
text
stringlengths 7
3.71M
| id
stringlengths 12
166
| metadata
dict | __index_level_0__
int64 0
658
|
|---|---|---|---|
import importlib
import shutil
import warnings
from typing import List
import fsspec
import fsspec.asyn
from fsspec.implementations.local import LocalFileSystem
from ..utils.deprecation_utils import deprecated
from . import compression
_has_s3fs = importlib.util.find_spec("s3fs") is not None
if _has_s3fs:
from .s3filesystem import S3FileSystem # noqa: F401
COMPRESSION_FILESYSTEMS: List[compression.BaseCompressedFileFileSystem] = [
compression.Bz2FileSystem,
compression.GzipFileSystem,
compression.Lz4FileSystem,
compression.XzFileSystem,
compression.ZstdFileSystem,
]
# Register custom filesystems
for fs_class in COMPRESSION_FILESYSTEMS:
if fs_class.protocol in fsspec.registry and fsspec.registry[fs_class.protocol] is not fs_class:
warnings.warn(f"A filesystem protocol was already set for {fs_class.protocol} and will be overwritten.")
fsspec.register_implementation(fs_class.protocol, fs_class, clobber=True)
@deprecated(
"This function is deprecated and will be removed in a future version. Please use `fsspec.core.strip_protocol` instead."
)
def extract_path_from_uri(dataset_path: str) -> str:
"""
Preprocesses `dataset_path` and removes remote filesystem (e.g. removing `s3://`).
Args:
dataset_path (`str`):
Path (e.g. `dataset/train`) or remote uri (e.g. `s3://my-bucket/dataset/train`) of the dataset directory.
"""
if "://" in dataset_path:
dataset_path = dataset_path.split("://")[1]
return dataset_path
def is_remote_filesystem(fs: fsspec.AbstractFileSystem) -> bool:
"""
Checks if `fs` is a remote filesystem.
Args:
fs (`fsspec.spec.AbstractFileSystem`):
An abstract super-class for pythonic file-systems, e.g. `fsspec.filesystem(\'file\')` or [`datasets.filesystems.S3FileSystem`].
"""
return not isinstance(fs, LocalFileSystem)
def rename(fs: fsspec.AbstractFileSystem, src: str, dst: str):
"""
Renames the file `src` in `fs` to `dst`.
"""
if not is_remote_filesystem(fs):
# LocalFileSystem.mv does copy + rm, it is more efficient to simply move a local directory
shutil.move(fs._strip_protocol(src), fs._strip_protocol(dst))
else:
fs.mv(src, dst, recursive=True)
| datasets/src/datasets/filesystems/__init__.py/0 | {
"file_path": "datasets/src/datasets/filesystems/__init__.py",
"repo_id": "datasets",
"token_count": 866
} | 190 |
import multiprocessing
import os
from typing import BinaryIO, Optional, Union
import fsspec
from .. import Dataset, Features, NamedSplit, config
from ..formatting import query_table
from ..packaged_modules.csv.csv import Csv
from ..utils import tqdm as hf_tqdm
from ..utils.typing import NestedDataStructureLike, PathLike
from .abc import AbstractDatasetReader
class CsvDatasetReader(AbstractDatasetReader):
def __init__(
self,
path_or_paths: NestedDataStructureLike[PathLike],
split: Optional[NamedSplit] = None,
features: Optional[Features] = None,
cache_dir: str = None,
keep_in_memory: bool = False,
streaming: bool = False,
num_proc: Optional[int] = None,
**kwargs,
):
super().__init__(
path_or_paths,
split=split,
features=features,
cache_dir=cache_dir,
keep_in_memory=keep_in_memory,
streaming=streaming,
num_proc=num_proc,
**kwargs,
)
path_or_paths = path_or_paths if isinstance(path_or_paths, dict) else {self.split: path_or_paths}
self.builder = Csv(
cache_dir=cache_dir,
data_files=path_or_paths,
features=features,
**kwargs,
)
def read(self):
# Build iterable dataset
if self.streaming:
dataset = self.builder.as_streaming_dataset(split=self.split)
# Build regular (map-style) dataset
else:
download_config = None
download_mode = None
verification_mode = None
base_path = None
self.builder.download_and_prepare(
download_config=download_config,
download_mode=download_mode,
verification_mode=verification_mode,
base_path=base_path,
num_proc=self.num_proc,
)
dataset = self.builder.as_dataset(
split=self.split, verification_mode=verification_mode, in_memory=self.keep_in_memory
)
return dataset
class CsvDatasetWriter:
def __init__(
self,
dataset: Dataset,
path_or_buf: Union[PathLike, BinaryIO],
batch_size: Optional[int] = None,
num_proc: Optional[int] = None,
storage_options: Optional[dict] = None,
**to_csv_kwargs,
):
if num_proc is not None and num_proc <= 0:
raise ValueError(f"num_proc {num_proc} must be an integer > 0.")
self.dataset = dataset
self.path_or_buf = path_or_buf
self.batch_size = batch_size if batch_size else config.DEFAULT_MAX_BATCH_SIZE
self.num_proc = num_proc
self.encoding = "utf-8"
self.storage_options = storage_options or {}
self.to_csv_kwargs = to_csv_kwargs
def write(self) -> int:
_ = self.to_csv_kwargs.pop("path_or_buf", None)
header = self.to_csv_kwargs.pop("header", True)
index = self.to_csv_kwargs.pop("index", False)
if isinstance(self.path_or_buf, (str, bytes, os.PathLike)):
with fsspec.open(self.path_or_buf, "wb", **(self.storage_options or {})) as buffer:
written = self._write(file_obj=buffer, header=header, index=index, **self.to_csv_kwargs)
else:
written = self._write(file_obj=self.path_or_buf, header=header, index=index, **self.to_csv_kwargs)
return written
def _batch_csv(self, args):
offset, header, index, to_csv_kwargs = args
batch = query_table(
table=self.dataset.data,
key=slice(offset, offset + self.batch_size),
indices=self.dataset._indices,
)
csv_str = batch.to_pandas().to_csv(
path_or_buf=None, header=header if (offset == 0) else False, index=index, **to_csv_kwargs
)
return csv_str.encode(self.encoding)
def _write(self, file_obj: BinaryIO, header, index, **to_csv_kwargs) -> int:
"""Writes the pyarrow table as CSV to a binary file handle.
Caller is responsible for opening and closing the handle.
"""
written = 0
if self.num_proc is None or self.num_proc == 1:
for offset in hf_tqdm(
range(0, len(self.dataset), self.batch_size),
unit="ba",
desc="Creating CSV from Arrow format",
):
csv_str = self._batch_csv((offset, header, index, to_csv_kwargs))
written += file_obj.write(csv_str)
else:
num_rows, batch_size = len(self.dataset), self.batch_size
with multiprocessing.Pool(self.num_proc) as pool:
for csv_str in hf_tqdm(
pool.imap(
self._batch_csv,
[(offset, header, index, to_csv_kwargs) for offset in range(0, num_rows, batch_size)],
),
total=(num_rows // batch_size) + 1 if num_rows % batch_size else num_rows // batch_size,
unit="ba",
desc="Creating CSV from Arrow format",
):
written += file_obj.write(csv_str)
return written
| datasets/src/datasets/io/csv.py/0 | {
"file_path": "datasets/src/datasets/io/csv.py",
"repo_id": "datasets",
"token_count": 2556
} | 191 |
from typing import List
import datasets
from datasets.tasks import AudioClassification
from ..folder_based_builder import folder_based_builder
logger = datasets.utils.logging.get_logger(__name__)
class AudioFolderConfig(folder_based_builder.FolderBasedBuilderConfig):
"""Builder Config for AudioFolder."""
drop_labels: bool = None
drop_metadata: bool = None
class AudioFolder(folder_based_builder.FolderBasedBuilder):
BASE_FEATURE = datasets.Audio
BASE_COLUMN_NAME = "audio"
BUILDER_CONFIG_CLASS = AudioFolderConfig
EXTENSIONS: List[str] # definition at the bottom of the script
CLASSIFICATION_TASK = AudioClassification(audio_column="audio", label_column="label")
# Obtained with:
# ```
# import soundfile as sf
#
# AUDIO_EXTENSIONS = [f".{format.lower()}" for format in sf.available_formats().keys()]
#
# # .mp3 is currently decoded via `torchaudio`, .opus decoding is supported if version of `libsndfile` >= 1.0.30:
# AUDIO_EXTENSIONS.extend([".mp3", ".opus"])
# ```
# We intentionally do not run this code on launch because:
# (1) Soundfile is an optional dependency, so importing it in global namespace is not allowed
# (2) To ensure the list of supported extensions is deterministic
AUDIO_EXTENSIONS = [
".aiff",
".au",
".avr",
".caf",
".flac",
".htk",
".svx",
".mat4",
".mat5",
".mpc2k",
".ogg",
".paf",
".pvf",
".raw",
".rf64",
".sd2",
".sds",
".ircam",
".voc",
".w64",
".wav",
".nist",
".wavex",
".wve",
".xi",
".mp3",
".opus",
]
AudioFolder.EXTENSIONS = AUDIO_EXTENSIONS
| datasets/src/datasets/packaged_modules/audiofolder/audiofolder.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/audiofolder/audiofolder.py",
"repo_id": "datasets",
"token_count": 618
} | 192 |
import itertools
from dataclasses import dataclass
from typing import List, Optional
import pyarrow as pa
import pyarrow.parquet as pq
import datasets
from datasets.table import table_cast
logger = datasets.utils.logging.get_logger(__name__)
@dataclass
class ParquetConfig(datasets.BuilderConfig):
"""BuilderConfig for Parquet."""
batch_size: Optional[int] = None
columns: Optional[List[str]] = None
features: Optional[datasets.Features] = None
class Parquet(datasets.ArrowBasedBuilder):
BUILDER_CONFIG_CLASS = ParquetConfig
def _info(self):
if (
self.config.columns is not None
and self.config.features is not None
and set(self.config.columns) != set(self.config.features)
):
raise ValueError(
"The columns and features argument must contain the same columns, but got ",
f"{self.config.columns} and {self.config.features}",
)
return datasets.DatasetInfo(features=self.config.features)
def _split_generators(self, dl_manager):
"""We handle string, list and dicts in datafiles"""
if not self.config.data_files:
raise ValueError(f"At least one data file must be specified, but got data_files={self.config.data_files}")
dl_manager.download_config.extract_on_the_fly = True
data_files = dl_manager.download_and_extract(self.config.data_files)
if isinstance(data_files, (str, list, tuple)):
files = data_files
if isinstance(files, str):
files = [files]
# Use `dl_manager.iter_files` to skip hidden files in an extracted archive
files = [dl_manager.iter_files(file) for file in files]
return [datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"files": files})]
splits = []
for split_name, files in data_files.items():
if isinstance(files, str):
files = [files]
# Use `dl_manager.iter_files` to skip hidden files in an extracted archive
files = [dl_manager.iter_files(file) for file in files]
# Infer features if they are stored in the arrow schema
if self.info.features is None:
for file in itertools.chain.from_iterable(files):
with open(file, "rb") as f:
self.info.features = datasets.Features.from_arrow_schema(pq.read_schema(f))
break
splits.append(datasets.SplitGenerator(name=split_name, gen_kwargs={"files": files}))
if self.config.columns is not None and set(self.config.columns) != set(self.info.features):
self.info.features = datasets.Features(
{col: feat for col, feat in self.info.features.items() if col in self.config.columns}
)
return splits
def _cast_table(self, pa_table: pa.Table) -> pa.Table:
if self.info.features is not None:
# more expensive cast to support nested features with keys in a different order
# allows str <-> int/float or str to Audio for example
pa_table = table_cast(pa_table, self.info.features.arrow_schema)
return pa_table
def _generate_tables(self, files):
if self.config.features is not None and self.config.columns is not None:
if sorted(field.name for field in self.info.features.arrow_schema) != sorted(self.config.columns):
raise ValueError(
f"Tried to load parquet data with columns '{self.config.columns}' with mismatching features '{self.info.features}'"
)
for file_idx, file in enumerate(itertools.chain.from_iterable(files)):
with open(file, "rb") as f:
parquet_file = pq.ParquetFile(f)
if parquet_file.metadata.num_row_groups > 0:
batch_size = self.config.batch_size or parquet_file.metadata.row_group(0).num_rows
try:
for batch_idx, record_batch in enumerate(
parquet_file.iter_batches(batch_size=batch_size, columns=self.config.columns)
):
pa_table = pa.Table.from_batches([record_batch])
# Uncomment for debugging (will print the Arrow table size and elements)
# logger.warning(f"pa_table: {pa_table} num rows: {pa_table.num_rows}")
# logger.warning('\n'.join(str(pa_table.slice(i, 1).to_pydict()) for i in range(pa_table.num_rows)))
yield f"{file_idx}_{batch_idx}", self._cast_table(pa_table)
except ValueError as e:
logger.error(f"Failed to read file '{file}' with error {type(e)}: {e}")
raise
| datasets/src/datasets/packaged_modules/parquet/parquet.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/parquet/parquet.py",
"repo_id": "datasets",
"token_count": 2220
} | 193 |
from typing import Optional
from ..utils.logging import get_logger
from .audio_classification import AudioClassification
from .automatic_speech_recognition import AutomaticSpeechRecognition
from .base import TaskTemplate
from .image_classification import ImageClassification
from .language_modeling import LanguageModeling
from .question_answering import QuestionAnsweringExtractive
from .summarization import Summarization
from .text_classification import TextClassification
__all__ = [
"AutomaticSpeechRecognition",
"AudioClassification",
"ImageClassification",
"LanguageModeling",
"QuestionAnsweringExtractive",
"Summarization",
"TaskTemplate",
"TextClassification",
]
logger = get_logger(__name__)
NAME2TEMPLATE = {
AutomaticSpeechRecognition.task: AutomaticSpeechRecognition,
AudioClassification.task: AudioClassification,
ImageClassification.task: ImageClassification,
LanguageModeling.task: LanguageModeling,
QuestionAnsweringExtractive.task: QuestionAnsweringExtractive,
Summarization.task: Summarization,
TextClassification.task: TextClassification,
}
def task_template_from_dict(task_template_dict: dict) -> Optional[TaskTemplate]:
"""Create one of the supported task templates in :py:mod:`datasets.tasks` from a dictionary."""
task_name = task_template_dict.get("task")
if task_name is None:
logger.warning(f"Couldn't find template for task '{task_name}'. Available templates: {list(NAME2TEMPLATE)}")
return None
template = NAME2TEMPLATE.get(task_name)
return template.from_dict(task_template_dict)
| datasets/src/datasets/tasks/__init__.py/0 | {
"file_path": "datasets/src/datasets/tasks/__init__.py",
"repo_id": "datasets",
"token_count": 506
} | 194 |
# deprecated, please use datasets.download.download_manager
| datasets/src/datasets/utils/download_manager.py/0 | {
"file_path": "datasets/src/datasets/utils/download_manager.py",
"repo_id": "datasets",
"token_count": 13
} | 195 |
name: "" # Filename comes here
allow_empty: false
allow_empty_text: true
subsections:
- name: "Dataset Card for X" # First-level markdown heading
allow_empty: false
allow_empty_text: true
subsections:
- name: "Table of Contents"
allow_empty: false
allow_empty_text: false
subsections: null # meaning it should not be checked.
- name: "Dataset Description"
allow_empty: false
allow_empty_text: false
subsections:
- name: "Dataset Summary"
allow_empty: false
allow_empty_text: false
subsections: null
- name: "Supported Tasks and Leaderboards"
allow_empty: true
allow_empty_text: true
subsections: null
- name: Languages
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Dataset Structure"
allow_empty: false
allow_empty_text: true
subsections:
- name: "Data Instances"
allow_empty: false
allow_empty_text: true
subsections: null
- name: "Data Fields"
allow_empty: false
allow_empty_text: true
subsections: null
- name: "Data Splits"
allow_empty: false
allow_empty_text: true
subsections: null
- name: "Dataset Creation"
allow_empty: false
allow_empty_text: true
subsections:
- name: "Curation Rationale"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Source Data"
allow_empty: false
allow_empty_text: true
subsections:
- name: "Initial Data Collection and Normalization"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Who are the source language producers?"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Annotations"
allow_empty: false
allow_empty_text: true
subsections:
- name: "Annotation process"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Who are the annotators?"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Personal and Sensitive Information"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Considerations for Using the Data"
allow_empty: true
allow_empty_text: true
subsections:
- name: "Social Impact of Dataset"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Discussion of Biases"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Other Known Limitations"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Additional Information"
allow_empty: true
allow_empty_text: true
subsections:
- name: "Dataset Curators"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Licensing Information"
allow_empty: true
allow_empty_text: true
subsections: null
- name: "Citation Information"
allow_empty: false
allow_empty_text: true
subsections: null
- name: "Contributions"
allow_empty: false
allow_empty_text: false
subsections: null
| datasets/src/datasets/utils/resources/readme_structure.yaml/0 | {
"file_path": "datasets/src/datasets/utils/resources/readme_structure.yaml",
"repo_id": "datasets",
"token_count": 1924
} | 196 |
import os
import tarfile
import warnings
from io import BytesIO
import numpy as np
import pandas as pd
import pyarrow as pa
import pytest
from datasets import Dataset, Features, Image, Sequence, Value, concatenate_datasets, load_dataset
from datasets.features.image import encode_np_array, image_to_bytes
from ..utils import require_pil
@pytest.fixture
def tar_jpg_path(shared_datadir, tmp_path_factory):
image_path = str(shared_datadir / "test_image_rgb.jpg")
path = tmp_path_factory.mktemp("data") / "image_data.jpg.tar"
with tarfile.TarFile(path, "w") as f:
f.add(image_path, arcname=os.path.basename(image_path))
return path
def iter_archive(archive_path):
with tarfile.open(archive_path) as tar:
for tarinfo in tar:
file_path = tarinfo.name
file_obj = tar.extractfile(tarinfo)
yield file_path, file_obj
def test_image_instantiation():
image = Image()
assert image.id is None
assert image.dtype == "PIL.Image.Image"
assert image.pa_type == pa.struct({"bytes": pa.binary(), "path": pa.string()})
assert image._type == "Image"
def test_image_feature_type_to_arrow():
features = Features({"image": Image()})
assert features.arrow_schema == pa.schema({"image": Image().pa_type})
features = Features({"struct_containing_an_image": {"image": Image()}})
assert features.arrow_schema == pa.schema({"struct_containing_an_image": pa.struct({"image": Image().pa_type})})
features = Features({"sequence_of_images": Sequence(Image())})
assert features.arrow_schema == pa.schema({"sequence_of_images": pa.list_(Image().pa_type)})
@require_pil
@pytest.mark.parametrize(
"build_example",
[
lambda image_path: image_path,
lambda image_path: open(image_path, "rb").read(),
lambda image_path: {"path": image_path},
lambda image_path: {"path": image_path, "bytes": None},
lambda image_path: {"path": image_path, "bytes": open(image_path, "rb").read()},
lambda image_path: {"path": None, "bytes": open(image_path, "rb").read()},
lambda image_path: {"bytes": open(image_path, "rb").read()},
],
)
def test_image_feature_encode_example(shared_datadir, build_example):
import PIL.Image
image_path = str(shared_datadir / "test_image_rgb.jpg")
image = Image()
encoded_example = image.encode_example(build_example(image_path))
assert isinstance(encoded_example, dict)
assert encoded_example.keys() == {"bytes", "path"}
assert encoded_example["bytes"] is not None or encoded_example["path"] is not None
decoded_example = image.decode_example(encoded_example)
assert isinstance(decoded_example, PIL.Image.Image)
@require_pil
def test_image_decode_example(shared_datadir):
import PIL.Image
image_path = str(shared_datadir / "test_image_rgb.jpg")
image = Image()
decoded_example = image.decode_example({"path": image_path, "bytes": None})
assert isinstance(decoded_example, PIL.Image.Image)
assert os.path.samefile(decoded_example.filename, image_path)
assert decoded_example.size == (640, 480)
assert decoded_example.mode == "RGB"
with pytest.raises(RuntimeError):
Image(decode=False).decode_example(image_path)
@require_pil
def test_image_decode_example_with_exif_orientation_tag(shared_datadir):
import PIL.Image
image_path = str(shared_datadir / "test_image_rgb.jpg")
buffer = BytesIO()
exif = PIL.Image.Exif()
exif[PIL.Image.ExifTags.Base.Orientation] = 8 # rotate the image for 90°
PIL.Image.open(image_path).save(buffer, format="JPEG", exif=exif.tobytes())
image = Image()
decoded_example = image.decode_example({"path": None, "bytes": buffer.getvalue()})
assert isinstance(decoded_example, PIL.Image.Image)
assert decoded_example.size == (480, 640) # rotated
assert decoded_example.mode == "RGB"
@require_pil
def test_image_change_mode(shared_datadir):
import PIL.Image
image_path = str(shared_datadir / "test_image_rgb.jpg")
image = Image(mode="YCbCr")
decoded_example = image.decode_example({"path": image_path, "bytes": None})
assert isinstance(decoded_example, PIL.Image.Image)
assert not hasattr(decoded_example, "filename") # changing the mode drops the filename
assert decoded_example.size == (640, 480)
assert decoded_example.mode == "YCbCr"
@require_pil
def test_dataset_with_image_feature(shared_datadir):
import PIL.Image
image_path = str(shared_datadir / "test_image_rgb.jpg")
data = {"image": [image_path]}
features = Features({"image": Image()})
dset = Dataset.from_dict(data, features=features)
item = dset[0]
assert item.keys() == {"image"}
assert isinstance(item["image"], PIL.Image.Image)
assert os.path.samefile(item["image"].filename, image_path)
assert item["image"].format == "JPEG"
assert item["image"].size == (640, 480)
assert item["image"].mode == "RGB"
batch = dset[:1]
assert len(batch) == 1
assert batch.keys() == {"image"}
assert isinstance(batch["image"], list) and all(isinstance(item, PIL.Image.Image) for item in batch["image"])
assert os.path.samefile(batch["image"][0].filename, image_path)
assert batch["image"][0].format == "JPEG"
assert batch["image"][0].size == (640, 480)
assert batch["image"][0].mode == "RGB"
column = dset["image"]
assert len(column) == 1
assert isinstance(column, list) and all(isinstance(item, PIL.Image.Image) for item in column)
assert os.path.samefile(column[0].filename, image_path)
assert column[0].format == "JPEG"
assert column[0].size == (640, 480)
assert column[0].mode == "RGB"
@require_pil
@pytest.mark.parametrize("infer_feature", [False, True])
def test_dataset_with_image_feature_from_pil_image(infer_feature, shared_datadir):
import PIL.Image
image_path = str(shared_datadir / "test_image_rgb.jpg")
data = {"image": [PIL.Image.open(image_path)]}
features = Features({"image": Image()}) if not infer_feature else None
dset = Dataset.from_dict(data, features=features)
item = dset[0]
assert item.keys() == {"image"}
assert isinstance(item["image"], PIL.Image.Image)
assert os.path.samefile(item["image"].filename, image_path)
assert item["image"].format == "JPEG"
assert item["image"].size == (640, 480)
assert item["image"].mode == "RGB"
batch = dset[:1]
assert len(batch) == 1
assert batch.keys() == {"image"}
assert isinstance(batch["image"], list) and all(isinstance(item, PIL.Image.Image) for item in batch["image"])
assert os.path.samefile(batch["image"][0].filename, image_path)
assert batch["image"][0].format == "JPEG"
assert batch["image"][0].size == (640, 480)
assert batch["image"][0].mode == "RGB"
column = dset["image"]
assert len(column) == 1
assert isinstance(column, list) and all(isinstance(item, PIL.Image.Image) for item in column)
assert os.path.samefile(column[0].filename, image_path)
assert column[0].format == "JPEG"
assert column[0].size == (640, 480)
assert column[0].mode == "RGB"
@require_pil
def test_dataset_with_image_feature_from_np_array():
import PIL.Image
image_array = np.arange(640 * 480, dtype=np.int32).reshape(480, 640)
data = {"image": [image_array]}
features = Features({"image": Image()})
dset = Dataset.from_dict(data, features=features)
item = dset[0]
assert item.keys() == {"image"}
assert isinstance(item["image"], PIL.Image.Image)
np.testing.assert_array_equal(np.array(item["image"]), image_array)
assert item["image"].filename == ""
assert item["image"].format in ["PNG", "TIFF"]
assert item["image"].size == (640, 480)
batch = dset[:1]
assert len(batch) == 1
assert batch.keys() == {"image"}
assert isinstance(batch["image"], list) and all(isinstance(item, PIL.Image.Image) for item in batch["image"])
np.testing.assert_array_equal(np.array(batch["image"][0]), image_array)
assert batch["image"][0].filename == ""
assert batch["image"][0].format in ["PNG", "TIFF"]
assert batch["image"][0].size == (640, 480)
column = dset["image"]
assert len(column) == 1
assert isinstance(column, list) and all(isinstance(item, PIL.Image.Image) for item in column)
np.testing.assert_array_equal(np.array(column[0]), image_array)
assert column[0].filename == ""
assert column[0].format in ["PNG", "TIFF"]
assert column[0].size == (640, 480)
@require_pil
def test_dataset_with_image_feature_tar_jpg(tar_jpg_path):
import PIL.Image
data = {"image": []}
for file_path, file_obj in iter_archive(tar_jpg_path):
data["image"].append({"path": file_path, "bytes": file_obj.read()})
break
features = Features({"image": Image()})
dset = Dataset.from_dict(data, features=features)
item = dset[0]
assert item.keys() == {"image"}
assert isinstance(item["image"], PIL.Image.Image)
assert item["image"].filename == ""
assert item["image"].format == "JPEG"
assert item["image"].size == (640, 480)
assert item["image"].mode == "RGB"
batch = dset[:1]
assert len(batch) == 1
assert batch.keys() == {"image"}
assert isinstance(batch["image"], list) and all(isinstance(item, PIL.Image.Image) for item in batch["image"])
assert batch["image"][0].filename == ""
assert batch["image"][0].format == "JPEG"
assert batch["image"][0].size == (640, 480)
assert batch["image"][0].mode == "RGB"
column = dset["image"]
assert len(column) == 1
assert isinstance(column, list) and all(isinstance(item, PIL.Image.Image) for item in column)
assert column[0].filename == ""
assert column[0].format == "JPEG"
assert column[0].size == (640, 480)
assert column[0].mode == "RGB"
@require_pil
def test_dataset_with_image_feature_with_none():
data = {"image": [None]}
features = Features({"image": Image()})
dset = Dataset.from_dict(data, features=features)
item = dset[0]
assert item.keys() == {"image"}
assert item["image"] is None
batch = dset[:1]
assert len(batch) == 1
assert batch.keys() == {"image"}
assert isinstance(batch["image"], list) and all(item is None for item in batch["image"])
column = dset["image"]
assert len(column) == 1
assert isinstance(column, list) and all(item is None for item in column)
# nested tests
data = {"images": [[None]]}
features = Features({"images": Sequence(Image())})
dset = Dataset.from_dict(data, features=features)
item = dset[0]
assert item.keys() == {"images"}
assert all(i is None for i in item["images"])
data = {"nested": [{"image": None}]}
features = Features({"nested": {"image": Image()}})
dset = Dataset.from_dict(data, features=features)
item = dset[0]
assert item.keys() == {"nested"}
assert item["nested"].keys() == {"image"}
assert item["nested"]["image"] is None
@require_pil
@pytest.mark.parametrize(
"build_data",
[
lambda image_path: {"image": [image_path]},
lambda image_path: {"image": [open(image_path, "rb").read()]},
lambda image_path: {"image": [{"path": image_path}]},
lambda image_path: {"image": [{"path": image_path, "bytes": None}]},
lambda image_path: {"image": [{"path": image_path, "bytes": open(image_path, "rb").read()}]},
lambda image_path: {"image": [{"path": None, "bytes": open(image_path, "rb").read()}]},
lambda image_path: {"image": [{"bytes": open(image_path, "rb").read()}]},
],
)
def test_dataset_cast_to_image_features(shared_datadir, build_data):
import PIL.Image
image_path = str(shared_datadir / "test_image_rgb.jpg")
data = build_data(image_path)
dset = Dataset.from_dict(data)
item = dset.cast(Features({"image": Image()}))[0]
assert item.keys() == {"image"}
assert isinstance(item["image"], PIL.Image.Image)
item = dset.cast_column("image", Image())[0]
assert item.keys() == {"image"}
assert isinstance(item["image"], PIL.Image.Image)
@require_pil
def test_dataset_concatenate_image_features(shared_datadir):
# we use a different data structure between 1 and 2 to make sure they are compatible with each other
image_path = str(shared_datadir / "test_image_rgb.jpg")
data1 = {"image": [image_path]}
dset1 = Dataset.from_dict(data1, features=Features({"image": Image()}))
data2 = {"image": [{"bytes": open(image_path, "rb").read()}]}
dset2 = Dataset.from_dict(data2, features=Features({"image": Image()}))
concatenated_dataset = concatenate_datasets([dset1, dset2])
assert len(concatenated_dataset) == len(dset1) + len(dset2)
assert concatenated_dataset[0]["image"] == dset1[0]["image"]
assert concatenated_dataset[1]["image"] == dset2[0]["image"]
@require_pil
def test_dataset_concatenate_nested_image_features(shared_datadir):
# we use a different data structure between 1 and 2 to make sure they are compatible with each other
image_path = str(shared_datadir / "test_image_rgb.jpg")
features = Features({"list_of_structs_of_images": [{"image": Image()}]})
data1 = {"list_of_structs_of_images": [[{"image": image_path}]]}
dset1 = Dataset.from_dict(data1, features=features)
data2 = {"list_of_structs_of_images": [[{"image": {"bytes": open(image_path, "rb").read()}}]]}
dset2 = Dataset.from_dict(data2, features=features)
concatenated_dataset = concatenate_datasets([dset1, dset2])
assert len(concatenated_dataset) == len(dset1) + len(dset2)
assert (
concatenated_dataset[0]["list_of_structs_of_images"][0]["image"]
== dset1[0]["list_of_structs_of_images"][0]["image"]
)
assert (
concatenated_dataset[1]["list_of_structs_of_images"][0]["image"]
== dset2[0]["list_of_structs_of_images"][0]["image"]
)
@require_pil
def test_dataset_with_image_feature_map(shared_datadir):
image_path = str(shared_datadir / "test_image_rgb.jpg")
data = {"image": [image_path], "caption": ["cats sleeping"]}
features = Features({"image": Image(), "caption": Value("string")})
dset = Dataset.from_dict(data, features=features)
for item in dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image", "caption"}
assert item == {"image": {"path": image_path, "bytes": None}, "caption": "cats sleeping"}
# no decoding
def process_caption(example):
example["caption"] = "Two " + example["caption"]
return example
processed_dset = dset.map(process_caption)
for item in processed_dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image", "caption"}
assert item == {"image": {"path": image_path, "bytes": None}, "caption": "Two cats sleeping"}
# decoding example
def process_image_by_example(example):
example["mode"] = example["image"].mode
return example
decoded_dset = dset.map(process_image_by_example)
for item in decoded_dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image", "caption", "mode"}
assert os.path.samefile(item["image"]["path"], image_path)
assert item["caption"] == "cats sleeping"
assert item["mode"] == "RGB"
# decoding batch
def process_image_by_batch(batch):
batch["mode"] = [image.mode for image in batch["image"]]
return batch
decoded_dset = dset.map(process_image_by_batch, batched=True)
for item in decoded_dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image", "caption", "mode"}
assert os.path.samefile(item["image"]["path"], image_path)
assert item["caption"] == "cats sleeping"
assert item["mode"] == "RGB"
@require_pil
def test_formatted_dataset_with_image_feature_map(shared_datadir):
image_path = str(shared_datadir / "test_image_rgb.jpg")
pil_image = Image().decode_example({"path": image_path, "bytes": None})
data = {"image": [image_path], "caption": ["cats sleeping"]}
features = Features({"image": Image(), "caption": Value("string")})
dset = Dataset.from_dict(data, features=features)
for item in dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image", "caption"}
assert item == {"image": {"path": image_path, "bytes": None}, "caption": "cats sleeping"}
def process_image_by_example(example):
example["num_channels"] = example["image"].shape[-1]
return example
decoded_dset = dset.with_format("numpy").map(process_image_by_example)
for item in decoded_dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image", "caption", "num_channels"}
assert item["image"] == encode_np_array(np.array(pil_image))
assert item["caption"] == "cats sleeping"
assert item["num_channels"] == 3
def process_image_by_batch(batch):
batch["num_channels"] = [image.shape[-1] for image in batch["image"]]
return batch
decoded_dset = dset.with_format("numpy").map(process_image_by_batch, batched=True)
for item in decoded_dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image", "caption", "num_channels"}
assert item["image"] == encode_np_array(np.array(pil_image))
assert item["caption"] == "cats sleeping"
assert item["num_channels"] == 3
@require_pil
def test_dataset_with_image_feature_map_change_image(shared_datadir):
import PIL.Image
image_path = str(shared_datadir / "test_image_rgb.jpg")
pil_image = Image().decode_example({"path": image_path, "bytes": None})
data = {"image": [image_path]}
features = Features({"image": Image()})
dset = Dataset.from_dict(data, features=features)
for item in dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image"}
assert item == {
"image": {
"bytes": None,
"path": image_path,
}
}
# return pil image
def process_image_resize_by_example(example):
example["image"] = example["image"].resize((100, 100))
return example
decoded_dset = dset.map(process_image_resize_by_example)
for item in decoded_dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image"}
assert item == {"image": {"bytes": image_to_bytes(pil_image.resize((100, 100))), "path": None}}
def process_image_resize_by_batch(batch):
batch["image"] = [image.resize((100, 100)) for image in batch["image"]]
return batch
decoded_dset = dset.map(process_image_resize_by_batch, batched=True)
for item in decoded_dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image"}
assert item == {"image": {"bytes": image_to_bytes(pil_image.resize((100, 100))), "path": None}}
# return np.ndarray (e.g. when using albumentations)
def process_image_resize_by_example_return_np_array(example):
example["image"] = np.array(example["image"].resize((100, 100)))
return example
decoded_dset = dset.map(process_image_resize_by_example_return_np_array)
for item in decoded_dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image"}
assert item == {
"image": {
"bytes": image_to_bytes(PIL.Image.fromarray(np.array(pil_image.resize((100, 100))))),
"path": None,
}
}
def process_image_resize_by_batch_return_np_array(batch):
batch["image"] = [np.array(image.resize((100, 100))) for image in batch["image"]]
return batch
decoded_dset = dset.map(process_image_resize_by_batch_return_np_array, batched=True)
for item in decoded_dset.cast_column("image", Image(decode=False)):
assert item.keys() == {"image"}
assert item == {
"image": {
"bytes": image_to_bytes(PIL.Image.fromarray(np.array(pil_image.resize((100, 100))))),
"path": None,
}
}
@require_pil
def test_formatted_dataset_with_image_feature(shared_datadir):
import PIL.Image
image_path = str(shared_datadir / "test_image_rgb.jpg")
data = {"image": [image_path, image_path]}
features = Features({"image": Image()})
dset = Dataset.from_dict(data, features=features)
with dset.formatted_as("numpy"):
item = dset[0]
assert item.keys() == {"image"}
assert isinstance(item["image"], np.ndarray)
assert item["image"].shape == (480, 640, 3)
batch = dset[:1]
assert batch.keys() == {"image"}
assert len(batch) == 1
assert isinstance(batch["image"], np.ndarray)
assert batch["image"].shape == (1, 480, 640, 3)
column = dset["image"]
assert len(column) == 2
assert isinstance(column, np.ndarray)
assert column.shape == (2, 480, 640, 3)
with dset.formatted_as("pandas"):
item = dset[0]
assert item.shape == (1, 1)
assert item.columns == ["image"]
assert isinstance(item["image"][0], PIL.Image.Image)
assert os.path.samefile(item["image"][0].filename, image_path)
assert item["image"][0].format == "JPEG"
assert item["image"][0].size == (640, 480)
assert item["image"][0].mode == "RGB"
batch = dset[:1]
assert batch.shape == (1, 1)
assert batch.columns == ["image"]
assert isinstance(batch["image"], pd.Series) and all(
isinstance(item, PIL.Image.Image) for item in batch["image"]
)
assert os.path.samefile(batch["image"][0].filename, image_path)
assert batch["image"][0].format == "JPEG"
assert batch["image"][0].size == (640, 480)
assert batch["image"][0].mode == "RGB"
column = dset["image"]
assert len(column) == 2
assert isinstance(column, pd.Series) and all(isinstance(item, PIL.Image.Image) for item in column)
assert os.path.samefile(column[0].filename, image_path)
assert column[0].format == "JPEG"
assert column[0].size == (640, 480)
assert column[0].mode == "RGB"
# Currently, the JSONL reader doesn't support complex feature types so we create a temporary dataset script
# to test streaming (without uploading the test dataset to the hub).
DATASET_LOADING_SCRIPT_NAME = "__dummy_dataset__"
DATASET_LOADING_SCRIPT_CODE = """
import os
import datasets
from datasets import DatasetInfo, Features, Image, Split, SplitGenerator, Value
class __DummyDataset__(datasets.GeneratorBasedBuilder):
def _info(self) -> DatasetInfo:
return DatasetInfo(features=Features({"image": Image(), "caption": Value("string")}))
def _split_generators(self, dl_manager):
return [
SplitGenerator(Split.TRAIN, gen_kwargs={"filepath": os.path.join(dl_manager.manual_dir, "train.txt")}),
]
def _generate_examples(self, filepath, **kwargs):
with open(filepath, encoding="utf-8") as f:
for i, line in enumerate(f):
image_path, caption = line.split(",")
yield i, {"image": image_path.strip(), "caption": caption.strip()}
"""
@pytest.fixture
def data_dir(shared_datadir, tmp_path):
data_dir = tmp_path / "dummy_dataset_data"
data_dir.mkdir()
image_path = str(shared_datadir / "test_image_rgb.jpg")
with open(data_dir / "train.txt", "w") as f:
f.write(f"{image_path},Two cats sleeping\n")
return str(data_dir)
@pytest.fixture
def dataset_loading_script_dir(tmp_path):
script_name = DATASET_LOADING_SCRIPT_NAME
script_dir = tmp_path / script_name
script_dir.mkdir()
script_path = script_dir / f"{script_name}.py"
with open(script_path, "w") as f:
f.write(DATASET_LOADING_SCRIPT_CODE)
return str(script_dir)
@require_pil
@pytest.mark.parametrize("streaming", [False, True])
def test_load_dataset_with_image_feature(shared_datadir, data_dir, dataset_loading_script_dir, streaming):
import PIL.Image
image_path = str(shared_datadir / "test_image_rgb.jpg")
dset = load_dataset(dataset_loading_script_dir, split="train", data_dir=data_dir, streaming=streaming)
item = dset[0] if not streaming else next(iter(dset))
assert item.keys() == {"image", "caption"}
assert isinstance(item["image"], PIL.Image.Image)
assert os.path.samefile(item["image"].filename, image_path)
assert item["image"].format == "JPEG"
assert item["image"].size == (640, 480)
assert item["image"].mode == "RGB"
@require_pil
def test_dataset_with_image_feature_undecoded(shared_datadir):
image_path = str(shared_datadir / "test_image_rgb.jpg")
data = {"image": [image_path]}
features = Features({"image": Image(decode=False)})
dset = Dataset.from_dict(data, features=features)
item = dset[0]
assert item.keys() == {"image"}
assert item["image"] == {"path": image_path, "bytes": None}
batch = dset[:1]
assert batch.keys() == {"image"}
assert len(batch["image"]) == 1
assert batch["image"][0] == {"path": image_path, "bytes": None}
column = dset["image"]
assert len(column) == 1
assert column[0] == {"path": image_path, "bytes": None}
@require_pil
def test_formatted_dataset_with_image_feature_undecoded(shared_datadir):
image_path = str(shared_datadir / "test_image_rgb.jpg")
data = {"image": [image_path]}
features = Features({"image": Image(decode=False)})
dset = Dataset.from_dict(data, features=features)
with dset.formatted_as("numpy"):
item = dset[0]
assert item.keys() == {"image"}
assert item["image"] == {"path": image_path, "bytes": None}
batch = dset[:1]
assert batch.keys() == {"image"}
assert len(batch["image"]) == 1
assert batch["image"][0] == {"path": image_path, "bytes": None}
column = dset["image"]
assert len(column) == 1
assert column[0] == {"path": image_path, "bytes": None}
with dset.formatted_as("pandas"):
item = dset[0]
assert item.shape == (1, 1)
assert item.columns == ["image"]
assert item["image"][0] == {"path": image_path, "bytes": None}
batch = dset[:1]
assert batch.shape == (1, 1)
assert batch.columns == ["image"]
assert batch["image"][0] == {"path": image_path, "bytes": None}
column = dset["image"]
assert len(column) == 1
assert column[0] == {"path": image_path, "bytes": None}
@require_pil
def test_dataset_with_image_feature_map_undecoded(shared_datadir):
image_path = str(shared_datadir / "test_image_rgb.jpg")
data = {"image": [image_path]}
features = Features({"image": Image(decode=False)})
dset = Dataset.from_dict(data, features=features)
def assert_image_example_undecoded(example):
assert example["image"] == {"path": image_path, "bytes": None}
dset.map(assert_image_example_undecoded)
def assert_image_batch_undecoded(batch):
for image in batch["image"]:
assert image == {"path": image_path, "bytes": None}
dset.map(assert_image_batch_undecoded, batched=True)
@require_pil
def test_image_embed_storage(shared_datadir):
image_path = str(shared_datadir / "test_image_rgb.jpg")
example = {"bytes": None, "path": image_path}
storage = pa.array([example], type=pa.struct({"bytes": pa.binary(), "path": pa.string()}))
embedded_storage = Image().embed_storage(storage)
embedded_example = embedded_storage.to_pylist()[0]
assert embedded_example == {"bytes": open(image_path, "rb").read(), "path": "test_image_rgb.jpg"}
@require_pil
@pytest.mark.parametrize(
"array, dtype_cast, expected_image_format",
[
(np.arange(16).reshape(4, 4).astype(np.uint8), "exact_match", "PNG"),
(np.arange(16).reshape(4, 4).astype(np.uint16), "exact_match", "TIFF"),
(np.arange(16).reshape(4, 4).astype(np.int64), "downcast->|i4", "TIFF"),
(np.arange(16).reshape(4, 4).astype(np.complex128), "error", None),
(np.arange(16).reshape(2, 2, 4).astype(np.uint8), "exact_match", "PNG"),
(np.arange(16).reshape(2, 2, 4), "downcast->|u1", "PNG"),
(np.arange(16).reshape(2, 2, 4).astype(np.float64), "error", None),
],
)
def test_encode_np_array(array, dtype_cast, expected_image_format):
if dtype_cast.startswith("downcast"):
_, dest_dtype = dtype_cast.split("->")
dest_dtype = np.dtype(dest_dtype)
with pytest.warns(UserWarning, match=f"Downcasting array dtype.+{dest_dtype}.+"):
encoded_image = Image().encode_example(array)
elif dtype_cast == "error":
with pytest.raises(TypeError):
Image().encode_example(array)
return
else: # exact_match (no warnings are raised)
with warnings.catch_warnings():
warnings.simplefilter("error")
encoded_image = Image().encode_example(array)
assert isinstance(encoded_image, dict)
assert encoded_image.keys() == {"path", "bytes"}
assert encoded_image["path"] is None
assert encoded_image["bytes"] is not None and isinstance(encoded_image["bytes"], bytes)
decoded_image = Image().decode_example(encoded_image)
assert decoded_image.format == expected_image_format
np.testing.assert_array_equal(np.array(decoded_image), array)
| datasets/tests/features/test_image.py/0 | {
"file_path": "datasets/tests/features/test_image.py",
"repo_id": "datasets",
"token_count": 11815
} | 197 |
from pathlib import Path
import pytest
from datasets import load_dataset
from datasets.packaged_modules.cache.cache import Cache
SAMPLE_DATASET_SINGLE_CONFIG_IN_METADATA = "hf-internal-testing/audiofolder_single_config_in_metadata"
SAMPLE_DATASET_TWO_CONFIG_IN_METADATA = "hf-internal-testing/audiofolder_two_configs_in_metadata"
SAMPLE_DATASET_CAPITAL_LETTERS_IN_NAME = "hf-internal-testing/DatasetWithCapitalLetters"
def test_cache(text_dir: Path, tmp_path: Path):
cache_dir = tmp_path / "test_cache"
ds = load_dataset(str(text_dir), cache_dir=str(cache_dir))
hash = Path(ds["train"].cache_files[0]["filename"]).parts[-2]
cache = Cache(cache_dir=str(cache_dir), dataset_name=text_dir.name, hash=hash)
reloaded = cache.as_dataset()
assert list(ds) == list(reloaded)
assert list(ds["train"]) == list(reloaded["train"])
def test_cache_streaming(text_dir: Path, tmp_path: Path):
cache_dir = tmp_path / "test_cache_streaming"
ds = load_dataset(str(text_dir), cache_dir=str(cache_dir))
hash = Path(ds["train"].cache_files[0]["filename"]).parts[-2]
cache = Cache(cache_dir=str(cache_dir), dataset_name=text_dir.name, hash=hash)
reloaded = cache.as_streaming_dataset()
assert list(ds) == list(reloaded)
assert list(ds["train"]) == list(reloaded["train"])
def test_cache_auto_hash(text_dir: Path, tmp_path: Path):
cache_dir = tmp_path / "test_cache_auto_hash"
ds = load_dataset(str(text_dir), cache_dir=str(cache_dir))
cache = Cache(cache_dir=str(cache_dir), dataset_name=text_dir.name, version="auto", hash="auto")
reloaded = cache.as_dataset()
assert list(ds) == list(reloaded)
assert list(ds["train"]) == list(reloaded["train"])
def test_cache_auto_hash_with_custom_config(text_dir: Path, tmp_path: Path):
cache_dir = tmp_path / "test_cache_auto_hash_with_custom_config"
ds = load_dataset(str(text_dir), sample_by="paragraph", cache_dir=str(cache_dir))
another_ds = load_dataset(str(text_dir), cache_dir=str(cache_dir))
cache = Cache(
cache_dir=str(cache_dir), dataset_name=text_dir.name, version="auto", hash="auto", sample_by="paragraph"
)
another_cache = Cache(cache_dir=str(cache_dir), dataset_name=text_dir.name, version="auto", hash="auto")
assert cache.config_id.endswith("paragraph")
assert not another_cache.config_id.endswith("paragraph")
reloaded = cache.as_dataset()
another_reloaded = another_cache.as_dataset()
assert list(ds) == list(reloaded)
assert list(ds["train"]) == list(reloaded["train"])
assert list(another_ds) == list(another_reloaded)
assert list(another_ds["train"]) == list(another_reloaded["train"])
def test_cache_missing(text_dir: Path, tmp_path: Path):
cache_dir = tmp_path / "test_cache_missing"
load_dataset(str(text_dir), cache_dir=str(cache_dir))
Cache(cache_dir=str(cache_dir), dataset_name=text_dir.name, version="auto", hash="auto").download_and_prepare()
with pytest.raises(ValueError):
Cache(cache_dir=str(cache_dir), dataset_name="missing", version="auto", hash="auto").download_and_prepare()
with pytest.raises(ValueError):
Cache(cache_dir=str(cache_dir), dataset_name=text_dir.name, hash="missing").download_and_prepare()
with pytest.raises(ValueError):
Cache(
cache_dir=str(cache_dir), dataset_name=text_dir.name, config_name="missing", version="auto", hash="auto"
).download_and_prepare()
@pytest.mark.integration
def test_cache_multi_configs(tmp_path: Path):
cache_dir = tmp_path / "test_cache_multi_configs"
repo_id = SAMPLE_DATASET_TWO_CONFIG_IN_METADATA
dataset_name = repo_id.split("/")[-1]
config_name = "v1"
ds = load_dataset(repo_id, config_name, cache_dir=str(cache_dir))
cache = Cache(
cache_dir=str(cache_dir),
dataset_name=dataset_name,
repo_id=repo_id,
config_name=config_name,
version="auto",
hash="auto",
)
reloaded = cache.as_dataset()
assert list(ds) == list(reloaded)
assert len(ds["train"]) == len(reloaded["train"])
with pytest.raises(ValueError) as excinfo:
Cache(
cache_dir=str(cache_dir),
dataset_name=dataset_name,
repo_id=repo_id,
config_name="missing",
version="auto",
hash="auto",
)
assert config_name in str(excinfo.value)
@pytest.mark.integration
def test_cache_single_config(tmp_path: Path):
cache_dir = tmp_path / "test_cache_single_config"
repo_id = SAMPLE_DATASET_SINGLE_CONFIG_IN_METADATA
dataset_name = repo_id.split("/")[-1]
config_name = "custom"
ds = load_dataset(repo_id, cache_dir=str(cache_dir))
cache = Cache(cache_dir=str(cache_dir), dataset_name=dataset_name, repo_id=repo_id, version="auto", hash="auto")
reloaded = cache.as_dataset()
assert list(ds) == list(reloaded)
assert len(ds["train"]) == len(reloaded["train"])
cache = Cache(
cache_dir=str(cache_dir),
dataset_name=dataset_name,
config_name=config_name,
repo_id=repo_id,
version="auto",
hash="auto",
)
reloaded = cache.as_dataset()
assert list(ds) == list(reloaded)
assert len(ds["train"]) == len(reloaded["train"])
with pytest.raises(ValueError) as excinfo:
Cache(
cache_dir=str(cache_dir),
dataset_name=dataset_name,
repo_id=repo_id,
config_name="missing",
version="auto",
hash="auto",
)
assert config_name in str(excinfo.value)
@pytest.mark.integration
def test_cache_capital_letters(tmp_path: Path):
cache_dir = tmp_path / "test_cache_capital_letters"
repo_id = SAMPLE_DATASET_CAPITAL_LETTERS_IN_NAME
dataset_name = repo_id.split("/")[-1]
ds = load_dataset(repo_id, cache_dir=str(cache_dir))
cache = Cache(cache_dir=str(cache_dir), dataset_name=dataset_name, repo_id=repo_id, version="auto", hash="auto")
reloaded = cache.as_dataset()
assert list(ds) == list(reloaded)
assert len(ds["train"]) == len(reloaded["train"])
cache = Cache(
cache_dir=str(cache_dir),
dataset_name=dataset_name,
repo_id=repo_id,
version="auto",
hash="auto",
)
reloaded = cache.as_dataset()
assert list(ds) == list(reloaded)
assert len(ds["train"]) == len(reloaded["train"])
| datasets/tests/packaged_modules/test_cache.py/0 | {
"file_path": "datasets/tests/packaged_modules/test_cache.py",
"repo_id": "datasets",
"token_count": 2721
} | 198 |
import os
import sys
from pathlib import Path
import pytest
from datasets import Dataset, IterableDataset
from datasets.distributed import split_dataset_by_node
from .utils import execute_subprocess_async, get_torch_dist_unique_port, require_torch
def test_split_dataset_by_node_map_style():
full_ds = Dataset.from_dict({"i": range(17)})
full_size = len(full_ds)
world_size = 3
datasets_per_rank = [
split_dataset_by_node(full_ds, rank=rank, world_size=world_size) for rank in range(world_size)
]
assert sum(len(ds) for ds in datasets_per_rank) == full_size
assert len({tuple(x.values()) for ds in datasets_per_rank for x in ds}) == full_size
def test_split_dataset_by_node_iterable():
def gen():
return ({"i": i} for i in range(17))
world_size = 3
full_ds = IterableDataset.from_generator(gen)
full_size = len(list(full_ds))
datasets_per_rank = [
split_dataset_by_node(full_ds, rank=rank, world_size=world_size) for rank in range(world_size)
]
assert sum(len(list(ds)) for ds in datasets_per_rank) == full_size
assert len({tuple(x.values()) for ds in datasets_per_rank for x in ds}) == full_size
@pytest.mark.parametrize("shards_per_node", [1, 2, 3])
def test_split_dataset_by_node_iterable_sharded(shards_per_node):
def gen(shards):
for shard in shards:
yield from ({"i": i, "shard": shard} for i in range(17))
world_size = 3
num_shards = shards_per_node * world_size
gen_kwargs = {"shards": [f"shard_{shard_idx}.txt" for shard_idx in range(num_shards)]}
full_ds = IterableDataset.from_generator(gen, gen_kwargs=gen_kwargs)
full_size = len(list(full_ds))
assert full_ds.n_shards == world_size * shards_per_node
datasets_per_rank = [
split_dataset_by_node(full_ds, rank=rank, world_size=world_size) for rank in range(world_size)
]
assert [ds.n_shards for ds in datasets_per_rank] == [shards_per_node] * world_size
assert sum(len(list(ds)) for ds in datasets_per_rank) == full_size
assert len({tuple(x.values()) for ds in datasets_per_rank for x in ds}) == full_size
def test_distributed_shuffle_iterable():
def gen():
return ({"i": i} for i in range(17))
world_size = 2
full_ds = IterableDataset.from_generator(gen)
full_size = len(list(full_ds))
ds_rank0 = split_dataset_by_node(full_ds, rank=0, world_size=world_size).shuffle(seed=42)
assert len(list(ds_rank0)) == 1 + full_size // world_size
with pytest.raises(RuntimeError):
split_dataset_by_node(full_ds, rank=0, world_size=world_size).shuffle()
ds_rank0 = split_dataset_by_node(full_ds.shuffle(seed=42), rank=0, world_size=world_size)
assert len(list(ds_rank0)) == 1 + full_size // world_size
with pytest.raises(RuntimeError):
split_dataset_by_node(full_ds.shuffle(), rank=0, world_size=world_size)
@pytest.mark.parametrize("streaming", [False, True])
@require_torch
@pytest.mark.skipif(os.name == "nt", reason="execute_subprocess_async doesn't support windows")
@pytest.mark.integration
def test_torch_distributed_run(streaming):
nproc_per_node = 2
master_port = get_torch_dist_unique_port()
test_script = Path(__file__).resolve().parent / "distributed_scripts" / "run_torch_distributed.py"
distributed_args = f"""
-m torch.distributed.run
--nproc_per_node={nproc_per_node}
--master_port={master_port}
{test_script}
""".split()
args = f"""
--streaming={streaming}
""".split()
cmd = [sys.executable] + distributed_args + args
execute_subprocess_async(cmd, env=os.environ.copy())
@pytest.mark.parametrize(
"nproc_per_node, num_workers",
[
(2, 2), # each node has 2 shards and each worker has 1 shards
(3, 2), # each node uses all the shards but skips examples, and each worker has 2 shards
],
)
@require_torch
@pytest.mark.skipif(os.name == "nt", reason="execute_subprocess_async doesn't support windows")
@pytest.mark.integration
def test_torch_distributed_run_streaming_with_num_workers(nproc_per_node, num_workers):
streaming = True
master_port = get_torch_dist_unique_port()
test_script = Path(__file__).resolve().parent / "distributed_scripts" / "run_torch_distributed.py"
distributed_args = f"""
-m torch.distributed.run
--nproc_per_node={nproc_per_node}
--master_port={master_port}
{test_script}
""".split()
args = f"""
--streaming={streaming}
--num_workers={num_workers}
""".split()
cmd = [sys.executable] + distributed_args + args
execute_subprocess_async(cmd, env=os.environ.copy())
| datasets/tests/test_distributed.py/0 | {
"file_path": "datasets/tests/test_distributed.py",
"repo_id": "datasets",
"token_count": 1926
} | 199 |
import re
import sys
import tempfile
import unittest
from pathlib import Path
import pytest
import yaml
from huggingface_hub import DatasetCard, DatasetCardData
from datasets.config import METADATA_CONFIGS_FIELD
from datasets.info import DatasetInfo
from datasets.utils.metadata import MetadataConfigs
def _dedent(string: str) -> str:
indent_level = min(re.search("^ +", t).end() if t.startswith(" ") else 0 for t in string.splitlines())
return "\n".join([line[indent_level:] for line in string.splitlines() if indent_level < len(line)])
README_YAML = """\
---
language:
- zh
- en
task_ids:
- sentiment-classification
---
# Begin of markdown
Some cool dataset card
"""
README_EMPTY_YAML = """\
---
---
# Begin of markdown
Some cool dataset card
"""
README_NO_YAML = """\
# Begin of markdown
Some cool dataset card
"""
README_METADATA_CONFIG_INCORRECT_FORMAT = f"""\
---
{METADATA_CONFIGS_FIELD}:
data_dir: v1
drop_labels: true
---
"""
README_METADATA_SINGLE_CONFIG = f"""\
---
{METADATA_CONFIGS_FIELD}:
- config_name: custom
data_dir: v1
drop_labels: true
---
"""
README_METADATA_TWO_CONFIGS_WITH_DEFAULT_FLAG = f"""\
---
{METADATA_CONFIGS_FIELD}:
- config_name: v1
data_dir: v1
drop_labels: true
- config_name: v2
data_dir: v2
drop_labels: false
default: true
---
"""
README_METADATA_TWO_CONFIGS_WITH_DEFAULT_NAME = f"""\
---
{METADATA_CONFIGS_FIELD}:
- config_name: custom
data_dir: custom
drop_labels: true
- config_name: default
data_dir: data
drop_labels: false
---
"""
EXPECTED_METADATA_SINGLE_CONFIG = {"custom": {"data_dir": "v1", "drop_labels": True}}
EXPECTED_METADATA_TWO_CONFIGS_DEFAULT_FLAG = {
"v1": {"data_dir": "v1", "drop_labels": True},
"v2": {"data_dir": "v2", "drop_labels": False, "default": True},
}
EXPECTED_METADATA_TWO_CONFIGS_DEFAULT_NAME = {
"custom": {"data_dir": "custom", "drop_labels": True},
"default": {"data_dir": "data", "drop_labels": False},
}
@pytest.fixture
def data_dir_with_two_subdirs(tmp_path):
data_dir = tmp_path / "data_dir_with_two_configs_in_metadata"
cats_data_dir = data_dir / "cats"
cats_data_dir.mkdir(parents=True)
dogs_data_dir = data_dir / "dogs"
dogs_data_dir.mkdir(parents=True)
with open(cats_data_dir / "cat.jpg", "wb") as f:
f.write(b"this_is_a_cat_image_bytes")
with open(dogs_data_dir / "dog.jpg", "wb") as f:
f.write(b"this_is_a_dog_image_bytes")
return str(data_dir)
class TestMetadataUtils(unittest.TestCase):
def test_metadata_dict_from_readme(self):
with tempfile.TemporaryDirectory() as tmp_dir:
path = Path(tmp_dir) / "README.md"
with open(path, "w+") as readme_file:
readme_file.write(README_YAML)
dataset_card_data = DatasetCard.load(path).data
self.assertDictEqual(
dataset_card_data.to_dict(), {"language": ["zh", "en"], "task_ids": ["sentiment-classification"]}
)
with open(path, "w+") as readme_file:
readme_file.write(README_EMPTY_YAML)
if (
sys.platform != "win32"
): # there is a bug on windows, see https://github.com/huggingface/huggingface_hub/issues/1546
dataset_card_data = DatasetCard.load(path).data
self.assertDictEqual(dataset_card_data.to_dict(), {})
with open(path, "w+") as readme_file:
readme_file.write(README_NO_YAML)
dataset_card_data = DatasetCard.load(path).data
self.assertEqual(dataset_card_data.to_dict(), {})
def test_from_yaml_string(self):
valid_yaml_string = _dedent(
"""\
annotations_creators:
- found
language_creators:
- found
language:
- en
license:
- unknown
multilinguality:
- monolingual
pretty_name: Test Dataset
size_categories:
- 10K<n<100K
source_datasets:
- extended|other-yahoo-webscope-l6
task_categories:
- question-answering
task_ids:
- open-domain-qa
"""
)
assert DatasetCardData(**yaml.safe_load(valid_yaml_string)).to_dict()
valid_yaml_with_optional_keys = _dedent(
"""\
annotations_creators:
- found
language_creators:
- found
language:
- en
license:
- unknown
multilinguality:
- monolingual
pretty_name: Test Dataset
size_categories:
- 10K<n<100K
source_datasets:
- extended|other-yahoo-webscope-l6
task_categories:
- text-classification
task_ids:
- multi-class-classification
paperswithcode_id:
- squad
configs:
- en
train-eval-index:
- config: en
task: text-classification
task_id: multi_class_classification
splits:
train_split: train
eval_split: test
col_mapping:
text: text
label: target
metrics:
- type: accuracy
name: Accuracy
extra_gated_prompt: |
By clicking on “Access repository” below, you also agree to ImageNet Terms of Access:
[RESEARCHER_FULLNAME] (the "Researcher") has requested permission to use the ImageNet database (the "Database") at Princeton University and Stanford University. In exchange for such permission, Researcher hereby agrees to the following terms and conditions:
1. Researcher shall use the Database only for non-commercial research and educational purposes.
extra_gated_fields:
Company: text
Country: text
I agree to use this model for non-commerical use ONLY: checkbox
"""
)
assert DatasetCardData(**yaml.safe_load(valid_yaml_with_optional_keys)).to_dict()
@pytest.mark.parametrize(
"readme_content, expected_metadata_configs_dict, expected_default_config_name",
[
(README_METADATA_SINGLE_CONFIG, EXPECTED_METADATA_SINGLE_CONFIG, "custom"),
(README_METADATA_TWO_CONFIGS_WITH_DEFAULT_FLAG, EXPECTED_METADATA_TWO_CONFIGS_DEFAULT_FLAG, "v2"),
(README_METADATA_TWO_CONFIGS_WITH_DEFAULT_NAME, EXPECTED_METADATA_TWO_CONFIGS_DEFAULT_NAME, "default"),
],
)
def test_metadata_configs_dataset_card_data(
readme_content, expected_metadata_configs_dict, expected_default_config_name
):
with tempfile.TemporaryDirectory() as tmp_dir:
path = Path(tmp_dir) / "README.md"
with open(path, "w+") as readme_file:
readme_file.write(readme_content)
dataset_card_data = DatasetCard.load(path).data
metadata_configs_dict = MetadataConfigs.from_dataset_card_data(dataset_card_data)
assert metadata_configs_dict == expected_metadata_configs_dict
assert metadata_configs_dict.get_default_config_name() == expected_default_config_name
def test_metadata_configs_incorrect_yaml():
with tempfile.TemporaryDirectory() as tmp_dir:
path = Path(tmp_dir) / "README.md"
with open(path, "w+") as readme_file:
readme_file.write(README_METADATA_CONFIG_INCORRECT_FORMAT)
dataset_card_data = DatasetCard.load(path).data
with pytest.raises(ValueError):
_ = MetadataConfigs.from_dataset_card_data(dataset_card_data)
def test_split_order_in_metadata_configs_from_exported_parquet_files_and_dataset_infos():
exported_parquet_files = [
{
"dataset": "beans",
"config": "default",
"split": "test",
"url": "https://huggingface.co/datasets/beans/resolve/refs%2Fconvert%2Fparquet/default/test/0000.parquet",
"filename": "0000.parquet",
"size": 17707203,
},
{
"dataset": "beans",
"config": "default",
"split": "train",
"url": "https://huggingface.co/datasets/beans/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet",
"filename": "0000.parquet",
"size": 143780164,
},
{
"dataset": "beans",
"config": "default",
"split": "validation",
"url": "https://huggingface.co/datasets/beans/resolve/refs%2Fconvert%2Fparquet/default/validation/0000.parquet",
"filename": "0000.parquet",
"size": 18500862,
},
]
dataset_infos = {
"default": DatasetInfo(
dataset_name="beans",
config_name="default",
version="0.0.0",
splits={
"train": {
"name": "train",
"num_bytes": 143996486,
"num_examples": 1034,
"shard_lengths": None,
"dataset_name": "beans",
},
"validation": {
"name": "validation",
"num_bytes": 18525985,
"num_examples": 133,
"shard_lengths": None,
"dataset_name": "beans",
},
"test": {
"name": "test",
"num_bytes": 17730506,
"num_examples": 128,
"shard_lengths": None,
"dataset_name": "beans",
},
},
download_checksums={
"https://huggingface.co/datasets/beans/resolve/main/data/train.zip": {
"num_bytes": 143812152,
"checksum": None,
},
"https://huggingface.co/datasets/beans/resolve/main/data/validation.zip": {
"num_bytes": 18504213,
"checksum": None,
},
"https://huggingface.co/datasets/beans/resolve/main/data/test.zip": {
"num_bytes": 17708541,
"checksum": None,
},
},
download_size=180024906,
post_processing_size=None,
dataset_size=180252977,
size_in_bytes=360277883,
)
}
metadata_configs = MetadataConfigs._from_exported_parquet_files_and_dataset_infos(
"123", exported_parquet_files, dataset_infos
)
split_names = [data_file["split"] for data_file in metadata_configs["default"]["data_files"]]
assert split_names == ["train", "validation", "test"]
| datasets/tests/test_metadata_util.py/0 | {
"file_path": "datasets/tests/test_metadata_util.py",
"repo_id": "datasets",
"token_count": 5453
} | 200 |
import pytest
from datasets.utils.version import Version
@pytest.mark.parametrize(
"other, expected_equality",
[
(Version("1.0.0"), True),
("1.0.0", True),
(Version("2.0.0"), False),
("2.0.0", False),
("1", False),
("a", False),
(1, False),
(None, False),
],
)
def test_version_equality_and_hash(other, expected_equality):
version = Version("1.0.0")
assert (version == other) is expected_equality
assert (version != other) is not expected_equality
assert (hash(version) == hash(other)) is expected_equality
| datasets/tests/test_version.py/0 | {
"file_path": "datasets/tests/test_version.py",
"repo_id": "datasets",
"token_count": 254
} | 201 |
# Train your first Deep Reinforcement Learning Agent 🤖 [[hands-on]]
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/notebooks/unit1/unit1.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
Now that you've studied the bases of Reinforcement Learning, you’re ready to train your first agent and share it with the community through the Hub 🔥:
A Lunar Lander agent that will learn to land correctly on the Moon 🌕
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/lunarLander.gif" alt="LunarLander">
And finally, you'll **upload this trained agent to the Hugging Face Hub 🤗, a free, open platform where people can share ML models, datasets, and demos.**
Thanks to our <a href="https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard">leaderboard</a>, you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 1 🏆?
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained model to the Hub and **get a result of >= 200**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
**If you don't find your model, go to the bottom of the page and click on the refresh button.**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
So let's get started! 🚀
**To start the hands-on click on Open In Colab button** 👇 :
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit1/unit1.ipynb)
We strongly **recommend students use Google Colab for the hands-on exercises** instead of running them on their personal computers.
By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects** of setting up your environments.
# Unit 1: Train your first Deep Reinforcement Learning Agent 🤖
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/thumbnail.jpg" alt="Unit 1 thumbnail" width="100%">
In this notebook, you'll train your **first Deep Reinforcement Learning agent** a Lunar Lander agent that will learn to **land correctly on the Moon 🌕**. Using [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) a Deep Reinforcement Learning library, share them with the community, and experiment with different configurations
### The environment 🎮
- [LunarLander-v2](https://gymnasium.farama.org/environments/box2d/lunar_lander/)
### The library used 📚
- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues).
## Objectives of this notebook 🏆
At the end of the notebook, you will:
- Be able to use **Gymnasium**, the environment library.
- Be able to use **Stable-Baselines3**, the deep reinforcement learning library.
- Be able to **push your trained agent to the Hub** with a nice video replay and an evaluation score 🔥.
## This notebook is from Deep Reinforcement Learning Course
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/deep-rl-course-illustration.jpg" alt="Deep RL Course illustration"/>
In this free course, you will:
- 📖 Study Deep Reinforcement Learning in **theory and practice**.
- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.
- 🤖 Train **agents in unique environments**
- 🎓 **Earn a certificate of completion** by completing 80% of the assignments.
And more!
Check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course
Don’t forget to **<a href="http://eepurl.com/ic5ZUD">sign up to the course</a>** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**
The best way to keep in touch and ask questions is **to join our discord server** to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5
## Prerequisites 🏗️
Before diving into the notebook, you need to:
🔲 📝 **[Read Unit 0](https://huggingface.co/deep-rl-course/unit0/introduction)** that gives you all the **information about the course and helps you to onboard** 🤗
🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by [reading Unit 1](https://huggingface.co/deep-rl-course/unit1/introduction).
## A small recap of Deep Reinforcement Learning 📚
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/RL_process_game.jpg" alt="The RL process" width="100%">
Let's do a small recap on what we learned in the first Unit:
- Reinforcement Learning is a **computational approach to learning from actions**. We build an agent that learns from the environment by **interacting with it through trial and error** and receiving rewards (negative or positive) as feedback.
- The goal of any RL agent is to **maximize its expected cumulative reward** (also called expected return) because RL is based on the _reward hypothesis_, which is that all goals can be described as the maximization of an expected cumulative reward.
- The RL process is a **loop that outputs a sequence of state, action, reward, and next state**.
- To calculate the expected cumulative reward (expected return), **we discount the rewards**: the rewards that come sooner (at the beginning of the game) are more probable to happen since they are more predictable than the long-term future reward.
- To solve an RL problem, you want to **find an optimal policy**; the policy is the "brain" of your AI that will tell us what action to take given a state. The optimal one is the one that gives you the actions that max the expected return.
There are **two** ways to find your optimal policy:
- By **training your policy directly**: policy-based methods.
- By **training a value function** that tells us the expected return the agent will get at each state and use this function to define our policy: value-based methods.
- Finally, we spoke about Deep RL because **we introduce deep neural networks to estimate the action to take (policy-based) or to estimate the value of a state (value-based) hence the name "deep."**
# Let's train our first Deep Reinforcement Learning agent and upload it to the Hub 🚀
## Get a certificate 🎓
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained model to the Hub and **get a result of >= 200**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
## Set the GPU 💪
- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step1.jpg" alt="GPU Step 1">
- `Hardware Accelerator > GPU`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step2.jpg" alt="GPU Step 2">
## Install dependencies and create a virtual screen 🔽
The first step is to install the dependencies, we’ll install multiple ones.
- `gymnasium[box2d]`: Contains the LunarLander-v2 environment 🌛
- `stable-baselines3[extra]`: The deep reinforcement learning library.
- `huggingface_sb3`: Additional code for Stable-baselines3 to load and upload models from the Hugging Face 🤗 Hub.
To make things easier, we created a script to install all these dependencies.
```bash
apt install swig cmake
```
```bash
pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit1/requirements-unit1.txt
```
During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
Hence the following cell will install virtual screen libraries and create and run a virtual screen 🖥
```bash
sudo apt-get update
apt install python-opengl
apt install ffmpeg
apt install xvfb
pip3 install pyvirtualdisplay
```
To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks to this trick, **we will be able to run our virtual screen.**
```python
import os
os.kill(os.getpid(), 9)
```
```python
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()
```
## Import the packages 📦
One additional library we import is huggingface_hub **to be able to upload and download trained models from the hub**.
The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
You can see here all the Deep reinforcement Learning models available here👉 https://huggingface.co/models?pipeline_tag=reinforcement-learning&sort=downloads
```python
import gymnasium
from huggingface_sb3 import load_from_hub, package_to_hub
from huggingface_hub import (
notebook_login,
) # To log to our Hugging Face account to be able to upload models to the Hub.
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.monitor import Monitor
```
## Understand Gymnasium and how it works 🤖
🏋 The library containing our environment is called Gymnasium.
**You'll use Gymnasium a lot in Deep Reinforcement Learning.**
Gymnasium is the **new version of Gym library** [maintained by the Farama Foundation](https://farama.org/).
The Gymnasium library provides two things:
- An interface that allows you to **create RL environments**.
- A **collection of environments** (gym-control, atari, box2D...).
Let's look at an example, but first let's recall the RL loop.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/RL_process_game.jpg" alt="The RL process" width="100%">
At each step:
- Our Agent receives a **state (S0)** from the **Environment** — we receive the first frame of our game (Environment).
- Based on that **state (S0),** the Agent takes an **action (A0)** — our Agent will move to the right.
- The environment transitions to a **new** **state (S1)** — new frame.
- The environment gives some **reward (R1)** to the Agent — we’re not dead *(Positive Reward +1)*.
With Gymnasium:
1️⃣ We create our environment using `gymnasium.make()`
2️⃣ We reset the environment to its initial state with `observation = env.reset()`
At each step:
3️⃣ Get an action using our model (in our example we take a random action)
4️⃣ Using `env.step(action)`, we perform this action in the environment and get
- `observation`: The new state (st+1)
- `reward`: The reward we get after executing the action
- `terminated`: Indicates if the episode terminated (agent reach the terminal state)
- `truncated`: Introduced with this new version, it indicates a timelimit or if an agent go out of bounds of the environment for instance.
- `info`: A dictionary that provides additional information (depends on the environment).
For more explanations check this 👉 https://gymnasium.farama.org/api/env/#gymnasium.Env.step
If the episode is terminated:
- We reset the environment to its initial state with `observation = env.reset()`
**Let's look at an example!** Make sure to read the code
```python
import gymnasium as gym
# First, we create our environment called LunarLander-v2
env = gym.make("LunarLander-v2")
# Then we reset this environment
observation, info = env.reset()
for _ in range(20):
# Take a random action
action = env.action_space.sample()
print("Action taken:", action)
# Do this action in the environment and get
# next_state, reward, terminated, truncated and info
observation, reward, terminated, truncated, info = env.step(action)
# If the game is terminated (in our case we land, crashed) or truncated (timeout)
if terminated or truncated:
# Reset the environment
print("Environment is reset")
observation, info = env.reset()
env.close()
```
## Create the LunarLander environment 🌛 and understand how it works
### The environment 🎮
In this first tutorial, we’re going to train our agent, a [Lunar Lander](https://gymnasium.farama.org/environments/box2d/lunar_lander/), **to land correctly on the moon**. To do that, the agent needs to learn **to adapt its speed and position (horizontal, vertical, and angular) to land correctly.**
---
💡 A good habit when you start to use an environment is to check its documentation
👉 https://gymnasium.farama.org/environments/box2d/lunar_lander/
---
Let's see what the Environment looks like:
```python
# We create our environment with gym.make("<name_of_the_environment>")
env = gym.make("LunarLander-v2")
env.reset()
print("_____OBSERVATION SPACE_____ \n")
print("Observation Space Shape", env.observation_space.shape)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
We see with `Observation Space Shape (8,)` that the observation is a vector of size 8, where each value contains different information about the lander:
- Horizontal pad coordinate (x)
- Vertical pad coordinate (y)
- Horizontal speed (x)
- Vertical speed (y)
- Angle
- Angular speed
- If the left leg contact point has touched the land (boolean)
- If the right leg contact point has touched the land (boolean)
```python
print("\n _____ACTION SPACE_____ \n")
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample()) # Take a random action
```
The action space (the set of possible actions the agent can take) is discrete with 4 actions available 🎮:
- Action 0: Do nothing,
- Action 1: Fire left orientation engine,
- Action 2: Fire the main engine,
- Action 3: Fire right orientation engine.
Reward function (the function that will give a reward at each timestep) 💰:
After every step a reward is granted. The total reward of an episode is the **sum of the rewards for all the steps within that episode**.
For each step, the reward:
- Is increased/decreased the closer/further the lander is to the landing pad.
- Is increased/decreased the slower/faster the lander is moving.
- Is decreased the more the lander is tilted (angle not horizontal).
- Is increased by 10 points for each leg that is in contact with the ground.
- Is decreased by 0.03 points each frame a side engine is firing.
- Is decreased by 0.3 points each frame the main engine is firing.
The episode receive an **additional reward of -100 or +100 points for crashing or landing safely respectively.**
An episode is **considered a solution if it scores at least 200 points.**
#### Vectorized Environment
- We create a vectorized environment (a method for stacking multiple independent environments into a single environment) of 16 environments, this way, **we'll have more diverse experiences during the training.**
```python
# Create the environment
env = make_vec_env("LunarLander-v2", n_envs=16)
```
## Create the Model 🤖
- We have studied our environment and we understood the problem: **being able to land the Lunar Lander to the Landing Pad correctly by controlling left, right and main orientation engine**. Now let's build the algorithm we're going to use to solve this Problem 🚀.
- To do so, we're going to use our first Deep RL library, [Stable Baselines3 (SB3)](https://stable-baselines3.readthedocs.io/en/master/).
- SB3 is a set of **reliable implementations of reinforcement learning algorithms in PyTorch**.
---
💡 A good habit when using a new library is to dive first on the documentation: https://stable-baselines3.readthedocs.io/en/master/ and then try some tutorials.
----
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/sb3.png" alt="Stable Baselines3">
To solve this problem, we're going to use SB3 **PPO**. [PPO (aka Proximal Policy Optimization) is one of the SOTA (state of the art) Deep Reinforcement Learning algorithms that you'll study during this course](https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#example%5D).
PPO is a combination of:
- *Value-based reinforcement learning method*: learning an action-value function that will tell us the **most valuable action to take given a state and action**.
- *Policy-based reinforcement learning method*: learning a policy that will **give us a probability distribution over actions**.
Stable-Baselines3 is easy to set up:
1️⃣ You **create your environment** (in our case it was done above)
2️⃣ You define the **model you want to use and instantiate this model** `model = PPO("MlpPolicy")`
3️⃣ You **train the agent** with `model.learn` and define the number of training timesteps
```
# Create environment
env = gym.make('LunarLander-v2')
# Instantiate the agent
model = PPO('MlpPolicy', env, verbose=1)
# Train the agent
model.learn(total_timesteps=int(2e5))
```
```python
# TODO: Define a PPO MlpPolicy architecture
# We use MultiLayerPerceptron (MLPPolicy) because the input is a vector,
# if we had frames as input we would use CnnPolicy
model =
```
#### Solution
```python
# SOLUTION
# We added some parameters to accelerate the training
model = PPO(
policy="MlpPolicy",
env=env,
n_steps=1024,
batch_size=64,
n_epochs=4,
gamma=0.999,
gae_lambda=0.98,
ent_coef=0.01,
verbose=1,
)
```
## Train the PPO agent 🏃
- Let's train our agent for 1,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~20min, but you can use fewer timesteps if you just want to try it out.
- During the training, take a ☕ break you deserved it 🤗
```python
# TODO: Train it for 1,000,000 timesteps
# TODO: Specify file name for model and save the model to file
model_name = "ppo-LunarLander-v2"
```
#### Solution
```python
# SOLUTION
# Train it for 1,000,000 timesteps
model.learn(total_timesteps=1000000)
# Save the model
model_name = "ppo-LunarLander-v2"
model.save(model_name)
```
## Evaluate the agent 📈
- Remember to wrap the environment in a [Monitor](https://stable-baselines3.readthedocs.io/en/master/common/monitor.html).
- Now that our Lunar Lander agent is trained 🚀, we need to **check its performance**.
- Stable-Baselines3 provides a method to do that: `evaluate_policy`.
- To fill that part you need to [check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/examples.html#basic-usage-training-saving-loading)
- In the next step, we'll see **how to automatically evaluate and share your agent to compete in a leaderboard, but for now let's do it ourselves**
💡 When you evaluate your agent, you should not use your training environment but create an evaluation environment.
```python
# TODO: Evaluate the agent
# Create a new environment for evaluation
eval_env =
# Evaluate the model with 10 evaluation episodes and deterministic=True
mean_reward, std_reward =
# Print the results
```
#### Solution
```python
# @title
eval_env = Monitor(gym.make("LunarLander-v2"))
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
```
- In my case, I got a mean reward of `200.20 +/- 20.80` after training for 1 million steps, which means that our lunar lander agent is ready to land on the moon 🌛🥳.
## Publish our trained model on the Hub 🔥
Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code.
📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
Here's an example of a Model Card (with Space Invaders):
By using `package_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
- You can **share with the community an agent that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account on Hugging Face ➡ https://huggingface.co/join
2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
- Copy the token
- Run the cell below and paste the token
```python
notebook_login()
!git config --global credential.helper store
```
If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function
Let's fill the `package_to_hub` function:
- `model`: our trained model.
- `model_name`: the name of the trained model that we defined in `model_save`
- `model_architecture`: the model architecture we used, in our case PPO
- `env_id`: the name of the environment, in our case `LunarLander-v2`
- `eval_env`: the evaluation environment defined in eval_env
- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `(repo_id = {username}/{repo_name})`
💡 **A good name is `{username}/{model_architecture}-{env_id}` **
- `commit_message`: message of the commit
```python
import gymnasium as gym
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.env_util import make_vec_env
from huggingface_sb3 import package_to_hub
## TODO: Define a repo_id
## repo_id is the id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name} for instance ThomasSimonini/ppo-LunarLander-v2
repo_id =
# TODO: Define the name of the environment
env_id =
# Create the evaluation env and set the render_mode="rgb_array"
eval_env = DummyVecEnv([lambda: gym.make(env_id, render_mode="rgb_array")])
# TODO: Define the model architecture we used
model_architecture = ""
## TODO: Define the commit message
commit_message = ""
# method save, evaluate, generate a model card and record a replay video of your agent before pushing the repo to the hub
package_to_hub(model=model, # Our trained model
model_name=model_name, # The name of our trained model
model_architecture=model_architecture, # The model architecture we used: in our case PPO
env_id=env_id, # Name of the environment
eval_env=eval_env, # Evaluation Environment
repo_id=repo_id, # id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name} for instance ThomasSimonini/ppo-LunarLander-v2
commit_message=commit_message)
```
#### Solution
```python
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.env_util import make_vec_env
from huggingface_sb3 import package_to_hub
# PLACE the variables you've just defined two cells above
# Define the name of the environment
env_id = "LunarLander-v2"
# TODO: Define the model architecture we used
model_architecture = "PPO"
## Define a repo_id
## repo_id is the id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name} for instance ThomasSimonini/ppo-LunarLander-v2
## CHANGE WITH YOUR REPO ID
repo_id = "ThomasSimonini/ppo-LunarLander-v2" # Change with your repo id, you can't push with mine 😄
## Define the commit message
commit_message = "Upload PPO LunarLander-v2 trained agent"
# Create the evaluation env and set the render_mode="rgb_array"
eval_env = DummyVecEnv([lambda: Monitor(gym.make(env_id, render_mode="rgb_array"))])
# PLACE the package_to_hub function you've just filled here
package_to_hub(
model=model, # Our trained model
model_name=model_name, # The name of our trained model
model_architecture=model_architecture, # The model architecture we used: in our case PPO
env_id=env_id, # Name of the environment
eval_env=eval_env, # Evaluation Environment
repo_id=repo_id, # id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name} for instance ThomasSimonini/ppo-LunarLander-v2
commit_message=commit_message,
)
```
Congrats 🥳 you've just trained and uploaded your first Deep Reinforcement Learning agent. The script above should have displayed a link to a model repository such as https://huggingface.co/osanseviero/test_sb3. When you go to this link, you can:
* See a video preview of your agent at the right.
* Click "Files and versions" to see all the files in the repository.
* Click "Use in stable-baselines3" to get a code snippet that shows how to load the model.
* A model card (`README.md` file) which gives a description of the model
Under the hood, the Hub uses git-based repositories (don't worry if you don't know what git is), which means you can update the model with new versions as you experiment and improve your agent.
Compare the results of your LunarLander-v2 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
## Load a saved LunarLander model from the Hub 🤗
Thanks to [ironbar](https://github.com/ironbar) for the contribution.
Loading a saved model from the Hub is really easy.
You go to https://huggingface.co/models?library=stable-baselines3 to see the list of all the Stable-baselines3 saved models.
1. You select one and copy its repo_id
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit1/copy-id.png" alt="Copy-id"/>
2. Then we just need to use load_from_hub with:
- The repo_id
- The filename: the saved model inside the repo and its extension (*.zip)
Because the model I download from the Hub was trained with Gym (the former version of Gymnasium) we need to install shimmy a API conversion tool that will help us to run the environment correctly.
Shimmy Documentation: https://github.com/Farama-Foundation/Shimmy
```python
!pip install shimmy
```
```python
from huggingface_sb3 import load_from_hub
repo_id = "Classroom-workshop/assignment2-omar" # The repo_id
filename = "ppo-LunarLander-v2.zip" # The model filename.zip
# When the model was trained on Python 3.8 the pickle protocol is 5
# But Python 3.6, 3.7 use protocol 4
# In order to get compatibility we need to:
# 1. Install pickle5 (we done it at the beginning of the colab)
# 2. Create a custom empty object we pass as parameter to PPO.load()
custom_objects = {
"learning_rate": 0.0,
"lr_schedule": lambda _: 0.0,
"clip_range": lambda _: 0.0,
}
checkpoint = load_from_hub(repo_id, filename)
model = PPO.load(checkpoint, custom_objects=custom_objects, print_system_info=True)
```
Let's evaluate this agent:
```python
# @title
eval_env = Monitor(gym.make("LunarLander-v2"))
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
```
## Some additional challenges 🏆
The best way to learn **is to try things by your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results!
In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?
Here are some ideas to achieve so:
* Train more steps
* Try different hyperparameters for `PPO`. You can see them at https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html#parameters.
* Check the [Stable-Baselines3 documentation](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) and try another model such as DQN.
* **Push your new trained model** on the Hub 🔥
**Compare the results of your LunarLander-v2 with your classmates** using the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) 🏆
Is moon landing too boring for you? Try to **change the environment**, why not use MountainCar-v0, CartPole-v1 or CarRacing-v0? Check how they work [using the gym documentation](https://www.gymlibrary.dev/) and have fun 🎉.
________________________________________________________________________
Congrats on finishing this chapter! That was the biggest one, **and there was a lot of information.**
If you’re still feel confused with all these elements...it's totally normal! **This was the same for me and for all people who studied RL.**
Take time to really **grasp the material before continuing and try the additional challenges**. It’s important to master these elements and have a solid foundations.
Naturally, during the course, we’re going to dive deeper into these concepts but **it’s better to have a good understanding of them now before diving into the next chapters.**
Next time, in the bonus unit 1, you'll train Huggy the Dog to fetch the stick.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit1/huggy.jpg" alt="Huggy"/>
## Keep learning, stay awesome 🤗
| deep-rl-class/units/en/unit1/hands-on.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit1/hands-on.mdx",
"repo_id": "deep-rl-class",
"token_count": 9469
} | 202 |
# Mid-way Recap [[mid-way-recap]]
Before diving into Q-Learning, let's summarize what we've just learned.
We have two types of value-based functions:
- State-value function: outputs the expected return if **the agent starts at a given state and acts according to the policy forever after.**
- Action-value function: outputs the expected return if **the agent starts in a given state, takes a given action at that state** and then acts accordingly to the policy forever after.
- In value-based methods, rather than learning the policy, **we define the policy by hand** and we learn a value function. If we have an optimal value function, we **will have an optimal policy.**
There are two types of methods to update the value function:
- With *the Monte Carlo method*, we update the value function from a complete episode, and so we **use the actual discounted return of this episode.**
- With *the TD Learning method,* we update the value function from a step, replacing the unknown \\(G_t\\) with **an estimated return called the TD target.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/summary-learning-mtds.jpg" alt="Summary"/>
| deep-rl-class/units/en/unit2/mid-way-recap.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit2/mid-way-recap.mdx",
"repo_id": "deep-rl-class",
"token_count": 317
} | 203 |
# Additional Readings
These are **optional readings** if you want to go deeper.
## Introduction to Policy Optimization
- [Part 3: Intro to Policy Optimization - Spinning Up documentation](https://spinningup.openai.com/en/latest/spinningup/rl_intro3.html)
## Policy Gradient
- [https://johnwlambert.github.io/policy-gradients/](https://johnwlambert.github.io/policy-gradients/)
- [RL - Policy Gradient Explained](https://jonathan-hui.medium.com/rl-policy-gradients-explained-9b13b688b146)
- [Chapter 13, Policy Gradient Methods; Reinforcement Learning, an introduction by Richard Sutton and Andrew G. Barto](http://incompleteideas.net/book/RLbook2020.pdf)
## Implementation
- [PyTorch Reinforce implementation](https://github.com/pytorch/examples/blob/main/reinforcement_learning/reinforce.py)
- [Implementations from DDPG to PPO](https://github.com/MrSyee/pg-is-all-you-need)
| deep-rl-class/units/en/unit4/additional-readings.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit4/additional-readings.mdx",
"repo_id": "deep-rl-class",
"token_count": 281
} | 204 |
# The Pyramid environment
The goal in this environment is to train our agent to **get the gold brick on the top of the Pyramid. To do that, it needs to press a button to spawn a Pyramid, navigate to the Pyramid, knock it over, and move to the gold brick at the top**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids.png" alt="Pyramids Environment"/>
## The reward function
The reward function is:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids-reward.png" alt="Pyramids Environment"/>
In terms of code, it looks like this
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids-reward-code.png" alt="Pyramids Reward"/>
To train this new agent that seeks that button and then the Pyramid to destroy, we’ll use a combination of two types of rewards:
- The *extrinsic one* given by the environment (illustration above).
- But also an *intrinsic* one called **curiosity**. This second will **push our agent to be curious, or in other terms, to better explore its environment**.
If you want to know more about curiosity, the next section (optional) will explain the basics.
## The observation space
In terms of observation, we **use 148 raycasts that can each detect objects** (switch, bricks, golden brick, and walls.)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids_raycasts.png"/>
We also use a **boolean variable indicating the switch state** (did we turn on or off the switch to spawn the Pyramid) and a vector that **contains the agent’s speed**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids-obs-code.png" alt="Pyramids obs code"/>
## The action space
The action space is **discrete** with four possible actions:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids-action.png" alt="Pyramids Environment"/>
| deep-rl-class/units/en/unit5/pyramids.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit5/pyramids.mdx",
"repo_id": "deep-rl-class",
"token_count": 645
} | 205 |
# Quiz
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: Chose the option which fits better when comparing different types of multi-agent environments
- Your agents aim to maximize common benefits in ____ environments
- Your agents aim to maximize common benefits while minimizing opponent's in ____ environments
<Question
choices={[
{
text: "competitive, cooperative",
explain: "You maximize common benefit in cooperative, while in competitive you also aim to reduce opponent's score",
correct: false,
},
{
text: "cooperative, competitive",
explain: "",
correct: true,
},
]}
/>
### Q2: Which of the following statements are true about `decentralized` learning?
<Question
choices={[
{
text: "Each agent is trained independently from the others",
explain: "",
correct: true,
},
{
text: "Inputs from other agents are just considered environment data",
explain: "",
correct: true,
},
{
text: "Considering other agents part of the environment makes the environment stationary",
explain: "In decentralized learning, agents ignore the existence of other agents and consider them part of the environment. However, this means the environment is in constant change, becoming non-stationary.",
correct: false,
},
]}
/>
### Q3: Which of the following statements are true about `centralized` learning?
<Question
choices={[
{
text: "It learns one common policy based on the learnings from all agents' interactions",
explain: "",
correct: true,
},
{
text: "The reward is global",
explain: "",
correct: true,
},
{
text: "The environment with this approach is stationary",
explain: "",
correct: true,
},
]}
/>
### Q4: Explain in your own words what is the `Self-Play` approach
<details>
<summary>Solution</summary>
`Self-play` is an approach to instantiate copies of agents with the same policy as your as opponents, so that your agent learns from agents with same training level.
</details>
### Q5: When configuring `Self-play`, several parameters are important. Could you identify, by their definition, which parameter are we talking about?
- The probability of playing against the current self vs an opponent from a pool
- Variety (dispersion) of training levels of the opponents you can face
- The number of training steps before spawning a new opponent
- Opponent change rate
<Question
choices={[
{
text: "window, play_against_latest_model_ratio, save_steps, swap_steps+team_change",
explain: "",
correct: false,
},
{
text: "play_against_latest_model_ratio, save_steps, window, swap_steps+team_change",
explain: "",
correct: false,
},
{
text: "play_against_latest_model_ratio, window, save_steps, swap_steps+team_change",
explain: "",
correct: true,
},
{
text: "swap_steps+team_change, save_steps, play_against_latest_model_ratio, window",
explain: "",
correct: false,
},
]}
/>
### Q6: What are the main motivations to use a ELO rating Score?
<Question
choices={[
{
text: "The score takes into account the different of skills between you and your opponent",
explain: "",
correct: true,
},
{
text: "Although more points can be exchanged depending on the result of the match and given the levels of the agents, the sum is always the same",
explain: "",
correct: true,
},
{
text: "It's easy for an agent to keep a high score rate",
explain: "That is called the `Rating deflation`: keeping a high rate requires much skill over time",
correct: false,
},
{
text: "It works well calculating the individual contributions of each player in a team",
explain: "ELO uses the score achieved by the whole team, but individual contributions are not calculated",
correct: false,
},
]}
/>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
| deep-rl-class/units/en/unit7/quiz.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit7/quiz.mdx",
"repo_id": "deep-rl-class",
"token_count": 1361
} | 206 |
# Let's train and play with Huggy 🐶 [[train]]
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/bonus-unit1/bonus-unit1.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
We strongly **recommend students use Google Colab for the hands-on exercises** instead of running them on their personal computers.
By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects** of setting up your environments.
## Let's train Huggy 🐶
**To start to train Huggy, click on Open In Colab button** 👇 :
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/bonus-unit1/bonus-unit1.ipynb)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit2/thumbnail.png" alt="Bonus Unit 1Thumbnail">
In this notebook, we'll reinforce what we learned in the first Unit by **teaching Huggy the Dog to fetch the stick and then play with it directly in your browser**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy.jpg" alt="Huggy"/>
### The environment 🎮
- Huggy the Dog, an environment created by [Thomas Simonini](https://twitter.com/ThomasSimonini) based on [Puppo The Corgi](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit)
### The library used 📚
- [MLAgents](https://github.com/Unity-Technologies/ml-agents)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues).
## Objectives of this notebook 🏆
At the end of the notebook, you will:
- Understand **the state space, action space, and reward function used to train Huggy**.
- **Train your own Huggy** to fetch the stick.
- Be able to play **with your trained Huggy directly in your browser**.
## Prerequisites 🏗️
Before diving into the notebook, you need to:
🔲 📚 **Develop an understanding of the foundations of Reinforcement learning** (MC, TD, Rewards hypothesis...) by doing Unit 1
🔲 📚 **Read the introduction to Huggy** by doing Bonus Unit 1
## Set the GPU 💪
- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step1.jpg" alt="GPU Step 1">
- `Hardware Accelerator > GPU`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step2.jpg" alt="GPU Step 2">
## Clone the repository and install the dependencies 🔽
- We need to clone the repository, that contains ML-Agents.
```bash
# Clone the repository (can take 3min)
git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
```
```bash
# Go inside the repository and install the package (can take 3min)
%cd ml-agents
pip3 install -e ./ml-agents-envs
pip3 install -e ./ml-agents
```
## Download and move the environment zip file in `./trained-envs-executables/linux/`
- Our environment executable is in a zip file.
- We need to download it and place it to `./trained-envs-executables/linux/`
```bash
mkdir ./trained-envs-executables
mkdir ./trained-envs-executables/linux
```
We downloaded the file Huggy.zip from https://github.com/huggingface/Huggy using `wget`
```bash
wget "https://github.com/huggingface/Huggy/raw/main/Huggy.zip" -O ./trained-envs-executables/linux/Huggy.zip
```
```bash
%%capture
unzip -d ./trained-envs-executables/linux/ ./trained-envs-executables/linux/Huggy.zip
```
Make sure your file is accessible
```bash
chmod -R 755 ./trained-envs-executables/linux/Huggy
```
## Let's recap how this environment works
### The State Space: what Huggy perceives.
Huggy doesn't "see" his environment. Instead, we provide him information about the environment:
- The target (stick) position
- The relative position between himself and the target
- The orientation of his legs.
Given all this information, Huggy **can decide which action to take next to fulfill his goal**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy.jpg" alt="Huggy" width="100%">
### The Action Space: what moves Huggy can do
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy-action.jpg" alt="Huggy action" width="100%">
**Joint motors drive huggy legs**. This means that to get the target, Huggy needs to **learn to rotate the joint motors of each of his legs correctly so he can move**.
### The Reward Function
The reward function is designed so that **Huggy will fulfill his goal** : fetch the stick.
Remember that one of the foundations of Reinforcement Learning is the *reward hypothesis*: a goal can be described as the **maximization of the expected cumulative reward**.
Here, our goal is that Huggy **goes towards the stick but without spinning too much**. Hence, our reward function must translate this goal.
Our reward function:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/reward.jpg" alt="Huggy reward function" width="100%">
- *Orientation bonus*: we **reward him for getting close to the target**.
- *Time penalty*: a fixed-time penalty given at every action to **force him to get to the stick as fast as possible**.
- *Rotation penalty*: we penalize Huggy if **he spins too much and turns too quickly**.
- *Getting to the target reward*: we reward Huggy for **reaching the target**.
## Check the Huggy config file
- In ML-Agents, you define the **training hyperparameters in config.yaml files.**
- For the scope of this notebook, we're not going to modify the hyperparameters, but if you want to try as an experiment, Unity provides very [good documentation explaining each of them here](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md).
- We need to create a config file for Huggy.
- Go to `/content/ml-agents/config/ppo`
- Create a new file called `Huggy.yaml`
- Copy and paste the content below 🔽
```
behaviors:
Huggy:
trainer_type: ppo
hyperparameters:
batch_size: 2048
buffer_size: 20480
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 512
num_layers: 3
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.995
strength: 1.0
checkpoint_interval: 200000
keep_checkpoints: 15
max_steps: 2e6
time_horizon: 1000
summary_freq: 50000
```
- Don't forget to save the file!
- **In the case you want to modify the hyperparameters**, in Google Colab notebook, you can click here to open the config.yaml: `/content/ml-agents/config/ppo/Huggy.yaml`
We’re now ready to train our agent 🔥.
## Train our agent
To train our agent, we just need to **launch mlagents-learn and select the executable containing the environment.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/mllearn.png" alt="ml learn function" width="100%">
With ML Agents, we run a training script. We define four parameters:
1. `mlagents-learn <config>`: the path where the hyperparameter config file is.
2. `--env`: where the environment executable is.
3. `--run-id`: the name you want to give to your training run id.
4. `--no-graphics`: to not launch the visualization during the training.
Train the model and use the `--resume` flag to continue training in case of interruption.
> It will fail first time when you use `--resume`, try running the block again to bypass the error.
The training will take 30 to 45min depending on your machine (don't forget to **set up a GPU**), go take a ☕️ you deserve it 🤗.
```bash
mlagents-learn ./config/ppo/Huggy.yaml --env=./trained-envs-executables/linux/Huggy/Huggy --run-id="Huggy" --no-graphics
```
## Push the agent to the 🤗 Hub
- Now that we trained our agent, we’re **ready to push it to the Hub to be able to play with Huggy on your browser🔥.**
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
2️⃣ Sign in and then get your token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
- Copy the token
- Run the cell below and paste the token
```python
from huggingface_hub import notebook_login
notebook_login()
```
If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
Then, we simply need to run `mlagents-push-to-hf`.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/mlpush.png" alt="ml learn function" width="100%">
And we define 4 parameters:
1. `--run-id`: the name of the training run id.
2. `--local-dir`: where the agent was saved, it’s results/<run_id name>, so in my case results/First Training.
3. `--repo-id`: the name of the Hugging Face repo you want to create or update. It’s always <your huggingface username>/<the repo name>
If the repo does not exist **it will be created automatically**
4. `--commit-message`: since HF repos are git repositories you need to give a commit message.
```bash
mlagents-push-to-hf --run-id="HuggyTraining" --local-dir="./results/Huggy" --repo-id="ThomasSimonini/ppo-Huggy" --commit-message="Huggy"
```
If everything worked you should see this at the end of the process (but with a different url 😆) :
```
Your model is pushed to the hub. You can view your model here: https://huggingface.co/ThomasSimonini/ppo-Huggy
```
It’s the link to your model repository. The repository contains a model card that explains how to use the model, your Tensorboard logs and your config file. **What’s awesome is that it’s a git repository, which means you can have different commits, update your repository with a new push, open Pull Requests, etc.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/modelcard.png" alt="ml learn function" width="100%">
But now comes the best part: **being able to play with Huggy online 👀.**
## Play with your Huggy 🐕
This step is the simplest:
- Open the Huggy game in your browser: https://huggingface.co/spaces/ThomasSimonini/Huggy
- Click on Play with my Huggy model
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/load-huggy.jpg" alt="load-huggy" width="100%">
1. In step 1, choose your model repository, which is the model id (in my case ThomasSimonini/ppo-Huggy).
2. In step 2, **choose which model you want to replay**:
- I have multiple ones, since we saved a model every 500000 timesteps.
- But since I want the most recent one, I choose `Huggy.onnx`
👉 It's good **to try with different models steps to see the improvement of the agent.**
Congrats on finishing this bonus unit!
You can now sit and enjoy playing with your Huggy 🐶. And don't **forget to spread the love by sharing Huggy with your friends 🤗**. And if you share about it on social media, **please tag us @huggingface and me @simoninithomas**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy-cover.jpeg" alt="Huggy cover" width="100%">
## Keep Learning, Stay awesome 🤗
| deep-rl-class/units/en/unitbonus1/train.mdx/0 | {
"file_path": "deep-rl-class/units/en/unitbonus1/train.mdx",
"repo_id": "deep-rl-class",
"token_count": 4009
} | 207 |
# Student Works
Since the launch of the Deep Reinforcement Learning Course, **many students have created amazing projects that you should check out and consider participating in**.
If you've created an interesting project, don't hesitate to [add it to this list by opening a pull request on the GitHub repository](https://github.com/huggingface/deep-rl-class).
The projects are **arranged based on the date of publication in this page**.
## Space Scavanger AI
This project is a space game environment with trained neural network for AI.
AI is trained by Reinforcement learning algorithm based on UnityMLAgents and RLlib frameworks.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/spacescavangerai.png" alt="Space Scavanger AI"/>
Play the Game here 👉 https://swingshuffle.itch.io/spacescalvagerai
Check the Unity project here 👉 https://github.com/HighExecutor/SpaceScalvagerAI
## Neural Nitro 🏎️
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/neuralnitro.png" alt="Neural Nitro" />
In this project, Sookeyy created a low poly racing game and trained a car to drive.
Check out the demo here 👉 https://sookeyy.itch.io/neuralnitro
## Space War 🚀
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/spacewar.jpg" alt="SpaceWar" />
In this project, Eric Dong recreates Bill Seiler's 1985 version of Space War in Pygame and uses reinforcement learning (RL) to train AI agents.
This project is currently in development!
### Demo
Dev/Edge version:
* https://e-dong.itch.io/spacewar-dev
Stable version:
* https://e-dong.itch.io/spacewar
* https://huggingface.co/spaces/EricofRL/SpaceWarRL
### Community blog posts
TBA
### Other links
Check out the source here 👉 https://github.com/e-dong/space-war-rl
Check out his blog here 👉 https://dev.to/edong/space-war-rl-0-series-introduction-25dh
| deep-rl-class/units/en/unitbonus3/student-works.mdx/0 | {
"file_path": "deep-rl-class/units/en/unitbonus3/student-works.mdx",
"repo_id": "deep-rl-class",
"token_count": 629
} | 208 |
<!---
Copyright 2022 - The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<p align="center">
<br>
<img src="https://raw.githubusercontent.com/huggingface/diffusers/main/docs/source/en/imgs/diffusers_library.jpg" width="400"/>
<br>
<p>
<p align="center">
<a href="https://github.com/huggingface/diffusers/blob/main/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/datasets.svg?color=blue">
</a>
<a href="https://github.com/huggingface/diffusers/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/diffusers.svg">
</a>
<a href="https://pepy.tech/project/diffusers">
<img alt="GitHub release" src="https://static.pepy.tech/badge/diffusers/month">
</a>
<a href="CODE_OF_CONDUCT.md">
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-2.1-4baaaa.svg">
</a>
<a href="https://twitter.com/diffuserslib">
<img alt="X account" src="https://img.shields.io/twitter/url/https/twitter.com/diffuserslib.svg?style=social&label=Follow%20%40diffuserslib">
</a>
</p>
🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or training your own diffusion models, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on [usability over performance](https://huggingface.co/docs/diffusers/conceptual/philosophy#usability-over-performance), [simple over easy](https://huggingface.co/docs/diffusers/conceptual/philosophy#simple-over-easy), and [customizability over abstractions](https://huggingface.co/docs/diffusers/conceptual/philosophy#tweakable-contributorfriendly-over-abstraction).
🤗 Diffusers offers three core components:
- State-of-the-art [diffusion pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) that can be run in inference with just a few lines of code.
- Interchangeable noise [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview) for different diffusion speeds and output quality.
- Pretrained [models](https://huggingface.co/docs/diffusers/api/models/overview) that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.
## Installation
We recommend installing 🤗 Diffusers in a virtual environment from PyPI or Conda. For more details about installing [PyTorch](https://pytorch.org/get-started/locally/) and [Flax](https://flax.readthedocs.io/en/latest/#installation), please refer to their official documentation.
### PyTorch
With `pip` (official package):
```bash
pip install --upgrade diffusers[torch]
```
With `conda` (maintained by the community):
```sh
conda install -c conda-forge diffusers
```
### Flax
With `pip` (official package):
```bash
pip install --upgrade diffusers[flax]
```
### Apple Silicon (M1/M2) support
Please refer to the [How to use Stable Diffusion in Apple Silicon](https://huggingface.co/docs/diffusers/optimization/mps) guide.
## Quickstart
Generating outputs is super easy with 🤗 Diffusers. To generate an image from text, use the `from_pretrained` method to load any pretrained diffusion model (browse the [Hub](https://huggingface.co/models?library=diffusers&sort=downloads) for 22000+ checkpoints):
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipeline.to("cuda")
pipeline("An image of a squirrel in Picasso style").images[0]
```
You can also dig into the models and schedulers toolbox to build your own diffusion system:
```python
from diffusers import DDPMScheduler, UNet2DModel
from PIL import Image
import torch
scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
model = UNet2DModel.from_pretrained("google/ddpm-cat-256").to("cuda")
scheduler.set_timesteps(50)
sample_size = model.config.sample_size
noise = torch.randn((1, 3, sample_size, sample_size), device="cuda")
input = noise
for t in scheduler.timesteps:
with torch.no_grad():
noisy_residual = model(input, t).sample
prev_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
input = prev_noisy_sample
image = (input / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
image = Image.fromarray((image * 255).round().astype("uint8"))
image
```
Check out the [Quickstart](https://huggingface.co/docs/diffusers/quicktour) to launch your diffusion journey today!
## How to navigate the documentation
| **Documentation** | **What can I learn?** |
|---------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Tutorial](https://huggingface.co/docs/diffusers/tutorials/tutorial_overview) | A basic crash course for learning how to use the library's most important features like using models and schedulers to build your own diffusion system, and training your own diffusion model. |
| [Loading](https://huggingface.co/docs/diffusers/using-diffusers/loading_overview) | Guides for how to load and configure all the components (pipelines, models, and schedulers) of the library, as well as how to use different schedulers. |
| [Pipelines for inference](https://huggingface.co/docs/diffusers/using-diffusers/pipeline_overview) | Guides for how to use pipelines for different inference tasks, batched generation, controlling generated outputs and randomness, and how to contribute a pipeline to the library. |
| [Optimization](https://huggingface.co/docs/diffusers/optimization/opt_overview) | Guides for how to optimize your diffusion model to run faster and consume less memory. |
| [Training](https://huggingface.co/docs/diffusers/training/overview) | Guides for how to train a diffusion model for different tasks with different training techniques. |
## Contribution
We ❤️ contributions from the open-source community!
If you want to contribute to this library, please check out our [Contribution guide](https://github.com/huggingface/diffusers/blob/main/CONTRIBUTING.md).
You can look out for [issues](https://github.com/huggingface/diffusers/issues) you'd like to tackle to contribute to the library.
- See [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute
- See [New model/pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) to contribute exciting new diffusion models / diffusion pipelines
- See [New scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
Also, say 👋 in our public Discord channel <a href="https://discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=discord&logoColor=white"></a>. We discuss the hottest trends about diffusion models, help each other with contributions, personal projects or just hang out ☕.
## Popular Tasks & Pipelines
<table>
<tr>
<th>Task</th>
<th>Pipeline</th>
<th>🤗 Hub</th>
</tr>
<tr style="border-top: 2px solid black">
<td>Unconditional Image Generation</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/ddpm"> DDPM </a></td>
<td><a href="https://huggingface.co/google/ddpm-ema-church-256"> google/ddpm-ema-church-256 </a></td>
</tr>
<tr style="border-top: 2px solid black">
<td>Text-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/text2img">Stable Diffusion Text-to-Image</a></td>
<td><a href="https://huggingface.co/runwayml/stable-diffusion-v1-5"> runwayml/stable-diffusion-v1-5 </a></td>
</tr>
<tr>
<td>Text-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/unclip">unCLIP</a></td>
<td><a href="https://huggingface.co/kakaobrain/karlo-v1-alpha"> kakaobrain/karlo-v1-alpha </a></td>
</tr>
<tr>
<td>Text-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/deepfloyd_if">DeepFloyd IF</a></td>
<td><a href="https://huggingface.co/DeepFloyd/IF-I-XL-v1.0"> DeepFloyd/IF-I-XL-v1.0 </a></td>
</tr>
<tr>
<td>Text-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/kandinsky">Kandinsky</a></td>
<td><a href="https://huggingface.co/kandinsky-community/kandinsky-2-2-decoder"> kandinsky-community/kandinsky-2-2-decoder </a></td>
</tr>
<tr style="border-top: 2px solid black">
<td>Text-guided Image-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/controlnet">ControlNet</a></td>
<td><a href="https://huggingface.co/lllyasviel/sd-controlnet-canny"> lllyasviel/sd-controlnet-canny </a></td>
</tr>
<tr>
<td>Text-guided Image-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/pix2pix">InstructPix2Pix</a></td>
<td><a href="https://huggingface.co/timbrooks/instruct-pix2pix"> timbrooks/instruct-pix2pix </a></td>
</tr>
<tr>
<td>Text-guided Image-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/img2img">Stable Diffusion Image-to-Image</a></td>
<td><a href="https://huggingface.co/runwayml/stable-diffusion-v1-5"> runwayml/stable-diffusion-v1-5 </a></td>
</tr>
<tr style="border-top: 2px solid black">
<td>Text-guided Image Inpainting</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/inpaint">Stable Diffusion Inpainting</a></td>
<td><a href="https://huggingface.co/runwayml/stable-diffusion-inpainting"> runwayml/stable-diffusion-inpainting </a></td>
</tr>
<tr style="border-top: 2px solid black">
<td>Image Variation</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/image_variation">Stable Diffusion Image Variation</a></td>
<td><a href="https://huggingface.co/lambdalabs/sd-image-variations-diffusers"> lambdalabs/sd-image-variations-diffusers </a></td>
</tr>
<tr style="border-top: 2px solid black">
<td>Super Resolution</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/upscale">Stable Diffusion Upscale</a></td>
<td><a href="https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler"> stabilityai/stable-diffusion-x4-upscaler </a></td>
</tr>
<tr>
<td>Super Resolution</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/latent_upscale">Stable Diffusion Latent Upscale</a></td>
<td><a href="https://huggingface.co/stabilityai/sd-x2-latent-upscaler"> stabilityai/sd-x2-latent-upscaler </a></td>
</tr>
</table>
## Popular libraries using 🧨 Diffusers
- https://github.com/microsoft/TaskMatrix
- https://github.com/invoke-ai/InvokeAI
- https://github.com/apple/ml-stable-diffusion
- https://github.com/Sanster/lama-cleaner
- https://github.com/IDEA-Research/Grounded-Segment-Anything
- https://github.com/ashawkey/stable-dreamfusion
- https://github.com/deep-floyd/IF
- https://github.com/bentoml/BentoML
- https://github.com/bmaltais/kohya_ss
- +9000 other amazing GitHub repositories 💪
Thank you for using us ❤️.
## Credits
This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
- @CompVis' latent diffusion models library, available [here](https://github.com/CompVis/latent-diffusion)
- @hojonathanho original DDPM implementation, available [here](https://github.com/hojonathanho/diffusion) as well as the extremely useful translation into PyTorch by @pesser, available [here](https://github.com/pesser/pytorch_diffusion)
- @ermongroup's DDIM implementation, available [here](https://github.com/ermongroup/ddim)
- @yang-song's Score-VE and Score-VP implementations, available [here](https://github.com/yang-song/score_sde_pytorch)
We also want to thank @heejkoo for the very helpful overview of papers, code and resources on diffusion models, available [here](https://github.com/heejkoo/Awesome-Diffusion-Models) as well as @crowsonkb and @rromb for useful discussions and insights.
## Citation
```bibtex
@misc{von-platen-etal-2022-diffusers,
author = {Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Dhruv Nair and Sayak Paul and William Berman and Yiyi Xu and Steven Liu and Thomas Wolf},
title = {Diffusers: State-of-the-art diffusion models},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/diffusers}}
}
```
| diffusers/README.md/0 | {
"file_path": "diffusers/README.md",
"repo_id": "diffusers",
"token_count": 5416
} | 209 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Inpainting
The Stable Diffusion model can also be applied to inpainting which lets you edit specific parts of an image by providing a mask and a text prompt using Stable Diffusion.
## Tips
It is recommended to use this pipeline with checkpoints that have been specifically fine-tuned for inpainting, such
as [runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting). Default
text-to-image Stable Diffusion checkpoints, such as
[runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) are also compatible but they might be less performant.
<Tip>
Make sure to check out the Stable Diffusion [Tips](overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
If you're interested in using one of the official checkpoints for a task, explore the [CompVis](https://huggingface.co/CompVis), [Runway](https://huggingface.co/runwayml), and [Stability AI](https://huggingface.co/stabilityai) Hub organizations!
</Tip>
## StableDiffusionInpaintPipeline
[[autodoc]] StableDiffusionInpaintPipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
- load_textual_inversion
- load_lora_weights
- save_lora_weights
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
## FlaxStableDiffusionInpaintPipeline
[[autodoc]] FlaxStableDiffusionInpaintPipeline
- all
- __call__
## FlaxStableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput
| diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.md/0 | {
"file_path": "diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.md",
"repo_id": "diffusers",
"token_count": 680
} | 210 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ONNX Runtime
🤗 [Optimum](https://github.com/huggingface/optimum) provides a Stable Diffusion pipeline compatible with ONNX Runtime. You'll need to install 🤗 Optimum with the following command for ONNX Runtime support:
```bash
pip install -q optimum["onnxruntime"]
```
This guide will show you how to use the Stable Diffusion and Stable Diffusion XL (SDXL) pipelines with ONNX Runtime.
## Stable Diffusion
To load and run inference, use the [`~optimum.onnxruntime.ORTStableDiffusionPipeline`]. If you want to load a PyTorch model and convert it to the ONNX format on-the-fly, set `export=True`:
```python
from optimum.onnxruntime import ORTStableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipeline = ORTStableDiffusionPipeline.from_pretrained(model_id, export=True)
prompt = "sailing ship in storm by Leonardo da Vinci"
image = pipeline(prompt).images[0]
pipeline.save_pretrained("./onnx-stable-diffusion-v1-5")
```
<Tip warning={true}>
Generating multiple prompts in a batch seems to take too much memory. While we look into it, you may need to iterate instead of batching.
</Tip>
To export the pipeline in the ONNX format offline and use it later for inference,
use the [`optimum-cli export`](https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli) command:
```bash
optimum-cli export onnx --model runwayml/stable-diffusion-v1-5 sd_v15_onnx/
```
Then to perform inference (you don't have to specify `export=True` again):
```python
from optimum.onnxruntime import ORTStableDiffusionPipeline
model_id = "sd_v15_onnx"
pipeline = ORTStableDiffusionPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Leonardo da Vinci"
image = pipeline(prompt).images[0]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/optimum/documentation-images/resolve/main/onnxruntime/stable_diffusion_v1_5_ort_sail_boat.png">
</div>
You can find more examples in 🤗 Optimum [documentation](https://huggingface.co/docs/optimum/), and Stable Diffusion is supported for text-to-image, image-to-image, and inpainting.
## Stable Diffusion XL
To load and run inference with SDXL, use the [`~optimum.onnxruntime.ORTStableDiffusionXLPipeline`]:
```python
from optimum.onnxruntime import ORTStableDiffusionXLPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipeline = ORTStableDiffusionXLPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Leonardo da Vinci"
image = pipeline(prompt).images[0]
```
To export the pipeline in the ONNX format and use it later for inference, use the [`optimum-cli export`](https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli) command:
```bash
optimum-cli export onnx --model stabilityai/stable-diffusion-xl-base-1.0 --task stable-diffusion-xl sd_xl_onnx/
```
SDXL in the ONNX format is supported for text-to-image and image-to-image.
| diffusers/docs/source/en/optimization/onnx.md/0 | {
"file_path": "diffusers/docs/source/en/optimization/onnx.md",
"repo_id": "diffusers",
"token_count": 1193
} | 211 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Kandinsky 2.2
<Tip warning={true}>
This script is experimental, and it's easy to overfit and run into issues like catastrophic forgetting. Try exploring different hyperparameters to get the best results on your dataset.
</Tip>
Kandinsky 2.2 is a multilingual text-to-image model capable of producing more photorealistic images. The model includes an image prior model for creating image embeddings from text prompts, and a decoder model that generates images based on the prior model's embeddings. That's why you'll find two separate scripts in Diffusers for Kandinsky 2.2, one for training the prior model and one for training the decoder model. You can train both models separately, but to get the best results, you should train both the prior and decoder models.
