
author stringlengths 2 29 ⌀ | cardData null | citation stringlengths 0 9.58k ⌀ | description stringlengths 0 5.93k ⌀ | disabled bool 1
class | downloads float64 1 1M ⌀ | gated bool 2
classes | id stringlengths 2 108 | lastModified stringlengths 24 24 | paperswithcode_id stringlengths 2 45 ⌀ | private bool 2
classes | sha stringlengths 40 40 | siblings list | tags list | readme_url stringlengths 57 163 | readme stringlengths 0 977k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
bigscience-catalogue-data | null | null | null | false | null | false | bigscience-catalogue-data/qadi | 2022-01-28T15:16:48.000Z | null | true | 6e379178c5e1ab8d16df91e8fe5810b3db22b121 | [] | [
"arxiv:2005.06557"
] | https://huggingface.co/datasets/bigscience-catalogue-data/qadi/resolve/main/README.md | |
bigscience-catalogue-data | null | null | null | false | null | false | bigscience-catalogue-data/shamela | 2022-01-27T13:00:02.000Z | null | true | 7a0b02491e95bde4afa067639947bf5d3e6ebb77 | [] | [] | https://huggingface.co/datasets/bigscience-catalogue-data/shamela/resolve/main/README.md | |
bigscience-catalogue-data | null | null | null | false | null | false | bigscience-catalogue-data/urdu-monolingual-corpus | 2022-02-03T17:53:35.000Z | null | true | 32717642149f7e0a4d1ae1c080d00e1fb7e8fcbc | [] | [
"license:cc-by-nc-sa-3.0"
] | https://huggingface.co/datasets/bigscience-catalogue-data/urdu-monolingual-corpus/resolve/main/README.md | |
bigscience-catalogue-data | null | null | null | false | null | false | bigscience-catalogue-data/lm_en_s2orc_ai2_abstracts | 2022-02-18T15:27:59.000Z | null | true | cb2c0402fd2d2dc8c764220acf063514af68b47a | [] | [
"license:cc-by-nc-4.0"
] | https://huggingface.co/datasets/bigscience-catalogue-data/lm_en_s2orc_ai2_abstracts/resolve/main/README.md | |
bigscience-catalogue-data | null | null | null | false | null | false | bigscience-catalogue-data/lm_en_s2orc_ai2_pdf_parses | 2022-02-18T16:53:55.000Z | null | true | 45b0212282017441962e69443342f02522c8f4e4 | [] | [
"license:cc-by-4.0"
] | https://huggingface.co/datasets/bigscience-catalogue-data/lm_en_s2orc_ai2_pdf_parses/resolve/main/README.md | |
bigscience-catalogue-data | null | null | null | false | null | false | bigscience-catalogue-data/lm_fr_wikihow_human_instructions | 2022-02-21T18:40:07.000Z | null | true | abe98fc2f59683b2e0d7d732d360e423ea613eb4 | [] | [
"license:cc-by-nc-sa-4.0"
] | https://huggingface.co/datasets/bigscience-catalogue-data/lm_fr_wikihow_human_instructions/resolve/main/README.md | |
bigscience-catalogue-data | null | null | Leipzig Wortschatz Crawl | false | null | false | bigscience-catalogue-data/lm_indic-ur_leipzig_wortschatz_urdu-pk_web_2019_sentences | 2022-02-05T03:22:53.000Z | null | true | c1669fade21f7b9356d1a134b18b72c64a1b1d1b | [] | [
"license:other"
] | https://huggingface.co/datasets/bigscience-catalogue-data/lm_indic-ur_leipzig_wortschatz_urdu-pk_web_2019_sentences/resolve/main/README.md | |
bigscience-catalogue-data | null | null | Leipzig Wortschatz Crawl | false | null | false | bigscience-catalogue-data/lm_indic-ur_leipzig_wortschatz_urdu_newscrawl_2016_sentences | 2022-02-05T03:22:07.000Z | null | true | 6652b75c24393140edaa111816c952ea1f279f99 | [] | [
"license:other"
] | https://huggingface.co/datasets/bigscience-catalogue-data/lm_indic-ur_leipzig_wortschatz_urdu_newscrawl_2016_sentences/resolve/main/README.md | |
bigscience-catalogue-data | null | null | We release a sizeable monolingual Urdu corpus automatically tagged with part-of-speech tags. We extend the work of Jawaid and Bojar (2012) who use three different taggers and then apply a voting scheme to disambiguate among the different choices suggested by each tagger. We run this complex ensemble on a large monoling... | false | null | false | bigscience-catalogue-data/lm_indic-ur_urdu-monolingual-corpus | 2022-02-05T03:23:47.000Z | null | true | f71f77f96ed747723b248890f70f40e0ac54d9d5 | [] | [
"license:cc-by-nc-sa-3.0"
] | https://huggingface.co/datasets/bigscience-catalogue-data/lm_indic-ur_urdu-monolingual-corpus/resolve/main/README.md | |
biu-nlp | null | @inproceedings{brook-weiss-etal-2021-qa,
title = "{QA}-Align: Representing Cross-Text Content Overlap by Aligning Question-Answer Propositions",
author = "Brook Weiss, Daniela and
Roit, Paul and
Klein, Ayal and
Ernst, Ori and
Dagan, Ido",
booktitle = "Proceedings of the 2021 Conf... | This dataset contains QA-Alignments - annotations of cross-text content overlap.
The task input is two sentences from two documents, roughly talking about the same event, along with their QA-SRL annotations
which capture verbal predicate-argument relations in question-answer format. The output is a cross-sentence ali... | false | 321 | false | biu-nlp/qa_align | 2021-11-19T01:01:40.000Z | null | false | d8ed6544788253c114d64a2ba69c0b6c0f2ffa2d | [] | [] | https://huggingface.co/datasets/biu-nlp/qa_align/resolve/main/README.md | # QA-Align
This dataset contains QA-Alignments --- fine-grained annotations of cross-text content overlap.
The task input is two sentences from two documents, roughly talking about the same event, along with their QA-SRL annotations
which capture verbal predicate-argument relations in question-answer format. The out... |
biu-nlp | null | @inproceedings{roit2020controlled,
title={Controlled Crowdsourcing for High-Quality QA-SRL Annotation},
author={Roit, Paul and Klein, Ayal and Stepanov, Daniela and Mamou, Jonathan and Michael, Julian and Stanovsky, Gabriel and Zettlemoyer, Luke and Dagan, Ido},
booktitle={Proceedings of the 58th Annual Meeting o... | The dataset contains question-answer pairs to model verbal predicate-argument structure.
The questions start with wh-words (Who, What, Where, What, etc.) and contain a verb predicate in the sentence; the answers are phrases in the sentence.
This dataset, a.k.a "QASRL-GS" (Gold Standard) or "QASRL-2020", was constructe... | false | 712 | false | biu-nlp/qa_srl2020 | 2022-10-17T20:49:01.000Z | null | false | 80e6b8ce552fc15f9ee698b414d677db1d6567fd | [] | [] | https://huggingface.co/datasets/biu-nlp/qa_srl2020/resolve/main/README.md | # QA-SRL 2020 (Gold Standard)
The dataset contains question-answer pairs to model verbal predicate-argument structure.
The questions start with wh-words (Who, What, Where, What, etc.) and contain a verb predicate in the sentence; the answers are phrases in the sentence.
This dataset, a.k.a "QASRL-GS" (Gold Standard) ... |
biu-nlp | null | @inproceedings{klein2020qanom,
title={QANom: Question-Answer driven SRL for Nominalizations},
author={Klein, Ayal and Mamou, Jonathan and Pyatkin, Valentina and Stepanov, Daniela and He, Hangfeng and Roth, Dan and Zettlemoyer, Luke and Dagan, Ido},
booktitle={Proceedings of the 28th International Conference on Co... | The dataset contains question-answer pairs to model predicate-argument structure of deverbal nominalizations.
The questions start with wh-words (Who, What, Where, What, etc.) and contain a the verbal form of a nominalization from the sentence;
the answers are phrases in the sentence.
See the paper for details: QANom... | false | 321 | false | biu-nlp/qanom | 2022-10-18T09:50:01.000Z | null | false | 5499db7c8223f09187bc8b4bc81d689758ceb5f8 | [] | [] | https://huggingface.co/datasets/biu-nlp/qanom/resolve/main/README.md | # QANom
This dataset contains question-answer pairs to model the predicate-argument structure of deverbal nominalizations.
The questions start with wh-words (Who, What, Where, What, etc.) and contain the verbal form of a nominalization from the sentence;
the answers are phrases in the sentence.
See the paper for ... |
blinoff | null | null | This dataset contains 190,335 Russian Q&A posts from a medical related forum. | false | 329 | false | blinoff/medical_qa_ru_data | 2022-07-02T06:24:13.000Z | null | false | b7c9fe729920578a60d6a294a6f6a81496d6c6fc | [] | [
"language:ru",
"license:unknown",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"task_categories:question-answering",
"task_ids:closed-domain-qa"
] | https://huggingface.co/datasets/blinoff/medical_qa_ru_data/resolve/main/README.md | ---
annotations_creators: []
language_creators: []
language:
- ru
license:
- unknown
multilinguality:
- monolingual
pretty_name: Medical Q&A Russian Data
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- question-answering
task_ids:
- closed-domain-qa
---
### Dataset Summary
This dataset cont... |
bs-modeling-metadata | null | null | null | false | 323 | false | bs-modeling-metadata/OSCAR_Entity_13_000 | 2021-09-15T14:20:53.000Z | null | false | 4949de27eaa80078f2253d1d254709a5e06a47a7 | [] | [] | https://huggingface.co/datasets/bs-modeling-metadata/OSCAR_Entity_13_000/resolve/main/README.md | The dataset is in the form of a json lines file with 10,657 examples, where an example consists of text (extracted from the first 13,000 rows of OSCAR unshuffled English dataset) and metadata fields (entities).
Structure of an example.
```
{
"text": "This is exactly the sort of article to raise the profile of the... |
bs-modeling-metadata | null | null | null | false | 322 | false | bs-modeling-metadata/website_metadata_c4 | 2021-11-24T14:04:30.000Z | null | false | f6cba351f9d1893a3b60f76455cdbd64fc0239c7 | [] | [] | https://huggingface.co/datasets/bs-modeling-metadata/website_metadata_c4/resolve/main/README.md | The dataset is in the form of a json lines file with 1,20,000 examples, where an example consists of text (extracted from C4 English dataset) and metadata fields (website description extracted from Wikipedia).
Example:
```
{
"text": "US10289222B2 - Handling of touch events in a browser environment - Google Patents... |
bsc | null | AnCora Catalan NER.
This is a dataset for Named Eentity Reacognition (NER) from Ancora corpus adapted for
Machine Learning and Language Model evaluation purposes.
