
text-classification bool 2
classes | text stringlengths 0 664k |
|---|---|
false |
# Dataset Card for Erhu Playing Technique Database(7-class)
## Dataset Description
- **Homepage:** <https://ccmusic-database.github.io>
- **Repository:** <https://huggingface.co/datasets/CCMUSIC/erhu_playing_tech_7>
- **Paper:** <https://doi.org/10.5281/zenodo.5676893>
- **Leaderboard:** <https://ccmusic-database.gi... |
false | # Dataset Card for Music Genre Database
## Dataset Description
- **Homepage:** <https://ccmusic-database.github.io>
- **Repository:** <https://huggingface.co/datasets/ccmusic-database/music_genre>
- **Paper:** <https://doi.org/10.5281/zenodo.5676893>
- **Leaderboard:** <https://ccmusic-database.github.io/team.html>
- *... |
false |
# ParaNMTDetox: Detoxification with Parallel Data (English)
This repository contains information about filtered [ParaNMT](https://aclanthology.org/P18-1042/) dataset for text detoxification task. Here, we have paraphrasing pairs where one text is toxic and another is non-toxic. Toxicity levels were defined by English... |
true | |
false | # Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/hugg... |
false | # Dataset Card for Timbre and Range Database
## Dataset Description
- **Homepage:** <https://ccmusic-database.github.io>
- **Repository:** <https://huggingface.co/datasets/ccmusic-database/vocal_range>
- **Paper:** <https://doi.org/10.5281/zenodo.5676893>
- **Leaderboard:** <https://ccmusic-database.github.io/team.html... |
false | |
false |
# Dataset Card for Common Voice Corpus 11.0
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [How to use](#how-to-use)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-field... |
true | |
false | # AutoTrain Dataset for project: musicprompt
## Dataset Description
This dataset has been automatically processed by AutoTrain for project musicprompt.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
... |
false | |
false |
# What is this?
This is a cleaned version of [Amazon Product Dataset 2020](https://www.kaggle.com/datasets/promptcloud/amazon-product-dataset-2020) from Kaggle.
# Why?
- Using via Hugging Face API is easier; Kaggle API is annoying because their [authentication](https://www.kaggle.com/docs/api) is having credentials i... |
true | https://arxiv.org/pdf/2008.09335.pdf
```
@article{li2020mtop,
title={MTOP: A comprehensive multilingual task-oriented semantic parsing benchmark},
author={Li, Haoran and Arora, Abhinav and Chen, Shuohui and Gupta, Anchit and Gupta, Sonal and Mehdad, Yashar},
journal={arXiv preprint arXiv:2008.09335},
year={2020... |
true | |
true |
MultiDoGo dialog dataset:
- paper: https://aclanthology.org/D19-1460/
- git repo: https://github.com/awslabs/multi-domain-goal-oriented-dialogues-dataset
*Abstract*
The need for high-quality, large-scale, goal-oriented dialogue datasets continues to grow as virtual assistants become increasingly wide-spread. However... |
false |
# Dataset Card for [Dataset Name]
## Table of Contents
- [Dataset Card for [Dataset Name]](#dataset-card-for-dataset-name)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#language... |
true |
## ReactionGIF
> From https://github.com/bshmueli/ReactionGIF

___
## Excerpt from original repo readme
ReactionGIF is a unique, first-of-its-kind dataset of 30K sarcastic tweets and their GIF reactions.
