
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
huggingface/swift-transformers
| 72
|
How to use BertTokenizer?
|
what is the best way to use the BertTokenizer? its not a public file so I'm not sure whats the best way to use it
|
https://github.com/huggingface/swift-transformers/issues/72
|
closed
|
[] | 2024-03-16T18:13:36Z
| 2024-03-22T10:29:54Z
| null |
jonathan-goodrx
|
huggingface/chat-ui
| 934
|
What are the rules to create a chatPromptTemplate in .env.local?
|
We know that chatPromptTemplate for google/gemma-7b-it in .env.local is:
"chatPromptTemplate" : "{{#each messages}}{{#ifUser}}<start_of_turn>user\n{{#if @first}}{{#if @root.preprompt}}{{@root.preprompt}}\n{{/if}}{{/if}}{{content}}<end_of_turn>\n<start_of_turn>model\n{{/ifUser}}{{#ifAssistant}}{{content}}<end_of_turn>\n{{/ifAssistant}}{{/each}}",
and its chat template is:
"chat_template": "{{ bos_token }}{% if messages[0]['role'] == 'system' %}{{ raise_exception('System role not supported') }}{% endif %}{% for message in messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if (message['role'] == 'assistant') %}{% set role = 'model' %}{% else %}{% set role = message['role'] %}{% endif %}{{ '<start_of_turn>' + role + '\n' + message['content'] | trim + '<end_of_turn>\n' }}{% endfor %}{% if add_generation_prompt %}{{'<start_of_turn>model\n'}}{% endif %}",
The question is:
Are there any rules that are used to create the chatPromptTemplate for a model? Usually we have
the chat template from the model. But when we need to use this model in chat-ui, we have to use chatPromptTemplate.
|
https://github.com/huggingface/chat-ui/issues/934
|
open
|
[
"question"
] | 2024-03-16T17:51:38Z
| 2024-04-04T14:02:20Z
| null |
houghtonweihu
|
huggingface/chat-ui
| 933
|
Why the chat template of google/gemma-7b-it is invalid josn format in .env.local?
|
I used the chat template from google/gemma-7b-it in .env.local, shown below:
"chat_template": "{{ bos_token }}{% if messages[0]['role'] == 'system' %}{{ raise_exception('System role not supported') }}{% endif %}{% for message in messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if (message['role'] == 'assistant') %}{% set role = 'model' %}{% else %}{% set role = message['role'] %}{% endif %}{{ '<start_of_turn>' + role + '\n' + message['content'] | trim + '<end_of_turn>\n' }}{% endfor %}{% if add_generation_prompt %}{{'<start_of_turn>model\n'}}{% endif %}",
I got this error:
[vite] Error when evaluating SSR module /src/lib/server/models.ts:
|- SyntaxError: Unexpected token ''', "'[" is not valid JSON
|
https://github.com/huggingface/chat-ui/issues/933
|
closed
|
[
"question"
] | 2024-03-15T20:34:11Z
| 2024-03-18T13:24:55Z
| null |
houghtonweihu
|
pytorch/xla
| 6,760
|
xla_model.RateTracker doesn't have a docstring and its behavior is subtle and potentially confusing.
|
## 📚 Documentation
The `RateTracker` class in https://github.com/pytorch/xla/blob/fe3f23c62c747da30595cb9906d929b926aae6e4/torch_xla/core/xla_model.py doesn't have a docstring. This class is [used in lots of tests](https://github.com/search?q=repo%3Apytorch%2Fxla%20RateTracker&type=code), including [this one](https://github.com/pytorch/xla/blob/master/test/test_train_mp_mnist.py) that is referenced from the [main documentation](https://pytorch.org/xla/release/2.2/index.html), so new PyTorch/XLA users may see it as a natural and supported way to track and report training efficiency metrics.
`RateTracker`'s behavior is subtle and potentially confusing, since tracking throughput can involve measuring data at different granularities (e.g. batch, example, or, for LLMs, tokens) and reporting per-accelerator, per-host, or globally. Here is what I think the answers to these are; please correct me.
Following the examples in those tests, (where the batch size is added to the tracker at each training step), I think that `rate` measures the examples (not tokens) per second seen during the last batch (specifically, since the last time `.rate()` was called) and `global_rate` measures the same for the whole training run. Therefore the expectation is that global_rate will be slow in the beginning but after compilation and other one-time costs it will rise and typically approach the per-batch training rate, though the latter may vary.
In terms of what granularity of devices the metrics reflect, for SPMD, I think these will be both global metrics (for the whole training job), but for other distribution strategies, I think they're per-device.
Is that right?
|
https://github.com/pytorch/xla/issues/6760
|
closed
|
[
"usability"
] | 2024-03-15T17:23:46Z
| 2025-04-18T13:52:01Z
| 10
|
ebreck
|
pytorch/xla
| 6,759
|
Do I have to implement PjRtLoadedExecutable::GetHloModules when `XLA_STABLEHLO_COMPILE=1` ?
|
## ❓ Questions and Help
Hi, I'm from a hardware vendor and we want to implement a PJRT plugin for our DSA accelerator. We have our own MLIR-based compiler stack and it takes StableHLO as the input IR.
I'm new to PJRT, according to the [description](https://opensource.googleblog.com/2024/03/pjrt-plugin-to-accelerate-machine-learning.html), PJRT API is supposed to be compiler-agnostic and should not assume a PJRT plugin's compiler backend must be XLA. However, in `PyTorch/XLA`'s PJRT runtime: `PjRtComputationClient::Compile`, it calls `PjRtLoadedExecutable::GetHloModules` (which we left unimplemented in our `PjRtLoadedExecutable` implementation) and expects returning of valid `xla::HloModule`:
https://github.com/pytorch/xla/blob/19b83830ac4ee3a39d99abaf154f485c2399f47a/torch_xla/csrc/runtime/pjrt_computation_client.cc#L585
My question is, does `PyTorch/XLA`'s `PjRtComputationClient` requires these `xla::HloModule` for execution? If not, when user set `XLA_STABLEHLO_COMPILE=1`, `PyTorch/XLA` should not expect the compiled `PjRtLoadedExecutable` has anything to do with XLA/HLO related stuff.
|
https://github.com/pytorch/xla/issues/6759
|
open
|
[
"question",
"stablehlo"
] | 2024-03-15T10:59:36Z
| 2025-04-18T13:58:24Z
| null |
Nullkooland
|
huggingface/diffusers
| 7,337
|
How to convert multiple piped files into a single SafeTensor file?
|
How to convert multiple piped files into a single SafeTensor file?
For example, from this address: https://huggingface.co/Vargol/sdxl-lightning-4-steps/tree/main
```python
import torch
from diffusers import StableDiffusionXLPipeline, EulerDiscreteScheduler
base = "Vargol/sdxl-lightning-4-steps"
pipe = StableDiffusionXLPipeline.from_pretrained(base, torch_dtype=torch.float16).to("cuda")
```
How can I convert `pipe` into a single SafeTensor file as a whole?
Just like the file `sd_xl_base_1.0_0.9vae.safetensors`, which contains the components needed from `diffusers`.
_Originally posted by @xddun in https://github.com/huggingface/diffusers/issues/5360#issuecomment-1998986263_
|
https://github.com/huggingface/diffusers/issues/7337
|
closed
|
[] | 2024-03-15T05:49:01Z
| 2024-03-15T06:51:24Z
| null |
xxddccaa
|
huggingface/transformers.js
| 648
|
`aggregation_strategy` in TokenClassificationPipeline
|
### Question
Hello, from Transformers original version they have aggregation_strategy parameter to group the token corresponding to the same entity together in the predictions or not. But in transformers.js version I haven't found this parameter. Is it possible to provide this parameter? I want the prediction result as same as the original version.
|
https://github.com/huggingface/transformers.js/issues/648
|
closed
|
[
"question"
] | 2024-03-15T04:07:22Z
| 2024-04-10T21:35:42Z
| null |
boat-p
|
pytorch/vision
| 8,317
|
position, colour, and background colour of text labels in draw_bounding_boxes
|
### 🚀 The feature
Text labels from `torchvision.utils.draw_bounding_boxes` are currently always inside the box with origin at the top left corner of the box, without a background colour, and the same colour as the bounding box itself. These are three things that would be nice to control.
### Motivation, pitch
The problem with the current implementation is that it makes it hard to read the label, particularly when the bounding box is filled (because the text has the same colour as the filling colour and is placed inside the box.
For example, this is the results from the current implementation:

Moving the label to outside the box already makes things better:

But by controlling those three things (placement of label, background colour behind the label, and text colour) one could fit to whatever they have. For what is worth, in the original issue for this feature, the only example image had labels outside the box, text coloured different from the box (black), and background of the same colour as the box. See https://github.com/pytorch/vision/issues/2556#issuecomment-671344086
I'm happy to contribute this but want to know if this will be accepted and with what interface.
|
https://github.com/pytorch/vision/issues/8317
|
open
|
[] | 2024-03-14T13:50:17Z
| 2025-04-17T13:28:39Z
| 9
|
carandraug
|
huggingface/transformers.js
| 646
|
Library no longer maintained?
|
### Question
1 year has passed since this PR is ready for merge: [Support React Native #118](https://github.com/xenova/transformers.js/pull/118)
Should we do our own fork of xenova/transformers.js ?
|
https://github.com/huggingface/transformers.js/issues/646
|
closed
|
[
"question"
] | 2024-03-14T10:37:33Z
| 2024-06-10T15:32:41Z
| null |
pax-k
|
pytorch/serve
| 3,026
|
Exception when using torchserve to deploy hugging face model: java.lang.InterruptedException: null
|
### 🐛 Describe the bug
I followed the tutorial as https://github.com/pytorch/serve/tree/master/examples/Huggingface_Transformers
First,
```
python Download_Transformer_models.py
```
Then,
```
torch-model-archiver --model-name BERTSeqClassification --version 1.0 --serialized-file Transformer_model/pytorch_model.bin --handler ./Transformer_handler_generalized.py --extra-files "Transformer_model/config.json,./setup_config.json,./Seq_classification_artifacts/index_to_name.json"
```
Finally,
```
torchserve --start --model-store model_store --models my_tc=BERTSeqClassification.mar --ncs
```
The system cannot start as usualy, it gives out the error log, throwing an Exception
```
java.lang.InterruptedException: null
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:1679) ~[?:?]
at java.util.concurrent.LinkedBlockingDeque.pollFirst(LinkedBlockingDeque.java:515) ~[?:?]
at java.util.concurrent.LinkedBlockingDeque.poll(LinkedBlockingDeque.java:677) ~[?:?]
at org.pytorch.serve.wlm.Model.pollBatch(Model.java:367) ~[model-server.jar:?]
at org.pytorch.serve.wlm.BatchAggregator.getRequest(BatchAggregator.java:36) ~[model-server.jar:?]
at org.pytorch.serve.wlm.WorkerThread.run(WorkerThread.java:194) [model-server.jar:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) [?:?]
at java.lang.Thread.run(Thread.java:833) [?:?]
```
I tried curl to check the model
```
root@0510f3693f42:/home/model-server# curl http://127.0.0.1:8081/models
{
"models": []
}
```
### Error logs
2024-03-14T07:34:24,938 [INFO ] epollEventLoopGroup-5-17 org.pytorch.serve.wlm.WorkerThread - 9015 Worker disconnected. WORKER_STARTED
2024-03-14T07:34:24,938 [INFO ] W-9015-my_tc_1.0-stdout MODEL_LOG - Connection accepted: /home/model-server/tmp/.ts.sock.9015.
2024-03-14T07:34:24,938 [DEBUG] W-9015-my_tc_1.0 org.pytorch.serve.wlm.WorkerThread - System state is : WORKER_STARTED
2024-03-14T07:34:24,938 [DEBUG] W-9015-my_tc_1.0 org.pytorch.serve.wlm.WorkerThread - Backend worker monitoring thread interrupted or backend worker process died.
java.lang.InterruptedException: null
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:1679) ~[?:?]
at java.util.concurrent.LinkedBlockingDeque.pollFirst(LinkedBlockingDeque.java:515) ~[?:?]
at java.util.concurrent.LinkedBlockingDeque.poll(LinkedBlockingDeque.java:677) ~[?:?]
at org.pytorch.serve.wlm.Model.pollBatch(Model.java:367) ~[model-server.jar:?]
at org.pytorch.serve.wlm.BatchAggregator.getRequest(BatchAggregator.java:36) ~[model-server.jar:?]
at org.pytorch.serve.wlm.WorkerThread.run(WorkerThread.java:194) [model-server.jar:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) [?:?]
at java.lang.Thread.run(Thread.java:833) [?:?]
2024-03-14T07:34:24,938 [DEBUG] W-9015-my_tc_1.0 org.pytorch.serve.wlm.WorkerThread - W-9015-my_tc_1.0 State change WORKER_STARTED -> WORKER_STOPPED
2024-03-14T07:34:24,938 [WARN ] W-9015-my_tc_1.0 org.pytorch.serve.wlm.WorkerThread - Auto recovery failed again
2024-03-14T07:34:24,939 [WARN ] W-9015-my_tc_1.0 org.pytorch.serve.wlm.WorkerLifeCycle - terminateIOStreams() threadName=W-9015-my_tc_1.0-stderr
2024-03-14T07:34:24,939 [WARN ] W-9015-my_tc_1.0 org.pytorch.serve.wlm.WorkerLifeCycle - terminateIOStreams() threadName=W-9015-my_tc_1.0-stdout
2024-03-14T07:34:24,939 [INFO ] W-9015-my_tc_1.0 org.pytorch.serve.wlm.WorkerThread - Retry worker: 9015 in 3 seconds.
2024-03-14T07:34:24,946 [INFO ] W-9015-my_tc_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - Stopped Scanner - W-9015-my_tc_1.0-stdout
2024-03-14T07:34:24,946 [INFO ] W-9015-my_tc_1.0-stderr org.pytorch.serve.wlm.WorkerLifeCycle - Stopped Scanner - W-9015-my_tc_1.0-stderr
2024-03-14T07:34:27,207 [DEBUG] W-9010-my_tc_1.0 org.pytorch.serve.wlm.WorkerLifeCycle - Worker cmdline: [/home/venv/bin/python, /home/venv/lib/python3.9/site-packages/ts/model_service_worker.py, --sock-type, unix, --sock-name, /home/model-server/tmp/.ts.sock.9010, --metrics-config, /home/venv/lib/python3.9/site-packages/ts/configs/metrics.yaml]
2024-03-14T07:34:27,489 [DEBUG] W-9012-my_tc_1.0 org.pytorch.serve.wlm.WorkerLifeCycle - Worker cmdline: [/home/venv/bin/python, /home/venv/lib/python3.9/site-packages/ts/model_service_worker.py, --sock-type, unix, --sock-name, /home/model-server/tmp/.ts.sock.9012, --metrics-config, /home/venv/lib/python3.9/site-packages/ts/configs/metrics.yaml]
2024-03-14T07:34:27,579 [DEBUG] W-9000-my_tc_1.0 org.pytorch.serve.wlm.WorkerLifeCycle - Wo
|
https://github.com/pytorch/serve/issues/3026
|
open
|
[
"help wanted",
"triaged",
"needs-reproduction"
] | 2024-03-14T07:56:57Z
| 2024-03-19T16:44:51Z
| 4
|
yolk-pie-L
|
pytorch/serve
| 3,025
|
torchserve output customization
|
Hi team
To process a inference request in torchserve, there are stages like initialize, preprocess, inference, postprocess.
If I want to convert the output format from tensor to my custom textual format, where and how can I carry this out ?