Since multiwords (including Named Entites) in the original Ancora corpus are aggregated as
... | false | 321 | false | bsc/ancora-ca-ner | 2021-08-30T17:06:55.000Z | null | false | 8bba9af9375dcac303653a5c392420bf1a53756e | [] | [] | https://huggingface.co/datasets/bsc/ancora-ca-ner/resolve/main/README.md | # Named Entites from Ancora Corpus
<font size="+2">
<strong>
<span style="color:red">
WARNING:
</span>
</strong>
</font>
This repository is now superseded by [BSC-TeMU/ancora-ca-ner](https://huggingface.co/datasets/BSC-TeMU/ancora-ca-ner). Future updates will be released in the new repository, so it is highly recomme... | |
bsc | null | Rodriguez-Penagos, Carlos Gerardo, Armentano-Oller, Carme, Gonzalez-Agirre, Aitor, & Gibert Bonet, Ona. (2021).
Semantic Textual Similarity in Catalan (Version 1.0.1) [Data set].
Zenodo. http://doi.org/10.5281/zenodo.4761434 | Semantic Textual Similarity in Catalan.
STS corpus is a benchmark for evaluating Semantic Text Similarity in Catalan.
It consists of more than 3000 sentence pairs, annotated with the semantic similarity between them,
using a scale from 0 (no similarity at all) to 5... | false | 324 | false | bsc/sts-ca | 2021-08-30T17:20:03.000Z | null | false | 724c570fd063a86bc0f6cf2d7be9dc4da0ded036 | [] | [] | https://huggingface.co/datasets/bsc/sts-ca/resolve/main/README.md | # Semantic Textual Similarity in Catalan
<font size="+2">
<strong>
<span style="color:red">
WARNING:
</span>
</strong>
</font>
This repository is now superseded by [BSC-TeMU/sts-ca](https://huggingface.co/datasets/BSC-TeMU/sts-ca). Future updates will be released in the new repository, so it is highly recommended to ... |
bsc | null | Carrino, Casimiro Pio, Rodriguez-Penagos, Carlos Gerardo, & Armentano-Oller, Carme. (2021).
TeCla: Text Classification Catalan dataset (Version 1.0) [Data set].
Zenodo. http://doi.org/10.5281/zenodo.4627198 | TeCla: Text Classification Catalan dataset
Catalan News corpus for Text classification, crawled from ACN (Catalan News Agency) site: www.acn.cat
Corpus de notícies en català per a classificació textual, extret del web de l'Agència Catalana de Notícies - www.acn.cat | false | 322 | false | bsc/tecla | 2021-08-30T17:12:59.000Z | null | false | 5c73e8058b6676acaa79f5a370c70c0ca2626b17 | [] | [] | https://huggingface.co/datasets/bsc/tecla/resolve/main/README.md | # TeCla (Text Classification) Catalan dataset
<font size="+2">
<strong>
<span style="color:red">
WARNING:
</span>
</strong>
</font>
This repository is now superseded by [BSC-TeMU/tecla](https://huggingface.co/datasets/BSC-TeMU/tecla). Future updates will be released in the new repository, so it is highly recommended ... |
bsc | null | Rodriguez-Penagos, Carlos Gerardo, & Armentano-Oller, Carme. (2021).
ViquiQuAD: an extractive QA dataset from Catalan Wikipedia (Version ViquiQuad_v.1.0.1)
[Data set]. Zenodo. http://doi.org/10.5281/zenodo.4761412 | ViquiQuAD: an extractive QA dataset from Catalan Wikipedia.
This dataset contains 3111 contexts extracted from a set of 597 high quality original (no translations)
articles in the Catalan Wikipedia "Viquipèdia" (ca.wikipedia.org), and 1 to 5 questions with their
an... | false | 326 | false | bsc/viquiquad | 2021-08-30T17:22:59.000Z | null | false | d7f76452359631f2be589609060b6de8eea90428 | [] | [] | https://huggingface.co/datasets/bsc/viquiquad/resolve/main/README.md | # ViquiQuAD, An extractive QA dataset for catalan, from the Wikipedia
<font size="+2">
<strong>
<span style="color:red">
WARNING:
</span>
</strong>
</font>
This repository is now superseded by [BSC-TeMU/viquiquad](https://huggingface.co/datasets/BSC-TeMU/viquiquad). Future updates will be released in the new reposito... |
bsc | null | Carlos Gerardo Rodriguez-Penagos, & Carme Armentano-Oller. (2021). XQuAD-ca [Data set].
Zenodo. http://doi.org/10.5281/zenodo.4757559 | Professional translation into Catalan of XQuAD dataset (https://github.com/deepmind/xquad).
XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating
cross-lingual question answering performance.
The dataset consists of a subset of 240... | false | 323 | false | bsc/xquad-ca | 2021-08-30T17:16:31.000Z | null | false | 34dc222345ef8a4ed8ae0a4d181f08c9e8cc548b | [] | [] | https://huggingface.co/datasets/bsc/xquad-ca/resolve/main/README.md | # XQuAD-Ca
<font size="+2">
<strong>
<span style="color:red">
WARNING:
</span>
</strong>
</font>
This repository is now superseded by [BSC-TeMU/xquad-ca](https://huggingface.co/datasets/BSC-TeMU/xquad-ca). Future updates will be released in the new repository, so it is highly recommended to load the dataset using the... |
caca | null | null | null | false | 166 | false | caca/zscczs | 2021-04-07T09:02:09.000Z | null | false | a77e6b9e25050d202bc69d78b3cdd9529ef10029 | [] | [] | https://huggingface.co/datasets/caca/zscczs/resolve/main/README.md | |
cahya | null | null | null | false | 166 | false | cahya/persona_empathetic | 2022-02-19T22:49:35.000Z | null | false | 47de2aba7b0adf7b8c37a568df2d4b69717d8dcb | [] | [
"license:mit"
] | https://huggingface.co/datasets/cahya/persona_empathetic/resolve/main/README.md | ---
license: mit
---
|
cakiki | null | @dataset{yamen_ajjour_2020_4139439,
author = {Yamen Ajjour and
Henning Wachsmuth and
Johannes Kiesel and
Martin Potthast and
Matthias Hagen and
Benno Stein},
title = {args.me corpus},
month = oct,
year ... | The args.me corpus (version 1.0, cleaned) comprises 382 545 arguments crawled from four debate portals in the middle of 2019. The debate portals are Debatewise, IDebate.org, Debatepedia, and Debate.org. The arguments are extracted using heuristics that are designed for each debate portal. | false | 640 | false | cakiki/args_me | 2022-10-25T09:07:25.000Z | null | false | da29f2b2fc7c86176813b8a6440f73e0823f05d3 | [] | [
"annotations_creators:machine-generated",
"language_creators:crowdsourced",
"language:'en-US'",
"license:cc-by-4.0",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"task_categories:text-retrieval",
"task_ids:document-retrieval"
] | https://huggingface.co/datasets/cakiki/args_me/resolve/main/README.md | ---
annotations_creators:
- machine-generated
language_creators:
- crowdsourced
language:
- '''en-US'''
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Webis args.me argument corpus
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-retrieval
task_ids:
- document-retrieval... |
cakiki | null | null | null | false | 167 | false | cakiki/arxiv-metadata | 2022-02-03T20:57:23.000Z | null | false | 3a0dac229b4e21cbde67cb06af07d11fd8bb7c75 | [] | [
"license:cc0-1.0"
] | https://huggingface.co/datasets/cakiki/arxiv-metadata/resolve/main/README.md | ---
license: cc0-1.0
---
|
cakiki | null | null | null | false | 325 | false | cakiki/en_wiki_quote | 2022-02-03T17:36:03.000Z | null | false | 0882808a91679e12e98407691dabd28115bff670 | [] | [
"license:cc-by-sa-3.0"
] | https://huggingface.co/datasets/cakiki/en_wiki_quote/resolve/main/README.md | ---
license: cc-by-sa-3.0
---
|
caltonji | null | null | null | false | 327 | false | caltonji/harrypotter_squad_v2_2 | 2021-12-31T20:01:23.000Z | null | false | aba728f708a01b22a508061490cf389dd15f6ca2 | [] | [] | https://huggingface.co/datasets/caltonji/harrypotter_squad_v2_2/resolve/main/README.md | ## Dataset Summary
Contains 15 Harry Potter trivia questions in Squadv2 format, 3 of which are unanswerable.
## Model Performance
[Test Notebook](https://colab.research.google.com/drive/1VFUJKV7eun68XgQDAHSHsbvoM_CGHzWA?usp=sharing)
| Model | exact | f1 |
| ----------- | ----------- | ----------- |
| Albert Ba... |
cassandra-themis | null | null | QR-AN Dataset: a classification dataset on french Parliament debates
This is a dataset for theme/topic classification, made of questions and answers from https://www2.assemblee-nationale.fr/recherche/resultats_questions.