Depending on your GPU, you may need to enable `gradient_checkpointing` (⚠️ not supported for the prior model!), `mixed_precision`, and `gradient_accumulation_steps` to help fit the model into memory and to speedup training. You can reduce your memory-usage even more by enabling memory-efficient attention with [xFormers](../optimization/xformers) (version [v0.0.16](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212) fails for training on some GPUs so you may need to install a development version instead).
This guide explores the [train_text_to_image_prior.py](https://github.com/huggingface/diffusers/blob/main/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py) and the [train_text_to_image_decoder.py](https://github.com/huggingface/diffusers/blob/main/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py) scripts to help you become more familiar with it, and how you can adapt it for your own use-case.
Before running the scripts, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies for the script you're using:
```bash
cd examples/kandinsky2_2/text_to_image
pip install -r requirements.txt
```
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```py
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
<Tip>
The following sections highlight parts of the training scripts that are important for understanding how to modify it, but it doesn't cover every aspect of the scripts in detail. If you're interested in learning more, feel free to read through the scripts and let us know if you have any questions or concerns.
</Tip>
## Script parameters
The training scripts provides many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L190) function. The training scripts provides default values for each parameter, such as the training batch size and learning rate, but you can also set your own values in the training command if you'd like.
For example, to speedup training with mixed precision using the fp16 format, add the `--mixed_precision` parameter to the training command:
```bash
accelerate launch train_text_to_image_prior.py \
--mixed_precision="fp16"
```
Most of the parameters are identical to the parameters in the [Text-to-image](text2image#script-parameters) training guide, so let's get straight to a walkthrough of the Kandinsky training scripts!
### Min-SNR weighting
The [Min-SNR](https://huggingface.co/papers/2303.09556) weighting strategy can help with training by rebalancing the loss to achieve faster convergence. The training script supports predicting `epsilon` (noise) or `v_prediction`, but Min-SNR is compatible with both prediction types. This weighting strategy is only supported by PyTorch and is unavailable in the Flax training script.
Add the `--snr_gamma` parameter and set it to the recommended value of 5.0:
```bash
accelerate launch train_text_to_image_prior.py \
--snr_gamma=5.0
```
## Training script
The training script is also similar to the [Text-to-image](text2image#training-script) training guide, but it's been modified to support training the prior and decoder models. This guide focuses on the code that is unique to the Kandinsky 2.2 training scripts.
<hfoptions id="script">
<hfoption id="prior model">
The [`main()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L441) function contains the code for preparing the dataset and training the model.
One of the main differences you'll notice right away is that the training script also loads a [`~transformers.CLIPImageProcessor`] - in addition to a scheduler and tokenizer - for preprocessing images and a [`~transformers.CLIPVisionModelWithProjection`] model for encoding the images:
```py
noise_scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2", prediction_type="sample")
image_processor = CLIPImageProcessor.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="image_processor"
)
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="tokenizer")
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="image_encoder", torch_dtype=weight_dtype
).eval()
text_encoder = CLIPTextModelWithProjection.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="text_encoder", torch_dtype=weight_dtype
).eval()
```
Kandinsky uses a [`PriorTransformer`] to generate the image embeddings, so you'll want to setup the optimizer to learn the prior mode's parameters.
```py
prior = PriorTransformer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="prior")
prior.train()
optimizer = optimizer_cls(
prior.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
Next, the input captions are tokenized, and images are [preprocessed](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L632) by the [`~transformers.CLIPImageProcessor`]:
```py
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["clip_pixel_values"] = image_processor(images, return_tensors="pt").pixel_values
examples["text_input_ids"], examples["text_mask"] = tokenize_captions(examples)
return examples
```
Finally, the [training loop](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L718) converts the input images into latents, adds noise to the image embeddings, and makes a prediction:
```py
model_pred = prior(
noisy_latents,
timestep=timesteps,
proj_embedding=prompt_embeds,
encoder_hidden_states=text_encoder_hidden_states,
attention_mask=text_mask,
).predicted_image_embedding
```
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
</hfoption>
<hfoption id="decoder model">
The [`main()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py#L440) function contains the code for preparing the dataset and training the model.
Unlike the prior model, the decoder initializes a [`VQModel`] to decode the latents into images and it uses a [`UNet2DConditionModel`]:
```py
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
vae = VQModel.from_pretrained(
args.pretrained_decoder_model_name_or_path, subfolder="movq", torch_dtype=weight_dtype
).eval()
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="image_encoder", torch_dtype=weight_dtype
).eval()
unet = UNet2DConditionModel.from_pretrained(args.pretrained_decoder_model_name_or_path, subfolder="unet")
```
Next, the script includes several image transforms and a [preprocessing](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py#L622) function for applying the transforms to the images and returning the pixel values:
```py
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["pixel_values"] = [train_transforms(image) for image in images]
examples["clip_pixel_values"] = image_processor(images, return_tensors="pt").pixel_values
return examples
```
Lastly, the [training loop](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py#L706) handles converting the images to latents, adding noise, and predicting the noise residual.
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
```py
model_pred = unet(noisy_latents, timesteps, None, added_cond_kwargs=added_cond_kwargs).sample[:, :4]
```
</hfoption>
</hfoptions>
## Launch the script
Once you’ve made all your changes or you’re okay with the default configuration, you’re ready to launch the training script! 🚀
You'll train on the [Naruto BLIP captions](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions) dataset to generate your own Naruto characters, but you can also create and train on your own dataset by following the [Create a dataset for training](create_dataset) guide. Set the environment variable `DATASET_NAME` to the name of the dataset on the Hub or if you're training on your own files, set the environment variable `TRAIN_DIR` to a path to your dataset.
If you’re training on more than one GPU, add the `--multi_gpu` parameter to the `accelerate launch` command.
<Tip>
To monitor training progress with Weights & Biases, add the `--report_to=wandb` parameter to the training command. You’ll also need to add the `--validation_prompt` to the training command to keep track of results. This can be really useful for debugging the model and viewing intermediate results.
</Tip>
<hfoptions id="training-inference">
<hfoption id="prior model">
```bash
export DATASET_NAME="lambdalabs/naruto-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_prior.py \
--dataset_name=$DATASET_NAME \
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--checkpoints_total_limit=3 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--validation_prompts="A robot naruto, 4k photo" \
--report_to="wandb" \
--push_to_hub \
--output_dir="kandi2-prior-naruto-model"
```
</hfoption>
<hfoption id="decoder model">
```bash
export DATASET_NAME="lambdalabs/naruto-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_decoder.py \
--dataset_name=$DATASET_NAME \
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--checkpoints_total_limit=3 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--validation_prompts="A robot naruto, 4k photo" \
--report_to="wandb" \
--push_to_hub \
--output_dir="kandi2-decoder-naruto-model"
```
</hfoption>
</hfoptions>
Once training is finished, you can use your newly trained model for inference!
<hfoptions id="training-inference">
<hfoption id="prior model">
```py
from diffusers import AutoPipelineForText2Image, DiffusionPipeline
import torch
prior_pipeline = DiffusionPipeline.from_pretrained(output_dir, torch_dtype=torch.float16)
prior_components = {"prior_" + k: v for k,v in prior_pipeline.components.items()}
pipeline = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", **prior_components, torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt="A robot naruto, 4k photo"
image = pipeline(prompt=prompt, negative_prompt=negative_prompt).images[0]
```
<Tip>
Feel free to replace `kandinsky-community/kandinsky-2-2-decoder` with your own trained decoder checkpoint!
</Tip>
</hfoption>
<hfoption id="decoder model">
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("path/to/saved/model", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
prompt="A robot naruto, 4k photo"
image = pipeline(prompt=prompt).images[0]
```
For the decoder model, you can also perform inference from a saved checkpoint which can be useful for viewing intermediate results. In this case, load the checkpoint into the UNet:
```py
from diffusers import AutoPipelineForText2Image, UNet2DConditionModel
unet = UNet2DConditionModel.from_pretrained("path/to/saved/model" + "/checkpoint-<N>/unet")
pipeline = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", unet=unet, torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
image = pipeline(prompt="A robot naruto, 4k photo").images[0]
```
</hfoption>
</hfoptions>
## Next steps
Congratulations on training a Kandinsky 2.2 model! To learn more about how to use your new model, the following guides may be helpful:
- Read the [Kandinsky](../using-diffusers/kandinsky) guide to learn how to use it for a variety of different tasks (text-to-image, image-to-image, inpainting, interpolation), and how it can be combined with a ControlNet.
- Check out the [DreamBooth](dreambooth) and [LoRA](lora) training guides to learn how to train a personalized Kandinsky model with just a few example images. These two training techniques can even be combined!
| diffusers/docs/source/en/training/kandinsky.md/0 | {
"file_path": "diffusers/docs/source/en/training/kandinsky.md",
"repo_id": "diffusers",
"token_count": 5050
} | 212 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Text-to-image
[[open-in-colab]]
When you think of diffusion models, text-to-image is usually one of the first things that come to mind. Text-to-image generates an image from a text description (for example, "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k") which is also known as a *prompt*.
From a very high level, a diffusion model takes a prompt and some random initial noise, and iteratively removes the noise to construct an image. The *denoising* process is guided by the prompt, and once the denoising process ends after a predetermined number of time steps, the image representation is decoded into an image.
<Tip>
Read the [How does Stable Diffusion work?](https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work) blog post to learn more about how a latent diffusion model works.
</Tip>
You can generate images from a prompt in 🤗 Diffusers in two steps:
1. Load a checkpoint into the [`AutoPipelineForText2Image`] class, which automatically detects the appropriate pipeline class to use based on the checkpoint:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
```
2. Pass a prompt to the pipeline to generate an image:
```py
image = pipeline(
"stained glass of darth vader, backlight, centered composition, masterpiece, photorealistic, 8k"
).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-vader.png"/>
</div>
## Popular models
The most common text-to-image models are [Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5), [Stable Diffusion XL (SDXL)](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), and [Kandinsky 2.2](https://huggingface.co/kandinsky-community/kandinsky-2-2-decoder). There are also ControlNet models or adapters that can be used with text-to-image models for more direct control in generating images. The results from each model are slightly different because of their architecture and training process, but no matter which model you choose, their usage is more or less the same. Let's use the same prompt for each model and compare their results.
### Stable Diffusion v1.5
[Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) is a latent diffusion model initialized from [Stable Diffusion v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4), and finetuned for 595K steps on 512x512 images from the LAION-Aesthetics V2 dataset. You can use this model like:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
generator = torch.Generator("cuda").manual_seed(31)
image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", generator=generator).images[0]
image
```
### Stable Diffusion XL
SDXL is a much larger version of the previous Stable Diffusion models, and involves a two-stage model process that adds even more details to an image. It also includes some additional *micro-conditionings* to generate high-quality images centered subjects. Take a look at the more comprehensive [SDXL](sdxl) guide to learn more about how to use it. In general, you can use SDXL like:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
generator = torch.Generator("cuda").manual_seed(31)
image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", generator=generator).images[0]
image
```
### Kandinsky 2.2
The Kandinsky model is a bit different from the Stable Diffusion models because it also uses an image prior model to create embeddings that are used to better align text and images in the diffusion model.
The easiest way to use Kandinsky 2.2 is:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16
).to("cuda")
generator = torch.Generator("cuda").manual_seed(31)
image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", generator=generator).images[0]
image
```
### ControlNet
ControlNet models are auxiliary models or adapters that are finetuned on top of text-to-image models, such as [Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5). Using ControlNet models in combination with text-to-image models offers diverse options for more explicit control over how to generate an image. With ControlNet, you add an additional conditioning input image to the model. For example, if you provide an image of a human pose (usually represented as multiple keypoints that are connected into a skeleton) as a conditioning input, the model generates an image that follows the pose of the image. Check out the more in-depth [ControlNet](controlnet) guide to learn more about other conditioning inputs and how to use them.
In this example, let's condition the ControlNet with a human pose estimation image. Load the ControlNet model pretrained on human pose estimations:
```py
from diffusers import ControlNetModel, AutoPipelineForText2Image
from diffusers.utils import load_image
import torch
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/control_v11p_sd15_openpose", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
pose_image = load_image("https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png")
```
Pass the `controlnet` to the [`AutoPipelineForText2Image`], and provide the prompt and pose estimation image:
```py
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16, variant="fp16"
).to("cuda")
generator = torch.Generator("cuda").manual_seed(31)
image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", image=pose_image, generator=generator).images[0]
image
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-1.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Stable Diffusion v1.5</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Stable Diffusion XL</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-2.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Kandinsky 2.2</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-3.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">ControlNet (pose conditioning)</figcaption>
</div>
</div>
## Configure pipeline parameters
There are a number of parameters that can be configured in the pipeline that affect how an image is generated. You can change the image's output size, specify a negative prompt to improve image quality, and more. This section dives deeper into how to use these parameters.
### Height and width
The `height` and `width` parameters control the height and width (in pixels) of the generated image. By default, the Stable Diffusion v1.5 model outputs 512x512 images, but you can change this to any size that is a multiple of 8. For example, to create a rectangular image:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
image = pipeline(
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", height=768, width=512
).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-hw.png"/>
</div>
<Tip warning={true}>
Other models may have different default image sizes depending on the image sizes in the training dataset. For example, SDXL's default image size is 1024x1024 and using lower `height` and `width` values may result in lower quality images. Make sure you check the model's API reference first!
</Tip>
### Guidance scale
The `guidance_scale` parameter affects how much the prompt influences image generation. A lower value gives the model "creativity" to generate images that are more loosely related to the prompt. Higher `guidance_scale` values push the model to follow the prompt more closely, and if this value is too high, you may observe some artifacts in the generated image.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
).to("cuda")
image = pipeline(
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", guidance_scale=3.5
).images[0]
image
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-guidance-scale-2.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 2.5</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-guidance-scale-7.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 7.5</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-guidance-scale-10.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 10.5</figcaption>
</div>
</div>
### Negative prompt
Just like how a prompt guides generation, a *negative prompt* steers the model away from things you don't want the model to generate. This is commonly used to improve overall image quality by removing poor or bad image features such as "low resolution" or "bad details". You can also use a negative prompt to remove or modify the content and style of an image.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
).to("cuda")
image = pipeline(
prompt="Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
negative_prompt="ugly, deformed, disfigured, poor details, bad anatomy",
).images[0]
image
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-neg-prompt-1.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">negative_prompt = "ugly, deformed, disfigured, poor details, bad anatomy"</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-neg-prompt-2.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">negative_prompt = "astronaut"</figcaption>
</div>
</div>
### Generator
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html#generator) object enables reproducibility in a pipeline by setting a manual seed. You can use a `Generator` to generate batches of images and iteratively improve on an image generated from a seed as detailed in the [Improve image quality with deterministic generation](reusing_seeds) guide.
You can set a seed and `Generator` as shown below. Creating an image with a `Generator` should return the same result each time instead of randomly generating a new image.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
).to("cuda")
generator = torch.Generator(device="cuda").manual_seed(30)
image = pipeline(
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
generator=generator,
).images[0]
image
```
## Control image generation
There are several ways to exert more control over how an image is generated outside of configuring a pipeline's parameters, such as prompt weighting and ControlNet models.
### Prompt weighting
Prompt weighting is a technique for increasing or decreasing the importance of concepts in a prompt to emphasize or minimize certain features in an image. We recommend using the [Compel](https://github.com/damian0815/compel) library to help you generate the weighted prompt embeddings.
<Tip>
Learn how to create the prompt embeddings in the [Prompt weighting](weighted_prompts) guide. This example focuses on how to use the prompt embeddings in the pipeline.
</Tip>
Once you've created the embeddings, you can pass them to the `prompt_embeds` (and `negative_prompt_embeds` if you're using a negative prompt) parameter in the pipeline.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
).to("cuda")
image = pipeline(
prompt_embeds=prompt_embeds, # generated from Compel
negative_prompt_embeds=negative_prompt_embeds, # generated from Compel
).images[0]
```
### ControlNet
As you saw in the [ControlNet](#controlnet) section, these models offer a more flexible and accurate way to generate images by incorporating an additional conditioning image input. Each ControlNet model is pretrained on a particular type of conditioning image to generate new images that resemble it. For example, if you take a ControlNet model pretrained on depth maps, you can give the model a depth map as a conditioning input and it'll generate an image that preserves the spatial information in it. This is quicker and easier than specifying the depth information in a prompt. You can even combine multiple conditioning inputs with a [MultiControlNet](controlnet#multicontrolnet)!
There are many types of conditioning inputs you can use, and 🤗 Diffusers supports ControlNet for Stable Diffusion and SDXL models. Take a look at the more comprehensive [ControlNet](controlnet) guide to learn how you can use these models.
## Optimize
Diffusion models are large, and the iterative nature of denoising an image is computationally expensive and intensive. But this doesn't mean you need access to powerful - or even many - GPUs to use them. There are many optimization techniques for running diffusion models on consumer and free-tier resources. For example, you can load model weights in half-precision to save GPU memory and increase speed or offload the entire model to the GPU to save even more memory.
PyTorch 2.0 also supports a more memory-efficient attention mechanism called [*scaled dot product attention*](../optimization/torch2.0#scaled-dot-product-attention) that is automatically enabled if you're using PyTorch 2.0. You can combine this with [`torch.compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) to speed your code up even more:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16").to("cuda")
pipeline.unet = torch.compile(pipeline.unet, mode="reduce-overhead", fullgraph=True)
```
For more tips on how to optimize your code to save memory and speed up inference, read the [Memory and speed](../optimization/fp16) and [Torch 2.0](../optimization/torch2.0) guides.
| diffusers/docs/source/en/using-diffusers/conditional_image_generation.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/conditional_image_generation.md",
"repo_id": "diffusers",
"token_count": 5136
} | 213 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Load different Stable Diffusion formats
[[open-in-colab]]
Stable Diffusion models are available in different formats depending on the framework they're trained and saved with, and where you download them from. Converting these formats for use in 🤗 Diffusers allows you to use all the features supported by the library, such as [using different schedulers](schedulers) for inference, [building your custom pipeline](write_own_pipeline), and a variety of techniques and methods for [optimizing inference speed](../optimization/opt_overview).
<Tip>
We highly recommend using the `.safetensors` format because it is more secure than traditional pickled files which are vulnerable and can be exploited to execute any code on your machine (learn more in the [Load safetensors](using_safetensors) guide).
</Tip>
This guide will show you how to convert other Stable Diffusion formats to be compatible with 🤗 Diffusers.
## PyTorch .ckpt
The checkpoint - or `.ckpt` - format is commonly used to store and save models. The `.ckpt` file contains the entire model and is typically several GBs in size. While you can load and use a `.ckpt` file directly with the [`~StableDiffusionPipeline.from_single_file`] method, it is generally better to convert the `.ckpt` file to 🤗 Diffusers so both formats are available.
There are two options for converting a `.ckpt` file: use a Space to convert the checkpoint or convert the `.ckpt` file with a script.
### Convert with a Space
The easiest and most convenient way to convert a `.ckpt` file is to use the [SD to Diffusers](https://huggingface.co/spaces/diffusers/sd-to-diffusers) Space. You can follow the instructions on the Space to convert the `.ckpt` file.
This approach works well for basic models, but it may struggle with more customized models. You'll know the Space failed if it returns an empty pull request or error. In this case, you can try converting the `.ckpt` file with a script.
### Convert with a script
🤗 Diffusers provides a [conversion script](https://github.com/huggingface/diffusers/blob/main/scripts/convert_original_stable_diffusion_to_diffusers.py) for converting `.ckpt` files. This approach is more reliable than the Space above.
Before you start, make sure you have a local clone of 🤗 Diffusers to run the script and log in to your Hugging Face account so you can open pull requests and push your converted model to the Hub.
```bash
huggingface-cli login
```
To use the script:
1. Git clone the repository containing the `.ckpt` file you want to convert. For this example, let's convert this [TemporalNet](https://huggingface.co/CiaraRowles/TemporalNet) `.ckpt` file:
```bash
git lfs install
git clone https://huggingface.co/CiaraRowles/TemporalNet
```
2. Open a pull request on the repository where you're converting the checkpoint from:
```bash
cd TemporalNet && git fetch origin refs/pr/13:pr/13
git checkout pr/13
```
3. There are several input arguments to configure in the conversion script, but the most important ones are:
- `checkpoint_path`: the path to the `.ckpt` file to convert.
- `original_config_file`: a YAML file defining the configuration of the original architecture. If you can't find this file, try searching for the YAML file in the GitHub repository where you found the `.ckpt` file.
- `dump_path`: the path to the converted model.
For example, you can take the `cldm_v15.yaml` file from the [ControlNet](https://github.com/lllyasviel/ControlNet/tree/main/models) repository because the TemporalNet model is a Stable Diffusion v1.5 and ControlNet model.
4. Now you can run the script to convert the `.ckpt` file:
```bash
python ../diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py --checkpoint_path temporalnetv3.ckpt --original_config_file cldm_v15.yaml --dump_path ./ --controlnet
```
5. Once the conversion is done, upload your converted model and test out the resulting [pull request](https://huggingface.co/CiaraRowles/TemporalNet/discussions/13)!
```bash
git push origin pr/13:refs/pr/13
```
## Keras .pb or .h5
<Tip warning={true}>
🧪 This is an experimental feature. Only Stable Diffusion v1 checkpoints are supported by the Convert KerasCV Space at the moment.
</Tip>
[KerasCV](https://keras.io/keras_cv/) supports training for [Stable Diffusion](https://github.com/keras-team/keras-cv/blob/master/keras_cv/models/stable_diffusion) v1 and v2. However, it offers limited support for experimenting with Stable Diffusion models for inference and deployment whereas 🤗 Diffusers has a more complete set of features for this purpose, such as different [noise schedulers](https://huggingface.co/docs/diffusers/using-diffusers/schedulers), [flash attention](https://huggingface.co/docs/diffusers/optimization/xformers), and [other
optimization techniques](https://huggingface.co/docs/diffusers/optimization/fp16).
The [Convert KerasCV](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers) Space converts `.pb` or `.h5` files to PyTorch, and then wraps them in a [`StableDiffusionPipeline`] so it is ready for inference. The converted checkpoint is stored in a repository on the Hugging Face Hub.
For this example, let's convert the [`sayakpaul/textual-inversion-kerasio`](https://huggingface.co/sayakpaul/textual-inversion-kerasio/tree/main) checkpoint which was trained with Textual Inversion. It uses the special token `<my-funny-cat>` to personalize images with cats.
The Convert KerasCV Space allows you to input the following:
* Your Hugging Face token.
* Paths to download the UNet and text encoder weights from. Depending on how the model was trained, you don't necessarily need to provide the paths to both the UNet and text encoder. For example, Textual Inversion only requires the embeddings from the text encoder and a text-to-image model only requires the UNet weights.
* Placeholder token is only applicable for textual inversion models.
* The `output_repo_prefix` is the name of the repository where the converted model is stored.
Click the **Submit** button to automatically convert the KerasCV checkpoint! Once the checkpoint is successfully converted, you'll see a link to the new repository containing the converted checkpoint. Follow the link to the new repository, and you'll see the Convert KerasCV Space generated a model card with an inference widget to try out the converted model.
If you prefer to run inference with code, click on the **Use in Diffusers** button in the upper right corner of the model card to copy and paste the code snippet:
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline", use_safetensors=True
)
```
Then, you can generate an image like:
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline", use_safetensors=True
)
pipeline.to("cuda")
placeholder_token = "<my-funny-cat-token>"
prompt = f"two {placeholder_token} getting married, photorealistic, high quality"
image = pipeline(prompt, num_inference_steps=50).images[0]
```
## A1111 LoRA files
[Automatic1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui) (A1111) is a popular web UI for Stable Diffusion that supports model sharing platforms like [Civitai](https://civitai.com/). Models trained with the Low-Rank Adaptation (LoRA) technique are especially popular because they're fast to train and have a much smaller file size than a fully finetuned model. 🤗 Diffusers supports loading A1111 LoRA checkpoints with [`~loaders.LoraLoaderMixin.load_lora_weights`]:
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_pretrained(
"Lykon/dreamshaper-xl-1-0", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
```
Download a LoRA checkpoint from Civitai; this example uses the [Blueprintify SD XL 1.0](https://civitai.com/models/150986/blueprintify-sd-xl-10) checkpoint, but feel free to try out any LoRA checkpoint!
```py
# uncomment to download the safetensor weights
#!wget https://civitai.com/api/download/models/168776 -O blueprintify.safetensors
```
Load the LoRA checkpoint into the pipeline with the [`~loaders.LoraLoaderMixin.load_lora_weights`] method:
```py
pipeline.load_lora_weights(".", weight_name="blueprintify.safetensors")
```
Now you can use the pipeline to generate images:
```py
prompt = "bl3uprint, a highly detailed blueprint of the empire state building, explaining how to build all parts, many txt, blueprint grid backdrop"
negative_prompt = "lowres, cropped, worst quality, low quality, normal quality, artifacts, signature, watermark, username, blurry, more than one bridge, bad architecture"
image = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
generator=torch.manual_seed(0),
).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/blueprint-lora.png"/>
</div>
| diffusers/docs/source/en/using-diffusers/other-formats.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/other-formats.md",
"repo_id": "diffusers",
"token_count": 2824
} | 214 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Understanding pipelines, models and schedulers
[[open-in-colab]]
🧨 Diffusers is designed to be a user-friendly and flexible toolbox for building diffusion systems tailored to your use-case. At the core of the toolbox are models and schedulers. While the [`DiffusionPipeline`] bundles these components together for convenience, you can also unbundle the pipeline and use the models and schedulers separately to create new diffusion systems.
In this tutorial, you'll learn how to use models and schedulers to assemble a diffusion system for inference, starting with a basic pipeline and then progressing to the Stable Diffusion pipeline.
## Deconstruct a basic pipeline
A pipeline is a quick and easy way to run a model for inference, requiring no more than four lines of code to generate an image:
```py
>>> from diffusers import DDPMPipeline
>>> ddpm = DDPMPipeline.from_pretrained("google/ddpm-cat-256", use_safetensors=True).to("cuda")
>>> image = ddpm(num_inference_steps=25).images[0]
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ddpm-cat.png" alt="Image of cat created from DDPMPipeline"/>
</div>
That was super easy, but how did the pipeline do that? Let's breakdown the pipeline and take a look at what's happening under the hood.
In the example above, the pipeline contains a [`UNet2DModel`] model and a [`DDPMScheduler`]. The pipeline denoises an image by taking random noise the size of the desired output and passing it through the model several times. At each timestep, the model predicts the *noise residual* and the scheduler uses it to predict a less noisy image. The pipeline repeats this process until it reaches the end of the specified number of inference steps.
To recreate the pipeline with the model and scheduler separately, let's write our own denoising process.
1. Load the model and scheduler:
```py
>>> from diffusers import DDPMScheduler, UNet2DModel
>>> scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
>>> model = UNet2DModel.from_pretrained("google/ddpm-cat-256", use_safetensors=True).to("cuda")
```
2. Set the number of timesteps to run the denoising process for:
```py
>>> scheduler.set_timesteps(50)
```
3. Setting the scheduler timesteps creates a tensor with evenly spaced elements in it, 50 in this example. Each element corresponds to a timestep at which the model denoises an image. When you create the denoising loop later, you'll iterate over this tensor to denoise an image:
```py
>>> scheduler.timesteps
tensor([980, 960, 940, 920, 900, 880, 860, 840, 820, 800, 780, 760, 740, 720,
700, 680, 660, 640, 620, 600, 580, 560, 540, 520, 500, 480, 460, 440,
420, 400, 380, 360, 340, 320, 300, 280, 260, 240, 220, 200, 180, 160,
140, 120, 100, 80, 60, 40, 20, 0])
```
4. Create some random noise with the same shape as the desired output:
```py
>>> import torch
>>> sample_size = model.config.sample_size
>>> noise = torch.randn((1, 3, sample_size, sample_size), device="cuda")
```
5. Now write a loop to iterate over the timesteps. At each timestep, the model does a [`UNet2DModel.forward`] pass and returns the noisy residual. The scheduler's [`~DDPMScheduler.step`] method takes the noisy residual, timestep, and input and it predicts the image at the previous timestep. This output becomes the next input to the model in the denoising loop, and it'll repeat until it reaches the end of the `timesteps` array.
```py
>>> input = noise
>>> for t in scheduler.timesteps:
... with torch.no_grad():
... noisy_residual = model(input, t).sample
... previous_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
... input = previous_noisy_sample
```
This is the entire denoising process, and you can use this same pattern to write any diffusion system.
6. The last step is to convert the denoised output into an image:
```py
>>> from PIL import Image
>>> import numpy as np
>>> image = (input / 2 + 0.5).clamp(0, 1).squeeze()
>>> image = (image.permute(1, 2, 0) * 255).round().to(torch.uint8).cpu().numpy()
>>> image = Image.fromarray(image)
>>> image
```
In the next section, you'll put your skills to the test and breakdown the more complex Stable Diffusion pipeline. The steps are more or less the same. You'll initialize the necessary components, and set the number of timesteps to create a `timestep` array. The `timestep` array is used in the denoising loop, and for each element in this array, the model predicts a less noisy image. The denoising loop iterates over the `timestep`'s, and at each timestep, it outputs a noisy residual and the scheduler uses it to predict a less noisy image at the previous timestep. This process is repeated until you reach the end of the `timestep` array.
Let's try it out!
## Deconstruct the Stable Diffusion pipeline
Stable Diffusion is a text-to-image *latent diffusion* model. It is called a latent diffusion model because it works with a lower-dimensional representation of the image instead of the actual pixel space, which makes it more memory efficient. The encoder compresses the image into a smaller representation, and a decoder to convert the compressed representation back into an image. For text-to-image models, you'll need a tokenizer and an encoder to generate text embeddings. From the previous example, you already know you need a UNet model and a scheduler.
As you can see, this is already more complex than the DDPM pipeline which only contains a UNet model. The Stable Diffusion model has three separate pretrained models.
<Tip>
💡 Read the [How does Stable Diffusion work?](https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work) blog for more details about how the VAE, UNet, and text encoder models work.
</Tip>
Now that you know what you need for the Stable Diffusion pipeline, load all these components with the [`~ModelMixin.from_pretrained`] method. You can find them in the pretrained [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) checkpoint, and each component is stored in a separate subfolder:
```py
>>> from PIL import Image
>>> import torch
>>> from transformers import CLIPTextModel, CLIPTokenizer
>>> from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
>>> vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae", use_safetensors=True)
>>> tokenizer = CLIPTokenizer.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="tokenizer")
>>> text_encoder = CLIPTextModel.from_pretrained(
... "CompVis/stable-diffusion-v1-4", subfolder="text_encoder", use_safetensors=True
... )
>>> unet = UNet2DConditionModel.from_pretrained(
... "CompVis/stable-diffusion-v1-4", subfolder="unet", use_safetensors=True
... )
```
Instead of the default [`PNDMScheduler`], exchange it for the [`UniPCMultistepScheduler`] to see how easy it is to plug a different scheduler in:
```py
>>> from diffusers import UniPCMultistepScheduler
>>> scheduler = UniPCMultistepScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
```
To speed up inference, move the models to a GPU since, unlike the scheduler, they have trainable weights:
```py
>>> torch_device = "cuda"
>>> vae.to(torch_device)
>>> text_encoder.to(torch_device)
>>> unet.to(torch_device)
```
### Create text embeddings
The next step is to tokenize the text to generate embeddings. The text is used to condition the UNet model and steer the diffusion process towards something that resembles the input prompt.
<Tip>
💡 The `guidance_scale` parameter determines how much weight should be given to the prompt when generating an image.
</Tip>
Feel free to choose any prompt you like if you want to generate something else!
```py
>>> prompt = ["a photograph of an astronaut riding a horse"]
>>> height = 512 # default height of Stable Diffusion
>>> width = 512 # default width of Stable Diffusion
>>> num_inference_steps = 25 # Number of denoising steps
>>> guidance_scale = 7.5 # Scale for classifier-free guidance
>>> generator = torch.manual_seed(0) # Seed generator to create the initial latent noise
>>> batch_size = len(prompt)
```
Tokenize the text and generate the embeddings from the prompt:
```py
>>> text_input = tokenizer(
... prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt"
... )
>>> with torch.no_grad():
... text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
```
You'll also need to generate the *unconditional text embeddings* which are the embeddings for the padding token. These need to have the same shape (`batch_size` and `seq_length`) as the conditional `text_embeddings`:
```py
>>> max_length = text_input.input_ids.shape[-1]
>>> uncond_input = tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt")
>>> uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
```
Let's concatenate the conditional and unconditional embeddings into a batch to avoid doing two forward passes:
```py
>>> text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
```
### Create random noise
Next, generate some initial random noise as a starting point for the diffusion process. This is the latent representation of the image, and it'll be gradually denoised. At this point, the `latent` image is smaller than the final image size but that's okay though because the model will transform it into the final 512x512 image dimensions later.
<Tip>
💡 The height and width are divided by 8 because the `vae` model has 3 down-sampling layers. You can check by running the following:
```py
2 ** (len(vae.config.block_out_channels) - 1) == 8
```
</Tip>
```py
>>> latents = torch.randn(
... (batch_size, unet.config.in_channels, height // 8, width // 8),
... generator=generator,
... device=torch_device,
... )
```
### Denoise the image
Start by scaling the input with the initial noise distribution, *sigma*, the noise scale value, which is required for improved schedulers like [`UniPCMultistepScheduler`]:
```py
>>> latents = latents * scheduler.init_noise_sigma
```
The last step is to create the denoising loop that'll progressively transform the pure noise in `latents` to an image described by your prompt. Remember, the denoising loop needs to do three things:
1. Set the scheduler's timesteps to use during denoising.
2. Iterate over the timesteps.
3. At each timestep, call the UNet model to predict the noise residual and pass it to the scheduler to compute the previous noisy sample.
```py
>>> from tqdm.auto import tqdm
>>> scheduler.set_timesteps(num_inference_steps)
>>> for t in tqdm(scheduler.timesteps):
... # expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
... latent_model_input = torch.cat([latents] * 2)
... latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
... # predict the noise residual
... with torch.no_grad():
... noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
... # perform guidance
... noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
... noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
... # compute the previous noisy sample x_t -> x_t-1
... latents = scheduler.step(noise_pred, t, latents).prev_sample
```
### Decode the image
The final step is to use the `vae` to decode the latent representation into an image and get the decoded output with `sample`:
```py
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
```
Lastly, convert the image to a `PIL.Image` to see your generated image!
```py
>>> image = (image / 2 + 0.5).clamp(0, 1).squeeze()
>>> image = (image.permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
>>> image = Image.fromarray(image)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/blog/assets/98_stable_diffusion/stable_diffusion_k_lms.png"/>
</div>
## Next steps
From basic to complex pipelines, you've seen that all you really need to write your own diffusion system is a denoising loop. The loop should set the scheduler's timesteps, iterate over them, and alternate between calling the UNet model to predict the noise residual and passing it to the scheduler to compute the previous noisy sample.
This is really what 🧨 Diffusers is designed for: to make it intuitive and easy to write your own diffusion system using models and schedulers.
For your next steps, feel free to:
* Learn how to [build and contribute a pipeline](../using-diffusers/contribute_pipeline) to 🧨 Diffusers. We can't wait and see what you'll come up with!
* Explore [existing pipelines](../api/pipelines/overview) in the library, and see if you can deconstruct and build a pipeline from scratch using the models and schedulers separately.
| diffusers/docs/source/en/using-diffusers/write_own_pipeline.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/write_own_pipeline.md",
"repo_id": "diffusers",
"token_count": 4145
} | 215 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Apple Silicon (M1/M2)에서 Stable Diffusion을 사용하는 방법
Diffusers는 Stable Diffusion 추론을 위해 PyTorch `mps`를 사용해 Apple 실리콘과 호환됩니다. 다음은 Stable Diffusion이 있는 M1 또는 M2 컴퓨터를 사용하기 위해 따라야 하는 단계입니다.
## 요구 사항
- Apple silicon (M1/M2) 하드웨어의 Mac 컴퓨터.
- macOS 12.6 또는 이후 (13.0 또는 이후 추천).
- Python arm64 버전
- PyTorch 2.0(추천) 또는 1.13(`mps`를 지원하는 최소 버전). Yhttps://pytorch.org/get-started/locally/의 지침에 따라 `pip` 또는 `conda`로 설치할 수 있습니다.
## 추론 파이프라인
아래 코도는 익숙한 `to()` 인터페이스를 사용하여 `mps` 백엔드로 Stable Diffusion 파이프라인을 M1 또는 M2 장치로 이동하는 방법을 보여줍니다.
<Tip warning={true}>
**PyTorch 1.13을 사용 중일 때 ** 추가 일회성 전달을 사용하여 파이프라인을 "프라이밍"하는 것을 추천합니다. 이것은 발견한 이상한 문제에 대한 임시 해결 방법입니다. 첫 번째 추론 전달은 후속 전달와 약간 다른 결과를 생성합니다. 이 전달은 한 번만 수행하면 되며 추론 단계를 한 번만 사용하고 결과를 폐기해도 됩니다.
</Tip>
이전 팁에서 설명한 것들을 포함한 여러 문제를 해결하므로 PyTorch 2 이상을 사용하는 것이 좋습니다.
```python
# `huggingface-cli login`에 로그인되어 있음을 확인
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipe = pipe.to("mps")
# 컴퓨터가 64GB 이하의 RAM 램일 때 추천
pipe.enable_attention_slicing()
prompt = "a photo of an astronaut riding a horse on mars"
# 처음 "워밍업" 전달 (위 설명을 보세요)
_ = pipe(prompt, num_inference_steps=1)
# 결과는 워밍업 전달 후의 CPU 장치의 결과와 일치합니다.
image = pipe(prompt).images[0]
```
## 성능 추천
M1/M2 성능은 메모리 압력에 매우 민감합니다. 시스템은 필요한 경우 자동으로 스왑되지만 스왑할 때 성능이 크게 저하됩니다.
특히 컴퓨터의 시스템 RAM이 64GB 미만이거나 512 × 512픽셀보다 큰 비표준 해상도에서 이미지를 생성하는 경우, 추론 중에 메모리 압력을 줄이고 스와핑을 방지하기 위해 *어텐션 슬라이싱*을 사용하는 것이 좋습니다. 어텐션 슬라이싱은 비용이 많이 드는 어텐션 작업을 한 번에 모두 수행하는 대신 여러 단계로 수행합니다. 일반적으로 범용 메모리가 없는 컴퓨터에서 ~20%의 성능 영향을 미치지만 64GB 이상이 아닌 경우 대부분의 Apple Silicon 컴퓨터에서 *더 나은 성능*이 관찰되었습니다.
```python
pipeline.enable_attention_slicing()
```
## Known Issues
- 여러 프롬프트를 배치로 생성하는 것은 [충돌이 발생하거나 안정적으로 작동하지 않습니다](https://github.com/huggingface/diffusers/issues/363). 우리는 이것이 [PyTorch의 `mps` 백엔드](https://github.com/pytorch/pytorch/issues/84039)와 관련이 있다고 생각합니다. 이 문제는 해결되고 있지만 지금은 배치 대신 반복 방법을 사용하는 것이 좋습니다. | diffusers/docs/source/ko/optimization/mps.md/0 | {
"file_path": "diffusers/docs/source/ko/optimization/mps.md",
"repo_id": "diffusers",
"token_count": 2532
} | 216 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Low-Rank Adaptation of Large Language Models (LoRA)
[[open-in-colab]]
<Tip warning={true}>
현재 LoRA는 [`UNet2DConditionalModel`]의 어텐션 레이어에서만 지원됩니다.
</Tip>
[LoRA(Low-Rank Adaptation of Large Language Models)](https://arxiv.org/abs/2106.09685)는 메모리를 적게 사용하면서 대규모 모델의 학습을 가속화하는 학습 방법입니다. 이는 rank-decomposition weight 행렬 쌍(**업데이트 행렬**이라고 함)을 추가하고 새로 추가된 가중치**만** 학습합니다. 여기에는 몇 가지 장점이 있습니다.
- 이전에 미리 학습된 가중치는 고정된 상태로 유지되므로 모델이 [치명적인 망각](https://www.pnas.org/doi/10.1073/pnas.1611835114) 경향이 없습니다.
- Rank-decomposition 행렬은 원래 모델보다 파라메터 수가 훨씬 적으므로 학습된 LoRA 가중치를 쉽게 끼워넣을 수 있습니다.
- LoRA 매트릭스는 일반적으로 원본 모델의 어텐션 레이어에 추가됩니다. 🧨 Diffusers는 [`~diffusers.loaders.UNet2DConditionLoadersMixin.load_attn_procs`] 메서드를 제공하여 LoRA 가중치를 모델의 어텐션 레이어로 불러옵니다. `scale` 매개변수를 통해 모델이 새로운 학습 이미지에 맞게 조정되는 범위를 제어할 수 있습니다.
- 메모리 효율성이 향상되어 Tesla T4, RTX 3080 또는 RTX 2080 Ti와 같은 소비자용 GPU에서 파인튜닝을 실행할 수 있습니다! T4와 같은 GPU는 무료이며 Kaggle 또는 Google Colab 노트북에서 쉽게 액세스할 수 있습니다.
<Tip>
💡 LoRA는 어텐션 레이어에만 한정되지는 않습니다. 저자는 언어 모델의 어텐션 레이어를 수정하는 것이 매우 효율적으로 죻은 성능을 얻기에 충분하다는 것을 발견했습니다. 이것이 LoRA 가중치를 모델의 어텐션 레이어에 추가하는 것이 일반적인 이유입니다. LoRA 작동 방식에 대한 자세한 내용은 [Using LoRA for effective Stable Diffusion fine-tuning](https://huggingface.co/blog/lora) 블로그를 확인하세요!
</Tip>
[cloneofsimo](https://github.com/cloneofsimo)는 인기 있는 [lora](https://github.com/cloneofsimo/lora) GitHub 리포지토리에서 Stable Diffusion을 위한 LoRA 학습을 최초로 시도했습니다. 🧨 Diffusers는 [text-to-image 생성](https://github.com/huggingface/diffusers/tree/main/examples/text_to_image#training-with-lora) 및 [DreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#training-with-low-rank-adaptation-of-large-language-models-lora)을 지원합니다. 이 가이드는 두 가지를 모두 수행하는 방법을 보여줍니다.
모델을 저장하거나 커뮤니티와 공유하려면 Hugging Face 계정에 로그인하세요(아직 계정이 없는 경우 [생성](hf.co/join)하세요):
```bash
huggingface-cli login
```
## Text-to-image
수십억 개의 파라메터들이 있는 Stable Diffusion과 같은 모델을 파인튜닝하는 것은 느리고 어려울 수 있습니다. LoRA를 사용하면 diffusion 모델을 파인튜닝하는 것이 훨씬 쉽고 빠릅니다. 8비트 옵티마이저와 같은 트릭에 의존하지 않고도 11GB의 GPU RAM으로 하드웨어에서 실행할 수 있습니다.
### 학습[[dreambooth-training]]
[Naruto BLIP 캡션](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions) 데이터셋으로 [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5)를 파인튜닝해 나만의 포켓몬을 생성해 보겠습니다.
시작하려면 `MODEL_NAME` 및 `DATASET_NAME` 환경 변수가 설정되어 있는지 확인하십시오. `OUTPUT_DIR` 및 `HUB_MODEL_ID` 변수는 선택 사항이며 허브에서 모델을 저장할 위치를 지정합니다.
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="/sddata/finetune/lora/naruto"
export HUB_MODEL_ID="naruto-lora"
export DATASET_NAME="lambdalabs/naruto-blip-captions"
```
학습을 시작하기 전에 알아야 할 몇 가지 플래그가 있습니다.
* `--push_to_hub`를 명시하면 학습된 LoRA 임베딩을 허브에 저장합니다.
* `--report_to=wandb`는 학습 결과를 가중치 및 편향 대시보드에 보고하고 기록합니다(예를 들어, 이 [보고서](https://wandb.ai/pcuenq/text2image-fine-tune/run/b4k1w0tn?workspace=user-pcuenq)를 참조하세요).
* `--learning_rate=1e-04`, 일반적으로 LoRA에서 사용하는 것보다 더 높은 학습률을 사용할 수 있습니다.
이제 학습을 시작할 준비가 되었습니다 (전체 학습 스크립트는 [여기](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py)에서 찾을 수 있습니다).
```bash
accelerate launch train_dreambooth_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="a photo of sks dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--checkpointing_steps=100 \
--learning_rate=1e-4 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--validation_prompt="A photo of sks dog in a bucket" \
--validation_epochs=50 \
--seed="0" \
--push_to_hub
```
### 추론[[dreambooth-inference]]
이제 [`StableDiffusionPipeline`]에서 기본 모델을 불러와 추론을 위해 모델을 사용할 수 있습니다:
```py
>>> import torch
>>> from diffusers import StableDiffusionPipeline
>>> model_base = "runwayml/stable-diffusion-v1-5"
>>> pipe = StableDiffusionPipeline.from_pretrained(model_base, torch_dtype=torch.float16)
```
*기본 모델의 가중치 위에* 파인튜닝된 DreamBooth 모델에서 LoRA 가중치를 불러온 다음, 더 빠른 추론을 위해 파이프라인을 GPU로 이동합니다. LoRA 가중치를 프리징된 사전 훈련된 모델 가중치와 병합할 때, 선택적으로 'scale' 매개변수로 어느 정도의 가중치를 병합할 지 조절할 수 있습니다:
<Tip>
💡 `0`의 `scale` 값은 LoRA 가중치를 사용하지 않아 원래 모델의 가중치만 사용한 것과 같고, `1`의 `scale` 값은 파인튜닝된 LoRA 가중치만 사용함을 의미합니다. 0과 1 사이의 값들은 두 결과들 사이로 보간됩니다.
</Tip>
```py
>>> pipe.unet.load_attn_procs(model_path)
>>> pipe.to("cuda")
# LoRA 파인튜닝된 모델의 가중치 절반과 기본 모델의 가중치 절반 사용
>>> image = pipe(
... "A picture of a sks dog in a bucket.",
... num_inference_steps=25,
... guidance_scale=7.5,
... cross_attention_kwargs={"scale": 0.5},
... ).images[0]
# 완전히 파인튜닝된 LoRA 모델의 가중치 사용
>>> image = pipe("A picture of a sks dog in a bucket.", num_inference_steps=25, guidance_scale=7.5).images[0]
>>> image.save("bucket-dog.png")
``` | diffusers/docs/source/ko/training/lora.md/0 | {
"file_path": "diffusers/docs/source/ko/training/lora.md",
"repo_id": "diffusers",
"token_count": 4734
} | 217 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# 파이프라인, 모델, 스케줄러 불러오기
기본적으로 diffusion 모델은 다양한 컴포넌트들(모델, 토크나이저, 스케줄러) 간의 복잡한 상호작용을 기반으로 동작합니다. 디퓨저스(Diffusers)는 이러한 diffusion 모델을 보다 쉽고 간편한 API로 제공하는 것을 목표로 설계되었습니다. [`DiffusionPipeline`]은 diffusion 모델이 갖는 복잡성을 하나의 파이프라인 API로 통합하고, 동시에 이를 구성하는 각각의 컴포넌트들을 태스크에 맞춰 유연하게 커스터마이징할 수 있도록 지원하고 있습니다.
diffusion 모델의 훈련과 추론에 필요한 모든 것은 [`DiffusionPipeline.from_pretrained`] 메서드를 통해 접근할 수 있습니다. (이 말의 의미는 다음 단락에서 보다 자세하게 다뤄보도록 하겠습니다.)
이 문서에서는 설명할 내용은 다음과 같습니다.
* 허브를 통해 혹은 로컬로 파이프라인을 불러오는 법
* 파이프라인에 다른 컴포넌트들을 적용하는 법
* 오리지널 체크포인트가 아닌 variant를 불러오는 법 (variant란 기본으로 설정된 `fp32`가 아닌 다른 부동 소수점 타입(예: `fp16`)을 사용하거나 Non-EMA 가중치를 사용하는 체크포인트들을 의미합니다.)
* 모델과 스케줄러를 불러오는 법
## Diffusion 파이프라인
<Tip>
💡 [`DiffusionPipeline`] 클래스가 동작하는 방식에 보다 자세한 내용이 궁금하다면, [DiffusionPipeline explained](#diffusionpipeline에-대해-알아보기) 섹션을 확인해보세요.
</Tip>
[`DiffusionPipeline`] 클래스는 diffusion 모델을 [허브](https://huggingface.co/models?library=diffusers)로부터 불러오는 가장 심플하면서 보편적인 방식입니다. [`DiffusionPipeline.from_pretrained`] 메서드는 적합한 파이프라인 클래스를 자동으로 탐지하고, 필요한 구성요소(configuration)와 가중치(weight) 파일들을 다운로드하고 캐싱한 다음, 해당 파이프라인 인스턴스를 반환합니다.
```python
from diffusers import DiffusionPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
pipe = DiffusionPipeline.from_pretrained(repo_id)
```
물론 [`DiffusionPipeline`] 클래스를 사용하지 않고, 명시적으로 직접 해당 파이프라인 클래스를 불러오는 것도 가능합니다. 아래 예시 코드는 위 예시와 동일한 인스턴스를 반환합니다.
```python
from diffusers import StableDiffusionPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(repo_id)
```
[CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)이나 [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) 같은 체크포인트들의 경우, 하나 이상의 다양한 태스크에 활용될 수 있습니다. (예를 들어 위의 두 체크포인트의 경우, text-to-image와 image-to-image에 모두 활용될 수 있습니다.) 만약 이러한 체크포인트들을 기본 설정 태스크가 아닌 다른 태스크에 활용하고자 한다면, 해당 태스크에 대응되는 파이프라인(task-specific pipeline)을 사용해야 합니다.
```python
from diffusers import StableDiffusionImg2ImgPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(repo_id)
```
### 로컬 파이프라인
파이프라인을 로컬로 불러오고자 한다면, `git-lfs`를 사용하여 직접 체크포인트를 로컬 디스크에 다운로드 받아야 합니다. 아래의 명령어를 실행하면 `./stable-diffusion-v1-5`란 이름으로 폴더가 로컬디스크에 생성됩니다.
```bash
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
```
그런 다음 해당 로컬 경로를 [`~DiffusionPipeline.from_pretrained`] 메서드에 전달합니다.
```python
from diffusers import DiffusionPipeline
repo_id = "./stable-diffusion-v1-5"
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id)
```
위의 예시코드처럼 만약 `repo_id`가 로컬 패스(local path)라면, [`~DiffusionPipeline.from_pretrained`] 메서드는 이를 자동으로 감지하여 허브에서 파일을 다운로드하지 않습니다. 만약 로컬 디스크에 저장된 파이프라인 체크포인트가 최신 버전이 아닐 경우에도, 최신 버전을 다운로드하지 않고 기존 로컬 디스크에 저장된 체크포인트를 사용한다는 것을 의미합니다.
### 파이프라인 내부의 컴포넌트 교체하기
파이프라인 내부의 컴포넌트들은 호환 가능한 다른 컴포넌트로 교체될 수 있습니다. 이와 같은 컴포넌트 교체가 중요한 이유는 다음과 같습니다.
- 어떤 스케줄러를 사용할 것인가는 생성속도와 생성품질 간의 트레이드오프를 정의하는 중요한 요소입니다.
- diffusion 모델 내부의 컴포넌트들은 일반적으로 각각 독립적으로 훈련되기 때문에, 더 좋은 성능을 보여주는 컴포넌트가 있다면 그걸로 교체하는 식으로 성능을 향상시킬 수 있습니다.
- 파인 튜닝 단계에서는 일반적으로 UNet 혹은 텍스트 인코더와 같은 일부 컴포넌트들만 훈련하게 됩니다.
어떤 스케줄러들이 호환가능한지는 `compatibles` 속성을 통해 확인할 수 있습니다.
```python
from diffusers import DiffusionPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id)
stable_diffusion.scheduler.compatibles
```
이번에는 [`SchedulerMixin.from_pretrained`] 메서드를 사용해서, 기존 기본 스케줄러였던 [`PNDMScheduler`]를 보다 우수한 성능의 [`EulerDiscreteScheduler`]로 바꿔봅시다. 스케줄러를 로드할 때는 `subfolder` 인자를 통해, 해당 파이프라인의 리포지토리에서 [스케줄러에 관한 하위폴더](https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main/scheduler)를 명시해주어야 합니다.
그 다음 새롭게 생성한 [`EulerDiscreteScheduler`] 인스턴스를 [`DiffusionPipeline`]의 `scheduler` 인자에 전달합니다.
```python
from diffusers import DiffusionPipeline, EulerDiscreteScheduler, DPMSolverMultistepScheduler
repo_id = "runwayml/stable-diffusion-v1-5"
scheduler = EulerDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id, scheduler=scheduler)
```
### 세이프티 체커
스테이블 diffusion과 같은 diffusion 모델들은 유해한 이미지를 생성할 수도 있습니다. 이를 예방하기 위해 디퓨저스는 생성된 이미지의 유해성을 판단하는 [세이프티 체커(safety checker)](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) 기능을 지원하고 있습니다. 만약 세이프티 체커의 사용을 원하지 않는다면, `safety_checker` 인자에 `None`을 전달해주시면 됩니다.
```python
from diffusers import DiffusionPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id, safety_checker=None)
```
### 컴포넌트 재사용
복수의 파이프라인에 동일한 모델이 반복적으로 사용한다면, 굳이 해당 모델의 동일한 가중치를 중복으로 RAM에 불러올 필요는 없을 것입니다. [`~DiffusionPipeline.components`] 속성을 통해 파이프라인 내부의 컴포넌트들을 참조할 수 있는데, 이번 단락에서는 이를 통해 동일한 모델 가중치를 RAM에 중복으로 불러오는 것을 방지하는 법에 대해 알아보겠습니다.
```python
from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline
model_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion_txt2img = StableDiffusionPipeline.from_pretrained(model_id)
components = stable_diffusion_txt2img.components
```
그 다음 위 예시 코드에서 선언한 `components` 변수를 다른 파이프라인에 전달함으로써, 모델의 가중치를 중복으로 RAM에 로딩하지 않고, 동일한 컴포넌트를 재사용할 수 있습니다.
```python
stable_diffusion_img2img = StableDiffusionImg2ImgPipeline(**components)
```
물론 각각의 컴포넌트들을 따로 따로 파이프라인에 전달할 수도 있습니다. 예를 들어 `stable_diffusion_txt2img` 파이프라인 안의 컴포넌트들 가운데서 세이프티 체커(`safety_checker`)와 피쳐 익스트랙터(`feature_extractor`)를 제외한 컴포넌트들만 `stable_diffusion_img2img` 파이프라인에서 재사용하는 방식 역시 가능합니다.
```python
from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline
model_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion_txt2img = StableDiffusionPipeline.from_pretrained(model_id)
stable_diffusion_img2img = StableDiffusionImg2ImgPipeline(
vae=stable_diffusion_txt2img.vae,
text_encoder=stable_diffusion_txt2img.text_encoder,
tokenizer=stable_diffusion_txt2img.tokenizer,
unet=stable_diffusion_txt2img.unet,
scheduler=stable_diffusion_txt2img.scheduler,
safety_checker=None,
feature_extractor=None,
requires_safety_checker=False,
)
```
## Checkpoint variants
Variant란 일반적으로 다음과 같은 체크포인트들을 의미합니다.
- `torch.float16`과 같이 정밀도는 더 낮지만, 용량 역시 더 작은 부동소수점 타입의 가중치를 사용하는 체크포인트. *(다만 이와 같은 variant의 경우, 추가적인 훈련과 CPU환경에서의 구동이 불가능합니다.)*
- Non-EMA 가중치를 사용하는 체크포인트. *(Non-EMA 가중치의 경우, 파인 튜닝 단계에서 사용하는 것이 권장되는데, 추론 단계에선 사용하지 않는 것이 권장됩니다.)*
<Tip>
💡 모델 구조는 동일하지만 서로 다른 학습 환경에서 서로 다른 데이터셋으로 학습된 체크포인트들이 있을 경우, 해당 체크포인트들은 variant 단계가 아닌 리포지토리 단계에서 분리되어 관리되어야 합니다. (즉, 해당 체크포인트들은 서로 다른 리포지토리에서 따로 관리되어야 합니다. 예시: [`stable-diffusion-v1-4`], [`stable-diffusion-v1-5`]).
</Tip>
| **checkpoint type** | **weight name** | **argument for loading weights** |
| ------------------- | ----------------------------------- | -------------------------------- |
| original | diffusion_pytorch_model.bin | |
| floating point | diffusion_pytorch_model.fp16.bin | `variant`, `torch_dtype` |
| non-EMA | diffusion_pytorch_model.non_ema.bin | `variant` |
variant를 로드할 때 2개의 중요한 argument가 있습니다.
* `torch_dtype`은 불러올 체크포인트의 부동소수점을 정의합니다. 예를 들어 `torch_dtype=torch.float16`을 명시함으로써 가중치의 부동소수점 타입을 `fl16`으로 변환할 수 있습니다. (만약 따로 설정하지 않을 경우, 기본값으로 `fp32` 타입의 가중치가 로딩됩니다.) 또한 `variant` 인자를 명시하지 않은 채로 체크포인트를 불러온 다음, 해당 체크포인트를 `torch_dtype=torch.float16` 인자를 통해 `fp16` 타입으로 변환하는 것 역시 가능합니다. 이 경우 기본으로 설정된 `fp32` 가중치가 먼저 다운로드되고, 해당 가중치들을 불러온 다음 `fp16` 타입으로 변환하게 됩니다.
* `variant` 인자는 리포지토리에서 어떤 variant를 불러올 것인가를 정의합니다. 가령 [`diffusers/stable-diffusion-variants`](https://huggingface.co/diffusers/stable-diffusion-variants/tree/main/unet) 리포지토리로부터 `non_ema` 체크포인트를 불러오고자 한다면, `variant="non_ema"` 인자를 전달해야 합니다.
```python
from diffusers import DiffusionPipeline
# load fp16 variant
stable_diffusion = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", variant="fp16", torch_dtype=torch.float16
)
# load non_ema variant
stable_diffusion = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", variant="non_ema")
```
다른 부동소수점 타입의 가중치 혹은 non-EMA 가중치를 사용하는 체크포인트를 저장하기 위해서는, [`DiffusionPipeline.save_pretrained`] 메서드를 사용해야 하며, 이 때 `variant` 인자를 명시해줘야 합니다. 원래의 체크포인트와 동일한 폴더에 variant를 저장해야 하며, 이렇게 하면 동일한 폴더에서 오리지널 체크포인트과 variant를 모두 불러올 수 있습니다.
```python
from diffusers import DiffusionPipeline
# save as fp16 variant
stable_diffusion.save_pretrained("runwayml/stable-diffusion-v1-5", variant="fp16")
# save as non-ema variant
stable_diffusion.save_pretrained("runwayml/stable-diffusion-v1-5", variant="non_ema")
```
만약 variant를 기존 폴더에 저장하지 않을 경우, `variant` 인자를 반드시 명시해야 합니다. 그렇게 하지 않을 경우 원래의 오리지널 체크포인트를 찾을 수 없게 되기 때문에 에러가 발생합니다.
```python
# 👎 this won't work
stable_diffusion = DiffusionPipeline.from_pretrained("./stable-diffusion-v1-5", torch_dtype=torch.float16)
# 👍 this works
stable_diffusion = DiffusionPipeline.from_pretrained(
"./stable-diffusion-v1-5", variant="fp16", torch_dtype=torch.float16
)
```
### 모델 불러오기
모델들은 [`ModelMixin.from_pretrained`] 메서드를 통해 불러올 수 있습니다. 해당 메서드는 최신 버전의 모델 가중치 파일과 설정 파일(configurations)을 다운로드하고 캐싱합니다. 만약 이러한 파일들이 최신 버전으로 로컬 캐시에 저장되어 있다면, [`ModelMixin.from_pretrained`]는 굳이 해당 파일들을 다시 다운로드하지 않으며, 그저 캐시에 있는 최신 파일들을 재사용합니다.
모델은 `subfolder` 인자에 명시된 하위 폴더로부터 로드됩니다. 예를 들어 `runwayml/stable-diffusion-v1-5`의 UNet 모델의 가중치는 [`unet`](https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main/unet) 폴더에 저장되어 있습니다.
```python
from diffusers import UNet2DConditionModel
repo_id = "runwayml/stable-diffusion-v1-5"
model = UNet2DConditionModel.from_pretrained(repo_id, subfolder="unet")
```
혹은 [해당 모델의 리포지토리](https://huggingface.co/google/ddpm-cifar10-32/tree/main)로부터 다이렉트로 가져오는 것 역시 가능합니다.
```python
from diffusers import UNet2DModel
repo_id = "google/ddpm-cifar10-32"
model = UNet2DModel.from_pretrained(repo_id)
```
또한 앞서 봤던 `variant` 인자를 명시함으로써, Non-EMA나 `fp16`의 가중치를 가져오는 것 역시 가능합니다.
```python
from diffusers import UNet2DConditionModel
model = UNet2DConditionModel.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="unet", variant="non-ema")
model.save_pretrained("./local-unet", variant="non-ema")
```
### 스케줄러
스케줄러들은 [`SchedulerMixin.from_pretrained`] 메서드를 통해 불러올 수 있습니다. 모델과 달리 스케줄러는 별도의 가중치를 갖지 않으며, 따라서 당연히 별도의 학습과정을 요구하지 않습니다. 이러한 스케줄러들은 (해당 스케줄러 하위폴더의) configration 파일을 통해 정의됩니다.
여러개의 스케줄러를 불러온다고 해서 많은 메모리를 소모하는 것은 아니며, 다양한 스케줄러들에 동일한 스케줄러 configration을 적용하는 것 역시 가능합니다. 다음 예시 코드에서 불러오는 스케줄러들은 모두 [`StableDiffusionPipeline`]과 호환되는데, 이는 곧 해당 스케줄러들에 동일한 스케줄러 configration 파일을 적용할 수 있음을 의미합니다.
```python
from diffusers import StableDiffusionPipeline
from diffusers import (
DDPMScheduler,
DDIMScheduler,
PNDMScheduler,
LMSDiscreteScheduler,
EulerDiscreteScheduler,
EulerAncestralDiscreteScheduler,
DPMSolverMultistepScheduler,
)
repo_id = "runwayml/stable-diffusion-v1-5"
ddpm = DDPMScheduler.from_pretrained(repo_id, subfolder="scheduler")
ddim = DDIMScheduler.from_pretrained(repo_id, subfolder="scheduler")
pndm = PNDMScheduler.from_pretrained(repo_id, subfolder="scheduler")
lms = LMSDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
euler_anc = EulerAncestralDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
euler = EulerDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
dpm = DPMSolverMultistepScheduler.from_pretrained(repo_id, subfolder="scheduler")
# replace `dpm` with any of `ddpm`, `ddim`, `pndm`, `lms`, `euler_anc`, `euler`
pipeline = StableDiffusionPipeline.from_pretrained(repo_id, scheduler=dpm)
```
### DiffusionPipeline에 대해 알아보기
클래스 메서드로서 [`DiffusionPipeline.from_pretrained`]은 2가지를 담당합니다.
- 첫째로, `from_pretrained` 메서드는 최신 버전의 파이프라인을 다운로드하고, 캐시에 저장합니다. 이미 로컬 캐시에 최신 버전의 파이프라인이 저장되어 있다면, [`DiffusionPipeline.from_pretrained`]은 해당 파일들을 다시 다운로드하지 않고, 로컬 캐시에 저장되어 있는 파이프라인을 불러옵니다.
- `model_index.json` 파일을 통해 체크포인트에 대응되는 적합한 파이프라인 클래스로 불러옵니다.
파이프라인의 폴더 구조는 해당 파이프라인 클래스의 구조와 직접적으로 일치합니다. 예를 들어 [`StableDiffusionPipeline`] 클래스는 [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) 리포지토리와 대응되는 구조를 갖습니다.
```python
from diffusers import DiffusionPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
pipeline = DiffusionPipeline.from_pretrained(repo_id)
print(pipeline)
```
위의 코드 출력 결과를 확인해보면, `pipeline`은 [`StableDiffusionPipeline`]의 인스턴스이며, 다음과 같이 총 7개의 컴포넌트로 구성된다는 것을 알 수 있습니다.
- `"feature_extractor"`: [`~transformers.CLIPFeatureExtractor`]의 인스턴스
- `"safety_checker"`: 유해한 컨텐츠를 스크리닝하기 위한 [컴포넌트](https://github.com/huggingface/diffusers/blob/e55687e1e15407f60f32242027b7bb8170e58266/src/diffusers/pipelines/stable_diffusion/safety_checker.py#L32)
- `"scheduler"`: [`PNDMScheduler`]의 인스턴스
- `"text_encoder"`: [`~transformers.CLIPTextModel`]의 인스턴스
- `"tokenizer"`: a [`~transformers.CLIPTokenizer`]의 인스턴스
- `"unet"`: [`UNet2DConditionModel`]의 인스턴스
- `"vae"` [`AutoencoderKL`]의 인스턴스
```json
StableDiffusionPipeline {
"feature_extractor": [
"transformers",
"CLIPImageProcessor"
],
"safety_checker": [
"stable_diffusion",
"StableDiffusionSafetyChecker"
],
"scheduler": [
"diffusers",
"PNDMScheduler"
],
"text_encoder": [
"transformers",
"CLIPTextModel"
],
"tokenizer": [
"transformers",
"CLIPTokenizer"
],
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
```
파이프라인 인스턴스의 컴포넌트들을 [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5)의 폴더 구조와 비교해볼 경우, 각각의 컴포넌트마다 별도의 폴더가 있음을 확인할 수 있습니다.
```
.
├── feature_extractor
│ └── preprocessor_config.json
├── model_index.json
├── safety_checker
│ ├── config.json
│ └── pytorch_model.bin
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ └── pytorch_model.bin
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet
│ ├── config.json
│ ├── diffusion_pytorch_model.bin
└── vae
├── config.json
├── diffusion_pytorch_model.bin
```
또한 각각의 컴포넌트들을 파이프라인 인스턴스의 속성으로써 참조할 수 있습니다.
```py
pipeline.tokenizer
```
```python
CLIPTokenizer(
name_or_path="/root/.cache/huggingface/hub/models--runwayml--stable-diffusion-v1-5/snapshots/39593d5650112b4cc580433f6b0435385882d819/tokenizer",
vocab_size=49408,
model_max_length=77,
is_fast=False,
padding_side="right",
truncation_side="right",
special_tokens={
"bos_token": AddedToken("<|startoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True),
"eos_token": AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True),
"unk_token": AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True),
"pad_token": "<|endoftext|>",
},
)
```
모든 파이프라인은 `model_index.json` 파일을 통해 [`DiffusionPipeline`]에 다음과 같은 정보를 전달합니다.
- `_class_name` 는 어떤 파이프라인 클래스를 사용해야 하는지에 대해 알려줍니다.
- `_diffusers_version`는 어떤 버전의 디퓨저스로 파이프라인 안의 모델들이 만들어졌는지를 알려줍니다.
- 그 다음은 각각의 컴포넌트들이 어떤 라이브러리의 어떤 클래스로 만들어졌는지에 대해 알려줍니다. (아래 예시에서 `"feature_extractor" : ["transformers", "CLIPImageProcessor"]`의 경우, `feature_extractor` 컴포넌트는 `transformers` 라이브러리의 `CLIPImageProcessor` 클래스를 통해 만들어졌다는 것을 의미합니다.)
```json
{
"_class_name": "StableDiffusionPipeline",
"_diffusers_version": "0.6.0",
"feature_extractor": [
"transformers",
"CLIPImageProcessor"
],
"safety_checker": [
"stable_diffusion",
"StableDiffusionSafetyChecker"
],
"scheduler": [
"diffusers",
"PNDMScheduler"
],
"text_encoder": [
"transformers",
"CLIPTextModel"
],
"tokenizer": [
"transformers",
"CLIPTokenizer"
],
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
```
| diffusers/docs/source/ko/using-diffusers/loading.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/loading.md",
"repo_id": "diffusers",
"token_count": 14650
} | 218 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
[[open-in-colab]]
# Tour rápido
Modelos de difusão são treinados para remover o ruído Gaussiano aleatório passo a passo para gerar uma amostra de interesse, como uma imagem ou áudio. Isso despertou um tremendo interesse em IA generativa, e você provavelmente já viu exemplos de imagens geradas por difusão na internet. 🧨 Diffusers é uma biblioteca que visa tornar os modelos de difusão amplamente acessíveis a todos.
Seja você um desenvolvedor ou um usuário, esse tour rápido irá introduzir você ao 🧨 Diffusers e ajudar você a começar a gerar rapidamente! Há três componentes principais da biblioteca para conhecer:
- O [`DiffusionPipeline`] é uma classe de alto nível de ponta a ponta desenhada para gerar rapidamente amostras de modelos de difusão pré-treinados para inferência.
- [Modelos](./api/models) pré-treinados populares e módulos que podem ser usados como blocos de construção para criar sistemas de difusão.
- Vários [Agendadores](./api/schedulers/overview) diferentes - algoritmos que controlam como o ruído é adicionado para treinamento, e como gerar imagens sem o ruído durante a inferência.
Esse tour rápido mostrará como usar o [`DiffusionPipeline`] para inferência, e então mostrará como combinar um modelo e um agendador para replicar o que está acontecendo dentro do [`DiffusionPipeline`].
<Tip>
Esse tour rápido é uma versão simplificada da introdução 🧨 Diffusers [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) para ajudar você a começar rápido. Se você quer aprender mais sobre o objetivo do 🧨 Diffusers, filosofia de design, e detalhes adicionais sobre a API principal, veja o notebook!
</Tip>
Antes de começar, certifique-se de ter todas as bibliotecas necessárias instaladas:
```py
# uncomment to install the necessary libraries in Colab
#!pip install --upgrade diffusers accelerate transformers
```
- [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) acelera o carregamento do modelo para geração e treinamento.
- [🤗 Transformers](https://huggingface.co/docs/transformers/index) é necessário para executar os modelos mais populares de difusão, como o [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview).
## DiffusionPipeline
O [`DiffusionPipeline`] é a forma mais fácil de usar um sistema de difusão pré-treinado para geração. É um sistema de ponta a ponta contendo o modelo e o agendador. Você pode usar o [`DiffusionPipeline`] pronto para muitas tarefas. Dê uma olhada na tabela abaixo para algumas tarefas suportadas, e para uma lista completa de tarefas suportadas, veja a tabela [Resumo do 🧨 Diffusers](./api/pipelines/overview#diffusers-summary).
| **Tarefa** | **Descrição** | **Pipeline** |
| -------------------------------------- | ------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------- |
| Unconditional Image Generation | gera uma imagem a partir do ruído Gaussiano | [unconditional_image_generation](./using-diffusers/unconditional_image_generation) |
| Text-Guided Image Generation | gera uma imagem a partir de um prompt de texto | [conditional_image_generation](./using-diffusers/conditional_image_generation) |
| Text-Guided Image-to-Image Translation | adapta uma imagem guiada por um prompt de texto | [img2img](./using-diffusers/img2img) |
| Text-Guided Image-Inpainting | preenche a parte da máscara da imagem, dado a imagem, a máscara e o prompt de texto | [inpaint](./using-diffusers/inpaint) |
| Text-Guided Depth-to-Image Translation | adapta as partes de uma imagem guiada por um prompt de texto enquanto preserva a estrutura por estimativa de profundidade | [depth2img](./using-diffusers/depth2img) |
Comece criando uma instância do [`DiffusionPipeline`] e especifique qual checkpoint do pipeline você gostaria de baixar.
Você pode usar o [`DiffusionPipeline`] para qualquer [checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads) armazenado no Hugging Face Hub.
Nesse quicktour, você carregará o checkpoint [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) para geração de texto para imagem.
<Tip warning={true}>
Para os modelos de [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion), por favor leia cuidadosamente a [licença](https://huggingface.co/spaces/CompVis/stable-diffusion-license) primeiro antes de rodar o modelo. 🧨 Diffusers implementa uma verificação de segurança: [`safety_checker`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) para prevenir conteúdo ofensivo ou nocivo, mas as capacidades de geração de imagem aprimorada do modelo podem ainda produzir conteúdo potencialmente nocivo.
</Tip>
Para carregar o modelo com o método [`~DiffusionPipeline.from_pretrained`]:
```python
>>> from diffusers import DiffusionPipeline
>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
```
O [`DiffusionPipeline`] baixa e armazena em cache todos os componentes de modelagem, tokenização, e agendamento. Você verá que o pipeline do Stable Diffusion é composto pelo [`UNet2DConditionModel`] e [`PNDMScheduler`] entre outras coisas:
```py
>>> pipeline
StableDiffusionPipeline {
"_class_name": "StableDiffusionPipeline",
"_diffusers_version": "0.13.1",
...,
"scheduler": [
"diffusers",
"PNDMScheduler"
],
...,
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
```
Nós fortemente recomendamos rodar o pipeline em uma placa de vídeo, pois o modelo consiste em aproximadamente 1.4 bilhões de parâmetros.
Você pode mover o objeto gerador para uma placa de vídeo, assim como você faria no PyTorch:
```python
>>> pipeline.to("cuda")
```
Agora você pode passar o prompt de texto para o `pipeline` para gerar uma imagem, e então acessar a imagem sem ruído. Por padrão, a saída da imagem é embrulhada em um objeto [`PIL.Image`](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class).
```python
>>> image = pipeline("An image of a squirrel in Picasso style").images[0]
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/image_of_squirrel_painting.png"/>
</div>
Salve a imagem chamando o `save`:
```python
>>> image.save("image_of_squirrel_painting.png")
```
### Pipeline local
Você também pode utilizar o pipeline localmente. A única diferença é que você precisa baixar os pesos primeiro:
```bash
!git lfs install
!git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
```
Assim carregue os pesos salvos no pipeline:
```python
>>> pipeline = DiffusionPipeline.from_pretrained("./stable-diffusion-v1-5", use_safetensors=True)
```
Agora você pode rodar o pipeline como você faria na seção acima.
### Troca dos agendadores
Agendadores diferentes tem diferentes velocidades de retirar o ruído e compensações de qualidade. A melhor forma de descobrir qual funciona melhor para você é testar eles! Uma das principais características do 🧨 Diffusers é permitir que você troque facilmente entre agendadores. Por exemplo, para substituir o [`PNDMScheduler`] padrão com o [`EulerDiscreteScheduler`], carregue ele com o método [`~diffusers.ConfigMixin.from_config`]:
```py
>>> from diffusers import EulerDiscreteScheduler
>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
```
Tente gerar uma imagem com o novo agendador e veja se você nota alguma diferença!
Na próxima seção, você irá dar uma olhada mais de perto nos componentes - o modelo e o agendador - que compõe o [`DiffusionPipeline`] e aprender como usar esses componentes para gerar uma imagem de um gato.
## Modelos
A maioria dos modelos recebe uma amostra de ruído, e em cada _timestep_ ele prevê o _noise residual_ (outros modelos aprendem a prever a amostra anterior diretamente ou a velocidade ou [`v-prediction`](https://github.com/huggingface/diffusers/blob/5e5ce13e2f89ac45a0066cb3f369462a3cf1d9ef/src/diffusers/schedulers/scheduling_ddim.py#L110)), a diferença entre uma imagem menos com ruído e a imagem de entrada. Você pode misturar e combinar modelos para criar outros sistemas de difusão.
Modelos são inicializados com o método [`~ModelMixin.from_pretrained`] que também armazena em cache localmente os pesos do modelo para que seja mais rápido na próxima vez que você carregar o modelo. Para o tour rápido, você irá carregar o [`UNet2DModel`], um modelo básico de geração de imagem incondicional com um checkpoint treinado em imagens de gato:
```py
>>> from diffusers import UNet2DModel
>>> repo_id = "google/ddpm-cat-256"
>>> model = UNet2DModel.from_pretrained(repo_id, use_safetensors=True)
```
Para acessar os parâmetros do modelo, chame `model.config`:
```py
>>> model.config
```
A configuração do modelo é um dicionário 🧊 congelado 🧊, o que significa que esses parâmetros não podem ser mudados depois que o modelo é criado. Isso é intencional e garante que os parâmetros usados para definir a arquitetura do modelo no início permaneçam os mesmos, enquanto outros parâmetros ainda podem ser ajustados durante a geração.
Um dos parâmetros mais importantes são:
- `sample_size`: a dimensão da altura e largura da amostra de entrada.
- `in_channels`: o número de canais de entrada da amostra de entrada.
- `down_block_types` e `up_block_types`: o tipo de blocos de downsampling e upsampling usados para criar a arquitetura UNet.
- `block_out_channels`: o número de canais de saída dos blocos de downsampling; também utilizado como uma order reversa do número de canais de entrada dos blocos de upsampling.
- `layers_per_block`: o número de blocks ResNet presentes em cada block UNet.
Para usar o modelo para geração, crie a forma da imagem com ruído Gaussiano aleatório. Deve ter um eixo `batch` porque o modelo pode receber múltiplos ruídos aleatórios, um eixo `channel` correspondente ao número de canais de entrada, e um eixo `sample_size` para a altura e largura da imagem:
```py
>>> import torch
>>> torch.manual_seed(0)
>>> noisy_sample = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
>>> noisy_sample.shape
torch.Size([1, 3, 256, 256])
```
Para geração, passe a imagem com ruído para o modelo e um `timestep`. O `timestep` indica o quão ruidosa a imagem de entrada é, com mais ruído no início e menos no final. Isso ajuda o modelo a determinar sua posição no processo de difusão, se está mais perto do início ou do final. Use o método `sample` para obter a saída do modelo:
```py
>>> with torch.no_grad():
... noisy_residual = model(sample=noisy_sample, timestep=2).sample
```
Para geração de exemplos reais, você precisará de um agendador para guiar o processo de retirada do ruído. Na próxima seção, você irá aprender como acoplar um modelo com um agendador.
## Agendadores
Agendadores gerenciam a retirada do ruído de uma amostra ruidosa para uma amostra menos ruidosa dado a saída do modelo - nesse caso, é o `noisy_residual`.
<Tip>
🧨 Diffusers é uma caixa de ferramentas para construir sistemas de difusão. Enquanto o [`DiffusionPipeline`] é uma forma conveniente de começar com um sistema de difusão pré-construído, você também pode escolher seus próprios modelos e agendadores separadamente para construir um sistema de difusão personalizado.
</Tip>
Para o tour rápido, você irá instanciar o [`DDPMScheduler`] com o método [`~diffusers.ConfigMixin.from_config`]:
```py
>>> from diffusers import DDPMScheduler
>>> scheduler = DDPMScheduler.from_config(repo_id)
>>> scheduler
DDPMScheduler {
"_class_name": "DDPMScheduler",
"_diffusers_version": "0.13.1",
"beta_end": 0.02,
"beta_schedule": "linear",
"beta_start": 0.0001,
"clip_sample": true,
"clip_sample_range": 1.0,
"num_train_timesteps": 1000,
"prediction_type": "epsilon",
"trained_betas": null,
"variance_type": "fixed_small"
}
```
<Tip>
💡 Perceba como o agendador é instanciado de uma configuração. Diferentemente de um modelo, um agendador não tem pesos treináveis e é livre de parâmetros!
</Tip>
Um dos parâmetros mais importante são:
- `num_train_timesteps`: o tamanho do processo de retirar ruído ou em outras palavras, o número de _timesteps_ necessários para o processo de ruídos Gausianos aleatórios dentro de uma amostra de dados.
- `beta_schedule`: o tipo de agendados de ruído para o uso de geração e treinamento.
- `beta_start` e `beta_end`: para começar e terminar os valores de ruído para o agendador de ruído.
Para predizer uma imagem com um pouco menos de ruído, passe o seguinte para o método do agendador [`~diffusers.DDPMScheduler.step`]: saída do modelo, `timestep`, e a atual `amostra`.
```py
>>> less_noisy_sample = scheduler.step(model_output=noisy_residual, timestep=2, sample=noisy_sample).prev_sample
>>> less_noisy_sample.shape
```
O `less_noisy_sample` pode ser passado para o próximo `timestep` onde ele ficará ainda com menos ruído! Vamos juntar tudo agora e visualizar o processo inteiro de retirada de ruído.
Comece, criando a função que faça o pós-processamento e mostre a imagem sem ruído como uma `PIL.Image`:
```py
>>> import PIL.Image
>>> import numpy as np
>>> def display_sample(sample, i):
... image_processed = sample.cpu().permute(0, 2, 3, 1)
... image_processed = (image_processed + 1.0) * 127.5
... image_processed = image_processed.numpy().astype(np.uint8)
... image_pil = PIL.Image.fromarray(image_processed[0])
... display(f"Image at step {i}")
... display(image_pil)
```
Para acelerar o processo de retirada de ruído, mova a entrada e o modelo para uma GPU:
```py
>>> model.to("cuda")
>>> noisy_sample = noisy_sample.to("cuda")
```
Agora, crie um loop de retirada de ruído que prediz o residual da amostra menos ruidosa, e computa a amostra menos ruidosa com o agendador:
```py
>>> import tqdm
>>> sample = noisy_sample
>>> for i, t in enumerate(tqdm.tqdm(scheduler.timesteps)):
... # 1. predict noise residual
... with torch.no_grad():
... residual = model(sample, t).sample
... # 2. compute less noisy image and set x_t -> x_t-1
... sample = scheduler.step(residual, t, sample).prev_sample
... # 3. optionally look at image
... if (i + 1) % 50 == 0:
... display_sample(sample, i + 1)
```
Sente-se e assista o gato ser gerado do nada além de ruído! 😻
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/diffusion-quicktour.png"/>
</div>
## Próximos passos
Esperamos que você tenha gerado algumas imagens legais com o 🧨 Diffusers neste tour rápido! Para suas próximas etapas, você pode
- Treine ou faça a configuração fina de um modelo para gerar suas próprias imagens no tutorial de [treinamento](./tutorials/basic_training).
- Veja exemplos oficiais e da comunidade de [scripts de treinamento ou configuração fina](https://github.com/huggingface/diffusers/tree/main/examples#-diffusers-examples) para os mais variados casos de uso.
- Aprenda sobre como carregar, acessar, mudar e comparar agendadores no guia [Usando diferentes agendadores](./using-diffusers/schedulers).
- Explore engenharia de prompt, otimizações de velocidade e memória, e dicas e truques para gerar imagens de maior qualidade com o guia [Stable Diffusion](./stable_diffusion).
- Se aprofunde em acelerar 🧨 Diffusers com guias sobre [PyTorch otimizado em uma GPU](./optimization/fp16), e guias de inferência para rodar [Stable Diffusion em Apple Silicon (M1/M2)](./optimization/mps) e [ONNX Runtime](./optimization/onnx).
| diffusers/docs/source/pt/quicktour.md/0 | {
"file_path": "diffusers/docs/source/pt/quicktour.md",
"repo_id": "diffusers",
"token_count": 6766
} | 219 |
import glob
import os
from typing import Dict, List, Union
import safetensors.torch
import torch
from huggingface_hub import snapshot_download
from huggingface_hub.utils import validate_hf_hub_args
from diffusers import DiffusionPipeline, __version__
from diffusers.schedulers.scheduling_utils import SCHEDULER_CONFIG_NAME
from diffusers.utils import CONFIG_NAME, ONNX_WEIGHTS_NAME, WEIGHTS_NAME
class CheckpointMergerPipeline(DiffusionPipeline):
"""
A class that supports merging diffusion models based on the discussion here:
https://github.com/huggingface/diffusers/issues/877
Example usage:-
pipe = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", custom_pipeline="checkpoint_merger.py")
merged_pipe = pipe.merge(["CompVis/stable-diffusion-v1-4","prompthero/openjourney"], interp = 'inv_sigmoid', alpha = 0.8, force = True)
merged_pipe.to('cuda')
prompt = "An astronaut riding a unicycle on Mars"
results = merged_pipe(prompt)
## For more details, see the docstring for the merge method.
"""
def __init__(self):
self.register_to_config()
super().__init__()
def _compare_model_configs(self, dict0, dict1):
if dict0 == dict1:
return True
else:
config0, meta_keys0 = self._remove_meta_keys(dict0)
config1, meta_keys1 = self._remove_meta_keys(dict1)
if config0 == config1:
print(f"Warning !: Mismatch in keys {meta_keys0} and {meta_keys1}.")
return True
return False
def _remove_meta_keys(self, config_dict: Dict):
meta_keys = []
temp_dict = config_dict.copy()
for key in config_dict.keys():
if key.startswith("_"):
temp_dict.pop(key)
meta_keys.append(key)
return (temp_dict, meta_keys)
@torch.no_grad()
@validate_hf_hub_args
def merge(self, pretrained_model_name_or_path_list: List[Union[str, os.PathLike]], **kwargs):
"""
Returns a new pipeline object of the class 'DiffusionPipeline' with the merged checkpoints(weights) of the models passed
in the argument 'pretrained_model_name_or_path_list' as a list.
Parameters:
-----------
pretrained_model_name_or_path_list : A list of valid pretrained model names in the HuggingFace hub or paths to locally stored models in the HuggingFace format.
**kwargs:
Supports all the default DiffusionPipeline.get_config_dict kwargs viz..
cache_dir, resume_download, force_download, proxies, local_files_only, token, revision, torch_dtype, device_map.
alpha - The interpolation parameter. Ranges from 0 to 1. It affects the ratio in which the checkpoints are merged. A 0.8 alpha
would mean that the first model checkpoints would affect the final result far less than an alpha of 0.2
interp - The interpolation method to use for the merging. Supports "sigmoid", "inv_sigmoid", "add_diff" and None.
Passing None uses the default interpolation which is weighted sum interpolation. For merging three checkpoints, only "add_diff" is supported.
force - Whether to ignore mismatch in model_config.json for the current models. Defaults to False.
variant - which variant of a pretrained model to load, e.g. "fp16" (None)
"""
# Default kwargs from DiffusionPipeline
cache_dir = kwargs.pop("cache_dir", None)
resume_download = kwargs.pop("resume_download", False)
force_download = kwargs.pop("force_download", False)
proxies = kwargs.pop("proxies", None)
local_files_only = kwargs.pop("local_files_only", False)
token = kwargs.pop("token", None)
variant = kwargs.pop("variant", None)
revision = kwargs.pop("revision", None)
torch_dtype = kwargs.pop("torch_dtype", None)
device_map = kwargs.pop("device_map", None)
alpha = kwargs.pop("alpha", 0.5)
interp = kwargs.pop("interp", None)
print("Received list", pretrained_model_name_or_path_list)
print(f"Combining with alpha={alpha}, interpolation mode={interp}")
checkpoint_count = len(pretrained_model_name_or_path_list)
# Ignore result from model_index_json comparison of the two checkpoints
force = kwargs.pop("force", False)
# If less than 2 checkpoints, nothing to merge. If more than 3, not supported for now.
if checkpoint_count > 3 or checkpoint_count < 2:
raise ValueError(
"Received incorrect number of checkpoints to merge. Ensure that either 2 or 3 checkpoints are being"
" passed."
)
print("Received the right number of checkpoints")
# chkpt0, chkpt1 = pretrained_model_name_or_path_list[0:2]
# chkpt2 = pretrained_model_name_or_path_list[2] if checkpoint_count == 3 else None
# Validate that the checkpoints can be merged
# Step 1: Load the model config and compare the checkpoints. We'll compare the model_index.json first while ignoring the keys starting with '_'
config_dicts = []
for pretrained_model_name_or_path in pretrained_model_name_or_path_list:
config_dict = DiffusionPipeline.load_config(
pretrained_model_name_or_path,
cache_dir=cache_dir,
resume_download=resume_download,
force_download=force_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
)
config_dicts.append(config_dict)
comparison_result = True
for idx in range(1, len(config_dicts)):
comparison_result &= self._compare_model_configs(config_dicts[idx - 1], config_dicts[idx])
if not force and comparison_result is False:
raise ValueError("Incompatible checkpoints. Please check model_index.json for the models.")
print("Compatible model_index.json files found")
# Step 2: Basic Validation has succeeded. Let's download the models and save them into our local files.
cached_folders = []
for pretrained_model_name_or_path, config_dict in zip(pretrained_model_name_or_path_list, config_dicts):
folder_names = [k for k in config_dict.keys() if not k.startswith("_")]
allow_patterns = [os.path.join(k, "*") for k in folder_names]
allow_patterns += [
WEIGHTS_NAME,
SCHEDULER_CONFIG_NAME,
CONFIG_NAME,
ONNX_WEIGHTS_NAME,
DiffusionPipeline.config_name,
]
requested_pipeline_class = config_dict.get("_class_name")
user_agent = {"diffusers": __version__, "pipeline_class": requested_pipeline_class}
cached_folder = (
pretrained_model_name_or_path
if os.path.isdir(pretrained_model_name_or_path)
else snapshot_download(
pretrained_model_name_or_path,
cache_dir=cache_dir,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
allow_patterns=allow_patterns,
user_agent=user_agent,
)
)
print("Cached Folder", cached_folder)
cached_folders.append(cached_folder)
# Step 3:-
# Load the first checkpoint as a diffusion pipeline and modify its module state_dict in place
final_pipe = DiffusionPipeline.from_pretrained(
cached_folders[0],
torch_dtype=torch_dtype,
device_map=device_map,
variant=variant,
)
final_pipe.to(self.device)
checkpoint_path_2 = None
if len(cached_folders) > 2:
checkpoint_path_2 = os.path.join(cached_folders[2])
if interp == "sigmoid":
theta_func = CheckpointMergerPipeline.sigmoid
elif interp == "inv_sigmoid":
theta_func = CheckpointMergerPipeline.inv_sigmoid
elif interp == "add_diff":
theta_func = CheckpointMergerPipeline.add_difference
else:
theta_func = CheckpointMergerPipeline.weighted_sum
# Find each module's state dict.
for attr in final_pipe.config.keys():
if not attr.startswith("_"):
checkpoint_path_1 = os.path.join(cached_folders[1], attr)
if os.path.exists(checkpoint_path_1):
files = [
*glob.glob(os.path.join(checkpoint_path_1, "*.safetensors")),
*glob.glob(os.path.join(checkpoint_path_1, "*.bin")),
]
checkpoint_path_1 = files[0] if len(files) > 0 else None
if len(cached_folders) < 3:
checkpoint_path_2 = None
else:
checkpoint_path_2 = os.path.join(cached_folders[2], attr)
if os.path.exists(checkpoint_path_2):
files = [
*glob.glob(os.path.join(checkpoint_path_2, "*.safetensors")),
*glob.glob(os.path.join(checkpoint_path_2, "*.bin")),
]
checkpoint_path_2 = files[0] if len(files) > 0 else None
# For an attr if both checkpoint_path_1 and 2 are None, ignore.
# If at least one is present, deal with it according to interp method, of course only if the state_dict keys match.
if checkpoint_path_1 is None and checkpoint_path_2 is None:
print(f"Skipping {attr}: not present in 2nd or 3d model")
continue
try:
module = getattr(final_pipe, attr)
if isinstance(module, bool): # ignore requires_safety_checker boolean
continue
theta_0 = getattr(module, "state_dict")
theta_0 = theta_0()
update_theta_0 = getattr(module, "load_state_dict")
theta_1 = (
safetensors.torch.load_file(checkpoint_path_1)
if (checkpoint_path_1.endswith(".safetensors"))
else torch.load(checkpoint_path_1, map_location="cpu")
)
theta_2 = None
if checkpoint_path_2:
theta_2 = (
safetensors.torch.load_file(checkpoint_path_2)
if (checkpoint_path_2.endswith(".safetensors"))
else torch.load(checkpoint_path_2, map_location="cpu")
)
if not theta_0.keys() == theta_1.keys():
print(f"Skipping {attr}: key mismatch")
continue
if theta_2 and not theta_1.keys() == theta_2.keys():
print(f"Skipping {attr}:y mismatch")
except Exception as e:
print(f"Skipping {attr} do to an unexpected error: {str(e)}")
continue
print(f"MERGING {attr}")
for key in theta_0.keys():
if theta_2:
theta_0[key] = theta_func(theta_0[key], theta_1[key], theta_2[key], alpha)
else:
theta_0[key] = theta_func(theta_0[key], theta_1[key], None, alpha)
del theta_1
del theta_2
update_theta_0(theta_0)
del theta_0
return final_pipe
@staticmethod
def weighted_sum(theta0, theta1, theta2, alpha):
return ((1 - alpha) * theta0) + (alpha * theta1)
# Smoothstep (https://en.wikipedia.org/wiki/Smoothstep)
@staticmethod
def sigmoid(theta0, theta1, theta2, alpha):
alpha = alpha * alpha * (3 - (2 * alpha))
return theta0 + ((theta1 - theta0) * alpha)
# Inverse Smoothstep (https://en.wikipedia.org/wiki/Smoothstep)
@staticmethod
def inv_sigmoid(theta0, theta1, theta2, alpha):
import math
alpha = 0.5 - math.sin(math.asin(1.0 - 2.0 * alpha) / 3.0)
return theta0 + ((theta1 - theta0) * alpha)
@staticmethod
def add_difference(theta0, theta1, theta2, alpha):
return theta0 + (theta1 - theta2) * (1.0 - alpha)
| diffusers/examples/community/checkpoint_merger.py/0 | {
"file_path": "diffusers/examples/community/checkpoint_merger.py",
"repo_id": "diffusers",
"token_count": 6138
} | 220 |
# Copyright 2024 Stanford University Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
# and https://github.com/hojonathanho/diffusion
import math
from dataclasses import dataclass
from typing import Any, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, ConfigMixin, DiffusionPipeline, SchedulerMixin, UNet2DConditionModel, logging
from diffusers.configuration_utils import register_to_config
from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.utils import BaseOutput
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class LatentConsistencyModelImg2ImgPipeline(DiffusionPipeline):
_optional_components = ["scheduler"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: "LCMSchedulerWithTimestamp",
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
scheduler = (
scheduler
if scheduler is not None
else LCMSchedulerWithTimestamp(
beta_start=0.00085, beta_end=0.0120, beta_schedule="scaled_linear", prediction_type="epsilon"
)
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
prompt_embeds: None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
"""
if prompt is not None and isinstance(prompt, str):
pass
elif prompt is not None and isinstance(prompt, list):
len(prompt)
else:
prompt_embeds.shape[0]
if prompt_embeds is None:
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# Don't need to get uncond prompt embedding because of LCM Guided Distillation
return prompt_embeds
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
def prepare_latents(
self,
image,
timestep,
batch_size,
num_channels_latents,
height,
width,
dtype,
device,
latents=None,
generator=None,
):
shape = (
batch_size,
num_channels_latents,
int(height) // self.vae_scale_factor,
int(width) // self.vae_scale_factor,
)
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
image = image.to(device=device, dtype=dtype)
# batch_size = batch_size * num_images_per_prompt
if image.shape[1] == 4:
init_latents = image
else:
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
elif isinstance(generator, list):
init_latents = [
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
]
init_latents = torch.cat(init_latents, dim=0)
else:
init_latents = self.vae.encode(image).latent_dist.sample(generator)
init_latents = self.vae.config.scaling_factor * init_latents
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
# expand init_latents for batch_size
(
f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
" images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
" that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
" your script to pass as many initial images as text prompts to suppress this warning."
)
# deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
additional_image_per_prompt = batch_size // init_latents.shape[0]
init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
raise ValueError(
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
)
else:
init_latents = torch.cat([init_latents], dim=0)
shape = init_latents.shape
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# get latents
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
def get_w_embedding(self, w, embedding_dim=512, dtype=torch.float32):
"""
see https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
Args:
timesteps: torch.Tensor: generate embedding vectors at these timesteps
embedding_dim: int: dimension of the embeddings to generate
dtype: data type of the generated embeddings
Returns:
embedding vectors with shape `(len(timesteps), embedding_dim)`
"""
assert len(w.shape) == 1
w = w * 1000.0
half_dim = embedding_dim // 2
emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
emb = w.to(dtype)[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
if embedding_dim % 2 == 1: # zero pad
emb = torch.nn.functional.pad(emb, (0, 1))
assert emb.shape == (w.shape[0], embedding_dim)
return emb
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
return timesteps, num_inference_steps - t_start
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: PipelineImageInput = None,
strength: float = 0.8,
height: Optional[int] = 768,
width: Optional[int] = 768,
guidance_scale: float = 7.5,
num_images_per_prompt: Optional[int] = 1,
latents: Optional[torch.Tensor] = None,
num_inference_steps: int = 4,
lcm_origin_steps: int = 50,
prompt_embeds: Optional[torch.Tensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
):
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# do_classifier_free_guidance = guidance_scale > 0.0 # In LCM Implementation: cfg_noise = noise_cond + cfg_scale * (noise_cond - noise_uncond) , (cfg_scale > 0.0 using CFG)
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
prompt_embeds=prompt_embeds,
)
# 3.5 encode image
image = self.image_processor.preprocess(image)
# 4. Prepare timesteps
self.scheduler.set_timesteps(strength, num_inference_steps, lcm_origin_steps)
# timesteps = self.scheduler.timesteps
# timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, 1.0, device)
timesteps = self.scheduler.timesteps
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
print("timesteps: ", timesteps)
# 5. Prepare latent variable
num_channels_latents = self.unet.config.in_channels
if latents is None:
latents = self.prepare_latents(
image,
latent_timestep,
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
latents,
)
bs = batch_size * num_images_per_prompt
# 6. Get Guidance Scale Embedding
w = torch.tensor(guidance_scale).repeat(bs)
w_embedding = self.get_w_embedding(w, embedding_dim=256).to(device=device, dtype=latents.dtype)
# 7. LCM MultiStep Sampling Loop:
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
ts = torch.full((bs,), t, device=device, dtype=torch.long)
latents = latents.to(prompt_embeds.dtype)
# model prediction (v-prediction, eps, x)
model_pred = self.unet(
latents,
ts,
timestep_cond=w_embedding,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)[0]
# compute the previous noisy sample x_t -> x_t-1
latents, denoised = self.scheduler.step(model_pred, i, t, latents, return_dict=False)
# # call the callback, if provided
# if i == len(timesteps) - 1:
progress_bar.update()
denoised = denoised.to(prompt_embeds.dtype)
if not output_type == "latent":
image = self.vae.decode(denoised / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = denoised
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
@dataclass
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->DDIM
class LCMSchedulerOutput(BaseOutput):
"""
Output class for the scheduler's `step` function output.
Args:
prev_sample (`torch.Tensor` of shape `(batch_size, num_channels, height, width)` for images):
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
denoising loop.
pred_original_sample (`torch.Tensor` of shape `(batch_size, num_channels, height, width)` for images):
The predicted denoised sample `(x_{0})` based on the model output from the current timestep.
`pred_original_sample` can be used to preview progress or for guidance.
"""
prev_sample: torch.Tensor
denoised: Optional[torch.Tensor] = None
# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
def betas_for_alpha_bar(
num_diffusion_timesteps,
max_beta=0.999,
alpha_transform_type="cosine",
):
"""
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
(1-beta) over time from t = [0,1].
Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
to that part of the diffusion process.
Args:
num_diffusion_timesteps (`int`): the number of betas to produce.
max_beta (`float`): the maximum beta to use; use values lower than 1 to
prevent singularities.
alpha_transform_type (`str`, *optional*, default to `cosine`): the type of noise schedule for alpha_bar.
Choose from `cosine` or `exp`
Returns:
betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
"""
if alpha_transform_type == "cosine":
def alpha_bar_fn(t):
return math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2
elif alpha_transform_type == "exp":
def alpha_bar_fn(t):
return math.exp(t * -12.0)
else:
raise ValueError(f"Unsupported alpha_transform_type: {alpha_transform_type}")
betas = []
for i in range(num_diffusion_timesteps):
t1 = i / num_diffusion_timesteps
t2 = (i + 1) / num_diffusion_timesteps
betas.append(min(1 - alpha_bar_fn(t2) / alpha_bar_fn(t1), max_beta))
return torch.tensor(betas, dtype=torch.float32)
def rescale_zero_terminal_snr(betas):
"""
Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
Args:
betas (`torch.Tensor`):
the betas that the scheduler is being initialized with.
Returns:
`torch.Tensor`: rescaled betas with zero terminal SNR
"""
# Convert betas to alphas_bar_sqrt
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_bar_sqrt = alphas_cumprod.sqrt()
# Store old values.
alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
# Shift so the last timestep is zero.
alphas_bar_sqrt -= alphas_bar_sqrt_T
# Scale so the first timestep is back to the old value.
alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
# Convert alphas_bar_sqrt to betas
alphas_bar = alphas_bar_sqrt**2 # Revert sqrt
alphas = alphas_bar[1:] / alphas_bar[:-1] # Revert cumprod
alphas = torch.cat([alphas_bar[0:1], alphas])
betas = 1 - alphas
return betas
class LCMSchedulerWithTimestamp(SchedulerMixin, ConfigMixin):
"""
This class modifies LCMScheduler to add a timestamp argument to set_timesteps
`LCMScheduler` extends the denoising procedure introduced in denoising diffusion probabilistic models (DDPMs) with
non-Markovian guidance.
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
methods the library implements for all schedulers such as loading and saving.
Args:
num_train_timesteps (`int`, defaults to 1000):
The number of diffusion steps to train the model.
beta_start (`float`, defaults to 0.0001):
The starting `beta` value of inference.
beta_end (`float`, defaults to 0.02):
The final `beta` value.
beta_schedule (`str`, defaults to `"linear"`):
The beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
`linear`, `scaled_linear`, or `squaredcos_cap_v2`.
trained_betas (`np.ndarray`, *optional*):
Pass an array of betas directly to the constructor to bypass `beta_start` and `beta_end`.
clip_sample (`bool`, defaults to `True`):
Clip the predicted sample for numerical stability.
clip_sample_range (`float`, defaults to 1.0):
The maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
set_alpha_to_one (`bool`, defaults to `True`):
Each diffusion step uses the alphas product value at that step and at the previous one. For the final step
there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
otherwise it uses the alpha value at step 0.
steps_offset (`int`, defaults to 0):
An offset added to the inference steps, as required by some model families.
prediction_type (`str`, defaults to `epsilon`, *optional*):
Prediction type of the scheduler function; can be `epsilon` (predicts the noise of the diffusion process),
`sample` (directly predicts the noisy sample`) or `v_prediction` (see section 2.4 of [Imagen
Video](https://imagen.research.google/video/paper.pdf) paper).
thresholding (`bool`, defaults to `False`):
Whether to use the "dynamic thresholding" method. This is unsuitable for latent-space diffusion models such
as Stable Diffusion.
dynamic_thresholding_ratio (`float`, defaults to 0.995):
The ratio for the dynamic thresholding method. Valid only when `thresholding=True`.
sample_max_value (`float`, defaults to 1.0):
The threshold value for dynamic thresholding. Valid only when `thresholding=True`.
timestep_spacing (`str`, defaults to `"leading"`):
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
rescale_betas_zero_snr (`bool`, defaults to `False`):
Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
dark samples instead of limiting it to samples with medium brightness. Loosely related to
[`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
"""
# _compatibles = [e.name for e in KarrasDiffusionSchedulers]
order = 1
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
beta_start: float = 0.0001,
beta_end: float = 0.02,
beta_schedule: str = "linear",
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
clip_sample: bool = True,
set_alpha_to_one: bool = True,
steps_offset: int = 0,
prediction_type: str = "epsilon",
thresholding: bool = False,
dynamic_thresholding_ratio: float = 0.995,
clip_sample_range: float = 1.0,
sample_max_value: float = 1.0,
timestep_spacing: str = "leading",
rescale_betas_zero_snr: bool = False,
):
if trained_betas is not None:
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
elif beta_schedule == "linear":
self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
elif beta_schedule == "scaled_linear":
# this schedule is very specific to the latent diffusion model.
self.betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
elif beta_schedule == "squaredcos_cap_v2":
# Glide cosine schedule
self.betas = betas_for_alpha_bar(num_train_timesteps)
else:
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
# Rescale for zero SNR
if rescale_betas_zero_snr:
self.betas = rescale_zero_terminal_snr(self.betas)
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
# At every step in ddim, we are looking into the previous alphas_cumprod
# For the final step, there is no previous alphas_cumprod because we are already at 0
# `set_alpha_to_one` decides whether we set this parameter simply to one or
# whether we use the final alpha of the "non-previous" one.
self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
# standard deviation of the initial noise distribution
self.init_noise_sigma = 1.0
# setable values
self.num_inference_steps = None
self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy().astype(np.int64))
def scale_model_input(self, sample: torch.Tensor, timestep: Optional[int] = None) -> torch.Tensor:
"""
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
current timestep.
Args:
sample (`torch.Tensor`):
The input sample.
timestep (`int`, *optional*):
The current timestep in the diffusion chain.
Returns:
`torch.Tensor`:
A scaled input sample.
"""
return sample
def _get_variance(self, timestep, prev_timestep):
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
return variance
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
def _threshold_sample(self, sample: torch.Tensor) -> torch.Tensor:
"""
"Dynamic thresholding: At each sampling step we set s to a certain percentile absolute pixel value in xt0 (the
prediction of x_0 at timestep t), and if s > 1, then we threshold xt0 to the range [-s, s] and then divide by
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
https://arxiv.org/abs/2205.11487
"""
dtype = sample.dtype
batch_size, channels, height, width = sample.shape
if dtype not in (torch.float32, torch.float64):
sample = sample.float() # upcast for quantile calculation, and clamp not implemented for cpu half
# Flatten sample for doing quantile calculation along each image
sample = sample.reshape(batch_size, channels * height * width)
abs_sample = sample.abs() # "a certain percentile absolute pixel value"
s = torch.quantile(abs_sample, self.config.dynamic_thresholding_ratio, dim=1)
s = torch.clamp(
s, min=1, max=self.config.sample_max_value
) # When clamped to min=1, equivalent to standard clipping to [-1, 1]
s = s.unsqueeze(1) # (batch_size, 1) because clamp will broadcast along dim=0
sample = torch.clamp(sample, -s, s) / s # "we threshold xt0 to the range [-s, s] and then divide by s"
sample = sample.reshape(batch_size, channels, height, width)
sample = sample.to(dtype)
return sample
def set_timesteps(
self, stength, num_inference_steps: int, lcm_origin_steps: int, device: Union[str, torch.device] = None
):
"""
Sets the discrete timesteps used for the diffusion chain (to be run before inference).
Args:
num_inference_steps (`int`):
The number of diffusion steps used when generating samples with a pre-trained model.
"""
if num_inference_steps > self.config.num_train_timesteps:
raise ValueError(
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"
f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
f" maximal {self.config.num_train_timesteps} timesteps."
)
self.num_inference_steps = num_inference_steps
# LCM Timesteps Setting: # Linear Spacing
c = self.config.num_train_timesteps // lcm_origin_steps
lcm_origin_timesteps = (
np.asarray(list(range(1, int(lcm_origin_steps * stength) + 1))) * c - 1
) # LCM Training Steps Schedule
skipping_step = len(lcm_origin_timesteps) // num_inference_steps
timesteps = lcm_origin_timesteps[::-skipping_step][:num_inference_steps] # LCM Inference Steps Schedule
self.timesteps = torch.from_numpy(timesteps.copy()).to(device)
def get_scalings_for_boundary_condition_discrete(self, t):
self.sigma_data = 0.5 # Default: 0.5
# By dividing 0.1: This is almost a delta function at t=0.
c_skip = self.sigma_data**2 / ((t / 0.1) ** 2 + self.sigma_data**2)
c_out = (t / 0.1) / ((t / 0.1) ** 2 + self.sigma_data**2) ** 0.5
return c_skip, c_out
def step(
self,
model_output: torch.Tensor,
timeindex: int,
timestep: int,
sample: torch.Tensor,
eta: float = 0.0,
use_clipped_model_output: bool = False,
generator=None,
variance_noise: Optional[torch.Tensor] = None,
return_dict: bool = True,
) -> Union[LCMSchedulerOutput, Tuple]:
"""
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
model_output (`torch.Tensor`):
The direct output from learned diffusion model.
timestep (`float`):
The current discrete timestep in the diffusion chain.
sample (`torch.Tensor`):
A current instance of a sample created by the diffusion process.
eta (`float`):
The weight of noise for added noise in diffusion step.
use_clipped_model_output (`bool`, defaults to `False`):
If `True`, computes "corrected" `model_output` from the clipped predicted original sample. Necessary
because predicted original sample is clipped to [-1, 1] when `self.config.clip_sample` is `True`. If no
clipping has happened, "corrected" `model_output` would coincide with the one provided as input and
`use_clipped_model_output` has no effect.
generator (`torch.Generator`, *optional*):
A random number generator.
variance_noise (`torch.Tensor`):
Alternative to generating noise with `generator` by directly providing the noise for the variance
itself. Useful for methods such as [`CycleDiffusion`].
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~schedulers.scheduling_lcm.LCMSchedulerOutput`] or `tuple`.
Returns:
[`~schedulers.scheduling_utils.LCMSchedulerOutput`] or `tuple`:
If return_dict is `True`, [`~schedulers.scheduling_lcm.LCMSchedulerOutput`] is returned, otherwise a
tuple is returned where the first element is the sample tensor.
"""
if self.num_inference_steps is None:
raise ValueError(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
# 1. get previous step value
prev_timeindex = timeindex + 1
if prev_timeindex < len(self.timesteps):
prev_timestep = self.timesteps[prev_timeindex]
else:
prev_timestep = timestep
# 2. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
# 3. Get scalings for boundary conditions
c_skip, c_out = self.get_scalings_for_boundary_condition_discrete(timestep)
# 4. Different Parameterization:
parameterization = self.config.prediction_type
if parameterization == "epsilon": # noise-prediction
pred_x0 = (sample - beta_prod_t.sqrt() * model_output) / alpha_prod_t.sqrt()
elif parameterization == "sample": # x-prediction
pred_x0 = model_output
elif parameterization == "v_prediction": # v-prediction
pred_x0 = alpha_prod_t.sqrt() * sample - beta_prod_t.sqrt() * model_output
# 4. Denoise model output using boundary conditions
denoised = c_out * pred_x0 + c_skip * sample
# 5. Sample z ~ N(0, I), For MultiStep Inference
# Noise is not used for one-step sampling.
if len(self.timesteps) > 1:
noise = torch.randn(model_output.shape).to(model_output.device)
prev_sample = alpha_prod_t_prev.sqrt() * denoised + beta_prod_t_prev.sqrt() * noise
else:
prev_sample = denoised
if not return_dict:
return (prev_sample, denoised)
return LCMSchedulerOutput(prev_sample=prev_sample, denoised=denoised)
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.add_noise
def add_noise(
self,
original_samples: torch.Tensor,
noise: torch.Tensor,
timesteps: torch.IntTensor,
) -> torch.Tensor:
# Make sure alphas_cumprod and timestep have same device and dtype as original_samples
alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.get_velocity
def get_velocity(self, sample: torch.Tensor, noise: torch.Tensor, timesteps: torch.IntTensor) -> torch.Tensor:
# Make sure alphas_cumprod and timestep have same device and dtype as sample
alphas_cumprod = self.alphas_cumprod.to(device=sample.device, dtype=sample.dtype)
timesteps = timesteps.to(sample.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(sample.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
return velocity
def __len__(self):
return self.config.num_train_timesteps
| diffusers/examples/community/latent_consistency_img2img.py/0 | {
"file_path": "diffusers/examples/community/latent_consistency_img2img.py",
"repo_id": "diffusers",
"token_count": 16086
} | 221 |
import inspect
import os
import random
import warnings
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
from diffusers.image_processor import VaeImageProcessor
from diffusers.loaders import (
FromSingleFileMixin,
LoraLoaderMixin,
TextualInversionLoaderMixin,
)
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.models.attention_processor import (
AttnProcessor2_0,
LoRAAttnProcessor2_0,
LoRAXFormersAttnProcessor,
XFormersAttnProcessor,
)
from diffusers.models.lora import adjust_lora_scale_text_encoder
from diffusers.pipelines.pipeline_utils import DiffusionPipeline, StableDiffusionMixin
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
is_accelerate_available,
is_accelerate_version,
is_invisible_watermark_available,
logging,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
if is_invisible_watermark_available():
from diffusers.pipelines.stable_diffusion_xl.watermark import (
StableDiffusionXLWatermarker,
)
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import StableDiffusionXLPipeline
>>> pipe = StableDiffusionXLPipeline.from_pretrained(
... "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
... )
>>> pipe = pipe.to("cuda")
>>> prompt = "a photo of an astronaut riding a horse on mars"
>>> image = pipe(prompt).images[0]
```
"""
def gaussian_kernel(kernel_size=3, sigma=1.0, channels=3):
x_coord = torch.arange(kernel_size)
gaussian_1d = torch.exp(-((x_coord - (kernel_size - 1) / 2) ** 2) / (2 * sigma**2))
gaussian_1d = gaussian_1d / gaussian_1d.sum()
gaussian_2d = gaussian_1d[:, None] * gaussian_1d[None, :]
kernel = gaussian_2d[None, None, :, :].repeat(channels, 1, 1, 1)
return kernel
def gaussian_filter(latents, kernel_size=3, sigma=1.0):
channels = latents.shape[1]
kernel = gaussian_kernel(kernel_size, sigma, channels).to(latents.device, latents.dtype)
blurred_latents = F.conv2d(latents, kernel, padding=kernel_size // 2, groups=channels)
return blurred_latents
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
# rescale the results from guidance (fixes overexposure)
noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
# mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
return noise_cfg
class DemoFusionSDXLPipeline(
DiffusionPipeline, StableDiffusionMixin, FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
):
r"""
Pipeline for text-to-image generation using Stable Diffusion XL.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
In addition the pipeline inherits the following loading methods:
- *LoRA*: [`StableDiffusionXLPipeline.load_lora_weights`]
- *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
as well as the following saving methods:
- *LoRA*: [`loaders.StableDiffusionXLPipeline.save_lora_weights`]
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion XL uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
text_encoder_2 ([` CLIPTextModelWithProjection`]):
Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection),
specifically the
[laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)
variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
tokenizer_2 (`CLIPTokenizer`):
Second Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
force_zeros_for_empty_prompt (`bool`, *optional*, defaults to `"True"`):
Whether the negative prompt embeddings shall be forced to always be set to 0. Also see the config of
`stabilityai/stable-diffusion-xl-base-1-0`.
add_watermarker (`bool`, *optional*):
Whether to use the [invisible_watermark library](https://github.com/ShieldMnt/invisible-watermark/) to
watermark output images. If not defined, it will default to True if the package is installed, otherwise no
watermarker will be used.
"""
model_cpu_offload_seq = "text_encoder->text_encoder_2->unet->vae"
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
text_encoder_2: CLIPTextModelWithProjection,
tokenizer: CLIPTokenizer,
tokenizer_2: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
force_zeros_for_empty_prompt: bool = True,
add_watermarker: Optional[bool] = None,
):
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
text_encoder_2=text_encoder_2,
tokenizer=tokenizer,
tokenizer_2=tokenizer_2,
unet=unet,
scheduler=scheduler,
)
self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.default_sample_size = self.unet.config.sample_size
add_watermarker = add_watermarker if add_watermarker is not None else is_invisible_watermark_available()
if add_watermarker:
self.watermark = StableDiffusionXLWatermarker()
else:
self.watermark = None
def encode_prompt(
self,
prompt: str,
prompt_2: Optional[str] = None,
device: Optional[torch.device] = None,
num_images_per_prompt: int = 1,
do_classifier_free_guidance: bool = True,
negative_prompt: Optional[str] = None,
negative_prompt_2: Optional[str] = None,
prompt_embeds: Optional[torch.Tensor] = None,
negative_prompt_embeds: Optional[torch.Tensor] = None,
pooled_prompt_embeds: Optional[torch.Tensor] = None,
negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
lora_scale: Optional[float] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
negative_prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
pooled_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
If not provided, pooled text embeddings will be generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
input argument.
lora_scale (`float`, *optional*):
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
"""
device = device or self._execution_device
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
adjust_lora_scale_text_encoder(self.text_encoder_2, lora_scale)
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
# Define tokenizers and text encoders
tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
text_encoders = (
[self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
)
if prompt_embeds is None:
prompt_2 = prompt_2 or prompt
# textual inversion: process multi-vector tokens if necessary
prompt_embeds_list = []
prompts = [prompt, prompt_2]
for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, tokenizer)
text_inputs = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = text_encoder(
text_input_ids.to(device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.hidden_states[-2]
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
# get unconditional embeddings for classifier free guidance
zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
negative_prompt_embeds = torch.zeros_like(prompt_embeds)
negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
elif do_classifier_free_guidance and negative_prompt_embeds is None:
negative_prompt = negative_prompt or ""
negative_prompt_2 = negative_prompt_2 or negative_prompt
uncond_tokens: List[str]
if prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt, negative_prompt_2]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = [negative_prompt, negative_prompt_2]
negative_prompt_embeds_list = []
for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
if isinstance(self, TextualInversionLoaderMixin):
negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = tokenizer(
negative_prompt,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
negative_prompt_embeds = text_encoder(
uncond_input.input_ids.to(device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
negative_pooled_prompt_embeds = negative_prompt_embeds[0]
negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
negative_prompt_embeds_list.append(negative_prompt_embeds)
negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
if do_classifier_free_guidance:
negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt=None,
negative_prompt_2=None,
prompt_embeds=None,
negative_prompt_embeds=None,
pooled_prompt_embeds=None,
negative_pooled_prompt_embeds=None,
num_images_per_prompt=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt_2 is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if prompt_embeds is not None and pooled_prompt_embeds is None:
raise ValueError(
"If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
)
if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
raise ValueError(
"If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
)
# DemoFusion specific checks
if max(height, width) % 1024 != 0:
raise ValueError(
f"the larger one of `height` and `width` has to be divisible by 1024 but are {height} and {width}."