I am able to receive output in json format. But I need to make some customizations. Is it possible in torchserve ?
regards
|
https://github.com/pytorch/serve/issues/3025
|
closed
|
[
"triaged"
] | 2024-03-13T20:37:39Z
| 2024-03-14T21:05:42Z
| 3
|
advaitraut
|
pytorch/executorch
| 2,397
|
How to perform inference and gathering accuracy metrics on executorch model
|
Hi, I am having trouble finding solid documentation that explains how to do the following with executorch (stable):
- Load in the exported .pte model
- Run inference with images
- Gather accuracy
I have applied quantization and other optimizations to the original model and exported it to .pte. I'd like to see the accuracy after these techniques were applied. I followed the following tutorial for exporting the model. If we can't do the above items on the directly exported .pte file, then is there a way we can based on the below steps for preparing the model for edge dialect?
https://pytorch.org/executorch/stable/tutorials/export-to-executorch-tutorial.html
cc @mergennachin @byjlw
|
https://github.com/pytorch/executorch/issues/2397
|
open
|
[
"module: doc",
"need-user-input",
"triaged"
] | 2024-03-13T14:40:01Z
| 2025-02-04T20:21:12Z
| null |
mmingo848
|
huggingface/tokenizers
| 1,469
|
How to load tokenizer trained by sentencepiece or tiktoken
|
Hi, does this lib supports loading pre-trained tokenizer trained by other libs, like `sentencepiece` and `tiktoken`? Many models on hf hub store tokenizer in these formats
|
https://github.com/huggingface/tokenizers/issues/1469
|
closed
|
[
"Stale",
"planned"
] | 2024-03-13T10:22:00Z
| 2024-04-30T10:15:32Z
| null |
jordane95
|
pytorch/pytorch
| 121,798
|
what is the match numpy verison, can not build from source
|
### 🐛 Describe the bug
what is the match numpy verison, can not build from source
after run ` python3 setup.py develop`
got this error
```
error: no member named 'elsize' in '_PyArray_Descr'
```
### Versions
OS: macOS 14.4 (arm64)
GCC version: Could not collect
Clang version: 15.0.0 (clang-1500.3.9.4)
CMake version: version 3.22.2
Libc version: N/A
Python version: 3.11.7 (main, Jan 16 2024, 14:42:22) [Clang 14.0.0 (clang-1400.0.29.202)] (64-bit runtime)
Python platform: macOS-14.4-arm64-arm-64bit
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
CPU:
Apple M1 Max
Versions of relevant libraries:
[pip3] numpy==2.0.0b1
[pip3] torch==2.3.0.dev20240311
[pip3] torchaudio==2.2.0.dev20240311
[pip3] torchvision==0.18.0.dev20240311
[conda] Could not collect
cc @malfet @seemethere @mruberry @rgommers
|
https://github.com/pytorch/pytorch/issues/121798
|
closed
|
[
"module: build",
"triaged",
"module: numpy"
] | 2024-03-13T09:52:46Z
| 2024-03-14T07:10:15Z
| null |
yourmoonlight
|
pytorch/functorch
| 1,142
|
Swapping 2 columns in a 2d tensor
|
I have a function ```tridiagonalization``` to tridiagonalize matrix (2d tensor), and I want to map it to batch. It involves a for loop and on each iteration a permutation of 2 columns and 2 rows inside it. I do not understand how to permute 2 columns without errors. So my code for rows works and looks as follows:
```
row_temp = matrix_stacked[pivot[None]][0]
matrix_stacked[[pivot[None]][0]] = matrix_stacked[i+1].clone()
matrix_stacked[i+1] = row_temp
```
Where ```pivot``` is a tensor and ```i``` is a Python integer variable. For columns I have something like this:
```
column_temp = matrix_stacked[:, [pivot[None]][0]]
matrix_stacked[:, [pivot[None]][0]] = matrix_stacked[:, [i+1]].clone()
matrix_stacked[:, i+1] = column_temp
```
It does not wotk because of issues with size. What should I do in order to permute ```i+1``` and ```pivot``` columns?
|
https://github.com/pytorch/functorch/issues/1142
|
open
|
[] | 2024-03-13T09:33:29Z
| 2024-03-13T09:33:29Z
| 0
|
Kreativshikkk
|
huggingface/transformers.js
| 644
|
Contribution Question-What's next after run scripts.convert?
|
### Question
Hi @xenova I am trying to figure out how to contribute. I am new to huggingface. Just 2 months down the rabbit hole.
I ran
`python -m scripts.convert --quantize --model_id SeaLLMs/SeaLLM-7B-v2`
command
Here is a list of file I got in `models/SeaLLMs/SeaLLM-7B-v2` folder
```
_model_layers.0_self_attn_rotary_emb_Constant_5_attr__value
_model_layers.0_self_attn_rotary_emb_Constant_attr__value
config.json
generation_config.json
model.onnx
model.onnx_data
special_tokens_map.json
tokenizer.json
tokenizer.model
tokenizer_config.json
```
Does it work?
What's next from here? Do I upload the models to huggingface?
Do you have example commits or PR I should take a look? I have been scanning the model PR but none of which mentioned what happen after you ran `scripts/convert`
I have seen some other issues mentioned the need for document. I know you don't have it yet. That's fine. That's why I am only asking for a hint or a little guidiance.
|
https://github.com/huggingface/transformers.js/issues/644
|
closed
|
[
"question"
] | 2024-03-13T08:51:37Z
| 2024-04-11T02:33:04Z
| null |
pacozaa
|
huggingface/making-games-with-ai-course
| 11
|
[UPDATE] Typo in Unit 1, "What is HF?" section. The word "Danse" should be "Dance"
|
# What do you want to improve?
There is a typo in Unit 1, "What is HF?" section.
The word "Danse" should be "Dance"
- Explain the typo/error or the part of the course you want to improve
There is a typo in Unit 1, "What is HF?" section.
The word "Danse" should be "Dance"
The English spelling doesn't seem to include the French spelling.
https://www.dictionary.com/browse/dance
I assume this will also come up in later places, but I haven't gotten that far yet. :)
# Actual Issue:
In this image:
https://huggingface.co/datasets/huggingface-ml-4-games-course/course-images/resolve/main/en/unit1/unity/models4.jpg
which is used here:
https://github.com/huggingface/making-games-with-ai-course/blob/main/units/en/unit1/what-is-hf.mdx
# **Also, don't hesitate to open a Pull Request with the update**. This way you'll be a contributor of the project.
Sorry, I have no access to the problematic image's source
|
https://github.com/huggingface/making-games-with-ai-course/issues/11
|
closed
|
[
"documentation"
] | 2024-03-12T17:12:20Z
| 2024-04-18T07:18:12Z
| null |
PaulForest
|
huggingface/transformers.js
| 642
|
RangeError: offset is out of bounds #601
|
### Question
```
class NsfwDetector {
constructor() {
this._threshold = 0.5;
this._nsfwLabels = [
'FEMALE_BREAST_EXPOSED',
'FEMALE_GENITALIA_EXPOSED',
'BUTTOCKS_EXPOSED',
'ANUS_EXPOSED',
'MALE_GENITALIA_EXPOSED',
'BLOOD_SHED',
'VIOLENCE',
'GORE',
'PORNOGRAPHY',
'DRUGS',
'ALCOHOL',
];
}
async isNsfw(imageUrl) {
let blobUrl = '';
try {
// Load and resize the image first
blobUrl = await this._loadAndResizeImage(imageUrl);
const classifier = await window.tensorflowPipeline('zero-shot-image-classification', 'Xenova/clip-vit-base-patch16');
const output = await classifier(blobUrl, this._nsfwLabels);
console.log(output);
const nsfwDetected = output.some(result => result.score > this._threshold);
return nsfwDetected;
} catch (error) {
console.error('Error during NSFW classification: ', error);
throw error;
} finally {
if (blobUrl) {
URL.revokeObjectURL(blobUrl); // Ensure blob URLs are revoked after use to free up memory
}
}
}
async _loadAndResizeImage(imageUrl) {
const img = await this._loadImage(imageUrl);
const offScreenCanvas = document.createElement('canvas');
const ctx = offScreenCanvas.getContext('2d');
offScreenCanvas.width = 224;
offScreenCanvas.height = 224;
ctx.drawImage(img, 0, 0, offScreenCanvas.width, offScreenCanvas.height);
return new Promise((resolve, reject) => {
offScreenCanvas.toBlob(blob => {
if (!blob) {
reject('Canvas to Blob conversion failed');
return;
}
const blobUrl = URL.createObjectURL(blob);
resolve(blobUrl);
}, 'image/jpeg');
});
}
async _loadImage(url) {
return new Promise((resolve, reject) => {
const img = new Image();
img.crossOrigin = 'anonymous';
img.onload = () => resolve(img);
img.onerror = () => reject(`Failed to load image: ${url}`);
img.src = url;
});
}
}
window.NsfwDetector = NsfwDetector;
```
when used on a bunch of images, it fails, "RangeError: offset is out of bounds".
|
https://github.com/huggingface/transformers.js/issues/642
|
closed
|
[
"question"
] | 2024-03-12T16:47:58Z
| 2024-03-13T05:57:23Z
| null |
vijishmadhavan
|
huggingface/chat-ui
| 926
|
AWS credentials resolution for Sagemaker models
|
chat-ui is excellent, thanks for all your amazing work here!
I have been experimenting with a model in Sagemaker and am having some issues with the model endpoint configuration. It currently requires credentials to be provided explicitly. This does work, but the ergonomics are not great for our use cases:
- in development, my team uses AWS SSO and it would be great to use our session credentials and not need to update our MODELS environment variable manually every time our sessions refresh
- in deployments, we would want to use an instance or task execution role to sign requests
In my investigation I found this area of code https://github.com/huggingface/chat-ui/blob/eb071be4c938b0a2cf2e89a152d68305d4714949/src/lib/server/endpoints/aws/endpointAws.ts#L22-L37, which uses the `aws4fetch` library that only support signing with explicitly passed AWS credentials.
I was able to update this area of code locally and support AWS credential resolution by switching this to use a different library [`aws-sigv4-fetch`](https://github.com/zirkelc/aws-sigv4-fetch) like so:
```ts
try {
createSignedFetcher = (await import("aws-sigv4-fetch")).createSignedFetcher;
} catch (e) {
throw new Error("Failed to import aws-sigv4-fetch");
}
const { url, accessKey, secretKey, sessionToken, model, region, service } =
endpointAwsParametersSchema.parse(input);
const signedFetch = createSignedFetcher({
service,
region,
credentials:
accessKey && secretKey
? { accessKeyId: accessKey, secretAccessKey: secretKey, sessionToken }
: undefined,
});
// Replacer `aws.fetch` with `signedFetch` below when passing `fetch` to `textGenerationStream#options`
```
My testing has found this supports passing credentials like today, or letting the AWS SDK resolve them through the default chain.
Would you be open to a PR with this change? Or is there a different/better/more suitable way to accomplish AWS credential resolution here?
|
https://github.com/huggingface/chat-ui/issues/926
|
open
|
[] | 2024-03-12T16:24:57Z
| 2024-03-13T10:30:52Z
| 1
|
nason
|
huggingface/optimum
| 1,754
|
How to tell whether the backend of ONNXRuntime accelerator is Intel VINO.
|
According to the [wiki](https://onnxruntime.ai/docs/execution-providers/#summary-of-supported-execution-providers), OpenVINO is one of the ONNXRuntime's execution providers.
I am deploying model on Intel Xeon Gold server, which supports AVX512 and which is compatible with Intel OpenVINO. How could I tell if the accelerator is Default CPU or OpenVINO?
```python
from sentence_transformers import SentenceTransformer, models
from optimum.onnxruntime import ORTModelForCustomTasks
from transformers import AutoTokenizer
ort_model = ORTModelForCustomTasks.from_pretrained('Geotrend/distilbert-base-zh-cased', export=True)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
ort_model.save_pretrained(save_directory + "/" + checkpoint)
tokenizer.save_pretrained(save_directory + "/" + checkpoint)
```
```shell
Framework not specified. Using pt to export to ONNX.
Using the export variant default. Available variants are:
- default: The default ONNX variant.
Using framework PyTorch: 2.1.2.post300
```
|
https://github.com/huggingface/optimum/issues/1754
|
closed
|
[] | 2024-03-12T08:54:01Z
| 2024-07-08T11:31:13Z
| null |
ghost
|
huggingface/alignment-handbook
| 134
|
Is there a way to freeze some layers of a model ?
|
Can we follow the normal way of:
```
for param in model.base_model.parameters():
param.requires_grad = False
```
|
https://github.com/huggingface/alignment-handbook/issues/134
|
open
|
[] | 2024-03-12T02:06:03Z
| 2024-03-12T02:06:03Z
| 0
|
shamanez
|
huggingface/diffusers
| 7,283
|
How to load lora trained with Stable Cascade?
|
I finished a lora traning based on Stable Cascade with onetrainer, but I cannot find a solution to load the load in diffusers pipeline. Anyone who can help me will be appreciated.
|
https://github.com/huggingface/diffusers/issues/7283
|
closed
|
[
"stale"
] | 2024-03-12T01:33:01Z
| 2024-06-29T13:35:45Z
| null |
zengjie617789
|
huggingface/datasets
| 6,729
|
Support zipfiles that span multiple disks?
|
See https://huggingface.co/datasets/PhilEO-community/PhilEO-downstream
The dataset viewer gives the following error:
```
Error code: ConfigNamesError
Exception: BadZipFile
Message: zipfiles that span multiple disks are not supported
Traceback: Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/dataset/config_names.py", line 67, in compute_config_names_response
get_dataset_config_names(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py", line 347, in get_dataset_config_names
dataset_module = dataset_module_factory(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 1871, in dataset_module_factory
raise e1 from None
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 1846, in dataset_module_factory
return HubDatasetModuleFactoryWithoutScript(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 1240, in get_module
module_name, default_builder_kwargs = infer_module_for_data_files(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 584, in infer_module_for_data_files
split_modules = {
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 585, in <dictcomp>
split: infer_module_for_data_files_list(data_files_list, download_config=download_config)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 526, in infer_module_for_data_files_list
return infer_module_for_data_files_list_in_archives(data_files_list, download_config=download_config)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 554, in infer_module_for_data_files_list_in_archives
for f in xglob(extracted, recursive=True, download_config=download_config)[
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py", line 576, in xglob
fs, *_ = fsspec.get_fs_token_paths(urlpath, storage_options=storage_options)
File "/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/core.py", line 622, in get_fs_token_paths
fs = filesystem(protocol, **inkwargs)
File "/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/registry.py", line 290, in filesystem
return cls(**storage_options)
File "/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/spec.py", line 79, in __call__
obj = super().__call__(*args, **kwargs)
File "/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/implementations/zip.py", line 57, in __init__
self.zip = zipfile.ZipFile(
File "/usr/local/lib/python3.9/zipfile.py", line 1266, in __init__
self._RealGetContents()
File "/usr/local/lib/python3.9/zipfile.py", line 1329, in _RealGetContents
endrec = _EndRecData(fp)
File "/usr/local/lib/python3.9/zipfile.py", line 286, in _EndRecData
return _EndRecData64(fpin, -sizeEndCentDir, endrec)
File "/usr/local/lib/python3.9/zipfile.py", line 232, in _EndRecData64
raise BadZipFile("zipfiles that span multiple disks are not supported")
zipfile.BadZipFile: zipfiles that span multiple disks are not supported
```
The files (https://huggingface.co/datasets/PhilEO-community/PhilEO-downstream/tree/main/data) are:
<img width="629" alt="Capture d’écran 2024-03-11 à 22 07 30" src="https://github.com/huggingface/datasets/assets/1676121/0bb15a51-d54f-4d73-8572-e427ea644b36">
|
https://github.com/huggingface/datasets/issues/6729
|
closed
|
[
"enhancement",
"question"
] | 2024-03-11T21:07:41Z
| 2024-06-26T05:08:59Z
| null |
severo
|
huggingface/candle
| 1,834
|
How to increase model performance?
|
Hello all,
I have recently benchmarked completion token time, which is 30ms on an H100. However, with llama.cpp it is 10ms. Because [mistral.rs](https://github.com/EricLBuehler/mistral.rs) is built on Candle, it inherits this performance deficit. In #1680, @guoqingbao said that the Candle implementation is not suitable for batched computing because of naive CUDA kernels. What other areas could be optimized?
|
https://github.com/huggingface/candle/issues/1834
|
closed
|
[] | 2024-03-11T12:36:45Z
| 2024-03-29T20:44:46Z
| null |
EricLBuehler
|
huggingface/transformers.js
| 638
|
Using an EfficientNet Model - Looking for advice
|
### Question
Discovered this project from the recent Syntax podcast episode (which was excellent) - it got my mind racing with different possibilities.
I got some of the example projects up and running without too much issue and naturally wanted to try something a little more outside the box, which of course has led me down some rabbit holes.
I came across this huggingface model;
https://huggingface.co/chriamue/bird-species-classifier
and https://huggingface.co/dennisjooo/Birds-Classifier-EfficientNetB2
Great, file size is only like 32 mb... however just swapping in this model into the example code didn't work - something about efficientnet models not supported yet. Okay I'll just try to convert this model with the provided script.
Similar error about EfficientNet... Okay I will clone the repo, and retrain using a different architecture... Then looking at the training data https://www.kaggle.com/datasets/gpiosenka/100-bird-species, it seems like maybe it's meant for efficientnet?
Also digging into how the above huggingface projects were done, I realized they are fine-tunes of other image classification models...
So my questions is, can I fine tune an existing transformer js image classification model? such as https://huggingface.co/Xenova/convnext-tiny-224 or am I better off using the original https://huggingface.co/facebook/convnext-tiny-224 model and creating a fine tune from there, then converting it to onnx using the script?