To find out more about Re... |
false |
# Dataset Card for kudo-research/mustc-en-es-text-only
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dat... |
false |
# Dataset Card for Demo
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
... |
false |
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-st... |
false |
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-st... |
false |
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-st... |
false |
This is the Icelandic Common Crawl Corpus (IC3).
|
false |
# Dataset Card for VoxDIY RusNews
## Dataset Description
- **Repository:** [GitHub](https://github.com/Toloka/CrowdSpeech)
- **Paper:** [Paper](https://openreview.net/forum?id=3_hgF1NAXU7)
- **Point of Contact:** research@toloka.ai
### Dataset Summary
VoxDIY RusNews is the first publicly available large-scale datas... |
false |
# Dataset Card for 12-factor
## Table of Contents
- [Dataset Description](#dataset-description)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Source Data](#source-data)
## Dataset Description
100+ news article URL scored on 12 different factors and assigned a single score
## Languages
The... |
false |
# Dataset Card for PoliticalBias
## Table of Contents
- [Dataset Description](#dataset-description)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Source Data](#source-data)
## Dataset Description
roughly 8200 articles written by the website’s editors, each article covering one topic with 3 ... |
false |
# Dataset Card for news-12factor
## Table of Contents
- [Dataset Description](#dataset-description)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Source Data](#source-data)
- [Annotations](#annotations)
## Dataset Description
~20k articles labeled left, right, or center by the editors of al... |
false |
# Dataset Card for PoliticalBias_Sources
## Table of Contents
- [Dataset Description](#dataset-description)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Source Data](#source-data)
## Dataset Description
908 rows of data containing source name of an article, the source bias and the type of ... |
true | |
false |
# Dataset Card for People's Speech
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data F... |
false | # Dataset Card for NBAiLab/nb_bert_debiased
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Data Fields](#data-fiels)
- [Dataset Creation](#dataset-creation)
- [Statistics](#statistics)
- [Document Types](#document-types)
- [Languages](#languages)
- [Publish... |
true |
# Dataset Card for LAMA: LAnguage Model Analysis - a dataset for probing and analyzing the factual and commonsense knowledge contained in pretrained language models.
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#suppo... |
true | # AutoTrain Dataset for project: Rule
## Dataset Descritpion
This dataset has been automatically processed by AutoTrain for project Rule.
### Languages
The BCP-47 code for the dataset's language is zh.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"text":... |
true | # AutoTrain Dataset for project: procell-expert
## Dataset Descritpion
This dataset has been automatically processed by AutoTrain for project procell-expert.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```j... |
false |
# Dataset Card for WMT21 Metrics Task
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#datase... |
false |
# Dataset Card for MNIST
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- ... |
false |
# Dataset Card for Something Something v2
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#da... |
false |
# Dataset Card for id_recipe
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
... |
false |
# Dataset Card for GEM/squality
## Dataset Description
- **Homepage:** https://github.com/nyu-mll/SQuALITY
- **Repository:** https://github.com/nyu-mll/SQuALITY/data
- **Paper:** https://arxiv.org/abs/2205.11465
- **Leaderboard:** N/A
- **Point of Contact:** Alex Wang
### Link to Main Data Card
You can find the ma... |
false |
# Dataset Card for 2ch_b_dialogues
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data F... |
false |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instan... |
false |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instan... |
false |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instan... |
false |
# Dataset Card for SRSD-Feynman (Hard set)
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#d... |
false | ## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Other Known Limitations](#other-known-limitations)
## Dataset Description
- **Point of Contact:** [Nart Tlisha](mailto:daniel.abzakh@... |
false |
# Dataset Card for syntactic_transformations
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
... |
true |
# Dataset Card for MAGPIE
## Table of Contents
- [Dataset Card for MAGPIE](#dataset-card-for-itacola)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [... |
true | # Dataset Card for financial_phrasebank
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-in... |
true | # AutoTrain Dataset for project: dontknowwhatImdoing
## Dataset Descritpion
This dataset has been automatically processed by AutoTrain for project dontknowwhatImdoing.
### Languages
The BCP-47 code for the dataset's language is en.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follo... |
false |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instan... |
false |
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instan... |
false |
# Dataset Card for CA-ZH Wikipedia datasets
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
... |
false |
# Dataset Card for askD
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
... |
false |
# CiteSum
## Description
CiteSum: Citation Text-guided Scientific Extreme Summarization and Low-resource Domain Adaptation.
CiteSum contains TLDR summaries for scientific papers from their citation texts without human annotation, making it around 30 times larger than the previous human-curated dataset SciTLDR.