)
if num_images_per_prompt != 1:
warnings.warn("num_images_per_prompt != 1 is not supported by DemoFusion and will be ignored.")
num_images_per_prompt = 1
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (
batch_size,
num_channels_latents,
int(height) // self.vae_scale_factor,
int(width) // self.vae_scale_factor,
)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
add_time_ids = list(original_size + crops_coords_top_left + target_size)
passed_add_embed_dim = (
self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
)
expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
if expected_add_embed_dim != passed_add_embed_dim:
raise ValueError(
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
)
add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
return add_time_ids
def get_views(self, height, width, window_size=128, stride=64, random_jitter=False):
height //= self.vae_scale_factor
width //= self.vae_scale_factor
num_blocks_height = int((height - window_size) / stride - 1e-6) + 2 if height > window_size else 1
num_blocks_width = int((width - window_size) / stride - 1e-6) + 2 if width > window_size else 1
total_num_blocks = int(num_blocks_height * num_blocks_width)
views = []
for i in range(total_num_blocks):
h_start = int((i // num_blocks_width) * stride)
h_end = h_start + window_size
w_start = int((i % num_blocks_width) * stride)
w_end = w_start + window_size
if h_end > height:
h_start = int(h_start + height - h_end)
h_end = int(height)
if w_end > width:
w_start = int(w_start + width - w_end)
w_end = int(width)
if h_start < 0:
h_end = int(h_end - h_start)
h_start = 0
if w_start < 0:
w_end = int(w_end - w_start)
w_start = 0
if random_jitter:
jitter_range = (window_size - stride) // 4
w_jitter = 0
h_jitter = 0
if (w_start != 0) and (w_end != width):
w_jitter = random.randint(-jitter_range, jitter_range)
elif (w_start == 0) and (w_end != width):
w_jitter = random.randint(-jitter_range, 0)
elif (w_start != 0) and (w_end == width):
w_jitter = random.randint(0, jitter_range)
if (h_start != 0) and (h_end != height):
h_jitter = random.randint(-jitter_range, jitter_range)
elif (h_start == 0) and (h_end != height):
h_jitter = random.randint(-jitter_range, 0)
elif (h_start != 0) and (h_end == height):
h_jitter = random.randint(0, jitter_range)
h_start += h_jitter + jitter_range
h_end += h_jitter + jitter_range
w_start += w_jitter + jitter_range
w_end += w_jitter + jitter_range
views.append((h_start, h_end, w_start, w_end))
return views
def tiled_decode(self, latents, current_height, current_width):
core_size = self.unet.config.sample_size // 4
core_stride = core_size
pad_size = self.unet.config.sample_size // 4 * 3
decoder_view_batch_size = 1
views = self.get_views(current_height, current_width, stride=core_stride, window_size=core_size)
views_batch = [views[i : i + decoder_view_batch_size] for i in range(0, len(views), decoder_view_batch_size)]
latents_ = F.pad(latents, (pad_size, pad_size, pad_size, pad_size), "constant", 0)
image = torch.zeros(latents.size(0), 3, current_height, current_width).to(latents.device)
count = torch.zeros_like(image).to(latents.device)
# get the latents corresponding to the current view coordinates
with self.progress_bar(total=len(views_batch)) as progress_bar:
for j, batch_view in enumerate(views_batch):
len(batch_view)
latents_for_view = torch.cat(
[
latents_[:, :, h_start : h_end + pad_size * 2, w_start : w_end + pad_size * 2]
for h_start, h_end, w_start, w_end in batch_view
]
)
image_patch = self.vae.decode(latents_for_view / self.vae.config.scaling_factor, return_dict=False)[0]
h_start, h_end, w_start, w_end = views[j]
h_start, h_end, w_start, w_end = (
h_start * self.vae_scale_factor,
h_end * self.vae_scale_factor,
w_start * self.vae_scale_factor,
w_end * self.vae_scale_factor,
)
p_h_start, p_h_end, p_w_start, p_w_end = (
pad_size * self.vae_scale_factor,
image_patch.size(2) - pad_size * self.vae_scale_factor,
pad_size * self.vae_scale_factor,
image_patch.size(3) - pad_size * self.vae_scale_factor,
)
image[:, :, h_start:h_end, w_start:w_end] += image_patch[:, :, p_h_start:p_h_end, p_w_start:p_w_end]
count[:, :, h_start:h_end, w_start:w_end] += 1
progress_bar.update()
image = image / count
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
def upcast_vae(self):
dtype = self.vae.dtype
self.vae.to(dtype=torch.float32)
use_torch_2_0_or_xformers = isinstance(
self.vae.decoder.mid_block.attentions[0].processor,
(
AttnProcessor2_0,
XFormersAttnProcessor,
LoRAXFormersAttnProcessor,
LoRAAttnProcessor2_0,
),
)
# if xformers or torch_2_0 is used attention block does not need
# to be in float32 which can save lots of memory
if use_torch_2_0_or_xformers:
self.vae.post_quant_conv.to(dtype)
self.vae.decoder.conv_in.to(dtype)
self.vae.decoder.mid_block.to(dtype)
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
prompt_2: Optional[Union[str, List[str]]] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
denoising_end: Optional[float] = None,
guidance_scale: float = 5.0,
negative_prompt: Optional[Union[str, List[str]]] = None,
negative_prompt_2: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.Tensor] = None,
prompt_embeds: Optional[torch.Tensor] = None,
negative_prompt_embeds: Optional[torch.Tensor] = None,
pooled_prompt_embeds: Optional[torch.Tensor] = None,
negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = False,
callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
guidance_rescale: float = 0.0,
original_size: Optional[Tuple[int, int]] = None,
crops_coords_top_left: Tuple[int, int] = (0, 0),
target_size: Optional[Tuple[int, int]] = None,
negative_original_size: Optional[Tuple[int, int]] = None,
negative_crops_coords_top_left: Tuple[int, int] = (0, 0),
negative_target_size: Optional[Tuple[int, int]] = None,
################### DemoFusion specific parameters ####################
view_batch_size: int = 16,
multi_decoder: bool = True,
stride: Optional[int] = 64,
cosine_scale_1: Optional[float] = 3.0,
cosine_scale_2: Optional[float] = 1.0,
cosine_scale_3: Optional[float] = 1.0,
sigma: Optional[float] = 0.8,
show_image: bool = False,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image. This is set to 1024 by default for the best results.
Anything below 512 pixels won't work well for
[stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
and checkpoints that are not specifically fine-tuned on low resolutions.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image. This is set to 1024 by default for the best results.
Anything below 512 pixels won't work well for
[stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
and checkpoints that are not specifically fine-tuned on low resolutions.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
denoising_end (`float`, *optional*):
When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
completed before it is intentionally prematurely terminated. As a result, the returned sample will
still retain a substantial amount of noise as determined by the discrete timesteps selected by the
scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
negative_prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.Tensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
pooled_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
If not provided, pooled text embeddings will be generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead
of a plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
[Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
`crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
`crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
`crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
For most cases, `target_size` should be set to the desired height and width of the generated image. If
not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
negative_original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
To negatively condition the generation process based on a specific image resolution. Part of SDXL's
micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
negative_crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
To negatively condition the generation process based on a specific crop coordinates. Part of SDXL's
micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
negative_target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
To negatively condition the generation process based on a target image resolution. It should be as same
as the `target_size` for most cases. Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
################### DemoFusion specific parameters ####################
view_batch_size (`int`, defaults to 16):
The batch size for multiple denoising paths. Typically, a larger batch size can result in higher
efficiency but comes with increased GPU memory requirements.
multi_decoder (`bool`, defaults to True):
Determine whether to use a tiled decoder. Generally, when the resolution exceeds 3072x3072,
a tiled decoder becomes necessary.
stride (`int`, defaults to 64):
The stride of moving local patches. A smaller stride is better for alleviating seam issues,
but it also introduces additional computational overhead and inference time.
cosine_scale_1 (`float`, defaults to 3):
Control the strength of skip-residual. For specific impacts, please refer to Appendix C
in the DemoFusion paper.
cosine_scale_2 (`float`, defaults to 1):
Control the strength of dilated sampling. For specific impacts, please refer to Appendix C
in the DemoFusion paper.
cosine_scale_3 (`float`, defaults to 1):
Control the strength of the gaussion filter. For specific impacts, please refer to Appendix C
in the DemoFusion paper.
sigma (`float`, defaults to 1):
The standerd value of the gaussian filter.
show_image (`bool`, defaults to False):
Determine whether to show intermediate results during generation.
Examples:
Returns:
a `list` with the generated images at each phase.
"""
# 0. Default height and width to unet
height = height or self.default_sample_size * self.vae_scale_factor
width = width or self.default_sample_size * self.vae_scale_factor
x1_size = self.default_sample_size * self.vae_scale_factor
height_scale = height / x1_size
width_scale = width / x1_size
scale_num = int(max(height_scale, width_scale))
aspect_ratio = min(height_scale, width_scale) / max(height_scale, width_scale)
original_size = original_size or (height, width)
target_size = target_size or (height, width)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt,
negative_prompt_2,
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
num_images_per_prompt,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
) = self.encode_prompt(
prompt=prompt,
prompt_2=prompt_2,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
negative_prompt_2=negative_prompt_2,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
lora_scale=text_encoder_lora_scale,
)
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height // scale_num,
width // scale_num,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7. Prepare added time ids & embeddings
add_text_embeds = pooled_prompt_embeds
add_time_ids = self._get_add_time_ids(
original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
)
if negative_original_size is not None and negative_target_size is not None:
negative_add_time_ids = self._get_add_time_ids(
negative_original_size,
negative_crops_coords_top_left,
negative_target_size,
dtype=prompt_embeds.dtype,
)
else:
negative_add_time_ids = add_time_ids
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
prompt_embeds = prompt_embeds.to(device)
add_text_embeds = add_text_embeds.to(device)
add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
# 8. Denoising loop
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
# 7.1 Apply denoising_end
if denoising_end is not None and isinstance(denoising_end, float) and denoising_end > 0 and denoising_end < 1:
discrete_timestep_cutoff = int(
round(
self.scheduler.config.num_train_timesteps
- (denoising_end * self.scheduler.config.num_train_timesteps)
)
)
num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
timesteps = timesteps[:num_inference_steps]
output_images = []
############################################################### Phase 1 #################################################################
print("### Phase 1 Denoising ###")
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
latents_for_view = latents
# expand the latents if we are doing classifier free guidance
latent_model_input = latents.repeat_interleave(2, dim=0) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred[::2], noise_pred[1::2]
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
anchor_mean = latents.mean()
anchor_std = latents.std()
if not output_type == "latent":
# make sure the VAE is in float32 mode, as it overflows in float16
needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
if needs_upcasting:
self.upcast_vae()
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
print("### Phase 1 Decoding ###")
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
# cast back to fp16 if needed
if needs_upcasting:
self.vae.to(dtype=torch.float16)
image = self.image_processor.postprocess(image, output_type=output_type)
if show_image:
plt.figure(figsize=(10, 10))
plt.imshow(image[0])
plt.axis("off") # Turn off axis numbers and ticks
plt.show()
output_images.append(image[0])
####################################################### Phase 2+ #####################################################
for current_scale_num in range(2, scale_num + 1):
print("### Phase {} Denoising ###".format(current_scale_num))
current_height = self.unet.config.sample_size * self.vae_scale_factor * current_scale_num
current_width = self.unet.config.sample_size * self.vae_scale_factor * current_scale_num
if height > width:
current_width = int(current_width * aspect_ratio)
else:
current_height = int(current_height * aspect_ratio)
latents = F.interpolate(
latents,
size=(int(current_height / self.vae_scale_factor), int(current_width / self.vae_scale_factor)),
mode="bicubic",
)
noise_latents = []
noise = torch.randn_like(latents)
for timestep in timesteps:
noise_latent = self.scheduler.add_noise(latents, noise, timestep.unsqueeze(0))
noise_latents.append(noise_latent)
latents = noise_latents[0]
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
count = torch.zeros_like(latents)
value = torch.zeros_like(latents)
cosine_factor = (
0.5
* (
1
+ torch.cos(
torch.pi
* (self.scheduler.config.num_train_timesteps - t)
/ self.scheduler.config.num_train_timesteps
)
).cpu()
)
c1 = cosine_factor**cosine_scale_1
latents = latents * (1 - c1) + noise_latents[i] * c1
############################################# MultiDiffusion #############################################
views = self.get_views(
current_height,
current_width,
stride=stride,
window_size=self.unet.config.sample_size,
random_jitter=True,
)
views_batch = [views[i : i + view_batch_size] for i in range(0, len(views), view_batch_size)]
jitter_range = (self.unet.config.sample_size - stride) // 4
latents_ = F.pad(latents, (jitter_range, jitter_range, jitter_range, jitter_range), "constant", 0)
count_local = torch.zeros_like(latents_)
value_local = torch.zeros_like(latents_)
for j, batch_view in enumerate(views_batch):
vb_size = len(batch_view)
# get the latents corresponding to the current view coordinates
latents_for_view = torch.cat(
[
latents_[:, :, h_start:h_end, w_start:w_end]
for h_start, h_end, w_start, w_end in batch_view
]
)
# expand the latents if we are doing classifier free guidance
latent_model_input = latents_for_view
latent_model_input = (
latent_model_input.repeat_interleave(2, dim=0)
if do_classifier_free_guidance
else latent_model_input
)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
prompt_embeds_input = torch.cat([prompt_embeds] * vb_size)
add_text_embeds_input = torch.cat([add_text_embeds] * vb_size)
add_time_ids_input = []
for h_start, h_end, w_start, w_end in batch_view:
add_time_ids_ = add_time_ids.clone()
add_time_ids_[:, 2] = h_start * self.vae_scale_factor
add_time_ids_[:, 3] = w_start * self.vae_scale_factor
add_time_ids_input.append(add_time_ids_)
add_time_ids_input = torch.cat(add_time_ids_input)
# predict the noise residual
added_cond_kwargs = {"text_embeds": add_text_embeds_input, "time_ids": add_time_ids_input}
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds_input,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred[::2], noise_pred[1::2]
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(
noise_pred, noise_pred_text, guidance_rescale=guidance_rescale
)
# compute the previous noisy sample x_t -> x_t-1
self.scheduler._init_step_index(t)
latents_denoised_batch = self.scheduler.step(
noise_pred, t, latents_for_view, **extra_step_kwargs, return_dict=False
)[0]
# extract value from batch
for latents_view_denoised, (h_start, h_end, w_start, w_end) in zip(
latents_denoised_batch.chunk(vb_size), batch_view
):
value_local[:, :, h_start:h_end, w_start:w_end] += latents_view_denoised
count_local[:, :, h_start:h_end, w_start:w_end] += 1
value_local = value_local[
:,
:,
jitter_range : jitter_range + current_height // self.vae_scale_factor,
jitter_range : jitter_range + current_width // self.vae_scale_factor,
]
count_local = count_local[
:,
:,
jitter_range : jitter_range + current_height // self.vae_scale_factor,
jitter_range : jitter_range + current_width // self.vae_scale_factor,
]
c2 = cosine_factor**cosine_scale_2
value += value_local / count_local * (1 - c2)
count += torch.ones_like(value_local) * (1 - c2)
############################################# Dilated Sampling #############################################
views = [[h, w] for h in range(current_scale_num) for w in range(current_scale_num)]
views_batch = [views[i : i + view_batch_size] for i in range(0, len(views), view_batch_size)]
h_pad = (current_scale_num - (latents.size(2) % current_scale_num)) % current_scale_num
w_pad = (current_scale_num - (latents.size(3) % current_scale_num)) % current_scale_num
latents_ = F.pad(latents, (w_pad, 0, h_pad, 0), "constant", 0)
count_global = torch.zeros_like(latents_)
value_global = torch.zeros_like(latents_)
c3 = 0.99 * cosine_factor**cosine_scale_3 + 1e-2
std_, mean_ = latents_.std(), latents_.mean()
latents_gaussian = gaussian_filter(
latents_, kernel_size=(2 * current_scale_num - 1), sigma=sigma * c3
)
latents_gaussian = (
latents_gaussian - latents_gaussian.mean()
) / latents_gaussian.std() * std_ + mean_
for j, batch_view in enumerate(views_batch):
latents_for_view = torch.cat(
[latents_[:, :, h::current_scale_num, w::current_scale_num] for h, w in batch_view]
)
latents_for_view_gaussian = torch.cat(
[latents_gaussian[:, :, h::current_scale_num, w::current_scale_num] for h, w in batch_view]
)
vb_size = latents_for_view.size(0)
# expand the latents if we are doing classifier free guidance
latent_model_input = latents_for_view_gaussian
latent_model_input = (
latent_model_input.repeat_interleave(2, dim=0)
if do_classifier_free_guidance
else latent_model_input
)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
prompt_embeds_input = torch.cat([prompt_embeds] * vb_size)
add_text_embeds_input = torch.cat([add_text_embeds] * vb_size)
add_time_ids_input = torch.cat([add_time_ids] * vb_size)
# predict the noise residual
added_cond_kwargs = {"text_embeds": add_text_embeds_input, "time_ids": add_time_ids_input}
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds_input,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred[::2], noise_pred[1::2]
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(
noise_pred, noise_pred_text, guidance_rescale=guidance_rescale
)
# compute the previous noisy sample x_t -> x_t-1
self.scheduler._init_step_index(t)
latents_denoised_batch = self.scheduler.step(
noise_pred, t, latents_for_view, **extra_step_kwargs, return_dict=False
)[0]
# extract value from batch
for latents_view_denoised, (h, w) in zip(latents_denoised_batch.chunk(vb_size), batch_view):
value_global[:, :, h::current_scale_num, w::current_scale_num] += latents_view_denoised
count_global[:, :, h::current_scale_num, w::current_scale_num] += 1
c2 = cosine_factor**cosine_scale_2
value_global = value_global[:, :, h_pad:, w_pad:]
value += value_global * c2
count += torch.ones_like(value_global) * c2
###########################################################
latents = torch.where(count > 0, value / count, value)
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
#########################################################################################################################################
latents = (latents - latents.mean()) / latents.std() * anchor_std + anchor_mean
if not output_type == "latent":
# make sure the VAE is in float32 mode, as it overflows in float16
needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
if needs_upcasting:
self.upcast_vae()
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
print("### Phase {} Decoding ###".format(current_scale_num))
if multi_decoder:
image = self.tiled_decode(latents, current_height, current_width)
else:
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
# cast back to fp16 if needed
if needs_upcasting:
self.vae.to(dtype=torch.float16)
else:
image = latents
if not output_type == "latent":
image = self.image_processor.postprocess(image, output_type=output_type)
if show_image:
plt.figure(figsize=(10, 10))
plt.imshow(image[0])
plt.axis("off") # Turn off axis numbers and ticks
plt.show()
output_images.append(image[0])
# Offload all models
self.maybe_free_model_hooks()
return output_images
# Override to properly handle the loading and unloading of the additional text encoder.
def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
# We could have accessed the unet config from `lora_state_dict()` too. We pass
# it here explicitly to be able to tell that it's coming from an SDXL
# pipeline.
# Remove any existing hooks.
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
from accelerate.hooks import AlignDevicesHook, CpuOffload, remove_hook_from_module
else:
raise ImportError("Offloading requires `accelerate v0.17.0` or higher.")
is_model_cpu_offload = False
is_sequential_cpu_offload = False
recursive = False
for _, component in self.components.items():
if isinstance(component, torch.nn.Module):
if hasattr(component, "_hf_hook"):
is_model_cpu_offload = isinstance(getattr(component, "_hf_hook"), CpuOffload)
is_sequential_cpu_offload = (
isinstance(getattr(component, "_hf_hook"), AlignDevicesHook)
or hasattr(component._hf_hook, "hooks")
and isinstance(component._hf_hook.hooks[0], AlignDevicesHook)
)
logger.info(
"Accelerate hooks detected. Since you have called `load_lora_weights()`, the previous hooks will be first removed. Then the LoRA parameters will be loaded and the hooks will be applied again."
)
recursive = is_sequential_cpu_offload
remove_hook_from_module(component, recurse=recursive)
state_dict, network_alphas = self.lora_state_dict(
pretrained_model_name_or_path_or_dict,
unet_config=self.unet.config,
**kwargs,
)
self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
if len(text_encoder_state_dict) > 0:
self.load_lora_into_text_encoder(
text_encoder_state_dict,
network_alphas=network_alphas,
text_encoder=self.text_encoder,
prefix="text_encoder",
lora_scale=self.lora_scale,
)
text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
if len(text_encoder_2_state_dict) > 0:
self.load_lora_into_text_encoder(
text_encoder_2_state_dict,
network_alphas=network_alphas,
text_encoder=self.text_encoder_2,
prefix="text_encoder_2",
lora_scale=self.lora_scale,
)
# Offload back.
if is_model_cpu_offload:
self.enable_model_cpu_offload()
elif is_sequential_cpu_offload:
self.enable_sequential_cpu_offload()
@classmethod
def save_lora_weights(
self,
save_directory: Union[str, os.PathLike],
unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
is_main_process: bool = True,
weight_name: str = None,
save_function: Callable = None,
safe_serialization: bool = True,
):
state_dict = {}
def pack_weights(layers, prefix):
layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
return layers_state_dict
if not (unet_lora_layers or text_encoder_lora_layers or text_encoder_2_lora_layers):
raise ValueError(
"You must pass at least one of `unet_lora_layers`, `text_encoder_lora_layers` or `text_encoder_2_lora_layers`."
)
if unet_lora_layers:
state_dict.update(pack_weights(unet_lora_layers, "unet"))
if text_encoder_lora_layers and text_encoder_2_lora_layers:
state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
self.write_lora_layers(
state_dict=state_dict,
save_directory=save_directory,
is_main_process=is_main_process,
weight_name=weight_name,
save_function=save_function,
safe_serialization=safe_serialization,
)
def _remove_text_encoder_monkey_patch(self):
self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
| diffusers/examples/community/pipeline_demofusion_sdxl.py/0 | {
"file_path": "diffusers/examples/community/pipeline_demofusion_sdxl.py",
"repo_id": "diffusers",
"token_count": 34796
} | 222 |
import argparse
import inspect
import os
import time
import warnings
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from PIL import Image
from transformers import CLIPTokenizer
from diffusers import OnnxRuntimeModel, StableDiffusionImg2ImgPipeline, UniPCMultistepScheduler
from diffusers.image_processor import VaeImageProcessor
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
deprecate,
logging,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> # !pip install opencv-python transformers accelerate
>>> from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel, UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> import numpy as np
>>> import torch
>>> import cv2
>>> from PIL import Image
>>> # download an image
>>> image = load_image(
... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
... )
>>> np_image = np.array(image)
>>> # get canny image
>>> np_image = cv2.Canny(np_image, 100, 200)
>>> np_image = np_image[:, :, None]
>>> np_image = np.concatenate([np_image, np_image, np_image], axis=2)
>>> canny_image = Image.fromarray(np_image)
>>> # load control net and stable diffusion v1-5
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
>>> pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
... )
>>> # speed up diffusion process with faster scheduler and memory optimization
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
>>> pipe.enable_model_cpu_offload()
>>> # generate image
>>> generator = torch.manual_seed(0)
>>> image = pipe(
... "futuristic-looking woman",
... num_inference_steps=20,
... generator=generator,
... image=image,
... control_image=canny_image,
... ).images[0]
```
"""
def prepare_image(image):
if isinstance(image, torch.Tensor):
# Batch single image
if image.ndim == 3:
image = image.unsqueeze(0)
image = image.to(dtype=torch.float32)
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
return image
class OnnxStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
vae_encoder: OnnxRuntimeModel
vae_decoder: OnnxRuntimeModel
text_encoder: OnnxRuntimeModel
tokenizer: CLIPTokenizer
unet: OnnxRuntimeModel
scheduler: KarrasDiffusionSchedulers
def __init__(
self,
vae_encoder: OnnxRuntimeModel,
vae_decoder: OnnxRuntimeModel,
text_encoder: OnnxRuntimeModel,
tokenizer: CLIPTokenizer,
unet: OnnxRuntimeModel,
scheduler: KarrasDiffusionSchedulers,
):
super().__init__()
self.register_modules(
vae_encoder=vae_encoder,
vae_decoder=vae_decoder,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
)
self.vae_scale_factor = 2 ** (4 - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
self.control_image_processor = VaeImageProcessor(
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
)
def _encode_prompt(
self,
prompt: Union[str, List[str]],
num_images_per_prompt: Optional[int],
do_classifier_free_guidance: bool,
negative_prompt: Optional[str],
prompt_embeds: Optional[np.ndarray] = None,
negative_prompt_embeds: Optional[np.ndarray] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`):
prompt to be encoded
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
prompt_embeds (`np.ndarray`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`np.ndarray`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="np",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="np").input_ids
if not np.array_equal(text_input_ids, untruncated_ids):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = self.text_encoder(input_ids=text_input_ids.astype(np.int32))[0]
prompt_embeds = np.repeat(prompt_embeds, num_images_per_prompt, axis=0)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt] * batch_size
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="np",
)
negative_prompt_embeds = self.text_encoder(input_ids=uncond_input.input_ids.astype(np.int32))[0]
if do_classifier_free_guidance:
negative_prompt_embeds = np.repeat(negative_prompt_embeds, num_images_per_prompt, axis=0)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = np.concatenate([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
warnings.warn(
"The decode_latents method is deprecated and will be removed in a future version. Please"
" use VaeImageProcessor instead",
FutureWarning,
)
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents, return_dict=False)[0]
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
num_controlnet,
prompt,
image,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
controlnet_conditioning_scale=1.0,
control_guidance_start=0.0,
control_guidance_end=1.0,
):
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
# Check `image`
if num_controlnet == 1:
self.check_image(image, prompt, prompt_embeds)
elif num_controlnet > 1:
if not isinstance(image, list):
raise TypeError("For multiple controlnets: `image` must be type `list`")
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in image):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif len(image) != num_controlnet:
raise ValueError(
f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(image)} images and {num_controlnet} ControlNets."
)
for image_ in image:
self.check_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `controlnet_conditioning_scale`
if num_controlnet == 1:
if not isinstance(controlnet_conditioning_scale, float):
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
elif num_controlnet > 1:
if isinstance(controlnet_conditioning_scale, list):
if any(isinstance(i, list) for i in controlnet_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif (
isinstance(controlnet_conditioning_scale, list)
and len(controlnet_conditioning_scale) != num_controlnet
):
raise ValueError(
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of controlnets"
)
else:
assert False
if len(control_guidance_start) != len(control_guidance_end):
raise ValueError(
f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
)
if num_controlnet > 1:
if len(control_guidance_start) != num_controlnet:
raise ValueError(
f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {num_controlnet} controlnets available. Make sure to provide {num_controlnet}."
)
for start, end in zip(control_guidance_start, control_guidance_end):
if start >= end:
raise ValueError(
f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
)
if start < 0.0:
raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
if end > 1.0:
raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
def check_image(self, image, prompt, prompt_embeds):
image_is_pil = isinstance(image, PIL.Image.Image)
image_is_tensor = isinstance(image, torch.Tensor)
image_is_np = isinstance(image, np.ndarray)
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
if (
not image_is_pil
and not image_is_tensor
and not image_is_np
and not image_is_pil_list
and not image_is_tensor_list
and not image_is_np_list
):
raise TypeError(
f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
)
if image_is_pil:
image_batch_size = 1
else:
image_batch_size = len(image)
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
if image_batch_size != 1 and image_batch_size != prompt_batch_size:
raise ValueError(
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
)
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
def prepare_control_image(
self,
image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance=False,
guess_mode=False,
):
image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
image_batch_size = image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
image = image.repeat_interleave(repeat_by, dim=0)
image = image.to(device=device, dtype=dtype)
if do_classifier_free_guidance and not guess_mode:
image = torch.cat([image] * 2)
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
return timesteps, num_inference_steps - t_start
def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
image = image.to(device=device, dtype=dtype)
batch_size = batch_size * num_images_per_prompt
if image.shape[1] == 4:
init_latents = image
else:
_image = image.cpu().detach().numpy()
init_latents = self.vae_encoder(sample=_image)[0]
init_latents = torch.from_numpy(init_latents).to(device=device, dtype=dtype)
init_latents = 0.18215 * init_latents
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
# expand init_latents for batch_size
deprecation_message = (
f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
" images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
" that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
" your script to pass as many initial images as text prompts to suppress this warning."
)
deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
additional_image_per_prompt = batch_size // init_latents.shape[0]
init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
raise ValueError(
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
)
else:
init_latents = torch.cat([init_latents], dim=0)
shape = init_latents.shape
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# get latents
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
num_controlnet: int,
fp16: bool = True,
prompt: Union[str, List[str]] = None,
image: Union[
torch.Tensor,
PIL.Image.Image,
np.ndarray,
List[torch.Tensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
control_image: Union[
torch.Tensor,
PIL.Image.Image,
np.ndarray,
List[torch.Tensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
height: Optional[int] = None,
width: Optional[int] = None,
strength: float = 0.8,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.Tensor] = None,
prompt_embeds: Optional[torch.Tensor] = None,
negative_prompt_embeds: Optional[torch.Tensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 0.8,
guess_mode: bool = False,
control_guidance_start: Union[float, List[float]] = 0.0,
control_guidance_end: Union[float, List[float]] = 1.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`torch.Tensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.Tensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.Tensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The initial image will be used as the starting point for the image generation process. Can also accept
image latents as `image`, if passing latents directly, it will not be encoded again.
control_image (`torch.Tensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.Tensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.Tensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
the type is specified as `torch.Tensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
specified in init, images must be passed as a list such that each element of the list can be correctly
batched for input to a single controlnet.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.Tensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting
than for [`~StableDiffusionControlNetPipeline.__call__`].
guess_mode (`bool`, *optional*, defaults to `False`):
In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
The percentage of total steps at which the controlnet starts applying.
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
The percentage of total steps at which the controlnet stops applying.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if fp16:
torch_dtype = torch.float16
np_dtype = np.float16
else:
torch_dtype = torch.float32
np_dtype = np.float32
# align format for control guidance
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
mult = num_controlnet
control_guidance_start, control_guidance_end = (
mult * [control_guidance_start],
mult * [control_guidance_end],
)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
num_controlnet,
prompt,
control_image,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
if num_controlnet > 1 and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * num_controlnet
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# 4. Prepare image
image = self.image_processor.preprocess(image).to(dtype=torch.float32)
# 5. Prepare controlnet_conditioning_image
if num_controlnet == 1:
control_image = self.prepare_control_image(
image=control_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=torch_dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
elif num_controlnet > 1:
control_images = []
for control_image_ in control_image:
control_image_ = self.prepare_control_image(
image=control_image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=torch_dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
control_images.append(control_image_)
control_image = control_images
else:
assert False
# 5. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 6. Prepare latent variables
latents = self.prepare_latents(
image,
latent_timestep,
batch_size,
num_images_per_prompt,
torch_dtype,
device,
generator,
)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7.1 Create tensor stating which controlnets to keep
controlnet_keep = []
for i in range(len(timesteps)):
keeps = [
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
for s, e in zip(control_guidance_start, control_guidance_end)
]
controlnet_keep.append(keeps[0] if num_controlnet == 1 else keeps)
# 8. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
# predict the noise residual
_latent_model_input = latent_model_input.cpu().detach().numpy()
_prompt_embeds = np.array(prompt_embeds, dtype=np_dtype)
_t = np.array([t.cpu().detach().numpy()], dtype=np_dtype)
if num_controlnet == 1:
control_images = np.array([control_image], dtype=np_dtype)
else:
control_images = []
for _control_img in control_image:
_control_img = _control_img.cpu().detach().numpy()
control_images.append(_control_img)
control_images = np.array(control_images, dtype=np_dtype)
control_scales = np.array(cond_scale, dtype=np_dtype)
control_scales = np.resize(control_scales, (num_controlnet, 1))
noise_pred = self.unet(
sample=_latent_model_input,
timestep=_t,
encoder_hidden_states=_prompt_embeds,
controlnet_conds=control_images,
conditioning_scales=control_scales,
)[0]
noise_pred = torch.from_numpy(noise_pred).to(device)
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
_latents = latents.cpu().detach().numpy() / 0.18215
_latents = np.array(_latents, dtype=np_dtype)
image = self.vae_decoder(latent_sample=_latents)[0]
image = torch.from_numpy(image).to(device, dtype=torch.float32)
has_nsfw_concept = None
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--sd_model",
type=str,
required=True,
help="Path to the `diffusers` checkpoint to convert (either a local directory or on the Hub).",
)
parser.add_argument(
"--onnx_model_dir",
type=str,
required=True,
help="Path to the ONNX directory",
)
parser.add_argument("--qr_img_path", type=str, required=True, help="Path to the qr code image")
args = parser.parse_args()
qr_image = Image.open(args.qr_img_path)
qr_image = qr_image.resize((512, 512))
# init stable diffusion pipeline
pipeline = StableDiffusionImg2ImgPipeline.from_pretrained(args.sd_model)
pipeline.scheduler = UniPCMultistepScheduler.from_config(pipeline.scheduler.config)
provider = ["CUDAExecutionProvider", "CPUExecutionProvider"]
onnx_pipeline = OnnxStableDiffusionControlNetImg2ImgPipeline(
vae_encoder=OnnxRuntimeModel.from_pretrained(
os.path.join(args.onnx_model_dir, "vae_encoder"), provider=provider
),
vae_decoder=OnnxRuntimeModel.from_pretrained(
os.path.join(args.onnx_model_dir, "vae_decoder"), provider=provider
),
text_encoder=OnnxRuntimeModel.from_pretrained(
os.path.join(args.onnx_model_dir, "text_encoder"), provider=provider
),
tokenizer=pipeline.tokenizer,
unet=OnnxRuntimeModel.from_pretrained(os.path.join(args.onnx_model_dir, "unet"), provider=provider),
scheduler=pipeline.scheduler,
)
onnx_pipeline = onnx_pipeline.to("cuda")
prompt = "a cute cat fly to the moon"
negative_prompt = "paintings, sketches, worst quality, low quality, normal quality, lowres, normal quality, monochrome, grayscale, skin spots, acnes, skin blemishes, age spot, glans, nsfw, nipples, necklace, worst quality, low quality, watermark, username, signature, multiple breasts, lowres, bad anatomy, bad hands, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet, single color, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, disfigured, bad anatomy, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, mutated hands, fused fingers, too many fingers, long neck, bad body perspect"
for i in range(10):
start_time = time.time()
image = onnx_pipeline(
num_controlnet=2,
prompt=prompt,
negative_prompt=negative_prompt,
image=qr_image,
control_image=[qr_image, qr_image],
width=512,
height=512,
strength=0.75,
num_inference_steps=20,
num_images_per_prompt=1,
controlnet_conditioning_scale=[0.8, 0.8],
control_guidance_start=[0.3, 0.3],
control_guidance_end=[0.9, 0.9],
).images[0]
print(time.time() - start_time)
image.save("output_qr_code.png")
| diffusers/examples/community/run_onnx_controlnet.py/0 | {
"file_path": "diffusers/examples/community/run_onnx_controlnet.py",
"repo_id": "diffusers",
"token_count": 19726
} | 223 |
#
# Copyright 2024 The HuggingFace Inc. team.
# SPDX-FileCopyrightText: Copyright (c) 1993-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import os
from collections import OrderedDict
from copy import copy
from typing import List, Optional, Union
import numpy as np
import onnx
import onnx_graphsurgeon as gs
import PIL.Image
import tensorrt as trt
import torch
from huggingface_hub import snapshot_download
from huggingface_hub.utils import validate_hf_hub_args
from onnx import shape_inference
from polygraphy import cuda
from polygraphy.backend.common import bytes_from_path
from polygraphy.backend.onnx.loader import fold_constants
from polygraphy.backend.trt import (
CreateConfig,
Profile,
engine_from_bytes,
engine_from_network,
network_from_onnx_path,
save_engine,
)
from polygraphy.backend.trt import util as trt_util
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import (
StableDiffusionImg2ImgPipeline,
StableDiffusionPipelineOutput,
StableDiffusionSafetyChecker,
)
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img import retrieve_latents
from diffusers.schedulers import DDIMScheduler
from diffusers.utils import logging
"""
Installation instructions
python3 -m pip install --upgrade transformers diffusers>=0.16.0
python3 -m pip install --upgrade tensorrt>=8.6.1
python3 -m pip install --upgrade polygraphy>=0.47.0 onnx-graphsurgeon --extra-index-url https://pypi.ngc.nvidia.com
python3 -m pip install onnxruntime
"""
TRT_LOGGER = trt.Logger(trt.Logger.ERROR)
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
# Map of numpy dtype -> torch dtype
numpy_to_torch_dtype_dict = {
np.uint8: torch.uint8,
np.int8: torch.int8,
np.int16: torch.int16,
np.int32: torch.int32,
np.int64: torch.int64,
np.float16: torch.float16,
np.float32: torch.float32,
np.float64: torch.float64,
np.complex64: torch.complex64,
np.complex128: torch.complex128,
}
if np.version.full_version >= "1.24.0":
numpy_to_torch_dtype_dict[np.bool_] = torch.bool
else:
numpy_to_torch_dtype_dict[np.bool] = torch.bool
# Map of torch dtype -> numpy dtype
torch_to_numpy_dtype_dict = {value: key for (key, value) in numpy_to_torch_dtype_dict.items()}
def device_view(t):
return cuda.DeviceView(ptr=t.data_ptr(), shape=t.shape, dtype=torch_to_numpy_dtype_dict[t.dtype])
def preprocess_image(image):
"""
image: torch.Tensor
"""
w, h = image.size
w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
image = image.resize((w, h))
image = np.array(image).astype(np.float32) / 255.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image).contiguous()
return 2.0 * image - 1.0
class Engine:
def __init__(self, engine_path):
self.engine_path = engine_path
self.engine = None
self.context = None
self.buffers = OrderedDict()
self.tensors = OrderedDict()
def __del__(self):
[buf.free() for buf in self.buffers.values() if isinstance(buf, cuda.DeviceArray)]
del self.engine
del self.context
del self.buffers
del self.tensors
def build(
self,
onnx_path,
fp16,
input_profile=None,
enable_preview=False,
enable_all_tactics=False,
timing_cache=None,
workspace_size=0,
):
logger.warning(f"Building TensorRT engine for {onnx_path}: {self.engine_path}")
p = Profile()
if input_profile:
for name, dims in input_profile.items():
assert len(dims) == 3
p.add(name, min=dims[0], opt=dims[1], max=dims[2])
config_kwargs = {}
config_kwargs["preview_features"] = [trt.PreviewFeature.DISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805]
if enable_preview:
# Faster dynamic shapes made optional since it increases engine build time.
config_kwargs["preview_features"].append(trt.PreviewFeature.FASTER_DYNAMIC_SHAPES_0805)
if workspace_size > 0:
config_kwargs["memory_pool_limits"] = {trt.MemoryPoolType.WORKSPACE: workspace_size}
if not enable_all_tactics:
config_kwargs["tactic_sources"] = []
engine = engine_from_network(
network_from_onnx_path(onnx_path, flags=[trt.OnnxParserFlag.NATIVE_INSTANCENORM]),
config=CreateConfig(fp16=fp16, profiles=[p], load_timing_cache=timing_cache, **config_kwargs),
save_timing_cache=timing_cache,
)
save_engine(engine, path=self.engine_path)
def load(self):
logger.warning(f"Loading TensorRT engine: {self.engine_path}")
self.engine = engine_from_bytes(bytes_from_path(self.engine_path))
def activate(self):
self.context = self.engine.create_execution_context()
def allocate_buffers(self, shape_dict=None, device="cuda"):
for idx in range(trt_util.get_bindings_per_profile(self.engine)):
binding = self.engine[idx]
if shape_dict and binding in shape_dict:
shape = shape_dict[binding]
else:
shape = self.engine.get_binding_shape(binding)
dtype = trt.nptype(self.engine.get_binding_dtype(binding))
if self.engine.binding_is_input(binding):
self.context.set_binding_shape(idx, shape)
tensor = torch.empty(tuple(shape), dtype=numpy_to_torch_dtype_dict[dtype]).to(device=device)
self.tensors[binding] = tensor
self.buffers[binding] = cuda.DeviceView(ptr=tensor.data_ptr(), shape=shape, dtype=dtype)
def infer(self, feed_dict, stream):
start_binding, end_binding = trt_util.get_active_profile_bindings(self.context)
# shallow copy of ordered dict
device_buffers = copy(self.buffers)
for name, buf in feed_dict.items():
assert isinstance(buf, cuda.DeviceView)
device_buffers[name] = buf
bindings = [0] * start_binding + [buf.ptr for buf in device_buffers.values()]
noerror = self.context.execute_async_v2(bindings=bindings, stream_handle=stream.ptr)
if not noerror:
raise ValueError("ERROR: inference failed.")
return self.tensors
class Optimizer:
def __init__(self, onnx_graph):
self.graph = gs.import_onnx(onnx_graph)
def cleanup(self, return_onnx=False):
self.graph.cleanup().toposort()
if return_onnx:
return gs.export_onnx(self.graph)
def select_outputs(self, keep, names=None):
self.graph.outputs = [self.graph.outputs[o] for o in keep]
if names:
for i, name in enumerate(names):
self.graph.outputs[i].name = name
def fold_constants(self, return_onnx=False):
onnx_graph = fold_constants(gs.export_onnx(self.graph), allow_onnxruntime_shape_inference=True)
self.graph = gs.import_onnx(onnx_graph)
if return_onnx:
return onnx_graph
def infer_shapes(self, return_onnx=False):
onnx_graph = gs.export_onnx(self.graph)
if onnx_graph.ByteSize() > 2147483648:
raise TypeError("ERROR: model size exceeds supported 2GB limit")
else:
onnx_graph = shape_inference.infer_shapes(onnx_graph)
self.graph = gs.import_onnx(onnx_graph)
if return_onnx:
return onnx_graph
class BaseModel:
def __init__(self, model, fp16=False, device="cuda", max_batch_size=16, embedding_dim=768, text_maxlen=77):
self.model = model
self.name = "SD Model"
self.fp16 = fp16
self.device = device
self.min_batch = 1
self.max_batch = max_batch_size
self.min_image_shape = 256 # min image resolution: 256x256
self.max_image_shape = 1024 # max image resolution: 1024x1024
self.min_latent_shape = self.min_image_shape // 8
self.max_latent_shape = self.max_image_shape // 8
self.embedding_dim = embedding_dim
self.text_maxlen = text_maxlen
def get_model(self):
return self.model
def get_input_names(self):
pass
def get_output_names(self):
pass
def get_dynamic_axes(self):
return None
def get_sample_input(self, batch_size, image_height, image_width):
pass
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
return None
def get_shape_dict(self, batch_size, image_height, image_width):
return None
def optimize(self, onnx_graph):
opt = Optimizer(onnx_graph)
opt.cleanup()
opt.fold_constants()
opt.infer_shapes()
onnx_opt_graph = opt.cleanup(return_onnx=True)
return onnx_opt_graph
def check_dims(self, batch_size, image_height, image_width):
assert batch_size >= self.min_batch and batch_size <= self.max_batch
assert image_height % 8 == 0 or image_width % 8 == 0
latent_height = image_height // 8
latent_width = image_width // 8
assert latent_height >= self.min_latent_shape and latent_height <= self.max_latent_shape
assert latent_width >= self.min_latent_shape and latent_width <= self.max_latent_shape
return (latent_height, latent_width)
def get_minmax_dims(self, batch_size, image_height, image_width, static_batch, static_shape):
min_batch = batch_size if static_batch else self.min_batch
max_batch = batch_size if static_batch else self.max_batch
latent_height = image_height // 8
latent_width = image_width // 8
min_image_height = image_height if static_shape else self.min_image_shape
max_image_height = image_height if static_shape else self.max_image_shape
min_image_width = image_width if static_shape else self.min_image_shape
max_image_width = image_width if static_shape else self.max_image_shape
min_latent_height = latent_height if static_shape else self.min_latent_shape
max_latent_height = latent_height if static_shape else self.max_latent_shape
min_latent_width = latent_width if static_shape else self.min_latent_shape
max_latent_width = latent_width if static_shape else self.max_latent_shape
return (
min_batch,
max_batch,
min_image_height,
max_image_height,
min_image_width,
max_image_width,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
)
def getOnnxPath(model_name, onnx_dir, opt=True):
return os.path.join(onnx_dir, model_name + (".opt" if opt else "") + ".onnx")
def getEnginePath(model_name, engine_dir):
return os.path.join(engine_dir, model_name + ".plan")
def build_engines(
models: dict,
engine_dir,
onnx_dir,
onnx_opset,
opt_image_height,
opt_image_width,
opt_batch_size=1,
force_engine_rebuild=False,
static_batch=False,
static_shape=True,
enable_preview=False,
enable_all_tactics=False,
timing_cache=None,
max_workspace_size=0,
):
built_engines = {}
if not os.path.isdir(onnx_dir):
os.makedirs(onnx_dir)
if not os.path.isdir(engine_dir):
os.makedirs(engine_dir)
# Export models to ONNX
for model_name, model_obj in models.items():
engine_path = getEnginePath(model_name, engine_dir)
if force_engine_rebuild or not os.path.exists(engine_path):
logger.warning("Building Engines...")
logger.warning("Engine build can take a while to complete")
onnx_path = getOnnxPath(model_name, onnx_dir, opt=False)
onnx_opt_path = getOnnxPath(model_name, onnx_dir)
if force_engine_rebuild or not os.path.exists(onnx_opt_path):
if force_engine_rebuild or not os.path.exists(onnx_path):
logger.warning(f"Exporting model: {onnx_path}")
model = model_obj.get_model()
with torch.inference_mode(), torch.autocast("cuda"):
inputs = model_obj.get_sample_input(opt_batch_size, opt_image_height, opt_image_width)
torch.onnx.export(
model,
inputs,
onnx_path,
export_params=True,
opset_version=onnx_opset,
do_constant_folding=True,
input_names=model_obj.get_input_names(),
output_names=model_obj.get_output_names(),
dynamic_axes=model_obj.get_dynamic_axes(),
)
del model
torch.cuda.empty_cache()
gc.collect()
else:
logger.warning(f"Found cached model: {onnx_path}")
# Optimize onnx
if force_engine_rebuild or not os.path.exists(onnx_opt_path):
logger.warning(f"Generating optimizing model: {onnx_opt_path}")
onnx_opt_graph = model_obj.optimize(onnx.load(onnx_path))
onnx.save(onnx_opt_graph, onnx_opt_path)
else:
logger.warning(f"Found cached optimized model: {onnx_opt_path} ")
# Build TensorRT engines
for model_name, model_obj in models.items():
engine_path = getEnginePath(model_name, engine_dir)
engine = Engine(engine_path)
onnx_path = getOnnxPath(model_name, onnx_dir, opt=False)
onnx_opt_path = getOnnxPath(model_name, onnx_dir)
if force_engine_rebuild or not os.path.exists(engine.engine_path):
engine.build(
onnx_opt_path,
fp16=True,
input_profile=model_obj.get_input_profile(
opt_batch_size,
opt_image_height,
opt_image_width,
static_batch=static_batch,
static_shape=static_shape,
),
enable_preview=enable_preview,
timing_cache=timing_cache,
workspace_size=max_workspace_size,
)
built_engines[model_name] = engine
# Load and activate TensorRT engines
for model_name, model_obj in models.items():
engine = built_engines[model_name]
engine.load()
engine.activate()
return built_engines
def runEngine(engine, feed_dict, stream):
return engine.infer(feed_dict, stream)
class CLIP(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(CLIP, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "CLIP"
def get_input_names(self):
return ["input_ids"]
def get_output_names(self):
return ["text_embeddings", "pooler_output"]
def get_dynamic_axes(self):
return {"input_ids": {0: "B"}, "text_embeddings": {0: "B"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
self.check_dims(batch_size, image_height, image_width)
min_batch, max_batch, _, _, _, _, _, _, _, _ = self.get_minmax_dims(
batch_size, image_height, image_width, static_batch, static_shape
)
return {
"input_ids": [(min_batch, self.text_maxlen), (batch_size, self.text_maxlen), (max_batch, self.text_maxlen)]
}
def get_shape_dict(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return {
"input_ids": (batch_size, self.text_maxlen),
"text_embeddings": (batch_size, self.text_maxlen, self.embedding_dim),
}
def get_sample_input(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return torch.zeros(batch_size, self.text_maxlen, dtype=torch.int32, device=self.device)
def optimize(self, onnx_graph):
opt = Optimizer(onnx_graph)
opt.select_outputs([0]) # delete graph output#1
opt.cleanup()
opt.fold_constants()
opt.infer_shapes()
opt.select_outputs([0], names=["text_embeddings"]) # rename network output
opt_onnx_graph = opt.cleanup(return_onnx=True)
return opt_onnx_graph
def make_CLIP(model, device, max_batch_size, embedding_dim, inpaint=False):
return CLIP(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class UNet(BaseModel):
def __init__(
self, model, fp16=False, device="cuda", max_batch_size=16, embedding_dim=768, text_maxlen=77, unet_dim=4
):
super(UNet, self).__init__(
model=model,
fp16=fp16,
device=device,
max_batch_size=max_batch_size,
embedding_dim=embedding_dim,
text_maxlen=text_maxlen,
)
self.unet_dim = unet_dim
self.name = "UNet"
def get_input_names(self):
return ["sample", "timestep", "encoder_hidden_states"]
def get_output_names(self):
return ["latent"]
def get_dynamic_axes(self):
return {
"sample": {0: "2B", 2: "H", 3: "W"},
"encoder_hidden_states": {0: "2B"},
"latent": {0: "2B", 2: "H", 3: "W"},
}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
_,
_,
_,
_,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"sample": [
(2 * min_batch, self.unet_dim, min_latent_height, min_latent_width),
(2 * batch_size, self.unet_dim, latent_height, latent_width),
(2 * max_batch, self.unet_dim, max_latent_height, max_latent_width),
],
"encoder_hidden_states": [
(2 * min_batch, self.text_maxlen, self.embedding_dim),
(2 * batch_size, self.text_maxlen, self.embedding_dim),
(2 * max_batch, self.text_maxlen, self.embedding_dim),
],
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"sample": (2 * batch_size, self.unet_dim, latent_height, latent_width),
"encoder_hidden_states": (2 * batch_size, self.text_maxlen, self.embedding_dim),
"latent": (2 * batch_size, 4, latent_height, latent_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
dtype = torch.float16 if self.fp16 else torch.float32
return (
torch.randn(
2 * batch_size, self.unet_dim, latent_height, latent_width, dtype=torch.float32, device=self.device
),
torch.tensor([1.0], dtype=torch.float32, device=self.device),
torch.randn(2 * batch_size, self.text_maxlen, self.embedding_dim, dtype=dtype, device=self.device),
)
def make_UNet(model, device, max_batch_size, embedding_dim, inpaint=False):
return UNet(
model,
fp16=True,
device=device,
max_batch_size=max_batch_size,
embedding_dim=embedding_dim,
unet_dim=(9 if inpaint else 4),
)
class VAE(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(VAE, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "VAE decoder"
def get_input_names(self):
return ["latent"]
def get_output_names(self):
return ["images"]
def get_dynamic_axes(self):
return {"latent": {0: "B", 2: "H", 3: "W"}, "images": {0: "B", 2: "8H", 3: "8W"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
_,
_,
_,
_,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"latent": [
(min_batch, 4, min_latent_height, min_latent_width),
(batch_size, 4, latent_height, latent_width),
(max_batch, 4, max_latent_height, max_latent_width),
]
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"latent": (batch_size, 4, latent_height, latent_width),
"images": (batch_size, 3, image_height, image_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return torch.randn(batch_size, 4, latent_height, latent_width, dtype=torch.float32, device=self.device)
def make_VAE(model, device, max_batch_size, embedding_dim, inpaint=False):
return VAE(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class TorchVAEEncoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.vae_encoder = model
def forward(self, x):
return retrieve_latents(self.vae_encoder.encode(x))
class VAEEncoder(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(VAEEncoder, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "VAE encoder"
def get_model(self):
vae_encoder = TorchVAEEncoder(self.model)
return vae_encoder
def get_input_names(self):
return ["images"]
def get_output_names(self):
return ["latent"]
def get_dynamic_axes(self):
return {"images": {0: "B", 2: "8H", 3: "8W"}, "latent": {0: "B", 2: "H", 3: "W"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
assert batch_size >= self.min_batch and batch_size <= self.max_batch
min_batch = batch_size if static_batch else self.min_batch
max_batch = batch_size if static_batch else self.max_batch
self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
min_image_height,
max_image_height,
min_image_width,
max_image_width,
_,
_,
_,
_,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"images": [
(min_batch, 3, min_image_height, min_image_width),
(batch_size, 3, image_height, image_width),
(max_batch, 3, max_image_height, max_image_width),
]
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"images": (batch_size, 3, image_height, image_width),
"latent": (batch_size, 4, latent_height, latent_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return torch.randn(batch_size, 3, image_height, image_width, dtype=torch.float32, device=self.device)
def make_VAEEncoder(model, device, max_batch_size, embedding_dim, inpaint=False):
return VAEEncoder(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class TensorRTStableDiffusionImg2ImgPipeline(StableDiffusionImg2ImgPipeline):
r"""
Pipeline for image-to-image generation using TensorRT accelerated Stable Diffusion.
This model inherits from [`StableDiffusionImg2ImgPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: DDIMScheduler,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPFeatureExtractor,
image_encoder: CLIPVisionModelWithProjection = None,
requires_safety_checker: bool = True,
stages=["clip", "unet", "vae", "vae_encoder"],
image_height: int = 512,
image_width: int = 512,
max_batch_size: int = 16,
# ONNX export parameters
onnx_opset: int = 17,
onnx_dir: str = "onnx",
# TensorRT engine build parameters
engine_dir: str = "engine",
build_preview_features: bool = True,
force_engine_rebuild: bool = False,
timing_cache: str = "timing_cache",
):
super().__init__(
vae,
text_encoder,
tokenizer,
unet,
scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
image_encoder=image_encoder,
requires_safety_checker=requires_safety_checker,
)
self.vae.forward = self.vae.decode
self.stages = stages
self.image_height, self.image_width = image_height, image_width
self.inpaint = False
self.onnx_opset = onnx_opset
self.onnx_dir = onnx_dir
self.engine_dir = engine_dir
self.force_engine_rebuild = force_engine_rebuild
self.timing_cache = timing_cache
self.build_static_batch = False
self.build_dynamic_shape = False
self.build_preview_features = build_preview_features
self.max_batch_size = max_batch_size
# TODO: Restrict batch size to 4 for larger image dimensions as a WAR for TensorRT limitation.
if self.build_dynamic_shape or self.image_height > 512 or self.image_width > 512:
self.max_batch_size = 4
self.stream = None # loaded in loadResources()
self.models = {} # loaded in __loadModels()
self.engine = {} # loaded in build_engines()
def __loadModels(self):
# Load pipeline models
self.embedding_dim = self.text_encoder.config.hidden_size
models_args = {
"device": self.torch_device,
"max_batch_size": self.max_batch_size,
"embedding_dim": self.embedding_dim,
"inpaint": self.inpaint,
}
if "clip" in self.stages:
self.models["clip"] = make_CLIP(self.text_encoder, **models_args)
if "unet" in self.stages:
self.models["unet"] = make_UNet(self.unet, **models_args)
if "vae" in self.stages:
self.models["vae"] = make_VAE(self.vae, **models_args)
if "vae_encoder" in self.stages:
self.models["vae_encoder"] = make_VAEEncoder(self.vae, **models_args)
@classmethod
@validate_hf_hub_args
def set_cached_folder(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], **kwargs):
cache_dir = kwargs.pop("cache_dir", None)
resume_download = kwargs.pop("resume_download", False)
proxies = kwargs.pop("proxies", None)
local_files_only = kwargs.pop("local_files_only", False)
token = kwargs.pop("token", None)
revision = kwargs.pop("revision", None)
cls.cached_folder = (
pretrained_model_name_or_path
if os.path.isdir(pretrained_model_name_or_path)
else snapshot_download(
pretrained_model_name_or_path,
cache_dir=cache_dir,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
)
)
def to(self, torch_device: Optional[Union[str, torch.device]] = None, silence_dtype_warnings: bool = False):
super().to(torch_device, silence_dtype_warnings=silence_dtype_warnings)
self.onnx_dir = os.path.join(self.cached_folder, self.onnx_dir)
self.engine_dir = os.path.join(self.cached_folder, self.engine_dir)
self.timing_cache = os.path.join(self.cached_folder, self.timing_cache)
# set device
self.torch_device = self._execution_device
logger.warning(f"Running inference on device: {self.torch_device}")
# load models
self.__loadModels()
# build engines
self.engine = build_engines(
self.models,
self.engine_dir,
self.onnx_dir,
self.onnx_opset,
opt_image_height=self.image_height,
opt_image_width=self.image_width,
force_engine_rebuild=self.force_engine_rebuild,
static_batch=self.build_static_batch,
static_shape=not self.build_dynamic_shape,
enable_preview=self.build_preview_features,
timing_cache=self.timing_cache,
)
return self
def __initialize_timesteps(self, timesteps, strength):
self.scheduler.set_timesteps(timesteps)
offset = self.scheduler.steps_offset if hasattr(self.scheduler, "steps_offset") else 0
init_timestep = int(timesteps * strength) + offset
init_timestep = min(init_timestep, timesteps)
t_start = max(timesteps - init_timestep + offset, 0)
timesteps = self.scheduler.timesteps[t_start:].to(self.torch_device)
return timesteps, t_start
def __preprocess_images(self, batch_size, images=()):
init_images = []
for image in images:
image = image.to(self.torch_device).float()
image = image.repeat(batch_size, 1, 1, 1)
init_images.append(image)
return tuple(init_images)
def __encode_image(self, init_image):
init_latents = runEngine(self.engine["vae_encoder"], {"images": device_view(init_image)}, self.stream)[
"latent"
]
init_latents = 0.18215 * init_latents
return init_latents
def __encode_prompt(self, prompt, negative_prompt):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
"""
# Tokenize prompt
text_input_ids = (
self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
.input_ids.type(torch.int32)
.to(self.torch_device)
)
text_input_ids_inp = device_view(text_input_ids)
# NOTE: output tensor for CLIP must be cloned because it will be overwritten when called again for negative prompt
text_embeddings = runEngine(self.engine["clip"], {"input_ids": text_input_ids_inp}, self.stream)[
"text_embeddings"
].clone()
# Tokenize negative prompt
uncond_input_ids = (
self.tokenizer(
negative_prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
.input_ids.type(torch.int32)
.to(self.torch_device)
)
uncond_input_ids_inp = device_view(uncond_input_ids)
uncond_embeddings = runEngine(self.engine["clip"], {"input_ids": uncond_input_ids_inp}, self.stream)[
"text_embeddings"
]
# Concatenate the unconditional and text embeddings into a single batch to avoid doing two forward passes for classifier free guidance
text_embeddings = torch.cat([uncond_embeddings, text_embeddings]).to(dtype=torch.float16)
return text_embeddings
def __denoise_latent(
self, latents, text_embeddings, timesteps=None, step_offset=0, mask=None, masked_image_latents=None
):
if not isinstance(timesteps, torch.Tensor):
timesteps = self.scheduler.timesteps
for step_index, timestep in enumerate(timesteps):
# Expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, timestep)
if isinstance(mask, torch.Tensor):
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
# Predict the noise residual
timestep_float = timestep.float() if timestep.dtype != torch.float32 else timestep
sample_inp = device_view(latent_model_input)
timestep_inp = device_view(timestep_float)
embeddings_inp = device_view(text_embeddings)
noise_pred = runEngine(
self.engine["unet"],
{"sample": sample_inp, "timestep": timestep_inp, "encoder_hidden_states": embeddings_inp},
self.stream,
)["latent"]
# Perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
latents = self.scheduler.step(noise_pred, timestep, latents).prev_sample
latents = 1.0 / 0.18215 * latents
return latents
def __decode_latent(self, latents):
images = runEngine(self.engine["vae"], {"latent": device_view(latents)}, self.stream)["images"]
images = (images / 2 + 0.5).clamp(0, 1)
return images.cpu().permute(0, 2, 3, 1).float().numpy()
def __loadResources(self, image_height, image_width, batch_size):
self.stream = cuda.Stream()
# Allocate buffers for TensorRT engine bindings
for model_name, obj in self.models.items():
self.engine[model_name].allocate_buffers(
shape_dict=obj.get_shape_dict(batch_size, image_height, image_width), device=self.torch_device
)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[torch.Tensor, PIL.Image.Image] = None,
strength: float = 0.8,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
"""
self.generator = generator
self.denoising_steps = num_inference_steps
self._guidance_scale = guidance_scale
# Pre-compute latent input scales and linear multistep coefficients
self.scheduler.set_timesteps(self.denoising_steps, device=self.torch_device)
# Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
prompt = [prompt]
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"Expected prompt to be of type list or str but got {type(prompt)}")
if negative_prompt is None:
negative_prompt = [""] * batch_size
if negative_prompt is not None and isinstance(negative_prompt, str):
negative_prompt = [negative_prompt]
assert len(prompt) == len(negative_prompt)
if batch_size > self.max_batch_size:
raise ValueError(
f"Batch size {len(prompt)} is larger than allowed {self.max_batch_size}. If dynamic shape is used, then maximum batch size is 4"
)
# load resources
self.__loadResources(self.image_height, self.image_width, batch_size)
with torch.inference_mode(), torch.autocast("cuda"), trt.Runtime(TRT_LOGGER):
# Initialize timesteps
timesteps, t_start = self.__initialize_timesteps(self.denoising_steps, strength)
latent_timestep = timesteps[:1].repeat(batch_size)
# Pre-process input image
if isinstance(image, PIL.Image.Image):
image = preprocess_image(image)
init_image = self.__preprocess_images(batch_size, (image,))[0]
# VAE encode init image
init_latents = self.__encode_image(init_image)
# Add noise to latents using timesteps
noise = torch.randn(
init_latents.shape, generator=self.generator, device=self.torch_device, dtype=torch.float32
)
latents = self.scheduler.add_noise(init_latents, noise, latent_timestep)
# CLIP text encoder
text_embeddings = self.__encode_prompt(prompt, negative_prompt)
# UNet denoiser
latents = self.__denoise_latent(latents, text_embeddings, timesteps=timesteps, step_offset=t_start)
# VAE decode latent
images = self.__decode_latent(latents)
images = self.numpy_to_pil(images)
return StableDiffusionPipelineOutput(images=images, nsfw_content_detected=None)
| diffusers/examples/community/stable_diffusion_tensorrt_img2img.py/0 | {
"file_path": "diffusers/examples/community/stable_diffusion_tensorrt_img2img.py",
"repo_id": "diffusers",
"token_count": 19789
} | 224 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The LCM team and the HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import copy
import functools
import gc
import logging
import math
import os
import random
import shutil
from contextlib import nullcontext
from pathlib import Path
import accelerate
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from packaging import version
from peft import LoraConfig, get_peft_model_state_dict, set_peft_model_state_dict
from torchvision import transforms
from torchvision.transforms.functional import crop
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
LCMScheduler,
StableDiffusionXLPipeline,
UNet2DConditionModel,
)
from diffusers.optimization import get_scheduler
from diffusers.training_utils import cast_training_params, resolve_interpolation_mode
from diffusers.utils import (
check_min_version,
convert_state_dict_to_diffusers,
convert_unet_state_dict_to_peft,
is_wandb_available,
)
from diffusers.utils.import_utils import is_xformers_available
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.28.0.dev0")
logger = get_logger(__name__)
DATASET_NAME_MAPPING = {
"lambdalabs/naruto-blip-captions": ("image", "text"),
}
class DDIMSolver:
def __init__(self, alpha_cumprods, timesteps=1000, ddim_timesteps=50):
# DDIM sampling parameters
step_ratio = timesteps // ddim_timesteps
self.ddim_timesteps = (np.arange(1, ddim_timesteps + 1) * step_ratio).round().astype(np.int64) - 1
self.ddim_alpha_cumprods = alpha_cumprods[self.ddim_timesteps]
self.ddim_alpha_cumprods_prev = np.asarray(
[alpha_cumprods[0]] + alpha_cumprods[self.ddim_timesteps[:-1]].tolist()
)
# convert to torch tensors
self.ddim_timesteps = torch.from_numpy(self.ddim_timesteps).long()
self.ddim_alpha_cumprods = torch.from_numpy(self.ddim_alpha_cumprods)
self.ddim_alpha_cumprods_prev = torch.from_numpy(self.ddim_alpha_cumprods_prev)
def to(self, device):
self.ddim_timesteps = self.ddim_timesteps.to(device)
self.ddim_alpha_cumprods = self.ddim_alpha_cumprods.to(device)
self.ddim_alpha_cumprods_prev = self.ddim_alpha_cumprods_prev.to(device)
return self
def ddim_step(self, pred_x0, pred_noise, timestep_index):
alpha_cumprod_prev = extract_into_tensor(self.ddim_alpha_cumprods_prev, timestep_index, pred_x0.shape)
dir_xt = (1.0 - alpha_cumprod_prev).sqrt() * pred_noise
x_prev = alpha_cumprod_prev.sqrt() * pred_x0 + dir_xt
return x_prev
def log_validation(vae, args, accelerator, weight_dtype, step, unet=None, is_final_validation=False):
logger.info("Running validation... ")
pipeline = StableDiffusionXLPipeline.from_pretrained(
args.pretrained_teacher_model,
vae=vae,
scheduler=LCMScheduler.from_pretrained(args.pretrained_teacher_model, subfolder="scheduler"),
revision=args.revision,
torch_dtype=weight_dtype,
).to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
to_load = None
if not is_final_validation:
if unet is None:
raise ValueError("Must provide a `unet` when doing intermediate validation.")
unet = accelerator.unwrap_model(unet)
state_dict = convert_state_dict_to_diffusers(get_peft_model_state_dict(unet))
to_load = state_dict
else:
to_load = args.output_dir
pipeline.load_lora_weights(to_load)
pipeline.fuse_lora()
if args.enable_xformers_memory_efficient_attention:
pipeline.enable_xformers_memory_efficient_attention()
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
validation_prompts = [
"cute sundar pichai character",
"robotic cat with wings",
"a photo of yoda",
"a cute creature with blue eyes",
]
image_logs = []
for _, prompt in enumerate(validation_prompts):
images = []
if torch.backends.mps.is_available():
autocast_ctx = nullcontext()
else:
autocast_ctx = torch.autocast(accelerator.device.type, dtype=weight_dtype)
with autocast_ctx:
images = pipeline(
prompt=prompt,
num_inference_steps=4,
num_images_per_prompt=4,
generator=generator,
guidance_scale=0.0,
).images
image_logs.append({"validation_prompt": prompt, "images": images})
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
formatted_images = []
for image in images:
formatted_images.append(np.asarray(image))
formatted_images = np.stack(formatted_images)
tracker.writer.add_images(validation_prompt, formatted_images, step, dataformats="NHWC")
elif tracker.name == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
logger_name = "test" if is_final_validation else "validation"
tracker.log({logger_name: formatted_images})
else:
logger.warning(f"image logging not implemented for {tracker.name}")
del pipeline
gc.collect()
torch.cuda.empty_cache()
return image_logs
def append_dims(x, target_dims):
"""Appends dimensions to the end of a tensor until it has target_dims dimensions."""
dims_to_append = target_dims - x.ndim
if dims_to_append < 0:
raise ValueError(f"input has {x.ndim} dims but target_dims is {target_dims}, which is less")
return x[(...,) + (None,) * dims_to_append]
# From LCMScheduler.get_scalings_for_boundary_condition_discrete
def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=10.0):
scaled_timestep = timestep_scaling * timestep
c_skip = sigma_data**2 / (scaled_timestep**2 + sigma_data**2)
c_out = scaled_timestep / (scaled_timestep**2 + sigma_data**2) ** 0.5
return c_skip, c_out
# Compare LCMScheduler.step, Step 4
def get_predicted_original_sample(model_output, timesteps, sample, prediction_type, alphas, sigmas):
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
if prediction_type == "epsilon":
pred_x_0 = (sample - sigmas * model_output) / alphas
elif prediction_type == "sample":
pred_x_0 = model_output
elif prediction_type == "v_prediction":
pred_x_0 = alphas * sample - sigmas * model_output
else:
raise ValueError(
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
f" are supported."
)
return pred_x_0
# Based on step 4 in DDIMScheduler.step
def get_predicted_noise(model_output, timesteps, sample, prediction_type, alphas, sigmas):
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
if prediction_type == "epsilon":
pred_epsilon = model_output
elif prediction_type == "sample":
pred_epsilon = (sample - alphas * model_output) / sigmas
elif prediction_type == "v_prediction":
pred_epsilon = alphas * model_output + sigmas * sample
else:
raise ValueError(
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
f" are supported."
)
return pred_epsilon
def extract_into_tensor(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
def import_model_class_from_model_name_or_path(
pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path, subfolder=subfolder, revision=revision
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "CLIPTextModelWithProjection":
from transformers import CLIPTextModelWithProjection
return CLIPTextModelWithProjection
else:
raise ValueError(f"{model_class} is not supported.")
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
# ----------Model Checkpoint Loading Arguments----------
parser.add_argument(
"--pretrained_teacher_model",
type=str,
default=None,
required=True,
help="Path to pretrained LDM teacher model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_model_name_or_path",
type=str,
default=None,
help="Path to pretrained VAE model with better numerical stability. More details: https://github.com/huggingface/diffusers/pull/4038.",
)
parser.add_argument(
"--teacher_revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM teacher model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM model identifier from huggingface.co/models.",
)
# ----------Training Arguments----------
# ----General Training Arguments----
parser.add_argument(
"--output_dir",
type=str,
default="lcm-xl-distilled",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
# ----Logging----
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
# ----Checkpointing----
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
# ----Image Processing----
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing an image."
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--resolution",
type=int,
default=1024,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--interpolation_type",
type=str,
default="bilinear",
help=(
"The interpolation function used when resizing images to the desired resolution. Choose between `bilinear`,"
" `bicubic`, `box`, `nearest`, `nearest_exact`, `hamming`, and `lanczos`."
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--encode_batch_size",
type=int,
default=8,
help="Batch size to use for VAE encoding of the images for efficient processing.",
)
# ----Dataloader----
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
# ----Batch Size and Training Steps----
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
# ----Learning Rate----
parser.add_argument(
"--learning_rate",
type=float,
default=1e-6,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
# ----Optimizer (Adam)----
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
# ----Diffusion Training Arguments----
# ----Latent Consistency Distillation (LCD) Specific Arguments----
parser.add_argument(
"--w_min",
type=float,
default=3.0,
required=False,
help=(
"The minimum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--w_max",
type=float,
default=15.0,
required=False,
help=(
"The maximum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--num_ddim_timesteps",
type=int,
default=50,
help="The number of timesteps to use for DDIM sampling.",
)
parser.add_argument(
"--loss_type",
type=str,
default="l2",
choices=["l2", "huber"],
help="The type of loss to use for the LCD loss.",
)
parser.add_argument(
"--huber_c",
type=float,
default=0.001,
help="The huber loss parameter. Only used if `--loss_type=huber`.",
)
parser.add_argument(
"--lora_rank",
type=int,
default=64,
help="The rank of the LoRA projection matrix.",
)
parser.add_argument(
"--lora_alpha",
type=int,
default=64,
help=(
"The value of the LoRA alpha parameter, which controls the scaling factor in front of the LoRA weight"
" update delta_W. No scaling will be performed if this value is equal to `lora_rank`."
),
)
parser.add_argument(
"--lora_dropout",
type=float,
default=0.0,
help="The dropout probability for the dropout layer added before applying the LoRA to each layer input.",
)
parser.add_argument(
"--lora_target_modules",
type=str,
default=None,
help=(
"A comma-separated string of target module keys to add LoRA to. If not set, a default list of modules will"
" be used. By default, LoRA will be applied to all conv and linear layers."
),
)
parser.add_argument(
"--vae_encode_batch_size",
type=int,
default=8,
required=False,
help=(
"The batch size used when encoding (and decoding) images to latents (and vice versa) using the VAE."
" Encoding or decoding the whole batch at once may run into OOM issues."
),
)
parser.add_argument(
"--timestep_scaling_factor",
type=float,
default=10.0,
help=(
"The multiplicative timestep scaling factor used when calculating the boundary scalings for LCM. The"
" higher the scaling is, the lower the approximation error, but the default value of 10.0 should typically"
" suffice."
),
)
# ----Mixed Precision----
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
# ----Training Optimizations----
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
# ----Distributed Training----
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
# ----------Validation Arguments----------
parser.add_argument(
"--validation_steps",
type=int,
default=200,
help="Run validation every X steps.",
)
# ----------Huggingface Hub Arguments-----------
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
# ----------Accelerate Arguments----------
parser.add_argument(
"--tracker_project_name",
type=str,
default="text2image-fine-tune",
help=(
"The `project_name` argument passed to Accelerator.init_trackers for"
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
),
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
return args
# Adapted from pipelines.StableDiffusionXLPipeline.encode_prompt
def encode_prompt(prompt_batch, text_encoders, tokenizers, is_train=True):
prompt_embeds_list = []
captions = []
for caption in prompt_batch:
if isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
with torch.no_grad():
for tokenizer, text_encoder in zip(tokenizers, text_encoders):
text_inputs = tokenizer(
captions,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
prompt_embeds = text_encoder(
text_input_ids.to(text_encoder.device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.hidden_states[-2]
bs_embed, seq_len, _ = prompt_embeds.shape
prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
return prompt_embeds, pooled_prompt_embeds
def main(args):
if args.report_to == "wandb" and args.hub_token is not None:
raise ValueError(
"You cannot use both --report_to=wandb and --hub_token due to a security risk of exposing your token."
" Please use `huggingface-cli login` to authenticate with the Hub."
)
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
split_batches=True, # It's important to set this to True when using webdataset to get the right number of steps for lr scheduling. If set to False, the number of steps will be devide by the number of processes assuming batches are multiplied by the number of processes
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name,
exist_ok=True,
token=args.hub_token,
private=True,
).repo_id
# 1. Create the noise scheduler and the desired noise schedule.
noise_scheduler = DDPMScheduler.from_pretrained(
args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
)
# DDPMScheduler calculates the alpha and sigma noise schedules (based on the alpha bars) for us
alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
# Initialize the DDIM ODE solver for distillation.
solver = DDIMSolver(
noise_scheduler.alphas_cumprod.numpy(),
timesteps=noise_scheduler.config.num_train_timesteps,
ddim_timesteps=args.num_ddim_timesteps,
)
# 2. Load tokenizers from SDXL checkpoint.
tokenizer_one = AutoTokenizer.from_pretrained(
args.pretrained_teacher_model, subfolder="tokenizer", revision=args.teacher_revision, use_fast=False
)
tokenizer_two = AutoTokenizer.from_pretrained(
args.pretrained_teacher_model, subfolder="tokenizer_2", revision=args.teacher_revision, use_fast=False
)
# 3. Load text encoders from SDXL checkpoint.
# import correct text encoder classes
text_encoder_cls_one = import_model_class_from_model_name_or_path(
args.pretrained_teacher_model, args.teacher_revision
)
text_encoder_cls_two = import_model_class_from_model_name_or_path(
args.pretrained_teacher_model, args.teacher_revision, subfolder="text_encoder_2"
)
text_encoder_one = text_encoder_cls_one.from_pretrained(
args.pretrained_teacher_model, subfolder="text_encoder", revision=args.teacher_revision
)
text_encoder_two = text_encoder_cls_two.from_pretrained(
args.pretrained_teacher_model, subfolder="text_encoder_2", revision=args.teacher_revision
)
# 4. Load VAE from SDXL checkpoint (or more stable VAE)
vae_path = (
args.pretrained_teacher_model
if args.pretrained_vae_model_name_or_path is None
else args.pretrained_vae_model_name_or_path
)
vae = AutoencoderKL.from_pretrained(
vae_path,
subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
revision=args.teacher_revision,
)
# 6. Freeze teacher vae, text_encoders.
vae.requires_grad_(False)
text_encoder_one.requires_grad_(False)
text_encoder_two.requires_grad_(False)
# 7. Create online student U-Net.
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
unet.requires_grad_(False)
# Check that all trainable models are in full precision
low_precision_error_string = (
" Please make sure to always have all model weights in full float32 precision when starting training - even if"
" doing mixed precision training, copy of the weights should still be float32."
)
if accelerator.unwrap_model(unet).dtype != torch.float32:
raise ValueError(
f"Controlnet loaded as datatype {accelerator.unwrap_model(unet).dtype}. {low_precision_error_string}"
)
# 8. Handle mixed precision and device placement
# For mixed precision training we cast all non-trainable weigths to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
# The VAE is in float32 to avoid NaN losses.
unet.to(accelerator.device, dtype=weight_dtype)
if args.pretrained_vae_model_name_or_path is None:
vae.to(accelerator.device, dtype=torch.float32)
else:
vae.to(accelerator.device, dtype=weight_dtype)
text_encoder_one.to(accelerator.device, dtype=weight_dtype)
text_encoder_two.to(accelerator.device, dtype=weight_dtype)
# 9. Add LoRA to the student U-Net, only the LoRA projection matrix will be updated by the optimizer.
if args.lora_target_modules is not None:
lora_target_modules = [module_key.strip() for module_key in args.lora_target_modules.split(",")]
else:
lora_target_modules = [
"to_q",
"to_k",
"to_v",
"to_out.0",
"proj_in",
"proj_out",
"ff.net.0.proj",
"ff.net.2",
"conv1",
"conv2",
"conv_shortcut",
"downsamplers.0.conv",
"upsamplers.0.conv",
"time_emb_proj",
]
lora_config = LoraConfig(
r=args.lora_rank,
target_modules=lora_target_modules,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout,
)
unet.add_adapter(lora_config)
# Also move the alpha and sigma noise schedules to accelerator.device.
alpha_schedule = alpha_schedule.to(accelerator.device)
sigma_schedule = sigma_schedule.to(accelerator.device)
solver = solver.to(accelerator.device)
# 10. Handle saving and loading of checkpoints
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
unet_ = accelerator.unwrap_model(unet)
# also save the checkpoints in native `diffusers` format so that it can be easily
# be independently loaded via `load_lora_weights()`.
state_dict = convert_state_dict_to_diffusers(get_peft_model_state_dict(unet_))
StableDiffusionXLPipeline.save_lora_weights(output_dir, unet_lora_layers=state_dict)
for _, model in enumerate(models):
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
# load the LoRA into the model
unet_ = accelerator.unwrap_model(unet)
lora_state_dict, _ = StableDiffusionXLPipeline.lora_state_dict(input_dir)
unet_state_dict = {
f'{k.replace("unet.", "")}': v for k, v in lora_state_dict.items() if k.startswith("unet.")
}
unet_state_dict = convert_unet_state_dict_to_peft(unet_state_dict)
incompatible_keys = set_peft_model_state_dict(unet_, unet_state_dict, adapter_name="default")
if incompatible_keys is not None:
# check only for unexpected keys
unexpected_keys = getattr(incompatible_keys, "unexpected_keys", None)
if unexpected_keys:
logger.warning(
f"Loading adapter weights from state_dict led to unexpected keys not found in the model: "
f" {unexpected_keys}. "
)
for _ in range(len(models)):
# pop models so that they are not loaded again
models.pop()
# Make sure the trainable params are in float32. This is again needed since the base models
# are in `weight_dtype`. More details:
# https://github.com/huggingface/diffusers/pull/6514#discussion_r1449796804
if args.mixed_precision == "fp16":
cast_training_params(unet_, dtype=torch.float32)
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
# 11. Enable optimizations
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warning(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# 12. Optimizer creation
params_to_optimize = filter(lambda p: p.requires_grad, unet.parameters())
optimizer = optimizer_class(
params_to_optimize,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# 13. Dataset creation and data processing
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
# Preprocessing the datasets.
column_names = dataset["train"].column_names
# Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.image_column is None:
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
interpolation_mode = resolve_interpolation_mode(args.interpolation_type)
train_resize = transforms.Resize(args.resolution, interpolation=interpolation_mode)
train_crop = transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution)
train_flip = transforms.RandomHorizontalFlip(p=1.0)
train_transforms = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
# image aug
original_sizes = []
all_images = []
crop_top_lefts = []
for image in images:
original_sizes.append((image.height, image.width))
image = train_resize(image)
if args.center_crop:
y1 = max(0, int(round((image.height - args.resolution) / 2.0)))
x1 = max(0, int(round((image.width - args.resolution) / 2.0)))
image = train_crop(image)
else:
y1, x1, h, w = train_crop.get_params(image, (args.resolution, args.resolution))
image = crop(image, y1, x1, h, w)
if args.random_flip and random.random() < 0.5:
# flip
x1 = image.width - x1
image = train_flip(image)
crop_top_left = (y1, x1)
crop_top_lefts.append(crop_top_left)
image = train_transforms(image)
all_images.append(image)
examples["original_sizes"] = original_sizes
examples["crop_top_lefts"] = crop_top_lefts
examples["pixel_values"] = all_images
examples["captions"] = list(examples[caption_column])
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
original_sizes = [example["original_sizes"] for example in examples]
crop_top_lefts = [example["crop_top_lefts"] for example in examples]
captions = [example["captions"] for example in examples]
return {
"pixel_values": pixel_values,
"captions": captions,
"original_sizes": original_sizes,
"crop_top_lefts": crop_top_lefts,
}
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# 14. Embeddings for the UNet.
# Adapted from pipeline.StableDiffusionXLPipeline._get_add_time_ids
def compute_embeddings(prompt_batch, original_sizes, crop_coords, text_encoders, tokenizers, is_train=True):
def compute_time_ids(original_size, crops_coords_top_left):
target_size = (args.resolution, args.resolution)
add_time_ids = list(original_size + crops_coords_top_left + target_size)
add_time_ids = torch.tensor([add_time_ids])
add_time_ids = add_time_ids.to(accelerator.device, dtype=weight_dtype)
return add_time_ids
prompt_embeds, pooled_prompt_embeds = encode_prompt(prompt_batch, text_encoders, tokenizers, is_train)
add_text_embeds = pooled_prompt_embeds
add_time_ids = torch.cat([compute_time_ids(s, c) for s, c in zip(original_sizes, crop_coords)])
prompt_embeds = prompt_embeds.to(accelerator.device)
add_text_embeds = add_text_embeds.to(accelerator.device)
unet_added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
return {"prompt_embeds": prompt_embeds, **unet_added_cond_kwargs}
text_encoders = [text_encoder_one, text_encoder_two]
tokenizers = [tokenizer_one, tokenizer_two]
compute_embeddings_fn = functools.partial(compute_embeddings, text_encoders=text_encoders, tokenizers=tokenizers)
# 15. LR Scheduler creation
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Make sure the trainable params are in float32.
if args.mixed_precision == "fp16":
# only upcast trainable parameters (LoRA) into fp32
cast_training_params(unet, dtype=torch.float32)
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
)
# 16. Prepare for training
# Prepare everything with our `accelerator`.
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
# 17. Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
unet.train()
for epoch in range(first_epoch, args.num_train_epochs):
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
# 1. Load and process the image and text conditioning
pixel_values, text, orig_size, crop_coords = (
batch["pixel_values"],
batch["captions"],
batch["original_sizes"],
batch["crop_top_lefts"],
)
encoded_text = compute_embeddings_fn(text, orig_size, crop_coords)
# encode pixel values with batch size of at most args.vae_encode_batch_size
pixel_values = pixel_values.to(dtype=vae.dtype)
latents = []
for i in range(0, pixel_values.shape[0], args.vae_encode_batch_size):
latents.append(vae.encode(pixel_values[i : i + args.vae_encode_batch_size]).latent_dist.sample())
latents = torch.cat(latents, dim=0)
latents = latents * vae.config.scaling_factor
if args.pretrained_vae_model_name_or_path is None:
latents = latents.to(weight_dtype)
# 2. Sample a random timestep for each image t_n from the ODE solver timesteps without bias.
# For the DDIM solver, the timestep schedule is [T - 1, T - k - 1, T - 2 * k - 1, ...]
bsz = latents.shape[0]
topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
start_timesteps = solver.ddim_timesteps[index]
timesteps = start_timesteps - topk
timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
# 3. Get boundary scalings for start_timesteps and (end) timesteps.
c_skip_start, c_out_start = scalings_for_boundary_conditions(
start_timesteps, timestep_scaling=args.timestep_scaling_factor
)
c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
c_skip, c_out = scalings_for_boundary_conditions(
timesteps, timestep_scaling=args.timestep_scaling_factor
)
c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
# 4. Sample noise from the prior and add it to the latents according to the noise magnitude at each
# timestep (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
noise = torch.randn_like(latents)
noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
# 5. Sample a random guidance scale w from U[w_min, w_max]
# Note that for LCM-LoRA distillation it is not necessary to use a guidance scale embedding
w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
w = w.reshape(bsz, 1, 1, 1)
w = w.to(device=latents.device, dtype=latents.dtype)
# 6. Prepare prompt embeds and unet_added_conditions
prompt_embeds = encoded_text.pop("prompt_embeds")
# 7. Get online LCM prediction on z_{t_{n + k}} (noisy_model_input), w, c, t_{n + k} (start_timesteps)
noise_pred = unet(
noisy_model_input,
start_timesteps,
encoder_hidden_states=prompt_embeds,
added_cond_kwargs=encoded_text,
).sample
pred_x_0 = get_predicted_original_sample(
noise_pred,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
# 8. Compute the conditional and unconditional teacher model predictions to get CFG estimates of the
# predicted noise eps_0 and predicted original sample x_0, then run the ODE solver using these
# estimates to predict the data point in the augmented PF-ODE trajectory corresponding to the next ODE
# solver timestep.
# With the adapters disabled, the `unet` is the regular teacher model.
accelerator.unwrap_model(unet).disable_adapters()
with torch.no_grad():
# 1. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and conditional embedding c
cond_teacher_output = unet(
noisy_model_input,
start_timesteps,
encoder_hidden_states=prompt_embeds,
added_cond_kwargs={k: v.to(weight_dtype) for k, v in encoded_text.items()},
).sample
cond_pred_x0 = get_predicted_original_sample(
cond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
cond_pred_noise = get_predicted_noise(
cond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# 2. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and unconditional embedding 0
uncond_prompt_embeds = torch.zeros_like(prompt_embeds)
uncond_pooled_prompt_embeds = torch.zeros_like(encoded_text["text_embeds"])
uncond_added_conditions = copy.deepcopy(encoded_text)
uncond_added_conditions["text_embeds"] = uncond_pooled_prompt_embeds
uncond_teacher_output = unet(
noisy_model_input,
start_timesteps,
encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
added_cond_kwargs={k: v.to(weight_dtype) for k, v in uncond_added_conditions.items()},
).sample
uncond_pred_x0 = get_predicted_original_sample(
uncond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
uncond_pred_noise = get_predicted_noise(
uncond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# 3. Calculate the CFG estimate of x_0 (pred_x0) and eps_0 (pred_noise)
# Note that this uses the LCM paper's CFG formulation rather than the Imagen CFG formulation
pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
pred_noise = cond_pred_noise + w * (cond_pred_noise - uncond_pred_noise)
# 4. Run one step of the ODE solver to estimate the next point x_prev on the
# augmented PF-ODE trajectory (solving backward in time)
# Note that the DDIM step depends on both the predicted x_0 and source noise eps_0.
x_prev = solver.ddim_step(pred_x0, pred_noise, index).to(unet.dtype)
# re-enable unet adapters to turn the `unet` into a student unet.
accelerator.unwrap_model(unet).enable_adapters()
# 9. Get target LCM prediction on x_prev, w, c, t_n (timesteps)
# Note that we do not use a separate target network for LCM-LoRA distillation.
with torch.no_grad():
target_noise_pred = unet(
x_prev,
timesteps,
encoder_hidden_states=prompt_embeds,
added_cond_kwargs={k: v.to(weight_dtype) for k, v in encoded_text.items()},
).sample
pred_x_0 = get_predicted_original_sample(
target_noise_pred,
timesteps,
x_prev,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
target = c_skip * x_prev + c_out * pred_x_0
# 10. Calculate loss
if args.loss_type == "l2":
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
elif args.loss_type == "huber":
loss = torch.mean(
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
)
# 11. Backpropagate on the online student model (`unet`) (only LoRA)
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(params_to_optimize, args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad(set_to_none=True)
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
if global_step % args.validation_steps == 0:
log_validation(
vae, args, accelerator, weight_dtype, global_step, unet=unet, is_final_validation=False
)
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
# Create the pipeline using using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
unet_lora_state_dict = convert_state_dict_to_diffusers(get_peft_model_state_dict(unet))
StableDiffusionXLPipeline.save_lora_weights(args.output_dir, unet_lora_layers=unet_lora_state_dict)
if args.push_to_hub:
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
del unet
torch.cuda.empty_cache()
# Final inference.
if args.validation_steps is not None:
log_validation(vae, args, accelerator, weight_dtype, step=global_step, unet=None, is_final_validation=True)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| diffusers/examples/consistency_distillation/train_lcm_distill_lora_sdxl.py/0 | {
"file_path": "diffusers/examples/consistency_distillation/train_lcm_distill_lora_sdxl.py",
"repo_id": "diffusers",
"token_count": 27478
} | 225 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import os
import sys
import tempfile
sys.path.append("..")
from test_examples_utils import ExamplesTestsAccelerate, run_command # noqa: E402
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger()
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
class CustomDiffusion(ExamplesTestsAccelerate):
def test_custom_diffusion(self):
with tempfile.TemporaryDirectory() as tmpdir:
test_args = f"""
examples/custom_diffusion/train_custom_diffusion.py
--pretrained_model_name_or_path hf-internal-testing/tiny-stable-diffusion-pipe
--instance_data_dir docs/source/en/imgs
--instance_prompt <new1>
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
--max_train_steps 2
--learning_rate 1.0e-05
--scale_lr
--lr_scheduler constant
--lr_warmup_steps 0
--modifier_token <new1>
--no_safe_serialization
--output_dir {tmpdir}
""".split()
run_command(self._launch_args + test_args)
# save_pretrained smoke test
self.assertTrue(os.path.isfile(os.path.join(tmpdir, "pytorch_custom_diffusion_weights.bin")))
self.assertTrue(os.path.isfile(os.path.join(tmpdir, "<new1>.bin")))
def test_custom_diffusion_checkpointing_checkpoints_total_limit(self):
with tempfile.TemporaryDirectory() as tmpdir:
test_args = f"""
examples/custom_diffusion/train_custom_diffusion.py
--pretrained_model_name_or_path=hf-internal-testing/tiny-stable-diffusion-pipe
--instance_data_dir=docs/source/en/imgs
--output_dir={tmpdir}
--instance_prompt=<new1>
--resolution=64
--train_batch_size=1
--modifier_token=<new1>
--dataloader_num_workers=0
--max_train_steps=6
--checkpoints_total_limit=2
--checkpointing_steps=2
--no_safe_serialization
""".split()
run_command(self._launch_args + test_args)
self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-4", "checkpoint-6"})
def test_custom_diffusion_checkpointing_checkpoints_total_limit_removes_multiple_checkpoints(self):
with tempfile.TemporaryDirectory() as tmpdir:
test_args = f"""
examples/custom_diffusion/train_custom_diffusion.py
--pretrained_model_name_or_path=hf-internal-testing/tiny-stable-diffusion-pipe
--instance_data_dir=docs/source/en/imgs
--output_dir={tmpdir}
--instance_prompt=<new1>
--resolution=64
--train_batch_size=1
--modifier_token=<new1>
--dataloader_num_workers=0
--max_train_steps=4
--checkpointing_steps=2
--no_safe_serialization
""".split()
run_command(self._launch_args + test_args)
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
{"checkpoint-2", "checkpoint-4"},
)
resume_run_args = f"""
examples/custom_diffusion/train_custom_diffusion.py
--pretrained_model_name_or_path=hf-internal-testing/tiny-stable-diffusion-pipe
--instance_data_dir=docs/source/en/imgs
--output_dir={tmpdir}
--instance_prompt=<new1>
--resolution=64
--train_batch_size=1
--modifier_token=<new1>
--dataloader_num_workers=0
--max_train_steps=8
--checkpointing_steps=2
--resume_from_checkpoint=checkpoint-4
--checkpoints_total_limit=2
--no_safe_serialization
""".split()
run_command(self._launch_args + resume_run_args)
self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-6", "checkpoint-8"})
| diffusers/examples/custom_diffusion/test_custom_diffusion.py/0 | {
"file_path": "diffusers/examples/custom_diffusion/test_custom_diffusion.py",
"repo_id": "diffusers",
"token_count": 2234
} | 226 |
import warnings
from diffusers import StableDiffusionInpaintPipeline as StableDiffusionInpaintPipeline # noqa F401
warnings.warn(
"The `inpainting.py` script is outdated. Please use directly `from diffusers import"
" StableDiffusionInpaintPipeline` instead."
)
| diffusers/examples/inference/inpainting.py/0 | {
"file_path": "diffusers/examples/inference/inpainting.py",
"repo_id": "diffusers",
"token_count": 89
} | 227 |
# [DreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth) by [colossalai](https://github.com/hpcaitech/ColossalAI.git)
[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
The `train_dreambooth_colossalai.py` script shows how to implement the training procedure and adapt it for stable diffusion.
By accommodating model data in CPU and GPU and moving the data to the computing device when necessary, [Gemini](https://www.colossalai.org/docs/advanced_tutorials/meet_gemini), the Heterogeneous Memory Manager of [Colossal-AI](https://github.com/hpcaitech/ColossalAI) can breakthrough the GPU memory wall by using GPU and CPU memory (composed of CPU DRAM or nvme SSD memory) together at the same time. Moreover, the model scale can be further improved by combining heterogeneous training with the other parallel approaches, such as data parallel, tensor parallel and pipeline parallel.
## Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
```bash
pip install -r requirements.txt
```
## Install [ColossalAI](https://github.com/hpcaitech/ColossalAI.git)
**From PyPI**
```bash
pip install colossalai
```
**From source**
```bash
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# install colossalai
pip install .
```
## Dataset for Teyvat BLIP captions
Dataset used to train [Teyvat characters text to image model](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion).
BLIP generated captions for characters images from [genshin-impact fandom wiki](https://genshin-impact.fandom.com/wiki/Character#Playable_Characters)and [biligame wiki for genshin impact](https://wiki.biligame.com/ys/%E8%A7%92%E8%89%B2).
For each row the dataset contains `image` and `text` keys. `image` is a varying size PIL png, and `text` is the accompanying text caption. Only a train split is provided.
The `text` include the tag `Teyvat`, `Name`,`Element`, `Weapon`, `Region`, `Model type`, and `Description`, the `Description` is captioned with the [pre-trained BLIP model](https://github.com/salesforce/BLIP).
## Training
The argument `placement` can be `cpu`, `auto`, `cuda`, with `cpu` the GPU RAM required can be minimized to 4GB but will deceleration, with `cuda` you can also reduce GPU memory by half but accelerated training, with `auto` a more balanced solution for speed and memory can be obtained。
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export INSTANCE_DIR="path-to-instance-images"
export OUTPUT_DIR="path-to-save-model"
torchrun --nproc_per_node 2 train_dreambooth_colossalai.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="a photo of sks dog" \
--resolution=512 \
--train_batch_size=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=400 \
--placement="cuda"
```
### Training with prior-preservation loss
Prior-preservation is used to avoid overfitting and language-drift. Refer to the paper to learn more about it. For prior-preservation we first generate images using the model with a class prompt and then use those during training along with our data.
According to the paper, it's recommended to generate `num_epochs * num_samples` images for prior-preservation. 200-300 works well for most cases. The `num_class_images` flag sets the number of images to generate with the class prompt. You can place existing images in `class_data_dir`, and the training script will generate any additional images so that `num_class_images` are present in `class_data_dir` during training time.
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
torchrun --nproc_per_node 2 train_dreambooth_colossalai.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=800 \
--placement="cuda"
```
## Inference
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `identifier`(e.g. sks in above example) in your prompt.
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "path-to-save-model"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
prompt = "A photo of sks dog in a bucket"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image.save("dog-bucket.png")
```
| diffusers/examples/research_projects/colossalai/README.md/0 | {
"file_path": "diffusers/examples/research_projects/colossalai/README.md",
"repo_id": "diffusers",
"token_count": 1659
} | 228 |
# Dreambooth for the inpainting model
This script was added by @thedarkzeno .
Please note that this script is not actively maintained, you can open an issue and tag @thedarkzeno or @patil-suraj though.
```bash
export MODEL_NAME="runwayml/stable-diffusion-inpainting"
export INSTANCE_DIR="path-to-instance-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth_inpaint.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="a photo of sks dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=400
```
### Training with prior-preservation loss
Prior-preservation is used to avoid overfitting and language-drift. Refer to the paper to learn more about it. For prior-preservation we first generate images using the model with a class prompt and then use those during training along with our data.
According to the paper, it's recommended to generate `num_epochs * num_samples` images for prior-preservation. 200-300 works well for most cases.
```bash
export MODEL_NAME="runwayml/stable-diffusion-inpainting"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth_inpaint.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
```
### Training with gradient checkpointing and 8-bit optimizer:
With the help of gradient checkpointing and the 8-bit optimizer from bitsandbytes it's possible to run train dreambooth on a 16GB GPU.
To install `bitandbytes` please refer to this [readme](https://github.com/TimDettmers/bitsandbytes#requirements--installation).
```bash
export MODEL_NAME="runwayml/stable-diffusion-inpainting"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth_inpaint.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=2 --gradient_checkpointing \
--use_8bit_adam \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
```
### Fine-tune text encoder with the UNet.
The script also allows to fine-tune the `text_encoder` along with the `unet`. It's been observed experimentally that fine-tuning `text_encoder` gives much better results especially on faces.
Pass the `--train_text_encoder` argument to the script to enable training `text_encoder`.
___Note: Training text encoder requires more memory, with this option the training won't fit on 16GB GPU. It needs at least 24GB VRAM.___
```bash
export MODEL_NAME="runwayml/stable-diffusion-inpainting"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth_inpaint.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_text_encoder \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--use_8bit_adam \
--gradient_checkpointing \
--learning_rate=2e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800
```
| diffusers/examples/research_projects/dreambooth_inpaint/README.md/0 | {
"file_path": "diffusers/examples/research_projects/dreambooth_inpaint/README.md",
"repo_id": "diffusers",
"token_count": 1502
} | 229 |
import argparse
import itertools
import math
import os
import random
from pathlib import Path
from typing import Iterable
import numpy as np
import PIL
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
from accelerate import Accelerator
from accelerate.utils import ProjectConfiguration, set_seed
from huggingface_hub import create_repo, upload_folder
from neural_compressor.utils import logger
from packaging import version
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel
from diffusers.optimization import get_scheduler
from diffusers.utils import make_image_grid
if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
PIL_INTERPOLATION = {
"linear": PIL.Image.Resampling.BILINEAR,
"bilinear": PIL.Image.Resampling.BILINEAR,
"bicubic": PIL.Image.Resampling.BICUBIC,
"lanczos": PIL.Image.Resampling.LANCZOS,
"nearest": PIL.Image.Resampling.NEAREST,
}
else:
PIL_INTERPOLATION = {
"linear": PIL.Image.LINEAR,
"bilinear": PIL.Image.BILINEAR,
"bicubic": PIL.Image.BICUBIC,
"lanczos": PIL.Image.LANCZOS,
"nearest": PIL.Image.NEAREST,
}
# ------------------------------------------------------------------------------
def save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path):
logger.info("Saving embeddings")
learned_embeds = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[placeholder_token_id]
learned_embeds_dict = {args.placeholder_token: learned_embeds.detach().cpu()}
torch.save(learned_embeds_dict, save_path)
def parse_args():
parser = argparse.ArgumentParser(description="Example of distillation for quantization on Textual Inversion.")
parser.add_argument(
"--save_steps",
type=int,
default=500,
help="Save learned_embeds.bin every X updates steps.",
)
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
)
parser.add_argument(
"--placeholder_token",
type=str,
default=None,
required=True,
help="A token to use as a placeholder for the concept.",
)
parser.add_argument(
"--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
)
parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
parser.add_argument(
"--output_dir",
type=str,
default="text-inversion-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=42, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution"
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=5000,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default="no",
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU."
),
)
parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--do_quantization", action="store_true", help="Whether or not to do quantization.")
parser.add_argument("--do_distillation", action="store_true", help="Whether or not to do distillation.")
parser.add_argument(
"--verify_loading", action="store_true", help="Whether or not to verify the loading of the quantized model."
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.train_data_dir is None:
raise ValueError("You must specify a train data directory.")
return args
imagenet_templates_small = [
"a photo of a {}",
"a rendering of a {}",
"a cropped photo of the {}",
"the photo of a {}",
"a photo of a clean {}",
"a photo of a dirty {}",
"a dark photo of the {}",
"a photo of my {}",
"a photo of the cool {}",
"a close-up photo of a {}",
"a bright photo of the {}",
"a cropped photo of a {}",
"a photo of the {}",
"a good photo of the {}",
"a photo of one {}",
"a close-up photo of the {}",
"a rendition of the {}",
"a photo of the clean {}",
"a rendition of a {}",
"a photo of a nice {}",
"a good photo of a {}",
"a photo of the nice {}",
"a photo of the small {}",
"a photo of the weird {}",
"a photo of the large {}",
"a photo of a cool {}",
"a photo of a small {}",
]
imagenet_style_templates_small = [
"a painting in the style of {}",
"a rendering in the style of {}",
"a cropped painting in the style of {}",
"the painting in the style of {}",
"a clean painting in the style of {}",
"a dirty painting in the style of {}",
"a dark painting in the style of {}",
"a picture in the style of {}",
"a cool painting in the style of {}",
"a close-up painting in the style of {}",
"a bright painting in the style of {}",
"a cropped painting in the style of {}",
"a good painting in the style of {}",
"a close-up painting in the style of {}",
"a rendition in the style of {}",
"a nice painting in the style of {}",
"a small painting in the style of {}",
"a weird painting in the style of {}",
"a large painting in the style of {}",
]
# Adapted from torch-ema https://github.com/fadel/pytorch_ema/blob/master/torch_ema/ema.py#L14
class EMAModel:
"""
Exponential Moving Average of models weights
"""
def __init__(self, parameters: Iterable[torch.nn.Parameter], decay=0.9999):
parameters = list(parameters)
self.shadow_params = [p.clone().detach() for p in parameters]
self.decay = decay
self.optimization_step = 0
def get_decay(self, optimization_step):
"""
Compute the decay factor for the exponential moving average.
"""
value = (1 + optimization_step) / (10 + optimization_step)
return 1 - min(self.decay, value)
@torch.no_grad()
def step(self, parameters):
parameters = list(parameters)
self.optimization_step += 1
self.decay = self.get_decay(self.optimization_step)
for s_param, param in zip(self.shadow_params, parameters):
if param.requires_grad:
tmp = self.decay * (s_param - param)
s_param.sub_(tmp)
else:
s_param.copy_(param)
torch.cuda.empty_cache()
def copy_to(self, parameters: Iterable[torch.nn.Parameter]) -> None:
"""
Copy current averaged parameters into given collection of parameters.
Args:
parameters: Iterable of `torch.nn.Parameter`; the parameters to be
updated with the stored moving averages. If `None`, the
parameters with which this `ExponentialMovingAverage` was
initialized will be used.
"""
parameters = list(parameters)
for s_param, param in zip(self.shadow_params, parameters):
param.data.copy_(s_param.data)
def to(self, device=None, dtype=None) -> None:
r"""Move internal buffers of the ExponentialMovingAverage to `device`.
Args:
device: like `device` argument to `torch.Tensor.to`
"""
# .to() on the tensors handles None correctly
self.shadow_params = [
p.to(device=device, dtype=dtype) if p.is_floating_point() else p.to(device=device)
for p in self.shadow_params
]
class TextualInversionDataset(Dataset):
def __init__(
self,
data_root,
tokenizer,
learnable_property="object", # [object, style]
size=512,
repeats=100,
interpolation="bicubic",
flip_p=0.5,
set="train",
placeholder_token="*",
center_crop=False,
):
self.data_root = data_root
self.tokenizer = tokenizer
self.learnable_property = learnable_property
self.size = size
self.placeholder_token = placeholder_token
self.center_crop = center_crop
self.flip_p = flip_p
self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
self.num_images = len(self.image_paths)
self._length = self.num_images
if set == "train":
self._length = self.num_images * repeats
self.interpolation = {
"linear": PIL_INTERPOLATION["linear"],
"bilinear": PIL_INTERPOLATION["bilinear"],
"bicubic": PIL_INTERPOLATION["bicubic"],
"lanczos": PIL_INTERPOLATION["lanczos"],
}[interpolation]
self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
def __len__(self):
return self._length
def __getitem__(self, i):
example = {}
image = Image.open(self.image_paths[i % self.num_images])
if not image.mode == "RGB":
image = image.convert("RGB")
placeholder_string = self.placeholder_token
text = random.choice(self.templates).format(placeholder_string)
example["input_ids"] = self.tokenizer(
text,
padding="max_length",
truncation=True,
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
).input_ids[0]
# default to score-sde preprocessing
img = np.array(image).astype(np.uint8)
if self.center_crop:
crop = min(img.shape[0], img.shape[1])
(
h,
w,
) = (
img.shape[0],
img.shape[1],
)
img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
image = Image.fromarray(img)
image = image.resize((self.size, self.size), resample=self.interpolation)
image = self.flip_transform(image)
image = np.array(image).astype(np.uint8)
image = (image / 127.5 - 1.0).astype(np.float32)
example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
return example
def freeze_params(params):
for param in params:
param.requires_grad = False
def generate_images(pipeline, prompt="", guidance_scale=7.5, num_inference_steps=50, num_images_per_prompt=1, seed=42):
generator = torch.Generator(pipeline.device).manual_seed(seed)
images = pipeline(
prompt,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
generator=generator,
num_images_per_prompt=num_images_per_prompt,
).images
_rows = int(math.sqrt(num_images_per_prompt))
grid = make_image_grid(images, rows=_rows, cols=num_images_per_prompt // _rows)
return grid
def main():
args = parse_args()
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with="tensorboard",
project_config=accelerator_project_config,
)
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load the tokenizer and add the placeholder token as a additional special token
if args.tokenizer_name:
tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
elif args.pretrained_model_name_or_path:
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
# Load models and create wrapper for stable diffusion
noise_scheduler = DDPMScheduler.from_config(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="text_encoder",
revision=args.revision,
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="vae",
revision=args.revision,
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="unet",
revision=args.revision,
)
train_unet = False
# Freeze vae and unet
freeze_params(vae.parameters())
if not args.do_quantization and not args.do_distillation:
# Add the placeholder token in tokenizer
num_added_tokens = tokenizer.add_tokens(args.placeholder_token)
if num_added_tokens == 0:
raise ValueError(
f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
" `placeholder_token` that is not already in the tokenizer."
)
# Convert the initializer_token, placeholder_token to ids
token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
# Check if initializer_token is a single token or a sequence of tokens
if len(token_ids) > 1:
raise ValueError("The initializer token must be a single token.")
initializer_token_id = token_ids[0]
placeholder_token_id = tokenizer.convert_tokens_to_ids(args.placeholder_token)
# Resize the token embeddings as we are adding new special tokens to the tokenizer
text_encoder.resize_token_embeddings(len(tokenizer))
# Initialise the newly added placeholder token with the embeddings of the initializer token
token_embeds = text_encoder.get_input_embeddings().weight.data
token_embeds[placeholder_token_id] = token_embeds[initializer_token_id]
freeze_params(unet.parameters())
# Freeze all parameters except for the token embeddings in text encoder
params_to_freeze = itertools.chain(
text_encoder.text_model.encoder.parameters(),
text_encoder.text_model.final_layer_norm.parameters(),
text_encoder.text_model.embeddings.position_embedding.parameters(),
)
freeze_params(params_to_freeze)
else:
train_unet = True
freeze_params(text_encoder.parameters())
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Initialize the optimizer
optimizer = torch.optim.AdamW(
# only optimize the unet or embeddings of text_encoder
unet.parameters() if train_unet else text_encoder.get_input_embeddings().parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
train_dataset = TextualInversionDataset(
data_root=args.train_data_dir,
tokenizer=tokenizer,
size=args.resolution,
placeholder_token=args.placeholder_token,
repeats=args.repeats,
learnable_property=args.learnable_property,
center_crop=args.center_crop,
set="train",
)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=args.train_batch_size, shuffle=True)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
)
if not train_unet:
text_encoder = accelerator.prepare(text_encoder)
unet.to(accelerator.device)
unet.eval()
else:
unet = accelerator.prepare(unet)
text_encoder.to(accelerator.device)
text_encoder.eval()
optimizer, train_dataloader, lr_scheduler = accelerator.prepare(optimizer, train_dataloader, lr_scheduler)
# Move vae to device
vae.to(accelerator.device)
# Keep vae in eval model as we don't train these
vae.eval()
compression_manager = None
def train_func(model):
if train_unet:
unet_ = model
text_encoder_ = text_encoder
else:
unet_ = unet
text_encoder_ = model
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("textual_inversion", config=vars(args))
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
progress_bar.set_description("Steps")
global_step = 0
if train_unet and args.use_ema:
ema_unet = EMAModel(unet_.parameters())
for epoch in range(args.num_train_epochs):
model.train()
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(model):
# Convert images to latent space
latents = vae.encode(batch["pixel_values"]).latent_dist.sample().detach()
latents = latents * 0.18215
# Sample noise that we'll add to the latents
noise = torch.randn(latents.shape).to(latents.device)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device
).long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder_(batch["input_ids"])[0]
# Predict the noise residual
model_pred = unet_(noisy_latents, timesteps, encoder_hidden_states).sample
loss = F.mse_loss(model_pred, noise, reduction="none").mean([1, 2, 3]).mean()
if train_unet and compression_manager:
unet_inputs = {
"sample": noisy_latents,
"timestep": timesteps,
"encoder_hidden_states": encoder_hidden_states,
}
loss = compression_manager.callbacks.on_after_compute_loss(unet_inputs, model_pred, loss)
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if train_unet:
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet_.parameters(), args.max_grad_norm)
else:
# Zero out the gradients for all token embeddings except the newly added
# embeddings for the concept, as we only want to optimize the concept embeddings
if accelerator.num_processes > 1:
grads = text_encoder_.module.get_input_embeddings().weight.grad
else:
grads = text_encoder_.get_input_embeddings().weight.grad
# Get the index for tokens that we want to zero the grads for
index_grads_to_zero = torch.arange(len(tokenizer)) != placeholder_token_id
grads.data[index_grads_to_zero, :] = grads.data[index_grads_to_zero, :].fill_(0)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
if train_unet and args.use_ema:
ema_unet.step(unet_.parameters())
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
if not train_unet and global_step % args.save_steps == 0:
save_path = os.path.join(args.output_dir, f"learned_embeds-steps-{global_step}.bin")
save_progress(text_encoder_, placeholder_token_id, accelerator, args, save_path)
logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
accelerator.wait_for_everyone()
if train_unet and args.use_ema:
ema_unet.copy_to(unet_.parameters())
if not train_unet:
return text_encoder_
if not train_unet:
text_encoder = train_func(text_encoder)
else:
import copy
model = copy.deepcopy(unet)
confs = []
if args.do_quantization:
from neural_compressor import QuantizationAwareTrainingConfig
q_conf = QuantizationAwareTrainingConfig()
confs.append(q_conf)
if args.do_distillation:
teacher_model = copy.deepcopy(model)
def attention_fetcher(x):
return x.sample
layer_mappings = [
[
[
"conv_in",
]
],
[
[
"time_embedding",
]
],
[["down_blocks.0.attentions.0", attention_fetcher]],
[["down_blocks.0.attentions.1", attention_fetcher]],
[
[
"down_blocks.0.resnets.0",
]
],
[
[
"down_blocks.0.resnets.1",
]
],
[
[
"down_blocks.0.downsamplers.0",
]
],
[["down_blocks.1.attentions.0", attention_fetcher]],
[["down_blocks.1.attentions.1", attention_fetcher]],
[
[
"down_blocks.1.resnets.0",
]
],
[
[
"down_blocks.1.resnets.1",
]
],
[
[
"down_blocks.1.downsamplers.0",
]
],
[["down_blocks.2.attentions.0", attention_fetcher]],
[["down_blocks.2.attentions.1", attention_fetcher]],
[
[
"down_blocks.2.resnets.0",
]
],
[
[
"down_blocks.2.resnets.1",
]
],
[
[
"down_blocks.2.downsamplers.0",
]
],
[
[
"down_blocks.3.resnets.0",
]
],
[
[
"down_blocks.3.resnets.1",
]
],
[
[
"up_blocks.0.resnets.0",
]
],
[
[
"up_blocks.0.resnets.1",
]
],
[
[
"up_blocks.0.resnets.2",
]
],
[
[
"up_blocks.0.upsamplers.0",
]
],
[["up_blocks.1.attentions.0", attention_fetcher]],
[["up_blocks.1.attentions.1", attention_fetcher]],
[["up_blocks.1.attentions.2", attention_fetcher]],
[
[
"up_blocks.1.resnets.0",
]
],
[
[
"up_blocks.1.resnets.1",
]
],
[
[
"up_blocks.1.resnets.2",
]
],
[
[
"up_blocks.1.upsamplers.0",
]
],
[["up_blocks.2.attentions.0", attention_fetcher]],
[["up_blocks.2.attentions.1", attention_fetcher]],
[["up_blocks.2.attentions.2", attention_fetcher]],
[
[
"up_blocks.2.resnets.0",
]
],
[
[
"up_blocks.2.resnets.1",
]
],
[
[
"up_blocks.2.resnets.2",
]
],
[
[
"up_blocks.2.upsamplers.0",
]
],
[["up_blocks.3.attentions.0", attention_fetcher]],
[["up_blocks.3.attentions.1", attention_fetcher]],
[["up_blocks.3.attentions.2", attention_fetcher]],
[
[
"up_blocks.3.resnets.0",
]
],
[
[
"up_blocks.3.resnets.1",
]
],
[
[
"up_blocks.3.resnets.2",
]
],
[["mid_block.attentions.0", attention_fetcher]],
[
[
"mid_block.resnets.0",
]
],
[
[
"mid_block.resnets.1",
]
],
[
[
"conv_out",
]
],
]
layer_names = [layer_mapping[0][0] for layer_mapping in layer_mappings]
if not set(layer_names).issubset([n[0] for n in model.named_modules()]):
raise ValueError(
"Provided model is not compatible with the default layer_mappings, "
'please use the model fine-tuned from "CompVis/stable-diffusion-v1-4", '
"or modify the layer_mappings variable to fit your model."
f"\nDefault layer_mappings are as such:\n{layer_mappings}"
)
from neural_compressor.config import DistillationConfig, IntermediateLayersKnowledgeDistillationLossConfig
distillation_criterion = IntermediateLayersKnowledgeDistillationLossConfig(
layer_mappings=layer_mappings,
loss_types=["MSE"] * len(layer_mappings),
loss_weights=[1.0 / len(layer_mappings)] * len(layer_mappings),
add_origin_loss=True,
)
d_conf = DistillationConfig(teacher_model=teacher_model, criterion=distillation_criterion)
confs.append(d_conf)
from neural_compressor.training import prepare_compression
compression_manager = prepare_compression(model, confs)
compression_manager.callbacks.on_train_begin()
model = compression_manager.model
train_func(model)
compression_manager.callbacks.on_train_end()
# Save the resulting model and its corresponding configuration in the given directory
model.save(args.output_dir)
logger.info(f"Optimized model saved to: {args.output_dir}.")
# change to framework model for further use
model = model.model
# Create the pipeline using using the trained modules and save it.
templates = imagenet_style_templates_small if args.learnable_property == "style" else imagenet_templates_small
prompt = templates[0].format(args.placeholder_token)
if accelerator.is_main_process:
pipeline = StableDiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
text_encoder=accelerator.unwrap_model(text_encoder),
vae=vae,
unet=accelerator.unwrap_model(unet),
tokenizer=tokenizer,
)
pipeline.save_pretrained(args.output_dir)
pipeline = pipeline.to(unet.device)
baseline_model_images = generate_images(pipeline, prompt=prompt, seed=args.seed)
baseline_model_images.save(
os.path.join(args.output_dir, "{}_baseline_model.png".format("_".join(prompt.split())))
)
if not train_unet:
# Also save the newly trained embeddings
save_path = os.path.join(args.output_dir, "learned_embeds.bin")
save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path)
else:
setattr(pipeline, "unet", accelerator.unwrap_model(model))
if args.do_quantization:
pipeline = pipeline.to(torch.device("cpu"))
optimized_model_images = generate_images(pipeline, prompt=prompt, seed=args.seed)
optimized_model_images.save(
os.path.join(args.output_dir, "{}_optimized_model.png".format("_".join(prompt.split())))
)
if args.push_to_hub:
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if args.do_quantization and args.verify_loading:
# Load the model obtained after Intel Neural Compressor quantization
from neural_compressor.utils.pytorch import load
loaded_model = load(args.output_dir, model=unet)
loaded_model.eval()
setattr(pipeline, "unet", loaded_model)
if args.do_quantization:
pipeline = pipeline.to(torch.device("cpu"))
loaded_model_images = generate_images(pipeline, prompt=prompt, seed=args.seed)
if loaded_model_images != optimized_model_images:
logger.info("The quantized model was not successfully loaded.")
else:
logger.info("The quantized model was successfully loaded.")
if __name__ == "__main__":
main()
| diffusers/examples/research_projects/intel_opts/textual_inversion_dfq/textual_inversion.py/0 | {
"file_path": "diffusers/examples/research_projects/intel_opts/textual_inversion_dfq/textual_inversion.py",
"repo_id": "diffusers",
"token_count": 18301
} | 230 |
## Diffusers examples with ONNXRuntime optimizations
**This research project is not actively maintained by the diffusers team. For any questions or comments, please contact Prathik Rao (prathikr), Sunghoon Choi (hanbitmyths), Ashwini Khade (askhade), or Peng Wang (pengwa) on github with any questions.**
This aims to provide diffusers examples with ONNXRuntime optimizations for training/fine-tuning unconditional image generation, text to image, and textual inversion. Please see individual directories for more details on how to run each task using ONNXRuntime.
| diffusers/examples/research_projects/onnxruntime/README.md/0 | {
"file_path": "diffusers/examples/research_projects/onnxruntime/README.md",
"repo_id": "diffusers",
"token_count": 134
} | 231 |
import os
from typing import List
import faiss
import numpy as np
import torch
from datasets import Dataset, load_dataset
from PIL import Image
from transformers import CLIPFeatureExtractor, CLIPModel, PretrainedConfig
from diffusers import logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def normalize_images(images: List[Image.Image]):
images = [np.array(image) for image in images]
images = [image / 127.5 - 1 for image in images]
return images
def preprocess_images(images: List[np.array], feature_extractor: CLIPFeatureExtractor) -> torch.Tensor:
"""
Preprocesses a list of images into a batch of tensors.