It contains 188 unbalanced classes, 80k questions-answers divided into 3 splits: train (60k), va... | false | 799 | false | cassandra-themis/QR-AN | 2022-10-24T20:31:22.000Z | null | false | 1059be355e830b808093595856135651e770d22c | [] | [
"language:fr",
"size_categories:10K<n<100K",
"task_categories:summarization",
"task_categories:text-classification",
"task_categories:text-generation",
"task_ids:multi-class-classification",
"task_ids:topic-classification",
"tags:conditional-text-generation"
] | https://huggingface.co/datasets/cassandra-themis/QR-AN/resolve/main/README.md | ---
language:
- fr
size_categories: 10K<n<100K
task_categories:
- summarization
- text-classification
- text-generation
task_ids:
- multi-class-classification
- topic-classification
tags:
- conditional-text-generation
---
**QR-AN Dataset: a classification and generation dataset of french Parliament questions-answers.*... |
castorini | null | @inproceedings{ogueji-etal-2021-small,
title = "Small Data? No Problem! Exploring the Viability of Pretrained Multilingual Language Models for Low-resourced Languages",
author = "Ogueji, Kelechi and
Zhu, Yuxin and
Lin, Jimmy",
booktitle = "Proceedings of the 1st Workshop on Multilingual Repres... | Corpus used for training AfriBERTa models | false | 1,812 | false | castorini/afriberta-corpus | 2022-10-19T21:33:04.000Z | null | false | d83da9653ef2a5f823c3693a28018e3009464522 | [] | [
"language:om",
"language:am",
"language:rw",
"language:rn",
"language:ha",
"language:ig",
"language:pcm",
"language:so",
"language:sw",
"language:ti",
"language:yo",
"language:multilingual",
"license:apache-2.0",
"task_categories:text-generation",
"task_ids:language-modeling"
] | https://huggingface.co/datasets/castorini/afriberta-corpus/resolve/main/README.md | ---
language:
- om
- am
- rw
- rn
- ha
- ig
- pcm
- so
- sw
- ti
- yo
- multilingual
license: apache-2.0
task_categories:
- text-generation
task_ids:
- language-modeling
---
# Dataset Card for AfriBERTa's Corpus
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-s... |
castorini | null | null | null | false | 2,411 | false | castorini/mr-tydi-corpus | 2022-10-12T20:25:51.000Z | null | false | 3a3aa212bbe94a8cc0dc858710a3dad49d532054 | [] | [
"language:ar",
"language:bn",
"language:en",
"language:fi",
"language:id",
"language:ja",
"language:ko",
"language:ru",
"language:sw",
"language:te",
"language:th",
"multilinguality:multilingual",
"task_categories:text-retrieval",
"license:apache-2.0"
] | https://huggingface.co/datasets/castorini/mr-tydi-corpus/resolve/main/README.md | ---
language:
- ar
- bn
- en
- fi
- id
- fi
- ja
- ko
- ru
- sw
- te
- th
multilinguality:
- multilingual
task_categories:
- text-retrieval
license: apache-2.0
---
# Dataset Summary
Mr. TyDi is a multi-lingual benchmark dataset built on TyDi, covering eleven typologically diverse l... |
castorini | null | null | null | false | 2,316 | false | castorini/mr-tydi | 2022-10-12T20:25:19.000Z | null | false | 1d43c80218d06d0ef80f5b172ccabd848b948bc1 | [] | [
"language:ar",
"language:bn",
"language:en",
"language:fi",
"language:id",
"language:ja",
"language:ko",
"language:ru",
"language:sw",
"language:te",
"language:th",
"multilinguality:multilingual",
"task_categories:text-retrieval",
"license:apache-2.0"
] | https://huggingface.co/datasets/castorini/mr-tydi/resolve/main/README.md | ---
language:
- ar
- bn
- en
- fi
- id
- fi
- ja
- ko
- ru
- sw
- te
- th
multilinguality:
- multilingual
task_categories:
- text-retrieval
license: apache-2.0
---
# Dataset Summary
Mr. TyDi is a multi-lingual benchmark dataset built on TyDi, covering eleven typologically diverse l... |
castorini | null | null | null | false | 323 | false | castorini/msmarco_v1_doc_doc2query-t5_expansions | 2022-07-02T19:16:12.000Z | null | false | 73205571221e7eac6953ed884e05c8625e06272c | [] | [
"language:en",
"license:apache-2.0"
] | https://huggingface.co/datasets/castorini/msmarco_v1_doc_doc2query-t5_expansions/resolve/main/README.md | ---
language:
- en
license: apache-2.0
---
# Dataset Summary
The repo provides queries generated for the MS MARCO V1 document corpus with docTTTTTquery (sometimes written as docT5query or doc2query-T5), the latest version of the doc2query family of document expansion models. The basic idea is to train a model, that ... |
castorini | null | null | null | false | 323 | false | castorini/msmarco_v1_doc_segmented_doc2query-t5_expansions | 2021-11-10T04:51:35.000Z | null | false | 4254f0bda2a6e562cb2e53001220e0f1f981d2b8 | [] | [
"language:English",
"license:Apache License 2.0"
] | https://huggingface.co/datasets/castorini/msmarco_v1_doc_segmented_doc2query-t5_expansions/resolve/main/README.md | ---
language:
- English
license: "Apache License 2.0"
---
# Dataset Summary
The repo provides queries generated for the MS MARCO V1 document segmented corpus with docTTTTTquery (sometimes written as docT5query or doc2query-T5), the latest version of the doc2query family of document expansion models. The basic idea i... |
castorini | null | null | null | false | 326 | false | castorini/msmarco_v1_passage_doc2query-t5_expansions | 2022-06-21T17:45:43.000Z | null | false | aca81f4eabebd63c46026565b9123b17269bb1c4 | [] | [
"language:English",
"license:Apache License 2.0"
] | https://huggingface.co/datasets/castorini/msmarco_v1_passage_doc2query-t5_expansions/resolve/main/README.md | ---
language:
- English
license: "Apache License 2.0"
---
# Dataset Summary
The repo provides queries generated for the MS MARCO V1 passage corpus with docTTTTTquery (sometimes written as docT5query or doc2query-T5), the latest version of the doc2query family of document expansion models. The basic idea is to train ... |
castorini | null | null | null | false | 322 | false | castorini/msmarco_v2_doc_doc2query-t5_expansions | 2021-11-11T17:41:32.000Z | null | false | cb336701cbfdf1de2df51de8315b27fcec566c56 | [] | [
"language:English",
"license:Apache License 2.0"
] | https://huggingface.co/datasets/castorini/msmarco_v2_doc_doc2query-t5_expansions/resolve/main/README.md | ---
language:
- English
license: "Apache License 2.0"
---
# Dataset Summary
The repo provides queries generated for the MS MARCO v2 document corpus with docTTTTTquery (sometimes written as docT5query or doc2query-T5), the latest version of the doc2query family of document expansion models. The basic idea is to ... |
castorini | null | null | null | false | 322 | false | castorini/msmarco_v2_doc_segmented_doc2query-t5_expansions | 2021-11-02T08:13:56.000Z | null | false | 61325a80b2ff2b81642bd532483dc51d0b46a8fb | [] | [
"language:English",
"license:Apache License 2.0"
] | https://huggingface.co/datasets/castorini/msmarco_v2_doc_segmented_doc2query-t5_expansions/resolve/main/README.md | ---
language:
- English
license: "Apache License 2.0"
---
# Dataset Summary
The repo provides queries generated for the MS MARCO v2 document segmented corpus with docTTTTTquery (sometimes written as docT5query or doc2query-T5), the latest version of the doc2query family of document expansion models. The basic i... |
castorini | null | null | null | false | 322 | false | castorini/msmarco_v2_passage_doc2query-t5_expansions | 2021-11-02T06:37:36.000Z | null | false | 22a0c06017015ef75b33d066711b1ebc2ddb7e8e | [] | [
"language:English",
"license:Apache License 2.0"
] | https://huggingface.co/datasets/castorini/msmarco_v2_passage_doc2query-t5_expansions/resolve/main/README.md | ---
language:
- English
license: "Apache License 2.0"
---
# Dataset Summary
The repo provides queries generated for the MS MARCO v2 passage corpus with docTTTTTquery (sometimes written as docT5query or doc2query-T5), the latest version of the doc2query family of document expansion models. The basic idea is to t... |
castorini | null | null | null | false | 324 | false | castorini/nq_gar-t5_expansions | 2022-02-17T00:52:17.000Z | null | false | 30ebb5b73cf4b3a1f65de6fbd0471840dc712d34 | [] | [
"language:English",
"license:Apache License 2.0"
] | https://huggingface.co/datasets/castorini/nq_gar-t5_expansions/resolve/main/README.md | ---
language:
- English
license: "Apache License 2.0"
---
# Dataset Summary
The repo provides answer,title and sentence expansions for the Natural Questions corpus with gar-T5.
# Dataset Structure
There are dev and test folds
An example data entry of the dev split looks as follows:
```
{
"id": "... |
castorini | null | null | null | false | 323 | false | castorini/triviaqa_gar-t5_expansions | 2022-02-17T00:58:32.000Z | null | false | 5e899a9b63776d2982c72aa242cc35ecdb7073a4 | [] | [
"language:English",
"license:Apache License 2.0"
] | https://huggingface.co/datasets/castorini/triviaqa_gar-t5_expansions/resolve/main/README.md | ---
language:
- English
license: "Apache License 2.0"
---
# Dataset Summary
The repo provides answer,title and sentence expansions for the Trivia QA corpus with gar-T5.
# Dataset Structure
There are dev and test folds
An example data entry of the dev split looks as follows:
```
{
"id": "1",
... |
ccdv | null | null | Arxiv Classification Dataset: a classification of Arxiv Papers (11 classes).
It contains 11 slightly unbalanced classes, 33k Arxiv Papers divided into 3 splits: train (23k), val (5k) and test (5k).
Copied from "Long Document Classification From Local Word Glimpses via Recurrent Attention Learning" by JUN HE LIQUN WAN... | false | 566 | false | ccdv/arxiv-classification | 2022-10-22T09:23:50.000Z | null | false | f9bd92144ed76200d6eb3ce73a8bd4eba9ffdc85 | [] | [
"language:en",
"task_categories:text-classification",
"tags:long context",
"task_ids:multi-class-classification",
"task_ids:topic-classification",
"size_categories:10K<n<100K"
] | https://huggingface.co/datasets/ccdv/arxiv-classification/resolve/main/README.md | ---
language: en
task_categories:
- text-classification
tags:
- long context
task_ids:
- multi-class-classification
- topic-classification
size_categories: 10K<n<100K
---
**Arxiv Classification: a classification of Arxiv Papers (11 classes).**
This dataset is intended for long context classification (documents have ... |
ccdv | null | @inproceedings{cohan-etal-2018-discourse,
title = "A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents",
author = "Cohan, Arman and
Dernoncourt, Franck and
Kim, Doo Soon and
Bui, Trung and
Kim, Seokhwan and
Chang, Walter and
Goharian, N... | Arxiv dataset for summarization.
From paper: A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents" by A. Cohan et al.
See: https://aclanthology.org/N18-2097.pdf
See: https://github.com/armancohan/long-summarization | false | 20,803 | false | ccdv/arxiv-summarization | 2022-10-24T20:31:40.000Z | null | false | d6b009c8dea00d6db75a680595b4340546ae4020 | [] | [
"language:en",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"task_categories:summarization",
"task_categories:text-generation",
"tags:conditional-text-generation"
] | https://huggingface.co/datasets/ccdv/arxiv-summarization/resolve/main/README.md | ---
language:
- en
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
task_categories:
- summarization
- text-generation
task_ids: []
tags:
- conditional-text-generation
---
# Arxiv dataset for summarization
Dataset for summarization of long documents.\
Adapted from this [repo](https://github.com/armancohan/... |
ccdv | null | @article{DBLP:journals/corr/SeeLM17,
author = {Abigail See and
Peter J. Liu and
Christopher D. Manning},
title = {Get To The Point: Summarization with Pointer-Generator Networks},
journal = {CoRR},
volume = {abs/1704.04368},
year = {2017},
url = {http://a... | CNN/DailyMail non-anonymized summarization dataset.
There are two features:
- article: text of news article, used as the document to be summarized
- highlights: joined text of highlights with <s> and </s> around each
highlight, which is the target summary | false | 3,691 | false | ccdv/cnn_dailymail | 2022-10-24T20:31:59.000Z | cnn-daily-mail-1 | false | dc2ce3bd19d8e323365bc1a244f3dd32e02d4f22 | [] | [
"annotations_creators:no-annotation",
"language_creators:found",
"language:en",
"license:apache-2.0",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"task_categories:summarization",
"task_categories:text-generation",
"tags:conditional-text-generation"
] | https://huggingface.co/datasets/ccdv/cnn_dailymail/resolve/main/README.md | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- summarization
- text-generation
task_ids: []
paperswithcode_id: cnn-daily-mail-1
pretty_name: CNN / Daily M... |
ccdv | null | @misc{huang2021efficient,
title={Efficient Attentions for Long Document Summarization},
author={Luyang Huang and Shuyang Cao and Nikolaus Parulian and Heng Ji and Lu Wang},
year={2021},
eprint={2104.02112},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
} | GovReport dataset for summarization.
From paper: Efficient Attentions for Long Document Summarization" by L. Huang et al.
