
id
int64 599M
2.47B
| url
stringlengths 58
61
| repository_url
stringclasses 1
value | events_url
stringlengths 65
68
| labels
listlengths 0
4
| active_lock_reason
null | updated_at
stringlengths 20
20
| assignees
listlengths 0
4
| html_url
stringlengths 46
51
| author_association
stringclasses 4
values | state_reason
stringclasses 3
values | draft
bool 2
classes | milestone
dict | comments
listlengths 0
30
| title
stringlengths 1
290
| reactions
dict | node_id
stringlengths 18
32
| pull_request
dict | created_at
stringlengths 20
20
| comments_url
stringlengths 67
70
| body
stringlengths 0
228k
⌀ | user
dict | labels_url
stringlengths 72
75
| timeline_url
stringlengths 67
70
| state
stringclasses 2
values | locked
bool 1
class | number
int64 1
7.11k
| performed_via_github_app
null | closed_at
stringlengths 20
20
⌀ | assignee
dict | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2,083,108,156 |
https://api.github.com/repos/huggingface/datasets/issues/6596
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6596/events
|
[] | null |
2024-01-16T17:16:16Z
|
[] |
https://github.com/huggingface/datasets/pull/6596
|
CONTRIBUTOR
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6596). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004768 / 0.011353 (-0.006585) | 0.003084 / 0.011008 (-0.007924) | 0.062775 / 0.038508 (0.024267) | 0.029909 / 0.023109 (0.006800) | 0.242905 / 0.275898 (-0.032993) | 0.265609 / 0.323480 (-0.057871) | 0.003856 / 0.007986 (-0.004130) | 0.002610 / 0.004328 (-0.001718) | 0.048631 / 0.004250 (0.044381) | 0.040464 / 0.037052 (0.003412) | 0.256023 / 0.258489 (-0.002467) | 0.285914 / 0.293841 (-0.007927) | 0.027305 / 0.128546 (-0.101241) | 0.010345 / 0.075646 (-0.065301) | 0.206264 / 0.419271 (-0.213008) | 0.035290 / 0.043533 (-0.008243) | 0.247785 / 0.255139 (-0.007353) | 0.267053 / 0.283200 (-0.016147) | 0.017910 / 0.141683 (-0.123773) | 1.166096 / 1.452155 (-0.286059) | 1.210717 / 1.492716 (-0.281999) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095759 / 0.018006 (0.077753) | 0.311030 / 0.000490 (0.310540) | 0.000234 / 0.000200 (0.000034) | 0.000042 / 0.000054 (-0.000013) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.017828 / 0.037411 (-0.019583) | 0.060123 / 0.014526 (0.045597) | 0.071947 / 0.176557 (-0.104610) | 0.119353 / 0.737135 (-0.617782) | 0.073529 / 0.296338 (-0.222809) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282737 / 0.215209 (0.067528) | 2.761914 / 2.077655 (0.684260) | 1.480310 / 1.504120 (-0.023810) | 1.329977 / 1.541195 (-0.211218) | 1.332686 / 1.468490 (-0.135804) | 0.566309 / 4.584777 (-4.018468) | 2.361838 / 3.745712 (-1.383874) | 2.775613 / 5.269862 (-2.494249) | 1.744985 / 4.565676 (-2.820692) | 0.063038 / 0.424275 (-0.361237) | 0.004969 / 0.007607 (-0.002638) | 0.335543 / 0.226044 (0.109499) | 3.293779 / 2.268929 (1.024851) | 1.816093 / 55.444624 (-53.628532) | 1.562658 / 6.876477 (-5.313819) | 1.544888 / 2.142072 (-0.597185) | 0.641762 / 4.805227 (-4.163465) | 0.117904 / 6.500664 (-6.382760) | 0.042534 / 0.075469 (-0.032935) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.935577 / 1.841788 (-0.906211) | 11.565833 / 8.074308 (3.491525) | 10.314723 / 10.191392 (0.123331) | 0.138912 / 0.680424 (-0.541512) | 0.013968 / 0.534201 (-0.520233) | 0.296270 / 0.579283 (-0.283013) | 0.266106 / 0.434364 (-0.168258) | 0.334729 / 0.540337 (-0.205609) | 0.443191 / 1.386936 (-0.943745) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004865 / 0.011353 (-0.006488) | 0.003523 / 0.011008 (-0.007485) | 0.049303 / 0.038508 (0.010795) | 0.029252 / 0.023109 (0.006143) | 0.271288 / 0.275898 (-0.004610) | 0.290529 / 0.323480 (-0.032951) | 0.003982 / 0.007986 (-0.004004) | 0.002740 / 0.004328 (-0.001589) | 0.048513 / 0.004250 (0.044262) | 0.044473 / 0.037052 (0.007420) | 0.282072 / 0.258489 (0.023583) | 0.311321 / 0.293841 (0.017480) | 0.028825 / 0.128546 (-0.099721) | 0.010311 / 0.075646 (-0.065335) | 0.057071 / 0.419271 (-0.362200) | 0.052629 / 0.043533 (0.009097) | 0.273134 / 0.255139 (0.017995) | 0.290989 / 0.283200 (0.007789) | 0.018074 / 0.141683 (-0.123609) | 1.171724 / 1.452155 (-0.280431) | 1.236178 / 1.492716 (-0.256538) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.097099 / 0.018006 (0.079093) | 0.309788 / 0.000490 (0.309298) | 0.000221 / 0.000200 (0.000021) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021703 / 0.037411 (-0.015708) | 0.076104 / 0.014526 (0.061578) | 0.088202 / 0.176557 (-0.088355) | 0.127351 / 0.737135 (-0.609784) | 0.089754 / 0.296338 (-0.206585) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.294574 / 0.215209 (0.079365) | 2.851581 / 2.077655 (0.773926) | 1.599117 / 1.504120 (0.094997) | 1.476183 / 1.541195 (-0.065012) | 1.512309 / 1.468490 (0.043819) | 0.559785 / 4.584777 (-4.024992) | 2.453287 / 3.745712 (-1.292425) | 2.660101 / 5.269862 (-2.609760) | 1.743043 / 4.565676 (-2.822633) | 0.063450 / 0.424275 (-0.360825) | 0.005019 / 0.007607 (-0.002589) | 0.351507 / 0.226044 (0.125462) | 3.431587 / 2.268929 (1.162658) | 1.943349 / 55.444624 (-53.501275) | 1.658706 / 6.876477 (-5.217771) | 1.780042 / 2.142072 (-0.362030) | 0.641364 / 4.805227 (-4.163863) | 0.118052 / 6.500664 (-6.382612) | 0.040961 / 0.075469 (-0.034508) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.974219 / 1.841788 (-0.867568) | 12.257824 / 8.074308 (4.183516) | 10.821225 / 10.191392 (0.629833) | 0.139399 / 0.680424 (-0.541025) | 0.015277 / 0.534201 (-0.518924) | 0.286975 / 0.579283 (-0.292309) | 0.283419 / 0.434364 (-0.150945) | 0.324299 / 0.540337 (-0.216039) | 0.424538 / 1.386936 (-0.962398) |\n\n</details>\n</details>\n\n\n"
] |
Drop redundant None guard.
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6596/reactions"
}
|
PR_kwDODunzps5kJceH
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6596.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6596",
"merged_at": "2024-01-16T17:05:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6596.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6596"
}
|
2024-01-16T06:31:54Z
|
https://api.github.com/repos/huggingface/datasets/issues/6596/comments
|
`xxx if xxx is not None else None` is no-op.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5203025?v=4",
"events_url": "https://api.github.com/users/xkszltl/events{/privacy}",
"followers_url": "https://api.github.com/users/xkszltl/followers",
"following_url": "https://api.github.com/users/xkszltl/following{/other_user}",
"gists_url": "https://api.github.com/users/xkszltl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/xkszltl",
"id": 5203025,
"login": "xkszltl",
"node_id": "MDQ6VXNlcjUyMDMwMjU=",
"organizations_url": "https://api.github.com/users/xkszltl/orgs",
"received_events_url": "https://api.github.com/users/xkszltl/received_events",
"repos_url": "https://api.github.com/users/xkszltl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/xkszltl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xkszltl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/xkszltl"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6596/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6596/timeline
|
closed
| false | 6,596 | null |
2024-01-16T17:05:52Z
| null | true |
2,082,896,148 |
https://api.github.com/repos/huggingface/datasets/issues/6595
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6595/events
|
[] | null |
2024-01-27T18:26:33Z
|
[] |
https://github.com/huggingface/datasets/issues/6595
|
NONE
|
completed
| null | null |
[
"Hi ! I think the issue comes from the \"float16\" features that are not supported yet in Parquet\r\n\r\nFeel free to open an issue in `pyarrow` about this. In the meantime, I'd encourage you to use \"float32\" for your \"pooled_prompt_embeds\" and \"prompt_embeds\" features.\r\n\r\nYou can cast them to \"float32\" using\r\n\r\n```python\r\nfrom datasets import Value\r\n\r\nds = ds.cast_column(\"pooled_prompt_embeds\", Value(\"float32\"))\r\nds = ds.cast_column(\"prompt_embeds\", Value(\"float32\"))\r\n```",
"@lhoestq hm. Thank you very much.\r\n\r\nDo you think it won't have any impact on the training? That it won't break it or the quality won't degrade because of this?\r\n\r\nI need to use it for [SDXL training](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_sdxl.py)",
"Increasing the precision should not degrade training (it only increases the precision), but make sure that it doesn't break your pytorch code (e.g. if it expects a float16 instead of a float32 somewhere)",
"@lhoestq just fyi pyarrow 15.0.0 (just released) supports float16 as the underlying parquetcpp does as well now :)",
"Oh that's amazing ! (and great timing ^^)\r\n\r\n@kopyl can you try to update `pyarrow` and try again ?\r\n\r\nBtw @assignUser there seems to be some casting implementations missing with float16 in 15.0.0, e.g.\r\n\r\n```\r\nArrowNotImplementedError: Unsupported cast from int64 to halffloat using function cast_half_float\r\n```\r\n\r\n```\r\nArrowNotImplementedError: Unsupported cast from double to halffloat using function cast_half_float\r\n```",
"Ah you are right casting is not implemented yet, it's even mentioned in the docs. This pr references the relevant issues if you'd like to track them\nhttps://github.com/apache/arrow/pull/38494",
"Cool thank you :)",
"@lhoestq i just recently found out that it's supported in 15.0.0, but wanted to try it first before telling you...\r\n\r\nTrying this right now and it seemingly works (although i need to wait till the end to make sure there is nothing wrong). Will update you when it's finished.\r\n\r\n<img width=\"918\" alt=\"image\" src=\"https://github.com/huggingface/datasets/assets/17604849/4821e215-e782-4736-8c76-d06187078175\">\r\n\r\nA couple of questions though:\r\n\r\n1. What does that missing casting implementation mean for my specific case and what does it mean in general?\r\n2. Do you know how to `push_to_hub` with multiple processes?",
"@lhoestq also it's strange that there was no error for a dataset with the same features, same data type, but smaller (much smaller).\r\n\r\nAltho i'm not sure about this, but chances are the dataset was loaded directly, not `load_from_disk`.... Maybe because of this.",
"> What does that missing casting implementation mean for my specific case and what does it mean in general?\r\n\r\nNothing for you, just that casting to float16 using `.cast_column(\"my_column_name\", Value(\"float16\"))` raises an error\r\n\r\n> Do you know how to push_to_hub with multiple processes?\r\n\r\nIt's not possible (yet ?). Mostly because we haven't implemented yet how to do parallel uploads to the Hub from `datasets`.\r\nThough if you want faster uploads you can already enable `hf_transfer` \r\n\r\n```\r\npip install hf_transfer\r\n```\r\n\r\nand setting `HF_HUB_ENABLE_HF_TRANSFER=1` as an environment variable\r\n\r\nsee https://huggingface.co/docs/huggingface_hub/guides/upload#tips-and-tricks-for-large-uploads",
"@lhoestq thank you very much.\r\n\r\nThat would be amazing, I need to create a feature request for this :)\r\n\r\nBy the way, in short, how does hf_transfer improves the upload speed under the hood?",
"@lhoestq i was just able to successfully upload without the dataset with the new pyarrow update and without increasing the precision :)",
"Awesome !\r\n\r\nRegarding hf_transfer: it's been optimized in rust ;)",
"@lhoestq wow, cool :)"
] |
Loading big dataset raises pyarrow.lib.ArrowNotImplementedError 2
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6595/reactions"
}
|
I_kwDODunzps58JnkU
| null |
2024-01-16T02:03:09Z
|
https://api.github.com/repos/huggingface/datasets/issues/6595/comments
|
### Describe the bug
I'm aware of the issue #5695 .
I'm using a modified SDXL trainer: https://github.com/kopyl/diffusers/blob/5e70f604155aeecee254a5c63c5e4236ad4a0d3d/examples/text_to_image/train_text_to_image_sdxl.py#L1027C16-L1027C16
So i
1. Map dataset
2. Save to disk
3. Try to upload:
```
import datasets
from datasets import load_from_disk
dataset = load_from_disk("ds")
datasets.config.DEFAULT_MAX_BATCH_SIZE = 1
dataset.push_to_hub("kopyl/ds", private=True, max_shard_size="500MB")
```
And i get this error:
`pyarrow.lib.ArrowNotImplementedError: Unhandled type for Arrow to Parquet schema conversion: halffloat`
Full traceback:
```
>>> dataset.push_to_hub("kopyl/3M_icons_monochrome_only_no_captioning_mapped-for-SDXL-2", private=True, max_shard_size="500MB")
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1451/1451 [00:00<00:00, 6827.40 examples/s]
Uploading the dataset shards: 0%| | 0/2099 [00:00<?, ?it/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.10/dist-packages/datasets/dataset_dict.py", line 1705, in push_to_hub
split_additions, uploaded_size, dataset_nbytes = self[split]._push_parquet_shards_to_hub(
File "/usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py", line 5208, in _push_parquet_shards_to_hub
shard.to_parquet(buffer)
File "/usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py", line 4931, in to_parquet
return ParquetDatasetWriter(self, path_or_buf, batch_size=batch_size, **parquet_writer_kwargs).write()
File "/usr/local/lib/python3.10/dist-packages/datasets/io/parquet.py", line 129, in write
written = self._write(file_obj=self.path_or_buf, batch_size=batch_size, **self.parquet_writer_kwargs)
File "/usr/local/lib/python3.10/dist-packages/datasets/io/parquet.py", line 141, in _write
writer = pq.ParquetWriter(file_obj, schema=schema, **parquet_writer_kwargs)
File "/usr/local/lib/python3.10/dist-packages/pyarrow/parquet/core.py", line 1016, in __init__
self.writer = _parquet.ParquetWriter(
File "pyarrow/_parquet.pyx", line 1869, in pyarrow._parquet.ParquetWriter.__cinit__
File "pyarrow/error.pxi", line 154, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 91, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Unhandled type for Arrow to Parquet schema conversion: halffloat
```
Smaller datasets with the same way of saving and pushing work wonders. Big ones are not.
I'm currently trying to upload dataset like this:
`HfApi().upload_folder...`
But i'm not sure that in this case "load_dataset" would work well.
This setting num_shards does not help too:
```
dataset.push_to_hub("kopyl/3M_icons_monochrome_only_no_captioning_mapped-for-SDXL-2", private=True, num_shards={'train': 500})
```
Tried 3000, 500, 478, 100
Also do you know if it's possible to push a dataset with multiple processes? It would take an eternity pushing 1TB...
### Steps to reproduce the bug
Described above
### Expected behavior
Should be able to upload...
### Environment info
Total dataset size: 978G
Amount of `.arrow` files: 2101
Each `.arrow` file size: 477M (i know 477 megabytes * 2101 does not equal 978G, but i just checked the size of a couple `.arrow` files, i don't know if some might have different size)
Some files:
- "ds/train/state.json": https://pastebin.com/tJ3ZLGAg
- "ds/train/dataset_info.json": https://pastebin.com/JdXMQ5ih
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17604849?v=4",
"events_url": "https://api.github.com/users/kopyl/events{/privacy}",
"followers_url": "https://api.github.com/users/kopyl/followers",
"following_url": "https://api.github.com/users/kopyl/following{/other_user}",
"gists_url": "https://api.github.com/users/kopyl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kopyl",
"id": 17604849,
"login": "kopyl",
"node_id": "MDQ6VXNlcjE3NjA0ODQ5",
"organizations_url": "https://api.github.com/users/kopyl/orgs",
"received_events_url": "https://api.github.com/users/kopyl/received_events",
"repos_url": "https://api.github.com/users/kopyl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kopyl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kopyl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kopyl"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6595/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6595/timeline
|
closed
| false | 6,595 | null |
2024-01-26T02:28:32Z
| null | false |
2,082,748,275 |
https://api.github.com/repos/huggingface/datasets/issues/6594
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6594/events
|
[] | null |
2024-01-15T22:25:10Z
|
[] |
https://github.com/huggingface/datasets/issues/6594
|
NONE
| null | null | null |
[] |
IterableDataset sharding logic needs improvement
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6594/reactions"
}
|
I_kwDODunzps58JDdz
| null |
2024-01-15T22:22:36Z
|
https://api.github.com/repos/huggingface/datasets/issues/6594/comments
|
### Describe the bug
The sharding of IterableDatasets with respect to distributed and dataloader worker processes appears problematic with significant performance traps and inconsistencies wrt to distributed train processes vs worker processes.
Splitting across num_workers (per train process loader processes) and world_size (distributed training processes) appears inconsistent.
* worker split: https://github.com/huggingface/datasets/blob/9d6d16117a30ba345b0236407975f701c5b288d4/src/datasets/iterable_dataset.py#L1266-L1283
* distributed split: https://github.com/huggingface/datasets/blob/9d6d16117a30ba345b0236407975f701c5b288d4/src/datasets/iterable_dataset.py#L1335-L1356
In the case of the distributed split, there is a modulus check that flips between two very different behaviours, why is this different than splitting across the data loader workers? For IterableDatasets the DataLoaders worker processes are independent, so whether it's workers within one train process or across a distributed world the shards should be distributed the same, across `world_size * num_worker` independent workers in either case...
Further, the fallback case when the `n_shards % world_size == 0` check fails is a rather extreme change. I argue it is not desirable to do that implicitly, it should be an explicit case for specific scenarios (ie reliable validation). A train scenario would likely be much better handled with improved wrapping / stopping behaviour to eg also fix #6437. Changing from stepping shards to stepping samples means that every single process reads ALL of the shards. This was never an intended default for sharded training, shards gain their performance advantage in large scale distributed training by explicitly avoiding the need to have every process overlapping in the data they read, by default, only the data allocated to each process via their assigned shards should be read in each pass of the dataset.
Using a large scale CLIP example, some of the larger datasets have 10-20k shards across 100+TB of data. Training with 1000 GPUs we are switching between reading 100 terabytes per epoch to 100 petabytes if say change 20k % 1000 and drop one gpu-node to 20k % 992.
The 'step over samples' case might be worth the overhead in specific validation scenarios where gaurantees of at least/most once samples seen are more important and do not make up a significant portion of train time or are done in smaller world sizes outside of train.
### Steps to reproduce the bug
N/A
### Expected behavior
We have an iterable dataset with N shards, to split across workers
* shuffle shards (same seed across all train processes)
* step shard iterator across distributed processes
* step shard iterator across dataloader worker processes
* shuffle samples in every worker via shuffle buffer (different seed in each worker, but ideally controllable (based on base seed + worker id + epoch).
* end up with (possibly uneven) number of shards per worker but each shard only ever accessed by 1 worker per pass (epoch)
### Environment info
N/A
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5702664?v=4",
"events_url": "https://api.github.com/users/rwightman/events{/privacy}",
"followers_url": "https://api.github.com/users/rwightman/followers",
"following_url": "https://api.github.com/users/rwightman/following{/other_user}",
"gists_url": "https://api.github.com/users/rwightman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rwightman",
"id": 5702664,
"login": "rwightman",
"node_id": "MDQ6VXNlcjU3MDI2NjQ=",
"organizations_url": "https://api.github.com/users/rwightman/orgs",
"received_events_url": "https://api.github.com/users/rwightman/received_events",
"repos_url": "https://api.github.com/users/rwightman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rwightman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rwightman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rwightman"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6594/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6594/timeline
|
open
| false | 6,594 | null | null | null | false |
2,082,410,257 |
https://api.github.com/repos/huggingface/datasets/issues/6592
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6592/events
|
[] | null |
2024-02-12T17:35:21Z
|
[] |
https://github.com/huggingface/datasets/issues/6592
|
NONE
|
not_planned
| null | null |
[
"Hi! `tqdm` doesn't work well in non-interactive environments, so there isn't much we can do about this. It's best to [disable it](https://huggingface.co/docs/datasets/v2.16.1/en/package_reference/utilities#datasets.disable_progress_bars) in such environments and instead use logging to track progress."
] |
Logs are delayed when doing .map when `docker logs`
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6592/reactions"
}
|
I_kwDODunzps58Hw8R
| null |
2024-01-15T17:05:21Z
|
https://api.github.com/repos/huggingface/datasets/issues/6592/comments
|
### Describe the bug
When I run my SD training in a Docker image and then listen to logs like `docker logs train -f`, the progress bar is delayed.
It's updating every few percent.
When you have a large dataset that has to be mapped (like 1+ million samples), it's crucial to see the updates in real-time, not every couple hours to make sure nothing got frozen or broken
### Steps to reproduce the bug
1. Run any huge dataset processing as a Docker image
2. `docker logs image_name` to it
### Expected behavior
...
### Environment info
...
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17604849?v=4",
"events_url": "https://api.github.com/users/kopyl/events{/privacy}",
"followers_url": "https://api.github.com/users/kopyl/followers",
"following_url": "https://api.github.com/users/kopyl/following{/other_user}",
"gists_url": "https://api.github.com/users/kopyl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kopyl",
"id": 17604849,
"login": "kopyl",
"node_id": "MDQ6VXNlcjE3NjA0ODQ5",
"organizations_url": "https://api.github.com/users/kopyl/orgs",
"received_events_url": "https://api.github.com/users/kopyl/received_events",
"repos_url": "https://api.github.com/users/kopyl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kopyl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kopyl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kopyl"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6592/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6592/timeline
|
closed
| false | 6,592 | null |
2024-02-12T17:35:21Z
| null | false |
2,082,378,957 |
https://api.github.com/repos/huggingface/datasets/issues/6591
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6591/events
|
[] | null |
2024-01-22T23:18:09Z
|
[] |
https://github.com/huggingface/datasets/issues/6591
|
NONE
|
completed
| null | null |
[
"Hi! Indeed, Dropbox is not a reliable host. I've just merged https://huggingface.co/datasets/PolyAI/minds14/discussions/24 to fix this by hosting the data files inside the repo."
] |
The datasets models housed in Dropbox can't support a lot of users downloading them
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6591/reactions"
}
|
I_kwDODunzps58HpTN
| null |
2024-01-15T16:43:38Z
|
https://api.github.com/repos/huggingface/datasets/issues/6591/comments
|
### Describe the bug
I'm using the datasets
```
from datasets import load_dataset, Audio
dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
And it seems that sometimes when I imagine a lot of users are accessing the same resources, the Dropbox host fails:
`raise ConnectionError(f"Couldn't reach {url} (error {response.status_code})") ConnectionError: Couldn't reach https://www.dropbox.com/s/e2us0hcs3ilr20e/MInDS-14.zip?dl=1 (error 429)`
My question is if we can somehow host these files elsewhere or can you change the limit of simultaneous users accessing those resources or any other solution?
Also, has anyone had this issue before?
Thanks
### Steps to reproduce the bug
1: Create a python script like so:
```
from datasets import load_dataset, Audio
dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
2: Execute this by a certain number of users at the same time
### Expected behavior
I woudl expect that this shouldnt happen unless its a huge amount of users, which it is not the case
### Environment info
This was done in an Ubuntu 22 environment.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4933774?v=4",
"events_url": "https://api.github.com/users/RDaneelOlivav/events{/privacy}",
"followers_url": "https://api.github.com/users/RDaneelOlivav/followers",
"following_url": "https://api.github.com/users/RDaneelOlivav/following{/other_user}",
"gists_url": "https://api.github.com/users/RDaneelOlivav/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/RDaneelOlivav",
"id": 4933774,
"login": "RDaneelOlivav",
"node_id": "MDQ6VXNlcjQ5MzM3NzQ=",
"organizations_url": "https://api.github.com/users/RDaneelOlivav/orgs",
"received_events_url": "https://api.github.com/users/RDaneelOlivav/received_events",
"repos_url": "https://api.github.com/users/RDaneelOlivav/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/RDaneelOlivav/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RDaneelOlivav/subscriptions",
"type": "User",
"url": "https://api.github.com/users/RDaneelOlivav"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6591/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6591/timeline
|
closed
| false | 6,591 | null |
2024-01-22T23:18:09Z
| null | false |
2,082,000,084 |
https://api.github.com/repos/huggingface/datasets/issues/6590
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6590/events
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null |
2024-01-15T13:07:07Z
|
[] |
https://github.com/huggingface/datasets/issues/6590
|
NONE
| null | null | null |
[] |
Feature request: Multi-GPU dataset mapping for SDXL training
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6590/reactions"
}
|
I_kwDODunzps58GMzU
| null |
2024-01-15T13:06:06Z
|
https://api.github.com/repos/huggingface/datasets/issues/6590/comments
|
### Feature request
We need to speed up SDXL dataset pre-process. Please make it possible to use multiple GPUs for the [official SDXL trainer](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_sdxl.py) :)
### Motivation
Pre-computing 3 million of images takes around 2 days.
Would be nice to be able to be able to do multi-GPU (or even better – multi-GPU + multi-node) vae and embedding precompute...
### Your contribution
I'm not sure i can wrap my head around the multi-GPU mapping...
Plus it's too expensive for me to take x2 A100 and spend a day just figuring out the staff since I don't have a job right now.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17604849?v=4",
"events_url": "https://api.github.com/users/kopyl/events{/privacy}",
"followers_url": "https://api.github.com/users/kopyl/followers",
"following_url": "https://api.github.com/users/kopyl/following{/other_user}",
"gists_url": "https://api.github.com/users/kopyl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kopyl",
"id": 17604849,
"login": "kopyl",
"node_id": "MDQ6VXNlcjE3NjA0ODQ5",
"organizations_url": "https://api.github.com/users/kopyl/orgs",
"received_events_url": "https://api.github.com/users/kopyl/received_events",
"repos_url": "https://api.github.com/users/kopyl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kopyl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kopyl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kopyl"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6590/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6590/timeline
|
open
| false | 6,590 | null | null | null | false |
2,081,358,619 |
https://api.github.com/repos/huggingface/datasets/issues/6589
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6589/events
|
[] | null |
2024-02-02T07:55:38Z
|
[] |
https://github.com/huggingface/datasets/issues/6589
|
NONE
|
completed
| null | null |
[
"We'll do a new release of `datasets` in the coming days with a fix !",
"@lhoestq Thank you very much!"
] |
After `2.16.0` version, there are `PermissionError` when users use shared cache_dir
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6589/reactions"
}
|
I_kwDODunzps58DwMb
| null |
2024-01-15T06:46:27Z
|
https://api.github.com/repos/huggingface/datasets/issues/6589/comments
|
### Describe the bug
- We use shared `cache_dir` using `HF_HOME="{shared_directory}"`
- After dataset version 2.16.0, datasets uses `filelock` package for file locking #6445
- But, `filelock` package make `.lock` file with `644` permission
- Dataset is not available to other users except the user who created the lock file via `load_dataset`.
### Steps to reproduce the bug
1. `pip install datasets==2.16.0`
2. `export HF_HOME="{shared_directory}"`
3. download dataset with `load_dataset`
4. logout and login another user
5. `pip install datasets==2.16.0`
6. `export HF_HOME="{shared_directory}"`
7. download dataset with `load_dataset`
8. `PermissionError` occurs
### Expected behavior
- Users can share `cache_dir` using environment variable `HF_HOME`
### Environment info
- python == 3.9.10
- datasets == 2.16.0
- ubuntu 22.04
- shared_directory has ACL
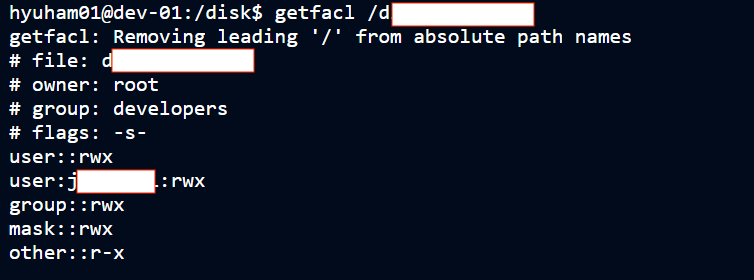
- users are same group (developers)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/106717516?v=4",
"events_url": "https://api.github.com/users/minhopark-neubla/events{/privacy}",
"followers_url": "https://api.github.com/users/minhopark-neubla/followers",
"following_url": "https://api.github.com/users/minhopark-neubla/following{/other_user}",
"gists_url": "https://api.github.com/users/minhopark-neubla/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/minhopark-neubla",
"id": 106717516,
"login": "minhopark-neubla",
"node_id": "U_kgDOBlxhTA",
"organizations_url": "https://api.github.com/users/minhopark-neubla/orgs",
"received_events_url": "https://api.github.com/users/minhopark-neubla/received_events",
"repos_url": "https://api.github.com/users/minhopark-neubla/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/minhopark-neubla/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/minhopark-neubla/subscriptions",
"type": "User",
"url": "https://api.github.com/users/minhopark-neubla"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6589/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6589/timeline
|
closed
| false | 6,589 | null |
2024-01-30T15:28:38Z
| null | false |
2,081,284,253 |
https://api.github.com/repos/huggingface/datasets/issues/6588
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6588/events
|
[] | null |
2024-01-24T10:08:29Z
|
[] |
https://github.com/huggingface/datasets/issues/6588
|
CONTRIBUTOR
|
completed
| null | null |
[] |
fix os.listdir return name is empty string
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6588/reactions"
}
|
I_kwDODunzps58DeCd
| null |
2024-01-15T05:34:36Z
|
https://api.github.com/repos/huggingface/datasets/issues/6588/comments
|
### Describe the bug
xlistdir return name is empty string
Overloaded os.listdir
### Steps to reproduce the bug
```python
from datasets.download.streaming_download_manager import xjoin
from datasets.download.streaming_download_manager import xlistdir
config = DownloadConfig(storage_options=options)
manger = StreamingDownloadManager("ILSVRC2012",download_config=config)
input_path = "lakefs://datalab/main/imagenet/ILSVRC2012.zip"
download_files = manger.download_and_extract(input_path)
current_dir = xjoin(download_files,"ILSVRC2012/Images/ILSVRC2012_img_train")
folder_list = xlistdir(current_dir)
```
in xlistdir function
Obj ["name"] ends with "/"
last return ""
### Expected behavior
Obj ["name"] ends with "/"
return folder name
### Environment info
no
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6588/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6588/timeline
|
closed
| false | 6,588 | null |
2024-01-24T10:08:29Z
| null | false |
2,080,348,016 |
https://api.github.com/repos/huggingface/datasets/issues/6587
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6587/events
|
[] | null |
2024-02-15T15:20:06Z
|
[] |
https://github.com/huggingface/datasets/pull/6587
|
CONTRIBUTOR
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6587). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"friendly bump",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005403 / 0.011353 (-0.005950) | 0.003807 / 0.011008 (-0.007201) | 0.063850 / 0.038508 (0.025342) | 0.028242 / 0.023109 (0.005132) | 0.242866 / 0.275898 (-0.033032) | 0.266015 / 0.323480 (-0.057464) | 0.004111 / 0.007986 (-0.003875) | 0.002816 / 0.004328 (-0.001513) | 0.048862 / 0.004250 (0.044611) | 0.043036 / 0.037052 (0.005984) | 0.255149 / 0.258489 (-0.003340) | 0.280105 / 0.293841 (-0.013736) | 0.028182 / 0.128546 (-0.100365) | 0.010997 / 0.075646 (-0.064649) | 0.208131 / 0.419271 (-0.211141) | 0.036030 / 0.043533 (-0.007502) | 0.241551 / 0.255139 (-0.013588) | 0.260741 / 0.283200 (-0.022459) | 0.018045 / 0.141683 (-0.123638) | 1.175308 / 1.452155 (-0.276847) | 1.192160 / 1.492716 (-0.300556) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094579 / 0.018006 (0.076573) | 0.309850 / 0.000490 (0.309360) | 0.000232 / 0.000200 (0.000032) | 0.000052 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019519 / 0.037411 (-0.017892) | 0.062201 / 0.014526 (0.047675) | 0.074017 / 0.176557 (-0.102539) | 0.121987 / 0.737135 (-0.615148) | 0.078958 / 0.296338 (-0.217380) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286306 / 0.215209 (0.071097) | 2.777004 / 2.077655 (0.699350) | 1.481445 / 1.504120 (-0.022675) | 1.348643 / 1.541195 (-0.192552) | 1.382257 / 1.468490 (-0.086234) | 0.571436 / 4.584777 (-4.013341) | 2.373279 / 3.745712 (-1.372433) | 2.749366 / 5.269862 (-2.520496) | 1.724937 / 4.565676 (-2.840739) | 0.062233 / 0.424275 (-0.362042) | 0.005013 / 0.007607 (-0.002594) | 0.339623 / 0.226044 (0.113579) | 3.385770 / 2.268929 (1.116842) | 1.832023 / 55.444624 (-53.612601) | 1.556172 / 6.876477 (-5.320305) | 1.573301 / 2.142072 (-0.568772) | 0.648866 / 4.805227 (-4.156361) | 0.121228 / 6.500664 (-6.379436) | 0.041684 / 0.075469 (-0.033786) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.974595 / 1.841788 (-0.867192) | 11.519692 / 8.074308 (3.445383) | 9.773075 / 10.191392 (-0.418317) | 0.138149 / 0.680424 (-0.542274) | 0.014068 / 0.534201 (-0.520133) | 0.288161 / 0.579283 (-0.291122) | 0.272832 / 0.434364 (-0.161532) | 0.324476 / 0.540337 (-0.215862) | 0.419962 / 1.386936 (-0.966974) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005668 / 0.011353 (-0.005685) | 0.003637 / 0.011008 (-0.007371) | 0.049582 / 0.038508 (0.011074) | 0.030982 / 0.023109 (0.007872) | 0.273036 / 0.275898 (-0.002862) | 0.297562 / 0.323480 (-0.025918) | 0.004382 / 0.007986 (-0.003603) | 0.002763 / 0.004328 (-0.001566) | 0.050807 / 0.004250 (0.046556) | 0.046914 / 0.037052 (0.009862) | 0.287443 / 0.258489 (0.028954) | 0.319694 / 0.293841 (0.025853) | 0.051110 / 0.128546 (-0.077436) | 0.010650 / 0.075646 (-0.064997) | 0.058254 / 0.419271 (-0.361018) | 0.033419 / 0.043533 (-0.010114) | 0.275634 / 0.255139 (0.020495) | 0.288618 / 0.283200 (0.005419) | 0.018004 / 0.141683 (-0.123678) | 1.134166 / 1.452155 (-0.317989) | 1.192533 / 1.492716 (-0.300183) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.098573 / 0.018006 (0.080566) | 0.308152 / 0.000490 (0.307662) | 0.000249 / 0.000200 (0.000049) | 0.000045 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022443 / 0.037411 (-0.014968) | 0.075628 / 0.014526 (0.061103) | 0.088807 / 0.176557 (-0.087750) | 0.127519 / 0.737135 (-0.609617) | 0.090156 / 0.296338 (-0.206182) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.294493 / 0.215209 (0.079284) | 2.862084 / 2.077655 (0.784429) | 1.585962 / 1.504120 (0.081842) | 1.466366 / 1.541195 (-0.074829) | 1.503306 / 1.468490 (0.034816) | 0.581524 / 4.584777 (-4.003253) | 2.475593 / 3.745712 (-1.270120) | 2.852014 / 5.269862 (-2.417847) | 1.834047 / 4.565676 (-2.731630) | 0.064009 / 0.424275 (-0.360266) | 0.005094 / 0.007607 (-0.002514) | 0.355960 / 0.226044 (0.129916) | 3.428849 / 2.268929 (1.159920) | 1.958501 / 55.444624 (-53.486124) | 1.675448 / 6.876477 (-5.201029) | 1.719960 / 2.142072 (-0.422113) | 0.659609 / 4.805227 (-4.145618) | 0.119036 / 6.500664 (-6.381628) | 0.041800 / 0.075469 (-0.033669) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.025955 / 1.841788 (-0.815833) | 12.432417 / 8.074308 (4.358108) | 10.444854 / 10.191392 (0.253462) | 0.130106 / 0.680424 (-0.550318) | 0.015655 / 0.534201 (-0.518546) | 0.288184 / 0.579283 (-0.291099) | 0.285023 / 0.434364 (-0.149340) | 0.329244 / 0.540337 (-0.211093) | 0.415484 / 1.386936 (-0.971452) |\n\n</details>\n</details>\n\n\n"
] |
Allow concatenation of datasets with mixed structs
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6587/reactions"
}
|
PR_kwDODunzps5kAT_5
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6587.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6587",
"merged_at": "2024-02-08T14:38:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6587.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6587"
}
|
2024-01-13T15:33:20Z
|
https://api.github.com/repos/huggingface/datasets/issues/6587/comments
|
Fixes #6466
The idea is to do a recursive check for structs. PyArrow handles it well enough.
For a demo you can do:
```python
from datasets import Dataset, concatenate_datasets
ds = Dataset.from_dict({'speaker': [{'name': 'Ben', 'email': None}]})
ds2 = Dataset.from_dict({'speaker': [{'name': 'Fred', 'email': 'abc@aol.com'}]})
print(concatenate_datasets([ds, ds2]).features)
print(concatenate_datasets([ds, ds2]).to_dict())
```
Now both the features and the rows are fixed.
I note that Sequence suffers from the same problem, so I can fix that in a future PR once this one is merged.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https://api.github.com/users/Dref360/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Dref360",
"id": 8976546,
"login": "Dref360",
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"organizations_url": "https://api.github.com/users/Dref360/orgs",
"received_events_url": "https://api.github.com/users/Dref360/received_events",
"repos_url": "https://api.github.com/users/Dref360/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Dref360/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dref360/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Dref360"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6587/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6587/timeline
|
closed
| false | 6,587 | null |
2024-02-08T14:38:32Z
| null | true |
2,079,192,651 |
https://api.github.com/repos/huggingface/datasets/issues/6586
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6586/events
|
[] | null |
2024-01-26T15:59:35Z
|
[] |
https://github.com/huggingface/datasets/pull/6586
|
CONTRIBUTOR
| null | false | null |
[
"@JochenSiegWork fyi, that seems to also affect the `trainer.push_to_hub()` method, which I guess also needs to parse that DatasetInfo from the `kwargs` used by `push_to_hub`.\r\nThere is short discussion about it [here](https://github.com/huggingface/blog/issues/1623).\r\nWould be great if you can check if your PR would also fix that!",
"> @JochenSiegWork fyi, that seems to also affect the `trainer.push_to_hub()` method, which I guess also needs to parse that DatasetInfo from the `kwargs` used by `push_to_hub`. There is short discussion about it [here](https://github.com/huggingface/blog/issues/1623). Would be great if you can check if your PR would also fix that!\r\n\r\nHi @thiagobarbosa, it might be related but I didn't worked with `push_to_hub` yet. I don't see a minimal example reproducing the specific error in your link. However, if you have a running version producing the error locally you can test it by pulling this PR and run your specific example locally. ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6586). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004729 / 0.011353 (-0.006624) | 0.002983 / 0.011008 (-0.008025) | 0.062482 / 0.038508 (0.023974) | 0.028406 / 0.023109 (0.005297) | 0.255896 / 0.275898 (-0.020002) | 0.276423 / 0.323480 (-0.047057) | 0.003828 / 0.007986 (-0.004157) | 0.002601 / 0.004328 (-0.001728) | 0.048954 / 0.004250 (0.044704) | 0.040661 / 0.037052 (0.003609) | 0.277710 / 0.258489 (0.019221) | 0.290360 / 0.293841 (-0.003481) | 0.027105 / 0.128546 (-0.101441) | 0.010168 / 0.075646 (-0.065478) | 0.206835 / 0.419271 (-0.212436) | 0.035226 / 0.043533 (-0.008306) | 0.262567 / 0.255139 (0.007428) | 0.273979 / 0.283200 (-0.009221) | 0.017576 / 0.141683 (-0.124106) | 1.125588 / 1.452155 (-0.326566) | 1.185018 / 1.492716 (-0.307698) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092192 / 0.018006 (0.074186) | 0.298350 / 0.000490 (0.297861) | 0.000217 / 0.000200 (0.000017) | 0.000051 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.017925 / 0.037411 (-0.019486) | 0.060285 / 0.014526 (0.045759) | 0.076579 / 0.176557 (-0.099978) | 0.118830 / 0.737135 (-0.618305) | 0.073017 / 0.296338 (-0.223322) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.288149 / 0.215209 (0.072940) | 2.840004 / 2.077655 (0.762349) | 1.495758 / 1.504120 (-0.008361) | 1.362338 / 1.541195 (-0.178857) | 1.389746 / 1.468490 (-0.078744) | 0.576891 / 4.584777 (-4.007886) | 2.375724 / 3.745712 (-1.369988) | 2.707405 / 5.269862 (-2.562457) | 1.719850 / 4.565676 (-2.845826) | 0.067055 / 0.424275 (-0.357220) | 0.005039 / 0.007607 (-0.002568) | 0.346626 / 0.226044 (0.120581) | 3.468346 / 2.268929 (1.199418) | 1.860686 / 55.444624 (-53.583938) | 1.582929 / 6.876477 (-5.293548) | 1.613131 / 2.142072 (-0.528941) | 0.659022 / 4.805227 (-4.146206) | 0.118477 / 6.500664 (-6.382187) | 0.041614 / 0.075469 (-0.033855) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.005062 / 1.841788 (-0.836726) | 11.203210 / 8.074308 (3.128902) | 10.320764 / 10.191392 (0.129372) | 0.128541 / 0.680424 (-0.551883) | 0.014646 / 0.534201 (-0.519555) | 0.285280 / 0.579283 (-0.294003) | 0.263613 / 0.434364 (-0.170751) | 0.321161 / 0.540337 (-0.219177) | 0.420565 / 1.386936 (-0.966371) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005288 / 0.011353 (-0.006065) | 0.003048 / 0.011008 (-0.007960) | 0.049196 / 0.038508 (0.010688) | 0.032104 / 0.023109 (0.008994) | 0.279345 / 0.275898 (0.003447) | 0.300194 / 0.323480 (-0.023286) | 0.004045 / 0.007986 (-0.003941) | 0.002594 / 0.004328 (-0.001735) | 0.047680 / 0.004250 (0.043430) | 0.044294 / 0.037052 (0.007241) | 0.292330 / 0.258489 (0.033841) | 0.318610 / 0.293841 (0.024769) | 0.050417 / 0.128546 (-0.078129) | 0.010326 / 0.075646 (-0.065320) | 0.057372 / 0.419271 (-0.361899) | 0.032985 / 0.043533 (-0.010548) | 0.277717 / 0.255139 (0.022579) | 0.295692 / 0.283200 (0.012493) | 0.017756 / 0.141683 (-0.123927) | 1.166277 / 1.452155 (-0.285877) | 1.213337 / 1.492716 (-0.279380) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091365 / 0.018006 (0.073359) | 0.296261 / 0.000490 (0.295772) | 0.000225 / 0.000200 (0.000025) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021973 / 0.037411 (-0.015438) | 0.074631 / 0.014526 (0.060106) | 0.085645 / 0.176557 (-0.090911) | 0.125181 / 0.737135 (-0.611955) | 0.086893 / 0.296338 (-0.209445) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.294110 / 0.215209 (0.078901) | 2.855531 / 2.077655 (0.777876) | 1.583204 / 1.504120 (0.079084) | 1.453911 / 1.541195 (-0.087284) | 1.467031 / 1.468490 (-0.001460) | 0.581214 / 4.584777 (-4.003562) | 2.423626 / 3.745712 (-1.322086) | 2.736665 / 5.269862 (-2.533197) | 1.707000 / 4.565676 (-2.858676) | 0.061171 / 0.424275 (-0.363104) | 0.004789 / 0.007607 (-0.002818) | 0.344546 / 0.226044 (0.118502) | 3.530955 / 2.268929 (1.262027) | 1.962532 / 55.444624 (-53.482092) | 1.670207 / 6.876477 (-5.206270) | 1.669041 / 2.142072 (-0.473031) | 0.642298 / 4.805227 (-4.162929) | 0.115503 / 6.500664 (-6.385161) | 0.040729 / 0.075469 (-0.034740) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.973101 / 1.841788 (-0.868687) | 11.823894 / 8.074308 (3.749586) | 10.664592 / 10.191392 (0.473200) | 0.139848 / 0.680424 (-0.540576) | 0.015728 / 0.534201 (-0.518473) | 0.289135 / 0.579283 (-0.290148) | 0.271325 / 0.434364 (-0.163039) | 0.332253 / 0.540337 (-0.208085) | 0.416982 / 1.386936 (-0.969954) |\n\n</details>\n</details>\n\n\n"
] |
keep more info in DatasetInfo.from_merge #6585
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6586/reactions"
}
|
PR_kwDODunzps5j8aJn
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6586.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6586",
"merged_at": "2024-01-26T15:53:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6586.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6586"
}
|
2024-01-12T16:08:16Z
|
https://api.github.com/repos/huggingface/datasets/issues/6586/comments
|
* try not to merge DatasetInfos if they're equal
* fixes losing DatasetInfo during parallel Dataset.map
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/135010976?v=4",
"events_url": "https://api.github.com/users/JochenSiegWork/events{/privacy}",
"followers_url": "https://api.github.com/users/JochenSiegWork/followers",
"following_url": "https://api.github.com/users/JochenSiegWork/following{/other_user}",
"gists_url": "https://api.github.com/users/JochenSiegWork/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JochenSiegWork",
"id": 135010976,
"login": "JochenSiegWork",
"node_id": "U_kgDOCAwaoA",
"organizations_url": "https://api.github.com/users/JochenSiegWork/orgs",
"received_events_url": "https://api.github.com/users/JochenSiegWork/received_events",
"repos_url": "https://api.github.com/users/JochenSiegWork/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JochenSiegWork/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JochenSiegWork/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JochenSiegWork"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6586/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6586/timeline
|
closed
| false | 6,586 | null |
2024-01-26T15:53:28Z
| null | true |
2,078,874,005 |
https://api.github.com/repos/huggingface/datasets/issues/6585
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6585/events
|
[] | null |
2024-01-12T14:08:24Z
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/135010976?v=4",
"events_url": "https://api.github.com/users/JochenSiegWork/events{/privacy}",
"followers_url": "https://api.github.com/users/JochenSiegWork/followers",
"following_url": "https://api.github.com/users/JochenSiegWork/following{/other_user}",
"gists_url": "https://api.github.com/users/JochenSiegWork/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JochenSiegWork",
"id": 135010976,
"login": "JochenSiegWork",
"node_id": "U_kgDOCAwaoA",
"organizations_url": "https://api.github.com/users/JochenSiegWork/orgs",
"received_events_url": "https://api.github.com/users/JochenSiegWork/received_events",
"repos_url": "https://api.github.com/users/JochenSiegWork/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JochenSiegWork/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JochenSiegWork/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JochenSiegWork"
}
] |
https://github.com/huggingface/datasets/issues/6585
|
CONTRIBUTOR
| null | null | null |
[
"Hi ! This issue comes from the fact that `map()` with `num_proc>1` shards the dataset in multiple chunks to be processed (one per process) and merges them. The DatasetInfos of each chunk are then merged together, but for some fields like `dataset_name` it's not been implemented and default to None.\r\n\r\nThe DatasetInfo merge is defined here, in case you'd like to contribute an improvement: \r\n\r\nhttps://github.com/huggingface/datasets/blob/d2e0034122a788015c0834a72e6c6279e7ecbac5/src/datasets/info.py#L269-L270",
"#self-assign"
] |
losing DatasetInfo in Dataset.map when num_proc > 1
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6585/reactions"
}
|
I_kwDODunzps576RmV
| null |
2024-01-12T13:39:19Z
|
https://api.github.com/repos/huggingface/datasets/issues/6585/comments
|
### Describe the bug
Hello and thanks for developing this package!
When I process a Dataset with the map function using multiple processors some set attributes of the DatasetInfo get lost and are None in the resulting Dataset.
### Steps to reproduce the bug
```python
from datasets import Dataset, DatasetInfo
def run_map(num_proc):
dataset = Dataset.from_dict(
{"col1": [0, 1], "col2": [3, 4]},
info=DatasetInfo(
dataset_name="my_dataset",
),
)
ds = dataset.map(lambda x: x, num_proc=num_proc)
print(ds.info.dataset_name)
run_map(1)
run_map(2)
```
This puts out:
```bash
Map: 100%|██████████| 2/2 [00:00<00:00, 724.66 examples/s]
my_dataset
Map (num_proc=2): 100%|██████████| 2/2 [00:00<00:00, 18.25 examples/s]
None
```
### Expected behavior
I expect the DatasetInfo to be kept as it was and there should be no difference in the output of running map with num_proc=1 and num_proc=2.