Args:
images (:obj:`List[Image.Image]`):
A list of images to preprocess.
Returns:
:obj:`torch.Tensor`: A batch of tensors.
"""
images = [np.array(image) for image in images]
images = [(image + 1.0) / 2.0 for image in images]
images = feature_extractor(images, return_tensors="pt").pixel_values
return images
class IndexConfig(PretrainedConfig):
def __init__(
self,
clip_name_or_path="openai/clip-vit-large-patch14",
dataset_name="Isamu136/oxford_pets_with_l14_emb",
image_column="image",
index_name="embeddings",
index_path=None,
dataset_set="train",
metric_type=faiss.METRIC_L2,
faiss_device=-1,
**kwargs,
):
super().__init__(**kwargs)
self.clip_name_or_path = clip_name_or_path
self.dataset_name = dataset_name
self.image_column = image_column
self.index_name = index_name
self.index_path = index_path
self.dataset_set = dataset_set
self.metric_type = metric_type
self.faiss_device = faiss_device
class Index:
"""
Each index for a retrieval model is specific to the clip model used and the dataset used.
"""
def __init__(self, config: IndexConfig, dataset: Dataset):
self.config = config
self.dataset = dataset
self.index_initialized = False
self.index_name = config.index_name
self.index_path = config.index_path
self.init_index()
def set_index_name(self, index_name: str):
self.index_name = index_name
def init_index(self):
if not self.index_initialized:
if self.index_path and self.index_name:
try:
self.dataset.add_faiss_index(
column=self.index_name, metric_type=self.config.metric_type, device=self.config.faiss_device
)
self.index_initialized = True
except Exception as e:
print(e)
logger.info("Index not initialized")
if self.index_name in self.dataset.features:
self.dataset.add_faiss_index(column=self.index_name)
self.index_initialized = True
def build_index(
self,
model=None,
feature_extractor: CLIPFeatureExtractor = None,
torch_dtype=torch.float32,
):
if not self.index_initialized:
model = model or CLIPModel.from_pretrained(self.config.clip_name_or_path).to(dtype=torch_dtype)
feature_extractor = feature_extractor or CLIPFeatureExtractor.from_pretrained(
self.config.clip_name_or_path
)
self.dataset = get_dataset_with_emb_from_clip_model(
self.dataset,
model,
feature_extractor,
image_column=self.config.image_column,
index_name=self.config.index_name,
)
self.init_index()
def retrieve_imgs(self, vec, k: int = 20):
vec = np.array(vec).astype(np.float32)
return self.dataset.get_nearest_examples(self.index_name, vec, k=k)
def retrieve_imgs_batch(self, vec, k: int = 20):
vec = np.array(vec).astype(np.float32)
return self.dataset.get_nearest_examples_batch(self.index_name, vec, k=k)
def retrieve_indices(self, vec, k: int = 20):
vec = np.array(vec).astype(np.float32)
return self.dataset.search(self.index_name, vec, k=k)
def retrieve_indices_batch(self, vec, k: int = 20):
vec = np.array(vec).astype(np.float32)
return self.dataset.search_batch(self.index_name, vec, k=k)
class Retriever:
def __init__(
self,
config: IndexConfig,
index: Index = None,
dataset: Dataset = None,
model=None,
feature_extractor: CLIPFeatureExtractor = None,
):
self.config = config
self.index = index or self._build_index(config, dataset, model=model, feature_extractor=feature_extractor)
@classmethod
def from_pretrained(
cls,
retriever_name_or_path: str,
index: Index = None,
dataset: Dataset = None,
model=None,
feature_extractor: CLIPFeatureExtractor = None,
**kwargs,
):
config = kwargs.pop("config", None) or IndexConfig.from_pretrained(retriever_name_or_path, **kwargs)
return cls(config, index=index, dataset=dataset, model=model, feature_extractor=feature_extractor)
@staticmethod
def _build_index(
config: IndexConfig, dataset: Dataset = None, model=None, feature_extractor: CLIPFeatureExtractor = None
):
dataset = dataset or load_dataset(config.dataset_name)
dataset = dataset[config.dataset_set]
index = Index(config, dataset)
index.build_index(model=model, feature_extractor=feature_extractor)
return index
def save_pretrained(self, save_directory):
os.makedirs(save_directory, exist_ok=True)
if self.config.index_path is None:
index_path = os.path.join(save_directory, "hf_dataset_index.faiss")
self.index.dataset.get_index(self.config.index_name).save(index_path)
self.config.index_path = index_path
self.config.save_pretrained(save_directory)
def init_retrieval(self):
logger.info("initializing retrieval")
self.index.init_index()
def retrieve_imgs(self, embeddings: np.ndarray, k: int):
return self.index.retrieve_imgs(embeddings, k)
def retrieve_imgs_batch(self, embeddings: np.ndarray, k: int):
return self.index.retrieve_imgs_batch(embeddings, k)
def retrieve_indices(self, embeddings: np.ndarray, k: int):
return self.index.retrieve_indices(embeddings, k)
def retrieve_indices_batch(self, embeddings: np.ndarray, k: int):
return self.index.retrieve_indices_batch(embeddings, k)
def __call__(
self,
embeddings,
k: int = 20,
):
return self.index.retrieve_imgs(embeddings, k)
def map_txt_to_clip_feature(clip_model, tokenizer, prompt):
text_inputs = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > tokenizer.model_max_length:
removed_text = tokenizer.batch_decode(text_input_ids[:, tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : tokenizer.model_max_length]
text_embeddings = clip_model.get_text_features(text_input_ids.to(clip_model.device))
text_embeddings = text_embeddings / torch.linalg.norm(text_embeddings, dim=-1, keepdim=True)
text_embeddings = text_embeddings[:, None, :]
return text_embeddings[0][0].cpu().detach().numpy()
def map_img_to_model_feature(model, feature_extractor, imgs, device):
for i, image in enumerate(imgs):
if not image.mode == "RGB":
imgs[i] = image.convert("RGB")
imgs = normalize_images(imgs)
retrieved_images = preprocess_images(imgs, feature_extractor).to(device)
image_embeddings = model(retrieved_images)
image_embeddings = image_embeddings / torch.linalg.norm(image_embeddings, dim=-1, keepdim=True)
image_embeddings = image_embeddings[None, ...]
return image_embeddings.cpu().detach().numpy()[0][0]
def get_dataset_with_emb_from_model(dataset, model, feature_extractor, image_column="image", index_name="embeddings"):
return dataset.map(
lambda example: {
index_name: map_img_to_model_feature(model, feature_extractor, [example[image_column]], model.device)
}
)
def get_dataset_with_emb_from_clip_model(
dataset, clip_model, feature_extractor, image_column="image", index_name="embeddings"
):
return dataset.map(
lambda example: {
index_name: map_img_to_model_feature(
clip_model.get_image_features, feature_extractor, [example[image_column]], clip_model.device
)
}
)
| diffusers/examples/research_projects/rdm/retriever.py/0 | {
"file_path": "diffusers/examples/research_projects/rdm/retriever.py",
"repo_id": "diffusers",
"token_count": 3957
} | 232 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Fine-tuning script for Stable Diffusion XL for text2image with support for LoRA."""
import argparse
import logging
import math
import os
import random
import shutil
from contextlib import nullcontext
from pathlib import Path
import datasets
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import DistributedDataParallelKwargs, DistributedType, ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from packaging import version
from peft import LoraConfig, set_peft_model_state_dict
from peft.utils import get_peft_model_state_dict
from torchvision import transforms
from torchvision.transforms.functional import crop
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
StableDiffusionXLPipeline,
UNet2DConditionModel,
)
from diffusers.loaders import LoraLoaderMixin
from diffusers.optimization import get_scheduler
from diffusers.training_utils import _set_state_dict_into_text_encoder, cast_training_params, compute_snr
from diffusers.utils import (
check_min_version,
convert_state_dict_to_diffusers,
convert_unet_state_dict_to_peft,
is_wandb_available,
)
from diffusers.utils.hub_utils import load_or_create_model_card, populate_model_card
from diffusers.utils.import_utils import is_torch_npu_available, is_xformers_available
from diffusers.utils.torch_utils import is_compiled_module
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.28.0.dev0")
logger = get_logger(__name__)
if is_torch_npu_available():
torch.npu.config.allow_internal_format = False
def save_model_card(
repo_id: str,
images: list = None,
base_model: str = None,
dataset_name: str = None,
train_text_encoder: bool = False,
repo_folder: str = None,
vae_path: str = None,
):
img_str = ""
if images is not None:
for i, image in enumerate(images):
image.save(os.path.join(repo_folder, f"image_{i}.png"))
img_str += f"\n"
model_description = f"""
# LoRA text2image fine-tuning - {repo_id}
These are LoRA adaption weights for {base_model}. The weights were fine-tuned on the {dataset_name} dataset. You can find some example images in the following. \n
{img_str}
LoRA for the text encoder was enabled: {train_text_encoder}.
Special VAE used for training: {vae_path}.
"""
model_card = load_or_create_model_card(
repo_id_or_path=repo_id,
from_training=True,
license="creativeml-openrail-m",
base_model=base_model,
model_description=model_description,
inference=True,
)
tags = [
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"diffusers",
"diffusers-training",
"lora",
]
model_card = populate_model_card(model_card, tags=tags)
model_card.save(os.path.join(repo_folder, "README.md"))
def import_model_class_from_model_name_or_path(
pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path, subfolder=subfolder, revision=revision
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "CLIPTextModelWithProjection":
from transformers import CLIPTextModelWithProjection
return CLIPTextModelWithProjection
else:
raise ValueError(f"{model_class} is not supported.")
def parse_args(input_args=None):
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_model_name_or_path",
type=str,
default=None,
help="Path to pretrained VAE model with better numerical stability. More details: https://github.com/huggingface/diffusers/pull/4038.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing an image."
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
help="A prompt that is used during validation to verify that the model is learning.",
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_epochs",
type=int,
default=1,
help=(
"Run fine-tuning validation every X epochs. The validation process consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`."
),
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="sd-model-finetuned-lora",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=1024,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--train_text_encoder",
action="store_true",
help="Whether to train the text encoder. If set, the text encoder should be float32 precision.",
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints can be used both as final"
" checkpoints in case they are better than the last checkpoint, and are also suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--snr_gamma",
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
"More details here: https://arxiv.org/abs/2303.09556.",
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--prediction_type",
type=str,
default=None,
help="The prediction_type that shall be used for training. Choose between 'epsilon' or 'v_prediction' or leave `None`. If left to `None` the default prediction type of the scheduler: `noise_scheduler.config.prediction_type` is chosen.",
)
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--enable_npu_flash_attention", action="store_true", help="Whether or not to use npu flash attention."
)
parser.add_argument("--noise_offset", type=float, default=0, help="The scale of noise offset.")
parser.add_argument(
"--rank",
type=int,
default=4,
help=("The dimension of the LoRA update matrices."),
)
parser.add_argument(
"--debug_loss",
action="store_true",
help="debug loss for each image, if filenames are awailable in the dataset",
)
if input_args is not None:
args = parser.parse_args(input_args)
else:
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
return args
DATASET_NAME_MAPPING = {
"lambdalabs/naruto-blip-captions": ("image", "text"),
}
def tokenize_prompt(tokenizer, prompt):
text_inputs = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
return text_input_ids
# Adapted from pipelines.StableDiffusionXLPipeline.encode_prompt
def encode_prompt(text_encoders, tokenizers, prompt, text_input_ids_list=None):
prompt_embeds_list = []
for i, text_encoder in enumerate(text_encoders):
if tokenizers is not None:
tokenizer = tokenizers[i]
text_input_ids = tokenize_prompt(tokenizer, prompt)
else:
assert text_input_ids_list is not None
text_input_ids = text_input_ids_list[i]
prompt_embeds = text_encoder(
text_input_ids.to(text_encoder.device), output_hidden_states=True, return_dict=False
)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds[-1][-2]
bs_embed, seq_len, _ = prompt_embeds.shape
prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
return prompt_embeds, pooled_prompt_embeds
def main(args):
if args.report_to == "wandb" and args.hub_token is not None:
raise ValueError(
"You cannot use both --report_to=wandb and --hub_token due to a security risk of exposing your token."
" Please use `huggingface-cli login` to authenticate with the Hub."
)
logging_dir = Path(args.output_dir, args.logging_dir)
if torch.backends.mps.is_available() and args.mixed_precision == "bf16":
# due to pytorch#99272, MPS does not yet support bfloat16.
raise ValueError(
"Mixed precision training with bfloat16 is not supported on MPS. Please use fp16 (recommended) or fp32 instead."
)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
kwargs = DistributedDataParallelKwargs(find_unused_parameters=True)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
kwargs_handlers=[kwargs],
)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load the tokenizers
tokenizer_one = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer",
revision=args.revision,
use_fast=False,
)
tokenizer_two = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer_2",
revision=args.revision,
use_fast=False,
)
# import correct text encoder classes
text_encoder_cls_one = import_model_class_from_model_name_or_path(
args.pretrained_model_name_or_path, args.revision
)
text_encoder_cls_two = import_model_class_from_model_name_or_path(
args.pretrained_model_name_or_path, args.revision, subfolder="text_encoder_2"
)
# Load scheduler and models
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder_one = text_encoder_cls_one.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
)
text_encoder_two = text_encoder_cls_two.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder_2", revision=args.revision, variant=args.variant
)
vae_path = (
args.pretrained_model_name_or_path
if args.pretrained_vae_model_name_or_path is None
else args.pretrained_vae_model_name_or_path
)
vae = AutoencoderKL.from_pretrained(
vae_path,
subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
revision=args.revision,
variant=args.variant,
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
# We only train the additional adapter LoRA layers
vae.requires_grad_(False)
text_encoder_one.requires_grad_(False)
text_encoder_two.requires_grad_(False)
unet.requires_grad_(False)
# For mixed precision training we cast all non-trainable weights (vae, non-lora text_encoder and non-lora unet) to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
# The VAE is in float32 to avoid NaN losses.
unet.to(accelerator.device, dtype=weight_dtype)
if args.pretrained_vae_model_name_or_path is None:
vae.to(accelerator.device, dtype=torch.float32)
else:
vae.to(accelerator.device, dtype=weight_dtype)
text_encoder_one.to(accelerator.device, dtype=weight_dtype)
text_encoder_two.to(accelerator.device, dtype=weight_dtype)
if args.enable_npu_flash_attention:
if is_torch_npu_available():
logger.info("npu flash attention enabled.")
unet.enable_npu_flash_attention()
else:
raise ValueError("npu flash attention requires torch_npu extensions and is supported only on npu devices.")
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warning(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# now we will add new LoRA weights to the attention layers
# Set correct lora layers
unet_lora_config = LoraConfig(
r=args.rank,
lora_alpha=args.rank,
init_lora_weights="gaussian",
target_modules=["to_k", "to_q", "to_v", "to_out.0"],
)
unet.add_adapter(unet_lora_config)
# The text encoder comes from 🤗 transformers, we will also attach adapters to it.
if args.train_text_encoder:
# ensure that dtype is float32, even if rest of the model that isn't trained is loaded in fp16
text_lora_config = LoraConfig(
r=args.rank,
lora_alpha=args.rank,
init_lora_weights="gaussian",
target_modules=["q_proj", "k_proj", "v_proj", "out_proj"],
)
text_encoder_one.add_adapter(text_lora_config)
text_encoder_two.add_adapter(text_lora_config)
def unwrap_model(model):
model = accelerator.unwrap_model(model)
model = model._orig_mod if is_compiled_module(model) else model
return model
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
# there are only two options here. Either are just the unet attn processor layers
# or there are the unet and text encoder attn layers
unet_lora_layers_to_save = None
text_encoder_one_lora_layers_to_save = None
text_encoder_two_lora_layers_to_save = None
for model in models:
if isinstance(unwrap_model(model), type(unwrap_model(unet))):
unet_lora_layers_to_save = convert_state_dict_to_diffusers(get_peft_model_state_dict(model))
elif isinstance(unwrap_model(model), type(unwrap_model(text_encoder_one))):
text_encoder_one_lora_layers_to_save = convert_state_dict_to_diffusers(
get_peft_model_state_dict(model)
)
elif isinstance(unwrap_model(model), type(unwrap_model(text_encoder_two))):
text_encoder_two_lora_layers_to_save = convert_state_dict_to_diffusers(
get_peft_model_state_dict(model)
)
else:
raise ValueError(f"unexpected save model: {model.__class__}")
# make sure to pop weight so that corresponding model is not saved again
if weights:
weights.pop()
StableDiffusionXLPipeline.save_lora_weights(
output_dir,
unet_lora_layers=unet_lora_layers_to_save,
text_encoder_lora_layers=text_encoder_one_lora_layers_to_save,
text_encoder_2_lora_layers=text_encoder_two_lora_layers_to_save,
)
def load_model_hook(models, input_dir):
unet_ = None
text_encoder_one_ = None
text_encoder_two_ = None
while len(models) > 0:
model = models.pop()
if isinstance(model, type(unwrap_model(unet))):
unet_ = model
elif isinstance(model, type(unwrap_model(text_encoder_one))):
text_encoder_one_ = model
elif isinstance(model, type(unwrap_model(text_encoder_two))):
text_encoder_two_ = model
else:
raise ValueError(f"unexpected save model: {model.__class__}")
lora_state_dict, _ = LoraLoaderMixin.lora_state_dict(input_dir)
unet_state_dict = {f'{k.replace("unet.", "")}': v for k, v in lora_state_dict.items() if k.startswith("unet.")}
unet_state_dict = convert_unet_state_dict_to_peft(unet_state_dict)
incompatible_keys = set_peft_model_state_dict(unet_, unet_state_dict, adapter_name="default")
if incompatible_keys is not None:
# check only for unexpected keys
unexpected_keys = getattr(incompatible_keys, "unexpected_keys", None)
if unexpected_keys:
logger.warning(
f"Loading adapter weights from state_dict led to unexpected keys not found in the model: "
f" {unexpected_keys}. "
)
if args.train_text_encoder:
_set_state_dict_into_text_encoder(lora_state_dict, prefix="text_encoder.", text_encoder=text_encoder_one_)
_set_state_dict_into_text_encoder(
lora_state_dict, prefix="text_encoder_2.", text_encoder=text_encoder_two_
)
# Make sure the trainable params are in float32. This is again needed since the base models
# are in `weight_dtype`. More details:
# https://github.com/huggingface/diffusers/pull/6514#discussion_r1449796804
if args.mixed_precision == "fp16":
models = [unet_]
if args.train_text_encoder:
models.extend([text_encoder_one_, text_encoder_two_])
cast_training_params(models, dtype=torch.float32)
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
if args.train_text_encoder:
text_encoder_one.gradient_checkpointing_enable()
text_encoder_two.gradient_checkpointing_enable()
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Make sure the trainable params are in float32.
if args.mixed_precision == "fp16":
models = [unet]
if args.train_text_encoder:
models.extend([text_encoder_one, text_encoder_two])
cast_training_params(models, dtype=torch.float32)
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# Optimizer creation
params_to_optimize = list(filter(lambda p: p.requires_grad, unet.parameters()))
if args.train_text_encoder:
params_to_optimize = (
params_to_optimize
+ list(filter(lambda p: p.requires_grad, text_encoder_one.parameters()))
+ list(filter(lambda p: p.requires_grad, text_encoder_two.parameters()))
)
optimizer = optimizer_class(
params_to_optimize,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name, args.dataset_config_name, cache_dir=args.cache_dir, data_dir=args.train_data_dir
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.image_column is None:
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
tokens_one = tokenize_prompt(tokenizer_one, captions)
tokens_two = tokenize_prompt(tokenizer_two, captions)
return tokens_one, tokens_two
# Preprocessing the datasets.
train_resize = transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR)
train_crop = transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution)
train_flip = transforms.RandomHorizontalFlip(p=1.0)
train_transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
# image aug
original_sizes = []
all_images = []
crop_top_lefts = []
for image in images:
original_sizes.append((image.height, image.width))
image = train_resize(image)
if args.random_flip and random.random() < 0.5:
# flip
image = train_flip(image)
if args.center_crop:
y1 = max(0, int(round((image.height - args.resolution) / 2.0)))
x1 = max(0, int(round((image.width - args.resolution) / 2.0)))
image = train_crop(image)
else:
y1, x1, h, w = train_crop.get_params(image, (args.resolution, args.resolution))
image = crop(image, y1, x1, h, w)
crop_top_left = (y1, x1)
crop_top_lefts.append(crop_top_left)
image = train_transforms(image)
all_images.append(image)
examples["original_sizes"] = original_sizes
examples["crop_top_lefts"] = crop_top_lefts
examples["pixel_values"] = all_images
tokens_one, tokens_two = tokenize_captions(examples)
examples["input_ids_one"] = tokens_one
examples["input_ids_two"] = tokens_two
if args.debug_loss:
fnames = [os.path.basename(image.filename) for image in examples[image_column] if image.filename]
if fnames:
examples["filenames"] = fnames
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train, output_all_columns=True)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
original_sizes = [example["original_sizes"] for example in examples]
crop_top_lefts = [example["crop_top_lefts"] for example in examples]
input_ids_one = torch.stack([example["input_ids_one"] for example in examples])
input_ids_two = torch.stack([example["input_ids_two"] for example in examples])
result = {
"pixel_values": pixel_values,
"input_ids_one": input_ids_one,
"input_ids_two": input_ids_two,
"original_sizes": original_sizes,
"crop_top_lefts": crop_top_lefts,
}
filenames = [example["filenames"] for example in examples if "filenames" in example]
if filenames:
result["filenames"] = filenames
return result
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
)
# Prepare everything with our `accelerator`.
if args.train_text_encoder:
unet, text_encoder_one, text_encoder_two, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, text_encoder_one, text_encoder_two, optimizer, train_dataloader, lr_scheduler
)
else:
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("text2image-fine-tune", config=vars(args))
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
unet.train()
if args.train_text_encoder:
text_encoder_one.train()
text_encoder_two.train()
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
# Convert images to latent space
if args.pretrained_vae_model_name_or_path is not None:
pixel_values = batch["pixel_values"].to(dtype=weight_dtype)
else:
pixel_values = batch["pixel_values"]
model_input = vae.encode(pixel_values).latent_dist.sample()
model_input = model_input * vae.config.scaling_factor
if args.pretrained_vae_model_name_or_path is None:
model_input = model_input.to(weight_dtype)
# Sample noise that we'll add to the latents
noise = torch.randn_like(model_input)
if args.noise_offset:
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
noise += args.noise_offset * torch.randn(
(model_input.shape[0], model_input.shape[1], 1, 1), device=model_input.device
)
bsz = model_input.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=model_input.device
)
timesteps = timesteps.long()
# Add noise to the model input according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_model_input = noise_scheduler.add_noise(model_input, noise, timesteps)
# time ids
def compute_time_ids(original_size, crops_coords_top_left):
# Adapted from pipeline.StableDiffusionXLPipeline._get_add_time_ids
target_size = (args.resolution, args.resolution)
add_time_ids = list(original_size + crops_coords_top_left + target_size)
add_time_ids = torch.tensor([add_time_ids])
add_time_ids = add_time_ids.to(accelerator.device, dtype=weight_dtype)
return add_time_ids
add_time_ids = torch.cat(
[compute_time_ids(s, c) for s, c in zip(batch["original_sizes"], batch["crop_top_lefts"])]
)
# Predict the noise residual
unet_added_conditions = {"time_ids": add_time_ids}
prompt_embeds, pooled_prompt_embeds = encode_prompt(
text_encoders=[text_encoder_one, text_encoder_two],
tokenizers=None,
prompt=None,
text_input_ids_list=[batch["input_ids_one"], batch["input_ids_two"]],
)
unet_added_conditions.update({"text_embeds": pooled_prompt_embeds})
model_pred = unet(
noisy_model_input,
timesteps,
prompt_embeds,
added_cond_kwargs=unet_added_conditions,
return_dict=False,
)[0]
# Get the target for loss depending on the prediction type
if args.prediction_type is not None:
# set prediction_type of scheduler if defined
noise_scheduler.register_to_config(prediction_type=args.prediction_type)
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(model_input, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
# Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
mse_loss_weights = torch.stack([snr, args.snr_gamma * torch.ones_like(timesteps)], dim=1).min(
dim=1
)[0]
if noise_scheduler.config.prediction_type == "epsilon":
mse_loss_weights = mse_loss_weights / snr
elif noise_scheduler.config.prediction_type == "v_prediction":
mse_loss_weights = mse_loss_weights / (snr + 1)
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
loss = loss.mean()
if args.debug_loss and "filenames" in batch:
for fname in batch["filenames"]:
accelerator.log({"loss_for_" + fname: loss}, step=global_step)
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(params_to_optimize, args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
# DeepSpeed requires saving weights on every device; saving weights only on the main process would cause issues.
if accelerator.distributed_type == DistributedType.DEEPSPEED or accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline
pipeline = StableDiffusionXLPipeline.from_pretrained(
args.pretrained_model_name_or_path,
vae=vae,
text_encoder=unwrap_model(text_encoder_one),
text_encoder_2=unwrap_model(text_encoder_two),
unet=unwrap_model(unet),
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
pipeline_args = {"prompt": args.validation_prompt}
if torch.backends.mps.is_available():
autocast_ctx = nullcontext()
else:
autocast_ctx = torch.autocast(accelerator.device.type)
with autocast_ctx:
images = [
pipeline(**pipeline_args, generator=generator).images[0]
for _ in range(args.num_validation_images)
]
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"validation": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
del pipeline
torch.cuda.empty_cache()
# Save the lora layers
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = unwrap_model(unet)
unet_lora_state_dict = convert_state_dict_to_diffusers(get_peft_model_state_dict(unet))
if args.train_text_encoder:
text_encoder_one = unwrap_model(text_encoder_one)
text_encoder_two = unwrap_model(text_encoder_two)
text_encoder_lora_layers = convert_state_dict_to_diffusers(get_peft_model_state_dict(text_encoder_one))
text_encoder_2_lora_layers = convert_state_dict_to_diffusers(get_peft_model_state_dict(text_encoder_two))
else:
text_encoder_lora_layers = None
text_encoder_2_lora_layers = None
StableDiffusionXLPipeline.save_lora_weights(
save_directory=args.output_dir,
unet_lora_layers=unet_lora_state_dict,
text_encoder_lora_layers=text_encoder_lora_layers,
text_encoder_2_lora_layers=text_encoder_2_lora_layers,
)
del unet
del text_encoder_one
del text_encoder_two
del text_encoder_lora_layers
del text_encoder_2_lora_layers
torch.cuda.empty_cache()
# Final inference
# Make sure vae.dtype is consistent with the unet.dtype
if args.mixed_precision == "fp16":
vae.to(weight_dtype)
# Load previous pipeline
pipeline = StableDiffusionXLPipeline.from_pretrained(
args.pretrained_model_name_or_path,
vae=vae,
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
# load attention processors
pipeline.load_lora_weights(args.output_dir)
# run inference
images = []
if args.validation_prompt and args.num_validation_images > 0:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
images = [
pipeline(args.validation_prompt, num_inference_steps=25, generator=generator).images[0]
for _ in range(args.num_validation_images)
]
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("test", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"test": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
if args.push_to_hub:
save_model_card(
repo_id,
images=images,
base_model=args.pretrained_model_name_or_path,
dataset_name=args.dataset_name,
train_text_encoder=args.train_text_encoder,
repo_folder=args.output_dir,
vae_path=args.pretrained_vae_model_name_or_path,
)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| diffusers/examples/text_to_image/train_text_to_image_lora_sdxl.py/0 | {
"file_path": "diffusers/examples/text_to_image/train_text_to_image_lora_sdxl.py",
"repo_id": "diffusers",
"token_count": 25448
} | 233 |
#!/usr/bin/env python3
import argparse
import math
import os
from copy import deepcopy
import requests
import torch
from audio_diffusion.models import DiffusionAttnUnet1D
from diffusion import sampling
from torch import nn
from diffusers import DanceDiffusionPipeline, IPNDMScheduler, UNet1DModel
MODELS_MAP = {
"gwf-440k": {
"url": "https://model-server.zqevans2.workers.dev/gwf-440k.ckpt",
"sample_rate": 48000,
"sample_size": 65536,
},
"jmann-small-190k": {
"url": "https://model-server.zqevans2.workers.dev/jmann-small-190k.ckpt",
"sample_rate": 48000,
"sample_size": 65536,
},
"jmann-large-580k": {
"url": "https://model-server.zqevans2.workers.dev/jmann-large-580k.ckpt",
"sample_rate": 48000,
"sample_size": 131072,
},
"maestro-uncond-150k": {
"url": "https://model-server.zqevans2.workers.dev/maestro-uncond-150k.ckpt",
"sample_rate": 16000,
"sample_size": 65536,
},
"unlocked-uncond-250k": {
"url": "https://model-server.zqevans2.workers.dev/unlocked-uncond-250k.ckpt",
"sample_rate": 16000,
"sample_size": 65536,
},
"honk-140k": {
"url": "https://model-server.zqevans2.workers.dev/honk-140k.ckpt",
"sample_rate": 16000,
"sample_size": 65536,
},
}
def alpha_sigma_to_t(alpha, sigma):
"""Returns a timestep, given the scaling factors for the clean image and for
the noise."""
return torch.atan2(sigma, alpha) / math.pi * 2
def get_crash_schedule(t):
sigma = torch.sin(t * math.pi / 2) ** 2
alpha = (1 - sigma**2) ** 0.5
return alpha_sigma_to_t(alpha, sigma)
class Object(object):
pass
class DiffusionUncond(nn.Module):
def __init__(self, global_args):
super().__init__()
self.diffusion = DiffusionAttnUnet1D(global_args, n_attn_layers=4)
self.diffusion_ema = deepcopy(self.diffusion)
self.rng = torch.quasirandom.SobolEngine(1, scramble=True)
def download(model_name):
url = MODELS_MAP[model_name]["url"]
r = requests.get(url, stream=True)
local_filename = f"./{model_name}.ckpt"
with open(local_filename, "wb") as fp:
for chunk in r.iter_content(chunk_size=8192):
fp.write(chunk)
return local_filename
DOWN_NUM_TO_LAYER = {
"1": "resnets.0",
"2": "attentions.0",
"3": "resnets.1",
"4": "attentions.1",
"5": "resnets.2",
"6": "attentions.2",
}
UP_NUM_TO_LAYER = {
"8": "resnets.0",
"9": "attentions.0",
"10": "resnets.1",
"11": "attentions.1",
"12": "resnets.2",
"13": "attentions.2",
}
MID_NUM_TO_LAYER = {
"1": "resnets.0",
"2": "attentions.0",
"3": "resnets.1",
"4": "attentions.1",
"5": "resnets.2",
"6": "attentions.2",
"8": "resnets.3",
"9": "attentions.3",
"10": "resnets.4",
"11": "attentions.4",
"12": "resnets.5",
"13": "attentions.5",
}
DEPTH_0_TO_LAYER = {
"0": "resnets.0",
"1": "resnets.1",
"2": "resnets.2",
"4": "resnets.0",
"5": "resnets.1",
"6": "resnets.2",
}
RES_CONV_MAP = {
"skip": "conv_skip",
"main.0": "conv_1",
"main.1": "group_norm_1",
"main.3": "conv_2",
"main.4": "group_norm_2",
}
ATTN_MAP = {
"norm": "group_norm",
"qkv_proj": ["query", "key", "value"],
"out_proj": ["proj_attn"],
}
def convert_resconv_naming(name):
if name.startswith("skip"):
return name.replace("skip", RES_CONV_MAP["skip"])
# name has to be of format main.{digit}
if not name.startswith("main."):
raise ValueError(f"ResConvBlock error with {name}")
return name.replace(name[:6], RES_CONV_MAP[name[:6]])
def convert_attn_naming(name):
for key, value in ATTN_MAP.items():
if name.startswith(key) and not isinstance(value, list):
return name.replace(key, value)
elif name.startswith(key):
return [name.replace(key, v) for v in value]
raise ValueError(f"Attn error with {name}")
def rename(input_string, max_depth=13):
string = input_string
if string.split(".")[0] == "timestep_embed":
return string.replace("timestep_embed", "time_proj")
depth = 0
if string.startswith("net.3."):
depth += 1
string = string[6:]
elif string.startswith("net."):
string = string[4:]
while string.startswith("main.7."):
depth += 1
string = string[7:]
if string.startswith("main."):
string = string[5:]
# mid block
if string[:2].isdigit():
layer_num = string[:2]
string_left = string[2:]
else:
layer_num = string[0]
string_left = string[1:]
if depth == max_depth:
new_layer = MID_NUM_TO_LAYER[layer_num]
prefix = "mid_block"
elif depth > 0 and int(layer_num) < 7:
new_layer = DOWN_NUM_TO_LAYER[layer_num]
prefix = f"down_blocks.{depth}"
elif depth > 0 and int(layer_num) > 7:
new_layer = UP_NUM_TO_LAYER[layer_num]
prefix = f"up_blocks.{max_depth - depth - 1}"
elif depth == 0:
new_layer = DEPTH_0_TO_LAYER[layer_num]
prefix = f"up_blocks.{max_depth - 1}" if int(layer_num) > 3 else "down_blocks.0"
if not string_left.startswith("."):
raise ValueError(f"Naming error with {input_string} and string_left: {string_left}.")
string_left = string_left[1:]
if "resnets" in new_layer:
string_left = convert_resconv_naming(string_left)
elif "attentions" in new_layer:
new_string_left = convert_attn_naming(string_left)
string_left = new_string_left
if not isinstance(string_left, list):
new_string = prefix + "." + new_layer + "." + string_left
else:
new_string = [prefix + "." + new_layer + "." + s for s in string_left]
return new_string
def rename_orig_weights(state_dict):
new_state_dict = {}
for k, v in state_dict.items():
if k.endswith("kernel"):
# up- and downsample layers, don't have trainable weights
continue
new_k = rename(k)
# check if we need to transform from Conv => Linear for attention
if isinstance(new_k, list):
new_state_dict = transform_conv_attns(new_state_dict, new_k, v)
else:
new_state_dict[new_k] = v
return new_state_dict
def transform_conv_attns(new_state_dict, new_k, v):
if len(new_k) == 1:
if len(v.shape) == 3:
# weight
new_state_dict[new_k[0]] = v[:, :, 0]
else:
# bias
new_state_dict[new_k[0]] = v
else:
# qkv matrices
trippled_shape = v.shape[0]
single_shape = trippled_shape // 3
for i in range(3):
if len(v.shape) == 3:
new_state_dict[new_k[i]] = v[i * single_shape : (i + 1) * single_shape, :, 0]
else:
new_state_dict[new_k[i]] = v[i * single_shape : (i + 1) * single_shape]
return new_state_dict
def main(args):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = args.model_path.split("/")[-1].split(".")[0]
if not os.path.isfile(args.model_path):
assert (
model_name == args.model_path
), f"Make sure to provide one of the official model names {MODELS_MAP.keys()}"
args.model_path = download(model_name)
sample_rate = MODELS_MAP[model_name]["sample_rate"]
sample_size = MODELS_MAP[model_name]["sample_size"]
config = Object()
config.sample_size = sample_size
config.sample_rate = sample_rate
config.latent_dim = 0
diffusers_model = UNet1DModel(sample_size=sample_size, sample_rate=sample_rate)
diffusers_state_dict = diffusers_model.state_dict()
orig_model = DiffusionUncond(config)
orig_model.load_state_dict(torch.load(args.model_path, map_location=device)["state_dict"])
orig_model = orig_model.diffusion_ema.eval()
orig_model_state_dict = orig_model.state_dict()
renamed_state_dict = rename_orig_weights(orig_model_state_dict)
renamed_minus_diffusers = set(renamed_state_dict.keys()) - set(diffusers_state_dict.keys())
diffusers_minus_renamed = set(diffusers_state_dict.keys()) - set(renamed_state_dict.keys())
assert len(renamed_minus_diffusers) == 0, f"Problem with {renamed_minus_diffusers}"
assert all(k.endswith("kernel") for k in list(diffusers_minus_renamed)), f"Problem with {diffusers_minus_renamed}"
for key, value in renamed_state_dict.items():
assert (
diffusers_state_dict[key].squeeze().shape == value.squeeze().shape
), f"Shape for {key} doesn't match. Diffusers: {diffusers_state_dict[key].shape} vs. {value.shape}"
if key == "time_proj.weight":
value = value.squeeze()
diffusers_state_dict[key] = value
diffusers_model.load_state_dict(diffusers_state_dict)
steps = 100
seed = 33
diffusers_scheduler = IPNDMScheduler(num_train_timesteps=steps)
generator = torch.manual_seed(seed)
noise = torch.randn([1, 2, config.sample_size], generator=generator).to(device)
t = torch.linspace(1, 0, steps + 1, device=device)[:-1]
step_list = get_crash_schedule(t)
pipe = DanceDiffusionPipeline(unet=diffusers_model, scheduler=diffusers_scheduler)
generator = torch.manual_seed(33)
audio = pipe(num_inference_steps=steps, generator=generator).audios
generated = sampling.iplms_sample(orig_model, noise, step_list, {})
generated = generated.clamp(-1, 1)
diff_sum = (generated - audio).abs().sum()
diff_max = (generated - audio).abs().max()
if args.save:
pipe.save_pretrained(args.checkpoint_path)
print("Diff sum", diff_sum)
print("Diff max", diff_max)
assert diff_max < 1e-3, f"Diff max: {diff_max} is too much :-/"
print(f"Conversion for {model_name} successful!")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--model_path", default=None, type=str, required=True, help="Path to the model to convert.")
parser.add_argument(
"--save", default=True, type=bool, required=False, help="Whether to save the converted model or not."
)
parser.add_argument("--checkpoint_path", default=None, type=str, required=True, help="Path to the output model.")
args = parser.parse_args()
main(args)
| diffusers/scripts/convert_dance_diffusion_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_dance_diffusion_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 4637
} | 234 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Conversion script for the LDM checkpoints."""
import argparse
import torch
from diffusers import UNet3DConditionModel
def assign_to_checkpoint(
paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
):
"""
This does the final conversion step: take locally converted weights and apply a global renaming to them. It splits
attention layers, and takes into account additional replacements that may arise.
Assigns the weights to the new checkpoint.
"""
assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
# Splits the attention layers into three variables.
if attention_paths_to_split is not None:
for path, path_map in attention_paths_to_split.items():
old_tensor = old_checkpoint[path]
channels = old_tensor.shape[0] // 3
target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
query, key, value = old_tensor.split(channels // num_heads, dim=1)
checkpoint[path_map["query"]] = query.reshape(target_shape)
checkpoint[path_map["key"]] = key.reshape(target_shape)
checkpoint[path_map["value"]] = value.reshape(target_shape)
for path in paths:
new_path = path["new"]
# These have already been assigned
if attention_paths_to_split is not None and new_path in attention_paths_to_split:
continue
if additional_replacements is not None:
for replacement in additional_replacements:
new_path = new_path.replace(replacement["old"], replacement["new"])
# proj_attn.weight has to be converted from conv 1D to linear
weight = old_checkpoint[path["old"]]
names = ["proj_attn.weight"]
names_2 = ["proj_out.weight", "proj_in.weight"]
if any(k in new_path for k in names):
checkpoint[new_path] = weight[:, :, 0]
elif any(k in new_path for k in names_2) and len(weight.shape) > 2 and ".attentions." not in new_path:
checkpoint[new_path] = weight[:, :, 0]
else:
checkpoint[new_path] = weight
def renew_attention_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside attentions to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item
# new_item = new_item.replace('norm.weight', 'group_norm.weight')
# new_item = new_item.replace('norm.bias', 'group_norm.bias')
# new_item = new_item.replace('proj_out.weight', 'proj_attn.weight')
# new_item = new_item.replace('proj_out.bias', 'proj_attn.bias')
# new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
mapping.append({"old": old_item, "new": new_item})
return mapping
def shave_segments(path, n_shave_prefix_segments=1):
"""
Removes segments. Positive values shave the first segments, negative shave the last segments.
"""
if n_shave_prefix_segments >= 0:
return ".".join(path.split(".")[n_shave_prefix_segments:])
else:
return ".".join(path.split(".")[:n_shave_prefix_segments])
def renew_temp_conv_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside resnets to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
mapping.append({"old": old_item, "new": old_item})
return mapping
def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside resnets to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item.replace("in_layers.0", "norm1")
new_item = new_item.replace("in_layers.2", "conv1")
new_item = new_item.replace("out_layers.0", "norm2")
new_item = new_item.replace("out_layers.3", "conv2")
new_item = new_item.replace("emb_layers.1", "time_emb_proj")
new_item = new_item.replace("skip_connection", "conv_shortcut")
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
if "temopral_conv" not in old_item:
mapping.append({"old": old_item, "new": new_item})
return mapping
def convert_ldm_unet_checkpoint(checkpoint, config, path=None, extract_ema=False):
"""
Takes a state dict and a config, and returns a converted checkpoint.
"""
# extract state_dict for UNet
unet_state_dict = {}
keys = list(checkpoint.keys())
unet_key = "model.diffusion_model."
# at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA
if sum(k.startswith("model_ema") for k in keys) > 100 and extract_ema:
print(f"Checkpoint {path} has both EMA and non-EMA weights.")
print(
"In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
" weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
)
for key in keys:
if key.startswith("model.diffusion_model"):
flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
else:
if sum(k.startswith("model_ema") for k in keys) > 100:
print(
"In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
" weights (usually better for inference), please make sure to add the `--extract_ema` flag."
)
for key in keys:
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
new_checkpoint = {}
new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
if config["class_embed_type"] is None:
# No parameters to port
...
elif config["class_embed_type"] == "timestep" or config["class_embed_type"] == "projection":
new_checkpoint["class_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
new_checkpoint["class_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
new_checkpoint["class_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
new_checkpoint["class_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
else:
raise NotImplementedError(f"Not implemented `class_embed_type`: {config['class_embed_type']}")
new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
first_temp_attention = [v for v in unet_state_dict if v.startswith("input_blocks.0.1")]
paths = renew_attention_paths(first_temp_attention)
meta_path = {"old": "input_blocks.0.1", "new": "transformer_in"}
assign_to_checkpoint(paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config)
new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
# Retrieves the keys for the input blocks only
num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
input_blocks = {
layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
for layer_id in range(num_input_blocks)
}
# Retrieves the keys for the middle blocks only
num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
middle_blocks = {
layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
for layer_id in range(num_middle_blocks)
}
# Retrieves the keys for the output blocks only
num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
output_blocks = {
layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
for layer_id in range(num_output_blocks)
}
for i in range(1, num_input_blocks):
block_id = (i - 1) // (config["layers_per_block"] + 1)
layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
resnets = [
key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
]
attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
temp_attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.2" in key]
if f"input_blocks.{i}.op.weight" in unet_state_dict:
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
f"input_blocks.{i}.op.weight"
)
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
f"input_blocks.{i}.op.bias"
)
paths = renew_resnet_paths(resnets)
meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
temporal_convs = [key for key in resnets if "temopral_conv" in key]
paths = renew_temp_conv_paths(temporal_convs)
meta_path = {
"old": f"input_blocks.{i}.0.temopral_conv",
"new": f"down_blocks.{block_id}.temp_convs.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
if len(attentions):
paths = renew_attention_paths(attentions)
meta_path = {"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
if len(temp_attentions):
paths = renew_attention_paths(temp_attentions)
meta_path = {
"old": f"input_blocks.{i}.2",
"new": f"down_blocks.{block_id}.temp_attentions.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
resnet_0 = middle_blocks[0]
temporal_convs_0 = [key for key in resnet_0 if "temopral_conv" in key]
attentions = middle_blocks[1]
temp_attentions = middle_blocks[2]
resnet_1 = middle_blocks[3]
temporal_convs_1 = [key for key in resnet_1 if "temopral_conv" in key]
resnet_0_paths = renew_resnet_paths(resnet_0)
meta_path = {"old": "middle_block.0", "new": "mid_block.resnets.0"}
assign_to_checkpoint(
resnet_0_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
)
temp_conv_0_paths = renew_temp_conv_paths(temporal_convs_0)
meta_path = {"old": "middle_block.0.temopral_conv", "new": "mid_block.temp_convs.0"}
assign_to_checkpoint(
temp_conv_0_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
)
resnet_1_paths = renew_resnet_paths(resnet_1)
meta_path = {"old": "middle_block.3", "new": "mid_block.resnets.1"}
assign_to_checkpoint(
resnet_1_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
)
temp_conv_1_paths = renew_temp_conv_paths(temporal_convs_1)
meta_path = {"old": "middle_block.3.temopral_conv", "new": "mid_block.temp_convs.1"}
assign_to_checkpoint(
temp_conv_1_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
)
attentions_paths = renew_attention_paths(attentions)
meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(
attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
temp_attentions_paths = renew_attention_paths(temp_attentions)
meta_path = {"old": "middle_block.2", "new": "mid_block.temp_attentions.0"}
assign_to_checkpoint(
temp_attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
for i in range(num_output_blocks):
block_id = i // (config["layers_per_block"] + 1)
layer_in_block_id = i % (config["layers_per_block"] + 1)
output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
output_block_list = {}
for layer in output_block_layers:
layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
if layer_id in output_block_list:
output_block_list[layer_id].append(layer_name)
else:
output_block_list[layer_id] = [layer_name]
if len(output_block_list) > 1:
resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
temp_attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.2" in key]
resnet_0_paths = renew_resnet_paths(resnets)
paths = renew_resnet_paths(resnets)
meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
temporal_convs = [key for key in resnets if "temopral_conv" in key]
paths = renew_temp_conv_paths(temporal_convs)
meta_path = {
"old": f"output_blocks.{i}.0.temopral_conv",
"new": f"up_blocks.{block_id}.temp_convs.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
output_block_list = {k: sorted(v) for k, v in output_block_list.items()}
if ["conv.bias", "conv.weight"] in output_block_list.values():
index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
f"output_blocks.{i}.{index}.conv.weight"
]
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
f"output_blocks.{i}.{index}.conv.bias"
]
# Clear attentions as they have been attributed above.
if len(attentions) == 2:
attentions = []
if len(attentions):
paths = renew_attention_paths(attentions)
meta_path = {
"old": f"output_blocks.{i}.1",
"new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
if len(temp_attentions):
paths = renew_attention_paths(temp_attentions)
meta_path = {
"old": f"output_blocks.{i}.2",
"new": f"up_blocks.{block_id}.temp_attentions.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
else:
resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
for path in resnet_0_paths:
old_path = ".".join(["output_blocks", str(i), path["old"]])
new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
new_checkpoint[new_path] = unet_state_dict[old_path]
temopral_conv_paths = [l for l in output_block_layers if "temopral_conv" in l]
for path in temopral_conv_paths:
pruned_path = path.split("temopral_conv.")[-1]
old_path = ".".join(["output_blocks", str(i), str(block_id), "temopral_conv", pruned_path])
new_path = ".".join(["up_blocks", str(block_id), "temp_convs", str(layer_in_block_id), pruned_path])
new_checkpoint[new_path] = unet_state_dict[old_path]
return new_checkpoint
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
)
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
args = parser.parse_args()
unet_checkpoint = torch.load(args.checkpoint_path, map_location="cpu")
unet = UNet3DConditionModel()
converted_ckpt = convert_ldm_unet_checkpoint(unet_checkpoint, unet.config)
diff_0 = set(unet.state_dict().keys()) - set(converted_ckpt.keys())
diff_1 = set(converted_ckpt.keys()) - set(unet.state_dict().keys())
assert len(diff_0) == len(diff_1) == 0, "Converted weights don't match"
# load state_dict
unet.load_state_dict(converted_ckpt)
unet.save_pretrained(args.dump_path)
# -- finish converting the unet --
| diffusers/scripts/convert_ms_text_to_video_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_ms_text_to_video_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 8415
} | 235 |
import argparse
import sys
import tensorrt as trt
def convert_models(onnx_path: str, num_controlnet: int, output_path: str, fp16: bool = False, sd_xl: bool = False):
"""
Function to convert models in stable diffusion controlnet pipeline into TensorRT format
Example:
python convert_stable_diffusion_controlnet_to_tensorrt.py
--onnx_path path-to-models-stable_diffusion/RevAnimated-v1-2-2/unet/model.onnx
--output_path path-to-models-stable_diffusion/RevAnimated-v1-2-2/unet/model.engine
--fp16
--num_controlnet 2
Example for SD XL:
python convert_stable_diffusion_controlnet_to_tensorrt.py
--onnx_path path-to-models-stable_diffusion/stable-diffusion-xl-base-1.0/unet/model.onnx
--output_path path-to-models-stable_diffusion/stable-diffusion-xl-base-1.0/unet/model.engine
--fp16
--num_controlnet 1
--sd_xl
Returns:
unet/model.engine
run test script in diffusers/examples/community
python test_onnx_controlnet.py
--sd_model danbrown/RevAnimated-v1-2-2
--onnx_model_dir path-to-models-stable_diffusion/RevAnimated-v1-2-2
--unet_engine_path path-to-models-stable_diffusion/stable-diffusion-xl-base-1.0/unet/model.engine
--qr_img_path path-to-qr-code-image
"""
# UNET
if sd_xl:
batch_size = 1
unet_in_channels = 4
unet_sample_size = 64
num_tokens = 77
text_hidden_size = 2048
img_size = 512
text_embeds_shape = (2 * batch_size, 1280)
time_ids_shape = (2 * batch_size, 6)
else:
batch_size = 1
unet_in_channels = 4
unet_sample_size = 64
num_tokens = 77
text_hidden_size = 768
img_size = 512
batch_size = 1
latents_shape = (2 * batch_size, unet_in_channels, unet_sample_size, unet_sample_size)
embed_shape = (2 * batch_size, num_tokens, text_hidden_size)
controlnet_conds_shape = (num_controlnet, 2 * batch_size, 3, img_size, img_size)
TRT_LOGGER = trt.Logger(trt.Logger.VERBOSE)
TRT_BUILDER = trt.Builder(TRT_LOGGER)
TRT_RUNTIME = trt.Runtime(TRT_LOGGER)
network = TRT_BUILDER.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
onnx_parser = trt.OnnxParser(network, TRT_LOGGER)
parse_success = onnx_parser.parse_from_file(onnx_path)
for idx in range(onnx_parser.num_errors):
print(onnx_parser.get_error(idx))
if not parse_success:
sys.exit("ONNX model parsing failed")
print("Load Onnx model done")
profile = TRT_BUILDER.create_optimization_profile()
profile.set_shape("sample", latents_shape, latents_shape, latents_shape)
profile.set_shape("encoder_hidden_states", embed_shape, embed_shape, embed_shape)
profile.set_shape("controlnet_conds", controlnet_conds_shape, controlnet_conds_shape, controlnet_conds_shape)
if sd_xl:
profile.set_shape("text_embeds", text_embeds_shape, text_embeds_shape, text_embeds_shape)
profile.set_shape("time_ids", time_ids_shape, time_ids_shape, time_ids_shape)
config = TRT_BUILDER.create_builder_config()
config.add_optimization_profile(profile)
config.set_preview_feature(trt.PreviewFeature.DISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805, True)
if fp16:
config.set_flag(trt.BuilderFlag.FP16)
plan = TRT_BUILDER.build_serialized_network(network, config)
if plan is None:
sys.exit("Failed building engine")
print("Succeeded building engine")
engine = TRT_RUNTIME.deserialize_cuda_engine(plan)
## save TRT engine
with open(output_path, "wb") as f:
f.write(engine.serialize())
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--sd_xl", action="store_true", default=False, help="SD XL pipeline")
parser.add_argument(
"--onnx_path",
type=str,
required=True,
help="Path to the onnx checkpoint to convert",
)
parser.add_argument("--num_controlnet", type=int)
parser.add_argument("--output_path", type=str, required=True, help="Path to the output model.")
parser.add_argument("--fp16", action="store_true", default=False, help="Export the models in `float16` mode")
args = parser.parse_args()
convert_models(args.onnx_path, args.num_controlnet, args.output_path, args.fp16, args.sd_xl)
| diffusers/scripts/convert_stable_diffusion_controlnet_to_tensorrt.py/0 | {
"file_path": "diffusers/scripts/convert_stable_diffusion_controlnet_to_tensorrt.py",
"repo_id": "diffusers",
"token_count": 1860
} | 236 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import inspect
import os
from pathlib import Path
from typing import Callable, Dict, List, Optional, Union
import safetensors
import torch
from huggingface_hub import model_info
from huggingface_hub.constants import HF_HUB_OFFLINE
from huggingface_hub.utils import validate_hf_hub_args
from packaging import version
from torch import nn
from .. import __version__
from ..models.modeling_utils import _LOW_CPU_MEM_USAGE_DEFAULT, load_state_dict
from ..utils import (
USE_PEFT_BACKEND,
_get_model_file,
convert_state_dict_to_diffusers,
convert_state_dict_to_peft,
convert_unet_state_dict_to_peft,
delete_adapter_layers,
get_adapter_name,
get_peft_kwargs,
is_accelerate_available,
is_peft_version,
is_transformers_available,
logging,
recurse_remove_peft_layers,
scale_lora_layers,
set_adapter_layers,
set_weights_and_activate_adapters,
)
from .lora_conversion_utils import _convert_kohya_lora_to_diffusers, _maybe_map_sgm_blocks_to_diffusers
if is_transformers_available():
from transformers import PreTrainedModel
from ..models.lora import text_encoder_attn_modules, text_encoder_mlp_modules
if is_accelerate_available():
from accelerate.hooks import AlignDevicesHook, CpuOffload, remove_hook_from_module
logger = logging.get_logger(__name__)
TEXT_ENCODER_NAME = "text_encoder"
UNET_NAME = "unet"
TRANSFORMER_NAME = "transformer"
LORA_WEIGHT_NAME = "pytorch_lora_weights.bin"
LORA_WEIGHT_NAME_SAFE = "pytorch_lora_weights.safetensors"
LORA_DEPRECATION_MESSAGE = "You are using an old version of LoRA backend. This will be deprecated in the next releases in favor of PEFT make sure to install the latest PEFT and transformers packages in the future."
class LoraLoaderMixin:
r"""
Load LoRA layers into [`UNet2DConditionModel`] and
[`CLIPTextModel`](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel).
"""
text_encoder_name = TEXT_ENCODER_NAME
unet_name = UNET_NAME
transformer_name = TRANSFORMER_NAME
num_fused_loras = 0
def load_lora_weights(
self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], adapter_name=None, **kwargs
):
"""
Load LoRA weights specified in `pretrained_model_name_or_path_or_dict` into `self.unet` and
`self.text_encoder`.
All kwargs are forwarded to `self.lora_state_dict`.
See [`~loaders.LoraLoaderMixin.lora_state_dict`] for more details on how the state dict is loaded.
See [`~loaders.LoraLoaderMixin.load_lora_into_unet`] for more details on how the state dict is loaded into
`self.unet`.
See [`~loaders.LoraLoaderMixin.load_lora_into_text_encoder`] for more details on how the state dict is loaded
into `self.text_encoder`.
Parameters:
pretrained_model_name_or_path_or_dict (`str` or `os.PathLike` or `dict`):
See [`~loaders.LoraLoaderMixin.lora_state_dict`].
kwargs (`dict`, *optional*):
See [`~loaders.LoraLoaderMixin.lora_state_dict`].
adapter_name (`str`, *optional*):
Adapter name to be used for referencing the loaded adapter model. If not specified, it will use
`default_{i}` where i is the total number of adapters being loaded.
"""
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
# if a dict is passed, copy it instead of modifying it inplace
if isinstance(pretrained_model_name_or_path_or_dict, dict):
pretrained_model_name_or_path_or_dict = pretrained_model_name_or_path_or_dict.copy()
# First, ensure that the checkpoint is a compatible one and can be successfully loaded.
state_dict, network_alphas = self.lora_state_dict(pretrained_model_name_or_path_or_dict, **kwargs)
is_correct_format = all("lora" in key or "dora_scale" in key for key in state_dict.keys())
if not is_correct_format:
raise ValueError("Invalid LoRA checkpoint.")
low_cpu_mem_usage = kwargs.pop("low_cpu_mem_usage", _LOW_CPU_MEM_USAGE_DEFAULT)
self.load_lora_into_unet(
state_dict,
network_alphas=network_alphas,
unet=getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet,
low_cpu_mem_usage=low_cpu_mem_usage,
adapter_name=adapter_name,
_pipeline=self,
)
self.load_lora_into_text_encoder(
state_dict,
network_alphas=network_alphas,
text_encoder=getattr(self, self.text_encoder_name)
if not hasattr(self, "text_encoder")
else self.text_encoder,
lora_scale=self.lora_scale,
low_cpu_mem_usage=low_cpu_mem_usage,
adapter_name=adapter_name,
_pipeline=self,
)
@classmethod
@validate_hf_hub_args
def lora_state_dict(
cls,
pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]],
**kwargs,
):
r"""
Return state dict for lora weights and the network alphas.
<Tip warning={true}>
We support loading A1111 formatted LoRA checkpoints in a limited capacity.
This function is experimental and might change in the future.
</Tip>
Parameters:
pretrained_model_name_or_path_or_dict (`str` or `os.PathLike` or `dict`):
Can be either:
- A string, the *model id* (for example `google/ddpm-celebahq-256`) of a pretrained model hosted on
the Hub.
- A path to a *directory* (for example `./my_model_directory`) containing the model weights saved
with [`ModelMixin.save_pretrained`].
- A [torch state
dict](https://pytorch.org/tutorials/beginner/saving_loading_models.html#what-is-a-state-dict).
cache_dir (`Union[str, os.PathLike]`, *optional*):
Path to a directory where a downloaded pretrained model configuration is cached if the standard cache
is not used.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
resume_download:
Deprecated and ignored. All downloads are now resumed by default when possible. Will be removed in v1
of Diffusers.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, for example, `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
local_files_only (`bool`, *optional*, defaults to `False`):
Whether to only load local model weights and configuration files or not. If set to `True`, the model
won't be downloaded from the Hub.
token (`str` or *bool*, *optional*):
The token to use as HTTP bearer authorization for remote files. If `True`, the token generated from
`diffusers-cli login` (stored in `~/.huggingface`) is used.
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, a commit id, or any identifier
allowed by Git.
subfolder (`str`, *optional*, defaults to `""`):
The subfolder location of a model file within a larger model repository on the Hub or locally.
low_cpu_mem_usage (`bool`, *optional*, defaults to `True` if torch version >= 1.9.0 else `False`):
Speed up model loading only loading the pretrained weights and not initializing the weights. This also
tries to not use more than 1x model size in CPU memory (including peak memory) while loading the model.
Only supported for PyTorch >= 1.9.0. If you are using an older version of PyTorch, setting this
argument to `True` will raise an error.
mirror (`str`, *optional*):
Mirror source to resolve accessibility issues if you're downloading a model in China. We do not
guarantee the timeliness or safety of the source, and you should refer to the mirror site for more
information.
"""
# Load the main state dict first which has the LoRA layers for either of
# UNet and text encoder or both.
cache_dir = kwargs.pop("cache_dir", None)
force_download = kwargs.pop("force_download", False)
resume_download = kwargs.pop("resume_download", None)
proxies = kwargs.pop("proxies", None)
local_files_only = kwargs.pop("local_files_only", None)
token = kwargs.pop("token", None)
revision = kwargs.pop("revision", None)
subfolder = kwargs.pop("subfolder", None)
weight_name = kwargs.pop("weight_name", None)
unet_config = kwargs.pop("unet_config", None)
use_safetensors = kwargs.pop("use_safetensors", None)
allow_pickle = False
if use_safetensors is None:
use_safetensors = True
allow_pickle = True
user_agent = {
"file_type": "attn_procs_weights",
"framework": "pytorch",
}
model_file = None
if not isinstance(pretrained_model_name_or_path_or_dict, dict):
# Let's first try to load .safetensors weights
if (use_safetensors and weight_name is None) or (
weight_name is not None and weight_name.endswith(".safetensors")
):
try:
# Here we're relaxing the loading check to enable more Inference API
# friendliness where sometimes, it's not at all possible to automatically
# determine `weight_name`.
if weight_name is None:
weight_name = cls._best_guess_weight_name(
pretrained_model_name_or_path_or_dict,
file_extension=".safetensors",
local_files_only=local_files_only,
)
model_file = _get_model_file(
pretrained_model_name_or_path_or_dict,
weights_name=weight_name or LORA_WEIGHT_NAME_SAFE,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
user_agent=user_agent,
)
state_dict = safetensors.torch.load_file(model_file, device="cpu")
except (IOError, safetensors.SafetensorError) as e:
if not allow_pickle:
raise e
# try loading non-safetensors weights
model_file = None
pass
if model_file is None:
if weight_name is None:
weight_name = cls._best_guess_weight_name(
pretrained_model_name_or_path_or_dict, file_extension=".bin", local_files_only=local_files_only
)
model_file = _get_model_file(
pretrained_model_name_or_path_or_dict,
weights_name=weight_name or LORA_WEIGHT_NAME,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
user_agent=user_agent,
)
state_dict = load_state_dict(model_file)
else:
state_dict = pretrained_model_name_or_path_or_dict
network_alphas = None
# TODO: replace it with a method from `state_dict_utils`
if all(
(
k.startswith("lora_te_")
or k.startswith("lora_unet_")
or k.startswith("lora_te1_")
or k.startswith("lora_te2_")
)
for k in state_dict.keys()
):
# Map SDXL blocks correctly.
if unet_config is not None:
# use unet config to remap block numbers
state_dict = _maybe_map_sgm_blocks_to_diffusers(state_dict, unet_config)
state_dict, network_alphas = _convert_kohya_lora_to_diffusers(state_dict)
return state_dict, network_alphas
@classmethod
def _best_guess_weight_name(
cls, pretrained_model_name_or_path_or_dict, file_extension=".safetensors", local_files_only=False
):
if local_files_only or HF_HUB_OFFLINE:
raise ValueError("When using the offline mode, you must specify a `weight_name`.")
targeted_files = []
if os.path.isfile(pretrained_model_name_or_path_or_dict):
return
elif os.path.isdir(pretrained_model_name_or_path_or_dict):
targeted_files = [
f for f in os.listdir(pretrained_model_name_or_path_or_dict) if f.endswith(file_extension)
]
else:
files_in_repo = model_info(pretrained_model_name_or_path_or_dict).siblings
targeted_files = [f.rfilename for f in files_in_repo if f.rfilename.endswith(file_extension)]
if len(targeted_files) == 0:
return
# "scheduler" does not correspond to a LoRA checkpoint.
# "optimizer" does not correspond to a LoRA checkpoint
# only top-level checkpoints are considered and not the other ones, hence "checkpoint".
unallowed_substrings = {"scheduler", "optimizer", "checkpoint"}
targeted_files = list(
filter(lambda x: all(substring not in x for substring in unallowed_substrings), targeted_files)
)
if any(f.endswith(LORA_WEIGHT_NAME) for f in targeted_files):
targeted_files = list(filter(lambda x: x.endswith(LORA_WEIGHT_NAME), targeted_files))
elif any(f.endswith(LORA_WEIGHT_NAME_SAFE) for f in targeted_files):
targeted_files = list(filter(lambda x: x.endswith(LORA_WEIGHT_NAME_SAFE), targeted_files))
if len(targeted_files) > 1:
raise ValueError(
f"Provided path contains more than one weights file in the {file_extension} format. Either specify `weight_name` in `load_lora_weights` or make sure there's only one `.safetensors` or `.bin` file in {pretrained_model_name_or_path_or_dict}."
)
weight_name = targeted_files[0]
return weight_name
@classmethod
def _optionally_disable_offloading(cls, _pipeline):
"""
Optionally removes offloading in case the pipeline has been already sequentially offloaded to CPU.
Args:
_pipeline (`DiffusionPipeline`):
The pipeline to disable offloading for.
Returns:
tuple:
A tuple indicating if `is_model_cpu_offload` or `is_sequential_cpu_offload` is True.
"""
is_model_cpu_offload = False
is_sequential_cpu_offload = False
if _pipeline is not None and _pipeline.hf_device_map is None:
for _, component in _pipeline.components.items():
if isinstance(component, nn.Module) and hasattr(component, "_hf_hook"):
if not is_model_cpu_offload:
is_model_cpu_offload = isinstance(component._hf_hook, CpuOffload)
if not is_sequential_cpu_offload:
is_sequential_cpu_offload = (
isinstance(component._hf_hook, AlignDevicesHook)
or hasattr(component._hf_hook, "hooks")
and isinstance(component._hf_hook.hooks[0], AlignDevicesHook)
)
logger.info(
"Accelerate hooks detected. Since you have called `load_lora_weights()`, the previous hooks will be first removed. Then the LoRA parameters will be loaded and the hooks will be applied again."
)
remove_hook_from_module(component, recurse=is_sequential_cpu_offload)
return (is_model_cpu_offload, is_sequential_cpu_offload)
@classmethod
def load_lora_into_unet(
cls, state_dict, network_alphas, unet, low_cpu_mem_usage=None, adapter_name=None, _pipeline=None
):
"""
This will load the LoRA layers specified in `state_dict` into `unet`.
Parameters:
state_dict (`dict`):
A standard state dict containing the lora layer parameters. The keys can either be indexed directly
into the unet or prefixed with an additional `unet` which can be used to distinguish between text
encoder lora layers.
network_alphas (`Dict[str, float]`):
See `LoRALinearLayer` for more details.
unet (`UNet2DConditionModel`):
The UNet model to load the LoRA layers into.
low_cpu_mem_usage (`bool`, *optional*, defaults to `True` if torch version >= 1.9.0 else `False`):
Speed up model loading only loading the pretrained weights and not initializing the weights. This also
tries to not use more than 1x model size in CPU memory (including peak memory) while loading the model.
Only supported for PyTorch >= 1.9.0. If you are using an older version of PyTorch, setting this
argument to `True` will raise an error.
adapter_name (`str`, *optional*):
Adapter name to be used for referencing the loaded adapter model. If not specified, it will use
`default_{i}` where i is the total number of adapters being loaded.
"""
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
from peft import LoraConfig, inject_adapter_in_model, set_peft_model_state_dict
low_cpu_mem_usage = low_cpu_mem_usage if low_cpu_mem_usage is not None else _LOW_CPU_MEM_USAGE_DEFAULT
# If the serialization format is new (introduced in https://github.com/huggingface/diffusers/pull/2918),
# then the `state_dict` keys should have `cls.unet_name` and/or `cls.text_encoder_name` as
# their prefixes.
keys = list(state_dict.keys())
if all(key.startswith(cls.unet_name) or key.startswith(cls.text_encoder_name) for key in keys):
# Load the layers corresponding to UNet.
logger.info(f"Loading {cls.unet_name}.")
unet_keys = [k for k in keys if k.startswith(cls.unet_name)]
state_dict = {k.replace(f"{cls.unet_name}.", ""): v for k, v in state_dict.items() if k in unet_keys}
if network_alphas is not None:
alpha_keys = [k for k in network_alphas.keys() if k.startswith(cls.unet_name)]
network_alphas = {
k.replace(f"{cls.unet_name}.", ""): v for k, v in network_alphas.items() if k in alpha_keys
}
else:
# Otherwise, we're dealing with the old format. This means the `state_dict` should only
# contain the module names of the `unet` as its keys WITHOUT any prefix.
if not USE_PEFT_BACKEND:
warn_message = "You have saved the LoRA weights using the old format. To convert the old LoRA weights to the new format, you can first load them in a dictionary and then create a new dictionary like the following: `new_state_dict = {f'unet.{module_name}': params for module_name, params in old_state_dict.items()}`."
logger.warning(warn_message)
if len(state_dict.keys()) > 0:
if adapter_name in getattr(unet, "peft_config", {}):
raise ValueError(
f"Adapter name {adapter_name} already in use in the Unet - please select a new adapter name."
)
state_dict = convert_unet_state_dict_to_peft(state_dict)
if network_alphas is not None:
# The alphas state dict have the same structure as Unet, thus we convert it to peft format using
# `convert_unet_state_dict_to_peft` method.
network_alphas = convert_unet_state_dict_to_peft(network_alphas)
rank = {}
for key, val in state_dict.items():
if "lora_B" in key:
rank[key] = val.shape[1]
lora_config_kwargs = get_peft_kwargs(rank, network_alphas, state_dict, is_unet=True)
if "use_dora" in lora_config_kwargs:
if lora_config_kwargs["use_dora"]:
if is_peft_version("<", "0.9.0"):
raise ValueError(
"You need `peft` 0.9.0 at least to use DoRA-enabled LoRAs. Please upgrade your installation of `peft`."
)
else:
if is_peft_version("<", "0.9.0"):
lora_config_kwargs.pop("use_dora")
lora_config = LoraConfig(**lora_config_kwargs)
# adapter_name
if adapter_name is None:
adapter_name = get_adapter_name(unet)
# In case the pipeline has been already offloaded to CPU - temporarily remove the hooks
# otherwise loading LoRA weights will lead to an error
is_model_cpu_offload, is_sequential_cpu_offload = cls._optionally_disable_offloading(_pipeline)
inject_adapter_in_model(lora_config, unet, adapter_name=adapter_name)
incompatible_keys = set_peft_model_state_dict(unet, state_dict, adapter_name)
if incompatible_keys is not None:
# check only for unexpected keys
unexpected_keys = getattr(incompatible_keys, "unexpected_keys", None)
if unexpected_keys:
logger.warning(
f"Loading adapter weights from state_dict led to unexpected keys not found in the model: "
f" {unexpected_keys}. "
)
# Offload back.
if is_model_cpu_offload:
_pipeline.enable_model_cpu_offload()
elif is_sequential_cpu_offload:
_pipeline.enable_sequential_cpu_offload()
# Unsafe code />
unet.load_attn_procs(
state_dict, network_alphas=network_alphas, low_cpu_mem_usage=low_cpu_mem_usage, _pipeline=_pipeline
)
@classmethod
def load_lora_into_text_encoder(
cls,
state_dict,
network_alphas,
text_encoder,
prefix=None,
lora_scale=1.0,
low_cpu_mem_usage=None,
adapter_name=None,
_pipeline=None,
):
"""
This will load the LoRA layers specified in `state_dict` into `text_encoder`
Parameters:
state_dict (`dict`):
A standard state dict containing the lora layer parameters. The key should be prefixed with an
additional `text_encoder` to distinguish between unet lora layers.
network_alphas (`Dict[str, float]`):
See `LoRALinearLayer` for more details.
text_encoder (`CLIPTextModel`):
The text encoder model to load the LoRA layers into.
prefix (`str`):
Expected prefix of the `text_encoder` in the `state_dict`.
lora_scale (`float`):
How much to scale the output of the lora linear layer before it is added with the output of the regular
lora layer.
low_cpu_mem_usage (`bool`, *optional*, defaults to `True` if torch version >= 1.9.0 else `False`):
Speed up model loading only loading the pretrained weights and not initializing the weights. This also
tries to not use more than 1x model size in CPU memory (including peak memory) while loading the model.
Only supported for PyTorch >= 1.9.0. If you are using an older version of PyTorch, setting this
argument to `True` will raise an error.
adapter_name (`str`, *optional*):
Adapter name to be used for referencing the loaded adapter model. If not specified, it will use
`default_{i}` where i is the total number of adapters being loaded.
"""
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
from peft import LoraConfig
low_cpu_mem_usage = low_cpu_mem_usage if low_cpu_mem_usage is not None else _LOW_CPU_MEM_USAGE_DEFAULT
# If the serialization format is new (introduced in https://github.com/huggingface/diffusers/pull/2918),
# then the `state_dict` keys should have `self.unet_name` and/or `self.text_encoder_name` as
# their prefixes.
keys = list(state_dict.keys())
prefix = cls.text_encoder_name if prefix is None else prefix
# Safe prefix to check with.
if any(cls.text_encoder_name in key for key in keys):
# Load the layers corresponding to text encoder and make necessary adjustments.
text_encoder_keys = [k for k in keys if k.startswith(prefix) and k.split(".")[0] == prefix]
text_encoder_lora_state_dict = {
k.replace(f"{prefix}.", ""): v for k, v in state_dict.items() if k in text_encoder_keys
}
if len(text_encoder_lora_state_dict) > 0:
logger.info(f"Loading {prefix}.")
rank = {}
text_encoder_lora_state_dict = convert_state_dict_to_diffusers(text_encoder_lora_state_dict)
# convert state dict
text_encoder_lora_state_dict = convert_state_dict_to_peft(text_encoder_lora_state_dict)
for name, _ in text_encoder_attn_modules(text_encoder):
rank_key = f"{name}.out_proj.lora_B.weight"
rank[rank_key] = text_encoder_lora_state_dict[rank_key].shape[1]
patch_mlp = any(".mlp." in key for key in text_encoder_lora_state_dict.keys())
if patch_mlp:
for name, _ in text_encoder_mlp_modules(text_encoder):
rank_key_fc1 = f"{name}.fc1.lora_B.weight"
rank_key_fc2 = f"{name}.fc2.lora_B.weight"
rank[rank_key_fc1] = text_encoder_lora_state_dict[rank_key_fc1].shape[1]
rank[rank_key_fc2] = text_encoder_lora_state_dict[rank_key_fc2].shape[1]
if network_alphas is not None:
alpha_keys = [
k for k in network_alphas.keys() if k.startswith(prefix) and k.split(".")[0] == prefix
]
network_alphas = {
k.replace(f"{prefix}.", ""): v for k, v in network_alphas.items() if k in alpha_keys
}
lora_config_kwargs = get_peft_kwargs(rank, network_alphas, text_encoder_lora_state_dict, is_unet=False)
if "use_dora" in lora_config_kwargs:
if lora_config_kwargs["use_dora"]:
if is_peft_version("<", "0.9.0"):
raise ValueError(
"You need `peft` 0.9.0 at least to use DoRA-enabled LoRAs. Please upgrade your installation of `peft`."
)
else:
if is_peft_version("<", "0.9.0"):
lora_config_kwargs.pop("use_dora")
lora_config = LoraConfig(**lora_config_kwargs)
# adapter_name
if adapter_name is None:
adapter_name = get_adapter_name(text_encoder)
is_model_cpu_offload, is_sequential_cpu_offload = cls._optionally_disable_offloading(_pipeline)
# inject LoRA layers and load the state dict
# in transformers we automatically check whether the adapter name is already in use or not
text_encoder.load_adapter(
adapter_name=adapter_name,
adapter_state_dict=text_encoder_lora_state_dict,
peft_config=lora_config,
)
# scale LoRA layers with `lora_scale`
scale_lora_layers(text_encoder, weight=lora_scale)
text_encoder.to(device=text_encoder.device, dtype=text_encoder.dtype)
# Offload back.
if is_model_cpu_offload:
_pipeline.enable_model_cpu_offload()
elif is_sequential_cpu_offload:
_pipeline.enable_sequential_cpu_offload()
# Unsafe code />
@classmethod
def load_lora_into_transformer(
cls, state_dict, network_alphas, transformer, low_cpu_mem_usage=None, adapter_name=None, _pipeline=None
):
"""
This will load the LoRA layers specified in `state_dict` into `transformer`.
Parameters:
state_dict (`dict`):
A standard state dict containing the lora layer parameters. The keys can either be indexed directly
into the unet or prefixed with an additional `unet` which can be used to distinguish between text
encoder lora layers.
network_alphas (`Dict[str, float]`):
See `LoRALinearLayer` for more details.
unet (`UNet2DConditionModel`):
The UNet model to load the LoRA layers into.
low_cpu_mem_usage (`bool`, *optional*, defaults to `True` if torch version >= 1.9.0 else `False`):
Speed up model loading only loading the pretrained weights and not initializing the weights. This also
tries to not use more than 1x model size in CPU memory (including peak memory) while loading the model.
Only supported for PyTorch >= 1.9.0. If you are using an older version of PyTorch, setting this
argument to `True` will raise an error.
adapter_name (`str`, *optional*):
Adapter name to be used for referencing the loaded adapter model. If not specified, it will use
`default_{i}` where i is the total number of adapters being loaded.
"""
from peft import LoraConfig, inject_adapter_in_model, set_peft_model_state_dict
low_cpu_mem_usage = low_cpu_mem_usage if low_cpu_mem_usage is not None else _LOW_CPU_MEM_USAGE_DEFAULT
keys = list(state_dict.keys())
transformer_keys = [k for k in keys if k.startswith(cls.transformer_name)]
state_dict = {
k.replace(f"{cls.transformer_name}.", ""): v for k, v in state_dict.items() if k in transformer_keys
}
if network_alphas is not None:
alpha_keys = [k for k in network_alphas.keys() if k.startswith(cls.transformer_name)]
network_alphas = {
k.replace(f"{cls.transformer_name}.", ""): v for k, v in network_alphas.items() if k in alpha_keys
}
if len(state_dict.keys()) > 0:
if adapter_name in getattr(transformer, "peft_config", {}):
raise ValueError(
f"Adapter name {adapter_name} already in use in the transformer - please select a new adapter name."
)
rank = {}
for key, val in state_dict.items():
if "lora_B" in key:
rank[key] = val.shape[1]
lora_config_kwargs = get_peft_kwargs(rank, network_alphas, state_dict)
if "use_dora" in lora_config_kwargs:
if lora_config_kwargs["use_dora"] and is_peft_version("<", "0.9.0"):
raise ValueError(
"You need `peft` 0.9.0 at least to use DoRA-enabled LoRAs. Please upgrade your installation of `peft`."
)
else:
lora_config_kwargs.pop("use_dora")
lora_config = LoraConfig(**lora_config_kwargs)
# adapter_name
if adapter_name is None:
adapter_name = get_adapter_name(transformer)
# In case the pipeline has been already offloaded to CPU - temporarily remove the hooks
# otherwise loading LoRA weights will lead to an error
is_model_cpu_offload, is_sequential_cpu_offload = cls._optionally_disable_offloading(_pipeline)
inject_adapter_in_model(lora_config, transformer, adapter_name=adapter_name)
incompatible_keys = set_peft_model_state_dict(transformer, state_dict, adapter_name)
if incompatible_keys is not None:
# check only for unexpected keys
unexpected_keys = getattr(incompatible_keys, "unexpected_keys", None)
if unexpected_keys:
logger.warning(
f"Loading adapter weights from state_dict led to unexpected keys not found in the model: "
f" {unexpected_keys}. "
)
# Offload back.
if is_model_cpu_offload:
_pipeline.enable_model_cpu_offload()
elif is_sequential_cpu_offload:
_pipeline.enable_sequential_cpu_offload()
# Unsafe code />
@property
def lora_scale(self) -> float:
# property function that returns the lora scale which can be set at run time by the pipeline.
# if _lora_scale has not been set, return 1
return self._lora_scale if hasattr(self, "_lora_scale") else 1.0
def _remove_text_encoder_monkey_patch(self):
remove_method = recurse_remove_peft_layers
if hasattr(self, "text_encoder"):
remove_method(self.text_encoder)
# In case text encoder have no Lora attached
if getattr(self.text_encoder, "peft_config", None) is not None:
del self.text_encoder.peft_config
self.text_encoder._hf_peft_config_loaded = None
if hasattr(self, "text_encoder_2"):
remove_method(self.text_encoder_2)
if getattr(self.text_encoder_2, "peft_config", None) is not None:
del self.text_encoder_2.peft_config
self.text_encoder_2._hf_peft_config_loaded = None
@classmethod
def save_lora_weights(
cls,
save_directory: Union[str, os.PathLike],
unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
text_encoder_lora_layers: Dict[str, torch.nn.Module] = None,
transformer_lora_layers: Dict[str, torch.nn.Module] = None,
is_main_process: bool = True,
weight_name: str = None,
save_function: Callable = None,
safe_serialization: bool = True,
):
r"""
Save the LoRA parameters corresponding to the UNet and text encoder.
Arguments:
save_directory (`str` or `os.PathLike`):
Directory to save LoRA parameters to. Will be created if it doesn't exist.
unet_lora_layers (`Dict[str, torch.nn.Module]` or `Dict[str, torch.Tensor]`):
State dict of the LoRA layers corresponding to the `unet`.
text_encoder_lora_layers (`Dict[str, torch.nn.Module]` or `Dict[str, torch.Tensor]`):
State dict of the LoRA layers corresponding to the `text_encoder`. Must explicitly pass the text
encoder LoRA state dict because it comes from 🤗 Transformers.
is_main_process (`bool`, *optional*, defaults to `True`):
Whether the process calling this is the main process or not. Useful during distributed training and you
need to call this function on all processes. In this case, set `is_main_process=True` only on the main
process to avoid race conditions.
save_function (`Callable`):
The function to use to save the state dictionary. Useful during distributed training when you need to
replace `torch.save` with another method. Can be configured with the environment variable
`DIFFUSERS_SAVE_MODE`.
safe_serialization (`bool`, *optional*, defaults to `True`):
Whether to save the model using `safetensors` or the traditional PyTorch way with `pickle`.
"""
state_dict = {}
def pack_weights(layers, prefix):
layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
return layers_state_dict
if not (unet_lora_layers or text_encoder_lora_layers or transformer_lora_layers):
raise ValueError(
"You must pass at least one of `unet_lora_layers`, `text_encoder_lora_layers`, or `transformer_lora_layers`."
)
if unet_lora_layers:
state_dict.update(pack_weights(unet_lora_layers, cls.unet_name))
if text_encoder_lora_layers:
state_dict.update(pack_weights(text_encoder_lora_layers, cls.text_encoder_name))
if transformer_lora_layers:
state_dict.update(pack_weights(transformer_lora_layers, "transformer"))
# Save the model
cls.write_lora_layers(
state_dict=state_dict,
save_directory=save_directory,
is_main_process=is_main_process,
weight_name=weight_name,
save_function=save_function,
safe_serialization=safe_serialization,
)
@staticmethod
def write_lora_layers(
state_dict: Dict[str, torch.Tensor],
save_directory: str,
is_main_process: bool,
weight_name: str,
save_function: Callable,
safe_serialization: bool,
):
if os.path.isfile(save_directory):
logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
return
if save_function is None:
if safe_serialization:
def save_function(weights, filename):
return safetensors.torch.save_file(weights, filename, metadata={"format": "pt"})
else:
save_function = torch.save
os.makedirs(save_directory, exist_ok=True)
if weight_name is None:
if safe_serialization:
weight_name = LORA_WEIGHT_NAME_SAFE
else:
weight_name = LORA_WEIGHT_NAME
save_path = Path(save_directory, weight_name).as_posix()
save_function(state_dict, save_path)
logger.info(f"Model weights saved in {save_path}")
def unload_lora_weights(self):
"""
Unloads the LoRA parameters.
Examples:
```python
>>> # Assuming `pipeline` is already loaded with the LoRA parameters.
>>> pipeline.unload_lora_weights()
>>> ...
```
"""
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
if not USE_PEFT_BACKEND:
if version.parse(__version__) > version.parse("0.23"):
logger.warning(
"You are using `unload_lora_weights` to disable and unload lora weights. If you want to iteratively enable and disable adapter weights,"
"you can use `pipe.enable_lora()` or `pipe.disable_lora()`. After installing the latest version of PEFT."
)
for _, module in unet.named_modules():
if hasattr(module, "set_lora_layer"):
module.set_lora_layer(None)
else:
recurse_remove_peft_layers(unet)
if hasattr(unet, "peft_config"):
del unet.peft_config
# Safe to call the following regardless of LoRA.
self._remove_text_encoder_monkey_patch()
def fuse_lora(
self,
fuse_unet: bool = True,
fuse_text_encoder: bool = True,
lora_scale: float = 1.0,
safe_fusing: bool = False,
adapter_names: Optional[List[str]] = None,
):
r"""
Fuses the LoRA parameters into the original parameters of the corresponding blocks.
<Tip warning={true}>
This is an experimental API.
</Tip>
Args:
fuse_unet (`bool`, defaults to `True`): Whether to fuse the UNet LoRA parameters.
fuse_text_encoder (`bool`, defaults to `True`):
Whether to fuse the text encoder LoRA parameters. If the text encoder wasn't monkey-patched with the
LoRA parameters then it won't have any effect.
lora_scale (`float`, defaults to 1.0):
Controls how much to influence the outputs with the LoRA parameters.
safe_fusing (`bool`, defaults to `False`):
Whether to check fused weights for NaN values before fusing and if values are NaN not fusing them.
adapter_names (`List[str]`, *optional*):
Adapter names to be used for fusing. If nothing is passed, all active adapters will be fused.
Example:
```py
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
).to("cuda")
pipeline.load_lora_weights("nerijs/pixel-art-xl", weight_name="pixel-art-xl.safetensors", adapter_name="pixel")
pipeline.fuse_lora(lora_scale=0.7)
```
"""
from peft.tuners.tuners_utils import BaseTunerLayer
if fuse_unet or fuse_text_encoder:
self.num_fused_loras += 1
if self.num_fused_loras > 1:
logger.warning(
"The current API is supported for operating with a single LoRA file. You are trying to load and fuse more than one LoRA which is not well-supported.",
)
if fuse_unet:
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
unet.fuse_lora(lora_scale, safe_fusing=safe_fusing, adapter_names=adapter_names)
def fuse_text_encoder_lora(text_encoder, lora_scale=1.0, safe_fusing=False, adapter_names=None):
merge_kwargs = {"safe_merge": safe_fusing}
for module in text_encoder.modules():
if isinstance(module, BaseTunerLayer):
if lora_scale != 1.0:
module.scale_layer(lora_scale)
# For BC with previous PEFT versions, we need to check the signature
# of the `merge` method to see if it supports the `adapter_names` argument.
supported_merge_kwargs = list(inspect.signature(module.merge).parameters)
if "adapter_names" in supported_merge_kwargs:
merge_kwargs["adapter_names"] = adapter_names
elif "adapter_names" not in supported_merge_kwargs and adapter_names is not None:
raise ValueError(
"The `adapter_names` argument is not supported with your PEFT version. "
"Please upgrade to the latest version of PEFT. `pip install -U peft`"
)
module.merge(**merge_kwargs)
if fuse_text_encoder:
if hasattr(self, "text_encoder"):
fuse_text_encoder_lora(self.text_encoder, lora_scale, safe_fusing, adapter_names=adapter_names)
if hasattr(self, "text_encoder_2"):
fuse_text_encoder_lora(self.text_encoder_2, lora_scale, safe_fusing, adapter_names=adapter_names)
def unfuse_lora(self, unfuse_unet: bool = True, unfuse_text_encoder: bool = True):
r"""
Reverses the effect of
[`pipe.fuse_lora()`](https://huggingface.co/docs/diffusers/main/en/api/loaders#diffusers.loaders.LoraLoaderMixin.fuse_lora).
<Tip warning={true}>
This is an experimental API.
</Tip>
Args:
unfuse_unet (`bool`, defaults to `True`): Whether to unfuse the UNet LoRA parameters.
unfuse_text_encoder (`bool`, defaults to `True`):
Whether to unfuse the text encoder LoRA parameters. If the text encoder wasn't monkey-patched with the
LoRA parameters then it won't have any effect.
"""
from peft.tuners.tuners_utils import BaseTunerLayer
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
if unfuse_unet:
for module in unet.modules():
if isinstance(module, BaseTunerLayer):
module.unmerge()
def unfuse_text_encoder_lora(text_encoder):
for module in text_encoder.modules():
if isinstance(module, BaseTunerLayer):
module.unmerge()
if unfuse_text_encoder:
if hasattr(self, "text_encoder"):
unfuse_text_encoder_lora(self.text_encoder)
if hasattr(self, "text_encoder_2"):
unfuse_text_encoder_lora(self.text_encoder_2)
self.num_fused_loras -= 1
def set_adapters_for_text_encoder(
self,
adapter_names: Union[List[str], str],
text_encoder: Optional["PreTrainedModel"] = None, # noqa: F821
text_encoder_weights: Optional[Union[float, List[float], List[None]]] = None,
):
"""
Sets the adapter layers for the text encoder.
Args:
adapter_names (`List[str]` or `str`):
The names of the adapters to use.
text_encoder (`torch.nn.Module`, *optional*):
The text encoder module to set the adapter layers for. If `None`, it will try to get the `text_encoder`
attribute.
text_encoder_weights (`List[float]`, *optional*):
The weights to use for the text encoder. If `None`, the weights are set to `1.0` for all the adapters.
"""
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
def process_weights(adapter_names, weights):
# Expand weights into a list, one entry per adapter
# e.g. for 2 adapters: 7 -> [7,7] ; [3, None] -> [3, None]
if not isinstance(weights, list):
weights = [weights] * len(adapter_names)
if len(adapter_names) != len(weights):
raise ValueError(
f"Length of adapter names {len(adapter_names)} is not equal to the length of the weights {len(weights)}"
)
# Set None values to default of 1.0
# e.g. [7,7] -> [7,7] ; [3, None] -> [3,1]
weights = [w if w is not None else 1.0 for w in weights]
return weights
adapter_names = [adapter_names] if isinstance(adapter_names, str) else adapter_names
text_encoder_weights = process_weights(adapter_names, text_encoder_weights)
text_encoder = text_encoder or getattr(self, "text_encoder", None)
if text_encoder is None:
raise ValueError(
"The pipeline does not have a default `pipe.text_encoder` class. Please make sure to pass a `text_encoder` instead."
)
set_weights_and_activate_adapters(text_encoder, adapter_names, text_encoder_weights)
def disable_lora_for_text_encoder(self, text_encoder: Optional["PreTrainedModel"] = None):
"""
Disables the LoRA layers for the text encoder.
Args:
text_encoder (`torch.nn.Module`, *optional*):
The text encoder module to disable the LoRA layers for. If `None`, it will try to get the
`text_encoder` attribute.
"""
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
text_encoder = text_encoder or getattr(self, "text_encoder", None)
if text_encoder is None:
raise ValueError("Text Encoder not found.")
set_adapter_layers(text_encoder, enabled=False)
def enable_lora_for_text_encoder(self, text_encoder: Optional["PreTrainedModel"] = None):
"""
Enables the LoRA layers for the text encoder.
Args:
text_encoder (`torch.nn.Module`, *optional*):
The text encoder module to enable the LoRA layers for. If `None`, it will try to get the `text_encoder`
attribute.
"""
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
text_encoder = text_encoder or getattr(self, "text_encoder", None)
if text_encoder is None:
raise ValueError("Text Encoder not found.")
set_adapter_layers(self.text_encoder, enabled=True)
def set_adapters(
self,
adapter_names: Union[List[str], str],
adapter_weights: Optional[Union[float, Dict, List[float], List[Dict]]] = None,
):
adapter_names = [adapter_names] if isinstance(adapter_names, str) else adapter_names
adapter_weights = copy.deepcopy(adapter_weights)
# Expand weights into a list, one entry per adapter
if not isinstance(adapter_weights, list):
adapter_weights = [adapter_weights] * len(adapter_names)
if len(adapter_names) != len(adapter_weights):
raise ValueError(
f"Length of adapter names {len(adapter_names)} is not equal to the length of the weights {len(adapter_weights)}"
)
# Decompose weights into weights for unet, text_encoder and text_encoder_2
unet_lora_weights, text_encoder_lora_weights, text_encoder_2_lora_weights = [], [], []
list_adapters = self.get_list_adapters() # eg {"unet": ["adapter1", "adapter2"], "text_encoder": ["adapter2"]}
all_adapters = {
adapter for adapters in list_adapters.values() for adapter in adapters
} # eg ["adapter1", "adapter2"]
invert_list_adapters = {
adapter: [part for part, adapters in list_adapters.items() if adapter in adapters]
for adapter in all_adapters
} # eg {"adapter1": ["unet"], "adapter2": ["unet", "text_encoder"]}
for adapter_name, weights in zip(adapter_names, adapter_weights):
if isinstance(weights, dict):
unet_lora_weight = weights.pop("unet", None)
text_encoder_lora_weight = weights.pop("text_encoder", None)
text_encoder_2_lora_weight = weights.pop("text_encoder_2", None)
if len(weights) > 0:
raise ValueError(
f"Got invalid key '{weights.keys()}' in lora weight dict for adapter {adapter_name}."
)
if text_encoder_2_lora_weight is not None and not hasattr(self, "text_encoder_2"):
logger.warning(
"Lora weight dict contains text_encoder_2 weights but will be ignored because pipeline does not have text_encoder_2."
)
# warn if adapter doesn't have parts specified by adapter_weights
for part_weight, part_name in zip(
[unet_lora_weight, text_encoder_lora_weight, text_encoder_2_lora_weight],
["unet", "text_encoder", "text_encoder_2"],
):
if part_weight is not None and part_name not in invert_list_adapters[adapter_name]:
logger.warning(
f"Lora weight dict for adapter '{adapter_name}' contains {part_name}, but this will be ignored because {adapter_name} does not contain weights for {part_name}. Valid parts for {adapter_name} are: {invert_list_adapters[adapter_name]}."
)
else:
unet_lora_weight = weights
text_encoder_lora_weight = weights
text_encoder_2_lora_weight = weights
unet_lora_weights.append(unet_lora_weight)
text_encoder_lora_weights.append(text_encoder_lora_weight)
text_encoder_2_lora_weights.append(text_encoder_2_lora_weight)
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
# Handle the UNET
unet.set_adapters(adapter_names, unet_lora_weights)
# Handle the Text Encoder
if hasattr(self, "text_encoder"):
self.set_adapters_for_text_encoder(adapter_names, self.text_encoder, text_encoder_lora_weights)
if hasattr(self, "text_encoder_2"):
self.set_adapters_for_text_encoder(adapter_names, self.text_encoder_2, text_encoder_2_lora_weights)
def disable_lora(self):
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
# Disable unet adapters
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
unet.disable_lora()
# Disable text encoder adapters
if hasattr(self, "text_encoder"):
self.disable_lora_for_text_encoder(self.text_encoder)
if hasattr(self, "text_encoder_2"):
self.disable_lora_for_text_encoder(self.text_encoder_2)
def enable_lora(self):
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
# Enable unet adapters
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
unet.enable_lora()
# Enable text encoder adapters
if hasattr(self, "text_encoder"):
self.enable_lora_for_text_encoder(self.text_encoder)
if hasattr(self, "text_encoder_2"):
self.enable_lora_for_text_encoder(self.text_encoder_2)
def delete_adapters(self, adapter_names: Union[List[str], str]):
"""
Args:
Deletes the LoRA layers of `adapter_name` for the unet and text-encoder(s).
adapter_names (`Union[List[str], str]`):
The names of the adapter to delete. Can be a single string or a list of strings
"""
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
if isinstance(adapter_names, str):
adapter_names = [adapter_names]
# Delete unet adapters
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
unet.delete_adapters(adapter_names)
for adapter_name in adapter_names:
# Delete text encoder adapters
if hasattr(self, "text_encoder"):
delete_adapter_layers(self.text_encoder, adapter_name)
if hasattr(self, "text_encoder_2"):
delete_adapter_layers(self.text_encoder_2, adapter_name)
def get_active_adapters(self) -> List[str]:
"""
Gets the list of the current active adapters.
Example:
```python
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
).to("cuda")
pipeline.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
pipeline.get_active_adapters()
```
"""
if not USE_PEFT_BACKEND:
raise ValueError(
"PEFT backend is required for this method. Please install the latest version of PEFT `pip install -U peft`"
)
from peft.tuners.tuners_utils import BaseTunerLayer
active_adapters = []
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
for module in unet.modules():
if isinstance(module, BaseTunerLayer):
active_adapters = module.active_adapters
break
return active_adapters
def get_list_adapters(self) -> Dict[str, List[str]]:
"""
Gets the current list of all available adapters in the pipeline.
"""
if not USE_PEFT_BACKEND:
raise ValueError(
"PEFT backend is required for this method. Please install the latest version of PEFT `pip install -U peft`"
)
set_adapters = {}
if hasattr(self, "text_encoder") and hasattr(self.text_encoder, "peft_config"):
set_adapters["text_encoder"] = list(self.text_encoder.peft_config.keys())
if hasattr(self, "text_encoder_2") and hasattr(self.text_encoder_2, "peft_config"):
set_adapters["text_encoder_2"] = list(self.text_encoder_2.peft_config.keys())
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
if hasattr(self, self.unet_name) and hasattr(unet, "peft_config"):
set_adapters[self.unet_name] = list(self.unet.peft_config.keys())
return set_adapters
def set_lora_device(self, adapter_names: List[str], device: Union[torch.device, str, int]) -> None:
"""
Moves the LoRAs listed in `adapter_names` to a target device. Useful for offloading the LoRA to the CPU in case
you want to load multiple adapters and free some GPU memory.
Args:
adapter_names (`List[str]`):
List of adapters to send device to.
device (`Union[torch.device, str, int]`):
Device to send the adapters to. Can be either a torch device, a str or an integer.
"""
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
from peft.tuners.tuners_utils import BaseTunerLayer
# Handle the UNET
unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
for unet_module in unet.modules():
if isinstance(unet_module, BaseTunerLayer):
for adapter_name in adapter_names:
unet_module.lora_A[adapter_name].to(device)
unet_module.lora_B[adapter_name].to(device)
# this is a param, not a module, so device placement is not in-place -> re-assign
if hasattr(unet_module, "lora_magnitude_vector") and unet_module.lora_magnitude_vector is not None:
unet_module.lora_magnitude_vector[adapter_name] = unet_module.lora_magnitude_vector[
adapter_name
].to(device)
# Handle the text encoder
modules_to_process = []
if hasattr(self, "text_encoder"):
modules_to_process.append(self.text_encoder)
if hasattr(self, "text_encoder_2"):
modules_to_process.append(self.text_encoder_2)
for text_encoder in modules_to_process:
# loop over submodules
for text_encoder_module in text_encoder.modules():
if isinstance(text_encoder_module, BaseTunerLayer):
for adapter_name in adapter_names:
text_encoder_module.lora_A[adapter_name].to(device)
text_encoder_module.lora_B[adapter_name].to(device)
# this is a param, not a module, so device placement is not in-place -> re-assign
if (
hasattr(text_encoder_module, "lora_magnitude_vector")
and text_encoder_module.lora_magnitude_vector is not None
):
text_encoder_module.lora_magnitude_vector[
adapter_name
] = text_encoder_module.lora_magnitude_vector[adapter_name].to(device)
class StableDiffusionXLLoraLoaderMixin(LoraLoaderMixin):
"""This class overrides `LoraLoaderMixin` with LoRA loading/saving code that's specific to SDXL"""
# Override to properly handle the loading and unloading of the additional text encoder.
def load_lora_weights(
self,
pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]],
adapter_name: Optional[str] = None,
**kwargs,
):
"""
Load LoRA weights specified in `pretrained_model_name_or_path_or_dict` into `self.unet` and
`self.text_encoder`.
All kwargs are forwarded to `self.lora_state_dict`.
See [`~loaders.LoraLoaderMixin.lora_state_dict`] for more details on how the state dict is loaded.
See [`~loaders.LoraLoaderMixin.load_lora_into_unet`] for more details on how the state dict is loaded into
`self.unet`.
See [`~loaders.LoraLoaderMixin.load_lora_into_text_encoder`] for more details on how the state dict is loaded
into `self.text_encoder`.
Parameters:
pretrained_model_name_or_path_or_dict (`str` or `os.PathLike` or `dict`):
See [`~loaders.LoraLoaderMixin.lora_state_dict`].
adapter_name (`str`, *optional*):
Adapter name to be used for referencing the loaded adapter model. If not specified, it will use
`default_{i}` where i is the total number of adapters being loaded.
kwargs (`dict`, *optional*):
See [`~loaders.LoraLoaderMixin.lora_state_dict`].
"""
if not USE_PEFT_BACKEND:
raise ValueError("PEFT backend is required for this method.")
# We could have accessed the unet config from `lora_state_dict()` too. We pass
# it here explicitly to be able to tell that it's coming from an SDXL
# pipeline.
# if a dict is passed, copy it instead of modifying it inplace
if isinstance(pretrained_model_name_or_path_or_dict, dict):
pretrained_model_name_or_path_or_dict = pretrained_model_name_or_path_or_dict.copy()
# First, ensure that the checkpoint is a compatible one and can be successfully loaded.
state_dict, network_alphas = self.lora_state_dict(
pretrained_model_name_or_path_or_dict,
unet_config=self.unet.config,
**kwargs,
)
is_correct_format = all("lora" in key or "dora_scale" in key for key in state_dict.keys())
if not is_correct_format:
raise ValueError("Invalid LoRA checkpoint.")
self.load_lora_into_unet(
state_dict, network_alphas=network_alphas, unet=self.unet, adapter_name=adapter_name, _pipeline=self
)
text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
if len(text_encoder_state_dict) > 0:
self.load_lora_into_text_encoder(
text_encoder_state_dict,
network_alphas=network_alphas,
text_encoder=self.text_encoder,
prefix="text_encoder",
lora_scale=self.lora_scale,
adapter_name=adapter_name,
_pipeline=self,
)
text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
if len(text_encoder_2_state_dict) > 0:
self.load_lora_into_text_encoder(
text_encoder_2_state_dict,
network_alphas=network_alphas,
text_encoder=self.text_encoder_2,
prefix="text_encoder_2",
lora_scale=self.lora_scale,
adapter_name=adapter_name,
_pipeline=self,
)
@classmethod
def save_lora_weights(
cls,
save_directory: Union[str, os.PathLike],
unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
is_main_process: bool = True,
weight_name: str = None,
save_function: Callable = None,
safe_serialization: bool = True,
):
r"""
Save the LoRA parameters corresponding to the UNet and text encoder.
Arguments:
save_directory (`str` or `os.PathLike`):
Directory to save LoRA parameters to. Will be created if it doesn't exist.
unet_lora_layers (`Dict[str, torch.nn.Module]` or `Dict[str, torch.Tensor]`):
State dict of the LoRA layers corresponding to the `unet`.
text_encoder_lora_layers (`Dict[str, torch.nn.Module]` or `Dict[str, torch.Tensor]`):
State dict of the LoRA layers corresponding to the `text_encoder`. Must explicitly pass the text
encoder LoRA state dict because it comes from 🤗 Transformers.
text_encoder_2_lora_layers (`Dict[str, torch.nn.Module]` or `Dict[str, torch.Tensor]`):
State dict of the LoRA layers corresponding to the `text_encoder_2`. Must explicitly pass the text
encoder LoRA state dict because it comes from 🤗 Transformers.
is_main_process (`bool`, *optional*, defaults to `True`):
Whether the process calling this is the main process or not. Useful during distributed training and you
need to call this function on all processes. In this case, set `is_main_process=True` only on the main
process to avoid race conditions.
save_function (`Callable`):
The function to use to save the state dictionary. Useful during distributed training when you need to
replace `torch.save` with another method. Can be configured with the environment variable
`DIFFUSERS_SAVE_MODE`.
safe_serialization (`bool`, *optional*, defaults to `True`):
Whether to save the model using `safetensors` or the traditional PyTorch way with `pickle`.
"""
state_dict = {}
def pack_weights(layers, prefix):
layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
return layers_state_dict
if not (unet_lora_layers or text_encoder_lora_layers or text_encoder_2_lora_layers):
raise ValueError(
"You must pass at least one of `unet_lora_layers`, `text_encoder_lora_layers` or `text_encoder_2_lora_layers`."
)
if unet_lora_layers:
state_dict.update(pack_weights(unet_lora_layers, "unet"))
if text_encoder_lora_layers:
state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
if text_encoder_2_lora_layers:
state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
cls.write_lora_layers(
state_dict=state_dict,
save_directory=save_directory,
is_main_process=is_main_process,
weight_name=weight_name,
save_function=save_function,
safe_serialization=safe_serialization,
)
def _remove_text_encoder_monkey_patch(self):
recurse_remove_peft_layers(self.text_encoder)
# TODO: @younesbelkada handle this in transformers side
if getattr(self.text_encoder, "peft_config", None) is not None:
del self.text_encoder.peft_config
self.text_encoder._hf_peft_config_loaded = None
recurse_remove_peft_layers(self.text_encoder_2)
if getattr(self.text_encoder_2, "peft_config", None) is not None:
del self.text_encoder_2.peft_config
self.text_encoder_2._hf_peft_config_loaded = None
| diffusers/src/diffusers/loaders/lora.py/0 | {
"file_path": "diffusers/src/diffusers/loaders/lora.py",
"repo_id": "diffusers",
"token_count": 32058
} | 237 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import math
from importlib import import_module
from typing import Callable, List, Optional, Union
import torch
import torch.nn.functional as F
from torch import nn
from ..image_processor import IPAdapterMaskProcessor
from ..utils import deprecate, logging
from ..utils.import_utils import is_torch_npu_available, is_xformers_available
from ..utils.torch_utils import maybe_allow_in_graph
from .lora import LoRALinearLayer
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
if is_torch_npu_available():
import torch_npu
if is_xformers_available():
import xformers
import xformers.ops
else:
xformers = None
@maybe_allow_in_graph
class Attention(nn.Module):
r"""
A cross attention layer.
Parameters:
query_dim (`int`):
The number of channels in the query.
cross_attention_dim (`int`, *optional*):
The number of channels in the encoder_hidden_states. If not given, defaults to `query_dim`.
heads (`int`, *optional*, defaults to 8):
The number of heads to use for multi-head attention.
dim_head (`int`, *optional*, defaults to 64):
The number of channels in each head.
dropout (`float`, *optional*, defaults to 0.0):
The dropout probability to use.
bias (`bool`, *optional*, defaults to False):
Set to `True` for the query, key, and value linear layers to contain a bias parameter.
upcast_attention (`bool`, *optional*, defaults to False):
Set to `True` to upcast the attention computation to `float32`.
upcast_softmax (`bool`, *optional*, defaults to False):
Set to `True` to upcast the softmax computation to `float32`.
cross_attention_norm (`str`, *optional*, defaults to `None`):
The type of normalization to use for the cross attention. Can be `None`, `layer_norm`, or `group_norm`.
cross_attention_norm_num_groups (`int`, *optional*, defaults to 32):
The number of groups to use for the group norm in the cross attention.
added_kv_proj_dim (`int`, *optional*, defaults to `None`):
The number of channels to use for the added key and value projections. If `None`, no projection is used.
norm_num_groups (`int`, *optional*, defaults to `None`):
The number of groups to use for the group norm in the attention.
spatial_norm_dim (`int`, *optional*, defaults to `None`):
The number of channels to use for the spatial normalization.
out_bias (`bool`, *optional*, defaults to `True`):
Set to `True` to use a bias in the output linear layer.
scale_qk (`bool`, *optional*, defaults to `True`):
Set to `True` to scale the query and key by `1 / sqrt(dim_head)`.
only_cross_attention (`bool`, *optional*, defaults to `False`):
Set to `True` to only use cross attention and not added_kv_proj_dim. Can only be set to `True` if
`added_kv_proj_dim` is not `None`.
eps (`float`, *optional*, defaults to 1e-5):
An additional value added to the denominator in group normalization that is used for numerical stability.
rescale_output_factor (`float`, *optional*, defaults to 1.0):
A factor to rescale the output by dividing it with this value.
residual_connection (`bool`, *optional*, defaults to `False`):
Set to `True` to add the residual connection to the output.
_from_deprecated_attn_block (`bool`, *optional*, defaults to `False`):
Set to `True` if the attention block is loaded from a deprecated state dict.
processor (`AttnProcessor`, *optional*, defaults to `None`):
The attention processor to use. If `None`, defaults to `AttnProcessor2_0` if `torch 2.x` is used and
`AttnProcessor` otherwise.
"""
def __init__(
self,
query_dim: int,
cross_attention_dim: Optional[int] = None,
heads: int = 8,
dim_head: int = 64,
dropout: float = 0.0,
bias: bool = False,
upcast_attention: bool = False,
upcast_softmax: bool = False,
cross_attention_norm: Optional[str] = None,
cross_attention_norm_num_groups: int = 32,
added_kv_proj_dim: Optional[int] = None,
norm_num_groups: Optional[int] = None,
spatial_norm_dim: Optional[int] = None,
out_bias: bool = True,
scale_qk: bool = True,
only_cross_attention: bool = False,
eps: float = 1e-5,
rescale_output_factor: float = 1.0,
residual_connection: bool = False,
_from_deprecated_attn_block: bool = False,
processor: Optional["AttnProcessor"] = None,
out_dim: int = None,
):
super().__init__()
self.inner_dim = out_dim if out_dim is not None else dim_head * heads
self.query_dim = query_dim
self.use_bias = bias
self.is_cross_attention = cross_attention_dim is not None
self.cross_attention_dim = cross_attention_dim if cross_attention_dim is not None else query_dim
self.upcast_attention = upcast_attention
self.upcast_softmax = upcast_softmax
self.rescale_output_factor = rescale_output_factor
self.residual_connection = residual_connection
self.dropout = dropout
self.fused_projections = False
self.out_dim = out_dim if out_dim is not None else query_dim
# we make use of this private variable to know whether this class is loaded
# with an deprecated state dict so that we can convert it on the fly
self._from_deprecated_attn_block = _from_deprecated_attn_block
self.scale_qk = scale_qk
self.scale = dim_head**-0.5 if self.scale_qk else 1.0
self.heads = out_dim // dim_head if out_dim is not None else heads
# for slice_size > 0 the attention score computation
# is split across the batch axis to save memory
# You can set slice_size with `set_attention_slice`
self.sliceable_head_dim = heads
self.added_kv_proj_dim = added_kv_proj_dim
self.only_cross_attention = only_cross_attention
if self.added_kv_proj_dim is None and self.only_cross_attention:
raise ValueError(
"`only_cross_attention` can only be set to True if `added_kv_proj_dim` is not None. Make sure to set either `only_cross_attention=False` or define `added_kv_proj_dim`."
)
if norm_num_groups is not None:
self.group_norm = nn.GroupNorm(num_channels=query_dim, num_groups=norm_num_groups, eps=eps, affine=True)
else:
self.group_norm = None
if spatial_norm_dim is not None:
self.spatial_norm = SpatialNorm(f_channels=query_dim, zq_channels=spatial_norm_dim)
else:
self.spatial_norm = None
if cross_attention_norm is None:
self.norm_cross = None
elif cross_attention_norm == "layer_norm":
self.norm_cross = nn.LayerNorm(self.cross_attention_dim)
elif cross_attention_norm == "group_norm":
if self.added_kv_proj_dim is not None:
# The given `encoder_hidden_states` are initially of shape
# (batch_size, seq_len, added_kv_proj_dim) before being projected
# to (batch_size, seq_len, cross_attention_dim). The norm is applied
# before the projection, so we need to use `added_kv_proj_dim` as
# the number of channels for the group norm.
norm_cross_num_channels = added_kv_proj_dim
else:
norm_cross_num_channels = self.cross_attention_dim
self.norm_cross = nn.GroupNorm(
num_channels=norm_cross_num_channels, num_groups=cross_attention_norm_num_groups, eps=1e-5, affine=True
)
else:
raise ValueError(
f"unknown cross_attention_norm: {cross_attention_norm}. Should be None, 'layer_norm' or 'group_norm'"
)
self.to_q = nn.Linear(query_dim, self.inner_dim, bias=bias)
if not self.only_cross_attention:
# only relevant for the `AddedKVProcessor` classes
self.to_k = nn.Linear(self.cross_attention_dim, self.inner_dim, bias=bias)
self.to_v = nn.Linear(self.cross_attention_dim, self.inner_dim, bias=bias)
else:
self.to_k = None
self.to_v = None
if self.added_kv_proj_dim is not None:
self.add_k_proj = nn.Linear(added_kv_proj_dim, self.inner_dim)
self.add_v_proj = nn.Linear(added_kv_proj_dim, self.inner_dim)
self.to_out = nn.ModuleList([])
self.to_out.append(nn.Linear(self.inner_dim, self.out_dim, bias=out_bias))
self.to_out.append(nn.Dropout(dropout))
# set attention processor
# We use the AttnProcessor2_0 by default when torch 2.x is used which uses
# torch.nn.functional.scaled_dot_product_attention for native Flash/memory_efficient_attention
# but only if it has the default `scale` argument. TODO remove scale_qk check when we move to torch 2.1
if processor is None:
processor = (
AttnProcessor2_0() if hasattr(F, "scaled_dot_product_attention") and self.scale_qk else AttnProcessor()
)
self.set_processor(processor)
def set_use_npu_flash_attention(self, use_npu_flash_attention: bool) -> None:
r"""
Set whether to use npu flash attention from `torch_npu` or not.
"""
if use_npu_flash_attention:
processor = AttnProcessorNPU()
else:
# set attention processor
# We use the AttnProcessor2_0 by default when torch 2.x is used which uses
# torch.nn.functional.scaled_dot_product_attention for native Flash/memory_efficient_attention
# but only if it has the default `scale` argument. TODO remove scale_qk check when we move to torch 2.1
processor = (
AttnProcessor2_0() if hasattr(F, "scaled_dot_product_attention") and self.scale_qk else AttnProcessor()
)
self.set_processor(processor)
def set_use_memory_efficient_attention_xformers(
self, use_memory_efficient_attention_xformers: bool, attention_op: Optional[Callable] = None
) -> None:
r"""
Set whether to use memory efficient attention from `xformers` or not.
Args:
use_memory_efficient_attention_xformers (`bool`):
Whether to use memory efficient attention from `xformers` or not.
attention_op (`Callable`, *optional*):
The attention operation to use. Defaults to `None` which uses the default attention operation from
`xformers`.
"""
is_lora = hasattr(self, "processor") and isinstance(
self.processor,
LORA_ATTENTION_PROCESSORS,
)
is_custom_diffusion = hasattr(self, "processor") and isinstance(
self.processor,
(CustomDiffusionAttnProcessor, CustomDiffusionXFormersAttnProcessor, CustomDiffusionAttnProcessor2_0),
)
is_added_kv_processor = hasattr(self, "processor") and isinstance(
self.processor,
(
AttnAddedKVProcessor,
AttnAddedKVProcessor2_0,
SlicedAttnAddedKVProcessor,
XFormersAttnAddedKVProcessor,
LoRAAttnAddedKVProcessor,
),
)
if use_memory_efficient_attention_xformers:
if is_added_kv_processor and (is_lora or is_custom_diffusion):
raise NotImplementedError(
f"Memory efficient attention is currently not supported for LoRA or custom diffusion for attention processor type {self.processor}"
)
if not is_xformers_available():
raise ModuleNotFoundError(
(
"Refer to https://github.com/facebookresearch/xformers for more information on how to install"
" xformers"
),
name="xformers",
)
elif not torch.cuda.is_available():
raise ValueError(
"torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is"
" only available for GPU "
)
else:
try:
# Make sure we can run the memory efficient attention
_ = xformers.ops.memory_efficient_attention(
torch.randn((1, 2, 40), device="cuda"),
torch.randn((1, 2, 40), device="cuda"),
torch.randn((1, 2, 40), device="cuda"),
)
except Exception as e:
raise e
if is_lora:
# TODO (sayakpaul): should we throw a warning if someone wants to use the xformers
# variant when using PT 2.0 now that we have LoRAAttnProcessor2_0?
processor = LoRAXFormersAttnProcessor(
hidden_size=self.processor.hidden_size,
cross_attention_dim=self.processor.cross_attention_dim,
rank=self.processor.rank,
attention_op=attention_op,
)
processor.load_state_dict(self.processor.state_dict())
processor.to(self.processor.to_q_lora.up.weight.device)
elif is_custom_diffusion:
processor = CustomDiffusionXFormersAttnProcessor(
train_kv=self.processor.train_kv,
train_q_out=self.processor.train_q_out,
hidden_size=self.processor.hidden_size,
cross_attention_dim=self.processor.cross_attention_dim,
attention_op=attention_op,
)
processor.load_state_dict(self.processor.state_dict())
if hasattr(self.processor, "to_k_custom_diffusion"):
processor.to(self.processor.to_k_custom_diffusion.weight.device)
elif is_added_kv_processor:
# TODO(Patrick, Suraj, William) - currently xformers doesn't work for UnCLIP
# which uses this type of cross attention ONLY because the attention mask of format
# [0, ..., -10.000, ..., 0, ...,] is not supported
# throw warning
logger.info(
"Memory efficient attention with `xformers` might currently not work correctly if an attention mask is required for the attention operation."