##... |
false |
# Dataset Card for Images of Cervical Cells with AgNOR Stain Technique
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structu... |
true |
# Dataset Card for "UnpredicTable-baseball-fantasysports-yahoo-com" - Dataset of Few-shot Tasks from Tables
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Struct... |
true |
# Dataset Card for Yincen/SalienceEvaluation
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](... |
true | # Dataset Card for Multilingual HateCheck
## Dataset Description
Multilingual HateCheck (MHC) is a suite of functional tests for hate speech detection models in 10 different languages: Arabic, Dutch, French, German, Hindi, Italian, Mandarin, Polish, Portuguese and Spanish.
For each language, there are 25+ functional t... |
false |
# Dataset Card for ogbg-code2
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [External Use](#external-use)
- [PyGeometric](#pygeometric)
-... |
false |
# Dataset Card for "SPECTER"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
... |
false |
SimulacraUnsupervised is a download of Simulacra Aesthetic Captions from JDP converted to a JPEG compressed parquet.
Under the BirdL-AirL License |
false | # Dataset Card for yaakov/wikipedia-de-splits
## Dataset Description
The only goal of this dataset is to have random German Wikipedia articles at
various dataset sizes: Small datasets for fast development and large datasets for statistically relevant measurements.
For this purpose, I loaded the 2665357 articles in t... |
true | |
false |
# BigScience BLOOM Evaluation Results
This repository contains evaluation results & original predictions of BLOOM & friends.
## Usage
You can load numeric results via:
```python
from datasets import load_dataset
ds = load_dataset("bigscience/evaluation-results", "bloom")
```
If it takes too long, it may be faster... |
false |
# YALTAi Segmonto Manuscript and Early Printed Book Dataset
## Table of Contents
- [YALTAi Segmonto Manuscript and Early Printed Book Dataset](#Segmonto Manuscript and Early Printed Book Dataset)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#datas... |
false |
This is the translation datasets collected by TextBox, including:
- WMT14 English-French (wmt14-fr-en)
- WMT16 Romanian-English (wmt16-ro-en)
- WMT16 German-English (wmt16-de-en)
- WMT19 Czech-English (wmt19-cs-en)
- WMT13 Spanish-English (wmt13-es-en)
- WMT19 Chinese-English (wmt19-zh-en)
- WMT19 Russian-English (wmt... |
false |
This is the paraphrase datasets collected by TextBox, including:
- Quora (a.k.a., QQP-Pos) (quora)
- ParaNMT-small (paranmt).
The detail and leaderboard of each dataset can be found in [TextBox page](https://github.com/RUCAIBox/TextBox#dataset). |
false |
# Dataset Card for Swedish Gigaword Dataset
The Swedish gigaword dataset has only been machine-translated to improve downstream fine-tuning on Swedish summarization tasks.
## Dataset Summary
Read about the full details at original English version: https://huggingface.co/datasets/gigaword
### Data Fields
- `document`... |
false |
# Dataset Card for Swedish pubmed Dataset
The Swedish pubmed dataset has only been machine-translated to improve downstream fine-tuning on Swedish summarization tasks.
## Dataset Summary
Read about the full details at original English version: https://huggingface.co/datasets/pubmed
### Data Fields
- `document`: a s... |
false |
# Dataset Card for Audio Keyword Spotting
## Table of Contents
- [Table of Contents](#table-of-contents)
## Dataset Description
- **Homepage:** https://sil.ai.org
- **Point of Contact:** [SIL AI email](mailto:idx_aqua@sil.org)
- **Source Data:** [MLCommons/ml_spoken_words](https://huggingface.co/datasets/MLCommons/... |
false |
# Digital Peter
The Peter dataset can be used for reading texts from the manuscripts written by Peter the Great. The dataset annotation contain end-to-end markup for training detection and OCR models, as well as an end-to-end model for reading text from pages.