Expected output:
```bash
Map: 100%|██████████| 2/2 [00:00<00:00, 724.66 examples/s]
my_dataset
Map (num_proc=2): 100%|██████████| 2/2 [00:00<00:00, 18.25 examples/s]
my_dataset
```
### Environment info
- `datasets` version: 2.16.1
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.17
- Python version: 3.8.18
- `huggingface_hub` version: 0.20.2
- PyArrow version: 12.0.1
- Pandas version: 2.0.3
- `fsspec` version: 2023.9.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/135010976?v=4",
"events_url": "https://api.github.com/users/JochenSiegWork/events{/privacy}",
"followers_url": "https://api.github.com/users/JochenSiegWork/followers",
"following_url": "https://api.github.com/users/JochenSiegWork/following{/other_user}",
"gists_url": "https://api.github.com/users/JochenSiegWork/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JochenSiegWork",
"id": 135010976,
"login": "JochenSiegWork",
"node_id": "U_kgDOCAwaoA",
"organizations_url": "https://api.github.com/users/JochenSiegWork/orgs",
"received_events_url": "https://api.github.com/users/JochenSiegWork/received_events",
"repos_url": "https://api.github.com/users/JochenSiegWork/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JochenSiegWork/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JochenSiegWork/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JochenSiegWork"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6585/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6585/timeline
|
open
| false | 6,585 | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/135010976?v=4",
"events_url": "https://api.github.com/users/JochenSiegWork/events{/privacy}",
"followers_url": "https://api.github.com/users/JochenSiegWork/followers",
"following_url": "https://api.github.com/users/JochenSiegWork/following{/other_user}",
"gists_url": "https://api.github.com/users/JochenSiegWork/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JochenSiegWork",
"id": 135010976,
"login": "JochenSiegWork",
"node_id": "U_kgDOCAwaoA",
"organizations_url": "https://api.github.com/users/JochenSiegWork/orgs",
"received_events_url": "https://api.github.com/users/JochenSiegWork/received_events",
"repos_url": "https://api.github.com/users/JochenSiegWork/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JochenSiegWork/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JochenSiegWork/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JochenSiegWork"
}
| false |
2,078,454,878 |
https://api.github.com/repos/huggingface/datasets/issues/6584
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6584/events
|
[] | null |
2024-01-15T05:20:50Z
|
[] |
https://github.com/huggingface/datasets/issues/6584
|
CONTRIBUTOR
| null | null | null |
[
"@lhoestq\r\nCan you provide me with some ideas?",
"Hi ! What's the error ?",
"@lhoestq \r\n```\r\nTraceback (most recent call last):\r\n File \"/home/dongzf/miniconda3/envs/dataset_ai/lib/python3.11/runpy.py\", line 198, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/dongzf/miniconda3/envs/dataset_ai/lib/python3.11/runpy.py\", line 88, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/__main__.py\", line 39, in <module>\r\n cli.main()\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py\", line 430, in main\r\n run()\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py\", line 284, in run_file\r\n runpy.run_path(target, run_name=\"__main__\")\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py\", line 321, in run_path\r\n return _run_module_code(code, init_globals, run_name,\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py\", line 135, in _run_module_code\r\n _run_code(code, mod_globals, init_globals,\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py\", line 124, in _run_code\r\n exec(code, run_globals)\r\n File \"/mnt/sda/code/dataset_ai/dataset_ai/example/test.py\", line 83, in <module>\r\n data = xnumpy_fromfile(current_dir, download_config=config,dtype=numpy.float32,)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/mnt/sda/code/dataset_ai/dataset_ai/src/datasets/download/streaming_download_manager.py\", line 765, in xnumpy_fromfile\r\n return np.fromfile(xopen(filepath_or_buffer, \"rb\", download_config=download_config).read(), *args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\nValueError: embedded null byte\r\n```",
" not add read() \r\nthe error is \r\n\r\nreturn np.fromfile(xopen(filepath_or_buffer, \"rb\", download_config=download_config), *args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\nio.UnsupportedOperation: fileno",
"xopen return obj do not have fileno function\r\nI don't know why?",
"I used this method to read point cloud data in the script\r\n\r\n\r\n```python\r\nwith open(velodyne_filepath,\"rb\") as obj:\r\n velodyne_data = numpy.frombuffer(obj.read(), dtype=numpy.float32).reshape([-1, 4])\r\n```"
] |
np.fromfile not supported
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6584/reactions"
}
|
I_kwDODunzps574rRe
| null |
2024-01-12T09:46:17Z
|
https://api.github.com/repos/huggingface/datasets/issues/6584/comments
|
How to do np.fromfile to use it like np.load
```python
def xnumpy_fromfile(filepath_or_buffer, *args, download_config: Optional[DownloadConfig] = None, **kwargs):
import numpy as np
if hasattr(filepath_or_buffer, "read"):
return np.fromfile(filepath_or_buffer, *args, **kwargs)
else:
filepath_or_buffer = str(filepath_or_buffer)
return np.fromfile(xopen(filepath_or_buffer, "rb", download_config=download_config).read(), *args, **kwargs)
```
this is not work
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6584/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6584/timeline
|
open
| false | 6,584 | null | null | null | false |
2,077,049,491 |
https://api.github.com/repos/huggingface/datasets/issues/6583
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6583/events
|
[] | null |
2024-01-11T16:15:34Z
|
[] |
https://github.com/huggingface/datasets/pull/6583
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6583). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005024 / 0.011353 (-0.006329) | 0.003172 / 0.011008 (-0.007836) | 0.062934 / 0.038508 (0.024426) | 0.031737 / 0.023109 (0.008628) | 0.249251 / 0.275898 (-0.026647) | 0.273084 / 0.323480 (-0.050396) | 0.002958 / 0.007986 (-0.005027) | 0.002726 / 0.004328 (-0.001603) | 0.048519 / 0.004250 (0.044269) | 0.043608 / 0.037052 (0.006556) | 0.253648 / 0.258489 (-0.004841) | 0.280095 / 0.293841 (-0.013746) | 0.027500 / 0.128546 (-0.101046) | 0.010545 / 0.075646 (-0.065101) | 0.206781 / 0.419271 (-0.212490) | 0.035515 / 0.043533 (-0.008018) | 0.259449 / 0.255139 (0.004310) | 0.271488 / 0.283200 (-0.011712) | 0.019352 / 0.141683 (-0.122331) | 1.152002 / 1.452155 (-0.300153) | 1.190325 / 1.492716 (-0.302391) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093253 / 0.018006 (0.075247) | 0.302182 / 0.000490 (0.301692) | 0.000216 / 0.000200 (0.000016) | 0.000047 / 0.000054 (-0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.017889 / 0.037411 (-0.019523) | 0.060292 / 0.014526 (0.045766) | 0.072640 / 0.176557 (-0.103917) | 0.121320 / 0.737135 (-0.615815) | 0.073866 / 0.296338 (-0.222472) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282910 / 0.215209 (0.067701) | 2.779815 / 2.077655 (0.702160) | 1.537929 / 1.504120 (0.033809) | 1.405990 / 1.541195 (-0.135205) | 1.407911 / 1.468490 (-0.060579) | 0.561551 / 4.584777 (-4.023226) | 2.368053 / 3.745712 (-1.377659) | 2.732608 / 5.269862 (-2.537254) | 1.710274 / 4.565676 (-2.855402) | 0.061925 / 0.424275 (-0.362350) | 0.004975 / 0.007607 (-0.002632) | 0.338843 / 0.226044 (0.112799) | 3.328579 / 2.268929 (1.059650) | 1.865994 / 55.444624 (-53.578631) | 1.603145 / 6.876477 (-5.273332) | 1.615440 / 2.142072 (-0.526633) | 0.635646 / 4.805227 (-4.169581) | 0.116185 / 6.500664 (-6.384479) | 0.041964 / 0.075469 (-0.033505) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.956977 / 1.841788 (-0.884811) | 11.539802 / 8.074308 (3.465494) | 10.048855 / 10.191392 (-0.142537) | 0.128758 / 0.680424 (-0.551666) | 0.013491 / 0.534201 (-0.520710) | 0.287330 / 0.579283 (-0.291953) | 0.262416 / 0.434364 (-0.171947) | 0.327327 / 0.540337 (-0.213011) | 0.418423 / 1.386936 (-0.968513) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004963 / 0.011353 (-0.006390) | 0.003335 / 0.011008 (-0.007673) | 0.052082 / 0.038508 (0.013574) | 0.029302 / 0.023109 (0.006192) | 0.284986 / 0.275898 (0.009088) | 0.304082 / 0.323480 (-0.019398) | 0.004065 / 0.007986 (-0.003921) | 0.002643 / 0.004328 (-0.001685) | 0.049504 / 0.004250 (0.045253) | 0.044514 / 0.037052 (0.007461) | 0.287064 / 0.258489 (0.028575) | 0.312921 / 0.293841 (0.019080) | 0.029195 / 0.128546 (-0.099351) | 0.010471 / 0.075646 (-0.065175) | 0.057620 / 0.419271 (-0.361651) | 0.050221 / 0.043533 (0.006689) | 0.285392 / 0.255139 (0.030253) | 0.302111 / 0.283200 (0.018912) | 0.018690 / 0.141683 (-0.122993) | 1.165637 / 1.452155 (-0.286518) | 1.203757 / 1.492716 (-0.288959) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095035 / 0.018006 (0.077028) | 0.304447 / 0.000490 (0.303957) | 0.000231 / 0.000200 (0.000031) | 0.000051 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022345 / 0.037411 (-0.015066) | 0.077195 / 0.014526 (0.062669) | 0.089564 / 0.176557 (-0.086992) | 0.129248 / 0.737135 (-0.607887) | 0.091974 / 0.296338 (-0.204365) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.300641 / 0.215209 (0.085432) | 2.936669 / 2.077655 (0.859014) | 1.649100 / 1.504120 (0.144980) | 1.510693 / 1.541195 (-0.030502) | 1.517011 / 1.468490 (0.048521) | 0.572511 / 4.584777 (-4.012266) | 2.442704 / 3.745712 (-1.303009) | 2.833089 / 5.269862 (-2.436772) | 1.762668 / 4.565676 (-2.803008) | 0.063754 / 0.424275 (-0.360521) | 0.005034 / 0.007607 (-0.002573) | 0.401631 / 0.226044 (0.175586) | 3.418986 / 2.268929 (1.150057) | 1.989639 / 55.444624 (-53.454986) | 1.695776 / 6.876477 (-5.180701) | 1.712822 / 2.142072 (-0.429250) | 0.654029 / 4.805227 (-4.151198) | 0.117624 / 6.500664 (-6.383040) | 0.041058 / 0.075469 (-0.034411) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.986008 / 1.841788 (-0.855779) | 12.146838 / 8.074308 (4.072530) | 11.105900 / 10.191392 (0.914508) | 0.139938 / 0.680424 (-0.540486) | 0.015117 / 0.534201 (-0.519084) | 0.286151 / 0.579283 (-0.293132) | 0.272960 / 0.434364 (-0.161404) | 0.323370 / 0.540337 (-0.216967) | 0.427379 / 1.386936 (-0.959557) |\n\n</details>\n</details>\n\n\n"
] |
remove eli5 test
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6583/reactions"
}
|
PR_kwDODunzps5j1DzY
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6583",
"merged_at": "2024-01-11T16:09:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6583"
}
|
2024-01-11T16:05:20Z
|
https://api.github.com/repos/huggingface/datasets/issues/6583/comments
|
since the dataset is defunct
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6583/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6583/timeline
|
closed
| false | 6,583 | null |
2024-01-11T16:09:24Z
| null | true |
2,076,072,101 |
https://api.github.com/repos/huggingface/datasets/issues/6582
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6582/events
|
[] | null |
2024-03-01T19:09:14Z
|
[] |
https://github.com/huggingface/datasets/pull/6582
|
CONTRIBUTOR
| null | false | null |
[
"A toy example to reveal the bug.\r\n\r\n```python\r\n\"\"\"\r\nDATASETS_VERBOSITY=debug torchrun --nproc-per-node 2 main.py \r\n\"\"\"\r\nimport torch.utils.data\r\nimport torch.distributed\r\nimport datasets.distributed\r\nimport datasets\r\n\r\n# num shards = 4\r\nshards = [(0, 100), (100, 200), (200, 300), (300, 400)]\r\n\r\n\r\ndef gen(shards):\r\n for st, ed in shards:\r\n yield from range(st, ed)\r\n\r\ntorch.distributed.init_process_group()\r\n\r\n# want to create total worker = world_size * 8\r\nds = datasets.IterableDataset.from_generator(gen, gen_kwargs={'shards': shards})\r\nds = datasets.distributed.split_dataset_by_node(\r\n ds,\r\n rank=torch.distributed.get_rank(),\r\n world_size=torch.distributed.get_world_size(),\r\n)\r\ndl = torch.utils.data.DataLoader(ds, batch_size=10, num_workers=8)\r\n\r\nfor x in dl:\r\n print(f\"RANK={torch.distributed.get_rank()} {x}\")\r\n```",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005401 / 0.011353 (-0.005952) | 0.004023 / 0.011008 (-0.006985) | 0.064601 / 0.038508 (0.026093) | 0.028567 / 0.023109 (0.005457) | 0.245476 / 0.275898 (-0.030422) | 0.292727 / 0.323480 (-0.030752) | 0.003080 / 0.007986 (-0.004905) | 0.002779 / 0.004328 (-0.001549) | 0.050046 / 0.004250 (0.045796) | 0.043906 / 0.037052 (0.006854) | 0.273896 / 0.258489 (0.015407) | 0.308430 / 0.293841 (0.014589) | 0.028442 / 0.128546 (-0.100104) | 0.010694 / 0.075646 (-0.064953) | 0.209048 / 0.419271 (-0.210223) | 0.036062 / 0.043533 (-0.007471) | 0.242689 / 0.255139 (-0.012450) | 0.261695 / 0.283200 (-0.021504) | 0.018519 / 0.141683 (-0.123163) | 1.122735 / 1.452155 (-0.329420) | 1.172680 / 1.492716 (-0.320036) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093827 / 0.018006 (0.075820) | 0.302650 / 0.000490 (0.302161) | 0.000218 / 0.000200 (0.000018) | 0.000045 / 0.000054 (-0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018778 / 0.037411 (-0.018633) | 0.067516 / 0.014526 (0.052990) | 0.079693 / 0.176557 (-0.096864) | 0.125907 / 0.737135 (-0.611228) | 0.081771 / 0.296338 (-0.214568) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.281809 / 0.215209 (0.066600) | 2.773937 / 2.077655 (0.696283) | 1.443622 / 1.504120 (-0.060497) | 1.334359 / 1.541195 (-0.206836) | 1.364813 / 1.468490 (-0.103677) | 0.561670 / 4.584777 (-4.023107) | 2.338292 / 3.745712 (-1.407420) | 2.807595 / 5.269862 (-2.462267) | 1.734162 / 4.565676 (-2.831514) | 0.063681 / 0.424275 (-0.360594) | 0.004934 / 0.007607 (-0.002673) | 0.336781 / 0.226044 (0.110737) | 3.311744 / 2.268929 (1.042815) | 1.826802 / 55.444624 (-53.617822) | 1.579604 / 6.876477 (-5.296872) | 1.620526 / 2.142072 (-0.521546) | 0.647061 / 4.805227 (-4.158166) | 0.117729 / 6.500664 (-6.382935) | 0.042216 / 0.075469 (-0.033253) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.994289 / 1.841788 (-0.847499) | 12.266185 / 8.074308 (4.191877) | 9.634035 / 10.191392 (-0.557357) | 0.144521 / 0.680424 (-0.535902) | 0.013787 / 0.534201 (-0.520414) | 0.288353 / 0.579283 (-0.290930) | 0.262183 / 0.434364 (-0.172181) | 0.336960 / 0.540337 (-0.203378) | 0.441142 / 1.386936 (-0.945794) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005678 / 0.011353 (-0.005675) | 0.004011 / 0.011008 (-0.006998) | 0.049319 / 0.038508 (0.010811) | 0.032543 / 0.023109 (0.009434) | 0.276389 / 0.275898 (0.000491) | 0.298495 / 0.323480 (-0.024985) | 0.004192 / 0.007986 (-0.003794) | 0.002765 / 0.004328 (-0.001563) | 0.048739 / 0.004250 (0.044489) | 0.046212 / 0.037052 (0.009160) | 0.286614 / 0.258489 (0.028125) | 0.315949 / 0.293841 (0.022108) | 0.029833 / 0.128546 (-0.098714) | 0.010762 / 0.075646 (-0.064884) | 0.058489 / 0.419271 (-0.360783) | 0.052258 / 0.043533 (0.008725) | 0.275873 / 0.255139 (0.020734) | 0.288668 / 0.283200 (0.005468) | 0.018828 / 0.141683 (-0.122855) | 1.140196 / 1.452155 (-0.311959) | 1.229500 / 1.492716 (-0.263217) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094161 / 0.018006 (0.076155) | 0.303519 / 0.000490 (0.303030) | 0.000219 / 0.000200 (0.000019) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022088 / 0.037411 (-0.015324) | 0.076376 / 0.014526 (0.061850) | 0.088705 / 0.176557 (-0.087851) | 0.127602 / 0.737135 (-0.609533) | 0.088689 / 0.296338 (-0.207649) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.292363 / 0.215209 (0.077154) | 2.859215 / 2.077655 (0.781561) | 1.566389 / 1.504120 (0.062270) | 1.439195 / 1.541195 (-0.102000) | 1.463805 / 1.468490 (-0.004685) | 0.551660 / 4.584777 (-4.033116) | 2.427462 / 3.745712 (-1.318250) | 2.712372 / 5.269862 (-2.557490) | 1.811331 / 4.565676 (-2.754346) | 0.061539 / 0.424275 (-0.362736) | 0.005062 / 0.007607 (-0.002545) | 0.341984 / 0.226044 (0.115940) | 3.352171 / 2.268929 (1.083242) | 1.917550 / 55.444624 (-53.527074) | 1.642668 / 6.876477 (-5.233809) | 1.817204 / 2.142072 (-0.324868) | 0.630849 / 4.805227 (-4.174379) | 0.115788 / 6.500664 (-6.384876) | 0.041041 / 0.075469 (-0.034428) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.017725 / 1.841788 (-0.824062) | 12.976994 / 8.074308 (4.902686) | 10.307414 / 10.191392 (0.116022) | 0.141090 / 0.680424 (-0.539334) | 0.015548 / 0.534201 (-0.518653) | 0.288184 / 0.579283 (-0.291099) | 0.276409 / 0.434364 (-0.157955) | 0.328289 / 0.540337 (-0.212048) | 0.429138 / 1.386936 (-0.957798) |\n\n</details>\n</details>\n\n\n"
] |
Fix for Incorrect ex_iterable used with multi num_worker
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6582/reactions"
}
|
PR_kwDODunzps5jxpry
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6582.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6582",
"merged_at": "2024-03-01T19:02:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6582.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6582"
}
|
2024-01-11T08:49:43Z
|
https://api.github.com/repos/huggingface/datasets/issues/6582/comments
|
Corrects an issue where `self._ex_iterable` was erroneously used instead of `ex_iterable`, when both Distributed Data Parallel (DDP) and multi num_worker are used concurrently. This improper usage led to the generation of incorrect `shards_indices`, subsequently causing issues with the control flow responsible for worker creation. The fix ensures the appropriate iterable is used, thus providing a more accurate determination of whether a new worker should be instantiated or not.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/136600500?v=4",
"events_url": "https://api.github.com/users/kq-chen/events{/privacy}",
"followers_url": "https://api.github.com/users/kq-chen/followers",
"following_url": "https://api.github.com/users/kq-chen/following{/other_user}",
"gists_url": "https://api.github.com/users/kq-chen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kq-chen",
"id": 136600500,
"login": "kq-chen",
"node_id": "U_kgDOCCRbtA",
"organizations_url": "https://api.github.com/users/kq-chen/orgs",
"received_events_url": "https://api.github.com/users/kq-chen/received_events",
"repos_url": "https://api.github.com/users/kq-chen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kq-chen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kq-chen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kq-chen"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6582/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6582/timeline
|
closed
| false | 6,582 | null |
2024-03-01T19:02:33Z
| null | true |
2,075,919,265 |
https://api.github.com/repos/huggingface/datasets/issues/6581
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6581/events
|
[] | null |
2024-01-24T10:14:43Z
|
[] |
https://github.com/huggingface/datasets/pull/6581
|
CONTRIBUTOR
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6581). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"\r\nObj [\"name\"] ends with \"/\"",
"@lhoestq \r\n\r\nhello,\r\nCan you help me check if there are any issues with this PR? Why hasn't anyone merged?\r\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004968 / 0.011353 (-0.006385) | 0.003516 / 0.011008 (-0.007492) | 0.063787 / 0.038508 (0.025279) | 0.031695 / 0.023109 (0.008586) | 0.240081 / 0.275898 (-0.035817) | 0.260984 / 0.323480 (-0.062496) | 0.003832 / 0.007986 (-0.004153) | 0.002680 / 0.004328 (-0.001648) | 0.049199 / 0.004250 (0.044948) | 0.044720 / 0.037052 (0.007668) | 0.255812 / 0.258489 (-0.002677) | 0.275923 / 0.293841 (-0.017918) | 0.026849 / 0.128546 (-0.101697) | 0.010473 / 0.075646 (-0.065174) | 0.209069 / 0.419271 (-0.210202) | 0.035731 / 0.043533 (-0.007802) | 0.246596 / 0.255139 (-0.008543) | 0.265889 / 0.283200 (-0.017311) | 0.017607 / 0.141683 (-0.124075) | 1.128648 / 1.452155 (-0.323507) | 1.174379 / 1.492716 (-0.318338) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.098214 / 0.018006 (0.080207) | 0.311969 / 0.000490 (0.311480) | 0.000266 / 0.000200 (0.000066) | 0.000056 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018401 / 0.037411 (-0.019010) | 0.061347 / 0.014526 (0.046821) | 0.073628 / 0.176557 (-0.102928) | 0.121359 / 0.737135 (-0.615776) | 0.075148 / 0.296338 (-0.221190) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.274098 / 0.215209 (0.058889) | 2.707633 / 2.077655 (0.629978) | 1.453615 / 1.504120 (-0.050504) | 1.311942 / 1.541195 (-0.229253) | 1.332394 / 1.468490 (-0.136096) | 0.566947 / 4.584777 (-4.017830) | 2.383291 / 3.745712 (-1.362421) | 2.754779 / 5.269862 (-2.515083) | 1.725164 / 4.565676 (-2.840512) | 0.062124 / 0.424275 (-0.362152) | 0.005111 / 0.007607 (-0.002496) | 0.334217 / 0.226044 (0.108173) | 3.271619 / 2.268929 (1.002690) | 1.776906 / 55.444624 (-53.667718) | 1.519238 / 6.876477 (-5.357239) | 1.534722 / 2.142072 (-0.607351) | 0.646143 / 4.805227 (-4.159084) | 0.117015 / 6.500664 (-6.383649) | 0.042578 / 0.075469 (-0.032891) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.948488 / 1.841788 (-0.893299) | 11.598027 / 8.074308 (3.523719) | 10.269199 / 10.191392 (0.077807) | 0.144887 / 0.680424 (-0.535537) | 0.014745 / 0.534201 (-0.519456) | 0.289185 / 0.579283 (-0.290099) | 0.275243 / 0.434364 (-0.159120) | 0.328088 / 0.540337 (-0.212250) | 0.430161 / 1.386936 (-0.956775) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005020 / 0.011353 (-0.006333) | 0.003246 / 0.011008 (-0.007762) | 0.049810 / 0.038508 (0.011302) | 0.032215 / 0.023109 (0.009105) | 0.271033 / 0.275898 (-0.004866) | 0.294957 / 0.323480 (-0.028523) | 0.004192 / 0.007986 (-0.003793) | 0.002652 / 0.004328 (-0.001677) | 0.049132 / 0.004250 (0.044881) | 0.047818 / 0.037052 (0.010766) | 0.292370 / 0.258489 (0.033881) | 0.316142 / 0.293841 (0.022301) | 0.049539 / 0.128546 (-0.079007) | 0.010533 / 0.075646 (-0.065113) | 0.058131 / 0.419271 (-0.361141) | 0.033807 / 0.043533 (-0.009725) | 0.277623 / 0.255139 (0.022484) | 0.292294 / 0.283200 (0.009094) | 0.021110 / 0.141683 (-0.120573) | 1.160997 / 1.452155 (-0.291157) | 1.213553 / 1.492716 (-0.279163) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.098220 / 0.018006 (0.080214) | 0.312342 / 0.000490 (0.311852) | 0.000231 / 0.000200 (0.000031) | 0.000052 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022893 / 0.037411 (-0.014519) | 0.075572 / 0.014526 (0.061046) | 0.088357 / 0.176557 (-0.088199) | 0.126354 / 0.737135 (-0.610782) | 0.089763 / 0.296338 (-0.206575) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.284368 / 0.215209 (0.069159) | 2.785497 / 2.077655 (0.707842) | 1.499364 / 1.504120 (-0.004756) | 1.376020 / 1.541195 (-0.165175) | 1.394270 / 1.468490 (-0.074220) | 0.571945 / 4.584777 (-4.012832) | 2.419148 / 3.745712 (-1.326564) | 2.796974 / 5.269862 (-2.472887) | 1.749531 / 4.565676 (-2.816145) | 0.064088 / 0.424275 (-0.360187) | 0.005294 / 0.007607 (-0.002313) | 0.336250 / 0.226044 (0.110206) | 3.315933 / 2.268929 (1.047004) | 1.877165 / 55.444624 (-53.567459) | 1.592336 / 6.876477 (-5.284140) | 1.599979 / 2.142072 (-0.542093) | 0.655617 / 4.805227 (-4.149610) | 0.117636 / 6.500664 (-6.383028) | 0.040813 / 0.075469 (-0.034656) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.976887 / 1.841788 (-0.864901) | 12.668753 / 8.074308 (4.594445) | 11.081253 / 10.191392 (0.889861) | 0.134494 / 0.680424 (-0.545930) | 0.016053 / 0.534201 (-0.518148) | 0.291607 / 0.579283 (-0.287676) | 0.287726 / 0.434364 (-0.146638) | 0.328108 / 0.540337 (-0.212229) | 0.425194 / 1.386936 (-0.961742) |\n\n</details>\n</details>\n\n\n"
] |
fix os.listdir return name is empty string
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6581/reactions"
}
|
PR_kwDODunzps5jxIbt
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6581.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6581",
"merged_at": "2024-01-24T10:08:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6581.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6581"
}
|
2024-01-11T07:10:55Z
|
https://api.github.com/repos/huggingface/datasets/issues/6581/comments
|
fix #6588
xlistdir return name is empty string
for example:
`
from datasets.download.streaming_download_manager import xjoin
from datasets.download.streaming_download_manager import xlistdir
config = DownloadConfig(storage_options=options)
manger = StreamingDownloadManager("ILSVRC2012",download_config=config)
input_path = "lakefs://datalab/main/imagenet/ILSVRC2012.zip"
download_files = manger.download_and_extract(input_path)
current_dir = xjoin(download_files,"ILSVRC2012/Images/ILSVRC2012_img_train")
folder_list = xlistdir(current_dir)
`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6581/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6581/timeline
|
closed
| false | 6,581 | null |
2024-01-24T10:08:28Z
| null | true |
2,075,645,042 |
https://api.github.com/repos/huggingface/datasets/issues/6580
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6580/events
|
[] | null |
2024-01-20T12:46:16Z
|
[] |
https://github.com/huggingface/datasets/issues/6580
|
NONE
|
completed
| null | null |
[] |
dataset cache only stores one config of the dataset in parquet dir, and uses that for all other configs resulting in showing same data in all configs.
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6580/reactions"
}
|
I_kwDODunzps57t9Ry
| null |
2024-01-11T03:14:18Z
|
https://api.github.com/repos/huggingface/datasets/issues/6580/comments
|
### Describe the bug
ds = load_dataset("ai2_arc", "ARC-Easy"), i have tried to force redownload, delete cache and changing the cache dir.
### Steps to reproduce the bug
dataset = []
dataset_name = "ai2_arc"
possible_configs = [
'ARC-Challenge',
'ARC-Easy'
]
for config in possible_configs:
dataset_slice = load_dataset(dataset_name, config,ignore_verifications=True,cache_dir='ai2_arc_files')
dataset.append(dataset_slice)
### Expected behavior
all configs should get saved in cache with their respective names.
### Environment info
ai2_arc
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/78641018?v=4",
"events_url": "https://api.github.com/users/kartikgupta321/events{/privacy}",
"followers_url": "https://api.github.com/users/kartikgupta321/followers",
"following_url": "https://api.github.com/users/kartikgupta321/following{/other_user}",
"gists_url": "https://api.github.com/users/kartikgupta321/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kartikgupta321",
"id": 78641018,
"login": "kartikgupta321",
"node_id": "MDQ6VXNlcjc4NjQxMDE4",
"organizations_url": "https://api.github.com/users/kartikgupta321/orgs",
"received_events_url": "https://api.github.com/users/kartikgupta321/received_events",
"repos_url": "https://api.github.com/users/kartikgupta321/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kartikgupta321/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kartikgupta321/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kartikgupta321"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6580/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6580/timeline
|
closed
| false | 6,580 | null |
2024-01-20T12:46:16Z
| null | false |
2,075,407,473 |
https://api.github.com/repos/huggingface/datasets/issues/6579
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6579/events
|
[] | null |
2024-01-11T09:19:18Z
|
[] |
https://github.com/huggingface/datasets/issues/6579
|
NONE
|
not_planned
| null | null |
[
"Hi @haok1402, I have created an issue in the Discussion tab of the corresponding dataset: https://huggingface.co/datasets/eli5/discussions/7\r\nLet's continue the discussion there!"
] |
Unable to load `eli5` dataset with streaming
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6579/reactions"
}
|
I_kwDODunzps57tDRx
| null |
2024-01-10T23:44:20Z
|
https://api.github.com/repos/huggingface/datasets/issues/6579/comments
|
### Describe the bug
Unable to load `eli5` dataset with streaming.
### Steps to reproduce the bug
This fails with FileNotFoundError: https://files.pushshift.io/reddit/submissions
```
from datasets import load_dataset
load_dataset("eli5", streaming=True)
```
This works correctly.
```
from datasets import load_dataset
load_dataset("eli5")
```
### Expected behavior
- Loading `eli5` dataset should not raise an error under the streaming mode.
- Or at the very least, show a warning that streaming mode is not supported with `eli5` dataset.
### Environment info
- `datasets` version: 2.16.1
- Platform: Linux-6.2.0-39-generic-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.19.4
- PyArrow version: 12.0.1
- Pandas version: 2.0.3
- `fsspec` version: 2023.6.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/89672451?v=4",
"events_url": "https://api.github.com/users/haok1402/events{/privacy}",
"followers_url": "https://api.github.com/users/haok1402/followers",
"following_url": "https://api.github.com/users/haok1402/following{/other_user}",
"gists_url": "https://api.github.com/users/haok1402/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/haok1402",
"id": 89672451,
"login": "haok1402",
"node_id": "MDQ6VXNlcjg5NjcyNDUx",
"organizations_url": "https://api.github.com/users/haok1402/orgs",
"received_events_url": "https://api.github.com/users/haok1402/received_events",
"repos_url": "https://api.github.com/users/haok1402/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/haok1402/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/haok1402/subscriptions",
"type": "User",
"url": "https://api.github.com/users/haok1402"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6579/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6579/timeline
|
closed
| false | 6,579 | null |
2024-01-11T09:19:17Z
| null | false |
2,074,923,321 |
https://api.github.com/repos/huggingface/datasets/issues/6578
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6578/events
|
[] | null |
2024-01-30T18:46:02Z
|
[] |
https://github.com/huggingface/datasets/pull/6578
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6578). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"I added faster streaming support using streaming Requests instances in `huggingface_hub` and will be available in 0.21.\r\n\r\nThis PR can be used with https://github.com/huggingface/huggingface_hub/pull/1967 to get fast WebDataset streaming",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004941 / 0.011353 (-0.006412) | 0.003431 / 0.011008 (-0.007577) | 0.062768 / 0.038508 (0.024260) | 0.029212 / 0.023109 (0.006103) | 0.253053 / 0.275898 (-0.022845) | 0.273061 / 0.323480 (-0.050419) | 0.004114 / 0.007986 (-0.003871) | 0.002713 / 0.004328 (-0.001616) | 0.048481 / 0.004250 (0.044231) | 0.040001 / 0.037052 (0.002949) | 0.268461 / 0.258489 (0.009971) | 0.287767 / 0.293841 (-0.006074) | 0.027885 / 0.128546 (-0.100661) | 0.010474 / 0.075646 (-0.065172) | 0.207989 / 0.419271 (-0.211282) | 0.035893 / 0.043533 (-0.007640) | 0.256833 / 0.255139 (0.001694) | 0.274197 / 0.283200 (-0.009003) | 0.017283 / 0.141683 (-0.124400) | 1.133597 / 1.452155 (-0.318558) | 1.206661 / 1.492716 (-0.286055) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.089610 / 0.018006 (0.071604) | 0.306051 / 0.000490 (0.305562) | 0.000217 / 0.000200 (0.000017) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018686 / 0.037411 (-0.018725) | 0.061253 / 0.014526 (0.046727) | 0.073654 / 0.176557 (-0.102903) | 0.120499 / 0.737135 (-0.616637) | 0.074827 / 0.296338 (-0.221511) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.293756 / 0.215209 (0.078547) | 2.897755 / 2.077655 (0.820100) | 1.558146 / 1.504120 (0.054026) | 1.458020 / 1.541195 (-0.083174) | 1.453489 / 1.468490 (-0.015001) | 0.576666 / 4.584777 (-4.008111) | 2.423441 / 3.745712 (-1.322271) | 2.727760 / 5.269862 (-2.542102) | 1.750287 / 4.565676 (-2.815390) | 0.062094 / 0.424275 (-0.362181) | 0.004940 / 0.007607 (-0.002667) | 0.338815 / 0.226044 (0.112770) | 3.342677 / 2.268929 (1.073748) | 1.928335 / 55.444624 (-53.516290) | 1.629965 / 6.876477 (-5.246511) | 1.651836 / 2.142072 (-0.490236) | 0.644354 / 4.805227 (-4.160874) | 0.117890 / 6.500664 (-6.382774) | 0.041907 / 0.075469 (-0.033562) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.984399 / 1.841788 (-0.857389) | 11.516572 / 8.074308 (3.442264) | 10.326922 / 10.191392 (0.135530) | 0.130821 / 0.680424 (-0.549603) | 0.014084 / 0.534201 (-0.520117) | 0.287078 / 0.579283 (-0.292205) | 0.263466 / 0.434364 (-0.170898) | 0.326867 / 0.540337 (-0.213470) | 0.425313 / 1.386936 (-0.961623) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005305 / 0.011353 (-0.006048) | 0.003646 / 0.011008 (-0.007362) | 0.049402 / 0.038508 (0.010894) | 0.031719 / 0.023109 (0.008610) | 0.272579 / 0.275898 (-0.003319) | 0.295241 / 0.323480 (-0.028239) | 0.004309 / 0.007986 (-0.003677) | 0.002781 / 0.004328 (-0.001548) | 0.048134 / 0.004250 (0.043883) | 0.044702 / 0.037052 (0.007650) | 0.288201 / 0.258489 (0.029712) | 0.320351 / 0.293841 (0.026510) | 0.051327 / 0.128546 (-0.077219) | 0.011019 / 0.075646 (-0.064628) | 0.057983 / 0.419271 (-0.361288) | 0.034211 / 0.043533 (-0.009322) | 0.272856 / 0.255139 (0.017717) | 0.290007 / 0.283200 (0.006807) | 0.018656 / 0.141683 (-0.123027) | 1.135017 / 1.452155 (-0.317138) | 1.183904 / 1.492716 (-0.308813) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.090854 / 0.018006 (0.072847) | 0.299654 / 0.000490 (0.299165) | 0.000224 / 0.000200 (0.000024) | 0.000063 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021882 / 0.037411 (-0.015529) | 0.075297 / 0.014526 (0.060771) | 0.086620 / 0.176557 (-0.089937) | 0.127125 / 0.737135 (-0.610011) | 0.088622 / 0.296338 (-0.207717) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.287104 / 0.215209 (0.071895) | 2.802723 / 2.077655 (0.725068) | 1.570137 / 1.504120 (0.066017) | 1.452234 / 1.541195 (-0.088961) | 1.465457 / 1.468490 (-0.003033) | 0.564965 / 4.584777 (-4.019812) | 2.416724 / 3.745712 (-1.328988) | 2.645057 / 5.269862 (-2.624805) | 1.727599 / 4.565676 (-2.838078) | 0.063338 / 0.424275 (-0.360937) | 0.005018 / 0.007607 (-0.002589) | 0.345280 / 0.226044 (0.119235) | 3.384323 / 2.268929 (1.115395) | 1.957227 / 55.444624 (-53.487397) | 1.667620 / 6.876477 (-5.208856) | 1.795339 / 2.142072 (-0.346733) | 0.642049 / 4.805227 (-4.163178) | 0.114853 / 6.500664 (-6.385811) | 0.040459 / 0.075469 (-0.035010) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.023640 / 1.841788 (-0.818147) | 11.998130 / 8.074308 (3.923822) | 10.858137 / 10.191392 (0.666744) | 0.130235 / 0.680424 (-0.550189) | 0.016201 / 0.534201 (-0.518000) | 0.289743 / 0.579283 (-0.289540) | 0.275100 / 0.434364 (-0.159264) | 0.329299 / 0.540337 (-0.211039) | 0.418632 / 1.386936 (-0.968304) |\n\n</details>\n</details>\n\n\n"
] |
Faster webdataset streaming
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6578/reactions"
}
|
PR_kwDODunzps5jtthB
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6578.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6578",
"merged_at": "2024-01-30T18:39:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6578.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6578"
}
|
2024-01-10T18:18:09Z
|
https://api.github.com/repos/huggingface/datasets/issues/6578/comments
|
requests.get(..., streaming=True) is faster than using HTTP range requests when streaming large TAR files
it can be enabled using block_size=0 in fsspec
cc @rwightman
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6578/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6578/timeline
|
closed
| false | 6,578 | null |
2024-01-30T18:39:51Z
| null | true |
2,074,790,848 |
https://api.github.com/repos/huggingface/datasets/issues/6577
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6577/events
|
[
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | null |
2024-02-12T11:46:03Z
|
[] |
https://github.com/huggingface/datasets/issues/6577
|
CONTRIBUTOR
|
completed
| null | null |
[
"cc @mariosasko @lhoestq ",
"Hi! We should be able to avoid this error by retrying to read the data when it happens. I'll open a PR in `huggingface_hub` to address this.",
"Thanks for the fix @mariosasko! Just wondering whether \"500 error\" should also be excluded? I got these errors overnight:\r\n\r\n```\r\nhuggingface_hub.utils._errors.HfHubHTTPError: 500 Server Error: Internal Server Error for url: https://huggingface.co/da\r\ntasets/sanchit-gandhi/concatenated-train-set-label-length-256/resolve/91e6a0cd0356605b021384ded813cfcf356a221c/train/tra\r\nin-02618-of-04012.parquet (Request ID: Root=1-65b18b81-627f2c2943bbb8ab68d19ee2;129537bd-1934-4257-a4d8-1cb774f8e1f8) \r\n \r\nInternal Error - We're working hard to fix this as soon as possible! \r\n```",
"Gently pining @mariosasko and @Wauplin - when trying to stream this large dataset from the HF Hub, I'm running into `500 Internal Server Errors` as described above. I'd love to be able to use the Hub exclusively to stream data when training, but this error pops up a few times a week, terminating training runs and causing me to have to rewind to the last saved checkpoint. Do we reckon there's a way we can protect Datasets' streaming against these errors? The same reproducer as the [original comment](https://github.com/huggingface/datasets/issues/6577#issue-2074790848) can be used, but it's somewhat random whether we hit a 500 error. Leaving the full traceback below: \r\n\r\n```\r\nTraceback (most recent call last): \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/_utils/worker.py\", line 308, in _worker_loo\r\np \r\n data = fetcher.fetch(index) \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py\", line 32, in fetch \r\n data.append(next(self.dataset_iter)) \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1367, in __iter__ \r\n yield from self._iter_pytorch() \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1302, in _iter_pytorch \r\n for key, example in ex_iterable: \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 987, in __iter__ \r\n for x in self.ex_iterable: \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 867, in __iter__ \r\n yield from self._iter() \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 904, in _iter \r\n for key, example in iterator: \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 679, in __iter__ \r\n yield from self._iter() \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 741, in _iter [235/1892]\r\n for key, example in iterator: \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1119, in __iter__ \r\n for key, example in self.ex_iterable: \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 282, in __iter__ \r\n for key, pa_table in self.generate_tables_fn(**self.kwargs): \r\n File \"/home/sanchitgandhi/datasets/src/datasets/packaged_modules/parquet/parquet.py\", line 87, in _generate_tables \r\n for batch_idx, record_batch in enumerate( \r\n File \"pyarrow/_parquet.pyx\", line 1587, in iter_batches \r\n File \"pyarrow/types.pxi\", line 88, in pyarrow.lib._datatype_to_pep3118 \r\n File \"/home/sanchitgandhi/datasets/src/datasets/download/streaming_download_manager.py\", line 342, in read_with_retrie\r\ns \r\n out = read(*args, **kwargs) \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/spec.py\", line 1856, in read \r\n out = self.cache._fetch(self.loc, self.loc + length) \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/caching.py\", line 189, in _fetch \r\n self.cache = self.fetcher(start, end) # new block replaces old \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/huggingface_hub/hf_file_system.py\", line 629, in _fetch_rang\r\ne \r\n hf_raise_for_status(r) \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py\", line 362, in hf_raise_for\r\n_status \r\n raise HfHubHTTPError(str(e), response=response) from e \r\nhuggingface_hub.utils._errors.HfHubHTTPError: 500 Server Error: Internal Server Error for url: https://huggingface.co/da\r\ntasets/sanchit-gandhi/concatenated-train-set-label-length-256-conditioned/resolve/3c3c0cce51df9f9d2e75968bb2a1851894f504\r\n0d/train/train-03515-of-04010.parquet (Request ID: Root=1-65c7c4c4-153fe71401558c8c2d272c8a;fec3ec68-4a0a-4bfd-95ba-b0a0\r\n5684d612) \r\n \r\nInternal Error - We're working hard to fix this as soon as possible! ",
"@sanchit-gandhi thanks for the feedback. I've opened https://github.com/huggingface/huggingface_hub/pull/2026 to make the download process more robust. I believe that you've witness this problem on Saturday due to the Hub outage. Hope the PR will make your life easier though :)",
"Awesome, thanks @Wauplin! Makes sense re the Hub outage"
] |
502 Server Errors when streaming large dataset
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6577/reactions"
}
|
I_kwDODunzps57qsvA
| null |
2024-01-10T16:59:36Z
|
https://api.github.com/repos/huggingface/datasets/issues/6577/comments
|
### Describe the bug
When streaming a [large ASR dataset](https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set) from the Hug (~3TB) I often encounter 502 Server Errors seemingly randomly during streaming:
```
huggingface_hub.utils._errors.HfHubHTTPError: 502 Server Error: Bad Gateway for url: https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set/resolve/7d2acc5c59de848e456e951a76e805304d6fb350/train/train-00288-of-07135.parquet
```
This is despite the parquet file definitely existing on the Hub: https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set/blob/main/train/train-00228-of-07135.parquet
And having the correct commit id: [7d2acc5c59de848e456e951a76e805304d6fb350](https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set/commits/main/train)
I’m wondering whether this is coming from datasets? Or from the Hub side?
### Steps to reproduce the bug
Reproducer:
```python
from datasets import load_dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
NUM_EPOCHS = 20
dataset = load_dataset("sanchit-gandhi/concatenated-train-set", "train", streaming=True)
dataset = dataset.with_format("torch")
dataloader = DataLoader(dataset["train"], batch_size=256, drop_last=True, pin_memory=True, num_workers=16)
for epoch in tqdm(range(NUM_EPOCHS), desc="Epoch", position=0):
for batch in tqdm(dataloader, desc="Batch", position=1):
continue
```
Running the above script tends to fail within about 2 hours with a traceback like the following:
<details>
<summary> Traceback: </summary>
```python
1029 for batch in train_loader:
1030 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 630, in __next__
1031 data = self._next_data()
1032 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1325, in _next_data
1033 return self._process_data(data)
1034 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1371, in _process_data
1035 data.reraise()
1036 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/_utils.py", line 694, in reraise
1037 raise exception
1038 huggingface_hub.utils._errors.HfHubHTTPError: Caught HfHubHTTPError in DataLoader worker process 10.
1039 Original Traceback (most recent call last):
1040 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/huggingface_hub/utils/_errors.py", line 286, in hf_raise_for_status
1041 response.raise_for_status()
1042 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/requests/models.py", line 1021, in raise_for_status
1043 raise HTTPError(http_error_msg, response=self)
1044 requests.exceptions.HTTPError: 502 Server Error: Bad Gateway for url: https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set/resolve/7d2acc5c59de848e456e951a76e805304d6fb350/train/train-00288-of-07135.parquet
1045 The above exception was the direct cause of the following exception:
1046 Traceback (most recent call last):
1047 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/_utils/worker.py", line 308, in _worker_loop
1048 data = fetcher.fetch(index)
1049 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 32, in fetch
1050 data.append(next(self.dataset_iter))
1051 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 1363, in __iter__
1052 yield from self._iter_pytorch()
1053 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 1298, in _iter_pytorch
1054 for key, example in ex_iterable:
1055 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 983, in __iter__
1056 for x in self.ex_iterable:
1057 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 863, in __iter__
1058 yield from self._iter()
1059 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 900, in _iter
1060 for key, example in iterator:
1061 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 679, in __iter__
1062 yield from self._iter()
1063 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 741, in _iter
1064 for key, example in iterator:
1065 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 863, in __iter__
1066 yield from self._iter()
1067 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 900, in _iter
1068 for key, example in iterator:
1069 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 1115, in __iter__
1070 for key, example in self.ex_iterable:
1071 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 679, in __iter__
1072 yield from self._iter()
1073 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 741, in _iter
1074 for key, example in iterator:
1075 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 1115, in __iter__
1076 for key, example in self.ex_iterable:
1077 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 282, in __iter__
1078 for key, pa_table in self.generate_tables_fn(**self.kwargs):
1079 File "/home/sanchitgandhi/datasets/src/datasets/packaged_modules/parquet/parquet.py", line 87, in _generate_tables
1080 for batch_idx, record_batch in enumerate(
1081 File "pyarrow/_parquet.pyx", line 1367, in iter_batches
1082 File "pyarrow/types.pxi", line 88, in pyarrow.lib._datatype_to_pep3118
1083 File "/home/sanchitgandhi/datasets/src/datasets/download/streaming_download_manager.py", line 341, in read_with_retries
1084 out = read(*args, **kwargs)
1085 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/fsspec/spec.py", line 1856, in read
1086 out = self.cache._fetch(self.loc, self.loc + length)
1087 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/fsspec/caching.py", line 189, in _fetch
1088 self.cache = self.fetcher(start, end) # new block replaces old
1089 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/huggingface_hub/hf_file_system.py", line 626, in _fetch_range
1090 hf_raise_for_status(r)
1091 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/huggingface_hub/utils/_errors.py", line 333, in hf_raise_for_status
1092 raise HfHubHTTPError(str(e), response=response) from e
1093 huggingface_hub.utils._errors.HfHubHTTPError: 502 Server Error: Bad Gateway for url: https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set/resolve/7d2acc5c59de848e456e951a76e805304d6fb350/train/train-00288-of-07135.parquet
```
</details>
### Expected behavior
Should be able to stream the dataset without any 502 error.
### Environment info
- `datasets` version: 2.16.2.dev0
- Platform: Linux-5.13.0-1023-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- `huggingface_hub` version: 0.20.1
- PyArrow version: 14.0.2
- Pandas version: 2.0.3
- `fsspec` version: 2023.10.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sanchit-gandhi",
"id": 93869735,
"login": "sanchit-gandhi",
"node_id": "U_kgDOBZhWpw",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sanchit-gandhi"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6577/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6577/timeline
|
closed
| false | 6,577 | null |
2024-01-15T16:05:44Z
| null | false |
2,073,710,124 |
https://api.github.com/repos/huggingface/datasets/issues/6576
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6576/events
|
[] | null |
2024-01-17T14:01:31Z
|
[] |
https://github.com/huggingface/datasets/issues/6576
|
NONE
|
completed
| null | null |
[
"Thanks for reporting! I've opened a PR with a fix."
] |
document page 404 not found after redirection
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6576/reactions"
}
|
I_kwDODunzps57mk4s
| null |
2024-01-10T06:48:14Z
|
https://api.github.com/repos/huggingface/datasets/issues/6576/comments
|
### Describe the bug
The redirected page encountered 404 not found.
### Steps to reproduce the bug
1. In this tutorial: https://huggingface.co/learn/nlp-course/chapter5/4?fw=pt
original md: https://github.com/huggingface/course/blob/2c733c2246b8b7e0e6f19a9e5d15bb12df43b2a3/chapters/en/chapter5/4.mdx#L49
```
By default, 🤗 Datasets will decompress the files needed to load a dataset. If you want to preserve hard drive space, you can pass `DownloadConfig(delete_extracted=True)` to the `download_config` argument of `load_dataset()`. See the [documentation](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig) for more details.
```
The documentation points to `https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig`
it shows `The documentation page PACKAGE_REFERENCE/BUILDER_CLASSES.HTML doesn’t exist in v2.16.1, but exists on the main version. Click [here](https://huggingface.co/docs/datasets/main/en/package_reference/builder_classes.html) to redirect to the main version of the documentation.`
But the redirected website `https://huggingface.co/docs/datasets/main/en/package_reference/builder_classes.html` is 404 not found.
### Expected behavior
I Guess the redirected webisite should be
`https://huggingface.co/docs/datasets/main/en/package_reference/builder_classes` (without `.html`)
or `https://huggingface.co/docs/datasets/main/en/package_reference/builder_classes#datasets.DownloadConfig`.
### Environment info
Datasets main
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/39179888?v=4",
"events_url": "https://api.github.com/users/annahung31/events{/privacy}",
"followers_url": "https://api.github.com/users/annahung31/followers",
"following_url": "https://api.github.com/users/annahung31/following{/other_user}",
"gists_url": "https://api.github.com/users/annahung31/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/annahung31",
"id": 39179888,
"login": "annahung31",
"node_id": "MDQ6VXNlcjM5MTc5ODg4",
"organizations_url": "https://api.github.com/users/annahung31/orgs",
"received_events_url": "https://api.github.com/users/annahung31/received_events",
"repos_url": "https://api.github.com/users/annahung31/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/annahung31/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/annahung31/subscriptions",
"type": "User",
"url": "https://api.github.com/users/annahung31"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6576/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6576/timeline
|
closed
| false | 6,576 | null |
2024-01-17T14:01:31Z
| null | false |
2,072,617,406 |
https://api.github.com/repos/huggingface/datasets/issues/6575
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6575/events
|
[] | null |
2024-01-11T16:16:54Z
|
[] |
https://github.com/huggingface/datasets/pull/6575
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6575). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005095 / 0.011353 (-0.006257) | 0.003531 / 0.011008 (-0.007478) | 0.063634 / 0.038508 (0.025126) | 0.031187 / 0.023109 (0.008078) | 0.246375 / 0.275898 (-0.029523) | 0.261204 / 0.323480 (-0.062276) | 0.002898 / 0.007986 (-0.005088) | 0.003280 / 0.004328 (-0.001049) | 0.050739 / 0.004250 (0.046488) | 0.042905 / 0.037052 (0.005852) | 0.244506 / 0.258489 (-0.013983) | 0.269403 / 0.293841 (-0.024438) | 0.027588 / 0.128546 (-0.100959) | 0.010860 / 0.075646 (-0.064787) | 0.208332 / 0.419271 (-0.210939) | 0.035762 / 0.043533 (-0.007771) | 0.244448 / 0.255139 (-0.010691) | 0.278464 / 0.283200 (-0.004735) | 0.019839 / 0.141683 (-0.121844) | 1.145340 / 1.452155 (-0.306815) | 1.173240 / 1.492716 (-0.319476) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.090472 / 0.018006 (0.072466) | 0.300883 / 0.000490 (0.300394) | 0.000202 / 0.000200 (0.000003) | 0.000049 / 0.000054 (-0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.017884 / 0.037411 (-0.019527) | 0.060629 / 0.014526 (0.046103) | 0.073157 / 0.176557 (-0.103400) | 0.120065 / 0.737135 (-0.617070) | 0.074519 / 0.296338 (-0.221820) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.289586 / 0.215209 (0.074377) | 2.821042 / 2.077655 (0.743387) | 1.515515 / 1.504120 (0.011395) | 1.390569 / 1.541195 (-0.150625) | 1.433238 / 1.468490 (-0.035252) | 0.567357 / 4.584777 (-4.017420) | 2.345483 / 3.745712 (-1.400229) | 2.803964 / 5.269862 (-2.465898) | 1.775343 / 4.565676 (-2.790334) | 0.063186 / 0.424275 (-0.361089) | 0.005013 / 0.007607 (-0.002594) | 0.335607 / 0.226044 (0.109562) | 3.307071 / 2.268929 (1.038143) | 1.875228 / 55.444624 (-53.569396) | 1.618286 / 6.876477 (-5.258191) | 1.615963 / 2.142072 (-0.526109) | 0.642633 / 4.805227 (-4.162594) | 0.117222 / 6.500664 (-6.383443) | 0.042590 / 0.075469 (-0.032879) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.960724 / 1.841788 (-0.881064) | 11.652978 / 8.074308 (3.578670) | 10.069318 / 10.191392 (-0.122074) | 0.128161 / 0.680424 (-0.552263) | 0.014095 / 0.534201 (-0.520106) | 0.288386 / 0.579283 (-0.290897) | 0.260373 / 0.434364 (-0.173991) | 0.327443 / 0.540337 (-0.212894) | 0.419020 / 1.386936 (-0.967916) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005018 / 0.011353 (-0.006335) | 0.003503 / 0.011008 (-0.007505) | 0.049718 / 0.038508 (0.011210) | 0.029311 / 0.023109 (0.006202) | 0.271097 / 0.275898 (-0.004801) | 0.297370 / 0.323480 (-0.026110) | 0.004230 / 0.007986 (-0.003755) | 0.002741 / 0.004328 (-0.001587) | 0.049686 / 0.004250 (0.045435) | 0.044171 / 0.037052 (0.007119) | 0.274851 / 0.258489 (0.016362) | 0.309554 / 0.293841 (0.015714) | 0.029488 / 0.128546 (-0.099058) | 0.010767 / 0.075646 (-0.064880) | 0.057739 / 0.419271 (-0.361532) | 0.053319 / 0.043533 (0.009786) | 0.277739 / 0.255139 (0.022600) | 0.291341 / 0.283200 (0.008142) | 0.019587 / 0.141683 (-0.122096) | 1.113823 / 1.452155 (-0.338332) | 1.169409 / 1.492716 (-0.323307) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091889 / 0.018006 (0.073883) | 0.309162 / 0.000490 (0.308672) | 0.000222 / 0.000200 (0.000022) | 0.000055 / 0.000054 (0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022202 / 0.037411 (-0.015209) | 0.076113 / 0.014526 (0.061587) | 0.088416 / 0.176557 (-0.088141) | 0.126822 / 0.737135 (-0.610314) | 0.089540 / 0.296338 (-0.206798) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.293697 / 0.215209 (0.078487) | 2.880680 / 2.077655 (0.803026) | 1.580122 / 1.504120 (0.076002) | 1.449492 / 1.541195 (-0.091703) | 1.478900 / 1.468490 (0.010410) | 0.563402 / 4.584777 (-4.021375) | 2.408692 / 3.745712 (-1.337020) | 2.794108 / 5.269862 (-2.475754) | 1.728549 / 4.565676 (-2.837128) | 0.063152 / 0.424275 (-0.361123) | 0.004985 / 0.007607 (-0.002622) | 0.343340 / 0.226044 (0.117295) | 3.426454 / 2.268929 (1.157525) | 1.932918 / 55.444624 (-53.511706) | 1.649533 / 6.876477 (-5.226944) | 1.673416 / 2.142072 (-0.468656) | 0.640000 / 4.805227 (-4.165227) | 0.115501 / 6.500664 (-6.385163) | 0.040756 / 0.075469 (-0.034713) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.992468 / 1.841788 (-0.849319) | 12.392072 / 8.074308 (4.317764) | 11.025362 / 10.191392 (0.833970) | 0.130788 / 0.680424 (-0.549635) | 0.015647 / 0.534201 (-0.518554) | 0.285914 / 0.579283 (-0.293369) | 0.277208 / 0.434364 (-0.157156) | 0.322917 / 0.540337 (-0.217420) | 0.427308 / 1.386936 (-0.959628) |\n\n</details>\n</details>\n\n\n"
] |
[IterableDataset] Fix `drop_last_batch`in map after shuffling or sharding
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6575/reactions"
}
|
PR_kwDODunzps5jl1V6
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6575.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6575",
"merged_at": "2024-01-11T16:10:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6575.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6575"
}
|
2024-01-09T15:35:31Z
|
https://api.github.com/repos/huggingface/datasets/issues/6575/comments
|
It was not taken into account e.g. when passing to a DataLoader with num_workers>0
Fix https://github.com/huggingface/datasets/issues/6565
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6575/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6575/timeline
|
closed
| false | 6,575 | null |
2024-01-11T16:10:30Z
| null | true |
2,072,579,549 |
https://api.github.com/repos/huggingface/datasets/issues/6574
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6574/events
|
[] | null |
2024-01-09T16:11:33Z
|
[] |
https://github.com/huggingface/datasets/pull/6574
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6574). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005447 / 0.011353 (-0.005906) | 0.004030 / 0.011008 (-0.006978) | 0.063770 / 0.038508 (0.025262) | 0.032602 / 0.023109 (0.009493) | 0.247722 / 0.275898 (-0.028176) | 0.286507 / 0.323480 (-0.036973) | 0.003035 / 0.007986 (-0.004951) | 0.003638 / 0.004328 (-0.000690) | 0.048790 / 0.004250 (0.044540) | 0.045358 / 0.037052 (0.008306) | 0.256308 / 0.258489 (-0.002181) | 0.286601 / 0.293841 (-0.007239) | 0.028644 / 0.128546 (-0.099903) | 0.011149 / 0.075646 (-0.064497) | 0.209796 / 0.419271 (-0.209475) | 0.036737 / 0.043533 (-0.006796) | 0.247427 / 0.255139 (-0.007712) | 0.274564 / 0.283200 (-0.008636) | 0.019717 / 0.141683 (-0.121966) | 1.107423 / 1.452155 (-0.344732) | 1.167830 / 1.492716 (-0.324886) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095695 / 0.018006 (0.077688) | 0.305675 / 0.000490 (0.305185) | 0.000211 / 0.000200 (0.000011) | 0.000054 / 0.000054 (-0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018969 / 0.037411 (-0.018443) | 0.063764 / 0.014526 (0.049239) | 0.075831 / 0.176557 (-0.100726) | 0.125340 / 0.737135 (-0.611795) | 0.077585 / 0.296338 (-0.218753) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.280876 / 0.215209 (0.065667) | 2.748107 / 2.077655 (0.670452) | 1.452201 / 1.504120 (-0.051919) | 1.328001 / 1.541195 (-0.213194) | 1.415581 / 1.468490 (-0.052909) | 0.568228 / 4.584777 (-4.016549) | 2.410486 / 3.745712 (-1.335226) | 2.975157 / 5.269862 (-2.294704) | 1.854096 / 4.565676 (-2.711581) | 0.063275 / 0.424275 (-0.361000) | 0.005121 / 0.007607 (-0.002487) | 0.340006 / 0.226044 (0.113961) | 3.362404 / 2.268929 (1.093476) | 1.803913 / 55.444624 (-53.640711) | 1.540557 / 6.876477 (-5.335919) | 1.629240 / 2.142072 (-0.512833) | 0.653595 / 4.805227 (-4.151632) | 0.119558 / 6.500664 (-6.381107) | 0.044365 / 0.075469 (-0.031104) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.964557 / 1.841788 (-0.877231) | 12.550303 / 8.074308 (4.475995) | 10.261302 / 10.191392 (0.069910) | 0.130834 / 0.680424 (-0.549589) | 0.014458 / 0.534201 (-0.519743) | 0.294833 / 0.579283 (-0.284450) | 0.268141 / 0.434364 (-0.166223) | 0.332492 / 0.540337 (-0.207845) | 0.427835 / 1.386936 (-0.959101) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005577 / 0.011353 (-0.005776) | 0.003823 / 0.011008 (-0.007185) | 0.050815 / 0.038508 (0.012307) | 0.031197 / 0.023109 (0.008088) | 0.269869 / 0.275898 (-0.006029) | 0.294371 / 0.323480 (-0.029109) | 0.004153 / 0.007986 (-0.003833) | 0.002884 / 0.004328 (-0.001445) | 0.048985 / 0.004250 (0.044735) | 0.047824 / 0.037052 (0.010772) | 0.270062 / 0.258489 (0.011573) | 0.306354 / 0.293841 (0.012514) | 0.030614 / 0.128546 (-0.097932) | 0.011209 / 0.075646 (-0.064438) | 0.058943 / 0.419271 (-0.360329) | 0.060824 / 0.043533 (0.017291) | 0.273580 / 0.255139 (0.018441) | 0.288375 / 0.283200 (0.005175) | 0.022097 / 0.141683 (-0.119585) | 1.159109 / 1.452155 (-0.293046) | 1.201463 / 1.492716 (-0.291253) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093024 / 0.018006 (0.075018) | 0.302838 / 0.000490 (0.302348) | 0.000223 / 0.000200 (0.000023) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022991 / 0.037411 (-0.014420) | 0.081575 / 0.014526 (0.067050) | 0.090134 / 0.176557 (-0.086423) | 0.129506 / 0.737135 (-0.607629) | 0.091747 / 0.296338 (-0.204592) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.294735 / 0.215209 (0.079525) | 2.857557 / 2.077655 (0.779902) | 1.590577 / 1.504120 (0.086457) | 1.479404 / 1.541195 (-0.061790) | 1.515746 / 1.468490 (0.047256) | 0.579934 / 4.584777 (-4.004843) | 2.462790 / 3.745712 (-1.282922) | 2.944498 / 5.269862 (-2.325363) | 1.836767 / 4.565676 (-2.728909) | 0.064899 / 0.424275 (-0.359376) | 0.005232 / 0.007607 (-0.002375) | 0.349708 / 0.226044 (0.123664) | 3.424801 / 2.268929 (1.155873) | 1.945331 / 55.444624 (-53.499294) | 1.688862 / 6.876477 (-5.187615) | 1.712593 / 2.142072 (-0.429480) | 0.665894 / 4.805227 (-4.139333) | 0.121356 / 6.500664 (-6.379308) | 0.046908 / 0.075469 (-0.028561) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.983507 / 1.841788 (-0.858280) | 13.279790 / 8.074308 (5.205482) | 11.623531 / 10.191392 (1.432139) | 0.144567 / 0.680424 (-0.535857) | 0.016253 / 0.534201 (-0.517948) | 0.291842 / 0.579283 (-0.287441) | 0.278389 / 0.434364 (-0.155975) | 0.328971 / 0.540337 (-0.211366) | 0.443204 / 1.386936 (-0.943732) |\n\n</details>\n</details>\n\n\n"
] |
Fix tests based on datasets that used to have scripts
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6574/reactions"
}
|
PR_kwDODunzps5jltBC
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6574.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6574",
"merged_at": "2024-01-09T16:05:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6574.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6574"
}
|
2024-01-09T15:16:16Z
|
https://api.github.com/repos/huggingface/datasets/issues/6574/comments
|
...now that `squad` and `paws` don't have a script anymore
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6574/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6574/timeline
|
closed
| false | 6,574 | null |
2024-01-09T16:05:13Z
| null | true |
2,072,553,951 |
https://api.github.com/repos/huggingface/datasets/issues/6573
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6573/events
|
[] | null |
2024-01-11T16:17:28Z
|
[] |
https://github.com/huggingface/datasets/pull/6573
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6573). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005421 / 0.011353 (-0.005932) | 0.003915 / 0.011008 (-0.007094) | 0.065109 / 0.038508 (0.026601) | 0.031274 / 0.023109 (0.008165) | 0.248702 / 0.275898 (-0.027196) | 0.275688 / 0.323480 (-0.047792) | 0.003007 / 0.007986 (-0.004978) | 0.002942 / 0.004328 (-0.001387) | 0.050928 / 0.004250 (0.046678) | 0.043751 / 0.037052 (0.006699) | 0.263860 / 0.258489 (0.005371) | 0.291499 / 0.293841 (-0.002342) | 0.028268 / 0.128546 (-0.100278) | 0.011467 / 0.075646 (-0.064180) | 0.210531 / 0.419271 (-0.208740) | 0.036302 / 0.043533 (-0.007231) | 0.251565 / 0.255139 (-0.003574) | 0.272001 / 0.283200 (-0.011199) | 0.020370 / 0.141683 (-0.121313) | 1.175493 / 1.452155 (-0.276662) | 1.229167 / 1.492716 (-0.263550) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095713 / 0.018006 (0.077707) | 0.308912 / 0.000490 (0.308422) | 0.000231 / 0.000200 (0.000031) | 0.000057 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019080 / 0.037411 (-0.018332) | 0.062043 / 0.014526 (0.047517) | 0.075642 / 0.176557 (-0.100915) | 0.122789 / 0.737135 (-0.614347) | 0.077507 / 0.296338 (-0.218831) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.279929 / 0.215209 (0.064720) | 2.773336 / 2.077655 (0.695682) | 1.481740 / 1.504120 (-0.022379) | 1.357207 / 1.541195 (-0.183987) | 1.414314 / 1.468490 (-0.054176) | 0.573776 / 4.584777 (-4.011000) | 2.399273 / 3.745712 (-1.346439) | 2.918885 / 5.269862 (-2.350977) | 1.798867 / 4.565676 (-2.766809) | 0.064352 / 0.424275 (-0.359923) | 0.005164 / 0.007607 (-0.002443) | 0.337141 / 0.226044 (0.111097) | 3.402291 / 2.268929 (1.133362) | 1.854308 / 55.444624 (-53.590317) | 1.555789 / 6.876477 (-5.320687) | 1.625873 / 2.142072 (-0.516199) | 0.658589 / 4.805227 (-4.146638) | 0.122273 / 6.500664 (-6.378391) | 0.043910 / 0.075469 (-0.031560) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.933127 / 1.841788 (-0.908660) | 12.436657 / 8.074308 (4.362348) | 10.891750 / 10.191392 (0.700358) | 0.143236 / 0.680424 (-0.537187) | 0.014636 / 0.534201 (-0.519565) | 0.290375 / 0.579283 (-0.288908) | 0.275473 / 0.434364 (-0.158891) | 0.327007 / 0.540337 (-0.213331) | 0.425888 / 1.386936 (-0.961048) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005820 / 0.011353 (-0.005533) | 0.003684 / 0.011008 (-0.007324) | 0.050234 / 0.038508 (0.011726) | 0.030744 / 0.023109 (0.007634) | 0.279560 / 0.275898 (0.003662) | 0.305829 / 0.323480 (-0.017651) | 0.004053 / 0.007986 (-0.003933) | 0.002743 / 0.004328 (-0.001585) | 0.051087 / 0.004250 (0.046836) | 0.047601 / 0.037052 (0.010549) | 0.290441 / 0.258489 (0.031951) | 0.326719 / 0.293841 (0.032878) | 0.030245 / 0.128546 (-0.098301) | 0.011508 / 0.075646 (-0.064139) | 0.058436 / 0.419271 (-0.360835) | 0.059235 / 0.043533 (0.015702) | 0.278978 / 0.255139 (0.023839) | 0.298146 / 0.283200 (0.014946) | 0.020926 / 0.141683 (-0.120757) | 1.205608 / 1.452155 (-0.246547) | 1.224920 / 1.492716 (-0.267796) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.098384 / 0.018006 (0.080378) | 0.307975 / 0.000490 (0.307485) | 0.000233 / 0.000200 (0.000033) | 0.000054 / 0.000054 (-0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023012 / 0.037411 (-0.014399) | 0.077450 / 0.014526 (0.062924) | 0.089314 / 0.176557 (-0.087242) | 0.128610 / 0.737135 (-0.608526) | 0.091521 / 0.296338 (-0.204818) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.310620 / 0.215209 (0.095411) | 3.030374 / 2.077655 (0.952720) | 1.653468 / 1.504120 (0.149348) | 1.526860 / 1.541195 (-0.014334) | 1.605328 / 1.468490 (0.136838) | 0.585444 / 4.584777 (-3.999333) | 2.471700 / 3.745712 (-1.274012) | 2.791268 / 5.269862 (-2.478594) | 1.815965 / 4.565676 (-2.749712) | 0.064713 / 0.424275 (-0.359562) | 0.005095 / 0.007607 (-0.002512) | 0.364843 / 0.226044 (0.138799) | 3.601633 / 2.268929 (1.332705) | 2.022642 / 55.444624 (-53.421982) | 1.737164 / 6.876477 (-5.139312) | 1.923636 / 2.142072 (-0.218437) | 0.670673 / 4.805227 (-4.134554) | 0.121547 / 6.500664 (-6.379117) | 0.042880 / 0.075469 (-0.032589) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.987873 / 1.841788 (-0.853914) | 13.279323 / 8.074308 (5.205015) | 11.480806 / 10.191392 (1.289414) | 0.142118 / 0.680424 (-0.538306) | 0.016486 / 0.534201 (-0.517715) | 0.291617 / 0.579283 (-0.287667) | 0.284639 / 0.434364 (-0.149725) | 0.329596 / 0.540337 (-0.210742) | 0.430168 / 1.386936 (-0.956768) |\n\n</details>\n</details>\n\n\n"
] |
[WebDataset] Audio support and bug fixes
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6573/reactions"
}
|
PR_kwDODunzps5jlnaj
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6573.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6573",
"merged_at": "2024-01-11T16:11:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6573.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6573"
}
|
2024-01-09T15:03:04Z
|
https://api.github.com/repos/huggingface/datasets/issues/6573/comments
|
- Add audio support
- Fix an issue where user-provided features with additional fields are not taken into account
Close https://github.com/huggingface/datasets/issues/6569
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6573/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6573/timeline
|
closed
| false | 6,573 | null |
2024-01-11T16:11:04Z
| null | true |
2,072,384,281 |
https://api.github.com/repos/huggingface/datasets/issues/6572
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6572/events
|
[] | null |
2024-02-25T08:13:01Z
|
[] |
https://github.com/huggingface/datasets/pull/6572
|
NONE
| null | false | null |
[
"On closer examination, this appears to be unnecessary. "
] |
Adding option for multipart achive download
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6572/reactions"
}
|
PR_kwDODunzps5jlCO5
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6572.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6572",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6572.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6572"
}
|
2024-01-09T13:35:44Z
|
https://api.github.com/repos/huggingface/datasets/issues/6572/comments
|
Right now we can only download multiple separate archives or a single file archive, but not multipart archives, such as those produced by `tar --multi-volume`. This PR allows for downloading and extraction of archives split into multiple parts.