Thanks for your help on this and for this awesome project. Really just looking for some direction.
|
https://github.com/huggingface/transformers.js/issues/638
|
closed
|
[
"question"
] | 2024-03-11T01:31:49Z
| 2024-03-11T17:42:31Z
| null |
ozzyonfire
|
pytorch/xla
| 6,710
|
Does XLA use the Nvidia GPU's tensor cores?
|
## ❓ Questions and Help
1. Does XLA use the Nvidia GPU's tensor cores?
2. Is Pytorch XLA only designed to accelerate neural network training or does it accelerate their inferencing as well?
|
https://github.com/pytorch/xla/issues/6710
|
closed
|
[] | 2024-03-11T00:55:36Z
| 2024-03-15T23:42:26Z
| 2
|
Demis6
|
huggingface/text-generation-inference
| 1,636
|
Need instructions for how to optimize for production serving (fast startup)
|
### Feature request
I suggest better educating developers how to download and optimize the model at build time (in container or in a volume) so that the command `text-generation-launcher` serves as fast as possible.
### Motivation
By default, when running TGI using Docker, the container downloads the model on the fly and spend a long time optimizing it.
The [quicktour](https://huggingface.co/docs/text-generation-inference/en/quicktour) recommends using a local volume, which is great, but this isn't really compatible with autoscaled cloud environments, where container startup as to be as fast as possible.
### Your contribution
As I explore this area, I will share my findings in this issue.
|
https://github.com/huggingface/text-generation-inference/issues/1636
|
closed
|
[
"Stale"
] | 2024-03-10T22:17:53Z
| 2024-04-15T02:49:03Z
| null |
steren
|
pytorch/tutorials
| 2,797
|
Contradiction in `save_for_backward`, what is permitted to be saved
|
https://pytorch.org/tutorials/beginner/examples_autograd/two_layer_net_custom_function.html
"ctx is a context object that can be used to stash information for backward computation. You can **cache arbitrary objects** for use in the backward pass using the ctx.save_for_backward method."
https://pytorch.org/docs/stable/generated/torch.autograd.function.FunctionCtx.save_for_backward.html
"save_for_backward should be called at most once, only from inside the forward() method, and **only with tensors**."
Most likely the second is correct, and the first is not. I haven't checked.
Suggestion: "You can cache **tensors** for use in the backward pass using the ctx.save_for_backward method. Other miscellaneous objects can be cached using ctx.my_object_name = object."
cc @albanD @jbschlosser
|
https://github.com/pytorch/tutorials/issues/2797
|
closed
|
[
"core",
"medium",
"docathon-h1-2025"
] | 2024-03-10T19:40:16Z
| 2025-06-04T21:11:21Z
| null |
ad8e
|
huggingface/optimum
| 1,752
|
Documentation for exporting openai/whisper-large-v3 to ONNX
|
### Feature request
Hello, I am exporting the [OpenAI Whisper-large0v3](https://huggingface.co/openai/whisper-large-v3) to ONNX and see it exports several files, most importantly in this case encoder (encoder_model.onnx & encoder_model.onnx.data) and decoder (decoder_model.onnx, decoder_model.onnx.data, decoder_with_past_model.onnx, decoder_with_past_model.onnx.data) files. I'd like to also be able to use as much as possible from the pipe in the new onnx files:
`pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=30,
batch_size=16,
return_timestamps=True,
torch_dtype=torch_dtype,
device=device,
)`
Is there documentation that explains how to incorporate all these different things? I know transformer models are much different in this whole process and I cannot find a clear A -> B process on how to export this model and perform tasks such as quantization, etc. I see I can do the following for the tokenizer with ONNX, but I'd like more insight about the rest I mentioned above (how to use the seperate onnx files & how to use as much as the preexisting pipeline).
`processor.tokenizer.save_pretrained(onnx_path)`
I also see I can do:
`model = ORTModelForSpeechSeq2Seq.from_pretrained(
model_id, export=True
)`
but I cannot find documentation on how to specify where it is exported to, which seem's like I am either missing something fairly simple or it is just not hyperlinked in the documentation.
### Motivation
I'd love to see further documentation on the entire export process for this highly popular model. Deployment is significantly slowed due to there not being a easy to find A -> B process for exporting the model and using the pipeline given in the vanilla model.
### Your contribution
I am able to provide additional information to make this process easier.
|
https://github.com/huggingface/optimum/issues/1752
|
open
|
[
"feature-request",
"onnx"
] | 2024-03-10T05:24:36Z
| 2024-10-09T09:18:27Z
| 10
|
mmingo848
|
huggingface/transformers
| 29,564
|
How to add new special tokens
|
### System Info
- `transformers` version: 4.38.0
- Platform: Linux-6.5.0-21-generic-x86_64-with-glibc2.35
- Python version: 3.10.13
- Huggingface_hub version: 0.20.2
- Safetensors version: 0.4.2
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.2.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes and no
- Using distributed or parallel set-up in script?: no
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Execute the code below:
```
from transformers import AutoTokenizer, AutoModel
import torch
import os
from datasets import load_dataset
dataset = load_dataset("ftopal/huggingface-datasets-processed")
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# device = torch.device("cpu")
checkpoint = 'intfloat/multilingual-e5-base'
model = AutoModel.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(
checkpoint,
additional_special_tokens=['<URL>']
)
model.to(device)
encoded_input = tokenizer(
dataset['train'][0]['input_texts'], # A tensor with 2, 512 shape
padding='max_length',
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
encoded_input_dict = {
k: v.to(device) for k, v in encoded_input.items()
}
with torch.no_grad():
model_output = model(**encoded_input_dict)
```
### Expected behavior
I expect this code to work however this results in very weird errors. More details on error stack trace can be found here: https://github.com/pytorch/pytorch/issues/121493
I found that if I remove `additional_special_tokens` param, code works. So that seems to be the problem. Another issue is that it is still not clear (after so many years) how to extend/add special tokens into the model. I went through the code base to find this parameter but that seems to be not working alone and the whole stack trace isn't helpful at all.
Questions from my side:
- What is the expected solution for this and could we document this somewhere? I can't find this anywhere or somehow i am not able to find this.
- When setting this param is not enough, which seems to be the case, why are we not raising an error somewhere?
|
https://github.com/huggingface/transformers/issues/29564
|
closed
|
[] | 2024-03-09T22:56:44Z
| 2024-04-17T08:03:43Z
| null |
lordsoffallen
|
pytorch/vision
| 8,305
|
aarch64 build for AWS Linux - Failed to load image Python extension
|
### 🐛 Describe the bug
Built Torch 2.1.2 and TorchVision 0.16.2 from source and running into the following problem:
/home/ec2-user/conda/envs/textgen/lib/python3.10/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: '/home/ec2-user/conda/envs/textgen/lib/python3.10/site-packages/torchvision/image.so: undefined symbol: _ZNK3c1017SymbolicShapeMeta18init_is_contiguousEv'If you don't plan on using image functionality from `torchvision.io`, you can ignore this warning. Otherwise, there might be something wrong with your environment. Did you have `libjpeg` or `libpng` installed before building `torchvision` from source?
previously the error was about missing libs and not undefined symbol, so I believe the libs are correctly installed now. Building says:
```
Compiling extensions with following flags:
FORCE_CUDA: False
FORCE_MPS: False
DEBUG: False
TORCHVISION_USE_PNG: True
TORCHVISION_USE_JPEG: True
TORCHVISION_USE_NVJPEG: True
TORCHVISION_USE_FFMPEG: True
TORCHVISION_USE_VIDEO_CODEC: True
NVCC_FLAGS:
Compiling with debug mode OFF
Found PNG library
Building torchvision with PNG image support
libpng version: 1.6.37
libpng include path: /home/ec2-user/conda/envs/textgen/include/libpng16
Running build on conda-build: False
Running build on conda: True
Building torchvision with JPEG image support
libjpeg include path: /home/ec2-user/conda/envs/textgen/include
libjpeg lib path: /home/ec2-user/conda/envs/textgen/lib
Building torchvision without NVJPEG image support
Building torchvision with ffmpeg support
ffmpeg version: b'ffmpeg version 4.2.2 Copyright (c) 2000-2019 the FFmpeg developers\nbuilt with gcc 10.2.0 (crosstool-NG 1.22.0.1750_510dbc6_dirty)\nconfiguration: --prefix=/opt/conda/conda-bld/ffmpeg_1622823166193/_h_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placeh --cc=/opt/conda/conda-bld/ffmpeg_1622823166193/_build_env/bin/aarch64-conda-linux-gnu-cc --disable-doc --enable-avresample --enable-gmp --enable-hardcoded-tables --enable-libfreetype --enable-libvpx --enable-pthreads --enable-libopus --enable-postproc --enable-pic --enable-pthreads --enable-shared --enable-static --enable-version3 --enable-zlib --enable-libmp3lame --disable-nonfree --enable-gpl --enable-gnutls --disable-openssl --enable-libopenh264 --enable-libx264\nlibavutil 56. 31.100 / 56. 31.100\nlibavcodec 58. 54.100 / 58. 54.100\nlibavformat 58. 29.100 / 58. 29.100\nlibavdevice 58. 8.100 / 58. 8.100\nlibavfilter 7. 57.100 / 7. 57.100\nlibavresample 4. 0. 0 / 4. 0. 0\nlibswscale 5. 5.100 / 5. 5.100\nlibswresample 3. 5.100 / 3. 5.100\nlibpostproc 55. 5.100 / 55. 5.100\n'
ffmpeg include path: ['/home/ec2-user/conda/envs/textgen/include']
ffmpeg library_dir: ['/home/ec2-user/conda/envs/textgen/lib']
Building torchvision without video codec support
```
So I believe I do have things set up correctly to be able to do image calls (I don't care about video). Any idea why I would still be getting the undefined symbol warning? Thanks!
### Versions
Collecting environment information...
PyTorch version: 2.1.2+cu121
Is debug build: False
CUDA used to build PyTorch: 12.2
ROCM used to build PyTorch: N/A
OS: Amazon Linux 2023.3.20240304 (aarch64)
GCC version: (GCC) 11.4.1 20230605 (Red Hat 11.4.1-2)
Clang version: Could not collect
CMake version: version 3.28.3
Libc version: glibc-2.34
Python version: 3.10.9 (main, Mar 8 2023, 10:41:45) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-6.1.79-99.164.amzn2023.aarch64-aarch64-with-glibc2.34
Is CUDA available: True
CUDA runtime version: 12.2.140
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA T4G
Nvidia driver version: 550.54.14
cuDNN version: Probably one of the following:
/usr/local/cuda-12.2/targets/sbsa-linux/lib/libcudnn.so.8.9.4
/usr/local/cuda-12.2/targets/sbsa-linux/lib/libcudnn_adv_infer.so.8.9.4
/usr/local/cuda-12.2/targets/sbsa-linux/lib/libcudnn_adv_train.so.8.9.4
/usr/local/cuda-12.2/targets/sbsa-linux/lib/libcudnn_cnn_infer.so.8.9.4
/usr/local/cuda-12.2/targets/sbsa-linux/lib/libcudnn_cnn_train.so.8.9.4
/usr/local/cuda-12.2/targets/sbsa-linux/lib/libcudnn_ops_infer.so.8.9.4
/usr/local/cuda-12.2/targets/sbsa-linux/lib/libcudnn_ops_train.so.8.9.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Vendor ID: ARM
Model name: Neoverse-N1
Model:
|
https://github.com/pytorch/vision/issues/8305
|
open
|
[] | 2024-03-09T20:13:46Z
| 2024-03-12T18:53:04Z
| 6
|
elkay
|
huggingface/datasets
| 6,726
|
Profiling for HF Filesystem shows there are easy performance gains to be made
|
### Describe the bug
# Let's make it faster
First, an evidence...

Figure 1: CProfile for loading 3 files from cerebras/SlimPajama-627B train split, and 3 files from test split using streaming=True. X axis is 1106 seconds long.
See? It's pretty slow.
What is resolve pattern doing?
```
resolve_pattern called with **/train/** and hf://datasets/cerebras/SlimPajama-627B@2d0accdd58c5d5511943ca1f5ff0e3eb5e293543
resolve_pattern took 20.815081119537354 seconds
```
Makes sense. How to improve it?
## Bigger project, biggest payoff
Databricks (and consequently, spark) store a compressed manifest file of the files contained in the remote filesystem.
Then, you download one tiny file, decompress it, and all the operations are local instead of this shenanigans.
It seems pretty straightforward to make dataset uploads compute a manifest and upload it alongside their data.
This would make resolution time so fast that nobody would ever think about it again.
It also means you either need to have the uploader compute it _every time_, or have a hook that computes it.
## Smaller project, immediate payoff: Be diligent in avoiding deepcopy
Revise the _ls_tree method to avoid deepcopy:
```
def _ls_tree(
self,
path: str,
recursive: bool = False,
refresh: bool = False,
revision: Optional[str] = None,
expand_info: bool = True,
):
..... omitted .....
for path_info in tree:
if isinstance(path_info, RepoFile):
cache_path_info = {
"name": root_path + "/" + path_info.path,
"size": path_info.size,
"type": "file",
"blob_id": path_info.blob_id,
"lfs": path_info.lfs,
"last_commit": path_info.last_commit,
"security": path_info.security,
}
else:
cache_path_info = {
"name": root_path + "/" + path_info.path,
"size": 0,
"type": "directory",
"tree_id": path_info.tree_id,
"last_commit": path_info.last_commit,
}
parent_path = self._parent(cache_path_info["name"])
self.dircache.setdefault(parent_path, []).append(cache_path_info)
out.append(cache_path_info)
return copy.deepcopy(out) # copy to not let users modify the dircache
```
Observe this deepcopy at the end. It is making a copy of a very simple data structure. We do not need to copy. We can simply generate the data structure twice instead. It will be much faster.
```
def _ls_tree(
self,
path: str,
recursive: bool = False,
refresh: bool = False,
revision: Optional[str] = None,
expand_info: bool = True,
):
..... omitted .....
def make_cache_path_info(path_info):
if isinstance(path_info, RepoFile):
return {
"name": root_path + "/" + path_info.path,
"size": path_info.size,
"type": "file",
"blob_id": path_info.blob_id,
"lfs": path_info.lfs,
"last_commit": path_info.last_commit,
"security": path_info.security,
}
else:
return {
"name": root_path + "/" + path_info.path,
"size": 0,
"type": "directory",
"tree_id": path_info.tree_id,
"last_commit": path_info.last_commit,
}
for path_info in tree:
cache_path_info = make_cache_path_info(path_info)
out_cache_path_info = make_cache_path_info(path_info) # copy to not let users modify the dircache
parent_path = self._parent(cache_path_info["name"])
self.dircache.setdefault(parent_path, []).append(cache_path_info)
out.append(out_cache_path_info)
return out
```
Note there is no longer a deepcopy in this method. We have replaced it with generating the output twice. This is substantially faster. For me, the entire resolution went from 1100s to 360s.
