrategy. Note that this is not currently supported, but is planned to be supported planned post 2.3. You can refer to the [chart here](https://www.tensorflow.org/guide/distributed_training#types_of_strategies) to see what is currently supported.",
"created_at": "2020-06-22T22:09:59Z"
},
{
"body": "This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2020-06-29T22:26:09Z"
},
{
"body": "Closing as stale. Please reopen if you'd like to work on this further.\n",
"created_at": "2020-07-06T23:19:36Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35017\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35017\">No</a>\n",
"created_at": "2020-07-06T23:19:39Z"
}
],
"number": 35017,
"title": "tensorflow 2.0 use ParameterServerStrategy error"
}
|
{
"body": "#35442 #35017\r\nWhen i tried to train a keras model using ParameterServerStrategy, i found the error message described in above issue. It says that 'trainable' property is not implemented.\r\nAnd i found AggregatingVariable which is a wrapper class used in ParameterServerStrategy doesn't override 'trainable' property. It should be fixed by overriding 'trainable' property.\r\nSo i simply fixed it by using unwrapped value's 'trainable' property.",
"number": 35886,
"review_comments": [],
"title": "add trainable property to AggregatingVariable"
}
|
{
"commits": [
{
"message": "add trainable property to AggregatingVariable"
}
],
"files": [
{
"diff": "@@ -1421,6 +1421,10 @@ def aggregation(self):\n def name(self):\n return self._v.name\n \n+ @property\n+ def trainable(self):\n+ return self._v.trainable\n+\n @property\n def dtype(self):\n return self._v.dtype",
"filename": "tensorflow/python/distribute/values.py",
"status": "modified"
}
]
}
|
{
"body": "```\r\nx = np.arange(10,dtype=np.float64).reshape(10,1)\r\n#x.shape = (10,1)\r\n\r\ny = np.arange(10,dtype=np.float64)\r\n#y.shape = (10,)\r\n\r\ntf.keras.losses.binary_crossentropy(y_true=y, y_pred=x)\r\n#this line does't raise error\r\n\r\ntf.keras.metrics.BinaryAccuracy()(y_true=y, y_pred=x)\r\n#this line neither\r\n\r\ntf.keras.metrics.Precision()(y_true=y, y_pred=x)\r\n#this line raise an error\r\n```\r\nI think ```binary_crossentropy``` and ```BinaryAccuracy``` should raise an ValueError like ```tf.keras.metrics.Precision```: \r\n```\r\nValueError: Shapes (128, 1) and (128,) are incompatible\r\n```",
"comments": [
{
"body": "@DachuanZhao ,\r\nI was able to replicate the issue with TF-1.5 and TF-2.0, kindly find the [gist](https://colab.sandbox.google.com/gist/oanush/febed084ad734e809b857a89164015ae/35490.ipynb) of colab.Thanks!",
"created_at": "2019-12-30T08:48:20Z"
},
{
"body": "Precision metric should actually not be raising an error. Have a change out to fix this.",
"created_at": "2020-01-14T01:40:15Z"
},
{
"body": "This is fixed now in : https://github.com/tensorflow/tensorflow/commit/ba8a0c934147fcf2a879f349677fc11676c73835#diff-1d3c0e76cc08b7d6e2e3a6ab89965a5c",
"created_at": "2020-01-22T20:00:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35490\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35490\">No</a>\n",
"created_at": "2020-01-22T20:00:50Z"
}
],
"number": 35490,
"title": "Why doesn't ```tf.keras.losses.binary_crossentropy``` raise error"
}
|
{
"body": "fixes #35490 \r\nRaises value error if `y_true` and `y_pred` have different shapes for computing BinaryAccuracy metric.",
"number": 35836,
"review_comments": [],
"title": "Update BinaryAccuracy for assert"
}
|
{
"commits": [
{
"message": "Update BinaryAccuracy for assert\n\nfixes #35490 \r\nRaises value error if `y_true` and `y_pred` have different shapes for computing BinaryAccuracy metric."
}
],
"files": [
{
"diff": "@@ -585,6 +585,8 @@ def update_state(self, y_true, y_pred, sample_weight=None):\n [y_true, y_pred], sample_weight = \\\n metrics_utils.ragged_assert_compatible_and_get_flat_values(\n [y_true, y_pred], sample_weight)\n+ #raises error if `y_true` and `y_pred` have different shapes\n+ y_pred.shape.assert_is_compatible_with(y_true.shape)\n y_pred, y_true = tf_losses_utils.squeeze_or_expand_dimensions(\n y_pred, y_true)\n ",
"filename": "tensorflow/python/keras/metrics.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): macos Catalina\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: n/a\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): `2.1.0`\r\n- Python version: `3.7`\r\n- Bazel version (if compiling from source): n/a\r\n- GCC/Compiler version (if compiling from source): n/a\r\n- CUDA/cuDNN version: n/a\r\n- GPU model and memory: n/a\r\n\r\n**Describe the current behavior**\r\nThe behavior of `tf.range` changed between `2.0.0` and `2.1.0`, such that `tf.range(limit, dtype=dtype)` fails when `limit` is type of `tf.int32` and `dtype` is `tf.int64`. Not sure if this is a bug or a feature but I would expect this to still work.\r\n\r\nThe documentation nor the `2.1.0` release notes don't explicitly mention anything about this.\r\n\r\n**Describe the expected behavior**\r\nThe behavior as it was in `2.0.0`, i.e. no exception is raised.\r\n\r\n**Code to reproduce the issue**\r\n```python\r\nimport tensorflow as tf\r\ntf.range(tf.constant(4, dtype=tf.int32), dtype=tf.int64)\r\n```\r\n\r\n**Other info / logs**\r\n\r\nWith `tensorflow == 2.1.0`:\r\n```bash\r\n$ python -c \"import tensorflow as tf; print(tf.__version__); print(tf.range(tf.constant(4, dtype=tf.int32), dtype=tf.int64))\"\r\n2.1.0\r\n2020-01-09 16:45:39.137901: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\r\n2020-01-09 16:45:39.151651: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7fa652c190b0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\r\n2020-01-09 16:45:39.151667: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/Users/hartikainen/conda/envs/bae/lib/python3.7/site-packages/tensorflow_core/python/ops/math_ops.py\", line 1430, in range\r\n limit = ops.convert_to_tensor(limit, dtype=dtype, name=\"limit\")\r\n File \"/Users/hartikainen/conda/envs/bae/lib/python3.7/site-packages/tensorflow_core/python/framework/ops.py\", line 1290, in convert_to_tensor\r\n (dtype.name, value.dtype.name, value))\r\nValueError: Tensor conversion requested dtype int64 for Tensor with dtype int32: <tf.Tensor: shape=(), dtype=int32, numpy=4>\r\n```\r\n\r\nWith `tensorflow==2.0.0`\r\n```bash\r\n$ python -c \"import tensorflow as tf; print(tf.__version__); print(tf.range(tf.constant(4, dtype=tf.int32), dtype=tf.int64))\"\r\n2.0.0\r\n2020-01-09 16:40:11.425955: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\r\n2020-01-09 16:40:11.439063: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7f8c6ccdfd00 executing computations on platform Host. Devices:\r\n2020-01-09 16:40:11.439079: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Host, Default Version\r\ntf.Tensor([0 1 2 3], shape=(4,), dtype=int64)\r\n```\r\n",
"comments": [
{
"body": "https://github.com/tensorflow/tensorflow/issues/29867 seems related but it's from time before this feature worked.",
"created_at": "2020-01-09T16:54:04Z"
},
{
"body": "@hartikainen \r\nI have tried on colab with TF version 2.1 and was able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/99ab8383b4ad24661d44b476fd4a903e/untitled545.ipynb).However i am not seeing any issue with TF 2.0. Thanks!",
"created_at": "2020-01-10T05:30:06Z"
},
{
"body": "@ravikyram Yeah, my point was that this seems like a regression from 2.0 to 2.1, since it behaves as I would expect on 2.0. What I'm not sure is if the \"regression\" is expected or not.",
"created_at": "2020-01-10T10:42:34Z"
},
{
"body": "Added a PR #35821 for the fix.",
"created_at": "2020-01-13T15:51:28Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35710\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35710\">No</a>\n",
"created_at": "2020-01-13T22:44:11Z"
},
{
"body": "Thanks for fixing this!\r\n\r\nAs a side note, the @tensorflow-bot's survey messages are completely useless, since once you have answered it once in another issue, you always just get a message saying \"You've already responded\". Is there a way to fix that?",
"created_at": "2020-01-14T08:41:10Z"
},
{
"body": "@hartikainen Thanks for bringing this @tensorflow-bot's survey issue. We will work on it soon. Thanks!",
"created_at": "2020-01-14T21:45:34Z"
}
],
"number": 35710,
"title": "tf.range fails when `limit` is type of `tf.int32` and `dtype` is `tf.int64`"
}
|
{
"body": "This PR tries to address the issue raised in #35710 where tf.range fails when `limit` is type of `tf.int32` and `dtype` is `tf.int64`.\r\n\r\nThe failure is a regression between TF 2.0.0 and 2.1.0\r\n\r\nThis fix adds additional cast to resolve the issue.\r\n\r\nThis fix fixes #35710.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 35821,
"review_comments": [
{
"body": "convert_to_tensor already is a no-op if the input is a tensor, so what is this doing?",
"created_at": "2020-01-13T20:51:10Z"
},
{
"body": "We don't want to do this; TF likes to fail loudly when mixing dtypes as it's not obvious what is the user intent (and casts can always be inserted at the call site)",
"created_at": "2020-01-13T20:51:45Z"
},
{
"body": "Thanks @alextp for the review. In #35710 the case was that the `dtype` passed along with `tf.range(start, limit, delta, dtype) ` is different from the tensor of the `start`/`limit`/`delta`. In other words, the following:\r\n```\r\ntf.range(tf.constant(4, dtype=tf.int32), dtype=tf.int64)\r\n```\r\n\r\nIn that case, `convert_to_tensor` will try to convert `tf.constant(4, dtype=tf.int32)` to `dtype=tf.int64` and that is returning an error. That is the issue from #35710 .",
"created_at": "2020-01-13T20:57:28Z"
}
],
"title": "Fix tf.range failure when `limit` is type of `tf.int32` and `dtype` is `tf.int64`"
}
|
{
"commits": [
{
"message": "Fix tf.range failure when `limit` is type of `tf.int32` and `dtype` is `tf.int64`\n\nThis PR tries to address the issue raised in 35710 where\ntf.range fails when `limit` is type of `tf.int32` and `dtype` is `tf.int64`.\n\nThe failure is a regression between 2.0.0 and 2.1.0\n\nThis fix adds additional cast to resolve the issue.\n\nThis fix fixes 35710.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub issue 35710\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Pylint fix\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -537,6 +537,12 @@ def testDType(self):\n math_ops.range(\n 0, 0, 1, dtype=dtypes.float64).dtype, dtypes.float64)\n \n+ def testMixedDType(self):\n+ # Test case for GitHub issue 35710\n+ tf_ans = math_ops.range(\n+ constant_op.constant(4, dtype=dtypes.int32), dtype=dtypes.int64)\n+ self.assertAllEqual(self.evaluate(tf_ans), np.array([0, 1, 2, 3]))\n+\n \n # TODO(vrv): move to sequence_ops_test?\n class LinSpaceTest(test.TestCase):",
"filename": "tensorflow/python/kernel_tests/init_ops_test.py",
"status": "modified"
},
{
"diff": "@@ -1487,9 +1487,12 @@ def range(start, limit=None, delta=1, dtype=None, name=\"range\"): # pylint: disa\n start, limit = 0, start\n \n with ops.name_scope(name, \"Range\", [start, limit, delta]) as name:\n- start = ops.convert_to_tensor(start, dtype=dtype, name=\"start\")\n- limit = ops.convert_to_tensor(limit, dtype=dtype, name=\"limit\")\n- delta = ops.convert_to_tensor(delta, dtype=dtype, name=\"delta\")\n+ if not isinstance(start, ops.Tensor):\n+ start = ops.convert_to_tensor(start, dtype=dtype, name=\"start\")\n+ if not isinstance(limit, ops.Tensor):\n+ limit = ops.convert_to_tensor(limit, dtype=dtype, name=\"limit\")\n+ if not isinstance(delta, ops.Tensor):\n+ delta = ops.convert_to_tensor(delta, dtype=dtype, name=\"delta\")\n \n # infer dtype if not explicitly provided\n if dtype is None:\n@@ -1499,10 +1502,14 @@ def range(start, limit=None, delta=1, dtype=None, name=\"range\"): # pylint: disa\n assert all(arg.dtype in dtype_hierarchy for arg in [start, limit, delta])\n inferred_dtype = max([arg.dtype for arg in [start, limit, delta]],\n key=dtype_hierarchy.index)\n-\n- start = cast(start, inferred_dtype)\n- limit = cast(limit, inferred_dtype)\n- delta = cast(delta, inferred_dtype)\n+ else:\n+ inferred_dtype = dtype\n+ # Always try perform a cast even start/limit/delta are already tensors.\n+ # This will revole the case where start/limit/delta's original's dtype\n+ # is different from provided dtype.\n+ start = cast(start, inferred_dtype)\n+ limit = cast(limit, inferred_dtype)\n+ delta = cast(delta, inferred_dtype)\n \n return gen_math_ops._range(start, limit, delta, name=name)\n ",
"filename": "tensorflow/python/ops/math_ops.py",
"status": "modified"
}
]
}
|
{
"body": "@tensorflow/micro\r\n\r\n**System information**\r\n- Host OS Platform and Distribution: Ubuntu 18.04\r\n- TensorFlow installed from: Source\r\n- Tensorflow version: 4b3c1199a97cb36b8866d98e7036f4ec3e70abd6\r\n- Target platform: Apollo3\r\n\r\n**Describe the problem**\r\n\r\nThe tflite micro softmax op in [tensorflow/lite/micro/kernels/softmax.cc](https://github.com/tensorflow/tensorflow/blob/4b3c1199a97cb36b8866d98e7036f4ec3e70abd6/tensorflow/lite/micro/kernels/softmax.cc) already has int8 input support.\r\nFrom what I understand this should be version 2 in [tensorflow/lite/micro/kernels/all_ops_resolver.cc](https://github.com/tensorflow/tensorflow/blob/4b3c1199a97cb36b8866d98e7036f4ec3e70abd6/tensorflow/lite/micro/kernels/all_ops_resolver.cc#L26)\r\n\r\n",
"comments": [
{
"body": "Thanks for reporting this bug. I have landed a patch to fix this operator as well as a handful of others internally and it should show up on Github soon.",
"created_at": "2020-01-13T23:36:13Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35748\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35748\">No</a>\n",
"created_at": "2020-01-13T23:36:15Z"
}
],
"number": 35748,
"title": "tflite micro softmax op is still version 1"
}
|
{
"body": "Fix for #35748",
"number": 35755,
"review_comments": [],
"title": " Upgrade tflite micro softmax op version"
}
|
{
"commits": [
{
"message": "Update all_ops_resolver.cc"
}
],
"files": [
{
"diff": "@@ -23,7 +23,7 @@ namespace micro {\n AllOpsResolver::AllOpsResolver() {\n AddBuiltin(BuiltinOperator_FULLY_CONNECTED, Register_FULLY_CONNECTED(), 1, 4);\n AddBuiltin(BuiltinOperator_MAX_POOL_2D, Register_MAX_POOL_2D());\n- AddBuiltin(BuiltinOperator_SOFTMAX, Register_SOFTMAX());\n+ AddBuiltin(BuiltinOperator_SOFTMAX, Register_SOFTMAX(), 1, 2);\n AddBuiltin(BuiltinOperator_LOGISTIC, Register_LOGISTIC());\n AddBuiltin(BuiltinOperator_SVDF, Register_SVDF());\n AddBuiltin(BuiltinOperator_CONV_2D, Register_CONV_2D(), 1, 3);",
"filename": "tensorflow/lite/micro/kernels/all_ops_resolver.cc",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): platform-independent\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.1\r\n- Python version: 3.7\r\n\r\n**Describe the current behavior**\r\n\r\n`tf.keras.layers.Wrapper.from_config` modifies its `config` parameter, which can cause unexpected side effects in calling code.\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/e5bf8de410005de06a7ff5393fafdf832ef1d4ad/tensorflow/python/keras/layers/wrappers.py#L83-L87\r\n\r\nSpecifically, `config.pop` in line 86 above mutates the `config` dict in a way that persists outside the `from_config` function call.\r\n\r\nElsewhere (e.g., in `tf.keras.layers.Bidirectional.from_config`) this is avoided by copying the `config` dict:\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/e5bf8de410005de06a7ff5393fafdf832ef1d4ad/tensorflow/python/keras/layers/wrappers.py#L743-L745\r\n\r\n**Describe the expected behavior**\r\n\r\nBeing able to call `tf.keras.layers.Wrapper.from_config(config)` without `config` changing.\r\n\r\nI have a use case where I am subclassing the `Wrapper` class and relying on its `from_config` method. My workaround is to call `from_config(config.copy())`, but I don't think this should be required.\r\n\r\n**Code to reproduce the issue**\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\n\r\nclass MyWrapper(tf.keras.layers.Wrapper):\r\n def call(self, inputs, *args, **kwargs):\r\n return self.layer(inputs, *args, **kwargs)\r\n\r\n\r\nwrapper = MyWrapper(tf.keras.layers.Dense(1))\r\nconfig = wrapper.get_config()\r\nconfig_copy = config.copy()\r\nassert config == config_copy\r\n\r\nwrapper_from_config = MyWrapper.from_config(config)\r\nnew_config = wrapper.get_config()\r\nassert new_config == config_copy\r\nassert config == config_copy # Fails! The 'layer' key has been popped from config\r\n```",
"comments": [
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35683\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35683\">No</a>\n",
"created_at": "2020-01-10T22:52:56Z"
}
],
"number": 35683,
"title": "Wrapper.from_config mutates its input"
}
|
{
"body": "Proposed fix for #35683\r\n\r\nDuplicate of #35684 but for the master branch",
"number": 35753,
"review_comments": [],
"title": "Making a copy of the the input dict in Wrapper.from_config"
}
|
{
"commits": [
{
"message": "Making a copy of config in from_config\n\nFixes #35683"
},
{
"message": "Added test for config mutation"
}
],
"files": [
{
"diff": "@@ -82,6 +82,8 @@ def get_config(self):\n @classmethod\n def from_config(cls, config, custom_objects=None):\n from tensorflow.python.keras.layers import deserialize as deserialize_layer # pylint: disable=g-import-not-at-top\n+ # Avoid mutating the input dict\n+ config = config.copy()\n layer = deserialize_layer(\n config.pop('layer'), custom_objects=custom_objects)\n return cls(layer, **config)",
"filename": "tensorflow/python/keras/layers/wrappers.py",
"status": "modified"
},
{
"diff": "@@ -1162,6 +1162,27 @@ def test_Bidirectional_ragged_input(self):\n # pylint: enable=g-long-lambda\n \n \n+class ExampleWrapper(keras.layers.Wrapper):\n+ \"\"\"Simple Wrapper subclass.\"\"\"\n+\n+ def call(self, inputs, *args, **kwargs):\n+ return self.layer(inputs, *args, **kwargs)\n+\n+\n+class WrapperTest(keras_parameterized.TestCase):\n+\n+ def test_wrapper_from_config_no_mutation(self):\n+ wrapper = ExampleWrapper(keras.layers.Dense(1))\n+ config = wrapper.get_config()\n+ config_copy = config.copy()\n+ self.assertEqual(config, config_copy)\n+\n+ wrapper_from_config = ExampleWrapper.from_config(config)\n+ new_config = wrapper.get_config()\n+ self.assertEqual(new_config, config_copy)\n+ self.assertEqual(config, config_copy)\n+\n+\n def _to_list(ls):\n if isinstance(ls, list):\n return ls",
"filename": "tensorflow/python/keras/layers/wrappers_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): platform-independent\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.1\r\n- Python version: 3.7\r\n\r\n**Describe the current behavior**\r\n\r\n`tf.keras.layers.Wrapper.from_config` modifies its `config` parameter, which can cause unexpected side effects in calling code.\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/e5bf8de410005de06a7ff5393fafdf832ef1d4ad/tensorflow/python/keras/layers/wrappers.py#L83-L87\r\n\r\nSpecifically, `config.pop` in line 86 above mutates the `config` dict in a way that persists outside the `from_config` function call.\r\n\r\nElsewhere (e.g., in `tf.keras.layers.Bidirectional.from_config`) this is avoided by copying the `config` dict:\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/e5bf8de410005de06a7ff5393fafdf832ef1d4ad/tensorflow/python/keras/layers/wrappers.py#L743-L745\r\n\r\n**Describe the expected behavior**\r\n\r\nBeing able to call `tf.keras.layers.Wrapper.from_config(config)` without `config` changing.\r\n\r\nI have a use case where I am subclassing the `Wrapper` class and relying on its `from_config` method. My workaround is to call `from_config(config.copy())`, but I don't think this should be required.\r\n\r\n**Code to reproduce the issue**\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\n\r\nclass MyWrapper(tf.keras.layers.Wrapper):\r\n def call(self, inputs, *args, **kwargs):\r\n return self.layer(inputs, *args, **kwargs)\r\n\r\n\r\nwrapper = MyWrapper(tf.keras.layers.Dense(1))\r\nconfig = wrapper.get_config()\r\nconfig_copy = config.copy()\r\nassert config == config_copy\r\n\r\nwrapper_from_config = MyWrapper.from_config(config)\r\nnew_config = wrapper.get_config()\r\nassert new_config == config_copy\r\nassert config == config_copy # Fails! The 'layer' key has been popped from config\r\n```",
"comments": [
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35683\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35683\">No</a>\n",
"created_at": "2020-01-10T22:52:56Z"
}
],
"number": 35683,
"title": "Wrapper.from_config mutates its input"
}
|
{
"body": "Proposed fix for #35683",
"number": 35684,
"review_comments": [],
"title": "Making a copy of the the input in from_config"
}
|
{
"commits": [
{
"message": "Making a copy of the the input in from_config\n\nFixes #35683"
},
{
"message": "Added test for config mutation"
}
],
"files": [
{
"diff": "@@ -82,6 +82,8 @@ def get_config(self):\n @classmethod\n def from_config(cls, config, custom_objects=None):\n from tensorflow.python.keras.layers import deserialize as deserialize_layer # pylint: disable=g-import-not-at-top\n+ # Avoid mutating the input dict\n+ config = config.copy()\n layer = deserialize_layer(\n config.pop('layer'), custom_objects=custom_objects)\n return cls(layer, **config)",
"filename": "tensorflow/python/keras/layers/wrappers.py",
"status": "modified"
},
{
"diff": "@@ -1153,6 +1153,27 @@ def test_Bidirectional_ragged_input(self):\n # pylint: enable=g-long-lambda\n \n \n+class ExampleWrapper(keras.layers.Wrapper):\n+ \"\"\"Simple Wrapper subclass.\"\"\"\n+\n+ def call(self, inputs, *args, **kwargs):\n+ return self.layer(inputs, *args, **kwargs)\n+\n+\n+class WrapperTest(keras_parameterized.TestCase):\n+\n+ def test_wrapper_from_config_no_mutation(self):\n+ wrapper = ExampleWrapper(keras.layers.Dense(1))\n+ config = wrapper.get_config()\n+ config_copy = config.copy()\n+ self.assertEqual(config, config_copy)\n+\n+ wrapper_from_config = ExampleWrapper.from_config(config)\n+ new_config = wrapper.get_config()\n+ self.assertEqual(new_config, config_copy)\n+ self.assertEqual(config, config_copy)\n+\n+\n def _to_list(ls):\n if isinstance(ls, list):\n return ls",
"filename": "tensorflow/python/keras/layers/wrappers_test.py",
"status": "modified"
}
]
}
|
{
"body": "@tensorflow/micro\r\n\r\n**System information**\r\n- Host OS Platform and Distribution (e.g., Linux Ubuntu 16.04): 18.04\r\n- TensorFlow installed from (source or binary): source\r\n- Tensorflow version (commit SHA if source): 2274eacd794d7e501849567811637b7921e52820\r\n- Target platform (e.g. Arm Mbed OS, Arduino Nano 33 etc.): ARM cmis-nn\r\n\r\n**Describe the problem**\r\n\r\nIssue reported by \"On-Device AI Co., Ltd. \" on tensorflow/sig-micro gitter\r\nLite/micro examples using CMIS-NN kernels no longer compile.\r\n\r\nRoot cause:\r\nThe PR: Lite: Kernel_util refactored #27019 did not refactor the cmis-nn specific add and mul kernels. Will submit PR request with the missing changes.\r\n\r\n**Please provide the exact sequence of commands/steps when you ran into the problem**\r\n```make -f tensorflow/lite/micro/tools/make/Makefile TARGET=sparkfun_edge TAGS=\"cmsis-nn\" micro_speech_bin\r\n\r\n......\r\n\r\narm-none-eabi-g++ -O3 -DNDEBUG -std=c++11 -g -DTF_LITE_STATIC_MEMORY -fno-rtti -DPART_apollo3 -DAM_PACKAGE_BGA -DAM_PART_APOLLO3 -DGEMMLOWP_ALLOW_SLOW_SCALAR_FALLBACK -DTF_LITE_STATIC_MEMORY -DNDEBUG -DTF_LITE_MCU_DEBUG_LOG -D __FPU_PRESENT=1 -DARM_MATH_CM4 -fno-rtti -fmessage-length=0 -fno-exceptions -fno-unwind-tables -fno-builtin -ffunction-sections -fdata-sections -funsigned-char -MMD -mcpu=cortex-m4 -mthumb -mfpu=fpv4-sp-d16 -mfloat-abi=hard -std=gnu++11 -Wvla -Wall -Wextra -Wno-unused-parameter -Wno-missing-field-initializers -Wno-write-strings -Wno-sign-compare -fno-delete-null-pointer-checks -fomit-frame-pointer -fpermissive -nostdlib -ggdb -O3 -DARM_MATH_DSP -DARM_MATH_LOOPUNROLL -I. -Itensorflow/lite/micro/tools/make/downloads/ -Itensorflow/lite/micro/tools/make/downloads/gemmlowp -Itensorflow/lite/micro/tools/make/downloads/flatbuffers/include -isystemtensorflow/lite/micro/tools/make/downloads/cmsis/CMSIS/Core/Include/ -isystemtensorflow/lite/micro/tools/make/downloads/cmsis/CMSIS/DSP/Include/ -Itensorflow/lite/micro/tools/make/downloads/CMSIS_ext/ -Itensorflow/lite/micro/tools/make/downloads/gcc_embedded//arm-none-eabi/ -Itensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/mcu/apollo3/ -Itensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/CMSIS/AmbiqMicro/Include/ -Itensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/boards/SparkFun_TensorFlow_Apollo3_BSP/bsp -Itensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/devices/ -Itensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/utils/ -Itensorflow/lite/micro/tools/make/downloads/cmsis//CMSIS/Core/Include -Itensorflow/lite/micro/tools/make/downloads/cmsis//CMSIS/NN/Include -Itensorflow/lite/micro/tools/make/downloads/cmsis//CMSIS/DSP/Include -Itensorflow/lite/micro/tools/make/downloads/kissfft -Itensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/boards/SparkFun_TensorFlow_Apollo3_BSP/examples/example1_edge_test/src/tf_accelerometer/ -Itensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/boards/SparkFun_TensorFlow_Apollo3_BSP/examples/example1_edge_test/src/tf_adc/ -c tensorflow/lite/micro/kernels/cmsis-nn/add.cc -o tensorflow/lite/micro/tools/make/gen/sparkfun_edge_cortex-m4/obj/tensorflow/lite/micro/kernels/cmsis-nn/add.o\r\ntensorflow/lite/micro/kernels/cmsis-nn/add.cc: In function 'TfLiteStatus tflite::ops::micro::add::CalculateOpData(TfLiteContext*, TfLiteAddParams*, const TfLiteTensor*, const TfLiteTensor*, TfLiteTensor*, tflite::ops::micro::add::OpData*)':\r\ntensorflow/lite/micro/kernels/cmsis-nn/add.cc:89:7: error: 'CalculateActivationRangeUint8' was not declared in this scope\r\n CalculateActivationRangeUint8(params->activation, output,\r\n ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~\r\ntensorflow/lite/micro/kernels/cmsis-nn/add.cc:89:7: note: suggested alternative: 'CalculateActivationRange'\r\n CalculateActivationRangeUint8(params->activation, output,\r\n ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~\r\n CalculateActivationRange\r\ntensorflow/lite/micro/kernels/cmsis-nn/add.cc:93:7: error: 'CalculateActivationRangeInt8' was not declared in this scope\r\n CalculateActivationRangeInt8(params->activation, output,\r\n ^~~~~~~~~~~~~~~~~~~~~~~~~~~~\r\ntensorflow/lite/micro/kernels/cmsis-nn/add.cc:93:7: note: suggested alternative: 'CalculateActivationRange'\r\n CalculateActivationRangeInt8(params->activation, output,\r\n ^~~~~~~~~~~~~~~~~~~~~~~~~~~~\r\n CalculateActivationRange\r\n.....\r\n```",
"comments": [
{
"body": "Fixed by #35613 ",
"created_at": "2020-01-06T19:44:26Z"
}
],
"number": 35612,
"title": "lite/micro/kernels/cmis-nn "
}
|
{
"body": "Fix for #35612 ",
"number": 35613,
"review_comments": [],
"title": "Fix lite/micro cmsis-nn kernels that were not refactored in #27019"
}
|
{
"commits": [
{
"message": "Fix lite/micro cmsis-nn kernels that were not refactored in #27019"
}
],
"files": [
{
"diff": "@@ -85,15 +85,9 @@ TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteAddParams* params,\n QuantizeMultiplierSmallerThanOneExp(\n real_output_multiplier, &data->output_multiplier, &data->output_shift);\n \n- if (output->type == kTfLiteUInt8) {\n- CalculateActivationRangeUint8(params->activation, output,\n- &data->output_activation_min,\n- &data->output_activation_max);\n- } else {\n- CalculateActivationRangeInt8(params->activation, output,\n- &data->output_activation_min,\n- &data->output_activation_max);\n- }\n+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(\n+ context, params->activation, output, &data->output_activation_min,\n+ &data->output_activation_max));\n }\n \n return kTfLiteOk;",
"filename": "tensorflow/lite/micro/kernels/cmsis-nn/add.cc",
"status": "modified"
},
{
"diff": "@@ -50,15 +50,9 @@ TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node,\n \n TF_LITE_ENSURE_EQ(context, input1->type, input2->type);\n \n- if (output->type == kTfLiteUInt8) {\n- CalculateActivationRangeUint8(params->activation, output,\n- &data->output_activation_min,\n- &data->output_activation_max);\n- } else if (output->type == kTfLiteInt8) {\n- CalculateActivationRangeInt8(params->activation, output,\n- &data->output_activation_min,\n- &data->output_activation_max);\n- }\n+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(\n+ context, params->activation, output, &data->output_activation_min,\n+ &data->output_activation_max));\n \n double real_multiplier =\n input1->params.scale * input2->params.scale / output->params.scale;",
"filename": "tensorflow/lite/micro/kernels/cmsis-nn/mul.cc",
"status": "modified"
}
]
}
|
{
"body": "@tensorflow/micro\r\n\r\n**System information**\r\n- Host OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- TensorFlow installed from (source or binary): source\r\n- Tensorflow version (commit SHA if source): e12ba3de80d9315b7174037081adb482689bc6d6\r\n- Target platform (e.g. Arm Mbed OS, Arduino Nano 33 etc.): all\r\n\r\n**Describe the problem**\r\n The tensor lifetime may be incorrectly calculated in MicroAllocator::FinishTensorAllocation() if the same sensor is used multiple times as inputs to different operations or is used as input/output or variable of the graph.\r\n\r\nThe relevant code section:\r\n```c\r\n // Figure out when the first and last use of each tensor is.\r\n for (int i = (operators_->size() - 1); i >= 0; --i) {\r\n const auto* op = operators_->Get(i);\r\n for (size_t n = 0; n < op->inputs()->size(); ++n) {\r\n const int tensor_index = op->inputs()->Get(n);\r\n TensorInfo* current = &tensor_info[tensor_index];\r\n if ((current->last_used == -1) || (current->last_used > i)) {\r\n current->last_used = i;\r\n }\r\n }\r\n for (size_t n = 0; n < op->outputs()->size(); ++n) {\r\n const int tensor_index = op->outputs()->Get(n);\r\n TensorInfo* current = &tensor_info[tensor_index];\r\n if ((current->first_created == -1) || (current->first_created < i)) {\r\n current->first_created = i;\r\n }\r\n }\r\n }\r\n```\r\nLooks just like the condition to update a valid lifetime is accidentally inverted.\r\nWill verify and submit PR\r\n\r\n**Please provide the exact sequence of commands/steps when you ran into the problem**\r\nCode review\r\n",
"comments": [
{
"body": "Resolved by #35123",
"created_at": "2020-02-12T17:16:19Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35121\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35121\">No</a>\n",
"created_at": "2020-02-12T17:16:21Z"
}
],
"number": 35121,
"title": "lite/micro: Tensor lifetime incorrectly calculated on multiple use"
}
|
{
"body": "Add a second operation to the MockModel sharing inputs with the first\r\noperation to catch #35121 (Tensor lifetime incorrectly calculated on\r\nmultiple use) and verify the fix.\r\n\r\nBoth micro_allocator_test and micro_interpreter_test will fail with this change until #35123 is merged.",
"number": 35294,
"review_comments": [],
"title": "lite/micro: Add tensor allocation tests for #35121"
}
|
{
"commits": [
{
"message": "lite/micro: Add tensor allocation tests for #35121\n\nAdd a second operation to the MockModel sharing inputs with the first\noperation to catch #35121 (Tensor lifetime incorrectly calculated on\nmultiple use) and verify the fix."
}
],
"files": [
{
"diff": "@@ -143,7 +143,7 @@ TF_LITE_MICRO_TEST(TestFinishTensorAllocation) {\n uint8_t arena[arena_size];\n tflite::MicroAllocator allocator(&context, model, arena, arena_size,\n micro_test::reporter);\n- TF_LITE_MICRO_EXPECT_EQ(3, context.tensors_size);\n+ TF_LITE_MICRO_EXPECT_EQ(4, context.tensors_size);\n \n TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, allocator.FinishTensorAllocation());\n // No allocation to be done afterwards.\n@@ -153,13 +153,20 @@ TF_LITE_MICRO_TEST(TestFinishTensorAllocation) {\n tflite::testing::VerifyMockTensor(&context.tensors[0]);\n tflite::testing::VerifyMockWeightTensor(&context.tensors[1]);\n tflite::testing::VerifyMockTensor(&context.tensors[2]);\n+ tflite::testing::VerifyMockTensor(&context.tensors[3]);\n \n TF_LITE_MICRO_EXPECT_NE(context.tensors[1].data.raw,\n context.tensors[0].data.raw);\n TF_LITE_MICRO_EXPECT_NE(context.tensors[2].data.raw,\n context.tensors[0].data.raw);\n TF_LITE_MICRO_EXPECT_NE(context.tensors[1].data.raw,\n context.tensors[2].data.raw);\n+ TF_LITE_MICRO_EXPECT_NE(context.tensors[3].data.raw,\n+ context.tensors[0].data.raw);\n+ TF_LITE_MICRO_EXPECT_NE(context.tensors[3].data.raw,\n+ context.tensors[1].data.raw);\n+ TF_LITE_MICRO_EXPECT_NE(context.tensors[3].data.raw,\n+ context.tensors[2].data.raw);\n }\n \n TF_LITE_MICRO_TEST(TestFinishComplexTensorAllocation) {",
"filename": "tensorflow/lite/micro/micro_allocator_test.cc",
"status": "modified"
},
{
"diff": "@@ -46,6 +46,7 @@ TfLiteStatus MockInvoke(TfLiteContext* context, TfLiteNode* node) {\n const uint8_t* weight_data = weight->data.uint8;\n TfLiteTensor* output = &context->tensors[node->outputs->data[0]];\n int32_t* output_data = output->data.i32;\n+ output_data[0] = 0; // Catch output tensor sharing memory with an input tensor\n output_data[0] = input_data[0] + weight_data[0];\n return kTfLiteOk;\n }\n@@ -83,7 +84,7 @@ TF_LITE_MICRO_TEST(TestInterpreter) {\n micro_test::reporter);\n TF_LITE_MICRO_EXPECT_EQ(interpreter.AllocateTensors(), kTfLiteOk);\n TF_LITE_MICRO_EXPECT_EQ(1, interpreter.inputs_size());\n- TF_LITE_MICRO_EXPECT_EQ(1, interpreter.outputs_size());\n+ TF_LITE_MICRO_EXPECT_EQ(2, interpreter.outputs_size());\n \n TfLiteTensor* input = interpreter.input(0);\n TF_LITE_MICRO_EXPECT_NE(nullptr, input);\n@@ -105,6 +106,15 @@ TF_LITE_MICRO_TEST(TestInterpreter) {\n TF_LITE_MICRO_EXPECT_NE(nullptr, output->data.i32);\n TF_LITE_MICRO_EXPECT_EQ(42, output->data.i32[0]);\n \n+ output = interpreter.output(1);\n+ TF_LITE_MICRO_EXPECT_NE(nullptr, output);\n+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, output->type);\n+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->size);\n+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[0]);\n+ TF_LITE_MICRO_EXPECT_EQ(4, output->bytes);\n+ TF_LITE_MICRO_EXPECT_NE(nullptr, output->data.i32);\n+ TF_LITE_MICRO_EXPECT_EQ(42, output->data.i32[0]);\n+\n // Just to make sure that this method works.\n tflite::PrintInterpreterState(&interpreter);\n }",
"filename": "tensorflow/lite/micro/micro_interpreter_test.cc",
"status": "modified"
},
{
"diff": "@@ -76,7 +76,7 @@ const Model* BuildSimpleMockModel() {\n builder->CreateVector(buffer_data, buffer_data_size))};\n constexpr size_t tensor_shape_size = 1;\n const int32_t tensor_shape[tensor_shape_size] = {1};\n- constexpr size_t tensors_size = 3;\n+ constexpr size_t tensors_size = 4;\n const Offset<Tensor> tensors[tensors_size] = {\n CreateTensor(*builder,\n builder->CreateVector(tensor_shape, tensor_shape_size),\n@@ -90,20 +90,36 @@ const Model* BuildSimpleMockModel() {\n builder->CreateVector(tensor_shape, tensor_shape_size),\n TensorType_INT32, 0,\n builder->CreateString(\"test_output_tensor\"), 0, false),\n+ CreateTensor(*builder,\n+ builder->CreateVector(tensor_shape, tensor_shape_size),\n+ TensorType_INT32, 0,\n+ builder->CreateString(\"test_output2_tensor\"), 0, false),\n };\n constexpr size_t inputs_size = 1;\n const int32_t inputs[inputs_size] = {0};\n- constexpr size_t outputs_size = 1;\n- const int32_t outputs[outputs_size] = {2};\n+ constexpr size_t outputs_size = 2;\n+ const int32_t outputs[outputs_size] = {2, 3};\n constexpr size_t operator_inputs_size = 2;\n const int32_t operator_inputs[operator_inputs_size] = {0, 1};\n constexpr size_t operator_outputs_size = 1;\n const int32_t operator_outputs[operator_outputs_size] = {2};\n- constexpr size_t operators_size = 1;\n- const Offset<Operator> operators[operators_size] = {CreateOperator(\n- *builder, 0, builder->CreateVector(operator_inputs, operator_inputs_size),\n- builder->CreateVector(operator_outputs, operator_outputs_size),\n- BuiltinOptions_NONE)};\n+ const int32_t operator2_outputs[operator_outputs_size] = {3};\n+ constexpr size_t operators_size = 2;\n+ const Offset<Operator> operators[operators_size] = {\n+ CreateOperator(*builder, 0,\n+\t\t builder->CreateVector(operator_inputs,\n+\t\t\t\t\t operator_inputs_size),\n+\t\t builder->CreateVector(operator_outputs,\n+\t\t\t\t\t operator_outputs_size),\n+\t\t BuiltinOptions_NONE),\n+ CreateOperator(\n+\t\t *builder, 0,\n+\t\t builder->CreateVector(operator_inputs,\n+\t\t\t\t\t operator_inputs_size),\n+\t\t builder->CreateVector(operator2_outputs,\n+\t\t\t\t\t operator_outputs_size),\n+\t\t BuiltinOptions_NONE),\n+ };\n constexpr size_t subgraphs_size = 1;\n const Offset<SubGraph> subgraphs[subgraphs_size] = {\n CreateSubGraph(*builder, builder->CreateVector(tensors, tensors_size),",
"filename": "tensorflow/lite/micro/test_helpers.cc",
"status": "modified"
}
]
}
|
{
"body": "I don't understand the cause of different handling of shapes for two methods, here is the snippet:\r\n\r\n```python\r\nimport tensorflow as tf\r\nimport tensorflow_probability as tfp\r\n\r\ndef _log_prob(x):\r\n x = tf.convert_to_tensor(x, name='x')\r\n distribution_log_probs = [x for i in range(5)]\r\n cat_log_probs = [x for i in range(5)]\r\n final_log_probs = [\r\n cat_lp + d_lp\r\n for (cat_lp, d_lp) in zip(cat_log_probs, distribution_log_probs)\r\n ]\r\n concat_log_probs = tf.stack(final_log_probs, 0)\r\n log_sum = tf.reduce_logsumexp(concat_log_probs, axis=[0])\r\n # log_sum = tf.reduce_sum(concat_log_probs, axis=[0])\r\n return log_sum\r\n\r\n@tf.function(autograph=False)\r\ndef f():\r\n log_prob = tf.vectorized_map(_log_prob, tf.ones((1,5)))\r\n print(log_prob.shape) # prints (None, 5) for `tf.reduce_logsumexp` and (1, 5) for `tf.reduce_sum`\r\n```\r\n\r\nSo basically `tf.reduce_logsumexp` gives dynamic shape for the output tensor while `tf.reduce_sum` assigns static shape. Can anybody please give some clear picture on such behaviour and is it expected?\r\n\r\n```\r\ntf: 2.0.0\r\ntfp: 0.8.0\r\n```",
"comments": [
{
"body": "#35073, tensorflow/probability#684",
"created_at": "2019-12-13T21:59:12Z"
},
{
"body": "I guess the problem is that v2 methods like `select_v2` are not correctly (or even not) exposed. Little fix will solve the problem with `reduce_logsumexp`. Not sure if I can open PR with more detailed review of the issues with imports.\r\n\r\n@ravikyram ",
"created_at": "2019-12-16T19:24:56Z"
},
{
"body": "\r\n\r\nI have tried in colab with TF 2.0, 2.1.0-rc1 and was able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/61ab1f7a87eae6ac1049881313c5b7bd/untitled482.ipynb). Thanks!",
"created_at": "2019-12-18T09:52:45Z"
},
{
"body": "@ravikyram great, does the PR solve the issue?",
"created_at": "2019-12-18T10:02:31Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35099\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35099\">No</a>\n",
"created_at": "2020-01-06T20:54:20Z"
},
{
"body": "@ravikyram @ymodak the previous code was merged again: [commit](https://github.com/tensorflow/tensorflow/commit/21882b67cbe63aaf1ee9c3d4e6f90d16cb08967d). Can you please give some info on the issue of compatibility? Do we have to wait until the next minor to update the implementation?",
"created_at": "2020-01-17T17:43:49Z"
},
{
"body": "@dynamicwebpaige could you give us some help here? We got a few things blocked by this.",
"created_at": "2020-01-20T16:28:50Z"
},
{
"body": "I also just encountered this issue, I was hoping to port my code from pymc3 to tensorflow but hit this.",
"created_at": "2020-03-15T03:11:05Z"
},
{
"body": "pinging a few more folks: @derifatives @brianwa84",
"created_at": "2020-03-15T07:44:58Z"
},
{
"body": "@agarwal-ashish \r\nIt's a difference related to `vectorized_map`. You can see by putting `assert log_prob.shape.is_fully_defined()` that both variants have a fully defined shape w/in `_log_prob`, but that they lose it when traced by vectorized_map.",
"created_at": "2020-03-16T18:31:44Z"
},
{
"body": "Here's my full repro against nightlies:\r\n```python\r\n%tensorflow_version 2.x\r\n!pip install --upgrade pip\r\n!python -m pip uninstall --yes tensorflow tensorflow-probability\r\n!python -m pip install -q tf-nightly-cpu tfp-nightly\r\nimport tensorflow as tf, tensorflow_probability as tfp\r\nprint(tf.__version__, tfp.__version__)\r\n\r\ndef _log_prob(fn):\r\n def _lp(x):\r\n x = tf.convert_to_tensor(x, name='x')\r\n distribution_log_probs = [x for i in range(5)]\r\n cat_log_probs = [x for i in range(5)]\r\n final_log_probs = [\r\n cat_lp + d_lp\r\n for (cat_lp, d_lp) in zip(cat_log_probs, distribution_log_probs)\r\n ]\r\n concat_log_probs = tf.stack(final_log_probs, 0)\r\n log_sum = fn(concat_log_probs, axis=[0])\r\n # log_sum = tf.reduce_sum(concat_log_probs, axis=[0])\r\n assert log_sum.shape.is_fully_defined()\r\n return log_sum\r\n return _lp\r\n\r\n@tf.function(autograph=False)\r\ndef f(fn):\r\n log_prob = tf.vectorized_map(_log_prob(fn), tf.ones((1,5)))\r\n print(fn, 'log_prob.shape = ', log_prob.shape) # prints (None, 5) for `tf.reduce_logsumexp` and (1, 5) for `tf.reduce_sum`\r\n\r\nfor fn in tf.reduce_sum, tf.reduce_logsumexp:\r\n f(fn)\r\n```\r\n=>\r\n```\r\n2.2.0-dev20200316 0.10.0-dev20200316\r\n<function reduce_sum at 0x7f7d850b2400> log_prob.shape = (1, 5)\r\n<function reduce_logsumexp at 0x7f7d850b6c80> log_prob.shape = (None, 5)\r\n```",
"created_at": "2020-03-16T18:32:35Z"
},
{
"body": "@brianwa84 the issue was fixed before and merged: #35162 (it was built in one of the nightly builds), but then the commit was reverted due to the forward compatibility issues. I'm still not aware how the commit was breaking the forward compatibility, so that what I was asking above.",
"created_at": "2020-03-19T22:34:05Z"
},
{
"body": "@rrkarim \r\nI ran the code on tf-nightly(2.4.0-dev20200811) ,please find the [gist here](https://colab.research.google.com/gist/Saduf2019/893f242891da72b30927815e155518b4/untitled359.ipynb) and [here](https://colab.research.google.com/gist/Saduf2019/4e4daa12e3b9b53c47c246bec5a4f33e/untitled359.ipynb).",
"created_at": "2020-08-11T18:21:21Z"
},
{
"body": "@Saduf2019 yeap, recently our PR also passed the tests so yeah (related to the inconsistency with shapes), so yeah I'm closing the issue. Thank you.",
"created_at": "2020-08-11T23:59:37Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35099\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35099\">No</a>\n",
"created_at": "2020-08-11T23:59:44Z"
}
],
"number": 35099,
"title": "Inconsistency with the shapes for `reduce_sum` and `reduce_logsumexp` for vectorized_map in graph mode"
}
|
{
"body": "Also adds docs for `select_v2` (maybe could be removed from PR since not relevant)\r\naddr: #35099",
"number": 35162,
"review_comments": [
{
"body": "This is a generated file; don't edit generated files.\r\n\r\nI believe this is generated from the api_def file for selectv2",
"created_at": "2019-12-17T16:34:42Z"
},
{
"body": "Why is the whole body inlined here instead of calling the non-deprecated version?",
"created_at": "2019-12-17T16:35:16Z"
},
{
"body": "Really sorry for that, was thinking it was the only solution (or helper function) yesterday at 4am. Fixing now. ",
"created_at": "2019-12-17T17:30:19Z"
},
{
"body": "I guess I don't really understand the semantics of the ops definitions, particularly the `endpoint` part. Guess it is not the critical part for now. If you could explain it, I can add it in PR too. Sorry for my lack of knowledge of the code base.",
"created_at": "2019-12-17T17:46:25Z"
}
],
"title": "Fixes issues with shape of output for `reduce_logsumexp` in graph mode"
}
|
{
"commits": [
{
"message": "quick fix for reduce_logsumexp in v2"
},
{
"message": "quick fix for reduce_logsumexp in tf2"
},
{
"message": "quick fix for reduce_logsumexp in tf2"
},
{
"message": "quick fix for reduce_logsumexp in tf2"
},
{
"message": "correct docs"
},
{
"message": "fix docs"
},
{
"message": "remove repetition"
},
{
"message": "remove docs for selectv2"
},
{
"message": "Merge branch 'master' into master"
}
],
"files": [
{
"diff": "@@ -2621,7 +2621,7 @@ def reduce_logsumexp(input_tensor, axis=None, keepdims=False, name=None):\n raw_max = reduce_max_with_dims(\n input_tensor, axis=axis, keepdims=True, dims=reduce_dim)\n my_max = array_ops.stop_gradient(\n- gen_math_ops.select(\n+ gen_math_ops.select_v2(\n gen_math_ops.is_finite(raw_max), raw_max,\n gen_array_ops.zeros_like(raw_max)))\n result = gen_math_ops.log(\n@@ -3366,6 +3366,7 @@ def cumsum(x, axis=0, exclusive=False, reverse=False, name=None):\n <tf.Tensor: shape=(4,), dtype=int32,\n numpy=array([ 2, 6, 12, 20], dtype=int32)>\n \n+\n >>> # using varying `axis` values\n >>> y = tf.constant([[2, 4, 6, 8], [1,3,5,7]])\n >>> tf.cumsum(y, axis=0)",
"filename": "tensorflow/python/ops/math_ops.py",
"status": "modified"
}
]
}
|
{
"body": "@tensorflow/micro\r\n\r\n**System information**\r\n- Host OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- TensorFlow installed from (source or binary): source\r\n- Tensorflow version (commit SHA if source): e12ba3de80d9315b7174037081adb482689bc6d6\r\n- Target platform (e.g. Arm Mbed OS, Arduino Nano 33 etc.): All\r\n\r\n**Describe the problem**\r\nThe feature provider accumulates feature slices using the input tensor in the arena as a buffer.\r\nHowever the lifetime of the input buffer is only the first operation of the model.\r\nAs such the feature buffer may be overwritten when the memory is reused for tensors with different lifetimes.\r\nThis is the case with the current model and the current greedy memory planner.\r\nAs only the front of the feature buffer is currently overwritten - and the front feature slice is never reused this does not currently impact the example. \r\nHowever using the example as a base of more complex models would trigger this problem.\r\n\r\nI will submit a PR to add a buffer to the feature provider.\r\nAlternatively the model could be changed to pass the input through to the output. (To keep the tensor alive) \r\n\r\n**Please provide the exact sequence of commands/steps when you ran into the problem**\r\nCode review\r\n",
"comments": [
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35117\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35117\">No</a>\n",
"created_at": "2020-02-04T09:48:55Z"
}
],
"number": 35117,
"title": "lite/micro: micro_speech example: input tensor lifetime assumption invalid"
}
|
{
"body": "This fixes #35117\r\n\r\nAccumulate feature slices in separate buffer.\r\nThe input tensor is not suitable for keeping state across interference\r\nas it has limited lifetime and the buffer space may be reused.",
"number": 35125,
"review_comments": [],
"title": "lite/micro: Add feature buffer to micro_speech example."
}
|
{
"commits": [
{
"message": "lite/micro: Add feature buffer to micro_speech example.\n\nThis fixes #35117\n\nAccumulate feature slices in separate buffer.\nThe input tensor is not suitable for keeping state across interference\nas it has limited lifetime and the buffer space may be reused."
}
],
"files": [
{
"diff": "@@ -43,6 +43,8 @@ int32_t previous_time = 0;\n // determined by experimentation.\n constexpr int kTensorArenaSize = 10 * 1024;\n uint8_t tensor_arena[kTensorArenaSize];\n+uint8_t feature_buffer[kFeatureElementCount];\n+uint8_t* model_input_buffer = nullptr;\n } // namespace\n \n // The name of this function is important for Arduino compatibility.\n@@ -104,12 +106,13 @@ void setup() {\n error_reporter->Report(\"Bad input tensor parameters in model\");\n return;\n }\n+ model_input_buffer = model_input->data.uint8;\n \n // Prepare to access the audio spectrograms from a microphone or other source\n // that will provide the inputs to the neural network.\n // NOLINTNEXTLINE(runtime-global-variables)\n static FeatureProvider static_feature_provider(kFeatureElementCount,\n- model_input->data.uint8);\n+ feature_buffer);\n feature_provider = &static_feature_provider;\n \n static RecognizeCommands static_recognizer(error_reporter);\n@@ -136,6 +139,11 @@ void loop() {\n return;\n }\n \n+ // Copy feature buffer to input tensor\n+ for(int i = 0; i < kFeatureElementCount; i++) {\n+ model_input_buffer[i] = feature_buffer[i];\n+ }\n+\n // Run the model on the spectrogram input and make sure it succeeds.\n TfLiteStatus invoke_status = interpreter->Invoke();\n if (invoke_status != kTfLiteOk) {",
"filename": "tensorflow/lite/micro/examples/micro_speech/main_functions.cc",
"status": "modified"
}
]
}
|
{
"body": "@tensorflow/micro\r\n\r\n**System information**\r\n- Host OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- TensorFlow installed from (source or binary): source\r\n- Tensorflow version (commit SHA if source): e12ba3de80d9315b7174037081adb482689bc6d6\r\n- Target platform (e.g. Arm Mbed OS, Arduino Nano 33 etc.): all\r\n\r\n**Describe the problem**\r\n The tensor lifetime may be incorrectly calculated in MicroAllocator::FinishTensorAllocation() if the same sensor is used multiple times as inputs to different operations or is used as input/output or variable of the graph.\r\n\r\nThe relevant code section:\r\n```c\r\n // Figure out when the first and last use of each tensor is.\r\n for (int i = (operators_->size() - 1); i >= 0; --i) {\r\n const auto* op = operators_->Get(i);\r\n for (size_t n = 0; n < op->inputs()->size(); ++n) {\r\n const int tensor_index = op->inputs()->Get(n);\r\n TensorInfo* current = &tensor_info[tensor_index];\r\n if ((current->last_used == -1) || (current->last_used > i)) {\r\n current->last_used = i;\r\n }\r\n }\r\n for (size_t n = 0; n < op->outputs()->size(); ++n) {\r\n const int tensor_index = op->outputs()->Get(n);\r\n TensorInfo* current = &tensor_info[tensor_index];\r\n if ((current->first_created == -1) || (current->first_created < i)) {\r\n current->first_created = i;\r\n }\r\n }\r\n }\r\n```\r\nLooks just like the condition to update a valid lifetime is accidentally inverted.\r\nWill verify and submit PR\r\n\r\n**Please provide the exact sequence of commands/steps when you ran into the problem**\r\nCode review\r\n",
"comments": [
{
"body": "Resolved by #35123",
"created_at": "2020-02-12T17:16:19Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35121\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/35121\">No</a>\n",
"created_at": "2020-02-12T17:16:21Z"
}
],
"number": 35121,
"title": "lite/micro: Tensor lifetime incorrectly calculated on multiple use"
}
|
{
"body": "Fix for issue #35121\r\n\r\nThe tensor lifetime may be incorrectly calculated in MicroAllocator::FinishTensorAllocation() if the same sensor is used multiple times as inputs to different operations or is used as input/output or variable of the graph.",
"number": 35123,
"review_comments": [],
"title": "lite/micro: Fix bug in tensor lifetime calculation."
