
issue
dict | pr
dict | pr_details
dict |
|---|---|---|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nYes\n\n### Source\n\nsource\n\n### Tensorflow Version\n\ntf 2.12.0\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\nwin11\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\nAccording to [doc](https://tensorflow.google.cn/api_docs/python/tf/eye), the param `num_rows` should be `Non-negative int32 scalar Tensor`. But below snippet code 1 indicates that the param `num_rows` cannot be zero which is inconsistent with doc. On the other hand, the param `num_rows` shouldnt be Bool Tensor, but when given bool tensor, `tf.eye` works, as below snippet code 2 shows.\n\n### Standalone code to reproduce the issue\n\n```shell\nsnippet code 1:\r\n\r\nimport tensorflow as tf\r\nresults={}\r\ntry:\r\n num_rows = \"1\"\r\n results[\"res\"] = tf.eye(num_rows=num_rows)\r\nexcept Exception as e:\r\n results[\"err\"] = \"Error:\"+str(e)\r\nprint(results)\r\n# results = Error:Arguments `num_rows` and `num_columns` must be positive integer values. Received: num_rows=1, num_columns=1\r\n```\r\n\r\nsnippet code 2:\r\n```\r\nimport tensorflow as tf\r\nresults={}\r\ntry:\r\n num_rows = True\r\n results[\"res\"] = tf.eye(num_rows=num_rows,)\r\nexcept Exception as e:\r\n results[\"err\"] = \"Error:\"+str(e)\r\nprint(results)\r\n# results = {'res': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>}\r\n```\n```\n\n\n### Relevant log output\n\n_No response_</details>",
"comments": [
{
"body": "Hi @cheyennee ,\r\n\r\nThanks for reporting. I need to cross check the implementation and let you update and do necessary. Thanks!",
"created_at": "2023-05-02T04:31:11Z"
},
{
"body": "Hi @cheyennee ,\r\n\r\n**For the code snippet 1:**\r\n\r\nSince you are passing `num_rows = \"1\"` as string and it is raising the error as intended and in the description it is printing num_rows=1, and here 1 is string not a number. By default if you won't provide any value to `num_columns` then `num_columns=num_rows` as per API, hence you are getting same value for both `num_rows` and `num_columns`.\r\n\r\nFor example if I pass `num_rows = \"anything\"` then the error description will be like below:\r\n\r\n\r\n> \r\n\r\n> TypeError: Arguments `num_rows` and `num_columns` must be positive integer values. Received: num_rows=anything, num_columns=anything\r\n\r\n\r\n\r\nI hope this will clarify your query and there is no need to change any description here.\r\n\r\n\r\n\r\n**For the code snippet 2:**\r\n\r\nIf you pass `num_rows = True`, here True will be converted as 1 and hence `num_rows=1` and `num_columns=1` and the output will be (1,1) shaped tensor.\r\n\r\nHope this clarify your queries. Thanks!",
"created_at": "2023-05-02T11:30:01Z"
},
{
"body": "@SuryanarayanaY I see many other APIs that don't convert type internally. So I am a little confused, which APIs will automatically convert type internally, and which ones will not?",
"created_at": "2023-05-03T11:09:37Z"
},
{
"body": "Hi @cheyennee ,\r\n\r\nI hope for `code snippet-1`, I have answered your query right?\r\n\r\nI am assuming your question is for `code snippet-2` where True is converted as '1'.Correct me if I am wrong. \r\n\r\nThe `tf.eye` API calls `tf.ones` internally and this is where booleans are converted into integer.Please refer the source code and the [gist](https://colab.research.google.com/gist/SuryanarayanaY/c434827ac7569eceb8b37a7f9ab28d50/60457.ipynb) to explain this.\r\n\r\n I think in the both APIs we need to change the description of argument `shape` that it also accepts boolean and converts them into integers 1 or 0.\r\n\r\nI think this documentation change will suffice the purpose of this issue right? Please confirm",
"created_at": "2023-05-03T17:05:04Z"
},
{
"body": "@SuryanarayanaY Yeah, you're right. I think the documentation should be changed since the argument `shape` can accepts both boolean and integer.",
"created_at": "2023-05-04T14:42:12Z"
},
{
"body": "You didn't pass a boolean tensor, you passed a Python boolean, which automatically gets converted to and integer when you do math on it. The function fails if you do actually try to pass a tensor of type `tf.bool`. It's not useful to document that `tf.ones(True)` happens to work - it has no valid semantic meaning.",
"created_at": "2023-06-01T15:27:17Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/60457\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/60457\">No</a>\n",
"created_at": "2023-06-01T15:27:20Z"
}
],
"number": 60457,
"title": "error message of tf.eye is inconsistent with doc"
}
|
{
"body": "At present as per documentation of `tf.zeros` and `tf.ones`, both APIs have argument `shape` which accepts \"A list of integers, a tuple of integers, or a 1-D Tensor of type int32 \". \r\n\r\nBut its find out that when Boolean data types `True, False` passed to the `shape` argument it also accepts it and convert them into 1, 0 respectively and outputs correct results. Hence i am proposing to add a note under the '`shape`' argument description that it also accepts boolean data types.\r\n\r\nAttaching the [gist](https://colab.research.google.com/gist/SuryanarayanaY/837bf1888c618e3585f4f7247c329885/tf-ones_tf-zeros_tf-eye.ipynb) also for referring the results. \r\n\r\nAlso fixes #60457 ",
"number": 60584,
"review_comments": [],
"title": "Update Args data types of tf.ones and tf.zeros"
}
|
{
"commits": [
{
"message": "Update Args data types of tf.ones and tf.zeros\n\nAt present as per documentation of tf.zeros and tf.ones, both APIs have argument shape which accepts \"A list of integers, a tuple of integers, or a 1-D Tensor of type int32 \". But its find out that when Boolean data types True, False passed to the same argument it also accepts it and convert them into 1,0 respectively and outputs correct results. Hence i am proposing to add a note under the 'shape' argument description that it also accepts boolean data types.\r\n\r\nAttaching the gist also for referring the results.\r\nhttps://colab.research.google.com/gist/SuryanarayanaY/837bf1888c618e3585f4f7247c329885/tf-ones_tf-zeros_tf-eye.ipynb"
},
{
"message": "Update supported dtypes of tf.eye num_rows argument \n\nAt present as per documentation the tf.eye API, the argument num_rows accepts \"Non-negative int32 scalar Tensor giving the number of rows in each batch matrix\".\r\n\r\nBut when tested with booleans True or False it also accepting these arguments and converting them to 1 or 0 respectively and generating desired output.This means bool data types also supported argument and hence I am proposing to add a note in the argument description that bool data types also supported.\r\n\r\nGist is attached here for reference of results.\r\n\r\nhttps://colab.research.google.com/gist/SuryanarayanaY/837bf1888c618e3585f4f7247c329885/tf-ones_tf-zeros_tf-eye.ipynb"
}
],
"files": [
{
"diff": "@@ -2832,6 +2832,8 @@ def zeros(shape, dtype=dtypes.float32, name=None):\n Args:\n shape: A `list` of integers, a `tuple` of integers, or\n a 1-D `Tensor` of type `int32`.\n+ Note: Boolean datatypes True,False also acceptable and converted\n+ into numerics 1,0 respectively.\n dtype: The DType of an element in the resulting `Tensor`.\n name: Optional string. A name for the operation.\n \n@@ -3090,6 +3092,8 @@ def ones(shape, dtype=dtypes.float32, name=None):\n Args:\n shape: A `list` of integers, a `tuple` of integers, or\n a 1-D `Tensor` of type `int32`.\n+ Note: Boolean datatypes True,False also acceptable and converted\n+ into numerics 1,0 respectively.\n dtype: Optional DType of an element in the resulting `Tensor`. Default is\n `tf.float32`.\n name: Optional string. A name for the operation.",
"filename": "tensorflow/python/ops/array_ops.py",
"status": "modified"
},
{
"diff": "@@ -219,6 +219,8 @@ def eye(num_rows,\n Args:\n num_rows: Non-negative `int32` scalar `Tensor` giving the number of rows\n in each batch matrix.\n+ Note: Boolean data types True,False also acceptable and converts into\n+ 1, 0 respectively.\n num_columns: Optional non-negative `int32` scalar `Tensor` giving the number\n of columns in each batch matrix. Defaults to `num_rows`.\n batch_shape: A list or tuple of Python integers or a 1-D `int32` `Tensor`.",
"filename": "tensorflow/python/ops/linalg_ops.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nYes\n\n### Source\n\nsource\n\n### Tensorflow Version\n\ntf 2.12.0\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\nwin11\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\nAccording to [doc](https://tensorflow.google.cn/api_docs/python/tf/nn/leaky_relu), the argument `features` can be `float16, float32, float64, int32, int64`. But the error message in following snippet code indicates that the type of `features` can only be `float16, float32, float64` without `int`.\n\n### Standalone code to reproduce the issue\n\n```shell\nimport tensorflow as tf\r\nresults={}\r\ntry:\r\n features = [True]\r\n results[\"res\"] = tf.nn.leaky_relu(features=features,)\r\nexcept Exception as e:\r\n results[\"err\"] = \"Error:\"+str(e)\r\nprint(results)\r\n# results={'err': \"Error:Value for attr 'T' of bool is not in the list of allowed values: half, bfloat16, float, double\\n\\t; NodeDef: {{node LeakyRelu}}; Op<name=LeakyRelu; signature=features:T -> activations:T; attr=alpha:float,default=0.2; attr=T:type,default=DT_FLOAT,allowed=[DT_HALF, DT_BFLOAT16, DT_FLOAT, DT_DOUBLE]> [Op:LeakyRelu]\"}\n```\n\n\n### Relevant log output\n\n_No response_</details>",
"comments": [
{
"body": "Hi. Is anyone working on the issue to update the docs/error message? Would love to take it up and start working on the issue",
"created_at": "2023-05-29T06:06:07Z"
}
],
"number": 60521,
"title": "error message is inconsistent with documentation in tf.nn.leaky_relu"
}
|
{
"body": "https://github.com/tensorflow/tensorflow/issues/60521 issue no. #60521\r\n\"According to doc(https://tensorflow.google.cn/api_docs/python/tf/nn/leaky_relu), the argument features can be float16, float32, float64, int32, int64. But the error message in following snippet code indicates that the type of features can only be float16, float32, float64 without int.\" This is my first contribution to open source so please excuse any mistake and please tell if anything is wrong.",
"number": 60522,
"review_comments": [],
"title": "Update LeakyRelu.pbtxt"
}
|
{
"commits": [
{
"message": "Update LeakyRelu.pbtxt\n\nhttps://github.com/tensorflow/tensorflow/issues/60521\r\nissue no. #60521\r\n\"According to doc(https://tensorflow.google.cn/api_docs/python/tf/nn/leaky_relu), the argument features can be float16, float32, float64, int32, int64. But the error message in following snippet code indicates that the type of features can only be float16, float32, float64 without int.\"\r\nThis is my contribution to open source so please excuse any mistake and please tell if anything is wrong."
},
{
"message": "add int value in allowed_values list \n\nif applied, this commit will add DT_INT as a type of value in allowed_values list in LeakyRelu.pbtxt file."
}
],
"files": [
{
"diff": "@@ -59,6 +59,7 @@ op {\n type: DT_BFLOAT16\n type: DT_FLOAT\n type: DT_DOUBLE\n+ type: DT_INT\n }\n }\n }",
"filename": "tensorflow/core/ops/compat/ops_history_v1/LeakyRelu.pbtxt",
"status": "modified"
},
{
"diff": "@@ -59,6 +59,7 @@ op {\n type: DT_BFLOAT16\n type: DT_FLOAT\n type: DT_DOUBLE\n+ type: DT_INT\n }\n }\n }",
"filename": "tensorflow/core/ops/compat/ops_history_v2/LeakyRelu.pbtxt",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nYes\n\n### Source\n\nsource\n\n### Tensorflow Version\n\n2.13.0-dev20230208\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\n_No response_\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\ntf.raw_ops.ResourceScatterUpdate crash with abortion\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport tensorflow as tf\r\nimport numpy as np\r\n\r\ninit = np.random.rand(20)\r\nupdate = np.random.rand(20)\r\n\r\nresource = tf.Variable(init, dtype=tf.float32)\r\nresource_var = resource.handle\r\nindices = np.array([1, 3, 5], dtype=np.int32)\r\ntf.raw_ops.ResourceScatterUpdate(resource=resource_var, indices=indices, updates=update)\n```\n\n\n### Relevant log output\n\n```shell\n2023-03-28 11:39:22.735062: F tensorflow/core/framework/tensor.cc:770] Check failed: dtype() == expected_dtype (1 vs. 2) double expected, got float\r\nAborted (core dumped)\n```\n</details>",
"comments": [
{
"body": "Try this below\r\n\r\nimport tensorflow as tf\r\nimport numpy as np\r\n\r\ninit = np.random.rand(20).astype(np.float32) # Convert to float32\r\n\r\nresource = tf.Variable(init, dtype=tf.float32)\r\nresource_var = resource.handle\r\nindices = np.array([1, 3, 5], dtype=np.int32)\r\n\r\n# Make sure the updates tensor has the correct shape: (len(indices),)\r\nupdate = np.random.rand(len(indices)).astype(np.float32) # Convert to float32\r\n\r\ntf.raw_ops.ResourceScatterUpdate(resource=resource_var, indices=indices, updates=update)\r\nNow, the 'updates' tensor has a shape that matches the size of the 'indices' tensor, and the error should be resolved.",
"created_at": "2023-03-31T20:21:23Z"
},
{
"body": "@trickiwoo Could you please let us know if the above workaround worked for you?\r\nThank you!",
"created_at": "2023-04-04T11:16:20Z"
},
{
"body": "This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you.",
"created_at": "2023-04-12T01:53:24Z"
},
{
"body": "Thanks for providing the workaround. However, in my understanding, crashes like this seem to be a vulnerability according to https://github.com/tensorflow/tensorflow/issues/60121#issuecomment-1485230826",
"created_at": "2023-04-15T20:04:57Z"
},
{
"body": "I was able to reproduce the issue in Tensorflow 2.12, please find the attached Gist [here](https://gist.github.com/sachinprasadhs/028763a39c0f83e59f6a5ba2807fef8a). Thanks!",
"created_at": "2023-04-18T20:57:02Z"
},
{
"body": "@trickiwoo,\r\nI tried to execute the mentioned code on tf-nightly and the code was executed with the error and also observed that the crash did not happen. And the same has been in the respective files. Kindly find the [gist](https://colab.research.google.com/gist/tilakrayal/58a438e3530de19720ef3cac0201383f/untitled1681.ipynb) for the [reference](https://colab.research.google.com/gist/tilakrayal/64c329a1db61dd97eaaffed5e04e2f54/untitled1682.ipynb).\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/quantize_and_dequantize_op.cc#L22 \r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/resource_variable_ops.cc#L1120\r\n\r\n> // Check data type of update and resource to scatter.\r\n> const DataType update_dtype = c->input(2).dtype();\r\n> OP_REQUIRES(c, v->tensor()->dtype() == update_dtype,\r\n> errors::InvalidArgument(\r\n> \"DType of scatter resource and updates does not match.\"));\r\n\r\nThank you!",
"created_at": "2024-01-25T12:55:14Z"
},
{
"body": "This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you.",
"created_at": "2024-02-02T01:47:25Z"
},
{
"body": "This issue was closed because it has been inactive for 7 days since being marked as stale. Please reopen if you'd like to work on this further.",
"created_at": "2024-02-10T01:46:04Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/60147\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/60147\">No</a>\n",
"created_at": "2024-02-10T01:46:10Z"
}
],
"number": 60147,
"title": "tf.raw_ops.ResourceScatterUpdate crash with abortion"
}
|
{
"body": "Add dtype checks to Scatter ops(Assign*VariableOp, ResourceScatter*) to report error instead of core dump.\r\nfix issues:\r\n#60147 \r\n#60121 \r\n",
"number": 60452,
"review_comments": [],
"title": "Add dtype checks to Scatter ops to report error instead of core dump"
}
|
{
"commits": [
{
"message": "Add dtype checks to Scatter ops to report error instead of core dump"
}
],
"files": [
{
"diff": "@@ -592,6 +592,14 @@ class AssignUpdateVariableOp : public OpKernel {\n // PrepareToUpdateVariable() for commutative operations like Op ==\n // ADD if value's refcount was 1.\n mutex_lock ml(*variable->mu());\n+ OP_REQUIRES(context,\n+ (variable->tensor()->dtype() == DT_INVALID &&\n+ !variable->is_initialized) ||\n+ variable->tensor()->dtype() == value.dtype(),\n+ errors::InvalidArgument(\n+ \"Trying to assign update var with wrong dtype. Expected \",\n+ DataTypeString(variable->tensor()->dtype()), \" got \",\n+ DataTypeString(value.dtype())));\n Tensor* var_tensor = variable->tensor();\n OP_REQUIRES_OK(context, ValidateAssignUpdateVariableOpShapes(\n var_tensor->shape(), value.shape()));\n@@ -1106,6 +1114,11 @@ class ResourceScatterUpdateOp : public OpKernel {\n \"updates.shape \", updates.shape().DebugString(),\n \", indices.shape \", indices.shape().DebugString(),\n \", params.shape \", params->shape().DebugString()));\n+ OP_REQUIRES(c, params->dtype() == updates.dtype(),\n+ errors::InvalidArgument(\n+ \"Trying to scatter update var with wrong dtype. Expected \",\n+ DataTypeString(params->dtype()), \" got \",\n+ DataTypeString(updates.dtype())));\n \n // Check that we have enough index space\n const int64_t N_big = indices.NumElements();",
"filename": "tensorflow/core/kernels/resource_variable_ops.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nYes\n\n### Source\n\nsource\n\n### Tensorflow Version\n\n2.13.0-dev20230208\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\n_No response_\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.9\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\ntf.raw_ops.AssignAddVariableOp crash with abortion\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport tensorflow as tf\r\nfrom tensorflow.python.eager import context\r\n\r\ninput1 = tf.raw_ops.VarHandleOp(dtype=tf.int32, shape=[2, 3], shared_name=context.anonymous_name())\r\ninput2 = tf.constant([],dtype=tf.float32)\r\n\r\ntf.raw_ops.AssignAddVariableOp(resource=input1, value=input2)\n```\n\n\n### Relevant log output\n\n```shell\n2023-03-26 18:39:30.729731: F tensorflow/core/framework/tensor.cc:770] Check failed: dtype() == expected_dtype (3 vs. 1) float expected, got int32\r\nAborted (core dumped\n```\n</details>",
"comments": [
{
"body": "https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md#reporting-vulnerabilities\r\n\r\n(if you want to be credited in advisories and Google VRP board)\r\n\r\nAlso, responsible disclosure.",
"created_at": "2023-03-27T14:35:58Z"
},
{
"body": "@sachinprasadhs,\r\nI was able to reproduce the issue on tensorflow v2.11, v2.12 and tf-nightly. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/363047ca6136212ebfc5820ba7525242/untitled1055.ipynb).",
"created_at": "2023-03-27T16:39:53Z"
},
{
"body": "@mihaimaruseac \r\nThank you for the great suggestion! I have reported this and other crash issues to the Google's Bug Hunting project.\r\n",
"created_at": "2023-03-27T17:09:59Z"
},
{
"body": "@trickiwoo what fuzzer you used to find this issue and another crashes?",
"created_at": "2023-04-03T00:24:05Z"
}
],
"number": 60121,
"title": "tf.raw_ops.AssignAddVariableOp crash with abortion"
}
|
{
"body": "Add dtype checks to Scatter ops(Assign*VariableOp, ResourceScatter*) to report error instead of core dump.\r\nfix issues:\r\n#60147 \r\n#60121 \r\n",
"number": 60452,
"review_comments": [],
"title": "Add dtype checks to Scatter ops to report error instead of core dump"
}
|
{
"commits": [
{
"message": "Add dtype checks to Scatter ops to report error instead of core dump"
}
],
"files": [
{
"diff": "@@ -592,6 +592,14 @@ class AssignUpdateVariableOp : public OpKernel {\n // PrepareToUpdateVariable() for commutative operations like Op ==\n // ADD if value's refcount was 1.\n mutex_lock ml(*variable->mu());\n+ OP_REQUIRES(context,\n+ (variable->tensor()->dtype() == DT_INVALID &&\n+ !variable->is_initialized) ||\n+ variable->tensor()->dtype() == value.dtype(),\n+ errors::InvalidArgument(\n+ \"Trying to assign update var with wrong dtype. Expected \",\n+ DataTypeString(variable->tensor()->dtype()), \" got \",\n+ DataTypeString(value.dtype())));\n Tensor* var_tensor = variable->tensor();\n OP_REQUIRES_OK(context, ValidateAssignUpdateVariableOpShapes(\n var_tensor->shape(), value.shape()));\n@@ -1106,6 +1114,11 @@ class ResourceScatterUpdateOp : public OpKernel {\n \"updates.shape \", updates.shape().DebugString(),\n \", indices.shape \", indices.shape().DebugString(),\n \", params.shape \", params->shape().DebugString()));\n+ OP_REQUIRES(c, params->dtype() == updates.dtype(),\n+ errors::InvalidArgument(\n+ \"Trying to scatter update var with wrong dtype. Expected \",\n+ DataTypeString(params->dtype()), \" got \",\n+ DataTypeString(updates.dtype())));\n \n // Check that we have enough index space\n const int64_t N_big = indices.NumElements();",
"filename": "tensorflow/core/kernels/resource_variable_ops.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nNo\n\n### Source\n\nsource\n\n### Tensorflow Version\n\n2.12.0\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nmacOS 13.3\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.10\n\n### Bazel version\n\n5.3.0\n\n### GCC/Compiler version\n\nXCode 14.3\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nUsing standard compiling procedure (no special flags), compilation of the external library: boringssl/src/crypto/x509 fails. Log attached below.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nCompile TF 2.12.0 using MacOS 13.x and XCode 14.3 (not earlier).\n```\n\n\n### Relevant log output\n\n```shell\n: /private/var/tmp/_bazel_alex/dc1a9368c8e4ba5b96348c2850b37ab0/external/boringssl/BUILD:161:11: Compiling src/crypto/x509/t_x509.c [for host] failed: (Exit 1): cc_wrapper.sh failed: error executing command external/local_config_cc/cc_wrapper.sh -U_FORTIFY_SOURCE -fstack-protector -Wall -Wthread-safety -Wself-assign -Wunused-but-set-parameter -Wno-free-nonheap-object -fcolor-diagnostics ... (remaining 44 arguments skipped)\r\nexternal/boringssl/src/crypto/x509/t_x509.c:321:18: error: variable 'l' set but not used [-Werror,-Wunused-but-set-variable]\r\n int ret = 0, l, i;\r\n ^\r\n1 error generated.\r\nTarget //tensorflow/tools/pip_package:build_pip_package failed to build\n```\n</details>",
"comments": [
{
"body": "The issue is related to an unused variable in `external/boringssl/src/crypto/x509/t_x509.c:321:18`. Removing that variable fixes the issue. See attached.\r\n\r\nPatch: [issue_60191_patch.txt](https://github.com/tensorflow/tensorflow/files/11149628/issue_60191_patch.txt)\r\n\r\n",
"created_at": "2023-04-01T04:52:54Z"
},
{
"body": "@feranick \r\nCould you please elaborate more and provide detailed steps to replicate the issue reported here ?\r\n\r\nThank you!",
"created_at": "2023-04-03T10:02:43Z"
},
{
"body": "> Could you please elaborate more and provide detailed steps to replicate the issue reported here ?\r\n\r\n1. Make sure you have `XCode 14.3` installed (earlier versions won't compile TF as per issue: https://github.com/tensorflow/tensorflow/issues/58368 )\r\n2. `git clone` TF and checkout version 2.12.0 (or 2.11.1)\r\n3. `cd` in the folder `tensorflow` run `./configure` with all default options. \r\n4. run compilation: `bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package --verbose_failures`\r\n\r\nAt some point compilation will stop with the error in this issue. \r\n\r\nTo fix it:\r\n1. run your text editor (I use nano) into the external folder with the problematic library boringssl: `nano /private/var/tmp/_bazel_YOU-AS-USER/SOME_ALPHANUMERIC/external/boringssl/src/crypto/x509/t_x509.c`\r\n2. modify the code according to the patch attached (essentially remove all references to the unused variable `l`)\r\n3. restart compilation: `bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package --verbose_failures`\r\n\r\nPatch: \r\n[issue_60191_patch.txt](https://github.com/tensorflow/tensorflow/files/11150058/issue_60191_patch.txt)\r\n\r\n\r\n\r\n",
"created_at": "2023-04-04T11:05:10Z"
},
{
"body": "There might be ways to disable the `-Wunused-but-set-variable` flag, but I prefer to actually fix the code by removing the useless variable in first place. \r\n\r\nRemoving the variable should be applied in the ustream version as well (or make it do something useful, if that was the intent)",
"created_at": "2023-04-04T11:07:10Z"
},
{
"body": "Note: the issue is not present in the master git for boringssl: \r\nhttps://boringssl.googlesource.com/boringssl/\r\n\r\nTh unused variable is simply removed as per my patch above. Therefore TF either needs to resync boringssl for a newer release or apply my patch (attached). \r\nPatch: \r\n[issue_60191_patch.txt](https://github.com/tensorflow/tensorflow/files/11149626/issue_60191_patch.txt)\r\n",
"created_at": "2023-04-04T14:28:04Z"
},
{
"body": "@feranick ,\r\n\r\nThanks for bringing this with the solution. If you are willing to contribute please feel free to raise a PR.\r\n\r\nThanks!",
"created_at": "2023-04-06T10:41:24Z"
},
{
"body": "I would... Unfortunately the library is not included in the main TF tree, as it is pulled from private google servers. It needs to be fixed internally. BTW, TF pulls a specific version (can't tell you which one), but the bug is no longer present in the current master for boringssl (basically it has my patch applied). So bazel or whatever software pulls boringssl from the server needs to be updated to pull a more recent version, something only people with access to Google boringssl private repo can do.\r\nhttps://boringssl.googlesource.com/boringssl/\r\nIt is also fixed in the github repo:\r\nhttps://github.com/google/boringssl\r\nSo all this really needs is to pull a more recent version of boringssl. ",
"created_at": "2023-04-06T10:48:08Z"
},
{
"body": "Also, correct me if I am wrong.The file you mentioned for correction seems to be a temp file generated during bazel build.Not sure we can fix this from TF source tree. May be its related to Bazel.\r\n\r\nI have gone through the bazel build docs in TF repo and found this one have some context for boring SSL. \r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/bc54be865c99c9c8b8174c98bf8665af4ab10949/tensorflow/workspace2.bzl#L557-L563\r\n\r\nWhether we can do something here by changing URL or any thing to rectify this problem ?",
"created_at": "2023-04-06T10:52:24Z"
},
{
"body": "> Whether we can do something here by changing URL or any thing to rectify this problem ?\r\n\r\nYes, you are correct. Bazel builds it within a temporary folder.\r\n\r\nAnd yes, I would think changing the URL might do it. However, I am not sure what URL/file to use from git as it probably uses an internal branch that is tar zipped. So the question is whether that package is there exclusively for TF... Maybe one can create a new package branched from main and placed in the same folder and then correct the reference URL in bazel.... ",
"created_at": "2023-04-06T11:01:56Z"
},
{
"body": "OK, on a deeper inspection, it seems that the link has been already fixed in TF master. When looking at `tensorflow/tensorflow/workspace2.bzl`\r\n\r\nTF Master:\r\n```\r\n tf_http_archive(\r\n name = \"boringssl\",\r\n sha256 = \"9dc53f851107eaf87b391136d13b815df97ec8f76dadb487b58b2fc45e624d2c\",\r\n strip_prefix = \"boringssl-c00d7ca810e93780bd0c8ee4eea28f4f2ea4bcdc\",\r\n system_build_file = \"//third_party/systemlibs:boringssl.BUILD\",\r\n urls = tf_mirror_urls(\"https://github.com/google/boringssl/archive/c00d7ca810e93780bd0c8ee4eea28f4f2ea4bcdc.tar.gz\"),\r\n )\r\n```\r\n\r\nwhile for TF 2.12.0:\r\n```\r\ntf_http_archive(\r\n name = \"boringssl\",\r\n sha256 = \"534fa658bd845fd974b50b10f444d392dfd0d93768c4a51b61263fd37d851c40\",\r\n strip_prefix = \"boringssl-b9232f9e27e5668bc0414879dcdedb2a59ea75f2\",\r\n system_build_file = \"//third_party/systemlibs:boringssl.BUILD\",\r\n urls = tf_mirror_urls(\"https://github.com/google/boringssl/archive/b9232f9e27e5668bc0414879dcdedb2a59ea75f2.tar.gz\"),\r\n )\r\n```\r\nSo, in principle, one would only need to replace the reference links in `workspace2.bzl`to the newer version now in master...",
"created_at": "2023-04-06T11:10:32Z"
},
{
"body": "I am doing a test build where I replaced the strings above from main. Will report shortly.",
"created_at": "2023-04-06T11:14:50Z"
},
{
"body": "So far compilation is proceeding normally, beyond the point where it would crash because of this issue. It seems like the proposed solution (swapping the `tf_http_archive` from master) will fix the issue, possibly also for the 2.12.0 branch.",
"created_at": "2023-04-06T14:08:33Z"
},
{
"body": "I can confirm that compilation proceeds correctly on any platform I tried (MacOSX, linux).",
"created_at": "2023-04-06T15:34:19Z"
},
{
"body": "> Thanks for bringing this with the solution. If you are willing to contribute please feel free to raise a PR.\r\n\r\nPull request is in https://github.com/tensorflow/tensorflow/pull/60259\r\n",
"created_at": "2023-04-06T23:00:05Z"
},
{
"body": "@feranick ,\r\n\r\nThanks for all your effort and time in resolving and raising the PR. Our Team will review and update.\r\n\r\nThanks!",
"created_at": "2023-04-10T06:32:45Z"
},
{
"body": "Hi @feranick ,\r\n\r\nI can see nightly build was updated as required.\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/0bc361b51ee4bad40392e77641ab74bd1ec4331a/tensorflow/workspace2.bzl#L569-L575\r\n\r\nCan we mark this as resolved. Please spare some time to verify and close the issue.\r\n\r\nThanks!",
"created_at": "2023-06-22T05:51:01Z"
},
{
"body": "It works now. Thanks for pushing it. Closing.",
"created_at": "2023-06-22T12:18:56Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/60191\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/60191\">No</a>\n",
"created_at": "2023-06-22T12:18:58Z"
}
],
"number": 60191,
"title": "Fail to compile TF 2.12.0 with XCode 14.3 due to Compiler flag in boringssl/src/crypto/x509"
}
|
{
"body": "Current version of boringssl pulled for TF 2.12.x does not compile with TF using XCode 14.3 due to an unused variable and an aggressive compiler flag (-Werror,-Wunused-but-set-variable) This patch adds links to an updated version of boringssl (used for TF Master), that fixes the issue. This fixes TF issue #60191",
"number": 60259,
"review_comments": [],
"title": "Update boringssl to allow compilation in MacOS XCode 14.3"
}
|
{
"commits": [
{
"message": "Update boringssl to allow compilation in MacOS XCode 14.3\n\nCurrent version of boringssl pulled for TF 2.12.x does not compile with TF using XCode 14.3\ndue to an unused variable and an aggressive compiler flag (-Werror,-Wunused-but-set-variable)\nThis patch adds links to an updated version of boringssl (used for TF Master), that\nfixes the issue. This fixes TF issue #60191"
}
],
"files": [
{
"diff": "@@ -567,10 +567,10 @@ def _tf_repositories():\n \n tf_http_archive(\n name = \"boringssl\",\n- sha256 = \"534fa658bd845fd974b50b10f444d392dfd0d93768c4a51b61263fd37d851c40\",\n- strip_prefix = \"boringssl-b9232f9e27e5668bc0414879dcdedb2a59ea75f2\",\n+ sha256 = \"9dc53f851107eaf87b391136d13b815df97ec8f76dadb487b58b2fc45e624d2c\",\n+ strip_prefix = \"boringssl-c00d7ca810e93780bd0c8ee4eea28f4f2ea4bcdc\",\n system_build_file = \"//third_party/systemlibs:boringssl.BUILD\",\n- urls = tf_mirror_urls(\"https://github.com/google/boringssl/archive/b9232f9e27e5668bc0414879dcdedb2a59ea75f2.tar.gz\"),\n+ urls = tf_mirror_urls(\"https://github.com/google/boringssl/archive/c00d7ca810e93780bd0c8ee4eea28f4f2ea4bcdc.tar.gz\"),\n )\n \n # Note: if you update this, you have to update libpng too. See cl/437813808",
"filename": "tensorflow/workspace2.bzl",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Have you reproduced the bug with TF nightly?\r\n\r\nNo\r\n\r\n### Source\r\n\r\nsource\r\n\r\n### Tensorflow Version\r\n\r\n2.11.0\r\n\r\n### Custom Code\r\n\r\nYes\r\n\r\n### OS Platform and Distribution\r\n\r\nMacOS 13.1\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.10.6\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\n_No response_\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\nThe documentation for `tf.image.ssim` claims to output\r\n\r\n> ... a tensor containing an SSIM value for each pixel for each image in batch if return_index_map is True\r\n\r\nHowever, the output image is smaller than the source image (see example below).\r\n\r\nUpon comparing with a more well-known library implemented in PyTorch, I believe the reason for such discrepency is due to the Conv2D padding used.\r\n\r\nIn PyTorch's implementation, a \"SAME\" padding is used\r\n\r\nhttps://github.com/Po-Hsun-Su/pytorch-ssim/blob/3add4532d3f633316cba235da1c69e90f0dfb952/pytorch_ssim/__init__.py#L25\r\n\r\nHowever, in the current Tensorflow implementation, \"VALID\" padding is used\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/d5b57ca93e506df258271ea00fc29cf98383a374/tensorflow/python/ops/image_ops_impl.py#L4340\r\n\r\nPlease verify if this is the case.\r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport numpy as np\r\nimport tensorflow as tf # tf.__version__ == \"2.11.0\"\r\n# B x T x n_mel\r\nshape = (16, 2106, 80, 1)\r\nimage1 = np.arange(np.prod(shape))\r\nimage1 = (image1 / np.max(image1)) * 10 + 100\r\nimage1 = np.reshape(image1, shape)\r\nimage2 = np.linspace(0, 1, np.prod(shape))\r\nimage2 = np.exp(image2)\r\nimage2 = (image2 / np.max(image2)) * 10 + 100\r\nimage2 = np.reshape(image2, shape)\r\n\r\nout_tf = tf.image.ssim(image1, image2, max_val=255, return_index_map=True)\r\n\r\n```\r\nwhich outputs a tensor of shape [16, 2096, 70].\r\n\r\n\r\n### Relevant log output\r\n\r\n_No response_</details>",
"comments": [
{
"body": "@sapphire008,\r\nI was facing a different issue/error while executing the mentioned code. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/a18c78fc2f901e1c2c54facba4f6548c/untitled829.ipynb) and provide the dependencies. Thank you!",
"created_at": "2023-01-02T12:32:14Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2023-01-09T12:39:12Z"
},
{
"body": "Closing as stale. Please reopen if you'd like to work on this further.\n",
"created_at": "2023-01-16T12:55:12Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59067\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59067\">No</a>\n",
"created_at": "2023-01-16T12:55:16Z"
},
{
"body": "@tilakrayal This is an issue with the latest release of tensorflow 2.11.0 as indicated in the original post under \"Tensorflow Version\". The default colab version is still using 2.9.2. `pip install tensorflow==2.11.0` and restart the runtime will get to the right version.\r\n\r\nPlease keep this issue open. Thank you.",
"created_at": "2023-01-21T04:37:32Z"
},
{
"body": "@sapphire008,\r\nThank you for the issue. In tf.image.ssim when we are using **return_index_map = True**, returns the **index map**; where as in the case of **return_index_map = False**, it should return the reduced **global value** which was working as expected. \r\n\r\n**O/p for return_index_map = True** :\r\n\r\n```\r\n2.12.0-dev20230201\r\n(2695680,)\r\n(2695680,)\r\n(16, 2106, 80, 1)\r\n(2695680,)\r\n(2695680,)\r\n(2695680,)\r\n(16, 2106, 80, 1)\r\n(16,)\r\n```\r\n\r\n**O/p for return_index_map = False** :\r\n\r\n```\r\n2.12.0-dev20230201\r\n(2695680,)\r\n(2695680,)\r\n(16, 2106, 80, 1)\r\n(2695680,)\r\n(2695680,)\r\n(2695680,)\r\n(16, 2106, 80, 1)\r\n(16, 2096, 70)\r\n```\r\nA tensor containing an SSIM value for each image in batch or a tensor containing an SSIM value for each pixel for each image in batch if **return_index_map** is True. Returned SSIM values are in range (-1, 1], when pixel values are non-negative. Returns a tensor with shape:\r\n```\r\n broadcast(img1.shape[:-3], img2.shape[:-3]) or broadcast(img1.shape[:-1],\r\n img2.shape[:-1]).\r\n```\r\n\r\nKindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/9af60d2910d739bfc1230eb296c8599c/untitled917.ipynb) and also please have a look at the reference where it is explicitly described that the global ssim value is the mean of the local ssim value: https://medium.com/srm-mic/all-about-structural-similarity-index-ssim-theory-code-in-pytorch-6551b455541e .",
"created_at": "2023-02-03T09:00:14Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2023-02-10T09:07:00Z"
},
{
"body": "@tilakrayal Thank you for your response. I believe in your response, the `return_index_map =True` and `return_index_map =False` cases are switched. However, the [gist](https://colab.research.google.com/gist/tilakrayal/9af60d2910d739bfc1230eb296c8599c/untitled917.ipynb) version correctly reproduced the problem I have described in the original post. Regardless, the output shape is (16, 2096, 70) when setting `return_index_map=True`, which is not consistent with the input shape of (16, 2106, 80). This is unexpected, because an index map of SSIM calculation is the scores corresponding to the original input, thus their shape should have been consistent. You can also find in my original post for a link to another implementation made in PyTorch, which does produce index map with shapes consistent with the inputs, and has been cited / reproduced by various repositories such as https://github.com/MoonInTheRiver/DiffSinger.",
"created_at": "2023-02-10T16:15:26Z"
},
{
"body": "Hi, @sapphire008 \r\n\r\nApologize for the delayed response and I was able to replicate the same issue and I have executed the same code multiple times and It seems like working as expected with `TF2.11` and I also tried with our latest pre-release `tensorflow==2.12.0rc1 `and `tensorflow==2.12.0rc0` for your reference I have added [gist-file](https://colab.research.google.com/gist/gaikwadrahul8/a332efd18ba5adb3e34a95ffa4abea92/-59067-test.ipynb) and I completely understood your point here the implementation in PyTorch with \"`SAME`\" padding but in Tensorflow we are using \"`VALID`\" padding, If have I missed something here please let me know ? Thank you!",
"created_at": "2023-03-09T14:04:55Z"
},
{
"body": "@gaikwadrahul8 Is there any reason why `VALID` padding is chosen instead of `SAME` padding in this specific implementation? The returned `index_map` is usually expected as the same size as the inputs, to my understanding. It's also how I see it could be used as a loss function.",
"created_at": "2023-03-20T13:59:55Z"
},
{
"body": "This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you.",
"created_at": "2023-03-28T01:58:14Z"
},
{
"body": "Hi, @SuryanarayanaY \r\n\r\nCould you please look into this issue ? Thank you!",
"created_at": "2023-03-29T06:13:10Z"
},
{
"body": "This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you.",
"created_at": "2023-04-06T01:53:50Z"
},
{
"body": "@sapphire008 ,\r\n\r\nThe shape mismatch might be due to the padding as you noticed. As per the documentation the API the output is:\r\n`Returns a tensor with shape: broadcast(img1.shape[:-3], img2.shape[:-3]) or broadcast(img1.shape[:-1], img2.shape[:-1])`.\r\n \r\nBut for our example the input is of shape (16, 2106, 80, 1) the API returns output of shape (16, 2096, 70) which seems incorrect and the root cause is due to the padding='VALID'\r\n\r\nI have tested the code by changing padding='SAME' and in this case the output is (16, 2106, 80).\r\n\r\nAll these details captured in attached [gist](https://colab.research.google.com/gist/SuryanarayanaY/d75ef4fcbd69b5211975fd4d29490084/59067_r1.ipynb#scrollTo=G24eYEw6Qi9Q).\r\n\r\nIt seems a bug for me and I am going to raise a PR for this. Thanks for reporting.",
"created_at": "2023-04-06T06:42:06Z"
}
],
"number": 59067,
"title": "TF 2.11.0: tf.image.ssim return_index_map=True outputs wrong shape"
}
|
{
"body": "Currently the API `tf.image.ssim` is using `padding='VALID'` internally. But with this padding the shape of the output is not matching with what documentation states. With `return_index_map=True` the output shape should be `broadcast(img1.shape[:-1], img2.shape[:-1])`. \r\n\r\nBut with` padding='VALID'`, for input of shape `(16, 2106, 80, 1)` the current output shape is `(16, 2096, 70)` which is not matching with the expected output which should be `(16, 2106, 80)`. With `padding='SAME'` the output is matching to the desired output. \r\n\r\nPlease refer to the attached [gist](https://colab.research.google.com/gist/SuryanarayanaY/d75ef4fcbd69b5211975fd4d29490084/59067_r1.ipynb) showcasing all the mentioned details. \r\n\r\nFixes #59067 ",
"number": 60251,
"review_comments": [],
"title": "Update padding='SAME' in tf.image.ssim API"
}
|
{
"commits": [
{
"message": "update padding='SAME' in tf.image.ssim API\n\nCurrently the API tf.image.ssim is using padding='VALID' internally. But with this padding the shape of the output is not matching with what documentation states. With return_index_map=True the output shape should be broadcast(img1.shape[:-1], img2.shape[:-1]). But with padding='VALID', for input of shape \r\n(16, 2106, 80, 1) the current output shape is (16, 2096, 70) which is not matching with the expected output which should be (16, 2106, 80). With padding='SAME' the output is matching to the desired output. \r\n\r\nPlease refer to the attached gist showcasing all the mentioned details.\r\nhttps://colab.research.google.com/gist/SuryanarayanaY/d75ef4fcbd69b5211975fd4d29490084/59067_r1.ipynb"
}
],
"files": [
{
"diff": "@@ -4348,7 +4348,7 @@ def _ssim_per_channel(img1,\n def reducer(x):\n shape = array_ops.shape(x)\n x = array_ops.reshape(x, shape=array_ops.concat([[-1], shape[-3:]], 0))\n- y = nn.depthwise_conv2d(x, kernel, strides=[1, 1, 1, 1], padding='VALID')\n+ y = nn.depthwise_conv2d(x, kernel, strides=[1, 1, 1, 1], padding='SAME')\n return array_ops.reshape(\n y, array_ops.concat([shape[:-3], array_ops.shape(y)[1:]], 0))\n ",
"filename": "tensorflow/python/ops/image_ops_impl.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Have you reproduced the bug with TF nightly?\r\n\r\nYes\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\nTF 2.12.0, TF nightly 2.13.0-dev20230404\r\n\r\n### Custom Code\r\n\r\nYes\r\n\r\n### OS Platform and Distribution\r\n\r\n_No response_\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n_No response_\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\n_No response_\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\nConsider the following code creating ragged batches using `tf.data.Dataset.ragged_batch`:\r\n\r\n```python\r\ndata = tf.data.Dataset.from_tensor_slices(tf.ragged.constant([[1, 2], [3]]))\r\nlist(data.ragged_batch(2))\r\n```\r\n\r\nThe above code works fine in normal mode. However, if you enable debug mode using `tf.data.experimental.enable_debug_mode()`, the same code crashes with an error.\r\n\r\n### Standalone code to reproduce the issue\r\n\r\nI reproduced the error in https://colab.research.google.com/drive/1nf1BHjssx2YhF0ZbbgPg1QSALSS4Z89r?usp=sharing , both for TF 2.12.0 and TF nightly 2.13.0-dev20230404.\r\n\r\nThe code for triggering the bug is the following:\r\n\r\n```python\r\ntf.data.experimental.enable_debug_mode()\r\ndata = tf.data.Dataset.from_tensor_slices(tf.ragged.constant([[1, 2], [3]]))\r\nlist(data.ragged_batch(2))\r\n```\r\n\r\n### Relevant log output\r\n\r\nHere is the error printed by TF 2.12.0\r\n\r\n```\r\n---------------------------------------------------------------------------\r\n\r\nInvalidArgumentError Traceback (most recent call last)\r\n\r\n<ipython-input-3-34b7e4bb8c4b> in <cell line: 4>()\r\n 2 tf.data.experimental.enable_debug_mode()\r\n 3 data = tf.data.Dataset.from_tensor_slices(tf.ragged.constant([[1, 2], [3]]))\r\n----> 4 list(data.ragged_batch(2))\r\n\r\n3 frames\r\n\r\n/usr/local/lib/python3.9/dist-packages/tensorflow/python/framework/ops.py in raise_from_not_ok_status(e, name)\r\n 6651 def raise_from_not_ok_status(e, name):\r\n 6652 e.message += (\" name: \" + str(name if name is not None else \"\"))\r\n-> 6653 raise core._status_to_exception(e) from None # pylint: disable=protected-access\r\n 6654 \r\n 6655 \r\n\r\nInvalidArgumentError: {{function_node __wrapped__IteratorGetNext_output_types_1_device_/job:localhost/replica:0/task:0/device:CPU:0}} ValueError: Value [1 2] is not convertible to a tensor with dtype <dtype: 'variant'> and shape ().\r\nTraceback (most recent call last):\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/data/util/structure.py\", line 347, in reduce_fn\r\n component = ops.convert_to_tensor(component, spec.dtype)\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/profiler/trace.py\", line 183, in wrapped\r\n return func(*args, **kwargs)\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/framework/ops.py\", line 1440, in convert_to_tensor\r\n return tensor_conversion_registry.convert(\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/framework/tensor_conversion_registry.py\", line 209, in convert\r\n return overload(dtype, name) # pylint: disable=not-callable\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/framework/ops.py\", line 1335, in __tf_tensor__\r\n return super().__tf_tensor__(dtype, name)\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/framework/ops.py\", line 967, in __tf_tensor__\r\n raise ValueError(\r\n\r\nValueError: Tensor conversion requested dtype variant for Tensor with dtype int32: <tf.Tensor: shape=(2,), dtype=int32, numpy=array([1, 2], dtype=int32)>\r\n\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\n\r\nTraceback (most recent call last):\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/ops/script_ops.py\", line 266, in __call__\r\n return func(device, token, args)\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/ops/script_ops.py\", line 144, in __call__\r\n outputs = self._call(device, args)\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/ops/script_ops.py\", line 151, in _call\r\n ret = self._func(*args)\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/autograph/impl/api.py\", line 643, in wrapper\r\n return func(*args, **kwargs)\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/data/ops/structured_function.py\", line 213, in py_function_wrapper\r\n ret = structure.to_tensor_list(self._output_structure, ret)\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/data/util/structure.py\", line 410, in to_tensor_list\r\n return _to_tensor_list_helper(\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/data/util/structure.py\", line 360, in _to_tensor_list_helper\r\n return functools.reduce(\r\n\r\n File \"/usr/local/lib/python3.9/dist-packages/tensorflow/python/data/util/structure.py\", line 349, in reduce_fn\r\n raise ValueError(\r\n\r\nValueError: Value [1 2] is not convertible to a tensor with dtype <dtype: 'variant'> and shape ().\r\n\r\n\r\n\t [[{{node EagerPyFunc}}]] [Op:IteratorGetNext] name:\r\n```\r\n</details>",
"comments": [],
"number": 60239,
"title": "In tf.data.experimental.enable_debug_mode, tf.data.Dataset.ragged_batch fails with an error"
}
|
{
"body": "Fixed bug with DEBUG_MODE bug when performing from_tensor_slices on a ragged tensor related to issue #60239\r\n\r\nThank you, if there are any suggestions feel free to comment.",
"number": 60250,
"review_comments": [],
"title": "Fixed bug with DEBUG_MODE bug when performing from_tensor_slices on a ragged tensor"
}
|
{
"commits": [
{
"message": "Update structured_function.py"
},
{
"message": "Merge branch 'tensorflow:master' into master"
},
{
"message": "Update structured_function.py"
}
],
"files": [
{
"diff": "@@ -247,7 +247,8 @@ def wrapped_fn(*args): # pylint: disable=missing-docstring\n else:\n defun_kwargs.update({\"func_name\": func_name})\n defun_kwargs.update({\"_tf_data_function\": True})\n- if debug_mode.DEBUG_MODE:\n+ element_spec_name = str(dataset.element_spec)[0:16]\n+ if debug_mode.DEBUG_MODE and element_spec_name != 'RaggedTensorSpec':\n fn_factory = trace_py_function(defun_kwargs)\n else:\n if def_function.functions_run_eagerly():",
"filename": "tensorflow/python/data/ops/structured_function.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Have you reproduced the bug with TF nightly?\r\n\r\nYes\r\n\r\n### Source\r\n\r\nsource\r\n\r\n### Tensorflow Version\r\n\r\ntf 2.12\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\n_No response_\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n_No response_\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\n_No response_\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\nVariable `dict` may be `nullptr` and is dereferenced on line 149 in `tensorflow/compiler/xla/mlir/backends/cpu/transforms/lmhlo_to_cpu_runtime.cc`. \r\n\r\n`dict` is initialized on line 146 and may equal `nullptr`. Then it is dereferenced on line 149. \r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nBug was found by Svace static analysis tool.\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n_No response_</details>",
"comments": [
{
"body": "@mihaimaruseac \r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/c1169a1ba98e1c5d0874cd44ffeb605bfd1cefba/tensorflow/compiler/xla/mlir/backends/cpu/transforms/lmhlo_to_cpu_runtime.cc#L145-L149",
"created_at": "2023-04-04T13:18:29Z"
},
{
"body": "@SweetVishnya Thanks for the PR.\r\n\r\n@PaDarochek The issue will be closed once the PR is merged.\r\n\r\nThanks.",
"created_at": "2023-04-06T12:45:18Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/60223\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/60223\">No</a>\n",
"created_at": "2023-04-27T17:54:24Z"
}
],
"number": 60223,
"title": "Null pointer dereference in lmhlo_to_cpu_runtime.cc"
}
|
{
"body": "The bug was found by Svace static analyzer:\r\n\r\n1. op.getBackendConfig() can be null\r\n2. dict will be nullptr\r\n3. dict.begin() dereferences a null pointer\r\n\r\nCloses #60223\r\n\r\ncc @mihaimaruseac",
"number": 60242,
"review_comments": [],
"title": "Fix null pointer dereference in xla::cpu::CustomCallOpLowering::rewriteTypedCustomCall()"
}
|
{
"commits": [
{
"message": "Fix null pointer dereference in xla::cpu::CustomCallOpLowering::rewriteTypedCustomCall()\n\nThe bug was found by Svace static analyzer:\n\n1. op.getBackendConfig() can be null\n2. dict will be nullptr\n3. dict.begin() dereferences a null pointer\n\nCloses #60223"
}
],
"files": [
{
"diff": "@@ -143,9 +143,10 @@ class CustomCallOpLowering : public OpRewritePattern<CustomCallOp> {\n callee->setAttr(\"rt.dynamic\", UnitAttr::get(b.getContext()));\n \n // Forward backend config to the custom call implementation.\n- auto dict = op.getBackendConfig()\n- ? op.getBackendConfig()->cast<mlir::DictionaryAttr>()\n- : nullptr;\n+ auto config = op.getBackendConfig();\n+ if (!config)\n+ return op.emitOpError(\"Failed to get backend config\");\n+ auto dict = config->cast<mlir::DictionaryAttr>();\n llvm::SmallVector<NamedAttribute> backend_config(dict.begin(), dict.end());\n \n // Call the custom call function forwarding user-defined attributes.",
"filename": "tensorflow/compiler/xla/mlir/backends/cpu/transforms/lmhlo_to_cpu_runtime.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nDocumentation Bug\n\n### Have you reproduced the bug with TF nightly?\n\nNo\n\n### Source\n\nsource\n\n### Tensorflow Version\n\n2.11\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\n_No response_\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nDocumentation links to .cc files are broken.\r\nhttps://www.tensorflow.org/lite/microcontrollers/get_started_low_level\r\n\r\nIn section 'Run Inference', link to 'hello_world_test.cc' and the other remaining .cc files linked cannot be opened.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nN/A\n```\n\n\n### Relevant log output\n\n_No response_</details>",
"comments": [
{
"body": "@acridland Thanks for reporting this.\r\n\r\nPR #59969 has been created. Issue will be closed once PR is merged.\r\n\r\nThanks.",
"created_at": "2023-03-13T17:18:45Z"
},
{
"body": "Hi @acridland \r\n\r\nThe Hello World example has been refactored with the commit https://github.com/tensorflow/tensorflow/commit/f263e19e227da0d325f15477f57a359291fc387c and broken links are fixed.\r\n\r\nThanks.",
"created_at": "2023-10-27T06:00:01Z"
},
{
"body": "This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you.",
"created_at": "2023-11-04T01:47:33Z"
},
{
"body": "This issue was closed because it has been inactive for 7 days since being marked as stale. Please reopen if you'd like to work on this further.",
"created_at": "2023-11-11T01:48:01Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59959\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59959\">No</a>\n",
"created_at": "2023-11-11T01:48:04Z"
}
],
"number": 59959,
"title": "Tensorflow lite for microcontrollers documentation has broken links to .cc files"
}
|
{
"body": "This commit updates the \"Hello World\" example documentation in the TensorFlow Lite for Microcontrollers repository to use the latest version of the `evaluate_test.cc`. \r\n\r\nAdditionally, the broken links in the example documentation have been fixed to ensure that users can access all the necessary resources. \r\n\r\nThese changes make it easier for users to get started with tflite on microcontrollers and ensure that the example document is up-to-date.\r\n\r\n Merging this closes the issue #59959",
"number": 59969,
"review_comments": [
{
"body": "```suggestion\r\n```\r\n\r\nPlease don't add empty lines that are not needed",
"created_at": "2023-09-01T11:31:59Z"
},
{
"body": "This seems to be doing something totally different than the original",
"created_at": "2023-09-01T11:32:38Z"
}
],
"title": "Update \"Hello World\" Example Doc and Fix Broken Links"
}
|
{
"commits": [
{
"message": "Update \"Hello World\" Example Doc and Fix Broken Links\n\nThis commit updates the \"Hello World\" example documentation in the TensorFlow Lite for Microcontrollers repository to use the latest version of the `evaluate_test.cc`. Additionally, the broken links in the example documentation have been fixed to ensure that users can access all the necessary resources. These changes make it easier for users to get started with machine learning on microcontrollers and ensure that the example document is up-to-date. Merging this closes the issue #59959"
},
{
"message": "Merge branch 'master' into pjpratik-patch-2"
},
{
"message": "Merge branch 'master' into pjpratik-patch-2"
},
{
"message": "Update tensorflow/lite/g3doc/microcontrollers/get_started_low_level.md\n\nCo-authored-by: Mihai Maruseac <mihaimaruseac@google.com>"
}
],
"files": [
{
"diff": "@@ -86,7 +86,7 @@ following header files:\n \n - [`micro_mutable_op_resolver.h`](https://github.com/tensorflow/tflite-micro/tree/main/tensorflow/lite/micro/micro_mutable_op_resolver.h)\n provides the operations used by the interpreter to run the model.\n-- [`micro_error_reporter.h`](https://github.com/tensorflow/tflite-micro/blob/main/tensorflow/lite/micro/tflite_bridge/micro_error_reporter.h)\n+- [`micro_log.h`](https://github.com/tensorflow/tflite-micro/blob/main/tensorflow/lite/micro/micro_log.h)\n outputs debug information.\n - [`micro_interpreter.h`](https://github.com/tensorflow/tflite-micro/tree/main/tensorflow/lite/micro/micro_interpreter.h)\n contains code to load and run models.\n@@ -99,11 +99,11 @@ following header files:\n ### 2. Include the model header\n \n The TensorFlow Lite for Microcontrollers interpreter expects the model to be\n-provided as a C++ array. The model is defined in `model.h` and `model.cc` files.\n+provided as a C++ array. The model is defined in `hello_world_float_model_data.h` and `hello_world_float_model_data.cc` files.\n The header is included with the following line:\n \n ```C++\n-#include \"tensorflow/lite/micro/examples/hello_world/model.h\"\n+#include \"tensorflow/lite/micro/examples/hello_world/models/hello_world_float_model_data.h\"\n ```\n \n ### 3. Include the unit test framework header\n@@ -120,7 +120,7 @@ The test is defined using the following macros:\n ```C++\n TF_LITE_MICRO_TESTS_BEGIN\n \n-TF_LITE_MICRO_TEST(LoadModelAndPerformInference) {\n+TF_LITE_MICRO_TEST(LoadFloatModelAndPerformInference) {\n . // add code here\n .\n }\n@@ -132,36 +132,38 @@ We now discuss the code included in the macro above.\n \n ### 4. Set up logging\n \n-To set up logging, a `tflite::ErrorReporter` pointer is created using a pointer\n-to a `tflite::MicroErrorReporter` instance:\n+To set up logging, `micro_log.h` is used.\n+\n+`MicroPrintf()` function can be used independent of the MicroErrorReporter to get\n+printf-like functionalitys and are common to all target platforms.\n+\n+### 5. Define the input and the expected output\n+\n+In the following lines, the input and the expected output are defined:\n \n ```C++\n-tflite::MicroErrorReporter micro_error_reporter;\n-tflite::ErrorReporter* error_reporter = µ_error_reporter;\n+ float x = 0.0f;\n+ float y_true = sin(x);\n ```\n \n-This variable will be passed into the interpreter, which allows it to write\n-logs. Since microcontrollers often have a variety of mechanisms for logging, the\n-implementation of `tflite::MicroErrorReporter` is designed to be customized for\n-your particular device.\n-\n-### 5. Load a model\n+### 6. Load a model\n \n In the following code, the model is instantiated using data from a `char` array,\n-`g_model`, which is declared in `model.h`. We then check the model to ensure its\n+`g_hello_world_float_model_data`, which is declared in `g_hello_world_float_model_data.h`.\n+We then check the model to ensure its\n schema version is compatible with the version we are using:\n \n ```C++\n-const tflite::Model* model = ::tflite::GetModel(g_model);\n+const tflite::Model* model = ::tflite::GetModel(g_hello_world_float_model_data);\n if (model->version() != TFLITE_SCHEMA_VERSION) {\n- TF_LITE_REPORT_ERROR(error_reporter,\n+ MIcroPrintf(\n \"Model provided is schema version %d not equal \"\n \"to supported version %d.\\n\",\n model->version(), TFLITE_SCHEMA_VERSION);\n }\n ```\n \n-### 6. Instantiate operations resolver\n+### 7. Instantiate operations resolver\n \n A\n [`MicroMutableOpResolver`](https://github.com/tensorflow/tflite-micro/tree/main/tensorflow/lite/micro/micro_mutable_op_resolver.h)\n@@ -187,40 +189,43 @@ TF_LITE_ENSURE_STATUS(RegisterOps(op_resolver));\n \n ```\n \n-### 7. Allocate memory\n+### 8. Allocate memory\n \n We need to preallocate a certain amount of memory for input, output, and\n intermediate arrays. This is provided as a `uint8_t` array of size\n `tensor_arena_size`:\n \n ```C++\n-const int tensor_arena_size = 2 * 1024;\n+const int tensor_arena_size = 2056;\n uint8_t tensor_arena[tensor_arena_size];\n ```\n \n The size required will depend on the model you are using, and may need to be\n determined by experimentation.\n \n-### 8. Instantiate interpreter\n+### 9. Instantiate interpreter\n \n We create a `tflite::MicroInterpreter` instance, passing in the variables\n created earlier:\n \n ```C++\n tflite::MicroInterpreter interpreter(model, resolver, tensor_arena,\n- tensor_arena_size, error_reporter);\n+ tensor_arena_size);\n ```\n \n-### 9. Allocate tensors\n+### 10. Allocate tensors\n \n We tell the interpreter to allocate memory from the `tensor_arena` for the\n-model's tensors:\n+model's tensors and throw error if failed:\n \n ```C++\n-interpreter.AllocateTensors();\n+if (interpreter.AllocateTensors() != kTfLiteOk) {\n+ MicroPrintf(\"Allocate tensor failed.\");\n+ return kTfLiteError;\n+ }\n ```\n \n-### 10. Validate input shape\n+### 11. Validate input shape\n \n The `MicroInterpreter` instance can provide us with a pointer to the model's\n input tensor by calling `.input(0)`, where `0` represents the first (and only)\n@@ -231,65 +236,51 @@ input tensor:\n TfLiteTensor* input = interpreter.input(0);\n ```\n \n-We then inspect this tensor to confirm that its shape and type are what we are\n-expecting:\n+We then inspect this tensor to confirm that it has properties what we\n+expect:\n \n ```C++\n-// Make sure the input has the properties we expect\n-TF_LITE_MICRO_EXPECT_NE(nullptr, input);\n-// The property \"dims\" tells us the tensor's shape. It has one element for\n-// each dimension. Our input is a 2D tensor containing 1 element, so \"dims\"\n-// should have size 2.\n-TF_LITE_MICRO_EXPECT_EQ(2, input->dims->size);\n-// The value of each element gives the length of the corresponding tensor.\n-// We should expect two single element tensors (one is contained within the\n-// other).\n-TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);\n-TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[1]);\n-// The input is a 32 bit floating point value\n-TF_LITE_MICRO_EXPECT_EQ(kTfLiteFloat32, input->type);\n+if (input == nullptr) {\n+ MicroPrintf(\"Input tensor in null.\");\n+ return kTfLiteError;\n+ }\n ```\n \n The enum value `kTfLiteFloat32` is a reference to one of the TensorFlow Lite\n data types, and is defined in\n [`common.h`](https://github.com/tensorflow/tflite-micro/tree/main/tensorflow/lite/c/common.h).\n \n-### 11. Provide an input value\n+### 12. Provide an input value\n \n-To provide an input to the model, we set the contents of the input tensor, as\n-follows:\n+To provide an input to the model, we set the contents of the input tensor,\n+as follows:\n \n ```C++\n-input->data.f[0] = 0.;\n+input->data.f[0] = x;\n ```\n \n-In this case, we input a floating point value representing `0`.\n+In this case, we input a quantized input `x`.\n \n-### 12. Run the model\n+### 13. Run the model\n \n To run the model, we can call `Invoke()` on our `tflite::MicroInterpreter`\n instance:\n \n ```C++\n TfLiteStatus invoke_status = interpreter.Invoke();\n if (invoke_status != kTfLiteOk) {\n- TF_LITE_REPORT_ERROR(error_reporter, \"Invoke failed\\n\");\n-}\n+ MicroPrintf(\"Interpreter invocation failed.\");\n+ return kTfLiteError;\n+ }\n ```\n \n We can check the return value, a `TfLiteStatus`, to determine if the run was\n successful. The possible values of `TfLiteStatus`, defined in\n [`common.h`](https://github.com/tensorflow/tflite-micro/tree/main/tensorflow/lite/c/common.h),\n are `kTfLiteOk` and `kTfLiteError`.\n \n-The following code asserts that the value is `kTfLiteOk`, meaning inference was\n-successfully run.\n \n-```C++\n-TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);\n-```\n-\n-### 13. Obtain the output\n+### 14. Obtain the output\n \n The model's output tensor can be obtained by calling `output(0)` on the\n `tflite::MicroInterpreter`, where `0` represents the first (and only) output\n@@ -300,41 +291,65 @@ within a 2D tensor:\n \n ```C++\n TfLiteTensor* output = interpreter.output(0);\n-TF_LITE_MICRO_EXPECT_EQ(2, output->dims->size);\n-TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);\n-TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[1]);\n-TF_LITE_MICRO_EXPECT_EQ(kTfLiteFloat32, output->type);\n ```\n \n We can read the value directly from the output tensor and assert that it is what\n we expect:\n \n ```C++\n // Obtain the output value from the tensor\n-float value = output->data.f[0];\n+float y_pred = output->data.f[0];\n // Check that the output value is within 0.05 of the expected value\n-TF_LITE_MICRO_EXPECT_NEAR(0., value, 0.05);\n+float epsilon = 0.05f;\n+ if (abs(y_true - y_pred) > epsilon) {\n+ MicroPrintf(\n+ \"Difference between predicted and actual y value \"\n+ \"is significant.\");\n+ return kTfLiteError;\n+ }\n ```\n \n-### 14. Run inference again\n+### 15. Run inference again\n \n The remainder of the code runs inference several more times. In each instance,\n we assign a value to the input tensor, invoke the interpreter, and read the\n result from the output tensor:\n \n ```C++\n-input->data.f[0] = 1.;\n-interpreter.Invoke();\n-value = output->data.f[0];\n-TF_LITE_MICRO_EXPECT_NEAR(0.841, value, 0.05);\n-\n-input->data.f[0] = 3.;\n-interpreter.Invoke();\n-value = output->data.f[0];\n-TF_LITE_MICRO_EXPECT_NEAR(0.141, value, 0.05);\n-\n-input->data.f[0] = 5.;\n-interpreter.Invoke();\n-value = output->data.f[0];\n-TF_LITE_MICRO_EXPECT_NEAR(-0.959, value, 0.05);\n+ x = 1.f;\n+ y_true = sin(x);\n+ input->data.f[0] = x;\n+ interpreter.Invoke();\n+ y_pred = output->data.f[0];\n+ if (abs(y_true - y_pred) > epsilon) {\n+ MicroPrintf(\n+ \"Difference between predicted and actual y value \"\n+ \"is significant.\");\n+ return kTfLiteError;\n+ }\n+\n+ x = 3.f;\n+ y_true = sin(x);\n+ input->data.f[0] = x;\n+ interpreter.Invoke();\n+ y_pred = output->data.f[0];\n+ if (abs(y_true - y_pred) > epsilon) {\n+ MicroPrintf(\n+ \"Difference between predicted and actual y value \"\n+ \"is significant.\");\n+ return kTfLiteError;\n+ }\n+\n+ x = 5.f;\n+ y_true = sin(x);\n+ input->data.f[0] = x;\n+ interpreter.Invoke();\n+ y_pred = output->data.f[0];\n+ if (abs(y_true - y_pred) > epsilon) {\n+ MicroPrintf(\n+ \"Difference between predicted and actual y value \"\n+ \"is significant.\");\n+ return kTfLiteError;\n+ }\n ```\n+",
"filename": "tensorflow/lite/g3doc/microcontrollers/get_started_low_level.md",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nsource\n\n### Tensorflow Version\n\nTF 2.11\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\n_No response_\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\nCUDA: 11.2 cuDNN 8.1\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nThe results of tf.image.convert_image_dtype running on CPU and GPU are very different.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nCPU code:\r\n\r\n import tensorflow as tf\r\n with tf.device('/CPU'):\r\n arg_0 = [[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]], [[7.0, 8.0, 9.0], [10.0, 11.0, 12.0]]]\r\n out = tf.image.convert_image_dtype(arg_0, dtype=tf.uint32, saturate=-1)\r\n print(out)\r\n\r\nGPU code:\r\n\r\n import tensorflow as tf\r\n with tf.device('/GPU:0'):\r\n arg_0 = [[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]], [[7.0, 8.0, 9.0], [10.0, 11.0, 12.0]]]\r\n out = tf.image.convert_image_dtype(arg_0, dtype=tf.uint32, saturate=-1)\r\n print(out)\n```\n\n\n### Relevant log output\n\n```shell\nCPU result: tf.Tensor(\r\n[[[0 0 0]\r\n [0 0 0]]\r\n\r\n [[0 0 0]\r\n [0 0 0]]], shape=(2, 2, 3), dtype=uint32)\r\n\r\n\r\nGPU result: tf.Tensor(\r\n[[[2147483647 2147483647 2147483647]\r\n [2147483647 2147483647 2147483647]]\r\n\r\n [[2147483647 2147483647 2147483647]\r\n [2147483647 2147483647 2147483647]]], shape=(2, 2, 3), dtype=uint32)\n```\n</details>",
"comments": [
{
"body": "Hi @triumph-wangyuyang ,\r\n\r\nThere is this condition mentioned in [API](https://www.tensorflow.org/api_docs/python/tf/image/convert_image_dtype).\r\n\r\n`Images that are represented using floating point values are expected to have values in the range [0,1).`\r\n\r\nHence there is inconsistency in the result. I have tried values within [0,1) and result same on both CPU & GPU.Please refer to attached [gist](https://colab.research.google.com/gist/SuryanarayanaY/7d212236f3088b3edbd7de35532eedc3/17282.ipynb#scrollTo=q6utqo90YELo).\r\n\r\nPlease check and close the issue if your query got resolved.\r\n\r\nThankyou!",
"created_at": "2022-12-02T06:01:16Z"
},
{
"body": "> Hi @triumph-wangyuyang ,\r\n> \r\n> There is this condition mentioned in [API](https://www.tensorflow.org/api_docs/python/tf/image/convert_image_dtype).\r\n> \r\n> `Images that are represented using floating point values are expected to have values in the range [0,1).`\r\n> \r\n> Hence there is inconsistency in the result. I have tried values within [0,1) and result same on both CPU & GPU.Please refer to attached [gist](https://colab.research.google.com/gist/SuryanarayanaY/7d212236f3088b3edbd7de35532eedc3/17282.ipynb#scrollTo=q6utqo90YELo).\r\n> \r\n> Please check and close the issue if your query got resolved.\r\n> \r\n> Thankyou!\r\n\r\nI am doing the tensorflow operator test, and then deliberately use illegal parameters to test the operator. In this test, I did not use [0,1), but use >=1 value, and then in this way on the CPU and GPU The above results are different. Can we make a preliminary judgment on the value of the Images parameter at the operator entry, and if it is not in [0,1), an exception will be thrown to prevent the program from continuing.",
"created_at": "2022-12-02T06:14:58Z"
},
{
"body": "@triumph-wangyuyang ,\r\n\r\nI agree to that.It is better to raise exception/warning regarding invalid inputs rather than continuing and generating inconsistent results.Lets see if i can do something on this.\r\n\r\nThankyou!\r\n\r\n",
"created_at": "2022-12-02T07:30:23Z"
},
{
"body": "Hi @triumph-wangyuyang ,\r\n\r\nThe above mention PR should address the issue.",
"created_at": "2023-02-21T10:44:32Z"
},
{
"body": "We make no guarantees that CPU and GPU results are identical, especially for garbage data. The input doesn't crash, so it's not a security issue. Error checking is expensive.\r\n\r\nThe GPU result is flushing all results to the max value (essentially saturating the input). We could potentially do the same on CPU. I wouldn't say it's a requirement though.",
"created_at": "2023-02-21T17:54:40Z"
},
{
"body": "Just noticed that `saturate` was set to `True` (indirectly via the -1 value), so this should actually have defined behavior and there is an issue with saturation. Will dig into it.",
"created_at": "2023-02-24T17:12:38Z"
},
{
"body": "The issue here is that `uint32.max` is not actually representable in `float32` - and rounds up when converting, from 4294967295 to 4294967300.0. This eventually leads to a cast overflow and undefined behavior - which is why we see different values between CPU and GPU.\r\n",
"created_at": "2023-03-13T22:55:55Z"
},
{
"body": "Hi @triumph-wangyuyang ,\r\n\r\nPlease refer to attached explanation in above [comment](https://github.com/tensorflow/tensorflow/issues/58749#issuecomment-1467086661).The cast overflow causing undefined behaviour and hence getting different results. This has been fixed with tf-nightly(2.14.0-dev20230503). Please refer to attached [gist](https://colab.research.google.com/gist/SuryanarayanaY/fdbe3aa4f57128d0aef6dc890294fd52/58749_final.ipynb#scrollTo=1jbL0o8JOfRD) which showing both CPU and GPU are now producing same results.\r\n\r\nThanks!",
"created_at": "2023-05-04T05:21:21Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58749\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58749\">No</a>\n",
"created_at": "2023-05-04T15:22:15Z"
},
{
"body": "I also observed the following API aliases can cause the same issue in older versions of tensorflow.\r\nUsers should be cautious when using them on the CPU up to tensorflow 2.12.0 (v2.12.0-rc1-12-g0db597d0d75).\r\n\r\n- `(tf.image.convert_image_dtype)`, `tf.compat.v1.image.convert_image_dtype`\r\n\r\n<details>\r\n <summary>Code to reproduce the issue in <code>tf.compat.v1.image.convert_image_dtype</code> in older versions</summary>\r\n\r\n```python\r\nimport tensorflow as tf\r\nprint(tf.version.GIT_VERSION, tf.version.VERSION, flush=True)\r\nprint(tf.config.list_physical_devices(), flush=True)\r\n\r\n\r\narg_0 = [[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]], [[7.0, 8.0, 9.0], [10.0, 11.0, 12.0]]]\r\nx1 = tf.compat.v1.image.convert_image_dtype(arg_0, dtype=tf.uint32, saturate=-1).numpy()\r\nprint(x1)\r\n```\r\n\r\nOn CPU, it outputs the following results:\r\n\r\n```text\r\nv2.12.0-rc1-12-g0db597d0d75 2.12.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')]\r\n[[[0 0 0]\r\n [0 0 0]]\r\n\r\n [[0 0 0]\r\n [0 0 0]]]\r\n```\r\n\r\nWhile on GPU, the results are as follows, which are inconsistent with the CPU:\r\n\r\n```text\r\nv2.12.0-rc1-12-g0db597d0d75 2.12.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]\r\n\r\n [[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]]\r\n```\r\n</details>\r\n\r\nIt seems to be fixed in tensorflow 2.13.0 (v2.13.0-rc2-7-g1cb1a030a62) and later versions.\r\n\r\nBesides, I also found that the outputs are not consistent across different versions, which should be noted when using them across different versions.\r\n\r\n<details>\r\n <summary>Show outputs of the inconsistent behavior across different versions</summary>\r\n\r\n```text\r\nv2.9.0-rc2-42-g8a20d54a3c1 2.9.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[2147483647 2147483647 2147483647]\r\n [2147483647 2147483647 2147483647]]\r\n\r\n [[2147483647 2147483647 2147483647]\r\n [2147483647 2147483647 2147483647]]]\r\n\r\nv2.9.2-107-ga5ed5f39b67 2.9.3\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[2147483647 2147483647 2147483647]\r\n [2147483647 2147483647 2147483647]]\r\n\r\n [[2147483647 2147483647 2147483647]\r\n [2147483647 2147483647 2147483647]]]\r\n\r\nv2.10.0-rc3-6-g359c3cdfc5f 2.10.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]\r\n\r\n [[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]]\r\n\r\nv2.10.0-76-gfdfc646704c 2.10.1\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]\r\n\r\n [[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]]\r\n\r\nv2.11.0-rc2-17-gd5b57ca93e5 2.11.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]\r\n\r\n [[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]]\r\n\r\nv2.11.0-94-ga3e2c692c18 2.11.1\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]\r\n\r\n [[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]]\r\n\r\nv2.12.0-rc1-12-g0db597d0d75 2.12.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]\r\n\r\n [[4294967295 4294967295 4294967295]\r\n [4294967295 4294967295 4294967295]]]\r\n\r\nv2.13.0-rc2-7-g1cb1a030a62 2.13.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[4294967040 4294967040 4294967040]\r\n [4294967040 4294967040 4294967040]]\r\n\r\n [[4294967040 4294967040 4294967040]\r\n [4294967040 4294967040 4294967040]]]\r\n\r\nv2.14.0-rc0-34-gdd01672d9a9 2.14.0-rc1\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[4294967040 4294967040 4294967040]\r\n [4294967040 4294967040 4294967040]]\r\n\r\n [[4294967040 4294967040 4294967040]\r\n [4294967040 4294967040 4294967040]]]\r\n\r\nv1.12.1-99436-g5e7d6faebab 2.15.0-dev20230904\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n[[[4294967040 4294967040 4294967040]\r\n [4294967040 4294967040 4294967040]]\r\n\r\n [[4294967040 4294967040 4294967040]\r\n [4294967040 4294967040 4294967040]]]\r\n```\r\n</details>\r\n",
"created_at": "2023-09-12T09:17:09Z"
}
],
"number": 58749,
"title": "The results of tf.image.convert_image_dtype running on CPU and GPU are very different."
}
|
{
"body": "Images that are represented using floating point values are expected to have values in the range [0,1) for the function `convert_image_dtype()`. But this is not scaled when the case `image `argument is of `float ` and `dtype` argument is `int` arises. Hence modified the code to bring the input values within [0,1). This also shall fix the issue #58749 .",
"number": 59755,
"review_comments": [
{
"body": "This is not correct.\r\n\r\nThe case covered here is the input being floating-point and the output being an integer type.\r\n\r\nLet's say you start with an image in the range [0, 1.0], then you are converting to uint8. You want 1.0 to map to 255. That's why the scale factor is by 255.5 - so that 255.5 * 1.0, rounded, is 255.",
"created_at": "2023-02-21T17:52:28Z"
},
{
"body": "Yes. I misunderstood `dtype` to `image.dtype`.\r\nI feel only thing we need to add is image values validation.The API expects image values to be within range[0,1). But its not validated. This might be causing inconsistent results on CPU and GPU as well. Refer #59704 \r\n\r\nIam proposing the below code to validate the same which needs to be inserted after converting input to tensor(after line no.2490 in master branch).This can raise proper User error and avoids unnecessary confusions.\r\n\r\n```\r\nif image.dtype.is_floating and (image.numpy().max()>=1 or image.numpy().min()<0):\r\n raise ValueError(f'image expects values to be in range [0,1).Got min value:{image.numpy().min()} and max value: {image.numpy().max()}')\r\n```\r\nPlease review whether raising user error if provided out of range values is OK? \r\n\r\n(Or)\r\n\r\nAlternatively we need to scale the image using `image = image/(image.dtype.max())` something of that sort which \r\n seems missing now for the case of **image as float and dtype as int** . \r\n\r\n",
"created_at": "2023-02-24T09:29:34Z"
},
{
"body": "No, we cannot do validation via numpy. Tensors may not even be evaluated yet in graph mode to be able to access numpy values.\r\n\r\nI don't think you should automatically scale the image either.\r\n\r\nIf `saturate` is `True`, it will do a saturated cast, which would clip anything outside of the range to the maximum value. I think this is already the best that could be done. Otherwise, if `saturate` is `False`, we do a blind cast which can result in integer overflows that cause values to wrap around. For signed integers, this is actually \"undefined behavior\", which is why we're seeing differences between devices - essentially the results can't be trusted in either case. The fact that we _already_ have a `saturate` option implies that some values may already be expected to be out of range, and explicitly setting `saturate=True` is the proper solution.",
"created_at": "2023-02-24T16:18:56Z"
}
],
"title": "Update image_ops_impl.convert_image_dtype.py"
}
|
{
"commits": [
{
"message": "Update image_ops_impl.convert_image_dtype.py\n\nImages that are represented using floating point values are expected to have values in the range [0,1) for the function `convert_image_dtype()`. \r\nBut this is not scaled when the case `image `argument is of `float ` and `dtype` argument is `int` arises. \r\nHence modified the code to bring the input values within [0,1).\r\nThis also shall fix the issue #58749 ."
}
],
"files": [
{
"diff": "@@ -2531,7 +2531,7 @@ def convert_image_dtype(image, dtype, saturate=False, name=None):\n return math_ops.multiply(cast, scale, name=name)\n else:\n # Converting from float: first scale, then cast\n- scale = dtype.max + 0.5 # avoid rounding problems in the cast\n+ scale = 1./(dtype.max + 0.5) # avoid rounding problems in the cast\n scaled = math_ops.multiply(image, scale)\n if saturate:\n return math_ops.saturate_cast(scaled, dtype, name=name)",
"filename": "tensorflow/python/ops/image_ops_impl.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nYes\n\n### Source\n\nsource\n\n### Tensorflow Version\n\ngit HEAD\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nRHEL 8.7\n\n### Mobile device\n\nn/a\n\n### Python version\n\n3.9.13\n\n### Bazel version\n\n5.3.0\n\n### GCC/Compiler version\n\n10.3.0\n\n### CUDA/cuDNN version\n\nn/a\n\n### GPU model and memory\n\nn/a\n\n### Current Behaviour?\n\n```shell\nWhen building for AARCH64 the unit test //tensorflow/tsl/framework/convolution:spatial_convolutions_test fails to build with\r\n\r\n./tensorflow/tsl/framework/convolution/eigen_spatial_convolutions-inl.h:1490:27: error: static assertion failed: YOU_MADE_A_PROGRAMMING_MISTAKE\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nbazel test --test_timeout=300,500,-1,-1 --flaky_test_attempts=3 --test_output=all --cache_test_results=no --noremote_accept_cached --config=mkl_aarch64_threadpool --copt=\"-mtune=generic\" --copt=\"-march=armv8-a\" --copt=\"-O3\" --build_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only,-no_aarch64,-requires-gpu --test_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only,-no_aarch64,-requires-gpu --verbose_failures --build_tests_only -- //tensorflow/tsl/framework/convolution:spatial_convolutions_test\n```\n\n\n### Relevant log output\n\n```shell\nERROR: /home/andrew/src/tensorflow/tensorflow/tsl/framework/convolution/BUILD:99:12: Compiling tensorflow/tsl/framework/convolution/eigen_spatial_convolutions_test.cc failed: (Exit 1): gcc failed: error executing command \r\n (cd /home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow && \\\r\n exec env - \\\r\n LD_LIBRARY_PATH=/opt/rh/gcc-toolset-10/root/usr/lib64:/opt/rh/gcc-toolset-10/root/usr/lib:/opt/rh/gcc-toolset-10/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-10/root/usr/lib/dyninst:/opt/rh/gcc-toolset-10/root/usr/lib64:/opt/rh/gcc-toolset-10/root/usr/lib \\\r\n PATH=/home/andrew/.cache/bazelisk/downloads/bazelbuild/bazel-5.3.0-linux-arm64/bin:/home/andrew/.local/bin:/home/andrew/bin:/usr/share/Modules/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin \\\r\n PWD=/proc/self/cwd \\\r\n PYTHON_BIN_PATH=/home/andrew/src/venv38/bin/python3 \\\r\n PYTHON_LIB_PATH=/home/andrew/src/venv38/lib/python3.8/site-packages \\\r\n TF2_BEHAVIOR=1 \\\r\n /opt/rh/gcc-toolset-10/root/usr/bin/gcc -U_FORTIFY_SOURCE -fstack-protector -Wall -Wunused-but-set-parameter -Wno-free-nonheap-object -fno-omit-frame-pointer -g0 -O2 '-D_FORTIFY_SOURCE=1' -DNDEBUG -ffunction-sections -fdata-sections '-std=c++0x' -MD -MF bazel-out/aarch64-opt/bin/tensorflow/tsl/framework/convolution/_objs/spatial_convolutions_test/eigen_spatial_convolutions_test.d '-frandom-seed=bazel-out/aarch64-opt/bin/tensorflow/tsl/framework/convolution/_objs/spatial_convolutions_test/eigen_spatial_convolutions_test.o' -DEIGEN_MPL2_ONLY '-DEIGEN_MAX_ALIGN_BYTES=64' -DTENSORFLOW_USE_CUSTOM_CONTRACTION_KERNEL -DGEMM_KERNEL_H '-DEIGEN_ALTIVEC_USE_CUSTOM_PACK=0' '-DEIGEN_NEON_GEBP_NR=4' -iquote . -iquote bazel-out/aarch64-opt/bin -iquote external/com_google_absl -iquote bazel-out/aarch64-opt/bin/external/com_google_absl -iquote external/eigen_archive -iquote bazel-out/aarch64-opt/bin/external/eigen_archive -iquote external/nsync -iquote bazel-out/aarch64-opt/bin/external/nsync -iquote external/double_conversion -iquote bazel-out/aarch64-opt/bin/external/double_conversion -iquote external/com_google_googletest -iquote bazel-out/aarch64-opt/bin/external/com_google_googletest -iquote external/com_google_benchmark -iquote bazel-out/aarch64-opt/bin/external/com_google_benchmark -iquote external/com_google_protobuf -iquote bazel-out/aarch64-opt/bin/external/com_google_protobuf -iquote external/zlib -iquote bazel-out/aarch64-opt/bin/external/zlib -iquote external/bazel_tools -iquote bazel-out/aarch64-opt/bin/external/bazel_tools -Ibazel-out/aarch64-opt/bin/external/com_google_benchmark/_virtual_includes/benchmark -isystem third_party/eigen3/mkl_include -isystem bazel-out/aarch64-opt/bin/third_party/eigen3/mkl_include -isystem external/eigen_archive -isystem bazel-out/aarch64-opt/bin/external/eigen_archive -isystem external/nsync/public -isystem bazel-out/aarch64-opt/bin/external/nsync/public -isystem external/com_google_googletest/googlemock -isystem bazel-out/aarch64-opt/bin/external/com_google_googletest/googlemock -isystem external/com_google_googletest/googlemock/include -isystem bazel-out/aarch64-opt/bin/external/com_google_googletest/googlemock/include -isystem external/com_google_googletest/googletest -isystem bazel-out/aarch64-opt/bin/external/com_google_googletest/googletest -isystem external/com_google_googletest/googletest/include -isystem bazel-out/aarch64-opt/bin/external/com_google_googletest/googletest/include -isystem external/com_google_protobuf/src -isystem bazel-out/aarch64-opt/bin/external/com_google_protobuf/src -isystem external/zlib -isystem bazel-out/aarch64-opt/bin/external/zlib -Wno-all -Wno-extra -Wno-deprecated -Wno-deprecated-declarations -Wno-ignored-attributes -Wno-array-bounds -Wunused-result '-Werror=unused-result' -Wswitch '-Werror=switch' '-Wno-error=unused-but-set-variable' -DAUTOLOAD_DYNAMIC_KERNELS '-mtune=generic' '-march=armv8-a' -O3 '-std=c++17' -fno-canonical-system-headers -Wno-builtin-macro-redefined '-D__DATE__=\"redacted\"' '-D__TIMESTAMP__=\"redacted\"' '-D__TIME__=\"redacted\"' -c tensorflow/tsl/framework/convolution/eigen_spatial_convolutions_test.cc -o bazel-out/aarch64-opt/bin/tensorflow/tsl/framework/convolution/_objs/spatial_convolutions_test/eigen_spatial_convolutions_test.o)\r\n# Configuration: 67e3477bbfd3aa6df692c90e4aaaf7a6ee0f55b121a5556fe852592ce2c633e2\r\n# Execution platform: @local_execution_config_platform//:platform\r\nIn file included from external/eigen_archive/unsupported/Eigen/CXX11/../../../Eigen/Core:162,\r\n from external/eigen_archive/unsupported/Eigen/CXX11/Tensor:14,\r\n from ./third_party/eigen3/unsupported/Eigen/CXX11/Tensor:1,\r\n from ./tensorflow/tsl/framework/convolution/eigen_spatial_convolutions.h:19,\r\n from tensorflow/tsl/framework/convolution/eigen_spatial_convolutions_test.cc:16:\r\n./tensorflow/tsl/framework/convolution/eigen_spatial_convolutions-inl.h: In instantiation of 'struct Eigen::internal::gemm_pack_rhs<Eigen::QInt8, long int, Eigen::internal::TensorContractionSubMapper<Eigen::QInt8, long int, 0, Eigen::TensorEvaluator<const Eigen::TensorReshapingOp<Eigen::DSizes<long int, 2>, const Eigen::TensorImagePatchOp<-1, -1, Eigen::TensorMap<Eigen::Tensor<Eigen::QInt8, 4, 0, long int>, 16, Eigen::MakePointer> > >, Eigen::DefaultDevice>, std::array<long int, 1>, std::array<long int, 1>, 1, true, false, 0, Eigen::MakePointer>, 1, 0, false, false>':\r\ntensorflow/tsl/framework/convolution/eigen_spatial_convolutions_test.cc:924:15: required from 'void Eigen::PackRhsHelper(benchmark::State&, int, int, int, int, int, int, int, Eigen::PaddingType, int, int, int, int, Eigen::Index, Eigen::Index) [with T = Eigen::QInt8; Eigen::Index = long int]'\r\ntensorflow/tsl/framework/convolution/eigen_spatial_convolutions_test.cc:1375:1: required from here\r\n./tensorflow/tsl/framework/convolution/eigen_spatial_convolutions-inl.h:1490:27: error: static assertion failed: YOU_MADE_A_PROGRAMMING_MISTAKE\r\n 1490 | EIGEN_STATIC_ASSERT((nr == 4), YOU_MADE_A_PROGRAMMING_MISTAKE)\r\n | ~~~~^~~~~\r\nTarget //tensorflow/tsl/framework/convolution:spatial_convolutions_test failed to build\r\nINFO: Elapsed time: 9.629s, Critical Path: 9.11s\r\nINFO: 3 processes: 2 internal, 1 local.\r\nFAILED: Build did NOT complete successfully\r\n//tensorflow/tsl/framework/convolution:spatial_convolutions_test FAILED TO BUILD\r\n\r\nFAILED: Build did NOT complete successfully\n```\n</details>",
"comments": [
{
"body": "@angerson",
"created_at": "2023-02-14T09:40:58Z"
},
{
"body": "Introduced by https://github.com/tensorflow/tensorflow/commit/397570c85afa4dacd0a10869a1463bac8872bfd7",
"created_at": "2023-02-14T09:41:31Z"
},
{
"body": "Hi, @elfringham \r\n\r\nThank you for noticing the issue and I see you've submitted PR [#59681](https://github.com/tensorflow/tensorflow/pull/59681) for this issue so this issue will be taken care once PR got merged after following the PR process. I really appreciate your efforts and time. Thank you!",
"created_at": "2023-02-17T12:03:03Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59680\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59680\">No</a>\n",
"created_at": "2023-02-20T18:46:14Z"
}
],
"number": 59680,
"title": "Unit test //tensorflow/tsl/framework/convolution:spatial_convolutions_test fails to build"
}
|
{
"body": "Ensure the expected value of nr is set for Neon optimised code\r\n\r\nFixes #59680 ",
"number": 59681,
"review_comments": [],
"title": "[Linaro:Neon] For Neon nr must be 4"
}
|
{
"commits": [
{
"message": "[Linaro:Neon] For Neon nr must be 4\n\nEnsure the expected value of nr is set for Neon optimised code"
}
],
"files": [
{
"diff": "@@ -39,7 +39,10 @@ limitations under the License.\n #include \"tensorflow/tsl/framework/fixedpoint/PacketMathAVX.h\"\n \n #elif defined EIGEN_VECTORIZE_NEON\n+#define EIGEN_USE_OPTIMIZED_INT8_INT8_MAT_MAT_PRODUCT\n #define EIGEN_USE_OPTIMIZED_INT8_UINT8_MAT_MAT_PRODUCT\n+#define EIGEN_USE_OPTIMIZED_UINT8_INT8_MAT_MAT_PRODUCT\n+#define EIGEN_USE_OPTIMIZED_INT16_INT16_MAT_MAT_PRODUCT\n #include \"tensorflow/tsl/framework/fixedpoint/MatMatProductNEON.h\"\n #endif\n ",
"filename": "tensorflow/tsl/framework/fixedpoint/FixedPoint.h",
"status": "modified"
},
{
"diff": "@@ -206,7 +206,7 @@ gebp_kernel<QInt8, QUInt8, Index, DataMapper, mr, nr, ConjugateLhs,\n }\n #endif\n \n-// This definition tackle the case where the khs is encoded using unsigned 8bit\n+// This definition tackle the case where the lhs is encoded using unsigned 8bit\n // integers and the rhs using signed 8bit integers.\n #ifndef EIGEN_USE_OPTIMIZED_UINT8_INT8_MAT_MAT_PRODUCT\n template <bool _ConjLhs, bool _ConjRhs>",
"filename": "tensorflow/tsl/framework/fixedpoint/MatMatProduct.h",
"status": "modified"
},
{
"diff": "@@ -19,9 +19,82 @@ limitations under the License.\n namespace Eigen {\n namespace internal {\n \n-// AVX2 optimized implementation of the case where the lhs is encoded using\n-// signed 8bit\n-// integers and the rhs using unsigned 8bit integers.\n+// Neon optimized implementation where both lhs and rhs are encoded using\n+// signed 8bit integers\n+#ifdef EIGEN_USE_OPTIMIZED_INT8_INT8_MAT_MAT_PRODUCT\n+\n+template <bool _ConjLhs, bool _ConjRhs>\n+class gebp_traits<QInt8, QInt8, _ConjLhs, _ConjRhs> {\n+ public:\n+ typedef QInt8 LhsScalar;\n+ typedef QInt8 RhsScalar;\n+ typedef QInt32 ResScalar;\n+\n+ enum {\n+ // register block size along the M and N directions\n+ // One for the current implementation\n+ nr = 4,\n+ mr = 1,\n+ // Progress made at each iteration of the product loop\n+ // also 1 for the current implementation\n+ LhsProgress = 1,\n+ RhsProgress = 1\n+ };\n+};\n+\n+// The signed 8bit Mat-Mat product itself.\n+template <typename Index, typename DataMapper, int mr, int nr,\n+ bool ConjugateLhs, bool ConjugateRhs>\n+struct gebp_kernel<QInt8, QInt8, Index, DataMapper, mr, nr, ConjugateLhs,\n+ ConjugateRhs> {\n+ EIGEN_DONT_INLINE\n+ void operator()(const DataMapper& res, const QInt8* blockA,\n+ const QInt8* blockB, Index rows, Index depth, Index cols,\n+ QInt32 alpha, Index strideA = -1, Index strideB = -1,\n+ Index offsetA = 0, Index offsetB = 0);\n+};\n+\n+template <typename Index, typename DataMapper, int mr, int nr,\n+ bool ConjugateLhs, bool ConjugateRhs>\n+EIGEN_DONT_INLINE void\n+gebp_kernel<QInt8, QInt8, Index, DataMapper, mr, nr, ConjugateLhs,\n+ ConjugateRhs>::operator()(const DataMapper& res,\n+ const QInt8* blockA, const QInt8* blockB,\n+ Index rows, Index depth, Index cols,\n+ QInt32 alpha, Index strideA,\n+ Index strideB, Index offsetA,\n+ Index offsetB) {\n+ EIGEN_STATIC_ASSERT(!ConjugateLhs, YOU_MADE_A_PROGRAMMING_MISTAKE);\n+ EIGEN_STATIC_ASSERT(!ConjugateRhs, YOU_MADE_A_PROGRAMMING_MISTAKE);\n+\n+ eigen_assert(alpha.value == 1);\n+ eigen_assert(strideA == -1);\n+ eigen_assert(strideB == -1);\n+ eigen_assert(offsetA == 0);\n+ eigen_assert(offsetB == 0);\n+\n+ eigen_assert(rows > 0);\n+ eigen_assert(cols > 0);\n+ eigen_assert(depth > 0);\n+ eigen_assert(blockA);\n+ eigen_assert(blockB);\n+\n+ for (Index j = 0; j < cols; ++j) {\n+ Index startB = j * depth;\n+\n+ for (Index i = 0; i < rows; ++i) {\n+ Index startA = i * depth;\n+\n+ for (Index k = 0; k < depth; ++k) {\n+ res(i, j) += blockA[startA + k] * blockB[startB + k];\n+ }\n+ }\n+ }\n+}\n+#endif\n+\n+// Neon optimized implementation of the case where the lhs is encoded using\n+// signed 8bit integers and the rhs using unsigned 8bit integers.\n #ifdef EIGEN_USE_OPTIMIZED_INT8_UINT8_MAT_MAT_PRODUCT\n \n template <bool _ConjLhs, bool _ConjRhs>\n@@ -33,11 +106,10 @@ class gebp_traits<QInt8, QUInt8, _ConjLhs, _ConjRhs> {\n \n enum {\n // register block size along the M and N directions\n- // One for the current implementation\n- nr = 1,\n+ nr = 4,\n mr = 1,\n // Progress made at each iteration of the product loop\n- // also 1 for the current implementation\n+ // 1 for the current implementation\n LhsProgress = 1,\n RhsProgress = 1\n };\n@@ -94,6 +166,150 @@ gebp_kernel<QInt8, QUInt8, Index, DataMapper, mr, nr, ConjugateLhs,\n }\n #endif\n \n+// Neon optimized implementation where the lhs is encoded using unsigned 8bit\n+// integers and the rhs using signed 8bit integers.\n+#ifdef EIGEN_USE_OPTIMIZED_UINT8_INT8_MAT_MAT_PRODUCT\n+template <bool _ConjLhs, bool _ConjRhs>\n+class gebp_traits<QUInt8, QInt8, _ConjLhs, _ConjRhs> {\n+ public:\n+ typedef QUInt8 LhsScalar;\n+ typedef QInt8 RhsScalar;\n+ typedef QInt32 ResScalar;\n+\n+ enum {\n+ // register block size along the M and N directions\n+ nr = 4,\n+ mr = 1,\n+ // Progress made at each iteration of the product loop\n+ // 1 for the current implementation\n+ LhsProgress = 1,\n+ RhsProgress = 1\n+ };\n+};\n+\n+// Mat-Mat product of an unsigned 8bit lhs with a signed 8bit rhs\n+template <typename Index, typename DataMapper, int mr, int nr,\n+ bool ConjugateLhs, bool ConjugateRhs>\n+struct gebp_kernel<QUInt8, QInt8, Index, DataMapper, mr, nr, ConjugateLhs,\n+ ConjugateRhs> {\n+ EIGEN_DONT_INLINE\n+ void operator()(const DataMapper& res, const QUInt8* blockA,\n+ const QInt8* blockB, Index rows, Index depth, Index cols,\n+ QInt32 alpha, Index strideA = -1, Index strideB = -1,\n+ Index offsetA = 0, Index offsetB = 0);\n+};\n+\n+template <typename Index, typename DataMapper, int mr, int nr,\n+ bool ConjugateLhs, bool ConjugateRhs>\n+EIGEN_DONT_INLINE void\n+gebp_kernel<QUInt8, QInt8, Index, DataMapper, mr, nr, ConjugateLhs,\n+ ConjugateRhs>::operator()(const DataMapper& res,\n+ const QUInt8* blockA, const QInt8* blockB,\n+ Index rows, Index depth, Index cols,\n+ QInt32 alpha, Index strideA,\n+ Index strideB, Index offsetA,\n+ Index offsetB) {\n+ EIGEN_STATIC_ASSERT(!ConjugateLhs, YOU_MADE_A_PROGRAMMING_MISTAKE);\n+ EIGEN_STATIC_ASSERT(!ConjugateRhs, YOU_MADE_A_PROGRAMMING_MISTAKE);\n+\n+ eigen_assert(alpha.value == 1);\n+ eigen_assert(strideA == -1);\n+ eigen_assert(strideB == -1);\n+ eigen_assert(offsetA == 0);\n+ eigen_assert(offsetB == 0);\n+\n+ eigen_assert(rows > 0);\n+ eigen_assert(cols > 0);\n+ eigen_assert(depth > 0);\n+ eigen_assert(blockA);\n+ eigen_assert(blockB);\n+\n+ for (Index j = 0; j < cols; ++j) {\n+ Index startB = j * depth;\n+\n+ for (Index i = 0; i < rows; ++i) {\n+ Index startA = i * depth;\n+\n+ for (Index k = 0; k < depth; ++k) {\n+ res(i, j) += blockA[startA + k] * blockB[startB + k];\n+ }\n+ }\n+ }\n+}\n+#endif\n+\n+#ifdef EIGEN_USE_OPTIMIZED_INT16_INT16_MAT_MAT_PRODUCT\n+\n+template <bool _ConjLhs, bool _ConjRhs>\n+class gebp_traits<QInt16, QInt16, _ConjLhs, _ConjRhs> {\n+ public:\n+ typedef QInt16 LhsScalar;\n+ typedef QInt16 RhsScalar;\n+ typedef QInt32 ResScalar;\n+\n+ enum {\n+ // register block size along the M and N directions\n+ // One for the current implementation\n+ nr = 4,\n+ mr = 1,\n+ // Progress made at each iteration of the product loop\n+ // also 1 for the current implementation\n+ LhsProgress = 1,\n+ RhsProgress = 1\n+ };\n+};\n+\n+// The signed 16bit Mat-Mat product itself.\n+template <typename Index, typename DataMapper, int mr, int nr,\n+ bool ConjugateLhs, bool ConjugateRhs>\n+struct gebp_kernel<QInt16, QInt16, Index, DataMapper, mr, nr, ConjugateLhs,\n+ ConjugateRhs> {\n+ EIGEN_DONT_INLINE\n+ void operator()(const DataMapper& res, const QInt16* blockA,\n+ const QInt16* blockB, Index rows, Index depth, Index cols,\n+ QInt32 alpha, Index strideA = -1, Index strideB = -1,\n+ Index offsetA = 0, Index offsetB = 0);\n+};\n+\n+template <typename Index, typename DataMapper, int mr, int nr,\n+ bool ConjugateLhs, bool ConjugateRhs>\n+EIGEN_DONT_INLINE void\n+gebp_kernel<QInt16, QInt16, Index, DataMapper, mr, nr, ConjugateLhs,\n+ ConjugateRhs>::operator()(const DataMapper& res,\n+ const QInt16* blockA,\n+ const QInt16* blockB, Index rows,\n+ Index depth, Index cols, QInt32 alpha,\n+ Index strideA, Index strideB,\n+ Index offsetA, Index offsetB) {\n+ EIGEN_STATIC_ASSERT(!ConjugateLhs, YOU_MADE_A_PROGRAMMING_MISTAKE);\n+ EIGEN_STATIC_ASSERT(!ConjugateRhs, YOU_MADE_A_PROGRAMMING_MISTAKE);\n+\n+ eigen_assert(alpha.value == 1);\n+ eigen_assert(strideA == -1);\n+ eigen_assert(strideB == -1);\n+ eigen_assert(offsetA == 0);\n+ eigen_assert(offsetB == 0);\n+\n+ eigen_assert(rows > 0);\n+ eigen_assert(cols > 0);\n+ eigen_assert(depth > 0);\n+ eigen_assert(blockA);\n+ eigen_assert(blockB);\n+\n+ for (Index j = 0; j < cols; ++j) {\n+ Index startB = j * depth;\n+\n+ for (Index i = 0; i < rows; ++i) {\n+ Index startA = i * depth;\n+\n+ for (Index k = 0; k < depth; ++k) {\n+ res(i, j) += blockA[startA + k] * blockB[startB + k];\n+ }\n+ }\n+ }\n+}\n+#endif\n+\n } // namespace internal\n } // namespace Eigen\n ",
"filename": "tensorflow/tsl/framework/fixedpoint/MatMatProductNEON.h",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nYes\n\n### Source\n\nsource\n\n### Tensorflow Version\n\ngit HEAD\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nCentOS 7\n\n### Mobile device\n\nn/a\n\n### Python version\n\n3.8.13\n\n### Bazel version\n\n5.3.0\n\n### GCC/Compiler version\n\n10.3.0\n\n### CUDA/cuDNN version\n\nn/a\n\n### GPU model and memory\n\nn/a\n\n### Current Behaviour?\n\n```shell\nUnit test //tensorflow/dtensor/python/tests:spmd_test_cpu fails when run with Python 3.8 and protobuf 4 is installed.\r\nInstalling protobuf 3.20.3 resolves the issue.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nbazel test --config=mkl_aarch64_threadpool --test_env=TF_ENABLE_ONEDNN_OPTS=1 --cache_test_results=no --test_timeout=500,900,-1,-1 --copt=\"-mtune=generic\" --copt=\"-march=armv8-a\" --copt=\"-O3\" --build_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only,-no_aarch64,-requires-gpu --test_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only,-no_aarch64,-requires-gpu --build_tests_only --jobs=100 -- //tensorflow/dtensor/python/tests:spmd_test_cpu\n```\n\n\n### Relevant log output\n\n```shell\nFatal Python error: Segmentation fault\r\n\r\nCurrent thread 0x0000ffffb7906370 (most recent call first):\r\n File \"/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/eager/context.py\", line 1108 in config\r\n File \"/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/eager/context.py\", line 568 in ensure_initialized\r\n File \"/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/eager/context.py\", line 1401 in remove_function\r\n File \"/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/eager/context.py\", line 2739 in remove_function\r\n File \"/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/eager/polymorphic_function/monomorphic_function.py\", line 172 in __del__\r\n*** Received signal 11 ***\r\n*** BEGIN MANGLED STACK TRACE ***\r\n/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/platform/../../../_solib_aarch64/_U_S_Stensorflow_Clibtensorflow_Uframework_Uimport_Ulib___Utensorflow/libtensorflow_framework.so.2(+0x15ae14c)[0xffff145de14c]\r\nlinux-vdso.so.1(__kernel_rt_sigreturn+0x0)[0xffffb78b07a0]\r\n/lib64/libpthread.so.0(raise+0xac)[0xffffb71b2af4]\r\nlinux-vdso.so.1(__kernel_rt_sigreturn+0x0)[0xffffb78b07a0]\r\n/lib64/libpython3.8.so.1.0(PyModule_GetState+0x4)[0xffffb72f9a3c]\r\n/home/andrew/src/venv38/lib64/python3.8/site-packages/google/_upb/_message.abi3.so(+0xa390)[0xffff1527a390]\r\n/home/andrew/src/venv38/lib64/python3.8/site-packages/google/_upb/_message.abi3.so(+0x13c9c)[0xffff15283c9c]\r\n/lib64/libpython3.8.so.1.0(_PyObject_MakeTpCall+0x1a8)[0xffffb72ed9c0]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalFrameDefault+0x53f4)[0xffffb73c1114]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalCodeWithName+0xc8c)[0xffffb7371fe4]\r\n/lib64/libpython3.8.so.1.0(_PyFunction_Vectorcall+0x474)[0xffffb73734b4]\r\n/lib64/libpython3.8.so.1.0(+0x12662c)[0xffffb734662c]\r\n/lib64/libpython3.8.so.1.0(PyObject_GetAttr+0x27c)[0xffffb7361e4c]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalFrameDefault+0xa08)[0xffffb73bc728]\r\n/lib64/libpython3.8.so.1.0(_PyFunction_Vectorcall+0x1d0)[0xffffb7373210]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalFrameDefault+0x884)[0xffffb73bc5a4]\r\n/lib64/libpython3.8.so.1.0(_PyFunction_Vectorcall+0x1d0)[0xffffb7373210]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalFrameDefault+0x884)[0xffffb73bc5a4]\r\n/lib64/libpython3.8.so.1.0(_PyFunction_Vectorcall+0x1d0)[0xffffb7373210]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalFrameDefault+0x4de8)[0xffffb73c0b08]\r\n/lib64/libpython3.8.so.1.0(_PyFunction_Vectorcall+0x1d0)[0xffffb7373210]\r\n/lib64/libpython3.8.so.1.0(+0x133640)[0xffffb7353640]\r\n/lib64/libpython3.8.so.1.0(+0x1f7248)[0xffffb7417248]\r\n/lib64/libpython3.8.so.1.0(+0xcc72c)[0xffffb72ec72c]\r\n/lib64/libpython3.8.so.1.0(_PyGC_CollectNoFail+0x38)[0xffffb745f060]\r\n/lib64/libpython3.8.so.1.0(PyImport_Cleanup+0x394)[0xffffb745f40c]\r\n/lib64/libpython3.8.so.1.0(Py_FinalizeEx+0x6c)[0xffffb7462c34]\r\n/lib64/libpython3.8.so.1.0(Py_Exit+0x14)[0xffffb72cb01c]\r\n/lib64/libpython3.8.so.1.0(+0xab060)[0xffffb72cb060]\r\n/lib64/libpython3.8.so.1.0(+0xab0b8)[0xffffb72cb0b8]\r\n/lib64/libpython3.8.so.1.0(PyRun_SimpleFileExFlags+0x3c4)[0xffffb72cbac0]\r\n/lib64/libpython3.8.so.1.0(Py_RunMain+0x2b8)[0xffffb74645d0]\r\n/lib64/libpython3.8.so.1.0(Py_BytesMain+0x3c)[0xffffb7464d1c]\r\n/lib64/libc.so.6(__libc_start_main+0xdc)[0xffffb6f14384]\r\n/home/andrew/src/venv38/bin/python3(+0x928)[0xaaaab41c0928]\r\n*** END MANGLED STACK TRACE ***\r\n\r\n*** Begin stack trace ***\r\n tsl::CurrentStackTrace[abi:cxx11]()\r\n\r\n __kernel_rt_sigreturn\r\n raise\r\n __kernel_rt_sigreturn\r\n PyModule_GetState\r\n\r\n\r\n _PyObject_MakeTpCall\r\n _PyEval_EvalFrameDefault\r\n _PyEval_EvalCodeWithName\r\n _PyFunction_Vectorcall\r\n\r\n PyObject_GetAttr\r\n _PyEval_EvalFrameDefault\r\n _PyFunction_Vectorcall\r\n _PyEval_EvalFrameDefault\r\n _PyFunction_Vectorcall\r\n _PyEval_EvalFrameDefault\r\n _PyFunction_Vectorcall\r\n _PyEval_EvalFrameDefault\r\n _PyFunction_Vectorcall\r\n\r\n\r\n\r\n _PyGC_CollectNoFail\r\n PyImport_Cleanup\r\n Py_FinalizeEx\r\n Py_Exit\r\n\r\n\r\n PyRun_SimpleFileExFlags\r\n Py_RunMain\r\n Py_BytesMain\r\n __libc_start_main\r\n\r\n*** End stack trace ***\n```\n</details>",
"comments": [
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59643\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59643\">No</a>\n",
"created_at": "2023-02-13T20:50:40Z"
}
],
"number": 59643,
"title": "protobuf 4 causes segmentation fault on Python 3.8 in unit test"
}
|
{
"body": "Currently there is only 1 relevant test which is tagged no_oss_py38 but it segfaults with Python 3.8 so should be excluded\r\n\r\nFixes #59643 ",
"number": 59664,
"review_comments": [],
"title": "[Linaro:ARM_CI] Add tag filters to exclude tests tagged no_oss_py3x"
}
|
{
"commits": [
{
"message": "Add tag filters to exclude tests tagged no_oss_py3x\n\nCurrently there is only 1 relevant test which is tagged\nno_oss_py38 but it segfaults with Python 3.8 so should\nbe excluded"
}
],
"files": [
{
"diff": "@@ -64,7 +64,7 @@ export TF_TEST_FLAGS=\"${TF_BUILD_FLAGS} \\\n --test_output=errors --verbose_failures=true --test_keep_going\"\n export TF_TEST_TARGETS=\"${DEFAULT_BAZEL_TARGETS} ${ARM_SKIP_TESTS}\"\n export TF_PIP_TESTS=\"test_pip_virtualenv_clean test_pip_virtualenv_oss_serial\"\n-export TF_TEST_FILTER_TAGS=\"-no_oss,-v1only,-benchmark-test,-no_aarch64\"\n+export TF_TEST_FILTER_TAGS=\"-no_oss,-v1only,-benchmark-test,-no_aarch64,-no_oss_py38,-no_oss_py39,-no_oss_py310\"\n export TF_PIP_TEST_ROOT=\"pip_test\"\n export TF_AUDITWHEEL_TARGET_PLAT=\"manylinux2014\"\n export TF_BUILD_INSTALL_EXTRA_PIP_PACKAGES=\"tensorflow-io\"",
"filename": "tensorflow/tools/ci_build/rel/ubuntu/cpu_arm64_pip.sh",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nNo\n\n### Source\n\nsource\n\n### Tensorflow Version\n\n2.10.0\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\nUbuntu 22.04\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.9\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nCheck failure when running with the following input combination:\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import gen_data_flow_ops\r\ntry:\r\n file_pattern = \"/tmp/record_input_test3nvh1t09/tmp3gauzk6b/basic.*\"\r\n file_buffer_size = -1\r\n file_parallelism = -1\r\n file_shuffle_shift_ratio = -2\r\n batch_size = -1\r\n file_random_seed = -2\r\n compression_type = \"\"\r\n out = gen_data_flow_ops.record_input(file_pattern=file_pattern,file_buffer_size=file_buffer_size,file_parallelism=file_parallelism,file_shuffle_shift_ratio=file_shuffle_shift_ratio,batch_size=batch_size,file_random_seed=file_random_seed,compression_type=compression_type,)\r\nexcept Exception as e:\r\n print(\"Error:\"+str(e))\r\n```\n```\n\n\n### Relevant log output\n\n```shell\n2023-01-05 22:01:15.270432: F tensorflow/core/platform/threadpool.cc:99] Check failed: num_threads >= 1 (1 vs. 0)\r\nAborted\r\n\r\n```\n```\n</details>",
"comments": [
{
"body": "Hi, any update?",
"created_at": "2023-01-13T15:43:32Z"
},
{
"body": "@nimashiri Sorry for the late response!\r\nI tried to execute the provided code and colab is crashing during execution.\r\nPlease check this [gist ](https://colab.research.google.com/gist/sushreebarsa/3e44c83f10a0e242e6c88958b0386e7d/59123.ipynb)and confirm the same?\r\nThank you!",
"created_at": "2023-01-18T17:00:03Z"
},
{
"body": "> @nimashiri Sorry for the late response! I tried to execute the provided code and colab is crashing during execution. Please check this [gist ](https://colab.research.google.com/gist/sushreebarsa/3e44c83f10a0e242e6c88958b0386e7d/59123.ipynb)and confirm the same? Thank you!\r\n\r\nCrash on 2.11:\r\n\r\n```\r\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import gen_data_flow_ops\r\ntry:\r\n file_pattern = \"nan\"\r\n file_buffer_size = -90\r\n file_parallelism = -438\r\n file_shuffle_shift_ratio = -784\r\n batch_size = -933\r\n file_random_seed = -678\r\n compression_type = \"nan\"\r\n out = gen_data_flow_ops.record_input(file_pattern=file_pattern,file_buffer_size=file_buffer_size,file_parallelism=file_parallelism,file_shuffle_shift_ratio=file_shuffle_shift_ratio,batch_size=batch_size,file_random_seed=file_random_seed,compression_type=compression_type,)\r\nexcept Exception as e:\r\n print(\"Error:\"+str(e))\r\n```",
"created_at": "2023-01-22T10:42:21Z"
},
{
"body": "@learning-to-play ",
"created_at": "2023-02-07T19:50:50Z"
},
{
"body": "Added PR #59661 for the fix.",
"created_at": "2023-02-13T01:59:47Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59123\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59123\">No</a>\n",
"created_at": "2023-02-14T04:24:14Z"
}
],
"number": 59123,
"title": "Check failure when running tensorflow.python.ops.gen_data_flow_ops.record_input"
}
|
{
"body": "This PR tries to fix #59123 where file_parallelism <0 will\r\ncause a crash in record_input.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 59661,
"review_comments": [],
"title": "Fix record_input bug when file_parallelism is less than 0"
}
|
{
"commits": [
{
"message": "Fix record_input bug when file_parallelism is less than 0\n\nThis PR tries to fix 59123 where file_parallelism <0 will\ncause a crash in record_input.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nAdd test for 59123 where file_parallelism <0 caused record_input crash\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nAdjust to combine multiple import"
}
],
"files": [
{
"diff": "@@ -41,6 +41,11 @@ class RecordInputOp : public OpKernel {\n \n OP_REQUIRES_OK(ctx, ctx->GetAttr(\"compression_type\", &compression_type));\n \n+ OP_REQUIRES(\n+ ctx, file_parallelism >= 0,\n+ errors::InvalidArgument(\n+ \"file_parallelism should >= 0, got \", file_parallelism));\n+\n RecordYielder::Options yopts;\n yopts.file_pattern = file_pattern;\n yopts.seed = file_random_seed;",
"filename": "tensorflow/core/kernels/record_input_op.cc",
"status": "modified"
},
{
"diff": "@@ -16,8 +16,8 @@\n \n import os\n \n+from tensorflow.python.framework import errors_impl\n from tensorflow.python.framework import test_util\n-from tensorflow.python.framework.errors_impl import NotFoundError\n from tensorflow.python.lib.io import tf_record\n from tensorflow.python.ops import data_flow_ops\n from tensorflow.python.ops import variables\n@@ -145,7 +145,7 @@ def testEmptyGlob(self):\n record_input = data_flow_ops.RecordInput(file_pattern=\"foo\")\n yield_op = record_input.get_yield_op()\n self.evaluate(variables.global_variables_initializer())\n- with self.assertRaises(NotFoundError):\n+ with self.assertRaises(errors_impl.NotFoundError):\n self.evaluate(yield_op)\n \n @test_util.run_deprecated_v1\n@@ -178,5 +178,18 @@ def testBufferTooSmall(self):\n self.assertTrue(r[0] not in epoch_set)\n epoch_set.add(r[0])\n \n+ def testInvalidParams(self):\n+ with self.session():\n+ with self.assertRaises(errors_impl.InvalidArgumentError):\n+ self.evaluate(data_flow_ops.gen_data_flow_ops.record_input(\n+ file_pattern=\"nan\",\n+ file_buffer_size=-90,\n+ file_parallelism=-438,\n+ file_shuffle_shift_ratio=-784,\n+ batch_size=-933,\n+ file_random_seed=-678,\n+ compression_type=\"nan\"))\n+\n+\n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/kernel_tests/io_ops/record_input_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Have you reproduced the bug with TF nightly?\r\n\r\nNo\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.13.0\r\n\r\n### Custom Code\r\n\r\nYes\r\n\r\n### OS Platform and Distribution\r\n\r\n22.04\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.9\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\n_No response_\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\nCrash when running .ragged_tensor_to_variant\r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import gen_ragged_conversion_ops\r\ntry:\r\n arg_0_0_tensor = tf.random.uniform([3], minval=-256, maxval=257, dtype=tf.int64)\r\n arg_0_0 = tf.identity(arg_0_0_tensor)\r\n arg_0 = [arg_0_0,]\r\n arg_1_tensor = tf.random.uniform([], minval=-256, maxval=257, dtype=tf.int32)\r\n arg_1 = tf.identity(arg_1_tensor)\r\n arg_2 = True\r\n arg_3 = None\r\n out = gen_ragged_conversion_ops.ragged_tensor_to_variant(arg_0,arg_1,arg_2,arg_3,)\r\nexcept Exception as e:\r\n print(\"Error:\"+str(e))\r\n```\r\n\r\n```\r\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import gen_ragged_conversion_ops\r\n\r\ntry:\r\n arg_0_0_tensor = tf.random.uniform([5], minval=-256, maxval=257, dtype=tf.int32)\r\n arg_0_0 = tf.identity(arg_0_0_tensor)\r\n arg_0 = [\r\n arg_0_0,\r\n ]\r\n arg_1_tensor = tf.random.uniform([], minval=-256, maxval=257, dtype=tf.int32)\r\n arg_1 = tf.identity(arg_1_tensor)\r\n arg_2 = True\r\n arg_3 = None\r\n out = gen_ragged_conversion_ops.ragged_tensor_to_variant(\r\n arg_0,\r\n arg_1,\r\n arg_2,\r\n arg_3,\r\n )\r\nexcept Exception as e:\r\n print(\"Error:\" + str(e))\r\n\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n2023-01-04 01:34:14.128060: F tensorflow/core/framework/tensor_shape.cc:585] Check failed: d < dims() (0 vs. 0)\r\nAborted\r\n```\r\n```\r\n</details>",
"comments": [
{
"body": "tf.ragged_ops are basically designed to be consumed by downstream library users, not end users.\r\nUsually, these APIs are less strict in terms of validation etc., which is fine since mainly library writers are supposed to use these symbols.\r\nIf available, please prefer a high level API for general use case scenarios.\r\nRefer this [RFC](https://github.com/tensorflow/community/blob/master/rfcs/20190430-tokenization-conventions.md#design-proposal-design-proposal) and [link](https://github.com/tensorflow/community/blob/892e9e5572507d4ac2cfe8a6aab3564f3fca6cd3/rfcs/20200721-extension-types.md) for more details. Thank you!",
"created_at": "2023-01-04T16:01:26Z"
},
{
"body": "> tf.ragged_ops are basically designed to be consumed by downstream library users, not end users. Usually, these APIs are less strict in terms of validation etc., which is fine since mainly library writers are supposed to use these symbols. If available, please prefer a high level API for general use case scenarios. Refer this [RFC](https://github.com/tensorflow/community/blob/master/rfcs/20190430-tokenization-conventions.md#design-proposal-design-proposal) and [link](https://github.com/tensorflow/community/blob/892e9e5572507d4ac2cfe8a6aab3564f3fca6cd3/rfcs/20200721-extension-types.md) for more details. Thank you!\r\n\r\nDo you think these APIs are exploitable by external attackers?",
"created_at": "2023-01-04T16:07:10Z"
},
{
"body": "TF-2.10 is crashes with check failure with the following test case:\r\n```\r\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import gen_ragged_conversion_ops\r\ntry:\r\n arg_0_0_tensor = tf.random.uniform([129], minval=-256, maxval=257, dtype=tf.int64)\r\n arg_0_0 = tf.identity(arg_0_0_tensor)\r\n arg_0 = [arg_0_0,]\r\n arg_1_tensor = tf.random.uniform([], dtype=tf.float32)\r\n arg_1 = tf.identity(arg_1_tensor)\r\n arg_2 = True\r\n arg_3 = None\r\n out = gen_ragged_conversion_ops.ragged_tensor_to_variant(arg_0,arg_1,arg_2,arg_3,)\r\nexcept Exception as e:\r\n print(\"Error:\"+str(e))\r\n```\r\n```\r\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import gen_ragged_conversion_ops\r\ntry:\r\n arg_0_0_tensor = tf.random.uniform([129], minval=-256, maxval=257, dtype=tf.int64)\r\n arg_0_0 = tf.identity(arg_0_0_tensor)\r\n arg_0 = [arg_0_0,]\r\n arg_1_tensor = tf.random.uniform([464], dtype=tf.float32)\r\n arg_1 = tf.identity(arg_1_tensor)\r\n arg_2 = True\r\n arg_3 = None\r\n out = gen_ragged_conversion_ops.ragged_tensor_to_variant(arg_0,arg_1,arg_2,arg_3,)\r\nexcept Exception as e:\r\n print(\"Error:\"+str(e))\r\n```\r\n\r\n\r\nThe log message:\r\n\r\n```\r\n2023-01-05 17:08:24.472946: F tensorflow/core/framework/tensor_shape.cc:570] Check failed: d < dims() (0 vs. 0)\r\nAborted\r\n```",
"created_at": "2023-01-05T22:28:18Z"
},
{