See: https://arxiv.org/pdf/2104.02112.pdf
See: https://github.com/luyang-huang96/LongDocSum | false | 453 | false | ccdv/govreport-summarization | 2022-10-24T20:32:47.000Z | null | false | b949637ab41c9f668a4b83cea46c80b489c02290 | [] | [
"arxiv:2104.02112",
"language:en",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"task_categories:summarization",
"task_categories:text-generation",
"tags:conditional-text-generation"
] | https://huggingface.co/datasets/ccdv/govreport-summarization/resolve/main/README.md | ---
language:
- en
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
task_categories:
- summarization
- text-generation
task_ids: []
tags:
- conditional-text-generation
---
# GovReport dataset for summarization
Dataset for summarization of long documents.\
Adapted from this [repo](https://github.com/luyang... |
ccdv | null | null | Patent Classification Dataset: a classification of Patents (9 classes).
It contains 9 unbalanced classes, 35k Patents and summaries divided into 3 splits: train (25k), val (5k) and test (5k).
Data are sampled from "BIGPATENT: A Large-Scale Dataset for Abstractive and Coherent Summarization." by Eva Sharma, Chen Li an... | false | 480 | false | ccdv/patent-classification | 2022-10-22T09:25:36.000Z | null | false | 2f38a1dfdecfacee0184d74eaeafd3c0fb49d2a6 | [] | [
"language:en",
"task_categories:text-classification",
"tags:long context",
"task_ids:multi-class-classification",
"task_ids:topic-classification",
"size_categories:10K<n<100K"
] | https://huggingface.co/datasets/ccdv/patent-classification/resolve/main/README.md | ---
language: en
task_categories:
- text-classification
tags:
- long context
task_ids:
- multi-class-classification
- topic-classification
size_categories: 10K<n<100K
---
**Patent Classification: a classification of Patents and abstracts (9 classes).**
This dataset is intended for long context classification (non ab... |
ccdv | null | @inproceedings{cohan-etal-2018-discourse,
title = "A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents",
author = "Cohan, Arman and
Dernoncourt, Franck and
Kim, Doo Soon and
Bui, Trung and
Kim, Seokhwan and
Chang, Walter and
Goharian, N... | PubMed dataset for summarization.
From paper: A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents" by A. Cohan et al.
See: https://aclanthology.org/N18-2097.pdf
See: https://github.com/armancohan/long-summarization | false | 7,727 | false | ccdv/pubmed-summarization | 2022-10-24T20:33:04.000Z | null | false | 26155ccf2b18393a38a05fafc26c66a068974839 | [] | [
"language:en",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"task_categories:summarization",
"task_categories:text-generation",
"tags:conditional-text-generation"
] | https://huggingface.co/datasets/ccdv/pubmed-summarization/resolve/main/README.md | ---
language:
- en
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
task_categories:
- summarization
- text-generation
task_ids: []
tags:
- conditional-text-generation
---
# PubMed dataset for summarization
Dataset for summarization of long documents.\
Adapted from this [repo](https://github.com/armancohan... |
cdleong | null | \\r\n@InProceedings{huggingface:dataset,
title = {A great new dataset},
author={huggingface, Inc.
},
year={2020}
} | \\r\nPig-latin machine and English parallel machine translation corpus.
Based on
The Project Gutenberg EBook of "De Bello Gallico" and Other Commentaries
https://www.gutenberg.org/ebooks/10657
Converted to pig-latin with https://github.com/bpabel/piglatin | false | 323 | false | cdleong/piglatin-mt | 2022-10-24T19:22:09.000Z | null | false | 464088ad69bd568eba869f3af6bc2f16a9cd9a5c | [] | [
"language:en",
"license:mit",
"multilinguality:translation",
"size_categories:10K<n<100K",
"source_datasets:original",
"task_categories:translation",
"language_details:eng and engyay"
] | https://huggingface.co/datasets/cdleong/piglatin-mt/resolve/main/README.md | ---
language:
- en
license:
- mit
multilinguality:
- translation
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- translation
task_ids: []
language_details: eng and engyay
---
## Dataset Description
- **Homepage:** cdleong.github.io
# Dataset Summary:
Pig-latin machine and English paralle... |
cdleong | null | @InProceedings{huggingface:dataset,
title = {A great new dataset},
author={huggingface, Inc.
},
year={2020}
} | This new dataset is designed to solve this great NLP task and is crafted with a lot of care. | false | 167 | false | cdleong/temp_africaNLP_keyword_spotting_for_african_languages | 2022-10-25T09:07:32.000Z | null | false | edb6563c1ba616922132466f1a969807bba8651e | [] | [
"language:wo",
"language:fuc",
"language:srr",
"language:mnk",
"language:snk"
] | https://huggingface.co/datasets/cdleong/temp_africaNLP_keyword_spotting_for_african_languages/resolve/main/README.md | ---
language:
- wo
- fuc
- srr
- mnk
- snk
---
## Dataset Description
- **Homepage:** https://zenodo.org/record/4661645
TEMPORARY TEST DATASET
Not for actual use! Attempting to test out a dataset script for loading https://zenodo.org/record/4661645
|
cemigo | null | null | null | false | 165 | false | cemigo/taylor_vs_shakes | 2021-03-14T23:45:59.000Z | null | false | 2784446f8e97c8a4a2ce7242bb8a7537b36ff3dc | [] | [] | https://huggingface.co/datasets/cemigo/taylor_vs_shakes/resolve/main/README.md | This dataset has 336 pieces of quotes from William Shakespeare and Taylor Swift (labeled) for supervised classification.
Source: https://www.kaggle.com/kellylougheed/tswift-vs-shakespeare |
cfilt | null | null | null | false | 499 | false | cfilt/iitb-english-hindi | 2022-04-26T13:50:22.000Z | null | false | 445aaa1baafa9bf671df3cffaeb149ec44410461 | [] | [] | https://huggingface.co/datasets/cfilt/iitb-english-hindi/resolve/main/README.md | <p align="center"><img src="https://huggingface.co/datasets/cfilt/HiNER-collapsed/raw/main/cfilt-dark-vec.png" alt="Computation for Indian Language Technology Logo" width="150" height="150"/></p>
# IITB-English-Hindi Parallel Corpus
[, with 7,000
points per class. There are 60,000 training points and 10,000 test points. | false | 326 | false | cgarciae/point-cloud-mnist | 2021-10-31T23:09:55.000Z | null | false | b88be4d36f97e51173120d42cd35ce2ffa074cc9 | [] | [] | https://huggingface.co/datasets/cgarciae/point-cloud-mnist/resolve/main/README.md | # Point CLoud MNIST
A point cloud version of the original MNIST.
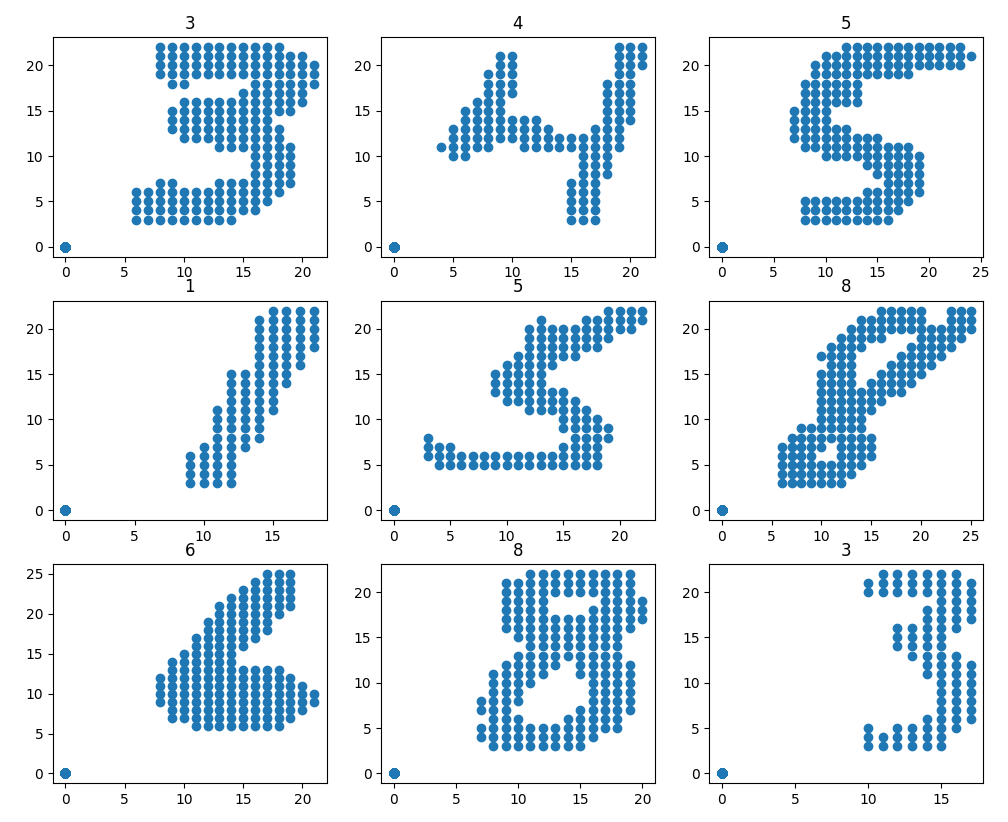
## Getting Started
```python
import matplotlib.pyplot as plt
import numpy as np
from datasets import load_dataset
# load dataset
dataset = load_datase... |
chau | null | null | null | false | 324 | false | chau/ink_test01 | 2022-02-15T09:15:56.000Z | null | false | 8b8191c92578f5f381bd7020eddbb7c334d414eb | [] | [
"license:other"
] | https://huggingface.co/datasets/chau/ink_test01/resolve/main/README.md | ---
license: other
---
|
chenghao | null | null | null | false | 324 | false | chenghao/scielo_books | 2022-07-01T18:34:59.000Z | null | false | c3d46ee0b1969347cb803449156be9a59e275ae7 | [] | [
"annotations_creators:no-annotation",
"language_creators:found",
"language:en",
"language:pt",
"language:es",
"license:cc-by-nc-sa-3.0",
"multilinguality:multilingual",
"size_categories:n<1K",
"source_datasets:original",
"task_ids:language-modeling"
] | https://huggingface.co/datasets/chenghao/scielo_books/resolve/main/README.md | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
- pt
- es
license:
- cc-by-nc-sa-3.0
multilinguality:
- multilingual
paperswithcode_id: null
size_categories:
- n<1K
source_datasets:
- original
task_categories:
- sequence-modeling
task_ids:
- language-modeling
---
## Dataset Descrip... |
cheulyop | null | @article{bang2020ksponspeech,
title={KsponSpeech: Korean spontaneous speech corpus for automatic speech recognition},
author={Bang, Jeong-Uk and Yun, Seung and Kim, Seung-Hi and Choi, Mu-Yeol and Lee, Min-Kyu and Kim, Yeo-Jeong and Kim, Dong-Hyun and Park, Jun and Lee, Young-Jik and Kim, Sang-Hun},
journal={Appli... | KsponSpeech is a large-scale spontaneous speech corpus of Korean conversations. This corpus contains 969 hrs of general open-domain dialog utterances, spoken by about 2,000 native Korean speakers in a clean environment. All data were constructed by recording the dialogue of two people freely conversing on a variety of ... | false | 327 | false | cheulyop/ksponspeech | 2021-10-02T04:27:13.000Z | null | false | d51bd8aa4dcb0d95600de289e7c6ea761d412c2d | [] | [] | https://huggingface.co/datasets/cheulyop/ksponspeech/resolve/main/README.md | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
---
# Dataset Card for [KsponSpeech]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported T... |
chitra | null | null | null | false | 322 | false | chitra/contradictionNLI | 2021-12-29T10:45:19.000Z | null | false | b1e632ba5e39486891c9ade0d6ba70561993c91d | [] | [] | https://huggingface.co/datasets/chitra/contradictionNLI/resolve/main/README.md | This data can help in solving contradiction detection problem. this data is picked from kaggle.