}
|
{
"commits": [
{
"message": "lite/micro: Fix bug in tensor lifetime calculation.\n\nFix for issue #35121\n\nTesting:\nAdd a second operation to the MockModel sharing inputs with the first\noperation to catch #35121 (Tensor lifetime incorrectly calculated on\nmultiple use) and verify the fix."
}
],
"files": [
{
"diff": "@@ -140,14 +140,14 @@ AllocationInfo* AllocateAndCalculateAllocationInfo(\n for (size_t n = 0; n < op->inputs()->size(); ++n) {\n const int tensor_index = op->inputs()->Get(n);\n AllocationInfo* current = &allocation_info[tensor_index];\n- if (((current->last_used == -1) || (current->last_used > i))) {\n+ if (((current->last_used == -1) || (current->last_used < i))) {\n current->last_used = i;\n }\n }\n for (size_t n = 0; n < op->outputs()->size(); ++n) {\n const int tensor_index = op->outputs()->Get(n);\n AllocationInfo* current = &allocation_info[tensor_index];\n- if ((current->first_created == -1) || (current->first_created < i)) {\n+ if ((current->first_created == -1) || (current->first_created > i)) {\n current->first_created = i;\n }\n }",
"filename": "tensorflow/lite/micro/micro_allocator.cc",
"status": "modified"
},
{
"diff": "@@ -143,7 +143,7 @@ TF_LITE_MICRO_TEST(TestFinishTensorAllocation) {\n uint8_t arena[arena_size];\n tflite::MicroAllocator allocator(&context, model, arena, arena_size,\n micro_test::reporter);\n- TF_LITE_MICRO_EXPECT_EQ(3, context.tensors_size);\n+ TF_LITE_MICRO_EXPECT_EQ(4, context.tensors_size);\n \n TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, allocator.FinishTensorAllocation());\n // No allocation to be done afterwards.\n@@ -153,13 +153,20 @@ TF_LITE_MICRO_TEST(TestFinishTensorAllocation) {\n tflite::testing::VerifyMockTensor(&context.tensors[0]);\n tflite::testing::VerifyMockWeightTensor(&context.tensors[1]);\n tflite::testing::VerifyMockTensor(&context.tensors[2]);\n+ tflite::testing::VerifyMockTensor(&context.tensors[3]);\n \n TF_LITE_MICRO_EXPECT_NE(context.tensors[1].data.raw,\n context.tensors[0].data.raw);\n TF_LITE_MICRO_EXPECT_NE(context.tensors[2].data.raw,\n context.tensors[0].data.raw);\n TF_LITE_MICRO_EXPECT_NE(context.tensors[1].data.raw,\n context.tensors[2].data.raw);\n+ TF_LITE_MICRO_EXPECT_NE(context.tensors[3].data.raw,\n+ context.tensors[0].data.raw);\n+ TF_LITE_MICRO_EXPECT_NE(context.tensors[3].data.raw,\n+ context.tensors[1].data.raw);\n+ TF_LITE_MICRO_EXPECT_NE(context.tensors[3].data.raw,\n+ context.tensors[2].data.raw);\n }\n \n TF_LITE_MICRO_TEST(TestFinishComplexTensorAllocation) {",
"filename": "tensorflow/lite/micro/micro_allocator_test.cc",
"status": "modified"
},
{
"diff": "@@ -46,6 +46,7 @@ TfLiteStatus MockInvoke(TfLiteContext* context, TfLiteNode* node) {\n const uint8_t* weight_data = weight->data.uint8;\n TfLiteTensor* output = &context->tensors[node->outputs->data[0]];\n int32_t* output_data = output->data.i32;\n+ output_data[0] = 0; // Catch output tensor sharing memory with an input tensor\n output_data[0] = input_data[0] + weight_data[0];\n return kTfLiteOk;\n }\n@@ -83,7 +84,7 @@ TF_LITE_MICRO_TEST(TestInterpreter) {\n micro_test::reporter);\n TF_LITE_MICRO_EXPECT_EQ(interpreter.AllocateTensors(), kTfLiteOk);\n TF_LITE_MICRO_EXPECT_EQ(1, interpreter.inputs_size());\n- TF_LITE_MICRO_EXPECT_EQ(1, interpreter.outputs_size());\n+ TF_LITE_MICRO_EXPECT_EQ(2, interpreter.outputs_size());\n \n TfLiteTensor* input = interpreter.input(0);\n TF_LITE_MICRO_EXPECT_NE(nullptr, input);\n@@ -105,6 +106,15 @@ TF_LITE_MICRO_TEST(TestInterpreter) {\n TF_LITE_MICRO_EXPECT_NE(nullptr, output->data.i32);\n TF_LITE_MICRO_EXPECT_EQ(42, output->data.i32[0]);\n \n+ output = interpreter.output(1);\n+ TF_LITE_MICRO_EXPECT_NE(nullptr, output);\n+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, output->type);\n+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->size);\n+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[0]);\n+ TF_LITE_MICRO_EXPECT_EQ(4, output->bytes);\n+ TF_LITE_MICRO_EXPECT_NE(nullptr, output->data.i32);\n+ TF_LITE_MICRO_EXPECT_EQ(42, output->data.i32[0]);\n+\n // Just to make sure that this method works.\n tflite::PrintInterpreterState(&interpreter);\n }",
"filename": "tensorflow/lite/micro/micro_interpreter_test.cc",
"status": "modified"
},
{
"diff": "@@ -76,7 +76,7 @@ const Model* BuildSimpleMockModel() {\n builder->CreateVector(buffer_data, buffer_data_size))};\n constexpr size_t tensor_shape_size = 1;\n const int32_t tensor_shape[tensor_shape_size] = {1};\n- constexpr size_t tensors_size = 3;\n+ constexpr size_t tensors_size = 4;\n const Offset<Tensor> tensors[tensors_size] = {\n CreateTensor(*builder,\n builder->CreateVector(tensor_shape, tensor_shape_size),\n@@ -90,20 +90,36 @@ const Model* BuildSimpleMockModel() {\n builder->CreateVector(tensor_shape, tensor_shape_size),\n TensorType_INT32, 0,\n builder->CreateString(\"test_output_tensor\"), 0, false),\n+ CreateTensor(*builder,\n+ builder->CreateVector(tensor_shape, tensor_shape_size),\n+ TensorType_INT32, 0,\n+ builder->CreateString(\"test_output2_tensor\"), 0, false),\n };\n constexpr size_t inputs_size = 1;\n const int32_t inputs[inputs_size] = {0};\n- constexpr size_t outputs_size = 1;\n- const int32_t outputs[outputs_size] = {2};\n+ constexpr size_t outputs_size = 2;\n+ const int32_t outputs[outputs_size] = {2, 3};\n constexpr size_t operator_inputs_size = 2;\n const int32_t operator_inputs[operator_inputs_size] = {0, 1};\n constexpr size_t operator_outputs_size = 1;\n const int32_t operator_outputs[operator_outputs_size] = {2};\n- constexpr size_t operators_size = 1;\n- const Offset<Operator> operators[operators_size] = {CreateOperator(\n- *builder, 0, builder->CreateVector(operator_inputs, operator_inputs_size),\n- builder->CreateVector(operator_outputs, operator_outputs_size),\n- BuiltinOptions_NONE)};\n+ const int32_t operator2_outputs[operator_outputs_size] = {3};\n+ constexpr size_t operators_size = 2;\n+ const Offset<Operator> operators[operators_size] = {\n+ CreateOperator(*builder, 0,\n+\t\t builder->CreateVector(operator_inputs,\n+\t\t\t\t\t operator_inputs_size),\n+\t\t builder->CreateVector(operator_outputs,\n+\t\t\t\t\t operator_outputs_size),\n+\t\t BuiltinOptions_NONE),\n+ CreateOperator(\n+\t\t *builder, 0,\n+\t\t builder->CreateVector(operator_inputs,\n+\t\t\t\t\t operator_inputs_size),\n+\t\t builder->CreateVector(operator2_outputs,\n+\t\t\t\t\t operator_outputs_size),\n+\t\t BuiltinOptions_NONE),\n+ };\n constexpr size_t subgraphs_size = 1;\n const Offset<SubGraph> subgraphs[subgraphs_size] = {\n CreateSubGraph(*builder, builder->CreateVector(tensors, tensors_size),",
"filename": "tensorflow/lite/micro/test_helpers.cc",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): macOS\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.0.0, 2.1-nightly\r\n- Python version: 3.7\r\n\r\n**Describe the current behavior**\r\n\r\n`AutoCastVariable` variable forwards `assign` and `scatter` to the underlying `float32` variable:\r\nhttps://github.com/tensorflow/tensorflow/blob/cee2a43b8184e92ba26ec0e3d6e00a3f8ca6e3c8/tensorflow/python/keras/mixed_precision/experimental/autocast_variable.py#L187-L188\r\nThus, the return value of `assign` methods with `read_value=True` is a normal `tf.Variable` and not an `AutoCastVariable`. This means that calculations directly depending on the assign operation, might run in `float32` instead of `float16`, or am I missing something?\r\n\r\n**Describe the expected behavior**\r\n`AutoCastVariable.assign*` should return an `AutoCastVariable` variable instead `tf.Variable` so that the `dtype` is preserved.\r\n\r\n@reedwm Is this intended behaviour?\r\n\r\n**Code to reproduce the issue**\r\n```python\r\nimport tensorflow as tf\r\nfrom tensorflow.python.keras.mixed_precision.experimental import autocast_variable\r\n\r\nvar = tf.Variable(0., dtype=tf.float32)\r\nvar = autocast_variable.AutoCastVariable(var)\r\n\r\nwith tf.compat.v1.get_default_graph()._enable_auto_casting_variables(tf.float16):\r\n assert var.dtype == tf.float16\r\n # assign should return an AutoCastVariable but returns tf.Variable\r\n var_assign = var.assign(5.)\r\n assert not isinstance(var_assign, autocast_variable.AutoCastVariable)\r\n assert var_assign.dtype == tf.float32\r\n```",
"comments": [
{
"body": "I have tried on colab with TF version 2.0 ,2.1.0-dev20191111 and was able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/4f70bc0621bc1d362ed8d465b7cb054a/untitled377.ipynb). Thanks!",
"created_at": "2019-11-18T09:05:06Z"
},
{
"body": "The current behavior was intended, but on second thought, I think you are right and that this behavior is incorrect. I previously incorrectly believed `Variable.assign` returned a tensor, not a Variable, and wanted the returned tensor to have the same dtype as the input tensor (float32).\r\n\r\nLuckily, this issue occurs relatively rarely. AutoCastVariables act identically to Variables outside `Layer.call`, and inside `Layer.call`, variables are rarely assigned to. Still, the current behavior is very confusing and so this should be fixed.\r\n\r\n@alextp, do you know what the purpose of the [`_UnreadVariable`](https://github.com/tensorflow/tensorflow/blob/2692ea8ec1953e42952597adb5b5099181a679b2/tensorflow/python/ops/resource_variable_ops.py#L1806) is, which is returned from [`ResourceVariable.assign`](https://github.com/tensorflow/tensorflow/blob/2692ea8ec1953e42952597adb5b5099181a679b2/tensorflow/python/ops/resource_variable_ops.py#L799)? Why not simply return the ResourceVariable? Do you think I should I create a `_UnreadAutoCastVariable` subclass?",
"created_at": "2019-11-19T01:38:39Z"
},
{
"body": "@reedwm Thanks for taking a look.\r\n\r\nThe reason why I am looking deeper at the implementation of `AutoCastVariable` is because we are in the process of subclassing `tf.Variable` in https://github.com/larq/larq/issues/306 with the goal to have a `QuantizedVariable` that can be used to define arbitrary fake quantizations like binary or ternary quantization which would allow easy research on extreme quantization. For this we are looking closely at the implementation of `AutoCastVariable`.\r\n\r\n@reedwm @alextp Do you think it makes sense to have a more formalized way to easily subclass `tf.Variable` or `tf.Tensor` in userland? It seams this already happens in a few places (e.g. `AutoCastVariable` or #34379) and would allow quite powerful use cases.",
"created_at": "2019-11-19T11:20:24Z"
},
{
"body": "@reedwm the purpose of `_UnreadVariable` is allowing code like `x = tf.assign_add(x, foo); x = tf.assign_add(x, bar)` which was possible with ref variables and so to ease the transition to resource variables I made `_UnreadVariable`\r\n\r\n@lgeiger I'm with you, I really don't like how complex variables are right now. I think if you control the variable creation site I recommend instead of subclassing variable you implement a tf.Module which implements the variable interface and has a tf.register_tensor_conversion_function for itself (so it can be implicitly cast to a tensor). If you cannot control the variable creation site I mostly recommend the same thing but you might want to use a variable_creation_scope to intercept variable creation and return your custom class. Just make sure to use the underlying creator when creating the variables inside your fake-variable.\r\n\r\nRe subclassing tensors, the answer is an emphatic no. We need to have Tensor be a C type (at least in eager mode) for performance in many places, as eventually tensors will have to be passed to kernels.",
"created_at": "2019-11-19T16:51:26Z"
},
{
"body": "> The reason why I am looking deeper at the implementation of AutoCastVariable is because we are in the process of subclassing tf.Variable in larq/larq#306\r\n\r\nI think having an implementation similar to `AutoCastVariable` is the way to go. I agree it would be nice to have a more formalized way to subclass `tf.Variable` but it currently doesn't exist unfortunately.\r\n\r\n> I think if you control the variable creation site I recommend instead of subclassing variable you implement a tf.Module\r\n\r\n@alextp, I would still recommend subclassing tf.Variable. I used to subclass Trackable, but I switched to tf.Variable in 74c52531846cc10a63fb244966ab6bfd000af747 as many parts of the code have isinstance checks on tf.Variable. DistributedVariable also subclasses Variable for a similar reason. And tf.Module has some extraneous properties that don't make a lot of sense on a Variable, such as `Module.trainable_variables`.\r\n\r\n> the purpose of _UnreadVariable is allowing code like x = tf.assign_add(x, foo); x = tf.assign_add(x, bar) \r\n\r\nAh I see, returning an `_UnreadVariable` instead of `self` allows this to properly work with Sessions and Graphs, which don't have automatic control dependencies. Otherwise, if `self` is returned, the variable assignment might not run.\r\n\r\nI could fix this by copying or subclassing `_UnreadVariable`. I could also just return `self`, which has slightly incorrect semantics when Sessions/Graphs are used with `tf.compat.v1`. I'll try to think of a better solution, especially considering QuantizedVariable will have the same issue. I'm pretty sure DistributedVariables also has this issue.\r\n\r\n",
"created_at": "2019-11-19T21:35:16Z"
},
{
"body": "Thanks a lot for the insights. It would be cool if we could come up with a simple solution for this.",
"created_at": "2019-11-23T11:18:27Z"
},
{
"body": "> I could fix this by copying or subclassing `_UnreadVariable`. I could also just return `self`, which has slightly incorrect semantics when Sessions/Graphs are used with `tf.compat.v1`\r\n\r\n@reedwm Since `AutoCastVariable` just wraps an other variable, what about returning a new instance wrapping the `_UnreadVariable` returned by the assign op. Would something like the following work?\r\n```python\r\ndef assign(self, value, use_locking=None, name=None, read_value=True):\r\n assign_op_or_var = self._variable.assign(value, use_locking, name, read_value)\r\n return self.__class__(assign_op_or_var) if read_value else assign_op_or_var\r\n# return AutoCastVariable(assign_op_or_var) if read_value else assign_op_or_var\r\n```",
"created_at": "2019-11-29T21:09:04Z"
},
{
"body": "I think that would work, and is very simple. I didn't think of that before. Thanks for the suggestion!\r\n\r\nDo you want to implement it for AutoCastVariable? If not, I'd be happy to.",
"created_at": "2019-12-02T20:53:31Z"
},
{
"body": "> I think that would work, and is very simple.\r\n\r\nGreat!\r\n\r\n> Do you want to implement it for AutoCastVariable? If not, I'd be happy to.\r\n\r\n:+1: Will send a PR and add some tests once TensorFlow finishes compiling on my machine.",
"created_at": "2019-12-02T21:28:12Z"
},
{
"body": "I opened a small PR: #34779",
"created_at": "2019-12-03T02:10:10Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34332\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34332\">No</a>\n",
"created_at": "2019-12-05T23:46:01Z"
},
{
"body": "#34779 doesn't fully close this issue since Distribution Strategy is not fully supported yet (see https://github.com/tensorflow/tensorflow/pull/34779#discussion_r353481035)",
"created_at": "2019-12-06T00:11:59Z"
},
{
"body": "You're right, reopening.\r\n\r\nOnce Distribution Strategy returns a variable from `DistributionVariable.assign`, this issue can be fixed.",
"created_at": "2019-12-06T00:13:36Z"
},
{
"body": ":+1: Thanks for the help with debugging",
"created_at": "2019-12-06T00:16:45Z"
},
{
"body": "@lgeiger Is this still an issue? Can you please check with `tf-nightly` and let us know. Thanks!",
"created_at": "2020-03-16T20:35:23Z"
},
{
"body": "This is still an issue. The `tf.distribute.Strategy` team is working on a way to return a variable from `DistributionVariable.assign` and until then, this issue cannot be fully fixed.",
"created_at": "2020-03-16T21:18:24Z"
},
{
"body": "@jvishnuvardhan Sorry for the late response. Indeed this is still an issue in the latest nightly. Here is an updated code example for the distribution case:\r\n```python\r\nimport tensorflow as tf\r\nfrom tensorflow.python.keras.mixed_precision.experimental import autocast_variable\r\nfrom tensorflow.python.distribute import strategy_combinations\r\n\r\nstrategy_combinations.set_virtual_cpus_to_at_least(3)\r\nwith tf.distribute.MirroredStrategy(['/cpu:1', '/cpu:2']).scope():\r\n var = tf.Variable(0., dtype=tf.float32)\r\n var = autocast_variable.AutoCastVariable(var)\r\n\r\n with tf.compat.v1.get_default_graph()._enable_auto_casting_variables(tf.float16):\r\n assert var.dtype == tf.float16\r\n # assign should return an AutoCastVariable but returns tf.Variable\r\n var_assign = var.assign(5.)\r\n assert not isinstance(var_assign, autocast_variable.AutoCastVariable)\r\n assert var_assign.dtype == tf.float32\r\n```",
"created_at": "2020-04-22T23:23:17Z"
},
{
"body": "Can we close this?",
"created_at": "2021-05-27T22:52:25Z"
},
{
"body": "> Can we close this?\r\n\r\nThis is still an issue in the latest nightly, but now only shows up in non eager mode. Before this happened in both execution contexts. Here is some updated code that reproduces the failure with the new API:\r\n```python\r\nimport tensorflow as tf\r\nfrom tensorflow.python.keras.mixed_precision import autocast_variable\r\nfrom tensorflow.python.distribute import strategy_combinations\r\ntf.compat.v1.disable_eager_execution()\r\n\r\nstrategy_combinations.set_virtual_cpus_to_at_least(3)\r\nwith tf.distribute.MirroredStrategy(['/cpu:1', '/cpu:2']).scope():\r\n var = tf.Variable(0., dtype=tf.float32)\r\n var = autocast_variable.AutoCastVariable(var)\r\n with autocast_variable.enable_auto_cast_variables(tf.float16):\r\n assert tf.identity(var).dtype == tf.float16\r\n # assign should return an AutoCastVariable but returns tf.Variable\r\n var_assign = var.assign(5.)\r\n assert isinstance(var_assign, autocast_variable.AutoCastVariable)\r\n assert tf.identity(var).dtype == tf.float16\r\n```\r\n ",
"created_at": "2021-05-28T10:02:34Z"
},
{
"body": "@lgeiger Do you think that you could add this with a minimal refactoring as a [DISABLED test](https://github.com/google/googletest/blob/master/docs/advanced.md#temporarily-disabling-tests)?",
"created_at": "2021-05-28T12:54:15Z"
},
{
"body": "> Do you think that you could add this with a minimal refactoring as a DISABLED test?\r\n\r\n@bhack These cases are already covered in [`tensorflow/python/keras/mixed_precision/autocast_variable_test.py`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/mixed_precision/autocast_variable_test.py).\r\n\r\nIn fact I just opened #49856 earlier today to enable the distribution strategy tests in eager mode which have been fixed.",
"created_at": "2021-05-28T13:23:31Z"
},
{
"body": "What I mean is that if we have DISABLED tests referencing specific tickets we could regularly check what is \"still not\" working as we expected and running the CI with an extra step on DISABLED tests (or any other semantic filter we want to use). \r\n\r\nIn this way we could see if the behavior is changed or if it solved when the specific test is failing. \r\nIn that case we could comment again or close the related ticket.\r\n\r\nSo in DISABLED tests we assert the BUG not the correct behavior.\r\n\r\nE.g. In this way we could have covered the evolution of this bug since 2019.\r\n\r\nThis is just an idea cause we currently don't run specific DISABLED tests (or any special test filter semantics) in the CI. \r\n\r\n/cc @mihaimaruseac @reedwm \r\n",
"created_at": "2021-05-28T13:42:40Z"
},
{
"body": "This is a good idea, but I personally don't think it's worth the infrastructure complexity of running DISABLED tests to check whether a bug is fixed. Typically if a bug is fixed, someone will write a corresponding unit test. This bug is an exception, but even so, it was not fully fixed (it still doesn't work with distribution strategies in graph mode).",
"created_at": "2021-06-02T20:58:34Z"
},
{
"body": "@reedwm I have an initial draft proposal about this internally, please ping me if you are interested.\r\n\r\n> Typically if a bug is fixed, someone will write a corresponding unit test.\r\n\r\nBut we still have some good side effects with DISABLED tests. \r\n\r\nJust to mention a few of these:\r\n\r\n- Improved triage. We will have a good proxy of the final test (the one when \"a bug is fixed, someone will write a corresponding unit test\")\r\n- We have for sure a more isolated code gist to reproduce the bug specially over the time axis (some tickets stay open for months, years).\r\n- We don't need to periodically ping and review all the old tickets about reproducibility with master or with last release often with an not so isolated gist or without the original submitter/subscribers availability.\r\n- We could run this on tf-nightly wheels without compiling TF.\r\n- If we exclude some complex env we could run these test on Github Action directly or on Self-hosted Github Action runners.",
"created_at": "2021-06-02T22:04:33Z"
},
{
"body": "Hi There,\r\n\r\n This is a stale issue. As you are using an older version of tensorflow, we are checking to see if you still need help on this issue. Please test the issue with the latest TensorFlow (TF2.7 and tf-nightly). If the issue still persists with the newer versions of TF, please feel free to open it in [keras-team/keras](https://github.com/keras-team/keras/issues) repository by providing details about the issue and a standalone code to reproduce the issue. Thanks! \r\n\r\n Please note that Keras development has moved to a separate Keras-team/keras repository to focus entirely on only Keras. Thanks! ",
"created_at": "2021-12-14T23:27:10Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34332\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34332\">No</a>\n",
"created_at": "2022-01-11T17:48:57Z"
}
],
"number": 34332,
"title": "AutoCastVariable.assign returns wrapped variable instead of casted version"
}
|
{
"body": "Assignments and sparse updates will now return a new instance of `AutoCastVariable`, wrapping the [`_UnreadVariable`](https://github.com/tensorflow/tensorflow/blob/2692ea8ec1953e42952597adb5b5099181a679b2/tensorflow/python/ops/resource_variable_ops.py#L1806) returned from the assignment op, so that the `dtype` is preserved.\r\n\r\nCloses #34332\r\n\r\n/cc @reedwm @alextp",
"number": 34779,
"review_comments": [
{
"body": "I don't think it is great to call `create_autocast_variable()` here, but `self.__class__()`, `AutoCastVariable()` or `super(AutoCastVariable, self).__init__()` would not work for distributed variables since either inheritance is wrong or since `__init__()` would expect different arguments.",
"created_at": "2019-12-03T02:08:07Z"
},
{
"body": "I think subclasses just have to override this. We shouldn't enforce a contract on how to initialize subclasses.",
"created_at": "2019-12-03T19:36:26Z"
},
{
"body": "I agree. Thinking about this again, it is not too bad after all :+1:",
"created_at": "2019-12-03T20:24:53Z"
},
{
"body": "This will fail with DistributionStrategy with at least two devices. The issue is that `MirroredVariable.assign` will (incorrectly) return a `Mirrored` value instead of a `MirroredVariable`. Following the logic, I think MirroredVariable eventually returns a `Mirrored` [here](https://github.com/tensorflow/tensorflow/blob/147de48ad973a6a05e8113af815988014652caf2/tensorflow/python/distribute/values.py#L1637). I'm guessing that with one device, it simply will return a normal non-mirrored variable.\r\n\r\nTo reproduce, on [this line](https://github.com/tensorflow/tensorflow/blob/147de48ad973a6a05e8113af815988014652caf2/tensorflow/python/keras/mixed_precision/experimental/autocast_variable_test.py#L64), change `['cpu:0']` to `['cpu:0', 'gpu:0']`. Since you do not have a GPU, also add the following two lines to the top of the file:\r\n\r\n```\r\nfrom tensorflow.python.framework import config\r\nconfig.set_soft_device_placement(True)\r\n```\r\n\r\nUnfortunately, soft placement seems to be broken in Eager mode (I'll ask internally to get this resolved), but the graph test is running first so you'll be able to reproduce the issue. If you can get it to pass in graph mode, chances are it will pass in eager.\r\n\r\nI can't think of an elegant way of fixing this, unfortunately. I think for now, you should simply return `assign_op` if it is `Mirrored` (or perhaps if `not resource_variable_ops.is_resource_variable(assign_op)`). This means #34332 won't be fixed in the distributed case for now, but that can be addressed later. Let me know if you can think of a better solution. \r\n\r\nIn the long term, we can fix this by having DistributionStrategy return a MirroredVariable instead of Mirrored from MirroredVariable.assign(). @guptapriya can you work on that?",
"created_at": "2019-12-03T23:39:58Z"
},
{
"body": "You should also test that you can assign the return value of `x.assign(8)`. And that if you pass `read_value=False`, the return value is an Operation or None instead of a variable.\r\n\r\nI would move the `assign`, `assign_add`, and `assign_sub` calls to a new test method as well.",
"created_at": "2019-12-03T23:41:39Z"
},
{
"body": ":+1: I added the tests in c87a0e20d31cccd70a0f1c9687221b45066786fa",
"created_at": "2019-12-04T00:33:50Z"
},
{
"body": "I see, thanks for the help debugging this.\r\n\r\n> I can't think of an elegant way of fixing this, unfortunately.\r\n\r\nProbably a dumb question, but is there a reason why we cannot allow `AutoCastVariable` to also wrap `Mirrored` and loosen the `is_resource_variable` check?",
"created_at": "2019-12-04T01:11:09Z"
},
{
"body": "The issue is `AutoCastVariable` subclasses from `tf.Variable` so it doesn't make sense to wrap `Mirrored`. It also defines many assignment methods.\r\n\r\nWe could create a base class, say `AutoCastTensor`, that could wrap Mirrored. `AutoCastVariable` would then subclass `AutoCastTensor` and `tf.Variable`. But this introduces complexity that I'd rather avoid. Fixing this by having MirroredVariable.assign return a MirroredVariable is a better solution.",
"created_at": "2019-12-04T01:26:53Z"
},
{
"body": "Makes sense, thanks for the explanation. I made the changes in 78fbe39329aaf4645c2a308eb805e3661e397bd3 to only wrap it if `is_resource_variable(assign_op) is True`.",
"created_at": "2019-12-04T10:20:24Z"
},
{
"body": "Move these three lines to a shared function, named something like _maybe_wrap. Also add a comment or docstring why this is necessary.",
"created_at": "2019-12-05T03:09:00Z"
},
{
"body": "I would also have the logic to not wrap here as well. Even though DistributedVariables currently don't support these scatter methods, they may add it in the future.",
"created_at": "2019-12-05T03:12:17Z"
},
{
"body": "Good point. Made the changes in 109a41e4c324a0ebfb1206979f724d8116f916c1",
"created_at": "2019-12-05T18:25:45Z"
},
{
"body": "@reedwm are you saying var.assign(..) should return a variable? that's not what tf.Variable docs say though: https://www.tensorflow.org/api_docs/python/tf/Variable#assign",
"created_at": "2019-12-05T23:00:55Z"
}
],
"title": "Return new instance of AutoCastVariable after assignment"
}
|
{
"commits": [
{
"message": "Return new instance of AutoCastVariable after assignment\n\nAssignments and sparse updates will now return a new instance of `AutoCastVariable` wrapping the [`_UnreadVariable`](https://github.com/tensorflow/tensorflow/blob/2692ea8ec1953e42952597adb5b5099181a679b2/tensorflow/python/ops/resource_variable_ops.py#L1806) returned from the assignment op."
},
{
"message": "Test multiple assignment and read_value=False"
},
{
"message": "Only wrap assignment in AutoCastVariable if resource variable"
},
{
"message": "Add _maybe_wrap function to simplify wrapping of AutoCastVariable"
}
],
"files": [
{
"diff": "@@ -185,46 +185,60 @@ def constraint(self):\n return self._variable.constraint\n \n def assign(self, value, use_locking=None, name=None, read_value=True):\n- return self._variable.assign(value, use_locking, name, read_value)\n+ assign_op = self._variable.assign(value, use_locking, name, read_value)\n+ return _maybe_wrap(assign_op, wrap=read_value)\n \n def assign_add(self, delta, use_locking=None, name=None, read_value=True):\n- return self._variable.assign_add(delta, use_locking, name, read_value)\n+ assign_op = self._variable.assign_add(delta, use_locking, name, read_value)\n+ return _maybe_wrap(assign_op, wrap=read_value)\n \n def assign_sub(self, delta, use_locking=None, name=None, read_value=True):\n- return self._variable.assign_sub(delta, use_locking, name, read_value)\n+ assign_op = self._variable.assign_sub(delta, use_locking, name, read_value)\n+ return _maybe_wrap(assign_op, wrap=read_value)\n \n def scatter_sub(self, sparse_delta, use_locking=False, name=None):\n- return self._variable.scatter_sub(sparse_delta, use_locking, name)\n+ var = self._variable.scatter_sub(sparse_delta, use_locking, name)\n+ return _maybe_wrap(var)\n \n def scatter_add(self, sparse_delta, use_locking=False, name=None):\n- return self._variable.scatter_add(sparse_delta, use_locking, name)\n+ var = self._variable.scatter_add(sparse_delta, use_locking, name)\n+ return _maybe_wrap(var)\n \n def scatter_max(self, sparse_delta, use_locking=False, name=None):\n- return self._variable.scatter_max(sparse_delta, use_locking, name)\n+ var = self._variable.scatter_max(sparse_delta, use_locking, name)\n+ return _maybe_wrap(var)\n \n def scatter_min(self, sparse_delta, use_locking=False, name=None):\n- return self._variable.scatter_min(sparse_delta, use_locking, name)\n+ var = self._variable.scatter_min(sparse_delta, use_locking, name)\n+ return _maybe_wrap(var)\n \n def scatter_mul(self, sparse_delta, use_locking=False, name=None):\n- return self._variable.scatter_mul(sparse_delta, use_locking, name)\n+ var = self._variable.scatter_mul(sparse_delta, use_locking, name)\n+ return _maybe_wrap(var)\n \n def scatter_div(self, sparse_delta, use_locking=False, name=None):\n- return self._variable.scatter_div(sparse_delta, use_locking, name)\n+ var = self._variable.scatter_div(sparse_delta, use_locking, name)\n+ return _maybe_wrap(var)\n \n def scatter_update(self, sparse_delta, use_locking=False, name=None):\n- return self._variable.scatter_update(sparse_delta, use_locking, name)\n+ var = self._variable.scatter_update(sparse_delta, use_locking, name)\n+ return _maybe_wrap(var)\n \n def batch_scatter_update(self, sparse_delta, use_locking=False, name=None):\n- return self._variable.batch_scatter_update(sparse_delta, use_locking, name)\n+ var = self._variable.batch_scatter_update(sparse_delta, use_locking, name)\n+ return _maybe_wrap(var)\n \n def scatter_nd_sub(self, indices, updates, name=None):\n- return self._variable.scatter_nd_sub(indices, updates, name)\n+ var = self._variable.scatter_nd_sub(indices, updates, name)\n+ return _maybe_wrap(var)\n \n def scatter_nd_add(self, indices, updates, name=None):\n- return self._variable.scatter_nd_add(indices, updates, name)\n+ var = self._variable.scatter_nd_add(indices, updates, name)\n+ return _maybe_wrap(var)\n \n def scatter_nd_update(self, indices, updates, name=None):\n- return self._variable.scatter_nd_update(indices, updates, name)\n+ var = self._variable.scatter_nd_update(indices, updates, name)\n+ return _maybe_wrap(var)\n \n def load(self, value, session=None):\n return self._variable.load(value, session)\n@@ -410,3 +424,24 @@ def __repr__(self):\n # pylint: enable=missing-format-attribute\n \n return AutoCastDistributedVariable(variable)\n+\n+\n+def _maybe_wrap(variable, wrap=True):\n+ \"\"\"Creates an AutoCastVariable that wraps another variable if applicable.\n+\n+ This function is used to wrap the return value of AutoCastVariable.assign.\n+ Unfortunately MirroredVariable.assign will (incorrectly) return a Mirrored\n+ value instead of a MirroredVariable. So we cannot properly wrap it in an\n+ AutoCastVariable. We return the original variable in that case.\n+\n+ Args:\n+ variable: A tf.Variable or op.\n+ wrap: A boolean to define whether to wrap the variable in an\n+ AutoCastVariable or not.\n+\n+ Returns:\n+ An AutoCastVariable if wrap is True and variable is a resource variable.\n+ \"\"\"\n+ if wrap and resource_variable_ops.is_resource_variable(variable):\n+ return create_autocast_variable(variable)\n+ return variable",
"filename": "tensorflow/python/keras/mixed_precision/experimental/autocast_variable.py",
"status": "modified"
},
{
"diff": "@@ -157,25 +157,35 @@ def test_method_delegations(self, distribute):\n # Test AutoCastVariable correctly delegates Variable methods to the\n # underlying variable.\n with get_distribute_scope(distribute):\n- evaluate = self.evaluate\n for read_dtype in (dtypes.float32, dtypes.float16):\n+ if distribute:\n+ # MirroredVariable.assign will (incorrectly) return a Mirrored value\n+ # instead of a MirroredVariable. So we cannot properly wrap it in an\n+ # AutoCastVariable.\n+ evaluate = self.evaluate\n+ else:\n+ def evaluate(var):\n+ self.assertIsInstance(var, autocast_variable.AutoCastVariable)\n+ self.assertEqual(var.dtype, read_dtype)\n+ return self.evaluate(var)\n+\n x = get_var(7., dtypes.float32)\n x = autocast_variable.create_autocast_variable(x)\n with ops.get_default_graph()._enable_auto_casting_variables(\n read_dtype):\n- evaluate(x.initializer)\n- self.assertEqual(evaluate(x.value()), 7)\n- self.assertEqual(evaluate(x.read_value()), 7)\n+ self.evaluate(x.initializer)\n+ self.assertEqual(self.evaluate(x.value()), 7)\n+ self.assertEqual(self.evaluate(x.read_value()), 7)\n self.assertTrue(x.trainable)\n self.assertEqual(x.synchronization, x._variable.synchronization)\n self.assertEqual(x.aggregation, x._variable.aggregation)\n- self.assertEqual(evaluate(x.initialized_value()), 7)\n+ self.assertEqual(self.evaluate(x.initialized_value()), 7)\n if not context.executing_eagerly():\n if not distribute:\n # These functions are not supported for DistributedVariables\n x.load(9)\n self.assertEqual(x.eval(), 9)\n- self.assertEqual(evaluate(x.initial_value), 7)\n+ self.assertEqual(self.evaluate(x.initial_value), 7)\n self.assertEqual(x.op, x._variable.op)\n self.assertEqual(x.graph, x._variable.graph)\n if not distribute:\n@@ -197,8 +207,8 @@ def test_method_delegations(self, distribute):\n x = autocast_variable.create_autocast_variable(x)\n with ops.get_default_graph()._enable_auto_casting_variables(\n read_dtype):\n- evaluate(x.initializer)\n- self.assertAllEqual(evaluate(x.value()), [7, 8])\n+ self.evaluate(x.initializer)\n+ self.assertAllEqual(self.evaluate(x.value()), [7, 8])\n \n def slices(val, index):\n return indexed_slices.IndexedSlices(\n@@ -305,6 +315,25 @@ def run_and_check():\n self.assertAllClose(3.14 * 2, self.evaluate(x.assign_add(3.14)))\n self.assertAllClose(3.14, self.evaluate(x.assign_sub(3.14)))\n \n+ # Assign multiple times\n+ assign = x.assign(1.)\n+ self.assertAllClose(1., self.evaluate(assign))\n+ self.assertAllClose(0., self.evaluate(assign.assign(0.)))\n+ assign_add = x.assign_add(3.14)\n+ self.assertAllClose(3.14, self.evaluate(assign_add))\n+ self.assertAllClose(3.14 * 2, self.evaluate(assign_add.assign_add(3.14)))\n+ assign_sub = x.assign_sub(3.14)\n+ self.assertAllClose(3.14, self.evaluate(assign_sub))\n+ self.assertAllClose(0., self.evaluate(assign_sub.assign_sub(3.14)))\n+\n+ # Assign with read_value=False\n+ self.assertIsNone(self.evaluate(x.assign(1., read_value=False)))\n+ self.assertAllClose(1., self.evaluate(x))\n+ self.assertIsNone(self.evaluate(x.assign_add(2., read_value=False)))\n+ self.assertAllClose(3., self.evaluate(x))\n+ self.assertIsNone(self.evaluate(x.assign_sub(3., read_value=False)))\n+ self.assertAllClose(0., self.evaluate(x))\n+\n # Use the tf.assign functions instead of the var.assign methods.\n self.assertAllClose(0., self.evaluate(state_ops.assign(x, 0.)))\n self.assertAllClose(3.14, self.evaluate(state_ops.assign(x, 3.14)))",
"filename": "tensorflow/python/keras/mixed_precision/experimental/autocast_variable_test.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): MacOS 10.14.5\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): v2.0.0-rc0-101-gd2d2566eef 2.0.0-rc1\r\n- Python version: Python 3.6.8 :: Anaconda, Inc.\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version:\r\n- GPU model and memory:\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\n\r\nA keras model containing a tf.tile op layer with a tensor in the `multiples` arg throws an exception when saving to hdf5.\r\n\r\n(I'm using tf.tile because RepeatVector(n) doesn't accept a tensor for n. The goal is to stack a 2d feature batch so it can be concatenated to a variable length 3d batch of sequence features.)\r\n\r\n**Describe the expected behavior**\r\n\r\nModel.save() should save the model.\r\n\r\n**Code to reproduce the issue**\r\n\r\nimport numpy as np\r\nimport tensorflow as tf\r\nfrom tensorflow.keras.layers import Input\r\nfrom tensorflow.keras import Model\r\n\r\na = Input(shape=(10,))\r\nout = tf.tile(a, (1, tf.shape(a)[0]))\r\nmodel = Model(a, out)\r\n\r\nx = np.zeros((50,10), dtype=np.float32)\r\nprint(model(x).numpy())\r\n\r\nmodel.save('my_model.h5')\r\n\r\n**Other info / logs**\r\n\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n<ipython-input-2-9b1429243599> in <module>\r\n 11 print(model(x).numpy())\r\n 12 \r\n---> 13 model.save(model_dir + '/my_model.h5')\r\n\r\n~/miniconda3/envs/tf20/lib/python3.6/site-packages/tensorflow_core/python/keras/engine/network.py in save(self, filepath, overwrite, include_optimizer, save_format, signatures, options)\r\n 1187 \"\"\"\r\n 1188 saving.save_model(self, filepath, overwrite, include_optimizer, save_format,\r\n-> 1189 signatures, options)\r\n 1190 \r\n 1191 def save_weights(self, filepath, overwrite=True, save_format=None):\r\n\r\n~/miniconda3/envs/tf20/lib/python3.6/site-packages/tensorflow_core/python/keras/saving/save.py in save_model(model, filepath, overwrite, include_optimizer, save_format, signatures, options)\r\n 110 'or using `save_weights`.')\r\n 111 hdf5_format.save_model_to_hdf5(\r\n--> 112 model, filepath, overwrite, include_optimizer)\r\n 113 else:\r\n 114 saved_model_save.save(model, filepath, overwrite, include_optimizer,\r\n\r\n~/miniconda3/envs/tf20/lib/python3.6/site-packages/tensorflow_core/python/keras/saving/hdf5_format.py in save_model_to_hdf5(model, filepath, overwrite, include_optimizer)\r\n 107 model_weights_group = f.create_group('model_weights')\r\n 108 model_layers = model.layers\r\n--> 109 save_weights_to_hdf5_group(model_weights_group, model_layers)\r\n 110 \r\n 111 # TODO(b/128683857): Add integration tests between tf.keras and external\r\n\r\n~/miniconda3/envs/tf20/lib/python3.6/site-packages/tensorflow_core/python/keras/saving/hdf5_format.py in save_weights_to_hdf5_group(f, layers)\r\n 623 \r\n 624 for layer in layers:\r\n--> 625 g = f.create_group(layer.name)\r\n 626 weights = _legacy_weights(layer)\r\n 627 weight_values = K.batch_get_value(weights)\r\n\r\n~/miniconda3/envs/tf20/lib/python3.6/site-packages/h5py/_hl/group.py in create_group(self, name, track_order)\r\n 66 name, lcpl = self._e(name, lcpl=True)\r\n 67 gcpl = Group._gcpl_crt_order if track_order else None\r\n---> 68 gid = h5g.create(self.id, name, lcpl=lcpl, gcpl=gcpl)\r\n 69 return Group(gid)\r\n 70 \r\n\r\nh5py/_objects.pyx in h5py._objects.with_phil.wrapper()\r\n\r\nh5py/_objects.pyx in h5py._objects.with_phil.wrapper()\r\n\r\nh5py/h5g.pyx in h5py.h5g.create()\r\n\r\nValueError: Unable to create group (name already exists)\r\n",
"comments": [
{
"body": "I was able to replicate the issue with given code for TF-2.0rc1, please find the [gist](https://colab.sandbox.google.com/gist/oanush/8ee3a61919408dadf12499d2d95792ca/32672.ipynb) of colab.Thanks!",
"created_at": "2019-09-20T06:47:15Z"
},
{
"body": "@currivan I Don't see any issue if you remove the \".h5\" from the `model.save`. I changed only last line from your code as follows.\r\n\r\n```\r\nimport numpy as np\r\nimport tensorflow as tf\r\nfrom tensorflow.keras.layers import Input\r\nfrom tensorflow.keras import Model\r\n\r\na = Input(shape=(10,))\r\nout = tf.tile(a, (1, tf.shape(a)[0]))\r\nmodel = Model(a, out)\r\n\r\nx = np.zeros((50,10), dtype=np.float32)\r\nprint(model(x).numpy())\r\n\r\nmodel.save('./my_model')\r\n```\r\nPlease check the [gist here](https://colab.sandbox.google.com/gist/jvishnuvardhan/9348e139288b969517ed527334e5fb57/32672.ipynb). Thanks!\r\n\r\nI am closing this issue as it was resolved. Please feel free to open it if the issue persists again. Thanks!",
"created_at": "2019-09-20T21:03:14Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=32672\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=32672\">No</a>\n",
"created_at": "2019-09-20T21:03:15Z"
},
{
"body": "This should not have been closed. Throwing an exception here is a bug, and the solution is unacceptable. Saving this type of model with h5 takes a second, and the proposed way it takes over a minute. Loading is also unacceptably slow. ",
"created_at": "2019-09-23T14:55:14Z"
},
{
"body": "@currivan In case If i need to use an op like `tf.tile` as in your case, I will call it with a lambda layer. So the code is as follows\r\n\r\n```\r\nimport numpy as np\r\nimport tensorflow as tf\r\nfrom tensorflow.keras.layers import Input, Lambda\r\nfrom tensorflow.keras import Model\r\n\r\ndef my_fun(a):\r\n out = tf.tile(a, (1, tf.shape(a)[0]))\r\n return out\r\n\r\na = Input(shape=(10,))\r\n#out = tf.tile(a, (1, tf.shape(a)[0]))\r\nout = Lambda(lambda x : my_fun(x))(a)\r\nmodel = Model(a, out)\r\n\r\nx = np.zeros((50,10), dtype=np.float32)\r\nprint(model(x).numpy())\r\n\r\nmodel.save('my_model.h5')\r\n\r\n#load the model\r\nnew_model=tf.keras.models.load_model(\"my_model.h5\")\r\n\r\n```\r\nPlease let me know what you think? Please check the [gist](https://colab.sandbox.google.com/gist/jvishnuvardhan/56a985172d3b0702b1eb0b0b2d263761/tf32672.ipynb). Thanks!\r\n",
"created_at": "2019-09-23T21:10:27Z"
},
{
"body": "@jvishnuvardhan thanks, I was also able to create a custom layer. In general I feel if a model can be executed, it should be savable by all standard methods without throwing an opaque exception. Someone should still fix the bug with saving op layers. \"ValueError: Unable to create group (name already exists)\" isn't the right way to handle this even if it's unsupported.",
"created_at": "2019-09-23T21:51:48Z"
},
{
"body": "@currivan I agree. May be we need to update the error description. Please note that fixing this is not simple.\r\n\r\n@k-w-w Could you please take a look at this issue?",
"created_at": "2019-09-23T22:14:57Z"
},
{
"body": "I believe that this is the same issue as #12195. When adding a `tf.tile` operation the keras model gets a `tf_op_layer_Title/multiples` layer added _before_ a `tf_op_layer_Tile` layer which I believe is what causes the problem. ",
"created_at": "2019-09-30T17:39:53Z"
},
{
"body": "@ELind77 : #12195 seems totally unrelated to this. Did you mean to link to a different issue?\r\n\r\n@currivan : One problem with using Lambda is that your layer won't have a proper shape defined in case following layers need that.",
"created_at": "2019-10-31T01:15:01Z"
},
{
"body": "@currivan I think this was resolved recently in `tf-nightly`. I ran it with `tf-nightly` without any issue. Please check the [gist here](https://colab.sandbox.google.com/gist/jvishnuvardhan/15f06ff402a678a77d0c47592a290701/32672.ipynb). Thanks!\r\n\r\nI am closing this issue as it was resolved. Please feel free to reopen. Thanks!",
"created_at": "2020-02-04T21:21:32Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32672\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32672\">No</a>\n",
"created_at": "2020-02-04T21:21:34Z"
},
{
"body": "I have a similar problem. I'm not using tf.tile, I have a custom layer which uses tf.concat, tf.map_fn, and tf.cast. The latest nightly (tf-nightly-2.2.0.dev20200226) seems to crash on my machine so I'm not able to test it fully.\r\n\r\nThe error message is the same (I found this issue by googling it).",
"created_at": "2020-02-26T20:39:42Z"
},
{
"body": "@jsilter Can you please create new issue with a standalone code to reproduce the issue? Thanks!",
"created_at": "2020-02-26T22:20:37Z"
},
{
"body": "This issue is happening for me with tf.clip_by_value(). I haven't tested the nightly build.",
"created_at": "2020-03-18T20:17:22Z"
}
],
"number": 32672,
"title": "A keras model containing a tf.tile op layer with a tensor in the `multiples` arg fails when saving to hdf5"
}
|
{
"body": "Issue #34479, #32672\r\n\r\nLayer names sometimes contain hierarchy char \"/\", e.g., \"Layer1\", \"Layer1/SubLayer1\", etc.. Since for each layer, we create a new group, so if we pass layers whose name like \"Layer1/SubLayer1\", it would create both \"Layer1\" and \"Layer1/SubLayer1\", afterwards, if we pass \"Layer1\", it will throw \"Unable to create group (name already exists)\" error. \r\n\r\nThis commit solves the issue by sorting the layers by name before the loop.",
"number": 34569,
"review_comments": [],
"title": "Sort layers before the loop"
}
|
{
"commits": [
{
"message": "Sort layers before the loop"
}
],
"files": [
{
"diff": "@@ -22,6 +22,8 @@\n import json\n import os\n \n+from operator import attrgetter\n+\n import numpy as np\n from six.moves import zip # pylint: disable=redefined-builtin\n \n@@ -621,6 +623,7 @@ def save_weights_to_hdf5_group(f, layers):\n f.attrs['backend'] = K.backend().encode('utf8')\n f.attrs['keras_version'] = str(keras_version).encode('utf8')\n \n+ layers.sort(key=attrgetter('name'))\n for layer in layers:\n g = f.create_group(layer.name)\n weights = _legacy_weights(layer)",
"filename": "tensorflow/python/keras/saving/hdf5_format.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): v2.0.0-rc2-26-g64c3d382ca\r\n- Python version: 3.7.3\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\nI'm currently building a YOLOv3 model, the training was good, but when I try to save the model to h5 format, it throws out the \"ValueError: Unable to create group (name already exists)\".\r\n\r\n**Describe the expected behavior**\r\nIt should finish the save process successfully.\r\n\r\n**Code to reproduce the issue**\r\n```\r\ntf.keras.models.save_model(model, \"model.h5\", save_format=\"h5\")\r\n```\r\n\r\n**Other info / logs**\r\nThe log:\r\n```\r\nTraceback (most recent call last):\r\n File \"image_demo.py\", line 58, in <module>\r\n tf.keras.models.save_model(model, \"model.h5\", save_format=\"h5\")\r\n File \"/Users/xhguo/Workspace/TensorFlow2.0-Examples/4-Object_Detection/YOLOV3/lib/python3.7/site-packages/tensorflow_core/python/keras/saving/save.py\", line 112, in save_model\r\n model, filepath, overwrite, include_optimizer)\r\n File \"/Users/xhguo/Workspace/TensorFlow2.0-Examples/4-Object_Detection/YOLOV3/lib/python3.7/site-packages/tensorflow_core/python/keras/saving/hdf5_format.py\", line 110, in save_model_to_hdf5\r\n save_weights_to_hdf5_group(model_weights_group, model_layers)\r\n File \"/Users/xhguo/Workspace/TensorFlow2.0-Examples/4-Object_Detection/YOLOV3/lib/python3.7/site-packages/tensorflow_core/python/keras/saving/hdf5_format.py\", line 627, in save_weights_to_hdf5_group\r\n g = f.create_group(layer.name)\r\n File \"/Users/xhguo/Workspace/TensorFlow2.0-Examples/4-Object_Detection/YOLOV3/lib/python3.7/site-packages/h5py/_hl/group.py\", line 61, in create_group\r\n gid = h5g.create(self.id, name, lcpl=lcpl, gcpl=gcpl)\r\n File \"h5py/_objects.pyx\", line 54, in h5py._objects.with_phil.wrapper\r\n File \"h5py/_objects.pyx\", line 55, in h5py._objects.with_phil.wrapper\r\n File \"h5py/h5g.pyx\", line 161, in h5py.h5g.create\r\nValueError: Unable to create group (name already exists)\r\n```",
"comments": [
{
"body": "@gekowa, Please provide the complete standalone code to reproduce the reported issue.Thanks!",
"created_at": "2019-11-22T08:19:09Z"
},
{
"body": "@gekowa, Similar issue [#32672](https://github.com/tensorflow/tensorflow/issues/32672). Thanks",
"created_at": "2019-11-22T08:27:17Z"
},
{
"body": "We are closing this issue for now due to lack of activity. Please comment if this is still an issue for you. Thanks!",
"created_at": "2020-01-06T12:31:57Z"
},
{
"body": "try to use tf.keras `Lambda` if you do some op on Inputs. ",
"created_at": "2020-05-21T12:47:06Z"
}
],
"number": 34479,
"title": "Got \"ValueError: Unable to create group (name already exists)\" when saving a convolutional model"
}
|
{
"body": "#34479",
"number": 34480,
"review_comments": [],
"title": "Resolve issue #34479"
}
|
{
"commits": [
{
"message": "Use the first available adapter"
},
{
"message": "Merge pull request #1 from tensorflow/master\n\nMerge from TensorFlow"
},
{
"message": "Sort the layers before saving to hdf5"
},
{
"message": "Revert imporper changes."