"body": "@nimashiri,\r\nUsually we request the community preferring a high level API for general use case scenarios which will be helpful to resoluve the issues.\r\nRefer this [RFC](https://github.com/tensorflow/community/blob/master/rfcs/20190430-tokenization-conventions.md#design-proposal-design-proposal) and [link](https://github.com/tensorflow/community/blob/892e9e5572507d4ac2cfe8a6aab3564f3fca6cd3/rfcs/20200721-extension-types.md) for more details. Thank you!",
"created_at": "2023-01-06T11:22:48Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2023-01-16T03:55:09Z"
},
{
"body": "Also this one:\r\n\r\n```\r\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import gen_ragged_conversion_ops\r\ntry:\r\n arg_0_0_tensor = tf.random.uniform([129], minval=-256, maxval=257, dtype=tf.int64)\r\n arg_0_0 = tf.identity(arg_0_0_tensor)\r\n arg_0 = [arg_0_0,]\r\n arg_1_tensor = tf.random.uniform([464], dtype=tf.float32)\r\n arg_1 = tf.identity(arg_1_tensor)\r\n arg_2 = True\r\n arg_3 = None\r\n out = gen_ragged_conversion_ops.ragged_tensor_to_variant(arg_0,arg_1,arg_2,arg_3,)\r\nexcept Exception as e:\r\n print(\"Error:\"+str(e))\r\n```",
"created_at": "2023-01-22T22:44:02Z"
},
{
"body": "@nimashiri,\r\nI tried to execute the code with the alternative appraoch by using **minval=256 and maxval=257** and it was executed without any issues. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/5d80558f394a63578cb8cc213554a5a5/untitled889.ipynb). Also the dtype will expect the positive input and throws an error otherwise. Thank you!\r\n\r\n",
"created_at": "2023-01-24T09:44:27Z"
},
{
"body": "> @nimashiri, I tried to execute the code with the alternative appraoch by using **minval=256 and maxval=257** and it was executed without any issues. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/5d80558f394a63578cb8cc213554a5a5/untitled889.ipynb). Also the dtype will expect the positive input and throws an error otherwise. Thank you! \r\n\r\n@tilakrayal I am running fuzzer on tensorflow. Those inputs are machine generated. Would you please test with my input and confirm if you get check failure?",
"created_at": "2023-01-29T03:37:09Z"
},
{
"body": "@dmc1778,\r\nWhen performing `tf.random.uniform` the type for the **minval** is a Tensor or Python value of type dtype, broadcastable with shape (for integer types, broadcasting is not supported, so it needs to be a scalar). The lower bound on the range of random values to generate (inclusive). **Defaults to 0**.\r\n As mentioned I was performing the test with minval=256 and maxval=257 and it was executed without any issues. Also the when dtype is -ve it will act as invalid and will expect the positive input & throw an error otherwise. Thank you!\r\n\r\n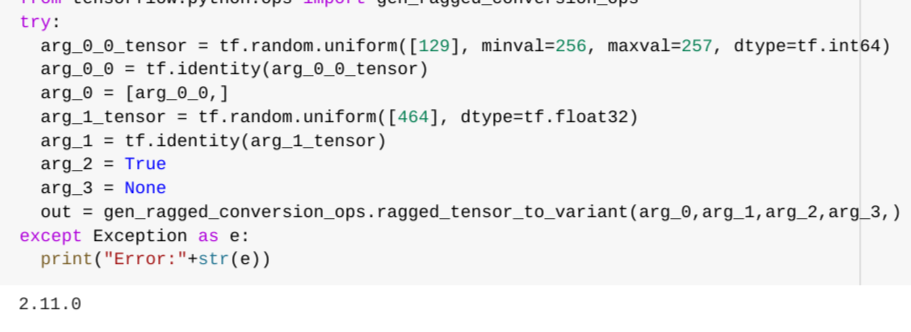\r\n\r\n\r\n\r\n\r\n\r\n",
"created_at": "2023-02-03T13:00:37Z"
},
{
"body": "@tilakrayal this is potentially a vulnerability. Don't add the awaiting response tag as that closes the issue before it gets fixed given team does not notice these.\r\n\r\nPlease test with nightly, not just last release.\r\n\r\n@dmc1778 Please stop posting vulenrabilities on GitHub page. It is not the usual procedure for reporting these.",
"created_at": "2023-02-03T18:32:22Z"
},
{
"body": "@dmc1778,\r\nI tried to execute the mentioned code on tf-nightly(2.13.0-dev20230228), the crash did not happen when invalid input was provided to ragged_tensor_to_variant. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/a39039cba5adacc7a775d5cf0bd1b1a3/untitled1000.ipynb) and also please find the reference of the ubuntu22.04.\r\n\r\n",
"created_at": "2023-03-01T04:56:21Z"
},
{
"body": "This looks to have been fixed. We can close it.",
"created_at": "2023-03-01T15:50:11Z"
},
{
"body": "Closing this as stale. Please reopen if this is still a valid request. Thank you!",
"created_at": "2023-03-23T02:33:22Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59084\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59084\">No</a>\n",
"created_at": "2023-03-23T02:33:25Z"
}
],
"number": 59084,
"title": "Check failure when running tensorflow.python.ops.gen_ragged_conversion_ops.ragged_tensor_to_variant"
}
|
{
"body": "This PR fixes #59084 by return error in case invalid shape set_dim is called.\r\n \r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 59660,
"review_comments": [
{
"body": "Can you use `assertRaisesRegex` to ensure we're catching the right exception?",
"created_at": "2023-02-13T16:25:33Z"
}
],
"title": "Fix crash when invalid input was provided to ragged_tensor_to_variant"
}
|
{
"commits": [
{
"message": "Fix crash when invalid input was provided to ragged_tensor_to_variant\n\nThis PR fixes 59084 by return error in case invalid shape set_dim is called.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nAdd test case for 59084 where invalid input triggered crash in ragged_tensor_to_variant\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -97,7 +97,7 @@ Status UnbatchRaggedZerothDim(\n auto start = batched_splits_top_vec(i);\n auto limit = batched_splits_top_vec(i + 1);\n auto num_values = limit - start;\n- values_shape.set_dim(0, num_values);\n+ TF_RETURN_IF_ERROR(values_shape.SetDimWithStatus(0, num_values));\n (*ragged_components)[i].set_values(\n Tensor(DataTypeToEnum<VALUE_TYPE>::value, values_shape));\n auto ragged_component_values_flat =\n@@ -154,7 +154,7 @@ Status UnbatchRaggedZerothDim(\n int64_t value_index = 0;\n for (auto i = decltype(num_components){}; i < num_components; i++) {\n SPLIT_TYPE num_values = ragged_component_values_size[i];\n- values_shape.set_dim(0, num_values);\n+ TF_RETURN_IF_ERROR(values_shape.SetDimWithStatus(0, num_values));\n (*ragged_components)[i].set_values(\n Tensor(DataTypeToEnum<VALUE_TYPE>::value, values_shape));\n auto ragged_component_values_flat =",
"filename": "tensorflow/core/kernels/ragged_tensor_to_variant_op.cc",
"status": "modified"
},
{
"diff": "@@ -2014,6 +2014,15 @@ def testRaggedTensorSetShapeInconsistentShapeError(self):\n with self.assertRaises(ValueError):\n rt._set_shape([5, None, None])\n \n+ def testToVariantInvalidInputs(self):\n+ self.assertRaisesRegex(\n+ (ValueError, errors.InvalidArgumentError),\n+ 'must be less than 0, got 0|Shape must be at least rank 1 but is rank 0',\n+ gen_ragged_conversion_ops.ragged_tensor_to_variant,\n+ rt_nested_splits=[[150, 38, -243]],\n+ rt_dense_values=198,\n+ batched_input=True)\n+\n \n @test_util.run_all_in_graph_and_eager_modes\n class RaggedTensorSpecTest(test_util.TensorFlowTestCase,",
"filename": "tensorflow/python/ops/ragged/ragged_tensor_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nNo\n\n### Source\n\nsource\n\n### Tensorflow Version\n\n2.10.0\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\n22.04\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nWhen running .ragged_cross with the following input combination, it results in segfault.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import gen_ragged_array_ops\r\ntry:\r\n ragged_values_0_tensor = tf.convert_to_tensor(np.ones([3], dtype=str))\r\n ragged_values_0 = tf.identity(ragged_values_0_tensor)\r\n ragged_values = [ragged_values_0,]\r\n ragged_row_splits_0_tensor = tf.random.uniform([4], minval=-256, maxval=257, dtype=tf.int64)\r\n ragged_row_splits_0 = tf.identity(ragged_row_splits_0_tensor)\r\n ragged_row_splits = [ragged_row_splits_0,]\r\n sparse_indices = []\r\n sparse_values = []\r\n sparse_shape = []\r\n dense_inputs = []\r\n input_order = \"R\"\r\n hashed_output = False\r\n num_buckets = 0\r\n hash_key = 956888297470\r\n out_values_type = 7\r\n out_row_splits_type = 9\r\n out = gen_ragged_array_ops.ragged_cross(ragged_values=ragged_values,ragged_row_splits=ragged_row_splits,sparse_indices=sparse_indices,sparse_values=sparse_values,sparse_shape=sparse_shape,dense_inputs=dense_inputs,input_order=input_order,hashed_output=hashed_output,num_buckets=num_buckets,hash_key=hash_key,out_values_type=out_values_type,out_row_splits_type=out_row_splits_type,)\r\nexcept Exception as e:\r\n print(\"Error:\"+str(e))\r\n```\n```\n\n\n### Relevant log output\n\n```shell\nThe only log message is:\r\n\r\n\r\nSegmentation fault\r\n```\n```\n</details>",
"comments": [
{
"body": "@nimashiri,\r\n**gen_ragged_array_ops.ragged_cross** is the generated OP wrapper. I tried to execute the code with the alternative approach and it was working as expected. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/ebf1cf103dd28abf059d4533eda80327/untitled839.ipynb) and also please take a look at the high level api of gen_ragged_array_ops.ragged_cross from the doc [link1](https://www.tensorflow.org/api_docs/python/tf/ragged/cross) and [link2](https://www.tensorflow.org/api_docs/python/tf/raw_ops/RaggedCross) for the reference. Thank you!",
"created_at": "2023-01-06T13:17:12Z"
},
{
"body": "> @nimashiri, **gen_ragged_array_ops.ragged_cross** is the generated OP wrapper. I tried to execute the code with the alternative approach and it was working as expected. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/ebf1cf103dd28abf059d4533eda80327/untitled839.ipynb) and also please take a look at the high level api of gen_ragged_array_ops.ragged_cross from the doc [link1](https://www.tensorflow.org/api_docs/python/tf/ragged/cross) and [link2](https://www.tensorflow.org/api_docs/python/tf/raw_ops/RaggedCross) for the reference. Thank you!\r\n\r\nThanks. I get segfault when running from my terminal, ubuntu 22.04:\r\n\r\n\r\n",
"created_at": "2023-01-06T13:51:19Z"
},
{
"body": "@sachinprasadhs,\r\nI was able to reproduce the issue on tensorflow v2.10, v2.11 and nightly. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/7cbeeca7fbd730100159b204ee9c5640/untitled868.ipynb).",
"created_at": "2023-01-12T09:33:23Z"
},
{
"body": "> @sachinprasadhs, I was able to reproduce the issue on tensorflow v2.10, v2.11 and nightly. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/7cbeeca7fbd730100159b204ee9c5640/untitled868.ipynb).\r\n\r\nAlso this one:\r\n\r\n```\r\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import gen_ragged_array_ops\r\ntry:\r\n ragged_values_0_tensor = tf.convert_to_tensor(np.ones([3], dtype=str))\r\n ragged_values_0 = tf.identity(ragged_values_0_tensor)\r\n ragged_values = [ragged_values_0,]\r\n ragged_row_splits_0_tensor = tf.random.uniform([4], minval=-256, maxval=257, dtype=tf.int64)\r\n ragged_row_splits_0 = tf.identity(ragged_row_splits_0_tensor)\r\n ragged_row_splits = [ragged_row_splits_0,]\r\n sparse_indices = []\r\n sparse_values = []\r\n sparse_shape = []\r\n dense_inputs = []\r\n input_order = \"R\"\r\n hashed_output = False\r\n num_buckets = 0\r\n hash_key = 0\r\n out_values_type = 7\r\n out_row_splits_type = 9\r\n out = gen_ragged_array_ops.ragged_cross(ragged_values=ragged_values,ragged_row_splits=ragged_row_splits,sparse_indices=sparse_indices,sparse_values=sparse_values,sparse_shape=sparse_shape,dense_inputs=dense_inputs,input_order=input_order,hashed_output=hashed_output,num_buckets=num_buckets,hash_key=hash_key,out_values_type=out_values_type,out_row_splits_type=out_row_splits_type,)\r\nexcept Exception as e:\r\n print(\"Error:\"+str(e))\r\n```",
"created_at": "2023-01-22T22:52:00Z"
},
{
"body": "@learning-to-play ",
"created_at": "2023-02-07T19:51:10Z"
},
{
"body": "Added a PR #59114 for the fix.",
"created_at": "2023-02-12T18:10:43Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59114\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59114\">No</a>\n",
"created_at": "2023-02-14T05:38:59Z"
}
],
"number": 59114,
"title": "Segmentation fault when running gen_ragged_array_ops.ragged_cross"
}
|
{
"body": "This PR tries to address the issue raised in #59114 where ragged_cross will crash when input is invalid.\r\n \r\nThis PR fixes #59114.\r\n \r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 59658,
"review_comments": [],
"title": "Fix crash in ragged_cross where the ragged tensor input is invalid"
}
|
{
"commits": [
{
"message": "Fix crash in ragged_cross where the ragged tensor input is invalid\n\nThis PR tries to address the issue raised in 59114 where\nragged_cross will crash when input is invalid.\n\nThis PR fixes 59114.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nAdd test case for GitHub issue 59114.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nAdd additional check to return back immediately\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -596,7 +596,11 @@ class RaggedCrossOp : public OpKernel {\n int64_t cross_count_total = 0;\n flat_row_splits(0) = 0;\n for (int64_t b = 0; b < batch_size; b++) {\n- cross_count_total += CrossCountByBatchIndex(features, b);\n+ int64_t cross_count_by_batch_index = CrossCountByBatchIndex(features, b);\n+ if (cross_count_by_batch_index < 0) {\n+ return errors::InvalidArgument(\"Invalid RaggedTensor\");\n+ }\n+ cross_count_total += cross_count_by_batch_index;\n flat_row_splits(b + 1) = cross_count_total;\n }\n \n@@ -613,6 +617,8 @@ class RaggedCrossOp : public OpKernel {\n int64_t cross_count = 1;\n for (int i = 0; i < features.size(); ++i) {\n const auto feature_count = features[i]->FeatureCount(batch_index);\n+ // If feature_count is invalid, return -1 to let caller know.\n+ if (feature_count < 0) return -1;\n if (feature_count == 0) return 0;\n cross_count *= feature_count;\n }",
"filename": "tensorflow/core/kernels/ragged_cross_op.cc",
"status": "modified"
},
{
"diff": "@@ -25,7 +25,9 @@\n from tensorflow.python.framework import sparse_tensor\n from tensorflow.python.framework import tensor_spec\n from tensorflow.python.framework import test_util\n+from tensorflow.python.ops import array_ops\n from tensorflow.python.ops import gen_ragged_array_ops\n+from tensorflow.python.ops import random_ops\n from tensorflow.python.ops import sparse_ops\n from tensorflow.python.ops.ragged import ragged_array_ops\n from tensorflow.python.ops.ragged import ragged_factory_ops\n@@ -456,6 +458,32 @@ def testRaggedValuesAndSplitsMustMatch(self):\n out_values_type=dtypes.string,\n out_row_splits_type=dtypes.int64))\n \n+ def testRaggedCrossInvalidValue(self):\n+ # Test case in GitHub isseu 59114.\n+ with self.assertRaisesRegex(\n+ (ValueError, errors.InvalidArgumentError),\n+ 'Invalid RaggedTensor'):\n+ ragged_values_0_tensor = ops.convert_to_tensor(np.ones([3], dtype=str))\n+ ragged_values_0 = array_ops.identity(ragged_values_0_tensor)\n+ ragged_values = [ragged_values_0,]\n+ ragged_row_splits_0_tensor = random_ops.random_uniform(\n+ [4], minval=-256, maxval=257, dtype=dtypes.int64)\n+ ragged_row_splits_0 = array_ops.identity(ragged_row_splits_0_tensor)\n+ ragged_row_splits = [ragged_row_splits_0,]\n+ self.evaluate(gen_ragged_array_ops.RaggedCross(\n+ ragged_values=ragged_values,\n+ ragged_row_splits=ragged_row_splits,\n+ sparse_indices=[],\n+ sparse_values=[],\n+ sparse_shape=[],\n+ dense_inputs=[],\n+ input_order='R',\n+ hashed_output=False,\n+ num_buckets=0,\n+ hash_key=956888297470,\n+ out_values_type=7,\n+ out_row_splits_type=9))\n+\n \n if __name__ == '__main__':\n googletest.main()",
"filename": "tensorflow/python/ops/ragged/ragged_cross_op_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nbinary\n\n### Tensorflow Version\n\ntf 2.9 and 2.12.0-dev20221018\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nLinux Ubuntu 20.04\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.8\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\nCUDA 11.5\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nA crash due to check fail can be triggered in MapPeek.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport os\r\nos.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'\r\nimport tensorflow as tf\r\nimport numpy as np\r\nprint(tf.__version__)\r\nfor _ in range(20):\r\n try:\r\n capacity = 0\r\n memory_limit = 0\r\n dtypes_0 = tf.uint64\r\n dtypes_1 = tf.float32\r\n dtypes = [dtypes_0, dtypes_1, ]\r\n container = \"\"\r\n shared_name = \"\"\r\n key = tf.saturate_cast(tf.random.uniform([6, 14, 4], minval=0, maxval=64, dtype=tf.int64), dtype=tf.int64)\r\n indices = tf.saturate_cast(tf.random.uniform([2], minval=0, maxval=64, dtype=tf.int64), dtype=tf.int32)\r\n res = tf.raw_ops.MapPeek(\r\n capacity=capacity,\r\n memory_limit=memory_limit,\r\n dtypes=dtypes,\r\n container=container,\r\n shared_name=shared_name,\r\n key=key,\r\n indices=indices,\r\n )\r\n except:\r\n pass\n```\n\n\n### Relevant log output\n\n```shell\nF tensorflow/core/framework/tensor.cc:733] Check failed: 1 == NumElements() (1 vs. 336)Must have a one element tensor\r\nAborted (core dumped)\n```\n</details>",
"comments": [
{
"body": "Same as the other issues. Can you try the same with the high level API?",
"created_at": "2022-10-25T14:07:48Z"
},
{
"body": "@shijy16,\r\nProbably there is a missing check in the low level API.\r\nCould you please try to reproduce your experiment with the high level API and let us know if you are facing same issue. Thank you!",
"created_at": "2022-10-27T09:30:05Z"
},
{
"body": "@tiruk007 Please check https://github.com/tensorflow/tensorflow/issues/58315#issuecomment-1293352092\n\n\nAs we need to have a common clear policy for this type of tickets.",
"created_at": "2022-10-27T11:00:41Z"
},
{
"body": "@bhack \r\nThanks for your response, I'll stop submitting check-fails in `tf.raw_ops.*` until the new policy is published. :)",
"created_at": "2022-10-28T12:01:44Z"
},
{
"body": "See https://github.com/tensorflow/tensorflow/blob/master/SECURITY.md, refactored now.\r\n\r\nAssertion failures, `CHECK`-fails, etc, should be treated just as bugs. They won't get CVEs, they won't be cherry-picked to old branches anymore. For these, please open an issue and create a PR to fix.\r\n\r\nFor other vulnerabilities, sure, it is easy to discover them via `tf.raw_ops.*`, but these symbols are not really used in real-life models. If you want $$ credit via OSS VRP, it is better to try to enlarge the scope and show how the issue you discovered in `tf.raw_ops.*` affects a real `SavedModel`. You could construct your own in the proof of concept (POC) or pick one from TF Hub and show how users of that model would be impacted by the vulnerability.",
"created_at": "2022-10-28T12:12:08Z"
},
{
"body": "@mihaimaruseac \r\nSorry, I just noticed that the security policy was updated recently. \r\nI understand that the unexploitable bugs are not vulnerabilities. \r\nDo you mean `tf.raw_ops.*` bugs that are not vulnerabilities should be submitted in issues in the following two ways:\r\n+ `CHECK`-fails should be submitted with a related PR.\r\n+ Other bugs in `tf.raw_ops.*` can be submitted directly, such as **CUDA Memory Errors**, **Floating Point Exceptions**, etc.",
"created_at": "2022-10-28T12:55:19Z"
},
{
"body": "> For these, please open an issue and create a PR to fix.\n\nIt would nice if we could add a specific label for these `asserts` bugs..",
"created_at": "2022-10-28T13:35:38Z"
},
{
"body": "`tf.raw_ops` are basically designed to be consumed by downstream library users, not end users.\r\nUsually, these APIs are less strict in terms of validation etc., which is fine since mainly library writers are supposed to use these symbols.\r\nIf available, please prefer high level API for general use case scenarios. \r\nRefer this [RFC](https://github.com/tensorflow/community/blob/master/rfcs/20181225-tf-raw-ops.md#design-proposal) for more details. Thanks!",
"created_at": "2022-12-09T08:07:14Z"
},
{
"body": "While these are internal APIs, the check failure could lead to denial of service. In the past this used to be considered a vulnerability, but since the impact is bounded and preventable, now the policy is for these to be files as issues and resolved whenever someone from community wants to pick them up (they're very good first issues). Please don't auto-close these!",
"created_at": "2022-12-09T16:04:32Z"
},
{
"body": "> While these are internal APIs, the check failure could lead to denial of service. In the past this used to be considered a vulnerability, but since the impact is bounded and preventable, now the policy is for these to be files as issues and resolved whenever someone from community wants to pick them up (they're very good first issues). Please don't auto-close these!\r\n\r\nYes I think that these are `contribution welcome` label (+ probably a specific label as we have many of these cases). \r\nBut currently we are not really maintaining an active contribution welcome program as we have many outdated/unmaintained contribution welcome labels in the repository so it is very hard to understand what it is still valid to pick and where we have reviewers resource to allocate.\r\n\r\nI've tried myself to fix some of this like in https://github.com/tensorflow/tensorflow/pull/58358 but as it is \"still\" quite hard/compute intensive to build TF on every PR and/or also quite expensive to prepare and test PR in the cloud I have not tried to submit other PRs of this type.\r\n\r\n",
"created_at": "2022-12-09T17:38:48Z"
},
{
"body": "Added a PR #59656 for the fix.",
"created_at": "2023-02-12T16:33:30Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58271\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58271\">No</a>\n",
"created_at": "2023-02-17T17:49:49Z"
}
],
"number": 58271,
"title": "A check fail can be triggered in MapPeek"
}
|
{
"body": "This PR tries to address the issue raised in #58271 where MapPeek\r\nwill crash when key is not a scaler.\r\n\r\nThis PR fixes #58271.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 59656,
"review_comments": [
{
"body": "I don't think we need this `with self.session()`. Can you remove if it still passes?",
"created_at": "2023-02-13T16:32:00Z"
},
{
"body": "This should be `self.evaluate(v)`",
"created_at": "2023-02-16T17:32:36Z"
}
],
"title": "Fix MapPeek crash when key is not a scaler"
}
|
{
"commits": [
{
"message": "Fix MapPeek crash when key is not a scaler\n\nThis PR tries to address the issue raised in 58271 where MapPeek\nwill crash when key is not a scaler.\n\nThis PR fixes 58271.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nAdd test case for Github issue 58271 where MapPeek will crash with non-scaler key\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nFix error message to match graph and eager mode\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\nAdjust review feedback\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -633,6 +633,9 @@ class MapPeekOp : public OpKernel {\n const Tensor* indices_tensor;\n \n OP_REQUIRES_OK(ctx, ctx->input(\"key\", &key_tensor));\n+ OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(key_tensor->shape()),\n+ errors::InvalidArgument(\"key must be an int64 scalar: \",\n+ key_tensor->shape().DebugString()));\n OP_REQUIRES_OK(ctx, ctx->input(\"indices\", &indices_tensor));\n OP_REQUIRES_OK(ctx, map->get(key_tensor, indices_tensor, &tuple));\n ",
"filename": "tensorflow/core/kernels/map_stage_op.cc",
"status": "modified"
},
{
"diff": "@@ -624,5 +624,19 @@ def testNonScalarKeyUnorderedMap(self):\n sess.run(t, feed_dict={x: 1})\n \n \n+ def testNonScalarKeyMapPeek(self):\n+ with self.assertRaisesRegex(errors.InvalidArgumentError,\n+ 'key must be an int64 scalar'):\n+ v = data_flow_ops.gen_data_flow_ops.map_peek(\n+ key=constant_op.constant(value=[1], shape=(1, 3), dtype=dtypes.int64),\n+ indices=np.array([[6]]),\n+ dtypes=[dtypes.int64],\n+ capacity=0,\n+ memory_limit=0,\n+ container='container1',\n+ shared_name='',\n+ name=None)\n+ self.evaluate(v)\n+\n if __name__ == '__main__':\n test.main()",
"filename": "tensorflow/python/kernel_tests/data_structures/map_stage_op_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nYes\n\n### Source\n\nsource\n\n### Tensorflow Version\n\ngit HEAD\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nCentOS 7\n\n### Mobile device\n\nn/a\n\n### Python version\n\n3.8.13\n\n### Bazel version\n\n5.3.0\n\n### GCC/Compiler version\n\n10.3.0\n\n### CUDA/cuDNN version\n\nn/a\n\n### GPU model and memory\n\nn/a\n\n### Current Behaviour?\n\n```shell\nUnit test //tensorflow/dtensor/python/tests:spmd_test_cpu fails when run with Python 3.8 and protobuf 4 is installed.\r\nInstalling protobuf 3.20.3 resolves the issue.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nbazel test --config=mkl_aarch64_threadpool --test_env=TF_ENABLE_ONEDNN_OPTS=1 --cache_test_results=no --test_timeout=500,900,-1,-1 --copt=\"-mtune=generic\" --copt=\"-march=armv8-a\" --copt=\"-O3\" --build_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only,-no_aarch64,-requires-gpu --test_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only,-no_aarch64,-requires-gpu --build_tests_only --jobs=100 -- //tensorflow/dtensor/python/tests:spmd_test_cpu\n```\n\n\n### Relevant log output\n\n```shell\nFatal Python error: Segmentation fault\r\n\r\nCurrent thread 0x0000ffffb7906370 (most recent call first):\r\n File \"/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/eager/context.py\", line 1108 in config\r\n File \"/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/eager/context.py\", line 568 in ensure_initialized\r\n File \"/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/eager/context.py\", line 1401 in remove_function\r\n File \"/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/eager/context.py\", line 2739 in remove_function\r\n File \"/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/eager/polymorphic_function/monomorphic_function.py\", line 172 in __del__\r\n*** Received signal 11 ***\r\n*** BEGIN MANGLED STACK TRACE ***\r\n/home/andrew/.cache/bazel/_bazel_andrew/c61c5f84d239689cb19a72cfde16be9f/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/dtensor/python/tests/spmd_test_cpu.runfiles/org_tensorflow/tensorflow/python/platform/../../../_solib_aarch64/_U_S_Stensorflow_Clibtensorflow_Uframework_Uimport_Ulib___Utensorflow/libtensorflow_framework.so.2(+0x15ae14c)[0xffff145de14c]\r\nlinux-vdso.so.1(__kernel_rt_sigreturn+0x0)[0xffffb78b07a0]\r\n/lib64/libpthread.so.0(raise+0xac)[0xffffb71b2af4]\r\nlinux-vdso.so.1(__kernel_rt_sigreturn+0x0)[0xffffb78b07a0]\r\n/lib64/libpython3.8.so.1.0(PyModule_GetState+0x4)[0xffffb72f9a3c]\r\n/home/andrew/src/venv38/lib64/python3.8/site-packages/google/_upb/_message.abi3.so(+0xa390)[0xffff1527a390]\r\n/home/andrew/src/venv38/lib64/python3.8/site-packages/google/_upb/_message.abi3.so(+0x13c9c)[0xffff15283c9c]\r\n/lib64/libpython3.8.so.1.0(_PyObject_MakeTpCall+0x1a8)[0xffffb72ed9c0]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalFrameDefault+0x53f4)[0xffffb73c1114]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalCodeWithName+0xc8c)[0xffffb7371fe4]\r\n/lib64/libpython3.8.so.1.0(_PyFunction_Vectorcall+0x474)[0xffffb73734b4]\r\n/lib64/libpython3.8.so.1.0(+0x12662c)[0xffffb734662c]\r\n/lib64/libpython3.8.so.1.0(PyObject_GetAttr+0x27c)[0xffffb7361e4c]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalFrameDefault+0xa08)[0xffffb73bc728]\r\n/lib64/libpython3.8.so.1.0(_PyFunction_Vectorcall+0x1d0)[0xffffb7373210]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalFrameDefault+0x884)[0xffffb73bc5a4]\r\n/lib64/libpython3.8.so.1.0(_PyFunction_Vectorcall+0x1d0)[0xffffb7373210]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalFrameDefault+0x884)[0xffffb73bc5a4]\r\n/lib64/libpython3.8.so.1.0(_PyFunction_Vectorcall+0x1d0)[0xffffb7373210]\r\n/lib64/libpython3.8.so.1.0(_PyEval_EvalFrameDefault+0x4de8)[0xffffb73c0b08]\r\n/lib64/libpython3.8.so.1.0(_PyFunction_Vectorcall+0x1d0)[0xffffb7373210]\r\n/lib64/libpython3.8.so.1.0(+0x133640)[0xffffb7353640]\r\n/lib64/libpython3.8.so.1.0(+0x1f7248)[0xffffb7417248]\r\n/lib64/libpython3.8.so.1.0(+0xcc72c)[0xffffb72ec72c]\r\n/lib64/libpython3.8.so.1.0(_PyGC_CollectNoFail+0x38)[0xffffb745f060]\r\n/lib64/libpython3.8.so.1.0(PyImport_Cleanup+0x394)[0xffffb745f40c]\r\n/lib64/libpython3.8.so.1.0(Py_FinalizeEx+0x6c)[0xffffb7462c34]\r\n/lib64/libpython3.8.so.1.0(Py_Exit+0x14)[0xffffb72cb01c]\r\n/lib64/libpython3.8.so.1.0(+0xab060)[0xffffb72cb060]\r\n/lib64/libpython3.8.so.1.0(+0xab0b8)[0xffffb72cb0b8]\r\n/lib64/libpython3.8.so.1.0(PyRun_SimpleFileExFlags+0x3c4)[0xffffb72cbac0]\r\n/lib64/libpython3.8.so.1.0(Py_RunMain+0x2b8)[0xffffb74645d0]\r\n/lib64/libpython3.8.so.1.0(Py_BytesMain+0x3c)[0xffffb7464d1c]\r\n/lib64/libc.so.6(__libc_start_main+0xdc)[0xffffb6f14384]\r\n/home/andrew/src/venv38/bin/python3(+0x928)[0xaaaab41c0928]\r\n*** END MANGLED STACK TRACE ***\r\n\r\n*** Begin stack trace ***\r\n tsl::CurrentStackTrace[abi:cxx11]()\r\n\r\n __kernel_rt_sigreturn\r\n raise\r\n __kernel_rt_sigreturn\r\n PyModule_GetState\r\n\r\n\r\n _PyObject_MakeTpCall\r\n _PyEval_EvalFrameDefault\r\n _PyEval_EvalCodeWithName\r\n _PyFunction_Vectorcall\r\n\r\n PyObject_GetAttr\r\n _PyEval_EvalFrameDefault\r\n _PyFunction_Vectorcall\r\n _PyEval_EvalFrameDefault\r\n _PyFunction_Vectorcall\r\n _PyEval_EvalFrameDefault\r\n _PyFunction_Vectorcall\r\n _PyEval_EvalFrameDefault\r\n _PyFunction_Vectorcall\r\n\r\n\r\n\r\n _PyGC_CollectNoFail\r\n PyImport_Cleanup\r\n Py_FinalizeEx\r\n Py_Exit\r\n\r\n\r\n PyRun_SimpleFileExFlags\r\n Py_RunMain\r\n Py_BytesMain\r\n __libc_start_main\r\n\r\n*** End stack trace ***\n```\n</details>",
"comments": [
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59643\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59643\">No</a>\n",
"created_at": "2023-02-13T20:50:40Z"
}
],
"number": 59643,
"title": "protobuf 4 causes segmentation fault on Python 3.8 in unit test"
}
|
{
"body": "protobuf 4 can lead to segmentation faults on Python 3.8 so prevent that from happening by using protobuf 3 but only for Python 3.8\r\n\r\nFixes #59643 ",
"number": 59644,
"review_comments": [],
"title": "[Linaro:ARM_CI] Prevent use of protobuf 4 on python 3.8"
}
|
{
"commits": [
{
"message": "[Linaro:ARM_CI] Prevent use of protobuf 4 on python 3.8\n\nprotobuf 4 can lead to segmentation faults on Python 3.8\nso prevent that from happening by using protobuf 3 but only\nfor Python 3.8"
}
],
"files": [
{
"diff": "@@ -104,7 +104,8 @@ def standard_or_nightly(standard, nightly):\n # See also: https://github.com/protocolbuffers/protobuf/issues/9954\n # See also: https://github.com/tensorflow/tensorflow/issues/56077\n # This is a temporary patch for now, to patch previous TF releases.\n- 'protobuf>=3.20.3,<5.0.0dev,!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5',\n+ 'protobuf~=3.20.3;python_version<\"3.9\"',\n+ 'protobuf>=3.20.3,<5.0.0dev,!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5;python_version>=\"3.9\"',\n 'setuptools',\n 'six >= 1.12.0',\n 'termcolor >= 1.1.0',",
"filename": "tensorflow/tools/pip_package/setup.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nbinary\n\n### Tensorflow Version\n\ntf 2.9 and 2.12.0-dev20221018\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nLinux Ubuntu 20.04\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.8\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\nCUDA 11.5\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nA crash due to check fail can be trigerred.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport os\r\nos.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'\r\nimport tensorflow as tf\r\nimport numpy as np\r\nprint(tf.__version__)\r\nfor _ in range(20):\r\n try:\r\n forget_bias = 112.66590343649887\r\n cell_clip = 67.12389445926587\r\n use_peephole = False\r\n x = tf.saturate_cast(tf.random.uniform([2, 16], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\n cs_prev = tf.saturate_cast(tf.random.uniform([2, 0], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\n h_prev = tf.saturate_cast(tf.random.uniform([2, 0], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\n w = tf.saturate_cast(tf.random.uniform([16, 0], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\n wci = tf.saturate_cast(tf.random.uniform([5], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\n wcf = tf.saturate_cast(tf.random.uniform([16], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\n wco = tf.saturate_cast(tf.random.uniform([13], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\n b = tf.saturate_cast(tf.random.uniform([0], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\n res = tf.raw_ops.LSTMBlockCell(\r\n forget_bias=forget_bias,\r\n cell_clip=cell_clip,\r\n use_peephole=use_peephole,\r\n x=x,\r\n cs_prev=cs_prev,\r\n h_prev=h_prev,\r\n w=w,\r\n wci=wci,\r\n wcf=wcf,\r\n wco=wco,\r\n b=b,\r\n )\r\n except:\r\n pass\n```\n\n\n### Relevant log output\n\n```shell\nF tensorflow/core/kernels/rnn/lstm_ops_gpu.cu.cc:277] Non-OK-status: GpuLaunchKernel( lstm_gates<T, false, gate_layout>, grid_dim_2d, block_dim_2d, 0, cu_stream, gates.data(), b.data(), cs_prev.data(), wci.data(), wcf.data(), wco.data(), o.data(), h.data(), ci.data(), cs.data(), co.data(), i.data(), f.data(), forget_bias, cell_clip, batch_size, cell_size) status: INTERNAL: invalid configuration argument\r\nAborted (core dumped)\n```\n</details>",
"comments": [
{
"body": "Same as the other issues. Can you try the same with the high level API?",
"created_at": "2022-10-25T14:08:51Z"
},
{
"body": "@sushreebarsa \r\nI was able to reproduce the issue on Colab using TF 2.10 GPU and it works fine inTF 2.10 CPU. Could you please find attached gists [GPU](https://colab.research.google.com/gist/tiruk007/5f7f43c52e93dd077e4ba86c4f80c66a/58270gpu.ipynb) and [CPU](https://colab.research.google.com/gist/tiruk007/594ecff94e3bd7be68e3b2e9e59d3208/58270cpu.ipynb) for reference.\r\n\r\nThank you!",
"created_at": "2022-10-26T17:57:46Z"
},
{
"body": "`tf.raw_ops` are basically designed to be consumed by downstream library users, not end users.\r\nUsually, these APIs are less strict in terms of validation etc which is fine since only library writers are supposed to use these symbols.\r\nIf available, please prefer high level API for general use case scenarios. \r\nRefer this [RFC](https://github.com/tensorflow/community/blob/master/rfcs/20181225-tf-raw-ops.md#design-proposal) for more details. Thanks!",
"created_at": "2022-12-09T08:02:24Z"
},
{
"body": "While these are internal APIs, the check failure could lead to denial of service. In the past this used to be considered a vulnerability, but since the impact is bounded and preventable, now the policy is for these to be files as issues and resolved whenever someone from community wants to pick them up (they're very good first issues). Please don't auto-close these!",
"created_at": "2022-12-09T17:06:03Z"
},
{
"body": "Same comment as in https://github.com/tensorflow/tensorflow/issues/58271#issuecomment-1344581838",
"created_at": "2022-12-09T17:39:31Z"
},
{
"body": "Hi @mihaimaruseac @bhack would it be alright if I worked on this?\r\n\r\nI've been digging around to get familiar with the code, and I can see the log is being made from these lines:\r\nhttps://github.com/tensorflow/tensorflow/blob/3e009869d30edf899200dda68f98294617a9628f/tensorflow/core/kernels/rnn/lstm_ops_gpu.cu.cc#L269-L283\r\nI tracked the `GpuLaunchKernel` down, and I see where the internal error is being returned, but I haven't been able to find the code for `cudaLaunchKernel`\r\nhttps://github.com/tensorflow/tensorflow/blob/3e009869d30edf899200dda68f98294617a9628f/tensorflow/core/util/gpu_kernel_helper.h#L102-L116\r\nI'm guessing that I need to add a check of some sort to the `LSTMBlockCellFpropWithCUDA`, but I'm not sure what that check needs to be. Any clues would be appreciated!",
"created_at": "2022-12-14T03:43:35Z"
},
{
"body": "E.g. check https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/sparse_to_dense_op.cc\n\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/sparse_to_dense_op_gpu.cu.cc#L121",
"created_at": "2022-12-14T04:01:15Z"
},
{
"body": "@bhack Ok, I think I see what you're getting at. Instead of using `TF_CHECK_OK`, I could create a function like `LaunchComputeKernels` to return a status, and then use `OP_REQUIRES_OK_ASYNC`. Or is that overcomplicating it? Could I just call `OP_REQUIRES_OK_ASYNC` on the `GpuLaunchKernel` since that returns a status?",
"created_at": "2022-12-16T05:29:50Z"
},
{
"body": "Yes the problem is that TF_CHECK_OK is an assert.\n\nI think you can try with async. \n\n/cc @reedwm what do you think?",
"created_at": "2022-12-16T09:35:31Z"
},
{
"body": "@bhack Actually the BlockLSTMOp class inherits from OpKernel and not AsyncOpKernel like in `sparse_to_dense_op.cc` so maybe no async",
"created_at": "2022-12-17T04:59:58Z"
},
{
"body": "So probably in this case is `OP_REQUIRES_OK`",
"created_at": "2022-12-17T09:52:41Z"
},
{
"body": "@bhack making the switch to `OP_REQUIRES_OK` causes the OP_REQUIRES errors to get logged, but it doesn't crash Python. Do you think I need to add/update any unit tests for this? And if so what file should I be looking in?",
"created_at": "2022-12-20T23:18:38Z"
},
{
"body": "Have you tried with https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/ops/cudnn_rnn_ops_test.cc ?",
"created_at": "2022-12-21T00:14:07Z"
},
{
"body": "No, I hadn't seen that. I'll check it out. Thanks!",
"created_at": "2022-12-21T03:49:26Z"
},
{
"body": "@bhack I'm a little lost looking at these unit tests. I can see how the tests in the file you linked earlier relate to ops registered in `cudnn_rnn_ops.cc`, but I am having trouble figuring out how I can test my code from this file. Do I need to register a new op? Or did you just intend that as a generic example, in which case should I create a test file specific to `lstm_ops_gpu.cu.cc`? Thanks for your patience. I'm pretty new to C++, and this is my first issue on the project.",
"created_at": "2023-01-04T05:09:32Z"
},
{
"body": "/cc @reedwm Do you know who is the owner of this component?",
"created_at": "2023-01-04T11:53:47Z"
},
{
"body": "[https://colab.research.google.com/drive/1ol-1151DaSH4HTK7MaAC_Ngrv-N2sfhP?usp=sharing](url)\r\nI guess there is no error when running it in google colab , do check this out",
"created_at": "2023-01-27T09:05:19Z"
},
{
"body": "I want to work on this Issue",
"created_at": "2023-01-29T21:45:16Z"
},
{
"body": "I actually already have a solution for this issue. I was just waiting on some guidance on the unit tests. I've been pretty busy over the last few weeks, but I'm planning on putting some time into it this week.",
"created_at": "2023-01-29T22:51:34Z"
},
{
"body": "I work on this issue. Please assign me.",
"created_at": "2023-02-06T19:38:12Z"
},
{
"body": "Folks, the way TF (and most OSS projects) work is whoever sends the PR that does the job gets the work. Especially for big projects it is very hard to keep assigning contributors to issues and then unassign when they turn inactive.\r\n",
"created_at": "2023-02-07T00:04:35Z"
},
{
"body": "I am attempting to reproduce the environment. I am using a virtual machine arm64 ubuntu 20.04. When doing a pip install for tensorflow==2.9,\r\n```python\r\nERROR: Could not find a version that satisfies the requirement tensorflow==2.9.0 (from versions: 2.10.0rc0, 2.10.0rc1, 2.10.0rc2, 2.10.0rc3, 2.10.0, 2.10.1, 2.11.0rc0, 2.11.0rc1, 2.11.0rc2, 2.11.0)\r\nERROR: No matching distribution found for tensorflow==2.9.0\r\n```\r\nBefore moving forward, am I allowed to use a later version like 2.10?\r\nThank you!",
"created_at": "2023-02-13T00:08:53Z"
},
{
"body": "2.9 is out of life, no longer updated. Always try to fix on master branch, test if the issue reproduces with nightly.",
"created_at": "2023-02-13T18:52:31Z"
},
{
"body": "@mihaimaruseac Understood. Thank you very much!",
"created_at": "2023-02-13T19:26:34Z"
},
{
"body": "Hey, I was just going through the code, I couldn't locate the `third_party/gpus/cuda/include` folder. Isn't it supposed to be there?",
"created_at": "2023-03-03T10:36:40Z"
},
{
"body": "Hello good greetings my name is Sahil and would love to contribute to Tensorflow could anyone help me with it 😊😊",
"created_at": "2023-03-05T06:46:24Z"
},
{
"body": "The issue can be resolved by disabling the use of oneDNN optimizations in TensorFlow by setting the environment variable \"TF_ENABLE_ONEDNN_OPTS\" to 0 before importing TensorFlow. (see below code)\r\nos.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'\r\n\r\nExplanation:\r\nThe provided code generates random values for inputs to the LSTMBlockCell operation and runs it in a loop for 20 iterations. The LSTMBlockCell operation implements the long short-term memory (LSTM) algorithm, which is a type of recurrent neural network commonly used for sequence processing tasks. The inputs to the LSTMBlockCell operation include the current input values, the previous cell state and output values, and the weights and biases of the LSTM cell.\r\n",
"created_at": "2023-03-12T06:10:42Z"
},
{
"body": "> The issue can be resolved by disabling the use of oneDNN optimizations in TensorFlow by setting the environment variable \"TF_ENABLE_ONEDNN_OPTS\" to 0 before importing TensorFlow. (see below code) os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'\r\n> \r\n> Explanation: The provided code generates random values for inputs to the LSTMBlockCell operation and runs it in a loop for 20 iterations. The LSTMBlockCell operation implements the long short-term memory (LSTM) algorithm, which is a type of recurrent neural network commonly used for sequence processing tasks. The inputs to the LSTMBlockCell operation include the current input values, the previous cell state and output values, and the weights and biases of the LSTM cell.\r\n\r\nassign this issue to me",
"created_at": "2023-03-12T06:12:00Z"
},
{
"body": "> > The issue can be resolved by disabling the use of oneDNN optimizations in TensorFlow by setting the environment variable \"TF_ENABLE_ONEDNN_OPTS\" to 0 before importing TensorFlow. (see below code) os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'\r\n> > Explanation: The provided code generates random values for inputs to the LSTMBlockCell operation and runs it in a loop for 20 iterations. The LSTMBlockCell operation implements the long short-term memory (LSTM) algorithm, which is a type of recurrent neural network commonly used for sequence processing tasks. The inputs to the LSTMBlockCell operation include the current input values, the previous cell state and output values, and the weights and biases of the LSTM cell.\r\n> \r\n> assign this issue to me\r\n\r\nimport os\r\nos.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'\r\nimport tensorflow as tf\r\nimport numpy as np\r\n\r\n# Set random values for inputs\r\nforget_bias = 112.66590343649887\r\ncell_clip = 67.12389445926587\r\nuse_peephole = False\r\nx = tf.saturate_cast(tf.random.uniform([2, 16], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\ncs_prev = tf.saturate_cast(tf.random.uniform([2, 0], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\nh_prev = tf.saturate_cast(tf.random.uniform([2, 0], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\nw = tf.saturate_cast(tf.random.uniform([16, 0], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\nwci = tf.saturate_cast(tf.random.uniform([5], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\nwcf = tf.saturate_cast(tf.random.uniform([16], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\nwco = tf.saturate_cast(tf.random.uniform([13], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\nb = tf.saturate_cast(tf.random.uniform([0], minval=0, maxval=64, dtype=tf.int64), dtype=tf.half)\r\n\r\n# Run LSTMBlockCell operation in a loop for 20 iterations\r\nfor _ in range(20):\r\n try:\r\n res = tf.raw_ops.LSTMBlockCell(\r\n forget_bias=forget_bias,\r\n cell_clip=cell_clip,\r\n use_peephole=use_peephole,\r\n x=x,\r\n cs_prev=cs_prev,\r\n h_prev=h_prev,\r\n w=w,\r\n wci=wci,\r\n wcf=wcf,\r\n wco=wco,\r\n b=b,\r\n )\r\n except:\r\n pass\r\n\r\nThis will be the corrected code for this issue.",
"created_at": "2023-03-12T06:12:35Z"
},
{
"body": "@shijy16 is this issue still open? I would like provide solution for the same.",
"created_at": "2023-03-16T19:31:21Z"
}
],
"number": 58270,
"title": "A check fail can be triggered in LSTMBlockCell"
}
|
{
"body": "Fixes #58270 ",
"number": 59534,
"review_comments": [
{
"body": "Since this is in a helper, you must also validate `ctx->Status` after each call of the helper, since `OP_REQUIRES_OK` in the end is just setting `ctx->Status` and then `return`-ing",
"created_at": "2023-02-14T00:36:59Z"
},
{
"body": "So I actually altered this in a more recent commit because the build fails when I call `OP_REQUIRES_OK` here with an `error: invalid use of void expression`. Instead, I implemented a check on `ctx->Status` like you're saying.",
"created_at": "2023-02-15T05:03:22Z"
},
{
"body": "This is adding a check fail back",
"created_at": "2023-03-19T21:05:21Z"
},
{
"body": "We should have the same behavior between CPU and GPU - so the test should be common. There may be differences in error messages, but this is usually handled by using a regex that accounts for both down below.",
"created_at": "2023-03-20T16:37:31Z"
},
{
"body": "use `assertRaisesRegex` to ensure we're triggering the desired error.",
"created_at": "2023-03-20T16:37:51Z"
},
{
"body": "my mistake. just removed",
"created_at": "2023-03-20T19:39:02Z"
},
{
"body": "This will now return an error if the tensor is empty - is this what we want? And is this a breaking change if the original CPU kernel previously returned empty tensors?\r\n\r\nWe should also add a test for this.",
"created_at": "2023-03-22T15:44:23Z"
},
{
"body": "Ok, yea, I'm actually not sure what we want here either, but `cs_prev_tensor` is the input that is causing the issue. From what I got testing, there are validations that prevent the other inputs from being empty unless this one is empty. I take it instead of returning an error we want to return an empty tensor for GPU as well as CPU? ",
"created_at": "2023-03-23T01:13:17Z"
},
{
"body": "Well, I guess that depends... if there's precedent here for returning an error for all empty tensors, then we can do that - and just hope that nobody was relying on the previous behavior on CPU. I'm okay with that.\r\n\r\nLet's add some tests for it though.",
"created_at": "2023-03-23T03:46:12Z"
},
{
"body": "Ok, sounds good. I'll add some tests. I did just confirm it fails with the invalid argument on CPU as well so the behavior is at least the same.",
"created_at": "2023-03-23T04:46:15Z"
},
{
"body": "Make the names more descriptive - like `testLSTMBlockCellEmptyInputRaisesError`\r\n\r\nYou can also put the inputs directly into the `gen_rnn_ops.lstm_block_cell` call, rather than defining them first and repeating them in `x=x, cs_prev=cs_prev,...`.\r\n\r\nI'm not sure you need two tests.",
"created_at": "2023-03-24T15:34:57Z"
}
],
"title": "Fix LSTMBlockCell Check Fail"
}
|
{
"commits": [
{
"message": "update error handling to avoid core dump"
},
{
"message": "add initial argument to OP_REQUIRES_OK"
},
{
"message": "stop kernel execution of validation fails"
},
{
"message": "fix logic checking status"
},
{
"message": "add unit tests"
},
{
"message": "Merge remote-tracking branch 'upstream/master' into lstm-block-cell-check-fail"
},
{
"message": "Merge remote-tracking branch 'upstream/master' into lstm-block-cell-check-fail"
},
{
"message": "set unit test to run only on gpu"
},
{
"message": "Merge remote-tracking branch 'upstream/master' into lstm-block-cell-check-fail"
},
{
"message": "Add null pointer check"
},
{
"message": "remove check"
},
{
"message": "add check for empty cs_prev_tensor"
},
{
"message": "update current and add new test case"
},
{
"message": "renamed test and removed unnecessary test"
},
{
"message": "Merge remote-tracking branch 'upstream/master' into\nlstm-block-cell-check-fail"
},
{
"message": "Merge remote-tracking branch 'upstream/master' into lstm-block-cell-check-fail"
}
],
"files": [
{
"diff": "@@ -424,6 +424,10 @@ class LSTMBlockCellOp : public OpKernel {\n ctx, cs_prev_tensor->dims() == 2,\n errors::InvalidArgument(\"cs_prev_tensor must be rank 2 but is rank \",\n cs_prev_tensor->dims(), \".\"));\n+ OP_REQUIRES(ctx, \n+ cs_prev_tensor->dim_size(0) > 0 && cs_prev_tensor->dim_size(1) > 0,\n+ errors::InvalidArgument(\"cs_prev_tensor is empty, has shape: (\",\n+ cs_prev_tensor->dim_size(0), \",\", cs_prev_tensor->dim_size(1), \").\"));\n OP_REQUIRES(\n ctx, h_prev_tensor->dims() == 2,\n errors::InvalidArgument(\"h_prev_tensor must be rank 2 but is rank \",\n@@ -1060,6 +1064,9 @@ class BlockLSTMOp : public OpKernel {\n cs_tensor.matrix<T>(), f_tensor.matrix<T>(), o_tensor.matrix<T>(),\n ci_tensor.matrix<T>(), co_tensor.matrix<T>(),\n gates_tensor.matrix<T>(), h_tensor.matrix<T>());\n+\n+ if (!ctx->status().ok()) return;\n+\n slicer.FinishTimeStep();\n }\n ",
"filename": "tensorflow/core/kernels/rnn/lstm_ops.cc",
"status": "modified"
},
{
"diff": "@@ -267,14 +267,14 @@ void LSTMBlockCellFpropWithCUDA(\n Eigen::divup(cell_size, static_cast<int>(block_dim_2d.y)));\n \n if (use_peephole) {\n- TF_CHECK_OK(GpuLaunchKernel(\n+ OP_REQUIRES_OK(ctx, GpuLaunchKernel(\n lstm_gates<T, true, gate_layout>, grid_dim_2d, block_dim_2d, 0,\n cu_stream, gates.data(), b.data(), cs_prev.data(), wci.data(),\n wcf.data(), wco.data(), o.data(), h.data(), ci.data(), cs.data(),\n co.data(), i.data(), f.data(), forget_bias, cell_clip, batch_size,\n cell_size));\n } else {\n- TF_CHECK_OK(GpuLaunchKernel(\n+ OP_REQUIRES_OK(ctx, GpuLaunchKernel(\n lstm_gates<T, false, gate_layout>, grid_dim_2d, block_dim_2d, 0,\n cu_stream, gates.data(), b.data(), cs_prev.data(), wci.data(),\n wcf.data(), wco.data(), o.data(), h.data(), ci.data(), cs.data(),",
"filename": "tensorflow/core/kernels/rnn/lstm_ops_gpu.cu.cc",
"status": "modified"
},
{
"diff": "@@ -24,6 +24,14 @@ limitations under the License.\n \n namespace tensorflow {\n \n+static string JoinedCopies(const string& s, int copies) {\n+ string res;\n+ for (int i = 0; i < copies; ++i) {\n+ strings::StrAppend(&res, i > 0 ? \";\" : \"\", s);\n+ }\n+ return res;\n+}\n+\n TEST(CudnnRNNOpsTest, ParamsSize_ShapeFn) {\n ShapeInferenceTestOp op(\"CudnnRNNParamsSize\");\n INFER_OK(op, \"[];[];[]\", \"[1]\");\n@@ -195,4 +203,83 @@ TEST(CudnnRNNOpsTest, ForwardV3Gru) {\n INFER_ERROR(\"Shape must be rank 1 \", op, \"[?,?,?];[?,?,?];[];[?];[]\");\n }\n \n+TEST(CudnnRNNOpsTest, LSTMBlockCell_ShapeFn) {\n+ ShapeInferenceTestOp op(\"LSTMBlockCell\");\n+\n+ // Last 6 inputs don't affect shape inference.\n+ string input_suffix = strings::StrCat(\";\", JoinedCopies(\"?\", 6));\n+\n+ // Rank checks.\n+ INFER_ERROR(\"must be rank 2\", op, \"[?];?\" + input_suffix);\n+ INFER_ERROR(\"must be rank 2\", op, \"?;[?]\" + input_suffix);\n+\n+ // Output\n+ INFER_OK(op, \"?;?\" + input_suffix, JoinedCopies(\"[?,?]\", 7));\n+ INFER_OK(op, \"[?,?];[?,?]\" + input_suffix, JoinedCopies(\"[d0_0,d1_1]\", 7));\n+}\n+\n+TEST(CudnnRNNOpsTest, BlockLSTM_ShapeFn) {\n+ ShapeInferenceTestOp op(\"BlockLSTM\");\n+\n+ TF_ASSERT_OK(NodeDefBuilder(\"test\", \"BlockLSTM\")\n+ .Input({\"seq_len_max\", 0, DT_INT64})\n+ .Input({\"x\", 0, DT_FLOAT})\n+ .Input({\"cs_prev\", 0, DT_FLOAT})\n+ .Input({\"h_prev\", 0, DT_FLOAT})\n+ .Input({\"w\", 0, DT_FLOAT})\n+ .Input({\"wci\", 0, DT_FLOAT})\n+ .Input({\"wcf\", 0, DT_FLOAT})\n+ .Input({\"wco\", 0, DT_FLOAT})\n+ .Input({\"b\", 0, DT_FLOAT})\n+ .Finalize(&op.node_def));\n+\n+ // Middle inputs don't affect shape inference.\n+ string infix = \";\" + JoinedCopies(\"?\", 6) + \";\";\n+\n+ // Rank checks.\n+ INFER_ERROR(\"must be rank 3\", op, \"?;[?]\" + infix + \"?\");\n+ INFER_ERROR(\"must be rank 1\", op, \"?;?\" + infix + \"[?,?]\");\n+\n+ // Output\n+ INFER_OK(op, \"?;?\" + infix + \"?\", JoinedCopies(\"[?,?,?]\", 7));\n+ INFER_OK(op, \"?;[?,?,?]\" + infix + \"?\", JoinedCopies(\"[d1_0,d1_1,?]\", 7));\n+ INFER_OK(op, \"?;[?,?,?]\" + infix + \"[?]\", JoinedCopies(\"[d1_0,d1_1,?]\", 7));\n+ INFER_OK(op, \"?;[?,?,?]\" + infix + \"[20]\", JoinedCopies(\"[d1_0,d1_1,5]\", 7));\n+\n+ // cell_size must be divisible by 4.\n+ INFER_ERROR(\"must be evenly divisible\", op, \"?;?\" + infix + \"[11]\");\n+}\n+\n+TEST(CudnnRNNOpsTest, BlockLSTMV2_ShapeFn) {\n+ ShapeInferenceTestOp op(\"BlockLSTMV2\");\n+\n+ TF_ASSERT_OK(NodeDefBuilder(\"test\", \"BlockLSTMV2\")\n+ .Input({\"seq_len_max\", 0, DT_INT64})\n+ .Input({\"x\", 0, DT_FLOAT})\n+ .Input({\"cs_prev\", 0, DT_FLOAT})\n+ .Input({\"h_prev\", 0, DT_FLOAT})\n+ .Input({\"w\", 0, DT_FLOAT})\n+ .Input({\"wci\", 0, DT_FLOAT})\n+ .Input({\"wcf\", 0, DT_FLOAT})\n+ .Input({\"wco\", 0, DT_FLOAT})\n+ .Input({\"b\", 0, DT_FLOAT})\n+ .Finalize(&op.node_def));\n+\n+ // Middle inputs don't affect shape inference.\n+ string infix = \";\" + JoinedCopies(\"?\", 6) + \";\";\n+\n+ // Rank checks.\n+ INFER_ERROR(\"must be rank 3\", op, \"?;[?]\" + infix + \"?\");\n+ INFER_ERROR(\"must be rank 1\", op, \"?;?\" + infix + \"[?,?]\");\n+\n+ // Output\n+ INFER_OK(op, \"?;?\" + infix + \"?\", JoinedCopies(\"[?,?,?]\", 7));\n+ INFER_OK(op, \"?;[?,?,?]\" + infix + \"?\", JoinedCopies(\"[d1_0,d1_1,?]\", 7));\n+ INFER_OK(op, \"?;[?,?,?]\" + infix + \"[?]\", JoinedCopies(\"[d1_0,d1_1,?]\", 7));\n+ INFER_OK(op, \"?;[?,?,?]\" + infix + \"[20]\", JoinedCopies(\"[d1_0,d1_1,5]\", 7));\n+\n+ // cell_size must be divisible by 4.\n+ INFER_ERROR(\"must be evenly divisible\", op, \"?;?\" + infix + \"[11]\");\n+}\n+\n } // end namespace tensorflow",
"filename": "tensorflow/core/ops/cudnn_rnn_ops_test.cc",
"status": "modified"
},
{
"diff": "@@ -1358,6 +1358,23 @@ def testLSTMBlockCellErrorHandling(self):\n forget_bias=forget_bias,\n cell_clip=cell_clip,\n use_peephole=use_peephole))\n+ \n+ @test_util.run_in_graph_and_eager_modes\n+ def testLSTMBlockCellEmptyInputRaisesError(self):\n+ with self.assertRaisesRegex(errors_impl.InvalidArgumentError, \"is empty\"):\n+ self.evaluate(\n+ gen_rnn_ops.lstm_block_cell(\n+ x=constant_op.constant(0, shape=[2, 16], dtype=dtypes.half),\n+ cs_prev=constant_op.constant(0, shape=[2, 0], dtype=dtypes.half),\n+ h_prev=constant_op.constant(0, shape=[2, 0], dtype=dtypes.half),\n+ w=constant_op.constant(0, shape=[16, 0], dtype=dtypes.half),\n+ wci=constant_op.constant(0, shape=[5], dtype=dtypes.half),\n+ wcf=constant_op.constant(0, shape=[16], dtype=dtypes.half),\n+ wco=constant_op.constant(0, shape=[13], dtype=dtypes.half),\n+ b=constant_op.constant(0, shape=[0], dtype=dtypes.half),\n+ forget_bias=112.66590343649887,\n+ cell_clip=67.12389445926587,\n+ use_peephole=False))\n \n @test_util.run_in_graph_and_eager_modes\n def testLSTMBlockCellGradErrorHandling(self):",
"filename": "tensorflow/python/kernel_tests/nn_ops/rnn_cell_test.py",
"status": "modified"
}
]
}
|
{
"body": " ### Issue Type\r\n\r\nBug\r\n\r\n### Current Behaviour?\r\n\r\nfrom the 2.11 version, we cannot serialize optimizers (the keras.optimizers.optimizer_experimental.optimizer.Optimizer hierarchy) anymore \r\ndue to its _distribution_strategy attribute of singleton type _DefaultDistributionStrategy\r\n\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\nthis was fine in 2.10.x:\r\n\r\n```shell\r\n\r\nimport tensorflow as tf\r\nfrom copy import deepcopy\r\n\r\noptimizer = tf.keras.optimizers.Adam()\r\ndeepcopy(optimizer)\r\n```\r\n\r\nwith 2.11.0 we have this error:\r\n```\r\nRuntimeError: Should only create a single instance of _DefaultDistributionStrategy\r\n```\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.11.0\r\n\r\n### OS Platform and Distribution\r\n\r\narchlinux/python3.10\r\n\r\n\r\n<details><summary>Click to expand!</summary> \r\n \r\n\r\n### Relevant log output\r\n\r\n```shell\r\nIn [4]: deepcopy(optimizer)\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\nCell In[4], line 1\r\n----> 1 deepcopy(optimizer)\r\n\r\nFile /usr/lib/python3.10/copy.py:172, in deepcopy(x, memo, _nil)\r\n 170 y = x\r\n 171 else:\r\n--> 172 y = _reconstruct(x, memo, *rv)\r\n 174 # If is its own copy, don't memoize.\r\n 175 if y is not x:\r\n\r\nFile /usr/lib/python3.10/copy.py:271, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)\r\n 269 if state is not None:\r\n 270 if deep:\r\n--> 271 state = deepcopy(state, memo)\r\n 272 if hasattr(y, '__setstate__'):\r\n 273 y.__setstate__(state)\r\n\r\nFile /usr/lib/python3.10/copy.py:146, in deepcopy(x, memo, _nil)\r\n 144 copier = _deepcopy_dispatch.get(cls)\r\n 145 if copier is not None:\r\n--> 146 y = copier(x, memo)\r\n 147 else:\r\n 148 if issubclass(cls, type):\r\n\r\nFile /usr/lib/python3.10/copy.py:231, in _deepcopy_dict(x, memo, deepcopy)\r\n 229 memo[id(x)] = y\r\n 230 for key, value in x.items():\r\n--> 231 y[deepcopy(key, memo)] = deepcopy(value, memo)\r\n 232 return y\r\n\r\nFile /usr/lib/python3.10/copy.py:153, in deepcopy(x, memo, _nil)\r\n 151 copier = getattr(x, \"__deepcopy__\", None)\r\n 152 if copier is not None:\r\n--> 153 y = copier(memo)\r\n 154 else:\r\n 155 reductor = dispatch_table.get(cls)\r\n\r\nFile /usr/lib/python3.10/site-packages/tensorflow/python/distribute/distribute_lib.py:3598, in _DefaultDistributionStrategy.__deepcopy__(***failed resolving arguments***)\r\n 3596 def __deepcopy__(self, memo):\r\n 3597 del memo\r\n-> 3598 raise RuntimeError(\"Should only create a single instance of \"\r\n 3599 \"_DefaultDistributionStrategy\")\r\n\r\nRuntimeError: Should only create a single instance of _DefaultDistributionStrategy\r\n```\r\n</details>",
"comments": [
{
"body": "Hi @jschueller !\r\nThanks for sharing your observation with respect to optimizer and Deepcopy.\r\nI could replicate this issue in 2.11 and nightly(2.12 dev) (not replicating in 2.9 and 2.10).\r\n\r\n@SuryanarayanaY !\r\nCould you look at this issue , Attached gist in [2.9](https://colab.sandbox.google.com/gist/mohantym/a20e7b3c8859d68909df1266932d2f74/git_58973_2-9.ipynb), [2.10](https://colab.sandbox.google.com/gist/mohantym/f35f26e9b9801ad9542e3fe6c5ddff1c/git_58973_2-9.ipynb#scrollTo=6KlMIwGndF-E), [2.11 ](https://colab.sandbox.google.com/gist/mohantym/e272bbea90e5c1fe91275e52d61f1877/git_58973_2-9.ipynb#scrollTo=6KlMIwGndF-E)and [2.12](https://colab.sandbox.google.com/gist/SuryanarayanaY/389599ba827c4c95d2d5430f60e90e6e/git_58973_2-12.ipynb) dev for reference. \r\n\r\nThank you!",
"created_at": "2022-12-22T04:35:46Z"
},
{
"body": "Hi @jschueller ,\r\n\r\nThanks for writing us. Yeah I can see the behaviour you mentioned.Could you please provide more context on how it affects Serialization of Optimizer ? \r\nI tried a simple `model.fit` and same model saved and loaded again and then trained using `reconstructed_model.fit` and done training again and i could not find any error w.r.t TF2.10 and 2.12(nightly) versions.Please refer to gists [2.10](https://colab.sandbox.google.com/gist/SuryanarayanaY/47ef1e5c038b3a664080bb804b33cd93/58973_2-10.ipynb) and [2.12(nightly)](https://colab.sandbox.google.com/gist/SuryanarayanaY/bab9b32f935c499761a56b275545c395/58973_2-12.ipynb). \r\n\r\nThank you!",
"created_at": "2022-12-29T13:04:18Z"
},
{
"body": "the save/load_model is a nice workaround indeed, but it doesnt apply easily in my case\r\n\r\nwe use deepcopy in a package called tensap to try incremental changes to our model:\r\nhttps://github.com/anthony-nouy/tensap/search?q=deepcopy\r\nand the recursive deepcopy of our objects ends up deepcopying a tensorflow Optimizer\r\n\r\n",
"created_at": "2023-01-01T12:06:37Z"
},
{
"body": "Hi, Could you please try if it is working with the legacy optimizer here https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/legacy/Optimizer and let us know if you still face an error. Thanks!",
"created_at": "2023-01-10T04:12:13Z"
},
{
"body": "yes, it works with tf.keras.optimizers.legacy.Adam()",
"created_at": "2023-01-10T07:53:50Z"
},
{
"body": "Thanks for confirming, since the `keras.optimizers` is implemented with new changes and does not have backward compatibility in most of the cases. \r\nIf you want old behavior you can always switch to `tf.keras.optimizers.legacy`.\r\nIf your issue is resolved, could you please close this issue. Thanks!",
"created_at": "2023-01-11T22:21:03Z"
},
{
"body": "The legacy algorithms will be deprecated at some point right ?\r\nThen I'll have no choice to use the new one and be stuck as well, so what do I do ?",
"created_at": "2023-01-12T08:06:05Z"
},
{
"body": "The previous optimizer code has been moved under `optimizers.legacy` to make use of old behavior, we don't have any plans to deprecate this but the implementations and code fixes will take place in new optimizer.",
"created_at": "2023-01-12T17:57:35Z"
},
{
"body": "Hi @chenmoneygithub, Can we make new optimizer to support deepcopy. Thanks!",
"created_at": "2023-01-12T18:28:15Z"
},
{
"body": "`deepcopy` is not supported due to the restriction on distribution strategy. you can actually bypass the issue by nullifying the `self._distribution_strategy`, i.e.,\r\n```\r\nstrategy = old_optimizer._distribution_strategy\r\nold_optimizer._distribution_strategy = None\r\nnew_optimizer = deepcopy(old_optimizer)\r\nnew_optimizer._distribution_strategy = strategy\r\n```\r\n\r\nAlso we will not deprecate the old optimizer, but not adding new features to it. ",
"created_at": "2023-01-12T18:53:33Z"
},
{
"body": "Possibly a stupid question, but is there a reason why `_DefaultDistributionStrategy` doesn't just return itself (the singleton instance) when deep-copied?",
"created_at": "2023-06-27T15:24:00Z"
},
{
"body": "@jschueller , Since the relevant PR is merged here https://github.com/keras-team/keras/pull/17463, Could you please close this issue. Thanks!",
"created_at": "2023-06-27T17:22:17Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58973\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58973\">No</a>\n",
"created_at": "2023-06-27T18:00:12Z"
}
],
"number": 58973,
"title": "cannot deepcopy Optimizer class anymore in tf>=2.11"
}
|
{
"body": "Closes #58973",
"number": 59322,
"review_comments": [],
"title": "OptimizerV2: Allow deepcopy"
}
|
{
"commits": [
{
"message": "OptimizerV2: Allow deepcopy\n\nCloses #58973"
}
],
"files": [
{
"diff": "@@ -17,6 +17,7 @@\n \n import abc\n import contextlib\n+from copy import deepcopy\n import functools\n import warnings\n \n@@ -413,6 +414,18 @@ def my_gradient_transformer(grads_and_vars):\n self.clipnorm, self.global_clipnorm))\n self.clipvalue = kwargs.pop(\"clipvalue\", None)\n \n+ def __deepcopy__(self, memo):\n+ cls = self.__class__\n+ result = cls.__new__(cls)\n+ memo[id(self)] = result\n+ for k, v in self.__dict__.items():\n+ # DistributionStrategy singleton cannot be serialized\n+ if k == \"_distribution_strategy\":\n+ continue\n+ setattr(result, k, deepcopy(v, memo))\n+ result._distribution_strategy = self._distribution_strategy\n+ return result\n+\n @property\n def clipnorm(self):\n \"\"\"`float` or `None`. If set, clips gradients to a maximum norm.\"\"\"",
"filename": "tensorflow/python/keras/optimizer_v2/optimizer_v2.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nDocumentation Bug\n\n### Source\n\nsource\n\n### Tensorflow Version\n\nTF 2.10\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\nwindows 11\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.8.15\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\nCUDA: 11.3 cuDNN 8.6.0\n\n### GPU model and memory\n\nRTX3060\n\n### Current Behaviour?\n\n```shell\ntf.image.convert_image_dtype(image, dtype, saturate=False, name=None), for image and dtype parameters can be uint8, uint16, uint32, uint64, int8, int16, int32, int64, float16, float32, float64, bfloat16. Then I set the image to complex64 and found it to work, so I don't know if the documentation is adequate.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport tensorflow as tf\r\n image = tf.constant([[[254 + 2j]], [[83]], [[72]]], dtype=tf.complex64)\r\n dtype = tf.float64\r\n out = tf.image.convert_image_dtype(image, dtype)\r\n print(out)\n```\n\n\n### Relevant log output\n\n```shell\nresult :\r\ntf.Tensor(\r\n [[[inf]]\r\n\r\n [[inf]]\r\n\r\n [[inf]]], shape=(3, 1, 1), dtype=float64)\n```\n</details>",
"comments": [
{
"body": "I think that an exception must be raised here. if not image.dtype.complex64 must be added in the convert_image_dtype method\r\n\r\nIn case of your code, it is written in the docs that when casting from imaginary to real, tensorflow only returns the real part. Hence, no error was thrown.",
"created_at": "2022-12-02T08:45:51Z"
},
{
"body": "@SuryanarayanaY \r\nI was able to reproduce the issue on Colab using Tf v2.11. Please find the gist [here](https://colab.research.google.com/gist/tiruk007/fcaf02ffba54de26fdd17bb12ebc4cac/58699.ipynb) for reference .\r\n\r\nThank you!",
"created_at": "2022-12-13T20:25:22Z"
},
{
"body": "Hi @triumph-wangyuyang ,\r\n\r\nThanks for highlighting the issue. I also validated the `dtype `argument to `complex64` & `complex128` and it is raising Attribute Error as per attached [gist](https://colab.research.google.com/gist/SuryanarayanaY/f5c8fc6f3a7967edaabb9e610aaf009d/58699-r1.ipynb). But for image argument it is not raising error and generated results seems to be random.We will go through it and update after review.\r\n\r\nThankyou!\r\n",
"created_at": "2022-12-14T16:56:03Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58699\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58699\">No</a>\n",
"created_at": "2023-03-15T22:18:51Z"
},
{
"body": "I also observed the following API aliases can cause the same issue in older versions of tensorflow.\r\nUsers should be cautious when using them on both CPU and GPU up to tensorflow 2.12.0 (v2.12.0-rc1-12-g0db597d0d75).\r\n\r\n- `(tf.image.convert_image_dtype)`, `tf.compat.v1.image.convert_image_dtype`\r\n\r\n<details>\r\n <summary>Code to reproduce the issue in <code>tf.compat.v1.image.convert_image_dtype</code> in older versions</summary>\r\n\r\n```python\r\nimport tensorflow as tf\r\nprint(tf.version.GIT_VERSION, tf.version.VERSION, flush=True)\r\nprint(tf.config.list_physical_devices(), flush=True)\r\n\r\n\r\nimage = tf.constant([[[254 + 2j]], [[83]], [[72]]], dtype=tf.complex64)\r\ndtype = tf.float64\r\nout = tf.compat.v1.image.convert_image_dtype(image, dtype)\r\nprint(out)\r\n```\r\n\r\nOn my GPU machine, the <code>inf</code> values are produced:\r\n\r\n```text\r\nv2.12.0-rc1-12-g0db597d0d75 2.12.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\ntf.Tensor(\r\n[[[inf]]\r\n\r\n [[inf]]\r\n\r\n [[inf]]], shape=(3, 1, 1), dtype=float64)\r\n```\r\n\r\nThis behavior is also reproducible on my CPU machine:\r\n\r\n```text\r\nv2.12.0-rc1-12-g0db597d0d75 2.12.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')]\r\ntf.Tensor(\r\n[[[inf]]\r\n\r\n [[inf]]\r\n\r\n [[inf]]], shape=(3, 1, 1), dtype=float64)\r\n```\r\n</details>\r\n\r\nIt seems to be fixed in tensorflow 2.13.0 (v2.13.0-rc2-7-g1cb1a030a62) and later versions.\r\n",
"created_at": "2023-09-12T09:17:42Z"
}
],
"number": 58699,
"title": "Question about tf.image.convert_image_dtype parameter type?"
}
|
{
"body": "At present the API tf.image.convert_image_dtype supports data types (for image and dtype) of uint8, uint16, uint32, uint64, int8, int16, int32, int64, float16, float32, float64, bfloat16 only.However passing complex data types like complex64,complex128 doesn't create error but outputs random(incorrect) results.\r\nHence raising this PR so that this API validate inputs for any complex dtypes and raise the Attribute Error.Please also refer to the attached [gist](https://colab.research.google.com/gist/SuryanarayanaY/bae13f4fb3a35afaa6be958bb8b2f273/tf-image-convert_image_dtype-testcase-58699.ipynb).\r\nRequest for review and needful.\r\nFixes #58699\r\nThank you!",
"number": 59313,
"review_comments": [
{
"body": "This doesn't capture the previous conditions.\r\nPreviously, this would fail for:\r\n```\r\n[tf.bool, tf.complex128, tf.complex64, tf.qint16, tf.qint32, tf.qint8, tf.quint16, tf.quint8, tf.resource, tf.string, tf.variant]\r\n```\r\nNote that in particular, `tf.complex64/128` are not `.is_floating`, so is already included. The only thing missing is checking the same conditions for `image.dtype`.",
"created_at": "2023-02-15T16:58:09Z"
},
{
"body": "In this case adding the below code to the original code shall validate the image dtype.\r\n```\r\nif not image.dtype.is_floating and not image.dtype.is_integer:\r\n raise AttributeError('Image dtype must be either floating point or integer')\r\n```\r\n(Or)\r\n \r\nTo validate both image dtype and output dtype we can use single block as like below by deleting lines 2491 & 2492 from original code.\r\n\r\n```\r\nif (not dtype.is_floating and not dtype.is_integer) or (not image_dtype.is_floating and not image_dtype.is_integer):\r\n raise AttributeError('data type must be either floating point or integer')\r\n```\r\n\r\nPlease refer to attached [gist](https://colab.research.google.com/gist/SuryanarayanaY/1eed84e157e6b1a29753b654f23fb21b/tf-image-convert_image_dtype-testcase-58699-_r2.ipynb).",
"created_at": "2023-02-22T17:54:28Z"
},
{
"body": "Correct",
"created_at": "2023-02-22T18:58:01Z"
}
],
"title": "convert_image_dtype to handle complex dtype"
}
|
{
"commits": [
{
"message": "Update api_def_Angle.pbtxt\n\nThe Example code shown in the api_def_Angle.pbtxt still using 1.x version code which will throw AttributeError: module 'tensorflow' has no attribute 'angle' if used in 2.x. Hence updating the example code suitable to 2.x version. Please also refer attached gist for details. https://colab.research.google.com/gist/SuryanarayanaY/c57df5a25572e7daebea235c633ce593/tf-math-angle.ipynb"
},
{
"message": "update convert_image_dtype API\n\nAt present the API tf.image.convert_image_dtype supports data types (for image and dtype) of uint8, uint16, uint32, uint64, int8, int16, int32, int64, float16, float32, float64, bfloat16 only.However passing complex data types like complex64,complex128 doesn't create error but outputs random(incorrect) results.\r\nHence raising this PR so that this API validate inputs for any complex dtypes and raise the Attribute Error.Please also refer to the attached gist.\r\nhttps://colab.research.google.com/gist/SuryanarayanaY/bae13f4fb3a35afaa6be958bb8b2f273/tf-image-convert_image_dtype-testcase-58699.ipynb\r\nRequest for review and needful.\r\nThank you!"
},
{
"message": "Update image_ops_impl.py\n\nUpdated the code to validate image.dtype to be either float or integer."
}
],
"files": [
{
"diff": "@@ -13,7 +13,7 @@ For example:\n \n ```\n # tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j]\n-tf.angle(input) ==> [2.0132, 1.056]\n+tf.math.angle(input) ==> [2.0132, 1.056]\n ```\n \n @compatibility(numpy)",
"filename": "tensorflow/core/api_def/base_api/api_def_Angle.pbtxt",
"status": "modified"
},
{
"diff": "@@ -2490,6 +2490,8 @@ def convert_image_dtype(image, dtype, saturate=False, name=None):\n dtype = dtypes.as_dtype(dtype)\n if not dtype.is_floating and not dtype.is_integer:\n raise AttributeError('dtype must be either floating point or integer')\n+ if not image.dtype.is_floating and not image.dtype.is_integer:\n+ raise AttributeError('image dtype must be either floating point or integer')\n if dtype == image.dtype:\n return array_ops.identity(image, name=name)\n ",
"filename": "tensorflow/python/ops/image_ops_impl.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Have you reproduced the bug with TF nightly?\r\n\r\nNo\r\n\r\n### Source\r\n\r\nsource\r\n\r\n### Tensorflow Version\r\n\r\n2.13.0\r\n\r\n### Custom Code\r\n\r\nYes\r\n\r\n### OS Platform and Distribution\r\n\r\nUbuntu 22.04\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.9\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\n_No response_\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\nSegfault\r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import bincount_ops\r\n\r\ntry:\r\n arg_0_tensor = tf.random.uniform([3, 1], minval=-256, maxval=257, dtype=tf.int32)\r\n arg_0 = tf.identity(arg_0_tensor)\r\n weights = None\r\n minlength = 2\r\n maxlength = 0\r\n dtype = \"float32\"\r\n axis = -1\r\n binary_output = True\r\n out = bincount_ops.bincount(\r\n arg_0,\r\n weights=weights,\r\n minlength=minlength,\r\n maxlength=maxlength,\r\n dtype=dtype,\r\n axis=axis,\r\n binary_output=binary_output,\r\n )\r\nexcept Exception as e:\r\n print(\"Error:\" + str(e))\r\n\r\n```\r\n```\r\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import bincount_ops\r\ntry:\r\n arg_0_tensor = tf.random.uniform([3, 1], minval=-256, maxval=257, dtype=tf.int32)\r\n arg_0 = tf.identity(arg_0_tensor)\r\n weights = None\r\n minlength = 4\r\n maxlength = 0\r\n dtype = \"float32\"\r\n axis = -1\r\n binary_output = True\r\n out = bincount_ops.bincount(arg_0,weights=weights,minlength=minlength,maxlength=maxlength,dtype=dtype,axis=axis,binary_output=binary_output,)\r\nexcept Exception as e:\r\n print(\"Error:\"+str(e))\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\nError:maxlength: Tensor conversion requested dtype int32 for Tensor with dtype float32: <tf.Tensor: shape=(), dtype=float32, numpy=0.5696368>\r\nError:arr: Tensor conversion requested dtype int32 for Tensor with dtype int64: <tf.Tensor: shape=(10000,), dtype=int64, numpy=array([-123, 137, 225, ..., -163, -81, 75])>\r\nError:Unsupported value for argument axis=-3. Only 0 and -1 are currently supported.\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nError:{{function_node __wrapped__Bincount_device_/job:localhost/replica:0/task:0/device:CPU:0}} Input arr must be non-negative! [Op:Bincount]\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nError:arr: Tensor conversion requested dtype int32 for Tensor with dtype int8: <tf.Tensor: shape=(10000,), dtype=int8, numpy=array([105, -62, 101, ..., 105, -43, -41], dtype=int8)>\r\nError:arr: Tensor conversion requested dtype int32 for Tensor with dtype int64: <tf.Tensor: shape=(10000,), dtype=int64, numpy=array([-159, -131, 160, ..., 169, 71, -14])>\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nError:arr: Tensor conversion requested dtype int32 for Tensor with dtype bool: <tf.Tensor: shape=(), dtype=bool, numpy=False>\r\nError:arr: Tensor conversion requested dtype int32 for Tensor with dtype int64: <tf.Tensor: shape=(10000,), dtype=int64, numpy=array([ 162, 215, -202, ..., -21, -92, 236])>\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nError:{{function_node __wrapped__Bincount_device_/job:localhost/replica:0/task:0/device:CPU:0}} Input arr must be non-negative! [Op:Bincount]\r\nError:{{function_node __wrapped__Bincount_device_/job:localhost/replica:0/task:0/device:CPU:0}} Input arr must be non-negative! [Op:Bincount]\r\nError:{{function_node __wrapped__Bincount_device_/job:localhost/replica:0/task:0/device:CPU:0}} Input arr must be non-negative! [Op:Bincount]\r\nError:Value for attr 'T' of uint32 is not in the list of allowed values: int32, int64, float, double\r\n\t; NodeDef: {{node Bincount}}; Op<name=Bincount; signature=arr:int32, size:int32, weights:T -> bins:T; attr=T:type,allowed=[DT_INT32, DT_INT64, DT_FLOAT, DT_DOUBLE]> [Op:Bincount]\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nError:arr: Tensor conversion requested dtype int32 for Tensor with dtype int64: <tf.Tensor: shape=(10000,), dtype=int64, numpy=array([-98, 135, 191, ..., 129, 218, 106])>\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nError:arr: Tensor conversion requested dtype int32 for Tensor with dtype int64: <tf.Tensor: shape=(1000,), dtype=int64, numpy=\r\narray([ -60, 157, 215, 79, 195, 18, -112, -82, -116, 31, 220,\r\n 218, 175, -7, -152, -37, -190, -253, 58, 63, 128, 117,\r\n -189, -4, -97, 9, 237, -33, -235, -211, 2, -244, 104,\r\n 5, -158, 144, 165, -19, -42, 234, -65, -207, -15, 81,\r\n 206, 135, -119, 97, 173, 254, 254, 122, -175, 229, -256,\r\n 61, 204, -32, -213, -238, -23, -221, -60, -229, 243, -9,\r\n 50, -243, -34, 103, -233, 183, 171, 228, -122, 234, 94,\r\n 161, -255, 184, -84, 215, -62, 69, 202, 64, -159, -256,\r\n -133, 127, -133, 135, -105, 129, 114, 49, -217, -209, 133,\r\n 252, 25, 66, 24, 208, -222, -206, -84, 58, 55, -130,\r\n 42, -23, 94, 68, 119, -53, -191, -146, 129, 98, -74,\r\n 172, 143, -93, 121, 175, 196, -245, -79, 26, 46, 132,\r\n -37, 141, 118, -160, -74, 108, -62, -241, 130, -173, 241,\r\n 71, 242, 34, 237, -4, -230, -122, -221, -185, 246, 39,\r\n -58, 42, 2, -252, 108, -246, -135, 211, 66, 18, 196,\r\n -146, 172, -87, 119, -91, -137, -120, 146, -139, 116, -25,\r\n -244, 19, 52, -241, 229, 177, -187, -89, -189, 41, -175,\r\n 31, 183, 191, 64, 113, 68, 114, -186, -73, -115, -38,\r\n -248, -228, 51, -1, 60, 150, 124, 169, -21, 202, -71,\r\n 112, 192, 182, 34, -95, 152, 58, 179, 23, 133, 38,\r\n 218, -154, 39, -70, -57, -230, -164, 14, 199, -182, 101,\r\n -241, -91, -133, -13, 240, 76, 142, -16, 3, 22, 249,\r\n -197, -101, -1, 155, -184, 178, -146, 92, -70, -154, -145,\r\n -112, -135, -233, -95, -7, -204, -99, 149, -201, -94, -15,\r\n 89, 31, 127, -14, -145, -191, -11, 23, -73, 238, -11,\r\n -93, 199, 145, 119, 18, 114, 240, 118, -101, -6, 63,\r\n -52, -50, 69, -77, -16, -91, -245, -98, -72, -27, 46,\r\n 241, 11, 239, 212, 252, -124, -213, -19, 104, -203, 70,\r\n 147, 94, -28, 99, -129, 20, -66, 175, -88, 244, 35,\r\n 117, -136, -14, 38, -216, 15, 69, -50, -206, -95, -203,\r\n 9, -15, -40, 183, 176, 210, 100, 73, -13, -76, -52,\r\n -249, -131, 255, 118, 175, -166, -211, 20, 211, 148, 164,\r\n 249, 252, -67, 164, -240, -174, 184, -64, -223, 35, 41,\r\n -151, 57, -140, 86, 93, -206, -188, -126, 117, -50, -246,\r\n -18, -251, -145, 79, -193, -120, -50, -32, 118, -215, -55,\r\n -9, 62, 190, -61, -3, 231, 133, -226, 11, -205, -155,\r\n -115, 125, 239, -186, 50, 179, 217, 48, 214, 171, 246,\r\n -243, 201, 50, 180, -35, 52, 1, -215, 183, -247, -138,\r\n 160, 249, 101, 150, -99, 43, -210, -180, -44, -12, 59,\r\n 124, 27, -247, 27, -19, -12, -172, -165, 190, 231, 52,\r\n 206, 170, 236, -132, -54, 163, -188, 235, -64, 101, 227,\r\n -188, 54, -119, 251, -199, 249, 26, -237, -170, 29, 87,\r\n 183, -139, -160, -119, 130, 195, -148, -85, 217, 53, -186,\r\n 243, -239, 132, 242, -56, 118, 102, -173, 209, -79, -80,\r\n 224, -92, 143, 127, -117, 72, -81, -159, 110, -45, 5,\r\n -97, 154, 123, -36, -144, 198, -119, -187, 37, 178, 16,\r\n 197, 240, 31, 26, -85, 60, -226, -145, -31, 221, -181,\r\n 193, -10, -112, -197, -203, 166, -111, -93, -189, -131, -226,\r\n 155, -124, -136, 92, 97, 124, 52, 209, 21, -81, 12,\r\n -71, -221, 54, -183, 96, 87, -202, 135, -83, 233, 56,\r\n 256, -27, -69, -42, 242, -151, -61, 209, 194, -137, -211,\r\n 197, 33, 24, 95, 1, 49, -168, 220, -188, 205, 206,\r\n 214, 59, -55, 131, -182, 108, 211, 15, -4, 82, -86,\r\n -135, 67, -44, 141, -52, -205, 90, -32, -128, -112, 213,\r\n -181, -134, 13, 195, 248, -81, 59, -148, -83, 132, -7,\r\n 158, 20, 202, 154, -147, -155, 8, -65, 59, 229, -16,\r\n -221, -227, -130, -104, -15, -194, 53, 80, 33, 128, 165,\r\n 153, -151, -83, -188, 72, -104, 15, -62, -31, 213, -4,\r\n 156, -170, 12, -70, 131, 154, -126, -230, 16, 195, -178,\r\n -252, 0, 20, -19, 192, -181, 85, 168, 195, -164, 156,\r\n -176, -81, -126, -123, 96, 30, 79, 247, -27, 54, 120,\r\n 100, 126, 108, -117, 122, 78, -108, 226, 77, 10, 53,\r\n -208, -35, -239, -149, -84, 14, 98, -179, 75, 172, -43,\r\n -209, -36, 239, -118, -232, -200, -230, -167, -9, -224, 195,\r\n -48, 224, 152, -20, -8, 112, -89, 159, 47, -27, -212,\r\n 51, 169, 121, 192, -236, -254, -252, -240, 95, 217, -17,\r\n -88, 70, 191, 59, -185, 234, 71, 83, -61, -147, 176,\r\n -61, 28, 44, -225, 8, -186, 77, 103, -186, -243, 72,\r\n 54, 0, 210, 88, 52, -182, 247, -181, 31, 164, 25,\r\n -144, 54, -57, 203, 15, 42, 207, -89, 12, -109, 28,\r\n -242, 110, 170, -25, 182, 20, 73, -135, -104, 221, -146,\r\n -199, -186, -231, -28, -68, 9, 158, 57, 78, -116, -167,\r\n -1, 117, -250, -118, 19, 171, 15, -73, -102, 137, 178,\r\n 166, 255, -59, 208, -77, -217, 239, -67, 84, -167, 194,\r\n 161, 222, -97, -193, 248, -145, 25, -139, -35, 226, 21,\r\n 91, -98, 189, -96, -14, -214, 218, 236, -32, -156, 49,\r\n -108, 81, -7, -160, 74, 17, -221, -160, 130, 39, 97,\r\n -108, 55, -23, -104, 191, -216, -175, 134, 109, 43, -102,\r\n -166, 73, -142, 240, 78, -112, 145, 67, 74, -207, 180,\r\n 100, 163, -148, -202, -122, 55, 70, -142, -197, -87, -254,\r\n -62, -129, -65, -106, -204, 140, 30, 160, -13, -167, -103,\r\n 250, -57, -123, 169, -64, -183, 19, -76, -207, -153, -128,\r\n 111, -85, -58, -148, -104, 91, 183, 212, 126, 122, 60,\r\n -207, -62, -201, 175, 221, 195, -189, -31, -193, -216, 165,\r\n 36, 240, -202, 156, -237, -94, -138, -82, -130, -73, -145,\r\n 24, 21, 237, 57, -213, -31, 187, 99, -173, -139, 181,\r\n -171, -62, 171, 178, -245, -75, -235, 20, -7, -15, 91,\r\n 199, -37, -245, -237, 164, -181, -42, 119, -1, 114, -200,\r\n 209, -42, 12, 113, -31, 31, -162, 191, 83, 217, 70,\r\n -2, -155, 57, 11, 232, -89, 163, -243, -113, 194, 95,\r\n -156, 251, -76, -154, -225, -126, 234, 148, -96, -105])>\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nError:Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.\r\nSegmentation fault\r\n\r\n```\r\n```\r\n</details>",
"comments": [
{
"body": "@nimashiri This issue will be closed once the PR is merged.\r\nThank you!",
"created_at": "2023-01-18T16:50:50Z"
},
{
"body": "@learning-to-play ",
"created_at": "2023-02-07T19:49:45Z"
},
{
"body": "> @learning-to-play\r\n\r\nSegfault exists on 2.13.0",
"created_at": "2023-09-17T16:04:27Z"
},
{
"body": "@dmc1778 It is good to follow up with the issue assignee who can help triage it to the right person.\r\n@sachinprasadhs Can you work with the TF Ops team to find the right person?",
"created_at": "2023-09-17T16:16:00Z"
}
],
"number": 59130,
"title": "Segfault on tensorflow.python.ops.bincount_ops.bincount"
}
|
{
"body": "This PR tries to address the issue raised in #59130 where bincount will crash when value is less than zero.\r\n\r\nThis PR fixes #59130.\r\n\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 59247,
"review_comments": [
{
"body": "positive -> non-negative?",
"created_at": "2023-01-13T00:16:36Z"
},
{
"body": "nit: value -> Value",
"created_at": "2023-01-13T00:17:04Z"
},
{
"body": "nit: arg_0 -> value, as other args are not using \"arg_x\" format",
"created_at": "2023-01-13T00:19:04Z"
},
{
"body": "Thanks @vufg. Updated.",
"created_at": "2023-01-13T08:49:56Z"
},
{
"body": "@vufg Updated.",
"created_at": "2023-01-13T08:50:14Z"
},
{
"body": "This isn't thread-safe. We may need an initial `in.minimum()` reduction (or `argmin()` if you want the bad input index) prior to launching the parallel-for.",
"created_at": "2023-01-17T16:47:55Z"
},
{
"body": "Can you put most of the values directly in the function call?\r\n\r\nAnd for the dtype, use `dtypes.float32` instead of the string.\r\n\r\nThanks!",
"created_at": "2023-02-01T18:12:47Z"
}
],
"title": "Fix bincount crash when value < 0"
}
|
{
"commits": [
{
"message": "Fix bincount crash when value < 0\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for bincount crash when value < 0\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Adjust PR for review feedback\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Address review comment to maintain thread-safety"
},
{
"message": "Address review feedback\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -172,6 +172,13 @@ struct BincountReduceFunctor<CPUDevice, Tidx, T, binary_output> {\n const typename TTypes<T, 2>::ConstTensor& weights,\n typename TTypes<T, 2>::Tensor& out,\n const Tidx num_bins) {\n+ Eigen::Tensor<Tidx, 0, Eigen::RowMajor> value_min_tensor = in.minimum();\n+ auto value_min = value_min_tensor();\n+ if (value_min < 0) {\n+ return errors::InvalidArgument(\n+ \"Value must be non-negative, got min value \", value_min);\n+ }\n+\n const int num_rows = out.dimension(0);\n const int num_cols = in.dimension(1);\n ThreadPool* thread_pool =",
"filename": "tensorflow/core/kernels/bincount_op.cc",
"status": "modified"
},
{
"diff": "@@ -178,6 +178,16 @@ def test_invalid_inputs(self):\n weights=weights,\n binary_output=binary_output))\n \n+ def test_negative_value(self):\n+ with self.assertRaises(errors.InvalidArgumentError):\n+ value_tensor = random_ops.random_uniform(\n+ [3, 1], minval=-256, maxval=257, dtype=dtypes.int32)\n+ value = array_ops.identity(value_tensor)\n+ out = bincount_ops.bincount(\n+ value, weights=None, minlength=2, maxlength=0,\n+ dtype=dtypes.float32, axis=-1, binary_output=True)\n+ self.evaluate(out)\n+\n \n class BincountOpTest(test_util.TensorFlowTestCase, parameterized.TestCase):\n ",
"filename": "tensorflow/python/kernel_tests/math_ops/bincount_op_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Have you reproduced the bug with TF nightly?\n\nYes\n\n### Source\n\nbinary\n\n### Tensorflow Version\n\n2.11.0\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nLinux\n\n### Mobile device\n\nN/A\n\n### Python version\n\n3.8\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nWhen setting the `TF_CPP_VLOG_FILENAME` env var it would be great to have all logs available almost immediately when written by the TF C++ library. At the moment the output file on non-Android platforms is opened with buffering which delays output:\r\nhttps://github.com/tensorflow/tensorflow/blob/548964d24666f9550e9a40249a917145bf9670fb/tensorflow/tsl/platform/default/logging.cc#L183-L191\r\n\r\nI think this works with stderr at the moment as the default behavior of fopen with stderr on most platforms is to flush after each line.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nHere's an example using a named pipe (fifo):\r\n\r\n\r\nrm test_fifo 2>/dev/null;\r\nmkfifo test_fifo;\r\n( TF_CPP_VLOG_FILENAME=$(readlink -f test_fifo) python -c 'import time; import tensorflow; time.sleep(5)' ) &\r\ndate;\r\ncat test_fifo | ts;\r\nrm test_fifo;\n```\n\n\n### Relevant log output\n\n```shell\nProduces:\r\n\r\n[1]+ Done ( TF_CPP_VLOG_FILENAME=$(readlink -f test_fifo) python -c 'import time; import tensorflow; time.sleep(5)' )\r\n[1] 20384\r\nThu Jan 5 14:35:28 PST 2023\r\nJan 05 14:35:36 2023-01-05 14:35:30.119875: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/nvidia/lib64:\r\nJan 05 14:35:36 2023-01-05 14:35:30.119923: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/nvidia/lib64:\r\nJan 05 14:35:36 2023-01-05 14:35:30.119929: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.\r\nJan 05 14:35:36 2023-01-05 14:35:29.256014: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA\r\nJan 05 14:35:36 To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\r\n```\r\n\r\nNotice the 5 second gap between the start of the Python process and the TF logs. This is due to the log buffer only being flushed on TF process close here:\r\nhttps://github.com/tensorflow/tensorflow/blob/548964d24666f9550e9a40249a917145bf9670fb/tensorflow/tsl/platform/default/logging.cc#L193-L197\n```\n</details>",
"comments": [
{
"body": "Essentially I would love to see:\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/548964d24666f9550e9a40249a917145bf9670fb/tensorflow/tsl/platform/default/logging.cc#L574-L576\r\n\r\nextended with:\r\n\r\n```c++\r\nfflush(vlog_file.FilePtr());\r\n```",
"created_at": "2023-01-05T22:46:11Z"
},
{
"body": "Hi @stewartmiles !\r\n\r\nThanks for the PR #59116 . This issue will be closed once It is merged.\r\n\r\nThank you.",
"created_at": "2023-01-06T10:58:22Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59115\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/59115\">No</a>\n",
"created_at": "2023-01-17T10:03:17Z"
}
],
"number": 59115,
"title": "TFDefaultLogSink::Send() uses buffered writes leading to delays writing to log file"
}
|
{
"body": "Fixes #59115",
"number": 59116,
"review_comments": [],
"title": "Always flush after each log."
}
|
{
"commits": [
{
"message": "Always flush after each log.\n\nFixes #59115"
}
],
"files": [
{
"diff": "@@ -574,6 +574,7 @@ void TFDefaultLogSink::Send(const TFLogEntry& entry) {\n fprintf(vlog_file.FilePtr(), \"%s.%06d: %c%s %s:%d] %s\\n\", time_buffer,\n micros_remainder, sev, tid_buffer, entry.FName().c_str(),\n entry.Line(), entry.ToString().c_str());\n+ fflush(vlog_file.FilePtr()); // Ensure logs are written immediately.\n #endif // PLATFORM_POSIX_ANDROID\n }\n ",
"filename": "tensorflow/tsl/platform/default/logging.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nbinary\n\n### Tensorflow Version\n\ntf 2.9 and 2.12.0-dev20221018\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nLinux Ubuntu 20.04\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.8\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\nCUDA 11.5\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nA check fail can be triggerred in GRUBlockCell, which can lead to a crash.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport tensorflow as tf\r\nimport numpy as np\r\nprint(tf.__version__)\r\nfor _ in range(20):\r\n try:\r\n x = tf.random.uniform([1, 0, 1], dtype=tf.float32)\r\n h_prev = tf.random.uniform([1, 1, 1], dtype=tf.float32)\r\n w_ru = tf.random.uniform([1, 2, 1, 1, 1, 1], dtype=tf.float32)\r\n w_c = tf.random.uniform([1, 1, 1], dtype=tf.float32)\r\n b_ru = tf.random.uniform([2], dtype=tf.float32)\r\n b_c = tf.random.uniform([1], dtype=tf.float32)\r\n res = tf.raw_ops.GRUBlockCell(\r\n x=x,\r\n h_prev=h_prev,\r\n w_ru=w_ru,\r\n w_c=w_c,\r\n b_ru=b_ru,\r\n b_c=b_c,\r\n )\r\n except:\r\n pass\n```\n\n\n### Relevant log output\n\n```shell\nF tensorflow/core/framework/tensor_shape.cc:45] Check failed: NDIMS == dims() (2 vs. 3)Asking for tensor of 2 dimensions from a tensor of 3 dimensions\r\nAborted (core dumped)\n```\n</details>",
"comments": [
{
"body": "The same issue exists in GRUBlockCellGrad too.\r\n\r\nCode:\r\n\r\n````\r\nimport tensorflow as tf\r\nimport numpy as np\r\nprint(tf.__version__)\r\nfor _ in range(20):\r\n try:\r\n x = tf.random.uniform([4, 0, 1], dtype=tf.float32)\r\n h_prev = tf.random.uniform([4, 1, 1], dtype=tf.float32)\r\n w_ru = tf.random.uniform([1, 2, 1], dtype=tf.float32)\r\n w_c = tf.random.uniform([1, 1, 1], dtype=tf.float32)\r\n b_ru = tf.random.uniform([2], dtype=tf.float32)\r\n b_c = tf.random.uniform([1], dtype=tf.float32)\r\n r = tf.random.uniform([4, 1, 1], dtype=tf.float32)\r\n u = tf.random.uniform([4, 1, 1], dtype=tf.float32)\r\n c = tf.random.uniform([4, 1, 1], dtype=tf.float32)\r\n d_h = tf.random.uniform([4, 1, 1], dtype=tf.float32)\r\n res = tf.raw_ops.GRUBlockCellGrad(\r\n x=x,\r\n h_prev=h_prev,\r\n w_ru=w_ru,\r\n w_c=w_c,\r\n b_ru=b_ru,\r\n b_c=b_c,\r\n r=r,\r\n u=u,\r\n c=c,\r\n d_h=d_h,\r\n )\r\n except:\r\n pass\r\n````\r\n\r\noutput:\r\n\r\n````\r\nF tensorflow/core/framework/tensor_shape.cc:45] Check failed: NDIMS == dims() (2 vs. 3)Asking for tensor of 2 dimensions from a tensor of 3 dimensions\r\nAborted (core dumped)\r\n````\r\n",
"created_at": "2022-10-22T13:08:24Z"
},
{
"body": "@sushreebarsa \r\nI was able to reproduce the issue on Colab using TF v2.10 . Please find the attached gists [GPU](https://colab.research.google.com/gist/tiruk007/8a35ab00ca7a7d4aed412fc465dc237b/58261gpu.ipynb) and [CPU](https://colab.research.google.com/gist/tiruk007/ce4f5549154d6066e7c96111453f06b4/58261.ipynb) for reference.\r\n\r\nThank you!",
"created_at": "2022-10-26T19:25:58Z"
},
{
"body": "`tf.raw_ops` are basically designed to be consumed by downstream library users, not end users.\r\nUsually, these APIs are less strict in terms of validation etc which is fine since only library writers are supposed to use these symbols.\r\nIf available, please prefer high level API for general use case scenarios. Thanks!",
"created_at": "2022-12-09T07:58:16Z"
},
{
"body": "While these are internal APIs, the check failure could lead to denial of service. In the past this used to be considered a vulnerability, but since the impact is bounded and preventable, now the policy is for these to be files as issues and resolved whenever someone from community wants to pick them up (they're very good first issues). Please don't auto-close these!",
"created_at": "2022-12-09T17:06:07Z"
},
{
"body": "Hi @mihaimaruseac, can I work on this issue? I will need clues to solve it but I would like to contribute to Tensorflow!",
"created_at": "2022-12-11T18:01:57Z"
},
{
"body": "Sure. Please look in `tensor_shape.cc`: https://github.com/tensorflow/tensorflow/blob/4abf9e92de46ee91df5d2fe3e23ab529b115e52f/tensorflow/core/framework/tensor_shape.cc#L44-L47\r\n\r\nThe issue is the `CHECK_EQ` line, that fails whenever the condition is false. You need to trace where the call comes from. Parent is https://github.com/tensorflow/tensorflow/blob/4abf9e92de46ee91df5d2fe3e23ab529b115e52f/tensorflow/core/framework/tensor_shape.h#L653-L657\r\n\r\nHowever, this parent is still too deep inside. You need to find a function for the `GRUBlockCell` kernel that returns a `Status` and which in the end will trigger this check failure. Then, in the function, compare the tensor elements and return an invalid status.",
"created_at": "2022-12-11T19:16:16Z"
},
{
"body": "@mihaimaruseac \r\nThanks for your comment!\r\n\r\nI'm trying to find a function for the `GRUBlockCell` kernel that returns a `Status` but I haven't found it yet... Do you know where it is?\r\n\r\nBasically I look into these 2 files.\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/rnn/gru_ops.cc\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/rnn/gru_ops.h",
"created_at": "2022-12-12T16:38:00Z"
},
{
"body": "https://github.com/tensorflow/tensorflow/blob/de8c87d351456d5f0d6fcf6b6d3c7d5e63c2b701/tensorflow/core/kernels/rnn/gru_ops.cc#L32-L35\r\n\r\n`OP_REQUIRES_OK` has a similar semantic, if the status is no `Ok` the macro finishes execution of the kernel and returns the invalid `Status` back to the user.",
"created_at": "2022-12-12T17:33:15Z"
},
{
"body": "Ah OK! Thanks a lot for your explanation!\r\n\r\nThere are a lot of `OP_REQUIRES_OK` in the file so I will look at them.",
"created_at": "2022-12-12T23:20:06Z"
},
{
"body": "You'll probably need to add your own, since each one of them checks one condition",
"created_at": "2022-12-13T01:20:05Z"
},
{
"body": "Sure! I thought I would need to add one for this issue because I couldn't find a suitable one \r\n\r\nThanks for your additional comment!",
"created_at": "2022-12-13T01:55:18Z"
},
{
"body": "Hi @mihaimaruseac \r\n\r\nI need your support again :pray: I created [a draft pull request](https://github.com/tensorflow/tensorflow/pull/58998) and added a `OP_REQUIRES_OK` for this issue. However, I don't know yet how I should add it.\r\n\r\nCan you give me more clues? Thanks in advance!",
"created_at": "2023-01-09T09:14:45Z"
},
{
"body": "I thought I can imitate this example of `OP_REQUIRES` because it checks `dim_size` but I need to refer to `OP_REQUIRES_OK`, right?\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/rnn/gru_ops.cc#L59-L62",
"created_at": "2023-01-09T09:20:06Z"
},
{
"body": "@mihaimaruseac could I too work alongside @shogohida on this bug",
"created_at": "2023-02-06T00:05:57Z"
},
{
"body": "The error you're encountering is likely due to the shape of the inputs to the GRUBlockCell operation. According to the TensorFlow documentation, the inputs x, h_prev, w_ru, w_c, b_ru, and b_c should have specific shapes based on the dimensions of the input and the parameters being passed to the GRU cell.\r\n\r\nIn the code you posted, it appears that the shapes of the inputs are not correctly specified. For example, the shape of x is [1, 0, 1], which is not valid.\r\n\r\nI would suggest reviewing the documentation and ensuring that the shapes of the inputs match the expected dimensions. You can also check that the shapes of the variables match the dimensions of your input data.",
"created_at": "2023-02-06T15:03:14Z"
},
{
"body": "@mihaimaruseac Is this already fixed as of v2.12.0-rc0, or does more remain to be done (besides a possible backport)? It seems that the GRU input validation in ff459137 prevents the crash.\r\n```\r\n504645490 by A. Unique TensorFlower<gardener@tensorflow.org>:\r\n\r\n Fix input validation for GRU ops.\r\n```\r\n\r\nInstead they're all caught by the `except` block in the reproducer now. Printing the exceptions, they look like this:\r\n```\r\n{{function_node __wrapped__GRUBlockCell_device_/job:localhost/replica:0/task:0/device:CPU:0}} Rank of x must be 23 vs. 2 [Op:GRUBlockCell]\r\n```\r\n\r\nOr for the `GRUBlockCellGrad` reproducer in https://github.com/tensorflow/tensorflow/issues/58261#issuecomment-1287786237:\r\n```\r\n{{function_node __wrapped__GRUBlockCellGrad_device_/job:localhost/replica:0/task:0/device:CPU:0}} Rank of x must be 2, got 3 [Op:GRUBlockCellGrad]\r\n```\r\n\r\nBTW, I'm new here too, so I apologize if I ask any obvious questions. I don't want to re-do work that's already been done though.",
"created_at": "2023-02-15T09:04:52Z"
},
{
"body": "I would install latest TF (RC0 or nightly) and test if this still reproduces there. If it doesn't then we can close this.",
"created_at": "2023-02-15T15:28:55Z"
},
{
"body": "@mihaimaruseac \r\n\r\nInstalled the nightly package on Colab and the issue doesn't reproduce. Output of both reproducers is just the version:\r\n```\r\n2.13.0-dev20230215\r\n```\r\n\r\nIf I print exceptions, the messages are the same as in https://github.com/tensorflow/tensorflow/issues/58261#issuecomment-1430978328.\r\n\r\nI think there's a typo in one of the validation messages though. Note \"must be 23 vs. 2.\": https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/rnn/gru_ops.cc#L54-L57. \"3 vs. 2\" would make more sense than \"23 vs. 2\", although \"must be 2, got 3\" seems more reasonable based on the test.\r\n\r\nBut that's a separate issue from the crash, so we might be good.",
"created_at": "2023-02-15T16:25:28Z"
},
{
"body": "Nice find!\r\n\r\nCan you send a PR to remove the 2 there, tag me in the PR and then we can close this?\r\n\r\nThank you very much!",
"created_at": "2023-02-15T16:38:12Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58261\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58261\">No</a>\n",
"created_at": "2023-02-16T19:25:17Z"
}
],
"number": 58261,
"title": "A Check Fail can be triggerred in GRUBlockCell"
}
|
{
"body": "Signed-off-by: Shogo Hida <shogo.hida@gmail.com>\r\n\r\nFixes #58261",
"number": 58998,
"review_comments": [],
"title": "Fix a check fail in GRUBlockCell"
}
|
{
"commits": [
{
"message": "Add example\n\nSigned-off-by: Shogo Hida <shogo.hida@gmail.com>"
}
],
"files": [
{
"diff": "@@ -121,6 +121,11 @@ class GRUCellBlockOp : public OpKernel {\n ctx, ctx->allocate_output(\"c\", TensorShape({batch_size, cell_size}),\n &c_tensor));\n \n+ Tensor* g_tensor = nullptr;\n+ OP_REQUIRES_OK(\n+ ctx, ctx->allocate_output(\"g\", TensorShape({batch_size, cell_size}),\n+ &g_tensor));\n+\n Tensor* h_tensor = nullptr;\n OP_REQUIRES_OK(ctx, ctx->forward_input_or_allocate_output(\n {\"h_prev\"}, \"h\",",
"filename": "tensorflow/core/kernels/rnn/gru_ops.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nbinary\n\n### Tensorflow Version\n\ntf 2.10\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\n_No response_\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nconverting following TF code:\r\nA = tf.reduce_sum(B, axis=3) \r\nwhere B has 5 dimensions, and is of type: tf.dtypes.float32\r\n\r\ngenerated a few MLIR lines, among them: \r\n%1 = \"tosa.transpose\"(%arg0, %0) : (tensor<10x20x30x40x50xf32>, tensor<5xi32>) -> tensor<10x20x30x50x40xi32>\r\n\r\nthis is illegal, since transpose operation is not supposed to change the type of the output.\r\n\r\nI would expect:\r\n%1 = \"tosa.transpose\"(%arg0, %0) : (tensor<10x20x30x40x50xf32>, tensor<5xi32>) -> tensor<10x20x30x50x40xf32>\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\n@tf.function\r\ndef transpose_type(inp_list, **kwargs):\r\n res = tf.reduce_sum(inp_list[0], axis=3)\r\n return res\r\n\r\ndef test_transpose_type():\r\n\r\n inputs = [\r\n tf.TensorSpec(shape=[10, 20, 30, 40, 50], dtype=tf.dtypes.float32),\r\n ]\r\n concrete_function = transpose_type.get_concrete_function(inputs)\r\n\r\n mlir = tf.mlir.experimental.convert_function(concrete_function,\r\n pass_pipeline=\"tf-standard-pipeline,tf-functional-control-flow-to-regions,func.func(tosa-legalize-tf), convert-tf-control-flow-to-scf\")\r\n #pass_pipeline=\"tf-standard-pipeline\"),#tf-functional-control-flow-to-regions,func.func(tosa-legalize-tf), convert-tf-control-flow-to-scf\"),\r\n # \"tf-standard-pipeline,builtin.module(convert-tf-control-flow-to-scf)\"))\r\n\r\n filename = \"transpose_type.mlir\"\r\n with open(filename, \"w\") as fd:\r\n print(mlir, file=fd)\r\n return True\n```\n\n\n### Relevant log output\n\n```shell\nmodule attributes {tf.versions = {bad_consumers = [], min_consumer = 0 : i32, producer = 1205 : i32}} {\r\n func.func @__inference_transpose_type_7(%arg0: tensor<10x20x30x40x50xf32> {tf._user_specified_name = \"inp_list\"}) -> tensor<10x20x30x50xf32> attributes {tf.entry_function = {control_outputs = \"\", inputs = \"inp_list\", outputs = \"identity_RetVal\"}} {\r\n %0 = \"tosa.const\"() {value = dense<[0, 1, 2, 4, 3]> : tensor<5xi32>} : () -> tensor<5xi32>\r\n %1 = \"tosa.transpose\"(%arg0, %0) : (tensor<10x20x30x40x50xf32>, tensor<5xi32>) -> tensor<10x20x30x50x40xi32>\r\n %2 = \"tosa.reshape\"(%1) {new_shape = [300000, 40]} : (tensor<10x20x30x50x40xi32>) -> tensor<300000x40xf32>\r\n %3 = \"tosa.reduce_sum\"(%2) {axis = 1 : i64} : (tensor<300000x40xf32>) -> tensor<300000x1xf32>\r\n %4 = \"tosa.reshape\"(%3) {new_shape = [10, 20, 30, 50]} : (tensor<300000x1xf32>) -> tensor<10x20x30x50xf32>\r\n return %4 : tensor<10x20x30x50xf32>\r\n }\r\n}\n```\n</details>",
"comments": [
{
"body": "@rsuderman @Jerry-Ge any insights here?",
"created_at": "2022-12-09T17:59:18Z"
},
{
"body": "I took a initial look at this and may need more investigation, here is my summary: \r\n\r\n- I can produce the same errors given the scripts provided above in a Colab environment. \r\n- I ran through all our `reduce_sum` tests generated from the [reference_model](https://www.mlplatform.org/tosa/software.html), they're all passing and didn't produce the errors like above. \r\n- I'm not too familiar with the `tf.mlir.experimental.convert_function` here and I suspect there're something missing there?\r\n- Will take a deeper look at this. \r\n\r\nJerry ",
"created_at": "2022-12-09T19:12:30Z"
},
{
"body": "Input\r\n\r\n```mlir\r\nmodule attributes {tf.versions = {bad_consumers = [], min_consumer = 0 : i32, producer = 1343 : i32}} {\r\n func.func @__inference_transpose_type_21(%arg0: tensor<10x20x30x40x50xf32> {tf._user_specified_name = \"inp_list\"}) -> tensor<10x20x30x50xf32> attributes {tf.entry_function = {control_outputs = \"\", inputs = \"inp_list\", outputs = \"identity_RetVal\"}} {\r\n %cst = \"tf.Const\"() {device = \"\", value = dense<3> : tensor<i32>} : () -> tensor<i32>\r\n %0 = \"tf.Sum\"(%arg0, %cst) {device = \"\", keep_dims = false} : (tensor<10x20x30x40x50xf32>, tensor<i32>) -> tensor<10x20x30x50xf32>\r\n %1 = \"tf.Identity\"(%0) {device = \"\"} : (tensor<10x20x30x50xf32>) -> tensor<10x20x30x50xf32>\r\n return %1 : tensor<10x20x30x50xf32>\r\n }\r\n}\r\n```\r\n\r\nwith `tf-opt --tosa-legalize-tf input.mlir --debug` shows\r\n\r\n```mlir\r\n// * Pattern mlir::tosa::(anonymous namespace)::ConvertTFSumOp : 'tf.Sum -> ()' {\r\n\r\nfunc.func @__inference_transpose_type_21(%arg0: tensor<10x20x30x40x50xf32> {tf._user_specified_name = \"inp_list\"}) -> tensor<10x20x30x50xf32> attributes {tf.entry_function = {control_outputs = \"\", inputs = \"inp_list\", outputs = \"identity_RetVal\"}} {\r\n %0 = \"tosa.const\"() {value = dense<3> : tensor<i32>} : () -> tensor<i32>\r\n %1 = \"tosa.const\"() {value = dense<[0, 1, 2, 4, 3]> : tensor<5xi32>} : () -> tensor<5xi32>\r\n %2 = \"tosa.transpose\"(%arg0, %1) : (tensor<10x20x30x40x50xf32>, tensor<5xi32>) -> tensor<10x20x30x50x40xi32>\r\n %3 = \"tosa.reshape\"(%2) {new_shape = [300000, 40]} : (tensor<10x20x30x50x40xi32>) -> tensor<300000x40xf32>\r\n %4 = \"tosa.reduce_sum\"(%3) {axis = 1 : i64} : (tensor<300000x40xf32>) -> tensor<300000x1xf32>\r\n %5 = \"tosa.reshape\"(%4) {new_shape = [10, 20, 30, 50]} : (tensor<300000x1xf32>) -> tensor<10x20x30x50xf32>\r\n %6 = \"tf.Identity\"(%5) {device = \"\"} : (tensor<10x20x30x50xf32>) -> tensor<10x20x30x50xf32>\r\n return %6 : tensor<10x20x30x50xf32>\r\n}\r\n``` \r\n\r\nwhich looks like a NOP transpose that changes type and a reshape that changes type too.",
"created_at": "2022-12-14T03:36:52Z"
},
{
"body": "Seems like it's an issue around here: https://github.com/tensorflow/tensorflow/blob/49361f70ba2d454fc3996fcddef493261bc1a91e/tensorflow/compiler/mlir/tosa/transforms/legalize_common.cc#L2681",
"created_at": "2022-12-14T04:52:44Z"
},
{
"body": "Yea, that's it. \r\n\r\n```\r\n// New Output\r\nmodule attributes {tf.versions = {bad_consumers = [], min_consumer = 0 : i32, producer = 1343 : i32}} {\r\n func.func @__inference_transpose_type_21(%arg0: tensor<10x20x30x40x50xf32> {tf._user_specified_name = \"inp_list\"}) -> tensor<10x20x30x50xf32> attributes {tf.entry_function = {control_outputs = \"\", inputs = \"inp_list\", outputs = \"identity_RetVal\"}} {\r\n %0 = \"tosa.const\"() {value = dense<[0, 1, 2, 4, 3]> : tensor<5xi32>} : () -> tensor<5xi32>\r\n %1 = \"tosa.transpose\"(%arg0, %0) : (tensor<10x20x30x40x50xf32>, tensor<5xi32>) -> tensor<10x20x30x50x40xf32>\r\n %2 = \"tosa.reshape\"(%1) {new_shape = [300000, 40]} : (tensor<10x20x30x50x40xf32>) -> tensor<300000x40xf32>\r\n %3 = \"tosa.reduce_sum\"(%2) {axis = 1 : i64} : (tensor<300000x40xf32>) -> tensor<300000x1xf32>\r\n %4 = \"tosa.reshape\"(%3) {new_shape = [10, 20, 30, 50]} : (tensor<300000x1xf32>) -> tensor<10x20x30x50xf32>\r\n return %4 : tensor<10x20x30x50xf32>\r\n }\r\n}\r\n```\r\n\r\nI will do a quick patch tomorrow. \r\n\r\nJerry",
"created_at": "2022-12-14T05:10:20Z"
},
{
"body": "@jpienaar Hi Jacques, created a PR here #58890. It's an one-line fix and guess can be quickly reviewed? Tks! \r\n\r\nJerry ",
"created_at": "2022-12-14T17:52:22Z"
},
{
"body": "@miritb The related PR has been merged, could you please verify and move this issue to closed status if it is resolved?\r\nThank you!",
"created_at": "2023-01-13T09:55:37Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2023-01-20T10:55:11Z"
},
{
"body": "Closing as stale. Please reopen if you'd like to work on this further.\n",
"created_at": "2023-01-27T11:33:27Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58714\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58714\">No</a>\n",
"created_at": "2023-01-27T11:33:32Z"
}
],
"number": 58714,
"title": "problem in 'tf.mlir.experimental.convert_function' translation to tosa of 'tf.reduce_sum' operation"
}
|
{
"body": "A quick fix for the issue from here: #58714 \r\n\r\nSigned-off-by: Jerry Ge <jerry.ge@arm.com>",
"number": 58890,
"review_comments": [],
"title": "[tosa] Fix wrong intermediate datatype for genericReduceOps"
}
|
{
"commits": [
{
"message": "[tosa] Fix wrong intermediate datatype for genericReduceOps\n\nSigned-off-by: Jerry Ge <jerry.ge@arm.com>"
}
],
"files": [
{
"diff": "@@ -294,6 +294,23 @@ func.func @test_reduce_sum(%arg0: tensor<13x21x3xf32>) -> tensor<21x3xf32> {\n \n // -----\n \n+// CHECK-LABEL: test_reduce_sum_nonzero_axis\n+// CHECK-SAME: %[[VAL_0:.*]]: tensor<10x20x30x40x50xf32>\n+// CHECK: %[[VAL_1:.*]] = \"tosa.const\"() {value = dense<[0, 1, 2, 4, 3]> : tensor<5xi32>} : () -> tensor<5xi32>\n+// CHECK: %[[VAL_2:.*]] = \"tosa.transpose\"(%[[VAL_0]], %[[VAL_1]]) : (tensor<10x20x30x40x50xf32>, tensor<5xi32>) -> tensor<10x20x30x50x40xf32>\n+// CHECK: %[[VAL_3:.*]] = \"tosa.reshape\"(%[[VAL_2]]) {new_shape = [300000, 40]} : (tensor<10x20x30x50x40xf32>) -> tensor<300000x40xf32>\n+// CHECK: %[[VAL_4:.*]] = \"tosa.reduce_sum\"(%[[VAL_3]]) {axis = 1 : i64} : (tensor<300000x40xf32>) -> tensor<300000x1xf32>\n+// CHECK: %[[VAL_5:.*]] = \"tosa.reshape\"(%[[VAL_4]]) {new_shape = [10, 20, 30, 50]} : (tensor<300000x1xf32>) -> tensor<10x20x30x50xf32>\n+// CHECK: return %[[VAL_5]] : tensor<10x20x30x50xf32>\n+func.func @test_reduce_sum_nonzero_axis(%arg0: tensor<10x20x30x40x50xf32> {tf._user_specified_name = \"inp_list\"}) -> tensor<10x20x30x50xf32> {\n+ %cst = \"tf.Const\"() {device = \"\", value = dense<3> : tensor<i32>} : () -> tensor<i32>\n+ %0 = \"tf.Sum\"(%arg0, %cst) {device = \"\", keep_dims = false} : (tensor<10x20x30x40x50xf32>, tensor<i32>) -> tensor<10x20x30x50xf32>\n+ %1 = \"tf.Identity\"(%0) {device = \"\"} : (tensor<10x20x30x50xf32>) -> tensor<10x20x30x50xf32>\n+ func.return %1 : tensor<10x20x30x50xf32>\n+}\n+\n+// -----\n+\n // CHECK-LABEL: test_reduce_mean\n // CHECK-DAG: %[[VAR0:.*]] = \"tosa.const\"() {value = dense<0.0769230798> : tensor<1x1xf32>}\n // CHECK-DAG: %[[VAR1:.*]] = \"tosa.reduce_sum\"(%arg0) {axis = 0 : i64}",
"filename": "tensorflow/compiler/mlir/tosa/tests/tf-to-tosa-pipeline.mlir",
"status": "modified"
},
{
"diff": "@@ -414,6 +414,22 @@ func.func @test_reduce_sum(%arg0: tensor<13x21x3xf32>) -> tensor<21x3xf32> {\n func.return %0 : tensor<21x3xf32>\n }\n \n+// CHECK-LABEL: test_reduce_sum_nonzero_axis\n+// CHECK-SAME: %[[VAL_0:.*]]: tensor<10x20x30x40x50xf32>\n+// CHECK: %[[VAL_1:.*]] = \"tosa.const\"() {value = dense<[0, 1, 2, 4, 3]> : tensor<5xi32>} : () -> tensor<5xi32>\n+// CHECK: %[[VAL_2:.*]] = \"tosa.transpose\"(%[[VAL_0]], %[[VAL_1]]) : (tensor<10x20x30x40x50xf32>, tensor<5xi32>) -> tensor<10x20x30x50x40xf32>\n+// CHECK: %[[VAL_3:.*]] = \"tosa.reshape\"(%[[VAL_2]]) {new_shape = [300000, 40]} : (tensor<10x20x30x50x40xf32>) -> tensor<300000x40xf32>\n+// CHECK: %[[VAL_4:.*]] = \"tosa.reduce_sum\"(%[[VAL_3]]) {axis = 1 : i64} : (tensor<300000x40xf32>) -> tensor<300000x1xf32>\n+// CHECK: %[[VAL_5:.*]] = \"tosa.reshape\"(%[[VAL_4]]) {new_shape = [10, 20, 30, 50]} : (tensor<300000x1xf32>) -> tensor<10x20x30x50xf32>\n+// CHECK: return %[[VAL_5]] : tensor<10x20x30x50xf32>\n+func.func @test_reduce_sum_nonzero_axis(%arg0: tensor<10x20x30x40x50xf32> {tf._user_specified_name = \"inp_list\"}) -> tensor<10x20x30x50xf32> {\n+ %cst = arith.constant dense<3> : tensor<i32>\n+ %0 = \"tfl.sum\"(%arg0, %cst) {device = \"\", keep_dims = false} : (tensor<10x20x30x40x50xf32>, tensor<i32>) -> tensor<10x20x30x50xf32>\n+ func.return %0 : tensor<10x20x30x50xf32>\n+}\n+\n+// -----\n+\n // -----\n \n // CHECK-LABEL: test_reduce_sum_5D",
"filename": "tensorflow/compiler/mlir/tosa/tests/tfl-to-tosa-pipeline.mlir",
"status": "modified"
},
{
"diff": "@@ -2679,7 +2679,7 @@ static Value convertGenericReduceOp(PatternRewriter& rewriter, Operation* op,\n .value();\n \n auto transpose_op = CreateOpAndInfer<tosa::TransposeOp>(\n- rewriter, loc, UnrankedTensorType::get(rewriter.getI32Type()), input,\n+ rewriter, loc, UnrankedTensorType::get(input_etype), input,\n perms_value);\n \n auto reshape_op = CreateOpAndInfer<tosa::ReshapeOp>(",
"filename": "tensorflow/compiler/mlir/tosa/transforms/legalize_common.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\ntf 2.11\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nLinux Ubuntu 22.04\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.10\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\nCUDA 11.2/cuDNN 8.2\r\n\r\n### GPU model and memory\r\n\r\nNvidia GeForce RTX 3090\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\nAfter disabling autotuning with environment variable TF_CUDNN_USE_AUTOTUNE=0 and disabling tensor cores with tf.config.experimental.enable_tensor_float_32_execution(False) I get an error\r\ntensorflow.python.framework.errors_impl.InvalidArgumentError: ... Algo requests disabled tensor op evaluation. [Op:Conv2D]\r\nI expect the default algorithm without tensor cores to be used.\r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport os\r\nos.environ['TF_CUDNN_USE_AUTOTUNE'] = '0'\r\nimport tensorflow as tf\r\ntf.config.experimental.enable_tensor_float_32_execution(False)\r\ntf.nn.conv2d(tf.zeros([1, 2, 5, 5]), tf.zeros([3, 3, 2, 4]), 1, 'VALID', 'NCHW')\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\nTraceback (most recent call last):\r\n File \"/tmp/bug.py\", line 5, in <module>\r\n tf.nn.conv2d(tf.zeros([1, 2, 5, 5]), tf.zeros([3, 3, 2, 4]), 1, 'VALID', 'NCHW')\r\n File \"/tmp/venv/tf-2.11/lib/python3.10/site-packages/tensorflow/python/util/traceback_utils.py\", line 153, in error_handler\r\n raise e.with_traceback(filtered_tb) from None\r\n File \"/tmp/venv/tf-2.11/lib/python3.10/site-packages/tensorflow/python/framework/ops.py\", line 7215, in raise_from_not_ok_status\r\n raise core._status_to_exception(e) from None # pylint: disable=protected-access\r\ntensorflow.python.framework.errors_impl.InvalidArgumentError: {{function_node __wrapped__Conv2D_device_/job:localhost/replica:0/task:0/device:GPU:0}} Algo requests disabled tensor op evaluation. [Op:Conv2D]\r\n```\r\n</details>",
"comments": [
{
"body": "@SuryanarayanaY \r\nI was able to reproduce the issue on Colab using Tf v2.11. Please find the gist [here](https://colab.research.google.com/gist/tiruk007/8a28822258a164504c47e7d374144dfc/58846.ipynb) for reference.\r\nThank you!",
"created_at": "2022-12-13T21:30:29Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58846\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58846\">No</a>\n",
"created_at": "2022-12-20T18:39:02Z"
}
],
"number": 58846,
"title": "tf.config.experimental.enable_tensor_float_32_execution(False) fails with TF_CUDNN_USE_AUTOTUNE=0"
}
|
{
"body": "resolves #58846 ",
"number": 58847,
"review_comments": [],
"title": "Select a convolution algorithm that does not use tensor cores when tensor cores are disabled and autotuning is disabled."