)
processor = XFormersAttnAddedKVProcessor(attention_op=attention_op)
else:
processor = XFormersAttnProcessor(attention_op=attention_op)
else:
if is_lora:
attn_processor_class = (
LoRAAttnProcessor2_0 if hasattr(F, "scaled_dot_product_attention") else LoRAAttnProcessor
)
processor = attn_processor_class(
hidden_size=self.processor.hidden_size,
cross_attention_dim=self.processor.cross_attention_dim,
rank=self.processor.rank,
)
processor.load_state_dict(self.processor.state_dict())
processor.to(self.processor.to_q_lora.up.weight.device)
elif is_custom_diffusion:
attn_processor_class = (
CustomDiffusionAttnProcessor2_0
if hasattr(F, "scaled_dot_product_attention")
else CustomDiffusionAttnProcessor
)
processor = attn_processor_class(
train_kv=self.processor.train_kv,
train_q_out=self.processor.train_q_out,
hidden_size=self.processor.hidden_size,
cross_attention_dim=self.processor.cross_attention_dim,
)
processor.load_state_dict(self.processor.state_dict())
if hasattr(self.processor, "to_k_custom_diffusion"):
processor.to(self.processor.to_k_custom_diffusion.weight.device)
else:
# set attention processor
# We use the AttnProcessor2_0 by default when torch 2.x is used which uses
# torch.nn.functional.scaled_dot_product_attention for native Flash/memory_efficient_attention
# but only if it has the default `scale` argument. TODO remove scale_qk check when we move to torch 2.1
processor = (
AttnProcessor2_0()
if hasattr(F, "scaled_dot_product_attention") and self.scale_qk
else AttnProcessor()
)
self.set_processor(processor)
def set_attention_slice(self, slice_size: int) -> None:
r"""
Set the slice size for attention computation.
Args:
slice_size (`int`):
The slice size for attention computation.
"""
if slice_size is not None and slice_size > self.sliceable_head_dim:
raise ValueError(f"slice_size {slice_size} has to be smaller or equal to {self.sliceable_head_dim}.")
if slice_size is not None and self.added_kv_proj_dim is not None:
processor = SlicedAttnAddedKVProcessor(slice_size)
elif slice_size is not None:
processor = SlicedAttnProcessor(slice_size)
elif self.added_kv_proj_dim is not None:
processor = AttnAddedKVProcessor()
else:
# set attention processor
# We use the AttnProcessor2_0 by default when torch 2.x is used which uses
# torch.nn.functional.scaled_dot_product_attention for native Flash/memory_efficient_attention
# but only if it has the default `scale` argument. TODO remove scale_qk check when we move to torch 2.1
processor = (
AttnProcessor2_0() if hasattr(F, "scaled_dot_product_attention") and self.scale_qk else AttnProcessor()
)
self.set_processor(processor)
def set_processor(self, processor: "AttnProcessor") -> None:
r"""
Set the attention processor to use.
Args:
processor (`AttnProcessor`):
The attention processor to use.
"""
# if current processor is in `self._modules` and if passed `processor` is not, we need to
# pop `processor` from `self._modules`
if (
hasattr(self, "processor")
and isinstance(self.processor, torch.nn.Module)
and not isinstance(processor, torch.nn.Module)
):
logger.info(f"You are removing possibly trained weights of {self.processor} with {processor}")
self._modules.pop("processor")
self.processor = processor
def get_processor(self, return_deprecated_lora: bool = False) -> "AttentionProcessor":
r"""
Get the attention processor in use.
Args:
return_deprecated_lora (`bool`, *optional*, defaults to `False`):
Set to `True` to return the deprecated LoRA attention processor.
Returns:
"AttentionProcessor": The attention processor in use.
"""
if not return_deprecated_lora:
return self.processor
# TODO(Sayak, Patrick). The rest of the function is needed to ensure backwards compatible
# serialization format for LoRA Attention Processors. It should be deleted once the integration
# with PEFT is completed.
is_lora_activated = {
name: module.lora_layer is not None
for name, module in self.named_modules()
if hasattr(module, "lora_layer")
}
# 1. if no layer has a LoRA activated we can return the processor as usual
if not any(is_lora_activated.values()):
return self.processor
# If doesn't apply LoRA do `add_k_proj` or `add_v_proj`
is_lora_activated.pop("add_k_proj", None)
is_lora_activated.pop("add_v_proj", None)
# 2. else it is not possible that only some layers have LoRA activated
if not all(is_lora_activated.values()):
raise ValueError(
f"Make sure that either all layers or no layers have LoRA activated, but have {is_lora_activated}"
)
# 3. And we need to merge the current LoRA layers into the corresponding LoRA attention processor
non_lora_processor_cls_name = self.processor.__class__.__name__
lora_processor_cls = getattr(import_module(__name__), "LoRA" + non_lora_processor_cls_name)
hidden_size = self.inner_dim
# now create a LoRA attention processor from the LoRA layers
if lora_processor_cls in [LoRAAttnProcessor, LoRAAttnProcessor2_0, LoRAXFormersAttnProcessor]:
kwargs = {
"cross_attention_dim": self.cross_attention_dim,
"rank": self.to_q.lora_layer.rank,
"network_alpha": self.to_q.lora_layer.network_alpha,
"q_rank": self.to_q.lora_layer.rank,
"q_hidden_size": self.to_q.lora_layer.out_features,
"k_rank": self.to_k.lora_layer.rank,
"k_hidden_size": self.to_k.lora_layer.out_features,
"v_rank": self.to_v.lora_layer.rank,
"v_hidden_size": self.to_v.lora_layer.out_features,
"out_rank": self.to_out[0].lora_layer.rank,
"out_hidden_size": self.to_out[0].lora_layer.out_features,
}
if hasattr(self.processor, "attention_op"):
kwargs["attention_op"] = self.processor.attention_op
lora_processor = lora_processor_cls(hidden_size, **kwargs)
lora_processor.to_q_lora.load_state_dict(self.to_q.lora_layer.state_dict())
lora_processor.to_k_lora.load_state_dict(self.to_k.lora_layer.state_dict())
lora_processor.to_v_lora.load_state_dict(self.to_v.lora_layer.state_dict())
lora_processor.to_out_lora.load_state_dict(self.to_out[0].lora_layer.state_dict())
elif lora_processor_cls == LoRAAttnAddedKVProcessor:
lora_processor = lora_processor_cls(
hidden_size,
cross_attention_dim=self.add_k_proj.weight.shape[0],
rank=self.to_q.lora_layer.rank,
network_alpha=self.to_q.lora_layer.network_alpha,
)
lora_processor.to_q_lora.load_state_dict(self.to_q.lora_layer.state_dict())
lora_processor.to_k_lora.load_state_dict(self.to_k.lora_layer.state_dict())
lora_processor.to_v_lora.load_state_dict(self.to_v.lora_layer.state_dict())
lora_processor.to_out_lora.load_state_dict(self.to_out[0].lora_layer.state_dict())
# only save if used
if self.add_k_proj.lora_layer is not None:
lora_processor.add_k_proj_lora.load_state_dict(self.add_k_proj.lora_layer.state_dict())
lora_processor.add_v_proj_lora.load_state_dict(self.add_v_proj.lora_layer.state_dict())
else:
lora_processor.add_k_proj_lora = None
lora_processor.add_v_proj_lora = None
else:
raise ValueError(f"{lora_processor_cls} does not exist.")
return lora_processor
def forward(
self,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
**cross_attention_kwargs,
) -> torch.Tensor:
r"""
The forward method of the `Attention` class.
Args:
hidden_states (`torch.Tensor`):
The hidden states of the query.
encoder_hidden_states (`torch.Tensor`, *optional*):
The hidden states of the encoder.
attention_mask (`torch.Tensor`, *optional*):
The attention mask to use. If `None`, no mask is applied.
**cross_attention_kwargs:
Additional keyword arguments to pass along to the cross attention.
Returns:
`torch.Tensor`: The output of the attention layer.
"""
# The `Attention` class can call different attention processors / attention functions
# here we simply pass along all tensors to the selected processor class
# For standard processors that are defined here, `**cross_attention_kwargs` is empty
attn_parameters = set(inspect.signature(self.processor.__call__).parameters.keys())
unused_kwargs = [k for k, _ in cross_attention_kwargs.items() if k not in attn_parameters]
if len(unused_kwargs) > 0:
logger.warning(
f"cross_attention_kwargs {unused_kwargs} are not expected by {self.processor.__class__.__name__} and will be ignored."
)
cross_attention_kwargs = {k: w for k, w in cross_attention_kwargs.items() if k in attn_parameters}
return self.processor(
self,
hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
def batch_to_head_dim(self, tensor: torch.Tensor) -> torch.Tensor:
r"""
Reshape the tensor from `[batch_size, seq_len, dim]` to `[batch_size // heads, seq_len, dim * heads]`. `heads`
is the number of heads initialized while constructing the `Attention` class.
Args:
tensor (`torch.Tensor`): The tensor to reshape.
Returns:
`torch.Tensor`: The reshaped tensor.
"""
head_size = self.heads
batch_size, seq_len, dim = tensor.shape
tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size // head_size, seq_len, dim * head_size)
return tensor
def head_to_batch_dim(self, tensor: torch.Tensor, out_dim: int = 3) -> torch.Tensor:
r"""
Reshape the tensor from `[batch_size, seq_len, dim]` to `[batch_size, seq_len, heads, dim // heads]` `heads` is
the number of heads initialized while constructing the `Attention` class.
Args:
tensor (`torch.Tensor`): The tensor to reshape.
out_dim (`int`, *optional*, defaults to `3`): The output dimension of the tensor. If `3`, the tensor is
reshaped to `[batch_size * heads, seq_len, dim // heads]`.
Returns:
`torch.Tensor`: The reshaped tensor.
"""
head_size = self.heads
if tensor.ndim == 3:
batch_size, seq_len, dim = tensor.shape
extra_dim = 1
else:
batch_size, extra_dim, seq_len, dim = tensor.shape
tensor = tensor.reshape(batch_size, seq_len * extra_dim, head_size, dim // head_size)
tensor = tensor.permute(0, 2, 1, 3)
if out_dim == 3:
tensor = tensor.reshape(batch_size * head_size, seq_len * extra_dim, dim // head_size)
return tensor
def get_attention_scores(
self, query: torch.Tensor, key: torch.Tensor, attention_mask: torch.Tensor = None
) -> torch.Tensor:
r"""
Compute the attention scores.
Args:
query (`torch.Tensor`): The query tensor.
key (`torch.Tensor`): The key tensor.
attention_mask (`torch.Tensor`, *optional*): The attention mask to use. If `None`, no mask is applied.
Returns:
`torch.Tensor`: The attention probabilities/scores.
"""
dtype = query.dtype
if self.upcast_attention:
query = query.float()
key = key.float()
if attention_mask is None:
baddbmm_input = torch.empty(
query.shape[0], query.shape[1], key.shape[1], dtype=query.dtype, device=query.device
)
beta = 0
else:
baddbmm_input = attention_mask
beta = 1
attention_scores = torch.baddbmm(
baddbmm_input,
query,
key.transpose(-1, -2),
beta=beta,
alpha=self.scale,
)
del baddbmm_input
if self.upcast_softmax:
attention_scores = attention_scores.float()
attention_probs = attention_scores.softmax(dim=-1)
del attention_scores
attention_probs = attention_probs.to(dtype)
return attention_probs
def prepare_attention_mask(
self, attention_mask: torch.Tensor, target_length: int, batch_size: int, out_dim: int = 3
) -> torch.Tensor:
r"""
Prepare the attention mask for the attention computation.
Args:
attention_mask (`torch.Tensor`):
The attention mask to prepare.
target_length (`int`):
The target length of the attention mask. This is the length of the attention mask after padding.
batch_size (`int`):
The batch size, which is used to repeat the attention mask.
out_dim (`int`, *optional*, defaults to `3`):
The output dimension of the attention mask. Can be either `3` or `4`.
Returns:
`torch.Tensor`: The prepared attention mask.
"""
head_size = self.heads
if attention_mask is None:
return attention_mask
current_length: int = attention_mask.shape[-1]
if current_length != target_length:
if attention_mask.device.type == "mps":
# HACK: MPS: Does not support padding by greater than dimension of input tensor.
# Instead, we can manually construct the padding tensor.
padding_shape = (attention_mask.shape[0], attention_mask.shape[1], target_length)
padding = torch.zeros(padding_shape, dtype=attention_mask.dtype, device=attention_mask.device)
attention_mask = torch.cat([attention_mask, padding], dim=2)
else:
# TODO: for pipelines such as stable-diffusion, padding cross-attn mask:
# we want to instead pad by (0, remaining_length), where remaining_length is:
# remaining_length: int = target_length - current_length
# TODO: re-enable tests/models/test_models_unet_2d_condition.py#test_model_xattn_padding
attention_mask = F.pad(attention_mask, (0, target_length), value=0.0)
if out_dim == 3:
if attention_mask.shape[0] < batch_size * head_size:
attention_mask = attention_mask.repeat_interleave(head_size, dim=0)
elif out_dim == 4:
attention_mask = attention_mask.unsqueeze(1)
attention_mask = attention_mask.repeat_interleave(head_size, dim=1)
return attention_mask
def norm_encoder_hidden_states(self, encoder_hidden_states: torch.Tensor) -> torch.Tensor:
r"""
Normalize the encoder hidden states. Requires `self.norm_cross` to be specified when constructing the
`Attention` class.
Args:
encoder_hidden_states (`torch.Tensor`): Hidden states of the encoder.
Returns:
`torch.Tensor`: The normalized encoder hidden states.
"""
assert self.norm_cross is not None, "self.norm_cross must be defined to call self.norm_encoder_hidden_states"
if isinstance(self.norm_cross, nn.LayerNorm):
encoder_hidden_states = self.norm_cross(encoder_hidden_states)
elif isinstance(self.norm_cross, nn.GroupNorm):
# Group norm norms along the channels dimension and expects
# input to be in the shape of (N, C, *). In this case, we want
# to norm along the hidden dimension, so we need to move
# (batch_size, sequence_length, hidden_size) ->
# (batch_size, hidden_size, sequence_length)
encoder_hidden_states = encoder_hidden_states.transpose(1, 2)
encoder_hidden_states = self.norm_cross(encoder_hidden_states)
encoder_hidden_states = encoder_hidden_states.transpose(1, 2)
else:
assert False
return encoder_hidden_states
@torch.no_grad()
def fuse_projections(self, fuse=True):
device = self.to_q.weight.data.device
dtype = self.to_q.weight.data.dtype
if not self.is_cross_attention:
# fetch weight matrices.
concatenated_weights = torch.cat([self.to_q.weight.data, self.to_k.weight.data, self.to_v.weight.data])
in_features = concatenated_weights.shape[1]
out_features = concatenated_weights.shape[0]
# create a new single projection layer and copy over the weights.
self.to_qkv = nn.Linear(in_features, out_features, bias=self.use_bias, device=device, dtype=dtype)
self.to_qkv.weight.copy_(concatenated_weights)
if self.use_bias:
concatenated_bias = torch.cat([self.to_q.bias.data, self.to_k.bias.data, self.to_v.bias.data])
self.to_qkv.bias.copy_(concatenated_bias)
else:
concatenated_weights = torch.cat([self.to_k.weight.data, self.to_v.weight.data])
in_features = concatenated_weights.shape[1]
out_features = concatenated_weights.shape[0]
self.to_kv = nn.Linear(in_features, out_features, bias=self.use_bias, device=device, dtype=dtype)
self.to_kv.weight.copy_(concatenated_weights)
if self.use_bias:
concatenated_bias = torch.cat([self.to_k.bias.data, self.to_v.bias.data])
self.to_kv.bias.copy_(concatenated_bias)
self.fused_projections = fuse
class AttnProcessor:
r"""
Default processor for performing attention-related computations.
"""
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
temb: Optional[torch.Tensor] = None,
*args,
**kwargs,
) -> torch.Tensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
residual = hidden_states
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
class CustomDiffusionAttnProcessor(nn.Module):
r"""
Processor for implementing attention for the Custom Diffusion method.
Args:
train_kv (`bool`, defaults to `True`):
Whether to newly train the key and value matrices corresponding to the text features.
train_q_out (`bool`, defaults to `True`):
Whether to newly train query matrices corresponding to the latent image features.
hidden_size (`int`, *optional*, defaults to `None`):
The hidden size of the attention layer.
cross_attention_dim (`int`, *optional*, defaults to `None`):
The number of channels in the `encoder_hidden_states`.
out_bias (`bool`, defaults to `True`):
Whether to include the bias parameter in `train_q_out`.
dropout (`float`, *optional*, defaults to 0.0):
The dropout probability to use.
"""
def __init__(
self,
train_kv: bool = True,
train_q_out: bool = True,
hidden_size: Optional[int] = None,
cross_attention_dim: Optional[int] = None,
out_bias: bool = True,
dropout: float = 0.0,
):
super().__init__()
self.train_kv = train_kv
self.train_q_out = train_q_out
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
# `_custom_diffusion` id for easy serialization and loading.
if self.train_kv:
self.to_k_custom_diffusion = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
self.to_v_custom_diffusion = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
if self.train_q_out:
self.to_q_custom_diffusion = nn.Linear(hidden_size, hidden_size, bias=False)
self.to_out_custom_diffusion = nn.ModuleList([])
self.to_out_custom_diffusion.append(nn.Linear(hidden_size, hidden_size, bias=out_bias))
self.to_out_custom_diffusion.append(nn.Dropout(dropout))
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
batch_size, sequence_length, _ = hidden_states.shape
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if self.train_q_out:
query = self.to_q_custom_diffusion(hidden_states).to(attn.to_q.weight.dtype)
else:
query = attn.to_q(hidden_states.to(attn.to_q.weight.dtype))
if encoder_hidden_states is None:
crossattn = False
encoder_hidden_states = hidden_states
else:
crossattn = True
if attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
if self.train_kv:
key = self.to_k_custom_diffusion(encoder_hidden_states.to(self.to_k_custom_diffusion.weight.dtype))
value = self.to_v_custom_diffusion(encoder_hidden_states.to(self.to_v_custom_diffusion.weight.dtype))
key = key.to(attn.to_q.weight.dtype)
value = value.to(attn.to_q.weight.dtype)
else:
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
if crossattn:
detach = torch.ones_like(key)
detach[:, :1, :] = detach[:, :1, :] * 0.0
key = detach * key + (1 - detach) * key.detach()
value = detach * value + (1 - detach) * value.detach()
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
if self.train_q_out:
# linear proj
hidden_states = self.to_out_custom_diffusion[0](hidden_states)
# dropout
hidden_states = self.to_out_custom_diffusion[1](hidden_states)
else:
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
return hidden_states
class AttnAddedKVProcessor:
r"""
Processor for performing attention-related computations with extra learnable key and value matrices for the text
encoder.
"""
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
*args,
**kwargs,
) -> torch.Tensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
residual = hidden_states
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
batch_size, sequence_length, _ = hidden_states.shape
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
query = attn.head_to_batch_dim(query)
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj)
encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj)
if not attn.only_cross_attention:
key = attn.to_k(hidden_states)
value = attn.to_v(hidden_states)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
key = torch.cat([encoder_hidden_states_key_proj, key], dim=1)
value = torch.cat([encoder_hidden_states_value_proj, value], dim=1)
else:
key = encoder_hidden_states_key_proj
value = encoder_hidden_states_value_proj
attention_probs = attn.get_attention_scores(query, key, attention_mask)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
hidden_states = hidden_states + residual
return hidden_states
class AttnAddedKVProcessor2_0:
r"""
Processor for performing scaled dot-product attention (enabled by default if you're using PyTorch 2.0), with extra
learnable key and value matrices for the text encoder.
"""
def __init__(self):
if not hasattr(F, "scaled_dot_product_attention"):
raise ImportError(
"AttnAddedKVProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0."
)
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
*args,
**kwargs,
) -> torch.Tensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
residual = hidden_states
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
batch_size, sequence_length, _ = hidden_states.shape
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size, out_dim=4)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
query = attn.head_to_batch_dim(query, out_dim=4)
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj, out_dim=4)
encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj, out_dim=4)
if not attn.only_cross_attention:
key = attn.to_k(hidden_states)
value = attn.to_v(hidden_states)
key = attn.head_to_batch_dim(key, out_dim=4)
value = attn.head_to_batch_dim(value, out_dim=4)
key = torch.cat([encoder_hidden_states_key_proj, key], dim=2)
value = torch.cat([encoder_hidden_states_value_proj, value], dim=2)
else:
key = encoder_hidden_states_key_proj
value = encoder_hidden_states_value_proj
# the output of sdp = (batch, num_heads, seq_len, head_dim)
# TODO: add support for attn.scale when we move to Torch 2.1
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, residual.shape[1])
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
hidden_states = hidden_states + residual
return hidden_states
class XFormersAttnAddedKVProcessor:
r"""
Processor for implementing memory efficient attention using xFormers.
Args:
attention_op (`Callable`, *optional*, defaults to `None`):
The base
[operator](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.AttentionOpBase) to
use as the attention operator. It is recommended to set to `None`, and allow xFormers to choose the best
operator.
"""
def __init__(self, attention_op: Optional[Callable] = None):
self.attention_op = attention_op
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
residual = hidden_states
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
batch_size, sequence_length, _ = hidden_states.shape
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
query = attn.head_to_batch_dim(query)
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj)
encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj)
if not attn.only_cross_attention:
key = attn.to_k(hidden_states)
value = attn.to_v(hidden_states)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
key = torch.cat([encoder_hidden_states_key_proj, key], dim=1)
value = torch.cat([encoder_hidden_states_value_proj, value], dim=1)
else:
key = encoder_hidden_states_key_proj
value = encoder_hidden_states_value_proj
hidden_states = xformers.ops.memory_efficient_attention(
query, key, value, attn_bias=attention_mask, op=self.attention_op, scale=attn.scale
)
hidden_states = hidden_states.to(query.dtype)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
hidden_states = hidden_states + residual
return hidden_states
class XFormersAttnProcessor:
r"""
Processor for implementing memory efficient attention using xFormers.
Args:
attention_op (`Callable`, *optional*, defaults to `None`):
The base
[operator](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.AttentionOpBase) to
use as the attention operator. It is recommended to set to `None`, and allow xFormers to choose the best
operator.
"""
def __init__(self, attention_op: Optional[Callable] = None):
self.attention_op = attention_op
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
temb: Optional[torch.Tensor] = None,
*args,
**kwargs,
) -> torch.Tensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
residual = hidden_states
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, key_tokens, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
attention_mask = attn.prepare_attention_mask(attention_mask, key_tokens, batch_size)
if attention_mask is not None:
# expand our mask's singleton query_tokens dimension:
# [batch*heads, 1, key_tokens] ->
# [batch*heads, query_tokens, key_tokens]
# so that it can be added as a bias onto the attention scores that xformers computes:
# [batch*heads, query_tokens, key_tokens]
# we do this explicitly because xformers doesn't broadcast the singleton dimension for us.
_, query_tokens, _ = hidden_states.shape
attention_mask = attention_mask.expand(-1, query_tokens, -1)
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query).contiguous()
key = attn.head_to_batch_dim(key).contiguous()
value = attn.head_to_batch_dim(value).contiguous()
hidden_states = xformers.ops.memory_efficient_attention(
query, key, value, attn_bias=attention_mask, op=self.attention_op, scale=attn.scale
)
hidden_states = hidden_states.to(query.dtype)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
class AttnProcessorNPU:
r"""
Processor for implementing flash attention using torch_npu. Torch_npu supports only fp16 and bf16 data types. If
fp32 is used, F.scaled_dot_product_attention will be used for computation, but the acceleration effect on NPU is
not significant.
"""
def __init__(self):
if not is_torch_npu_available():
raise ImportError("AttnProcessorNPU requires torch_npu extensions and is supported only on npu devices.")
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
temb: Optional[torch.Tensor] = None,
*args,
**kwargs,
) -> torch.Tensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
residual = hidden_states
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
if attention_mask is not None:
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
# scaled_dot_product_attention expects attention_mask shape to be
# (batch, heads, source_length, target_length)
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
if query.dtype in (torch.float16, torch.bfloat16):
hidden_states = torch_npu.npu_fusion_attention(
query,
key,
value,
attn.heads,
input_layout="BNSD",
pse=None,
atten_mask=attention_mask,
scale=1.0 / math.sqrt(query.shape[-1]),
pre_tockens=65536,
next_tockens=65536,
keep_prob=1.0,
sync=False,
inner_precise=0,
)[0]
else:
# TODO: add support for attn.scale when we move to Torch 2.1
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
class AttnProcessor2_0:
r"""
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
"""
def __init__(self):
if not hasattr(F, "scaled_dot_product_attention"):
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
temb: Optional[torch.Tensor] = None,
*args,
**kwargs,
) -> torch.Tensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
residual = hidden_states
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
if attention_mask is not None:
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
# scaled_dot_product_attention expects attention_mask shape to be
# (batch, heads, source_length, target_length)
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
# TODO: add support for attn.scale when we move to Torch 2.1
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
class FusedAttnProcessor2_0:
r"""
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0). It uses
fused projection layers. For self-attention modules, all projection matrices (i.e., query, key, value) are fused.
For cross-attention modules, key and value projection matrices are fused.
<Tip warning={true}>
This API is currently 🧪 experimental in nature and can change in future.
</Tip>
"""
def __init__(self):
if not hasattr(F, "scaled_dot_product_attention"):
raise ImportError(
"FusedAttnProcessor2_0 requires at least PyTorch 2.0, to use it. Please upgrade PyTorch to > 2.0."
)
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
temb: Optional[torch.Tensor] = None,
*args,
**kwargs,
) -> torch.Tensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
residual = hidden_states
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
if attention_mask is not None:
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
# scaled_dot_product_attention expects attention_mask shape to be
# (batch, heads, source_length, target_length)
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
if encoder_hidden_states is None:
qkv = attn.to_qkv(hidden_states)
split_size = qkv.shape[-1] // 3
query, key, value = torch.split(qkv, split_size, dim=-1)
else:
if attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
query = attn.to_q(hidden_states)
kv = attn.to_kv(encoder_hidden_states)
split_size = kv.shape[-1] // 2
key, value = torch.split(kv, split_size, dim=-1)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
# TODO: add support for attn.scale when we move to Torch 2.1
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
class CustomDiffusionXFormersAttnProcessor(nn.Module):
r"""
Processor for implementing memory efficient attention using xFormers for the Custom Diffusion method.
Args:
train_kv (`bool`, defaults to `True`):
Whether to newly train the key and value matrices corresponding to the text features.
train_q_out (`bool`, defaults to `True`):
Whether to newly train query matrices corresponding to the latent image features.
hidden_size (`int`, *optional*, defaults to `None`):
The hidden size of the attention layer.
cross_attention_dim (`int`, *optional*, defaults to `None`):
The number of channels in the `encoder_hidden_states`.
out_bias (`bool`, defaults to `True`):
Whether to include the bias parameter in `train_q_out`.
dropout (`float`, *optional*, defaults to 0.0):
The dropout probability to use.
attention_op (`Callable`, *optional*, defaults to `None`):
The base
[operator](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.AttentionOpBase) to use
as the attention operator. It is recommended to set to `None`, and allow xFormers to choose the best operator.
"""
def __init__(
self,
train_kv: bool = True,
train_q_out: bool = False,
hidden_size: Optional[int] = None,
cross_attention_dim: Optional[int] = None,
out_bias: bool = True,
dropout: float = 0.0,
attention_op: Optional[Callable] = None,
):
super().__init__()
self.train_kv = train_kv
self.train_q_out = train_q_out
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
self.attention_op = attention_op
# `_custom_diffusion` id for easy serialization and loading.
if self.train_kv:
self.to_k_custom_diffusion = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
self.to_v_custom_diffusion = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
if self.train_q_out:
self.to_q_custom_diffusion = nn.Linear(hidden_size, hidden_size, bias=False)
self.to_out_custom_diffusion = nn.ModuleList([])
self.to_out_custom_diffusion.append(nn.Linear(hidden_size, hidden_size, bias=out_bias))
self.to_out_custom_diffusion.append(nn.Dropout(dropout))
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if self.train_q_out:
query = self.to_q_custom_diffusion(hidden_states).to(attn.to_q.weight.dtype)
else:
query = attn.to_q(hidden_states.to(attn.to_q.weight.dtype))
if encoder_hidden_states is None:
crossattn = False
encoder_hidden_states = hidden_states
else:
crossattn = True
if attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
if self.train_kv:
key = self.to_k_custom_diffusion(encoder_hidden_states.to(self.to_k_custom_diffusion.weight.dtype))
value = self.to_v_custom_diffusion(encoder_hidden_states.to(self.to_v_custom_diffusion.weight.dtype))
key = key.to(attn.to_q.weight.dtype)
value = value.to(attn.to_q.weight.dtype)
else:
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
if crossattn:
detach = torch.ones_like(key)
detach[:, :1, :] = detach[:, :1, :] * 0.0
key = detach * key + (1 - detach) * key.detach()
value = detach * value + (1 - detach) * value.detach()
query = attn.head_to_batch_dim(query).contiguous()
key = attn.head_to_batch_dim(key).contiguous()
value = attn.head_to_batch_dim(value).contiguous()
hidden_states = xformers.ops.memory_efficient_attention(
query, key, value, attn_bias=attention_mask, op=self.attention_op, scale=attn.scale
)
hidden_states = hidden_states.to(query.dtype)
hidden_states = attn.batch_to_head_dim(hidden_states)
if self.train_q_out:
# linear proj
hidden_states = self.to_out_custom_diffusion[0](hidden_states)
# dropout
hidden_states = self.to_out_custom_diffusion[1](hidden_states)
else:
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
return hidden_states
class CustomDiffusionAttnProcessor2_0(nn.Module):
r"""
Processor for implementing attention for the Custom Diffusion method using PyTorch 2.0’s memory-efficient scaled
dot-product attention.
Args:
train_kv (`bool`, defaults to `True`):
Whether to newly train the key and value matrices corresponding to the text features.
train_q_out (`bool`, defaults to `True`):
Whether to newly train query matrices corresponding to the latent image features.
hidden_size (`int`, *optional*, defaults to `None`):
The hidden size of the attention layer.
cross_attention_dim (`int`, *optional*, defaults to `None`):
The number of channels in the `encoder_hidden_states`.
out_bias (`bool`, defaults to `True`):
Whether to include the bias parameter in `train_q_out`.
dropout (`float`, *optional*, defaults to 0.0):
The dropout probability to use.
"""
def __init__(
self,
train_kv: bool = True,
train_q_out: bool = True,
hidden_size: Optional[int] = None,
cross_attention_dim: Optional[int] = None,
out_bias: bool = True,
dropout: float = 0.0,
):
super().__init__()
self.train_kv = train_kv
self.train_q_out = train_q_out
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
# `_custom_diffusion` id for easy serialization and loading.
if self.train_kv:
self.to_k_custom_diffusion = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
self.to_v_custom_diffusion = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
if self.train_q_out:
self.to_q_custom_diffusion = nn.Linear(hidden_size, hidden_size, bias=False)
self.to_out_custom_diffusion = nn.ModuleList([])
self.to_out_custom_diffusion.append(nn.Linear(hidden_size, hidden_size, bias=out_bias))
self.to_out_custom_diffusion.append(nn.Dropout(dropout))
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
batch_size, sequence_length, _ = hidden_states.shape
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if self.train_q_out:
query = self.to_q_custom_diffusion(hidden_states)
else:
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
crossattn = False
encoder_hidden_states = hidden_states
else:
crossattn = True
if attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
if self.train_kv:
key = self.to_k_custom_diffusion(encoder_hidden_states.to(self.to_k_custom_diffusion.weight.dtype))
value = self.to_v_custom_diffusion(encoder_hidden_states.to(self.to_v_custom_diffusion.weight.dtype))
key = key.to(attn.to_q.weight.dtype)
value = value.to(attn.to_q.weight.dtype)
else:
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
if crossattn:
detach = torch.ones_like(key)
detach[:, :1, :] = detach[:, :1, :] * 0.0
key = detach * key + (1 - detach) * key.detach()
value = detach * value + (1 - detach) * value.detach()
inner_dim = hidden_states.shape[-1]
head_dim = inner_dim // attn.heads
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
# TODO: add support for attn.scale when we move to Torch 2.1
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
if self.train_q_out:
# linear proj
hidden_states = self.to_out_custom_diffusion[0](hidden_states)
# dropout
hidden_states = self.to_out_custom_diffusion[1](hidden_states)
else:
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
return hidden_states
class SlicedAttnProcessor:
r"""
Processor for implementing sliced attention.
Args:
slice_size (`int`, *optional*):
The number of steps to compute attention. Uses as many slices as `attention_head_dim // slice_size`, and
`attention_head_dim` must be a multiple of the `slice_size`.
"""
def __init__(self, slice_size: int):
self.slice_size = slice_size
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
residual = hidden_states
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
dim = query.shape[-1]
query = attn.head_to_batch_dim(query)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
batch_size_attention, query_tokens, _ = query.shape
hidden_states = torch.zeros(
(batch_size_attention, query_tokens, dim // attn.heads), device=query.device, dtype=query.dtype
)
for i in range(batch_size_attention // self.slice_size):
start_idx = i * self.slice_size
end_idx = (i + 1) * self.slice_size
query_slice = query[start_idx:end_idx]
key_slice = key[start_idx:end_idx]
attn_mask_slice = attention_mask[start_idx:end_idx] if attention_mask is not None else None
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
hidden_states[start_idx:end_idx] = attn_slice
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
class SlicedAttnAddedKVProcessor:
r"""
Processor for implementing sliced attention with extra learnable key and value matrices for the text encoder.
Args:
slice_size (`int`, *optional*):
The number of steps to compute attention. Uses as many slices as `attention_head_dim // slice_size`, and
`attention_head_dim` must be a multiple of the `slice_size`.
"""
def __init__(self, slice_size):
self.slice_size = slice_size
def __call__(
self,
attn: "Attention",
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
temb: Optional[torch.Tensor] = None,
) -> torch.Tensor:
residual = hidden_states
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
batch_size, sequence_length, _ = hidden_states.shape
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
dim = query.shape[-1]
query = attn.head_to_batch_dim(query)
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj)
encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj)
if not attn.only_cross_attention:
key = attn.to_k(hidden_states)
value = attn.to_v(hidden_states)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
key = torch.cat([encoder_hidden_states_key_proj, key], dim=1)
value = torch.cat([encoder_hidden_states_value_proj, value], dim=1)
else:
key = encoder_hidden_states_key_proj
value = encoder_hidden_states_value_proj
batch_size_attention, query_tokens, _ = query.shape
hidden_states = torch.zeros(
(batch_size_attention, query_tokens, dim // attn.heads), device=query.device, dtype=query.dtype
)
for i in range(batch_size_attention // self.slice_size):
start_idx = i * self.slice_size
end_idx = (i + 1) * self.slice_size
query_slice = query[start_idx:end_idx]
key_slice = key[start_idx:end_idx]
attn_mask_slice = attention_mask[start_idx:end_idx] if attention_mask is not None else None
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
hidden_states[start_idx:end_idx] = attn_slice
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
hidden_states = hidden_states + residual
return hidden_states
class SpatialNorm(nn.Module):
"""
Spatially conditioned normalization as defined in https://arxiv.org/abs/2209.09002.
Args:
f_channels (`int`):
The number of channels for input to group normalization layer, and output of the spatial norm layer.
zq_channels (`int`):
The number of channels for the quantized vector as described in the paper.
"""
def __init__(
self,
f_channels: int,
zq_channels: int,
):
super().__init__()
self.norm_layer = nn.GroupNorm(num_channels=f_channels, num_groups=32, eps=1e-6, affine=True)
self.conv_y = nn.Conv2d(zq_channels, f_channels, kernel_size=1, stride=1, padding=0)
self.conv_b = nn.Conv2d(zq_channels, f_channels, kernel_size=1, stride=1, padding=0)
def forward(self, f: torch.Tensor, zq: torch.Tensor) -> torch.Tensor:
f_size = f.shape[-2:]
zq = F.interpolate(zq, size=f_size, mode="nearest")
norm_f = self.norm_layer(f)
new_f = norm_f * self.conv_y(zq) + self.conv_b(zq)
return new_f
class LoRAAttnProcessor(nn.Module):
def __init__(
self,
hidden_size: int,
cross_attention_dim: Optional[int] = None,
rank: int = 4,
network_alpha: Optional[int] = None,
**kwargs,
):
deprecation_message = "Using LoRAAttnProcessor is deprecated. Please use the PEFT backend for all things LoRA. You can install PEFT by running `pip install peft`."
deprecate("LoRAAttnProcessor", "0.30.0", deprecation_message, standard_warn=False)
super().__init__()
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
self.rank = rank
q_rank = kwargs.pop("q_rank", None)
q_hidden_size = kwargs.pop("q_hidden_size", None)
q_rank = q_rank if q_rank is not None else rank
q_hidden_size = q_hidden_size if q_hidden_size is not None else hidden_size
v_rank = kwargs.pop("v_rank", None)
v_hidden_size = kwargs.pop("v_hidden_size", None)
v_rank = v_rank if v_rank is not None else rank
v_hidden_size = v_hidden_size if v_hidden_size is not None else hidden_size
out_rank = kwargs.pop("out_rank", None)
out_hidden_size = kwargs.pop("out_hidden_size", None)
out_rank = out_rank if out_rank is not None else rank
out_hidden_size = out_hidden_size if out_hidden_size is not None else hidden_size
self.to_q_lora = LoRALinearLayer(q_hidden_size, q_hidden_size, q_rank, network_alpha)
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
self.to_v_lora = LoRALinearLayer(cross_attention_dim or v_hidden_size, v_hidden_size, v_rank, network_alpha)
self.to_out_lora = LoRALinearLayer(out_hidden_size, out_hidden_size, out_rank, network_alpha)
def __call__(self, attn: Attention, hidden_states: torch.Tensor, **kwargs) -> torch.Tensor:
self_cls_name = self.__class__.__name__
deprecate(
self_cls_name,
"0.26.0",
(
f"Make sure use {self_cls_name[4:]} instead by setting"
"LoRA layers to `self.{to_q,to_k,to_v,to_out[0]}.lora_layer` respectively. This will be done automatically when using"
" `LoraLoaderMixin.load_lora_weights`"
),
)
attn.to_q.lora_layer = self.to_q_lora.to(hidden_states.device)
attn.to_k.lora_layer = self.to_k_lora.to(hidden_states.device)
attn.to_v.lora_layer = self.to_v_lora.to(hidden_states.device)
attn.to_out[0].lora_layer = self.to_out_lora.to(hidden_states.device)
attn._modules.pop("processor")
attn.processor = AttnProcessor()
return attn.processor(attn, hidden_states, **kwargs)
class LoRAAttnProcessor2_0(nn.Module):
def __init__(
self,
hidden_size: int,
cross_attention_dim: Optional[int] = None,
rank: int = 4,
network_alpha: Optional[int] = None,
**kwargs,
):
deprecation_message = "Using LoRAAttnProcessor is deprecated. Please use the PEFT backend for all things LoRA. You can install PEFT by running `pip install peft`."
deprecate("LoRAAttnProcessor2_0", "0.30.0", deprecation_message, standard_warn=False)
super().__init__()
if not hasattr(F, "scaled_dot_product_attention"):
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
self.rank = rank
q_rank = kwargs.pop("q_rank", None)
q_hidden_size = kwargs.pop("q_hidden_size", None)
q_rank = q_rank if q_rank is not None else rank
q_hidden_size = q_hidden_size if q_hidden_size is not None else hidden_size
v_rank = kwargs.pop("v_rank", None)
v_hidden_size = kwargs.pop("v_hidden_size", None)
v_rank = v_rank if v_rank is not None else rank
v_hidden_size = v_hidden_size if v_hidden_size is not None else hidden_size
out_rank = kwargs.pop("out_rank", None)
out_hidden_size = kwargs.pop("out_hidden_size", None)
out_rank = out_rank if out_rank is not None else rank
out_hidden_size = out_hidden_size if out_hidden_size is not None else hidden_size
self.to_q_lora = LoRALinearLayer(q_hidden_size, q_hidden_size, q_rank, network_alpha)
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
self.to_v_lora = LoRALinearLayer(cross_attention_dim or v_hidden_size, v_hidden_size, v_rank, network_alpha)
self.to_out_lora = LoRALinearLayer(out_hidden_size, out_hidden_size, out_rank, network_alpha)
def __call__(self, attn: Attention, hidden_states: torch.Tensor, **kwargs) -> torch.Tensor:
self_cls_name = self.__class__.__name__
deprecate(
self_cls_name,
"0.26.0",
(
f"Make sure use {self_cls_name[4:]} instead by setting"
"LoRA layers to `self.{to_q,to_k,to_v,to_out[0]}.lora_layer` respectively. This will be done automatically when using"
" `LoraLoaderMixin.load_lora_weights`"
),
)
attn.to_q.lora_layer = self.to_q_lora.to(hidden_states.device)
attn.to_k.lora_layer = self.to_k_lora.to(hidden_states.device)
attn.to_v.lora_layer = self.to_v_lora.to(hidden_states.device)
attn.to_out[0].lora_layer = self.to_out_lora.to(hidden_states.device)
attn._modules.pop("processor")
attn.processor = AttnProcessor2_0()
return attn.processor(attn, hidden_states, **kwargs)
class LoRAXFormersAttnProcessor(nn.Module):
r"""
Processor for implementing the LoRA attention mechanism with memory efficient attention using xFormers.
Args:
hidden_size (`int`, *optional*):
The hidden size of the attention layer.
cross_attention_dim (`int`, *optional*):
The number of channels in the `encoder_hidden_states`.
rank (`int`, defaults to 4):
The dimension of the LoRA update matrices.
attention_op (`Callable`, *optional*, defaults to `None`):
The base
[operator](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.AttentionOpBase) to
use as the attention operator. It is recommended to set to `None`, and allow xFormers to choose the best
operator.
network_alpha (`int`, *optional*):
Equivalent to `alpha` but it's usage is specific to Kohya (A1111) style LoRAs.
kwargs (`dict`):
Additional keyword arguments to pass to the `LoRALinearLayer` layers.
"""
def __init__(
self,
hidden_size: int,
cross_attention_dim: int,
rank: int = 4,
attention_op: Optional[Callable] = None,
network_alpha: Optional[int] = None,
**kwargs,
):
super().__init__()
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
self.rank = rank
self.attention_op = attention_op
q_rank = kwargs.pop("q_rank", None)
q_hidden_size = kwargs.pop("q_hidden_size", None)
q_rank = q_rank if q_rank is not None else rank
q_hidden_size = q_hidden_size if q_hidden_size is not None else hidden_size
v_rank = kwargs.pop("v_rank", None)
v_hidden_size = kwargs.pop("v_hidden_size", None)
v_rank = v_rank if v_rank is not None else rank
v_hidden_size = v_hidden_size if v_hidden_size is not None else hidden_size
out_rank = kwargs.pop("out_rank", None)
out_hidden_size = kwargs.pop("out_hidden_size", None)
out_rank = out_rank if out_rank is not None else rank
out_hidden_size = out_hidden_size if out_hidden_size is not None else hidden_size
self.to_q_lora = LoRALinearLayer(q_hidden_size, q_hidden_size, q_rank, network_alpha)
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
self.to_v_lora = LoRALinearLayer(cross_attention_dim or v_hidden_size, v_hidden_size, v_rank, network_alpha)
self.to_out_lora = LoRALinearLayer(out_hidden_size, out_hidden_size, out_rank, network_alpha)
def __call__(self, attn: Attention, hidden_states: torch.Tensor, **kwargs) -> torch.Tensor:
self_cls_name = self.__class__.__name__
deprecate(
self_cls_name,
"0.26.0",
(
f"Make sure use {self_cls_name[4:]} instead by setting"
"LoRA layers to `self.{to_q,to_k,to_v,add_k_proj,add_v_proj,to_out[0]}.lora_layer` respectively. This will be done automatically when using"
" `LoraLoaderMixin.load_lora_weights`"
),
)
attn.to_q.lora_layer = self.to_q_lora.to(hidden_states.device)
attn.to_k.lora_layer = self.to_k_lora.to(hidden_states.device)
attn.to_v.lora_layer = self.to_v_lora.to(hidden_states.device)
attn.to_out[0].lora_layer = self.to_out_lora.to(hidden_states.device)
attn._modules.pop("processor")
attn.processor = XFormersAttnProcessor()
return attn.processor(attn, hidden_states, **kwargs)
class LoRAAttnAddedKVProcessor(nn.Module):
r"""
Processor for implementing the LoRA attention mechanism with extra learnable key and value matrices for the text
encoder.
Args:
hidden_size (`int`, *optional*):
The hidden size of the attention layer.
cross_attention_dim (`int`, *optional*, defaults to `None`):
The number of channels in the `encoder_hidden_states`.
rank (`int`, defaults to 4):
The dimension of the LoRA update matrices.
network_alpha (`int`, *optional*):
Equivalent to `alpha` but it's usage is specific to Kohya (A1111) style LoRAs.
kwargs (`dict`):
Additional keyword arguments to pass to the `LoRALinearLayer` layers.
"""
def __init__(
self,
hidden_size: int,
cross_attention_dim: Optional[int] = None,
rank: int = 4,
network_alpha: Optional[int] = None,
):
super().__init__()
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
self.rank = rank
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
self.add_k_proj_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
self.add_v_proj_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
self.to_k_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
self.to_v_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
def __call__(self, attn: Attention, hidden_states: torch.Tensor, **kwargs) -> torch.Tensor:
self_cls_name = self.__class__.__name__
deprecate(
self_cls_name,
"0.26.0",
(
f"Make sure use {self_cls_name[4:]} instead by setting"
"LoRA layers to `self.{to_q,to_k,to_v,add_k_proj,add_v_proj,to_out[0]}.lora_layer` respectively. This will be done automatically when using"
" `LoraLoaderMixin.load_lora_weights`"
),
)
attn.to_q.lora_layer = self.to_q_lora.to(hidden_states.device)
attn.to_k.lora_layer = self.to_k_lora.to(hidden_states.device)
attn.to_v.lora_layer = self.to_v_lora.to(hidden_states.device)
attn.to_out[0].lora_layer = self.to_out_lora.to(hidden_states.device)
attn._modules.pop("processor")
attn.processor = AttnAddedKVProcessor()
return attn.processor(attn, hidden_states, **kwargs)
class IPAdapterAttnProcessor(nn.Module):
r"""
Attention processor for Multiple IP-Adapters.
Args:
hidden_size (`int`):
The hidden size of the attention layer.
cross_attention_dim (`int`):
The number of channels in the `encoder_hidden_states`.
num_tokens (`int`, `Tuple[int]` or `List[int]`, defaults to `(4,)`):
The context length of the image features.
scale (`float` or List[`float`], defaults to 1.0):
the weight scale of image prompt.
"""
def __init__(self, hidden_size, cross_attention_dim=None, num_tokens=(4,), scale=1.0):
super().__init__()
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
if not isinstance(num_tokens, (tuple, list)):
num_tokens = [num_tokens]
self.num_tokens = num_tokens
if not isinstance(scale, list):
scale = [scale] * len(num_tokens)
if len(scale) != len(num_tokens):
raise ValueError("`scale` should be a list of integers with the same length as `num_tokens`.")
self.scale = scale
self.to_k_ip = nn.ModuleList(
[nn.Linear(cross_attention_dim, hidden_size, bias=False) for _ in range(len(num_tokens))]
)
self.to_v_ip = nn.ModuleList(
[nn.Linear(cross_attention_dim, hidden_size, bias=False) for _ in range(len(num_tokens))]
)
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
temb: Optional[torch.Tensor] = None,
scale: float = 1.0,
ip_adapter_masks: Optional[torch.Tensor] = None,
):
residual = hidden_states
# separate ip_hidden_states from encoder_hidden_states
if encoder_hidden_states is not None:
if isinstance(encoder_hidden_states, tuple):
encoder_hidden_states, ip_hidden_states = encoder_hidden_states
else:
deprecation_message = (
"You have passed a tensor as `encoder_hidden_states`. This is deprecated and will be removed in a future release."
" Please make sure to update your script to pass `encoder_hidden_states` as a tuple to suppress this warning."
)
deprecate("encoder_hidden_states not a tuple", "1.0.0", deprecation_message, standard_warn=False)
end_pos = encoder_hidden_states.shape[1] - self.num_tokens[0]
encoder_hidden_states, ip_hidden_states = (
encoder_hidden_states[:, :end_pos, :],
[encoder_hidden_states[:, end_pos:, :]],
)
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
if ip_adapter_masks is not None:
if not isinstance(ip_adapter_masks, List):
# for backward compatibility, we accept `ip_adapter_mask` as a tensor of shape [num_ip_adapter, 1, height, width]
ip_adapter_masks = list(ip_adapter_masks.unsqueeze(1))
if not (len(ip_adapter_masks) == len(self.scale) == len(ip_hidden_states)):
raise ValueError(
f"Length of ip_adapter_masks array ({len(ip_adapter_masks)}) must match "
f"length of self.scale array ({len(self.scale)}) and number of ip_hidden_states "
f"({len(ip_hidden_states)})"
)
else:
for index, (mask, scale, ip_state) in enumerate(zip(ip_adapter_masks, self.scale, ip_hidden_states)):
if not isinstance(mask, torch.Tensor) or mask.ndim != 4:
raise ValueError(
"Each element of the ip_adapter_masks array should be a tensor with shape "
"[1, num_images_for_ip_adapter, height, width]."
" Please use `IPAdapterMaskProcessor` to preprocess your mask"
)
if mask.shape[1] != ip_state.shape[1]:
raise ValueError(
f"Number of masks ({mask.shape[1]}) does not match "
f"number of ip images ({ip_state.shape[1]}) at index {index}"
)
if isinstance(scale, list) and not len(scale) == mask.shape[1]:
raise ValueError(
f"Number of masks ({mask.shape[1]}) does not match "
f"number of scales ({len(scale)}) at index {index}"
)
else:
ip_adapter_masks = [None] * len(self.scale)
# for ip-adapter
for current_ip_hidden_states, scale, to_k_ip, to_v_ip, mask in zip(
ip_hidden_states, self.scale, self.to_k_ip, self.to_v_ip, ip_adapter_masks
):
skip = False
if isinstance(scale, list):
if all(s == 0 for s in scale):
skip = True
elif scale == 0:
skip = True
if not skip:
if mask is not None:
if not isinstance(scale, list):
scale = [scale] * mask.shape[1]
current_num_images = mask.shape[1]
for i in range(current_num_images):
ip_key = to_k_ip(current_ip_hidden_states[:, i, :, :])
ip_value = to_v_ip(current_ip_hidden_states[:, i, :, :])
ip_key = attn.head_to_batch_dim(ip_key)
ip_value = attn.head_to_batch_dim(ip_value)
ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
_current_ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
_current_ip_hidden_states = attn.batch_to_head_dim(_current_ip_hidden_states)
mask_downsample = IPAdapterMaskProcessor.downsample(
mask[:, i, :, :],
batch_size,
_current_ip_hidden_states.shape[1],
_current_ip_hidden_states.shape[2],
)
mask_downsample = mask_downsample.to(dtype=query.dtype, device=query.device)
hidden_states = hidden_states + scale[i] * (_current_ip_hidden_states * mask_downsample)
else:
ip_key = to_k_ip(current_ip_hidden_states)
ip_value = to_v_ip(current_ip_hidden_states)
ip_key = attn.head_to_batch_dim(ip_key)
ip_value = attn.head_to_batch_dim(ip_value)
ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
current_ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
current_ip_hidden_states = attn.batch_to_head_dim(current_ip_hidden_states)
hidden_states = hidden_states + scale * current_ip_hidden_states
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
class IPAdapterAttnProcessor2_0(torch.nn.Module):
r"""
Attention processor for IP-Adapter for PyTorch 2.0.
Args:
hidden_size (`int`):
The hidden size of the attention layer.
cross_attention_dim (`int`):
The number of channels in the `encoder_hidden_states`.
num_tokens (`int`, `Tuple[int]` or `List[int]`, defaults to `(4,)`):
The context length of the image features.
scale (`float` or `List[float]`, defaults to 1.0):
the weight scale of image prompt.
"""
def __init__(self, hidden_size, cross_attention_dim=None, num_tokens=(4,), scale=1.0):
super().__init__()
if not hasattr(F, "scaled_dot_product_attention"):
raise ImportError(
f"{self.__class__.__name__} requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0."
)
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
if not isinstance(num_tokens, (tuple, list)):
num_tokens = [num_tokens]
self.num_tokens = num_tokens
if not isinstance(scale, list):
scale = [scale] * len(num_tokens)
if len(scale) != len(num_tokens):
raise ValueError("`scale` should be a list of integers with the same length as `num_tokens`.")
self.scale = scale
self.to_k_ip = nn.ModuleList(
[nn.Linear(cross_attention_dim, hidden_size, bias=False) for _ in range(len(num_tokens))]
)
self.to_v_ip = nn.ModuleList(
[nn.Linear(cross_attention_dim, hidden_size, bias=False) for _ in range(len(num_tokens))]
)
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
temb: Optional[torch.Tensor] = None,
scale: float = 1.0,
ip_adapter_masks: Optional[torch.Tensor] = None,
):
residual = hidden_states
# separate ip_hidden_states from encoder_hidden_states
if encoder_hidden_states is not None:
if isinstance(encoder_hidden_states, tuple):
encoder_hidden_states, ip_hidden_states = encoder_hidden_states
else:
deprecation_message = (
"You have passed a tensor as `encoder_hidden_states`. This is deprecated and will be removed in a future release."
" Please make sure to update your script to pass `encoder_hidden_states` as a tuple to suppress this warning."
)
deprecate("encoder_hidden_states not a tuple", "1.0.0", deprecation_message, standard_warn=False)
end_pos = encoder_hidden_states.shape[1] - self.num_tokens[0]
encoder_hidden_states, ip_hidden_states = (
encoder_hidden_states[:, :end_pos, :],
[encoder_hidden_states[:, end_pos:, :]],
)
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
if attention_mask is not None:
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
# scaled_dot_product_attention expects attention_mask shape to be
# (batch, heads, source_length, target_length)
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
# TODO: add support for attn.scale when we move to Torch 2.1
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
if ip_adapter_masks is not None:
if not isinstance(ip_adapter_masks, List):
# for backward compatibility, we accept `ip_adapter_mask` as a tensor of shape [num_ip_adapter, 1, height, width]
ip_adapter_masks = list(ip_adapter_masks.unsqueeze(1))
if not (len(ip_adapter_masks) == len(self.scale) == len(ip_hidden_states)):
raise ValueError(
f"Length of ip_adapter_masks array ({len(ip_adapter_masks)}) must match "
f"length of self.scale array ({len(self.scale)}) and number of ip_hidden_states "
f"({len(ip_hidden_states)})"
)
else:
for index, (mask, scale, ip_state) in enumerate(zip(ip_adapter_masks, self.scale, ip_hidden_states)):
if not isinstance(mask, torch.Tensor) or mask.ndim != 4:
raise ValueError(
"Each element of the ip_adapter_masks array should be a tensor with shape "
"[1, num_images_for_ip_adapter, height, width]."
" Please use `IPAdapterMaskProcessor` to preprocess your mask"
)
if mask.shape[1] != ip_state.shape[1]:
raise ValueError(
f"Number of masks ({mask.shape[1]}) does not match "
f"number of ip images ({ip_state.shape[1]}) at index {index}"
)
if isinstance(scale, list) and not len(scale) == mask.shape[1]:
raise ValueError(
f"Number of masks ({mask.shape[1]}) does not match "
f"number of scales ({len(scale)}) at index {index}"
)
else:
ip_adapter_masks = [None] * len(self.scale)
# for ip-adapter
for current_ip_hidden_states, scale, to_k_ip, to_v_ip, mask in zip(
ip_hidden_states, self.scale, self.to_k_ip, self.to_v_ip, ip_adapter_masks
):
skip = False
if isinstance(scale, list):
if all(s == 0 for s in scale):
skip = True
elif scale == 0:
skip = True
if not skip:
if mask is not None:
if not isinstance(scale, list):
scale = [scale] * mask.shape[1]
current_num_images = mask.shape[1]
for i in range(current_num_images):
ip_key = to_k_ip(current_ip_hidden_states[:, i, :, :])
ip_value = to_v_ip(current_ip_hidden_states[:, i, :, :])
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
# TODO: add support for attn.scale when we move to Torch 2.1
_current_ip_hidden_states = F.scaled_dot_product_attention(
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
)
_current_ip_hidden_states = _current_ip_hidden_states.transpose(1, 2).reshape(
batch_size, -1, attn.heads * head_dim
)
_current_ip_hidden_states = _current_ip_hidden_states.to(query.dtype)
mask_downsample = IPAdapterMaskProcessor.downsample(
mask[:, i, :, :],
batch_size,
_current_ip_hidden_states.shape[1],
_current_ip_hidden_states.shape[2],
)
mask_downsample = mask_downsample.to(dtype=query.dtype, device=query.device)
hidden_states = hidden_states + scale[i] * (_current_ip_hidden_states * mask_downsample)
else:
ip_key = to_k_ip(current_ip_hidden_states)
ip_value = to_v_ip(current_ip_hidden_states)
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
# TODO: add support for attn.scale when we move to Torch 2.1
current_ip_hidden_states = F.scaled_dot_product_attention(
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
)
current_ip_hidden_states = current_ip_hidden_states.transpose(1, 2).reshape(
batch_size, -1, attn.heads * head_dim
)
current_ip_hidden_states = current_ip_hidden_states.to(query.dtype)
hidden_states = hidden_states + scale * current_ip_hidden_states
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
LORA_ATTENTION_PROCESSORS = (
LoRAAttnProcessor,
LoRAAttnProcessor2_0,
LoRAXFormersAttnProcessor,
LoRAAttnAddedKVProcessor,
)
ADDED_KV_ATTENTION_PROCESSORS = (
AttnAddedKVProcessor,
SlicedAttnAddedKVProcessor,
AttnAddedKVProcessor2_0,
XFormersAttnAddedKVProcessor,
LoRAAttnAddedKVProcessor,
)
CROSS_ATTENTION_PROCESSORS = (
AttnProcessor,
AttnProcessor2_0,
XFormersAttnProcessor,
SlicedAttnProcessor,
LoRAAttnProcessor,
LoRAAttnProcessor2_0,
LoRAXFormersAttnProcessor,
IPAdapterAttnProcessor,
IPAdapterAttnProcessor2_0,
)
AttentionProcessor = Union[
AttnProcessor,
AttnProcessor2_0,
FusedAttnProcessor2_0,
XFormersAttnProcessor,
SlicedAttnProcessor,
AttnAddedKVProcessor,
SlicedAttnAddedKVProcessor,
AttnAddedKVProcessor2_0,
XFormersAttnAddedKVProcessor,
CustomDiffusionAttnProcessor,
CustomDiffusionXFormersAttnProcessor,
CustomDiffusionAttnProcessor2_0,
# deprecated
LoRAAttnProcessor,
LoRAAttnProcessor2_0,
LoRAXFormersAttnProcessor,
LoRAAttnAddedKVProcessor,
]
| diffusers/src/diffusers/models/attention_processor.py/0 | {
"file_path": "diffusers/src/diffusers/models/attention_processor.py",
"repo_id": "diffusers",
"token_count": 54238
} | 238 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch - Flax general utilities."""
import re
import jax.numpy as jnp
from flax.traverse_util import flatten_dict, unflatten_dict
from jax.random import PRNGKey
from ..utils import logging
logger = logging.get_logger(__name__)
def rename_key(key):
regex = r"\w+[.]\d+"
pats = re.findall(regex, key)
for pat in pats:
key = key.replace(pat, "_".join(pat.split(".")))
return key
#####################
# PyTorch => Flax #
#####################
# Adapted from https://github.com/huggingface/transformers/blob/c603c80f46881ae18b2ca50770ef65fa4033eacd/src/transformers/modeling_flax_pytorch_utils.py#L69
# and https://github.com/patil-suraj/stable-diffusion-jax/blob/main/stable_diffusion_jax/convert_diffusers_to_jax.py
def rename_key_and_reshape_tensor(pt_tuple_key, pt_tensor, random_flax_state_dict):
"""Rename PT weight names to corresponding Flax weight names and reshape tensor if necessary"""
# conv norm or layer norm
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("scale",)
# rename attention layers
if len(pt_tuple_key) > 1:
for rename_from, rename_to in (
("to_out_0", "proj_attn"),
("to_k", "key"),
("to_v", "value"),
("to_q", "query"),
):
if pt_tuple_key[-2] == rename_from:
weight_name = pt_tuple_key[-1]
weight_name = "kernel" if weight_name == "weight" else weight_name
renamed_pt_tuple_key = pt_tuple_key[:-2] + (rename_to, weight_name)
if renamed_pt_tuple_key in random_flax_state_dict:
assert random_flax_state_dict[renamed_pt_tuple_key].shape == pt_tensor.T.shape
return renamed_pt_tuple_key, pt_tensor.T
if (
any("norm" in str_ for str_ in pt_tuple_key)
and (pt_tuple_key[-1] == "bias")
and (pt_tuple_key[:-1] + ("bias",) not in random_flax_state_dict)
and (pt_tuple_key[:-1] + ("scale",) in random_flax_state_dict)
):
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("scale",)
return renamed_pt_tuple_key, pt_tensor
elif pt_tuple_key[-1] in ["weight", "gamma"] and pt_tuple_key[:-1] + ("scale",) in random_flax_state_dict:
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("scale",)
return renamed_pt_tuple_key, pt_tensor
# embedding
if pt_tuple_key[-1] == "weight" and pt_tuple_key[:-1] + ("embedding",) in random_flax_state_dict:
pt_tuple_key = pt_tuple_key[:-1] + ("embedding",)
return renamed_pt_tuple_key, pt_tensor
# conv layer
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
if pt_tuple_key[-1] == "weight" and pt_tensor.ndim == 4:
pt_tensor = pt_tensor.transpose(2, 3, 1, 0)
return renamed_pt_tuple_key, pt_tensor
# linear layer
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
if pt_tuple_key[-1] == "weight":
pt_tensor = pt_tensor.T
return renamed_pt_tuple_key, pt_tensor
# old PyTorch layer norm weight
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("weight",)
if pt_tuple_key[-1] == "gamma":
return renamed_pt_tuple_key, pt_tensor
# old PyTorch layer norm bias
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("bias",)
if pt_tuple_key[-1] == "beta":
return renamed_pt_tuple_key, pt_tensor
return pt_tuple_key, pt_tensor
def convert_pytorch_state_dict_to_flax(pt_state_dict, flax_model, init_key=42):
# Step 1: Convert pytorch tensor to numpy
pt_state_dict = {k: v.numpy() for k, v in pt_state_dict.items()}
# Step 2: Since the model is stateless, get random Flax params
random_flax_params = flax_model.init_weights(PRNGKey(init_key))
random_flax_state_dict = flatten_dict(random_flax_params)
flax_state_dict = {}
# Need to change some parameters name to match Flax names
for pt_key, pt_tensor in pt_state_dict.items():
renamed_pt_key = rename_key(pt_key)
pt_tuple_key = tuple(renamed_pt_key.split("."))
# Correctly rename weight parameters
flax_key, flax_tensor = rename_key_and_reshape_tensor(pt_tuple_key, pt_tensor, random_flax_state_dict)
if flax_key in random_flax_state_dict:
if flax_tensor.shape != random_flax_state_dict[flax_key].shape:
raise ValueError(
f"PyTorch checkpoint seems to be incorrect. Weight {pt_key} was expected to be of shape "
f"{random_flax_state_dict[flax_key].shape}, but is {flax_tensor.shape}."
)
# also add unexpected weight so that warning is thrown
flax_state_dict[flax_key] = jnp.asarray(flax_tensor)
return unflatten_dict(flax_state_dict)
| diffusers/src/diffusers/models/modeling_flax_pytorch_utils.py/0 | {
"file_path": "diffusers/src/diffusers/models/modeling_flax_pytorch_utils.py",
"repo_id": "diffusers",
"token_count": 2325
} | 239 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from dataclasses import dataclass
from typing import Any, Dict, Optional
import torch
import torch.nn.functional as F
from torch import nn
from ...configuration_utils import ConfigMixin, register_to_config
from ...utils import BaseOutput, deprecate, is_torch_version, logging
from ..attention import BasicTransformerBlock
from ..embeddings import ImagePositionalEmbeddings, PatchEmbed, PixArtAlphaTextProjection
from ..modeling_utils import ModelMixin
from ..normalization import AdaLayerNormSingle
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
@dataclass
class Transformer2DModelOutput(BaseOutput):
"""
The output of [`Transformer2DModel`].
Args:
sample (`torch.Tensor` of shape `(batch_size, num_channels, height, width)` or `(batch size, num_vector_embeds - 1, num_latent_pixels)` if [`Transformer2DModel`] is discrete):
The hidden states output conditioned on the `encoder_hidden_states` input. If discrete, returns probability
distributions for the unnoised latent pixels.
"""
sample: torch.Tensor
class Transformer2DModel(ModelMixin, ConfigMixin):
"""
A 2D Transformer model for image-like data.
Parameters:
num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
in_channels (`int`, *optional*):
The number of channels in the input and output (specify if the input is **continuous**).
num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
cross_attention_dim (`int`, *optional*): The number of `encoder_hidden_states` dimensions to use.
sample_size (`int`, *optional*): The width of the latent images (specify if the input is **discrete**).
This is fixed during training since it is used to learn a number of position embeddings.
num_vector_embeds (`int`, *optional*):
The number of classes of the vector embeddings of the latent pixels (specify if the input is **discrete**).
Includes the class for the masked latent pixel.
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to use in feed-forward.
num_embeds_ada_norm ( `int`, *optional*):
The number of diffusion steps used during training. Pass if at least one of the norm_layers is
`AdaLayerNorm`. This is fixed during training since it is used to learn a number of embeddings that are
added to the hidden states.
During inference, you can denoise for up to but not more steps than `num_embeds_ada_norm`.
attention_bias (`bool`, *optional*):
Configure if the `TransformerBlocks` attention should contain a bias parameter.
"""
_supports_gradient_checkpointing = True
_no_split_modules = ["BasicTransformerBlock"]
@register_to_config
def __init__(
self,
num_attention_heads: int = 16,
attention_head_dim: int = 88,
in_channels: Optional[int] = None,
out_channels: Optional[int] = None,
num_layers: int = 1,
dropout: float = 0.0,
norm_num_groups: int = 32,
cross_attention_dim: Optional[int] = None,
attention_bias: bool = False,
sample_size: Optional[int] = None,
num_vector_embeds: Optional[int] = None,
patch_size: Optional[int] = None,
activation_fn: str = "geglu",
num_embeds_ada_norm: Optional[int] = None,
use_linear_projection: bool = False,
only_cross_attention: bool = False,
double_self_attention: bool = False,
upcast_attention: bool = False,
norm_type: str = "layer_norm", # 'layer_norm', 'ada_norm', 'ada_norm_zero', 'ada_norm_single', 'ada_norm_continuous', 'layer_norm_i2vgen'
norm_elementwise_affine: bool = True,
norm_eps: float = 1e-5,
attention_type: str = "default",
caption_channels: int = None,
interpolation_scale: float = None,
use_additional_conditions: Optional[bool] = None,
):
super().__init__()
# Validate inputs.
if patch_size is not None:
if norm_type not in ["ada_norm", "ada_norm_zero", "ada_norm_single"]:
raise NotImplementedError(
f"Forward pass is not implemented when `patch_size` is not None and `norm_type` is '{norm_type}'."
)
elif norm_type in ["ada_norm", "ada_norm_zero"] and num_embeds_ada_norm is None:
raise ValueError(
f"When using a `patch_size` and this `norm_type` ({norm_type}), `num_embeds_ada_norm` cannot be None."
)
# Set some common variables used across the board.
self.use_linear_projection = use_linear_projection
self.interpolation_scale = interpolation_scale
self.caption_channels = caption_channels
self.num_attention_heads = num_attention_heads
self.attention_head_dim = attention_head_dim
self.inner_dim = self.config.num_attention_heads * self.config.attention_head_dim
self.in_channels = in_channels
self.out_channels = in_channels if out_channels is None else out_channels
self.gradient_checkpointing = False
if use_additional_conditions is None:
if norm_type == "ada_norm_single" and sample_size == 128:
use_additional_conditions = True
else:
use_additional_conditions = False
self.use_additional_conditions = use_additional_conditions
# 1. Transformer2DModel can process both standard continuous images of shape `(batch_size, num_channels, width, height)` as well as quantized image embeddings of shape `(batch_size, num_image_vectors)`
# Define whether input is continuous or discrete depending on configuration
self.is_input_continuous = (in_channels is not None) and (patch_size is None)
self.is_input_vectorized = num_vector_embeds is not None
self.is_input_patches = in_channels is not None and patch_size is not None
if norm_type == "layer_norm" and num_embeds_ada_norm is not None:
deprecation_message = (
f"The configuration file of this model: {self.__class__} is outdated. `norm_type` is either not set or"
" incorrectly set to `'layer_norm'`. Make sure to set `norm_type` to `'ada_norm'` in the config."
" Please make sure to update the config accordingly as leaving `norm_type` might led to incorrect"
" results in future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it"
" would be very nice if you could open a Pull request for the `transformer/config.json` file"
)
deprecate("norm_type!=num_embeds_ada_norm", "1.0.0", deprecation_message, standard_warn=False)
norm_type = "ada_norm"
if self.is_input_continuous and self.is_input_vectorized:
raise ValueError(
f"Cannot define both `in_channels`: {in_channels} and `num_vector_embeds`: {num_vector_embeds}. Make"
" sure that either `in_channels` or `num_vector_embeds` is None."
)
elif self.is_input_vectorized and self.is_input_patches:
raise ValueError(
f"Cannot define both `num_vector_embeds`: {num_vector_embeds} and `patch_size`: {patch_size}. Make"
" sure that either `num_vector_embeds` or `num_patches` is None."
)
elif not self.is_input_continuous and not self.is_input_vectorized and not self.is_input_patches:
raise ValueError(
f"Has to define `in_channels`: {in_channels}, `num_vector_embeds`: {num_vector_embeds}, or patch_size:"
f" {patch_size}. Make sure that `in_channels`, `num_vector_embeds` or `num_patches` is not None."
)
# 2. Initialize the right blocks.
# These functions follow a common structure:
# a. Initialize the input blocks. b. Initialize the transformer blocks.
# c. Initialize the output blocks and other projection blocks when necessary.
if self.is_input_continuous:
self._init_continuous_input(norm_type=norm_type)
elif self.is_input_vectorized:
self._init_vectorized_inputs(norm_type=norm_type)
elif self.is_input_patches:
self._init_patched_inputs(norm_type=norm_type)
def _init_continuous_input(self, norm_type):
self.norm = torch.nn.GroupNorm(
num_groups=self.config.norm_num_groups, num_channels=self.in_channels, eps=1e-6, affine=True
)
if self.use_linear_projection:
self.proj_in = torch.nn.Linear(self.in_channels, self.inner_dim)
else:
self.proj_in = torch.nn.Conv2d(self.in_channels, self.inner_dim, kernel_size=1, stride=1, padding=0)
self.transformer_blocks = nn.ModuleList(
[
BasicTransformerBlock(
self.inner_dim,
self.config.num_attention_heads,
self.config.attention_head_dim,
dropout=self.config.dropout,
cross_attention_dim=self.config.cross_attention_dim,
activation_fn=self.config.activation_fn,
num_embeds_ada_norm=self.config.num_embeds_ada_norm,
attention_bias=self.config.attention_bias,
only_cross_attention=self.config.only_cross_attention,
double_self_attention=self.config.double_self_attention,
upcast_attention=self.config.upcast_attention,
norm_type=norm_type,
norm_elementwise_affine=self.config.norm_elementwise_affine,
norm_eps=self.config.norm_eps,
attention_type=self.config.attention_type,
)
for _ in range(self.config.num_layers)
]
)
if self.use_linear_projection:
self.proj_out = torch.nn.Linear(self.inner_dim, self.out_channels)
else:
self.proj_out = torch.nn.Conv2d(self.inner_dim, self.out_channels, kernel_size=1, stride=1, padding=0)
def _init_vectorized_inputs(self, norm_type):
assert self.config.sample_size is not None, "Transformer2DModel over discrete input must provide sample_size"
assert (
self.config.num_vector_embeds is not None
), "Transformer2DModel over discrete input must provide num_embed"
self.height = self.config.sample_size
self.width = self.config.sample_size
self.num_latent_pixels = self.height * self.width
self.latent_image_embedding = ImagePositionalEmbeddings(
num_embed=self.config.num_vector_embeds, embed_dim=self.inner_dim, height=self.height, width=self.width
)
self.transformer_blocks = nn.ModuleList(
[
BasicTransformerBlock(
self.inner_dim,
self.config.num_attention_heads,
self.config.attention_head_dim,
dropout=self.config.dropout,
cross_attention_dim=self.config.cross_attention_dim,
activation_fn=self.config.activation_fn,
num_embeds_ada_norm=self.config.num_embeds_ada_norm,
attention_bias=self.config.attention_bias,
only_cross_attention=self.config.only_cross_attention,
double_self_attention=self.config.double_self_attention,
upcast_attention=self.config.upcast_attention,
norm_type=norm_type,
norm_elementwise_affine=self.config.norm_elementwise_affine,
norm_eps=self.config.norm_eps,
attention_type=self.config.attention_type,
)
for _ in range(self.config.num_layers)
]
)
self.norm_out = nn.LayerNorm(self.inner_dim)
self.out = nn.Linear(self.inner_dim, self.config.num_vector_embeds - 1)
def _init_patched_inputs(self, norm_type):
assert self.config.sample_size is not None, "Transformer2DModel over patched input must provide sample_size"
self.height = self.config.sample_size
self.width = self.config.sample_size
self.patch_size = self.config.patch_size
interpolation_scale = (
self.config.interpolation_scale
if self.config.interpolation_scale is not None
else max(self.config.sample_size // 64, 1)
)
self.pos_embed = PatchEmbed(
height=self.config.sample_size,
width=self.config.sample_size,
patch_size=self.config.patch_size,
in_channels=self.in_channels,
embed_dim=self.inner_dim,
interpolation_scale=interpolation_scale,
)
self.transformer_blocks = nn.ModuleList(
[
BasicTransformerBlock(
self.inner_dim,
self.config.num_attention_heads,
self.config.attention_head_dim,
dropout=self.config.dropout,
cross_attention_dim=self.config.cross_attention_dim,
activation_fn=self.config.activation_fn,
num_embeds_ada_norm=self.config.num_embeds_ada_norm,
attention_bias=self.config.attention_bias,
only_cross_attention=self.config.only_cross_attention,
double_self_attention=self.config.double_self_attention,
upcast_attention=self.config.upcast_attention,
norm_type=norm_type,
norm_elementwise_affine=self.config.norm_elementwise_affine,
norm_eps=self.config.norm_eps,
attention_type=self.config.attention_type,
)
for _ in range(self.config.num_layers)
]
)
if self.config.norm_type != "ada_norm_single":
self.norm_out = nn.LayerNorm(self.inner_dim, elementwise_affine=False, eps=1e-6)
self.proj_out_1 = nn.Linear(self.inner_dim, 2 * self.inner_dim)
self.proj_out_2 = nn.Linear(
self.inner_dim, self.config.patch_size * self.config.patch_size * self.out_channels
)
elif self.config.norm_type == "ada_norm_single":
self.norm_out = nn.LayerNorm(self.inner_dim, elementwise_affine=False, eps=1e-6)
self.scale_shift_table = nn.Parameter(torch.randn(2, self.inner_dim) / self.inner_dim**0.5)
self.proj_out = nn.Linear(
self.inner_dim, self.config.patch_size * self.config.patch_size * self.out_channels
)
# PixArt-Alpha blocks.
self.adaln_single = None
if self.config.norm_type == "ada_norm_single":
# TODO(Sayak, PVP) clean this, for now we use sample size to determine whether to use
# additional conditions until we find better name
self.adaln_single = AdaLayerNormSingle(
self.inner_dim, use_additional_conditions=self.use_additional_conditions
)
self.caption_projection = None
if self.caption_channels is not None:
self.caption_projection = PixArtAlphaTextProjection(
in_features=self.caption_channels, hidden_size=self.inner_dim
)
def _set_gradient_checkpointing(self, module, value=False):
if hasattr(module, "gradient_checkpointing"):
module.gradient_checkpointing = value
def forward(
self,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
timestep: Optional[torch.LongTensor] = None,
added_cond_kwargs: Dict[str, torch.Tensor] = None,
class_labels: Optional[torch.LongTensor] = None,
cross_attention_kwargs: Dict[str, Any] = None,
attention_mask: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
return_dict: bool = True,
):
"""
The [`Transformer2DModel`] forward method.
Args:
hidden_states (`torch.LongTensor` of shape `(batch size, num latent pixels)` if discrete, `torch.Tensor` of shape `(batch size, channel, height, width)` if continuous):
Input `hidden_states`.
encoder_hidden_states ( `torch.Tensor` of shape `(batch size, sequence len, embed dims)`, *optional*):
Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
self-attention.
timestep ( `torch.LongTensor`, *optional*):
Used to indicate denoising step. Optional timestep to be applied as an embedding in `AdaLayerNorm`.
class_labels ( `torch.LongTensor` of shape `(batch size, num classes)`, *optional*):
Used to indicate class labels conditioning. Optional class labels to be applied as an embedding in
`AdaLayerZeroNorm`.
cross_attention_kwargs ( `Dict[str, Any]`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
attention_mask ( `torch.Tensor`, *optional*):
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
negative values to the attention scores corresponding to "discard" tokens.
encoder_attention_mask ( `torch.Tensor`, *optional*):
Cross-attention mask applied to `encoder_hidden_states`. Two formats supported:
* Mask `(batch, sequence_length)` True = keep, False = discard.
* Bias `(batch, 1, sequence_length)` 0 = keep, -10000 = discard.
If `ndim == 2`: will be interpreted as a mask, then converted into a bias consistent with the format
above. This bias will be added to the cross-attention scores.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~models.unets.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
tuple.
Returns:
If `return_dict` is True, an [`~models.transformer_2d.Transformer2DModelOutput`] is returned, otherwise a
`tuple` where the first element is the sample tensor.
"""
if cross_attention_kwargs is not None:
if cross_attention_kwargs.get("scale", None) is not None:
logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension.
# we may have done this conversion already, e.g. if we came here via UNet2DConditionModel#forward.
# we can tell by counting dims; if ndim == 2: it's a mask rather than a bias.
# expects mask of shape:
# [batch, key_tokens]
# adds singleton query_tokens dimension:
# [batch, 1, key_tokens]
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
if attention_mask is not None and attention_mask.ndim == 2:
# assume that mask is expressed as:
# (1 = keep, 0 = discard)
# convert mask into a bias that can be added to attention scores:
# (keep = +0, discard = -10000.0)
attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0
attention_mask = attention_mask.unsqueeze(1)
# convert encoder_attention_mask to a bias the same way we do for attention_mask
if encoder_attention_mask is not None and encoder_attention_mask.ndim == 2:
encoder_attention_mask = (1 - encoder_attention_mask.to(hidden_states.dtype)) * -10000.0
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
# 1. Input
if self.is_input_continuous:
batch_size, _, height, width = hidden_states.shape
residual = hidden_states
hidden_states, inner_dim = self._operate_on_continuous_inputs(hidden_states)
elif self.is_input_vectorized:
hidden_states = self.latent_image_embedding(hidden_states)
elif self.is_input_patches:
height, width = hidden_states.shape[-2] // self.patch_size, hidden_states.shape[-1] // self.patch_size
hidden_states, encoder_hidden_states, timestep, embedded_timestep = self._operate_on_patched_inputs(
hidden_states, encoder_hidden_states, timestep, added_cond_kwargs
)
# 2. Blocks
for block in self.transformer_blocks:
if self.training and self.gradient_checkpointing:
def create_custom_forward(module, return_dict=None):
def custom_forward(*inputs):
if return_dict is not None:
return module(*inputs, return_dict=return_dict)
else:
return module(*inputs)
return custom_forward
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(block),
hidden_states,
attention_mask,
encoder_hidden_states,
encoder_attention_mask,
timestep,
cross_attention_kwargs,
class_labels,
**ckpt_kwargs,
)
else:
hidden_states = block(
hidden_states,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
timestep=timestep,
cross_attention_kwargs=cross_attention_kwargs,
class_labels=class_labels,
)
# 3. Output
if self.is_input_continuous:
output = self._get_output_for_continuous_inputs(
hidden_states=hidden_states,
residual=residual,
batch_size=batch_size,
height=height,
width=width,
inner_dim=inner_dim,
)
elif self.is_input_vectorized:
output = self._get_output_for_vectorized_inputs(hidden_states)
elif self.is_input_patches:
output = self._get_output_for_patched_inputs(
hidden_states=hidden_states,
timestep=timestep,
class_labels=class_labels,
embedded_timestep=embedded_timestep,
height=height,
width=width,
)
if not return_dict:
return (output,)
return Transformer2DModelOutput(sample=output)
def _operate_on_continuous_inputs(self, hidden_states):
batch, _, height, width = hidden_states.shape
hidden_states = self.norm(hidden_states)
if not self.use_linear_projection:
hidden_states = self.proj_in(hidden_states)
inner_dim = hidden_states.shape[1]
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
else:
inner_dim = hidden_states.shape[1]
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
hidden_states = self.proj_in(hidden_states)
return hidden_states, inner_dim
def _operate_on_patched_inputs(self, hidden_states, encoder_hidden_states, timestep, added_cond_kwargs):
batch_size = hidden_states.shape[0]
hidden_states = self.pos_embed(hidden_states)
embedded_timestep = None
if self.adaln_single is not None:
if self.use_additional_conditions and added_cond_kwargs is None:
raise ValueError(
"`added_cond_kwargs` cannot be None when using additional conditions for `adaln_single`."
)
timestep, embedded_timestep = self.adaln_single(
timestep, added_cond_kwargs, batch_size=batch_size, hidden_dtype=hidden_states.dtype
)
if self.caption_projection is not None:
encoder_hidden_states = self.caption_projection(encoder_hidden_states)
encoder_hidden_states = encoder_hidden_states.view(batch_size, -1, hidden_states.shape[-1])
return hidden_states, encoder_hidden_states, timestep, embedded_timestep
def _get_output_for_continuous_inputs(self, hidden_states, residual, batch_size, height, width, inner_dim):
if not self.use_linear_projection:
hidden_states = (
hidden_states.reshape(batch_size, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
)
hidden_states = self.proj_out(hidden_states)
else:
hidden_states = self.proj_out(hidden_states)
hidden_states = (
hidden_states.reshape(batch_size, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
)
output = hidden_states + residual
return output
def _get_output_for_vectorized_inputs(self, hidden_states):
hidden_states = self.norm_out(hidden_states)
logits = self.out(hidden_states)
# (batch, self.num_vector_embeds - 1, self.num_latent_pixels)
logits = logits.permute(0, 2, 1)
# log(p(x_0))
output = F.log_softmax(logits.double(), dim=1).float()
return output
def _get_output_for_patched_inputs(
self, hidden_states, timestep, class_labels, embedded_timestep, height=None, width=None
):
if self.config.norm_type != "ada_norm_single":
conditioning = self.transformer_blocks[0].norm1.emb(
timestep, class_labels, hidden_dtype=hidden_states.dtype
)
shift, scale = self.proj_out_1(F.silu(conditioning)).chunk(2, dim=1)
hidden_states = self.norm_out(hidden_states) * (1 + scale[:, None]) + shift[:, None]
hidden_states = self.proj_out_2(hidden_states)
elif self.config.norm_type == "ada_norm_single":
shift, scale = (self.scale_shift_table[None] + embedded_timestep[:, None]).chunk(2, dim=1)
hidden_states = self.norm_out(hidden_states)
# Modulation
hidden_states = hidden_states * (1 + scale) + shift
hidden_states = self.proj_out(hidden_states)
hidden_states = hidden_states.squeeze(1)
# unpatchify
if self.adaln_single is None:
height = width = int(hidden_states.shape[1] ** 0.5)
hidden_states = hidden_states.reshape(
shape=(-1, height, width, self.patch_size, self.patch_size, self.out_channels)
)
hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
output = hidden_states.reshape(
shape=(-1, self.out_channels, height * self.patch_size, width * self.patch_size)
)
return output
| diffusers/src/diffusers/models/transformers/transformer_2d.py/0 | {
"file_path": "diffusers/src/diffusers/models/transformers/transformer_2d.py",
"repo_id": "diffusers",
"token_count": 13062
} | 240 |
# Copyright 2024 Alibaba DAMO-VILAB and The HuggingFace Team. All rights reserved.
# Copyright 2024 The ModelScope Team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from dataclasses import dataclass
from typing import Any, Dict, List, Optional, Tuple, Union
import torch
import torch.nn as nn
import torch.utils.checkpoint
from ...configuration_utils import ConfigMixin, register_to_config
from ...loaders import UNet2DConditionLoadersMixin
from ...utils import BaseOutput, deprecate, logging
from ..activations import get_activation
from ..attention_processor import (
ADDED_KV_ATTENTION_PROCESSORS,
CROSS_ATTENTION_PROCESSORS,
Attention,
AttentionProcessor,
AttnAddedKVProcessor,
AttnProcessor,
)
from ..embeddings import TimestepEmbedding, Timesteps
from ..modeling_utils import ModelMixin
from ..transformers.transformer_temporal import TransformerTemporalModel
from .unet_3d_blocks import (
CrossAttnDownBlock3D,
CrossAttnUpBlock3D,
DownBlock3D,
UNetMidBlock3DCrossAttn,
UpBlock3D,
get_down_block,
get_up_block,
)
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
@dataclass
class UNet3DConditionOutput(BaseOutput):
"""
The output of [`UNet3DConditionModel`].
Args:
sample (`torch.Tensor` of shape `(batch_size, num_channels, num_frames, height, width)`):
The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
"""
sample: torch.Tensor
class UNet3DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
r"""
A conditional 3D UNet model that takes a noisy sample, conditional state, and a timestep and returns a sample
shaped output.
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
for all models (such as downloading or saving).
Parameters:
sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
Height and width of input/output sample.
in_channels (`int`, *optional*, defaults to 4): The number of channels in the input sample.
out_channels (`int`, *optional*, defaults to 4): The number of channels in the output.
down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock3D", "CrossAttnDownBlock3D", "CrossAttnDownBlock3D", "DownBlock3D")`):
The tuple of downsample blocks to use.
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock3D", "CrossAttnUpBlock3D", "CrossAttnUpBlock3D", "CrossAttnUpBlock3D")`):
The tuple of upsample blocks to use.
block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
The tuple of output channels for each block.
layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
If `None`, normalization and activation layers is skipped in post-processing.
norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
cross_attention_dim (`int`, *optional*, defaults to 1024): The dimension of the cross attention features.
attention_head_dim (`int`, *optional*, defaults to 64): The dimension of the attention heads.
num_attention_heads (`int`, *optional*): The number of attention heads.
time_cond_proj_dim (`int`, *optional*, defaults to `None`):
The dimension of `cond_proj` layer in the timestep embedding.
"""
_supports_gradient_checkpointing = False
@register_to_config
def __init__(
self,
sample_size: Optional[int] = None,
in_channels: int = 4,
out_channels: int = 4,
down_block_types: Tuple[str, ...] = (
"CrossAttnDownBlock3D",
"CrossAttnDownBlock3D",
"CrossAttnDownBlock3D",
"DownBlock3D",
),
up_block_types: Tuple[str, ...] = (
"UpBlock3D",
"CrossAttnUpBlock3D",
"CrossAttnUpBlock3D",
"CrossAttnUpBlock3D",
),
block_out_channels: Tuple[int, ...] = (320, 640, 1280, 1280),
layers_per_block: int = 2,
downsample_padding: int = 1,
mid_block_scale_factor: float = 1,
act_fn: str = "silu",
norm_num_groups: Optional[int] = 32,
norm_eps: float = 1e-5,
cross_attention_dim: int = 1024,
attention_head_dim: Union[int, Tuple[int]] = 64,
num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
time_cond_proj_dim: Optional[int] = None,
):
super().__init__()
self.sample_size = sample_size
if num_attention_heads is not None:
raise NotImplementedError(
"At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
)
# If `num_attention_heads` is not defined (which is the case for most models)
# it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
# The reason for this behavior is to correct for incorrectly named variables that were introduced
# when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
# Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
# which is why we correct for the naming here.
num_attention_heads = num_attention_heads or attention_head_dim
# Check inputs
if len(down_block_types) != len(up_block_types):
raise ValueError(
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
)
if len(block_out_channels) != len(down_block_types):
raise ValueError(
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
)
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
raise ValueError(
f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
)
# input
conv_in_kernel = 3
conv_out_kernel = 3
conv_in_padding = (conv_in_kernel - 1) // 2
self.conv_in = nn.Conv2d(
in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
)
# time
time_embed_dim = block_out_channels[0] * 4
self.time_proj = Timesteps(block_out_channels[0], True, 0)
timestep_input_dim = block_out_channels[0]
self.time_embedding = TimestepEmbedding(
timestep_input_dim,
time_embed_dim,
act_fn=act_fn,
cond_proj_dim=time_cond_proj_dim,
)
self.transformer_in = TransformerTemporalModel(
num_attention_heads=8,
attention_head_dim=attention_head_dim,
in_channels=block_out_channels[0],
num_layers=1,
norm_num_groups=norm_num_groups,
)
# class embedding
self.down_blocks = nn.ModuleList([])
self.up_blocks = nn.ModuleList([])
if isinstance(num_attention_heads, int):
num_attention_heads = (num_attention_heads,) * len(down_block_types)
# down
output_channel = block_out_channels[0]
for i, down_block_type in enumerate(down_block_types):
input_channel = output_channel
output_channel = block_out_channels[i]
is_final_block = i == len(block_out_channels) - 1
down_block = get_down_block(
down_block_type,
num_layers=layers_per_block,
in_channels=input_channel,
out_channels=output_channel,
temb_channels=time_embed_dim,
add_downsample=not is_final_block,
resnet_eps=norm_eps,
resnet_act_fn=act_fn,
resnet_groups=norm_num_groups,
cross_attention_dim=cross_attention_dim,
num_attention_heads=num_attention_heads[i],
downsample_padding=downsample_padding,
dual_cross_attention=False,
)
self.down_blocks.append(down_block)
# mid
self.mid_block = UNetMidBlock3DCrossAttn(
in_channels=block_out_channels[-1],
temb_channels=time_embed_dim,
resnet_eps=norm_eps,
resnet_act_fn=act_fn,
output_scale_factor=mid_block_scale_factor,
cross_attention_dim=cross_attention_dim,
num_attention_heads=num_attention_heads[-1],
resnet_groups=norm_num_groups,
dual_cross_attention=False,
)
# count how many layers upsample the images
self.num_upsamplers = 0
# up
reversed_block_out_channels = list(reversed(block_out_channels))
reversed_num_attention_heads = list(reversed(num_attention_heads))
output_channel = reversed_block_out_channels[0]
for i, up_block_type in enumerate(up_block_types):
is_final_block = i == len(block_out_channels) - 1
prev_output_channel = output_channel
output_channel = reversed_block_out_channels[i]
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
# add upsample block for all BUT final layer
if not is_final_block:
add_upsample = True
self.num_upsamplers += 1
else:
add_upsample = False
up_block = get_up_block(
up_block_type,
num_layers=layers_per_block + 1,
in_channels=input_channel,
out_channels=output_channel,
prev_output_channel=prev_output_channel,
temb_channels=time_embed_dim,
add_upsample=add_upsample,
resnet_eps=norm_eps,
resnet_act_fn=act_fn,
resnet_groups=norm_num_groups,
cross_attention_dim=cross_attention_dim,
num_attention_heads=reversed_num_attention_heads[i],
dual_cross_attention=False,
resolution_idx=i,
)
self.up_blocks.append(up_block)
prev_output_channel = output_channel
# out
if norm_num_groups is not None:
self.conv_norm_out = nn.GroupNorm(
num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
)
self.conv_act = get_activation("silu")
else:
self.conv_norm_out = None
self.conv_act = None
conv_out_padding = (conv_out_kernel - 1) // 2
self.conv_out = nn.Conv2d(
block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
)
@property
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.attn_processors
def attn_processors(self) -> Dict[str, AttentionProcessor]:
r"""
Returns:
`dict` of attention processors: A dictionary containing all attention processors used in the model with
indexed by its weight name.
"""
# set recursively
processors = {}
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
if hasattr(module, "get_processor"):
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
for sub_name, child in module.named_children():
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
return processors
for name, module in self.named_children():
fn_recursive_add_processors(name, module, processors)
return processors
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_attention_slice
def set_attention_slice(self, slice_size: Union[str, int, List[int]]) -> None:
r"""
Enable sliced attention computation.
When this option is enabled, the attention module splits the input tensor in slices to compute attention in
several steps. This is useful for saving some memory in exchange for a small decrease in speed.
Args:
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
`"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
must be a multiple of `slice_size`.
"""
sliceable_head_dims = []
def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
if hasattr(module, "set_attention_slice"):
sliceable_head_dims.append(module.sliceable_head_dim)
for child in module.children():
fn_recursive_retrieve_sliceable_dims(child)
# retrieve number of attention layers
for module in self.children():
fn_recursive_retrieve_sliceable_dims(module)
num_sliceable_layers = len(sliceable_head_dims)
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = [dim // 2 for dim in sliceable_head_dims]
elif slice_size == "max":
# make smallest slice possible
slice_size = num_sliceable_layers * [1]
slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
if len(slice_size) != len(sliceable_head_dims):
raise ValueError(
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
)
for i in range(len(slice_size)):
size = slice_size[i]
dim = sliceable_head_dims[i]
if size is not None and size > dim:
raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
# Recursively walk through all the children.
# Any children which exposes the set_attention_slice method
# gets the message
def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
if hasattr(module, "set_attention_slice"):
module.set_attention_slice(slice_size.pop())
for child in module.children():
fn_recursive_set_attention_slice(child, slice_size)
reversed_slice_size = list(reversed(slice_size))
for module in self.children():
fn_recursive_set_attention_slice(module, reversed_slice_size)
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_attn_processor
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
r"""
Sets the attention processor to use to compute attention.
Parameters:
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
The instantiated processor class or a dictionary of processor classes that will be set as the processor
for **all** `Attention` layers.
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
processor. This is strongly recommended when setting trainable attention processors.
"""
count = len(self.attn_processors.keys())
if isinstance(processor, dict) and len(processor) != count:
raise ValueError(
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
)
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
if hasattr(module, "set_processor"):
if not isinstance(processor, dict):
module.set_processor(processor)
else:
module.set_processor(processor.pop(f"{name}.processor"))
for sub_name, child in module.named_children():
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
for name, module in self.named_children():
fn_recursive_attn_processor(name, module, processor)
def enable_forward_chunking(self, chunk_size: Optional[int] = None, dim: int = 0) -> None:
"""
Sets the attention processor to use [feed forward
chunking](https://huggingface.co/blog/reformer#2-chunked-feed-forward-layers).
Parameters:
chunk_size (`int`, *optional*):
The chunk size of the feed-forward layers. If not specified, will run feed-forward layer individually
over each tensor of dim=`dim`.
dim (`int`, *optional*, defaults to `0`):
The dimension over which the feed-forward computation should be chunked. Choose between dim=0 (batch)
or dim=1 (sequence length).
"""
if dim not in [0, 1]:
raise ValueError(f"Make sure to set `dim` to either 0 or 1, not {dim}")
# By default chunk size is 1
chunk_size = chunk_size or 1
def fn_recursive_feed_forward(module: torch.nn.Module, chunk_size: int, dim: int):
if hasattr(module, "set_chunk_feed_forward"):
module.set_chunk_feed_forward(chunk_size=chunk_size, dim=dim)
for child in module.children():
fn_recursive_feed_forward(child, chunk_size, dim)
for module in self.children():
fn_recursive_feed_forward(module, chunk_size, dim)
def disable_forward_chunking(self):
def fn_recursive_feed_forward(module: torch.nn.Module, chunk_size: int, dim: int):
if hasattr(module, "set_chunk_feed_forward"):
module.set_chunk_feed_forward(chunk_size=chunk_size, dim=dim)
for child in module.children():
fn_recursive_feed_forward(child, chunk_size, dim)
for module in self.children():
fn_recursive_feed_forward(module, None, 0)
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
def set_default_attn_processor(self):
"""
Disables custom attention processors and sets the default attention implementation.
"""
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
processor = AttnAddedKVProcessor()
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
processor = AttnProcessor()
else:
raise ValueError(
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
)
self.set_attn_processor(processor)
def _set_gradient_checkpointing(self, module, value: bool = False) -> None:
if isinstance(module, (CrossAttnDownBlock3D, DownBlock3D, CrossAttnUpBlock3D, UpBlock3D)):
module.gradient_checkpointing = value
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.enable_freeu
def enable_freeu(self, s1, s2, b1, b2):
r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
The suffixes after the scaling factors represent the stage blocks where they are being applied.
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of values that
are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
Args:
s1 (`float`):
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
mitigate the "oversmoothing effect" in the enhanced denoising process.
s2 (`float`):
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
mitigate the "oversmoothing effect" in the enhanced denoising process.
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
"""
for i, upsample_block in enumerate(self.up_blocks):
setattr(upsample_block, "s1", s1)
setattr(upsample_block, "s2", s2)
setattr(upsample_block, "b1", b1)
setattr(upsample_block, "b2", b2)
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.disable_freeu
def disable_freeu(self):
"""Disables the FreeU mechanism."""
freeu_keys = {"s1", "s2", "b1", "b2"}
for i, upsample_block in enumerate(self.up_blocks):
for k in freeu_keys:
if hasattr(upsample_block, k) or getattr(upsample_block, k, None) is not None:
setattr(upsample_block, k, None)
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.fuse_qkv_projections
def fuse_qkv_projections(self):
"""
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query, key, value)
are fused. For cross-attention modules, key and value projection matrices are fused.
<Tip warning={true}>
This API is 🧪 experimental.
</Tip>
"""
self.original_attn_processors = None
for _, attn_processor in self.attn_processors.items():
if "Added" in str(attn_processor.__class__.__name__):
raise ValueError("`fuse_qkv_projections()` is not supported for models having added KV projections.")
self.original_attn_processors = self.attn_processors
for module in self.modules():
if isinstance(module, Attention):
module.fuse_projections(fuse=True)
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.unfuse_qkv_projections
def unfuse_qkv_projections(self):
"""Disables the fused QKV projection if enabled.
<Tip warning={true}>
This API is 🧪 experimental.
</Tip>
"""
if self.original_attn_processors is not None:
self.set_attn_processor(self.original_attn_processors)
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.unload_lora
def unload_lora(self):
"""Unloads LoRA weights."""
deprecate(
"unload_lora",
"0.28.0",
"Calling `unload_lora()` is deprecated and will be removed in a future version. Please install `peft` and then call `disable_adapters().",
)
for module in self.modules():
if hasattr(module, "set_lora_layer"):
module.set_lora_layer(None)
def forward(
self,
sample: torch.Tensor,
timestep: Union[torch.Tensor, float, int],
encoder_hidden_states: torch.Tensor,
class_labels: Optional[torch.Tensor] = None,
timestep_cond: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
mid_block_additional_residual: Optional[torch.Tensor] = None,
return_dict: bool = True,
) -> Union[UNet3DConditionOutput, Tuple[torch.Tensor]]:
r"""
The [`UNet3DConditionModel`] forward method.
Args:
sample (`torch.Tensor`):
The noisy input tensor with the following shape `(batch, num_channels, num_frames, height, width`.
timestep (`torch.Tensor` or `float` or `int`): The number of timesteps to denoise an input.
encoder_hidden_states (`torch.Tensor`):
The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
class_labels (`torch.Tensor`, *optional*, defaults to `None`):
Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
timestep_cond: (`torch.Tensor`, *optional*, defaults to `None`):
Conditional embeddings for timestep. If provided, the embeddings will be summed with the samples passed
through the `self.time_embedding` layer to obtain the timestep embeddings.
attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
negative values to the attention scores corresponding to "discard" tokens.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
down_block_additional_residuals: (`tuple` of `torch.Tensor`, *optional*):
A tuple of tensors that if specified are added to the residuals of down unet blocks.
mid_block_additional_residual: (`torch.Tensor`, *optional*):
A tensor that if specified is added to the residual of the middle unet block.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~models.unet_3d_condition.UNet3DConditionOutput`] instead of a plain
tuple.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
Returns:
[`~models.unet_3d_condition.UNet3DConditionOutput`] or `tuple`:
If `return_dict` is True, an [`~models.unet_3d_condition.UNet3DConditionOutput`] is returned, otherwise
a `tuple` is returned where the first element is the sample tensor.
"""
# By default samples have to be AT least a multiple of the overall upsampling factor.
# The overall upsampling factor is equal to 2 ** (# num of upsampling layears).
# However, the upsampling interpolation output size can be forced to fit any upsampling size
# on the fly if necessary.
default_overall_up_factor = 2**self.num_upsamplers
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
forward_upsample_size = False
upsample_size = None
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
logger.info("Forward upsample size to force interpolation output size.")
forward_upsample_size = True
# prepare attention_mask
if attention_mask is not None:
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
attention_mask = attention_mask.unsqueeze(1)
# 1. time
timesteps = timestep
if not torch.is_tensor(timesteps):
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
# This would be a good case for the `match` statement (Python 3.10+)
is_mps = sample.device.type == "mps"
if isinstance(timestep, float):
dtype = torch.float32 if is_mps else torch.float64
else:
dtype = torch.int32 if is_mps else torch.int64
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
elif len(timesteps.shape) == 0:
timesteps = timesteps[None].to(sample.device)
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
num_frames = sample.shape[2]
timesteps = timesteps.expand(sample.shape[0])
t_emb = self.time_proj(timesteps)
# timesteps does not contain any weights and will always return f32 tensors
# but time_embedding might actually be running in fp16. so we need to cast here.
# there might be better ways to encapsulate this.
t_emb = t_emb.to(dtype=self.dtype)
emb = self.time_embedding(t_emb, timestep_cond)
emb = emb.repeat_interleave(repeats=num_frames, dim=0)
encoder_hidden_states = encoder_hidden_states.repeat_interleave(repeats=num_frames, dim=0)
# 2. pre-process
sample = sample.permute(0, 2, 1, 3, 4).reshape((sample.shape[0] * num_frames, -1) + sample.shape[3:])
sample = self.conv_in(sample)
sample = self.transformer_in(
sample,
num_frames=num_frames,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)[0]
# 3. down
down_block_res_samples = (sample,)
for downsample_block in self.down_blocks:
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
sample, res_samples = downsample_block(
hidden_states=sample,
temb=emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
num_frames=num_frames,
cross_attention_kwargs=cross_attention_kwargs,
)
else:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb, num_frames=num_frames)
down_block_res_samples += res_samples
if down_block_additional_residuals is not None:
new_down_block_res_samples = ()
for down_block_res_sample, down_block_additional_residual in zip(
down_block_res_samples, down_block_additional_residuals
):
down_block_res_sample = down_block_res_sample + down_block_additional_residual
new_down_block_res_samples += (down_block_res_sample,)
down_block_res_samples = new_down_block_res_samples
# 4. mid
if self.mid_block is not None:
sample = self.mid_block(
sample,
emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
num_frames=num_frames,
cross_attention_kwargs=cross_attention_kwargs,
)
if mid_block_additional_residual is not None:
sample = sample + mid_block_additional_residual
# 5. up
for i, upsample_block in enumerate(self.up_blocks):
is_final_block = i == len(self.up_blocks) - 1
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
# if we have not reached the final block and need to forward the
# upsample size, we do it here
if not is_final_block and forward_upsample_size:
upsample_size = down_block_res_samples[-1].shape[2:]
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
sample = upsample_block(
hidden_states=sample,
temb=emb,
res_hidden_states_tuple=res_samples,
encoder_hidden_states=encoder_hidden_states,
upsample_size=upsample_size,
attention_mask=attention_mask,
num_frames=num_frames,
cross_attention_kwargs=cross_attention_kwargs,
)
else:
sample = upsample_block(
hidden_states=sample,
temb=emb,
res_hidden_states_tuple=res_samples,
upsample_size=upsample_size,
num_frames=num_frames,
)
# 6. post-process
if self.conv_norm_out:
sample = self.conv_norm_out(sample)
sample = self.conv_act(sample)
sample = self.conv_out(sample)
# reshape to (batch, channel, framerate, width, height)
sample = sample[None, :].reshape((-1, num_frames) + sample.shape[1:]).permute(0, 2, 1, 3, 4)
if not return_dict:
return (sample,)
return UNet3DConditionOutput(sample=sample)
| diffusers/src/diffusers/models/unets/unet_3d_condition.py/0 | {
"file_path": "diffusers/src/diffusers/models/unets/unet_3d_condition.py",
"repo_id": "diffusers",
"token_count": 15223
} | 241 |
# Copyright 2024 Salesforce.com, inc.
# Copyright 2024 The HuggingFace Team. All rights reserved.#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import List, Optional, Union
import PIL.Image
import torch
from transformers import CLIPTokenizer
from ...models import AutoencoderKL, UNet2DConditionModel
from ...schedulers import PNDMScheduler
from ...utils import (
logging,
replace_example_docstring,
)
from ...utils.torch_utils import randn_tensor
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
from .blip_image_processing import BlipImageProcessor
from .modeling_blip2 import Blip2QFormerModel
from .modeling_ctx_clip import ContextCLIPTextModel
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> from diffusers.pipelines import BlipDiffusionPipeline
>>> from diffusers.utils import load_image
>>> import torch
>>> blip_diffusion_pipe = BlipDiffusionPipeline.from_pretrained(
... "Salesforce/blipdiffusion", torch_dtype=torch.float16
... ).to("cuda")
>>> cond_subject = "dog"
>>> tgt_subject = "dog"
>>> text_prompt_input = "swimming underwater"
>>> cond_image = load_image(
... "https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog.jpg"
... )
>>> guidance_scale = 7.5
>>> num_inference_steps = 25
>>> negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
>>> output = blip_diffusion_pipe(
... text_prompt_input,
... cond_image,
... cond_subject,
... tgt_subject,
... guidance_scale=guidance_scale,
... num_inference_steps=num_inference_steps,
... neg_prompt=negative_prompt,
... height=512,
... width=512,
... ).images
>>> output[0].save("image.png")
```
"""
class BlipDiffusionPipeline(DiffusionPipeline):
"""
Pipeline for Zero-Shot Subject Driven Generation using Blip Diffusion.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
tokenizer ([`CLIPTokenizer`]):
Tokenizer for the text encoder
text_encoder ([`ContextCLIPTextModel`]):
Text encoder to encode the text prompt
vae ([`AutoencoderKL`]):
VAE model to map the latents to the image
unet ([`UNet2DConditionModel`]):
Conditional U-Net architecture to denoise the image embedding.
scheduler ([`PNDMScheduler`]):
A scheduler to be used in combination with `unet` to generate image latents.
qformer ([`Blip2QFormerModel`]):
QFormer model to get multi-modal embeddings from the text and image.
image_processor ([`BlipImageProcessor`]):
Image Processor to preprocess and postprocess the image.
ctx_begin_pos (int, `optional`, defaults to 2):
Position of the context token in the text encoder.
"""
model_cpu_offload_seq = "qformer->text_encoder->unet->vae"
def __init__(
self,
tokenizer: CLIPTokenizer,
text_encoder: ContextCLIPTextModel,
vae: AutoencoderKL,
unet: UNet2DConditionModel,
scheduler: PNDMScheduler,
qformer: Blip2QFormerModel,
image_processor: BlipImageProcessor,
ctx_begin_pos: int = 2,
mean: List[float] = None,
std: List[float] = None,
):
super().__init__()
self.register_modules(
tokenizer=tokenizer,
text_encoder=text_encoder,
vae=vae,
unet=unet,
scheduler=scheduler,
qformer=qformer,
image_processor=image_processor,
)
self.register_to_config(ctx_begin_pos=ctx_begin_pos, mean=mean, std=std)
def get_query_embeddings(self, input_image, src_subject):
return self.qformer(image_input=input_image, text_input=src_subject, return_dict=False)
# from the original Blip Diffusion code, speciefies the target subject and augments the prompt by repeating it
def _build_prompt(self, prompts, tgt_subjects, prompt_strength=1.0, prompt_reps=20):
rv = []
for prompt, tgt_subject in zip(prompts, tgt_subjects):
prompt = f"a {tgt_subject} {prompt.strip()}"
# a trick to amplify the prompt
rv.append(", ".join([prompt] * int(prompt_strength * prompt_reps)))
return rv
# Copied from diffusers.pipelines.consistency_models.pipeline_consistency_models.ConsistencyModelPipeline.prepare_latents
def prepare_latents(self, batch_size, num_channels, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels, height, width)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device=device, dtype=dtype)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def encode_prompt(self, query_embeds, prompt, device=None):
device = device or self._execution_device
# embeddings for prompt, with query_embeds as context
max_len = self.text_encoder.text_model.config.max_position_embeddings
max_len -= self.qformer.config.num_query_tokens
tokenized_prompt = self.tokenizer(
prompt,
padding="max_length",
truncation=True,
max_length=max_len,
return_tensors="pt",
).to(device)
batch_size = query_embeds.shape[0]
ctx_begin_pos = [self.config.ctx_begin_pos] * batch_size
text_embeddings = self.text_encoder(
input_ids=tokenized_prompt.input_ids,
ctx_embeddings=query_embeds,
ctx_begin_pos=ctx_begin_pos,
)[0]
return text_embeddings
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: List[str],
reference_image: PIL.Image.Image,
source_subject_category: List[str],
target_subject_category: List[str],
latents: Optional[torch.Tensor] = None,
guidance_scale: float = 7.5,
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
neg_prompt: Optional[str] = "",
prompt_strength: float = 1.0,
prompt_reps: int = 20,
output_type: Optional[str] = "pil",
return_dict: bool = True,
):
"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`List[str]`):
The prompt or prompts to guide the image generation.
reference_image (`PIL.Image.Image`):
The reference image to condition the generation on.
source_subject_category (`List[str]`):
The source subject category.
target_subject_category (`List[str]`):
The target subject category.
latents (`torch.Tensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by random sampling.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
height (`int`, *optional*, defaults to 512):
The height of the generated image.
width (`int`, *optional*, defaults to 512):
The width of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
neg_prompt (`str`, *optional*, defaults to ""):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
prompt_strength (`float`, *optional*, defaults to 1.0):
The strength of the prompt. Specifies the number of times the prompt is repeated along with prompt_reps
to amplify the prompt.
prompt_reps (`int`, *optional*, defaults to 20):
The number of times the prompt is repeated along with prompt_strength to amplify the prompt.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
(`np.array`) or `"pt"` (`torch.Tensor`).
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
Examples:
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`
"""
device = self._execution_device
reference_image = self.image_processor.preprocess(
reference_image, image_mean=self.config.mean, image_std=self.config.std, return_tensors="pt"
)["pixel_values"]
reference_image = reference_image.to(device)
if isinstance(prompt, str):
prompt = [prompt]
if isinstance(source_subject_category, str):
source_subject_category = [source_subject_category]
if isinstance(target_subject_category, str):
target_subject_category = [target_subject_category]
batch_size = len(prompt)
prompt = self._build_prompt(
prompts=prompt,
tgt_subjects=target_subject_category,
prompt_strength=prompt_strength,
prompt_reps=prompt_reps,
)
query_embeds = self.get_query_embeddings(reference_image, source_subject_category)
text_embeddings = self.encode_prompt(query_embeds, prompt, device)
do_classifier_free_guidance = guidance_scale > 1.0
if do_classifier_free_guidance:
max_length = self.text_encoder.text_model.config.max_position_embeddings
uncond_input = self.tokenizer(
[neg_prompt] * batch_size,
padding="max_length",
max_length=max_length,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(
input_ids=uncond_input.input_ids.to(device),
ctx_embeddings=None,
)[0]
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
scale_down_factor = 2 ** (len(self.unet.config.block_out_channels) - 1)
latents = self.prepare_latents(
batch_size=batch_size,
num_channels=self.unet.config.in_channels,
height=height // scale_down_factor,
width=width // scale_down_factor,
generator=generator,
latents=latents,
dtype=self.unet.dtype,
device=device,
)
# set timesteps
extra_set_kwargs = {}
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
for i, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
# expand the latents if we are doing classifier free guidance
do_classifier_free_guidance = guidance_scale > 1.0
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
noise_pred = self.unet(
latent_model_input,
timestep=t,
encoder_hidden_states=text_embeddings,
down_block_additional_residuals=None,
mid_block_additional_residual=None,
)["sample"]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
latents = self.scheduler.step(
noise_pred,
t,
latents,
)["prev_sample"]
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image = self.image_processor.postprocess(image, output_type=output_type)
# Offload all models
self.maybe_free_model_hooks()
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
| diffusers/src/diffusers/pipelines/blip_diffusion/pipeline_blip_diffusion.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/blip_diffusion/pipeline_blip_diffusion.py",
"repo_id": "diffusers",
"token_count": 6480
} | 242 |
from typing import TYPE_CHECKING
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
_import_structure = {"pipeline_dance_diffusion": ["DanceDiffusionPipeline"]}
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
from .pipeline_dance_diffusion import DanceDiffusionPipeline
else:
import sys
sys.modules[__name__] = _LazyModule(
__name__,
globals()["__file__"],
_import_structure,
module_spec=__spec__,
)
| diffusers/src/diffusers/pipelines/dance_diffusion/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/dance_diffusion/__init__.py",
"repo_id": "diffusers",
"token_count": 189
} | 243 |
from typing import List
import PIL.Image
import torch
from PIL import Image
from ...configuration_utils import ConfigMixin
from ...models.modeling_utils import ModelMixin
from ...utils import PIL_INTERPOLATION
class IFWatermarker(ModelMixin, ConfigMixin):
def __init__(self):
super().__init__()
self.register_buffer("watermark_image", torch.zeros((62, 62, 4)))
self.watermark_image_as_pil = None
def apply_watermark(self, images: List[PIL.Image.Image], sample_size=None):
# copied from https://github.com/deep-floyd/IF/blob/b77482e36ca2031cb94dbca1001fc1e6400bf4ab/deepfloyd_if/modules/base.py#L287
h = images[0].height
w = images[0].width
sample_size = sample_size or h
coef = min(h / sample_size, w / sample_size)
img_h, img_w = (int(h / coef), int(w / coef)) if coef < 1 else (h, w)
S1, S2 = 1024**2, img_w * img_h
K = (S2 / S1) ** 0.5
wm_size, wm_x, wm_y = int(K * 62), img_w - int(14 * K), img_h - int(14 * K)
if self.watermark_image_as_pil is None:
watermark_image = self.watermark_image.to(torch.uint8).cpu().numpy()
watermark_image = Image.fromarray(watermark_image, mode="RGBA")
self.watermark_image_as_pil = watermark_image
wm_img = self.watermark_image_as_pil.resize(
(wm_size, wm_size), PIL_INTERPOLATION["bicubic"], reducing_gap=None
)
for pil_img in images:
pil_img.paste(wm_img, box=(wm_x - wm_size, wm_y - wm_size, wm_x, wm_y), mask=wm_img.split()[-1])
return images
| diffusers/src/diffusers/pipelines/deepfloyd_if/watermark.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deepfloyd_if/watermark.py",
"repo_id": "diffusers",
"token_count": 736
} | 244 |
# Copyright 2024 ETH Zurich Computer Vision Lab and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from ....models import UNet2DModel
from ....schedulers import RePaintScheduler
from ....utils import PIL_INTERPOLATION, deprecate, logging
from ....utils.torch_utils import randn_tensor
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess
def _preprocess_image(image: Union[List, PIL.Image.Image, torch.Tensor]):
deprecation_message = "The preprocess method is deprecated and will be removed in diffusers 1.0.0. Please use VaeImageProcessor.preprocess(...) instead"
deprecate("preprocess", "1.0.0", deprecation_message, standard_warn=False)
if isinstance(image, torch.Tensor):
return image
elif isinstance(image, PIL.Image.Image):
image = [image]
if isinstance(image[0], PIL.Image.Image):
w, h = image[0].size
w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
image = np.concatenate(image, axis=0)
image = np.array(image).astype(np.float32) / 255.0
image = image.transpose(0, 3, 1, 2)
image = 2.0 * image - 1.0
image = torch.from_numpy(image)
elif isinstance(image[0], torch.Tensor):
image = torch.cat(image, dim=0)
return image
def _preprocess_mask(mask: Union[List, PIL.Image.Image, torch.Tensor]):
if isinstance(mask, torch.Tensor):
return mask
elif isinstance(mask, PIL.Image.Image):
mask = [mask]
if isinstance(mask[0], PIL.Image.Image):
w, h = mask[0].size
w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
mask = [np.array(m.convert("L").resize((w, h), resample=PIL_INTERPOLATION["nearest"]))[None, :] for m in mask]
mask = np.concatenate(mask, axis=0)
mask = mask.astype(np.float32) / 255.0
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
mask = torch.from_numpy(mask)
elif isinstance(mask[0], torch.Tensor):
mask = torch.cat(mask, dim=0)
return mask
class RePaintPipeline(DiffusionPipeline):
r"""
Pipeline for image inpainting using RePaint.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
Parameters:
unet ([`UNet2DModel`]):
A `UNet2DModel` to denoise the encoded image latents.
scheduler ([`RePaintScheduler`]):
A `RePaintScheduler` to be used in combination with `unet` to denoise the encoded image.