},
{
"message": "Remove unnecessary blank lines"
}
],
"files": [
{
"diff": "@@ -22,6 +22,8 @@\n import json\n import os\n \n+from operator import attrgetter\n+\n import numpy as np\n from six.moves import zip # pylint: disable=redefined-builtin\n \n@@ -621,6 +623,7 @@ def save_weights_to_hdf5_group(f, layers):\n f.attrs['backend'] = K.backend().encode('utf8')\n f.attrs['keras_version'] = str(keras_version).encode('utf8')\n \n+ layers.sort(key=attrgetter('name'))\n for layer in layers:\n g = f.create_group(layer.name)\n weights = _legacy_weights(layer)",
"filename": "tensorflow/python/keras/saving/hdf5_format.py",
"status": "modified"
}
]
}
|
{
"body": "**Describe the current behavior**\r\n```\r\norg.tensorflow.NativeLibrary: tryLoadLibraryFailed: no tensorflow_jni in java.library.path\r\norg.tensorflow.NativeLibrary: jniResourceName: org/tensorflow/native/linux-x86_64/libtensorflow_jni.so\r\norg.tensorflow.NativeLibrary: frameworkResourceName: org/tensorflow/native/linux-x86_64/libtensorflow_framework.so\r\norg.tensorflow.NativeLibrary: org/tensorflow/native/linux-x86_64/libtensorflow_framework.so not found. This is fine assuming org/tensorflow/native/linux-x86_64/libtensorflow_jni.so is not built to depend on it.\r\norg.tensorflow.NativeLibrary: extracting native library to: /xxx/tmp/tensorflow_native_libraries-1573652659702-0/libtensorflow_jni.so\r\norg.tensorflow.NativeLibrary: copied 154073736 bytes to /xxx/tmp/tensorflow_native_libraries-1573652659702-0/libtensorflow_jni.so\r\njava.lang.UnsatisfiedLinkError:/xxx/tmp/tensorflow_native_libraries-1573652659702-0/libtensorflow_jni.so: libtensorflow_framework.so.1: 无法打开共享对象文件: 没有那个文件或目录\r\n\tat java.lang.ClassLoader$NativeLibrary.load(Native Method)\r\n\tat java.lang.ClassLoader.loadLibrary0(ClassLoader.java:1941)\r\n\tat java.lang.ClassLoader.loadLibrary(ClassLoader.java:1824)\r\n\tat java.lang.Runtime.load0(Runtime.java:809)\r\n\tat java.lang.System.load(System.java:1086)\r\n\tat org.tensorflow.NativeLibrary.load(NativeLibrary.java:101)\r\n\tat org.tensorflow.TensorFlow.init(TensorFlow.java:67)\r\n\tat org.tensorflow.TensorFlow.<clinit>(TensorFlow.java:82)\r\n\tat org.tensorflow.SavedModelBundle.<clinit>(SavedModelBundle.java:170)\r\n```\r\n\r\n**Describe the expected behavior**\r\nno exceptions\r\n",
"comments": [
{
"body": "I found the tensorflow jar does not include `org/tensorflow/native/linux-x86_64/libtensorflow_framework.so`, but include `org/tensorflow/native/linux-x86_64/libtensorflow_framework.so.1`, so it failed to copy `libtensorflow_framework.so` to tmp directory when loading the native library.",
"created_at": "2019-11-14T01:49:43Z"
},
{
"body": "`NativeLibrary.getMajorVersionNumber` returns `null` when libtensorflow and libtensorflow_jni jar were shaded to my jar",
"created_at": "2019-11-14T04:32:30Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34256\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34256\">No</a>\n",
"created_at": "2020-01-15T21:38:40Z"
},
{
"body": "I had the same problem (using a shaded jar, `NativeLibrary.getMajorVersionNumber` returned null). But since your fix wasn't yet available in the 1.15 release, I worked around it by adding an `Implementation-Version` that starts with `1.` to the shaded jar's manifest using Maven's `ManifestResourceTransformer`.",
"created_at": "2020-03-09T17:29:55Z"
},
{
"body": "@mttsndrs Could you share what you did with the manifest resource transformer? I'm having a similar problem.",
"created_at": "2021-02-23T21:10:34Z"
},
{
"body": "@geometrikal I added this to the pom.xml:\r\n```\r\n <properties>\r\n <tensorflow.version>1.15.0</tensorflow.version>\r\n </properties>\r\n\r\n <build>\r\n <plugins>\r\n <plugin>\r\n <groupId>org.apache.maven.plugins</groupId>\r\n <artifactId>maven-shade-plugin</artifactId>\r\n <configuration>\r\n <transformers combine.self=\"override\">\r\n <transformer implementation=\"org.apache.maven.plugins.shade.resource.ManifestResourceTransformer\">\r\n <manifestEntries>\r\n <!--\r\n Note: When loaded from a jar, tensorflow will use the\r\n \"Implementation-Version\" tag in the jar's manifest to identify the\r\n tensorflow_framework lib to extract. When packaged in a shaded jar,\r\n this can cause problems locating the correct version of the\r\n tensorflow library.\r\n By overriding the \"Implementation-Version\" tag here, we ensure that\r\n the correct tensorflow_framework lib gets extracted at runtime.\r\n -->\r\n <Implementation-Version>${tensorflow.version}</Implementation-Version>\r\n </manifestEntries>\r\n </transformer>\r\n </transformers>\r\n </configuration>\r\n </plugin>\r\n </plugins>\r\n </build>\r\n```",
"created_at": "2021-02-23T21:57:24Z"
}
],
"number": 34256,
"title": "tensorflow java 1.15.0 failed to load native lib"
}
|
{
"body": "fix #34256\r\n\r\nCurrently, `NativeLibrary.getMajorVersionNumber` return \"1\" by hard coding. It is very ugly and not friendly for tf-2.x. we can pack version info to jar, and load the version at runtime.",
"number": 34453,
"review_comments": [],
"title": "Avoid hard coding in getMajorVersionNumber"
}
|
{
"commits": [
{
"message": "Avoid hard coding in NativeLibrary.getMajorVersionNumber"
}
],
"files": [
{
"diff": "@@ -5,6 +5,7 @@ load(\":build_defs.bzl\", \"JAVACOPTS\")\n load(\":src/gen/gen_ops.bzl\", \"tf_java_op_gen_srcjar\")\n load(\n \"//tensorflow:tensorflow.bzl\",\n+ \"VERSION\",\n \"tf_binary_additional_srcs\",\n \"tf_cc_binary\",\n \"tf_cc_test\",\n@@ -27,9 +28,26 @@ java_library(\n data = tf_binary_additional_srcs() + [\":libtensorflow_jni\"],\n javacopts = JAVACOPTS,\n plugins = [\":processor\"],\n+ resources = [\":java_resources\"],\n visibility = [\"//visibility:public\"],\n )\n \n+genrule(\n+ name = \"version-info\",\n+ outs = [\"src/main/resources/tensorflow-version-info\"],\n+ cmd = \"echo version=%s > $@\" % VERSION,\n+ output_to_bindir = 1,\n+)\n+\n+filegroup(\n+ name = \"java_resources\",\n+ srcs = [\":version-info\"],\n+ visibility = [\n+ \"//tensorflow/contrib/android:__pkg__\",\n+ \"//tensorflow/java:__pkg__\",\n+ ],\n+)\n+\n # NOTE(ashankar): Rule to include the Java API in the Android Inference Library\n # .aar. At some point, might make sense for a .aar rule here instead.\n filegroup(",
"filename": "tensorflow/java/BUILD",
"status": "modified"
},
{
"diff": "@@ -19,6 +19,7 @@\n import java.io.FileOutputStream;\n import java.io.IOException;\n import java.io.InputStream;\n+import java.util.Properties;\n \n /**\n * Helper class for loading the TensorFlow Java native library.\n@@ -169,19 +170,30 @@ private static String getVersionedLibraryName(String libFilename) {\n * determined.\n */\n private static String getMajorVersionNumber() {\n- // getImplementationVersion() retrun null.\n- String version = NativeLibrary.class.getPackage().getImplementationVersion();\n- // expecting a string like 1.14.0, we want to get the first '1'.\n- int dotIndex;\n- if (version == null || (dotIndex = version.indexOf('.')) == -1) {\n- // we want to get the version 1.\n- return \"1\";\n+ InputStream resourceStream = NativeLibrary.class.getClassLoader()\n+ .getResourceAsStream(\"tensorflow-version-info\");\n+ if (resourceStream == null) {\n+ return null;\n }\n- String majorVersion = version.substring(0, dotIndex);\n+\n try {\n- Integer.parseInt(majorVersion);\n- return majorVersion;\n- } catch (NumberFormatException unused) {\n+ Properties props = new Properties();\n+ props.load(resourceStream);\n+ String version = props.getProperty(\"version\");\n+ // expecting a string like 1.14.0, we want to get the first '1'.\n+ int dotIndex;\n+ if (version == null || (dotIndex = version.indexOf('.')) == -1) {\n+ return null;\n+ }\n+ String majorVersion = version.substring(0, dotIndex);\n+ try {\n+ Integer.parseInt(majorVersion);\n+ return majorVersion;\n+ } catch (NumberFormatException unused) {\n+ return null;\n+ }\n+ } catch (IOException e) {\n+ log(\"failed to load tensorflow version info.\");\n return null;\n }\n }",
"filename": "tensorflow/java/src/main/java/org/tensorflow/NativeLibrary.java",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- OS Platform and Distribution: Android 5.1.1, API 22\r\n- Mobile device: Xiaomi Redmi 3\r\n- TensorFlow installed from: official binary\r\n- TensorFlow version : tensorflow-lite:1.14.0\r\n\r\n**Describe the current behavior**\r\nTensorflow-lite 1.13.1 works fine on all devices I tested. Whereas tensorflow-lite 1.14.0 is broken for Xiaomi Redmi 3 (Android 5.1.1, API 22), other devices are ok.\r\nI get a runtime error when `Interpreter` is created.\r\n\r\n**Describe the expected behavior**\r\nNo error.\r\n\r\n**Code to reproduce the issue**\r\n```\r\ninterpreter = new Interpreter(tfliteModel, null);\r\n```\r\n\r\n**Other info / logs**\r\n```\r\nW/linker: /data/app/eu.yesse.readerdemo.debug-2/lib/arm64/libtensorflowlite_jni.so: unused DT entry: type 0x6ffffffe arg 0x2020\r\n /data/app/eu.yesse.readerdemo.debug-2/lib/arm64/libtensorflowlite_jni.so: unused DT entry: type 0x6fffffff arg 0x3\r\nE/art: dlopen(\"/data/app/eu.yesse.readerdemo.debug-2/lib/arm64/libtensorflowlite_jni.so\", RTLD_LAZY) failed: dlopen failed: cannot locate symbol \"__register_atfork\" referenced by \"/data/app/eu.yesse.readerdemo.debug-2/lib/arm64/libtensorflowlite_jni.so\"...\r\nW/System.err: TensorFlowLite: failed to load native library: dlopen failed: cannot locate symbol \"__register_atfork\" referenced by \"/data/app/eu.yesse.readerdemo.debug-2/lib/arm64/libtensorflowlite_jni.so\"...\r\nW/linker: /data/app/eu.yesse.readerdemo.debug-2/lib/arm64/libtensorflowlite_jni.so: unused DT entry: type 0x6ffffffe arg 0x2020\r\n /data/app/eu.yesse.readerdemo.debug-2/lib/arm64/libtensorflowlite_jni.so: unused DT entry: type 0x6fffffff arg 0x3\r\nE/art: dlopen(\"/data/app/eu.yesse.readerdemo.debug-2/lib/arm64/libtensorflowlite_jni.so\", RTLD_LAZY) failed: dlopen failed: cannot locate symbol \"__register_atfork\" referenced by \"/data/app/eu.yesse.readerdemo.debug-2/lib/arm64/libtensorflowlite_jni.so\"...\r\nW/System.err: TensorFlowLite: failed to load native library: dlopen failed: cannot locate symbol \"__register_atfork\" referenced by \"/data/app/eu.yesse.readerdemo.debug-2/lib/arm64/libtensorflowlite_jni.so\"...\r\nE/art: No implementation found for long org.tensorflow.lite.NativeInterpreterWrapper.createErrorReporter(int) (tried Java_org_tensorflow_lite_NativeInterpreterWrapper_createErrorReporter and Java_org_tensorflow_lite_NativeInterpreterWrapper_createErrorReporter__I)\r\nD/AndroidRuntime: Shutting down VM\r\nE/AndroidRuntime: FATAL EXCEPTION: main\r\n Process: eu.yesse.readerdemo.debug, PID: 12710\r\n java.lang.UnsatisfiedLinkError: No implementation found for long org.tensorflow.lite.NativeInterpreterWrapper.createErrorReporter(int) (tried Java_org_tensorflow_lite_NativeInterpreterWrapper_createErrorReporter and Java_org_tensorflow_lite_NativeInterpreterWrapper_createErrorReporter__I)\r\n at org.tensorflow.lite.NativeInterpreterWrapper.createErrorReporter(Native Method)\r\n at org.tensorflow.lite.NativeInterpreterWrapper.<init>(NativeInterpreterWrapper.java:58)\r\n at org.tensorflow.lite.Interpreter.<init>(Interpreter.java:224)\r\n at eu.yesse.reader.commons.internal.detector.BlockingCornersClassSingleDetector.<init>(BlockingCornersClassSingleDetector.java:76)\r\n at eu.yesse.reader.commons.internal.detector.BlockingCornersClassMultiDetector.<init>(BlockingCornersClassMultiDetector.java:25)\r\n at eu.yesse.reader.commons.shared.detector.AsyncCornersClassMultiDetectorImpl.<init>(AsyncCornersClassMultiDetectorImpl.java:36)\r\n at eu.yesse.reader.tempregdoc.internal.TempRegDocReaderManager.createDetector(TempRegDocReaderManager.java:79)\r\n at eu.yesse.reader.tempregdoc.internal.TempRegDocReaderManager.<init>(TempRegDocReaderManager.java:48)\r\n at eu.yesse.reader.TempRegDocReader.getReader(TempRegDocReader.java:20)\r\n at eu.yesse.readerdemo.activities.TempRegDocActivity.onCreate(TempRegDocActivity.java:24)\r\n at android.app.Activity.performCreate(Activity.java:6093)\r\n at android.app.Instrumentation.callActivityOnCreate(Instrumentation.java:1106)\r\n at android.app.ActivityThread.performLaunchActivity(ActivityThread.java:2295)\r\n at android.app.ActivityThread.handleLaunchActivity(ActivityThread.java:2404)\r\n at android.app.ActivityThread.access$900(ActivityThread.java:154)\r\n at android.app.ActivityThread$H.handleMessage(ActivityThread.java:1315)\r\n at android.os.Handler.dispatchMessage(Handler.java:102)\r\n at android.os.Looper.loop(Looper.java:135)\r\n at android.app.ActivityThread.main(ActivityThread.java:5296)\r\n at java.lang.reflect.Method.invoke(Native Method)\r\n at java.lang.reflect.Method.invoke(Method.java:372)\r\n at com.android.internal.os.ZygoteInit$MethodAndArgsCaller.run(ZygoteInit.java:912)\r\n at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:707)\r\n```\r\n",
"comments": [
{
"body": "Did you solve it?\r\n\r\nFirebase crashlytics reports this issue for Android 5 users of my app\r\n\r\nI added Tensorflow like this:\r\n\r\n implementation 'org.tensorflow:tensorflow-lite:0.0.0-nightly'\r\n implementation 'org.tensorflow:tensorflow-lite-gpu:0.0.0-nightly'\r\n\r\n`Fatal Exception: java.lang.UnsatisfiedLinkError\r\nNo implementation found for long org.tensorflow.lite.NativeInterpreterWrapper.createErrorReporter(int) (tried Java_org_tensorflow_lite_NativeInterpreterWrapper_createErrorReporter and Java_org_tensorflow_lite_NativeInterpreterWrapper_createErrorReporter__I)`",
"created_at": "2019-07-29T06:55:43Z"
},
{
"body": ">Did you solve it?\r\n\r\n@anonym24 nope :( I guess we can't do much about it without a fix in tf. BTW I guess you should not put both `org.tensorflow:tensorflow-lite` and `org.tensorflow:tensorflow-lite-gpu` in your gradle file at the same time (?). But that's not the issue here anyway... \r\nFrom crashlitics: does the crash affects only Android 5.*.* and all of them?",
"created_at": "2019-07-29T10:44:25Z"
},
{
"body": "@wosiu yes, we need them both: https://www.tensorflow.org/lite/performance/gpu\r\n\r\n\r\n",
"created_at": "2019-07-29T11:07:25Z"
},
{
"body": "@wosiu \r\nin my case, yes (only Android 5):\r\n\r\n\r\n\r\n",
"created_at": "2019-07-29T13:37:34Z"
},
{
"body": "@liyunlu0618 are there any updates on that?",
"created_at": "2019-08-07T01:21:21Z"
},
{
"body": "I also encounter this problem, I resolve this by reconfigure my ndk abifilter settings. My project originally was only built for 'armeabi' architecture. When I add any other abi options, it works like a charm. However, I'm still confused because on the tutorial page of Tensorflow Lite, it says that the library support all kinds of architecture(which should include armeabi). Or is it because arm support was removed in ndk r17? Hope someone can help me to find a workaround for tflite to run on armeabi devices.",
"created_at": "2019-08-23T10:07:11Z"
},
{
"body": "Did anyone find solution for this? I am also facing the same issue.\r\nI tested in Oneplus3.\r\n2019-09-06 08:28:18.799 15233-15233/ai.fritz.tflitedemo E/ritz.tflitedem: No implementation found for long org.tensorflow.lite.NativeInterpreterWrapper.createErrorReporter(int) (tried Java_org_tensorflow_lite_NativeInterpreterWrapper_createErrorReporter and Java_org_tensorflow_lite_NativeInterpreterWrapper_createErrorReporter__I)\r\n2019-09-06 08:28:18.802 15233-15233/ai.fritz.tflitedemo E/AndroidRuntime: FATAL EXCEPTION: main\r\n Process: ai.fritz.tflitedemo, PID: 15233\r\n java.lang.UnsatisfiedLinkError: No implementation found for long org.tensorflow.lite.NativeInterpreterWrapper.createErrorReporter(int) (tried Java_org_tensorflow_lite_NativeInterpreterWrapper_createErrorReporter and Java_org_tensorflow_lite_NativeInterpreterWrapper_createErrorReporter__I)\r\n at org.tensorflow.lite.NativeInterpreterWrapper.createErrorReporter(Native Method)\r\n\r\nGradle:\r\n implementation 'org.tensorflow:tensorflow-lite:0.1.2-nightly'\r\n implementation 'org.tensorflow:tensorflow-lite:0.1'\r\n implementation 'org.tensorflow:tensorflow-lite-gpu:0.0.0-nightly'",
"created_at": "2019-09-06T03:02:54Z"
},
{
"body": "Any update on this? I'm also facing the same issue on 1.14.0",
"created_at": "2019-09-19T14:03:39Z"
},
{
"body": "I'm also got this crash",
"created_at": "2019-09-21T15:53:08Z"
},
{
"body": "I had a similar issue from NDK, namely that arm64 Android 5.x devices failed to load the shared library libtensorflowlite.so because of __register_atfork being missing.\r\n\r\nThe problem is that for at least arm64, __register_atfork usage is somehow generated in the shared library, but [this function is introduced in Android 6](https://android.googlesource.com/platform/bionic/+/master/android-changes-for-ndk-developers.md). As suggested in the link, I tried compiling with lower NDK target API level, but this didn't seem to help. I also tried searching for \"atfork\" in tensorflow lite's source code, but couldn't find any.\r\n\r\n**Workaround for at least NDK users:** Disassembling libtensorflowlite.so left an impression that __register_atfork is only called while reporting errors, so at least theoretically it shouldn't be called in production anyway. The workaround was thus to introduce fake __register_atfork() declaration and definition in cpp and h files, so that linker wouldn't complain anymore. So I put\r\n\r\n```\r\nextern \"C\" {\r\n int __register_atfork(void (*prepare) (void), void (*parent) (void), void (*child) (void), void *__dso_handle);\r\n}\r\n```\r\n\r\ninto tensorflow/lite/util.h, and\r\n\r\n```\r\n#include <cassert>\r\nextern \"C\" {\r\n int __register_atfork(void (*prepare) (void), void (*parent) (void), void (*child) (void), void *__dso_handle) {\r\n assert(0 && \"Using dummy __register_atfork(). This is dangerous, so asserting.\");\r\n return 0; // Avoid warning\r\n }\r\n}\r\n```\r\n\r\ninto tensorflow/lite/util.cc (the exact files aren't important, the definition just has to be compiled and linked to libtensorflowlite.so) and recompiled. After that neural networks seem to work fine on all devices. I guess something similar should work for JNI users as well.",
"created_at": "2019-09-23T10:15:16Z"
},
{
"body": "I had the same issue. I fixed it by adding \r\n```\r\nndk {\r\n abiFilters \"armeabi-v7a\", \"x86\"\r\n }\r\n```\r\nto the `defaultConfig` in `app/build.gradle` file. ",
"created_at": "2019-10-19T12:40:38Z"
},
{
"body": "@kongaskristjan and @FunmiKesa - big thanks for investigating and sharing that! Said that, I feel propsed changes are more like workarounds and not solutions. It still would be nice to have a fix inside the tensorflow lib.",
"created_at": "2019-10-19T13:31:31Z"
},
{
"body": "Any updates on this? It's still happening on 1.15.0! This seems like a critical bug to me, tflite instantly crashes on some devices.\r\n\r\nI will bump my minApi to 23 for a while, and later revert to 21 when this gets fixed :)\r\n\r\nEDIT: Excluding 64bit architectures as some of you are doing is not a viable solution, Google Play store enforces all apps to support 64bit since 1st of August 2019: https://android-developers.googleblog.com/2019/01/get-your-apps-ready-for-64-bit.html",
"created_at": "2019-10-31T10:08:21Z"
},
{
"body": "Hi all, apologies for the delayed response, just now seeing this issue.\r\n\r\nWe set our Android NDK API level to 18 when building, but it's possible there's something wrong with the config and it's assuming API 23. I'll take a look.\r\n\r\n",
"created_at": "2019-11-15T22:05:47Z"
},
{
"body": "This is fixed in the latest nightly, and we'll try to pull the fix in to the 2.1 release (https://github.com/tensorflow/tensorflow/pull/34419). Thanks again for your patience.",
"created_at": "2019-11-19T16:42:06Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/31114\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/31114\">No</a>\n",
"created_at": "2019-11-19T16:42:08Z"
},
{
"body": "Hi @jdduke , thanks for the fix. Just to understand how we can resolve this issue on android, would we be able to pull in the nightly build of TFL in gradle and have this fixed\r\n\r\n```\r\ndependencies: {\r\n implementation 'org.tensorflow:tensorflow-lite:0.0.0-nightly'\r\n}\r\n```\r\n\r\nor do we have to also reconvert our models to TFL using the nightly build?",
"created_at": "2019-11-19T17:19:11Z"
},
{
"body": "@jdduke are you going to backport the fix to 1.* version?",
"created_at": "2019-11-19T17:22:21Z"
},
{
"body": "There won't be any backport, however, you can safely use the latest 2.x or nightly version with both 1.X and 2.X TF models.",
"created_at": "2019-11-19T17:31:53Z"
},
{
"body": "Hello @jdduke, please show me what I need to put in gradle.build to use latest fix",
"created_at": "2019-11-19T22:03:02Z"
},
{
"body": "@runnableapps \r\nAnswer:\r\n```\r\ndependencies: {\r\n implementation 'org.tensorflow:tensorflow-lite:0.0.0-nightly'\r\n}\r\n```\r\nor wait for `2.1` release.",
"created_at": "2019-11-19T22:33:01Z"
},
{
"body": " implementation 'org.tensorflow:tensorflow-lite:0.0.0-nightly'\r\ndoes not fix crash",
"created_at": "2019-11-21T10:12:53Z"
},
{
"body": "You might need to [clear your gradle cache](https://stackoverflow.com/questions/23025433/how-to-clear-gradle-cache). I've manually inspected the [nightly build](https://bintray.com/google/tensorflow/tensorflow-lite#files/org%2Ftensorflow%2Ftensorflow-lite%2F0.0.0-nightly) and verified that `__register_atfork` is no longer referenced. There might be another issue with your usage, in which case please attach the log from adb.",
"created_at": "2019-11-21T17:30:55Z"
},
{
"body": "Got the same problem with org.tensorflow:tensorflow-lite:2.0.0\r\nDevice T8-PLUS, Android 5.1",
"created_at": "2019-12-21T11:25:12Z"
},
{
"body": "@alexeyvasilyev the fix did not make it into 2.0, but it will be in the upcoming 2.1 release (expected to be finalized soon). In the meantime, please try the nightly build.",
"created_at": "2019-12-26T18:21:07Z"
},
{
"body": "@jdduke Thanks. Lets hope nightly build can sort out this issue in android 5.",
"created_at": "2020-01-09T11:45:02Z"
},
{
"body": "The 2.1 release is now available (`org.tensorflow:tensorflow-lite:2.1.0`), please give it a try.",
"created_at": "2020-01-09T18:06:28Z"
},
{
"body": "I confirm - 2.1.0 works on the device I originally issued the problem with :) Big thanks to all contributors! 🥇 ",
"created_at": "2020-01-10T05:07:22Z"
}
],
"number": 31114,
"title": "TFLite No implementation found for long org.tensorflow.lite.NativeInterpreterWrapper.createErrorReporter(int)"
}
|
{
"body": "This resolves an issue where the arm64 build was incorrectly targeting API 28, leading to unexpected behavior on pre-API 28 devices.\r\n\r\nFixes #31114 \r\n\r\nPiperOrigin-RevId: 280766624\r\nChange-Id: I8500b69a5f6bebbeb0aafcf5744f5be5944738b9",
"number": 34419,
"review_comments": [],
"title": "Switch to NDK API level 21"
}
|
{
"commits": [
{
"message": "Switch to NDK API level 21\n\nPiperOrigin-RevId: 280766624\nChange-Id: I8500b69a5f6bebbeb0aafcf5744f5be5944738b9"
}
],
"files": [
{
"diff": "@@ -817,7 +817,7 @@ def valid_api_level(api_level):\n android_ndk_api_level = prompt_loop_or_load_from_env(\n environ_cp,\n var_name='ANDROID_NDK_API_LEVEL',\n- var_default='18', # 18 is required for GPU acceleration.\n+ var_default='21', # 21 is required for ARM64 support.\n ask_for_var=('Please specify the (min) Android NDK API level to use. '\n '[Available levels: %s]') % api_levels,\n check_success=valid_api_level,",
"filename": "configure.py",
"status": "modified"
},
{
"diff": "@@ -132,7 +132,7 @@ in the `.tf_configure.bazelrc` file in the root folder:\n \n ```shell\n build --action_env ANDROID_NDK_HOME=\"/usr/local/android/android-ndk-r17c\"\n-build --action_env ANDROID_NDK_API_LEVEL=\"18\"\n+build --action_env ANDROID_NDK_API_LEVEL=\"21\"\n build --action_env ANDROID_BUILD_TOOLS_VERSION=\"28.0.3\"\n build --action_env ANDROID_SDK_API_LEVEL=\"23\"\n build --action_env ANDROID_SDK_HOME=\"/usr/local/android/android-sdk-linux\"",
"filename": "tensorflow/lite/g3doc/guide/android.md",
"status": "modified"
},
{
"diff": "@@ -29,7 +29,7 @@ RUN mkdir -p ${ANDROID_DEV_HOME}\n ENV ANDROID_SDK_FILENAME tools_r25.2.5-linux.zip\n ENV ANDROID_SDK_URL https://dl.google.com/android/repository/${ANDROID_SDK_FILENAME}\n ENV ANDROID_API_LEVEL 23\n-ENV ANDROID_NDK_API_LEVEL 18\n+ENV ANDROID_NDK_API_LEVEL 21\n # Build Tools Version liable to change.\n ENV ANDROID_BUILD_TOOLS_VERSION 28.0.0\n ENV ANDROID_SDK_HOME ${ANDROID_DEV_HOME}/sdk",
"filename": "tensorflow/tools/ci_build/Dockerfile.android",
"status": "modified"
},
{
"diff": "@@ -235,7 +235,7 @@ android_sdk_repository(\n android_ndk_repository(\n name=\"androidndk\",\n path=\"${ANDROID_NDK_HOME}\",\n- api_level=18)\n+ api_level=21)\n EOF\n fi\n fi",
"filename": "tensorflow/tools/ci_build/builds/builds_common.sh",
"status": "modified"
}
]
}
|
{
"body": "```\r\n>>> import tensorflow as tf\r\n>>> scalar = tf.zeros(shape=())\r\n>>> array = tf.zeros(shape=(1,))\r\n\r\n>>> tf.random.uniform(shape=(),minval = scalar)\r\n<tf.Tensor: id=25, shape=(), dtype=float32, numpy=0.021499991>\r\n\r\n>>> tf.random.uniform(shape=(),minval = array)\r\n<tf.Tensor: id=31, shape=(1,), dtype=float32, numpy=array([0.9388697], dtype=float32)>\r\n```\r\nExpected behavior is to either trow an error or treat single element tensor as scalar and return a scalar.\r\n\r\n-win10, tf2, cuda",
"comments": [
{
"body": "@Pixel-Therapy,\r\nCorrect me if I am wrong but, From this [TF Link](https://www.tensorflow.org/api_docs/python/tf/random/uniform) and [The Source Code](https://github.com/tensorflow/tensorflow/blob/r2.0/tensorflow/python/ops/random_ops.py#L186-L252), it is mentioned that `random.uniform()` returns a Tensor but it is not mentioned that it will be a Scalar Tensor.\r\n\r\nCan you please provide the reference where it mentions `random.uniform` returns a Scalar Tensor. Thanks!",
"created_at": "2019-11-18T08:21:38Z"
},
{
"body": "> @Pixel-Therapy,\r\n> Correct me if I am wrong but, From this [TF Link](https://www.tensorflow.org/api_docs/python/tf/random/uniform) and [The Source Code](https://github.com/tensorflow/tensorflow/blob/r2.0/tensorflow/python/ops/random_ops.py#L186-L252), it is mentioned that `random.uniform()` returns a Tensor but it is not mentioned that it will be a Scalar Tensor.\r\n> \r\n> Can you please provide the reference where it mentions `random.uniform` returns a Scalar Tensor. Thanks!\r\n\r\nThe first argument in random.uniform asks for shape, ill edit my example as shape = ().\r\nIt seems that random.uniform always follows this shape except in the above case.",
"created_at": "2019-11-18T11:50:06Z"
},
{
"body": "The issue is that in one code path, math_ops.add was called which implicitly broadcast.\r\n\r\nCreated a PR #34399 for the fix.",
"created_at": "2019-11-19T02:10:01Z"
},
{
"body": "This issue is still being worked on. PR #34399 depends on PR #38544. Once PR #38544 is merged, PR #34399 will be reopened and this issue will be fixed by then.",
"created_at": "2020-04-14T16:59:55Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">No</a>\n",
"created_at": "2020-04-15T16:06:14Z"
},
{
"body": "PR #38544 has been merged. However, the issue is not fixed yet. Will re-submit the PR of PR #34399 to eventually fix this issue.",
"created_at": "2020-04-15T16:12:14Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34363\">No</a>\n",
"created_at": "2020-05-27T20:04:13Z"
}
],
"number": 34363,
"title": "random.uniform((),minval,maxval) returns array instead of scalar tensor when min or maxval is not a scalar tensor"
}
|
{
"body": "This PR tries to address the issue raised in #34363 where\r\ninvalid shape passed to minval/maxval (expected to be 0-D)\r\ndoes not raise an error.\r\n\r\nThe issue was that in most of the scenarios the shape was\r\nchecked inside the C++ kernel ops.\r\n\r\nHowever, in one condition math_ops.add was used which will\r\nimplicitly do broadcast when necessarily.\r\nThis results in maxval/minval's shape getting carried.\r\n\r\nThis PR adds the shape check before math_ops.add, to make\r\nsure the shape is guaranteed.\r\n\r\nThis PR fixes #34363.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 34399,
"review_comments": [],
"title": "Fix invalid shape issue in random.uniform"
}
|
{
"commits": [
{
"message": "Fix invalid shape issue in random.uniform\n\nThis PR tries to address the issue raised in 34363 where\ninvalid shape passed to minval/maxval (expected to be 0-D)\ndoes not raise an error.\n\nThe issue was that in most of the scenarios the shape was\nchecked inside the C++ kernel ops.\n\nHowever, in one condition math_ops.add was used which will\nimplicitly do broadcast when necessarily.\nThis results in maxval/minval's shape getting carried.\n\nThis PR adds the shape check before math_ops.add, to make\nsure the shape is guaranteed.\n\nThis PR fixes 34363.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Remove name field to make test compatible\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix failed tests\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix failed //tensorflow/python:matmul_benchmark_test_gpu\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -81,9 +81,9 @@ def testMemoryEstimates(self):\n self.assertLessEqual(1, len(peak_mem))\n snapshot = peak_mem['/job:localhost/replica:0/task:0/device:CPU:0']\n peak_usage = snapshot[0]\n- self.assertEqual(52, peak_usage)\n+ self.assertEqual(68, peak_usage)\n live_tensors = snapshot[1]\n- self.assertEqual(15, len(live_tensors))\n+ self.assertEqual(19, len(live_tensors))\n \n def testVirtualCluster(self):\n with ops.Graph().as_default() as g:\n@@ -108,7 +108,7 @@ def testVirtualCluster(self):\n devices=[named_device])\n op_perfs, run_time, _ = grappler_cluster.MeasureCosts(grappler_item)\n self.assertEqual(run_time, 0.000545)\n- self.assertEqual(len(op_perfs), 15)\n+ self.assertEqual(len(op_perfs), 19)\n \n estimated_perf = grappler_cluster.EstimatePerformance(named_device)\n self.assertEqual(7680.0, estimated_perf)",
"filename": "tensorflow/python/grappler/cluster_test.py",
"status": "modified"
},
{
"diff": "@@ -23,6 +23,7 @@\n \n from tensorflow.python.eager import context\n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors\n from tensorflow.python.framework import ops\n from tensorflow.python.framework import random_seed\n from tensorflow.python.framework import test_util\n@@ -413,6 +414,15 @@ def testSingleSessionGraphSeedNotConstant(self):\n use_gpu=use_gpu,\n graph_seed=965)\n \n+ def testUniformWithInvalidMaxMindShape(self):\n+ # Test case for GitHub issue 34363.\n+ with self.assertRaisesRegexp(\n+ errors.InvalidArgumentError,\n+ \"is not compatible with expected shape\"):\n+ array = array_ops.zeros(shape=(1,))\n+ random_ops.random_uniform(shape=(), minval=array)\n+\n+\n \n class RandomShapeTest(test.TestCase):\n ",
"filename": "tensorflow/python/kernel_tests/random/random_ops_test.py",
"status": "modified"
},
{
"diff": "@@ -80,19 +80,23 @@ def _VerifyBuildGraph(self, n, m, k, transpose_a, transpose_b, dtype):\n node { name: \"random_uniform/min\" op: \"Const\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"random_uniform/max\" op: \"Const\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"random_uniform/RandomUniform\" op: \"RandomUniform\" input: \"random_uniform/shape\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n- node { name: \"random_uniform/sub\" op: \"Sub\" input: \"random_uniform/max\" input: \"random_uniform/min\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n+ node { name: \"random_uniform/EnsureShape\" op: \"EnsureShape\" input: \"random_uniform/max\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n+ node { name: \"random_uniform/EnsureShape_1\" op: \"EnsureShape\" input: \"random_uniform/min\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n+ node { name: \"random_uniform/sub\" op: \"Sub\" input: \"random_uniform/EnsureShape\" input: \"random_uniform/EnsureShape_1\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"random_uniform/mul\" op: \"Mul\" input: \"random_uniform/RandomUniform\" input: \"random_uniform/sub\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n- node { name: \"random_uniform\" op: \"Add\" input: \"random_uniform/mul\" input: \"random_uniform/min\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n+ node { name: \"random_uniform\" op: \"Add\" input: \"random_uniform/mul\" input: \"random_uniform/EnsureShape_1\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"Variable\" op: \"VariableV2\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"Variable/Assign\" op: \"Assign\" input: \"Variable\" input: \"random_uniform\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"Variable/read\" op: \"Identity\" input: \"Variable\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"random_uniform_1/shape\" op: \"Const\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"random_uniform_1/min\" op: \"Const\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"random_uniform_1/max\" op: \"Const\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"random_uniform_1/RandomUniform\" op: \"RandomUniform\" input: \"random_uniform_1/shape\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n- node { name: \"random_uniform_1/sub\" op: \"Sub\" input: \"random_uniform_1/max\" input: \"random_uniform_1/min\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n+ node { name: \"random_uniform_1/EnsureShape\" op: \"EnsureShape\" input: \"random_uniform_1/max\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n+ node { name: \"random_uniform_1/EnsureShape_1\" op: \"EnsureShape\" input: \"random_uniform_1/min\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n+ node { name: \"random_uniform_1/sub\" op: \"Sub\" input: \"random_uniform_1/EnsureShape\" input: \"random_uniform_1/EnsureShape_1\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"random_uniform_1/mul\" op: \"Mul\" input: \"random_uniform_1/RandomUniform\" input: \"random_uniform_1/sub\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n- node { name: \"random_uniform_1\" op: \"Add\" input: \"random_uniform_1/mul\" input: \"random_uniform_1/min\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n+ node { name: \"random_uniform_1\" op: \"Add\" input: \"random_uniform_1/mul\" input: \"random_uniform_1/EnsureShape_1\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"Variable_1\" op: \"VariableV2\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"Variable_1/Assign\" op: \"Assign\" input: \"Variable_1\" input: \"random_uniform_1\" device: \\\"\"\"\" + dev + \"\"\"\\\" }\n node { name: \"Variable_1/read\" op: \"Identity\" input: \"Variable_1\" device: \\\"\"\"\" + dev + \"\"\"\\\" }",
"filename": "tensorflow/python/ops/matmul_benchmark_test.py",
"status": "modified"
},
{
"diff": "@@ -285,6 +285,8 @@ def random_uniform(shape,\n if not maxval_is_one:\n result = result * maxval\n else:\n+ maxval = array_ops.ensure_shape(maxval, ())\n+ minval = array_ops.ensure_shape(minval, ())\n result = math_ops.add(result * (maxval - minval), minval, name=name)\n else:\n minval = ops.convert_to_tensor(minval, dtype=dtype, name=\"min\")\n@@ -296,6 +298,8 @@ def random_uniform(shape,\n else:\n rnd = gen_random_ops.random_uniform(\n shape, dtype, seed=seed1, seed2=seed2)\n+ maxval = array_ops.ensure_shape(maxval, ())\n+ minval = array_ops.ensure_shape(minval, ())\n result = math_ops.add(rnd * (maxval - minval), minval, name=name)\n # TODO(b/132092188): C++ shape inference inside functional ops does not\n # cross FuncGraph boundaries since that information is only available in",
"filename": "tensorflow/python/ops/random_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Google Colab \r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: NN\r\n- TensorFlow installed from (source or binary): NN\r\n- TensorFlow version (use command below): 2.0.0\r\n- Python version: 3.6\r\n- Bazel version (if compiling from source): NN\r\n- GCC/Compiler version (if compiling from source): NN\r\n- CUDA/cuDNN version: NN\r\n- GPU model and memory: NN\r\n\r\n**Describe the current behavior**\r\ntf.keras.Model.save shows confusing behavior with the save_format argument.\r\nSee [gist](https://colab.research.google.com/gist/nikochiko/7a624ae90563b831d5229eb0ee5b0d41/tf_model_save_buggy.ipynb).\r\nEven when save_format is set as 'tf', the model is saved as 'h5' if the filepath ends in suffix '.h5'\r\nAlso, it defaults random string arguments to tf format. \r\n\r\n**Describe the expected behavior**\r\nThe value of the save_format argument should be the format of the saved file irrespective of the filepath. \r\nOr else, there should be a boolean argument like 'save_as_h5' instead.\r\n\r\n**Code to reproduce the issue**\r\nhttps://colab.research.google.com/gist/nikochiko/7a624ae90563b831d5229eb0ee5b0d41/tf_model_save_buggy.ipynb#scrollTo=1H73RxH5sTgl\r\n\r\n**Other info / logs**\r\n[Source code](https://github.com/tensorflow/tensorflow/blob/r2.0/tensorflow/python/keras/engine/network.py#L923-L975)\r\n[Outdated documentation](https://www.tensorflow.org/api_docs/python/tf/keras/Model#save)\r\nUpdated docs for current behavior in [PR](https://github.com/tensorflow/tensorflow/pull/34347/files)\r\n\r\n**More details**\r\nmodel.save_weights handles it better: see [gist](https://colab.research.google.com/gist/nikochiko/ff693562546dbda5d5868ec7e7d75bad/tf_save_weights.ipynb)",
"comments": [
{
"body": "Could reproduce the issue with TF Version 2.0. Here is the [Gist](https://colab.sandbox.google.com/gist/rmothukuru/565a2bee7543a888a9677813b9e0447a/tf_model_save_buggy.ipynb).",
"created_at": "2019-11-18T10:03:22Z"
},
{
"body": "@rmothukuru @k-w-w I can make a fix for this in accordance with the `save_weights` method. Shall I start working?",
"created_at": "2019-11-18T14:27:45Z"
},
{
"body": "That would be great! Reviewing the PR now",
"created_at": "2019-11-18T18:54:15Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34348\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/34348\">No</a>\n",
"created_at": "2020-02-20T23:22:11Z"
}
],
"number": 34348,
"title": "save method shows buggy/confusing behaviour"
}
|
{
"body": "Fix #34348 .\r\nNotes:\r\n- Documentation needs to be changed (in multiple places) after final changes in code.\r\n- Changed code for deciding whether to save file as h5 or tf.\r\n- Removed the unncessary _HDF5_EXTENSIONS list. Will have to make sure it wasn't used elsewhere.\r\n- Added 4 new ValueError raises.",
"number": 34388,
"review_comments": [
{
"body": "Prefer importing the module instead of individual functions.\r\n\r\n(You might have to disable the pylint check, see https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/engine/training.py#L231)",
"created_at": "2019-11-18T18:56:41Z"
},
{
"body": "Perhaps refactor out this part of the code to a separate function that is called by both `save_weights()` and `save()`. \r\n\r\nAlso, it would be useful to have unit tests to make sure that the save format returned by the function is correct",
"created_at": "2019-11-18T19:01:09Z"
},
{
"body": "Done. ",
"created_at": "2019-11-19T07:02:05Z"
},
{
"body": "There's an internal bug, so this has to use double quotes:\r\n```\r\n# pylint:disable=g-inconsistent-quotes\r\nnetwork = LazyLoader(\r\n \"network\", globals(),\r\n \"tensorflow.python.keras.engine.network\")\r\n# pylint:enable=g-inconsistent-quotes\r\n```",
"created_at": "2020-02-19T21:30:29Z"
},
{
"body": "Thanks!",
"created_at": "2020-02-20T11:47:38Z"
},
{
"body": "Done! :+1:",
"created_at": "2020-02-20T11:52:04Z"
}
],
"title": "Update save.py"
}
|
{
"commits": [
{
"message": "Update array_ops.py\n\nUpdate documentation, formatting and fix typos for `tf.broadcast_dynamic_shape`, `tf.broadcast_static_shape`, `tf.boolean_mask`"
},
{
"message": "Update docstrings\n\nUpdated docstrings for `tf.convert_to_tensor` and `tf.edit_distance`.\n`tf.convert_to_tensor`: Put example in \"For example:\" section and switch to carets from backticks.\n`tf.edit_distance`: Updated documentatoin, fixed example."
},
{
"message": "Update save.py\n\nFix https://github.com/tensorflow/tensorflow/issues/34348 .\nNotes:\n- Documentation needs to be changed (in multiple places) after final changes in code.\n- Changed code for deciding whether to save file as h5 or tf.\n- Removed the unncessary _HDF5_EXTENSIONS list. Will have to make sure it wasn't used elsewhere.\n- Added 4 new ValueError raises."
},
{
"message": "Revert \"Update docstrings\"\n\nThis reverts commit 2a6efd2e668f8418bdf1c60e8218791559724dc4."
},
{
"message": "Revert \"Update array_ops.py\"\n\nThis reverts commit 4c9ee36f03d9b01b4d8598905aa26bbf81b380b4."
},
{
"message": "Added new function process_save_format\n\n- Added new function `validate_save_format` as requested by @k-w-w inside `network.py`.\n- Using `validate_save_format` for validating save_format in `save.save_model` and `network.save_weights`\n\nAlthough, the a few updates will have to be made in `save_weights` because\n- `validate_save_format` is designed to work with path as well as h5py.File objects. This works with `save.save_model` but not with `network.save_weights` which accepts only String as the path.\n- Does it make sense to add functionality to save_weights to save it to a h5py.File object?"
},
{
"message": "Merge branch 'master' into fix-save-model"
},
{
"message": "Update save.py"
},
{
"message": "Update network.py"
},
{
"message": "Fix sanity"
},
{
"message": "Add tests"
},
{
"message": "Fix typo"
},
{
"message": "Fix typo"
},
{
"message": "Fix spacing"
},
{
"message": "Merge branch 'master' into fix-save-model"
},
{
"message": "Use LazyLoader to import network in save.py"
},
{
"message": "Fix typo"
},
{
"message": "Fix typo"
},
{
"message": "Fix linting"
},
{
"message": "Single quotes -> double quotes for LazyLoader"
},
{
"message": "Make pylint comments consistent"
}
],
"files": [
{
"diff": "@@ -30,6 +30,7 @@\n import six\n from six.moves import zip # pylint: disable=redefined-builtin\n \n+from tensorflow.python import tf2\n from tensorflow.python.eager import context\n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import errors\n@@ -1094,28 +1095,7 @@ def save_weights(self, filepath, overwrite=True, save_format=None):\n ValueError: For invalid/unknown format arguments.\n \"\"\"\n self._assert_weights_created()\n- filepath_is_h5 = _is_hdf5_filepath(filepath)\n- if save_format is None:\n- if filepath_is_h5:\n- save_format = 'h5'\n- else:\n- save_format = 'tf'\n- else:\n- user_format = save_format.lower().strip()\n- if user_format in ('tensorflow', 'tf'):\n- save_format = 'tf'\n- elif user_format in ('hdf5', 'h5', 'keras'):\n- save_format = 'h5'\n- else:\n- raise ValueError(\n- 'Unknown format \"%s\". Was expecting one of {\"tf\", \"h5\"}.' % (\n- save_format,))\n- if save_format == 'tf' and filepath_is_h5:\n- raise ValueError(\n- ('save_weights got save_format=\"tf\"/\"tensorflow\", but the '\n- 'filepath (\"%s\") looks like an HDF5 file. Omit the \".h5\"/\".keras\" '\n- 'when saving in TensorFlow format.')\n- % filepath)\n+ save_format = validate_save_format(filepath, save_format)\n \n if save_format == 'h5' and h5py is None:\n raise ImportError(\n@@ -2053,3 +2033,68 @@ def get_network_config(network, serialize_layer_fn=None):\n model_outputs = tf_utils.convert_inner_node_data(model_outputs)\n config['output_layers'] = model_outputs\n return config\n+\n+\n+def validate_save_format(filepath, save_format):\n+ \"\"\"Validates `save_format` argument passed to methods used for saving.\n+\n+ Returns either 'tf' or 'h5', indicating whether to save the model\n+ to Tensorflow SavedModel or HDF5. Output will default to 'tf' in TF2.X and\n+ 'h5' in TF1.X.\n+\n+ Defaults to 'h5' if `filepath` is a path to a hdf5 file (having suffix '.h5'\n+ or '.hdf5' or '.keras') or is an h5py.File object.\n+\n+ Args:\n+ filepath: Value of the `filepath` argument passed to the method.\n+ Can be:\n+ - String\n+ - h5py.File object\n+ save_format: String, value of the 'save_format' argument as passed.\n+\n+ Returns:\n+ save_format: String, 'h5' or 'tf'. The processed\n+ value of the `save_format` argument.\n+\n+ Raises:\n+ ValueError: If\n+ - `filepath` is not a String or an h5py.File object.\n+ - `save_format` is not valid. Valid values are \"tensorflow\", \"tf\" for\n+ saving in SavedModel format, and \"hdf5\", \"keras\" or \"h5\" for saving in\n+ h5 format.\n+ - `save_format` is \"tf\" but `filepath` is a path to a h5 file.\n+ - `save_format` is \"tf\" but `filepath` is an h5py.File object.\n+ \"\"\"\n+ if type(filepath) != str and not isinstance(filepath, h5py.File):\n+ raise ValueError(\n+ 'Expected `filepath` to be a String or h5py.File object. Got '\n+ 'unsupported value %s of type %s'\n+ % (filepath, type(filepath)))\n+\n+ filepath_is_h5py_file = h5py is not None and isinstance(filepath, h5py.File)\n+ filepath_is_h5 = type(filepath) == str and _is_hdf5_filepath(filepath)\n+ if save_format is None:\n+ if filepath_is_h5 or filepath_is_h5py_file:\n+ save_format = 'h5'\n+ else:\n+ save_format = 'tf' if tf2.enabled() else 'h5'\n+ else:\n+ user_format = save_format.lower().strip()\n+ if user_format in ('tensorflow', 'tf'):\n+ save_format = 'tf'\n+ elif user_format in ('hdf5', 'h5', 'keras'):\n+ save_format = 'h5'\n+ else:\n+ raise ValueError(\n+ 'Unknown format \"%s\". Was expecting one of {\"tf\", \"h5\"}.'\n+ % (save_format))\n+ if save_format == 'tf' and filepath_is_h5:\n+ raise ValueError(\n+ ('Got save_format=\"tf\"/\"tensorflow\", but the filepath (\"%s\") looks '\n+ 'like an HDF5 file. Omit the \".h5\"/\".keras\" when saving in '\n+ 'TensorFlow format.') % filepath)\n+ if save_format == 'tf' and filepath_is_h5py_file:\n+ raise ValueError(\n+ 'Got save_format=\"tf\"/\"tensorflow\", but the given `filepath`'\n+ 'is an h5py.File object.')\n+ return save_format",
"filename": "tensorflow/python/keras/engine/network.py",
"status": "modified"
},
{
"diff": "@@ -21,6 +21,7 @@\n import numpy as np\n \n from tensorflow.python import keras\n+from tensorflow.python import tf2\n from tensorflow.python.eager import context\n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n@@ -1824,6 +1825,45 @@ def layer_and_network_test(self):\n self.assertEqual(network.stateful, False)\n \n \n+class SaveFormatValidationTest(keras_parameterized.TestCase):\n+\n+ def test_save_format_validation(self):\n+ filepath = 'file/path'\n+ h5_filepath = 'h5_filepath.h5'\n+ h5_filepath_2 = 'h5_filepath.hdf5'\n+ h5_filepath_3 = 'h5_filepath.keras'\n+\n+ tf2.disable()\n+ self.assertEqual(network_lib.validate_save_format(filepath, None), 'h5')\n+\n+ tf2.enable()\n+ self.assertEqual(network_lib.validate_save_format(filepath, None), 'tf')\n+\n+ self.assertEqual(network_lib.validate_save_format(filepath, 'h5'), 'h5')\n+ self.assertEqual(network_lib.validate_save_format(h5_filepath, None), 'h5')\n+ self.assertEqual(\n+ network_lib.validate_save_format(h5_filepath_2, None), 'h5')\n+ self.assertEqual(\n+ network_lib.validate_save_format(h5_filepath_3, None), 'h5')\n+ self.assertEqual(\n+ network_lib.validate_save_format(h5_filepath, 'hdf5'), 'h5')\n+ self.assertEqual(\n+ network_lib.validate_save_format(h5_filepath, 'keras'), 'h5')\n+\n+ self.assertEqual(network_lib.validate_save_format(filepath, 'tf'), 'tf')\n+ self.assertEqual(\n+ network_lib.validate_save_format(filepath, 'tensorflow'), 'tf')\n+\n+ with self.assertRaises(ValueError):\n+ network_lib.validate_save_format(42, 'h5')\n+\n+ with self.assertRaises(ValueError):\n+ network_lib.validate_save_format(filepath, 'unknown_format')\n+\n+ with self.assertRaises(ValueError):\n+ network_lib.validate_save_format(h5_filepath, 'tf')\n+\n+\n \n if __name__ == '__main__':\n test.main()",
"filename": "tensorflow/python/keras/engine/network_test.py",
"status": "modified"
},
{
"diff": "@@ -18,18 +18,23 @@\n from __future__ import division\n from __future__ import print_function\n \n-import os\n import sys\n \n import six\n \n-from tensorflow.python import tf2\n from tensorflow.python.keras.saving import hdf5_format\n from tensorflow.python.keras.saving.saved_model import load as saved_model_load\n from tensorflow.python.keras.saving.saved_model import save as saved_model_save\n from tensorflow.python.saved_model import loader_impl\n+from tensorflow.python.util.lazy_loader import LazyLoader\n from tensorflow.python.util.tf_export import keras_export\n \n+# pylint: disable=g-inconsistent-quotes\n+network = LazyLoader(\n+ \"network\", globals(),\n+ \"tensorflow.python.keras.engine.network\")\n+# pylint: enable=g-inconsistent-quotes\n+\n # pylint: disable=g-import-not-at-top\n if sys.version_info >= (3, 4):\n import pathlib\n@@ -39,9 +44,6 @@\n h5py = None\n # pylint: enable=g-import-not-at-top\n \n-_HDF5_EXTENSIONS = ['.h5', '.hdf5', '.keras']\n-\n-\n # TODO(kathywu): Remove this when Keras SavedModel is not experimental.\n _KERAS_SAVED_MODEL_STILL_EXPERIMENTAL = True\n \n@@ -95,15 +97,12 @@ def save_model(model,\n \"\"\"\n from tensorflow.python.keras.engine import sequential # pylint: disable=g-import-not-at-top\n \n- default_format = 'tf' if tf2.enabled() else 'h5'\n- save_format = save_format or default_format\n-\n if sys.version_info >= (3, 4) and isinstance(filepath, pathlib.Path):\n filepath = str(filepath)\n \n- if (save_format == 'h5' or\n- (h5py is not None and isinstance(filepath, h5py.File)) or\n- os.path.splitext(filepath)[1] in _HDF5_EXTENSIONS):\n+ save_format = network.validate_save_format(filepath, save_format)\n+\n+ if save_format == 'h5':\n # TODO(b/130258301): add utility method for detecting model type.\n if (not model._is_graph_network and # pylint:disable=protected-access\n not isinstance(model, sequential.Sequential)):",
"filename": "tensorflow/python/keras/saving/save.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Windows 10\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): Binary, pip install \r\n- TensorFlow version (use command below): tensorflow-gpu==2.0.0-beta1\r\n- Python version: 3.6\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n\r\n**Describe the current behavior**\r\nError arises during Concatenate when I run the following code:\r\n\r\n```\r\nimport tensorflow as tf\r\nfrom tensorflow import keras\r\nfrom tensorflow.keras.layers import Conv2D, Concatenate\r\n\r\ninputs = keras.Input(shape=(256,256,3))\r\nx = Conv2D(16,3, padding='same',activation='relu')(inputs)\r\nx_list = [x]\r\nfor i in range(3):\r\n x = Conv2D(16,3, padding='same',activation='relu')(x)\r\n x_list.append(x)\r\n x = Concatenate(3)(x_list)\r\n\r\nmodel = keras.Model(inputs=inputs, outputs=x)\r\nmodel.summary()\r\n```\r\n\r\n`ValueError: Graph disconnected: cannot obtain value for tensor Tensor(\"conv2d_31/Identity:0\", shape=(None, 256, 256, 16), dtype=float32) at layer \"concatenate_8\". The following previous layers were accessed without issue: ['input_9', 'conv2d_29', 'conv2d_30']`\r\n\r\nThis issue does not occur in a Tensorflow 1.X environment, only TF 2.0\r\n\r\n**Describe the expected behavior**\r\nNow the Concatenate function works properly when using a sequential model. That is, if I swap in \"for i in range(1):\" rather than \"for i in range(3):\" above, the code executes cleanly. However, the non-sequential repeated Concatenation in the loop leaves the a Graph disconnected error.\r\n\r\nFurthermore, the error is also eliminated when using tf.concat, so the following code also executes cleanly.\r\n\r\n```\r\nimport tensorflow as tf\r\nfrom tensorflow import keras\r\nfrom tensorflow.keras.layers import Conv2D, Concatenate\r\n\r\ninputs = keras.Input(shape=(256,256,3))\r\nx = Conv2D(16,3, padding='same',activation='relu')(inputs)\r\nx_list = [x]\r\nfor i in range(3):\r\n x = Conv2D(16,3, padding='same',activation='relu')(x)\r\n x_list.append(x)\r\n x = tf.concat(x_list, 3)\r\n\r\nmodel = keras.Model(inputs=inputs, outputs=x)\r\nmodel.summary()\r\n```\r\n\r\nTherefore, I do have a working alternative, but there does appear to be an issue with the keras Concatenate function",
"comments": [
{
"body": "@mketcha Just to verify, Which Concatenate function of Keras did you use.I could find tf.keras.backend.concatenate and tf.keras.layers.Concatenate on Tensorflow website. Thanks! ",
"created_at": "2019-07-04T08:32:25Z"
},
{
"body": "@mketcha If it is tf.keras.layers.Concatenate then Concatenate function takes at least two list and syntax will be\r\n `x = Concatenate(3)([list1,list2])` \r\nLet us know if this helps. Thanks!",
"created_at": "2019-07-04T08:43:34Z"
},
{
"body": "It is the tf.keras.layers.Concatenate.\r\n\r\n I don't believe it is an issue with my arguments as analagous code works in tensorflow 1.13, and the argument passes cleanly if I use \"for i in range(1):\"\r\n\r\nIt seems to be an issue with passing an argument that had previously already been used in a concatenation call",
"created_at": "2019-07-05T14:45:35Z"
},
{
"body": "same error here,\r\nbut the tf.concat works as a workaround as @mketcha mentioned",
"created_at": "2019-08-01T16:27:08Z"
},
{
"body": "@mketcha I changed one line in your code to append all the three layers to `x_list` and then applied `concatenation` and the [gist is here](https://colab.sandbox.google.com/gist/jvishnuvardhan/d6f7c83b0315f3051023e8f915cce1ba/untitled527.ipynb). With that modification, it runs without any error. \r\n\r\n## I have also plotted the model and is shown below. \r\n\r\n\r\n## When I plot your workaround using tf.concat(), model looks like this shown below. Note that number of training params also increases (more than double)\r\n\r\n\r\nPlease let us know what you think. If this was resolved, please close the issue. Thanks!\r\n",
"created_at": "2019-10-02T23:11:03Z"
},
{
"body": "@jvishnuvardhan While your workaround may run, it does not achieve the same desired architecture",
"created_at": "2019-10-04T17:57:19Z"
},
{
"body": "Hi, this is a regression in TF Keras. In standalone Keras, it was fixed by https://github.com/keras-team/keras/pull/6035 .\r\n\r\nAnd it seems to be a duplicate of https://github.com/tensorflow/tensorflow/issues/32023 .\r\n\r\nThe workaround in user code is to copy the list at call time, e.g. by changing above example to:\r\n```\r\n x = Concatenate(3)(x_list[:])\r\n```\r\n\r\nThe fix for TF would be to copy the list at call time of the layer object, to prevent later outside modification.",
"created_at": "2019-11-13T10:27:59Z"
},
{
"body": "Thanks for the issue!\r\n\r\nThis commit fixes the issue: \r\n\r\nhttps://github.com/tensorflow/tensorflow/commit/816ec796ea6a96940188356628566ed11a11c186\r\n\r\nThe fix should be available in tomorrow's nightly build",
"created_at": "2020-03-15T05:39:13Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/30355\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/30355\">No</a>\n",
"created_at": "2020-03-15T05:39:15Z"
}
],
"number": 30355,
"title": "[TF 2.0 keras] tf.keras.Concatenate Graph Disconnected when concatenating non-sequentially"
}
|
{
"body": "To prevent disconnected graph errors, which can occur if the list input to (concatenate) layers is modified after calling them, as it a common approach to build certain types of network graphs, e.g. DenseNets.\r\n\r\nFixes #30355 and #32023. Similar to https://github.com/keras-team/keras/pull/6035 of standalone Keras.",
"number": 34239,
"review_comments": [],
"title": "Duplicating tf.keras.layers.Layer inputs to prevent \"Graph disconnected\" errors"
}
|
{
"commits": [
{
"message": "Duplicating tf.keras.layers.Layer inputs.\n\nTo prevent disconnected graph errors, which can occur if the inputs\nto concatenate layers is modified after calling them.\n\nFixes #30355 and #32023 .\nSimilar to https://github.com/keras-team/keras/pull/6035 of standalone Keras."