}
|
{
"commits": [
{
"message": "Select a convolution algorithm that does not use tensor cores when tensor cores are disabled and autotuning is disabled."
}
],
"files": [
{
"diff": "@@ -914,8 +914,9 @@ static bool TensorOpMathAvailable(\n return cuda_compute_capability.IsAtLeast(7);\n }\n \n-static bool IsTensorMathEnabled(Stream* stream, dnn::DataType input_type) {\n- if (!TensorOpMathAvailable(stream->GetCudaComputeCapability())) {\n+static bool IsTensorMathEnabled(\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type) {\n+ if (!TensorOpMathAvailable(cuda_compute_capability)) {\n return false;\n }\n if (input_type == dnn::DataType::kFloat) {\n@@ -930,6 +931,10 @@ static bool IsTensorMathEnabled(Stream* stream, dnn::DataType input_type) {\n return true;\n }\n \n+static bool IsTensorMathEnabled(Stream* stream, dnn::DataType input_type) {\n+ return IsTensorMathEnabled(stream->GetCudaComputeCapability(), input_type);\n+}\n+\n // Turns a PoolingDescriptor structure into a cudnn pooling descriptor handle\n // within a scope.\n class CudnnPoolingDescriptor {\n@@ -4858,14 +4863,17 @@ port::Status CudnnSupport::GetConvolveRunners(\n return port::InternalError(absl::StrFormat(\n \"Unknown ConvolutionKind for unfused conv: %d\", kind));\n case dnn::ConvolutionKind::FORWARD:\n- got_algos = GetConvolveAlgorithms(cuda_compute_capability, &algorithms);\n+ got_algos = GetConvolveAlgorithms(cuda_compute_capability, input_type,\n+ &algorithms);\n break;\n case dnn::ConvolutionKind::BACKWARD_FILTER:\n got_algos = GetConvolveBackwardFilterAlgorithms(cuda_compute_capability,\n+ input_type,\n &algorithms);\n break;\n case dnn::ConvolutionKind::BACKWARD_DATA:\n got_algos = GetConvolveBackwardDataAlgorithms(cuda_compute_capability,\n+ input_type,\n &algorithms);\n break;\n }\n@@ -5320,7 +5328,8 @@ port::Status CudnnSupport::GetFusedConvolveRunners(\n std::vector<dnn::AlgorithmDesc> algorithms;\n \n auto cuda_compute_capability = stream->GetCudaComputeCapability();\n- if (!GetConvolveAlgorithms(cuda_compute_capability, &algorithms)) {\n+ if (!GetConvolveAlgorithms(cuda_compute_capability, input_type,\n+ &algorithms)) {\n return port::Status(port::error::UNKNOWN,\n \"Listing fused convolve algorithms failed.\");\n }\n@@ -5414,12 +5423,12 @@ port::Status CudnnSupport::GetFusedMatmulRunners(\n }\n \n bool CudnnSupport::GetConvolveAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) {\n PreloadCudnnSubLibs(PreloadCudnnType::ConvFwd);\n \n bool tensor_op_math_available =\n- TensorOpMathAvailable(cuda_compute_capability);\n+ IsTensorMathEnabled(cuda_compute_capability, input_type);\n out_algorithms->clear();\n \n std::vector<dnn::AlgorithmDesc::Index> algo_types;\n@@ -5473,12 +5482,12 @@ bool CudnnSupport::GetRnnAlgorithms(\n }\n \n bool CudnnSupport::GetConvolveBackwardDataAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) {\n PreloadCudnnSubLibs(PreloadCudnnType::ConvBwdData);\n \n bool tensor_op_math_available =\n- TensorOpMathAvailable(cuda_compute_capability);\n+ IsTensorMathEnabled(cuda_compute_capability, input_type);\n out_algorithms->clear();\n \n std::vector<dnn::AlgorithmDesc::Index> algo_types = {\n@@ -5508,12 +5517,12 @@ bool CudnnSupport::GetConvolveBackwardDataAlgorithms(\n }\n \n bool CudnnSupport::GetConvolveBackwardFilterAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) {\n PreloadCudnnSubLibs(PreloadCudnnType::ConvBwdFilter);\n \n bool tensor_op_math_available =\n- TensorOpMathAvailable(cuda_compute_capability);\n+ IsTensorMathEnabled(cuda_compute_capability, input_type);\n out_algorithms->clear();\n \n std::vector<dnn::AlgorithmDesc::Index> algo_types = {",
"filename": "tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc",
"status": "modified"
},
{
"diff": "@@ -216,7 +216,7 @@ class CudnnSupport : public dnn::DnnSupport {\n dnn::ProfileResult* output_profile_result) override;\n \n bool GetConvolveAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) override;\n \n port::Status GetConvolveRunners(\n@@ -280,11 +280,11 @@ class CudnnSupport : public dnn::DnnSupport {\n std::vector<dnn::AlgorithmDesc>* out_algorithms) override;\n \n bool GetConvolveBackwardDataAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) override;\n \n bool GetConvolveBackwardFilterAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) override;\n \n bool DoBatchNormalizationForward(",
"filename": "tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.h",
"status": "modified"
},
{
"diff": "@@ -114,7 +114,7 @@ std::vector<std::pair<int64_t, int64_t>> AlgorithmDesc::TuningKnobs() const {\n }\n \n bool DnnSupport::GetConvolveAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<AlgorithmDesc>* out_algorithms) {\n return false;\n }\n@@ -206,13 +206,13 @@ bool DnnSupport::GetRnnAlgorithms(std::vector<AlgorithmDesc>* out_algorithms) {\n }\n \n bool DnnSupport::GetConvolveBackwardDataAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<AlgorithmDesc>* out_algorithms) {\n return false;\n }\n \n bool DnnSupport::GetConvolveBackwardFilterAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<AlgorithmDesc>* out_algorithms) {\n return false;\n }",
"filename": "tensorflow/compiler/xla/stream_executor/dnn.cc",
"status": "modified"
},
{
"diff": "@@ -1430,7 +1430,7 @@ class DnnSupport {\n // Return a list of algorithms supported by the forward convolution pass.\n // cc_major and cc_minor are the compute capabilities of the device.\n virtual bool GetConvolveAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<AlgorithmDesc>* out_algorithms);\n \n virtual port::Status GetConvolveRunners(\n@@ -1550,13 +1550,13 @@ class DnnSupport {\n // Return a list of algorithms supported by the backward convolution pass for\n // data.\n virtual bool GetConvolveBackwardDataAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<AlgorithmDesc>* out_algorithms);\n \n // Return a list of algorithms supported by the backward convolution pass for\n // filters.\n virtual bool GetConvolveBackwardFilterAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<AlgorithmDesc>* out_algorithms);\n \n // Fully connects the \"nodes\" (float values) in input_data with",
"filename": "tensorflow/compiler/xla/stream_executor/dnn.h",
"status": "modified"
},
{
"diff": "@@ -3120,7 +3120,7 @@ port::Status MIOpenSupport::DoConvolve(\n \n bool MIOpenSupport::GetConvolveAlgorithms(\n // ROCM TODO: refactor cc_major / cc_minor\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) {\n out_algorithms->assign({\n // clang-format off\n@@ -3597,7 +3597,7 @@ bool MIOpenSupport::GetRnnAlgorithms(\n \n bool MIOpenSupport::GetConvolveBackwardDataAlgorithms(\n // ROCM TODO: refactor cc_major / cc_minor\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) {\n out_algorithms->assign({\n // clang-format off\n@@ -3612,7 +3612,7 @@ bool MIOpenSupport::GetConvolveBackwardDataAlgorithms(\n \n bool MIOpenSupport::GetConvolveBackwardFilterAlgorithms(\n // ROCM TODO: refactor cc_major / cc_minor\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) {\n out_algorithms->assign({\n // clang-format off",
"filename": "tensorflow/compiler/xla/stream_executor/rocm/rocm_dnn.cc",
"status": "modified"
},
{
"diff": "@@ -234,7 +234,7 @@ class MIOpenSupport : public dnn::DnnSupport {\n dnn::ProfileResult* output_profile_result) override;\n \n bool GetConvolveAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) override;\n \n port::Status GetConvolveRunners(\n@@ -273,11 +273,11 @@ class MIOpenSupport : public dnn::DnnSupport {\n std::vector<dnn::AlgorithmDesc>* out_algorithms) override;\n \n bool GetConvolveBackwardDataAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) override;\n \n bool GetConvolveBackwardFilterAlgorithms(\n- CudaComputeCapability cuda_compute_capability,\n+ CudaComputeCapability cuda_compute_capability, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) override;\n \n bool DoBatchNormalizationForward(",
"filename": "tensorflow/compiler/xla/stream_executor/rocm/rocm_dnn.h",
"status": "modified"
},
{
"diff": "@@ -277,7 +277,7 @@ bool StreamExecutor::SupportsDnn() const {\n }\n \n bool StreamExecutor::GetConvolveAlgorithms(\n- dnn::ConvolutionKind kind,\n+ dnn::ConvolutionKind kind, dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms) {\n dnn::DnnSupport* dnn_support = AsDnn();\n if (!dnn_support) {\n@@ -289,13 +289,16 @@ bool StreamExecutor::GetConvolveAlgorithms(\n case dnn::ConvolutionKind::FORWARD:\n case dnn::ConvolutionKind::FORWARD_BIAS_ACTIVATION:\n return dnn_support->GetConvolveAlgorithms(\n- GetDeviceDescription().cuda_compute_capability(), out_algorithms);\n+ GetDeviceDescription().cuda_compute_capability(), input_type,\n+ out_algorithms);\n case dnn::ConvolutionKind::BACKWARD_DATA:\n return dnn_support->GetConvolveBackwardDataAlgorithms(\n- GetDeviceDescription().cuda_compute_capability(), out_algorithms);\n+ GetDeviceDescription().cuda_compute_capability(), input_type,\n+ out_algorithms);\n case dnn::ConvolutionKind::BACKWARD_FILTER:\n return dnn_support->GetConvolveBackwardFilterAlgorithms(\n- GetDeviceDescription().cuda_compute_capability(), out_algorithms);\n+ GetDeviceDescription().cuda_compute_capability(), input_type,\n+ out_algorithms);\n }\n }\n ",
"filename": "tensorflow/compiler/xla/stream_executor/stream_executor_pimpl.cc",
"status": "modified"
},
{
"diff": "@@ -380,6 +380,7 @@ class StreamExecutor {\n // Returns the list of supported algorithms for the specified convolution\n // operation.\n bool GetConvolveAlgorithms(dnn::ConvolutionKind kind,\n+ dnn::DataType input_type,\n std::vector<dnn::AlgorithmDesc>* out_algorithms);\n \n // Returns the supported algorithms / execution plans for a convolution.",
"filename": "tensorflow/compiler/xla/stream_executor/stream_executor_pimpl.h",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nDocumentation Bug\r\n\r\n### Source\r\n\r\nsource\r\n\r\n### Tensorflow Version\r\n\r\nTF 2.4\r\n\r\n### Custom Code\r\n\r\nYes\r\n\r\n### OS Platform and Distribution\r\n\r\nwindows 11\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.8.15\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\nCUDA: 11.3 cuDNN 8.6.0\r\n\r\n### GPU model and memory\r\n\r\nRTX3060\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\nThe seed in the tf.image.stateless_random_hue(image, max_delta, seed) operator parameter, the requirement in the document is \"A shape [2] Tensor, the seed to the random number generator. Must have dtype int32 or int64. (When using XLA, only int32 is allowed.)\", you can clearly see ''When using XLA, only int32 is allowed.'', for this situation, I used the official test case, and used XLA, and then set the type of seed It is not designed to be int32, but int64. I found that the program can still run through, so I don't understand why the document is restricted''When using XLA, only int32 is allowed.''\r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport os\r\n import tensorflow as tf\r\n\r\n os.environ['TF_XLA_FLAGS'] = '--tf_xla_enable_xla_devices'\r\n os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\r\n with tf.device(\"/device:XLA_CPU:0\"):\r\n x = [[[1.0, 2.0, 3.0],\r\n [4.0, 5.0, 6.0]],\r\n [[7.0, 8.0, 9.0],\r\n [10.0, 11.0, 12.0]]]\r\n seed = tf.constant([1, 2], dtype=tf.int64)\r\n out = tf.image.stateless_random_hue(x, 0.2, seed)\r\n print(out)\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\nresult:\r\n tf.Tensor(\r\n [[[ 1.6514893 1. 3. ]\r\n [ 4.6514893 4. 6. ]]\r\n\r\n [[ 7.6514893 7. 9. ]\r\n [10.651489 10. 12. ]]], shape=(2, 2, 3), dtype=float32)\r\n```\r\n\r\ntf.image.stateless_random_brightness, tf.image.stateless_sample_distorted_bounding_box, tf.image.stateless_random_flip_up_down, tf.image.stateless_random_flip_left_right, etc. all have the same problem.\r\n\r\n\r\n\r\n</details>",
"comments": [
{
"body": "@triumph-wangyuyang \r\nThis issue is closed when [PR](https://github.com/tensorflow/tensorflow/pull/58725) is merged.\r\nThank you!\r\n",
"created_at": "2022-11-29T12:16:00Z"
},
{
"body": "@triumph-wangyuyang,\r\nHave you got the chance to have a look at this related PR(https://github.com/tensorflow/tensorflow/pull/58725/files) which was merged and also I checked the official document of tf.image.stateless_random_hue w.r.t v2.14 and v2.4 where the document was updated without **When using XLA, only int32 is allowed** for the seed. Reference [Gist](https://colab.research.google.com/gist/tilakrayal/4b3e334eda78a126f060bcf41a152204/untitled1636.ipynb)\r\n\r\n2.14:\r\nhttps://www.tensorflow.org/api_docs/python/tf/image/stateless_random_hue#args\r\n\r\n2.4:\r\nhttps://www.tensorflow.org/versions/r2.4/api_docs/python/tf/image/stateless_random_hue#args\r\n\r\nThank you!",
"created_at": "2023-12-15T06:41:52Z"
},
{
"body": "This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you.",
"created_at": "2023-12-23T01:47:45Z"
},
{
"body": "This issue was closed because it has been inactive for 7 days since being marked as stale. Please reopen if you'd like to work on this further.",
"created_at": "2023-12-30T01:48:18Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58703\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58703\">No</a>\n",
"created_at": "2023-12-30T01:48:27Z"
}
],
"number": 58703,
"title": "Type restrictions on seeds in the tf.image.stateless_random_hue documentation."
}
|
{
"body": "Fix for #58703 and please find the gist [here](https://colab.research.google.com/gist/tiruk007/06aae2e97f70571eebde88d8b0703bbe/58703.ipynb) for reference.",
"number": 58725,
"review_comments": [],
"title": "Updated image_ops_impl.py"
}
|
{
"commits": [
{
"message": "Updated image_ops_impl.py\n\nFix for #58703 and please find the gist [here](https://colab.research.google.com/gist/tiruk007/fea66f842b905fa2988c3758f5ce6a46/58703.ipynb) for reference."
}
],
"files": [
{
"diff": "@@ -2693,7 +2693,7 @@ def stateless_random_hue(image, max_delta, seed):\n image: RGB image or images. The size of the last dimension must be 3.\n max_delta: float. The maximum value for the random delta.\n seed: A shape [2] Tensor, the seed to the random number generator. Must have\n- dtype `int32` or `int64`. (When using XLA, only `int32` is allowed.)\n+ dtype `int32` or `int64`.\n \n Returns:\n Adjusted image(s), same shape and DType as `image`.",
"filename": "tensorflow/python/ops/image_ops_impl.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): UB18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: NA\r\n- TensorFlow installed from (source or binary): source\r\n- TensorFlow version (use command below): 2.2.1\r\n- Python version: 3.6.9\r\n- Bazel version (if compiling from source): bazel 2.0.0- (@non-git)\r\n- GCC/Compiler version (if compiling from source): gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\nThis issue is created for tracking purposes in respect to the discussion done in PR request #44063 \r\n@jdduke Thank you for offering to look into this issue and letting me tag you here.\r\n\r\nThe problem is that the TfLite saved models only support Little Endian format by default. When loading these model, flatbuffer is not able to handle some non-native data types like Tensor. We need some extra efforts on both the saving side and loading side to manually do the byte-swap on Big-Endian machine. \r\n\r\n**Describe the expected behavior**\r\nWe should be able to address the endianness issue while keeping the saved model in Little-Endian format. \r\n\r\n",
"comments": [
{
"body": "Thanks for the report! I've filed an internal tracking bug to figure out next steps, will keep you posted on progress.",
"created_at": "2020-11-19T20:00:39Z"
},
{
"body": "Hi @jdduke, I think I just got some useful information in addressing this issue.\r\nBased on my investigation, the issue here is not limited to serialize and deserialize tflite flatbuffer models, because I also identified this issue when using the experimental `mlir_quantizier`, in which case the flatbuffer model is converted into a mlir module then quantized and converted back.\r\nI believe the major issue is related to the `buffers` field as defined in the [schema](https://github.com/tensorflow/tensorflow/blob/47764eaf7473224cd3fe3cfb34706cfd219c532c/tensorflow/lite/schema/schema.fbs#L1154). The `Buffer` data type is 1 byte long but they actually represent data of longer bytes like `int` or `float`, which may cause the data in the `buffers` field not to be stored in little-endian, while flatbuffer objects should always be stored in little-endian.\r\nWhen the `buffers` field of the model is populated, it is using methods similar to `memcpy`, like in the old tflite toco converter [here](https://github.com/tensorflow/tensorflow/blob/47764eaf7473224cd3fe3cfb34706cfd219c532c/tensorflow/lite/toco/tflite/export.cc#L227) and in the new mlir converter [here](https://github.com/tensorflow/tensorflow/blob/47764eaf7473224cd3fe3cfb34706cfd219c532c/tensorflow/compiler/mlir/lite/flatbuffer_export.cc#L694). As a result, the underlying data in the `buffers` field is in host machine native endianness rather than little-endian.\r\nIn comparison, other fields in the schema like `quantization_parameters` or `shape` are all typed values, so when populating them in the model, flatbuffer compiler will handle the endianness automatically (i.e. always store them in little endian, byteswap when needed).\r\n\r\nThe issue with the `buffers` field is a fundamental thing that needs to be fixed for big-endian machines to use tflite properly, but currently, it is not entirely broken because of the following reasons:\r\n1. Both write and read to `buffers` field is using host endianness, so the issue will not emerge if the flatbuffer model is untouched - it only emerges when the flatbuffer model is exported or converted, like serialized into a `.tflite` file and being read on another machine, or being converted into a mlir module as I mentioned above.\r\n2. I am not sure about this one but the `buffers` field seems only being used for constant operator tensors. It looks like those tensors are the only tensors whose values are stored in the model `buffers`. So the tensors whose values are calculated after model evaluation will not have this issue.\r\n\r\nDue to the schema definition, we could not rely on any flatbuffer API changes to fix this issue. I think to fix this, we need to deal with the endianness manually whenever we try to populate the `buffers` field in the tflite model (like in the two converters I mentioned above) or read the `buffers` field of a finished model (like in `InterpreterBuilder` and maybe somewhere else). It looks to me that we need to do a case split for the data type every single time when `buffers` field is accessed, which is a bit annoying to be honest. I hope you guys could come up with something more element to deal with this issue, and please let me know if there is anything I could help, thanks.",
"created_at": "2020-12-07T15:58:12Z"
},
{
"body": "You're right, that does leave us in a tricky situation.\r\n\r\nFor my own understanding, are you most interested in supporting the (big endian) -> (big endian) path, where both the conversion and execution take place on a big-endian machine? Or all potential permutations of little/big endian conversion and deployment?",
"created_at": "2020-12-09T19:59:15Z"
},
{
"body": "For me, it will be best if we could settle this once and for all - i.e. make sure it is consistent across all platforms so that the entire flatbuffer models will work seamlessly across different machines and converters. So I think the second approach would be more preferred (while the first approach could be a temporary workaround for us).\r\nMy ideal solution on this would be implementing something similar to [byte_swap.cc](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/util/tensor_bundle/byte_swap.cc) or other flatbuffer native method like EndianScalar at all the places where the `buffers` field is read or write (I hope there are not too many places besides the 2 converts and the `ParseTensors` call in `interpreter_builder.cc`). But I'm afraid it has to be more complicated as we will have to enumerate through the buffer vector to implement the byte-swap so we could not use those straightforward methods like `memcpy` anymore.",
"created_at": "2020-12-09T21:51:54Z"
},
{
"body": "> For me, it will be best if we could settle this once and for all\r\n\r\nAgreed, my question is more toward determining next steps and ordering. There could be a few simple tweaks we could make to get big -> big working, on the way toward full generality, if that is a blocker for any specific use-cases or project you're working on. If not, then the order of work doesn't necessarily matter and we can focus on the general solution.",
"created_at": "2020-12-09T22:58:06Z"
},
{
"body": "Sure, thanks for being so thoughtful! I think the big -> big route does not have a general blocker right now. As mentioned before, to save and load `.tflite` binary model on the same machine does not have any issues.\r\nWhat I did notice that may require a bit of tweaks is [here](https://github.com/tensorflow/tensorflow/blob/fcc4b966f1265f466e82617020af93670141b009/tensorflow/compiler/mlir/lite/flatbuffer_import.cc#L269). In this function and some lines below we are trying to access the buffer data in little-endian format. This method is taking endianness into consideration but unfortunately, they will retrieve the wrong data on big-endian machines right now. Do you think it will be necessary if we change this code into reading host endianness as a workaround and then change it back once we fix the `buffer` issue?",
"created_at": "2020-12-10T00:28:25Z"
},
{
"body": "According to this,\r\nhttps://google.github.io/flatbuffers/md__internals.html\r\n`A FlatBuffer is a binary file and in-memory format consisting mostly of scalars of various sizes, all aligned to their own size. Each scalar is also always represented in little-endian format, as this corresponds to all commonly used CPUs today. FlatBuffers will also work on big-endian machines, but will be slightly slower because of additional byte-swap intrinsics.`\r\n\r\nSo, it looks like we'd better use little-endian for `buffers` for consistency.",
"created_at": "2020-12-10T02:52:58Z"
},
{
"body": "> According to this,\r\n> https://google.github.io/flatbuffers/md__internals.html\r\n> `A FlatBuffer is a binary file and in-memory format consisting mostly of scalars of various sizes, all aligned to their own size. Each scalar is also always represented in little-endian format, as this corresponds to all commonly used CPUs today. FlatBuffers will also work on big-endian machines, but will be slightly slower because of additional byte-swap intrinsics.`\r\n> \r\n> So, it looks like we'd better use little-endian for `buffers` for consistency.\r\n\r\nYes, that is true, and I think this is basically what we intend to achieve at last. Currently, all the other fields defined in the schema (which have types) are working properly except `buffers`, so it would make sense to fix `buffers` to use little-endian.\r\n\r\n\r\nOn the other hand, for those fields that are correctly stored in little-endian format, there do exists some places in the codebase where the access to these flatbuffer data is a bit careless, like the issue you are mentioning. It will be better to access data only using flatbuffer methods rather than the raw data pointer because flatbuffer methods will handle the endianness automatically. I am working on a PR for this particular issue and I will also keep an eye on any other similar issue related to flatbuffer endianness.",
"created_at": "2020-12-10T03:58:41Z"
},
{
"body": "A short update: I forgot to mention this before, that the `CustomQuantization` field and `custom_options` field may also require similar fixes as `buffers` field as per [schema definition](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/schema/schema.fbs). I did not encounter these two fields frequently but theoretically they have the same issue as `buffers` field as they are also `ubyte` typed. ",
"created_at": "2020-12-11T20:43:20Z"
},
{
"body": "I think I also encountered similar issues when I ran the test case `//tensorflow/lite/tools/optimize:quantize_model_test` on BE machines.\r\n\r\nThe `LSTM` related tests in this test case would fail on BE platforms due to the following reasons:\r\n1. `LSTM` related binary model files are not loaded correctly on BE machines since the tensor data is stored in LE format.\r\n2. In certain quantization process, values should be copied into buffers from the tail on BE machines but actually they are not.\r\n\r\nI made the code changes below to make this test case pass on BE machines:\r\n1. Swap the buffer data once the binary model files are loaded.\r\n2. Fill the buffers from the tail in two quantization related functions: `SymmetricQuantizeFloatsToInt16()` (in `tensorflow/lite/tools/optimize/quantization_utils.cc`) and `PortableSymmetricQuantizeFloats()` (in `tensorflow/lite/kernels/internal/reference/portable_tensor_utils.cc`) .\r\n\r\nThe code change would make this test case pass. However, it would cause regression on test cases like `//tensorflow/lite/kernels:lstm_test` and `//tensorflow/lite/kernels:svdf_test`. \r\n\r\nI believe the reason of this regression is that there are other code snippets in the execution path of these TCs which also need to be updated, so that the buffer loading (filling) behaviour on BE machines would become consistent, just as @Sidong-Wei mentioned in https://github.com/tensorflow/tensorflow/issues/45009#issuecomment-740008230.\r\n\r\nIt looks like this flatbuffer endianness issue still needs an overall solution. @jdduke @terryheo Any updates from internal tracking? Thank you very much!\r\n",
"created_at": "2021-06-23T19:02:09Z"
},
{
"body": "Hi @jdduke @terryheo , hope all is well.\r\n\r\nWonder if you have any updates reg this issue? Thanks!",
"created_at": "2022-02-23T16:33:52Z"
},
{
"body": "@terryheo @karimnosseir Wanted to follow-up on this issue - is there something we could do to assist with debugging it further?\r\n\r\nThanks!",
"created_at": "2022-06-22T17:29:38Z"
},
{
"body": "I don't have a plan to work on this now. But if there are any open source contributors, I'm willing to review their PRs.",
"created_at": "2022-06-22T17:40:56Z"
},
{
"body": "Thanks @terryheo - I understand that an internal tracking bug already exists for this issue. Presumably it is a matter of prioritizing this task. Failing any immediate contributions do you have any rough idea when will this happen?\r\n\r\n",
"created_at": "2022-06-24T12:57:31Z"
},
{
"body": "This issue could be closed since it has been addressed by PR #58494.",
"created_at": "2023-03-17T12:32:39Z"
},
{
"body": "Hi @skribm9 \r\n\r\nAs this [comment](https://github.com/tensorflow/tensorflow/issues/45009#issuecomment-1473762657) suggests, can you please confirm if this issue is addressed with the PR [#58494](https://github.com/tensorflow/tensorflow/pull/58494) ?\r\n\r\nThanks.",
"created_at": "2023-04-10T14:59:15Z"
},
{
"body": "Hi @pjpratik ,\r\n\r\n@skribm9 was my colleague. Yes, PR https://github.com/tensorflow/tensorflow/pull/58494 has added big-endian support to TFLite FlatBuffers models, so that this issue could be closed.\r\n\r\nThank you!",
"created_at": "2023-04-10T15:10:07Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/45009\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/45009\">No</a>\n",
"created_at": "2023-04-12T06:10:25Z"
}
],
"number": 45009,
"title": "TF Lite issue when loading a saved TF Lite model on platforms with different endianness"
}
|
{
"body": "This PR aims to achieve a holistic/generic solution for TFLite FlatBuffers endianness issue on s390x(big-endian machines). It follows the below guidelines on BE machines:\r\n\r\n1. Provide the endianness conversion feature for constant buffers in a TFLite model, both in C++ and Python code.\r\n2. Convert the buffers from LE(little-endian) to BE(big-endian) format when loading a TFLite model from a file.\r\n3. Convert the buffers from BE to LE format when writing a serialized string of TFLite model to a file.\r\n4. Keep the buffers in BE format when the model/buffer is in memory.\r\n\r\nThis PR won't cause regression on LE machines. After applying this patch, LE format serialized TFLite model files (.tflite or .bin) could be used across platforms with different endianness format.\r\n\r\nThe following test case failures could be fixed by this code change on BE machines:\r\n \r\n```bash\r\n--- In lite module:\r\n//tensorflow/lite:signature_runner_test\r\n//tensorflow/lite/c:c_api_signature_runner_test\r\n//tensorflow/lite/c:c_test\r\n//tensorflow/lite/experimental/acceleration/mini_benchmark:validator_runner_impl_test\r\n//tensorflow/lite/experimental/acceleration/mini_benchmark:validator_runner_test\r\n//tensorflow/lite/experimental/acceleration/mini_benchmark:validator_test\r\n//tensorflow/lite/experimental/acceleration/mini_benchmark/metrics:blazeface_mlkit_v1_validation_regression_test\r\n//tensorflow/lite/experimental/acceleration/mini_benchmark/metrics:mobilenet_float_validation_test\r\n//tensorflow/lite/experimental/acceleration/mini_benchmark/metrics:mobilenet_quant_validation_test\r\n//tensorflow/lite/experimental/acceleration/mini_benchmark/model_modifier:custom_validation_embedder_test\r\n//tensorflow/lite/python:util_test\r\n//tensorflow/lite/testing:zip_test_expand_dims_mlir-quant\r\n//tensorflow/lite/testing:zip_test_fully_connected_mlir-quant\r\n//tensorflow/lite/testing:zip_test_mean_mlir-quant\r\n//tensorflow/lite/testing:zip_test_mirror_pad_mlir-quant\r\n//tensorflow/lite/testing:zip_test_pad_mlir-quant\r\n//tensorflow/lite/testing:zip_test_reduce_max_mlir-quant\r\n//tensorflow/lite/testing:zip_test_reduce_min_mlir-quant\r\n//tensorflow/lite/testing:zip_test_reshape_mlir-quant\r\n//tensorflow/lite/testing:zip_test_resize_bilinear_mlir-quant\r\n//tensorflow/lite/testing:zip_test_resize_bilinear_mlir-quant_xnnpack\r\n//tensorflow/lite/testing:zip_test_resize_nearest_neighbor_mlir-quant\r\n//tensorflow/lite/testing:zip_test_resize_nearest_neighbor_mlir-quant_xnnpack\r\n//tensorflow/lite/testing:zip_test_slice_mlir-quant\r\n//tensorflow/lite/testing:zip_test_softmax_mlir-quant\r\n//tensorflow/lite/testing:zip_test_softmax_mlir-quant_xnnpack\r\n//tensorflow/lite/testing:zip_test_split_mlir-quant\r\n//tensorflow/lite/testing:zip_test_split_mlir-quant_xnnpack\r\n//tensorflow/lite/testing:zip_test_squeeze_mlir-quant\r\n//tensorflow/lite/testing:zip_test_strided_slice_mlir-quant\r\n//tensorflow/lite/testing:zip_test_transpose_conv_mlir-quant\r\n//tensorflow/lite/testing:zip_test_transpose_conv_mlir-quant_xnnpack\r\n//tensorflow/lite/testing:zip_test_transpose_mlir-quant\r\n//tensorflow/lite/testing:zip_test_where_mlir-quant\r\n//tensorflow/lite/tools/optimize/calibration:calibrator_test\r\n//tensorflow/lite/tools/optimize/debugging/python:debugger_test\r\n//tensorflow/lite/tools/optimize/python:modify_model_interface_lib_test\r\n//tensorflow/lite/python:lite_v2_test\r\n\r\n--- In compiler module:\r\n//tensorflow/compiler/mlir/lite/quantization/lite:quantize_model_test\r\n//tensorflow/compiler/mlir/lite/quantization/lite:quantize_weights_test\r\n//tensorflow/compiler/mlir/lite/tests/flatbuffer2mlir:constants.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/flatbuffer2mlir:importer_test_min_max.cc.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/flatbuffer2mlir:importer_test_min_max.cc.test\r\n//tensorflow/compiler/mlir/lite/tests/flatbuffer2mlir:math.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/flatbuffer2mlir:quantization.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/flatbuffer2mlir:reshape.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/flatbuffer2mlir:simple.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:bucketize.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:custom_op_with_tflite_op.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:depthwise_conv2d.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:depthwise_conv2d_v2.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:disable_flex_enable_builtin.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:flex_op_with_tflite_op.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:math.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:quantization.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:reshape.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:signature_def_output_override.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:simple.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:simple_with_connected_control_nodes.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:simple_with_unconnected_control_nodes.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:tf_entry_function.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:tfl_while_op.mlir.test\r\n//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer:while_op.mlir.test\r\n```\r\n\r\nThis PR will also fix issue #45009 and PR #57065.\r\n\r\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>",
"number": 58494,
"review_comments": [
{
"body": "Why is this needed?",
"created_at": "2022-11-14T17:19:42Z"
},
{
"body": "Is the target always writable?\r\nWhat happens if the target memory is mmaped ?",
"created_at": "2022-11-14T17:21:56Z"
},
{
"body": "Who does define this?",
"created_at": "2022-11-14T17:22:33Z"
},
{
"body": "for what?",
"created_at": "2022-11-14T17:22:51Z"
},
{
"body": "This line was added here so that `FlatBufferModel::ByteSwapSerializedModel()` could be invoked in `tensorflow/compiler/mlir/lite/flatbuffer_to_string.cc`. \r\n\r\nThe conversion could fix a series of `//tensorflow/compiler/mlir/lite/tests/mlir2flatbuffer` test cases in `compiler` module on BE machines.",
"created_at": "2022-11-14T18:03:32Z"
},
{
"body": "Yes, I think so. I've tested the code on s390x when using mmap (`MMAPAllocation::IsSupported()` is true), the code works as expected.",
"created_at": "2022-11-14T18:03:47Z"
},
{
"body": "`FLATBUFFERS_LITTLEENDIAN` is defined in the `flatbuffers` header file here: https://github.com/google/flatbuffers/blob/6f895f54c25aa19f5d84ac6cf7fa8bc955a14e1d/include/flatbuffers/base.h#L119-L139",
"created_at": "2022-11-14T18:04:01Z"
},
{
"body": "The built `constant_tensor` has a total of 1 * 2 * 5 = 10 bytes data. If the TensorType is set to 0 (FLOAT32), These 10 bytes are not enough for 3 FLOAT32 data which needs 12 bytes. \r\n\r\nThis will cause error when doing LE/BE conversion and it's also a potential bug on LE platform. I think setting the TensorType to 3 (UINT8) is an easy solution for this issue.",
"created_at": "2022-11-14T18:04:05Z"
},
{
"body": "Actually `FlatBufferModel::ByteSwapFlatBufferModel()` will allocate a new `FlatBufferModel` instance for byte swapping and return its handler.",
"created_at": "2022-11-15T16:53:57Z"
},
{
"body": "If you want to use FlatBufferModel::ByteSwapSerializedModel(), isn't `model_builder` sufficient?",
"created_at": "2022-12-08T17:11:26Z"
},
{
"body": "Tensor can share buffers. We need to do swap only once.",
"created_at": "2022-12-08T17:20:53Z"
},
{
"body": "Then will it increase memory consumption?\r\n\r\nRandom thoughts, how about creating a separate tool to update LE buffers to BE buffers?",
"created_at": "2022-12-08T18:13:11Z"
},
{
"body": "Isn't it better to use \"#ifdef FLATBUFFERS_LITTLEENDIAN\" ?",
"created_at": "2022-12-08T18:14:16Z"
},
{
"body": "Got it. Then `schema_fb.TensorAddType(builder, TensorType_UINT8)` ?",
"created_at": "2022-12-08T18:16:16Z"
},
{
"body": "I also want to add conditional building (`#ifdef FLATBUFFERS_LITTLEENDIAN`) for all swapping functions which are only needed for BE targets.",
"created_at": "2022-12-08T18:17:46Z"
},
{
"body": "Yes, I'll improve the code to use `model_builder` only. Thanks!",
"created_at": "2022-12-08T19:27:27Z"
},
{
"body": "Yes, it will increase memory consumption on BE platforms, but only during the model loading/saving phase, so I think it will not incur big impact to the performance.\r\n\r\nCreating a separate tool will also work, but it will bring extra steps such as using the tool to convert the .tflite files on BE platforms before running TensorFlow code. I think embedding the byte swapping code in TensorFlow code base would be more convenient for the users, thus they can use the same steps and .tflite files across LE and BE platforms, without the need to mark which .tflite files are in which endianness format or do the conversion manually. The endianness issue then becomes transparent to the users.",
"created_at": "2022-12-08T19:37:47Z"
},
{
"body": "Yes, I'll adjust the code accordingly. Thanks!",
"created_at": "2022-12-08T19:38:17Z"
},
{
"body": "Yes, using `TensorType_UINT8` is better. I'll update the code. Thanks!",
"created_at": "2022-12-08T19:38:23Z"
},
{
"body": "I see. Will adjust the code to do swap only once. Thanks!",
"created_at": "2022-12-08T19:38:35Z"
},
{
"body": "Yes, that makes sense. I'll add the macro conditional statement for them. Thank you very much for all the valuable comments!",
"created_at": "2022-12-08T19:38:51Z"
},
{
"body": "Done.",
"created_at": "2022-12-09T18:33:39Z"
},
{
"body": "Done.",
"created_at": "2022-12-09T18:34:34Z"
},
{
"body": "Used `schema_fb.TensorType.UINT8` instead of value `3`. ",
"created_at": "2022-12-09T18:35:30Z"
},
{
"body": "Both the C++ code and Python code were updated to ensure the swapping would be done only once.",
"created_at": "2022-12-09T18:37:10Z"
},
{
"body": "Done.",
"created_at": "2022-12-09T18:37:40Z"
},
{
"body": "We don't indent for \"#if\" \"#endif\". Plz update all.",
"created_at": "2023-01-13T23:38:01Z"
},
{
"body": "Could you run formatter? https://www.tensorflow.org/community/contribute/code_style#c_coding_style\r\n\r\nNeed a space before '{'",
"created_at": "2023-01-13T23:39:32Z"
},
{
"body": "Done. Thanks!",
"created_at": "2023-01-16T16:27:32Z"
},
{
"body": "I've run the formatter and updated the code. Thanks!",
"created_at": "2023-01-16T16:29:15Z"
}
],
"title": "Add big-endian support to TFLite FlatBuffers"
}
|
{
"commits": [
{
"message": "Add BE support to TFLite FlatBuffers\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Fix the PyLint format issue\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Fix the endianness issue in mini_benchmark test group on BE machines\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Merge branch 'master' into add_big_endian_support_to_tflite_flatbuffers\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Merge branch 'master' into add_big_endian_support_to_tflite_flatbuffers\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Update the code change as per the review comments:\n1. Do byte swapping only once on buffers\n2. Add conditional building for all swapping functions\n3. Use schema_fb.TensorType.UINT8 instead of value `3`\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Use schema_fb.TensorType in byte_swap Python code\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Merge branch 'master' into add_big_endian_support_to_tflite_flatbuffers\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Merge branch 'master' into add_big_endian_support_to_tflite_flatbuffers\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Run formatter to make the code conform to Google style\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Merge branch 'master' into add_big_endian_support_to_tflite_flatbuffers\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Merge branch 'master' into add_big_endian_support_to_tflite_flatbuffers\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Merge branch 'master' into add_big_endian_support_to_tflite_flatbuffers\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Remove unnecessary ending white spaces in model_builder.h\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Merge branch 'master' into add_big_endian_support_to_tflite_flatbuffers\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
},
{
"message": "Update the function descriptions in flatbuffer_utils.py\n\nSigned-off-by: Kun-Lu <kun.lu@ibm.com>"
}
],
"files": [
{
"diff": "@@ -919,6 +919,7 @@ tf_native_cc_binary(\n name = \"flatbuffer_to_string\",\n srcs = [\"flatbuffer_to_string.cc\"],\n deps = [\n+ \"//tensorflow/lite/core:model_builder\",\n \"//tensorflow/lite/schema:schema_fbs_with_reflection\",\n \"@flatbuffers\",\n ],",
"filename": "tensorflow/compiler/mlir/lite/BUILD",
"status": "modified"
},
{
"diff": "@@ -338,11 +338,11 @@ std::string GetMlirOpName(const tflite::OperatorT& op,\n }\n \n // The buffers in TFLite flatbuffers have their contents stored as a vector of\n-// bytes that represent little-endian values.\n+// bytes that represent host endianness values.\n // The read_size parameter is present to allow reading both float16 and float32s\n // without a case split.\n template <typename T>\n-std::vector<T> ReadAsLittleEndian(ArrayRef<uint8_t> bytes) {\n+std::vector<T> ReadAsHostEndian(ArrayRef<uint8_t> bytes) {\n std::vector<T> ret;\n size_t read_size = sizeof(T);\n int bytes_len = bytes.size();\n@@ -353,9 +353,9 @@ std::vector<T> ReadAsLittleEndian(ArrayRef<uint8_t> bytes) {\n \n const char* data_ptr = reinterpret_cast<const char*>(bytes.data());\n for (int i = 0; i < elem_count; i++) {\n- ret.push_back(\n- llvm::support::endian::readNext<T, llvm::support::little,\n- llvm::support::unaligned>(data_ptr));\n+ ret.push_back(llvm::support::endian::readNext<\n+ T, llvm::support::endian::system_endianness(),\n+ llvm::support::unaligned>(data_ptr));\n }\n return ret;\n }\n@@ -401,9 +401,9 @@ StatusOr<mlir::ElementsAttr> ConvertFloatBuffer(\n auto& semantics = elem_type.getFloatSemantics();\n \n for (int i = 0; i < elem_count; i++) {\n- uint16_t bit_repr =\n- llvm::support::endian::readNext<uint16_t, llvm::support::little,\n- llvm::support::unaligned>(data);\n+ uint16_t bit_repr = llvm::support::endian::readNext<\n+ uint16_t, llvm::support::endian::system_endianness(),\n+ llvm::support::unaligned>(data);\n llvm::APInt int_repr(16, bit_repr);\n values.emplace_back(semantics, int_repr);\n }\n@@ -419,9 +419,9 @@ StatusOr<mlir::ElementsAttr> ConvertFloatBuffer(\n const char* data = reinterpret_cast<const char*>(buffer.data());\n \n for (int i = 0; i < elem_count; i++) {\n- uint32_t bit_repr =\n- llvm::support::endian::readNext<uint32_t, llvm::support::little,\n- llvm::support::unaligned>(data);\n+ uint32_t bit_repr = llvm::support::endian::readNext<\n+ uint32_t, llvm::support::endian::system_endianness(),\n+ llvm::support::unaligned>(data);\n values.push_back(absl::bit_cast<float>(bit_repr));\n }\n return mlir::ElementsAttr(\n@@ -436,9 +436,9 @@ StatusOr<mlir::ElementsAttr> ConvertFloatBuffer(\n const char* data = reinterpret_cast<const char*>(buffer.data());\n \n for (int i = 0; i < elem_count; i++) {\n- uint64_t bit_repr =\n- llvm::support::endian::readNext<uint64_t, llvm::support::little,\n- llvm::support::unaligned>(data);\n+ uint64_t bit_repr = llvm::support::endian::readNext<\n+ uint64_t, llvm::support::endian::system_endianness(),\n+ llvm::support::unaligned>(data);\n values.push_back(absl::bit_cast<double>(bit_repr));\n }\n return mlir::ElementsAttr(\n@@ -486,17 +486,17 @@ StatusOr<mlir::ElementsAttr> ConvertIntBuffer(\n DenseElementsAttr::get(shaped_type, ArrayRef<uint8_t>(buffer)));\n }\n case 16: {\n- auto values = ReadAsLittleEndian<uint16_t>(buffer);\n+ auto values = ReadAsHostEndian<uint16_t>(buffer);\n return mlir::ElementsAttr(\n DenseElementsAttr::get(shaped_type, ArrayRef<uint16_t>(values)));\n }\n case 32: {\n- auto values = ReadAsLittleEndian<uint32_t>(buffer);\n+ auto values = ReadAsHostEndian<uint32_t>(buffer);\n return mlir::ElementsAttr(\n DenseElementsAttr::get(shaped_type, ArrayRef<uint32_t>(values)));\n }\n case 64: {\n- auto values = ReadAsLittleEndian<uint64_t>(buffer);\n+ auto values = ReadAsHostEndian<uint64_t>(buffer);\n return mlir::ElementsAttr(\n DenseElementsAttr::get(shaped_type, ArrayRef<uint64_t>(values)));\n }",
"filename": "tensorflow/compiler/mlir/lite/flatbuffer_import.cc",
"status": "modified"
},
{
"diff": "@@ -26,6 +26,9 @@ limitations under the License.\n #include \"flatbuffers/flatbuffers.h\" // from @flatbuffers\n #include \"flatbuffers/minireflect.h\" // from @flatbuffers\n #include \"tensorflow/lite/schema/reflection/schema_generated.h\"\n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+#include \"tensorflow/lite/core/model_builder.h\"\n+#endif\n \n namespace tflite {\n namespace {\n@@ -137,6 +140,9 @@ int main(int argc, char** argv) {\n \n std::string serialized_model;\n if (tflite::ReadAndVerify(argv[1], &serialized_model)) return 1;\n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+ tflite::FlatBufferModel::ByteSwapSerializedModel(&serialized_model);\n+#endif\n tflite::ToString(serialized_model);\n return 0;\n }",
"filename": "tensorflow/compiler/mlir/lite/flatbuffer_to_string.cc",
"status": "modified"
},
{
"diff": "@@ -21,6 +21,7 @@ limitations under the License.\n #include <string>\n #include <utility>\n \n+#include \"flatbuffers/flatbuffers.h\" // from @flatbuffers\n #include \"tensorflow/lite/allocation.h\"\n #include \"tensorflow/lite/core/api/error_reporter.h\"\n #include \"tensorflow/lite/core/api/verifier.h\"\n@@ -58,17 +59,27 @@ namespace impl {\n std::unique_ptr<FlatBufferModel> FlatBufferModel::BuildFromFile(\n const char* filename, ErrorReporter* error_reporter) {\n error_reporter = ValidateErrorReporter(error_reporter);\n- return BuildFromAllocation(GetAllocationFromFile(filename, error_reporter),\n- error_reporter);\n+ std::unique_ptr<FlatBufferModel> model = BuildFromAllocation(\n+ GetAllocationFromFile(filename, error_reporter), error_reporter);\n+#if FLATBUFFERS_LITTLEENDIAN == 1\n+ return model;\n+#else\n+ return ByteConvertModel(std::move(model), error_reporter);\n+#endif\n }\n \n std::unique_ptr<FlatBufferModel> FlatBufferModel::VerifyAndBuildFromFile(\n const char* filename, TfLiteVerifier* extra_verifier,\n ErrorReporter* error_reporter) {\n error_reporter = ValidateErrorReporter(error_reporter);\n- return VerifyAndBuildFromAllocation(\n+ std::unique_ptr<FlatBufferModel> model = VerifyAndBuildFromAllocation(\n GetAllocationFromFile(filename, error_reporter), extra_verifier,\n error_reporter);\n+#if FLATBUFFERS_LITTLEENDIAN == 1\n+ return model;\n+#else\n+ return ByteConvertModel(std::move(model), error_reporter);\n+#endif\n }\n \n } // namespace impl\n@@ -94,6 +105,124 @@ std::unique_ptr<FlatBufferModel> FlatBufferModel::VerifyAndBuildFromBuffer(\n error_reporter);\n }\n \n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+\n+void FlatBufferModel::ByteSwapSerializedModel(std::string* serialized_model) {\n+ const uint8_t* buffer =\n+ reinterpret_cast<const uint8_t*>(serialized_model->c_str());\n+ const tflite::Model* input_model = tflite::GetModel(buffer);\n+ ByteSwapTFLiteModel(input_model);\n+}\n+\n+void FlatBufferModel::ByteSwapBuffer(int8_t tensor_type, size_t buffer_size,\n+ uint8_t* buffer) {\n+ switch (tensor_type) {\n+ // 16-bit types\n+ case tflite::TensorType_FLOAT16:\n+ case tflite::TensorType_INT16:\n+ case tflite::TensorType_UINT16: {\n+ auto bp = reinterpret_cast<uint16_t*>(buffer);\n+ for (int i = 0; i < buffer_size / 2; i++)\n+ bp[i] = flatbuffers::EndianSwap(bp[i]);\n+ break;\n+ }\n+ // 32-bit types\n+ case tflite::TensorType_FLOAT32:\n+ case tflite::TensorType_INT32:\n+ case tflite::TensorType_UINT32:\n+ case tflite::TensorType_COMPLEX64: {\n+ auto bp = reinterpret_cast<uint32_t*>(buffer);\n+ for (int i = 0; i < buffer_size / 4; i++)\n+ bp[i] = flatbuffers::EndianSwap(bp[i]);\n+ break;\n+ }\n+ // 64-bit types\n+ case tflite::TensorType_INT64:\n+ case tflite::TensorType_FLOAT64:\n+ case tflite::TensorType_UINT64:\n+ case tflite::TensorType_COMPLEX128: {\n+ auto bp = reinterpret_cast<uint64_t*>(buffer);\n+ for (int i = 0; i < buffer_size / 8; i++)\n+ bp[i] = flatbuffers::EndianSwap(bp[i]);\n+ break;\n+ }\n+ default:\n+ break;\n+ }\n+}\n+\n+void FlatBufferModel::ByteSwapTFLiteModel(const tflite::Model* tfl_model) {\n+ bool buffer_swapped[tfl_model->buffers()->size()] = {};\n+ for (size_t subgraph_idx = 0; subgraph_idx < tfl_model->subgraphs()->size();\n+ subgraph_idx++) {\n+ const tflite::SubGraph* subgraph =\n+ tfl_model->subgraphs()->Get(subgraph_idx);\n+ for (size_t ts_idx = 0; ts_idx < subgraph->tensors()->size(); ts_idx++) {\n+ const tflite::Tensor* tensor = subgraph->tensors()->Get(ts_idx);\n+ if (tensor->buffer() > 0 &&\n+ tensor->buffer() < tfl_model->buffers()->size() &&\n+ !buffer_swapped[tensor->buffer()]) {\n+ const tflite::Buffer* buffer_ =\n+ (*tfl_model->buffers())[tensor->buffer()];\n+ if (!buffer_ || !buffer_->data()) continue;\n+ auto* buffer = buffer_->data();\n+ uint8_t* buff_ = const_cast<uint8_t*>(buffer->data());\n+ ByteSwapBuffer(tensor->type(), buffer->size(), buff_);\n+ buffer_swapped[tensor->buffer()] = true;\n+ }\n+ }\n+ }\n+}\n+\n+std::unique_ptr<FlatBufferModel> FlatBufferModel::ByteConvertModel(\n+ std::unique_ptr<FlatBufferModel> model, ErrorReporter* error_reporter) {\n+ if (model == nullptr) return model;\n+ auto tfl_model = model->GetModel();\n+ if (tfl_model->subgraphs()->size() == 0) return model;\n+ if (tfl_model->subgraphs()->Get(0)->tensors()->size() == 0) return model;\n+ return ByteSwapFlatBufferModel(std::move(model), error_reporter);\n+}\n+\n+std::unique_ptr<FlatBufferModel> FlatBufferModel::ByteSwapFlatBufferModel(\n+ std::unique_ptr<FlatBufferModel> model, ErrorReporter* error_reporter) {\n+ FlatBufferModel* modelp = model.release();\n+ auto tflite_model = modelp->GetModel();\n+ auto copied_model = std::make_unique<tflite::ModelT>();\n+ tflite_model->UnPackTo(copied_model.get(), nullptr);\n+ ByteSwapTFLiteModelT(copied_model.get());\n+ std::unique_ptr<flatbuffers::FlatBufferBuilder> builder(\n+ new flatbuffers::FlatBufferBuilder());\n+ auto packed_model = tflite::Model::Pack(*builder, copied_model.get());\n+ tflite::FinishModelBuffer(*builder, packed_model);\n+ flatbuffers::FlatBufferBuilder* builder_ = builder.release();\n+ return BuildFromBuffer(\n+ reinterpret_cast<const char*>(builder_->GetBufferPointer()),\n+ builder_->GetSize(), error_reporter);\n+}\n+\n+void FlatBufferModel::ByteSwapTFLiteModelT(tflite::ModelT* tfl_modelt) {\n+ size_t bytes_per_elem = 0;\n+ bool buffer_swapped[tfl_modelt->buffers.size()] = {};\n+ for (size_t subgraph_idx = 0; subgraph_idx < tfl_modelt->subgraphs.size();\n+ subgraph_idx++) {\n+ tflite::SubGraphT* subgraph = tfl_modelt->subgraphs.at(subgraph_idx).get();\n+ for (size_t ts_idx = 0; ts_idx < subgraph->tensors.size(); ts_idx++) {\n+ tflite::TensorT* tensor = subgraph->tensors[ts_idx].get();\n+ if (tensor->buffer > 0 && tensor->buffer < tfl_modelt->buffers.size() &&\n+ !buffer_swapped[tensor->buffer]) {\n+ const auto* buffer = &(tfl_modelt->buffers[tensor->buffer].get()->data);\n+ if (buffer && buffer->data()) {\n+ uint8_t* buff_ = const_cast<uint8_t*>(buffer->data());\n+ ByteSwapBuffer(tensor->type, buffer->size(), buff_);\n+ buffer_swapped[tensor->buffer] = true;\n+ }\n+ }\n+ }\n+ }\n+}\n+\n+#endif\n+\n void FlatBufferModel::ValidateModelBuffers(ErrorReporter* error_reporter) {\n auto buffers = model_->buffers();\n if (buffers && buffers->size() > 0) {",
"filename": "tensorflow/lite/core/model_builder.cc",
"status": "modified"
},
{
"diff": "@@ -155,6 +155,33 @@ class FlatBufferModel {\n const tflite::Model* caller_owned_model_spec,\n ErrorReporter* error_reporter = DefaultErrorReporter());\n \n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+ /// Byte swap a constant buffer in place.\n+ static void ByteSwapBuffer(int8_t tensor_type, size_t buffer_size,\n+ uint8_t* buffer);\n+\n+ /// Byte swap the buffers field of a TFLite Model instance in place.\n+ static void ByteSwapTFLiteModel(const tflite::Model* tfl_model);\n+\n+ /// Byte swap the buffers field of a TFLite ModelT instance in place.\n+ static void ByteSwapTFLiteModelT(tflite::ModelT* tfl_modelt);\n+\n+ /// Convert the TFLite buffers field between LE and BE format in a\n+ /// FlatBufferModel which is not empty and return the converted instance.\n+ static std::unique_ptr<FlatBufferModel> ByteConvertModel(\n+ std::unique_ptr<FlatBufferModel> model,\n+ ErrorReporter* error_reporter = DefaultErrorReporter());\n+\n+ /// Byte Swap the TFLite buffers field in a FlatBufferModel and return the\n+ /// swapped instance.\n+ static std::unique_ptr<FlatBufferModel> ByteSwapFlatBufferModel(\n+ std::unique_ptr<FlatBufferModel> model,\n+ ErrorReporter* error_reporter = DefaultErrorReporter());\n+\n+ /// Byte Swap the serialized String of a TFLite model in place.\n+ static void ByteSwapSerializedModel(std::string* serialized_model);\n+#endif\n+\n // Releases memory or unmaps mmaped memory.\n ~FlatBufferModel();\n \n@@ -186,7 +213,7 @@ class FlatBufferModel {\n // See Metadata table in TFLite schema.\n static std::map<std::string, std::string> ReadAllMetadata(\n const ::tflite::Model* model);\n- \n+\n // Validates if the FlatBufferModel's buffer is well-formed. Specifically, it\n // checks if the 0th entry of the model buffers is an empty buffer (sentinel).\n // This is a convention so that tensors without a buffer can provide 0",
"filename": "tensorflow/lite/core/model_builder.h",
"status": "modified"
},
{
"diff": "@@ -965,6 +965,7 @@ cc_test(\n \"@com_google_googletest//:gtest_main\",\n \"@flatbuffers//:runtime_cc\",\n \"@flatbuffers\",\n+ \"//tensorflow/lite/core:model_builder\",\n \"//tensorflow/lite/experimental/acceleration/mini_benchmark/model_modifier:custom_validation_embedder\",\n \"//tensorflow/lite/schema:schema_fbs_with_mutable\",\n \"//tensorflow/lite/experimental/acceleration/configuration:configuration_cc_proto\",",
"filename": "tensorflow/lite/experimental/acceleration/mini_benchmark/BUILD",
"status": "modified"
},
{
"diff": "@@ -39,6 +39,7 @@\n # conversion in v2.\n import tensorflow.compat.v1 as tf\n from tensorflow.lite.experimental.acceleration.mini_benchmark.metrics import kl_divergence\n+from tensorflow.lite.tools import flatbuffer_utils\n \n parser = argparse.ArgumentParser(\n description='Script to generate a metrics model for the Blazeface.')\n@@ -112,6 +113,9 @@ def main(output_path):\n ], [kld_metric, box_mse, ok])\n converter.experimental_new_converter = True\n tflite_model = converter.convert()\n+ if sys.byteorder == 'big':\n+ tflite_model = flatbuffer_utils.byte_swap_tflite_buffer(\n+ tflite_model, \"big\", \"little\")\n open(output_path, 'wb').write(tflite_model)\n \n ",
"filename": "tensorflow/lite/experimental/acceleration/mini_benchmark/metrics/blazeface_metrics.py",
"status": "modified"
},
{
"diff": "@@ -28,6 +28,7 @@\n # conversion in v2.\n import tensorflow.compat.v1 as tf\n from tensorflow.lite.experimental.acceleration.mini_benchmark.metrics import kl_divergence\n+from tensorflow.lite.tools import flatbuffer_utils\n \n parser = argparse.ArgumentParser(\n description='Script to generate a metrics model for mobilenet v1.')\n@@ -56,6 +57,9 @@ def main(output_path):\n ], [kld_metric, mse, ok])\n converter.experimental_new_converter = True\n tflite_model = converter.convert()\n+ if sys.byteorder == 'big':\n+ tflite_model = flatbuffer_utils.byte_swap_tflite_buffer(\n+ tflite_model, \"big\", \"little\")\n open(output_path, 'wb').write(tflite_model)\n \n ",
"filename": "tensorflow/lite/experimental/acceleration/mini_benchmark/metrics/mobilenet.py",
"status": "modified"
},
{
"diff": "@@ -80,6 +80,7 @@ cc_binary(\n \":embedder\",\n \"//tensorflow/lite:framework\",\n \"//tensorflow/lite/core:framework\",\n+ \"//tensorflow/lite/core:model_builder\",\n \"//tensorflow/lite/experimental/acceleration/mini_benchmark:call\",\n \"//tensorflow/lite/experimental/acceleration/mini_benchmark:decode_jpeg\",\n \"//tensorflow/lite/schema:schema_fbs_with_reflection\",",
"filename": "tensorflow/lite/experimental/acceleration/mini_benchmark/model_modifier/BUILD",
"status": "modified"
},
{
"diff": "@@ -29,6 +29,9 @@ limitations under the License.\n #include \"flatbuffers/util.h\" // from @flatbuffers\n #include \"tensorflow/lite/core/interpreter.h\"\n #include \"tensorflow/lite/core/interpreter_builder.h\"\n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+#include \"tensorflow/lite/core/model_builder.h\"\n+#endif\n #include \"tensorflow/lite/experimental/acceleration/mini_benchmark/call_register.h\"\n #include \"tensorflow/lite/experimental/acceleration/mini_benchmark/decode_jpeg_register.h\"\n #include \"tensorflow/lite/experimental/acceleration/mini_benchmark/model_modifier/embedder.h\"\n@@ -69,6 +72,9 @@ int RunEmbedder(const EmbedderOptions& options) {\n << std::endl;\n return 3;\n }\n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+ tflite::FlatBufferModel::ByteSwapSerializedModel(&main_model_contents);\n+#endif\n const Model* main_model =\n flatbuffers::GetRoot<Model>(main_model_contents.data());\n \n@@ -80,6 +86,9 @@ int RunEmbedder(const EmbedderOptions& options) {\n << std::endl;\n return 4;\n }\n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+ tflite::FlatBufferModel::ByteSwapSerializedModel(&metrics_model_contents);\n+#endif\n const Model* metrics_model =\n flatbuffers::GetRoot<Model>(metrics_model_contents.data());\n \n@@ -124,6 +133,9 @@ int RunEmbedder(const EmbedderOptions& options) {\n << \" for writing failed: \" << strerror(errno) << std::endl;\n return 7;\n }\n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+ tflite::FlatBufferModel::ByteSwapSerializedModel(&binary);\n+#endif\n f << binary;\n f.close();\n if (!f.good()) {",
"filename": "tensorflow/lite/experimental/acceleration/mini_benchmark/model_modifier/embedder_main.cc",
"status": "modified"
},
{
"diff": "@@ -22,6 +22,10 @@ limitations under the License.\n #include <vector>\n \n #include <gtest/gtest.h>\n+#include \"flatbuffers/flatbuffers.h\" // from @flatbuffers\n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+#include \"tensorflow/lite/core/model_builder.h\"\n+#endif\n #include \"tensorflow/lite/experimental/acceleration/configuration/configuration.pb.h\"\n #include \"tensorflow/lite/experimental/acceleration/configuration/configuration_generated.h\"\n #include \"tensorflow/lite/experimental/acceleration/configuration/proto_to_flatbuffer.h\"\n@@ -113,9 +117,16 @@ TEST_F(ValidatorTest, HappyPathOnCpuWithCustomValidation) {\n model_with_input),\n kMinibenchmarkSuccess);\n // Dump the model with input to temp.\n- std::string model_path = MiniBenchmarkTestHelper::DumpToTempFile(\n- \"mobilenet_quant_with_input.tflite\", model_with_input.GetBufferPointer(),\n+ std::string serialized_str(\n+ reinterpret_cast<const char*>(model_with_input.GetBufferPointer()),\n model_with_input.GetSize());\n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+ tflite::FlatBufferModel::ByteSwapSerializedModel(&serialized_str);\n+#endif\n+ std::string model_path = MiniBenchmarkTestHelper::DumpToTempFile(\n+ \"mobilenet_quant_with_input.tflite\", \n+ reinterpret_cast<const unsigned char*>(serialized_str.c_str()),\n+ serialized_str.size());\n ASSERT_TRUE(!model_path.empty());\n auto model_loader = std::make_unique<tools::PathModelLoader>(model_path);\n ",
"filename": "tensorflow/lite/experimental/acceleration/mini_benchmark/validator_test.cc",
"status": "modified"
},
{
"diff": "@@ -20,6 +20,7 @@\n import os\n import re\n import string\n+import sys\n import tempfile\n import traceback\n import zipfile\n@@ -30,6 +31,7 @@\n from google.protobuf import text_format\n from tensorflow.lite.testing import _pywrap_string_util\n from tensorflow.lite.testing import generate_examples_report as report_lib\n+from tensorflow.lite.tools import flatbuffer_utils\n from tensorflow.python.framework import convert_to_constants\n from tensorflow.python.saved_model import signature_constants\n \n@@ -623,6 +625,9 @@ def build_example(label, param_dict_real, zip_path_label):\n baseline_input_map, baseline_output_map = generate_inputs_outputs(\n tflite_model_binary, min_value=0, max_value=255)\n zipinfo = zipfile.ZipInfo(zip_path_label + \".bin\")\n+ if sys.byteorder == 'big':\n+ tflite_model_binary = flatbuffer_utils.byte_swap_tflite_buffer(\n+ tflite_model_binary, \"big\", \"little\")\n archive.writestr(zipinfo, tflite_model_binary, zipfile.ZIP_DEFLATED)\n \n example = {",
"filename": "tensorflow/lite/testing/zip_test_utils.py",
"status": "modified"
},
{
"diff": "@@ -25,6 +25,7 @@\n import random\n import re\n import struct\n+import sys\n \n import flatbuffers\n from tensorflow.lite.python import schema_py_generated as schema_fb\n@@ -57,7 +58,10 @@ def read_model(input_tflite_file):\n raise RuntimeError('Input file not found at %r\\n' % input_tflite_file)\n with gfile.GFile(input_tflite_file, 'rb') as input_file_handle:\n model_bytearray = bytearray(input_file_handle.read())\n- return convert_bytearray_to_object(model_bytearray)\n+ model = convert_bytearray_to_object(model_bytearray)\n+ if sys.byteorder == 'big':\n+ byte_swap_tflite_model_obj(model, \"little\", \"big\")\n+ return model\n \n \n def read_model_with_mutable_tensors(input_tflite_file):\n@@ -99,6 +103,9 @@ def write_model(model_object, output_tflite_file):\n Raises:\n IOError: If output_tflite_file path is invalid or cannot be opened.\n \"\"\"\n+ if sys.byteorder == 'big':\n+ model_object = copy.deepcopy(model_object)\n+ byte_swap_tflite_model_obj(model_object, \"big\", \"little\")\n model_bytearray = convert_object_to_bytearray(model_object)\n with gfile.GFile(output_tflite_file, 'wb') as output_file_handle:\n output_file_handle.write(model_bytearray)\n@@ -274,6 +281,81 @@ def xxd_output_to_object(input_cc_file):\n return convert_bytearray_to_object(model_bytes)\n \n \n+def byte_swap_buffer_content(buffer, chunksize, from_endiness, to_endiness):\n+ \"\"\"Helper function for byte-swapping the buffers field.\"\"\"\n+ to_swap = [buffer.data[i:i+chunksize] for i in range(\n+ 0, len(buffer.data), chunksize)]\n+ buffer.data = b''.join([int.from_bytes(\n+ byteswap, from_endiness).to_bytes(\n+ chunksize, to_endiness) for byteswap in to_swap])\n+\n+\n+def byte_swap_tflite_model_obj(model, from_endiness, to_endiness):\n+ \"\"\"Byte swaps the buffers field in a TFLite model.\n+\n+ Args:\n+ model: TFLite model object of from_endiness format.\n+ from_endiness: The original endianness format of the buffers in model.\n+ to_endiness: The destined endianness format of the buffers in model.\n+ \"\"\"\n+ if model is None:\n+ return\n+ # Get all the constant buffers, byte swapping them as per their data types\n+ buffer_swapped = []\n+ types_of_16_bits = [schema_fb.TensorType.FLOAT16,\n+ schema_fb.TensorType.INT16, schema_fb.TensorType.UINT16]\n+ types_of_32_bits = [schema_fb.TensorType.FLOAT32,\n+ schema_fb.TensorType.INT32, schema_fb.TensorType.COMPLEX64,\n+ schema_fb.TensorType.UINT32]\n+ types_of_64_bits = [schema_fb.TensorType.INT64,\n+ schema_fb.TensorType.FLOAT64, schema_fb.TensorType.COMPLEX128,\n+ schema_fb.TensorType.UINT64]\n+ for subgraph in model.subgraphs:\n+ for tensor in subgraph.tensors:\n+ if (tensor.buffer>0 and tensor.buffer<len(model.buffers) and \n+ tensor.buffer not in buffer_swapped and \n+ model.buffers[tensor.buffer].data is not None):\n+ if tensor.type in types_of_16_bits: \n+ byte_swap_buffer_content(model.buffers[tensor.buffer], \n+ 2, from_endiness, to_endiness)\n+ elif tensor.type in types_of_32_bits:\n+ byte_swap_buffer_content(model.buffers[tensor.buffer], \n+ 4, from_endiness, to_endiness)\n+ elif tensor.type in types_of_64_bits:\n+ byte_swap_buffer_content(model.buffers[tensor.buffer], \n+ 8, from_endiness, to_endiness)\n+ else:\n+ continue\n+ buffer_swapped.append(tensor.buffer)\n+\n+\n+def byte_swap_tflite_buffer(tflite_model, from_endiness, to_endiness):\n+ \"\"\"Generates a new model byte array after byte swapping its buffers field.\n+\n+ Args:\n+ tflite_model: TFLite flatbuffer in a byte array.\n+ from_endiness: The original endianness format of the buffers in \n+ tflite_model.\n+ to_endiness: The destined endianness format of the buffers in \n+ tflite_model.\n+\n+ Returns:\n+ TFLite flatbuffer in a byte array, after being byte swapped to to_endiness\n+ format.\n+ \"\"\"\n+ if tflite_model is None:\n+ return None\n+ # Load TFLite Flatbuffer byte array into an object.\n+ model = convert_bytearray_to_object(tflite_model)\n+\n+ # Byte swapping the constant buffers as per their data types\n+ byte_swap_tflite_model_obj(model, from_endiness, to_endiness)\n+\n+ # Return a TFLite flatbuffer as a byte array.\n+ return convert_object_to_bytearray(model)\n+\n+\n+\n def count_resource_variables(model):\n \"\"\"Calculates the number of unique resource variables in a model.\n ",
"filename": "tensorflow/lite/tools/flatbuffer_utils.py",
"status": "modified"
},
{
"diff": "@@ -16,6 +16,7 @@\n import copy\n import os\n import subprocess\n+import sys\n \n from tensorflow.lite.tools import flatbuffer_utils\n from tensorflow.lite.tools import test_utils\n@@ -225,6 +226,9 @@ def testXxdOutputToBytes(self):\n \n # 4. VALIDATE\n final_bytes = flatbuffer_utils.xxd_output_to_bytes(input_cc_file)\n+ if sys.byteorder == 'big':\n+ final_bytes = flatbuffer_utils.byte_swap_tflite_buffer(\n+ final_bytes, \"little\", \"big\")\n \n # Validate that the initial and final bytearray are the same\n self.assertEqual(initial_bytes, final_bytes)",
"filename": "tensorflow/lite/tools/flatbuffer_utils_test.py",
"status": "modified"
},
{
"diff": "@@ -74,6 +74,9 @@ bool MmapModelLoader::InitInternal() {\n return false;\n }\n model_ = FlatBufferModel::VerifyAndBuildFromAllocation(std::move(allocation));\n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+ model_ = FlatBufferModel::ByteConvertModel(std::move(model_));\n+#endif\n return true;\n }\n ",
"filename": "tensorflow/lite/tools/model_loader.cc",
"status": "modified"
},
{
"diff": "@@ -42,6 +42,7 @@ cc_library(\n \"//tensorflow/lite:framework\",\n \"//tensorflow/lite:schema_fbs_version\",\n \"//tensorflow/lite/core:framework_stable\",\n+ \"//tensorflow/lite/core:model_builder\",\n \"//tensorflow/lite/core/c:common\",\n \"//tensorflow/lite/schema:schema_conversion_utils\",\n \"//tensorflow/lite/schema:schema_fbs_with_mutable\",",
"filename": "tensorflow/lite/tools/serialization/BUILD",
"status": "modified"
},
{
"diff": "@@ -29,6 +29,9 @@ limitations under the License.\n #include \"tensorflow/lite/builtin_op_data.h\"\n #include \"tensorflow/lite/context_util.h\"\n #include \"tensorflow/lite/core/c/common.h\"\n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+#include \"tensorflow/lite/core/model_builder.h\"\n+#endif\n #include \"tensorflow/lite/core/subgraph.h\"\n #include \"tensorflow/lite/schema/mutable/schema_generated.h\"\n #include \"tensorflow/lite/schema/schema_conversion_utils.h\"\n@@ -70,6 +73,11 @@ TfLiteStatus WriteImpl(const std::string& filename, void* data, size_t size) {\n FILE* fp = fopen(filename.c_str(), \"wb\");\n if (!fp) return kTfLiteError;\n \n+#if FLATBUFFERS_LITTLEENDIAN == 0\n+ const tflite::Model* input_model = tflite::GetModel(data);\n+ tflite::FlatBufferModel::ByteSwapTFLiteModel(input_model);\n+#endif\n+\n const int result_size = fwrite(data, 1, size, fp);\n fclose(fp);\n if (result_size != size) return kTfLiteError;",
"filename": "tensorflow/lite/tools/serialization/writer_lib.cc",
"status": "modified"
},
{
"diff": "@@ -119,7 +119,7 @@ def build_mock_flatbuffer_model():\n schema_fb.TensorStart(builder)\n schema_fb.TensorAddName(builder, string1_offset)\n schema_fb.TensorAddShape(builder, shape1_offset)\n- schema_fb.TensorAddType(builder, 0)\n+ schema_fb.TensorAddType(builder, schema_fb.TensorType.UINT8)\n schema_fb.TensorAddBuffer(builder, 1)\n schema_fb.TensorAddQuantization(builder, quantization1_offset)\n tensor1_offset = schema_fb.TensorEnd(builder)",
"filename": "tensorflow/lite/tools/test_utils.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Windows 10\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): pip\r\n- TensorFlow version (use command below): 2.6.0\r\n- Python version: 3.6\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version: 11.2/8.1.0.77\r\n- GPU model and memory: GTX 1060 6GB\r\n\r\n\r\n\r\nHey everyone,\r\n\r\nI am experiencing a strange issue when trying to train a 3DConv with Custom data generator.\r\nWhne I call `model.fit(train_data,epochs=10)` where `train_data` is the generator I get this GPU related error\r\n`2021-09-02 12:27:24.281505: F .\\tensorflow/core/util/gpu_launch_config.h:129] Check failed: work_element_count > 0 (0 vs. 0)`\r\nThe error seems to disappear when not using GPU \r\nI\r\n\r\nThe generator is this:\r\n\r\n```python\r\nclass Dataset(tf.keras.utils.Sequence):\r\n def __init__(self, data, batch_size=BATCH_SIZE, shuffle=True):\r\n self.data = np.array(data)\r\n self.batch_size = batch_size\r\n self.shuffle = shuffle\r\n self.indices = data.index.tolist()\r\n\r\n # @staticmethod\r\n def __load_dicom_image(self,path, img_size=IMAGE_SIZE, voi_lut=True, rotate=0):\r\n dicom = pydicom.read_file(path)\r\n data = dicom.pixel_array\r\n if voi_lut:\r\n data = apply_voi_lut(dicom.pixel_array, dicom)\r\n else:\r\n data = dicom.pixel_array\r\n\r\n if rotate > 0:\r\n rot_choices = [0, cv2.ROTATE_90_CLOCKWISE, cv2.ROTATE_90_COUNTERCLOCKWISE, cv2.ROTATE_180]\r\n data = cv2.rotate(data, rot_choices[rotate])\r\n\r\n data = cv2.resize(data, (img_size, img_size))\r\n return data\r\n\r\n \r\n\r\n def __load_dicom_images_3d(self, scan_id, num_imgs=NUM_IMAGES, img_size=IMAGE_SIZE, mri_type=\"FLAIR\", split=\"train\",\r\n rotate=0):\r\n\r\n files = sorted(glob.glob(f\"{data_directory}/{split}/{scan_id}/{mri_type}/*.dcm\"),\r\n key=lambda var: [int(x) if x.isdigit() else x for x in re.findall(r'[^0-9]|[0-9]+', var)])\r\n\r\n middle = len(files) // 2\r\n num_imgs2 = num_imgs // 2\r\n p1 = max(0, middle - num_imgs2)\r\n p2 = min(len(files), middle + num_imgs2)\r\n img3d = np.stack([self.__load_dicom_image(f, rotate=rotate) for f in files[p1:p2]]).T\r\n if img3d.shape[-1] < num_imgs:\r\n n_zero = np.zeros((img_size, img_size, num_imgs - img3d.shape[-1]))\r\n img3d = np.concatenate((img3d, n_zero), axis=-1)\r\n\r\n if np.min(img3d) < np.max(img3d):\r\n img3d = img3d - np.min(img3d)\r\n img3d = img3d / np.max(img3d)\r\n\r\n return np.expand_dims(img3d, 0)\r\n\r\n def __len__(self):\r\n return len(self.indices) // self.batch_size\r\n\r\n def __get_data(self, data):\r\n data = np.array(data)\r\n images = []\r\n X = []\r\n Y = []\r\n for id in data:\r\n images.append([self.__load_dicom_images_3d(scan_id=id[0]), id[1]])\r\n for img in images:\r\n X.append(img[0])\r\n Y.append(img[1])\r\n Y = list(map(int,Y))\r\n return np.array(X), np.array(Y)\r\n\r\n def __getitem__(self, index):\r\n print(index)\r\n data = self.data[index * self.batch_size:(index + 1) * self.batch_size]\r\n x, y = self.__get_data(data)\r\n \r\n return x, y\r\n```\r\n\r\nand the 3D CovNet is this:\r\n\r\n```python\r\nclass MultiBranchCNN(tf.keras.Model):\r\n def __init__(self):\r\n super(MultiBranchCNN,self).__init__()\r\n # self.inputA = tf.keras.Input(shape=(1,256,256,64))\r\n\r\n self.conv3d = Conv3D(64, input_shape=(1,256,256,64),kernel_size=(3, 3,3), activation='relu', padding='same')\r\n self.maxpool3d = MaxPool3D(pool_size=(3,3, 3))\r\n self.conv3d2 = Conv3D(64, kernel_size=(3,3, 3), activation='relu', padding='same')\r\n self.maxpool3d2 = MaxPool3D(pool_size=(3,3 ,3))\r\n self.conv3d3 = Conv3D(64, kernel_size=(3,3, 3), activation='relu', padding='same')\r\n self.maxpool3d3 = MaxPool3D(pool_size=(3,3, 3))\r\n self.Flatten = Flatten()\r\n self.Dense = Dense(512, activation='relu')\r\n self.Dropout = Dropout(0.1)\r\n self.Dense2 = Dense(1, activation='sigmoid')\r\n\r\n def call(self, inputs):\r\n print(type(inputs))\r\n # x = self.inputA(inputs)\r\n x = self.conv3d(inputs)\r\n x = self.maxpool3d(x)\r\n x = self.conv3d2(x)\r\n x = self.maxpool3d2(x)\r\n x = self.conv3d3(x)\r\n x = self.maxpool3d3(x)\r\n x = self.Flatten(x)\r\n x = self.Dense(x)\r\n x = self.Dropout(x)\r\n x = self.Dense2(x)\r\n return x\r\n\r\n```\r\nThis error occurs in `Epoch 1/10` (no train happens at all)\r\nI've been trying to change the model architecture and Dataset shape but with no luck.\r\n \r\nIs this a bug or I am doing something wrong?\r\nThanks in advance\r\n",
"comments": [
{
"body": "@makisgrammenos,\r\n\r\nCan you take a look at this similar issues [link1](https://github.com/keras-team/keras/issues/9870), [link2](https://github.com/matterport/Mask_RCNN/issues/521) and this [SO thread](https://stackoverflow.com/questions/51704365/tensorflow-check-failed-work-element-count-0/53586477)",
"created_at": "2021-09-03T15:42:04Z"
},
{
"body": "Already checked them but nothing helped so far.\r\n I have added some print functions to help debug this problem int `__getitem__` (data generator) and in `__call__` (model)\r\nhere is the updated version\r\n\r\nget item\r\n```python\r\n def __getitem__(self, index):\r\n \r\n data = self.data[index * self.batch_size:(index + 1) * self.batch_size]\r\n x, y = self.__get_data(data)\r\n print(x.shape , y.shape , index)\r\n \r\n return x, y\r\n```\r\n\r\n\r\ncall function:\r\n```python\r\n\r\ndef call(self, inputs):\r\n print(type(inputs))\r\n print(inputs)\r\n # x = self.inputA(inputs)\r\n x = self.conv3d(inputs)\r\n \r\n x = self.maxpool3d(x)\r\n \r\n x = self.conv3d2(x)\r\n \r\n x = self.maxpool3d2(x)\r\n \r\n x = self.conv3d3(x)\r\n \r\n x = self.maxpool3d3(x)\r\n \r\n x = self.Flatten(x)\r\n \r\n x = self.Dense(x)\r\n \r\n x = self.Dropout(x)\r\n \r\n return self.Dense2(x)\r\n```\r\n\r\nand here is the output:\r\n```\r\n2021-09-04 17:30:08.821150: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2\r\nTo enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\r\n2021-09-04 17:30:10.758939: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 4628 MB memory: -> device: 0, name: GeForce GTX 1060 6GB, pci bus id: 0000:01:00.0, compute capability: 6.1\r\n(4, 1, 256, 256, 64) (4,) 0\r\n<class 'tensorflow.python.framework.ops.EagerTensor'>\r\ntf.Tensor(\r\n[[[[[0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n ...\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]]\r\n\r\n [[0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n ...\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]]\r\n\r\n [[0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n ...\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]]\r\n\r\n ...\r\n\r\n [[0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n ...\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]]\r\n\r\n [[0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n ...\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]]\r\n\r\n [[0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n ...\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]\r\n [0.00025782 0.00025896 0. ... 0.00019592 0.\r\n 0. ]]]]\r\n\r\n\r\n\r\n [[[[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]\r\n\r\n [[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]\r\n\r\n [[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]\r\n\r\n ...\r\n\r\n [[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]\r\n\r\n [[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]\r\n\r\n [[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]]]\r\n\r\n\r\n\r\n [[[[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]\r\n\r\n [[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]\r\n\r\n [[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]\r\n\r\n ...\r\n\r\n [[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]\r\n\r\n [[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]\r\n\r\n [[0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n ...\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]\r\n [0. 0. 0. ... 0. 0.\r\n 0. ]]]]\r\n\r\n\r\n\r\n [[[[0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n ...\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]]\r\n\r\n [[0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n ...\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]]\r\n\r\n [[0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n ...\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]]\r\n\r\n ...\r\n\r\n [[0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n ...\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]]\r\n\r\n [[0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n ...\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]]\r\n\r\n [[0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n ...\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]\r\n [0.00016502 0. 0.00016319 ... 0. 0.00019763\r\n 0. ]]]]], shape=(4, 1, 256, 256, 64), dtype=float32)\r\n2021-09-04 17:30:16.534560: I tensorflow/stream_executor/cuda/cuda_dnn.cc:369] Loaded cuDNN version 8100\r\n2021-09-04 17:30:20.413557: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)\r\nEpoch 1/10\r\n<class 'tensorflow.python.framework.ops.Tensor'>\r\nTensor(\"IteratorGetNext:0\", shape=(None, None, None, None, None), dtype=float32)\r\n<class 'tensorflow.python.framework.ops.Tensor'>\r\nTensor(\"IteratorGetNext:0\", shape=(None, None, None, None, None), dtype=float32)\r\n(4, 1, 256, 256, 64) (4,) 125\r\n2021-09-04 17:30:25.331454: F .\\tensorflow/core/util/gpu_launch_config.h:129] Check failed: work_element_count > 0 (0 vs. 0)\r\n\r\n(ai) C:\\Users\\makis\\rsna>\r\n```\r\n\r\nIt seems the tensors with ` shape=(None, None, None, None, None)` are causing the error but I can't figure out why since the data generator returns the batch normaly as it should\r\n\r\nPS: sorry for the long post",
"created_at": "2021-09-04T14:35:41Z"
},
{
"body": "Still no solution found.\r\nAnyone know how to fix it?\r\n",
"created_at": "2021-09-10T10:05:03Z"
},
{
"body": "After hours of searching it seems that there's a bug in tensorflow when it comes to subclass a model using GPU with this model architecture.\r\nBy using the functional API and the same model architecture everythign seems to work fine and the model trains as it should",
"created_at": "2021-09-12T22:15:19Z"
},
{
"body": "I personally experienced this problem due to model.call being called outside the train_step with raw data from a custom data generator. When a model is not yet built you would expect it to be built upon first calling it within the overwritten train_step, however this already happens before that when the data adapter is initialized. This situation can be avoided by either doing preprocessing in the data generator or in the model.call itself. ",
"created_at": "2022-09-14T12:51:16Z"
},
{
"body": "hello, @makisgrammenos @H0lzm1ch3l i still cant solve this problem, may i ask how to solve it? i am a new one in tensorflow, and train my autoencoder model with hyperband and big data. Tensorflow always tell me this question.",
"created_at": "2022-10-02T09:50:29Z"
},
{
"body": "For reference, others report (https://github.com/matterport/Mask_RCNN/issues/521#issuecomment-780459992):\r\n\r\n> I had accidentally created a Dense layer with zero \"units\" (layers in the output)\r\n\r\nThe error likely originates from sth like that.\r\n",
"created_at": "2022-10-27T08:16:00Z"
},
{
"body": "I have the same crash, with TF 2.3 (https://github.com/rwth-i6/returnn/issues/1190). Here some C++ stacktrace:\r\n```\r\nThread 12 \"python3\" received signal SIGABRT, Aborted.\r\n[Switching to Thread 0x7fff917cd700 (LWP 28017)]\r\n0x00007ffff7282438 in __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:54\r\n54 ../sysdeps/unix/sysv/linux/raise.c: No such file or directory.\r\n(gdb) bt\r\n#0 0x00007ffff7282438 in __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:54\r\n#1 0x00007ffff728403a in __GI_abort () at abort.c:89\r\n#2 0x00007fffd9decfe7 in tensorflow::internal::LogMessageFatal::~LogMessageFatal() ()\r\n from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so\r\n#3 0x00007fffd69a948d in tensorflow::GpuLaunchConfig tensorflow::GetGpuLaunchConfig<void (*)(tensorflow::random::UniformFullIntDistribution<tensorflow::random::PhiloxRandom, unsigned long long>, long long, long long, long long*, unsigned long long*)>(int, Eigen::GpuDevice const&, void (*)(tensorflow::random::UniformFullIntDistribution<tensorflow::random::PhiloxRandom, unsigned long long>, long long, long long, long long*, unsigned long long*), unsigned long, int) ()\r\n from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so\r\n#4 0x00007fffd69aa3cd in tensorflow::UpdateVariableAndFill_Philox<Eigen::GpuDevice, tensorflow::random::UniformDistribution<tensorflow::random::PhiloxRandom, int> >::operator()(tensorflow::OpKernelContext*, Eigen::GpuDevice const&, tensorflow::random::UniformDistribution<tensorflow::random::PhiloxRandom, int>, tensorflow::UpdateVariableAndFill_Philox_Arg*, int*) ()\r\n from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so\r\n#5 0x00007fffd69a6369 in tensorflow::Status tensorflow::UpdateVariableAndFill<Eigen::GpuDevice, tensorflow::random::UniformDistribution<tensorflow::random::PhiloxRandom, int> >(tensorflow::OpKernelContext*, tensorflow::random::UniformDistribution<tensorflow::random::PhiloxRandom, int>, int, bool, long long, long long, tensorflow::random::UniformDistribution<tensorflow::random::PhiloxRandom, int>::ResultElementType*) ()\r\n from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so\r\n#6 0x00007fffd69a64af in void tensorflow::StatefulRandomCompute<Eigen::GpuDevice, tensorflow::random::UniformDistribution<tensorflow::random::PhiloxRandom, int> >(tensorflow::OpKernelContext*, tensorflow::random::UniformDistribution<tensorflow::random::PhiloxRandom, int>, int, int, bool, long long) ()\r\n from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so\r\n#7 0x00007fffd69a6642 in tensorflow::StatefulUniformIntOp<Eigen::GpuDevice, int>::Compute(tensorflow::OpKernelContext*) () from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so\r\n#8 0x00007fffcb97c65c in tensorflow::BaseGPUDevice::Compute(tensorflow::OpKernel*, tensorflow::OpKernelContext*) () from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/../libtensorflow_framework.so.2\r\n#9 0x00007fffcba402d4 in tensorflow::(anonymous namespace)::ExecutorState<tensorflow::PropagatorState>::Process(tensorflow::PropagatorState::TaggedNode, long long) ()\r\n from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/../libtensorflow_framework.so.2\r\n#10 0x00007fffcba40d7f in std::_Function_handler<void (), tensorflow::(anonymous namespace)::ExecutorState<tensorflow::PropagatorState>::ScheduleReady(absl::lts_2020_02_25::InlinedVector<tensorflow::PropagatorState::TaggedNode, 8ul, std::allocator<tensorflow::PropagatorState::TaggedNode> >*, tensorflow::PropagatorState::TaggedNodeReadyQueue*)::{lambda()#2}>::_M_invoke(std::_Any_data const&) ()\r\n from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/../libtensorflow_framework.so.2\r\n#11 0x00007fffcbaecb92 in Eigen::ThreadPoolTempl<tensorflow::thread::EigenEnvironment>::WorkerLoop(int) ()\r\n from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/../libtensorflow_framework.so.2\r\n#12 0x00007fffcbae9008 in std::_Function_handler<void (), tensorflow::thread::EigenEnvironment::CreateThread(std::function<void ()>)::{lambda()#1}>::_M_invoke(std::_Any_data const&) ()\r\n from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/../libtensorflow_framework.so.2\r\n#13 0x00007fffcbada539 in tensorflow::(anonymous namespace)::PThread::ThreadFn(void*) ()\r\n from /u/zeyer/.local/lib/python3.8/site-packages/tensorflow/python/../libtensorflow_framework.so.2\r\n#14 0x00007ffff761e6ba in start_thread (arg=0x7fff917cd700) at pthread_create.c:333\r\n#15 0x00007ffff735451d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:109\r\n```\r\nSo, as you see, it appears in `StatefulUniformIntOp`, so some of the random ops. Likely they were called for some zero shape.\r\n",
"created_at": "2022-10-27T08:17:51Z"
}
],
"number": 51803,
"title": "GPU Error: Check failed: work_element_count > 0 (0 vs. 0) "
}
|
{
"body": "Fix #51803 for stateful random ops.",
"number": 58336,
"review_comments": [],
"title": "stateful random ops, fix crash for empty output"
}
|
{
"commits": [
{
"message": "stateful random ops, fix crash for empty output\n\nFix #51803 for stateful random ops."