"""
unet: UNet2DModel
scheduler: RePaintScheduler
model_cpu_offload_seq = "unet"
def __init__(self, unet, scheduler):
super().__init__()
self.register_modules(unet=unet, scheduler=scheduler)
@torch.no_grad()
def __call__(
self,
image: Union[torch.Tensor, PIL.Image.Image],
mask_image: Union[torch.Tensor, PIL.Image.Image],
num_inference_steps: int = 250,
eta: float = 0.0,
jump_length: int = 10,
jump_n_sample: int = 10,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
) -> Union[ImagePipelineOutput, Tuple]:
r"""
The call function to the pipeline for generation.
Args:
image (`torch.Tensor` or `PIL.Image.Image`):
The original image to inpaint on.
mask_image (`torch.Tensor` or `PIL.Image.Image`):
The mask_image where 0.0 define which part of the original image to inpaint.
num_inference_steps (`int`, *optional*, defaults to 1000):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
eta (`float`):
The weight of the added noise in a diffusion step. Its value is between 0.0 and 1.0; 0.0 corresponds to
DDIM and 1.0 is the DDPM scheduler.
jump_length (`int`, *optional*, defaults to 10):
The number of steps taken forward in time before going backward in time for a single jump ("j" in
RePaint paper). Take a look at Figure 9 and 10 in the [paper](https://arxiv.org/pdf/2201.09865.pdf).
jump_n_sample (`int`, *optional*, defaults to 10):
The number of times to make a forward time jump for a given chosen time sample. Take a look at Figure 9
and 10 in the [paper](https://arxiv.org/pdf/2201.09865.pdf).
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
output_type (`str`, `optional`, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`ImagePipelineOutput`] instead of a plain tuple.
Example:
```py
>>> from io import BytesIO
>>> import torch
>>> import PIL
>>> import requests
>>> from diffusers import RePaintPipeline, RePaintScheduler
>>> def download_image(url):
... response = requests.get(url)
... return PIL.Image.open(BytesIO(response.content)).convert("RGB")
>>> img_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/repaint/celeba_hq_256.png"
>>> mask_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/repaint/mask_256.png"
>>> # Load the original image and the mask as PIL images
>>> original_image = download_image(img_url).resize((256, 256))
>>> mask_image = download_image(mask_url).resize((256, 256))
>>> # Load the RePaint scheduler and pipeline based on a pretrained DDPM model
>>> scheduler = RePaintScheduler.from_pretrained("google/ddpm-ema-celebahq-256")
>>> pipe = RePaintPipeline.from_pretrained("google/ddpm-ema-celebahq-256", scheduler=scheduler)
>>> pipe = pipe.to("cuda")
>>> generator = torch.Generator(device="cuda").manual_seed(0)
>>> output = pipe(
... image=original_image,
... mask_image=mask_image,
... num_inference_steps=250,
... eta=0.0,
... jump_length=10,
... jump_n_sample=10,
... generator=generator,
... )
>>> inpainted_image = output.images[0]
```
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.ImagePipelineOutput`] is returned, otherwise a `tuple` is
returned where the first element is a list with the generated images.
"""
original_image = image
original_image = _preprocess_image(original_image)
original_image = original_image.to(device=self._execution_device, dtype=self.unet.dtype)
mask_image = _preprocess_mask(mask_image)
mask_image = mask_image.to(device=self._execution_device, dtype=self.unet.dtype)
batch_size = original_image.shape[0]
# sample gaussian noise to begin the loop
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
image_shape = original_image.shape
image = randn_tensor(image_shape, generator=generator, device=self._execution_device, dtype=self.unet.dtype)
# set step values
self.scheduler.set_timesteps(num_inference_steps, jump_length, jump_n_sample, self._execution_device)
self.scheduler.eta = eta
t_last = self.scheduler.timesteps[0] + 1
generator = generator[0] if isinstance(generator, list) else generator
for i, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
if t < t_last:
# predict the noise residual
model_output = self.unet(image, t).sample
# compute previous image: x_t -> x_t-1
image = self.scheduler.step(model_output, t, image, original_image, mask_image, generator).prev_sample
else:
# compute the reverse: x_t-1 -> x_t
image = self.scheduler.undo_step(image, t_last, generator)
t_last = t
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
| diffusers/src/diffusers/pipelines/deprecated/repaint/pipeline_repaint.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/repaint/pipeline_repaint.py",
"repo_id": "diffusers",
"token_count": 4200
} | 245 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import List, Optional, Tuple, Union
import torch
from ....models import UNet2DModel
from ....schedulers import KarrasVeScheduler
from ....utils.torch_utils import randn_tensor
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
class KarrasVePipeline(DiffusionPipeline):
r"""
Pipeline for unconditional image generation.
Parameters:
unet ([`UNet2DModel`]):
A `UNet2DModel` to denoise the encoded image.
scheduler ([`KarrasVeScheduler`]):
A scheduler to be used in combination with `unet` to denoise the encoded image.
"""
# add type hints for linting
unet: UNet2DModel
scheduler: KarrasVeScheduler
def __init__(self, unet: UNet2DModel, scheduler: KarrasVeScheduler):
super().__init__()
self.register_modules(unet=unet, scheduler=scheduler)
@torch.no_grad()
def __call__(
self,
batch_size: int = 1,
num_inference_steps: int = 50,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
**kwargs,
) -> Union[Tuple, ImagePipelineOutput]:
r"""
The call function to the pipeline for generation.
Args:
batch_size (`int`, *optional*, defaults to 1):
The number of images to generate.
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`ImagePipelineOutput`] instead of a plain tuple.
Example:
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.ImagePipelineOutput`] is returned, otherwise a `tuple` is
returned where the first element is a list with the generated images.
"""
img_size = self.unet.config.sample_size
shape = (batch_size, 3, img_size, img_size)
model = self.unet
# sample x_0 ~ N(0, sigma_0^2 * I)
sample = randn_tensor(shape, generator=generator, device=self.device) * self.scheduler.init_noise_sigma
self.scheduler.set_timesteps(num_inference_steps)
for t in self.progress_bar(self.scheduler.timesteps):
# here sigma_t == t_i from the paper
sigma = self.scheduler.schedule[t]
sigma_prev = self.scheduler.schedule[t - 1] if t > 0 else 0
# 1. Select temporarily increased noise level sigma_hat
# 2. Add new noise to move from sample_i to sample_hat
sample_hat, sigma_hat = self.scheduler.add_noise_to_input(sample, sigma, generator=generator)
# 3. Predict the noise residual given the noise magnitude `sigma_hat`
# The model inputs and output are adjusted by following eq. (213) in [1].
model_output = (sigma_hat / 2) * model((sample_hat + 1) / 2, sigma_hat / 2).sample
# 4. Evaluate dx/dt at sigma_hat
# 5. Take Euler step from sigma to sigma_prev
step_output = self.scheduler.step(model_output, sigma_hat, sigma_prev, sample_hat)
if sigma_prev != 0:
# 6. Apply 2nd order correction
# The model inputs and output are adjusted by following eq. (213) in [1].
model_output = (sigma_prev / 2) * model((step_output.prev_sample + 1) / 2, sigma_prev / 2).sample
step_output = self.scheduler.step_correct(
model_output,
sigma_hat,
sigma_prev,
sample_hat,
step_output.prev_sample,
step_output["derivative"],
)
sample = step_output.prev_sample
sample = (sample / 2 + 0.5).clamp(0, 1)
image = sample.cpu().permute(0, 2, 3, 1).numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
| diffusers/src/diffusers/pipelines/deprecated/stochastic_karras_ve/pipeline_stochastic_karras_ve.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/stochastic_karras_ve/pipeline_stochastic_karras_ve.py",
"repo_id": "diffusers",
"token_count": 2264
} | 246 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Callable, List, Optional, Union
import PIL.Image
import torch
from transformers import (
CLIPImageProcessor,
CLIPTextModelWithProjection,
CLIPTokenizer,
CLIPVisionModelWithProjection,
XLMRobertaTokenizer,
)
from ...models import PriorTransformer, UNet2DConditionModel, VQModel
from ...schedulers import DDIMScheduler, DDPMScheduler, UnCLIPScheduler
from ...utils import (
replace_example_docstring,
)
from ..pipeline_utils import DiffusionPipeline
from .pipeline_kandinsky import KandinskyPipeline
from .pipeline_kandinsky_img2img import KandinskyImg2ImgPipeline
from .pipeline_kandinsky_inpaint import KandinskyInpaintPipeline
from .pipeline_kandinsky_prior import KandinskyPriorPipeline
from .text_encoder import MultilingualCLIP
TEXT2IMAGE_EXAMPLE_DOC_STRING = """
Examples:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained(
"kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16
)
pipe.enable_model_cpu_offload()
prompt = "A lion in galaxies, spirals, nebulae, stars, smoke, iridescent, intricate detail, octane render, 8k"
image = pipe(prompt=prompt, num_inference_steps=25).images[0]
```
"""
IMAGE2IMAGE_EXAMPLE_DOC_STRING = """
Examples:
```py
from diffusers import AutoPipelineForImage2Image
import torch
import requests
from io import BytesIO
from PIL import Image
import os
pipe = AutoPipelineForImage2Image.from_pretrained(
"kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16
)
pipe.enable_model_cpu_offload()
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
image.thumbnail((768, 768))
image = pipe(prompt=prompt, image=original_image, num_inference_steps=25).images[0]
```
"""
INPAINT_EXAMPLE_DOC_STRING = """
Examples:
```py
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image
import torch
import numpy as np
pipe = AutoPipelineForInpainting.from_pretrained(
"kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16
)
pipe.enable_model_cpu_offload()
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
original_image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
)
mask = np.zeros((768, 768), dtype=np.float32)
# Let's mask out an area above the cat's head
mask[:250, 250:-250] = 1
image = pipe(prompt=prompt, image=original_image, mask_image=mask, num_inference_steps=25).images[0]
```
"""
class KandinskyCombinedPipeline(DiffusionPipeline):
"""
Combined Pipeline for text-to-image generation using Kandinsky
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
text_encoder ([`MultilingualCLIP`]):
Frozen text-encoder.
tokenizer ([`XLMRobertaTokenizer`]):
Tokenizer of class
scheduler (Union[`DDIMScheduler`,`DDPMScheduler`]):
A scheduler to be used in combination with `unet` to generate image latents.
unet ([`UNet2DConditionModel`]):
Conditional U-Net architecture to denoise the image embedding.
movq ([`VQModel`]):
MoVQ Decoder to generate the image from the latents.
prior_prior ([`PriorTransformer`]):
The canonical unCLIP prior to approximate the image embedding from the text embedding.
prior_image_encoder ([`CLIPVisionModelWithProjection`]):
Frozen image-encoder.
prior_text_encoder ([`CLIPTextModelWithProjection`]):
Frozen text-encoder.
prior_tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
prior_scheduler ([`UnCLIPScheduler`]):
A scheduler to be used in combination with `prior` to generate image embedding.
"""
_load_connected_pipes = True
model_cpu_offload_seq = "text_encoder->unet->movq->prior_prior->prior_image_encoder->prior_text_encoder"
_exclude_from_cpu_offload = ["prior_prior"]
def __init__(
self,
text_encoder: MultilingualCLIP,
tokenizer: XLMRobertaTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, DDPMScheduler],
movq: VQModel,
prior_prior: PriorTransformer,
prior_image_encoder: CLIPVisionModelWithProjection,
prior_text_encoder: CLIPTextModelWithProjection,
prior_tokenizer: CLIPTokenizer,
prior_scheduler: UnCLIPScheduler,
prior_image_processor: CLIPImageProcessor,
):
super().__init__()
self.register_modules(
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
movq=movq,
prior_prior=prior_prior,
prior_image_encoder=prior_image_encoder,
prior_text_encoder=prior_text_encoder,
prior_tokenizer=prior_tokenizer,
prior_scheduler=prior_scheduler,
prior_image_processor=prior_image_processor,
)
self.prior_pipe = KandinskyPriorPipeline(
prior=prior_prior,
image_encoder=prior_image_encoder,
text_encoder=prior_text_encoder,
tokenizer=prior_tokenizer,
scheduler=prior_scheduler,
image_processor=prior_image_processor,
)
self.decoder_pipe = KandinskyPipeline(
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
movq=movq,
)
def enable_xformers_memory_efficient_attention(self, attention_op: Optional[Callable] = None):
self.decoder_pipe.enable_xformers_memory_efficient_attention(attention_op)
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models (`unet`, `text_encoder`, `vae`, and `safety checker` state dicts) to CPU using 🤗
Accelerate, significantly reducing memory usage. Models are moved to a `torch.device('meta')` and loaded on a
GPU only when their specific submodule's `forward` method is called. Offloading happens on a submodule basis.
Memory savings are higher than using `enable_model_cpu_offload`, but performance is lower.
"""
self.prior_pipe.enable_sequential_cpu_offload(gpu_id=gpu_id)
self.decoder_pipe.enable_sequential_cpu_offload(gpu_id=gpu_id)
def progress_bar(self, iterable=None, total=None):
self.prior_pipe.progress_bar(iterable=iterable, total=total)
self.decoder_pipe.progress_bar(iterable=iterable, total=total)
self.decoder_pipe.enable_model_cpu_offload()
def set_progress_bar_config(self, **kwargs):
self.prior_pipe.set_progress_bar_config(**kwargs)
self.decoder_pipe.set_progress_bar_config(**kwargs)
@torch.no_grad()
@replace_example_docstring(TEXT2IMAGE_EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]],
negative_prompt: Optional[Union[str, List[str]]] = None,
num_inference_steps: int = 100,
guidance_scale: float = 4.0,
num_images_per_prompt: int = 1,
height: int = 512,
width: int = 512,
prior_guidance_scale: float = 4.0,
prior_num_inference_steps: int = 25,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.Tensor] = None,
output_type: Optional[str] = "pil",
callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
callback_steps: int = 1,
return_dict: bool = True,
):
"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
prior_num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.Tensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
(`np.array`) or `"pt"` (`torch.Tensor`).
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
Examples:
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`
"""
prior_outputs = self.prior_pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=prior_num_inference_steps,
generator=generator,
latents=latents,
guidance_scale=prior_guidance_scale,
output_type="pt",
return_dict=False,
)
image_embeds = prior_outputs[0]
negative_image_embeds = prior_outputs[1]
prompt = [prompt] if not isinstance(prompt, (list, tuple)) else prompt
if len(prompt) < image_embeds.shape[0] and image_embeds.shape[0] % len(prompt) == 0:
prompt = (image_embeds.shape[0] // len(prompt)) * prompt
outputs = self.decoder_pipe(
prompt=prompt,
image_embeds=image_embeds,
negative_image_embeds=negative_image_embeds,
width=width,
height=height,
num_inference_steps=num_inference_steps,
generator=generator,
guidance_scale=guidance_scale,
output_type=output_type,
callback=callback,
callback_steps=callback_steps,
return_dict=return_dict,
)
self.maybe_free_model_hooks()
return outputs
class KandinskyImg2ImgCombinedPipeline(DiffusionPipeline):
"""
Combined Pipeline for image-to-image generation using Kandinsky
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
text_encoder ([`MultilingualCLIP`]):
Frozen text-encoder.
tokenizer ([`XLMRobertaTokenizer`]):
Tokenizer of class
scheduler (Union[`DDIMScheduler`,`DDPMScheduler`]):
A scheduler to be used in combination with `unet` to generate image latents.
unet ([`UNet2DConditionModel`]):
Conditional U-Net architecture to denoise the image embedding.
movq ([`VQModel`]):
MoVQ Decoder to generate the image from the latents.
prior_prior ([`PriorTransformer`]):
The canonical unCLIP prior to approximate the image embedding from the text embedding.
prior_image_encoder ([`CLIPVisionModelWithProjection`]):
Frozen image-encoder.
prior_text_encoder ([`CLIPTextModelWithProjection`]):
Frozen text-encoder.
prior_tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
prior_scheduler ([`UnCLIPScheduler`]):
A scheduler to be used in combination with `prior` to generate image embedding.
"""
_load_connected_pipes = True
model_cpu_offload_seq = "prior_text_encoder->prior_image_encoder->prior_prior->" "text_encoder->unet->movq"
_exclude_from_cpu_offload = ["prior_prior"]
def __init__(
self,
text_encoder: MultilingualCLIP,
tokenizer: XLMRobertaTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, DDPMScheduler],
movq: VQModel,
prior_prior: PriorTransformer,
prior_image_encoder: CLIPVisionModelWithProjection,
prior_text_encoder: CLIPTextModelWithProjection,
prior_tokenizer: CLIPTokenizer,
prior_scheduler: UnCLIPScheduler,
prior_image_processor: CLIPImageProcessor,
):
super().__init__()
self.register_modules(
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
movq=movq,
prior_prior=prior_prior,
prior_image_encoder=prior_image_encoder,
prior_text_encoder=prior_text_encoder,
prior_tokenizer=prior_tokenizer,
prior_scheduler=prior_scheduler,
prior_image_processor=prior_image_processor,
)
self.prior_pipe = KandinskyPriorPipeline(
prior=prior_prior,
image_encoder=prior_image_encoder,
text_encoder=prior_text_encoder,
tokenizer=prior_tokenizer,
scheduler=prior_scheduler,
image_processor=prior_image_processor,
)
self.decoder_pipe = KandinskyImg2ImgPipeline(
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
movq=movq,
)
def enable_xformers_memory_efficient_attention(self, attention_op: Optional[Callable] = None):
self.decoder_pipe.enable_xformers_memory_efficient_attention(attention_op)
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
Note that offloading happens on a submodule basis. Memory savings are higher than with
`enable_model_cpu_offload`, but performance is lower.
"""
self.prior_pipe.enable_sequential_cpu_offload(gpu_id=gpu_id)
self.decoder_pipe.enable_sequential_cpu_offload(gpu_id=gpu_id)
def progress_bar(self, iterable=None, total=None):
self.prior_pipe.progress_bar(iterable=iterable, total=total)
self.decoder_pipe.progress_bar(iterable=iterable, total=total)
self.decoder_pipe.enable_model_cpu_offload()
def set_progress_bar_config(self, **kwargs):
self.prior_pipe.set_progress_bar_config(**kwargs)
self.decoder_pipe.set_progress_bar_config(**kwargs)
@torch.no_grad()
@replace_example_docstring(IMAGE2IMAGE_EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]],
image: Union[torch.Tensor, PIL.Image.Image, List[torch.Tensor], List[PIL.Image.Image]],
negative_prompt: Optional[Union[str, List[str]]] = None,
num_inference_steps: int = 100,
guidance_scale: float = 4.0,
num_images_per_prompt: int = 1,
strength: float = 0.3,
height: int = 512,
width: int = 512,
prior_guidance_scale: float = 4.0,
prior_num_inference_steps: int = 25,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.Tensor] = None,
output_type: Optional[str] = "pil",
callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
callback_steps: int = 1,
return_dict: bool = True,
):
"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
image (`torch.Tensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.Tensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process. Can also accept image latents as `image`, if passing latents directly, it will not be encoded
again.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
strength (`float`, *optional*, defaults to 0.3):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
prior_num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.Tensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
(`np.array`) or `"pt"` (`torch.Tensor`).
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
Examples:
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`
"""
prior_outputs = self.prior_pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=prior_num_inference_steps,
generator=generator,
latents=latents,
guidance_scale=prior_guidance_scale,
output_type="pt",
return_dict=False,
)
image_embeds = prior_outputs[0]
negative_image_embeds = prior_outputs[1]
prompt = [prompt] if not isinstance(prompt, (list, tuple)) else prompt
image = [image] if isinstance(prompt, PIL.Image.Image) else image
if len(prompt) < image_embeds.shape[0] and image_embeds.shape[0] % len(prompt) == 0:
prompt = (image_embeds.shape[0] // len(prompt)) * prompt
if (
isinstance(image, (list, tuple))
and len(image) < image_embeds.shape[0]
and image_embeds.shape[0] % len(image) == 0
):
image = (image_embeds.shape[0] // len(image)) * image
outputs = self.decoder_pipe(
prompt=prompt,
image=image,
image_embeds=image_embeds,
negative_image_embeds=negative_image_embeds,
strength=strength,
width=width,
height=height,
num_inference_steps=num_inference_steps,
generator=generator,
guidance_scale=guidance_scale,
output_type=output_type,
callback=callback,
callback_steps=callback_steps,
return_dict=return_dict,
)
self.maybe_free_model_hooks()
return outputs
class KandinskyInpaintCombinedPipeline(DiffusionPipeline):
"""
Combined Pipeline for generation using Kandinsky
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
text_encoder ([`MultilingualCLIP`]):
Frozen text-encoder.
tokenizer ([`XLMRobertaTokenizer`]):
Tokenizer of class
scheduler (Union[`DDIMScheduler`,`DDPMScheduler`]):
A scheduler to be used in combination with `unet` to generate image latents.
unet ([`UNet2DConditionModel`]):
Conditional U-Net architecture to denoise the image embedding.
movq ([`VQModel`]):
MoVQ Decoder to generate the image from the latents.
prior_prior ([`PriorTransformer`]):
The canonical unCLIP prior to approximate the image embedding from the text embedding.
prior_image_encoder ([`CLIPVisionModelWithProjection`]):
Frozen image-encoder.
prior_text_encoder ([`CLIPTextModelWithProjection`]):
Frozen text-encoder.
prior_tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
prior_scheduler ([`UnCLIPScheduler`]):
A scheduler to be used in combination with `prior` to generate image embedding.
"""
_load_connected_pipes = True
model_cpu_offload_seq = "prior_text_encoder->prior_image_encoder->prior_prior->text_encoder->unet->movq"
_exclude_from_cpu_offload = ["prior_prior"]
def __init__(
self,
text_encoder: MultilingualCLIP,
tokenizer: XLMRobertaTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, DDPMScheduler],
movq: VQModel,
prior_prior: PriorTransformer,
prior_image_encoder: CLIPVisionModelWithProjection,
prior_text_encoder: CLIPTextModelWithProjection,
prior_tokenizer: CLIPTokenizer,
prior_scheduler: UnCLIPScheduler,
prior_image_processor: CLIPImageProcessor,
):
super().__init__()
self.register_modules(
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
movq=movq,
prior_prior=prior_prior,
prior_image_encoder=prior_image_encoder,
prior_text_encoder=prior_text_encoder,
prior_tokenizer=prior_tokenizer,
prior_scheduler=prior_scheduler,
prior_image_processor=prior_image_processor,
)
self.prior_pipe = KandinskyPriorPipeline(
prior=prior_prior,
image_encoder=prior_image_encoder,
text_encoder=prior_text_encoder,
tokenizer=prior_tokenizer,
scheduler=prior_scheduler,
image_processor=prior_image_processor,
)
self.decoder_pipe = KandinskyInpaintPipeline(
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
movq=movq,
)
def enable_xformers_memory_efficient_attention(self, attention_op: Optional[Callable] = None):
self.decoder_pipe.enable_xformers_memory_efficient_attention(attention_op)
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
Note that offloading happens on a submodule basis. Memory savings are higher than with
`enable_model_cpu_offload`, but performance is lower.
"""
self.prior_pipe.enable_sequential_cpu_offload(gpu_id=gpu_id)
self.decoder_pipe.enable_sequential_cpu_offload(gpu_id=gpu_id)
def progress_bar(self, iterable=None, total=None):
self.prior_pipe.progress_bar(iterable=iterable, total=total)
self.decoder_pipe.progress_bar(iterable=iterable, total=total)
self.decoder_pipe.enable_model_cpu_offload()
def set_progress_bar_config(self, **kwargs):
self.prior_pipe.set_progress_bar_config(**kwargs)
self.decoder_pipe.set_progress_bar_config(**kwargs)
@torch.no_grad()
@replace_example_docstring(INPAINT_EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]],
image: Union[torch.Tensor, PIL.Image.Image, List[torch.Tensor], List[PIL.Image.Image]],
mask_image: Union[torch.Tensor, PIL.Image.Image, List[torch.Tensor], List[PIL.Image.Image]],
negative_prompt: Optional[Union[str, List[str]]] = None,
num_inference_steps: int = 100,
guidance_scale: float = 4.0,
num_images_per_prompt: int = 1,
height: int = 512,
width: int = 512,
prior_guidance_scale: float = 4.0,
prior_num_inference_steps: int = 25,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.Tensor] = None,
output_type: Optional[str] = "pil",
callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
callback_steps: int = 1,
return_dict: bool = True,
):
"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
image (`torch.Tensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.Tensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process. Can also accept image latents as `image`, if passing latents directly, it will not be encoded
again.
mask_image (`np.array`):
Tensor representing an image batch, to mask `image`. White pixels in the mask will be repainted, while
black pixels will be preserved. If `mask_image` is a PIL image, it will be converted to a single
channel (luminance) before use. If it's a tensor, it should contain one color channel (L) instead of 3,
so the expected shape would be `(B, H, W, 1)`.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
prior_num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.Tensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
(`np.array`) or `"pt"` (`torch.Tensor`).
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
Examples:
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`
"""
prior_outputs = self.prior_pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=prior_num_inference_steps,
generator=generator,
latents=latents,
guidance_scale=prior_guidance_scale,
output_type="pt",
return_dict=False,
)
image_embeds = prior_outputs[0]
negative_image_embeds = prior_outputs[1]
prompt = [prompt] if not isinstance(prompt, (list, tuple)) else prompt
image = [image] if isinstance(prompt, PIL.Image.Image) else image
mask_image = [mask_image] if isinstance(mask_image, PIL.Image.Image) else mask_image
if len(prompt) < image_embeds.shape[0] and image_embeds.shape[0] % len(prompt) == 0:
prompt = (image_embeds.shape[0] // len(prompt)) * prompt
if (
isinstance(image, (list, tuple))
and len(image) < image_embeds.shape[0]
and image_embeds.shape[0] % len(image) == 0
):
image = (image_embeds.shape[0] // len(image)) * image
if (
isinstance(mask_image, (list, tuple))
and len(mask_image) < image_embeds.shape[0]
and image_embeds.shape[0] % len(mask_image) == 0
):
mask_image = (image_embeds.shape[0] // len(mask_image)) * mask_image
outputs = self.decoder_pipe(
prompt=prompt,
image=image,
mask_image=mask_image,
image_embeds=image_embeds,
negative_image_embeds=negative_image_embeds,
width=width,
height=height,
num_inference_steps=num_inference_steps,
generator=generator,
guidance_scale=guidance_scale,
output_type=output_type,
callback=callback,
callback_steps=callback_steps,
return_dict=return_dict,
)
self.maybe_free_model_hooks()
return outputs
| diffusers/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_combined.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_combined.py",
"repo_id": "diffusers",
"token_count": 16947
} | 247 |
from typing import Callable, Dict, List, Optional, Union
import torch
from transformers import T5EncoderModel, T5Tokenizer
from ...loaders import LoraLoaderMixin
from ...models import Kandinsky3UNet, VQModel
from ...schedulers import DDPMScheduler
from ...utils import (
deprecate,
logging,
replace_example_docstring,
)
from ...utils.torch_utils import randn_tensor
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> from diffusers import AutoPipelineForText2Image
>>> import torch
>>> pipe = AutoPipelineForText2Image.from_pretrained(
... "kandinsky-community/kandinsky-3", variant="fp16", torch_dtype=torch.float16
... )
>>> pipe.enable_model_cpu_offload()
>>> prompt = "A photograph of the inside of a subway train. There are raccoons sitting on the seats. One of them is reading a newspaper. The window shows the city in the background."
>>> generator = torch.Generator(device="cpu").manual_seed(0)
>>> image = pipe(prompt, num_inference_steps=25, generator=generator).images[0]
```
"""
def downscale_height_and_width(height, width, scale_factor=8):
new_height = height // scale_factor**2
if height % scale_factor**2 != 0:
new_height += 1
new_width = width // scale_factor**2
if width % scale_factor**2 != 0:
new_width += 1
return new_height * scale_factor, new_width * scale_factor
class Kandinsky3Pipeline(DiffusionPipeline, LoraLoaderMixin):
model_cpu_offload_seq = "text_encoder->unet->movq"
_callback_tensor_inputs = [
"latents",
"prompt_embeds",
"negative_prompt_embeds",
"negative_attention_mask",
"attention_mask",
]
def __init__(
self,
tokenizer: T5Tokenizer,
text_encoder: T5EncoderModel,
unet: Kandinsky3UNet,
scheduler: DDPMScheduler,
movq: VQModel,
):
super().__init__()
self.register_modules(
tokenizer=tokenizer, text_encoder=text_encoder, unet=unet, scheduler=scheduler, movq=movq
)
def process_embeds(self, embeddings, attention_mask, cut_context):
if cut_context:
embeddings[attention_mask == 0] = torch.zeros_like(embeddings[attention_mask == 0])
max_seq_length = attention_mask.sum(-1).max() + 1
embeddings = embeddings[:, :max_seq_length]
attention_mask = attention_mask[:, :max_seq_length]
return embeddings, attention_mask
@torch.no_grad()
def encode_prompt(
self,
prompt,
do_classifier_free_guidance=True,
num_images_per_prompt=1,
device=None,
negative_prompt=None,
prompt_embeds: Optional[torch.Tensor] = None,
negative_prompt_embeds: Optional[torch.Tensor] = None,
_cut_context=False,
attention_mask: Optional[torch.Tensor] = None,
negative_attention_mask: Optional[torch.Tensor] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`, *optional*):
torch device to place the resulting embeddings on
num_images_per_prompt (`int`, *optional*, defaults to 1):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`, *optional*, defaults to `True`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
attention_mask (`torch.Tensor`, *optional*):
Pre-generated attention mask. Must provide if passing `prompt_embeds` directly.
negative_attention_mask (`torch.Tensor`, *optional*):
Pre-generated negative attention mask. Must provide if passing `negative_prompt_embeds` directly.
"""
if prompt is not None and negative_prompt is not None:
if type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
if device is None:
device = self._execution_device
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
max_length = 128
if prompt_embeds is None:
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids.to(device)
attention_mask = text_inputs.attention_mask.to(device)
prompt_embeds = self.text_encoder(
text_input_ids,
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
prompt_embeds, attention_mask = self.process_embeds(prompt_embeds, attention_mask, _cut_context)
prompt_embeds = prompt_embeds * attention_mask.unsqueeze(2)
if self.text_encoder is not None:
dtype = self.text_encoder.dtype
else:
dtype = None
prompt_embeds = prompt_embeds.to(dtype=dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
attention_mask = attention_mask.repeat(num_images_per_prompt, 1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
if negative_prompt is not None:
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=128,
truncation=True,
return_attention_mask=True,
return_tensors="pt",
)
text_input_ids = uncond_input.input_ids.to(device)
negative_attention_mask = uncond_input.attention_mask.to(device)
negative_prompt_embeds = self.text_encoder(
text_input_ids,
attention_mask=negative_attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
negative_prompt_embeds = negative_prompt_embeds[:, : prompt_embeds.shape[1]]
negative_attention_mask = negative_attention_mask[:, : prompt_embeds.shape[1]]
negative_prompt_embeds = negative_prompt_embeds * negative_attention_mask.unsqueeze(2)
else:
negative_prompt_embeds = torch.zeros_like(prompt_embeds)
negative_attention_mask = torch.zeros_like(attention_mask)
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=dtype, device=device)
if negative_prompt_embeds.shape != prompt_embeds.shape:
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
negative_attention_mask = negative_attention_mask.repeat(num_images_per_prompt, 1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
else:
negative_prompt_embeds = None
negative_attention_mask = None
return prompt_embeds, negative_prompt_embeds, attention_mask, negative_attention_mask
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
latents = latents.to(device)
latents = latents * scheduler.init_noise_sigma
return latents
def check_inputs(
self,
prompt,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
callback_on_step_end_tensor_inputs=None,
attention_mask=None,
negative_attention_mask=None,
):
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if negative_prompt_embeds is not None and negative_attention_mask is None:
raise ValueError("Please provide `negative_attention_mask` along with `negative_prompt_embeds`")
if negative_prompt_embeds is not None and negative_attention_mask is not None:
if negative_prompt_embeds.shape[:2] != negative_attention_mask.shape:
raise ValueError(
"`negative_prompt_embeds` and `negative_attention_mask` must have the same batch_size and token length when passed directly, but"
f" got: `negative_prompt_embeds` {negative_prompt_embeds.shape[:2]} != `negative_attention_mask`"
f" {negative_attention_mask.shape}."
)
if prompt_embeds is not None and attention_mask is None:
raise ValueError("Please provide `attention_mask` along with `prompt_embeds`")
if prompt_embeds is not None and attention_mask is not None:
if prompt_embeds.shape[:2] != attention_mask.shape:
raise ValueError(
"`prompt_embeds` and `attention_mask` must have the same batch_size and token length when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape[:2]} != `attention_mask`"
f" {attention_mask.shape}."
)
@property
def guidance_scale(self):
return self._guidance_scale
@property
def do_classifier_free_guidance(self):
return self._guidance_scale > 1
@property
def num_timesteps(self):
return self._num_timesteps
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
num_inference_steps: int = 25,
guidance_scale: float = 3.0,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
height: Optional[int] = 1024,
width: Optional[int] = 1024,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
prompt_embeds: Optional[torch.Tensor] = None,
negative_prompt_embeds: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
negative_attention_mask: Optional[torch.Tensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
latents=None,
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
**kwargs,
):
"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
num_inference_steps (`int`, *optional*, defaults to 25):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
timesteps (`List[int]`, *optional*):
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 3.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
height (`int`, *optional*, defaults to self.unet.config.sample_size):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
attention_mask (`torch.Tensor`, *optional*):
Pre-generated attention mask. Must provide if passing `prompt_embeds` directly.
negative_attention_mask (`torch.Tensor`, *optional*):
Pre-generated negative attention mask. Must provide if passing `negative_prompt_embeds` directly.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.IFPipelineOutput`] instead of a plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
clean_caption (`bool`, *optional*, defaults to `True`):
Whether or not to clean the caption before creating embeddings. Requires `beautifulsoup4` and `ftfy` to
be installed. If the dependencies are not installed, the embeddings will be created from the raw
prompt.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
Examples:
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`
"""
callback = kwargs.pop("callback", None)
callback_steps = kwargs.pop("callback_steps", None)
if callback is not None:
deprecate(
"callback",
"1.0.0",
"Passing `callback` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
)
if callback_steps is not None:
deprecate(
"callback_steps",
"1.0.0",
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
cut_context = True
device = self._execution_device
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
callback_on_step_end_tensor_inputs,
attention_mask,
negative_attention_mask,
)
self._guidance_scale = guidance_scale
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
# 3. Encode input prompt
prompt_embeds, negative_prompt_embeds, attention_mask, negative_attention_mask = self.encode_prompt(
prompt,
self.do_classifier_free_guidance,
num_images_per_prompt=num_images_per_prompt,
device=device,
negative_prompt=negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
_cut_context=cut_context,
attention_mask=attention_mask,
negative_attention_mask=negative_attention_mask,
)
if self.do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
attention_mask = torch.cat([negative_attention_mask, attention_mask]).bool()
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latents
height, width = downscale_height_and_width(height, width, 8)
latents = self.prepare_latents(
(batch_size * num_images_per_prompt, 4, height, width),
prompt_embeds.dtype,
device,
generator,
latents,
self.scheduler,
)
if hasattr(self, "text_encoder_offload_hook") and self.text_encoder_offload_hook is not None:
self.text_encoder_offload_hook.offload()
# 7. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
self._num_timesteps = len(timesteps)
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
encoder_attention_mask=attention_mask,
return_dict=False,
)[0]
if self.do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = (guidance_scale + 1.0) * noise_pred_text - guidance_scale * noise_pred_uncond
# noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(
noise_pred,
t,
latents,
generator=generator,
).prev_sample
if callback_on_step_end is not None:
callback_kwargs = {}
for k in callback_on_step_end_tensor_inputs:
callback_kwargs[k] = locals()[k]
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
latents = callback_outputs.pop("latents", latents)
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
attention_mask = callback_outputs.pop("attention_mask", attention_mask)
negative_attention_mask = callback_outputs.pop("negative_attention_mask", negative_attention_mask)
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# post-processing
if output_type not in ["pt", "np", "pil", "latent"]:
raise ValueError(
f"Only the output types `pt`, `pil`, `np` and `latent` are supported not output_type={output_type}"
)
if not output_type == "latent":
image = self.movq.decode(latents, force_not_quantize=True)["sample"]
if output_type in ["np", "pil"]:
image = image * 0.5 + 0.5
image = image.clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
else:
image = latents
self.maybe_free_model_hooks()
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
| diffusers/src/diffusers/pipelines/kandinsky3/pipeline_kandinsky3.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/kandinsky3/pipeline_kandinsky3.py",
"repo_id": "diffusers",
"token_count": 12614
} | 248 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import torch
from torch import nn
from transformers import CLIPPreTrainedModel, CLIPVisionModel
from ...models.attention import BasicTransformerBlock
from ...utils import logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class PaintByExampleImageEncoder(CLIPPreTrainedModel):
def __init__(self, config, proj_size=None):
super().__init__(config)
self.proj_size = proj_size or getattr(config, "projection_dim", 768)
self.model = CLIPVisionModel(config)
self.mapper = PaintByExampleMapper(config)
self.final_layer_norm = nn.LayerNorm(config.hidden_size)
self.proj_out = nn.Linear(config.hidden_size, self.proj_size)
# uncondition for scaling
self.uncond_vector = nn.Parameter(torch.randn((1, 1, self.proj_size)))
def forward(self, pixel_values, return_uncond_vector=False):
clip_output = self.model(pixel_values=pixel_values)
latent_states = clip_output.pooler_output
latent_states = self.mapper(latent_states[:, None])
latent_states = self.final_layer_norm(latent_states)
latent_states = self.proj_out(latent_states)
if return_uncond_vector:
return latent_states, self.uncond_vector
return latent_states
class PaintByExampleMapper(nn.Module):
def __init__(self, config):
super().__init__()
num_layers = (config.num_hidden_layers + 1) // 5
hid_size = config.hidden_size
num_heads = 1
self.blocks = nn.ModuleList(
[
BasicTransformerBlock(hid_size, num_heads, hid_size, activation_fn="gelu", attention_bias=True)
for _ in range(num_layers)
]
)
def forward(self, hidden_states):
for block in self.blocks:
hidden_states = block(hidden_states)
return hidden_states
| diffusers/src/diffusers/pipelines/paint_by_example/image_encoder.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/paint_by_example/image_encoder.py",
"repo_id": "diffusers",
"token_count": 942
} | 249 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
from typing import Any, Callable, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTokenizer
from ...configuration_utils import FrozenDict
from ...schedulers import DDPMScheduler, KarrasDiffusionSchedulers
from ...utils import deprecate, logging
from ..onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
from ..pipeline_utils import DiffusionPipeline
from . import StableDiffusionPipelineOutput
logger = logging.get_logger(__name__)
def preprocess(image):
if isinstance(image, torch.Tensor):
return image
elif isinstance(image, PIL.Image.Image):
image = [image]
if isinstance(image[0], PIL.Image.Image):
w, h = image[0].size
w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 32
image = [np.array(i.resize((w, h)))[None, :] for i in image]
image = np.concatenate(image, axis=0)
image = np.array(image).astype(np.float32) / 255.0
image = image.transpose(0, 3, 1, 2)
image = 2.0 * image - 1.0
image = torch.from_numpy(image)
elif isinstance(image[0], torch.Tensor):
image = torch.cat(image, dim=0)
return image
class OnnxStableDiffusionUpscalePipeline(DiffusionPipeline):
vae: OnnxRuntimeModel
text_encoder: OnnxRuntimeModel
tokenizer: CLIPTokenizer
unet: OnnxRuntimeModel
low_res_scheduler: DDPMScheduler
scheduler: KarrasDiffusionSchedulers
safety_checker: OnnxRuntimeModel
feature_extractor: CLIPImageProcessor
_optional_components = ["safety_checker", "feature_extractor"]
_is_onnx = True
def __init__(
self,
vae: OnnxRuntimeModel,
text_encoder: OnnxRuntimeModel,
tokenizer: Any,
unet: OnnxRuntimeModel,
low_res_scheduler: DDPMScheduler,
scheduler: KarrasDiffusionSchedulers,
safety_checker: Optional[OnnxRuntimeModel] = None,
feature_extractor: Optional[CLIPImageProcessor] = None,
max_noise_level: int = 350,
num_latent_channels=4,
num_unet_input_channels=7,
requires_safety_checker: bool = True,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
" `clip_sample` should be set to False in the configuration file. Please make sure to update the"
" config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
" future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
" nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
)
deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["clip_sample"] = False
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
low_res_scheduler=low_res_scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.register_to_config(
max_noise_level=max_noise_level,
num_latent_channels=num_latent_channels,
num_unet_input_channels=num_unet_input_channels,
)
def check_inputs(
self,
prompt: Union[str, List[str]],
image,
noise_level,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
):
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if (
not isinstance(image, torch.Tensor)
and not isinstance(image, PIL.Image.Image)
and not isinstance(image, np.ndarray)
and not isinstance(image, list)
):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `np.ndarray`, `PIL.Image.Image` or `list` but is {type(image)}"
)
# verify batch size of prompt and image are same if image is a list or tensor or numpy array
if isinstance(image, list) or isinstance(image, np.ndarray):
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if isinstance(image, list):
image_batch_size = len(image)
else:
image_batch_size = image.shape[0]
if batch_size != image_batch_size:
raise ValueError(
f"`prompt` has batch size {batch_size} and `image` has batch size {image_batch_size}."
" Please make sure that passed `prompt` matches the batch size of `image`."
)
# check noise level
if noise_level > self.config.max_noise_level:
raise ValueError(f"`noise_level` has to be <= {self.config.max_noise_level} but is {noise_level}")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, generator, latents=None):
shape = (batch_size, num_channels_latents, height, width)
if latents is None:
latents = generator.randn(*shape).astype(dtype)
elif latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
return latents
def decode_latents(self, latents):
latents = 1 / 0.08333 * latents
image = self.vae(latent_sample=latents)[0]
image = np.clip(image / 2 + 0.5, 0, 1)
image = image.transpose((0, 2, 3, 1))
return image
def _encode_prompt(
self,
prompt: Union[str, List[str]],
num_images_per_prompt: Optional[int],
do_classifier_free_guidance: bool,
negative_prompt: Optional[str],
prompt_embeds: Optional[np.ndarray] = None,
negative_prompt_embeds: Optional[np.ndarray] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`):
prompt to be encoded
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
prompt_embeds (`np.ndarray`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`np.ndarray`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="np",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="np").input_ids
if not np.array_equal(text_input_ids, untruncated_ids):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = self.text_encoder(input_ids=text_input_ids.astype(np.int32))[0]
prompt_embeds = np.repeat(prompt_embeds, num_images_per_prompt, axis=0)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt] * batch_size
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="np",
)
negative_prompt_embeds = self.text_encoder(input_ids=uncond_input.input_ids.astype(np.int32))[0]
if do_classifier_free_guidance:
negative_prompt_embeds = np.repeat(negative_prompt_embeds, num_images_per_prompt, axis=0)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = np.concatenate([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def __call__(
self,
prompt: Union[str, List[str]],
image: Union[np.ndarray, PIL.Image.Image, List[PIL.Image.Image]],
num_inference_steps: int = 75,
guidance_scale: float = 9.0,
noise_level: int = 20,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[np.random.RandomState, List[np.random.RandomState]]] = None,
latents: Optional[np.ndarray] = None,
prompt_embeds: Optional[np.ndarray] = None,
negative_prompt_embeds: Optional[np.ndarray] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
callback_steps: Optional[int] = 1,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
image (`np.ndarray` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
noise_level (`float`, defaults to 0.2):
Deteremines the amount of noise to add to the initial image before performing upscaling.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`np.random.RandomState`, *optional*):
A np.random.RandomState to make generation deterministic.
latents (`torch.Tensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`np.ndarray`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`np.ndarray`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: np.ndarray)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 1. Check inputs
self.check_inputs(
prompt,
image,
noise_level,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if generator is None:
generator = np.random
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
prompt_embeds = self._encode_prompt(
prompt,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
latents_dtype = prompt_embeds.dtype
image = preprocess(image).cpu().numpy()
height, width = image.shape[2:]
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
self.config.num_latent_channels,
height,
width,
latents_dtype,
generator,
)
image = image.astype(latents_dtype)
self.scheduler.set_timesteps(num_inference_steps)
timesteps = self.scheduler.timesteps
# Scale the initial noise by the standard deviation required by the scheduler
latents = latents * np.float64(self.scheduler.init_noise_sigma)
# 5. Add noise to image
noise_level = np.array([noise_level]).astype(np.int64)
noise = generator.randn(*image.shape).astype(latents_dtype)
image = self.low_res_scheduler.add_noise(
torch.from_numpy(image), torch.from_numpy(noise), torch.from_numpy(noise_level)
)
image = image.numpy()
batch_multiplier = 2 if do_classifier_free_guidance else 1
image = np.concatenate([image] * batch_multiplier * num_images_per_prompt)
noise_level = np.concatenate([noise_level] * image.shape[0])
# 7. Check that sizes of image and latents match
num_channels_image = image.shape[1]
if self.config.num_latent_channels + num_channels_image != self.config.num_unet_input_channels:
raise ValueError(
"Incorrect configuration settings! The config of `pipeline.unet` expects"
f" {self.config.num_unet_input_channels} but received `num_channels_latents`: {self.config.num_latent_channels} +"
f" `num_channels_image`: {num_channels_image} "
f" = {self.config.num_latent_channels + num_channels_image}. Please verify the config of"
" `pipeline.unet` or your `image` input."
)
# 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
timestep_dtype = next(
(input.type for input in self.unet.model.get_inputs() if input.name == "timestep"), "tensor(float)"
)
timestep_dtype = ORT_TO_NP_TYPE[timestep_dtype]
# 9. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
# concat latents, mask, masked_image_latents in the channel dimension
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
latent_model_input = np.concatenate([latent_model_input, image], axis=1)
# timestep to tensor
timestep = np.array([t], dtype=timestep_dtype)
# predict the noise residual
noise_pred = self.unet(
sample=latent_model_input,
timestep=timestep,
encoder_hidden_states=prompt_embeds,
class_labels=noise_level,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = np.split(noise_pred, 2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(
torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs
).prev_sample
latents = latents.numpy()
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# 10. Post-processing
image = self.decode_latents(latents)
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(
self.numpy_to_pil(image), return_tensors="np"
).pixel_values.astype(image.dtype)
images, has_nsfw_concept = [], []
for i in range(image.shape[0]):
image_i, has_nsfw_concept_i = self.safety_checker(
clip_input=safety_checker_input[i : i + 1], images=image[i : i + 1]
)
images.append(image_i)
has_nsfw_concept.append(has_nsfw_concept_i[0])
image = np.concatenate(images)
else:
has_nsfw_concept = None
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py",
"repo_id": "diffusers",
"token_count": 12561
} | 250 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import math
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import torch
from torch.nn import functional as F
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from ...image_processor import VaeImageProcessor
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
from ...models import AutoencoderKL, UNet2DConditionModel
from ...models.attention_processor import Attention
from ...models.lora import adjust_lora_scale_text_encoder
from ...schedulers import KarrasDiffusionSchedulers
from ...utils import (
USE_PEFT_BACKEND,
deprecate,
logging,
replace_example_docstring,
scale_lora_layers,
unscale_lora_layers,
)
from ...utils.torch_utils import randn_tensor
from ..pipeline_utils import DiffusionPipeline, StableDiffusionMixin
from ..stable_diffusion import StableDiffusionPipelineOutput
from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
logger = logging.get_logger(__name__)
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import StableDiffusionAttendAndExcitePipeline
>>> pipe = StableDiffusionAttendAndExcitePipeline.from_pretrained(
... "CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
... ).to("cuda")
>>> prompt = "a cat and a frog"
>>> # use get_indices function to find out indices of the tokens you want to alter
>>> pipe.get_indices(prompt)
{0: '<|startoftext|>', 1: 'a</w>', 2: 'cat</w>', 3: 'and</w>', 4: 'a</w>', 5: 'frog</w>', 6: '<|endoftext|>'}
>>> token_indices = [2, 5]
>>> seed = 6141
>>> generator = torch.Generator("cuda").manual_seed(seed)
>>> images = pipe(
... prompt=prompt,
... token_indices=token_indices,
... guidance_scale=7.5,
... generator=generator,
... num_inference_steps=50,
... max_iter_to_alter=25,
... ).images
>>> image = images[0]
>>> image.save(f"../images/{prompt}_{seed}.png")
```
"""
class AttentionStore:
@staticmethod
def get_empty_store():
return {"down": [], "mid": [], "up": []}
def __call__(self, attn, is_cross: bool, place_in_unet: str):
if self.cur_att_layer >= 0 and is_cross:
if attn.shape[1] == np.prod(self.attn_res):
self.step_store[place_in_unet].append(attn)
self.cur_att_layer += 1
if self.cur_att_layer == self.num_att_layers:
self.cur_att_layer = 0
self.between_steps()
def between_steps(self):
self.attention_store = self.step_store
self.step_store = self.get_empty_store()
def get_average_attention(self):
average_attention = self.attention_store
return average_attention
def aggregate_attention(self, from_where: List[str]) -> torch.Tensor:
"""Aggregates the attention across the different layers and heads at the specified resolution."""
out = []
attention_maps = self.get_average_attention()
for location in from_where:
for item in attention_maps[location]:
cross_maps = item.reshape(-1, self.attn_res[0], self.attn_res[1], item.shape[-1])
out.append(cross_maps)
out = torch.cat(out, dim=0)
out = out.sum(0) / out.shape[0]
return out
def reset(self):
self.cur_att_layer = 0
self.step_store = self.get_empty_store()
self.attention_store = {}
def __init__(self, attn_res):
"""
Initialize an empty AttentionStore :param step_index: used to visualize only a specific step in the diffusion
process
"""
self.num_att_layers = -1
self.cur_att_layer = 0
self.step_store = self.get_empty_store()
self.attention_store = {}
self.curr_step_index = 0
self.attn_res = attn_res
class AttendExciteAttnProcessor:
def __init__(self, attnstore, place_in_unet):
super().__init__()
self.attnstore = attnstore
self.place_in_unet = place_in_unet
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
batch_size, sequence_length, _ = hidden_states.shape
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
query = attn.to_q(hidden_states)
is_cross = encoder_hidden_states is not None
encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
# only need to store attention maps during the Attend and Excite process
if attention_probs.requires_grad:
self.attnstore(attention_probs, is_cross, self.place_in_unet)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
return hidden_states
class StableDiffusionAttendAndExcitePipeline(DiffusionPipeline, StableDiffusionMixin, TextualInversionLoaderMixin):
r"""
Pipeline for text-to-image generation using Stable Diffusion and Attend-and-Excite.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
The pipeline also inherits the following loading methods:
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
text_encoder ([`~transformers.CLIPTextModel`]):
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
tokenizer ([`~transformers.CLIPTokenizer`]):
A `CLIPTokenizer` to tokenize text.
unet ([`UNet2DConditionModel`]):
A `UNet2DConditionModel` to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
about a model's potential harms.
feature_extractor ([`~transformers.CLIPImageProcessor`]):
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
"""
model_cpu_offload_seq = "text_encoder->unet->vae"
_optional_components = ["safety_checker", "feature_extractor"]
_exclude_from_cpu_offload = ["safety_checker"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.register_to_config(requires_safety_checker=requires_safety_checker)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.Tensor] = None,
negative_prompt_embeds: Optional[torch.Tensor] = None,
lora_scale: Optional[float] = None,
**kwargs,
):
deprecation_message = "`_encode_prompt()` is deprecated and it will be removed in a future version. Use `encode_prompt()` instead. Also, be aware that the output format changed from a concatenated tensor to a tuple."
deprecate("_encode_prompt()", "1.0.0", deprecation_message, standard_warn=False)
prompt_embeds_tuple = self.encode_prompt(
prompt=prompt,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=lora_scale,
**kwargs,
)
# concatenate for backwards comp
prompt_embeds = torch.cat([prompt_embeds_tuple[1], prompt_embeds_tuple[0]])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_prompt
def encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.Tensor] = None,
negative_prompt_embeds: Optional[torch.Tensor] = None,
lora_scale: Optional[float] = None,
clip_skip: Optional[int] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
lora_scale (`float`, *optional*):
A LoRA scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
"""
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
else:
scale_lora_layers(self.text_encoder, lora_scale)
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
if clip_skip is None:
prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)
prompt_embeds = prompt_embeds[0]
else:
prompt_embeds = self.text_encoder(
text_input_ids.to(device), attention_mask=attention_mask, output_hidden_states=True
)
# Access the `hidden_states` first, that contains a tuple of
# all the hidden states from the encoder layers. Then index into
# the tuple to access the hidden states from the desired layer.
prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
# We also need to apply the final LayerNorm here to not mess with the
# representations. The `last_hidden_states` that we typically use for
# obtaining the final prompt representations passes through the LayerNorm
# layer.
prompt_embeds = self.text_encoder.text_model.final_layer_norm(prompt_embeds)
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
if isinstance(self, LoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder, lora_scale)
return prompt_embeds, negative_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
deprecation_message = "The decode_latents method is deprecated and will be removed in 1.0.0. Please use VaeImageProcessor.postprocess(...) instead"
deprecate("decode_latents", "1.0.0", deprecation_message, standard_warn=False)
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents, return_dict=False)[0]
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
prompt,
indices,
height,
width,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
indices_is_list_ints = isinstance(indices, list) and isinstance(indices[0], int)
indices_is_list_list_ints = (
isinstance(indices, list) and isinstance(indices[0], list) and isinstance(indices[0][0], int)
)
if not indices_is_list_ints and not indices_is_list_list_ints:
raise TypeError("`indices` must be a list of ints or a list of a list of ints")
if indices_is_list_ints:
indices_batch_size = 1
elif indices_is_list_list_ints:
indices_batch_size = len(indices)
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
if indices_batch_size != prompt_batch_size:
raise ValueError(
f"indices batch size must be same as prompt batch size. indices batch size: {indices_batch_size}, prompt batch size: {prompt_batch_size}"
)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (
batch_size,
num_channels_latents,
int(height) // self.vae_scale_factor,
int(width) // self.vae_scale_factor,
)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
@staticmethod
def _compute_max_attention_per_index(
attention_maps: torch.Tensor,
indices: List[int],
) -> List[torch.Tensor]:
"""Computes the maximum attention value for each of the tokens we wish to alter."""
attention_for_text = attention_maps[:, :, 1:-1]
attention_for_text *= 100
attention_for_text = torch.nn.functional.softmax(attention_for_text, dim=-1)
# Shift indices since we removed the first token
indices = [index - 1 for index in indices]
# Extract the maximum values
max_indices_list = []
for i in indices:
image = attention_for_text[:, :, i]
smoothing = GaussianSmoothing().to(attention_maps.device)
input = F.pad(image.unsqueeze(0).unsqueeze(0), (1, 1, 1, 1), mode="reflect")
image = smoothing(input).squeeze(0).squeeze(0)
max_indices_list.append(image.max())
return max_indices_list
def _aggregate_and_get_max_attention_per_token(
self,
indices: List[int],
):
"""Aggregates the attention for each token and computes the max activation value for each token to alter."""
attention_maps = self.attention_store.aggregate_attention(
from_where=("up", "down", "mid"),
)
max_attention_per_index = self._compute_max_attention_per_index(
attention_maps=attention_maps,
indices=indices,
)
return max_attention_per_index
@staticmethod
def _compute_loss(max_attention_per_index: List[torch.Tensor]) -> torch.Tensor:
"""Computes the attend-and-excite loss using the maximum attention value for each token."""
losses = [max(0, 1.0 - curr_max) for curr_max in max_attention_per_index]
loss = max(losses)
return loss
@staticmethod
def _update_latent(latents: torch.Tensor, loss: torch.Tensor, step_size: float) -> torch.Tensor:
"""Update the latent according to the computed loss."""
grad_cond = torch.autograd.grad(loss.requires_grad_(True), [latents], retain_graph=True)[0]
latents = latents - step_size * grad_cond
return latents
def _perform_iterative_refinement_step(
self,
latents: torch.Tensor,
indices: List[int],
loss: torch.Tensor,
threshold: float,
text_embeddings: torch.Tensor,
step_size: float,
t: int,
max_refinement_steps: int = 20,
):
"""
Performs the iterative latent refinement introduced in the paper. Here, we continuously update the latent code
according to our loss objective until the given threshold is reached for all tokens.
"""
iteration = 0
target_loss = max(0, 1.0 - threshold)
while loss > target_loss:
iteration += 1
latents = latents.clone().detach().requires_grad_(True)
self.unet(latents, t, encoder_hidden_states=text_embeddings).sample
self.unet.zero_grad()
# Get max activation value for each subject token
max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
indices=indices,
)
loss = self._compute_loss(max_attention_per_index)
if loss != 0:
latents = self._update_latent(latents, loss, step_size)
logger.info(f"\t Try {iteration}. loss: {loss}")
if iteration >= max_refinement_steps:
logger.info(f"\t Exceeded max number of iterations ({max_refinement_steps})! ")
break
# Run one more time but don't compute gradients and update the latents.
# We just need to compute the new loss - the grad update will occur below
latents = latents.clone().detach().requires_grad_(True)
_ = self.unet(latents, t, encoder_hidden_states=text_embeddings).sample
self.unet.zero_grad()
# Get max activation value for each subject token
max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
indices=indices,
)
loss = self._compute_loss(max_attention_per_index)
logger.info(f"\t Finished with loss of: {loss}")
return loss, latents, max_attention_per_index
def register_attention_control(self):
attn_procs = {}
cross_att_count = 0
for name in self.unet.attn_processors.keys():
if name.startswith("mid_block"):
place_in_unet = "mid"
elif name.startswith("up_blocks"):
place_in_unet = "up"
elif name.startswith("down_blocks"):
place_in_unet = "down"
else:
continue
cross_att_count += 1
attn_procs[name] = AttendExciteAttnProcessor(attnstore=self.attention_store, place_in_unet=place_in_unet)
self.unet.set_attn_processor(attn_procs)
self.attention_store.num_att_layers = cross_att_count
def get_indices(self, prompt: str) -> Dict[str, int]:
"""Utility function to list the indices of the tokens you wish to alte"""
ids = self.tokenizer(prompt).input_ids
indices = {i: tok for tok, i in zip(self.tokenizer.convert_ids_to_tokens(ids), range(len(ids)))}
return indices
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]],
token_indices: Union[List[int], List[List[int]]],
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: int = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.Tensor] = None,
prompt_embeds: Optional[torch.Tensor] = None,
negative_prompt_embeds: Optional[torch.Tensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.Tensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
max_iter_to_alter: int = 25,
thresholds: dict = {0: 0.05, 10: 0.5, 20: 0.8},
scale_factor: int = 20,
attn_res: Optional[Tuple[int]] = (16, 16),
clip_skip: Optional[int] = None,
):
r"""
The call function to the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
token_indices (`List[int]`):
The token indices to alter with attend-and-excite.
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
latents (`torch.Tensor`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor is generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
provided, text embeddings are generated from the `prompt` input argument.
negative_prompt_embeds (`torch.Tensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.Tensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
max_iter_to_alter (`int`, *optional*, defaults to `25`):
Number of denoising steps to apply attend-and-excite. The `max_iter_to_alter` denoising steps are when
attend-and-excite is applied. For example, if `max_iter_to_alter` is `25` and there are a total of `30`
denoising steps, the first `25` denoising steps applies attend-and-excite and the last `5` will not.
thresholds (`dict`, *optional*, defaults to `{0: 0.05, 10: 0.5, 20: 0.8}`):
Dictionary defining the iterations and desired thresholds to apply iterative latent refinement in.
scale_factor (`int`, *optional*, default to 20):
Scale factor to control the step size of each attend-and-excite update.
attn_res (`tuple`, *optional*, default computed from width and height):
The 2D resolution of the semantic attention map.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
otherwise a `tuple` is returned where the first element is a list with the generated images and the
second element is a list of `bool`s indicating whether the corresponding generated image contains
"not-safe-for-work" (nsfw) content.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
token_indices,
height,
width,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
clip_skip=clip_skip,
)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
if attn_res is None:
attn_res = int(np.ceil(width / 32)), int(np.ceil(height / 32))
self.attention_store = AttentionStore(attn_res)
original_attn_proc = self.unet.attn_processors
self.register_attention_control()
# default config for step size from original repo
scale_range = np.linspace(1.0, 0.5, len(self.scheduler.timesteps))
step_size = scale_factor * np.sqrt(scale_range)
text_embeddings = (
prompt_embeds[batch_size * num_images_per_prompt :] if do_classifier_free_guidance else prompt_embeds
)
if isinstance(token_indices[0], int):
token_indices = [token_indices]
indices = []
for ind in token_indices:
indices = indices + [ind] * num_images_per_prompt
# 7. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# Attend and excite process
with torch.enable_grad():
latents = latents.clone().detach().requires_grad_(True)
updated_latents = []
for latent, index, text_embedding in zip(latents, indices, text_embeddings):
# Forward pass of denoising with text conditioning
latent = latent.unsqueeze(0)
text_embedding = text_embedding.unsqueeze(0)
self.unet(
latent,
t,
encoder_hidden_states=text_embedding,
cross_attention_kwargs=cross_attention_kwargs,
).sample
self.unet.zero_grad()
# Get max activation value for each subject token
max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
indices=index,
)
loss = self._compute_loss(max_attention_per_index=max_attention_per_index)
# If this is an iterative refinement step, verify we have reached the desired threshold for all
if i in thresholds.keys() and loss > 1.0 - thresholds[i]:
loss, latent, max_attention_per_index = self._perform_iterative_refinement_step(
latents=latent,
indices=index,
loss=loss,
threshold=thresholds[i],
text_embeddings=text_embedding,
step_size=step_size[i],
t=t,
)
# Perform gradient update
if i < max_iter_to_alter:
if loss != 0:
latent = self._update_latent(
latents=latent,
loss=loss,
step_size=step_size[i],
)
logger.info(f"Iteration {i} | Loss: {loss:0.4f}")
updated_latents.append(latent)
latents = torch.cat(updated_latents, dim=0)
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# 8. Post-processing
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
self.maybe_free_model_hooks()
# make sure to set the original attention processors back
self.unet.set_attn_processor(original_attn_proc)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
class GaussianSmoothing(torch.nn.Module):
"""
Arguments:
Apply gaussian smoothing on a 1d, 2d or 3d tensor. Filtering is performed seperately for each channel in the input
using a depthwise convolution.
channels (int, sequence): Number of channels of the input tensors. Output will
have this number of channels as well.
kernel_size (int, sequence): Size of the gaussian kernel. sigma (float, sequence): Standard deviation of the
gaussian kernel. dim (int, optional): The number of dimensions of the data.
Default value is 2 (spatial).
"""
# channels=1, kernel_size=kernel_size, sigma=sigma, dim=2
def __init__(
self,
channels: int = 1,
kernel_size: int = 3,
sigma: float = 0.5,
dim: int = 2,
):
super().__init__()
if isinstance(kernel_size, int):
kernel_size = [kernel_size] * dim
if isinstance(sigma, float):
sigma = [sigma] * dim
# The gaussian kernel is the product of the
# gaussian function of each dimension.
kernel = 1
meshgrids = torch.meshgrid([torch.arange(size, dtype=torch.float32) for size in kernel_size])
for size, std, mgrid in zip(kernel_size, sigma, meshgrids):
mean = (size - 1) / 2
kernel *= 1 / (std * math.sqrt(2 * math.pi)) * torch.exp(-(((mgrid - mean) / (2 * std)) ** 2))
# Make sure sum of values in gaussian kernel equals 1.
kernel = kernel / torch.sum(kernel)
# Reshape to depthwise convolutional weight
kernel = kernel.view(1, 1, *kernel.size())
kernel = kernel.repeat(channels, *[1] * (kernel.dim() - 1))
self.register_buffer("weight", kernel)
self.groups = channels
if dim == 1:
self.conv = F.conv1d
elif dim == 2:
self.conv = F.conv2d
elif dim == 3:
self.conv = F.conv3d
else:
raise RuntimeError("Only 1, 2 and 3 dimensions are supported. Received {}.".format(dim))
def forward(self, input):
"""
Arguments:
Apply gaussian filter to input.
input (torch.Tensor): Input to apply gaussian filter on.
Returns:
filtered (torch.Tensor): Filtered output.
"""
return self.conv(input, weight=self.weight.to(input.dtype), groups=self.groups)
| diffusers/src/diffusers/pipelines/stable_diffusion_attend_and_excite/pipeline_stable_diffusion_attend_and_excite.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion_attend_and_excite/pipeline_stable_diffusion_attend_and_excite.py",
"repo_id": "diffusers",
"token_count": 22718
} | 251 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import torch
import torch.nn as nn
from transformers import CLIPConfig, CLIPVisionModel, PreTrainedModel
from ...utils import logging
logger = logging.get_logger(__name__)
def cosine_distance(image_embeds, text_embeds):
normalized_image_embeds = nn.functional.normalize(image_embeds)
normalized_text_embeds = nn.functional.normalize(text_embeds)
return torch.mm(normalized_image_embeds, normalized_text_embeds.t())
class SafeStableDiffusionSafetyChecker(PreTrainedModel):
config_class = CLIPConfig
_no_split_modules = ["CLIPEncoderLayer"]
def __init__(self, config: CLIPConfig):
super().__init__(config)
self.vision_model = CLIPVisionModel(config.vision_config)
self.visual_projection = nn.Linear(config.vision_config.hidden_size, config.projection_dim, bias=False)
self.concept_embeds = nn.Parameter(torch.ones(17, config.projection_dim), requires_grad=False)
self.special_care_embeds = nn.Parameter(torch.ones(3, config.projection_dim), requires_grad=False)
self.concept_embeds_weights = nn.Parameter(torch.ones(17), requires_grad=False)
self.special_care_embeds_weights = nn.Parameter(torch.ones(3), requires_grad=False)
@torch.no_grad()
def forward(self, clip_input, images):
pooled_output = self.vision_model(clip_input)[1] # pooled_output
image_embeds = self.visual_projection(pooled_output)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds).cpu().float().numpy()
cos_dist = cosine_distance(image_embeds, self.concept_embeds).cpu().float().numpy()
result = []
batch_size = image_embeds.shape[0]
for i in range(batch_size):
result_img = {"special_scores": {}, "special_care": [], "concept_scores": {}, "bad_concepts": []}
# increase this value to create a stronger `nfsw` filter
# at the cost of increasing the possibility of filtering benign images
adjustment = 0.0
for concept_idx in range(len(special_cos_dist[0])):
concept_cos = special_cos_dist[i][concept_idx]
concept_threshold = self.special_care_embeds_weights[concept_idx].item()
result_img["special_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3)
if result_img["special_scores"][concept_idx] > 0:
result_img["special_care"].append({concept_idx, result_img["special_scores"][concept_idx]})
adjustment = 0.01
for concept_idx in range(len(cos_dist[0])):
concept_cos = cos_dist[i][concept_idx]
concept_threshold = self.concept_embeds_weights[concept_idx].item()
result_img["concept_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3)
if result_img["concept_scores"][concept_idx] > 0:
result_img["bad_concepts"].append(concept_idx)
result.append(result_img)
has_nsfw_concepts = [len(res["bad_concepts"]) > 0 for res in result]
return images, has_nsfw_concepts
@torch.no_grad()
def forward_onnx(self, clip_input: torch.Tensor, images: torch.Tensor):
pooled_output = self.vision_model(clip_input)[1] # pooled_output
image_embeds = self.visual_projection(pooled_output)
special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds)
cos_dist = cosine_distance(image_embeds, self.concept_embeds)
# increase this value to create a stronger `nsfw` filter
# at the cost of increasing the possibility of filtering benign images
adjustment = 0.0
special_scores = special_cos_dist - self.special_care_embeds_weights + adjustment
# special_scores = special_scores.round(decimals=3)
special_care = torch.any(special_scores > 0, dim=1)
special_adjustment = special_care * 0.01
special_adjustment = special_adjustment.unsqueeze(1).expand(-1, cos_dist.shape[1])
concept_scores = (cos_dist - self.concept_embeds_weights) + special_adjustment
# concept_scores = concept_scores.round(decimals=3)
has_nsfw_concepts = torch.any(concept_scores > 0, dim=1)
return images, has_nsfw_concepts
| diffusers/src/diffusers/pipelines/stable_diffusion_safe/safety_checker.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion_safe/safety_checker.py",
"repo_id": "diffusers",
"token_count": 1962
} | 252 |
from typing import TYPE_CHECKING
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and is_torch_available()):
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
from ...utils import dummy_torch_and_transformers_objects # noqa F403
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
else:
_import_structure["pipeline_output"] = ["TextToVideoSDPipelineOutput"]
_import_structure["pipeline_text_to_video_synth"] = ["TextToVideoSDPipeline"]
_import_structure["pipeline_text_to_video_synth_img2img"] = ["VideoToVideoSDPipeline"]
_import_structure["pipeline_text_to_video_zero"] = ["TextToVideoZeroPipeline"]
_import_structure["pipeline_text_to_video_zero_sdxl"] = ["TextToVideoZeroSDXLPipeline"]
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
try:
if not (is_transformers_available() and is_torch_available()):
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
from ...utils.dummy_torch_and_transformers_objects import * # noqa F403
else:
from .pipeline_output import TextToVideoSDPipelineOutput
from .pipeline_text_to_video_synth import TextToVideoSDPipeline
from .pipeline_text_to_video_synth_img2img import VideoToVideoSDPipeline
from .pipeline_text_to_video_zero import TextToVideoZeroPipeline
from .pipeline_text_to_video_zero_sdxl import TextToVideoZeroSDXLPipeline
else:
import sys
sys.modules[__name__] = _LazyModule(
__name__,
globals()["__file__"],
_import_structure,
module_spec=__spec__,
)
for name, value in _dummy_objects.items():
setattr(sys.modules[__name__], name, value)
| diffusers/src/diffusers/pipelines/text_to_video_synthesis/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/text_to_video_synthesis/__init__.py",
"repo_id": "diffusers",
"token_count": 788
} | 253 |
import torch
import torch.nn as nn
from ...models.attention_processor import Attention
class WuerstchenLayerNorm(nn.LayerNorm):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, x):
x = x.permute(0, 2, 3, 1)
x = super().forward(x)
return x.permute(0, 3, 1, 2)
class TimestepBlock(nn.Module):
def __init__(self, c, c_timestep):
super().__init__()
self.mapper = nn.Linear(c_timestep, c * 2)
def forward(self, x, t):
a, b = self.mapper(t)[:, :, None, None].chunk(2, dim=1)
return x * (1 + a) + b
class ResBlock(nn.Module):
def __init__(self, c, c_skip=0, kernel_size=3, dropout=0.0):
super().__init__()
self.depthwise = nn.Conv2d(c + c_skip, c, kernel_size=kernel_size, padding=kernel_size // 2, groups=c)
self.norm = WuerstchenLayerNorm(c, elementwise_affine=False, eps=1e-6)
self.channelwise = nn.Sequential(
nn.Linear(c, c * 4), nn.GELU(), GlobalResponseNorm(c * 4), nn.Dropout(dropout), nn.Linear(c * 4, c)
)
def forward(self, x, x_skip=None):
x_res = x
if x_skip is not None:
x = torch.cat([x, x_skip], dim=1)
x = self.norm(self.depthwise(x)).permute(0, 2, 3, 1)
x = self.channelwise(x).permute(0, 3, 1, 2)
return x + x_res
# from https://github.com/facebookresearch/ConvNeXt-V2/blob/3608f67cc1dae164790c5d0aead7bf2d73d9719b/models/utils.py#L105
class GlobalResponseNorm(nn.Module):
def __init__(self, dim):
super().__init__()
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
def forward(self, x):
agg_norm = torch.norm(x, p=2, dim=(1, 2), keepdim=True)
stand_div_norm = agg_norm / (agg_norm.mean(dim=-1, keepdim=True) + 1e-6)
return self.gamma * (x * stand_div_norm) + self.beta + x
class AttnBlock(nn.Module):
def __init__(self, c, c_cond, nhead, self_attn=True, dropout=0.0):
super().__init__()
self.self_attn = self_attn
self.norm = WuerstchenLayerNorm(c, elementwise_affine=False, eps=1e-6)
self.attention = Attention(query_dim=c, heads=nhead, dim_head=c // nhead, dropout=dropout, bias=True)
self.kv_mapper = nn.Sequential(nn.SiLU(), nn.Linear(c_cond, c))
def forward(self, x, kv):
kv = self.kv_mapper(kv)
norm_x = self.norm(x)
if self.self_attn:
batch_size, channel, _, _ = x.shape
kv = torch.cat([norm_x.view(batch_size, channel, -1).transpose(1, 2), kv], dim=1)
x = x + self.attention(norm_x, encoder_hidden_states=kv)
return x
| diffusers/src/diffusers/pipelines/wuerstchen/modeling_wuerstchen_common.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/wuerstchen/modeling_wuerstchen_common.py",
"repo_id": "diffusers",
"token_count": 1322
} | 254 |
# Copyright 2024 Stanford University Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
# and https://github.com/hojonathanho/diffusion
from dataclasses import dataclass
from typing import Optional, Tuple, Union
import flax
import jax.numpy as jnp
from ..configuration_utils import ConfigMixin, register_to_config
from .scheduling_utils_flax import (
CommonSchedulerState,
FlaxKarrasDiffusionSchedulers,
FlaxSchedulerMixin,
FlaxSchedulerOutput,
add_noise_common,
get_velocity_common,
)
@flax.struct.dataclass
class DDIMSchedulerState:
common: CommonSchedulerState
final_alpha_cumprod: jnp.ndarray
# setable values
init_noise_sigma: jnp.ndarray
timesteps: jnp.ndarray
num_inference_steps: Optional[int] = None
@classmethod
def create(
cls,
common: CommonSchedulerState,
final_alpha_cumprod: jnp.ndarray,
init_noise_sigma: jnp.ndarray,
timesteps: jnp.ndarray,
):
return cls(
common=common,
final_alpha_cumprod=final_alpha_cumprod,
init_noise_sigma=init_noise_sigma,
timesteps=timesteps,
)
@dataclass
class FlaxDDIMSchedulerOutput(FlaxSchedulerOutput):
state: DDIMSchedulerState
class FlaxDDIMScheduler(FlaxSchedulerMixin, ConfigMixin):
"""
Denoising diffusion implicit models is a scheduler that extends the denoising procedure introduced in denoising
diffusion probabilistic models (DDPMs) with non-Markovian guidance.
[`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
[`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
[`~SchedulerMixin.from_pretrained`] functions.
For more details, see the original paper: https://arxiv.org/abs/2010.02502
Args:
num_train_timesteps (`int`): number of diffusion steps used to train the model.
beta_start (`float`): the starting `beta` value of inference.
beta_end (`float`): the final `beta` value.
beta_schedule (`str`):
the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
`linear`, `scaled_linear`, or `squaredcos_cap_v2`.
trained_betas (`jnp.ndarray`, optional):
option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
clip_sample (`bool`, default `True`):
option to clip predicted sample between for numerical stability. The clip range is determined by
`clip_sample_range`.
clip_sample_range (`float`, default `1.0`):
the maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
set_alpha_to_one (`bool`, default `True`):
each diffusion step uses the value of alphas product at that step and at the previous one. For the final
step there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
otherwise it uses the value of alpha at step 0.
steps_offset (`int`, default `0`):
An offset added to the inference steps, as required by some model families.
prediction_type (`str`, default `epsilon`):
indicates whether the model predicts the noise (epsilon), or the samples. One of `epsilon`, `sample`.
`v-prediction` is not supported for this scheduler.
dtype (`jnp.dtype`, *optional*, defaults to `jnp.float32`):
the `dtype` used for params and computation.
"""
_compatibles = [e.name for e in FlaxKarrasDiffusionSchedulers]
dtype: jnp.dtype
@property
def has_state(self):
return True
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
beta_start: float = 0.0001,
beta_end: float = 0.02,
beta_schedule: str = "linear",
trained_betas: Optional[jnp.ndarray] = None,
clip_sample: bool = True,
clip_sample_range: float = 1.0,
set_alpha_to_one: bool = True,
steps_offset: int = 0,
prediction_type: str = "epsilon",
dtype: jnp.dtype = jnp.float32,
):
self.dtype = dtype
def create_state(self, common: Optional[CommonSchedulerState] = None) -> DDIMSchedulerState:
if common is None:
common = CommonSchedulerState.create(self)
# At every step in ddim, we are looking into the previous alphas_cumprod
# For the final step, there is no previous alphas_cumprod because we are already at 0
# `set_alpha_to_one` decides whether we set this parameter simply to one or
# whether we use the final alpha of the "non-previous" one.
final_alpha_cumprod = (
jnp.array(1.0, dtype=self.dtype) if self.config.set_alpha_to_one else common.alphas_cumprod[0]
)
# standard deviation of the initial noise distribution
init_noise_sigma = jnp.array(1.0, dtype=self.dtype)
timesteps = jnp.arange(0, self.config.num_train_timesteps).round()[::-1]
return DDIMSchedulerState.create(
common=common,
final_alpha_cumprod=final_alpha_cumprod,
init_noise_sigma=init_noise_sigma,
timesteps=timesteps,
)
def scale_model_input(
self, state: DDIMSchedulerState, sample: jnp.ndarray, timestep: Optional[int] = None
) -> jnp.ndarray:
"""
Args:
state (`PNDMSchedulerState`): the `FlaxPNDMScheduler` state data class instance.
sample (`jnp.ndarray`): input sample
timestep (`int`, optional): current timestep
Returns:
`jnp.ndarray`: scaled input sample
"""
return sample
def set_timesteps(
self, state: DDIMSchedulerState, num_inference_steps: int, shape: Tuple = ()
) -> DDIMSchedulerState:
"""
Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
Args:
state (`DDIMSchedulerState`):
the `FlaxDDIMScheduler` state data class instance.
num_inference_steps (`int`):
the number of diffusion steps used when generating samples with a pre-trained model.
"""
step_ratio = self.config.num_train_timesteps // num_inference_steps
# creates integer timesteps by multiplying by ratio
# rounding to avoid issues when num_inference_step is power of 3
timesteps = (jnp.arange(0, num_inference_steps) * step_ratio).round()[::-1] + self.config.steps_offset
return state.replace(
num_inference_steps=num_inference_steps,
timesteps=timesteps,
)
def _get_variance(self, state: DDIMSchedulerState, timestep, prev_timestep):
alpha_prod_t = state.common.alphas_cumprod[timestep]
alpha_prod_t_prev = jnp.where(
prev_timestep >= 0, state.common.alphas_cumprod[prev_timestep], state.final_alpha_cumprod
)
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
return variance
def step(
self,
state: DDIMSchedulerState,
model_output: jnp.ndarray,
timestep: int,
sample: jnp.ndarray,
eta: float = 0.0,
return_dict: bool = True,
) -> Union[FlaxDDIMSchedulerOutput, Tuple]:
"""
Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
state (`DDIMSchedulerState`): the `FlaxDDIMScheduler` state data class instance.
model_output (`jnp.ndarray`): direct output from learned diffusion model.
timestep (`int`): current discrete timestep in the diffusion chain.
sample (`jnp.ndarray`):
current instance of sample being created by diffusion process.
return_dict (`bool`): option for returning tuple rather than FlaxDDIMSchedulerOutput class
Returns:
[`FlaxDDIMSchedulerOutput`] or `tuple`: [`FlaxDDIMSchedulerOutput`] if `return_dict` is True, otherwise a
`tuple`. When returning a tuple, the first element is the sample tensor.
"""
if state.num_inference_steps is None:
raise ValueError(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
# See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
# Ideally, read DDIM paper in-detail understanding
# Notation (<variable name> -> <name in paper>
# - pred_noise_t -> e_theta(x_t, t)
# - pred_original_sample -> f_theta(x_t, t) or x_0
# - std_dev_t -> sigma_t
# - eta -> η
# - pred_sample_direction -> "direction pointing to x_t"
# - pred_prev_sample -> "x_t-1"
# 1. get previous step value (=t-1)
prev_timestep = timestep - self.config.num_train_timesteps // state.num_inference_steps
alphas_cumprod = state.common.alphas_cumprod
final_alpha_cumprod = state.final_alpha_cumprod
# 2. compute alphas, betas
alpha_prod_t = alphas_cumprod[timestep]
alpha_prod_t_prev = jnp.where(prev_timestep >= 0, alphas_cumprod[prev_timestep], final_alpha_cumprod)
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
pred_epsilon = model_output
elif self.config.prediction_type == "sample":
pred_original_sample = model_output
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
elif self.config.prediction_type == "v_prediction":
pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
else:
raise ValueError(
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
" `v_prediction`"
)
# 4. Clip or threshold "predicted x_0"
if self.config.clip_sample:
pred_original_sample = pred_original_sample.clip(
-self.config.clip_sample_range, self.config.clip_sample_range
)
# 4. compute variance: "sigma_t(η)" -> see formula (16)
# σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
variance = self._get_variance(state, timestep, prev_timestep)
std_dev_t = eta * variance ** (0.5)
# 5. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
# 6. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
if not return_dict:
return (prev_sample, state)
return FlaxDDIMSchedulerOutput(prev_sample=prev_sample, state=state)
def add_noise(
self,
state: DDIMSchedulerState,
original_samples: jnp.ndarray,
noise: jnp.ndarray,
timesteps: jnp.ndarray,
) -> jnp.ndarray:
return add_noise_common(state.common, original_samples, noise, timesteps)
def get_velocity(
self,
state: DDIMSchedulerState,
sample: jnp.ndarray,
noise: jnp.ndarray,
timesteps: jnp.ndarray,
) -> jnp.ndarray:
return get_velocity_common(state.common, sample, noise, timesteps)
def __len__(self):
return self.config.num_train_timesteps
| diffusers/src/diffusers/schedulers/scheduling_ddim_flax.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_ddim_flax.py",
"repo_id": "diffusers",
"token_count": 5537
} | 255 |
# Copyright 2024 Katherine Crowson and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import numpy as np
import torch
from ..configuration_utils import ConfigMixin, register_to_config
from ..utils import BaseOutput, logging
from ..utils.torch_utils import randn_tensor
from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
@dataclass
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->EulerDiscrete
class EulerDiscreteSchedulerOutput(BaseOutput):
"""
Output class for the scheduler's `step` function output.
Args:
prev_sample (`torch.Tensor` of shape `(batch_size, num_channels, height, width)` for images):
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
denoising loop.
pred_original_sample (`torch.Tensor` of shape `(batch_size, num_channels, height, width)` for images):
The predicted denoised sample `(x_{0})` based on the model output from the current timestep.
`pred_original_sample` can be used to preview progress or for guidance.
"""
prev_sample: torch.Tensor
pred_original_sample: Optional[torch.Tensor] = None
# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
def betas_for_alpha_bar(
num_diffusion_timesteps,
max_beta=0.999,
alpha_transform_type="cosine",
):
"""
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
(1-beta) over time from t = [0,1].
Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
to that part of the diffusion process.
Args:
num_diffusion_timesteps (`int`): the number of betas to produce.
max_beta (`float`): the maximum beta to use; use values lower than 1 to
prevent singularities.
alpha_transform_type (`str`, *optional*, default to `cosine`): the type of noise schedule for alpha_bar.
Choose from `cosine` or `exp`
Returns:
betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
"""
if alpha_transform_type == "cosine":
def alpha_bar_fn(t):
return math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2
elif alpha_transform_type == "exp":
def alpha_bar_fn(t):
return math.exp(t * -12.0)
else:
raise ValueError(f"Unsupported alpha_transform_type: {alpha_transform_type}")
betas = []
for i in range(num_diffusion_timesteps):
t1 = i / num_diffusion_timesteps
t2 = (i + 1) / num_diffusion_timesteps
betas.append(min(1 - alpha_bar_fn(t2) / alpha_bar_fn(t1), max_beta))
return torch.tensor(betas, dtype=torch.float32)
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
Args:
betas (`torch.Tensor`):
the betas that the scheduler is being initialized with.
Returns:
`torch.Tensor`: rescaled betas with zero terminal SNR
"""
# Convert betas to alphas_bar_sqrt
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_bar_sqrt = alphas_cumprod.sqrt()
# Store old values.
alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
# Shift so the last timestep is zero.
alphas_bar_sqrt -= alphas_bar_sqrt_T
# Scale so the first timestep is back to the old value.
alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
# Convert alphas_bar_sqrt to betas
alphas_bar = alphas_bar_sqrt**2 # Revert sqrt
alphas = alphas_bar[1:] / alphas_bar[:-1] # Revert cumprod
alphas = torch.cat([alphas_bar[0:1], alphas])
betas = 1 - alphas
return betas
class EulerDiscreteScheduler(SchedulerMixin, ConfigMixin):
"""
Euler scheduler.
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
methods the library implements for all schedulers such as loading and saving.
Args:
num_train_timesteps (`int`, defaults to 1000):
The number of diffusion steps to train the model.
beta_start (`float`, defaults to 0.0001):
The starting `beta` value of inference.
beta_end (`float`, defaults to 0.02):
The final `beta` value.
beta_schedule (`str`, defaults to `"linear"`):
The beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
`linear` or `scaled_linear`.
trained_betas (`np.ndarray`, *optional*):
Pass an array of betas directly to the constructor to bypass `beta_start` and `beta_end`.
prediction_type (`str`, defaults to `epsilon`, *optional*):
Prediction type of the scheduler function; can be `epsilon` (predicts the noise of the diffusion process),
`sample` (directly predicts the noisy sample`) or `v_prediction` (see section 2.4 of [Imagen
Video](https://imagen.research.google/video/paper.pdf) paper).
interpolation_type(`str`, defaults to `"linear"`, *optional*):
The interpolation type to compute intermediate sigmas for the scheduler denoising steps. Should be on of
`"linear"` or `"log_linear"`.
use_karras_sigmas (`bool`, *optional*, defaults to `False`):
Whether to use Karras sigmas for step sizes in the noise schedule during the sampling process. If `True`,
the sigmas are determined according to a sequence of noise levels {σi}.
timestep_spacing (`str`, defaults to `"linspace"`):
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
steps_offset (`int`, defaults to 0):
An offset added to the inference steps, as required by some model families.
rescale_betas_zero_snr (`bool`, defaults to `False`):
Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
dark samples instead of limiting it to samples with medium brightness. Loosely related to
[`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
final_sigmas_type (`str`, defaults to `"zero"`):
The final `sigma` value for the noise schedule during the sampling process. If `"sigma_min"`, the final
sigma is the same as the last sigma in the training schedule. If `zero`, the final sigma is set to 0.
"""
_compatibles = [e.name for e in KarrasDiffusionSchedulers]
order = 1
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
beta_start: float = 0.0001,
beta_end: float = 0.02,
beta_schedule: str = "linear",
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
prediction_type: str = "epsilon",
interpolation_type: str = "linear",
use_karras_sigmas: Optional[bool] = False,
sigma_min: Optional[float] = None,
sigma_max: Optional[float] = None,
timestep_spacing: str = "linspace",
timestep_type: str = "discrete", # can be "discrete" or "continuous"
steps_offset: int = 0,
rescale_betas_zero_snr: bool = False,
final_sigmas_type: str = "zero", # can be "zero" or "sigma_min"
):
if trained_betas is not None:
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
elif beta_schedule == "linear":
self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
elif beta_schedule == "scaled_linear":
# this schedule is very specific to the latent diffusion model.
self.betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
elif beta_schedule == "squaredcos_cap_v2":
# Glide cosine schedule
self.betas = betas_for_alpha_bar(num_train_timesteps)
else:
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
if rescale_betas_zero_snr:
self.betas = rescale_zero_terminal_snr(self.betas)
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
if rescale_betas_zero_snr:
# Close to 0 without being 0 so first sigma is not inf
# FP16 smallest positive subnormal works well here
self.alphas_cumprod[-1] = 2**-24
sigmas = (((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5).flip(0)
timesteps = np.linspace(0, num_train_timesteps - 1, num_train_timesteps, dtype=float)[::-1].copy()
timesteps = torch.from_numpy(timesteps).to(dtype=torch.float32)
# setable values
self.num_inference_steps = None
# TODO: Support the full EDM scalings for all prediction types and timestep types
if timestep_type == "continuous" and prediction_type == "v_prediction":
self.timesteps = torch.Tensor([0.25 * sigma.log() for sigma in sigmas])
else:
self.timesteps = timesteps
self.sigmas = torch.cat([sigmas, torch.zeros(1, device=sigmas.device)])
self.is_scale_input_called = False
self.use_karras_sigmas = use_karras_sigmas
self._step_index = None
self._begin_index = None
self.sigmas = self.sigmas.to("cpu") # to avoid too much CPU/GPU communication
@property
def init_noise_sigma(self):
# standard deviation of the initial noise distribution
max_sigma = max(self.sigmas) if isinstance(self.sigmas, list) else self.sigmas.max()
if self.config.timestep_spacing in ["linspace", "trailing"]:
return max_sigma
return (max_sigma**2 + 1) ** 0.5
@property
def step_index(self):
"""
The index counter for current timestep. It will increase 1 after each scheduler step.
"""
return self._step_index
@property
def begin_index(self):
"""
The index for the first timestep. It should be set from pipeline with `set_begin_index` method.
"""
return self._begin_index
# Copied from diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler.set_begin_index
def set_begin_index(self, begin_index: int = 0):
"""
Sets the begin index for the scheduler. This function should be run from pipeline before the inference.
Args:
begin_index (`int`):
The begin index for the scheduler.
"""
self._begin_index = begin_index
def scale_model_input(self, sample: torch.Tensor, timestep: Union[float, torch.Tensor]) -> torch.Tensor:
"""
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
current timestep. Scales the denoising model input by `(sigma**2 + 1) ** 0.5` to match the Euler algorithm.
Args:
sample (`torch.Tensor`):
The input sample.
timestep (`int`, *optional*):
The current timestep in the diffusion chain.
Returns:
`torch.Tensor`:
A scaled input sample.
"""
if self.step_index is None:
self._init_step_index(timestep)
sigma = self.sigmas[self.step_index]
sample = sample / ((sigma**2 + 1) ** 0.5)
self.is_scale_input_called = True
return sample
def set_timesteps(
self,
num_inference_steps: int = None,
device: Union[str, torch.device] = None,
timesteps: Optional[List[int]] = None,
sigmas: Optional[List[float]] = None,
):
"""
Sets the discrete timesteps used for the diffusion chain (to be run before inference).
Args:
num_inference_steps (`int`):
The number of diffusion steps used when generating samples with a pre-trained model.
device (`str` or `torch.device`, *optional*):
The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
timesteps (`List[int]`, *optional*):
Custom timesteps used to support arbitrary timesteps schedule. If `None`, timesteps will be generated
based on the `timestep_spacing` attribute. If `timesteps` is passed, `num_inference_steps` and `sigmas`
must be `None`, and `timestep_spacing` attribute will be ignored.
sigmas (`List[float]`, *optional*):
Custom sigmas used to support arbitrary timesteps schedule schedule. If `None`, timesteps and sigmas
will be generated based on the relevant scheduler attributes. If `sigmas` is passed,
`num_inference_steps` and `timesteps` must be `None`, and the timesteps will be generated based on the
custom sigmas schedule.
"""
if timesteps is not None and sigmas is not None:
raise ValueError("Only one of `timesteps` or `sigmas` should be set.")
if num_inference_steps is None and timesteps is None and sigmas is None:
raise ValueError("Must pass exactly one of `num_inference_steps` or `timesteps` or `sigmas.")
if num_inference_steps is not None and (timesteps is not None or sigmas is not None):
raise ValueError("Can only pass one of `num_inference_steps` or `timesteps` or `sigmas`.")
if timesteps is not None and self.config.use_karras_sigmas:
raise ValueError("Cannot set `timesteps` with `config.use_karras_sigmas = True`.")
if (
timesteps is not None
and self.config.timestep_type == "continuous"
and self.config.prediction_type == "v_prediction"
):
raise ValueError(
"Cannot set `timesteps` with `config.timestep_type = 'continuous'` and `config.prediction_type = 'v_prediction'`."
)
if num_inference_steps is None:
num_inference_steps = len(timesteps) if timesteps is not None else len(sigmas) - 1
self.num_inference_steps = num_inference_steps
if sigmas is not None:
log_sigmas = np.log(np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5))
sigmas = np.array(sigmas).astype(np.float32)
timesteps = np.array([self._sigma_to_t(sigma, log_sigmas) for sigma in sigmas[:-1]])
else:
if timesteps is not None:
timesteps = np.array(timesteps).astype(np.float32)
else:
# "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = np.linspace(
0, self.config.num_train_timesteps - 1, num_inference_steps, dtype=np.float32
)[::-1].copy()
elif self.config.timestep_spacing == "leading":
step_ratio = self.config.num_train_timesteps // self.num_inference_steps
# creates integer timesteps by multiplying by ratio
# casting to int to avoid issues when num_inference_step is power of 3
timesteps = (
(np.arange(0, num_inference_steps) * step_ratio).round()[::-1].copy().astype(np.float32)
)
timesteps += self.config.steps_offset
elif self.config.timestep_spacing == "trailing":
step_ratio = self.config.num_train_timesteps / self.num_inference_steps
# creates integer timesteps by multiplying by ratio
# casting to int to avoid issues when num_inference_step is power of 3
timesteps = (
(np.arange(self.config.num_train_timesteps, 0, -step_ratio)).round().copy().astype(np.float32)
)
timesteps -= 1
else:
raise ValueError(
f"{self.config.timestep_spacing} is not supported. Please make sure to choose one of 'linspace', 'leading' or 'trailing'."
)
sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
log_sigmas = np.log(sigmas)
if self.config.interpolation_type == "linear":
sigmas = np.interp(timesteps, np.arange(0, len(sigmas)), sigmas)
elif self.config.interpolation_type == "log_linear":
sigmas = torch.linspace(np.log(sigmas[-1]), np.log(sigmas[0]), num_inference_steps + 1).exp().numpy()
else:
raise ValueError(
f"{self.config.interpolation_type} is not implemented. Please specify interpolation_type to either"
" 'linear' or 'log_linear'"
)
if self.config.use_karras_sigmas:
sigmas = self._convert_to_karras(in_sigmas=sigmas, num_inference_steps=self.num_inference_steps)
timesteps = np.array([self._sigma_to_t(sigma, log_sigmas) for sigma in sigmas])
if self.config.final_sigmas_type == "sigma_min":
sigma_last = ((1 - self.alphas_cumprod[0]) / self.alphas_cumprod[0]) ** 0.5
elif self.config.final_sigmas_type == "zero":
sigma_last = 0
else:
raise ValueError(
f"`final_sigmas_type` must be one of 'zero', or 'sigma_min', but got {self.config.final_sigmas_type}"
)
sigmas = np.concatenate([sigmas, [sigma_last]]).astype(np.float32)
sigmas = torch.from_numpy(sigmas).to(dtype=torch.float32, device=device)
# TODO: Support the full EDM scalings for all prediction types and timestep types
if self.config.timestep_type == "continuous" and self.config.prediction_type == "v_prediction":
self.timesteps = torch.Tensor([0.25 * sigma.log() for sigma in sigmas[:-1]]).to(device=device)
else:
self.timesteps = torch.from_numpy(timesteps.astype(np.float32)).to(device=device)
self._step_index = None
self._begin_index = None
self.sigmas = sigmas.to("cpu") # to avoid too much CPU/GPU communication
def _sigma_to_t(self, sigma, log_sigmas):
# get log sigma
log_sigma = np.log(np.maximum(sigma, 1e-10))
# get distribution
dists = log_sigma - log_sigmas[:, np.newaxis]
# get sigmas range
low_idx = np.cumsum((dists >= 0), axis=0).argmax(axis=0).clip(max=log_sigmas.shape[0] - 2)
high_idx = low_idx + 1
low = log_sigmas[low_idx]
high = log_sigmas[high_idx]
# interpolate sigmas
w = (low - log_sigma) / (low - high)
w = np.clip(w, 0, 1)
# transform interpolation to time range
t = (1 - w) * low_idx + w * high_idx
t = t.reshape(sigma.shape)
return t
# Copied from https://github.com/crowsonkb/k-diffusion/blob/686dbad0f39640ea25c8a8c6a6e56bb40eacefa2/k_diffusion/sampling.py#L17
def _convert_to_karras(self, in_sigmas: torch.Tensor, num_inference_steps) -> torch.Tensor:
"""Constructs the noise schedule of Karras et al. (2022)."""
# Hack to make sure that other schedulers which copy this function don't break
# TODO: Add this logic to the other schedulers
if hasattr(self.config, "sigma_min"):
sigma_min = self.config.sigma_min
else:
sigma_min = None
if hasattr(self.config, "sigma_max"):
sigma_max = self.config.sigma_max
else:
sigma_max = None
sigma_min = sigma_min if sigma_min is not None else in_sigmas[-1].item()
sigma_max = sigma_max if sigma_max is not None else in_sigmas[0].item()
rho = 7.0 # 7.0 is the value used in the paper
ramp = np.linspace(0, 1, num_inference_steps)
min_inv_rho = sigma_min ** (1 / rho)
max_inv_rho = sigma_max ** (1 / rho)
sigmas = (max_inv_rho + ramp * (min_inv_rho - max_inv_rho)) ** rho
return sigmas
def index_for_timestep(self, timestep, schedule_timesteps=None):
if schedule_timesteps is None:
schedule_timesteps = self.timesteps
indices = (schedule_timesteps == timestep).nonzero()
# The sigma index that is taken for the **very** first `step`
# is always the second index (or the last index if there is only 1)
# This way we can ensure we don't accidentally skip a sigma in
# case we start in the middle of the denoising schedule (e.g. for image-to-image)
pos = 1 if len(indices) > 1 else 0
return indices[pos].item()
def _init_step_index(self, timestep):
if self.begin_index is None:
if isinstance(timestep, torch.Tensor):
timestep = timestep.to(self.timesteps.device)
self._step_index = self.index_for_timestep(timestep)
else:
self._step_index = self._begin_index
def step(
self,
model_output: torch.Tensor,
timestep: Union[float, torch.Tensor],
sample: torch.Tensor,
s_churn: float = 0.0,
s_tmin: float = 0.0,
s_tmax: float = float("inf"),
s_noise: float = 1.0,
generator: Optional[torch.Generator] = None,
return_dict: bool = True,
) -> Union[EulerDiscreteSchedulerOutput, Tuple]:
"""
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
model_output (`torch.Tensor`):
The direct output from learned diffusion model.
timestep (`float`):
The current discrete timestep in the diffusion chain.
sample (`torch.Tensor`):
A current instance of a sample created by the diffusion process.
s_churn (`float`):
s_tmin (`float`):
s_tmax (`float`):
s_noise (`float`, defaults to 1.0):
Scaling factor for noise added to the sample.
generator (`torch.Generator`, *optional*):
A random number generator.
return_dict (`bool`):
Whether or not to return a [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or
tuple.
Returns:
[`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or `tuple`:
If return_dict is `True`, [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] is
returned, otherwise a tuple is returned where the first element is the sample tensor.
"""
if (
isinstance(timestep, int)
or isinstance(timestep, torch.IntTensor)
or isinstance(timestep, torch.LongTensor)
):
raise ValueError(
(
"Passing integer indices (e.g. from `enumerate(timesteps)`) as timesteps to"
" `EulerDiscreteScheduler.step()` is not supported. Make sure to pass"
" one of the `scheduler.timesteps` as a timestep."
),
)
if not self.is_scale_input_called:
logger.warning(
"The `scale_model_input` function should be called before `step` to ensure correct denoising. "
"See `StableDiffusionPipeline` for a usage example."
)
if self.step_index is None:
self._init_step_index(timestep)
# Upcast to avoid precision issues when computing prev_sample
sample = sample.to(torch.float32)
sigma = self.sigmas[self.step_index]
gamma = min(s_churn / (len(self.sigmas) - 1), 2**0.5 - 1) if s_tmin <= sigma <= s_tmax else 0.0
noise = randn_tensor(
model_output.shape, dtype=model_output.dtype, device=model_output.device, generator=generator
)
eps = noise * s_noise
sigma_hat = sigma * (gamma + 1)
if gamma > 0:
sample = sample + eps * (sigma_hat**2 - sigma**2) ** 0.5
# 1. compute predicted original sample (x_0) from sigma-scaled predicted noise
# NOTE: "original_sample" should not be an expected prediction_type but is left in for
# backwards compatibility
if self.config.prediction_type == "original_sample" or self.config.prediction_type == "sample":
pred_original_sample = model_output
elif self.config.prediction_type == "epsilon":
pred_original_sample = sample - sigma_hat * model_output
elif self.config.prediction_type == "v_prediction":
# denoised = model_output * c_out + input * c_skip
pred_original_sample = model_output * (-sigma / (sigma**2 + 1) ** 0.5) + (sample / (sigma**2 + 1))
else:
raise ValueError(
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`"
)
# 2. Convert to an ODE derivative
derivative = (sample - pred_original_sample) / sigma_hat
dt = self.sigmas[self.step_index + 1] - sigma_hat
prev_sample = sample + derivative * dt
# Cast sample back to model compatible dtype
prev_sample = prev_sample.to(model_output.dtype)
# upon completion increase step index by one
self._step_index += 1
if not return_dict:
return (prev_sample,)
return EulerDiscreteSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
def add_noise(
self,
original_samples: torch.Tensor,
noise: torch.Tensor,
timesteps: torch.Tensor,
) -> torch.Tensor:
# Make sure sigmas and timesteps have the same device and dtype as original_samples
sigmas = self.sigmas.to(device=original_samples.device, dtype=original_samples.dtype)
if original_samples.device.type == "mps" and torch.is_floating_point(timesteps):
# mps does not support float64
schedule_timesteps = self.timesteps.to(original_samples.device, dtype=torch.float32)
timesteps = timesteps.to(original_samples.device, dtype=torch.float32)
else:
schedule_timesteps = self.timesteps.to(original_samples.device)
timesteps = timesteps.to(original_samples.device)
# self.begin_index is None when scheduler is used for training, or pipeline does not implement set_begin_index
if self.begin_index is None:
step_indices = [self.index_for_timestep(t, schedule_timesteps) for t in timesteps]
elif self.step_index is not None:
# add_noise is called after first denoising step (for inpainting)
step_indices = [self.step_index] * timesteps.shape[0]
else:
# add noise is called before first denoising step to create initial latent(img2img)
step_indices = [self.begin_index] * timesteps.shape[0]
sigma = sigmas[step_indices].flatten()
while len(sigma.shape) < len(original_samples.shape):
sigma = sigma.unsqueeze(-1)
noisy_samples = original_samples + noise * sigma
return noisy_samples
def get_velocity(self, sample: torch.Tensor, noise: torch.Tensor, timesteps: torch.Tensor) -> torch.Tensor:
if (
isinstance(timesteps, int)
or isinstance(timesteps, torch.IntTensor)
or isinstance(timesteps, torch.LongTensor)
):
raise ValueError(
(
"Passing integer indices (e.g. from `enumerate(timesteps)`) as timesteps to"
" `EulerDiscreteScheduler.get_velocity()` is not supported. Make sure to pass"
" one of the `scheduler.timesteps` as a timestep."
),
)
if sample.device.type == "mps" and torch.is_floating_point(timesteps):
# mps does not support float64
schedule_timesteps = self.timesteps.to(sample.device, dtype=torch.float32)
timesteps = timesteps.to(sample.device, dtype=torch.float32)
else:
schedule_timesteps = self.timesteps.to(sample.device)
timesteps = timesteps.to(sample.device)
step_indices = [self.index_for_timestep(t, schedule_timesteps) for t in timesteps]
alphas_cumprod = self.alphas_cumprod.to(sample)
sqrt_alpha_prod = alphas_cumprod[step_indices] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(sample.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[step_indices]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
return velocity
def __len__(self):
return self.config.num_train_timesteps
| diffusers/src/diffusers/schedulers/scheduling_euler_discrete.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_euler_discrete.py",
"repo_id": "diffusers",
"token_count": 13580
} | 256 |
# Copyright 2024 Stanford University Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
# and https://github.com/hojonathanho/diffusion
import math
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import numpy as np
import torch
from ..configuration_utils import ConfigMixin, register_to_config
from ..schedulers.scheduling_utils import SchedulerMixin
from ..utils import BaseOutput, logging
from ..utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
@dataclass
class TCDSchedulerOutput(BaseOutput):
"""
Output class for the scheduler's `step` function output.
Args:
prev_sample (`torch.Tensor` of shape `(batch_size, num_channels, height, width)` for images):
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
denoising loop.
pred_noised_sample (`torch.Tensor` of shape `(batch_size, num_channels, height, width)` for images):
The predicted noised sample `(x_{s})` based on the model output from the current timestep.
"""
prev_sample: torch.Tensor
pred_noised_sample: Optional[torch.Tensor] = None
# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
def betas_for_alpha_bar(
num_diffusion_timesteps,
max_beta=0.999,
alpha_transform_type="cosine",
):
"""
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
(1-beta) over time from t = [0,1].
Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
to that part of the diffusion process.
Args:
num_diffusion_timesteps (`int`): the number of betas to produce.
max_beta (`float`): the maximum beta to use; use values lower than 1 to
prevent singularities.
alpha_transform_type (`str`, *optional*, default to `cosine`): the type of noise schedule for alpha_bar.
Choose from `cosine` or `exp`
Returns:
betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
"""
if alpha_transform_type == "cosine":
def alpha_bar_fn(t):
return math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2
elif alpha_transform_type == "exp":
def alpha_bar_fn(t):
return math.exp(t * -12.0)
else:
raise ValueError(f"Unsupported alpha_transform_type: {alpha_transform_type}")
betas = []
for i in range(num_diffusion_timesteps):
t1 = i / num_diffusion_timesteps
t2 = (i + 1) / num_diffusion_timesteps
betas.append(min(1 - alpha_bar_fn(t2) / alpha_bar_fn(t1), max_beta))
return torch.tensor(betas, dtype=torch.float32)
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas: torch.Tensor) -> torch.Tensor:
"""
Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
Args:
betas (`torch.Tensor`):
the betas that the scheduler is being initialized with.
Returns:
`torch.Tensor`: rescaled betas with zero terminal SNR
"""
# Convert betas to alphas_bar_sqrt
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_bar_sqrt = alphas_cumprod.sqrt()
# Store old values.
alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
# Shift so the last timestep is zero.
alphas_bar_sqrt -= alphas_bar_sqrt_T
# Scale so the first timestep is back to the old value.
alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
# Convert alphas_bar_sqrt to betas
alphas_bar = alphas_bar_sqrt**2 # Revert sqrt
alphas = alphas_bar[1:] / alphas_bar[:-1] # Revert cumprod
alphas = torch.cat([alphas_bar[0:1], alphas])
betas = 1 - alphas
return betas
class TCDScheduler(SchedulerMixin, ConfigMixin):
"""
`TCDScheduler` incorporates the `Strategic Stochastic Sampling` introduced by the paper `Trajectory Consistency
Distillation`, extending the original Multistep Consistency Sampling to enable unrestricted trajectory traversal.
This code is based on the official repo of TCD(https://github.com/jabir-zheng/TCD).
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. [`~ConfigMixin`] takes care of storing all config
attributes that are passed in the scheduler's `__init__` function, such as `num_train_timesteps`. They can be
accessed via `scheduler.config.num_train_timesteps`. [`SchedulerMixin`] provides general loading and saving
functionality via the [`SchedulerMixin.save_pretrained`] and [`~SchedulerMixin.from_pretrained`] functions.
Args:
num_train_timesteps (`int`, defaults to 1000):
The number of diffusion steps to train the model.
beta_start (`float`, defaults to 0.0001):
The starting `beta` value of inference.
beta_end (`float`, defaults to 0.02):
The final `beta` value.
beta_schedule (`str`, defaults to `"linear"`):
The beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
`linear`, `scaled_linear`, or `squaredcos_cap_v2`.
trained_betas (`np.ndarray`, *optional*):
Pass an array of betas directly to the constructor to bypass `beta_start` and `beta_end`.
original_inference_steps (`int`, *optional*, defaults to 50):
The default number of inference steps used to generate a linearly-spaced timestep schedule, from which we
will ultimately take `num_inference_steps` evenly spaced timesteps to form the final timestep schedule.
clip_sample (`bool`, defaults to `True`):
Clip the predicted sample for numerical stability.
clip_sample_range (`float`, defaults to 1.0):
The maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
set_alpha_to_one (`bool`, defaults to `True`):
Each diffusion step uses the alphas product value at that step and at the previous one. For the final step
there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
otherwise it uses the alpha value at step 0.
steps_offset (`int`, defaults to 0):
An offset added to the inference steps, as required by some model families.
prediction_type (`str`, defaults to `epsilon`, *optional*):
Prediction type of the scheduler function; can be `epsilon` (predicts the noise of the diffusion process),
`sample` (directly predicts the noisy sample`) or `v_prediction` (see section 2.4 of [Imagen
Video](https://imagen.research.google/video/paper.pdf) paper).
thresholding (`bool`, defaults to `False`):
Whether to use the "dynamic thresholding" method. This is unsuitable for latent-space diffusion models such
as Stable Diffusion.
dynamic_thresholding_ratio (`float`, defaults to 0.995):
The ratio for the dynamic thresholding method. Valid only when `thresholding=True`.
sample_max_value (`float`, defaults to 1.0):
The threshold value for dynamic thresholding. Valid only when `thresholding=True`.
timestep_spacing (`str`, defaults to `"leading"`):
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
timestep_scaling (`float`, defaults to 10.0):
The factor the timesteps will be multiplied by when calculating the consistency model boundary conditions
`c_skip` and `c_out`. Increasing this will decrease the approximation error (although the approximation
error at the default of `10.0` is already pretty small).
rescale_betas_zero_snr (`bool`, defaults to `False`):
Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
dark samples instead of limiting it to samples with medium brightness. Loosely related to
[`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
"""
order = 1
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
beta_start: float = 0.00085,
beta_end: float = 0.012,
beta_schedule: str = "scaled_linear",
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
original_inference_steps: int = 50,
clip_sample: bool = False,
clip_sample_range: float = 1.0,
set_alpha_to_one: bool = True,
steps_offset: int = 0,
prediction_type: str = "epsilon",
thresholding: bool = False,
dynamic_thresholding_ratio: float = 0.995,
sample_max_value: float = 1.0,
timestep_spacing: str = "leading",
timestep_scaling: float = 10.0,
rescale_betas_zero_snr: bool = False,
):
if trained_betas is not None:
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
elif beta_schedule == "linear":
self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
elif beta_schedule == "scaled_linear":
# this schedule is very specific to the latent diffusion model.
self.betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
elif beta_schedule == "squaredcos_cap_v2":
# Glide cosine schedule
self.betas = betas_for_alpha_bar(num_train_timesteps)
else:
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
# Rescale for zero SNR
if rescale_betas_zero_snr:
self.betas = rescale_zero_terminal_snr(self.betas)
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
# At every step in ddim, we are looking into the previous alphas_cumprod
# For the final step, there is no previous alphas_cumprod because we are already at 0
# `set_alpha_to_one` decides whether we set this parameter simply to one or
# whether we use the final alpha of the "non-previous" one.
self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
# standard deviation of the initial noise distribution
self.init_noise_sigma = 1.0
# setable values
self.num_inference_steps = None
self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy().astype(np.int64))
self.custom_timesteps = False
self._step_index = None
self._begin_index = None
# Copied from diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler.index_for_timestep
def index_for_timestep(self, timestep, schedule_timesteps=None):
if schedule_timesteps is None:
schedule_timesteps = self.timesteps
indices = (schedule_timesteps == timestep).nonzero()
# The sigma index that is taken for the **very** first `step`
# is always the second index (or the last index if there is only 1)
# This way we can ensure we don't accidentally skip a sigma in
# case we start in the middle of the denoising schedule (e.g. for image-to-image)
pos = 1 if len(indices) > 1 else 0
return indices[pos].item()
# Copied from diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler._init_step_index
def _init_step_index(self, timestep):
if self.begin_index is None:
if isinstance(timestep, torch.Tensor):
timestep = timestep.to(self.timesteps.device)
self._step_index = self.index_for_timestep(timestep)
else:
self._step_index = self._begin_index
@property
def step_index(self):
return self._step_index
@property
def begin_index(self):
"""
The index for the first timestep. It should be set from pipeline with `set_begin_index` method.
"""
return self._begin_index
# Copied from diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler.set_begin_index
def set_begin_index(self, begin_index: int = 0):
"""
Sets the begin index for the scheduler. This function should be run from pipeline before the inference.
Args:
begin_index (`int`):
The begin index for the scheduler.
"""
self._begin_index = begin_index
def scale_model_input(self, sample: torch.Tensor, timestep: Optional[int] = None) -> torch.Tensor:
"""
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
current timestep.
Args:
sample (`torch.Tensor`):
The input sample.
timestep (`int`, *optional*):
The current timestep in the diffusion chain.
Returns:
`torch.Tensor`:
A scaled input sample.
"""
return sample
# Copied from diffusers.schedulers.scheduling_ddim.DDIMScheduler._get_variance
def _get_variance(self, timestep, prev_timestep):
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
return variance
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
def _threshold_sample(self, sample: torch.Tensor) -> torch.Tensor:
"""
"Dynamic thresholding: At each sampling step we set s to a certain percentile absolute pixel value in xt0 (the
prediction of x_0 at timestep t), and if s > 1, then we threshold xt0 to the range [-s, s] and then divide by
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
https://arxiv.org/abs/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
if dtype not in (torch.float32, torch.float64):
sample = sample.float() # upcast for quantile calculation, and clamp not implemented for cpu half
# Flatten sample for doing quantile calculation along each image
sample = sample.reshape(batch_size, channels * np.prod(remaining_dims))
abs_sample = sample.abs() # "a certain percentile absolute pixel value"
s = torch.quantile(abs_sample, self.config.dynamic_thresholding_ratio, dim=1)
s = torch.clamp(
s, min=1, max=self.config.sample_max_value
) # When clamped to min=1, equivalent to standard clipping to [-1, 1]
s = s.unsqueeze(1) # (batch_size, 1) because clamp will broadcast along dim=0
sample = torch.clamp(sample, -s, s) / s # "we threshold xt0 to the range [-s, s] and then divide by s"
sample = sample.reshape(batch_size, channels, *remaining_dims)
sample = sample.to(dtype)
return sample
def set_timesteps(
self,
num_inference_steps: Optional[int] = None,
device: Union[str, torch.device] = None,
original_inference_steps: Optional[int] = None,
timesteps: Optional[List[int]] = None,
strength: float = 1.0,
):
"""
Sets the discrete timesteps used for the diffusion chain (to be run before inference).
Args:
num_inference_steps (`int`, *optional*):
The number of diffusion steps used when generating samples with a pre-trained model. If used,
`timesteps` must be `None`.
device (`str` or `torch.device`, *optional*):
The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
original_inference_steps (`int`, *optional*):
The original number of inference steps, which will be used to generate a linearly-spaced timestep
schedule (which is different from the standard `diffusers` implementation). We will then take
`num_inference_steps` timesteps from this schedule, evenly spaced in terms of indices, and use that as
our final timestep schedule. If not set, this will default to the `original_inference_steps` attribute.
timesteps (`List[int]`, *optional*):
Custom timesteps used to support arbitrary spacing between timesteps. If `None`, then the default
timestep spacing strategy of equal spacing between timesteps on the training/distillation timestep
schedule is used. If `timesteps` is passed, `num_inference_steps` must be `None`.
strength (`float`, *optional*, defaults to 1.0):
Used to determine the number of timesteps used for inference when using img2img, inpaint, etc.
"""
# 0. Check inputs
if num_inference_steps is None and timesteps is None:
raise ValueError("Must pass exactly one of `num_inference_steps` or `custom_timesteps`.")
if num_inference_steps is not None and timesteps is not None:
raise ValueError("Can only pass one of `num_inference_steps` or `custom_timesteps`.")
# 1. Calculate the TCD original training/distillation timestep schedule.
original_steps = (
original_inference_steps if original_inference_steps is not None else self.config.original_inference_steps
)
if original_inference_steps is None:
# default option, timesteps align with discrete inference steps
if original_steps > self.config.num_train_timesteps:
raise ValueError(
f"`original_steps`: {original_steps} cannot be larger than `self.config.train_timesteps`:"
f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
f" maximal {self.config.num_train_timesteps} timesteps."
)
# TCD Timesteps Setting
# The skipping step parameter k from the paper.
k = self.config.num_train_timesteps // original_steps
# TCD Training/Distillation Steps Schedule
tcd_origin_timesteps = np.asarray(list(range(1, int(original_steps * strength) + 1))) * k - 1
else:
# customised option, sampled timesteps can be any arbitrary value
tcd_origin_timesteps = np.asarray(list(range(0, int(self.config.num_train_timesteps * strength))))
# 2. Calculate the TCD inference timestep schedule.
if timesteps is not None:
# 2.1 Handle custom timestep schedules.
train_timesteps = set(tcd_origin_timesteps)
non_train_timesteps = []
for i in range(1, len(timesteps)):
if timesteps[i] >= timesteps[i - 1]:
raise ValueError("`custom_timesteps` must be in descending order.")
if timesteps[i] not in train_timesteps:
non_train_timesteps.append(timesteps[i])
if timesteps[0] >= self.config.num_train_timesteps:
raise ValueError(
f"`timesteps` must start before `self.config.train_timesteps`:"
f" {self.config.num_train_timesteps}."