}
],
"files": [
{
"diff": "@@ -651,6 +651,10 @@ def __call__(self, inputs, *args, **kwargs):\n ValueError: if the layer's `call` method returns None (an invalid value).\n \"\"\"\n call_context = base_layer_utils.call_context()\n+\n+ if isinstance(inputs, list):\n+ inputs = inputs[:]\n+\n input_list = nest.flatten(inputs)\n \n # We will attempt to build a TF graph if & only if all inputs are symbolic.",
"filename": "tensorflow/python/keras/engine/base_layer.py",
"status": "modified"
},
{
"diff": "@@ -189,6 +189,11 @@ def test_merge_concatenate(self):\n concat_layer.compute_mask(\n [i1, i2], [K.variable(x1), K.variable(x2)]))))\n \n+ concat_list = [i1, i1]\n+ concat_list += [concat_layer(concat_list)]\n+ recursive_output = concat_layer(concat_list)\n+ keras.models.Model([i1, i2], recursive_output)\n+\n with self.assertRaisesRegexp(ValueError, '`mask` should be a list.'):\n concat_layer.compute_mask([i1, i2], x1)\n with self.assertRaisesRegexp(ValueError, '`inputs` should be a list.'):",
"filename": "tensorflow/python/keras/layers/merge_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Android/Ubuntu\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): Source\r\n- TensorFlow version: 1.15.0\r\n- Python version: 3.6.8\r\n- Installed using virtualenv? pip? conda?: ip\r\n- Bazel version (if compiling from source): 0.24.1\r\n- GCC/Compiler version (if compiling from source): NDK r17b clang\r\n- CUDA/cuDNN version: -\r\n- GPU model and memory: -\r\n\r\n\r\n**Describe the problem**\r\nCurrently libtensorflowlite.so is build with `\"-Wl,--version-script,$(location //tensorflow/lite:tflite_version_script.lds)\"`\r\n\r\nThe same is not done for gpu delegates.\r\nIs there any particular reason for that?\r\nI believe it should be applied to gpu delegate libraries too, as currently you'll need \r\nI don't believe any symbol other than tflite related symbols are necessary.\r\nIf `visibility=hidden` by default is ok (since I think we only need C API from GPU Delegate), then shouldn't it be default flag for the library?\r\n\r\nInconsistent symbol hiding makes it confusing when building both main library and gpu delegates\r\nWould it be acceptable to hide symbols by default or use linker script as in main tflite library?\r\n\r\n**Provide the exact sequence of commands / steps that you executed before running into the problem**\r\n\r\n\r\n**Any other info / logs**\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\n",
"comments": [
{
"body": "@DoumanAsh \r\n\r\nSorry for the late reply; I've been out on a conference.\r\n\r\nHm, I'm not sure what that flag does, and re: your question of:\r\n\r\n> Is there any particular reason for that?\r\n\r\nThe people owning TFLite and who delivers the TFLite GPU are different set of people with the latter (I belong here) being more agnostic of what the proper way is :p \r\n\r\nPlease feel free to send a PR to me and @jdduke ",
"created_at": "2019-11-08T18:25:29Z"
},
{
"body": "Hi @DoumanAsh, thanks for flagging, we should absolutely be consistent. If you want to propose a PR, feel free to, otherwise I can take a look.",
"created_at": "2019-11-08T18:56:59Z"
},
{
"body": "Looking over at the delegate API, I see only C API (which is marked visible in code).\r\nSo I think the simplest approach would be is to by default build with `hidden` visibility.\r\nWhich doesn't require any extra linking script (this is also what we do internally when we build delegate)\r\n\r\nSo I'd suggest it as PR with visibility hidden by default for now as all vital APIs are marked with `TFL_CAPI_EXPORT` which resolves to corresponding attribute.\r\n@jdduke does it sound good to you?",
"created_at": "2019-11-08T19:19:06Z"
},
{
"body": "As a side question.\r\nI noticed that 1.15 brought a new GPU Delegate.\r\nAre there any plans for which is going to be a final one?",
"created_at": "2019-11-08T19:36:44Z"
},
{
"body": "The new GPU delegate you are referring to probably has the logic of \"try to use OpenCL if available, fallback to OpenGL otherwise\". I'm not 100% certain whether we will kill off the \"old\" OpenGL delegate, but chances are high.",
"created_at": "2019-11-08T19:46:44Z"
},
{
"body": "Hi @DoumanAsh, the V2 delegate is going to be the default going forward. The pre-compiled GPU delegate (on JCenter/Maven) has already been updated to use this variant, as has our benchmark tooling. We're preparing a blog post, and will likely deprecate the \"V1\" API at some point.",
"created_at": "2019-11-08T19:47:13Z"
},
{
"body": "Good to know, I will be shifting our code base to use it then",
"created_at": "2019-11-08T19:58:07Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33676\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33676\">No</a>\n",
"created_at": "2019-11-27T19:47:20Z"
}
],
"number": 33676,
"title": "TF lite GPU delegates should use the same linker script as main library"
}
|
{
"body": "Fixes #33676\r\n\r\nThere is no C++ API in OpenGL delegate code and it manually exports necessary symbols.\r\nSo `visibility=hidden` should suffice on gcc/clang targets\r\nOn msvc symbols are hidden by default.",
"number": 34108,
"review_comments": [],
"title": "TfLite GL delegate is built with visibility hidden"
}
|
{
"commits": [
{
"message": "TfLite GL delegate is built with visibility hidden"
},
{
"message": "Add visibility default on android select\n\nAccording to docs, default kicks in only when nothing else matches"
}
],
"files": [
{
"diff": "@@ -106,7 +106,7 @@ objc_library(\n ],\n )\n \n-# build -c opt --config android_arm64 --copt -Os --copt -DTFLITE_GPU_BINARY_RELEASE --copt -fvisibility=hidden --linkopt -s --strip always :libtensorflowlite_gpu_gl.so\n+# build -c opt --config android_arm64 --copt -Os --copt -DTFLITE_GPU_BINARY_RELEASE --copt --linkopt -s --strip always :libtensorflowlite_gpu_gl.so\n cc_binary(\n name = \"libtensorflowlite_gpu_gl.so\",\n linkopts = [\n@@ -115,8 +115,12 @@ cc_binary(\n \"//tensorflow:android\": [\n \"-lEGL\",\n \"-lGLESv3\",\n+ \"-fvisibility=hidden\",\n+ ],\n+ \"//tensorflow:windows\": [],\n+ \"//conditions:default\": [\n+ \"-fvisibility=hidden\",\n ],\n- \"//conditions:default\": [],\n }),\n linkshared = 1,\n linkstatic = 1,\n@@ -127,7 +131,7 @@ cc_binary(\n deps = [\":gl_delegate\"],\n )\n \n-# build -c opt --config android_arm64 --copt -Os --copt -DTFLITE_GPU_BINARY_RELEASE --copt -fvisibility=hidden --linkopt -s --strip always :libtensorflowlite_gpu_delegate.so\n+# build -c opt --config android_arm64 --copt -Os --copt -DTFLITE_GPU_BINARY_RELEASE --copt --linkopt -s --strip always :libtensorflowlite_gpu_delegate.so\n cc_binary(\n name = \"libtensorflowlite_gpu_delegate.so\",\n linkopts = [\n@@ -136,8 +140,12 @@ cc_binary(\n \"//tensorflow:android\": [\n \"-lEGL\",\n \"-lGLESv3\",\n+ \"-fvisibility=hidden\",\n+ ],\n+ \"//tensorflow:windows\": [],\n+ \"//conditions:default\": [\n+ \"-fvisibility=hidden\",\n ],\n- \"//conditions:default\": [],\n }),\n linkshared = 1,\n linkstatic = 1,",
"filename": "tensorflow/lite/delegates/gpu/BUILD",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.0.0\r\n- Python version: 3.7\r\n\r\n**Describe the current behavior**\r\nValueError: Unknown metric function: CustomMetric occurs when trying to load a tf saved model using tf.keras.models.load_model with a custom metric. If you look at the code for load_model, it is clear the load_model currently ignores the custom_objects dict for the tf saved model format.\r\n\r\n**Describe the expected behavior**\r\nload_model loads the custom metric successfully either just implicitly or through the custom_objects dict. \r\n\r\n**Code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nfrom tensorflow import keras\r\nfrom tensorflow.keras import layers\r\nfrom tensorflow.keras.metrics import Metric\r\nimport numpy as np\r\n\r\nclass CustomMetric(Metric):\r\n def __init__(self,\r\n name='score',\r\n dtype=tf.float32):\r\n super(CustomMetric, self).__init__(name=name)\r\n self.true_positives = self.add_weight(\r\n 'true_positives',\r\n shape=[10],\r\n initializer='zeros',\r\n dtype=self.dtype)\r\n\r\n\r\n def update_state(self, y_true, y_pred, sample_weight=None):\r\n pass\r\n\r\n def result(self):\r\n return 0\r\n\r\n def get_config(self):\r\n \"\"\"Returns the serializable config of the metric.\"\"\"\r\n config = {}\r\n base_config = super(CustomMetric, self).get_config()\r\n return dict(list(base_config.items()) + list(config.items()))\r\n\r\n def reset_states(self):\r\n self.true_positives.assign(np.zeros(self.num_classes), np.float32)\r\n self.weights_intermediate.assign(\r\n np.zeros(self.num_classes), np.float32)\r\n \r\ninputs = keras.Input(shape=(784,), name='digits')\r\nx = layers.Dense(64, activation='relu', name='dense_1')(inputs)\r\nx = layers.Dense(64, activation='relu', name='dense_2')(x)\r\noutputs = layers.Dense(10, activation='softmax', name='predictions')(x)\r\nmodel = keras.Model(inputs=inputs, outputs=outputs, name='3_layer_mlp')\r\n\r\nmodel.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Adam(lr=.001), metrics=[CustomMetric()])\r\n\r\nmodel.save(\"model/\", save_format='tf')\r\n\r\nnew_model = keras.models.load_model('model/', tf.keras.models.load_model ={'score': CustomMetric})\r\n```\r\n\r\n**Other info / logs**\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/sentim/Website/model_prediction/test_load_saved_model.py\", line 46, in <module>\r\n new_model = keras.models.load_model('model/', custom_objects={'score': CustomMetric})\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/keras/saving/save.py\", line 150, in load_model\r\n return saved_model_load.load(filepath, compile)\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/keras/saving/saved_model/load.py\", line 93, in load\r\n model._training_config)) # pylint: disable=protected-access\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/training/tracking/base.py\", line 457, in _method_wrapper\r\n result = method(self, *args, **kwargs)\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training.py\", line 356, in compile\r\n self._cache_output_metric_attributes(metrics, weighted_metrics)\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training.py\", line 1901, in _cache_output_metric_attributes\r\n metrics, self.output_names, output_shapes, self.loss_functions)\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training_utils.py\", line 813, in collect_per_output_metric_info\r\n metric_name = get_metric_name(metric, is_weighted)\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/keras/engine/training_utils.py\", line 987, in get_metric_name\r\n metric = metrics_module.get(metric)\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/keras/metrics.py\", line 2857, in get\r\n return deserialize(identifier)\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/keras/metrics.py\", line 2851, in deserialize\r\n printable_module_name='metric function')\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/keras/utils/generic_utils.py\", line 180, in deserialize_keras_object\r\n config, module_objects, custom_objects, printable_module_name)\r\n File \"/home/sentim/anaconda3/envs/py37/lib/python3.7/site-packages/tensorflow_core/python/keras/utils/generic_utils.py\", line 165, in class_and_config_for_serialized_keras_object\r\n raise ValueError('Unknown ' + printable_module_name + ': ' + class_name)\r\nValueError: Unknown metric function: CustomMetric\r\n```\r\n\r\n",
"comments": [
{
"body": "I have tried on colab with TF version 2.0 and was able to reproduce the issue.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/1c9190b3588867fa05dd7103b212bccb/untitled296.ipynb). Thanks!",
"created_at": "2019-10-24T09:01:32Z"
},
{
"body": "@AndersonHappens I think there is an issue with saving a model in *.tf version when the model has custom metrics. I have saved the model in *.h5 format and everything works as expected. Please check the [gist here](https://colab.sandbox.google.com/gist/jvishnuvardhan/5cd85f60f1d6e975ce65675227422b3e/untitled296.ipynb). Thanks!\r\n\r\nPlease close the issue if it was resolved for you. Thanks!",
"created_at": "2019-10-26T00:08:26Z"
},
{
"body": "@jvishnuvardhan While it does work in the h5 format, if I have saved a model to the tf format, I cannot load the model to resave it to the h5 format later (since I can't load the model in the first place), so ultimately this is still an issue that needs to be addressed.",
"created_at": "2019-10-28T16:09:49Z"
},
{
"body": "Here is a workaround for the meantime:\r\n```python\r\nfrom tensorflow.python.saved_model import loader_impl\r\nfrom tensorflow.python.keras.saving.saved_model import load as saved_model_load\r\n\r\nloader_impl.parse_saved_model(load_path)\r\nmodel = saved_model_load.load(load_path, custom_objects={\"custom_metric\": custom_metric})\r\n```",
"created_at": "2019-11-06T17:49:11Z"
},
{
"body": "same issue here, when you save the model in tf format, you can't re-load the model with custom_objects, this should be fixed.",
"created_at": "2019-12-12T01:48:11Z"
},
{
"body": "> Here is a workaround for the meantime:\r\n> \r\n> ```python\r\n> from tensorflow.python.saved_model import loader_impl\r\n> from tensorflow.python.keras.saving.saved_model import load as saved_model_load\r\n> \r\n> loader_impl.parse_saved_model(load_path)\r\n> model = saved_model_load.load(load_path, custom_objects={\"custom_metric\": custom_metric})\r\n> ```\r\n\r\nnot working at keras 2.3.1, tf 2.0.0\r\n```\r\nTypeError: load() got an unexpected keyword argument 'custom_objects'\r\n```",
"created_at": "2019-12-12T02:04:54Z"
},
{
"body": "> @jvishnuvardhan While it does work in the h5 format, if I have saved a model to the tf format, I cannot load the model to resave it to the h5 format later (since I can't load the model in the first place), so ultimately this is still an issue that needs to be addressed.\r\n\r\n@AndersonHappens Can you please check with the `tf-nightly`. I saved model in \"tf\" format, then loaded model and saved in \"h5\" format without any issues. Please check the [gist here](https://colab.sandbox.google.com/gist/jvishnuvardhan/9f3c879cdb48821e6b7554e4fe700e0b/untitled702.ipynb).\r\n\r\nPlease let us know what you think. Thanks.\r\n@JustinhoCHN can you please try `tf-nightly`. If you still have an issue, please open a new issue with a standalone code to reproduce the error.\r\n\r\nI am closing this issue as it was resolved in recent `tf-nightly`. Please feel free to open if the issue persists again. Thanks!",
"created_at": "2019-12-12T17:30:35Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33646\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33646\">No</a>\n",
"created_at": "2019-12-12T17:30:37Z"
},
{
"body": "@jvishnuvardhan This issue should not be closed. The loading as in your gist works, but once you use the model, e.g. to further train it you will get an error that the custom object is unkown.",
"created_at": "2019-12-15T17:07:52Z"
},
{
"body": "Here is a new workaround, not sure what changed that the old one does not work anymore:\r\n\r\n```python\r\nfrom tensorflow.python.saved_model import load as tf_load\r\nfrom tensorflow.python.keras.saving.saved_model.load import KerasObjectLoader, RevivedModel\r\nfrom tensorflow.python.keras.saving import saving_utils\r\n\r\ncustom_objects = {\"compute_loss\": loss}\r\nmodel = tf_load.load_internal(PATH_TO_MODEL, loader_cls=KerasObjectLoader)\r\nif isinstance(model, RevivedModel) and compile:\r\n if model._training_config is not None:\r\n model.compile(**saving_utils.compile_args_from_training_config(\r\n model._training_config, custom_objects))\r\n```",
"created_at": "2019-12-15T17:09:45Z"
},
{
"body": "@j-o-d-o Can you try adding one more line as follows and train the model (`loaded_my_new_model_saved_in_h5`).\r\n\r\n`loaded_my_new_model_saved_in_h5.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Adam(lr=.001), metrics=[CustomMetric()])`\r\n\r\nThanks!",
"created_at": "2019-12-16T18:58:02Z"
},
{
"body": "The models saved in h5 format seem to work fine, the issue is about models saved with SavedModel format (as explained here https://www.tensorflow.org/guide/saved_model)\r\n\r\nWhat is working is setting the compile flag to False and then compiling it on its own e.g.:\r\n```python\r\nimport tensorflow as tf\r\n\r\n# Save Keras Model as SavedModel (Keras model has some custom objects e.g. custom loss function)\r\ntf.saved_model.save(my_keras_model, EXPORT_DIR)\r\n...\r\n# Load the model and compile on its own (working)\r\nloaded_model = tf.keras.model.load(EXPORT_DIR, custom_objects={\"custom_loss\": my_custom_loss}, compile=False)\r\nmodel.compile(optimizer=my_optimizer, loss=my_custom_loss)\r\n# Load the model while also loading optimizer and compiling (failing with \"Unkown loss function: my_custom_loss\")\r\nloaded_model = tf.keras.model.load(EXPORT_DIR, custom_objects={\"custom_loss\": my_custom_loss}) # compile is set to True by default\r\n```\r\n\r\nThe point is:\r\n1) The default way of loading models fails if there are custom objects involved.\r\n2) By compiling yourself you are setting up a new optimizer instead of loading the previously trained models optimizer weights.\r\n\r\nMoreover I already submited a PR that would fix this: https://github.com/tensorflow/tensorflow/pull/34048. But it seems nobody bothers about it : /",
"created_at": "2019-12-17T08:16:18Z"
},
{
"body": "@j-o-d-o Can you please check using `model.save` after compile and the use `keras.models.load_model` to load the model. I tried it without any issue. [Here](https://colab.sandbox.google.com/gist/jvishnuvardhan/0f8c9294cfd1e8ae945f9edae36831ad/untitled702.ipynb) is the gist. Please run it with `tf-nightly`. Thanks!",
"created_at": "2020-02-04T21:58:51Z"
},
{
"body": "I am closing this issue as it was resolved. Please feel free to reopen if the issue didn't resolve for you. Thanks!",
"created_at": "2020-03-03T20:43:17Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33646\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33646\">No</a>\n",
"created_at": "2020-03-03T20:43:19Z"
},
{
"body": "@jvishnuvardhan `tf-nightly` works, but doesn't run on the GPU.\r\nPs.: regular `tensorflow` does run on GPU as expected.\r\n\r\nAlso, isn't nightly an unstable build?\r\nIs there a stable solution to the problem?\r\nOr when is the regular `tensorflow` expected to be fixed?",
"created_at": "2020-04-01T19:51:59Z"
},
{
"body": "@rodrigoruiz Can you please open a new issue with details and a simple standalone code to reproduce the issue? Currently `TF2.2.0rc2` is the latest release candidate. I expect there will be TF2.2 stable version will be released in the near future. Thanks!",
"created_at": "2020-04-01T20:28:12Z"
},
{
"body": "@jvishnuvardhan I think i figured it out, `tf-nightly` does not run on GPU, `tf-nightly-gpu` does... It's just that this is not specified in the docs.\r\nI'll just wait for the stable version I guess.",
"created_at": "2020-04-01T20:32:06Z"
},
{
"body": "Just tried this on 2.2.0. While it doesn't run into error, it seems to load an empty model. I'm using Feature Column API.",
"created_at": "2020-05-09T19:35:56Z"
},
{
"body": "@timatim Please create a new issue with a simple standalone to reproduce the issue. Thanks!",
"created_at": "2020-05-09T21:15:49Z"
},
{
"body": "I have this problem loading an .h5 model on TF 2.3.0.",
"created_at": "2020-11-06T17:35:31Z"
},
{
"body": "I am using tensorflow v 2.3 in R, saving and loading the model with save_model_tf() , load_model_tf() and I get the same error because of my custom metric balanced accuracy.\r\n\r\nI can't compile it afterwards because I am running a grid search for the optimizer learning rate, so it wont be practical.\r\n\r\nmy issue was resolved by adding my custom metric in the custom_objects:\r\nload_model_tf(path, custom_objects=list(\"CustomLayer\" = CustomLayer))",
"created_at": "2021-01-21T01:22:24Z"
}
],
"number": 33646,
"title": "ValueError: Unknown metric function: CustomMetric using custom metrics when loading tf saved model type with tf.keras.models.load_model "
}
|
{
"body": "```python\r\n# this fails if the loaded model is a SavedModel (saved with format=\"tf\") \r\nfrom tensorflow.keras import models\r\nmodel = models.load_model(\"/path/to/tf_model\", custom_objects={\"custom_loss\": custom_loss})\r\n```\r\n\r\nThe `custom_object` should be passed to the compile correctly (as it is with when loading a h5 file).\r\n\r\nShould fix: #33646\r\n",
"number": 34048,
"review_comments": [],
"title": "fix(keras): load_model should pass custom_objects when loading models in tf format"
}
|
{
"commits": [
{
"message": "keras: add custom objs loading tf format models"
}
],
"files": [
{
"diff": "@@ -147,7 +147,7 @@ def load_model(filepath, custom_objects=None, compile=True): # pylint: disable=\n \n if isinstance(filepath, six.string_types):\n loader_impl.parse_saved_model(filepath)\n- return saved_model_load.load(filepath, compile)\n+ return saved_model_load.load(filepath, custom_objects, compile)\n \n raise IOError(\n 'Unable to load model. Filepath is not an hdf5 file (or h5py is not '",
"filename": "tensorflow/python/keras/saving/save.py",
"status": "modified"
},
{
"diff": "@@ -63,7 +63,7 @@\n PUBLIC_ATTRIBUTES.add(constants.KERAS_ATTR)\n \n \n-def load(path, compile=True): # pylint: disable=redefined-builtin\n+def load(path, custom_objects=None, compile=True): # pylint: disable=redefined-builtin\n \"\"\"Loads Keras objects from a SavedModel.\n \n Any Keras layer or model saved to the SavedModel will be loaded back\n@@ -79,11 +79,17 @@ def load(path, compile=True): # pylint: disable=redefined-builtin\n \n Args:\n path: Path to SavedModel.\n+ custom_objects: Optional dictionary mapping names\n+ (strings) to custom classes or functions to be\n+ considered during deserialization.\n compile: If true, compile the model after loading it.\n \n Returns:\n Object loaded from SavedModel.\n \"\"\"\n+ if not custom_objects:\n+ custom_objects = {}\n+\n # TODO(kathywu): Add saving/loading of optimizer, compiled losses and metrics.\n # TODO(kathywu): Add code to load from objects that contain all endpoints\n model = tf_load.load_internal(path, loader_cls=KerasObjectLoader)\n@@ -96,7 +102,7 @@ def load(path, compile=True): # pylint: disable=redefined-builtin\n 'training_config', None)\n if training_config is not None:\n model.compile(**saving_utils.compile_args_from_training_config(\n- training_config))\n+ training_config, custom_objects))\n # pylint: disable=protected-access\n \n return model",
"filename": "tensorflow/python/keras/saving/saved_model/load.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): See script from Tensorflow training session and uploaded file below. Nb: There is no error with TF2.0.0 and python 3.6 or 3.7. The error occurs with TF2.0.0 and python 3.8.\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- TensorFlow installed from (source or binary): source\r\n- TensorFlow version (use command below): 2.0.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): 0.26.1\r\n- GCC/Compiler version (if compiling from source): 7.4.0\r\n- CUDA/cuDNN version: CUDA 10/cuDNN 7.6.4\r\n- GPU model and memory: NVidia RTX 2080 TI and 2080 MaxQ\r\n\r\n**Describe the current behavior**\r\n\r\nAfter running the code below (with the attached file), you get the following error:\r\n\r\n---------------------------------------------------------------------------\r\nAssertionError Traceback (most recent call last)\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/impl/api.py in converted_call(f, args, kwargs, caller_fn_scope, options)\r\n 525 options=options, autograph_module=tf_inspect.getmodule(converted_call))\r\n--> 526 converted_f = conversion.convert(target_entity, program_ctx)\r\n 527 \r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/impl/conversion.py in convert(entity, program_ctx)\r\n 324 \r\n--> 325 converted_entity_info = _convert_with_cache(entity, program_ctx,\r\n 326 free_nonglobal_var_names)\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/impl/conversion.py in _convert_with_cache(entity, program_ctx, free_nonglobal_var_names)\r\n 238 \r\n--> 239 nodes, converted_name, entity_info = convert_entity_to_ast(\r\n 240 entity, program_ctx)\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/impl/conversion.py in convert_entity_to_ast(o, program_ctx)\r\n 474 elif tf_inspect.ismethod(o):\r\n--> 475 nodes, name, entity_info = convert_func_to_ast(o, program_ctx)\r\n 476 elif hasattr(o, '__class__'):\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/impl/conversion.py in convert_func_to_ast(f, program_ctx, do_rename)\r\n 672 context = converter.EntityContext(namer, entity_info, program_ctx, new_name)\r\n--> 673 node = node_to_graph(node, context)\r\n 674 \r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/impl/conversion.py in node_to_graph(node, context)\r\n 702 node = converter.standard_analysis(node, context, is_initial=True)\r\n--> 703 node = converter.apply_(node, context, function_scopes)\r\n 704 node = converter.apply_(node, context, arg_defaults)\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/core/converter.py in apply_(node, context, converter_module)\r\n 408 node = standard_analysis(node, context)\r\n--> 409 node = converter_module.transform(node, context)\r\n 410 return node\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/converters/function_scopes.py in transform(node, ctx)\r\n 119 def transform(node, ctx):\r\n--> 120 return FunctionBodyTransformer(ctx).visit(node)\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/core/converter.py in visit(self, node)\r\n 345 try:\r\n--> 346 return super(Base, self).visit(node)\r\n 347 finally:\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/pyct/transformer.py in visit(self, node)\r\n 479 if not anno.hasanno(node, anno.Basic.SKIP_PROCESSING):\r\n--> 480 result = super(Base, self).visit(node)\r\n 481 self.ctx.current_origin = parent_origin\r\n\r\n/usr/local/lib/python3.8/ast.py in visit(self, node)\r\n 359 visitor = getattr(self, method, self.generic_visit)\r\n--> 360 return visitor(node)\r\n 361 \r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/converters/function_scopes.py in visit_FunctionDef(self, node)\r\n 101 \"\"\"\r\n--> 102 wrapped_body = templates.replace(\r\n 103 template,\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/pyct/templates.py in replace(template, **replacements)\r\n 268 for node in nodes:\r\n--> 269 node = ReplaceTransformer(replacements).visit(node)\r\n 270 if isinstance(node, (list, tuple)):\r\n\r\n/usr/local/lib/python3.8/ast.py in visit(self, node)\r\n 359 visitor = getattr(self, method, self.generic_visit)\r\n--> 360 return visitor(node)\r\n 361 \r\n\r\n/usr/local/lib/python3.8/ast.py in generic_visit(self, node)\r\n 435 if isinstance(value, AST):\r\n--> 436 value = self.visit(value)\r\n 437 if value is None:\r\n\r\n/usr/local/lib/python3.8/ast.py in visit(self, node)\r\n 359 visitor = getattr(self, method, self.generic_visit)\r\n--> 360 return visitor(node)\r\n 361 \r\n\r\n/usr/local/lib/python3.8/ast.py in generic_visit(self, node)\r\n 444 elif isinstance(old_value, AST):\r\n--> 445 new_node = self.visit(old_value)\r\n 446 if new_node is None:\r\n\r\n/usr/local/lib/python3.8/ast.py in visit(self, node)\r\n 359 visitor = getattr(self, method, self.generic_visit)\r\n--> 360 return visitor(node)\r\n 361 \r\n\r\n/usr/local/lib/python3.8/ast.py in generic_visit(self, node)\r\n 435 if isinstance(value, AST):\r\n--> 436 value = self.visit(value)\r\n 437 if value is None:\r\n\r\n/usr/local/lib/python3.8/ast.py in visit(self, node)\r\n 359 visitor = getattr(self, method, self.generic_visit)\r\n--> 360 return visitor(node)\r\n 361 \r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/pyct/templates.py in visit_Name(self, node)\r\n 199 \r\n--> 200 new_nodes = self._prepare_replacement(node, node.id)\r\n 201 \r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/pyct/templates.py in _prepare_replacement(self, replaced, key)\r\n 138 \r\n--> 139 new_nodes = ast_util.copy_clean(repl, preserve_annos=self.preserved_annos)\r\n 140 if isinstance(new_nodes, gast.AST):\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/pyct/ast_util.py in copy_clean(node, preserve_annos)\r\n 75 \"\"\"\r\n---> 76 return CleanCopier(preserve_annos).copy(node)\r\n 77 \r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/pyct/ast_util.py in copy(self, node)\r\n 53 if not f.startswith('__') and hasattr(node, f):\r\n---> 54 new_fields[f] = self.copy(getattr(node, f))\r\n 55 new_node = type(node)(**new_fields)\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/pyct/ast_util.py in copy(self, node)\r\n 40 if isinstance(node, list):\r\n---> 41 return [self.copy(n) for n in node]\r\n 42 elif isinstance(node, tuple):\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/pyct/ast_util.py in <listcomp>(.0)\r\n 40 if isinstance(node, list):\r\n---> 41 return [self.copy(n) for n in node]\r\n 42 elif isinstance(node, tuple):\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/pyct/ast_util.py in copy(self, node)\r\n 54 new_fields[f] = self.copy(getattr(node, f))\r\n---> 55 new_node = type(node)(**new_fields)\r\n 56 \r\n\r\n~/tf38/lib/python3.8/site-packages/gast/gast.py in create_node(self, *args, **kwargs)\r\n 9 nbparam = len(args) + len(kwargs)\r\n---> 10 assert nbparam in (0, len(Fields)), \\\r\n 11 \"Bad argument number for {}: {}, expecting {}\".\\\r\n\r\nAssertionError: Bad argument number for keyword: 1, expecting 2\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-10-8b26b7af23a7> in <module>\r\n----> 1 tf_model.fit(Xs_train[:, 0:1], y_train.reshape(-1, 1));\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/eager/def_function.py in __call__(self, *args, **kwds)\r\n 566 xla_context.Exit()\r\n 567 else:\r\n--> 568 result = self._call(*args, **kwds)\r\n 569 \r\n 570 if tracing_count == self._get_tracing_count():\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/eager/def_function.py in _call(self, *args, **kwds)\r\n 613 # This is the first call of __call__, so we have to initialize.\r\n 614 initializers = []\r\n--> 615 self._initialize(args, kwds, add_initializers_to=initializers)\r\n 616 finally:\r\n 617 # At this point we know that the initialization is complete (or less\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/eager/def_function.py in _initialize(self, args, kwds, add_initializers_to)\r\n 494 self._graph_deleter = FunctionDeleter(self._lifted_initializer_graph)\r\n 495 self._concrete_stateful_fn = (\r\n--> 496 self._stateful_fn._get_concrete_function_internal_garbage_collected( # pylint: disable=protected-access\r\n 497 *args, **kwds))\r\n 498 \r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/eager/function.py in _get_concrete_function_internal_garbage_collected(self, *args, **kwargs)\r\n 2363 args, kwargs = None, None\r\n 2364 with self._lock:\r\n-> 2365 graph_function, _, _ = self._maybe_define_function(args, kwargs)\r\n 2366 return graph_function\r\n 2367 \r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/eager/function.py in _maybe_define_function(self, args, kwargs)\r\n 2671 \r\n 2672 self._function_cache.missed.add(call_context_key)\r\n-> 2673 graph_function = self._create_graph_function(args, kwargs)\r\n 2674 self._function_cache.primary[cache_key] = graph_function\r\n 2675 return graph_function, args, kwargs\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/eager/function.py in _create_graph_function(self, args, kwargs, override_flat_arg_shapes)\r\n 2551 arg_names = base_arg_names + missing_arg_names\r\n 2552 graph_function = ConcreteFunction(\r\n-> 2553 func_graph_module.func_graph_from_py_func(\r\n 2554 self._name,\r\n 2555 self._python_function,\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/framework/func_graph.py in func_graph_from_py_func(name, python_func, args, kwargs, signature, func_graph, autograph, autograph_options, add_control_dependencies, arg_names, op_return_value, collections, capture_by_value, override_flat_arg_shapes)\r\n 956 converted_func)\r\n 957 \r\n--> 958 func_outputs = python_func(*func_args, **func_kwargs)\r\n 959 \r\n 960 # invariant: `func_outputs` contains only Tensors, CompositeTensors,\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/eager/def_function.py in wrapped_fn(*args, **kwds)\r\n 437 # __wrapped__ allows AutoGraph to swap in a converted function. We give\r\n 438 # the function a weak reference to itself to avoid a reference cycle.\r\n--> 439 return weak_wrapped_fn().__wrapped__(*args, **kwds)\r\n 440 weak_wrapped_fn = weakref.ref(wrapped_fn)\r\n 441 \r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/eager/function.py in bound_method_wrapper(*args, **kwargs)\r\n 3179 # However, the replacer is still responsible for attaching self properly.\r\n 3180 # TODO(mdan): Is it possible to do it here instead?\r\n-> 3181 return wrapped_fn(*args, **kwargs)\r\n 3182 weak_bound_method_wrapper = weakref.ref(bound_method_wrapper)\r\n 3183 \r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/framework/func_graph.py in wrapper(*args, **kwargs)\r\n 935 # TODO(mdan): Push this block higher in tf.function's call stack.\r\n 936 try:\r\n--> 937 return autograph.converted_call(\r\n 938 original_func,\r\n 939 args,\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/impl/api.py in converted_call(f, args, kwargs, caller_fn_scope, options)\r\n 552 'Cause: %s', target_entity, e)\r\n 553 else:\r\n--> 554 logging.warn(\r\n 555 'AutoGraph could not transform %s and will run it as-is.\\n'\r\n 556 'Please report this to the TensorFlow team. When filing the bug, set'\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/autograph/utils/ag_logging.py in warn(msg, *args, **kwargs)\r\n 144 \r\n 145 def warn(msg, *args, **kwargs):\r\n--> 146 logging.warn(msg, *args, **kwargs)\r\n 147 if echo_log_to_stdout:\r\n 148 _output_to_stdout('WARNING: ' + msg, *args, **kwargs)\r\n\r\n~/tf38/lib/python3.8/site-packages/tensorflow_core/python/platform/tf_logging.py in warn(msg, *args, **kwargs)\r\n 159 @tf_export(v1=['logging.warn'])\r\n 160 def warn(msg, *args, **kwargs):\r\n--> 161 get_logger().warning(msg, *args, **kwargs)\r\n 162 \r\n 163 \r\n\r\n/usr/local/lib/python3.8/logging/__init__.py in warning(self, msg, *args, **kwargs)\r\n 1444 \"\"\"\r\n 1445 if self.isEnabledFor(WARNING):\r\n-> 1446 self._log(WARNING, msg, args, **kwargs)\r\n 1447 \r\n 1448 def warn(self, msg, *args, **kwargs):\r\n\r\n/usr/local/lib/python3.8/logging/__init__.py in _log(self, level, msg, args, exc_info, extra, stack_info, stacklevel)\r\n 1563 #IronPython can use logging.\r\n 1564 try:\r\n-> 1565 fn, lno, func, sinfo = self.findCaller(stack_info, stacklevel)\r\n 1566 except ValueError: # pragma: no cover\r\n 1567 fn, lno, func = \"(unknown file)\", 0, \"(unknown function)\"\r\n\r\nTypeError: _logger_find_caller() takes from 0 to 1 positional arguments but 2 were given\r\n\r\n**Describe the expected behavior**\r\n\r\nThere should be no error. It works fine with TF2.0.0 and Python 3.6 or Python 3.7.\r\n\r\n**Code to reproduce the issue**\r\nProvide a reproducible test case that is the bare minimum necessary to generate the problem.\r\n\r\nimport tensorflow as tf\r\nimport numpy as np\r\nimport gzip\r\nimport json\r\nfrom sklearn.model_selection import ShuffleSplit\r\n\r\nwith gzip.open(\"small_data/cal_house.json.gz\", \"r\") as fin:\r\n housing = json.load(fin)\r\n \r\nfor train, test in ShuffleSplit(1, 0.2, random_state=42).split(housing['data']):\r\n X_train = np.array(housing['data'])[train].astype(np.float32)\r\n y_train = np.array(housing['target'])[train].astype(np.float32)\r\n X_test = np.array(housing['data'])[test].astype(np.float32)\r\n y_test = np.array(housing['target'])[test].astype(np.float32)\r\n\r\nX_mean = X_train.mean(axis=0)\r\nX_std = X_train.std(axis=0)\r\n\r\nXs_train = (X_train - X_mean) / X_std\r\nXs_test = (X_test - X_mean) / X_std\r\n\r\nclass LinearRegressionTF():\r\n def __init__(self, eta=.1):\r\n self.W = tf.Variable(0.)\r\n self.b = tf.Variable(0.)\r\n self.opt = tf.keras.optimizers.SGD(learning_rate=eta)\r\n \r\n def loss(self, X, y, return_func=False):\r\n def loss_():\r\n return tf.reduce_mean(tf.square(X * self.W + self.b - y))\r\n \r\n if not return_func:\r\n return loss_()\r\n \r\n return loss_\r\n\r\n @tf.function\r\n def fit(self, X, y, steps=1):\r\n for _ in range(steps):\r\n self.opt.minimize(self.loss(X, y, return_func=True), [self.W, self.b])\r\n\r\ntf_model = LinearRegressionTF()\r\n\r\ntf_model.fit(Xs_train[:, 0:1], y_train.reshape(-1, 1));\r\n\r\n[cal_house.json.gz](https://github.com/tensorflow/tensorflow/files/3780890/cal_house.json.gz)\r\n\r\n**Other info / logs**\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\nNil",
"comments": [
{
"body": "@dbonner \r\n\r\nI tried to reproduce the issue. However i am seeing the different error.`AttributeError: 'LinearRegressionTF' object has no attribute 'fit'` .Please, help me with the reproducible code . It helps in localizing the issue faster.",
"created_at": "2019-10-29T05:49:28Z"
},
{
"body": "@ravikyram \r\nI'm sorry the code is not properly indented in a number of places when it appears in github. I can't seem to edit it to get it to show properly. Please find an attached file (moved to next post) with the properly indented code that reproduces this error on my system when running in one cell in Jupyter Notebook.\r\nApologies .... See the next post for the correct file.",
"created_at": "2019-10-29T15:33:28Z"
},
{
"body": "@ravikyram \r\nI've finally got this right. Sorry to mess you around with this. Github markdown removed the underscores on the init part of the LinearRegressionTF() class when I pasted it in. This got transferred through to the code file. The correct code is attached. It runs fine in Python 3.7 but errors in Python 3.8. I have also removed the reference to the subdirectory \"small_data\" so you can run the code with the file \"cal_house.json.gz\" in the current working directory.\r\n[code_py38_tf2_error.txt](https://github.com/tensorflow/tensorflow/files/3786825/code_py38_tf2_error.txt)\r\n[cal_house.json.gz](https://github.com/tensorflow/tensorflow/files/3786826/cal_house.json.gz)\r\n\r\n",
"created_at": "2019-10-30T03:48:54Z"
},
{
"body": "Hi @ymodak,\r\nHave you had a chance to test the python 3.8 error I reported (Issue: #33799).\r\nAll the best,\r\nDan",
"created_at": "2019-11-03T06:33:12Z"
},
{
"body": "I am able to reproduce the issue with the following command on python 3.8 (master build):\r\n```\r\nbazel test -s --verbose_failures --disk_cache=/home/ubuntu/bazel \\\r\n //tensorflow/python:image_ops_test\r\n```\r\n\r\nHaven't figure out the reason yet.",
"created_at": "2019-11-03T17:48:31Z"
},
{
"body": "@dbonner @ymodak Added a PR #33953 for the fix. Please take a look.",
"created_at": "2019-11-03T20:02:57Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33799\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33799\">No</a>\n",
"created_at": "2019-11-07T11:24:21Z"
},
{
"body": "I recieved this error also when using tensorflow 1.13.2 + python 3.8 I am considering opening a separate issue. ",
"created_at": "2019-11-12T09:54:19Z"
}
],
"number": 33799,
"title": "TF 2.0.0 Python 3.8 TypeError: _logger_find_caller() takes from 0 to 1 positional arguments but 2 were given"
}
|
{
"body": "This fix tries to address the issue raised in #33799 where running tensorflow on python 3.8 (Ubuntu 18.04) raised the following error:\r\n```\r\nTypeError: _logger_find_caller() takes from 0 to 1 positional arguments but 2 were given\r\n```\r\n\r\nThe issue was that findCaller changed in Python 3.8\r\n\r\nThis PR fixes the issue.\r\n\r\nThis PR fixes #33799\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 33953,
"review_comments": [],
"title": "Fix TensorFlow on Python 3.8 logger issue"
}
|
{
"commits": [
{
"message": "Fix TensorFlow on Python 3.8 logger issue\n\nThis fix tries to address the issue raised in 33799\nwhere running tensorflow on python 3.8 (Ubuntu 18.04)\nraised the following error:\n```\nTypeError: _logger_find_caller() takes from 0 to 1 positional arguments but 2 were given\n```\n\nThe issue was that findCaller changed in Python 3.8\n\nThis PR fixes the issue.\n\nThis PR fixes 33799\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update comment explaining python 3.8 change for findCaller\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -57,9 +57,19 @@ def _get_caller(offset=3):\n f = f.f_back\n return None, None\n \n-\n-# The definition of `findCaller` changed in Python 3.2\n-if _sys.version_info.major >= 3 and _sys.version_info.minor >= 2:\n+# The definition of `findCaller` changed in Python 3.2,\n+# and further changed in Python 3.8\n+if _sys.version_info.major >= 3 and _sys.version_info.minor >= 8:\n+ def _logger_find_caller(stack_info=False, stacklevel=1): # pylint: disable=g-wrong-blank-lines\n+ code, frame = _get_caller(4)\n+ sinfo = None\n+ if stack_info:\n+ sinfo = '\\n'.join(_traceback.format_stack())\n+ if code:\n+ return (code.co_filename, frame.f_lineno, code.co_name, sinfo)\n+ else:\n+ return '(unknown file)', 0, '(unknown function)', sinfo\n+elif _sys.version_info.major >= 3 and _sys.version_info.minor >= 2:\n def _logger_find_caller(stack_info=False): # pylint: disable=g-wrong-blank-lines\n code, frame = _get_caller(4)\n sinfo = None",
"filename": "tensorflow/python/platform/tf_logging.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): just testing this https://www.tensorflow.org/tutorials/keras/basic_classification\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Windows 10 fully updated\r\n- TensorFlow installed from (source or binary): `pip3 install --user tensorflow-gpu==2.0.0-rc0`\r\n- TensorFlow version (use command below): `v2.0.0-beta1-5101-gc75bb66a99 2.0.0-rc0`\r\n- Python version: 3.7.4\r\n- CUDA/cuDNN version: 10.0\r\n- GPU model and memory: GeForce GTX 1660 Ti, 6 GB\r\n\r\n**Describe the current behavior**\r\nJust running a basic image classifier with Keras. Import data, create model, train, evaluate.\r\nI run `python script-name.py` in the Command Prompt.\r\n`model.evaluate()` prints out an insanely long progress bar at the end. It's many, MANY pages long, with Command Prompt already maximized (so one page is already a lot of characters). I have to scroll WAAAY UP to see the previous output.\r\n\r\n**Describe the expected behavior**\r\nI know I could turn off verbosity, but I would expect sane defaults for the progress bars printed by TF/Keras. And with `verbose=1` that thing is so huge, it's useless.\r\n\r\n**Code to reproduce the issue**\r\n```python\r\nfrom __future__ import absolute_import, division, print_function, unicode_literals\r\n\r\n# TensorFlow and tf.keras\r\nimport tensorflow as tf\r\nfrom tensorflow import keras\r\n\r\n# Helper libraries\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom pprint import pprint\r\n\r\n# CUDA vs CPU\r\nimport os\r\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = \"-1\"\r\n\r\nprint(tf.__version__)\r\n\r\n# load train/test data\r\nfashion_mnist = keras.datasets.fashion_mnist\r\n(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()\r\nclass_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',\r\n 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']\r\n\r\n# print shape/size for train/test data\r\nprint(train_images.shape, len(train_labels), test_images.shape, len(test_labels))\r\n\r\n# show first image\r\nplt.figure()\r\nplt.imshow(train_images[0])\r\nplt.colorbar()\r\nplt.grid(False)\r\n#plt.show()\r\n\r\n# normalize pixel values (0...1)\r\ntrain_images = train_images / 255.0\r\ntest_images = test_images / 255.0\r\n\r\n# show first 25 images, sanity check\r\nplt.figure(figsize=(10,10))\r\nfor i in range(25):\r\n plt.subplot(5,5,i+1)\r\n plt.xticks([])\r\n plt.yticks([])\r\n plt.grid(False)\r\n plt.imshow(train_images[i], cmap=plt.cm.binary)\r\n plt.xlabel(class_names[train_labels[i]])\r\n#plt.show()\r\n\r\n# build the model\r\n# flat 1D layer\r\n# dense 128-node layer\r\n# dense softmax output layer\r\nmodel = keras.Sequential([\r\n keras.layers.Flatten(input_shape=(28, 28)),\r\n keras.layers.Dense(128, activation=tf.nn.relu),\r\n keras.layers.Dense(10, activation=tf.nn.softmax)\r\n])\r\n\r\n# compile the model\r\nmodel.compile(optimizer='adam',\r\n loss='sparse_categorical_crossentropy',\r\n metrics=['accuracy'])\r\n\r\n# train the model\r\nmodel.fit(train_images, train_labels, epochs=5)\r\n\r\n# evaluate the model\r\ntest_loss, test_acc = model.evaluate(test_images, test_labels)\r\nprint('Test accuracy:', test_acc)\r\n```\r\n",