}
],
"files": [
{
"diff": "@@ -116,6 +116,10 @@ Status UpdateVariableAndFill(\n OpKernelContext* ctx, Distribution dist, int state_input_idx,\n bool read_alg_from_state, ConcreteRngAlgorithm alg, int64_t output_size,\n typename Distribution::ResultElementType* output_data) {\n+ if (output_size == 0)\n+ // Some CUDA kernels might crash otherwise (#51803):\n+ // Check failed: work_element_count > 0\n+ return OkStatus();\n Var* var = nullptr;\n TF_RETURN_IF_ERROR(\n LookupResource(ctx, HandleFromInput(ctx, state_input_idx), &var));",
"filename": "tensorflow/core/kernels/stateful_random_ops.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nsource\n\n### Tensorflow Version\n\ntf-nightly 2.11\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nmacOS\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.7, 3.8, 3.9, 3.10\n\n### Bazel version\n\n5.3.0\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\n[PR 55941](https://github.com/tensorflow/tensorflow/pull/55941) refactored and deduplicated TensorFlow C++ dependencies from _pywrap_tensorflow_internal.so into libtensorflow_cc.so. This change increased the size of macOS pip package from 240 MB to 350 MB.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/ci_build/rel/macos/cpu_py310_pip.sh\n```\n\n\n### Relevant log output\n\n_No response_</details>",
"comments": [
{
"body": "I think the size increase is from these two copies of `libtensorflow_cc.dylib` in the wheel. It looks like `libtensorflow_framework.dylib` was also duplicated, even before #55941.\r\n\r\nTo fix this, we can probably change one of them to a symlink or adjust the dependencies to match linux which only uses the major version numbered lib (`libtensorflow_cc.2.dylib` and `libtensorflow_framework.2.dylib`).\r\n\r\n```\r\n-rwxr-xr-x 1 tester admin 488M Oct 12 15:22 libtensorflow_cc.2.11.0.dylib\r\n-rwxr-xr-x 1 tester admin 488M Oct 12 15:22 libtensorflow_cc.2.dylib\r\n-rwxr-xr-x 1 tester admin 32M Oct 12 15:22 libtensorflow_framework.2.11.0.dylib\r\n-rwxr-xr-x 1 tester admin 32M Oct 12 15:22 libtensorflow_framework.2.dylib\r\n-rwxr-xr-x 1 tester admin 32M Oct 12 15:22 libtensorflow_framework.dylib\r\n```",
"created_at": "2022-10-19T18:42:51Z"
},
{
"body": "Hi @learning-to-play, thanks for filing this issue! I've just opened a PR with a potential fix. Could you check if the wheel size improves for you with this change? On my Mac machine, I'm now seeing 185mb.",
"created_at": "2022-10-19T22:31:14Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58164\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/58164\">No</a>\n",
"created_at": "2022-10-20T02:50:17Z"
}
],
"number": 58164,
"title": "Significant increase in the size of macOS wheel"
}
|
{
"body": "Fixes #58164\r\n\r\nOn Mac, copying the runfiles with `-L` duplicates the symlinked dylibs. On Linux, the duplicate copies are removed during the wheel build, so this PR does the same for Mac.\r\n\r\nBefore\r\n```\r\n-rwxr-xr-x 1 tester wheel 473M Oct 19 2022 libtensorflow_cc.2.12.0.dylib\r\n-rwxr-xr-x 1 tester wheel 473M Oct 19 2022 libtensorflow_cc.2.dylib\r\n-rwxr-xr-x 1 tester wheel 32M Oct 19 2022 libtensorflow_framework.2.12.0.dylib\r\n-rwxr-xr-x 1 tester wheel 32M Oct 19 2022 libtensorflow_framework.2.dylib\r\n-rwxr-xr-x 1 tester wheel 32M Oct 19 2022 libtensorflow_framework.dylib\r\n```\r\n\r\nAfter\r\n```\r\n-rwxr-xr-x 1 tester wheel 473M Oct 19 2022 libtensorflow_cc.2.dylib\r\n-rwxr-xr-x 1 tester wheel 32M Oct 19 2022 libtensorflow_framework.2.dylib\r\n```\r\n\r\ncc @learning-to-play ",
"number": 58174,
"review_comments": [],
"title": "Fix duplicated dylibs in Mac pip wheel"
}
|
{
"commits": [
{
"message": "Fix duplicated dylibs in Mac pip wheel"
}
],
"files": [
{
"diff": "@@ -217,6 +217,12 @@ function prepare_src() {\n rm -f ${TMPDIR}/tensorflow/libtensorflow_framework.so\n rm -f ${TMPDIR}/tensorflow/libtensorflow_framework.so.[0-9].*\n \n+ # Copying symlinks with -L duplicates these libraries.\n+ rm -f ${TMPDIR}/tensorflow/libtensorflow_framework.dylib\n+ rm -f ${TMPDIR}/tensorflow/libtensorflow_framework.[0-9].*.dylib\n+ rm -f ${TMPDIR}/tensorflow/libtensorflow_cc.dylib\n+ rm -f ${TMPDIR}/tensorflow/libtensorflow_cc.[0-9].*.dylib\n+\n # TODO(annarev): copy over API files from tensorflow/api/_vN to tensorflow/\n # except tensorflow/api/_vN/lite/.\n ",
"filename": "tensorflow/tools/pip_package/build_pip_package.sh",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\ntf 2.10 and 2.11.0-dev20221005\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nLinux Ubuntu 20.04\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.8\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\nCUDA 11.5\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\nIn current implementation of Conv2DBackpropFilter, arguments' shapes are not checked carefully. As a result, a Check-fail can be triggered, which can lead to a crash and DoS.\r\nThe bug can be replicated when running with GPU.\r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport os\r\nos.environ['TF_ENABLE_ONEDNN_OPTS'] = '1'\r\nimport tensorflow as tf\r\nprint(tf.__version__)\r\nwith tf.device(\"GPU:0\"):\r\n input = tf.random.uniform([1, 1, 1, 1, 1, 1], dtype=tf.bfloat16)\r\n filter_sizes = tf.saturate_cast(tf.random.uniform([1], minval=-128, maxval=129, dtype=tf.int64), dtype=tf.int32)\r\n out_backprop = tf.random.uniform([], dtype=tf.bfloat16)\r\n strides = [1, 1, 1, 1, 1, 1]\r\n use_cudnn_on_gpu = True\r\n padding = \"VALID\"\r\n explicit_paddings = []\r\n data_format = \"NHWC\"\r\n dilations = [1, 1, 1, 1]\r\n res = tf.raw_ops.Conv2DBackpropFilter(\r\n input=input,\r\n filter_sizes=filter_sizes,\r\n out_backprop=out_backprop,\r\n strides=strides,\r\n use_cudnn_on_gpu=use_cudnn_on_gpu,\r\n padding=padding,\r\n explicit_paddings=explicit_paddings,\r\n data_format=data_format,\r\n dilations=dilations,\r\n )\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n2022-10-05 16:49:28.663172: F tensorflow/core/kernels/mkl/mkl_conv_grad_filter_ops.cc:671] Check failed: TensorShapeUtils::MakeShape(filter_tensor.vec<int32>(), &filter_tf_shape) .ok() == true (0 vs. 1)\r\nAborted (core dumped)\r\n```\r\n</details>",
"comments": [
{
"body": "Added a PR #57984 for the fix.",
"created_at": "2022-10-05T15:43:35Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57980\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57980\">No</a>\n",
"created_at": "2022-11-23T21:31:58Z"
}
],
"number": 57980,
"title": "Check-fail in Conv2DBackpropFilter"
}
|
{
"body": "This PR tries to address the issue raised in #57980 where Conv2DBackpropFilter (MKL) will crash in certain situations.\r\n\r\nThis PR fixes #57980.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57984,
"review_comments": [],
"title": "Fix crash of Conv2DBackpropFilter"
}
|
{
"commits": [
{
"message": "Fix crash of Conv2DBackpropFilter\n\nThis PR tries to address the issue raised in 57980 where\nConv2DBackpropFilter (MKL) will crash in certain situations.\n\nThis PR fixes 57980.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -388,7 +388,8 @@ class MklConvCustomBackpropFilterOp\n \"filter_sizes shape must be rank 1 but is rank \",\n filter_tensor.shape().dims()));\n }\n- TensorShape filter_tf_shape = MakeFilterTfShape(context, filter_tensor);\n+ TensorShape filter_tf_shape;\n+ OP_REQUIRES_OK(context, MakeFilterTfShape(context, filter_tensor, &filter_tf_shape));\n TensorShape diff_dst_tf_shape =\n GetTfShape(context, kDiffDstIdx, native_format);\n \n@@ -664,15 +665,12 @@ class MklConvCustomBackpropFilterOp\n }\n \n // Get TensorFlow shape of filter tensor.\n- TensorShape MakeFilterTfShape(OpKernelContext* context,\n- const Tensor& filter_tensor) {\n- TensorShape filter_tf_shape;\n- CHECK_EQ(TensorShapeUtils::IsVector(filter_tensor.shape()), true);\n- CHECK_EQ(TensorShapeUtils::MakeShape(filter_tensor.vec<int32>(),\n- &filter_tf_shape)\n- .ok(),\n- true);\n- return filter_tf_shape;\n+ Status MakeFilterTfShape(OpKernelContext* context,\n+ const Tensor& filter_tensor, TensorShape *filter_tf_shape) {\n+ if (!TensorShapeUtils::IsVector(filter_tensor.shape())) {\n+ return errors::InvalidArgument(\"filter_tensor must be a vecotr, got \", filter_tensor.shape());\n+ }\n+ return TensorShapeUtils::MakeShape(filter_tensor.vec<int32>(), filter_tf_shape);\n }\n \n // Get Tensorflow shape of output tensor (diff_filter),",
"filename": "tensorflow/core/kernels/mkl/mkl_conv_grad_filter_ops.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.10.0\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nUbuntu 18.04.4 LTS (x86_64)\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.7.6\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\nN/A\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\ntf.nn.conv2d_transpose crash with abort with large `output_shape`\r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport numpy as np\r\nimport tensorflow as tf\r\ntf.nn.conv2d_transpose(input=np.ones((2,2,2,2)), output_shape=[114078056, 179835296], strides=[10], filters=1)\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n2022-10-03 23:45:34.556541: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory\r\n2022-10-03 23:45:34.556569: W tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:265] failed call to cuInit: UNKNOWN ERROR (303)\r\n2022-10-03 23:45:34.556596: I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:163] no NVIDIA GPU device is present: /dev/nvidia0 does not exist\r\n2022-10-03 23:45:34.556893: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA\r\nTo enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\r\n2022-10-03 23:45:34.595200: F tensorflow/core/framework/tensor_shape.cc:201] Non-OK-status: InitDims(dim_sizes) status: INVALID_ARGUMENT: Encountered overflow when multiplying 41030521935729152 with 22001, result: -1\r\nAborted (core dumped)\r\n```\r\n</details>",
"comments": [
{
"body": "Added a PR #57983 for the fix.",
"created_at": "2022-10-05T14:38:43Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57958\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57958\">No</a>\n",
"created_at": "2022-12-02T23:24:35Z"
}
],
"number": 57958,
"title": "tf.nn.conv2d_transpose abort with large `output_shape`"
}
|
{
"body": "This PR tries to address the issue in #57958 where tf.nn.conv2d_transpose will crash when output shape is invalid.\r\n\r\nThis PR adds a warpper ShapeFromFormatWithStatus (previously ShapeFromFormat) so that it is possible to return status.\r\n\r\nNote the change can be applied to other places to address similar crashs. Will create follow up PRs to cover other places once this PR is merged.\r\n\r\nThis PR fixes #57958.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57983,
"review_comments": [
{
"body": "We want to avoid these kinds of `CHECK`s in general. Ideally we would eliminate all uses of `ShapeFromFormat`, instead using your new `Status` version.. There doesn't seem to be _too_ many usages in TensorFlow, but I'm not sure how large of a change it would be to eliminate this entirely. Can you investigate?",
"created_at": "2022-10-05T20:35:54Z"
},
{
"body": "Let's remove this, and see what the damage is.",
"created_at": "2022-10-27T16:33:25Z"
},
{
"body": "Were these ones replaced as well?",
"created_at": "2022-10-27T16:33:40Z"
}
],
"title": " Fix crash in tf.nn.conv2d_transpose when output shape is invalid"
}
|
{
"commits": [
{
"message": "Fix crash in tf.nn.conv2d_transpose when output shape is invalid\n\nThis PR tries to address the issue in tf.nn.conv2d_transpose where\ncrash will happen when output shape is invalid.\n\nThis PR adds a warpper ShapeFromFormatWithStatus (previously ShapeFromFormat)\nso that it is possible to return status.\n\nNote the change can be applied to other places to address similar crashs.\nWill create follow up PRs to cover other places once this PR is merged.\n\nThis PR fixes 57958.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Test case for GitHub issue 57958 on tf.nn.conv2d_transpose crash.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix ShapeFromFormat to ShapeFromFormatWithStatus in fused_batch_norm_op.cc\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix ShapeFromFormat to ShapeFromFormatWithStatus in lrn_op.cc\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix ShapeFromFormat to ShapeFromFormatWithStatus in pooling_ops_common.[h|cc]\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Replace params.forward_output_shape with Status version to avoid crash.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix ShapeFromFormat to ShapeFromFormatWithStatus in conv_grad filters.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix ShapeFromFormat to ShapeFromFormatWithStatus in conv_ops.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix build failures\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Replace unsafe ShapeFromFormat functions with safe WithStatus version\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Replace unsafe ShapeFromFormat functions with safe WithStatus\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Replace unsafe ShapeFromFormat functions with safe WithStatus\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix ShapeFromFormat to ShapeFromFormatWithStatus, and fix build failures\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix build failures\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Remove ShapeFromFormat from header files\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Replace ShapeFromFormat in conv_ops_test.cc\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix build caused by merge conflict\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Additional fixes to resolve merge conflict\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix unclosed `)` (typo in last update)\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -106,8 +106,10 @@ class AvgPoolingOp : public UnaryOp<T> {\n errors::InvalidArgument(\"tensor_in must be 4-dimensional\"));\n \n Tensor* output = nullptr;\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n OP_REQUIRES_OK(context, context->allocate_output(\n- 0, params.forward_output_shape(), &output));\n+ 0, params_forward_output_shape, &output));\n \n SpatialAvgPool<Device, T>(context, output, tensor_in, params, padding_);\n }\n@@ -185,7 +187,8 @@ class AvgPoolingOp<GPUDevice, T> : public UnaryOp<T> {\n OP_REQUIRES(context, tensor_in.dims() == 4,\n errors::InvalidArgument(\"tensor_in must be 4-dimensional\"));\n \n- TensorShape output_shape = params.forward_output_shape();\n+ TensorShape output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(&output_shape));\n if (output_shape.num_elements() == 0) {\n Tensor* output = nullptr;\n OP_REQUIRES_OK(context,",
"filename": "tensorflow/core/kernels/avgpooling_op.cc",
"status": "modified"
},
{
"diff": "@@ -723,11 +723,16 @@ void LaunchConv2DBackpropFilterOpImpl(\n const int64_t input_pad_bottom = padding_bottom - common_padding_rows;\n const int64_t input_pad_left = padding_left - common_padding_cols;\n const int64_t input_pad_right = padding_right - common_padding_cols;\n+ TensorShape compatible_input_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(data_format, dims.batch_size, new_in_rows,\n+ new_in_cols, dims.in_depth,\n+ &compatible_input_shape));\n OP_REQUIRES_OK(\n ctx, ctx->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(data_format, dims.batch_size, new_in_rows,\n- new_in_cols, dims.in_depth),\n+ compatible_input_shape,\n &compatible_input));\n \n functor::PadInput<GPUDevice, T, int, 4>()(\n@@ -818,9 +823,13 @@ void LaunchConv2DBackpropFilterOpImpl(\n Tensor transformed_out_backprop;\n if (data_format == FORMAT_NHWC && compute_data_format == FORMAT_NCHW) {\n VLOG(4) << \"Convert the `out_backprop` tensor from NHWC to NCHW.\";\n- TensorShape compute_shape = ShapeFromFormat(\n- compute_data_format, dims.batch_size, dims.spatial_dims[0].output_size,\n- dims.spatial_dims[1].output_size, dims.out_depth);\n+ TensorShape compute_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ compute_data_format, dims.batch_size, dims.spatial_dims[0].output_size,\n+ dims.spatial_dims[1].output_size, dims.out_depth,\n+ &compute_shape));\n if (dims.out_depth > 1) {\n OP_REQUIRES_OK(ctx,\n ctx->allocate_temp(DataTypeToEnum<T>::value, compute_shape,\n@@ -839,11 +848,15 @@ void LaunchConv2DBackpropFilterOpImpl(\n Tensor transformed_input;\n if (data_format == FORMAT_NHWC && compute_data_format == FORMAT_NCHW) {\n VLOG(4) << \"Convert the `input` tensor from NHWC to NCHW.\";\n- TensorShape compute_shape = ShapeFromFormat(\n- compute_data_format, GetTensorDim(compatible_input, data_format, 'N'),\n- GetTensorDim(compatible_input, data_format, 'H'),\n- GetTensorDim(compatible_input, data_format, 'W'),\n- GetTensorDim(compatible_input, data_format, 'C'));\n+ TensorShape compute_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ compute_data_format, GetTensorDim(compatible_input, data_format, 'N'),\n+ GetTensorDim(compatible_input, data_format, 'H'),\n+ GetTensorDim(compatible_input, data_format, 'W'),\n+ GetTensorDim(compatible_input, data_format, 'C'),\n+ &compute_shape));\n if (compute_shape.dim_size(1) > 1) {\n OP_REQUIRES_OK(ctx,\n ctx->allocate_temp(DataTypeToEnum<T>::value, compute_shape,",
"filename": "tensorflow/core/kernels/conv_grad_filter_ops.cc",
"status": "modified"
},
{
"diff": "@@ -202,8 +202,11 @@ void LaunchConv2DBackpropInputOpGpuImpl(\n dims.spatial_dims[0].input_size + padding_rows_diff;\n const int64_t new_in_cols =\n dims.spatial_dims[1].input_size + padding_cols_diff;\n- compatible_input_shape = ShapeFromFormat(\n- data_format, dims.batch_size, new_in_rows, new_in_cols, dims.in_depth);\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ data_format, dims.batch_size, new_in_rows, new_in_cols, dims.in_depth,\n+ &compatible_input_shape));\n } else {\n compatible_input_shape = input_shape;\n }\n@@ -306,9 +309,13 @@ void LaunchConv2DBackpropInputOpGpuImpl(\n Tensor transformed_out_backprop;\n if (data_format == FORMAT_NHWC && compute_data_format == FORMAT_NCHW) {\n VLOG(4) << \"Convert the `out_backprop` tensor from NHWC to NCHW.\";\n- TensorShape compute_shape = ShapeFromFormat(\n- compute_data_format, dims.batch_size, dims.spatial_dims[0].output_size,\n- dims.spatial_dims[1].output_size, dims.out_depth);\n+ TensorShape compute_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ compute_data_format, dims.batch_size, dims.spatial_dims[0].output_size,\n+ dims.spatial_dims[1].output_size, dims.out_depth,\n+ &compute_shape));\n if (dims.out_depth > 1) {\n OP_REQUIRES_OK(ctx,\n ctx->allocate_temp(DataTypeToEnum<T>::value, compute_shape,\n@@ -325,15 +332,20 @@ void LaunchConv2DBackpropInputOpGpuImpl(\n }\n \n Tensor pre_transformed_in_backprop;\n+ TensorShape pre_transformed_in_backprop_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ compute_data_format,\n+ GetTensorDim(compatible_input_shape, data_format, 'N'),\n+ GetTensorDim(compatible_input_shape, data_format, 'H'),\n+ GetTensorDim(compatible_input_shape, data_format, 'W'),\n+ GetTensorDim(compatible_input_shape, data_format, 'C'),\n+ &pre_transformed_in_backprop_shape));\n OP_REQUIRES_OK(\n ctx, ctx->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(\n- compute_data_format,\n- GetTensorDim(compatible_input_shape, data_format, 'N'),\n- GetTensorDim(compatible_input_shape, data_format, 'H'),\n- GetTensorDim(compatible_input_shape, data_format, 'W'),\n- GetTensorDim(compatible_input_shape, data_format, 'C')),\n+ pre_transformed_in_backprop_shape,\n &pre_transformed_in_backprop));\n \n auto out_backprop_ptr =\n@@ -391,14 +403,20 @@ void LaunchConv2DBackpropInputOpGpuImpl(\n \n if (padding_top != padding_bottom || padding_left != padding_right) {\n Tensor in_backprop_remove_padding;\n+ TensorShape in_backprop_remove_padding_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ compute_data_format,\n+ GetTensorDim(input_shape, data_format, 'N'),\n+ GetTensorDim(input_shape, data_format, 'H'),\n+ GetTensorDim(input_shape, data_format, 'W'),\n+ GetTensorDim(input_shape, data_format, 'C'),\n+ &in_backprop_remove_padding_shape));\n OP_REQUIRES_OK(\n ctx, ctx->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(compute_data_format,\n- GetTensorDim(input_shape, data_format, 'N'),\n- GetTensorDim(input_shape, data_format, 'H'),\n- GetTensorDim(input_shape, data_format, 'W'),\n- GetTensorDim(input_shape, data_format, 'C')),\n+ in_backprop_remove_padding_shape,\n &in_backprop_remove_padding));\n \n // Remove the padding that was added to the input shape above.",
"filename": "tensorflow/core/kernels/conv_grad_input_ops.cc",
"status": "modified"
},
{
"diff": "@@ -1449,15 +1449,20 @@ void LaunchConvBackpropInputOpImpl(\n }\n // Shape: batch, filters, z, y, x.\n Tensor pre_transformed_in_backprop;\n+ TensorShape pre_transformed_in_backprop_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(compute_data_format,\n+ compatible_input_shape.dim_size(0),\n+ {{compatible_input_shape.dim_size(2),\n+ compatible_input_shape.dim_size(3),\n+ compatible_input_shape.dim_size(4)}},\n+ compatible_input_shape.dim_size(1),\n+ &pre_transformed_in_backprop_shape));\n OP_REQUIRES_OK(context,\n context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(compute_data_format,\n- compatible_input_shape.dim_size(0),\n- {{compatible_input_shape.dim_size(2),\n- compatible_input_shape.dim_size(3),\n- compatible_input_shape.dim_size(4)}},\n- compatible_input_shape.dim_size(1)),\n+ pre_transformed_in_backprop_shape,\n &pre_transformed_in_backprop));\n \n auto out_backprop_ptr =\n@@ -1517,13 +1522,18 @@ void LaunchConvBackpropInputOpImpl(\n \n if (rows_odd || cols_odd || planes_odd) {\n Tensor in_backprop_remove_padding;\n+ TensorShape in_backprop_remove_padding_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+\tShapeFromFormatWithStatus(compute_data_format, dims.batch_size,\n+ {{dims.input_size(0), dims.input_size(1),\n+ dims.input_size(2)}},\n+ dims.in_depth,\n+ &in_backprop_remove_padding_shape));\n OP_REQUIRES_OK(context,\n context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(compute_data_format, dims.batch_size,\n- {{dims.input_size(0), dims.input_size(1),\n- dims.input_size(2)}},\n- dims.in_depth),\n+ in_backprop_remove_padding_shape,\n &in_backprop_remove_padding));\n \n // Remove the padding for odd spatial dimensions.\n@@ -1803,14 +1813,19 @@ void LaunchConvBackpropFilterOpImpl(\n \n Tensor compatible_input;\n if (rows_odd || cols_odd || planes_odd) {\n+ TensorShape compatible_input_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(data_format, dims.batch_size,\n+ {{dims.input_size(0) + planes_odd,\n+ dims.input_size(1) + rows_odd,\n+ dims.input_size(2) + cols_odd}},\n+ dims.in_depth,\n+ &compatible_input_shape));\n OP_REQUIRES_OK(context,\n context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(data_format, dims.batch_size,\n- {{dims.input_size(0) + planes_odd,\n- dims.input_size(1) + rows_odd,\n- dims.input_size(2) + cols_odd}},\n- dims.in_depth),\n+ compatible_input_shape,\n &compatible_input));\n functor::PadInput<GPUDevice, T, int, 5>()(\n context->template eigen_device<GPUDevice>(),",
"filename": "tensorflow/core/kernels/conv_grad_ops_3d.cc",
"status": "modified"
},
{
"diff": "@@ -196,9 +196,8 @@ Status Conv2DBackpropComputeInputShape(const Tensor& input_sizes,\n \"Conv2DBackpropInput: elements of input_sizes must be >= 0, not \",\n output_height, \"x\", output_width);\n }\n- *input_shape = ShapeFromFormat(data_format, batch_size, output_height,\n- output_width, output_depth);\n- return OkStatus();\n+ return ShapeFromFormatWithStatus(data_format, batch_size, output_height,\n+ output_width, output_depth, input_shape);\n }\n \n return errors::InvalidArgument(",
"filename": "tensorflow/core/kernels/conv_grad_shape_utils.cc",
"status": "modified"
},
{
"diff": "@@ -617,9 +617,12 @@ class Conv2DOp : public BinaryOp<T> {\n OP_REQUIRES_OK(context,\n ComputeConv2DDimension(params_, input, filter, &dimensions));\n \n- TensorShape out_shape = ShapeFromFormat(\n- params_.data_format, dimensions.batch, dimensions.out_rows,\n- dimensions.out_cols, dimensions.out_depth);\n+ TensorShape out_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ params_.data_format, dimensions.batch, dimensions.out_rows,\n+ dimensions.out_cols, dimensions.out_depth, &out_shape));\n \n // Output tensor is of the following dimensions:\n // [ in_batch, out_rows, out_cols, out_depth ]\n@@ -875,10 +878,15 @@ void LaunchConv2DOpImpl(OpKernelContext* ctx, bool use_cudnn,\n const int64_t padding_cols_diff = std::abs(padding_right - padding_left);\n const int64_t new_in_rows = in_rows + padding_rows_diff;\n const int64_t new_in_cols = in_cols + padding_cols_diff;\n+ TensorShape transformed_input_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ data_format, in_batch, new_in_rows,\n+ new_in_cols, in_depths, &transformed_input_shape));\n OP_REQUIRES_OK(ctx, ctx->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(data_format, in_batch, new_in_rows,\n- new_in_cols, in_depths),\n+ transformed_input_shape,\n &transformed_input));\n \n const int64_t input_pad_top = padding_top - common_padding_rows;\n@@ -910,8 +918,12 @@ void LaunchConv2DOpImpl(OpKernelContext* ctx, bool use_cudnn,\n if (data_format == FORMAT_NHWC && compute_data_format == FORMAT_NCHW) {\n VLOG(4) << \"Convert the input tensor from NHWC to NCHW.\";\n \n- TensorShape nchw_shape =\n- ShapeFromFormat(FORMAT_NCHW, in_batch, in_rows, in_cols, in_depths);\n+ TensorShape nchw_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, in_batch, in_rows, in_cols, in_depths,\n+ &nchw_shape));\n if (in_depths > 1) {\n Tensor transformed_input;\n OP_REQUIRES_OK(ctx, ctx->allocate_temp(DataTypeToEnum<T>::value,\n@@ -1012,10 +1024,15 @@ void LaunchConv2DOpImpl(OpKernelContext* ctx, bool use_cudnn,\n Tensor transformed_output;\n if (data_format != compute_data_format) {\n VLOG(4) << \"Allocate temporary memory for output in compute data format\";\n+ TensorShape transformed_output_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ compute_data_format, out_batch,\n+ out_rows, out_cols, out_depths, &transformed_output_shape));\n OP_REQUIRES_OK(\n ctx, ctx->allocate_temp(DataTypeToEnum<T>::value,\n- ShapeFromFormat(compute_data_format, out_batch,\n- out_rows, out_cols, out_depths),\n+ transformed_output_shape,\n &transformed_output));\n } else {\n transformed_output = *output;",
"filename": "tensorflow/core/kernels/conv_ops.cc",
"status": "modified"
},
{
"diff": "@@ -183,8 +183,12 @@ class Conv3DOp : public BinaryOp<T> {\n OP_REQUIRES_OK(\n context, Get3dOutputSizeV2(input_size, filter_size, dilations, strides,\n padding_, &out, &padding));\n- TensorShape out_shape = ShapeFromFormat(\n- data_format_, in_batch, {{out[0], out[1], out[2]}}, out_depth);\n+ TensorShape out_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ data_format_, in_batch, {{out[0], out[1], out[2]}}, out_depth,\n+ &out_shape));\n Tensor* output;\n OP_REQUIRES_OK(context, context->allocate_output(0, out_shape, &output));\n \n@@ -328,9 +332,12 @@ void LaunchConvOpImpl(OpKernelContext* ctx, bool cudnn_use_autotune,\n const int64_t new_in_planes = in_planes + planes_odd;\n \n Tensor transformed_input;\n- TensorShape transformed_shape = ShapeFromFormat(\n- data_format, in_batch, {{new_in_planes, new_in_rows, new_in_cols}},\n- in_depth);\n+ TensorShape transformed_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ data_format, in_batch, {{new_in_planes, new_in_rows, new_in_cols}},\n+ in_depth, &transformed_shape));\n OP_REQUIRES_OK(\n ctx, ctx->allocate_temp(DataTypeToEnum<T>::value, transformed_shape,\n &transformed_input));\n@@ -359,8 +366,11 @@ void LaunchConvOpImpl(OpKernelContext* ctx, bool cudnn_use_autotune,\n \n if (data_format == FORMAT_NHWC && compute_data_format == FORMAT_NCHW) {\n VLOG(4) << \"Convert the input tensor from NDHWC to NCDHW.\";\n- const TensorShape nchw_shape = ShapeFromFormat(\n- FORMAT_NCHW, in_batch, {{in_planes, in_rows, in_cols}}, in_depth);\n+ TensorShape nchw_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, in_batch, {{in_planes, in_rows, in_cols}}, in_depth, &nchw_shape));\n if (in_depth > 1) {\n Tensor transformed_input;\n OP_REQUIRES_OK(ctx, ctx->allocate_temp(DataTypeToEnum<T>::value,\n@@ -458,11 +468,16 @@ void LaunchConvOpImpl(OpKernelContext* ctx, bool cudnn_use_autotune,\n Tensor transformed_output;\n if (data_format != compute_data_format) {\n VLOG(4) << \"Allocate temporary memory for output in compute data format\";\n+ TensorShape transformed_output_shape;\n+ OP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(FORMAT_NCHW, in_batch,\n+ {{out_planes, out_rows, out_cols}}, out_depth,\n+ &transformed_output_shape));\n OP_REQUIRES_OK(\n ctx, ctx->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, in_batch,\n- {{out_planes, out_rows, out_cols}}, out_depth),\n+ transformed_output_shape,\n &transformed_output));\n } else {\n transformed_output = *output;",
"filename": "tensorflow/core/kernels/conv_ops_3d.cc",
"status": "modified"
},
{
"diff": "@@ -830,8 +830,11 @@ class FusedResizeConv2DUsingGemmOp : public OpKernel {\n OP_REQUIRES_OK(context,\n GetWindowedOutputSize(padded_cols, filter_cols, stride_cols,\n padding_, &out_cols, &pad_cols));\n- TensorShape out_shape =\n- ShapeFromFormat(FORMAT_NHWC, batch, out_rows, out_cols, out_depth);\n+ TensorShape out_shape;\n+ OP_REQUIRES_OK(\n+ context, \n+ ShapeFromFormatWithStatus(\n+ FORMAT_NHWC, batch, out_rows, out_cols, out_depth, &out_shape));\n OP_REQUIRES(context, (out_shape.num_elements() > 0),\n errors::InvalidArgument(\"Output tensor can't be empty\"));\n ",
"filename": "tensorflow/core/kernels/conv_ops_fused_image_transform.cc",
"status": "modified"
},
{
"diff": "@@ -401,11 +401,16 @@ struct LaunchFusedConv2DOp<GPUDevice, T> {\n std::abs(dimensions.pad_cols_after - dimensions.pad_cols_before);\n const int64_t new_in_rows = in_rows + padding_rows_diff;\n const int64_t new_in_cols = in_cols + padding_cols_diff;\n+ TensorShape transformed_input_shape;\n+ OP_REQUIRES_OK(context,\n+ ShapeFromFormatWithStatus(\n+ params.data_format, in_batch,\n+ new_in_rows, new_in_cols, in_depths,\n+ &transformed_input_shape));\n OP_REQUIRES_OK(context,\n context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(params.data_format, in_batch,\n- new_in_rows, new_in_cols, in_depths),\n+ transformed_input_shape,\n &transformed_input));\n const int64_t input_pad_top =\n dimensions.pad_rows_before - common_padding_rows;\n@@ -441,8 +446,12 @@ struct LaunchFusedConv2DOp<GPUDevice, T> {\n se::CudaComputeCapability::VOLTA);\n if (!compute_in_nhwc && params.data_format == FORMAT_NHWC) {\n // Convert the input tensor from NHWC to NCHW.\n- TensorShape nchw_shape =\n- ShapeFromFormat(FORMAT_NCHW, in_batch, in_rows, in_cols, in_depths);\n+ TensorShape nchw_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, in_batch, in_rows, in_cols, in_depths,\n+ &nchw_shape));\n if (in_depths > 1) {\n Tensor transformed_input;\n OP_REQUIRES_OK(context,\n@@ -557,11 +566,15 @@ struct LaunchFusedConv2DOp<GPUDevice, T> {\n Tensor transformed_output;\n if (!compute_in_nhwc && params.data_format == FORMAT_NHWC) {\n // Only allocate temporary memory when a layout transformation is needed.\n+ TensorShape transformed_output_shape;\n+ OP_REQUIRES_OK(context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, out_batch, out_rows,\n+ out_cols, out_depths, &transformed_output_shape));\n OP_REQUIRES_OK(context,\n context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, out_batch, out_rows,\n- out_cols, out_depths),\n+ transformed_output_shape,\n &transformed_output));\n } else {\n transformed_output = *output;\n@@ -755,9 +768,10 @@ class FusedConv2DOp : public OpKernel {\n OP_REQUIRES_OK(context,\n ComputeConv2DDimension(params_, input, filter, &dimensions));\n \n- TensorShape out_shape = ShapeFromFormat(\n+ TensorShape out_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(\n params_.data_format, dimensions.batch, dimensions.out_rows,\n- dimensions.out_cols, dimensions.out_depth);\n+ dimensions.out_cols, dimensions.out_depth, &out_shape));\n \n // Output tensor is of the following dimensions:\n // [ in_batch, out_rows, out_cols, out_depth ]",
"filename": "tensorflow/core/kernels/conv_ops_fused_impl.h",
"status": "modified"
},
{
"diff": "@@ -443,12 +443,17 @@ void operator()(\n using VectT = int32;\n auto pad_data_format = FORMAT_NCHW;\n \n+\tTensorShape maybe_padded_conv_input_shape;\n+\tOP_REQUIRES_OK(\n+ ctx,\n+ ShapeFromFormatWithStatus(\n+ data_format, batch_size, new_conv_input_rows,\n+ new_conv_input_cols, conv_input_depth, &maybe_padded_conv_input_shape));\n OP_REQUIRES_OK(\n ctx,\n ctx->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(data_format, batch_size, new_conv_input_rows,\n- new_conv_input_cols, conv_input_depth),\n+ maybe_padded_conv_input_shape,\n &maybe_padded_conv_input));\n \n auto conv_input_eigen_tensor =",
"filename": "tensorflow/core/kernels/conv_ops_fused_int8.cc",
"status": "modified"
},
{
"diff": "@@ -745,8 +745,9 @@ class FusedConv2DOpTest : public OpsTestBase {\n \n if (v > 1) {\n {\n- Tensor input_data_nchwv(\n- dtype, ShapeFromFormat(FORMAT_NCHW_VECT_C, n, h, w, ic));\n+ TensorShape shape;\n+ TF_EXPECT_OK(ShapeFromFormatWithStatus(FORMAT_NCHW_VECT_C, n, h, w, ic, &shape));\n+ Tensor input_data_nchwv(dtype, shape);\n input_data_nchwv.tensor<T, 5>() =\n input_data.shaped<T, 5>({n, h, w, ic / v, v})\n .shuffle(Eigen::array<int, 5>{0, 3, 1, 2, 4});\n@@ -810,8 +811,9 @@ class FusedConv2DOpTest : public OpsTestBase {\n ASSERT_TRUE(\n GetWindowedOutputSize(w, kw, stride, padding_type, &ow, &ow_padding)\n .ok());\n- side_input =\n- Tensor(dtype, ShapeFromFormat(FORMAT_NCHW_VECT_C, n, oh, ow, oc));\n+ TensorShape shape;\n+ TF_EXPECT_OK(ShapeFromFormatWithStatus(FORMAT_NCHW_VECT_C, n, oh, ow, oc, &shape));\n+ side_input = Tensor(dtype, shape);\n side_input.flat<T>() = side_input.flat<T>().setConstant(0);\n }\n \n@@ -863,7 +865,9 @@ class FusedConv2DOpTest : public OpsTestBase {\n // Convert the output from NCHW_VECT_C to NHWC\n const int oh = GetTensorDim(*output, FORMAT_NCHW_VECT_C, 'H');\n const int ow = GetTensorDim(*output, FORMAT_NCHW_VECT_C, 'W');\n- Tensor output_nhwc(dtype, ShapeFromFormat(FORMAT_NHWC, n, oh, ow, oc));\n+ TensorShape shape;\n+ TF_EXPECT_OK(ShapeFromFormatWithStatus(FORMAT_NHWC, n, oh, ow, oc, &shape));\n+ Tensor output_nhwc(dtype, shape);\n output_nhwc.tensor<T, 4>() =\n output->tensor<T, 5>()\n .shuffle(Eigen::array<int, 5>{0, 2, 3, 1, 4})",
"filename": "tensorflow/core/kernels/conv_ops_test.cc",
"status": "modified"
},
{
"diff": "@@ -526,8 +526,11 @@ class Conv2DUsingGemmOp : public BinaryOp<T> {\n OP_REQUIRES_OK(context,\n GetWindowedOutputSize(input_cols, filter_cols, stride_cols,\n padding_, &out_cols, &pad_cols));\n- TensorShape out_shape =\n- ShapeFromFormat(data_format_, batch, out_rows, out_cols, out_depth);\n+ TensorShape out_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ data_format_, batch, out_rows, out_cols, out_depth, &out_shape));\n \n // Output tensor is of the following dimensions:\n // [ in_batch, out_rows, out_cols, out_depth ]",
"filename": "tensorflow/core/kernels/conv_ops_using_gemm.cc",
"status": "modified"
},
{
"diff": "@@ -47,10 +47,15 @@ void DnnPooling3dOp<T>::Compute(OpKernelContext* context,\n \n Tensor transformed_input;\n if (data_format == FORMAT_NHWC) {\n+ TensorShape transformed_input_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, tensor_in.shape(),\n+ data_format, &transformed_input_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, tensor_in.shape(),\n- data_format),\n+ transformed_input_shape,\n &transformed_input));\n functor::NHWCToNCHW<GPUDevice, T, 5>()(context->eigen_device<GPUDevice>(),\n tensor_in.tensor<T, 5>(),\n@@ -60,10 +65,15 @@ void DnnPooling3dOp<T>::Compute(OpKernelContext* context,\n }\n Tensor transformed_output;\n if (data_format == FORMAT_NHWC) {\n+ TensorShape transformed_output_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, out_shape, data_format, &transformed_output_shape));\n OP_REQUIRES_OK(context,\n context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, out_shape, data_format),\n+ transformed_output_shape,\n &transformed_output));\n } else {\n transformed_output = *output;\n@@ -148,8 +158,10 @@ void DnnPooling3dGradOp<T>::Compute(\n Tensor transformed_input;\n TensorShape transformed_input_shape;\n if (data_format == FORMAT_NHWC || tensor_in == nullptr) {\n- transformed_input_shape =\n- ShapeFromFormat(FORMAT_NCHW, tensor_in_shape, data_format);\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, tensor_in_shape, data_format, &transformed_input_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(DataTypeToEnum<T>::value,\n transformed_input_shape,\n &transformed_input));\n@@ -159,8 +171,10 @@ void DnnPooling3dGradOp<T>::Compute(\n Tensor transformed_output;\n TensorShape transformed_output_shape;\n if (data_format == FORMAT_NHWC || tensor_out == nullptr) {\n- transformed_output_shape =\n- ShapeFromFormat(FORMAT_NCHW, out_backprop.shape(), data_format);\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, out_backprop.shape(), data_format, &transformed_output_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(DataTypeToEnum<T>::value,\n transformed_output_shape,\n &transformed_output));",
"filename": "tensorflow/core/kernels/cudnn_pooling_gpu.cc",
"status": "modified"
},
{
"diff": "@@ -103,11 +103,16 @@ class DepthToSpaceOp : public OpKernel {\n \n // Allocate output tensor.\n Tensor* outputs_tensor = nullptr;\n+ TensorShape outputs_tensor_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ data_format_, batch_size, output_height,\n+ output_width, output_depth, &outputs_tensor_shape));\n OP_REQUIRES_OK(context,\n context->allocate_output(\n 0,\n- ShapeFromFormat(data_format_, batch_size, output_height,\n- output_width, output_depth),\n+ outputs_tensor_shape,\n &outputs_tensor));\n auto Tinput = input.tensor<T, kDims>();\n auto Toutput = outputs_tensor->tensor<T, kDims>();",
"filename": "tensorflow/core/kernels/depthtospace_op.cc",
"status": "modified"
},
{
"diff": "@@ -417,8 +417,11 @@ class DepthwiseConv2dNativeOp : public BinaryOp<T> {\n OP_REQUIRES_OK(context, GetWindowedOutputSizeVerbose(\n input_cols, filter_cols, stride_, padding_,\n &out_cols, &pad_left, &pad_right));\n- TensorShape out_shape =\n- ShapeFromFormat(data_format_, batch, out_rows, out_cols, out_depth);\n+ TensorShape out_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ data_format_, batch, out_rows, out_cols, out_depth, &out_shape));\n OP_REQUIRES(\n context,\n (!std::is_same<Device, GPUDevice>::value ||",
"filename": "tensorflow/core/kernels/depthwise_conv_op.cc",
"status": "modified"
},
{
"diff": "@@ -132,15 +132,21 @@ struct FusedBatchNorm<CPUDevice, T, U, /* is_training= */ true> {\n const int64_t in_rows = GetTensorDim(x_input, tensor_format, 'H');\n const int64_t in_cols = GetTensorDim(x_input, tensor_format, 'W');\n const int64_t in_depths = GetTensorDim(x_input, tensor_format, 'C');\n+ TensorShape transformed_x_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(FORMAT_NHWC, in_batch,\n+ in_rows, in_cols, in_depths,\n+ &transformed_x_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NHWC, in_batch,\n- in_rows, in_cols, in_depths),\n+\t\t\t\t transformed_x_shape,\n &transformed_x));\n+ TensorShape transformed_y_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(FORMAT_NHWC, in_batch,\n+ in_rows, in_cols, in_depths,\n+ &transformed_y_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NHWC, in_batch,\n- in_rows, in_cols, in_depths),\n+\t\t\t\t transformed_y_shape,\n &transformed_y));\n // Perform NCHW to NHWC\n std::vector<int32> perm = {0, 2, 3, 1};\n@@ -273,15 +279,21 @@ struct FusedBatchNorm<CPUDevice, T, U, /* is_training= */ false> {\n const int64_t in_rows = GetTensorDim(x_input, tensor_format, 'H');\n const int64_t in_cols = GetTensorDim(x_input, tensor_format, 'W');\n const int64_t in_depths = GetTensorDim(x_input, tensor_format, 'C');\n+ TensorShape transformed_x_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(FORMAT_NHWC, in_batch,\n+ in_rows, in_cols, in_depths,\n+ &transformed_x_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NHWC, in_batch,\n- in_rows, in_cols, in_depths),\n+ transformed_x_shape,\n &transformed_x));\n+ TensorShape transformed_y_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(FORMAT_NHWC, in_batch,\n+ in_rows, in_cols, in_depths,\n+ &transformed_y_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NHWC, in_batch,\n- in_rows, in_cols, in_depths),\n+ transformed_y_shape,\n &transformed_y));\n // Perform NCHW to NHWC\n std::vector<int32> perm = {0, 2, 3, 1};\n@@ -374,20 +386,29 @@ struct FusedBatchNormGrad<CPUDevice, T, U> {\n const int64_t in_rows = GetTensorDim(x_input, tensor_format, 'H');\n const int64_t in_cols = GetTensorDim(x_input, tensor_format, 'W');\n const int64_t in_depths = GetTensorDim(x_input, tensor_format, 'C');\n+ TensorShape transformed_y_backprop_input_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(FORMAT_NHWC, in_batch,\n+ in_rows, in_cols, in_depths,\n+ &transformed_y_backprop_input_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NHWC, in_batch,\n- in_rows, in_cols, in_depths),\n+ transformed_y_backprop_input_shape,\n &transformed_y_backprop_input));\n+ TensorShape transformed_x_input_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(FORMAT_NHWC, in_batch,\n+ in_rows, in_cols, in_depths,\n+ &transformed_x_input_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NHWC, in_batch,\n- in_rows, in_cols, in_depths),\n+ transformed_x_input_shape,\n &transformed_x_input));\n+ TensorShape transformed_x_backprop_output_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(FORMAT_NHWC, in_batch,\n+ in_rows, in_cols, in_depths,\n+ &transformed_x_backprop_output_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NHWC, in_batch,\n- in_rows, in_cols, in_depths),\n+ transformed_x_backprop_output_shape,\n &transformed_x_backprop_output));\n // Perform NCHW to NHWC\n std::vector<int32> perm = {0, 2, 3, 1};\n@@ -869,21 +890,27 @@ struct FusedBatchNorm<GPUDevice, T, U, is_training> {\n if (tensor_format == compute_format) {\n y_ptr = StreamExecutorUtil::AsDeviceMemory<T>(*y);\n } else if (tensor_format == FORMAT_NHWC && compute_format == FORMAT_NCHW) {\n+ TensorShape x_transformed_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(compute_format, batch_size,\n+ height, width, channels,\n+ &x_transformed_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(compute_format, batch_size,\n- height, width, channels),\n+ x_transformed_shape,\n &x_transformed));\n functor::NHWCToNCHW<GPUDevice, T, 4>()(\n context->eigen_device<GPUDevice>(),\n const_cast<const Tensor&>(x_maybe_transformed).tensor<T, 4>(),\n x_transformed.tensor<T, 4>());\n x_maybe_transformed = x_transformed;\n \n+ TensorShape y_transformed_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(compute_format, batch_size,\n+ height, width, channels,\n+ &y_transformed_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(compute_format, batch_size,\n- height, width, channels),\n+ y_transformed_shape,\n &y_transformed));\n y_ptr = StreamExecutorUtil::AsDeviceMemory<T>(y_transformed);\n } else {\n@@ -1050,10 +1077,13 @@ struct FusedBatchNormGrad<GPUDevice, T, U> {\n x_backprop_ptr = StreamExecutorUtil::AsDeviceMemory<T>(*x_backprop);\n } else if (tensor_format == FORMAT_NHWC && compute_format == FORMAT_NCHW) {\n // Transform inputs from 'NHWC' to 'NCHW'\n+ TensorShape y_backprop_transformed_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(FORMAT_NCHW, batch_size,\n+ height, width, channels,\n+ &y_backprop_transformed_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, batch_size,\n- height, width, channels),\n+ y_backprop_transformed_shape,\n &y_backprop_transformed));\n functor::NHWCToNCHW<GPUDevice, T, 4>()(\n context->eigen_device<GPUDevice>(),\n@@ -1062,10 +1092,13 @@ struct FusedBatchNormGrad<GPUDevice, T, U> {\n y_backprop_transformed.tensor<T, 4>());\n y_backprop_maybe_transformed = y_backprop_transformed;\n \n+ TensorShape x_transformed_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(FORMAT_NCHW, batch_size,\n+ height, width, channels,\n+ &x_transformed_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, batch_size,\n- height, width, channels),\n+ x_transformed_shape,\n &x_transformed));\n functor::NHWCToNCHW<GPUDevice, T, 4>()(\n context->eigen_device<GPUDevice>(),\n@@ -1074,10 +1107,13 @@ struct FusedBatchNormGrad<GPUDevice, T, U> {\n x_maybe_transformed = x_transformed;\n \n // Allocate memory for transformed outputs in 'NCHW'\n+ TensorShape x_backprop_transformed_shape;\n+ OP_REQUIRES_OK(context, ShapeFromFormatWithStatus(FORMAT_NCHW, batch_size,\n+ height, width, channels,\n+ &x_backprop_transformed_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, batch_size,\n- height, width, channels),\n+ x_backprop_transformed_shape,\n &x_backprop_transformed));\n x_backprop_ptr =\n StreamExecutorUtil::AsDeviceMemory<T>(x_backprop_transformed);\n@@ -1299,8 +1335,11 @@ class FusedBatchNormOpBase : public OpKernel {\n int64_t in_rows = GetTensorDim(x, tensor_format_, '1');\n int64_t in_cols = GetTensorDim(x, tensor_format_, '2');\n const int64_t in_depth = GetTensorDim(x, tensor_format_, 'C');\n- dest_shape = ShapeFromFormat(tensor_format_, in_batch,\n- {{in_planes, in_rows * in_cols}}, in_depth);\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(tensor_format_, in_batch,\n+ {{in_planes, in_rows * in_cols}}, in_depth,\n+ &dest_shape));\n OP_REQUIRES(context, x.CopyFrom(x, dest_shape),\n errors::InvalidArgument(\"Error during tensor copy.\"));\n }\n@@ -1544,8 +1583,11 @@ class FusedBatchNormGradOpBase : public OpKernel {\n int64_t in_rows = GetTensorDim(x, tensor_format_, '1');\n int64_t in_cols = GetTensorDim(x, tensor_format_, '2');\n const int64_t in_depth = GetTensorDim(x, tensor_format_, 'C');\n- dest_shape = ShapeFromFormat(tensor_format_, in_batch,\n- {{in_planes, in_rows * in_cols}}, in_depth);\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ tensor_format_, in_batch,\n+ {{in_planes, in_rows * in_cols}}, in_depth, &dest_shape));\n OP_REQUIRES(context, x.CopyFrom(x, dest_shape),\n errors::InvalidArgument(\"Error during tensor copy.\"));\n OP_REQUIRES(context, y_backprop.CopyFrom(y_backprop, dest_shape),",
"filename": "tensorflow/core/kernels/fused_batch_norm_op.cc",
"status": "modified"
},
{
"diff": "@@ -237,20 +237,31 @@ struct LaunchLRN<GPUDevice, T> {\n const int depth = static_cast<int>(in.dim_size(3));\n \n Tensor transformed_input;\n+ TensorShape transformed_input_shape;\n+ OP_REQUIRES_OK(context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, in.shape(), FORMAT_NHWC,\n+ &transformed_input_shape));\n OP_REQUIRES_OK(context,\n context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, in.shape(), FORMAT_NHWC),\n+ transformed_input_shape,\n &transformed_input));\n functor::NHWCToNCHW<GPUDevice, T, 4>()(context->eigen_device<GPUDevice>(),\n in.tensor<T, 4>(),\n transformed_input.tensor<T, 4>());\n \n Tensor transformed_output;\n+ TensorShape transformed_output_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, output->shape(), FORMAT_NHWC,\n+ &transformed_output_shape));\n OP_REQUIRES_OK(\n context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, output->shape(), FORMAT_NHWC),\n+ transformed_output_shape,\n &transformed_output));\n \n perftools::gputools::dnn::BatchDescriptor dimensions_desc;\n@@ -531,40 +542,61 @@ struct LaunchLRNGrad<GPUDevice, T> {\n const int64 depth = in_grads.dim_size(3);\n \n Tensor transformed_in_grads;\n+ TensorShape transformed_in_grads_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, in_grads.shape(),\n+ FORMAT_NHWC, &transformed_in_grads_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, in_grads.shape(),\n- FORMAT_NHWC),\n+ transformed_in_grads_shape,\n &transformed_in_grads));\n functor::NHWCToNCHW<GPUDevice, T, 4>()(context->eigen_device<GPUDevice>(),\n in_grads.tensor<T, 4>(),\n transformed_in_grads.tensor<T, 4>());\n \n Tensor transformed_in_image;\n+ TensorShape transformed_in_image_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, in_image.shape(),\n+ FORMAT_NHWC, &transformed_in_image_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, in_image.shape(),\n- FORMAT_NHWC),\n+ transformed_in_image_shape,\n &transformed_in_image));\n functor::NHWCToNCHW<GPUDevice, T, 4>()(context->eigen_device<GPUDevice>(),\n in_image.tensor<T, 4>(),\n transformed_in_image.tensor<T, 4>());\n \n Tensor transformed_out_image;\n+ TensorShape transformed_out_image_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, out_image.shape(),\n+ FORMAT_NHWC, &transformed_out_image_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, out_image.shape(),\n- FORMAT_NHWC),\n+ transformed_out_image_shape,\n &transformed_out_image));\n functor::NHWCToNCHW<GPUDevice, T, 4>()(\n context->eigen_device<GPUDevice>(), out_image.tensor<T, 4>(),\n transformed_out_image.tensor<T, 4>());\n \n Tensor transformed_output;\n+ TensorShape transformed_output_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, output->shape(),\n+ FORMAT_NHWC, &transformed_output_shape));\n OP_REQUIRES_OK(\n context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, output->shape(), FORMAT_NHWC),\n+ transformed_output_shape,\n &transformed_output));\n \n perftools::gputools::dnn::BatchDescriptor dimensions_desc;",
"filename": "tensorflow/core/kernels/lrn_op.cc",
"status": "modified"
},
{
"diff": "@@ -325,13 +325,16 @@ class MaxPoolingGradOp : public OpKernel {\n if (!context->status().ok()) {\n return;\n }\n- OP_REQUIRES(context, tensor_out.shape() == params.forward_output_shape(),\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ OP_REQUIRES(context, tensor_out.shape() == params_forward_output_shape,\n errors::InvalidArgument(\"Expected orig_output shape to be \",\n- params.forward_output_shape(),\n+ params_forward_output_shape,\n \", but got \", tensor_out.shape()));\n- OP_REQUIRES(context, out_backprop.shape() == params.forward_output_shape(),\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ OP_REQUIRES(context, out_backprop.shape() == params_forward_output_shape,\n errors::InvalidArgument(\"Expected grad shape to be \",\n- params.forward_output_shape(),\n+ params_forward_output_shape,\n \", but got \", out_backprop.shape()));\n \n Tensor* output = nullptr;\n@@ -549,9 +552,11 @@ class MaxPoolingGradGradOp : public OpKernel {\n if (!context->status().ok()) {\n return;\n }\n- OP_REQUIRES(context, tensor_out.shape() == params.forward_output_shape(),\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ OP_REQUIRES(context, tensor_out.shape() == params_forward_output_shape,\n errors::InvalidArgument(\"Expected orig_output shape to be \",\n- params.forward_output_shape(),\n+ params_forward_output_shape,\n \", but got \", tensor_out.shape()));\n OP_REQUIRES(\n context, out_grad_backprop.shape() == tensor_in.shape(),\n@@ -765,9 +770,11 @@ class MaxPoolingGradGradOp<Eigen::GpuDevice, T> : public OpKernel {\n if (!context->status().ok()) {\n return;\n }\n- OP_REQUIRES(context, tensor_out.shape() == params.forward_output_shape(),\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ OP_REQUIRES(context, tensor_out.shape() == params_forward_output_shape,\n errors::InvalidArgument(\"Expected orig_output shape to be \",\n- params.forward_output_shape(),\n+ params_forward_output_shape,\n \", but got \", tensor_out.shape()));\n OP_REQUIRES(\n context, out_grad_backprop.shape() == tensor_in.shape(),\n@@ -1127,13 +1134,16 @@ class MaxPoolingGradWithArgmaxOp : public OpKernel {\n if (!context->status().ok()) {\n return;\n }\n- OP_REQUIRES(context, grad_in.shape() == params.forward_output_shape(),\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ OP_REQUIRES(context, grad_in.shape() == params_forward_output_shape,\n errors::InvalidArgument(\"Expected grad shape to be \",\n- params.forward_output_shape(),\n+ params_forward_output_shape,\n \", but got \", grad_in.shape()));\n- OP_REQUIRES(context, argmax.shape() == params.forward_output_shape(),\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ OP_REQUIRES(context, argmax.shape() == params_forward_output_shape,\n errors::InvalidArgument(\"Expected argmax shape to be \",\n- params.forward_output_shape(),\n+ params_forward_output_shape,\n \", but got \", argmax.shape()));\n \n TensorShape out_shape({params.tensor_in_batch, params.tensor_in_rows,\n@@ -1199,9 +1209,11 @@ class MaxPoolingGradGradWithArgmaxOp : public OpKernel {\n context, grad_in.shape() == tensor_in.shape(),\n errors::InvalidArgument(\"Expected grad shape to be \", tensor_in.shape(),\n \", but got \", grad_in.shape()));\n- OP_REQUIRES(context, argmax.shape() == params.forward_output_shape(),\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ OP_REQUIRES(context, argmax.shape() == params_forward_output_shape,\n errors::InvalidArgument(\"Expected argmax shape to be \",\n- params.forward_output_shape(),\n+ params_forward_output_shape,\n \", but got \", argmax.shape()));\n \n TensorShape out_shape({params.tensor_in_batch, params.out_height,\n@@ -1264,9 +1276,12 @@ class MaxPoolingNoMaskOp<GPUDevice, T> : public OpKernel {\n return;\n }\n \n- TensorShape out_shape =\n- ShapeFromFormat(data_format_, params.tensor_in_batch, params.out_height,\n- params.out_width, params.depth);\n+ TensorShape out_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ data_format_, params.tensor_in_batch, params.out_height,\n+ params.out_width, params.depth, &out_shape));\n \n // Degenerate pooling output should return an empty tensor.\n if (out_shape.num_elements() == 0) {\n@@ -1399,9 +1414,12 @@ class MaxPoolingNoMaskV2Op<GPUDevice, T> : public OpKernel {\n return;\n }\n \n- TensorShape out_shape =\n- ShapeFromFormat(data_format_, params.tensor_in_batch, params.out_height,\n- params.out_width, params.depth);\n+ TensorShape out_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ data_format_, params.tensor_in_batch, params.out_height,\n+ params.out_width, params.depth, &out_shape));\n if (data_format_ == FORMAT_NCHW) {\n DnnPoolingOp<T>::Compute(context, se::dnn::PoolingMode::kMaximum, ksize,\n stride, padding_, explicit_paddings_,",
"filename": "tensorflow/core/kernels/maxpooling_op.cc",
"status": "modified"
},
{
"diff": "@@ -494,12 +494,20 @@ class MklDnnConvUtil {\n // Conv2D: NHWC or NCHW\n // Conv3D: NDHWC or NCDHW\n // oneDNN uses asymmetric padding.\n- TensorShape out_shape =\n- is_conv2d\n- ? ShapeFromFormat(data_format_, out_batch, out_rows, out_cols,\n- out_depth)\n- : ShapeFromFormat(data_format_, out_batch,\n- {{out_planes, out_rows, out_cols}}, out_depth);\n+ TensorShape out_shape;\n+ if (is_conv2d) {\n+ OP_REQUIRES_OK(\n+ context_,\n+ ShapeFromFormatWithStatus(\n+ data_format_, out_batch, out_rows, out_cols,\n+ out_depth, &out_shape));\n+ } else {\n+ OP_REQUIRES_OK(\n+ context_,\n+ ShapeFromFormatWithStatus(\n+ data_format_, out_batch,\n+ {{out_planes, out_rows, out_cols}}, out_depth, &out_shape));\n+ }\n *output_dims_tf_order = TFShapeToMklDnnDims(out_shape);\n if (is_grouped_convolution) {\n int out_depth = GetTensorDim(out_shape, data_format_, 'C');",
"filename": "tensorflow/core/kernels/mkl/mkl_conv_ops.h",
"status": "modified"
},
{
"diff": "@@ -87,9 +87,9 @@ Pool3dParameters::Pool3dParameters(OpKernelContext* context,\n padding, &out_width, &pad_cols));\n }\n \n-TensorShape Pool3dParameters::forward_output_shape() {\n- return ShapeFromFormat(data_format, tensor_in_batch,\n- {{out_plane, out_height, out_width}}, depth);\n+Status Pool3dParameters::forward_output_shape(TensorShape *shape) {\n+ return ShapeFromFormatWithStatus(data_format, tensor_in_batch,\n+ {{out_plane, out_height, out_width}}, depth, shape);\n }\n \n template <typename T>\n@@ -187,8 +187,11 @@ class Pooling3DOp : public UnaryOp<T> {\n OP_REQUIRES_OK(context, Get3dOutputSize(input_size, window, stride,\n padding_, &out, &padding));\n \n- TensorShape out_shape = ShapeFromFormat(data_format_, in_batch,\n- {{out[2], out[1], out[0]}}, depth);\n+ TensorShape out_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(data_format_, in_batch,\n+ {{out[2], out[1], out[0]}}, depth, &out_shape));\n Tensor* output;\n OP_REQUIRES_OK(context, context->allocate_output(0, out_shape, &output));\n if (out_shape.num_elements() == 0) return;\n@@ -365,8 +368,12 @@ class MaxPooling3dGradOp : public OpKernel {\n \n const int64_t depth = GetTensorDim(tensor_in, data_format_, 'C');\n const int64_t in_batch = GetTensorDim(tensor_in, data_format_, 'N');\n- TensorShape out_shape = ShapeFromFormat(data_format_, in_batch,\n- {{out[2], out[1], out[0]}}, depth);\n+ TensorShape out_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ data_format_, in_batch,\n+ {{out[2], out[1], out[0]}}, depth, &out_shape));\n OP_REQUIRES(\n context, tensor_out.shape() == out_shape,\n errors::InvalidArgument(\"Expected orig_output shape to be \", out_shape,\n@@ -717,9 +724,11 @@ class MaxPooling3dGradGradOp : public OpKernel {\n Pool3dParameters params{context, ksize_, stride_,\n padding_, data_format_, tensor_in.shape()};\n if (!context->status().ok()) return; // params is invalid\n- OP_REQUIRES(context, tensor_out.shape() == params.forward_output_shape(),\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ OP_REQUIRES(context, tensor_out.shape() == params_forward_output_shape,\n errors::InvalidArgument(\"Expected orig_output shape to be \",\n- params.forward_output_shape(),\n+ params_forward_output_shape,\n \", but got \", tensor_out.shape()));\n OP_REQUIRES(\n context, out_grad_backprop.shape() == tensor_in.shape(),",
"filename": "tensorflow/core/kernels/pooling_ops_3d.cc",
"status": "modified"
},
{
"diff": "@@ -45,7 +45,7 @@ struct Pool3dParameters {\n const TensorShape& tensor_in_shape);\n \n // Returns the shape of the output for \"forward\" pooling operations.\n- TensorShape forward_output_shape();\n+ Status forward_output_shape(TensorShape *shape);\n \n int depth;\n ",
"filename": "tensorflow/core/kernels/pooling_ops_3d.h",
"status": "modified"
},
{
"diff": "@@ -198,16 +198,18 @@ PoolParameters::PoolParameters(OpKernelContext* context,\n }\n }\n \n-TensorShape PoolParameters::forward_output_shape() {\n+Status PoolParameters::forward_output_shape(TensorShape *shape) {\n if (depth_window == 1) {\n // Spatial pooling\n- return ShapeFromFormat(data_format, tensor_in_batch, out_height, out_width,\n- depth);\n+ return ShapeFromFormatWithStatus(\n+ data_format, tensor_in_batch, out_height, out_width,\n+ depth, shape);\n } else {\n // Depthwise pooling\n- return TensorShape(\n+ *shape = TensorShape(\n {tensor_in_batch, tensor_in_rows, tensor_in_cols, out_depth});\n }\n+ return OkStatus();\n }\n \n #if GOOGLE_CUDA || TENSORFLOW_USE_ROCM\n@@ -245,10 +247,15 @@ void DnnPoolingOp<T>::Compute(OpKernelContext* context,\n /// to NCHW before calling cudnn. We need to get rid of this once it is done\n Tensor transformed_input;\n if (data_format == FORMAT_NHWC) {\n+ TensorShape transformed_input_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, tensor_in.shape(),\n+ data_format, &transformed_input_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, tensor_in.shape(),\n- data_format),\n+ transformed_input_shape,\n &transformed_input));\n functor::NHWCToNCHW<GPUDevice, T, 4>()(context->eigen_device<Device>(),\n tensor_in.tensor<T, 4>(),\n@@ -258,10 +265,15 @@ void DnnPoolingOp<T>::Compute(OpKernelContext* context,\n }\n Tensor transformed_output;\n if (data_format == FORMAT_NHWC) {\n+ TensorShape transformed_output_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, tensor_out_shape, data_format,\n+ &transformed_output_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(FORMAT_NCHW, tensor_out_shape,\n- data_format),\n+ transformed_output_shape,\n &transformed_output));\n } else {\n transformed_output = *tensor_out;\n@@ -314,11 +326,16 @@ void DnnPoolingOp<T>::Compute(OpKernelContext* context,\n const int64_t new_in_rows = tensor_in_rows + padding_rows_diff;\n const int64_t new_in_cols = tensor_in_cols + padding_cols_diff;\n \n+ TensorShape padded_input_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ data_format, batch_size,\n+ new_in_rows, new_in_cols, depth, &padded_input_shape));\n OP_REQUIRES_OK(\n context,\n context->allocate_temp(DataTypeToEnum<T>::value,\n- ShapeFromFormat(data_format, batch_size,\n- new_in_rows, new_in_cols, depth),\n+ padded_input_shape,\n &padded_input));\n const int64_t input_pad_top = params.pad_top - common_padding_rows;\n const int64_t input_pad_bottom = params.pad_bottom - common_padding_rows;\n@@ -462,14 +479,18 @@ void DnnPoolingGradOp<T>::Compute(\n return;\n }\n if (tensor_out) {\n- OP_REQUIRES(context, tensor_out->shape() == params.forward_output_shape(),\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ OP_REQUIRES(context, tensor_out->shape() == params_forward_output_shape,\n errors::InvalidArgument(\"Expected orig_output shape to be \",\n- params.forward_output_shape(),\n+ params_forward_output_shape,\n \", but got \", tensor_out->shape()));\n }\n- OP_REQUIRES(context, out_backprop.shape() == params.forward_output_shape(),\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ OP_REQUIRES(context, out_backprop.shape() == params_forward_output_shape,\n errors::InvalidArgument(\"Expected grad shape to be \",\n- params.forward_output_shape(),\n+ params_forward_output_shape,\n \", but got \", out_backprop.shape()));\n \n TensorFormat transformed_input_data_format = data_format;\n@@ -480,8 +501,10 @@ void DnnPoolingGradOp<T>::Compute(\n Tensor transformed_input;\n TensorShape transformed_input_shape;\n if (data_format == FORMAT_NHWC || !tensor_in) {\n- transformed_input_shape =\n- ShapeFromFormat(FORMAT_NCHW, tensor_in_shape, data_format);\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, tensor_in_shape, data_format, &transformed_input_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(DataTypeToEnum<T>::value,\n transformed_input_shape,\n &transformed_input));\n@@ -491,8 +514,10 @@ void DnnPoolingGradOp<T>::Compute(\n Tensor transformed_output;\n TensorShape transformed_output_shape;\n if (data_format == FORMAT_NHWC || !tensor_out) {\n- transformed_output_shape =\n- ShapeFromFormat(FORMAT_NCHW, out_backprop.shape(), data_format);\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ FORMAT_NCHW, out_backprop.shape(), data_format, transformed_output_shape));\n OP_REQUIRES_OK(context, context->allocate_temp(DataTypeToEnum<T>::value,\n transformed_output_shape,\n &transformed_output));\n@@ -619,18 +644,29 @@ void DnnPoolingGradOp<T>::Compute(\n << params.window_rows << \" kernel_col\" << params.window_cols\n << \" stride_rows\" << params.row_stride;\n \n+ TensorShape padded_input_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+\tShapeFromFormatWithStatus(\n+ transformed_input_data_format, batch_size,\n+ new_in_rows, new_in_cols, depth, &padded_input_shape));\n OP_REQUIRES_OK(\n context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(transformed_input_data_format, batch_size,\n- new_in_rows, new_in_cols, depth),\n+ padded_input_shape,\n &padded_input));\n \n+ TensorShape transformed_and_padded_input_backprop_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+\tShapeFromFormatWithStatus(\n+ transformed_input_data_format, batch_size,\n+ new_in_rows, new_in_cols, depth,\n+ &transformed_and_padded_input_backprop_shape));\n OP_REQUIRES_OK(\n context, context->allocate_temp(\n DataTypeToEnum<T>::value,\n- ShapeFromFormat(transformed_input_data_format, batch_size,\n- new_in_rows, new_in_cols, depth),\n+ transformed_and_padded_input_backprop_shape,\n &transformed_and_padded_input_backprop));\n \n input_pad_top = params.pad_top - common_padding_rows;",
"filename": "tensorflow/core/kernels/pooling_ops_common.cc",
"status": "modified"
},
{
"diff": "@@ -53,7 +53,7 @@ struct PoolParameters {\n TensorFormat data_format, const TensorShape& tensor_in_shape);\n \n // Returns the shape of the output for \"forward\" pooling operations.\n- TensorShape forward_output_shape();\n+ Status forward_output_shape(TensorShape *shape);\n \n int depth;\n \n@@ -136,8 +136,10 @@ class MaxPoolingOp : public OpKernel {\n }\n \n Tensor* output = nullptr;\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n OP_REQUIRES_OK(context, context->allocate_output(\n- 0, params.forward_output_shape(), &output));\n+ 0, params_forward_output_shape, &output));\n \n if (params.depth_window > 1) {\n // Validate spec against the current implementation. A\n@@ -405,8 +407,10 @@ class MaxPoolingV2Op : public OpKernel {\n }\n \n Tensor* output = nullptr;\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n OP_REQUIRES_OK(context, context->allocate_output(\n- 0, params.forward_output_shape(), &output));\n+ 0, params_forward_output_shape, &output));\n \n if (params.depth_window > 1) {\n // Validate spec against the current implementation. A",
"filename": "tensorflow/core/kernels/pooling_ops_common.h",
"status": "modified"
},
{
"diff": "@@ -90,14 +90,17 @@ class QuantizedAvgPoolingOp : public OpKernel {\n errors::InvalidArgument(\"tensor_in must be 4-dimensional\"));\n \n Tensor* output = nullptr;\n+ TensorShape params_forward_output_shape;\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n OP_REQUIRES_OK(context, context->allocate_output(\n- 0, params.forward_output_shape(), &output));\n+ 0, params_forward_output_shape, &output));\n const int32_t highest = static_cast<int32>(Eigen::NumTraits<T>::highest());\n const int32_t lowest = static_cast<int32>(Eigen::NumTraits<T>::lowest());\n \n // TODO(vrv): Switch this to the Eigen::Tensor version of\n // SpatialAvgPooling once that version is running quickly.\n- Tensor int32_output(DT_INT32, params.forward_output_shape());\n+ OP_REQUIRES_OK(context, params.forward_output_shape(¶ms_forward_output_shape));\n+ Tensor int32_output(DT_INT32, params_forward_output_shape);\n // Cast input to int32 tensor and call SpatialAvgPool.\n Tensor int32_input(DT_INT32, tensor_in.shape());\n int32_input.flat<int32>() = tensor_in.flat<T>().template cast<int32>();",
"filename": "tensorflow/core/kernels/quantized_pooling_ops.cc",
"status": "modified"
},
{
"diff": "@@ -119,11 +119,16 @@ class SpaceToDepthOp : public OpKernel {\n \n // Allocate output tensor.\n Tensor* outputs_tensor = nullptr;\n+ TensorShape outputs_tensor_shape;\n+ OP_REQUIRES_OK(\n+ context,\n+ ShapeFromFormatWithStatus(\n+ data_format_, batch_size, output_height,\n+ output_width, output_depth, &outputs_tensor_shape));\n OP_REQUIRES_OK(context,\n context->allocate_output(\n 0,\n- ShapeFromFormat(data_format_, batch_size, output_height,\n- output_width, output_depth),\n+ outputs_tensor_shape,\n &outputs_tensor));\n \n if (std::is_same<Device, GPUDevice>::value) {",
"filename": "tensorflow/core/kernels/spacetodepth_op.cc",
"status": "modified"
},
{
"diff": "@@ -519,9 +519,9 @@ std::string GetConvnetDataFormat2D3DAttrString();\n // FORMAT_NCHW: (N, C, spatial); rank = spatial.size() + 2\n // FORMAT_NCHW_VECT_C: (N, C, spatial, InnerC); rank = spatial.size() + 3\n // FORMAT_NHWC_VECT_W: (N, spatial, C, InnerW); rank = spatial.size() + 3\n-inline TensorShape ShapeFromFormat(TensorFormat format, int64_t N,\n- gtl::ArraySlice<int64_t> spatial,\n- int64_t C) {\n+inline Status ShapeFromFormatWithStatus(TensorFormat format, int64_t N,\n+ gtl::ArraySlice<int64_t> spatial,\n+ int64_t C, TensorShape *shape) {\n const int dims = GetTensorDimsFromSpatialDims(spatial.size(), format);\n gtl::InlinedVector<int64_t, 6> dim_sizes(dims);\n dim_sizes[GetTensorBatchDimIndex(dims, format)] = N;\n@@ -546,7 +546,7 @@ inline TensorShape ShapeFromFormat(TensorFormat format, int64_t N,\n dim_sizes[GetTensorInnerFeatureDimIndex(dims, format)] = 4;\n }\n dim_sizes[feature_index] = C;\n- return TensorShape(dim_sizes);\n+ return TensorShapeUtils::MakeShape(dim_sizes, shape);\n }\n \n // Return a tensor shape of the specified 'format', and dimensions.\n@@ -574,9 +574,9 @@ inline TensorShape ShapeFromFilterTensorFormat(FilterTensorFormat format,\n }\n \n // Return a tensor shape of the specified 'format', and dimensions.\n-inline TensorShape ShapeFromFormat(TensorFormat format, int64_t N, int64_t H,\n- int64_t W, int64_t C) {\n- return ShapeFromFormat(format, N, {H, W}, C);\n+inline Status ShapeFromFormatWithStatus(TensorFormat format, int64_t N, int64_t H,\n+ int64_t W, int64_t C, TensorShape *shape) {\n+ return ShapeFromFormatWithStatus(format, N, {H, W}, C, shape);\n }\n \n // Return a filter tensor shape of the specified 'format', and dimensions.\n@@ -588,11 +588,13 @@ inline TensorShape ShapeFromFilterTensorFormat(FilterTensorFormat format,\n \n // Returns a copy of the specified tensor 'src_shape' converted from\n // 'src_format' to 'dst_format'.\n-inline TensorShape ShapeFromFormat(TensorFormat dst_format,\n- const TensorShape& src_shape,\n- TensorFormat src_format) {\n+inline Status ShapeFromFormatWithStatus(TensorFormat dst_format,\n+ const TensorShape& src_shape,\n+ TensorFormat src_format,\n+ TensorShape *shape) {\n if (src_format == dst_format) {\n- return src_shape;\n+ *shape = src_shape;\n+ return OkStatus();\n }\n \n const int64_t batch = GetTensorDim(src_shape, src_format, 'N');\n@@ -609,7 +611,7 @@ inline TensorShape ShapeFromFormat(TensorFormat dst_format,\n if (src_format == FORMAT_NHWC_VECT_W) {\n spatial_dims[num_src_spatial_dims - 1] *= 4;\n }\n- return ShapeFromFormat(dst_format, batch, {spatial_dims}, channels);\n+ return ShapeFromFormatWithStatus(dst_format, batch, {spatial_dims}, channels, shape);\n }\n \n // Returns a copy of the specified filter tensor 'src_shape' converted from",
"filename": "tensorflow/core/util/tensor_format.h",
"status": "modified"
},
{
"diff": "@@ -319,5 +319,15 @@ def testConv2DTransposeInvalidOutputShape(self):\n strides=[1])\n self.evaluate(op)\n \n+ def testConv2DTransposeLargeOutputShape(self):\n+ with self.session():\n+ with self.assertRaises((errors.InvalidArgumentError, ValueError)):\n+ op = nn_ops.conv2d_transpose(\n+ input=np.ones((2, 2, 2, 2)),\n+ output_shape=[114078056, 179835296],\n+ strides=[10],\n+ filters=1)\n+ self.evaluate(op)\n+\n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/kernel_tests/nn_ops/conv2d_transpose_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.11.0-dev20220921\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nUbuntu 18.04.4 LTS (x86_64)\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.7.6\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\nN/A\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n`tf.image.resize` crash with abort when `antialias` is set to True. It doesn't not abort when `antialias=False`\r\n\r\nAlso reproduced in this [gist](https://colab.research.google.com/drive/1W3ZKTuk3eaPRCc88HHv_9vwftUhHE1oA?usp=sharing)\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport numpy as np\r\nimport tensorflow as tf \r\ntf.image.resize(images=np.ones((2,2,2,2)), size=[1801181592, 1846789676], antialias=True)\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n2022-09-28 20:12:18.701544: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory\r\n2022-09-28 20:12:18.701595: W tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:265] failed call to cuInit: UNKNOWN ERROR (303)\r\n2022-09-28 20:12:18.701648: I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:163] no NVIDIA GPU device is present: /dev/nvidia0 does not exist\r\n2022-09-28 20:12:18.702226: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA\r\nTo enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\r\n2022-09-28 20:12:19.021252: F tensorflow/core/framework/tensor_shape.cc:186] Non-OK-status: InitDims(dim_sizes) status: INVALID_ARGUMENT: Encountered overflow when multiplying 6652807137413688384 with 2, result: -5141129798882174848\r\nAborted (core dumped)\r\n```\r\n</details>",
"comments": [
{
"body": "Hi @gadagashwini !\r\nCould you look at this issue. Attached gist in [2.9](https://colab.sandbox.google.com/gist/mohantym/58bedc1c21b47bedb636f09468ac09c9/git_57897_2-8.ipynb#scrollTo=5HcGry1qXbHV) and [2.10](https://colab.sandbox.google.com/gist/mohantym/2e8bcb171e08935ec8f8b9e017b61b3c/git_57897_2-8.ipynb#scrollTo=2QoSPpmvpjB6) and [nightly ](https://colab.sandbox.google.com/gist/mohantym/fe3806759d6f946be56a780a9ed126f4/git_57897_2-8.ipynb#scrollTo=sa5bldWLpnMe)for reference.\r\nThank you!",
"created_at": "2022-09-29T08:31:49Z"
},
{
"body": "Created a PR #57929 for the fix.",
"created_at": "2022-10-01T10:47:03Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57897\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57897\">No</a>\n",
"created_at": "2023-01-05T16:51:46Z"
}
],
"number": 57897,
"title": "tf.image.resize crash with abort when `antialias` is set to True"
}
|
{
"body": "This PR tries to fix the issue raised in #57897 where tf.image.resize\r\nwill crash when antialias is True and size is large.\r\n\r\nThis PR fixes #57897.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57929,
"review_comments": [],
"title": "Fix crash in tf.image.resize when antialias is True and size is large"
}
|
{
"commits": [
{
"message": "Fix crash in tf.image.resize when antialias is True and size is large\n\nThis PR tries to fix the issue raised in 57897 where tf.image.resize\nwill crash when antialias is True and size is large.\n\nThis PR fixes 57897.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub issue 57897 for tf.image.resize crash\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -323,10 +323,13 @@ class ScaleAndTranslateOp : public OpKernel {\n GetValues(context, 3, &row_translation, &col_translation);\n \n Tensor* output = nullptr;\n+ TensorShape output_shape;\n+ OP_REQUIRES_OK(context, output_shape.AddDimWithStatus(input.dim_size(0)));\n+ OP_REQUIRES_OK(context, output_shape.AddDimWithStatus(output_height));\n+ OP_REQUIRES_OK(context, output_shape.AddDimWithStatus(output_width));\n+ OP_REQUIRES_OK(context, output_shape.AddDimWithStatus(input.dim_size(3)));\n OP_REQUIRES_OK(context, context->allocate_output(\n- 0,\n- TensorShape({input.dim_size(0), output_height,\n- output_width, input.dim_size(3)}),\n+ 0, output_shape,\n &output));\n if (!context->status().ok()) return;\n ",
"filename": "tensorflow/core/kernels/image/scale_and_translate_op.cc",
"status": "modified"
},
{
"diff": "@@ -4031,6 +4031,15 @@ def testPad(self):\n \n self._assertReturns(x, x_shape, y, y_shape)\n \n+ def testImageResizeAntialiasWithInvalidInput(self):\n+ with self.session():\n+ with self.assertRaises((errors.InvalidArgumentError, ValueError)):\n+ op = image_ops.resize_images_v2(\n+ images=np.ones((2, 2, 2, 2)),\n+ size=[1801181592, 1846789676],\n+ antialias=True)\n+ self.evaluate(op)\n+\n \n # half_pixel_centers not supported by XLA\n @test_util.for_all_test_methods(test_util.disable_xla, \"b/127616992\")",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.11.0-dev20220914\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nUbuntu 18.04.4 LTS (x86_64)\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.7.6\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\nN/A\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n\r\n`tf.quantization.quantize_and_dequantize` and `tf.quantization.quantize_and_dequantize_v2` crash with abortion\r\n\r\nAlso reproduced in the [gist](https://colab.research.google.com/drive/1gr2mX4G2qWQanate4tslrQNByU-sqI0s?usp=sharing)\r\n\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport numpy as np\r\nimport tensorflow as tf\r\ntf.quantization.quantize_and_dequantize_v2(input=np.ones((10)),input_min=-1,input_max=[-1,1], range_given=True)\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n2022-09-15 19:54:27.500788: F tensorflow/core/framework/tensor.cc:733] Check failed: 1 == NumElements() (1 vs. 2)Must have a one element tensor\r\nAborted (core dumped)\r\n```\r\n</details>",
"comments": [
{
"body": "Related\r\n[CVE-2020-15265](https://github.com/advisories/GHSA-rrfp-j2mp-hq9c)",
"created_at": "2022-09-15T20:22:37Z"
},
{
"body": "@gadagashwini,\r\nI was able to reproduce the issue on tensorflow v2.8, v2.9 and nightly. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/ca24b813866ca784f5b25677e7ec9495/untitled600.ipynb).",
"created_at": "2022-09-16T10:52:22Z"
},
{
"body": "@DNXie,\r\nI tried to execute the mentioned code on tf-nightly and the code was executed with the error and also observed that the crash did not happen. And the same has been updated in the respective files.\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/quantize_and_dequantize_op.cc#L22\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/resource_variable_ops.cc#L1120\r\n\r\n```python\r\n// Check data type of update and resource to scatter.\r\nconst DataType update_dtype = c->input(2).dtype();\r\nOP_REQUIRES(c, v->tensor()->dtype() == update_dtype,\r\nerrors::InvalidArgument(\r\n\"DType of scatter resource and updates does not match.\"));\r\n```\r\n\r\n\r\n",
"created_at": "2024-04-08T18:26:21Z"
},
{
"body": "This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you.",
"created_at": "2024-04-16T01:47:55Z"
},
{
"body": "This issue was closed because it has been inactive for 7 days since being marked as stale. Please reopen if you'd like to work on this further.",
"created_at": "2024-04-23T01:48:19Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57714\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57714\">No</a>\n",
"created_at": "2024-04-23T01:48:23Z"
}
],
"number": 57714,
"title": "tf.quantization.quantize_and_dequantize (and v2) crash (abort)"
}
|
{
"body": "This PR tries to fix the issue raised in #57714 where\r\ntf.quantization.quantize_and_dequantize_v2 will crash\r\nwith invalid values.\r\n\r\nThis PR fixes #57714.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57891,
"review_comments": [
{
"body": "Sorry, just noticed the doubled TestTest in the name. Can you fix?",
"created_at": "2022-09-30T17:27:49Z"
},
{
"body": "This test fails with XLA:\r\n```\r\ntensorflow.python.framework.errors_impl.InvalidArgumentError: {{function_node __wrapped__QuantizeAndDequantizeV4_device_/job:localhost/replica:0/task:0/device:GPU:0}} Broadcast dimension -1 is out of bound\r\n\t [[{{node QuantizeAndDequantizeV4}}]] [Op:QuantizeAndDequantizeV4]\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/build/work/1fbd0b4b75334c3083689021c2de3e907091/runfiles/tensorflow/python/kernel_tests/array_ops/array_ops_test.py\", line 1936, in testInvalidArgs\r\n self.evaluate(q)\r\nAssertionError: \".*should be scalar.*\" does not match \"{{function_node __wrapped__QuantizeAndDequantizeV4_device_/job:localhost/replica:0/task:0/device:GPU:0}} Broadcast dimension -1 is out of bound\r\n\t [[{{node QuantizeAndDequantizeV4}}]] [Op:QuantizeAndDequantizeV4]\"\r\n```\r\nLooks like a different error is thrown.",
"created_at": "2022-11-21T16:55:46Z"
},
{
"body": "This triggers completely different errors in TF vs XLA. I think it would be better to remove the -1 from the test so that both error out for the same reason.",
"created_at": "2022-11-22T17:52:20Z"
},
{
"body": "@cantonios Sorry for the late reply. I have update the test to remove the `-1`.",
"created_at": "2023-02-15T05:08:02Z"
},
{
"body": "I meant these -1's, so that the two paths are failing for the \"should be scalar\" reason. i.e. replace them with a 2 or something so the inputs are within bounds, but that there should only be a single value.",
"created_at": "2023-02-15T16:18:21Z"
}
],
"title": "Fix crash in tf.quantization.quantize_and_dequantize_v2"
}
|
{
"commits": [
{
"message": "Fix crash in tf.quantization.quantize_and_dequantize_v2\n\nThis PR tries to fix the issue raised in 57714 where\ntf.quantization.quantize_and_dequantize_v2 will crash\nwith invalid values.\n\nThis PR fixes 57714.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub issue 57714.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix TestTest typo\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix internal test failure.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Additional fix to cover XLA error capturing\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update error message to try to pass XLA test\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -90,6 +90,10 @@ class QuantizeAndDequantizeV2Op : public OpKernel {\n input_min_tensor = ctx->input(1);\n input_max_tensor = ctx->input(2);\n if (axis_ == -1) {\n+ OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(input_min_tensor.shape()),\n+ InvalidArgument(\"input_min_tensor should be scalar, got \", input_min_tensor.shape()));\n+ OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(input_max_tensor.shape()),\n+ InvalidArgument(\"input_max_tensor should be scalar, got \", input_max_tensor.shape()));\n auto min_val = input_min_tensor.scalar<T>()();\n auto max_val = input_max_tensor.scalar<T>()();\n OP_REQUIRES(ctx, min_val <= max_val,",
"filename": "tensorflow/core/kernels/quantize_and_dequantize_op.cc",
"status": "modified"
},
{
"diff": "@@ -1923,6 +1923,19 @@ def test_quantize_and_dequantize_v4_grad():\n test_quantize_and_dequantize_v4_grad()\n \n \n+class QuantizeAndDequantizeV2Test(test_util.TensorFlowTestCase):\n+\n+ def testInvalidArgs(self):\n+ with self.assertRaisesRegex((errors.InvalidArgumentError, ValueError),\n+ r\"(.*should be scalar.*|.*out of bound.*)\"):\n+ q, _, _ = array_ops.quantize_and_dequantize_v2(\n+ input=np.ones((10)),\n+ input_min=[-1, 1],\n+ input_max=[-1, 1],\n+ range_given=True)\n+ self.evaluate(q)\n+\n+\n @test_util.run_all_in_graph_and_eager_modes\n class SortedSearchTest(test_util.TensorFlowTestCase):\n ",
"filename": "tensorflow/python/kernel_tests/array_ops/array_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n**Describe the current behavior**\r\n`tf.nn.atrous_conv2d` crashes(aborts) when `rate` is large value\r\n\r\n**Describe the expected behavior**\r\nexpect an exception message if the input unexpected instead of crash. \r\n\r\n\r\n\r\n**Standalone code to reproduce the issue**\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.nn.atrous_conv2d(value=np.ones((1,1,1,5)), filters=np.ones((1,1,5,1)), rate=2147483647, padding='SAME')\r\n~~~\r\n\r\n~~~python\r\n2021-02-04 04:47:25.891213: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "I have tried in colab with TF versions 2.1, 2.4, nightly versions (`2.5.0-dev20210203`) and was able to reproduce the issue. Please, find the gist [here](https://colab.research.google.com/gist/ravikyram/1fda44be7360e4382bedf8f9c6c8dfb9/untitled658.ipynb). Thanks!",
"created_at": "2021-02-04T09:20:03Z"
},
{
"body": "BTW, `tf.nn.atrous_conv2d_transpose` has similar crash which is due to large `rate`.\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.nn.atrous_conv2d_transpose(value=np.ones((10,1,1,1)), filters=np.ones((1,1,1,1)), rate=1356819205, padding='SAME', output_shape=[1,1,1,1])\r\n~~~\r\n\r\nError Message:\r\n~~~python\r\n2021-04-15 00:08:19.741409: F tensorflow/core/framework/tensor_shape.cc:397] Check failed: size >= 0 (-37160523141231366 vs. 0)\r\nAborted (core dumped)\r\n~~~",
"created_at": "2021-04-15T00:09:40Z"
},
{
"body": "Colab crashes in TF Nightly 2.6 as well.Please find the gist [here](https://colab.research.google.com/gist/saikumarchalla/b44477be4d8ec2fdc1028f4684ec4cdf/untitled92.ipynb).Thanks!",
"created_at": "2021-05-29T05:12:57Z"
},
{
"body": "I was able to reproduce the issue on tf-nightly 2.10.0-dev20220719. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/1b101bc302a95283ff9ba66e46d1cb4d/untitled46915.ipynb). Thank you!\r\n\r\n",
"created_at": "2022-07-19T10:25:02Z"
},
{
"body": "Added a PR #57854 for the fix.",
"created_at": "2022-09-27T04:58:00Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46915\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46915\">No</a>\n",
"created_at": "2022-09-30T18:09:11Z"
}
],
"number": 46915,
"title": "tf.nn.atrous_conv2d crashes(aborts) when rate is large value"
}
|
{
"body": "This PR tries to address the issue raised in #46915 where\r\ntf.nn.atrous_conv2d will crash when rate is larger than 2^31.\r\n\r\nThis PR fixes #46915.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57854,
"review_comments": [
{
"body": "Does this needed the `run_deprecated_v1` and `with self.session()`? We're trying to slowly update all these tests to run in V2 mode.",
"created_at": "2022-09-27T15:31:45Z"
}
],
"title": "Fix crash in tf.nn.atrous_conv2d with large rate"
}
|
{
"commits": [
{
"message": "Fix crash in tf.nn.atrous_conv2d with large rate\n\nThis PR tries to address the issue raised in 46915 where\ntf.nn.atrous_conv2d will crash when rate is larger than 2^31.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Test case for GitHub issue 46915\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub issue 46915 with tf.nn.atrous_conv2d_transpose\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Remove @test_util.run_deprecated_v1\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -144,16 +144,16 @@ Status SpaceToBatchOpCompute(OpKernelContext* context,\n \"Negative output dimension size caused by overflow when multiplying \",\n orig_input_tensor.dim_size(0), \" and \", block_shape_product);\n }\n- external_output_shape.AddDim(output_shape);\n+ TF_RETURN_IF_ERROR(external_output_shape.AddDimWithStatus(output_shape));\n \n int64_t input_batch_size = orig_input_tensor.dim_size(0);\n for (int block_dim = 0; block_dim < removed_prefix_block_dims; ++block_dim) {\n const int64_t size = orig_input_tensor.dim_size(block_dim + 1);\n input_batch_size *= size;\n- external_output_shape.AddDim(size);\n+ TF_RETURN_IF_ERROR(external_output_shape.AddDimWithStatus(size));\n }\n- internal_input_shape.AddDim(input_batch_size);\n- internal_output_shape.AddDim(input_batch_size * block_shape_product);\n+ TF_RETURN_IF_ERROR(internal_input_shape.AddDimWithStatus(input_batch_size));\n+ TF_RETURN_IF_ERROR(internal_output_shape.AddDimWithStatus(input_batch_size * block_shape_product));\n \n for (int block_dim = removed_prefix_block_dims;\n block_dim < block_dims - removed_suffix_block_dims; ++block_dim) {\n@@ -171,21 +171,21 @@ Status SpaceToBatchOpCompute(OpKernelContext* context,\n \" is not divisible by block_shape[\",\n block_dim, \"]=\", block_shape_value);\n }\n- internal_input_shape.AddDim(input_size);\n+ TF_RETURN_IF_ERROR(internal_input_shape.AddDimWithStatus(input_size));\n const int64_t output_size = padded_size / block_shape_value;\n- internal_output_shape.AddDim(output_size);\n- external_output_shape.AddDim(output_size);\n+ TF_RETURN_IF_ERROR(internal_output_shape.AddDimWithStatus(output_size));\n+ TF_RETURN_IF_ERROR(external_output_shape.AddDimWithStatus(output_size));\n }\n \n int64_t depth = 1;\n for (int dim = block_dims - removed_suffix_block_dims + 1; dim < input_dims;\n ++dim) {\n const int64_t size = orig_input_tensor.dim_size(dim);\n- external_output_shape.AddDim(size);\n+ TF_RETURN_IF_ERROR(external_output_shape.AddDimWithStatus(size));\n depth *= size;\n }\n- internal_input_shape.AddDim(depth);\n- internal_output_shape.AddDim(depth);\n+ TF_RETURN_IF_ERROR(internal_input_shape.AddDimWithStatus(depth));\n+ TF_RETURN_IF_ERROR(internal_output_shape.AddDimWithStatus(depth));\n \n // Allocate output tensor.\n Tensor* output_tensor = nullptr;",
"filename": "tensorflow/core/kernels/spacetobatch_op.cc",
"status": "modified"
},
{
"diff": "@@ -18,6 +18,7 @@\n \n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors\n from tensorflow.python.framework import test_util\n from tensorflow.python.ops import array_ops\n from tensorflow.python.ops import gradient_checker\n@@ -157,6 +158,17 @@ def testGradient(self):\n err_tolerance = 4e-3 if test_util.is_xla_enabled() else 1e-3\n self.assertLess(err, err_tolerance)\n \n+ @test_util.run_deprecated_v1\n+ def testAtrousConv2DInvalid(self):\n+ with self.session():\n+ with self.assertRaises((errors.InvalidArgumentError, ValueError)):\n+ op = nn_ops.atrous_conv2d(\n+ value=np.ones((1, 1, 1, 5)),\n+ filters=np.ones((1, 1, 5, 1)),\n+ rate=2147483647,\n+ padding='SAME')\n+ self.evaluate(op)\n+\n \n class AtrousConv2DTransposeTest(test.TestCase):\n \n@@ -196,6 +208,17 @@ def testAtrousConv2DTransposeForward(self):\n x, f_up, y_shape, strides=[1, 1, 1, 1], padding=padding)\n self.assertAllClose(y1, y2, rtol=1e-3, atol=1e-3)\n \n+ def testAtrousConv2DTransposeInvalid(self):\n+ with self.session():\n+ with self.assertRaises((errors.InvalidArgumentError, ValueError)):\n+ op = nn_ops.atrous_conv2d_transpose(\n+ value=np.ones((10, 1, 1, 1)),\n+ filters=np.ones((1, 1, 1, 1)),\n+ rate=1356819205,\n+ padding='SAME',\n+ output_shape=[1, 1, 1, 1])\n+ self.evaluate(op)\n+\n \n class AtrousDepthwiseConv2DTest(test.TestCase):\n ",
"filename": "tensorflow/python/kernel_tests/nn_ops/atrous_conv2d_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nbinary\n\n### Tensorflow Version\n\n2.11.0-dev20220914\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nUbuntu 18.04.4 LTS (x86_64)\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.7.6\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\nN/A\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\ntf.random.poisson crash(abort)\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport numpy as np\r\nimport tensorflow as tf \r\ntf.random.poisson(lam=np.ones((10,10,11,2)), shape=[27, 187, 229])\n```\n\n\n### Relevant log output\n\n```shell\n2022-09-16 19:45:10.220556: F tensorflow/core/util/work_sharder.cc:34] Check failed: total >= 0 (0 vs. -1751281096)\r\nAborted (core dumped)\n```\n</details>",
"comments": [
{
"body": "@DNXie,\r\nCould you please refer to the comment https://github.com/tensorflow/tensorflow/issues/57711#issuecomment-1249679156 which explains about the OOM/Resource exhausted issue. Thanks!",
"created_at": "2022-09-19T15:39:56Z"
},
{
"body": "@tilakrayal Thanks for looking into this. With the input I provided, I see a crash (abortion) instead of an OOM error.\r\nAs public APIs, it would be great to have the functions kindly throw exceptions for these cases instead of crashing. Also replied in #57711. Thank you!",
"created_at": "2022-09-19T23:41:54Z"
},
{
"body": "@sachinprasadhs,\r\nI was able to reproduce the issue on tensorflow v2.8, v2.9 and nightly. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/5b51e660cd19f9634949649af9eb0ea5/untitled605.ipynb).",
"created_at": "2022-09-20T06:58:34Z"
},
{
"body": "Added a PR #57852 for the fix.",
"created_at": "2022-09-27T03:51:42Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57728\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57728\">No</a>\n",
"created_at": "2022-09-30T18:11:31Z"
}
],
"number": 57728,
"title": "tf.random.poisson crash(abort)"
}
|
{
"body": "This PR tries to address the issue raised in #57728 where tf.random.poisson will crash when total shards is larger than 2^31.\r\n\r\nThe issue was that the defined type was incorrectly casted into int (down from int64) when passed to function, resulting in CHECK failure and crash. This PR correct the type to be int64.\r\n\r\nThis PR fixes #57728.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57852,
"review_comments": [],
"title": "Fix crash of tf.random.poisson when total shards is larger than 2^31"
}
|
{
"commits": [
{
"message": "Fix crash of tf.random.poisson when total shards is larger than 2^31\n\nThis PR tries to address the issue raised in 57728 where tf.random.poisson\nwill crash when total shards is larger than 2^31.\n\nThe issue was that the defined type was incorrectly casted into int (down from int64)\nwhen passed to function, resulting in CHECK failure and crash. This PR correct the type to be int64.\n\nThis PR fixes 57728.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -71,7 +71,7 @@ namespace functor {\n template <typename T, typename U>\n struct PoissonFunctor<CPUDevice, T, U> {\n void operator()(OpKernelContext* ctx, const CPUDevice& d, const T* rate_flat,\n- int num_rate, int num_samples,\n+ int64_t num_rate, int64_t num_samples,\n const random::PhiloxRandom& rng, U* samples_flat) {\n // Two different algorithms are employed, depending on the size of\n // rate.",
"filename": "tensorflow/core/kernels/random_poisson_op.cc",
"status": "modified"
},
{
"diff": "@@ -27,7 +27,7 @@ namespace functor {\n template <typename Device, typename T /* rate */, typename U /* output */>\n struct PoissonFunctor {\n void operator()(OpKernelContext* ctx, const Device& d, const T* rate_flat,\n- int num_rate, int num_samples,\n+ int64_t num_rate, int64_t num_samples,\n const random::PhiloxRandom& rng, U* samples_flat);\n };\n ",
"filename": "tensorflow/core/kernels/random_poisson_op.h",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nbinary\n\n### Tensorflow Version\n\ntf 2.9\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\nLinux Ubuntu 20.04\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.9\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nNotFoundError raises when calling `tf.sparse.to_dense` with qint input.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport tensorflow as tf\r\nnum_rows = tf.random.uniform([], minval=0, maxval=5, dtype=tf.int32)\r\n\r\nnum_columns = None\r\ndtype = tf.qint16\r\ny = tf.sparse.eye(num_rows, num_columns=num_columns, dtype=dtype, )\r\nprint(y)\r\nx = tf.sparse.to_dense(y)\n```\n\n\n### Relevant log output\n\n```shell\nSparseTensor(indices=tf.Tensor(\r\n[[0 0]\r\n [1 1]\r\n [2 2]], shape=(3, 2), dtype=int64), values=tf.Tensor([1 1 1], shape=(3,), dtype=qint16), dense_shape=tf.Tensor([3 3], shape=(2,), dtype=int64))\r\ntensorflow.python.framework.errors_impl.NotFoundError: Could not find device for node: {{node SparseToDense}} = SparseToDense[T=DT_QINT16, Tindices=DT_INT64, validate_indices=true]\r\nAll kernels registered for op SparseToDense:\r\n device='CPU'; T in [DT_COMPLEX128]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_COMPLEX128]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_COMPLEX64]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_COMPLEX64]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_STRING]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_STRING]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_BOOL]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_BOOL]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_DOUBLE]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_DOUBLE]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_FLOAT]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_FLOAT]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_BFLOAT16]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_BFLOAT16]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_HALF]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_HALF]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_INT32]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_INT32]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_INT8]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_INT8]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_UINT8]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_UINT8]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_INT16]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_INT16]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_UINT16]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_UINT16]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_UINT32]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_UINT32]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_INT64]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_INT64]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_UINT64]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_UINT64]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_BOOL]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_BOOL]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_INT32]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_INT32]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_INT8]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_INT8]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_UINT8]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_UINT8]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_INT16]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_INT16]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_UINT16]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_UINT16]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_UINT32]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_UINT32]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_INT64]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_INT64]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_UINT64]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_UINT64]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_DOUBLE]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_DOUBLE]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_FLOAT]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_FLOAT]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_HALF]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_HALF]; Tindices in [DT_INT32]\r\n [Op:SparseToDense]\n```\n</details>",
"comments": [
{
"body": "@VictoriaGriffith,\r\nCould you please provide any reference link or the documentation link which mentioned that **tf.sparse.to_dense** supports the **qint**. Thank you!",
"created_at": "2022-08-29T10:38:30Z"
},
{
"body": "Hi @tilakrayal , the document does not make it clear whether this API or the `tf.sparse.*` APIs supports the qint (and could be improved by including this information). \r\nHowever, I believe that this should be consistent across `SparseTensor`: if users are allowed to create such a sparse tensor with qint, we expect the **basic support like `sparse.to_dense/from_dense`**. For example, I tried a few APIs that supports `qint`.\r\n```\r\nimport tensorflow as tf\r\ndtype = tf.qint16\r\nx = tf.sparse.eye(3, num_columns=3, dtype=dtype, )\r\nx = tf.sparse.expand_dims(x, -1) # Pass\r\n```\r\nWhile some others does not:\r\n```\r\nimport tensorflow as tf\r\ndtype = tf.qint16\r\nx = tf.random.uniform([2, 2], minval=0, maxval=5, dtype=tf.int32)\r\nx = tf.cast(x, tf.qint16)\r\ny = tf.sparse.from_dense(x) # NotFoundError\r\n```",
"created_at": "2022-08-29T12:13:39Z"
},
{
"body": "@gadagashwini,\r\nI was able to reproduce the issue on tensorflow v2.8, v2.9 and nightly. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/a2d2250bc9ad1c071939b80b5cf508a3/untitled551.ipynb).",
"created_at": "2022-09-02T03:40:56Z"
},
{
"body": "Feel free to submit a PR to add support.\r\n\r\nNot all ops are registered for all types. They are typically registered as they are needed. This helps us keep the TensorFlow binary size lower.",
"created_at": "2022-09-14T05:46:59Z"
},
{
"body": "Added a PR #57793 for qint support.",
"created_at": "2022-09-22T01:58:12Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57489\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57489\">No</a>\n",
"created_at": "2022-09-30T17:49:56Z"
}
],
"number": 57489,
"title": "`tf.sparse.to_dense` lack support for qint"
}
|
{
"body": "This PR tries to address the issue raised in #57489 where there is not qint support for tf.sparse.to_dense.\r\n\r\nThis PR fixes #57489.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57793,
"review_comments": [],
"title": "Add qint support for tf.sparse.to_dense"
}
|
{
"commits": [
{
"message": "Add qint support for tf.sparse.to_dense\n\nThis PR tries to address the issue raised in 57489 where there is\nnot qint support for tf.sparse.to_dense.\n\nThis PR fixes 57489.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add tf.quint8/quint16 support for tf.sparse.to_dense\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub isseu 57489 tf.qint support for tf.sparse.to_dense\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -189,6 +189,10 @@ REGISTER_KERNELS_ALL(bool);\n REGISTER_KERNELS_ALL(tstring);\n REGISTER_KERNELS_ALL(complex64);\n REGISTER_KERNELS_ALL(complex128);\n+REGISTER_KERNELS_ALL(qint8);\n+REGISTER_KERNELS_ALL(qint16);\n+REGISTER_KERNELS_ALL(quint8);\n+REGISTER_KERNELS_ALL(quint16);\n \n #undef REGISTER_KERNELS_ALL\n #undef REGISTER_KERNELS",
"filename": "tensorflow/core/kernels/sparse_to_dense_op.cc",
"status": "modified"
},
{
"diff": "@@ -231,6 +231,23 @@ def testConstantStringToSparse(self):\n self.assertAllEqual([b'a', b'b', b'a', b'b', b'a'], result.values)\n self.assertAllEqual([5], result.dense_shape)\n \n+ def testSparseTensorToDenseQint(self):\n+ x = np.asarray([1, 2])\n+ y = np.asarray([[1, 0, 0], [0, 0, 2]])\n+ for dtype in [\n+ dtypes.qint8,\n+ dtypes.qint16,\n+ dtypes.quint8,\n+ dtypes.quint16]:\n+ sp = sparse_tensor.SparseTensor(\n+ indices=[[0, 0], [1, 2]],\n+ values=x.astype(dtype.as_numpy_dtype),\n+ dense_shape=[2, 3])\n+ v = self.evaluate(sparse_ops.sparse_tensor_to_dense(sp))\n+ self.assertAllEqual(\n+ y.astype(dtype.as_numpy_dtype),\n+ v.astype(dtype.as_numpy_dtype))\n+\n \n @test_util.run_all_in_graph_and_eager_modes\n class RawOpsTest(test_util.TensorFlowTestCase, parameterized.TestCase):",
"filename": "tensorflow/python/ops/sparse_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.8.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nparams = tf.random.uniform([3, 1, 12, 64], dtype=tf.float32)\r\nindices = tf.random.uniform([35, 2], minval=0, maxval=1, dtype=tf.int64)\r\nbatch_dims = False\r\ntf.gather_nd(params, indices, batch_dims=batch_dims) # Pass\r\ntf.gather(params, indices, batch_dims=batch_dims) # InvalidArgumentError\r\n```\r\nDetailed error message:\r\n```\r\nInvalidArgumentError: Value for attr 'Taxis' of bool is not in the list of allowed values: int32, int64\r\n\t; NodeDef: {{node GatherV2}}; Op<name=GatherV2; signature=params:Tparams, indices:Tindices, axis:Taxis -> output:Tparams; attr=batch_dims:int,default=0; attr=Tparams:type; attr=Tindices:type,allowed=[DT_INT32, DT_INT64]; attr=Taxis:type,allowed=[DT_INT32, DT_INT64]> [Op:GatherV2]\r\n```\r\n\r\n**Describe the current behavior**\r\nIn the above code, `batch_dims` is a `bool`, not a `int`. `tf.gather` complains about this type mismatch and throws `InvalidArgumentError`. However, `tf.gather_nd` would do implicit conversion and convert `False` to `0`. There is an inconsistency in the type checking.\r\n\r\n**Describe the expected behavior**\r\nEither allow implicit `bool`-`int` conversion in all cases, or throw an Error in all cases.",
"comments": [
{
"body": "Added a PR #55210 for the fix.",
"created_at": "2022-03-12T02:45:27Z"
}
],
"number": 55203,
"title": "`tf.gather_nd` and `tf.gather` have inconsistent type check for `batch_dims`"
}
|
{
"body": "\r\nThis PR tries to address the issue raised in #55203 where\r\ninvalid batch_dim (bool) was passed to tf.gather_nd\r\nwith error output returned silently.\r\nThis PR fixes #55203.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57792,
"review_comments": [
{
"body": "Can you use `assertRaisesRegex` to ensure we're catching the expected error?",
"created_at": "2023-08-25T19:27:38Z"
},
{
"body": "Removing the `int` will prevent `bool` from being allowed, but it might have other unintended consequences. Bools in python are generally treated as integers with value of 0 or 1, so I'm not sure how bad the original bug report actually is.",
"created_at": "2023-08-25T19:30:08Z"
}
],
"title": "Fix invalid input for tf.gather_nd with batch_dims"
}
|
{
"commits": [
{
"message": "Fix invalid input for tf.gather_nd with batch_dims\n\nThis PR tries to address the issue raised in 55203 where\ninvalid batch_dim (bool) was passed to tf.gather_nd\nwith error output returned silently.\nThis PR fixes 55203.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix test failure\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix lint\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -22,6 +22,7 @@\n from tensorflow.python.eager import context\n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors\n from tensorflow.python.framework import indexed_slices\n from tensorflow.python.framework import ops\n from tensorflow.python.framework import tensor_shape\n@@ -380,6 +381,18 @@ def testGatherNdResourceVariable(self):\n self.assertEqual(\"ResourceGatherNd\", gather.op.inputs[0].op.type)\n self.assertAllEqual([2, 5], gather)\n \n+ def testInvalidBatchDims(self):\n+ with self.session():\n+ with self.assertRaises(\n+ (errors.InvalidArgumentError, ValueError, TypeError)):\n+ indices = [[0, 0], [1, 1]]\n+ params = [[0, 1], [2, 3]]\n+ gather_nd = array_ops.gather_nd(\n+ indices=[[1], [0], [4], [2], [1]],\n+ params=array_ops.zeros([5, 7, 3]),\n+ batch_dims=True)\n+ self.evaluate(gather_nd)\n+\n \n class GatherNdOpBenchmark(test.Benchmark):\n ",
"filename": "tensorflow/python/kernel_tests/array_ops/gather_nd_op_test.py",
"status": "modified"
},
{
"diff": "@@ -5714,7 +5714,7 @@ def gather_nd(params, indices, name=None, batch_dims=0):\n \"\"\"\n batch_dims_ = tensor_util.constant_value(batch_dims)\n if batch_dims_ is not None:\n- batch_dims = int(batch_dims_)\n+ batch_dims = batch_dims_\n if batch_dims == 0:\n try:\n # TODO(apassos) find a less bad way of detecting resource variables",
"filename": "tensorflow/python/ops/array_ops.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.11.0-dev20220914\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nUbuntu 18.04.4 LTS (x86_64)\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.7.6\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\nN/A\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n\r\n`tf.keras.backend.eye` and `tf.eye` crash (abort) with large input\r\n\r\nAlso reproduced in this [gist](https://colab.research.google.com/drive/1UEeiUYXSKSU1cBqUs01d_M1RkXgSflEw?usp=sharing)\r\n\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport tensorflow as tf\r\ntf.keras.backend.eye(size=2752212975)\r\n```\r\n\r\n```shell\r\nimport tensorflow as tf\r\ntf.eye(2752212975)\r\n```\r\n\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n2022-09-15 18:51:32.477313: F tensorflow/core/framework/tensor_shape.cc:572] Check failed: size >= 0 (0 vs. -1542754321)\r\nAborted (core dumped)\r\n```\r\n</details>",
"comments": [
{
"body": "@sachinprasadhs, \r\nI was able to reproduce the issue on tensorflow v2.8, v2.9 and nightly. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/1e6f4f263815f9f0a3ab18cc034bbaaa/untitled597.ipynb).",
"created_at": "2022-09-16T09:51:55Z"
},
{
"body": "This is due to the very large input which is causing OOM/ memory overflow with large input, when you try large value like tf.int32.max, you will get the error output.\r\nBelow is the error output.\r\n\r\n```\r\nimport tensorflow as tf\r\ntf.eye(2147483647)\r\n\r\nResourceExhaustedError: OOM when allocating tensor with shape[2147483647,2147483647] and type float on /job:localhost/replica:0/task:0/device:CPU:0 by allocator cpu [Op:MatrixDiagV3] name: diag \r\n```",
"created_at": "2022-09-16T18:29:56Z"
},
{
"body": "@sachinprasadhs Hi, Thanks for looking into this. With the input I provided, I see a crash (abortion) instead of an OOM error. \r\n\r\nAs public APIs, it would be great to have the functions kindly throw exceptions for these cases instead of crashing. ",
"created_at": "2022-09-19T23:39:39Z"
},
{
"body": "Added a PR #57790 for the fix.",
"created_at": "2022-09-21T23:46:33Z"
},
{
"body": "@DNXie,\r\nWhen I tried to execute the code on tf-nightly, I observed that the crash happened in colab where in the run time logs it mentioned the OOM error as the warning for the large input. Kindly find the screenshots for the reference\r\n\r\n\r\n\r\n\r\n\r\n\r\n",
"created_at": "2024-05-16T12:57:10Z"
}
],
"number": 57711,
"title": "tf.keras.backend.eye crash (abort) with large input"
}
|
{
"body": "This PR tries to fix the issue raised in #57711 where tf.eye will crash when input is large.\r\nThis PR fixes #57711.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57790,
"review_comments": [],
"title": "Fix crash in tf.eye when input is large"
}
|
{
"commits": [
{
"message": "Fix crash in tf.eye when input is large\n\nThis PR tries to fix the issue raised in 57711 where tf.eye will crash when\ninput is large.\nThis PR fixes 57711.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Test case for GitHub issue 57711 for tf.eye crash.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update to address the internal test failure.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -264,7 +264,7 @@ class MatrixDiagOp : public OpKernel {\n \n TensorShape output_shape = diagonal_shape;\n if (num_diags == 1) { // Output has rank `rank+1`.\n- output_shape.set_dim(diag_rank - 1, num_rows);\n+ OP_REQUIRES_OK(context, output_shape.SetDimWithStatus(diag_rank - 1, num_rows));\n output_shape.AddDim(num_cols);\n } else { // Output has rank `rank`.\n output_shape.set_dim(diag_rank - 2, num_rows);",
"filename": "tensorflow/core/kernels/linalg/matrix_diag_op.cc",
"status": "modified"
},
{
"diff": "@@ -22,6 +22,7 @@\n \n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors\n from tensorflow.python.framework import ops\n from tensorflow.python.framework import test_util\n from tensorflow.python.ops import array_ops\n@@ -259,6 +260,18 @@ def test_eye_with_placeholder(\n })\n self.assertAllEqual(eye_np, eye_tf)\n \n+ def testInvalidInput(self):\n+ # Test case for GitHub issue 57790.\n+ # Note in case of non-eager mode, the input value validation\n+ # is going through a different path and will not hit the crash\n+ # described in GitHub issue 57790.\n+ if not context.executing_eagerly():\n+ return\n+ with self.session():\n+ with self.assertRaises((errors.InvalidArgumentError, ValueError)):\n+ op = linalg_ops.eye(2752212975)\n+ self.evaluate(op)\n+\n \n class _MatrixRankTest(object):\n ",
"filename": "tensorflow/python/kernel_tests/linalg/linalg_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.11.0-dev20220914\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nUbuntu 18.04.4 LTS (x86_64)\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.7.6\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\nN/A\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n\r\ntf.linalg.diag crash (abort)\r\n\r\nAlso reproduced in the [gist](https://colab.research.google.com/drive/18ixYmcwDLRbqTLbD4AHXq1Qqt74aDY5v?usp=sharing)\r\n\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport numpy as np\r\nimport tensorflow as tf\r\ntf.linalg.diag(k=1070828000000, diagonal=np.ones((2,2,2,2)))\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n2022-09-15 19:38:46.149294: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory\r\n2022-09-15 19:38:46.149328: W tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:265] failed call to cuInit: UNKNOWN ERROR (303)\r\n2022-09-15 19:38:46.149367: I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:163] no NVIDIA GPU device is present: /dev/nvidia0 does not exist\r\n2022-09-15 19:38:46.149684: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA\r\nTo enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\r\n2022-09-15 19:38:46.188085: F tensorflow/core/framework/tensor_shape.cc:404] Check failed: 0 <= new_num_elements (0 vs. -3186289596827017184)\r\nAborted (core dumped)\r\n```\r\n</details>",
"comments": [
{
"body": "@DNXie,\r\nI was facing a different error stating **OOM when allocating tensor with shape[1381143300,1381143300]** while executing the given code. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/b0acb10dc1dad096ca0d33b3f58ac3b3/untitled599.ipynb). Thank you!",
"created_at": "2022-09-16T10:41:35Z"
},
{
"body": "@tilakrayal Hi, thanks for looking into this. I got this crash on version 2.11.0-dev20220914. Please also check the [gist](https://colab.research.google.com/drive/18ixYmcwDLRbqTLbD4AHXq1Qqt74aDY5v?usp=sharing)",
"created_at": "2022-09-16T14:18:42Z"
},
{
"body": "@gadagashwini ,\r\nI was able to reproduce the issue on tensorflow v2.8, v2.9 and nightly. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/91728b9e9b57d3ebd102eac2462bde17/untitled604.ipynb).",
"created_at": "2022-09-19T10:54:03Z"
},
{
"body": "Created a PR #57788 for the fix.",
"created_at": "2022-09-21T23:23:13Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57713\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57713\">No</a>\n",
"created_at": "2022-11-25T21:30:53Z"
},
{
"body": "I also observed the following API aliases can cause the same issue in older versions of tensorflow.\r\nUsers should be cautious when using them on both CPU and GPU up to tensorflow 2.11.1 (v2.11.0-94-ga3e2c692c18).\r\n\r\n- `(tf.linalg.diag)`, `tf.compat.v1.linalg.diag`, `tf.compat.v1.matrix_diag`\r\n\r\n<details>\r\n <summary>Code to reproduce the issue in <code>tf.compat.v1.linalg.diag</code> APIs in older versions</summary>\r\n\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\nprint(tf.version.GIT_VERSION, tf.version.VERSION, flush=True)\r\nprint(tf.config.list_physical_devices(), flush=True)\r\n\r\n\r\ntry:\r\n # tf.linalg.diag(k=1070828000000, diagonal=np.ones((2,2,2,2)))\r\n tf.compat.v1.linalg.diag(k=1070828000000, diagonal=np.ones((2,2,2,2)))\r\n # tf.compat.v1.matrix_diag(k=1070828000000, diagonal=np.ones((2,2,2,2)))\r\nexcept Exception as e:\r\n print(\"Error:\", str(e), flush=True)\r\nprint(\"Success!\", flush=True)\r\n```\r\n\r\nOn GPU, the Check failed error occurs:\r\n\r\n```text\r\nv2.11.0-94-ga3e2c692c18 2.11.1\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n2023-09-07 14:33:25.148489: F tensorflow/core/framework/tensor_shape.cc:419] Check failed: 0 <= new_num_elements (0 vs. -3186289596827017184)\r\nAborted (core dumped)\r\n```\r\n\r\nThis behavior is also reproducible on my CPU machine:\r\n\r\n```text\r\nv2.11.0-94-ga3e2c692c18 2.11.1\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')]\r\n2023-09-07 14:33:25.148489: F tensorflow/core/framework/tensor_shape.cc:419] Check failed: 0 <= new_num_elements (0 vs. -3186289596827017184)\r\nAborted (core dumped)\r\n```\r\n</details>\r\n\r\nIt seems to be fixed in tensorflow 2.12.0 (v2.12.0-rc1-12-g0db597d0d75) and later versions.\r\n",
"created_at": "2023-09-12T09:18:03Z"
}
],
"number": 57713,
"title": "tf.linalg.diag crash (abort)"
}
|
{
"body": "This PR fixes issues raise in #57713 where tf.linalg.diag will crash if the input is invalid.\r\n\r\nThis PR fixes #57713.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57788,
"review_comments": [],
"title": "Fix crash in tf.linalg.diag when input is too large"
}
|
{
"commits": [
{
"message": "Fix crash in tf.linalg.diag when input is too large\n\nThis PR fixes issues raise in 57713 where tf.linalg.diag will crash\nif the input is invalid.\n\nThis PR fixes 57713.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Test case for GitHub issue 57713 for crash in tf.linalg.diag\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -265,7 +265,7 @@ class MatrixDiagOp : public OpKernel {\n TensorShape output_shape = diagonal_shape;\n if (num_diags == 1) { // Output has rank `rank+1`.\n output_shape.set_dim(diag_rank - 1, num_rows);\n- output_shape.AddDim(num_cols);\n+ OP_REQUIRES_OK(context, output_shape.AddDimWithStatus(num_cols));\n } else { // Output has rank `rank`.\n output_shape.set_dim(diag_rank - 2, num_rows);\n output_shape.set_dim(diag_rank - 1, num_cols);",
"filename": "tensorflow/core/kernels/linalg/matrix_diag_op.cc",
"status": "modified"
},
{
"diff": "@@ -19,6 +19,7 @@\n \n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes as dtypes_lib\n+from tensorflow.python.framework import errors\n from tensorflow.python.framework import ops\n from tensorflow.python.framework import test_util\n from tensorflow.python.ops import array_ops\n@@ -1065,6 +1066,13 @@ def testInvalidRank(self):\n with self.assertRaisesRegex(ValueError, \"must be at least rank 1\"):\n array_ops.diag(0.0)\n \n+ def testInvalidInput(self):\n+ with self.session():\n+ with self.assertRaises((errors.InvalidArgumentError, ValueError)):\n+ op = array_ops.matrix_diag(\n+ k=1070828000000, diagonal=np.ones((2, 2, 2, 2)))\n+ self.evaluate(op)\n+\n \n class DiagPartOpTest(test.TestCase):\n ",
"filename": "tensorflow/python/kernel_tests/array_ops/diag_op_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.11.0-dev20220914\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nUbuntu 18.04.4 LTS (x86_64)\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.7.6\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\nN/A\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n\r\n`tf.nn.conv2d_transpose` crash with abort whtn `output_shape` has negative value\r\n\r\nAlso reproduced in this [gist](https://colab.research.google.com/drive/1Yx5pvWM7HoVpwAmCfzU5DIi1Y9IRsHrP?usp=sharing)\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport numpy as np\r\nimport tensorflow as tf\r\ntf.nn.conv2d_transpose(input=np.ones((1,1,1,1)), filters=np.ones((1,1,1,1)), output_shape=[2,-2], strides=[1])\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n2022-09-15 20:35:37.763729: F tensorflow/core/framework/tensor_shape.cc:186] Non-OK-status: InitDims(dim_sizes) status: INVALID_ARGUMENT: Expected shape dimensions to be non-negative, got -2\r\nAborted (core dumped)\r\n```\r\n</details>",
"comments": [
{
"body": "@gadagashwini \r\nI was able to reproduce the issue on Colab using TF v2.10. Please find the gist [here](https://colab.research.google.com/gist/tiruk007/b4a7e48d9c5111053b5cd3b8a809b464/57715.ipynb) for reference\r\nThank you!",
"created_at": "2022-09-18T22:06:07Z"
},
{
"body": "Created a PR #57787 for the fix.",
"created_at": "2022-09-21T22:59:41Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57715\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57715\">No</a>\n",
"created_at": "2022-09-26T20:40:56Z"
}
],
"number": 57715,
"title": "tf.nn.conv2d_transpose crash with abort whtn `output_shape` has negative value"
}
|
{
"body": "This PR tries to address the issue raised in #57715 where\r\ntf.nn.conv2d_transpose will crash if any elements in shape is negative.\r\n\r\nThis PR fixes #57715.\r\nThis PR fixes #57709.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57787,
"review_comments": [],
"title": "Fix crash in tf.nn.conv2d_transpose when shape is negative"
}
|
{
"commits": [
{
"message": "Fix crash in tf.nn.conv2d_transpose when shape is negative\n\nThis PR tries to address the issue raised in 57715 where\ntf.nn.conv2d_transpose will crash if any elements in shape is negative.\n\nThis PR fixes 57715.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Test case for GitHub issue 57715\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -191,6 +191,11 @@ Status Conv2DBackpropComputeInputShape(const Tensor& input_sizes,\n const int output_height = input_sizes.vec<int32>()(0);\n const int output_width = input_sizes.vec<int32>()(1);\n const int output_depth = filter_shape.dim_size(2);\n+ if (output_height < 0 || output_width < 0) {\n+ return errors::InvalidArgument(\n+ \"Conv2DBackpropInput: elements of input_sizes must be >= 0, not \",\n+ output_height, \"x\", output_width);\n+ }\n *input_shape = ShapeFromFormat(data_format, batch_size, output_height,\n output_width, output_depth);\n return OkStatus();",
"filename": "tensorflow/core/kernels/conv_grad_shape_utils.cc",
"status": "modified"
},
{
"diff": "@@ -18,6 +18,7 @@\n \n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors\n from tensorflow.python.framework import test_util\n from tensorflow.python.ops import array_ops\n from tensorflow.python.ops import gradient_checker\n@@ -308,6 +309,15 @@ def testConv2DTransposeShapeInference(self):\n x, f, f_shape, strides=[1, 1, 1, 1], padding=\"SAME\")\n self.assertEqual(output.get_shape().as_list(), [3, 10, 5, 5])\n \n+ def testConv2DTransposeInvalidOutputShape(self):\n+ with self.session():\n+ with self.assertRaises((errors.InvalidArgumentError, ValueError)):\n+ op = nn_ops.conv2d_transpose(\n+ input=np.ones((1, 1, 1, 1)),\n+ filters=np.ones((1, 1, 1, 1)),\n+ output_shape=[2, -2],\n+ strides=[1])\n+ self.evaluate(op)\n \n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/kernel_tests/nn_ops/conv2d_transpose_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.11.0-dev20220914\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nUbuntu 18.04.4 LTS (x86_64)\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.7.6\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\nN/A\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n`tf.math.unsorted_segment_min`, `tf.math.unsorted_segment_max`, `tf.math.unsorted_segment_sum`, `tf.math.unsorted_segment_prod` crash with abortion.\r\n\r\nAlso reproduced in the [gist](https://colab.research.google.com/drive/1BM8HWcrSTH6qyPwujFl5QjhB_BlT8Nat?usp=sharing)\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport numpy as np\r\nimport tensorflow as tf\r\ntf.math.unsorted_segment_min(data=np.ones((3)),segment_ids=898042203, num_segments=8327099846119777499)\r\n\r\n\r\n\r\nimport numpy as np\r\nimport tensorflow as tf\r\ntf.math.unsorted_segment_max(data=np.ones((3)),segment_ids=898042203, num_segments=8327099846119777499)\r\n\r\n\r\n\r\nimport numpy as np\r\nimport tensorflow as tf\r\ntf.math.unsorted_segment_sum(data=np.ones((3)),segment_ids=898042203, num_segments=8327099846119777499)\r\n\r\n\r\n\r\nimport numpy as np\r\nimport tensorflow as tf\r\ntf.math.unsorted_segment_prod(data=np.ones((3)),segment_ids=898042203, num_segments=8327099846119777499)\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n2022-09-15 21:11:52.268123: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory\r\n2022-09-15 21:11:52.268149: W tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:265] failed call to cuInit: UNKNOWN ERROR (303)\r\n2022-09-15 21:11:52.268205: I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:163] no NVIDIA GPU device is present: /dev/nvidia0 does not exist\r\n2022-09-15 21:11:52.268549: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA\r\nTo enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\r\n2022-09-15 21:11:52.305843: F tensorflow/core/framework/tensor_shape.cc:404] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n```\r\n</details>",
"comments": [
{
"body": "Was able to reproduce the issue with `tf-2.11.0-dev20220915`. Please find the [gist](https://colab.research.google.com/drive/1-PXHtwdjtwfjJGL0XckX-auzdBBDBWXF?usp=sharing) here. Thank you!",
"created_at": "2022-09-16T07:23:42Z"
},
{
"body": "Could you please refer the comment [here](https://github.com/tensorflow/tensorflow/issues/57711#issuecomment-1249679156) which explains about OOM/Resource exhausted issue. Thanks! ",
"created_at": "2022-09-16T19:15:13Z"
},
{
"body": "@sachinprasadhs Hi, Thanks for looking into this. With the input I provided, I see a crash (abortion) instead of an OOM error.\r\nAs public APIs, it would be great to have the functions kindly throw exceptions for these cases instead of crashing. Also replied in #57711. Thank you!",
"created_at": "2022-09-19T23:41:31Z"
},
{
"body": "Created a PR #57785 for the fix.",
"created_at": "2022-09-21T22:16:40Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57716\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57716\">No</a>\n",
"created_at": "2022-09-26T20:36:51Z"
}
],
"number": 57716,
"title": "tf.math.unsorted_segment_min (max/sum/prod) crash (abort)"
}
|
{
"body": "This PR tries to address the issue raised in #57716 where tf.math.unsorted_segment_min/max/sum\r\nwill crash when num_segments is not valid.\r\n\r\nThis PR fixes #57716.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57785,
"review_comments": [],
"title": "Fix crash in tf.math.unsorted_segment_min/max/sum caused by invalid num_segments"
}
|
{
"commits": [
{
"message": "Fix crash in tf.math.unsorted_segment_min/max/sum caused by invalid num_segments\n\nThis PR tries to address the issue raised in 57716 where tf.math.unsorted_segment_min/max/sum\nwill crash when num_segments is not valid.\n\nThis PR fixes 57716.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Test case for GitHub issue 57716 crash in tf.math.unsorted_segment_min\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -490,9 +490,9 @@ class UnsortedSegmentReductionOp : public OpKernel {\n errors::InvalidArgument(\"Input num_segments == \", output_rows,\n \" must not be negative.\"));\n TensorShape output_shape;\n- output_shape.AddDim(output_rows);\n+ OP_REQUIRES_OK(context, output_shape.AddDimWithStatus(output_rows));\n for (int i = segment_ids.dims(); i < data.dims(); i++) {\n- output_shape.AddDim(data.dim_size(i));\n+ OP_REQUIRES_OK(context, output_shape.AddDimWithStatus(data.dim_size(i)));\n }\n Tensor* output = nullptr;\n OP_REQUIRES_OK(context, context->allocate_output(0, output_shape, &output));",
"filename": "tensorflow/core/kernels/segment_reduction_ops_impl.h",
"status": "modified"
},
{
"diff": "@@ -528,6 +528,18 @@ def testAllNegatives(self):\n unsorted = math_ops.unsorted_segment_sum(data, segment_ids, 2)\n self.assertAllClose(unsorted.eval(), np.zeros((2, 1), dtype=np.float32))\n \n+ @test_util.run_deprecated_v1\n+ def testBadNumSegments(self):\n+ with self.session(use_gpu=False):\n+ num_segments = 8327099846119777499\n+ unsorted = math_ops.unsorted_segment_sum(\n+ np.ones((3)),\n+ segment_ids=898042203,\n+ num_segments=num_segments)\n+ with self.assertRaisesOpError(\n+ \"Encountered overflow when multiplying\"):\n+ self.evaluate(unsorted)\n+\n \n class SparseSegmentReductionHelper(SegmentReductionHelper):\n ",
"filename": "tensorflow/python/kernel_tests/math_ops/segment_reduction_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nbinary\n\n### Tensorflow Version\n\n2.11.0-dev20220916\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nUbuntu 18.04.4 LTS (x86_64)\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.7.6\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\nN/A\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\ntf.image.crop_and_resize crash (abort) when given num_boxes=0\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nimport numpy as np\r\nimport tensorflow as tf\r\ntf.image.crop_and_resize(crop_size=[1,1], box_indices=np.ones((0,1)), boxes=np.ones((0,4)), image=np.ones((2,2,2,2)))\n```\n\n\n### Relevant log output\n\n```shell\n2022-09-19 20:55:05.906144: F tensorflow/core/framework/tensor_shape.cc:45] Check failed: NDIMS == dims() (1 vs. 2)Asking for tensor of 1 dimensions from a tensor of 2 dimensions\r\nAborted (core dumped)\n```\n</details>",
"comments": [
{
"body": "@DNXie \r\nI tried to reproduce the issue on Colab using TF v2.10 but Colab crashes. Could you please find the gist [here](https://colab.research.google.com/gist/tiruk007/db2b2a94917c3e04ec473c83aec3bfb2/57754.ipynb) and confirm the issue?\r\nThank you!",
"created_at": "2022-09-21T19:06:49Z"
},
{
"body": "Created a PR #57783 for the fix.",
"created_at": "2022-09-21T21:22:46Z"
},
{
"body": "@DNXie \r\nThis issue is closed when the [PR](https://github.com/tensorflow/tensorflow/pull/57783) is merged.\r\n\r\nThank you!",
"created_at": "2022-09-24T07:02:40Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57754\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57754\">No</a>\n",
"created_at": "2022-10-20T21:57:13Z"
}
],
"number": 57754,
"title": "tf.image.crop_and_resize crash (abort) when given num_boxes=0"
}
|
{
"body": "This PR tries to address the issue in #57754 where tf.image.crop_and_resize\r\nwill crach when box_indices is invalid (should be 1-D, as was specified in doc).\r\n\r\nThis PR fixes #57754.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 57783,
"review_comments": [
{
"body": "We shouldn't need this `with self.session()`. That has been deprecated.\r\n\r\n",
"created_at": "2022-10-17T17:10:14Z"
},
{
"body": "Can you `assertRaisesRegex`, and ensure the error message between graph/eager mode is somewhat consistent?",
"created_at": "2022-10-17T17:10:44Z"
},
{
"body": "nit: can you use `TensorShapeUtils::IsVector(box_index.shape())` here instead?",
"created_at": "2022-10-17T17:12:14Z"
}
],
"title": "Fix crash in tf.image.crop_and_resize caused by invalid box_indices"
}
|
{
"commits": [
{
"message": "Fix crash in tf.image.crop_and_resize caused by invalid box_indices\n\nThis PR tries to address the issue in 57754 where tf.image.crop_and_resize\nwill crach when box_indices is invalid (should be 1-D, as was specified in doc).\n\nThis PR fixes 57754.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test for GitHub issue 57754.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Address review feedback\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -148,6 +148,10 @@ class CropAndResizeOp : public AsyncOpKernel {\n OP_REQUIRES_ASYNC(\n context, image_height > 0 && image_width > 0,\n errors::InvalidArgument(\"image dimensions must be positive\"), done);\n+ OP_REQUIRES_ASYNC(context, TensorShapeUtils::IsVector(box_index.shape()),\n+ errors::InvalidArgument(\"box_indices must be rank 1 but is shape \",\n+ box_index.shape().DebugString()),\n+ done);\n int num_boxes = 0;\n OP_REQUIRES_OK_ASYNC(\n context, ParseAndCheckBoxSizes(boxes, box_index, &num_boxes), done);",
"filename": "tensorflow/core/kernels/image/crop_and_resize_op.cc",
"status": "modified"
},
{
"diff": "@@ -6288,6 +6288,16 @@ def testImageCropAndResizeWithInvalidInput(self):\n crop_size=[2065374891, 1145309325])\n self.evaluate(op)\n \n+ def testImageCropAndResizeWithNon1DBoxes(self):\n+ with self.assertRaisesRegex(\n+ (errors.InvalidArgumentError, ValueError), \"must be rank 1\"):\n+ op = image_ops_impl.crop_and_resize_v2(\n+ image=np.ones((2, 2, 2, 2)),\n+ boxes=np.ones((0, 4)),\n+ box_indices=np.ones((0, 1)),\n+ crop_size=[1, 1])\n+ self.evaluate(op)\n+\n @parameterized.named_parameters(\n (\"_jpeg\", \"JPEG\", \"jpeg_merge_test1.jpg\"),\n (\"_png\", \"PNG\", \"lena_rgba.png\"),",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nsource\r\n\r\n### Tensorflow Version\r\n\r\n2.0+\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nCentos 6.0\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.10\r\n\r\n### Bazel version\r\n\r\n5.2.0\r\n\r\n### GCC/Compiler version\r\n\r\n7.1.0\r\n\r\n### CUDA/cuDNN version\r\n\r\n_No response_\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\nINFO: Analyzed target //tensorflow/lite/c:tensorflowlite_c (0 packages loaded, 0 targets configured).\r\nINFO: Found 1 target...\r\nERROR: /root/tensorflow-2.10.0/tensorflow/lite/BUILD:505:11: Compiling tensorflow/lite/interpreter_builder.cc failed: (Exit 1): gcc failed: error executing command /usr/local/bin/gcc -U_FORTIFY_SOURCE -fstack-protector -Wall -Wunused-but-set-parameter -Wno-free-nonheap-object -fno-omit-frame-pointer -g0 -O2 '-D_FORTIFY_SOURCE=1' -DNDEBUG -ffunction-sections ... (remaining 47 arguments skipped)\r\ntensorflow/lite/interpreter_builder.cc: In member function 'virtual void* tflite::{anonymous}::MallocDataAllocator::Allocate(size_t, size_t)':\r\ntensorflow/lite/interpreter_builder.cc:312:12: error: 'aligned_alloc' was not declared in this scope\r\n return aligned_alloc(used_alignment, used_size);\r\n ^~~~~~~~~~~~~\r\nTarget //tensorflow/lite/c:tensorflowlite_c failed to build\r\n```\r\n\r\n\r\nAligned alloc is not defined for a gcc compiler of version 7.1.0 (stdc11 and c++14):\r\n\r\n```shell\r\n[root]# gcc -dM -E - < /dev/null | grep STDC_VERSION\r\n#define __STDC_VERSION__ 201112L\r\n\r\n[root]# echo '#include<iostream>\r\n\r\nint main() {\r\n if (__cplusplus == 201703L) std::cout << \"C++17\\n\";\r\n else if (__cplusplus == 201402L) std::cout << \"C++14\\n\";\r\n else if (__cplusplus == 201103L) std::cout << \"C++11\\n\";\r\n else if (__cplusplus == 199711L) std::cout << \"C++98\\n\";\r\n else std::cout << \"pre-standard C++\\n\";\r\n}' | g++ -x c++ -\r\n\r\n[root]# ./a.out \r\nC++14\r\n\r\n```\r\n\r\n\r\nIf we refer to [your code](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/interpreter_builder.cc#L312) you need `TFLITE_USE_STD_ALIGNED_ALLOC` to be defined which happens with [all those conditions](https://github.com/tensorflow/tensorflow/blob/00a049661641ff13e0dd666fa692c97fb079e4bd/tensorflow/lite/interpreter_builder.cc#L49-L57)\r\n```c\r\n// aligned_alloc is available (via cstdlib/stdlib.h) with C++17/C11.\r\n#if __cplusplus >= 201703L || __STDC_VERSION__ >= 201112L\r\n#if !defined(__ANDROID__) || __ANDROID_API__ >= 28\r\n// Neither Apple nor Windows provide aligned_alloc.\r\n#if !defined(__APPLE__) && !defined(_WIN32)\r\n#define TFLITE_USE_STD_ALIGNED_ALLOC\r\n#endif\r\n#endif\r\n#endif\r\n```\r\n\r\nHowever having c11 is not enough, aligned_malloc was mainly shipped with c++17 so the first condition should have been `#if __cplusplus >= 201703L && __STDC_VERSION__ >= 201112L` and not a simple or.\r\n\r\n[This](https://github.com/tensorflow/tensorflow/blob/4ea1236a02160e0c9bd8c3673cfae66dfb3f1b9b/tensorflow/lite/kernels/internal/optimized/neon_tensor_utils.cc#L39) also need to change\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nJust run the compilation with gcc 7.1.0\r\nbuild -c opt //tensorflow/lite/c:tensorflowlite_c\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\nINFO: Analyzed target //tensorflow/lite/c:tensorflowlite_c (0 packages loaded, 0 targets configured).\r\nINFO: Found 1 target...\r\nERROR: /root/tensorflow-2.10.0/tensorflow/lite/BUILD:505:11: Compiling tensorflow/lite/interpreter_builder.cc failed: (Exit 1): gcc failed: error executing command /usr/local/bin/gcc -U_FORTIFY_SOURCE -fstack-protector -Wall -Wunused-but-set-parameter -Wno-free-nonheap-object -fno-omit-frame-pointer -g0 -O2 '-D_FORTIFY_SOURCE=1' -DNDEBUG -ffunction-sections ... (remaining 47 arguments skipped)\r\ntensorflow/lite/interpreter_builder.cc: In member function 'virtual void* tflite::{anonymous}::MallocDataAllocator::Allocate(size_t, size_t)':\r\ntensorflow/lite/interpreter_builder.cc:312:12: error: 'aligned_alloc' was not declared in this scope\r\n return aligned_alloc(used_alignment, used_size);\r\n ^~~~~~~~~~~~~\r\nTarget //tensorflow/lite/c:tensorflowlite_c failed to build\r\n```\r\n</details>",
"comments": [
{
"body": "I have been able to successfully compile with those two changes:\r\n```shell\r\nsed -i \"s/201703L ||/201703L \\&\\&/\" tensorflow/lite/kernels/internal/optimized/neon_tensor_utils.cc\r\nsed -i \"s/201703L ||/201703L \\&\\&/\" tensorflow/lite/interpreter_builder.cc\r\n```",
"created_at": "2022-09-15T07:59:56Z"
},
{
"body": "Hi @ETKNeil !\r\nCould you raise a PR from your end.\r\nThank you!",
"created_at": "2022-09-15T09:45:47Z"
},
{
"body": "Hi @ETKNeil \r\n\r\nA new PR #61176 has been created as the original PR #57707 has been closed.\r\n\r\nThe issue will be closed once the PR is merged.\r\n\r\nThanks.",
"created_at": "2023-07-05T08:56:52Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57706\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57706\">No</a>\n",
"created_at": "2023-07-26T21:24:46Z"
}
],
"number": 57706,
"title": "Aligned alloc might not be defined"
}
|
{
"body": "See #57706 but the gist is aligned_alloc was introduced in the std c11 but was fully implemented in C++17 however a C++14 might be C11 compliant without that feature (eg GCC 7.1.0)\r\n\r\nI just forced the condition to be both std c11 and C++17 to ensure at 100% the feature is here and fall back to the less effective method otherwise.",
"number": 57707,
"review_comments": [],
"title": "Fix aligned alloc on C++14 compiler as it is only C++17"
}
|
{
"commits": [
{
"message": "Update neon_tensor_utils.cc"
},
{
"message": "Update interpreter_builder.cc"
}
],
"files": [
{
"diff": "@@ -46,8 +46,8 @@ limitations under the License.\n #include \"tensorflow/lite/util.h\"\n #include \"tensorflow/lite/version.h\"\n \n-// aligned_alloc is available (via cstdlib/stdlib.h) with C++17/C11.\n-#if __cplusplus >= 201703L || __STDC_VERSION__ >= 201112L\n+// aligned_alloc is available (via cstdlib/stdlib.h) with C++17/C11 (introduced in stdc11 but realized in C++17).\n+#if __cplusplus >= 201703L && __STDC_VERSION__ >= 201112L\n #if !defined(__ANDROID__) || __ANDROID_API__ >= 28\n // Neither Apple nor Windows provide aligned_alloc.\n #if !defined(__APPLE__) && !defined(_WIN32)",
"filename": "tensorflow/lite/interpreter_builder.cc",
"status": "modified"
},
{
"diff": "@@ -35,8 +35,8 @@ limitations under the License.\n \n #ifdef USE_NEON\n \n-// aligned_alloc is available (via cstdlib/stdlib.h) with C++17/C11.\n-#if __cplusplus >= 201703L || __STDC_VERSION__ >= 201112L\n+// aligned_alloc is available (via cstdlib/stdlib.h) with C++17/C11 (introduced in stdc11 but realized in C++17).\n+#if __cplusplus >= 201703L && __STDC_VERSION__ >= 201112L\n #if !defined(__ANDROID__) || __ANDROID_API__ >= 28\n // Neither Apple nor Windows provide aligned_alloc.\n #if !defined(__APPLE__) && !defined(_WIN32)",
"filename": "tensorflow/lite/kernels/internal/optimized/neon_tensor_utils.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nsource\n\n### Tensorflow Version\n\ntf2.9.1\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\n_No response_\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nhttps://github.com/tensorflow/tensorflow/blob/v2.9.1/tensorflow/core/framework/tensor.cc#L699\r\n\r\nThere is a problem with the constructor of tensor, passing datatype to shape.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nTensor::Tensor(DataType type) : shape_(type), buf_(nullptr) {}\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/v2.9.1/tensorflow/core/framework/tensor.cc#L699\n```\n\n\n### Relevant log output\n\n_No response_</details>",
"comments": [
{
"body": "@luliyucoordinate,\r\nThis issue will move to closed status once the respective PR is merged. Thank you!",
"created_at": "2022-08-16T06:55:45Z"
},
{
"body": "@luliyucoordinate,\r\nThe related [PR](https://github.com/tensorflow/tensorflow/pull/57143) which was raised got merged and also the files are also changed with the **set_dtype(type)**\r\n\r\nhttps://github.com/tensorflow/tensorflow/pull/57143/files\r\n\r\n\r\n```\r\nTensor::Tensor(DataType type) : shape_(TensorShape({})), buf_(nullptr) {\r\n set_dtype(type);\r\n```\r\n\r\nThank you!",
"created_at": "2023-11-25T07:12:51Z"
},
{
"body": "OK",
"created_at": "2023-11-25T07:48:56Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57142\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/57142\">No</a>\n",
"created_at": "2023-11-25T07:49:09Z"
}
],
"number": 57142,
"title": "Problem with constructor of tensor"
}
|
{
"body": "#57142 ",
"number": 57143,
"review_comments": [],
"title": "Fix Tensor constructor with DataType"
}
|
{
"commits": [
{
"message": "Fix Tensor constructor with DataType"
}
],
"files": [
{
"diff": "@@ -696,7 +696,9 @@ void UnrefIfNonNull(core::RefCounted* buf) {\n \n Tensor::Tensor() : Tensor(DT_FLOAT) {}\n \n-Tensor::Tensor(DataType type) : shape_(type), buf_(nullptr) {}\n+Tensor::Tensor(DataType type) : shape_(TensorShape({})), buf_(nullptr) {\n+ set_dtype(type);\n+}\n \n Tensor::Tensor(DataType type, const TensorShape& shape, TensorBuffer* buf)\n : shape_(shape), buf_(buf) {",
"filename": "tensorflow/core/framework/tensor.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.9.1\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\nLinux Ubuntu 20.04\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.9\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\n_No response_\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\n\r\n**Error**: When using shape inference c api, `TF_ShapeInferenceContextGetInput` and `TF_ShapeInferenceContextSetOutput`, \r\neven the index is not out of range, there is an out of range error. \r\n\r\n**Cause**: Checking the source code, we can see the condition `0 < i || i >= cc_ctx->num_inputs()`, \r\nwhich is wrong obviously.\r\n\r\n**Source code**: Here is source code [link](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/c/ops.cc#L146)\r\n\r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nNo standalone test needed\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```shell\r\nCheck failed: TF_OK == TF_GetCode(status) (0 vs. 3)\r\n```\r\n</details>",
"comments": [
{
"body": "Hi @Wanzizhu !\r\nCould you please share your code and results with a gist . I could not find any issue while doing unit test of this op. Attached [gist ](https://colab.sandbox.google.com/gist/mohantym/0ccc54941f7f0c784cc0da5389e540b8/tensorflow-ranking.ipynb#scrollTo=tlf7PgzQ2JtS)for reference. \r\n\r\nThank you!",
"created_at": "2022-07-27T01:53:05Z"
},
{
"body": "hi, @mohantym , current uint test doesn't cover the issue case, so no issue for current unit test. I added below test and tested on my local machine. Below are the added test and failed result. \r\n\r\n- Test\r\n\r\n```\r\nTEST(OpsTest, ShapeInferenceMultiInput) {\r\n NodeDef def;\r\n shape_inference::InferenceContext c(\r\n 0, def, MakeOpDef(1, 0), {S({10, 20, 30, 40, 50}), S({10})}, {}, {}, {});\r\n ASSERT_EQ(\"[10]\", c.DebugString(c.input(1)));\r\n\r\n TF_ShapeHandle* handle = TF_NewShapeHandle();\r\n TF_Status* status = TF_NewStatus();\r\n TF_ShapeInferenceContextGetInput(C_CTX(&c), 1, handle, status);\r\n ASSERT_EQ(TF_OK, TF_GetCode(status)) << TF_Message(status);\r\n ASSERT_EQ(\r\n \"[10]\",\r\n c.DebugString(*reinterpret_cast<shape_inference::ShapeHandle*>(handle)));\r\n TF_DeleteStatus(status);\r\n TF_DeleteShapeHandle(handle);\r\n}\r\n\r\nvoid multi_output_shape_fn(TF_ShapeInferenceContext* ctx, TF_Status* status) {\r\n TF_ShapeHandle* handle = TF_NewShapeHandle();\r\n TF_ShapeInferenceContextGetInput(ctx, 0, handle, status);\r\n ASSERT_EQ(TF_OK, TF_GetCode(status)) << TF_Message(status);\r\n\r\n TF_ShapeInferenceContextSetOutput(ctx, 0, handle, status);\r\n ASSERT_EQ(TF_OK, TF_GetCode(status)) << TF_Message(status);\r\n TF_ShapeInferenceContextSetOutput(ctx, 1, handle, status);\r\n ASSERT_EQ(TF_OK, TF_GetCode(status)) << TF_Message(status);\r\n TF_DeleteShapeHandle(handle);\r\n}\r\n\r\nTEST(OpsTest, TestShapeInference_MultiOutput) {\r\n ShapeInferenceTestOp op(\"MultioutputTestOp\");\r\n\r\n TF_OpDefinitionBuilder* builder =\r\n TF_NewOpDefinitionBuilder(\"MultioutputTestOp\");\r\n TF_OpDefinitionBuilderAddInput(builder, \"input1: uint8\");\r\n TF_OpDefinitionBuilderAddOutput(builder, \"output1: uint8\");\r\n TF_OpDefinitionBuilderAddOutput(builder, \"output2: uint8\");\r\n\r\n TF_OpDefinitionBuilderSetShapeInferenceFunction(builder, &multi_output_shape_fn); \r\n \r\n TF_Status* status = TF_NewStatus();\r\n TF_RegisterOpDefinition(builder, status); \r\n ASSERT_EQ(TF_OK, TF_GetCode(status)) << TF_Message(status);\r\n TF_ASSERT_OK(\r\n shape_inference::ShapeInferenceTestutil::InferShapes(op, \"[1,2]\", \"in0;in0\")); \r\n TF_DeleteStatus(status);\r\n}\r\n```\r\n- Result\r\n```\r\n[ RUN ] OpsTest.TestShapeInference_MultiOutput\r\ntensorflow/c/ops_test.cc:92: Failure\r\nExpected equality of these values:\r\n TF_OK\r\n Which is: 0\r\n TF_GetCode(status)\r\n Which is: 3\r\noutput index out of range\r\ntensorflow/c/ops_test.cc:110: Failure\r\nExpected equality of these values:\r\n ::tensorflow::Status::OK()\r\n Which is: OK\r\n (shape_inference::ShapeInferenceTestutil::InferShapes(op, \"[1,2]\", \"in0;in0\"))\r\n Which is: INVALID_ARGUMENT: output index out of range for '{{node }} = []()' with input shapes: [1,2].\r\n[ FAILED ] OpsTest.TestShapeInference_MultiOutput (0 ms)\r\n[ RUN ] OpsTest.ShapeInferenceMultiInput\r\ntensorflow/c/ops_test.cc:369: Failure\r\nExpected equality of these values:\r\n TF_OK\r\n Which is: 0\r\n TF_GetCode(status)\r\n Which is: 3\r\ninput index out of range\r\n[ FAILED ] OpsTest.ShapeInferenceMultiInput (0 ms)\r\n```",
"created_at": "2022-07-28T03:09:19Z"
},
{
"body": "@mohantym, maybe it 's a typo in source code [here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/c/ops.cc#L146) and [here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/c/ops.cc#L166)",
"created_at": "2022-07-28T03:25:50Z"
},
{
"body": "Ok @Wanzizhu !\r\nThanks for the update. @sachinprasadhs ! Could you please look at this issue.\r\nThank you!",
"created_at": "2022-07-28T06:09:12Z"
},
{
"body": "Are you suggesting the existing condition to change it to `0 <= i || i >= cc_ctx->num_inputs()` for your tests to pass?",
"created_at": "2022-07-28T21:11:04Z"
},
{
"body": "@sachinprasadhs , i am suggesting to change ` 0 < i` to`i < 0` in both `TF_ShapeInferenceContextGetInput` and `TF_ShapeInferenceContextSetOutput`, as `0 < i` is not out of range.",
"created_at": "2022-07-28T22:14:02Z"
},
{
"body": "Thanks for the clarification, I will create a PR for the above mentioned changes.",
"created_at": "2022-07-28T22:38:01Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56906\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56906\">No</a>\n",
"created_at": "2022-08-05T18:55:45Z"
}
],
"number": 56906,
"title": "[C API] Index error in ShapeInference C API"
}
|
{
"body": "Updated the out of range index logic from the invalid range.\r\nFixes: #56906",
"number": 56939,
"review_comments": [],
"title": "Fix out of range index error."