## Medium project, medium payoff
After the above change, we have this profile:
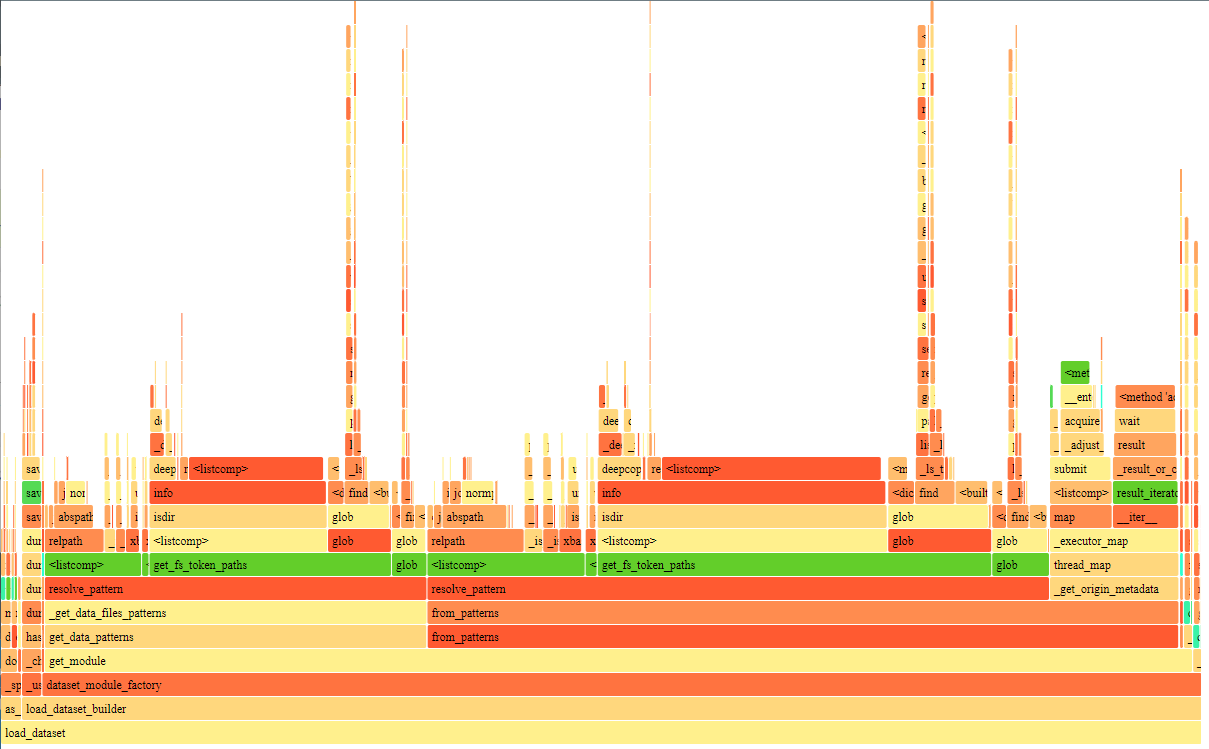
Figure 2: x-axis is 355 seconds. Note that globbing and _ls_tree deep copy is gone. No surprise there. It's much faster now, but we still spend ~187seconds i
|
https://github.com/huggingface/datasets/issues/6726
|
open
|
[] | 2024-03-09T07:08:45Z
| 2024-03-09T07:11:08Z
| 2
|
awgr
|
huggingface/alignment-handbook
| 133
|
Early Stopping Issue when used with ConstantLengthDataset
|
Hello
I modified the code to include the Constant Length Dataset and it's early stopping at around 15% of the training. This issue doesn't occur when not used with the normal code given. Is there an issue with constant length dataset? I used it with SFTTrainer.
|
https://github.com/huggingface/alignment-handbook/issues/133
|
open
|
[] | 2024-03-08T23:08:08Z
| 2024-03-08T23:08:08Z
| 0
|
sankydesai
|
pytorch/serve
| 3,008
|
very high QueueTime
|
Hi, I am seeing a very high queue time in my torchserve setup.
if I am considering correctly the `QueueTime.ms:19428` means this particular request had to wait for 19 sec for processing
while the QueTime just before that request was `QueueTime.ms:0` so why suddenly 18 sec delay
If I am wrong then what does this QueueTime parameter represent?
my env torch131+cu117, torchserve 0.7.2, and the model used is yolov5s which is a very small model, in input I am accepting an s3 uri downloading the image internally, and then processing
attaching the logs here any idea what could be happening here
```
2024-03-08T08:44:35,261 [INFO ] W-9003-vehicledetection TS_METRICS - QueueTime.ms:0|#Level:Host|#hostname:ai-gpu-service-5b585f9b9d-x4r7z,timestamp:1709887475
2024-03-08T08:44:35,261 [INFO ] W-9003-vehicledetection TS_METRICS - WorkerThreadTime.ms:0|#Level:Host|#hostname:ai-gpu-service-5b585f9b9d-x4r7z,timestamp:1709887475
2024-03-08T08:44:35,261 [INFO ] W-9003-vehicledetection org.pytorch.serve.wlm.WorkerThread - Flushing req. to backend at: 1709887475261
2024-03-08T08:44:35,262 [INFO ] W-9003-vehicledetection-stdout MODEL_LOG - Backend received inference at: 1709887475
2024-03-08T08:44:35,262 [INFO ] W-9003-vehicledetection-stdout MODEL_LOG - Received backend request -> {'image_uri': 's3://mubucket/062c650b3213.jpeg', 'conf_thresh': 0.5}
2024-03-08T08:44:35,282 [INFO ] W-9003-vehicledetection-stdout MODEL_LOG - completed processing results
2024-03-08T08:44:35,283 [INFO ] W-9003-vehicledetection-stdout MODEL_METRICS - HandlerTime.Milliseconds:20.93|#ModelName:vehicledetection,Level:Model|#hostname:ai-gpu-service-5b585f9b9d-x4r7z,requestID:3a44a9f4-4f5d-4ead-8f1f-153ecf6b001f,timestamp:1709887475
2024-03-08T08:44:35,283 [INFO ] W-9003-vehicledetection-stdout MODEL_METRICS - PredictionTime.Milliseconds:21.03|#ModelName:vehicledetection,Level:Model|#hostname:ai-gpu-service-5b585f9b9d-x4r7z,requestID:3a44a9f4-4f5d-4ead-8f1f-153ecf6b001f,timestamp:1709887475
2024-03-08T08:44:35,283 [INFO ] W-9003-vehicledetection org.pytorch.serve.wlm.WorkerThread - Backend response time: 22
2024-03-08T08:44:35,283 [INFO ] W-9003-vehicledetection ACCESS_LOG - /xxx.xx.xxx.xxx:18363 "POST /predictions/vehicledetection HTTP/1.1" 200 19450
2024-03-08T08:44:35,283 [INFO ] W-9003-vehicledetection TS_METRICS - Requests2XX.Count:1|#Level:Host|#hostname:ai-gpu-service-5b585f9b9d-x4r7z,timestamp:1706999000
2024-03-08T08:44:35,283 [DEBUG] W-9003-vehicledetection org.pytorch.serve.job.Job - Waiting time ns: 19428751625, Backend time ns: 21770097
2024-03-08T08:44:35,283 [INFO ] W-9003-vehicledetection TS_METRICS - QueueTime.ms:19428|#Level:Host|#hostname:ai-gpu-service-5b585f9b9d-x4r7z,timestamp:1709887475
```
|
https://github.com/pytorch/serve/issues/3008
|
closed
|
[] | 2024-03-08T14:52:09Z
| 2024-03-09T17:12:37Z
| 0
|
PushpakBhoge512
|
huggingface/transformers.js
| 635
|
Failed to process file. and Failed to upload.
|
### Question
I am hosting Supabase on Docker in Ubuntu, and I am facing file upload failures on the chatbot-ui. The error messages displayed are "Failed to process file" and "Failed to upload." The console output error messages are as follows:
- POST https://chat.example.com/api/retrieval/process 500 (Internal Server Error)
- GET https://supa.example.com/rest/v1/files?select=*&id=eq.5186a7c7-ff34-4a40-98c1-db8d36e47896 406 (Not Acceptable)
File uploads fail regardless of the file type - whether it's a file with a purely English filename, a .txt file, or a .docx file.
Additionally, registration, login, chatting, and uploading images are functioning properly.
|
https://github.com/huggingface/transformers.js/issues/635
|
closed
|
[
"question"
] | 2024-03-08T13:07:18Z
| 2024-03-08T13:22:57Z
| null |
chawaa
|
huggingface/peft
| 1,545
|
How to use lora finetune moe model
|
https://github.com/huggingface/peft/issues/1545
|
closed
|
[] | 2024-03-08T11:45:09Z
| 2024-04-16T15:03:39Z
| null |
Minami-su
|
|
huggingface/datatrove
| 119
|
how about make a ray executor to deduplication
|
- https://github.com/ChenghaoMou/text-dedup/blob/main/text_dedup/minhash_spark.py
- reference:https://github.com/alibaba/data-juicer/blob/main/data_juicer/core/ray_executor.py
- Ray is simpler and faster than Spark
|
https://github.com/huggingface/datatrove/issues/119
|
closed
|
[] | 2024-03-08T11:37:13Z
| 2024-04-11T12:48:53Z
| null |
simplew2011
|
huggingface/transformers.js
| 634
|
For nomic-ai/nomic-embed-text-v1 8192 context length
|
### Question
As per document: https://huggingface.co/nomic-ai/nomic-embed-text-v1
Model supports 8192 context length, however, in transformers.js model_max_length: 512.
Any guidance how to use full context (8192) instead of 512?
|
https://github.com/huggingface/transformers.js/issues/634
|
closed
|
[
"question"
] | 2024-03-08T05:33:39Z
| 2025-10-13T04:57:49Z
| null |
faizulhaque
|
huggingface/diffusers
| 7,254
|
Request proper examples on how to training a diffusion models with diffusers on large scale dataset like LAION
|
Hi, I do not see any examples in diffusers/examples on how to training a diffusion models with diffusers on large scale dataset like LAION. However, it is important since many works and models is willing integrate their models into diffusers, so if they can train their models in diffusers, it would be more easy when they want to do it.
|
https://github.com/huggingface/diffusers/issues/7254
|
closed
|
[
"stale"
] | 2024-03-08T01:31:33Z
| 2024-06-30T05:27:57Z
| null |
Luciennnnnnn
|
huggingface/swift-transformers
| 56
|
How to get models?
|
Missing in docu?
|
https://github.com/huggingface/swift-transformers/issues/56
|
closed
|
[] | 2024-03-07T15:47:54Z
| 2025-02-11T11:41:32Z
| null |
pannous
|
huggingface/datasets
| 6,721
|
Hi,do you know how to load the dataset from local file now?
|
Hi, if I want to load the dataset from local file, then how to specify the configuration name?
_Originally posted by @WHU-gentle in https://github.com/huggingface/datasets/issues/2976#issuecomment-1333455222_
|
https://github.com/huggingface/datasets/issues/6721
|
open
|
[] | 2024-03-07T13:58:40Z
| 2024-03-31T08:09:25Z
| null |
Gera001
|
pytorch/executorch
| 2,293
|
How to analyze executorch .pte file performance?
|
I am looking for a way to either benchmark the .pte files performance, the final state of the ExecutorchProgramManager object, or similar after following [this](https://pytorch.org/executorch/stable/tutorials/export-to-executorch-tutorial.html) tutorial. I used the PyTorch profiler on the model before putting it through executorch. I can’t find a way to use any one of the above on the profiler. I’d like to use the same or similar to compare the original model to the executorch model with quantization to see the performance differences. Thanks!
|
https://github.com/pytorch/executorch/issues/2293
|
closed
|
[
"module: devtools"
] | 2024-03-07T12:12:41Z
| 2025-02-03T22:04:48Z
| null |
mmingo848
|
huggingface/transformers.js
| 633
|
Is 'aggregation_strategy' parameter available for token classification pipeline?
|
### Question
Hi. I have question.
From HuggingFace Transformers documentation, they have **'aggregation_strategy'** parameter in token classification pipeline. [Link](https://huggingface.co/docs/transformers/en/main_classes/pipelines#transformers.TokenClassificationPipeline.aggregation_strategy)
Need to know in this library provide this parameter?
Thanks.
|
https://github.com/huggingface/transformers.js/issues/633
|
open
|
[
"help wanted",
"good first issue",
"question"
] | 2024-03-07T07:02:55Z
| 2024-06-09T15:16:56Z
| null |
boat-p
|
pytorch/xla
| 6,674
|
How to minimize memory expansion due to padding during sharding
|
Hello
For a model that can be sharded in model parallelization in TPUv4 (4x32) device, I am getting the error below at the beginning of the training on TPUv3 (8x16) device. There is `4x expansion` with respect to console message. Even if both both TPUv4 and TPUv3 devices have same total memory I cannot run the training on TPUv3 device.
```
Program hbm requirement 15.45G:
global 2.36M
scoped 3.88M
HLO temp 15.45G (60.9% utilization: Unpadded (9.40G) Padded (15.44G), 0.0% fragmentation (5.52M))
Largest program allocations in hbm:
1. Size: 4.00G
Shape: bf16[2048,1,2048,128]{0,1,3,2:T(4,128)(2,1)}
Unpadded size: 1.00G
Extra memory due to padding: 3.00G (4.0x expansion)
XLA label: broadcast.6042.remat3 = broadcast(bitcast.26), dimensions={2,3}
Allocation type: HLO temp
==========================
2. Size: 4.00G
Shape: bf16[2048,1,2048,128]{0,1,3,2:T(4,128)(2,1)}
Unpadded size: 1.00G
Extra memory due to padding: 3.00G (4.0x expansion)
XLA label: broadcast.6043.remat3 = broadcast(bitcast.27), dimensions={0,3}
Allocation type: HLO temp
==========================
```
The lines that causes `4x expansion` is below:
```
def forward(self, x): # Activation map volume = 1,128,2048,1
...
...
x = torch.transpose(x, 1, 3) # Activation map volume = 1,1,2048,128
x_batch_0 = x.expand(2048, -1, -1, -1) # Activation map volume = 2048,1,2048,128
x_batch_1 = x.repeat_interleave(2048, dim=2).reshape(2048, 1, 2048, 128) # Activation map volume = 2048,1,2048,128
x_batch = torch.cat((x_batch_0, x_batch_1), dim=1) # Activation map volume = 2048,2,2048,128
...
...
```
Here are the sharding properties that I set.
```
mesh_shape = (num_devices, 1, 1, 1)
mesh = xs.Mesh(device_ids, mesh_shape, ('w', 'x', 'y', 'z'))
partition_spec = (0, 1, 2, 3) # Apply sharding along all axes
for name, layer in model.named_modules():
if ( 'conv2d' in name ):
xs.mark_sharding(layer.weight, mesh, partition_spec)
```
How can I prevent `4x expansion`?
|
https://github.com/pytorch/xla/issues/6674
|
open
|
[
"performance",
"distributed"
] | 2024-03-06T15:23:31Z
| 2025-04-18T18:42:38Z
| null |
mfatih7
|
huggingface/swift-coreml-diffusers
| 93
|
Blocked at "loading" screen - how to reset the app / cache ?
|
After playing a bit with the app, it now stays in "Loading" state at startup (see screenshot)
I tried to remove the cache in `~/Library/Application Support/hf-diffusion-models` but it just cause a re-download.
How can I reset the app, delete all files created and start like on a fresh machine again ?
Alternatively, how can I pass the "Loading" screen ?
<img width="1016" alt="image" src="https://github.com/huggingface/swift-coreml-diffusers/assets/401798/15c7c67a-f61f-4855-a11e-ea7bd61b0a09">
|
https://github.com/huggingface/swift-coreml-diffusers/issues/93
|
open
|
[] | 2024-03-06T12:50:29Z
| 2024-03-10T11:24:49Z
| null |
sebsto
|
huggingface/chat-ui
| 905
|
Fail to create assistant.
|
I use the docker image chat-ui-db as the frontend, text-generation-inference as the inference backend, and meta-llamaLlama-2-70b-chat-hf as the model. Using the image and model mentioned above, I set up a large language model dialog service on server A. Assume that the IP address of the server A is x.x.x.x.
I use docker compose to deploy it. The content of docker-compose.yml is as follows:
```
services:
chat-ui:
image: chat-ui-db:latest
ports:
- "3000:3000"
restart: unless-stopped
textgen:
image: huggingface/text-generation-inference:1.4
ports:
- "8080:80"
command: ["--model-id", "/data/models/meta-llamaLlama-2-70b-chat-hf"]
volumes:
- /home/test/llm-test/serving/data:/data
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 8
capabilities: [gpu]
restart: unless-stopped
```
I set ENABLE_ASSISTANTS=true in .env.local to enable assistants feature.
I logged into localhost:3000 using chrome, clicked the settings button, and then clicked the create new assistant button. Enter the information in the Name and Description text boxes, select a model, and enter the information in the User start messages and Instructions (system prompt) text boxes. Finally, click the Create button. I can create an assistant just fine.
When I go to xxxx:3000 from a browser on a different server and access the service. (One may ask, how can I achieve access to server A's services from other servers without logging. The solution is to use nginx as a http to https anti-proxy(https://www.inovex.de/de/blog/code-assistant-how-to-self-host-your-own/)). I clicked the settings button, and then clicked the create new assistant button. Enter the information in the Name and Description text boxes, select a model, and enter the information in the User start messages and Instructions (system prompt) text boxes. Finally, click the Create button. The webpage is not responding. The container logs don't show anything either. I couldn't create an assistant.
What should i do?
Do I have to enable login authentication to create an assistant? unless I'm accessing it from localhost. I'm on a LAN and I can't get user authentication through Huggingface or google. I have also tried to set up a user authentication service using keycloak and configure .env.local to enable open id login. But the attempt failed. See this page(https://github.com/huggingface/chat-ui/issues/896) for the specific problem.
|
https://github.com/huggingface/chat-ui/issues/905
|
open
|
[] | 2024-03-06T08:33:03Z
| 2024-03-06T08:33:03Z
| 0
|
majestichou
|
pytorch/serve
| 3,004
|
How to 'Create model archive pod and run model archive file generation script' in the ‘User Guide’
|
### 🐛 Describe the bug
I'm reading the User Guide of KServe doc. One part of the 'Deploy a PyTorch Model with TorchServe InferenceService' is hard to understand.