"comments": [
{
"body": "I tried on Google colab but it is working as expected.Please see the gist [here](https://colab.sandbox.google.com/gist/gadagashwini/4e8b0ca20a27ab518f6329aaf5479dd6/untitled127.ipynb).\r\nAnd, I could replicate the issue on my system by running it on terminal. Please see the screenshot below.\r\n\r\n Thnaks!",
"created_at": "2019-09-09T05:53:36Z"
},
{
"body": "Same problem here.\r\n\r\nCode:\r\n```python\r\nimport tensorflow as tf\r\nfrom tensorflow import keras\r\nprint('Version of TensorFlow:', tf.__version__)\r\nprint('Version of tf.keras:', tf.keras.__version__)\r\n\r\n# Import dataset\r\nfashion_mnist = keras.datasets.fashion_mnist\r\n(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()\r\n\r\n# Build and Compile the model\r\nmodel = keras.Sequential([\r\n keras.layers.Flatten(input_shape=(28, 28)),\r\n keras.layers.Dense(10, activation='softmax')\r\n])\r\nmodel.compile(optimizer='adam',\r\n loss='sparse_categorical_crossentropy',\r\n metrics=['accuracy']\r\n )\r\n\r\n# Train the model\r\nprint('Training')\r\nmodel.fit(train_images, train_labels, epochs=5)\r\n\r\n# Evaluate the model\r\nprint('Evaluating')\r\ntest_loss, test_acc = model.evaluate(test_images, test_labels, verbose=1)\r\nprint('\\nTest accuracy:', test_acc)\r\n```\r\n\r\nOutput:\r\n\r\nNotice how short the slider is. It is all filled with \"=\" signs.",
"created_at": "2019-09-09T08:38:13Z"
},
{
"body": "I confirm I am seeing the issue too. The eval progress bar seems to be broken. Adding a batch size and a number of steps does not change the erroneous behavior:\r\n\r\nmodel.evaluate(test_images, test_labels, verbose=1, batch_size=1000, steps=10)\r\nExpecting exactly 10 progress steps with an eval dataset of 10,000 elements\r\nGetting many many steps....",
"created_at": "2019-09-09T21:24:35Z"
},
{
"body": "Same issue here. Even on the official tutorial page, the progress bar is extremely long. \r\n[https://www.tensorflow.org/tutorials/keras/classification](url)",
"created_at": "2019-10-01T03:59:30Z"
},
{
"body": "@qlzh727 Could this be related to the training_v2 loop?",
"created_at": "2019-10-01T18:44:02Z"
},
{
"body": "Very likely.",
"created_at": "2019-10-01T18:59:24Z"
},
{
"body": "https://github.com/tensorflow/tensorflow/blob/f9ad945a479caccca9002dcfe0e9623e3b753360/tensorflow/python/keras/engine/training_v2.py#L448\r\n`samples=use_sample` should be `samples=total_samples`",
"created_at": "2019-11-01T17:42:12Z"
},
{
"body": "@djshen Thanks for the find! Agreed, would you please submit a PR to fix this? You can add me as a reviewer, I will approve",
"created_at": "2019-11-01T18:26:53Z"
},
{
"body": "@omalleyt12 I created a PR https://github.com/tensorflow/tensorflow/pull/33921",
"created_at": "2019-11-01T19:38:46Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32320\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32320\">No</a>\n",
"created_at": "2019-11-01T21:39:50Z"
},
{
"body": "same here, is going to be merged in 2.1?",
"created_at": "2019-12-28T18:14:22Z"
},
{
"body": "Yes this should be fixed in 2.1",
"created_at": "2020-01-02T18:41:43Z"
}
],
"number": 32320,
"title": "keras model.evaluate() progress bar WAY too long by default"
}
|
{
"body": "Fix #32320 and #32286\r\n\r\nI also wrote a simple test case to check the value of `params.['samples']` after `model.evaluate()`.\r\n```python\r\nimport numpy as np\r\nfrom tensorflow.python import keras\r\nfrom tensorflow.python.keras import keras_parameterized\r\nfrom tensorflow.python.keras import testing_utils\r\nfrom tensorflow.python.keras.callbacks import Callback\r\nfrom tensorflow.python.platform import test\r\n\r\n\r\nclass TestCase(keras_parameterized.TestCase):\r\n def test_callback_params_samples(self):\r\n x, y = np.ones((64, 3)), np.ones((64, 2))\r\n model = testing_utils.get_small_sequential_mlp(\r\n num_hidden=10, num_classes=2, input_dim=3)\r\n model.compile('sgd', 'mse')\r\n callback = Callback()\r\n model.evaluate(x, y, callbacks=[callback])\r\n self.assertEqual(callback.params['samples'], 64)\r\n\r\n\r\nif __name__ == '__main__':\r\n test.main()\r\n```\r\nWhere should I put this test case?\r\n\r\nThe test output before this PR:\r\n```\r\n64/1 [================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================] - 0s 845us/sample - loss: 0.3011\r\n[ FAILED ] TestCase.test_callback_params_samples\r\n[ RUN ] TestCase.test_session\r\n[ SKIPPED ] TestCase.test_session\r\n======================================================================\r\nFAIL: test_callback_params_samples (__main__.TestCase)\r\ntest_callback_params_samples (__main__.TestCase)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"d.py\", line 17, in test_callback_params_samples\r\n self.assertEqual(callback.params['samples'], 64)\r\nAssertionError: True != 64\r\n\r\n----------------------------------------------------------------------\r\nRan 2 tests in 0.240s\r\n\r\nFAILED (failures=1, skipped=1)\r\n```\r\nThe test output after this PR:\r\n```\r\n64/64 [==============================] - 0s 1ms/sample - loss: 0.3011\r\n[ OK ] TestCase.test_callback_params_samples\r\n[ RUN ] TestCase.test_session\r\n[ SKIPPED ] TestCase.test_session\r\n----------------------------------------------------------------------\r\nRan 2 tests in 0.261s\r\n\r\nOK (skipped=1)\r\n```",
"number": 33921,
"review_comments": [],
"title": "Fix the progress bar of keras.Model.evaluate()"
}
|
{
"commits": [
{
"message": "Fix the progress bar of keras.Model.evaluate()"
},
{
"message": "Update callbacks_test.py\n\nAdd a test case to check the value of `callback.params['samples']` after `model.evaluate()`"
}
],
"files": [
{
"diff": "@@ -1377,6 +1377,15 @@ def test_RemoteMonitorWithJsonPayload(self):\n validation_data=(x_test, y_test),\n callbacks=cbks,\n epochs=1)\n+ \n+ def test_callback_params_samples(self):\n+ x, y = np.ones((64, 3)), np.ones((64, 2))\n+ model = testing_utils.get_small_sequential_mlp(\n+ num_hidden=10, num_classes=2, input_dim=3)\n+ model.compile('sgd', 'mse')\n+ callback = keras.callbacks.Callback()\n+ model.evaluate(x, y, callbacks=[callback])\n+ self.assertEqual(callback.params['samples'], 64)\n \n \n # A summary that was emitted during a test. Fields:",
"filename": "tensorflow/python/keras/callbacks_test.py",
"status": "modified"
},
{
"diff": "@@ -445,7 +445,7 @@ def _model_iteration(\n batch_size=batch_size,\n epochs=1,\n steps_per_epoch=steps,\n- samples=use_sample,\n+ samples=total_samples,\n count_mode='samples' if use_sample else 'steps',\n verbose=0, # Handle ProgBarLogger separately in this loop.\n mode=mode)",
"filename": "tensorflow/python/keras/engine/training_v2.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):\r\n - **Fedora 30**\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary):\r\n - **(binary): pip install tensorflow==2.0.0-rc0**\r\n- TensorFlow version (use command below):\r\n - **v2.0.0-beta1-5101-gc75bb66 2.0.0-rc0**\r\n- Python version:\r\n - **Python 3.7.4**\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version:\r\n- GPU model and memory:\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\n\r\nRunning the code, I get an output flooded with hundreds of thousands of `=` characters when calling `model.evaluate()`.\r\n\r\n```\r\nTrain on 60000 samples\r\nEpoch 1/5\r\n60000/60000 [==============================] - 3s 43us/sample - loss: 0.5010 - accuracy: 0.8228\r\nEpoch 2/5\r\n60000/60000 [==============================] - 2s 38us/sample - loss: 0.3766 - accuracy: 0.8639\r\nEpoch 3/5\r\n60000/60000 [==============================] - 2s 38us/sample - loss: 0.3408 - accuracy: 0.8753\r\nEpoch 4/5\r\n60000/60000 [==============================] - 2s 37us/sample - loss: 0.3155 - accuracy: 0.8839\r\nEpoch 5/5\r\n60000/60000 [==============================] - 2s 38us/sample - loss: 0.2980 - accuracy: 0.8903\r\n10000/1 [==================================================================\r\n===========================================================================\r\n===========================================================================\r\n===========================================================================\r\n===========================================================================\r\n===========================================================================\r\n===========================================================================\r\n===========================================================================\r\n...\r\n... Literally hundreds of thousands of `=` ...\r\n...\r\n===========================================================================\r\n===========================================================================\r\n===========================================================================\r\n===========================================================================\r\n===========================================================================\r\n===========================================================================\r\n===========================================] - 0s 26us/sample - loss: 0.2803 - accuracy: 0.8673\r\n\r\n```\r\n\r\n**Describe the expected behavior**\r\n\r\n```\r\nTrain on 60000 samples\r\nEpoch 1/5\r\n60000/60000 [==============================] - 3s 43us/sample - loss: 0.5010 - accuracy: 0.8228\r\nEpoch 2/5\r\n60000/60000 [==============================] - 2s 38us/sample - loss: 0.3766 - accuracy: 0.8639\r\nEpoch 3/5\r\n60000/60000 [==============================] - 2s 38us/sample - loss: 0.3408 - accuracy: 0.8753\r\nEpoch 4/5\r\n60000/60000 [==============================] - 2s 37us/sample - loss: 0.3155 - accuracy: 0.8839\r\nEpoch 5/5\r\n60000/60000 [==============================] - 2s 38us/sample - loss: 0.2980 - accuracy: 0.8903\r\n10000/10000 [==============================] - 0s 26us/sample - loss: 0.2803 - accuracy: 0.8673\r\n```\r\n\r\n**Code to reproduce the issue**\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\nmnist = tf.keras.datasets.fashion_mnist\r\n(training_images, training_labels), (test_images, test_labels) = mnist.load_data()\r\ntraining_images = training_images / 255.0\r\ntest_images = test_images / 255.0\r\nmodel = tf.keras.models.Sequential([\r\n tf.keras.layers.Flatten(),\r\n tf.keras.layers.Dense(128, activation=tf.nn.relu),\r\n tf.keras.layers.Dense(10, activation=tf.nn.softmax)\r\n])\r\nmodel.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])\r\nmodel.fit(training_images, training_labels, epochs=5)\r\n\r\ntest_loss = model.evaluate(test_images, test_labels)\r\n```\r\n\r\n**Other info / logs**\r\n\r\nRunning this code in a Jupyter Notebook results in a performance penalty for the huge, unnecessary output.\r\n",
"comments": [
{
"body": "Perhaps you can use semi-verbose by setting ```verbose=2``` to avoid repeated logging of ```=``` character.\r\n[GitHub_Gist](https://colab.sandbox.google.com/gist/ymodak/da242ce544a5102fce8eddf002b9ef10/github_issue_32286.ipynb)\r\n```python\r\ntest_loss = model.evaluate(test_images, test_labels, verbose=2)\r\n```",
"created_at": "2019-09-06T17:02:16Z"
},
{
"body": "@ymodak Yeah, that is not a problem, I can set verbose to 0 as well, but I think it is a bug anyway. Note the `10000/1` in the progress bar, instead of `10000/10000`. I think that is unexpected. :wink:",
"created_at": "2019-09-06T17:49:37Z"
},
{
"body": "same problem here\r\nhttps://github.com/tensorflow/tensorflow/issues/32320#issuecomment-548883188",
"created_at": "2019-11-01T17:45:37Z"
},
{
"body": "@Peque This has been resolved recently in `tf-nightly` which is `2.1.0-dev20191108` that will be released in the future. I am closing this issue. Please check the gist [here](https://colab.sandbox.google.com/gist/jvishnuvardhan/5ead8e4a4613f9bf58996093154d1290/untitled634.ipynb).\r\n\r\nPlease feel free to open the issue if it persists again. Thanks!",
"created_at": "2019-11-08T16:44:49Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32286\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32286\">No</a>\n",
"created_at": "2019-11-08T16:44:51Z"
},
{
"body": "this issue still seems to still persist with the current tf-nightly - has anyone found a solution? ",
"created_at": "2020-07-10T20:07:28Z"
},
{
"body": "@warriorgiggles Can you please create a new issue with a simple standalone code to reproduce the issue? Thanks!",
"created_at": "2020-07-10T20:21:36Z"
}
],
"number": 32286,
"title": "Simple `model.evaluate()` example floods output with `=` characters"
}
|
{
"body": "Fix #32320 and #32286\r\n\r\nI also wrote a simple test case to check the value of `params.['samples']` after `model.evaluate()`.\r\n```python\r\nimport numpy as np\r\nfrom tensorflow.python import keras\r\nfrom tensorflow.python.keras import keras_parameterized\r\nfrom tensorflow.python.keras import testing_utils\r\nfrom tensorflow.python.keras.callbacks import Callback\r\nfrom tensorflow.python.platform import test\r\n\r\n\r\nclass TestCase(keras_parameterized.TestCase):\r\n def test_callback_params_samples(self):\r\n x, y = np.ones((64, 3)), np.ones((64, 2))\r\n model = testing_utils.get_small_sequential_mlp(\r\n num_hidden=10, num_classes=2, input_dim=3)\r\n model.compile('sgd', 'mse')\r\n callback = Callback()\r\n model.evaluate(x, y, callbacks=[callback])\r\n self.assertEqual(callback.params['samples'], 64)\r\n\r\n\r\nif __name__ == '__main__':\r\n test.main()\r\n```\r\nWhere should I put this test case?\r\n\r\nThe test output before this PR:\r\n```\r\n64/1 [================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================] - 0s 845us/sample - loss: 0.3011\r\n[ FAILED ] TestCase.test_callback_params_samples\r\n[ RUN ] TestCase.test_session\r\n[ SKIPPED ] TestCase.test_session\r\n======================================================================\r\nFAIL: test_callback_params_samples (__main__.TestCase)\r\ntest_callback_params_samples (__main__.TestCase)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"d.py\", line 17, in test_callback_params_samples\r\n self.assertEqual(callback.params['samples'], 64)\r\nAssertionError: True != 64\r\n\r\n----------------------------------------------------------------------\r\nRan 2 tests in 0.240s\r\n\r\nFAILED (failures=1, skipped=1)\r\n```\r\nThe test output after this PR:\r\n```\r\n64/64 [==============================] - 0s 1ms/sample - loss: 0.3011\r\n[ OK ] TestCase.test_callback_params_samples\r\n[ RUN ] TestCase.test_session\r\n[ SKIPPED ] TestCase.test_session\r\n----------------------------------------------------------------------\r\nRan 2 tests in 0.261s\r\n\r\nOK (skipped=1)\r\n```",
"number": 33921,
"review_comments": [],
"title": "Fix the progress bar of keras.Model.evaluate()"
}
|
{
"commits": [
{
"message": "Fix the progress bar of keras.Model.evaluate()"
},
{
"message": "Update callbacks_test.py\n\nAdd a test case to check the value of `callback.params['samples']` after `model.evaluate()`"
}
],
"files": [
{
"diff": "@@ -1377,6 +1377,15 @@ def test_RemoteMonitorWithJsonPayload(self):\n validation_data=(x_test, y_test),\n callbacks=cbks,\n epochs=1)\n+ \n+ def test_callback_params_samples(self):\n+ x, y = np.ones((64, 3)), np.ones((64, 2))\n+ model = testing_utils.get_small_sequential_mlp(\n+ num_hidden=10, num_classes=2, input_dim=3)\n+ model.compile('sgd', 'mse')\n+ callback = keras.callbacks.Callback()\n+ model.evaluate(x, y, callbacks=[callback])\n+ self.assertEqual(callback.params['samples'], 64)\n \n \n # A summary that was emitted during a test. Fields:",
"filename": "tensorflow/python/keras/callbacks_test.py",
"status": "modified"
},
{
"diff": "@@ -445,7 +445,7 @@ def _model_iteration(\n batch_size=batch_size,\n epochs=1,\n steps_per_epoch=steps,\n- samples=use_sample,\n+ samples=total_samples,\n count_mode='samples' if use_sample else 'steps',\n verbose=0, # Handle ProgBarLogger separately in this loop.\n mode=mode)",
"filename": "tensorflow/python/keras/engine/training_v2.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04 aarch64\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): source\r\n- TensorFlow version (use command below) 2.0.0\r\n- Python version: 3.6.8\r\n- Bazel version (if compiling from source): 0.29.0\r\n- GCC/Compiler version (if compiling from source): 7.4\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\nWhen fitting a model with ImageDataGenerator, it raises this error \"Data adapters should be mutually exclusive for handling inputs. Found multiple adapters 'GeneratorDataAdapter', 'KerasSequenceAdapter' to handle\". \r\n\r\n**Describe the expected behavior**\r\n1. Log warning message if multiple data adapters found, instead of raising an error\r\n2. Use the first available data adapter\r\n\r\n**Code to reproduce the issue**\r\nPlease refer to link below:\r\nhttps://colab.research.google.com/github/tensorflow/examples/blob/master/courses/udacity_intro_to_tensorflow_for_deep_learning/l05c02_dogs_vs_cats_with_augmentation.ipynb\r\n\r\nI connected to my local jupyter instance with Colab UI.\r\n\r\n```python\r\nBATCH_SIZE = 100\r\nIMG_SHAPE = 150\r\n\r\nimage_gen = ImageDataGenerator(rescale=1./255, horizontal_flip=True)\r\ntrain_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE,\r\n directory=train_dir,\r\n shuffle=True,\r\n target_size=(IMG_SHAPE,IMG_SHAPE))\r\nval_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE,\r\n directory=val_dir,\r\n shuffle=True,\r\n target_size=(IMG_SHAPE,IMG_SHAPE))\r\nmodel = tf.keras.models.Sequential([\r\n tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)),\r\n tf.keras.layers.MaxPooling2D(2, 2),\r\n\r\n tf.keras.layers.Conv2D(64, (3,3), activation='relu'),\r\n tf.keras.layers.MaxPooling2D(2,2),\r\n\r\n tf.keras.layers.Conv2D(128, (3,3), activation='relu'),\r\n tf.keras.layers.MaxPooling2D(2,2),\r\n\r\n tf.keras.layers.Conv2D(128, (3,3), activation='relu'),\r\n tf.keras.layers.MaxPooling2D(2,2),\r\n\r\n tf.keras.layers.Dropout(0.5),\r\n tf.keras.layers.Flatten(),\r\n tf.keras.layers.Dense(512, activation='relu'),\r\n tf.keras.layers.Dense(2, activation='softmax')\r\n])\r\nmodel.compile(optimizer='adam',\r\n loss='sparse_categorical_crossentropy',\r\n metrics=['accuracy'])\r\nepochs = 100\r\nmodel.fit(\r\n train_data_gen,\r\n steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))),\r\n epochs=epochs,\r\n validation_data=val_data_gen, \r\n validation_steps=int(np.ceil(total_val / float(BATCH_SIZE)))\r\n)\r\n```\r\n\r\nTo avoid this issue, I'll have to manually exclude \"KerasSequenceAdapter\" before calling `model.fit`\r\n\r\n```python\r\nfrom tensorflow.python.keras.engine import data_adapter\r\nfrom tensorflow.python.keras.engine.data_adapter import ListsOfScalarsDataAdapter\r\nfrom tensorflow.python.keras.engine.data_adapter import TensorLikeDataAdapter\r\nfrom tensorflow.python.keras.engine.data_adapter import GenericArrayLikeDataAdapter\r\nfrom tensorflow.python.keras.engine.data_adapter import DatasetAdapter\r\nfrom tensorflow.python.keras.engine.data_adapter import GeneratorDataAdapter\r\nfrom tensorflow.python.keras.engine.data_adapter import CompositeTensorDataAdapter\r\n\r\ndata_adapter.ALL_ADAPTER_CLS = [\r\n ListsOfScalarsDataAdapter,\r\n TensorLikeDataAdapter,\r\n GenericArrayLikeDataAdapter,\r\n DatasetAdapter,\r\n GeneratorDataAdapter,\r\n# tensorflow.python.keras.engine.data_adapter.KerasSequenceAdapter,\r\n CompositeTensorDataAdapter \r\n]\r\n\r\ndata_adapter.ALL_ADAPTER_CLS\r\n```\r\n\r\n**Other info / logs**\r\nN/A.\r\n",
"comments": [
{
"body": "Humm, seems that the Image Iterator class implements the interface for both generator and keras sequence object. Let me take a closer look to fix the issue.",
"created_at": "2019-11-01T20:11:31Z"
},
{
"body": "Hey, I think we did some recent update for data_adapter which might fix this issue. Could u have a try with latest nightly?\r\n\r\nhttps://github.com/tensorflow/tensorflow/commit/ac20030c96d37e980333b604402ef6dba48ef5e2",
"created_at": "2019-11-14T18:09:21Z"
},
{
"body": "Sure I will, thanks btw~",
"created_at": "2019-11-15T02:14:49Z"
},
{
"body": "@qlzh727 The fix works! Thank you!\r\n\r\n",
"created_at": "2019-11-27T11:24:24Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33811\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33811\">No</a>\n",
"created_at": "2019-11-27T11:24:26Z"
},
{
"body": "@qlzh727, I'm having this same problem under TF 2.2, TF2.3, and tf-nightly (as of yesterday). The problem seems to be identical in description to that of @gekowa. Any advice? Here is my system info...\r\n\r\n**System information**\r\n\r\n Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n TensorFlow installed from (source or binary): binary\r\n TensorFlow version (use command below): 2.2.0 (also tried 2.3 and tf-nightly)\r\n Python version: 3.6.9\r\n Bazel version (if compiling from source):\r\n GCC/Compiler version (if compiling from source):\r\n CUDA/cuDNN version: 10.1 / 7.6.5\r\n GPU model and memory: RTX 2080 Super, 8 GB\r\n",
"created_at": "2020-07-11T15:18:14Z"
}
],
"number": 33811,
"title": "Got \"Data adapters should be mutually exclusive for handling inputs. Found multiple adapters to handle\" error when calling `model.fit` with ImageDataGenerator"
}
|
{
"body": "Hopefully can solve issue #33811",
"number": 33904,
"review_comments": [],
"title": "Hopefully can solve issue #33811"
}
|
{
"commits": [
{
"message": "Use the first available adapter"
},
{
"message": "Merge pull request #1 from tensorflow/master\n\nMerge from TensorFlow"
},
{
"message": "Sort the layers before saving to hdf5"
}
],
"files": [
{
"diff": "@@ -987,7 +987,7 @@ def select_data_adapter(x, y):\n \"input: {}, {}\".format(\n _type_name(x), _type_name(y)))\n elif len(adapter_cls) > 1:\n- raise RuntimeError(\n+ logging.warn(\n \"Data adapters should be mutually exclusive for \"\n \"handling inputs. Found multiple adapters {} to handle \"\n \"input: {}, {}\".format(",
"filename": "tensorflow/python/keras/engine/data_adapter.py",
"status": "modified"
},
{
"diff": "@@ -19,9 +19,12 @@\n from __future__ import division\n from __future__ import print_function\n \n+\n import json\n import os\n \n+from operator import attrgetter\n+\n import numpy as np\n from six.moves import zip # pylint: disable=redefined-builtin\n \n@@ -621,6 +624,7 @@ def save_weights_to_hdf5_group(f, layers):\n f.attrs['backend'] = K.backend().encode('utf8')\n f.attrs['keras_version'] = str(keras_version).encode('utf8')\n \n+ layers.sort(key=attrgetter('name'))\n for layer in layers:\n g = f.create_group(layer.name)\n weights = _legacy_weights(layer)",
"filename": "tensorflow/python/keras/saving/hdf5_format.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):\r\nyes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):\r\nLinux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\nna\r\n- TensorFlow installed from (source or binary):\r\nbinary\r\n- TensorFlow version (use command below):\r\nv2.0.0-rc2-26-g64c3d38 2.0.0\r\n- Python version:\r\nPython 3.7.4\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version:\r\ncuda 10.0\r\n- GPU model and memory:\r\nP100 / 16GB\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\n\r\nWhen an error is caught using the `tf.data.experimental.ignore_errors` on a zipped dataset, only the faulty dataset drops an element. The datasets are therefore desynchronized.\r\n\r\n**Describe the expected behavior**\r\n\r\nDatasets should stay synchronized by dropping an element from both datasets.\r\n\r\n**Code to reproduce the issue**\r\n\r\n```\r\ngood_dataset = tf.data.Dataset.from_tensor_slices([1., 2., 0., 4.])\r\nbad_dataset = good_dataset.map(lambda x: tf.debugging.check_numerics(1. / x, \"error\"))\r\n\r\ndataset = tf.data.Dataset.zip((bad_dataset, good_dataset))\r\ndataset = dataset.apply(tf.data.experimental.ignore_errors())\r\n\r\nfor bad, good in dataset:\r\n print(float(good), float(bad))\r\n\r\n1.0 1.0\r\n2.0 0.5\r\n0.0 0.25\r\n```\r\n\r\n\r\n**Other info / logs**\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\n",
"comments": [
{
"body": "I could reproduce the issue with Tf 2.0.0. Please see the gist [here](https://colab.sandbox.google.com/gist/gadagashwini/48e54114ef599b79cd9d09e4a7fb9736/untitled201.ipynb). Thanks!",
"created_at": "2019-10-16T06:52:50Z"
},
{
"body": "This is working as intended. The good dataset dropped `0.0` while the bad dataset dropped `1 / 0.0`.\r\n\r\n@scharron What output would you expect for your example?",
"created_at": "2019-10-30T00:31:24Z"
},
{
"body": "@jsimsa Oops sorry I went too fast, I fixed the code to reproduce\r\n\r\n(if zipping `good` then `bad` it works, but the reverse does not)\r\n ",
"created_at": "2019-10-31T10:25:17Z"
},
{
"body": "I think the issue is that, in case of zip, when error or end-of-sequence encountered the remaining components are not \"flushed out\". So out-of-sync happens when ignore_errors is in play.\r\n\r\nCreated a PR #33887, think this could fix the issue.",
"created_at": "2019-10-31T15:12:27Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33383\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33383\">No</a>\n",
"created_at": "2019-11-01T23:01:08Z"
},
{
"body": "Thanks !\r\n\r\nWouldn't it be possible and useful to also issue a warning if the `tf.data.experimental.ignore_errors` is applied to any Dataset used as input to `tf.data.Dataset.zip`.\r\n\r\nThis could also result in datasets desynchronization if any of the zipped datasets drops any item, and in my opinion shouldn't be the behaviour of a `zip` function.\r\n\r\n\r\n\r\n ",
"created_at": "2019-11-04T14:35:26Z"
}
],
"number": 33383,
"title": "Desynchronized zipped datasets when using tf.data.experimental.ignore_errors"
}
|
{
"body": "This PR tries to address the issue raised in #33383 where ignore_errors combined with tf.data.Dataset.zip will be out-of-sync for component.\r\n\r\nThe issue was that, in case of zip, remaining components were\r\nnot flushed out when end-of-sequence of error encountered.\r\n\r\nThis PR fixes the isuse.\r\n\r\nThis PR fixes #33383.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 33887,
"review_comments": [
{
"body": "This could be `*end_of_sequence |= end_of_sequence_component`",
"created_at": "2019-10-31T15:59:04Z"
},
{
"body": "This could be `status.Update(status_component)`.",
"created_at": "2019-10-31T15:59:23Z"
},
{
"body": "nit: rename `end_of_sequence_component` to `component_end_of_sequence`",
"created_at": "2019-10-31T15:59:47Z"
},
{
"body": "nit: rename `status_component` to `component_status`",
"created_at": "2019-10-31T16:00:04Z"
},
{
"body": "I don't think you need to do the flush for `*end_of_sequence == true`.",
"created_at": "2019-10-31T16:01:24Z"
},
{
"body": "This comment should be updated to:\r\n\r\n```\r\n// Even if an error is encountered for one of the components, we need to make sure\r\n// to advance all components, to keep them in sync.",
"created_at": "2019-10-31T18:08:31Z"
},
{
"body": "Thanks @jsimsa! Yes there is no need to flush the remaining components when EOF is reached.",
"created_at": "2019-10-31T21:55:20Z"
},
{
"body": "You don't need the if statement. `status.Update(component_status)` only updates `status` if it is OK.",
"created_at": "2019-10-31T22:03:54Z"
},
{
"body": "indentation seems off here",
"created_at": "2019-10-31T22:04:10Z"
},
{
"body": "@jsimsa Thanks! Didn't know this usage before. Updated.",
"created_at": "2019-10-31T22:21:23Z"
},
{
"body": "Updated.",
"created_at": "2019-10-31T22:21:35Z"
},
{
"body": "This could be further simplified to:\r\n\r\n```\r\nstatus.Update(input_impl->GetNext(ctx, &input_tensors, &component_end_of_sequence));\r\n*end_of_sequence |= component_end_of_sequence;\r\n```",
"created_at": "2019-10-31T22:48:35Z"
},
{
"body": "Thanks @jsimsa! This looks even better.",
"created_at": "2019-10-31T23:33:09Z"
}
],
"title": "Fix out-of-sync issue in ignore_errors with tf.data.Dataset.zip"
}
|
{
"commits": [
{
"message": "Fix out-of-sync issue in ignore_errors with tf.data.Dataset.zip\n\nThis PR tries to address the issue raised in 33383 where\nignore_errors combined with tf.data.Dataset.zip will be out-of-sync\nfor component.\n\nThe issue was that, in case of zip, remaining components were\nnot flushed out when end-of-sequence of error encountered.\n\nThis PR fixes the isuse.\n\nThis PR fixes 33383.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub issue 33383\n\nwhere ignore_erorrs combined with tf.data.Dataset.zip could\ncause out-of-sync for remaining components.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update based on feedback, as there is no need to flush when end-of-sequence is encountered.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Use status.Update(component_status) and removed unneeded check\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -136,21 +136,31 @@ class ZipDatasetOp::Dataset : public DatasetBase {\n }\n out_tensors->clear();\n out_tensors->reserve(dataset()->output_dtypes().size());\n+ Status status = Status::OK();\n+ *end_of_sequence = false;\n for (const auto& input_impl : input_impls_) {\n std::vector<Tensor> input_tensors;\n- TF_RETURN_IF_ERROR(\n- input_impl->GetNext(ctx, &input_tensors, end_of_sequence));\n+ bool component_end_of_sequence = false;\n+ status.Update(input_impl->GetNext(ctx, &input_tensors, &component_end_of_sequence));\n+ *end_of_sequence |= component_end_of_sequence;\n+ // Even if an error is encountered for one of the components,\n+ // we need to make sure to advance all components, to keep them in sync.\n+ if (!status.ok()) {\n+ continue;\n+ }\n if (*end_of_sequence) {\n break;\n }\n out_tensors->insert(out_tensors->end(), input_tensors.begin(),\n input_tensors.end());\n }\n- if (*end_of_sequence) {\n+ if (*end_of_sequence || !status.ok()) {\n out_tensors->clear();\n+ }\n+ if (*end_of_sequence) {\n input_impls_.clear();\n }\n- return Status::OK();\n+ return status;\n }\n \n protected:",
"filename": "tensorflow/core/kernels/data/zip_dataset_op.cc",
"status": "modified"
},
{
"diff": "@@ -126,6 +126,19 @@ def testTFRecordDatasetIgnoreError(self):\n with self.assertRaises(errors.OutOfRangeError):\n self.evaluate(get_next())\n \n+ def testZipIgnoreError(self):\n+ a = dataset_ops.Dataset.from_tensor_slices([1., 2., 0., 4.])\n+ b = a.map(lambda x: array_ops.check_numerics(1. / x, \"error\"))\n+\n+ dataset = dataset_ops.Dataset.zip(\n+ (b, a)).apply(error_ops.ignore_errors())\n+ get_next = self.getNext(dataset)\n+\n+ for x in [1., 2., 4.]:\n+ self.assertEqual((1. / x, x), self.evaluate(get_next()))\n+ with self.assertRaises(errors.OutOfRangeError):\n+ self.evaluate(get_next())\n+\n \n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/data/experimental/kernel_tests/ignore_errors_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 19.04 s390x\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: NA\r\n- TensorFlow installed from (source or binary): Source\r\n- TensorFlow version (use command below): 2.0.0\r\n- Python version: 2.7.16\r\n- Bazel version (if compiling from source): 0.26.1\r\n- GCC/Compiler version (if compiling from source): gcc (Ubuntu 8.3.0-6ubuntu1) 8.3.0\r\n- CUDA/cuDNN version: NA\r\n- GPU model and memory: NA\r\n\r\n**Describe the current behavior**\r\nThe above test fails with the output array mismatch in [testToComplex64](https://github.com/tensorflow/tensorflow/blob/v2.0.0/tensorflow/python/kernel_tests/decode_raw_op_test.py#L105) and [testToComplex128](https://github.com/tensorflow/tensorflow/blob/v2.0.0/tensorflow/python/kernel_tests/decode_raw_op_test.py#L118).\r\n\r\nThe cause of failure seems to be in the byte swapping code to solve endianness problem [here](https://github.com/tensorflow/tensorflow/blob/v2.0.0/tensorflow/core/kernels/decode_raw_op.cc#L88). The code doesn't seem to work as intentioned for **complex data**.\r\n\r\n\r\n**Describe the expected behavior**\r\nThe test should pass on s390x.\r\n\r\n**Code to reproduce the issue**\r\n```\r\nbazel test //tensorflow/python/kernel_tests:decode_raw_op_test\r\n```\r\n\r\n**Other info / logs**\r\n```\r\nAssertionError:\r\nArrays are not equal\r\n\r\nnot equal where = (array([0, 0]), array([1, 2]))\r\nnot equal lhs = [[ 2.-2.j -3.+3.j]]\r\nnot equal rhs = [-2.+2.j 3.-3.j]\r\nMismatch: 0%\r\nMax absolute difference: 8.48528137\r\nMax relative difference: 2.\r\n x: matrix([[ 1.+1.j, 2.-2.j, -3.+3.j, -4.-4.j]])\r\n y: array([[ 1.+1.j, -2.+2.j, 3.-3.j, -4.-4.j]])\r\n\r\n======================================================================\r\nFAIL: testToComplex64 (__main__.DecodeRawOpTest)\r\ntestToComplex64 (__main__.DecodeRawOpTest)\r\n----------------------------------------------------------------------\r\nAssertionError:\r\nArrays are not equal\r\n\r\nnot equal where = (array([0, 0]), array([1, 2]))\r\nnot equal lhs = [[ 2.-2.j -3.+3.j]]\r\nnot equal rhs = [-2.+2.j 3.-3.j]\r\nMismatch: 0%\r\nMax absolute difference: 8.485281\r\nMax relative difference: 2.\r\n x: matrix([[ 1.+1.j, 2.-2.j, -3.+3.j, -4.-4.j]], dtype=complex64)\r\n y: array([[ 1.+1.j, -2.+2.j, 3.-3.j, -4.-4.j]], dtype=complex64)\r\n\r\n----------------------------------------------------------------------\r\n```\r\n",
"comments": [
{
"body": "Further Analysis shows that the real and imaginary components in the output are getting swapped with each other causing the array mismatch on Big Endian.\r\n@jiefangxuanyan I could see [PR](https://github.com/tensorflow/tensorflow/pull/9876) for fixing endianness problem in the `decode_raw_op` functionality. However, the tests for complex data types have been recently added and need more changes for incorporating this particular case.\r\nCould you please have a look?",
"created_at": "2019-10-18T05:37:38Z"
},
{
"body": "@abhay1722,\r\nIn the process of reproducing the error, I have cloned the Branch corresponding to TF Version 2.0 and ran the command, \r\n\r\n`bazel test //usr/local/google/home/mothukuru/tensorflow- 2.0/tensorflow/python/kernel_tests:decode_raw_op_test` but it resulted in the below error, \r\n\r\n```\r\nERROR: The 'test' command is only supported from within a workspace (below a directory having a WORKSPACE file).\r\nSee documentation at https://docs.bazel.build/versions/master/build-ref.html#workspace\r\nINFO: Writing tracer profile to '/usr/local/google/home/mothukuru/.cache/bazel/_bazel_mothukuru/d41d8cd98f00b204e9800998ecf8427e/command.profile.gz'\r\nWARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command \"bazel shutdown\".\r\n```\r\n\r\nCan you please help us reproduce the error. Thanks!",
"created_at": "2019-10-21T10:58:34Z"
},
{
"body": "> @abhay1722,\r\n> In the process of reproducing the error, I have cloned the Branch corresponding to TF Version 2.0 and ran the command,\r\n> \r\n> `bazel test //usr/local/google/home/mothukuru/tensorflow- 2.0/tensorflow/python/kernel_tests:decode_raw_op_test` but it resulted in the below error,\r\n> \r\n> ```\r\n> ERROR: The 'test' command is only supported from within a workspace (below a directory having a WORKSPACE file).\r\n> See documentation at https://docs.bazel.build/versions/master/build-ref.html#workspace\r\n> INFO: Writing tracer profile to '/usr/local/google/home/mothukuru/.cache/bazel/_bazel_mothukuru/d41d8cd98f00b204e9800998ecf8427e/command.profile.gz'\r\n> WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command \"bazel shutdown\".\r\n> ```\r\n> \r\n> Can you please help us reproduce the error. Thanks!\r\n\r\n@rmothukuru I suggest that you run the test from the location where you have cloned the Tensorflow repo.\r\nFor instance, If I clone the [repo](https://github.com/tensorflow/tensorflow.git) in the `/home/test` folder, then I must do the following:-\r\n```\r\ncd /home/test/tensorflow/\r\nbazel test //tensorflow/python/kernel_tests:decode_raw_op_test\r\n```",
"created_at": "2019-11-01T09:52:21Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33496\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33496\">No</a>\n",
"created_at": "2019-11-19T17:40:47Z"
}
],
"number": 33496,
"title": "//tensorflow/python/kernel_tests:decode_raw_op_test fails with Assertion error"
}
|
{
"body": "The //tensorflow/python/kernel_tests:decode_raw_op_test fails as the current code for handling reversal of byte ordering of elements on big endian does not handle complex numbers correctly.\r\nFixes #33496",
"number": 33816,
"review_comments": [
{
"body": "Can you change the test to `(out_type_ == DT_COMPLEX64) || (out_type_ == DT_COMPLEX128)` in order to avoid the string conversion?",
"created_at": "2019-11-11T22:03:31Z"
},
{
"body": "Corrected, Thank you!",
"created_at": "2019-11-12T10:27:43Z"
}
],
"title": "Fixing decode_raw_op for complex numbers on big endian"
}
|
{
"commits": [
{
"message": "Fixing decode_raw_op for complex numbers on big endian"
},
{
"message": "Correcting alignment"
},
{
"message": "Update decode_raw_op.cc\n\nChanging as per review comments to avoid string conversion"
},
{
"message": "Merge remote-tracking branch 'upstream/master' into TensorFlow_decoderawcomplex\nFor Pull request"
},
{
"message": "Adding endianness test for complex numbers"
},
{
"message": "Fixing Ubuntu Sanity errors"
}
],
"files": [
{
"diff": "@@ -87,14 +87,21 @@ class DecodeRawOp : public OpKernel {\n } else {\n // Otherwise, the data is not in the host's byte order, and rather than a\n // direct copy, we need to reverse the byte ordering of each element.\n+ int64 element_size;\n+ if (out_type_ == DT_COMPLEX64 || out_type_ == DT_COMPLEX128) {\n+ // For Complex data type, real and imaginary parts need to be swapped separately\n+ element_size = sizeof(T)/2;\n+ } else {\n+ element_size = sizeof(T);\n+ }\n for (int64 i = 0; i < flat_in.size(); ++i) {\n const char* in_data_bytes =\n reinterpret_cast<const char*>(flat_in(i).data());\n char* out_data_bytes = reinterpret_cast<char*>(out_data);\n const char* p = in_data_bytes;\n char* q = out_data_bytes;\n- for (; p < in_data_bytes + str_size; p += sizeof(T), q += sizeof(T)) {\n- std::reverse_copy(p, p + sizeof(T), q);\n+ for (; p < in_data_bytes + str_size; p += element_size, q += element_size) {\n+ std::reverse_copy(p, p + element_size, q);\n }\n out_data += added_dim;\n }",
"filename": "tensorflow/core/kernels/decode_raw_op.cc",
"status": "modified"
},
{
"diff": "@@ -72,6 +72,16 @@ def testEndianness(self):\n [[0x01020304]],\n parsing_ops.decode_raw(\n [\"\\x01\\x02\\x03\\x04\"], dtypes.int32, little_endian=False))\n+ self.assertAllEqual(\n+ [[1+2j]],\n+ parsing_ops.decode_raw(\n+ [b'\\x00\\x00\\x80?\\x00\\x00\\x00@'], dtypes.complex64,\n+ little_endian=True))\n+ self.assertAllEqual(\n+ [[1+2j]],\n+ parsing_ops.decode_raw(\n+ [b'?\\x80\\x00\\x00@\\x00\\x00\\x00'], dtypes.complex64,\n+ little_endian=False))\n \n def testToFloat16(self):\n result = np.matrix([[1, -2, -3, 4]], dtype=\"<f2\")",
"filename": "tensorflow/python/kernel_tests/decode_raw_op_test.py",
"status": "modified"
}
]
}
|
{
"body": "The intended target ( `make -f tensorflow/lite/experimental/micro/tools/make/Makefile TARGET=riscv32_mcu`) should be `all` , as in the README.md\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/experimental/micro/README.md.\r\nBut in fact it's not `all' by default.",
"comments": [
{
"body": "Fixed by pull request https://github.com/tensorflow/tensorflow/pull/33680, waiting for review.",
"created_at": "2019-10-25T07:28:23Z"
},
{
"body": "Looks like @nkreeger has commented on your pull request.",
"created_at": "2019-11-11T16:58:14Z"
},
{
"body": "@zhoupeng PR is already merged. Please go ahead and close the issue if you don't have any further queries.",
"created_at": "2021-06-02T13:06:55Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33677\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33677\">No</a>\n",
"created_at": "2021-06-02T14:13:48Z"
}
],
"number": 33677,
"title": "tflite:experimental:micro:riscv: the default build target is wrong."
}
|
{
"body": "The default target (all) should appear before any target in Makefile, to let\r\nmake -f tensorflow/lite/experimental/micro/tools/make/Makefile TARGET=riscv32_mcu\r\nget to the intendend all target by default.\r\n\r\nThis patch fix the issue #33677 ",
"number": 33680,
"review_comments": [
{
"body": "I think these should stay the same - please see the comment on the root platform riscv makefile. Sorry we don't have a great canonical example - but this PR can be! ",
"created_at": "2019-11-06T19:11:38Z"
},
{
"body": "Please revert these changes for all of the root example `Makefile.inc`",
"created_at": "2019-11-06T19:12:06Z"
},
{
"body": "We looked at this change - any reason why you needed to move this rule up?",
"created_at": "2019-11-06T19:13:19Z"
},
{
"body": "Sorry this might be confusing - but we prefer to keep platform specific overrides in the actual example folder. This file should only include the bare-bones parts for building for this platform.\r\n\r\nFor example, you'll need to create a `riscv32_mcu` folder in each example directory. In those directories, you'll create a new `Makefile.inc` that adds these rules. To give you an example - see this:\r\n\r\nThe `person_detection` example root Makefile.inc:\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/experimental/micro/examples/person_detection/Makefile.inc#L52\r\n\r\nThat Makefile.inc includes platform specifics at L52, such as this one: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/experimental/micro/examples/person_detection/himax_driver/Makefile.inc\r\n\r\nExtra source files are added in that new Makefile.inc. \r\n\r\nThat would be great if you could do that here - it would help others from getting caught up on Makefile initialization.",
"created_at": "2019-11-06T19:17:04Z"
},
{
"body": "I have revert these changes in the new patch version. The branch is here https://github.com/zhoupeng/tensorflow/tree/fix_wrapfunction .\r\nSorry, I don't konw if I need to create new PR after update the patch as you review suggestion.\r\n",
"created_at": "2019-11-15T12:43:33Z"
},
{
"body": "To let `make -f tensorflow/lite/experimental/micro/tools/make/Makefile TARGET=riscv32_mcu` (call the default make target implicitly), works the same as `make -f tensorflow/lite/experimental/micro/tools/make/Makefile TARGET=riscv32_mcu all`(call the all target explicitly).\r\nThe upmost make target is the default target for Make, if without this patch, the default target looks unexpected.\r\n\r\nMove this rule up to let `all` be the upmost Make target.\r\n\r\nDescribed in this issue.\r\nhttps://github.com/tensorflow/tensorflow/issues/33677",
"created_at": "2019-11-15T12:54:08Z"
},
{
"body": "I have update the patch as you suggest, pls revew if I caught all.\r\nThe branch is here https://github.com/zhoupeng/tensorflow/tree/fix_wrapfunction .\r\nSorry, I don't know if I need to create new PR after update the patch.",
"created_at": "2019-11-15T12:58:09Z"
}
],
"title": "tflite:experimental:micro:riscv: Fix default target bug in Makefile."
}
|
{
"commits": [],
"files": []
}
|
{
"body": "The intended target ( `make -f tensorflow/lite/experimental/micro/tools/make/Makefile TARGET=riscv32_mcu`) should be `all` , as in the README.md\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/experimental/micro/README.md.\r\nBut in fact it's not `all' by default.",
"comments": [
{
"body": "Fixed by pull request https://github.com/tensorflow/tensorflow/pull/33680, waiting for review.",
"created_at": "2019-10-25T07:28:23Z"
},
{
"body": "Looks like @nkreeger has commented on your pull request.",
"created_at": "2019-11-11T16:58:14Z"
},
{
"body": "@zhoupeng PR is already merged. Please go ahead and close the issue if you don't have any further queries.",
"created_at": "2021-06-02T13:06:55Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33677\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33677\">No</a>\n",
"created_at": "2021-06-02T14:13:48Z"
}
],
"number": 33677,
"title": "tflite:experimental:micro:riscv: the default build target is wrong."
}
|
{
"body": "The default target (`all`) should appear before any target in Makefile, to let\r\n`make -f tensorflow/lite/experimental/micro/tools/make/Makefile TARGET=riscv32_mcu`\r\nget to the intendend `all` target by default.\r\n\r\nThis patch fix the issue #33677 \r\n",
"number": 33678,
"review_comments": [],
"title": "tflite:experimental:micro:riscv: Fix default target bug in Makefile."
}
|
{
"commits": [
{
"message": "tflite:experimental:micro:riscv: Fix default target bug in Makefile.\n\nThe default target (`all`) should appear before any target in Makefile, to let\n`make -f tensorflow/lite/experimental/micro/tools/make/Makefile TARGET=riscv32_mcu`\nget to the intendend `all` target by default."