reference - Contradictory, My DWatson |
chmanoj | null | null | null | false | 320 | false | chmanoj/ai4bharat__samanantar_processed_te | 2022-02-05T04:02:51.000Z | null | false | de949e03d6bdecb42f9300fb9be8f5a9b5acf5f4 | [] | [] | https://huggingface.co/datasets/chmanoj/ai4bharat__samanantar_processed_te/resolve/main/README.md | This is extracted from telugu subset from https://huggingface.co/datasets/ai4bharat/samanantar - used to create telugu kenLM models for ASR decoding. |
chopey | null | null | null | false | 321 | false | chopey/dhivehi | 2021-11-30T03:41:11.000Z | null | false | 24fba98c601fcde47d5a50fe72d54fdf70b69e11 | [] | [] | https://huggingface.co/datasets/chopey/dhivehi/resolve/main/README.md | Dhivehi dataset for MNT |
clarin-pl | null | """
_DESCRIPTION = | This dataset is designed to be used in training models
that restore punctuation marks from the output of
Automatic Speech Recognition system for Polish language. | false | 319 | false | clarin-pl/2021-punctuation-restoration | 2022-08-29T16:39:18.000Z | null | false | 6051cc3ed097fbbe93c7cc2c480279e230f43e93 | [] | [
"annotations_creators:crowdsourced",
"language:pl",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:n<1K",
"task_categories:automatic-speech-recognition"
] | https://huggingface.co/datasets/clarin-pl/2021-punctuation-restoration/resolve/main/README.md | ---
annotations_creators:
- crowdsourced
language:
- pl
language_creators:
- crowdsourced
license: []
multilinguality:
- monolingual
pretty_name: 2021-punctuation-restoration
size_categories:
- n<1K
source_datasets: []
tags: []
task_categories:
- automatic-speech-recognition
task_ids: []
---
# Punctuation restoration ... |
clarin-pl | null | @misc{11321/849,
title = {{AspectEmo} 1.0: Multi-Domain Corpus of Consumer Reviews for Aspect-Based Sentiment Analysis},
author = {Koco{\'n}, Jan and Radom, Jarema and Kaczmarz-Wawryk, Ewa and Wabnic, Kamil and Zaj{\c a}czkowska, Ada and Za{\'s}ko-Zieli{\'n}ska, Monika},
url = {http://hdl.handle.net/11321/849},
... | AspectEmo dataset: Multi-Domain Corpus of Consumer Reviews for Aspect-Based
Sentiment Analysis | false | 355 | false | clarin-pl/aspectemo | 2022-08-29T16:39:32.000Z | null | false | 55467c09094ac3a0d8261013f884f8f3247b53a0 | [] | [
"annotations_creators:expert-generated",
"language_creators:other",
"language:pl",
"license:mit",
"multilinguality:monolingual",
"size_categories:1K",
"size_categories:1K<n<10K",
"source_datasets:original",
"task_categories:token-classification",
"task_ids:sentiment-classification"
] | https://huggingface.co/datasets/clarin-pl/aspectemo/resolve/main/README.md | ---
annotations_creators:
- expert-generated
language_creators:
- other
language:
- pl
license:
- mit
multilinguality:
- monolingual
pretty_name: 'AspectEmo'
size_categories:
- 1K
- 1K<n<10K
source_datasets:
- original
task_categories:
- token-classification
task_ids:
- sentiment-classification
---
# AspectE... |
clarin-pl | null | null | KPWR-NER tagging dataset. | false | 1,248 | false | clarin-pl/kpwr-ner | 2022-08-29T16:39:44.000Z | null | false | 6fd17a22c100eb9039060e986cc5b97d2831fdab | [] | [
"annotations_creators:expert-generated",
"language_creators:found",
"language:pl",
"license:cc-by-3.0",
"multilinguality:monolingual",
"size_categories:18K",
"size_categories:10K<n<100K",
"source_datasets:original",
"task_ids:named-entity-recognition"
] | https://huggingface.co/datasets/clarin-pl/kpwr-ner/resolve/main/README.md | ---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- pl
license:
- cc-by-3.0
multilinguality:
- monolingual
pretty_name: 'KPWr-NER'
size_categories:
- 18K
- 10K<n<100K
source_datasets:
- original
task_categories:
- structure-prediction
task_ids:
- named-entity-recognition
---
# KPWR-NER
... |
clarin-pl | null | null | NKJP-POS tagging dataset. | false | 431 | false | clarin-pl/nkjp-pos | 2022-08-29T16:39:54.000Z | null | false | 03b3c3c98a06e64e47878ddfd67ae69f03bf2419 | [] | [
"annotations_creators:expert-generated",
"language_creators:other",
"language:pl",
"license:gpl-3.0",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"task_ids:part-of-speech-tagging"
] | https://huggingface.co/datasets/clarin-pl/nkjp-pos/resolve/main/README.md | ---
annotations_creators:
- expert-generated
language_creators:
- other
language:
- pl
license:
- gpl-3.0
multilinguality:
- monolingual
pretty_name: 'nkjp-pos'
size_categories:
- unknown
source_datasets:
- original
task_categories:
- structure-prediction
task_ids:
- part-of-speech-tagging
---
# nkjp-pos
## Descripti... |
clarin-pl | null | @inproceedings{kocon-etal-2019-multi,
title = "Multi-Level Sentiment Analysis of {P}ol{E}mo 2.0: Extended Corpus of Multi-Domain Consumer Reviews",
author = "Koco{\'n}, Jan and
Mi{\l}kowski, Piotr and
Za{\'s}ko-Zieli{\'n}ska, Monika",
booktitle = "Proceedings of the 23rd Conference on Computat... | PolEmo 2.0: Corpus of Multi-Domain Consumer Reviews, evaluation data for article presented at CoNLL. | false | 2,959 | false | clarin-pl/polemo2-official | 2022-08-29T16:40:01.000Z | null | false | 802e35d2b12bae84bb07911d841e8f046dc2fcef | [] | [
"annotations_creators:expert-generated",
"language_creators:other",
"language:pl",
"license:cc-by-sa-4.0",
"multilinguality:monolingual",
"size_categories:8K",
"size_categories:1K<n<10K",
"source_datasets:original",
"task_categories:text-classification",
"task_ids:sentiment-classification"
] | https://huggingface.co/datasets/clarin-pl/polemo2-official/resolve/main/README.md | ---
annotations_creators:
- expert-generated
language_creators:
- other
language:
- pl
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
pretty_name: 'Polemo2'
size_categories:
- 8K
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- sentiment-classification
---
# P... |
classla | null | @misc{ljubešić2019frenk,
title={The FRENK Datasets of Socially Unacceptable Discourse in Slovene and English},
author={Nikola Ljubešić and Darja Fišer and Tomaž Erjavec},
year={2019},
eprint={1906.02045},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/... | The FRENK Datasets of Socially Unacceptable Discourse in English. | false | 489 | false | classla/FRENK-hate-en | 2022-10-21T07:52:06.000Z | null | false | 52483dba0ff23291271ee9249839865e3c3e7e50 | [] | [
"arxiv:1906.02045",
"language:en",
"license:other",
"size_categories:1K<n<10K",
"task_categories:text-classification",
"tags:hate-speech-detection",
"tags:offensive-language"
] | https://huggingface.co/datasets/classla/FRENK-hate-en/resolve/main/README.md | ---
language:
- en
license:
- other
size_categories:
- 1K<n<10K
task_categories:
- text-classification
task_ids: []
tags:
- hate-speech-detection
- offensive-language
---
# Offensive language dataset of Croatian comments FRENK 1.0
English subset of the [FRENK dataset](http://hdl.handle.net/11356/1433). Also available... |
classla | null | @misc{ljubešić2019frenk,
title={The FRENK Datasets of Socially Unacceptable Discourse in Slovene and English},
author={Nikola Ljubešić and Darja Fišer and Tomaž Erjavec},
year={2019},
eprint={1906.02045},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/... | The FRENK Datasets of Socially Unacceptable Discourse in Croatian. | false | 483 | false | classla/FRENK-hate-hr | 2022-10-21T07:46:28.000Z | null | false | e7fc9f3d8d6c5640a26679d8a50b1666b02cc41f | [] | [
"arxiv:1906.02045",
"language:hr",
"license:other",
"size_categories:1K<n<10K",
"task_categories:text-classification",
"tags:hate-speech-detection",
"tags:offensive-language"
] | https://huggingface.co/datasets/classla/FRENK-hate-hr/resolve/main/README.md | ---
language:
- hr
license:
- other
size_categories:
- 1K<n<10K
task_categories:
- text-classification
task_ids: []
tags:
- hate-speech-detection
- offensive-language
---
# Offensive language dataset of Croatian comments FRENK 1.0
Croatian subset of the [FRENK dataset](http://hdl.handle.net/11356/1433). Also availabl... |
classla | null | @misc{ljubešić2019frenk,
title={The FRENK Datasets of Socially Unacceptable Discourse in Slovene and English},
author={Nikola Ljubešić and Darja Fišer and Tomaž Erjavec},
year={2019},
eprint={1906.02045},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/... | The FRENK Datasets of Socially Unacceptable Discourse in Slovene. | false | 482 | false | classla/FRENK-hate-sl | 2022-10-21T07:46:11.000Z | null | false | 37c8b42c63d4eb75f549679158a85eb5bd984caa | [] | [
"arxiv:1906.02045",
"language:sl",
"license:other",
"size_categories:1K<n<10K",
"task_categories:text-classification",
"tags:hate-speech-detection",
"tags:offensive-language"
] | https://huggingface.co/datasets/classla/FRENK-hate-sl/resolve/main/README.md | ---
language:
- sl
license:
- other
size_categories:
- 1K<n<10K
task_categories:
- text-classification
task_ids: []
tags:
- hate-speech-detection
- offensive-language
---
Slovenian subset of the [FRENK dataset](http://hdl.handle.net/11356/1433). Also available on HuggingFace dataset hub: [English subset](https://hugg... |
classla | null | @article{DBLP:journals/corr/abs-2104-09243,
author = {Nikola Ljubesic and
Davor Lauc},
title = {BERTi{\'{c}} - The Transformer Language Model for Bosnian, Croatian,
Montenegrin and Serbian},
journal = {CoRR},
volume = {abs/2104.09243},
year = {2021},
url ... | The COPA-HR dataset (Choice of plausible alternatives in Croatian) is a translation
of the English COPA dataset (https://people.ict.usc.edu/~gordon/copa.html) by following the
XCOPA dataset translation methodology (https://arxiv.org/abs/2005.00333). The dataset consists of 1000 premises
(My body cast a shadow over t... | false | 681 | false | classla/copa_hr | 2022-10-25T07:32:15.000Z | null | false | f3f3a4708e6f8b92915ab02c20ac7fb829e45173 | [] | [
"arxiv:2005.00333",
"arxiv:2104.09243",
"language:hr",
"license:cc-by-sa-4.0",
"task_categories:text-classification",
"task_ids:natural-language-inference",
"tags:causal-reasoning",
"tags:textual-entailment",
"tags:commonsense-reasoning"
] | https://huggingface.co/datasets/classla/copa_hr/resolve/main/README.md | ---
language:
- hr
license:
- cc-by-sa-4.0
task_categories:
- text-classification
task_ids:
- natural-language-inference
tags:
- causal-reasoning
- textual-entailment
- commonsense-reasoning
---
The COPA-HR dataset (Choice of plausible alternatives in Croatian) is a translation
of the English COPA dataset (https://peo... |
classla | null | null | The hr500k training corpus contains about 500,000 tokens manually annotated on the levels of
tokenisation, sentence segmentation, morphosyntactic tagging, lemmatisation and named entities.