3 'Create model archive pod and run model archive file generation script'
3.1 Create model archive pod and run model archive file generation script[¶](https://kserve.github.io/website/0.11/modelserving/v1beta1/torchserve/model-archiver/#31-create-model-archive-pod-and-run-model-archive-file-generation-script)
kubectl apply -f model-archiver.yaml -n kserve-test
(https://kserve.github.io/website/0.11/modelserving/v1beta1/torchserve/model-archiver/)
Idk how to write the model-archiver.yaml and the model archive file generation script. I would be very grateful if anyone can help me!
### Error logs
Not yet
### Installation instructions
Yes
yes
### Model Packaing
Not yet
### config.properties
_No response_
### Versions
aiohttp==3.8.6
aiohttp-cors==0.7.0
aiorwlock==1.3.0
aiosignal==1.3.1
anyio==4.0.0
async-timeout==4.0.3
attrs==23.1.0
azure-core==1.29.5
azure-identity==1.15.0
azure-storage-blob==12.18.3
azure-storage-file-share==12.14.2
blessed==1.20.0
#boto==31.28.73
botocore==1.31.73
cachetools==5.3.2
captum==0.6.0
certifi==2023.7.22
cffi==1.16.0
charset-normalizer==3.3.0
click==8.1.7
cloudevents==1.10.1
colorful==0.5.5
contourpy==1.1.1
cryptography==41.0.5
cuda-python==12.3.0
cycler==0.12.1
Cython==0.29.34
deprecation==2.1.0
distlib==0.3.7
enum-compat==0.0.3
exceptiongroup==1.1.3
fastapi==0.95.2
filelock==3.12.4
fonttools==4.43.1
frozenlist==1.4.0
fsspec==2023.9.2
google-api-core==2.12.0
google-auth==2.23.3
google-cloud-core==2.3.3
google-cloud-storage==1.44.0
#google-crc==32c1.5.0
google-resumable-media==2.6.0
googleapis-common-protos==1.61.0
gpustat==1.1.1
grpcio==1.51.3
grpcio-tools==1.48.2
#h==110.14.0
httpcore==0.16.3
httptools==0.6.1
httpx==0.23.3
huggingface-hub==0.17.3
idna==3.4
importlib-resources==6.1.0
isodate==0.6.1
#Jinja==23.1.2
jmespath==1.0.1
jsonschema==4.19.2
jsonschema-specifications==2023.7.1
kiwisolver==1.4.5
kserve==0.11.1
kubernetes==28.1.0
MarkupSafe==2.1.3
matplotlib==3.8.0
mpmath==1.3.0
msal==1.24.1
msal-extensions==1.0.0
msgpack==1.0.7
multidict==6.0.4
networkx==3.1
numpy==1.24.3
nvidia-ml-py==12.535.108
oauthlib==3.2.2
opencensus==0.11.3
opencensus-context==0.1.3
orjson==3.9.10
packaging==23.2
pandas==2.1.2
Pillow==10.0.1
#pip==23.3.1
platformdirs==3.11.0
portalocker==2.8.2
prometheus-client==0.13.1
protobuf==3.20.3
psutil==5.9.5
py-spy==0.3.14
#pyasn==10.5.0
#pyasn==1-modules0.3.0
pycparser==2.21
pydantic==1.10.13
PyJWT==2.8.0
pynvml==11.4.1
pyparsing==3.1.1
python-dateutil==2.8.2
python-dotenv==1.0.0
python-rapidjson==1.13
pytz==2023.3.post1
PyYAML==6.0
ray==2.4.0
referencing==0.30.2
regex==2023.10.3
requests==2.31.0
requests-oauthlib==1.3.1
#rfc==39861.5.0
rpds-py==0.10.6
rsa==4.9
#s==3transfer0.7.0
safetensors==0.4.0
setuptools==68.2.2
six==1.16.0
smart-open==6.4.0
sniffio==1.3.0
starlette==0.27.0
sympy==1.12
tabulate==0.9.0
timing-asgi==0.3.1
tokenizers==0.14.1
torch==2.1.0
torch-model-archiver==0.9.0
torch-workflow-archiver==0.2.11
torchaudio==2.1.0
torchdata==0.7.0
torchserve==0.9.0
torchtext==0.16.0
torchvision==0.16.0
tqdm==4.66.1
transformers==4.34.1
tritonclient==2.39.0
typing_extensions==4.8.0
tzdata==2023.3
#urllib==31.26.18
uvicorn==0.19.0
#uvloop==0.19.0
virtualenv==20.21.0
watchfiles==0.21.0
wcwidth==0.2.8
websocket-client==1.6.4
websockets==12.0
wheel==0.40.0
yarl==1.9.2
zipp==3.17.0
### Repro instructions
None
### Possible Solution
_No response_
|
https://github.com/pytorch/serve/issues/3004
|
open
|
[
"triaged",
"kfserving"
] | 2024-03-06T07:42:50Z
| 2024-03-07T07:06:52Z
| null |
Enochlove
|
huggingface/chat-ui
| 904
|
Running the project with `npm run dev`, but it does not hot reload.
|
Am I alone in this issue or are you just developing without hot reload? Does anyone have any ideas on how to resolve it?
**UPDATES:**
It has to do whenever you're running it on WSL.
I guess this is an unrelated issue so feel free to close, but would still be nice to know how to resolve this.
|
https://github.com/huggingface/chat-ui/issues/904
|
closed
|
[] | 2024-03-06T03:34:21Z
| 2024-03-06T16:07:11Z
| 2
|
CakeCrusher
|
huggingface/dataset-viewer
| 2,550
|
More precise dataset size computation
|
Currently, the Hub uses the `/size` endpoint's `num_bytes_original_files` value to display the `Size of downloaded dataset files` on a dataset's card page. However, this value does not consider a possible overlap between the configs' data files (and simply [sums](https://github.com/huggingface/datasets-server/blob/e4aac49c4d3c245cb3c0e48695b7d24a934a8377/services/worker/src/worker/job_runners/dataset/size.py#L97-L98) all the configs' sizes up), in which case the shared files need to be downloaded only once. Both `datasets` and `hfh` recognize this (by downloading them once), so the size computation should account for it, too.
cc @guipenedo who reported this behavior first
|
https://github.com/huggingface/dataset-viewer/issues/2550
|
open
|
[
"question",
"P2"
] | 2024-03-05T22:22:24Z
| 2024-05-24T20:59:36Z
| null |
mariosasko
|
pytorch/serve
| 3,001
|
Clean up metrics documentation
|
### 📚 The doc issue
Metrics documentation has a lot of information and information is spread across different subsections finding it difficult to know whats the right way to use metrics
### Suggest a potential alternative/fix
For older versions of TorchServe, one can always go to the tag and check the Readme.
Clean up the README to show only what is relevant now
|
https://github.com/pytorch/serve/issues/3001
|
closed
|
[
"documentation",
"internal"
] | 2024-03-05T20:49:32Z
| 2024-04-26T21:32:45Z
| 0
|
agunapal
|
huggingface/datasets
| 6,719
|
Is there any way to solve hanging of IterableDataset using split by node + filtering during inference
|
### Describe the bug
I am using an iterable dataset in a multi-node setup, trying to do training/inference while filtering the data on the fly. I usually do not use `split_dataset_by_node` but it is very slow using the IterableDatasetShard in `accelerate` and `transformers`. When I filter after applying `split_dataset_by_node`, it results in shards that are not equal sizes due to unequal samples filtered from each one.
The distributed process hangs when trying to accomplish this. Is there any way to resolve this or is it impossible to implement?
### Steps to reproduce the bug
Here is a toy example of what I am trying to do that reproduces the behavior
```
# torchrun --nproc-per-node 2 file.py
import os
import pandas as pd
import torch
from accelerate import Accelerator
from datasets import Features, Value, load_dataset
from datasets.distributed import split_dataset_by_node
from torch.utils.data import DataLoader
accelerator = Accelerator(device_placement=True, dispatch_batches=False)
if accelerator.is_main_process:
if not os.path.exists("scratch_data"):
os.mkdir("scratch_data")
n_shards = 4
for i in range(n_shards):
df = pd.DataFrame({"id": list(range(10 * i, 10 * (i + 1)))})
df.to_parquet(f"scratch_data/shard_{i}.parquet")
world_size = accelerator.num_processes
local_rank = accelerator.process_index
def collate_fn(examples):
input_ids = []
for example in examples:
input_ids.append(example["id"])
return torch.LongTensor(input_ids)
dataset = load_dataset(
"parquet", data_dir="scratch_data", split="train", streaming=True
)
dataset = (
split_dataset_by_node(dataset, rank=local_rank, world_size=world_size)
.filter(lambda x: x["id"] < 35)
.shuffle(seed=42, buffer_size=100)
)
batch_size = 2
train_dataloader = DataLoader(
dataset,
batch_size=batch_size,
collate_fn=collate_fn,
num_workers=2
)
for x in train_dataloader:
x = x.to(accelerator.device)
print({"rank": local_rank, "id": x})
y = accelerator.gather_for_metrics(x)
if accelerator.is_main_process:
print("gathered", y)
```
### Expected behavior
Is there any way to continue training/inference on the GPUs that have remaining data left without waiting for the others? Is it impossible to filter when
### Environment info
- `datasets` version: 2.18.0
- Platform: Linux-5.10.209-198.812.amzn2.x86_64-x86_64-with-glibc2.31
- Python version: 3.10.13
- `huggingface_hub` version: 0.21.3
- PyArrow version: 15.0.0
- Pandas version: 2.2.1
- `fsspec` version: 2023.6.0
|
https://github.com/huggingface/datasets/issues/6719
|
open
|
[] | 2024-03-05T15:55:13Z
| 2024-03-05T15:55:13Z
| 0
|
ssharpe42
|
huggingface/chat-ui
| 899
|
Bug--Llama-2-70b-chat-hf error: `truncate` must be strictly positive and less than 1024. Given: 3072
|
I use the docker image chat-ui-db as the frontend, text-generation-inference as the inference backend, and meta-llamaLlama-2-70b-chat-hf as the model.
In the model field of the .env.local file, I have the following settings
```
MODELS=`[
{
"name": "meta-llama/Llama-2-70b-chat-hf",
"endpoints": [{
"type" : "tgi",
"url": "http://textgen:80",
}],
"preprompt": " ",
"chatPromptTemplate" : "<s>[INST] <<SYS>>\n{{preprompt}}\n<</SYS>>\n\n{{#each messages}}{{#ifUser}}{{content}} [/INST] {{/ifUser}}{{#ifAssistant}}{{content}} </s><s>[INST] {{/ifAssistant}}{{/each}}",
"promptExamples": [
{
"title": "Write an email from bullet list",
"prompt": "As a restaurant owner, write a professional email to the supplier to get these products every week: \n\n- Wine (x10)\n- Eggs (x24)\n- Bread (x12)"
}, {
"title": "Code a snake game",
"prompt": "Code a basic snake game in python, give explanations for each step."
}, {
"title": "Assist in a task",
"prompt": "How do I make a delicious lemon cheesecake?"
}
],
"parameters": {
"temperature": 0.1,
"top_p": 0.95,
"repetition_penalty": 1.2,
"top_k": 50,
"truncate": 3072,
"max_new_tokens": 1024,
"stop" : ["</s>", "</s><s>[INST]"]
}
}
]`
```
This setting is the same as the setting for Llama-2-70b-chat-hf in the .env.template file in the chat-ui repository.
Then I type the question in the input box. An error has occurred.
The following error information is found in the log:
```
textgen | 2024-03-05T20:00:38.883413Z ERROR compat_generate{default_return_full_text=false compute_type=Extension(ComputeType("8-nvidia-a100-sxm4-40gb"))}:generate_stream{parameters=GenerateParameters { best_of: None, temperature: Some(0.1), repetition_penalty: Some(1.2), frequency_penalty: None, top_k: Some(50), top_p: Some(0.95), typical_p: None, do_sample: false, max_new_tokens: Some(1024), return_full_text: Some(false), stop: ["</s>", "</s><s>[INST]"], truncate: Some(3072), watermark: false, details: false, decoder_input_details: false, seed: None, top_n_tokens: None, grammar: None }}:async_stream:generate_stream: text_generation_router::infer: router/src/infer.rs:123: `truncate` must be strictly positive and less than 1024. Given: 3072
chat-ui | Error: Input validation error: `truncate` must be strictly positive and less than 1024. Given: 3072
chat-ui | at streamingRequest (file:///app/node_modules/@huggingface/inference/dist/index.mjs:323:19)
chat-ui | at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
chat-ui | at async textGenerationStream (file:///app/node_modules/@huggingface/inference/dist/index.mjs:673:3)
chat-ui | at async generateFromDefaultEndpoint (file:///app/.svelte-kit/output/server/entries/endpoints/conversation/_id_/_server.ts.js:39:20)
chat-ui | at async summarize (file:///app/.svelte-kit/output/server/entries/endpoints/conversation/_id_/_server.ts.js:287:10)
chat-ui | at async file:///app/.svelte-kit/output/server/entries/endpoints/conversation/_id_/_server.ts.js:607:26
textgen | 2024-03-05T20:00:38.910266Z ERROR compat_generate{default_return_full_text=false compute_type=Extension(ComputeType("8-nvidia-a100-sxm4-40gb"))}:generate_stream{parameters=GenerateParameters { best_of: None, temperature: Some(0.1), repetition_penalty: Some(1.2), frequency_penalty: None, top_k: Some(50), top_p: Some(0.95), typical_p: None, do_sample: false, max_new_tokens: Some(1024), return_full_text: Some(false), stop: ["</s>", "</s><s>[INST]"], truncate: Some(3072), watermark: false, details: false, decoder_input_details: false, seed: None, top_n_tokens: None, grammar: None }}:async_stream:generate_stream: text_generation_router::infer: router/src/infer.rs:123: `truncate` must be strictly positive and less than 1024. Given: 3072
```
I set "truncate" to 1000, everything is ok.
**"truncate" for Llama-2-70b-chat-hf in the .env.template file in the chat-ui repository is 3072. I think the 3072 should work fine. I don't know how webpage https://huggingface.co/chat/ sets this parameter.**
|
https://github.com/huggingface/chat-ui/issues/899
|
open
|
[
"support",
"models"
] | 2024-03-05T12:27:45Z
| 2024-03-06T00:59:10Z
| 4
|
majestichou
|
huggingface/tokenizers
| 1,468
|
How to convert tokenizers.tokenizer to XXTokenizerFast in transformers?
|
### Motivation
I followed the guide [build-a-tokenizer-from-scratch](https://huggingface.co/docs/tokenizers/quicktour#build-a-tokenizer-from-scratch) and got a single tokenizer.json from my corpus. Since I'm not sure if it is compatible with the trainer, I want to convert it back to XXTokenizerFast in transformers.
### Observation
In [llama2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf/tree/main), tokenizer file seems consist of
[tokenizer.json](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/main/tokenizer.json) ✅ I have
[tokenizer.model](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/main/tokenizer.model) ✖ I don't have, not sure its usage
[tokenizer_config.json](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/main/tokenizer_config.json) ✖ I don't have, but this looks like not that important. I can manually set this.
Initialize a LlamaTokenizerFast from scratch through \_\_init\_\_ function seems to require tokenizer.model and tokenizer.json, but I don't get a tokenizer.model.
```
def __init__(
self,
vocab_file=None,
tokenizer_file=None,
clean_up_tokenization_spaces=False,
unk_token="<unk>",
bos_token="<s>",
eos_token="</s>",
add_bos_token=True,
add_eos_token=False,
use_default_system_prompt=False,
add_prefix_space=None,
**kwargs,
):
```
After dive deeper in [transformers.PreTrainedTokenizerFast._save_pretrained](https://github.com/huggingface/transformers/blob/4fc708f98c9c8d5cb48e8a2639e3f7a21c65802f/src/transformers/tokenization_utils_fast.py#L678), I found a code snippet in which fastTokenizer in transformers seems save tokenizer.json only without tokenizer.model
```
if save_fast:
tokenizer_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + TOKENIZER_FILE
)
self.backend_tokenizer.save(tokenizer_file)
file_names = file_names + (tokenizer_file,)
```
### Trial
So I just typically use xxTokenizerFast.from_pretrained('dir_contained_my_tokenizer.json'), and it works with default config, I can modified it manually and save_pretrained to get tokenizer_config.json
### Query
I still have some query needed help.
1. What's the role of tokenizer.model? Is it a subset of tokenizer.json ?
2. Is my conversion method correct ? or is there any better method?
|
https://github.com/huggingface/tokenizers/issues/1468
|
closed
|
[
"Stale",
"planned"
] | 2024-03-05T06:32:27Z
| 2024-07-21T01:57:17Z
| null |
rangehow
|
pytorch/pytorch
| 121,203
|
How to clear GPU memory without restarting kernel when using a PyTorch model
|
## Issue description
I am currently using pytorch's model on my windows computer, using python scripts running on vscode.