}
],
"files": [
{
"diff": "@@ -225,6 +225,10 @@ CXX := $(CC_PREFIX)${TARGET_TOOLCHAIN_PREFIX}${CXX_TOOL}\n CC := $(CC_PREFIX)${TARGET_TOOLCHAIN_PREFIX}${CC_TOOL}\n AR := $(CC_PREFIX)${TARGET_TOOLCHAIN_PREFIX}${AR_TOOL}\n \n+# Default target must appear before any target, \n+# which is compiled if there's no command-line arguments\n+all: $(MICROLITE_LIB_PATH)\n+\n # Load the examples.\n include $(wildcard tensorflow/lite/experimental/micro/examples/*/Makefile.inc)\n \n@@ -254,9 +258,6 @@ $(OBJDIR)%.o: %.S third_party_downloads\n \t@mkdir -p $(dir $@)\n \t$(CC) $(CCFLAGS) $(INCLUDES) -c $< -o $@\n \n-# The target that's compiled if there's no command-line arguments.\n-all: $(MICROLITE_LIB_PATH)\n-\n microlite: $(MICROLITE_LIB_PATH)\n \n # Hack for generating schema file bypassing flatbuffer parsing",
"filename": "tensorflow/lite/experimental/micro/tools/make/Makefile",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary):binary\r\n- TensorFlow version (use command below):1.15.0\r\n- Python version:3.6.8\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version:\r\n- GPU model and memory:\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\nAttributeError: 'tensorflow.python.framework.ops.EagerTensor' object has no attribute 'to_sparse'\r\n**Describe the expected behavior**\r\nThe op should return SparseTensor or RaggedTensor\r\n**Code to reproduce the issue**\r\nProvide a reproducible test case that is the bare minimum necessary to generate the problem.\r\n```python\r\nimport tensorflow as tf\r\ntf.strings.split('a b')\r\n```\r\n**Other info / logs**\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\n\r\n[colab](https://colab.research.google.com/drive/1PrFuL7hC25yRGmFfbwwRK1if9N8d1M9A)",
"comments": [
{
"body": "You need brackets for the input. Try this:\r\n```\r\nc = tf.strings.split(['a b'])\r\nc.values\r\n```\r\n\r\n",
"created_at": "2019-10-24T09:22:28Z"
},
{
"body": "> You need brackets for the input. Try this:\r\n> \r\n> ```\r\n> c = tf.strings.split(['a b'])\r\n> c.values\r\n> ```\r\n\r\ntf.strings.split('a b',result_type='RaggedTensor') works and returns a Tensor.In fact, it should return a RaggedTensor",
"created_at": "2019-10-24T11:27:09Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33623\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33623\">No</a>\n",
"created_at": "2019-11-18T21:26:42Z"
}
],
"number": 33623,
"title": "tf.strings.split bug"
}
|
{
"body": "fix #33623",
"number": 33625,
"review_comments": [
{
"body": "`FAIL: Found 1 non-whitelisted pylint errors:\r\ntensorflow/python/kernel_tests/string_split_op_test.py:362: [W0622(redefined-builtin), StringSplitV2OpTest.testSplitV1] Redefining built-in 'input'\r\n\r\n\r\n\r\n=== Sanity check step 3 of 15: do_pylint PYTHON3 (Python 3 pylint) ===`",
"created_at": "2019-11-14T20:13:03Z"
},
{
"body": "can you please fix this sanity errors ? \r\nlink: https://source.cloud.google.com/results/invocations/f0c921f7-3aa0-4705-aa15-661c770c53e0/log",
"created_at": "2019-11-14T20:13:43Z"
},
{
"body": "Changed.@rthadur",
"created_at": "2019-11-17T05:47:12Z"
}
],
"title": "fix strings.split"
}
|
{
"commits": [
{
"message": "fix strings.split"
},
{
"message": "remove useless code"
},
{
"message": "Fix test case"
},
{
"message": "Format code"
},
{
"message": "format code"
}
],
"files": [
{
"diff": "@@ -267,35 +267,128 @@ def testSplitV2(self,\n # correctly.\n expected_ragged = ragged_factory_ops.constant(\n expected, ragged_rank=input.shape.ndims)\n- actual_ragged_v1 = ragged_string_ops.strings_split_v1(\n- input, result_type=\"RaggedTensor\", **kwargs)\n- actual_ragged_v1_input_kwarg = ragged_string_ops.strings_split_v1(\n- input=input, result_type=\"RaggedTensor\", **kwargs)\n- actual_ragged_v1_source_kwarg = ragged_string_ops.strings_split_v1(\n- source=input, result_type=\"RaggedTensor\", **kwargs)\n actual_ragged_v2 = ragged_string_ops.string_split_v2(input, **kwargs)\n actual_ragged_v2_input_kwarg = ragged_string_ops.string_split_v2(\n input=input, **kwargs)\n- self.assertAllEqual(expected_ragged, actual_ragged_v1)\n- self.assertAllEqual(expected_ragged, actual_ragged_v1_input_kwarg)\n- self.assertAllEqual(expected_ragged, actual_ragged_v1_source_kwarg)\n self.assertAllEqual(expected_ragged, actual_ragged_v2)\n self.assertAllEqual(expected_ragged, actual_ragged_v2_input_kwarg)\n \n # Check that the internal version (which returns a SparseTensor) works\n # correctly. Note: the internal version oly supports vector inputs.\n if input.shape.ndims == 1:\n expected_sparse = self.evaluate(expected_ragged.to_sparse())\n- actual_sparse_v1 = ragged_string_ops.strings_split_v1(\n- input, result_type=\"SparseTensor\", **kwargs)\n actual_sparse_v2 = string_ops.string_split_v2(input, **kwargs)\n- for actual_sparse in [actual_sparse_v1, actual_sparse_v2]:\n- self.assertEqual(expected_sparse.indices.tolist(),\n- self.evaluate(actual_sparse.indices).tolist())\n- self.assertEqual(expected_sparse.values.tolist(),\n- self.evaluate(actual_sparse.values).tolist())\n- self.assertEqual(expected_sparse.dense_shape.tolist(),\n- self.evaluate(actual_sparse.dense_shape).tolist())\n+ self.assertEqual(expected_sparse.indices.tolist(),\n+ self.evaluate(actual_sparse_v2.indices).tolist())\n+ self.assertEqual(expected_sparse.values.tolist(),\n+ self.evaluate(actual_sparse_v2.values).tolist())\n+ self.assertEqual(expected_sparse.dense_shape.tolist(),\n+ self.evaluate(actual_sparse_v2.dense_shape).tolist())\n+\n+ @parameterized.named_parameters([\n+ {\"testcase_name\": \"Simple\",\n+ \"input\": [b\"pigs on the wing\", b\"animals\"],\n+ \"expected\": [[b\"pigs\", b\"on\", b\"the\", b\"wing\"], [b\"animals\"]]},\n+\n+ {\"testcase_name\": \"MultiCharSeparator\",\n+ \"input\": [b\"1<>2<>3\", b\"<><>4<>5<><>6<>\"],\n+ \"sep\": b\"<>\",\n+ \"expected\": [[b\"1\", b\"2\", b\"3\"],\n+ [b\"\", b\"\", b\"4\", b\"5\", b\"\", b\"6\", b\"\"]]},\n+\n+ {\"testcase_name\": \"SimpleSeparator\",\n+ \"input\": [b\"1,2,3\", b\"4,5,,6,\"],\n+ \"sep\": b\",\",\n+ \"expected\": [[b\"1\", b\"2\", b\"3\"], [b\"4\", b\"5\", b\"\", b\"6\", b\"\"]]},\n+\n+ {\"testcase_name\": \"EmptySeparator\",\n+ \"input\": [b\"1 2 3\", b\" 4 5 6 \"],\n+ \"expected\": [[b\"1\", b\"2\", b\"3\"], [b\"4\", b\"5\", b\"6\"]]},\n+\n+ {\"testcase_name\": \"EmptySeparatorEmptyInputString\",\n+ \"input\": [b\"\"],\n+ \"expected\": [[]]},\n+\n+ {\"testcase_name\": \"SimpleSeparatorMaxSplit\",\n+ \"input\": [b\"1,2,3\", b\"4,5,,6,\"],\n+ \"sep\": b\",\",\n+ \"maxsplit\": 1,\n+ \"expected\": [[b\"1\", b\"2,3\"], [b\"4\", b\"5,,6,\"]]},\n+\n+ {\"testcase_name\": \"EmptySeparatorMaxSplit\",\n+ \"input\": [b\"1 2 3\", b\" 4 5 6 \"],\n+ \"maxsplit\": 1,\n+ \"expected\": [[b\"1\", b\"2 3\"], [b\"4\", b\"5 6 \"]]},\n+\n+ {\"testcase_name\": \"ScalarInput\",\n+ \"input\": b\"1,2,3\",\n+ \"sep\": b\",\",\n+ \"expected\": [[b\"1\", b\"2\", b\"3\"]]},\n+\n+ {\"testcase_name\": \"Dense2DInput\",\n+ \"input\": [[b\"1,2,3\", b\"4\"], [b\"5,6\", b\"7,8,9\"]],\n+ \"sep\": b\",\",\n+ \"expected\": [[[b\"1\", b\"2\", b\"3\"], [b\"4\"]],\n+ [[b\"5\", b\"6\"], [b\"7\", b\"8\", b\"9\"]]]},\n+\n+ {\"testcase_name\": \"Ragged2DInput\",\n+ \"input\": [[b\"1,2,3\", b\"4\"], [b\"5,6\"]],\n+ \"input_is_ragged\": True,\n+ \"sep\": b\",\",\n+ \"expected\": [[[b\"1\", b\"2\", b\"3\"], [b\"4\"]], [[b\"5\", b\"6\"]]]},\n+\n+ {\"testcase_name\": \"Ragged3DInput\",\n+ \"input\": [[[b\"1,2,3\", b\"4\"], [b\"5,6\"]], [[b\"7,8,9\"]]],\n+ \"input_is_ragged\": True,\n+ \"sep\": b\",\",\n+ \"expected\": [[[[b\"1\", b\"2\", b\"3\"], [b\"4\"]], [[b\"5\", b\"6\"]]],\n+ [[[b\"7\", b\"8\", b\"9\"]]]]},\n+\n+ {\"testcase_name\": \"Ragged4DInput\",\n+ \"input\": [[[[b\"1,2,3\", b\"4\"], [b\"5,6\"]], [[b\"7,8,9\"]]], [[[b\"\"]]]],\n+ \"input_is_ragged\": True,\n+ \"sep\": b\",\",\n+ \"expected\": [[[[[b\"1\", b\"2\", b\"3\"], [b\"4\"]], [[b\"5\", b\"6\"]]],\n+ [[[b\"7\", b\"8\", b\"9\"]]]], [[[[b\"\"]]]]]},\n+\n+ {\"testcase_name\": \"Ragged4DInputEmptySeparator\",\n+ \"input\": [[[[b\"1 2 3\", b\"4\"], [b\"5 6\"]], [[b\"7 8 9\"]]], [[[b\"\"]]]],\n+ \"input_is_ragged\": True,\n+ \"expected\": [[[[[b\"1\", b\"2\", b\"3\"], [b\"4\"]], [[b\"5\", b\"6\"]]],\n+ [[[b\"7\", b\"8\", b\"9\"]]]], [[[[]]]]]},\n+\n+ ]) # pyformat: disable\n+ def testSplitV1(self,\n+ input,\n+ expected,\n+ input_is_ragged=False,\n+ **kwargs): # pylint: disable=redefined-builtin\n+ # Prepare the input tensor.\n+ if input_is_ragged:\n+ input = ragged_factory_ops.constant(input, dtype=dtypes.string)\n+ else:\n+ input = constant_op.constant(input, dtype=dtypes.string)\n+\n+ expected_ragged = ragged_factory_ops.constant(\n+ expected)\n+ actual_ragged_v1 = ragged_string_ops.strings_split_v1(\n+ input, result_type=\"RaggedTensor\", **kwargs)\n+ actual_ragged_v1_input_kwarg = ragged_string_ops.strings_split_v1(\n+ input=input, result_type=\"RaggedTensor\", **kwargs)\n+ actual_ragged_v1_source_kwarg = ragged_string_ops.strings_split_v1(\n+ source=input, result_type=\"RaggedTensor\", **kwargs)\n+ self.assertAllEqual(expected_ragged, actual_ragged_v1)\n+ self.assertAllEqual(expected_ragged, actual_ragged_v1_input_kwarg)\n+ self.assertAllEqual(expected_ragged, actual_ragged_v1_source_kwarg)\n+ expected_sparse = self.evaluate(expected_ragged.to_sparse())\n+ actual_sparse_v1 = ragged_string_ops.strings_split_v1(\n+ input, result_type=\"SparseTensor\", **kwargs)\n+ self.assertEqual(expected_sparse.indices.tolist(),\n+ self.evaluate(actual_sparse_v1.indices).tolist())\n+ self.assertEqual(expected_sparse.values.tolist(),\n+ self.evaluate(actual_sparse_v1.values).tolist())\n+ self.assertEqual(expected_sparse.dense_shape.tolist(),\n+ self.evaluate(actual_sparse_v1.dense_shape).tolist())\n \n def _py_split(self, strings, **kwargs):\n if isinstance(strings, compat.bytes_or_text_types):",
"filename": "tensorflow/python/kernel_tests/string_split_op_test.py",
"status": "modified"
},
{
"diff": "@@ -22,6 +22,7 @@\n from tensorflow.python.framework import ops\n from tensorflow.python.ops import array_ops\n from tensorflow.python.ops import gen_string_ops\n+from tensorflow.python.ops import gen_array_ops\n from tensorflow.python.ops import string_ops\n from tensorflow.python.ops.ragged import ragged_array_ops\n from tensorflow.python.ops.ragged import ragged_math_ops\n@@ -627,9 +628,9 @@ def strings_split_v1(input=None, sep=None, maxsplit=-1, # pylint: disable=redef\n with ops.name_scope(name, \"StringSplit\", [input]):\n input = ragged_tensor.convert_to_tensor_or_ragged_tensor(\n input, dtype=dtypes.string, name=\"input\")\n- if result_type == \"SparseTensor\" and input.shape.rank == 1:\n- return string_ops.string_split_v2(input, sep=sep, maxsplit=maxsplit)\n \n+ if input.shape.rank == 0:\n+ input = gen_array_ops.expand_dims(input, 0)\n ragged_result = string_split_v2(input, sep=sep, maxsplit=maxsplit)\n if result_type == \"SparseTensor\":\n return ragged_result.to_sparse()",
"filename": "tensorflow/python/ops/ragged/ragged_string_ops.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): **No**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): **Windows 10**\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: **-**\r\n- TensorFlow installed from (source or binary): **binary**\r\n- TensorFlow version (use command below): **2.0.0**\r\n- Python version: **3.6.x**\r\n- CUDA/cuDNN version: **10.0/7.6.1**\r\n- GPU model and memory: \r\n\r\n\r\n---\r\n**Describe the current behavior**\r\n\r\nWhen fitting (.fit) a keras Model on a tf.data.Dataset, the dataset size is not inferred. Because of this, when setting `verbose=1`, during the first epoch the log becomes `current_step/Unknown`. Also the following is thrown (though it does not cause crashing):\r\n```\r\n[[{{node IteratorGetNext}}]]\r\n\t [[IteratorGetNext/_2]]\r\n2019-10-10 18:41:50.728985: W tensorflow/core/common_runtime/base_collective_executor.cc:216] BaseCollectiveExecutor::StartAbort Out of range: End of sequence\r\n\t [[{{node IteratorGetNext}}]]\r\n```\r\n**Describe the expected behavior**\r\n\r\nI would expect to see the number of samples/batches/etc.\r\n\r\n**Code to reproduce the issue**\r\n\r\nI created a small Colab notebook to demonstrate the issue: https://colab.research.google.com/drive/1-S787cE6BWhXJ_0BeAb6EGq4GaXAFwmu\r\nI recommend downloading the .py file and running it in command line (so colab logging doesn't interfere), because after the epoch is done, the correct batch number is found. The problem is during the epoch.\r\n \r\n**Other info / logs**\r\n\r\nI found that the dataset size inferring is actually run, but the returned value is not stored or used anywhere, it is only to throw a warning if the initialization made by the user is faulty in some way.\r\nI am referring to this line: [https://github.com/tensorflow/tensorflow/blob/r2.0/tensorflow/python/keras/engine/training_v2.py#L247](https://github.com/tensorflow/tensorflow/blob/r2.0/tensorflow/python/keras/engine/training_v2.py#L247)\r\nThe above problem would be eliminated with something like this (or the like):\r\n```\r\nsteps_per_epoch = training_utils.infer_steps_for_dataset(training_dataset, steps_per_epoch, \r\n steps_name='steps_per_epoch',epochs=0) \r\n if steps_per_epoch is None else steps_per_epoch\r\n```\r\n",
"comments": [
{
"body": "@angeliand \r\nI am able to successfully execute Colab notebook provided by you with a warning message.Please, find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/d23afdb38149eeb3fc179a6e30d20721/untitled254.ipynb).Please, let me know is this still an issue?.Thanks!",
"created_at": "2019-10-11T06:20:04Z"
},
{
"body": "As I have said, the problem is with what gets logged **during** the epoch. Not after. In your notebook you did not interrupt the training to view the printed log during the epoch. If interrupted the described behaviour can still be seen.\r\nAlso, I recommend running the script in command line (or anywhere, where the output is printed line by line), where the problem can be viewed without stopping the training.",
"created_at": "2019-10-11T07:09:40Z"
},
{
"body": "@angeliand \r\nI tried running in command line and i am able to execute the .py file successfully. Please find the log file in the attachment.Is this the expected output?\r\n[text.txt.tar.gz](https://github.com/tensorflow/tensorflow/files/3716797/text.txt.tar.gz).I could reproduce the issue in colab when i interrupted during training.Thanks!\r\n",
"created_at": "2019-10-11T09:52:22Z"
},
{
"body": "As I have stated in the original post, the bug does not cause crashing, but it is still inconvenient and can be avoided easily with a minor fix (I have also offered a solution).\r\nIf logging is line by line (so when it doesn’t refresh) eg. in PyCharm or when logging to file, the problem can be viewed easier. It appears during the first epoch and ceases when that is done. (Probably because after the first epoch, we know the number of steps.) This is why training has to be interrupted in colab to view the issue (or you can check the runtime logs in colab!).\r\nAlso the IteratorGetNext warning appears at the end of the first epoch before validating steps. This is because the training loop does not know the number of steps to take (—> times to “query” the dataset) and the dataset runs out. \r\n\r\nAll in all, this is not huge but still not what would be the expected behaviour. \r\nI will provide a log file from PyCharm in a few hours. ",
"created_at": "2019-10-11T10:17:29Z"
},
{
"body": "PyCharm output is line-by-line, so the problem can be seen better. Here is the output without the proposed solution: \r\n[keras_bug_op.txt](https://github.com/tensorflow/tensorflow/files/3717600/keras_bug_op.txt)\r\nAnd here is the correct (expected) output after using the proposed solution:\r\n[keras_bug_sol.txt](https://github.com/tensorflow/tensorflow/files/3717605/keras_bug_sol.txt)\r\nHope this helps.\r\n",
"created_at": "2019-10-11T12:48:23Z"
},
{
"body": "@angeliand Are you willing to contribute through PR to update relevant codes? Thanks!",
"created_at": "2019-10-14T16:58:49Z"
},
{
"body": "Sure. I'm busy in the next few days, but I will do it after that.",
"created_at": "2019-10-16T07:51:47Z"
},
{
"body": "It has been 14 days with no activity and the `awaiting response` label was assigned. Is this still an issue?",
"created_at": "2019-10-31T12:34:35Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33216\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33216\">No</a>\n",
"created_at": "2019-11-01T19:07:38Z"
}
],
"number": 33216,
"title": "[TF 2.0.0] Training keras Model on tf.data.Dataset causes small bug in logging"
}
|
{
"body": "fix #33216 issue",
"number": 33610,
"review_comments": [
{
"body": "`FAIL: Found 1 non-whitelisted pylint errors:\r\ntensorflow/python/keras/engine/training_v2.py:260: [C0301(line-too-long), ] Line too long (86/80)`\r\ncan you please check this lint error",
"created_at": "2019-10-25T18:20:44Z"
},
{
"body": "Hi! Sorry for the late reply. Added some line-breaks according to Google Style Guide, hope it's good now. ",
"created_at": "2019-10-31T12:34:16Z"
}
],
"title": "fix tf.data.Dataset size inferring issue in TF 2.0 keras training loop"
}
|
{
"commits": [
{
"message": "fix training dataset steps_per_epoch bug"
},
{
"message": "fixing pylint error\n\nfixing pylint error according to: https://github.com/google/styleguide/blob/gh-pages/pyguide.md#2114-decision"
}
],
"files": [
{
"diff": "@@ -250,13 +250,18 @@ def fit(\n # Raise an error if steps_per_epoch isn't specified but the dataset\n # is infinite.\n # TODO(scottzhu): This check should probably happen in the adapter\n- training_utils.infer_steps_for_dataset(\n+ inferred_steps = training_utils.infer_steps_for_dataset(\n model,\n training_dataset,\n steps_per_epoch,\n steps_name='steps_per_epoch',\n epochs=0)\n-\n+ \n+ steps_per_epoch = (\n+ inferred_steps\n+ if steps_per_epoch is None\n+ else steps_per_epoch)\n+ \n training_dataset = strategy.experimental_distribute_dataset(\n training_dataset)\n ",
"filename": "tensorflow/python/keras/engine/training_v2.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu\r\n- TensorFlow installed from (source or binary): source internal Google\r\n- TensorFlow version (use command below): 1.5.0, internal Google\r\n- Python version: 3.6.7\r\n\r\n**Describe the current behavior**\r\nCalling 'read(X)' on the text files opened with GFile in python3 doesn't work properly (it fetches X bytes rather than X characters). This often results with the UnicodeDecodeError (as the read can happen in the middle of the unicode character).\r\n\r\n**Describe the expected behavior**\r\nIt should behave like python3: reading the X characters.\r\n\r\n**Code to reproduce the issue**\r\nProvide a reproducible test case that is the bare minimum necessary to generate the problem.\r\n\r\n```python\r\nmy_text = 'Bären'\r\nwith open('/tmp/ex1', 'w') as f:\r\n f.write(my_text)\r\n\r\n// Will read the whole string correctly.\r\nwith open('/tmp/ex1', 'r') as f:\r\n print(f.read())\r\n\r\n// This will print 2 chars Ba\r\nwith open('/tmp/ex1', 'r') as f:\r\n print(f.read(2))\r\n\r\n// This will print 3 chars: Bar\r\nwith open('/tmp/ex1', 'r') as f:\r\n print(f.read(3))\r\n\r\n// This will print the whole thing.\r\nwith tf.io.gfile.GFile('/tmp/ex1', 'r') as f:\r\n print(f.read())\r\n\r\n// This will crash.. :-(\r\nwith tf.io.gfile.GFile('/tmp/ex1', 'r') as f:\r\n print(f.read(2))\r\n```\r\n\r\n**Other info / logs**\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\n\r\nThe error will be:\r\n```\r\nUnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 1: unexpected end of data\r\n```\r\n",
"comments": [
{
"body": "Confirmed in tf-nightly and python3.7",
"created_at": "2019-10-21T16:20:36Z"
},
{
"body": "I think it is possible to check the utf8 length while reading, and compensate the remaining bytes. Created a PR #33590 for the fix.",
"created_at": "2019-10-22T04:22:00Z"
},
{
"body": "Hi There,\n\n We are checking to see if you still need help on this, as you are using an older version of tensorflow which is officially considered end of life . We recommend that you upgrade to the latest 2.x version and let us know if the issue still persists in newer versions. Please open a new issue for any help you need against 2.x, and we will get you the right help. \n\n This issue will be closed automatically 7 days from now. If you still need help with this issue, please provide us with more information.",
"created_at": "2021-02-01T14:10:13Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33563\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33563\">No</a>\n",
"created_at": "2021-02-09T05:56:09Z"
}
],
"number": 33563,
"title": "tf.io.GFIle not working correctly with UTF-8 files and Python3"
}
|
{
"body": "This PR tries to address the issue raised in #33563 where\r\ntf.io.GFile behavior is different from python file for utf8.\r\n\r\nThe issue was that tf.io.GFile's read does not take utf8 into\r\nconsideration for non binary mode.\r\n\r\nThis PR fixes the discrepancy.\r\n\r\nThis PR fixes #33563\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 33590,
"review_comments": [
{
"body": "Should this be `std::string` or `tensorflow::tstring`? Afaik, `tensorflow:tstring` should be used only if the string is in a tensor. Adding @gharibian to confirm",
"created_at": "2019-10-22T16:11:48Z"
},
{
"body": "Let's extract the `0xe0`, `0xc0`, `0xf0` and `0xf8` magic constants to same named constants to increase readability",
"created_at": "2019-10-22T16:13:57Z"
},
{
"body": "Let's write these as\r\n\r\n```\r\nif (...) {\r\n ...\r\n} else if (...) {\r\n ...\r\n} else {\r\n ...\r\n}\r\n```",
"created_at": "2019-10-22T16:14:32Z"
},
{
"body": "Let's move these to a comment in the header of the function, not in the `while` loop.",
"created_at": "2019-10-22T16:15:46Z"
}
],
"title": "Fix behavior difference between tf.io.GFile and python file for utf8"
}
|
{
"commits": [
{
"message": "Fix behavior difference between tf.io.GFile and python file for utf8\n\nThis PR tries to address the issue raised in 33563 where\ntf.io.GFile behavior is different from python file for utf8.\n\nThe issue was that tf.io.GFile's read does not take utf8 into\nconsideration for non binary mode.\n\nThis PR fixes the discrepancy.\n\nThis PR fixes 33563\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nPylint fix\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nAdd test case for GitHub issue 33563.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Move read_utf8 from pywrapper to pybind11\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Address review comments\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -118,6 +118,8 @@ def read(self, n=-1):\n if n == -1:\n length = self.size() - self.tell()\n else:\n+ if not self._binary_mode:\n+ return self._prepare_value(self._read_buf.readutf8(n))\n length = n\n return self._prepare_value(self._read_buf.read(length))\n ",
"filename": "tensorflow/python/lib/io/file_io.py",
"status": "modified"
},
{
"diff": "@@ -676,6 +676,19 @@ def testFileSeekableWithZip(self):\n def testHasAtomicMove(self):\n self.assertTrue(file_io.has_atomic_move(\"/a/b/c\"))\n \n+ def testReadWriteNonBinaryModeUTF8(self):\n+ # Test case for GitHub issue 33563\n+ file_path = os.path.join(self._base_dir, \"temp_file\")\n+ file_io.FileIO(file_path, \"wb\").write('Bären')\n+ # read whole file should match\n+ with open(file_path, 'r') as f:\n+ with file_io.FileIO(file_path, mode=\"r\") as g:\n+ self.assertEqual(g.read(), f.read())\n+ # read partial file should also match\n+ with open(file_path, 'r') as f:\n+ with file_io.FileIO(file_path, mode=\"r\") as g:\n+ self.assertEqual(g.read(2), f.read(2))\n+\n \n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/lib/io/file_io_test.py",
"status": "modified"
},
{
"diff": "@@ -45,6 +45,13 @@ inline TransactionToken* TokenFromPyToken(PyTransactionToken* t) {\n namespace {\n namespace py = pybind11;\n \n+const int kUTF8TwoBytesMask = 0xe0;\n+const int kUTF8TwoBytesValue = 0xc0;\n+const int kUTF8ThreeBytesMask = 0xf0;\n+const int kUTF8ThreeBytesValue = 0xe0;\n+const int kUTF8FourBytesMask = 0xf8;\n+const int kUTF8FourBytesValue = 0xf0;\n+\n PYBIND11_MODULE(_pywrap_file_io, m) {\n using tensorflow::PyTransactionToken;\n using tensorflow::TransactionToken;\n@@ -305,6 +312,65 @@ PYBIND11_MODULE(_pywrap_file_io, m) {\n py::gil_scoped_acquire acquire;\n return py::bytes(result);\n })\n+ .def(\"readutf8\",\n+ [](BufferedInputStream* self, tensorflow::int64 bytes) {\n+ py::gil_scoped_release release;\n+ tensorflow::tstring result;\n+ // Avoid over read:\n+ // 1) read at least bytes (utf8 could be 1/2/3/4)\n+ // 2) if string ends with partial utf8 (2/3/4),\n+ // read remaining (< 4) bytes.\n+ // 3) repeat until bytes == utf8 chars\n+ size_t total = 0;\n+ while (total < bytes) {\n+ // 1) read at least bytes - total\n+\t size_t bytes_to_read = bytes - total;\n+ tensorflow::tstring result_read;\n+ const auto s = self->ReadNBytes(bytes_to_read, &result_read);\n+ if (!s.ok() && s.code() != tensorflow::error::OUT_OF_RANGE) {\n+ result.clear();\n+ tensorflow::MaybeRaiseRegisteredFromStatusWithGIL(s);\n+ break;\n+ }\n+ result.append(result_read);\n+ if (s.code() == tensorflow::error::OUT_OF_RANGE) {\n+ break;\n+ }\n+\t // 2) find partial utf8, and read remain (< 4) bytes.\n+ size_t remain = 0;\n+ for (size_t i = 0; i < result_read.size(); i++) {\n+ if (remain > 0) {\n+ remain--;\n+ continue;\n+ }\n+ if ((result_read[i] & kUTF8TwoBytesMask) == kUTF8TwoBytesValue) {\n+ // n = 2\n+ remain = 1;\n+ } else if ((result_read[i] & kUTF8ThreeBytesMask) == kUTF8ThreeBytesValue) {\n+ // n = 3\n+ remain = 2;\n+ } else if ((result_read[i] & kUTF8FourBytesMask) == kUTF8FourBytesValue) {\n+ // n = 4\n+ remain = 3;\n+ }\n+ total++;\n+ }\n+ if (remain > 0) {\n+ const auto s = self->ReadNBytes(remain, &result_read);\n+ if (!s.ok() && s.code() != tensorflow::error::OUT_OF_RANGE) {\n+ result.clear();\n+ tensorflow::MaybeRaiseRegisteredFromStatusWithGIL(s);\n+\t break;\n+ }\n+ result.append(result_read);\n+ if (s.code() == tensorflow::error::OUT_OF_RANGE) {\n+ break;\n+ }\n+ }\n+ }\n+ py::gil_scoped_acquire acquire;\n+ return py::bytes(result);\n+ })\n .def(\"readline\",\n [](BufferedInputStream* self) {\n py::gil_scoped_release release;",
"filename": "tensorflow/python/lib/io/file_io_wrapper.cc",
"status": "modified"
}
]
}
|
{
"body": "**Describe the current behavior**\r\nWhen running the following code in the [documentation](https://www.tensorflow.org/api_docs/python/tf/keras/losses/SparseCategoricalCrossentropy) of `SparseCategoricalCrossentropy`:\r\n\r\n```\r\ncce = tf.keras.losses.SparseCategoricalCrossentropy()\r\nloss = cce(\r\n [0, 1, 2],\r\n [[.9, .05, .05], [.5, .89, .6], [.05, .01, .94]])\r\nprint('Loss: ', loss.numpy()) # Loss: 0.3239\r\n```\r\n\r\nI obtained the following error:\r\n\r\n> ---------------------------------------------------------------------------\r\n> AttributeError Traceback (most recent call last)\r\n> <ipython-input-2-e7331c659215> in <module>()\r\n> 3 loss = cce(\r\n> 4 [0, 1, 2],\r\n> ----> 5 [[.9, .05, .05], [.5, .89, .6], [.05, .01, .94]])\r\n> 6 print('Loss: ', loss.numpy()) # Loss: 0.3239\r\n> \r\n> 3 frames\r\n> /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/backend.py in sparse_categorical_crossentropy(target, output, from_logits, axis)\r\n> 4397 if not from_logits:\r\n> 4398 if (isinstance(output, (ops.EagerTensor, variables_module.Variable)) or\r\n> -> 4399 output.op.type != 'Softmax'):\r\n> 4400 epsilon_ = _constant_to_tensor(epsilon(), output.dtype.base_dtype)\r\n> 4401 output = clip_ops.clip_by_value(output, epsilon_, 1 - epsilon_)\r\n> \r\n> AttributeError: 'list' object has no attribute 'op'\r\n\r\n",
"comments": [
{
"body": "Added a PR #33406 for the fix.",
"created_at": "2019-10-16T04:40:25Z"
},
{
"body": "@netw0rkf10w The above PR will fix the issue for you. In the mean time you can provide converted tensors of `y_pred` and `y_true` as follows. Thanks!\r\n`loss = cce(\r\n tf.convert_to_tensor([0, 1, 2]),\r\n tf.convert_to_tensor([[.9, .05, .05], [.5, .89, .6], [.05, .01, .94]]))` ",
"created_at": "2019-10-29T17:18:48Z"
},
{
"body": "@jvishnuvardhan Thanks a lot!",
"created_at": "2019-10-29T20:15:24Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33394\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33394\">No</a>\n",
"created_at": "2019-10-29T20:15:30Z"
},
{
"body": "Still doesn't work. Can't reproduce the example from documentation.\r\n`---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n<ipython-input-21-8338a7552986> in <module>()\r\n----> 1 sce(y_true, y_pred)\r\n\r\n/opt/local/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/tensorflow_core/python/keras/losses.py in __call__(self, y_true, y_pred, sample_weight)\r\n 124 y_true, y_pred, sample_weight)\r\n 125 with K.name_scope(scope_name or self.__class__.__name__), graph_ctx:\r\n--> 126 losses = self.call(y_true, y_pred)\r\n 127 return losses_utils.compute_weighted_loss(\r\n 128 losses, sample_weight, reduction=self._get_reduction())\r\n\r\n/opt/local/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/tensorflow_core/python/keras/losses.py in call(self, y_true, y_pred)\r\n 219 y_pred, y_true = tf_losses_util.squeeze_or_expand_dimensions(\r\n 220 y_pred, y_true)\r\n--> 221 return self.fn(y_true, y_pred, **self._fn_kwargs)\r\n 222 \r\n 223 def get_config(self):\r\n\r\n/opt/local/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/tensorflow_core/python/keras/losses.py in sparse_categorical_crossentropy(y_true, y_pred, from_logits, axis)\r\n 976 def sparse_categorical_crossentropy(y_true, y_pred, from_logits=False, axis=-1):\r\n 977 return K.sparse_categorical_crossentropy(\r\n--> 978 y_true, y_pred, from_logits=from_logits, axis=axis)\r\n 979 \r\n 980 \r\n\r\n/opt/local/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/tensorflow_core/python/keras/backend.py in sparse_categorical_crossentropy(target, output, from_logits, axis)\r\n 4528 if not from_logits:\r\n 4529 if (isinstance(output, (ops.EagerTensor, variables_module.Variable)) or\r\n-> 4530 output.op.type != 'Softmax'):\r\n 4531 epsilon_ = _constant_to_tensor(epsilon(), output.dtype.base_dtype)\r\n 4532 output = clip_ops.clip_by_value(output, epsilon_, 1 - epsilon_)\r\n\r\nAttributeError: 'list' object has no attribute 'op'`",
"created_at": "2020-06-24T11:14:24Z"
},
{
"body": "@ilyarudyak Can you please create a new issue and provide a standalone code to reproduce the issue? Please ping me in that issue. Thanks!",
"created_at": "2020-06-24T17:47:28Z"
},
{
"body": "I'm getting `AttributeError: 'list' object has no attribute 'op'` when I try to get the output node name of a loaded model as follows:\r\n\r\n```\r\nmodel = tf.keras.models.load_model('test_model.h5')\r\noutput_names = model.outputs.op.name\r\n```\r\n\r\nMy Tensorflow version is: 2.5.0",
"created_at": "2021-08-19T13:45:17Z"
}
],
"number": 33394,
"title": "AttributeError: 'list' object has no attribute 'op' when calling SparseCategoricalCrossentropy"
}
|
{
"body": "This fix tries to address the issue raised in #33394 where usage of SparseCategoricalCrossentropy causes the issue:\r\n```\r\nAttributeError: 'list' object has no attribute 'op'\r\n```\r\nwhen values are passed directly (not calling ops.convert_to_tensor first).\r\n\r\nThis fix fixes the issue by performing the ops.convert_to_tensor\r\non y_true and y_pred, similiar to what are done in other losses.\r\n\r\nThis fix fixes #33394.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 33406,
"review_comments": [],
"title": "Fix issue with SparseCategoricalCrossentropy: 'list' object has no attribute 'op'"
}
|
{
"commits": [
{
"message": "Fix issue with SparseCategoricalCrossentropy: 'list' object has no attribute 'op'\n\nThis fix tries to address the issue raised in 33394 where\nusage of SparseCategoricalCrossentropy causes the issue:\n```\nAttributeError: 'list' object has no attribute 'op'\n```\nwhen values are passed directly (not calling ops.convert_to_tensor first).\n\nThis fix fixes the issue by performing the ops.convert_to_tensor\non y_true and y_pred, similiar to what are done in other losses.\n\nThis fix fixes 33394.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub issue 33394\n\nfor fixing of AttributeError: 'list' object has no attribute 'op' when calling SparseCategoricalCrossentropy\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -974,6 +974,8 @@ def _smooth_labels():\n @keras_export('keras.metrics.sparse_categorical_crossentropy',\n 'keras.losses.sparse_categorical_crossentropy')\n def sparse_categorical_crossentropy(y_true, y_pred, from_logits=False, axis=-1):\n+ y_pred = ops.convert_to_tensor(y_pred)\n+ y_true = math_ops.cast(y_true, y_pred.dtype)\n return K.sparse_categorical_crossentropy(\n y_true, y_pred, from_logits=from_logits, axis=axis)\n ",
"filename": "tensorflow/python/keras/losses.py",
"status": "modified"
},
{
"diff": "@@ -1003,6 +1003,14 @@ def test_no_reduction(self):\n loss = cce_obj(y_true, logits)\n self.assertAllClose((0.001822, 0.000459, 0.169846), self.evaluate(loss), 3)\n \n+ def test_non_tensor(self):\n+ # Test case for GitHub issue 33394.\n+ cce_obj = keras.losses.SparseCategoricalCrossentropy()\n+ y_true = [[0], [1], [2]]\n+ y_pred = [[.9, .05, .05], [.5, .89, .6], [.05, .01, .94]]\n+ loss = cce_obj(y_true, y_pred, sample_weight=2.3)\n+ self.assertAlmostEqual(self.evaluate(loss), .7449, 3)\n+\n \n @test_util.run_all_in_graph_and_eager_modes\n class HingeTest(test.TestCase):",
"filename": "tensorflow/python/keras/losses_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n\r\n- Have I written custom code: Yes\r\n- OS Platform and Distribution: Linux Ubuntu 18.04\r\n- TensorFlow installed from: binary\r\n- TensorFlow version: v1.14.0-rc1-22-gaf24dc9 1.14.0\r\n- Python version: 3.6\r\n\r\n**Describe the current behavior**\r\nDirectories created with `tf.io.gfile.mkdir()` on Linux does not have the w mode bit set for group and other even if allowed by the umask and ACL.\r\n\r\n**Describe the expected behavior**\r\nDirectories created with `tf.io.gfile.mkdir` should have the maximum permissions allowed by the umask and ACL, which is the way `os.mkdir()` in Python works.\r\nI think this behavior is caused by the fact that [TF always calls mkdir with mode 0755](https://github.com/tensorflow/tensorflow/blob/r1.14/tensorflow/core/platform/posix/posix_file_system.cc#L281) while [Python calls mkdir with mode 511 (= 777 in octal)](https://github.com/python/cpython/blob/3.7/Modules/clinic/posixmodule.c.h#L1094) if no mode is given .\r\n\r\n**Code to reproduce the issue**\r\n\r\n```\r\nimport tensorflow as tf\r\nimport stat\r\nimport os\r\n\r\nos.umask(0000)\r\n\r\ntf_dir = \"test1\"\r\nos_dir = \"test2\"\r\n\r\ntf.io.gfile.mkdir(tf_dir)\r\ntf_mode = os.stat(tf_dir).st_mode\r\n\r\nos.mkdir(os_dir)\r\nos_mode = os.stat(os_dir).st_mode\r\n\r\nif (tf_mode != os_mode):\r\n print(\"File mode differs:\")\r\n print(\"TF: {}, OS: {}\".format(stat.filemode(tf_mode), stat.filemode(os_mode)))\r\n\r\n```",
"comments": [
{
"body": "Added a PR #33312 for the fix.",
"created_at": "2019-10-13T18:55:22Z"
},
{
"body": "Hi There,\n\n We are checking to see if you still need help on this, as you are using an older version of tensorflow which is officially considered end of life . We recommend that you upgrade to the latest 2.x version and let us know if the issue still persists in newer versions. Please open a new issue for any help you need against 2.x, and we will get you the right help. \n\n This issue will be closed automatically 7 days from now. If you still need help with this issue, please provide us with more information.",
"created_at": "2021-02-01T14:08:23Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32963\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32963\">No</a>\n",
"created_at": "2021-02-09T05:57:39Z"
}
],
"number": 32963,
"title": "tf.io.gfile.mkdir restricts directory mode/(permissions)"
}
|
{
"body": "This fix tries to address the issue raised in #32963 where the modes of the directory created between tf.io.gfile.mkdir and os.mkdir are different (one is 0777 and another is 0755).\r\n\r\nThis fix fixes the issue.\r\n\r\nThis fix fixes #32963.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\n",
"number": 33312,
"review_comments": [],
"title": "Fix discrepancy between tf.io.gfile.mkdir and os.mkdir's created mode"
}
|
{
"commits": [
{
"message": "Fix discrepancy between tf.io.gfile.mkdir and os.mkdir's created mode\n\nThis fix tries to address the issue raised in 32963 where\nthe modes of the directory created between tf.io.gfile.mkdir and os.mkdir\nare different (one is 0777 and another is 0755).\n\nThis fix fixes the issue.\n\nThis fix fixes 32963.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub isseu 32963 (tf.io.gfile.mkdir and os.mkdir's created mode difference)\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Restore the default mask\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -278,7 +278,8 @@ Status PosixFileSystem::CreateDir(const string& name) {\n if (translated.empty()) {\n return errors::AlreadyExists(name);\n }\n- if (mkdir(translated.c_str(), 0755) != 0) {\n+ // Note: 0777 (511) matches python's default behavior\n+ if (mkdir(translated.c_str(), 0777) != 0) {\n return IOError(name, errno);\n }\n return Status::OK();",
"filename": "tensorflow/core/platform/default/posix_file_system.cc",
"status": "modified"
},
{
"diff": "@@ -616,6 +616,22 @@ def testFileSeekableWithZip(self):\n info = np.load(f, allow_pickle=True)\n _ = [i for i in info.items()]\n \n+ def testCreateDirMode(self):\n+ oldmask = os.umask(0000)\n+\n+ tf_dir = os.path.join(self._base_dir, \"temp_dir_test1\")\n+ os_dir = os.path.join(self._base_dir, \"temp_dir_test2\")\n+\n+ file_io.create_dir_v2(tf_dir)\n+ tf_mode = os.stat(tf_dir).st_mode\n+\n+ os.mkdir(os_dir)\n+ os_mode = os.stat(os_dir).st_mode\n+\n+ os.umask(oldmask)\n+\n+ self.assertEqual(tf_mode, os_mode)\n+\n \n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/lib/io/file_io_test.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): MacOS 10.14.5\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.0.0-beta1\r\n- Python version: 3.6\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version:\r\n- GPU model and memory:\r\n\r\n**Describe the current behavior**\r\nUsing `tf.function` when enumerating a dataset will cause an infinite loop.\r\n\r\n**Describe the expected behavior**\r\nUsing `tf.function` when enumerating a dataset should not change the looping behavior.\r\n\r\n**Code to reproduce the issue**\r\nThe code snippet below will hang after the last function call. I'm not printing anything because calling `tf.print` results in a syntax error on colab and I know that these snippets are being run on colab by you. When printing the variable `i`, it's clear that the loop just never stops, i.e. `i` increase indefinitely.\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\nds = tf.data.Dataset.from_tensor_slices([1,2,3,4])\r\n\r\ndef test_loop_without_enumerate_without_decorator(ds):\r\n for val in ds:\r\n pass\r\n\r\n@tf.function\r\ndef test_loop_without_enumerate_with_decorator(ds):\r\n for val in ds:\r\n pass\r\n\r\ndef test_loop_with_enumerate_without_decorator(ds):\r\n for i, val in enumerate(ds):\r\n pass\r\n\r\n@tf.function\r\ndef test_loop_with_enumerate_with_decorator(ds):\r\n for i, val in enumerate(ds):\r\n pass\r\n\r\nprint(\"Without tf.function and without enumerate\")\r\ntest_loop_without_enumerate_without_decorator(ds)\r\n\r\nprint(\"Without tf.function and with enumerate\")\r\ntest_loop_with_enumerate_without_decorator(ds)\r\n\r\nprint(\"With tf.function and without enumerate\")\r\ntest_loop_without_enumerate_with_decorator(ds)\r\n\r\nprint(\"With tf.function and with enumerate\")\r\ntest_loop_with_enumerate_with_decorator(ds)\r\n```\r\n\r\n**Other info / logs**\r\nOutput of the above snippet:\r\n```\r\nWithout tf.function and without enumerate\r\nWithout tf.function and with enumerate\r\nWith tf.function and without enumerate\r\nWith tf.function and with enumerate\r\n**HANGS HERE**\r\n```\r\n",
"comments": [
{
"body": "I was able to reproduce the issue on Colab with Tensorflow 2.0.0.beta1. Please have a look at gist of [Colab](https://colab.research.google.com/drive/1UXGUopt4bVq-NUslCJVxw_BHeOlq0Rkz) link. Thanks ",
"created_at": "2019-07-18T09:45:09Z"
},
{
"body": "AutoGraph does not currently override `enumerate`, so it has the wrong behavior in graph mode. It would be a nice feature to add, and it shouldn't be too hard to do it.\r\n\r\nIn the mean time, to enumerate over datasets, please use `ds.enumerate()`. It works both inside and outside `tf.function`:\r\n\r\n```\r\ndef test_loop_with_ds_enumerate_without_decorator(ds):\r\n for i, val in ds.enumerate():\r\n tf.print(i, val)\r\n\r\n@tf.function\r\ndef test_loop_with_ds_enumerate_with_decorator(ds):\r\n for i, val in ds.enumerate():\r\n tf.print(i, val)\r\n\r\nprint(\"Without tf.function and ds.enumerate\")\r\ntest_loop_with_ds_enumerate_without_decorator(ds)\r\n\r\nprint(\"With tf.function and ds.enumerate\")\r\ntest_loop_with_ds_enumerate_with_decorator(ds)\r\n```\r\n```\r\nWithout tf.function and ds.enumerate\r\n0 1\r\n1 2\r\n2 3\r\n3 4\r\nWith tf.function and ds.enumerate\r\n0 1\r\n1 2\r\n2 3\r\n3 4\r\n```",
"created_at": "2019-07-22T14:26:49Z"
},
{
"body": "@mdanatg thank you, that worked for me. I'm gonna let this issue stay open, as the underlying problem hasn't been fixed yet, but feel free to close if you need to.",
"created_at": "2019-07-22T14:56:29Z"
},
{
"body": "@mdanatg I'm interested in working on this! I'm confused on how to get started. I've read the documentation on AutoGraph & tf.function decorator as well as [the code](https://github.com/tensorflow/tensorflow/blob/r2.0/tensorflow/python/eager/def_function.py#L725-L1027) and I can't spot which code is responsible for overriding such action. Pardon my inexperience.",
"created_at": "2019-07-25T13:12:35Z"
},
{
"body": "@ilhamfp that's great, happy to help you get started!\r\n\r\nThe dynamic dispatch can indeed make things a bit confusing.\r\n\r\nThe place to add this is in the Python builtin overloads file: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/autograph/operators/py_builtins.py\r\n\r\nThe file contains a number of overloads, check out `len` for instance, that you can use as a model. Then, once you have the overload of `enumerate`, you just need to add it to the lists at the bottom of the file, `SUPPORTED_BUILTINS` and `BUILTIN_FUNCTIONS_MAP` (there's a bit of duplication there). That should be it - the overload for function calls (https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/autograph/impl/api.py#L390, placed in the `api` module for various reasons) should pick it up at Python runtime.",
"created_at": "2019-07-25T13:38:46Z"
},
{
"body": "> AutoGraph does not currently override `enumerate`, so it has the wrong behavior in graph mode.\r\n\r\nHi @mdanatg . Just out of curiosity, what do you mean by \"wrong behavior in graph mode\"? With `tensorflow==2.0alpha0`, I often use `enumerate` to iterate over a list of layers within a call function as follows:\r\n```\r\nIn [2]: import tensorflow as tf\r\n\r\nIn [3]: tf.__version__\r\nOut[3]: '2.0.0-alpha0'\r\n\r\nIn [4]: from tensorflow.keras.layers import Dense\r\n\r\nIn [5]: layers = [Dense(10), Dense(20), Dense(30)]\r\n\r\nIn [6]: @tf.function\r\n ...: def call(x):\r\n ...: for i, layer in enumerate(layers):\r\n ...: x = layer(x)\r\n ...: return x\r\n\r\nIn [7]: y = call(tf.random.uniform((10, 20)))\r\n```\r\nIt would be grateful if you could explain a bit more.",
"created_at": "2019-08-20T14:51:42Z"
},
{
"body": "@llan-ml I was referring to calling `enumerate` with a `tf.data.Dataset` argument. Called with Python lists it was working fine. See the original post - before #31038, calling `test_loop_with_enumerate_with_decorator` in the original example caused an infinite loop, which was incorrect. At any rate, `enumerate` should now be fully supported for datasets.",
"created_at": "2019-08-20T15:14:28Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=30802\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=30802\">No</a>\n",
"created_at": "2019-08-20T15:14:29Z"
},
{
"body": "@mdanatg\r\n\r\n> AutoGraph does not currently override enumerate, so it has the wrong behavior in graph mode. It would be a nice feature to add, and it shouldn't be too hard to do it.\r\n\r\nCould you guys add this to [the documentation](https://www.tensorflow.org/api_docs/python/tf/data/Dataset) for tf.Dataset? Seems like a quick addition that would prove super valuable. Thanks!",
"created_at": "2020-02-17T13:31:14Z"
},
{
"body": "@tgsmith61591 This issue should be resolved - enumerate should now work correctly with datasets in tf.function, with TF >= 1.5. Have you been still experiencing issues?",
"created_at": "2020-02-17T14:10:39Z"
}
],
"number": 30802,
"title": "Using tf.function while enumerating a dataset causes an infinite loop"
}
|
{
"body": "`filter` is one of the builtin functions in python, though it is not supported with dataset in autograph yet (as opposed to `enumerate/map`).\r\n\r\ntf.data.Dataset already have filter support so adding it makes sense I think.\r\n\r\nThis PR adds the filter support for autograph with dataset.\r\n\r\nThis PR is related to #30802 (which adds `enumerate` support)\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 33310,
"review_comments": [],
"title": "Add filter support for autograph with dataset"
}
|
{
"commits": [
{
"message": "Add filter support for autograph\n\nfilter is one of the builtin functions in python, though it is not supported\nwith dataset in autograph yet (as opposed to enumerate/map).\n\ntf.data.Dataset already have filter support so adding it makes sense I think.\n\nThis PR adds the filter support for autograph with dataset.\n\nThis PR is related to 30802 (which adds enumerate support)\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Pylint fix\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for filter support in autograph with dataset\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -370,7 +370,21 @@ def _py_map(fn, *iterables):\n return map(fn, *iterables)\n \n \n-SUPPORTED_BUILTINS = (abs, float, int, len, print, range, enumerate, zip, map)\n+def filter_(function, iterable):\n+ if isinstance(iterable, dataset_ops.DatasetV2):\n+ return _tf_dataset_filter(function, iterable)\n+ return _py_filter(function, iterable)\n+\n+\n+def _tf_dataset_filter(function, iterable):\n+ return iterable.filter(function)\n+\n+\n+def _py_filter(function, iterable):\n+ return filter(function, iterable)\n+\n+SUPPORTED_BUILTINS = (\n+ abs, float, int, len, print, range, enumerate, zip, map, filter)\n \n if six.PY2:\n SUPPORTED_BUILTINS += (xrange,)\n@@ -387,4 +401,5 @@ def _py_map(fn, *iterables):\n 'enumerate': enumerate_,\n 'zip': zip_,\n 'map': map_,\n+ 'filter': filter_,\n }",
"filename": "tensorflow/python/autograph/operators/py_builtins.py",
"status": "modified"
},
{
"diff": "@@ -279,6 +279,19 @@ def test_method(self):\n tc = TestSubclass()\n self.assertEqual(tc.test_method(), 21)\n \n+ def test_filter(self):\n+ self.assertListEqual(\n+ list(py_builtins.filter_(lambda x: x == 'b', ['a', 'b', 'c'])), ['b'])\n+ self.assertListEqual(\n+ list(py_builtins.filter_(lambda x: x < 3, [3, 2, 1])), [2, 1])\n+\n+ def test_filter_dataset(self):\n+ dataset = dataset_ops.DatasetV2.from_tensor_slices([3, 2, 1])\n+ dataset = py_builtins.filter_(lambda x: x < 3, dataset)\n+ iterator = dataset_ops.make_one_shot_iterator(dataset)\n+ with self.cached_session() as sess:\n+ self.assertAllEqual(self.evaluate(iterator.get_next()), 2)\n+ self.assertAllEqual(self.evaluate(iterator.get_next()), 1)\n \n if __name__ == '__main__':\n test.main()",
"filename": "tensorflow/python/autograph/operators/py_builtins_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- TensorFlow installed from (source or binary): issue is reproducible with both\r\n- TensorFlow version (use command below): Confirmed on 2.0 and 1.14 \r\n- Python version: python2\r\n\r\n**Describe the current behavior**\r\nAfter creating a `tf.data.experimental.SqlDataset()` and performing a map and batch operaion, the dataset fails to raise a StopIteration after going through the entire database, and begins to repeat / recycle values incorrectly. \r\n\r\n**Describe the expected behavior**\r\nThe dataset stops after returning all the records in the sqlite database.\r\n\r\n**Code to reproduce the issue**\r\n```python\r\n# --- Create a dummy sqlite database ---\r\nimport os\r\nimport sqlite3\r\npth = \"/tmp/bug-report.sqlite\"\r\nif os.path.exists(pth): os.unlink(pth)\r\n\r\nquery = 'SELECT * FROM data'\r\n\r\ncon = sqlite3.connect(pth)\r\nc = con.cursor()\r\nc.execute('CREATE TABLE data (col1 Int)')\r\n\r\nfor i in range(3):\r\n c.execute('INSERT INTO data VALUES (' + str(i) + ')')\r\n\r\ncon.commit()\r\n\r\n# print the db, just to show what's in there\r\nc.execute(query)\r\nprint \"Actual query results: \", c.fetchall()\r\ncon.close()\r\n\r\n# --- create a tf sqlite dataset ---\r\nimport tensorflow as tf\r\nprint tf.version.VERSION\r\n\r\nds = tf.data.experimental.SqlDataset('sqlite', pth, query, (tf.int32))\r\nds = ds.map(lambda x: tf.identity(x))\r\n\r\n\r\n# this is supposed to terminate after only two batchs since the sqlite db only\r\n# has 2 entries, but it goes forever\r\nprint \"Batch size of 2:\"\r\ni = 0\r\nfor e in ds.batch(2):\r\n print e\r\n \r\n i += 1\r\n if i > 2: print \" Should have stopped by now\"\r\n if i > 10: print \" breaking early\"; break\r\n \r\n# if batch size is larger than the db size, it also fails to stop\r\nprint \"Batch size of 4:\"\r\ni = 0\r\nfor e in ds.batch(4):\r\n print e\r\n \r\n i += 1\r\n if i > 1: print \" Should have stopped by now\"\r\n if i > 10: print \" breaking early\"; break\r\n\r\n# if batch size is exactly a multiple of the sqlite db size, then it does\r\n# raise a StopIteration correctly\r\nprint \"Batch size of 3:\"\r\nfor e in ds.batch(3):\r\n print e\r\n```\r\n\r\n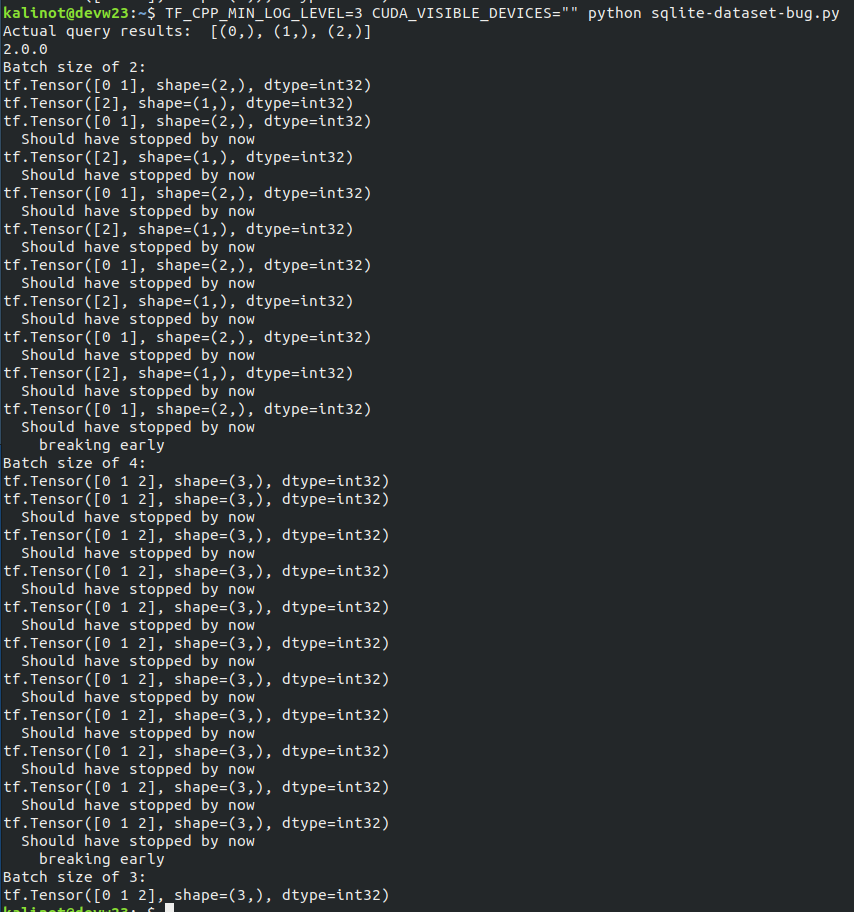\r\n\r\n\r\n**Other info / logs**\r\nThis has been reproduced on tensorflow versions 2.0, 1.14 and 1.15\r\n",
"comments": [
{
"body": "Added PR #33271 for the fix.",
"created_at": "2019-10-12T00:40:51Z"
},
{
"body": "Thank you for the quick fix! Any chance this could make it into 1.15 too?",
"created_at": "2019-10-14T13:08:40Z"
},
{
"body": "@t-kalinowski We will have to wait for the PR to be merged into master. Once it is in the master, it might be cherry-picked into release 1.15 or 2.0. Though given 1.15's release schedule, I would not count on this fix being picked up in 1.15.",
"created_at": "2019-10-15T04:50:14Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33253\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/33253\">No</a>\n",
"created_at": "2019-10-15T12:08:07Z"
}
],
"number": 33253,
"title": "sqlite dataset fails to raise a StopIteration: incorrect result"
}
|
{
"body": "This fix fixes the issue raised in #33253 where SqlDataset fails to raise StopIteration when combined with batch(). The reason was that after all records have been consumed, the extra `next` in the kernel does not return empty record so the iteration will continue in the next round. This fix fixes the issue.\r\n\r\nThis fix fixes #33253.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 33271,
"review_comments": [],
"title": "Fix SqlDataset fails to raise StopIteration issue when combined with batch"
}
|
{
"commits": [
{
"message": "Fix SqlDataset fails to raise StopIteration issue when combined with batch\n\nThis fix fixes the issue raised in 33253 where SqlDataset fails to raise\nStopIteration when combined with batch(). The reason was that after all records\nhave been consumed, the extra `next` in the kernel does not return empty record\nso the iteration will continue in the next round. This fix fixes the issue.\n\nThis fix fixes 33253.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for 33253 where SqlDataset fails to raise a StopIteration when combined with batch\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -142,8 +142,13 @@ class SqlDatasetOp : public DatasetOpKernel {\n if (!query_connection_initialized_) {\n TF_RETURN_IF_ERROR(InitializeQueryConnection());\n }\n- next_calls_++;\n- return query_connection_->GetNext(ctx, out_tensors, end_of_sequence);\n+\tStatus status = Status::OK();\n+\tif (!end_of_sequence_) {\n+ next_calls_++;\n+ status = query_connection_->GetNext(ctx, out_tensors, &end_of_sequence_);\n+\t}\n+\t*end_of_sequence = end_of_sequence_;\n+\treturn status;\n }\n \n protected:\n@@ -170,21 +175,23 @@ class SqlDatasetOp : public DatasetOpKernel {\n reader->ReadScalar(full_name(\"next_calls\"), &next_calls_));\n int64 rem_next_calls = next_calls_;\n std::vector<Tensor> out_tensors;\n- bool end_of_sequence = false;\n+ end_of_sequence_ = false;\n while (rem_next_calls--) {\n TF_RETURN_IF_ERROR(query_connection_->GetNext(ctx, &out_tensors,\n- &end_of_sequence));\n+ &end_of_sequence_));\n out_tensors.clear();\n }\n } else {\n query_connection_initialized_ = false;\n+ end_of_sequence_ = false;\n }\n return Status::OK();\n }\n \n private:\n Status InitializeQueryConnection() EXCLUSIVE_LOCKS_REQUIRED(mu_) {\n query_connection_initialized_ = true;\n+ end_of_sequence_ = false;\n query_connection_ =\n sql::DriverManager::CreateQueryConnection(dataset()->driver_name_);\n Status s = query_connection_->Open(dataset()->data_source_name_,\n@@ -203,6 +210,7 @@ class SqlDatasetOp : public DatasetOpKernel {\n int64 next_calls_ GUARDED_BY(mu_) = 0;\n std::unique_ptr<sql::QueryConnection> query_connection_ GUARDED_BY(mu_);\n bool query_connection_initialized_ GUARDED_BY(mu_) = false;\n+ bool end_of_sequence_ GUARDED_BY(mu_) = false;\n };\n const tstring driver_name_;\n const tstring data_source_name_;",
"filename": "tensorflow/core/kernels/data/experimental/sql_dataset_op.cc",
"status": "modified"
},
{
"diff": "@@ -22,6 +22,7 @@\n from tensorflow.python.framework import dtypes\n from tensorflow.python.framework import errors\n from tensorflow.python.framework import test_util\n+from tensorflow.python.ops import array_ops\n from tensorflow.python.platform import test\n \n \n@@ -470,6 +471,18 @@ def testReadResultSetFloat64LargestConsecutiveWholeNumbersNotEqual(self):\n with self.assertRaises(errors.OutOfRangeError):\n self.evaluate(get_next())\n \n+ # Test that SqlDataset can stop correctly when combined with batch\n+ def testReadResultSetWithBatchStop(self):\n+ dataset = self._createSqlDataset(\n+ query=\"SELECT * FROM data\",\n+ output_types=(dtypes.int32))\n+ dataset = dataset.map(lambda x: array_ops.identity(x))\n+ get_next = self.getNext(dataset.batch(2))\n+ self.assertAllEqual(self.evaluate(get_next()), [0, 1])\n+ self.assertAllEqual(self.evaluate(get_next()), [2])\n+ with self.assertRaises(errors.OutOfRangeError):\n+ self.evaluate(get_next())\n+\n \n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/data/experimental/kernel_tests/sql_dataset_test.py",
"status": "modified"
},
{
"diff": "@@ -47,6 +47,7 @@ def setUp(self):\n c.execute(\"DROP TABLE IF EXISTS students\")\n c.execute(\"DROP TABLE IF EXISTS people\")\n c.execute(\"DROP TABLE IF EXISTS townspeople\")\n+ c.execute(\"DROP TABLE IF EXISTS data\")\n c.execute(\n \"CREATE TABLE IF NOT EXISTS students (id INTEGER NOT NULL PRIMARY KEY, \"\n \"first_name VARCHAR(100), last_name VARCHAR(100), motto VARCHAR(100), \"\n@@ -86,5 +87,9 @@ def setUp(self):\n (\"John\", \"Adams\", -19.95,\n 1331241321342132321324589798264627463827647382647382643874.0,\n 9007199254740992.0)])\n+ c.execute(\"CREATE TABLE IF NOT EXISTS data (col1 INTEGER)\")\n+ c.executemany(\n+ \"INSERT INTO DATA VALUES (?)\",\n+ [(0,), (1,), (2,)])\n conn.commit()\n conn.close()",
"filename": "tensorflow/python/data/experimental/kernel_tests/sql_dataset_test_base.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): gLinux (like Debian)\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): tf-nightly-2.0-preview==2.0.0.dev20190807\r\n- TensorFlow version (use command below): v1.12.1-8193-ge7d48dc 2.0.0-dev20190807\r\n- Python version: 3.6.6\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: None\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\n\r\nCalling `tf.image.encode_png` kills the process with SIGABRT if you pass\r\na tensor that has no elements.\r\n\r\n**Describe the expected behavior**\r\n\r\nIt should never SIGABRT.\r\n\r\n**Code to reproduce the issue**\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\nimage = tf.cast(tf.tile([[[0, 0, 0]]], [0, 0, 1]), tf.uint8)\r\n# Or: = tf.cast(tf.reshape([], [0, 0, 3]))\r\ntry:\r\n tf.print(image)\r\n tf.print(tf.shape(image))\r\n tf.image.encode_png(image)\r\nfinally:\r\n print(\"We never get here!\")\r\n```\r\n\r\n```\r\n$ TF_CPP_MIN_LOG_LEVEL=1 python test.py\r\n[]\r\n[0 0 3]\r\n2019-08-07 16:32:12.864303: F tensorflow/core/lib/png/png_io.cc:347] 'image' Must be non NULL\r\nAborted\r\n$ echo $?\r\n134\r\n```\r\n\r\n**Other info / logs**\r\n\r\nThis also affects `tf.summary.image`.\r\n",
"comments": [
{
"body": "Issue replicating with tf-nightly-2.0-preview, please find the [gist](https://colab.sandbox.google.com/gist/oanush/3e90e50f2c711e628cf859a71d55dafa/31429.ipynb) of colab.Thanks",
"created_at": "2019-08-08T06:55:00Z"
},
{
"body": "Beginner here. Would like to work on this issue. Any leads?",
"created_at": "2019-08-08T14:21:30Z"
},
{
"body": "@Soniyanayak51 check `tensorflow/core/kernels/encode_png_op.cc`, in `Compute`, just before the `png::WriteImageToBuffer` gets called, `image.flat<..>.data()` should be checked. It currently returns nullptr which then causes the abort.",
"created_at": "2019-08-08T15:58:05Z"
},
{
"body": "Thanks for the reply. On it",
"created_at": "2019-08-08T17:28:25Z"
},
{