With the new `multi_part` field of the `DownloadConfig` set, the downloader will first retrieve all the files and attempt to concatenate them before starting extraction. This will obviously fail if files retrieved are actually multiple separate archives, so the option is set to `False` by default.
Tests and docs incoming.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/66251151?v=4",
"events_url": "https://api.github.com/users/jpodivin/events{/privacy}",
"followers_url": "https://api.github.com/users/jpodivin/followers",
"following_url": "https://api.github.com/users/jpodivin/following{/other_user}",
"gists_url": "https://api.github.com/users/jpodivin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jpodivin",
"id": 66251151,
"login": "jpodivin",
"node_id": "MDQ6VXNlcjY2MjUxMTUx",
"organizations_url": "https://api.github.com/users/jpodivin/orgs",
"received_events_url": "https://api.github.com/users/jpodivin/received_events",
"repos_url": "https://api.github.com/users/jpodivin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jpodivin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jpodivin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jpodivin"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6572/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6572/timeline
|
closed
| false | 6,572 | null |
2024-02-25T08:13:01Z
| null | true |
2,072,111,000 |
https://api.github.com/repos/huggingface/datasets/issues/6571
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6571/events
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null |
2024-01-09T10:45:17Z
|
[] |
https://github.com/huggingface/datasets/issues/6571
|
MEMBER
| null | null | null |
[] |
Make DatasetDict.column_names return a list instead of dict
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6571/reactions"
}
|
I_kwDODunzps57geeY
| null |
2024-01-09T10:45:17Z
|
https://api.github.com/repos/huggingface/datasets/issues/6571/comments
|
Currently, `DatasetDict.column_names` returns a dict, with each split name as keys and the corresponding list of column names as values.
However, by construction, all splits have the same column names.
I think it makes more sense to return a single list with the column names, which is the same for all the split keys.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6571/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6571/timeline
|
open
| false | 6,571 | null | null | null | false |
2,071,805,265 |
https://api.github.com/repos/huggingface/datasets/issues/6570
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6570/events
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | null |
2024-01-09T16:45:50Z
|
[] |
https://github.com/huggingface/datasets/issues/6570
|
MEMBER
|
completed
| null | null |
[
"Though the `build / build_main_documentation` CI job ran for 2.16.0: https://github.com/huggingface/datasets/actions/runs/7300836845/job/19896275099 🤔 ",
"Yes, I saw it. Maybe @mishig25 can give us some hint...",
"fixed https://huggingface.co/docs/datasets/v2.16.0/en/index",
"Still missing 2.16.1.",
"> Still missing 2.16.1.\r\n\r\nre-running the doc-buld job for the missing ones should fix\r\n\r\n",
"Re-running the job for the 2.16.1 release: https://github.com/huggingface/datasets/actions/runs/7365231552/job/20310278583",
"Fixed for 2.16.1: https://huggingface.co/docs/datasets/v2.16.1/en/index"
] |
No online docs for 2.16 release
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6570/reactions"
}
|
I_kwDODunzps57fT1R
| null |
2024-01-09T07:43:30Z
|
https://api.github.com/repos/huggingface/datasets/issues/6570/comments
|
We do not have the online docs for the latest minor release 2.16 (2.16.0 nor 2.16.1).
In the online docs, the latest version appearing is 2.15.0: https://huggingface.co/docs/datasets/index

|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6570/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6570/timeline
|
closed
| false | 6,570 | null |
2024-01-09T16:45:50Z
| null | false |
2,070,251,122 |
https://api.github.com/repos/huggingface/datasets/issues/6569
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6569/events
|
[] | null |
2024-01-11T16:11:06Z
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] |
https://github.com/huggingface/datasets/issues/6569
|
MEMBER
|
completed
| null | null |
[] |
WebDataset ignores features defined in YAML or passed to load_dataset
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6569/reactions"
}
|
I_kwDODunzps57ZYZy
| null |
2024-01-08T11:24:21Z
|
https://api.github.com/repos/huggingface/datasets/issues/6569/comments
|
we should not override if the features exist already
https://github.com/huggingface/datasets/blob/d26abadce0b884db32382b92422d8a6aa997d40a/src/datasets/packaged_modules/webdataset/webdataset.py#L78-L85
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6569/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6569/timeline
|
closed
| false | 6,569 | null |
2024-01-11T16:11:05Z
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
| false |
2,069,922,151 |
https://api.github.com/repos/huggingface/datasets/issues/6568
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6568/events
|
[] | null |
2024-01-13T04:53:04Z
|
[] |
https://github.com/huggingface/datasets/issues/6568
|
NONE
| null | null | null |
[
"Seems like I just used the old code which did not have `keep_in_memory=True` argument, sorry.\r\n\r\nAlthough i encountered a different problem – at 97% my python process just hung for around 11 minutes with no logs (when running dataset.map without `keep_in_memory=True` over around 3 million of dataset samples)...",
"Can you open a new issue and provide a bit more details ? What kind of map operations did you run ?",
"Hey. I will try to find some free time to describe it.\r\n\r\n(can't do it now, cause i need to reproduce it myself to be sure about everything, which requires spinning a new Azuree VM, copying a huge dataset to drive from network disk for a long time etc...)",
"@lhoestq loading dataset like this does not spawn 50 python processes:\r\n\r\n```\r\ndatasets.load_dataset(\"/preprocessed_2256k/train\", num_proc=50)\r\n```\r\n\r\nI have 64 vCPU so i hoped it could speed up the dataset loading...\r\n\r\nMy dataset onlly has images and metadata.csv with text column alongside image file path column",
"now noticed\r\n```\r\n'Setting num_proc from 50 back to 1 for the train split to disable multiprocessing as it only contains one shard\r\n```\r\n\r\nAny way to work around this?",
"@lhoestq thanks, [this helped](https://github.com/huggingface/datasets/blob/9d6d16117a30ba345b0236407975f701c5b288d4/src/datasets/arrow_dataset.py#L1053)\r\n\r\n"
] |
keep_in_memory=True does not seem to work
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6568/reactions"
}
|
I_kwDODunzps57YIFn
| null |
2024-01-08T08:03:58Z
|
https://api.github.com/repos/huggingface/datasets/issues/6568/comments
|
UPD: [Fixed](https://github.com/huggingface/datasets/issues/6568#issuecomment-1880817794) . But a new issue came up :(
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17604849?v=4",
"events_url": "https://api.github.com/users/kopyl/events{/privacy}",
"followers_url": "https://api.github.com/users/kopyl/followers",
"following_url": "https://api.github.com/users/kopyl/following{/other_user}",
"gists_url": "https://api.github.com/users/kopyl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kopyl",
"id": 17604849,
"login": "kopyl",
"node_id": "MDQ6VXNlcjE3NjA0ODQ5",
"organizations_url": "https://api.github.com/users/kopyl/orgs",
"received_events_url": "https://api.github.com/users/kopyl/received_events",
"repos_url": "https://api.github.com/users/kopyl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kopyl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kopyl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kopyl"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6568/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6568/timeline
|
open
| false | 6,568 | null | null | null | false |
2,069,808,842 |
https://api.github.com/repos/huggingface/datasets/issues/6567
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6567/events
|
[] | null |
2024-01-08T11:56:19Z
|
[] |
https://github.com/huggingface/datasets/issues/6567
|
NONE
|
completed
| null | null |
[
"I think you are reporting an issue with the `transformers` library. Note this is the repository of the `datasets` library. I recommend that you open an issue in their repository: https://github.com/huggingface/transformers/issues\r\n\r\nEDIT: I have not the rights to transfer the issue\r\n~~I am transferring your issue to their repository.~~",
"Thanks, I hope someone from transformers library addresses this issue.\r\n\r\nOn Mon, Jan 8, 2024 at 15:29 Albert Villanova del Moral <\r\n***@***.***> wrote:\r\n\r\n> I think you are reporting an issue with the transformers library. Note\r\n> this is the repository of the datasets library. I am transferring your\r\n> issue to their repository.\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/datasets/issues/6567#issuecomment-1880688586>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AE4LJNOYMD6WJMXFKPMH6DLYNO7PJAVCNFSM6AAAAABBQ63HWOVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMYTQOBQGY4DQNJYGY>\r\n> .\r\n> You are receiving this because you authored the thread.Message ID:\r\n> ***@***.***>\r\n>\r\n",
"@andysingal, I recommend that you open an issue in their repository: https://github.com/huggingface/transformers/issues\r\nI don't have the rights to transfer this issue to their repo."
] |
AttributeError: 'str' object has no attribute 'to'
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6567/reactions"
}
|
I_kwDODunzps57XsbK
| null |
2024-01-08T06:40:21Z
|
https://api.github.com/repos/huggingface/datasets/issues/6567/comments
|
### Describe the bug
```
--------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
[<ipython-input-6-80c6086794e8>](https://localhost:8080/#) in <cell line: 10>()
8 report_to="wandb")
9
---> 10 trainer = Trainer(
11 model=model,
12 args=training_args,
1 frames
[/usr/local/lib/python3.10/dist-packages/transformers/trainer.py](https://localhost:8080/#) in _move_model_to_device(self, model, device)
688
689 def _move_model_to_device(self, model, device):
--> 690 model = model.to(device)
691 # Moving a model to an XLA device disconnects the tied weights, so we have to retie them.
692 if self.args.parallel_mode == ParallelMode.TPU and hasattr(model, "tie_weights"):
AttributeError: 'str' object has no attribute 'to'
```
### Steps to reproduce the bug
here is the notebook:
```
https://colab.research.google.com/drive/10JDBNsLlYrQdnI2FWfDK3F5M8wvVUDXG?usp=sharing
```
### Expected behavior
run the Training
### Environment info
Colab Notebook , T4
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url": "https://api.github.com/users/andysingal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/andysingal",
"id": 20493493,
"login": "andysingal",
"node_id": "MDQ6VXNlcjIwNDkzNDkz",
"organizations_url": "https://api.github.com/users/andysingal/orgs",
"received_events_url": "https://api.github.com/users/andysingal/received_events",
"repos_url": "https://api.github.com/users/andysingal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/andysingal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andysingal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/andysingal"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6567/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6567/timeline
|
closed
| false | 6,567 | null |
2024-01-08T10:03:17Z
| null | false |
2,069,495,429 |
https://api.github.com/repos/huggingface/datasets/issues/6566
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6566/events
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | null |
2024-06-02T14:24:39Z
|
[] |
https://github.com/huggingface/datasets/issues/6566
|
NONE
|
completed
| null | null |
[
"I also see the same error and get passed it by casting that line to float. \r\n\r\nso `for x in obj.detach().cpu().numpy()` becomes `for x in obj.detach().to(torch.float).cpu().numpy()`\r\n\r\nI got the idea from [this ](https://github.com/kohya-ss/sd-webui-additional-networks/pull/128/files) PR where someone was facing a similar issue (in a different repository). I guess numpy doesn't support bfloat16.\r\n\r\n"
] |
I train controlnet_sdxl in bf16 datatype, got unsupported ERROR in datasets
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6566/reactions"
}
|
I_kwDODunzps57Wf6F
| null |
2024-01-08T02:37:03Z
|
https://api.github.com/repos/huggingface/datasets/issues/6566/comments
|
### Describe the bug
```
Traceback (most recent call last):
File "train_controlnet_sdxl.py", line 1252, in <module>
main(args)
File "train_controlnet_sdxl.py", line 1013, in main
train_dataset = train_dataset.map(compute_embeddings_fn, batched=True, new_fingerprint=new_fingerprint)
File "/home/miniconda3/envs/mhh_df/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 592, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home/miniconda3/envs/mhh_df/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 557, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home/miniconda3/envs/mhh_df/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 3093, in map
for rank, done, content in Dataset._map_single(**dataset_kwargs):
File "/home/miniconda3/envs/mhh_df/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 3489, in _map_single
writer.write_batch(batch)
File "/home/miniconda3/envs/mhh_df/lib/python3.8/site-packages/datasets/arrow_writer.py", line 557, in write_batch
arrays.append(pa.array(typed_sequence))
File "pyarrow/array.pxi", line 248, in pyarrow.lib.array
File "pyarrow/array.pxi", line 113, in pyarrow.lib._handle_arrow_array_protocol
File "/home/miniconda3/envs/mhh_df/lib/python3.8/site-packages/datasets/arrow_writer.py", line 191, in __arrow_array__
out = pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))
File "/home/miniconda3/envs/mhh_df/lib/python3.8/site-packages/datasets/features/features.py", line 447, in cast_to_python_objects
return _cast_to_python_objects(
File "/home/miniconda3/envs/mhh_df/lib/python3.8/site-packages/datasets/features/features.py", line 324, in _cast_to_python_objects
for x in obj.detach().cpu().numpy()
TypeError: Got unsupported ScalarType BFloat16
```
### Steps to reproduce the bug
Here is my train script I use BF16 type,I use diffusers train my model
```
export MODEL_DIR="/home/mhh/sd_models/stable-diffusion-xl-base-1.0"
export OUTPUT_DIR="./control_net"
export VAE_NAME="/home/mhh/sd_models/sdxl-vae-fp16-fix"
accelerate launch train_controlnet_sdxl.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=/home/mhh/sd_datasets/fusing/fill50k \
--mixed_precision="bf16" \
--resolution=1024 \
--learning_rate=1e-5 \
--max_train_steps=200 \
--validation_image "/home/mhh/sd_datasets/controlnet_image/conditioning_image_1.png" "/home/mhh/sd_datasets/controlnet_image/conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--validation_steps=50 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--report_to="wandb" \
--seed=42 \
```
### Expected behavior
When I changed the data type to fp16, it worked.
### Environment info
datasets 2.16.1
numpy 1.24.4
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/25008090?v=4",
"events_url": "https://api.github.com/users/HelloWorldBeginner/events{/privacy}",
"followers_url": "https://api.github.com/users/HelloWorldBeginner/followers",
"following_url": "https://api.github.com/users/HelloWorldBeginner/following{/other_user}",
"gists_url": "https://api.github.com/users/HelloWorldBeginner/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/HelloWorldBeginner",
"id": 25008090,
"login": "HelloWorldBeginner",
"node_id": "MDQ6VXNlcjI1MDA4MDkw",
"organizations_url": "https://api.github.com/users/HelloWorldBeginner/orgs",
"received_events_url": "https://api.github.com/users/HelloWorldBeginner/received_events",
"repos_url": "https://api.github.com/users/HelloWorldBeginner/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/HelloWorldBeginner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HelloWorldBeginner/subscriptions",
"type": "User",
"url": "https://api.github.com/users/HelloWorldBeginner"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6566/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6566/timeline
|
closed
| false | 6,566 | null |
2024-05-17T09:40:14Z
| null | false |
2,068,939,670 |
https://api.github.com/repos/huggingface/datasets/issues/6565
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6565/events
|
[] | null |
2024-01-11T16:10:31Z
|
[] |
https://github.com/huggingface/datasets/issues/6565
|
NONE
|
completed
| null | null |
[
"My current workaround this issue is to return `None` in the second element and then filter out samples which have `None` in them.\r\n\r\n```python\r\ndef merge_samples(batch):\r\n if len(batch['a']) == 1:\r\n batch['c'] = [batch['a'][0]]\r\n batch['d'] = [None]\r\n else:\r\n batch['c'] = [batch['a'][0]]\r\n batch['d'] = [batch['a'][1]]\r\n return batch\r\n \r\ndef filter_fn(x):\r\n return x['d'] is not None\r\n\r\n# other code...\r\nmapped = mapped.filter(filter_fn)\r\n```"
] |
`drop_last_batch=True` for IterableDataset map function is ignored with multiprocessing DataLoader
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6565/reactions"
}
|
I_kwDODunzps57UYOW
| null |
2024-01-07T02:46:50Z
|
https://api.github.com/repos/huggingface/datasets/issues/6565/comments
|
### Describe the bug
Scenario:
- Interleaving two iterable datasets of unequal lengths (`all_exhausted`), followed by a batch mapping with batch size 2 to effectively merge the two datasets and get a sample from each dataset in a single batch, with `drop_last_batch=True` to skip the last batch in case it doesn't have two samples.
What works:
- Using DataLoader with `num_workers=0`
What does not work:
- Using DataLoader with `num_workers=1`, errors in the last batch.
Basically, `drop_last_batch=True` is ignored when using multiple dataloading workers.
Please take a look at the minimal repro script below.
### Steps to reproduce the bug
```python
from datasets import Dataset, interleave_datasets
from torch.utils.data import DataLoader
def merge_samples(batch):
assert len(batch['a']) == 2, "Batch size must be 2"
batch['c'] = [batch['a'][0]]
batch['d'] = [batch['a'][1]]
return batch
def gen1():
for ii in range(1, 8385):
yield {"a": ii}
def gen2():
for ii in range(1, 5302):
yield {"a": ii}
if __name__ == '__main__':
dataset1 = Dataset.from_generator(gen1).to_iterable_dataset(num_shards=1024)
dataset2 = Dataset.from_generator(gen2).to_iterable_dataset(num_shards=1024)
interleaved = interleave_datasets([dataset1, dataset2], stopping_strategy="all_exhausted")
mapped = interleaved.map(merge_samples, batched=True, batch_size=2, remove_columns=interleaved.column_names,
drop_last_batch=True)
# Works
loader = DataLoader(mapped, batch_size=32, num_workers=0)
i = 0
for b in loader:
print(i, b['c'].shape, b['d'].shape)
i += 1
print("DataLoader with num_workers=0 works")
# Doesn't work
loader = DataLoader(mapped, batch_size=32, num_workers=1)
i = 0
for b in loader:
print(i, b['c'].shape, b['d'].shape)
i += 1
```
### Expected behavior
`drop_last_batch=True` should have same behaviour for `num_workers=0` and `num_workers>=1`
### Environment info
- `datasets` version: 2.16.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.10.12
- `huggingface_hub` version: 0.20.2
- PyArrow version: 12.0.1
- Pandas version: 2.0.3
- `fsspec` version: 2023.6.0
I have also tested on Linux and got the same behavior.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12119806?v=4",
"events_url": "https://api.github.com/users/naba89/events{/privacy}",
"followers_url": "https://api.github.com/users/naba89/followers",
"following_url": "https://api.github.com/users/naba89/following{/other_user}",
"gists_url": "https://api.github.com/users/naba89/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/naba89",
"id": 12119806,
"login": "naba89",
"node_id": "MDQ6VXNlcjEyMTE5ODA2",
"organizations_url": "https://api.github.com/users/naba89/orgs",
"received_events_url": "https://api.github.com/users/naba89/received_events",
"repos_url": "https://api.github.com/users/naba89/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/naba89/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/naba89/subscriptions",
"type": "User",
"url": "https://api.github.com/users/naba89"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6565/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6565/timeline
|
closed
| false | 6,565 | null |
2024-01-11T16:10:31Z
| null | false |
2,068,893,194 |
https://api.github.com/repos/huggingface/datasets/issues/6564
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6564/events
|
[] | null |
2024-01-29T16:36:55Z
|
[] |
https://github.com/huggingface/datasets/issues/6564
|
NONE
|
completed
| null | null |
[
"Thanks for reporting! I've opened a PR with a fix",
"@mariosasko thank you very much :)"
] |
`Dataset.filter` missing `with_rank` parameter
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6564/reactions"
}
|
I_kwDODunzps57UM4K
| null |
2024-01-06T23:48:13Z
|
https://api.github.com/repos/huggingface/datasets/issues/6564/comments
|
### Describe the bug
The issue shall be open: https://github.com/huggingface/datasets/issues/6435
When i try to pass `with_rank` to `Dataset.filter()`, i get this:
`Dataset.filter() got an unexpected keyword argument 'with_rank'`
### Steps to reproduce the bug
Run notebook:
https://colab.research.google.com/drive/1WUNKph8BdP0on5ve3gQnh_PE0cFLQqTn?usp=sharing
### Expected behavior
Should work?
### Environment info
NVIDIA RTX 4090
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17604849?v=4",
"events_url": "https://api.github.com/users/kopyl/events{/privacy}",
"followers_url": "https://api.github.com/users/kopyl/followers",
"following_url": "https://api.github.com/users/kopyl/following{/other_user}",
"gists_url": "https://api.github.com/users/kopyl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kopyl",
"id": 17604849,
"login": "kopyl",
"node_id": "MDQ6VXNlcjE3NjA0ODQ5",
"organizations_url": "https://api.github.com/users/kopyl/orgs",
"received_events_url": "https://api.github.com/users/kopyl/received_events",
"repos_url": "https://api.github.com/users/kopyl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kopyl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kopyl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kopyl"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6564/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6564/timeline
|
closed
| false | 6,564 | null |
2024-01-29T16:36:54Z
| null | false |
2,068,302,402 |
https://api.github.com/repos/huggingface/datasets/issues/6563
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6563/events
|
[] | null |
2024-03-14T02:59:42Z
|
[] |
https://github.com/huggingface/datasets/issues/6563
|
NONE
|
completed
| null | null |
[
"@Wauplin Do you happen to know what's up?",
"<del>Installing `datasets` from `main` did the trick so I guess it will be fixed in the next release.\r\n\r\nNVM https://github.com/huggingface/datasets/blob/d26abadce0b884db32382b92422d8a6aa997d40a/src/datasets/utils/info_utils.py#L5",
"@wasertech upgrading `huggingface_hub` to a newer version should fix your issue. Latest version is 0.20.2. ",
"Ha yes I had pinned `tokenizers` to an old version so it downgraded `huggingface_hub`. Note to myself keep HuggingFace modules relatively close together chronologically release wise.",
"Glad to know your problem's solved! ",
"@Wauplin Thanks for your insight 👍",
"pip install --upgrade huggingface-hub"
] |
`ImportError`: cannot import name 'insecure_hashlib' from 'huggingface_hub.utils' (.../huggingface_hub/utils/__init__.py)
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6563/reactions"
}
|
I_kwDODunzps57R8pC
| null |
2024-01-06T02:28:54Z
|
https://api.github.com/repos/huggingface/datasets/issues/6563/comments
|
### Describe the bug
Yep its not [there](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/utils/__init__.py) anymore.
```text
+ python /home/trainer/sft_train.py --model_name cognitivecomputations/dolphin-2.2.1-mistral-7b --dataset_name wasertech/OneOS --load_in_4bit --use_peft --batch_size 4 --num_train_epochs 1 --learning_rate 1.41e-5 --gradient_accumulation_steps 8 --seq_length 4096 --output_dir output --log_with wandb
Traceback (most recent call last):
File "/home/trainer/sft_train.py", line 22, in <module>
from datasets import load_dataset
File "/home/trainer/llm-train/lib/python3.8/site-packages/datasets/__init__.py", line 22, in <module>
from .arrow_dataset import Dataset
File "/home/trainer/llm-train/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 66, in <module>
from .arrow_reader import ArrowReader
File "/home/trainer/llm-train/lib/python3.8/site-packages/datasets/arrow_reader.py", line 30, in <module>
from .download.download_config import DownloadConfig
File "/home/trainer/llm-train/lib/python3.8/site-packages/datasets/download/__init__.py", line 9, in <module>
from .download_manager import DownloadManager, DownloadMode
File "/home/trainer/llm-train/lib/python3.8/site-packages/datasets/download/download_manager.py", line 31, in <module>
from ..utils import tqdm as hf_tqdm
File "/home/trainer/llm-train/lib/python3.8/site-packages/datasets/utils/__init__.py", line 19, in <module>
from .info_utils import VerificationMode
File "/home/trainer/llm-train/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 5, in <module>
from huggingface_hub.utils import insecure_hashlib
ImportError: cannot import name 'insecure_hashlib' from 'huggingface_hub.utils' (/home/trainer/llm-train/lib/python3.8/site-packages/huggingface_hub/utils/__init__.py)
```
### Steps to reproduce the bug
Using `datasets==2.16.1` and `huggingface_hub== 0.17.3`, load a dataset with `load_dataset`.
### Expected behavior
The dataset should be (downloaded - if needed - and) returned.
### Environment info
```text
trainer@a311ae86939e:/mnt$ pip show datasets
Name: datasets
Version: 2.16.1
Summary: HuggingFace community-driven open-source library of datasets
Home-page: https://github.com/huggingface/datasets
Author: HuggingFace Inc.
Author-email: thomas@huggingface.co
License: Apache 2.0
Location: /home/trainer/llm-train/lib/python3.8/site-packages
Requires: packaging, pyyaml, multiprocess, pyarrow-hotfix, pandas, pyarrow, xxhash, dill, numpy, aiohttp, tqdm, fsspec, requests, filelock, huggingface-hub
Required-by: trl, lm-eval, evaluate
trainer@a311ae86939e:/mnt$ pip show huggingface_hub
Name: huggingface-hub
Version: 0.17.3
Summary: Client library to download and publish models, datasets and other repos on the huggingface.co hub
Home-page: https://github.com/huggingface/huggingface_hub
Author: Hugging Face, Inc.
Author-email: julien@huggingface.co
License: Apache
Location: /home/trainer/llm-train/lib/python3.8/site-packages
Requires: requests, pyyaml, packaging, typing-extensions, tqdm, filelock, fsspec
Required-by: transformers, tokenizers, peft, evaluate, datasets, accelerate
trainer@a311ae86939e:/mnt$ huggingface-cli env
Copy-and-paste the text below in your GitHub issue.
- huggingface_hub version: 0.17.3
- Platform: Linux-6.5.13-7-MANJARO-x86_64-with-glibc2.29
- Python version: 3.8.10
- Running in iPython ?: No
- Running in notebook ?: No
- Running in Google Colab ?: No
- Token path ?: /home/trainer/.cache/huggingface/token
- Has saved token ?: True
- Who am I ?: wasertech
- Configured git credential helpers:
- FastAI: N/A
- Tensorflow: N/A
- Torch: 2.1.2
- Jinja2: 3.1.2
- Graphviz: N/A
- Pydot: N/A
- Pillow: 10.2.0
- hf_transfer: N/A
- gradio: N/A
- tensorboard: N/A
- numpy: 1.24.4
- pydantic: N/A
- aiohttp: 3.9.1
- ENDPOINT: https://huggingface.co
- HUGGINGFACE_HUB_CACHE: /home/trainer/.cache/huggingface/hub
- HUGGINGFACE_ASSETS_CACHE: /home/trainer/.cache/huggingface/assets
- HF_TOKEN_PATH: /home/trainer/.cache/huggingface/token
- HF_HUB_OFFLINE: False
- HF_HUB_DISABLE_TELEMETRY: False
- HF_HUB_DISABLE_PROGRESS_BARS: None
- HF_HUB_DISABLE_SYMLINKS_WARNING: False
- HF_HUB_DISABLE_EXPERIMENTAL_WARNING: False
- HF_HUB_DISABLE_IMPLICIT_TOKEN: False
- HF_HUB_ENABLE_HF_TRANSFER: False
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79070834?v=4",
"events_url": "https://api.github.com/users/wasertech/events{/privacy}",
"followers_url": "https://api.github.com/users/wasertech/followers",
"following_url": "https://api.github.com/users/wasertech/following{/other_user}",
"gists_url": "https://api.github.com/users/wasertech/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wasertech",
"id": 79070834,
"login": "wasertech",
"node_id": "MDQ6VXNlcjc5MDcwODM0",
"organizations_url": "https://api.github.com/users/wasertech/orgs",
"received_events_url": "https://api.github.com/users/wasertech/received_events",
"repos_url": "https://api.github.com/users/wasertech/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wasertech/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wasertech/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wasertech"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6563/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6563/timeline
|
closed
| false | 6,563 | null |
2024-01-06T16:13:27Z
| null | false |
2,067,904,504 |
https://api.github.com/repos/huggingface/datasets/issues/6562
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6562/events
|
[] | null |
2024-01-05T19:10:25Z
|
[] |
https://github.com/huggingface/datasets/issues/6562
|
NONE
| null | null | null |
[] |
datasets.DownloadMode.FORCE_REDOWNLOAD use cache to download dataset features with load_dataset function
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6562/reactions"
}
|
I_kwDODunzps57Qbf4
| null |
2024-01-05T19:10:25Z
|
https://api.github.com/repos/huggingface/datasets/issues/6562/comments
|
### Describe the bug
I have updated my dataset by adding a new feature, and push it to the hub. When I want to download it on my machine which contain the old version by using `datasets.load_dataset("your_dataset_name", download_mode=datasets.DownloadMode.FORCE_REDOWNLOAD)` I get an error (paste bellow).
Seems that the load_dataset function still use the old features schema instead of downloading everything new from the HUB.
I find a way to go around this issue by manually deleting the old dataset cache. But from my understanding of `datasets.DownloadMode.FORCE_REDOWNLOAD` option, the dataset cache should be ignored.
### Steps to reproduce the bug
1. Download your dataset in your machine using `datasets.load_dataset`
2. Create a new feature in your dataset and push it to the hub
3. On the same machine redownload your dataset using `datasets.load_dataset("your_dataset_name", download_mode=datasets.DownloadMode.FORCE_REDOWNLOAD)`
### Expected behavior
`
ValueError: Couldn't cast
id: string
level: string
context: list<element: string>
child 0, element: string
type: string
answer: string
question: string
supporting_facts: list<element: string>
child 0, element: string
fra_answer: string
fra_question: string
-- schema metadata --
huggingface: '{"info": {"features": {"id": {"dtype": "string", "_type": "' + 490
to
{'id': Value(dtype='string', id=None), 'level': Value(dtype='string', id=None), 'context': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), 'type': Value(dtype='string', id=None), 'answer': Value(dtype='string', id=None), 'question': Value(dtype='string', id=None), 'supporting_facts': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)}
because column names don't match
The above exception was the direct cause of the following exception:
DatasetGenerationError
...
DatasetGenerationError: An error occurred while generating the dataset`
### Environment info
datasets-2.16.1 huggingface-hub-0.20.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/73234162?v=4",
"events_url": "https://api.github.com/users/LsTam91/events{/privacy}",
"followers_url": "https://api.github.com/users/LsTam91/followers",
"following_url": "https://api.github.com/users/LsTam91/following{/other_user}",
"gists_url": "https://api.github.com/users/LsTam91/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LsTam91",
"id": 73234162,
"login": "LsTam91",
"node_id": "MDQ6VXNlcjczMjM0MTYy",
"organizations_url": "https://api.github.com/users/LsTam91/orgs",
"received_events_url": "https://api.github.com/users/LsTam91/received_events",
"repos_url": "https://api.github.com/users/LsTam91/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LsTam91/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LsTam91/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LsTam91"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6562/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6562/timeline
|
open
| false | 6,562 | null | null | null | false |
2,067,404,951 |
https://api.github.com/repos/huggingface/datasets/issues/6561
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6561/events
|
[
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | null |
2024-01-05T14:06:18Z
|
[] |
https://github.com/huggingface/datasets/issues/6561
|
CONTRIBUTOR
| null | null | null |
[
"In particular, I would like to have an example of how to replace the following configuration (from https://huggingface.co/docs/hub/datasets-manual-configuration#splits)\r\n\r\n```\r\n---\r\nconfigs:\r\n- config_name: default\r\n data_files:\r\n - split: train\r\n path: \"data/*.csv\"\r\n - split: test\r\n path: \"holdout/*.csv\"\r\n---\r\n```\r\n\r\nwith the `data_dir` field."
] |
Document YAML configuration with "data_dir"
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6561/reactions"
}
|
I_kwDODunzps57OhiX
| null |
2024-01-05T14:03:33Z
|
https://api.github.com/repos/huggingface/datasets/issues/6561/comments
|
See https://huggingface.co/datasets/uonlp/CulturaX/discussions/15#6597e83f185db94370d6bf50 for reference
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6561/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6561/timeline
|
open
| false | 6,561 | null | null | null | false |
2,065,637,625 |
https://api.github.com/repos/huggingface/datasets/issues/6560
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6560/events
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null |
2024-01-04T13:10:58Z
|
[] |
https://github.com/huggingface/datasets/issues/6560
|
NONE
| null | null | null |
[] |
Support Video
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6560/reactions"
}
|
I_kwDODunzps57HyD5
| null |
2024-01-04T13:10:58Z
|
https://api.github.com/repos/huggingface/datasets/issues/6560/comments
|
### Feature request
HF datasets are awesome in supporting text and images. Will be great to see such a support in videos :)
### Motivation
Video generation :)
### Your contribution
Will probably be limited to raising this feature request ;)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"gists_url": "https://api.github.com/users/yuvalkirstain/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yuvalkirstain",
"id": 57996478,
"login": "yuvalkirstain",
"node_id": "MDQ6VXNlcjU3OTk2NDc4",
"organizations_url": "https://api.github.com/users/yuvalkirstain/orgs",
"received_events_url": "https://api.github.com/users/yuvalkirstain/received_events",
"repos_url": "https://api.github.com/users/yuvalkirstain/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yuvalkirstain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuvalkirstain/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yuvalkirstain"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6560/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6560/timeline
|
open
| false | 6,560 | null | null | null | false |
2,065,118,332 |
https://api.github.com/repos/huggingface/datasets/issues/6559
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6559/events
|
[] | null |
2024-04-03T10:40:53Z
|
[] |
https://github.com/huggingface/datasets/issues/6559
|
NONE
|
completed
| null | null |
[
"Hi ! The \"allenai--c4\" config doesn't exist (this naming schema comes from old versions of `datasets`)\r\n\r\nYou can load it this way instead:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\ncache_dir = 'path/to/your/cache/directory'\r\ndataset = load_dataset('allenai/c4', data_files={'train': 'en/c4-train.00000-of-01024.json.gz'}, split='train', cache_dir=cache_dir)\r\n```",
"> Hi ! The \"allenai--c4\" config doesn't exist (this naming schema comes from old versions of `datasets`)\r\n> \r\n> You can load it this way instead:\r\n> \r\n> ```python\r\n> from datasets import load_dataset\r\n> cache_dir = 'path/to/your/cache/directory'\r\n> dataset = load_dataset('allenai/c4', data_files={'train': 'en/c4-train.00000-of-01024.json.gz'}, split='train', cache_dir=cache_dir)\r\n> ```\r\n\r\nthanks, the command run successfully in the latest version\r\n",
"> Hi ! The \"allenai--c4\" config doesn't exist (this naming schema comes from old versions of `datasets`)\r\n> \r\n> You can load it this way instead:\r\n> \r\n> ```python\r\n> from datasets import load_dataset\r\n> cache_dir = 'path/to/your/cache/directory'\r\n> dataset = load_dataset('allenai/c4', data_files={'train': 'en/c4-train.00000-of-01024.json.gz'}, split='train', cache_dir=cache_dir)\r\n> ```\r\n\r\n@lhoestq \r\nIn this case, should we traverse through al 1024 json files to load the whole dataset?\r\nThanks!",
"It will only load the first file (`data_files={'train': 'en/c4-train.00000-of-01024.json.gz'}` only mentions one file)",
"> It will only load the first file (`data_files={'train': 'en/c4-train.00000-of-01024.json.gz'}` only mentions one file)\r\n\r\nThen what if we want to load the whole dataset?",
"There is a \"en\" subset that you can load (see the list in the \"subset\" dropdown at https://huggingface.co/datasets/allenai/c4)\r\n\r\n```python\r\ndataset = load_dataset('allenai/c4', 'en', split=\"train\")\r\n```\r\n\r\nalternatively you can specify all the the files yourself using a glob pattern (or a list):\r\n\r\n```python\r\ndataset = load_dataset('allenai/c4', data_files='en/c4-train.00000-of-*.json.gz', split=\"train\")\r\n```",
"> There is a \"en\" subset that you can load (see the list in the \"subset\" dropdown at https://huggingface.co/datasets/allenai/c4)\r\n> \r\n> ```python\r\n> dataset = load_dataset('allenai/c4', 'en', split=\"train\")\r\n> ```\r\n> \r\n> alternatively you can specify all the the files yourself using a glob pattern (or a list):\r\n> \r\n> ```python\r\n> dataset = load_dataset('allenai/c4', data_files='en/c4-train.00000-of-*.json.gz', split=\"train\")\r\n> ```\r\n\r\nThanks, the second solution works. The first line simply fails due to missing schema specific to this dataset.",
"The latest version of `datasets` seems to have broken my dataset for my users (see this Hugging Face issue: https://huggingface.co/datasets/umarbutler/open-australian-legal-corpus/discussions/3). I changed it by renaming my dataset's config to `default` instead of `train` and then updating my dataset card accordingly."
] |
Latest version 2.16.1, when load dataset error occurs. ValueError: BuilderConfig 'allenai--c4' not found. Available: ['default']
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6559/reactions"
}
|
I_kwDODunzps57FzR8
| null |
2024-01-04T07:04:48Z
|
https://api.github.com/repos/huggingface/datasets/issues/6559/comments
|
### Describe the bug
python script is:
```
from datasets import load_dataset
cache_dir = 'path/to/your/cache/directory'
dataset = load_dataset('allenai/c4','allenai--c4', data_files={'train': 'en/c4-train.00000-of-01024.json.gz'}, split='train', use_auth_token=False, cache_dir=cache_dir)
```
the script success when datasets version is 2.14.7.
when using 2.16.1, error occurs
`
ValueError: BuilderConfig 'allenai--c4' not found. Available: ['default']`
### Steps to reproduce the bug
1. pip install datasets==2.16.1
2. run python script:
```
from datasets import load_dataset
cache_dir = 'path/to/your/cache/directory'
dataset = load_dataset('allenai/c4','allenai--c4', data_files={'train': 'en/c4-train.00000-of-01024.json.gz'}, split='train', use_auth_token=False, cache_dir=cache_dir)
```
### Expected behavior
the dataset should be loaded successful in the latest version.
### Environment info
datasets 2.16.1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/145004780?v=4",
"events_url": "https://api.github.com/users/zhulinJulia24/events{/privacy}",
"followers_url": "https://api.github.com/users/zhulinJulia24/followers",
"following_url": "https://api.github.com/users/zhulinJulia24/following{/other_user}",
"gists_url": "https://api.github.com/users/zhulinJulia24/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zhulinJulia24",
"id": 145004780,
"login": "zhulinJulia24",
"node_id": "U_kgDOCKSY7A",
"organizations_url": "https://api.github.com/users/zhulinJulia24/orgs",
"received_events_url": "https://api.github.com/users/zhulinJulia24/received_events",
"repos_url": "https://api.github.com/users/zhulinJulia24/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zhulinJulia24/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhulinJulia24/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zhulinJulia24"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6559/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6559/timeline
|
closed
| false | 6,559 | null |
2024-01-05T01:26:25Z
| null | false |
2,064,885,984 |
https://api.github.com/repos/huggingface/datasets/issues/6558
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6558/events
|
[] | null |
2024-02-21T00:38:12Z
|
[] |
https://github.com/huggingface/datasets/issues/6558
|
NONE
|
completed
| null | null |
[
"You can add \r\n\r\n```python\r\nfrom PIL import ImageFile\r\nImageFile.LOAD_TRUNCATED_IMAGES = True\r\n```\r\n\r\nafter the imports to be able to read truncated images."
] |
OSError: image file is truncated (1 bytes not processed) #28323
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6558/reactions"
}
|
I_kwDODunzps57E6jg
| null |
2024-01-04T02:15:13Z
|
https://api.github.com/repos/huggingface/datasets/issues/6558/comments
|
### Describe the bug
```
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
Cell In[24], line 28
23 return example
25 # Filter the dataset
26 # filtered_dataset = dataset.filter(contains_number)
27 # Add the 'label' field in the dataset
---> 28 labeled_dataset = dataset.filter(contains_number).map(add_label)
29 # View the structure of the updated dataset
30 print(labeled_dataset)
File /usr/local/lib/python3.10/dist-packages/datasets/dataset_dict.py:975, in DatasetDict.filter(self, function, with_indices, input_columns, batched, batch_size, keep_in_memory, load_from_cache_file, cache_file_names, writer_batch_size, fn_kwargs, num_proc, desc)
972 if cache_file_names is None:
973 cache_file_names = {k: None for k in self}
974 return DatasetDict(
--> 975 {
976 k: dataset.filter(
977 function=function,
978 with_indices=with_indices,
979 input_columns=input_columns,
980 batched=batched,
981 batch_size=batch_size,
982 keep_in_memory=keep_in_memory,
983 load_from_cache_file=load_from_cache_file,
984 cache_file_name=cache_file_names[k],
985 writer_batch_size=writer_batch_size,
986 fn_kwargs=fn_kwargs,
987 num_proc=num_proc,
988 desc=desc,
989 )
990 for k, dataset in self.items()
991 }
992 )
File /usr/local/lib/python3.10/dist-packages/datasets/dataset_dict.py:976, in <dictcomp>(.0)
972 if cache_file_names is None:
973 cache_file_names = {k: None for k in self}
974 return DatasetDict(
975 {
--> 976 k: dataset.filter(
977 function=function,
978 with_indices=with_indices,
979 input_columns=input_columns,
980 batched=batched,
981 batch_size=batch_size,
982 keep_in_memory=keep_in_memory,
983 load_from_cache_file=load_from_cache_file,
984 cache_file_name=cache_file_names[k],
985 writer_batch_size=writer_batch_size,
986 fn_kwargs=fn_kwargs,
987 num_proc=num_proc,
988 desc=desc,
989 )
990 for k, dataset in self.items()
991 }
992 )
File /usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py:557, in transmit_format.<locals>.wrapper(*args, **kwargs)
550 self_format = {
551 "type": self._format_type,
552 "format_kwargs": self._format_kwargs,
553 "columns": self._format_columns,
554 "output_all_columns": self._output_all_columns,
555 }
556 # apply actual function
--> 557 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
558 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
559 # re-apply format to the output
File /usr/local/lib/python3.10/dist-packages/datasets/fingerprint.py:481, in fingerprint_transform.<locals>._fingerprint.<locals>.wrapper(*args, **kwargs)
477 validate_fingerprint(kwargs[fingerprint_name])
479 # Call actual function
--> 481 out = func(dataset, *args, **kwargs)
483 # Update fingerprint of in-place transforms + update in-place history of transforms
485 if inplace: # update after calling func so that the fingerprint doesn't change if the function fails
File /usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py:3623, in Dataset.filter(self, function, with_indices, input_columns, batched, batch_size, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, fn_kwargs, num_proc, suffix_template, new_fingerprint, desc)
3620 if len(self) == 0:
3621 return self
-> 3623 indices = self.map(
3624 function=partial(
3625 get_indices_from_mask_function, function, batched, with_indices, input_columns, self._indices
3626 ),
3627 with_indices=True,
3628 features=Features({"indices": Value("uint64")}),
3629 batched=True,
3630 batch_size=batch_size,
3631 remove_columns=self.column_names,
3632 keep_in_memory=keep_in_memory,
3633 load_from_cache_file=load_from_cache_file,
3634 cache_file_name=cache_file_name,
3635 writer_batch_size=writer_batch_size,
3636 fn_kwargs=fn_kwargs,
3637 num_proc=num_proc,
3638 suffix_template=suffix_template,
3639 new_fingerprint=new_fingerprint,
3640 input_columns=input_columns,
3641 desc=desc or "Filter",
3642 )
3643 new_dataset = copy.deepcopy(self)
3644 new_dataset._indices = indices.data
File /usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py:592, in transmit_tasks.<locals>.wrapper(*args, **kwargs)
590 self: "Dataset" = kwargs.pop("self")
591 # apply actual function
--> 592 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
593 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
594 for dataset in datasets:
595 # Remove task templates if a column mapping of the template is no longer valid
File /usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py:557, in transmit_format.<locals>.wrapper(*args, **kwargs)
550 self_format = {
551 "type": self._format_type,
552 "format_kwargs": self._format_kwargs,
553 "columns": self._format_columns,
554 "output_all_columns": self._output_all_columns,
555 }
556 # apply actual function
--> 557 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
558 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
559 # re-apply format to the output
File /usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py:3093, in Dataset.map(self, function, with_indices, with_rank, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint, desc)
3087 if transformed_dataset is None:
3088 with hf_tqdm(
3089 unit=" examples",
3090 total=pbar_total,
3091 desc=desc or "Map",
3092 ) as pbar:
-> 3093 for rank, done, content in Dataset._map_single(**dataset_kwargs):
3094 if done:
3095 shards_done += 1
File /usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py:3470, in Dataset._map_single(shard, function, with_indices, with_rank, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, new_fingerprint, rank, offset)
3466 indices = list(
3467 range(*(slice(i, i + batch_size).indices(shard.num_rows)))
3468 ) # Something simpler?
3469 try:
-> 3470 batch = apply_function_on_filtered_inputs(
3471 batch,
3472 indices,
3473 check_same_num_examples=len(shard.list_indexes()) > 0,
3474 offset=offset,
3475 )
3476 except NumExamplesMismatchError:
3477 raise DatasetTransformationNotAllowedError(
3478 "Using `.map` in batched mode on a dataset with attached indexes is allowed only if it doesn't create or remove existing examples. You can first run `.drop_index() to remove your index and then re-add it."
3479 ) from None
File /usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py:3349, in Dataset._map_single.<locals>.apply_function_on_filtered_inputs(pa_inputs, indices, check_same_num_examples, offset)
3347 if with_rank:
3348 additional_args += (rank,)
-> 3349 processed_inputs = function(*fn_args, *additional_args, **fn_kwargs)
3350 if isinstance(processed_inputs, LazyDict):
3351 processed_inputs = {
3352 k: v for k, v in processed_inputs.data.items() if k not in processed_inputs.keys_to_format
3353 }
File /usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py:6212, in get_indices_from_mask_function(function, batched, with_indices, input_columns, indices_mapping, *args, **fn_kwargs)
6209 if input_columns is None:
6210 # inputs only contains a batch of examples
6211 batch: dict = inputs[0]
-> 6212 num_examples = len(batch[next(iter(batch.keys()))])
6213 for i in range(num_examples):
6214 example = {key: batch[key][i] for key in batch}
File /usr/local/lib/python3.10/dist-packages/datasets/formatting/formatting.py:272, in LazyDict.__getitem__(self, key)
270 value = self.data[key]
271 if key in self.keys_to_format:
--> 272 value = self.format(key)
273 self.data[key] = value
274 self.keys_to_format.remove(key)
File /usr/local/lib/python3.10/dist-packages/datasets/formatting/formatting.py:375, in LazyBatch.format(self, key)
374 def format(self, key):
--> 375 return self.formatter.format_column(self.pa_table.select([key]))
File /usr/local/lib/python3.10/dist-packages/datasets/formatting/formatting.py:442, in PythonFormatter.format_column(self, pa_table)
440 def format_column(self, pa_table: pa.Table) -> list:
441 column = self.python_arrow_extractor().extract_column(pa_table)
--> 442 column = self.python_features_decoder.decode_column(column, pa_table.column_names[0])
443 return column
File /usr/local/lib/python3.10/dist-packages/datasets/formatting/formatting.py:218, in PythonFeaturesDecoder.decode_column(self, column, column_name)
217 def decode_column(self, column: list, column_name: str) -> list:
--> 218 return self.features.decode_column(column, column_name) if self.features else column
File /usr/local/lib/python3.10/dist-packages/datasets/features/features.py:1951, in Features.decode_column(self, column, column_name)
1938 def decode_column(self, column: list, column_name: str):
1939 """Decode column with custom feature decoding.
1940
1941 Args:
(...)
1948 `list[Any]`
1949 """
1950 return (
-> 1951 [decode_nested_example(self[column_name], value) if value is not None else None for value in column]
1952 if self._column_requires_decoding[column_name]
1953 else column
1954 )
File /usr/local/lib/python3.10/dist-packages/datasets/features/features.py:1951, in <listcomp>(.0)
1938 def decode_column(self, column: list, column_name: str):
1939 """Decode column with custom feature decoding.
1940
1941 Args:
(...)
1948 `list[Any]`
1949 """
1950 return (
-> 1951 [decode_nested_example(self[column_name], value) if value is not None else None for value in column]
1952 if self._column_requires_decoding[column_name]
1953 else column
1954 )
File /usr/local/lib/python3.10/dist-packages/datasets/features/features.py:1339, in decode_nested_example(schema, obj, token_per_repo_id)
1336 elif isinstance(schema, (Audio, Image)):
1337 # we pass the token to read and decode files from private repositories in streaming mode
1338 if obj is not None and schema.decode:
-> 1339 return schema.decode_example(obj, token_per_repo_id=token_per_repo_id)
1340 return obj
File /usr/local/lib/python3.10/dist-packages/datasets/features/image.py:185, in Image.decode_example(self, value, token_per_repo_id)
183 else:
184 image = PIL.Image.open(BytesIO(bytes_))
--> 185 image.load() # to avoid "Too many open files" errors
186 return image
File /usr/local/lib/python3.10/dist-packages/PIL/ImageFile.py:254, in ImageFile.load(self)
252 break
253 else:
--> 254 raise OSError(
255 "image file is truncated "
256 f"({len(b)} bytes not processed)"
257 )
259 b = b + s
260 n, err_code = decoder.decode(b)
OSError: image file is truncated (1 bytes not processed)
```
### Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset("mehul7/captioned_military_aircraft")
from transformers import AutoImageProcessor
checkpoint = "microsoft/resnet-50"
image_processor = AutoImageProcessor.from_pretrained(checkpoint)
import re
from PIL import Image
import io
def contains_number(example):
try:
image = Image.open(io.BytesIO(example["image"]['bytes']))
t = image_processor(images=image, return_tensors="pt")['pixel_values']
except Exception as e:
print(f"Error processing image:{example['text']}")
return False
return bool(re.search(r'\d', example['text']))
# Define a function to add the 'label' field
def add_label(example):
lab = example['text'].split()
temp = 'NOT'
for item in lab:
if str(item[-1]).isdigit():
temp = item
break
example['label'] = temp
return example
# Filter the dataset
# filtered_dataset = dataset.filter(contains_number)
# Add the 'label' field in the dataset
labeled_dataset = dataset.filter(contains_number).map(add_label)
# View the structure of the updated dataset
print(labeled_dataset)
```
### Expected behavior
needs to form labels
same as : https://www.kaggle.com/code/jiabaowangts/dataset-air/notebook
### Environment info
Kaggle notebook P100
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url": "https://api.github.com/users/andysingal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/andysingal",
"id": 20493493,
"login": "andysingal",
"node_id": "MDQ6VXNlcjIwNDkzNDkz",
"organizations_url": "https://api.github.com/users/andysingal/orgs",
"received_events_url": "https://api.github.com/users/andysingal/received_events",
"repos_url": "https://api.github.com/users/andysingal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/andysingal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andysingal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/andysingal"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6558/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6558/timeline
|
closed
| false | 6,558 | null |
2024-02-21T00:38:12Z
| null | false |
2,064,341,965 |
https://api.github.com/repos/huggingface/datasets/issues/6557
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6557/events
|
[] | null |
2024-01-11T17:59:51Z
|
[] |
https://github.com/huggingface/datasets/pull/6557
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6557). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"@lhoestq \r\nhello\r\nI think it should be defined in config.py\r\nDATASET_ README_ FILENAME=\"README. md\"\r\nThis can replace all \"README. md\"\r\n",
"Thanks for the feedback :) merging now",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004890 / 0.011353 (-0.006463) | 0.003535 / 0.011008 (-0.007473) | 0.062894 / 0.038508 (0.024386) | 0.029133 / 0.023109 (0.006024) | 0.242387 / 0.275898 (-0.033511) | 0.262720 / 0.323480 (-0.060760) | 0.002880 / 0.007986 (-0.005106) | 0.002674 / 0.004328 (-0.001655) | 0.048932 / 0.004250 (0.044682) | 0.041669 / 0.037052 (0.004617) | 0.255922 / 0.258489 (-0.002567) | 0.282106 / 0.293841 (-0.011734) | 0.028137 / 0.128546 (-0.100409) | 0.010620 / 0.075646 (-0.065026) | 0.207799 / 0.419271 (-0.211473) | 0.035499 / 0.043533 (-0.008034) | 0.246158 / 0.255139 (-0.008981) | 0.262671 / 0.283200 (-0.020528) | 0.017297 / 0.141683 (-0.124386) | 1.118681 / 1.452155 (-0.333474) | 1.156732 / 1.492716 (-0.335985) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091670 / 0.018006 (0.073664) | 0.300327 / 0.000490 (0.299837) | 0.000212 / 0.000200 (0.000012) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018080 / 0.037411 (-0.019332) | 0.060357 / 0.014526 (0.045831) | 0.072221 / 0.176557 (-0.104336) | 0.119281 / 0.737135 (-0.617855) | 0.073861 / 0.296338 (-0.222477) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.289848 / 0.215209 (0.074639) | 2.845203 / 2.077655 (0.767549) | 1.531271 / 1.504120 (0.027152) | 1.366110 / 1.541195 (-0.175085) | 1.395041 / 1.468490 (-0.073449) | 0.563353 / 4.584777 (-4.021424) | 2.389074 / 3.745712 (-1.356638) | 2.752960 / 5.269862 (-2.516901) | 1.715508 / 4.565676 (-2.850168) | 0.063063 / 0.424275 (-0.361212) | 0.004967 / 0.007607 (-0.002640) | 0.340757 / 0.226044 (0.114713) | 3.387667 / 2.268929 (1.118739) | 1.845182 / 55.444624 (-53.599442) | 1.569616 / 6.876477 (-5.306861) | 1.571393 / 2.142072 (-0.570679) | 0.643455 / 4.805227 (-4.161772) | 0.116919 / 6.500664 (-6.383745) | 0.042551 / 0.075469 (-0.032918) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.943761 / 1.841788 (-0.898027) | 11.481068 / 8.074308 (3.406760) | 10.422180 / 10.191392 (0.230788) | 0.132015 / 0.680424 (-0.548408) | 0.013932 / 0.534201 (-0.520268) | 0.288340 / 0.579283 (-0.290943) | 0.263695 / 0.434364 (-0.170669) | 0.324459 / 0.540337 (-0.215878) | 0.415204 / 1.386936 (-0.971732) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005042 / 0.011353 (-0.006310) | 0.003465 / 0.011008 (-0.007543) | 0.050107 / 0.038508 (0.011599) | 0.029542 / 0.023109 (0.006433) | 0.273645 / 0.275898 (-0.002253) | 0.293661 / 0.323480 (-0.029818) | 0.004099 / 0.007986 (-0.003887) | 0.002667 / 0.004328 (-0.001661) | 0.048281 / 0.004250 (0.044030) | 0.044406 / 0.037052 (0.007353) | 0.284245 / 0.258489 (0.025756) | 0.312303 / 0.293841 (0.018462) | 0.030057 / 0.128546 (-0.098489) | 0.010675 / 0.075646 (-0.064971) | 0.058404 / 0.419271 (-0.360868) | 0.051874 / 0.043533 (0.008342) | 0.273308 / 0.255139 (0.018169) | 0.289356 / 0.283200 (0.006157) | 0.018628 / 0.141683 (-0.123055) | 1.148764 / 1.452155 (-0.303391) | 1.194181 / 1.492716 (-0.298535) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091383 / 0.018006 (0.073376) | 0.300221 / 0.000490 (0.299731) | 0.000232 / 0.000200 (0.000032) | 0.000044 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021814 / 0.037411 (-0.015597) | 0.076420 / 0.014526 (0.061894) | 0.087404 / 0.176557 (-0.089152) | 0.126184 / 0.737135 (-0.610951) | 0.089738 / 0.296338 (-0.206600) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.299839 / 0.215209 (0.084630) | 2.929260 / 2.077655 (0.851605) | 1.608327 / 1.504120 (0.104207) | 1.479757 / 1.541195 (-0.061437) | 1.494768 / 1.468490 (0.026278) | 0.563873 / 4.584777 (-4.020904) | 2.434442 / 3.745712 (-1.311270) | 2.641384 / 5.269862 (-2.628478) | 1.724222 / 4.565676 (-2.841454) | 0.062125 / 0.424275 (-0.362150) | 0.004994 / 0.007607 (-0.002613) | 0.350895 / 0.226044 (0.124851) | 3.448550 / 2.268929 (1.179621) | 1.928910 / 55.444624 (-53.515714) | 1.669887 / 6.876477 (-5.206590) | 1.781304 / 2.142072 (-0.360768) | 0.649301 / 4.805227 (-4.155926) | 0.116255 / 6.500664 (-6.384409) | 0.040947 / 0.075469 (-0.034522) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.977537 / 1.841788 (-0.864251) | 12.119913 / 8.074308 (4.045605) | 10.874078 / 10.191392 (0.682686) | 0.130174 / 0.680424 (-0.550250) | 0.016176 / 0.534201 (-0.518025) | 0.287967 / 0.579283 (-0.291316) | 0.280591 / 0.434364 (-0.153773) | 0.324332 / 0.540337 (-0.216005) | 0.419479 / 1.386936 (-0.967457) |\n\n</details>\n</details>\n\n\n"
] |
Support standalone yaml
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6557/reactions"
}
|
PR_kwDODunzps5jJ63z
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6557.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6557",
"merged_at": "2024-01-11T17:53:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6557.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6557"
}
|
2024-01-03T16:47:35Z
|
https://api.github.com/repos/huggingface/datasets/issues/6557/comments
|
see (internal) https://huggingface.slack.com/archives/C02V51Q3800/p1703885853581679
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6557/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6557/timeline
|
closed
| false | 6,557 | null |
2024-01-11T17:53:42Z
| null | true |
2,064,018,208 |
https://api.github.com/repos/huggingface/datasets/issues/6556
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6556/events
|
[] | null |
2024-02-12T21:57:34Z
|
[] |
https://github.com/huggingface/datasets/pull/6556
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6556). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Fixed in dataset viewer: https://huggingface.co/datasets/multimodalart/repro_1_image\r\n\r\n<img width=\"682\" alt=\"Capture d’écran 2024-02-12 à 22 57 08\" src=\"https://github.com/huggingface/datasets/assets/1676121/be9a8dbc-2d78-4ffc-aed4-293a7c57bc0d\">\r\n"
] |
Fix imagefolder with one image
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6556/reactions"
}
|
PR_kwDODunzps5jI0nN
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6556.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6556",
"merged_at": "2024-01-09T13:06:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6556.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6556"
}
|
2024-01-03T13:13:02Z
|
https://api.github.com/repos/huggingface/datasets/issues/6556/comments
|
A dataset repository with one image and one metadata file was considered a JSON dataset instead of an ImageFolder dataset. This is because we pick the dataset type with the most compatible data file extensions present in the repository and it results in a tie in this case.
e.g. for https://huggingface.co/datasets/multimodalart/repro_1_image
I fixed this by deprioritizing metadata files in the count.
fix https://github.com/huggingface/datasets/issues/6545
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6556/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6556/timeline
|
closed
| false | 6,556 | null |
2024-01-09T13:06:30Z
| null | true |
2,063,841,286 |
https://api.github.com/repos/huggingface/datasets/issues/6555
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6555/events
|
[] | null |
2024-02-02T10:41:33Z
|
[] |
https://github.com/huggingface/datasets/pull/6555
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6555). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"As shared on slack, `HubDatasetModuleFactoryWithParquetExport` raises a `DatasetsServerError` already if the user tries to load another revision that the one from the parquet export. And therefore it fall backs on using `HubDatasetModuleFactoryWithScript`",
"@lhoestq I would say that although current implementation finally returns `HubDatasetModuleFactoryWithScript` as expected, with this PR we avoid the useless call to `HubDatasetModuleFactoryWithParquetExport.get_module`, so this is more optimal.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005596 / 0.011353 (-0.005757) | 0.004022 / 0.011008 (-0.006986) | 0.064041 / 0.038508 (0.025533) | 0.030683 / 0.023109 (0.007574) | 0.245236 / 0.275898 (-0.030662) | 0.269657 / 0.323480 (-0.053823) | 0.003142 / 0.007986 (-0.004844) | 0.002821 / 0.004328 (-0.001507) | 0.048774 / 0.004250 (0.044523) | 0.043771 / 0.037052 (0.006719) | 0.258202 / 0.258489 (-0.000287) | 0.288381 / 0.293841 (-0.005460) | 0.028154 / 0.128546 (-0.100392) | 0.011071 / 0.075646 (-0.064576) | 0.209836 / 0.419271 (-0.209436) | 0.035923 / 0.043533 (-0.007609) | 0.248361 / 0.255139 (-0.006777) | 0.268728 / 0.283200 (-0.014472) | 0.019982 / 0.141683 (-0.121701) | 1.172330 / 1.452155 (-0.279824) | 1.192262 / 1.492716 (-0.300455) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.089231 / 0.018006 (0.071225) | 0.299192 / 0.000490 (0.298702) | 0.000214 / 0.000200 (0.000014) | 0.000054 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018358 / 0.037411 (-0.019053) | 0.062633 / 0.014526 (0.048107) | 0.076276 / 0.176557 (-0.100280) | 0.120862 / 0.737135 (-0.616274) | 0.075958 / 0.296338 (-0.220380) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.291575 / 0.215209 (0.076366) | 2.855908 / 2.077655 (0.778253) | 1.459891 / 1.504120 (-0.044229) | 1.374945 / 1.541195 (-0.166250) | 1.333759 / 1.468490 (-0.134731) | 0.575428 / 4.584777 (-4.009348) | 2.414253 / 3.745712 (-1.331459) | 2.768222 / 5.269862 (-2.501639) | 1.705005 / 4.565676 (-2.860672) | 0.063406 / 0.424275 (-0.360869) | 0.004981 / 0.007607 (-0.002626) | 0.343826 / 0.226044 (0.117781) | 3.418143 / 2.268929 (1.149215) | 1.856571 / 55.444624 (-53.588053) | 1.571318 / 6.876477 (-5.305159) | 1.609897 / 2.142072 (-0.532175) | 0.646779 / 4.805227 (-4.158448) | 0.118143 / 6.500664 (-6.382521) | 0.042408 / 0.075469 (-0.033061) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.965091 / 1.841788 (-0.876697) | 11.569655 / 8.074308 (3.495347) | 10.587818 / 10.191392 (0.396426) | 0.128518 / 0.680424 (-0.551905) | 0.013954 / 0.534201 (-0.520247) | 0.287244 / 0.579283 (-0.292039) | 0.263755 / 0.434364 (-0.170609) | 0.321661 / 0.540337 (-0.218676) | 0.428753 / 1.386936 (-0.958183) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005568 / 0.011353 (-0.005785) | 0.003755 / 0.011008 (-0.007253) | 0.049134 / 0.038508 (0.010626) | 0.032113 / 0.023109 (0.009004) | 0.276645 / 0.275898 (0.000747) | 0.299240 / 0.323480 (-0.024240) | 0.004297 / 0.007986 (-0.003689) | 0.002727 / 0.004328 (-0.001602) | 0.048420 / 0.004250 (0.044170) | 0.045070 / 0.037052 (0.008017) | 0.288597 / 0.258489 (0.030108) | 0.320824 / 0.293841 (0.026983) | 0.053293 / 0.128546 (-0.075253) | 0.011002 / 0.075646 (-0.064644) | 0.057747 / 0.419271 (-0.361524) | 0.034389 / 0.043533 (-0.009143) | 0.277914 / 0.255139 (0.022775) | 0.292919 / 0.283200 (0.009719) | 0.018252 / 0.141683 (-0.123431) | 1.187245 / 1.452155 (-0.264910) | 1.199823 / 1.492716 (-0.292893) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.088338 / 0.018006 (0.070332) | 0.297498 / 0.000490 (0.297008) | 0.000206 / 0.000200 (0.000006) | 0.000048 / 0.000054 (-0.000007) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021445 / 0.037411 (-0.015966) | 0.075522 / 0.014526 (0.060996) | 0.086010 / 0.176557 (-0.090546) | 0.124938 / 0.737135 (-0.612197) | 0.087542 / 0.296338 (-0.208796) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.292460 / 0.215209 (0.077251) | 2.841290 / 2.077655 (0.763635) | 1.537941 / 1.504120 (0.033821) | 1.409903 / 1.541195 (-0.131291) | 1.435339 / 1.468490 (-0.033151) | 0.578967 / 4.584777 (-4.005810) | 2.398588 / 3.745712 (-1.347125) | 2.662342 / 5.269862 (-2.607520) | 1.743055 / 4.565676 (-2.822622) | 0.064043 / 0.424275 (-0.360232) | 0.005030 / 0.007607 (-0.002577) | 0.348542 / 0.226044 (0.122498) | 3.395854 / 2.268929 (1.126926) | 1.918935 / 55.444624 (-53.525689) | 1.639320 / 6.876477 (-5.237157) | 1.740406 / 2.142072 (-0.401666) | 0.653346 / 4.805227 (-4.151881) | 0.117298 / 6.500664 (-6.383366) | 0.040635 / 0.075469 (-0.034834) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.008277 / 1.841788 (-0.833510) | 12.069369 / 8.074308 (3.995061) | 10.967322 / 10.191392 (0.775930) | 0.131938 / 0.680424 (-0.548486) | 0.015418 / 0.534201 (-0.518783) | 0.297257 / 0.579283 (-0.282026) | 0.270742 / 0.434364 (-0.163622) | 0.332296 / 0.540337 (-0.208042) | 0.421606 / 1.386936 (-0.965330) |\n\n</details>\n</details>\n\n\n"
] |
Do not use Parquet exports if revision is passed
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6555/reactions"
}
|
PR_kwDODunzps5jIM79
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6555.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6555",
"merged_at": "2024-02-02T10:35:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6555.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6555"
}
|
2024-01-03T11:33:10Z
|
https://api.github.com/repos/huggingface/datasets/issues/6555/comments
|
Fix #6554.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6555/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6555/timeline
|
closed
| false | 6,555 | null |
2024-02-02T10:35:28Z
| null | true |
2,063,839,916 |
https://api.github.com/repos/huggingface/datasets/issues/6554
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6554/events
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | null |
2024-02-02T10:35:29Z
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] |
https://github.com/huggingface/datasets/issues/6554
|
MEMBER
|
completed
| null | null |
[
"I don't think this bug is a thing ? Do you have some code that leads to this issue ?"