On the sentence level, the dataset contains 20159 training samples, 1963 validation samples and 2672 test samples
across the re... | false | 637 | false | classla/hr500k | 2022-10-25T07:32:05.000Z | null | false | 708662e326e2e0ee4ce0fb7fa4e41db6c93771f0 | [] | [
"language:hr",
"license:cc-by-sa-4.0",
"task_categories:other",
"task_ids:lemmatization",
"task_ids:named-entity-recognition",
"task_ids:part-of-speech",
"tags:structure-prediction",
"tags:normalization",
"tags:tokenization"
] | https://huggingface.co/datasets/classla/hr500k/resolve/main/README.md | ---
language:
- hr
license:
- cc-by-sa-4.0
task_categories:
- other
task_ids:
- lemmatization
- named-entity-recognition
- part-of-speech
tags:
- structure-prediction
- normalization
- tokenization
---
The hr500k training corpus contains 506,457 Croatian tokens manually annotated on the levels of tokenisation, sentenc... |
classla | null | null | The dataset contains 6273 training samples, 762 validation samples and 749 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent_id'),
list of tokens ('tokens'), list of normalised word forms ('norms'), list of lemmas ('lemmas'),
list of Multext-East tags ('xpos_tags... | false | 323 | false | classla/janes_tag | 2022-10-25T07:31:04.000Z | null | false | ba014295e666710c5dfe6215338933ecf235156c | [] | [
"language:si",
"license:cc-by-sa-4.0",
"task_categories:other",
"task_ids:lemmatization",
"task_ids:part-of-speech",
"tags:structure-prediction",
"tags:normalization",
"tags:tokenization"
] | https://huggingface.co/datasets/classla/janes_tag/resolve/main/README.md | ---
language:
- si
license:
- cc-by-sa-4.0
task_categories:
- other
task_ids:
- lemmatization
- part-of-speech
tags:
- structure-prediction
- normalization
- tokenization
---
The dataset contains 6273 training samples, 762 validation samples and 749 test samples.
Each sample represents a sentence and includes the foll... |
classla | null | null | The dataset contains 6339 training samples, 815 validation samples and 785 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent_id'),
list of tokens ('tokens'), list of lemmas ('lemmas'), list of UPOS tags ('upos_tags'),
list of Multext-East tags ('xpos_tags), list ... | false | 324 | false | classla/reldi_hr | 2022-10-25T07:30:56.000Z | null | false | da293b9a70a87a936777e93dd59046ddbc6399ce | [] | [
"language:hr",
"license:cc-by-sa-4.0",
"task_categories:other",
"task_ids:lemmatization",
"task_ids:named-entity-recognition",
"task_ids:part-of-speech",
"tags:structure-prediction",
"tags:normalization",
"tags:tokenization"
] | https://huggingface.co/datasets/classla/reldi_hr/resolve/main/README.md | ---
language:
- hr
license:
- cc-by-sa-4.0
task_categories:
- other
task_ids:
- lemmatization
- named-entity-recognition
- part-of-speech
tags:
- structure-prediction
- normalization
- tokenization
---
This dataset is based on 3,871 Croatian tweets that were segmented into sentences, tokens, and annotated with normaliz... |
classla | null | null | The dataset contains 5462 training samples, 711 validation samples and 725 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent_id'),
list of tokens ('tokens'), list of lemmas ('lemmas'), list of UPOS tags ('upos_tags'),
list of Multext-East tags ('xpos_tags), list ... | false | 323 | false | classla/reldi_sr | 2022-10-25T07:30:33.000Z | null | false | 10a37a1a9ea782093646e0b03d5ef05b3e1e11d5 | [] | [
"language:sr",
"license:cc-by-sa-4.0",
"task_categories:other",
"task_ids:lemmatization",
"task_ids:named-entity-recognition",
"task_ids:part-of-speech",
"tags:structure-prediction",
"tags:normalization",
"tags:tokenization"
] | https://huggingface.co/datasets/classla/reldi_sr/resolve/main/README.md | ---
language:
- sr
license:
- cc-by-sa-4.0
task_categories:
- other
task_ids:
- lemmatization
- named-entity-recognition
- part-of-speech
tags:
- structure-prediction
- normalization
- tokenization
---
This dataset is based on 3,748 Serbian tweets that were segmented into sentences, tokens, and annotated with normalize... |
classla | null | null | SETimes_sr is a Serbian dataset annotated for morphosyntactic information and named entities.
The dataset contains 3177 training samples, 395 validation samples and 319 test samples
across the respective data splits. Each sample represents a sentence and includes the following features:
sentence ID ('sent_id'), sente... | false | 637 | false | classla/setimes_sr | 2022-10-25T07:30:04.000Z | null | false | 42861d4054bc5fb993e6606e3c70a2957ec52e91 | [] | [
"language:sr",
"license:cc-by-sa-4.0",
"task_categories:other",
"task_ids:lemmatization",
"task_ids:named-entity-recognition",
"task_ids:part-of-speech",
"tags:structure-prediction",
"tags:normalization",
"tags:tokenization"
] | https://huggingface.co/datasets/classla/setimes_sr/resolve/main/README.md | ---
language:
- sr
license:
- cc-by-sa-4.0
task_categories:
- other
task_ids:
- lemmatization
- named-entity-recognition
- part-of-speech
tags:
- structure-prediction
- normalization
- tokenization
---
The SETimes\_sr training corpus contains 86,726 Serbian tokens manually annotated on the levels of tokenisation, sent... |
classla | null | null | The dataset contains 7432 training samples, 1164 validation samples and 893 test samples.
Each sample represents a sentence and includes the following features: sentence ID ('sent_id'),
list of tokens ('tokens'), list of lemmas ('lemmas'),
list of Multext-East tags ('xpos_tags), list of UPOS tags ('upos_tags'), list... | false | 637 | false | classla/ssj500k | 2022-10-28T05:37:22.000Z | null | false | 446b04c97cb43772a229cebbb8da0ce05ee03d2d | [] | [
"language:sl",
"license:cc-by-sa-4.0",
"task_categories:token-classification",
"task_ids:lemmatization",
"task_ids:named-entity-recognition",
"task_ids:parsing",
"task_ids:part-of-speech",
"tags:structure-prediction",
"tags:tokenization",
"tags:dependency-parsing"
] | https://huggingface.co/datasets/classla/ssj500k/resolve/main/README.md | ---
language:
- sl
license:
- cc-by-sa-4.0
task_categories:
- token-classification
task_ids:
- lemmatization
- named-entity-recognition
- parsing
- part-of-speech
tags:
- structure-prediction
- tokenization
- dependency-parsing
---
The dataset contains 7432 training samples, 1164 validation samples and 893 test samples... |
clem | null | null | null | false | 166 | false | clem/autonlp-data-french_word_detection | 2021-09-14T09:45:38.000Z | null | false | dcbb0c37d501225a976dc9e8a12bf0e20c8e2e04 | [] | [] | https://huggingface.co/datasets/clem/autonlp-data-french_word_detection/resolve/main/README.md | This is a very good dataset! |
clips | null | @InProceedings{mfaq_a_multilingual_dataset,
title={MFAQ: a Multilingual FAQ Dataset},
author={Maxime {De Bruyn} and Ehsan Lotfi and Jeska Buhmann and Walter Daelemans},
year={2021},
booktitle={MRQA @ EMNLP 2021}
} | We present the first multilingual FAQ dataset publicly available. We collected around 6M FAQ pairs from the web, in 21 different languages. | false | 7,127 | false | clips/mfaq | 2022-10-20T11:32:50.000Z | null | false | 87a7bada8da4fe2a7b738c6d3e549153383198ad | [] | [
"arxiv:2109.12870",
"annotations_creators:no-annotation",
"language_creators:other",
"language:cs",
"language:da",
"language:de",
"language:en",
"language:es",
"language:fi",
"language:fr",
"language:he",
"language:hr",
"language:hu",
"language:id",
"language:it",
"language:nl",
"lan... | https://huggingface.co/datasets/clips/mfaq/resolve/main/README.md | ---
annotations_creators:
- no-annotation
language_creators:
- other
language:
- cs
- da
- de
- en
- es
- fi
- fr
- he
- hr
- hu
- id
- it
- nl
- 'no'
- pl
- pt
- ro
- ru
- sv
- tr
- vi
license:
- cc0-1.0
multilinguality:
- multilingual
pretty_name: MFAQ - a Multilingual FAQ Dataset
size_categories:
- unknown
source_da... |
clips | null | @misc{debruyn2021mfaq,
title={MFAQ: a Multilingual FAQ Dataset},
author={Maxime {De Bruyn} and Ehsan Lotfi and Jeska Buhmann and Walter Daelemans},
year={2021},
booktitle={MRQA@EMNLP2021},
} | MQA is a multilingual corpus of questions and answers parsed from the Common Crawl. Questions are divided between Frequently Asked Questions (FAQ) pages and Community Question Answering (CQA) pages. | false | 42,844 | false | clips/mqa | 2022-09-27T12:38:50.000Z | null | false | 27eebc4a00d229f8dd4ae2a6d9f1e4ad45781f3b | [] | [
"annotations_creators:no-annotation",
"language_creators:other",
"language:ca",
"language:en",
"language:de",
"language:es",
"language:fr",
"language:ru",
"language:ja",
"language:it",
"language:zh",
"language:pt",
"language:nl",
"language:tr",
"language:pl",
"language:vi",
"language... | https://huggingface.co/datasets/clips/mqa/resolve/main/README.md | ---
annotations_creators:
- no-annotation
language_creators:
- other
language:
- ca
- en
- de
- es
- fr
- ru
- ja
- it
- zh
- pt
- nl
- tr
- pl
- vi
- ar
- id
- uk
- ro
- no
- th
- sv
- el
- fi
- he
- da
- cs
- ko
- fa
- hi
- hu
- sk
- lt
- et
- hr
- is
- lv
- ms
- bg
- sr
- ca
license:
- cc0-1.0
multilinguality:
- mu... |
cnrcastroli | null | null | null | false | 164 | false | cnrcastroli/aaaa | 2021-03-04T21:51:21.000Z | null | false | 3a1dc9acf1e9957e628865fa9937a70f71cf5f3f | [] | [] | https://huggingface.co/datasets/cnrcastroli/aaaa/resolve/main/README.md | fwefwefewf |
coastalcph | null | @inproceedings{chalkidis-etal-2022-fairlex,
author={Chalkidis, Ilias and Passini, Tommaso and Zhang, Sheng and
Tomada, Letizia and Schwemer, Sebastian Felix and Søgaard, Anders},