"body": "@oanush: Not sure what you mean. Your Colab is not publicly visible, and\r\nI can reproduce this in a fresh virtualenv:\r\n\r\n```\r\n$ cd \"$(mktemp -d)\"\r\n$ virtualenv -q -p python3.6 ./ve\r\n$ . ./ve/bin/activate\r\n(ve) $ pip install -q tf-nightly-2.0-preview==2.0.0.dev20190807\r\n(ve) $ python\r\nPython 3.6.7 (default, Oct 21 2018, 08:08:16) \r\n[GCC 8.2.0] on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import tensorflow as tf\r\n>>> tf.__version__\r\n'2.0.0-dev20190807'\r\n>>> image = tf.cast(tf.tile([[[0, 0, 0]]], [0, 0, 1]), tf.uint8)\r\n>>> tf.print(image)\r\n[]\r\n>>> tf.print(tf.shape(image))\r\n[0 0 3]\r\n>>> tf.image.encode_png(image)\r\n2019-08-08 10:28:38.860641: F tensorflow/core/lib/png/png_io.cc:347] 'image' Must be non NULL\r\nAborted\r\n(ve) $ echo $?\r\n134\r\n```\r\n",
"created_at": "2019-08-08T17:30:15Z"
},
{
"body": "@mihaimaruseac \r\nSorry, I am stuck with running tests here. Any leads on how to test code easily before raising a PR?",
"created_at": "2019-08-12T10:15:08Z"
},
{
"body": "I would build a pip package, install it in a virtualenv and test with the code to reproduce posted at the beginning of the issue.\r\n\r\nSee https://www.tensorflow.org/install/source for how to build the pip package.\r\n\r\nThen, if that works, we can continue making this either a Python integration test or converting it to a C++ test.",
"created_at": "2019-08-12T15:33:32Z"
},
{
"body": "Added a PR #33220 for the fix. /cc @mihaimaruseac please take a look.",
"created_at": "2019-10-10T19:32:23Z"
},
{
"body": "Was able to reproduce the issue with [TF v2.1](https://colab.research.google.com/gist/amahendrakar/855918e07fcb96fe091964a7b0c543be/2-1-template.ipynb) and [TF-nightly](https://colab.research.google.com/gist/amahendrakar/343256a8d0c24e08a95b050b90bc5942/tf-nightly.ipynb#scrollTo=ieAW-NK5iqpf) i.e. v2.2.0-dev20200327. Session crashes in both the cases. Please find the attached gist. Thanks!",
"created_at": "2020-03-27T20:38:36Z"
},
{
"body": "@amahendrakar there is no attached gist",
"created_at": "2020-03-28T17:20:14Z"
},
{
"body": "@mihaimaruseac,\r\nTF 2.1 - https://colab.research.google.com/gist/amahendrakar/855918e07fcb96fe091964a7b0c543be/2-1-template.ipynb\r\n\r\nTF-nightly - https://colab.research.google.com/gist/amahendrakar/343256a8d0c24e08a95b050b90bc5942/tf-nightly.ipynb#scrollTo=ieAW-NK5iqpf\r\n\r\nHere are the direct links. Could you please check if these work? Thanks!\r\n",
"created_at": "2020-03-28T17:33:39Z"
},
{
"body": "\r\nWas able to reproduce the issue with TF v2.3 and [TF-nightly ](https://colab.research.google.com/gist/Saduf2019/007bcd1a40306bb9c57096a9c7bd1e8c/untitled359.ipynb)",
"created_at": "2020-08-11T18:30:46Z"
},
{
"body": "@wchargin I tried to reproduce the issue in TF 2.5 and the session is not crashing but facing different error. Please check the gist [here](https://colab.research.google.com/gist/saikumarchalla/74fcac3ed929e5823b6400ea886e556e/untitled78.ipynb).Thanks!",
"created_at": "2021-05-20T09:39:22Z"
},
{
"body": "This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2021-05-27T09:48:13Z"
},
{
"body": "Closing as stale. Please reopen if you'd like to work on this further.\n",
"created_at": "2021-06-03T10:01:05Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/31429\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/31429\">No</a>\n",
"created_at": "2021-06-03T10:01:08Z"
},
{
"body": "The error in the recent gist is the supposed error to prevent the crash. This is now fixed.",
"created_at": "2021-06-08T20:23:51Z"
}
],
"number": 31429,
"title": "SIGABRT on `tf.image.encode_png` with empty tensor"
}
|
{
"body": "This fix address the issue raised in #31429 where SIGABRT was thrown on `tf.image.encode_png` with empty tensor.\r\n\r\nInstead of thrown out SIGABRT, this fix adds the error checking so that InvalidArgument was returned gracefully.\r\n\r\nThis fix fixes #31429\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 33220,
"review_comments": [
{
"body": "`File \"/third_party/py/absl/third_party/unittest3_backport/case.py\", line 37, in testPartExecutor\r\n yield\r\n File \"third_party/py/absl/third_party/unittest3_backport/case.py\", line 162, in run\r\n testMethod()\r\n File \"third_party/tensorflow/python/ops/image_ops_test.py\", line 4082, in testEmptyTensor\r\n png = image_ops.encode_png(image)\r\n File \"<embedded stdlib>/contextlib.py\", line 24, in __exit__\r\n self.gen.next()\r\n File \"third_party/tensorflow/python/framework/test_util.py\", line 2808, in assertRaisesWithPredicateMatch\r\n (str(type(e)), str(e)))\r\nAssertionError: Exception of type <type 'exceptions.AssertionError'>: OpError not raised`",
"created_at": "2019-10-25T18:04:56Z"
},
{
"body": "@yongtang can you please fix above error ?",
"created_at": "2019-10-25T18:05:11Z"
},
{
"body": "Hi @yongtang \r\nFailing with similar error internally , can you please check once,\r\n`Traceback (most recent call last):\r\n /unittest/case.py\", line 59, in testPartExecutor\r\n yield\r\n /unittest/case.py\", line 605, in run\r\n testMethod()\r\n File \"/google3/runfiles/google3/third_party/tensorflow/python/ops/image_ops_test.py\", line 4079, in testEmptyTensor\r\n png = image_ops.encode_png(image)\r\n File \"contextlib.py\", line 88, in __exit__\r\n next(self.gen)\r\n File \"google3/runfiles/google3/third_party/tensorflow/python/framework/test_util.py\", line 2819, in assertRaisesWithPredicateMatch\r\n (str(type(e)), str(e)))\r\nAssertionError: Exception of type <class 'AssertionError'>: OpError not raised`",
"created_at": "2020-01-02T18:58:39Z"
},
{
"body": "So, I tested internally and the error doesn't seem to be raised always, that's why the test fails (in 1 / 4 attempts).",
"created_at": "2020-01-23T23:57:22Z"
}
],
"title": "Fix SIGABRT on `tf.image.encode_png` with empty tensor"
}
|
{
"commits": [
{
"message": "Fix SIGABRT on `tf.image.encode_png` with empty tensor\n\nThis fix address the issue raised in 31429 where\nSIGABRT was thrown on `tf.image.encode_png` with empty tensor.\n\nInstead of thrown out SIGABRT, this fix adds the error checking\nso that InvalidArgument was returned gracefully.\n\nThis fix fixes 31429\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for encode_png with empty tensor\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -72,6 +72,10 @@ class EncodePngOp : public OpKernel {\n errors::InvalidArgument(\n \"image must have 1, 2, 3, or 4 channels, got \", channels));\n \n+ OP_REQUIRES(context, (image.NumElements() > 0),\n+ errors::InvalidArgument(\n+ \"image data should not be empty\"));\n+\n // Encode image to png string\n Tensor* output = nullptr;\n OP_REQUIRES_OK(context,",
"filename": "tensorflow/core/kernels/encode_png_op.cc",
"status": "modified"
},
{
"diff": "@@ -4071,6 +4071,14 @@ def testShape(self):\n self.assertEqual(image.get_shape().as_list(),\n [None, None, channels or None])\n \n+ def testEmptyTensor(self):\n+ with self.cached_session(use_gpu=True) as sess:\n+ image = array_ops.reshape(\n+ constant_op.constant([], dtypes.uint8), [0, 0, 3])\n+ with self.assertRaisesOpError(r\"image data should not be empty\"):\n+ png = image_ops.encode_png(image)\n+\n+\n \n class GifTest(test_util.TensorFlowTestCase):\n ",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):\r\nYes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):\r\nDarwin Kernel Version 18.6.0\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\nN/A\r\n- TensorFlow installed from (source or binary):\r\nbinary\r\n- TensorFlow version (use command below):\r\n2.0.0-dev20190827\r\n- Python version:\r\nPython 3.6.8 :: Anaconda, Inc.\r\n- Bazel version (if compiling from source):\r\nN/A\r\n- GCC/Compiler version (if compiling from source):\r\nN/A\r\n- CUDA/cuDNN version:\r\nN/A\r\n- GPU model and memory:\r\nN/A\r\n\r\n**Describe the current behavior**\r\n`tf.assert_equal([], [1.0])` doesn't raise any error. \r\n\r\n**Code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\n\r\ntf.assert_equal([], [1.0])\r\n```\r\n\r\n**Other info / logs**\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\n",
"comments": [
{
"body": "@David-Mao I could reproduce the issue. Are you interested in raising PR to update code/doc accordingly? Thanks!",
"created_at": "2019-08-30T10:44:07Z"
},
{
"body": "I think the reason for the issue is that, `tf.assert_equal` follows the same as `==` which automatically broadcast. With braodcast `tf.assert_equal([], [1.0])` is correct. A similar case below shows the same that will broadcast:\r\n\r\n```python\r\nimport tensorflow as tf\r\ntf.assert_equal([[1.0, 2.0], [1.0, 2.0]], [1.0, 2.0])\r\n```\r\n\r\nFrom that standpoint the behavior of `tf.assert_equal` works as expected, though indeed it might be misleading.\r\n\r\nWondering if it makes sense to have an additional arg of `broadcast=[True|False]` to explicitly call out broadcast or not?",
"created_at": "2019-08-30T16:15:33Z"
},
{
"body": "@yongtang \r\n> I think the reason for the issue is that, `tf.assert_equal` follows the same as `==` which automatically broadcast. With braodcast `tf.assert_equal([], [1.0])` is correct. \r\n\r\nBefore I submitted this ticket I carefully read the API doc and I noticed the broadcast thing, but I still think it's too anti-intuitive an argument to be made here. At least in this case it seems to me more of a bug than a feature. \r\n\r\nI like the idea of adding the broadcast arg (and maybe have broadcast=False to be the default value).\r\n\r\n@jvishnuvardhan I read the source code and it seems to be a non-trivial fix. I'm not sure I can make the PR easily...",
"created_at": "2019-08-30T16:51:27Z"
},
{
"body": "Empty list should not broadcast to list of one element; broadcasting should just add dimensions or expand dimensions sized 1 to larger sizes",
"created_at": "2019-09-04T20:29:06Z"
},
{
"body": "I think it was resolved. I am closing the issue. But, please let me know if I'm mistaken. Thanks!\r\n\r\nPlease feel free to open a PR to update docs to reflect @alextp comments so that community will get benefited. Thanks!",
"created_at": "2019-09-24T00:02:33Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=32082\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=32082\">No</a>\n",
"created_at": "2019-09-24T00:02:35Z"
},
{
"body": "@jvishnuvardhan \r\nI just upgrade to tf-nightly-2.0-preview-2.0.0.dev20190923 and `tf.assert_equal([], [1.0])\r\n` still passes? I think @alextp 's comment was saying that this is indeed a bug, not work as expected?\r\n\r\n> I think it was resolved. I am closing the issue. But, please let me know if I'm mistaken. Thanks!\r\n> \r\n> Please feel free to open a PR to update docs to reflect @alextp comments so that community will get benefited. Thanks!\r\n\r\n",
"created_at": "2019-09-24T05:22:05Z"
},
{
"body": "When I said \"should\" I didn't mean it actually does right now...\n\nOn Mon, Sep 23, 2019 at 10:30 PM David-Mao <notifications@github.com> wrote:\n\n> I just upgrade to tf-nightly-2.0-preview-2.0.0.dev20190923 and tf.assert_equal([],\n> [1.0]) still passes?\n>\n> I think it was resolved. I am closing the issue. But, please let me know\n> if I'm mistaken. Thanks!\n>\n> Please feel free to open a PR to update docs to reflect @alextp\n> <https://github.com/alextp> comments so that community will get\n> benefited. Thanks!\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/tensorflow/tensorflow/issues/32082?email_source=notifications&email_token=AAABHRIT4DLP3ZJ2EX37UEDQLGQVXA5CNFSM4ISAY2UKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD7NDGHQ#issuecomment-534393630>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/AAABHRM4NA3Z3RXIPL5VJJLQLGQVXANCNFSM4ISAY2UA>\n> .\n>\n\n\n-- \n - Alex\n",
"created_at": "2019-09-24T14:44:36Z"
},
{
"body": "@jvishnuvardhan I think @alextp was saying empty list `[]` should do broadcast first, when shape does not match for cwise ops. Let's re-open the issue. I think I might be able to take a look at the code path and see if I can have a fix.",
"created_at": "2019-09-24T15:52:12Z"
},
{
"body": "Update:\r\n\r\n~~was saying empty list [] should do broadcast first, when shape does not match for cwise ops~~\r\n\r\nThere was a typo in the last message:\r\nwas saying empty list [] should **not** do broadcast first, when shape does not match for cwise ops\r\n\r\n",
"created_at": "2019-09-24T15:56:08Z"
},
{
"body": "...and even if you do broadcast the empty list should broadcast to 0, not\nto 1, I think\n\nOn Tue, Sep 24, 2019 at 9:03 AM Yong Tang <notifications@github.com> wrote:\n\n> Update:\n>\n> was saying empty list [] should do broadcast first, when shape does not\n> match for cwise ops\n>\n> There was a typo in the last message:\n> was saying empty list [] should *not* do broadcast first, when shape does\n> not match for cwise ops\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/tensorflow/tensorflow/issues/32082?email_source=notifications&email_token=AAABHRJO6RVCLI5FT7Y6BHDQLI24BA5CNFSM4ISAY2UKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD7O3UZY#issuecomment-534624871>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/AAABHRMY7GT6J32C3UD5SILQLI24BANCNFSM4ISAY2UA>\n> .\n>\n\n\n-- \n - Alex\n",
"created_at": "2019-09-24T16:06:41Z"
},
{
"body": "Sorry for misunderstanding @alextp comments. Thanks @yongtang for reopening the issue. ",
"created_at": "2019-09-24T16:37:11Z"
},
{
"body": "Added a PR #33066 for the fix.",
"created_at": "2019-10-05T07:37:00Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32082\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32082\">No</a>\n",
"created_at": "2019-11-15T21:53:15Z"
},
{
"body": "This issue still appears in TensorFlow 2.2.0. Here is the [Colab](https://colab.research.google.com/drive/1f8zX66XM71aYxfxvU9UieakaQKAyz_Mg?usp=sharing) that reproduce this issue.",
"created_at": "2020-05-18T07:28:47Z"
},
{
"body": "> This issue still appears in TensorFlow 2.2.0. Here is the [Colab](https://colab.research.google.com/drive/1f8zX66XM71aYxfxvU9UieakaQKAyz_Mg?usp=sharing) that reproduce this issue.\r\n\r\nYes indeed. ping @yongtang ",
"created_at": "2020-05-19T07:04:10Z"
},
{
"body": "Looks like the PR was rolled back at some point in 1d5fb46b89611b95c8fda8f2f3d597d88455f5f2 , will take a look and see if I can resubmit.",
"created_at": "2020-05-19T15:59:12Z"
},
{
"body": "This doesn't seem to need API Review, removing the label. Please re-add if needed.",
"created_at": "2021-02-15T19:04:16Z"
},
{
"body": "Error exists with `TF Version 2.4.1` as well. Please find [the Gist](https://colab.research.google.com/gist/rmothukuru/a7fbe746814ddcfe80c7e5abd9f2595b/tensorflow-issue-32082.ipynb).",
"created_at": "2021-04-28T12:01:47Z"
},
{
"body": "Was able to replicate the issue with TF v2.5,please find the gist [here ](https://colab.research.google.com/gist/sushreebarsa/33af09960a5643137c5fa270292ec06d/tensorflow-issue-32082.ipynb#scrollTo=bIPYVTSiKGic)..Thanks!",
"created_at": "2021-06-24T17:56:53Z"
},
{
"body": "Checked in `TF 2.6.0` and the issue still persists. Please find the [gist here](https://colab.research.google.com/gist/sanatmpa1/c239a0283aaa27bdf633529e04134458/32082.ipynb)",
"created_at": "2021-09-08T15:33:46Z"
},
{
"body": "@David-Mao Was able to replicate the issue in 2.10.0-dev20220719, please find the gist [here](https://colab.sandbox.google.com/gist/chunduriv/8ab2be3fbb8351934ba4fe536bdf56cf/32082.ipynb). Thanks!",
"created_at": "2021-11-16T17:03:53Z"
},
{
"body": "Hi @David-Mao ,\r\nI have tested the issue with tf-nightly(2.12.0.dev20221215) and now it is raising the `InvalidArgumentError` as intended. Please refer the attached [gist](https://colab.sandbox.google.com/gist/SuryanarayanaY/0d44edc45c79e08a59e83a6db15acd14/32082-nightly-2-12.ipynb).Same works with TF2.11V also which is also mentioned in attached gist.\r\n\r\nPlease go through the issue and close the issue as it resolved with TF2.11V and tf-nightly as well.",
"created_at": "2022-12-19T09:13:50Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2022-12-26T09:57:11Z"
},
{
"body": "Closing as stale. Please reopen if you'd like to work on this further.\n",
"created_at": "2023-01-02T10:19:43Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32082\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32082\">No</a>\n",
"created_at": "2023-01-02T10:19:46Z"
}
],
"number": 32082,
"title": "[TF 2.0] tf.assert_equal([], [1.0]) doesn't raise error"
}
|
{
"body": "This fix tries to address the issue raised in #32082 where tf.assert_equal([], [1.0]) doesn't raise error.\r\nThe reason was that in assert_equal `[1.0]` was broadcasted as `[]` and equal was in place in that situation.\r\n\r\nThis PR updates the _binary_asesert so that it will check if x, y are both empty or both non-empty. If one is empty and another is non-empty, then assertion throws exception. This change is to not impact other ops that depends on the broadcast behavior.\r\n\r\nThis fix fixes #32082.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 33066,
"review_comments": [
{
"body": "`InvalidArgumentError: assertion failed: [`Tensor(\\\"Placeholder:0\\\", dtype=int32)` elements must be either positive integers or `-1`.] [Condition x >= y did not hold element-wise:] [x (Placeholder:0) = ] [] [y (reshape/assert_greater_equal/y:0) = ] [-1]\r\n\t [[node reshape/assert_greater_equal/Assert/Assert (defined at /tensorflow/contrib/distributions/python/kernel_tests/bijectors/reshape_test.py:111) ]]\r\n\r\nErrors may have originated from an input operation.\r\nInput Source operations connected to node reshape/assert_greater_equal/Assert/Assert:\r\n```suggestion\r\n static_func(x_static, y_static))` \r\nWe can see the above internal error, can please fix it.",
"created_at": "2019-10-16T04:17:00Z"
}
],
"title": "Fix tf.assert_equal issue when one tenor is empty and another is non-empty"
}
|
{
"commits": [
{
"message": "Fix tf.assert_equal issue when one tenor is empty and another is non-empty\n\nThis fix tries to address the issue raised in 32082 where\ntf.assert_equal([], [1.0]) doesn't raise error.\nThe reason was that in assert_equal `[1.0]` was broadcasted\nas `[]` and equal was in place in that situation.\n\nThis PR updates the _binary_asesert so that it will check if\nx, y are both empty or both non-empty. If one is empty and another is\nnon-empty, then assertion throws exception. This change is to not impact\nother ops that depends on the broadcast behavior.\n\nThis fix fixes 32082.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Adjust assert_negative/positive/non_negative/positive\n\nas they are unary assertion\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for 32082\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Pylint fix\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix failed test\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -315,6 +315,17 @@ def test_noop_when_both_identical(self):\n else:\n self.assertEqual(check_op.type, \"NoOp\")\n \n+ @test_util.run_in_graph_and_eager_modes\n+ def test_raises_when_empty_and_non_equal_shapes(self):\n+ value = constant_op.constant([1.0], name=\"value\")\n+ empty = constant_op.constant([], name=\"empty\")\n+ with self.assertRaisesRegexp(\n+ (errors.InvalidArgumentError, ValueError),\n+ (r\"Condition x == y did not hold\")):\n+ with ops.control_dependencies([check_ops.assert_equal(value, empty)]):\n+ out = array_ops.identity(value)\n+ self.evaluate(out)\n+\n \n class AssertNoneEqualTest(test.TestCase):\n ",
"filename": "tensorflow/python/kernel_tests/check_ops_test.py",
"status": "modified"
},
{
"diff": "@@ -295,9 +295,27 @@ def _pretty_print(data_item, summarize):\n else:\n return str(data_item)\n \n+def _binary_all_empty_or_all_non_empty(x, y):\n+ \"\"\"Chek if x and y are either all empty or all non-empty.\n+\n+ Args:\n+ x: A `Tensor`.\n+ y: A `Tensor`.\n+\n+ Returns:\n+ True if x and y are either all empty or all non-empty\n+ \"\"\"\n+ all_empty = math_ops.logical_and(\n+ math_ops.equal(array_ops.size(x), 0),\n+ math_ops.equal(array_ops.size(y), 0))\n+ all_non_empty = math_ops.logical_and(\n+ math_ops.not_equal(array_ops.size(x), 0),\n+ math_ops.not_equal(array_ops.size(y), 0))\n+ return math_ops.logical_or(all_empty, all_non_empty)\n+\n \n def _binary_assert(sym, opname, op_func, static_func, x, y, data, summarize,\n- message, name):\n+ message, name, allow_empty=False):\n \"\"\"Generic binary elementwise assertion.\n \n Implements the behavior described in _binary_assert_doc() above.\n@@ -329,7 +347,12 @@ def _binary_assert(sym, opname, op_func, static_func, x, y, data, summarize,\n \n if context.executing_eagerly():\n test_op = op_func(x, y)\n- condition = math_ops.reduce_all(test_op)\n+ if allow_empty:\n+ condition = math_ops.reduce_all(test_op)\n+ else:\n+ empty_check = _binary_all_empty_or_all_non_empty(x, y)\n+ condition = math_ops.logical_and(\n+ empty_check, math_ops.reduce_all(test_op))\n if condition:\n return\n \n@@ -362,11 +385,22 @@ def _binary_assert(sym, opname, op_func, static_func, x, y, data, summarize,\n ]\n if message is not None:\n data = [message] + list(data)\n- condition = math_ops.reduce_all(op_func(x, y))\n+ if allow_empty:\n+ condition = math_ops.reduce_all(op_func(x, y))\n+ else:\n+ empty_check = _binary_all_empty_or_all_non_empty(x, y)\n+ condition = math_ops.logical_and(\n+ empty_check, math_ops.reduce_all(op_func(x, y)))\n x_static = tensor_util.constant_value(x)\n y_static = tensor_util.constant_value(y)\n if x_static is not None and y_static is not None:\n- condition_static = np.all(static_func(x_static, y_static))\n+ if allow_empty:\n+ condition_static = np.all(static_func(x_static, y_static))\n+ else:\n+ empty_check_static = ((x_static.size == 0 and y_static.size == 0) or\n+ (x_static.size != 0 and y_static.size != 0))\n+ condition_static = empty_check_static and np.all(\n+ static_func(x_static, y_static))\n _assert_static(condition_static, data)\n return control_flow_ops.Assert(condition, data, summarize=summarize)\n \n@@ -451,7 +485,9 @@ def assert_negative(x, data=None, summarize=None, message=None, name=None): # p\n 'Condition x < 0 did not hold element-wise:',\n 'x (%s) = ' % name, x]\n zero = ops.convert_to_tensor(0, dtype=x.dtype)\n- return assert_less(x, zero, data=data, summarize=summarize)\n+ return _binary_assert('<', 'assert_less', math_ops.less, np.less,\n+ x, zero, data, summarize,\n+ message=None, name=None, allow_empty=True)\n \n \n @tf_export('debugging.assert_positive', v1=[])\n@@ -502,7 +538,9 @@ def assert_positive(x, data=None, summarize=None, message=None, name=None): # p\n message, 'Condition x > 0 did not hold element-wise:',\n 'x (%s) = ' % name, x]\n zero = ops.convert_to_tensor(0, dtype=x.dtype)\n- return assert_less(zero, x, data=data, summarize=summarize)\n+ return _binary_assert('<', 'assert_less', math_ops.less, np.less,\n+ zero, x, data, summarize,\n+ message=None, name=None, allow_empty=True)\n \n \n @tf_export('debugging.assert_non_negative', v1=[])\n@@ -556,7 +594,10 @@ def assert_non_negative(x, data=None, summarize=None, message=None, name=None):\n 'Condition x >= 0 did not hold element-wise:',\n 'x (%s) = ' % name, x]\n zero = ops.convert_to_tensor(0, dtype=x.dtype)\n- return assert_less_equal(zero, x, data=data, summarize=summarize)\n+ return _binary_assert('<=', 'assert_less_equal',\n+ math_ops.less_equal, np.less_equal,\n+ zero, x, data, summarize,\n+ message=None, name=None, allow_empty=True)\n \n \n @tf_export('debugging.assert_non_positive', v1=[])\n@@ -610,7 +651,10 @@ def assert_non_positive(x, data=None, summarize=None, message=None, name=None):\n 'Condition x <= 0 did not hold element-wise:'\n 'x (%s) = ' % name, x]\n zero = ops.convert_to_tensor(0, dtype=x.dtype)\n- return assert_less_equal(x, zero, data=data, summarize=summarize)\n+ return _binary_assert('<=', 'assert_less_equal',\n+ math_ops.less_equal, np.less_equal,\n+ x, zero, data, summarize,\n+ message=None, name=None, allow_empty=True)\n \n \n @tf_export('debugging.assert_equal', 'assert_equal', v1=[])",
"filename": "tensorflow/python/ops/check_ops.py",
"status": "modified"
},
{
"diff": "@@ -619,9 +619,8 @@ def stack_dynamic_partitions(data, partitions, num_partitions, name=None):\n permutation = sort_ops.argsort(partitions, stable=True)\n value_rowids = array_ops.gather(partitions, permutation)\n values = array_ops.gather(data, permutation)\n- check = check_ops.assert_less(\n- value_rowids[-1:],\n- num_partitions,\n+ check = check_ops.assert_negative(\n+ value_rowids[-1:] - num_partitions,\n message='partitions must be less than num_partitions')\n with ops.control_dependencies([check]):\n return ragged_tensor.RaggedTensor.from_value_rowids(",
"filename": "tensorflow/python/ops/ragged/ragged_array_ops.py",
"status": "modified"
},
{
"diff": "@@ -398,7 +398,7 @@ def from_value_rowids(cls,\n check_ops.assert_equal(nvals1, nvals2, message=msg),\n check_ops.assert_non_negative(value_rowids[:1], message=msg),\n _assert_monotonic_increasing(value_rowids, message=msg),\n- check_ops.assert_less(value_rowids[-1:], nrows, message=msg),\n+ check_ops.assert_negative(value_rowids[-1:] - nrows, message=msg),\n ]\n if not isinstance(values, RaggedTensor):\n checks.append(check_ops.assert_rank_at_least(values, 1))",
"filename": "tensorflow/python/ops/ragged/ragged_tensor.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): no\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary):\r\n- TensorFlow version (use command below): nightly\r\n- Python version: 3.6.8\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version:\r\n- GPU model and memory:\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with: 1. TF 1.0: `python -c \"import\r\ntensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"` 2. TF 2.0: `python -c\r\n\"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\nTypeError: Value passed to parameter 'images' has DataType bfloat16 not in list of allowed values: int8, uint8, int16, uint16, int32, int64, float16, float32, float64\r\n**Describe the expected behavior**\r\nsupport bfloat16\r\n**Code to reproduce the issue**\r\nProvide a reproducible test case that is the bare minimum necessary to generate the problem.\r\n``` python\r\nimport tensorflow as tf\r\ninput = tf.keras.Input(shape=(28, 28, 1), name='img',dtype=tf.bfloat16)\r\nx = tf.keras.layers.UpSampling2D(3)(input)\r\n```\r\n**Other info / logs**\r\nInclude any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.\r\n",
"comments": [
{
"body": "@fsx950223 I could reproduce the issue with `TF1.15.0`. Here is the [gist](https://colab.sandbox.google.com/gist/jvishnuvardhan/371cabae8a54797e13b887103170f6c6/untitled629.ipynb) with `TF1.15.0`.\r\n\r\nHowever, your code works without an issue using `TF2.0`. Please take a look at the [gist](https://colab.sandbox.google.com/gist/jvishnuvardhan/701fd556c91f231b7cc2316fe53d62d4/untitled628.ipynb). \r\n\r\nI think there may not be any updates to `TF1.15.0` unless the issue is related to security. Are you willing to upgrade to `TF2.0`? Thanks!",
"created_at": "2019-11-07T23:28:08Z"
},
{
"body": "> @fsx950223 I could reproduce the issue with `TF1.15.0`. Here is the [gist](https://colab.sandbox.google.com/gist/jvishnuvardhan/371cabae8a54797e13b887103170f6c6/untitled629.ipynb) with `TF1.15.0`.\r\n> \r\n> However, your code works without an issue using `TF2.0`. Please take a look at the [gist](https://colab.sandbox.google.com/gist/jvishnuvardhan/701fd556c91f231b7cc2316fe53d62d4/untitled628.ipynb).\r\n> \r\n> I think there may not be any updates to `TF1.15.0` unless the issue is related to security. Are you willing to upgrade to `TF2.0`? Thanks!\r\n\r\nYes",
"created_at": "2019-11-08T01:35:24Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32801\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32801\">No</a>\n",
"created_at": "2019-11-08T01:35:26Z"
},
{
"body": "I'm getting this same issue in TF2.1:\r\n```import tensorflow as tf\r\n\r\ntf.keras.mixed_precision.experimental.set_policy('mixed_bfloat16')\r\n\r\noptimizer = tf.optimizers.SGD(learning_rate=0.1, momentum=0.9)\r\n\r\ninput=tf.keras.layers.Input(shape=(256, 256, 3))\r\n\r\nx=tf.keras.layers.Conv2D(32,(3,3))(input)\r\nx=tf.keras.layers.UpSampling2D()(x)\r\n\r\nx=tf.keras.layers.Conv2D(32,(3,3))(x)\r\nout=tf.keras.layers.Activation('sigmoid', dtype='float32')(x)\r\n\r\nmy_model = tf.keras.models.Model(inputs=input, outputs=out)\r\n\r\noptimizer = tf.keras.optimizers.RMSprop()\r\n```\r\n\r\n> line 10, in <module>\r\n> x=tf.keras.layers.UpSampling2D()(x)\r\n> File \"C:\\Users\\mdlambe1\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\keras\\engine\\base_layer.py\", line 773, in __call__\r\n> outputs = call_fn(cast_inputs, *args, **kwargs)\r\n> File \"C:\\Users\\mdlambe1\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\keras\\layers\\convolutional.py\", line 2004, in call\r\n> interpolation=self.interpolation)\r\n> File \"C:\\Users\\mdlambe1\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\keras\\backend.py\", line 2782, in resize_images\r\n> x, new_shape, method=image_ops.ResizeMethod.NEAREST_NEIGHBOR)\r\n> File \"C:\\Users\\mdlambe1\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\ops\\image_ops_impl.py\", line 1357, in resize_images_v2\r\n> skip_resize_if_same=False)\r\n> File \"C:\\Users\\mdlambe1\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\ops\\image_ops_impl.py\", line 1133, in _resize_images_common\r\n> images = resizer_fn(images, size)\r\n> File \"C:\\Users\\mdlambe1\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\ops\\image_ops_impl.py\", line 1337, in resize_fn\r\n> images_t, new_size, half_pixel_centers=True)\r\n> File \"C:\\Users\\mdlambe1\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\ops\\gen_image_ops.py\", line 3419, in resize_nearest_neighbor\r\n> name=name)\r\n> File \"C:\\Users\\mdlambe1\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\framework\\op_def_library.py\", line 576, in _apply_op_helper\r\n> param_name=input_name)\r\n> File \"C:\\Users\\mdlambe1\\AppData\\Local\\Continuum\\anaconda3\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\framework\\op_def_library.py\", line 61, in _SatisfiesTypeConstraint\r\n> \", \".join(dtypes.as_dtype(x).name for x in allowed_list)))\r\n> TypeError: Value passed to parameter 'images' has DataType bfloat16 not in list of allowed values: int8, uint8, int16, uint16, int32, int64, float16, float32, float64",
"created_at": "2020-02-11T22:06:35Z"
},
{
"body": "@LambertMark Please create a new issue with details and a simple standalone code to reproduce the issue. Thanks!",
"created_at": "2020-02-11T22:40:44Z"
}
],
"number": 32801,
"title": "UpSampling2D doesn't support bfloat16"
}
|
{
"body": "Fix #32801",
"number": 32803,
"review_comments": [],
"title": "ResizeNearestNeighbor support bfloat16"
}
|
{
"commits": [
{
"message": "ResizeNearestNeighbor support bfloat16"
}
],
"files": [
{
"diff": "@@ -337,7 +337,7 @@ REGISTER_OP(\"ResizeNearestNeighbor\")\n .Input(\"images: T\")\n .Input(\"size: int32\")\n .Output(\"resized_images: T\")\n- .Attr(\"T: {int8, uint8, int16, uint16, int32, int64, half, float, double}\")\n+ .Attr(\"T: {int8, uint8, int16, uint16, int32, int64, half, bfloat16, float, double}\")\n .Attr(\"align_corners: bool = false\")\n .Attr(\"half_pixel_centers: bool = false\")\n .SetShapeFn(ResizeShapeFn);",
"filename": "tensorflow/core/ops/image_ops.cc",
"status": "modified"
}
]
}
|
{
"body": "The Tensorflow implementation of RemoteMonitor callback raises the error\r\n`Object of type float32 is not JSON serializable.`\r\n\r\nKeras own implementation works fine with the same code.\r\n\r\nI think the relevant code difference is \r\n \r\n```\r\nfor k, v in logs.items():\r\n send[k] = v\r\n\r\n```\r\nin the Tensorflow implementation and\r\n\r\n```\r\nfor k, v in logs.items():\r\n if isinstance(v, (np.ndarray, np.generic)):\r\n send[k] = v.item()\r\n else:\r\n send[k] = v\r\n```\r\n\r\nin the Keras implementation.\r\n",
"comments": [
{
"body": "Please provide details about what platform you are using (operating system, architecture). Also include your TensorFlow version. Also, did you compile from source or install a binary?\r\n\r\nMake sure you also include the minimal code snippet to reproduce the issue. If you are unclear what to include see the issue template displayed in [the Github new issue template](https://github.com/tensorflow/tensorflow/issues/new/choose).\r\n\r\nWe ask for this in the issue submission template, because it is really difficult to help without that information. Thanks!\r\n",
"created_at": "2019-09-04T06:08:52Z"
},
{
"body": "My description above was a little bit short. It was meant as a short notice that the tensorflow.keras RemoteMonitor class has a bug which the Keras RemoteMonitor class does not have. Let me explain it with a little bit more detail.\r\n\r\nI have made a quick example which shows the error.\r\n\r\n```\r\nimport tensorflow as tf\r\nimport numpy as np\r\nimport tensorflow.keras as keras\r\nfrom tensorflow.keras.models import Sequential\r\nfrom tensorflow.keras.datasets import fashion_mnist\r\nfrom tensorflow.keras.layers import Dense, Conv2D, Flatten, Activation, BatchNormalization, MaxPool2D\r\nfrom tensorflow.keras.optimizers import Adam, Adadelta\r\nimport tensorflow.keras.losses as losses\r\nimport tensorflow.keras.metrics as metrics\r\nfrom tensorflow.keras.callbacks import RemoteMonitor, LambdaCallback, Callback\r\n\r\n(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()\r\n\r\nx_train = x_train.reshape(-1,28,28,1) / 255\r\nx_test = x_test.reshape(-1,28,28,1) / 255\r\n\r\ny_train = y_train.astype(np.int32)\r\ny_test = y_test.astype(np.int32)\r\n\r\nremote_cb = RemoteMonitor(root=\"http://localhost:9000\", path=\"/publish/epoch/end/\", send_as_json=True)\r\n\r\nmodel = Sequential()\r\nmodel.add(Conv2D(64,(3,3), activation=\"relu\", input_shape=(28,28,1)))\r\nmodel.add(MaxPool2D((2,2)))\r\nmodel.add(BatchNormalization())\r\nmodel.add(Flatten())\r\nmodel.add(Dense(256, activation=\"relu\"))\r\nmodel.add(Dense(10, activation=\"softmax\"))\r\n\r\nmodel.compile(loss=losses.sparse_categorical_crossentropy, optimizer=Adam(),\r\n metrics = [\"accuracy\"])\r\n\r\nmodel.fit(x_train[:3000], y_train[:3000], epochs=5, batch_size=64, callbacks=[remote_cb])\r\n```\r\n\r\nThis code gives a error \r\n`Object of type float32 is not JSON serializable`.\r\n\r\nBut when delete the Tensorflow from the imports, so using the keras implementation, then the above code works fine.\r\n\r\nSo I looked at the tensorflow.keras [RemoteMonitor class](https://github.com/tensorflow/tensorflow/blob/r1.14/tensorflow/python/keras/callbacks.py#L1264-L1316) and compared it to the [Remote Monitor class](https://github.com/keras-team/keras/blob/master/keras/callbacks.py#L847) from keras.\r\n\r\nAs stated above the relevant difference is\r\n\r\n```\r\nfor k, v in logs.items():\r\n send[k] = v\r\n```\r\n\r\nin the Tensorflow.keras and \r\n\r\n```\r\nfor k, v in logs.items():\r\n if isinstance(v, (np.ndarray, np.generic)):\r\n send[k] = v.item()\r\n else:\r\n send[k] = v\r\n```\r\n\r\nin the keras implementation.\r\n\r\nI have also tried to replace the lines in the Tensorflow.keras callback.py file with the lines from the keras callbacks.py file and then the code works with the Tensorflow imports.",
"created_at": "2019-09-04T12:08:37Z"
},
{
"body": "I have tried on colab with 2.0.0-rc0 and was able to reproduce the issue.Please,find the [gist ](https://colab.sandbox.google.com/gist/ravikyram/bf10dde754b4e8d73d8c021e4e014120/untitled156.ipynb) here.Please, let us know which TensorFlow version you are using?.Thanks!",
"created_at": "2019-09-05T12:29:35Z"
},
{
"body": "I have used 1.14.0, but the class RemoteMonitor is in 1.14.0 and 2.0.0-rc0 identical.",
"created_at": "2019-09-05T12:43:35Z"
},
{
"body": "I have tried on colab with 2.0.0-rc0,1.14,TF nightly versions and was able to reproduce the issue.Please,find the gist [here](https://colab.sandbox.google.com/gist/ravikyram/1be5308bed758dc9cedb42e2a866983b/untitled156.ipynb).Thanks!",
"created_at": "2019-09-06T12:40:19Z"
},
{
"body": "Hi, I would like to work on fixing this.",
"created_at": "2019-09-23T18:21:41Z"
},
{
"body": "As the PR has been merged, close the bug for now. Feel free to reopen it if needed.",
"created_at": "2020-03-26T18:50:16Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32192\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32192\">No</a>\n",
"created_at": "2020-03-26T18:50:18Z"
},
{
"body": "Is this issue resolved, which build has this issue resolved?",
"created_at": "2020-04-22T13:57:09Z"
}
],
"number": 32192,
"title": "JSON serializable issue at RemoteMonitor"
}
|
{
"body": "Checks for np.ndarray and np.generic for logs.item to fix JSON Serializable issues in tenorflow.keras.RemoteMonitor class #32192 ",
"number": 32734,
"review_comments": [
{
"body": "Can you add a comment why these two types are special cases?",
"created_at": "2019-09-27T16:35:55Z"
},
{
"body": "Do those two tests cover both np.ndarray and np.generic cases? Is it possible to assert the `send` dict to make sure the items are expected?",
"created_at": "2019-09-27T16:36:59Z"
},
{
"body": "Done",
"created_at": "2019-09-28T06:15:03Z"
},
{
"body": "yes, added assertions",
"created_at": "2019-09-28T06:15:24Z"
},
{
"body": "Please fix the typo.",
"created_at": "2019-10-04T21:28:44Z"
},
{
"body": "Fixed.",
"created_at": "2019-10-04T21:41:16Z"
},
{
"body": "` File \"<embedded module '_launcher'>\", line 149, in run_filename_as_main\r\n File \"<embedded module '_launcher'>\", line 33, in _run_code_in_main\r\n File \"third_party/tensorflow/python/keras/callbacks_test.py\", line 26, in <module>\r\n import requests\r\nImportError: No module named requests\r\n-- Forge runner: Test failed with exit code 1 while running`",
"created_at": "2019-11-15T19:25:47Z"
},
{
"body": "I added `requests` imports to `tensorflow/tools/ci_build/install/install_pip_packages.sh` to avoid this. Does that not work? An alternative is to do a try catch around the import and not run the test if requests is not available. However that is a less preferable option as this code would not be tested.\r\n",
"created_at": "2019-11-15T22:03:54Z"
},
{
"body": "@mihaimaruseac any thoughts on this ?",
"created_at": "2019-11-15T22:32:25Z"
},
{
"body": "I might have to do some extra setup internally. Please remind me about this on Monday if I don't get to it by then",
"created_at": "2019-11-16T01:00:27Z"
},
{
"body": "@mihaimaruseac friendly reminder",
"created_at": "2019-12-05T10:46:20Z"
},
{
"body": "This is already imported in a try block on line 60.",
"created_at": "2020-01-11T00:55:51Z"
},
{
"body": "If possible, make this test pass unconditially if `requests` is `None`.\r\n\r\nOtherwise, we might need to drop the tests or rewrite them to not use `requests`.",
"created_at": "2020-01-11T00:57:11Z"
},
{
"body": "Added a guard for this.",
"created_at": "2020-01-11T05:58:11Z"
},
{
"body": "removed",
"created_at": "2020-01-11T06:04:20Z"
},
{
"body": "@ashahab here is the internal error , can you please take a look \r\n`Traceback (most recent call last):\r\n File \"<embedded module '_launcher'>\", line 165, in run_filename_as_main\r\n File \"<embedded module '_launcher'>\", line 39, in _run_code_in_main\r\n File \"/build/work/google3/runfiles/google3/third_party/tensorflow/python/keras/callbacks_test.py\", line 26, in <module>\r\n import requests\r\nModuleNotFoundError: No module named 'requests'\r\n-- Forge runner: Test failed with exit code 1 `",
"created_at": "2020-01-13T21:16:40Z"
},
{
"body": "replaced this with a context block after the check",
"created_at": "2020-01-14T18:47:29Z"
},
{
"body": "Do we know for sure that we'll get only scalar-shaped `numpy.ndarray`s? I understand that in many cases, this is just a numpy scalar. But I don't know if it's possible that the value can be a non-scalar shape (e.g., `(1, 2)`) now or in the future. \r\n\r\ncc @karmel @fchollet \r\n\r\nThere are two options:\r\n1. You may want to add a check of `len(v.shape) == 0` above. \r\n2. Call `v.tolist()` instead.\r\n\r\nI think 2 is the better option, as it works for scalar and non-scalar shapes alike.",
"created_at": "2020-01-18T18:24:46Z"
},
{
"body": "Followed up in latter conversations.",
"created_at": "2020-01-23T22:03:56Z"
},
{
"body": "From @qlzh727: Should we expect the value of a here?",
"created_at": "2020-01-27T18:41:04Z"
},
{
"body": "Follow-up: Can we update the value of a to be not 0?",
"created_at": "2020-01-27T18:41:34Z"
}
],
"title": "JSON Serializable checks for array and structs"
}
|
{
"commits": [
{
"message": "JSON Serializable checks for array and structs\n\nChecks for np.ndarray and np.generic for logs.item to fix JSON Serializable issues in tenorflow.keral.RemoteMonitor class #32192"
}
],
"files": [
{
"diff": "@@ -1391,7 +1391,13 @@ def on_epoch_end(self, epoch, logs=None):\n send = {}\n send['epoch'] = epoch\n for k, v in logs.items():\n- send[k] = v\n+ # np.ndarray and np.generic are not scalar types\n+ # therefore we must unwrap their scalar values and\n+ # pass to the json-serializable dict 'send'\n+ if isinstance(v, (np.ndarray, np.generic)):\n+ send[k] = v.item()\n+ else:\n+ send[k] = v\n try:\n if self.send_as_json:\n requests.post(self.root + self.path, json=send, headers=self.headers)",
"filename": "tensorflow/python/keras/callbacks.py",
"status": "modified"
},
{
"diff": "@@ -1350,6 +1350,32 @@ def target():\n t.join()\n assert not t.is_alive()\n \n+ def test_RemoteMonitor_np_array(self):\n+ if requests is None:\n+ self.skipTest('`requests` required to run this test')\n+ with test.mock.patch.object(requests, 'post') as requests_post:\n+ monitor = keras.callbacks.RemoteMonitor(send_as_json=True)\n+ a = np.arange(1) # a 1 by 1 array\n+ logs = {'loss': 0., \"val\": a}\n+ monitor.on_epoch_end(0, logs=logs)\n+ send = {'loss': 0., \"epoch\": 0, \"val\": 0}\n+ requests_post.assert_called_once_with(\n+ monitor.root + monitor.path, json=send, headers=monitor.headers)\n+\n+ def test_RemoteMonitor_np_float32(self):\n+ if requests is None:\n+ self.skipTest('`requests` required to run this test')\n+\n+ with test.mock.patch.object(requests, 'post') as requests_post:\n+ monitor = keras.callbacks.RemoteMonitor(send_as_json=True)\n+ a = np.float32(1.0) # a float32 generic type\n+ logs = {'loss': 0., \"val\": a}\n+ monitor.on_epoch_end(0, logs=logs)\n+ send = {'loss': 0., \"epoch\": 0, \"val\": 1.0}\n+ requests_post.assert_called_once_with(\n+ monitor.root + monitor.path, json=send, headers=monitor.headers)\n+\n+\n def test_RemoteMonitorWithJsonPayload(self):\n if requests is None:\n self.skipTest('`requests` required to run this test')",
"filename": "tensorflow/python/keras/callbacks_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): MacOS Mojave 10.14.6\r\n- TensorFlow installed from (source or binary): pip install tensorflow==2.0.0rc0\r\n- TensorFlow version (use command below): 2.0.0-rc0\r\n- Python version: 3.7.4\r\n\r\n**Describe the current behavior**\r\n\r\nUpon attempting to create a custom dynamic keras layer, keras seems to incorrectly interpret the output of `compute_output_shape`.\r\n\r\n**Describe the expected behavior**\r\n\r\nIn the example code below, `model.summary()` outputs `[(None, (2,))]` for the output shape. According to the docs/examples, I would expect that to be `[(None, 2)]`. When attempting to place layers after this, it returns two placeholders, despite the output shape only defining one.\r\n\r\n**Code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nimport numpy as np\r\n\r\nclass Example(tf.keras.layers.Layer):\r\n def __init__(self, **kwargs):\r\n kwargs[\"dynamic\"] = True\r\n super(Example, self).__init__(**kwargs)\r\n\r\n def call(self, inputs):\r\n return inputs\r\n\r\n def compute_output_shape(self, input_shape):\r\n return [(None, 2)]\r\n\r\ninp = tf.keras.layers.Input(batch_shape=(None, 1))\r\ncomp = Example()(inp)\r\n\r\nmodel = tf.keras.models.Model(inputs=[inp], outputs=[comp])\r\nmodel.summary()\r\n```\r\nIn my code, the input layer's `batch_shape` and the content of `call` are arbitrary. If I remove `dynamic=True`, then it gives the expected shape based on the contents of `call`. \r\n\r\nThere seems to be no semantic difference in output if `compute_output_shapes` returns `[(None, 2)]`, `(None, 2)`, or `[None, 2]`\r\n\r\n**Other info / logs**\r\n\r\nHere's what I am seeing from model.summary()\r\n```\r\nModel: \"model\"\r\n_________________________________________________________________\r\nLayer (type) Output Shape Param #\r\n=================================================================\r\ninput_1 (InputLayer) [(None, 1)] 0\r\n_________________________________________________________________\r\nexample (Example) [(None, (2,))] 0\r\n=================================================================\r\nTotal params: 0\r\nTrainable params: 0\r\nNon-trainable params: 0\r\n_________________________________________________________________\r\n```\r\n",
"comments": [
{
"body": "I reproduced the issue on Colab with tf 2.0.0rc0. Find a Colab gist [here](https://colab.sandbox.google.com/gist/gadagashwini/56a82640d89c5c26555da2d6aa1f4a57/untitled149.ipynb). Thanks ",
"created_at": "2019-09-13T11:30:26Z"
},
{
"body": "It looks like using `tf.TensorShape` works properly. See:\r\n\r\n```\r\nimport tensorflow as tf\r\nimport numpy as np\r\n\r\nclass Example(tf.keras.layers.Layer):\r\n def __init__(self, **kwargs):\r\n kwargs[\"dynamic\"] = True\r\n super(Example, self).__init__(**kwargs)\r\n\r\n def call(self, inputs):\r\n return inputs\r\n\r\n def compute_output_shape(self, input_shape):\r\n return tf.TensorShape([None, 2])\r\n\r\ninp = tf.keras.layers.Input(batch_shape=(None, 1))\r\ncomp = Example()(inp)\r\n\r\nmodel = tf.keras.models.Model(inputs=[inp], outputs=[comp])\r\nmodel.summary()\r\n```\r\n\r\nThis outputs:\r\n```\r\nModel: \"model_5\"\r\n_________________________________________________________________\r\nLayer (type) Output Shape Param # \r\n=================================================================\r\ninput_9 (InputLayer) [(None, 1)] 0 \r\n_________________________________________________________________\r\nexample_8 (Example) (None, 2) 0 \r\n=================================================================\r\nTotal params: 0\r\nTrainable params: 0\r\nNon-trainable params: 0\r\n_________________________________________________________________\r\n```\r\n\r\nSee [updated Colab](https://colab.research.google.com/gist/porgull/c93dce7d1039b3ccacc1c9c16b956fa4/untitled149.ipynb).",
"created_at": "2019-09-17T16:27:51Z"
},
{
"body": "@porgull this issue is no longer seen with 2.2.0-rc0. Can you please check and close this issue if it is resolved for you ?\r\n\r\nThanks!",
"created_at": "2020-03-18T06:08:19Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32476\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32476\">No</a>\n",
"created_at": "2020-03-18T11:10:26Z"
}
],
"number": 32476,
"title": "Unexpected output shape on custom keras dynamic layer"
}
|
{
"body": "Fixes #32476\r\n\r\nIf you return a tuple in compute_output_shapes of a subclassed dynamic Keras Layer, it will be incorrectly interpreted (see #32476). In that case, map_structure will map to each item in the tuple individually, giving an incorrect output, as if each item in the tuple was intended to be a separate vector, which is incongruous to the [Keras docs](https://keras.io/layers/writing-your-own-keras-layers/). In this edge case, it will convert the tuple to a TensorShape directly.\r\n\r\nThis is my first PR for Tensorflow, so let me know if there's anything I should change.",
"number": 32597,
"review_comments": [],
"title": "Add explicit TensorShape conversion to Keras Base Layer"
}
|
{
"commits": [
{
"message": "Add explicit TensorShape conversion"
},
{
"message": "Add TensorShape conversion for tuples inside of a list"
},
{
"message": "Fix tuple conversion to TensorShape"
},
{
"message": "Fix as_list call"
}
],
"files": [
{
"diff": "@@ -45,6 +45,7 @@\n from tensorflow.python.framework import sparse_tensor\n from tensorflow.python.framework import tensor_spec\n from tensorflow.python.framework import tensor_util\n+from tensorflow.python.framework.tensor_shape import TensorShape\n from tensorflow.python.keras import backend\n from tensorflow.python.keras import constraints\n from tensorflow.python.keras import initializers\n@@ -672,7 +673,8 @@ def check_type_return_shape(s):\n 'but saw signature signature entry: {}.'.format(s))\n return s.shape\n input_shape = nest.map_structure(check_type_return_shape, input_signature)\n- output_shape = self.compute_output_shape(input_shape)\n+ output_shape = self._parse_output_shape(self.compute_output_shape(input_shape))\n+\n dtype = self._compute_dtype\n if dtype is None:\n input_dtypes = [s.dtype for s in nest.flatten(input_signature)]\n@@ -2169,15 +2171,31 @@ def _maybe_build(self, inputs):\n \n def _symbolic_call(self, inputs):\n input_shapes = nest.map_structure(lambda x: x.shape, inputs)\n- output_shapes = self.compute_output_shape(input_shapes)\n-\n+ output_shapes = self._parse_output_shape(self.compute_output_shape(input_shapes))\n+ \n def _make_placeholder_like(shape):\n ph = backend.placeholder(shape=shape, dtype=self.dtype)\n ph._keras_mask = None\n return ph\n \n return nest.map_structure(_make_placeholder_like, output_shapes)\n \n+ def _parse_output_shape(self, output_shape):\n+ \"\"\"Converts a user given shape (tuples, lists) to TensorShapes\n+\n+ Returns:\n+ The output shape with any tuples converted to TensorShapes \n+ \"\"\"\n+ def _convert_tuple_to_tensorshape(input_tuple):\n+ return TensorShape(tuple(map(lambda x: x.as_list() if isinstance(x, TensorShape) else x, input_tuple)))\n+\n+ if isinstance(output_shape, tuple):\n+ output_shape = _convert_tuple_to_tensorshape(output_shape)\n+ elif isinstance(output_shape, list):\n+ output_shape = list(map(lambda x: _convert_tuple_to_tensorshape(x) if isinstance(x, tuple) else x, output_shape))\n+\n+ return output_shape\n+\n def _get_trainable_state(self):\n \"\"\"Get the `trainable` state of each sublayer.\n ",
"filename": "tensorflow/python/keras/engine/base_layer.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): MacOS Mojave 10.14.6\r\n- TensorFlow installed from (source or binary): pip install tensorflow==2.0.0rc0\r\n- TensorFlow version (use command below): 2.0.0-rc0\r\n- Python version: 3.7.4\r\n\r\n**Describe the current behavior**\r\n\r\nUpon attempting to create a custom dynamic keras layer, keras seems to incorrectly interpret the output of `compute_output_shape`.\r\n\r\n**Describe the expected behavior**\r\n\r\nIn the example code below, `model.summary()` outputs `[(None, (2,))]` for the output shape. According to the docs/examples, I would expect that to be `[(None, 2)]`. When attempting to place layers after this, it returns two placeholders, despite the output shape only defining one.\r\n\r\n**Code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nimport numpy as np\r\n\r\nclass Example(tf.keras.layers.Layer):\r\n def __init__(self, **kwargs):\r\n kwargs[\"dynamic\"] = True\r\n super(Example, self).__init__(**kwargs)\r\n\r\n def call(self, inputs):\r\n return inputs\r\n\r\n def compute_output_shape(self, input_shape):\r\n return [(None, 2)]\r\n\r\ninp = tf.keras.layers.Input(batch_shape=(None, 1))\r\ncomp = Example()(inp)\r\n\r\nmodel = tf.keras.models.Model(inputs=[inp], outputs=[comp])\r\nmodel.summary()\r\n```\r\nIn my code, the input layer's `batch_shape` and the content of `call` are arbitrary. If I remove `dynamic=True`, then it gives the expected shape based on the contents of `call`. \r\n\r\nThere seems to be no semantic difference in output if `compute_output_shapes` returns `[(None, 2)]`, `(None, 2)`, or `[None, 2]`\r\n\r\n**Other info / logs**\r\n\r\nHere's what I am seeing from model.summary()\r\n```\r\nModel: \"model\"\r\n_________________________________________________________________\r\nLayer (type) Output Shape Param #\r\n=================================================================\r\ninput_1 (InputLayer) [(None, 1)] 0\r\n_________________________________________________________________\r\nexample (Example) [(None, (2,))] 0\r\n=================================================================\r\nTotal params: 0\r\nTrainable params: 0\r\nNon-trainable params: 0\r\n_________________________________________________________________\r\n```\r\n",
"comments": [
{
"body": "I reproduced the issue on Colab with tf 2.0.0rc0. Find a Colab gist [here](https://colab.sandbox.google.com/gist/gadagashwini/56a82640d89c5c26555da2d6aa1f4a57/untitled149.ipynb). Thanks ",
"created_at": "2019-09-13T11:30:26Z"
},
{
"body": "It looks like using `tf.TensorShape` works properly. See:\r\n\r\n```\r\nimport tensorflow as tf\r\nimport numpy as np\r\n\r\nclass Example(tf.keras.layers.Layer):\r\n def __init__(self, **kwargs):\r\n kwargs[\"dynamic\"] = True\r\n super(Example, self).__init__(**kwargs)\r\n\r\n def call(self, inputs):\r\n return inputs\r\n\r\n def compute_output_shape(self, input_shape):\r\n return tf.TensorShape([None, 2])\r\n\r\ninp = tf.keras.layers.Input(batch_shape=(None, 1))\r\ncomp = Example()(inp)\r\n\r\nmodel = tf.keras.models.Model(inputs=[inp], outputs=[comp])\r\nmodel.summary()\r\n```\r\n\r\nThis outputs:\r\n```\r\nModel: \"model_5\"\r\n_________________________________________________________________\r\nLayer (type) Output Shape Param # \r\n=================================================================\r\ninput_9 (InputLayer) [(None, 1)] 0 \r\n_________________________________________________________________\r\nexample_8 (Example) (None, 2) 0 \r\n=================================================================\r\nTotal params: 0\r\nTrainable params: 0\r\nNon-trainable params: 0\r\n_________________________________________________________________\r\n```\r\n\r\nSee [updated Colab](https://colab.research.google.com/gist/porgull/c93dce7d1039b3ccacc1c9c16b956fa4/untitled149.ipynb).",
"created_at": "2019-09-17T16:27:51Z"
},
{
"body": "@porgull this issue is no longer seen with 2.2.0-rc0. Can you please check and close this issue if it is resolved for you ?\r\n\r\nThanks!",
"created_at": "2020-03-18T06:08:19Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32476\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32476\">No</a>\n",
"created_at": "2020-03-18T11:10:26Z"
}
],
"number": 32476,
"title": "Unexpected output shape on custom keras dynamic layer"
}
|
{
"body": "Fixes #32476 \r\n\r\nIf you return a tuple in `compute_output_shapes` of a subclassed dynamic Keras Layer, it will be incorrectly interpreted (see #32476). The behavior doesn't occur when the output is, instead, a TensorShape. Since tf.TensorShape(tensor_shape) just returns tensor_shape, it is safe to add an explicit conversion to a TensorShape. This should address all potential return values of `compute_output_shapes` to make it inline with the Keras documentation (see: [Keras docs on custom layers](https://keras.io/layers/writing-your-own-keras-layers/)).\r\n\r\nThis is my first PR for Tensorflow, so let me know if there's anything I should change.",
"number": 32595,
"review_comments": [],
"title": "Add explicit TensorShape conversion to Keras Layer"
}
|
{
"commits": [
{
"message": "Add explicit TensorShape conversion"
}
],
"files": [
{
"diff": "@@ -45,6 +45,7 @@\n from tensorflow.python.framework import sparse_tensor\n from tensorflow.python.framework import tensor_spec\n from tensorflow.python.framework import tensor_util\n+from tensorflow.python.framework.tensor_shape import TensorShape\n from tensorflow.python.keras import backend\n from tensorflow.python.keras import constraints\n from tensorflow.python.keras import initializers\n@@ -672,7 +673,7 @@ def check_type_return_shape(s):\n 'but saw signature signature entry: {}.'.format(s))\n return s.shape\n input_shape = nest.map_structure(check_type_return_shape, input_signature)\n- output_shape = self.compute_output_shape(input_shape)\n+ output_shape = TensorShape(self.compute_output_shape(input_shape))\n dtype = self._compute_dtype\n if dtype is None:\n input_dtypes = [s.dtype for s in nest.flatten(input_signature)]\n@@ -2169,7 +2170,7 @@ def _maybe_build(self, inputs):\n \n def _symbolic_call(self, inputs):\n input_shapes = nest.map_structure(lambda x: x.shape, inputs)\n- output_shapes = self.compute_output_shape(input_shapes)\n+ output_shapes = TensorShape(self.compute_output_shape(input_shapes))\n \n def _make_placeholder_like(shape):\n ph = backend.placeholder(shape=shape, dtype=self.dtype)",
"filename": "tensorflow/python/keras/engine/base_layer.py",
"status": "modified"
}
]
}
|
{
"body": "https://github.com/tensorflow/tensorflow/blob/8c0df1fa0b0490d8b1e54d7b019e2b2242ad6718/tensorflow/lite/experimental/micro/memory_planner/greedy_memory_planner.h#L43\r\n\r\ndoes not override `void operator delete(void *p)` which results in link time error.",
"comments": [
{
"body": "@csukuangfj Is this resolved or still an issue? Thanks!",
"created_at": "2019-12-23T23:27:06Z"
},
{
"body": "@jvishnuvardhan \r\nwhen this pullrequest https://github.com/tensorflow/tensorflow/pull/32417 is merged,\r\nthis issue should be closed by GitHub automatically; but more than 3 months have passed,\r\nit is still not merged.\r\n\r\n",
"created_at": "2019-12-24T13:29:16Z"
},
{
"body": "@csukuangfj I see the reviewer approved the PR. So it will be merged soon. Thanks!",
"created_at": "2019-12-26T00:18:41Z"
},
{
"body": "@jvishnuvardhan \r\n\r\nThings are not always that easy like you thought. You can see that the pullrequest\r\nhas been approved for multiple times, but nothing happens when the`ready to pull`\r\nlabel is added.",
"created_at": "2019-12-26T02:23:11Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32416\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32416\">No</a>\n",
"created_at": "2020-01-09T23:04:34Z"
}
],
"number": 32416,
"title": "[lite/micro] missing delete() in GreedyMemoryPlanner"
}
|
{
"body": "Fix #32416 .\r\nOverride operator delete.",
"number": 32417,
"review_comments": [
{
"body": "> Here is the internal error we are getting , can you please check this.\r\n/third_party/tensorflow/lite/experimental/micro/memory_planner/greedy_memory_planner.h:19:10: fatal error: 'third_party/tensorflow/lite/experimental/micro/compatibility.h' file not found\r\n#include \"third_party/tensorflow/lite/experimental/micro/compatibility.h\"\r\ncc @petewarden @wangtz",
"created_at": "2019-11-21T06:10:38Z"
}
],
"title": "[lite/micro] Override operator delete in memory planner"
}
|
{
"commits": [
{
"message": "fix #32416.\n\nOverride operator delete."