] |
Parquet exports are used even if revision is passed
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6554/reactions"
}
|
I_kwDODunzps57A7Ks
| null |
2024-01-03T11:32:26Z
|
https://api.github.com/repos/huggingface/datasets/issues/6554/comments
|
We should not used Parquet exports if `revision` is passed.
I think this is a regression.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6554/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6554/timeline
|
closed
| false | 6,554 | null |
2024-02-02T10:35:29Z
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
| false |
2,063,474,183 |
https://api.github.com/repos/huggingface/datasets/issues/6553
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6553/events
|
[] | null |
2024-02-21T00:38:24Z
|
[] |
https://github.com/huggingface/datasets/issues/6553
|
NONE
|
completed
| null | null |
[
"I don't know My conpany conputer cannot work. but in my computer, it work?",
"Do you have a folder in your working directory called datasets?"
] |
Cannot import name 'load_dataset' from .... module ‘datasets’
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6553/reactions"
}
|
I_kwDODunzps56_h4H
| null |
2024-01-03T08:18:21Z
|
https://api.github.com/repos/huggingface/datasets/issues/6553/comments
|
### Describe the bug
use python -m pip install datasets to install
### Steps to reproduce the bug
from datasets import load_dataset
### Expected behavior
it doesn't work
### Environment info
datasets version==2.15.0
python == 3.10.12
linux version I don't know??
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/83450192?v=4",
"events_url": "https://api.github.com/users/ciaoyizhen/events{/privacy}",
"followers_url": "https://api.github.com/users/ciaoyizhen/followers",
"following_url": "https://api.github.com/users/ciaoyizhen/following{/other_user}",
"gists_url": "https://api.github.com/users/ciaoyizhen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ciaoyizhen",
"id": 83450192,
"login": "ciaoyizhen",
"node_id": "MDQ6VXNlcjgzNDUwMTky",
"organizations_url": "https://api.github.com/users/ciaoyizhen/orgs",
"received_events_url": "https://api.github.com/users/ciaoyizhen/received_events",
"repos_url": "https://api.github.com/users/ciaoyizhen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ciaoyizhen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ciaoyizhen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ciaoyizhen"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6553/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6553/timeline
|
closed
| false | 6,553 | null |
2024-02-21T00:38:24Z
| null | false |
2,063,157,187 |
https://api.github.com/repos/huggingface/datasets/issues/6552
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6552/events
|
[] | null |
2024-01-08T10:09:04Z
|
[] |
https://github.com/huggingface/datasets/issues/6552
|
NONE
|
completed
| null | null |
[
"This bug comes from the `huggingface_hub` library, see: https://github.com/huggingface/huggingface_hub/issues/1952\r\n\r\nA fix is provided at https://github.com/huggingface/huggingface_hub/pull/1953. Feel free to install `huggingface_hub` from this PR, or wait for it to be merged and the new version of `huggingface_hub` to be released",
"Thanks!"
] |
Loading a dataset from Google Colab hangs at "Resolving data files".
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6552/reactions"
}
|
I_kwDODunzps56-UfD
| null |
2024-01-03T02:18:17Z
|
https://api.github.com/repos/huggingface/datasets/issues/6552/comments
|
### Describe the bug
Hello,
I'm trying to load a dataset from Google Colab but the process hangs at `Resolving data files`:

It is happening when the `_get_origin_metadata` definition is invoked:
```python
def _get_origin_metadata(
data_files: List[str],
max_workers=64,
download_config: Optional[DownloadConfig] = None,
) -> Tuple[str]:
return thread_map(
partial(_get_single_origin_metadata, download_config=download_config),
data_files,
max_workers=max_workers,
tqdm_class=hf_tqdm,
desc="Resolving data files",
disable=len(data_files) <= 16,
```
The thread is then stuck at `waiter.acquire()` in the builtin `threading.py` file.
I can load the dataset just fine on my machine.
Cheers,
Thomas
### Steps to reproduce the bug
In Google Colab:
```python
!pip install datasets
from datasets import load_dataset
dataset = load_dataset("colour-science/color-checker-detection-dataset")
```
### Expected behavior
The dataset should be loaded.
### Environment info
- `datasets` version: 2.16.1
- Platform: Linux-6.1.58+-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.20.1
- PyArrow version: 10.0.1
- Pandas version: 1.5.3
- `fsspec` version: 2023.6.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/99779?v=4",
"events_url": "https://api.github.com/users/KelSolaar/events{/privacy}",
"followers_url": "https://api.github.com/users/KelSolaar/followers",
"following_url": "https://api.github.com/users/KelSolaar/following{/other_user}",
"gists_url": "https://api.github.com/users/KelSolaar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/KelSolaar",
"id": 99779,
"login": "KelSolaar",
"node_id": "MDQ6VXNlcjk5Nzc5",
"organizations_url": "https://api.github.com/users/KelSolaar/orgs",
"received_events_url": "https://api.github.com/users/KelSolaar/received_events",
"repos_url": "https://api.github.com/users/KelSolaar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/KelSolaar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KelSolaar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/KelSolaar"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6552/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6552/timeline
|
closed
| false | 6,552 | null |
2024-01-08T10:09:04Z
| null | false |
2,062,768,400 |
https://api.github.com/repos/huggingface/datasets/issues/6551
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6551/events
|
[] | null |
2024-01-06T20:14:57Z
|
[] |
https://github.com/huggingface/datasets/pull/6551
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6551). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005002 / 0.011353 (-0.006350) | 0.003300 / 0.011008 (-0.007708) | 0.062509 / 0.038508 (0.024001) | 0.029807 / 0.023109 (0.006698) | 0.249935 / 0.275898 (-0.025963) | 0.264320 / 0.323480 (-0.059160) | 0.003790 / 0.007986 (-0.004195) | 0.002554 / 0.004328 (-0.001774) | 0.048207 / 0.004250 (0.043956) | 0.042033 / 0.037052 (0.004981) | 0.245725 / 0.258489 (-0.012764) | 0.276695 / 0.293841 (-0.017146) | 0.026502 / 0.128546 (-0.102044) | 0.010379 / 0.075646 (-0.065268) | 0.207002 / 0.419271 (-0.212269) | 0.034648 / 0.043533 (-0.008885) | 0.247957 / 0.255139 (-0.007182) | 0.263921 / 0.283200 (-0.019278) | 0.017710 / 0.141683 (-0.123973) | 1.105851 / 1.452155 (-0.346304) | 1.163315 / 1.492716 (-0.329401) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.089842 / 0.018006 (0.071836) | 0.352499 / 0.000490 (0.352009) | 0.000201 / 0.000200 (0.000001) | 0.000054 / 0.000054 (-0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018094 / 0.037411 (-0.019317) | 0.060463 / 0.014526 (0.045937) | 0.073257 / 0.176557 (-0.103300) | 0.119771 / 0.737135 (-0.617364) | 0.075210 / 0.296338 (-0.221128) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.288365 / 0.215209 (0.073156) | 2.825377 / 2.077655 (0.747722) | 1.532436 / 1.504120 (0.028316) | 1.393475 / 1.541195 (-0.147719) | 1.381859 / 1.468490 (-0.086632) | 0.564155 / 4.584777 (-4.020622) | 2.398177 / 3.745712 (-1.347535) | 2.730271 / 5.269862 (-2.539590) | 1.713779 / 4.565676 (-2.851898) | 0.062789 / 0.424275 (-0.361486) | 0.004991 / 0.007607 (-0.002616) | 0.340789 / 0.226044 (0.114744) | 3.323543 / 2.268929 (1.054615) | 1.861925 / 55.444624 (-53.582700) | 1.555181 / 6.876477 (-5.321296) | 1.559512 / 2.142072 (-0.582560) | 0.634565 / 4.805227 (-4.170663) | 0.116529 / 6.500664 (-6.384135) | 0.041312 / 0.075469 (-0.034157) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.945739 / 1.841788 (-0.896049) | 11.376130 / 8.074308 (3.301822) | 10.007752 / 10.191392 (-0.183640) | 0.126815 / 0.680424 (-0.553609) | 0.013898 / 0.534201 (-0.520303) | 0.287438 / 0.579283 (-0.291845) | 0.261532 / 0.434364 (-0.172832) | 0.320197 / 0.540337 (-0.220140) | 0.414444 / 1.386936 (-0.972492) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004994 / 0.011353 (-0.006359) | 0.003407 / 0.011008 (-0.007601) | 0.049281 / 0.038508 (0.010773) | 0.042815 / 0.023109 (0.019706) | 0.268291 / 0.275898 (-0.007607) | 0.285877 / 0.323480 (-0.037603) | 0.004006 / 0.007986 (-0.003980) | 0.002607 / 0.004328 (-0.001721) | 0.047682 / 0.004250 (0.043431) | 0.044281 / 0.037052 (0.007228) | 0.268287 / 0.258489 (0.009798) | 0.298649 / 0.293841 (0.004808) | 0.028607 / 0.128546 (-0.099939) | 0.010367 / 0.075646 (-0.065279) | 0.057114 / 0.419271 (-0.362158) | 0.053753 / 0.043533 (0.010220) | 0.269010 / 0.255139 (0.013871) | 0.285057 / 0.283200 (0.001858) | 0.017693 / 0.141683 (-0.123990) | 1.134718 / 1.452155 (-0.317436) | 1.186609 / 1.492716 (-0.306107) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091109 / 0.018006 (0.073103) | 0.298603 / 0.000490 (0.298113) | 0.000216 / 0.000200 (0.000016) | 0.000050 / 0.000054 (-0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022125 / 0.037411 (-0.015286) | 0.076570 / 0.014526 (0.062044) | 0.088903 / 0.176557 (-0.087654) | 0.126427 / 0.737135 (-0.610708) | 0.091001 / 0.296338 (-0.205338) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.300332 / 0.215209 (0.085123) | 2.971106 / 2.077655 (0.893452) | 1.617886 / 1.504120 (0.113766) | 1.476679 / 1.541195 (-0.064516) | 1.483750 / 1.468490 (0.015260) | 0.582569 / 4.584777 (-4.002208) | 2.441804 / 3.745712 (-1.303908) | 2.753927 / 5.269862 (-2.515935) | 1.733546 / 4.565676 (-2.832130) | 0.062653 / 0.424275 (-0.361622) | 0.005019 / 0.007607 (-0.002588) | 0.355556 / 0.226044 (0.129512) | 3.497431 / 2.268929 (1.228503) | 1.951711 / 55.444624 (-53.492913) | 1.663874 / 6.876477 (-5.212602) | 1.657363 / 2.142072 (-0.484709) | 0.653488 / 4.805227 (-4.151739) | 0.117055 / 6.500664 (-6.383609) | 0.040687 / 0.075469 (-0.034782) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.969485 / 1.841788 (-0.872303) | 12.064793 / 8.074308 (3.990485) | 10.851531 / 10.191392 (0.660139) | 0.129060 / 0.680424 (-0.551364) | 0.015339 / 0.534201 (-0.518862) | 0.287215 / 0.579283 (-0.292069) | 0.276545 / 0.434364 (-0.157819) | 0.322748 / 0.540337 (-0.217589) | 0.421363 / 1.386936 (-0.965573) |\n\n</details>\n</details>\n\n\n",
"@lhoestq \r\n<img width=\"1015\" alt=\"image\" src=\"https://github.com/huggingface/datasets/assets/17604849/b19b9d92-c6f7-4e3a-8c9d-1178e56c67ea\">\r\nit's still not fixed =(",
"@lhoestq i was thinking uninstalling `datasets` and then `pip install git+https://github.com/huggingface/datasets.git` has to fix it. Buuuuut. I'm not sure what's going on actually...\r\n\r\nNow instead of showing progress bars one after another it seems to be downloading the dataset way way way faster (like 4 mins instead of 58, thank you very much) but does not show any progress bars related to downloading at all.\r\n\r\n<img width=\"1170\" alt=\"image\" src=\"https://github.com/huggingface/datasets/assets/17604849/21a84908-c44d-41b4-bb0d-8061cab3bc64\">\r\n\r\n<img width=\"1159\" alt=\"image\" src=\"https://github.com/huggingface/datasets/assets/17604849/26684a8a-c10a-4fa2-bd84-cab4f938ffcc\">\r\n"
] |
Fix parallel downloads for datasets without scripts
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6551/reactions"
}
|
PR_kwDODunzps5jEi1C
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6551.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6551",
"merged_at": "2024-01-03T13:19:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6551.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6551"
}
|
2024-01-02T18:06:18Z
|
https://api.github.com/repos/huggingface/datasets/issues/6551/comments
|
Enable parallel downloads using multiprocessing when `num_proc` is passed to `load_dataset`.
It was enabled for datasets with scripts already (if they passed lists to `dl_manager.download`) but not for no-script datasets (we pass dicts {split: [list of files]} to `dl_manager.download` for those ones).
I fixed this by parallelising on the lists contained in the data files dicts when possible.
I also added a context manager `stack_multiprocessing_download_progress_bars` in `DownloadManager` to stack the progress bard of the downloads (from `cached_path(...)` calls). Otherwise the progress bars overlap each other with an annoying flickering effect.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6551/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6551/timeline
|
closed
| false | 6,551 | null |
2024-01-03T13:19:48Z
| null | true |
2,062,556,493 |
https://api.github.com/repos/huggingface/datasets/issues/6550
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6550/events
|
[] | null |
2024-01-31T13:45:15Z
|
[] |
https://github.com/huggingface/datasets/pull/6550
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6550). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Thanks @lhoestq . This is a very important fix for code to run on multiple GPUs. Otherwise, only one GPU is working. I wish it can be merged soon. \r\nI also wrote a [blog post](https://forrestbao.github.io/2024/01/30/datasets_map_with_rank_multiple_GPUs.html) with a complete example in case it can be helpful to someone. Please feel free to use complete example in any documentation. \r\n",
"Thanks a lot @forrestbao ! I reused parts of your code for the documentation, I'm sure it will be useful to many people !",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005662 / 0.011353 (-0.005691) | 0.003930 / 0.011008 (-0.007078) | 0.063807 / 0.038508 (0.025299) | 0.030227 / 0.023109 (0.007118) | 0.235338 / 0.275898 (-0.040560) | 0.264433 / 0.323480 (-0.059047) | 0.004226 / 0.007986 (-0.003759) | 0.002847 / 0.004328 (-0.001481) | 0.048998 / 0.004250 (0.044747) | 0.042713 / 0.037052 (0.005660) | 0.250504 / 0.258489 (-0.007985) | 0.281101 / 0.293841 (-0.012740) | 0.029123 / 0.128546 (-0.099423) | 0.011388 / 0.075646 (-0.064258) | 0.211342 / 0.419271 (-0.207930) | 0.036437 / 0.043533 (-0.007096) | 0.238909 / 0.255139 (-0.016230) | 0.255853 / 0.283200 (-0.027347) | 0.018852 / 0.141683 (-0.122831) | 1.131870 / 1.452155 (-0.320284) | 1.209007 / 1.492716 (-0.283710) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092433 / 0.018006 (0.074427) | 0.303045 / 0.000490 (0.302556) | 0.000291 / 0.000200 (0.000091) | 0.000079 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018349 / 0.037411 (-0.019062) | 0.062527 / 0.014526 (0.048002) | 0.075347 / 0.176557 (-0.101210) | 0.120587 / 0.737135 (-0.616549) | 0.075171 / 0.296338 (-0.221167) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.288364 / 0.215209 (0.073155) | 2.775779 / 2.077655 (0.698124) | 1.490875 / 1.504120 (-0.013245) | 1.375451 / 1.541195 (-0.165744) | 1.398923 / 1.468490 (-0.069567) | 0.588659 / 4.584777 (-3.996117) | 2.458114 / 3.745712 (-1.287598) | 2.928910 / 5.269862 (-2.340951) | 1.834221 / 4.565676 (-2.731456) | 0.064503 / 0.424275 (-0.359772) | 0.005028 / 0.007607 (-0.002580) | 0.340386 / 0.226044 (0.114341) | 3.408697 / 2.268929 (1.139769) | 1.843613 / 55.444624 (-53.601012) | 1.569300 / 6.876477 (-5.307177) | 1.636761 / 2.142072 (-0.505312) | 0.687854 / 4.805227 (-4.117374) | 0.123462 / 6.500664 (-6.377202) | 0.042877 / 0.075469 (-0.032593) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.984054 / 1.841788 (-0.857734) | 12.243934 / 8.074308 (4.169626) | 10.835244 / 10.191392 (0.643852) | 0.131609 / 0.680424 (-0.548815) | 0.014000 / 0.534201 (-0.520201) | 0.292070 / 0.579283 (-0.287213) | 0.271958 / 0.434364 (-0.162406) | 0.326866 / 0.540337 (-0.213471) | 0.440880 / 1.386936 (-0.946056) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005954 / 0.011353 (-0.005399) | 0.004123 / 0.011008 (-0.006885) | 0.050371 / 0.038508 (0.011863) | 0.034387 / 0.023109 (0.011277) | 0.273254 / 0.275898 (-0.002644) | 0.297785 / 0.323480 (-0.025695) | 0.004619 / 0.007986 (-0.003367) | 0.002884 / 0.004328 (-0.001444) | 0.050236 / 0.004250 (0.045986) | 0.048586 / 0.037052 (0.011533) | 0.283878 / 0.258489 (0.025389) | 0.315218 / 0.293841 (0.021377) | 0.060688 / 0.128546 (-0.067859) | 0.011991 / 0.075646 (-0.063655) | 0.059518 / 0.419271 (-0.359753) | 0.036113 / 0.043533 (-0.007420) | 0.274767 / 0.255139 (0.019628) | 0.290620 / 0.283200 (0.007420) | 0.020070 / 0.141683 (-0.121613) | 1.164635 / 1.452155 (-0.287519) | 1.189482 / 1.492716 (-0.303234) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095171 / 0.018006 (0.077165) | 0.307129 / 0.000490 (0.306639) | 0.000227 / 0.000200 (0.000027) | 0.000045 / 0.000054 (-0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022777 / 0.037411 (-0.014634) | 0.076761 / 0.014526 (0.062235) | 0.087654 / 0.176557 (-0.088902) | 0.126729 / 0.737135 (-0.610406) | 0.089491 / 0.296338 (-0.206847) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.292208 / 0.215209 (0.076999) | 2.890491 / 2.077655 (0.812836) | 1.625696 / 1.504120 (0.121576) | 1.463484 / 1.541195 (-0.077710) | 1.490889 / 1.468490 (0.022399) | 0.582155 / 4.584777 (-4.002622) | 2.492209 / 3.745712 (-1.253503) | 2.817020 / 5.269862 (-2.452842) | 1.806812 / 4.565676 (-2.758864) | 0.065830 / 0.424275 (-0.358445) | 0.005089 / 0.007607 (-0.002518) | 0.356067 / 0.226044 (0.130022) | 3.489652 / 2.268929 (1.220723) | 1.959276 / 55.444624 (-53.485348) | 1.678819 / 6.876477 (-5.197657) | 1.853581 / 2.142072 (-0.288491) | 0.660515 / 4.805227 (-4.144712) | 0.119884 / 6.500664 (-6.380780) | 0.041713 / 0.075469 (-0.033757) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.021701 / 1.841788 (-0.820087) | 12.918290 / 8.074308 (4.843982) | 11.469371 / 10.191392 (1.277979) | 0.144830 / 0.680424 (-0.535594) | 0.015858 / 0.534201 (-0.518343) | 0.290136 / 0.579283 (-0.289148) | 0.277894 / 0.434364 (-0.156470) | 0.330091 / 0.540337 (-0.210247) | 0.422697 / 1.386936 (-0.964240) |\n\n</details>\n</details>\n\n\n"
] |
Multi gpu docs
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6550/reactions"
}
|
PR_kwDODunzps5jD1OL
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6550.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6550",
"merged_at": "2024-01-31T13:38:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6550.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6550"
}
|
2024-01-02T15:11:58Z
|
https://api.github.com/repos/huggingface/datasets/issues/6550/comments
|
after discussions in https://github.com/huggingface/datasets/pull/6415
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6550/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6550/timeline
|
closed
| false | 6,550 | null |
2024-01-31T13:38:59Z
| null | true |
2,062,420,259 |
https://api.github.com/repos/huggingface/datasets/issues/6549
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6549/events
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null |
2024-01-02T14:06:49Z
|
[] |
https://github.com/huggingface/datasets/issues/6549
|
MEMBER
| null | null | null |
[
"Maybe we can add a helper message like `Maybe try again using \"hf://path/without/resolve\"` if the path contains `/resolve/` ?\r\n\r\ne.g.\r\n\r\n```\r\nFileNotFoundError: Unable to find 'hf://datasets/HuggingFaceTB/eval_data/resolve/main/eval_data_context_and_answers.json'\r\nIt looks like you used parts of the URL of the file from the Hugging Face website, but you should remove the \"/resolve/<revision>\" part to have a valid `hf://` path.\r\nPlease try again using this path instead:\r\n hf://datasets/HuggingFaceTB/eval_data/eval_data_context_and_answers.json\r\n```\r\n\r\nand suggest `f\"hf://datasets/HuggingFaceTB/eval_data@{revision}/eval_data_context_and_answers.json\"` if revision != \"main\"\r\n\r\nEDIT: I think this message should also be raised from the `huggingface_hub`'s `HfFileSystem` implementation"
] |
Loading from hf hub with clearer error message
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6549/reactions"
}
|
I_kwDODunzps567gkj
| null |
2024-01-02T13:26:34Z
|
https://api.github.com/repos/huggingface/datasets/issues/6549/comments
|
### Feature request
Shouldn't this kinda work ?
```
Dataset.from_json("hf://datasets/HuggingFaceTB/eval_data/resolve/main/eval_data_context_and_answers.json")
```
I got an error
```
File ~/miniconda3/envs/datatrove/lib/python3.10/site-packages/datasets/data_files.py:380, in resolve_pattern(pattern, base_path, allowed_extensions, download_config)
378 if allowed_extensions is not None:
379 error_msg += f" with any supported extension {list(allowed_extensions)}"
--> 380 raise FileNotFoundError(error_msg)
381 return out
FileNotFoundError: Unable to find 'hf://datasets/HuggingFaceTB/eval_data/resolve/main/eval_data_context_and_answers.json'
(I'm logged in)
```
Fix: the correct path is
```
hf://datasets/HuggingFaceTB/eval_data/eval_data_context_and_answers.json
```
Proposal: raise a clearer error
### Motivation
Clearer error message
### Your contribution
Can open a PR
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6549/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6549/timeline
|
open
| false | 6,549 | null | null | null | false |
2,061,047,984 |
https://api.github.com/repos/huggingface/datasets/issues/6548
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6548/events
|
[] | null |
2024-01-02T10:33:17Z
|
[] |
https://github.com/huggingface/datasets/issues/6548
|
NONE
| null | null | null |
[
"It looks like a transient DNS issue. It should work fine now if you try again.\r\n\r\nThere is no parameter in load_dataset to skip failed downloads. In your case it would have skipped every single subsequent download until the DNS issue was resolved anyway."
] |
Skip if a dataset has issues
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6548/reactions"
}
|
I_kwDODunzps562Riw
| null |
2023-12-31T12:41:26Z
|
https://api.github.com/repos/huggingface/datasets/issues/6548/comments
|
### Describe the bug
Hello everyone,
I'm using **load_datasets** from **huggingface** to download the datasets and I'm facing an issue, the download starts but it reaches some state and then fails with the following error:
Couldn't reach https://huggingface.co/datasets/wikimedia/wikipedia/resolve/4cb9b0d719291f1a10f96f67d609c5d442980dc9/20231101.ext/train-00000-of-00001.parquet
Failed to resolve \'huggingface.co\' ([Errno -3] Temporary failure in name resolution)"))')))

so I was wondering is there a parameter to be passed to load_dataset() to skip files that can't be downloaded??
### Steps to reproduce the bug
Parameter to be passed to load_dataset() of huggingface to skip files that can't be downloaded??
### Expected behavior
load_dataset() finishes without error
### Environment info
None
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/143214684?v=4",
"events_url": "https://api.github.com/users/hadianasliwa/events{/privacy}",
"followers_url": "https://api.github.com/users/hadianasliwa/followers",
"following_url": "https://api.github.com/users/hadianasliwa/following{/other_user}",
"gists_url": "https://api.github.com/users/hadianasliwa/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hadianasliwa",
"id": 143214684,
"login": "hadianasliwa",
"node_id": "U_kgDOCIlIXA",
"organizations_url": "https://api.github.com/users/hadianasliwa/orgs",
"received_events_url": "https://api.github.com/users/hadianasliwa/received_events",
"repos_url": "https://api.github.com/users/hadianasliwa/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hadianasliwa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hadianasliwa/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hadianasliwa"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6548/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6548/timeline
|
open
| false | 6,548 | null | null | null | false |
2,060,796,927 |
https://api.github.com/repos/huggingface/datasets/issues/6547
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6547/events
|
[] | null |
2023-12-30T16:53:38Z
|
[] |
https://github.com/huggingface/datasets/pull/6547
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6547). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004855 / 0.011353 (-0.006498) | 0.003552 / 0.011008 (-0.007456) | 0.062328 / 0.038508 (0.023820) | 0.031142 / 0.023109 (0.008032) | 0.247726 / 0.275898 (-0.028172) | 0.270951 / 0.323480 (-0.052528) | 0.002887 / 0.007986 (-0.005099) | 0.002663 / 0.004328 (-0.001665) | 0.047888 / 0.004250 (0.043638) | 0.042932 / 0.037052 (0.005880) | 0.253660 / 0.258489 (-0.004829) | 0.274997 / 0.293841 (-0.018844) | 0.027200 / 0.128546 (-0.101347) | 0.010851 / 0.075646 (-0.064796) | 0.206566 / 0.419271 (-0.212706) | 0.035311 / 0.043533 (-0.008222) | 0.254146 / 0.255139 (-0.000993) | 0.269074 / 0.283200 (-0.014126) | 0.019221 / 0.141683 (-0.122462) | 1.101986 / 1.452155 (-0.350169) | 1.155541 / 1.492716 (-0.337175) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004749 / 0.018006 (-0.013257) | 0.301627 / 0.000490 (0.301138) | 0.000208 / 0.000200 (0.000008) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018205 / 0.037411 (-0.019206) | 0.060420 / 0.014526 (0.045894) | 0.072533 / 0.176557 (-0.104023) | 0.119807 / 0.737135 (-0.617328) | 0.073249 / 0.296338 (-0.223089) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.284947 / 0.215209 (0.069738) | 2.796939 / 2.077655 (0.719285) | 1.486076 / 1.504120 (-0.018043) | 1.358247 / 1.541195 (-0.182948) | 1.383680 / 1.468490 (-0.084811) | 0.550253 / 4.584777 (-4.034524) | 2.364783 / 3.745712 (-1.380929) | 2.765631 / 5.269862 (-2.504230) | 1.695694 / 4.565676 (-2.869983) | 0.061519 / 0.424275 (-0.362756) | 0.004914 / 0.007607 (-0.002693) | 0.340370 / 0.226044 (0.114325) | 3.313175 / 2.268929 (1.044247) | 1.805421 / 55.444624 (-53.639203) | 1.532151 / 6.876477 (-5.344325) | 1.541195 / 2.142072 (-0.600878) | 0.625266 / 4.805227 (-4.179961) | 0.119980 / 6.500664 (-6.380684) | 0.042334 / 0.075469 (-0.033135) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.952893 / 1.841788 (-0.888895) | 11.322232 / 8.074308 (3.247924) | 9.982108 / 10.191392 (-0.209284) | 0.130034 / 0.680424 (-0.550389) | 0.013192 / 0.534201 (-0.521009) | 0.286041 / 0.579283 (-0.293243) | 0.269802 / 0.434364 (-0.164562) | 0.323582 / 0.540337 (-0.216755) | 0.428641 / 1.386936 (-0.958295) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005071 / 0.011353 (-0.006282) | 0.003368 / 0.011008 (-0.007640) | 0.049003 / 0.038508 (0.010495) | 0.029507 / 0.023109 (0.006398) | 0.271859 / 0.275898 (-0.004039) | 0.294660 / 0.323480 (-0.028820) | 0.004218 / 0.007986 (-0.003767) | 0.002686 / 0.004328 (-0.001642) | 0.047947 / 0.004250 (0.043696) | 0.044499 / 0.037052 (0.007447) | 0.273982 / 0.258489 (0.015493) | 0.303393 / 0.293841 (0.009552) | 0.029649 / 0.128546 (-0.098898) | 0.010555 / 0.075646 (-0.065091) | 0.057553 / 0.419271 (-0.361718) | 0.051686 / 0.043533 (0.008153) | 0.274079 / 0.255139 (0.018940) | 0.292535 / 0.283200 (0.009335) | 0.019211 / 0.141683 (-0.122472) | 1.130629 / 1.452155 (-0.321526) | 1.196791 / 1.492716 (-0.295925) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093617 / 0.018006 (0.075611) | 0.302698 / 0.000490 (0.302209) | 0.000222 / 0.000200 (0.000022) | 0.000046 / 0.000054 (-0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022830 / 0.037411 (-0.014581) | 0.077061 / 0.014526 (0.062535) | 0.089464 / 0.176557 (-0.087092) | 0.127487 / 0.737135 (-0.609649) | 0.092133 / 0.296338 (-0.204205) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295362 / 0.215209 (0.080153) | 2.902251 / 2.077655 (0.824596) | 1.600508 / 1.504120 (0.096388) | 1.477763 / 1.541195 (-0.063431) | 1.492242 / 1.468490 (0.023752) | 0.569347 / 4.584777 (-4.015430) | 2.449873 / 3.745712 (-1.295839) | 2.787207 / 5.269862 (-2.482655) | 1.723852 / 4.565676 (-2.841825) | 0.063076 / 0.424275 (-0.361199) | 0.005060 / 0.007607 (-0.002547) | 0.349614 / 0.226044 (0.123569) | 3.429735 / 2.268929 (1.160806) | 1.953883 / 55.444624 (-53.490741) | 1.664232 / 6.876477 (-5.212245) | 1.648864 / 2.142072 (-0.493209) | 0.640295 / 4.805227 (-4.164932) | 0.117053 / 6.500664 (-6.383611) | 0.041314 / 0.075469 (-0.034156) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.970663 / 1.841788 (-0.871125) | 12.144810 / 8.074308 (4.070502) | 10.938985 / 10.191392 (0.747593) | 0.140502 / 0.680424 (-0.539922) | 0.015522 / 0.534201 (-0.518679) | 0.286629 / 0.579283 (-0.292654) | 0.283695 / 0.434364 (-0.150669) | 0.327298 / 0.540337 (-0.213039) | 0.424635 / 1.386936 (-0.962301) |\n\n</details>\n</details>\n\n\n"
] |
set dev version
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6547/reactions"
}
|
PR_kwDODunzps5i-Jni
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6547.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6547",
"merged_at": "2023-12-30T16:47:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6547.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6547"
}
|
2023-12-30T16:47:17Z
|
https://api.github.com/repos/huggingface/datasets/issues/6547/comments
| null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6547/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6547/timeline
|
closed
| false | 6,547 | null |
2023-12-30T16:47:27Z
| null | true |
2,060,796,369 |
https://api.github.com/repos/huggingface/datasets/issues/6546
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6546/events
|
[] | null |
2023-12-30T16:52:07Z
|
[] |
https://github.com/huggingface/datasets/pull/6546
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6546). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005415 / 0.011353 (-0.005938) | 0.003733 / 0.011008 (-0.007275) | 0.064178 / 0.038508 (0.025670) | 0.033162 / 0.023109 (0.010053) | 0.249799 / 0.275898 (-0.026099) | 0.274875 / 0.323480 (-0.048605) | 0.002977 / 0.007986 (-0.005009) | 0.002696 / 0.004328 (-0.001633) | 0.050042 / 0.004250 (0.045792) | 0.047127 / 0.037052 (0.010074) | 0.250865 / 0.258489 (-0.007624) | 0.289758 / 0.293841 (-0.004083) | 0.028007 / 0.128546 (-0.100539) | 0.010671 / 0.075646 (-0.064975) | 0.207123 / 0.419271 (-0.212148) | 0.036403 / 0.043533 (-0.007130) | 0.261527 / 0.255139 (0.006388) | 0.277277 / 0.283200 (-0.005922) | 0.019418 / 0.141683 (-0.122264) | 1.118019 / 1.452155 (-0.334136) | 1.180254 / 1.492716 (-0.312462) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004604 / 0.018006 (-0.013402) | 0.308129 / 0.000490 (0.307639) | 0.000202 / 0.000200 (0.000002) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018400 / 0.037411 (-0.019011) | 0.060777 / 0.014526 (0.046251) | 0.073059 / 0.176557 (-0.103498) | 0.119677 / 0.737135 (-0.617458) | 0.074076 / 0.296338 (-0.222263) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.275353 / 0.215209 (0.060144) | 2.694079 / 2.077655 (0.616424) | 1.419670 / 1.504120 (-0.084450) | 1.302079 / 1.541195 (-0.239116) | 1.342077 / 1.468490 (-0.126413) | 0.549794 / 4.584777 (-4.034983) | 2.377149 / 3.745712 (-1.368563) | 2.800362 / 5.269862 (-2.469500) | 1.728152 / 4.565676 (-2.837524) | 0.061774 / 0.424275 (-0.362501) | 0.004898 / 0.007607 (-0.002709) | 0.330996 / 0.226044 (0.104952) | 3.262010 / 2.268929 (0.993082) | 1.761106 / 55.444624 (-53.683518) | 1.489783 / 6.876477 (-5.386694) | 1.532470 / 2.142072 (-0.609602) | 0.648814 / 4.805227 (-4.156414) | 0.116893 / 6.500664 (-6.383771) | 0.042167 / 0.075469 (-0.033303) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.937679 / 1.841788 (-0.904109) | 11.621632 / 8.074308 (3.547324) | 10.226177 / 10.191392 (0.034785) | 0.129242 / 0.680424 (-0.551182) | 0.014884 / 0.534201 (-0.519317) | 0.287619 / 0.579283 (-0.291664) | 0.261677 / 0.434364 (-0.172687) | 0.336361 / 0.540337 (-0.203976) | 0.426461 / 1.386936 (-0.960475) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005246 / 0.011353 (-0.006106) | 0.003533 / 0.011008 (-0.007475) | 0.051691 / 0.038508 (0.013182) | 0.031551 / 0.023109 (0.008442) | 0.297884 / 0.275898 (0.021986) | 0.323100 / 0.323480 (-0.000380) | 0.004101 / 0.007986 (-0.003884) | 0.002668 / 0.004328 (-0.001661) | 0.048764 / 0.004250 (0.044513) | 0.045429 / 0.037052 (0.008377) | 0.300107 / 0.258489 (0.041618) | 0.335650 / 0.293841 (0.041809) | 0.030061 / 0.128546 (-0.098485) | 0.010878 / 0.075646 (-0.064768) | 0.058561 / 0.419271 (-0.360710) | 0.052829 / 0.043533 (0.009296) | 0.302704 / 0.255139 (0.047565) | 0.320527 / 0.283200 (0.037327) | 0.018995 / 0.141683 (-0.122688) | 1.144050 / 1.452155 (-0.308105) | 1.255275 / 1.492716 (-0.237441) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092708 / 0.018006 (0.074701) | 0.305204 / 0.000490 (0.304714) | 0.000224 / 0.000200 (0.000024) | 0.000055 / 0.000054 (0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021607 / 0.037411 (-0.015805) | 0.075938 / 0.014526 (0.061412) | 0.090864 / 0.176557 (-0.085693) | 0.128248 / 0.737135 (-0.608887) | 0.090322 / 0.296338 (-0.206017) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.302095 / 0.215209 (0.086886) | 2.925686 / 2.077655 (0.848032) | 1.617767 / 1.504120 (0.113648) | 1.477975 / 1.541195 (-0.063220) | 1.508576 / 1.468490 (0.040086) | 0.574376 / 4.584777 (-4.010401) | 2.467483 / 3.745712 (-1.278229) | 2.832500 / 5.269862 (-2.437362) | 1.765233 / 4.565676 (-2.800443) | 0.064105 / 0.424275 (-0.360170) | 0.005090 / 0.007607 (-0.002517) | 0.349819 / 0.226044 (0.123774) | 3.468916 / 2.268929 (1.199987) | 1.946499 / 55.444624 (-53.498126) | 1.684369 / 6.876477 (-5.192107) | 1.711036 / 2.142072 (-0.431036) | 0.650153 / 4.805227 (-4.155075) | 0.116598 / 6.500664 (-6.384066) | 0.041213 / 0.075469 (-0.034256) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.990842 / 1.841788 (-0.850946) | 12.348468 / 8.074308 (4.274160) | 11.174441 / 10.191392 (0.983049) | 0.140950 / 0.680424 (-0.539473) | 0.016100 / 0.534201 (-0.518101) | 0.286486 / 0.579283 (-0.292797) | 0.282054 / 0.434364 (-0.152310) | 0.324261 / 0.540337 (-0.216076) | 0.420717 / 1.386936 (-0.966219) |\n\n</details>\n</details>\n\n\n"
] |
Release: 2.16.1
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6546/reactions"
}
|
PR_kwDODunzps5i-Jgv
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6546.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6546",
"merged_at": "2023-12-30T16:45:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6546.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6546"
}
|
2023-12-30T16:44:51Z
|
https://api.github.com/repos/huggingface/datasets/issues/6546/comments
| null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6546/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6546/timeline
|
closed
| false | 6,546 | null |
2023-12-30T16:45:52Z
| null | true |
2,060,789,507 |
https://api.github.com/repos/huggingface/datasets/issues/6545
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6545/events
|
[] | null |
2024-01-09T13:06:31Z
|
[] |
https://github.com/huggingface/datasets/issues/6545
|
NONE
|
completed
| null | null |
[] |
`image` column not automatically inferred if image dataset only contains 1 image
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6545/reactions"
}
|
I_kwDODunzps561ScD
| null |
2023-12-30T16:17:29Z
|
https://api.github.com/repos/huggingface/datasets/issues/6545/comments
|
### Describe the bug
By default, the standard Image Dataset maps out `file_name` to `image` when loading an Image Dataset.
However, if the dataset contains only 1 image, this does not take place
### Steps to reproduce the bug
Input
(dataset with one image `multimodalart/repro_1_image`)
```py
from datasets import load_dataset
dataset = load_dataset("multimodalart/repro_1_image")
dataset
```
Output:
```py
DatasetDict({
train: Dataset({
features: ['file_name', 'prompt'],
num_rows: 1
})
})
```
Input
(dataset with 2+ images `multimodalart/repro_2_image`)
```py
from datasets import load_dataset
dataset = load_dataset("multimodalart/repro_2_image")
dataset
```
Output:
```py
DatasetDict({
train: Dataset({
features: ['image', 'prompt'],
num_rows: 2
})
})
```
### Expected behavior
Expected to map `file_name` → `image` for all dataset sizes, including 1.
### Environment info
Both latest main and 2.16.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/788417?v=4",
"events_url": "https://api.github.com/users/apolinario/events{/privacy}",
"followers_url": "https://api.github.com/users/apolinario/followers",
"following_url": "https://api.github.com/users/apolinario/following{/other_user}",
"gists_url": "https://api.github.com/users/apolinario/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/apolinario",
"id": 788417,
"login": "apolinario",
"node_id": "MDQ6VXNlcjc4ODQxNw==",
"organizations_url": "https://api.github.com/users/apolinario/orgs",
"received_events_url": "https://api.github.com/users/apolinario/received_events",
"repos_url": "https://api.github.com/users/apolinario/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/apolinario/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/apolinario/subscriptions",
"type": "User",
"url": "https://api.github.com/users/apolinario"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6545/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6545/timeline
|
closed
| false | 6,545 | null |
2024-01-09T13:06:31Z
| null | false |
2,060,782,594 |
https://api.github.com/repos/huggingface/datasets/issues/6544
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6544/events
|
[] | null |
2024-01-02T11:02:39Z
|
[] |
https://github.com/huggingface/datasets/pull/6544
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6544). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005462 / 0.011353 (-0.005891) | 0.003918 / 0.011008 (-0.007090) | 0.065021 / 0.038508 (0.026513) | 0.032620 / 0.023109 (0.009511) | 0.249794 / 0.275898 (-0.026104) | 0.277330 / 0.323480 (-0.046150) | 0.002962 / 0.007986 (-0.005023) | 0.003435 / 0.004328 (-0.000894) | 0.048992 / 0.004250 (0.044742) | 0.046841 / 0.037052 (0.009788) | 0.252459 / 0.258489 (-0.006030) | 0.287889 / 0.293841 (-0.005952) | 0.028322 / 0.128546 (-0.100224) | 0.011214 / 0.075646 (-0.064432) | 0.208555 / 0.419271 (-0.210717) | 0.037004 / 0.043533 (-0.006529) | 0.262537 / 0.255139 (0.007398) | 0.307418 / 0.283200 (0.024218) | 0.021552 / 0.141683 (-0.120131) | 1.144252 / 1.452155 (-0.307903) | 1.195687 / 1.492716 (-0.297029) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004766 / 0.018006 (-0.013240) | 0.301926 / 0.000490 (0.301436) | 0.000218 / 0.000200 (0.000018) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.017891 / 0.037411 (-0.019521) | 0.066848 / 0.014526 (0.052322) | 0.075522 / 0.176557 (-0.101035) | 0.120762 / 0.737135 (-0.616374) | 0.075980 / 0.296338 (-0.220359) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.284843 / 0.215209 (0.069634) | 2.816260 / 2.077655 (0.738605) | 1.484370 / 1.504120 (-0.019750) | 1.362090 / 1.541195 (-0.179104) | 1.421729 / 1.468490 (-0.046762) | 0.561673 / 4.584777 (-4.023104) | 2.370793 / 3.745712 (-1.374919) | 2.982639 / 5.269862 (-2.287223) | 1.834614 / 4.565676 (-2.731063) | 0.063158 / 0.424275 (-0.361117) | 0.005044 / 0.007607 (-0.002563) | 0.339834 / 0.226044 (0.113790) | 3.369051 / 2.268929 (1.100122) | 1.821040 / 55.444624 (-53.623584) | 1.544009 / 6.876477 (-5.332468) | 1.603902 / 2.142072 (-0.538171) | 0.638151 / 4.805227 (-4.167076) | 0.117012 / 6.500664 (-6.383652) | 0.042999 / 0.075469 (-0.032470) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.941809 / 1.841788 (-0.899978) | 12.279635 / 8.074308 (4.205326) | 10.212876 / 10.191392 (0.021484) | 0.129904 / 0.680424 (-0.550519) | 0.014210 / 0.534201 (-0.519991) | 0.286140 / 0.579283 (-0.293143) | 0.267453 / 0.434364 (-0.166911) | 0.324417 / 0.540337 (-0.215921) | 0.428262 / 1.386936 (-0.958674) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005351 / 0.011353 (-0.006002) | 0.003591 / 0.011008 (-0.007417) | 0.048755 / 0.038508 (0.010247) | 0.030857 / 0.023109 (0.007748) | 0.270301 / 0.275898 (-0.005597) | 0.294459 / 0.323480 (-0.029021) | 0.004265 / 0.007986 (-0.003720) | 0.002712 / 0.004328 (-0.001616) | 0.047725 / 0.004250 (0.043475) | 0.048392 / 0.037052 (0.011339) | 0.274226 / 0.258489 (0.015737) | 0.304010 / 0.293841 (0.010169) | 0.029283 / 0.128546 (-0.099263) | 0.011196 / 0.075646 (-0.064450) | 0.057213 / 0.419271 (-0.362058) | 0.057504 / 0.043533 (0.013971) | 0.266091 / 0.255139 (0.010952) | 0.285991 / 0.283200 (0.002791) | 0.020030 / 0.141683 (-0.121653) | 1.121514 / 1.452155 (-0.330641) | 1.192608 / 1.492716 (-0.300108) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095041 / 0.018006 (0.077035) | 0.301255 / 0.000490 (0.300765) | 0.000218 / 0.000200 (0.000018) | 0.000044 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022265 / 0.037411 (-0.015146) | 0.078416 / 0.014526 (0.063890) | 0.091097 / 0.176557 (-0.085460) | 0.129864 / 0.737135 (-0.607272) | 0.091683 / 0.296338 (-0.204655) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.294104 / 0.215209 (0.078895) | 2.886809 / 2.077655 (0.809154) | 1.601931 / 1.504120 (0.097811) | 1.469353 / 1.541195 (-0.071842) | 1.525132 / 1.468490 (0.056642) | 0.565164 / 4.584777 (-4.019613) | 2.432873 / 3.745712 (-1.312839) | 2.885849 / 5.269862 (-2.384013) | 1.780474 / 4.565676 (-2.785203) | 0.064358 / 0.424275 (-0.359917) | 0.005186 / 0.007607 (-0.002421) | 0.349374 / 0.226044 (0.123329) | 3.424751 / 2.268929 (1.155823) | 1.956874 / 55.444624 (-53.487750) | 1.679002 / 6.876477 (-5.197475) | 1.718821 / 2.142072 (-0.423252) | 0.656974 / 4.805227 (-4.148254) | 0.120645 / 6.500664 (-6.380019) | 0.042355 / 0.075469 (-0.033114) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.001923 / 1.841788 (-0.839864) | 13.208127 / 8.074308 (5.133819) | 11.164863 / 10.191392 (0.973471) | 0.131964 / 0.680424 (-0.548460) | 0.015344 / 0.534201 (-0.518857) | 0.287961 / 0.579283 (-0.291322) | 0.273986 / 0.434364 (-0.160378) | 0.327280 / 0.540337 (-0.213058) | 0.426761 / 1.386936 (-0.960175) |\n\n</details>\n</details>\n\n\n",
"Thanks for the fix and the patch release. This confirms that, as I suggested in the Summer, maybe we should avoid making a release right before leaving on holidays."
] |
Fix custom configs from script
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6544/reactions"
}
|
PR_kwDODunzps5i-G4_
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6544.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6544",
"merged_at": "2023-12-30T16:09:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6544.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6544"
}
|
2023-12-30T15:51:25Z
|
https://api.github.com/repos/huggingface/datasets/issues/6544/comments
|
We should not use the parquet export when the user is passing config_kwargs
I also fixed a regression that would disallow creating a custom config when a dataset has multiple predefined configs
fix https://github.com/huggingface/datasets/issues/6533
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6544/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6544/timeline
|
closed
| false | 6,544 | null |
2023-12-30T16:09:49Z
| null | true |
2,060,776,174 |
https://api.github.com/repos/huggingface/datasets/issues/6543
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6543/events
|
[] | null |
2023-12-30T16:00:06Z
|
[] |
https://github.com/huggingface/datasets/pull/6543
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6543). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004950 / 0.011353 (-0.006403) | 0.003502 / 0.011008 (-0.007506) | 0.062517 / 0.038508 (0.024009) | 0.030965 / 0.023109 (0.007856) | 0.250661 / 0.275898 (-0.025237) | 0.279165 / 0.323480 (-0.044314) | 0.002960 / 0.007986 (-0.005026) | 0.003382 / 0.004328 (-0.000946) | 0.048174 / 0.004250 (0.043923) | 0.042975 / 0.037052 (0.005922) | 0.248079 / 0.258489 (-0.010410) | 0.283770 / 0.293841 (-0.010070) | 0.027935 / 0.128546 (-0.100611) | 0.010634 / 0.075646 (-0.065012) | 0.207039 / 0.419271 (-0.212233) | 0.035863 / 0.043533 (-0.007670) | 0.257426 / 0.255139 (0.002287) | 0.274222 / 0.283200 (-0.008978) | 0.017590 / 0.141683 (-0.124093) | 1.126889 / 1.452155 (-0.325266) | 1.160795 / 1.492716 (-0.331921) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004298 / 0.018006 (-0.013708) | 0.301366 / 0.000490 (0.300876) | 0.000202 / 0.000200 (0.000002) | 0.000050 / 0.000054 (-0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018159 / 0.037411 (-0.019252) | 0.060566 / 0.014526 (0.046041) | 0.072500 / 0.176557 (-0.104057) | 0.119612 / 0.737135 (-0.617523) | 0.074467 / 0.296338 (-0.221871) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.281859 / 0.215209 (0.066650) | 2.760157 / 2.077655 (0.682502) | 1.450632 / 1.504120 (-0.053487) | 1.326636 / 1.541195 (-0.214559) | 1.363381 / 1.468490 (-0.105109) | 0.576199 / 4.584777 (-4.008578) | 2.355776 / 3.745712 (-1.389936) | 2.807308 / 5.269862 (-2.462553) | 1.745449 / 4.565676 (-2.820228) | 0.063413 / 0.424275 (-0.360862) | 0.004978 / 0.007607 (-0.002630) | 0.332738 / 0.226044 (0.106693) | 3.267677 / 2.268929 (0.998748) | 1.766074 / 55.444624 (-53.678551) | 1.500853 / 6.876477 (-5.375624) | 1.532434 / 2.142072 (-0.609639) | 0.648238 / 4.805227 (-4.156989) | 0.116030 / 6.500664 (-6.384634) | 0.042018 / 0.075469 (-0.033451) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.934325 / 1.841788 (-0.907463) | 11.439765 / 8.074308 (3.365457) | 9.958624 / 10.191392 (-0.232768) | 0.130295 / 0.680424 (-0.550129) | 0.014437 / 0.534201 (-0.519764) | 0.286073 / 0.579283 (-0.293210) | 0.262430 / 0.434364 (-0.171934) | 0.323905 / 0.540337 (-0.216432) | 0.416615 / 1.386936 (-0.970321) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005149 / 0.011353 (-0.006204) | 0.003517 / 0.011008 (-0.007491) | 0.048658 / 0.038508 (0.010150) | 0.029638 / 0.023109 (0.006529) | 0.271002 / 0.275898 (-0.004896) | 0.324910 / 0.323480 (0.001430) | 0.004086 / 0.007986 (-0.003900) | 0.002609 / 0.004328 (-0.001719) | 0.047806 / 0.004250 (0.043556) | 0.045422 / 0.037052 (0.008369) | 0.274317 / 0.258489 (0.015828) | 0.304544 / 0.293841 (0.010703) | 0.029318 / 0.128546 (-0.099229) | 0.010626 / 0.075646 (-0.065020) | 0.057838 / 0.419271 (-0.361434) | 0.052408 / 0.043533 (0.008875) | 0.267736 / 0.255139 (0.012597) | 0.292024 / 0.283200 (0.008824) | 0.019244 / 0.141683 (-0.122439) | 1.167728 / 1.452155 (-0.284427) | 1.226364 / 1.492716 (-0.266352) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092441 / 0.018006 (0.074435) | 0.310316 / 0.000490 (0.309827) | 0.000218 / 0.000200 (0.000018) | 0.000049 / 0.000054 (-0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021818 / 0.037411 (-0.015594) | 0.076515 / 0.014526 (0.061989) | 0.089179 / 0.176557 (-0.087377) | 0.127034 / 0.737135 (-0.610102) | 0.089646 / 0.296338 (-0.206692) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.292056 / 0.215209 (0.076847) | 2.841410 / 2.077655 (0.763756) | 1.550626 / 1.504120 (0.046506) | 1.426204 / 1.541195 (-0.114990) | 1.445838 / 1.468490 (-0.022652) | 0.555777 / 4.584777 (-4.029000) | 2.441077 / 3.745712 (-1.304635) | 2.773445 / 5.269862 (-2.496416) | 1.728951 / 4.565676 (-2.836726) | 0.062579 / 0.424275 (-0.361697) | 0.005063 / 0.007607 (-0.002544) | 0.350749 / 0.226044 (0.124705) | 3.461702 / 2.268929 (1.192773) | 1.892506 / 55.444624 (-53.552118) | 1.625958 / 6.876477 (-5.250519) | 1.649175 / 2.142072 (-0.492898) | 0.636123 / 4.805227 (-4.169105) | 0.116548 / 6.500664 (-6.384116) | 0.041174 / 0.075469 (-0.034295) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.973468 / 1.841788 (-0.868320) | 12.104761 / 8.074308 (4.030453) | 11.131691 / 10.191392 (0.940299) | 0.132309 / 0.680424 (-0.548115) | 0.016191 / 0.534201 (-0.518010) | 0.284748 / 0.579283 (-0.294535) | 0.282661 / 0.434364 (-0.151703) | 0.323797 / 0.540337 (-0.216540) | 0.417767 / 1.386936 (-0.969169) |\n\n</details>\n</details>\n\n\n"
] |
Fix dl_manager.extract returning FileNotFoundError
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6543/reactions"
}
|
PR_kwDODunzps5i-Frx
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6543.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6543",
"merged_at": "2023-12-30T15:53:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6543.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6543"
}
|
2023-12-30T15:24:50Z
|
https://api.github.com/repos/huggingface/datasets/issues/6543/comments
|
The dl_manager base path is remote (e.g. a hf:// path), so local cached paths should be passed as absolute paths.