Paper is available at http://arxiv.org/abs/2103.09354
... |
true | # Dataset Card for Auditor_Review
This file is a copy, the original version is hosted at [data.world](https://data.world/rshah/diabetes) |
true |
# STT-2 Spanish
## A Spanish translation (using [EasyNMT](https://github.com/UKPLab/EasyNMT)) of the [SST-2 Dataset](https://huggingface.co/datasets/sst2)
#### For more information check the official [Model Card](https://huggingface.co/datasets/sst2) |
false |
# Dataset Card for FaQuAD
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)... |
false | |
false |
This is a copy of the [WCEP-10](https://huggingface.co/datasets/ccdv/WCEP-10) dataset, except the input source documents of its `test` split have been replaced by a __sparse__ retriever. The retrieval pipeline used:
- __query__: The `summary` field of each example
- __corpus__: The union of all documents in the `trai... |
false |
# Dataset Card for RSDO4 en-sl parallel corpus
### Dataset Summary
The RSDO4 parallel corpus of English-Slovene and Slovene-English translation pairs was collected as part of work package 4 of the Slovene in the Digital Environment project. It contains texts collected from public institutions and texts submitted by ... |
false |
# Dataset Card for MSMARCO - Natural Language Generation Task
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Da... |
false | # AutoTrain Dataset for project: chest-xray-demo
## Dataset Description
This dataset has been automatically processed by AutoTrain for project chest-xray-demo.
The original dataset is located at https://www.kaggle.com/datasets/paultimothymooney/chest-xray-pneumonia
## Dataset Structure
```
├── train
│ ├── NORMAL... |
true |
# Dataset Card for Wiki Academic Disciplines`
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure]... |
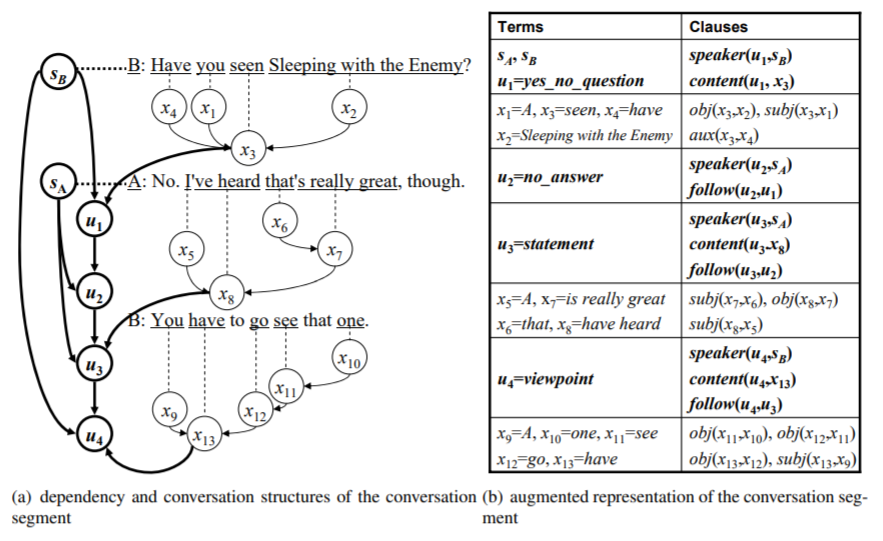
true | # Conversation-Entailment
Official dataset for [Towards Conversation Entailment: An Empirical Investigation](https://sled.eecs.umich.edu/publication/dblp-confemnlp-zhang-c-10/). *Chen Zhang, Joyce Chai*. EMNLP, 2010
## Ove... |
false |
## inverse-scaling/hindsight-neglect-10shot (‘The Floating Droid’)
### General description
This task tests whether language models are able to assess whether a bet was worth taking based on its expected value. The author provides few shot examples in which the model predicts whether a bet is worthwhile by correctly ... |
true |
# Dataset Card for `wiki-paragraphs`
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data... |
false |
# Dataset Card for MNIST
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- ... |
false | ---
# booksum short
`BookSum` but all summaries with length greater than 512 `long-t5` tokens are filtered out.