I want to be able to load and release the model repeatedly in a resident process, where releasing the model requires fully freeing the memory of the currently used GPU, including freeing the cache and cuda context.
I have now tried to use del xxx, torch.cuda.empty_cache(), but this can only free up the amount of cache memory occupied by models and variables, in fact, there is still cuda context not free, so I also tried to use numba.cuda, pycuda.driver and other third-party libraries to free this part of the memory, the results show that this is effective, it can clean up the GPU memory to a clean state, but when I re-initialize the same model in the process, there is an error, so it seems that the process of freeing the cuda context is irreversible for pytorch.
Now to fully free the GPU's memory, I can only shut down the current process, which is not what I want. I would like to know what pytorch does to the cuda context when initializing the model, and if there are other ways to meet my requirements?
## Code example
## System Info
- PyTorch or Caffe2: PyTorch
- How you installed PyTorch (conda, pip, source): pip
- Build command you used (if compiling from source): pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu117
- OS: Windows 10
- PyTorch version:2.0.1
- Python version:3.8.18
- CUDA/cuDNN version:11.7/8.4
- GPU models and configuration:
- GCC version (if compiling from source):
- CMake version:
- Versions of any other relevant libraries:
cc @ptrblck
|
https://github.com/pytorch/pytorch/issues/121203
|
open
|
[
"module: cuda",
"triaged"
] | 2024-03-05T05:58:49Z
| 2024-03-06T15:21:20Z
| null |
Doctor-Damu
|
huggingface/gsplat.js
| 71
|
How to support VR?
|
It's great to be able to use vr on a vr device.
|
https://github.com/huggingface/gsplat.js/issues/71
|
closed
|
[] | 2024-03-05T05:03:17Z
| 2024-03-05T07:55:53Z
| null |
did66
|
huggingface/tgi-gaudi
| 95
|
How to use FP8 feature in TGI-gaudi
|
### System Info
The FP8 quantization feature has been incorporated into the TGI-Gaudi branch. However, guidance is needed on how to utilize this feature. The process involves running the FP8 quantization through Measurement Mode and Quantization Mode. How to enable FP8 using the TGI 'docker run' command? Could you kindly provide a step-by-step guide on utilizing this feature?"
### Information
- [ ] Docker
- [ ] The CLI directly
### Tasks
- [ ] An officially supported command
- [ ] My own modifications
### Reproduction
Run the FP8 quantization feature using "docker run" command.
### Expected behavior
A clear guide can be provided to use the FP8 quantization feature.
|
https://github.com/huggingface/tgi-gaudi/issues/95
|
closed
|
[] | 2024-03-05T02:50:08Z
| 2024-05-06T09:03:15Z
| null |
lvliang-intel
|
huggingface/accelerate
| 2,521
|
how to set `num_processes` in multi-node training
|
Is it the total num of gpus or the number of gpus on a single node?
I have seen contradictory signals in the code.
https://github.com/huggingface/accelerate/blob/ee004674b9560976688e1a701b6d3650a09b2100/docs/source/usage_guides/ipex.md?plain=1#L139 https://github.com/huggingface/accelerate/blob/ee004674b9560976688e1a701b6d3650a09b2100/src/accelerate/state.py#L154
here, it seems like the total number of gpus.
https://github.com/huggingface/accelerate/blob/ee004674b9560976688e1a701b6d3650a09b2100/examples/slurm/submit_multigpu.sh#L27
here, it sees like the number of gpus per node.
|
https://github.com/huggingface/accelerate/issues/2521
|
closed
|
[] | 2024-03-04T13:03:57Z
| 2025-12-22T01:53:32Z
| null |
lxww302
|
huggingface/distil-whisper
| 95
|
How to use distil-whisper-large-v3-de-kd model from HF?
|
Officially, multi-language support is still not implemented in distil-whisper.
But I noticed, that the esteemed @sanchit-gandhi uploaded a German model for distil-whisper to HuggingFace, called 'distil-whisper-large-v3-de-kd'
How can I use this specific model for transcribing something?
|
https://github.com/huggingface/distil-whisper/issues/95
|
open
|
[] | 2024-03-04T12:01:13Z
| 2024-04-02T09:40:46Z
| null |
Arche151
|
huggingface/transformers.js
| 623
|
Converted QA model answers in lower case, original model does not. What am I doing wrong?
|
### Question
I have converted [deutsche-telekom/electra-base-de-squad2](https://huggingface.co/deutsche-telekom/electra-base-de-squad2) to ONNX using ```python -m scripts.convert --quantize --model_id deutsche-telekom/electra-base-de-squad2```. The ONNX model, used with the same code, yields returns in lower case, whereas the original model returns the answer respecting case sensitivity. I noticed that the ```tokenizer_config.json" in the original model contains ```"do_lower_case": false```. But even setting this to ```true``` before converting does not work. What am I dpoing wrong?
Code is straight forward:
```javascript
import { pipeline } from '@xenova/transformers';
const pipe = await pipeline('question-answering', 'conventic/electra-base-de-squad2-onnx');
const context = "<context here, cased>";
const question = "<question here, cased>";
const out = await pipe(question, context);
console.log(out);
´´´
|
https://github.com/huggingface/transformers.js/issues/623
|
open
|
[
"question"
] | 2024-03-04T11:56:44Z
| 2024-03-04T11:56:44Z
| null |
MarceloEmmerich
|
pytorch/kineto
| 885
|
How to add customized metadata with on demand profiling ?
|
When profiling with `torch.profiler.profile` , generated json file has a section called `distributedInfo` shown as below
```json
{
"distributedInfo": {"backend": "nccl", "rank": 0, "world_size": 2}
}
```
But there's no such section in generated file when on-demand profiling is triggered. As a result, Holistic Trace Analysis cannot be used to analysis those files.
Is this by design or there's something to do to make those file generated by `kineto` have `distributedInfo` as well? Hoping some one can help. Thanks.
|
https://github.com/pytorch/kineto/issues/885
|
closed
|
[
"bug"
] | 2024-03-04T09:41:04Z
| 2024-07-08T21:53:03Z
| null |
staugust
|
pytorch/executorch
| 2,226
|
How do you get executorch to run within Mbed OS?
|
Hi guys,
We serialized a PyTorch module to a .pte file for Cortex-M architecture by doing this example:
https://pytorch.org/executorch/stable/executorch-arm-delegate-tutorial.html). Additionally, we have a P-Nucleo-WB55 development platform. We want to run the module on the development platform using Mbed OS. How do we get the following "torch::executor"-namespace accessible in Mbed OS before we build the binaries that we flash later on the P-Nucleo-WB55? Following is an example of how we would like to do it in Mbed OS:
```
using namespace torch::executor;
Result<util::FileDataLoader> loader =
util::FileDataLoader::from("/tmp/model.pte");
assert(loader.ok());
Result<Program> program =
torch::executor::Program::load(loader.get());
assert(program.ok());
```
Or is there a better way of integrating the executorch runtime into Mbed OS, or how would you accomplish this task (getting executorch running in Mbed OS on Cortex-M)?
Cheers,
Christoph
|
https://github.com/pytorch/executorch/issues/2226
|
closed
|
[] | 2024-03-04T08:52:58Z
| 2024-05-16T11:07:20Z
| null |
ChristophKarlHeck
|
pytorch/test-infra
| 4,980
|
Provide the range of commits where a disabled test is effectively disabled
|
In the current implementation, disabling a test or enabling it (via a GitHub issues) take effect globally across all trunk and PR jobs. The good thing about this approach is that disabling a test is trivial. However, enabling them is still a tricky business. A common scenario is that a forward fix will address the issue and close it, but it will cause the test to fail on PRs everywhere unless people do a rebase to pull in the fix. We see this happening many times like the recent https://github.com/pytorch/pytorch/issues/114831, which is directly responsible for a large spike of force merges.
After chatting with @clee2000 on the topic, there are several potential ideas for this:
* We can provide the range of commits where a disabled test is effectively disabled. If the base commit of a PR is within the range, the test will still be disabled even if the issue has been closed. This seems like the best option.
* At a coarse grain, we might be able to version the entire disabled tests JSON file. For example, a PR that has an older base commit will use an older version of the JSON file with the test still disabled
The same solution could also be applied to slow tests.
cc @clee2000
|
https://github.com/pytorch/test-infra/issues/4980
|
open
|
[
"enhancement"
] | 2024-03-02T06:58:40Z
| 2024-03-02T06:58:40Z
| null |
huydhn
|
huggingface/transformers.js
| 618
|
How do I convert a DistilBERT Model to Quantized ONNX -
|
### Question
Note, https://huggingface.co/docs/transformers.js/en/index#convert-your-models-to-onnx is a broken link.
I have a simple DistilBERT model I'm trying to load with the examples/next-server (wdavies/public-question-in-text)
I tried the simplest version of converting to ONNX (wdavies/public-onnx-test following https://huggingface.co/docs/transformers/en/serialization#exporting-a--transformers-model-to-onnx-with-optimumonnxruntime), but I'm still getting an error message saying its looking for quantized_onnx.
According to all I can see, including this blog post, you seem to have choose a specific hardware architecture? Is this true? How will I know what the client browser (or even mine) is running on? Help? I just want to run this simple model in example/next-server ?
https://huggingface.co/blog/optimum-inference#34-use-the-ortquantizer-to-apply-dynamic-quantization
|
https://github.com/huggingface/transformers.js/issues/618
|
closed
|
[
"question"
] | 2024-03-01T16:55:16Z
| 2024-03-02T00:47:40Z
| null |
davies-w
|
huggingface/sentence-transformers
| 2,521
|
Is the implementation of `MultipleNegativesRankingLoss` right?
|
It is confusing why the labels are `range(len(scores))`.
```python
class MultipleNegativesRankingLoss(nn.Module):
def __init__(self, model: SentenceTransformer, scale: float = 20.0, similarity_fct=util.cos_sim):
super(MultipleNegativesRankingLoss, self).__init__()
self.model = model
self.scale = scale
self.similarity_fct = similarity_fct
self.cross_entropy_loss = nn.CrossEntropyLoss()
def forward(self, sentence_features: Iterable[Dict[str, Tensor]], labels: Tensor):
reps = [self.model(sentence_feature)["sentence_embedding"] for sentence_feature in sentence_features]
embeddings_a = reps[0]
embeddings_b = torch.cat(reps[1:])
scores = self.similarity_fct(embeddings_a, embeddings_b) * self.scale
labels = torch.tensor(
range(len(scores)), dtype=torch.long, device=scores.device
) # Example a[i] should match with b[i]
return self.cross_entropy_loss(scores, labels)
def get_config_dict(self):
return {"scale": self.scale, "similarity_fct": self.similarity_fct.__name__}
```
|
https://github.com/huggingface/sentence-transformers/issues/2521
|
closed
|
[
"question"
] | 2024-03-01T10:13:35Z
| 2024-03-04T07:01:12Z
| null |
ghost
|
huggingface/text-embeddings-inference
| 178
|
How to specify a local model
|
### Feature request
model=BAAI/bge-reranker-large
volume=$PWD/data
docker run -p 8080:80 -v $volume:/data --pull always ghcr.io/huggingface/text-embeddings-inference:cpu-1.0 --model-id $model
### Motivation
model=BAAI/bge-reranker-large
volume=$PWD/data
docker run -p 8080:80 -v $volume:/data --pull always ghcr.io/huggingface/text-embeddings-inference:cpu-1.0 --model-id $model
### Your contribution
null
|
https://github.com/huggingface/text-embeddings-inference/issues/178
|
closed
|
[] | 2024-03-01T09:40:07Z
| 2024-03-01T16:54:27Z
| null |
yuanjie-ai
|
huggingface/chat-ui
| 889
|
How does huggingchat prompt the model to generate HTML output?
|
How does Huggingchat prompt the LLM to generate HTML output? Where can I find that prompt? I'd like to tweak it. thanks!
|
https://github.com/huggingface/chat-ui/issues/889
|
open
|
[] | 2024-02-29T17:20:01Z
| 2024-03-05T18:45:56Z
| null |
vgoklani
|
huggingface/chat-ui
| 888
|
Code LLAMA doesn't work
|
I am simply entering this prompt:
```
You're given the following regex in python: \| *([^|]+?) *\|
This captures text values in markdown tables but fails to capture numbers. Update this regex to capture numbers as well
```
Then what happens is that my 1 core of CPU is used 100% for at least for 5 mins until I close the browser. Not sure what is going on?
Same prompt works when I use the Mistral 8 X 7B
|
https://github.com/huggingface/chat-ui/issues/888
|
closed
|
[] | 2024-02-29T12:44:20Z
| 2025-01-01T11:54:48Z
| 1
|
lordsoffallen
|
huggingface/text-generation-inference
| 1,615
|
How to use the grammar support feature?
|
### Feature request

Can you please clarify how we can use this? what is it for?
### Motivation

Can you please clarify how we can use this? what is it for?
### Your contribution

Can you please clarify how we can use this? what is it for?
|
https://github.com/huggingface/text-generation-inference/issues/1615
|
closed
|
[] | 2024-02-29T12:35:24Z
| 2024-03-04T14:49:39Z
| null |
Stealthwriter
|
pytorch/torchx
| 834
|
HuggingFace accelerate component
|
## Description
<!-- concise description of the feature/enhancement -->
HuggingFace accelerate is used for some OSS models. It would be great to have support for it as a component in addition to dist.ddp.
## Motivation/Background
<!-- why is this feature/enhancement important? provide background context -->
## Detailed Proposal
<!-- provide a detailed proposal -->
## Alternatives
<!-- discuss the alternatives considered and their pros/cons -->
## Additional context/links
<!-- link to code, documentation, etc. -->
|
https://github.com/meta-pytorch/torchx/issues/834
|
open
|
[] | 2024-02-28T18:33:38Z
| 2024-02-28T18:33:38Z
| 0
|
d4l3k
|
huggingface/datasets
| 6,700
|
remove_columns is not in-place but the doc shows it is in-place
|
### Describe the bug
The doc of `datasets` v2.17.0/v2.17.1 shows that `remove_columns` is in-place. [link](https://huggingface.co/docs/datasets/v2.17.1/en/package_reference/main_classes#datasets.DatasetDict.remove_columns)
In the text classification example of transformers v4.38.1, the columns are not removed.
https://github.com/huggingface/transformers/blob/a0857740c0e6127485c11476650314df3accc2b6/examples/pytorch/text-classification/run_classification.py#L421
### Steps to reproduce the bug
https://github.com/huggingface/transformers/blob/a0857740c0e6127485c11476650314df3accc2b6/examples/pytorch/text-classification/run_classification.py#L421
### Expected behavior
Actually remove the columns.
### Environment info
1. datasets v2.17.0
2. transformers v4.38.1
|
https://github.com/huggingface/datasets/issues/6700
|
closed
|
[] | 2024-02-28T12:36:22Z
| 2024-04-02T17:15:28Z
| 3
|
shelfofclub
|
pytorch/serve
| 2,978
|
Broken example for a custom Counter metrics
|
### 📚 The doc issue
The example in the section [Add Counter based metrics](https://github.com/pytorch/serve/blob/18d56ff56e05de48af0dfabe0019f437f332a868/docs/metrics.md#add-counter-based-metrics) shows how to add custom Counter metric:
```
# Create a counter with name 'LoopCount' and dimensions, initial value
metrics.add_counter('LoopCount', 1, None, dimensions)
# Increment counter by 2
metrics.add_counter('LoopCount', 2 , None, dimensions)
# Decrement counter by 1
metrics.add_counter('LoopCount', -1, None, dimensions)
```
I tried to copy this example to my custom handler:
```
dims = [Dimension('ModelName', 'doc_model')]
self.metrics.add_counter('LoopCount', 1, None, dimensions=dims)
# Increment counter by 2
self.metrics.add_counter('LoopCount', 2 , None, dimensions=dims)
# Decrement counter by 1
self.metrics.add_counter('LoopCount', -1, None, dimensions=dims)
```
When I call API for inference I got an error in the terminal:
```
2024-02-28T15:23:57,011 [ERROR] W-9000-doc_model_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - Failed to parse metrics line: "[METRICS]Failed to update metric with name:LoopCount and dimensions: ModelName:doc_model,Level:Model with value: -1: Counter metric update value cannot be negative".