This could happen if users provide a relative path as `cache_dir`
fix https://github.com/huggingface/datasets/issues/6536
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6543/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6543/timeline
|
closed
| false | 6,543 | null |
2023-12-30T15:53:59Z
| null | true |
2,059,198,575 |
https://api.github.com/repos/huggingface/datasets/issues/6542
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6542/events
|
[] | null |
2024-01-02T13:21:06Z
|
[] |
https://github.com/huggingface/datasets/issues/6542
|
NONE
|
completed
| null | null |
[
"Hi ! We now recommend using the `wikimedia/wikipedia` dataset, can you try loading this one instead ?\r\n\r\n```python\r\nwiki_dataset = load_dataset(\"wikimedia/wikipedia\", \"20231101.en\")\r\n```",
"This bug has been fixed in `2.16.1` thanks to https://github.com/huggingface/datasets/pull/6544, feel free to update `datasets` and re-run your code :)\r\n\r\n```\r\npip install -U datasets\r\n```"
] |
Datasets : wikipedia 20220301.en error
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6542/reactions"
}
|
I_kwDODunzps56vOBv
| null |
2023-12-29T08:34:51Z
|
https://api.github.com/repos/huggingface/datasets/issues/6542/comments
|
### Describe the bug
When I used load_dataset to download this data set, the following error occurred. The main problem was that the target data did not exist.
### Steps to reproduce the bug
1.I tried downloading directly.
```python
wiki_dataset = load_dataset("wikipedia", "20220301.en")
```
An exception occurred
```
MissingBeamOptions: Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, Spark, etc. More information about Apache Beam runners at https://beam.apache.org/documentation/runners/capability-matrix/
If you really want to run it locally because you feel like the Dataset is small enough, you can use the local beam runner called `DirectRunner` (you may run out of memory).
Example of usage:
`load_dataset('wikipedia', '20220301.en', beam_runner='DirectRunner')`
```
2.I modified the code as prompted.
```python
wiki_dataset = load_dataset('wikipedia', '20220301.en', beam_runner='DirectRunner')
```
An exception occurred:
```
FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/enwiki/20220301/dumpstatus.json
```
### Expected behavior
I searched in the parent directory of the corresponding URL, but there was no corresponding "20220301" directory.
I really need this data set and hope to provide a download method.
### Environment info
python 3.8
datasets 2.16.0
apache-beam 2.52.0
dill 0.3.7
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/53203620?v=4",
"events_url": "https://api.github.com/users/ppx666/events{/privacy}",
"followers_url": "https://api.github.com/users/ppx666/followers",
"following_url": "https://api.github.com/users/ppx666/following{/other_user}",
"gists_url": "https://api.github.com/users/ppx666/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ppx666",
"id": 53203620,
"login": "ppx666",
"node_id": "MDQ6VXNlcjUzMjAzNjIw",
"organizations_url": "https://api.github.com/users/ppx666/orgs",
"received_events_url": "https://api.github.com/users/ppx666/received_events",
"repos_url": "https://api.github.com/users/ppx666/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ppx666/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ppx666/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ppx666"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6542/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6542/timeline
|
closed
| false | 6,542 | null |
2024-01-02T13:20:30Z
| null | false |
2,058,983,826 |
https://api.github.com/repos/huggingface/datasets/issues/6541
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6541/events
|
[] | null |
2024-01-17T00:40:46Z
|
[] |
https://github.com/huggingface/datasets/issues/6541
|
NONE
|
completed
| null | null |
[
"This is a problem with your environment. You should be able to fix it by upgrading `numpy` based on [this](https://github.com/numpy/numpy/issues/23570) issue.",
"Bro I already update numpy package.",
"Then, this shouldn't throw an error on your machine:\r\n```python\r\nimport numpy\r\nnumpy._no_nep50_warning\r\n```\r\n\r\nIf it does, run `python -m pip install numpy` to ensure the correct `pip` is used for the package installation.",
"Your suggestion to run `python -m pip install numpy` proved to be successful, and my issue has been resolved. I am grateful for your assistance, @mariosasko"
] |
Dataset not loading successfully.
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6541/reactions"
}
|
I_kwDODunzps56uZmS
| null |
2023-12-29T01:35:47Z
|
https://api.github.com/repos/huggingface/datasets/issues/6541/comments
|
### Describe the bug
When I run down the below code shows this error: AttributeError: module 'numpy' has no attribute '_no_nep50_warning'
I also added this issue in transformers library please check out: [link](https://github.com/huggingface/transformers/issues/28099)
### Steps to reproduce the bug
## Reproduction
Hi, please check this line of code, when I run Show attribute error.
```
from datasets import load_dataset
from transformers import WhisperProcessor, WhisperForConditionalGeneration
# Select an audio file and read it:
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
audio_sample = ds[0]["audio"]
waveform = audio_sample["array"]
sampling_rate = audio_sample["sampling_rate"]
# Load the Whisper model in Hugging Face format:
processor = WhisperProcessor.from_pretrained("openai/whisper-tiny.en")
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
# Use the model and processor to transcribe the audio:
input_features = processor(
waveform, sampling_rate=sampling_rate, return_tensors="pt"
).input_features
# Generate token ids
predicted_ids = model.generate(input_features)
# Decode token ids to text
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
transcription[0]
```
**Attribute Error**
```
AttributeError Traceback (most recent call last)
Cell In[9], line 6
4 # Select an audio file and read it:
5 ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
----> 6 audio_sample = ds[0]["audio"]
7 waveform = audio_sample["array"]
8 sampling_rate = audio_sample["sampling_rate"]
File /opt/pytorch/lib/python3.8/site-packages/datasets/arrow_dataset.py:2795, in Dataset.__getitem__(self, key)
2793 def __getitem__(self, key): # noqa: F811
2794 """Can be used to index columns (by string names) or rows (by integer index or iterable of indices or bools)."""
-> 2795 return self._getitem(key)
File /opt/pytorch/lib/python3.8/site-packages/datasets/arrow_dataset.py:2780, in Dataset._getitem(self, key, **kwargs)
2778 formatter = get_formatter(format_type, features=self._info.features, **format_kwargs)
2779 pa_subtable = query_table(self._data, key, indices=self._indices if self._indices is not None else None)
-> 2780 formatted_output = format_table(
2781 pa_subtable, key, formatter=formatter, format_columns=format_columns, output_all_columns=output_all_columns
2782 )
2783 return formatted_output
File /opt/pytorch/lib/python3.8/site-packages/datasets/formatting/formatting.py:629, in format_table(table, key, formatter, format_columns, output_all_columns)
627 python_formatter = PythonFormatter(features=formatter.features)
628 if format_columns is None:
--> 629 return formatter(pa_table, query_type=query_type)
630 elif query_type == "column":
631 if key in format_columns:
File /opt/pytorch/lib/python3.8/site-packages/datasets/formatting/formatting.py:396, in Formatter.__call__(self, pa_table, query_type)
394 def __call__(self, pa_table: pa.Table, query_type: str) -> Union[RowFormat, ColumnFormat, BatchFormat]:
395 if query_type == "row":
--> 396 return self.format_row(pa_table)
397 elif query_type == "column":
398 return self.format_column(pa_table)
File /opt/pytorch/lib/python3.8/site-packages/datasets/formatting/formatting.py:437, in PythonFormatter.format_row(self, pa_table)
435 return LazyRow(pa_table, self)
436 row = self.python_arrow_extractor().extract_row(pa_table)
--> 437 row = self.python_features_decoder.decode_row(row)
438 return row
File /opt/pytorch/lib/python3.8/site-packages/datasets/formatting/formatting.py:215, in PythonFeaturesDecoder.decode_row(self, row)
214 def decode_row(self, row: dict) -> dict:
--> 215 return self.features.decode_example(row) if self.features else row
File /opt/pytorch/lib/python3.8/site-packages/datasets/features/features.py:1917, in Features.decode_example(self, example, token_per_repo_id)
1903 def decode_example(self, example: dict, token_per_repo_id: Optional[Dict[str, Union[str, bool, None]]] = None):
1904 """Decode example with custom feature decoding.
1905
1906 Args:
(...)
1914 `dict[str, Any]`
1915 """
-> 1917 return {
1918 column_name: decode_nested_example(feature, value, token_per_repo_id=token_per_repo_id)
1919 if self._column_requires_decoding[column_name]
1920 else value
1921 for column_name, (feature, value) in zip_dict(
1922 {key: value for key, value in self.items() if key in example}, example
1923 )
1924 }
File /opt/pytorch/lib/python3.8/site-packages/datasets/features/features.py:1918, in <dictcomp>(.0)
1903 def decode_example(self, example: dict, token_per_repo_id: Optional[Dict[str, Union[str, bool, None]]] = None):
1904 """Decode example with custom feature decoding.
1905
1906 Args:
(...)
1914 `dict[str, Any]`
1915 """
1917 return {
-> 1918 column_name: decode_nested_example(feature, value, token_per_repo_id=token_per_repo_id)
1919 if self._column_requires_decoding[column_name]
1920 else value
1921 for column_name, (feature, value) in zip_dict(
1922 {key: value for key, value in self.items() if key in example}, example
1923 )
1924 }
File /opt/pytorch/lib/python3.8/site-packages/datasets/features/features.py:1339, in decode_nested_example(schema, obj, token_per_repo_id)
1336 elif isinstance(schema, (Audio, Image)):
1337 # we pass the token to read and decode files from private repositories in streaming mode
1338 if obj is not None and schema.decode:
-> 1339 return schema.decode_example(obj, token_per_repo_id=token_per_repo_id)
1340 return obj
File /opt/pytorch/lib/python3.8/site-packages/datasets/features/audio.py:191, in Audio.decode_example(self, value, token_per_repo_id)
189 array = array.T
190 if self.mono:
--> 191 array = librosa.to_mono(array)
192 if self.sampling_rate and self.sampling_rate != sampling_rate:
193 array = librosa.resample(array, orig_sr=sampling_rate, target_sr=self.sampling_rate)
File /opt/pytorch/lib/python3.8/site-packages/lazy_loader/__init__.py:78, in attach.<locals>.__getattr__(name)
76 submod_path = f"{package_name}.{attr_to_modules[name]}"
77 submod = importlib.import_module(submod_path)
---> 78 attr = getattr(submod, name)
80 # If the attribute lives in a file (module) with the same
81 # name as the attribute, ensure that the attribute and *not*
82 # the module is accessible on the package.
83 if name == attr_to_modules[name]:
File /opt/pytorch/lib/python3.8/site-packages/lazy_loader/__init__.py:77, in attach.<locals>.__getattr__(name)
75 elif name in attr_to_modules:
76 submod_path = f"{package_name}.{attr_to_modules[name]}"
---> 77 submod = importlib.import_module(submod_path)
78 attr = getattr(submod, name)
80 # If the attribute lives in a file (module) with the same
81 # name as the attribute, ensure that the attribute and *not*
82 # the module is accessible on the package.
File /usr/lib/python3.8/importlib/__init__.py:127, in import_module(name, package)
125 break
126 level += 1
--> 127 return _bootstrap._gcd_import(name[level:], package, level)
File <frozen importlib._bootstrap>:1014, in _gcd_import(name, package, level)
File <frozen importlib._bootstrap>:991, in _find_and_load(name, import_)
File <frozen importlib._bootstrap>:975, in _find_and_load_unlocked(name, import_)
File <frozen importlib._bootstrap>:671, in _load_unlocked(spec)
File <frozen importlib._bootstrap_external>:848, in exec_module(self, module)
File <frozen importlib._bootstrap>:219, in _call_with_frames_removed(f, *args, **kwds)
File /opt/pytorch/lib/python3.8/site-packages/librosa/core/audio.py:13
11 import audioread
12 import numpy as np
---> 13 import scipy.signal
14 import soxr
15 import lazy_loader as lazy
File /opt/pytorch/lib/python3.8/site-packages/scipy/signal/__init__.py:323
314 from ._spline import ( # noqa: F401
315 cspline2d,
316 qspline2d,
(...)
319 symiirorder2,
320 )
322 from ._bsplines import *
--> 323 from ._filter_design import *
324 from ._fir_filter_design import *
325 from ._ltisys import *
File /opt/pytorch/lib/python3.8/site-packages/scipy/signal/_filter_design.py:16
13 from numpy.polynomial.polynomial import polyval as npp_polyval
14 from numpy.polynomial.polynomial import polyvalfromroots
---> 16 from scipy import special, optimize, fft as sp_fft
17 from scipy.special import comb
18 from scipy._lib._util import float_factorial
File /opt/pytorch/lib/python3.8/site-packages/scipy/optimize/__init__.py:405
1 """
2 =====================================================
3 Optimization and root finding (:mod:`scipy.optimize`)
(...)
401
402 """
404 from ._optimize import *
--> 405 from ._minimize import *
406 from ._root import *
407 from ._root_scalar import *
File /opt/pytorch/lib/python3.8/site-packages/scipy/optimize/_minimize.py:26
24 from ._trustregion_krylov import _minimize_trust_krylov
25 from ._trustregion_exact import _minimize_trustregion_exact
---> 26 from ._trustregion_constr import _minimize_trustregion_constr
28 # constrained minimization
29 from ._lbfgsb_py import _minimize_lbfgsb
File /opt/pytorch/lib/python3.8/site-packages/scipy/optimize/_trustregion_constr/__init__.py:4
1 """This module contains the equality constrained SQP solver."""
----> 4 from .minimize_trustregion_constr import _minimize_trustregion_constr
6 __all__ = ['_minimize_trustregion_constr']
File /opt/pytorch/lib/python3.8/site-packages/scipy/optimize/_trustregion_constr/minimize_trustregion_constr.py:5
3 from scipy.sparse.linalg import LinearOperator
4 from .._differentiable_functions import VectorFunction
----> 5 from .._constraints import (
6 NonlinearConstraint, LinearConstraint, PreparedConstraint, strict_bounds)
7 from .._hessian_update_strategy import BFGS
8 from .._optimize import OptimizeResult
File /opt/pytorch/lib/python3.8/site-packages/scipy/optimize/_constraints.py:8
6 from ._optimize import OptimizeWarning
7 from warnings import warn, catch_warnings, simplefilter
----> 8 from numpy.testing import suppress_warnings
9 from scipy.sparse import issparse
12 def _arr_to_scalar(x):
13 # If x is a numpy array, return x.item(). This will
14 # fail if the array has more than one element.
File /opt/pytorch/lib/python3.8/site-packages/numpy/testing/__init__.py:11
8 from unittest import TestCase
10 from . import _private
---> 11 from ._private.utils import *
12 from ._private.utils import (_assert_valid_refcount, _gen_alignment_data)
13 from ._private import extbuild, decorators as dec
File /opt/pytorch/lib/python3.8/site-packages/numpy/testing/_private/utils.py:480
476 pprint.pprint(desired, msg)
477 raise AssertionError(msg.getvalue())
--> 480 @np._no_nep50_warning()
481 def assert_almost_equal(actual,desired,decimal=7,err_msg='',verbose=True):
482 """
483 Raises an AssertionError if two items are not equal up to desired
484 precision.
(...)
548
549 """
550 __tracebackhide__ = True # Hide traceback for py.test
File /opt/pytorch/lib/python3.8/site-packages/numpy/__init__.py:313, in __getattr__(attr)
305 raise AttributeError(__former_attrs__[attr])
307 # Importing Tester requires importing all of UnitTest which is not a
308 # cheap import Since it is mainly used in test suits, we lazy import it
309 # here to save on the order of 10 ms of import time for most users
310 #
311 # The previous way Tester was imported also had a side effect of adding
312 # the full `numpy.testing` namespace
--> 313 if attr == 'testing':
314 import numpy.testing as testing
315 return testing
AttributeError: module 'numpy' has no attribute '_no_nep50_warning'
```
### Expected behavior
``` ' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.' ```
Also, make sure this script is provided for your official website so please update:
[script](https://huggingface.co/docs/transformers/model_doc/whisper)
### Environment info
**System Info**
* transformers -> 4.36.1
* datasets -> 2.15.0
* huggingface_hub -> 0.19.4
* python -> 3.8.10
* accelerate -> 0.25.0
* pytorch -> 2.0.1+cpu
* Using GPU in Script -> No
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/93595990?v=4",
"events_url": "https://api.github.com/users/hi-sushanta/events{/privacy}",
"followers_url": "https://api.github.com/users/hi-sushanta/followers",
"following_url": "https://api.github.com/users/hi-sushanta/following{/other_user}",
"gists_url": "https://api.github.com/users/hi-sushanta/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hi-sushanta",
"id": 93595990,
"login": "hi-sushanta",
"node_id": "U_kgDOBZQpVg",
"organizations_url": "https://api.github.com/users/hi-sushanta/orgs",
"received_events_url": "https://api.github.com/users/hi-sushanta/received_events",
"repos_url": "https://api.github.com/users/hi-sushanta/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hi-sushanta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hi-sushanta/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hi-sushanta"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6541/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6541/timeline
|
closed
| false | 6,541 | null |
2024-01-17T00:40:45Z
| null | false |
2,058,965,157 |
https://api.github.com/repos/huggingface/datasets/issues/6540
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6540/events
|
[] | null |
2023-12-30T15:05:48Z
|
[] |
https://github.com/huggingface/datasets/issues/6540
|
NONE
| null | null | null |
[
"Concatenating datasets doesn't create any indices mapping - so flattening indices is not needed (unless you shuffle the dataset).\r\nCan you share the snippet of code you are using to merge your datasets and save them to disk ?"
] |
Extreme inefficiency for `save_to_disk` when merging datasets
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6540/reactions"
}
|
I_kwDODunzps56uVCl
| null |
2023-12-29T00:44:35Z
|
https://api.github.com/repos/huggingface/datasets/issues/6540/comments
|
### Describe the bug
Hi, I tried to merge in total 22M sequences of data, where each sequence is of maximum length 2000. I found that merging these datasets and then `save_to_disk` is extremely slow because of flattening the indices. Wondering if you have any suggestions or guidance on this. Thank you very much!
### Steps to reproduce the bug
The source data is too big to demonstrate
### Expected behavior
The source data is too big to demonstrate
### Environment info
python 3.9.0
datasets 2.7.0
pytorch 2.0.0
tokenizers 0.13.1
transformers 4.31.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43512683?v=4",
"events_url": "https://api.github.com/users/KatarinaYuan/events{/privacy}",
"followers_url": "https://api.github.com/users/KatarinaYuan/followers",
"following_url": "https://api.github.com/users/KatarinaYuan/following{/other_user}",
"gists_url": "https://api.github.com/users/KatarinaYuan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/KatarinaYuan",
"id": 43512683,
"login": "KatarinaYuan",
"node_id": "MDQ6VXNlcjQzNTEyNjgz",
"organizations_url": "https://api.github.com/users/KatarinaYuan/orgs",
"received_events_url": "https://api.github.com/users/KatarinaYuan/received_events",
"repos_url": "https://api.github.com/users/KatarinaYuan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/KatarinaYuan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KatarinaYuan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/KatarinaYuan"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6540/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6540/timeline
|
open
| false | 6,540 | null | null | null | false |
2,058,493,960 |
https://api.github.com/repos/huggingface/datasets/issues/6539
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6539/events
|
[] | null |
2023-12-28T14:18:37Z
|
[] |
https://github.com/huggingface/datasets/issues/6539
|
NONE
| null | null | null |
[] |
'Repo card metadata block was not found' when loading a pragmeval dataset
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6539/reactions"
}
|
I_kwDODunzps56siAI
| null |
2023-12-28T14:18:25Z
|
https://api.github.com/repos/huggingface/datasets/issues/6539/comments
|
### Describe the bug
I can't load dataset subsets of 'pragmeval'.
The funny thing is I ran the dataset author's [colab notebook](https://colab.research.google.com/drive/1sg--LF4z7XR1wxAOfp0-3d4J6kQ9nj_A?usp=sharing) and it works just fine. I tried to install exactly the same packages that are installed on colab using poetry, so my environment info only differs from the one from colab in linux version - I still get the same bug outside colab.
### Steps to reproduce the bug
Install dependencies with poetry
pyproject.toml
```
[tool.poetry]
name = "project"
version = "0.1.0"
description = ""
authors = []
[tool.poetry.dependencies]
python = "^3.10"
datasets = "2.16.0"
pandas = "1.5.3"
pyarrow = "10.0.1"
huggingface-hub = "0.19.4"
fsspec = "2023.6.0"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
```
`poetry run python -c "import datasets; print(datasets.get_dataset_config_names('pragmeval'))`
prints ['default']
### Expected behavior
The command should print
```
['emergent',
'emobank-arousal',
'emobank-dominance',
'emobank-valence',
'gum',
'mrda',
'pdtb',
'persuasiveness-claimtype',
'persuasiveness-eloquence',
'persuasiveness-premisetype',
'persuasiveness-relevance',
'persuasiveness-specificity',
'persuasiveness-strength',
'sarcasm',
'squinky-formality',
'squinky-implicature',
'squinky-informativeness',
'stac',
'switchboard',
'verifiability']
```
### Environment info
- `datasets` version: 2.16.0
- Platform: Linux-6.2.0-37-generic-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.19.4
- PyArrow version: 10.0.1
- Pandas version: 1.5.3
- `fsspec` version: 2023.6.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3647577?v=4",
"events_url": "https://api.github.com/users/lambdaofgod/events{/privacy}",
"followers_url": "https://api.github.com/users/lambdaofgod/followers",
"following_url": "https://api.github.com/users/lambdaofgod/following{/other_user}",
"gists_url": "https://api.github.com/users/lambdaofgod/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lambdaofgod",
"id": 3647577,
"login": "lambdaofgod",
"node_id": "MDQ6VXNlcjM2NDc1Nzc=",
"organizations_url": "https://api.github.com/users/lambdaofgod/orgs",
"received_events_url": "https://api.github.com/users/lambdaofgod/received_events",
"repos_url": "https://api.github.com/users/lambdaofgod/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lambdaofgod/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lambdaofgod/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lambdaofgod"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6539/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6539/timeline
|
open
| false | 6,539 | null | null | null | false |
2,057,377,630 |
https://api.github.com/repos/huggingface/datasets/issues/6538
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6538/events
|
[] | null |
2024-01-03T10:06:47Z
|
[] |
https://github.com/huggingface/datasets/issues/6538
|
NONE
|
completed
| null | null |
[
"Hi ! Are you sure you have `datasets` 2.16 ? I just checked and on 2.16 I can run `from datasets.arrow_writer import SchemaInferenceError` without error",
"I have the same issue - using with datasets version 2.16.1. Also this is on a kaggle notebook - other people with the same issue also seem to be having it on kaggle?",
"I have the same issue now and didn't have this problem around 2 weeks ago.",
"> Hi ! Are you sure you have `datasets` 2.16 ? I just checked and on 2.16 I can run `from datasets.arrow_writer import SchemaInferenceError` without error\r\n\r\nYes, I am sure\r\n\r\n```\r\n!pip show datasets\r\nName: datasets\r\nVersion: 2.16.1\r\nSummary: HuggingFace community-driven open-source library of datasets\r\nHome-page: https://github.com/huggingface/datasets\r\nAuthor: HuggingFace Inc.\r\nAuthor-email: thomas@huggingface.co\r\nLicense: Apache 2.0\r\nLocation: /opt/conda/lib/python3.10/site-packages\r\nRequires: aiohttp, dill, filelock, fsspec, huggingface-hub, multiprocess, numpy, packaging, pandas, pyarrow, pyarrow-hotfix, pyyaml, requests, tqdm, xxhash\r\nRequired-by: trl\r\n```",
"> I have the same issue - using with datasets version 2.16.1. Also this is on a kaggle notebook - other people with the same issue also seem to be having it on kaggle?\r\n\r\nDon't know about other people. But I am having this issue whose solution I can't find anywhere. And this issue still persists. ",
"> I have the same issue now and didn't have this problem around 2 weeks ago.\r\n\r\nSame here",
"I was having the same issue but the datasets version was 2.6.1, after I updated it to latest(2.16), error is gone while importing.\r\n",
"> I was having the same issue but the datasets version was 2.6.1, after I updated it to latest(2.16), error is gone while importing.\r\n\r\nI also have datasets version 2.16, but the error is still there.",
"Can you try re-installing `datasets` ?",
"> Can you try re-installing `datasets` ?\r\n\r\nI tried re-installing. Still getting the same error. \r\n",
"> > Can you try re-installing `datasets` ?\r\n> \r\n> I tried re-installing. Still getting the same error.\r\n\r\nIn kaggle I used:\r\n- `%pip install -U datasets`\r\nand then restarted runtime and then everything works fine.",
"> > > Can you try re-installing `datasets` ?\r\n> > \r\n> > \r\n> > I tried re-installing. Still getting the same error.\r\n> \r\n> In kaggle I used:\r\n> \r\n> * `%pip install -U datasets`\r\n> and then restarted runtime and then everything works fine.\r\n\r\nYes, this is working. When I restart the runtime after installing packages, it's working perfectly. Thank you so much. But why do we need to restart runtime every time after installing packages?",
"> > > > Can you try re-installing `datasets` ?\r\n> > > \r\n> > > \r\n> > > I tried re-installing. Still getting the same error.\r\n> > \r\n> > \r\n> > In kaggle I used:\r\n> > \r\n> > * `%pip install -U datasets`\r\n> > and then restarted runtime and then everything works fine.\r\n> \r\n> Yes, this is working. When I restart the runtime after installing packages, it's working perfectly. Thank you so much. But why do we need to restart runtime every time after installing packages?\r\nFor some packages it is required.\r\nhttps://stackoverflow.com/questions/57831187/need-to-restart-runtime-before-import-an-installed-package-in-colab\r\n",
"> > > > > Can you try re-installing `datasets` ?\r\n> > > > \r\n> > > > \r\n> > > > I tried re-installing. Still getting the same error.\r\n> > > \r\n> > > \r\n> > > In kaggle I used:\r\n> > > \r\n> > > * `%pip install -U datasets`\r\n> > > and then restarted runtime and then everything works fine.\r\n> > \r\n> > \r\n> > Yes, this is working. When I restart the runtime after installing packages, it's working perfectly. Thank you so much. But why do we need to restart runtime every time after installing packages?\r\n> > For some packages it is required.\r\n> > https://stackoverflow.com/questions/57831187/need-to-restart-runtime-before-import-an-installed-package-in-colab\r\n\r\nThank you for your assistance. I dedicated the past 2-3 weeks to resolving this issue. Interestingly, it runs flawlessly in Colab without requiring a runtime restart. However, the problem persisted exclusively in Kaggle. I appreciate your help once again. Thank you.",
"Closing this issue as it is not related to the datasets library; rather, it's linked to platform-related issues."
] |
ImportError: cannot import name 'SchemaInferenceError' from 'datasets.arrow_writer' (/opt/conda/lib/python3.10/site-packages/datasets/arrow_writer.py)
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6538/reactions"
}
|
I_kwDODunzps56oRde
| null |
2023-12-27T13:31:16Z
|
https://api.github.com/repos/huggingface/datasets/issues/6538/comments
|
### Describe the bug
While importing from packages getting the error
Code:
```
import os
import torch
from datasets import load_dataset, Dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
from huggingface_hub import login
import pandas as pd
```
Error:
````
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[5], line 14
4 from transformers import (
5 AutoModelForCausalLM,
6 AutoTokenizer,
(...)
11 logging
12 )
13 from peft import LoraConfig, PeftModel
---> 14 from trl import SFTTrainer
15 from huggingface_hub import login
16 import pandas as pd
File /opt/conda/lib/python3.10/site-packages/trl/__init__.py:21
8 from .import_utils import (
9 is_diffusers_available,
10 is_npu_available,
(...)
13 is_xpu_available,
14 )
15 from .models import (
16 AutoModelForCausalLMWithValueHead,
17 AutoModelForSeq2SeqLMWithValueHead,
18 PreTrainedModelWrapper,
19 create_reference_model,
20 )
---> 21 from .trainer import (
22 DataCollatorForCompletionOnlyLM,
23 DPOTrainer,
24 IterativeSFTTrainer,
25 PPOConfig,
26 PPOTrainer,
27 RewardConfig,
28 RewardTrainer,
29 SFTTrainer,
30 )
33 if is_diffusers_available():
34 from .models import (
35 DDPOPipelineOutput,
36 DDPOSchedulerOutput,
37 DDPOStableDiffusionPipeline,
38 DefaultDDPOStableDiffusionPipeline,
39 )
File /opt/conda/lib/python3.10/site-packages/trl/trainer/__init__.py:44
42 from .ppo_trainer import PPOTrainer
43 from .reward_trainer import RewardTrainer, compute_accuracy
---> 44 from .sft_trainer import SFTTrainer
45 from .training_configs import RewardConfig
File /opt/conda/lib/python3.10/site-packages/trl/trainer/sft_trainer.py:23
21 import torch.nn as nn
22 from datasets import Dataset
---> 23 from datasets.arrow_writer import SchemaInferenceError
24 from datasets.builder import DatasetGenerationError
25 from transformers import (
26 AutoModelForCausalLM,
27 AutoTokenizer,
(...)
33 TrainingArguments,
34 )
ImportError: cannot import name 'SchemaInferenceError' from 'datasets.arrow_writer' (/opt/conda/lib/python3.10/site-packages/datasets/arrow_writer.py
````
transformers version: 4.36.2
python version: 3.10.12
datasets version: 2.16.1
### Steps to reproduce the bug
1. Install packages
```
!pip install -U datasets trl accelerate peft bitsandbytes transformers trl huggingface_hub
```
2. import packages
```
import os
import torch
from datasets import load_dataset, Dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
from huggingface_hub import login
import pandas as pd
```
### Expected behavior
No error while importing
### Environment info
- `datasets` version: 2.16.0
- Platform: Linux-5.15.133+-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.20.1
- PyArrow version: 11.0.0
- Pandas version: 2.1.4
- `fsspec` version: 2023.10.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/131662185?v=4",
"events_url": "https://api.github.com/users/Sonali-Behera-TRT/events{/privacy}",
"followers_url": "https://api.github.com/users/Sonali-Behera-TRT/followers",
"following_url": "https://api.github.com/users/Sonali-Behera-TRT/following{/other_user}",
"gists_url": "https://api.github.com/users/Sonali-Behera-TRT/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Sonali-Behera-TRT",
"id": 131662185,
"login": "Sonali-Behera-TRT",
"node_id": "U_kgDOB9kBaQ",
"organizations_url": "https://api.github.com/users/Sonali-Behera-TRT/orgs",
"received_events_url": "https://api.github.com/users/Sonali-Behera-TRT/received_events",
"repos_url": "https://api.github.com/users/Sonali-Behera-TRT/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Sonali-Behera-TRT/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sonali-Behera-TRT/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Sonali-Behera-TRT"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6538/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6538/timeline
|
closed
| false | 6,538 | null |
2024-01-03T10:04:58Z
| null | false |
2,057,132,173 |
https://api.github.com/repos/huggingface/datasets/issues/6537
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6537/events
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null |
2023-12-27T20:46:53Z
|
[] |
https://github.com/huggingface/datasets/issues/6537
|
NONE
| null | null | null |
[
"Related to #3113 ",
"Conceptually, we can use xarray to load the netCDF file, then xarray -> pandas -> pyarrow.",
"I'd still need to verify that such a conversion would be lossless, especially for multi-dimensional data."
] |
Adding support for netCDF (*.nc) files
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6537/reactions"
}
|
I_kwDODunzps56nViN
| null |
2023-12-27T09:27:29Z
|
https://api.github.com/repos/huggingface/datasets/issues/6537/comments
|
### Feature request
netCDF (*.nc) is a file format for storing multidimensional scientific data, which is used by packages like `xarray` (labelled multi-dimensional arrays in Python). It would be nice to have native support for netCDF in `datasets`.
### Motivation
When uploading *.nc files onto Huggingface Hub through the `datasets` API, I would like to be able to preview the dataset without converting it to another format.
### Your contribution
I can submit a PR, provided I have the time.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12627125?v=4",
"events_url": "https://api.github.com/users/shermansiu/events{/privacy}",
"followers_url": "https://api.github.com/users/shermansiu/followers",
"following_url": "https://api.github.com/users/shermansiu/following{/other_user}",
"gists_url": "https://api.github.com/users/shermansiu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shermansiu",
"id": 12627125,
"login": "shermansiu",
"node_id": "MDQ6VXNlcjEyNjI3MTI1",
"organizations_url": "https://api.github.com/users/shermansiu/orgs",
"received_events_url": "https://api.github.com/users/shermansiu/received_events",
"repos_url": "https://api.github.com/users/shermansiu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shermansiu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shermansiu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shermansiu"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6537/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6537/timeline
|
open
| false | 6,537 | null | null | null | false |
2,056,863,239 |
https://api.github.com/repos/huggingface/datasets/issues/6536
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6536/events
|
[] | null |
2023-12-30T18:58:04Z
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] |
https://github.com/huggingface/datasets/issues/6536
|
NONE
|
completed
| null | null |
[
"Hi ! Thanks for reporting\r\n\r\nThis is a bug in 2.16.0 for some datasets when `cache_dir` is a relative path. I opened https://github.com/huggingface/datasets/pull/6543 to fix this",
"We just released 2.16.1 with a fix:\r\n\r\n```\r\npip install -U datasets\r\n```"
] |
datasets.load_dataset raises FileNotFoundError for datasets==2.16.0
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6536/reactions"
}
|
I_kwDODunzps56mT4H
| null |
2023-12-27T03:15:48Z
|
https://api.github.com/repos/huggingface/datasets/issues/6536/comments
|
### Describe the bug
Seems `datasets.load_dataset` raises FileNotFoundError for some hub datasets with the latest `datasets==2.16.0`
### Steps to reproduce the bug
For example `pip install datasets==2.16.0`
then
```python
import datasets
datasets.load_dataset("wentingzhao/anthropic-hh-first-prompt", cache_dir='cache1')["train"]
```
This will raise:
```bash
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/load.py", line 2545, in load_dataset
builder_instance.download_and_prepare(
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/builder.py", line 1003, in download_and_prepare
self._download_and_prepare(
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/builder.py", line 1076, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/packaged_modules/parquet/parquet.py", line 43, in _split_generators
data_files = dl_manager.download_and_extract(self.config.data_files)
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/download/download_manager.py", line 566, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/download/download_manager.py", line 539, in extract
extracted_paths = map_nested(
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/utils/py_utils.py", line 466, in map_nested
mapped = [
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/utils/py_utils.py", line 467, in <listcomp>
_single_map_nested((function, obj, types, None, True, None))
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/utils/py_utils.py", line 387, in _single_map_nested
mapped = [_single_map_nested((function, v, types, None, True, None)) for v in pbar]
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/utils/py_utils.py", line 387, in <listcomp>
mapped = [_single_map_nested((function, v, types, None, True, None)) for v in pbar]
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/utils/py_utils.py", line 370, in _single_map_nested
return function(data_struct)
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/download/download_manager.py", line 451, in _download
out = cached_path(url_or_filename, download_config=download_config)
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/utils/file_utils.py", line 188, in cached_path
output_path = get_from_cache(
File "/Users/xxx/miniconda3/envs/env/lib/python3.9/site-packages/datasets/utils/file_utils.py", line 570, in get_from_cache
raise FileNotFoundError(f"Couldn't find file at {url}")
FileNotFoundError: Couldn't find file at https://huggingface.co/datasets/wentingzhao/anthropic-hh-first-prompt/resolve/11b393a5545f706a357ebcd4a5285d93db176715/cache1/downloads/87d66c365626feca116cba323c4856c9aae056e4503f09f23e34aa085eb9de15
```
However, seems it works fine for some datasets, for example, if works fine for `datasets.load_dataset("ag_news", cache_dir='cache2')["test"]`
But the dataset works fine for datasets==2.15.0, for example `pip install datasets==2.15.0`,
then
```python
import datasets
datasets.load_dataset("wentingzhao/anthropic-hh-first-prompt", cache_dir='cache3')["train"]
Dataset({
features: ['user', 'system', 'source'],
num_rows: 8552
})
```
### Expected behavior
2.16.0 should work as same as 2.15.0 for all datasets
### Environment info
python3.9
conda env
tested on MacOS and Linux
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/46237844?v=4",
"events_url": "https://api.github.com/users/ArvinZhuang/events{/privacy}",
"followers_url": "https://api.github.com/users/ArvinZhuang/followers",
"following_url": "https://api.github.com/users/ArvinZhuang/following{/other_user}",
"gists_url": "https://api.github.com/users/ArvinZhuang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ArvinZhuang",
"id": 46237844,
"login": "ArvinZhuang",
"node_id": "MDQ6VXNlcjQ2MjM3ODQ0",
"organizations_url": "https://api.github.com/users/ArvinZhuang/orgs",
"received_events_url": "https://api.github.com/users/ArvinZhuang/received_events",
"repos_url": "https://api.github.com/users/ArvinZhuang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ArvinZhuang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArvinZhuang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ArvinZhuang"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6536/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6536/timeline
|
closed
| false | 6,536 | null |
2023-12-30T15:54:00Z
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
| false |
2,056,264,339 |
https://api.github.com/repos/huggingface/datasets/issues/6535
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6535/events
|
[] | null |
2024-02-05T08:42:31Z
|
[] |
https://github.com/huggingface/datasets/issues/6535
|
NONE
| null | null | null |
[
"@sabman @pvl @kashif @vigsterkr ",
"This is surely the same issue as https://discuss.huggingface.co/t/indexerror-invalid-key-16-is-out-of-bounds-for-size-0/14298/25 that comes from the `transformers` `Trainer`. You should add `remove_unused_columns=False` to `TrainingArguments`\r\n\r\nAlso check your logs: the `Trainer` should log the length of your dataset before training starts and it surely showed length=0.",
"the same error \r\nIndexError: Invalid key: 22330 is out of bounds for size 0"
] |
IndexError: Invalid key: 47682 is out of bounds for size 0 while using PEFT
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6535/reactions"
}
|
I_kwDODunzps56kBqT
| null |
2023-12-26T10:14:33Z
|
https://api.github.com/repos/huggingface/datasets/issues/6535/comments
|
### Describe the bug
I am trying to fine-tune the t5 model on the paraphrasing task. While running the same code without-
model = get_peft_model(model, config)
the model trains without any issues. However, using the model returned from get_peft_model raises the following error due to datasets-
IndexError: Invalid key: 47682 is out of bounds for size 0.
I had raised this in https://github.com/huggingface/peft/issues/1299#issue-2056173386 and they suggested that I raise it here.
Here is the complete error-
IndexError Traceback (most recent call last)
in <cell line: 1>()
----> 1 trainer.train()
11 frames
[/usr/local/lib/python3.10/dist-packages/transformers/trainer.py](https://localhost:8080/#) in train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1553 hf_hub_utils.enable_progress_bars()
1554 else:
-> 1555 return inner_training_loop(
1556 args=args,
1557 resume_from_checkpoint=resume_from_checkpoint,
[/usr/local/lib/python3.10/dist-packages/transformers/trainer.py](https://localhost:8080/#) in _inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)
1836
1837 step = -1
-> 1838 for step, inputs in enumerate(epoch_iterator):
1839 total_batched_samples += 1
1840 if rng_to_sync:
[/usr/local/lib/python3.10/dist-packages/accelerate/data_loader.py](https://localhost:8080/#) in iter(self)
446 # We iterate one batch ahead to check when we are at the end
447 try:
--> 448 current_batch = next(dataloader_iter)
449 except StopIteration:
450 yield
[/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py](https://localhost:8080/#) in next(self)
628 # TODO(https://github.com/pytorch/pytorch/issues/76750)
629 self._reset() # type: ignore[call-arg]
--> 630 data = self._next_data()
631 self._num_yielded += 1
632 if self._dataset_kind == _DatasetKind.Iterable and \
[/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py](https://localhost:8080/#) in _next_data(self)
672 def _next_data(self):
673 index = self._next_index() # may raise StopIteration
--> 674 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
675 if self._pin_memory:
676 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
[/usr/local/lib/python3.10/dist-packages/torch/utils/data/_utils/fetch.py](https://localhost:8080/#) in fetch(self, possibly_batched_index)
47 if self.auto_collation:
48 if hasattr(self.dataset, "getitems") and self.dataset.getitems:
---> 49 data = self.dataset.getitems(possibly_batched_index)
50 else:
51 data = [self.dataset[idx] for idx in possibly_batched_index]
[/usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py](https://localhost:8080/#) in getitems(self, keys)
2802 def getitems(self, keys: List) -> List:
2803 """Can be used to get a batch using a list of integers indices."""
-> 2804 batch = self.getitem(keys)
2805 n_examples = len(batch[next(iter(batch))])
2806 return [{col: array[i] for col, array in batch.items()} for i in range(n_examples)]
[/usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py](https://localhost:8080/#) in getitem(self, key)
2798 def getitem(self, key): # noqa: F811
2799 """Can be used to index columns (by string names) or rows (by integer index or iterable of indices or bools)."""
-> 2800 return self._getitem(key)
2801
2802 def getitems(self, keys: List) -> List:
[/usr/local/lib/python3.10/dist-packages/datasets/arrow_dataset.py](https://localhost:8080/#) in _getitem(self, key, **kwargs)
2782 format_kwargs = format_kwargs if format_kwargs is not None else {}
2783 formatter = get_formatter(format_type, features=self._info.features, **format_kwargs)
-> 2784 pa_subtable = query_table(self._data, key, indices=self._indices if self._indices is not None else None)
2785 formatted_output = format_table(
2786 pa_subtable, key, formatter=formatter, format_columns=format_columns, output_all_columns=output_all_columns
[/usr/local/lib/python3.10/dist-packages/datasets/formatting/formatting.py](https://localhost:8080/#) in query_table(table, key, indices)
581 else:
582 size = indices.num_rows if indices is not None else table.num_rows
--> 583 _check_valid_index_key(key, size)
584 # Query the main table
585 if indices is None:
[/usr/local/lib/python3.10/dist-packages/datasets/formatting/formatting.py](https://localhost:8080/#) in _check_valid_index_key(key, size)
534 elif isinstance(key, Iterable):
535 if len(key) > 0:
--> 536 _check_valid_index_key(int(max(key)), size=size)
537 _check_valid_index_key(int(min(key)), size=size)
538 else:
[/usr/local/lib/python3.10/dist-packages/datasets/formatting/formatting.py](https://localhost:8080/#) in _check_valid_index_key(key, size)
524 if isinstance(key, int):
525 if (key < 0 and key + size < 0) or (key >= size):
--> 526 raise IndexError(f"Invalid key: {key} is out of bounds for size {size}")
527 return
528 elif isinstance(key, slice):
IndexError: Invalid key: 47682 is out of bounds for size 0
### Steps to reproduce the bug
device = "cuda:0" if torch.cuda.is_available() else "cpu"
#defining model name for tokenizer and model loading
model_name= "t5-small"
#loading the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
def preprocess_function(data, tokenizer):
inputs = [f"Paraphrase this sentence: {doc}" for doc in data["text"]]
model_inputs = tokenizer(inputs, max_length=150, truncation=True)
labels = [ast.literal_eval(i)[0] for i in data['paraphrases']]
labels = tokenizer(labels, max_length=150, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
train_dataset = load_dataset("humarin/chatgpt-paraphrases", split="train").shuffle(seed=42).select(range(50000))
val_dataset = load_dataset("humarin/chatgpt-paraphrases", split="train").shuffle(seed=42).select(range(50000,55000))
tokenized_train = train_dataset.map(lambda batch: preprocess_function(batch, tokenizer), batched=True)
tokenized_val = val_dataset.map(lambda batch: preprocess_function(batch, tokenizer), batched=True)
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
config = LoraConfig(
r=16, #attention heads
lora_alpha=32, #alpha scaling
lora_dropout=0.05,
bias="none",
task_type="Seq2Seq"
)
#loading the model
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
model = get_peft_model(model, config)
print_trainable_parameters(model)
#loading the data collator
data_collator = DataCollatorForSeq2Seq(
tokenizer=tokenizer,
model=model,
label_pad_token_id=-100,
padding="longest"
)
#defining the training arguments
training_args = Seq2SeqTrainingArguments(
output_dir=os.getcwd(),
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
weight_decay=1e-3,
save_total_limit=3,
load_best_model_at_end=True,
num_train_epochs=1,
predict_with_generate=True
)
def compute_metric_with_extra(tokenizer):
def compute_metrics(eval_preds):
metric = evaluate.load('rouge')
preds, labels = eval_preds
# decode preds and labels
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# rougeLSum expects newline after each sentence
decoded_preds = ["\n".join(nltk.sent_tokenize(pred.strip())) for pred in decoded_preds]
decoded_labels = ["\n".join(nltk.sent_tokenize(label.strip())) for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
return result
return compute_metrics
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_val,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics= compute_metric_with_extra(tokenizer)
)
trainer.train()
### Expected behavior
I would want the trainer to train normally as it was before I used-
model = get_peft_model(model, config)
### Environment info
datasets version- 2.16.0
peft version- 0.7.1
transformers version- 4.35.2
accelerate version- 0.25.0
python- 3.10.12
enviroment- google colab
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/57484266?v=4",
"events_url": "https://api.github.com/users/MahavirDabas18/events{/privacy}",
"followers_url": "https://api.github.com/users/MahavirDabas18/followers",
"following_url": "https://api.github.com/users/MahavirDabas18/following{/other_user}",
"gists_url": "https://api.github.com/users/MahavirDabas18/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MahavirDabas18",
"id": 57484266,
"login": "MahavirDabas18",
"node_id": "MDQ6VXNlcjU3NDg0MjY2",
"organizations_url": "https://api.github.com/users/MahavirDabas18/orgs",
"received_events_url": "https://api.github.com/users/MahavirDabas18/received_events",
"repos_url": "https://api.github.com/users/MahavirDabas18/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MahavirDabas18/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MahavirDabas18/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MahavirDabas18"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6535/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6535/timeline
|
open
| false | 6,535 | null | null | null | false |
2,056,002,548 |
https://api.github.com/repos/huggingface/datasets/issues/6534
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6534/events
|
[] | null |
2023-12-26T06:31:16Z
|
[] |
https://github.com/huggingface/datasets/issues/6534
|
CONTRIBUTOR
| null | null | null |
[
"@albertvillanova"
] |
How to configure multiple folders in the same zip package
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6534/reactions"
}
|
I_kwDODunzps56jBv0
| null |
2023-12-26T03:56:20Z
|
https://api.github.com/repos/huggingface/datasets/issues/6534/comments
|
How should I write "config" in readme when all the data, such as train test, is in a zip file
train floder and test floder in data.zip
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6534/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6534/timeline
|
open
| false | 6,534 | null | null | null | false |
2,055,929,101 |
https://api.github.com/repos/huggingface/datasets/issues/6533
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6533/events
|
[] | null |
2023-12-30T18:58:21Z
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] |
https://github.com/huggingface/datasets/issues/6533
|
NONE
|
completed
| null | null |
[
"Hi ! Thanks for reporting. I opened https://github.com/huggingface/datasets/pull/6544 to fix this",
"We just released 2.16.1 with a fix:\r\n\r\n```\r\npip install -U datasets\r\n```"
] |
ted_talks_iwslt | Error: Config name is missing
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6533/reactions"
}
|
I_kwDODunzps56iv0N
| null |
2023-12-26T00:38:18Z
|
https://api.github.com/repos/huggingface/datasets/issues/6533/comments
|
### Describe the bug
Running load_dataset using the newest `datasets` library like below on the ted_talks_iwslt using year pair data will throw an error "Config name is missing"
see also:
https://huggingface.co/datasets/ted_talks_iwslt/discussions/3
likely caused by #6493, where the `and not config_kwargs` part in the if logic was removed
https://github.com/huggingface/datasets/blob/ef3b5dd3633995c95d77f35fb17f89ff44990bc4/src/datasets/builder.py#L512
### Steps to reproduce the bug
run:
```python
load_dataset("ted_talks_iwslt", language_pair=("ja", "en"), year="2015")
```
### Expected behavior
Load the data without error
### Environment info
datasets 2.16.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35850903?v=4",
"events_url": "https://api.github.com/users/rayliuca/events{/privacy}",
"followers_url": "https://api.github.com/users/rayliuca/followers",
"following_url": "https://api.github.com/users/rayliuca/following{/other_user}",
"gists_url": "https://api.github.com/users/rayliuca/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rayliuca",
"id": 35850903,
"login": "rayliuca",
"node_id": "MDQ6VXNlcjM1ODUwOTAz",
"organizations_url": "https://api.github.com/users/rayliuca/orgs",
"received_events_url": "https://api.github.com/users/rayliuca/received_events",
"repos_url": "https://api.github.com/users/rayliuca/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rayliuca/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rayliuca/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rayliuca"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6533/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6533/timeline
|
closed
| false | 6,533 | null |
2023-12-30T16:09:50Z
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
| false |
2,055,631,201 |
https://api.github.com/repos/huggingface/datasets/issues/6532
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6532/events
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null |
2024-08-03T11:00:30Z
|
[] |
https://github.com/huggingface/datasets/issues/6532
|
NONE
| null | null | null |
[
"You can simply use a python dict as index:\r\n\r\n```python\r\n>>> from datasets import load_dataset\r\n>>> ds = load_dataset(\"BeIR/dbpedia-entity\", \"corpus\", split=\"corpus\")\r\n>>> index = {key: idx for idx, key in enumerate(ds[\"_id\"])}\r\n>>> ds[index[\"<dbpedia:Pikachu>\"]]\r\n{'_id': '<dbpedia:Pikachu>',\r\n 'title': 'Pikachu',\r\n 'text': 'Pikachu (Japanese: ピカチュウ) are a fictional species of Pokémon. Pokémon are fictional creatures that appear in an assortment of comic books, animated movies and television shows, video games, and trading card games licensed by The Pokémon Company, a Japanese corporation. The Pikachu design was conceived by Ken Sugimori.'}\r\n```",
"Thanks for your reply. Yes, I can do that, but it is time-consuming to do that every time I launch the program (some datasets are extremely big). HF Datasets has a nice feature to support instant data loading and efficient random access via row ids. I'm curious if this beneficial feature could be further extended to custom data columns.\r\n",
"+1 on the issue I think it would be extremely useful",
"+1. This could be very useful.",
"+1 - currently having to manually implement this",
"If anyone has an idea how to do this in the right way (perhaps @albertvillanova ?) I would be happy to implement it"
] |
[Feature request] Indexing datasets by a customly-defined id field to enable random access dataset items via the id
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6532/reactions"
}
|
I_kwDODunzps56hnFh
| null |
2023-12-25T11:37:10Z
|
https://api.github.com/repos/huggingface/datasets/issues/6532/comments
|
### Feature request
Some datasets may contain an id-like field, for example the `id` field in [wikimedia/wikipedia](https://huggingface.co/datasets/wikimedia/wikipedia) and the `_id` field in [BeIR/dbpedia-entity](https://huggingface.co/datasets/BeIR/dbpedia-entity). HF datasets support efficient random access via row, but not via this kinds of id fields. I wonder if it is possible to add support for indexing by a custom "id-like" field to enable random access via such ids. The ids may be numbers or strings.
### Motivation
In some cases, especially during inference/evaluation, I may want to find out the item that has a specified id, defined by the dataset itself.
For example, in a typical re-ranking setting in information retrieval, the user may want to re-rank the set of candidate documents of each query. The input is usually presented in a TREC-style run file, with the following format:
```
<qid> Q0 <docno> <rank> <score> <tag>
```
The re-ranking program should be able to fetch the queries and documents according to the `<qid>` and `<docno>`, which are the original id defined in the query/document datasets. To accomplish this, I have to iterate over the whole HF dataset to get the mapping from real ids to row ids every time I start the program, which is time-consuming. Thus I want HF dataset to provide options for users to index by a custom id column, not by row.
### Your contribution
I'm not an expert in this project and I'm afraid that I'm not able to make contributions on the code.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3377221?v=4",
"events_url": "https://api.github.com/users/Yu-Shi/events{/privacy}",
"followers_url": "https://api.github.com/users/Yu-Shi/followers",
"following_url": "https://api.github.com/users/Yu-Shi/following{/other_user}",
"gists_url": "https://api.github.com/users/Yu-Shi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Yu-Shi",
"id": 3377221,
"login": "Yu-Shi",
"node_id": "MDQ6VXNlcjMzNzcyMjE=",
"organizations_url": "https://api.github.com/users/Yu-Shi/orgs",
"received_events_url": "https://api.github.com/users/Yu-Shi/received_events",
"repos_url": "https://api.github.com/users/Yu-Shi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Yu-Shi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Yu-Shi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Yu-Shi"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6532/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6532/timeline
|
open
| false | 6,532 | null | null | null | false |
2,055,201,605 |
https://api.github.com/repos/huggingface/datasets/issues/6531
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6531/events
|
[] | null |
2024-03-08T19:29:25Z
|
[] |
https://github.com/huggingface/datasets/pull/6531
|
CONTRIBUTOR
| null | false | null |
[
"Hi ! thanks for adding polars support :)\r\n\r\nYou added from_polars in arrow_dataset.py but not to_polars, is this on purpose ?\r\n\r\nAlso no need to touch table.py imo, which is for arrow-only logic (tables are just wrappers of pyarrow.Table with the exact same methods + optimization to existing methods + separation between in-memory and memory-mapped)",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6531). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Hi @lhoestq, thanks for pointing out the missing `to_polars` method.\r\n\r\nI see your point about `table.py` so I removed them.\r\n\r\nI also added tests in `test_arrow_dataset.py`, `test_dataset_dict.py`, and `test_formatting.py`. Let me know if I am missing any. ",
"duckdb index files were deleted yesterday in dataset_with_script@ref/convert/parquet so I changed the hash to reflect the new SHA.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004993 / 0.011353 (-0.006360) | 0.003658 / 0.011008 (-0.007350) | 0.063868 / 0.038508 (0.025360) | 0.030022 / 0.023109 (0.006912) | 0.246359 / 0.275898 (-0.029539) | 0.273409 / 0.323480 (-0.050070) | 0.003091 / 0.007986 (-0.004894) | 0.003383 / 0.004328 (-0.000945) | 0.050666 / 0.004250 (0.046415) | 0.040609 / 0.037052 (0.003557) | 0.267250 / 0.258489 (0.008761) | 0.289823 / 0.293841 (-0.004018) | 0.027635 / 0.128546 (-0.100911) | 0.010786 / 0.075646 (-0.064860) | 0.208442 / 0.419271 (-0.210830) | 0.036627 / 0.043533 (-0.006906) | 0.254116 / 0.255139 (-0.001023) | 0.274368 / 0.283200 (-0.008832) | 0.018222 / 0.141683 (-0.123460) | 1.184472 / 1.452155 (-0.267683) | 1.194309 / 1.492716 (-0.298407) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092861 / 0.018006 (0.074855) | 0.304736 / 0.000490 (0.304246) | 0.000219 / 0.000200 (0.000019) | 0.000175 / 0.000054 (0.000121) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019378 / 0.037411 (-0.018034) | 0.062342 / 0.014526 (0.047817) | 0.074107 / 0.176557 (-0.102450) | 0.121746 / 0.737135 (-0.615390) | 0.075657 / 0.296338 (-0.220681) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286474 / 0.215209 (0.071265) | 2.832043 / 2.077655 (0.754389) | 1.453520 / 1.504120 (-0.050600) | 1.324714 / 1.541195 (-0.216480) | 1.335439 / 1.468490 (-0.133051) | 0.571753 / 4.584777 (-4.013024) | 2.427361 / 3.745712 (-1.318352) | 2.899838 / 5.269862 (-2.370024) | 1.775754 / 4.565676 (-2.789922) | 0.064177 / 0.424275 (-0.360098) | 0.004978 / 0.007607 (-0.002629) | 0.343585 / 0.226044 (0.117541) | 3.368494 / 2.268929 (1.099565) | 1.819825 / 55.444624 (-53.624800) | 1.502633 / 6.876477 (-5.373844) | 1.549182 / 2.142072 (-0.592891) | 0.658245 / 4.805227 (-4.146983) | 0.120052 / 6.500664 (-6.380612) | 0.043051 / 0.075469 (-0.032419) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.977055 / 1.841788 (-0.864733) | 11.595567 / 8.074308 (3.521259) | 9.450951 / 10.191392 (-0.740441) | 0.141060 / 0.680424 (-0.539364) | 0.014359 / 0.534201 (-0.519842) | 0.289938 / 0.579283 (-0.289345) | 0.266035 / 0.434364 (-0.168329) | 0.326802 / 0.540337 (-0.213536) | 0.431913 / 1.386936 (-0.955023) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005391 / 0.011353 (-0.005961) | 0.003724 / 0.011008 (-0.007284) | 0.050432 / 0.038508 (0.011924) | 0.029904 / 0.023109 (0.006794) | 0.270870 / 0.275898 (-0.005028) | 0.296773 / 0.323480 (-0.026706) | 0.004265 / 0.007986 (-0.003721) | 0.002751 / 0.004328 (-0.001577) | 0.050366 / 0.004250 (0.046116) | 0.046415 / 0.037052 (0.009363) | 0.283272 / 0.258489 (0.024783) | 0.320188 / 0.293841 (0.026347) | 0.029827 / 0.128546 (-0.098719) | 0.010736 / 0.075646 (-0.064910) | 0.059541 / 0.419271 (-0.359731) | 0.057080 / 0.043533 (0.013548) | 0.270653 / 0.255139 (0.015514) | 0.291235 / 0.283200 (0.008035) | 0.018590 / 0.141683 (-0.123093) | 1.129402 / 1.452155 (-0.322752) | 1.194499 / 1.492716 (-0.298217) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.102220 / 0.018006 (0.084214) | 0.302176 / 0.000490 (0.301686) | 0.000229 / 0.000200 (0.000029) | 0.000056 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022809 / 0.037411 (-0.014602) | 0.076054 / 0.014526 (0.061528) | 0.087466 / 0.176557 (-0.089091) | 0.128495 / 0.737135 (-0.608640) | 0.089933 / 0.296338 (-0.206406) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.296546 / 0.215209 (0.081337) | 2.898693 / 2.077655 (0.821039) | 1.605002 / 1.504120 (0.100883) | 1.468370 / 1.541195 (-0.072825) | 1.503541 / 1.468490 (0.035051) | 0.577233 / 4.584777 (-4.007544) | 2.460154 / 3.745712 (-1.285558) | 2.755651 / 5.269862 (-2.514211) | 1.777711 / 4.565676 (-2.787966) | 0.063137 / 0.424275 (-0.361138) | 0.005056 / 0.007607 (-0.002551) | 0.350189 / 0.226044 (0.124145) | 3.485473 / 2.268929 (1.216545) | 1.952553 / 55.444624 (-53.492072) | 1.669108 / 6.876477 (-5.207369) | 1.788504 / 2.142072 (-0.353569) | 0.672869 / 4.805227 (-4.132359) | 0.117717 / 6.500664 (-6.382948) | 0.040499 / 0.075469 (-0.034970) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.048187 / 1.841788 (-0.793601) | 12.663229 / 8.074308 (4.588921) | 10.316487 / 10.191392 (0.125095) | 0.142537 / 0.680424 (-0.537887) | 0.016024 / 0.534201 (-0.518177) | 0.292735 / 0.579283 (-0.286548) | 0.273294 / 0.434364 (-0.161069) | 0.327636 / 0.540337 (-0.212701) | 0.443062 / 1.386936 (-0.943874) |\n\n</details>\n</details>\n\n\n",
"I'm so excited I tweeted about it: https://x.com/qlhoest/status/1766135995513082086?s=20 I hope it's fine !",
"Thanks @lhoestq for the support and totally fine with the share! Happy to see people excited for this 😃 "
] |
Add polars compatibility
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 4,
"hooray": 2,
"laugh": 0,
"rocket": 0,
"total_count": 8,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6531/reactions"
}
|
PR_kwDODunzps5it5Sm
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6531.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6531",
"merged_at": "2024-03-08T15:22:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6531.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6531"
}
|
2023-12-24T20:03:23Z
|
https://api.github.com/repos/huggingface/datasets/issues/6531/comments
|
Hey there,
I've just finished adding support to convert and format to `polars.DataFrame`. This was in response to the open issue about integrating Polars [#3334](https://github.com/huggingface/datasets/issues/3334). Datasets can be switched to Polars format via `Dataset.set_format("polars")`. I've also included `to_polars` and `from_polars`. All polars functions are checked via config.POLARS_AVAILABLE.