The columns `chapter_length` and `summary_length` **in this dataset** have been updated to reflect the total of Long-T5 tokens in the respective source text.
## Token Length Distribution for inputs
 for _what_ this is and why it exists.
The maximum input length is 16384 tokens, and the maximum output length is 1024 tokens (measured with the L... |
false |
# Dataset Card for bace_classification
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#datas... |
false | # Dataset Card for "eclassTrainST"
This NLI-Dataset can be used to fine-tune Models for the task of sentence-simularity. It consists of names and descriptions of pump-properties from the ECLASS-standard. |
false | ## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Citation Information](#citation-information)
- [... |
false |
# wikipedia persons masked: A filtered version of the wikipedia dataset, with only pages of people
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leade... |
false |
# Dataset Card for "squad_v2_dutch"
## Dataset Description
- **Homepage:** [https://rajpurkar.github.io/SQuAD-explorer/](https://rajpurkar.github.io/SQuAD-explorer/)
## Dataset Summary
The squad_v2_dutch dataset is a machine-translated version of the SQuAD v2 dataset from English to Dutch.
The SQuAD v2 dataset com... |
false | # Dataset Card for "HebrewStageAndLyricsWithNewLines"
* Contains poems and stories from "New Stage" ("במה חדשה")
* Contains text lines from various Hebrew song lyrics
* Data contains new-line characters
* Generated from a text file in which different poems were seperated using a double new-line character
* The script ... |
false |
# Dataset Card for `clinicaltrials/2017`
The `clinicaltrials/2017` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
For more information about the dataset, see the [documentation](https://ir-datasets.com/clinicaltrials#clinicaltrials/2017).
# Data
This dataset provides:
- `docs` (documents... |
false |
# Dataset Card for `disks45/nocr/trec-robust-2004`
The `disks45/nocr/trec-robust-2004` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
For more information about the dataset, see the [documentation](https://ir-datasets.com/disks45#disks45/nocr/trec-robust-2004).
# Data
This dataset provide... |
false |
# Dataset Card for `trec-arabic`
The `trec-arabic` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
For more information about the dataset, see the [documentation](https://ir-datasets.com/trec-arabic#trec-arabic).
# Data
This dataset provides:
- `docs` (documents, i.e., the corpus); count=... |
false |
# Dataset Card for `wapo/v2/trec-core-2018`
The `wapo/v2/trec-core-2018` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
For more information about the dataset, see the [documentation](https://ir-datasets.com/wapo#wapo/v2/trec-core-2018).
# Data
This dataset provides:
- `queries` (i.e., t... |
false |
### Dataset Summary
A Hebrew Deduplicated and Cleaned Common Crawl Corpus. A thoroughly cleaned and
approximately deduplicated dataset for unsupervised learning.
### Citing
If you use HeDC4 in your research, please cite [HeRo: RoBERTa and Longformer Hebrew Language Models](http://arxiv.org/abs/2304.11077).
```
@ar... |
true | # Dataset Card for "talkrl-podcast"
This dataset is sourced from the [TalkRL Podcast website](https://www.talkrl.com/) and contains English transcripts of wonderful TalkRL podcast episodes. The transcripts were generated using OpenAI's base Whisper model |
true |
# PLANE Out-of-Distribution Sets
PLANE (phrase-level adjective-noun entailment) is a benchmark to test models on fine-grained compositional inference.
The current dataset contains five sampled splits, used in the supervised experiments of [Bertolini et al., 22](https://aclanthology.org/2022.coling-1.359/).
## Data... |
false |
# Multiclass Semantic Segmentation Duckietown Dataset
A dataset of multiclass semantic segmentation image annotations for the first 250 images of the ["Duckietown Object Detection Dataset"](https://docs.duckietown.org/daffy/AIDO/out/object_detection_dataset.html).
| Raw Image | Segmentated Image |
| --- | --- |
| <im... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.