title={FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing},
booktitle={Proceedings of... | Fairlex: A multilingual benchmark for evaluating fairness in legal text processing. | false | 142 | false | coastalcph/fairlex | 2022-10-20T19:44:27.000Z | null | false | 9c674e0bf7afe89ab6e6de354594081955248a05 | [] | [
"arxiv:2103.13868",
"arxiv:2105.03887",
"annotations_creators:found",
"annotations_creators:machine-generated",
"language_creators:found",
"language:en",
"language:de",
"language:fr",
"language:it",
"language:zh",
"license:cc-by-nc-sa-4.0",
"multilinguality:monolingual",
"multilinguality:mul... | https://huggingface.co/datasets/coastalcph/fairlex/resolve/main/README.md | ---
annotations_creators:
- found
- machine-generated
language_creators:
- found
language:
- en
- en
- de
- fr
- it
- zh
license:
- cc-by-nc-sa-4.0
multilinguality:
ecthr:
- monolingual
scotus:
- monolingual
fscs:
- multilingual
cail:
- monolingual
size_categories:
ecthr:
- 10K<n<100K
scotus:
- ... |
codeceejay | null | null | null | false | 165 | false | codeceejay/ng_accent | 2022-01-28T16:41:32.000Z | null | false | 6e4bef0cfa6a9570ba29b06ca47a2db111f71cc0 | [] | [] | https://huggingface.co/datasets/codeceejay/ng_accent/resolve/main/README.md | |
cointegrated | null | null | null | false | 322 | false | cointegrated/ru-paraphrase-NMT-Leipzig | 2022-10-23T12:23:15.000Z | null | false | 9070da7298a73ea6129f711916f17e52d82884de | [] | [
"annotations_creators:no-annotation",
"language_creators:machine-generated",
"language:ru",
"license:cc-by-4.0",
"multilinguality:translation",
"size_categories:100K<n<1M",
"source_datasets:extended|other",
"task_categories:text-generation",
"tags:conditional-text-generation",
"tags:paraphrase-gen... | https://huggingface.co/datasets/cointegrated/ru-paraphrase-NMT-Leipzig/resolve/main/README.md | ---
annotations_creators:
- no-annotation
language_creators:
- machine-generated
language:
- ru
license:
- cc-by-4.0
multilinguality:
- translation
size_categories:
- 100K<n<1M
source_datasets:
- extended|other
task_categories:
- text-generation
pretty_name: ru-paraphrase-NMT-Leipzig
tags:
- conditional-text-generatio... |
collectivat | null | @inproceedings{kulebi18_iberspeech,
author={Baybars Külebi and Alp Öktem},
title={{Building an Open Source Automatic Speech Recognition System for Catalan}},
year=2018,
booktitle={Proc. IberSPEECH 2018},
pages={25--29},
doi={10.21437/IberSPEECH.2018-6}
} | This corpus includes 240 hours of Catalan speech from broadcast material.
The details of segmentation, data processing and also model training are explained in Külebi, Öktem; 2018.
The content is owned by Corporació Catalana de Mitjans Audiovisuals, SA (CCMA);
we processed their material and hereby making it available ... | false | 320 | false | collectivat/tv3_parla | 2022-10-25T11:46:40.000Z | null | false | c7c41c1de61a15c5e4990b3574c2c3baa2119e41 | [] | [
"annotations_creators:found",
"language_creators:found",
"language:ca",
"license:cc-by-nc-4.0",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"task_categories:automatic-speech-recognition",
"task_categories:text-generation",
"task_ids:language-modeling"
] | https://huggingface.co/datasets/collectivat/tv3_parla/resolve/main/README.md | ---
annotations_creators:
- found
language_creators:
- found
language:
- ca
license:
- cc-by-nc-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- automatic-speech-recognition
- text-generation
task_ids:
- language-modeling
pretty_name: TV3Parla
---
# Dataset... |
comodoro | null | null | null | false | 319 | false | comodoro/pscr | 2022-02-08T07:07:49.000Z | null | false | 853146eccb23be28175456f81456e82cba2f83f1 | [] | [
"license:cc-by-nc-3.0"
] | https://huggingface.co/datasets/comodoro/pscr/resolve/main/README.md | ---
license: cc-by-nc-3.0
---
|
comodoro | null | @misc{11234/1-1740,
title = {Vystadial 2016 – Czech data},
author = {Pl{\'a}tek, Ond{\v r}ej and Du{\v s}ek, Ond{\v r}ej and Jur{\v c}{\'{\i}}{\v c}ek, Filip},
url = {http://hdl.handle.net/11234/1-1740},
note = {{LINDAT}/{CLARIAH}-{CZ} digital library at the Institute of Formal and Applied Linguistics ({{\'U}FAL})... | This is the Czech data collected during the `VYSTADIAL` project. It is an extension of the 'Vystadial 2013' Czech part data release. The dataset comprises of telephone conversations in Czech, developed for training acoustic models for automatic speech recognition in spoken dialogue systems. | false | 319 | false | comodoro/vystadial2016_asr | 2022-09-02T08:41:16.000Z | null | false | 219094aed954b897758697a8921a854f5e199b70 | [] | [
"license:cc-by-nc-3.0"
] | https://huggingface.co/datasets/comodoro/vystadial2016_asr/resolve/main/README.md | ---
license: cc-by-nc-3.0
---
|
corypaik | null | @misc{paik2021world,
title={The World of an Octopus: How Reporting Bias Influences a Language Model's Perception of Color},
author={Cory Paik and Stéphane Aroca-Ouellette and Alessandro Roncone and Katharina Kann},
year={2021},
eprint={2110.08182},
archivePrefix={arXiv},
primaryClass... | *The Color Dataset* (CoDa) is a probing dataset to evaluate the representation of visual properties in language models. CoDa consists of color distributions for 521 common objects, which are split into 3 groups: Single, Multi, and Any. | false | 518 | false | corypaik/coda | 2022-10-20T16:57:23.000Z | coda | false | 9f47e7ea19a1f969027a138c92e4e3a71b5537d3 | [] | [
"arxiv:2110.08182",
"annotations_creators:crowdsourced",
"language_creators:expert-generated",
"language:en",
"language_bcp47:en-US",
"license:apache-2.0",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"task_ids:text-scoring-other-distribution-prediction"... | https://huggingface.co/datasets/corypaik/coda/resolve/main/README.md | ---
annotations_creators:
- crowdsourced
language_creators:
- expert-generated
language:
- en
language_bcp47:
- en-US
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: CoDa
paperswithcode_id: coda
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-scoring
task_ids:
- text-... |
corypaik | null | @inproceedings{aroca-ouellette-etal-2021-prost,
title = "{PROST}: {P}hysical Reasoning about Objects through Space and Time",
author = "Aroca-Ouellette, St{\'e}phane and
Paik, Cory and
Roncone, Alessandro and
Kann, Katharina",
booktitle = "Findings of the Association for Computational Linguistics: ... | *Physical Reasoning about Objects Through Space and Time* (PROST) is a probing dataset to evaluate the ability of pretrained LMs to understand and reason about the physical world. PROST consists of 18,736 cloze-style multiple choice questions from 14 manually curated templates, covering 10 physical reasoning concepts: ... | false | 779 | false | corypaik/prost | 2022-10-25T09:07:34.000Z | prost | false | b3efebf08969fc19335ba894353316878b6fa493 | [] | [
"arxiv:2106.03634",
"annotations_creators:expert-generated",
"extended:original",
"language_creators:expert-generated",
"language:en-US",
"license:apache-2.0",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"task_categories:question-answering",
"task_ids... | https://huggingface.co/datasets/corypaik/prost/resolve/main/README.md | ---
annotations_creators:
- expert-generated
extended:
- original
language_creators:
- expert-generated
language:
- en-US
license:
- apache-2.0
multilinguality:
- monolingual
paperswithcode_id: prost
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- question-answering
task_ids:
- multiple-cho... |
coyotte508 | null | null | null | false | 322 | false | coyotte508/dataset | 2022-07-08T11:20:09.000Z | wider-face-1 | false | 9dd3cd583a7f1f4400a53ab0c9fc4b3dec4d5071 | [] | [
"arxiv:1511.06523",
"annotations_creators:expert-generated",
"language_creators:found",
"language:en",
"license:cc-by-nc-nd-4.0",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other-wider",
"task_categories:object-detection",
"task_ids:face-detection"
] | https://huggingface.co/datasets/coyotte508/dataset/resolve/main/README.md | ---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- en
license:
- cc-by-nc-nd-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|other-wider
task_categories:
- object-detection
task_ids:
- face-detection
paperswithcode_id: wider-face-1
pretty_nam... |
csarron | null | null | null | false | 9 | false | csarron/25m-img-caps | 2022-03-28T18:51:26.000Z | null | false | bfd4f4689c343cabfc936eb4c12f026df15cf977 | [] | [] | https://huggingface.co/datasets/csarron/25m-img-caps/resolve/main/README.md | see https://huggingface.co/datasets/csarron/4m-img-caps for example usage |
csarron | null | null | null | false | 10 | false | csarron/4m-img-caps | 2022-03-28T18:50:53.000Z | null | false | b27ebb236e94f8d090891e010f93832dccb034d3 | [] | [] | https://huggingface.co/datasets/csarron/4m-img-caps/resolve/main/README.md | see [read_pyarrow.py](https://gist.github.com/csarron/df712e53c9e0dcaad4eb6843e7a3d51c#file-read_pyarrow-py) for how to read one pyarrow file.
example PyTorch dataset:
```python
from torch.utils.data import Dataset
class ImageCaptionArrowDataset(Dataset):
def __init__(
self,
dataset_file,
... |
csebuetnlp | null | @inproceedings{hasan-etal-2021-xl,
title = "{XL}-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages",
author = "Hasan, Tahmid and
Bhattacharjee, Abhik and
Islam, Md. Saiful and
Mubasshir, Kazi and
Li, Yuan-Fang and
Kang, Yong-Bin and
Rahman, M. Soh... | We present XLSum, a comprehensive and diverse dataset comprising 1.35 million professionally
annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics.