A few notes:
This only supports `DataFrames` and not `LazyFrames`. This probably could be integrated fairly easily via `is_lazy` args in `set_format`, and `to_polars`.
Let me know your feedbacks.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11325244?v=4",
"events_url": "https://api.github.com/users/psmyth94/events{/privacy}",
"followers_url": "https://api.github.com/users/psmyth94/followers",
"following_url": "https://api.github.com/users/psmyth94/following{/other_user}",
"gists_url": "https://api.github.com/users/psmyth94/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/psmyth94",
"id": 11325244,
"login": "psmyth94",
"node_id": "MDQ6VXNlcjExMzI1MjQ0",
"organizations_url": "https://api.github.com/users/psmyth94/orgs",
"received_events_url": "https://api.github.com/users/psmyth94/received_events",
"repos_url": "https://api.github.com/users/psmyth94/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/psmyth94/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/psmyth94/subscriptions",
"type": "User",
"url": "https://api.github.com/users/psmyth94"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6531/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6531/timeline
|
closed
| false | 6,531 | null |
2024-03-08T15:22:58Z
| null | true |
2,054,817,609 |
https://api.github.com/repos/huggingface/datasets/issues/6530
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6530/events
|
[] | null |
2023-12-24T09:40:30Z
|
[] |
https://github.com/huggingface/datasets/issues/6530
|
NONE
| null | null | null |
[
"I solved it with `train_dataset.with_format(None)`\r\nBut then faced some more issues (which i later solved too).\r\n\r\nHuggingface does not seem to care, so I do. Here is an updated training script which saves a pre-processed (mapped) dataset to your local directory if you specify `--save_precomputed_data_dir=DIR_NAME`. Then use `--train_precomputed_data_dir` with the same dir to load it instead of `--dataset_name`.\r\n\r\n[Proper SDXL trainer code](https://github.com/kopyl/diffusers/blob/main/examples/text_to_image/train_text_to_image_sdxl.py)\r\n[Notebook for pre-computing a dataset and saving locally](https://colab.research.google.com/drive/17Yo08hePx-NlHs99RecdeiNc8CQg4O7l?usp=sharing)\r\n\r\nExample:\r\n\r\n1st run (nothing is pre-computed yet):\r\n```\r\naccelerate launch train_text_to_image_sdxl.py \\\r\n --pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0 \\\r\n --pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix \\\r\n --dataset_name=lambdalabs/pokemon-blip-captions \\\r\n --save_precomputed_data_dir=\"test-5\"\r\n```\r\n\r\n2nd run (the pre-computed dataset is saved to `test-5` directory):\r\n```\r\naccelerate launch train_text_to_image_sdxl.py \\\r\n --pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0 \\\r\n --pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix \\\r\n --train_precomputed_data_dir test-5\r\n```\r\n\r\nThis way when you're gonna be using your pre-computed dataset you don't need to worry about re-mapping your dataset when you change an argument for your trainer script"
] |
Impossible to save a mapped dataset to disk
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6530/reactions"
}
|
I_kwDODunzps56egdJ
| null |
2023-12-23T15:18:27Z
|
https://api.github.com/repos/huggingface/datasets/issues/6530/comments
|
### Describe the bug
I want to play around with different hyperparameters when training but don't want to re-map my dataset with 3 million samples each time for tens of hours when I [fully fine-tune SDXL](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_sdxl.py).
After I do the mapping like this:
```
train_dataset = train_dataset.map(compute_embeddings_fn, batched=True)
train_dataset = train_dataset.map(
compute_vae_encodings_fn,
batched=True,
batch_size=16,
)
```
and try to save it like this:
`train_dataset.save_to_disk("test")`
i get this error ([full traceback](https://pastebin.com/kq3vt739)):
```
TypeError: Object of type function is not JSON serializable
The format kwargs must be JSON serializable, but key 'transform' isn't.
```
But what is interesting is that pushing to hub works like that:
`train_dataset.push_to_hub("kopyl/mapped-833-icons-sdxl-1024-dataset", token=True)`
Here is the link of the pushed dataset: https://huggingface.co/datasets/kopyl/mapped-833-icons-sdxl-1024-dataset
### Steps to reproduce the bug
Here is the self-contained notebook:
https://colab.research.google.com/drive/1RtCsEMVcwWcMwlWURk_cj_9xUBHz065M?usp=sharing
### Expected behavior
It should be easily saved to disk
### Environment info
NVIDIA A100, Linux (NC24ads A100 v4 from Azure), CUDA 12.2.
[pip freeze](https://pastebin.com/QTNb6iru)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17604849?v=4",
"events_url": "https://api.github.com/users/kopyl/events{/privacy}",
"followers_url": "https://api.github.com/users/kopyl/followers",
"following_url": "https://api.github.com/users/kopyl/following{/other_user}",
"gists_url": "https://api.github.com/users/kopyl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kopyl",
"id": 17604849,
"login": "kopyl",
"node_id": "MDQ6VXNlcjE3NjA0ODQ5",
"organizations_url": "https://api.github.com/users/kopyl/orgs",
"received_events_url": "https://api.github.com/users/kopyl/received_events",
"repos_url": "https://api.github.com/users/kopyl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kopyl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kopyl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kopyl"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6530/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6530/timeline
|
open
| false | 6,530 | null | null | null | false |
2,054,209,449 |
https://api.github.com/repos/huggingface/datasets/issues/6529
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6529/events
|
[] | null |
2024-02-02T00:05:04Z
|
[] |
https://github.com/huggingface/datasets/issues/6529
|
NONE
| null | null | null |
[
"The only way right now is to load with streaming=True",
"This feature has been proposed for a long time. I'm looking forward to the implementation. On clusters `streaming=True` is not an option since we do not have Internet on compute nodes. See: https://github.com/huggingface/datasets/discussions/1896#discussioncomment-2359593"
] |
Impossible to only download a test split
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6529/reactions"
}
|
I_kwDODunzps56cL-p
| null |
2023-12-22T16:56:32Z
|
https://api.github.com/repos/huggingface/datasets/issues/6529/comments
|
I've spent a significant amount of time trying to locate the split object inside my _split_generators() custom function.
Then after diving [in the code](https://github.com/huggingface/datasets/blob/5ff3670c18ed34fa8ddfa70a9aa403ae6cc9ad54/src/datasets/load.py#L2558) I realized that `download_and_prepare` is executed before! split is passed to the dataset builder in `as_dataset`.
If I'm not missing something, this seems like bad design, for the following use case:
> Imagine there is a huge dataset that has an evaluation test set and you want to just download and run just to compare your method.
Is there a current workaround that can help me achieve the same result?
Thank you,
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/28439529?v=4",
"events_url": "https://api.github.com/users/ysig/events{/privacy}",
"followers_url": "https://api.github.com/users/ysig/followers",
"following_url": "https://api.github.com/users/ysig/following{/other_user}",
"gists_url": "https://api.github.com/users/ysig/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ysig",
"id": 28439529,
"login": "ysig",
"node_id": "MDQ6VXNlcjI4NDM5NTI5",
"organizations_url": "https://api.github.com/users/ysig/orgs",
"received_events_url": "https://api.github.com/users/ysig/received_events",
"repos_url": "https://api.github.com/users/ysig/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ysig/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ysig/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ysig"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6529/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6529/timeline
|
open
| false | 6,529 | null | null | null | false |
2,053,996,494 |
https://api.github.com/repos/huggingface/datasets/issues/6528
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6528/events
|
[] | null |
2023-12-22T14:31:42Z
|
[] |
https://github.com/huggingface/datasets/pull/6528
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6528). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004875 / 0.011353 (-0.006478) | 0.003501 / 0.011008 (-0.007507) | 0.062604 / 0.038508 (0.024096) | 0.031916 / 0.023109 (0.008806) | 0.256138 / 0.275898 (-0.019760) | 0.278514 / 0.323480 (-0.044966) | 0.002917 / 0.007986 (-0.005069) | 0.002636 / 0.004328 (-0.001693) | 0.049154 / 0.004250 (0.044904) | 0.041985 / 0.037052 (0.004933) | 0.256857 / 0.258489 (-0.001632) | 0.282628 / 0.293841 (-0.011213) | 0.027506 / 0.128546 (-0.101041) | 0.010736 / 0.075646 (-0.064910) | 0.207268 / 0.419271 (-0.212003) | 0.035312 / 0.043533 (-0.008221) | 0.259274 / 0.255139 (0.004135) | 0.281463 / 0.283200 (-0.001737) | 0.019905 / 0.141683 (-0.121778) | 1.108719 / 1.452155 (-0.343435) | 1.177871 / 1.492716 (-0.314845) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004435 / 0.018006 (-0.013571) | 0.310643 / 0.000490 (0.310153) | 0.000243 / 0.000200 (0.000043) | 0.000044 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018013 / 0.037411 (-0.019398) | 0.060702 / 0.014526 (0.046176) | 0.073243 / 0.176557 (-0.103314) | 0.119523 / 0.737135 (-0.617613) | 0.074204 / 0.296338 (-0.222134) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.281075 / 0.215209 (0.065866) | 2.722154 / 2.077655 (0.644499) | 1.441052 / 1.504120 (-0.063068) | 1.305940 / 1.541195 (-0.235255) | 1.356752 / 1.468490 (-0.111738) | 0.570399 / 4.584777 (-4.014378) | 2.329158 / 3.745712 (-1.416554) | 2.749093 / 5.269862 (-2.520768) | 1.717752 / 4.565676 (-2.847925) | 0.063228 / 0.424275 (-0.361047) | 0.004981 / 0.007607 (-0.002626) | 0.330601 / 0.226044 (0.104557) | 3.300987 / 2.268929 (1.032059) | 1.778673 / 55.444624 (-53.665951) | 1.507841 / 6.876477 (-5.368636) | 1.520454 / 2.142072 (-0.621619) | 0.650816 / 4.805227 (-4.154412) | 0.118606 / 6.500664 (-6.382058) | 0.042199 / 0.075469 (-0.033271) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.919668 / 1.841788 (-0.922119) | 11.293437 / 8.074308 (3.219129) | 9.928525 / 10.191392 (-0.262867) | 0.127142 / 0.680424 (-0.553282) | 0.013470 / 0.534201 (-0.520731) | 0.284648 / 0.579283 (-0.294636) | 0.264942 / 0.434364 (-0.169422) | 0.321866 / 0.540337 (-0.218471) | 0.414513 / 1.386936 (-0.972423) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005052 / 0.011353 (-0.006301) | 0.003204 / 0.011008 (-0.007804) | 0.051102 / 0.038508 (0.012594) | 0.032105 / 0.023109 (0.008996) | 0.273923 / 0.275898 (-0.001976) | 0.297031 / 0.323480 (-0.026449) | 0.004002 / 0.007986 (-0.003984) | 0.002636 / 0.004328 (-0.001693) | 0.047696 / 0.004250 (0.043445) | 0.044086 / 0.037052 (0.007034) | 0.277779 / 0.258489 (0.019289) | 0.306678 / 0.293841 (0.012837) | 0.028557 / 0.128546 (-0.099989) | 0.010631 / 0.075646 (-0.065015) | 0.056419 / 0.419271 (-0.362852) | 0.054285 / 0.043533 (0.010752) | 0.276506 / 0.255139 (0.021367) | 0.296315 / 0.283200 (0.013116) | 0.018642 / 0.141683 (-0.123040) | 1.146926 / 1.452155 (-0.305229) | 1.257625 / 1.492716 (-0.235092) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094231 / 0.018006 (0.076225) | 0.302805 / 0.000490 (0.302315) | 0.000229 / 0.000200 (0.000029) | 0.000051 / 0.000054 (-0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022510 / 0.037411 (-0.014901) | 0.076092 / 0.014526 (0.061566) | 0.090642 / 0.176557 (-0.085915) | 0.127016 / 0.737135 (-0.610120) | 0.089169 / 0.296338 (-0.207169) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.290812 / 0.215209 (0.075603) | 2.858528 / 2.077655 (0.780873) | 1.577555 / 1.504120 (0.073436) | 1.447810 / 1.541195 (-0.093384) | 1.447546 / 1.468490 (-0.020944) | 0.559118 / 4.584777 (-4.025659) | 2.408930 / 3.745712 (-1.336782) | 2.733761 / 5.269862 (-2.536101) | 1.700107 / 4.565676 (-2.865570) | 0.062447 / 0.424275 (-0.361828) | 0.004999 / 0.007607 (-0.002608) | 0.340207 / 0.226044 (0.114162) | 3.344131 / 2.268929 (1.075203) | 1.902289 / 55.444624 (-53.542335) | 1.628226 / 6.876477 (-5.248251) | 1.629435 / 2.142072 (-0.512637) | 0.625011 / 4.805227 (-4.180216) | 0.119929 / 6.500664 (-6.380735) | 0.041097 / 0.075469 (-0.034372) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.977461 / 1.841788 (-0.864327) | 12.303189 / 8.074308 (4.228881) | 11.008743 / 10.191392 (0.817351) | 0.128578 / 0.680424 (-0.551845) | 0.015305 / 0.534201 (-0.518896) | 0.286468 / 0.579283 (-0.292816) | 0.275824 / 0.434364 (-0.158540) | 0.321487 / 0.540337 (-0.218851) | 0.420591 / 1.386936 (-0.966345) |\n\n</details>\n</details>\n\n\n"
] |
set dev version
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6528/reactions"
}
|
PR_kwDODunzps5ip9JH
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6528.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6528",
"merged_at": "2023-12-22T14:25:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6528.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6528"
}
|
2023-12-22T14:23:18Z
|
https://api.github.com/repos/huggingface/datasets/issues/6528/comments
| null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6528/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6528/timeline
|
closed
| false | 6,528 | null |
2023-12-22T14:25:34Z
| null | true |
2,053,966,748 |
https://api.github.com/repos/huggingface/datasets/issues/6527
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6527/events
|
[] | null |
2023-12-22T14:24:12Z
|
[] |
https://github.com/huggingface/datasets/pull/6527
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6527). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004870 / 0.011353 (-0.006483) | 0.003606 / 0.011008 (-0.007402) | 0.062719 / 0.038508 (0.024211) | 0.031785 / 0.023109 (0.008676) | 0.238809 / 0.275898 (-0.037089) | 0.263000 / 0.323480 (-0.060480) | 0.002844 / 0.007986 (-0.005142) | 0.002698 / 0.004328 (-0.001631) | 0.048070 / 0.004250 (0.043819) | 0.042333 / 0.037052 (0.005280) | 0.243032 / 0.258489 (-0.015457) | 0.273197 / 0.293841 (-0.020644) | 0.027498 / 0.128546 (-0.101048) | 0.010592 / 0.075646 (-0.065055) | 0.204770 / 0.419271 (-0.214502) | 0.034837 / 0.043533 (-0.008696) | 0.242518 / 0.255139 (-0.012621) | 0.267461 / 0.283200 (-0.015739) | 0.018479 / 0.141683 (-0.123204) | 1.105444 / 1.452155 (-0.346710) | 1.163659 / 1.492716 (-0.329057) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004717 / 0.018006 (-0.013289) | 0.303338 / 0.000490 (0.302849) | 0.000221 / 0.000200 (0.000021) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018298 / 0.037411 (-0.019113) | 0.061225 / 0.014526 (0.046699) | 0.073514 / 0.176557 (-0.103043) | 0.120230 / 0.737135 (-0.616905) | 0.076195 / 0.296338 (-0.220144) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.284731 / 0.215209 (0.069522) | 2.773463 / 2.077655 (0.695809) | 1.498239 / 1.504120 (-0.005881) | 1.372143 / 1.541195 (-0.169052) | 1.448949 / 1.468490 (-0.019542) | 0.572516 / 4.584777 (-4.012261) | 2.404041 / 3.745712 (-1.341671) | 2.763047 / 5.269862 (-2.506814) | 1.722419 / 4.565676 (-2.843257) | 0.063104 / 0.424275 (-0.361172) | 0.004989 / 0.007607 (-0.002618) | 0.341864 / 0.226044 (0.115820) | 3.391635 / 2.268929 (1.122707) | 1.872694 / 55.444624 (-53.571931) | 1.594490 / 6.876477 (-5.281987) | 1.596940 / 2.142072 (-0.545132) | 0.645265 / 4.805227 (-4.159962) | 0.117408 / 6.500664 (-6.383256) | 0.042405 / 0.075469 (-0.033064) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.963207 / 1.841788 (-0.878580) | 11.676551 / 8.074308 (3.602243) | 10.194287 / 10.191392 (0.002895) | 0.130329 / 0.680424 (-0.550094) | 0.015381 / 0.534201 (-0.518820) | 0.288848 / 0.579283 (-0.290435) | 0.264781 / 0.434364 (-0.169583) | 0.321212 / 0.540337 (-0.219126) | 0.418308 / 1.386936 (-0.968628) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005533 / 0.011353 (-0.005819) | 0.003733 / 0.011008 (-0.007276) | 0.048877 / 0.038508 (0.010369) | 0.030263 / 0.023109 (0.007154) | 0.281161 / 0.275898 (0.005263) | 0.302971 / 0.323480 (-0.020509) | 0.003943 / 0.007986 (-0.004043) | 0.002717 / 0.004328 (-0.001612) | 0.047845 / 0.004250 (0.043594) | 0.045809 / 0.037052 (0.008757) | 0.283337 / 0.258489 (0.024848) | 0.312914 / 0.293841 (0.019073) | 0.029074 / 0.128546 (-0.099472) | 0.010775 / 0.075646 (-0.064871) | 0.057461 / 0.419271 (-0.361810) | 0.053756 / 0.043533 (0.010223) | 0.281809 / 0.255139 (0.026670) | 0.298339 / 0.283200 (0.015139) | 0.019270 / 0.141683 (-0.122413) | 1.117575 / 1.452155 (-0.334580) | 1.191703 / 1.492716 (-0.301013) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093513 / 0.018006 (0.075507) | 0.301267 / 0.000490 (0.300777) | 0.000211 / 0.000200 (0.000012) | 0.000045 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022278 / 0.037411 (-0.015133) | 0.076805 / 0.014526 (0.062279) | 0.088820 / 0.176557 (-0.087736) | 0.127903 / 0.737135 (-0.609233) | 0.092988 / 0.296338 (-0.203350) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.297787 / 0.215209 (0.082578) | 2.899652 / 2.077655 (0.821997) | 1.598830 / 1.504120 (0.094710) | 1.469398 / 1.541195 (-0.071797) | 1.511099 / 1.468490 (0.042609) | 0.559785 / 4.584777 (-4.024992) | 2.426448 / 3.745712 (-1.319264) | 2.798811 / 5.269862 (-2.471051) | 1.737790 / 4.565676 (-2.827887) | 0.062219 / 0.424275 (-0.362056) | 0.005120 / 0.007607 (-0.002487) | 0.351051 / 0.226044 (0.125007) | 3.492063 / 2.268929 (1.223134) | 1.965674 / 55.444624 (-53.478950) | 1.672874 / 6.876477 (-5.203603) | 1.709700 / 2.142072 (-0.432373) | 0.639347 / 4.805227 (-4.165880) | 0.126383 / 6.500664 (-6.374281) | 0.042731 / 0.075469 (-0.032738) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.968619 / 1.841788 (-0.873168) | 12.671030 / 8.074308 (4.596722) | 11.125347 / 10.191392 (0.933955) | 0.142983 / 0.680424 (-0.537441) | 0.015726 / 0.534201 (-0.518475) | 0.288610 / 0.579283 (-0.290673) | 0.276473 / 0.434364 (-0.157891) | 0.326590 / 0.540337 (-0.213748) | 0.423832 / 1.386936 (-0.963104) |\n\n</details>\n</details>\n\n\n"
] |
Release: 2.16.0
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6527/reactions"
}
|
PR_kwDODunzps5ip2vd
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6527.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6527",
"merged_at": "2023-12-22T14:17:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6527.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6527"
}
|
2023-12-22T13:59:56Z
|
https://api.github.com/repos/huggingface/datasets/issues/6527/comments
| null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6527/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6527/timeline
|
closed
| false | 6,527 | null |
2023-12-22T14:17:55Z
| null | true |
2,053,726,451 |
https://api.github.com/repos/huggingface/datasets/issues/6526
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6526/events
|
[] | null |
2023-12-22T11:42:22Z
|
[] |
https://github.com/huggingface/datasets/pull/6526
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6526). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005101 / 0.011353 (-0.006252) | 0.003471 / 0.011008 (-0.007537) | 0.062293 / 0.038508 (0.023785) | 0.032650 / 0.023109 (0.009541) | 0.249241 / 0.275898 (-0.026657) | 0.277079 / 0.323480 (-0.046400) | 0.002971 / 0.007986 (-0.005015) | 0.002637 / 0.004328 (-0.001691) | 0.048415 / 0.004250 (0.044165) | 0.042832 / 0.037052 (0.005779) | 0.247840 / 0.258489 (-0.010649) | 0.283994 / 0.293841 (-0.009847) | 0.027764 / 0.128546 (-0.100782) | 0.010544 / 0.075646 (-0.065102) | 0.208810 / 0.419271 (-0.210462) | 0.035744 / 0.043533 (-0.007789) | 0.252811 / 0.255139 (-0.002328) | 0.276163 / 0.283200 (-0.007036) | 0.018581 / 0.141683 (-0.123102) | 1.130043 / 1.452155 (-0.322112) | 1.194298 / 1.492716 (-0.298418) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004488 / 0.018006 (-0.013518) | 0.302072 / 0.000490 (0.301582) | 0.000211 / 0.000200 (0.000012) | 0.000044 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.017799 / 0.037411 (-0.019613) | 0.061146 / 0.014526 (0.046620) | 0.081796 / 0.176557 (-0.094761) | 0.120407 / 0.737135 (-0.616729) | 0.075211 / 0.296338 (-0.221127) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295349 / 0.215209 (0.080140) | 2.953511 / 2.077655 (0.875857) | 1.495332 / 1.504120 (-0.008788) | 1.364144 / 1.541195 (-0.177051) | 1.429562 / 1.468490 (-0.038928) | 0.574325 / 4.584777 (-4.010452) | 2.384352 / 3.745712 (-1.361360) | 2.843625 / 5.269862 (-2.426236) | 1.806802 / 4.565676 (-2.758875) | 0.065076 / 0.424275 (-0.359199) | 0.004970 / 0.007607 (-0.002638) | 0.339935 / 0.226044 (0.113891) | 3.375103 / 2.268929 (1.106175) | 1.822921 / 55.444624 (-53.621703) | 1.546126 / 6.876477 (-5.330350) | 1.573630 / 2.142072 (-0.568442) | 0.655081 / 4.805227 (-4.150146) | 0.122446 / 6.500664 (-6.378218) | 0.042220 / 0.075469 (-0.033249) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.942127 / 1.841788 (-0.899661) | 11.470401 / 8.074308 (3.396093) | 10.025961 / 10.191392 (-0.165431) | 0.129087 / 0.680424 (-0.551337) | 0.014141 / 0.534201 (-0.520060) | 0.285470 / 0.579283 (-0.293813) | 0.266755 / 0.434364 (-0.167608) | 0.323391 / 0.540337 (-0.216947) | 0.427645 / 1.386936 (-0.959291) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005578 / 0.011353 (-0.005775) | 0.003734 / 0.011008 (-0.007274) | 0.049200 / 0.038508 (0.010692) | 0.030981 / 0.023109 (0.007872) | 0.281195 / 0.275898 (0.005297) | 0.309950 / 0.323480 (-0.013530) | 0.004046 / 0.007986 (-0.003939) | 0.002709 / 0.004328 (-0.001620) | 0.048505 / 0.004250 (0.044254) | 0.046245 / 0.037052 (0.009193) | 0.280130 / 0.258489 (0.021641) | 0.313739 / 0.293841 (0.019898) | 0.029828 / 0.128546 (-0.098718) | 0.011152 / 0.075646 (-0.064495) | 0.057753 / 0.419271 (-0.361518) | 0.055112 / 0.043533 (0.011580) | 0.281861 / 0.255139 (0.026722) | 0.304402 / 0.283200 (0.021203) | 0.019931 / 0.141683 (-0.121752) | 1.150585 / 1.452155 (-0.301570) | 1.217850 / 1.492716 (-0.274866) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091552 / 0.018006 (0.073546) | 0.301772 / 0.000490 (0.301282) | 0.000225 / 0.000200 (0.000025) | 0.000046 / 0.000054 (-0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023189 / 0.037411 (-0.014223) | 0.078741 / 0.014526 (0.064216) | 0.092320 / 0.176557 (-0.084236) | 0.129636 / 0.737135 (-0.607500) | 0.091673 / 0.296338 (-0.204665) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.298542 / 0.215209 (0.083333) | 2.899358 / 2.077655 (0.821703) | 1.673896 / 1.504120 (0.169776) | 1.489518 / 1.541195 (-0.051677) | 1.542853 / 1.468490 (0.074363) | 0.559843 / 4.584777 (-4.024934) | 2.422101 / 3.745712 (-1.323611) | 2.844592 / 5.269862 (-2.425270) | 1.794527 / 4.565676 (-2.771150) | 0.064615 / 0.424275 (-0.359660) | 0.005078 / 0.007607 (-0.002530) | 0.355112 / 0.226044 (0.129068) | 3.462129 / 2.268929 (1.193200) | 1.975393 / 55.444624 (-53.469231) | 1.706513 / 6.876477 (-5.169963) | 1.716954 / 2.142072 (-0.425118) | 0.642094 / 4.805227 (-4.163133) | 0.119215 / 6.500664 (-6.381449) | 0.041941 / 0.075469 (-0.033528) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.986774 / 1.841788 (-0.855014) | 12.702049 / 8.074308 (4.627741) | 11.727663 / 10.191392 (1.536271) | 0.135008 / 0.680424 (-0.545416) | 0.016055 / 0.534201 (-0.518146) | 0.293564 / 0.579283 (-0.285719) | 0.284884 / 0.434364 (-0.149480) | 0.332524 / 0.540337 (-0.207814) | 0.425392 / 1.386936 (-0.961544) |\n\n</details>\n</details>\n\n\n"
] |
Preserve order of configs and splits when using Parquet exports
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6526/reactions"
}
|
PR_kwDODunzps5ipB5v
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6526.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6526",
"merged_at": "2023-12-22T11:36:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6526.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6526"
}
|
2023-12-22T10:35:56Z
|
https://api.github.com/repos/huggingface/datasets/issues/6526/comments
|
Preserve order of configs and splits, as defined in dataset infos.
Fix #6521.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6526/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6526/timeline
|
closed
| false | 6,526 | null |
2023-12-22T11:36:14Z
| null | true |
2,053,119,357 |
https://api.github.com/repos/huggingface/datasets/issues/6525
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6525/events
|
[] | null |
2024-01-11T06:34:51Z
|
[] |
https://github.com/huggingface/datasets/pull/6525
|
MEMBER
| null | true | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6525). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"closing in favor of other ideas that would not involve any typing"
] |
BBox type
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6525/reactions"
}
|
PR_kwDODunzps5im-lL
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6525.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6525",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6525.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6525"
}
|
2023-12-21T22:13:27Z
|
https://api.github.com/repos/huggingface/datasets/issues/6525/comments
|
see [internal discussion](https://huggingface.slack.com/archives/C02EK7C3SHW/p1703097195609209)
Draft to get some feedback on a possible `BBox` feature type that can be used to get object detection bounding boxes data in one format or another.
```python
>>> from datasets import load_dataset, BBox
>>> ds = load_dataset("svhn", "full_numbers", split="train")
>>> ds[0]
{
'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=107x46 at 0x126409BE0>,
'digits': {'bbox': [[38, 1, 21, 40], [57, 3, 16, 40]], 'label': [4, 6]}
}
>>> ds = ds.rename_column("digits", "annotations").cast_column("annotations", BBox(format="coco"))
>>> ds[0]
{
'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=107x46 at 0x147730070>,
'annotations': [{'bbox': [38, 1, 21, 40], 'category_id': 4}, {'bbox': [57, 3, 16, 40], 'category_id': 6}]
}
```
note that it's a type for a list of bounding boxes, not just one - which would be needed to switch from a format to another using type casting.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6525/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6525/timeline
|
closed
| false | 6,525 | null |
2023-12-21T22:39:27Z
| null | true |
2,053,076,311 |
https://api.github.com/repos/huggingface/datasets/issues/6524
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6524/events
|
[] | null |
2023-12-22T09:17:05Z
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] |
https://github.com/huggingface/datasets/issues/6524
|
NONE
|
completed
| null | null |
[
"Hello @FelixLabelle,\r\n\r\nAs you can see in the Community tab of the corresponding dataset, it is a known issue: https://huggingface.co/datasets/EleutherAI/pile/discussions/15\r\n\r\nThe data has been taken down due to reported copyright infringement.\r\n\r\nFeel free to continue the discussion there."
] |
Streaming the Pile: Missing Files
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6524/reactions"
}
|
I_kwDODunzps56X3VX
| null |
2023-12-21T21:25:09Z
|
https://api.github.com/repos/huggingface/datasets/issues/6524/comments
|
### Describe the bug
The pile does not stream, a "File not Found error" is returned. It looks like the Pile's files have been moved.
### Steps to reproduce the bug
To reproduce run the following code:
```
from datasets import load_dataset
dataset = load_dataset('EleutherAI/pile', 'en', split='train', streaming=True)
next(iter(dataset))
```
I get the following error:
`FileNotFoundError: https://the-eye.eu/public/AI/pile/train/00.jsonl.zst`
### Expected behavior
Return the data in a stream.
### Environment info
- `datasets` version: 2.12.0
- Platform: Windows-10-10.0.22621-SP0
- Python version: 3.11.5
- Huggingface_hub version: 0.15.1
- PyArrow version: 11.0.0
- Pandas version: 2.0.3
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23347756?v=4",
"events_url": "https://api.github.com/users/FelixLabelle/events{/privacy}",
"followers_url": "https://api.github.com/users/FelixLabelle/followers",
"following_url": "https://api.github.com/users/FelixLabelle/following{/other_user}",
"gists_url": "https://api.github.com/users/FelixLabelle/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/FelixLabelle",
"id": 23347756,
"login": "FelixLabelle",
"node_id": "MDQ6VXNlcjIzMzQ3NzU2",
"organizations_url": "https://api.github.com/users/FelixLabelle/orgs",
"received_events_url": "https://api.github.com/users/FelixLabelle/received_events",
"repos_url": "https://api.github.com/users/FelixLabelle/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/FelixLabelle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FelixLabelle/subscriptions",
"type": "User",
"url": "https://api.github.com/users/FelixLabelle"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6524/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6524/timeline
|
closed
| false | 6,524 | null |
2023-12-22T09:17:05Z
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
| false |
2,052,643,484 |
https://api.github.com/repos/huggingface/datasets/issues/6523
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6523/events
|
[] | null |
2023-12-21T15:56:54Z
|
[] |
https://github.com/huggingface/datasets/pull/6523
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6523). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005160 / 0.011353 (-0.006192) | 0.003962 / 0.011008 (-0.007046) | 0.064952 / 0.038508 (0.026444) | 0.053291 / 0.023109 (0.030182) | 0.237182 / 0.275898 (-0.038716) | 0.263855 / 0.323480 (-0.059625) | 0.004157 / 0.007986 (-0.003829) | 0.002901 / 0.004328 (-0.001428) | 0.050679 / 0.004250 (0.046428) | 0.044885 / 0.037052 (0.007832) | 0.243806 / 0.258489 (-0.014683) | 0.273828 / 0.293841 (-0.020013) | 0.028681 / 0.128546 (-0.099866) | 0.011086 / 0.075646 (-0.064560) | 0.211987 / 0.419271 (-0.207285) | 0.035881 / 0.043533 (-0.007652) | 0.249618 / 0.255139 (-0.005521) | 0.262880 / 0.283200 (-0.020319) | 0.017788 / 0.141683 (-0.123895) | 1.209060 / 1.452155 (-0.243094) | 1.272143 / 1.492716 (-0.220574) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004594 / 0.018006 (-0.013412) | 0.305188 / 0.000490 (0.304698) | 0.000213 / 0.000200 (0.000013) | 0.000052 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019526 / 0.037411 (-0.017886) | 0.062280 / 0.014526 (0.047754) | 0.074983 / 0.176557 (-0.101573) | 0.123466 / 0.737135 (-0.613670) | 0.076240 / 0.296338 (-0.220099) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.276001 / 0.215209 (0.060792) | 2.689614 / 2.077655 (0.611959) | 1.441092 / 1.504120 (-0.063028) | 1.319775 / 1.541195 (-0.221419) | 1.386904 / 1.468490 (-0.081587) | 0.561388 / 4.584777 (-4.023389) | 2.386718 / 3.745712 (-1.358994) | 2.813959 / 5.269862 (-2.455903) | 1.727447 / 4.565676 (-2.838230) | 0.061965 / 0.424275 (-0.362310) | 0.004977 / 0.007607 (-0.002630) | 0.335077 / 0.226044 (0.109032) | 3.313860 / 2.268929 (1.044932) | 1.814018 / 55.444624 (-53.630606) | 1.542840 / 6.876477 (-5.333637) | 1.586887 / 2.142072 (-0.555185) | 0.643225 / 4.805227 (-4.162002) | 0.117834 / 6.500664 (-6.382830) | 0.044024 / 0.075469 (-0.031445) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.952804 / 1.841788 (-0.888984) | 12.447378 / 8.074308 (4.373070) | 11.281734 / 10.191392 (1.090342) | 0.143407 / 0.680424 (-0.537017) | 0.014749 / 0.534201 (-0.519452) | 0.289298 / 0.579283 (-0.289985) | 0.268217 / 0.434364 (-0.166146) | 0.327995 / 0.540337 (-0.212343) | 0.430302 / 1.386936 (-0.956634) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005683 / 0.011353 (-0.005670) | 0.003813 / 0.011008 (-0.007195) | 0.048943 / 0.038508 (0.010435) | 0.060730 / 0.023109 (0.037621) | 0.266925 / 0.275898 (-0.008973) | 0.292553 / 0.323480 (-0.030927) | 0.004236 / 0.007986 (-0.003750) | 0.002790 / 0.004328 (-0.001538) | 0.048962 / 0.004250 (0.044711) | 0.040354 / 0.037052 (0.003302) | 0.266353 / 0.258489 (0.007864) | 0.298397 / 0.293841 (0.004556) | 0.029977 / 0.128546 (-0.098570) | 0.010788 / 0.075646 (-0.064858) | 0.057529 / 0.419271 (-0.361743) | 0.032896 / 0.043533 (-0.010636) | 0.266696 / 0.255139 (0.011557) | 0.283422 / 0.283200 (0.000223) | 0.020939 / 0.141683 (-0.120744) | 1.169867 / 1.452155 (-0.282287) | 1.213586 / 1.492716 (-0.279130) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.097035 / 0.018006 (0.079029) | 0.306968 / 0.000490 (0.306478) | 0.000234 / 0.000200 (0.000034) | 0.000046 / 0.000054 (-0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023343 / 0.037411 (-0.014068) | 0.078238 / 0.014526 (0.063712) | 0.091083 / 0.176557 (-0.085474) | 0.131487 / 0.737135 (-0.605649) | 0.092614 / 0.296338 (-0.203724) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.294454 / 0.215209 (0.079245) | 2.881053 / 2.077655 (0.803398) | 1.623934 / 1.504120 (0.119814) | 1.509001 / 1.541195 (-0.032194) | 1.567541 / 1.468490 (0.099051) | 0.574326 / 4.584777 (-4.010451) | 2.476826 / 3.745712 (-1.268886) | 2.826183 / 5.269862 (-2.443678) | 1.771949 / 4.565676 (-2.793727) | 0.063663 / 0.424275 (-0.360613) | 0.005039 / 0.007607 (-0.002568) | 0.354861 / 0.226044 (0.128816) | 3.397655 / 2.268929 (1.128727) | 1.961958 / 55.444624 (-53.482666) | 1.694795 / 6.876477 (-5.181682) | 1.719459 / 2.142072 (-0.422614) | 0.654512 / 4.805227 (-4.150715) | 0.119285 / 6.500664 (-6.381379) | 0.042146 / 0.075469 (-0.033323) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.982187 / 1.841788 (-0.859601) | 12.944627 / 8.074308 (4.870319) | 11.370381 / 10.191392 (1.178989) | 0.142759 / 0.680424 (-0.537665) | 0.016319 / 0.534201 (-0.517882) | 0.291339 / 0.579283 (-0.287944) | 0.276842 / 0.434364 (-0.157522) | 0.324285 / 0.540337 (-0.216052) | 0.426234 / 1.386936 (-0.960702) |\n\n</details>\n</details>\n\n\n"
] |
fix tests
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6523/reactions"
}
|
PR_kwDODunzps5ilV6d
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6523.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6523",
"merged_at": "2023-12-21T15:50:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6523.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6523"
}
|
2023-12-21T15:36:21Z
|
https://api.github.com/repos/huggingface/datasets/issues/6523/comments
| null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6523/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6523/timeline
|
closed
| false | 6,523 | null |
2023-12-21T15:50:38Z
| null | true |
2,052,332,528 |
https://api.github.com/repos/huggingface/datasets/issues/6522
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6522/events
|
[] | null |
2023-12-21T13:24:31Z
|
[] |
https://github.com/huggingface/datasets/issues/6522
|
NONE
| null | null | null |
[] |
Loading HF Hub Dataset (private org repo) fails to load all features
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6522/reactions"
}
|
I_kwDODunzps56VBvw
| null |
2023-12-21T12:26:35Z
|
https://api.github.com/repos/huggingface/datasets/issues/6522/comments
|
### Describe the bug
When pushing a `Dataset` with multiple `Features` (`input`, `output`, `tags`) to Huggingface Hub (private org repo), and later downloading the `Dataset`, only `input` and `output` load - I believe the expected behavior is for all `Features` to be loaded by default?
### Steps to reproduce the bug
Pushing the data. `data_concat` is a `list` of `dict`s.
```python
for datum in data_concat:
datum_tags = {d["key"]: d["value"] for d in datum["tags"]}
split_fraction = # some logic that generates a train/test split number
if split_faction < test_fraction:
data_test.append(datum)
else:
data_train.append(datum)
dataset = DatasetDict(
{
"train": Dataset.from_list(data_train),
"test": Dataset.from_list(data_test),
"full": Dataset.from_list(data_concat),
},
)
dataset_shuffled = dataset.shuffle(seed=shuffle_seed)
dataset_shuffled.push_to_hub(
repo_id=hf_repo_id,
private=True,
config_name=m,
revision=revision,
token=hf_token,
)
```
Loading it later:
```python
dataset = datasets.load_dataset(
path=hf_repo_id,
name=name,
token=hf_token,
)
```
Produces:
```
DatasetDict({
train: Dataset({
features: ['input', 'output'],
num_rows: <obfuscated>
})
test: Dataset({
features: ['input', 'output'],
num_rows: <obfuscated>
})
full: Dataset({
features: ['input', 'output'],
num_rows: <obfuscated>
})
})
```
### Expected behavior
The expected result is below:
```
DatasetDict({
train: Dataset({
features: ['input', 'output', 'tags'],
num_rows: <obfuscated>
})
test: Dataset({
features: ['input', 'output', 'tags'],
num_rows: <obfuscated>
})
full: Dataset({
features: ['input', 'output', 'tags'],
num_rows: <obfuscated>
})
})
```
My workaround is as follows:
```python
dsinfo = datasets.get_dataset_config_info(
path=data_files,
config_name=data_config,
token=hf_token,
)
allfeatures = dsinfo.features.copy()
if "tags" not in allfeatures:
allfeatures["tags"] = [{"key": Value(dtype="string", id=None), "value": Value(dtype="string", id=None)}]
dataset = datasets.load_dataset(
path=data_files,
name=data_config,
features=allfeatures,
token=hf_token,
)
```
Interestingly enough (and perhaps a related bug?), if I don't add the `tags` to `allfeatures` above (i.e. only loading `input` and `output`), it throws an error when executing `load_dataset`:
```
ValueError: Couldn't cast
tags: list<element: struct<key: string, value: string>>
child 0, element: struct<key: string, value: string>
child 0, key: string
child 1, value: string
input: <obfuscated>
output: <obfuscated>
-- schema metadata --
huggingface: '{"info": {"features": {"tags": [{"key": {"dtype": "string",' + 532
to
{'input': <obfuscated>, 'output': <obfuscated>
because column names don't match
```
Traceback for this:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/bt/github/core/.venv/lib/python3.11/site-packages/datasets/load.py", line 2152, in load_dataset
builder_instance.download_and_prepare(
File "/Users/bt/github/core/.venv/lib/python3.11/site-packages/datasets/builder.py", line 948, in download_and_prepare
self._download_and_prepare(
File "/Users/bt/github/core/.venv/lib/python3.11/site-packages/datasets/builder.py", line 1043, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/bt/github/core/.venv/lib/python3.11/site-packages/datasets/builder.py", line 1805, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/Users/bt/github/core/.venv/lib/python3.11/site-packages/datasets/builder.py", line 1950, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Environment info
- `datasets` version: 2.15.0
- Platform: macOS-14.0-arm64-arm-64bit
- Python version: 3.11.5
- `huggingface_hub` version: 0.19.4
- PyArrow version: 14.0.1
- Pandas version: 2.1.4
- `fsspec` version: 2023.10.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6579034?v=4",
"events_url": "https://api.github.com/users/versipellis/events{/privacy}",
"followers_url": "https://api.github.com/users/versipellis/followers",
"following_url": "https://api.github.com/users/versipellis/following{/other_user}",
"gists_url": "https://api.github.com/users/versipellis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/versipellis",
"id": 6579034,
"login": "versipellis",
"node_id": "MDQ6VXNlcjY1NzkwMzQ=",
"organizations_url": "https://api.github.com/users/versipellis/orgs",
"received_events_url": "https://api.github.com/users/versipellis/received_events",
"repos_url": "https://api.github.com/users/versipellis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/versipellis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/versipellis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/versipellis"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6522/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6522/timeline
|
open
| false | 6,522 | null | null | null | false |
2,052,229,538 |
https://api.github.com/repos/huggingface/datasets/issues/6521
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6521/events
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | null |
2023-12-22T11:36:15Z
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] |
https://github.com/huggingface/datasets/issues/6521
|
MEMBER
|
completed
| null | null |
[
"After investigation, I think the issue was introduced by the use of the Parquet export:\r\n- #6448\r\n\r\nI am proposing a fix.\r\n\r\nCC: @lhoestq "
] |
The order of the splits is not preserved
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6521/reactions"
}
|
I_kwDODunzps56Uomi
| null |
2023-12-21T11:17:27Z
|
https://api.github.com/repos/huggingface/datasets/issues/6521/comments
|
We had a regression and the order of the splits is not preserved. They are alphabetically sorted, instead of preserving original "train", "validation", "test" order.
Check: In branch "main"
```python
In [9]: dataset = load_dataset("adversarial_qa", '"adversarialQA")
In [10]: dataset
Out[10]:
DatasetDict({
test: Dataset({
features: ['id', 'title', 'context', 'question', 'answers', 'metadata'],
num_rows: 3000
})
train: Dataset({
features: ['id', 'title', 'context', 'question', 'answers', 'metadata'],
num_rows: 30000
})
validation: Dataset({
features: ['id', 'title', 'context', 'question', 'answers', 'metadata'],
num_rows: 3000
})
})
```
Before (2.15.0) it was:
```python
DatasetDict({
train: Dataset({
features: ['id', 'title', 'context', 'question', 'answers', 'metadata'],
num_rows: 30000
})
validation: Dataset({
features: ['id', 'title', 'context', 'question', 'answers', 'metadata'],
num_rows: 3000
})
test: Dataset({
features: ['id', 'title', 'context', 'question', 'answers', 'metadata'],
num_rows: 3000
})
})
```
See issues:
- https://huggingface.co/datasets/adversarial_qa/discussions/3
- https://huggingface.co/datasets/beans/discussions/4
This is a regression because it was previously fixed. See:
- #6196
- #5728
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6521/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6521/timeline
|
closed
| false | 6,521 | null |
2023-12-22T11:36:15Z
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
| false |
2,052,059,078 |
https://api.github.com/repos/huggingface/datasets/issues/6520
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6520/events
|
[] | null |
2023-12-21T14:49:47Z
|
[] |
https://github.com/huggingface/datasets/pull/6520
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6520). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005484 / 0.011353 (-0.005869) | 0.003537 / 0.011008 (-0.007471) | 0.062631 / 0.038508 (0.024123) | 0.048037 / 0.023109 (0.024927) | 0.240342 / 0.275898 (-0.035556) | 0.268103 / 0.323480 (-0.055377) | 0.002927 / 0.007986 (-0.005059) | 0.002609 / 0.004328 (-0.001719) | 0.048112 / 0.004250 (0.043862) | 0.046111 / 0.037052 (0.009058) | 0.249249 / 0.258489 (-0.009240) | 0.277723 / 0.293841 (-0.016118) | 0.028374 / 0.128546 (-0.100172) | 0.010900 / 0.075646 (-0.064746) | 0.206252 / 0.419271 (-0.213019) | 0.035262 / 0.043533 (-0.008271) | 0.247438 / 0.255139 (-0.007701) | 0.270003 / 0.283200 (-0.013197) | 0.019157 / 0.141683 (-0.122526) | 1.116833 / 1.452155 (-0.335322) | 1.174495 / 1.492716 (-0.318221) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092490 / 0.018006 (0.074484) | 0.302794 / 0.000490 (0.302304) | 0.000213 / 0.000200 (0.000013) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018669 / 0.037411 (-0.018743) | 0.061902 / 0.014526 (0.047376) | 0.073612 / 0.176557 (-0.102945) | 0.121196 / 0.737135 (-0.615940) | 0.075960 / 0.296338 (-0.220378) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286983 / 0.215209 (0.071774) | 2.836819 / 2.077655 (0.759165) | 1.506635 / 1.504120 (0.002515) | 1.387134 / 1.541195 (-0.154061) | 1.442310 / 1.468490 (-0.026180) | 0.571281 / 4.584777 (-4.013496) | 2.440220 / 3.745712 (-1.305492) | 2.775306 / 5.269862 (-2.494555) | 1.727047 / 4.565676 (-2.838630) | 0.064955 / 0.424275 (-0.359320) | 0.004982 / 0.007607 (-0.002625) | 0.343153 / 0.226044 (0.117108) | 3.388745 / 2.268929 (1.119817) | 1.878983 / 55.444624 (-53.565641) | 1.592642 / 6.876477 (-5.283835) | 1.601037 / 2.142072 (-0.541035) | 0.636882 / 4.805227 (-4.168345) | 0.117804 / 6.500664 (-6.382861) | 0.042467 / 0.075469 (-0.033002) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.941534 / 1.841788 (-0.900254) | 12.093230 / 8.074308 (4.018922) | 10.590854 / 10.191392 (0.399462) | 0.136636 / 0.680424 (-0.543788) | 0.015244 / 0.534201 (-0.518957) | 0.300216 / 0.579283 (-0.279067) | 0.267622 / 0.434364 (-0.166742) | 0.337526 / 0.540337 (-0.202811) | 0.426856 / 1.386936 (-0.960080) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005282 / 0.011353 (-0.006071) | 0.003595 / 0.011008 (-0.007413) | 0.049237 / 0.038508 (0.010729) | 0.054057 / 0.023109 (0.030948) | 0.269781 / 0.275898 (-0.006117) | 0.293544 / 0.323480 (-0.029936) | 0.003991 / 0.007986 (-0.003995) | 0.002705 / 0.004328 (-0.001623) | 0.048755 / 0.004250 (0.044505) | 0.040425 / 0.037052 (0.003373) | 0.264753 / 0.258489 (0.006264) | 0.312773 / 0.293841 (0.018932) | 0.030011 / 0.128546 (-0.098535) | 0.010707 / 0.075646 (-0.064939) | 0.058164 / 0.419271 (-0.361107) | 0.033365 / 0.043533 (-0.010168) | 0.268854 / 0.255139 (0.013715) | 0.283618 / 0.283200 (0.000418) | 0.019571 / 0.141683 (-0.122111) | 1.114738 / 1.452155 (-0.337417) | 1.178990 / 1.492716 (-0.313726) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092183 / 0.018006 (0.074177) | 0.303797 / 0.000490 (0.303307) | 0.000218 / 0.000200 (0.000018) | 0.000052 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023088 / 0.037411 (-0.014323) | 0.079813 / 0.014526 (0.065287) | 0.089593 / 0.176557 (-0.086964) | 0.128127 / 0.737135 (-0.609008) | 0.091578 / 0.296338 (-0.204761) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.300153 / 0.215209 (0.084944) | 2.919532 / 2.077655 (0.841877) | 1.587870 / 1.504120 (0.083750) | 1.459031 / 1.541195 (-0.082164) | 1.483305 / 1.468490 (0.014815) | 0.555865 / 4.584777 (-4.028912) | 2.388350 / 3.745712 (-1.357362) | 2.817947 / 5.269862 (-2.451914) | 1.764446 / 4.565676 (-2.801230) | 0.067142 / 0.424275 (-0.357133) | 0.005148 / 0.007607 (-0.002460) | 0.347998 / 0.226044 (0.121953) | 3.431208 / 2.268929 (1.162280) | 1.942175 / 55.444624 (-53.502450) | 1.676606 / 6.876477 (-5.199871) | 1.692431 / 2.142072 (-0.449641) | 0.645974 / 4.805227 (-4.159253) | 0.117729 / 6.500664 (-6.382935) | 0.041670 / 0.075469 (-0.033799) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.981554 / 1.841788 (-0.860234) | 12.671959 / 8.074308 (4.597650) | 11.230694 / 10.191392 (1.039302) | 0.132694 / 0.680424 (-0.547730) | 0.015694 / 0.534201 (-0.518507) | 0.290271 / 0.579283 (-0.289013) | 0.279358 / 0.434364 (-0.155006) | 0.326515 / 0.540337 (-0.213823) | 0.421755 / 1.386936 (-0.965181) |\n\n</details>\n</details>\n\n\n"
] |
Support commit_description parameter in push_to_hub
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6520/reactions"
}
|
PR_kwDODunzps5ijUiw
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6520.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6520",
"merged_at": "2023-12-21T14:43:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6520.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6520"
}
|
2023-12-21T09:36:11Z
|
https://api.github.com/repos/huggingface/datasets/issues/6520/comments
|
Support `commit_description` parameter in `push_to_hub`.
CC: @Wauplin
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6520/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6520/timeline
|
closed
| false | 6,520 | null |
2023-12-21T14:43:35Z
| null | true |
2,050,759,824 |
https://api.github.com/repos/huggingface/datasets/issues/6519
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6519/events
|
[] | null |
2023-12-21T14:48:20Z
|
[] |
https://github.com/huggingface/datasets/pull/6519
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6519). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"nice catch @albertvillanova ",
"@huggingface/datasets this PR is ready for review.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005306 / 0.011353 (-0.006047) | 0.003454 / 0.011008 (-0.007555) | 0.062157 / 0.038508 (0.023649) | 0.051945 / 0.023109 (0.028835) | 0.241834 / 0.275898 (-0.034064) | 0.265590 / 0.323480 (-0.057890) | 0.003149 / 0.007986 (-0.004837) | 0.002695 / 0.004328 (-0.001633) | 0.049197 / 0.004250 (0.044947) | 0.045576 / 0.037052 (0.008524) | 0.242866 / 0.258489 (-0.015623) | 0.280963 / 0.293841 (-0.012878) | 0.028466 / 0.128546 (-0.100080) | 0.010670 / 0.075646 (-0.064976) | 0.206501 / 0.419271 (-0.212771) | 0.035314 / 0.043533 (-0.008219) | 0.240893 / 0.255139 (-0.014246) | 0.264762 / 0.283200 (-0.018438) | 0.019988 / 0.141683 (-0.121695) | 1.095222 / 1.452155 (-0.356933) | 1.144051 / 1.492716 (-0.348666) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.098034 / 0.018006 (0.080028) | 0.308541 / 0.000490 (0.308051) | 0.000261 / 0.000200 (0.000061) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018646 / 0.037411 (-0.018766) | 0.062881 / 0.014526 (0.048355) | 0.074062 / 0.176557 (-0.102494) | 0.120860 / 0.737135 (-0.616276) | 0.075388 / 0.296338 (-0.220951) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282974 / 0.215209 (0.067765) | 2.755589 / 2.077655 (0.677934) | 1.459536 / 1.504120 (-0.044584) | 1.364543 / 1.541195 (-0.176652) | 1.429860 / 1.468490 (-0.038630) | 0.573277 / 4.584777 (-4.011500) | 2.422983 / 3.745712 (-1.322730) | 3.257258 / 5.269862 (-2.012603) | 1.930053 / 4.565676 (-2.635623) | 0.067476 / 0.424275 (-0.356799) | 0.005612 / 0.007607 (-0.001995) | 0.351538 / 0.226044 (0.125494) | 3.380356 / 2.268929 (1.111427) | 1.837887 / 55.444624 (-53.606738) | 1.537994 / 6.876477 (-5.338483) | 1.623630 / 2.142072 (-0.518442) | 0.662652 / 4.805227 (-4.142576) | 0.127074 / 6.500664 (-6.373590) | 0.049311 / 0.075469 (-0.026158) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.151273 / 1.841788 (-0.690515) | 12.766622 / 8.074308 (4.692314) | 10.967610 / 10.191392 (0.776218) | 0.131305 / 0.680424 (-0.549119) | 0.014227 / 0.534201 (-0.519974) | 0.292054 / 0.579283 (-0.287229) | 0.262737 / 0.434364 (-0.171627) | 0.334360 / 0.540337 (-0.205978) | 0.446711 / 1.386936 (-0.940225) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005194 / 0.011353 (-0.006159) | 0.003508 / 0.011008 (-0.007500) | 0.049287 / 0.038508 (0.010779) | 0.052109 / 0.023109 (0.029000) | 0.271501 / 0.275898 (-0.004397) | 0.290959 / 0.323480 (-0.032521) | 0.004347 / 0.007986 (-0.003638) | 0.002659 / 0.004328 (-0.001669) | 0.048769 / 0.004250 (0.044518) | 0.039388 / 0.037052 (0.002336) | 0.272811 / 0.258489 (0.014322) | 0.305632 / 0.293841 (0.011791) | 0.028419 / 0.128546 (-0.100127) | 0.010617 / 0.075646 (-0.065029) | 0.057433 / 0.419271 (-0.361838) | 0.032383 / 0.043533 (-0.011149) | 0.266566 / 0.255139 (0.011427) | 0.290993 / 0.283200 (0.007794) | 0.019939 / 0.141683 (-0.121743) | 1.157623 / 1.452155 (-0.294532) | 1.183298 / 1.492716 (-0.309419) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.099074 / 0.018006 (0.081068) | 0.315282 / 0.000490 (0.314792) | 0.000235 / 0.000200 (0.000035) | 0.000057 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022692 / 0.037411 (-0.014719) | 0.076455 / 0.014526 (0.061929) | 0.089094 / 0.176557 (-0.087462) | 0.126407 / 0.737135 (-0.610728) | 0.089588 / 0.296338 (-0.206750) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.338853 / 0.215209 (0.123644) | 2.809843 / 2.077655 (0.732188) | 1.538262 / 1.504120 (0.034143) | 1.418290 / 1.541195 (-0.122905) | 1.435145 / 1.468490 (-0.033345) | 0.565763 / 4.584777 (-4.019014) | 2.491525 / 3.745712 (-1.254187) | 2.944879 / 5.269862 (-2.324983) | 1.835840 / 4.565676 (-2.729837) | 0.065101 / 0.424275 (-0.359174) | 0.005196 / 0.007607 (-0.002412) | 0.345291 / 0.226044 (0.119247) | 3.399658 / 2.268929 (1.130729) | 1.892321 / 55.444624 (-53.552303) | 1.608293 / 6.876477 (-5.268184) | 1.651188 / 2.142072 (-0.490884) | 0.647806 / 4.805227 (-4.157421) | 0.119318 / 6.500664 (-6.381346) | 0.043058 / 0.075469 (-0.032412) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.983956 / 1.841788 (-0.857831) | 13.516125 / 8.074308 (5.441817) | 11.712571 / 10.191392 (1.521179) | 0.134253 / 0.680424 (-0.546171) | 0.015844 / 0.534201 (-0.518357) | 0.292444 / 0.579283 (-0.286839) | 0.282182 / 0.434364 (-0.152182) | 0.329327 / 0.540337 (-0.211010) | 0.419960 / 1.386936 (-0.966976) |\n\n</details>\n</details>\n\n\n"
] |
Support push_to_hub canonical datasets
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6519/reactions"
}
|
PR_kwDODunzps5ie4MA
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6519.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6519",
"merged_at": "2023-12-21T14:40:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6519.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6519"
}
|
2023-12-20T15:16:45Z
|
https://api.github.com/repos/huggingface/datasets/issues/6519/comments
|
Support `push_to_hub` canonical datasets.