}
|
{
"commits": [
{
"message": "Fix out of range index error.\n\nUpdated the out of range index logic from the invalid range."
},
{
"message": "Merge pull request #57012 from tensorflow/master\n\nCloning from master"
}
],
"files": [
{
"diff": "@@ -143,7 +143,7 @@ void TF_ShapeInferenceContextGetInput(TF_ShapeInferenceContext* ctx, int i,\n TF_Status* status) {\n TF_SetStatus(status, TF_OK, \"\");\n auto* cc_ctx = reinterpret_cast<InferenceContext*>(ctx);\n- if (0 < i || i >= cc_ctx->num_inputs()) {\n+ if (i < 0 || i >= cc_ctx->num_inputs()) {\n TF_SetStatus(status, TF_INVALID_ARGUMENT, \"input index out of range\");\n }\n if (TF_GetCode(status) == TF_OK) {\n@@ -163,7 +163,7 @@ void TF_ShapeInferenceContextSetOutput(TF_ShapeInferenceContext* ctx, int i,\n TF_Status* status) {\n TF_SetStatus(status, TF_OK, \"\");\n auto* cc_ctx = reinterpret_cast<InferenceContext*>(ctx);\n- if (0 < i || i >= cc_ctx->num_outputs()) {\n+ if (i < 0 || i >= cc_ctx->num_outputs()) {\n TF_SetStatus(status, TF_INVALID_ARGUMENT, \"output index out of range\");\n }\n if (TF_GetCode(status) == TF_OK) {",
"filename": "tensorflow/c/ops.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nsource\n\n### Tensorflow Version\n\ngit HEAD\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nCentOS 7\n\n### Mobile device\n\nn/a\n\n### Python version\n\n3.8.10\n\n### Bazel version\n\n5.1.1\n\n### GCC/Compiler version\n\n10.2.1\n\n### CUDA/cuDNN version\n\nn/a\n\n### GPU model and memory\n\nn/a\n\n### Current Behaviour?\n\n```shell\nUnit test //tensorflow/python/kernel_tests/quantization_ops:quantization_ops_test fails with segfault introduced by https://github.com/tensorflow/tensorflow/commit/7cdf9d4d2083b739ec81cfdace546b0c99f50622\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nbazel test --test_timeout=300,500,-1,-1 --flaky_test_attempts=3 --test_output=all --cache_test_results=no --noremote_accept_cached --config=nonccl --config=mkl_aarch64 --copt=\"-mtune=generic\" --copt=\"-march=armv8-a\" --copt=\"-O3\" --test_env=TF_ENABLE_ONEDNN_OPTS=1 --copt=\"-fopenmp\" --linkopt=\"-lgomp\" --build_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only,-no_aarch64,-requires-gpu --test_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only,-no_aarch64,-requires-gpu --verbose_failures --build_tests_only --jobs=75 -- //tensorflow/python/kernel_tests/quantization_ops:quantization_ops_test\n```\n\n\n### Relevant log output\n\n```shell\n==================== Test output for //tensorflow/python/kernel_tests/quantization_ops:quantization_ops_test:\r\n2022-07-22 11:25:14.622796: I tensorflow/core/util/util.cc:175] Experimental oneDNN custom operations are on. If you experience issues, please turn them off by setting the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.\r\nRunning tests under Python 3.8.13: /tmp/workspace/venv-cp38-cp38/bin/python3\r\n[ RUN ] FakeQuantWithMinMaxVarsOpTest.test_invalid_inputs\r\nINFO:tensorflow:Running test_invalid_inputs in GRAPH mode.\r\nI0722 11:25:15.747941 281472890588256 test_util.py:1490] Running test_invalid_inputs in GRAPH mode.\r\nWARNING:tensorflow:From /opt/python/cp38-cp38/lib/python3.8/contextlib.py:83: TensorFlowTestCase.test_session (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.\r\nInstructions for updating:\r\nUse `self.session()` or `self.cached_session()` instead.\r\nW0722 11:25:15.748297 281472890588256 deprecation.py:350] From /opt/python/cp38-cp38/lib/python3.8/contextlib.py:83: TensorFlowTestCase.test_session (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.\r\nInstructions for updating:\r\nUse `self.session()` or `self.cached_session()` instead.\r\nINFO:tensorflow:time(__main__.FakeQuantWithMinMaxVarsOpTest.test_invalid_inputs): 0.08s\r\nI0722 11:25:15.824039 281472890588256 test_util.py:2460] time(__main__.FakeQuantWithMinMaxVarsOpTest.test_invalid_inputs): 0.08s\r\nINFO:tensorflow:Running test_invalid_inputs in EAGER mode.\r\nI0722 11:25:15.824797 281472890588256 test_util.py:1499] Running test_invalid_inputs in EAGER mode.\r\nINFO:tensorflow:time(__main__.FakeQuantWithMinMaxVarsOpTest.test_invalid_inputs): 0.05s\r\nI0722 11:25:15.870929 281472890588256 test_util.py:2460] time(__main__.FakeQuantWithMinMaxVarsOpTest.test_invalid_inputs): 0.05s\r\n[ OK ] FakeQuantWithMinMaxVarsOpTest.test_invalid_inputs\r\n[ RUN ] FakeQuantWithMinMaxVarsOpTest.test_session\r\n[ SKIPPED ] FakeQuantWithMinMaxVarsOpTest.test_session\r\n[ RUN ] FakeQuantWithMinMaxVarsPerChannelOpTest.test_invalid_inputs\r\nINFO:tensorflow:Running test_invalid_inputs in GRAPH mode.\r\nI0722 11:25:15.872137 281472890588256 test_util.py:1490] Running test_invalid_inputs in GRAPH mode.\r\nINFO:tensorflow:time(__main__.FakeQuantWithMinMaxVarsPerChannelOpTest.test_invalid_inputs): 0.01s\r\nI0722 11:25:15.883851 281472890588256 test_util.py:2460] time(__main__.FakeQuantWithMinMaxVarsPerChannelOpTest.test_invalid_inputs): 0.01s\r\nINFO:tensorflow:Running test_invalid_inputs in EAGER mode.\r\nI0722 11:25:15.884400 281472890588256 test_util.py:1499] Running test_invalid_inputs in EAGER mode.\r\nINFO:tensorflow:time(__main__.FakeQuantWithMinMaxVarsPerChannelOpTest.test_invalid_inputs): 0.01s\r\nI0722 11:25:15.890146 281472890588256 test_util.py:2460] time(__main__.FakeQuantWithMinMaxVarsPerChannelOpTest.test_invalid_inputs): 0.01s\r\n[ OK ] FakeQuantWithMinMaxVarsPerChannelOpTest.test_invalid_inputs\r\n[ RUN ] FakeQuantWithMinMaxVarsPerChannelOpTest.test_session\r\n[ SKIPPED ] FakeQuantWithMinMaxVarsPerChannelOpTest.test_session\r\n[ RUN ] QuantizeDownAndShrinkRangeOpTest.test_invalid_inputs\r\nINFO:tensorflow:Running test_invalid_inputs in GRAPH mode.\r\nI0722 11:25:15.891172 281472890588256 test_util.py:1490] Running test_invalid_inputs in GRAPH mode.\r\nINFO:tensorflow:time(__main__.QuantizeDownAndShrinkRangeOpTest.test_invalid_inputs): 0.0s\r\nI0722 11:25:15.895756 281472890588256 test_util.py:2460] time(__main__.QuantizeDownAndShrinkRangeOpTest.test_invalid_inputs): 0.0s\r\nINFO:tensorflow:Running test_invalid_inputs in EAGER mode.\r\nI0722 11:25:15.896286 281472890588256 test_util.py:1499] Running test_invalid_inputs in EAGER mode.\r\nINFO:tensorflow:time(__main__.QuantizeDownAndShrinkRangeOpTest.test_invalid_inputs): 0.02s\r\nI0722 11:25:15.911795 281472890588256 test_util.py:2460] time(__main__.QuantizeDownAndShrinkRangeOpTest.test_invalid_inputs): 0.02s\r\n[ OK ] QuantizeDownAndShrinkRangeOpTest.test_invalid_inputs\r\n[ RUN ] QuantizeDownAndShrinkRangeOpTest.test_session\r\n[ SKIPPED ] QuantizeDownAndShrinkRangeOpTest.test_session\r\n[ RUN ] QuantizedAddOpTest.test_invalid_inputs\r\nINFO:tensorflow:Running test_invalid_inputs in GRAPH mode.\r\nI0722 11:25:15.912965 281472890588256 test_util.py:1490] Running test_invalid_inputs in GRAPH mode.\r\nINFO:tensorflow:time(__main__.QuantizedAddOpTest.test_invalid_inputs): 0.01s\r\nI0722 11:25:15.919473 281472890588256 test_util.py:2460] time(__main__.QuantizedAddOpTest.test_invalid_inputs): 0.01s\r\nINFO:tensorflow:Running test_invalid_inputs in EAGER mode.\r\nI0722 11:25:15.920017 281472890588256 test_util.py:1499] Running test_invalid_inputs in EAGER mode.\r\nINFO:tensorflow:time(__main__.QuantizedAddOpTest.test_invalid_inputs): 0.01s\r\nI0722 11:25:15.933510 281472890588256 test_util.py:2460] time(__main__.QuantizedAddOpTest.test_invalid_inputs): 0.01s\r\n[ OK ] QuantizedAddOpTest.test_invalid_inputs\r\n[ RUN ] QuantizedAddOpTest.test_session\r\n[ SKIPPED ] QuantizedAddOpTest.test_session\r\n[ RUN ] QuantizedAvgPoolingOpTest.test_invalid_inputs\r\nINFO:tensorflow:Running test_invalid_inputs in GRAPH mode.\r\nI0722 11:25:15.934696 281472890588256 test_util.py:1490] Running test_invalid_inputs in GRAPH mode.\r\nINFO:tensorflow:time(__main__.QuantizedAvgPoolingOpTest.test_invalid_inputs): 0.01s\r\nI0722 11:25:15.941932 281472890588256 test_util.py:2460] time(__main__.QuantizedAvgPoolingOpTest.test_invalid_inputs): 0.01s\r\nINFO:tensorflow:Running test_invalid_inputs in EAGER mode.\r\nI0722 11:25:15.942471 281472890588256 test_util.py:1499] Running test_invalid_inputs in EAGER mode.\r\nFatal Python error: Segmentation fault\r\n\r\nCurrent thread 0x0000ffff83a84c60 (most recent call first):\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/eager/execute.py\", line 54 in quick_execute\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/ops/gen_nn_ops.py\", line 6987 in quantized_avg_pool_eager_fallback\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/ops/gen_nn_ops.py\", line 6934 in quantized_avg_pool\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.py\", line 170 in test_invalid_inputs\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/framework/test_util.py\", line 1504 in run_eagerly\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/framework/test_util.py\", line 1520 in decorated\r\n File \"/opt/python/cp38-cp38/lib/python3.8/unittest/case.py\", line 633 in _callTestMethod\r\n File \"/opt/python/cp38-cp38/lib/python3.8/unittest/case.py\", line 676 in run\r\n File \"/opt/python/cp38-cp38/lib/python3.8/unittest/case.py\", line 736 in __call__\r\n File \"/opt/python/cp38-cp38/lib/python3.8/unittest/suite.py\", line 122 in run\r\n File \"/opt/python/cp38-cp38/lib/python3.8/unittest/suite.py\", line 84 in __call__\r\n File \"/opt/python/cp38-cp38/lib/python3.8/unittest/suite.py\", line 122 in run\r\n File \"/opt/python/cp38-cp38/lib/python3.8/unittest/suite.py\", line 84 in __call__\r\n File \"/opt/python/cp38-cp38/lib/python3.8/unittest/runner.py\", line 176 in run\r\n File \"/opt/python/cp38-cp38/lib/python3.8/unittest/main.py\", line 271 in runTests\r\n File \"/opt/python/cp38-cp38/lib/python3.8/unittest/main.py\", line 101 in __init__\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/absl_py/absl/testing/absltest.py\", line 2537 in _run_and_get_tests_result\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/absl_py/absl/testing/absltest.py\", line 2568 in run_tests\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/absl_py/absl/testing/absltest.py\", line 2156 in _run_in_app\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/absl_py/absl/testing/absltest.py\", line 2049 in main\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/platform/googletest.py\", line 51 in g_main\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/absl_py/absl/app.py\", line 258 in _run_main\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/absl_py/absl/app.py\", line 312 in run\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/platform/googletest.py\", line 60 in main_wrapper\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/platform/benchmark.py\", line 503 in benchmarks_main\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/platform/googletest.py\", line 62 in main\r\n File \"/root/.cache/bazel/_bazel_root/7043a081cadd05f91bd91c35f2a2c120/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.runfiles/org_tensorflow/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test.py\", line 347 in <module>\r\n================================================================================\r\nTarget //tensorflow/python/kernel_tests/quantization_ops:quantization_ops_test up-to-date:\r\n bazel-bin/tensorflow/python/kernel_tests/quantization_ops/quantization_ops_test\r\nINFO: Elapsed time: 156.845s, Critical Path: 120.79s\r\nINFO: 216 processes: 1 internal, 215 local.\r\nINFO: Build completed, 1 test FAILED, 216 total actions\r\n//tensorflow/python/kernel_tests/quantization_ops:quantization_ops_test FAILED in 3 out of 3 in 2.7s\n```\n</details>",
"comments": [
{
"body": "@cfRod @nSircombe @cantonios ",
"created_at": "2022-07-22T11:57:41Z"
},
{
"body": "I ran the test through asan, and found nothing. My best guess is this is an Mkl op issue. Maybe in `MklAvgPoolingOp`? I'm not familiar with the code.\r\n\r\nThe linked change was in response to a security issue report where passing empty tensors for quantization parameters triggered segfaults. Sounds like it's the same issue here for Mkl.\r\n\r\n",
"created_at": "2022-07-22T19:04:40Z"
},
{
"body": "@penpornk FYI",
"created_at": "2022-07-25T17:05:21Z"
},
{
"body": "cc @TensorFlow-MKL ",
"created_at": "2022-07-25T17:24:53Z"
},
{
"body": "We are looking into this issue and will get back soon",
"created_at": "2022-07-25T18:29:01Z"
},
{
"body": "Hi @penpornk : we can reproduce this issue internally. We are working to fix it.",
"created_at": "2022-07-25T19:56:15Z"
},
{
"body": "@preethivenkatesh @gaurides Thank you very much for looking into this!",
"created_at": "2022-07-25T19:59:23Z"
},
{
"body": "@aice-support FYI\r\n",
"created_at": "2022-07-27T22:24:00Z"
},
{
"body": "@elfringham This issue has been fixed and merged to master branch.\r\nCould you build the latest TF and verify it?\r\nOr wait for the next official release of TF.\r\n\r\nThank you!",
"created_at": "2022-07-28T02:07:48Z"
},
{
"body": "Thank you, that has resolved this issue.",
"created_at": "2022-07-28T13:08:34Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56861\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56861\">No</a>\n",
"created_at": "2022-07-28T13:08:36Z"
},
{
"body": "> Thank you, that has resolved this issue.\r\n\r\n@elfringham - we would be safe to remove this from the skip list now I take it?",
"created_at": "2022-07-28T13:12:57Z"
},
{
"body": "@nSircombe yes and some others [PR](https://github.com/tensorflow/tensorflow/pull/56933)",
"created_at": "2022-07-28T13:15:07Z"
},
{
"body": "That's great - thanks @elfringham!",
"created_at": "2022-07-28T13:16:47Z"
}
],
"number": 56861,
"title": "Unit test quantization_ops:quantization_ops_test fails on mkl_aarch64"
}
|
{
"body": "This is a workaround until the issue #56861 can be resolved.",
"number": 56900,
"review_comments": [],
"title": "Disable running of quantization_ops_test on AARCH64 MKL build"
}
|
{
"commits": [
{
"message": "Disable running of quantization_ops_test on AARCH64 MKL build\n\nThis is a workaround until the issue #56861 can be resolved."
}
],
"files": [
{
"diff": "@@ -93,6 +93,7 @@ export TF_TEST_TARGETS=\"${DEFAULT_BAZEL_TARGETS} \\\n -//tensorflow/python/kernel_tests/nn_ops:conv3d_backprop_filter_v2_grad_test \\\n -//tensorflow/python/kernel_tests/nn_ops:atrous_conv2d_test \\\n -//tensorflow/python/kernel_tests/nn_ops:pooling_ops_3d_test_cpu \\\n+ -//tensorflow/python/kernel_tests/quantization_ops:quantization_ops_test \\\n -//tensorflow/python/ops/parallel_for:math_test \\\n -//tensorflow/python/training:server_lib_test\"\n export TF_PIP_TESTS=\"test_pip_virtualenv_clean\"",
"filename": "tensorflow/tools/ci_build/rel/ubuntu/cpu_arm64_pip.sh",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nsource\n\n### Tensorflow Version\n\ngit HEAD\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nCentOS 7\n\n### Mobile device\n\nn/a\n\n### Python version\n\n3.8.10\n\n### Bazel version\n\n5.1.1\n\n### GCC/Compiler version\n\n10.2.1\n\n### CUDA/cuDNN version\n\nn/a\n\n### GPU model and memory\n\nn/a\n\n### Current Behaviour?\n\n```shell\n//tensorflow/python/data/experimental/kernel_tests/service:cross_trainer_cache_test fails if there are more than 48 CPU cores in the machine being used to test.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nbazel test --test_timeout=300,500,-1,-1 --flaky_test_attempts=2 --test_output=all --cache_test_results=no --config=nonccl --copt=-mtune=generic --copt=-march=armv8-a --copt=-O3 --verbose_failures --build_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only,-no_aarch64,-requires-gpu --test_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only,-no_aarch64,-requires-gpu --build_tests_only -- //tensorflow/python/data/experimental/kernel_tests/service:cross_trainer_cache_test\n```\n\n\n### Relevant log output\n\n```shell\nFAIL: testConcurrentReaders_test_mode_graph_tfapiversion_2 (__main__.CrossTrainerCacheTest)\r\nCrossTrainerCacheTest.testConcurrentReaders_test_mode_graph_tfapiversion_2\r\ntestConcurrentReaders_test_mode_graph_tfapiversion_2(mode='graph', tf_api_version=2)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/home/builder/.cache/bazel/_bazel_builder/9dc2dbd69dc3512cedb530e1521082e7/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/data/experimental/kernel_tests/service/cross_trainer_cache_test.runfiles/absl_py/absl/testing/parameterized.py\", line 314, in bound_param_test\r\n return test_method(self, **testcase_params)\r\n File \"/home/builder/.cache/bazel/_bazel_builder/9dc2dbd69dc3512cedb530e1521082e7/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/data/experimental/kernel_tests/service/cross_trainer_cache_test.runfiles/org_tensorflow/tensorflow/python/framework/test_combinations.py\", line 362, in decorated\r\n execute_test_method()\r\n File \"/home/builder/.cache/bazel/_bazel_builder/9dc2dbd69dc3512cedb530e1521082e7/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/data/experimental/kernel_tests/service/cross_trainer_cache_test.runfiles/org_tensorflow/tensorflow/python/framework/test_combinations.py\", line 345, in execute_test_method\r\n test_method(**kwargs_to_pass)\r\n File \"/home/builder/.cache/bazel/_bazel_builder/9dc2dbd69dc3512cedb530e1521082e7/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/data/experimental/kernel_tests/service/cross_trainer_cache_test.runfiles/org_tensorflow/tensorflow/python/data/experimental/kernel_tests/service/cross_trainer_cache_test.py\", line 97, in testConcurrentReaders\r\n self.assertEqual(self.evaluate(iterators[j]()), i)\r\nAssertionError: 9 != 0\r\n\r\n----------------------------------------------------------------------\n```\n</details>",
"comments": [
{
"body": "@cfRod @nSircombe ",
"created_at": "2022-07-20T13:47:46Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56840\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56840\">No</a>\n",
"created_at": "2022-07-22T19:57:05Z"
}
],
"number": 56840,
"title": "Unit test failure on high CPU core count machines"
}
|
{
"body": "The element size in this case is 363 bytes which only allows for\r\n49 entries in the cache with a size of 18000. So instead make\r\nthe size of cache dependent on the number of CPU cores.\r\nThe count of CPU cores is relevant as the elements of the dataset\r\nare pre-fetched, once per CPU core. This means that if the cache\r\nis too small for the number of CPU cores then the sliding window\r\nwill have moved away from the original element read thus making\r\nthe cache pointless.\r\n\r\nFixes #56840 ",
"number": 56841,
"review_comments": [
{
"body": "Could you add a comment for what this means? Thank you.",
"created_at": "2022-07-20T22:57:03Z"
},
{
"body": "Comment added.",
"created_at": "2022-07-21T08:34:29Z"
}
],
"title": "Cache size is too small for machines with more than 49 CPU cores"
}
|
{
"commits": [
{
"message": "Cache size is too small for machines with more than 49 CPU cores\n\nThe element size in this case is 363 bytes which only allows for\n49 entries in the cache with a size of 18000. So instead make\nthe size of cache dependent on the number of CPU cores.\nThe count of CPU cores is relevant as the elements of the dataset\nare pre-fetched, once per CPU core. This means that if the cache\nis too small for the number of CPU cores then the sliding window\nwill have moved away from the original element read thus making\nthe cache pointless."
}
],
"files": [
{
"diff": "@@ -24,6 +24,8 @@\n from tensorflow.python.framework import errors\n from tensorflow.python.platform import test\n \n+import multiprocessing\n+\n \n class CrossTrainerCacheTest(data_service_test_base.TestBase,\n parameterized.TestCase):\n@@ -71,8 +73,18 @@ def testDisableCrossTrainerCacheByDefault(self):\n combinations.times(\n combinations.combine(tf_api_version=2, mode=[\"eager\", \"graph\"])))\n def testConcurrentReaders(self):\n+ # Fetching an element from the dataset will trigger prefetches of more\n+ # elements, one per CPU core which will be placed in the cache.\n+ # However if the number of prefetches exceeds the space available in\n+ # the cache then the sliding window will be moved forward away from\n+ # the element just read thus negating the use of the cache as other\n+ # trainers will not get the correct element.\n+ # Hence the need to calculate the size of the cache based on the\n+ # number of CPU cores and the element size of 363. The extra 8\n+ # entries are simply a bit of margin.\n+ num_cpus = multiprocessing.cpu_count()\n cluster = self._create_cluster(\n- num_workers=1, cross_trainer_cache_size_bytes=18000)\n+ num_workers=1, cross_trainer_cache_size_bytes=(num_cpus + 8) * 363)\n num_readers = 20\n num_elements = 50\n dataset = dataset_ops.Dataset.range(10000000).repeat()",
"filename": "tensorflow/python/data/experimental/kernel_tests/service/cross_trainer_cache_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): RHEL 7.9\r\n- TensorFlow installed from (source or binary): source\r\n- TensorFlow version (use command below): 2.5.0\r\n- Python version: 3.8.6\r\n- Bazel version (if compiling from source): 3.7.2\r\n- GCC/Compiler version (if compiling from source): 10.2.0\r\n- CUDA/cuDNN version: 11.1.1\r\n- GPU model and memory: A100\r\n\r\n**Describe the current behavior**\r\n\r\nWhen running the distributed training, i.e. with MultiWorkerMirroredStrategy, the application runs through and then crashes with \"terminate called without an active exception\"\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\nTaken from #50790: \r\n\r\n```\r\nimport tensorflow as tf\r\nfrom mpi_cluster_resolver import MPIClusterResolver\r\n\r\nresolver = MPIClusterResolver()\r\nstrategy = tf.distribute.MultiWorkerMirroredStrategy(cluster_resolver=resolver)\r\n\r\nwith strategy.scope():\r\n (x_train, y_train), _ = tf.keras.datasets.mnist.load_data()\r\n x_train = x_train / 255.0\r\n train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(128)\r\n\r\n model = tf.keras.models.Sequential([\r\n tf.keras.layers.Flatten(input_shape=(28, 28)),\r\n tf.keras.layers.Dense(128, activation='relu'),\r\n tf.keras.layers.Dense(10),\r\n ])\r\n\r\n model.compile(\r\n optimizer=tf.keras.optimizers.SGD(),\r\n loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),\r\n metrics=['accuracy'])\r\n\r\nis_master = resolver.task_id == 0\r\nverbose = 2 if is_master else 0\r\nmodel.fit(train_data.repeat(), epochs=1, steps_per_epoch=10, verbose=verbose)\r\n```\r\n\r\nWith \r\n[mpi_cluster_resolver.py.txt](https://github.com/tensorflow/tensorflow/files/6823734/mpi_cluster_resolver.py.txt)\r\n\r\n**Other info / logs**\r\nI traced the crash to `TF_DeleteGraph` Python wrapper by following the stacktrace and inserting debug information: \r\n[tf.txt](https://github.com/tensorflow/tensorflow/files/6848724/tf.txt)\r\n\r\nAs you can see the code is called during runtime shutdown and ultimately reaches pybind11s `~gil_scoped_release` which calls `PyEval_RestoreThread`. This is documented as terminating when the runtime is finalized: https://docs.python.org/3/c-api/init.html#c.PyEval_RestoreThread\r\n\r\nSo to fix this either all threads created by TF must be collected and freed before python starts finalizing or the `pybind11::gil_scoped_release` must be removed from cleanup functions\r\nSee also https://github.com/pybind/pybind11/pull/2657",
"comments": [
{
"body": "does this has a workaround?",
"created_at": "2021-11-02T00:27:22Z"
},
{
"body": "Workaround/fix is https://github.com/tensorflow/tensorflow/pull/56634",
"created_at": "2023-01-13T14:03:39Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/50853\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/50853\">No</a>\n",
"created_at": "2023-01-18T10:20:20Z"
}
],
"number": 50853,
"title": "Crash/Force termination in distributed training"
}
|
{
"body": "Releasing and reaquiring the GIL during Python shutdown is not possible and leads to force termination.\r\nRemove that.\r\n\r\nFixes #50853",
"number": 56634,
"review_comments": [],
"title": "Fix crash during shutdown in distributed training"
}
|
{
"commits": [
{
"message": "Fix crash during shutdown in distributed training\n\nReleasing and reaquiring the GIL during Python shutdown is not possible and leads to force termination.\nRemove that.\n\nFixes #50853"
}
],
"files": [
{
"diff": "@@ -564,8 +564,11 @@ PYBIND11_MODULE(_pywrap_tf_session, m) {\n \n m.def(\"TF_NewGraph\", TF_NewGraph, py::return_value_policy::reference,\n py::call_guard<py::gil_scoped_release>());\n- m.def(\"TF_DeleteGraph\", TF_DeleteGraph,\n- py::call_guard<py::gil_scoped_release>());\n+ // Note: Do not use gil_scoped_release here which eventually (re)aquires the GIL.\n+ // As graphs may be (automatically) freed from threads still running after\n+ // Python already started to finalize this will lead to force-termination.\n+ // See https://github.com/tensorflow/tensorflow/issues/50853\n+ m.def(\"TF_DeleteGraph\", TF_DeleteGraph);\n \n m.def(\"TF_GraphGetOpDef\",\n [](TF_Graph* graph, const char* op_name, TF_Buffer* output_op_def) {",
"filename": "tensorflow/python/client/tf_session_wrapper.cc",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.5.0\r\n- Python version: 3.9\r\n\r\n**Describe the current behavior**\r\n\r\nOn doing `import tensorflow` a warning is shown 2 times:\r\n\r\n```\r\nsched_getaffinity: Invalid argument\r\ncan't determine number of CPU cores: assuming 4\r\n```\r\n\r\n**Describe the expected behavior**\r\n\r\nTF works correctly on large systems\r\n\r\n**Other info / logs**\r\n\r\nThe reason is, that the default struct for the CPU set contains only space for 1024 cores, so it will fail with EINVAL on systems with more cores, even when they are inactive.\r\nThe solution is more or less simple, by using the macros of glibc to allocate a larger struct. See e.g. the CPython os Module implementation.",
"comments": [
{
"body": "@Flamefire,\r\nCan you please elaborate about your issue so that everyone could understand what the issue exactly is? Thanks!",
"created_at": "2021-05-28T11:26:31Z"
},
{
"body": "Sure:\r\nThe call at https://github.com/tensorflow/tensorflow/blob/5dcfc51118817f27fad5246812d83e5dccdc5f72/tensorflow/core/platform/default/port.cc#L75 only works for systems with at most 1024 cores\r\nThis is due to the usage of the default `cpu_set_t` at https://github.com/tensorflow/tensorflow/blob/5dcfc51118817f27fad5246812d83e5dccdc5f72/tensorflow/core/platform/default/port.cc#L74 which has only enough space for 1024 cores.\r\n\r\nHence: When using TF on a system with more than 1024 cores the call to `sched_getaffinity` will fail and TF will fallback to using only 4 cores as indicated by the warning.\r\n\r\nThe solution is to use the macros `CPU_ALLOC_SIZE` and `CPU_ALLOC` provided by glibc to dynamically increase the size of the struct passed to `sched_getaffinity` until there is enough space for all CPUs. See e.g. https://github.com/python/cpython/blob/0fa282c55f1a45765340cb24ed65c90ffe2aa405/Modules/posixmodule.c#L7129",
"created_at": "2021-05-28T11:34:51Z"
},
{
"body": "This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2021-06-04T12:01:04Z"
},
{
"body": "This issue is not stale!",
"created_at": "2021-06-04T12:02:27Z"
},
{
"body": "This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2021-06-11T12:46:55Z"
},
{
"body": "This issue is not stale!",
"created_at": "2021-06-11T13:03:09Z"
},
{
"body": "This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2021-06-18T13:15:50Z"
},
{
"body": "This issue is not stale!",
"created_at": "2021-06-21T07:08:35Z"
},
{
"body": "@Flamefire,\r\nSorry for the inconvenience caused by the Stale Bot. It doesn't bother you anymore. Thanks! ",
"created_at": "2021-06-21T10:37:42Z"
},
{
"body": "@Flamefire \r\nplease confirm if this is still an issue in latest tf version.",
"created_at": "2021-10-21T10:33:17Z"
},
{
"body": "@Saduf2019 as the problematic code linked at https://github.com/tensorflow/tensorflow/issues/49833#issuecomment-850355351 is still current, yes the issue still persists",
"created_at": "2021-10-21T12:03:31Z"
},
{
"body": "I opened a PR with an implementation based on CPythons `os.sched_getaffinity` and used as a patch for building TF with EasyBuild for a while now: #56633",
"created_at": "2022-06-30T09:58:15Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/49833\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/49833\">No</a>\n",
"created_at": "2022-08-02T14:03:59Z"
}
],
"number": 49833,
"title": "sched_getaffinity fails on systems with more than 1024 cores"
}
|
{
"body": "In systems with large core counts the default size of `cpu_set_t` is not large enough to hold a space for each of them.\r\nUse the `CPU_ALLOC` macro to dynamically create space while doubling the number of possible CPUs (and hence required space) when `sched_getaffinity` fails with `EINVAL`.\r\n\r\nCode based on CPythons implementation of `os.sched_getaffinity`\r\nSee https://github.com/python/cpython/blob/21cbdae90ffdac047d27d1b83a5442fabcf89f7c/Modules/posixmodule.c#L7197-L7214\r\n\r\nFixes #49833",
"number": 56633,
"review_comments": [],
"title": "Enhance NumSchedulableCPUs to allow for nodes with more than 1024 cores"
}
|
{
"commits": [
{
"message": "Enhance NumSchedulableCPUs to allow for nodes with more than 1024 cores\n\nOn systems with large core counts the default size of `cpu_set_t` is not\nlarge enough to hold a space for each of them.\nUse the `CPU_ALLOC` macro to dynamically create space while doubling the\nnumber of possible CPUs (and hence required space) when\n`sched_getaffinity` fails with `EINVAL`.\nCode based on CPythons implementation of `os.sched_getaffinity`\nSee https://github.com/python/cpython/blob/21cbdae90ffdac047d27d1b83a5442fabcf89f7c/Modules/posixmodule.c#L7197-L7214\n\nFixes #49833"
}
],
"files": [
{
"diff": "@@ -88,9 +88,19 @@ int64_t JobUid() { return -1; }\n \n int NumSchedulableCPUs() {\n #if defined(__linux__) && !defined(__ANDROID__)\n- cpu_set_t cpuset;\n- if (sched_getaffinity(0, sizeof(cpu_set_t), &cpuset) == 0) {\n- return CPU_COUNT(&cpuset);\n+ for(int ncpus = 1024; ncpus < std::numeric_limits<int>::max() / 2; ncpus *= 2) {\n+ size_t setsize = CPU_ALLOC_SIZE(ncpus);\n+ cpu_set_t* mask = CPU_ALLOC(ncpus);\n+ if (!mask)\n+ break;\n+ if (sched_getaffinity(0, setsize, mask) == 0) {\n+ int result = CPU_COUNT_S(setsize, mask);\n+ CPU_FREE(mask);\n+ return result;\n+ }\n+ CPU_FREE(mask);\n+ if (errno != EINVAL)\n+ break;\n }\n perror(\"sched_getaffinity\");\n #endif",
"filename": "tensorflow/core/platform/default/port.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nsource\n\n### Tensorflow Version\n\nv2.9.1 (or master)\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nRaspberry Pi OS (bullseye)\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\ngcc version 10.2.1 20210110 (Debian 10.2.1-6) \n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nBuild tensorflow-lite and label_image from source (with CMake).\r\nExecute with the `--xnnpack_delegate` option.\r\n\r\nlabel_image \\\r\n --tflite_model /tmp/mobilenet_v1_1.0_224.tflite \\\r\n --labels /tmp/labels.txt \\\r\n --image tensorflow/lite/examples/label_image/testdata/grace_hopper.bmp \\\r\n --xnnpack_delegate 1\r\nType mismatch while accessing parameter.\r\nAbort\r\n```\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nClone repository.\r\n\r\ngit clone -b v2.9.1 https://github.com/tensorflow/tensorflow.git\r\n```\r\n\r\nBuild tensorflow-lite and label_image\r\n```\r\nmkdir build && cd build\r\ncmake ../tensorflow/tensorflow/lite/\r\ncmake --build . -j$(nproc)\r\ncmake --build . -j$(nproc) -t label_image\r\n```\r\n\r\nDownload tflite model\r\n```\r\nwget https://storage.googleapis.com/download.tensorflow.org/models/mobilenet_v1_2018_02_22/mobilenet_v1_1.0_224.tgz\r\ntar xf mobilenet_v1_1.0_224.tgz\r\nwget https://storage.googleapis.com/download.tensorflow.org/models/mobilenet_v1_1.0_224_frozen.tgz\r\ntar xf mobilenet_v1_1.0_224_frozen.tgz\r\ncp mobilenet_v1_1.0_224/labels.txt ./\r\n```\r\n\r\nExec label_image (with use_xnnpack option)\r\n```\r\n./examples/label_image/label_image \\\r\n --tflite_model ./mobilenet_v1_1.0_224.tflite \\\r\n --labels ./labels.txt \\\r\n --image ../tensorflow/tensorflow/lite/examples/label_image/testdata/grace_hopper.bmp\r\n```\n```\n\n\n### Relevant log output\n\n_No response_</details>",
"comments": [
{
"body": "Abort is caused by the following code in label_image.\r\nhttps://github.com/tensorflow/tensorflow/blob/v2.9.1/tensorflow/lite/examples/label_image/label_image.cc#L129\r\n\r\nThe correct type of num_threads is i`nt32_t`, not `bool`.\r\nhttps://github.com/tensorflow/tensorflow/blob/v2.9.1/tensorflow/lite/tools/delegates/default_execution_provider.cc#L30\r\n\r\nThis error occurs on Raspberry Pi OS 64bit (bullseye) and Fedora 36.\r\nOn Ubuntu 22.04, the process is completed without Abort. For unknown reasons, xnnpack delegate does not take effect. It may be one of the possibilities of #55476.",
"created_at": "2022-06-06T12:25:14Z"
},
{
"body": "Hi @NobuoTsukamoto ! Thanks for reporting this bug. This issue will be closed once PR #56369 is merged. ",
"created_at": "2022-06-06T12:58:58Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56367\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56367\">No</a>\n",
"created_at": "2022-06-12T22:30:33Z"
}
],
"number": 56367,
"title": "[TensorFlow Lite label_image] Abort occurs with xnnpack_delegate option."
}
|
{
"body": "Fixed #56367 .",
"number": 56369,
"review_comments": [
{
"body": "So it interfered xnnpack delegate option?",
"created_at": "2022-06-06T19:09:12Z"
},
{
"body": "Yes. Cannot be executed with the xnnpack delegate option.\r\n```\r\nType mismatch while accessing parameter.\r\nAbort\r\n```\r\n\r\n\r\nWhen specifying the xnnpack delegate option, the specification in `Interpreter::SetNumThreads` does not work. Must be specified in `DelegateProviders`.",
"created_at": "2022-06-06T22:24:43Z"
},
{
"body": "Got it. Thanks for the confirmation.",
"created_at": "2022-06-06T22:28:04Z"
}
],
"title": "Fixed a bug in the xnnpack delegate option for label_image."
}
|
{
"commits": [
{
"message": "Fixed a bug in the xnnpack delegate option for label_image."
}
],
"files": [
{
"diff": "@@ -126,7 +126,7 @@ class DelegateProviders {\n \"XNNPACK delegate isn't supported on the platform!\";\n } else {\n params_.Set<bool>(\"use_xnnpack\", true);\n- params_.Set<bool>(\"num_threads\", s.number_of_threads);\n+ params_.Set<int32_t>(\"num_threads\", s.number_of_threads);\n }\n }\n }",
"filename": "tensorflow/lite/examples/label_image/label_image.cc",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nBug\n\n### Source\n\nsource\n\n### Tensorflow Version\n\nv2.9.1 (or master)\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\nRaspberry Pi OS (bullseye)\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\ngcc version 10.2.1 20210110 (Debian 10.2.1-6) \n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nBuild tensorflow-lite and label_image from source (with CMake).\r\nExecute with the `--xnnpack_delegate` option.\r\n\r\nlabel_image \\\r\n --tflite_model /tmp/mobilenet_v1_1.0_224.tflite \\\r\n --labels /tmp/labels.txt \\\r\n --image tensorflow/lite/examples/label_image/testdata/grace_hopper.bmp \\\r\n --xnnpack_delegate 1\r\nType mismatch while accessing parameter.\r\nAbort\r\n```\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nClone repository.\r\n\r\ngit clone -b v2.9.1 https://github.com/tensorflow/tensorflow.git\r\n```\r\n\r\nBuild tensorflow-lite and label_image\r\n```\r\nmkdir build && cd build\r\ncmake ../tensorflow/tensorflow/lite/\r\ncmake --build . -j$(nproc)\r\ncmake --build . -j$(nproc) -t label_image\r\n```\r\n\r\nDownload tflite model\r\n```\r\nwget https://storage.googleapis.com/download.tensorflow.org/models/mobilenet_v1_2018_02_22/mobilenet_v1_1.0_224.tgz\r\ntar xf mobilenet_v1_1.0_224.tgz\r\nwget https://storage.googleapis.com/download.tensorflow.org/models/mobilenet_v1_1.0_224_frozen.tgz\r\ntar xf mobilenet_v1_1.0_224_frozen.tgz\r\ncp mobilenet_v1_1.0_224/labels.txt ./\r\n```\r\n\r\nExec label_image (with use_xnnpack option)\r\n```\r\n./examples/label_image/label_image \\\r\n --tflite_model ./mobilenet_v1_1.0_224.tflite \\\r\n --labels ./labels.txt \\\r\n --image ../tensorflow/tensorflow/lite/examples/label_image/testdata/grace_hopper.bmp\r\n```\n```\n\n\n### Relevant log output\n\n_No response_</details>",
"comments": [
{
"body": "Abort is caused by the following code in label_image.\r\nhttps://github.com/tensorflow/tensorflow/blob/v2.9.1/tensorflow/lite/examples/label_image/label_image.cc#L129\r\n\r\nThe correct type of num_threads is i`nt32_t`, not `bool`.\r\nhttps://github.com/tensorflow/tensorflow/blob/v2.9.1/tensorflow/lite/tools/delegates/default_execution_provider.cc#L30\r\n\r\nThis error occurs on Raspberry Pi OS 64bit (bullseye) and Fedora 36.\r\nOn Ubuntu 22.04, the process is completed without Abort. For unknown reasons, xnnpack delegate does not take effect. It may be one of the possibilities of #55476.",
"created_at": "2022-06-06T12:25:14Z"
},
{
"body": "Hi @NobuoTsukamoto ! Thanks for reporting this bug. This issue will be closed once PR #56369 is merged. ",
"created_at": "2022-06-06T12:58:58Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56367\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56367\">No</a>\n",
"created_at": "2022-06-12T22:30:33Z"
}
],
"number": 56367,
"title": "[TensorFlow Lite label_image] Abort occurs with xnnpack_delegate option."
}
|
{
"body": "FIxed #56367 .",
"number": 56368,
"review_comments": [],
"title": "Fixed a bug in the xnnpack delegate option for label_image."
}
|
{
"commits": [
{
"message": "Add release notes for manylinux2014 and libcxx ABI change\n\nPiperOrigin-RevId: 438633589"
},
{
"message": "Insert release notes place-fill"
},
{
"message": "Merge pull request #55456 from angerson/r2.9-update\n\nAdd release notes for manylinux2014 and libcxx ABI change"
},
{
"message": "Update RELEASE.md\n\nUpdate the release notes with the contributer's list"
},
{
"message": "Update RELEASE.md"
},
{
"message": "Update RELEASE.md"
},
{
"message": "Merge branch 'r2.9' into relnotes-2.9.0rc0-16917"
},
{
"message": "Update version numbers to 2.9.0-rc0"
},
{
"message": "Merge pull request #55457 from tensorflow-jenkins/relnotes-2.9.0rc0-16917\n\nUpdate release notes for TensorFlow 2.9.0"
},
{
"message": "Merge pull request #55458 from tensorflow-jenkins/version-numbers-2.9.0rc0-32183\n\nUpdate version numbers for TensorFlow 2.9.0-rc0"
},
{
"message": "Update setup.py\n\nUpdating the setup.py to update estimator and keras versions for 2.9 release-"
},
{
"message": "Merge pull request #55488 from tensorflow/pranve-patch-1\n\nUpdate versions for estimator and Keras"
},
{
"message": "Update setup.py\n\nUpdating the version for estimator lower bound for 2.9 release"
},
{
"message": "Merge pull request #55489 from tensorflow/pranve-patch-1\n\nUpdate lower bound for estimator to also include RC0"
},
{
"message": "Add mesh_util and tpu_util functions to public dtensor API.\n\nThis change removes the dependency edge :mesh_util -> :core and :tpu_util -> :core.\n\nThe main reason the functions are exported under dtensor, not tf.e.dtensor.mesh_util/tf.e.dtensor.tpu_util, is because I was unable to figure out how to add dtensor.mesh_util as a tf_export module. Although maybe it is desirable to have a flatter structure given our fan-out is still manageable.\n\nPiperOrigin-RevId: 439449814"
},
{
"message": "Merge pull request #55490 from tensorflow/r2.9-4f736fe226f\n\nr2.9 cherry-pick: 4f736fe226f \"Add mesh_util and tpu_util functions to public dtensor API.\""
},
{
"message": "Tweak the lower bound for the keras to include Rc0\n\nAdjusting the lower bound for the keras to also include Rc0"
},
{
"message": "Merge pull request #55501 from tensorflow/pranve-patch-1\n\nTweak the lower bound for the keras to include Rc0"
},
{
"message": "call_with_layout shall pin to the mesh of the layout.\n\n... instead of using the default mesh. This is only applicable in eager mode.\n\nThis means call_with_layout always follow the mesh of the output, and likely\nimplies the inputs must be explicitly copied to the mesh.\n\nThis model is easier to reason than the default mesh logic, and likely will not\ncause un-avoidable communication overhead.\n\nFix reentrance of dtensor.run_on(). Before this CL with dtensor.run_on() always\nrestore to the global default mesh, which is undesirable if there are nested\nrun_on ops. (e.g. call_with_layout inside a default mesh scope).\n\nPiperOrigin-RevId: 439700696"
},
{
"message": "Don't build nightly wheels on macos release\n\nPiperOrigin-RevId: 440122636"
},
{
"message": "Merge pull request #55533 from tensorflow/r2.9-8ea604d4c2c\n\nr2.9 cherry-pick: 8ea604d4c2c \"Don't build nightly wheels on macos release\""
},
{
"message": "Update documentation for DTensor's `pack`, `unpack` and `fetch_layout` functions.\n\nMove most of the documentation from dtensor_device.py to api.py since api.py is the publicly-visible API entrypoint.\n\nPiperOrigin-RevId: 440148022"
},
{
"message": "Fix pylint violations in dtensor_device.py.\n\nThese were previously hidden by disabled `name-error` pylints and causing r2.9 cherry picks to fail pylint.\n\nTested using:\n```\npylint --rcfile=tensorflow/tools/ci_build/pylintrc tensorflow/dtensor/python/dtensor_device.py\n```\n\nPreviously:\n```\n************* Module python.dtensor_device\nthird_party/tensorflow/dtensor/python/dtensor_device.py:171:0: C0301: Line too long (81/80) (line-too-long)\nthird_party/tensorflow/dtensor/python/dtensor_device.py:446:48: E0601: Using variable 'previous_graph_size' before assignment (used-before-assignment)\nthird_party/tensorflow/dtensor/python/dtensor_device.py:458:36: E0601: Using variable 'previous_default' before assignment (used-before-assignment)\n\n-----------------------------------\nYour code has been rated at 9.39/10\n```\n\nNow:\n```\n-------------------------------------------------------------------\nYour code has been rated at 10.00/10 (previous run: 9.39/10, +0.61)\n```\nPiperOrigin-RevId: 440204827"
},
{
"message": "Use tf_kernel_library instead of cc_library to pass the correct copts.\nAdd necessary compatible_with tags to DTensor files.\n\nPiperOrigin-RevId: 439752665"
},
{
"message": "Update documentation for `Mesh` and `Layout`.\n\nAlso clean up other docstrings in api.py\n\nPiperOrigin-RevId: 441292565"
},
{
"message": "Merge pull request #55516 from tensorflow/r2.9-c2c81d8a45f\n\nr2.9 cherry-pick: c2c81d8a45f \"call_with_layout shall pin to the mesh of the layout.\""
},
{
"message": "Merge pull request #55535 from tensorflow/r2.9-b5948699e20\n\nr2.9 cherry-pick: b5948699e20 \"Update documentation for DTensor's `pack`, `unpack` and `fetch_layout` functions.\""
},
{
"message": "Merge pull request #55539 from tensorflow/r2.9-296cdc612c7\n\nr2.9 cherry-pick: 296cdc612c7 \"Fix pylint violations in dtensor_device.py.\""
},
{
"message": "Merge pull request #55541 from tensorflow/r2.9-85a6eab2899\n\nr2.9 cherry-pick: 85a6eab2899 \"Use tf_kernel_library instead of cc_library to pass the correct copts. Add necessary compatible_with tags to DTensor files.\""
},
{
"message": "Mention DTensor in 2.9 release notes"
}
],
"files": [
{
"diff": "@@ -195,6 +195,8 @@ build:ios_armv7 --config=ios\n build:ios_armv7 --cpu=ios_armv7\n build:ios_arm64 --config=ios\n build:ios_arm64 --cpu=ios_arm64\n+build:ios_sim_arm64 --config=ios\n+build:ios_sim_arm64 --cpu=ios_sim_arm64\n build:ios_i386 --config=ios\n build:ios_i386 --cpu=ios_i386\n build:ios_x86_64 --config=ios\n@@ -223,9 +225,7 @@ build:mkl_threadpool --define=build_with_mkl_opensource=true\n build:mkl_threadpool -c opt\n \n # Config setting to build oneDNN with Compute Library for the Arm Architecture (ACL).\n-# This build is for the inference regime only.\n build:mkl_aarch64 --define=build_with_mkl_aarch64=true\n-build:mkl_aarch64 --define=tensorflow_mkldnn_contraction_kernel=0\n build:mkl_aarch64 --define=build_with_openmp=true\n build:mkl_aarch64 -c opt\n ",
"filename": ".bazelrc",
"status": "modified"
},
{
"diff": "@@ -0,0 +1,57 @@\n+# Copyright 2022 The TensorFlow Authors. All Rights Reserved.\n+#\n+# Licensed under the Apache License, Version 2.0 (the \"License\");\n+# you may not use this file except in compliance with the License.\n+# You may obtain a copy of the License at\n+#\n+# http://www.apache.org/licenses/LICENSE-2.0\n+#\n+# Unless required by applicable law or agreed to in writing, software\n+# distributed under the License is distributed on an \"AS IS\" BASIS,\n+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n+# See the License for the specific language governing permissions and\n+# limitations under the License.\n+# ==============================================================================\n+\n+name: ARM CD\n+\n+on:\n+ push:\n+ tags:\n+ - v2.**\n+ branches:\n+ - r2.9\n+ schedule:\n+ - cron: '0 8 * * *'\n+\n+jobs:\n+ build:\n+ runs-on: [self-hosted, linux, ARM64]\n+ strategy:\n+ matrix:\n+ pyver: ['3.7', '3.8', '3.9', '3.10']\n+ steps:\n+ - name: Stop old running containers (if any)\n+ shell: bash\n+ run: |\n+ running_containers=$(docker ps -q) && \\\n+ if [[ $running_containers == \"\" ]]; then\n+ echo \"No running containers\";\n+ else\n+ echo \"Running container(s) found\" && \\\n+ docker stop $running_containers;\n+ fi\n+ docker container prune -f\n+ - name: Clean repository\n+ shell: bash\n+ run: find /home/ubuntu/actions-runner/_work/tensorflow/tensorflow/. -name . -o -prune -exec sudo rm -rf -- {} + || true\n+ - name: Checkout repository\n+ uses: actions/checkout@v3\n+ - name: Build and test pip wheel\n+ shell: bash\n+ run: |\n+ CI_DOCKER_BUILD_EXTRA_PARAMS='--build-arg py_major_minor_version=${{ matrix.pyver }}' \\\n+ ./tensorflow/tools/ci_build/ci_build.sh cpu.arm64 bash tensorflow/tools/ci_build/rel/ubuntu/cpu_arm64_pip.sh\n+ - name: Upload pip wheel to PyPI\n+ shell: bash\n+ run: python3 -m twine upload --verbose /home/ubuntu/actions-runner/_work/tensorflow/tensorflow/whl/* -u \"__token__\" -p ${{ secrets.AWS_PYPI_ACCOUNT_TOKEN }}",
"filename": ".github/workflows/arm-cd.yml",
"status": "added"
},
{
"diff": "@@ -0,0 +1,57 @@\n+# Copyright 2022 The TensorFlow Authors. All Rights Reserved.\n+#\n+# Licensed under the Apache License, Version 2.0 (the \"License\");\n+# you may not use this file except in compliance with the License.\n+# You may obtain a copy of the License at\n+#\n+# http://www.apache.org/licenses/LICENSE-2.0\n+#\n+# Unless required by applicable law or agreed to in writing, software\n+# distributed under the License is distributed on an \"AS IS\" BASIS,\n+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n+# See the License for the specific language governing permissions and\n+# limitations under the License.\n+# ==============================================================================\n+\n+name: ARM CI\n+\n+on:\n+ pull_request:\n+ types: [opened, synchronize, reopened]\n+ branches:\n+ - master\n+ - r2.**\n+\n+jobs:\n+ build:\n+ runs-on: [self-hosted, linux, ARM64]\n+ strategy:\n+ matrix:\n+ pyver: ['3.7', '3.8', '3.9', '3.10']\n+ steps:\n+ - name: Stop old running containers (if any)\n+ shell: bash\n+ run: |\n+ running_containers=$(docker ps -q) && \\\n+ if [[ $running_containers == \"\" ]]; then\n+ echo \"No running containers\";\n+ else\n+ echo \"Running container(s) found\" && \\\n+ docker stop $running_containers;\n+ fi\n+ docker container prune -f\n+ - name: Clean repository\n+ shell: bash\n+ run: find /home/ubuntu/actions-runner/_work/tensorflow/tensorflow/. -name . -o -prune -exec sudo rm -rf -- {} + || true\n+ - name: Checkout repository\n+ uses: actions/checkout@v3\n+ - name: Build and test pip wheel\n+ shell: bash\n+ run: |\n+ CI_DOCKER_BUILD_EXTRA_PARAMS='--build-arg py_major_minor_version=${{ matrix.pyver }}' \\\n+ ./tensorflow/tools/ci_build/ci_build.sh cpu.arm64 bash tensorflow/tools/ci_build/rel/ubuntu/cpu_arm64_pip.sh\n+ - name: Upload pip wheel to GitHub\n+ uses: actions/upload-artifact@v3\n+ with:\n+ name: tensorflow_py${{ matrix.pyver }}_wheel\n+ path: /home/ubuntu/actions-runner/_work/tensorflow/tensorflow/whl/*.whl",
"filename": ".github/workflows/arm-ci.yml",
"status": "added"
},
{
"diff": "@@ -1,212 +1,139 @@\n-# Release 2.9.0\n+# Release 2.9.1\n+\n+Add an upper bound for `protobuf` in `setup.py` since `protobuf` after version 3.20 is currently incompatible with TensorFlow. See https://github.com/tensorflow/tensorflow/issues/53234, https://github.com/protocolbuffers/protobuf/issues/9954 and https://github.com/tensorflow/tensorflow/issues/56077.\n \n-<INSERT SMALL BLURB ABOUT RELEASE FOCUS AREA AND POTENTIAL TOOLCHAIN CHANGES>\n+# Release 2.9.0\n \n # Breaking Changes\n \n-* The `tf.keras.mixed_precision.experimental` API has been removed. The\n- non-experimental symbols under `tf.keras.mixed_precision` have been\n- available since TensorFlow 2.4 and should be used instead.\n- * The non-experimental API has some minor differences from the experimental\n- API. In most cases, you only need to make three minor changes:\n- 1. Remove the word \"experimental\" from `tf.keras.mixed_precision` symbols.\n- E.g., replace `tf.keras.mixed_precision.experimental.global_policy`\n- with `tf.keras.mixed_precision.global_policy`.\n- 2. Replace `tf.keras.mixed_precision.experimental.set_policy` with\n- `tf.keras.mixed_precision.set_global_policy`. The experimental symbol\n- `set_policy` was renamed to `set_global_policy` in the non-experimental\n- API.\n- 3. Replace `LossScaleOptimizer(opt, \"dynamic\")` with\n- `LossScaleOptimizer(opt)`. If you pass anything other than `\"dynamic\"`\n- to the second argument, see (1) of the next section.\n- * In the following rare cases, you need to make more changes when switching\n- to the non-experimental API:\n- 1. If you passed anything other than `\"dynamic\"` to the `loss_scale`\n- argument (the second argument) of `LossScaleOptimizer`:\n- * The LossScaleOptimizer constructor takes in different arguments.\n- See the\n- [TF 2.7 documentation of tf.keras.mixed_precision.experimental.LossScaleOptimizer](https://www.tensorflow.org/versions/r2.7/api_docs/python/tf/keras/mixed_precision/experimental/LossScaleOptimizer)\n- for details on the differences, which has examples on how to convert\n- to the non-experimental LossScaleOptimizer.\n- 2. If you passed a value to the `loss_scale` argument (the second\n- argument) of `Policy`:\n- * The experimental version of `Policy` optionally took in a\n- `tf.compat.v1.mixed_precision.LossScale` in the constructor, which\n- defaulted to a dynamic loss scale for the `\"mixed_float16\"` policy\n- and no loss scale for other policies. In `Model.compile`, if the\n- model's policy had a loss scale, the optimizer would be wrapped with\n- a `LossScaleOptimizer`. With the non-experimental `Policy`, there is\n- no loss scale associated with the `Policy`, and `Model.compile`\n- wraps the optimizer with a `LossScaleOptimizer` if and only if the\n- policy is a `\"mixed_float16\"` policy. If you previously passed a\n- `LossScale` to the experimental `Policy`, consider just removing it,\n- as the default loss scaling behavior is usually what you want. If\n- you really want to customize the loss scaling behavior, you can wrap\n- your optimizer with a `LossScaleOptimizer` before passing it to\n- `Model.compile`.\n- 3. If you use the very rarely-used function\n- `tf.keras.mixed_precision.experimental.get_layer_policy`:\n- * Replace\n- `tf.keras.mixed_precision.experimental.get_layer_policy(layer)` with\n- `layer.dtype_policy`.\n-* `tf.mixed_precision.experimental.LossScale` and its subclasses have been\n- removed from the TF2 namespace. This symbols were very rarely used and were\n- only useful in TF2 for use in the now-removed\n- `tf.keras.mixed_precision.experimental` API. The symbols are still available\n- under `tf.compat.v1.mixed_precision`.\n-\n-* The `experimental_relax_shapes` heuristic for `tf.function` has been\n- deprecated and replaced with `reduce_retracing` which encompasses broader\n- heuristics to reduce the number of retraces (see below).\n-\n-# Known Caveats\n-\n-* <CAVEATS REGARDING THE RELEASE (BUT NOT BREAKING CHANGES).>\n-* <ADDING/BUMPING DEPENDENCIES SHOULD GO HERE>\n-* <KNOWN LACK OF SUPPORT ON SOME PLATFORM, SHOULD GO HERE>\n+* Due to security issues in TF 2.8, all boosted trees code has now been removed (after being deprecated in TF 2.8). Users should switch to [TensorFlow Decision Forests](https://github.com/tensorflow/decision-forests).\n+* Build, Compilation and Packaging\n+ * TensorFlow is now compiled with `_GLIBCXX_USE_CXX11_ABI=1`. Downstream projects that encounter `std::__cxx11` or `[abi:cxx11]` linker errors will need to adopt this compiler option. See [the GNU C++ Library docs on Dual ABI](https://gcc.gnu.org/onlinedocs/libstdc++/manual/using_dual_abi.html).\n+ * TensorFlow Python wheels now specifically conform to [manylinux2014](https://peps.python.org/pep-0599/), an upgrade from manylinux2010. The minimum Pip version supporting manylinux2014 is Pip 19.3 (see [pypa/manylinux](https://github.com/pypa/manylinux). This change may affect you if you have been using TensorFlow on a very old platform equivalent to CentOS 6, as manylinux2014 targets CentOS 7 as a compatibility base. Note that TensorFlow does not officially support either platform.\n+ * Discussion for these changes can be found on SIG Build's [TensorFlow Community Forum thread](https://discuss.tensorflow.org/t/tensorflow-linux-wheels-are-being-upgraded-to-manylinux2014/8339)\n+* The `tf.keras.mixed_precision.experimental` API has been removed. The non-experimental symbols under `tf.keras.mixed_precision` have been available since TensorFlow 2.4 and should be used instead.\n+ * The non-experimental API has some minor differences from the experimental API. In most cases, you only need to make three minor changes:\n+ * Remove the word \"experimental\" from `tf.keras.mixed_precision` symbols. E.g., replace `tf.keras.mixed_precision.experimental.global_policy` with `tf.keras.mixed_precision.global_policy`.\n+ * Replace `tf.keras.mixed_precision.experimental.set_policy` with `tf.keras.mixed_precision.set_global_policy`. The experimental symbol `set_policy` was renamed to `set_global_policy` in the non-experimental API.\n+ * Replace `LossScaleOptimizer(opt, \"dynamic\")` with `LossScaleOptimizer(opt)`. If you pass anything other than `\"dynamic\"` to the second argument, see (1) of the next section.\n+ * In the following rare cases, you need to make more changes when switching to the non-experimental API:\n+ * If you passed anything other than `\"dynamic\"` to the `loss_scale` argument (the second argument) of `LossScaleOptimizer`:\n+ * The LossScaleOptimizer constructor takes in different arguments. See the [TF 2.7 documentation of tf.keras.mixed_precision.experimental.LossScaleOptimizer](https://www.tensorflow.org/versions/r2.7/api_docs/python/tf/keras/mixed_precision/experimental/LossScaleOptimizer) for details on the differences, which has examples on how to convert to the non-experimental LossScaleOptimizer.\n+ * If you passed a value to the `loss_scale` argument (the second argument) of `Policy`:\n+ * The experimental version of `Policy` optionally took in a `tf.compat.v1.mixed_precision.LossScale` in the constructor, which defaulted to a dynamic loss scale for the `\"mixed_float16\"` policy and no loss scale for other policies. In `Model.compile`, if the model's policy had a loss scale, the optimizer would be wrapped with a `LossScaleOptimizer`. With the non-experimental `Policy`, there is no loss scale associated with the `Policy`, and `Model.compile` wraps the optimizer with a `LossScaleOptimizer` if and only if the policy is a `\"mixed_float16\"` policy. If you previously passed a `LossScale` to the experimental `Policy`, consider just removing it, as the default loss scaling behavior is usually what you want. If you really want to customize the loss scaling behavior, you can wrap your optimizer with a `LossScaleOptimizer` before passing it to `Model.compile`.\n+ * If you use the very rarely-used function `tf.keras.mixed_precision.experimental.get_layer_policy`:\n+ * Replace `tf.keras.mixed_precision.experimental.get_layer_policy(layer)` with `layer.dtype_policy`.\n+* `tf.mixed_precision.experimental.LossScale` and its subclasses have been removed from the TF2 namespace. This symbols were very rarely used and were only useful in TF2 for use in the now-removed `tf.keras.mixed_precision.experimental` API. The symbols are still available under `tf.compat.v1.mixed_precision`.\n+* The `experimental_relax_shapes` heuristic for `tf.function` has been deprecated and replaced with `reduce_retracing` which encompasses broader heuristics to reduce the number of retraces (see below)\n \n # Major Features and Improvements\n \n * `tf.keras`:\n- * Added `tf.keras.applications.resnet_rs` models. This includes the\n- `ResNetRS50`, `ResNetRS101`, `ResNetRS152`, `ResNetRS200`,\n- `ResNetRS270`, `ResNetRS350` and `ResNetRS420` model architectures.\n- The ResNetRS models are based on the architecture described in\n- [Revisiting ResNets: Improved Training and Scaling Strategies](https://arxiv.org/pdf/2103.07579.pdf)\n- * Added `tf.keras.optimizers.experimental.Optimizer`. The reworked\n- optimizer gives more control over different phases of optimizer calls,\n- and is easier to customize. We provide Adam, SGD, Adadelta, AdaGrad and\n- RMSprop optimizers based on\n- `tf.keras.optimizers.experimental.Optimizer`. Generally the new\n- optimizers work in the same way as the old ones, but support new\n- constructor arguments. In the future, the symbols\n- `tf.keras.optimizers.Optimizer`/`Adam`/etc will point to the new\n- optimizers, and the previous generation of optimizers will be moved to\n- `tf.keras.optimizers.legacy.Optimizer`/`Adam`/etc.\n+ * Added `tf.keras.applications.resnet_rs` models. This includes the `ResNetRS50`, `ResNetRS101`, `ResNetRS152`, `ResNetRS200`, `ResNetRS270`, `ResNetRS350` and `ResNetRS420` model architectures. The ResNetRS models are based on the architecture described in [Revisiting ResNets: Improved Training and Scaling Strategies](https://arxiv.org/pdf/2103.07579.pdf)\n+ * Added `tf.keras.optimizers.experimental.Optimizer`. The reworked optimizer gives more control over different phases of optimizer calls, and is easier to customize. We provide Adam, SGD, Adadelta, AdaGrad and RMSprop optimizers based on `tf.keras.optimizers.experimental.Optimizer`. Generally the new optimizers work in the same way as the old ones, but support new constructor arguments. In the future, the symbols `tf.keras.optimizers.Optimizer`/`Adam`/etc will point to the new optimizers, and the previous generation of optimizers will be moved to `tf.keras.optimizers.legacy.Optimizer`/`Adam`/etc.\n * Added L2 unit normalization layer `tf.keras.layers.UnitNormalization`.\n- * Added `tf.keras.regularizers.OrthogonalRegularizer`, a new regularizer\n- that encourages orthogonality between the rows (or columns) or a\n- weight matrix.\n+ * Added `tf.keras.regularizers.OrthogonalRegularizer`, a new regularizer that encourages orthogonality between the rows (or columns) or a weight matrix.\n * Added `tf.keras.layers.RandomBrightness` layer for image preprocessing.\n- * Added APIs for switching between interactive logging and absl logging.\n- By default, Keras always writes the logs to stdout. However, this is not\n- optimal in a non-interactive environment, where you don't have access to\n- stdout, but can only view the logs. You can use\n- `tf.keras.utils.disable_interactive_logging()` to write the logs to absl\n- logging. You can also use `tf.keras.utils.enable_interactive_logging()`\n- to change it back to stdout, or\n- `tf.keras.utils.is_interactive_logging_enabled()` to check if\n- interactive logging is enabled.\n- * Changed default value for the `verbose` argument of `Model.evaluate()`\n- and `Model.predict()` to `\"auto\"`, which defaults to `verbose=1` for\n- most cases and defaults to `verbose=2` when used with\n- `ParameterServerStrategy` or with interactive logging disabled.\n- * Argument `jit_compile` in `Model.compile()` now applies\n- to `Model.evaluate()` and `Model.predict()`.\n- Setting `jit_compile=True` in `compile()` compiles the model's\n- training, evaluation, and inference steps to\n- [XLA](https://www.tensorflow.org/xla).\n- Note that `jit_compile=True` may not necessarily work for all models.\n- * Added DTensor-related Keras APIs under `tf.keras.dtensor` namespace.\n- The APIs are still classified as experimental. You are welcome to try it\n- out. Please check the tutoral and guide on https://www.tensorflow.org/\n- for more details about DTensor.\n+ * Added APIs for switching between interactive logging and absl logging. By default, Keras always writes the logs to stdout. However, this is not optimal in a non-interactive environment, where you don't have access to stdout, but can only view the logs. You can use `tf.keras.utils.disable_interactive_logging()` to write the logs to ABSL logging. You can also use `tf.keras.utils.enable_interactive_logging()` to change it back to stdout, or `tf.keras.utils.is_interactive_logging_enabled()` to check if interactive logging is enabled.\n+ * Changed default value for the `verbose` argument of `Model.evaluate()` and `Model.predict()` to `\"auto\"`, which defaults to `verbose=1` for most cases and defaults to `verbose=2` when used with `ParameterServerStrategy` or with interactive logging disabled.\n+ * Argument `jit_compile` in `Model.compile()` now applies to `Model.evaluate()` and `Model.predict()`. Setting `jit_compile=True` in `compile()` compiles the model's training, evaluation, and inference steps to [XLA](https://www.tensorflow.org/xla). Note that `jit_compile=True` may not necessarily work for all models.\n+ * Added DTensor-related Keras APIs under `tf.keras.dtensor` namespace. The APIs are still classified as experimental. You are welcome to try it out. Please check the tutoral and guide on https://www.tensorflow.org/ for more details about DTensor.\n \n * `tf.lite`:\n-\n * Added TFLite builtin op support for the following TF ops:\n- * `tf.math.argmin`/`tf.math.argmax` for input data type `tf.bool` on\n- CPU.\n- * `tf.nn.gelu` op for output data type `tf.float32` and quantization\n- on CPU.\n- * Add nominal support for unsigned 16-bit integer tensor types. Note that\n- very few TFLite kernels support this type natively, so its use in mobile\n- ML authoring is generally discouraged.\n+ * `tf.math.argmin`/`tf.math.argmax` for input data type `tf.bool` on CPU.\n+ * `tf.nn.gelu` op for output data type `tf.float32` and quantization on CPU.\n+ * Add nominal support for unsigned 16-bit integer tensor types. Note that very few TFLite kernels support this type natively, so its use in mobile ML authoring is generally discouraged.\n * Add support for unsigned 16-bit integer tensor types in cast op.\n- * Experimental support for lowering `list_ops.tensor_list_set_item` with\n- `DynamicUpdateSlice`.\n+ * Experimental support for lowering `list_ops.tensor_list_set_item` with `DynamicUpdateSlice`.\n * Enabled a new MLIR-based dynamic range quantization backend by default\n- * The new backend is used for post-training int8 dynamic range\n- quantization and post-training float16 quantization.\n- * Set `experimental_new_dynamic_range_quantizer` in\n- tf.lite.TFLiteConverter to False to disable this change\n- * Native TF Lite variables are now enabled during conversion by default\n- on all v2 TfLiteConverter entry points.\n- `experimental_enable_resource_variables` on tf.lite.TFLiteConverter\n- is now True by default and will be removed in the future.\n+ * The new backend is used for post-training int8 dynamic range quantization and post-training float16 quantization.\n+ * Set `experimental_new_dynamic_range_quantizer` in tf.lite.TFLiteConverter to False to disable this change\n+ * Native TF Lite variables are now enabled during conversion by default on all v2 TfLiteConverter entry points. `experimental_enable_resource_variables` on tf.lite.TFLiteConverter is now True by default and will be removed in the future.\n \n * `tf.function`:\n-\n- * Custom classes used as arguments for `tf.function` can now specify\n- rules regarding when retracing needs to occur by implementing the\n- Tracing Protocol available through\n- `tf.types.experimental.SupportsTracingProtocol`.\n- * `TypeSpec` classes (as associated with `ExtensionTypes`) also implement\n- the Tracing Protocol which can be overriden if necessary.\n- * The newly introduced `reduce_retracing` option also uses the Tracing\n- Protocol to proactively generate generalized traces similar to\n- `experimental_relax_shapes` (which has now been deprecated).\n+ * Custom classes used as arguments for `tf.function` can now specify rules regarding when retracing needs to occur by implementing the Tracing Protocol available through `tf.types.experimental.SupportsTracingProtocol`.\n+ * `TypeSpec` classes (as associated with `ExtensionTypes`) also implement the Tracing Protocol which can be overriden if necessary.\n+ * The newly introduced `reduce_retracing` option also uses the Tracing Protocol to proactively generate generalized traces similar to `experimental_relax_shapes` (which has now been deprecated).\n \n * Unified eager and `tf.function` execution:\n-\n- * Eager mode can now execute each op as a `tf.function`, allowing for more\n- consistent feature support in future releases.\n+ * Eager mode can now execute each op as a `tf.function`, allowing for more consistent feature support in future releases.\n * It is available for immediate use.\n- * See the `TF_RUN_EAGER_OP_AS_FUNCTION` environment variable in\n- [eager context](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/eager/context.py).\n+ * See the `TF_RUN_EAGER_OP_AS_FUNCTION` environment variable in [eager context](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/eager/context.py).\n * Eager performance should be similar with this feature enabled.\n- * A roughly 5us per-op overhead may be observed when running many\n- small functions.\n- * Note a\n- [known issue](https://github.com/tensorflow/tensorflow/issues/55414)\n- with GPU performance.\n+ * A roughly 5us per-op overhead may be observed when running many small functions.\n+ * Note a [known issue](https://github.com/tensorflow/tensorflow/issues/55414) with GPU performance.\n * The behavior of `tf.function` itself is unaffected.\n- * Note: This feature will be enabled by default in an upcoming version of\n- TensorFlow.\n+ * Note: This feature will be enabled by default in an upcoming version of TensorFlow.\n \n-# Bug Fixes and Other Changes\n+* `tf.experimental.dtensor`: Added DTensor, an extension to TensorFlow for large-scale modeling with minimal changes to user code. You are welcome to try it out, though be aware that the DTensor API is experimental and up-to backward-incompatible changes. DTensor and Keras integration is published under `tf.keras.dtensor` in this release (refer to the `tf.keras` entry). The tutoral and guide for DTensor will be published on https://www.tensorflow.org/. Please stay tuned.\n \n-* `tf.data`:\n+* [oneDNN CPU performance optimizations](https://github.com/tensorflow/community/blob/master/rfcs/20210930-enable-onednn-ops.md) are available in Linux x86, Windows x86, and Linux aarch64 packages.\n+ * **Linux x86 packages:**\n+ * oneDNN optimizations are *enabled by default* on CPUs with neural-network-focused hardware features such as AVX512_VNNI, AVX512_BF16, AMX, etc. ([Intel Cascade Lake](https://www.intel.com/content/www/us/en/products/platforms/details/cascade-lake.html) and newer CPUs.) \n+ * [Example performance speedups.](https://medium.com/intel-analytics-software/leverage-intel-deep-learning-optimizations-in-tensorflow-129faa80ee07)\n+ * For older CPUs, oneDNN optimizations are disabled by default.\n+ * **Windows x86 package:** oneDNN optimizations are disabled by default.\n+ * **Linux aach64 (`--config=mkl_aarch64`) package:**\n+ * Experimental oneDNN optimizations are disabled by default.\n+ * If you experience issues with oneDNN optimizations on, we recommend turning them off. \n+ * To explicitly enable or disable oneDNN optimizations, set the environment variable `TF_ENABLE_ONEDNN_OPTS` to `1` (enable) or `0` (disable) before running TensorFlow. (The variable is checked during `import tensorflow`.) To fall back to default settings, unset the environment variable.\n+ * These optimizations can yield slightly different numerical results from when they are off due to floating-point round-off errors from different computation approaches and orders.\n+ * To verify that the optimizations are on, look for a message with *\"oneDNN custom operations are on\"* in the log. If the exact phrase is not there, it means they are off.\n \n- * Fixed bug in `tf.data.experimental.parse_example_dataset` when\n- `tf.io.RaggedFeatures` would specify `value_key` but no `partitions`.\n- Before the fix, setting `value_key` but no `partitions` would result in\n- the feature key being replaced by the value key, e.g.\n- `{'value_key': <RaggedTensor>}` instead of `{'key': <RaggedTensor>}`.\n- Now the correct feature key will be used. This aligns the behavior of\n- `tf.data.experimental.parse_example_dataset` to match the behavior of\n- `tf.io.parse_example`.\n \n- * Added a new field, `filter_parallelization`, to\n- `tf.data.experimental.OptimizationOptions`. If it is set to `True`,\n- tf.data will run `Filter` transformation with multiple threads. Its\n- default value is `False` if not specified.\n+# Bug Fixes and Other Changes\n \n-* `tf.keras`:\n+* `tf.data`:\n+ * Fixed bug in `tf.data.experimental.parse_example_dataset` when `tf.io.RaggedFeatures` would specify `value_key` but no `partitions`. Before the fix, setting `value_key` but no `partitions` would result in the feature key being replaced by the value key, e.g. `{'value_key': <RaggedTensor>}` instead of `{'key': <RaggedTensor>}`. Now the correct feature key will be used. This aligns the behavior of `tf.data.experimental.parse_example_dataset` to match the behavior of `tf.io.parse_example`.\n+ * Added a new field, `filter_parallelization`, to `tf.data.experimental.OptimizationOptions`. If it is set to `True`, tf.data will run `Filter` transformation with multiple threads. Its default value is `False` if not specified.\n \n- * Fixed bug in optimizers that prevented them from properly checkpointing\n- slot variables when they are `ShardedVariable`s (used for training with\n- `tf.distribute.experimental.ParameterServerStrategy`).\n+* `tf.keras`:\n+ * Fixed bug in optimizers that prevented them from properly checkpointing slot variables when they are `ShardedVariable`s (used for training with `tf.distribute.experimental.ParameterServerStrategy`).\n \n-* `tf.random`\n- * Added `tf.random.experimental.index_shuffle`, for shuffling a sequence\n- without materializing the sequence in memory.\n+* `tf.random`:\n+ * Added `tf.random.experimental.index_shuffle`, for shuffling a sequence without materializing the sequence in memory.\n \n * `tf.RaggedTensor`:\n- * Introduced `tf.experimental.RowPartition`, which encodes how one\n- dimension in a RaggedTensor relates to another, into the public API.\n- * Introduced `tf.experimental.DynamicRaggedShape`, which represents the\n- shape of a RaggedTensor.\n+ * Introduced `tf.experimental.RowPartition`, which encodes how one dimension in a RaggedTensor relates to another, into the public API.\n+ * Introduced `tf.experimental.DynamicRaggedShape`, which represents the shape of a RaggedTensor.\n+\n+## Security\n+\n+* Fixes a code injection in `saved_model_cli` ([CVE-2022-29216](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29216))\n+* Fixes a missing validation which causes `TensorSummaryV2` to crash ([CVE-2022-29193](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29193))\n+* Fixes a missing validation which crashes `QuantizeAndDequantizeV4Grad` ([CVE-2022-29192](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29192))\n+* Fixes a missing validation which causes denial of service via `DeleteSessionTensor` ([CVE-2022-29194](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29194))\n+* Fixes a missing validation which causes denial of service via `GetSessionTensor` ([CVE-2022-29191](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29191))\n+* Fixes a missing validation which causes denial of service via `StagePeek` ([CVE-2022-29195](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29195))\n+* Fixes a missing validation which causes denial of service via `UnsortedSegmentJoin` ([CVE-2022-29197](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29197))\n+* Fixes a missing validation which causes denial of service via `LoadAndRemapMatrix` ([CVE-2022-29199](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29199))\n+* Fixes a missing validation which causes denial of service via `SparseTensorToCSRSparseMatrix` ([CVE-2022-29198](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29198))\n+* Fixes a missing validation which causes denial of service via `LSTMBlockCell` ([CVE-2022-29200](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29200))\n+* Fixes a missing validation which causes denial of service via `Conv3DBackpropFilterV2` ([CVE-2022-29196](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29196))\n+* Fixes a `CHECK` failure in depthwise ops via overflows ([CVE-2021-41197](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-41197))\n+* Fixes issues arising from undefined behavior stemming from users supplying invalid resource handles ([CVE-2022-29207](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29207))\n+* Fixes a segfault due to missing support for quantized types ([CVE-2022-29205](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29205))\n+* Fixes a missing validation which results in undefined behavior in `SparseTensorDenseAdd` ([CVE-2022-29206](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29206))\n+* Fixes a missing validation which results in undefined behavior in `QuantizedConv2D` ([CVE-2022-29201](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29201))\n+* Fixes an integer overflow in `SpaceToBatchND` ([CVE-2022-29203](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29203))\n+* Fixes a segfault and OOB write due to incomplete validation in `EditDistance` ([CVE-2022-29208](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29208))\n+* Fixes a missing validation which causes denial of service via `Conv3DBackpropFilterV2` ([CVE-2022-29204](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29204))\n+* Fixes a denial of service in `tf.ragged.constant` due to lack of validation ([CVE-2022-29202](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29202))\n+* Fixes a segfault when `tf.histogram_fixed_width` is called with NaN values ([CVE-2022-29211](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29211))\n+* Fixes a core dump when loading TFLite models with quantization ([CVE-2022-29212](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29212))\n+* Fixes crashes stemming from incomplete validation in signal ops ([CVE-2022-29213](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29213))\n+* Fixes a type confusion leading to `CHECK`-failure based denial of service ([CVE-2022-29209](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29209))\n+* Fixes a heap buffer overflow due to incorrect hash function ([CVE-2022-29210](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29210))\n+* Updates `curl` to `7.83.1` to handle ([CVE-2022-22576](https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-22576), ([CVE-2022-27774](https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27774), ([CVE-2022-27775](https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27775), ([CVE-2022-27776](https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27776), ([CVE-2022-27778](https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27778), ([CVE-2022-27779](https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27779), ([CVE-2022-27780](https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27780), ([CVE-2022-27781](https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27781), ([CVE-2022-27782](https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27782) and ([CVE-2022-30115](https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-30115)\n+* Updates `zlib` to `1.2.12` after `1.2.11` was pulled due to [security issue](https://www.openwall.com/lists/oss-security/2022/03/28/1)\n \n-* <SIMILAR TO ABOVE SECTION, BUT FOR OTHER IMPORTANT CHANGES / BUG FIXES>\n-* <IF A CHANGE CLOSES A GITHUB ISSUE, IT SHOULD BE DOCUMENTED HERE>\n-* <NOTES SHOULD BE GROUPED PER AREA>\n \n # Thanks to our Contributors\n \n This release contains contributions from many people at Google, as well as:\n \n-<INSERT>, <NAME>, <HERE>, <USING>, <GITHUB>, <HANDLE>\n+Aaron Debattista, Abel Soares Siqueira, Abhishek Varma, Andrei Ivanov, andreii, Andrew Goodbody, apeltop, Arnab Dutta, Ashiq Imran, Banikumar Maiti (Intel Aipg), Ben Greiner, Benjamin Peterson, bhack, Christopher Bate, chunduriv, Copybara-Service, DEKHTIARJonathan, Deven Desai, Duncan Riach, Eric Kunze, Everton Constantino, Faruk D, Fredrik Knutsson, gadagashwini, Gauri1 Deshpande, gtiHibGele, Guozhong Zhuang, Islem-Esi, Ivanov Viktor, Jason Furmanek, Jason Zaman, Jim, Jinzhe Zeng, John Laxson, Jonas Eschle, Jonas Eschle 'Mayou36, Jonathan Dekhtiar, Kaixi Hou, Kanvi Khanna, KaurkerDevourer, Koan-Sin Tan, kushanam, Laramie Leavitt, Li-Wen Chang, lipracer, Louis Sugy, Lu Teng, Mahmoud Abuzaina, Malcolm Slaney, Malik Shahzad Muzaffar, Marek Šuppa, Matt Conley, Michael Melesse, Milos Puzovic, mohantym, Nathan John Sircombe, Nathan Luehr, Nilesh Agarwalla, Patrice Vignola, peterjc123, Philip Turner, Rajeshwar Reddy T, Robert Kalmar, Rodrigo Formigone, Rohit Santhanam, rui, Sachin Muradi, Saduf2019, sandip, Scott Leishman, Serge Panev, Shi,Guangyong, Srinivasan Narayanamoorthy, stanley, Steven I Reeves, stevenireeves, sushreebarsa, Tamas Bela Feher, Tao He, Thomas Schmeyer, Tiago Almeida, Trevor Morris, Uday Bondhugula, Uwe L. Korn, Varghese, Jojimon, Vishnuvardhan Janapati, William Muir, William Raveane, xutianming, Yasuhiro Matsumoto, Yimei Sun, Yong Tang, Yu Feng, Yuriy Chernyshov, zhaozheng09\n \n # Release 2.8.0\n ",
"filename": "RELEASE.md",
"status": "modified"
},
{
"diff": "@@ -17,6 +17,7 @@\n import numpy as np\n \n from tensorflow.compiler.tests import xla_test\n+from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n from tensorflow.python.ops import array_ops\n from tensorflow.python.ops import gen_array_ops\n@@ -145,6 +146,29 @@ def testLargerInputBatch2x2(self):\n self._testOne(x_np, block_size, x_out)\n \n \n+class SpaceToBatchNDErrorHandlingTest(xla_test.XLATestCase):\n+\n+ def testInvalidBlockShape(self):\n+ with self.assertRaisesRegex(ValueError, \"block_shape must be positive\"):\n+ with self.session() as sess, self.test_scope():\n+ tf_in = constant_op.constant(\n+ -3.5e+35, shape=[10, 20, 20], dtype=dtypes.float32)\n+ block_shape = constant_op.constant(-10, shape=[2], dtype=dtypes.int64)\n+ paddings = constant_op.constant(0, shape=[2, 2], dtype=dtypes.int32)\n+ sess.run(array_ops.space_to_batch_nd(tf_in, block_shape, paddings))\n+\n+ def testOutputSizeOutOfBounds(self):\n+ with self.assertRaisesRegex(ValueError,\n+ \"Negative.* dimension size caused by overflow\"):\n+ with self.session() as sess, self.test_scope():\n+ tf_in = constant_op.constant(\n+ -3.5e+35, shape=[10, 19, 22], dtype=dtypes.float32)\n+ block_shape = constant_op.constant(\n+ 1879048192, shape=[2], dtype=dtypes.int64)\n+ paddings = constant_op.constant(0, shape=[2, 2], dtype=dtypes.int32)\n+ sess.run(array_ops.space_to_batch_nd(tf_in, block_shape, paddings))\n+\n+\n class SpaceToBatchNDTest(xla_test.XLATestCase):\n \"\"\"Tests input-output pairs for the SpaceToBatchND and BatchToSpaceND ops.\"\"\"\n ",
"filename": "tensorflow/compiler/tests/spacetobatch_op_test.py",
"status": "modified"
},
{
"diff": "@@ -209,6 +209,7 @@ tf_kernel_library(\n \"//tensorflow/core/kernels:stateful_random_ops_header\",\n \"//tensorflow/core/kernels:stateless_random_ops_v2_header\",\n \"//tensorflow/core/tpu:tpu_defs\",\n+ \"//tensorflow/core/util:overflow\",\n \"//tensorflow/stream_executor/lib\",\n \"@com_google_absl//absl/algorithm:container\",\n \"@com_google_absl//absl/container:flat_hash_map\",",
"filename": "tensorflow/compiler/tf2xla/kernels/BUILD",
"status": "modified"
},
{
"diff": "@@ -17,6 +17,7 @@ limitations under the License.\n #include \"tensorflow/compiler/tf2xla/xla_op_kernel.h\"\n #include \"tensorflow/compiler/tf2xla/xla_op_registry.h\"\n #include \"tensorflow/compiler/xla/client/xla_builder.h\"\n+#include \"tensorflow/core/util/overflow.h\"\n \n namespace tensorflow {\n namespace {\n@@ -60,10 +61,14 @@ void SpaceToBatch(XlaOpKernelContext* ctx, const xla::XlaOp& input,\n int64_t pad_end = paddings.Get<int64_t>({i, 1});\n OP_REQUIRES(ctx, pad_start >= 0 && pad_end >= 0,\n errors::InvalidArgument(\"Paddings must be non-negative\"));\n+ OP_REQUIRES(ctx, block_shape[i] >= 1,\n+ errors::InvalidArgument(\n+ \"All values in block_shape must be positive, got value, \",\n+ block_shape[i], \" at index \", i, \".\"));\n dim->set_edge_padding_low(pad_start);\n dim->set_edge_padding_high(pad_end);\n padded_shape[1 + i] += pad_start + pad_end;\n- block_num_elems *= block_shape[i];\n+ block_num_elems = MultiplyWithoutOverflow(block_num_elems, block_shape[i]);\n }\n // Don't pad the remainder dimensions.\n for (int i = 0; i < remainder_shape.size(); ++i) {\n@@ -72,6 +77,16 @@ void SpaceToBatch(XlaOpKernelContext* ctx, const xla::XlaOp& input,\n OP_REQUIRES(ctx, block_num_elems > 0,\n errors::InvalidArgument(\n \"The product of the block dimensions must be positive\"));\n+ const int64_t batch_size = input_shape[0];\n+ const int64_t output_dim =\n+ MultiplyWithoutOverflow(batch_size, block_num_elems);\n+ if (output_dim < 0) {\n+ OP_REQUIRES(\n+ ctx, output_dim >= 0,\n+ errors::InvalidArgument(\"Negative output dimension size caused by \"\n+ \"overflow when multiplying \",\n+ batch_size, \" and \", block_num_elems));\n+ }\n \n xla::XlaOp padded =\n xla::Pad(input, XlaHelpers::Zero(b, input_dtype), padding_config);\n@@ -85,7 +100,6 @@ void SpaceToBatch(XlaOpKernelContext* ctx, const xla::XlaOp& input,\n // padded_shape[M] / block_shape[M-1],\n // block_shape[M-1]] +\n // remaining_shape\n- const int64_t batch_size = input_shape[0];\n std::vector<int64_t> reshaped_padded_shape(input_rank + block_rank);\n reshaped_padded_shape[0] = batch_size;\n for (int i = 0; i < block_rank; ++i) {\n@@ -134,7 +148,7 @@ void SpaceToBatch(XlaOpKernelContext* ctx, const xla::XlaOp& input,\n // Determine the length of the prefix of block dims that can be combined\n // into the batch dimension due to having no padding and block_shape=1.\n std::vector<int64_t> output_shape(input_rank);\n- output_shape[0] = batch_size * block_num_elems;\n+ output_shape[0] = output_dim;\n for (int i = 0; i < block_rank; ++i) {\n output_shape[1 + i] = padded_shape[1 + i] / block_shape[i];\n }",
"filename": "tensorflow/compiler/tf2xla/kernels/spacetobatch_op.cc",
"status": "modified"
},
{
"diff": "@@ -304,6 +304,9 @@ Status GetDeviceForInput(const EagerContext& ctx, TensorHandle* tensor_handle,\n const Tensor* tensor;\n // TODO(fishx): Avoid blocking here.\n TF_RETURN_IF_ERROR(tensor_handle->Tensor(&tensor));\n+ if (tensor->NumElements() == 0) {\n+ return errors::InvalidArgument(\"Empty resource handle\");\n+ }\n const ResourceHandle& handle = tensor->flat<ResourceHandle>()(0);\n device_name = handle.device();\n \n@@ -1286,7 +1289,7 @@ Status EagerLocalExecute(EagerOperation* op, TensorHandle** retvals,\n auto status = GetOrCreateKernelAndDevice(op, retvals, num_retvals, &kernel);\n \n #ifdef INTEL_MKL\n- if (IsMKLEnabled() && kernel != nullptr && !ctx.RunEagerOpAsFunction() &&\n+ if (IsMKLEnabled() && kernel != nullptr &&\n op->Device() == kVariantDeviceNull) {\n // oneDNN optimization pass relies on the op's assigned device to determine\n // whether it can be rewritten.",
"filename": "tensorflow/core/common_runtime/eager/execute.cc",
"status": "modified"
},
{
"diff": "@@ -172,10 +172,6 @@ bool MklEagerOpRewrite::ShouldRewriteOp(EagerOperation* op) {\n if (!IsMKLEnabled()) {\n return false;\n }\n- // Don't rewrite the op if it should run as a function.\n- if (op->EagerContext().RunEagerOpAsFunction()) {\n- return false;\n- }\n DataType data_type;\n if (op->Attrs().Get(\"T\", &data_type) != Status::OK()) {\n return false;",
"filename": "tensorflow/core/common_runtime/eager/mkl_eager_op_rewrite.cc",
"status": "modified"
},
{
"diff": "@@ -886,6 +886,7 @@ cc_library(\n \"//tensorflow/core/lib/strings:scanner\",\n \"//tensorflow/core/lib/strings:str_util\",\n \"//tensorflow/core/platform:macros\",\n+ \"//tensorflow/core/util:overflow\",\n \"@com_google_absl//absl/memory\",\n ],\n )",
"filename": "tensorflow/core/framework/BUILD",
"status": "modified"
},
{
"diff": "@@ -26,6 +26,7 @@ limitations under the License.\n #include \"tensorflow/core/lib/strings/numbers.h\"\n #include \"tensorflow/core/lib/strings/scanner.h\"\n #include \"tensorflow/core/lib/strings/str_util.h\"\n+#include \"tensorflow/core/util/overflow.h\"\n \n namespace tensorflow {\n namespace shape_inference {\n@@ -1098,7 +1099,7 @@ Status InferenceContext::Multiply(DimensionHandle first,\n *out = UnknownDim();\n } else {\n // Invariant: Both values are known and greater than 1.\n- const int64_t product = first_value * second_value;\n+ const int64_t product = MultiplyWithoutOverflow(first_value, second_value);\n if (product < 0) {\n return errors::InvalidArgument(\n \"Negative dimension size caused by overflow when multiplying \",",
"filename": "tensorflow/core/framework/shape_inference.cc",
"status": "modified"
},
{
"diff": "@@ -16,6 +16,7 @@ limitations under the License.\n #define TENSORFLOW_CORE_FRAMEWORK_TENSOR_KEY_H_\n \n #include \"tensorflow/core/framework/tensor.h\"\n+#include \"tensorflow/core/framework/types.h\"\n \n namespace tensorflow {\n \n@@ -32,8 +33,7 @@ class TensorKey : public Tensor {\n }\n if (DataTypeCanUseMemcpy(t1.dtype())) {\n return t1.tensor_data() == t2.tensor_data();\n- }\n- if (t1.dtype() == DT_STRING) {\n+ } else if (t1.dtype() == DT_STRING) {\n const auto s1 = t1.unaligned_flat<tstring>();\n const auto s2 = t2.unaligned_flat<tstring>();\n for (int64_t i = 0, n = t1.NumElements(); i < n; ++i) {\n@@ -42,6 +42,9 @@ class TensorKey : public Tensor {\n }\n }\n return true;\n+ } else {\n+ DCHECK(false) << \"Unimplemented dtype \" << DataTypeString(t1.dtype())\n+ << std::endl;\n }\n return false;\n }\n@@ -53,14 +56,19 @@ class TensorKey : public Tensor {\n // Needed for absl hash function.\n template <typename H>\n friend H AbslHashValue(H h, const TensorKey& k) {\n- const uint8* d = static_cast<uint8*>(k.data());\n- size_t s = k.AllocatedBytes();\n- std::vector<uint8> vec;\n- vec.reserve(s);\n- for (int i = 0; i < s; i++) {\n- vec.push_back(d[i]);\n+ if (DataTypeCanUseMemcpy(k.dtype())) {\n+ return H::combine(std::move(h), k.tensor_data());\n+ } else if (k.dtype() == DT_STRING) {\n+ const auto strs = k.unaligned_flat<tstring>();\n+ for (int64_t i = 0, n = k.NumElements(); i < n; ++i) {\n+ h = H::combine(std::move(h), strs(i));\n+ }\n+ return h;\n+ } else {\n+ DCHECK(false) << \"Unimplemented dtype \" << DataTypeString(k.dtype())\n+ << std::endl;\n }\n- return H::combine(std::move(h), s);\n+ return h;\n }\n };\n ",
"filename": "tensorflow/core/framework/tensor_key.h",
"status": "modified"
},
{
"diff": "@@ -537,16 +537,35 @@ bool IsBiasSemanticAdd(const RemapperContext& ctx,\n return true;\n };\n \n+ // This is used only for MatMul+Add fusion.\n+ const auto is_matmul_supported_shape =\n+ [](const TensorShapeProto& shape,\n+ const TensorShapeProto& bcast_shape) -> bool {\n+ if (shape.dim_size() < 2 || bcast_shape.dim_size() != 1) return false;\n+ int channel_dim = shape.dim(shape.dim_size() - 1).size();\n+ return (channel_dim == bcast_shape.dim(0).size());\n+ };\n+\n if (ShapesSymbolicallyEqual(prot0_shape, prot1_shape) ||\n !ShapesBroadcastable(prot0_shape, prot1_shape))\n return false;\n \n+ // For now block MatMul+Add fusion if Bias dims are more than one.\n+ // TODO(intel-tf): Enable this fusion once it is properly tested.\n if (IsConvOrMatMul(*node_def_0)) {\n bias_port = 1;\n- return (is_supported_shape(prot0_shape, prot1_shape));\n+ if (IsMatMul(*node_def_0)) {\n+ return (is_matmul_supported_shape(prot0_shape, prot1_shape));\n+ } else {\n+ return (is_supported_shape(prot0_shape, prot1_shape));\n+ }\n } else if (IsConvOrMatMul(*node_def_1)) {\n bias_port = 0;\n- return (is_supported_shape(prot1_shape, prot0_shape));\n+ if (IsMatMul(*node_def_1)) {\n+ return (is_matmul_supported_shape(prot1_shape, prot0_shape));\n+ } else {\n+ return (is_supported_shape(prot1_shape, prot0_shape));\n+ }\n }\n return false;\n }",
"filename": "tensorflow/core/grappler/optimizers/remapper.cc",
"status": "modified"
},
{
"diff": "@@ -26,6 +26,10 @@ load(\n \"tf_fingerprint_deps\",\n \"tf_kernel_tests_linkstatic\",\n )\n+load(\n+ \"//third_party/mkl:build_defs.bzl\",\n+ \"mkl_deps\",\n+)\n \n # buildifier: disable=same-origin-load\n load(\"//tensorflow:tensorflow.bzl\", \"cc_header_only_library\")\n@@ -57,10 +61,6 @@ load(\n \"//tensorflow/core/platform:build_config_root.bzl\",\n \"tf_cuda_tests_tags\",\n )\n-load(\n- \"//third_party/mkl:build_defs.bzl\",\n- \"mkl_deps\",\n-)\n load(\"@local_config_cuda//cuda:build_defs.bzl\", \"if_cuda\")\n load(\n \"@local_config_rocm//rocm:build_defs.bzl\",\n@@ -4561,6 +4561,7 @@ tf_kernel_library(\n \"//tensorflow/core:framework\",\n \"//tensorflow/core:lib\",\n \"//tensorflow/core/framework:bounds_check\",\n+ \"//tensorflow/core/util:overflow\",\n \"//third_party/eigen3\",\n ],\n )",
"filename": "tensorflow/core/kernels/BUILD",
"status": "modified"
},
{
"diff": "@@ -741,6 +741,10 @@ class Conv3DBackpropFilterOp : public OpKernel {\n TensorShape filter_shape;\n if (takes_shape_) {\n const Tensor& filter_sizes = context->input(1);\n+ OP_REQUIRES(context, TensorShapeUtils::IsVector(filter_sizes.shape()),\n+ errors::InvalidArgument(\n+ \"filter_sizes shape must be rank 1 but is rank \",\n+ filter_sizes.shape().dims()));\n OP_REQUIRES_OK(context, TensorShapeUtils::MakeShape(\n filter_sizes.vec<int32>(), &filter_shape));\n } else {\n@@ -875,6 +879,10 @@ class Conv3DCustomBackpropFilterOp : public OpKernel {\n TensorShape filter_shape;\n if (takes_shape_) {\n const Tensor& filter_sizes = context->input(1);\n+ OP_REQUIRES(context, TensorShapeUtils::IsVector(filter_sizes.shape()),\n+ errors::InvalidArgument(\n+ \"filter_sizes shape must be rank 1 but is rank \",\n+ filter_sizes.shape().dims()));\n OP_REQUIRES_OK(context, TensorShapeUtils::MakeShape(\n filter_sizes.vec<int32>(), &filter_shape));\n } else {\n@@ -1638,6 +1646,10 @@ class Conv3DBackpropFilterOp<GPUDevice, T> : public OpKernel {\n TensorShape filter_shape;\n if (takes_shape_) {\n const Tensor& filter_sizes = context->input(1);\n+ OP_REQUIRES(context, TensorShapeUtils::IsVector(filter_sizes.shape()),\n+ errors::InvalidArgument(\n+ \"filter_sizes shape must be rank 1 but is rank \",\n+ filter_sizes.shape().dims()));\n OP_REQUIRES_OK(context, tensor::MakeShape(filter_sizes, &filter_shape));\n } else {\n filter_shape = context->input(1).shape();",
"filename": "tensorflow/core/kernels/conv_grad_ops_3d.cc",
"status": "modified"
},
{
"diff": "@@ -623,7 +623,7 @@ class DepthwiseConv2dNativeBackpropInputOp : public OpKernel {\n OP_REQUIRES(context, in_sizes_data[i] >= 0,\n errors::InvalidArgument(\"Dimension \", i,\n \" of input_sizes must be >= 0\"));\n- input_shape.AddDim(in_sizes_data[i]);\n+ OP_REQUIRES_OK(context, input_shape.AddDimWithStatus(in_sizes_data[i]));\n }\n const TensorShape& filter_shape = filter.shape();\n EXTRACT_AND_VERIFY_DIMENSIONS(\"DepthwiseConv2DBackpropInput\");\n@@ -1120,7 +1120,8 @@ class DepthwiseConv2dNativeBackpropFilterOp : public OpKernel {\n OP_REQUIRES(context, filter_sizes_data[i] >= 0,\n errors::InvalidArgument(\"Dimension \", i,\n \" of filter_sizes must be >= 0\"));\n- filter_shape.AddDim(filter_sizes_data[i]);\n+ OP_REQUIRES_OK(context,\n+ filter_shape.AddDimWithStatus(filter_sizes_data[i]));\n }\n const TensorShape& input_shape = input.shape();\n ",
"filename": "tensorflow/core/kernels/depthwise_conv_grad_op.cc",
"status": "modified"
},
{
"diff": "@@ -203,9 +203,9 @@ class EditDistanceOp : public OpKernel {\n auto loc = std::inner_product(g_truth.begin(), g_truth.end(),\n output_strides.begin(), int64_t{0});\n OP_REQUIRES(\n- ctx, loc < output_elements,\n+ ctx, 0 <= loc && loc < output_elements,\n errors::Internal(\"Got an inner product \", loc,\n- \" which would require in writing to outside of \"\n+ \" which would require writing to outside of \"\n \"the buffer for the output tensor (max elements \",\n output_elements, \")\"));\n output_t(loc) =\n@@ -218,9 +218,9 @@ class EditDistanceOp : public OpKernel {\n auto loc = std::inner_product(g_hypothesis.begin(), g_hypothesis.end(),\n output_strides.begin(), int64_t{0});\n OP_REQUIRES(\n- ctx, loc < output_elements,\n+ ctx, 0 <= loc && loc < output_elements,\n errors::Internal(\"Got an inner product \", loc,\n- \" which would require in writing to outside of \"\n+ \" which would require writing to outside of \"\n \"the buffer for the output tensor (max elements \",\n output_elements, \")\"));\n output_t(loc) = hypothesis_seq.size();\n@@ -232,9 +232,9 @@ class EditDistanceOp : public OpKernel {\n auto loc = std::inner_product(g_truth.begin(), g_truth.end(),\n output_strides.begin(), int64_t{0});\n OP_REQUIRES(\n- ctx, loc < output_elements,\n+ ctx, 0 <= loc && loc < output_elements,\n errors::Internal(\"Got an inner product \", loc,\n- \" which would require in writing to outside of \"\n+ \" which would require writing to outside of \"\n \"the buffer for the output tensor (max elements \",\n output_elements, \")\"));\n output_t(loc) = (normalize_) ? 1.0 : truth_seq.size();\n@@ -248,9 +248,9 @@ class EditDistanceOp : public OpKernel {\n auto loc = std::inner_product(g_hypothesis.begin(), g_hypothesis.end(),\n output_strides.begin(), int64_t{0});\n OP_REQUIRES(\n- ctx, loc < output_elements,\n+ ctx, 0 <= loc && loc < output_elements,\n errors::Internal(\"Got an inner product \", loc,\n- \" which would require in writing to outside of the \"\n+ \" which would require writing to outside of the \"\n \"buffer for the output tensor (max elements \",\n output_elements, \")\"));\n output_t(loc) = hypothesis_seq.size();\n@@ -266,9 +266,9 @@ class EditDistanceOp : public OpKernel {\n auto loc = std::inner_product(g_truth.begin(), g_truth.end(),\n output_strides.begin(), int64_t{0});\n OP_REQUIRES(\n- ctx, loc < output_elements,\n+ ctx, 0 <= loc && loc < output_elements,\n errors::Internal(\"Got an inner product \", loc,\n- \" which would require in writing to outside of the \"\n+ \" which would require writing to outside of the \"\n \"buffer for the output tensor (max elements \",\n output_elements, \")\"));\n output_t(loc) = (normalize_) ? 1.0 : truth_seq.size();",
"filename": "tensorflow/core/kernels/edit_distance_op.cc",
"status": "modified"
},
{
"diff": "@@ -40,10 +40,13 @@ namespace tensorflow {\n // Outputs nudged_min, nudged_max, nudged_scale.\n EIGEN_DEVICE_FUNC EIGEN_ALWAYS_INLINE void Nudge(\n const float min, const float max, const int quant_min, const int quant_max,\n- float* nudged_min, float* nudged_max, float* scale) {\n+ float* nudged_min, float* nudged_max, float* scale, float* inv_scale) {\n const float quant_min_float = static_cast<float>(quant_min);\n const float quant_max_float = static_cast<float>(quant_max);\n *scale = (max - min) / (quant_max_float - quant_min_float);\n+ // Re-calculate the inverse to avoid loss of precision which would result\n+ // from simply taking the reciprocal of *scale\n+ *inv_scale = (quant_max_float - quant_min_float) / (max - min);\n const float zero_point_from_min = quant_min_float - min / *scale;\n const uint16 nudged_zero_point = [zero_point_from_min, quant_min,\n quant_min_float, quant_max,\n@@ -84,11 +87,10 @@ struct FakeQuantWithMinMaxArgsFunctor {\n eigen_assert(max >= 0.0f && \"max should be >= 0.0\");\n eigen_assert(min < max && \"min should be < max\");\n \n- float nudged_min, nudged_max, nudged_scale;\n+ float nudged_min, nudged_max, nudged_scale, inv_nudged_scale;\n Nudge(min, max, quant_min, quant_max, &nudged_min, &nudged_max,\n- &nudged_scale);\n+ &nudged_scale, &inv_nudged_scale);\n \n- const float inv_nudged_scale = 1.0f / nudged_scale;\n const float quant_zero = floor(-nudged_min * inv_nudged_scale + 0.5f);\n \n auto clamped = inputs.cwiseMin(nudged_max).cwiseMax(nudged_min);\n@@ -111,9 +113,9 @@ struct FakeQuantWithMinMaxArgsGradientFunctor {\n eigen_assert(max >= 0.0f && \"max should be >= 0.0\");\n eigen_assert(min < max && \"min should be < max\");\n \n- float nudged_min, nudged_max, nudged_scale;\n+ float nudged_min, nudged_max, nudged_scale, inv_nudged_scale;\n Nudge(min, max, quant_min, quant_max, &nudged_min, &nudged_max,\n- &nudged_scale);\n+ &nudged_scale, &inv_nudged_scale);\n \n auto between_nudged_min_max =\n (inputs >= nudged_min && inputs <= nudged_max)\n@@ -137,11 +139,10 @@ struct FakeQuantWithMinMaxVarsFunctor {\n outputs.device(d) = outputs.constant(0.0f);\n return;\n }\n- float nudged_min, nudged_max, nudged_scale;\n+ float nudged_min, nudged_max, nudged_scale, inv_nudged_scale;\n Nudge(min_val, max_val, quant_min, quant_max, &nudged_min, &nudged_max,\n- &nudged_scale);\n+ &nudged_scale, &inv_nudged_scale);\n \n- const float inv_nudged_scale = 1.0f / nudged_scale;\n const float quant_zero = floor(-nudged_min * inv_nudged_scale + 0.5f);\n const auto nudged_scale_repl = inputs.constant(nudged_scale);\n // const auto inv_nudged_scale_repl = inputs.constant(inv_nudged_scale);\n@@ -173,9 +174,9 @@ struct FakeQuantWithMinMaxVarsGradientFunctor {\n backprop_wrt_max.device(d) = backprop_wrt_max.constant(0.0f);\n return;\n }\n- float nudged_min, nudged_max, nudged_scale;\n+ float nudged_min, nudged_max, nudged_scale, inv_nudged_scale;\n Nudge(min_val, max_val, quant_min, quant_max, &nudged_min, &nudged_max,\n- &nudged_scale);\n+ &nudged_scale, &inv_nudged_scale);\n \n const auto between_min_max =\n (inputs >= nudged_min && inputs <= nudged_max)\n@@ -215,11 +216,10 @@ struct FakeQuantWithMinMaxVarsPerChannelFunctor {\n chip.device(d) = chip.constant(0.0f);\n continue;\n }\n- float nudged_min, nudged_max, nudged_scale;\n+ float nudged_min, nudged_max, nudged_scale, inv_nudged_scale;\n Nudge(min_val, max_val, quant_min, quant_max, &nudged_min, &nudged_max,\n- &nudged_scale);\n+ &nudged_scale, &inv_nudged_scale);\n \n- const float inv_nudged_scale = 1.0f / nudged_scale;\n const float quant_zero = floor(-nudged_min * inv_nudged_scale + 0.5f);\n \n const auto clamped =\n@@ -259,9 +259,9 @@ struct FakeQuantWithMinMaxVarsPerChannelGradientFunctor {\n max_chip.device(d) = max_chip.constant(0.0f);\n continue;\n }\n- float nudged_min, nudged_max, nudged_scale;\n+ float nudged_min, nudged_max, nudged_scale, inv_nudged_scale;\n Nudge(min_val, max_val, quant_min, quant_max, &nudged_min, &nudged_max,\n- &nudged_scale);\n+ &nudged_scale, &inv_nudged_scale);\n \n const auto between_min_max =\n (inputs_chip >= nudged_min && inputs_chip <= nudged_max)",
"filename": "tensorflow/core/kernels/fake_quant_ops_functor.h",
"status": "modified"
},
{
"diff": "@@ -50,6 +50,15 @@ struct HistogramFixedWidthFunctor<CPUDevice, T, Tout> {\n static_cast<double>(nbins);\n const double nbins_minus_1 = static_cast<double>(nbins - 1);\n \n+ // We cannot handle NANs in the algorithm below (due to the case to int32)\n+ const Eigen::Tensor<int32, 1, 1> nans_tensor =\n+ values.isnan().template cast<int32>();\n+ const Eigen::Tensor<int32, 0, 1> reduced_tensor = nans_tensor.sum();\n+ const int num_nans = reduced_tensor(0);\n+ if (num_nans > 0) {\n+ return errors::InvalidArgument(\"Histogram values must not contain NaN\");\n+ }\n+\n // The calculation is done by finding the slot of each value in `values`.\n // With [a, b]:\n // step = (b - a) / nbins\n@@ -98,12 +107,12 @@ class HistogramFixedWidthOp : public OpKernel {\n const auto nbins = nbins_tensor.scalar<int32>()();\n \n OP_REQUIRES(\n- ctx, (value_range(0) < value_range(1)),\n+ ctx, value_range(0) < value_range(1),\n errors::InvalidArgument(\"value_range should satisfy value_range[0] < \"\n \"value_range[1], but got '[\",\n value_range(0), \", \", value_range(1), \"]'\"));\n OP_REQUIRES(\n- ctx, (nbins > 0),\n+ ctx, nbins > 0,\n errors::InvalidArgument(\"nbins should be a positive number, but got '\",\n nbins, \"'\"));\n ",
"filename": "tensorflow/core/kernels/histogram_op.cc",
"status": "modified"
},
{
"diff": "@@ -74,6 +74,11 @@ class LoadAndRemapMatrixOp : public OpKernel {\n std::vector<bool> row_id_present;\n const Tensor* row_remapping_t;\n OP_REQUIRES_OK(context, context->input(\"row_remapping\", &row_remapping_t));\n+ OP_REQUIRES(\n+ context, row_remapping_t->dims() == 1,\n+ errors::InvalidArgument(\"The `row_remapping` tensor must be 1-D, got \"\n+ \"a tensor of shape \",\n+ row_remapping_t->shape().DebugString()));\n const auto row_remapping = row_remapping_t->vec<int64_t>();\n OP_REQUIRES(context, row_remapping.size() == num_rows_,\n errors::InvalidArgument(strings::StrCat(",
"filename": "tensorflow/core/kernels/load_and_remap_matrix_op.cc",
"status": "modified"
},
{
"diff": "@@ -143,8 +143,8 @@ class BatchMatMulMkl : public OpKernel {\n // For matmul, the previous approach (PR #47775) of using Tensor addresses\n // does not work, as the addresses are re-used in matmul with different data\n // The counter ensure we still benefit from caching via SetMklMatmul().\n- static int counter = 1;\n- params->aarch64_counter = counter++;\n+ params->aarch64_counter =\n+ MklMatMulPrimitiveFactory<float, Tlhs, Trhs, Toutput>::IncrementCounter();\n #endif\n this->ExtendMklMatMulParams(ctx, *params);\n ",
"filename": "tensorflow/core/kernels/mkl/mkl_batch_matmul_op.cc",
"status": "modified"
},
{
"diff": "@@ -32,6 +32,9 @@ limitations under the License.\n #include \"tensorflow/core/lib/core/status.h\"\n #include \"tensorflow/core/platform/types.h\"\n #include \"tensorflow/core/util/mkl_util.h\"\n+#ifdef DNNL_AARCH64_USE_ACL\n+#include \"tensorflow/core/platform/mutex.h\"\n+#endif\n \n using dnnl::concat;\n using dnnl::stream;\n@@ -279,6 +282,9 @@ class MklConcatFwdPrimitive : public MklPrimitive {\n const dnnl::memory& dst_data,\n const MklConcatFwdParams& concat_fwd_dims,\n std::shared_ptr<stream> fwd_stream) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n DCHECK_EQ(in_data.size(), context_.data_mem.size());\n for (size_t i = 0; i < concat_fwd_dims.num_inputs; i++) {\n #ifndef ENABLE_ONEDNN_OPENMP\n@@ -375,6 +381,10 @@ class MklConcatFwdPrimitive : public MklPrimitive {\n }\n \n struct ConcatFwdContext context_;\n+\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n // Class to create/cache the mkl concat primitives based on the",
"filename": "tensorflow/core/kernels/mkl/mkl_concat_op.cc",
"status": "modified"
},
{
"diff": "@@ -23,6 +23,9 @@ limitations under the License.\n #include \"tensorflow/core/kernels/mkl/mkl_conv_ops.h\"\n #include \"tensorflow/core/util/use_cudnn.h\"\n #include \"tensorflow/core/util/work_sharder.h\"\n+#ifdef DNNL_AARCH64_USE_ACL\n+#include \"tensorflow/core/platform/mutex.h\"\n+#endif\n \n using dnnl::convolution_backward_weights;\n using dnnl::memory;\n@@ -88,6 +91,9 @@ class MklConvBwdFilterPrimitive : public MklPrimitive {\n void Execute(const T* src_data, const T* diff_filter_data,\n const T* diff_bias_data, const T* diff_dst_data,\n std::shared_ptr<stream> bwd_filter_stream) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n #ifndef ENABLE_ONEDNN_OPENMP\n // TODO(intel-tf): Create a common function and avoid the duplicate code\n context_.src_mem->set_data_handle(\n@@ -273,6 +279,10 @@ class MklConvBwdFilterPrimitive : public MklPrimitive {\n }\n \n struct ConvBwdFilterContext context_;\n+\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n template <typename T>",
"filename": "tensorflow/core/kernels/mkl/mkl_conv_grad_filter_ops.cc",
"status": "modified"
},
{
"diff": "@@ -30,6 +30,9 @@ limitations under the License.\n #include \"tensorflow/core/kernels/mkl/mkl_conv_ops.h\"\n #include \"tensorflow/core/util/use_cudnn.h\"\n #include \"tensorflow/core/util/work_sharder.h\"\n+#ifdef DNNL_AARCH64_USE_ACL\n+#include \"tensorflow/core/platform/mutex.h\"\n+#endif\n \n using dnnl::convolution_backward_data;\n using dnnl::prop_kind;\n@@ -90,6 +93,9 @@ class MklConvBwdInputPrimitive : public MklPrimitive {\n void Execute(const T* diff_src_data, const T* filter_data,\n const T* diff_dst_data,\n std::shared_ptr<stream> bwd_input_stream) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n #ifndef ENABLE_ONEDNN_OPENMP\n // TODO(intel-tf): Create a common function and avoid the duplicate code\n context_.diff_src_mem->set_data_handle(\n@@ -219,6 +225,9 @@ class MklConvBwdInputPrimitive : public MklPrimitive {\n }\n \n struct ConvBwdInputContext context_;\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n template <typename T>",
"filename": "tensorflow/core/kernels/mkl/mkl_conv_grad_input_ops.cc",
"status": "modified"
},
{
"diff": "@@ -26,6 +26,9 @@ limitations under the License.\n #include \"absl/strings/str_join.h\"\n #include \"tensorflow/core/kernels/mkl/mkl_quantized_conv_ops.h\"\n #include \"tensorflow/core/kernels/no_op.h\"\n+#ifdef DNNL_AARCH64_USE_ACL\n+#include \"tensorflow/core/platform/mutex.h\"\n+#endif\n \n using dnnl::convolution_forward;\n using dnnl::prop_kind;\n@@ -113,6 +116,12 @@ class MklConvFwdPrimitive : public MklPrimitive {\n const Tinput* bn_scale_data, const Tinput* bn_mean_data,\n const Tinput* bn_offset_data, const Tinput* bn_rsqrt_data,\n std::shared_ptr<stream> fwd_stream, void* sp_data) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ // When we are using single global cache then in this case we can have\n+ // multiple threads running the same primitive that we created so this\n+ // should happen under the lock.\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n #ifndef ENABLE_ONEDNN_OPENMP\n // TODO(intel-tf): Create a common function and avoid the duplicate code\n context_.src_mem->set_data_handle(\n@@ -418,6 +427,11 @@ class MklConvFwdPrimitive : public MklPrimitive {\n }\n \n struct ConvFwdContext context_;\n+\n+#ifdef DNNL_AARCH64_USE_ACL\n+ // Guards Execution()\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n // TODO(intel-tf): We should not require passing a type to MklPrimitiveFactory.",
"filename": "tensorflow/core/kernels/mkl/mkl_conv_ops.cc",
"status": "modified"
},
{
"diff": "@@ -30,6 +30,9 @@ limitations under the License.\n #include \"tensorflow/core/framework/tensor.h\"\n #include \"tensorflow/core/lib/core/errors.h\"\n #include \"tensorflow/core/util/mkl_util.h\"\n+#ifdef DNNL_AARCH64_USE_ACL\n+#include \"tensorflow/core/platform/mutex.h\"\n+#endif\n \n using dnnl::algorithm;\n using dnnl::eltwise_forward;\n@@ -76,6 +79,9 @@ class MklEltwiseFwdPrimitive : public MklPrimitive {\n // src_data: input data buffer of src\n // dst_data: output data buffer of dst\n void Execute(const T* src_data, T* dst_data, OpKernelContext* op_context) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n context_.src_mem->set_data_handle(\n static_cast<void*>(const_cast<T*>(src_data)));\n context_.dst_mem->set_data_handle(static_cast<void*>(dst_data));\n@@ -159,6 +165,10 @@ class MklEltwiseFwdPrimitive : public MklPrimitive {\n }\n \n struct EltwiseFwdContext context_;\n+\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n template <typename T>",
"filename": "tensorflow/core/kernels/mkl/mkl_eltwise_activation_base_op.h",
"status": "modified"
},
{
"diff": "@@ -24,6 +24,9 @@ limitations under the License.\n #include \"tensorflow/core/kernels/no_op.h\"\n #include \"tensorflow/core/util/mkl_util.h\"\n #include \"tensorflow/core/util/tensor_format.h\"\n+#ifdef DNNL_AARCH64_USE_ACL\n+#include \"tensorflow/core/platform/mutex.h\"\n+#endif\n \n #define GET_FLAG(bn_flag) static_cast<int>(dnnl::normalization_flags::bn_flag)\n #define IS_SET(cflag) (context_.flags & GET_FLAG(cflag))\n@@ -82,6 +85,9 @@ class MklFusedBatchNormFwdPrimitive : public MklPrimitive {\n void Execute(const T* src_data, const U* weights_data, T* dst_data,\n U* mean_data, U* variance_data,\n std::shared_ptr<stream> fwd_stream, U* workspace_data) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n #ifndef ENABLE_ONEDNN_OPENMP\n // TODO(intel-tf): Create a common function and avoid the duplicate code\n context_.src_mem->set_data_handle(\n@@ -323,6 +329,10 @@ class MklFusedBatchNormFwdPrimitive : public MklPrimitive {\n }\n \n struct BatchNormFwdContext context_;\n+\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n template <typename T, typename U>\n@@ -428,6 +438,9 @@ class MklFusedBatchNormBwdPrimitive : public MklPrimitive {\n const T* diff_dst_data, const U* weights_data, T* diff_src_data,\n U* diff_weights_data, U* res_space_data,\n std::shared_ptr<stream> bwd_stream) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n #ifndef ENABLE_ONEDNN_OPENMP\n // TODO(intel-tf): Create a common function and avoid the duplicate code\n context_.src_mem->set_data_handle(\n@@ -584,6 +597,10 @@ class MklFusedBatchNormBwdPrimitive : public MklPrimitive {\n }\n \n struct BatchNormBwdContext context_;\n+\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n template <typename T, typename U>",
"filename": "tensorflow/core/kernels/mkl/mkl_fused_batch_norm_op.cc",
"status": "modified"
},
{