}
],
"files": [
{
"diff": "@@ -125,6 +125,8 @@ class GreedyMemoryPlanner : public MemoryPlanner {\n \n // Whether buffers have been added since the last plan was calculated.\n bool need_to_calculate_offsets_;\n+\n+ TF_LITE_REMOVE_VIRTUAL_DELETE\n };\n \n } // namespace tflite",
"filename": "tensorflow/lite/micro/memory_planner/greedy_memory_planner.h",
"status": "modified"
},
{
"diff": "@@ -40,6 +40,8 @@ class LinearMemoryPlanner : public MemoryPlanner {\n int buffer_offsets_[kMaxBufferCount];\n int current_buffer_count_;\n int next_free_offset_;\n+\n+ TF_LITE_REMOVE_VIRTUAL_DELETE\n };\n \n } // namespace tflite",
"filename": "tensorflow/lite/micro/memory_planner/linear_memory_planner.h",
"status": "modified"
}
]
}
|
{
"body": "This commit:\r\nhttps://github.com/tensorflow/tensorflow/commit/9480262cbbfc2430b0c53424f0fc133418d7ae3f\r\nwas included in TF 1.15rc0.\r\n\r\nHowever, this commit has a bug as pointed out in https://github.com/tensorflow/tensorflow/pull/28745#issuecomment-512949342.\r\n\r\nThe bug is fixed in https://github.com/tensorflow/tensorflow/commit/5d6158e0d4a736a8ad2fc98b717fed519e4080f0, which is not included in TF 1.15rc0.\r\n\r\nI expect TF 1.15rc0 to include the bugfix for the GPU version of NMS kernel.",
"comments": [
{
"body": "Can you make a cherry-pick of https://github.com/tensorflow/tensorflow/commit/5d6158e0d4a736a8ad2fc98b717fed519e4080f0 please? Assign to me",
"created_at": "2019-09-10T23:55:36Z"
},
{
"body": "I merged the cherry-pick, it will land in the final release/next RC (whichever comes first).\r\n\r\nThank you",
"created_at": "2019-09-12T15:32:44Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=32401\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=32401\">No</a>\n",
"created_at": "2019-09-12T15:32:45Z"
}
],
"number": 32401,
"title": "GPU NMS kernel in TF 1.15rc0 was not fixed"
}
|
{
"body": "fix #32401 \r\n\r\n@mihaimaruseac ",
"number": 32403,
"review_comments": [],
"title": "[r1.15Cherrypick]: Cherry-pick #30893 to r1.15"
}
|
{
"commits": [
{
"message": "Cherry-pick #30893 to r1.15"
}
],
"files": [
{
"diff": "@@ -15,6 +15,8 @@ limitations under the License.\n \n #if GOOGLE_CUDA\n #define EIGEN_USE_GPU\n+#include <limits>\n+\n #include \"absl/strings/str_cat.h\"\n #include \"third_party/eigen3/unsupported/Eigen/CXX11/Tensor\"\n #include \"third_party/cub/device/device_radix_sort.cuh\"\n@@ -83,8 +85,8 @@ __device__ EIGEN_STRONG_INLINE void Swap(T& a, T& b) {\n // Check whether two boxes have an IoU greater than threshold.\n template <typename T>\n __device__ EIGEN_STRONG_INLINE bool OverThreshold(const Box* a, const Box* b,\n- float a_area,\n- T iou_threshold) {\n+ const float a_area,\n+ const T iou_threshold) {\n const float b_area = (b->x2 - b->x1) * (b->y2 - b->y1);\n if (a_area == 0.0f || b_area == 0.0f) return false;\n const float xx1 = fmaxf(a->x1, b->x1);\n@@ -93,8 +95,8 @@ __device__ EIGEN_STRONG_INLINE bool OverThreshold(const Box* a, const Box* b,\n const float yy2 = fminf(a->y2, b->y2);\n \n // fdimf computes the positive difference between xx2+1 and xx1.\n- const float w = fdimf(xx2 + 1.0f, xx1);\n- const float h = fdimf(yy2 + 1.0f, yy1);\n+ const float w = fdimf(xx2, xx1);\n+ const float h = fdimf(yy2, yy1);\n const float intersection = w * h;\n \n // Testing for aa/bb > t\n@@ -117,6 +119,47 @@ __device__ EIGEN_STRONG_INLINE void Flipped<true>(Box& box) {\n if (box.x1 > box.x2) Swap(box.x1, box.x2);\n if (box.y1 > box.y2) Swap(box.y1, box.y2);\n }\n+template <typename T>\n+__device__ EIGEN_STRONG_INLINE bool CheckBit(T* bit_mask, int bit) {\n+ constexpr int kShiftLen = NumBits(8 * sizeof(T)) - 1;\n+ constexpr int kRemainderMask = 8 * sizeof(T) - 1;\n+ int bin = bit >> kShiftLen;\n+ return (bit_mask[bin] >> (bit & kRemainderMask)) & 1;\n+}\n+\n+// Produce a global bitmask (result_mask) of selected boxes from bitmask\n+// generated by NMSKernel Abort early if max_boxes boxes are selected. Bitmask\n+// is num_boxes*bit_mask_len bits indicating whether to keep or remove a box.\n+__global__ void NMSReduce(const int* bitmask, const int bit_mask_len,\n+ const int num_boxes, const int max_boxes,\n+ char* result_mask) {\n+ extern __shared__ int local[];\n+ // set global mask to accept all boxes\n+ for (int box : CudaGridRangeX(bit_mask_len)) {\n+ local[box] = 0xFFFFFFFF;\n+ }\n+ __syncthreads();\n+ int accepted_boxes = 0;\n+ for (int box = 0; box < num_boxes - 1; ++box) {\n+ // if current box is masked by an earlier box, skip it.\n+ if (!CheckBit(local, box)) {\n+ continue;\n+ }\n+ accepted_boxes += 1;\n+ int offset = box * bit_mask_len;\n+ // update global mask with current box's mask\n+ for (int b : CudaGridRangeX(bit_mask_len)) {\n+ local[b] &= ~bitmask[offset + b];\n+ }\n+ __syncthreads();\n+ if (accepted_boxes > max_boxes) break;\n+ }\n+ // copy global mask to result_max char array. char array is needed for\n+ // cub::DeviceSelect later.\n+ for (int box : CudaGridRangeX(num_boxes)) {\n+ result_mask[box] = CheckBit(local, box);\n+ }\n+}\n \n // For each box, compute a bitmask of boxes which has an overlap with given box\n // above threshold.\n@@ -172,8 +215,8 @@ __launch_bounds__(kNmsBlockDim* kNmsBlockDim, 4) __global__\n Box j_box = d_desc_sorted_boxes[j];\n const Box i_box = shared_i_boxes[threadIdx.x];\n Flipped<flip_box>(j_box);\n- if (OverThreshold(&i_box, &j_box, shared_i_areas[threadIdx.x],\n- iou_threshold)) {\n+ if (OverThreshold<float>(&i_box, &j_box, shared_i_areas[threadIdx.x],\n+ iou_threshold)) {\n // we have score[j] <= score[i].\n above_threshold |= (1U << ib);\n }\n@@ -224,15 +267,15 @@ __global__ void Iota(const int num_elements, const T offset, T* to_fill) {\n \n Status NmsGpu(const float* d_sorted_boxes_float_ptr, const int num_boxes,\n const float iou_threshold, int* d_selected_indices, int* h_nkeep,\n- OpKernelContext* context, bool flip_boxes) {\n+ OpKernelContext* context, const int max_boxes, bool flip_boxes) {\n // Making sure we respect the __align(16)__\n // we promised to the compiler.\n auto iptr = reinterpret_cast<std::uintptr_t>(d_sorted_boxes_float_ptr);\n if ((iptr & 15) != 0) {\n return errors::InvalidArgument(\"Boxes should be aligned to 16 Bytes.\");\n }\n // allocate bitmask arrays on host and on device\n- Tensor h_nms_mask, d_nms_mask;\n+ Tensor h_num_selected, d_nms_mask;\n const int bit_mask_len =\n (num_boxes + kNmsBoxesPerThread - 1) / kNmsBoxesPerThread;\n \n@@ -252,12 +295,11 @@ Status NmsGpu(const float* d_sorted_boxes_float_ptr, const int num_boxes,\n alloc_attr.set_gpu_compatible(true);\n // Size of this buffer can be reduced to kNmsChunkSize*bit_mask_len*2 and\n // using it as a ring buffer. However savings should be a few MB .\n- TF_RETURN_IF_ERROR(context->allocate_temp(DataType::DT_INT32,\n- TensorShape({max_nms_mask_size}),\n- &h_nms_mask, alloc_attr));\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_INT32, TensorShape({1}), &h_num_selected, alloc_attr));\n \n int* d_delete_mask = d_nms_mask.flat<int>().data();\n- int* h_delete_mask = h_nms_mask.flat<int>().data();\n+ int* h_selected_count = h_num_selected.flat<int>().data();\n const Box* d_sorted_boxes =\n reinterpret_cast<const Box*>(d_sorted_boxes_float_ptr);\n dim3 block_dim, thread_block;\n@@ -281,58 +323,222 @@ Status NmsGpu(const float* d_sorted_boxes_float_ptr, const int num_boxes,\n TF_RETURN_IF_CUDA_ERROR(cudaGetLastError());\n // Overlapping CPU computes and D2H memcpy\n // both take about the same time\n- int num_to_copy = std::min(kNmsChunkSize, num_boxes);\n+\n+ config = GetGpuLaunchConfig(num_boxes, device);\n+ Tensor selected_boxes;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_INT8, TensorShape({num_boxes}), &selected_boxes));\n+ Tensor d_indices;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_INT32, TensorShape({num_boxes}), &d_indices));\n+ TF_CHECK_OK(GpuLaunchKernel(Iota<int>, config.block_count,\n+ config.thread_per_block, 0, device.stream(),\n+ config.virtual_thread_count, 0,\n+ d_indices.flat<int>().data()));\n+\n+ char* selected = (char*)(selected_boxes.flat<int8>().data());\n+ TF_CHECK_OK(GpuLaunchKernel(NMSReduce, 1, 1024, bit_mask_len * sizeof(int),\n+ device.stream(), d_delete_mask, bit_mask_len,\n+ num_boxes, max_boxes, selected));\n+ TF_RETURN_IF_CUDA_ERROR(cudaGetLastError());\n+ // do Cub::deviceSelect::flagged\n+ size_t flagged_buffer_size = 0;\n+ cub::DeviceSelect::Flagged(static_cast<void*>(nullptr), // temp_storage\n+ flagged_buffer_size,\n+ static_cast<int*>(nullptr), // input\n+ static_cast<char*>(nullptr), // selection flag\n+ static_cast<int*>(nullptr), // selected items\n+ static_cast<int*>(nullptr), // num_selected\n+ num_boxes, device.stream());\n+ Tensor cub_scratch;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_INT8, TensorShape({(int64)flagged_buffer_size}),\n+ &cub_scratch));\n+ Tensor d_num_selected;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(DataType::DT_INT32,\n+ TensorShape({1}), &d_num_selected));\n+\n+ cub::DeviceSelect::Flagged(\n+ (void*)cub_scratch.flat<int8>().data(), // temp_storage\n+ flagged_buffer_size,\n+ d_indices.flat<int>().data(), // input\n+ selected, // selection flag\n+ d_selected_indices, // selected items\n+ d_num_selected.flat<int>().data(), num_boxes, device.stream());\n cudaEvent_t copy_done;\n- cudaEventCreate(©_done);\n- device.memcpyDeviceToHost(&h_delete_mask[0], &d_delete_mask[0],\n- num_to_copy * bit_mask_len * sizeof(int));\n+ TF_RETURN_IF_CUDA_ERROR(\n+ cudaEventCreateWithFlags(©_done, cudaEventDisableTiming));\n+ device.memcpyDeviceToHost(h_selected_count, d_num_selected.flat<int>().data(),\n+ sizeof(int));\n TF_RETURN_IF_CUDA_ERROR(cudaEventRecord(copy_done, device.stream()));\n- int offset = 0;\n- std::vector<int> h_selected_indices;\n- // Reserve worst case scenario. Since box count is not huge, this should have\n- // negligible footprint.\n- h_selected_indices.reserve(num_boxes);\n- std::vector<int> to_remove(bit_mask_len, 0);\n- while (offset < num_boxes) {\n- const int num_copied = num_to_copy;\n- int next_offset = offset + num_copied;\n- num_to_copy = std::min(kNmsChunkSize, num_boxes - next_offset);\n- if (num_to_copy > 0) {\n- device.memcpyDeviceToHost(&h_delete_mask[next_offset * bit_mask_len],\n- &d_delete_mask[next_offset * bit_mask_len],\n- num_to_copy * bit_mask_len * sizeof(int));\n- }\n- // Waiting for previous copy\n- TF_RETURN_IF_CUDA_ERROR(cudaEventSynchronize(copy_done));\n- if (num_to_copy > 0) {\n- TF_RETURN_IF_CUDA_ERROR(cudaEventRecord(copy_done, device.stream()));\n- }\n- // Starting from highest scoring box, mark any box with iou>threshold and\n- // lower score for deletion if current box is not marked for deletion. Add\n- // current box to to_keep list.\n- for (int i = offset; i < next_offset; ++i) {\n- // See the comment at the beginning of the file.\n- // Bit shift and logical And operations are used\n- // instead of division and modulo operations.\n- int iblock = i >> kNmsBoxesPerThreadShiftBits;\n- int inblock = i & kNmsBoxesPerThreadModuloMask;\n- if (!(to_remove[iblock] & (1 << inblock))) {\n- h_selected_indices.push_back(i);\n- int* p = &h_delete_mask[i * bit_mask_len];\n- for (int ib = 0; ib < bit_mask_len; ++ib) {\n- to_remove[ib] |= p[ib];\n- }\n- }\n- }\n- offset = next_offset;\n- }\n+ TF_RETURN_IF_CUDA_ERROR(cudaEventSynchronize(copy_done));\n+ *h_nkeep = *h_selected_count;\n cudaEventDestroy(copy_done);\n+ return Status::OK();\n+}\n \n- const int nkeep = h_selected_indices.size();\n- device.memcpyHostToDevice(d_selected_indices, &h_selected_indices[0],\n- nkeep * sizeof(int));\n+struct GreaterThanCubOp {\n+ float threshold_;\n+ __host__ __device__ __forceinline__ GreaterThanCubOp(float threshold)\n+ : threshold_(threshold) {}\n+ __host__ __device__ __forceinline__ bool operator()(const float& val) const {\n+ return (val > threshold_);\n+ }\n+};\n+// Use DeviceSelect::If to count number of elements.\n+// TODO(sami) Not really a good way. Perhaps consider using thrust?\n+template <typename Op>\n+Status CountIf(OpKernelContext* context, const float* dev_array, const Op& op,\n+ int num_elements, int* result) {\n+ Tensor scratch_output;\n+ Tensor workspace;\n+ Tensor element_count;\n+ size_t workspace_size = 0;\n+ auto cuda_stream = tensorflow::GetGpuStream(context);\n+ auto device = context->eigen_gpu_device();\n+ cub::DeviceSelect::If(nullptr, workspace_size, static_cast<float*>(nullptr),\n+ static_cast<float*>(nullptr),\n+ static_cast<int*>(nullptr), num_elements, op);\n \n- *h_nkeep = nkeep;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_FLOAT, TensorShape({num_elements}), &scratch_output));\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_INT8, TensorShape({(int64)workspace_size}), &workspace));\n+ TF_RETURN_IF_ERROR(context->allocate_temp(DataType::DT_INT32,\n+ TensorShape({1}), &element_count));\n+ cudaEvent_t copy_done;\n+ TF_RETURN_IF_CUDA_ERROR(\n+ cudaEventCreateWithFlags(©_done, cudaEventDisableTiming));\n+ TF_RETURN_IF_CUDA_ERROR(cub::DeviceSelect::If(\n+ workspace.flat<int8>().data(), workspace_size, dev_array,\n+ scratch_output.flat<float>().data(), element_count.flat<int32>().data(),\n+ num_elements, op, cuda_stream));\n+ device.memcpyDeviceToHost(result, element_count.flat<int32>().data(),\n+ sizeof(int));\n+ TF_RETURN_IF_CUDA_ERROR(cudaEventRecord(copy_done, device.stream()));\n+ TF_RETURN_IF_CUDA_ERROR(cudaEventSynchronize(copy_done));\n+ return Status::OK();\n+}\n+\n+Status DoNMS(OpKernelContext* context, const Tensor& boxes,\n+ const Tensor& scores, const int64_t max_output_size,\n+ const float iou_threshold_val, const float score_threshold) {\n+ const int output_size = max_output_size;\n+ int num_boxes = boxes.dim_size(0);\n+ size_t cub_sort_temp_storage_bytes = 0;\n+ auto cuda_stream = GetGpuStream(context);\n+ auto device = context->eigen_gpu_device();\n+ // Calling cub with nullptrs as inputs will make it return\n+ // workspace size needed for the operation instead of doing the operation.\n+ // In this specific instance, cub_sort_temp_storage_bytes will contain the\n+ // necessary workspace size for sorting after the call.\n+ if (num_boxes == 0) {\n+ Tensor* output_indices = nullptr;\n+ TF_RETURN_IF_ERROR(\n+ context->allocate_output(0, TensorShape({0}), &output_indices));\n+ return Status::OK();\n+ }\n+\n+ cudaError_t cuda_ret = cub::DeviceRadixSort::SortPairsDescending(\n+ nullptr, cub_sort_temp_storage_bytes,\n+ static_cast<float*>(nullptr), // scores\n+ static_cast<float*>(nullptr), // sorted scores\n+ static_cast<int*>(nullptr), // input indices\n+ static_cast<int*>(nullptr), // sorted indices\n+ num_boxes, // num items\n+ 0, 8 * sizeof(float), // sort all bits\n+ cuda_stream);\n+ TF_RETURN_IF_CUDA_ERROR(cuda_ret);\n+ Tensor d_cub_sort_buffer;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_INT8, TensorShape({(int64)cub_sort_temp_storage_bytes}),\n+ &d_cub_sort_buffer));\n+ Tensor d_indices;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_INT32, TensorShape({num_boxes}), &d_indices));\n+ Tensor d_sorted_indices;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_INT32, TensorShape({num_boxes}), &d_sorted_indices));\n+ Tensor d_selected_indices;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_INT32, TensorShape({num_boxes}), &d_selected_indices));\n+ Tensor d_sorted_scores;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_FLOAT, TensorShape({num_boxes}), &d_sorted_scores));\n+ Tensor d_sorted_boxes;\n+ TF_RETURN_IF_ERROR(context->allocate_temp(\n+ DataType::DT_FLOAT, TensorShape({num_boxes, 4}), &d_sorted_boxes));\n+\n+ // this will return sorted scores and their indices\n+ auto config = GetGpuLaunchConfig(num_boxes, device);\n+ // initialize box and score indices\n+ TF_CHECK_OK(GpuLaunchKernel(Iota<int>, config.block_count,\n+ config.thread_per_block, 0, device.stream(),\n+ config.virtual_thread_count, 0,\n+ d_indices.flat<int>().data()));\n+ TF_RETURN_IF_CUDA_ERROR(cudaGetLastError());\n+ cuda_ret = cub::DeviceRadixSort::SortPairsDescending(\n+ d_cub_sort_buffer.flat<int8>().data(), cub_sort_temp_storage_bytes,\n+ scores.flat<float>().data(), d_sorted_scores.flat<float>().data(),\n+ d_indices.flat<int>().data(), d_sorted_indices.flat<int>().data(),\n+ num_boxes, 0,\n+ 8 * sizeof(float), // sort all bits\n+ cuda_stream);\n+ TF_RETURN_IF_CUDA_ERROR(cuda_ret);\n+\n+ // get pointers for easy access\n+ const float4* original_boxes =\n+ reinterpret_cast<const float4*>(boxes.flat<float>().data());\n+ float4* sorted_boxes =\n+ reinterpret_cast<float4*>(d_sorted_boxes.flat<float>().data());\n+ const int* sorted_indices = d_sorted_indices.flat<int>().data();\n+ // sort boxes using indices\n+ TF_CHECK_OK(GpuLaunchKernel(IndexMultiSelect<int, float4>, config.block_count,\n+ config.thread_per_block, 0, device.stream(),\n+ config.virtual_thread_count, sorted_indices,\n+ original_boxes, sorted_boxes));\n+ int limited_num_boxes = num_boxes;\n+ // filter boxes by scores if nms v3\n+ if (score_threshold > std::numeric_limits<float>::lowest()) {\n+ GreaterThanCubOp score_limit(score_threshold);\n+ TF_RETURN_IF_ERROR(CountIf(context, d_sorted_scores.flat<float>().data(),\n+ score_limit, num_boxes, &limited_num_boxes));\n+ if (limited_num_boxes == 0) {\n+ Tensor* output_indices = nullptr;\n+ VLOG(1) << \"Number of boxes above score threshold \" << score_threshold\n+ << \" is 0\";\n+ TF_RETURN_IF_ERROR(\n+ context->allocate_output(0, TensorShape({0}), &output_indices));\n+ return Status::OK();\n+ } else {\n+ VLOG(2) << \"Number of boxes above threshold=\" << score_threshold << \" is \"\n+ << limited_num_boxes;\n+ }\n+ }\n+ int num_to_keep = 0;\n+ // There is no guarantee that boxes are given in the for x1<x2 and/or y1<y2,\n+ // flip boxes if necessary!\n+ const bool flip_boxes = true;\n+ auto status = NmsGpu(d_sorted_boxes.flat<float>().data(), limited_num_boxes,\n+ iou_threshold_val, d_selected_indices.flat<int>().data(),\n+ &num_to_keep, context, output_size, flip_boxes);\n+ TF_RETURN_IF_CUDA_ERROR(cudaGetLastError());\n+ if (!status.ok()) {\n+ context->SetStatus(status);\n+ return status;\n+ }\n+ Tensor* output_indices = nullptr;\n+ int num_outputs = std::min(num_to_keep, output_size); // no padding!\n+ TF_RETURN_IF_ERROR(\n+ context->allocate_output(0, TensorShape({num_outputs}), &output_indices));\n+ if (num_outputs == 0) return Status::OK();\n+ config = GetGpuLaunchConfig(num_outputs, device);\n+ TF_CHECK_OK(GpuLaunchKernel(\n+ IndexMultiSelect<int, int>, config.block_count, config.thread_per_block,\n+ 0, device.stream(), config.virtual_thread_count,\n+ d_selected_indices.flat<int>().data(), sorted_indices,\n+ (*output_indices).flat<int>().data()));\n+ TF_RETURN_IF_CUDA_ERROR(cudaGetLastError());\n return Status::OK();\n }\n \n@@ -379,112 +585,84 @@ class NonMaxSuppressionV2GPUOp : public OpKernel {\n &output_indices));\n return;\n }\n- const int output_size = max_output_size.scalar<int>()();\n- size_t cub_sort_temp_storage_bytes = 0;\n- auto cuda_stream = GetGpuStream(context);\n- auto device = context->eigen_gpu_device();\n- // Calling cub with nullptrs as inputs will make it return\n- // workspace size needed for the operation instead of doing the operation.\n- // In this specific instance, cub_sort_temp_storage_bytes will contain the\n- // necessary workspace size for sorting after the call.\n- cudaError_t cuda_ret = cub::DeviceRadixSort::SortPairsDescending(\n- nullptr, cub_sort_temp_storage_bytes,\n- static_cast<float*>(nullptr), // scores\n- static_cast<float*>(nullptr), // sorted scores\n- static_cast<int*>(nullptr), // input indices\n- static_cast<int*>(nullptr), // sorted indices\n- num_boxes, // num items\n- 0, 8 * sizeof(float), // sort all bits\n- cuda_stream);\n- TF_OP_REQUIRES_CUDA_SUCCESS(context, cuda_ret);\n- Tensor d_cub_sort_buffer;\n- OP_REQUIRES_OK(context,\n- context->allocate_temp(\n- DataType::DT_INT8,\n- TensorShape({(int64)cub_sort_temp_storage_bytes}),\n- &d_cub_sort_buffer));\n- Tensor d_indices;\n+ const int64_t output_size = max_output_size.scalar<int>()();\n OP_REQUIRES_OK(\n- context, context->allocate_temp(DataType::DT_INT32,\n- TensorShape({num_boxes}), &d_indices));\n- Tensor d_sorted_indices;\n- OP_REQUIRES_OK(context, context->allocate_temp(DataType::DT_INT32,\n- TensorShape({num_boxes}),\n- &d_sorted_indices));\n- Tensor d_selected_indices;\n- OP_REQUIRES_OK(context, context->allocate_temp(DataType::DT_INT32,\n- TensorShape({num_boxes}),\n- &d_selected_indices));\n- Tensor d_sorted_scores;\n- OP_REQUIRES_OK(context, context->allocate_temp(DataType::DT_FLOAT,\n- TensorShape({num_boxes}),\n- &d_sorted_scores));\n- Tensor d_sorted_boxes;\n- OP_REQUIRES_OK(context, context->allocate_temp(DataType::DT_FLOAT,\n- TensorShape({num_boxes, 4}),\n- &d_sorted_boxes));\n-\n- // this will return sorted scores and their indices\n- auto config = GetGpuLaunchConfig(num_boxes, device);\n- // initialize box and score indices\n- TF_CHECK_OK(GpuLaunchKernel(Iota<int>, config.block_count,\n- config.thread_per_block, 0, device.stream(),\n- config.virtual_thread_count, 0,\n- d_indices.flat<int>().data()));\n- TF_OP_REQUIRES_CUDA_SUCCESS(context, cudaGetLastError());\n- cuda_ret = cub::DeviceRadixSort::SortPairsDescending(\n- d_cub_sort_buffer.flat<int8>().data(), cub_sort_temp_storage_bytes,\n- scores.flat<float>().data(), d_sorted_scores.flat<float>().data(),\n- d_indices.flat<int>().data(), d_sorted_indices.flat<int>().data(),\n- num_boxes, 0,\n- 8 * sizeof(float), // sort all bits\n- cuda_stream);\n- TF_OP_REQUIRES_CUDA_SUCCESS(context, cuda_ret);\n-\n- // get pointers for easy access\n- const float4* original_boxes =\n- reinterpret_cast<const float4*>(boxes.flat<float>().data());\n- float4* sorted_boxes =\n- reinterpret_cast<float4*>(d_sorted_boxes.flat<float>().data());\n- const int* sorted_indices = d_sorted_indices.flat<int>().data();\n- // sort boxes using indices\n- TF_CHECK_OK(GpuLaunchKernel(IndexMultiSelect<int, float4>,\n- config.block_count, config.thread_per_block, 0,\n- device.stream(), config.virtual_thread_count,\n- sorted_indices, original_boxes, sorted_boxes));\n-\n- int num_to_keep = 0;\n- // There is no guarantee that boxes are given in the for x1<x2 and/or y1<y2,\n- // flip boxes if necessary!\n- const bool flip_boxes = true;\n- auto status =\n- NmsGpu(d_sorted_boxes.flat<float>().data(), num_boxes,\n- iou_threshold_val, d_selected_indices.flat<int>().data(),\n- &num_to_keep, context, flip_boxes);\n- TF_OP_REQUIRES_CUDA_SUCCESS(context, cudaGetLastError());\n- if (!status.ok()) {\n- context->SetStatus(status);\n+ context,\n+ DoNMS(context, boxes, scores, output_size, iou_threshold_val,\n+ /*score_threshold is float min if score threshold is disabled*/\n+ std::numeric_limits<float>::lowest()));\n+ }\n+};\n+\n+class NonMaxSuppressionV3GPUOp : public OpKernel {\n+ public:\n+ explicit NonMaxSuppressionV3GPUOp(OpKernelConstruction* context)\n+ : OpKernel(context) {}\n+\n+ void Compute(OpKernelContext* context) override {\n+ // boxes: [num_boxes, 4]\n+ const Tensor& boxes = context->input(0);\n+ // scores: [num_boxes]\n+ const Tensor& scores = context->input(1);\n+ // max_output_size: scalar\n+ const Tensor& max_output_size = context->input(2);\n+ OP_REQUIRES(\n+ context, TensorShapeUtils::IsScalar(max_output_size.shape()),\n+ errors::InvalidArgument(\"max_output_size must be 0-D, got shape \",\n+ max_output_size.shape().DebugString()));\n+ // iou_threshold: scalar\n+ const Tensor& iou_threshold = context->input(3);\n+ OP_REQUIRES(context, TensorShapeUtils::IsScalar(iou_threshold.shape()),\n+ errors::InvalidArgument(\"iou_threshold must be 0-D, got shape \",\n+ iou_threshold.shape().DebugString()));\n+ const float iou_threshold_val = iou_threshold.scalar<float>()();\n+\n+ const Tensor& score_threshold = context->input(4);\n+ OP_REQUIRES(\n+ context, TensorShapeUtils::IsScalar(score_threshold.shape()),\n+ errors::InvalidArgument(\"score_threshold must be 0-D, got shape \",\n+ score_threshold.shape().DebugString()));\n+ const float score_threshold_val = score_threshold.scalar<float>()();\n+\n+ OP_REQUIRES(context, iou_threshold_val >= 0 && iou_threshold_val <= 1,\n+ errors::InvalidArgument(\"iou_threshold must be in [0, 1]\"));\n+ OP_REQUIRES(context, boxes.dims() == 2,\n+ errors::InvalidArgument(\"boxes must be a rank 2 tensor!\"));\n+ int num_boxes = boxes.dim_size(0);\n+ OP_REQUIRES(context, boxes.dim_size(1) == 4,\n+ errors::InvalidArgument(\"boxes must be Nx4\"));\n+ OP_REQUIRES(context, scores.dims() == 1,\n+ errors::InvalidArgument(\"scores must be a vector!\"));\n+ OP_REQUIRES(\n+ context, scores.dim_size(0) == num_boxes,\n+ errors::InvalidArgument(\n+ \"scores has incompatible shape\")); // message must be exactly this\n+ // otherwise tests fail!\n+ if (num_boxes == 0) {\n+ Tensor* output_indices = nullptr;\n+ OP_REQUIRES_OK(context, context->allocate_output(0, TensorShape({0}),\n+ &output_indices));\n return;\n }\n- Tensor* output_indices = nullptr;\n- int num_outputs = std::min(num_to_keep, output_size); // no padding!\n- OP_REQUIRES_OK(context,\n- context->allocate_output(0, TensorShape({num_outputs}),\n- &output_indices));\n- if (num_outputs == 0) return;\n- config = GetGpuLaunchConfig(num_outputs, device);\n- TF_CHECK_OK(GpuLaunchKernel(\n- IndexMultiSelect<int, int>, config.block_count, config.thread_per_block,\n- 0, device.stream(), config.virtual_thread_count,\n- d_selected_indices.flat<int>().data(), sorted_indices,\n- (*output_indices).flat<int>().data()));\n- TF_OP_REQUIRES_CUDA_SUCCESS(context, cudaGetLastError());\n+ const int output_size = max_output_size.scalar<int>()();\n+ OP_REQUIRES_OK(context, DoNMS(context, boxes, scores, output_size,\n+ iou_threshold_val, score_threshold_val));\n }\n };\n \n-REGISTER_KERNEL_BUILDER(\n- Name(\"NonMaxSuppressionV2\").TypeConstraint<float>(\"T\").Device(DEVICE_GPU),\n- NonMaxSuppressionV2GPUOp);\n+REGISTER_KERNEL_BUILDER(Name(\"NonMaxSuppressionV2\")\n+ .TypeConstraint<float>(\"T\")\n+ .Device(DEVICE_GPU)\n+ .HostMemory(\"iou_threshold\")\n+ .HostMemory(\"max_output_size\"),\n+ NonMaxSuppressionV2GPUOp);\n+REGISTER_KERNEL_BUILDER(Name(\"NonMaxSuppressionV3\")\n+ .TypeConstraint<float>(\"T\")\n+ .Device(DEVICE_GPU)\n+ .HostMemory(\"iou_threshold\")\n+ .HostMemory(\"max_output_size\")\n+ .HostMemory(\"score_threshold\"),\n+ NonMaxSuppressionV3GPUOp);\n \n } // namespace tensorflow\n #endif",
"filename": "tensorflow/core/kernels/non_max_suppression_op.cu.cc",
"status": "modified"
},
{
"diff": "@@ -54,7 +54,7 @@ extern const int kNmsBoxesPerTread;\n Status NmsGpu(const float* d_sorted_boxes_float_ptr, const int num_boxes,\n const float iou_threshold, int* d_selected_indices,\n int* h_num_boxes_to_keep, OpKernelContext* context,\n- bool flip_boxes = false);\n+ const int max_boxes, bool flip_boxes = false);\n #endif\n \n } // namespace tensorflow",
"filename": "tensorflow/core/kernels/non_max_suppression_op.h",
"status": "modified"
},
{
"diff": "@@ -203,6 +203,222 @@ TEST_F(NonMaxSuppressionV2GPUOpTest, TestEmptyInput) {\n test::ExpectTensorEqual<int>(expected, *GetOutput(0));\n }\n \n+//\n+// NonMaxSuppressionV3GPUOp Tests\n+// Copied from CPU tests\n+\n+class NonMaxSuppressionV3GPUOpTest : public OpsTestBase {\n+ protected:\n+ void MakeOp() {\n+ SetDevice(DEVICE_GPU,\n+ std::unique_ptr<tensorflow::Device>(DeviceFactory::NewDevice(\n+ \"GPU\", {}, \"/job:a/replica:0/task:0\")));\n+\n+ TF_EXPECT_OK(NodeDefBuilder(\"non_max_suppression_op\", \"NonMaxSuppressionV3\")\n+ .Input(FakeInput(DT_FLOAT))\n+ .Input(FakeInput(DT_FLOAT))\n+ .Input(FakeInput(DT_INT32))\n+ .Input(FakeInput(DT_FLOAT))\n+ .Input(FakeInput(DT_FLOAT))\n+ .Finalize(node_def()));\n+ TF_EXPECT_OK(InitOp());\n+ }\n+};\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest, TestSelectFromThreeClusters) {\n+ MakeOp();\n+ AddInputFromArray<float>(\n+ TensorShape({6, 4}),\n+ {0, 0, 1, 1, 0, 0.1f, 1, 1.1f, 0, -0.1f, 1, 0.9f,\n+ 0, 10, 1, 11, 0, 10.1f, 1, 11.1f, 0, 100, 1, 101});\n+ AddInputFromArray<float>(TensorShape({6}), {.9f, .75f, .6f, .95f, .5f, .3f});\n+ AddInputFromArray<int>(TensorShape({}), {3});\n+ AddInputFromArray<float>(TensorShape({}), {.5f});\n+ AddInputFromArray<float>(TensorShape({}), {0.0f});\n+ TF_ASSERT_OK(RunOpKernel());\n+\n+ Tensor expected(allocator(), DT_INT32, TensorShape({3}));\n+ test::FillValues<int>(&expected, {3, 0, 5});\n+ test::ExpectTensorEqual<int>(expected, *GetOutput(0));\n+}\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest,\n+ TestSelectFromThreeClustersWithScoreThreshold) {\n+ MakeOp();\n+ AddInputFromArray<float>(\n+ TensorShape({6, 4}),\n+ {0, 0, 1, 1, 0, 0.1f, 1, 1.1f, 0, -0.1f, 1, 0.9f,\n+ 0, 10, 1, 11, 0, 10.1f, 1, 11.1f, 0, 100, 1, 101});\n+ AddInputFromArray<float>(TensorShape({6}), {.9f, .75f, .6f, .95f, .5f, .3f});\n+ AddInputFromArray<int>(TensorShape({}), {3});\n+ AddInputFromArray<float>(TensorShape({}), {0.5f});\n+ AddInputFromArray<float>(TensorShape({}), {0.4f});\n+ TF_ASSERT_OK(RunOpKernel());\n+\n+ Tensor expected(allocator(), DT_INT32, TensorShape({2}));\n+ test::FillValues<int>(&expected, {3, 0});\n+ test::ExpectTensorEqual<int>(expected, *GetOutput(0));\n+}\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest,\n+ TestSelectFromThreeClustersWithScoreThresholdZeroScores) {\n+ MakeOp();\n+ AddInputFromArray<float>(\n+ TensorShape({6, 4}),\n+ {0, 0, 1, 1, 0, 0.1f, 1, 1.1f, 0, -0.1f, 1, 0.9f,\n+ 0, 10, 1, 11, 0, 10.1f, 1, 11.1f, 0, 100, 1, 101});\n+ AddInputFromArray<float>(TensorShape({6}), {.1, 0, 0, .3, .2, -5.0});\n+ // If we ask for more boxes than we actually expect to get back;\n+ // should still only get 2 boxes back.\n+ AddInputFromArray<int>(TensorShape({}), {6});\n+ AddInputFromArray<float>(TensorShape({}), {0.5f});\n+ AddInputFromArray<float>(TensorShape({}), {-3.0f});\n+ TF_ASSERT_OK(RunOpKernel());\n+\n+ Tensor expected(allocator(), DT_INT32, TensorShape({2}));\n+ test::FillValues<int>(&expected, {3, 0});\n+\n+ test::ExpectTensorEqual<int>(expected, *GetOutput(0));\n+}\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest,\n+ TestSelectFromThreeClustersFlippedCoordinates) {\n+ MakeOp();\n+ AddInputFromArray<float>(TensorShape({6, 4}),\n+ {1, 1, 0, 0, 0, 0.1f, 1, 1.1f, 0, .9f, 1, -0.1f,\n+ 0, 10, 1, 11, 1, 10.1f, 0, 11.1f, 1, 101, 0, 100});\n+ AddInputFromArray<float>(TensorShape({6}), {.9f, .75f, .6f, .95f, .5f, .3f});\n+ AddInputFromArray<int>(TensorShape({}), {3});\n+ AddInputFromArray<float>(TensorShape({}), {.5f});\n+ AddInputFromArray<float>(TensorShape({}), {0.0f});\n+ TF_ASSERT_OK(RunOpKernel());\n+\n+ Tensor expected(allocator(), DT_INT32, TensorShape({3}));\n+ test::FillValues<int>(&expected, {3, 0, 5});\n+ test::ExpectTensorEqual<int>(expected, *GetOutput(0));\n+}\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest,\n+ TestSelectAtMostTwoBoxesFromThreeClusters) {\n+ MakeOp();\n+ AddInputFromArray<float>(\n+ TensorShape({6, 4}),\n+ {0, 0, 1, 1, 0, 0.1f, 1, 1.1f, 0, -0.1f, 1, 0.9f,\n+ 0, 10, 1, 11, 0, 10.1f, 1, 11.1f, 0, 100, 1, 101});\n+ AddInputFromArray<float>(TensorShape({6}), {.9f, .75f, .6f, .95f, .5f, .3f});\n+ AddInputFromArray<int>(TensorShape({}), {2});\n+ AddInputFromArray<float>(TensorShape({}), {.5f});\n+ AddInputFromArray<float>(TensorShape({}), {0.0f});\n+ TF_ASSERT_OK(RunOpKernel());\n+\n+ Tensor expected(allocator(), DT_INT32, TensorShape({2}));\n+ test::FillValues<int>(&expected, {3, 0});\n+ test::ExpectTensorEqual<int>(expected, *GetOutput(0));\n+}\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest,\n+ TestSelectAtMostThirtyBoxesFromThreeClusters) {\n+ MakeOp();\n+ AddInputFromArray<float>(\n+ TensorShape({6, 4}),\n+ {0, 0, 1, 1, 0, 0.1f, 1, 1.1f, 0, -0.1f, 1, 0.9f,\n+ 0, 10, 1, 11, 0, 10.1f, 1, 11.1f, 0, 100, 1, 101});\n+ AddInputFromArray<float>(TensorShape({6}), {.9f, .75f, .6f, .95f, .5f, .3f});\n+ AddInputFromArray<int>(TensorShape({}), {30});\n+ AddInputFromArray<float>(TensorShape({}), {.5f});\n+ AddInputFromArray<float>(TensorShape({}), {0.0f});\n+ TF_ASSERT_OK(RunOpKernel());\n+\n+ Tensor expected(allocator(), DT_INT32, TensorShape({3}));\n+ test::FillValues<int>(&expected, {3, 0, 5});\n+ test::ExpectTensorEqual<int>(expected, *GetOutput(0));\n+}\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest, TestSelectSingleBox) {\n+ MakeOp();\n+ AddInputFromArray<float>(TensorShape({1, 4}), {0, 0, 1, 1});\n+ AddInputFromArray<float>(TensorShape({1}), {.9f});\n+ AddInputFromArray<int>(TensorShape({}), {3});\n+ AddInputFromArray<float>(TensorShape({}), {.5f});\n+ AddInputFromArray<float>(TensorShape({}), {0.0f});\n+ TF_ASSERT_OK(RunOpKernel());\n+\n+ Tensor expected(allocator(), DT_INT32, TensorShape({1}));\n+ test::FillValues<int>(&expected, {0});\n+ test::ExpectTensorEqual<int>(expected, *GetOutput(0));\n+}\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest, TestSelectFromTenIdenticalBoxes) {\n+ MakeOp();\n+\n+ int num_boxes = 10;\n+ std::vector<float> corners(num_boxes * 4);\n+ std::vector<float> scores(num_boxes);\n+ for (int i = 0; i < num_boxes; ++i) {\n+ corners[i * 4 + 0] = 0;\n+ corners[i * 4 + 1] = 0;\n+ corners[i * 4 + 2] = 1;\n+ corners[i * 4 + 3] = 1;\n+ scores[i] = .9;\n+ }\n+ AddInputFromArray<float>(TensorShape({num_boxes, 4}), corners);\n+ AddInputFromArray<float>(TensorShape({num_boxes}), scores);\n+ AddInputFromArray<int>(TensorShape({}), {3});\n+ AddInputFromArray<float>(TensorShape({}), {.5f});\n+ AddInputFromArray<float>(TensorShape({}), {0.0f});\n+ TF_ASSERT_OK(RunOpKernel());\n+\n+ Tensor expected(allocator(), DT_INT32, TensorShape({1}));\n+ test::FillValues<int>(&expected, {0});\n+ test::ExpectTensorEqual<int>(expected, *GetOutput(0));\n+}\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest, TestInconsistentBoxAndScoreShapes) {\n+ MakeOp();\n+ AddInputFromArray<float>(\n+ TensorShape({6, 4}),\n+ {0, 0, 1, 1, 0, 0.1f, 1, 1.1f, 0, -0.1f, 1, 0.9f,\n+ 0, 10, 1, 11, 0, 10.1f, 1, 11.1f, 0, 100, 1, 101});\n+ AddInputFromArray<float>(TensorShape({5}), {.9f, .75f, .6f, .95f, .5f});\n+ AddInputFromArray<int>(TensorShape({}), {30});\n+ AddInputFromArray<float>(TensorShape({}), {.5f});\n+ AddInputFromArray<float>(TensorShape({}), {0.0f});\n+ Status s = RunOpKernel();\n+\n+ ASSERT_FALSE(s.ok());\n+ EXPECT_TRUE(absl::StrContains(s.ToString(), \"scores has incompatible shape\"))\n+ << s;\n+}\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest, TestInvalidIOUThreshold) {\n+ MakeOp();\n+ AddInputFromArray<float>(TensorShape({1, 4}), {0, 0, 1, 1});\n+ AddInputFromArray<float>(TensorShape({1}), {.9f});\n+ AddInputFromArray<int>(TensorShape({}), {3});\n+ AddInputFromArray<float>(TensorShape({}), {1.2f});\n+ AddInputFromArray<float>(TensorShape({}), {0.0f});\n+ Status s = RunOpKernel();\n+\n+ ASSERT_FALSE(s.ok());\n+ EXPECT_TRUE(\n+ absl::StrContains(s.ToString(), \"iou_threshold must be in [0, 1]\"))\n+ << s;\n+}\n+\n+TEST_F(NonMaxSuppressionV3GPUOpTest, TestEmptyInput) {\n+ MakeOp();\n+ AddInputFromArray<float>(TensorShape({0, 4}), {});\n+ AddInputFromArray<float>(TensorShape({0}), {});\n+ AddInputFromArray<int>(TensorShape({}), {30});\n+ AddInputFromArray<float>(TensorShape({}), {.5f});\n+ AddInputFromArray<float>(TensorShape({}), {0.0f});\n+ TF_ASSERT_OK(RunOpKernel());\n+\n+ Tensor expected(allocator(), DT_INT32, TensorShape({0}));\n+ test::FillValues<int>(&expected, {});\n+ test::ExpectTensorEqual<int>(expected, *GetOutput(0));\n+}\n+\n #endif\n \n } // namespace tensorflow",
"filename": "tensorflow/core/kernels/non_max_suppression_op_gpu_test.cc",
"status": "modified"
}
]
}
|
{
"body": "/tensorflow/core/kernels/deep_conv2d.cc: ln 74,\r\nstatic int64 GetDirectConvCost(int filter_rows, int filter_cols, int in_depth,\r\nint out_depth, int out_rows, int out_cols) {\r\nreturn filter_rows * filter_cols * in_depth * out_depth * out_rows * out_cols;\r\n}\r\n\r\nCan lead to integer overflow and weird results\r\nI think, it should be smth like that\r\nreturn (int64)filter_rows * (int64)filter_cols * (int64)in_depth * (int64)out_depth * (int64)out_rows * (int64)out_cols;",
"comments": [
{
"body": "@iur-kvasniuk That makes sense. Are you willing to create a PR for that?",
"created_at": "2019-08-28T15:16:40Z"
},
{
"body": "Ok, I will create a PR tomorrow morning. Thanks for reply!\n\nСр, 28 авг. 2019 г. в 18:24, Yong Tang <notifications@github.com>:\n\n> @iur-kvasniuk <https://github.com/iur-kvasniuk> That makes sense. Are you\n> willing to create a PR for that?\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/tensorflow/tensorflow/issues/32045?email_source=notifications&email_token=ANAZPT44S3JEJKU4WRLX3RTQG2KC5A5CNFSM4IRG4QXKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD5LPHSA#issuecomment-525792200>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/ANAZPT6BCNSI4ZFINLAPKNTQG2KC5ANCNFSM4IRG4QXA>\n> .\n>\n",
"created_at": "2019-08-28T15:59:07Z"
},
{
"body": "Please provide details about what platform you are using (operating system, architecture). Also include your TensorFlow version. Also, did you compile from source or install a binary?\r\n\r\nMake sure you also include the exact command if possible to produce the output included in your test case. If you are unclear what to include see the issue template displayed in [the Github new issue template](https://github.com/tensorflow/tensorflow/issues/new/choose).\r\n\r\nWe ask for this in the issue submission template, because it is really difficult to help without that information. Thanks!\r\n\r\n\r\n\r\n\r\n\r\n",
"created_at": "2019-08-29T09:33:28Z"
},
{
"body": "- OS Platform and Distribution: Linux Ubuntu 16.04 LTS\r\n- TensorFlow built from source (tf_nightly-1.14.0-cp35-cp35m-linux_x86_64)\r\n- For Conv2D parameters\r\nin_depth = 4, input_cols = 1920, filter_cols = 3, input_rows = 1080, filter_rows = 3, out_depth = 32\r\noutput of GetDirectConvCost function: -1906180096, but should be 2388787200\r\n- For Conv2D parameters\r\nin_depth = 32, input_cols = 1920, filter_cols = 3, input_rows = 1080, filter_rows = 3, out_depth = 32\r\noutput of CanUseDeepConv2D function - false (deep_direct_ratio: 7.14965), but should be true (deep_direct_ratio: 0.722222)",
"created_at": "2019-08-29T11:39:23Z"
},
{
"body": "The function clearly overflows, but the fix suggested is not enough.",
"created_at": "2019-08-29T17:04:35Z"
},
{
"body": "created new PR with additional checks: #32120",
"created_at": "2019-08-30T17:12:06Z"
},
{
"body": "~~The caller should check, this is defined behavior. It's very probable that the caller already has all checks in place, if not, that's where they should go~~\r\n\r\nEdit, I was wrong, __signed__ integer overflow is UB.",
"created_at": "2019-09-05T01:11:32Z"
},
{
"body": "There are more issues in that file. I'll handle those changes this week",
"created_at": "2019-09-05T16:05:59Z"
},
{
"body": "Hi There,\n\n We are checking to see if you still need help on this, as you are using an older version of tensorflow which is officially considered end of life . We recommend that you upgrade to the latest 2.x version and let us know if the issue still persists in newer versions. Please open a new issue for any help you need against 2.x, and we will get you the right help. \n\n This issue will be closed automatically 7 days from now. If you still need help with this issue, please provide us with more information.",
"created_at": "2021-02-01T14:06:19Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32045\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/32045\">No</a>\n",
"created_at": "2021-02-09T05:59:36Z"
}
],
"number": 32045,
"title": "static int64 GetDirectConvCost - Integer overflow"
}
|
{
"body": "The current code can lead to integer overflow and weird results\r\n\r\nstatic int64 GetDirectConvCost f-n can lead to integer overflow and weird results \r\n issue: #32045\r\n\r\n\r\n",
"number": 32225,
"review_comments": [
{
"body": "Unrelated changes and also illegal ones. Copyright notices should not be altered",
"created_at": "2019-09-05T15:35:13Z"
}
],
"title": "fixed integer overflow and add warning"
}
|
{
"commits": [
{
"message": "fixed integer overflow and add waring"
}
],
"files": [
{
"diff": "@@ -1,11 +1,8 @@\n /* Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n-\n Licensed under the Apache License, Version 2.0 (the \"License\");\n you may not use this file except in compliance with the License.\n You may obtain a copy of the License at\n-\n http://www.apache.org/licenses/LICENSE-2.0\n-\n Unless required by applicable law or agreed to in writing, software\n distributed under the License is distributed on an \"AS IS\" BASIS,\n WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n@@ -19,6 +16,7 @@ limitations under the License.\n #include \"tensorflow/core/kernels/deep_conv2d.h\"\n \n #include <stdlib.h>\n+#include <limits.h>\n \n #include \"tensorflow/core/framework/op_kernel.h\"\n #include \"tensorflow/core/kernels/winograd_transform.h\"\n@@ -73,7 +71,40 @@ static int64 GetDeepConvCost(int input_tile_rows, int input_tile_cols,\n \n static int64 GetDirectConvCost(int filter_rows, int filter_cols, int in_depth,\n int out_depth, int out_rows, int out_cols) {\n- return filter_rows * filter_cols * in_depth * out_depth * out_rows * out_cols;\n+ int64 res = filter_rows;\n+ const int64 max_int64 = std::numeric_limits<int64>::max();\n+ // Check for integer overflow\n+ if( res < max_int64 / filter_cols)\n+ {\n+ res *= filter_cols;\n+ if( res < max_int64 / in_depth)\n+ {\n+ res *= in_depth;\n+ if( res < max_int64 / out_depth)\n+ {\n+ res *= out_depth;\n+ if( res < max_int64 / out_rows)\n+ {\n+ res *= out_rows;\n+ if( res <= max_int64 / out_cols)\n+ {\n+ res *= out_cols;\n+ return res;\n+ }\n+ }\n+ }\n+ }\n+ }\n+ LOG(WARNING) << \"GetDirectConvCost\"\n+ << \" Conv2d parameters: filter_rows = \" << filter_rows\n+ << \", filter_cols = \" << filter_cols\n+ << \", in_depth = \" << in_depth\n+ << \", out_depth = \" << out_depth\n+ << \", out_rows = \" << out_rows\n+ << \", out_cols = \" << out_cols\n+ << \" caused integer overflow.\"\n+ << \" Return value was clamped to max_int64.\";\n+ return max_int64;\n }\n \n // Reads environment variable 'env_var_name'.",
"filename": "tensorflow/core/kernels/deep_conv2d.cc",
"status": "modified"
}
]
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.