This is necessary in the Space to convert script-datasets to Parquet: https://huggingface.co/spaces/albertvillanova/convert-dataset-to-parquet
Note that before this PR, the `repo_id` "dataset_name" was transformed to "user/dataset_name". This behavior was introduced by:
- #6269
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6519/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6519/timeline
|
closed
| false | 6,519 | null |
2023-12-21T14:40:57Z
| null | true |
2,050,137,038 |
https://api.github.com/repos/huggingface/datasets/issues/6518
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6518/events
|
[] | null |
2023-12-21T15:14:17Z
|
[] |
https://github.com/huggingface/datasets/pull/6518
|
CONTRIBUTOR
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6518). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"hello!\r\n@albertvillanova \r\nThank you very much for your recognition。\r\nWhen can this PR be merged?",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005205 / 0.011353 (-0.006148) | 0.003730 / 0.011008 (-0.007278) | 0.063195 / 0.038508 (0.024687) | 0.052329 / 0.023109 (0.029219) | 0.247299 / 0.275898 (-0.028599) | 0.269600 / 0.323480 (-0.053880) | 0.004801 / 0.007986 (-0.003185) | 0.002728 / 0.004328 (-0.001600) | 0.049195 / 0.004250 (0.044944) | 0.044859 / 0.037052 (0.007807) | 0.253047 / 0.258489 (-0.005442) | 0.277253 / 0.293841 (-0.016588) | 0.028370 / 0.128546 (-0.100176) | 0.011095 / 0.075646 (-0.064551) | 0.211090 / 0.419271 (-0.208182) | 0.035944 / 0.043533 (-0.007589) | 0.252755 / 0.255139 (-0.002384) | 0.269466 / 0.283200 (-0.013733) | 0.017514 / 0.141683 (-0.124169) | 1.107815 / 1.452155 (-0.344339) | 1.154989 / 1.492716 (-0.337728) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093925 / 0.018006 (0.075919) | 0.300923 / 0.000490 (0.300433) | 0.000219 / 0.000200 (0.000019) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018268 / 0.037411 (-0.019143) | 0.060508 / 0.014526 (0.045983) | 0.074564 / 0.176557 (-0.101992) | 0.121523 / 0.737135 (-0.615612) | 0.077394 / 0.296338 (-0.218945) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.275859 / 0.215209 (0.060650) | 2.707593 / 2.077655 (0.629938) | 1.419178 / 1.504120 (-0.084942) | 1.286737 / 1.541195 (-0.254458) | 1.350504 / 1.468490 (-0.117986) | 0.570461 / 4.584777 (-4.014316) | 2.400795 / 3.745712 (-1.344917) | 2.840876 / 5.269862 (-2.428986) | 1.724044 / 4.565676 (-2.841633) | 0.063819 / 0.424275 (-0.360456) | 0.004961 / 0.007607 (-0.002647) | 0.342537 / 0.226044 (0.116492) | 3.370942 / 2.268929 (1.102013) | 1.788659 / 55.444624 (-53.655966) | 1.501921 / 6.876477 (-5.374556) | 1.535352 / 2.142072 (-0.606721) | 0.651838 / 4.805227 (-4.153390) | 0.118979 / 6.500664 (-6.381685) | 0.047796 / 0.075469 (-0.027673) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.949850 / 1.841788 (-0.891937) | 11.581988 / 8.074308 (3.507680) | 10.462837 / 10.191392 (0.271445) | 0.133298 / 0.680424 (-0.547125) | 0.015008 / 0.534201 (-0.519193) | 0.299265 / 0.579283 (-0.280018) | 0.268864 / 0.434364 (-0.165500) | 0.332888 / 0.540337 (-0.207450) | 0.420423 / 1.386936 (-0.966513) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005309 / 0.011353 (-0.006044) | 0.003628 / 0.011008 (-0.007380) | 0.049545 / 0.038508 (0.011036) | 0.054095 / 0.023109 (0.030985) | 0.270679 / 0.275898 (-0.005219) | 0.295744 / 0.323480 (-0.027736) | 0.004131 / 0.007986 (-0.003855) | 0.002732 / 0.004328 (-0.001596) | 0.048714 / 0.004250 (0.044464) | 0.039916 / 0.037052 (0.002863) | 0.272354 / 0.258489 (0.013865) | 0.310553 / 0.293841 (0.016712) | 0.029525 / 0.128546 (-0.099021) | 0.011322 / 0.075646 (-0.064324) | 0.058007 / 0.419271 (-0.361265) | 0.032883 / 0.043533 (-0.010650) | 0.273609 / 0.255139 (0.018470) | 0.291780 / 0.283200 (0.008581) | 0.020538 / 0.141683 (-0.121145) | 1.118031 / 1.452155 (-0.334123) | 1.160777 / 1.492716 (-0.331940) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092966 / 0.018006 (0.074959) | 0.301432 / 0.000490 (0.300943) | 0.000225 / 0.000200 (0.000025) | 0.000044 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022736 / 0.037411 (-0.014676) | 0.077655 / 0.014526 (0.063129) | 0.093386 / 0.176557 (-0.083171) | 0.129694 / 0.737135 (-0.607441) | 0.092790 / 0.296338 (-0.203548) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.299161 / 0.215209 (0.083952) | 2.923300 / 2.077655 (0.845645) | 1.629661 / 1.504120 (0.125541) | 1.510797 / 1.541195 (-0.030398) | 1.507269 / 1.468490 (0.038778) | 0.574346 / 4.584777 (-4.010431) | 2.454396 / 3.745712 (-1.291316) | 2.843402 / 5.269862 (-2.426460) | 1.774815 / 4.565676 (-2.790861) | 0.063601 / 0.424275 (-0.360674) | 0.004977 / 0.007607 (-0.002630) | 0.347693 / 0.226044 (0.121649) | 3.430054 / 2.268929 (1.161126) | 1.987308 / 55.444624 (-53.457316) | 1.682756 / 6.876477 (-5.193721) | 1.688463 / 2.142072 (-0.453609) | 0.646449 / 4.805227 (-4.158778) | 0.117860 / 6.500664 (-6.382804) | 0.041305 / 0.075469 (-0.034164) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.987355 / 1.841788 (-0.854433) | 12.398721 / 8.074308 (4.324412) | 11.070442 / 10.191392 (0.879050) | 0.134946 / 0.680424 (-0.545477) | 0.016172 / 0.534201 (-0.518029) | 0.293359 / 0.579283 (-0.285924) | 0.282271 / 0.434364 (-0.152093) | 0.331919 / 0.540337 (-0.208418) | 0.432137 / 1.386936 (-0.954799) |\n\n</details>\n</details>\n\n\n"
] |
fix get_metadata_patterns function args error
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6518/reactions"
}
|
PR_kwDODunzps5icu-W
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6518.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6518",
"merged_at": "2023-12-21T15:07:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6518.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6518"
}
|
2023-12-20T09:06:22Z
|
https://api.github.com/repos/huggingface/datasets/issues/6518/comments
|
Bug get_metadata_patterns arg error https://github.com/huggingface/datasets/issues/6517
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6518/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6518/timeline
|
closed
| false | 6,518 | null |
2023-12-21T15:07:57Z
| null | true |
2,050,121,588 |
https://api.github.com/repos/huggingface/datasets/issues/6517
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6517/events
|
[] | null |
2023-12-22T00:24:23Z
|
[] |
https://github.com/huggingface/datasets/issues/6517
|
CONTRIBUTOR
|
completed
| null | null |
[] |
Bug get_metadata_patterns arg error
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6517/reactions"
}
|
I_kwDODunzps56Ml90
| null |
2023-12-20T08:56:44Z
|
https://api.github.com/repos/huggingface/datasets/issues/6517/comments
|
https://github.com/huggingface/datasets/blob/3f149204a2a5948287adcade5e90707aa5207a92/src/datasets/load.py#L1240C1-L1240C69
metadata_patterns = get_metadata_patterns(base_path, download_config=self.download_config)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6517/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6517/timeline
|
closed
| false | 6,517 | null |
2023-12-22T00:24:23Z
| null | false |
2,050,033,322 |
https://api.github.com/repos/huggingface/datasets/issues/6516
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6516/events
|
[] | null |
2023-12-20T08:51:34Z
|
[] |
https://github.com/huggingface/datasets/pull/6516
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6516). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005309 / 0.011353 (-0.006044) | 0.003231 / 0.011008 (-0.007777) | 0.062690 / 0.038508 (0.024182) | 0.050811 / 0.023109 (0.027701) | 0.258319 / 0.275898 (-0.017579) | 0.275977 / 0.323480 (-0.047503) | 0.002842 / 0.007986 (-0.005143) | 0.002606 / 0.004328 (-0.001723) | 0.048672 / 0.004250 (0.044421) | 0.038730 / 0.037052 (0.001677) | 0.258531 / 0.258489 (0.000042) | 0.289327 / 0.293841 (-0.004514) | 0.027994 / 0.128546 (-0.100552) | 0.010446 / 0.075646 (-0.065200) | 0.207152 / 0.419271 (-0.212119) | 0.035839 / 0.043533 (-0.007693) | 0.258416 / 0.255139 (0.003277) | 0.274348 / 0.283200 (-0.008851) | 0.019661 / 0.141683 (-0.122022) | 1.103688 / 1.452155 (-0.348466) | 1.207711 / 1.492716 (-0.285006) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.090693 / 0.018006 (0.072687) | 0.300648 / 0.000490 (0.300158) | 0.000215 / 0.000200 (0.000015) | 0.000053 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018589 / 0.037411 (-0.018822) | 0.061056 / 0.014526 (0.046530) | 0.074512 / 0.176557 (-0.102044) | 0.121260 / 0.737135 (-0.615875) | 0.073111 / 0.296338 (-0.223227) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.285811 / 0.215209 (0.070602) | 2.785081 / 2.077655 (0.707426) | 1.469493 / 1.504120 (-0.034627) | 1.346389 / 1.541195 (-0.194806) | 1.391866 / 1.468490 (-0.076624) | 0.567304 / 4.584777 (-4.017473) | 2.407150 / 3.745712 (-1.338562) | 2.809915 / 5.269862 (-2.459946) | 1.741185 / 4.565676 (-2.824491) | 0.063073 / 0.424275 (-0.361202) | 0.004974 / 0.007607 (-0.002633) | 0.336431 / 0.226044 (0.110386) | 3.331371 / 2.268929 (1.062443) | 1.841466 / 55.444624 (-53.603159) | 1.559065 / 6.876477 (-5.317411) | 1.585033 / 2.142072 (-0.557039) | 0.647469 / 4.805227 (-4.157759) | 0.117488 / 6.500664 (-6.383176) | 0.042535 / 0.075469 (-0.032934) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.936409 / 1.841788 (-0.905379) | 11.301514 / 8.074308 (3.227206) | 10.500465 / 10.191392 (0.309073) | 0.131316 / 0.680424 (-0.549107) | 0.014007 / 0.534201 (-0.520194) | 0.286932 / 0.579283 (-0.292351) | 0.263516 / 0.434364 (-0.170848) | 0.340883 / 0.540337 (-0.199454) | 0.443589 / 1.386936 (-0.943347) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005204 / 0.011353 (-0.006149) | 0.003472 / 0.011008 (-0.007536) | 0.049235 / 0.038508 (0.010727) | 0.050668 / 0.023109 (0.027559) | 0.270198 / 0.275898 (-0.005700) | 0.293942 / 0.323480 (-0.029538) | 0.003964 / 0.007986 (-0.004022) | 0.002596 / 0.004328 (-0.001733) | 0.048654 / 0.004250 (0.044404) | 0.039411 / 0.037052 (0.002358) | 0.271938 / 0.258489 (0.013449) | 0.304308 / 0.293841 (0.010467) | 0.029042 / 0.128546 (-0.099504) | 0.010414 / 0.075646 (-0.065232) | 0.058273 / 0.419271 (-0.360999) | 0.032507 / 0.043533 (-0.011025) | 0.271671 / 0.255139 (0.016532) | 0.289850 / 0.283200 (0.006650) | 0.017292 / 0.141683 (-0.124391) | 1.126160 / 1.452155 (-0.325995) | 1.177365 / 1.492716 (-0.315351) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091158 / 0.018006 (0.073152) | 0.299143 / 0.000490 (0.298653) | 0.000217 / 0.000200 (0.000017) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022558 / 0.037411 (-0.014853) | 0.076139 / 0.014526 (0.061613) | 0.088344 / 0.176557 (-0.088212) | 0.126640 / 0.737135 (-0.610495) | 0.089736 / 0.296338 (-0.206602) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295351 / 0.215209 (0.080142) | 2.895779 / 2.077655 (0.818125) | 1.585886 / 1.504120 (0.081766) | 1.458601 / 1.541195 (-0.082594) | 1.468880 / 1.468490 (0.000390) | 0.554686 / 4.584777 (-4.030091) | 2.466276 / 3.745712 (-1.279437) | 2.741938 / 5.269862 (-2.527924) | 1.711793 / 4.565676 (-2.853883) | 0.062928 / 0.424275 (-0.361347) | 0.005177 / 0.007607 (-0.002430) | 0.343908 / 0.226044 (0.117863) | 3.393360 / 2.268929 (1.124431) | 1.928800 / 55.444624 (-53.515824) | 1.652181 / 6.876477 (-5.224296) | 1.643667 / 2.142072 (-0.498405) | 0.632829 / 4.805227 (-4.172398) | 0.114583 / 6.500664 (-6.386081) | 0.041248 / 0.075469 (-0.034221) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.986196 / 1.841788 (-0.855592) | 12.006772 / 8.074308 (3.932464) | 10.522661 / 10.191392 (0.331269) | 0.133710 / 0.680424 (-0.546713) | 0.016714 / 0.534201 (-0.517487) | 0.286502 / 0.579283 (-0.292781) | 0.280090 / 0.434364 (-0.154273) | 0.326063 / 0.540337 (-0.214275) | 0.548485 / 1.386936 (-0.838452) |\n\n</details>\n</details>\n\n\n"
] |
Support huggingface-hub pre-releases
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6516/reactions"
}
|
PR_kwDODunzps5icYX0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6516.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6516",
"merged_at": "2023-12-20T08:44:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6516.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6516"
}
|
2023-12-20T07:52:29Z
|
https://api.github.com/repos/huggingface/datasets/issues/6516/comments
|
Support `huggingface-hub` pre-releases.
This way we will have our CI green when testing `huggingface-hub` release candidates. See: https://github.com/huggingface/datasets/tree/ci-test-huggingface-hub-v0.20.0.rc1
Close #6513.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6516/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6516/timeline
|
closed
| false | 6,516 | null |
2023-12-20T08:44:44Z
| null | true |
2,049,724,251 |
https://api.github.com/repos/huggingface/datasets/issues/6515
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6515/events
|
[] | null |
2023-12-26T05:35:46Z
|
[] |
https://github.com/huggingface/datasets/issues/6515
|
CONTRIBUTOR
|
completed
| null | null |
[] |
Why call http_head() when fsspec_head() succeeds
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6515/reactions"
}
|
I_kwDODunzps56LE9b
| null |
2023-12-20T02:25:51Z
|
https://api.github.com/repos/huggingface/datasets/issues/6515/comments
|
https://github.com/huggingface/datasets/blob/a91582de288d98e94bcb5ab634ca1cfeeff544c5/src/datasets/utils/file_utils.py#L510C1-L523C14
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6515/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6515/timeline
|
closed
| false | 6,515 | null |
2023-12-26T05:35:46Z
| null | false |
2,049,600,663 |
https://api.github.com/repos/huggingface/datasets/issues/6514
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6514/events
|
[] | null |
2023-12-21T21:14:11Z
|
[] |
https://github.com/huggingface/datasets/pull/6514
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6514). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"it's hard to tell if this works as expected without a test but i guess it's not trivial to implement such a test.\r\n\r\ni tried to reproduce locally (with this branch merged into the lazy-resolve-and-cache-reload) and it didn't work. \r\nI run:\r\n```\r\n ds = load_dataset(\"polinaeterna/audiofolder_two_configs_in_metadata\", \"v2\", data_files=\"v2/train/*\") \r\n```\r\nand i got this in the cache:\r\n```\r\nv2-374bfde4f55442bc/\r\n└── 0.0.0\r\n ├── 5a2339ad2bb7caf6a6daf2f213204e3ac03a13a5 # - from this pr\r\n │ ├── audiofolder_two_configs_in_metadata-train.arrow\r\n │ └── dataset_info.json\r\n ├── 5a2339ad2bb7caf6a6daf2f213204e3ac03a13a5_builder.lock\r\n ├── 5a2339ad2bb7caf6a6daf2f213204e3ac03a13a5.incomplete_info.lock\r\n ├── 7896925d64deea5d # from 2.15.0\r\n │ ├── audiofolder_two_configs_in_metadata-train.arrow\r\n │ └── dataset_info.json\r\n ├── 7896925d64deea5d_builder.lock\r\n └── 7896925d64deea5d.incomplete_info.lock\r\n```\r\nso the first hash (the top-level dir v2-374bfde4f55442bc) matches but the second (after version) doesn't.\r\nmaybe i did something wrong though.\r\n\r\nalso i'm not sure if this is worth too much effort, maybe nobody notices if their datasets will be generated again :D idk",
"I just pushed a fix, it should work just fine now :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004798 / 0.011353 (-0.006555) | 0.003203 / 0.011008 (-0.007805) | 0.062247 / 0.038508 (0.023738) | 0.029906 / 0.023109 (0.006797) | 0.259370 / 0.275898 (-0.016528) | 0.276084 / 0.323480 (-0.047396) | 0.002910 / 0.007986 (-0.005076) | 0.002364 / 0.004328 (-0.001964) | 0.048080 / 0.004250 (0.043830) | 0.041168 / 0.037052 (0.004116) | 0.259833 / 0.258489 (0.001343) | 0.289882 / 0.293841 (-0.003959) | 0.026790 / 0.128546 (-0.101756) | 0.010336 / 0.075646 (-0.065311) | 0.209628 / 0.419271 (-0.209643) | 0.035080 / 0.043533 (-0.008452) | 0.256278 / 0.255139 (0.001139) | 0.279502 / 0.283200 (-0.003697) | 0.019755 / 0.141683 (-0.121928) | 1.121552 / 1.452155 (-0.330602) | 1.174360 / 1.492716 (-0.318356) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093510 / 0.018006 (0.075504) | 0.302065 / 0.000490 (0.301575) | 0.000214 / 0.000200 (0.000014) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.017652 / 0.037411 (-0.019759) | 0.060512 / 0.014526 (0.045986) | 0.072441 / 0.176557 (-0.104115) | 0.118058 / 0.737135 (-0.619078) | 0.072657 / 0.296338 (-0.223682) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.283949 / 0.215209 (0.068740) | 2.803275 / 2.077655 (0.725620) | 1.527353 / 1.504120 (0.023233) | 1.408176 / 1.541195 (-0.133019) | 1.375335 / 1.468490 (-0.093155) | 0.546426 / 4.584777 (-4.038351) | 2.402210 / 3.745712 (-1.343502) | 2.765879 / 5.269862 (-2.503982) | 1.703722 / 4.565676 (-2.861955) | 0.062669 / 0.424275 (-0.361606) | 0.005006 / 0.007607 (-0.002601) | 0.337941 / 0.226044 (0.111897) | 3.385494 / 2.268929 (1.116566) | 1.817360 / 55.444624 (-53.627264) | 1.548594 / 6.876477 (-5.327883) | 1.548610 / 2.142072 (-0.593463) | 0.630188 / 4.805227 (-4.175040) | 0.117079 / 6.500664 (-6.383585) | 0.042077 / 0.075469 (-0.033392) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.941606 / 1.841788 (-0.900182) | 11.226277 / 8.074308 (3.151969) | 10.118005 / 10.191392 (-0.073387) | 0.130408 / 0.680424 (-0.550015) | 0.014419 / 0.534201 (-0.519782) | 0.284812 / 0.579283 (-0.294471) | 0.266951 / 0.434364 (-0.167413) | 0.322251 / 0.540337 (-0.218087) | 0.415014 / 1.386936 (-0.971922) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005192 / 0.011353 (-0.006161) | 0.003028 / 0.011008 (-0.007980) | 0.048322 / 0.038508 (0.009814) | 0.030550 / 0.023109 (0.007441) | 0.264360 / 0.275898 (-0.011538) | 0.289544 / 0.323480 (-0.033936) | 0.004053 / 0.007986 (-0.003933) | 0.002480 / 0.004328 (-0.001848) | 0.048215 / 0.004250 (0.043964) | 0.044208 / 0.037052 (0.007156) | 0.263943 / 0.258489 (0.005454) | 0.297648 / 0.293841 (0.003807) | 0.029315 / 0.128546 (-0.099231) | 0.010533 / 0.075646 (-0.065114) | 0.057021 / 0.419271 (-0.362251) | 0.053751 / 0.043533 (0.010218) | 0.265153 / 0.255139 (0.010014) | 0.284988 / 0.283200 (0.001788) | 0.018459 / 0.141683 (-0.123224) | 1.225657 / 1.452155 (-0.226498) | 1.195737 / 1.492716 (-0.296979) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093030 / 0.018006 (0.075024) | 0.301022 / 0.000490 (0.300533) | 0.000228 / 0.000200 (0.000028) | 0.000052 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022073 / 0.037411 (-0.015339) | 0.075912 / 0.014526 (0.061386) | 0.087628 / 0.176557 (-0.088929) | 0.125607 / 0.737135 (-0.611529) | 0.088568 / 0.296338 (-0.207770) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.303482 / 0.215209 (0.088273) | 2.965987 / 2.077655 (0.888333) | 1.615273 / 1.504120 (0.111153) | 1.482851 / 1.541195 (-0.058344) | 1.562627 / 1.468490 (0.094137) | 0.563626 / 4.584777 (-4.021151) | 2.448741 / 3.745712 (-1.296971) | 2.761006 / 5.269862 (-2.508855) | 1.711242 / 4.565676 (-2.854434) | 0.064593 / 0.424275 (-0.359682) | 0.005044 / 0.007607 (-0.002563) | 0.354131 / 0.226044 (0.128087) | 3.511698 / 2.268929 (1.242770) | 1.951087 / 55.444624 (-53.493538) | 1.682171 / 6.876477 (-5.194305) | 1.666330 / 2.142072 (-0.475742) | 0.654880 / 4.805227 (-4.150347) | 0.118544 / 6.500664 (-6.382120) | 0.040753 / 0.075469 (-0.034717) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.967771 / 1.841788 (-0.874017) | 12.017277 / 8.074308 (3.942969) | 10.624947 / 10.191392 (0.433555) | 0.128834 / 0.680424 (-0.551590) | 0.015739 / 0.534201 (-0.518462) | 0.285906 / 0.579283 (-0.293377) | 0.273659 / 0.434364 (-0.160705) | 0.324044 / 0.540337 (-0.216293) | 0.419469 / 1.386936 (-0.967467) |\n\n</details>\n</details>\n\n\n"
] |
Cache backward compatibility with 2.15.0
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6514/reactions"
}
|
PR_kwDODunzps5ia6Os
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6514.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6514",
"merged_at": "2023-12-21T21:07:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6514.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6514"
}
|
2023-12-19T23:52:25Z
|
https://api.github.com/repos/huggingface/datasets/issues/6514/comments
|
...for datasets without scripts
It takes into account the changes in cache from
- https://github.com/huggingface/datasets/pull/6493: switch to `config/version/commit_sha` schema
- https://github.com/huggingface/datasets/pull/6454: fix `DataFilesDict` keys ordering when hashing
requires https://github.com/huggingface/datasets/pull/6493 to be merged
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6514/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6514/timeline
|
closed
| false | 6,514 | null |
2023-12-21T21:07:55Z
| null | true |
2,048,869,151 |
https://api.github.com/repos/huggingface/datasets/issues/6513
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6513/events
|
[] | null |
2023-12-20T08:44:45Z
|
[] |
https://github.com/huggingface/datasets/issues/6513
|
MEMBER
|
completed
| null | null |
[] |
Support huggingface-hub 0.20.0
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6513/reactions"
}
|
I_kwDODunzps56H0Mf
| null |
2023-12-19T15:15:46Z
|
https://api.github.com/repos/huggingface/datasets/issues/6513/comments
|
CI to test the support of `huggingface-hub` 0.20.0: https://github.com/huggingface/datasets/compare/main...ci-test-huggingface-hub-v0.20.0.rc1
We need to merge:
- #6510
- #6512
- #6516
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6513/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6513/timeline
|
closed
| false | 6,513 | null |
2023-12-20T08:44:45Z
| null | false |
2,048,795,819 |
https://api.github.com/repos/huggingface/datasets/issues/6512
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6512/events
|
[] | null |
2023-12-19T20:21:13Z
|
[] |
https://github.com/huggingface/datasets/pull/6512
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6512). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005468 / 0.011353 (-0.005885) | 0.003447 / 0.011008 (-0.007561) | 0.062569 / 0.038508 (0.024061) | 0.049427 / 0.023109 (0.026318) | 0.238463 / 0.275898 (-0.037435) | 0.268320 / 0.323480 (-0.055159) | 0.002834 / 0.007986 (-0.005151) | 0.002679 / 0.004328 (-0.001649) | 0.048613 / 0.004250 (0.044363) | 0.038793 / 0.037052 (0.001741) | 0.247710 / 0.258489 (-0.010779) | 0.277557 / 0.293841 (-0.016284) | 0.027134 / 0.128546 (-0.101412) | 0.010346 / 0.075646 (-0.065301) | 0.205782 / 0.419271 (-0.213490) | 0.035549 / 0.043533 (-0.007983) | 0.241667 / 0.255139 (-0.013472) | 0.268358 / 0.283200 (-0.014842) | 0.017119 / 0.141683 (-0.124563) | 1.108487 / 1.452155 (-0.343668) | 1.177519 / 1.492716 (-0.315197) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.090925 / 0.018006 (0.072919) | 0.310422 / 0.000490 (0.309932) | 0.000212 / 0.000200 (0.000012) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018912 / 0.037411 (-0.018499) | 0.061534 / 0.014526 (0.047008) | 0.073608 / 0.176557 (-0.102949) | 0.119278 / 0.737135 (-0.617858) | 0.074698 / 0.296338 (-0.221640) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.287224 / 0.215209 (0.072014) | 2.792022 / 2.077655 (0.714367) | 1.474605 / 1.504120 (-0.029515) | 1.348714 / 1.541195 (-0.192481) | 1.381339 / 1.468490 (-0.087151) | 0.553033 / 4.584777 (-4.031744) | 2.360745 / 3.745712 (-1.384967) | 2.779281 / 5.269862 (-2.490580) | 1.743922 / 4.565676 (-2.821754) | 0.063817 / 0.424275 (-0.360458) | 0.004954 / 0.007607 (-0.002653) | 0.340039 / 0.226044 (0.113994) | 3.336771 / 2.268929 (1.067843) | 1.825573 / 55.444624 (-53.619051) | 1.525362 / 6.876477 (-5.351115) | 1.578793 / 2.142072 (-0.563280) | 0.638432 / 4.805227 (-4.166795) | 0.117601 / 6.500664 (-6.383063) | 0.041890 / 0.075469 (-0.033579) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.936896 / 1.841788 (-0.904892) | 11.426979 / 8.074308 (3.352671) | 10.636043 / 10.191392 (0.444651) | 0.136172 / 0.680424 (-0.544252) | 0.014249 / 0.534201 (-0.519952) | 0.287806 / 0.579283 (-0.291477) | 0.266046 / 0.434364 (-0.168318) | 0.326155 / 0.540337 (-0.214183) | 0.455508 / 1.386936 (-0.931428) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005199 / 0.011353 (-0.006154) | 0.003476 / 0.011008 (-0.007532) | 0.050519 / 0.038508 (0.012011) | 0.050732 / 0.023109 (0.027623) | 0.270140 / 0.275898 (-0.005758) | 0.295539 / 0.323480 (-0.027941) | 0.004057 / 0.007986 (-0.003928) | 0.002771 / 0.004328 (-0.001558) | 0.049157 / 0.004250 (0.044906) | 0.039863 / 0.037052 (0.002811) | 0.275934 / 0.258489 (0.017445) | 0.306971 / 0.293841 (0.013130) | 0.029405 / 0.128546 (-0.099141) | 0.010746 / 0.075646 (-0.064900) | 0.058427 / 0.419271 (-0.360845) | 0.032448 / 0.043533 (-0.011085) | 0.271851 / 0.255139 (0.016712) | 0.290337 / 0.283200 (0.007138) | 0.019145 / 0.141683 (-0.122538) | 1.112232 / 1.452155 (-0.339922) | 1.215153 / 1.492716 (-0.277564) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.088590 / 0.018006 (0.070584) | 0.299047 / 0.000490 (0.298558) | 0.000219 / 0.000200 (0.000019) | 0.000050 / 0.000054 (-0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022755 / 0.037411 (-0.014656) | 0.078720 / 0.014526 (0.064194) | 0.089051 / 0.176557 (-0.087505) | 0.129330 / 0.737135 (-0.607805) | 0.090645 / 0.296338 (-0.205693) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.294083 / 0.215209 (0.078874) | 2.907195 / 2.077655 (0.829540) | 1.607392 / 1.504120 (0.103272) | 1.481931 / 1.541195 (-0.059263) | 1.486934 / 1.468490 (0.018444) | 0.574093 / 4.584777 (-4.010684) | 2.439775 / 3.745712 (-1.305937) | 2.739818 / 5.269862 (-2.530044) | 1.753922 / 4.565676 (-2.811755) | 0.063738 / 0.424275 (-0.360537) | 0.005219 / 0.007607 (-0.002388) | 0.350342 / 0.226044 (0.124297) | 3.463644 / 2.268929 (1.194716) | 1.971598 / 55.444624 (-53.473026) | 1.671752 / 6.876477 (-5.204724) | 1.686504 / 2.142072 (-0.455569) | 0.655870 / 4.805227 (-4.149357) | 0.117580 / 6.500664 (-6.383084) | 0.041210 / 0.075469 (-0.034259) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.996305 / 1.841788 (-0.845482) | 12.426361 / 8.074308 (4.352053) | 10.600309 / 10.191392 (0.408917) | 0.129728 / 0.680424 (-0.550695) | 0.015267 / 0.534201 (-0.518934) | 0.285444 / 0.579283 (-0.293839) | 0.272375 / 0.434364 (-0.161989) | 0.323478 / 0.540337 (-0.216860) | 0.547566 / 1.386936 (-0.839370) |\n\n</details>\n</details>\n\n\n"
] |
Remove deprecated HfFolder
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6512/reactions"
}
|
PR_kwDODunzps5iYI5z
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6512.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6512",
"merged_at": "2023-12-19T20:14:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6512.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6512"
}
|
2023-12-19T14:40:49Z
|
https://api.github.com/repos/huggingface/datasets/issues/6512/comments
|
...and use `huggingface_hub.get_token()` instead
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6512/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6512/timeline
|
closed
| false | 6,512 | null |
2023-12-19T20:14:30Z
| null | true |
2,048,465,958 |
https://api.github.com/repos/huggingface/datasets/issues/6511
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6511/events
|
[] | null |
2023-12-21T14:48:57Z
|
[] |
https://github.com/huggingface/datasets/pull/6511
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6511). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"@huggingface/datasets, this PR is ready for review.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005343 / 0.011353 (-0.006010) | 0.003521 / 0.011008 (-0.007487) | 0.061835 / 0.038508 (0.023327) | 0.052633 / 0.023109 (0.029524) | 0.243897 / 0.275898 (-0.032001) | 0.272961 / 0.323480 (-0.050519) | 0.003013 / 0.007986 (-0.004973) | 0.002692 / 0.004328 (-0.001636) | 0.050099 / 0.004250 (0.045848) | 0.045381 / 0.037052 (0.008329) | 0.249981 / 0.258489 (-0.008508) | 0.276789 / 0.293841 (-0.017052) | 0.027929 / 0.128546 (-0.100617) | 0.010933 / 0.075646 (-0.064714) | 0.206757 / 0.419271 (-0.212514) | 0.035334 / 0.043533 (-0.008199) | 0.249411 / 0.255139 (-0.005728) | 0.268893 / 0.283200 (-0.014306) | 0.019175 / 0.141683 (-0.122507) | 1.106932 / 1.452155 (-0.345223) | 1.177819 / 1.492716 (-0.314897) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092895 / 0.018006 (0.074889) | 0.303658 / 0.000490 (0.303169) | 0.000214 / 0.000200 (0.000014) | 0.000050 / 0.000054 (-0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018978 / 0.037411 (-0.018434) | 0.060459 / 0.014526 (0.045934) | 0.072900 / 0.176557 (-0.103657) | 0.119803 / 0.737135 (-0.617332) | 0.074349 / 0.296338 (-0.221989) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.283715 / 0.215209 (0.068505) | 2.752394 / 2.077655 (0.674739) | 1.446619 / 1.504120 (-0.057501) | 1.319612 / 1.541195 (-0.221582) | 1.374769 / 1.468490 (-0.093721) | 0.571543 / 4.584777 (-4.013234) | 2.389106 / 3.745712 (-1.356607) | 2.797837 / 5.269862 (-2.472025) | 1.737615 / 4.565676 (-2.828062) | 0.063268 / 0.424275 (-0.361007) | 0.005118 / 0.007607 (-0.002489) | 0.340238 / 0.226044 (0.114193) | 3.366207 / 2.268929 (1.097278) | 1.845934 / 55.444624 (-53.598690) | 1.540640 / 6.876477 (-5.335837) | 1.585489 / 2.142072 (-0.556584) | 0.641178 / 4.805227 (-4.164049) | 0.118701 / 6.500664 (-6.381964) | 0.042719 / 0.075469 (-0.032750) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.946706 / 1.841788 (-0.895082) | 11.846230 / 8.074308 (3.771921) | 10.459268 / 10.191392 (0.267876) | 0.130557 / 0.680424 (-0.549867) | 0.014292 / 0.534201 (-0.519909) | 0.287455 / 0.579283 (-0.291828) | 0.265213 / 0.434364 (-0.169151) | 0.325670 / 0.540337 (-0.214667) | 0.422800 / 1.386936 (-0.964136) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005454 / 0.011353 (-0.005899) | 0.003567 / 0.011008 (-0.007441) | 0.048696 / 0.038508 (0.010188) | 0.058844 / 0.023109 (0.035735) | 0.277011 / 0.275898 (0.001113) | 0.302544 / 0.323480 (-0.020936) | 0.004077 / 0.007986 (-0.003908) | 0.002720 / 0.004328 (-0.001609) | 0.058251 / 0.004250 (0.054001) | 0.040946 / 0.037052 (0.003893) | 0.276261 / 0.258489 (0.017772) | 0.352827 / 0.293841 (0.058986) | 0.029915 / 0.128546 (-0.098632) | 0.010562 / 0.075646 (-0.065084) | 0.057836 / 0.419271 (-0.361436) | 0.033129 / 0.043533 (-0.010404) | 0.276053 / 0.255139 (0.020914) | 0.292045 / 0.283200 (0.008846) | 0.020504 / 0.141683 (-0.121179) | 1.129746 / 1.452155 (-0.322409) | 1.190888 / 1.492716 (-0.301829) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095202 / 0.018006 (0.077196) | 0.303956 / 0.000490 (0.303466) | 0.000226 / 0.000200 (0.000026) | 0.000054 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021960 / 0.037411 (-0.015451) | 0.076209 / 0.014526 (0.061683) | 0.088813 / 0.176557 (-0.087744) | 0.129061 / 0.737135 (-0.608074) | 0.091202 / 0.296338 (-0.205136) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.301394 / 0.215209 (0.086185) | 2.948057 / 2.077655 (0.870403) | 1.591371 / 1.504120 (0.087251) | 1.463515 / 1.541195 (-0.077680) | 1.516477 / 1.468490 (0.047987) | 0.577223 / 4.584777 (-4.007554) | 2.506716 / 3.745712 (-1.238996) | 2.833385 / 5.269862 (-2.436477) | 1.808896 / 4.565676 (-2.756781) | 0.063241 / 0.424275 (-0.361034) | 0.005057 / 0.007607 (-0.002550) | 0.350108 / 0.226044 (0.124063) | 3.470252 / 2.268929 (1.201324) | 1.925689 / 55.444624 (-53.518935) | 1.667521 / 6.876477 (-5.208955) | 1.690909 / 2.142072 (-0.451164) | 0.647070 / 4.805227 (-4.158157) | 0.117596 / 6.500664 (-6.383068) | 0.042431 / 0.075469 (-0.033038) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.977297 / 1.841788 (-0.864490) | 12.947399 / 8.074308 (4.873091) | 10.964949 / 10.191392 (0.773557) | 0.130905 / 0.680424 (-0.549518) | 0.015207 / 0.534201 (-0.518994) | 0.288151 / 0.579283 (-0.291132) | 0.281817 / 0.434364 (-0.152547) | 0.326398 / 0.540337 (-0.213940) | 0.421354 / 1.386936 (-0.965582) |\n\n</details>\n</details>\n\n\n"
] |
Implement get dataset default config name
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6511/reactions"
}
|
PR_kwDODunzps5iXAXR
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6511.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6511",
"merged_at": "2023-12-21T14:42:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6511.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6511"
}
|
2023-12-19T11:26:19Z
|
https://api.github.com/repos/huggingface/datasets/issues/6511/comments
|
Implement `get_dataset_default_config_name`.
Now that we support setting a configuration as default in `push_to_hub` (see #6500), we need a programmatically way to know in advance which is the default configuration. This will be used in the Space to convert script-datasets to Parquet: https://huggingface.co/spaces/albertvillanova/convert-dataset-to-parquet
Follow-up of:
- #6500
CC: @severo
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6511/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6511/timeline
|
closed
| false | 6,511 | null |
2023-12-21T14:42:41Z
| null | true |
2,046,928,742 |
https://api.github.com/repos/huggingface/datasets/issues/6510
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6510/events
|
[] | null |
2023-12-19T18:05:47Z
|
[] |
https://github.com/huggingface/datasets/pull/6510
|
COLLABORATOR
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6510). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"CI errors are unrelated to the changes, so I'm merging.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005161 / 0.011353 (-0.006192) | 0.003494 / 0.011008 (-0.007515) | 0.062601 / 0.038508 (0.024093) | 0.052876 / 0.023109 (0.029767) | 0.255595 / 0.275898 (-0.020303) | 0.283108 / 0.323480 (-0.040371) | 0.003856 / 0.007986 (-0.004130) | 0.002686 / 0.004328 (-0.001642) | 0.048604 / 0.004250 (0.044353) | 0.037886 / 0.037052 (0.000834) | 0.252902 / 0.258489 (-0.005587) | 0.286906 / 0.293841 (-0.006935) | 0.028570 / 0.128546 (-0.099976) | 0.010684 / 0.075646 (-0.064962) | 0.208154 / 0.419271 (-0.211118) | 0.036169 / 0.043533 (-0.007364) | 0.276026 / 0.255139 (0.020887) | 0.272274 / 0.283200 (-0.010925) | 0.017690 / 0.141683 (-0.123993) | 1.202400 / 1.452155 (-0.249755) | 1.231223 / 1.492716 (-0.261494) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095229 / 0.018006 (0.077222) | 0.302205 / 0.000490 (0.301716) | 0.000226 / 0.000200 (0.000026) | 0.000045 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018877 / 0.037411 (-0.018534) | 0.062286 / 0.014526 (0.047760) | 0.075191 / 0.176557 (-0.101366) | 0.121419 / 0.737135 (-0.615716) | 0.075641 / 0.296338 (-0.220697) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282914 / 0.215209 (0.067705) | 2.769156 / 2.077655 (0.691501) | 1.480219 / 1.504120 (-0.023901) | 1.355742 / 1.541195 (-0.185453) | 1.399740 / 1.468490 (-0.068750) | 0.556365 / 4.584777 (-4.028412) | 2.399679 / 3.745712 (-1.346033) | 2.850510 / 5.269862 (-2.419351) | 1.781428 / 4.565676 (-2.784249) | 0.063045 / 0.424275 (-0.361230) | 0.004931 / 0.007607 (-0.002676) | 0.343743 / 0.226044 (0.117698) | 3.374907 / 2.268929 (1.105978) | 1.857774 / 55.444624 (-53.586851) | 1.577154 / 6.876477 (-5.299323) | 1.626597 / 2.142072 (-0.515475) | 0.653991 / 4.805227 (-4.151236) | 0.121306 / 6.500664 (-6.379358) | 0.042131 / 0.075469 (-0.033339) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.948826 / 1.841788 (-0.892962) | 11.922497 / 8.074308 (3.848188) | 10.592334 / 10.191392 (0.400942) | 0.129145 / 0.680424 (-0.551279) | 0.014652 / 0.534201 (-0.519549) | 0.286074 / 0.579283 (-0.293210) | 0.265338 / 0.434364 (-0.169026) | 0.346872 / 0.540337 (-0.193466) | 0.450480 / 1.386936 (-0.936456) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005305 / 0.011353 (-0.006048) | 0.003583 / 0.011008 (-0.007426) | 0.049855 / 0.038508 (0.011347) | 0.052882 / 0.023109 (0.029773) | 0.268429 / 0.275898 (-0.007469) | 0.293375 / 0.323480 (-0.030105) | 0.004052 / 0.007986 (-0.003934) | 0.002685 / 0.004328 (-0.001644) | 0.049206 / 0.004250 (0.044955) | 0.040187 / 0.037052 (0.003135) | 0.270112 / 0.258489 (0.011623) | 0.306380 / 0.293841 (0.012539) | 0.029161 / 0.128546 (-0.099386) | 0.010948 / 0.075646 (-0.064698) | 0.057721 / 0.419271 (-0.361550) | 0.032628 / 0.043533 (-0.010905) | 0.267458 / 0.255139 (0.012319) | 0.291905 / 0.283200 (0.008705) | 0.018096 / 0.141683 (-0.123587) | 1.112744 / 1.452155 (-0.339410) | 1.161962 / 1.492716 (-0.330754) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.097449 / 0.018006 (0.079443) | 0.304270 / 0.000490 (0.303780) | 0.000235 / 0.000200 (0.000035) | 0.000060 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023550 / 0.037411 (-0.013861) | 0.078246 / 0.014526 (0.063720) | 0.091229 / 0.176557 (-0.085327) | 0.130624 / 0.737135 (-0.606511) | 0.092767 / 0.296338 (-0.203571) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.284962 / 0.215209 (0.069753) | 2.761090 / 2.077655 (0.683435) | 1.545409 / 1.504120 (0.041289) | 1.424573 / 1.541195 (-0.116622) | 1.438869 / 1.468490 (-0.029621) | 0.571281 / 4.584777 (-4.013496) | 2.419493 / 3.745712 (-1.326219) | 2.802611 / 5.269862 (-2.467251) | 1.749880 / 4.565676 (-2.815796) | 0.062566 / 0.424275 (-0.361709) | 0.005243 / 0.007607 (-0.002364) | 0.344653 / 0.226044 (0.118608) | 3.367488 / 2.268929 (1.098559) | 1.925871 / 55.444624 (-53.518754) | 1.624258 / 6.876477 (-5.252219) | 1.663742 / 2.142072 (-0.478330) | 0.634553 / 4.805227 (-4.170675) | 0.116745 / 6.500664 (-6.383919) | 0.041734 / 0.075469 (-0.033735) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.006808 / 1.841788 (-0.834980) | 12.499711 / 8.074308 (4.425403) | 10.956260 / 10.191392 (0.764868) | 0.132393 / 0.680424 (-0.548031) | 0.015924 / 0.534201 (-0.518277) | 0.289837 / 0.579283 (-0.289446) | 0.281565 / 0.434364 (-0.152799) | 0.337393 / 0.540337 (-0.202945) | 0.560385 / 1.386936 (-0.826551) |\n\n</details>\n</details>\n\n\n"
] |
Replace `list_files_info` with `list_repo_tree` in `push_to_hub`
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6510/reactions"
}
|
PR_kwDODunzps5iRyiV
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6510.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6510",
"merged_at": "2023-12-19T17:58:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6510.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6510"
}
|
2023-12-18T15:34:19Z
|
https://api.github.com/repos/huggingface/datasets/issues/6510/comments
|
Starting from `huggingface_hub` 0.20.0, `list_files_info` will be deprecated in favor of `list_repo_tree` (see https://github.com/huggingface/huggingface_hub/pull/1910)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6510/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6510/timeline
|
closed
| false | 6,510 | null |
2023-12-19T17:58:34Z
| null | true |
2,046,720,869 |
https://api.github.com/repos/huggingface/datasets/issues/6509
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6509/events
|
[] | null |
2023-12-19T09:37:12Z
|
[] |
https://github.com/huggingface/datasets/pull/6509
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6509). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"I created `DatatasetGenerationCastError` in `exceptions.py` that inherits from `DatasetGenerationError` (for backward compatibility) that inherits from `DatasetsError`.\r\n\r\nI also added a help message at the end of the error:\r\n\r\n```\r\nPlease either edit the data files to have matching columns, or separate them into different configurations (see docs at https://hf.co/docs/hub/datasets-manual-configuration#multiple-configurations)\r\n```",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004991 / 0.011353 (-0.006361) | 0.003362 / 0.011008 (-0.007646) | 0.062093 / 0.038508 (0.023585) | 0.051533 / 0.023109 (0.028424) | 0.247508 / 0.275898 (-0.028390) | 0.275593 / 0.323480 (-0.047886) | 0.003828 / 0.007986 (-0.004158) | 0.002573 / 0.004328 (-0.001755) | 0.047727 / 0.004250 (0.043477) | 0.037029 / 0.037052 (-0.000023) | 0.250359 / 0.258489 (-0.008130) | 0.282640 / 0.293841 (-0.011201) | 0.027853 / 0.128546 (-0.100693) | 0.010247 / 0.075646 (-0.065400) | 0.206826 / 0.419271 (-0.212445) | 0.035837 / 0.043533 (-0.007695) | 0.251795 / 0.255139 (-0.003344) | 0.275654 / 0.283200 (-0.007545) | 0.017722 / 0.141683 (-0.123960) | 1.120287 / 1.452155 (-0.331868) | 1.203087 / 1.492716 (-0.289630) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092320 / 0.018006 (0.074314) | 0.300079 / 0.000490 (0.299589) | 0.000211 / 0.000200 (0.000011) | 0.000044 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018193 / 0.037411 (-0.019218) | 0.061310 / 0.014526 (0.046784) | 0.072433 / 0.176557 (-0.104124) | 0.119092 / 0.737135 (-0.618043) | 0.074044 / 0.296338 (-0.222294) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.297184 / 0.215209 (0.081975) | 2.805197 / 2.077655 (0.727543) | 1.521326 / 1.504120 (0.017206) | 1.374321 / 1.541195 (-0.166874) | 1.388767 / 1.468490 (-0.079723) | 0.571865 / 4.584777 (-4.012912) | 2.385213 / 3.745712 (-1.360499) | 2.726840 / 5.269862 (-2.543021) | 1.725352 / 4.565676 (-2.840325) | 0.063012 / 0.424275 (-0.361263) | 0.004911 / 0.007607 (-0.002697) | 0.336430 / 0.226044 (0.110385) | 3.390616 / 2.268929 (1.121688) | 1.846398 / 55.444624 (-53.598227) | 1.576797 / 6.876477 (-5.299680) | 1.579445 / 2.142072 (-0.562627) | 0.652515 / 4.805227 (-4.152712) | 0.118393 / 6.500664 (-6.382271) | 0.042155 / 0.075469 (-0.033314) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.942269 / 1.841788 (-0.899518) | 11.318258 / 8.074308 (3.243950) | 10.299948 / 10.191392 (0.108556) | 0.136088 / 0.680424 (-0.544336) | 0.013682 / 0.534201 (-0.520519) | 0.287549 / 0.579283 (-0.291734) | 0.258346 / 0.434364 (-0.176018) | 0.337146 / 0.540337 (-0.203191) | 0.443922 / 1.386936 (-0.943014) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005302 / 0.011353 (-0.006051) | 0.003234 / 0.011008 (-0.007774) | 0.049159 / 0.038508 (0.010651) | 0.050459 / 0.023109 (0.027350) | 0.273718 / 0.275898 (-0.002180) | 0.296997 / 0.323480 (-0.026483) | 0.003948 / 0.007986 (-0.004038) | 0.002590 / 0.004328 (-0.001739) | 0.048129 / 0.004250 (0.043879) | 0.039369 / 0.037052 (0.002317) | 0.276469 / 0.258489 (0.017980) | 0.306359 / 0.293841 (0.012519) | 0.028864 / 0.128546 (-0.099682) | 0.010253 / 0.075646 (-0.065394) | 0.058264 / 0.419271 (-0.361008) | 0.032451 / 0.043533 (-0.011082) | 0.277336 / 0.255139 (0.022197) | 0.296137 / 0.283200 (0.012937) | 0.018094 / 0.141683 (-0.123589) | 1.119539 / 1.452155 (-0.332615) | 1.163116 / 1.492716 (-0.329600) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092578 / 0.018006 (0.074572) | 0.300756 / 0.000490 (0.300267) | 0.000222 / 0.000200 (0.000022) | 0.000044 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022333 / 0.037411 (-0.015078) | 0.076632 / 0.014526 (0.062107) | 0.087829 / 0.176557 (-0.088727) | 0.127686 / 0.737135 (-0.609449) | 0.091314 / 0.296338 (-0.205024) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.297499 / 0.215209 (0.082290) | 2.889775 / 2.077655 (0.812120) | 1.598976 / 1.504120 (0.094856) | 1.478805 / 1.541195 (-0.062389) | 1.481818 / 1.468490 (0.013328) | 0.557972 / 4.584777 (-4.026804) | 2.453248 / 3.745712 (-1.292464) | 2.771823 / 5.269862 (-2.498039) | 1.721527 / 4.565676 (-2.844150) | 0.062786 / 0.424275 (-0.361489) | 0.005298 / 0.007607 (-0.002309) | 0.346660 / 0.226044 (0.120615) | 3.412262 / 2.268929 (1.143334) | 1.940240 / 55.444624 (-53.504384) | 1.654015 / 6.876477 (-5.222461) | 1.652039 / 2.142072 (-0.490034) | 0.636870 / 4.805227 (-4.168357) | 0.116213 / 6.500664 (-6.384451) | 0.040937 / 0.075469 (-0.034532) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.001605 / 1.841788 (-0.840183) | 11.986592 / 8.074308 (3.912284) | 10.231288 / 10.191392 (0.039896) | 0.130242 / 0.680424 (-0.550182) | 0.015764 / 0.534201 (-0.518437) | 0.289257 / 0.579283 (-0.290026) | 0.275996 / 0.434364 (-0.158368) | 0.323089 / 0.540337 (-0.217248) | 0.556383 / 1.386936 (-0.830553) |\n\n</details>\n</details>\n\n\n"
] |
Better cast error when generating dataset
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6509/reactions"
}
|
PR_kwDODunzps5iREyE
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6509.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6509",
"merged_at": "2023-12-19T09:31:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6509.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6509"
}
|
2023-12-18T13:57:24Z
|
https://api.github.com/repos/huggingface/datasets/issues/6509/comments
|
I want to improve the error message for datasets like https://huggingface.co/datasets/m-a-p/COIG-CQIA
Cc @albertvillanova @severo is this new error ok ? Or should I use a dedicated error class ?
New:
```python
Traceback (most recent call last):
File "/Users/quentinlhoest/hf/datasets/src/datasets/builder.py", line 1920, in _prepare_split_single
writer.write_table(table)
File "/Users/quentinlhoest/hf/datasets/src/datasets/arrow_writer.py", line 574, in write_table
pa_table = table_cast(pa_table, self._schema)
File "/Users/quentinlhoest/hf/datasets/src/datasets/table.py", line 2322, in table_cast
return cast_table_to_schema(table, schema)
File "/Users/quentinlhoest/hf/datasets/src/datasets/table.py", line 2276, in cast_table_to_schema
raise CastError(
datasets.table.CastError: Couldn't cast
instruction: string
other: string
index: string
domain: list<item: string>
child 0, item: string
output: string
task_type: struct<major: list<item: string>, minor: list<item: string>>
child 0, major: list<item: string>
child 0, item: string
child 1, minor: list<item: string>
child 0, item: string
task_name_in_eng: string
input: string
to
{'answer_from': Value(dtype='string', id=None), 'instruction': Value(dtype='string', id=None), 'human_verified': Value(dtype='bool', id=None), 'domain': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), 'output': Value(dtype='string', id=None), 'task_type': {'major': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), 'minor': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)}, 'copyright': Value(dtype='string', id=None), 'input': Value(dtype='string', id=None)}
because column names don't match
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/quentinlhoest/hf/datasets/playground/ttest.py", line 74, in <module>
load_dataset("m-a-p/COIG-CQIA")
File "/Users/quentinlhoest/hf/datasets/src/datasets/load.py", line 2529, in load_dataset
builder_instance.download_and_prepare(
File "/Users/quentinlhoest/hf/datasets/src/datasets/builder.py", line 936, in download_and_prepare
self._download_and_prepare(
File "/Users/quentinlhoest/hf/datasets/src/datasets/builder.py", line 1031, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/quentinlhoest/hf/datasets/src/datasets/builder.py", line 1791, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/Users/quentinlhoest/hf/datasets/src/datasets/builder.py", line 1922, in _prepare_split_single
raise DatasetGenerationCastError.from_cast_error(
datasets.exceptions.DatasetGenerationCastError: An error occurred while generating the dataset
All the data files must have the same columns, but at some point there are 3 new columns (other, index, task_name_in_eng) and 3 missing columns (answer_from, copyright, human_verified).