"diff": "@@ -27,6 +27,9 @@ limitations under the License.\n #include \"tensorflow/core/framework/op_kernel.h\"\n #include \"tensorflow/core/util/mkl_util.h\"\n #include \"tensorflow/core/util/onednn_env_vars.h\"\n+#ifdef DNNL_AARCH64_USE_ACL\n+#include \"tensorflow/core/platform/mutex.h\"\n+#endif\n \n using dnnl::inner_product_forward;\n using dnnl::primitive_attr;\n@@ -122,6 +125,9 @@ class MklDnnMatMulFwdPrimitive : public MklPrimitive {\n void Execute(const Tinput* src_data, const Tweight* weight_data,\n const Tbias* bias_data, Toutput* dst_data, void* sp_data,\n std::shared_ptr<stream> fwd_stream) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n #ifndef ENABLE_ONEDNN_OPENMP\n context_.src_mem->set_data_handle(\n static_cast<void*>(const_cast<Tinput*>(src_data)), *fwd_stream);\n@@ -339,6 +345,11 @@ class MklDnnMatMulFwdPrimitive : public MklPrimitive {\n }\n \n struct MklDnnMatMulFwdContext context_;\n+\n+#ifdef DNNL_AARCH64_USE_ACL\n+ // Guards Execution()\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n template <typename T, typename Tinput, typename Tweight, typename Tbias,\n@@ -615,6 +626,9 @@ class MklMatMulPrimitive : public MklPrimitive {\n void Execute(const std::shared_ptr<stream>& stream, const Tlhs* a_data,\n const Trhs* b_data, const Toutput* c_data, void* sp_data,\n void* mul_data = nullptr, void* add_data = nullptr) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n #ifndef ENABLE_ONEDNN_OPENMP\n context_.a_mem->set_data_handle(\n static_cast<void*>(const_cast<Tlhs*>(a_data)), *stream);\n@@ -783,6 +797,9 @@ class MklMatMulPrimitive : public MklPrimitive {\n }\n \n struct MklMatMulContext context_;\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n template <typename T, typename Tlhs, typename Trhs, typename Toutput>",
"filename": "tensorflow/core/kernels/mkl/mkl_matmul_ops_common.h",
"status": "modified"
},
{
"diff": "@@ -86,6 +86,9 @@ template <typename T>\n void MklPoolingFwdPrimitive<T>::Execute(const T* src_data, T* dst_data,\n void* ws_data,\n std::shared_ptr<stream> fwd_stream) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n #ifndef ENABLE_ONEDNN_OPENMP\n context_.src_mem->set_data_handle(\n static_cast<void*>(const_cast<T*>(src_data)), *fwd_stream);\n@@ -186,6 +189,9 @@ template <typename T>\n void MklPoolingBwdPrimitive<T>::Execute(const T* diff_dst_data,\n T* diff_src_data, const void* ws_data,\n std::shared_ptr<stream> bwd_stream) {\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex_lock lock(primitive_execution_mu_);\n+#endif\n #ifndef ENABLE_ONEDNN_OPENMP\n context_.diff_dst_mem->set_data_handle(\n static_cast<void*>(const_cast<T*>(diff_dst_data)), *bwd_stream);",
"filename": "tensorflow/core/kernels/mkl/mkl_pooling_ops_common.cc",
"status": "modified"
},
{
"diff": "@@ -25,6 +25,9 @@ limitations under the License.\n #include \"dnnl.hpp\"\n #include \"tensorflow/core/util/mkl_util.h\"\n #include \"tensorflow/core/util/padding.h\"\n+#ifdef DNNL_AARCH64_USE_ACL\n+#include \"tensorflow/core/platform/mutex.h\"\n+#endif\n \n namespace tensorflow {\n \n@@ -147,6 +150,10 @@ class MklPoolingFwdPrimitive : public MklPrimitive {\n };\n \n struct PoolingFwdContext context_;\n+\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n template <typename T>\n@@ -292,6 +299,9 @@ class MklPoolingBwdPrimitive : public MklPrimitive {\n };\n \n struct PoolingBwdContext context_;\n+#ifdef DNNL_AARCH64_USE_ACL\n+ mutex primitive_execution_mu_;\n+#endif\n };\n \n template <typename T>",
"filename": "tensorflow/core/kernels/mkl/mkl_pooling_ops_common.h",
"status": "modified"
}
]
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nsource\r\n\r\n### Tensorflow Version\r\n\r\nmaster\r\n\r\n### Custom Code\r\n\r\nNo\r\n\r\n### OS Platform and Distribution\r\n\r\n_No response_\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n_No response_\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\n_No response_\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\nWe have an inconsistent behavior with lambda variables in a loop in pure python and graph mode:\r\nhttps://docs.python.org/3/faq/programming.html#why-do-lambdas-defined-in-a-loop-with-different-values-all-return-the-same-result\r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nimport tensorflow as tf\r\n\r\ndef test_a():\r\n fns = []\r\n for i in range(3):\r\n fns.append(lambda: print(i))\r\n for f in fns:\r\n f()\r\n\r\n@tf.function\r\ndef test_b():\r\n fns = []\r\n for i in range(3):\r\n fns.append(lambda: print(i))\r\n for f in fns:\r\n f()\r\n\r\ndef test_c():\r\n fns = []\r\n for i in range(3):\r\n fns.append(lambda i=i: print(i))\r\n for f in fns:\r\n f()\r\n\r\n@tf.function \r\ndef test_d():\r\n fns = []\r\n for i in range(3):\r\n fns.append(lambda i=i: print(i))\r\n for f in fns:\r\n f()\r\n\r\ntest_a() \r\nprint(\"==\"*10)\r\ntf.config.run_functions_eagerly(False)\r\ntest_b()\r\nprint(\"==\"*10)\r\ntf.config.run_functions_eagerly(True)\r\ntest_b()\r\nprint(\"==\"*10)\r\ntest_c() \r\nprint(\"==\"*10)\r\ntf.config.run_functions_eagerly(False)\r\ntest_d()\r\nprint(\"==\"*10)\r\ntf.config.run_functions_eagerly(True)\r\ntest_d() \r\n```\r\n\r\n```python\r\n2\r\n2\r\n2\r\n====================\r\n0\r\n1\r\n2\r\n====================\r\n2\r\n2\r\n2\r\n====================\r\n0\r\n1\r\n2\r\n====================\r\n0\r\n1\r\n2\r\n====================\r\n0\r\n1\r\n2\r\n```\r\n### Relevant log output\r\n\r\n`test_b` is wrongly working \"as expected\" in graph mode:\r\n\r\n\r\n```python\r\n# coding=utf-8\r\ndef tf__test():\r\n with ag__.FunctionScope('test', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:\r\n fns = []\r\n\r\n def get_state():\r\n return ()\r\n\r\n def set_state(block_vars):\r\n pass\r\n\r\n def loop_body(itr):\r\n i = itr\r\n ag__.converted_call(ag__.ld(fns).append, (ag__.autograph_artifact((lambda : ag__.ld(print)(ag__.ld(i)))),), None, fscope)\r\n i = ag__.Undefined('i')\r\n ag__.for_stmt(ag__.converted_call(ag__.ld(range), (3,), None, fscope), None, loop_body, get_state, set_state, (), {'iterate_names': 'i'})\r\n\r\n def get_state_1():\r\n return ()\r\n\r\n def set_state_1(block_vars):\r\n pass\r\n\r\n def loop_body_1(itr_1):\r\n f = itr_1\r\n ag__.converted_call(ag__.ld(f), (), None, fscope)\r\n f = ag__.Undefined('f')\r\n ag__.for_stmt(ag__.ld(fns), None, loop_body_1, get_state_1, set_state_1, (), {'iterate_names': 'f'})\r\n```\r\n</details>",
"comments": [
{
"body": "See more at https://github.com/keras-team/keras-cv/pull/432\r\n\r\n/cc @mdanatg",
"created_at": "2022-05-12T22:20:00Z"
},
{
"body": "As referenced in the official Python FAQ:\r\n\r\n> Note that this behaviour is not peculiar to lambdas, but applies to regular functions too.",
"created_at": "2022-05-12T23:31:19Z"
},
{
"body": "I think it's because we pass the loop variable through a function argument, which is enough to avoid the closure aliasing:\r\n\r\n```\r\n def loop_body(itr):\r\n i = itr\r\n ag__.converted_call(ag__.ld(fns).append, (ag__.autograph_artifact((lambda : ag__.ld(i))),), None, fscope)\r\n```\r\n\r\nIn the code above, the lambda would close over the local `i` which has a copy of the value.\r\n\r\nThis only happens for the `for_stmt` operator, which passes the iterate as an argument. If we rewrite the test as a while loop, so that `i` is closed-ver by the function body, things are once again quirky as intended:\r\n\r\n```\r\nimport tensorflow as tf\r\n\r\ndef test():\r\n fns = []\r\n i = 0\r\n while i < 3:\r\n fns.append(lambda: print(i))\r\n i += 1\r\n for f in fns:\r\n f()\r\n\r\ntest()\r\n\r\n\r\ntf.autograph.set_verbosity(0, True)\r\n\r\n@tf.function(autograph=True)\r\ndef test():\r\n fns = []\r\n i = 0\r\n while i < 3:\r\n fns.append(lambda: print(i))\r\n i += 1\r\n for f in fns:\r\n f()\r\n\r\ntest()\r\n```\r\n\r\nThis means that the fix is also to avoid passing the iterate as argument to the loop body, and instead rely on the `get_state`/`set_state` functions, as is the case of the while loop.",
"created_at": "2022-05-13T02:16:20Z"
},
{
"body": "Yes is what I have suspected:\r\n\r\n```python\r\nfrom tensorflow.python.autograph.impl import api\r\nag__ = api._TRANSPILER.get_extra_locals()['ag__'] # pylint:disable=protected-access\r\ndef tf__test_for():\r\n with ag__.FunctionScope('test', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:\r\n fns = []\r\n\r\n def get_state():\r\n return ()\r\n\r\n def set_state(block_vars):\r\n pass\r\n\r\n def loop_body(itr):\r\n i = itr\r\n ag__.converted_call(ag__.ld(fns).append, (ag__.autograph_artifact((lambda : ag__.ld(print)((ag__.converted_call(ag__.ld(str), (ag__.ld(i),), None, fscope))))),), None, fscope)\r\n i = ag__.Undefined('i')\r\n ag__.for_stmt(ag__.converted_call(ag__.ld(range), (3,), None, fscope), None, loop_body, get_state, set_state, (), {'iterate_names': 'i'})\r\n\r\n def get_state_1():\r\n return ()\r\n\r\n def set_state_1(block_vars):\r\n pass\r\n\r\n def loop_body_1(itr_1):\r\n f = itr_1\r\n ag__.converted_call(ag__.ld(f), (), None, fscope)\r\n f = ag__.Undefined('f')\r\n ag__.for_stmt(ag__.ld(fns), None, loop_body_1, get_state_1, set_state_1, (), {'iterate_names': 'f'})\r\n\r\ndef tf__test_while():\r\n with ag__.FunctionScope('test_while', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:\r\n fns = []\r\n i = 0\r\n\r\n def get_state():\r\n return (i,)\r\n\r\n def set_state(vars_):\r\n nonlocal i\r\n (i,) = vars_\r\n\r\n def loop_body():\r\n nonlocal i\r\n ag__.converted_call(ag__.ld(fns).append, (ag__.autograph_artifact((lambda : ag__.ld(print)(ag__.ld(i)))),), None, fscope)\r\n i = ag__.ld(i)\r\n i += 1\r\n\r\n def loop_test():\r\n return (ag__.ld(i) < 3)\r\n ag__.while_stmt(loop_test, loop_body, get_state, set_state, ('i',), {})\r\n\r\n def get_state_1():\r\n return ()\r\n\r\n def set_state_1(block_vars):\r\n pass\r\n\r\n def loop_body_1(itr):\r\n f = itr\r\n ag__.converted_call(ag__.ld(f), (), None, fscope)\r\n f = ag__.Undefined('f')\r\n ag__.for_stmt(ag__.ld(fns), None, loop_body_1, get_state_1, set_state_1, (), {'iterate_names': 'f'})\r\ntf__test_for()\r\nprint(\"====\")\r\ntf__test_while()\r\n```\r\n```python\r\n0\r\n1\r\n2\r\n====\r\n3\r\n3\r\n3\r\n\r\n```\r\n\r\nAnd modify your while example to correctly get the output we \"expect\":\r\n\r\n```python\r\nimport tensorflow as tf\r\n\r\ndef test():\r\n fns = []\r\n i = 0\r\n while i < 3:\r\n fns.append(lambda i=i: print(i))\r\n i += 1\r\n for f in fns:\r\n f()\r\n\r\ntest()\r\n\r\n\r\ntf.autograph.set_verbosity(0, True)\r\n\r\n@tf.function(autograph=True)\r\ndef test():\r\n fns = []\r\n i = 0\r\n while i < 3:\r\n fns.append(lambda i=i: print(i))\r\n i += 1\r\n for f in fns:\r\n f()\r\n\r\ntest()\r\n```\r\n\r\n```python\r\n0\r\n1\r\n2\r\n0\r\n1\r\n2\r\n```",
"created_at": "2022-05-13T11:43:12Z"
},
{
"body": "@mdanatg I've manually rewritten the transformation output. Do we need to produce something like this for the `lambda:` case?\r\n\r\n```python\r\n\r\nfrom tensorflow.python.autograph.impl import api\r\nag__ = api._TRANSPILER.get_extra_locals()['ag__'] # pylint:disable=protected-access\r\ndef tf__test_for():\r\n with ag__.FunctionScope('test', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:\r\n fns = []\r\n i = 0\r\n def get_state():\r\n return (i,)\r\n\r\n def set_state(block_vars):\r\n nonlocal i\r\n (i,) = block_vars\r\n\r\n def loop_body(itr):\r\n nonlocal i\r\n ag__.converted_call(ag__.ld(fns).append, (ag__.autograph_artifact((lambda : ag__.ld(print)((ag__.converted_call(ag__.ld(str), (ag__.ld(i),), None, fscope))))),), None, fscope)\r\n i = ag__.ld(i)\r\n i += 1\r\n ag__.for_stmt(ag__.converted_call(ag__.ld(range), (3,), None, fscope), None, loop_body, get_state, set_state, (), {'iterate_names': 'i'})\r\n\r\n def get_state_1():\r\n return ()\r\n\r\n def set_state_1(block_vars):\r\n pass\r\n\r\n def loop_body_1(itr_1):\r\n f = itr_1\r\n ag__.converted_call(ag__.ld(f), (), None, fscope)\r\n f = ag__.Undefined('f')\r\n ag__.for_stmt(ag__.ld(fns), None, loop_body_1, get_state_1, set_state_1, (), {'iterate_names': 'f'})\r\n\r\n```",
"created_at": "2022-05-13T14:04:25Z"
},
{
"body": "Yes, something like that. And then the loop_body function would be a regular thunk: `def loop_body():`. We may also need to initialize `i` with Undefined, rather than 0, and might also need to replace `(), {'iterate_names': 'i'}` with just `('i',)`, but not sure.",
"created_at": "2022-05-13T14:55:17Z"
},
{
"body": "Do we want to handle `iter` as `nolocal`? As in the helper function above it is only in the `undefined` bucket:\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/44e84cebef5a89a0840f8d401819c25af41ec3db/tensorflow/python/autograph/converters/control_flow.py#L170-L199\r\n\r\n\r\n",
"created_at": "2022-05-13T19:36:00Z"
},
{
"body": "Yes, I think we do.",
"created_at": "2022-05-13T19:46:49Z"
},
{
"body": "I don't know if it makes sense:\r\n\r\nI've changed:\r\n\r\n```python\r\n if s in live_in or s in live_out or s in nonlocals or \\\r\n (s not in live_in and s not in live_out):\r\n```\r\n\r\n```python \r\nimport tensorflow as tf\r\ntf.autograph.set_verbosity(0, True)\r\n@tf.function\r\ndef test_b():\r\n fns = []\r\n for i in range(3):\r\n fns.append(lambda: print(i))\r\n for f in fns:\r\n f()\r\ntest_b()\r\n```\r\n\r\n```python \r\n2\r\n2\r\n2\r\n```\r\n\r\nAnd\r\n\r\n```python\r\nimport tensorflow as tf\r\ntf.autograph.set_verbosity(0, True)\r\n@tf.function\r\ndef test_b():\r\n fns = []\r\n for i in range(3):\r\n fns.append(lambda i=i: print(i))\r\n for f in fns:\r\n f()\r\ntest_b()\r\n```\r\n\r\n```python\r\n0\r\n1\r\n2\r\n```\r\n\r\nSo the output is correct but the transformation, surely, it is still quite ugly:\r\n\r\n```python\r\n\r\n# coding=utf-8\r\ndef tf__test_b():\r\n with ag__.FunctionScope('test_b', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:\r\n fns = []\r\n\r\n def get_state():\r\n return (i,)\r\n\r\n def set_state(vars_):\r\n nonlocal i\r\n (i,) = vars_\r\n\r\n def loop_body(itr):\r\n nonlocal i\r\n i = itr\r\n ag__.converted_call(ag__.ld(fns).append, (ag__.autograph_artifact((lambda : ag__.ld(print)(ag__.ld(i)))),), None, fscope)\r\n i = ag__.Undefined('i')\r\n ag__.for_stmt(ag__.converted_call(ag__.ld(range), (3,), None, fscope), None, loop_body, get_state, set_state, ('i',), {'iterate_names': 'i'})\r\n\r\n def get_state_1():\r\n return (f,)\r\n\r\n def set_state_1(vars_):\r\n nonlocal f\r\n (f,) = vars_\r\n\r\n def loop_body_1(itr_1):\r\n nonlocal f\r\n f = itr_1\r\n ag__.converted_call(ag__.ld(f), (), None, fscope)\r\n f = ag__.Undefined('f')\r\n ag__.for_stmt(ag__.ld(fns), None, loop_body_1, get_state_1, set_state_1, ('f',), {'iterate_names': 'f'})\r\n```",
"created_at": "2022-05-13T20:34:40Z"
},
{
"body": "P.s. as a side note, in the `BUILD` the loop scoping integration test is not registered. How the CI is running this currently?:\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/f2edfb6331c0563957bee6f73da9b2e09a7a8750/tensorflow/python/autograph/tests/BUILD#L26-L27\r\n\r\nIf it is activated some loop_scoping tests are failing:\r\n```bazel\r\n# # Scoping and modularity\r\nreference_test(name = \"loop_scoping_test\")\r\n```",
"created_at": "2022-05-13T22:54:13Z"
},
{
"body": "Ah, that's not intended. Can add it to the build file and mark the failing ones with self.skipTest, then file an issue to get them to pass?\r\n\r\nFor the transformation, I'm not sure, the rules are quite finnicky, and I'm not sure I'd change them without extensive testing. Likely still safer to manually add the iterate to the list of loop_vars.",
"created_at": "2022-05-13T23:24:16Z"
},
{
"body": "Side note - I just realized the limitations section of autograph does seem to document this case: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/autograph/g3doc/reference/limitations.md#variables-closed-over-by-lambda-functions",
"created_at": "2022-05-23T20:13:00Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56089\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/56089\">No</a>\n",
"created_at": "2022-08-02T17:32:35Z"
},
{
"body": "Hello, I have just discovered this in my app logs:\r\n\r\n```\r\nWARNING:tensorflow:From /home/clime/.virtualenvs/keras/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23.\r\nInstructions for updating:\r\nLambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089\r\n```\r\n\r\nIs there anything I should look for in my code or is this a generic warning that displays to anyone? To be more precise, does the fact that I am seeing this warning mean that I am actually using something which is now deprecated?",
"created_at": "2023-02-04T16:35:36Z"
},
{
"body": "@clime We hope to align to the python behavior after the deprecation:\n\nhttps://docs.python.org/3/faq/programming.html#why-do-lambdas-defined-in-a-loop-with-different-values-all-return-the-same-result",
"created_at": "2023-02-04T17:01:13Z"
},
{
"body": "> @clime We hope to align to the python behavior after the deprecation:\r\n> \r\n> https://docs.python.org/3/faq/programming.html#why-do-lambdas-defined-in-a-loop-with-different-values-all-return-the-same-result\r\n\r\nMy question rather is, if seeing that warning on my screen necessarily means that I am triggering that deprecated behavior (i.e. I am using lambda somewhere in @tf.function or similar).",
"created_at": "2023-02-04T18:49:02Z"
},
{
"body": "Do you have a small code gist to reproduce this?",
"created_at": "2023-02-04T19:18:39Z"
},
{
"body": "> Do you have a small code gist to reproduce this?\r\n\r\nSorry, I don't understand what I should be reproducing. I just have a pretty big code base and I just want to know how much relevant the warning is for me :). ",
"created_at": "2023-02-04T19:26:03Z"
},
{
"body": "I guess the answer is here: https://github.com/tensorflow/tensorflow/commit/6197fa37555b710a35e84c1b8e1aab2bcce9d46b",
"created_at": "2023-02-04T19:29:35Z"
},
{
"body": "If it was internal someone introduced a new deprecation case internally ignoring the warning.\n",
"created_at": "2023-02-04T20:50:10Z"
},
{
"body": "Are there any instructions on how to hide this warning? :P \r\n```\r\npython3.7/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23.\r\nInstructions for updating:\r\nLambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089\r\n```",
"created_at": "2023-02-14T06:10:37Z"
},
{
"body": "It is suppressed in nightly and in the next release ",
"created_at": "2023-02-14T09:09:52Z"
},
{
"body": "Hi,\r\nHow can one disable this warning so that it is not printed? I am using TF 2.11.1 and I cant really change my TF version.\r\n\r\n> It is suppressed in nightly and in the next release\r\n\r\n",
"created_at": "2023-10-09T07:52:41Z"
}
],
"number": 56089,
"title": "[Autograph] Inconsistent behaviour with lambda variable in loop"
}
|
{
"body": "Add a test to cover and then fix #56089\r\n\r\n\r\n~This is based on https://github.com/tensorflow/tensorflow/pull/56106 and it will be semplified/rebased when merged.~\r\n\r\n/cc @mdanatg \r\nLet me know about the test design here and how we want to cover also the original case. \r\n\r\nWhen we are satisfied by the test coverage we could start to try some fixes.",
"number": 56119,
"review_comments": [
{
"body": "I think it's a bit overkill to thread it through arguments. I'd say, just add the symbols to loop_vars directly here, after having called _get_block_vars.",
"created_at": "2022-05-17T14:16:41Z"
},
{
"body": "Once we do this, we also need to remove the iterate arg from e.g. here: `def body_name(iterate_arg_name):`. In essence, we're changing how the iterate variable is passed to the loop body.",
"created_at": "2022-05-17T14:18:02Z"
},
{
"body": "Yes I've tried to do this but If I remember correctly there was a side effect so I've not commited that part.\nI need to check It again.",
"created_at": "2022-05-17T14:35:02Z"
},
{
"body": "Oh and what you want to add to `loop_vars` is not iter_scope.bound, but the `iter_arg_name` being created further below. So basically if you have `for x, y in something:` then you still want just: (1) one `itr` and a `x, y = itr` in the loop body.\r\n\r\nSo it's definitely a more invasive change.",
"created_at": "2022-05-17T14:42:22Z"
},
{
"body": "I've recovered the original API here.",
"created_at": "2022-05-17T17:34:29Z"
},
{
"body": "> remove the iterate arg from e.g. here: def body_name(iterate_arg_name)\r\n\r\nThis requires to modify the template right?\r\n",
"created_at": "2022-05-17T17:36:06Z"
},
{
"body": "@mdanatg We could remove this when you are satisfied with the converted output",
"created_at": "2022-05-19T17:52:49Z"
},
{
"body": "Don't forget to remove these.",
"created_at": "2022-05-19T19:06:16Z"
},
{
"body": "If I did a thorough job adding tests, you might need to update liveness_test.py as well.",
"created_at": "2022-05-19T19:06:37Z"
},
{
"body": "Done",
"created_at": "2022-05-19T19:18:29Z"
},
{
"body": "Done",
"created_at": "2022-05-19T19:18:37Z"
},
{
"body": "@mdanatg This is just quick hack to pass the test. \r\nI suppose this emerged as now variables captured in lamba are `live_out` so `_verify_tf_cond_branch_` check in the autograph operator has a constrain check to have these in the else branch.\r\n",
"created_at": "2022-05-19T23:40:56Z"
},
{
"body": "@mdanatg This is just quick hack to pass the test.\r\nI suppose this emerged as now variables captured in `lamba` are `live_out` so `_verify_tf_cond_branch_ check` in the autograph operator does a constrain check to have these initialized in the \"augmented\" else branch.",
"created_at": "2022-05-20T09:41:39Z"
},
{
"body": "We are not covering this case with the current tests at:\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/191f0fe3e9de8a7f708a8b0106a1654c797cc573/tensorflow/python/autograph/operators/control_flow_test.py#L1274-L1280",
"created_at": "2022-05-20T09:45:18Z"
},
{
"body": "This is the full conversion:\r\n```python\r\n# coding=utf-8\r\ndef tf__non_max_suppression_padded_v2(boxes, scores, max_output_size, iou_threshold=None, score_threshold=None, sorted_input=None, canonicalized_coordinates=None, tile_size=None):\r\n \r\n with ag__.FunctionScope('non_max_suppression_padded_v2', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:\r\n do_return = False\r\n retval_ = ag__.UndefinedReturnValue()\r\n\r\n @ag__.autograph_artifact\r\n def _sort_scores_and_boxes(scores, boxes):\r\n with ag__.FunctionScope('_sort_scores_and_boxes', 'fscope_1', ag__.STD) as fscope_1:\r\n do_return_1 = False\r\n retval__1 = ag__.UndefinedReturnValue()\r\n with ag__.ld(ops).name_scope('sort_scores_and_boxes'):\r\n batch_size = ag__.converted_call(ag__.ld(array_ops).shape, (ag__.ld(boxes),), None, fscope_1)[0]\r\n num_boxes = ag__.converted_call(ag__.ld(array_ops).shape, (ag__.ld(boxes),), None, fscope_1)[1]\r\n sorted_scores_indices = ag__.converted_call(ag__.ld(sort_ops).argsort, (ag__.ld(scores),), dict(axis=1, direction='DESCENDING'), fscope_1)\r\n index_offsets = ag__.converted_call(ag__.ld(math_ops).range, (ag__.ld(batch_size),), None, fscope_1) * ag__.ld(num_boxes)\r\n indices = ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.ld(sorted_scores_indices) + ag__.converted_call(ag__.ld(array_ops).expand_dims, (ag__.ld(index_offsets), 1), None, fscope_1), [-1]), None, fscope_1)\r\n sorted_scores = ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.converted_call(ag__.ld(array_ops).gather, (ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.ld(scores), [-1]), None, fscope_1), ag__.ld(indices)), None, fscope_1), [ag__.ld(batch_size), -1]), None, fscope_1)\r\n sorted_boxes = ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.converted_call(ag__.ld(array_ops).gather, (ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.ld(boxes), [-1, 4]), None, fscope_1), ag__.ld(indices)), None, fscope_1), [ag__.ld(batch_size), -1, 4]), None, fscope_1)\r\n try:\r\n do_return_1 = True\r\n retval__1 = (ag__.ld(sorted_scores), ag__.ld(sorted_boxes), ag__.ld(sorted_scores_indices))\r\n except:\r\n do_return_1 = False\r\n raise\r\n return fscope_1.ret(retval__1, do_return_1)\r\n batch_dims = ag__.converted_call(ag__.ld(array_ops).shape, (ag__.ld(boxes),), None, fscope)[:-2]\r\n num_boxes = ag__.converted_call(ag__.ld(array_ops).shape, (ag__.ld(boxes),), None, fscope)[-2]\r\n boxes = ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.ld(boxes), [-1, ag__.ld(num_boxes), 4]), None, fscope)\r\n scores = ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.ld(scores), [-1, ag__.ld(num_boxes)]), None, fscope)\r\n batch_size = ag__.converted_call(ag__.ld(array_ops).shape, (ag__.ld(boxes),), None, fscope)[0]\r\n\r\n def get_state():\r\n return (boxes, scores)\r\n\r\n def set_state(vars_):\r\n nonlocal boxes, scores\r\n (boxes, scores) = vars_\r\n\r\n def if_body():\r\n nonlocal boxes, scores\r\n with ag__.ld(ops).name_scope('filter_by_score'):\r\n score_mask = ag__.converted_call(ag__.ld(math_ops).cast, (ag__.ld(scores) > ag__.ld(score_threshold), ag__.ld(scores).dtype), None, fscope)\r\n scores = ag__.ld(scores)\r\n scores *= score_mask\r\n box_mask = ag__.converted_call(ag__.ld(array_ops).expand_dims, (ag__.converted_call(ag__.ld(math_ops).cast, (ag__.ld(score_mask), ag__.ld(boxes).dtype), None, fscope), 2), None, fscope)\r\n boxes = ag__.ld(boxes)\r\n boxes *= box_mask\r\n\r\n def else_body():\r\n nonlocal boxes, scores\r\n pass\r\n score_mask = ag__.Undefined('score_mask')\r\n box_mask = ag__.Undefined('box_mask')\r\n ag__.if_stmt(ag__.ld(score_threshold) != ag__.converted_call(ag__.ld(float), ('-inf',), None, fscope), if_body, else_body, get_state, set_state, ('boxes', 'scores'), 2)\r\n\r\n def get_state_1():\r\n return (boxes, x_1, x_2, y_1, y_2)\r\n\r\n def set_state_1(vars_):\r\n nonlocal x_1, boxes, y_2, x_2, y_1\r\n (boxes, x_1, x_2, y_1, y_2) = vars_\r\n\r\n def if_body_1():\r\n nonlocal x_1, boxes, y_2, x_2, y_1\r\n with ag__.ld(ops).name_scope('canonicalize_coordinates'):\r\n (y_1, x_1, y_2, x_2) = ag__.converted_call(ag__.ld(array_ops).split, (), dict(value=ag__.ld(boxes), num_or_size_splits=4, axis=2), fscope)\r\n y_1_is_min = ag__.converted_call(ag__.ld(math_ops).reduce_all, (ag__.converted_call(ag__.ld(math_ops).less_equal, (ag__.ld(y_1)[0, 0, 0], ag__.ld(y_2)[0, 0, 0]), None, fscope),), None, fscope)\r\n (y_min, y_max) = ag__.converted_call(ag__.ld(control_flow_ops).cond, (ag__.ld(y_1_is_min), ag__.autograph_artifact(lambda : (ag__.ld(y_1), ag__.ld(y_2))), ag__.autograph_artifact(lambda : (ag__.ld(y_2), ag__.ld(y_1)))), None, fscope)\r\n x_1_is_min = ag__.converted_call(ag__.ld(math_ops).reduce_all, (ag__.converted_call(ag__.ld(math_ops).less_equal, (ag__.ld(x_1)[0, 0, 0], ag__.ld(x_2)[0, 0, 0]), None, fscope),), None, fscope)\r\n (x_min, x_max) = ag__.converted_call(ag__.ld(control_flow_ops).cond, (ag__.ld(x_1_is_min), ag__.autograph_artifact(lambda : (ag__.ld(x_1), ag__.ld(x_2))), ag__.autograph_artifact(lambda : (ag__.ld(x_2), ag__.ld(x_1)))), None, fscope)\r\n boxes = ag__.converted_call(ag__.ld(array_ops).concat, ([ag__.ld(y_min), ag__.ld(x_min), ag__.ld(y_max), ag__.ld(x_max)],), dict(axis=2), fscope)\r\n\r\n def else_body_1():\r\n nonlocal x_1, boxes, y_2, x_2, y_1\r\n pass\r\n x_1 = ag__.Undefined('x_1')\r\n x_max = ag__.Undefined('x_max')\r\n x_min = ag__.Undefined('x_min')\r\n x_2 = ag__.Undefined('x_2')\r\n y_2 = ag__.Undefined('y_2')\r\n y_min = ag__.Undefined('y_min')\r\n y_1_is_min = ag__.Undefined('y_1_is_min')\r\n x_1_is_min = ag__.Undefined('x_1_is_min')\r\n y_max = ag__.Undefined('y_max')\r\n y_1 = ag__.Undefined('y_1')\r\n ag__.if_stmt(ag__.not_(ag__.ld(canonicalized_coordinates)), if_body_1, else_body_1, get_state_1, set_state_1, ('boxes', 'x_1', 'x_2', 'y_1', 'y_2'), 5)\r\n\r\n def get_state_2():\r\n return (boxes, scores, sorted_indices)\r\n\r\n def set_state_2(vars_):\r\n nonlocal boxes, scores, sorted_indices\r\n (boxes, scores, sorted_indices) = vars_\r\n\r\n def if_body_2():\r\n nonlocal boxes, scores, sorted_indices\r\n (scores, boxes, sorted_indices) = ag__.converted_call(ag__.ld(_sort_scores_and_boxes), (ag__.ld(scores), ag__.ld(boxes)), None, fscope)\r\n\r\n def else_body_2():\r\n nonlocal boxes, scores, sorted_indices\r\n sorted_indices = ag__.converted_call(ag__.ld(array_ops).zeros_like, (ag__.ld(scores),), dict(dtype=ag__.ld(dtypes).int32), fscope)\r\n sorted_indices = ag__.Undefined('sorted_indices')\r\n ag__.if_stmt(ag__.not_(ag__.ld(sorted_input)), if_body_2, else_body_2, get_state_2, set_state_2, ('boxes', 'scores', 'sorted_indices'), 3)\r\n pad = ag__.converted_call(ag__.ld(math_ops).cast, (ag__.converted_call(ag__.ld(math_ops).ceil, (ag__.converted_call(ag__.ld(math_ops).cast, (ag__.converted_call(ag__.ld(math_ops).maximum, (ag__.ld(num_boxes), ag__.ld(max_output_size)), None, fscope), ag__.ld(dtypes).float32), None, fscope) / ag__.converted_call(ag__.ld(math_ops).cast, (ag__.ld(tile_size), ag__.ld(dtypes).float32), None, fscope),), None, fscope), ag__.ld(dtypes).int32), None, fscope) * ag__.ld(tile_size) - ag__.ld(num_boxes)\r\n boxes = ag__.converted_call(ag__.ld(array_ops).pad, (ag__.converted_call(ag__.ld(math_ops).cast, (ag__.ld(boxes), ag__.ld(dtypes).float32), None, fscope), [[0, 0], [0, ag__.ld(pad)], [0, 0]]), None, fscope)\r\n scores = ag__.converted_call(ag__.ld(array_ops).pad, (ag__.converted_call(ag__.ld(math_ops).cast, (ag__.ld(scores), ag__.ld(dtypes).float32), None, fscope), [[0, 0], [0, ag__.ld(pad)]]), None, fscope)\r\n num_boxes_after_padding = ag__.ld(num_boxes) + ag__.ld(pad)\r\n num_iterations = ag__.ld(num_boxes_after_padding) // ag__.ld(tile_size)\r\n\r\n @ag__.autograph_artifact\r\n def _loop_cond(unused_boxes, unused_threshold, output_size, idx):\r\n with ag__.FunctionScope('_loop_cond', 'fscope_2', ag__.STD) as fscope_2:\r\n do_return_2 = False\r\n retval__2 = ag__.UndefinedReturnValue()\r\n try:\r\n do_return_2 = True\r\n retval__2 = ag__.converted_call(ag__.ld(math_ops).logical_and, (ag__.converted_call(ag__.ld(math_ops).reduce_min, (ag__.ld(output_size),), None, fscope_2) < ag__.ld(max_output_size), ag__.ld(idx) < ag__.ld(num_iterations)), None, fscope_2)\r\n except:\r\n do_return_2 = False\r\n raise\r\n return fscope_2.ret(retval__2, do_return_2)\r\n\r\n @ag__.autograph_artifact\r\n def suppression_loop_body(boxes, iou_threshold, output_size, idx):\r\n with ag__.FunctionScope('suppression_loop_body', 'fscope_3', ag__.STD) as fscope_3:\r\n do_return_3 = False\r\n retval__3 = ag__.UndefinedReturnValue()\r\n try:\r\n do_return_3 = True\r\n retval__3 = ag__.converted_call(ag__.ld(_suppression_loop_body), (ag__.ld(boxes), ag__.ld(iou_threshold), ag__.ld(output_size), ag__.ld(idx), ag__.ld(tile_size)), None, fscope_3)\r\n except:\r\n do_return_3 = False\r\n raise\r\n return fscope_3.ret(retval__3, do_return_3)\r\n (selected_boxes, _, output_size, _) = ag__.converted_call(ag__.ld(control_flow_ops).while_loop, (ag__.ld(_loop_cond), ag__.ld(suppression_loop_body), [ag__.ld(boxes), ag__.ld(iou_threshold), ag__.converted_call(ag__.ld(array_ops).zeros, ([ag__.ld(batch_size)], ag__.ld(dtypes).int32), None, fscope), ag__.converted_call(ag__.ld(constant_op).constant, (0,), None, fscope)]), dict(shape_invariants=[ag__.converted_call(ag__.ld(tensor_shape).TensorShape, ([None, None, 4],), None, fscope), ag__.converted_call(ag__.ld(tensor_shape).TensorShape, ([],), None, fscope), ag__.converted_call(ag__.ld(tensor_shape).TensorShape, ([None],), None, fscope), ag__.converted_call(ag__.ld(tensor_shape).TensorShape, ([],), None, fscope)]), fscope)\r\n num_valid = ag__.converted_call(ag__.ld(math_ops).minimum, (ag__.ld(output_size), ag__.ld(max_output_size)), None, fscope)\r\n idx = ag__.ld(num_boxes_after_padding) - ag__.converted_call(ag__.ld(math_ops).cast, (ag__.converted_call(ag__.ld(nn_ops).top_k, (ag__.converted_call(ag__.ld(math_ops).cast, (ag__.converted_call(ag__.ld(math_ops).reduce_any, (ag__.ld(selected_boxes) > 0, [2]), None, fscope), ag__.ld(dtypes).int32), None, fscope) * ag__.converted_call(ag__.ld(array_ops).expand_dims, (ag__.converted_call(ag__.ld(math_ops).range, (ag__.ld(num_boxes_after_padding), 0, -1), None, fscope), 0), None, fscope), ag__.ld(max_output_size)), None, fscope)[0], ag__.ld(dtypes).int32), None, fscope)\r\n idx = ag__.converted_call(ag__.ld(math_ops).minimum, (ag__.ld(idx), ag__.ld(num_boxes) - 1), None, fscope)\r\n\r\n def get_state_3():\r\n return (idx,)\r\n\r\n def set_state_3(vars_):\r\n nonlocal idx\r\n (idx,) = vars_\r\n\r\n def if_body_3():\r\n nonlocal idx\r\n index_offsets = ag__.converted_call(ag__.ld(math_ops).range, (ag__.ld(batch_size),), None, fscope) * ag__.ld(num_boxes)\r\n gather_idx = ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.ld(idx) + ag__.converted_call(ag__.ld(array_ops).expand_dims, (ag__.ld(index_offsets), 1), None, fscope), [-1]), None, fscope)\r\n idx = ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.converted_call(ag__.ld(array_ops).gather, (ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.ld(sorted_indices), [-1]), None, fscope), ag__.ld(gather_idx)), None, fscope), [ag__.ld(batch_size), -1]), None, fscope)\r\n\r\n def else_body_3():\r\n nonlocal idx\r\n pass\r\n index_offsets = ag__.Undefined('index_offsets')\r\n gather_idx = ag__.Undefined('gather_idx')\r\n ag__.if_stmt(ag__.not_(ag__.ld(sorted_input)), if_body_3, else_body_3, get_state_3, set_state_3, ('idx',), 1)\r\n invalid_index = ag__.converted_call(ag__.ld(array_ops).zeros, ([ag__.ld(batch_size), ag__.ld(max_output_size)],), dict(dtype=ag__.ld(dtypes).int32), fscope)\r\n idx_index = ag__.converted_call(ag__.ld(array_ops).expand_dims, (ag__.converted_call(ag__.ld(math_ops).range, (ag__.ld(max_output_size),), None, fscope), 0), None, fscope)\r\n num_valid_expanded = ag__.converted_call(ag__.ld(array_ops).expand_dims, (ag__.ld(num_valid), 1), None, fscope)\r\n idx = ag__.converted_call(ag__.ld(array_ops).where, (ag__.ld(idx_index) < ag__.ld(num_valid_expanded), ag__.ld(idx), ag__.ld(invalid_index)), None, fscope)\r\n num_valid = ag__.converted_call(ag__.ld(array_ops).reshape, (ag__.ld(num_valid), ag__.ld(batch_dims)), None, fscope)\r\n try:\r\n do_return = True\r\n retval_ = (ag__.ld(idx), ag__.ld(num_valid))\r\n except:\r\n do_return = False\r\n raise\r\n return fscope.ret(retval_, do_return)\r\n```",
"created_at": "2022-05-20T20:09:16Z"
},
{
"body": "So if you see the problem is exactly here. \r\nThis is the `else_body` (augmented) but without our \"dummy\" else implementation:\r\n```python \r\nif not canonicalized_coordinates: \r\n```\r\n\r\n```python\r\ndef else_body_1():\r\n nonlocal x_1, boxes, y_2, x_2, y_1\r\n pass\r\n```\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/7806ae568aba65ed87fccec95d72151f0365939c/tensorflow/python/ops/image_ops_impl.py#L5573-L5585",
"created_at": "2022-05-20T20:34:05Z"
},
{
"body": "Implementing our else workarund is:\r\n```python\r\ndef else_body_1():\r\n nonlocal x_1, boxes, y_2, y_1, x_2\r\n (y_1, x_1, y_2, x_2) = ag__.converted_call(ag__.ld(array_ops).split, (), dict(value=ag__.ld(boxes), num_or_size_splits=4, axis=2), fscope)\r\n```\r\nhttps://github.com/tensorflow/tensorflow/blob/7bcaba629b7d5022b654ba6ed78ad7470ce412aa/tensorflow/python/ops/image_ops_impl.py#L5571-L5589\r\n\r\nAnd it passes the check.",
"created_at": "2022-05-20T20:43:35Z"
},
{
"body": "Basically it is the same case of few line below in master `sorted_indices` (nonlocal and undefined like are our lambda args):\r\n\r\nhttps://github.com/tensorflow/tensorflow/blob/7806ae568aba65ed87fccec95d72151f0365939c/tensorflow/python/ops/image_ops_impl.py#L5587-L5591",
"created_at": "2022-05-20T21:03:53Z"
},
{
"body": "Very nice analysis! I agree with your conclusions, but I fear that even though correct, we would cause quite a bit of disruption for many users; most might be unable to fix it quickly. \r\n\r\nEven with safeguards in place, we might still break enough people to force a rollback, but I think that's worth giving a shot.\r\n\r\nSo what I'm thinking is adding an AST annotation to all the lambdas we create internally, to denote them to be \"used locally\", and that static analysis can assume they will not be used later.",
"created_at": "2022-05-23T13:46:10Z"
},
{
"body": "Just a reminder. We decided that we need to talk about how to track in source lambdas when they are stored in non-local containers (for a late evaluation).",
"created_at": "2022-05-23T16:31:30Z"
},
{
"body": "A small example:\r\n```python\r\nimport tensorflow as tf\r\n@tf.function\r\ndef test(b):\r\n if (b):\r\n x=1\r\n y=2\r\n z=3\r\n p = tf.cond([True], lambda: x, lambda: y)\r\n else:\r\n p = 0\r\n x = 0\r\n y = 0\r\n return(p)\r\nprint(test(tf.constant(True)))\r\n```\r\n\r\nWe cannot explicit remove the else branch or remove `p, x, y` initializations in the else branch as these are mandatory. Of course we could exclude `z` init in the else branch:\r\n\r\n ```python\r\nValueError: 'p' must also be initialized in the else branch\r\n````\r\n\r\n\r\n```python\r\ndef tf__test(b):\r\n with ag__.FunctionScope('test', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:\r\n do_return = False\r\n retval_ = ag__.UndefinedReturnValue()\r\n\r\n def get_state_1():\r\n return (p, x, y)\r\n\r\n def set_state_1(vars_):\r\n nonlocal y, p, x\r\n (p, x, y) = vars_\r\n\r\n def if_body():\r\n nonlocal y, p, x\r\n x = 1\r\n y = 2\r\n z = 3\r\n\r\n def get_state():\r\n return (p,)\r\n\r\n def set_state(vars_):\r\n nonlocal p\r\n (p,) = vars_\r\n\r\n def loop_body(itr):\r\n nonlocal p\r\n i = itr\r\n p = ag__.converted_call(ag__.ld(tf).cond, ([True], ag__.autograph_artifact((lambda : ag__.ld(x))), ag__.autograph_artifact((lambda : ag__.ld(y)))), None, fscope)\r\n i = ag__.Undefined('i')\r\n p = ag__.Undefined('p')\r\n ag__.for_stmt([0, 1, 2], None, loop_body, get_state, set_state, ('p',), {'iterate_names': 'i'})\r\n\r\n def else_body():\r\n nonlocal y, p, x\r\n p = 0\r\n x = 0\r\n y = 0\r\n i = ag__.Undefined('i')\r\n z = ag__.Undefined('z')\r\n p = ag__.Undefined('p')\r\n y = ag__.Undefined('y')\r\n x = ag__.Undefined('x')\r\n ag__.if_stmt(ag__.ld(b), if_body, else_body, get_state_1, set_state_1, ('p', 'x', 'y'), 3)\r\n try:\r\n do_return = True\r\n retval_ = ag__.ld(p)\r\n except:\r\n do_return = False\r\n raise\r\n return fscope.ret(retval_, do_return)\r\n```",
"created_at": "2022-05-23T19:04:38Z"
},
{
"body": "I've removed this as OSS tests are passing. Let me know about internal tests.",
"created_at": "2022-05-24T11:29:35Z"
}
],
"title": "Add lamba var loop test"
}
|
{
"commits": [
{
"message": "Add lamba var loop test"
},
{
"message": "enable type"
},
{
"message": "Adapt test"
},
{
"message": "Remove duplicate input parem"
},
{
"message": "Still failing to inizialize without loop"
},
{
"message": "Fix style"
},
{
"message": "Readd empty input and tensor"
},
{
"message": "set default value"
},
{
"message": "Reset converter changes"
},
{
"message": "Add test"
},
{
"message": "Change input param"
},
{
"message": "Remove space"
},
{
"message": "Small hack"
},
{
"message": "Make lint happy"
},
{
"message": "Add tuple input params"
},
{
"message": "Refector, removing lambda special case"
},
{
"message": "Remove verbose log"
},
{
"message": "Remove comment\nUpdate liveness test"
},
{
"message": "Temp workaround"
},
{
"message": "Pylint"
},
{
"message": "Init else branch var with None"
},
{
"message": "Update image_ops_impl.py"
},
{
"message": "Add not none output"
},
{
"message": "Remove todo"
},
{
"message": "Remove lambda exception"
},
{
"message": "Remove lambda limit in doc"
}
],
"files": [
{
"diff": "@@ -337,61 +337,6 @@ of [namedtuple](https://docs.python.org/3/library/collections.html#collections.n\n or other types that [tf.nest](https://www.tensorflow.org/api_docs/python/tf/nest/map_structure)\n recognizes.\n \n-#### Variables closed over by lambda functions\n-\n-AutoGraph assumes that variables that local functions close over may be used\n-anywhere in the parent function, because in general it is possible to hide a\n-function call in almost any Python statement). For this reason, these variables\n-are accounted within TensorFlow loops.\n-\n-For example, the following code correctly captures `a` in the TensorFlow loop\n-variables:\n-\n-```\n-a = 0\n-def f():\n- tf.print(a)\n-for i in tf.range(3):\n- a = i\n-f() # Prints 2\n-```\n-\n-An consequence is that these variables must be defined before the loop (see\n-Undefined and None values above). So the following code will raise an error,\n-even if the variable is never used after the loop:\n-\n-```\n-def f():\n- tf.print(a)\n-for i in tf.range(3): # Error -- `a` must be defined before the loop.\n- a = i\n-```\n-\n-However, lambda functions are handled differently, for reasons of backward\n-compatibility. Lambda functions are assumed to be used in the statement where\n-they are used, or at least in the same block.\n-\n-```\n-a = 0\n-foo(lambda: a) # This lambda is not expected to be called anywhere else.\n-for i in tf.range(3): # Okay -- `a` is local to the loop.\n- a = i\n-```\n-\n-Due to that reason, the following code will not work as expected for TensorFlow\n-loops.\n-\n-```\n-a = 0\n-l = lambda: tf.print(a)\n-for i in tf.range(3):\n- a = i # `a` is considered local to the loop\n-l() # Prints 0!\n-```\n-\n-Note that none of these restrictions only apply to TensorFlow loops; Python\n-loops correctly handle closures in all cases.\n-\n ### Python collections in TensorFlow control flow\n \n Key Point: Use TensorFlow collection classes instead of Python collections.",
"filename": "tensorflow/python/autograph/g3doc/reference/limitations.md",
"status": "modified"
},
{
"diff": "@@ -634,11 +634,6 @@ def visit_Lambda(self, node):\n lambda_scope = self.scope\n self._exit_and_record_scope(node, NodeAnno.ARGS_AND_BODY_SCOPE)\n \n- # Exception: lambdas are assumed to be used in the place where\n- # they are defined. Therefore, their activity is passed on to the\n- # calling statement.\n- self.scope.read.update(lambda_scope.read - lambda_scope.bound)\n-\n return node\n \n def visit_With(self, node):",
"filename": "tensorflow/python/autograph/pyct/static_analysis/activity.py",
"status": "modified"
},
{
"diff": "@@ -65,10 +65,6 @@ def visit_node(self, node):\n reaching_functions = anno.getanno(\n node.ast_node, anno.Static.DEFINED_FNS_IN)\n for fn_ast_node in reaching_functions:\n- if isinstance(fn_ast_node, gast.Lambda):\n- # Exception: lambda functions are assumed to be used only in the\n- # place where they are defined, and not later.\n- continue\n fn_scope = anno.getanno(fn_ast_node, annos.NodeAnno.ARGS_AND_BODY_SCOPE)\n # Any closure of a reaching function definition is conservatively\n # considered live.",
"filename": "tensorflow/python/autograph/pyct/static_analysis/liveness.py",
"status": "modified"
},
{
"diff": "@@ -238,7 +238,7 @@ def test_fn(a, b):\n fn_body = node.body\n \n self.assertHasLiveOut(fn_body[0], ('a', 'b'))\n- self.assertHasLiveOut(fn_body[2], ('foo',))\n+ self.assertHasLiveOut(fn_body[2], ('a', 'foo'))\n \n def test_live_out_nested_functions_hidden_by_argument(self):\n ",
"filename": "tensorflow/python/autograph/pyct/static_analysis/liveness_test.py",
"status": "modified"
},
{
"diff": "@@ -38,6 +38,23 @@ def while_with_local_var(x):\n x -= 1\n return s\n \n+def for_with_lambda_iter(l):\n+ fns = []\n+ results = []\n+ for i in l:\n+ fns.append(lambda: i)\n+ for f in fns:\n+ results.append(f())\n+ return results\n+\n+def for_with_lambda_iter_local_var(l):\n+ fns = []\n+ results = []\n+ for i in l:\n+ fns.append(lambda i=i: i)\n+ for f in fns:\n+ results.append(f())\n+ return results\n \n def for_initializes_local_var(l):\n s = 0\n@@ -121,6 +138,23 @@ def test_for_with_local_var_range(self, l, type_):\n l = type_(l)\n self.assertFunctionMatchesEager(for_with_local_var, l)\n \n+ @parameterized.parameters(*itertools.product(\n+ ([], [1], [1, 2], [(1,2),(3,4)]),\n+ (list, list),\n+ ))\n+ def test_for_with_lambda_iter(self, l, type_):\n+ l = type_(l)\n+ self.assertFunctionMatchesEager(for_with_lambda_iter, l)\n+\n+ @parameterized.parameters(*itertools.product(\n+ ([], [1], [1, 2], [(1,2),(3,4)]),\n+ (list, list),\n+ ))\n+\n+ def test_for_with_lambda_iter_local_var(self, l, type_):\n+ l = type_(l)\n+ self.assertFunctionMatchesEager(for_with_lambda_iter_local_var, l)\n+\n @parameterized.parameters(*itertools.product(\n (0, 1, 2),\n (int, _int_tensor),",
"filename": "tensorflow/python/autograph/tests/loop_scoping_test.py",
"status": "modified"
},
{
"diff": "@@ -5581,6 +5581,9 @@ def _sort_scores_and_boxes(scores, boxes):\n x_min, x_max = control_flow_ops.cond(\n x_1_is_min, lambda: (x_1, x_2), lambda: (x_2, x_1))\n boxes = array_ops.concat([y_min, x_min, y_max, x_max], axis=2)\n+ else:\n+ y_1, x_1, y_2, x_2 = array_ops.split(\n+ value=boxes, num_or_size_splits=4, axis=2)\n \n if not sorted_input:\n scores, boxes, sorted_indices = _sort_scores_and_boxes(scores, boxes)",
"filename": "tensorflow/python/ops/image_ops_impl.py",
"status": "modified"
}
]
}
|
{
"body": "\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 20.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: No\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.8.0\r\n- Python version: 3.7.12\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\nGiven the following code snippet:\r\n```\r\nimport tensorflow as tf\r\n\r\ntry:\r\n tf.strings.unsorted_segment_join(inputs=['123'],segment_ids=[0],num_segments=-1)\r\nexcept Exception:\r\n print('an exception should be thrown, but unsorted_segment_join crashes')\r\n\r\nprint('Not reached')\r\n```\r\nthe call to `tf.strings.unsorted_segment_join` causes a crash.\r\n\r\n**Describe the expected behavior**\r\n\r\nSince `num_segments` is negative, an exception should be thrown (perhaps an `InvalidArgumentError` or `ValueError`. The code should not crash.\r\n\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\nThe code snippet above should reproduce the issue. \r\n\r\nThe following colab notebook (running the notebook should crash the session) demonstrates the issue: https://colab.research.google.com/drive/1zoYVGQXY9MlYgbtW4N3lC51yC8wQh5J2?usp=sharing\r\n\r\n",
"comments": [
{
"body": "Hi @chunduriv ! Could you please look at this issue? It is replicating[ 2.7](https://colab.sandbox.google.com/gist/mohantym/250cc06f9006f7f406e88a64a3d97988/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=fwNys377gUGZ), [2.8 ](https://colab.sandbox.google.com/gist/mohantym/d226528fd7dca6e208a7c9b3ebbc18c4/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=fwNys377gUGZ)and [nightly](https://colab.sandbox.google.com/gist/mohantym/3a38571d2f553145bb038109198167f5/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=_f0oULUsaDZd).",
"created_at": "2022-03-21T10:53:57Z"
},
{
"body": "Reproduced\r\n\r\n```\r\nIn [6]: tf.strings.unsorted_segment_join(inputs=['123'],segment_ids=[0],num_segments=-1)\r\nF0322 11:23:25.727334 1107260 tensor_shape.cc:396] Check failed: size >= 0 (-1 vs. 0) \r\n```",
"created_at": "2022-03-22T18:23:50Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55305\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55305\">No</a>\n",
"created_at": "2022-04-15T17:39:18Z"
}
],
"number": 55305,
"title": "`tf.strings.unsorted_segment_join` crashes unexpectedly when `num_segments` is negative"
}
|
{
"body": "Fixes #55305",
"number": 56002,
"review_comments": [],
"title": "Validate `num_segments >= 0` in `unsorted_segment_join`"
}
|
{
"commits": [
{
"message": "Validate `num_segments >= 0` in `unsorted_segment_join`\n\nFixes #55305"
}
],
"files": [
{
"diff": "@@ -95,7 +95,12 @@ class UnsortedSegmentJoinOp : public OpKernel {\n OP_REQUIRES(context,\n TensorShapeUtils::IsScalar(num_segments_tensor.shape()),\n errors::InvalidArgument(\"Number of segments must be a scalar\"));\n+\n auto num_segments = num_segments_tensor.scalar<NUM_SEGMENTS_TYPE>()();\n+ OP_REQUIRES(\n+ context, num_segments >= 0,\n+ errors::InvalidArgument(\n+ \"Number of segments must be non-negative but got \", num_segments));\n \n OP_REQUIRES(context, segment_dims != 0,\n errors::InvalidArgument(\"Segment_id cannot have rank 0\"));",
"filename": "tensorflow/core/kernels/unsorted_segment_join_op.cc",
"status": "modified"
}
]
}
|
{
"body": "\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 20.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: No\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.8.0\r\n- Python version: 3.7.12\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\nGiven the following code snippet:\r\n```\r\nimport tensorflow as tf\r\n\r\ntry:\r\n tf.strings.unsorted_segment_join(inputs=['123'],segment_ids=[0],num_segments=-1)\r\nexcept Exception:\r\n print('an exception should be thrown, but unsorted_segment_join crashes')\r\n\r\nprint('Not reached')\r\n```\r\nthe call to `tf.strings.unsorted_segment_join` causes a crash.\r\n\r\n**Describe the expected behavior**\r\n\r\nSince `num_segments` is negative, an exception should be thrown (perhaps an `InvalidArgumentError` or `ValueError`. The code should not crash.\r\n\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\nThe code snippet above should reproduce the issue. \r\n\r\nThe following colab notebook (running the notebook should crash the session) demonstrates the issue: https://colab.research.google.com/drive/1zoYVGQXY9MlYgbtW4N3lC51yC8wQh5J2?usp=sharing\r\n\r\n",
"comments": [
{
"body": "Hi @chunduriv ! Could you please look at this issue? It is replicating[ 2.7](https://colab.sandbox.google.com/gist/mohantym/250cc06f9006f7f406e88a64a3d97988/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=fwNys377gUGZ), [2.8 ](https://colab.sandbox.google.com/gist/mohantym/d226528fd7dca6e208a7c9b3ebbc18c4/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=fwNys377gUGZ)and [nightly](https://colab.sandbox.google.com/gist/mohantym/3a38571d2f553145bb038109198167f5/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=_f0oULUsaDZd).",
"created_at": "2022-03-21T10:53:57Z"
},
{
"body": "Reproduced\r\n\r\n```\r\nIn [6]: tf.strings.unsorted_segment_join(inputs=['123'],segment_ids=[0],num_segments=-1)\r\nF0322 11:23:25.727334 1107260 tensor_shape.cc:396] Check failed: size >= 0 (-1 vs. 0) \r\n```",
"created_at": "2022-03-22T18:23:50Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55305\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55305\">No</a>\n",
"created_at": "2022-04-15T17:39:18Z"
}
],
"number": 55305,
"title": "`tf.strings.unsorted_segment_join` crashes unexpectedly when `num_segments` is negative"
}
|
{
"body": "Fixes #55305",
"number": 56001,
"review_comments": [],
"title": "Validate `num_segments >= 0` in `unsorted_segment_join`"
}
|
{
"commits": [
{
"message": "Validate `num_segments >= 0` in `unsorted_segment_join`\n\nFixes #55305"
}
],
"files": [
{
"diff": "@@ -95,7 +95,12 @@ class UnsortedSegmentJoinOp : public OpKernel {\n OP_REQUIRES(context,\n TensorShapeUtils::IsScalar(num_segments_tensor.shape()),\n errors::InvalidArgument(\"Number of segments must be a scalar\"));\n+\n auto num_segments = num_segments_tensor.scalar<NUM_SEGMENTS_TYPE>()();\n+ OP_REQUIRES(\n+ context, num_segments >= 0,\n+ errors::InvalidArgument(\n+ \"Number of segments must be non-negative but got \", num_segments));\n \n OP_REQUIRES(context, segment_dims != 0,\n errors::InvalidArgument(\"Segment_id cannot have rank 0\"));",
"filename": "tensorflow/core/kernels/unsorted_segment_join_op.cc",
"status": "modified"
}
]
}
|
{
"body": "\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 20.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: No\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.8.0\r\n- Python version: 3.7.12\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\nGiven the following code snippet:\r\n```\r\nimport tensorflow as tf\r\n\r\ntry:\r\n tf.strings.unsorted_segment_join(inputs=['123'],segment_ids=[0],num_segments=-1)\r\nexcept Exception:\r\n print('an exception should be thrown, but unsorted_segment_join crashes')\r\n\r\nprint('Not reached')\r\n```\r\nthe call to `tf.strings.unsorted_segment_join` causes a crash.\r\n\r\n**Describe the expected behavior**\r\n\r\nSince `num_segments` is negative, an exception should be thrown (perhaps an `InvalidArgumentError` or `ValueError`. The code should not crash.\r\n\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\nThe code snippet above should reproduce the issue. \r\n\r\nThe following colab notebook (running the notebook should crash the session) demonstrates the issue: https://colab.research.google.com/drive/1zoYVGQXY9MlYgbtW4N3lC51yC8wQh5J2?usp=sharing\r\n\r\n",
"comments": [
{
"body": "Hi @chunduriv ! Could you please look at this issue? It is replicating[ 2.7](https://colab.sandbox.google.com/gist/mohantym/250cc06f9006f7f406e88a64a3d97988/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=fwNys377gUGZ), [2.8 ](https://colab.sandbox.google.com/gist/mohantym/d226528fd7dca6e208a7c9b3ebbc18c4/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=fwNys377gUGZ)and [nightly](https://colab.sandbox.google.com/gist/mohantym/3a38571d2f553145bb038109198167f5/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=_f0oULUsaDZd).",
"created_at": "2022-03-21T10:53:57Z"
},
{
"body": "Reproduced\r\n\r\n```\r\nIn [6]: tf.strings.unsorted_segment_join(inputs=['123'],segment_ids=[0],num_segments=-1)\r\nF0322 11:23:25.727334 1107260 tensor_shape.cc:396] Check failed: size >= 0 (-1 vs. 0) \r\n```",
"created_at": "2022-03-22T18:23:50Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55305\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55305\">No</a>\n",
"created_at": "2022-04-15T17:39:18Z"
}
],
"number": 55305,
"title": "`tf.strings.unsorted_segment_join` crashes unexpectedly when `num_segments` is negative"
}
|
{
"body": "Fixes #55305",
"number": 56000,
"review_comments": [],
"title": "Validate `num_segments >= 0` in `unsorted_segment_join`"
}
|
{
"commits": [
{
"message": "Validate `num_segments >= 0` in `unsorted_segment_join`\n\nFixes #55305"
}
],
"files": [
{
"diff": "@@ -95,7 +95,12 @@ class UnsortedSegmentJoinOp : public OpKernel {\n OP_REQUIRES(context,\n TensorShapeUtils::IsScalar(num_segments_tensor.shape()),\n errors::InvalidArgument(\"Number of segments must be a scalar\"));\n+\n auto num_segments = num_segments_tensor.scalar<NUM_SEGMENTS_TYPE>()();\n+ OP_REQUIRES(\n+ context, num_segments >= 0,\n+ errors::InvalidArgument(\n+ \"Number of segments must be non-negative but got \", num_segments));\n \n OP_REQUIRES(context, segment_dims != 0,\n errors::InvalidArgument(\"Segment_id cannot have rank 0\"));",
"filename": "tensorflow/core/kernels/unsorted_segment_join_op.cc",
"status": "modified"
}
]
}
|
{
"body": "\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 20.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: No\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.8.0\r\n- Python version: 3.7.12\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\nGiven the following code snippet:\r\n```\r\nimport tensorflow as tf\r\n\r\ntry:\r\n tf.strings.unsorted_segment_join(inputs=['123'],segment_ids=[0],num_segments=-1)\r\nexcept Exception:\r\n print('an exception should be thrown, but unsorted_segment_join crashes')\r\n\r\nprint('Not reached')\r\n```\r\nthe call to `tf.strings.unsorted_segment_join` causes a crash.\r\n\r\n**Describe the expected behavior**\r\n\r\nSince `num_segments` is negative, an exception should be thrown (perhaps an `InvalidArgumentError` or `ValueError`. The code should not crash.\r\n\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\nThe code snippet above should reproduce the issue. \r\n\r\nThe following colab notebook (running the notebook should crash the session) demonstrates the issue: https://colab.research.google.com/drive/1zoYVGQXY9MlYgbtW4N3lC51yC8wQh5J2?usp=sharing\r\n\r\n",
"comments": [
{
"body": "Hi @chunduriv ! Could you please look at this issue? It is replicating[ 2.7](https://colab.sandbox.google.com/gist/mohantym/250cc06f9006f7f406e88a64a3d97988/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=fwNys377gUGZ), [2.8 ](https://colab.sandbox.google.com/gist/mohantym/d226528fd7dca6e208a7c9b3ebbc18c4/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=fwNys377gUGZ)and [nightly](https://colab.sandbox.google.com/gist/mohantym/3a38571d2f553145bb038109198167f5/unexpected-crash-on-unsorted_segment_join-due-to-invalid-value-of-num_segments.ipynb#scrollTo=_f0oULUsaDZd).",
"created_at": "2022-03-21T10:53:57Z"
},
{
"body": "Reproduced\r\n\r\n```\r\nIn [6]: tf.strings.unsorted_segment_join(inputs=['123'],segment_ids=[0],num_segments=-1)\r\nF0322 11:23:25.727334 1107260 tensor_shape.cc:396] Check failed: size >= 0 (-1 vs. 0) \r\n```",
"created_at": "2022-03-22T18:23:50Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55305\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55305\">No</a>\n",
"created_at": "2022-04-15T17:39:18Z"
}
],
"number": 55305,
"title": "`tf.strings.unsorted_segment_join` crashes unexpectedly when `num_segments` is negative"
}
|
{
"body": "Fixes #55305",
"number": 55999,
"review_comments": [],
"title": "Validate `num_segments >= 0` in `unsorted_segment_join`"
}
|
{
"commits": [
{
"message": "Validate `num_segments >= 0` in `unsorted_segment_join`\n\nFixes #55305"
}
],
"files": []
}
|
{
"body": "<details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nBug\r\n\r\n### Source\r\n\r\nsource\r\n\r\n### Tensorflow Version\r\n\r\n2.9\r\n\r\n### Current Behaviour?\r\n\r\nOn a model with a loop (see simple reproducer below), `wrap_function.function_from_graph_def` fails with a `ValueError` (see log output below). This happens when the model has been frozen and optimized with Grappler. In particular, this seems to happen only if the `\"common_subgraph_elimination\"` optimizer is run.\r\n\r\nI have some understanding of what is happening:\r\n- `lift_to_graph` tries to do a topological sort of the graph. However, because of the loop, it is undefined, so some nodes are not in topological order.\r\n- In `_copy_non_source`, when a node is processed and its inputs haven't been added to the `op_map` yet, a placeholder of the right shape and type is created.\r\n- When the node needs to read its input int32 tensor to get a shape, if the input is a placeholder it results in the exception below.\r\n- The bug is non-deterministic, which might be due to getting the next element in a Python set? So the failure is intermittent, with the pseudo-topological order sometimes being accidentally correct enough.\r\n\r\nI'm not sure if the common subgraph elimination is necessary for this bug to happen, but so far I haven't reproduced it without it.\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```python\r\nimport tensorflow as tf\r\nfrom tensorflow.python.grappler import tf_optimizer\r\nfrom tensorflow.core.protobuf import meta_graph_pb2\r\nfrom tensorflow.python.training.saver import export_meta_graph\r\nfrom tensorflow.core.protobuf import config_pb2\r\nfrom tensorflow.python.eager import wrap_function\r\nfrom tensorflow.python.eager import context\r\nfrom tensorflow.python.framework import convert_to_constants\r\n\r\n\r\nclass MyModel(tf.Module):\r\n \"\"\"Simple Fibonacci model.\r\n To get this bug, I need a loop and two tensor arrays of the same dimensions,\r\n using a different dtype so the TensorListReserve nodes don't get merged.\r\n \"\"\"\r\n @tf.function\r\n def __call__(self, n):\r\n ta = tf.TensorArray(tf.float32, size=n)\r\n tb = tf.TensorArray(tf.int32, size=n)\r\n ta = ta.write(0, 0.)\r\n ta = ta.write(1, 1.)\r\n tb = tb.write(0, 0)\r\n tb = tb.write(1, 1)\r\n\r\n for i in range(2, n):\r\n ta = ta.write(i, ta.read(i - 1) + ta.read(i - 2))\r\n tb = tb.write(i, tb.read(i - 1) + tb.read(i - 2))\r\n\r\n return ta.stack() + tf.cast(tb.stack(), dtype=tf.float32)\r\n\r\n\r\ndef run_grappler(func, graph_def):\r\n meta_graph = export_meta_graph(graph_def=graph_def, graph=func.graph)\r\n\r\n # Add a collection 'train_op' so that Grappler knows the outputs.\r\n fetch_collection = meta_graph_pb2.CollectionDef()\r\n for array in func.inputs + func.outputs:\r\n fetch_collection.node_list.value.append(array.name)\r\n meta_graph.collection_def[\"train_op\"].CopyFrom(fetch_collection)\r\n\r\n # Configure Grappler to execute one pass of common subgraph elimination.\r\n config = config_pb2.ConfigProto()\r\n rewrite_options = config.graph_options.rewrite_options\r\n rewrite_options.optimizers.extend([\r\n \"common_subgraph_elimination\"\r\n ])\r\n rewrite_options.meta_optimizer_iterations = 1\r\n return tf_optimizer.OptimizeGraph(config, meta_graph)\r\n\r\nmy_model = MyModel()\r\nfunc = my_model.__call__.get_concrete_function(\r\n tf.TensorSpec([], tf.int32))\r\n\r\n# Freeze the function\r\nfrozen_func = convert_to_constants.convert_variables_to_constants_v2(func)\r\n\r\n# Run common subgraph elimination\r\ngraph_def = frozen_func.graph.as_graph_def()\r\nnew_graph_def = run_grappler(func, graph_def)\r\n\r\n# Remove the old functions from the context\r\nfor f in new_graph_def.library.function:\r\n while context.context().has_function(f.signature.name):\r\n context.context().remove_function(f.signature.name)\r\n\r\n# Reconstruct a function from the graph definition\r\nnew_func = wrap_function.function_from_graph_def(\r\n new_graph_def,\r\n [tensor.name for tensor in frozen_func.inputs],\r\n [tensor.name for tensor in frozen_func.outputs])\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"reproducer.py\", line 67, in <module>\r\n new_func = wrap_function.function_from_graph_def(\r\n File \"/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/wrap_function.py\", line 657, in function_from_graph_def\r\n return wrapped_import.prune(\r\n File \"/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/wrap_function.py\", line 332, in prune\r\n lift_map = lift_to_graph.lift_to_graph(\r\n File \"/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/lift_to_graph.py\", line 336, in lift_to_graph\r\n new_input_mutations, new_control_mutations = _copy_non_source(\r\n File \"/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/lift_to_graph.py\", line 122, in _copy_non_source\r\n copied_op = graph.create_op(\r\n File \"/usr/local/lib/python3.8/dist-packages/tensorflow/python/util/deprecation.py\", line 561, in new_func\r\n return func(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/dist-packages/tensorflow/python/util/traceback_utils.py\", line 153, in error_handler\r\n raise e.with_traceback(filtered_tb) from None\r\n File \"/usr/local/lib/python3.8/dist-packages/tensorflow/python/framework/ops.py\", line 1970, in _create_c_op\r\n raise ValueError(e.message)\r\nValueError: Received a shape scalar with unknown static value. A static value of '-1' is required to represent an unknown shape.\r\n```\r\n</details>",
"comments": [
{
"body": "@sachinprasadhs ,\r\nI was able to reproduce the issue in tf v2.7, v2.8 and nightly.Please find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/b4dd948df3412185a3cb46be70a3aff9/55736.ipynb).",
"created_at": "2022-04-26T09:39:46Z"
},
{
"body": "Hi, the PR mentioned above solves the exception for the given code sample, but it isn't an exhaustive fix, only a temporary solution for some failing models.",
"created_at": "2022-05-02T11:25:31Z"
},
{
"body": "@Nyrio,\r\nI tried to execute the mentioned code on tf-nigthly-gpu(2.15.0-dev20230918) and it was executed without any issue/error. Kindly find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/06f37179d2d450f1aa305cbdc22e4d63/_55736.ipynb). Thank you!",
"created_at": "2023-10-26T17:04:08Z"
},
{
"body": "This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you.",
"created_at": "2023-11-03T01:48:18Z"
},
{
"body": "This issue was closed because it has been inactive for 7 days since being marked as stale. Please reopen if you'd like to work on this further.",
"created_at": "2023-11-10T01:48:39Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55736\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55736\">No</a>\n",
"created_at": "2023-11-10T01:48:43Z"
}
],
"number": 55736,
"title": "`function_from_graph_def` failure on a model with a loop after Grappler optimization"
}
|
{
"body": "This is a temporary fix to make some models affected by the bug described in #55736 work.\r\nIn models with loops, when the topological order isn't defined, I have observed cases where an op appeared before its inputs in the topological order, despite those inputs being constants. Performing a stable sort based on whether an op has inputs or not conserves a topological order, and can improve a non-topological order and in many cases prevent the exceptions I have observed. Note that this isn't a proper fix for the aforementioned issue.",
"number": 55820,
"review_comments": [],
"title": "Force ops without inputs to the start of the pseudo-topological order in `lift_to_graph`"
}
|
{
"commits": [
{
"message": "Force nodes without inputs at the start of the pseudo-topological sort in lift_to_graph"
}
],
"files": [
{
"diff": "@@ -287,6 +287,13 @@ def lift_to_graph(tensors,\n # we'll do ugly post-hoc mutations instead.\n ops_to_visit.append(next(iter(unvisited_ops)))\n \n+ # When the topological sort fails due to loops, it can result in exceptions\n+ # later when copying a node which inputs haven't been copied yet. We can\n+ # improve that pseudo-topological order slightly by putting the ops without\n+ # inputs, such as constants, at the start of the topological order (i.e at\n+ # the end of ops_to_copy).\n+ ops_to_copy.sort(key=(lambda op: len(op_selector.graph_inputs(op)) == 0))\n+\n # When lifting from one FuncGraph to another, we will need to capture the\n # relevant tensors as well.\n captures = []",
"filename": "tensorflow/python/eager/lift_to_graph.py",
"status": "modified"
}
]
}
|
{
"body": "EDIT: PR fixing this issue is https://github.com/tensorflow/tensorflow/pull/55730\r\n\r\n<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): no\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): source\r\n- TensorFlow version (use command below): v2.8.0-2-ge994fb9c3ad 2.8.0\r\n- Python version: 3.8.3\r\n- Bazel version (if compiling from source): 0.25.2\r\n- GCC/Compiler version (if compiling from source): gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\n\r\ntest fails\r\n\r\n**Describe the expected behavior**\r\n\r\ntest passes\r\n\r\n**[Contributing](https://www.tensorflow.org/community/contribute)**\r\n\r\n- Do you want to contribute a PR? (yes/no): yes\r\n- Briefly describe your candidate solution(if contributing):\r\n\r\n[EDIT: Removed incorrect hypothesis]\r\n\r\n**Standalone code to reproduce the issue**\r\nProvide a reproducible test case that is the bare minimum necessary to generate\r\nthe problem. If possible, please share a link to Colab/Jupyter/any notebook.\r\n\r\n```\r\n$ git checkout r2.8\r\n$ bazel --host_jvm_args=-Xmx32g test --jobs=12 --config=dbg --verbose_failures -k //tensorflow/core:__tensorflow_core_lib_math_math_util_test \r\n```\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\ndiagnose the problem. If including tracebacks, please include the full\r\ntraceback. Large logs and files should be attached.\r\n\r\n[test.log](https://github.com/tensorflow/tensorflow/files/8443281/t.log)\r\n\r\n",
"comments": [
{
"body": "Update: \r\ntest still fails on commit `55645ca964508507890529a71591f51a344a6356` April 9\r\n\r\ntest passes with ``--config=opt``",
"created_at": "2022-04-09T15:05:37Z"
},
{
"body": "@awf\r\nPlease let us know if this issue is resolved for you in a recent commit ?Thanks!",
"created_at": "2022-04-11T08:00:08Z"
},
{
"body": "Still present in 55645c from 2 days ago.\r\nI'll take a look, but I don't see anything more recent that might have fixed it.\r\n",
"created_at": "2022-04-11T13:03:04Z"
},
{
"body": "Confirmed on\r\n```\r\ncommit c44d14f2194cf4c4b4060fd4141194ee62792ca8 (HEAD -> master, upstream/master, origin/master, origin/HEAD)\r\nDate: Mon Apr 11 05:36:24 2022 -0700\r\n```",
"created_at": "2022-04-11T15:16:18Z"
},
{
"body": "Note I'm happy to submit a PR, but there are a few options, as listed above, so seeking guidance on which one to implement.",
"created_at": "2022-04-12T09:41:40Z"
},
{
"body": "PR fixing this issue is #55730 ",
"created_at": "2022-04-26T11:37:16Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55530\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55530\">No</a>\n",
"created_at": "2022-04-28T21:42:10Z"
}
],
"number": 55530,
"title": "Test fail on r2.8: core:__tensorflow_core_lib_math_math_util_test "
}
|
{
"body": "Previously, there was custom logic for `size_t` vs `int` instances of `CHECK_OP`.\r\n\r\nHowever the logic was correct only for equality ops, not != or greater/less than.\r\n\r\nExample: Before\r\n```\r\nbazel test --jobs=40 --config=dbg --verbose_failures //tensorflow/core:__tensorflow_core_lib_math_math_util_test\r\n...\r\n-----------------------------------------------------------------------------\r\n[==========] Running 5 tests from 1 test suite.\r\n[----------] Global test environment set-up.\r\n[----------] 5 tests from MathUtil\r\n[ RUN ] MathUtil.CeilOfRatio\r\n2022-04-25 13:53:45.485294: F ./tensorflow/core/lib/math/math_util.h:123] Check failed: 0 != denominator (0 vs. 18446744073709551615)Division by zero is not supported.\r\n*** Received signal 6 ***\r\n```\r\n\r\nAfter: test passes.\r\n\r\nFixes #55530",
"number": 55730,
"review_comments": [],
"title": "Fix `size_t` vs int logic in `CHECK_OP`"
}
|
{
"commits": [
{
"message": "Fixe size_t vs int logic in CHECK_OP"
},
{
"message": "clang-format"
},
{
"message": "Clang format version mismatch"
}
],
"files": [
{
"diff": "@@ -85,7 +85,7 @@ class LogMessage : public std::basic_ostringstream<char> {\n // that the ternary VLOG() implementation is balanced, type wise.\n struct Voidifier {\n template <typename T>\n- void operator&(const T&)const {}\n+ void operator&(const T&) const {}\n };\n \n // LogMessageFatal ensures the process will exit in failure after\n@@ -348,11 +348,13 @@ string* MakeCheckOpString(const T1& v1, const T2& v2, const char* exprtext) {\n }\n \n // Helper functions for CHECK_OP macro.\n-// The (int, int) specialization works around the issue that the compiler\n+// We use the full name Check_EQ, Check_NE, etc. in case the file including\n+// base/logging.h provides its own #defines for the simpler names EQ, NE, etc.\n+// This happens if, for example, those are used as token names in a\n+// yacc grammar.\n+// The (int, int) overload works around the issue that the compiler\n // will not instantiate the template version of the function on values of\n // unnamed enum type - see comment below.\n-// The (size_t, int) and (int, size_t) specialization are to handle unsigned\n-// comparison errors while still being thorough with the comparison.\n #define TF_DEFINE_CHECK_OP_IMPL(name, op) \\\n template <typename T1, typename T2> \\\n inline string* name##Impl(const T1& v1, const T2& v2, \\\n@@ -364,34 +366,77 @@ string* MakeCheckOpString(const T1& v1, const T2& v2, const char* exprtext) {\n } \\\n inline string* name##Impl(int v1, int v2, const char* exprtext) { \\\n return name##Impl<int, int>(v1, v2, exprtext); \\\n- } \\\n- inline string* name##Impl(const size_t v1, const int v2, \\\n- const char* exprtext) { \\\n- if (TF_PREDICT_FALSE(v2 < 0)) { \\\n- return ::tensorflow::internal::MakeCheckOpString(v1, v2, exprtext); \\\n- } \\\n- return name##Impl<size_t, size_t>(v1, v2, exprtext); \\\n- } \\\n- inline string* name##Impl(const int v1, const size_t v2, \\\n- const char* exprtext) { \\\n- if (TF_PREDICT_FALSE(v2 >= std::numeric_limits<int>::max())) { \\\n- return ::tensorflow::internal::MakeCheckOpString(v1, v2, exprtext); \\\n- } \\\n- const size_t uval = (size_t)((unsigned)v2); \\\n- return name##Impl<size_t, size_t>(v1, uval, exprtext); \\\n }\n \n-// We use the full name Check_EQ, Check_NE, etc. in case the file including\n-// base/logging.h provides its own #defines for the simpler names EQ, NE, etc.\n-// This happens if, for example, those are used as token names in a\n-// yacc grammar.\n-TF_DEFINE_CHECK_OP_IMPL(Check_EQ,\n- ==) // Compilation error with CHECK_EQ(NULL, x)?\n-TF_DEFINE_CHECK_OP_IMPL(Check_NE, !=) // Use CHECK(x == NULL) instead.\n+// The (size_t, int) and (int, size_t) specialization are to handle unsigned\n+// comparison errors while still being thorough with the comparison.\n+\n+TF_DEFINE_CHECK_OP_IMPL(Check_EQ, ==)\n+// Compilation error with CHECK_EQ(NULL, x)?\n+// Use CHECK(x == NULL) instead.\n+\n+inline string* Check_EQImpl(int v1, size_t v2, const char* exprtext) {\n+ if (TF_PREDICT_FALSE(v1 < 0))\n+ ::tensorflow::internal::MakeCheckOpString(v1, v2, exprtext);\n+\n+ return Check_EQImpl(size_t(v1), v2, exprtext);\n+}\n+\n+inline string* Check_EQImpl(size_t v1, int v2, const char* exprtext) {\n+ return Check_EQImpl(v2, v1, exprtext);\n+}\n+\n+TF_DEFINE_CHECK_OP_IMPL(Check_NE, !=)\n+\n+inline string* Check_NEImpl(int v1, size_t v2, const char* exprtext) {\n+ if (v1 < 0) return NULL;\n+\n+ return Check_NEImpl(size_t(v1), v2, exprtext);\n+}\n+\n+inline string* Check_NEImpl(size_t v1, int v2, const char* exprtext) {\n+ return Check_NEImpl(v2, v1, exprtext);\n+}\n+\n TF_DEFINE_CHECK_OP_IMPL(Check_LE, <=)\n+\n+inline string* Check_LEImpl(int v1, size_t v2, const char* exprtext) {\n+ if (v1 <= 0) return NULL;\n+\n+ return Check_LEImpl(size_t(v1), v2, exprtext);\n+}\n+\n+inline string* Check_LEImpl(size_t v1, int v2, const char* exprtext) {\n+ if (TF_PREDICT_FALSE(v2 < 0))\n+ return ::tensorflow::internal::MakeCheckOpString(v1, v2, exprtext);\n+ return Check_LEImpl(v1, size_t(v2), exprtext);\n+}\n+\n TF_DEFINE_CHECK_OP_IMPL(Check_LT, <)\n-TF_DEFINE_CHECK_OP_IMPL(Check_GE, >=)\n-TF_DEFINE_CHECK_OP_IMPL(Check_GT, >)\n+\n+inline string* Check_LTImpl(int v1, size_t v2, const char* exprtext) {\n+ if (v1 < 0) return NULL;\n+\n+ return Check_LTImpl(size_t(v1), v2, exprtext);\n+}\n+\n+inline string* Check_LTImpl(size_t v1, int v2, const char* exprtext) {\n+ if (v2 < 0)\n+ return ::tensorflow::internal::MakeCheckOpString(v1, v2, exprtext);\n+ return Check_LTImpl(v1, size_t(v2), exprtext);\n+}\n+\n+// Implement GE,GT in terms of LE,LT\n+template <typename T1, typename T2>\n+inline string* Check_GEImpl(const T1& v1, const T2& v2, const char* exprtext) {\n+ return Check_LEImpl(v2, v1, exprtext);\n+}\n+\n+template <typename T1, typename T2>\n+inline string* Check_GTImpl(const T1& v1, const T2& v2, const char* exprtext) {\n+ return Check_LTImpl(v2, v1, exprtext);\n+}\n+\n #undef TF_DEFINE_CHECK_OP_IMPL\n \n // In optimized mode, use CheckOpString to hint to compiler that",
"filename": "tensorflow/core/platform/default/logging.h",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nx = tf.random.uniform([5])\r\nprint(tf.experimental.numpy.stack(x, axis=-2)) # Outputs a shape [5] tensor\r\n```\r\n\r\n**Describe the current behavior**\r\nIn the above example, the input is a rank-1 tensor, so `axis` cannot be -2. `tf.experimental.numpy.stack` did not check the argument `axis`.\r\n\r\nExpect it to throw an error like `tf.stack`:\r\n```\r\n\r\nimport tensorflow as tf\r\nx = tf.random.uniform([5])\r\ntf.stack(x, axis=-1) # Pass\r\ntf.stack(x, axis=-2) # ValueError: Argument `axis` = -2 not in range [-1, 1)\r\n```\r\n\r\n",
"comments": [
{
"body": "Hi @ArrowIntoTheSky !\r\nI am able to replicate this issue in 2.11 . Attached [gist](https://colab.sandbox.google.com/gist/mohantym/f8df98b39364928b5cd88d3d91c42c3a/git_55217_2-11.ipynb) for reference.\r\nThank you!",
"created_at": "2023-01-30T13:17:42Z"
}
],
"number": 55217,
"title": "`tf.experimental.numpy.stack` should check out-of-bound `axis` "
}
|
{
"body": "Added validation to check axis is within the range [-Rank(array),Rank(array)) as per the issue #55217",
"number": 55329,
"review_comments": [
{
"body": "Can you add a test for this in np_array_ops_test.py?",
"created_at": "2022-11-15T17:18:09Z"
},
{
"body": "Please add spaces before and after the `<=` and `<` symbols ",
"created_at": "2022-11-15T17:19:10Z"
},
{
"body": "Please change `tf.rank` to `array_ops.rank`",
"created_at": "2023-01-30T20:38:52Z"
},
{
"body": "updated requested changes.Please review and confirm if anything missing.",
"created_at": "2023-03-03T07:29:34Z"
},
{
"body": "`-(array_ops.rank(arrays))`\r\nThe outer brackets seem unnecessary. Can you please verify?\r\n\r\nMore importantly I just realized that `array_ops.stack` already has the axis range validation inplace: https://github.com/tensorflow/tensorflow/blob/04ea1a50df9c8bd11cf740b20139ab7a7d18c349/tensorflow/python/ops/array_ops.py#L1497 This PR seems unnecessary. Otherwise can you please add a test to demonstrate?",
"created_at": "2023-03-03T18:50:13Z"
}
],
"title": "Add axis validations for tf.experimental.numpy.stack"
}
|
{
"commits": [
{
"message": "Add axis validations for tf.experimental.numpy.stack\n\nSolves issue #55217"
},
{
"message": "Merge branch 'tensorflow:master' into master"
},
{
"message": "Added spaces as suggested by reviewer \n\nAdded spaces as suggested by reviewer on behalf of author."
},
{
"message": "Update np_array_ops.py\n\nupdated tf.rank to array_ops.rank in np_array_ops.py."
},
{
"message": "Update np_array_ops.py\n\nDone the changes.Thank you!"
}
],
"files": [
{
"diff": "@@ -1027,16 +1027,19 @@ def broadcast_to(array, shape): # pylint: disable=redefined-outer-name\n \n @np_utils.np_doc('stack')\n def stack(arrays, axis=0): # pylint: disable=missing-function-docstring\n- if isinstance(arrays, (np_arrays.ndarray, ops.Tensor)):\n- arrays = asarray(arrays)\n- if axis == 0:\n- return arrays\n- else:\n- return swapaxes(arrays, 0, axis)\n- arrays = _promote_dtype(*arrays) # pylint: disable=protected-access\n- unwrapped_arrays = [\n+ if -array_ops.rank(arrays) <= axis < array_ops.rank(arrays):\n+ if isinstance(arrays, (np_arrays.ndarray, ops.Tensor)):\n+ arrays = asarray(arrays)\n+ if axis == 0:\n+ return arrays\n+ else:\n+ return swapaxes(arrays, 0, axis)\n+ arrays = _promote_dtype(*arrays) # pylint: disable=protected-access\n+ unwrapped_arrays = [\n a if isinstance(a, np_arrays.ndarray) else a for a in arrays\n- ]\n+ ]\n+ else:\n+ raise AxisError('Axis must be in range [-Rank(array),Rank(array))') \n return asarray(array_ops.stack(unwrapped_arrays, axis))\n \n ",
"filename": "tensorflow/python/ops/numpy_ops/np_array_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): N/A\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.8.0\r\n- Python version:3.7.12\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version: 11.2 (based on a colab notebook)\r\n- GPU model and memory: Tesla T4, 15109MiB (based on a colab notebook)\r\n\r\n**Describe the current behavior**\r\n\r\nThe following code snippets lead to crashes when executed:\r\n\r\n```\r\nimport numpy as np\r\nimport tensorflow as tf\r\n\r\na = np.empty([6, 0])\r\nb = np.array([1, -1])\r\ntry:\r\n tf.compat.v1.signal.rfft2d(input_tensor=a,fft_length=b)\r\n # on a different machine: Check failed: size >= 0 (-9223372036854775808 vs. 0)\r\n # Aborted (core dumped)\r\nexcept:\r\n pass\r\n\r\nprint('execution does not reach this line')\r\n```\r\n\r\nand\r\n\r\n```\r\nimport numpy as np\r\nimport tensorflow as tf\r\n\r\na = np.empty([6, 1, 1])\r\nb = np.array([1, 2, 0])\r\n\r\ntry:\r\n tf.compat.v1.signal.irfft3d(input_tensor=a,fft_length=b)\r\n # on a different machine: failed to initialize batched cufft plan with customized allocator: Failed to make cuFFT batched plan.\r\n # Aborted (core dumped)\r\nexcept:\r\n pass\r\nprint('execution does not reach this line')\r\n```\r\n\r\nIn either case, the inputs do not quite make sense, and tensorflow should throw.\r\n\r\n**Describe the expected behavior**\r\n\r\nTensorflow should throw exceptions instead of crashing.\r\n\r\n**[Contributing](https://www.tensorflow.org/community/contribute)**\r\n\r\n- Do you want to contribute a PR? (yes/no):\r\n- Briefly describe your candidate solution(if contributing):\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\nHere is a colab notebook:\r\nhttps://colab.research.google.com/drive/168jYG6MqnW4jpJdIXFMUBkyiaweA43aP?usp=sharing\r\nEdit: the notebook has to be run with GPU \r\n\r\nThe code snippets above should also reproduce the issue.\r\n\r\n",
"comments": [
{
"body": "Added PR #55274 for the fix.",
"created_at": "2022-03-17T19:13:17Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55263\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/55263\">No</a>\n",
"created_at": "2022-03-23T16:05:25Z"
}
],
"number": 55263,
"title": "`tf.compat.v1.signal.rfft2d` and `rfft3d` lacks input validation leading to crashes"
}
|
{
"body": "This PR tries to address the issue raised in #55263 where\r\ntf.single.rfft2d will crash when length contains negative value.\r\n\r\nThis PR fixes #55263\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 55274,
"review_comments": [],
"title": "Add necessary check in fft ops to fix crash"
}
|
{
"commits": [
{
"message": "Add necessary check in fft ops to fix crash\n\nThis PR tries to address the issue raised in 55263 where\ntf.single.rfft2d will crash when length contains negative value.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub issue 55623 for tf.signal.rfft2d crash when length < 0\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -66,6 +66,12 @@ class FFTBase : public OpKernel {\n \n auto fft_length_as_vec = fft_length.vec<int32>();\n for (int i = 0; i < fft_rank; ++i) {\n+ OP_REQUIRES(\n+ ctx,\n+ fft_length_as_vec(i) >= 0,\n+ errors::InvalidArgument(\n+ \"fft_length[\" , i,\n+ \"] must >= 0, but got: \", fft_length_as_vec(i)));\n fft_shape[i] = fft_length_as_vec(i);\n // Each input dimension must have length of at least fft_shape[i]. For\n // IRFFTs, the inner-most input dimension must have length of at least",
"filename": "tensorflow/core/kernels/fft_ops.cc",
"status": "modified"
},
{
"diff": "@@ -609,6 +609,16 @@ def test_grad_random(self, rank, extra_dims, size, np_rtype):\n self._tf_ifft_for_rank(rank), re, im, result_is_complex=False,\n rtol=tol, atol=tol)\n \n+ def test_invalid_args(self):\n+ # Test case for GitHub issue 55263\n+ a = np.empty([6, 0])\n+ b = np.array([1, -1])\n+ with self.assertRaisesRegex(\n+ errors.InvalidArgumentError, \"must >= 0\"):\n+ with self.session():\n+ v = fft_ops.rfft2d(input_tensor=a,fft_length=b)\n+ self.evaluate(v)\n+\n \n @test_util.run_all_in_graph_and_eager_modes\n class FFTShiftTest(test.TestCase, parameterized.TestCase):",
"filename": "tensorflow/python/kernel_tests/signal/fft_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.8.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nparams = tf.random.uniform([3, 1, 12, 64], dtype=tf.float32)\r\nindices = tf.random.uniform([35, 2], minval=0, maxval=1, dtype=tf.int64)\r\nbatch_dims = False\r\ntf.gather_nd(params, indices, batch_dims=batch_dims) # Pass\r\ntf.gather(params, indices, batch_dims=batch_dims) # InvalidArgumentError\r\n```\r\nDetailed error message:\r\n```\r\nInvalidArgumentError: Value for attr 'Taxis' of bool is not in the list of allowed values: int32, int64\r\n\t; NodeDef: {{node GatherV2}}; Op<name=GatherV2; signature=params:Tparams, indices:Tindices, axis:Taxis -> output:Tparams; attr=batch_dims:int,default=0; attr=Tparams:type; attr=Tindices:type,allowed=[DT_INT32, DT_INT64]; attr=Taxis:type,allowed=[DT_INT32, DT_INT64]> [Op:GatherV2]\r\n```\r\n\r\n**Describe the current behavior**\r\nIn the above code, `batch_dims` is a `bool`, not a `int`. `tf.gather` complains about this type mismatch and throws `InvalidArgumentError`. However, `tf.gather_nd` would do implicit conversion and convert `False` to `0`. There is an inconsistency in the type checking.\r\n\r\n**Describe the expected behavior**\r\nEither allow implicit `bool`-`int` conversion in all cases, or throw an Error in all cases.",
"comments": [
{
"body": "Added a PR #55210 for the fix.",
"created_at": "2022-03-12T02:45:27Z"
}
],
"number": 55203,
"title": "`tf.gather_nd` and `tf.gather` have inconsistent type check for `batch_dims`"
}
|
{
"body": "This PR tries to address the issue raised in #55203 where\r\ninvalid batch_dim (bool) was passed to tf.gather_nd\r\nwith error output returned silently.\r\nThe reason was that `int()` was applied incorrectly, which always cast\r\nany value to integer.\r\nThis PR fixes #55203.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 55210,
"review_comments": [],
"title": "Fix invalid input for `tf.gather_nd` with `batch_dims`"
}
|
{
"commits": [
{
"message": "Fix invalid input for tf.gather_nd with batch_dims\n\nThis PR tries to address the issue raised in 55203 where\ninvalid batch_dim (bool) was passed to tf.gather_nd\nwith error output returned silently.\nThis PR fixes 55203.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -380,6 +380,17 @@ def testGatherNdResourceVariable(self):\n self.assertEqual(\"ResourceGatherNd\", gather.op.inputs[0].op.type)\n self.assertAllEqual([2, 5], gather)\n \n+ def testInvalidBatchDims(self):\n+ with self.session():\n+ indices = [[0, 0], [1, 1]]\n+ params = [[0, 1], [2, 3]]\n+ with self.assertRaisesOpError(r\"but is a bool tensor\"):\n+ gather_nd = array_ops.gather_nd(\n+ indices=[[1], [0], [4], [2], [1]],\n+ params=array_ops.zeros([5, 7, 3]),\n+ batch_dims=True)\n+ self.evaluate(gather_nd)\n+\n \n class GatherNdOpBenchmark(test.Benchmark):\n ",
"filename": "tensorflow/python/kernel_tests/array_ops/gather_nd_op_test.py",
"status": "modified"
},
{
"diff": "@@ -5678,7 +5678,7 @@ def gather_nd(params, indices, name=None, batch_dims=0):\n \"\"\"\n batch_dims_ = tensor_util.constant_value(batch_dims)\n if batch_dims_ is not None:\n- batch_dims = int(batch_dims_)\n+ batch_dims = batch_dims_\n if batch_dims == 0:\n try:\n # TODO(apassos) find a less bad way of detecting resource variables",
"filename": "tensorflow/python/ops/array_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nimages = tf.random.uniform([1, 1, 3], dtype=tf.bfloat16)\r\ntf.raw_ops.RGBToHSV(images=images)\r\n```\r\nthrows error:\r\n```\r\nNotFoundError: Could not find device for node: {{node RGBToHSV}} = RGBToHSV[T=DT_BFLOAT16]\r\nAll kernels registered for op RGBToHSV:\r\n device='CPU'; T in [DT_DOUBLE]\r\n device='CPU'; T in [DT_FLOAT]\r\n device='GPU'; T in [DT_DOUBLE]\r\n device='GPU'; T in [DT_FLOAT]\r\n [Op:RGBToHSV]\r\n```\r\n**Describe the current behavior**\r\n[`tf.raw_ops.RGBToHSV`](https://www.tensorflow.org/api_docs/python/tf/raw_ops/RGBToHSV) should support half, bfloat16, float32, float64 according to the document.",
"comments": [
{
"body": "@chunduriv Was able to replicate the issue on colab using TF v2.8.0 and tf-nightly(2.9.0.dev20220303), please find the gist [here](https://colab.research.google.com/gist/sushreebarsa/edac82db0255229e1a8a06989716e6d9/54855.ipynb#scrollTo=BxmihNCvCOid).Thanks!",
"created_at": "2022-03-03T13:53:02Z"
},
{
"body": "Added a PR #54972 for the fix.",
"created_at": "2022-03-04T06:53:44Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54855\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54855\">No</a>\n",
"created_at": "2022-03-07T18:20:12Z"
}
],
"number": 54855,
"title": "`tf.raw_ops.RGBToHSV` lack support for bfloat16"
}
|
{
"body": "This PR addresses the issue raised in #54855 where there was no float16\r\nand bfloat16 support for tf.image.rgb_to_hsv/tf.image.hsv_to_rgb\r\n\r\nThis PR fixes #54855.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 54972,
"review_comments": [],
"title": "Add float16 and bfloat16 support for tf.image.rgb_to_hsv/tf.image.hsv_to_rgb"
}
|
{
"commits": [
{
"message": "Add float16 and bfloat16 support for tf.image.rgb_to_hsv/tf.image.hsv_to_rgb\n\nThis PR addresses the issue raised in 54855 where there was no float16\nand bfloat16 support for tf.image.rgb_to_hsv/tf.image.hsv_to_rgb\n\nThis PR fixes 54855.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for float16 and bfloat16 support of tf.image.rgb_to_hsv\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix clang-format issue\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -21,7 +21,6 @@ limitations under the License.\n #include <algorithm>\n #include <cmath>\n \n-#include \"third_party/eigen3/unsupported/Eigen/CXX11/Tensor\"\n #include \"tensorflow/core/framework/op_kernel.h\"\n #include \"tensorflow/core/framework/register_types.h\"\n #include \"tensorflow/core/framework/tensor.h\"\n@@ -31,6 +30,7 @@ limitations under the License.\n #include \"tensorflow/core/lib/core/status.h\"\n #include \"tensorflow/core/platform/logging.h\"\n #include \"tensorflow/core/platform/types.h\"\n+#include \"third_party/eigen3/unsupported/Eigen/CXX11/Tensor\"\n \n namespace tensorflow {\n \n@@ -116,6 +116,8 @@ class HSVToRGBOp : public OpKernel {\n template class HSVToRGBOp<CPUDevice, T>;\n TF_CALL_float(REGISTER_CPU);\n TF_CALL_double(REGISTER_CPU);\n+TF_CALL_half(REGISTER_CPU);\n+TF_CALL_bfloat16(REGISTER_CPU);\n \n #if (defined(GOOGLE_CUDA) && GOOGLE_CUDA) || \\\n (defined(TENSORFLOW_USE_ROCM) && TENSORFLOW_USE_ROCM)\n@@ -147,5 +149,4 @@ TF_CALL_float(REGISTER_GPU);\n TF_CALL_double(REGISTER_GPU);\n #endif\n \n-\n } // namespace tensorflow",
"filename": "tensorflow/core/kernels/image/colorspace_op.cc",
"status": "modified"
},
{
"diff": "@@ -95,6 +95,20 @@ def testRGBToHSVRoundTrip(self):\n rgb_tf = self.evaluate(rgb)\n self.assertAllClose(rgb_tf, rgb_np)\n \n+ def testRGBToHSVDataTypes(self):\n+ # Test case for GitHub issue 54855.\n+ data = [0, 5, 13, 54, 135, 226, 37, 8, 234, 90, 255, 1]\n+ for dtype in [\n+ dtypes.float32, dtypes.float64,\n+ dtypes.float16, dtypes.bfloat16]:\n+ with self.cached_session(use_gpu=False):\n+ rgb = math_ops.cast(\n+ np.array(data, np.float32).reshape([2, 2, 3]) / 255., dtype = dtype)\n+ hsv = image_ops.rgb_to_hsv(rgb)\n+ val = image_ops.hsv_to_rgb(hsv)\n+ out = self.evaluate(val)\n+ self.assertAllClose(rgb, out, atol=1e-2)\n+\n \n class RGBToYIQTest(test_util.TensorFlowTestCase):\n ",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "Android NN API only supported tensor rank: up to 4. So maybe need to add rank restriction on TF Lite nnapi delegate. If not, some models which have reshape op(rank > 4) will be failed on Android platform.\r\n\r\nFor example:\r\ntensorflow/lite/delegates/nnapi/nnapi_delegate.cc:\r\n\r\n```c++\r\nbool NNAPIDelegateKernel::Validate(\r\n const TfLiteContext* context, int builtin_code, int version,\r\n int android_sdk_version, const TfLiteNode* node,\r\n bool is_accelerator_specified,\r\n std::vector<NNAPIValidationFailure>* map_failures) {\r\n...\r\ncase kTfLiteBuiltinReshape: {\r\n...\r\n // add these lines for rank restriction\r\n const auto& input = context->tensors[node->inputs->data[0]];\r\n Expect(input.dims->size <= 4,\r\n NNAPIValidationFailureType::kUnsupportedOperandRank,\r\n \"Input rank should be <= 4\", &val_ctx);\r\n...\r\n}\r\n...\r\n}\r\n```\r\n",
"comments": [
{
"body": "@miaowang14 could you review this suggestion regarding shape op validation in NNAPI?",
"created_at": "2021-03-04T01:53:16Z"
},
{
"body": "@antkillerfarm good idea, would you like to create a PR implementing this? I am happy to review and approve it.",
"created_at": "2021-04-02T21:48:10Z"
},
{
"body": "@antkillerfarm The restriction for input and output shape has been now [updated](https://github.com/tensorflow/tensorflow/blob/6a0cfcc56d09643a0cf8292c1b6d0eb0aec92a5d/tensorflow/lite/delegates/nnapi/nnapi_delegate.cc#L2546) for nnapi delegate. Could you please check [this](https://github.com/tensorflow/tensorflow/blob/6a0cfcc56d09643a0cf8292c1b6d0eb0aec92a5d/tensorflow/lite/delegates/nnapi/nnapi_delegate.cc#L2546) and confirm? Thanks.",
"created_at": "2023-02-16T17:27:46Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2023-02-23T18:07:00Z"
},
{
"body": "Closing as stale. Please reopen if you'd like to work on this further. Thanks.",
"created_at": "2023-03-10T07:12:49Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/47546\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/47546\">No</a>\n",
"created_at": "2023-03-10T07:12:51Z"
}
],
"number": 47546,
"title": "About reshape op on TF Lite nnapi delegate"
}
|
{
"body": "FIXES github issue #47546\n",
"number": 54912,
"review_comments": [],
"title": "FIXES github issue #47546"
}
|
{
"commits": [
{
"message": "FIXES github issue #47546\n\nPiperOrigin-RevId: 432125716"
}
],
"files": [
{
"diff": "@@ -2495,6 +2495,14 @@ bool NNAPIDelegateKernel::Validate(\n } else {\n ExpectIsFloatQuant8OrInt32Operator(context, node, &val_ctx);\n }\n+ const auto& input = context->tensors[node->inputs->data[0]];\n+ Expect(input.dims->size <= 4,\n+ NNAPIValidationFailureType::kUnsupportedOperandRank,\n+ \"Input rank should be <= 4\", &val_ctx);\n+ const auto& output = context->tensors[node->outputs->data[0]];\n+ Expect(output.dims->size <= 4,\n+ NNAPIValidationFailureType::kUnsupportedOperandRank,\n+ \"Output rank should be <= 4\", &val_ctx);\n if (node->inputs->size >= 2) {\n Expect(context->tensors[node->inputs->data[1]].allocation_type ==\n kTfLiteMmapRo,",
"filename": "tensorflow/lite/delegates/nnapi/nnapi_delegate.cc",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nbytes_or_text = \"hello\"\r\nencoding = \"valid\"\r\nt1 = tf.compat.as_text(bytes_or_text, encoding=encoding)\r\nprint(t1) # hello\r\nt2 = tf.compat.as_bytes(bytes_or_text,encoding=encoding)\r\n# LookupError: unknown encoding: valid\r\n```\r\n\r\n**Describe the current behavior**\r\n`\"valid\"` is not valid value for `encoding`, as we can see that `tf.compat.as_bytes` would throw an `LoopupError`. However, `tf.compat.as_text` does not perform any validity checking and can accept it and even give an output.\r\n\r\n\r\n**Describe the expected behavior**\r\n`tf.compat.as_text` should check the validity of `encoding`.\r\n",
"comments": [
{
"body": "@ArrowIntoTheSky ,\r\nPlease find the difference between tf.compat.as_text and tf.compat.as_bytes.\r\ntf.compat.as_text:Converts any string-like python input types to unicode.\r\ntf.compat.as_bytes:Converts bytearray, bytes, or unicode python input types to bytes",
"created_at": "2022-02-17T12:33:11Z"
},
{
"body": "@tilakrayal \r\nYes, they are different APIs. I just use `tf.compat.as_bytes` to show the correct error handling of a **wrong** encoding string. It is obvious that `encoding` cannot be `valid` or `hi` as in the following example:\r\n```\r\nimport tensorflow as tf\r\nbytes_or_text = \"hello\"\r\nencoding = \"hi\"\r\nt1 = tf.compat.as_text(bytes_or_text, encoding=encoding) # This pass! But it should not.\r\n```",
"created_at": "2022-02-17T16:51:56Z"
},
{
"body": "@gadagashwini ,\r\nI was able to reproduce the issue in tf v2.7, v2.8 and nightly.Please find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/00dfd63ad2db6914065b7d00893cfc41/54413.ipynb).",
"created_at": "2022-02-18T09:48:11Z"
},
{
"body": "Added a PR #54503 for the fix.",
"created_at": "2022-02-23T20:53:11Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54413\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54413\">No</a>\n",
"created_at": "2022-02-28T22:10:34Z"
}
],
"number": 54413,
"title": "`tf.compat.as_bytes` does not check the encoding string"
}
|
{
"body": "PR #54503: Add appropriate encoding check for `tf.compat.as_bytes`/`as_text`\n\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/54503\n\nThis PR tries to address the issue raised in #54413 where\nthere were no encoding check for tf.compat.as_bytes/as_text.\nAs a result, invalid encoding input will silently\nreturn incorrect result, e.g.:\n```\nbytes_or_text = \"hello\"\nt1 = tf.compat.as_text(bytes_or_text, encoding=\"valid\")\nprint(t1) # hello\n```\n\nThis PR looks up python encoding to make sure it is valid.\n\nThis PR fixes #54413.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCopybara import of the project:\n\n--\n8e3b32d37ce22c07c21f508b2835456f3ca97531 by Yong Tang <yong.tang.github@outlook.com>:\n\nAdd appropriate encoding check for tf.compat.as_bytes/as_text\n\nThis PR tries to address the issue raised in 54413 where\nthere were no encoding check for tf.compat.as_bytes/as_text.\nAs a result, invalid encoding input will silently\nreturn incorrect result, e.g.:\n```\nbytes_or_text = \"hello\"\nt1 = tf.compat.as_text(bytes_or_text, encoding=\"valid\")\nprint(t1) # hello\n```\n\nThis PR looks up python encoding to make sure it is valid.\n\nThis PR fixes 54413.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\n--\n6099ca6e0e75e9ba2f1f9c48ecacd0523a507f1a by Yong Tang <yong.tang.github@outlook.com>:\n\nAdd test case for tf.compat.as_bytes/as_text\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nFUTURE_COPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/54503 from yongtang:54413-tf.compat.as_bytes-encoding 6099ca6e0e75e9ba2f1f9c48ecacd0523a507f1a\n",
"number": 54715,
"review_comments": [],
"title": "PR #54503: Add appropriate encoding check for `tf.compat.as_bytes`/`as_text`"
}
|
{
"commits": [
{
"message": "PR #54503: Add appropriate encoding check for `tf.compat.as_bytes`/`as_text`\n\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/54503\n\nThis PR tries to address the issue raised in #54413 where\nthere were no encoding check for tf.compat.as_bytes/as_text.\nAs a result, invalid encoding input will silently\nreturn incorrect result, e.g.:\n```\nbytes_or_text = \"hello\"\nt1 = tf.compat.as_text(bytes_or_text, encoding=\"valid\")\nprint(t1) # hello\n```\n\nThis PR looks up python encoding to make sure it is valid.\n\nThis PR fixes #54413.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCopybara import of the project:\n\n--\n8e3b32d37ce22c07c21f508b2835456f3ca97531 by Yong Tang <yong.tang.github@outlook.com>:\n\nAdd appropriate encoding check for tf.compat.as_bytes/as_text\n\nThis PR tries to address the issue raised in 54413 where\nthere were no encoding check for tf.compat.as_bytes/as_text.\nAs a result, invalid encoding input will silently\nreturn incorrect result, e.g.:\n```\nbytes_or_text = \"hello\"\nt1 = tf.compat.as_text(bytes_or_text, encoding=\"valid\")\nprint(t1) # hello\n```\n\nThis PR looks up python encoding to make sure it is valid.\n\nThis PR fixes 54413.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\n\n--\n6099ca6e0e75e9ba2f1f9c48ecacd0523a507f1a by Yong Tang <yong.tang.github@outlook.com>:\n\nAdd test case for tf.compat.as_bytes/as_text\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nFUTURE_COPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/54503 from yongtang:54413-tf.compat.as_bytes-encoding 6099ca6e0e75e9ba2f1f9c48ecacd0523a507f1a\nPiperOrigin-RevId: 431515245"
}
],
"files": [
{
"diff": "@@ -108,6 +108,7 @@ py_strict_test(\n srcs = [\"runtime_client_test.py\"],\n main = \"runtime_client_test.py\",\n python_version = \"PY3\",\n+ tags = [\"no_oss\"], # b/219089812\n deps = [\n \":runtime_client_py\",\n \"//tensorflow/core/framework:function_proto_py\",",
"filename": "tensorflow/core/function/BUILD",
"status": "modified"
},
{
"diff": "@@ -16,6 +16,7 @@ limitations under the License.\n // See docs in ../ops/array_ops.cc.\n \n #include \"tensorflow/core/kernels/shape_ops.h\"\n+\n #include \"tensorflow/core/framework/node_def.pb.h\"\n #include \"tensorflow/core/framework/register_types.h\"\n \n@@ -503,34 +504,32 @@ class EnsureShapeOp : public OpKernel {\n // constraints.\n REGISTER_KERNEL_BUILDER(Name(\"EnsureShape\").Device(DEVICE_CPU), EnsureShapeOp);\n \n-#define REGISTER_GPU_KERNEL(type) \\\n- REGISTER_KERNEL_BUILDER( \\\n- Name(\"EnsureShape\").Device(DEVICE_GPU).TypeConstraint<type>(\"T\"), \\\n+#define REGISTER_DEVICE_KERNEL(type) \\\n+ REGISTER_KERNEL_BUILDER( \\\n+ Name(\"EnsureShape\").Device(DEVICE_DEFAULT).TypeConstraint<type>(\"T\"), \\\n EnsureShapeOp)\n \n-TF_CALL_NUMBER_TYPES_NO_INT32(REGISTER_GPU_KERNEL);\n-REGISTER_GPU_KERNEL(Variant);\n+TF_CALL_NUMBER_TYPES_NO_INT32(REGISTER_DEVICE_KERNEL);\n+REGISTER_DEVICE_KERNEL(Variant);\n \n-#undef REGISTER_GPU_KERNEL\n+#undef REGISTER_DEVICE_KERNEL\n \n-#if GOOGLE_CUDA || TENSORFLOW_USE_ROCM\n-// A special GPU kernel for int32 and bool.\n+// A special DEVICE_DEFAULT kernel for int32 and bool.\n // TODO(b/25387198): Also enable int32 in device memory. This kernel\n // registration requires all int32 inputs and outputs to be in host memory.\n-#define REGISTER_GPU_HOST_KERNEL(type) \\\n+#define REGISTER_DEVICE_HOST_KERNEL(type) \\\n REGISTER_KERNEL_BUILDER(Name(\"EnsureShape\") \\\n- .Device(DEVICE_GPU) \\\n+ .Device(DEVICE_DEFAULT) \\\n .HostMemory(\"input\") \\\n .HostMemory(\"output\") \\\n .TypeConstraint<type>(\"T\"), \\\n EnsureShapeOp)\n \n-REGISTER_GPU_HOST_KERNEL(int32);\n-REGISTER_GPU_HOST_KERNEL(bool);\n-REGISTER_GPU_HOST_KERNEL(tstring);\n-REGISTER_GPU_HOST_KERNEL(ResourceHandle);\n+REGISTER_DEVICE_HOST_KERNEL(int32);\n+REGISTER_DEVICE_HOST_KERNEL(bool);\n+REGISTER_DEVICE_HOST_KERNEL(tstring);\n+REGISTER_DEVICE_HOST_KERNEL(ResourceHandle);\n \n-#undef REGISTER_GPU_HOST_KERNEL\n+#undef REGISTER_DEVICE_HOST_KERNEL\n \n-#endif\n } // namespace tensorflow",
"filename": "tensorflow/core/kernels/shape_ops.cc",
"status": "modified"
},
{
"diff": "@@ -223,15 +223,16 @@ cc_library(\n \"//tensorflow/lite/delegates/gpu/gl:api2\",\n ],\n }) + [\n+ \":api\",\n \"@com_google_absl//absl/container:flat_hash_map\",\n \"@com_google_absl//absl/container:flat_hash_set\",\n \"@com_google_absl//absl/memory\",\n \"@com_google_absl//absl/types:span\",\n+ \"//tensorflow/lite/kernels:kernel_util\",\n \"//tensorflow/lite:kernel_api\",\n \"//tensorflow/lite:minimal_logging\",\n \"//tensorflow/lite/c:common\",\n \"//tensorflow/lite/delegates:serialization\",\n- \"//tensorflow/lite/delegates/gpu:api\",\n \"//tensorflow/lite/delegates/gpu/cl:api\",\n \"//tensorflow/lite/delegates/gpu/cl:opencl_wrapper\",\n \"//tensorflow/lite/delegates/gpu/cl:tensor_type_util\",",
"filename": "tensorflow/lite/delegates/gpu/BUILD",
"status": "modified"
},
{
"diff": "@@ -38,6 +38,7 @@ limitations under the License.\n #include \"tensorflow/lite/delegates/gpu/common/status.h\"\n #include \"tensorflow/lite/delegates/serialization.h\"\n #include \"tensorflow/lite/kernels/internal/optimized/optimized_ops.h\"\n+#include \"tensorflow/lite/kernels/kernel_util.h\"\n #include \"tensorflow/lite/minimal_logging.h\"\n \n #ifndef CL_DELEGATE_NO_GL\n@@ -176,8 +177,8 @@ class DelegateKernel {\n }\n }\n \n- // At this point tflite didn't allocate tensors yet, therefore, collect\n- // indices and set all input and output tensors from tflite later.\n+ // At this point, TFLite hasn't allocated tensors yet, therefore, collect\n+ // indices and set all input and output tensors from TFLite later.\n input_indices_.reserve(input_refs.size());\n for (uint32_t tensor_index : input_refs) {\n const int64_t object_index = input_indices_.size();\n@@ -286,17 +287,46 @@ class DelegateKernel {\n RETURN_IF_ERROR(BuildFinalModel(context, delegate_params, graph));\n }\n \n+ // TfLiteDelegateParams.input_tensors is an array of all input tensors\n+ // including static weights. GraphFloat32.inputs() is an array of runtime\n+ // tensors that don't have a producer and the order may not be the same as\n+ // defined by TfLiteDelegateParams.input_tensors. These two sets are not\n+ // the same, especially on a multi-partition delegation. These are matched\n+ // by filtering TfLiteDelegateParams.input_tensors with\n+ // !tflite::IsConstantTensor() and then inserting them in the order\n+ // specified by TfLiteDelegateParams.input_tensors. This logic is shared\n+ // with ModelBuilder::PrecreateIOTensors() which is eventually called with\n+ // BuildFinalModel() above.\n+ //\n+ // Similarly, TfLiteDelegateParams.output_tensors is an array of all output\n+ // tensors, and can contain static tensors with buggy conversion.\n+ // GraphFloat32.outputs() is an array of runtime tensors that don't have a\n+ // consumer (this is a bug in the assumption) and the order may not be the\n+ // same as defined by TfLiteDelegateParams.output_tensors. Again, these two\n+ // sets are not the same, especially on a multi-partition delegation. These\n+ // are matched by inserting the tensors by the order defined by\n+ // TfLiteDelegateParams.output_tensors. Similarly, this logic is shared\n+ // with ModelBuilder::PrecreateIOTensors() which is eventually called with\n+ // BuildFinalModel() above.\n+ //\n+ // The aforementioned matching in BuildFinalModel() is ported here to match\n+ // input/output_refs.\n+ // TODO(b/211393366): Fix this at GraphFloat32.inputs/outputs() level.\n+ const std::vector<Value*> inputs = graph->inputs();\n input_refs->clear();\n- output_refs->clear();\n- const auto inputs = graph->inputs();\n- input_refs->reserve(inputs.size());\n- for (const auto& input : inputs) {\n- input_refs->push_back(input->tensor.ref);\n+ input_refs->reserve(delegate_params->input_tensors->size);\n+ for (int i = 0, j = 0; i < delegate_params->input_tensors->size; ++i) {\n+ const TfLiteTensor* tensor =\n+ context->tensors + delegate_params->input_tensors->data[i];\n+ if (tflite::IsConstantTensor(tensor)) continue;\n+ input_refs->push_back(inputs[j]->tensor.ref);\n+ ++j;\n }\n- const auto outputs = graph->outputs();\n- output_refs->reserve(outputs.size());\n- for (const auto& output : outputs) {\n- output_refs->push_back(output->tensor.ref);\n+ const std::vector<Value*> outputs = graph->outputs();\n+ output_refs->clear();\n+ output_refs->reserve(delegate_params->output_tensors->size);\n+ for (int i = 0; i < delegate_params->output_tensors->size; ++i) {\n+ output_refs->push_back(outputs[i]->tensor.ref);\n }\n \n return absl::OkStatus();",
"filename": "tensorflow/lite/delegates/gpu/delegate.cc",
"status": "modified"
},
{
"diff": "@@ -662,8 +662,17 @@ void ReduceAllDims(const T* input_data, const int* input_dims,\n // Fetch backend context and number of threads.\n CpuBackendContext* cpu_backend_context =\n CpuBackendContext::GetFromContext(context);\n- const int thread_count = cpu_backend_context->max_num_threads();\n-\n+ int thread_count = cpu_backend_context->max_num_threads();\n+ const int kMinElementsPerThread = 1024;\n+ if (num_elems / thread_count < kMinElementsPerThread) thread_count = 1;\n+\n+ if (thread_count == 1) {\n+ output_data[0] = num_elems > 0 ? input_data[0] : init_value;\n+ for (int i = 1; i < num_elems; ++i) {\n+ output_data[0] = reducer(output_data[0], input_data[i]);\n+ }\n+ return;\n+ }\n std::vector<ReduceWorkerTask<T>> tasks;\n std::vector<EvalData<T>> data;\n tasks.reserve(thread_count);",
"filename": "tensorflow/lite/kernels/reduce.cc",
"status": "modified"
},
{
"diff": "@@ -711,3 +711,14 @@ filegroup(\n name = \"util_hdr\",\n srcs = [\"util.h\"],\n )\n+\n+tf_py_test(\n+ name = \"compat_test\",\n+ srcs = [\"compat_test.py\"],\n+ python_version = \"PY3\",\n+ deps = [\n+ \":util\",\n+ \"//tensorflow/python:client_testlib\",\n+ \"//tensorflow/python:platform\",\n+ ],\n+)",
"filename": "tensorflow/python/util/BUILD",
"status": "modified"
},
{
"diff": "@@ -47,6 +47,7 @@\n \n import numpy as _np\n import six as _six\n+import codecs\n \n from tensorflow.python.util.tf_export import tf_export\n \n@@ -72,6 +73,8 @@ def as_bytes(bytes_or_text, encoding='utf-8'):\n Raises:\n TypeError: If `bytes_or_text` is not a binary or unicode string.\n \"\"\"\n+ # Validate encoding, a LookupError will be raised if invalid.\n+ encoding = codecs.lookup(encoding).name\n if isinstance(bytes_or_text, bytearray):\n return bytes(bytes_or_text)\n elif isinstance(bytes_or_text, _six.text_type):\n@@ -99,6 +102,8 @@ def as_text(bytes_or_text, encoding='utf-8'):\n Raises:\n TypeError: If `bytes_or_text` is not a binary or unicode string.\n \"\"\"\n+ # Validate encoding, a LookupError will be raised if invalid.\n+ encoding = codecs.lookup(encoding).name\n if isinstance(bytes_or_text, _six.text_type):\n return bytes_or_text\n elif isinstance(bytes_or_text, bytes):",
"filename": "tensorflow/python/util/compat.py",
"status": "modified"
},
{
"diff": "@@ -0,0 +1,36 @@\n+# Copyright 2022 The TensorFlow Authors. All Rights Reserved.\n+#\n+# Licensed under the Apache License, Version 2.0 (the \"License\");\n+# you may not use this file except in compliance with the License.\n+# You may obtain a copy of the License at\n+#\n+# http://www.apache.org/licenses/LICENSE-2.0\n+#\n+# Unless required by applicable law or agreed to in writing, software\n+# distributed under the License is distributed on an \"AS IS\" BASIS,\n+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n+# See the License for the specific language governing permissions and\n+# limitations under the License.\n+# ==============================================================================\n+\"\"\"Compat tests.\"\"\"\n+\n+from tensorflow.python.platform import test\n+from tensorflow.python.util import compat\n+\n+\n+class CompatTest(test.TestCase):\n+\n+ def testCompatValidEncoding(self):\n+ self.assertEqual(compat.as_bytes(\"hello\", \"utf8\"), b\"hello\")\n+ self.assertEqual(compat.as_text(b\"hello\", \"utf-8\"), \"hello\")\n+\n+ def testCompatInvalidEncoding(self):\n+ with self.assertRaises(LookupError):\n+ compat.as_bytes(\"hello\", \"invalid\")\n+\n+ with self.assertRaises(LookupError):\n+ compat.as_text(b\"hello\", \"invalid\")\n+\n+\n+if __name__ == \"__main__\":\n+ test.main()",
"filename": "tensorflow/python/util/compat_test.py",
"status": "added"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nfeatures = tf.zeros([3, 4], dtype=tf.uint16)\r\ntf.nn.gelu(features)\r\n```\r\nThrows `TypeError`\r\n```\r\nTypeError: Cannot convert 0.5 to EagerTensor of dtype uint16\r\n```\r\n**Describe the current behavior**\r\nThe current message is misleading, as it seems to be some computation error. If `tf.nn.gelu` does not accept `uint16` inputs, the message should be a standard message like\r\n```\r\nValue for attr 'T' of uint16 is not in the list of allowed values:\r\n```\r\nSimilar to `tf.nn.crelu`:\r\n```\r\nimport tensorflow as tf\r\nfeatures = tf.zeros([3, 4], dtype=tf.uint16)\r\ntf.nn.crelu(features)\r\n# InvalidArgumentError: Value for attr 'T' of uint16 is not in the list of allowed values: bfloat16, half, float, double, int8, int16, int32, int64, complex64, complex128; NodeDef: {{node Neg}}; Op<name=Neg; signature=x:T -> y:T; attr=T:type,allowed=[DT_BFLOAT16, DT_HALF, DT_FLOAT, DT_DOUBLE, DT_INT8, DT_INT16, DT_INT32, DT_INT64, DT_COMPLEX64, DT_COMPLEX128]> [Op:Neg]\r\n```\r\n\r\n\r\n**Describe the expected behavior**\r\n`tf.nn.gelu` should have better error message in this case.",
"comments": [
{
"body": "Thank you for reporting , will update the code soon. ",
"created_at": "2022-02-22T19:31:34Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54475\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54475\">No</a>\n",
"created_at": "2022-03-01T00:19:48Z"
}
],
"number": 54475,
"title": "Error message of `tf.nn.gelu` with `uint16` input is misleading "
}
|
{
"body": "Allow only float values for gelu.\n\nFixes #54475\n",
"number": 54550,
"review_comments": [],
"title": "Allow only float values for gelu."