```
### Suggest a potential alternative/fix
_No response_
|
https://github.com/pytorch/serve/issues/2978
|
closed
|
[
"triaged"
] | 2024-02-28T12:26:30Z
| 2024-03-20T21:56:12Z
| 3
|
feeeper
|
pytorch/TensorRT
| 2,665
|
❓ [Question] operator being decomposed rather than being converted when a corresponding converter exists?
|
## ❓ Question
From the debug log below, it seems that the `aten.grid_sampler_2d` operator gets decomposed into several lower-level operators. But isn't there a corresponding [converter](https://github.com/pytorch/TensorRT/blob/9a100b6414bee175040bcaa275ecb71df54836e4/py/torch_tensorrt/dynamo/conversion/aten_ops_converters.py#L333-L358) which should be used?
## What you have already tried
```py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch_tensorrt
class MyModule(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input, grid):
return F.grid_sample(input, grid, mode="bilinear", padding_mode="border", align_corners=True)
model = MyModule().eval().cuda()
inputs = [
torch.randn((1, 3, 8, 8), dtype=torch.float, device="cuda"),
torch.randn((1, 16, 16, 2), dtype=torch.float, device="cuda")
]
optimized_model = torch_tensorrt.compile(
model,
ir="dynamo",
inputs=inputs,
enabled_precisions={torch.float},
debug=True,
min_block_size=1,
truncate_long_and_double=True,
output_format="fx",
)
```
```
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_1 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_1 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_2 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_2 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_3 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_3 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_4 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_4 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_5 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_5 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_6 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_6 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_7 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_7 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.partitioning._global_partitioner:
Supported Nodes:
- torch.ops.aten.reshape.default + Operator Count: 13
- torch.ops.aten.expand.default + Operator Count: 1
- torch.ops.aten.select.int + Operator Count: 2
- torch.ops.aten.mul.Tensor + Operator Count: 10
- torch.ops.aten.add.Tensor + Operator Count: 7
- torch.ops.aten.clamp.default + Operator Count: 2
- torch.ops.aten.floor.default + Operator Count: 2
- torch.ops.aten.sub.Tensor + Operator Count: 8
- torch.ops.aten.ge.Scalar + Operator Count: 8
- torch.ops.aten.lt.Scalar + Operator Count: 8
- torch.ops.aten.logical_and.default + Operator Count: 12
- torch.ops.aten.where.self + Operator Count: 12
- torch.ops.aten.index.Tensor + Operator Count: 4
DEBUG:torch_tensorrt.dynamo.partitioning._global_partitioner:
Unsupported or Excluded Nodes:
- torch.ops.aten._to_copy.default + Operator Count: 8
DEBUG:torch_tensorrt.dynamo._compiler:Detected support for 89 operators out of 97 in subgraph.
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_1 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_1 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_2 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten_ops_converters:_to_copy converter rejected node _to_copy_2 with dtype torch.int64
DEBUG:torch_tensorrt.dynamo.conversion.aten
|
https://github.com/pytorch/TensorRT/issues/2665
|
closed
|
[
"question"
] | 2024-02-28T06:35:20Z
| 2024-07-27T08:20:37Z
| null |
HolyWu
|
huggingface/optimum
| 1,729
|
tflite support for gemma
|
### Feature request
As per the title, is there plans to support gemma in tfilte
### Motivation
necessary format for current work
### Your contribution
no
|
https://github.com/huggingface/optimum/issues/1729
|
closed
|
[
"feature-request",
"tflite",
"Stale"
] | 2024-02-27T17:15:54Z
| 2025-01-19T02:04:34Z
| 2
|
Kaya-P
|
huggingface/huggingface_hub
| 2,051
|
How edit cache dir and in bad net download how to redownload with last download point
|
OSError: Consistency check failed: file should be of size 1215993967 but has size 118991296 (pytorch_model.bin).
We are sorry for the inconvenience. Please retry download and pass `force_download=True, resume_download=False` as argument.
If the issue persists, please let us know by opening an issue on https://github.com/huggingface/huggingface_hub.
Downloading pytorch_model.bin: 10%|████▌ | 119M/1.22G [06:51<1:03:13, 289kB/s]
Hi , I use this in windows and space C: is not enouth space, I want to set download or install cache dir is in D: ,how to do this.
And beacuse I have bad network so it is everytime error in one big file download, and how to download this file in a bad network.
|
https://github.com/huggingface/huggingface_hub/issues/2051
|
closed
|
[] | 2024-02-27T14:45:10Z
| 2024-02-27T15:59:35Z
| null |
caihua
|
huggingface/candle
| 1,769
|
[Question] How to modify Mistral to enable multiple batches?
|
Hello everybody,
I am attempting to implement multiple batches for the Mistral forward pass. However, the `forward` method takes an argument `seqlen_offset` which seems to be specific to the batch. I have attempted to implement it with a `position_ids` tensor in [this](https://github.com/EricLBuehler/mistral.rs/blob/mistralrunner/mistralrs-core/src/models/mistral.rs) file.
Specifically, I rewrote the rotary embedding function:
```rust
fn apply_rotary_emb_qkv(
&self,
q: &Tensor,
k: &Tensor,
position_ids: &Tensor,
) -> Result<(Tensor, Tensor)> {
let cos = self.cos.i(position_ids)?;
let sin = self.sin.i(position_ids)?;
let q_embed = (q.broadcast_mul(&cos)? + rotate_half(q)?.broadcast_mul(&sin))?;
let k_embed = (k.broadcast_mul(&cos)? + rotate_half(k)?.broadcast_mul(&sin))?;
Ok((q_embed, k_embed))
}
```
I create the position ids with the following line:
```rust
let position_ids = Tensor::arange(
past_key_values_length as i64,
(past_key_values_length + seq_len) as i64,
input_ids.device(),
)?;
```
With `past_key_values_length` as the result of
```rust
fn calculate_past_kv_len(&self, seq_len: usize) -> Result<usize> {
let kv_cache_1 = &self.layers.first().as_ref().unwrap().self_attn.kv_cache;
if kv_cache_1.is_none() {
return Ok(0);
}
let k_cache_1 = &kv_cache_1.as_ref().unwrap().0;
if k_cache_1.dims()[0] <= seq_len {
Ok(0)
} else {
let indexed = k_cache_1.i(seq_len)?;
let dims = indexed.dims();
Ok(dims[dims.len() - 2])
}
}
```
My implementation attempts to follow the [transformers implementation of calculating position ids](https://github.com/huggingface/transformers/blob/main/src/transformers/models/mistral/modeling_mistral.py#L977-L985) and for the [implementation of `apply_rotary_emb_qkv`](https://github.com/huggingface/transformers/blob/5c341d4555ba3e4b656053317e372ebed0c5af37/src/transformers/models/mistral/modeling_mistral.py#L139-L164). However, when I copy and run the candle-examples inference script, with the only change being that I do not pass the `seqlen_offset` variable, it does not produce coherent output. While the model runs, it does not "work".
How can I implement multiple-batch forward passes? Is there a way to do it using the `seqlen_offset` variable? Thank you for any help.
|
https://github.com/huggingface/candle/issues/1769
|
closed
|
[] | 2024-02-27T13:18:18Z
| 2024-03-01T14:01:21Z
| null |
EricLBuehler
|
huggingface/datatrove
| 108
|
How to load a dataset with the output a tokenizer?
|
I planned to use datatrove to apply my tokenizer so that data is ready to use with nanotron.
I am using DocumentTokenizer[Merger] which produces *.ds and *ds.index binary files, although, from what I understood, nanotron is expecting datasets (with "input_ids" keys).
I see that things like ParquetWriter cannot be piped after DocumentTokenizer.
Am I missing a piece?
Are there some helpers to convert ds files into parquet files (or something loadable with datasets) for a given context size?
|
https://github.com/huggingface/datatrove/issues/108
|
closed
|
[] | 2024-02-27T08:58:09Z
| 2024-05-07T12:33:47Z
| null |
Jeronymous
|
pytorch/audio
| 3,750
|
I have some questions about RNNT loss.
|
hello
I would like to ask you a question that may be somewhat trivial.
The shape of logits of RNN T loss is Batch, max_seq_len, max_target_len+1, class.
Why is max_target_len+1 here?
Shouldn't the number of classes be +1 to the size of the total vocab? Because blank is included.
I don't understand at all.
Is there anyone who can help?
https://pytorch.org/audio/main/generated/torchaudio.functional.rnnt_loss.html
|
https://github.com/pytorch/audio/issues/3750
|
open
|
[] | 2024-02-26T11:39:39Z
| 2024-02-26T13:09:30Z
| 6
|
girlsending0
|
huggingface/chat-ui
| 875
|
Difficulty configuring multiple instances of the same model with distinct parameters
|
I am currently self-deploying an application that requires setting up multiple instances of the same model, each configured with different parameters. For example:
```
MODELS=`[{
"name": "gpt-4-0125-preview",
"displayName": "GPT 4",
"endpoints" : [{
"type": "openai"
}]
},
{
"name": "gpt-4-0125-preview",
"displayName": "GPT 4 temp 0",
"parameters": {
"temperature": 0.0
},
"endpoints" : [{
"type": "openai"
}]
}
]`
```
This results in a state which looks like that both models are active simultaneously.

However, in practice, I cannot activate the second model ("GPT 4 temp 0"); only "GPT 4" is utilized during chat operations. It appears as if the system defaults to the first model instance and ignores subsequent ones with the same model name.
I tried to distinguish between the models by modifying the `name` field and introducing an `id` field, using the appropriate model identifier. However, this approach resulted in a loss of model reference, indicating that these fields cannot be arbitrarily configured on the client side.
Is there a recommended approach to deploying two instances of the same model with varying parameters? Any guidance or suggestions on how to achieve this would be greatly appreciated.
|
https://github.com/huggingface/chat-ui/issues/875
|
open
|
[] | 2024-02-26T10:48:43Z
| 2024-02-27T17:28:21Z
| 1
|
mmtpo
|
huggingface/optimum-nvidia
| 76
|
How to install optimum-nvidia properly without building a docker image
|
It's quite hard for me to build a docker image, so I started from a docker environment with TensorRT LLM 0.6.1 inside.
I checked your dockerfile, followed the process, and built TensorRT LLM using (I am using 4090 so that cuda arch is 89):
```
python3 scripts/build_wheel.py -j --trt_root /usr/local/tensorrt --python_bindings --cuda_architectures="89-real" --clean
```
Afterwards, I copied the resulting bindings*.so into tensorrt_llm's directory inside the dist-packages dir -- according to the dockerfile. Then I followed it to install nvidia-ammo 0.3, then added the optimum-nvidia dir to python path.
I also went into optimum-nvidia directory, and ran `pip install -e .`, so that in my environment, when using `pip list | grep optimum` I could get:
```
optimum 1.17.1
optimum-nvidia 0.1.0b2 /root/autodl-tmp/optimum-nvidia
```
However, I still could not import optimum.nvidia properly, while it's okay to `import tensorrt_llm` and `tensorrt_llm.bindings`.
```
>>> from optimum.nvidia.pipelines import pipeline
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'optimum.nvidia'
>>>
```
Could someone please help me on how to install optimum nvidia properly without building a new image or pulling from dockerhub?
Thank you!
|
https://github.com/huggingface/optimum-nvidia/issues/76
|
closed
|
[] | 2024-02-26T05:05:24Z
| 2024-03-11T13:36:18Z
| null |
Yuchen-Cao
|
pytorch/examples
| 1,235
|
Testing a C++ case with MPI failed.
|
### 🐛 Describe the bug
I am testing the following example:
https://github.com/pytorch/examples/blob/main/cpp/distributed/dist-mnist.cpp
I get the following error:
[ 50%] Building CXX object CMakeFiles/awcm.dir/xdist.cxx.o
/home/alamj/TestCases/tests/xtorch/xdist/xdist.cxx:1:10: fatal error: c10d/ProcessGroupMPI.hpp: No such file or directory
1 | #include <c10d/ProcessGroupMPI.hpp>
I changed the top line with full path to ensure that hpp file gets available
#include </project/def-alamj/shared/libtorch/include/torch/csrc/distributed/c10d/ProcessGroupMPI.hpp>
The new error indicates something else I need to know, which is given in the tutorial.
[ 50%] Building CXX object CMakeFiles/awcm.dir/xdist.cxx.o
/home/alamj/TestCases/tests/xtorch/xdist/xdist.cxx:38:21: error: ‘c10d’ was not declared in this scope; did you mean ‘c10’?
38 | std::shared_ptr<c10d::ProcessGroupMPI> pg,
| ^~~~
| c10
Please let me know how do I get a work around to fix this.
### Error logs
_No response_
### Minified repro
_No response_
### Versions
I think this field is not needed as I am running C++ code.
cc @ezyang @msaroufim @bdhirsh @anijain2305 @zou3519
|
https://github.com/pytorch/examples/issues/1235
|
open
|
[] | 2024-02-25T19:34:24Z
| 2024-12-04T15:08:51Z
| 1
|
alamj
|
huggingface/diffusers
| 7,088
|
Vague error: `ValueError: With local_files_only set to False, you must first locally save the tokenizer in the following path: 'openai/clip-vit-large-patch14'.` how to fix?
|
Trying to convert a .safetensors stable diffusion model to whatever the format is that hugging face requires. It throws a vague nonsequitur of an error:
`pipe = diffusers.StableDiffusionPipeline.from_single_file(str(aPathlibPath/"vodkaByFollowfoxAI_v40.safetensors") )`
```...
[1241](file:///C:/Users/openSourcerer9000/anaconda3/envs/fuze/lib/site-packages/diffusers/loaders/single_file_utils.py:1241) )
[1242](file:///C:/Users/openSourcerer9000/anaconda3/envs/fuze/lib/site-packages/diffusers/loaders/single_file_utils.py:1242) else:
[1243](file:///C:/Users/openSourcerer9000/anaconda3/envs/fuze/lib/site-packages/diffusers/loaders/single_file_utils.py:1243) return {"text_encoder": text_encoder, "tokenizer": tokenizer}
ValueError: With local_files_only set to False, you must first locally save the tokenizer in the following path: 'openai/clip-vit-large-patch14'.
```
What tokenizer? What path? Where would I get this file? This script already downloaded something locally, why not download this extra thing as well instead of throwing an error?
When I pass local_files_only=True, it says the SAME thing:
`ValueError: With local_files_only set to True, you must first locally save the tokenizer in the following path: 'openai/clip-vit-large-patch14'.`
|
https://github.com/huggingface/diffusers/issues/7088
|
closed
|
[
"stale",
"single_file"
] | 2024-02-25T15:03:07Z
| 2024-09-17T21:56:26Z
| null |
openSourcerer9000
|
huggingface/diffusers
| 7,085
|
how to train controlnet with lora?
|
train full controlnet need much resource and time, so how to train controlnet with lora?
|
https://github.com/huggingface/diffusers/issues/7085
|
closed
|
[
"should-move-to-discussion"
] | 2024-02-25T06:31:47Z
| 2024-03-03T06:38:35Z
| null |
akk-123
|
huggingface/optimum-benchmark
| 138
|
How to set trt llm backend parameters
|
I am trying to run the trt_llama example: https://github.com/huggingface/optimum-benchmark/blob/main/examples/trt_llama.yaml
It seems optimem-benchmark will automatically transform the huggingface model to inference engine file then benchmarking its performance. When we use tensorrt llm, there is a model "build" process (during which we set some quantization parameters) in order to get the `.engine` file. How can we set these parameters when using optimum benchmark?
|
https://github.com/huggingface/optimum-benchmark/issues/138
|
closed
|
[] | 2024-02-24T17:12:12Z
| 2024-02-27T12:48:44Z
| null |
Yuchen-Cao
|
huggingface/optimum-nvidia
| 75
|
How to build this environment without docker?
|
My computer does not support the use of docker. How do I deploy this environment on my computer?
|
https://github.com/huggingface/optimum-nvidia/issues/75
|
open
|
[] | 2024-02-24T16:59:37Z
| 2024-03-06T13:45:18Z
| null |
lemon-little
|
huggingface/accelerate
| 2,485
|
How to log information into a local logging file?
|
### System Info
```Shell
Hi, I want to save a copy of logs to a local file, how to achieve this? Specifically, I want accelerator.log also write information in my local file.
```
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] One of the scripts in the examples/ folder of Accelerate or an officially supported `no_trainer` script in the `examples` folder of the `transformers` repo (such as `run_no_trainer_glue.py`)
- [X] My own task or dataset (give details below)
### Reproduction
Hi, I want to save a copy of logs to a local file, how to achieve this? Specifically, I want accelerator.log also write information in my local file.