)
# Raise warning if timestep schedule does not start with self.config.num_train_timesteps - 1
if strength == 1.0 and timesteps[0] != self.config.num_train_timesteps - 1:
logger.warning(
f"The first timestep on the custom timestep schedule is {timesteps[0]}, not"
f" `self.config.num_train_timesteps - 1`: {self.config.num_train_timesteps - 1}. You may get"
f" unexpected results when using this timestep schedule."
)
# Raise warning if custom timestep schedule contains timesteps not on original timestep schedule
if non_train_timesteps:
logger.warning(
f"The custom timestep schedule contains the following timesteps which are not on the original"
f" training/distillation timestep schedule: {non_train_timesteps}. You may get unexpected results"
f" when using this timestep schedule."
)
# Raise warning if custom timestep schedule is longer than original_steps
if original_steps is not None:
if len(timesteps) > original_steps:
logger.warning(
f"The number of timesteps in the custom timestep schedule is {len(timesteps)}, which exceeds the"
f" the length of the timestep schedule used for training: {original_steps}. You may get some"
f" unexpected results when using this timestep schedule."
)
else:
if len(timesteps) > self.config.num_train_timesteps:
logger.warning(
f"The number of timesteps in the custom timestep schedule is {len(timesteps)}, which exceeds the"
f" the length of the timestep schedule used for training: {self.config.num_train_timesteps}. You may get some"
f" unexpected results when using this timestep schedule."
)
timesteps = np.array(timesteps, dtype=np.int64)
self.num_inference_steps = len(timesteps)
self.custom_timesteps = True
# Apply strength (e.g. for img2img pipelines) (see StableDiffusionImg2ImgPipeline.get_timesteps)
init_timestep = min(int(self.num_inference_steps * strength), self.num_inference_steps)
t_start = max(self.num_inference_steps - init_timestep, 0)
timesteps = timesteps[t_start * self.order :]
# TODO: also reset self.num_inference_steps?
else:
# 2.2 Create the "standard" TCD inference timestep schedule.
if num_inference_steps > self.config.num_train_timesteps:
raise ValueError(
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"
f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
f" maximal {self.config.num_train_timesteps} timesteps."
)
if original_steps is not None:
skipping_step = len(tcd_origin_timesteps) // num_inference_steps
if skipping_step < 1:
raise ValueError(
f"The combination of `original_steps x strength`: {original_steps} x {strength} is smaller than `num_inference_steps`: {num_inference_steps}. Make sure to either reduce `num_inference_steps` to a value smaller than {int(original_steps * strength)} or increase `strength` to a value higher than {float(num_inference_steps / original_steps)}."
)
self.num_inference_steps = num_inference_steps
if original_steps is not None:
if num_inference_steps > original_steps:
raise ValueError(
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `original_inference_steps`:"
f" {original_steps} because the final timestep schedule will be a subset of the"
f" `original_inference_steps`-sized initial timestep schedule."
)
else:
if num_inference_steps > self.config.num_train_timesteps:
raise ValueError(
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `num_train_timesteps`:"
f" {self.config.num_train_timesteps} because the final timestep schedule will be a subset of the"
f" `num_train_timesteps`-sized initial timestep schedule."
)
# TCD Inference Steps Schedule
tcd_origin_timesteps = tcd_origin_timesteps[::-1].copy()
# Select (approximately) evenly spaced indices from tcd_origin_timesteps.
inference_indices = np.linspace(0, len(tcd_origin_timesteps), num=num_inference_steps, endpoint=False)
inference_indices = np.floor(inference_indices).astype(np.int64)
timesteps = tcd_origin_timesteps[inference_indices]
self.timesteps = torch.from_numpy(timesteps).to(device=device, dtype=torch.long)
self._step_index = None
self._begin_index = None
def step(
self,
model_output: torch.Tensor,
timestep: int,
sample: torch.Tensor,
eta: float = 0.3,
generator: Optional[torch.Generator] = None,
return_dict: bool = True,
) -> Union[TCDSchedulerOutput, Tuple]:
"""
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
model_output (`torch.Tensor`):
The direct output from learned diffusion model.
timestep (`int`):
The current discrete timestep in the diffusion chain.
sample (`torch.Tensor`):
A current instance of a sample created by the diffusion process.
eta (`float`):
A stochastic parameter (referred to as `gamma` in the paper) used to control the stochasticity in every
step. When eta = 0, it represents deterministic sampling, whereas eta = 1 indicates full stochastic
sampling.
generator (`torch.Generator`, *optional*):
A random number generator.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~schedulers.scheduling_tcd.TCDSchedulerOutput`] or `tuple`.
Returns:
[`~schedulers.scheduling_utils.TCDSchedulerOutput`] or `tuple`:
If return_dict is `True`, [`~schedulers.scheduling_tcd.TCDSchedulerOutput`] is returned, otherwise a
tuple is returned where the first element is the sample tensor.
"""
if self.num_inference_steps is None:
raise ValueError(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
if self.step_index is None:
self._init_step_index(timestep)
assert 0 <= eta <= 1.0, "gamma must be less than or equal to 1.0"
# 1. get previous step value
prev_step_index = self.step_index + 1
if prev_step_index < len(self.timesteps):
prev_timestep = self.timesteps[prev_step_index]
else:
prev_timestep = torch.tensor(0)
timestep_s = torch.floor((1 - eta) * prev_timestep).to(dtype=torch.long)
# 2. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
alpha_prod_s = self.alphas_cumprod[timestep_s]
beta_prod_s = 1 - alpha_prod_s
# 3. Compute the predicted noised sample x_s based on the model parameterization
if self.config.prediction_type == "epsilon": # noise-prediction
pred_original_sample = (sample - beta_prod_t.sqrt() * model_output) / alpha_prod_t.sqrt()
pred_epsilon = model_output
pred_noised_sample = alpha_prod_s.sqrt() * pred_original_sample + beta_prod_s.sqrt() * pred_epsilon
elif self.config.prediction_type == "sample": # x-prediction
pred_original_sample = model_output
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
pred_noised_sample = alpha_prod_s.sqrt() * pred_original_sample + beta_prod_s.sqrt() * pred_epsilon
elif self.config.prediction_type == "v_prediction": # v-prediction
pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
pred_noised_sample = alpha_prod_s.sqrt() * pred_original_sample + beta_prod_s.sqrt() * pred_epsilon
else:
raise ValueError(
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample` or"
" `v_prediction` for `TCDScheduler`."
)
# 4. Sample and inject noise z ~ N(0, I) for MultiStep Inference
# Noise is not used on the final timestep of the timestep schedule.
# This also means that noise is not used for one-step sampling.
# Eta (referred to as "gamma" in the paper) was introduced to control the stochasticity in every step.
# When eta = 0, it represents deterministic sampling, whereas eta = 1 indicates full stochastic sampling.
if eta > 0:
if self.step_index != self.num_inference_steps - 1:
noise = randn_tensor(
model_output.shape, generator=generator, device=model_output.device, dtype=pred_noised_sample.dtype
)
prev_sample = (alpha_prod_t_prev / alpha_prod_s).sqrt() * pred_noised_sample + (
1 - alpha_prod_t_prev / alpha_prod_s
).sqrt() * noise
else:
prev_sample = pred_noised_sample
else:
prev_sample = pred_noised_sample
# upon completion increase step index by one
self._step_index += 1
if not return_dict:
return (prev_sample, pred_noised_sample)
return TCDSchedulerOutput(prev_sample=prev_sample, pred_noised_sample=pred_noised_sample)
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.add_noise
def add_noise(
self,
original_samples: torch.Tensor,
noise: torch.Tensor,
timesteps: torch.IntTensor,
) -> torch.Tensor:
# Make sure alphas_cumprod and timestep have same device and dtype as original_samples
# Move the self.alphas_cumprod to device to avoid redundant CPU to GPU data movement
# for the subsequent add_noise calls
self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device)
alphas_cumprod = self.alphas_cumprod.to(dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.get_velocity
def get_velocity(self, sample: torch.Tensor, noise: torch.Tensor, timesteps: torch.IntTensor) -> torch.Tensor:
# Make sure alphas_cumprod and timestep have same device and dtype as sample
self.alphas_cumprod = self.alphas_cumprod.to(device=sample.device)
alphas_cumprod = self.alphas_cumprod.to(dtype=sample.dtype)
timesteps = timesteps.to(sample.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(sample.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
return velocity
def __len__(self):
return self.config.num_train_timesteps
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.previous_timestep
def previous_timestep(self, timestep):
if self.custom_timesteps:
index = (self.timesteps == timestep).nonzero(as_tuple=True)[0][0]
if index == self.timesteps.shape[0] - 1:
prev_t = torch.tensor(-1)
else:
prev_t = self.timesteps[index + 1]
else:
num_inference_steps = (
self.num_inference_steps if self.num_inference_steps else self.config.num_train_timesteps
)
prev_t = timestep - self.config.num_train_timesteps // num_inference_steps
return prev_t
| diffusers/src/diffusers/schedulers/scheduling_tcd.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_tcd.py",
"repo_id": "diffusers",
"token_count": 14780
} | 257 |
# This file is autogenerated by the command `make fix-copies`, do not edit.
from ..utils import DummyObject, requires_backends
class AsymmetricAutoencoderKL(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoencoderKL(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoencoderKLTemporalDecoder(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoencoderTiny(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ConsistencyDecoderVAE(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ControlNetModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ControlNetXSAdapter(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class I2VGenXLUNet(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class Kandinsky3UNet(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ModelMixin(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class MotionAdapter(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class MultiAdapter(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class PriorTransformer(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class T2IAdapter(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class T5FilmDecoder(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class Transformer2DModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNet1DModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNet2DConditionModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNet2DModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNet3DConditionModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNetControlNetXSModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNetMotionModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNetSpatioTemporalConditionModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UVit2DModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class VQModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
def get_constant_schedule(*args, **kwargs):
requires_backends(get_constant_schedule, ["torch"])
def get_constant_schedule_with_warmup(*args, **kwargs):
requires_backends(get_constant_schedule_with_warmup, ["torch"])
def get_cosine_schedule_with_warmup(*args, **kwargs):
requires_backends(get_cosine_schedule_with_warmup, ["torch"])
def get_cosine_with_hard_restarts_schedule_with_warmup(*args, **kwargs):
requires_backends(get_cosine_with_hard_restarts_schedule_with_warmup, ["torch"])
def get_linear_schedule_with_warmup(*args, **kwargs):
requires_backends(get_linear_schedule_with_warmup, ["torch"])
def get_polynomial_decay_schedule_with_warmup(*args, **kwargs):
requires_backends(get_polynomial_decay_schedule_with_warmup, ["torch"])
def get_scheduler(*args, **kwargs):
requires_backends(get_scheduler, ["torch"])
class AudioPipelineOutput(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoPipelineForImage2Image(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoPipelineForInpainting(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoPipelineForText2Image(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class BlipDiffusionControlNetPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class BlipDiffusionPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class CLIPImageProjection(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ConsistencyModelPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DanceDiffusionPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDIMPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDPMPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DiffusionPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DiTPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ImagePipelineOutput(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class KarrasVePipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class LDMPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class LDMSuperResolutionPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class PNDMPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class RePaintPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ScoreSdeVePipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class StableDiffusionMixin(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AmusedScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class CMStochasticIterativeScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDIMInverseScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDIMParallelScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDIMScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDPMParallelScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDPMScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDPMWuerstchenScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DEISMultistepScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DPMSolverMultistepInverseScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DPMSolverMultistepScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DPMSolverSinglestepScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class EDMDPMSolverMultistepScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class EDMEulerScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class EulerAncestralDiscreteScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class EulerDiscreteScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class HeunDiscreteScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class IPNDMScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class KarrasVeScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class KDPM2AncestralDiscreteScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class KDPM2DiscreteScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class LCMScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class PNDMScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class RePaintScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class SASolverScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class SchedulerMixin(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ScoreSdeVeScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class TCDScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UnCLIPScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UniPCMultistepScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class VQDiffusionScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class EMAModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
| diffusers/src/diffusers/utils/dummy_pt_objects.py/0 | {
"file_path": "diffusers/src/diffusers/utils/dummy_pt_objects.py",
"repo_id": "diffusers",
"token_count": 13106
} | 258 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
PEFT utilities: Utilities related to peft library
"""
import collections
import importlib
from typing import Optional
from packaging import version
from .import_utils import is_peft_available, is_torch_available
if is_torch_available():
import torch
def recurse_remove_peft_layers(model):
r"""
Recursively replace all instances of `LoraLayer` with corresponding new layers in `model`.
"""
from peft.tuners.tuners_utils import BaseTunerLayer
has_base_layer_pattern = False
for module in model.modules():
if isinstance(module, BaseTunerLayer):
has_base_layer_pattern = hasattr(module, "base_layer")
break
if has_base_layer_pattern:
from peft.utils import _get_submodules
key_list = [key for key, _ in model.named_modules() if "lora" not in key]
for key in key_list:
try:
parent, target, target_name = _get_submodules(model, key)
except AttributeError:
continue
if hasattr(target, "base_layer"):
setattr(parent, target_name, target.get_base_layer())
else:
# This is for backwards compatibility with PEFT <= 0.6.2.
# TODO can be removed once that PEFT version is no longer supported.
from peft.tuners.lora import LoraLayer
for name, module in model.named_children():
if len(list(module.children())) > 0:
## compound module, go inside it
recurse_remove_peft_layers(module)
module_replaced = False
if isinstance(module, LoraLayer) and isinstance(module, torch.nn.Linear):
new_module = torch.nn.Linear(
module.in_features,
module.out_features,
bias=module.bias is not None,
).to(module.weight.device)
new_module.weight = module.weight
if module.bias is not None:
new_module.bias = module.bias
module_replaced = True
elif isinstance(module, LoraLayer) and isinstance(module, torch.nn.Conv2d):
new_module = torch.nn.Conv2d(
module.in_channels,
module.out_channels,
module.kernel_size,
module.stride,
module.padding,
module.dilation,
module.groups,
).to(module.weight.device)
new_module.weight = module.weight
if module.bias is not None:
new_module.bias = module.bias
module_replaced = True
if module_replaced:
setattr(model, name, new_module)
del module
if torch.cuda.is_available():
torch.cuda.empty_cache()
return model
def scale_lora_layers(model, weight):
"""
Adjust the weightage given to the LoRA layers of the model.
Args:
model (`torch.nn.Module`):
The model to scale.
weight (`float`):
The weight to be given to the LoRA layers.
"""
from peft.tuners.tuners_utils import BaseTunerLayer
if weight == 1.0:
return
for module in model.modules():
if isinstance(module, BaseTunerLayer):
module.scale_layer(weight)
def unscale_lora_layers(model, weight: Optional[float] = None):
"""
Removes the previously passed weight given to the LoRA layers of the model.
Args:
model (`torch.nn.Module`):
The model to scale.
weight (`float`, *optional*):
The weight to be given to the LoRA layers. If no scale is passed the scale of the lora layer will be
re-initialized to the correct value. If 0.0 is passed, we will re-initialize the scale with the correct
value.
"""
from peft.tuners.tuners_utils import BaseTunerLayer
if weight == 1.0:
return
for module in model.modules():
if isinstance(module, BaseTunerLayer):
if weight is not None and weight != 0:
module.unscale_layer(weight)
elif weight is not None and weight == 0:
for adapter_name in module.active_adapters:
# if weight == 0 unscale should re-set the scale to the original value.
module.set_scale(adapter_name, 1.0)
def get_peft_kwargs(rank_dict, network_alpha_dict, peft_state_dict, is_unet=True):
rank_pattern = {}
alpha_pattern = {}
r = lora_alpha = list(rank_dict.values())[0]
if len(set(rank_dict.values())) > 1:
# get the rank occuring the most number of times
r = collections.Counter(rank_dict.values()).most_common()[0][0]
# for modules with rank different from the most occuring rank, add it to the `rank_pattern`
rank_pattern = dict(filter(lambda x: x[1] != r, rank_dict.items()))
rank_pattern = {k.split(".lora_B.")[0]: v for k, v in rank_pattern.items()}
if network_alpha_dict is not None and len(network_alpha_dict) > 0:
if len(set(network_alpha_dict.values())) > 1:
# get the alpha occuring the most number of times
lora_alpha = collections.Counter(network_alpha_dict.values()).most_common()[0][0]
# for modules with alpha different from the most occuring alpha, add it to the `alpha_pattern`
alpha_pattern = dict(filter(lambda x: x[1] != lora_alpha, network_alpha_dict.items()))
if is_unet:
alpha_pattern = {
".".join(k.split(".lora_A.")[0].split(".")).replace(".alpha", ""): v
for k, v in alpha_pattern.items()
}
else:
alpha_pattern = {".".join(k.split(".down.")[0].split(".")[:-1]): v for k, v in alpha_pattern.items()}
else:
lora_alpha = set(network_alpha_dict.values()).pop()
# layer names without the Diffusers specific
target_modules = list({name.split(".lora")[0] for name in peft_state_dict.keys()})
use_dora = any("lora_magnitude_vector" in k for k in peft_state_dict)
lora_config_kwargs = {
"r": r,
"lora_alpha": lora_alpha,
"rank_pattern": rank_pattern,
"alpha_pattern": alpha_pattern,
"target_modules": target_modules,
"use_dora": use_dora,
}
return lora_config_kwargs
def get_adapter_name(model):
from peft.tuners.tuners_utils import BaseTunerLayer
for module in model.modules():
if isinstance(module, BaseTunerLayer):
return f"default_{len(module.r)}"
return "default_0"
def set_adapter_layers(model, enabled=True):
from peft.tuners.tuners_utils import BaseTunerLayer
for module in model.modules():
if isinstance(module, BaseTunerLayer):
# The recent version of PEFT needs to call `enable_adapters` instead
if hasattr(module, "enable_adapters"):
module.enable_adapters(enabled=enabled)
else:
module.disable_adapters = not enabled
def delete_adapter_layers(model, adapter_name):
from peft.tuners.tuners_utils import BaseTunerLayer
for module in model.modules():
if isinstance(module, BaseTunerLayer):
if hasattr(module, "delete_adapter"):
module.delete_adapter(adapter_name)
else:
raise ValueError(
"The version of PEFT you are using is not compatible, please use a version that is greater than 0.6.1"
)
# For transformers integration - we need to pop the adapter from the config
if getattr(model, "_hf_peft_config_loaded", False) and hasattr(model, "peft_config"):
model.peft_config.pop(adapter_name, None)
# In case all adapters are deleted, we need to delete the config
# and make sure to set the flag to False
if len(model.peft_config) == 0:
del model.peft_config
model._hf_peft_config_loaded = None
def set_weights_and_activate_adapters(model, adapter_names, weights):
from peft.tuners.tuners_utils import BaseTunerLayer
def get_module_weight(weight_for_adapter, module_name):
if not isinstance(weight_for_adapter, dict):
# If weight_for_adapter is a single number, always return it.
return weight_for_adapter
for layer_name, weight_ in weight_for_adapter.items():
if layer_name in module_name:
return weight_
parts = module_name.split(".")
# e.g. key = "down_blocks.1.attentions.0"
key = f"{parts[0]}.{parts[1]}.attentions.{parts[3]}"
block_weight = weight_for_adapter.get(key, 1.0)
return block_weight
# iterate over each adapter, make it active and set the corresponding scaling weight
for adapter_name, weight in zip(adapter_names, weights):
for module_name, module in model.named_modules():
if isinstance(module, BaseTunerLayer):
# For backward compatbility with previous PEFT versions
if hasattr(module, "set_adapter"):
module.set_adapter(adapter_name)
else:
module.active_adapter = adapter_name
module.set_scale(adapter_name, get_module_weight(weight, module_name))
# set multiple active adapters
for module in model.modules():
if isinstance(module, BaseTunerLayer):
# For backward compatbility with previous PEFT versions
if hasattr(module, "set_adapter"):
module.set_adapter(adapter_names)
else:
module.active_adapter = adapter_names
def check_peft_version(min_version: str) -> None:
r"""
Checks if the version of PEFT is compatible.
Args:
version (`str`):
The version of PEFT to check against.
"""
if not is_peft_available():
raise ValueError("PEFT is not installed. Please install it with `pip install peft`")
is_peft_version_compatible = version.parse(importlib.metadata.version("peft")) > version.parse(min_version)
if not is_peft_version_compatible:
raise ValueError(
f"The version of PEFT you are using is not compatible, please use a version that is greater"
f" than {min_version}"
)
| diffusers/src/diffusers/utils/peft_utils.py/0 | {
"file_path": "diffusers/src/diffusers/utils/peft_utils.py",
"repo_id": "diffusers",
"token_count": 4779
} | 259 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
import torch
from diffusers.models import ModelMixin, UNet3DConditionModel
from diffusers.utils import logging
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.testing_utils import enable_full_determinism, floats_tensor, skip_mps, torch_device
from ..test_modeling_common import ModelTesterMixin, UNetTesterMixin
enable_full_determinism()
logger = logging.get_logger(__name__)
@skip_mps
class UNet3DConditionModelTests(ModelTesterMixin, UNetTesterMixin, unittest.TestCase):
model_class = UNet3DConditionModel
main_input_name = "sample"
@property
def dummy_input(self):
batch_size = 4
num_channels = 4
num_frames = 4
sizes = (16, 16)
noise = floats_tensor((batch_size, num_channels, num_frames) + sizes).to(torch_device)
time_step = torch.tensor([10]).to(torch_device)
encoder_hidden_states = floats_tensor((batch_size, 4, 8)).to(torch_device)
return {"sample": noise, "timestep": time_step, "encoder_hidden_states": encoder_hidden_states}
@property
def input_shape(self):
return (4, 4, 16, 16)
@property
def output_shape(self):
return (4, 4, 16, 16)
def prepare_init_args_and_inputs_for_common(self):
init_dict = {
"block_out_channels": (4, 8),
"norm_num_groups": 4,
"down_block_types": (
"CrossAttnDownBlock3D",
"DownBlock3D",
),
"up_block_types": ("UpBlock3D", "CrossAttnUpBlock3D"),
"cross_attention_dim": 8,
"attention_head_dim": 2,
"out_channels": 4,
"in_channels": 4,
"layers_per_block": 1,
"sample_size": 16,
}
inputs_dict = self.dummy_input
return init_dict, inputs_dict
@unittest.skipIf(
torch_device != "cuda" or not is_xformers_available(),
reason="XFormers attention is only available with CUDA and `xformers` installed",
)
def test_xformers_enable_works(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
model = self.model_class(**init_dict)
model.enable_xformers_memory_efficient_attention()
assert (
model.mid_block.attentions[0].transformer_blocks[0].attn1.processor.__class__.__name__
== "XFormersAttnProcessor"
), "xformers is not enabled"
# Overriding to set `norm_num_groups` needs to be different for this model.
def test_forward_with_norm_groups(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
init_dict["block_out_channels"] = (32, 64)
init_dict["norm_num_groups"] = 32
model = self.model_class(**init_dict)
model.to(torch_device)
model.eval()
with torch.no_grad():
output = model(**inputs_dict)
if isinstance(output, dict):
output = output.sample
self.assertIsNotNone(output)
expected_shape = inputs_dict["sample"].shape
self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
# Overriding since the UNet3D outputs a different structure.
def test_determinism(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
model = self.model_class(**init_dict)
model.to(torch_device)
model.eval()
with torch.no_grad():
# Warmup pass when using mps (see #372)
if torch_device == "mps" and isinstance(model, ModelMixin):
model(**self.dummy_input)
first = model(**inputs_dict)
if isinstance(first, dict):
first = first.sample
second = model(**inputs_dict)
if isinstance(second, dict):
second = second.sample
out_1 = first.cpu().numpy()
out_2 = second.cpu().numpy()
out_1 = out_1[~np.isnan(out_1)]
out_2 = out_2[~np.isnan(out_2)]
max_diff = np.amax(np.abs(out_1 - out_2))
self.assertLessEqual(max_diff, 1e-5)
def test_model_attention_slicing(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
init_dict["block_out_channels"] = (16, 32)
init_dict["attention_head_dim"] = 8
model = self.model_class(**init_dict)
model.to(torch_device)
model.eval()
model.set_attention_slice("auto")
with torch.no_grad():
output = model(**inputs_dict)
assert output is not None
model.set_attention_slice("max")
with torch.no_grad():
output = model(**inputs_dict)
assert output is not None
model.set_attention_slice(2)
with torch.no_grad():
output = model(**inputs_dict)
assert output is not None
def test_feed_forward_chunking(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
init_dict["block_out_channels"] = (32, 64)
init_dict["norm_num_groups"] = 32
model = self.model_class(**init_dict)
model.to(torch_device)
model.eval()
with torch.no_grad():
output = model(**inputs_dict)[0]
model.enable_forward_chunking()
with torch.no_grad():
output_2 = model(**inputs_dict)[0]
self.assertEqual(output.shape, output_2.shape, "Shape doesn't match")
assert np.abs(output.cpu() - output_2.cpu()).max() < 1e-2
| diffusers/tests/models/unets/test_models_unet_3d_condition.py/0 | {
"file_path": "diffusers/tests/models/unets/test_models_unet_3d_condition.py",
"repo_id": "diffusers",
"token_count": 2728
} | 260 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import unittest
import pytest
from diffusers import __version__
from diffusers.utils import deprecate
from diffusers.utils.testing_utils import str_to_bool
# Used to test the hub
USER = "__DUMMY_TRANSFORMERS_USER__"
ENDPOINT_STAGING = "https://hub-ci.huggingface.co"
# Not critical, only usable on the sandboxed CI instance.
TOKEN = "hf_94wBhPGp6KrrTH3KDchhKpRxZwd6dmHWLL"
class DeprecateTester(unittest.TestCase):
higher_version = ".".join([str(int(__version__.split(".")[0]) + 1)] + __version__.split(".")[1:])
lower_version = "0.0.1"
def test_deprecate_function_arg(self):
kwargs = {"deprecated_arg": 4}
with self.assertWarns(FutureWarning) as warning:
output = deprecate("deprecated_arg", self.higher_version, "message", take_from=kwargs)
assert output == 4
assert (
str(warning.warning)
== f"The `deprecated_arg` argument is deprecated and will be removed in version {self.higher_version}."
" message"
)
def test_deprecate_function_arg_tuple(self):
kwargs = {"deprecated_arg": 4}
with self.assertWarns(FutureWarning) as warning:
output = deprecate(("deprecated_arg", self.higher_version, "message"), take_from=kwargs)
assert output == 4
assert (
str(warning.warning)
== f"The `deprecated_arg` argument is deprecated and will be removed in version {self.higher_version}."
" message"
)
def test_deprecate_function_args(self):
kwargs = {"deprecated_arg_1": 4, "deprecated_arg_2": 8}
with self.assertWarns(FutureWarning) as warning:
output_1, output_2 = deprecate(
("deprecated_arg_1", self.higher_version, "Hey"),
("deprecated_arg_2", self.higher_version, "Hey"),
take_from=kwargs,
)
assert output_1 == 4
assert output_2 == 8
assert (
str(warning.warnings[0].message)
== "The `deprecated_arg_1` argument is deprecated and will be removed in version"
f" {self.higher_version}. Hey"
)
assert (
str(warning.warnings[1].message)
== "The `deprecated_arg_2` argument is deprecated and will be removed in version"
f" {self.higher_version}. Hey"
)
def test_deprecate_function_incorrect_arg(self):
kwargs = {"deprecated_arg": 4}
with self.assertRaises(TypeError) as error:
deprecate(("wrong_arg", self.higher_version, "message"), take_from=kwargs)
assert "test_deprecate_function_incorrect_arg in" in str(error.exception)
assert "line" in str(error.exception)
assert "got an unexpected keyword argument `deprecated_arg`" in str(error.exception)
def test_deprecate_arg_no_kwarg(self):
with self.assertWarns(FutureWarning) as warning:
deprecate(("deprecated_arg", self.higher_version, "message"))
assert (
str(warning.warning)
== f"`deprecated_arg` is deprecated and will be removed in version {self.higher_version}. message"
)
def test_deprecate_args_no_kwarg(self):
with self.assertWarns(FutureWarning) as warning:
deprecate(
("deprecated_arg_1", self.higher_version, "Hey"),
("deprecated_arg_2", self.higher_version, "Hey"),
)
assert (
str(warning.warnings[0].message)
== f"`deprecated_arg_1` is deprecated and will be removed in version {self.higher_version}. Hey"
)
assert (
str(warning.warnings[1].message)
== f"`deprecated_arg_2` is deprecated and will be removed in version {self.higher_version}. Hey"
)
def test_deprecate_class_obj(self):
class Args:
arg = 5
with self.assertWarns(FutureWarning) as warning:
arg = deprecate(("arg", self.higher_version, "message"), take_from=Args())
assert arg == 5
assert (
str(warning.warning)
== f"The `arg` attribute is deprecated and will be removed in version {self.higher_version}. message"
)
def test_deprecate_class_objs(self):
class Args:
arg = 5
foo = 7
with self.assertWarns(FutureWarning) as warning:
arg_1, arg_2 = deprecate(
("arg", self.higher_version, "message"),
("foo", self.higher_version, "message"),
("does not exist", self.higher_version, "message"),
take_from=Args(),
)
assert arg_1 == 5
assert arg_2 == 7
assert (
str(warning.warning)
== f"The `arg` attribute is deprecated and will be removed in version {self.higher_version}. message"
)
assert (
str(warning.warnings[0].message)
== f"The `arg` attribute is deprecated and will be removed in version {self.higher_version}. message"
)
assert (
str(warning.warnings[1].message)
== f"The `foo` attribute is deprecated and will be removed in version {self.higher_version}. message"
)
def test_deprecate_incorrect_version(self):
kwargs = {"deprecated_arg": 4}
with self.assertRaises(ValueError) as error:
deprecate(("wrong_arg", self.lower_version, "message"), take_from=kwargs)
assert (
str(error.exception)
== "The deprecation tuple ('wrong_arg', '0.0.1', 'message') should be removed since diffusers' version"
f" {__version__} is >= {self.lower_version}"
)
def test_deprecate_incorrect_no_standard_warn(self):
with self.assertWarns(FutureWarning) as warning:
deprecate(("deprecated_arg", self.higher_version, "This message is better!!!"), standard_warn=False)
assert str(warning.warning) == "This message is better!!!"
def test_deprecate_stacklevel(self):
with self.assertWarns(FutureWarning) as warning:
deprecate(("deprecated_arg", self.higher_version, "This message is better!!!"), standard_warn=False)
assert str(warning.warning) == "This message is better!!!"
assert "diffusers/tests/others/test_utils.py" in warning.filename
def parse_flag_from_env(key, default=False):
try:
value = os.environ[key]
except KeyError:
# KEY isn't set, default to `default`.
_value = default
else:
# KEY is set, convert it to True or False.
try:
_value = str_to_bool(value)
except ValueError:
# More values are supported, but let's keep the message simple.
raise ValueError(f"If set, {key} must be yes or no.")
return _value
_run_staging = parse_flag_from_env("HUGGINGFACE_CO_STAGING", default=False)
def is_staging_test(test_case):
"""
Decorator marking a test as a staging test.
Those tests will run using the staging environment of huggingface.co instead of the real model hub.
"""
if not _run_staging:
return unittest.skip("test is staging test")(test_case)
else:
return pytest.mark.is_staging_test()(test_case)
| diffusers/tests/others/test_utils.py/0 | {
"file_path": "diffusers/tests/others/test_utils.py",
"repo_id": "diffusers",
"token_count": 3332
} | 261 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
import torch
from PIL import Image
from transformers import CLIPTokenizer
from transformers.models.blip_2.configuration_blip_2 import Blip2Config
from transformers.models.clip.configuration_clip import CLIPTextConfig
from diffusers import AutoencoderKL, BlipDiffusionPipeline, PNDMScheduler, UNet2DConditionModel
from diffusers.utils.testing_utils import enable_full_determinism
from src.diffusers.pipelines.blip_diffusion.blip_image_processing import BlipImageProcessor
from src.diffusers.pipelines.blip_diffusion.modeling_blip2 import Blip2QFormerModel
from src.diffusers.pipelines.blip_diffusion.modeling_ctx_clip import ContextCLIPTextModel
from ..test_pipelines_common import PipelineTesterMixin
enable_full_determinism()
class BlipDiffusionPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
pipeline_class = BlipDiffusionPipeline
params = [
"prompt",
"reference_image",
"source_subject_category",
"target_subject_category",
]
batch_params = [
"prompt",
"reference_image",
"source_subject_category",
"target_subject_category",
]
required_optional_params = [
"generator",
"height",
"width",
"latents",
"guidance_scale",
"num_inference_steps",
"neg_prompt",
"guidance_scale",
"prompt_strength",
"prompt_reps",
]
def get_dummy_components(self):
torch.manual_seed(0)
text_encoder_config = CLIPTextConfig(
vocab_size=1000,
hidden_size=8,
intermediate_size=8,
projection_dim=8,
num_hidden_layers=1,
num_attention_heads=1,
max_position_embeddings=77,
)
text_encoder = ContextCLIPTextModel(text_encoder_config)
vae = AutoencoderKL(
in_channels=4,
out_channels=4,
down_block_types=("DownEncoderBlock2D",),
up_block_types=("UpDecoderBlock2D",),
block_out_channels=(8,),
norm_num_groups=8,
layers_per_block=1,
act_fn="silu",
latent_channels=4,
sample_size=8,
)
blip_vision_config = {
"hidden_size": 8,
"intermediate_size": 8,
"num_hidden_layers": 1,
"num_attention_heads": 1,
"image_size": 224,
"patch_size": 14,
"hidden_act": "quick_gelu",
}
blip_qformer_config = {
"vocab_size": 1000,
"hidden_size": 8,
"num_hidden_layers": 1,
"num_attention_heads": 1,
"intermediate_size": 8,
"max_position_embeddings": 512,
"cross_attention_frequency": 1,
"encoder_hidden_size": 8,
}
qformer_config = Blip2Config(
vision_config=blip_vision_config,
qformer_config=blip_qformer_config,
num_query_tokens=8,
tokenizer="hf-internal-testing/tiny-random-bert",
)
qformer = Blip2QFormerModel(qformer_config)
unet = UNet2DConditionModel(
block_out_channels=(8, 16),
norm_num_groups=8,
layers_per_block=1,
sample_size=16,
in_channels=4,
out_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
cross_attention_dim=8,
)
tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
scheduler = PNDMScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
set_alpha_to_one=False,
skip_prk_steps=True,
)
vae.eval()
qformer.eval()
text_encoder.eval()
image_processor = BlipImageProcessor()
components = {
"text_encoder": text_encoder,
"vae": vae,
"qformer": qformer,
"unet": unet,
"tokenizer": tokenizer,
"scheduler": scheduler,
"image_processor": image_processor,
}
return components
def get_dummy_inputs(self, device, seed=0):
np.random.seed(seed)
reference_image = np.random.rand(32, 32, 3) * 255
reference_image = Image.fromarray(reference_image.astype("uint8")).convert("RGBA")
if str(device).startswith("mps"):
generator = torch.manual_seed(seed)
else:
generator = torch.Generator(device=device).manual_seed(seed)
inputs = {
"prompt": "swimming underwater",
"generator": generator,
"reference_image": reference_image,
"source_subject_category": "dog",
"target_subject_category": "dog",
"height": 32,
"width": 32,
"guidance_scale": 7.5,
"num_inference_steps": 2,
"output_type": "np",
}
return inputs
def test_blipdiffusion(self):
device = "cpu"
components = self.get_dummy_components()
pipe = self.pipeline_class(**components)
pipe = pipe.to(device)
pipe.set_progress_bar_config(disable=None)
image = pipe(**self.get_dummy_inputs(device))[0]
image_slice = image[0, -3:, -3:, 0]
assert image.shape == (1, 16, 16, 4)
expected_slice = np.array(
[0.5329548, 0.8372512, 0.33269387, 0.82096875, 0.43657133, 0.3783, 0.5953028, 0.51934963, 0.42142007]
)
assert (
np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
), f" expected_slice {image_slice.flatten()}, but got {image_slice.flatten()}"
| diffusers/tests/pipelines/blipdiffusion/test_blipdiffusion.py/0 | {
"file_path": "diffusers/tests/pipelines/blipdiffusion/test_blipdiffusion.py",
"repo_id": "diffusers",
"token_count": 3098
} | 262 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import unittest
import numpy as np
import torch
from diffusers import DanceDiffusionPipeline, IPNDMScheduler, UNet1DModel
from diffusers.utils.testing_utils import enable_full_determinism, nightly, require_torch_gpu, skip_mps, torch_device
from ..pipeline_params import UNCONDITIONAL_AUDIO_GENERATION_BATCH_PARAMS, UNCONDITIONAL_AUDIO_GENERATION_PARAMS
from ..test_pipelines_common import PipelineTesterMixin
enable_full_determinism()
class DanceDiffusionPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
pipeline_class = DanceDiffusionPipeline
params = UNCONDITIONAL_AUDIO_GENERATION_PARAMS
required_optional_params = PipelineTesterMixin.required_optional_params - {
"callback",
"latents",
"callback_steps",
"output_type",
"num_images_per_prompt",
}
batch_params = UNCONDITIONAL_AUDIO_GENERATION_BATCH_PARAMS
test_attention_slicing = False
def get_dummy_components(self):
torch.manual_seed(0)
unet = UNet1DModel(
block_out_channels=(32, 32, 64),
extra_in_channels=16,
sample_size=512,
sample_rate=16_000,
in_channels=2,
out_channels=2,
flip_sin_to_cos=True,
use_timestep_embedding=False,
time_embedding_type="fourier",
mid_block_type="UNetMidBlock1D",
down_block_types=("DownBlock1DNoSkip", "DownBlock1D", "AttnDownBlock1D"),
up_block_types=("AttnUpBlock1D", "UpBlock1D", "UpBlock1DNoSkip"),
)
scheduler = IPNDMScheduler()
components = {
"unet": unet,
"scheduler": scheduler,
}
return components
def get_dummy_inputs(self, device, seed=0):
if str(device).startswith("mps"):
generator = torch.manual_seed(seed)
else:
generator = torch.Generator(device=device).manual_seed(seed)
inputs = {
"batch_size": 1,
"generator": generator,
"num_inference_steps": 4,
}
return inputs
def test_dance_diffusion(self):
device = "cpu" # ensure determinism for the device-dependent torch.Generator
components = self.get_dummy_components()
pipe = DanceDiffusionPipeline(**components)
pipe = pipe.to(device)
pipe.set_progress_bar_config(disable=None)
inputs = self.get_dummy_inputs(device)
output = pipe(**inputs)
audio = output.audios
audio_slice = audio[0, -3:, -3:]
assert audio.shape == (1, 2, components["unet"].sample_size)
expected_slice = np.array([-0.7265, 1.0000, -0.8388, 0.1175, 0.9498, -1.0000])
assert np.abs(audio_slice.flatten() - expected_slice).max() < 1e-2
@skip_mps
def test_save_load_local(self):
return super().test_save_load_local()
@skip_mps
def test_dict_tuple_outputs_equivalent(self):
return super().test_dict_tuple_outputs_equivalent(expected_max_difference=3e-3)
@skip_mps
def test_save_load_optional_components(self):
return super().test_save_load_optional_components()
@skip_mps
def test_attention_slicing_forward_pass(self):
return super().test_attention_slicing_forward_pass()
def test_inference_batch_single_identical(self):
super().test_inference_batch_single_identical(expected_max_diff=3e-3)
@nightly
@require_torch_gpu
class PipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
torch.cuda.empty_cache()
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
torch.cuda.empty_cache()
def test_dance_diffusion(self):
device = torch_device
pipe = DanceDiffusionPipeline.from_pretrained("harmonai/maestro-150k")
pipe = pipe.to(device)
pipe.set_progress_bar_config(disable=None)
generator = torch.manual_seed(0)
output = pipe(generator=generator, num_inference_steps=100, audio_length_in_s=4.096)
audio = output.audios
audio_slice = audio[0, -3:, -3:]
assert audio.shape == (1, 2, pipe.unet.config.sample_size)
expected_slice = np.array([-0.0192, -0.0231, -0.0318, -0.0059, 0.0002, -0.0020])
assert np.abs(audio_slice.flatten() - expected_slice).max() < 1e-2
def test_dance_diffusion_fp16(self):
device = torch_device
pipe = DanceDiffusionPipeline.from_pretrained("harmonai/maestro-150k", torch_dtype=torch.float16)
pipe = pipe.to(device)
pipe.set_progress_bar_config(disable=None)
generator = torch.manual_seed(0)
output = pipe(generator=generator, num_inference_steps=100, audio_length_in_s=4.096)
audio = output.audios
audio_slice = audio[0, -3:, -3:]
assert audio.shape == (1, 2, pipe.unet.config.sample_size)
expected_slice = np.array([-0.0367, -0.0488, -0.0771, -0.0525, -0.0444, -0.0341])
assert np.abs(audio_slice.flatten() - expected_slice).max() < 1e-2
| diffusers/tests/pipelines/dance_diffusion/test_dance_diffusion.py/0 | {
"file_path": "diffusers/tests/pipelines/dance_diffusion/test_dance_diffusion.py",
"repo_id": "diffusers",
"token_count": 2496
} | 263 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import unittest
import numpy as np
import torch
from transformers import (
CLIPImageProcessor,
CLIPVisionModelWithProjection,
)
from diffusers import (
StableDiffusionImg2ImgPipeline,
StableDiffusionInpaintPipeline,
StableDiffusionPipeline,
StableDiffusionXLImg2ImgPipeline,
StableDiffusionXLInpaintPipeline,
StableDiffusionXLPipeline,
)
from diffusers.image_processor import IPAdapterMaskProcessor
from diffusers.utils import load_image
from diffusers.utils.testing_utils import (
enable_full_determinism,
is_flaky,
load_pt,
numpy_cosine_similarity_distance,
require_torch_gpu,
slow,
torch_device,
)
enable_full_determinism()
class IPAdapterNightlyTestsMixin(unittest.TestCase):
dtype = torch.float16
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
torch.cuda.empty_cache()
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
torch.cuda.empty_cache()
def get_image_encoder(self, repo_id, subfolder):
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
repo_id, subfolder=subfolder, torch_dtype=self.dtype
).to(torch_device)
return image_encoder
def get_image_processor(self, repo_id):
image_processor = CLIPImageProcessor.from_pretrained(repo_id)
return image_processor
def get_dummy_inputs(
self, for_image_to_image=False, for_inpainting=False, for_sdxl=False, for_masks=False, for_instant_style=False
):
image = load_image(
"https://user-images.githubusercontent.com/24734142/266492875-2d50d223-8475-44f0-a7c6-08b51cb53572.png"
)
if for_sdxl:
image = image.resize((1024, 1024))
input_kwargs = {
"prompt": "best quality, high quality",
"negative_prompt": "monochrome, lowres, bad anatomy, worst quality, low quality",
"num_inference_steps": 5,
"generator": torch.Generator(device="cpu").manual_seed(33),
"ip_adapter_image": image,
"output_type": "np",
}
if for_image_to_image:
image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/vermeer.jpg")
ip_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/river.png")
if for_sdxl:
image = image.resize((1024, 1024))
ip_image = ip_image.resize((1024, 1024))
input_kwargs.update({"image": image, "ip_adapter_image": ip_image})
elif for_inpainting:
image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/inpaint_image.png")
mask = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/mask.png")
ip_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/girl.png")
if for_sdxl:
image = image.resize((1024, 1024))
mask = mask.resize((1024, 1024))
ip_image = ip_image.resize((1024, 1024))
input_kwargs.update({"image": image, "mask_image": mask, "ip_adapter_image": ip_image})
elif for_masks:
face_image1 = load_image(
"https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_girl1.png"
)
face_image2 = load_image(
"https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_girl2.png"
)
mask1 = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_mask1.png")
mask2 = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_mask2.png")
input_kwargs.update(
{
"ip_adapter_image": [[face_image1], [face_image2]],
"cross_attention_kwargs": {"ip_adapter_masks": [mask1, mask2]},
}
)
elif for_instant_style:
composition_mask = load_image(
"https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/1024_whole_mask.png"
)
female_mask = load_image(
"https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/ip_adapter_None_20240321125641_mask.png"
)
male_mask = load_image(
"https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/ip_adapter_None_20240321125344_mask.png"
)
background_mask = load_image(
"https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/ip_adapter_6_20240321130722_mask.png"
)
ip_composition_image = load_image(
"https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/ip_adapter__20240321125152.png"
)
ip_female_style = load_image(
"https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/ip_adapter__20240321125625.png"
)
ip_male_style = load_image(
"https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/ip_adapter__20240321125329.png"
)
ip_background = load_image(
"https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/ip_adapter__20240321130643.png"
)
input_kwargs.update(
{
"ip_adapter_image": [ip_composition_image, [ip_female_style, ip_male_style, ip_background]],
"cross_attention_kwargs": {
"ip_adapter_masks": [[composition_mask], [female_mask, male_mask, background_mask]]
},
}
)
return input_kwargs
@slow
@require_torch_gpu
class IPAdapterSDIntegrationTests(IPAdapterNightlyTestsMixin):
def test_text_to_image(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", image_encoder=image_encoder, safety_checker=None, torch_dtype=self.dtype
)
pipeline.to(torch_device)
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter_sd15.bin")
inputs = self.get_dummy_inputs()
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array([0.80810547, 0.88183594, 0.9296875, 0.9189453, 0.9848633, 1.0, 0.97021484, 1.0, 1.0])
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter-plus_sd15.bin")
inputs = self.get_dummy_inputs()
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[0.30444336, 0.26513672, 0.22436523, 0.2758789, 0.25585938, 0.20751953, 0.25390625, 0.24633789, 0.21923828]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
def test_image_to_image(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionImg2ImgPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", image_encoder=image_encoder, safety_checker=None, torch_dtype=self.dtype
)
pipeline.to(torch_device)
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter_sd15.bin")
inputs = self.get_dummy_inputs(for_image_to_image=True)
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[0.22167969, 0.21875, 0.21728516, 0.22607422, 0.21948242, 0.23925781, 0.22387695, 0.25268555, 0.2722168]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter-plus_sd15.bin")
inputs = self.get_dummy_inputs(for_image_to_image=True)
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[0.35913086, 0.265625, 0.26367188, 0.24658203, 0.19750977, 0.39990234, 0.15258789, 0.20336914, 0.5517578]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
def test_inpainting(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionInpaintPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", image_encoder=image_encoder, safety_checker=None, torch_dtype=self.dtype
)
pipeline.to(torch_device)
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter_sd15.bin")
inputs = self.get_dummy_inputs(for_inpainting=True)
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[0.27148438, 0.24047852, 0.22167969, 0.23217773, 0.21118164, 0.21142578, 0.21875, 0.20751953, 0.20019531]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter-plus_sd15.bin")
inputs = self.get_dummy_inputs(for_inpainting=True)
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
def test_text_to_image_model_cpu_offload(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", image_encoder=image_encoder, safety_checker=None, torch_dtype=self.dtype
)
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter_sd15.bin")
pipeline.to(torch_device)
inputs = self.get_dummy_inputs()
output_without_offload = pipeline(**inputs).images
pipeline.enable_model_cpu_offload()
inputs = self.get_dummy_inputs()
output_with_offload = pipeline(**inputs).images
max_diff = np.abs(output_with_offload - output_without_offload).max()
self.assertLess(max_diff, 1e-3, "CPU offloading should not affect the inference results")
offloaded_modules = [
v
for k, v in pipeline.components.items()
if isinstance(v, torch.nn.Module) and k not in pipeline._exclude_from_cpu_offload
]
(
self.assertTrue(all(v.device.type == "cpu" for v in offloaded_modules)),
f"Not offloaded: {[v for v in offloaded_modules if v.device.type != 'cpu']}",
)
def test_text_to_image_full_face(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", image_encoder=image_encoder, safety_checker=None, torch_dtype=self.dtype
)
pipeline.to(torch_device)
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter-full-face_sd15.bin")
pipeline.set_ip_adapter_scale(0.7)
inputs = self.get_dummy_inputs()
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array([0.1704, 0.1296, 0.1272, 0.2212, 0.1514, 0.1479, 0.4172, 0.4263, 0.4360])
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
def test_unload(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", image_encoder=image_encoder, safety_checker=None, torch_dtype=self.dtype
)
before_processors = [attn_proc.__class__ for attn_proc in pipeline.unet.attn_processors.values()]
pipeline.to(torch_device)
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="models", weight_name="ip-adapter_sd15.bin")
pipeline.set_ip_adapter_scale(0.7)
pipeline.unload_ip_adapter()
assert getattr(pipeline, "image_encoder") is None
assert getattr(pipeline, "feature_extractor") is not None
after_processors = [attn_proc.__class__ for attn_proc in pipeline.unet.attn_processors.values()]
assert before_processors == after_processors
@is_flaky
def test_multi(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", image_encoder=image_encoder, safety_checker=None, torch_dtype=self.dtype
)
pipeline.to(torch_device)
pipeline.load_ip_adapter(
"h94/IP-Adapter", subfolder="models", weight_name=["ip-adapter_sd15.bin", "ip-adapter-plus_sd15.bin"]
)
pipeline.set_ip_adapter_scale([0.7, 0.3])
inputs = self.get_dummy_inputs()
ip_adapter_image = inputs["ip_adapter_image"]
inputs["ip_adapter_image"] = [ip_adapter_image, [ip_adapter_image] * 2]
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array([0.5234, 0.5352, 0.5625, 0.5713, 0.5947, 0.6206, 0.5786, 0.6187, 0.6494])
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
def test_text_to_image_face_id(self):
pipeline = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, torch_dtype=self.dtype
)
pipeline.to(torch_device)
pipeline.load_ip_adapter(
"h94/IP-Adapter-FaceID",
subfolder=None,
weight_name="ip-adapter-faceid_sd15.bin",
image_encoder_folder=None,
)
pipeline.set_ip_adapter_scale(0.7)
inputs = self.get_dummy_inputs()
id_embeds = load_pt("https://huggingface.co/datasets/fabiorigano/testing-images/resolve/main/ai_face2.ipadpt")[
0
]
id_embeds = id_embeds.reshape((2, 1, 1, 512))
inputs["ip_adapter_image_embeds"] = [id_embeds]
inputs["ip_adapter_image"] = None
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[0.32714844, 0.3239746, 0.3466797, 0.31835938, 0.30004883, 0.3251953, 0.3215332, 0.3552246, 0.3251953]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
@slow
@require_torch_gpu
class IPAdapterSDXLIntegrationTests(IPAdapterNightlyTestsMixin):
def test_text_to_image_sdxl(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="sdxl_models/image_encoder")
feature_extractor = self.get_image_processor("laion/CLIP-ViT-bigG-14-laion2B-39B-b160k")
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
image_encoder=image_encoder,
feature_extractor=feature_extractor,
torch_dtype=self.dtype,
)
pipeline.enable_model_cpu_offload()
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
inputs = self.get_dummy_inputs()
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[
0.09630299,
0.09551358,
0.08480701,
0.09070173,
0.09437338,
0.09264627,
0.08883232,
0.09287417,
0.09197289,
]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
image_encoder=image_encoder,
feature_extractor=feature_extractor,
torch_dtype=self.dtype,
)
pipeline.to(torch_device)
pipeline.load_ip_adapter(
"h94/IP-Adapter",
subfolder="sdxl_models",
weight_name="ip-adapter-plus_sdxl_vit-h.bin",
)
inputs = self.get_dummy_inputs()
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[0.0576596, 0.05600825, 0.04479006, 0.05288461, 0.05461192, 0.05137569, 0.04867965, 0.05301541, 0.04939842]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
def test_image_to_image_sdxl(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="sdxl_models/image_encoder")
feature_extractor = self.get_image_processor("laion/CLIP-ViT-bigG-14-laion2B-39B-b160k")
pipeline = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
image_encoder=image_encoder,
feature_extractor=feature_extractor,
torch_dtype=self.dtype,
)
pipeline.enable_model_cpu_offload()
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
inputs = self.get_dummy_inputs(for_image_to_image=True)
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[
0.06513795,
0.07009393,
0.07234055,
0.07426041,
0.07002589,
0.06415862,
0.07827643,
0.07962808,
0.07411247,
]
)
assert np.allclose(image_slice, expected_slice, atol=1e-3)
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
feature_extractor = self.get_image_processor("laion/CLIP-ViT-bigG-14-laion2B-39B-b160k")
pipeline = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
image_encoder=image_encoder,
feature_extractor=feature_extractor,
torch_dtype=self.dtype,
)
pipeline.to(torch_device)
pipeline.load_ip_adapter(
"h94/IP-Adapter",
subfolder="sdxl_models",
weight_name="ip-adapter-plus_sdxl_vit-h.bin",
)
inputs = self.get_dummy_inputs(for_image_to_image=True)
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[
0.07126552,
0.07025367,
0.07348302,
0.07580167,
0.07467338,
0.06918576,
0.07480252,
0.08279955,
0.08547315,
]
)
assert np.allclose(image_slice, expected_slice, atol=1e-3)
def test_inpainting_sdxl(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="sdxl_models/image_encoder")
feature_extractor = self.get_image_processor("laion/CLIP-ViT-bigG-14-laion2B-39B-b160k")
pipeline = StableDiffusionXLInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
image_encoder=image_encoder,
feature_extractor=feature_extractor,
torch_dtype=self.dtype,
)
pipeline.enable_model_cpu_offload()
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
inputs = self.get_dummy_inputs(for_inpainting=True)
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
image_slice.tolist()
expected_slice = np.array(
[0.14181179, 0.1493012, 0.14283323, 0.14602411, 0.14915377, 0.15015268, 0.14725655, 0.15009224, 0.15164584]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
feature_extractor = self.get_image_processor("laion/CLIP-ViT-bigG-14-laion2B-39B-b160k")
pipeline = StableDiffusionXLInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
image_encoder=image_encoder,
feature_extractor=feature_extractor,
torch_dtype=self.dtype,
)
pipeline.to(torch_device)
pipeline.load_ip_adapter(
"h94/IP-Adapter",
subfolder="sdxl_models",
weight_name="ip-adapter-plus_sdxl_vit-h.bin",
)
inputs = self.get_dummy_inputs(for_inpainting=True)
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
image_slice.tolist()
expected_slice = np.array([0.1398, 0.1476, 0.1407, 0.1442, 0.1470, 0.1480, 0.1449, 0.1481, 0.1494])
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
def test_ip_adapter_single_mask(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
image_encoder=image_encoder,
torch_dtype=self.dtype,
)
pipeline.enable_model_cpu_offload()
pipeline.load_ip_adapter(
"h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter-plus-face_sdxl_vit-h.safetensors"
)
pipeline.set_ip_adapter_scale(0.7)
inputs = self.get_dummy_inputs(for_masks=True)
mask = inputs["cross_attention_kwargs"]["ip_adapter_masks"][0]
processor = IPAdapterMaskProcessor()
mask = processor.preprocess(mask)
inputs["cross_attention_kwargs"]["ip_adapter_masks"] = mask
inputs["ip_adapter_image"] = inputs["ip_adapter_image"][0]
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[0.7307304, 0.73450166, 0.73731124, 0.7377061, 0.7318013, 0.73720926, 0.74746597, 0.7409929, 0.74074936]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
def test_ip_adapter_multiple_masks(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
image_encoder=image_encoder,
torch_dtype=self.dtype,
)
pipeline.enable_model_cpu_offload()
pipeline.load_ip_adapter(
"h94/IP-Adapter", subfolder="sdxl_models", weight_name=["ip-adapter-plus-face_sdxl_vit-h.safetensors"] * 2
)
pipeline.set_ip_adapter_scale([0.7] * 2)
inputs = self.get_dummy_inputs(for_masks=True)
masks = inputs["cross_attention_kwargs"]["ip_adapter_masks"]
processor = IPAdapterMaskProcessor()
masks = processor.preprocess(masks)
inputs["cross_attention_kwargs"]["ip_adapter_masks"] = masks
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[0.79474676, 0.7977683, 0.8013954, 0.7988008, 0.7970615, 0.8029355, 0.80614823, 0.8050743, 0.80627424]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
def test_instant_style_multiple_masks(self):
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
"h94/IP-Adapter", subfolder="models/image_encoder", torch_dtype=torch.float16
).to("cuda")
pipeline = StableDiffusionXLPipeline.from_pretrained(
"RunDiffusion/Juggernaut-XL-v9", torch_dtype=torch.float16, image_encoder=image_encoder, variant="fp16"
).to("cuda")
pipeline.enable_model_cpu_offload()
pipeline.load_ip_adapter(
["ostris/ip-composition-adapter", "h94/IP-Adapter"],
subfolder=["", "sdxl_models"],
weight_name=[
"ip_plus_composition_sdxl.safetensors",
"ip-adapter_sdxl_vit-h.safetensors",
],
image_encoder_folder=None,
)
scale_1 = {
"down": [[0.0, 0.0, 1.0]],
"mid": [[0.0, 0.0, 1.0]],
"up": {"block_0": [[0.0, 0.0, 1.0], [1.0, 1.0, 1.0], [0.0, 0.0, 1.0]], "block_1": [[0.0, 0.0, 1.0]]},
}
pipeline.set_ip_adapter_scale([1.0, scale_1])
inputs = self.get_dummy_inputs(for_instant_style=True)
processor = IPAdapterMaskProcessor()
masks1 = inputs["cross_attention_kwargs"]["ip_adapter_masks"][0]
masks2 = inputs["cross_attention_kwargs"]["ip_adapter_masks"][1]
masks1 = processor.preprocess(masks1, height=1024, width=1024)
masks2 = processor.preprocess(masks2, height=1024, width=1024)
masks2 = masks2.reshape(1, masks2.shape[0], masks2.shape[2], masks2.shape[3])
inputs["cross_attention_kwargs"]["ip_adapter_masks"] = [masks1, masks2]
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[0.23551631, 0.20476806, 0.14099443, 0.0, 0.07675594, 0.05672678, 0.0, 0.0, 0.02099729]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
def test_ip_adapter_multiple_masks_one_adapter(self):
image_encoder = self.get_image_encoder(repo_id="h94/IP-Adapter", subfolder="models/image_encoder")
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
image_encoder=image_encoder,
torch_dtype=self.dtype,
)
pipeline.enable_model_cpu_offload()
pipeline.load_ip_adapter(
"h94/IP-Adapter", subfolder="sdxl_models", weight_name=["ip-adapter-plus-face_sdxl_vit-h.safetensors"]
)
pipeline.set_ip_adapter_scale([[0.7, 0.7]])
inputs = self.get_dummy_inputs(for_masks=True)
masks = inputs["cross_attention_kwargs"]["ip_adapter_masks"]
processor = IPAdapterMaskProcessor()
masks = processor.preprocess(masks)
masks = masks.reshape(1, masks.shape[0], masks.shape[2], masks.shape[3])
inputs["cross_attention_kwargs"]["ip_adapter_masks"] = [masks]
ip_images = inputs["ip_adapter_image"]
inputs["ip_adapter_image"] = [[image[0] for image in ip_images]]
images = pipeline(**inputs).images
image_slice = images[0, :3, :3, -1].flatten()
expected_slice = np.array(
[0.79474676, 0.7977683, 0.8013954, 0.7988008, 0.7970615, 0.8029355, 0.80614823, 0.8050743, 0.80627424]
)
max_diff = numpy_cosine_similarity_distance(image_slice, expected_slice)
assert max_diff < 5e-4
| diffusers/tests/pipelines/ip_adapters/test_ip_adapter_stable_diffusion.py/0 | {
"file_path": "diffusers/tests/pipelines/ip_adapters/test_ip_adapter_stable_diffusion.py",
"repo_id": "diffusers",
"token_count": 14211
} | 264 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import unittest
import numpy as np
import torch
from transformers import CLIPTextConfig, CLIPTextModelWithProjection, CLIPTokenizer
from diffusers import DDPMWuerstchenScheduler, StableCascadeDecoderPipeline
from diffusers.models import StableCascadeUNet
from diffusers.pipelines.wuerstchen import PaellaVQModel
from diffusers.utils.testing_utils import (
enable_full_determinism,
load_numpy,
load_pt,
numpy_cosine_similarity_distance,
require_torch_gpu,
skip_mps,
slow,
torch_device,
)
from diffusers.utils.torch_utils import randn_tensor
from ..test_pipelines_common import PipelineTesterMixin
enable_full_determinism()
class StableCascadeDecoderPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
pipeline_class = StableCascadeDecoderPipeline
params = ["prompt"]
batch_params = ["image_embeddings", "prompt", "negative_prompt"]
required_optional_params = [
"num_images_per_prompt",
"num_inference_steps",
"latents",
"negative_prompt",
"guidance_scale",
"output_type",
"return_dict",
]
test_xformers_attention = False
callback_cfg_params = ["image_embeddings", "text_encoder_hidden_states"]
@property
def text_embedder_hidden_size(self):
return 32
@property
def time_input_dim(self):
return 32
@property
def block_out_channels_0(self):
return self.time_input_dim
@property
def time_embed_dim(self):
return self.time_input_dim * 4
@property
def dummy_tokenizer(self):
tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
return tokenizer
@property
def dummy_text_encoder(self):
torch.manual_seed(0)
config = CLIPTextConfig(
bos_token_id=0,
eos_token_id=2,
projection_dim=self.text_embedder_hidden_size,
hidden_size=self.text_embedder_hidden_size,
intermediate_size=37,
layer_norm_eps=1e-05,
num_attention_heads=4,
num_hidden_layers=5,
pad_token_id=1,
vocab_size=1000,
)
return CLIPTextModelWithProjection(config).eval()
@property
def dummy_vqgan(self):
torch.manual_seed(0)
model_kwargs = {
"bottleneck_blocks": 1,
"num_vq_embeddings": 2,
}
model = PaellaVQModel(**model_kwargs)
return model.eval()
@property
def dummy_decoder(self):
torch.manual_seed(0)
model_kwargs = {
"in_channels": 4,
"out_channels": 4,
"conditioning_dim": 128,
"block_out_channels": [16, 32, 64, 128],
"num_attention_heads": [-1, -1, 1, 2],
"down_num_layers_per_block": [1, 1, 1, 1],
"up_num_layers_per_block": [1, 1, 1, 1],
"down_blocks_repeat_mappers": [1, 1, 1, 1],
"up_blocks_repeat_mappers": [3, 3, 2, 2],
"block_types_per_layer": [
["SDCascadeResBlock", "SDCascadeTimestepBlock"],
["SDCascadeResBlock", "SDCascadeTimestepBlock"],
["SDCascadeResBlock", "SDCascadeTimestepBlock", "SDCascadeAttnBlock"],
["SDCascadeResBlock", "SDCascadeTimestepBlock", "SDCascadeAttnBlock"],
],
"switch_level": None,
"clip_text_pooled_in_channels": 32,
"dropout": [0.1, 0.1, 0.1, 0.1],
}
model = StableCascadeUNet(**model_kwargs)
return model.eval()
def get_dummy_components(self):
decoder = self.dummy_decoder
text_encoder = self.dummy_text_encoder
tokenizer = self.dummy_tokenizer
vqgan = self.dummy_vqgan
scheduler = DDPMWuerstchenScheduler()
components = {
"decoder": decoder,
"vqgan": vqgan,
"text_encoder": text_encoder,
"tokenizer": tokenizer,
"scheduler": scheduler,
"latent_dim_scale": 4.0,
}
return components
def get_dummy_inputs(self, device, seed=0):
if str(device).startswith("mps"):
generator = torch.manual_seed(seed)
else:
generator = torch.Generator(device=device).manual_seed(seed)
inputs = {
"image_embeddings": torch.ones((1, 4, 4, 4), device=device),
"prompt": "horse",
"generator": generator,
"guidance_scale": 2.0,
"num_inference_steps": 2,
"output_type": "np",
}
return inputs
def test_wuerstchen_decoder(self):
device = "cpu"
components = self.get_dummy_components()
pipe = self.pipeline_class(**components)
pipe = pipe.to(device)
pipe.set_progress_bar_config(disable=None)
output = pipe(**self.get_dummy_inputs(device))
image = output.images
image_from_tuple = pipe(**self.get_dummy_inputs(device), return_dict=False)
image_slice = image[0, -3:, -3:, -1]
image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
assert image.shape == (1, 64, 64, 3)
expected_slice = np.array([0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 1.0, 1.0, 0.0])
assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
@skip_mps
def test_inference_batch_single_identical(self):
self._test_inference_batch_single_identical(expected_max_diff=1e-2)
@skip_mps
def test_attention_slicing_forward_pass(self):
test_max_difference = torch_device == "cpu"
test_mean_pixel_difference = False
self._test_attention_slicing_forward_pass(
test_max_difference=test_max_difference,
test_mean_pixel_difference=test_mean_pixel_difference,
)
@unittest.skip(reason="fp16 not supported")
def test_float16_inference(self):
super().test_float16_inference()
def test_stable_cascade_decoder_prompt_embeds(self):
device = "cpu"
components = self.get_dummy_components()
pipe = StableCascadeDecoderPipeline(**components)
pipe.set_progress_bar_config(disable=None)
inputs = self.get_dummy_inputs(device)
image_embeddings = inputs["image_embeddings"]
prompt = "A photograph of a shiba inu, wearing a hat"
(
prompt_embeds,
prompt_embeds_pooled,
negative_prompt_embeds,
negative_prompt_embeds_pooled,
) = pipe.encode_prompt(device, 1, 1, False, prompt=prompt)
generator = torch.Generator(device=device)
decoder_output_prompt = pipe(
image_embeddings=image_embeddings,
prompt=prompt,
num_inference_steps=1,
output_type="np",
generator=generator.manual_seed(0),
)
decoder_output_prompt_embeds = pipe(
image_embeddings=image_embeddings,
prompt=None,
prompt_embeds=prompt_embeds,
prompt_embeds_pooled=prompt_embeds_pooled,
negative_prompt_embeds=negative_prompt_embeds,
negative_prompt_embeds_pooled=negative_prompt_embeds_pooled,
num_inference_steps=1,
output_type="np",
generator=generator.manual_seed(0),
)
assert np.abs(decoder_output_prompt.images - decoder_output_prompt_embeds.images).max() < 1e-5
def test_stable_cascade_decoder_single_prompt_multiple_image_embeddings(self):
device = "cpu"
components = self.get_dummy_components()
pipe = StableCascadeDecoderPipeline(**components)
pipe.set_progress_bar_config(disable=None)
prior_num_images_per_prompt = 2
decoder_num_images_per_prompt = 2
prompt = ["a cat"]
batch_size = len(prompt)
generator = torch.Generator(device)
image_embeddings = randn_tensor(
(batch_size * prior_num_images_per_prompt, 4, 4, 4), generator=generator.manual_seed(0)
)
decoder_output = pipe(
image_embeddings=image_embeddings,
prompt=prompt,
num_inference_steps=1,
output_type="np",
guidance_scale=0.0,
generator=generator.manual_seed(0),
num_images_per_prompt=decoder_num_images_per_prompt,
)
assert decoder_output.images.shape[0] == (
batch_size * prior_num_images_per_prompt * decoder_num_images_per_prompt
)
def test_stable_cascade_decoder_single_prompt_multiple_image_embeddings_with_guidance(self):
device = "cpu"
components = self.get_dummy_components()
pipe = StableCascadeDecoderPipeline(**components)
pipe.set_progress_bar_config(disable=None)
prior_num_images_per_prompt = 2
decoder_num_images_per_prompt = 2
prompt = ["a cat"]
batch_size = len(prompt)
generator = torch.Generator(device)
image_embeddings = randn_tensor(
(batch_size * prior_num_images_per_prompt, 4, 4, 4), generator=generator.manual_seed(0)
)
decoder_output = pipe(
image_embeddings=image_embeddings,
prompt=prompt,
num_inference_steps=1,
output_type="np",
guidance_scale=2.0,
generator=generator.manual_seed(0),
num_images_per_prompt=decoder_num_images_per_prompt,
)
assert decoder_output.images.shape[0] == (
batch_size * prior_num_images_per_prompt * decoder_num_images_per_prompt
)
@slow
@require_torch_gpu
class StableCascadeDecoderPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
torch.cuda.empty_cache()
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
torch.cuda.empty_cache()
def test_stable_cascade_decoder(self):
pipe = StableCascadeDecoderPipeline.from_pretrained(
"stabilityai/stable-cascade", variant="bf16", torch_dtype=torch.bfloat16
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
prompt = "A photograph of the inside of a subway train. There are raccoons sitting on the seats. One of them is reading a newspaper. The window shows the city in the background."
generator = torch.Generator(device="cpu").manual_seed(0)
image_embedding = load_pt(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_cascade/image_embedding.pt"
)
image = pipe(
prompt=prompt,
image_embeddings=image_embedding,
output_type="np",
num_inference_steps=2,
generator=generator,
).images[0]
assert image.shape == (1024, 1024, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_cascade/stable_cascade_decoder_image.npy"
)
max_diff = numpy_cosine_similarity_distance(image.flatten(), expected_image.flatten())
assert max_diff < 1e-4
| diffusers/tests/pipelines/stable_cascade/test_stable_cascade_decoder.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_cascade/test_stable_cascade_decoder.py",
"repo_id": "diffusers",
"token_count": 5590
} | 265 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import unittest
from diffusers import FlaxDPMSolverMultistepScheduler, FlaxStableDiffusionPipeline
from diffusers.utils import is_flax_available
from diffusers.utils.testing_utils import nightly, require_flax
if is_flax_available():
import jax
import jax.numpy as jnp
from flax.jax_utils import replicate
from flax.training.common_utils import shard
@nightly
@require_flax
class FlaxStableDiffusion2PipelineIntegrationTests(unittest.TestCase):
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
def test_stable_diffusion_flax(self):
sd_pipe, params = FlaxStableDiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2",
revision="bf16",
dtype=jnp.bfloat16,
)
prompt = "A painting of a squirrel eating a burger"
num_samples = jax.device_count()
prompt = num_samples * [prompt]
prompt_ids = sd_pipe.prepare_inputs(prompt)
params = replicate(params)
prompt_ids = shard(prompt_ids)
prng_seed = jax.random.PRNGKey(0)
prng_seed = jax.random.split(prng_seed, jax.device_count())
images = sd_pipe(prompt_ids, params, prng_seed, num_inference_steps=25, jit=True)[0]
assert images.shape == (jax.device_count(), 1, 768, 768, 3)
images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
image_slice = images[0, 253:256, 253:256, -1]
output_slice = jnp.asarray(jax.device_get(image_slice.flatten()))
expected_slice = jnp.array([0.4238, 0.4414, 0.4395, 0.4453, 0.4629, 0.4590, 0.4531, 0.45508, 0.4512])
print(f"output_slice: {output_slice}")
assert jnp.abs(output_slice - expected_slice).max() < 1e-2
@nightly
@require_flax
class FlaxStableDiffusion2PipelineNightlyTests(unittest.TestCase):
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
def test_stable_diffusion_dpm_flax(self):
model_id = "stabilityai/stable-diffusion-2"
scheduler, scheduler_params = FlaxDPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler")
sd_pipe, params = FlaxStableDiffusionPipeline.from_pretrained(
model_id,
scheduler=scheduler,
revision="bf16",
dtype=jnp.bfloat16,
)
params["scheduler"] = scheduler_params
prompt = "A painting of a squirrel eating a burger"
num_samples = jax.device_count()
prompt = num_samples * [prompt]
prompt_ids = sd_pipe.prepare_inputs(prompt)
params = replicate(params)
prompt_ids = shard(prompt_ids)
prng_seed = jax.random.PRNGKey(0)
prng_seed = jax.random.split(prng_seed, jax.device_count())
images = sd_pipe(prompt_ids, params, prng_seed, num_inference_steps=25, jit=True)[0]
assert images.shape == (jax.device_count(), 1, 768, 768, 3)
images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
image_slice = images[0, 253:256, 253:256, -1]
output_slice = jnp.asarray(jax.device_get(image_slice.flatten()))
expected_slice = jnp.array([0.4336, 0.42969, 0.4453, 0.4199, 0.4297, 0.4531, 0.4434, 0.4434, 0.4297])
print(f"output_slice: {output_slice}")
assert jnp.abs(output_slice - expected_slice).max() < 1e-2
| diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_flax.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_flax.py",
"repo_id": "diffusers",
"token_count": 1712
} | 266 |
import gc
import unittest
import torch
from transformers import CLIPTextConfig, CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DDPMScheduler,
PriorTransformer,
StableUnCLIPPipeline,
UNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion.stable_unclip_image_normalizer import StableUnCLIPImageNormalizer
from diffusers.utils.testing_utils import enable_full_determinism, load_numpy, nightly, require_torch_gpu, torch_device
from ..pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_IMAGE_PARAMS, TEXT_TO_IMAGE_PARAMS
from ..test_pipelines_common import (
PipelineKarrasSchedulerTesterMixin,
PipelineLatentTesterMixin,
PipelineTesterMixin,
assert_mean_pixel_difference,
)
enable_full_determinism()
class StableUnCLIPPipelineFastTests(
PipelineLatentTesterMixin, PipelineKarrasSchedulerTesterMixin, PipelineTesterMixin, unittest.TestCase
):
pipeline_class = StableUnCLIPPipeline
params = TEXT_TO_IMAGE_PARAMS
batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
image_params = TEXT_TO_IMAGE_IMAGE_PARAMS
image_latents_params = TEXT_TO_IMAGE_IMAGE_PARAMS
# TODO(will) Expected attn_bias.stride(1) == 0 to be true, but got false
test_xformers_attention = False
def get_dummy_components(self):
embedder_hidden_size = 32
embedder_projection_dim = embedder_hidden_size
# prior components
torch.manual_seed(0)
prior_tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
torch.manual_seed(0)
prior_text_encoder = CLIPTextModelWithProjection(
CLIPTextConfig(
bos_token_id=0,
eos_token_id=2,
hidden_size=embedder_hidden_size,
projection_dim=embedder_projection_dim,
intermediate_size=37,
layer_norm_eps=1e-05,
num_attention_heads=4,
num_hidden_layers=5,
pad_token_id=1,
vocab_size=1000,
)
)
torch.manual_seed(0)
prior = PriorTransformer(
num_attention_heads=2,
attention_head_dim=12,
embedding_dim=embedder_projection_dim,
num_layers=1,
)
torch.manual_seed(0)
prior_scheduler = DDPMScheduler(
variance_type="fixed_small_log",
prediction_type="sample",
num_train_timesteps=1000,
clip_sample=True,
clip_sample_range=5.0,
beta_schedule="squaredcos_cap_v2",
)
# regular denoising components
torch.manual_seed(0)
image_normalizer = StableUnCLIPImageNormalizer(embedding_dim=embedder_hidden_size)
image_noising_scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2")
torch.manual_seed(0)
tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
torch.manual_seed(0)
text_encoder = CLIPTextModel(
CLIPTextConfig(
bos_token_id=0,
eos_token_id=2,
hidden_size=embedder_hidden_size,
projection_dim=32,
intermediate_size=37,
layer_norm_eps=1e-05,
num_attention_heads=4,
num_hidden_layers=5,
pad_token_id=1,
vocab_size=1000,
)
)
torch.manual_seed(0)
unet = UNet2DConditionModel(
sample_size=32,
in_channels=4,
out_channels=4,
down_block_types=("CrossAttnDownBlock2D", "DownBlock2D"),
up_block_types=("UpBlock2D", "CrossAttnUpBlock2D"),
block_out_channels=(32, 64),
attention_head_dim=(2, 4),
class_embed_type="projection",
# The class embeddings are the noise augmented image embeddings.
# I.e. the image embeddings concated with the noised embeddings of the same dimension
projection_class_embeddings_input_dim=embedder_projection_dim * 2,
cross_attention_dim=embedder_hidden_size,
layers_per_block=1,
upcast_attention=True,
use_linear_projection=True,
)
torch.manual_seed(0)
scheduler = DDIMScheduler(
beta_schedule="scaled_linear",
beta_start=0.00085,
beta_end=0.012,
prediction_type="v_prediction",
set_alpha_to_one=False,
steps_offset=1,
)
torch.manual_seed(0)
vae = AutoencoderKL()
components = {
# prior components
"prior_tokenizer": prior_tokenizer,
"prior_text_encoder": prior_text_encoder,
"prior": prior,
"prior_scheduler": prior_scheduler,
# image noising components
"image_normalizer": image_normalizer,
"image_noising_scheduler": image_noising_scheduler,
# regular denoising components
"tokenizer": tokenizer,
"text_encoder": text_encoder,
"unet": unet,
"scheduler": scheduler,
"vae": vae,
}
return components
def get_dummy_inputs(self, device, seed=0):
if str(device).startswith("mps"):
generator = torch.manual_seed(seed)
else:
generator = torch.Generator(device=device).manual_seed(seed)
inputs = {
"prompt": "A painting of a squirrel eating a burger",
"generator": generator,
"num_inference_steps": 2,
"prior_num_inference_steps": 2,
"output_type": "np",
}
return inputs
# Overriding PipelineTesterMixin::test_attention_slicing_forward_pass
# because UnCLIP GPU undeterminism requires a looser check.
def test_attention_slicing_forward_pass(self):
test_max_difference = torch_device == "cpu"
self._test_attention_slicing_forward_pass(test_max_difference=test_max_difference)
# Overriding PipelineTesterMixin::test_inference_batch_single_identical
# because UnCLIP undeterminism requires a looser check.
def test_inference_batch_single_identical(self):
self._test_inference_batch_single_identical(expected_max_diff=1e-3)
@nightly
@require_torch_gpu
class StableUnCLIPPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
torch.cuda.empty_cache()
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
torch.cuda.empty_cache()
def test_stable_unclip(self):
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/stable_unclip_2_1_l_anime_turtle_fp16.npy"
)
pipe = StableUnCLIPPipeline.from_pretrained("fusing/stable-unclip-2-1-l", torch_dtype=torch.float16)
pipe.to(torch_device)
pipe.set_progress_bar_config(disable=None)
# stable unclip will oom when integration tests are run on a V100,
# so turn on memory savings
pipe.enable_attention_slicing()
pipe.enable_sequential_cpu_offload()
generator = torch.Generator(device="cpu").manual_seed(0)
output = pipe("anime turle", generator=generator, output_type="np")
image = output.images[0]
assert image.shape == (768, 768, 3)
assert_mean_pixel_difference(image, expected_image)
def test_stable_unclip_pipeline_with_sequential_cpu_offloading(self):
torch.cuda.empty_cache()
torch.cuda.reset_max_memory_allocated()
torch.cuda.reset_peak_memory_stats()
pipe = StableUnCLIPPipeline.from_pretrained("fusing/stable-unclip-2-1-l", torch_dtype=torch.float16)
pipe = pipe.to(torch_device)
pipe.set_progress_bar_config(disable=None)
pipe.enable_attention_slicing()
pipe.enable_sequential_cpu_offload()
_ = pipe(
"anime turtle",
prior_num_inference_steps=2,
num_inference_steps=2,
output_type="np",
)
mem_bytes = torch.cuda.max_memory_allocated()
# make sure that less than 7 GB is allocated
assert mem_bytes < 7 * 10**9
| diffusers/tests/pipelines/stable_unclip/test_stable_unclip.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_unclip/test_stable_unclip.py",
"repo_id": "diffusers",
"token_count": 4059
} | 267 |
import tempfile
import torch
from diffusers import (
DEISMultistepScheduler,
DPMSolverMultistepScheduler,
DPMSolverSinglestepScheduler,
UniPCMultistepScheduler,
)
from .test_schedulers import SchedulerCommonTest
class DEISMultistepSchedulerTest(SchedulerCommonTest):
scheduler_classes = (DEISMultistepScheduler,)
forward_default_kwargs = (("num_inference_steps", 25),)
def get_scheduler_config(self, **kwargs):
config = {
"num_train_timesteps": 1000,
"beta_start": 0.0001,
"beta_end": 0.02,
"beta_schedule": "linear",
"solver_order": 2,
}
config.update(**kwargs)
return config
def check_over_configs(self, time_step=0, **config):
kwargs = dict(self.forward_default_kwargs)
num_inference_steps = kwargs.pop("num_inference_steps", None)
sample = self.dummy_sample
residual = 0.1 * sample
dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
for scheduler_class in self.scheduler_classes:
scheduler_config = self.get_scheduler_config(**config)
scheduler = scheduler_class(**scheduler_config)
scheduler.set_timesteps(num_inference_steps)
# copy over dummy past residuals
scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
with tempfile.TemporaryDirectory() as tmpdirname:
scheduler.save_config(tmpdirname)
new_scheduler = scheduler_class.from_pretrained(tmpdirname)
new_scheduler.set_timesteps(num_inference_steps)
# copy over dummy past residuals
new_scheduler.model_outputs = dummy_past_residuals[: new_scheduler.config.solver_order]
output, new_output = sample, sample
for t in range(time_step, time_step + scheduler.config.solver_order + 1):
t = scheduler.timesteps[t]
output = scheduler.step(residual, t, output, **kwargs).prev_sample
new_output = new_scheduler.step(residual, t, new_output, **kwargs).prev_sample
assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
def test_from_save_pretrained(self):
pass
def check_over_forward(self, time_step=0, **forward_kwargs):
kwargs = dict(self.forward_default_kwargs)
num_inference_steps = kwargs.pop("num_inference_steps", None)
sample = self.dummy_sample
residual = 0.1 * sample
dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
for scheduler_class in self.scheduler_classes:
scheduler_config = self.get_scheduler_config()
scheduler = scheduler_class(**scheduler_config)
scheduler.set_timesteps(num_inference_steps)
# copy over dummy past residuals (must be after setting timesteps)
scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
with tempfile.TemporaryDirectory() as tmpdirname:
scheduler.save_config(tmpdirname)
new_scheduler = scheduler_class.from_pretrained(tmpdirname)
# copy over dummy past residuals
new_scheduler.set_timesteps(num_inference_steps)
# copy over dummy past residual (must be after setting timesteps)
new_scheduler.model_outputs = dummy_past_residuals[: new_scheduler.config.solver_order]
output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
def full_loop(self, scheduler=None, **config):
if scheduler is None:
scheduler_class = self.scheduler_classes[0]
scheduler_config = self.get_scheduler_config(**config)
scheduler = scheduler_class(**scheduler_config)
scheduler_class = self.scheduler_classes[0]
scheduler_config = self.get_scheduler_config(**config)
scheduler = scheduler_class(**scheduler_config)
num_inference_steps = 10
model = self.dummy_model()
sample = self.dummy_sample_deter
scheduler.set_timesteps(num_inference_steps)
for i, t in enumerate(scheduler.timesteps):
residual = model(sample, t)
sample = scheduler.step(residual, t, sample).prev_sample
return sample
def test_step_shape(self):
kwargs = dict(self.forward_default_kwargs)
num_inference_steps = kwargs.pop("num_inference_steps", None)
for scheduler_class in self.scheduler_classes:
scheduler_config = self.get_scheduler_config()
scheduler = scheduler_class(**scheduler_config)
sample = self.dummy_sample
residual = 0.1 * sample
if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
scheduler.set_timesteps(num_inference_steps)
elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
kwargs["num_inference_steps"] = num_inference_steps
# copy over dummy past residuals (must be done after set_timesteps)
dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
time_step_0 = scheduler.timesteps[5]
time_step_1 = scheduler.timesteps[6]
output_0 = scheduler.step(residual, time_step_0, sample, **kwargs).prev_sample
output_1 = scheduler.step(residual, time_step_1, sample, **kwargs).prev_sample
self.assertEqual(output_0.shape, sample.shape)
self.assertEqual(output_0.shape, output_1.shape)
def test_switch(self):
# make sure that iterating over schedulers with same config names gives same results
# for defaults
scheduler = DEISMultistepScheduler(**self.get_scheduler_config())
sample = self.full_loop(scheduler=scheduler)
result_mean = torch.mean(torch.abs(sample))
assert abs(result_mean.item() - 0.23916) < 1e-3
scheduler = DPMSolverSinglestepScheduler.from_config(scheduler.config)
scheduler = DPMSolverMultistepScheduler.from_config(scheduler.config)
scheduler = UniPCMultistepScheduler.from_config(scheduler.config)
scheduler = DEISMultistepScheduler.from_config(scheduler.config)
sample = self.full_loop(scheduler=scheduler)
result_mean = torch.mean(torch.abs(sample))
assert abs(result_mean.item() - 0.23916) < 1e-3
def test_timesteps(self):
for timesteps in [25, 50, 100, 999, 1000]:
self.check_over_configs(num_train_timesteps=timesteps)
def test_thresholding(self):
self.check_over_configs(thresholding=False)
for order in [1, 2, 3]:
for solver_type in ["logrho"]:
for threshold in [0.5, 1.0, 2.0]:
for prediction_type in ["epsilon", "sample"]:
self.check_over_configs(
thresholding=True,
prediction_type=prediction_type,
sample_max_value=threshold,
algorithm_type="deis",
solver_order=order,
solver_type=solver_type,
)
def test_prediction_type(self):
for prediction_type in ["epsilon", "v_prediction"]:
self.check_over_configs(prediction_type=prediction_type)
def test_solver_order_and_type(self):
for algorithm_type in ["deis"]:
for solver_type in ["logrho"]:
for order in [1, 2, 3]:
for prediction_type in ["epsilon", "sample"]:
self.check_over_configs(
solver_order=order,
solver_type=solver_type,
prediction_type=prediction_type,
algorithm_type=algorithm_type,
)
sample = self.full_loop(
solver_order=order,
solver_type=solver_type,
prediction_type=prediction_type,
algorithm_type=algorithm_type,
)
assert not torch.isnan(sample).any(), "Samples have nan numbers"
def test_lower_order_final(self):
self.check_over_configs(lower_order_final=True)
self.check_over_configs(lower_order_final=False)
def test_inference_steps(self):
for num_inference_steps in [1, 2, 3, 5, 10, 50, 100, 999, 1000]:
self.check_over_forward(num_inference_steps=num_inference_steps, time_step=0)
def test_full_loop_no_noise(self):
sample = self.full_loop()
result_mean = torch.mean(torch.abs(sample))
assert abs(result_mean.item() - 0.23916) < 1e-3
def test_full_loop_with_v_prediction(self):
sample = self.full_loop(prediction_type="v_prediction")
result_mean = torch.mean(torch.abs(sample))
assert abs(result_mean.item() - 0.091) < 1e-3
def test_fp16_support(self):
scheduler_class = self.scheduler_classes[0]
scheduler_config = self.get_scheduler_config(thresholding=True, dynamic_thresholding_ratio=0)
scheduler = scheduler_class(**scheduler_config)
num_inference_steps = 10
model = self.dummy_model()
sample = self.dummy_sample_deter.half()
scheduler.set_timesteps(num_inference_steps)
for i, t in enumerate(scheduler.timesteps):
residual = model(sample, t)
sample = scheduler.step(residual, t, sample).prev_sample
assert sample.dtype == torch.float16
def test_full_loop_with_noise(self):
scheduler_class = self.scheduler_classes[0]
scheduler_config = self.get_scheduler_config()
scheduler = scheduler_class(**scheduler_config)
num_inference_steps = 10
t_start = 8
model = self.dummy_model()
sample = self.dummy_sample_deter
scheduler.set_timesteps(num_inference_steps)
# add noise
noise = self.dummy_noise_deter
timesteps = scheduler.timesteps[t_start * scheduler.order :]
sample = scheduler.add_noise(sample, noise, timesteps[:1])
for i, t in enumerate(timesteps):
residual = model(sample, t)
sample = scheduler.step(residual, t, sample).prev_sample
result_sum = torch.sum(torch.abs(sample))
result_mean = torch.mean(torch.abs(sample))
assert abs(result_sum.item() - 315.3016) < 1e-2, f" expected result sum 315.3016, but get {result_sum}"
assert abs(result_mean.item() - 0.41054) < 1e-3, f" expected result mean 0.41054, but get {result_mean}"
| diffusers/tests/schedulers/test_scheduler_deis.py/0 | {
"file_path": "diffusers/tests/schedulers/test_scheduler_deis.py",
"repo_id": "diffusers",
"token_count": 5267
} | 268 |
import tempfile
import torch
from diffusers import PNDMScheduler
from .test_schedulers import SchedulerCommonTest
class PNDMSchedulerTest(SchedulerCommonTest):
scheduler_classes = (PNDMScheduler,)
forward_default_kwargs = (("num_inference_steps", 50),)
def get_scheduler_config(self, **kwargs):
config = {
"num_train_timesteps": 1000,
"beta_start": 0.0001,
"beta_end": 0.02,
"beta_schedule": "linear",
}
config.update(**kwargs)
return config
def check_over_configs(self, time_step=0, **config):
kwargs = dict(self.forward_default_kwargs)
num_inference_steps = kwargs.pop("num_inference_steps", None)
sample = self.dummy_sample
residual = 0.1 * sample
dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05]
for scheduler_class in self.scheduler_classes:
scheduler_config = self.get_scheduler_config(**config)
scheduler = scheduler_class(**scheduler_config)
scheduler.set_timesteps(num_inference_steps)
# copy over dummy past residuals
scheduler.ets = dummy_past_residuals[:]
with tempfile.TemporaryDirectory() as tmpdirname:
scheduler.save_config(tmpdirname)
new_scheduler = scheduler_class.from_pretrained(tmpdirname)
new_scheduler.set_timesteps(num_inference_steps)
# copy over dummy past residuals
new_scheduler.ets = dummy_past_residuals[:]
output = scheduler.step_prk(residual, time_step, sample, **kwargs).prev_sample
new_output = new_scheduler.step_prk(residual, time_step, sample, **kwargs).prev_sample
assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
output = scheduler.step_plms(residual, time_step, sample, **kwargs).prev_sample
new_output = new_scheduler.step_plms(residual, time_step, sample, **kwargs).prev_sample
assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
def test_from_save_pretrained(self):
pass
def check_over_forward(self, time_step=0, **forward_kwargs):
kwargs = dict(self.forward_default_kwargs)
num_inference_steps = kwargs.pop("num_inference_steps", None)
sample = self.dummy_sample
residual = 0.1 * sample
dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05]
for scheduler_class in self.scheduler_classes:
scheduler_config = self.get_scheduler_config()
scheduler = scheduler_class(**scheduler_config)
scheduler.set_timesteps(num_inference_steps)
# copy over dummy past residuals (must be after setting timesteps)
scheduler.ets = dummy_past_residuals[:]
with tempfile.TemporaryDirectory() as tmpdirname:
scheduler.save_config(tmpdirname)
new_scheduler = scheduler_class.from_pretrained(tmpdirname)
# copy over dummy past residuals
new_scheduler.set_timesteps(num_inference_steps)
# copy over dummy past residual (must be after setting timesteps)
new_scheduler.ets = dummy_past_residuals[:]
output = scheduler.step_prk(residual, time_step, sample, **kwargs).prev_sample
new_output = new_scheduler.step_prk(residual, time_step, sample, **kwargs).prev_sample
assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
output = scheduler.step_plms(residual, time_step, sample, **kwargs).prev_sample
new_output = new_scheduler.step_plms(residual, time_step, sample, **kwargs).prev_sample
assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
def full_loop(self, **config):
scheduler_class = self.scheduler_classes[0]
scheduler_config = self.get_scheduler_config(**config)
scheduler = scheduler_class(**scheduler_config)
num_inference_steps = 10
model = self.dummy_model()
sample = self.dummy_sample_deter
scheduler.set_timesteps(num_inference_steps)
for i, t in enumerate(scheduler.prk_timesteps):
residual = model(sample, t)
sample = scheduler.step_prk(residual, t, sample).prev_sample
for i, t in enumerate(scheduler.plms_timesteps):
residual = model(sample, t)
sample = scheduler.step_plms(residual, t, sample).prev_sample
return sample
def test_step_shape(self):
kwargs = dict(self.forward_default_kwargs)
num_inference_steps = kwargs.pop("num_inference_steps", None)
for scheduler_class in self.scheduler_classes:
scheduler_config = self.get_scheduler_config()
scheduler = scheduler_class(**scheduler_config)
sample = self.dummy_sample
residual = 0.1 * sample
if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
scheduler.set_timesteps(num_inference_steps)
elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
kwargs["num_inference_steps"] = num_inference_steps
# copy over dummy past residuals (must be done after set_timesteps)
dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05]
scheduler.ets = dummy_past_residuals[:]
output_0 = scheduler.step_prk(residual, 0, sample, **kwargs).prev_sample
output_1 = scheduler.step_prk(residual, 1, sample, **kwargs).prev_sample
self.assertEqual(output_0.shape, sample.shape)
self.assertEqual(output_0.shape, output_1.shape)
output_0 = scheduler.step_plms(residual, 0, sample, **kwargs).prev_sample
output_1 = scheduler.step_plms(residual, 1, sample, **kwargs).prev_sample
self.assertEqual(output_0.shape, sample.shape)
self.assertEqual(output_0.shape, output_1.shape)
def test_timesteps(self):
for timesteps in [100, 1000]:
self.check_over_configs(num_train_timesteps=timesteps)
def test_steps_offset(self):
for steps_offset in [0, 1]:
self.check_over_configs(steps_offset=steps_offset)
scheduler_class = self.scheduler_classes[0]
scheduler_config = self.get_scheduler_config(steps_offset=1)
scheduler = scheduler_class(**scheduler_config)
scheduler.set_timesteps(10)
assert torch.equal(
scheduler.timesteps,
torch.LongTensor(
[901, 851, 851, 801, 801, 751, 751, 701, 701, 651, 651, 601, 601, 501, 401, 301, 201, 101, 1]
),
)
def test_betas(self):
for beta_start, beta_end in zip([0.0001, 0.001], [0.002, 0.02]):
self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
def test_schedules(self):
for schedule in ["linear", "squaredcos_cap_v2"]:
self.check_over_configs(beta_schedule=schedule)
def test_prediction_type(self):
for prediction_type in ["epsilon", "v_prediction"]:
self.check_over_configs(prediction_type=prediction_type)
def test_time_indices(self):
for t in [1, 5, 10]:
self.check_over_forward(time_step=t)
def test_inference_steps(self):
for t, num_inference_steps in zip([1, 5, 10], [10, 50, 100]):
self.check_over_forward(num_inference_steps=num_inference_steps)
def test_pow_of_3_inference_steps(self):
# earlier version of set_timesteps() caused an error indexing alpha's with inference steps as power of 3
num_inference_steps = 27
for scheduler_class in self.scheduler_classes:
sample = self.dummy_sample
residual = 0.1 * sample
scheduler_config = self.get_scheduler_config()
scheduler = scheduler_class(**scheduler_config)
scheduler.set_timesteps(num_inference_steps)
# before power of 3 fix, would error on first step, so we only need to do two
for i, t in enumerate(scheduler.prk_timesteps[:2]):
sample = scheduler.step_prk(residual, t, sample).prev_sample
def test_inference_plms_no_past_residuals(self):
with self.assertRaises(ValueError):
scheduler_class = self.scheduler_classes[0]
scheduler_config = self.get_scheduler_config()
scheduler = scheduler_class(**scheduler_config)
scheduler.step_plms(self.dummy_sample, 1, self.dummy_sample).prev_sample
def test_full_loop_no_noise(self):
sample = self.full_loop()
result_sum = torch.sum(torch.abs(sample))
result_mean = torch.mean(torch.abs(sample))
assert abs(result_sum.item() - 198.1318) < 1e-2
assert abs(result_mean.item() - 0.2580) < 1e-3
def test_full_loop_with_v_prediction(self):
sample = self.full_loop(prediction_type="v_prediction")
result_sum = torch.sum(torch.abs(sample))
result_mean = torch.mean(torch.abs(sample))
assert abs(result_sum.item() - 67.3986) < 1e-2
assert abs(result_mean.item() - 0.0878) < 1e-3
def test_full_loop_with_set_alpha_to_one(self):
# We specify different beta, so that the first alpha is 0.99
sample = self.full_loop(set_alpha_to_one=True, beta_start=0.01)
result_sum = torch.sum(torch.abs(sample))
result_mean = torch.mean(torch.abs(sample))
assert abs(result_sum.item() - 230.0399) < 1e-2
assert abs(result_mean.item() - 0.2995) < 1e-3
def test_full_loop_with_no_set_alpha_to_one(self):
# We specify different beta, so that the first alpha is 0.99
sample = self.full_loop(set_alpha_to_one=False, beta_start=0.01)
result_sum = torch.sum(torch.abs(sample))
result_mean = torch.mean(torch.abs(sample))
assert abs(result_sum.item() - 186.9482) < 1e-2
assert abs(result_mean.item() - 0.2434) < 1e-3
| diffusers/tests/schedulers/test_scheduler_pndm.py/0 | {
"file_path": "diffusers/tests/schedulers/test_scheduler_pndm.py",
"repo_id": "diffusers",
"token_count": 4654
} | 269 |
import gc
import unittest
import torch
from diffusers import (
StableDiffusionImg2ImgPipeline,
)
from diffusers.utils import load_image
from diffusers.utils.testing_utils import (
enable_full_determinism,
require_torch_gpu,
slow,
)
from .single_file_testing_utils import SDSingleFileTesterMixin
enable_full_determinism()
@slow
@require_torch_gpu
class StableDiffusionImg2ImgPipelineSingleFileSlowTests(unittest.TestCase, SDSingleFileTesterMixin):
pipeline_class = StableDiffusionImg2ImgPipeline
ckpt_path = "https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/v1-5-pruned-emaonly.safetensors"
original_config = (
"https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml"
)
repo_id = "runwayml/stable-diffusion-v1-5"
def setUp(self):
super().setUp()
gc.collect()
torch.cuda.empty_cache()
def tearDown(self):
super().tearDown()
gc.collect()
torch.cuda.empty_cache()
def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
generator = torch.Generator(device=generator_device).manual_seed(seed)
init_image = load_image(
"https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
"/stable_diffusion_img2img/sketch-mountains-input.png"
)
inputs = {
"prompt": "a fantasy landscape, concept art, high resolution",
"image": init_image,
"generator": generator,
"num_inference_steps": 3,
"strength": 0.75,
"guidance_scale": 7.5,
"output_type": "np",
}
return inputs
def test_single_file_format_inference_is_same_as_pretrained(self):
super().test_single_file_format_inference_is_same_as_pretrained(expected_max_diff=1e-3)
@slow
@require_torch_gpu
class StableDiffusion21Img2ImgPipelineSingleFileSlowTests(unittest.TestCase, SDSingleFileTesterMixin):
pipeline_class = StableDiffusionImg2ImgPipeline
ckpt_path = "https://huggingface.co/stabilityai/stable-diffusion-2-1/blob/main/v2-1_768-ema-pruned.safetensors"
original_config = "https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml"
repo_id = "stabilityai/stable-diffusion-2-1"
def setUp(self):
super().setUp()
gc.collect()
torch.cuda.empty_cache()
def tearDown(self):
super().tearDown()
gc.collect()
torch.cuda.empty_cache()
def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
generator = torch.Generator(device=generator_device).manual_seed(seed)
init_image = load_image(
"https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
"/stable_diffusion_img2img/sketch-mountains-input.png"
)
inputs = {
"prompt": "a fantasy landscape, concept art, high resolution",
"image": init_image,
"generator": generator,
"num_inference_steps": 3,
"strength": 0.75,
"guidance_scale": 7.5,
"output_type": "np",
}
return inputs
def test_single_file_format_inference_is_same_as_pretrained(self):
super().test_single_file_format_inference_is_same_as_pretrained(expected_max_diff=1e-3)
| diffusers/tests/single_file/test_stable_diffusion_img2img_single_file.py/0 | {
"file_path": "diffusers/tests/single_file/test_stable_diffusion_img2img_single_file.py",
"repo_id": "diffusers",
"token_count": 1546
} | 270 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that sorts the imports in the custom inits of Diffusers. Diffusers uses init files that delay the
import of an object to when it's actually needed. This is to avoid the main init importing all models, which would
make the line `import transformers` very slow when the user has all optional dependencies installed. The inits with
delayed imports have two halves: one defining a dictionary `_import_structure` which maps modules to the name of the
objects in each module, and one in `TYPE_CHECKING` which looks like a normal init for type-checkers. `isort` or `ruff`
properly sort the second half which looks like traditionl imports, the goal of this script is to sort the first half.
Use from the root of the repo with:
```bash
python utils/custom_init_isort.py
```
which will auto-sort the imports (used in `make style`).
For a check only (as used in `make quality`) run:
```bash
python utils/custom_init_isort.py --check_only
```
"""
import argparse
import os
import re
from typing import Any, Callable, List, Optional
# Path is defined with the intent you should run this script from the root of the repo.
PATH_TO_TRANSFORMERS = "src/diffusers"
# Pattern that looks at the indentation in a line.
_re_indent = re.compile(r"^(\s*)\S")
# Pattern that matches `"key":" and puts `key` in group 0.
_re_direct_key = re.compile(r'^\s*"([^"]+)":')
# Pattern that matches `_import_structure["key"]` and puts `key` in group 0.
_re_indirect_key = re.compile(r'^\s*_import_structure\["([^"]+)"\]')
# Pattern that matches `"key",` and puts `key` in group 0.
_re_strip_line = re.compile(r'^\s*"([^"]+)",\s*$')
# Pattern that matches any `[stuff]` and puts `stuff` in group 0.
_re_bracket_content = re.compile(r"\[([^\]]+)\]")
def get_indent(line: str) -> str:
"""Returns the indent in given line (as string)."""
search = _re_indent.search(line)
return "" if search is None else search.groups()[0]
def split_code_in_indented_blocks(
code: str, indent_level: str = "", start_prompt: Optional[str] = None, end_prompt: Optional[str] = None
) -> List[str]:
"""
Split some code into its indented blocks, starting at a given level.
Args:
code (`str`): The code to split.
indent_level (`str`): The indent level (as string) to use for identifying the blocks to split.
start_prompt (`str`, *optional*): If provided, only starts splitting at the line where this text is.
end_prompt (`str`, *optional*): If provided, stops splitting at a line where this text is.
Warning:
The text before `start_prompt` or after `end_prompt` (if provided) is not ignored, just not split. The input `code`
can thus be retrieved by joining the result.
Returns:
`List[str]`: The list of blocks.
"""
# Let's split the code into lines and move to start_index.
index = 0
lines = code.split("\n")
if start_prompt is not None:
while not lines[index].startswith(start_prompt):
index += 1
blocks = ["\n".join(lines[:index])]
else:
blocks = []
# This variable contains the block treated at a given time.
current_block = [lines[index]]
index += 1
# We split into blocks until we get to the `end_prompt` (or the end of the file).
while index < len(lines) and (end_prompt is None or not lines[index].startswith(end_prompt)):
# We have a non-empty line with the proper indent -> start of a new block
if len(lines[index]) > 0 and get_indent(lines[index]) == indent_level:
# Store the current block in the result and rest. There are two cases: the line is part of the block (like
# a closing parenthesis) or not.
if len(current_block) > 0 and get_indent(current_block[-1]).startswith(indent_level + " "):
# Line is part of the current block
current_block.append(lines[index])
blocks.append("\n".join(current_block))
if index < len(lines) - 1:
current_block = [lines[index + 1]]
index += 1
else:
current_block = []
else:
# Line is not part of the current block
blocks.append("\n".join(current_block))
current_block = [lines[index]]
else:
# Just add the line to the current block
current_block.append(lines[index])
index += 1
# Adds current block if it's nonempty.
if len(current_block) > 0:
blocks.append("\n".join(current_block))
# Add final block after end_prompt if provided.
if end_prompt is not None and index < len(lines):
blocks.append("\n".join(lines[index:]))
return blocks
def ignore_underscore_and_lowercase(key: Callable[[Any], str]) -> Callable[[Any], str]:
"""
Wraps a key function (as used in a sort) to lowercase and ignore underscores.
"""
def _inner(x):
return key(x).lower().replace("_", "")
return _inner
def sort_objects(objects: List[Any], key: Optional[Callable[[Any], str]] = None) -> List[Any]:
"""
Sort a list of objects following the rules of isort (all uppercased first, camel-cased second and lower-cased
last).
Args:
objects (`List[Any]`):
The list of objects to sort.
key (`Callable[[Any], str]`, *optional*):
A function taking an object as input and returning a string, used to sort them by alphabetical order.
If not provided, will default to noop (so a `key` must be provided if the `objects` are not of type string).
Returns:
`List[Any]`: The sorted list with the same elements as in the inputs
"""
# If no key is provided, we use a noop.
def noop(x):
return x
if key is None:
key = noop
# Constants are all uppercase, they go first.
constants = [obj for obj in objects if key(obj).isupper()]
# Classes are not all uppercase but start with a capital, they go second.
classes = [obj for obj in objects if key(obj)[0].isupper() and not key(obj).isupper()]
# Functions begin with a lowercase, they go last.
functions = [obj for obj in objects if not key(obj)[0].isupper()]
# Then we sort each group.
key1 = ignore_underscore_and_lowercase(key)
return sorted(constants, key=key1) + sorted(classes, key=key1) + sorted(functions, key=key1)
def sort_objects_in_import(import_statement: str) -> str:
"""
Sorts the imports in a single import statement.
Args:
import_statement (`str`): The import statement in which to sort the imports.
Returns:
`str`: The same as the input, but with objects properly sorted.
"""
# This inner function sort imports between [ ].
def _replace(match):
imports = match.groups()[0]
# If there is one import only, nothing to do.
if "," not in imports:
return f"[{imports}]"
keys = [part.strip().replace('"', "") for part in imports.split(",")]
# We will have a final empty element if the line finished with a comma.
if len(keys[-1]) == 0:
keys = keys[:-1]
return "[" + ", ".join([f'"{k}"' for k in sort_objects(keys)]) + "]"
lines = import_statement.split("\n")
if len(lines) > 3:
# Here we have to sort internal imports that are on several lines (one per name):
# key: [
# "object1",
# "object2",
# ...
# ]
# We may have to ignore one or two lines on each side.
idx = 2 if lines[1].strip() == "[" else 1
keys_to_sort = [(i, _re_strip_line.search(line).groups()[0]) for i, line in enumerate(lines[idx:-idx])]
sorted_indices = sort_objects(keys_to_sort, key=lambda x: x[1])
sorted_lines = [lines[x[0] + idx] for x in sorted_indices]
return "\n".join(lines[:idx] + sorted_lines + lines[-idx:])
elif len(lines) == 3:
# Here we have to sort internal imports that are on one separate line:
# key: [
# "object1", "object2", ...
# ]
if _re_bracket_content.search(lines[1]) is not None:
lines[1] = _re_bracket_content.sub(_replace, lines[1])
else:
keys = [part.strip().replace('"', "") for part in lines[1].split(",")]
# We will have a final empty element if the line finished with a comma.
if len(keys[-1]) == 0:
keys = keys[:-1]
lines[1] = get_indent(lines[1]) + ", ".join([f'"{k}"' for k in sort_objects(keys)])
return "\n".join(lines)
else:
# Finally we have to deal with imports fitting on one line
import_statement = _re_bracket_content.sub(_replace, import_statement)
return import_statement
def sort_imports(file: str, check_only: bool = True):
"""
Sort the imports defined in the `_import_structure` of a given init.
Args:
file (`str`): The path to the init to check/fix.
check_only (`bool`, *optional*, defaults to `True`): Whether or not to just check (and not auto-fix) the init.
"""
with open(file, encoding="utf-8") as f:
code = f.read()
# If the file is not a custom init, there is nothing to do.
if "_import_structure" not in code:
return
# Blocks of indent level 0
main_blocks = split_code_in_indented_blocks(
code, start_prompt="_import_structure = {", end_prompt="if TYPE_CHECKING:"
)
# We ignore block 0 (everything untils start_prompt) and the last block (everything after end_prompt).
for block_idx in range(1, len(main_blocks) - 1):
# Check if the block contains some `_import_structure`s thingy to sort.
block = main_blocks[block_idx]
block_lines = block.split("\n")
# Get to the start of the imports.
line_idx = 0
while line_idx < len(block_lines) and "_import_structure" not in block_lines[line_idx]:
# Skip dummy import blocks
if "import dummy" in block_lines[line_idx]:
line_idx = len(block_lines)
else:
line_idx += 1
if line_idx >= len(block_lines):
continue
# Ignore beginning and last line: they don't contain anything.
internal_block_code = "\n".join(block_lines[line_idx:-1])
indent = get_indent(block_lines[1])
# Slit the internal block into blocks of indent level 1.
internal_blocks = split_code_in_indented_blocks(internal_block_code, indent_level=indent)
# We have two categories of import key: list or _import_structure[key].append/extend
pattern = _re_direct_key if "_import_structure = {" in block_lines[0] else _re_indirect_key
# Grab the keys, but there is a trap: some lines are empty or just comments.
keys = [(pattern.search(b).groups()[0] if pattern.search(b) is not None else None) for b in internal_blocks]
# We only sort the lines with a key.
keys_to_sort = [(i, key) for i, key in enumerate(keys) if key is not None]
sorted_indices = [x[0] for x in sorted(keys_to_sort, key=lambda x: x[1])]
# We reorder the blocks by leaving empty lines/comments as they were and reorder the rest.
count = 0
reordered_blocks = []
for i in range(len(internal_blocks)):
if keys[i] is None:
reordered_blocks.append(internal_blocks[i])
else:
block = sort_objects_in_import(internal_blocks[sorted_indices[count]])
reordered_blocks.append(block)
count += 1
# And we put our main block back together with its first and last line.
main_blocks[block_idx] = "\n".join(block_lines[:line_idx] + reordered_blocks + [block_lines[-1]])
if code != "\n".join(main_blocks):
if check_only:
return True
else:
print(f"Overwriting {file}.")
with open(file, "w", encoding="utf-8") as f:
f.write("\n".join(main_blocks))
def sort_imports_in_all_inits(check_only=True):
"""
Sort the imports defined in the `_import_structure` of all inits in the repo.
Args:
check_only (`bool`, *optional*, defaults to `True`): Whether or not to just check (and not auto-fix) the init.
"""
failures = []
for root, _, files in os.walk(PATH_TO_TRANSFORMERS):
if "__init__.py" in files:
result = sort_imports(os.path.join(root, "__init__.py"), check_only=check_only)
if result:
failures = [os.path.join(root, "__init__.py")]
if len(failures) > 0:
raise ValueError(f"Would overwrite {len(failures)} files, run `make style`.")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--check_only", action="store_true", help="Whether to only check or fix style.")
args = parser.parse_args()
sort_imports_in_all_inits(check_only=args.check_only)
| diffusers/utils/custom_init_isort.py/0 | {
"file_path": "diffusers/utils/custom_init_isort.py",
"repo_id": "diffusers",
"token_count": 5346
} | 271 |
<jupyter_start><jupyter_text>Diffusion Models from ScratchSometimes it is helpful to consider the simplest possible version of something to better understand how it works. We're going to try that in this notebook, beginning with a 'toy' diffusion model to see how the different pieces work, and then examining how they differ from a more complex implementation. We will look at - The corruption process (adding noise to data)- What a UNet is, and how to implement an extremely minimal one from scratch- Diffusion model training- Sampling theoryThen we'll compare our versions with the diffusers DDPM implementation, exploring- Improvements over our mini UNet- The DDPM noise schedule- Differences in training objective- Timestep conditioning- Sampling approachesThis notebook is fairly in-depth, and can safely be skipped if you're not excited about a from-scratch deep dive! It is also worth noting that most of the code here is for illustrative purposes, and I wouldn't recommend directly adopting any of it for your own work (unless you're just trying improve on the examples shown here for learning purposes). Setup and Imports:<jupyter_code>%pip install -q diffusers
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')<jupyter_output>Using device: cuda<jupyter_text>The DataHere we're going to test things with a very small dataset: mnist. If you'd like to give the model a slightly harder challenge without changing anything else, torchvision.datasets.FashionMNIST should work as a drop-in replacement.<jupyter_code>dataset = torchvision.datasets.MNIST(root="mnist/", train=True, download=True, transform=torchvision.transforms.ToTensor())
train_dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
x, y = next(iter(train_dataloader))
print('Input shape:', x.shape)
print('Labels:', y)
plt.imshow(torchvision.utils.make_grid(x)[0], cmap='Greys');<jupyter_output>Input shape: torch.Size([8, 1, 28, 28])
Labels: tensor([1, 9, 7, 3, 5, 2, 1, 4])<jupyter_text>Each image is a greyscale 28px by 28px drawing of a digit, with values ranging from 0 to 1. The Corruption ProcessPretend you haven't read any diffusion model papers, but you know the process involves adding noise. How would you do it?We probably want an easy way to control the amount of corruption. So what if we take in a parameter for the `amount` of noise to add, and then we do:`noise = torch.rand_like(x)` `noisy_x = (1-amount)*x + amount*noise`If amount = 0, we get back the input without any changes. If amount gets up to 1, we get back noise with no trace of the input x. By mixing the input with noise this way, we keep the output in the same range (0 to 1).We can implement this fairly easily (just watch the shapes so you don't get burnt by broadcasting rules):<jupyter_code>def corrupt(x, amount):
"""Corrupt the input `x` by mixing it with noise according to `amount`"""
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1) # Sort shape so broadcasting works
return x*(1-amount) + noise*amount<jupyter_output><empty_output><jupyter_text>And looking at the results visually to see that it works as expected:<jupyter_code># Plotting the input data
fig, axs = plt.subplots(2, 1, figsize=(12, 5))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0], cmap='Greys')
# Adding noise
amount = torch.linspace(0, 1, x.shape[0]) # Left to right -> more corruption
noised_x = corrupt(x, amount)
# Plotting the noised version
axs[1].set_title('Corrupted data (-- amount increases -->)')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0], cmap='Greys');<jupyter_output><empty_output><jupyter_text>As noise amount approaches one, our data begins to look like pure random noise. But for most noise amounts, you can guess the digit fairly well. Do you think this is optimal? The ModelWe'd like a model that takes in a 28px noisy images and outputs a prediction of the same shape. A popular choice here is an architecture called a UNet. [Originally invented for segmentation tasks in medical imagery](https://arxiv.org/abs/1505.04597), a UNet consists of a 'constricting path' through which data is compressed down and an 'expanding path' through which it expands back up to the original dimension (similar to an autoencoder) but also features skip connections that allow for information and gradients to flow across at different levels. Some UNets feature complex blocks at each stage, but for this toy demo we'll build a minimal example that takes in a one-channel image and passes it through three convolutional layers on the down path (the down_layers in the diagram and code) and three on the up path, with skip connections between the down and up layers. We'll use max pooling for downsampling and `nn.Upsample` for upsampling rather than relying on learnable layers like more complex UNets. Here is the rough architecture showing the number of channels in the output of each layer:  This is what that looks like in code:<jupyter_code>class BasicUNet(nn.Module):
"""A minimal UNet implementation."""
def __init__(self, in_channels=1, out_channels=1):
super().__init__()
self.down_layers = torch.nn.ModuleList([
nn.Conv2d(in_channels, 32, kernel_size=5, padding=2),
nn.Conv2d(32, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 64, kernel_size=5, padding=2),
])
self.up_layers = torch.nn.ModuleList([
nn.Conv2d(64, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 32, kernel_size=5, padding=2),
nn.Conv2d(32, out_channels, kernel_size=5, padding=2),
])
self.act = nn.SiLU() # The activation function
self.downscale = nn.MaxPool2d(2)
self.upscale = nn.Upsample(scale_factor=2)
def forward(self, x):
h = []
for i, l in enumerate(self.down_layers):
x = self.act(l(x)) # Through the layer and the activation function
if i < 2: # For all but the third (final) down layer:
h.append(x) # Storing output for skip connection
x = self.downscale(x) # Downscale ready for the next layer
for i, l in enumerate(self.up_layers):
if i > 0: # For all except the first up layer
x = self.upscale(x) # Upscale
x += h.pop() # Fetching stored output (skip connection)
x = self.act(l(x)) # Through the layer and the activation function
return x<jupyter_output><empty_output><jupyter_text>We can verify that the output shape is the same as the input, as we expect:<jupyter_code>net = BasicUNet()
x = torch.rand(8, 1, 28, 28)
net(x).shape<jupyter_output><empty_output><jupyter_text>This network has just over 300,000 parameters:<jupyter_code>sum([p.numel() for p in net.parameters()])<jupyter_output><empty_output><jupyter_text>You can explore changing the number of channels in each layer or swapping in different architectures if you want. Training the networkSo what should the model do, exactly? Again, there are various takes on this but for this demo let's pick a simple framing: given a corrupted input noisy_x the model should output its best guess for what the original x looks like. We will compare this to the actual value via the mean squared error.We can now have a go at training the network. - Get a batch of data- Corrupt it by random amounts- Feed it through the model- Compare the model predictions with the clean images to calculate our loss- Update the model's parameters accordingly.Feel free to modify this and see if you can get it working better!<jupyter_code># Dataloader (you can mess with batch size)
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# How many runs through the data should we do?
n_epochs = 3
# Create the network
net = BasicUNet()
net.to(device)
# Our loss function
loss_fn = nn.MSELoss()
# The optimizer
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
# Keeping a record of the losses for later viewing
losses = []
# The training loop
for epoch in range(n_epochs):
for x, y in train_dataloader:
# Get some data and prepare the corrupted version
x = x.to(device) # Data on the GPU
noise_amount = torch.rand(x.shape[0]).to(device) # Pick random noise amounts
noisy_x = corrupt(x, noise_amount) # Create our noisy x
# Get the model prediction
pred = net(noisy_x)
# Calculate the loss
loss = loss_fn(pred, x) # How close is the output to the true 'clean' x?