}
|
{
"commits": [
{
"message": "Allow only float values for gelu.\n\nFixes #54475\n\nPiperOrigin-RevId: 430806132"
}
],
"files": [
{
"diff": "@@ -3699,6 +3699,10 @@ def gelu(features, approximate=False, name=None):\n \"\"\"\n with ops.name_scope(name, \"Gelu\", [features]):\n features = ops.convert_to_tensor(features, name=\"features\")\n+ if not features.dtype.is_floating:\n+ raise ValueError(\n+ \"`features.dtype` must be a floating point tensor.\"\n+ f\"Received:features.dtype={features.dtype}\")\n if approximate:\n coeff = math_ops.cast(0.044715, features.dtype)\n return 0.5 * features * (",
"filename": "tensorflow/python/ops/nn_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nbytes_or_text = \"hello\"\r\nencoding = \"valid\"\r\nt1 = tf.compat.as_text(bytes_or_text, encoding=encoding)\r\nprint(t1) # hello\r\nt2 = tf.compat.as_bytes(bytes_or_text,encoding=encoding)\r\n# LookupError: unknown encoding: valid\r\n```\r\n\r\n**Describe the current behavior**\r\n`\"valid\"` is not valid value for `encoding`, as we can see that `tf.compat.as_bytes` would throw an `LoopupError`. However, `tf.compat.as_text` does not perform any validity checking and can accept it and even give an output.\r\n\r\n\r\n**Describe the expected behavior**\r\n`tf.compat.as_text` should check the validity of `encoding`.\r\n",
"comments": [
{
"body": "@ArrowIntoTheSky ,\r\nPlease find the difference between tf.compat.as_text and tf.compat.as_bytes.\r\ntf.compat.as_text:Converts any string-like python input types to unicode.\r\ntf.compat.as_bytes:Converts bytearray, bytes, or unicode python input types to bytes",
"created_at": "2022-02-17T12:33:11Z"
},
{
"body": "@tilakrayal \r\nYes, they are different APIs. I just use `tf.compat.as_bytes` to show the correct error handling of a **wrong** encoding string. It is obvious that `encoding` cannot be `valid` or `hi` as in the following example:\r\n```\r\nimport tensorflow as tf\r\nbytes_or_text = \"hello\"\r\nencoding = \"hi\"\r\nt1 = tf.compat.as_text(bytes_or_text, encoding=encoding) # This pass! But it should not.\r\n```",
"created_at": "2022-02-17T16:51:56Z"
},
{
"body": "@gadagashwini ,\r\nI was able to reproduce the issue in tf v2.7, v2.8 and nightly.Please find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/00dfd63ad2db6914065b7d00893cfc41/54413.ipynb).",
"created_at": "2022-02-18T09:48:11Z"
},
{
"body": "Added a PR #54503 for the fix.",
"created_at": "2022-02-23T20:53:11Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54413\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54413\">No</a>\n",
"created_at": "2022-02-28T22:10:34Z"
}
],
"number": 54413,
"title": "`tf.compat.as_bytes` does not check the encoding string"
}
|
{
"body": "This PR tries to address the issue raised in #54413 where\r\nthere were no encoding check for tf.compat.as_bytes/as_text.\r\nAs a result, invalid encoding input will silently\r\nreturn incorrect result, e.g.:\r\n```\r\nbytes_or_text = \"hello\"\r\nt1 = tf.compat.as_text(bytes_or_text, encoding=\"valid\")\r\nprint(t1) # hello\r\n```\r\n\r\nThis PR looks up python encoding to make sure it is valid.\r\n\r\nThis PR fixes #54413.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 54503,
"review_comments": [],
"title": "Add appropriate encoding check for `tf.compat.as_bytes`/`as_text`"
}
|
{
"commits": [
{
"message": "Add appropriate encoding check for tf.compat.as_bytes/as_text\n\nThis PR tries to address the issue raised in 54413 where\nthere were no encoding check for tf.compat.as_bytes/as_text.\nAs a result, invalid encoding input will silently\nreturn incorrect result, e.g.:\n```\nbytes_or_text = \"hello\"\nt1 = tf.compat.as_text(bytes_or_text, encoding=\"valid\")\nprint(t1) # hello\n```\n\nThis PR looks up python encoding to make sure it is valid.\n\nThis PR fixes 54413.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for tf.compat.as_bytes/as_text\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -711,3 +711,14 @@ filegroup(\n name = \"util_hdr\",\n srcs = [\"util.h\"],\n )\n+\n+tf_py_test(\n+ name = \"compat_test\",\n+ srcs = [\"compat_test.py\"],\n+ python_version = \"PY3\",\n+ deps = [\n+ \":util\",\n+ \"//tensorflow/python:client_testlib\",\n+ \"//tensorflow/python:platform\",\n+ ],\n+)",
"filename": "tensorflow/python/util/BUILD",
"status": "modified"
},
{
"diff": "@@ -47,6 +47,7 @@\n \n import numpy as _np\n import six as _six\n+import codecs\n \n from tensorflow.python.util.tf_export import tf_export\n \n@@ -72,6 +73,8 @@ def as_bytes(bytes_or_text, encoding='utf-8'):\n Raises:\n TypeError: If `bytes_or_text` is not a binary or unicode string.\n \"\"\"\n+ # Validate encoding, a LookupError will be raised if invalid.\n+ encoding = codecs.lookup(encoding).name\n if isinstance(bytes_or_text, bytearray):\n return bytes(bytes_or_text)\n elif isinstance(bytes_or_text, _six.text_type):\n@@ -99,6 +102,8 @@ def as_text(bytes_or_text, encoding='utf-8'):\n Raises:\n TypeError: If `bytes_or_text` is not a binary or unicode string.\n \"\"\"\n+ # Validate encoding, a LookupError will be raised if invalid.\n+ encoding = codecs.lookup(encoding).name\n if isinstance(bytes_or_text, _six.text_type):\n return bytes_or_text\n elif isinstance(bytes_or_text, bytes):",
"filename": "tensorflow/python/util/compat.py",
"status": "modified"
},
{
"diff": "@@ -0,0 +1,37 @@\n+# Copyright 2022 The TensorFlow Authors. All Rights Reserved.\n+#\n+# Licensed under the Apache License, Version 2.0 (the \"License\");\n+# you may not use this file except in compliance with the License.\n+# You may obtain a copy of the License at\n+#\n+# http://www.apache.org/licenses/LICENSE-2.0\n+#\n+# Unless required by applicable law or agreed to in writing, software\n+# distributed under the License is distributed on an \"AS IS\" BASIS,\n+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n+# See the License for the specific language governing permissions and\n+# limitations under the License.\n+# ==============================================================================\n+\"\"\"Compat tests.\"\"\"\n+\n+from tensorflow.python.platform import test\n+from tensorflow.python.util import compat\n+\n+\n+class CompatTest(test.TestCase):\n+\n+ def testCompatValidEncoding(self):\n+ self.assertEqual(compat.as_bytes(\"hello\", \"utf8\"), b\"hello\")\n+ self.assertEqual(compat.as_text(b\"hello\", \"utf-8\"), \"hello\")\n+\n+\n+ def testCompatInvalidEncoding(self):\n+ with self.assertRaises(LookupError):\n+ compat.as_bytes(\"hello\", \"invalid\")\n+\n+ with self.assertRaises(LookupError):\n+ compat.as_text(b\"hello\", \"invalid\")\n+\n+\n+if __name__ == \"__main__\":\n+ test.main()",
"filename": "tensorflow/python/util/compat_test.py",
"status": "added"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\ntensor = [0,1,2,3]\r\nmask = tf.random.uniform([4], dtype=tf.float64)\r\ntf.boolean_mask(tensor, mask) \r\n# Outputs: <tf.Tensor: shape=(4,), dtype=int32, numpy=array([0, 1, 2, 3], dtype=int32)>\r\n```\r\n\r\n**Describe the current behavior**\r\n`tf.boolean_mask` has an argument `mask` which should be a `bool` tensor. However, it does not perform any validity checking and can accept a `float64` value. \r\n\r\n\r\n**Describe the expected behavior**\r\n`tf.boolean_mask` should check the dtype of input tensor `mask`.\r\n\r\nFor example, `tf.math.reduce_any` would check the first argument and throw an `InvalidArgumentError` for non-boolean inputs.\r\n```\r\nimport tensorflow as tf\r\ninput_tensor = tf.random.uniform([4], dtype=tf.float64)\r\ntf.math.reduce_any(input_tensor) # InvalidArgumentError: cannot compute Any as input #0(zero-based) was expected to be a bool tensor but is a double tensor [Op:Any]\r\n```\r\n",
"comments": [
{
"body": "Added a PR #54412 for the fix.",
"created_at": "2022-02-18T00:06:15Z"
},
{
"body": "@ArrowIntoTheSky, The issue will move to closed status once the https://github.com/tensorflow/tensorflow/pull/54432 is merged. Thanks!",
"created_at": "2022-02-18T04:56:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54412\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54412\">No</a>\n",
"created_at": "2022-03-07T18:04:24Z"
}
],
"number": 54412,
"title": "`tf.boolean_mask` lack checking for bool arguments"
}
|
{
"body": "This PR tries to address the issue raised in #54412 where\r\nmask's dtype was checked in tf.boolean_mask and an invalid\r\nresult has been returned instead.\r\n\r\nThis PR fixes #54412.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 54432,
"review_comments": [],
"title": "Add appropriate dtype check for `tf.boolean_mask`'s mask"
}
|
{
"commits": [
{
"message": "Add appropriate dtype check for tf.boolean_mask's mask\n\nThis PR tries to address the issue raised in 54412 where\nmask's dtype was checked in tf.boolean_mask and an invalid\nresult has been returned instead.\n\nThis PR fixes 54412.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for mask's dtype check for tf.boolean_mask\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix pylint error\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -318,6 +318,13 @@ def f(axis):\n self.assertAllEqual(\n self.evaluate(f(constant_op.constant(0, dtype=dtypes.int32))), [1, 3])\n \n+ def testMaskWithNonBoolTensor(self):\n+ mask = [1, 2, 3]\n+ tensor = [1, 2, 3]\n+ with self.session():\n+ with self.assertRaisesRegex(TypeError, \"expected bool but got\"):\n+ self.evaluate(array_ops.boolean_mask(tensor, mask))\n+\n \n @test_util.run_all_in_graph_and_eager_modes\n class OperatorShapeTest(test_util.TensorFlowTestCase):",
"filename": "tensorflow/python/kernel_tests/array_ops/array_ops_test.py",
"status": "modified"
},
{
"diff": "@@ -1881,6 +1881,9 @@ def _apply_mask_1d(reshaped_tensor, mask, axis=None):\n with ops.name_scope(name, values=[tensor, mask]):\n tensor = ops.convert_to_tensor(tensor, name=\"tensor\")\n mask = ops.convert_to_tensor(mask, name=\"mask\")\n+ if mask.dtype != dtypes.bool:\n+ raise TypeError(\n+ \"Invalid `mask`: expected bool but got %s.\" % mask.dtype)\n \n shape_mask = mask.get_shape()\n ndims_mask = shape_mask.ndims",
"filename": "tensorflow/python/ops/array_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\n\r\nx = tf.constant([[1, 2, 3, 4, 5]], dtype=tf.float32)\r\nclip_norm = -6.0\r\nx_clipped = tf.clip_by_norm(x, clip_norm, )\r\nprint(x)\r\nprint(x_clipped)\r\n\r\n```\r\nOutputs:\r\n```\r\ntf.Tensor([[1. 2. 3. 4. 5.]], shape=(1, 5), dtype=float32)\r\ntf.Tensor([[-0.80903983 -1.6180797 -2.4271195 -3.2361593 -4.0451994 ]], shape=(1, 5), dtype=float32)\r\n```\r\n\r\n**Describe the current behavior**\r\n`tf.clip_by_norm` has an argument `clip_norm` which should be a **positive** floating point. However, it does not perform any validity checking and can accept a negative value like `-6.0`. When applied to a tensor, it produces wrong output silently.\r\n\r\n\r\n**Describe the expected behavior**\r\n`tf.clip_by_norm` should check the value of `clip_norm`.\r\n",
"comments": [
{
"body": "Added PR #54430 for the fix.",
"created_at": "2022-02-17T23:42:36Z"
},
{
"body": "Was able to reproduce the issue `tf-nightly-2.11.0-dev20220829`. Please find the gist [here](https://colab.research.google.com/drive/1gyQwlf1upuIl4SOEaRXmv0EoN3FfkpJ-?usp=sharing). Thank you!",
"created_at": "2022-08-30T07:46:20Z"
}
],
"number": 54414,
"title": "`tf.clip_by_norm` gives WRONG results when given negative `norm`"
}
|
{
"body": "This PR tries to address the issue raised in #54414 where\r\nthere is no check for clip_norm for tf.clip_by_norm.\r\nAs a result an invalid result was silently returned.\r\n\r\nThis PR fixes #54414.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\n",
"number": 54430,
"review_comments": [],
"title": "Add appropriate value check for `tf.clip_by_norm`"
}
|
{
"commits": [
{
"message": "Add appropriate value check for tf.clip_by_norm\n\nThis PR tries to address the issue raised in 54414 where\nthere is no check for clip_norm for tf.clip_by_norm.\nAs a result an invalid result was silently returned.\n\nThis PR fixes 54414.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for tf.clip_by_norm with invalid clip_norm\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -18,6 +18,7 @@\n \n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors\n from tensorflow.python.framework import indexed_slices as indexed_slices_lib\n from tensorflow.python.framework import test_util\n from tensorflow.python.ops import array_ops\n@@ -531,6 +532,15 @@ def testClipByValueEmptyTensor(self):\n with self.session() as sess:\n sess.run([x, y, z, w], feed_dict={zero: np.zeros((7, 0))})\n \n+ def testClipByNormNegative(self):\n+ with self.assertRaisesRegex(\n+ (errors.InvalidArgumentError, ValueError), \"must > 0\"):\n+ with self.session():\n+ x = constant_op.constant([-3.0, 0.0, 0.0, 4.0, 0.0, 0.0], shape=[2, 3])\n+ clip_norm = -4.0\n+ ans = clip_ops.clip_by_norm(x, clip_norm)\n+ self.evaluate(ans)\n+\n \n if __name__ == '__main__':\n test.main()",
"filename": "tensorflow/python/kernel_tests/math_ops/clip_ops_test.py",
"status": "modified"
},
{
"diff": "@@ -19,6 +19,7 @@\n from tensorflow.python.framework import indexed_slices\n from tensorflow.python.framework import ops\n from tensorflow.python.ops import array_ops\n+from tensorflow.python.ops import control_flow_ops\n from tensorflow.python.ops import gen_array_ops\n from tensorflow.python.ops import gen_nn_ops\n from tensorflow.python.ops import math_ops\n@@ -214,6 +215,10 @@ def clip_by_norm(t, clip_norm, axes=None, name=None):\n t.values if isinstance(t, indexed_slices.IndexedSlices) else t,\n name=\"t\")\n \n+ check = control_flow_ops.Assert(\n+ math_ops.greater(clip_norm, 0), [\"clip_norm %s must > 0\" % clip_norm])\n+ clip_norm = control_flow_ops.with_dependencies([check], clip_norm)\n+\n # Calculate L2-norm, clip elements by ratio of clip_norm to L2-norm\n l2sum = math_ops.reduce_sum(values * values, axes, keepdims=True)\n pred = l2sum > 0",
"filename": "tensorflow/python/ops/clip_ops.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nnbins = -16\r\nvalue_range = [0.0, 5.0]\r\nnew_values = [-1.0, 0.0, 1.5, 2.0, 5.0, 15]\r\nindices = tf.histogram_fixed_width_bins(new_values, value_range, nbins=nbins)\r\nindices.numpy()\r\n```\r\nOutputs:\r\n```\r\narray([0, 0, 0, 0, 0, 0], dtype=int32)\r\n```\r\n\r\n**Describe the current behavior**\r\n`tf.histogram_fixed_width_bins` has an argument `nbins` which should be a **positive** integer. However, it does not perform any validity checking and can accept a **negative** value like `-16`. `tf.histogram_fixed_width` (another API with similar functionality) can detect this error and raise an `InvalidArgumentError`:\r\n```\r\nimport tensorflow as tf\r\nnbins = -16\r\nvalue_range = [0.0, 5.0]\r\nnew_values = [-1.0, 0.0, 1.5, 2.0, 5.0, 15]\r\nindices = tf.histogram_fixed_width(new_values, value_range, nbins=nbins)\r\nindices.numpy()\r\n# InvalidArgumentError: nbins should be a positive number, but got '-16' [Op:HistogramFixedWidth]\r\n```\r\n\r\n\r\n**Describe the expected behavior**\r\n`tf.histogram_fixed_width_bins` should have better input checking.\r\n",
"comments": [
{
"body": "Hi @chunduriv ! Could you please look at this issue? It is replicating in TF 2.7 and 2.8. Attaching gist in [2.8 ](https://colab.sandbox.google.com/gist/mohantym/422bcc9269550d072870afe4f0b3c578/github_54415_2-8.ipynb#scrollTo=7AJOJUOiT-Gu) and [2.7](https://colab.sandbox.google.com/gist/mohantym/c3e643aa8b2ac6ec0ae83b37b25c5465/github_54415_2-8.ipynb#scrollTo=Fhee8nopUdjy) for reference. Thanks!",
"created_at": "2022-02-17T06:21:22Z"
},
{
"body": "Added a PR #54429 for the fix.",
"created_at": "2022-02-17T23:21:47Z"
},
{
"body": "@ArrowIntoTheSky, The issue will move to closed status once the https://github.com/tensorflow/tensorflow/pull/54429 is merged. Thanks!",
"created_at": "2022-02-18T04:52:13Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54415\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54415\">No</a>\n",
"created_at": "2022-02-22T16:44:10Z"
}
],
"number": 54415,
"title": "`tf.histogram_fixed_width_bins` lack checking for `nbins`"
}
|
{
"body": "This PR tries to address the issue raised in #54415 where\r\nnbins was not checked for tf.histogram_fixed_width_bins\r\nand an incorrect result was returned when nbins < 0.\r\n\r\nThis PR fixes #54415.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 54429,
"review_comments": [],
"title": "Add appropriate error check for nbins in `tf.histogram_fixed_width_bins`"
}
|
{
"commits": [
{
"message": "Add appropriate error check for nbins in tf.histogram_fixed_width_bins\n\nThis PR tries to address the issue raised in 54415 where\nnbins was not checked for tf.histogram_fixed_width_bins\nand an incorrect result was returned when nbins < 0.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for nbins < 0 with tf.histogram_fixed_width_bins\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -20,6 +20,7 @@\n from tensorflow.python.framework import ops\n from tensorflow.python.ops import array_ops\n from tensorflow.python.ops import clip_ops\n+from tensorflow.python.ops import control_flow_ops\n from tensorflow.python.ops import gen_math_ops\n from tensorflow.python.ops import math_ops\n from tensorflow.python.util import dispatch\n@@ -77,6 +78,9 @@ def histogram_fixed_width_bins(values,\n values = array_ops.reshape(values, [-1])\n value_range = ops.convert_to_tensor(value_range, name='value_range')\n nbins = ops.convert_to_tensor(nbins, dtype=dtypes.int32, name='nbins')\n+ check = control_flow_ops.Assert(\n+ math_ops.greater(nbins, 0), [\"nbins %s must > 0\" % nbins])\n+ nbins = control_flow_ops.with_dependencies([check], nbins)\n nbins_float = math_ops.cast(nbins, values.dtype)\n \n # Map tensor values that fall within value_range to [0, 1].",
"filename": "tensorflow/python/ops/histogram_ops.py",
"status": "modified"
},
{
"diff": "@@ -17,6 +17,7 @@\n import numpy as np\n \n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors\n from tensorflow.python.framework import test_util\n from tensorflow.python.framework import constant_op\n from tensorflow.python.ops import array_ops\n@@ -75,6 +76,17 @@ def test_2d_values(self):\n self.assertEqual(dtypes.int32, bins.dtype)\n self.assertAllClose(expected_bins, self.evaluate(bins))\n \n+ def test_negative_nbins(self):\n+ value_range = [0.0, 5.0]\n+ values = []\n+ with self.assertRaisesRegex(\n+ (errors.InvalidArgumentError, ValueError), \"must > 0\"):\n+ with self.session():\n+ bins = histogram_ops.histogram_fixed_width_bins(\n+ values, value_range, nbins=-1)\n+ self.evaluate(bins)\n+\n+\n \n class HistogramFixedWidthTest(test.TestCase):\n ",
"filename": "tensorflow/python/ops/histogram_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\ndata = tf.complex(tf.random.uniform([3, 4], dtype=tf.float64),tf.random.uniform([3, 4], dtype=tf.float64))\r\nsegment_ids = [0,0,1]\r\nres = tf.math.segment_sum(data=data,segment_ids=segment_ids) # pass\r\nres_sp = tf.sparse.segment_sum(data=data,indices=tf.constant([0, 1, 2]),segment_ids=segment_ids) # InvalidArgumentError\r\n```\r\n\r\n**Describe the current behavior**\r\n`tf.sparse.segment_sum` cannot accept a tensor of type `complex128`. However, `tf.math.segment_sum` do support it. \r\nFor the above code snippet, the error message is:\r\n```\r\nInvalidArgumentError: Value for attr 'T' of complex128 is not in the list of allowed values: float, double, int32, uint8, int16, int8, int64, bfloat16, uint16, half, uint32, uint64\r\n\t; NodeDef: {{node SparseSegmentSum}}; Op<name=SparseSegmentSum; signature=data:T, indices:Tidx, segment_ids:Tsegmentids -> output:T; attr=T:type,allowed=[DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT16, DT_INT8, DT_INT64, DT_BFLOAT16, DT_UINT16, DT_HALF, DT_UINT32, DT_UINT64]; attr=Tidx:type,default=DT_INT32,allowed=[DT_INT32, DT_INT64]; attr=Tsegmentids:type,default=DT_INT32,allowed=[DT_INT32, DT_INT64]> [Op:SparseSegmentSum]\r\n```\r\n\r\n**Describe the expected behavior**\r\n`tf.sparse.segment_sum` should also support complex dtypes. Actually I would expect the valid types of `data` of `tf.sparse.segment_sum` to be the same as `tf.math.segment_sum`, since the document of `tf.sparse.segment_sum` does not have this information.\r\n",
"comments": [
{
"body": "Hi @Saduf2019! Could you please look at this issue. Attaching Gist in [2.6](https://colab.sandbox.google.com/gist/mohantym/82bdcdd01364e838e17ba09bdc46fe35/github_53655.ipynb#scrollTo=bP0HkuagQpt8) ,[2.7](https://colab.sandbox.google.com/gist/mohantym/f118d8aac7af27e0a9a5e5d61f3a25c7/github_53655.ipynb#scrollTo=2-mrSko-tzOy) and [nightly ](https://colab.sandbox.google.com/gist/mohantym/f118d8aac7af27e0a9a5e5d61f3a25c7/github_53655.ipynb#scrollTo=2-mrSko-tzOy)for reference. Thank you!\r\n\r\n**Updated**\r\nWas able to reproduce the issue with `Tf-nightly-2.11.0-dev20220829` . Please find the gist [here](https://colab.research.google.com/drive/10b12R4fNY8IfcyjG0CYYjb3q0j1sYwix?usp=sharing). Thank you!",
"created_at": "2022-01-07T09:35:35Z"
},
{
"body": "Added PR #54357 for complex support of tf.sparse.segment_sum.",
"created_at": "2022-02-12T04:45:54Z"
},
{
"body": "Hi @ArrowIntoTheSky !\r\nI am able to replicate this issue in 2.11 . Attached [gist](https://colab.sandbox.google.com/gist/mohantym/8fa5b93f4c0e7fb76d2cf18b752d4793/-53655.ipynb#scrollTo=RycgtC8AKNgi) for reference. \r\nThank you!\r\n",
"created_at": "2023-01-24T08:59:59Z"
},
{
"body": "@ArrowIntoTheSky,\r\nThe **tf.sparse.segment_sum** performs efficient summation operations on sparse tensors, and the complex numbers introduce additional computational complexity that can decrease the performance of the function.\r\n\r\nIf you need to perform segment-wise summation on sparse tensors with complex values, As the temporary workaround you can try using custom TensorFlow operations or consider alternative approach like `converting the complex values to real or imaginary components and performing the summation separately`.\r\nThank you!",
"created_at": "2023-11-25T16:10:30Z"
},
{
"body": "This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you.",
"created_at": "2023-12-03T01:49:40Z"
},
{
"body": "This issue was closed because it has been inactive for 7 days since being marked as stale. Please reopen if you'd like to work on this further.",
"created_at": "2023-12-10T01:50:17Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53655\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53655\">No</a>\n",
"created_at": "2023-12-10T01:50:20Z"
}
],
"number": 53655,
"title": "tf.sparse.segment_sum doesn't support complex dtypes"
}
|
{
"body": "This PR address the issue raised in #53655 where tf.sparse.segment_sum does not have complex support (while tf.math.segment_sum has). This PR adds complex support for tf.sparse.segment_sum.\r\n\r\nThis PR fixes #53655.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 54357,
"review_comments": [],
"title": "Add complex support for `tf.sparse.segment_sum`"
}
|
{
"commits": [
{
"message": "Add complex support for tf.sparse.segment_sum\n\nThis PR address the issue raised in 53655 where\ntf.sparse.segment_sum does not have complex support (while tf.math.segment_sum has).\nThis PR adds complex support for tf.sparse.segment_sum.\n\nThis PR fixes 53655.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for complex support of tf.sparse.segment_sum\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update ops.pbtxt\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -43,6 +43,8 @@ namespace tensorflow {\n SparseSegmentReductionSumWithNumSegmentsOp<CPUDevice, type, index_type, \\\n segment_ids_type>);\n TF_CALL_REAL_NUMBER_TYPES(REGISTER_CPU_SPARSE_KERNELS_FOR_EACH_INDEX_TYPE);\n+REGISTER_CPU_SPARSE_KERNELS_FOR_EACH_INDEX_TYPE(complex64);\n+REGISTER_CPU_SPARSE_KERNELS_FOR_EACH_INDEX_TYPE(complex128);\n #undef REGISTER_CPU_SPARSE_KERNELS\n \n #define REGISTER_CPU_SPARSE_KERNELS(type, index_type, segment_ids_type) \\",
"filename": "tensorflow/core/kernels/segment_reduction_ops_impl_5.cc",
"status": "modified"
},
{
"diff": "@@ -267,3 +267,73 @@ op {\n }\n }\n }\n+op {\n+ name: \"SparseSegmentSum\"\n+ input_arg {\n+ name: \"data\"\n+ type_attr: \"T\"\n+ }\n+ input_arg {\n+ name: \"indices\"\n+ type_attr: \"Tidx\"\n+ }\n+ input_arg {\n+ name: \"segment_ids\"\n+ type_attr: \"Tsegmentids\"\n+ }\n+ output_arg {\n+ name: \"output\"\n+ type_attr: \"T\"\n+ }\n+ attr {\n+ name: \"T\"\n+ type: \"type\"\n+ allowed_values {\n+ list {\n+ type: DT_FLOAT\n+ type: DT_DOUBLE\n+ type: DT_INT32\n+ type: DT_UINT8\n+ type: DT_INT16\n+ type: DT_INT8\n+ type: DT_COMPLEX64\n+ type: DT_INT64\n+ type: DT_QINT8\n+ type: DT_QUINT8\n+ type: DT_QINT32\n+ type: DT_BFLOAT16\n+ type: DT_UINT16\n+ type: DT_COMPLEX128\n+ type: DT_HALF\n+ type: DT_UINT32\n+ type: DT_UINT64\n+ }\n+ }\n+ }\n+ attr {\n+ name: \"Tidx\"\n+ type: \"type\"\n+ default_value {\n+ type: DT_INT32\n+ }\n+ allowed_values {\n+ list {\n+ type: DT_INT32\n+ type: DT_INT64\n+ }\n+ }\n+ }\n+ attr {\n+ name: \"Tsegmentids\"\n+ type: \"type\"\n+ default_value {\n+ type: DT_INT32\n+ }\n+ allowed_values {\n+ list {\n+ type: DT_INT32\n+ type: DT_INT64\n+ }\n+ }\n+ }\n+}",
"filename": "tensorflow/core/ops/compat/ops_history_v2/SparseSegmentSum.pbtxt",
"status": "modified"
},
{
"diff": "@@ -1351,7 +1351,7 @@ REGISTER_OP(\"SparseSegmentSum\")\n .Input(\"indices: Tidx\")\n .Input(\"segment_ids: Tsegmentids\")\n .Output(\"output: T\")\n- .Attr(\"T: realnumbertype\")\n+ .Attr(\"T: numbertype\")\n .Attr(\"Tidx: {int32, int64} = DT_INT32\")\n .Attr(\"Tsegmentids: {int32, int64} = DT_INT32\")\n .SetShapeFn(SparseSegmentReductionShapeFn);",
"filename": "tensorflow/core/ops/math_ops.cc",
"status": "modified"
},
{
"diff": "@@ -52735,9 +52735,14 @@ op {\n type: DT_UINT8\n type: DT_INT16\n type: DT_INT8\n+ type: DT_COMPLEX64\n type: DT_INT64\n+ type: DT_QINT8\n+ type: DT_QUINT8\n+ type: DT_QINT32\n type: DT_BFLOAT16\n type: DT_UINT16\n+ type: DT_COMPLEX128\n type: DT_HALF\n type: DT_UINT32\n type: DT_UINT64",
"filename": "tensorflow/core/ops/ops.pbtxt",
"status": "modified"
},
{
"diff": "@@ -569,7 +569,7 @@ class SparseSegmentReductionOpTest(SparseSegmentReductionHelper):\n def testValues(self):\n dtypes = [\n dtypes_lib.float32, dtypes_lib.float64, dtypes_lib.int64,\n- dtypes_lib.int32\n+ dtypes_lib.int32, dtypes_lib.complex64, dtypes_lib.complex128\n ]\n \n index_dtypes = [dtypes_lib.int32, dtypes_lib.int64]",
"filename": "tensorflow/python/kernel_tests/math_ops/segment_reduction_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\n\r\nx = tf.complex(tf.random.uniform([4], dtype=tf.float64),tf.random.uniform([4], dtype=tf.float64))\r\nprint(tf.math.asin(x))\r\n# Could not find device for node: {{node Asin}} = Asin[T=DT_COMPLEX128]\r\n```\r\n\r\n**Expected output**\r\nAccording to the document [tf.math.asin](https://www.tensorflow.org/api_docs/python/tf/math/asin), it should be able to accept a complex input.",
"comments": [
{
"body": "@chunduriv ,\r\nI was able to reproduce the issue in tf v2.7, v2.8 and nightly.Please find the gist of it [here](https://colab.research.google.com/gist/tilakrayal/e984b885c1efc3c9cc06b3659914c4da/54317.ipynb).",
"created_at": "2022-02-10T14:45:04Z"
},
{
"body": "Added a PR #54356 for the complex support of tf.math.asin.",
"created_at": "2022-02-12T04:17:26Z"
},
{
"body": "@ArrowIntoTheSky, The issue will move to closed status once the https://github.com/tensorflow/tensorflow/pull/54356 is merged. Thanks!",
"created_at": "2022-02-14T09:11:28Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54317\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/54317\">No</a>\n",
"created_at": "2022-02-16T17:36:41Z"
}
],
"number": 54317,
"title": "`tf.math.asin` lack support for complex"
}
|
{
"body": "This PR address the feature requested by #54317 in adding complex support for tf.math.asin.\r\n\r\nThis PR fixes #54317.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 54356,
"review_comments": [],
"title": "Add complex support for `tf.math.asin`"
}
|
{
"commits": [
{
"message": "Add complex support for tf.math.asin\n\nThis PR address the feature requested by 54317 in adding\ncomplex support for tf.math.asin.\n\nThis PR fixes 54317.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for complex support of tf.math.asin\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -16,8 +16,8 @@ limitations under the License.\n #include \"tensorflow/core/kernels/cwise_ops_common.h\"\n \n namespace tensorflow {\n-REGISTER4(UnaryOp, CPU, \"Asin\", functor::asin, Eigen::half, bfloat16, float,\n- double);\n+REGISTER6(UnaryOp, CPU, \"Asin\", functor::asin, Eigen::half, bfloat16, float,\n+ double, complex64, complex128);\n \n #if GOOGLE_CUDA || TENSORFLOW_USE_ROCM\n #if !defined(MLIR_GENERATED_GPU_KERNELS_ENABLED)",
"filename": "tensorflow/core/kernels/cwise_op_asin.cc",
"status": "modified"
},
{
"diff": "@@ -533,6 +533,7 @@ def testComplex64Basic(self):\n self._compareCpu(x, np.sinh, math_ops.sinh)\n self._compareCpu(x, np.cosh, math_ops.cosh)\n self._compareCpu(x, np.tanh, math_ops.tanh)\n+ self._compareCpu(x, np.arcsin, math_ops.asin)\n \n # Complex64 versions of asinh() and acosh() in libstdc++ only have 6 digits\n # of precision.\n@@ -583,6 +584,7 @@ def testComplex128Basic(self):\n self._compareCpu(x, self._sigmoid, math_ops.sigmoid)\n self._compareCpu(x, np.sin, math_ops.sin)\n self._compareCpu(x, np.cos, math_ops.cos)\n+ self._compareCpu(x, np.arcsin, math_ops.asin)\n \n self._compareBothSparse(x, np.abs, math_ops.abs)\n self._compareBothSparse(x, np.negative, math_ops.negative)",
"filename": "tensorflow/python/kernel_tests/math_ops/cwise_ops_unary_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nlogits = tf.random.uniform([16, 1, 10], dtype=tf.float16)\r\nr1 = tf.nn.softmax(logits,axis=-1) # pass\r\nlogits_sp = tf.sparse.from_dense(logits)\r\nr2 = tf.sparse.softmax(logits_sp) # InvalidArgumentError\r\n```\r\n\r\n**Describe the current behavior**\r\n`tf.sparse.softmax` cannot accept a tensor of type `float16`. However, `tf.nn.softmax` do support `half`. \r\nFor the above code snippet, the error message is:\r\n```\r\nInvalidArgumentError: Value for attr 'T' of half is not in the list of allowed values: float, double\r\n\t; NodeDef: {{node SparseSoftmax}}; Op<name=SparseSoftmax; signature=sp_indices:int64, sp_values:T, sp_shape:int64 -> output:T; attr=T:type,allowed=[DT_FLOAT, DT_DOUBLE]> [Op:SparseSoftmax]\r\n```\r\n\r\n**Describe the expected behavior**\r\nAccording to the document for `tf.sparse.softmax`, it is equivalent to `tf.nn.softmax` (but for sparse tensors), so `tf.sparse.softmax` should also support `float16` inputs.\r\n",
"comments": [
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2022-01-13T09:51:27Z"
},
{
"body": "@ArrowIntoTheSky ,\r\nThe issue will move to closed status once the PR is merged.",
"created_at": "2022-02-04T11:31:57Z"
},
{
"body": "Was able to reproduce the issue with `tf-nightly-2.11.0-dev20220829` . Please find the gist [here](https://colab.research.google.com/drive/1MYXLhHnH2NoX9ktS4FtAc-jnznNtPRQj?usp=sharing). Thank you!",
"created_at": "2022-08-30T05:52:41Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53657\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53657\">No</a>\n",
"created_at": "2022-09-23T19:40:31Z"
}
],
"number": 53657,
"title": "tf.sparse.softmax lack support for float16"
}
|
{
"body": "This PR tries to address the issue raised in #53657 where float16 was not supported for tf.sparse.softmax, while the counterpart of tf.nn.softmax has the float16 support.\r\nThis PR adds float16 support.\r\n\r\nThis PR fixes #53657.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 53741,
"review_comments": [],
"title": "Add float16 support for tf.sparse.softmax"
}
|
{
"commits": [
{
"message": "Add float16 support for tf.sparse.softmax\n\nThis PR tries to address the issue raised in 53657 where\nfloat16 was not supported for tf.sparse.softmax, while\nthe counterpart of tf.nn.softmax has the float16 support.\nThis PR adds float16 support.\n\nThis PR fixes 53657.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update test case to include float16 data type for tf.sparse.softmax\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Change to assertAllCloseAccordingToType to have more tolerance on error bounds\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -126,6 +126,7 @@ class SparseSoftmaxOp : public OpKernel {\n Name(\"SparseSoftmax\").Device(DEVICE_CPU).TypeConstraint<T>(\"T\"), \\\n SparseSoftmaxOp<CPUDevice, T>)\n \n+REGISTER_KERNEL(Eigen::half);\n REGISTER_KERNEL(float);\n REGISTER_KERNEL(double);\n #undef REGISTER_KERNEL",
"filename": "tensorflow/core/kernels/sparse_softmax_op.cc",
"status": "modified"
},
{
"diff": "@@ -507,7 +507,7 @@ REGISTER_OP(\"SparseSoftmax\")\n .Input(\"sp_values: T\")\n .Input(\"sp_shape: int64\")\n .Output(\"output: T\")\n- .Attr(\"T: {float, double}\")\n+ .Attr(\"T: {half, float, double}\")\n .SetShapeFn([](InferenceContext* c) {\n ShapeHandle unused;\n ShapeHandle values;",
"filename": "tensorflow/core/ops/sparse_ops.cc",
"status": "modified"
},
{
"diff": "@@ -987,7 +987,7 @@ def testEquivalentToDensified(self):\n np.random.seed(1618)\n n, m = np.random.choice(20, size=2)\n \n- for dtype in [np.float32, np.float64]:\n+ for dtype in [np.float16, np.float32, np.float64]:\n sp_vals_np = np.random.rand(n, m).astype(dtype)\n \n batched_sp_t, unused_nnz1 = _sparsify(\n@@ -1000,7 +1000,7 @@ def testEquivalentToDensified(self):\n sparse_ops.sparse_softmax(batched_sp_t)).values.reshape((n, m))\n dense_result = nn_ops.softmax(densified)\n \n- self.assertAllClose(dense_result, sp_result)\n+ self.assertAllCloseAccordingToType(dense_result, sp_result)\n \n def testHigherRanks(self):\n # For the first shape:",
"filename": "tensorflow/python/kernel_tests/sparse_ops/sparse_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Y\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nx = tf.cast(tf.constant([1.0, 2.0]), tf.complex128)\r\nx_sparse = tf.sparse.from_dense(x)\r\nprint(\"from_dense pass:\", x_sparse) # pass\r\nx_dense = tf.sparse.to_dense(x_sparse) # fail\r\nprint(\"to_dense pass:\", x_dense) \r\n```\r\n**Describe the current behavior**\r\n`tf.sparse.from_dense` can convert a complex dense tensor to a sparse tensor, however, `tf.sparse.to_dense` fails to convert a complex sparse tensor back to a dense tensor.\r\nFor the above code snippet, the output is:\r\n```\r\nfrom_dense pass: SparseTensor(...)\r\nNotFoundError: Could not find device for node: {{node SparseToDense}} = SparseToDense[T=DT_COMPLEX128, Tindices=DT_INT64, validate_indices=true]\r\nAll kernels registered for op SparseToDense:\r\n device='CPU'; T in [DT_STRING]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_STRING]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_BOOL]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_BOOL]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_DOUBLE]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_DOUBLE]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_FLOAT]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_FLOAT]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_BFLOAT16]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_BFLOAT16]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_HALF]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_HALF]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_INT32]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_INT32]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_INT8]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_INT8]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_UINT8]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_UINT8]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_INT16]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_INT16]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_UINT16]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_UINT16]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_UINT32]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_UINT32]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_INT64]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_INT64]; Tindices in [DT_INT32]\r\n device='CPU'; T in [DT_UINT64]; Tindices in [DT_INT64]\r\n device='CPU'; T in [DT_UINT64]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_BOOL]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_BOOL]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_INT32]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_INT32]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_INT8]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_INT8]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_UINT8]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_UINT8]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_INT16]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_INT16]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_UINT16]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_UINT16]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_UINT32]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_UINT32]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_INT64]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_INT64]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_UINT64]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_UINT64]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_DOUBLE]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_DOUBLE]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_FLOAT]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_FLOAT]; Tindices in [DT_INT32]\r\n device='GPU'; T in [DT_HALF]; Tindices in [DT_INT64]\r\n device='GPU'; T in [DT_HALF]; Tindices in [DT_INT32]\r\n [Op:SparseToDense] \r\n```\r\n**Describe the expected behavior**\r\n`tf.sparse.to_dense` should also support complex dtypes.",
"comments": [
{
"body": "Added PR #53694 for the fix.",
"created_at": "2022-01-07T18:29:44Z"
}
],
"number": 53653,
"title": "tf.sparse.to_dense don't support complex dtypes"
}
|
{
"body": "This PR tries to fix the issue raised in #53653 where `tf.sparse.to_dense` does not support complex64 or complex128\r\n(`tf.sparse.from_dense` support complex dtypes).\r\n\r\nThis PR adds complex64/complex128 support for `tf.sparse.to_dense`.\r\n\r\nThis PR fixes #53653.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 53694,
"review_comments": [],
"title": "Add complex data type support to tf.sparse.to_dense"
}
|
{
"commits": [
{
"message": "Add complex data type support to tf.sparse.to_dense\n\nThis PR tries to fix the issue raised in 53653 where\ntf.sparse.to_dense does not support complex64 or complex128\n(tf.sparse.from_dense support complex dtypes).\n\nThis PR adds complex64/complex128 support for tf.sparse.to_dense.\n\nThis PR fixes 53653.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for complex data type support for tf.sparse.to_dense\n\nfor GitHub issue 53653.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -187,6 +187,8 @@ class SparseToDense : public OpKernel {\n TF_CALL_REAL_NUMBER_TYPES(REGISTER_KERNELS_ALL);\n REGISTER_KERNELS_ALL(bool);\n REGISTER_KERNELS_ALL(tstring);\n+REGISTER_KERNELS_ALL(complex64);\n+REGISTER_KERNELS_ALL(complex128);\n \n #undef REGISTER_KERNELS_ALL\n #undef REGISTER_KERNELS",
"filename": "tensorflow/core/kernels/sparse_to_dense_op.cc",
"status": "modified"
},
{
"diff": "@@ -16,11 +16,13 @@\n \n import numpy as np\n \n+from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n from tensorflow.python.framework import errors\n from tensorflow.python.framework import ops\n from tensorflow.python.framework import test_util\n from tensorflow.python.ops import array_ops\n+from tensorflow.python.ops import math_ops\n from tensorflow.python.ops import sparse_ops\n from tensorflow.python.platform import test\n \n@@ -38,6 +40,13 @@ def testFloat(self):\n np_ans = np.array([0, 1, 0, 1, 0]).astype(np.float32)\n self.assertAllClose(np_ans, tf_ans)\n \n+ def testComplex(self):\n+ for dtype in [dtypes.complex64, dtypes.complex128]:\n+ tf_val = math_ops.cast(\n+ constant_op.constant([1.0 + 1.0j, 2.0 - 2.0j]), dtypes.complex128)\n+ tf_ans = sparse_ops.sparse_tensor_to_dense(sparse_ops.from_dense(tf_val))\n+ self.assertAllClose(tf_val, tf_ans)\n+\n def testEmptyNonZeros(self):\n indices = array_ops.constant([], dtype=dtypes.int32)\n values = array_ops.constant([], dtype=dtypes.float32)",
"filename": "tensorflow/python/kernel_tests/sparse_ops/sparse_to_dense_op_py_test.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: No\r\n- TensorFlow installed from (source or binary): source \r\n- TensorFlow version (use command below): master\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): 0.24.1\r\n- GCC/Compiler version (if compiling from source): 4.8.5\r\n- CUDA/cuDNN version: 11.2\r\n- GPU model and memory: ?? yes\r\n\r\n**Describe the current behavior**\r\nxla_run will move const type output from Host to Device in every steps.\r\n\r\n**Describe the expected behavior**\r\nFill output from cache instead of H2D\r\n\r\n**[Contributing](https://www.tensorflow.org/community/contribute)**\r\n\r\n- Do you want to contribute a PR? (yes/no):yes\r\n- Briefly describe your candidate solution(if contributing):\r\n1. Record xla const output: \r\n```\r\nmap<output_idx, output_const_tensors> cache_;\r\n```\r\n2. Get output from cache; \r\n```\r\nfor (int i = 0; i < ctx->num_outputs(); ++i) {\r\n ...\r\n if (kernel->outputs[i].is_constant) {\r\n ctx->allocate_output(i, const_tensor.shape(), &output_tensor));\r\n output_tensor = cache_[i];\r\n else(others) {\r\n ...\r\n }\r\n ...\r\n}\r\n```\r\n\r\n### Background\r\n1. GPU training data H2D:\r\n Training data in CPU and model in GPU, so we need to move training data from host to device.We want to Increase training speed so we use ```prefetch_to_device``` to async H2D and training.\r\n2. XLA H2D:\r\n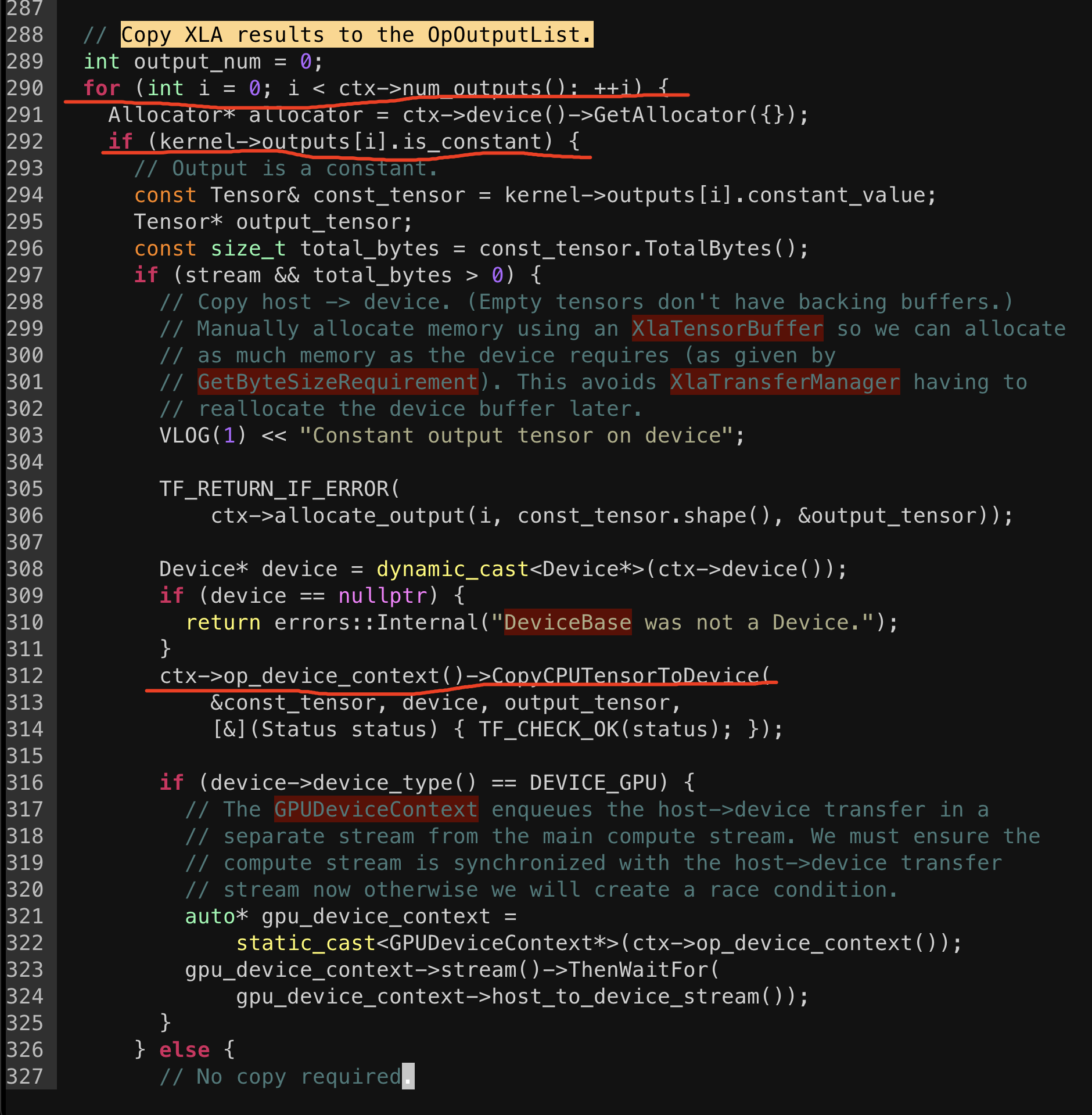\r\n(tensorflow/compiler/jit/xla_launch_util.cc:290, Status XlaComputationLaunchContext::PopulateOutputs)\r\n### Problem\r\n Background 1 and Background 2 is in two completely unrelated threads, so XLA H2D maybe wait until features H2D done, like:\r\n\r\n### Solution\r\n I think that the output of the constant type has the same value at each step, so we don't need to have H2D for each step. We should cache the output in the device, and then get the result in the cache.\r\n I try to cache device tensor, like:\r\n\r\n",
"comments": [
{
"body": "@zhaozheng09 ,\r\nIn order to expedite the trouble-shooting process, could you please provide the complete code and dataset to reproduce the issue reported here.\r\n",
"created_at": "2022-01-03T10:22:27Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2022-01-10T10:51:26Z"
},
{
"body": "Closing as stale. Please reopen if you'd like to work on this further.\n",
"created_at": "2022-01-17T11:01:14Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53609\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53609\">No</a>\n",
"created_at": "2022-01-17T11:01:19Z"
}
],
"number": 53609,
"title": "[XLA] The output of const type have some redundancy H2D ops"
}
|
{
"body": "#53609\r\n\r\n**Problem overview:** the const outputs of xla executable is kept in host memory. if the const output of executable need a device tensor, we need to do an H2D(host memory to device memory) .\r\n\r\n**Ideas overview:** cache the const output of xla executable to device memory, then replace H2D with lookup from cache.\r\n\r\n**Background(features async H2D)** :\r\n\r\nThe total ops in out model are set on the gpu device, so model spends data very fast, but the data part(parsing the data from TFRecord to Features) complete run on host memory, so we need copy features from host to device, this H2D will launch lots of requests of H2D on H2D stream. we use prefetch_to_device to overlap the time required for feature H2D.(prefetch_to_device: async copy features from host to device. The method of model obtaining data is replaced from synchronous H2D to obtain from cache)\r\n\r\n**Problem**:\r\n\r\nWe use xla to increase speed of training, but we found gpu util is 0 after xla run and model hung, As follows:\r\n\r\nWe carefully analyse nsys profiling file, found xla brought H2D once, and this H2D will block by features H2D in background.\r\n\r\n**Solution**:\r\n\r\nWe found that this H2D is generated by the xla op, and then we read the code about xla carefully, we found that the const output tensor of the executable is placed on the host, and then copy to the device side through memcpyH2D.\r\n\r\nWe can add a cache<executable output index, device tensor> on device. We put pair<executable output index, device tensor> to cache in the first time, and the next time replace to get device tensor from synchronous H2D to get device tensor from cache.\r\n\r\n**result(special model)**:\r\n\r\nno prefetch_to_device: No performance drop.\r\n\r\nprefetch_to_device: preformance 15%↑\r\n\r\nIs there a pr template? It's a little late in China, can I change it tomorrow?",
"number": 53627,
"review_comments": [
{
"body": "Compiler error: ignoring return value of function declared with 'warn_unused_result' attribute [-Werror,-Wunused-result]\r\n\r\nI think you may need a TF_RETURN_IF_ERROR macro around this call.",
"created_at": "2022-01-26T10:13:04Z"
},
{
"body": "The race seems to be between this line and the assignment of cache_ in rm_->LookupOrCreate.\r\nSo I think you need a mutex lock here around this block (and I guess everywhere where cache_ is accessed).",
"created_at": "2022-02-07T10:27:35Z"
}
],
"title": "Xla const output cache on GPU "
}
|
{
"commits": [
{
"message": "Add xla op const output cache on gpu."
},
{
"message": "code review 0"
}
],
"files": [
{
"diff": "@@ -168,7 +168,21 @@ XlaLocalLaunchBase::XlaLocalLaunchBase(OpKernelConstruction* ctx,\n resources_(resources),\n function_(function),\n platform_info_(XlaPlatformInfoFromDevice(ctx->device())),\n- has_ref_vars_(has_ref_vars) {}\n+ has_ref_vars_(has_ref_vars),\n+ cache_(nullptr),\n+ rm_(nullptr) {}\n+\n+XlaLocalLaunchBase::~XlaLocalLaunchBase() {\n+ if (cache_ != nullptr) {\n+ cache_->Unref();\n+ if (!rm_->template Delete<XlaConstantOutputResource>(def().name(),\n+ def().name())\n+ .ok()) {\n+ // Do nothing; the resource can have been deleted by session resets.\n+ }\n+ }\n+}\n+\n \n static Status CompileToLocalExecutable(\n OpKernelContext* ctx, const NameAttrList& function, bool has_ref_vars,\n@@ -307,11 +321,26 @@ void XlaLocalLaunchBase::Compute(OpKernelContext* ctx) {\n \n auto elapsed = env->NowMicros() - start_time;\n VLOG(2) << \"Elapsed time: \" << elapsed << \"us\";\n+\n+ if (cache_ == nullptr) {\n+ rm_ = ctx->resource_manager();\n+ OP_REQUIRES_OK(ctx, rm_->LookupOrCreate<XlaConstantOutputResource>(\n+ def().name(), def().name(), &cache_,\n+ [](XlaConstantOutputResource** ret) {\n+ *ret = new XlaConstantOutputResource();\n+ return Status::OK();\n+ }));\n+ }\n+ // Create a cache for each executable .\n+ XlaConstOutputCache& const_output_cache =\n+ cache_->FindConstOutput(executable->executable());\n+\n+\n OP_REQUIRES_OK(\n ctx, launch_context.PopulateOutputs(\n ctx, compilation_result, execution_output->ConsumeResult(),\n /*missing_ctx_input_prefix=*/0, absl::MakeSpan(variable_infos),\n- input_output_alias, resource_var_ptrs));\n+ input_output_alias, resource_var_ptrs, const_output_cache));\n \n VLOG(1) << \"Done\";\n }\n@@ -481,7 +510,21 @@ void XlaCompileOp::Compute(OpKernelContext* ctx) {\n }\n \n XlaRunOp::XlaRunOp(OpKernelConstruction* ctx)\n- : OpKernel(ctx), platform_info_(XlaPlatformInfoFromDevice(ctx->device())) {}\n+ : OpKernel(ctx),\n+ platform_info_(XlaPlatformInfoFromDevice(ctx->device())),\n+ cache_(nullptr),\n+ rm_(nullptr) {}\n+\n+XlaRunOp::~XlaRunOp() {\n+ if (cache_ != nullptr) {\n+ cache_->Unref();\n+ if (!rm_->template Delete<XlaConstantOutputResource>(def().name(),\n+ def().name())\n+ .ok()) {\n+ // Do nothing; the resource can have been deleted by session resets.\n+ }\n+ }\n+}\n \n void XlaRunOp::Compute(OpKernelContext* ctx) {\n VLOG(3) << \"XlaRunOp \" << def().name();\n@@ -562,12 +605,26 @@ void XlaRunOp::Compute(OpKernelContext* ctx) {\n ctx, *closure.compilation_result(), closure.num_constant_args());\n OP_REQUIRES_OK(ctx, variable_infos.status());\n OP_REQUIRES_OK(ctx, LockVariables(absl::MakeSpan(*variable_infos)));\n+\n+ if (cache_ == nullptr) {\n+ rm_ = ctx->resource_manager();\n+ OP_REQUIRES_OK(ctx, rm_->LookupOrCreate<XlaConstantOutputResource>(\n+ def().name(), def().name(), &cache_,\n+ [](XlaConstantOutputResource** ret) {\n+ *ret = new XlaConstantOutputResource();\n+ return Status::OK();\n+ }));\n+ }\n+ // Create a cache for each executable .\n+ XlaConstOutputCache& const_output_cache =\n+ cache_->FindConstOutput(closure.executable()->executable());\n+\n OP_REQUIRES_OK(\n ctx,\n launch_context.PopulateOutputs(\n ctx, closure.compilation_result(), execution_output->ConsumeResult(),\n /*missing_ctx_input_prefix=*/closure.num_constant_args(),\n- absl::MakeSpan(*variable_infos), input_output_alias, snapshot_ptrs));\n+ absl::MakeSpan(*variable_infos), input_output_alias, snapshot_ptrs, const_output_cache));\n }\n \n XlaMergeOp::XlaMergeOp(OpKernelConstruction* ctx) : OpKernel(ctx) {}",
"filename": "tensorflow/compiler/jit/kernels/xla_ops.cc",
"status": "modified"
},
{
"diff": "@@ -52,7 +52,7 @@ class XlaLocalLaunchBase : public OpKernel {\n const NameAttrList& function, bool has_ref_vars);\n XlaLocalLaunchBase(const XlaLocalLaunchBase&) = delete;\n XlaLocalLaunchBase& operator=(const XlaLocalLaunchBase&) = delete;\n- ~XlaLocalLaunchBase() override = default;\n+ ~XlaLocalLaunchBase() override;\n \n void Compute(OpKernelContext* ctx) override;\n \n@@ -66,6 +66,9 @@ class XlaLocalLaunchBase : public OpKernel {\n const XlaPlatformInfo platform_info_;\n \n bool has_ref_vars_;\n+ // Cache GPU const output tensor .\n+ XlaConstantOutputResource* cache_;\n+ ResourceMgr* rm_;\n };\n \n // XlaLocalLaunchOp is used to replace a region of the TensorFlow graph\n@@ -123,8 +126,13 @@ class XlaRunOp : public OpKernel {\n \n void Compute(OpKernelContext* ctx) override;\n \n+ ~XlaRunOp() override;\n+\n private:\n const XlaPlatformInfo platform_info_;\n+ // Cache GPU const output tensor .\n+ XlaConstantOutputResource* cache_;\n+ ResourceMgr* rm_;\n };\n \n class XlaMergeOp : public OpKernel {",
"filename": "tensorflow/compiler/jit/kernels/xla_ops.h",
"status": "modified"
},
{
"diff": "@@ -96,10 +96,24 @@ Status XlaCompileOnDemandOp::Run(OpKernelContext* ctx,\n GatherVariableInfo(ctx, *result, 0);\n TF_RETURN_IF_ERROR(variable_infos.status());\n TF_RETURN_IF_ERROR(LockVariables(absl::MakeSpan(*variable_infos)));\n+\n+ if (cache_ == nullptr) {\n+ rm_ = ctx->resource_manager();\n+ TF_RETURN_IF_ERROR(rm_->LookupOrCreate<XlaConstantOutputResource>(\n+ def().name(), def().name(), &cache_,\n+ [](XlaConstantOutputResource** ret) {\n+ *ret = new XlaConstantOutputResource();\n+ return Status::OK();\n+ }));\n+ }\n+ // Create a cache for each executable .\n+ XlaConstOutputCache& const_output_cache =\n+ cache_->FindConstOutput(executable->executable());\n+\n TF_RETURN_IF_ERROR(launch_context.PopulateOutputs(\n ctx, result, execution_output.ConsumeResult(),\n /*missing_ctx_input_prefix=*/0, absl::MakeSpan(*variable_infos),\n- input_output_alias, snapshot_ptrs));\n+ input_output_alias, snapshot_ptrs, const_output_cache));\n return Status::OK();\n }\n \n@@ -181,4 +195,15 @@ void XlaCompileOnDemandOp::Compute(OpKernelContext* ctx) {\n OP_REQUIRES_OK(ctx, Run(ctx, cache, result, executable, variable_args));\n }\n \n+XlaCompileOnDemandOp::~XlaCompileOnDemandOp() {\n+ if (cache_ != nullptr) {\n+ cache_->Unref();\n+ if (!rm_->template Delete<XlaConstantOutputResource>(def().name(),\n+ def().name())\n+ .ok()) {\n+ // Do nothing; the resource can have been deleted by session resets.\n+ }\n+ }\n+}\n+\n } // namespace tensorflow",
"filename": "tensorflow/compiler/jit/xla_compile_on_demand_op.cc",
"status": "modified"
},
{
"diff": "@@ -38,8 +38,11 @@ class XlaCompileOnDemandOp : public OpKernel {\n public:\n explicit XlaCompileOnDemandOp(OpKernelConstruction* ctx)\n : OpKernel(ctx),\n- platform_info_(XlaPlatformInfoFromDevice(ctx->device())) {}\n+ platform_info_(XlaPlatformInfoFromDevice(ctx->device())),\n+ cache_(nullptr),\n+ rm_(nullptr) {}\n void Compute(OpKernelContext* ctx) override;\n+ ~XlaCompileOnDemandOp() override;\n \n private:\n XlaCompiler::Argument CreateCompilerArgument(OpKernelContext* ctx, int64_t i);\n@@ -55,6 +58,9 @@ class XlaCompileOnDemandOp : public OpKernel {\n const ResourceVarsSnapshot& variable_args);\n \n const XlaPlatformInfo platform_info_;\n+ // Cache GPU const output tensor .\n+ XlaConstantOutputResource* cache_;\n+ ResourceMgr* rm_;\n };\n \n } // namespace tensorflow",
"filename": "tensorflow/compiler/jit/xla_compile_on_demand_op.h",
"status": "modified"
},
{
"diff": "@@ -102,6 +102,41 @@ VariableInfo::~VariableInfo() {\n }\n }\n \n+bool XlaConstOutputCache::FindConstOutput(const int64 output_idx,\n+ Tensor* output) {\n+ const auto iter = cache_.find(output_idx);\n+ if (iter == cache_.end()) {\n+ return false;\n+ } else {\n+ *output = iter->second;\n+ return true;\n+ }\n+}\n+\n+string XlaConstOutputCache::DebugString() const {\n+ string debug_string;\n+ for (const auto& const_output : cache_) {\n+ debug_string.append(std::to_string(const_output.first));\n+ debug_string.append(\":\");\n+ debug_string.append(const_output.second.DebugString());\n+ }\n+ return debug_string;\n+}\n+\n+string XlaConstantOutputResource::DebugString() const {\n+ string debug_string;\n+ for (const auto& cluster : cache_) {\n+ debug_string.append(\"XlaConstantCache save | \");\n+ debug_string.append(std::to_string(int64(cluster.first)));\n+ debug_string.append(\":[\");\n+ cluster.second.DebugString();\n+ debug_string.append(\"],\");\n+ }\n+ debug_string.append(\"].\");\n+ return debug_string;\n+}\n+\n+\n Status GetVariableInfosFromInputs(ResourceMgr* rm, DeviceBase* dev,\n absl::Span<const Tensor* const> inputs,\n absl::Span<const int> variable_indices,\n@@ -456,7 +491,8 @@ Status XlaComputationLaunchContext::PopulateOutputs(\n ScopedShapedBuffer output, int missing_ctx_input_prefix,\n absl::Span<VariableInfo> variable_infos,\n const xla::HloInputOutputAliasConfig& input_output_alias,\n- const std::map<int, const Tensor*>& resource_vars) {\n+ const std::map<int, const Tensor*>& resource_vars,\n+ XlaConstOutputCache& cache) {\n se::Stream* stream =\n ctx->op_device_context() ? ctx->op_device_context()->stream() : nullptr;\n Allocator* allocator = ctx->device()->GetAllocator({});",
"filename": "tensorflow/compiler/jit/xla_launch_util.cc",
"status": "modified"
},
{
"diff": "@@ -38,6 +38,41 @@ namespace tensorflow {\n // parameter number to values at execution time. If the resource variable is not\n // initialized, the value will not be present.\n using ResourceVarsSnapshot = absl::flat_hash_map<int, absl::optional<Tensor>>;\n+// We add a cache, which will cache the output of const type of xla op on the\n+// GPU, it avoild host output tensor H2D at every steps.\n+class XlaConstOutputCache {\n+ public:\n+ // output_idx: output index in the output of xla op;output: GPU output tensor;\n+ bool FindConstOutput(const int64 output_idx, Tensor* output);\n+\n+ void SetConstOutput(const int64 output_idx, Tensor* output) {\n+ cache_[output_idx] = Tensor(*output);\n+ }\n+\n+ string DebugString() const;\n+\n+ private:\n+ typedef std::map<int64, Tensor> ConstOutputCache;\n+ ConstOutputCache cache_;\n+};\n+\n+// The output of the const type of the executable has the same value in each\n+// steps, and some executables output const value on CPU, so we have to memcpy\n+// from CPU to GPU(H2D).We think this H2D is redundant, so we add\n+// XlaConstantOutputResource for every executable to directly cache GPU const\n+// output .\n+class XlaConstantOutputResource : public ResourceBase {\n+ public:\n+ XlaConstOutputCache& FindConstOutput(const xla::Executable* exec) {\n+ return cache_[exec];\n+ }\n+\n+ virtual string DebugString() const override;\n+\n+ private:\n+ typedef std::map<const xla::Executable*, XlaConstOutputCache> ClusterCache;\n+ ClusterCache cache_;\n+};\n \n // Information about the state of a variable passed as input to the _XlaCompile\n // and _XlaRun operators. Unlocks the resource variable and decrements its\n@@ -184,7 +219,8 @@ class XlaComputationLaunchContext {\n xla::ScopedShapedBuffer output, int missing_ctx_input_prefix,\n absl::Span<VariableInfo> variable_infos,\n const xla::HloInputOutputAliasConfig& input_output_alias,\n- const std::map<int, const Tensor*>& resource_vars);\n+ const std::map<int, const Tensor*>& resource_vars,\n+ XlaConstOutputCache& cache);\n \n private:\n xla::LocalClient* client_;",
"filename": "tensorflow/compiler/jit/xla_launch_util.h",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: n/a\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.7.0 and 2.8.0-dev20211203 (nightly)\r\n- Python version: 3.6.8\r\n- Bazel version (if compiling from source): n/a\r\n- GCC/Compiler version (if compiling from source): n/a\r\n- CUDA/cuDNN version: n/a\r\n- GPU model and memory: n/a\r\n\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nx = tf.random.uniform(shape=[0,3])\r\ny = tf.random.uniform(shape=[1,3])\r\nprint(tf.stack([x,y]).shape)\r\n```\r\n\r\n**Describe the current behavior**\r\nOutputs:\r\n```\r\n(2, 0, 3)\r\n```\r\nStacking `x` and `y`, and we got an empty tensor! \r\nI found that this issue occurs in both tf2.7.0 and tf-nightly.\r\n\r\n**Describe the expected behavior**\r\nAccording to the documentation, the stacked tensors should have the same shape. Here the input tensor `x` and `y` don't have the same shape, so an `InvalidArgumentError` error should be raised.",
"comments": [
{
"body": "Added a PR #53367 for the fix.",
"created_at": "2021-12-09T08:06:27Z"
},
{
"body": "Fixed by PR #53367 by @yongtang.",
"created_at": "2022-03-14T16:49:54Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53300\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53300\">No</a>\n",
"created_at": "2022-03-14T16:49:57Z"
}
],
"number": 53300,
"title": "tf.stack silently output wrong result with 0-dimension tensor"
}
|
{
"body": "This PR tries to address the issue raised in #53300 where\r\ntf.stack will silently output wrong result with 0-dimension tensor.\r\nThe issue was that the shape check was skipped when num of output elements\r\nwas zero. This PR fixed the issue.\r\n\r\nThis PR fixes #53300.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 53367,
"review_comments": [],
"title": "Fix wrong output of tf.stack with 0-dimension tensor"
}
|
{
"commits": [
{
"message": "Fix wrong output of tf.stack with 0-dimension tensor\n\nThis PR tries to address the issue raised in 53300 where\ntf.stack will silently output wrong result with 0-dimension tensor.\nThe issue was that the shape check was skipped when num of output elements\nwas zero. This PR fixed the issue.\n\nThis PR fixes 53300.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub issue 53300.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Fix failed tests\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -87,25 +87,25 @@ class PackOp : public OpKernel {\n const int64_t axis_dim = output_shape.dim_size(axis);\n \n const int64_t output_size = output->NumElements();\n+ auto output_flat =\n+ output->shaped<T, 2>({before_dim, after_dim * axis_dim});\n+\n+ // Except for shapes, pack is a special case of concat, so we reuse the\n+ // same computational kernels.\n+ ConstMatrixVector inputs_flat;\n+ inputs_flat.reserve(num);\n+ for (int i = 0; i < num; ++i) {\n+ const Tensor& input = c->input(i);\n+ OP_REQUIRES(c, first_input.shape().IsSameSize(input.shape()),\n+ errors::InvalidArgument(\n+ \"Shapes of all inputs must match: values[0].shape = \",\n+ first_input.shape().DebugString(), \" != values[\", i,\n+ \"].shape = \", input.shape().DebugString()));\n+\n+ inputs_flat.emplace_back(new typename TTypes<T, 2>::ConstMatrix(\n+ input.shaped<T, 2>({before_dim, after_dim})));\n+ }\n if (output_size > 0) {\n- auto output_flat =\n- output->shaped<T, 2>({before_dim, after_dim * axis_dim});\n-\n- // Except for shapes, pack is a special case of concat, so we reuse the\n- // same computational kernels.\n- ConstMatrixVector inputs_flat;\n- inputs_flat.reserve(num);\n- for (int i = 0; i < num; ++i) {\n- const Tensor& input = c->input(i);\n- OP_REQUIRES(c, first_input.shape().IsSameSize(input.shape()),\n- errors::InvalidArgument(\n- \"Shapes of all inputs must match: values[0].shape = \",\n- first_input.shape().DebugString(), \" != values[\", i,\n- \"].shape = \", input.shape().DebugString()));\n-\n- inputs_flat.emplace_back(new typename TTypes<T, 2>::ConstMatrix(\n- input.shaped<T, 2>({before_dim, after_dim})));\n- }\n #if GOOGLE_CUDA || TENSORFLOW_USE_ROCM\n if (std::is_same<Device, GPUDevice>::value) {\n ConcatGPU<T>(c, inputs_flat, output, &output_flat);",
"filename": "tensorflow/core/kernels/pack_op.cc",
"status": "modified"
},
{
"diff": "@@ -288,6 +288,16 @@ def testComplex(self):\n c = array_ops.stack(xs)\n self.assertAllEqual(self.evaluate(c), data)\n \n+ def testZeroDimUnmatch(self):\n+ # Test case for GitHub issue 53300.\n+ # Error message is `Shapes of all inputs must match` in eager mode,\n+ # and `Shapes ...` in graph mode. Below is to capture both:\n+ with self.assertRaisesRegex((errors.InvalidArgumentError, ValueError),\n+ r\"Shapes\"):\n+ with self.session():\n+ t = [array_ops.zeros([0, 3]), array_ops.zeros([1, 3])]\n+ self.evaluate(array_ops.stack(t))\n+\n \n class AutomaticStackingTest(test.TestCase):\n ",
"filename": "tensorflow/python/kernel_tests/array_ops/stack_op_test.py",
"status": "modified"
},
{
"diff": "@@ -109,6 +109,8 @@ def _verifyLu(self, x, output_idx_type=dtypes.int64):\n array_ops.broadcast_to(\n math_ops.range(batch_size)[:, None], perm_reshaped.shape),\n dtype=output_idx_type)\n+ if inv_perm_reshaped.shape == [0]:\n+ inv_perm_reshaped = array_ops.zeros_like(batch_indices)\n permuted_verification_reshaped = array_ops.gather_nd(\n verification_reshaped,\n array_ops.stack([batch_indices, inv_perm_reshaped], axis=-1))",
"filename": "tensorflow/python/kernel_tests/linalg/lu_op_test.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): no\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: n/a\r\n- TensorFlow installed from (source or binary): source\r\n- TensorFlow version (use command below): git HEAD\r\n- Python version: 3.8.10\r\n- Bazel version (if compiling from source): 3.7.2\r\n- GCC/Compiler version (if compiling from source): 11.2.0\r\n- CUDA/cuDNN version: n/a\r\n- GPU model and memory: n/a\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with:\r\n1. TF 1.0: `python -c \"import tensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"`\r\n2. TF 2.0: `python -c \"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\n\r\nTest fails with the following error\r\nFAIL: testRaggedDispatch18 (op=<function unsorted_segment_sqrt_n at 0xffff18e41f70>, kwargs={'data': tf.RaggedTensorValue(values=array([1., 2., 3., 4., 6.]), row_splits=array([0, 2, 5])), 'segment_ids': tf.RaggedTensorValue(values=array([0, 1, 0, 0, 0]), row_splits=array([0, 2, 5])), 'num_segments': 2}, expected=[7.0, 2.0]) (_main_.RaggedDispatchTest)\r\nRaggedDispatchTest.testRaggedDispatch18 (op=<function unsorted_segment_sqrt_n at 0xffff18e41f70>, kwargs={'data': tf.RaggedTensorValue(values=array([1., 2., 3., 4., 6.]), row_splits=array([0, 2, 5])), 'segment_ids': tf.RaggedTensorValue(values=array([0, 1, 0, 0, 0]), row_splits=array([0, 2, 5])), 'num_segments': 2}, expected=[7.0, 2.0])\r\ntestRaggedDispatch(op=<function unsorted_segment_sqrt_n at 0xffff18e41f70>, kwargs={'data': tf.RaggedTensorValue(values=array([1., 2., 3., 4., 6.]), row_splits=array([0, 2, 5])), 'segment_ids': tf.RaggedTensorValue(values=array([0, 1, 0, 0, 0]), row_splits=array([0, 2, 5])), 'num_segments': 2}, expected=[7.0, 2.0])\r\n----------------------------------------------------------------------\r\n\r\nTraceback (most recent call last):\r\nFile \"/home/builder/.cache/bazel/_bazel_builder/9dc2dbd69dc3512cedb530e1521082e7/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/ops/ragged/ragged_dispatch_test.runfiles/org_tensorflow/tensorflow/python/framework/test_util.py\", line 1407, in decorated\r\nf(self, *args, **kwargs)\r\nFile \"/home/builder/.cache/bazel/_bazel_builder/9dc2dbd69dc3512cedb530e1521082e7/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/ops/ragged/ragged_dispatch_test.runfiles/absl_py/absl/testing/parameterized.py\", line 314, in bound_param_test\r\nreturn test_method(self, **testcase_params)\r\nFile \"/home/builder/.cache/bazel/_bazel_builder/9dc2dbd69dc3512cedb530e1521082e7/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/ops/ragged/ragged_dispatch_test.runfiles/org_tensorflow/tensorflow/python/ops/ragged/ragged_dispatch_test.py\", line 892, in testRaggedDispatch\r\nassert_fn(result, expected)\r\nFile \"/home/builder/.cache/bazel/_bazel_builder/9dc2dbd69dc3512cedb530e1521082e7/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/ops/ragged/ragged_dispatch_test.runfiles/org_tensorflow/tensorflow/python/framework/test_util.py\", line 1447, in decorated\r\nreturn f(*args, **kwds)\r\nFile \"/home/builder/.cache/bazel/_bazel_builder/9dc2dbd69dc3512cedb530e1521082e7/execroot/org_tensorflow/bazel-out/aarch64-opt/bin/tensorflow/python/ops/ragged/ragged_dispatch_test.runfiles/org_tensorflow/tensorflow/python/framework/test_util.py\", line 3163, in assertAllEqual\r\nnp.testing.assert_array_equal(a, b, err_msg=\"\\n\".join(msgs))\r\nFile \"/usr/local/lib/python3.8/dist-packages/numpy/testing/_private/utils.py\", line 930, in assert_array_equal\r\nassert_array_compare(operator._eq_, x, y, err_msg=err_msg,\r\nFile \"/usr/local/lib/python3.8/dist-packages/numpy/testing/_private/utils.py\", line 840, in assert_array_compare\r\nraise AssertionError(msg)\r\nAssertionError:\r\nArrays are not equal\r\n\r\nnot equal where = (array([0, 1]),)\r\nnot equal lhs = array([7., 2.])\r\nnot equal rhs = array([7., 2.])\r\nMismatched elements: 2 / 2 (100%)\r\nMax absolute difference: 8.8817842e-16\r\nMax relative difference: 1.26882631e-16\r\nx: array([7., 2.])\r\ny: array([7., 2.])\r\n\r\n**Describe the expected behavior**\r\n\r\nTest passes\r\n\r\n**[Contributing](https://www.tensorflow.org/community/contribute)**\r\n\r\n- Do you want to contribute a PR? (yes/no): yes\r\n- Briefly describe your candidate solution(if contributing): Add a tolerance value to the test to allow minor difference in value\r\n\r\n**Standalone code to reproduce the issue**\r\nProvide a reproducible test case that is the bare minimum necessary to generate\r\nthe problem. If possible, please share a link to Colab/Jupyter/any notebook.\r\n\r\nbazel test --test_timeout=300,500,-1,-1 --flaky_test_attempts=3 --test_output=all --cache_test_results=no --remote_http_cache=\"\" --remote_cache_proxy=\"\" --noremote_accept_cached --config=nonccl --build_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only --test_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only --copt=-ffp-contract=off --verbose_failures -- //tensorflow/python/ops/ragged:ragged_dispatch_test\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\ndiagnose the problem. If including tracebacks, please include the full\r\ntraceback. Large logs and files should be attached.\r\n",
"comments": [
{
"body": "@cfRod @nSircombe ",
"created_at": "2021-12-06T17:13:22Z"
},
{
"body": "@elfringham This issue will be closed once the [PR](https://github.com/tensorflow/tensorflow/pull/53323) is merged. Thanks!",
"created_at": "2021-12-21T17:09:06Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53322\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53322\">No</a>\n",
"created_at": "2022-01-12T17:38:06Z"
}
],
"number": 53322,
"title": "Unit test //tensorflow/python/ops/ragged:ragged_dispatch_test fails on AARCH64"
}
|
{
"body": "Fixes #53322 ",
"number": 53323,
"review_comments": [],
"title": "Add tolerance to ragged square root test so it passes on AARCH64"
}
|
{
"commits": [
{
"message": "Add tolerance to ragged square root test so it passes on AARCH64"
}
],
"files": [
{
"diff": "@@ -687,7 +687,9 @@ def testBinaryOpSparseAndRagged(self):\n 'num_segments':\n 2\n },\n- expected=[7.0, 2.0]),\n+ expected=[7.0, 2.0],\n+ rtol=1e-12,\n+ ),\n dict(\n op=math_ops.reduce_sum,\n kwargs={",
"filename": "tensorflow/python/ops/ragged/ragged_dispatch_test.py",
"status": "modified"
}
]
}
|
{
"body": "<em>Please make sure that this is a bug. As per our\r\n[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),\r\nwe only address code/doc bugs, performance issues, feature requests and\r\nbuild/installation issues on GitHub. tag:bug_template</em>\r\n\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: n/a\r\n- TensorFlow installed from (source or binary): source\r\n- TensorFlow version (use command below): git HEAD\r\n- Python version: 3.8.10\r\n- Bazel version (if compiling from source): 3.7.2\r\n- GCC/Compiler version (if compiling from source): 11.2.0\r\n- CUDA/cuDNN version: n/a\r\n- GPU model and memory: n/a\r\n\r\nYou can collect some of this information using our environment capture\r\n[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)\r\nYou can also obtain the TensorFlow version with:\r\n1. TF 1.0: `python -c \"import tensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)\"`\r\n2. TF 2.0: `python -c \"import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)\"`\r\n\r\n**Describe the current behavior**\r\n\r\nTest fails as illegal instruction is thrown.\r\n\r\n**Describe the expected behavior**\r\n\r\nTest passes\r\n\r\n**[Contributing](https://www.tensorflow.org/community/contribute)**\r\n\r\n- Do you want to contribute a PR? (yes/no): no\r\n- Briefly describe your candidate solution(if contributing):\r\n\r\n**Standalone code to reproduce the issue**\r\nProvide a reproducible test case that is the bare minimum necessary to generate\r\nthe problem. If possible, please share a link to Colab/Jupyter/any notebook.\r\n\r\nbazel test --test_timeout=300,500,-1,-1 --flaky_test_attempts=3 --test_output=all --cache_test_results=no --remote_http_cache=\"\" --remote_cache_proxy=\"\" --noremote_accept_cached --config=nonccl --build_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only --test_tag_filters=-no_oss,-oss_serial,-gpu,-tpu,-benchmark-test,-v1only --copt=-ffp-contract=off --cxxopt=-ffp-contract=off --copt=-Og --copt=-ggdb --verbose_failures -- //tensorflow/compiler/xla/tests:xla_hlo_profile_test_cpu\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\ndiagnose the problem. If including tracebacks, please include the full\r\ntraceback. Large logs and files should be attached.\r\n\r\nbazel-bin/tensorflow/compiler/xla/tests/xla_hlo_profile_test_cpu\r\n[==========] Running 2 tests from 1 test suite.\r\n[----------] Global test environment set-up.\r\n[----------] 2 tests from HloProfileTest\r\n[ RUN ] HloProfileTest.ProfileSingleComputation\r\n2021-11-24 17:03:03.560320: I tensorflow/compiler/xla/service/service.cc:171] XLA service 0x3c904070 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\r\n2021-11-24 17:03:03.560415: I tensorflow/compiler/xla/service/service.cc:179] StreamExecutor device (0): Host, Default Version\r\n2021-11-24 17:03:03.560854: I tensorflow/compiler/xla/service/service.cc:171] XLA service 0x3c904d60 initialized for platform Interpreter (this does not guarantee that XLA will be used). Devices:\r\n2021-11-24 17:03:03.560885: I tensorflow/compiler/xla/service/service.cc:179] StreamExecutor device (0): Interpreter, <undefined>\r\nIllegal instruction (core dumped)\r\n\r\nWhen running under gdb\r\n\r\nThread 70 \"xla_hlo_profile\" received signal SIGILL, Illegal instruction.\r\n[Switching to Thread 0xfffec6ffcd80 (LWP 420853)]\r\n0x0000fffff7ff8014 in ProfileSingleComputation.5 ()\r\n(gdb) disass\r\nDump of assembler code for function ProfileSingleComputation.5:\r\n 0x0000fffff7ff8000 <+0>:\tstr\td12, [sp, #-48]!\r\n 0x0000fffff7ff8004 <+4>:\tstp\td11, d10, [sp, #16]\r\n 0x0000fffff7ff8008 <+8>:\tstp\td9, d8, [sp, #32]\r\n 0x0000fffff7ff800c <+12>:\tmov\tx10, xzr\r\n 0x0000fffff7ff8010 <+16>:\tldp\tx9, x13, [x3, #8]\r\n=> 0x0000fffff7ff8014 <+20>:\tmrs\tx8, pmccntr_el0\r\n 0x0000fffff7ff8018 <+24>:\tadd\tx11, x9, #0x20\r\n 0x0000fffff7ff801c <+28>:\tldr\tx9, [x3]\r\n 0x0000fffff7ff8020 <+32>:\tadd\tx12, x9, #0x30\r\n 0x0000fffff7ff8024 <+36>:\tadd\tx13, x13, #0x20\r\n 0x0000fffff7ff8028 <+40>:\tmov\tx14, xzr\r\n 0x0000fffff7ff802c <+44>:\tadd\tx15, x11, x14\r\n 0x0000fffff7ff8030 <+48>:\tadd\tx16, x13, x14\r\n 0x0000fffff7ff8034 <+52>:\tldp\tq0, q1, [x15, #-32]\r\n 0x0000fffff7ff8038 <+56>:\tldp\tq2, q3, [x16, #-32]\r\n 0x0000fffff7ff803c <+60>:\tldp\tq4, q5, [x15]\r\n 0x0000fffff7ff8040 <+64>:\tfadd\tv0.4s, v0.4s, v2.4s\r\n 0x0000fffff7ff8044 <+68>:\tfadd\tv1.4s, v1.4s, v3.4s\r\n 0x0000fffff7ff8048 <+72>:\tldp\tq2, q3, [x16]\r\n 0x0000fffff7ff804c <+76>:\tfadd\tv2.4s, v4.4s, v2.4s\r\n 0x0000fffff7ff8050 <+80>:\tadd\tx15, x12, x14\r\n 0x0000fffff7ff8054 <+84>:\tstp\tq0, q1, [x15, #-48]\r\n 0x0000fffff7ff8058 <+88>:\tfadd\tv0.4s, v5.4s, v3.4s\r\n 0x0000fffff7ff805c <+92>:\tstp\tq2, q0, [x15, #-16]\r\n 0x0000fffff7ff8060 <+96>:\tadd\tx14, x14, #0x40\r\n 0x0000fffff7ff8064 <+100>:\tcmp\tx14, #0x400\r\n 0x0000fffff7ff8068 <+104>:\tb.ne\t0xfffff7ff802c <ProfileSingleComputation.5+44> // b.any\r\n 0x0000fffff7ff806c <+108>:\tadd\tx10, x10, #0x1\r\n 0x0000fffff7ff8070 <+112>:\tadd\tx11, x11, #0x400\r\n 0x0000fffff7ff8074 <+116>:\tadd\tx12, x12, #0x400\r\n 0x0000fffff7ff8078 <+120>:\tadd\tx13, x13, #0x400\r\n 0x0000fffff7ff807c <+124>:\tcmp\tx10, #0x100\r\n 0x0000fffff7ff8080 <+128>:\tb.ne\t0xfffff7ff8028 <ProfileSingleComputation.5+40> // b.any\r\n 0x0000fffff7ff8084 <+132>:\tmov\tx10, xzr\r\n 0x0000fffff7ff8088 <+136>:\tmrs\tx11, pmccntr_el0\r\n 0x0000fffff7ff808c <+140>:\tmov\tw12, #0xb717 \t// #46871\r\n 0x0000fffff7ff8090 <+144>:\tmovk\tw12, #0x39d1, lsl #16\r\n 0x0000fffff7ff8094 <+148>:\tdup\tv0.4s, w12\r\n 0x0000fffff7ff8098 <+152>:\tmov\tw12, #0x25c0 \t// #9664\r\n 0x0000fffff7ff809c <+156>:\tmovk\tw12, #0xa59f, lsl #16\r\n 0x0000fffff7ff80a0 <+160>:\tdup\tv1.4s, w12\r\n 0x0000fffff7ff80a4 <+164>:\tmov\tw12, #0x337e \t// #13182\r\n 0x0000fffff7ff80a8 <+168>:\tmovk\tw12, #0x2a61, lsl #16\r\n 0x0000fffff7ff80ac <+172>:\tdup\tv2.4s, w12\r\n 0x0000fffff7ff80b0 <+176>:\tmov\tw12, #0x37ff \t// #14335\r\n 0x0000fffff7ff80b4 <+180>:\tmovk\tw12, #0xaebd, lsl #16\r\n 0x0000fffff7ff80b8 <+184>:\tdup\tv3.4s, w12\r\n 0x0000fffff7ff80bc <+188>:\tldr\tx12, [x5, #24]\r\n 0x0000fffff7ff80c0 <+192>:\tsub\tx11, x11, x8\r\n 0x0000fffff7ff80c4 <+196>:\tadd\tx11, x11, x12\r\n 0x0000fffff7ff80c8 <+200>:\tstr\tx11, [x5, #24]\r\n 0x0000fffff7ff80cc <+204>:\tmov\tw11, #0x41 \t// #65\r\n 0x0000fffff7ff80d0 <+208>:\tmovk\tw11, #0x335c, lsl #16\r\n--Type <RET> for more, q to quit, c to continue without paging--q\r\n\r\nSo the problem seems to be reading the performance counter register as the illegal instruction flagged is \"mrs\tx8, pmccntr_el0\"",
"comments": [
{
"body": "@cfRod @nSircombe ",
"created_at": "2021-11-24T17:16:01Z"
},
{
"body": "Hi @sanatmpa1! Could you please look at this issue?",
"created_at": "2021-11-25T04:08:27Z"
},
{
"body": "Reading the documentation at https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/arm64/cpu-feature-registers.rst?h=v5.16-rc2 it seems that it is not possible for a user space application like TensorFlow to read the performance counters directly on AARCH64 Linux.",
"created_at": "2021-11-25T09:17:29Z"
},
{
"body": "It seems like the use of llvm::Intrinsic::readcyclecounter at https://github.com/tensorflow/tensorflow/blob/f37b7b1f619a424b420fcaebb7826c76a6eb9627/tensorflow/compiler/xla/service/cpu/ir_emitter.cc#L2939 is not going to work on AARCH64 Linux.",
"created_at": "2021-11-25T11:49:45Z"
},
{
"body": "XLA's profiling feature is not going to work on ARM/AArch64 unless the system is configured to set `PMUSERENR.EN`. I think the only reasonable thing we can do for now is disabling that test on ARM.\r\n\r\nDo you want to send a PR for that? Otherwise I can take a look.",
"created_at": "2021-12-01T13:38:43Z"
},
{
"body": "I propose to add the same tag as suggested in #53068 to exclude the test. I will add a PR for this shortly.\r\n\r\nThis does only deal with the unit tests however. It still leaves the feature in TF and if ever anyone attempts to make use of it on AARCH64, it will fail with SIGILL which is not really that nice for the unlucky user. So if you have some idea of how best to avoid that situation, that would be great, thanks @d0k .",
"created_at": "2021-12-01T14:36:23Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53189\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53189\">No</a>\n",
"created_at": "2021-12-08T00:45:59Z"
}
],
"number": 53189,
"title": "Unit test //tensorflow/compiler/xla/tests:xla_hlo_profile_test_cpu gives illegal instruction on AARCH64"
}
|
{
"body": "Fixes #53189 ",
"number": 53274,
"review_comments": [],
"title": "Add tag to tests to allow exclusion on AARCH64"
}
|
{
"commits": [
{
"message": "Add tag to tests to allow exclusion on AARCH64"
}
],
"files": [
{
"diff": "@@ -497,6 +497,7 @@ xla_test(\n # Hlo profiles are not supported on the interpreter backend.\n \"interpreter\",\n ],\n+ tags = [\"no_aarch64\"],\n deps = [\n \":client_library_test_base\",\n \":test_macros_header\",\n@@ -2273,6 +2274,7 @@ xla_test(\n # Hlo profiles are not supported on the interpreter backend.\n \"interpreter\",\n ],\n+ tags = [\"no_aarch64\"],\n deps = [\n \":client_library_test_base\",\n \":test_macros_header\",",
"filename": "tensorflow/compiler/xla/tests/BUILD",
"status": "modified"
}
]
}
|
{
"body": "**System information** \r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): n/a\r\n- OS Platform and Distribution (e.g.,Linux Ubuntu 16.04): n/a\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: n/a\r\n- TensorFlow installed from (source orbinary): n/a\r\n- TensorFlow version (use command below): n/a\r\n- Python version: n/a\r\n- Bazel version (if compiling from source): n/a\r\n- GCC/Compiler version (if compiling from source): n/a\r\n- CUDA/cuDNN version: n/a\r\n- GPU model and memory: n/a\r\n\r\nThe source code in current master branch has this:\r\nhttps://github.com/tensorflow/tensorflow/blob/0c853d6cadf055be10562cfec92a93776fafd555/tensorflow/python/ops/nn_impl.py#L1516-L1519\r\n\r\nHowever, the statement in the comment is no longer correct, according to https://docs.nvidia.com/deeplearning/sdk/cudnn-release-notes/rel_750.html:\r\n> the value of epsilon is required to be greater or equal to CUDNN_BN_MIN_EPSILON which was defined in the cudnn.h file to the value 1e-5. This threshold value is now lowered to 0.0 to allow a wider range of epsilon value.\r\n\r\nIf compatibility with earlier version of cudnn is needed, the minimum should be obtained by using the `CUDNN_BN_MIN_EPSILON` constant defined by `cudnn.h`. \r\nOr, maybe it's better to just throw an error when a wrong epsilon is provided by the user. Personally I don't like my parameter to be silently changed -- this can cause issues like `nn.fused_batch_norm` and `nn.batch_normalization` producing different results.",
"comments": [
{
"body": "@ppwwyyxx \r\ncould you please share simple stand alone code along with tensor flow version for us to replicate the issue faced",
"created_at": "2020-03-23T09:12:58Z"
},
{
"body": "The issue is clearly written in TensorFlow source code which I pasted above.",
"created_at": "2020-03-23T09:33:57Z"
},
{
"body": "Hi @ppwwyyxx! Could you cross check the pull request #53065 ?",
"created_at": "2021-11-16T03:30:38Z"
},
{
"body": "Ok @ppwwyyxx! This issue will be closed one Above PR is merged. Thanks!",
"created_at": "2021-11-22T10:33:47Z"
},
{
"body": "Hi @ppwwyyxx ! Internal tests are failing for above changes. Could you let us know the epsilon value in Cuda 8.1 for 2.8 version? Thanks! ",
"created_at": "2022-04-19T15:18:02Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2022-04-26T15:22:29Z"
},
{
"body": "@google-ml-butler the issue is not fixed yet:\r\n https://github.com/tensorflow/tensorflow/blob/091d5534c70022824f61b5d0127d8f1461a38419/tensorflow/python/ops/nn_impl.py#L1686-L1688",
"created_at": "2022-04-26T16:16:36Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37768\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/37768\">No</a>\n",
"created_at": "2022-11-21T21:32:14Z"
}
],
"number": 37768,
"title": "min_epsilon of fused_batch_norm is incorrect"
}
|
{
"body": "Compiling issue #37768 on epsilon condition as per users input `\"the value of epsilon is required to be greater or equal to CUDNN_BN_MIN_EPSILON which was defined in the cudnn.h file to the value 1e-5. This threshold value is now lowered to 0.0 to allow a wider range of epsilon value.` in this [document ](https://docs.nvidia.com/deeplearning/cudnn/release-notes/)",
"number": 53065,
"review_comments": [
{
"body": "Comment is now wrong.",
"created_at": "2021-11-16T17:02:57Z"
},
{
"body": "updated comment. Thanks!",
"created_at": "2021-11-17T11:03:36Z"
},
{
"body": "Please don't add new empty lines",
"created_at": "2021-11-17T17:02:24Z"
},
{
"body": "This change does not matter",
"created_at": "2021-12-21T21:27:57Z"
}
],
"title": "Change `min_epsilon` to 0"
}
|
{
"commits": [
{
"message": "Fixes #37768 by updating '>\" with \">=\"\n\nCompiling issue #37768 on epsilon condition as per users input"
},
{
"message": "Updating minimum epsilon to 0 \n\nUpdating minimum epsilon to 0 as per authors confirmation."
},
{
"message": "Formatted min_epsilon to 0.0 \n\nreplaced 0 (int value) with 0.0(float value) as per author's input"
},
{
"message": "updated comment\n\nupdated comment as per review."
},
{
"message": "Removed empty line \n\nRemoved empty line as per review."
},
{
"message": "Updated as per review \n\nUpdated as per review from author and reviewer"
},
{
"message": "Updating code readability in backprop.py\n\nTrying to fix issue #53499"
},
{
"message": "Rolling back changes\n\nRolling back changes intended to be separate bug fix."
},
{
"message": "Updated minimum epsilon 0.\n\nUpdated minimum epsilon 0. as per earlier comment by author."
}
],
"files": [
{
"diff": "@@ -1670,10 +1670,10 @@ def fused_batch_norm(\n if variance is None:\n variance = constant_op.constant([])\n \n- # Set a minimum epsilon to 1.001e-5, which is a requirement by CUDNN to\n+ # Set a minimum epsilon to 0., which is a requirement by CUDNN to\n # prevent exception (see cudnn.h).\n- min_epsilon = 1.001e-5\n- epsilon = epsilon if epsilon > min_epsilon else min_epsilon\n+ min_epsilon = 0.\n+ epsilon = epsilon if epsilon >= min_epsilon else min_epsilon\n \n y, running_mean, running_var, _, _, _ = gen_nn_ops.fused_batch_norm_v3(\n x,",
"filename": "tensorflow/python/ops/nn_impl.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No.\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04 (x64) and Raspberry Pi OS 64bit (raspios_arm64-2021-04-09)\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: Raspberry Pi 4\r\n- TensorFlow installed from (source or binary): Source\r\n- TensorFlow version (use command below): v2.7.0 and 7b290f9fd9fbf2ac4352b3cbe327e1067e5a3574\r\n- Python version: 3.7.3 (Raspberry Pi OS 64bit)\r\n- Bazel version (if compiling from source): - (Build with CMake)\r\n- GCC/Compiler version (if compiling from source): 8.3.0 (Raspberry Pi OS 64bit)\r\n- CUDA/cuDNN version: - \r\n- GPU model and memory: -\r\n\r\n**Describe the current behavior**\r\nXNNPACK delegate not enabled in TensorFlow Lite Python Interpreter. \r\nBuilding with either CMake or Bazel will not take effect.\r\nThe following log is not output.\r\n> INFO: Created TensorFlow Lite XNNPACK delegate for CPU.\r\n \r\n \r\nDelegate lazy initialization was included in the 3d3c6db1ca2d50f6f07722cd800144f8f736167c commit.\r\nFor C ++ IF, Interpreter::AllocateTensors calls ApplyLazyDelegateProviders to enable the XNNPACK delegate.\r\nhttps://github.com/tensorflow/tensorflow/blob/v2.7.0/tensorflow/lite/interpreter.cc#L176\r\n\r\nHowever, for Python IF, the XNNPACK delegate is not enabled because ApplyLazyDelegateProviders is not called in InterpreterWrapper::AllocateTensors.\r\nhttps://github.com/tensorflow/tensorflow/blob/v2.7.0/tensorflow/lite/python/interpreter_wrapper/interpreter_wrapper.cc#L259\r\n\r\n**Describe the expected behavior**\r\nThe XNNPACK delegate is enabled in the TensorFlow Lite Python Interpreter.\r\n\r\n**[Contributing](https://www.tensorflow.org/community/contribute)**\r\n\r\n- Do you want to contribute a PR? (yes/no): Yes\r\n- Briefly describe your candidate solution(if contributing): \r\n\r\n**Standalone code to reproduce the issue**\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\n",
"comments": [
{
"body": "@NobuoTsukamoto ,\r\nThe issue will move to closed status once the PR is merged.",
"created_at": "2021-11-14T05:16:56Z"
},
{
"body": "Many thanks for catching this issue and contributing the fix! Just posted a comment to https://github.com/tensorflow/tensorflow/pull/53044/",
"created_at": "2021-11-16T02:47:12Z"
},
{
"body": "I was able to delegate XNNPACK with 365a3b68471f158defc3aea79a25fdaa56be4ac8 commits.\r\n- I built it with build_pip_package_with_cmake.sh on Raspberry Pi OS 64 bit.\r\n- I confirmed that the following log is output.\r\n INFO: Created TensorFlow Lite XNNPACK delegate for CPU.\r\n- The value specified for the num_threads argument of tf.lite.Interpreter was specified in the thread pool of XNNPACK.\r\n\r\n\r\nThank you very much. I would like to close this issue.",
"created_at": "2021-11-17T12:33:10Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53042\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/53042\">No</a>\n",
"created_at": "2021-11-17T12:33:12Z"
}
],
"number": 53042,
"title": "XNNPACK delegate not enabled in TensorFlow Lite Python Interpreter."
}
|
{
"body": "Fixed #53042 .\r\nEnable XNNPACK delegate in TensorFlow Lite Python Interpreter.",
"number": 53044,
"review_comments": [
{
"body": "Thanks for spotting the issue in Python! However, we think it's better not to call this private function here. We are preparing an alternative fix now, and we will get it out asap.",
"created_at": "2021-11-16T02:37:51Z"
}
],
"title": "[TFLite] Enable ApplyLazyDelegateProviders in TF-Lite Python Interpreter."
}
|
{
"commits": [
{
"message": "Enable ApplyLazyDelegateProviders in TF-Lite Python Interpreter."