### Expected behavior
Hi, I want to save a copy of logs to a local file, how to achieve this? Specifically, I want accelerator.log also write information in my local file.
|
https://github.com/huggingface/accelerate/issues/2485
|
closed
|
[] | 2024-02-24T07:52:55Z
| 2024-04-03T15:06:24Z
| null |
Luciennnnnnn
|
huggingface/optimum-benchmark
| 136
|
(question)When I use the memory tracking feature on the GPU, I find that my VRAM is reported as 0. Is this normal, and what might be causing it?
|

|
https://github.com/huggingface/optimum-benchmark/issues/136
|
closed
|
[] | 2024-02-24T02:57:49Z
| 2024-03-08T16:59:41Z
| null |
WCSY-YG
|
huggingface/optimum
| 1,716
|
Optimum for Jetson Orin Nano
|
### System Info
```shell
optimum version: 1.17.1
platform: Jetson Orin Nano, Jetpack 6.0
Python: 3.10.13
CUDA: 12.2
```
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction (minimal, reproducible, runnable)
Here is how I installed.
1. install Pytorch 2.2.0 following https://elinux.org/Jetson_Zoo
2. install onnxruntime-gpu 1.17.0 following following https://elinux.org/Jetson_Zoo
3. install Optimum by using `pip install optimum[onnxruntime-gpu]`
### Expected behavior
The Optimum installed on my Jetson Orin Nano not support GPU for Jetpack 6.0 and Python 3.10.13.
Can anybody let me know how to install it?
|
https://github.com/huggingface/optimum/issues/1716
|
open
|
[
"bug"
] | 2024-02-23T23:22:08Z
| 2024-02-26T10:03:59Z
| 1
|
JunyiYe
|
huggingface/transformers
| 29,244
|
Google Gemma don't know what 1+1 is equal to?
|
### System Info
[v4.38.1](https://github.com/huggingface/transformers/releases/tag/v4.38.1)
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("./gemma_2B")
model = AutoModelForCausalLM.from_pretrained("./gemma_2B", device_map="auto", torch_dtype=torch.float32)
input_text = "1+1=?"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids,max_length=50)
# print(outputs)
print(tokenizer.decode(outputs[0]))
```
### Expected behavior
output is bellow
```
<bos>1+1=?
1+1=?
1+1=?
1+1=?
1+1=?
1+1=?
1+1=?
1+1=?
1
```
|
https://github.com/huggingface/transformers/issues/29244
|
closed
|
[] | 2024-02-23T12:16:17Z
| 2024-03-07T10:54:09Z
| null |
zhaoyun0071
|
huggingface/optimum
| 1,713
|
Issue converting owlv2 model to ONNX format
|
Hi Team,
I hope this message finds you well.
I've been working with the owlv2 model and have encountered an issue while attempting to convert it into ONNX format using the provided command:
`! optimum-cli export onnx -m google/owlv2-base-patch16 --task 'zero-shot-object-detection' --framework 'pt' owlv2_onnx`
Unfortunately, I'm facing the following error:
`ValueError: Trying to export a owlv2 model, that is a custom or unsupported architecture, but no custom onnx configuration was passed as `custom_onnx_configs`.`
As I am relatively new to this process, I'm unsure about the necessity and usage of custom ONNX configuration. Could you please provide some guidance on how to address this issue? Any assistance or insights would be greatly appreciated.
Thank you for your attention to this matter.
|
https://github.com/huggingface/optimum/issues/1713
|
closed
|
[
"feature-request",
"onnx",
"exporters"
] | 2024-02-23T05:55:23Z
| 2025-09-10T23:26:13Z
| 6
|
n9s8a
|
huggingface/optimum-benchmark
| 135
|
How to import and use the quantized model with AutoGPTQ?
|
https://github.com/huggingface/optimum-benchmark/issues/135
|
closed
|
[] | 2024-02-23T03:13:28Z
| 2024-02-23T05:03:06Z
| null |
jhrsya
|
|
pytorch/serve
| 2,962
|
Update documentation on deprecating mac x86 support
|
### 🐛 Describe the bug
PyTorch is deprecating support for x86 macs. TorchServe will also do the same.
### Error logs
N/A
### Installation instructions
N/A
### Model Packaing
N/A
### config.properties
_No response_
### Versions
N/A
### Repro instructions
N/A
### Possible Solution
_No response_
|
https://github.com/pytorch/serve/issues/2962
|
open
|
[
"documentation"
] | 2024-02-22T22:53:33Z
| 2024-03-26T20:58:19Z
| 0
|
agunapal
|
huggingface/optimum
| 1,710
|
Native Support for Gemma
|
### System Info
```shell
python version : 3.10.12
optimum version : built from github
openvino : 2024.1.0-14548-688c71ce0ed
transformers : 4.38.1
```
### Who can help?
@JingyaHuang @echarlaix
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction (minimal, reproducible, runnable)
Currently there is no support to export gemma, google's new opensource model.
After connecting to huggingface and requesting permission to access the gemma repo
running the following line
`model_ov = OVModelForCausalLM.from_pretrained("google/gemma-2b", export = True)`
produces the following error
`
ValueError: Trying to export a gemma model, that is a custom or unsupported architecture, but no custom onnx configuration was passed as `custom_onnx_configs`. Please refer to https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model#custom-export-of-transformers-models for an example on how to export custom models. Please open an issue at https://github.com/huggingface/optimum/issues if you would like the model type gemma to be supported natively in the ONNX export.`
### Expected behavior
Expected behavior is for the line of code to successfully run and such that we can export the IR format of the model as well.
|
https://github.com/huggingface/optimum/issues/1710
|
closed
|
[
"feature-request",
"onnx",
"exporters"
] | 2024-02-22T17:15:08Z
| 2024-02-28T08:37:36Z
| 5
|
Kaya-P
|
huggingface/sentence-transformers
| 2,499
|
how can i save fine_tuned cross-encoder to HF and then download it from HF
|
I'm looking for ways to share fine-tuned cross-encoder with my teacher.
Cross encoder model does not have native push_to_hub() method. So i decided to use general approach:
```
from transformers import AutoModelForSequenceClassification
import torch
# read from disk, model was saved as ft_model.save("model/crerankingeval-30e-4000-ms-marco-MiniLM-L-6-v2")
cross_ft_model = AutoModelForSequenceClassification.from_pretrained("model\\crerankingeval-30e-4000-ms-marco-MiniLM-L-6-v2")
# push to hub
cross_ft_model.push_to_hub("satyroffrost/crerankingeval-30e-4000-ms-marco-MiniLM-L-6-v2")
```
Now model is available on HF. Commit info was like:
CommitInfo(commit_url='https://huggingface.co/satyroffrost/crerankingeval-30e-4000-ms-marco-MiniLM-L-6-v2/commit/d81fe317cb037940e09db256d8a0926e80c358e5', commit_message='Upload BertForSequenceClassification', commit_description='', oid='d81fe317cb037940e09db256d8a0926e80c358e5', pr_url=None, pr_revision=None, pr_num=None)
then i decided to ensure the model is workable:
```
cross_ft_model = CrossEncoder("satyroffrost/crerankingeval-30e-4000-ms-marco-MiniLM-L-6-v2")
cross_ft_model.predict([('SentenceTransformer is well-documented library','but saving crossencoder to HF is a bit tricky')])
```
and get the error:
_Traceback (most recent call last):
Cell In[18], line 1
cross_ft_model = CrossEncoder("satyroffrost/crerankingeval-30e-4000-ms-marco-MiniLM-L-6-v2")
File ~\anaconda3\Lib\site-packages\sentence_transformers\cross_encoder\CrossEncoder.py:72 in __init__
self.tokenizer = AutoTokenizer.from_pretrained(model_name, **tokenizer_args)
File ~\anaconda3\Lib\site-packages\transformers\models\auto\tokenization_auto.py:745 in from_pretrained
return tokenizer_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File ~\anaconda3\Lib\site-packages\transformers\tokenization_utils_base.py:1838 in from_pretrained
raise EnvironmentError(
OSError: Can't load tokenizer for 'satyroffrost/crerankingeval-30e-4000-ms-marco-MiniLM-L-6-v2'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'satyroffrost/crerankingeval-30e-4000-ms-marco-MiniLM-L-6-v2' is the correct path to a directory containing all relevant files for a BertTokenizerFast tokenizer._
I compare local model folder and uploaded HF model files, last ones don't include tokenizer files. Uploaded model don't work on HF too. How can i correctly upload model with tokenizer to HF and the use it from HF like model = CrossEncoder(path_to_hf)?
|
https://github.com/huggingface/sentence-transformers/issues/2499
|
closed
|
[
"good first issue"
] | 2024-02-22T15:29:37Z
| 2025-03-25T16:07:25Z
| null |
satyrmipt
|
huggingface/transformers
| 29,214
|
How to get input embeddings from PatchTST with (batch_size, sequence_length, hidden_size) dimensions
|
### System Info
-
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
The following snippet outputs the last hidden state but it has (batch_size, num_channels, num_patches, d_model) dimensions
`inputs = encoder(
past_values=series_list, output_hidden_states=True
).last_hidden_state`
Here, series_list has (batch_size, sequence_length, num_input_channels) shape.
To incorporate this with [EncoderDecoderModel](https://huggingface.co/docs/transformers/v4.37.2/en/model_doc/encoder-decoder#transformers.EncoderDecoderModel), I want the dimensions of the input embedding to be (batch_size, sequence_length, hidden_size). How do you get that?
### Expected behavior
-
|
https://github.com/huggingface/transformers/issues/29214
|
open
|
[
"Feature request"
] | 2024-02-22T14:17:10Z
| 2024-03-25T03:56:58Z
| null |
nikhilajoshy
|
pytorch/TensorRT
| 2,653
|
❓ [Question] Can torch_tensorRT be used in C++ with multiprocessing using fork?
|
## ❓ Question
Can torch_tensorRT be used in C++ with multiprocessing using fork?
## What you have already tried
I have doubts if this library can be used in C++ multiprocessing (using fork()) where each process loads a TorchScript model compiled for Torch-TensorRT. I have the pipeline that works with no Torch-TensorRT but it fails when I try to load models from it with `torch::jit::load` (with Torch-TensorRT installed). Related issue: https://github.com/pytorch/TensorRT/issues/758. I have not put this as a bug because I have seen in forums that NVIDIA does not recommend using TensorRT with multiprocessing. Mi error is the following on `torch::jit::load`:
```
terminate called after throwing an instance of 'torch_tensorrt::Error'
what(): [Error thrown at /home/eduardo/project/TensorRT/core/runtime/runtime.cpp:99] Expected (cudaGetDevice(reinterpret_cast<int*>(&device)) == cudaSuccess) to be true but got false
Unable to get current device (runtime.get_current_device)
```
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 2.2.0
- CPU Architecture: amd64
- OS (e.g., Linux): Ubuntu 22.04
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): libtorch + Torch-TensorRT (source) compiled on tag v2.2.0
- Build command you used (if compiling from source): on tag v2.2.0: `cmake -S. -Bbuild -DcuDNN_ROOT_DIR=~/Documents/project/deps/cudnn -DCMAKE_MODULE_PATH=cmake/Modules -DTorch_DIR=/usr/local/libtorch/share/cmake/Torch -DTensorRT_ROOT=~/Documents/TensorRT-8.6.1.6/ -DCMAKE_BUILD_TYPE=Debug`
- Are you using local sources or building from archives:
- G++ version: 11.4.0
- CUDA version:12.1
- GPU models and configuration: rtx 4090
- Any other relevant information:
## Additional context
Sorry but I am new to C++ and I may have made a mistake somewhere in the compilation or in linking the libraries.
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/2653
|
open
|
[
"question"
] | 2024-02-22T14:10:57Z
| 2024-02-23T22:04:21Z
| null |
peduajo
|
huggingface/huggingface_hub
| 2,039
|
How to find out the type of files in the repository
|
Hello
Is there an option to determine the type of file in the repository, such as "Checkpoint", "LORA", "Textual_Inversion", etc?
I didn't know where to ask the question so sorry if I'm wrong.
|
https://github.com/huggingface/huggingface_hub/issues/2039
|
closed
|
[] | 2024-02-22T01:41:29Z
| 2024-03-25T11:39:31Z
| null |
suzukimain
|
pytorch/serve
| 2,955
|
CPP backend debugging and troubleshooting
|
### 🚀 The feature
For ease of debugging and troubleshooting for the CPP backend add following:
- [ ] In the TS startup logs, add explicit log line for successful startup of CPP backend
- [x] In the TS print environment add details for the CPP backend
- [x] Cleanup steps for the build script
- [x] FAQ page for troubleshooting
- [x] Build scripts for simple example (or option to do selective build for an example only)
### Motivation, pitch
To simplify the troubleshooting and debugging experience
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/pytorch/serve/issues/2955
|
open
|
[
"documentation"
] | 2024-02-22T01:34:36Z
| 2024-03-26T20:59:22Z
| 0
|
chauhang
|
huggingface/datasets
| 6,686
|
Question: Is there any way for uploading a large image dataset?
|
I am uploading an image dataset like this:
```
dataset = load_dataset(
"json",
data_files={"train": "data/custom_dataset/train.json", "validation": "data/custom_dataset/val.json"},
)
dataset = dataset.cast_column("images", Sequence(Image()))
dataset.push_to_hub("StanfordAIMI/custom_dataset", max_shard_size="1GB")
```
where it takes a long time in the `Map` process. Do you think I can use multi-processing to map all the image data to the memory first? For the `Map()` function, I can set `num_proc`. But for `push_to_hub` and `cast_column`, I can not find it.
Thanks in advance!
Best,
|
https://github.com/huggingface/datasets/issues/6686
|
open
|
[] | 2024-02-21T22:07:21Z
| 2024-05-02T03:44:59Z
| 1
|
zhjohnchan
|
pytorch/tutorials
| 2,773
|
pipeline_tutorial failing due to dead torchtext link
|
Line 55 of https://github.com/pytorch/tutorials/blob/082c8b1bddb48b75f59860db3679d8c439238f10/intermediate_source/pipeline_tutorial.py is using torchtext to download a dataset that can’t be accessed right now (maybe got taken down, I’m looking for an alternative link but torchtext is no longer maintained)
Can this tutorial be rewritten to use a different dataset? Can the entire tutorial be deprecated?
Ex: https://github.com/pytorch/tutorials/actions/runs/7992713944/job/21826864521
`requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip`
cc @kwen2501 @H-Huang @wconstab
|
https://github.com/pytorch/tutorials/issues/2773
|
closed
|
[] | 2024-02-21T21:02:25Z
| 2024-05-15T16:36:22Z
| 3
|
clee2000
|
pytorch/TensorRT
| 2,649
|
❓ [Question] torch_tensorrt.dynamo.compile hangs indefinitely mid compilation?
|
## ❓ Question
torch_tensorrt.dynamo.compile hangs indefinitely mid compilation cpu usage is through the roof and having debug = True shows that there's a step where it fails
## What you have already tried
I tried compiling with torchscript and it works well enough but i wanted to test the dynamo backend
## Environment
Python 3.9.2
torch 2.2+cu118
torch_tensorrt 2.2+cu118
tensorrt 8.6
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 2.2
- CPU Architecture: x86_64
- OS (e.g., Linux): debian 11
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip install torch torchvision torch_tensorrt --index-url https://download.pytorch.org/whl/cu118
- Build command you used (if compiling from source):
``` python
import torch
import torch_tensorrt
from gfpgan.archs.gfpganv1_clean_arch import GFPGANv1Clean
gfpgan = GFPGANv1Clean(
out_size=512,
num_style_feat=512,
channel_multiplier=2,
decoder_load_path=None,
fix_decoder=False,
num_mlp=8,
input_is_latent=True,
different_w=True,
narrow=1,
sft_half=True)
model_path="./experiments/pretrained_models/GFPGANv1.3.pth"
loadnet = torch.load(model_path)
if 'params_ema' in loadnet:
keyname = 'params_ema'
else:
keyname = 'params'
gfpgan.load_state_dict(loadnet[keyname], strict=True)
gfpgan = gfpgan.eval()
inputs=[torch.randn([8, 3, 512, 512],dtype=torch.float32).cuda()]
if torch.cuda.is_available():
gfpgan = gfpgan.cuda().eval()
torch.set_float32_matmul_precision('high')
compiled = torch.compile(gfpgan,
backend="aot_torch_tensorrt_aten",
options={
"truncate_long_and_double":True,
"debug":True
})
print("EXPORTING")
import time
start= time.time()
print(compiled(*inputs))
print(time.time()-start)
torch.save(compiled, "compiled.ts")
```
- Are you using local sources or building from archives:
- Python version: 3.9.2
- CUDA version: 118 (12.3 installed on OS)
- GPU models and configuration: nvidia A100 80gb and nvidia L4 both have the same behavior
- Any other relevant information:
private fork based on https://github.com/TencentARC/GFPGAN
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/2649
|
open
|
[
"question"
] | 2024-02-21T16:27:28Z
| 2024-02-26T18:07:44Z
| null |
Antonyesk601
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.