# Backprop and update the params:
opt.zero_grad()
loss.backward()
opt.step()
# Store the loss for later
losses.append(loss.item())
# Print our the average of the loss values for this epoch:
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss:05f}')
# View the loss curve
plt.plot(losses)
plt.ylim(0, 0.1);<jupyter_output>Finished epoch 0. Average loss for this epoch: 0.026736
Finished epoch 1. Average loss for this epoch: 0.020692
Finished epoch 2. Average loss for this epoch: 0.018887<jupyter_text>We can try to see what the model predictions look like by grabbing a batch of data, corrupting it by different amounts and then seeing the models predictions:<jupyter_code>#@markdown Visualizing model predictions on noisy inputs:
# Fetch some data
x, y = next(iter(train_dataloader))
x = x[:8] # Only using the first 8 for easy plotting
# Corrupt with a range of amounts
amount = torch.linspace(0, 1, x.shape[0]) # Left to right -> more corruption
noised_x = corrupt(x, amount)
# Get the model predictions
with torch.no_grad():
preds = net(noised_x.to(device)).detach().cpu()
# Plot
fig, axs = plt.subplots(3, 1, figsize=(12, 7))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0].clip(0, 1), cmap='Greys')
axs[1].set_title('Corrupted data')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0].clip(0, 1), cmap='Greys')
axs[2].set_title('Network Predictions')
axs[2].imshow(torchvision.utils.make_grid(preds)[0].clip(0, 1), cmap='Greys');<jupyter_output><empty_output><jupyter_text>You can see that for the lower amounts the predictions are pretty good! But as the level gets very high there is less for the model to work with, and by the time we get to amount=1 it outputs a blurry mess close to the mean of the dataset to try and hedge its bets on what the output might look like... SamplingIf our predictions at high noise levels aren't very good, how do we generate images?Well, what if we start from random noise, look at the model predictions but then only move a small amount towards that prediction - say, 20% of the way there. Now we have a very noisy image in which there is perhaps a hint of structure, which we can feed into the model to get a new prediction. The hope is that this new prediction is slightly better than the first one (since our starting point is slightly less noisy) and so we can take another small step with this new, better prediction.Repeat a few times and (if all goes well) we get an image out! Here is that process illustrated over just 5 steps, visualizing the model input (left) and the predicted denoised images (right) at each stage. Note that even though the model predicts the denoised image even at step 1, we only move x part of the way there. Over a few steps the structures appear and are refined, until we get our final outputs.<jupyter_code>#@markdown Sampling strategy: Break the process into 5 steps and move 1/5'th of the way there each time:
n_steps = 5
x = torch.rand(8, 1, 28, 28).to(device) # Start from random
step_history = [x.detach().cpu()]
pred_output_history = []
for i in range(n_steps):
with torch.no_grad(): # No need to track gradients during inference
pred = net(x) # Predict the denoised x0
pred_output_history.append(pred.detach().cpu()) # Store model output for plotting
mix_factor = 1/(n_steps - i) # How much we move towards the prediction
x = x*(1-mix_factor) + pred*mix_factor # Move part of the way there
step_history.append(x.detach().cpu()) # Store step for plotting
fig, axs = plt.subplots(n_steps, 2, figsize=(9, 4), sharex=True)
axs[0,0].set_title('x (model input)')
axs[0,1].set_title('model prediction')
for i in range(n_steps):
axs[i, 0].imshow(torchvision.utils.make_grid(step_history[i])[0].clip(0, 1), cmap='Greys')
axs[i, 1].imshow(torchvision.utils.make_grid(pred_output_history[i])[0].clip(0, 1), cmap='Greys')<jupyter_output><empty_output><jupyter_text>We can split the process up into more steps, and hope for better images that way:<jupyter_code>#@markdown Showing more results, using 40 sampling steps
n_steps = 40
x = torch.rand(64, 1, 28, 28).to(device)
for i in range(n_steps):
noise_amount = torch.ones((x.shape[0], )).to(device) * (1-(i/n_steps)) # Starting high going low
with torch.no_grad():
pred = net(x)
mix_factor = 1/(n_steps - i)
x = x*(1-mix_factor) + pred*mix_factor
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
ax.imshow(torchvision.utils.make_grid(x.detach().cpu(), nrow=8)[0].clip(0, 1), cmap='Greys')<jupyter_output><empty_output><jupyter_text>Not great, but there are some recognizable digits there! You can experiment with training for longer (say, 10 or 20 epochs) and tweaking model config, learning rate, optimizer and so on. Also, don't forget that fashionMNIST is a one-line replacement if you want a slightly harder dataset to try. Comparison To DDPMIn this section we'll take a look at how our toy implementation differs from the approach used in the other notebook ([Introduction to Diffusers](https://github.com/huggingface/diffusion-models-class/blob/main/unit1/01_introduction_to_diffusers.ipynb)), which is based on the DDPM paper.We'll see that* The diffusers `UNet2DModel` is a bit more advanced than our BasicUNet* The corruption process in handled differently* The training objective is different, involving predicting the noise rather than the denoised image* The model is conditioned on the amount of noise present via timestep conditioning, where t is passed as an additional argument to the forward method.* There are a number of different sampling strategies available, which should work better than our simplistic version above.There have been a number of improvements suggested since the DDPM paper came out, but this example is hopefully instructive as to the different available design decisions. Once you've read through this, you may enjoy diving into the paper ['Elucidating the Design Space of Diffusion-Based Generative Models'](https://arxiv.org/abs/2206.00364) which explores all of these components in some detail and makes new recommendations for how to get the best performance. If all of this is too technical or intimidating, don't worry! Feel free to skip the rest of this notebook or save it for a rainy day. The UNetThe diffusers UNet2DModel model has a number of improvements over our basic UNet above:* GroupNorm applies group normalization to the inputs of each block* Dropout layers for smoother training* Multiple resnet layers per block (if layers_per_block isn't set to 1)* Attention (usually used only at lower resolution blocks)* Conditioning on the timestep. * Downsampling and upsampling blocks with learnable parametersLet's create and inspect a UNet2DModel:<jupyter_code>model = UNet2DModel(
sample_size=28, # the target image resolution
in_channels=1, # the number of input channels, 3 for RGB images
out_channels=1, # the number of output channels
layers_per_block=2, # how many ResNet layers to use per UNet block
block_out_channels=(32, 64, 64), # Roughly matching our basic unet example
down_block_types=(
"DownBlock2D", # a regular ResNet downsampling block
"AttnDownBlock2D", # a ResNet downsampling block with spatial self-attention
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # a ResNet upsampling block with spatial self-attention
"UpBlock2D", # a regular ResNet upsampling block
),
)
print(model)<jupyter_output>UNet2DModel(
(conv_in): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_proj): Timesteps()
(time_embedding): TimestepEmbedding(
(linear_1): Linear(in_features=32, out_features=128, bias=True)
(act): SiLU()
(linear_2): Linear(in_features=128, out_features=128, bias=True)
)
(down_blocks): ModuleList(
(0): DownBlock2D(
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 32, eps=1e-05, affine=True)
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=32, bias=True)
(norm2): GroupNorm(32, 32, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 32, eps=1e-05, affine=True)
(conv1): Con[...]<jupyter_text>As you can see, a little more going on! It also has significantly more parameters than our BasicUNet:<jupyter_code>sum([p.numel() for p in model.parameters()]) # 1.7M vs the ~309k parameters of the BasicUNet<jupyter_output><empty_output><jupyter_text>We can replicate the training shown above using this model in place of our original one. We need to pass both x and timestep to the model (here I always pass t=0 to show that it works without this timestep conditioning and to keep the sampling code easy, but you can also try feeding in `(amount*1000)` to get a timestep equivalent from the corruption amount). Lines changed are shown with `<<<` if you want to inspect the code.<jupyter_code>#@markdown Trying UNet2DModel instead of BasicUNet:
# Dataloader (you can mess with batch size)
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# How many runs through the data should we do?
n_epochs = 3
# Create the network
net = UNet2DModel(
sample_size=28, # the target image resolution
in_channels=1, # the number of input channels, 3 for RGB images
out_channels=1, # the number of output channels
layers_per_block=2, # how many ResNet layers to use per UNet block
block_out_channels=(32, 64, 64), # Roughly matching our basic unet example
down_block_types=(
"DownBlock2D", # a regular ResNet downsampling block
"AttnDownBlock2D", # a ResNet downsampling block with spatial self-attention
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # a ResNet upsampling block with spatial self-attention
"UpBlock2D", # a regular ResNet upsampling block
),
) #<<<
net.to(device)
# Our loss finction
loss_fn = nn.MSELoss()
# The optimizer
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
# Keeping a record of the losses for later viewing
losses = []
# The training loop
for epoch in range(n_epochs):
for x, y in train_dataloader:
# Get some data and prepare the corrupted version
x = x.to(device) # Data on the GPU
noise_amount = torch.rand(x.shape[0]).to(device) # Pick random noise amounts
noisy_x = corrupt(x, noise_amount) # Create our noisy x
# Get the model prediction
pred = net(noisy_x, 0).sample #<<< Using timestep 0 always, adding .sample
# Calculate the loss
loss = loss_fn(pred, x) # How close is the output to the true 'clean' x?
# Backprop and update the params:
opt.zero_grad()
loss.backward()
opt.step()
# Store the loss for later
losses.append(loss.item())
# Print our the average of the loss values for this epoch:
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss:05f}')
# Plot losses and some samples
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
# Losses
axs[0].plot(losses)
axs[0].set_ylim(0, 0.1)
axs[0].set_title('Loss over time')
# Samples
n_steps = 40
x = torch.rand(64, 1, 28, 28).to(device)
for i in range(n_steps):
noise_amount = torch.ones((x.shape[0], )).to(device) * (1-(i/n_steps)) # Starting high going low
with torch.no_grad():
pred = net(x, 0).sample
mix_factor = 1/(n_steps - i)
x = x*(1-mix_factor) + pred*mix_factor
axs[1].imshow(torchvision.utils.make_grid(x.detach().cpu(), nrow=8)[0].clip(0, 1), cmap='Greys')
axs[1].set_title('Generated Samples');<jupyter_output>Finished epoch 0. Average loss for this epoch: 0.018925
Finished epoch 1. Average loss for this epoch: 0.012785
Finished epoch 2. Average loss for this epoch: 0.011694<jupyter_text>This looks quite a bit better than our first set of results! You can explore tweaking the unet configuration or training for longer to get even better performance. The Corruption ProcessThe DDPM paper describes a corruption process that adds a small amount of noise for every 'timestep'. Given $x_{t-1}$ for some timestep, we can get the next (slightly more noisy) version $x_t$ with:$q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t\mathbf{I}) \quadq(\mathbf{x}_{1:T} \vert \mathbf{x}_0) = \prod^T_{t=1} q(\mathbf{x}_t \vert \mathbf{x}_{t-1})$That is, we take $x_{t-1}$, scale it by $\sqrt{1 - \beta_t}$ and add noise scaled by $\beta_t$. This $\beta$ is defined for every t according to some schedule, and determines how much noise is added per timestep. Now, we don't necessarily want to do this operation 500 times to get $x_{500}$ so we have another formula to get $x_t$ for any t given $x_0$: $\begin{aligned}q(\mathbf{x}_t \vert \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, \sqrt{(1 - \bar{\alpha}_t)} \mathbf{I})\end{aligned}$ where $\bar{\alpha}_t = \prod_{i=1}^T \alpha_i$ and $\alpha_i = 1-\beta_i$The maths notation always looks scary! Luckily the scheduler handles all that for us (uncomment the next cell to check out the code). We can plot $\sqrt{\bar{\alpha}_t}$ (labelled as `sqrt_alpha_prod`) and $\sqrt{(1 - \bar{\alpha}_t)}$ (labelled as `sqrt_one_minus_alpha_prod`) to view how the input (x) and the noise are scaled and mixed across different timesteps:<jupyter_code>#??noise_scheduler.add_noise
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
plt.plot(noise_scheduler.alphas_cumprod.cpu() ** 0.5, label=r"${\sqrt{\bar{\alpha}_t}}$")
plt.plot((1 - noise_scheduler.alphas_cumprod.cpu()) ** 0.5, label=r"$\sqrt{(1 - \bar{\alpha}_t)}$")
plt.legend(fontsize="x-large");<jupyter_output><empty_output><jupyter_text>Initially, the noisy x is mostly x (sqrt_alpha_prod ~= 1) but over time the contribution of x drops and the noise component increases. Unlike our linear mix of x and noise according to `amount`, this one gets noisy relatively quickly. We can visualize this on some data:<jupyter_code>#@markdown visualize the DDPM noising process for different timesteps:
# Noise a batch of images to view the effect
fig, axs = plt.subplots(3, 1, figsize=(16, 10))
xb, yb = next(iter(train_dataloader))
xb = xb.to(device)[:8]
xb = xb * 2. - 1. # Map to (-1, 1)
print('X shape', xb.shape)
# Show clean inputs
axs[0].imshow(torchvision.utils.make_grid(xb[:8])[0].detach().cpu(), cmap='Greys')
axs[0].set_title('Clean X')
# Add noise with scheduler
timesteps = torch.linspace(0, 999, 8).long().to(device)
noise = torch.randn_like(xb) # << NB: randn not rand
noisy_xb = noise_scheduler.add_noise(xb, noise, timesteps)
print('Noisy X shape', noisy_xb.shape)
# Show noisy version (with and without clipping)
axs[1].imshow(torchvision.utils.make_grid(noisy_xb[:8])[0].detach().cpu().clip(-1, 1), cmap='Greys')
axs[1].set_title('Noisy X (clipped to (-1, 1)')
axs[2].imshow(torchvision.utils.make_grid(noisy_xb[:8])[0].detach().cpu(), cmap='Greys')
axs[2].set_title('Noisy X');<jupyter_output>X shape torch.Size([8, 1, 28, 28])
Noisy X shape torch.Size([8, 1, 28, 28]) | diffusion-models-class/unit1/02_diffusion_models_from_scratch.ipynb/0 | {
"file_path": "diffusion-models-class/unit1/02_diffusion_models_from_scratch.ipynb",
"repo_id": "diffusion-models-class",
"token_count": 52297
} | 272 |
<jupyter_start><jupyter_text>Diffusion for Audio In this notebook, we're going to take a brief look at generating audio with diffusion models. What you will learn:- How audio is represented in a computer- Methods to convert between raw audio data and spectrograms- How to prepare a dataloader with a custom collate function to convert audio slices into spectrograms- Fine-tuning an existing audio diffusion model on a specific genre of music- Uploading your custom pipeline to the Hugging Face hubCaveat: This is mostly for educational purposes - no guarantees our model will sound good 😉.Let's get started! Setup and Imports<jupyter_code>%pip install -q datasets diffusers torchaudio accelerate
import torch, random
import numpy as np
import torch.nn.functional as F
from tqdm.auto import tqdm
from IPython.display import Audio
from matplotlib import pyplot as plt
from diffusers import DiffusionPipeline
from torchaudio import transforms as AT
from torchvision import transforms as IT<jupyter_output><empty_output><jupyter_text>Sampling from a Pre-Trained Audio PipelineLet's begin by following the [Audio Diffusion docs](https://huggingface.co/docs/diffusers/api/pipelines/audio_diffusion) to load a pre-existing audio diffusion model pipeline:<jupyter_code># Load a pre-trained audio diffusion pipeline
device = "mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained("teticio/audio-diffusion-instrumental-hiphop-256").to(device)<jupyter_output><empty_output><jupyter_text>As with the pipelines we've used in previous units, we can create samples by calling the pipeline like so:<jupyter_code># Sample from the pipeline and display the outputs
output = pipe()
display(output.images[0])
display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))<jupyter_output><empty_output><jupyter_text>Here, the `rate` argument specifies the _sampling rate_ for the audio; we'll take a deeper look at this later. You'll also notice there are multiple things returned by the pipeline. What's going on here? Let's take a closer look at both outputs.The first is an array of data, representing the generated audio:<jupyter_code># The audio array
output.audios[0].shape<jupyter_output><empty_output><jupyter_text>The second looks like a greyscale image:<jupyter_code># The output image (spectrogram)
output.images[0].size<jupyter_output><empty_output><jupyter_text>This gives us a hint at how this pipeline works. The audio is not directly generated with diffusion - instead, the pipeline has the same kind of 2D UNet as the unconditional image generation pipelines we saw in [Unit 1](https://github.com/huggingface/diffusion-models-class/tree/main/unit1) that is used to generate the spectrogram, which is then post-processed into the final audio.The pipe has an extra component that handles these conversions, which we can access via `pipe.mel`:<jupyter_code>pipe.mel<jupyter_output><empty_output><jupyter_text>From Audio to Image and Back Again An audio 'waveform' encodes the raw audio samples over time - this could be the electrical signal received from a microphone, for example. Working with this 'Time Domain' representation can be tricky, so it is a common practice to convert it into some other form, commonly something called a spectrogram. A spectrogram shows the intensity of different frequencies (y axis) vs time (x axis):<jupyter_code># Calculate and show a spectrogram for our generated audio sample using torchaudio
spec_transform = AT.Spectrogram(power=2)
spectrogram = spec_transform(torch.tensor(output.audios[0]))
print(spectrogram.min(), spectrogram.max())
log_spectrogram = spectrogram.log()
plt.imshow(log_spectrogram[0], cmap='gray');<jupyter_output>tensor(0.) tensor(6.0842)<jupyter_text>The spectrogram we just made has values between 0.0000000000001 and 1, with most being close to the low end of that range. This is not ideal for visualization or modelling - in fact we had to take the log of these values to get a greyscale plot that showed any detail. For this reason, we typically use a special kind of spectrogram called a Mel spectrogram, which is designed to capture the kinds of information which are important for human hearing by applying some transforms to the different frequency components of the signal. 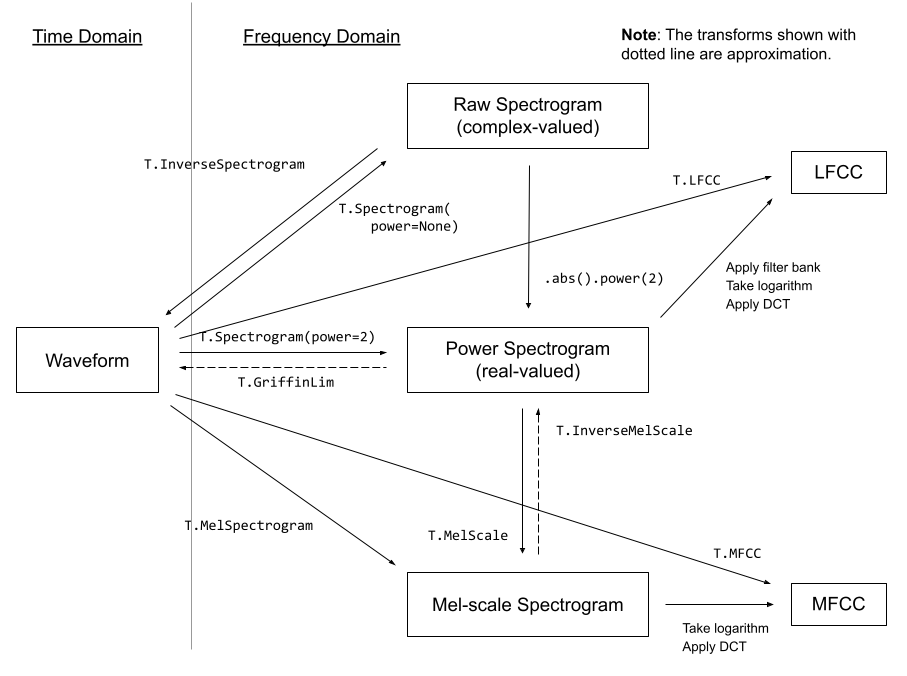_Some audio transforms from the [torchaudio docs](https://pytorch.org/audio/stable/transforms.html)_ Luckily for us, we don't even need to worry too much about these transforms - the pipeline's `mel` functionality handles these details for us. Using this, we can convert a spectrogram image to audio like so:<jupyter_code>a = pipe.mel.image_to_audio(output.images[0])
a.shape<jupyter_output><empty_output><jupyter_text>And we can convert an array of audio data into a spectrogram images by first loading the raw audio data and then calling the `audio_slice_to_image()` function. Longer clips are automatically sliced into chunks of the correct length to produce a 256x256 spectrogram image:<jupyter_code>pipe.mel.load_audio(raw_audio=a)
im = pipe.mel.audio_slice_to_image(0)
im<jupyter_output><empty_output><jupyter_text>The audio is represented as a long array of numbers. To play this out loud we need one more key piece of information: the sample rate. How many samples (individual values) do we use to represent a single second of audio? We can see the sample rate used during training of this pipeline with:<jupyter_code>sample_rate_pipeline = pipe.mel.get_sample_rate()
sample_rate_pipeline<jupyter_output><empty_output><jupyter_text>If we specify the sample rate incorrectly, we get audio that is sped up or slowed down:<jupyter_code>display(Audio(output.audios[0], rate=44100)) # 2x speed<jupyter_output><empty_output><jupyter_text>Fine-Tuning the pipeline Now that we have a rough understanding of how the pipeline works, let's fine-tune it on some new audio data! The dataset is a collection of audio clips in different genres, which we can load from the hub like so:<jupyter_code>from datasets import load_dataset
dataset = load_dataset('lewtun/music_genres', split='train')
dataset<jupyter_output>Using custom data configuration lewtun--music_genres-2cfa9201f94788d8
Found cached dataset parquet (/home/ubuntu/.cache/huggingface/datasets/lewtun___parquet/lewtun--music_genres-2cfa9201f94788d8/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec)<jupyter_text>You can use the code below to see the different genres in the dataset and how many samples are contained in each:<jupyter_code>for g in list(set(dataset['genre'])):
print(g, sum(x==g for x in dataset['genre']))<jupyter_output>Pop 945
Blues 58
Punk 2582
Old-Time / Historic 408
Experimental 1800
Folk 1214
Electronic 3071
Spoken 94
Classical 495
Country 142
Instrumental 1044
Chiptune / Glitch 1181
International 814
Ambient Electronic 796
Jazz 306
Soul-RnB 94
Hip-Hop 1757
Easy Listening 13
Rock 3095<jupyter_text>The dataset has the audio as arrays:<jupyter_code>audio_array = dataset[0]['audio']['array']
sample_rate_dataset = dataset[0]['audio']['sampling_rate']
print('Audio array shape:', audio_array.shape)
print('Sample rate:', sample_rate_dataset)
display(Audio(audio_array, rate=sample_rate_dataset))<jupyter_output>Audio array shape: (1323119,)
Sample rate: 44100<jupyter_text>Note that the sample rate of this audio is higher - if we want to use the existing pipeline we'll need to 'resample' it to match. The clips are also longer than the ones the pipeline is set up for. Fortunately, when we load the audio using `pipe.mel` it automatically slices the clip into smaller sections:<jupyter_code>a = dataset[0]['audio']['array'] # Get the audio array
pipe.mel.load_audio(raw_audio=a) # Load it with pipe.mel
pipe.mel.audio_slice_to_image(0) # View the first 'slice' as a spectrogram<jupyter_output><empty_output><jupyter_text>We need to remember to adjust the sampling rate, since the data from this dataset has twice as many samples per second:<jupyter_code>sample_rate_dataset = dataset[0]['audio']['sampling_rate']
sample_rate_dataset<jupyter_output><empty_output><jupyter_text>Here we use torchaudio's transforms (imported as AT) to do the resampling, the pipe's `mel` to turn audio into an image and torchvision's transforms (imported as IT) to turn images into tensors. This gives us a function that turns an audio clip into a spectrogram tensor that we can use for training:<jupyter_code>resampler = AT.Resample(sample_rate_dataset, sample_rate_pipeline, dtype=torch.float32)
to_t = IT.ToTensor()
def to_image(audio_array):
audio_tensor = torch.tensor(audio_array).to(torch.float32)
audio_tensor = resampler(audio_tensor)
pipe.mel.load_audio(raw_audio=np.array(audio_tensor))
num_slices = pipe.mel.get_number_of_slices()
slice_idx = random.randint(0, num_slices-1) # Pic a random slice each time (excluding the last short slice)
im = pipe.mel.audio_slice_to_image(slice_idx)
return im<jupyter_output><empty_output><jupyter_text>We'll use our `to_image()` function as part of a custom collate function to turn our dataset into a dataloader we can use for training. The collate function defines how to transform a batch of examples from the dataset into the final batch of data ready for training. In this case we turn each audio sample into a spectrogram image and stack the resulting tensors together:<jupyter_code>def collate_fn(examples):
# to image -> to tensor -> rescale to (-1, 1) -> stack into batch
audio_ims = [to_t(to_image(x['audio']['array']))*2-1 for x in examples]
return torch.stack(audio_ims)
# Create a dataset with only the 'Chiptune / Glitch' genre of songs
batch_size = 4 # 4 on colab, 12 on A100
chosen_genre = 'Electronic' # <<< Try training on different genres <<<
indexes = [i for i, g in enumerate(dataset['genre']) if g == chosen_genre]
filtered_dataset = dataset.select(indexes)
dl = torch.utils.data.DataLoader(filtered_dataset.shuffle(), batch_size=batch_size, collate_fn=collate_fn, shuffle=True)
batch = next(iter(dl))
print(batch.shape)<jupyter_output>torch.Size([4, 1, 256, 256])<jupyter_text>**NB: You will need to use a lower batch size (e.g., 4) unless you have plenty of GPU vRAM available.** Training LoopHere is a simple training loop that runs through the dataloader for a few epochs to fine-tune the pipeline's UNet. You can also skip this cell and load the pipeline with the code in the following cell.<jupyter_code>epochs = 3
lr = 1e-4
pipe.unet.train()
pipe.scheduler.set_timesteps(1000)
optimizer = torch.optim.AdamW(pipe.unet.parameters(), lr=lr)
for epoch in range(epochs):
for step, batch in tqdm(enumerate(dl), total=len(dl)):
# Prepare the input images
clean_images = batch.to(device)
bs = clean_images.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, pipe.scheduler.num_train_timesteps, (bs,), device=clean_images.device
).long()
# Add noise to the clean images according to the noise magnitude at each timestep
noise = torch.randn(clean_images.shape).to(clean_images.device)
noisy_images = pipe.scheduler.add_noise(clean_images, noise, timesteps)
# Get the model prediction
noise_pred = pipe.unet(noisy_images, timesteps, return_dict=False)[0]
# Calculate the loss
loss = F.mse_loss(noise_pred, noise)
loss.backward(loss)
# Update the model parameters with the optimizer
optimizer.step()
optimizer.zero_grad()
# OR: Load the version I trained earlier
pipe = DiffusionPipeline.from_pretrained("johnowhitaker/Electronic_test").to(device)
output = pipe()
display(output.images[0])
display(Audio(output.audios[0], rate=22050))
# Make a longer sample by passing in a starting noise tensor with a different shape
noise = torch.randn(1, 1, pipe.unet.sample_size[0], pipe.unet.sample_size[1]*4).to(device)
output = pipe(noise=noise)
display(output.images[0])
display(Audio(output.audios[0], rate=22050))<jupyter_output><empty_output><jupyter_text>Not the most amazing-sounding outputs, but it's a start :) Explore tweaking the learning rate and number of epochs, and share your best results on Discord so we can improve together! Some things to consider:- We're working with 256px square spectrogram images which limits our batch size. Can you recover audio of sufficient quality from a 128x128 spectrogram?- In place of random image augmentation we're picking different slices of the audio clip each time, but could this be improved with some different kinds of augmentation when training for many epochs?- How else might we use this to generate longer clips? Perhaps you could generate a 5s starting clip and then use inpainting-inspired ideas to continue to generate additional segments of audio that follow on from the initial clip...- What is the equivalent of image-to-image in this spectrogram diffusion context? Push to HubOnce you're happy with your model, you can save it and push it to the hub for others to enjoy:<jupyter_code>from huggingface_hub import get_full_repo_name, HfApi, create_repo, ModelCard
# Pick a name for the model
model_name = "audio-diffusion-electronic"
hub_model_id = get_full_repo_name(model_name)
# Save the pipeline locally
pipe.save_pretrained(model_name)
# Inspect the folder contents
!ls {model_name}
# Create a repository
create_repo(hub_model_id)
# Upload the files
api = HfApi()
api.upload_folder(
folder_path=f"{model_name}/scheduler", path_in_repo="scheduler", repo_id=hub_model_id
)
api.upload_folder(
folder_path=f"{model_name}/mel", path_in_repo="mel", repo_id=hub_model_id
)
api.upload_folder(folder_path=f"{model_name}/unet", path_in_repo="unet", repo_id=hub_model_id)
api.upload_file(
path_or_fileobj=f"{model_name}/model_index.json",
path_in_repo="model_index.json",
repo_id=hub_model_id,
)
# Push a model card
content = f"""
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-audio-generation
- diffusion-models-class
---
# Model Card for Unit 4 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional audio generation of music in the genre {chosen_genre}
## Usage
<pre>
from IPython.display import Audio
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("{hub_model_id}")
output = pipe()
display(output.images[0])
display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
</pre>
"""
card = ModelCard(content)
card.push_to_hub(hub_model_id)<jupyter_output><empty_output> | diffusion-models-class/unit4/02_diffusion_for_audio.ipynb/0 | {
"file_path": "diffusion-models-class/unit4/02_diffusion_for_audio.ipynb",
"repo_id": "diffusion-models-class",
"token_count": 4592
} | 273 |
## Training Distil-Whisper
This sub-folder contains all the scripts required to train a Distil-Whisper model in your choice of language. They are
slightly modified from the original scripts used to distill Whisper for English ASR (as-per the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430)).
The main difference is that these scripts are written in [PyTorch](https://pytorch.org), whereas the original scripts
are in [JAX](https://jax.readthedocs.io/en/latest/#)/[Flax](https://flax.readthedocs.io/en/latest/). These scripts are
also made to be easier to run end-to-end, whereas the original scripts require more steps and are somewhat hard-coded
for English ASR. Both sets of scripts achieve equivalent downstream results when the hyper-parameters are set equal.
If you are interested in reproducing the original Distil-Whisper checkpoints, we refer you to the sub-folder [Flax Training](./flax/README.md).
Otherwise, if you wish to distill Whisper on your own language/dataset, we recommend you use these scripts for ease of use
and the configurability they provide.
Reproducing the Distil-Whisper project requires four stages to be completed in successive order:
1. [Pseudo-labelling](#1-pseudo-labelling)
2. [Initialisation](#2-initialisation)
3. [Training](#3-training)
4. [Evaluation](#4-evaluation)
This README is partitioned according to the four stages. Each section provides a minimal example for running the
scripts used in the project. We will use a running example of distilling the Whisper model for Hindi speech recognition
on the Common Voice dataset. Note that this dataset only contains ~20 hours of audio data. Thus, it can be run extremely
quickly, but does not provide sufficient data to achieve optimal performance. We recommend training on upwards of 1000
hours of data should you want to match the performance of Whisper on high-resource languages.
## Requirements
The Distil-Whisper training code is written in [PyTorch](https://pytorch.org) and [Accelerate](https://huggingface.co/docs/accelerate/index).
It heavily leverages the Whisper implementation in [🤗 Transformers](https://github.com/huggingface/transformers) for both
training and inference.
The instructions for installing the package are as follows:
1. Install PyTorch from the [official instructions](https://pytorch.org/get-started/locally/), ensuring you install the correct version for your hardware and CUDA version.
2. Fork the `distil-whisper` repository by clicking on the [fork](https://github.com/huggingface/distil-whisper/fork) button on the reopsitory's page
3. Clone the `distil-whisper` repository and add the base repository as a remote. This will allow you to "pull" any upstream changes that are made to the base repository:
```bash
git clone https://github.com/<your GitHub handle>/distil-whisper.git
cd distil-whisper
git remote add upstream https://github.com/huggingface/distil-whisper.git
```
4. pip install the required packages from the [setup.py](./setup.py) file:
```bash
cd training
pip install -e .
cd ../..
```
5. Configure Accelerate by running the following command. Note that you should set the number of GPUs you wish to use for distillation, and also the data type (dtype) to your preferred dtype for training/inference (e.g. `bfloat16` on A100 GPUs, `float16` on V100 GPUs, etc.):
```bash
accelerate config
```
6. The last thing we need to do is link our Hugging Face account so that we can pull/push model repositories on the Hub. This will allow us to save our final distilled weights on the Hub so that we can share them with the community. Run the command:
```bash
git config --global credential.helper store
huggingface-cli login
```
And then enter an authentication token from https://huggingface.co/settings/tokens. Create a new token if you do not have one already. You should make sure that this token has "write" privileges.
To confirm that you have a working environment, first accept the terms of use of the Common Voice 16.1 dataset on the Hub: https://huggingface.co/datasets/mozilla-foundation/common_voice_16_1
You can run the following code cell to stream one sample of data from the Common Voice dataset, and check that you can
perform inference using the "tiny" Whisper model:
```python
from transformers import WhisperProcessor, WhisperForConditionalGeneration
from datasets import load_dataset, Audio
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny", low_cpu_mem_usage=True)
processor = WhisperProcessor.from_pretrained("openai/whisper-tiny")
model.to("cuda")
common_voice = load_dataset("mozilla-foundation/common_voice_16_1", "en", split="validation", streaming=True)
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=processor.feature_extractor.sampling_rate))
inputs = processor(next(iter(common_voice))["audio"]["array"], sampling_rate=16000, return_tensors="pt")
input_features = inputs.input_features
generated_ids = model.generate(input_features.to("cuda"), max_new_tokens=128)
pred_text = processor.decode(generated_ids[0], skip_special_tokens=True)
print("Pred text:", pred_text)
print("Environment set up successful?", generated_ids.shape[-1] == 20)
```
## 1. Pseudo-Labelling
The python script [`run_pseudo_labelling.py`](run_pseudo_labelling.py) is a flexible inference script that can be used
to generate pseudo-labels under a range of settings, including using both greedy and beam-search. It is also compatible
with [🤗 Datasets](https://github.com/huggingface/datasets) *streaming mode*, allowing users to load massive audio
datasets with **no disk space requirements**. For more information on streaming mode, the reader is referred to the
blog post: [A Complete Guide to Audio Datasets](https://huggingface.co/blog/audio-datasets#streaming-mode-the-silver-bullet).
> As of the latest Distil-Whisper release, [`distil-large-v3`](https://huggingface.co/distil-whisper/distil-large-v3), this
pseudo-labelling script also performs the added operation of concatenating (or packing) the audio inputs to 30-seconds.
Not only does this lead to a WER improvement when using sequential long-form decoding algorithm, but concatenating audios
to 30-seconds also improves the throughput during training, since the amount of zero-padding on the audio inputs is minimised.
The following script demonstrates how to pseudo-label the Hindi split of the Common Voice 16.1 dataset with greedy sampling:
```bash
#!/usr/bin/env bash
accelerate launch run_pseudo_labelling.py \
--model_name_or_path "openai/whisper-large-v3" \
--dataset_name "mozilla-foundation/common_voice_16_1" \
--dataset_config_name "hi" \
--dataset_split_name "train+validation+test" \
--text_column_name "sentence" \
--id_column_name "path" \
--output_dir "./common_voice_16_1_hi_pseudo_labelled" \
--wandb_project "distil-whisper-labelling" \
--per_device_eval_batch_size 64 \
--dtype "bfloat16" \
--attn_implementation "sdpa" \
--logging_steps 500 \
--max_label_length 256 \
--concatenate_audio \
--preprocessing_batch_size 500 \
--preprocessing_num_workers 8 \
--dataloader_num_workers 8 \
--report_to "wandb" \
--language "hi" \
--task "transcribe" \
--return_timestamps \
--streaming False \
--generation_num_beams 1 \
--push_to_hub
```
On an 80 GB A100 GPU, the following script takes approximately 5 minutes to concatenate and pre-process the 20 hours of
audio data, and a further 10 minutes to transcribe the pseudo-labels. The pseudo-labelled dataset corresponding to this
script is available on the Hugging Face Hub under [sanchit-gandhi/common_voice_16_1_hi_pseudo_labelled](https://huggingface.co/datasets/sanchit-gandhi/common_voice_16_1_hi_pseudo_labelled).
The WER of the pre-trained Whisper large-v3 model is 17.2% on the test split. We will compare the performance of our distilled model against this number.
There are two noteworthy arguments that configure the dataset concatenation (or packing) process:
1. `concatenate_audio`: whether or not to concatenate (or pack) the audios to 30-second chunks. The latest Distil-Whisper model, [`distil-large-v3`](https://huggingface.co/distil-whisper/distil-large-v3#differences-with-distil-large-v2), highlights the WER improvements obtained using the sequential long-form decoding algorithm when concatenated audios are used. Concatenating audios to 30-seconds also improves the throughput during training, since the amount of zero-padding on the audio inputs is minimised. Hence, it is highly recommended to set `--concatenate_audio=True`.
2. `preprocessing_batch_size`: the batch size to use when concatenating (or packing) the audios. Using a larger batch size results in a greater portion of audio samples being packed to 30-seconds, at the expense of higher memory consumption. If you exceed your system's RAM when performing the concatenation operation, reduce the `preprocessing_batch_size` by a factor of 2 to 250 or even 125.
3. `preprocessing_num_workers`: the number of multiprocessing workers to use when concatenating the audios. Using more workers will result in faster pre-processing, at the expense of higher memory consumption. Ensure you do not exceed the maximum number of CPUs on your device.
In addition, the following arguments configure the inference of the Whisper model:
1. `language`: explicitly setting the language token during inference substantially improves the generation performance of the Whisper model, since the model is forced always to predict in the given language. We recommend you set the language to the language you wish to distil the Whisper model on. The only exception is when distilling an English-only model (i.e. where the model id is appended with an `.en`, e.g. `small.en`), the language argument should be set to None, since there is no language token used during training/inference.
2. `return_timestamps`: whether or not to predict timestamps in the pseudo-labels. Timestamp prediction is required should you want your distilled model to be able to predict timestamps at inference time (e.g. for the original OpenAI long-form transcription algorithm). However, the pseudo-labels are marginally less accurate than not using timestamps. We recommend pseudo-labelling **with** timestamps to ensure the distilled model is as general as possible.
3. `attn_implementation`: which attention implementation to use for inference. Set to `sdpa` for [PyTorch SDPA](https://huggingface.co/docs/transformers/v4.35.2/en/perf_infer_gpu_one#bettertransformer), or `flash_attn_2` if your hardware supports Flash Attention 2 and you have the [package installed](https://github.com/Dao-AILab/flash-attention).
4. `streaming`: whether or not to use Datasets' streaming mode. If enabled, the audio data will be streamed from the Hugging Face Hub with no disk space requirements. However, the user is then responsible for adding the pseudo-labels to the dataset script in a follow-up step (see [Using Streaming Mode](#TODO)). If set to `False`, the audio data will be downloaded and pre-processed offline. At the end of pseudo-labelling, the pseudo-labels will be automatically appended to the original dataset, meaning the dataset is ready to be used for the subsequent training step without any additional steps.
5. `generation_num_beams`: how many beams to use while decoding. In practice, we found the distilled model to perform comparably when the data was pseudo-labelled with `generation_num_beams=1` (greedy) or `generation_num_beams>1` (beam). This is likely because the WER filter compensates for the lower quality pseudo-labels obtained using greedy search. However, using `generation_num_beams=1` gives substantially faster inference time for the pseudo-labelling step, and so we recommend this configuration.
Should you have your own audio dataset, you can first [convert it](https://huggingface.co/docs/datasets/audio_dataset) to
Hugging Face Datasets format and push it to the Hugging Face Hub. You can then pseudo-label it using the script above,
replacing the `--dataset_name` with the name of your dataset on the Hub.
Otherwise, you may wish to use an open-source dataset already available on the Hugging Face Hub. We provide a summary of
the three most popular multilingual datasets in the table below. For more details, refer to the blog post: [A Complete Guide to Audio Datasets](https://huggingface.co/blog/audio-datasets#multilingual-speech-recognition).
| Dataset | Languages | Domain | Speaking Style | License | Text Column | ID Column |
|-----------------------------------------------------------------------------------------------|-----------|---------------------------------------|----------------|-----------|---------------------|--------------|
| [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) | 6 | Audiobooks | Narrated | CC-BY-4.0 | `"text"` | `"id"` |
| [Common Voice 16](https://huggingface.co/datasets/mozilla-foundation/common_voice_16_1) | 120 | Wikipedia text & crowd-sourced speech | Narrated | CC0-1.0 | `"sentence"` | `"path"` |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 15 | European Parliament recordings | Spontaneous | CC0 | `"normalized_text"` | `"audio_id"` |
To achieve *robustness* to different distributions of audio data, it is recommended to train on multiple datasets where possible.
For example, the above three datasets all have splits for the German language. Thus, if distilling a Whisper model for German,
it would be wise to use a combination of the three datasets during training, in order to cover at least three distinct domains
(audiobooks, crowd-sourced speech, parliament recordings). You may wish to use a combination of open-source datasets, or
a combination of open-source and individually owned datasets to cover multiple distributions and domains. Moreover, if you were to train on low-resource datasets (<500 hours), you could experiment with [language mixing](#3-language-mixing) to improve robustness.
## 2. Initialisation
The script [`create_student_model.py`](create_student_model.py) can be used to initialise a small student model
from a large teacher model. When initialising a student model with fewer layers than the teacher model, the student is
initialised by copying maximally spaced layers from the teacher, as per the [DistilBart](https://arxiv.org/abs/2010.13002)
recommendations.
First, we need to create a model repository on the Hugging Face Hub. This repository will contain all the required files
to reproduce the training run, alongside model weights, training logs and a README.md card. You can either create a model
repository directly on the Hugging Face Hub using the link: https://huggingface.co/new. Or, via the CLI, as we'll show here.
Let's pick a name for our distilled model: `distil-whisper-large-v3-hi`. We can run the following command to create a repository under this name:
```bash
huggingface-cli repo create distil-whisper-large-v3-hi
```
We can now see the model on the Hub, e.g. under https://huggingface.co/sanchit-gandhi/distil-whisper-large-v3-hi
Let's clone the repository so that we can place our training script and model weights inside:
```bash
git lfs install
git clone https://huggingface.co/sanchit-gandhi/distil-whisper-large-v3-hi
```
Be sure to change the repo address to `https://huggingface.co/<your-user-name>/<your-repo-name>`
We can now copy the relevant training scrips to the repository:
```bash
cd distil-whisper-large-v3-hi
cp ../distil-whisper/training/create_student_model.py .
cp ../distil-whisper/training/run_distillation.py .
```
The following command demonstrates how to initialise a student model from the Whisper [large-v3](https://huggingface.co/openai/whisper-large-v3)
checkpoint, with all 32 encoder layer and 2 decoder layers. The 2 student decoder layers are copied from teacher layers
1 and 32 respectively, as the maximally spaced layers:
```bash
#!/usr/bin/env bash
python create_student_model.py \
--teacher_checkpoint "openai/whisper-large-v3" \
--encoder_layers 32 \
--decoder_layers 2 \
--save_dir "./distil-large-v3-init"
```
The initialised model will be saved to the sub-directory `distil-large-v3-init` in our model repository.
**Note:** You can leverage language transfer by setting `--teacher_checkpoint` to "distil-whisper/distil-large-v3", see [language transfer](#22-language-transfer) for more details.
## 3. Training
The script [`run_distillation.py`](run_distillation.py) is an end-to-end script for loading multiple
datasets, a student model, a teacher model, and performing teacher-student distillation. It uses the loss formulation
from the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430), which is a weighted sum of the cross-entropy and
KL-divergence loss terms.
The following command takes the Common Voice dataset that was pseudo-labelled in the first stage and trains the
2-layer decoder model intialised in the previous step. We pass the local path to the pseudo-labelled Common Voice dataset
(`../common_voice_16_1_hi_pseudo_labelled`), which you can change to the path where your local pseudo-labelled dataset is
saved.
In this example, we will combine the train and validation splits to give our training set, and evaluate on the test split
only. This is purely to demonstrate how to combine multiple pseudo-labelled datasets for training, rather than recommended
advice for defining train/validation splits. We advise that you train on the train splits of your dataset, evaluate and
tune hyper-parameters on the validation split, and only test the final checkpoint on the test split. Note how multiple
training datasets and splits can be loaded by separating the dataset arguments by `+` symbols. Thus, the script generalises
to any number of training datasets.
```bash
#!/usr/bin/env bash
accelerate launch run_distillation.py \
--model_name_or_path "./distil-large-v3-init" \
--teacher_model_name_or_path "openai/whisper-large-v3" \
--train_dataset_name "../common_voice_16_1_hi_pseudo_labelled+../common_voice_16_1_hi_pseudo_labelled" \
--train_split_name "train+validation" \
--text_column_name "sentence+sentence" \
--train_dataset_samples "7+4" \
--eval_dataset_name "../common_voice_16_1_hi_pseudo_labelled" \
--eval_split_name "test" \
--eval_text_column_name "sentence" \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 50 \
--learning_rate 0.0001 \
--lr_scheduler_type "constant_with_warmup" \
--timestamp_probability 0.2 \
--condition_on_prev_probability 0.2 \
--language "hi" \
--task "transcribe" \
--logging_steps 25 \
--save_total_limit 1 \
--max_steps 5000 \
--wer_threshold 20 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--dataloader_num_workers 8 \
--preprocessing_num_workers 8 \
--ddp_timeout 7200 \
--dtype "bfloat16" \
--attn_implementation "sdpa" \
--output_dir "./" \
--do_train \
--do_eval \
--gradient_checkpointing \
--overwrite_output_dir \
--predict_with_generate \
--freeze_encoder \
--freeze_embed_positions \
--streaming False \
--push_to_hub
```
The above training script will take approximately 3 hours to complete on an 80 GB A100 GPU and yield a final WER of 76%.
While the generations are starting to take form, there is still a 59% WER gap to the teacher model. This is hardly
surprising give we only have 15 hours of un-filtered data, and closer to just 1.5 hours with data filtering.
As mentioned above, using upwards of 1000 hours of data and training for 10k steps will likely yield
more competitive performance. For the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430), we trained on 21k hours
of audio data for 80k steps. We found that upwards of 13k hours of audio data was required to reach convergence on English
ASR (see Section 9.2 of the [paper](https://arxiv.org/abs/2311.00430)), so the more data you have, the better!
Scaling to multiple GPUs using [distributed data parallelism (DDP)](https://pytorch.org/tutorials/beginner/ddp_series_theory.html)
is trivial: simply run `accelerate config` and select the multi-GPU option, specifying the IDs of the GPUs you wish to use. The
above script can then be run using DDP with no code changes.
Training logs will be reported to TensorBoard and WandB, provided the relevant packages are available. An example of a
saved checkpoint pushed to the Hugging Face Hub can be found here: [sanchit-gandhi/distil-whisper-large-v3-hi](https://huggingface.co/sanchit-gandhi/distil-whisper-large-v3-hi).
There are a few noteworthy data arguments:
1. `train_dataset_samples`: defines the number of training samples in each dataset. Used to calculate the sampling probabilities in the dataloader. A good starting point is setting the samples to the number of hours of audio data in each split. A more refined strategy is setting it to the number of training samples in each split, however this might require downloading the dataset offline to compute these statistics.
2. `wer_threshold`: sets the WER threshold between the normalised pseudo-labels and normalised ground truth labels. Any samples with WER > `wer_threshold` are discarded from the training data. This is beneficial to avoid training the student model on pseudo-labels where Whisper hallucinated or got the predictions grossly wrong. In our English distillation experiments, we found a WER threshold of 10% provides the optimal trade-off between ensuring high-quality transcriptions, and not filtering unnecessary amounts of training data. For multilingual distillation, the threshold should be set in accordance with the WER achieved by the pre-trained model on the test set.
3. `streaming`: whether or not to use Datasets' streaming mode. Recommended for large datasets, where the audio data can be streamed from the Hugging Face Hub with no disk space requirements.
4. `timestamp_probability`: the per-sample probability for retaining timestamp tokens in the labels (should they contain them). Retaining some portion of timestamp tokens in the training data is required to ensure the distilled model can predict timestamps at inference time. In our experiments, we found that training on timestamps with high-probability hurts the distilled model's transcription performance. Thus, we recommend setting this to a value below 0.5. Typically, a value of 0.2 works well, giving good transcription and timestamp performance.
5. `condition_on_prev_probability`: the per-sample probability for conditioning on previous labels. Conditioning on previous tokens is required to ensure the distilled model can be used with the "sequential" long-form transcription algorithm at inference time. We did not experiment with this parameter, but found values around 0.2 to provide adequate performance. OpenAI pre-trained Whisper on with a 50% probability for conditioning on previous tokens. Thus, you might wish to try higher values.
As well as a few noteworthy model arguments that can be configured to give optimal training performance:
1. `freeze_encoder`: whether to freeze the entire encoder of the student model during training. Beneficial when the student encoder is copied exactly from the teacher encoder. In this case, the encoder hidden-states from the teacher model are re-used for the student model. Stopping the gradient computation through the encoder and sharing the encoder hidden-states provides a significant memory saving, and can enable up to 2x batch sizes.
2. `freeze_embed_positions`: whether to freeze the student model's decoder positional embeddings. Using the same embed positions as the teacher model, which is designed to handle context lengths up to 448 tokens, helps the student model retain its input id representation up to the full max input length.
3. `dtype`: data type (dtype) in which the model computation should be performed. Note that this only controls the dtype of the computations (forward and backward pass), and not the dtype of the parameters or optimiser states.
4. `freeze_decoder`: whether to freeze the student model's decoder. Note that the input tokens embeddings and language modelling head will remain trainable.
And finally, a few noteworthy training arguments:
1. `max_steps`: defines the total number of optimisation steps (forward + backward pass) during training. To reach convergence, you should use a dataset of at least 1k hours and train for a minimum of 50k steps.
2. `lr_scheduler_stype`: defines the learning rate schedule, one of `constant_with_warmup` or `linear`. When experimenting with a training set-up or training for very few steps (< 5k), using `constant_with_warmup` is typically beneficial, since the learning rate remains high over the short training run. When performing long training runs (> 5k), using a `linear` schedule generally results in superior downstream performance of the distilled model.
TODO:
- [ ] Template for model cards
## 4. Evaluation
There are four types of evaluation performed in Distil-Whisper:
1. Short form: evaluation on audio samples less than 30s in duration. Examples include typical ASR test sets, such as the LibriSpeech validation set.
2. Sequential long form: evaluation on audio samples longer than 30s in duration using the original "sequential" long-form algorithm. Examples include entire TED talks or earnings calls.
3. Chunked long form: evaluation on audio samples longer than 30s in duration using the Transformers "chunked" long-form algorithm.
4. Speculative decoding: evaluation on audio samples less than 30s in duration, where a faster, distilled model is used as the assistant to a slower, teacher model.
All four forms of evaluation are performed using the script [`run_eval.py`](run_eval.py). Unlike the pseudo-labelling
and training scripts, the evaluation script assumes that only one GPU accelerator is used. We can copy the corresponding
evaluation script to the model repository using the following command:
```bash
cp ../distil-whisper/training/run_eval.py .
```
Models are assessed jointly using:
1. The *word-error rate (WER)* metric: measures the number of substitution, deletion and insertion errors relative to the total number of words. A lower WER indicates a more accurate model.
2. The *inverse real-time factor (RTFx)* metric: measures the ratio of `audio input time : model compute time`. A higher RTFx indicates a faster model. Note that this metric is WER-dependent, meaning that it makes sense to compare two models' *RTFx* only at fixed *WER* performances. Indeed, deletions could lead to early stopping of token generation, resulting in higher *WER* and lower *RTFx*.
3. Token generation speed: This refers to the number of tokens generated per second. As with *RTFx*, this metric is dependent on the *WER* since token generation time is not linear. By default, this metric is calculated by averaging the total number of `generated tokens : generation time` (full forward pass of the model) when evaluating on the given test set. However, using the `--precise_tok_generation` flag will compute this metric separately for a fixed number of tokens.
In all cases, it is particularly important to evaluate the final model on data that is *out-of-distribution (OOD)* with
the training data. Evaluating on OOD data provides insight as to how well the distilled model is likely to generalise to
different audio distributions at inference time. In our example, the Common Voice test set is *in-distribution (ID)*
with our training data, since it is taken from the same distribution as the Common Voice training set. Whereas the FLEURS
test set is OOD, since it is not used as part of the training set. See [Datasets](#1-datasets) section for recommendations.
### Short Form
The script [`run_eval.py`](run_eval.py) can be used to evaluate a trained student model over multiple short-form
validation sets. The following example demonstrates how to evaluate the student model trained in the previous step on
the Common Voice `test` set (ID) and also the FLEURS `test` set (OOD). Again, it leverages streaming mode to bypass
the need to download the data offline:
```bash
#!/usr/bin/env bash
python run_eval.py \
--model_name_or_path "./" \
--dataset_name "../common_voice_16_1_hi_pseudo_labelled+google/fleurs" \
--dataset_config_name "default+hi_in" \
--dataset_split_name "test+test" \
--text_column_name "sentence+transcription" \
--batch_size 16 \
--dtype "bfloat16" \
--generation_max_length 256 \
--language "hi" \
--attn_implementation "sdpa" \
--streaming
```
The student model achieves an average WER of TODO% with an RTFx of TODO for a batch size of 16. We can easily adapt the above
script to evaluate the teacher model, simply by switching the `model_name_or_path` to `openai/whisper-large-v3`, which
achieves an average WER of TODO% with an RTFx of TODO. Therefore, for a batch size of 16, the student model is a factor of TODO
times faster than the teacher. The WER gap can be closed by training on more data (at least 1k hours) for more training
steps (at least 50k).
### Sequential Long Form
The original Whisper paper presents a long-form transcription algorithm that sequentially transcribes 30-second segments
of audio and shifts the sliding window according to the timestamps predicted by the model. This style of sequential
inference is performed directly using the [`.generate`](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperForConditionalGeneration.generate)
method in Transformers.
The script [`run_eval.py`](run_eval.py) can be used to evaluate the trained student model on an arbitrary number of
long-form evaluation sets using the sequential algorithm. Since we don't have a long-form validation set for Hindi to hand,
in this example we'll evaluate the official Distil-Whisper model [`distil-large-v3`](https://huggingface.co/distil-whisper/distil-large-v3)
on the TED-LIUM validation set:
```bash
#!/usr/bin/env bash
accelerate launch run_eval.py \
--model_name_or_path "distil-whisper/distil-large-v3" \
--dataset_name "distil-whisper/tedlium-long-form" \
--dataset_config_name "default" \
--dataset_split_name "validation" \
--text_column_name "text" \
--batch_size 16 \
--dtype "bfloat16" \
--generation_max_length 256 \
--language "en" \
--attn_implementation "sdpa" \
--streaming
```
### Chunked Long Form
Chunked long form evaluation runs on the premise that a single long audio file can be *chunked* into smaller segments and
inferred in parallel. The resulting transcriptions are then joined at the boundaries to give the final text prediction.
A small overlap (or *stride*) is used between adjacent segments to ensure a continuous transcription across chunks.
This style of chunked inference is performed using the [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines)
class, which provides a wrapper around the [`.generate`](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperForConditionalGeneration.generate)
function for long-form inference.
The script [`run_eval.py`](run_eval.py) can be used to evaluate the trained student model on an arbitrary number of
long-form evaluation sets using the pipeline class. Again, in this example we'll evaluate distil-large-v3 on the
TED-LIUM validation set:
```bash
#!/usr/bin/env bash
python run_eval.py \
--model_name_or_path "openai/whisper-large-v3" \
--dataset_name "distil-whisper/tedlium-long-form" \
--dataset_config_name "default" \
--dataset_split_name "validation" \
--text_column_name "text" \
--use_pipeline \
--chunk_length_s 25.0 \
--language "en" \
--return_timestamps \
--dtype "bfloat16" \
--streaming
```
The argument `chunk_length_s` controls the length of the chunked audio samples. It should be set to match the typical
length of audio the student model was trained on. If unsure about what value of `chunk_length_s` is optimal for your case,
it is recommended to run a *sweep* over all possible values. A template script for running a [WandB sweep](https://docs.wandb.ai/guides/sweeps)
can be found under [`run_chunk_length_s_sweep.yaml`](flax/long_form_transcription_scripts/run_chunk_length_s_sweep.yaml).
### Speculative Decoding
Speculative decoding, or assisted generation, relies on the premise that a faster, assistant model can be used to speed-up
the generation of a slower, assistant model. Speculative decoding mathematically ensures that exactly the same outputs as
Whisper are obtained, while being ~2 times faster. This makes it the perfect drop-in replacement for existing Whisper
pipelines, since exactly the same outputs are guaranteed.
Distil-Whisper checkpoints can be designed to be efficient assistant models to Whisper for speculative decoding. More precisely,
by freezing the encoder during training, the distilled model can share the same encoder weights as Whisper during inference, since
the encoder weights are un-changed. In doing so, only the distilled 2-layer decoder has to be loaded in addition to the
original Whisper model, which is approximately an 8% increase to the total parameter count, with up to 2x faster inference
for low batch sizes. For more details on speculative decoding, the reader is advised to refer to the following blog post:
[Speculative Decoding for 2x Faster Whisper Inference](https://huggingface.co/blog/whisper-speculative-decoding).
In the example below, we use our distilled model as an assistant to the large-v3 teacher model during inference:
```bash
#!/usr/bin/env bash
python run_eval.py \
--model_name_or_path "openai/whisper-large-v3" \
--assistant_model_name_or_path "./" \
--dataset_name "../common_voice_16_1_hi_pseudo_labelled+google/fleurs" \
--dataset_config_name "default+hi_in" \
--dataset_split_name "test+test" \
--text_column_name "sentence+transcription" \
--batch_size 16 \
--dtype "bfloat16" \
--generation_max_length 256 \
--language "hi" \
--attn_implementation "sdpa" \
--streaming
```
We see that we achieve a WER of TODO%, the same as what we obtained with the large-v3 model, but with an RTFx of TODO,
a factor of TODO faster than using the large-v3 model alone. The RTFx value can be improved by training the student on
more data and for more training steps, since this will improve the number of predicted tokens that match the teacher
predictions.
## Recommendations and guidelines
### 1. Datasets
As explained, ideally, you should aim for ~1000 hours of audio data for training a distilled model via KD. Moreover, you should evaluate your model on out-of-distribution test sets to assess generalization capacities. With at least 1500 hours of audio data for German, Dutch, French and Spanish, 600 hours for Italian, and 300 hours for Portuguese and Polish (which can be supplemented with your own datasets), a good setup to start with is:
- **Training datasets:** [Common Voice 17](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0) and [Multilingual Librispeech](https://huggingface.co/datasets/facebook/multilingual_librispeech). Use the `train` split for training, and the `validation` and `test` splits for in-distribution testing.
- **Test datasets:** [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) and [Fleurs](https://huggingface.co/datasets/google/fleurs). Use the `validation` and `test` splits for out-of-distribution testing.
### 2. Student model's decoder
#### 2.1 Number of Decoder Layers
We recommend using a 2-layers decoder (see language transfer below). However, you can adjust the number of decoder layers when initializing the student model to balance between inference speed and accuracy. Experimentation has revealed that the Pareto optimal points are with 2, 3, and 4-layers decoders. For indicative results, after 10,000 training steps and inference on an 80GB Nvidia H100 with a batch size of 16 and 20 tokens generation, compared to [Whiper *large-v3*](https://huggingface.co/openai/whisper-large-v3) baseline:
<center>
| | rel. token gen. speed | ΔWER(%) |
|----------|:-------------:|------:|
| 2 layers | $3.66$ | $-3.5$ |
| 3 layers | $3.35$ | $-2.3$ |
| 4 layers | $3.11$ | $-1.8$ |
</center>
#### 2.2 Language Transfer
If you opt for a 2-layers decoder, consider leveraging language transfer by initializing the student model from the [distil-large-v3 English distilled model](https://huggingface.co/distil-whisper/distil-large-v3). For French, this method has shown performance improvements of ΔWER=-1.9% (compared to a 2-layers decoder initialized from [Whiper *large-v3*](https://huggingface.co/openai/whisper-large-v3)) after 10,000 training steps.
```diff
- --teacher_checkpoint "openai/whisper-large-v3" \
+ --teacher_checkpoint "distil-whisper/distil-large-v3" \
```
### 3. Language mixing
If you're working with low-resource languages (<500 hours of audio data), consider mixing your training data with a closely related language (for example, mix French and Spanish) to leverage knowledge transfer between languages. Experiments showed that mixing ~400 hours of French (which resulted in a model with poor generalization capacities) with ~500 hours of Spanish improved the model's out-of-distribution performance on French by ΔWER=-7.5%.
To do this:
1. Run [pseudo labeling](#1-pseudo-labelling) for each training dataset, setting the `--language` flag to the language of the respective dataset. In the example of mixing French and Spanish, simply modify the given [pseudo labeling](#1-pseudo-labelling) command with:
* pseudo labelling the French dataset
```diff
- --dataset_config_name "hi" \
- --output_dir "./common_voice_16_1_hi_pseudo_labelled" \
- --language "hi" \
+ --dataset_config_name "fr" \
+ --output_dir "./common_voice_16_1_fr_pseudo_labelled" \
+ --language "fr" \
```
* pseudo labelling the Spanish dataset
```diff
- --dataset_config_name "hi" \
- --output_dir "./common_voice_16_1_hi_pseudo_labelled" \
- --language "hi" \
+ --dataset_config_name "es" \
+ --output_dir "./common_voice_16_1_es_pseudo_labelled" \
+ --language "es" \
```
2. Conduct [training](#3-training) on these pseudo-labeled datasets, using the `--language` flag set to your targeted language. Note that this flag is only used for evaluation purposes, so you set it to the targeted language. The language token used for forwarding the teacher and student model decoders is the one used and saved in pseudo labels during pseudo-labeling, ensuring it's the correct one for the considered sample. In the example of mixing French and Spanish, simply modify the given [training](#1-pseudo-labelling) command with:
```diff
- --train_dataset_name "../common_voice_16_1_hi_pseudo_labelled+../common_voice_16_1_hi_pseudo_labelled" \
- --train_split_name "train+validation" \
- --eval_dataset_name "../common_voice_16_1_hi_pseudo_labelled" \
- --eval_split_name "test" \
+ --train_dataset_name "../common_voice_17_0_fr_pseudo_labelled+../common_voice_17_0_es_pseudo_labelled" \
+ --train_split_name "train+train" \
+ --eval_dataset_name "../common_voice_16_1_fr_pseudo_labelled" \
+ --eval_split_name "validation" \
```
## Overview of Training Methods
### 1. Fine-Tuning
For fine-tuning, we take the original Whisper checkpoint and train it on one or more datasets using the standard
cross-entropy loss. As such, there is no involvement from the teacher checkpoint during training, and so the fine-tuned
model is permitted to *overfit* to the distribution of the training data we provide. This makes it appealing for "low-resource"
languages where the original Whisper model performs poorly, since we can boost the performance of the model on a single
language by *overfitting* to that distribution of data. Note that this means the fine-tuned model is prone to loosing
its robustness to different audio distributions, which is the trade-off with improving performance on a specified dataset.
As a rule of thumb, fine-tuning is appropriate for languages where the original Whisper model performs > 20% WER, and we
have a relatively small quantity of training data available (< 1000 hours). With fine-tuning, we require as little as **10 hours**
of training data to significantly boost the performance of the Whisper model. For an in-depth guide to fine-tuning Whisper,
the reader is advised to refer to the blog post: [Fine-Tune Whisper For Multilingual ASR with 🤗 Transformers](https://huggingface.co/blog/fine-tune-whisper).
### 2. Shrink and Fine-Tune
Shrink and fine-tune (SFT) is a knowledge distillation (KD) technique in which we first *shrink* the teacher model to a
smaller student model by copying maximally spaced layers, and then *fine-tune* the student model on the cross-entropy loss
as described above. Typically, we retain the full encoder from the Whisper model and only shrink the decoder. Retaining
the entire encoder helps significantly with maintaining Whisper's robustness to different audio distributions (_c.f._
Section 9.3 of the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430)).
We can either train the student model on a dataset of (audio, text) pairs as above. Or, we can use the pre-trained
Whisper model to generate *pseudo-labels* for our audio data, and train on the (audio, pseudo-label) pairs.
Pseudo-labels can be used when either:
1. The original text transcriptions are normalised (lower-cased or no punctuation): the Whisper generated pseudo-labels contain both punctuation and casing, and so can be used as a substitute for the normalised transcriptions
2. The pre-trained Whisper model achieves < 20% WER on the languages: we then know the majority of the pseudo-labels will be accurate enough for us to train on.
They are not recommended when both of the following are true:
1. The original text is punctuated and cased
2. The pre-trained Whisper model achieves > 20% WER on the languages: in this case, we want to overfit to the particular distribution of the language, and so train directly on the original text data
To discard inaccurate pseudo-labels during training, we employ a simple WER heuristic to filter our pseudo-labelled
training data. We first normalise the original text and the pseudo-labelled text using the Whisper normaliser. If the
WER between the normalised text exceeds a 10% WER threshold, we discard the training sample. Else, we retain it for training.
Section 9.1 of the Distil-Whisper [paper](https://arxiv.org/abs/2311.00430) demonstrates the importance of using this
threshold for training.
### 3. KL Divergence
In the KL Divergence setting, the student model is initialised by shrinking the teacher as before, and then trained to
match the predictions of the teacher during training.
### Summary of Methods
The following table summarises the two training paradigms: fine-tuning and knowledge distillation (KD). It suggests
minimum values for the pre-trained WER / training data to achieve reasonable performance:
| Method | Pre-Trained WER / % | Training Data / h |
|-------------|---------------------|-------------------|
| Fine-tuning | > 20 | < 1000 |
| KD | < 20 | > 1000 |
## Acknowledgements
* OpenAI for the Whisper [model](https://huggingface.co/openai/whisper-large-v3) and [original codebase](https://github.com/openai/whisper)
* Hugging Face 🤗 [Transformers](https://github.com/huggingface/transformers) for the Whisper model implementation
* Google's [TPU Research Cloud (TRC)](https://sites.research.google/trc/about/) program for Cloud TPU v4s used to train the official Distil-Whisper models
* The Hugging Face 🤗 cluster for enabling experimentation with the PyTorch scripts
## Citation
If you use this code-base, please consider citing the Distil-Whisper paper:
```
@misc{gandhi2023distilwhisper,
title={Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling},
author={Sanchit Gandhi and Patrick von Platen and Alexander M. Rush},
year={2023},
eprint={2311.00430},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| distil-whisper/training/README.md/0 | {
"file_path": "distil-whisper/training/README.md",
"repo_id": "distil-whisper",
"token_count": 12816
} | 274 |
#!/usr/bin/env bash
python run_distillation.py \
--model_name_or_path "distil-whisper/tiny-random-whisper-2-1" \
--teacher_model_name_or_path "distil-whisper/tiny-random-whisper" \
--train_dataset_name "distil-whisper/librispeech_asr+distil-whisper/librispeech_asr-timestamped" \
--train_dataset_config_name "all+all" \
--train_dataset_samples "100+360" \
--train_split_name "train.clean.100+train.clean.360" \
--eval_dataset_name "distil-whisper/gigaspeech-l+esb/diagnostic-dataset" \
--eval_dataset_config_name "l+librispeech" \
--eval_split_name "validation+clean" \
--eval_text_column_name "text+ortho_transcript" \
--max_train_samples 1024 \
--max_eval_samples 32 \
--cache_dir "/home/sanchitgandhi/.cache" \
--dataset_cache_dir "/home/sanchitgandhi/.cache" \
--wandb_dir "/home/sanchitgandhi/.cache" \
--output_dir "./" \
--do_train \
--do_eval \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--max_steps 10 \
--eval_steps 5 \
--dataloader_num_workers 14 \
--save_steps 5 \
--wer_threshold 10 \
--wandb_project "distil-whisper-debug" \
--logging_steps 1 \
--use_scan \
--gradient_checkpointing \
--overwrite_output_dir \
--predict_with_generate \
--return_timestamps \
--timestamp_probability 1 \
--freeze_encoder
| distil-whisper/training/flax/distillation_scripts/run_librispeech_streaming_dummy.sh/0 | {
"file_path": "distil-whisper/training/flax/distillation_scripts/run_librispeech_streaming_dummy.sh",
"repo_id": "distil-whisper",
"token_count": 552
} | 275 |
command:
- python3
- ${program}
- --do_train
- --do_eval
- --use_scan
- --gradient_checkpointing
- --overwrite_output_dir
- --predict_with_generate
- ${args}
method: random
metric:
goal: minimize
name: eval/wer
parameters:
model_name_or_path:
value: distil-whisper/large-32-2
dataset_name:
value: distil-whisper/librispeech_asr
dataset_config_name:
value: all
train_split_name:
value: train.clean.100+train.clean.360+train.other.500
eval_split_name:
value: validation.clean
text_column_name:
value: whisper_transcript
cache_dir:
value: /home/sanchitgandhi/cache
dataset_cache_dir:
value: /home/sanchitgandhi/cache
output_dir:
value: ./
per_device_train_batch_size:
value: 32
per_device_eval_batch_size:
value: 16
dtype:
value: bfloat16
learning_rate:
distribution: log_uniform
max: -6.91
min: -11.51
warmup_steps:
value 500
num_train_epochs:
value: 1
preprocessing_num_workers:
value: 16
dataloader_num_workers:
value: 16
logging_steps:
value: 25
freeze_encoder:
values:
- True
- False
program: run_finetuning.py
project: distil-whisper
| distil-whisper/training/flax/finetuning_scripts/run_librispeech_sweep.yaml/0 | {
"file_path": "distil-whisper/training/flax/finetuning_scripts/run_librispeech_sweep.yaml",
"repo_id": "distil-whisper",
"token_count": 505
} | 276 |
command:
- python3
- ${program}
- --streaming
- --do_sample
- ${args}
method: grid
metric:
goal: minimize
name: tedlium-long-form/validation/wer
parameters:
model_name_or_path:
value: sanchit-gandhi/large-32-2-ts-freeze-28k-wer-10
subfolder:
value: checkpoint-15000
dataset_name:
value: distil-whisper/tedlium-long-form
dataset_config_name:
value: all
dataset_split_name:
value: validation
cache_dir:
value: /home/sanchitgandhi/.cache
dataset_cache_dir:
value: /home/sanchitgandhi/.cache
output_dir:
value: ./
wandb_dir:
value: /home/sanchitgandhi/.cache
per_device_eval_batch_size:
value: 32
dtype:
value: bfloat16
report_to:
value: wandb
generation_num_beams:
value: 1
generation_max_length:
value: 256
temperature:
values:
- 0.2
- 0.4
- 0.6
- 0.8
- 1.0
- 1.2
chunk_length_s:
value: 20
program: run_long_form_transcription.py
project: distil-whisper-long-form | distil-whisper/training/flax/long_form_transcription_scripts/run_top_k_temperature_sweep.yaml/0 | {
"file_path": "distil-whisper/training/flax/long_form_transcription_scripts/run_top_k_temperature_sweep.yaml",
"repo_id": "distil-whisper",
"token_count": 451
} | 277 |
[tool.black]
line-length = 119
target-version = ['py37']
[tool.ruff]
# Never enforce `E501` (line length violations).
ignore = ["C901", "E501", "E741", "W605"]
select = ["C", "E", "F", "I", "W"]
line-length = 119
# Ignore import violations in all `__init__.py` files.
[tool.ruff.per-file-ignores]
"__init__.py" = ["E402", "F401", "F403", "F811"]
[tool.ruff.isort]
lines-after-imports = 2
known-first-party = ["distil_whisper"] | distil-whisper/training/flax/pyproject.toml/0 | {
"file_path": "distil-whisper/training/flax/pyproject.toml",
"repo_id": "distil-whisper",
"token_count": 174
} | 278 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Evaluating a Whisper model on one or more speech recognition datasets.
"""
# You can also adapt this script for your own speech recognition validation. Pointers for this are left as comments.
import json
import logging
import os
import sys
import tempfile
import time
from dataclasses import dataclass, field
from typing import Optional
import datasets
import evaluate
import numpy as np
import torch
import transformers
from datasets import DatasetDict, IterableDatasetDict, load_dataset
from tqdm import tqdm
from transformers import (
HfArgumentParser,
WhisperForConditionalGeneration,
WhisperProcessor,
is_wandb_available,
pipeline,
set_seed,
)
from transformers.models.whisper.english_normalizer import EnglishTextNormalizer, BasicTextNormalizer
from transformers.models.whisper.modeling_whisper import WhisperForCausalLM
from transformers.utils import check_min_version, is_accelerate_available
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.34.0.dev0")
require_version("datasets>=2.14.6", "To fix: `pip install --upgrade datasets`")
logger = logging.getLogger(__name__)
PIPELINE_BATCH_SIZE = 16
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: str = field(
default=None,
metadata={
"help": "The name of the dataset to use (via the datasets library). Load and combine "
"multiple datasets by separating dataset hours by a '+' symbol."
},
)
model_name_or_path: str = field(
default=None,
metadata={"help": "The name of the model to use (via the transformers library). "},
)
subfolder: str = field(
default="",
metadata={"help": "If specified load weights from a subfolder in the model repository"},
)
model_variant: str = field(
default=None,
metadata={"help": "If specified load weights from `variant` filename, *e.g.* pytorch_model.<variant>.bin. "},
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
)
assistant_model_name_or_path: str = field(
default=None,
metadata={
"help": "The name of the assistant model to use to do speculative decoding. If None, no speculative decoding will be done."
},
)
dtype: Optional[str] = field(
default="float16",
metadata={
"help": (
"Floating-point format in which the model weights should be initialized"
" and the computations run. Choose one of `[float32, float16, bfloat16]`."
)
},
)
use_pipeline: bool = field(
default=False,
metadata={"help": "Whether to evaluate with Transformers pipeline"},
)
chunk_length_s: float = field(
default=30.0, metadata={"help": "Chunk length to use when `use_pipeline` is enabled."}
)
return_timestamps: bool = field(
default=True,
metadata={
"help": "Whether to decode with timestamps. This can help for improved WER for long form evaluation."
},
)
language: str = field(
default=None,
metadata={
"help": (
"Language for multilingual evaluation. This argument should be set for multilingual evaluation "
"only. For English speech recognition, it should be left as `None`."
)
},
)
task: str = field(
default="transcribe",
metadata={
"help": "Task, either `transcribe` for speech recognition or `translate` for speech translation."
"This argument should be set for multilingual evaluation only. For English speech recognition, it should be left as `None`."
},
)
attn_implementation: Optional[str] = field(
default=None,
metadata={"help": "Which attn type to use: ['eager', 'sdpa', 'flash_attention_2']"},
)
batch_size: int = field(
default=1,
metadata={"help": "The batch size to be used for generation."},
)
num_beams: int = field(
default=1,
metadata={"help": "The beam size to be used for evaluation. Set to 1 for greedy, or >1 for beam search."},
)
temperature_fallback: bool = field(
default=True,
metadata={"help": "Whether to use temperature fallback for evaluation."},
)
logprob_threshold: float = field(
default=-1.0,
metadata={"help": "Whether to use temperature fallback for evaluation."},
)
no_speech_threshold: float = field(
default=0.6,
metadata={
"help": "Only relevant for long-form transcription. If defined, the 'no-speech' token combined with the `logprob_threshold`"
"is used to determine whether a segment contains only silence. In this case, the transcription for this segment"
"is skipped."
},
)
compression_ratio_threshold: float = field(
default=1.35,
metadata={
"help": "Only relevant for long-form transcription. If defined, the zlib compression rate of each segment will be computed. If the compression rate of"
"a segment is higher than `compression_ratio_threshold`, temperature fallback is activated: the generated segment is discarded and the generation is"
"repeated using a higher temperature. The intuition behind this feature is that segments with very high compression rates"
"suffer from a lot of repetition. The unwanted repetition can be reduced by injecting more randomness by increasing the temperature. "
"If `compression_ratio_threshold` is defined make sure that `temperature` is a list of values. The default value for `compression_ratio_threshold` is 1.35."
},
)
condition_on_prev_tokens: bool = field(
default=False,
metadata={"help": "Whether to condition on previous tokens or not"},
)
samples_per_dataset: Optional[int] = field(
default=None,
metadata={"help": "Number of samples per dataset used to measure speed."},
)
dataset_config_name: Optional[str] = field(
default=None,
metadata={"help": "The configuration name of the dataset to use (via the datasets library)."},
)
dataset_split_name: Optional[str] = field(
default=None,
metadata={"help": "The split name of the dataset to use (via the datasets library)."},
)
dataset_cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Path to cache directory for saving and loading datasets"},
)
overwrite_cache: bool = field(
default=False,
metadata={"help": "Overwrite the cached training and evaluation sets"},
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
audio_column_name: str = field(
default="audio",
metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
)
text_column_name: str = field(
default=None,
metadata={"help": "The name of the dataset column containing the text data. Defaults to `text`."},
)
generation_max_length: int = field(
default=256, metadata={"help": "Generate up until `generation_max_length` tokens."}
)
log_predictions: Optional[bool] = field(
default=True,
metadata={"help": "Whether or not to log the ground truths / pred text to the wandb logger."},
)
preprocessing_only: bool = field(
default=False,
metadata={
"help": (
"Whether to only do data preprocessing and skip training. This is"
" especially useful when data preprocessing errors out in distributed"
" training due to timeout. In this case, one should run the"
" preprocessing in a non-distributed setup with"
" `preprocessing_only=True` so that the cached datasets can"
" consequently be loaded in distributed training"
)
},
)
wandb_project: str = field(
default="distil-whisper-speed-benchmark",
metadata={"help": "The name of the wandb project."},
)
wandb_name: str = field(
default=None,
metadata={"help": "The name of the wandb run."},
)
wandb_job_type: str = field(
default="distil-whisper",
metadata={"help": "The name of the wandb job type."},
)
wandb_dir: str = field(
default=None,
metadata={"help": "The absolute path to save the wandb logs."},
)
save_code_to_wandb: bool = field(
default=False,
metadata={
"help": (
"Whether to save main script to wandb. This is valuable for improving"
" experiment reproducibility and to diff code across experiments in"
" the UI."
)
},
)
streaming: bool = field(
default=True,
metadata={"help": "Whether to use Datasets' streaming mode to load and the data."},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={"help": "For debugging purposes, truncate the number of eval examples to this value if set."},
)
seed: int = field(default=42, metadata={"help": "RNG seed for reproducibility."})
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
prompt_text: str = field(
default=None,
metadata={
"help": "Text prompt to condition the generation on. Useful for controlling the style of transcription and predicting named entities."
},
)
def write_metric(summary_writer, eval_metrics, step, prefix="eval"):
for metric_name, value in eval_metrics.items():
summary_writer.scalar(f"{prefix}/{metric_name}", value, step)
def write_wandb_metric(wandb_logger, metrics, prefix):
log_metrics = {}
for k, v in metrics.items():
log_metrics[f"{prefix}/{k}"] = v
wandb_logger.log(log_metrics)
def write_wandb_pred(
wandb_logger,
pred_str,
label_str,
norm_pred_str,
norm_label_str,
wer_per_sample,
prefix="eval",
):
columns = ["WER", "Target", "Pred", "Norm Target", "Norm Pred"]
# convert str data to a wandb compatible format
str_data = [
[wer_per_sample[i], label_str[i], pred_str[i], norm_label_str[i], norm_pred_str[i]]
for i in range(len(pred_str))
]
# log as a table with the appropriate headers
wandb_logger.log(
{f"{prefix}/predictions": wandb_logger.Table(columns=columns, data=str_data)},
)
def convert_dataset_str_to_list(
dataset_names, dataset_config_names, splits=None, text_column_names=None, dataset_hours=None, default_split="train"
):
if isinstance(dataset_names, str):
dataset_names = dataset_names.split("+")
# we assume that all the datasets we're using derive from the distil-whisper org on the Hub - prepend the org name if necessary
for i in range(len(dataset_names)):
ds_name = dataset_names[i]
dataset_names[i] = f"distil-whisper/{ds_name}" if "/" not in ds_name else ds_name
dataset_config_names = dataset_config_names.split("+") if dataset_config_names is not None else None
splits = splits.split("+") if splits is not None else None
text_column_names = text_column_names.split("+") if text_column_names is not None else None
dataset_hours = dataset_hours.split("+") if dataset_hours is not None else None
# basic checks to ensure we've got the right number of datasets/configs/splits/columns/probs
if dataset_config_names is not None and len(dataset_names) != len(dataset_config_names):
raise ValueError(
f"Ensure one config is passed for each dataset, got {len(dataset_names)} datasets and"
f" {len(dataset_config_names)} configs."
)
if splits is not None and len(splits) != len(dataset_names):
raise ValueError(
f"Ensure one split is passed for each dataset, got {len(dataset_names)} datasets and {len(splits)} splits."
)
if text_column_names is not None and len(text_column_names) != len(dataset_names):
raise ValueError(
f"Ensure one text column name is passed for each dataset, got {len(dataset_names)} datasets and"
f" {len(text_column_names)} text column names."
)
if dataset_hours is not None:
if len(dataset_hours) != len(dataset_names):
raise ValueError(
f"Ensure one probability is passed for each dataset, got {len(dataset_names)} datasets and "
f"{len(dataset_hours)} hours."
)
dataset_hours = [float(ds_hours) for ds_hours in dataset_hours]
else:
dataset_hours = [None] * len(dataset_names)
dataset_config_names = (
dataset_config_names if dataset_config_names is not None else ["default" for _ in range(len(dataset_names))]
)
text_column_names = (
text_column_names if text_column_names is not None else ["text" for _ in range(len(dataset_names))]
)
splits = splits if splits is not None else [default_split for _ in range(len(dataset_names))]
dataset_names_dict = []
for i, ds_name in enumerate(dataset_names):
dataset_names_dict.append(
{
"name": ds_name,
"config": dataset_config_names[i],
"split": splits[i],
"text_column_name": text_column_names[i],
"hours": dataset_hours[i],
}
)
return dataset_names_dict
def main():
# 1. Parse input arguments
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser([DataTrainingArguments])
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
data_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))[0]
else:
data_args = parser.parse_args_into_dataclasses()[0]
# 2. Setup logging
# Make one log on every process with the configuration for debugging.
logger.setLevel(logging.INFO)
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
# 3. Set seed for reproducibility
set_seed(data_args.seed)
if data_args.use_pipeline and data_args.batch_size > 1:
raise ValueError("Make sure that `batch_size` is set to 1 when `use_pipeline=True`.")
has_wandb = is_wandb_available()
if has_wandb:
import wandb
import wandb as wandb_logger
# store generation HPs for runs
generation_arguments = {
"torch_version": str(torch.__version__),
"transformers_version": str(transformers.__version__),
"attn_implementation": data_args.attn_implementation,
"model_name_or_path": data_args.model_name_or_path,
"subfolder": data_args.subfolder,
"assistant_model_name_or_path": data_args.assistant_model_name_or_path,
"seed": data_args.seed,
"batch_size": data_args.batch_size,
"num_beams": data_args.num_beams,
"return_timestamps": data_args.return_timestamps,
"condition_on_prev_tokens": data_args.condition_on_prev_tokens,
"temperature_fallback": data_args.temperature_fallback,
"logprob_threshold": data_args.logprob_threshold,
"no_speech_threshold": data_args.no_speech_threshold,
"use_pipeline": data_args.use_pipeline,
"chunk_length_s": data_args.chunk_length_s,
}
# Set up wandb run
wandb_logger.init(
project=data_args.wandb_project,
name=data_args.wandb_name,
job_type=data_args.wandb_job_type,
dir=data_args.wandb_dir,
save_code=data_args.save_code_to_wandb,
config=generation_arguments,
)
else:
raise ValueError("Wandb logging requires wandb to be installed. Run `pip install wandb` to enable.")
# 3. Load dataset
raw_datasets = IterableDatasetDict()
# Convert lists of dataset names/configs/splits to a dict
# names: "librispeech_asr+gigaspeech", configs: "all+l", splits: "validation.clean+validation"
# -> [{"name: "librispeech_asr": "config": "all", "split": "validation.clean"}, {"name: "gigaspeech": "config": "l", "split": "validation"}
dataset_names_dict = convert_dataset_str_to_list(
data_args.dataset_name,
data_args.dataset_config_name,
splits=data_args.dataset_split_name,
text_column_names=data_args.text_column_name,
)
# load multiple eval sets
for dataset_dict in tqdm(dataset_names_dict, desc="Loading datasets..."):
sub_dataset = load_dataset(
dataset_dict["name"],
dataset_dict["config"],
split=dataset_dict["split"],
cache_dir=data_args.dataset_cache_dir,
streaming=data_args.streaming,
num_proc=data_args.preprocessing_num_workers,
)
if dataset_dict["text_column_name"] not in list(sub_dataset.features.keys()):
raise ValueError(
f"`--text_column_name` {dataset_dict['text_column_name']} not found in the evaluation "
f"dataset {dataset_dict['name']}. Ensure `text_column_name` is set to the correct column "
f"for the target text. Should be one of {' '.join(list(sub_dataset.features.keys()))}"
)
if dataset_dict["text_column_name"] != "text":
sub_dataset = sub_dataset.rename_column(dataset_dict["text_column_name"], "text")
if not data_args.streaming:
sub_dataset = sub_dataset.to_iterable_dataset()
# Clean-up the dataset name for pretty logging
# ("distil-whisper/librispeech_asr", "validation.clean") -> "librispeech_asr/validation-clean"
pretty_name = f"{dataset_dict['name'].split('/')[-1]}/{dataset_dict['split'].replace('.', '-')}"
raw_datasets[pretty_name] = sub_dataset
# 5. Load pretrained model, tokenizer, and feature extractor
processor = WhisperProcessor.from_pretrained(
data_args.model_name_or_path,
subfolder=data_args.subfolder,
cache_dir=data_args.cache_dir,
use_fast=data_args.use_fast_tokenizer,
)
dtype = getattr(torch, data_args.dtype)
model = WhisperForConditionalGeneration.from_pretrained(
data_args.model_name_or_path,
subfolder=data_args.subfolder,
torch_dtype=dtype,
attn_implementation=data_args.attn_implementation,
low_cpu_mem_usage=is_accelerate_available(),
cache_dir=data_args.cache_dir,
variant=data_args.model_variant,
)
model.to("cuda:0", dtype=dtype)
model_pipeline = None
if data_args.use_pipeline:
model_pipeline = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=dtype,
device=model.device,
chunk_length_s=data_args.chunk_length_s,
)
model_pipeline_forward = model_pipeline._forward
assistant_model = None
if data_args.assistant_model_name_or_path is not None:
logger.info("Loading assistant model...")
if data_args.assistant_model_name_or_path.startswith("openai"):
assistant_model = WhisperForConditionalGeneration.from_pretrained(
data_args.assistant_model_name_or_path,
torch_dtype=dtype,
attn_implementation=data_args.attn_implementation,
low_cpu_mem_usage=is_accelerate_available(),
cache_dir=data_args.cache_dir,
)
else:
assistant_model = WhisperForCausalLM.from_pretrained(
data_args.assistant_model_name_or_path,
torch_dtype=dtype,
attn_implementation=data_args.attn_implementation,
low_cpu_mem_usage=is_accelerate_available(),
cache_dir=data_args.cache_dir,
)
assistant_model.cuda()
# 6. Resample speech dataset: `datasets` takes care of automatically loading and resampling the audio,
# so we just need to set the correct target sampling rate.
raw_datasets = raw_datasets.cast_column(
data_args.audio_column_name,
datasets.features.Audio(sampling_rate=processor.feature_extractor.sampling_rate),
)
# 7. Preprocessing the datasets.
# We need to read the audio files as arrays and tokenize the targets.
audio_column_name = data_args.audio_column_name
normalizer = (
BasicTextNormalizer() if data_args.language is not None
else EnglishTextNormalizer(processor.tokenizer.english_spelling_normalizer)
)
sampling_rate = processor.feature_extractor.sampling_rate
if data_args.samples_per_dataset is not None:
for split in raw_datasets:
raw_datasets[split] = raw_datasets[split].take(data_args.samples_per_dataset)
def prepare_dataset(batch):
# process audio
audio = [sample["array"].astype(np.float32) for sample in batch[audio_column_name]]
if model_pipeline is None:
inputs = processor.feature_extractor(
audio,
sampling_rate=sampling_rate,
return_tensors="pt",
truncation=False,
padding="longest",
return_attention_mask=True,
)
if inputs.input_features.shape[-1] < 3000:
inputs = processor.feature_extractor(
audio,
sampling_rate=sampling_rate,
return_tensors="pt",
return_attention_mask=True,
)
batch["input_features"] = inputs.input_features.to(dtype)
batch["attention_mask"] = inputs.attention_mask
else:
batch["input_features"] = audio
# process audio length
batch["length_in_s"] = [len(sample) / sampling_rate for sample in audio]
# process targets
batch["reference"] = batch["text"]
return batch
vectorized_datasets = IterableDatasetDict()
for split in raw_datasets:
raw_datasets_features = list(raw_datasets[split].features.keys())
vectorized_datasets[split] = raw_datasets[split].map(
function=prepare_dataset,
remove_columns=raw_datasets_features,
batch_size=data_args.batch_size,
batched=True,
)
# for large datasets it is advised to run the preprocessing on a
# single machine first with `args.preprocessing_only` since there will mostly likely
# be a timeout when running the script in distributed mode.
# In a second step `args.preprocessing_only` can then be set to `False` to load the
# cached dataset
if data_args.preprocessing_only:
cache = {k: v.cache_files for k, v in vectorized_datasets.items()}
logger.info(f"Data preprocessing finished. Files cached at {cache}.")
return
metric = evaluate.load("wer")
def compute_metrics(pred_str, label_str):
# normalize everything and re-compute the WER
norm_pred_str = [normalizer(pred) for pred in pred_str]
norm_label_str = [normalizer(label) for label in label_str]
# filtering step to only evaluate the samples that correspond to non-zero normalized references:
norm_pred_str = [norm_pred_str[i] for i in range(len(norm_pred_str)) if len(norm_label_str[i]) > 0]
norm_label_str = [norm_label_str[i] for i in range(len(norm_label_str)) if len(norm_label_str[i]) > 0]
wer = 100 * metric.compute(predictions=norm_pred_str, references=norm_label_str)
return wer
gen_kwargs = {
"max_length": data_args.generation_max_length,
"return_timestamps": data_args.return_timestamps,
"num_beams": data_args.num_beams,
"top_k": 0,
}
if hasattr(model.generation_config, "is_multilingual") and model.generation_config.is_multilingual:
gen_kwargs["language"] = data_args.language
gen_kwargs["task"] = data_args.task
elif data_args.language is not None:
raise ValueError(
"Setting language token for an English-only checkpoint is not permitted. The language argument should "
"only be set for multilingual checkpoints."
)
if assistant_model is not None:
gen_kwargs["assistant_model"] = assistant_model
if data_args.prompt_text is not None:
gen_kwargs["prompt_ids"] = processor.get_prompt_ids(data_args.prompt_text, return_tensors="pt").to("cuda:0")
long_form_gen_kwargs = {
"condition_on_prev_tokens": data_args.condition_on_prev_tokens,
"compression_ratio_threshold": data_args.compression_ratio_threshold,
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0) if data_args.temperature_fallback else 0,
"logprob_threshold": data_args.logprob_threshold,
"no_speech_threshold": data_args.no_speech_threshold,
}
def benchmark(batch):
if model_pipeline is None:
inputs = torch.stack(batch["input_features"], dim=0).cuda()
attention_mask = torch.stack(batch["attention_mask"], dim=0).cuda()
# automatically use long-form args if required
inner_batch_size, num_mels, seq_len = inputs.shape
if seq_len == 3000:
batch_gen_kwargs = gen_kwargs
else:
batch_gen_kwargs = {**gen_kwargs, **long_form_gen_kwargs}
set_seed(data_args.seed)
start_time = time.time()
output_ids = model.generate(inputs, attention_mask=attention_mask, **batch_gen_kwargs)
batch["time"] = inner_batch_size * [(time.time() - start_time) / inner_batch_size]
batch["transcription"] = processor.batch_decode(
output_ids, skip_special_tokens=True, decode_with_timestamps=data_args.return_timestamps
)
else:
inputs = batch["input_features"]
# Time forward: let's make sure that only forward is timed and not pre- and post-processing
time_result = []
def _forward_time(*args, **kwargs):
start_time = time.time()
result = model_pipeline_forward(*args, **kwargs)
end_time = time.time() - start_time
time_result.append(end_time)
return result
model_pipeline._forward = _forward_time
result = model_pipeline(inputs, batch_size=PIPELINE_BATCH_SIZE, generate_kwargs=gen_kwargs)[0]["text"]
batch["transcription"] = [result]
batch["time"] = [sum(time_result)]
batch["num_words"] = [len(r.split()) for r in batch["reference"]]
return batch
result_datasets = DatasetDict()
for split in vectorized_datasets:
result_datasets[split] = vectorized_datasets[split].map(
function=benchmark,
remove_columns=["input_features"],
batch_size=data_args.batch_size,
batched=True,
)
stats_dataset = DatasetDict()
all_stats = {"rtf": 0, "wer": 0}
rtf_stats = {
"times_audio_total": 0,
"times_transcription_total": 0,
}
logger.info("***** Running Evaluation *****")
for key in generation_arguments:
logger.info(f" {key}: {generation_arguments[key]}")
datasets_evaluated_progress_bar = tqdm(result_datasets, desc="Datasets", position=0)
for split in datasets_evaluated_progress_bar:
transcriptions = []
references = []
stats = {}
times_audio_total = 0
times_transcription_total = 0
datasets_evaluated_progress_bar.write(f"Start benchmarking {split}...")
result_iter = iter(result_datasets[split])
for result in tqdm(result_iter, desc="Samples", position=1):
times_audio_total += result["length_in_s"]
times_transcription_total += result["time"]
# ensure prompt is removed from the transcription (awaiting fix in Transformers)
if data_args.prompt_text is not None:
result["transcription"] = result["transcription"].replace(data_args.prompt_text, "")
transcriptions.append(result["transcription"])
references.append(result["reference"])
norm_transcriptions = [normalizer(pred) for pred in transcriptions]
norm_references = [normalizer(label) for label in references]
transcriptions = [transcriptions[i] for i in range(len(transcriptions)) if len(norm_references[i]) > 0]
references = [references[i] for i in range(len(references)) if len(norm_references[i]) > 0]
norm_transcriptions = [
norm_transcriptions[i] for i in range(len(norm_transcriptions)) if len(norm_references[i]) > 0
]
norm_references = [norm_references[i] for i in range(len(norm_references)) if len(norm_references[i]) > 0]
stats["wer"] = compute_metrics(norm_transcriptions, norm_references)
wer_per_sample = []
for pred, ref in zip(norm_transcriptions, norm_references):
wer_per_sample.append(compute_metrics([pred], [ref]))
stats["rtf"] = times_audio_total / times_transcription_total
stats_dataset[split] = stats
wer_desc = " ".join([f"Eval {key}: {value} |" for key, value in stats.items()])
datasets_evaluated_progress_bar.write(wer_desc)
write_wandb_metric(wandb_logger, stats, prefix=split)
if data_args.log_predictions:
write_wandb_pred(
wandb_logger,
transcriptions,
references,
norm_transcriptions,
norm_references,
wer_per_sample,
prefix=split,
)
rtf_stats["times_audio_total"] += times_audio_total
rtf_stats["times_transcription_total"] += times_transcription_total
all_stats["wer"] += stats["wer"]
all_stats["wer"] = all_stats["wer"] / len(result_datasets)
# technically this is the reciprocal of the RTF, but it makes the scale easier to read on wandb
all_stats["rtf"] = rtf_stats["times_audio_total"] / rtf_stats["times_transcription_total"]
stats_dataset["all"] = all_stats
write_wandb_metric(wandb_logger, all_stats, prefix="all")
benchmark_artifact = wandb.Artifact("Benchmark", type="datasets")
with tempfile.TemporaryDirectory() as temp_dir:
for split in stats_dataset:
file_name = os.path.join(temp_dir, f"{'_'.join(split.split('/'))}.json")
with open(file_name, "w") as json_file:
json.dump(stats_dataset[split], json_file)
benchmark_artifact.add_file(file_name, split)
wandb_logger.log_artifact(benchmark_artifact)
if __name__ == "__main__":
main()
| distil-whisper/training/run_eval.py/0 | {
"file_path": "distil-whisper/training/run_eval.py",
"repo_id": "distil-whisper",
"token_count": 13590
} | 279 |
# Using the `evaluator` with custom pipelines
The evaluator is designed to work with `transformer` pipelines out-of-the-box. However, in many cases you might have a model or pipeline that's not part of the `transformer` ecosystem. You can still use `evaluator` to easily compute metrics for them. In this guide we show how to do this for a Scikit-Learn [pipeline](https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html#sklearn.pipeline.Pipeline) and a Spacy [pipeline](https://spacy.io). Let's start with the Scikit-Learn case.
## Scikit-Learn
First we need to train a model. We'll train a simple text classifier on the [IMDb dataset](https://huggingface.co/datasets/imdb), so let's start by downloading the dataset:
```py
from datasets import load_dataset
ds = load_dataset("imdb")
```
Then we can build a simple TF-IDF preprocessor and Naive Bayes classifier wrapped in a `Pipeline`:
```py
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
text_clf = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('clf', MultinomialNB()),
])
text_clf.fit(ds["train"]["text"], ds["train"]["label"])
```
Following the convention in the `TextClassificationPipeline` of `transformers` our pipeline should be callable and return a list of dictionaries. In addition we use the `task` attribute to check if the pipeline is compatible with the `evaluator`. We can write a small wrapper class for that purpose:
```py
class ScikitEvalPipeline:
def __init__(self, pipeline):
self.pipeline = pipeline
self.task = "text-classification"
def __call__(self, input_texts, **kwargs):
return [{"label": p} for p in self.pipeline.predict(input_texts)]
pipe = ScikitEvalPipeline(text_clf)
```
We can now pass this `pipeline` to the `evaluator`:
```py
from evaluate import evaluator
task_evaluator = evaluator("text-classification")
task_evaluator.compute(pipe, ds["test"], "accuracy")
>>> {'accuracy': 0.82956}
```
Implementing that simple wrapper is all that's needed to use any model from any framework with the `evaluator`. In the `__call__` you can implement all logic necessary for efficient forward passes through your model.
## Spacy
We'll use the `polarity` feature of the `spacytextblob` project to get a simple sentiment analyzer. First you'll need to install the project and download the resources:
```bash
pip install spacytextblob
python -m textblob.download_corpora
python -m spacy download en_core_web_sm
```
Then we can simply load the `nlp` pipeline and add the `spacytextblob` pipeline:
```py
import spacy
nlp = spacy.load('en_core_web_sm')
nlp.add_pipe('spacytextblob')
```
This snippet shows how we can use the `polarity` feature added with `spacytextblob` to get the sentiment of a text:
```py
texts = ["This movie is horrible", "This movie is awesome"]
results = nlp.pipe(texts)
for txt, res in zip(texts, results):
print(f"{text} | Polarity: {res._.blob.polarity}")
```
Now we can wrap it in a simple wrapper class like in the Scikit-Learn example before. It just has to return a list of dictionaries with the predicted lables. If the polarity is larger than 0 we'll predict positive sentiment and negative otherwise:
```py
class SpacyEvalPipeline:
def __init__(self, nlp):
self.nlp = nlp
self.task = "text-classification"
def __call__(self, input_texts, **kwargs):
results =[]
for p in self.nlp.pipe(input_texts):
if p._.blob.polarity>=0:
results.append({"label": 1})
else:
results.append({"label": 0})
return results
pipe = SpacyEvalPipeline(nlp)
```
That class is compatible with the `evaluator` and we can use the same instance from the previous examlpe along with the IMDb test set:
```py
eval.compute(pipe, ds["test"], "accuracy")
>>> {'accuracy': 0.6914}
```
This will take a little longer than the Scikit-Learn example but after roughly 10-15min you will have the evaluation results!
| evaluate/docs/source/custom_evaluator.mdx/0 | {
"file_path": "evaluate/docs/source/custom_evaluator.mdx",
"repo_id": "evaluate",
"token_count": 1433
} | 280 |
import evaluate
from evaluate.utils import launch_gradio_widget
module = evaluate.load("honest", "en")
launch_gradio_widget(module)
| evaluate/measurements/honest/app.py/0 | {
"file_path": "evaluate/measurements/honest/app.py",
"repo_id": "evaluate",
"token_count": 39
} | 281 |
import evaluate
from evaluate.utils import launch_gradio_widget
module = evaluate.load("text_duplicates")
launch_gradio_widget(module)
| evaluate/measurements/text_duplicates/app.py/0 | {
"file_path": "evaluate/measurements/text_duplicates/app.py",
"repo_id": "evaluate",
"token_count": 39
} | 282 |
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Accuracy metric."""
import datasets
from sklearn.metrics import accuracy_score
import evaluate
_DESCRIPTION = """
Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Where:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
"""
_KWARGS_DESCRIPTION = """
Args:
predictions (`list` of `int`): Predicted labels.
references (`list` of `int`): Ground truth labels.
normalize (`boolean`): If set to False, returns the number of correctly classified samples. Otherwise, returns the fraction of correctly classified samples. Defaults to True.
sample_weight (`list` of `float`): Sample weights Defaults to None.
Returns:
accuracy (`float` or `int`): Accuracy score. Minimum possible value is 0. Maximum possible value is 1.0, or the number of examples input, if `normalize` is set to `True`.. A higher score means higher accuracy.
Examples:
Example 1-A simple example
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])
>>> print(results)
{'accuracy': 0.5}
Example 2-The same as Example 1, except with `normalize` set to `False`.
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], normalize=False)
>>> print(results)
{'accuracy': 3.0}
Example 3-The same as Example 1, except with `sample_weight` set.
>>> accuracy_metric = evaluate.load("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], sample_weight=[0.5, 2, 0.7, 0.5, 9, 0.4])
>>> print(results)
{'accuracy': 0.8778625954198473}
"""
_CITATION = """
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
"""
@evaluate.utils.file_utils.add_start_docstrings(_DESCRIPTION, _KWARGS_DESCRIPTION)
class Accuracy(evaluate.Metric):
def _info(self):
return evaluate.MetricInfo(
description=_DESCRIPTION,
citation=_CITATION,
inputs_description=_KWARGS_DESCRIPTION,
features=datasets.Features(
{
"predictions": datasets.Sequence(datasets.Value("int32")),
"references": datasets.Sequence(datasets.Value("int32")),
}
if self.config_name == "multilabel"
else {
"predictions": datasets.Value("int32"),
"references": datasets.Value("int32"),
}
),
reference_urls=["https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html"],
)
def _compute(self, predictions, references, normalize=True, sample_weight=None):
return {
"accuracy": float(
accuracy_score(references, predictions, normalize=normalize, sample_weight=sample_weight)
)
}
| evaluate/metrics/accuracy/accuracy.py/0 | {
"file_path": "evaluate/metrics/accuracy/accuracy.py",
"repo_id": "evaluate",
"token_count": 1601
} | 283 |
---
title: Brier Score
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
The Brier score is a measure of the error between two probability distributions.
---
# Metric Card for Brier Score
## Metric Description
Brier score is a type of evaluation metric for classification tasks, where you predict outcomes such as win/lose, spam/ham, click/no-click etc.
`BrierScore = 1/N * sum( (p_i - o_i)^2 )`
Where `p_i` is the prediction probability of occurrence of the event, and the term `o_i` is equal to 1 if the event occurred and 0 if not. Which means: the lower the value of this score, the better the prediction.
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> brier_score = evaluate.load("brier_score")
>>> predictions = np.array([0, 0, 1, 1])
>>> references = np.array([0.1, 0.9, 0.8, 0.3])
>>> results = brier_score.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `pos_label`: the label of the positive class. The default is `1`.
### Output Values
This metric returns a dictionary with the following keys:
- `brier_score (float)`: the computed Brier score.
Output Example(s):
```python
{'brier_score': 0.5}
```
#### Values from Popular Papers
### Examples
```python
>>> brier_score = evaluate.load("brier_score")
>>> predictions = np.array([0, 0, 1, 1])
>>> references = np.array([0.1, 0.9, 0.8, 0.3])
>>> results = brier_score.compute(predictions=predictions, references=references)
>>> print(results)
{'brier_score': 0.3375}
```
Example with `y_true` contains string, an error will be raised and `pos_label` should be explicitly specified.
```python
>>> brier_score_metric = evaluate.load("brier_score")
>>> predictions = np.array(["spam", "ham", "ham", "spam"])
>>> references = np.array([0.1, 0.9, 0.8, 0.3])
>>> results = brier_score.compute(predictions, references, pos_label="ham")
>>> print(results)
{'brier_score': 0.0374}
```
## Limitations and Bias
The [brier_score](https://huggingface.co/metrics/brier_score) is appropriate for binary and categorical outcomes that can be structured as true or false, but it is inappropriate for ordinal variables which can take on three or more values.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
@Article{brier1950verification,
title={Verification of forecasts expressed in terms of probability},
author={Brier, Glenn W and others},
journal={Monthly weather review},
volume={78},
number={1},
pages={1--3},
year={1950}
}
```
## Further References
- [Brier Score - Wikipedia](https://en.wikipedia.org/wiki/Brier_score) | evaluate/metrics/brier_score/README.md/0 | {
"file_path": "evaluate/metrics/brier_score/README.md",
"repo_id": "evaluate",
"token_count": 1200
} | 284 |
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Accuracy metric for the Mathematics Aptitude Test of Heuristics (MATH) dataset."""
import datasets
import math_equivalence # From: git+https://github.com/hendrycks/math.git
import evaluate
_CITATION = """\
@article{hendrycksmath2021,
title={Measuring Mathematical Problem Solving With the MATH Dataset},
author={Dan Hendrycks
and Collin Burns
and Saurav Kadavath
and Akul Arora
and Steven Basart
and Eric Tang
and Dawn Song
and Jacob Steinhardt},
journal={arXiv preprint arXiv:2103.03874},
year={2021}
}
"""
_DESCRIPTION = """\
This metric is used to assess performance on the Mathematics Aptitude Test of Heuristics (MATH) dataset.
It first canonicalizes the inputs (e.g., converting "1/2" to "\\frac{1}{2}") and then computes accuracy.
"""
_KWARGS_DESCRIPTION = r"""
Calculates accuracy after canonicalizing inputs.
Args:
predictions: list of predictions to score. Each prediction
is a string that contains natural language and LaTex.
references: list of reference for each prediction. Each
reference is a string that contains natural language
and LaTex.
Returns:
accuracy: accuracy after canonicalizing inputs
(e.g., converting "1/2" to "\\frac{1}{2}")
Examples:
>>> metric = evaluate.load("competition_math")
>>> results = metric.compute(references=["\\frac{1}{2}"], predictions=["1/2"])
>>> print(results)
{'accuracy': 1.0}
"""
@datasets.utils.file_utils.add_end_docstrings(_DESCRIPTION, _KWARGS_DESCRIPTION)
class CompetitionMathMetric(evaluate.Metric):
"""Accuracy metric for the MATH dataset."""
def _info(self):
return evaluate.MetricInfo(
description=_DESCRIPTION,
citation=_CITATION,
inputs_description=_KWARGS_DESCRIPTION,
features=datasets.Features(
{
"predictions": datasets.Value("string"),
"references": datasets.Value("string"),
}
),
# Homepage of the metric for documentation
homepage="https://github.com/hendrycks/math",
# Additional links to the codebase or references
codebase_urls=["https://github.com/hendrycks/math"],
)
def _compute(self, predictions, references):
"""Returns the scores"""
n_correct = 0.0
for i, j in zip(predictions, references):
n_correct += 1.0 if math_equivalence.is_equiv(i, j) else 0.0
accuracy = n_correct / len(predictions)
return {
"accuracy": accuracy,
}
| evaluate/metrics/competition_math/competition_math.py/0 | {
"file_path": "evaluate/metrics/competition_math/competition_math.py",
"repo_id": "evaluate",
"token_count": 1179
} | 285 |
import evaluate
from evaluate.utils import launch_gradio_widget
module = evaluate.load("exact_match")
launch_gradio_widget(module)
| evaluate/metrics/exact_match/app.py/0 | {
"file_path": "evaluate/metrics/exact_match/app.py",
"repo_id": "evaluate",
"token_count": 38
} | 286 |
import evaluate
from evaluate.utils import launch_gradio_widget
module = evaluate.load("google_bleu")
launch_gradio_widget(module)
| evaluate/metrics/google_bleu/app.py/0 | {
"file_path": "evaluate/metrics/google_bleu/app.py",
"repo_id": "evaluate",
"token_count": 38
} | 287 |
---
title: MAPE
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Mean Absolute Percentage Error (MAPE) is the mean percentage error difference between the predicted and actual
values.
---
# Metric Card for MAPE
## Metric Description
Mean Absolute Error (MAPE) is the mean of the percentage error of difference between the predicted $x_i$ and actual $y_i$ numeric values:
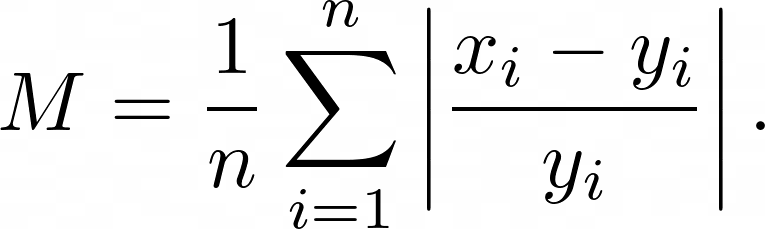
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> mape_metric = evaluate.load("mape")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mape_metric.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
- `raw_values` returns a full set of errors in case of multioutput input.
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
- the array-like value defines weights used to average errors.
### Output Values
This metric outputs a dictionary, containing the mean absolute error score, which is of type:
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
Each MAPE `float` value is postive with the best value being 0.0.
Output Example(s):
```python
{'mape': 0.5}
```
If `multioutput="raw_values"`:
```python
{'mape': array([0.5, 1. ])}
```
#### Values from Popular Papers
### Examples
Example with the `uniform_average` config:
```python
>>> mape_metric = evaluate.load("mape")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mape_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mape': 0.3273...}
```
Example with multi-dimensional lists, and the `raw_values` config:
```python
>>> mape_metric = evaluate.load("mape", "multilist")
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
>>> references = [[0.1, 2], [-1, 2], [8, -5]]
>>> results = mape_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mape': 0.8874...}
>>> results = mape_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
>>> print(results)
{'mape': array([1.3749..., 0.4])}
```
## Limitations and Bias
One limitation of MAPE is that it cannot be used if the ground truth is zero or close to zero. This metric is also asymmetric in that it puts a heavier penalty on predictions less than the ground truth and a smaller penalty on predictions bigger than the ground truth and thus can lead to a bias of methods being select which under-predict if selected via this metric.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
```bibtex
@article{DEMYTTENAERE201638,
title = {Mean Absolute Percentage Error for regression models},
journal = {Neurocomputing},
volume = {192},
pages = {38--48},
year = {2016},
note = {Advances in artificial neural networks, machine learning and computational intelligence},
issn = {0925-2312},
doi = {https://doi.org/10.1016/j.neucom.2015.12.114},
url = {https://www.sciencedirect.com/science/article/pii/S0925231216003325},
author = {Arnaud {de Myttenaere} and Boris Golden and Bénédicte {Le Grand} and Fabrice Rossi},
}
```
## Further References
- [Mean absolute percentage error - Wikipedia](https://en.wikipedia.org/wiki/Mean_absolute_percentage_error)
| evaluate/metrics/mape/README.md/0 | {
"file_path": "evaluate/metrics/mape/README.md",
"repo_id": "evaluate",
"token_count": 1586
} | 288 |
---
title: Mean IoU
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
IoU is the area of overlap between the predicted segmentation and the ground truth divided by the area of union
between the predicted segmentation and the ground truth. For binary (two classes) or multi-class segmentation,
the mean IoU of the image is calculated by taking the IoU of each class and averaging them.
---
# Metric Card for Mean IoU
## Metric Description
IoU (Intersection over Union) is the area of overlap between the predicted segmentation and the ground truth divided by the area of union between the predicted segmentation and the ground truth.
For binary (two classes) or multi-class segmentation, the *mean IoU* of the image is calculated by taking the IoU of each class and averaging them.
## How to Use
The Mean IoU metric takes two lists of numeric 2D arrays as input corresponding to the predicted and ground truth segmentations:
```python
>>> import numpy as np
>>> mean_iou = evaluate.load("mean_iou")
>>> predicted = np.array([[2, 2, 3], [8, 2, 4], [3, 255, 2]])
>>> ground_truth = np.array([[1, 2, 2], [8, 2, 1], [3, 255, 1]])
>>> results = mean_iou.compute(predictions=[predicted], references=[ground_truth], num_labels=10, ignore_index=255)
```
### Inputs
**Mandatory inputs**
- `predictions` (`List[ndarray]`): List of predicted segmentation maps, each of shape (height, width). Each segmentation map can be of a different size.
- `references` (`List[ndarray]`): List of ground truth segmentation maps, each of shape (height, width). Each segmentation map can be of a different size.
- `num_labels` (`int`): Number of classes (categories).
- `ignore_index` (`int`): Index that will be ignored during evaluation.
**Optional inputs**
- `nan_to_num` (`int`): If specified, NaN values will be replaced by the number defined by the user.
- `label_map` (`dict`): If specified, dictionary mapping old label indices to new label indices.
- `reduce_labels` (`bool`): Whether or not to reduce all label values of segmentation maps by 1. Usually used for datasets where 0 is used for background, and background itself is not included in all classes of a dataset (e.g. ADE20k). The background label will be replaced by 255. The default value is `False`.
### Output Values
The metric returns a dictionary with the following elements:
- `mean_iou` (`float`): Mean Intersection-over-Union (IoU averaged over all categories).
- `mean_accuracy` (`float`): Mean accuracy (averaged over all categories).
- `overall_accuracy` (`float`): Overall accuracy on all images.
- `per_category_accuracy` (`ndarray` of shape `(num_labels,)`): Per category accuracy.
- `per_category_iou` (`ndarray` of shape `(num_labels,)`): Per category IoU.
The values of all of the scores reported range from from `0.0` (minimum) and `1.0` (maximum).
Output Example:
```python
{'mean_iou': 0.47750000000000004, 'mean_accuracy': 0.5916666666666666, 'overall_accuracy': 0.5263157894736842, 'per_category_iou': array([0. , 0. , 0.375, 0.4 , 0.5 , 0. , 0.5 , 1. , 1. , 1. ]), 'per_category_accuracy': array([0. , 0. , 0.75 , 0.66666667, 1. , 0. , 0.5 , 1. , 1. , 1. ])}
```
#### Values from Popular Papers
The [leaderboard for the CityScapes dataset](https://paperswithcode.com/sota/semantic-segmentation-on-cityscapes) reports a Mean IOU ranging from 64 to 84; that of [ADE20k](https://paperswithcode.com/sota/semantic-segmentation-on-ade20k) ranges from 30 to a peak of 59.9, indicating that the dataset is more difficult for current approaches (as of 2022).
### Examples
```python
>>> import numpy as np
>>> mean_iou = evaluate.load("mean_iou")
>>> # suppose one has 3 different segmentation maps predicted
>>> predicted_1 = np.array([[1, 2], [3, 4], [5, 255]])
>>> actual_1 = np.array([[0, 3], [5, 4], [6, 255]])
>>> predicted_2 = np.array([[2, 7], [9, 2], [3, 6]])
>>> actual_2 = np.array([[1, 7], [9, 2], [3, 6]])
>>> predicted_3 = np.array([[2, 2, 3], [8, 2, 4], [3, 255, 2]])
>>> actual_3 = np.array([[1, 2, 2], [8, 2, 1], [3, 255, 1]])
>>> predictions = [predicted_1, predicted_2, predicted_3]
>>> references = [actual_1, actual_2, actual_3]
>>> results = mean_iou.compute(predictions=predictions, references=references, num_labels=10, ignore_index=255, reduce_labels=False)
>>> print(results) # doctest: +NORMALIZE_WHITESPACE
{'mean_iou': 0.47750000000000004, 'mean_accuracy': 0.5916666666666666, 'overall_accuracy': 0.5263157894736842, 'per_category_iou': array([0. , 0. , 0.375, 0.4 , 0.5 , 0. , 0.5 , 1. , 1. , 1. ]), 'per_category_accuracy': array([0. , 0. , 0.75 , 0.66666667, 1. , 0. , 0.5 , 1. , 1. , 1. ])}
```
## Limitations and Bias
Mean IOU is an average metric, so it will not show you where model predictions differ from the ground truth (i.e. if there are particular regions or classes that the model does poorly on). Further error analysis is needed to gather actional insights that can be used to inform model improvements.
## Citation(s)
```bibtex
@software{MMSegmentation_Contributors_OpenMMLab_Semantic_Segmentation_2020,
author = {{MMSegmentation Contributors}},
license = {Apache-2.0},
month = {7},
title = {{OpenMMLab Semantic Segmentation Toolbox and Benchmark}},
url = {https://github.com/open-mmlab/mmsegmentation},
year = {2020}
}"
```
## Further References
- [Wikipedia article - Jaccard Index](https://en.wikipedia.org/wiki/Jaccard_index)
| evaluate/metrics/mean_iou/README.md/0 | {
"file_path": "evaluate/metrics/mean_iou/README.md",
"repo_id": "evaluate",
"token_count": 1939
} | 289 |