}
],
"files": [
{
"diff": "@@ -259,6 +259,7 @@ InterpreterWrapper::~InterpreterWrapper() {}\n PyObject* InterpreterWrapper::AllocateTensors(int subgraph_index) {\n TFLITE_PY_ENSURE_VALID_INTERPRETER();\n TFLITE_PY_SUBGRAPH_BOUNDS_CHECK(subgraph_index);\n+ TFLITE_PY_CHECK(interpreter_->ApplyLazyDelegateProviders());\n TFLITE_PY_CHECK(interpreter_->subgraph(subgraph_index)->AllocateTensors());\n Py_RETURN_NONE;\n }",
"filename": "tensorflow/lite/python/interpreter_wrapper/interpreter_wrapper.cc",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n\r\n**Describe the current behavior**\r\nThe following APIs crash(abortion) when the given size is large\r\n- tf.image.resiz\r\n- tf.image.resize_with_crop_or_pad\r\n- tf.image.pad_to_bounding_box\r\n- tf.image.extract_glimpse\r\n- `tf.keras.backend.resize_images`\r\n\r\n**Describe the expected behavior**\r\nexpect exception messages if the input is not expected instead of crash\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\n### `tf.image.resize`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize(images=np.ones((5,5,5)), size=[2065374891,1145309325])\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:41:13.484992: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -6619278462293758741)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.resize_with_crop_or_pad`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_crop_or_pad(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470)\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:42:15.468265: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.pad_to_bounding_box`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.pad_to_bounding_box(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470, offset_height=1, offset_width=1)\r\n~~~\r\nOutput\r\n~~~python\r\n2021-02-03 17:42:52.556583: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.extract_glimpse`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.extract_glimpse(input=np.ones((5,5,5,5)), size=[1574700351, 451745106], offsets=np.ones((5,2)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:43:30.140277: F tensorflow/core/framework/tensor_shape.cc:338] Check failed: 0 <= n (0 vs. -662664649191246466)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.keras.backend.resize_image`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.backend.resize_images(x=np.ones((1,5,3,15)), height_factor=5628955348197345288, width_factor=5628955348197345288, data_format='channels_last')\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:54:01.192819: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5948468124908472256)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "@rmothukuru \r\nI ran the code on tf 2.4 and nightly, colab crashes. please find the [gist here](\r\nhttps://colab.research.google.com/gist/Saduf2019/fd4dfbdc07480e95a5694b336944c4f8/untitled520.ipynb)",
"created_at": "2021-02-04T06:35:03Z"
},
{
"body": "BTW, I also find it in `tf.image.crop_and_resize` and `tf.image.resize_with_pad`\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.crop_and_resize(image=np.ones((1,1,1,1)), boxes=np.ones((11,4)), box_indices=np.ones((11)), crop_size=[2065374891,1145309325])\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-05 17:02:57.884394: F tensorflow/core/framework/tensor_shape.cc:187] Non-OK-status: InitDims(dim_sizes) status: Internal: Encountered overflow when multiplying 22719123801 with 1145309325, result: -1\r\nAborted (core dumped)\r\n~~~\r\n\r\n\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_pad(image=np.ones((5,5,5)), target_height=1635057735, target_width=1635057735)\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-19 22:28:03.322414: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\n2021-02-19 22:28:03.332536: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5079675089792900491)\r\nAborted (core dumped)\r\n~~~",
"created_at": "2021-02-05T17:04:08Z"
},
{
"body": "Was able to reproduce the issue in TF 2.6.0-dev20210528 & colab crashes ,please find the gist [here](https://colab.research.google.com/gist/sushreebarsa/2f0930249cfea6fd3be6c8f9ec4fca21/untitled41.ipynb#scrollTo=vkKKum0ltdoP)..Thanks !",
"created_at": "2021-05-28T11:32:22Z"
},
{
"body": "Update:\r\n1. `tf.image.resize` fixed aleady\r\n2. `tf.image.resize_with_crop_or_pad` to be fixed (PR #51717)\r\n3. `tf.image.pad_to_bounding_box` to be fixed (PR #51717)\r\n4. `tf.keras.backend.resize_image` fixed already\r\n5. `tf.image.crop_and_resize` to be fixed (PR #51732)\r\n5. `tf.image.resize_with_pad` fixed already",
"created_at": "2021-08-28T16:40:51Z"
},
{
"body": "@DNXie Could you please let us know if we can closed the issue with this [PR](https://github.com/tensorflow/tensorflow/pull/51732) ?Thank you!",
"created_at": "2021-09-02T16:01:00Z"
},
{
"body": "There are still a few PRs that need to land here.",
"created_at": "2021-09-03T00:58:51Z"
},
{
"body": "I think all of these landed",
"created_at": "2021-10-27T23:23:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">No</a>\n",
"created_at": "2021-10-27T23:23:50Z"
}
],
"number": 46890,
"title": "tf.image.resize/resize_with_crop_or_pad/pad_to_bounding_box/extract_glimpse crash(abort)"
}
|
{
"body": "…number\r\n\r\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\r\n\r\nThis PR is part of the effort in #46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCopybara import of the project:\r\n\r\n--\r\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\r\n\r\nFix crash of tf.image.crop_and_resize when input is large number\r\n\r\nThis PR is part of the effort in 46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\r\nPiperOrigin-RevId: 394109830\r\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4",
"number": 52843,
"review_comments": [],
"title": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large …"
}
|
{
"commits": [
{
"message": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large number\n\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\n\nThis PR is part of the effort in #46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCopybara import of the project:\n\n--\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\n\nFix crash of tf.image.crop_and_resize when input is large number\n\nThis PR is part of the effort in 46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\nPiperOrigin-RevId: 394109830\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4"
}
],
"files": [
{
"diff": "@@ -169,14 +169,15 @@ class CropAndResizeOp : public AsyncOpKernel {\n context, crop_height > 0 && crop_width > 0,\n errors::InvalidArgument(\"crop dimensions must be positive\"), done);\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(num_boxes), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({num_boxes, crop_height, crop_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& image = context->input(0);\n@@ -407,14 +408,15 @@ class CropAndResizeGradImageOp : public AsyncOpKernel {\n context, grads.dim_size(3) == depth,\n errors::InvalidArgument(\"image_size and grads are incompatible\"), done);\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(batch_size), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({batch_size, image_height, image_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& grads = context->input(0);",
"filename": "tensorflow/core/kernels/image/crop_and_resize_op.cc",
"status": "modified"
},
{
"diff": "@@ -5777,6 +5777,16 @@ def testImageCropAndResize(self):\n crop_size=[1, 1])\n self.evaluate(op)\n \n+ def testImageCropAndResizeWithInvalidInput(self):\n+ with self.session():\n+ with self.assertRaises((errors.InternalError, ValueError)):\n+ op = image_ops_impl.crop_and_resize_v2(\n+ image=np.ones((1, 1, 1, 1)),\n+ boxes=np.ones((11, 4)),\n+ box_indices=np.ones((11)),\n+ crop_size=[2065374891, 1145309325])\n+ self.evaluate(op)\n+\n @parameterized.named_parameters(\n (\"_jpeg\", \"JPEG\", \"jpeg_merge_test1.jpg\"),\n (\"_png\", \"PNG\", \"lena_rgba.png\"),",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n\r\n**Describe the current behavior**\r\nThe following APIs crash(abortion) when the given size is large\r\n- tf.image.resiz\r\n- tf.image.resize_with_crop_or_pad\r\n- tf.image.pad_to_bounding_box\r\n- tf.image.extract_glimpse\r\n- `tf.keras.backend.resize_images`\r\n\r\n**Describe the expected behavior**\r\nexpect exception messages if the input is not expected instead of crash\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\n### `tf.image.resize`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize(images=np.ones((5,5,5)), size=[2065374891,1145309325])\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:41:13.484992: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -6619278462293758741)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.resize_with_crop_or_pad`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_crop_or_pad(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470)\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:42:15.468265: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.pad_to_bounding_box`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.pad_to_bounding_box(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470, offset_height=1, offset_width=1)\r\n~~~\r\nOutput\r\n~~~python\r\n2021-02-03 17:42:52.556583: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.extract_glimpse`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.extract_glimpse(input=np.ones((5,5,5,5)), size=[1574700351, 451745106], offsets=np.ones((5,2)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:43:30.140277: F tensorflow/core/framework/tensor_shape.cc:338] Check failed: 0 <= n (0 vs. -662664649191246466)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.keras.backend.resize_image`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.backend.resize_images(x=np.ones((1,5,3,15)), height_factor=5628955348197345288, width_factor=5628955348197345288, data_format='channels_last')\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:54:01.192819: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5948468124908472256)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "@rmothukuru \r\nI ran the code on tf 2.4 and nightly, colab crashes. please find the [gist here](\r\nhttps://colab.research.google.com/gist/Saduf2019/fd4dfbdc07480e95a5694b336944c4f8/untitled520.ipynb)",
"created_at": "2021-02-04T06:35:03Z"
},
{
"body": "BTW, I also find it in `tf.image.crop_and_resize` and `tf.image.resize_with_pad`\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.crop_and_resize(image=np.ones((1,1,1,1)), boxes=np.ones((11,4)), box_indices=np.ones((11)), crop_size=[2065374891,1145309325])\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-05 17:02:57.884394: F tensorflow/core/framework/tensor_shape.cc:187] Non-OK-status: InitDims(dim_sizes) status: Internal: Encountered overflow when multiplying 22719123801 with 1145309325, result: -1\r\nAborted (core dumped)\r\n~~~\r\n\r\n\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_pad(image=np.ones((5,5,5)), target_height=1635057735, target_width=1635057735)\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-19 22:28:03.322414: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\n2021-02-19 22:28:03.332536: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5079675089792900491)\r\nAborted (core dumped)\r\n~~~",
"created_at": "2021-02-05T17:04:08Z"
},
{
"body": "Was able to reproduce the issue in TF 2.6.0-dev20210528 & colab crashes ,please find the gist [here](https://colab.research.google.com/gist/sushreebarsa/2f0930249cfea6fd3be6c8f9ec4fca21/untitled41.ipynb#scrollTo=vkKKum0ltdoP)..Thanks !",
"created_at": "2021-05-28T11:32:22Z"
},
{
"body": "Update:\r\n1. `tf.image.resize` fixed aleady\r\n2. `tf.image.resize_with_crop_or_pad` to be fixed (PR #51717)\r\n3. `tf.image.pad_to_bounding_box` to be fixed (PR #51717)\r\n4. `tf.keras.backend.resize_image` fixed already\r\n5. `tf.image.crop_and_resize` to be fixed (PR #51732)\r\n5. `tf.image.resize_with_pad` fixed already",
"created_at": "2021-08-28T16:40:51Z"
},
{
"body": "@DNXie Could you please let us know if we can closed the issue with this [PR](https://github.com/tensorflow/tensorflow/pull/51732) ?Thank you!",
"created_at": "2021-09-02T16:01:00Z"
},
{
"body": "There are still a few PRs that need to land here.",
"created_at": "2021-09-03T00:58:51Z"
},
{
"body": "I think all of these landed",
"created_at": "2021-10-27T23:23:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">No</a>\n",
"created_at": "2021-10-27T23:23:50Z"
}
],
"number": 46890,
"title": "tf.image.resize/resize_with_crop_or_pad/pad_to_bounding_box/extract_glimpse crash(abort)"
}
|
{
"body": "…number\r\n\r\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\r\n\r\nThis PR is part of the effort in #46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCopybara import of the project:\r\n\r\n--\r\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\r\n\r\nFix crash of tf.image.crop_and_resize when input is large number\r\n\r\nThis PR is part of the effort in 46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\r\nPiperOrigin-RevId: 394109830\r\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4",
"number": 52842,
"review_comments": [],
"title": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large …"
}
|
{
"commits": [
{
"message": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large number\n\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\n\nThis PR is part of the effort in #46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCopybara import of the project:\n\n--\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\n\nFix crash of tf.image.crop_and_resize when input is large number\n\nThis PR is part of the effort in 46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\nPiperOrigin-RevId: 394109830\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4"
}
],
"files": [
{
"diff": "@@ -169,14 +169,15 @@ class CropAndResizeOp : public AsyncOpKernel {\n context, crop_height > 0 && crop_width > 0,\n errors::InvalidArgument(\"crop dimensions must be positive\"), done);\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(num_boxes), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({num_boxes, crop_height, crop_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& image = context->input(0);\n@@ -407,14 +408,15 @@ class CropAndResizeGradImageOp : public AsyncOpKernel {\n context, grads.dim_size(3) == depth,\n errors::InvalidArgument(\"image_size and grads are incompatible\"), done);\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(batch_size), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({batch_size, image_height, image_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& grads = context->input(0);",
"filename": "tensorflow/core/kernels/image/crop_and_resize_op.cc",
"status": "modified"
},
{
"diff": "@@ -6034,6 +6034,16 @@ def testImageCropAndResize(self):\n crop_size=[1, 1])\n self.evaluate(op)\n \n+ def testImageCropAndResizeWithInvalidInput(self):\n+ with self.session():\n+ with self.assertRaises((errors.InternalError, ValueError)):\n+ op = image_ops_impl.crop_and_resize_v2(\n+ image=np.ones((1, 1, 1, 1)),\n+ boxes=np.ones((11, 4)),\n+ box_indices=np.ones((11)),\n+ crop_size=[2065374891, 1145309325])\n+ self.evaluate(op)\n+\n @parameterized.named_parameters(\n (\"_jpeg\", \"JPEG\", \"jpeg_merge_test1.jpg\"),\n (\"_png\", \"PNG\", \"lena_rgba.png\"),",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n\r\n**Describe the current behavior**\r\nThe following APIs crash(abortion) when the given size is large\r\n- tf.image.resiz\r\n- tf.image.resize_with_crop_or_pad\r\n- tf.image.pad_to_bounding_box\r\n- tf.image.extract_glimpse\r\n- `tf.keras.backend.resize_images`\r\n\r\n**Describe the expected behavior**\r\nexpect exception messages if the input is not expected instead of crash\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\n### `tf.image.resize`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize(images=np.ones((5,5,5)), size=[2065374891,1145309325])\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:41:13.484992: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -6619278462293758741)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.resize_with_crop_or_pad`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_crop_or_pad(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470)\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:42:15.468265: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.pad_to_bounding_box`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.pad_to_bounding_box(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470, offset_height=1, offset_width=1)\r\n~~~\r\nOutput\r\n~~~python\r\n2021-02-03 17:42:52.556583: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.extract_glimpse`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.extract_glimpse(input=np.ones((5,5,5,5)), size=[1574700351, 451745106], offsets=np.ones((5,2)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:43:30.140277: F tensorflow/core/framework/tensor_shape.cc:338] Check failed: 0 <= n (0 vs. -662664649191246466)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.keras.backend.resize_image`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.backend.resize_images(x=np.ones((1,5,3,15)), height_factor=5628955348197345288, width_factor=5628955348197345288, data_format='channels_last')\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:54:01.192819: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5948468124908472256)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "@rmothukuru \r\nI ran the code on tf 2.4 and nightly, colab crashes. please find the [gist here](\r\nhttps://colab.research.google.com/gist/Saduf2019/fd4dfbdc07480e95a5694b336944c4f8/untitled520.ipynb)",
"created_at": "2021-02-04T06:35:03Z"
},
{
"body": "BTW, I also find it in `tf.image.crop_and_resize` and `tf.image.resize_with_pad`\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.crop_and_resize(image=np.ones((1,1,1,1)), boxes=np.ones((11,4)), box_indices=np.ones((11)), crop_size=[2065374891,1145309325])\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-05 17:02:57.884394: F tensorflow/core/framework/tensor_shape.cc:187] Non-OK-status: InitDims(dim_sizes) status: Internal: Encountered overflow when multiplying 22719123801 with 1145309325, result: -1\r\nAborted (core dumped)\r\n~~~\r\n\r\n\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_pad(image=np.ones((5,5,5)), target_height=1635057735, target_width=1635057735)\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-19 22:28:03.322414: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\n2021-02-19 22:28:03.332536: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5079675089792900491)\r\nAborted (core dumped)\r\n~~~",
"created_at": "2021-02-05T17:04:08Z"
},
{
"body": "Was able to reproduce the issue in TF 2.6.0-dev20210528 & colab crashes ,please find the gist [here](https://colab.research.google.com/gist/sushreebarsa/2f0930249cfea6fd3be6c8f9ec4fca21/untitled41.ipynb#scrollTo=vkKKum0ltdoP)..Thanks !",
"created_at": "2021-05-28T11:32:22Z"
},
{
"body": "Update:\r\n1. `tf.image.resize` fixed aleady\r\n2. `tf.image.resize_with_crop_or_pad` to be fixed (PR #51717)\r\n3. `tf.image.pad_to_bounding_box` to be fixed (PR #51717)\r\n4. `tf.keras.backend.resize_image` fixed already\r\n5. `tf.image.crop_and_resize` to be fixed (PR #51732)\r\n5. `tf.image.resize_with_pad` fixed already",
"created_at": "2021-08-28T16:40:51Z"
},
{
"body": "@DNXie Could you please let us know if we can closed the issue with this [PR](https://github.com/tensorflow/tensorflow/pull/51732) ?Thank you!",
"created_at": "2021-09-02T16:01:00Z"
},
{
"body": "There are still a few PRs that need to land here.",
"created_at": "2021-09-03T00:58:51Z"
},
{
"body": "I think all of these landed",
"created_at": "2021-10-27T23:23:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">No</a>\n",
"created_at": "2021-10-27T23:23:50Z"
}
],
"number": 46890,
"title": "tf.image.resize/resize_with_crop_or_pad/pad_to_bounding_box/extract_glimpse crash(abort)"
}
|
{
"body": "…number\r\n\r\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\r\n\r\nThis PR is part of the effort in #46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCopybara import of the project:\r\n\r\n--\r\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\r\n\r\nFix crash of tf.image.crop_and_resize when input is large number\r\n\r\nThis PR is part of the effort in 46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\r\nPiperOrigin-RevId: 394109830\r\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4",
"number": 52841,
"review_comments": [],
"title": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large …"
}
|
{
"commits": [
{
"message": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large number\n\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\n\nThis PR is part of the effort in #46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCopybara import of the project:\n\n--\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\n\nFix crash of tf.image.crop_and_resize when input is large number\n\nThis PR is part of the effort in 46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\nPiperOrigin-RevId: 394109830\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4"
}
],
"files": [
{
"diff": "@@ -170,14 +170,15 @@ class CropAndResizeOp : public AsyncOpKernel {\n context, crop_height > 0 && crop_width > 0,\n errors::InvalidArgument(\"crop dimensions must be positive\"), done);\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(num_boxes), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({num_boxes, crop_height, crop_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& image = context->input(0);\n@@ -417,14 +418,15 @@ class CropAndResizeGradImageOp : public AsyncOpKernel {\n done);\n }\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(batch_size), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({batch_size, image_height, image_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& grads = context->input(0);",
"filename": "tensorflow/core/kernels/image/crop_and_resize_op.cc",
"status": "modified"
},
{
"diff": "@@ -6036,6 +6036,16 @@ def testImageCropAndResize(self):\n crop_size=[1, 1])\n self.evaluate(op)\n \n+ def testImageCropAndResizeWithInvalidInput(self):\n+ with self.session():\n+ with self.assertRaises((errors.InternalError, ValueError)):\n+ op = image_ops_impl.crop_and_resize_v2(\n+ image=np.ones((1, 1, 1, 1)),\n+ boxes=np.ones((11, 4)),\n+ box_indices=np.ones((11)),\n+ crop_size=[2065374891, 1145309325])\n+ self.evaluate(op)\n+\n @parameterized.named_parameters(\n (\"_jpeg\", \"JPEG\", \"jpeg_merge_test1.jpg\"),\n (\"_png\", \"PNG\", \"lena_rgba.png\"),",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n\r\n**Describe the current behavior**\r\nThe following APIs crash(abortion) when the given size is large\r\n- tf.image.resiz\r\n- tf.image.resize_with_crop_or_pad\r\n- tf.image.pad_to_bounding_box\r\n- tf.image.extract_glimpse\r\n- `tf.keras.backend.resize_images`\r\n\r\n**Describe the expected behavior**\r\nexpect exception messages if the input is not expected instead of crash\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\n### `tf.image.resize`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize(images=np.ones((5,5,5)), size=[2065374891,1145309325])\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:41:13.484992: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -6619278462293758741)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.resize_with_crop_or_pad`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_crop_or_pad(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470)\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:42:15.468265: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.pad_to_bounding_box`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.pad_to_bounding_box(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470, offset_height=1, offset_width=1)\r\n~~~\r\nOutput\r\n~~~python\r\n2021-02-03 17:42:52.556583: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.extract_glimpse`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.extract_glimpse(input=np.ones((5,5,5,5)), size=[1574700351, 451745106], offsets=np.ones((5,2)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:43:30.140277: F tensorflow/core/framework/tensor_shape.cc:338] Check failed: 0 <= n (0 vs. -662664649191246466)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.keras.backend.resize_image`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.backend.resize_images(x=np.ones((1,5,3,15)), height_factor=5628955348197345288, width_factor=5628955348197345288, data_format='channels_last')\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:54:01.192819: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5948468124908472256)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "@rmothukuru \r\nI ran the code on tf 2.4 and nightly, colab crashes. please find the [gist here](\r\nhttps://colab.research.google.com/gist/Saduf2019/fd4dfbdc07480e95a5694b336944c4f8/untitled520.ipynb)",
"created_at": "2021-02-04T06:35:03Z"
},
{
"body": "BTW, I also find it in `tf.image.crop_and_resize` and `tf.image.resize_with_pad`\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.crop_and_resize(image=np.ones((1,1,1,1)), boxes=np.ones((11,4)), box_indices=np.ones((11)), crop_size=[2065374891,1145309325])\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-05 17:02:57.884394: F tensorflow/core/framework/tensor_shape.cc:187] Non-OK-status: InitDims(dim_sizes) status: Internal: Encountered overflow when multiplying 22719123801 with 1145309325, result: -1\r\nAborted (core dumped)\r\n~~~\r\n\r\n\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_pad(image=np.ones((5,5,5)), target_height=1635057735, target_width=1635057735)\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-19 22:28:03.322414: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\n2021-02-19 22:28:03.332536: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5079675089792900491)\r\nAborted (core dumped)\r\n~~~",
"created_at": "2021-02-05T17:04:08Z"
},
{
"body": "Was able to reproduce the issue in TF 2.6.0-dev20210528 & colab crashes ,please find the gist [here](https://colab.research.google.com/gist/sushreebarsa/2f0930249cfea6fd3be6c8f9ec4fca21/untitled41.ipynb#scrollTo=vkKKum0ltdoP)..Thanks !",
"created_at": "2021-05-28T11:32:22Z"
},
{
"body": "Update:\r\n1. `tf.image.resize` fixed aleady\r\n2. `tf.image.resize_with_crop_or_pad` to be fixed (PR #51717)\r\n3. `tf.image.pad_to_bounding_box` to be fixed (PR #51717)\r\n4. `tf.keras.backend.resize_image` fixed already\r\n5. `tf.image.crop_and_resize` to be fixed (PR #51732)\r\n5. `tf.image.resize_with_pad` fixed already",
"created_at": "2021-08-28T16:40:51Z"
},
{
"body": "@DNXie Could you please let us know if we can closed the issue with this [PR](https://github.com/tensorflow/tensorflow/pull/51732) ?Thank you!",
"created_at": "2021-09-02T16:01:00Z"
},
{
"body": "There are still a few PRs that need to land here.",
"created_at": "2021-09-03T00:58:51Z"
},
{
"body": "I think all of these landed",
"created_at": "2021-10-27T23:23:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">No</a>\n",
"created_at": "2021-10-27T23:23:50Z"
}
],
"number": 46890,
"title": "tf.image.resize/resize_with_crop_or_pad/pad_to_bounding_box/extract_glimpse crash(abort)"
}
|
{
"body": "…number\r\n\r\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\r\n\r\nThis PR is part of the effort in #46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCopybara import of the project:\r\n\r\n--\r\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\r\n\r\nFix crash of tf.image.crop_and_resize when input is large number\r\n\r\nThis PR is part of the effort in 46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\r\nPiperOrigin-RevId: 394109830\r\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4",
"number": 52792,
"review_comments": [],
"title": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large …"
}
|
{
"commits": [
{
"message": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large number\n\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\n\nThis PR is part of the effort in #46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCopybara import of the project:\n\n--\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\n\nFix crash of tf.image.crop_and_resize when input is large number\n\nThis PR is part of the effort in 46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\nPiperOrigin-RevId: 394109830\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4"
}
],
"files": [
{
"diff": "@@ -169,14 +169,15 @@ class CropAndResizeOp : public AsyncOpKernel {\n context, crop_height > 0 && crop_width > 0,\n errors::InvalidArgument(\"crop dimensions must be positive\"), done);\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(num_boxes), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({num_boxes, crop_height, crop_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& image = context->input(0);\n@@ -407,14 +408,25 @@ class CropAndResizeGradImageOp : public AsyncOpKernel {\n context, grads.dim_size(3) == depth,\n errors::InvalidArgument(\"image_size and grads are incompatible\"), done);\n \n+\n+ if (std::is_same<Device, GPUDevice>::value) {\n+ OP_REQUIRES_ASYNC(\n+ context, !OpDeterminismRequired(),\n+ errors::Unimplemented(\n+ \"Deterministic GPU implementation of CropAndResizeBackpropImage\"\n+ \" not available.\"),\n+ done);\n+ }\n+\n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(batch_size), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({batch_size, image_height, image_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& grads = context->input(0);",
"filename": "tensorflow/core/kernels/image/crop_and_resize_op.cc",
"status": "modified"
},
{
"diff": "@@ -5777,6 +5777,16 @@ def testImageCropAndResize(self):\n crop_size=[1, 1])\n self.evaluate(op)\n \n+ def testImageCropAndResizeWithInvalidInput(self):\n+ with self.session():\n+ with self.assertRaises((errors.InternalError, ValueError)):\n+ op = image_ops_impl.crop_and_resize_v2(\n+ image=np.ones((1, 1, 1, 1)),\n+ boxes=np.ones((11, 4)),\n+ box_indices=np.ones((11)),\n+ crop_size=[2065374891, 1145309325])\n+ self.evaluate(op)\n+\n @parameterized.named_parameters(\n (\"_jpeg\", \"JPEG\", \"jpeg_merge_test1.jpg\"),\n (\"_png\", \"PNG\", \"lena_rgba.png\"),",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n\r\n**Describe the current behavior**\r\nThe following APIs crash(abortion) when the given size is large\r\n- tf.image.resiz\r\n- tf.image.resize_with_crop_or_pad\r\n- tf.image.pad_to_bounding_box\r\n- tf.image.extract_glimpse\r\n- `tf.keras.backend.resize_images`\r\n\r\n**Describe the expected behavior**\r\nexpect exception messages if the input is not expected instead of crash\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\n### `tf.image.resize`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize(images=np.ones((5,5,5)), size=[2065374891,1145309325])\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:41:13.484992: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -6619278462293758741)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.resize_with_crop_or_pad`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_crop_or_pad(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470)\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:42:15.468265: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.pad_to_bounding_box`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.pad_to_bounding_box(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470, offset_height=1, offset_width=1)\r\n~~~\r\nOutput\r\n~~~python\r\n2021-02-03 17:42:52.556583: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.extract_glimpse`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.extract_glimpse(input=np.ones((5,5,5,5)), size=[1574700351, 451745106], offsets=np.ones((5,2)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:43:30.140277: F tensorflow/core/framework/tensor_shape.cc:338] Check failed: 0 <= n (0 vs. -662664649191246466)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.keras.backend.resize_image`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.backend.resize_images(x=np.ones((1,5,3,15)), height_factor=5628955348197345288, width_factor=5628955348197345288, data_format='channels_last')\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:54:01.192819: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5948468124908472256)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "@rmothukuru \r\nI ran the code on tf 2.4 and nightly, colab crashes. please find the [gist here](\r\nhttps://colab.research.google.com/gist/Saduf2019/fd4dfbdc07480e95a5694b336944c4f8/untitled520.ipynb)",
"created_at": "2021-02-04T06:35:03Z"
},
{
"body": "BTW, I also find it in `tf.image.crop_and_resize` and `tf.image.resize_with_pad`\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.crop_and_resize(image=np.ones((1,1,1,1)), boxes=np.ones((11,4)), box_indices=np.ones((11)), crop_size=[2065374891,1145309325])\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-05 17:02:57.884394: F tensorflow/core/framework/tensor_shape.cc:187] Non-OK-status: InitDims(dim_sizes) status: Internal: Encountered overflow when multiplying 22719123801 with 1145309325, result: -1\r\nAborted (core dumped)\r\n~~~\r\n\r\n\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_pad(image=np.ones((5,5,5)), target_height=1635057735, target_width=1635057735)\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-19 22:28:03.322414: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\n2021-02-19 22:28:03.332536: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5079675089792900491)\r\nAborted (core dumped)\r\n~~~",
"created_at": "2021-02-05T17:04:08Z"
},
{
"body": "Was able to reproduce the issue in TF 2.6.0-dev20210528 & colab crashes ,please find the gist [here](https://colab.research.google.com/gist/sushreebarsa/2f0930249cfea6fd3be6c8f9ec4fca21/untitled41.ipynb#scrollTo=vkKKum0ltdoP)..Thanks !",
"created_at": "2021-05-28T11:32:22Z"
},
{
"body": "Update:\r\n1. `tf.image.resize` fixed aleady\r\n2. `tf.image.resize_with_crop_or_pad` to be fixed (PR #51717)\r\n3. `tf.image.pad_to_bounding_box` to be fixed (PR #51717)\r\n4. `tf.keras.backend.resize_image` fixed already\r\n5. `tf.image.crop_and_resize` to be fixed (PR #51732)\r\n5. `tf.image.resize_with_pad` fixed already",
"created_at": "2021-08-28T16:40:51Z"
},
{
"body": "@DNXie Could you please let us know if we can closed the issue with this [PR](https://github.com/tensorflow/tensorflow/pull/51732) ?Thank you!",
"created_at": "2021-09-02T16:01:00Z"
},
{
"body": "There are still a few PRs that need to land here.",
"created_at": "2021-09-03T00:58:51Z"
},
{
"body": "I think all of these landed",
"created_at": "2021-10-27T23:23:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">No</a>\n",
"created_at": "2021-10-27T23:23:50Z"
}
],
"number": 46890,
"title": "tf.image.resize/resize_with_crop_or_pad/pad_to_bounding_box/extract_glimpse crash(abort)"
}
|
{
"body": "…number\r\n\r\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\r\n\r\nThis PR is part of the effort in #46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCopybara import of the project:\r\n\r\n--\r\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\r\n\r\nFix crash of tf.image.crop_and_resize when input is large number\r\n\r\nThis PR is part of the effort in 46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\r\nPiperOrigin-RevId: 394109830\r\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4",
"number": 52791,
"review_comments": [],
"title": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large …"
}
|
{
"commits": [
{
"message": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large number\n\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\n\nThis PR is part of the effort in #46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCopybara import of the project:\n\n--\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\n\nFix crash of tf.image.crop_and_resize when input is large number\n\nThis PR is part of the effort in 46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\nPiperOrigin-RevId: 394109830\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4"
}
],
"files": [
{
"diff": "@@ -169,14 +169,15 @@ class CropAndResizeOp : public AsyncOpKernel {\n context, crop_height > 0 && crop_width > 0,\n errors::InvalidArgument(\"crop dimensions must be positive\"), done);\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(num_boxes), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({num_boxes, crop_height, crop_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& image = context->input(0);\n@@ -407,14 +408,25 @@ class CropAndResizeGradImageOp : public AsyncOpKernel {\n context, grads.dim_size(3) == depth,\n errors::InvalidArgument(\"image_size and grads are incompatible\"), done);\n \n+\n+ if (std::is_same<Device, GPUDevice>::value) {\n+ OP_REQUIRES_ASYNC(\n+ context, !OpDeterminismRequired(),\n+ errors::Unimplemented(\n+ \"Deterministic GPU implementation of CropAndResizeBackpropImage\"\n+ \" not available.\"),\n+ done);\n+ }\n+\n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(batch_size), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({batch_size, image_height, image_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& grads = context->input(0);",
"filename": "tensorflow/core/kernels/image/crop_and_resize_op.cc",
"status": "modified"
},
{
"diff": "@@ -6034,6 +6034,16 @@ def testImageCropAndResize(self):\n crop_size=[1, 1])\n self.evaluate(op)\n \n+ def testImageCropAndResizeWithInvalidInput(self):\n+ with self.session():\n+ with self.assertRaises((errors.InternalError, ValueError)):\n+ op = image_ops_impl.crop_and_resize_v2(\n+ image=np.ones((1, 1, 1, 1)),\n+ boxes=np.ones((11, 4)),\n+ box_indices=np.ones((11)),\n+ crop_size=[2065374891, 1145309325])\n+ self.evaluate(op)\n+\n @parameterized.named_parameters(\n (\"_jpeg\", \"JPEG\", \"jpeg_merge_test1.jpg\"),\n (\"_png\", \"PNG\", \"lena_rgba.png\"),",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n\r\n**Describe the current behavior**\r\nThe following APIs crash(abortion) when the given size is large\r\n- tf.image.resiz\r\n- tf.image.resize_with_crop_or_pad\r\n- tf.image.pad_to_bounding_box\r\n- tf.image.extract_glimpse\r\n- `tf.keras.backend.resize_images`\r\n\r\n**Describe the expected behavior**\r\nexpect exception messages if the input is not expected instead of crash\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\n### `tf.image.resize`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize(images=np.ones((5,5,5)), size=[2065374891,1145309325])\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:41:13.484992: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -6619278462293758741)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.resize_with_crop_or_pad`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_crop_or_pad(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470)\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:42:15.468265: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.pad_to_bounding_box`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.pad_to_bounding_box(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470, offset_height=1, offset_width=1)\r\n~~~\r\nOutput\r\n~~~python\r\n2021-02-03 17:42:52.556583: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.extract_glimpse`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.extract_glimpse(input=np.ones((5,5,5,5)), size=[1574700351, 451745106], offsets=np.ones((5,2)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:43:30.140277: F tensorflow/core/framework/tensor_shape.cc:338] Check failed: 0 <= n (0 vs. -662664649191246466)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.keras.backend.resize_image`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.backend.resize_images(x=np.ones((1,5,3,15)), height_factor=5628955348197345288, width_factor=5628955348197345288, data_format='channels_last')\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:54:01.192819: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5948468124908472256)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "@rmothukuru \r\nI ran the code on tf 2.4 and nightly, colab crashes. please find the [gist here](\r\nhttps://colab.research.google.com/gist/Saduf2019/fd4dfbdc07480e95a5694b336944c4f8/untitled520.ipynb)",
"created_at": "2021-02-04T06:35:03Z"
},
{
"body": "BTW, I also find it in `tf.image.crop_and_resize` and `tf.image.resize_with_pad`\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.crop_and_resize(image=np.ones((1,1,1,1)), boxes=np.ones((11,4)), box_indices=np.ones((11)), crop_size=[2065374891,1145309325])\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-05 17:02:57.884394: F tensorflow/core/framework/tensor_shape.cc:187] Non-OK-status: InitDims(dim_sizes) status: Internal: Encountered overflow when multiplying 22719123801 with 1145309325, result: -1\r\nAborted (core dumped)\r\n~~~\r\n\r\n\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_pad(image=np.ones((5,5,5)), target_height=1635057735, target_width=1635057735)\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-19 22:28:03.322414: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\n2021-02-19 22:28:03.332536: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5079675089792900491)\r\nAborted (core dumped)\r\n~~~",
"created_at": "2021-02-05T17:04:08Z"
},
{
"body": "Was able to reproduce the issue in TF 2.6.0-dev20210528 & colab crashes ,please find the gist [here](https://colab.research.google.com/gist/sushreebarsa/2f0930249cfea6fd3be6c8f9ec4fca21/untitled41.ipynb#scrollTo=vkKKum0ltdoP)..Thanks !",
"created_at": "2021-05-28T11:32:22Z"
},
{
"body": "Update:\r\n1. `tf.image.resize` fixed aleady\r\n2. `tf.image.resize_with_crop_or_pad` to be fixed (PR #51717)\r\n3. `tf.image.pad_to_bounding_box` to be fixed (PR #51717)\r\n4. `tf.keras.backend.resize_image` fixed already\r\n5. `tf.image.crop_and_resize` to be fixed (PR #51732)\r\n5. `tf.image.resize_with_pad` fixed already",
"created_at": "2021-08-28T16:40:51Z"
},
{
"body": "@DNXie Could you please let us know if we can closed the issue with this [PR](https://github.com/tensorflow/tensorflow/pull/51732) ?Thank you!",
"created_at": "2021-09-02T16:01:00Z"
},
{
"body": "There are still a few PRs that need to land here.",
"created_at": "2021-09-03T00:58:51Z"
},
{
"body": "I think all of these landed",
"created_at": "2021-10-27T23:23:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">No</a>\n",
"created_at": "2021-10-27T23:23:50Z"
}
],
"number": 46890,
"title": "tf.image.resize/resize_with_crop_or_pad/pad_to_bounding_box/extract_glimpse crash(abort)"
}
|
{
"body": "…number\r\n\r\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\r\n\r\nThis PR is part of the effort in #46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCopybara import of the project:\r\n\r\n--\r\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\r\n\r\nFix crash of tf.image.crop_and_resize when input is large number\r\n\r\nThis PR is part of the effort in 46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\r\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\r\nPiperOrigin-RevId: 394109830\r\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4",
"number": 52762,
"review_comments": [],
"title": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large …"
}
|
{
"commits": [
{
"message": "PR #51732: Fix crash of tf.image.crop_and_resize when input is large number\n\nImported from GitHub PR https://github.com/tensorflow/tensorflow/pull/51732\n\nThis PR is part of the effort in #46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCopybara import of the project:\n\n--\nc8d87055a56d8740d27ad8bdc74a7459ede6900e by Yong Tang <yong.tang.github@outlook.com>:\n\nFix crash of tf.image.crop_and_resize when input is large number\n\nThis PR is part of the effort in 46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>\nCOPYBARA_INTEGRATE_REVIEW=https://github.com/tensorflow/tensorflow/pull/51732 from yongtang:46890-tf.image.crop_and_resize c8d87055a56d8740d27ad8bdc74a7459ede6900e\nPiperOrigin-RevId: 394109830\nChange-Id: If049dad0844df9353722029ee95bc76819eda1f4"
}
],
"files": [
{
"diff": "@@ -170,14 +170,15 @@ class CropAndResizeOp : public AsyncOpKernel {\n context, crop_height > 0 && crop_width > 0,\n errors::InvalidArgument(\"crop dimensions must be positive\"), done);\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(num_boxes), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({num_boxes, crop_height, crop_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& image = context->input(0);\n@@ -417,14 +418,15 @@ class CropAndResizeGradImageOp : public AsyncOpKernel {\n done);\n }\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(batch_size), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n- OP_REQUIRES_OK_ASYNC(\n- context,\n- context->allocate_output(\n- 0, TensorShape({batch_size, image_height, image_width, depth}),\n- &output),\n- done);\n+ OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, shape, &output),\n+ done);\n \n auto compute_callback = [this, context, output]() {\n const Tensor& grads = context->input(0);",
"filename": "tensorflow/core/kernels/image/crop_and_resize_op.cc",
"status": "modified"
},
{
"diff": "@@ -6036,6 +6036,16 @@ def testImageCropAndResize(self):\n crop_size=[1, 1])\n self.evaluate(op)\n \n+ def testImageCropAndResizeWithInvalidInput(self):\n+ with self.session():\n+ with self.assertRaises((errors.InternalError, ValueError)):\n+ op = image_ops_impl.crop_and_resize_v2(\n+ image=np.ones((1, 1, 1, 1)),\n+ boxes=np.ones((11, 4)),\n+ box_indices=np.ones((11)),\n+ crop_size=[2065374891, 1145309325])\n+ self.evaluate(op)\n+\n @parameterized.named_parameters(\n (\"_jpeg\", \"JPEG\", \"jpeg_merge_test1.jpg\"),\n (\"_png\", \"PNG\", \"lena_rgba.png\"),",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "Tensorflow crashes when following current guide.\r\n\r\n**System information**\r\nTensorflow Version: \r\nv2.4.0-49-g85c8b2a817f 2.4.1\r\n\r\n**Describe the current behavior**\r\nFollowing the [guide](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/replica_device_setter) on how to use `replica_device_setter`, the code crashes with the error: `RuntimeError: tf.device does not support functions.`\r\n\r\n\r\n**Describe the expected behavior**\r\nIt should not crash\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\ncluster_spec = {\"ps\": [\"ps0:2222\"],\"worker\": [\"worker0:2222\", \"worker1:2222\"]}\r\nwith tf.device(tf.compat.v1.train.replica_device_setter(cluster=cluster_spec)):\r\n pass\r\n```\r\n\r\n**Other info / logs** Include any logs or source code that would be helpful to\r\n```\r\n...\r\n/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/ops.py in device_v2(device_name)\r\n 5271 \"\"\"\r\n 5272 if callable(device_name):\r\n-> 5273 raise RuntimeError(\"tf.device does not support functions.\")\r\n 5274 return device(device_name)\r\n 5275 \r\n\r\nRuntimeError: tf.device does not support functions.\r\n```\r\n",
"comments": [
{
"body": "@amahendrakar \r\n\r\nI reproduced the code in tf 2.5rc1 ,tf-nightly and tf2.4.1,but facing the same [error.](https://colab.research.google.com/gist/UsharaniPagadala/98d5766b0cb51c516dddf2c32f8ec1c9/-48684.ipynb) Could you please look at this issue .Thanks",
"created_at": "2021-04-22T08:32:33Z"
},
{
"body": "After digging though ops.py, I saw that I could call the old v1 method, and fixed the error by changing to\r\n```\r\nimport tensorflow as tf\r\ncluster_spec = {\"ps\": [\"ps0:2222\"],\"worker\": [\"worker0:2222\", \"worker1:2222\"]}\r\nwith tf.compat.v1.device(tf.compat.v1.train.replica_device_setter(cluster=cluster_spec)):\r\n pass\r\n```\r\n\r\nSo I guess the guide needs to be updated or `device_v2()` to fall back on `device()` if a function is provided?",
"created_at": "2021-04-22T20:27:19Z"
},
{
"body": "As part of the migration to TF2, we explicitly disabled functions as input to tf.device. So we should just update the guide to call tf.compat.v1.device instead of tf.device. It'll be great if you wanted to contribute a PR with the documentation fix! ",
"created_at": "2021-05-13T18:45:58Z"
},
{
"body": "Since the above [PR](https://github.com/tensorflow/tensorflow/pull/52095) was merged. I am closing this issue. Please feel free to reopen the issue if you still have a concern. Thanks!",
"created_at": "2021-09-29T11:56:00Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/48684\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/48684\">No</a>\n",
"created_at": "2021-09-29T11:56:02Z"
}
],
"number": 48684,
"title": "Error: tf.device does not support functions"
}
|
{
"body": "I came across a problem from the #48684 issue. Updating the doc to fix the example.",
"number": 52095,
"review_comments": [],
"title": "Update device_setter guide for v1 compatibility"
}
|
{
"commits": [
{
"message": "update guide"
}
],
"files": [
{
"diff": "@@ -166,7 +166,7 @@ def replica_device_setter(ps_tasks=0,\n \"ps\": [\"ps0:2222\", \"ps1:2222\"],\n \"worker\": [\"worker0:2222\", \"worker1:2222\", \"worker2:2222\"]}\n with\n- tf.device(tf.compat.v1.train.replica_device_setter(cluster=cluster_spec)):\n+ tf.compat.v1.device(tf.compat.v1.train.replica_device_setter(cluster=cluster_spec)):\n # Build your graph\n v1 = tf.Variable(...) # assigned to /job:ps/task:0\n v2 = tf.Variable(...) # assigned to /job:ps/task:1",
"filename": "tensorflow/python/training/device_setter.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: n/a\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.6.0\r\n- Python version: 3.6.8\r\n- Bazel version (if compiling from source): n/a\r\n- GCC/Compiler version (if compiling from source): n/a\r\n- CUDA/cuDNN version: n/a\r\n- GPU model and memory: n/a\r\n\r\n**Describe the current behavior**\r\n`tf.keras.layers.MaxPooling3D` crashes when `pool_size` contains `0`, and outputs a all-inf tensor when `pool_size` contains negative values.\r\n\r\n**Describe the expected behavior**\r\nExpect a `ValueError` to be thrown if the input `pool_size` contains zero or negative values.\r\n\r\n\r\n**Standalone code to reproduce the issue**\r\nIf the `pool_size` has `0`:\r\n```\r\nimport tensorflow as tf\r\npool_size = [2, 2, 0]\r\nlayer = tf.keras.layers.MaxPooling3D(strides=1, pool_size=pool_size)\r\ninput_tensor = tf.random.uniform([3, 4, 10, 11, 12], dtype=tf.float32)\r\nres = layer(input_tensor) # crash\r\n```\r\nOutputs:\r\n```\r\nFloating point exception (core dumped)\r\n```\r\nIf the `pool_size` has negative values:\r\n```\r\nimport tensorflow as tf\r\npool_size = [2, 2, -2]\r\nlayer = tf.keras.layers.MaxPooling3D(strides=1, pool_size=pool_size,)\r\ninput_tensor = tf.random.uniform([3, 4, 10, 11, 12], dtype=tf.float32)\r\nres = layer(input_tensor)\r\nprint(res)\r\n```\r\nThe output is a tensor with `shape`=`(3, 3, 9, 14, 12)` and all `inf` values.",
"comments": [
{
"body": "It turns out that `tf.keras.layers.AveragePooling3D` also crashes when `pool_size` contains `0`.",
"created_at": "2021-09-12T01:06:46Z"
},
{
"body": "@lugalUrim Please post this issue on [keras-team/keras repo.](https://github.com/keras-team/keras/issues)\r\nTo know more see;\r\n[https://discuss.tensorflow.org/t/keras-project-moved-to-new-repository-in-https-github-com-keras-team-keras/1999](https://discuss.tensorflow.org/t/keras-project-moved-to-new-repository-in-https-github-com-keras-team-keras/1999)\r\nThank you!",
"created_at": "2021-09-12T06:16:13Z"
},
{
"body": "Hi, I have created a [PR](https://github.com/keras-team/keras/pull/15356) for Keras to solve this issue.",
"created_at": "2021-09-12T13:04:31Z"
},
{
"body": "While the original issue is coming from tf.keras.layers.MaxPooling3D, the issue is triggered when max_pool3d is called directly with tensorflow itself. For that PR #51975 has been created to fix the issue inside tensorflow.",
"created_at": "2021-09-13T01:19:14Z"
},
{
"body": "Thanks for the information @sushreebarsa, I will post new issues in the keras repo, but I guess we can keep this issue in tensorflow, as mentioned by @yongtang there are related bugs in the tensorflow operator implementations as well.",
"created_at": "2021-09-15T02:26:58Z"
},
{
"body": "Thank you @WingsBrokenAngel and @yongtang for your PRs! Actually here are more crash bugs I find when `pool_size`/`k_size` <= 0, so we may want to fix all of these in the codebase and also cover them in the unit tests.\r\n- `tf.keras.layers.AveragePooling1D`, `tf.keras.layers.AveragePooling2D`, `tf.keras.layers.AveragePooling3D`\r\n- `tf.keras.layers.MaxPooling1D`, `tf.keras.layers.MaxPooling2D`, `tf.keras.layers.MaxPooling3D`\r\n- `tf.nn.avg_pool1d`, `tf.nn.avg_pool2d`, `tf.nn.avg_pool3d`\r\n- `tf.nn.max_pool1d`, `tf.nn.max_pool2d`, `tf.nn.max_pool3d`\r\n",
"created_at": "2021-09-15T02:36:55Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51936\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51936\">No</a>\n",
"created_at": "2021-10-06T15:15:57Z"
},
{
"body": "I also observed the following API aliases or similar APIs can cause the same issue in some older versions of tensorflow.\r\nUsers should be cautious when using them on CPU up to tensorflow 2.6.0 (v2.6.0-rc2-32-g919f693420e).\r\n\r\n> Besides, in tensorflow 2.6.0 (v2.6.0-rc2-32-g919f693420e) and previous versions, it throws the InternalError Exception on GPU, which is acceptable.\r\n\r\n- `(tf.keras.layers.MaxPooling3D)`, `tf.keras.layers.MaxPool3D`, `tf.compat.v1.keras.layers.MaxPooling3D`, `tf.compat.v1.keras.layers.MaxPool3D`\r\n- `tf.keras.layers.AveragePooling3D`, `tf.keras.layers.AvgPool3D`, `tf.compat.v1.keras.layers.AveragePooling3D`, `tf.compat.v1.keras.layers.AvgPool3D`\r\n\r\n<details>\r\n <summary>Code to reproduce the issue for the above APIs in older versions</summary>\r\n\r\n- `(tf.keras.layers.MaxPooling3D)`, `tf.keras.layers.MaxPool3D`, `tf.compat.v1.keras.layers.MaxPooling3D`, `tf.compat.v1.keras.layers.MaxPool3D`\r\n- `tf.keras.layers.AveragePooling3D`, `tf.keras.layers.AvgPool3D`, `tf.compat.v1.keras.layers.AveragePooling3D`, `tf.compat.v1.keras.layers.AvgPool3D`\r\n\r\n```python\r\nimport tensorflow as tf\r\nprint(tf.version.GIT_VERSION, tf.version.VERSION, flush=True)\r\nprint(tf.config.list_physical_devices(), flush=True)\r\n\r\n\r\npool_size = [2, 2, 0]\r\n# layer = tf.keras.layers.MaxPooling3D(strides=1, pool_size=pool_size)\r\nlayer = tf.keras.layers.MaxPool3D(strides=1, pool_size=pool_size)\r\n# layer = tf.compat.v1.keras.layers.MaxPooling3D(strides=1, pool_size=pool_size)\r\n# layer = tf.compat.v1.keras.layers.MaxPool3D(strides=1, pool_size=pool_size)\r\n# layer = tf.keras.layers.AveragePooling3D(strides=1, pool_size=pool_size)\r\n# layer = tf.keras.layers.AvgPool3D(strides=1, pool_size=pool_size)\r\n# layer = tf.compat.v1.keras.layers.AveragePooling3D(strides=1, pool_size=pool_size)\r\n# layer = tf.compat.v1.keras.layers.AvgPool3D(strides=1, pool_size=pool_size)\r\ninput_tensor = tf.random.uniform([3, 4, 10, 11, 12], dtype=tf.float32)\r\nres = layer(input_tensor) # crash\r\nprint(res)\r\n```\r\n\r\nOn CPU, the process aborts with a Floating point exception(core dumped), which is not expected.\r\n\r\n```text\r\nv2.6.0-rc2-32-g919f693420e 2.6.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')]\r\nFloating point exception(core dumped)\r\n```\r\n\r\nWhile on GPU, it throws the InternalError Exception:\r\n\r\n```text\r\nv2.6.0-rc2-32-g919f693420e 2.6.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\nTraceback (most recent call last):\r\n File \"51936-6-s/tf.keras.layers.MaxPool3D.py\", line 8, in <module>\r\n res = layer(input_tensor) # crash\r\n File \"/usr/local/lib/python3.6/dist-packages/keras/engine/base_layer.py\", line 1037, in __call__\r\n outputs = call_fn(inputs, *args, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/keras/layers/pooling.py\", line 700, in call\r\n padding=self.padding.upper())\r\n File \"/usr/local/lib/python3.6/dist-packages/tensorflow/python/util/dispatch.py\", line 206, in wrapper\r\n return target(*args, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/nn_ops.py\", line 4935, in max_pool3d\r\n name=name)\r\n File \"/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/gen_nn_ops.py\", line 5430, in max_pool3d\r\n _ops.raise_from_not_ok_status(e, name)\r\n File \"/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py\", line 6941, in raise_from_not_ok_status\r\n six.raise_from(core._status_to_exception(e.code, message), None)\r\n File \"<string>\", line 3, in raise_from\r\ntensorflow.python.framework.errors_impl.InternalError: dnn PoolForward launch failed [Op:MaxPool3D]\r\n```\r\n</details>\r\n\r\nIt seems to be fixed in tensorflow 2.6.1 (v2.6.0-101-g3aa40c3ce9d) and later versions.\r\nNote that, in tensorflow 2.6.1 (v2.6.0-101-g3aa40c3ce9d), it throws the InvalidArgumentError Exception, and in later versions, it throws the ValueError Exception, which is expected.\r\n",
"created_at": "2023-09-12T09:23:02Z"
}
],
"number": 51936,
"title": "tf.keras.layers.MaxPooling3D crashes"
}
|
{
"body": "This PR tries to address the issue raised in #51936 where\r\nmax_pool3d will crash when any dim of ksize is 0 or negative.\r\n\r\nWhile the original issue was raised toward tf.keras.layers.MaxPooling3D,\r\nthe issue can also be triggered when max_pool3d is called directly\r\nwith tensorflow itself.\r\n\r\nFor that reason a separate fix inside tensorflow is also fixed here.\r\n\r\nThis PR fixes #51936.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 51975,
"review_comments": [],
"title": "Fix crash of max_pool3d when ksize is 0 or negative"
}
|
{
"commits": [
{
"message": "Fix crash of max_pool3d when ksize is 0 or negative\n\nThis PR tries to address the issue raised in 51936 where\nmax_pool3d will crash when any dim of ksize is 0 or negative.\n\nWhile the original issue was raised toward tf.keras.layers.MaxPooling3D,\nthe issue can also be triggered when max_pool3d is called directly\nwith tensorflow itself.\n\nFor that reason a separate fix inside tensorflow is also fixed here.\n\nThis PR fixes 51936.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Update test to include avg_pool3d with ksize 0\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -141,6 +141,11 @@ class Pooling3DOp : public UnaryOp<T> {\n OP_REQUIRES(context, ksize_.size() == 5,\n errors::InvalidArgument(\"Sliding window ksize field must \"\n \"specify 5 dimensions\"));\n+ bool non_negative = std::all_of(\n+ ksize_.begin(), ksize_.end(), [](int k) { return k > 0; });\n+ OP_REQUIRES(context, non_negative,\n+ errors::InvalidArgument(\"Sliding window ksize field must \"\n+ \"have non-negative dimensions\"));\n OP_REQUIRES_OK(context, context->GetAttr(\"strides\", &stride_));\n OP_REQUIRES(context, stride_.size() == 5,\n errors::InvalidArgument(\"Sliding window stride field must \"",
"filename": "tensorflow/core/kernels/pooling_ops_3d.cc",
"status": "modified"
},
{
"diff": "@@ -21,6 +21,7 @@\n import numpy as np\n \n from tensorflow.python.framework import constant_op\n+from tensorflow.python.framework import errors\n from tensorflow.python.framework import test_util\n from tensorflow.python.ops import gradient_checker\n from tensorflow.python.ops import gradients_impl\n@@ -505,6 +506,23 @@ def testAvgPoolGradSamePadding3_1_3d(self):\n strides=(1, 1, 1),\n padding=\"SAME\")\n \n+ def testMaxPool3DZeroPoolSize(self):\n+ # Test case for GitHub issue 51936.\n+ for f in [nn_ops.max_pool3d, nn_ops.avg_pool3d]:\n+ with self.session():\n+ with self.assertRaises((errors.InvalidArgumentError, ValueError)):\n+ input_sizes = [3, 4, 10, 11, 12]\n+\n+ input_data = 1.\n+ input_tensor = constant_op.constant(\n+ input_data, shape=input_sizes, name=\"input\")\n+ pool_3d = f(\n+ input_tensor,\n+ ksize=[2, 2, 0],\n+ strides=1,\n+ padding=\"VALID\")\n+ self.evaluate(pool_3d)\n+\n \n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/kernel_tests/pooling_ops_3d_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.6.0\r\n- Python version: 3.6.8\r\n- Bazel version (if compiling from source): N/A\r\n- GCC/Compiler version (if compiling from source): N/A\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\n`tf.pad` crashes when the argument \"paddings\" has large values.\r\n\r\n**Describe the expected behavior**\r\nExpect an exception to be thrown if the input `paddings` is unexpected.\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\ninput_tensor = tf.random.uniform([1, 32, 32, 3], dtype=tf.float32)\r\npaddings = [[125106557, 1415887920], [747509374, 2136925906], [413308538, 904601717], [1900762018, 831358864]]\r\nres = tf.pad(input_tensor,paddings)\r\n```\r\noutputs:\r\n```\r\n2021-09-09 12:46:38.123113: F tensorflow/core/framework/tensor_shape.cc:352] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n```\r\n",
"comments": [
{
"body": "@lugalUrim Could you please have a look at the[ link](https://www.tensorflow.org/api_docs/python/tf/pad), and similar [issue](https://github.com/tensorflow/tensorflow/issues/42293) ,Please let us know if it helps ?Thanks!",
"created_at": "2021-09-10T12:14:54Z"
},
{
"body": "Yes, thanks @sushreebarsa for pointing to that. I will close this issue.",
"created_at": "2021-09-10T21:12:08Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51908\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51908\">No</a>\n",
"created_at": "2021-09-10T21:12:09Z"
},
{
"body": "In case of check failure, tensorflow should return an error gracefully instead of crash with undefined behaviors. Created a PR #51973 for the fix.",
"created_at": "2021-09-13T00:39:36Z"
}
],
"number": 51908,
"title": "tf.pad crashes with large paddings"
}
|
{
"body": "This PR tries to address the issue raised in #51908 where\r\ntf.pad crashes with large paddings.\r\nIn any case, instead of a crash with undefined behavior,\r\ntensorflow should return an error gracefully.\r\n\r\nThis PR fixes the issue by adding the necessary checks.\r\n\r\nThis PR fixes #51908.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 51973,
"review_comments": [],
"title": "Fix tf.pad crashes with large paddings"
}
|
{
"commits": [
{
"message": "Fix tf.pad crashes with large paddings\n\nThis PR tries to address the issue raised in 51908 where\ntf.pad crashes with large paddings.\nIn any case, instead of a crash with undefined behavior,\ntensorflow should return an error gracefully.\n\nThis PR fixes the issue by adding the necessary checks.\n\nThis PR fixes 51908.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -85,7 +85,8 @@ class PadOp : public OpKernel {\n errors::InvalidArgument(\"Paddings must be non-negative: \",\n before_d, \" \", after_d));\n const int64_t size_d = in0.dim_size(d);\n- output_shape.AddDim(before_d + size_d + after_d);\n+ OP_REQUIRES_OK(\n+ context, output_shape.AddDimWithStatus(before_d + size_d + after_d));\n }\n \n // If there is no padding to be done, forward the input to output.",
"filename": "tensorflow/core/kernels/pad_op.cc",
"status": "modified"
},
{
"diff": "@@ -431,6 +431,18 @@ def testCollapseAdjacentNonPaddedDimensions(self):\n np.zeros([row[1] for row in paddings_value]),\n self.evaluate(right))\n \n+ def testWithLargePadding(self):\n+ # Test case for GitHub issue 51908.\n+ with self.session():\n+ input_tensor = array_ops.zeros([1, 32, 32, 3], dtype=dtypes.float32)\n+ paddings = [[125106557, 1415887920],\n+ [747509374, 2136925906],\n+ [413308538, 904601717],\n+ [1900762018, 831358864]]\n+ with self.assertRaises((ValueError, errors.InternalError)):\n+ res = array_ops.pad(input_tensor,paddings)\n+ self.evaluate(res)\n+\n \n if __name__ == \"__main__\":\n test.main()",
"filename": "tensorflow/python/kernel_tests/pad_op_test.py",
"status": "modified"
}
]
}
|
{
"body": "\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Windows 10\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.5.0\r\n- Python version: 3.8.8\r\n- Bazel version (if compiling from source):\r\n- GCC/Compiler version (if compiling from source):\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n**Describe the current behavior**\r\nWhen calling deprecated functions using Python C API, they fail with\r\n\r\n> AttributeError: 'NoneType' object has no attribute 'f_back'\r\n\r\nBecause there's not enough Python stack to be walked\r\n\r\nAny deprecated function will fail with this error.\r\n\r\n**Describe the expected behavior**\r\n\r\nIt should be possible to call deprecated functions using Python C APIs.\r\n\r\n**[Contributing](https://www.tensorflow.org/community/contribute)**\r\n- Do you want to contribute a PR? (yes/no): yes\r\n- Briefly describe your candidate solution (if contributing): revert [offending commit](https://github.com/tensorflow/tensorflow/commit/42aab9b1f03713757d7c027b23f1113ea80f73ad) or add a check for `f == None` in [this line](https://github.com/tensorflow/tensorflow/blob/704610e1d21288482bf77923b387f9bb6c119318/tensorflow/python/util/deprecation.py#L105)\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\n```c\r\nPy_Initialize();\r\nPyObject* tf_test = PyImport_ImportModule(\"tensorflow.test\");\r\nPyObject* is_gpu_available = PyObject_GetAttrString(tf_test, \"is_gpu_available\");\r\nPyObject* haveGpu = PyObject_CallObject(is_gpu_available, NULL); // will return NULL and set Python error state\r\n```\r\n",
"comments": [
{
"body": "/cc @mdanatg ",
"created_at": "2021-05-17T06:48:43Z"
},
{
"body": "Looks most likely like a bug in the deprecation API: https://github.com/tensorflow/tensorflow/blob/5fca930c7fb1b302c6d7f1d05a80724028764480/tensorflow/python/util/deprecation.py#L101 \r\n\r\nIt should be straightforward to add a test an an extra check.",
"created_at": "2021-05-17T12:16:42Z"
},
{
"body": "@lostmsu Do you want to contribute a PR?",
"created_at": "2021-05-17T16:36:34Z"
},
{
"body": "I would like to contribute. This might be my first contribution for tensorflow! So, just a check for `f == None` right?",
"created_at": "2021-09-12T22:20:31Z"
},
{
"body": "I have made a pull request. Can you please review it and let me know if this was the expected thing?",
"created_at": "2021-09-12T22:53:15Z"
},
{
"body": "I hope we can close this issue.",
"created_at": "2021-09-14T17:56:57Z"
},
{
"body": "@mdanatg Can you close this?",
"created_at": "2021-09-14T20:01:28Z"
},
{
"body": "Sure. BTW, if you add \"Fixed <issue number>\" to your PR then it gets closed automatically.",
"created_at": "2021-09-14T20:06:11Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/49225\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/49225\">No</a>\n",
"created_at": "2021-09-14T20:06:13Z"
},
{
"body": "> if you add \"Fixed \" to your PR then it gets closed automatically.\r\n\r\nThanks, It is what I suggest also to the triage and review teams. To check if the submitted PR is linked or not the issue as they have the permission to link it. Sometimes contributors don't put the auto-connection string in the PR description.",
"created_at": "2021-09-14T20:13:34Z"
},
{
"body": "@bhack What is an auto-connection string?",
"created_at": "2021-09-14T21:51:09Z"
},
{
"body": "> @bhack What is an auto-connection string?\r\n\r\nYou need to use [one of these keywords](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword)\r\n",
"created_at": "2021-09-14T21:53:03Z"
},
{
"body": "Oh great, I didn't know about that! Thank you for sharing! I will definitely use that from next time.",
"created_at": "2021-09-14T21:56:42Z"
}
],
"number": 49225,
"title": "Can't call deprecated functions when embedding Python"
}
|
{
"body": "Fixes #49225 ",
"number": 51972,
"review_comments": [
{
"body": "This would change the type of parent. Try this instead:\r\n\r\n```\r\nparent = f.f_back if f is not None else None\r\n```",
"created_at": "2021-09-13T13:04:34Z"
},
{
"body": "@mdanatg Thank you for the feedback. I am using short-circuiting to do the same thing which you mentioned because I thought it would look cleaner. Please check the screenshot below, I know it is a small change, but I'm not sure how it would change the type of `parent`. If `parent` becomes `NoneType` then that check is handled in line 111.\r\nKindly correct me if I'm going wrong.\r\n\r\n",
"created_at": "2021-09-13T19:54:42Z"
},
{
"body": "Ah I forgot about the short circuiting. LGTM then.",
"created_at": "2021-09-13T20:06:14Z"
},
{
"body": "Yes. Thank you!",
"created_at": "2021-09-13T20:13:41Z"
}
],
"title": "Added a check"
}
|
{
"commits": [
{
"message": "Added a check"
}
],
"files": [
{
"diff": "@@ -107,7 +107,7 @@ def _call_location(outer=False):\n # DISABLE_IMPORT_INSPECT_CHECK=TRUE to your cl description. Using it caused\n # test timeouts (b/189384061).\n f = inspect.currentframe().f_back.f_back\n- parent = f.f_back\n+ parent = f and f.f_back\n if outer and parent is not None:\n f = parent\n return '{}:{}'.format(f.f_code.co_filename, f.f_lineno)",
"filename": "tensorflow/python/util/deprecation.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): no\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Debian \r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): source\r\n- TensorFlow version (use command below): git\r\n- Python version: 3.9\r\n- Bazel version (if compiling from source): 4.2\r\n- GCC/Compiler version (if compiling from source): gcc-10\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n\r\n**Describe the current behavior**\r\n`tf.nn.weighted_moments` produces NaNs when all weights are zeros.\r\n**Describe the expected behavior**\r\nCorrect result in this case should be zeros.\r\n\r\n**[Contributing](https://www.tensorflow.org/community/contribute)**\r\n\r\n- Do you want to contribute a PR? (yes/no): yes\r\n- Briefly describe your candidate solution(if contributing):\r\nDo not divide by 0 unless you are Chuck Norris.\r\n\r\n**Standalone code to reproduce the issue**\r\n```python\r\nx = tf.random.uniform((5, 3))\r\nw = tf.zeros((5, 1))\r\n\r\ntf.nn.weighted_moments(x, axes=0, frequency_weights=w)\r\n\r\n(<tf.Tensor: shape=(3,), dtype=float32, numpy=array([nan, nan, nan], dtype=float32)>,\r\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([nan, nan, nan], dtype=float32)>)\r\n\r\n\r\n```\r\n\r\n\r\n",
"comments": [
{
"body": "Hi @eli-osherovich !You should provide only positive weights in w , Here 0's are not positive weights.\r\nReference -https://www.tensorflow.org/api_docs/python/tf/nn/weighted_moments#args",
"created_at": "2021-09-02T08:09:08Z"
},
{
"body": "I understand the rationale, yet, I believe that all-zeros is still a valid case. Obviously, the weights are expected to be non-negative.",
"created_at": "2021-09-02T08:40:36Z"
},
{
"body": "Hi @Saduf2019 , Could you look into this please . providing[ gist](https://colab.research.google.com/gist/mohantym/bfc557013a0db04183e0c2d2ba4cec79/github_51792.ipynb) for reference . issue is replicating in 2.5 ,2.6 and nightly",
"created_at": "2021-09-03T08:27:17Z"
},
{
"body": "@eli-osherovich \r\nThe weighted_moments function sums your weights with zero vector and then determines the divisor by taking a reciprocal of the broadcasted vector. In this case, your sum will be zero and since the reciprocal of zero is infinity, nans are appearing.\r\nDon't use zero weights, logically it makes no sense, instead 1's weight every element equally.\r\nFor any further queries i suggest to open an issue at tf [discussion forum](https://discuss.tensorflow.org/) as there is a larger community to support/respond.",
"created_at": "2021-09-06T07:02:51Z"
},
{
"body": "@Saduf2019 \r\nI know why it happens. Let me assure you zeroes are perfectly logical. I do not see why zeros should be replaced with ones....\r\n\r\nP. S. \r\nIt is a bit difficult to understand is this the TF team answer or a recommendation from a fellow user....",
"created_at": "2021-09-06T07:40:57Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51792\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51792\">No</a>\n",
"created_at": "2021-10-06T15:09:48Z"
},
{
"body": "The PR was reverted :( The issue still exists.",
"created_at": "2021-10-29T13:40:59Z"
}
],
"number": 51792,
"title": "weighted_moments produces NaNs when weights are all zeros"
}
|
{
"body": "Fixes #51792",
"number": 51966,
"review_comments": [],
"title": "Fixes NaNs in weighted_moments with all-zeros weights."
}
|
{
"commits": [
{
"message": "Fixes NaNs in weighted_moments with all-zeros weights."
}
],
"files": [
{
"diff": "@@ -1416,7 +1416,7 @@ def weighted_moments(x, axes, frequency_weights, name=None, keep_dims=None,\n x: A tensor.\n axes: 1-d tensor of int32 values; these are the axes along which\n to compute mean and variance.\n- frequency_weights: A tensor of positive weights which can be\n+ frequency_weights: A tensor of non-negative weights which can be\n broadcast with x.\n name: Name used to scope the operation.\n keep_dims: Produce moments with the same dimensionality as the input.\n@@ -1460,7 +1460,7 @@ def weighted_moments(x, axes, frequency_weights, name=None, keep_dims=None,\n sum_of_weights = math_ops.reduce_sum(\n broadcasted_weights, axes, name=\"sum_of_weights\", keepdims=True)\n \n- divisor = math_ops.reciprocal(sum_of_weights, name=\"inv_weight_sum\")\n+ divisor = math_ops.reciprocal_no_nan(sum_of_weights, name=\"inv_weight_sum\")\n \n weighted_mean = math_ops.multiply(weighted_input_sum, divisor)\n \n@@ -1494,7 +1494,7 @@ def weighted_moments_v2(x, axes, frequency_weights, keepdims=False, name=None):\n x: A tensor.\n axes: 1-d tensor of int32 values; these are the axes along which\n to compute mean and variance.\n- frequency_weights: A tensor of positive weights which can be\n+ frequency_weights: A tensor of non-negative weights which can be\n broadcast with x.\n keepdims: Produce moments with the same dimensionality as the input.\n name: Name used to scope the operation.",
"filename": "tensorflow/python/ops/nn_impl.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): no\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Debian \r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): source\r\n- TensorFlow version (use command below): git\r\n- Python version: 3.9\r\n- Bazel version (if compiling from source): 4.2\r\n- GCC/Compiler version (if compiling from source): gcc-10\r\n- CUDA/cuDNN version: N/A\r\n- GPU model and memory: N/A\r\n\r\n\r\n**Describe the current behavior**\r\n`tf.nn.weighted_moments` produces NaNs when all weights are zeros.\r\n**Describe the expected behavior**\r\nCorrect result in this case should be zeros.\r\n\r\n**[Contributing](https://www.tensorflow.org/community/contribute)**\r\n\r\n- Do you want to contribute a PR? (yes/no): yes\r\n- Briefly describe your candidate solution(if contributing):\r\nDo not divide by 0 unless you are Chuck Norris.\r\n\r\n**Standalone code to reproduce the issue**\r\n```python\r\nx = tf.random.uniform((5, 3))\r\nw = tf.zeros((5, 1))\r\n\r\ntf.nn.weighted_moments(x, axes=0, frequency_weights=w)\r\n\r\n(<tf.Tensor: shape=(3,), dtype=float32, numpy=array([nan, nan, nan], dtype=float32)>,\r\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([nan, nan, nan], dtype=float32)>)\r\n\r\n\r\n```\r\n\r\n\r\n",
"comments": [
{
"body": "Hi @eli-osherovich !You should provide only positive weights in w , Here 0's are not positive weights.\r\nReference -https://www.tensorflow.org/api_docs/python/tf/nn/weighted_moments#args",
"created_at": "2021-09-02T08:09:08Z"
},
{
"body": "I understand the rationale, yet, I believe that all-zeros is still a valid case. Obviously, the weights are expected to be non-negative.",
"created_at": "2021-09-02T08:40:36Z"
},
{
"body": "Hi @Saduf2019 , Could you look into this please . providing[ gist](https://colab.research.google.com/gist/mohantym/bfc557013a0db04183e0c2d2ba4cec79/github_51792.ipynb) for reference . issue is replicating in 2.5 ,2.6 and nightly",
"created_at": "2021-09-03T08:27:17Z"
},
{
"body": "@eli-osherovich \r\nThe weighted_moments function sums your weights with zero vector and then determines the divisor by taking a reciprocal of the broadcasted vector. In this case, your sum will be zero and since the reciprocal of zero is infinity, nans are appearing.\r\nDon't use zero weights, logically it makes no sense, instead 1's weight every element equally.\r\nFor any further queries i suggest to open an issue at tf [discussion forum](https://discuss.tensorflow.org/) as there is a larger community to support/respond.",
"created_at": "2021-09-06T07:02:51Z"
},
{
"body": "@Saduf2019 \r\nI know why it happens. Let me assure you zeroes are perfectly logical. I do not see why zeros should be replaced with ones....\r\n\r\nP. S. \r\nIt is a bit difficult to understand is this the TF team answer or a recommendation from a fellow user....",
"created_at": "2021-09-06T07:40:57Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51792\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51792\">No</a>\n",
"created_at": "2021-10-06T15:09:48Z"
},
{
"body": "The PR was reverted :( The issue still exists.",
"created_at": "2021-10-29T13:40:59Z"
}
],
"number": 51792,
"title": "weighted_moments produces NaNs when weights are all zeros"
}
|
{
"body": "Fixes #51792 ",
"number": 51965,
"review_comments": [],
"title": "B51792"
}
|
{
"commits": [
{
"message": "Adding mhlo Einsum to LinalgGeneric Lowering"
},
{
"message": "Call plane-level functions to process HostThreads in ConvertXSpaceToOpStats\n\nPiperOrigin-RevId: 385613476\nChange-Id: I31a82fa89dd92191094de134f694a5a90a7c8d2b"
},
{
"message": "Integrate LLVM at llvm/llvm-project@50302feb1d2c\n\nUpdates LLVM usage to match\n[50302feb1d2c](https://github.com/llvm/llvm-project/commit/50302feb1d2c)\n\nPiperOrigin-RevId: 385616402\nChange-Id: I4e3fd34bb0409bf17df9307463d40f9ecf57e0c9"
},
{
"message": "[XLA/GPU][NFC] re-generate some tests with function signatures for easier debugging.\n\nPiperOrigin-RevId: 385616704\nChange-Id: I935bf8898ef88ef809b7feac54163991af2a31b0"
},
{
"message": "Use cudnn errata engine filter"
},
{
"message": "Cache JSON handle"
},
{
"message": "Revert \"With the new cuDNN frontend, do not use engine0. This speeds up the autotuning by a lot.\"\n\nThis reverts commit 47f53336e2ade0f31c7b1a74154328cb4c46556a."
},
{
"message": "Separate functions"
},
{
"message": "Update TFRT dependency to use revision\nhttp://github.com/tensorflow/runtime/commit/5988fa73c970a3f1c0d756245e4a4a2c10a8c079.\n\nPiperOrigin-RevId: 385624614\nChange-Id: Ic2855d3d9c47780504580a502c2dc12ff2ad30a9"
},
{
"message": "Gracefully handle encoding WAV files with zero length.\n\nRemoves checks for positive frames and non-nullptr audio in EncodeAudioAsS16LEWav.\n\nWhen creating audio summaries for zero length tensors, the backing data pointer for the tensor of samples is nullptr which causes EncodeAudioAsS16LEWav to return an InvalidArgument. When the number of frames to encode is zero, it is ok for the audio pointer to be null.\n\nTESTED:\n- unit test\nPiperOrigin-RevId: 385625443\nChange-Id: I9364283ba801650a432b56950a73a1ee522e6ff6"
},
{
"message": "Disable a flaky GPU test.\n\nPiperOrigin-RevId: 385628885\nChange-Id: Icd0260028b807322bfcc1fe25599c75a708178b7"
},
{
"message": "Prevent Adam GPU kernel crash when the variable has zero element.\n\nThe Adam CPU kernel does not crash the whole program but GPU kernel would crash\nthe whole program. This change makes GPU kernel to do nothing in that case.\n\nPiperOrigin-RevId: 385638126\nChange-Id: I60adc45af34d02954783c5986c23a67a08a1f82d"
},
{
"message": "[XLA] Factor out CreateStartIndicesForCollectiveDecomposition into a separate lib.\n- Factor out CreateStartIndicesForCollectiveDecomposition into a separate lib and\n use it in all gather decomposer.\n- Fix incorrect handling of CrossReplicaAndPartition mode in\n CreateStartIndicesForCollectiveDecomposition. We need to map the replica_id to\n replica_index and then flatten the (replica_index, partition_id) pair.\n- Also added a optimization when the replica_groups is a single singleton group. That\n helps all_gather_decomposer to continue to generate the same code as it does today.\n\nPiperOrigin-RevId: 385638901\nChange-Id: I7cc1f488f3bfff9d8298b00f09a8f383a6626e24"
},
{
"message": "Clarify calling strategy of set_logical_device_configuration.\n\nPiperOrigin-RevId: 385642194\nChange-Id: Id8d2da1e3216802dc5ffee767ec1ecf22fe1cc23"
},
{
"message": "Remove realpath installation\n\nThis is no longer needed since \"realpath\" is part of \"coreutils\" in Ubuntu18+.\n\nPiperOrigin-RevId: 385643094\nChange-Id: Iae99df38b10b18f0fa948b527565caff3aefffa3"
},
{
"message": "[PJRT] Refactor transpose plan representation to use a dense vector of nodes for a plan, rather than using pointer jumping.\n\nPiperOrigin-RevId: 385644497\nChange-Id: I25f0e0881e2723ccaeb2abd771f2212c5dff573e"
},
{
"message": "[TF Numerics] Add remat memory test cases with XLA.\n\nThe remat XLA tests run on CPU, GPU, and TPU. The tests work by calling the experimental_get_compiler_ir API to trigger XLA compilation and retrieve the HLO proto string. From the HLO proto string, the memory usage is calculated.\n\nPiperOrigin-RevId: 385648033\nChange-Id: I3cdd15944edf9c3ba6a7484073dd8966724c34e5"
},
{
"message": "Update TFRT dependency to use revision\nhttp://github.com/tensorflow/runtime/commit/02393b42f01dcf861461ebdea8fd95e5b8a211fd.\n\nPiperOrigin-RevId: 385650678\nChange-Id: I33c6c1a57454be37fa2d45f1bb932e0f5db66d63"
},
{
"message": "Return an error if user provided sharding is invalid\n\nPiperOrigin-RevId: 385653633\nChange-Id: Iebc9d99c576eb1445dadd1e93ce47c9671072138"
},
{
"message": "Use TF_TensorToMaybeAliasedPyArray in TensorToNdarray to avoid copying.\n\nPiperOrigin-RevId: 385654083\nChange-Id: I7e5589a57d3c4cebfb91f3111f9200840a52ee6b"
},
{
"message": "[tf:tfrt] Move TensorShape into the newly constructed Tensor\n\nPiperOrigin-RevId: 385654698\nChange-Id: Ia546544ddf56808d55f13bbae62d35662b6f48cb"
},
{
"message": "Integrate LLVM at llvm/llvm-project@5994201c8e4c\n\nUpdates LLVM usage to match\n[5994201c8e4c](https://github.com/llvm/llvm-project/commit/5994201c8e4c)\n\nPiperOrigin-RevId: 385657588\nChange-Id: Ifc367b252b70de00320e521ffeb93632c9b0e014"
},
{
"message": "[tf.data] Use `tf.data.Dataset.scan(...) instead of deprecated scan ops.\n\nPiperOrigin-RevId: 385659766\nChange-Id: I4765e00127b71709a973ef5cb53a03edad1aac14"
},
{
"message": "Update TFRT dependency to use revision\nhttp://github.com/tensorflow/runtime/commit/fcad567dbb85629cc462b34ca4758b21786fb480.\n\nPiperOrigin-RevId: 385662994\nChange-Id: I0a808de39c69deafe651870355b2279686c53536"
},
{
"message": "(lite/java) Separate out NativeInterpreterWrapper parts that depend on experimental APIs.\n\nSplit some parts of NativeInterpreterWrapper which depend on experimental APIs\ninto a separate derived class NativeInterpreterWrapperExperimental,\nand don't include that derived class in the \"stable\" build targets.\n\nIn particular NativeInterpreterWrapper.resetVariableTensors depends on\nthe C++ Interpreter::ResetVariableTensors method, which is experimental,\nso we want to avoid depending on that from the \"stable\" build targets.\n\n(Note that parts which depend on Interpreter::ModifyGraphWithDelegate\nhave NOT been moved to NativeInterpreterWrapperExperimental. The tentative\nplan for those is to instead refactor them to use InterpreterBuilder::AddDelegate, and to promote that API to stable, in subsequent CLs.)\n\nPiperOrigin-RevId: 385662997\nChange-Id: I8a3e0ef9e573b75b9429facda0fc4fb2e92a869a"
},
{
"message": "Adds automatic ref-counting (on the underlying resource) to ResourceHandle.\n\nThis CL adds an option for ResourceHandle to hold on to a pointer to a resource, in which case the ResourceHandle will call `Ref` on the resource when the handle is copied, and call `Unref` on the resource when the handle is destroyed. This feature will serve as an automatic life-cycle management system for resources.\n\nResources under this life-cycle management system will bypass ResourceMgr.\n\nThis CL doesn't opt in any existing resources to this new life-cycle management system. Follow-up CLs will opt them in gradually.\n\nPiperOrigin-RevId: 385665188\nChange-Id: Ic15367a2b860f0cc768bca762590036a746e30a0"
},
{
"message": "Run pyformat\n\nA few small differences had accumulated.\n\nPiperOrigin-RevId: 385668414\nChange-Id: I02ebfb0ceaf3e15623bcbc73686c306d5b6512dd"
},
{
"message": "Fix a typo in the tag that disables the test in tap.\n\nPiperOrigin-RevId: 385672989\nChange-Id: I658215f68849ab61230251cd3352bd3b04d197fd"
},
{
"message": "Add tests for quant_act_range, which was rolled back\n\nPiperOrigin-RevId: 385673729\nChange-Id: Ib38cb1a79f3dbbe81e58a608bb454993e7f923ef"
},
{
"message": "[tf.data] Increasing rollout of map parallelization experiment to 50%.\n\nPiperOrigin-RevId: 385677059\nChange-Id: I4c09c658bee7c491d8aaba579c5ece680c26a57a"
}
],
"files": [
{
"diff": "@@ -1416,7 +1416,7 @@ def weighted_moments(x, axes, frequency_weights, name=None, keep_dims=None,\n x: A tensor.\n axes: 1-d tensor of int32 values; these are the axes along which\n to compute mean and variance.\n- frequency_weights: A tensor of positive weights which can be\n+ frequency_weights: A tensor of non-negative weights which can be\n broadcast with x.\n name: Name used to scope the operation.\n keep_dims: Produce moments with the same dimensionality as the input.\n@@ -1460,7 +1460,7 @@ def weighted_moments(x, axes, frequency_weights, name=None, keep_dims=None,\n sum_of_weights = math_ops.reduce_sum(\n broadcasted_weights, axes, name=\"sum_of_weights\", keepdims=True)\n \n- divisor = math_ops.reciprocal(sum_of_weights, name=\"inv_weight_sum\")\n+ divisor = math_ops.reciprocal_no_nan(sum_of_weights, name=\"inv_weight_sum\")\n \n weighted_mean = math_ops.multiply(weighted_input_sum, divisor)\n \n@@ -1494,7 +1494,7 @@ def weighted_moments_v2(x, axes, frequency_weights, keepdims=False, name=None):\n x: A tensor.\n axes: 1-d tensor of int32 values; these are the axes along which\n to compute mean and variance.\n- frequency_weights: A tensor of positive weights which can be\n+ frequency_weights: A tensor of non-negative weights which can be\n broadcast with x.\n keepdims: Produce moments with the same dimensionality as the input.\n name: Name used to scope the operation.",
"filename": "tensorflow/python/ops/nn_impl.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Windows 10\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):\r\ntensorflow 2.5.0\r\ntensorflow-estimator 2.5.0\r\ntensorflow-probability 0.12.2\r\n\r\n- Python version: 3.8\r\n- CUDA/cuDNN version: 8101\r\n- GPU model and memory: GeForce GTX 1060\r\n\r\n**Describe the current behavior**\r\nTrying to train a component of my model throws an error during backprop calculation inside `grads = tape.gradient(loss, varibs)`. The error isn't very clear about what I'm doing wrong. Other parts of the model are training okay, but one section is throwing the following error.\r\n\r\n```\r\n grads = tape.gradient(loss, varibs)\r\n File \"C:\\Users\\Luke\\Anaconda3\\envs\\ScDreamer\\lib\\site-packages\\tensorflow\\python\\eager\\backprop.py\", line 1074, in gradient\r\n flat_grad = imperative_grad.imperative_grad(\r\n File \"C:\\Users\\Luke\\Anaconda3\\envs\\ScDreamer\\lib\\site-packages\\tensorflow\\python\\eager\\imperative_grad.py\", line 71, in imperative_grad\r\n return pywrap_tfe.TFE_Py_TapeGradient(\r\n File \"C:\\Users\\Luke\\Anaconda3\\envs\\ScDreamer\\lib\\site-packages\\tensorflow\\python\\eager\\backprop.py\", line 159, in _gradient_function\r\n return grad_fn(mock_op, *out_grads)\r\n File \"C:\\Users\\Luke\\Anaconda3\\envs\\ScDreamer\\lib\\site-packages\\tensorflow\\python\\ops\\array_grad.py\", line 229, in _ConcatGradV2\r\n return _ConcatGradHelper(\r\n File \"C:\\Users\\Luke\\Anaconda3\\envs\\ScDreamer\\lib\\site-packages\\tensorflow\\python\\ops\\array_grad.py\", line 119, in _ConcatGradHelper\r\n concat_dim._numpy().item(0) % input_values[0]._rank()) # pylint: disable=protected-access\r\nZeroDivisionError: integer division or modulo by zero\r\n```\r\n\r\nInvestigating the line of code, the issue is the rank of a scalar is being used in the modulo\r\n\r\n\r\nI'm not sure what I've done wrong that has caused this.\r\n\r\n**Describe the expected behavior**\r\nIdeally the error would be caught before getting this deep and suggest a proper fix. At the moment, being told \"ZeroDivisionError: integer division or modulo by zero\" isn't helping me figure out what is wrong.\r\n\r\n**Standalone code to reproduce the issue**\r\nI don't really understand what the issue is here so I'm not sure where to start to try and reproduce this. If I can be pointed in the right direction to reproduce, I'll be happy to write some code.\r\n",
"comments": [
{
"body": "I figured out a workaround, but I'm pretty sure that this is a bug.\r\n\r\nThe very last step of my loss calculation was concatenating a bunch of scalars together and taking the mean, by changing them from scalars to rank 1 tensors with keep_dims, the error no longer occurs.\r\n\r\nsome pseudo-code:\r\n\r\n```\r\nactor_losses = []\r\nfor e in error:\r\n actor_loss = -tf.reduce_mean(e, axis=0, keepdims=True) # removing axis & keepdims args will result in scalar output, causing error\r\n actor_losses.append(actor_loss)\r\ntotal_loss = tf.reduce_mean(tf.concat(actor_losses, axis=0))\r\n```\r\n\r\n",
"created_at": "2021-08-24T15:43:38Z"
},
{
"body": "@LukeBolly ,\r\n In order to expedite the trouble-shooting process, could you please provide a complete code and the dataset you are using.Also please refer to these links [1](https://github.com/google/emoji-scavenger-hunt/issues/28) and [2](https://stackoverflow.com/questions/44998778/keras-zerodivisionerror-integer-division-or-modulo-by-zero) and let us know if it helped.Thanks!\r\n",
"created_at": "2021-08-25T05:33:08Z"
},
{
"body": "Hi! I am new at open source contribution. Is this issue still open? I would like to work on it.",
"created_at": "2021-08-28T20:24:56Z"
},
{
"body": "> Hi! I am new at open source contribution. Is this issue still open? I would like to work on it.\r\n\r\nYep, I probably won't have time to work on this for a while so it's all yours if you like. Let me know if you need any more information to reproduce the issue\r\n",
"created_at": "2021-08-30T01:37:56Z"
},
{
"body": "@LukeBolly Can you please help me with the review on my PR? It says to add a test for the behavior you're fixing.\r\n\r\n\r\n",
"created_at": "2021-08-30T16:44:07Z"
},
{
"body": "I think you need to add a bug reproduce into\r\nhttps://github.com/tensorflow/tensorflow/tree/master/tensorflow/python/kernel_tests\r\nI'm not 100% if bug repros go into kernel_tests, maybe one of the TF team can advise you on where the most appropriate location is.\r\n\r\nThe idea is that you write the test that causes the bug, then fix the code so that the test passes.",
"created_at": "2021-08-31T01:36:02Z"
},
{
"body": "@LukeBolly Could you help me reproduce the bug?",
"created_at": "2021-08-31T18:26:25Z"
},
{
"body": "What do you have so far? I don't have much time at the moment so I can't write the repro for you, but the gist of the error is that backpropagating through a list of scalars should trigger it.",
"created_at": "2021-09-01T01:18:51Z"
},
{
"body": "@LukeBolly ,\r\n\r\nPlease check the above [comment](https://github.com/tensorflow/tensorflow/issues/51653#issuecomment-905196574) and provide the complete code to reproduce the issue.Thanks!",
"created_at": "2021-09-03T10:38:40Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2021-09-10T10:42:11Z"
},
{
"body": "how do I create unit tests?",
"created_at": "2021-09-10T13:32:05Z"
},
{
"body": "Closing as stale. Please reopen if you'd like to work on this further.\n",
"created_at": "2021-09-17T13:55:22Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51653\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51653\">No</a>\n",
"created_at": "2021-09-17T13:55:24Z"
}
],
"number": 51653,
"title": "\"ZeroDivisionError: integer division or modulo by zero\" while backpropagating"
}
|
{
"body": "\"ZeroDivisionError: integer division or modulo by zero\" while backpropagating #51653\r\nlogic reference:\r\nhttps://github.com/tensorflow/tensorflow/issues/51653#issuecomment-904756234",
"number": 51747,
"review_comments": [
{
"body": "This seems unused",
"created_at": "2021-08-30T15:19:59Z"
},
{
"body": "Wouldn't this cause problems if it shape was (), not (1,)? Not sure I see what this is fixing; consider adding an explanatory comment.",
"created_at": "2021-08-30T15:22:29Z"
}
],
"title": "\"ZeroDivisionError: integer division or modulo by zero\" while backpropagating #51653"
}
|
{
"commits": [
{
"message": "Update array_grad.py\n\n\"ZeroDivisionError: integer division or modulo by zero\" while backpropagating #51653\r\nlogic reference:\r\nhttps://github.com/tensorflow/tensorflow/issues/51653#issuecomment-904756234"
}
],
"files": [
{
"diff": "@@ -17,7 +17,7 @@\n from __future__ import absolute_import\n from __future__ import division\n from __future__ import print_function\n-\n+import numpy\n from tensorflow.compiler.tf2xla.ops import gen_xla_ops\n from tensorflow.python import pywrap_tfe\n from tensorflow.python.client import pywrap_tf_session\n@@ -115,6 +115,8 @@ def _ExtractInputShapes(inputs):\n if context.executing_eagerly() or isinstance(concat_dim, ops.EagerTensor):\n # Using mod here for convenience since concat_dim is already verified\n # in concat implementation to be within the allowed [-rank, rank) range.\n+ if(input_value[0].shape==(1,)):\n+ input_values[0]=convert_to_tensor(input_values)\n non_neg_concat_dim = (\n concat_dim._numpy().item(0) % input_values[0]._rank()) # pylint: disable=protected-access\n # All inputs are guaranteed to be EagerTensors in eager mode",
"filename": "tensorflow/python/ops/array_grad.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n\r\n**Describe the current behavior**\r\ntf.math.segment_max/min/mean/sun/prod crashes(aborts) when `segment_ids` is large\r\n\r\n**Describe the expected behavior**\r\nexpect an exception message if the input is unexpected instead of crash\r\n\r\n**Standalone code to reproduce the issue**\r\n~~~python\r\ntf.math.segment_max(data=np.ones((1,10,1)), segment_ids=[1676240524292489355])\r\ntf.math.segment_min(data=np.ones((1,10,1)), segment_ids=[1676240524292489355])\r\ntf.math.segment_mean(data=np.ones((1,10,1)), segment_ids=[1676240524292489355])\r\ntf.math.segment_sum(data=np.ones((1,10,1)), segment_ids=[1676240524292489355])\r\ntf.math.segment_prod(data=np.ones((1,10,1)), segment_ids=[1676240524292489355])\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 16:44:25.849065: F tensorflow/core/framework/tensor_shape.cc:405] Check failed: 0 <= new_num_elements (0 vs. -1684338830784658056)\r\nAborted (core dumped)\r\n~~~\r\n\r\nRelated issue: #46696",
"comments": [
{
"body": "Was able to reproduce the issue with TF v2.3, TF v2.4 and TF-nightly. Please find the gist of it [here](https://colab.research.google.com/gist/amahendrakar/26149c9c28de86ef49b179c9ce6425a0/46888.ipynb). Thanks!",
"created_at": "2021-02-04T07:13:02Z"
},
{
"body": "Was able to reproduce this issue in TF 2.6.0-dev20210528,please find the gist [here ](https://colab.research.google.com/gist/sushreebarsa/380145e341cb9341b9af8743ad359a46/untitled43.ipynb#scrollTo=fX4HwL-Fxk0D)..Thanks !",
"created_at": "2021-05-28T11:47:12Z"
},
{
"body": "Added a PR #51733 for the fix.",
"created_at": "2021-08-28T17:18:07Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46888\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46888\">No</a>\n",
"created_at": "2021-10-28T00:38:22Z"
}
],
"number": 46888,
"title": "tf.math.segment_max/min/mean/sun/prod crashes(aborts) when segment_ids is large"
}
|
{
"body": "This PR fixes the issue raised in #46888 where tf.math.segment_max/min/mean/sun/prod crashes(aborts) when segment_ids is large.\r\n \r\nThis PR fixes #46888.\r\n \r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 51733,
"review_comments": [
{
"body": "Why doesn't the \r\n\r\n```\r\n OP_REQUIRES(context, output_rows >= 0,\r\n errors::InvalidArgument(\"segment ids must be >= 0\"));\r\n```\r\n\r\ncheck above catch this?",
"created_at": "2021-08-31T03:42:09Z"
},
{
"body": "What error is this catching?",
"created_at": "2021-08-31T03:42:29Z"
},
{
"body": "`SetDim` also checks that the total tensor size does not overflow.",
"created_at": "2021-08-31T16:09:37Z"
},
{
"body": "Thanks, maybe add a comment?",
"created_at": "2021-09-03T01:36:53Z"
},
{
"body": "Added in the manual import.",
"created_at": "2021-10-27T17:09:42Z"
},
{
"body": "I don't think this is needed. Reverted in the local import.",
"created_at": "2021-10-27T17:10:30Z"
}
],
"title": "Fix tf.math.segment_max/min/mean/sun/prod crashes(aborts) when segment_ids is large"
}
|
{
"commits": [
{
"message": "Fix tf.math.segment_max/min/mean/sun/prod crashes(aborts) when segment_ids is large\n\nThis PR fixes the issue raised in 46888 where\ntf.math.segment_max/min/mean/sun/prod crashes(aborts) when segment_ids is large.\n\nThis PR fixes 46888.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Add test case for GitHub isseu 46888.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -110,7 +110,7 @@ class SegmentReductionOp : public OpKernel {\n errors::InvalidArgument(\"Shape must be at least rank 1\"));\n \n TensorShape output_shape = input.shape();\n- output_shape.set_dim(0, output_rows);\n+ OP_REQUIRES_OK(context, output_shape.SetDimWithStatus(0, output_rows));\n \n // Note that we do not initialize the output buffer with a default value, so\n // we need to explicitly set missing indices to the default value.\n@@ -250,7 +250,7 @@ class SegmentReductionGPUOp : public AsyncOpKernel {\n \n if (num_indices == 0) {\n TensorShape output_shape = input.shape();\n- output_shape.set_dim(0, 0);\n+ OP_REQUIRES_OK_ASYNC(context, output_shape.SetDimWithStatus(0, 0), done);\n \n Tensor* output = nullptr;\n OP_REQUIRES_OK_ASYNC(",
"filename": "tensorflow/core/kernels/segment_reduction_ops_impl.h",
"status": "modified"
},
{
"diff": "@@ -267,6 +267,20 @@ def testDataInvalid(self):\n data=np.uint16(10), segment_ids=np.array([]).astype(\"int64\"))\n self.evaluate(s)\n \n+ def testInvalidIds(self):\n+ # Test case for GitHub issue 46888.\n+ for op in [\n+ math_ops.segment_max,\n+ math_ops.segment_min,\n+ math_ops.segment_mean,\n+ math_ops.segment_sum,\n+ math_ops.segment_prod,\n+ ]:\n+ with self.cached_session():\n+ with self.assertRaises((ValueError, errors_impl.InternalError)):\n+ s = op(data=np.ones((1, 10, 1)), segment_ids=[1676240524292489355])\n+ self.evaluate(s)\n+\n \n class UnsortedSegmentTest(SegmentReductionHelper):\n ",
"filename": "tensorflow/python/kernel_tests/segment_reduction_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n\r\n**Describe the current behavior**\r\nThe following APIs crash(abortion) when the given size is large\r\n- tf.image.resiz\r\n- tf.image.resize_with_crop_or_pad\r\n- tf.image.pad_to_bounding_box\r\n- tf.image.extract_glimpse\r\n- `tf.keras.backend.resize_images`\r\n\r\n**Describe the expected behavior**\r\nexpect exception messages if the input is not expected instead of crash\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\n### `tf.image.resize`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize(images=np.ones((5,5,5)), size=[2065374891,1145309325])\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:41:13.484992: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -6619278462293758741)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.resize_with_crop_or_pad`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_crop_or_pad(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470)\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:42:15.468265: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.pad_to_bounding_box`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.pad_to_bounding_box(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470, offset_height=1, offset_width=1)\r\n~~~\r\nOutput\r\n~~~python\r\n2021-02-03 17:42:52.556583: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.extract_glimpse`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.extract_glimpse(input=np.ones((5,5,5,5)), size=[1574700351, 451745106], offsets=np.ones((5,2)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:43:30.140277: F tensorflow/core/framework/tensor_shape.cc:338] Check failed: 0 <= n (0 vs. -662664649191246466)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.keras.backend.resize_image`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.backend.resize_images(x=np.ones((1,5,3,15)), height_factor=5628955348197345288, width_factor=5628955348197345288, data_format='channels_last')\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:54:01.192819: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5948468124908472256)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "@rmothukuru \r\nI ran the code on tf 2.4 and nightly, colab crashes. please find the [gist here](\r\nhttps://colab.research.google.com/gist/Saduf2019/fd4dfbdc07480e95a5694b336944c4f8/untitled520.ipynb)",
"created_at": "2021-02-04T06:35:03Z"
},
{
"body": "BTW, I also find it in `tf.image.crop_and_resize` and `tf.image.resize_with_pad`\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.crop_and_resize(image=np.ones((1,1,1,1)), boxes=np.ones((11,4)), box_indices=np.ones((11)), crop_size=[2065374891,1145309325])\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-05 17:02:57.884394: F tensorflow/core/framework/tensor_shape.cc:187] Non-OK-status: InitDims(dim_sizes) status: Internal: Encountered overflow when multiplying 22719123801 with 1145309325, result: -1\r\nAborted (core dumped)\r\n~~~\r\n\r\n\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_pad(image=np.ones((5,5,5)), target_height=1635057735, target_width=1635057735)\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-19 22:28:03.322414: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\n2021-02-19 22:28:03.332536: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5079675089792900491)\r\nAborted (core dumped)\r\n~~~",
"created_at": "2021-02-05T17:04:08Z"
},
{
"body": "Was able to reproduce the issue in TF 2.6.0-dev20210528 & colab crashes ,please find the gist [here](https://colab.research.google.com/gist/sushreebarsa/2f0930249cfea6fd3be6c8f9ec4fca21/untitled41.ipynb#scrollTo=vkKKum0ltdoP)..Thanks !",
"created_at": "2021-05-28T11:32:22Z"
},
{
"body": "Update:\r\n1. `tf.image.resize` fixed aleady\r\n2. `tf.image.resize_with_crop_or_pad` to be fixed (PR #51717)\r\n3. `tf.image.pad_to_bounding_box` to be fixed (PR #51717)\r\n4. `tf.keras.backend.resize_image` fixed already\r\n5. `tf.image.crop_and_resize` to be fixed (PR #51732)\r\n5. `tf.image.resize_with_pad` fixed already",
"created_at": "2021-08-28T16:40:51Z"
},
{
"body": "@DNXie Could you please let us know if we can closed the issue with this [PR](https://github.com/tensorflow/tensorflow/pull/51732) ?Thank you!",
"created_at": "2021-09-02T16:01:00Z"
},
{
"body": "There are still a few PRs that need to land here.",
"created_at": "2021-09-03T00:58:51Z"
},
{
"body": "I think all of these landed",
"created_at": "2021-10-27T23:23:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">No</a>\n",
"created_at": "2021-10-27T23:23:50Z"
}
],
"number": 46890,
"title": "tf.image.resize/resize_with_crop_or_pad/pad_to_bounding_box/extract_glimpse crash(abort)"
}
|
{
"body": "This PR is part of the effort in #46890 where\r\ntf.image.crop_and_resize will crash if shape consists of large number.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 51732,
"review_comments": [
{
"body": "The issue is that this produces a tensor with a shape that describes a number of elements that can't be represented in an int64_t, do we need such a large size here? Surely we can't execute anything like this right?",
"created_at": "2021-09-11T03:31:48Z"
}
],
"title": "Fix crash of tf.image.crop_and_resize when input is large number"
}
|
{
"commits": [
{
"message": "Fix crash of tf.image.crop_and_resize when input is large number\n\nThis PR is part of the effort in 46890 where\ntf.image.crop_and_resize will crash if shape consists of large number.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -170,12 +170,17 @@ class CropAndResizeOp : public AsyncOpKernel {\n context, crop_height > 0 && crop_width > 0,\n errors::InvalidArgument(\"crop dimensions must be positive\"), done);\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(num_boxes), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(crop_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n OP_REQUIRES_OK_ASYNC(\n context,\n context->allocate_output(\n- 0, TensorShape({num_boxes, crop_height, crop_width, depth}),\n+ 0, shape,\n &output),\n done);\n \n@@ -417,12 +422,17 @@ class CropAndResizeGradImageOp : public AsyncOpKernel {\n done);\n }\n \n+ TensorShape shape;\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(batch_size), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_height), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(image_width), done);\n+ OP_REQUIRES_OK_ASYNC(context, shape.AddDimWithStatus(depth), done);\n // Allocate output tensor.\n Tensor* output = nullptr;\n OP_REQUIRES_OK_ASYNC(\n context,\n context->allocate_output(\n- 0, TensorShape({batch_size, image_height, image_width, depth}),\n+ 0, shape,\n &output),\n done);\n ",
"filename": "tensorflow/core/kernels/image/crop_and_resize_op.cc",
"status": "modified"
},
{
"diff": "@@ -6075,6 +6075,16 @@ def testImageCropAndResize(self):\n crop_size=[1, 1])\n self.evaluate(op)\n \n+ def testImageCropAndResizeWithInvalidInput(self):\n+ with self.session():\n+ with self.assertRaises((errors.InternalError, ValueError)):\n+ op = image_ops_impl.crop_and_resize_v2(\n+ image=np.ones((1, 1, 1, 1)),\n+ boxes=np.ones((11, 4)),\n+ box_indices=np.ones((11)),\n+ crop_size=[2065374891, 1145309325])\n+ self.evaluate(op)\n+\n @parameterized.named_parameters(\n (\"_jpeg\", \"JPEG\", \"jpeg_merge_test1.jpg\"),\n (\"_png\", \"PNG\", \"lena_rgba.png\"),",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n\r\n**Describe the current behavior**\r\nThe following APIs crash(abortion) when the given size is large\r\n- tf.image.resiz\r\n- tf.image.resize_with_crop_or_pad\r\n- tf.image.pad_to_bounding_box\r\n- tf.image.extract_glimpse\r\n- `tf.keras.backend.resize_images`\r\n\r\n**Describe the expected behavior**\r\nexpect exception messages if the input is not expected instead of crash\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\n### `tf.image.resize`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize(images=np.ones((5,5,5)), size=[2065374891,1145309325])\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:41:13.484992: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -6619278462293758741)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.resize_with_crop_or_pad`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_crop_or_pad(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470)\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-03 17:42:15.468265: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.pad_to_bounding_box`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.pad_to_bounding_box(image=np.ones((1,1,1)), target_height=5191549470, target_width=5191549470, offset_height=1, offset_width=1)\r\n~~~\r\nOutput\r\n~~~python\r\n2021-02-03 17:42:52.556583: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.image.extract_glimpse`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.extract_glimpse(input=np.ones((5,5,5,5)), size=[1574700351, 451745106], offsets=np.ones((5,2)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:43:30.140277: F tensorflow/core/framework/tensor_shape.cc:338] Check failed: 0 <= n (0 vs. -662664649191246466)\r\nAborted (core dumped)\r\n~~~\r\n\r\n### `tf.keras.backend.resize_image`\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.backend.resize_images(x=np.ones((1,5,3,15)), height_factor=5628955348197345288, width_factor=5628955348197345288, data_format='channels_last')\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-03 17:54:01.192819: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5948468124908472256)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "@rmothukuru \r\nI ran the code on tf 2.4 and nightly, colab crashes. please find the [gist here](\r\nhttps://colab.research.google.com/gist/Saduf2019/fd4dfbdc07480e95a5694b336944c4f8/untitled520.ipynb)",
"created_at": "2021-02-04T06:35:03Z"
},
{
"body": "BTW, I also find it in `tf.image.crop_and_resize` and `tf.image.resize_with_pad`\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.crop_and_resize(image=np.ones((1,1,1,1)), boxes=np.ones((11,4)), box_indices=np.ones((11)), crop_size=[2065374891,1145309325])\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-05 17:02:57.884394: F tensorflow/core/framework/tensor_shape.cc:187] Non-OK-status: InitDims(dim_sizes) status: Internal: Encountered overflow when multiplying 22719123801 with 1145309325, result: -1\r\nAborted (core dumped)\r\n~~~\r\n\r\n\r\n\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.image.resize_with_pad(image=np.ones((5,5,5)), target_height=1635057735, target_width=1635057735)\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-19 22:28:03.322414: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\r\n2021-02-19 22:28:03.332536: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5079675089792900491)\r\nAborted (core dumped)\r\n~~~",
"created_at": "2021-02-05T17:04:08Z"
},
{
"body": "Was able to reproduce the issue in TF 2.6.0-dev20210528 & colab crashes ,please find the gist [here](https://colab.research.google.com/gist/sushreebarsa/2f0930249cfea6fd3be6c8f9ec4fca21/untitled41.ipynb#scrollTo=vkKKum0ltdoP)..Thanks !",
"created_at": "2021-05-28T11:32:22Z"
},
{
"body": "Update:\r\n1. `tf.image.resize` fixed aleady\r\n2. `tf.image.resize_with_crop_or_pad` to be fixed (PR #51717)\r\n3. `tf.image.pad_to_bounding_box` to be fixed (PR #51717)\r\n4. `tf.keras.backend.resize_image` fixed already\r\n5. `tf.image.crop_and_resize` to be fixed (PR #51732)\r\n5. `tf.image.resize_with_pad` fixed already",
"created_at": "2021-08-28T16:40:51Z"
},
{
"body": "@DNXie Could you please let us know if we can closed the issue with this [PR](https://github.com/tensorflow/tensorflow/pull/51732) ?Thank you!",
"created_at": "2021-09-02T16:01:00Z"
},
{
"body": "There are still a few PRs that need to land here.",
"created_at": "2021-09-03T00:58:51Z"
},
{
"body": "I think all of these landed",
"created_at": "2021-10-27T23:23:48Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46890\">No</a>\n",
"created_at": "2021-10-27T23:23:50Z"
}
],
"number": 46890,
"title": "tf.image.resize/resize_with_crop_or_pad/pad_to_bounding_box/extract_glimpse crash(abort)"
}
|
{
"body": "This PR tries to address one of the issues raised in #46890\r\nwhere tf.image.pad_to_bounding_box will crash with large input\r\nvalue.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 51717,
"review_comments": [],
"title": "Fix crash of tf.image.pad_to_bounding_box with large input value."
}
|
{
"commits": [
{
"message": "Fix crash of tf.image.pad_to_bounding_box with large input value.\n\nThis PR tries to address one of the issues raised in 46890\nwhere tf.image.pad_to_bounding_box will crash with large input\nvalue.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -85,7 +85,8 @@ class PadOp : public OpKernel {\n errors::InvalidArgument(\"Paddings must be non-negative: \",\n before_d, \" \", after_d));\n const int64_t size_d = in0.dim_size(d);\n- output_shape.AddDim(before_d + size_d + after_d);\n+ OP_REQUIRES_OK(\n+ context, output_shape.AddDimWithStatus(before_d + size_d + after_d));\n }\n \n // If there is no padding to be done, forward the input to output.",
"filename": "tensorflow/core/kernels/pad_op.cc",
"status": "modified"
},
{
"diff": "@@ -2293,6 +2293,17 @@ def testNameScope(self):\n y = image_ops.pad_to_bounding_box(image, 0, 0, 55, 66)\n self.assertTrue(y.op.name.startswith(\"pad_to_bounding_box\"))\n \n+ def testInvalidInput(self):\n+ # Test case for GitHub issue 46890.\n+ with self.session():\n+ with self.assertRaises(errors_impl.InternalError):\n+ v = image_ops.pad_to_bounding_box(\n+ image=np.ones((1, 1, 1)),\n+ target_height=5191549470,\n+ target_width=5191549470,\n+ offset_height=1, offset_width=1)\n+ self.evaluate(v)\n+\n \n class SelectDistortedCropBoxTest(test_util.TensorFlowTestCase):\n ",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n**Describe the current behavior**\r\n`tf.summary.create_file_writer` crash (abort)\r\n\r\n**Describe the expected behavior**\r\nexpect an exception message if the input unexpected instead of crash. \r\n\r\n**Standalone code to reproduce the issue**\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.summary.create_file_writer(logdir='', flush_millis=np.ones((1,2)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-04 03:59:32.339427: F tensorflow/core/framework/tensor.cc:669] Check failed: 1 == NumElements() (1 vs. 2)Must have a one element tensor\r\nAborted (core dumped)\r\n~~~\r\n",
"comments": [
{
"body": "I have tried in colab with TF versions 2.1,2.4,nightly versions(`2.5.0-dev20210203`) and was able to reproduce the issue.Please, find the gist [here](https://colab.research.google.com/gist/ravikyram/9329366f22f1d5559d31065583e6f21e/untitled656.ipynb). Thanks!",
"created_at": "2021-02-04T09:05:39Z"
},
{
"body": "Colab is still crashing in TF 2.6 when I executed the code. Please find the gist [here](https://colab.research.google.com/gist/saikumarchalla/4d07531868b085424317d42652909927/untitled92.ipynb#scrollTo=RvUKM453ViFa).Thanks!",
"created_at": "2021-05-29T04:17:42Z"
},
{
"body": "Created a PR #51715 for the fix.",
"created_at": "2021-08-27T16:19:12Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46909\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46909\">No</a>\n",
"created_at": "2021-08-31T23:59:30Z"
}
],
"number": 46909,
"title": "tf.summary.create_file_writer aborts "
}
|
{
"body": "This PR tries to fix the issue raised in #46909 where\r\ntf.summary.create_file_writer crashes when non-scalar values are passed.\r\n\r\nThis PR fixes #46909.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 51715,
"review_comments": [],
"title": "Fix crash with tf.summary.create_file_writer when non-scalar values are passed"
}
|
{
"commits": [
{
"message": "Fix crash with tf.summary.create_file_writer when non-scalar values are passed\n\nThis PR tries to fix the issue raised in 46909 where\ntf.summary.create_file_writer crashes when non-scalar values are passed.\n\nThis PR fixes 46909.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -38,12 +38,20 @@ class CreateSummaryFileWriterOp : public OpKernel {\n void Compute(OpKernelContext* ctx) override {\n const Tensor* tmp;\n OP_REQUIRES_OK(ctx, ctx->input(\"logdir\", &tmp));\n+ OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(tmp->shape()),\n+ errors::InvalidArgument(\"logdir must be a scalar\"));\n const string logdir = tmp->scalar<tstring>()();\n OP_REQUIRES_OK(ctx, ctx->input(\"max_queue\", &tmp));\n+ OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(tmp->shape()),\n+ errors::InvalidArgument(\"max_queue must be a scalar\"));\n const int32_t max_queue = tmp->scalar<int32>()();\n OP_REQUIRES_OK(ctx, ctx->input(\"flush_millis\", &tmp));\n+ OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(tmp->shape()),\n+ errors::InvalidArgument(\"flush_millis must be a scalar\"));\n const int32_t flush_millis = tmp->scalar<int32>()();\n OP_REQUIRES_OK(ctx, ctx->input(\"filename_suffix\", &tmp));\n+ OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(tmp->shape()),\n+ errors::InvalidArgument(\"filename_suffix must be a scalar\"));\n const string filename_suffix = tmp->scalar<tstring>()();\n \n core::RefCountPtr<SummaryWriterInterface> s;",
"filename": "tensorflow/core/kernels/summary_kernels.cc",
"status": "modified"
},
{
"diff": "@@ -34,6 +34,7 @@\n from tensorflow.python.client import session\n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors_impl\n from tensorflow.python.framework import meta_graph\n from tensorflow.python.framework import ops\n from tensorflow.python.framework import test_util\n@@ -685,6 +686,15 @@ def testSharing_withExplicitSummaryFileWriters(self):\n # No more files\n self.assertRaises(StopIteration, lambda: next(event_paths))\n \n+ def testSummaryFileWritersInvalidInput(self):\n+ # Test case for GitHub issue 46909\n+ logdir = self.get_temp_dir()\n+ with session.Session() as sess:\n+ with self.assertRaises(errors_impl.InvalidArgumentError):\n+ writer = summary_ops_v2.create_file_writer(\n+ logdir=logdir, flush_millis=[1, 2])\n+ sess.run(writer.init())\n+ sess.run(writer.flush())\n \n class FileWriterCacheTest(test.TestCase):\n \"\"\"FileWriterCache tests.\"\"\"",
"filename": "tensorflow/python/summary/writer/writer_test.py",
"status": "modified"
}
]
}
|
{
"body": "\r\n**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 16.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: No\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.4\r\n- Python version: 3.6\r\n\r\n**Standalone code to reproduce the issue**\r\n```\r\nimport tensorflow as tf\r\nimport numpy as np\r\nx = np.arange(9).reshape([1,3,3,1])\r\nres = tf.image.extract_glimpse(x, size=[1023, -63], offsets=[1023, 63], centered=False, normalized=False) # Crash\r\n```\r\n\r\n**Describe the current behavior**\r\n\r\nIt crashes when I execute the above code.\r\n\r\n**Describe the expected behavior**\r\nShould throw a `ValueError`.\r\n\r\n",
"comments": [
{
"body": "Happy to add the `app.log` from Google Colab executing above snippet for the latest version `2.6.0`.\r\n\r\nSeems to me like the call of `CHECK_LT()` in `tensorflow/core/framework/tensor_shape.cc:569` defined at `tensorflow/core/platform/default/logging.h:413` causes that issue.\r\n\r\nHowever, I am not a C++ expert, so I don't get any much further than that for now.\r\n\r\n<html><body>\r\n<!--StartFragment-->\r\n\r\nTimestamp | Level | Message\r\n-- | -- | --\r\nAug 22, 2021, 12:34:44 AM | WARNING | WARNING:root:kernel 8e337399-7e5c-4782-aaa6-34f661e5c692 restarted\r\nAug 22, 2021, 12:34:44 AM | INFO | KernelRestarter: restarting kernel (1/5), keep random ports\r\nAug 22, 2021, 12:34:44 AM | WARNING | 2021-08-21 22:34:44.441658: F tensorflow/core/framework/tensor_shape.cc:569] Check failed: size >= 0 (-63 vs. 0)\r\nAug 22, 2021, 12:34:44 AM | WARNING | 2021-08-21 22:34:44.376372: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (c679a9bf8bfa): /proc/driver/nvidia/version does not exist\r\nAug 22, 2021, 12:34:44 AM | WARNING | 2021-08-21 22:34:44.375437: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected\r\nAug 22, 2021, 12:34:37 AM | INFO | Adapting to protocol v5.1 for kernel 8e337399-7e5c-4782-aaa6-34f661e5c692\r\nAug 22, 2021, 12:34:35 AM | INFO | Kernel started: 8e337399-7e5c-4782-aaa6-34f661e5c692\r\nAug 22, 2021, 12:33:19 AM | INFO | Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).\r\nAug 22, 2021, 12:33:19 AM | INFO | http://172.28.0.12:9000/\r\nAug 22, 2021, 12:33:19 AM | INFO | The Jupyter Notebook is running at:\r\nAug 22, 2021, 12:33:19 AM | INFO | Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).\r\nAug 22, 2021, 12:33:19 AM | INFO | http://172.28.0.2:9000/\r\nAug 22, 2021, 12:33:19 AM | INFO | The Jupyter Notebook is running at:\r\nAug 22, 2021, 12:33:19 AM | INFO | 0 active kernels\r\nAug 22, 2021, 12:33:19 AM | INFO | Serving notebooks from local directory: /\r\nAug 22, 2021, 12:33:19 AM | INFO | 0 active kernels\r\nAug 22, 2021, 12:33:19 AM | INFO | Serving notebooks from local directory: /\r\nAug 22, 2021, 12:33:19 AM | INFO | google.colab serverextension initialized.\r\nAug 22, 2021, 12:33:19 AM | INFO | google.colab serverextension initialized.\r\nAug 22, 2021, 12:33:19 AM | INFO | Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret\r\nAug 22, 2021, 12:33:19 AM | INFO | Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret\r\n\r\n<!--EndFragment-->\r\n</body>\r\n</html>",
"created_at": "2021-08-21T22:50:55Z"
},
{
"body": "@lugalUrim Could you please refer to the [link](https://www.tensorflow.org/api_docs/python/tf/image/extract_glimpse) . Please try to upgrade the TF version 2.4 to 2.6.0 and refer to the above [comment](https://github.com/tensorflow/tensorflow/issues/51618#issuecomment-903185385).Please let us know if it helps ?",
"created_at": "2021-08-23T06:38:41Z"
},
{
"body": "Added a PR #51618 for the fix.",
"created_at": "2021-08-24T18:48:13Z"
},
{
"body": "@lugalUrim This issue will be closed once the PR is merged! Thanks! ",
"created_at": "2021-08-31T02:16:14Z"
},
{
"body": "This issue has been automatically marked as stale because it has no recent activity. It will be closed if no further activity occurs. Thank you.\n",
"created_at": "2021-09-07T03:05:57Z"
},
{
"body": "Closing as stale. Please reopen if you'd like to work on this further.\n",
"created_at": "2021-09-14T03:42:13Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51618\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51618\">No</a>\n",
"created_at": "2021-09-14T03:42:16Z"
},
{
"body": "I also observed the following API aliases or similar APIs can cause the same issue in older versions of tensorflow.\r\nUsers should be cautious when using them on both CPU and GPU up to tensorflow 2.7.4 (v2.7.3-139-ga73cc22ba39) except for tensorflow 2.6.1 (v2.6.0-101-g3aa40c3ce9d).\r\n\r\n- `(tf.image.extract_glimpse)`, `tf.compat.v1.image.extract_glimpse`\r\n\r\n<details>\r\n <summary>Code to reproduce the issue in <code>tf.compat.v1.image.extract_glimpse</code> in older versions</summary>\r\n\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\nprint(tf.version.GIT_VERSION, tf.version.VERSION, flush=True)\r\nprint(tf.config.list_physical_devices(), flush=True)\r\n\r\n\r\ntry:\r\n x = np.arange(9).reshape([1,3,3,1])\r\n res = tf.compat.v1.image.extract_glimpse(x, size=[1023, -63], offsets=[1023, 63], centered=False, normalized=False) # Crash\r\nexcept Exception as e:\r\n print(\"Error:\", str(e), flush=True)\r\nprint(\"Success!\", flush=True)\r\n```\r\n\r\nOn GPU, the Check failed error occurs:\r\n\r\n```text\r\nv2.7.3-139-ga73cc22ba39 2.7.4\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n2023-09-08 02:15:16.158398: F tensorflow/core/framework/tensor_shape.cc:573] Check failed: size >= 0 (0 vs. -63)\r\nAborted (core dumped)\r\n```\r\n\r\nThis behavior is also reproducible on my CPU machine:\r\n\r\n```text\r\nv2.7.3-139-ga73cc22ba39 2.7.4\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')]\r\n2023-09-08 02:15:10.646207: F tensorflow/core/framework/tensor_shape.cc:573] Check failed: size >= 0 (0 vs. -63)\r\nAborted (core dumped)\r\n```\r\n</details>\r\n\r\nIt seems to be fixed in tensorflow 2.8.0 (v2.8.0-rc1-32-g3f878cff5b6) and later versions.\r\n",
"created_at": "2023-09-12T09:23:39Z"
}
],
"number": 51618,
"title": "tf.image.extract_glimpse crashes with negative input"
}
|
{
"body": "This PR tries to fix the issue raised in #51618 where\r\ntf.image.extract_glimpse will crash in case of negative input.\r\n\r\nThis PR adds additional checking to allow graceful error message.\r\n\r\nThis PR fixes #51618.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 51658,
"review_comments": [],
"title": "Fix crash of tf.image.extract_glimpse with negative input"
}
|
{
"commits": [
{
"message": "Fix crash of tf.image.extract_glimpse with negative input\n\nThis PR tries to fix the issue raised in 51618 where\ntf.image.extract_glimpse will crash in case of negative input.\n\nThis PR adds additional checking to allow graceful error message.\n\nThis PR fixes 51618.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Capture additional ValueError in case of graph/eager mode\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -87,9 +87,10 @@ class ExtractGlimpseOp : public OpKernel {\n \n const int64_t output_height = window_size.tensor<int, 1>()(0);\n const int64_t output_width = window_size.tensor<int, 1>()(1);\n+\n TensorShape output_shape = input_shape;\n- output_shape.set_dim(1, output_height);\n- output_shape.set_dim(2, output_width);\n+ OP_REQUIRES_OK(context, output_shape.SetDimWithStatus(1, output_height));\n+ OP_REQUIRES_OK(context, output_shape.SetDimWithStatus(2, output_width));\n \n const Tensor& offsets = context->input(2);\n OP_REQUIRES(context, offsets.shape().dims() == 2,",
"filename": "tensorflow/core/kernels/image/attention_ops.cc",
"status": "modified"
},
{
"diff": "@@ -22,6 +22,7 @@\n \n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors\n from tensorflow.python.ops import array_ops\n from tensorflow.python.ops import gen_image_ops\n from tensorflow.python.ops import image_ops\n@@ -301,6 +302,15 @@ def testGlimpseNonNormalizedNonCentered(self):\n np.asarray([[5, 6, 7], [10, 11, 12], [15, 16, 17]]),\n self.evaluate(result2)[0, :, :, 0])\n \n+ def testGlimpseNegativeInput(self):\n+ img = np.arange(9).reshape([1,3,3,1])\n+ with self.test_session():\n+ with self.assertRaises((errors.InternalError, ValueError)):\n+ result = image_ops.extract_glimpse_v2(\n+ img, size=[1023, -63], offsets=[1023, 63],\n+ centered=False, normalized=False)\n+ self.evaluate(result)\n+\n \n if __name__ == '__main__':\n test.main()",
"filename": "tensorflow/python/kernel_tests/attention_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n\r\n**Describe the current behavior**\r\n`tf.keras.layers.UpSampling2D` crashes(aborts) when `size` is large\r\n**Describe the expected behavior**\r\nexpect an exception message if the input unexpected instead of crash. \r\n\r\n\r\n**Standalone code to reproduce the issue**\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.layers.UpSampling2D(size=1610637938, data_format='channels_first', interpolation='bilinear')(np.ones((5,1,1,1)))\r\n~~~\r\nOutput:\r\n~~~python\r\n2021-02-04 04:44:48.936606: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -5475971237085092396)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "Was able to reproduce the issue with TF v2.3, TF v2.4 and TF-nightly. Please find the gist of it [here](https://colab.research.google.com/gist/amahendrakar/d0a9213b5a7d785b1aa18665710c18e8/46929.ipynb). Thanks!",
"created_at": "2021-02-04T16:41:05Z"
},
{
"body": "Colab crashes till in TF 2.6 Nightly as well. Please find the gist [here](https://colab.research.google.com/gist/saikumarchalla/2904b0ac3ee60c44defe00f3f2f5e72d/untitled93.ipynb).Thanks!",
"created_at": "2021-05-29T05:09:32Z"
},
{
"body": "Added a PR #51497 for the fix.",
"created_at": "2021-08-15T04:25:18Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46914\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46914\">No</a>\n",
"created_at": "2021-08-18T00:21:16Z"
},
{
"body": "I also observed the following API aliases or similar APIs can cause the same issue in older versions of tensorflow.\r\nUsers should be cautious when using them on both CPU and GPU up to tensorflow 2.6.0 (v2.6.0-rc2-32-g919f693420e).\r\n\r\n- `(tf.keras.layers.UpSampling2D)`, `tf.compat.v1.keras.layers.UpSampling2D`\r\n- `tf.keras.layers.UpSampling1D`, `tf.compat.v1.keras.layers.UpSampling1D`\r\n- `tf.keras.layers.UpSampling3D`, `tf.compat.v1.keras.layers.UpSampling3D`\r\n\r\n<details>\r\n <summary>Code to reproduce the issue for above APIs in older versions</summary>\r\n\r\n- <code>(tf.keras.layers.UpSampling2D)</code>, <code>tf.compat.v1.keras.layers.UpSampling2D</code>\r\n\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\nprint(tf.version.GIT_VERSION, tf.version.VERSION, flush=True)\r\nprint(tf.config.list_physical_devices(), flush=True)\r\n\r\n\r\ntry:\r\n # tf.keras.layers.UpSampling2D(size=1610637938, data_format='channels_first', interpolation='bilinear')(np.ones((5,1,1,1)))\r\n tf.compat.v1.keras.layers.UpSampling2D(size=1610637938, data_format='channels_first', interpolation='bilinear')(np.ones((5,1,1,1)))\r\nexcept Exception as e:\r\n print(\"Error:\", str(e), flush=True)\r\nprint(\"Success!\", flush=True)\r\n```\r\n\r\n- <code>tf.keras.layers.UpSampling1D</code>, <code>tf.compat.v1.keras.layers.UpSampling1D</code>\r\n\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\nprint(tf.version.GIT_VERSION, tf.version.VERSION, flush=True)\r\nprint(tf.config.list_physical_devices(), flush=True)\r\n\r\n\r\ntry:\r\n tf.keras.layers.UpSampling1D(size=1610637938)(np.ones((5, 1, 1)))\r\n # tf.compat.v1.keras.layers.UpSampling1D(size=1610637938)(np.ones((5, 1, 1)))\r\nexcept Exception as e:\r\n print(\"Error:\", str(e), flush=True)\r\nprint(\"Success!\", flush=True)\r\n```\r\n\r\n- <code>tf.keras.layers.UpSampling3D</code>, <code>tf.compat.v1.keras.layers.UpSampling3D</code>\r\n\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\nprint(tf.version.GIT_VERSION, tf.version.VERSION, flush=True)\r\nprint(tf.config.list_physical_devices(), flush=True)\r\n\r\n\r\ntry:\r\n tf.keras.layers.UpSampling3D(size=1610637938, data_format='channels_first')(np.ones((5, 1, 1, 1, 1)))\r\n # tf.compat.v1.keras.layers.UpSampling3D(size=1610637938, data_format='channels_first')(np.ones((5, 1, 1, 1, 1)))\r\nexcept Exception as e:\r\n print(\"Error:\", str(e), flush=True)\r\nprint(\"Success!\", flush=True)\r\n```\r\n\r\nThe above code will cause the process to be aborted on both CPU and GPU, which is unexpected.\r\n\r\nThe following are the outputs of the above code on my GPU machine:\r\n\r\n```text\r\nv2.6.0-rc2-32-g919f693420e 2.6.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\r\n2023-09-08 09:24:30.615084: F tensorflow/core/framework/tensor_shape.cc:187] Non-OK-status: InitDims(dim_sizes) status: Internal: Encountered overflow when multiplying 8053189690 with 1610637938, result: -5475971237085092396\r\nAborted (core dumped)\r\n```\r\n\r\nOn CPU:\r\n\r\n```text\r\nv2.6.0-rc2-32-g919f693420e 2.6.0\r\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')]\r\n2023-09-08 09:24:18.882704: F tensorflow/core/framework/tensor_shape.cc:187] Non-OK-status: InitDims(dim_sizes) status: Internal: Encountered overflow when multiplying 8053189690 with 1610637938, result: -5475971237085092396\r\nAborted (core dumped)\r\n```\r\n</details>\r\n\r\nIt seems to be fixed in tensorflow 2.6.1 (v2.6.0-101-g3aa40c3ce9d) and later versions.\r\n",
"created_at": "2023-09-12T09:25:26Z"
}
],
"number": 46914,
"title": "tf.keras.layers.UpSampling2D crashes(aborts) when size is large"
}
|
{
"body": "This PR tries to address the issue raised in #46914 where tf.image.resize will crash if size is large, (implicitly causes tf.keras.layers.UpSampling2D to crash).\r\n\r\nThis PR adds necessary shape overflow check to prevent crash.\r\n\r\nThis PR fixes #46914.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 51497,
"review_comments": [],
"title": "Fix crash with tf.image.resize if size is large"
}
|
{
"commits": [
{
"message": "Fix crash with tf.image.resize if size is large\n\nThis PR tries to address the issue raised in 46914 where\ntf.image.resize will crash if size is large, (implicitly\ncauses tf.keras.layers.UpSampling2D to crash).\n\nThis PR adds necessary shape overflow check to prevent\ncrash.\n\nThis PR fixes 46914.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -143,11 +143,17 @@ struct ImageResizerState {\n void ValidateAndCreateOutput(OpKernelContext* context) {\n ValidateAndCalculateOutputSize(context);\n if (!context->status().ok()) return;\n+\n+ TensorShape shape;\n+ // Guard against shape overflow\n+ OP_REQUIRES_OK(context, shape.AddDimWithStatus(batch_size));\n+ OP_REQUIRES_OK(context, shape.AddDimWithStatus(out_height));\n+ OP_REQUIRES_OK(context, shape.AddDimWithStatus(out_width));\n+ OP_REQUIRES_OK(context, shape.AddDimWithStatus(channels));\n+\n OP_REQUIRES_OK(\n context,\n- context->allocate_output(\n- 0, TensorShape({batch_size, out_height, out_width, channels}),\n- &output));\n+ context->allocate_output( 0, shape, &output));\n }\n \n int64_t batch_size;",
"filename": "tensorflow/core/util/image_resizer_state.h",
"status": "modified"
},
{
"diff": "@@ -3161,6 +3161,14 @@ def testPreserveAspectRatioSquare(self):\n \n self._assertResizeCheckShape(x, x_shape, [320, 320], [320, 320, 3])\n \n+ def testLargeDim(self):\n+ with self.session():\n+ with self.assertRaises(errors.InternalError):\n+ x = np.ones((5, 1, 1, 2))\n+ v = image_ops.resize_images_v2(\n+ x, [1610637938, 1610637938], image_ops.ResizeMethod.BILINEAR)\n+ _ = self.evaluate(v)\n+\n \n class ResizeImagesTest(test_util.TensorFlowTestCase,\n parameterized.TestCase):",
"filename": "tensorflow/python/ops/image_ops_test.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 20.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: n/a\r\n- TensorFlow installed from (source or binary): both\r\n- TensorFlow version (use command below): 2.6.0\r\n- Python version: 3.8\r\n- Bazel version (if compiling from source): n/a\r\n- GCC/Compiler version (if compiling from source): n/a\r\n- CUDA/cuDNN version: n/a\r\n- GPU model and memory: n/a\r\n\r\n**Describe the current behavior**\r\n\r\nWhen multiple tensorflow instances are installed in different parts of your python path, TensorFlow will attempt to load kernel libraries from all of them, potentially resulting in an ABI mismatch.\r\n\r\n```\r\n$ python3 -c \"import tensorflow\"\r\nNo protocol specified\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/home/sclarkson/.local/lib/python3.8/site-packages/tensorflow/__init__.py\", line 438, in <module>\r\n _ll.load_library(_main_dir)\r\n File \"/home/sclarkson/.local/lib/python3.8/site-packages/tensorflow/python/framework/load_library.py\", line 154, in load_library\r\n py_tf.TF_LoadLibrary(lib)\r\ntensorflow.python.framework.errors_impl.NotFoundError: /usr/lib/python3/dist-packages/tensorflow/core/kernels/libtfkernel_sobol_op.so: undefined symbol: _ZNK10tensorflow8OpKernel11TraceStringB5cxx11ERKNS_15OpKernelContextEb\r\n\r\n```\r\n\r\nObserve above, the TensorFlow instance in `~/.local/lib/python3/` attempting to load a shared library from `/usr/lib/python3/`. Because of different compilation options, the library from the system-wide install is expecting symbols that do not exist in the pip install.\r\n\r\n**Describe the expected behavior**\r\n\r\nTensorFlow should only load kernels from its own install.\r\n\r\n**[Contributing](https://www.tensorflow.org/community/contribute)**\r\n\r\n- Do you want to contribute a PR? (yes/no): yes\r\n- Briefly describe your candidate solution(if contributing): modify kernel preloading to only use its own install\r\n\r\n**Standalone code to reproduce the issue**\r\n\r\nCompile TensorFlow from source and install system-wide.\r\nInstall TensorFlow from pip with `pip install --user tensorflow`\r\nThen run `python -c \"import tensorflow\"`\r\n\r\n**Other info**\r\n\r\nThis is a continuation of #42978",
"comments": [
{
"body": "@sclarkson The issue will move to closed status once the PR is merged.Thank you!",
"created_at": "2021-08-13T07:46:11Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51451\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/51451\">No</a>\n",
"created_at": "2021-08-18T17:53:25Z"
}
],
"number": 51451,
"title": "Multiple versions of TensorFlow co-installed potentially cause ABI mismatch"
}
|
{
"body": "Previously, kernels from every installed instance of TensorFlow would be\r\npreloaded, causing potential ABI conflicts.\r\n\r\nFixes #51451",
"number": 51452,
"review_comments": [],
"title": "Only preload kernels from running TF instance"
}
|
{
"commits": [
{
"message": "Only preload kernels from running TF instance\n\nPreviously, kernels from every installed instance of TensorFlow would be\npreloaded, causing potential ABI conflicts."
}
],
"files": [
{
"diff": "@@ -135,13 +135,15 @@ def _running_from_pip_package():\n \n if _running_from_pip_package():\n # TODO(gunan): Add sanity checks to loaded modules here.\n- for _s in _site_packages_dirs:\n- # Load first party dynamic kernels.\n- _main_dir = _os.path.join(_s, 'tensorflow/core/kernels')\n- if _os.path.exists(_main_dir):\n- _ll.load_library(_main_dir)\n \n- # Load third party dynamic kernels.\n+ # Load first party dynamic kernels.\n+ _tf_dir = _os.path.dirname(_current_file_location)\n+ _kernel_dir = _os.path.join(_tf_dir, 'core', 'kernels')\n+ if _os.path.exists(_kernel_dir):\n+ _ll.load_library(_kernel_dir)\n+\n+ # Load third party dynamic kernels.\n+ for _s in _site_packages_dirs:\n _plugin_dir = _os.path.join(_s, 'tensorflow-plugins')\n if _os.path.exists(_plugin_dir):\n _ll.load_library(_plugin_dir)",
"filename": "tensorflow/api_template.__init__.py",
"status": "modified"
},
{
"diff": "@@ -167,13 +167,15 @@ def _running_from_pip_package():\n \n if _running_from_pip_package():\n # TODO(gunan): Add sanity checks to loaded modules here.\n- for _s in _site_packages_dirs:\n- # Load first party dynamic kernels.\n- _main_dir = _os.path.join(_s, 'tensorflow/core/kernels')\n- if _os.path.exists(_main_dir):\n- _ll.load_library(_main_dir)\n \n- # Load third party dynamic kernels.\n+ # Load first party dynamic kernels.\n+ _tf_dir = _os.path.dirname(_current_file_location)\n+ _kernel_dir = _os.path.join(_tf_dir, 'core', 'kernels')\n+ if _os.path.exists(_kernel_dir):\n+ _ll.load_library(_kernel_dir)\n+\n+ # Load third party dynamic kernels.\n+ for _s in _site_packages_dirs:\n _plugin_dir = _os.path.join(_s, 'tensorflow-plugins')\n if _os.path.exists(_plugin_dir):\n _ll.load_library(_plugin_dir)",
"filename": "tensorflow/api_template_v1.__init__.py",
"status": "modified"
}
]
}
|
{
"body": "**System information**\r\n- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 18.04\r\n- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: N/A\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below):2.1.0\r\n- Python version:3.7.6\r\n- Bazel version (if compiling from source):N/A\r\n- GCC/Compiler version (if compiling from source):N/A\r\n- CUDA/cuDNN version:N/A\r\n- GPU model and memory:N/A\r\n\r\n**Describe the current behavior**\r\n`tf.keras.layers.RepeatVector` crashes(aborts) when `n` is large\r\n\r\n**Describe the expected behavior**\r\nexpect an exception message if the input unexpected instead of crash. \r\n\r\n**Standalone code to reproduce the issue**\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.layers.RepeatVector(n=9223372036854775807)(np.ones((3, 1)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\n2021-02-04 04:42:07.262027: F tensorflow/core/framework/tensor_shape.cc:353] Check failed: 0 <= new_num_elements (0 vs. -1)\r\nAborted (core dumped)\r\n~~~",
"comments": [
{
"body": "@rmothukuru \r\nI ran the code shared on tf 2.4 and nightly, colab crashes. Please find the [gist here](https://colab.research.google.com/gist/Saduf2019/a19ece73799cb1d602387e840fe98574/untitled520.ipynb).",
"created_at": "2021-02-04T04:58:45Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46913\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46913\">No</a>\n",
"created_at": "2021-02-19T22:31:34Z"
},
{
"body": "BTW, tf.keras.layers.RepeatVector thorws segmentation fault when data is empty:\r\n~~~python\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.layers.RepeatVector(n=9223372036854775807)(np.ones((0,0)))\r\n~~~\r\n\r\nOutput:\r\n~~~python\r\nSegmentation fault (core dumped)\r\n~~~",
"created_at": "2021-02-19T22:35:20Z"
},
{
"body": "Colab crashes in TF 2.6 as well. Please find the gist [here](https://colab.research.google.com/gist/saikumarchalla/4ef0fe758f11af629a9485dbfaa17e17/untitled93.ipynb).",
"created_at": "2021-05-29T05:06:49Z"
},
{
"body": "Added a PR #51359 for the fix.",
"created_at": "2021-08-07T17:25:43Z"
},
{
"body": "Are you satisfied with the resolution of your issue?\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=Yes&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46913\">Yes</a>\n<a href=\"https://docs.google.com/forms/d/e/1FAIpQLSfaP12TRhd9xSxjXZjcZFNXPGk4kc1-qMdv3gc6bEP90vY1ew/viewform?entry.85265664=No&entry.2137816233=https://github.com/tensorflow/tensorflow/issues/46913\">No</a>\n",
"created_at": "2021-08-18T15:16:01Z"
},
{
"body": "This second input still crashes in the nightly version, see [gist](https://colab.research.google.com/drive/1eGLreialnwDETqk5LipkD1mLd7v5N9vP?usp=sharing) @yongtang \r\n\r\n```\r\nimport tensorflow as tf\r\nimport numpy as np\r\ntf.keras.layers.RepeatVector(n=9223372036854775807)(np.ones((0,0)))\r\n```",
"created_at": "2022-05-05T14:59:22Z"
}
],
"number": 46913,
"title": "tf.keras.layers.RepeatVector crashes(aborts) when n is large"
}
|
{
"body": "This PR tries to address the issue raised in #46913 where\r\ntf.range (and implicitly tf.keras.layers.RepeatVector)\r\nwill overflow/crash when limits is large.\r\n\r\nThe reason of the overflow is that while calculating\r\nthe size within the kernel, the conditional statements\r\ncomes with `int64 = cond ? int64 : double` will implicitly\r\nconvert to double first and then cast back to int64, causing\r\nthe overflow and crash.\r\n\r\nThis PR fixes the issue by casting to int64 in both selections\r\nwithin the conditional statements first.\r\n\r\nThis PR fixes #46913.\r\n\r\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>",
"number": 51359,
"review_comments": [
{
"body": "Let's separate each branch to a separate expression to ease in readability.",
"created_at": "2021-08-09T15:01:14Z"
}
],
"title": "Fix overflow/crash in tf.range when limits is large"
}
|
{
"commits": [
{
"message": "Fix overflow/crash in tf.range when limits is large\n\nThis PR tries to address the issue raised in 46913 where\ntf.range (and implicitly tf.keras.layers.RepeatVector)\nwill overflow/crash when limits is large.\n\nThe reason of the overflow is that while calculating\nthe size within the kernel, the conditional statements\ncomes with `int64 = cond ? int64 : double` will implicitly\nconvert to double first and then cast back to int64, causing\nthe overflow and crash.\n\nThis PR fixes the issue by casting to int64 in both selections\nwithin the conditional statements first.\n\nThis PR fixes 46913.\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
},
{
"message": "Convert conditional statement to if..else.. to address review feedback\n\nSigned-off-by: Yong Tang <yong.tang.github@outlook.com>"
}
],
"files": [
{
"diff": "@@ -71,10 +71,14 @@ class RangeOp : public OpKernel {\n errors::InvalidArgument(\n \"Requires start >= limit when delta < 0: \", start, \"/\", limit));\n }\n- int64_t size = (std::is_integral<T>::value\n- ? ((std::abs(limit - start) + std::abs(delta) - 1) /\n- std::abs(delta))\n- : std::ceil(std::abs((limit - start) / delta)));\n+ int64_t size = 0;\n+ if (std::is_integral<T>::value) {\n+ size = static_cast<int64>(\n+ (std::abs(limit - start) + std::abs(delta) - 1) / std::abs(delta));\n+ } else {\n+ size = static_cast<int64>(\n+ std::ceil(std::abs((limit - start) / delta)));\n+ }\n Tensor* out = nullptr;\n OP_REQUIRES_OK(context,\n context->allocate_output(0, TensorShape({size}), &out));",
"filename": "tensorflow/core/kernels/sequence_ops.cc",
"status": "modified"
},
{
"diff": "@@ -23,6 +23,7 @@\n \n from tensorflow.python.framework import constant_op\n from tensorflow.python.framework import dtypes\n+from tensorflow.python.framework import errors_impl\n from tensorflow.python.framework import ops\n from tensorflow.python.framework import random_seed\n from tensorflow.python.framework import test_util\n@@ -542,6 +543,13 @@ def testMixedDType(self):\n constant_op.constant(4, dtype=dtypes.int32), dtype=dtypes.int64)\n self.assertAllEqual(self.evaluate(tf_ans), np.array([0, 1, 2, 3]))\n \n+ def testLargeLimits(self):\n+ # Test case for GitHub issue 46913.\n+ with self.session():\n+ with self.assertRaises(errors_impl.ResourceExhaustedError):\n+ v = math_ops.range(0, 9223372036854775807)\n+ self.evaluate(v)\n+\n \n # TODO(vrv): move to sequence_ops_test?\n class LinSpaceTest(test.TestCase):",
"filename": "tensorflow/python/kernel_tests/init_ops_test.py",
"status": "modified"
}
]
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.