The dataset covers 45 languages ranging from low to high-resource, for many of which no
public dataset is currently available. X... | false | 7,806 | false | csebuetnlp/xlsum | 2022-08-10T11:33:03.000Z | xl-sum | false | 33bf2120fc639aac8c9ebc3248d77618efb9d7d6 | [] | [
"arxiv:1607.01759",
"task_ids:summarization",
"language:am",
"language:ar",
"language:az",
"language:bn",
"language:my",
"language:zh",
"language:en",
"language:fr",
"language:gu",
"language:ha",
"language:hi",
"language:ig",
"language:id",
"language:ja",
"language:rn",
"language:k... | https://huggingface.co/datasets/csebuetnlp/xlsum/resolve/main/README.md | ---
task_categories:
- conditional-text-generation
task_ids:
- summarization
language:
- am
- ar
- az
- bn
- my
- zh
- en
- fr
- gu
- ha
- hi
- ig
- id
- ja
- rn
- ko
- ky
- mr
- ne
- om
- ps
- fa
- pcm
- pt
- pa
- ru
- gd
- sr
- si
- so
- es
- sw
- ta
- te
- th
- ti
- tr
- uk
- ur
- uz
- vi
- cy
- yo
size_categories:
... |
csebuetnlp | null | @misc{bhattacharjee2021banglabert,
title={BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding},
author={Abhik Bhattacharjee and Tahmid Hasan and Kazi Samin and Md Saiful Islam and M. Sohel Rahman and Anindya Iqbal and Rifat Shahriyar},
year={2021},
... | This is a Natural Language Inference (NLI) dataset for Bengali, curated using the subset of
MNLI data used in XNLI and state-of-the-art English to Bengali translation model. | false | 339 | false | csebuetnlp/xnli_bn | 2022-08-21T13:14:56.000Z | null | false | a18ecb62d7ffd4a6bff5756afb6e799bbb91dd3e | [] | [
"arxiv:2101.00204",
"arxiv:2007.01852",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:extended",
"task_categories:text-classification",
"task_ids:natural-language-inference",
"language:bn",
"licen... | https://huggingface.co/datasets/csebuetnlp/xnli_bn/resolve/main/README.md | ---
annotations_creators:
- machine-generated
language_creators:
- found
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- extended
task_categories:
- text-classification
task_ids:
- natural-language-inference
language:
- bn
license:
- cc-by-nc-sa-4.0
---
# Dataset Card for `xnli_bn`
## T... |
cstrathe435 | null | null | null | false | 324 | false | cstrathe435/Task2Dial | 2022-02-03T12:55:28.000Z | null | false | d810e76b4b49ceffb417666524b0daabd94c059c | [] | [] | https://huggingface.co/datasets/cstrathe435/Task2Dial/resolve/main/README.md | # Dataset Card for Task2Dial
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](... |
ctu-aic | null | @article{DBLP:journals/corr/abs-2201-11115,
author = {Jan Drchal and
Herbert Ullrich and
Martin R{\'{y}}par and
Hana Vincourov{\'{a}} and
V{\'{a}}clav Moravec},
title = {CsFEVER and CTKFacts: Czech Datasets for Fact Verification},
journal = {CoR... | CsFEVER is a Czech localisation of the English FEVER datgaset. | false | 321 | false | ctu-aic/csfever | 2022-11-01T05:56:15.000Z | null | false | c9f2ce78fc92e19353b7f1cb3f4b68f15d32eb1c | [] | [
"arxiv:1803.05355",
"arxiv:2201.11115",
"license:cc-by-sa-3.0"
] | https://huggingface.co/datasets/ctu-aic/csfever/resolve/main/README.md | ---
license: cc-by-sa-3.0
---
# CsFEVER experimental Fact-Checking dataset
Czech dataset for fact verification localized from the data points of [FEVER](https://arxiv.org/abs/1803.05355) using the localization scheme described in the [CTKFacts: Czech Datasets for Fact Verification](https://arxiv.org/abs/2201.1111... |
ctu-aic | null | todo | CsfeverNLI is a NLI version of the Czech Csfever dataset | false | 321 | false | ctu-aic/csfever_nli | 2022-02-22T11:13:35.000Z | null | false | 69d0247380ab01c39f2920974a1736e92fe45783 | [] | [] | https://huggingface.co/datasets/ctu-aic/csfever_nli/resolve/main/README.md | |
ctu-aic | null | @article{DBLP:journals/corr/abs-2201-11115,
author = {Jan Drchal and
Herbert Ullrich and
Martin R{\'{y}}par and
Hana Vincourov{\'{a}} and
V{\'{a}}clav Moravec},
title = {CsFEVER and CTKFacts: Czech Datasets for Fact Verification},
journal = {CoR... | CtkFactsNLI is a NLI version of the Czech CTKFacts dataset | false | 322 | false | ctu-aic/ctkfacts_nli | 2022-11-01T06:35:47.000Z | null | false | 387ae4582c8054cb52ef57ef0941f19bd8012abf | [] | [
"arxiv:2201.11115"
] | https://huggingface.co/datasets/ctu-aic/ctkfacts_nli/resolve/main/README.md | # CTKFacts dataset for Natural Language Inference
Czech Natural Language Inference dataset of ~3K *evidence*-*claim* pairs labelled with SUPPORTS, REFUTES or NOT ENOUGH INFO veracity labels. Extracted from a round of fact-checking experiments concluded and described within the CsFEVER and [CTKFacts: Czech Datasets for... |
cylee | null | null | null | false | 322 | false | cylee/github-issues | 2021-12-19T19:12:55.000Z | null | false | 3768a20ee7e29288ea5feb4531fc5ab68ca8c2f2 | [] | [
"arxiv:2005.00614"
] | https://huggingface.co/datasets/cylee/github-issues/resolve/main/README.md | # Dataset Card for GitHub Issues
## Dataset Description
This dataset is created for the Hugging Face Datasets library course
### Dataset Summary
GitHub Issues is a dataset consisting of GitHub issues and pull requests associated with the 🤗 Datasets [repository](https://github.com/huggingface/datasets). It is int... |
dalle-mini | null | @article{thomee2016yfcc100m,
author = "Bart Thomee and David A. Shamma and Gerald Friedland and Benjamin Elizalde and Karl Ni and Douglas Poland and Damian Borth and Li-Jia Li",
title = "{YFCC100M}: The New Data in Multimedia Research",
journal = "Communications of the {ACM}",
volume = "59",
number = "2",
pages = "64--... | The YFCC100M is one of the largest publicly and freely useable multimedia collection, containing the metadata of around 99.2 million photos and 0.8 million videos from Flickr, all of which were shared under one of the various Creative Commons licenses.
This version is a subset defined in openai/CLIP. | false | 475 | false | dalle-mini/YFCC100M_OpenAI_subset | 2021-08-26T17:56:01.000Z | null | false | 986e65392adb1f3bdab07c25ed9a23cb83a0b354 | [] | [
"arxiv:1503.01817"
] | https://huggingface.co/datasets/dalle-mini/YFCC100M_OpenAI_subset/resolve/main/README.md | # YFCC100M subset from OpenAI
Subset of [YFCC100M](https://arxiv.org/abs/1503.01817) used by OpenAI for [CLIP](https://github.com/openai/CLIP/blob/main/data/yfcc100m.md), filtered to contain only the images that we could retrieve.
| Split | train | validation |
| --- | --- | --- |
| Number of samples | 14,808,859 | 1... |
damlab | null | null | null | false | 319 | false | damlab/HIV_FLT | 2022-02-08T20:58:56.000Z | null | false | a8e47c9a43d12564240e175708fe4e9424d275f0 | [] | [] | https://huggingface.co/datasets/damlab/HIV_FLT/resolve/main/README.md | # Dataset Description
## Dataset Summary
This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.
It contains the most recent version (2016-Full-genome), composed of 1,609 high-quality full-length genomes.
The genes within these sequences were processed using the GeneCutter ... |
damlab | null | null | null | false | 319 | false | damlab/HIV_PI | 2022-03-09T19:48:01.000Z | null | false | f0bada3a186a6ab795d578088eaff9cae1ee7106 | [] | [
"license:mit"
] | https://huggingface.co/datasets/damlab/HIV_PI/resolve/main/README.md | ---
license: mit
---
# Dataset Description
## Dataset Summary
This dataset was derived from the Stanford HIV Genotype-Phenotype database and contains 1,733 HIV protease sequences. A
pproximately half of the sequences are resistant to at least one antiretroviral therapeutic (ART).
Supported Tasks and... |
damlab | null | null | null | false | 321 | false | damlab/HIV_V3_bodysite | 2022-02-08T21:12:25.000Z | null | false | 7c81ad7c34d35f0ea4cabc28c24dc79c299dd6b3 | [] | [
"license:mit"
] | https://huggingface.co/datasets/damlab/HIV_V3_bodysite/resolve/main/README.md | # Dataset Description
## Dataset Summary
This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.
It contains 5,510 unique V3 sequences, each annotated with its corresponding bodysite that it was associated with.
Supported Tasks and Leaderboards: None
Languages: English
... |
damlab | null | null | null | false | 321 | false | damlab/HIV_V3_coreceptor | 2022-02-08T21:09:21.000Z | null | false | e6aae6b448d287929238c39a8bb880ae93ab4211 | [] | [] | https://huggingface.co/datasets/damlab/HIV_V3_coreceptor/resolve/main/README.md | # Dataset Description
## Dataset Summary
This dataset was derived from the Los Alamos National Laboratory HIV sequence (LANL) database.
It contains 2,935 HIV V3 loop protein sequences, which can interact with either CCR5 receptors on T-Cells or CXCR4 receptors on macrophages.
Supported Tasks and Leaderboards: No... |
dansbecker | null | null | null | false | 320 | false | dansbecker/hackernews_hiring_posts | 2021-12-07T13:46:20.000Z | null | false | 68844f7ae036f6901f3b08526c45f6026ea26997 | [] | [] | https://huggingface.co/datasets/dansbecker/hackernews_hiring_posts/resolve/main/README.md | This dataset contains postings and comments from the following recurring threads on [Hacker News](http://news.ycombinator.com/)
1. Ask HN: Who is hiring?
2. Ask HN: Who wants to be hired?
3. Freelancer? Seeking freelancer?
These post types are stored in datasets called `hiring`, `wants_to_be_hired` and `freelancer` r... |
davanstrien | null | null | null | false | null | false | davanstrien/MOH | 2021-10-24T13:14:53.000Z | null | true | c87dbb18c233a2b410dd54de0bbf876a3bb0dcbb | [] | [] | https://huggingface.co/datasets/davanstrien/MOH/resolve/main/README.md | |
davanstrien | null | null | null | false | null | false | davanstrien/test | 2021-11-10T17:08:18.000Z | null | true | 8a1d1f51a14f5a5a5081e6165379ee48cd3c8cdc | [] | [
"annotations_creators:no-annotation",
"language_creators:other",
"licenses:cc0-1.0",
"multilinguality:multilingual",
"size_categories:unknown",
"source_datasets:original",
"task_categories:other",
"task_ids:language-modeling",
"task_ids:other-other-digital-humanities-research"
] | https://huggingface.co/datasets/davanstrien/test/resolve/main/README.md |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.