This happened while the json dataset builder was generating data using
hf://datasets/m-a-p/COIG-CQIA/coig_pc/coig_pc_core_sample.json (at revision b7b7ecf290f6515036c7c04bd8537228ac2eb474)
Please either edit the data files to have matching columns, or separate them into different configurations (see docs at https://hf.co/docs/hub/datasets-manual-configuration#multiple-configurations)
```
Previously:
```python
Traceback (most recent call last):
File "/Users/quentinlhoest/hf/datasets/src/datasets/builder.py", line 1931, in _prepare_split_single
writer.write_table(table)
File "/Users/quentinlhoest/hf/datasets/src/datasets/arrow_writer.py", line 574, in write_table
pa_table = table_cast(pa_table, self._schema)
File "/Users/quentinlhoest/hf/datasets/src/datasets/table.py", line 2295, in table_cast
return cast_table_to_schema(table, schema)
File "/Users/quentinlhoest/hf/datasets/src/datasets/table.py", line 2253, in cast_table_to_schema
raise ValueError(f"Couldn't cast\n{table.schema}\nto\n{features}\nbecause column names don't match")
ValueError: Couldn't cast
task_type: struct<major: list<item: string>, minor: list<item: string>>
child 0, major: list<item: string>
child 0, item: string
child 1, minor: list<item: string>
child 0, item: string
other: string
instruction: string
task_name_in_eng: string
domain: list<item: string>
child 0, item: string
index: string
output: string
input: string
to
{'human_verified': Value(dtype='bool', id=None), 'task_type': {'major': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), 'minor': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)}, 'answer_from': Value(dtype='string', id=None), 'copyright': Value(dtype='string', id=None), 'instruction': Value(dtype='string', id=None), 'domain': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), 'output': Value(dtype='string', id=None), 'input': Value(dtype='string', id=None)}
because column names don't match
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/quentinlhoest/hf/datasets/playground/ttest.py", line 74, in <module>
load_dataset("m-a-p/COIG-CQIA")
File "/Users/quentinlhoest/hf/datasets/src/datasets/load.py", line 2529, in load_dataset
builder_instance.download_and_prepare(
File "/Users/quentinlhoest/hf/datasets/src/datasets/builder.py", line 949, in download_and_prepare
self._download_and_prepare(
File "/Users/quentinlhoest/hf/datasets/src/datasets/builder.py", line 1044, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/quentinlhoest/hf/datasets/src/datasets/builder.py", line 1804, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/Users/quentinlhoest/hf/datasets/src/datasets/builder.py", line 1949, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6509/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6509/timeline
|
closed
| false | 6,509 | null |
2023-12-19T09:31:03Z
| null | true |
2,045,733,273 |
https://api.github.com/repos/huggingface/datasets/issues/6508
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6508/events
|
[] | null |
2024-01-26T18:22:35Z
|
[] |
https://github.com/huggingface/datasets/pull/6508
|
CONTRIBUTOR
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6508). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Cool ! Do you mind writing a test using a geoparquet file in `tests/io/test_parquet.py` ?\r\n\r\nI'm not too familiar with geoparquet, does it use e.g. pyarrow extension types ? or schema metadata ?",
"> Geometry columns MUST be stored using the BYTE_ARRAY parquet type. They MUST be encoded as [WKB](https://en.wikipedia.org/wiki/Well-known_text_representation_of_geometry#Well-known_binary).\r\n\r\nhttps://github.com/opengeospatial/geoparquet/blob/main/format-specs/geoparquet.md#geometry-columns\r\n\r\nIt has metadata:\r\n\r\n> File metadata indicating things like the version of this specification used\r\n> Column metadata with additional metadata for each geometry column\r\n\r\nhttps://github.com/opengeospatial/geoparquet/blob/main/format-specs/geoparquet.md#metadata",
"The specification is very short by the way:\r\n\r\nhttps://github.com/opengeospatial/geoparquet/blob/main/format-specs/geoparquet.md",
"https://github.com/opengeospatial/geoparquet/blob/main/format-specs/compatible-parquet.md is also worth reading for this PR",
"> Cool ! Do you mind writing a test using a geoparquet file in `tests/io/test_parquet.py` ?\r\n\r\nYep, let me do that do that later today!\r\n\r\n> I'm not too familiar with geoparquet, does it use e.g. pyarrow extension types ? or schema metadata ?\r\n\r\nGeoParquet is a Parquet file with a `geometry` column that is encoded in a Binary format (technically WKB as @severo mentioned above). It is not a pyarrow extension type (though that would be cool). Regular `parquet` readers such as `pyarrow` would thus see the column as a binary column, while libraries such as `geopandas` which implement a GeoParquet reader would look at the schema metadata.\r\n\r\nE.g. taking this [file](https://huggingface.co/datasets/weiji14/clay_vector_embeddings/resolve/862b1602f326421adc99375912c08603a9f2cc5c/32VLM_v01.gpq) as an example, this is how the 'geo' schema looks like:\r\n\r\n```python\r\nimport pyarrow.parquet as pq\r\n\r\nschema = pq.read_schema(where=\"32VLM_v01.gpq\")\r\nprint(schema.metadata[b\"geo\"])\r\n```\r\n\r\n```\r\n{\r\n \"primary_column\": \"geometry\",\r\n \"columns\": {\r\n \"geometry\": {\r\n \"encoding\": \"WKB\",\r\n \"crs\": {\r\n \"$schema\": \"https://proj.org/schemas/v0.7/projjson.schema.json\",\r\n \"type\": \"GeographicCRS\",\r\n \"name\": \"WGS 84 (CRS84)\",\r\n \"datum_ensemble\": {\r\n \"name\": \"World Geodetic System 1984 ensemble\",\r\n \"members\": [\r\n {\"name\": \"World Geodetic System 1984 (Transit)\"},\r\n {\"name\": \"World Geodetic System 1984 (G730)\"},\r\n {\"name\": \"World Geodetic System 1984 (G873)\"},\r\n {\"name\": \"World Geodetic System 1984 (G1150)\"},\r\n {\"name\": \"World Geodetic System 1984 (G1674)\"},\r\n {\"name\": \"World Geodetic System 1984 (G1762)\"},\r\n {\"name\": \"World Geodetic System 1984 (G2139)\"},\r\n ],\r\n \"ellipsoid\": {\r\n \"name\": \"WGS 84\",\r\n \"semi_major_axis\": 6378137,\r\n \"inverse_flattening\": 298.257223563,\r\n },\r\n \"accuracy\": \"2.0\",\r\n \"id\": {\"authority\": \"EPSG\", \"code\": 6326},\r\n },\r\n \"coordinate_system\": {\r\n \"subtype\": \"ellipsoidal\",\r\n \"axis\": [\r\n {\r\n \"name\": \"Geodetic longitude\",\r\n \"abbreviation\": \"Lon\",\r\n \"direction\": \"east\",\r\n \"unit\": \"degree\",\r\n },\r\n {\r\n \"name\": \"Geodetic latitude\",\r\n \"abbreviation\": \"Lat\",\r\n \"direction\": \"north\",\r\n \"unit\": \"degree\",\r\n },\r\n ],\r\n },\r\n \"scope\": \"Not known.\",\r\n \"area\": \"World.\",\r\n \"bbox\": {\r\n \"south_latitude\": -90,\r\n \"west_longitude\": -180,\r\n \"north_latitude\": 90,\r\n \"east_longitude\": 180,\r\n },\r\n \"id\": {\"authority\": \"OGC\", \"code\": \"CRS84\"},\r\n },\r\n \"geometry_types\": [\"Polygon\"],\r\n \"bbox\": [\r\n 5.370542846111244,\r\n 59.42344573656881,\r\n 7.368267282586697,\r\n 60.42591328670696,\r\n ],\r\n }\r\n },\r\n \"version\": \"1.0.0\",\r\n \"creator\": {\"library\": \"geopandas\", \"version\": \"0.14.1\"},\r\n}\r\n```\r\n\r\nWe can continue the discussion on how to handle this extra 'geo' schema metadata in #6438. I'd like to keep this PR small by just piggy-backing off the default Parquet reader for now, which would just show the 'geometry' column as a binary column.",
"Thanks ! Also if you can make sure that doing `ds.to_parquet(\"path/to/output.geoparquet\")` also saves as a valid geoparquet files (including the schema metadata) that would be awesome.\r\n\r\nIt would also enable `push_to_hub` to save geoparquet files",
"> Thanks ! Also if you can make sure that doing `ds.to_parquet(\"path/to/output.geoparquet\")` also saves as a valid geoparquet files (including the schema metadata) that would be awesome.\r\n> \r\n> It would also enable `push_to_hub` to save geoparquet files\r\n\r\nHmm, it should be possible to let PyArrow save a Parquet file with a geometry WKB column, but saving the GeoParquet schema metadata won't be easy without introducing [`geopandas`](https://github.com/geopandas/geopandas) as a dependency. Does this need to be done in this PR, or can it be a separate one?",
"I see, then let's keep it like this for now.\r\nI just checked and it would require to add support for keeping the schema metadata in `Features` anyway.\r\n\r\nFeel free to fix your code formatting using\r\n\r\n```\r\nmake style\r\n```\r\n\r\nand we can merge this PR :)\r\n\r\n",
"Cool, linted to remove the extra blank line at 7088f585557807a63673cdc58900d7ce56146cf7. :rocket:",
"The previous CI failure at https://github.com/huggingface/datasets/actions/runs/7482863299/job/20668381959#step:6:5299 says `datasets.exceptions.DefunctDatasetError: Dataset 'eli5' is defunct and no longer accessible due to unavailability of the source data` which seems unrelated, might be to do with https://github.com/huggingface/datasets/issues/6605. I've updated the PR branch with changes from `main` again, could someone re-run the tests and merge if ok? Thanks!",
"sorry, it took me some time to fix the CI on the `main` branch\r\n\r\nwill merge once it's green :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005467 / 0.011353 (-0.005886) | 0.003696 / 0.011008 (-0.007313) | 0.063298 / 0.038508 (0.024790) | 0.032209 / 0.023109 (0.009100) | 0.246307 / 0.275898 (-0.029591) | 0.276864 / 0.323480 (-0.046616) | 0.003941 / 0.007986 (-0.004044) | 0.002616 / 0.004328 (-0.001713) | 0.049543 / 0.004250 (0.045292) | 0.044886 / 0.037052 (0.007833) | 0.266502 / 0.258489 (0.008013) | 0.288401 / 0.293841 (-0.005440) | 0.027911 / 0.128546 (-0.100635) | 0.011011 / 0.075646 (-0.064636) | 0.207972 / 0.419271 (-0.211299) | 0.036324 / 0.043533 (-0.007209) | 0.259450 / 0.255139 (0.004311) | 0.267317 / 0.283200 (-0.015883) | 0.018857 / 0.141683 (-0.122826) | 1.145350 / 1.452155 (-0.306805) | 1.204204 / 1.492716 (-0.288513) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.103864 / 0.018006 (0.085858) | 0.306941 / 0.000490 (0.306451) | 0.000218 / 0.000200 (0.000018) | 0.000044 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018391 / 0.037411 (-0.019020) | 0.064600 / 0.014526 (0.050074) | 0.075454 / 0.176557 (-0.101102) | 0.120913 / 0.737135 (-0.616223) | 0.076998 / 0.296338 (-0.219341) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.279491 / 0.215209 (0.064282) | 2.742471 / 2.077655 (0.664816) | 1.447980 / 1.504120 (-0.056140) | 1.328202 / 1.541195 (-0.212992) | 1.397291 / 1.468490 (-0.071199) | 0.585726 / 4.584777 (-3.999051) | 2.385132 / 3.745712 (-1.360580) | 2.874888 / 5.269862 (-2.394974) | 1.820177 / 4.565676 (-2.745500) | 0.063876 / 0.424275 (-0.360399) | 0.004946 / 0.007607 (-0.002661) | 0.336445 / 0.226044 (0.110401) | 3.396813 / 2.268929 (1.127885) | 1.832644 / 55.444624 (-53.611981) | 1.581304 / 6.876477 (-5.295172) | 1.607243 / 2.142072 (-0.534829) | 0.662752 / 4.805227 (-4.142476) | 0.119494 / 6.500664 (-6.381170) | 0.042573 / 0.075469 (-0.032896) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.936784 / 1.841788 (-0.905003) | 12.154288 / 8.074308 (4.079980) | 10.944835 / 10.191392 (0.753443) | 0.132856 / 0.680424 (-0.547568) | 0.015197 / 0.534201 (-0.519004) | 0.290647 / 0.579283 (-0.288636) | 0.273498 / 0.434364 (-0.160866) | 0.324893 / 0.540337 (-0.215444) | 0.427905 / 1.386936 (-0.959032) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005695 / 0.011353 (-0.005658) | 0.003562 / 0.011008 (-0.007446) | 0.050117 / 0.038508 (0.011608) | 0.033876 / 0.023109 (0.010767) | 0.275514 / 0.275898 (-0.000384) | 0.298460 / 0.323480 (-0.025020) | 0.004240 / 0.007986 (-0.003745) | 0.002738 / 0.004328 (-0.001591) | 0.048518 / 0.004250 (0.044268) | 0.049064 / 0.037052 (0.012012) | 0.287094 / 0.258489 (0.028605) | 0.314281 / 0.293841 (0.020440) | 0.057861 / 0.128546 (-0.070686) | 0.010893 / 0.075646 (-0.064753) | 0.062251 / 0.419271 (-0.357020) | 0.036788 / 0.043533 (-0.006745) | 0.272431 / 0.255139 (0.017292) | 0.292022 / 0.283200 (0.008822) | 0.019874 / 0.141683 (-0.121809) | 1.156939 / 1.452155 (-0.295216) | 1.237966 / 1.492716 (-0.254751) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.096156 / 0.018006 (0.078150) | 0.306652 / 0.000490 (0.306162) | 0.000230 / 0.000200 (0.000031) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022965 / 0.037411 (-0.014447) | 0.081349 / 0.014526 (0.066823) | 0.089035 / 0.176557 (-0.087521) | 0.128831 / 0.737135 (-0.608304) | 0.090321 / 0.296338 (-0.206017) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.293110 / 0.215209 (0.077901) | 2.884493 / 2.077655 (0.806839) | 1.582522 / 1.504120 (0.078402) | 1.518977 / 1.541195 (-0.022218) | 1.528449 / 1.468490 (0.059959) | 0.577369 / 4.584777 (-4.007408) | 2.473060 / 3.745712 (-1.272652) | 3.104363 / 5.269862 (-2.165499) | 1.916529 / 4.565676 (-2.649147) | 0.064594 / 0.424275 (-0.359682) | 0.005386 / 0.007607 (-0.002221) | 0.353336 / 0.226044 (0.127292) | 3.471914 / 2.268929 (1.202985) | 1.959222 / 55.444624 (-53.485402) | 1.677153 / 6.876477 (-5.199324) | 1.716961 / 2.142072 (-0.425112) | 0.658355 / 4.805227 (-4.146873) | 0.117296 / 6.500664 (-6.383368) | 0.041139 / 0.075469 (-0.034330) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.025220 / 1.841788 (-0.816567) | 14.510987 / 8.074308 (6.436679) | 11.851428 / 10.191392 (1.660036) | 0.143759 / 0.680424 (-0.536665) | 0.015644 / 0.534201 (-0.518557) | 0.296824 / 0.579283 (-0.282459) | 0.281566 / 0.434364 (-0.152798) | 0.335094 / 0.540337 (-0.205244) | 0.425199 / 1.386936 (-0.961737) |\n\n</details>\n</details>\n\n\n"
] |
Read GeoParquet files using parquet reader
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6508/reactions"
}
|
PR_kwDODunzps5iNvAu
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6508.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6508",
"merged_at": "2024-01-26T16:18:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6508.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6508"
}
|
2023-12-18T04:50:37Z
|
https://api.github.com/repos/huggingface/datasets/issues/6508/comments
|
Let GeoParquet files with the file extension `*.geoparquet` or `*.gpq` be readable by the default parquet reader.
Those two file extensions are the ones most commonly used for GeoParquet files, and is included in the `gpq` validator tool at https://github.com/planetlabs/gpq/blob/e5576b4ee7306b4d2259d56c879465a9364dab90/cmd/gpq/command/convert.go#L73-L75
Addresses https://github.com/huggingface/datasets/issues/6438
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23487320?v=4",
"events_url": "https://api.github.com/users/weiji14/events{/privacy}",
"followers_url": "https://api.github.com/users/weiji14/followers",
"following_url": "https://api.github.com/users/weiji14/following{/other_user}",
"gists_url": "https://api.github.com/users/weiji14/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/weiji14",
"id": 23487320,
"login": "weiji14",
"node_id": "MDQ6VXNlcjIzNDg3MzIw",
"organizations_url": "https://api.github.com/users/weiji14/orgs",
"received_events_url": "https://api.github.com/users/weiji14/received_events",
"repos_url": "https://api.github.com/users/weiji14/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/weiji14/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/weiji14/subscriptions",
"type": "User",
"url": "https://api.github.com/users/weiji14"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6508/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6508/timeline
|
closed
| false | 6,508 | null |
2024-01-26T16:18:41Z
| null | true |
2,045,152,928 |
https://api.github.com/repos/huggingface/datasets/issues/6507
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6507/events
|
[] | null |
2023-12-18T11:42:49Z
|
[] |
https://github.com/huggingface/datasets/issues/6507
|
NONE
|
not_planned
| null | null |
[] |
where is glue_metric.py> @Frankie123421 what was the resolution to this?
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6507/reactions"
}
|
I_kwDODunzps555o6g
| null |
2023-12-17T09:58:25Z
|
https://api.github.com/repos/huggingface/datasets/issues/6507/comments
|
> @Frankie123421 what was the resolution to this?
use glue_metric.py instead of glue.py in load_metric
_Originally posted by @Frankie123421 in https://github.com/huggingface/datasets/issues/2117#issuecomment-905093763_
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/119146162?v=4",
"events_url": "https://api.github.com/users/Mcccccc1024/events{/privacy}",
"followers_url": "https://api.github.com/users/Mcccccc1024/followers",
"following_url": "https://api.github.com/users/Mcccccc1024/following{/other_user}",
"gists_url": "https://api.github.com/users/Mcccccc1024/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Mcccccc1024",
"id": 119146162,
"login": "Mcccccc1024",
"node_id": "U_kgDOBxoGsg",
"organizations_url": "https://api.github.com/users/Mcccccc1024/orgs",
"received_events_url": "https://api.github.com/users/Mcccccc1024/received_events",
"repos_url": "https://api.github.com/users/Mcccccc1024/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Mcccccc1024/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mcccccc1024/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Mcccccc1024"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6507/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6507/timeline
|
closed
| false | 6,507 | null |
2023-12-18T11:42:49Z
| null | false |
2,044,975,038 |
https://api.github.com/repos/huggingface/datasets/issues/6506
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6506/events
|
[] | null |
2023-12-21T09:57:57Z
|
[] |
https://github.com/huggingface/datasets/issues/6506
|
NONE
|
completed
| null | null |
[
"As this is a specific issue of the \"glue\" dataset, I have transferred it to the dataset Discussion page: https://huggingface.co/datasets/glue/discussions/15\r\n\r\nLet's continue the discussion there!"
] |
Incorrect test set labels for RTE and CoLA datasets via load_dataset
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6506/reactions"
}
|
I_kwDODunzps5549e-
| null |
2023-12-16T22:06:08Z
|
https://api.github.com/repos/huggingface/datasets/issues/6506/comments
|
### Describe the bug
The test set labels for the RTE and CoLA datasets when loading via datasets load_dataset are all -1.
Edit: It appears this is also the case for every other dataset except for MRPC (stsb, sst2, qqp, mnli (both matched and mismatched), qnli, wnli, ax). Is this intended behavior to safeguard the test set for evaluation purposes?
### Steps to reproduce the bug
!pip install datasets
from datasets import load_dataset
rte_data = load_dataset('glue', 'rte')
cola_data = load_dataset('glue', 'cola')
print(rte_data['test'][0:30]['label'])
print(cola_data['test'][0:30]['label'])
Output:
[-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
[-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
The non-label test data seems to be fine:
e.g. rte_data['test'][1] is:
{'sentence1': "Authorities in Brazil say that more than 200 people are being held hostage in a prison in the country's remote, Amazonian-jungle state of Rondonia.",
'sentence2': 'Authorities in Brazil hold 200 people as hostage.',
'label': -1,
'idx': 1}
Training and validation data are also fine:
e.g. rte_data['train][0] is:
{'sentence1': 'No Weapons of Mass Destruction Found in Iraq Yet.',
'sentence2': 'Weapons of Mass Destruction Found in Iraq.',
'label': 1,
'idx': 0}
### Expected behavior
Expected the labels to be binary 0/1 values; Got all -1s instead
### Environment info
- `datasets` version: 2.15.0
- Platform: Linux-6.1.58+-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.19.4
- PyArrow version: 10.0.1
- Pandas version: 1.5.3
- `fsspec` version: 2023.6.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/73316684?v=4",
"events_url": "https://api.github.com/users/emreonal11/events{/privacy}",
"followers_url": "https://api.github.com/users/emreonal11/followers",
"following_url": "https://api.github.com/users/emreonal11/following{/other_user}",
"gists_url": "https://api.github.com/users/emreonal11/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/emreonal11",
"id": 73316684,
"login": "emreonal11",
"node_id": "MDQ6VXNlcjczMzE2Njg0",
"organizations_url": "https://api.github.com/users/emreonal11/orgs",
"received_events_url": "https://api.github.com/users/emreonal11/received_events",
"repos_url": "https://api.github.com/users/emreonal11/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/emreonal11/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/emreonal11/subscriptions",
"type": "User",
"url": "https://api.github.com/users/emreonal11"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6506/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6506/timeline
|
closed
| false | 6,506 | null |
2023-12-21T09:57:57Z
| null | false |
2,044,721,288 |
https://api.github.com/repos/huggingface/datasets/issues/6505
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6505/events
|
[] | null |
2024-05-10T05:01:52Z
|
[] |
https://github.com/huggingface/datasets/issues/6505
|
NONE
| null | null | null |
[
"I ran into the same problem when I used a server cluster (Slurm system managed) that couldn't load any of the huggingface datasets or models, but it worked on my laptop. I suspected some system configuration-related problem, but I had no idea. \r\nMy problems are consistent with [issue #2618](https://github.com/huggingface/datasets/issues/2618). All the huggingface-related libraries I use are the latest versions.\r\n\r\n",
"> I ran into the same problem when I used a server cluster (Slurm system managed) that couldn't load any of the huggingface datasets or models, but it worked on my laptop. I suspected some system configuration-related problem, but I had no idea. My problems are consistent with [issue #2618](https://github.com/huggingface/datasets/issues/2618). All the huggingface-related libraries I use are the latest versions.\r\n\r\nhave you solved this issue yet? i met the same problem on server but everything works on laptop. I think maybe the filelock repo is contradictory with file system.",
"I am having the same issue on a computing cluster but this works on my laptop as well. I instead have this error:\r\n`/home/.conda/envs/py10/lib/python3.10/site-packages/filelock/_unix.py\", line 43, in _acquire\r\n fcntl.flock(fd, fcntl.LOCK_EX | fcntl.LOCK_NB)\r\nOSError: [Errno 5] Input/output error`\r\n\r\nthe load_dataset command does not work on server for local or hosted hugging-face datasets, and I have tried for several files",
"Same here. Is there any solution?",
"In my case, `.cahce` was in a shared folder. Moving it into the user's home folder fixed the problem. #2618 for more details",
"> In my case, `.cahce` was in a shared folder. Moving it into the user's home folder fixed the problem. #2618 for more details在我的情况下, `.cahce` 在一个共享文件夹中。将其移动到用户的主文件夹中解决了问题。 #2618 获取更多详细信息。\r\n\r\nCan you be more specific? thank."
] |
Got stuck when I trying to load a dataset
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6505/reactions"
}
|
I_kwDODunzps553_iI
| null |
2023-12-16T11:51:07Z
|
https://api.github.com/repos/huggingface/datasets/issues/6505/comments
|
### Describe the bug
Hello, everyone. I met a problem when I am trying to load a data file using load_dataset method on a Debian 10 system. The data file is not very large, only 1.63MB with 600 records.
Here is my code:
from datasets import load_dataset
dataset = load_dataset('json', data_files='mypath/oaast_rm_zh.json')
I waited it for 20 minutes. It still no response. I cannot using Ctrl+C to cancel the command. I have to use Ctrl+Z to kill it. I also try it with a txt file, it still no response in a long time.
I can load the same file successfully using my laptop (windows 10, python 3.8.5, datasets==2.14.5). I can also make it on another computer (Ubuntu 20.04.5 LTS, python 3.10.13, datasets 2.14.7). It only takes me 1-2 miniutes.
Could you give me some suggestions? Thank you.
### Steps to reproduce the bug
from datasets import load_dataset
dataset = load_dataset('json', data_files='mypath/oaast_rm_zh.json')
### Expected behavior
I hope it can load the file successfully.
### Environment info
OS: Debian GNU/Linux 10
Python: Python 3.10.13
Pip list:
Package Version
------------------------- ------------
accelerate 0.25.0
addict 2.4.0
aiofiles 23.2.1
aiohttp 3.9.1
aiosignal 1.3.1
aliyun-python-sdk-core 2.14.0
aliyun-python-sdk-kms 2.16.2
altair 5.2.0
annotated-types 0.6.0
anyio 3.7.1
async-timeout 4.0.3
attrs 23.1.0
certifi 2023.11.17
cffi 1.16.0
charset-normalizer 3.3.2
click 8.1.7
contourpy 1.2.0
crcmod 1.7
cryptography 41.0.7
cycler 0.12.1
datasets 2.14.7
dill 0.3.7
docstring-parser 0.15
einops 0.7.0
exceptiongroup 1.2.0
fastapi 0.105.0
ffmpy 0.3.1
filelock 3.13.1
fonttools 4.46.0
frozenlist 1.4.1
fsspec 2023.10.0
gast 0.5.4
gradio 3.50.2
gradio_client 0.6.1
h11 0.14.0
httpcore 1.0.2
httpx 0.25.2
huggingface-hub 0.19.4
idna 3.6
importlib-metadata 7.0.0
importlib-resources 6.1.1
jieba 0.42.1
Jinja2 3.1.2
jmespath 0.10.0
joblib 1.3.2
jsonschema 4.20.0
jsonschema-specifications 2023.11.2
kiwisolver 1.4.5
markdown-it-py 3.0.0
MarkupSafe 2.1.3
matplotlib 3.8.2
mdurl 0.1.2
modelscope 1.10.0
mpmath 1.3.0
multidict 6.0.4
multiprocess 0.70.15
networkx 3.2.1
nltk 3.8.1
numpy 1.26.2
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.18.1
nvidia-nvjitlink-cu12 12.3.101
nvidia-nvtx-cu12 12.1.105
orjson 3.9.10
oss2 2.18.3
packaging 23.2
pandas 2.1.4
peft 0.7.1
Pillow 10.1.0
pip 23.3.1
platformdirs 4.1.0
protobuf 4.25.1
psutil 5.9.6
pyarrow 14.0.1
pyarrow-hotfix 0.6
pycparser 2.21
pycryptodome 3.19.0
pydantic 2.5.2
pydantic_core 2.14.5
pydub 0.25.1
Pygments 2.17.2
pyparsing 3.1.1
python-dateutil 2.8.2
python-multipart 0.0.6
pytz 2023.3.post1
PyYAML 6.0.1
referencing 0.32.0
regex 2023.10.3
requests 2.31.0
rich 13.7.0
rouge-chinese 1.0.3
rpds-py 0.13.2
safetensors 0.4.1
scipy 1.11.4
semantic-version 2.10.0
sentencepiece 0.1.99
setuptools 68.2.2
shtab 1.6.5
simplejson 3.19.2
six 1.16.0
sniffio 1.3.0
sortedcontainers 2.4.0
sse-starlette 1.8.2
starlette 0.27.0
sympy 1.12
tiktoken 0.5.2
tokenizers 0.15.0
tomli 2.0.1
toolz 0.12.0
torch 2.1.2
tqdm 4.66.1
transformers 4.36.1
triton 2.1.0
trl 0.7.4
typing_extensions 4.9.0
tyro 0.6.0
tzdata 2023.3
urllib3 2.1.0
uvicorn 0.24.0.post1
websockets 11.0.3
wheel 0.41.2
xxhash 3.4.1
yapf 0.40.2
yarl 1.9.4
zipp 3.17.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/18232551?v=4",
"events_url": "https://api.github.com/users/yirenpingsheng/events{/privacy}",
"followers_url": "https://api.github.com/users/yirenpingsheng/followers",
"following_url": "https://api.github.com/users/yirenpingsheng/following{/other_user}",
"gists_url": "https://api.github.com/users/yirenpingsheng/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yirenpingsheng",
"id": 18232551,
"login": "yirenpingsheng",
"node_id": "MDQ6VXNlcjE4MjMyNTUx",
"organizations_url": "https://api.github.com/users/yirenpingsheng/orgs",
"received_events_url": "https://api.github.com/users/yirenpingsheng/received_events",
"repos_url": "https://api.github.com/users/yirenpingsheng/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yirenpingsheng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yirenpingsheng/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yirenpingsheng"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6505/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6505/timeline
|
open
| false | 6,505 | null | null | null | false |
2,044,541,154 |
https://api.github.com/repos/huggingface/datasets/issues/6504
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6504/events
|
[] | null |
2023-12-16T06:20:53Z
|
[] |
https://github.com/huggingface/datasets/issues/6504
|
NONE
|
completed
| null | null |
[] |
Error Pushing to Hub
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6504/reactions"
}
|
I_kwDODunzps553Tji
| null |
2023-12-16T01:05:22Z
|
https://api.github.com/repos/huggingface/datasets/issues/6504/comments
|
### Describe the bug
Error when trying to push a dataset in a special format to hub
### Steps to reproduce the bug
```
import datasets
from datasets import Dataset
dataset_dict = {
"filename": ["apple", "banana"],
"token": [[[1,2],[3,4]],[[1,2],[3,4]]],
"label": [0, 1],
}
dataset = Dataset.from_dict(dataset_dict)
dataset = dataset.cast_column("token", datasets.features.features.Array2D(shape=(2, 2),dtype="int16"))
dataset.push_to_hub("SequenceModel/imagenet_val_256")
```
Error:
```
...
ConstructorError: could not determine a constructor for the tag 'tag:yaml.org,2002:python/tuple'
in "<unicode string>", line 8, column 16:
shape: !!python/tuple
^
```
### Expected behavior
Dataset being pushed to hub
### Environment info
- `datasets` version: 2.15.0
- Platform: Linux-5.19.0-1022-gcp-x86_64-with-glibc2.35
- Python version: 3.11.5
- `huggingface_hub` version: 0.19.4
- PyArrow version: 14.0.1
- Pandas version: 2.1.4
- `fsspec` version: 2023.10.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/55055083?v=4",
"events_url": "https://api.github.com/users/Jiayi-Pan/events{/privacy}",
"followers_url": "https://api.github.com/users/Jiayi-Pan/followers",
"following_url": "https://api.github.com/users/Jiayi-Pan/following{/other_user}",
"gists_url": "https://api.github.com/users/Jiayi-Pan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Jiayi-Pan",
"id": 55055083,
"login": "Jiayi-Pan",
"node_id": "MDQ6VXNlcjU1MDU1MDgz",
"organizations_url": "https://api.github.com/users/Jiayi-Pan/orgs",
"received_events_url": "https://api.github.com/users/Jiayi-Pan/received_events",
"repos_url": "https://api.github.com/users/Jiayi-Pan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Jiayi-Pan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jiayi-Pan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Jiayi-Pan"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6504/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6504/timeline
|
closed
| false | 6,504 | null |
2023-12-16T06:20:53Z
| null | false |
2,043,847,591 |
https://api.github.com/repos/huggingface/datasets/issues/6503
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6503/events
|
[] | null |
2023-12-15T14:51:06Z
|
[] |
https://github.com/huggingface/datasets/pull/6503
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6503). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005003 / 0.011353 (-0.006350) | 0.003020 / 0.011008 (-0.007988) | 0.061370 / 0.038508 (0.022862) | 0.050996 / 0.023109 (0.027887) | 0.243434 / 0.275898 (-0.032464) | 0.266317 / 0.323480 (-0.057163) | 0.003888 / 0.007986 (-0.004098) | 0.002607 / 0.004328 (-0.001721) | 0.047541 / 0.004250 (0.043290) | 0.037933 / 0.037052 (0.000881) | 0.259695 / 0.258489 (0.001206) | 0.279374 / 0.293841 (-0.014467) | 0.027258 / 0.128546 (-0.101288) | 0.010184 / 0.075646 (-0.065462) | 0.207412 / 0.419271 (-0.211860) | 0.034978 / 0.043533 (-0.008554) | 0.247871 / 0.255139 (-0.007267) | 0.265273 / 0.283200 (-0.017927) | 0.017886 / 0.141683 (-0.123796) | 1.090451 / 1.452155 (-0.361704) | 1.152034 / 1.492716 (-0.340682) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094383 / 0.018006 (0.076377) | 0.301151 / 0.000490 (0.300661) | 0.000211 / 0.000200 (0.000011) | 0.000049 / 0.000054 (-0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018927 / 0.037411 (-0.018484) | 0.062152 / 0.014526 (0.047626) | 0.072177 / 0.176557 (-0.104380) | 0.119792 / 0.737135 (-0.617343) | 0.073333 / 0.296338 (-0.223005) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282671 / 0.215209 (0.067462) | 2.721148 / 2.077655 (0.643494) | 1.472689 / 1.504120 (-0.031431) | 1.355226 / 1.541195 (-0.185969) | 1.375935 / 1.468490 (-0.092556) | 0.562600 / 4.584777 (-4.022177) | 2.364046 / 3.745712 (-1.381666) | 2.714984 / 5.269862 (-2.554878) | 1.738413 / 4.565676 (-2.827263) | 0.062564 / 0.424275 (-0.361711) | 0.004964 / 0.007607 (-0.002643) | 0.341300 / 0.226044 (0.115255) | 3.345187 / 2.268929 (1.076259) | 1.857822 / 55.444624 (-53.586803) | 1.581002 / 6.876477 (-5.295475) | 1.585919 / 2.142072 (-0.556153) | 0.640105 / 4.805227 (-4.165122) | 0.117880 / 6.500664 (-6.382784) | 0.042032 / 0.075469 (-0.033437) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.962701 / 1.841788 (-0.879086) | 11.309251 / 8.074308 (3.234943) | 10.462520 / 10.191392 (0.271128) | 0.127399 / 0.680424 (-0.553025) | 0.014549 / 0.534201 (-0.519652) | 0.297017 / 0.579283 (-0.282266) | 0.266152 / 0.434364 (-0.168212) | 0.349252 / 0.540337 (-0.191085) | 0.457015 / 1.386936 (-0.929921) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005341 / 0.011353 (-0.006012) | 0.003108 / 0.011008 (-0.007900) | 0.048862 / 0.038508 (0.010353) | 0.053354 / 0.023109 (0.030245) | 0.274499 / 0.275898 (-0.001399) | 0.296698 / 0.323480 (-0.026782) | 0.003974 / 0.007986 (-0.004012) | 0.002631 / 0.004328 (-0.001697) | 0.048013 / 0.004250 (0.043762) | 0.040416 / 0.037052 (0.003363) | 0.276581 / 0.258489 (0.018092) | 0.301296 / 0.293841 (0.007455) | 0.029049 / 0.128546 (-0.099497) | 0.010253 / 0.075646 (-0.065393) | 0.057157 / 0.419271 (-0.362114) | 0.031830 / 0.043533 (-0.011703) | 0.274341 / 0.255139 (0.019202) | 0.292583 / 0.283200 (0.009383) | 0.018449 / 0.141683 (-0.123234) | 1.145099 / 1.452155 (-0.307055) | 1.192958 / 1.492716 (-0.299758) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091596 / 0.018006 (0.073590) | 0.300917 / 0.000490 (0.300427) | 0.000225 / 0.000200 (0.000025) | 0.000054 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021657 / 0.037411 (-0.015754) | 0.068464 / 0.014526 (0.053938) | 0.079869 / 0.176557 (-0.096687) | 0.117523 / 0.737135 (-0.619613) | 0.081257 / 0.296338 (-0.215082) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.294876 / 0.215209 (0.079667) | 2.879372 / 2.077655 (0.801718) | 1.619887 / 1.504120 (0.115767) | 1.482154 / 1.541195 (-0.059041) | 1.494656 / 1.468490 (0.026166) | 0.558914 / 4.584777 (-4.025862) | 2.420948 / 3.745712 (-1.324765) | 2.728992 / 5.269862 (-2.540869) | 1.722135 / 4.565676 (-2.843542) | 0.062182 / 0.424275 (-0.362093) | 0.004933 / 0.007607 (-0.002674) | 0.342759 / 0.226044 (0.116715) | 3.424083 / 2.268929 (1.155154) | 1.950673 / 55.444624 (-53.493951) | 1.683126 / 6.876477 (-5.193351) | 1.673135 / 2.142072 (-0.468937) | 0.633711 / 4.805227 (-4.171516) | 0.114898 / 6.500664 (-6.385766) | 0.040332 / 0.075469 (-0.035137) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.975102 / 1.841788 (-0.866685) | 11.975731 / 8.074308 (3.901423) | 10.961103 / 10.191392 (0.769711) | 0.131152 / 0.680424 (-0.549272) | 0.016268 / 0.534201 (-0.517933) | 0.285031 / 0.579283 (-0.294252) | 0.279556 / 0.434364 (-0.154808) | 0.324183 / 0.540337 (-0.216154) | 0.571404 / 1.386936 (-0.815532) |\n\n</details>\n</details>\n\n\n"
] |
Fix streaming xnli
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6503/reactions"
}
|
PR_kwDODunzps5iHgZf
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6503.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6503",
"merged_at": "2023-12-15T14:44:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6503.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6503"
}
|
2023-12-15T14:40:57Z
|
https://api.github.com/repos/huggingface/datasets/issues/6503/comments
|
This code was failing
```python
In [1]: from datasets import load_dataset
In [2]:
...: ds = load_dataset("xnli", "all_languages", split="test", streaming=True)
...:
...: sample_data = next(iter(ds))["premise"] # pick up one data
...: input_text = list(sample_data.values())
```
```
File ~/hf/datasets/src/datasets/features/translation.py:104, in TranslationVariableLanguages.encode_example(self, translation_dict)
102 return translation_dict
103 elif self.languages and set(translation_dict) - lang_set:
--> 104 raise ValueError(
105 f'Some languages in example ({", ".join(sorted(set(translation_dict) - lang_set))}) are not in valid set ({", ".join(lang_set)}).'
106 )
108 # Convert dictionary into tuples, splitting out cases where there are
109 # multiple translations for a single language.
110 translation_tuples = []
ValueError: Some languages in example (language, translation) are not in valid set (ur, fr, hi, sw, vi, el, de, th, en, tr, zh, ar, bg, ru, es).
```
because in streaming mode we expect features encode methods to be no-ops if the example is already encoded.
I fixed `TranslationVariableLanguages` to account for that
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6503/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6503/timeline
|
closed
| false | 6,503 | null |
2023-12-15T14:44:47Z
| null | true |
2,043,771,731 |
https://api.github.com/repos/huggingface/datasets/issues/6502
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6502/events
|
[] | null |
2023-12-15T15:04:33Z
|
[] |
https://github.com/huggingface/datasets/pull/6502
|
COLLABORATOR
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6502). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005472 / 0.011353 (-0.005881) | 0.003715 / 0.011008 (-0.007293) | 0.063257 / 0.038508 (0.024749) | 0.060683 / 0.023109 (0.037574) | 0.250885 / 0.275898 (-0.025013) | 0.271685 / 0.323480 (-0.051795) | 0.003051 / 0.007986 (-0.004934) | 0.002799 / 0.004328 (-0.001530) | 0.049113 / 0.004250 (0.044863) | 0.038965 / 0.037052 (0.001912) | 0.252688 / 0.258489 (-0.005801) | 0.282536 / 0.293841 (-0.011305) | 0.028722 / 0.128546 (-0.099824) | 0.010586 / 0.075646 (-0.065060) | 0.205145 / 0.419271 (-0.214127) | 0.036996 / 0.043533 (-0.006537) | 0.248874 / 0.255139 (-0.006265) | 0.266148 / 0.283200 (-0.017051) | 0.018540 / 0.141683 (-0.123143) | 1.120216 / 1.452155 (-0.331938) | 1.191072 / 1.492716 (-0.301644) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095721 / 0.018006 (0.077714) | 0.313401 / 0.000490 (0.312911) | 0.000234 / 0.000200 (0.000034) | 0.000053 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018604 / 0.037411 (-0.018807) | 0.061571 / 0.014526 (0.047045) | 0.075343 / 0.176557 (-0.101213) | 0.121272 / 0.737135 (-0.615864) | 0.076448 / 0.296338 (-0.219890) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286885 / 0.215209 (0.071676) | 2.809100 / 2.077655 (0.731445) | 1.485365 / 1.504120 (-0.018755) | 1.367672 / 1.541195 (-0.173523) | 1.423570 / 1.468490 (-0.044920) | 0.571063 / 4.584777 (-4.013714) | 2.385248 / 3.745712 (-1.360464) | 2.855251 / 5.269862 (-2.414610) | 1.799371 / 4.565676 (-2.766306) | 0.063491 / 0.424275 (-0.360784) | 0.004942 / 0.007607 (-0.002665) | 0.346181 / 0.226044 (0.120137) | 3.388123 / 2.268929 (1.119195) | 1.819093 / 55.444624 (-53.625532) | 1.552998 / 6.876477 (-5.323479) | 1.627930 / 2.142072 (-0.514143) | 0.653438 / 4.805227 (-4.151789) | 0.123831 / 6.500664 (-6.376833) | 0.043340 / 0.075469 (-0.032129) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.952167 / 1.841788 (-0.889621) | 12.149515 / 8.074308 (4.075207) | 10.665085 / 10.191392 (0.473693) | 0.127768 / 0.680424 (-0.552656) | 0.014022 / 0.534201 (-0.520179) | 0.285959 / 0.579283 (-0.293324) | 0.269727 / 0.434364 (-0.164637) | 0.336646 / 0.540337 (-0.203692) | 0.442932 / 1.386936 (-0.944005) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005351 / 0.011353 (-0.006002) | 0.003561 / 0.011008 (-0.007448) | 0.048890 / 0.038508 (0.010382) | 0.054093 / 0.023109 (0.030984) | 0.274397 / 0.275898 (-0.001501) | 0.296980 / 0.323480 (-0.026500) | 0.004126 / 0.007986 (-0.003860) | 0.002751 / 0.004328 (-0.001578) | 0.049131 / 0.004250 (0.044880) | 0.040769 / 0.037052 (0.003716) | 0.279147 / 0.258489 (0.020658) | 0.302014 / 0.293841 (0.008173) | 0.029847 / 0.128546 (-0.098699) | 0.010710 / 0.075646 (-0.064936) | 0.057626 / 0.419271 (-0.361645) | 0.032801 / 0.043533 (-0.010732) | 0.272698 / 0.255139 (0.017559) | 0.289238 / 0.283200 (0.006039) | 0.017876 / 0.141683 (-0.123807) | 1.152059 / 1.452155 (-0.300096) | 1.212289 / 1.492716 (-0.280427) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092914 / 0.018006 (0.074908) | 0.303092 / 0.000490 (0.302603) | 0.000214 / 0.000200 (0.000014) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022074 / 0.037411 (-0.015337) | 0.070109 / 0.014526 (0.055583) | 0.083360 / 0.176557 (-0.093196) | 0.122445 / 0.737135 (-0.614690) | 0.083625 / 0.296338 (-0.212714) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282788 / 0.215209 (0.067579) | 2.789229 / 2.077655 (0.711574) | 1.571077 / 1.504120 (0.066957) | 1.452627 / 1.541195 (-0.088567) | 1.493176 / 1.468490 (0.024686) | 0.556892 / 4.584777 (-4.027885) | 2.442771 / 3.745712 (-1.302941) | 2.826316 / 5.269862 (-2.443545) | 1.758276 / 4.565676 (-2.807401) | 0.063039 / 0.424275 (-0.361236) | 0.004928 / 0.007607 (-0.002679) | 0.338247 / 0.226044 (0.112202) | 3.346344 / 2.268929 (1.077416) | 1.952520 / 55.444624 (-53.492104) | 1.664520 / 6.876477 (-5.211956) | 1.701528 / 2.142072 (-0.440544) | 0.634746 / 4.805227 (-4.170481) | 0.116879 / 6.500664 (-6.383786) | 0.040990 / 0.075469 (-0.034479) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.969521 / 1.841788 (-0.872267) | 12.431395 / 8.074308 (4.357087) | 10.907503 / 10.191392 (0.716111) | 0.131028 / 0.680424 (-0.549396) | 0.015239 / 0.534201 (-0.518962) | 0.290793 / 0.579283 (-0.288490) | 0.275072 / 0.434364 (-0.159292) | 0.331036 / 0.540337 (-0.209301) | 0.567858 / 1.386936 (-0.819078) |\n\n</details>\n</details>\n\n\n"
] |
Pickle support for `torch.Generator` objects
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6502/reactions"
}
|
PR_kwDODunzps5iHPt-
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6502.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6502",
"merged_at": "2023-12-15T14:58:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6502.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6502"
}
|
2023-12-15T13:55:12Z
|
https://api.github.com/repos/huggingface/datasets/issues/6502/comments
|
Fix for https://discuss.huggingface.co/t/caching-a-dataset-processed-with-randomness/65616
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6502/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6502/timeline
|
closed
| false | 6,502 | null |
2023-12-15T14:58:22Z
| null | true |
2,043,377,240 |
https://api.github.com/repos/huggingface/datasets/issues/6501
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6501/events
|
[] | null |
2023-12-15T10:10:21Z
|
[] |
https://github.com/huggingface/datasets/issues/6501
|
NONE
| null | null | null |
[] |
OverflowError: value too large to convert to int32_t
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6501/reactions"
}
|
I_kwDODunzps55y3ZY
| null |
2023-12-15T10:10:21Z
|
https://api.github.com/repos/huggingface/datasets/issues/6501/comments
|
### Describe the bug

### Steps to reproduce the bug
just loading datasets
### Expected behavior
how can I fix it
### Environment info
pip install /mnt/cluster/zhangfan/study_info/LLaMA-Factory/peft-0.6.0-py3-none-any.whl
pip install huggingface_hub-0.19.4-py3-none-any.whl tokenizers-0.15.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl transformers-4.36.1-py3-none-any.whl pyarrow_hotfix-0.6-py3-none-any.whl datasets-2.15.0-py3-none-any.whl tyro-0.5.18-py3-none-any.whl trl-0.7.4-py3-none-any.whl
done
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47747764?v=4",
"events_url": "https://api.github.com/users/zhangfan-algo/events{/privacy}",
"followers_url": "https://api.github.com/users/zhangfan-algo/followers",
"following_url": "https://api.github.com/users/zhangfan-algo/following{/other_user}",
"gists_url": "https://api.github.com/users/zhangfan-algo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zhangfan-algo",
"id": 47747764,
"login": "zhangfan-algo",
"node_id": "MDQ6VXNlcjQ3NzQ3NzY0",
"organizations_url": "https://api.github.com/users/zhangfan-algo/orgs",
"received_events_url": "https://api.github.com/users/zhangfan-algo/received_events",
"repos_url": "https://api.github.com/users/zhangfan-algo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zhangfan-algo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhangfan-algo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zhangfan-algo"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6501/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6501/timeline
|
open
| false | 6,501 | null | null | null | false |
2,043,258,633 |
https://api.github.com/repos/huggingface/datasets/issues/6500
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6500/events
|
[] | null |
2023-12-18T11:56:11Z
|
[] |
https://github.com/huggingface/datasets/pull/6500
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6500). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"This is ready for review @huggingface/datasets. ",
"Also what if the config is being overwritten and it was the default config and the user doesn't pass `set_default` ?\r\nI'd expect the config to keep being the default one but lmk what you think",
"How can you unset a config as the default one? In the case you mentioned, I would expect the config not being the default one.",
"Maybe by passing `set_default=False` ? (set_default can be None by default)",
"I think that way we are unnecessarily complicating the logic of `push_to_hub` and as I told you, I would expect the contrary: the result of calling `push_to_hub` with a determined set of arguments should always be the same, independently of previous calls and the current state of the config on the Hub. Push to hub should be somehow stateless in that sense, and IMO the user expects that the push overwrites previous config if already present on the Hub. I find very confusing making it to partially update the config on the Hub.",
"That makes sense, having it stateless is simpler and no need to do something too fancy indeed",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005329 / 0.011353 (-0.006024) | 0.002998 / 0.011008 (-0.008010) | 0.063756 / 0.038508 (0.025248) | 0.051713 / 0.023109 (0.028603) | 0.248135 / 0.275898 (-0.027763) | 0.269136 / 0.323480 (-0.054344) | 0.002970 / 0.007986 (-0.005015) | 0.002566 / 0.004328 (-0.001763) | 0.048110 / 0.004250 (0.043859) | 0.038415 / 0.037052 (0.001363) | 0.254012 / 0.258489 (-0.004477) | 0.281915 / 0.293841 (-0.011926) | 0.027503 / 0.128546 (-0.101043) | 0.010370 / 0.075646 (-0.065276) | 0.208965 / 0.419271 (-0.210306) | 0.035508 / 0.043533 (-0.008024) | 0.249116 / 0.255139 (-0.006023) | 0.266350 / 0.283200 (-0.016850) | 0.018440 / 0.141683 (-0.123243) | 1.101089 / 1.452155 (-0.351066) | 1.164870 / 1.492716 (-0.327847) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.090909 / 0.018006 (0.072903) | 0.298041 / 0.000490 (0.297551) | 0.000211 / 0.000200 (0.000012) | 0.000051 / 0.000054 (-0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018137 / 0.037411 (-0.019275) | 0.059574 / 0.014526 (0.045048) | 0.071754 / 0.176557 (-0.104803) | 0.117980 / 0.737135 (-0.619155) | 0.072903 / 0.296338 (-0.223435) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282844 / 0.215209 (0.067635) | 2.740916 / 2.077655 (0.663261) | 1.444546 / 1.504120 (-0.059574) | 1.321904 / 1.541195 (-0.219291) | 1.356957 / 1.468490 (-0.111533) | 0.568389 / 4.584777 (-4.016388) | 2.354042 / 3.745712 (-1.391671) | 2.719427 / 5.269862 (-2.550435) | 1.719616 / 4.565676 (-2.846061) | 0.062537 / 0.424275 (-0.361738) | 0.004915 / 0.007607 (-0.002692) | 0.334716 / 0.226044 (0.108672) | 3.299499 / 2.268929 (1.030571) | 1.814629 / 55.444624 (-53.629996) | 1.515245 / 6.876477 (-5.361232) | 1.553085 / 2.142072 (-0.588987) | 0.643859 / 4.805227 (-4.161368) | 0.116650 / 6.500664 (-6.384014) | 0.041432 / 0.075469 (-0.034037) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.948227 / 1.841788 (-0.893561) | 11.331103 / 8.074308 (3.256795) | 10.209658 / 10.191392 (0.018266) | 0.126721 / 0.680424 (-0.553703) | 0.013638 / 0.534201 (-0.520563) | 0.282540 / 0.579283 (-0.296743) | 0.262635 / 0.434364 (-0.171729) | 0.335357 / 0.540337 (-0.204981) | 0.441798 / 1.386936 (-0.945138) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005200 / 0.011353 (-0.006153) | 0.003012 / 0.011008 (-0.007996) | 0.047571 / 0.038508 (0.009063) | 0.055069 / 0.023109 (0.031959) | 0.271150 / 0.275898 (-0.004748) | 0.294957 / 0.323480 (-0.028523) | 0.003922 / 0.007986 (-0.004064) | 0.002627 / 0.004328 (-0.001702) | 0.047777 / 0.004250 (0.043527) | 0.039507 / 0.037052 (0.002454) | 0.276314 / 0.258489 (0.017825) | 0.300436 / 0.293841 (0.006595) | 0.028951 / 0.128546 (-0.099595) | 0.010583 / 0.075646 (-0.065063) | 0.056535 / 0.419271 (-0.362737) | 0.032654 / 0.043533 (-0.010879) | 0.272945 / 0.255139 (0.017806) | 0.291909 / 0.283200 (0.008709) | 0.017545 / 0.141683 (-0.124138) | 1.195897 / 1.452155 (-0.256258) | 1.171855 / 1.492716 (-0.320861) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091919 / 0.018006 (0.073913) | 0.299297 / 0.000490 (0.298807) | 0.000225 / 0.000200 (0.000025) | 0.000051 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022271 / 0.037411 (-0.015140) | 0.068903 / 0.014526 (0.054377) | 0.083767 / 0.176557 (-0.092790) | 0.120239 / 0.737135 (-0.616896) | 0.083448 / 0.296338 (-0.212891) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295353 / 0.215209 (0.080144) | 2.911452 / 2.077655 (0.833798) | 1.577941 / 1.504120 (0.073821) | 1.454514 / 1.541195 (-0.086681) | 1.459575 / 1.468490 (-0.008915) | 0.572475 / 4.584777 (-4.012302) | 2.443634 / 3.745712 (-1.302078) | 2.801171 / 5.269862 (-2.468691) | 1.724214 / 4.565676 (-2.841462) | 0.063539 / 0.424275 (-0.360736) | 0.004939 / 0.007607 (-0.002668) | 0.347705 / 0.226044 (0.121660) | 3.489591 / 2.268929 (1.220663) | 1.944952 / 55.444624 (-53.499672) | 1.652810 / 6.876477 (-5.223667) | 1.656361 / 2.142072 (-0.485712) | 0.647052 / 4.805227 (-4.158176) | 0.117286 / 6.500664 (-6.383379) | 0.040979 / 0.075469 (-0.034490) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.971761 / 1.841788 (-0.870027) | 11.770547 / 8.074308 (3.696239) | 10.402502 / 10.191392 (0.211110) | 0.128280 / 0.680424 (-0.552144) | 0.015160 / 0.534201 (-0.519041) | 0.286706 / 0.579283 (-0.292578) | 0.274539 / 0.434364 (-0.159825) | 0.324591 / 0.540337 (-0.215747) | 0.573846 / 1.386936 (-0.813090) |\n\n</details>\n</details>\n\n\n"
] |
Enable setting config as default when push_to_hub
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6500/reactions"
}
|
PR_kwDODunzps5iFc6e
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6500.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6500",
"merged_at": "2023-12-18T11:50:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6500.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6500"
}
|
2023-12-15T09:17:41Z
|
https://api.github.com/repos/huggingface/datasets/issues/6500/comments
|
Fix #6497.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6500/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6500/timeline
|
closed
| false | 6,500 | null |
2023-12-18T11:50:03Z
| null | true |
2,043,166,976 |
https://api.github.com/repos/huggingface/datasets/issues/6499
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6499/events
|
[] | null |
2023-12-15T11:48:47Z
|
[] |
https://github.com/huggingface/datasets/pull/6499
|
CONTRIBUTOR
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6499). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005701 / 0.011353 (-0.005652) | 0.003546 / 0.011008 (-0.007463) | 0.063335 / 0.038508 (0.024827) | 0.051987 / 0.023109 (0.028878) | 0.240429 / 0.275898 (-0.035469) | 0.260659 / 0.323480 (-0.062820) | 0.003866 / 0.007986 (-0.004120) | 0.002617 / 0.004328 (-0.001712) | 0.048653 / 0.004250 (0.044403) | 0.038176 / 0.037052 (0.001124) | 0.245496 / 0.258489 (-0.012993) | 0.277141 / 0.293841 (-0.016700) | 0.027886 / 0.128546 (-0.100660) | 0.010738 / 0.075646 (-0.064908) | 0.211255 / 0.419271 (-0.208016) | 0.045205 / 0.043533 (0.001672) | 0.243062 / 0.255139 (-0.012077) | 0.262877 / 0.283200 (-0.020323) | 0.023426 / 0.141683 (-0.118257) | 1.092247 / 1.452155 (-0.359908) | 1.161074 / 1.492716 (-0.331642) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.090488 / 0.018006 (0.072482) | 0.300993 / 0.000490 (0.300504) | 0.000212 / 0.000200 (0.000012) | 0.000044 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018543 / 0.037411 (-0.018868) | 0.061418 / 0.014526 (0.046892) | 0.073242 / 0.176557 (-0.103314) | 0.120757 / 0.737135 (-0.616378) | 0.073967 / 0.296338 (-0.222372) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282341 / 0.215209 (0.067132) | 2.741106 / 2.077655 (0.663451) | 1.416573 / 1.504120 (-0.087547) | 1.287904 / 1.541195 (-0.253291) | 1.309425 / 1.468490 (-0.159065) | 0.582592 / 4.584777 (-4.002184) | 2.404866 / 3.745712 (-1.340846) | 2.895397 / 5.269862 (-2.374464) | 1.799864 / 4.565676 (-2.765812) | 0.064386 / 0.424275 (-0.359889) | 0.004920 / 0.007607 (-0.002687) | 0.330879 / 0.226044 (0.104835) | 3.287064 / 2.268929 (1.018135) | 1.765169 / 55.444624 (-53.679456) | 1.490442 / 6.876477 (-5.386034) | 1.530960 / 2.142072 (-0.611113) | 0.655939 / 4.805227 (-4.149288) | 0.118529 / 6.500664 (-6.382135) | 0.042350 / 0.075469 (-0.033119) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.959027 / 1.841788 (-0.882761) | 11.911284 / 8.074308 (3.836976) | 10.576898 / 10.191392 (0.385506) | 0.141038 / 0.680424 (-0.539386) | 0.014184 / 0.534201 (-0.520017) | 0.305335 / 0.579283 (-0.273948) | 0.267531 / 0.434364 (-0.166832) | 0.353362 / 0.540337 (-0.186975) | 0.466258 / 1.386936 (-0.920678) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005194 / 0.011353 (-0.006159) | 0.003561 / 0.011008 (-0.007448) | 0.049181 / 0.038508 (0.010673) | 0.056664 / 0.023109 (0.033555) | 0.267142 / 0.275898 (-0.008756) | 0.291871 / 0.323480 (-0.031609) | 0.003996 / 0.007986 (-0.003990) | 0.003147 / 0.004328 (-0.001181) | 0.048527 / 0.004250 (0.044276) | 0.040239 / 0.037052 (0.003187) | 0.269728 / 0.258489 (0.011239) | 0.295531 / 0.293841 (0.001690) | 0.030316 / 0.128546 (-0.098231) | 0.010666 / 0.075646 (-0.064981) | 0.058176 / 0.419271 (-0.361095) | 0.033218 / 0.043533 (-0.010315) | 0.265383 / 0.255139 (0.010244) | 0.285102 / 0.283200 (0.001902) | 0.018295 / 0.141683 (-0.123388) | 1.117830 / 1.452155 (-0.334325) | 1.196919 / 1.492716 (-0.295798) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.088547 / 0.018006 (0.070541) | 0.293220 / 0.000490 (0.292730) | 0.000211 / 0.000200 (0.000011) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022060 / 0.037411 (-0.015351) | 0.071973 / 0.014526 (0.057448) | 0.081721 / 0.176557 (-0.094836) | 0.119990 / 0.737135 (-0.617145) | 0.081639 / 0.296338 (-0.214700) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.293712 / 0.215209 (0.078503) | 2.872986 / 2.077655 (0.795331) | 1.568944 / 1.504120 (0.064824) | 1.434555 / 1.541195 (-0.106639) | 1.457747 / 1.468490 (-0.010743) | 0.559296 / 4.584777 (-4.025481) | 2.471845 / 3.745712 (-1.273867) | 2.840916 / 5.269862 (-2.428946) | 1.754909 / 4.565676 (-2.810768) | 0.064585 / 0.424275 (-0.359690) | 0.004992 / 0.007607 (-0.002615) | 0.349149 / 0.226044 (0.123104) | 3.385906 / 2.268929 (1.116977) | 1.940644 / 55.444624 (-53.503980) | 1.638300 / 6.876477 (-5.238177) | 1.649939 / 2.142072 (-0.492133) | 0.645680 / 4.805227 (-4.159547) | 0.118080 / 6.500664 (-6.382584) | 0.040643 / 0.075469 (-0.034826) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.969965 / 1.841788 (-0.871822) | 12.099766 / 8.074308 (4.025457) | 10.550650 / 10.191392 (0.359258) | 0.131736 / 0.680424 (-0.548688) | 0.015483 / 0.534201 (-0.518718) | 0.289231 / 0.579283 (-0.290052) | 0.287505 / 0.434364 (-0.146858) | 0.327326 / 0.540337 (-0.213011) | 0.570364 / 1.386936 (-0.816572) |\n\n</details>\n</details>\n\n\n"
] |
docs: add reference Git over SSH
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6499/reactions"
}
|
PR_kwDODunzps5iFIUF
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6499.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6499",
"merged_at": "2023-12-15T11:42:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6499.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6499"
}
|
2023-12-15T08:38:31Z
|
https://api.github.com/repos/huggingface/datasets/issues/6499/comments
|
see https://discuss.huggingface.co/t/update-datasets-getting-started-to-new-git-security/65893
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6499/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6499/timeline
|
closed
| false | 6,499 | null |
2023-12-15T11:42:38Z
| null | true |
2,042,075,969 |
https://api.github.com/repos/huggingface/datasets/issues/6498
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6498/events
|
[] | null |
2023-12-15T13:16:56Z
|
[] |
https://github.com/huggingface/datasets/pull/6498
|
MEMBER
| null | false | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6498). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"> I was just thinking: what if the user does not pass a config name and the dataset has only a config with a name different from \"default\"?\r\n\r\nYou mean if there is a DEFAULT_CONFIG_NAME defined in the script but the dataset only has one configuration ? We can't easily get the number of configs without running the python code so I don't think we can support detect this case\r\n",
"Most datasets with a script don't define DEFAULT_CONFIG_NAME if there is only one configuration anyway.\r\n\r\nSo there is no issue e.g. for `squad`",
"> I was trying to mean the case where DEFAULT_CONFIG_NAME is None but there is only a single config in BUILDER_CONFIGS, with a name different from \"default\".\r\n\r\nIn this case we can detect if \"DEFAULT_CONFIG_NAME\" is not mentioned and use the Parquet export. If it is mentioned (and maybe it is set to None or to the single config) I consider that it may have multiple configs and fall back on using the script",
"... but the user does not pass the config name.",
"In this case we load the single configuration (this is how a DatasetBuilder works)",
"see \r\n\r\nhttps://github.com/huggingface/datasets/blob/2feaa589de86dd85941301fc8c3fa091731a67c0/src/datasets/builder.py#L532-L532",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005122 / 0.011353 (-0.006231) | 0.003565 / 0.011008 (-0.007443) | 0.062706 / 0.038508 (0.024198) | 0.049314 / 0.023109 (0.026205) | 0.247325 / 0.275898 (-0.028573) | 0.269788 / 0.323480 (-0.053692) | 0.003895 / 0.007986 (-0.004090) | 0.002788 / 0.004328 (-0.001540) | 0.048615 / 0.004250 (0.044365) | 0.037591 / 0.037052 (0.000539) | 0.253495 / 0.258489 (-0.004994) | 0.281200 / 0.293841 (-0.012641) | 0.027712 / 0.128546 (-0.100834) | 0.010901 / 0.075646 (-0.064745) | 0.205577 / 0.419271 (-0.213694) | 0.035989 / 0.043533 (-0.007544) | 0.252978 / 0.255139 (-0.002161) | 0.268042 / 0.283200 (-0.015157) | 0.017857 / 0.141683 (-0.123826) | 1.096633 / 1.452155 (-0.355521) | 1.147026 / 1.492716 (-0.345691) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095609 / 0.018006 (0.077603) | 0.311941 / 0.000490 (0.311451) | 0.000211 / 0.000200 (0.000011) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019042 / 0.037411 (-0.018369) | 0.060549 / 0.014526 (0.046023) | 0.074761 / 0.176557 (-0.101796) | 0.121729 / 0.737135 (-0.615406) | 0.075661 / 0.296338 (-0.220677) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.284774 / 0.215209 (0.069565) | 2.764576 / 2.077655 (0.686921) | 1.489926 / 1.504120 (-0.014194) | 1.387276 / 1.541195 (-0.153919) | 1.400931 / 1.468490 (-0.067559) | 0.555623 / 4.584777 (-4.029154) | 2.409488 / 3.745712 (-1.336224) | 2.781053 / 5.269862 (-2.488808) | 1.750472 / 4.565676 (-2.815204) | 0.062232 / 0.424275 (-0.362043) | 0.004974 / 0.007607 (-0.002633) | 0.336324 / 0.226044 (0.110280) | 3.286619 / 2.268929 (1.017691) | 1.825070 / 55.444624 (-53.619554) | 1.537993 / 6.876477 (-5.338484) | 1.586520 / 2.142072 (-0.555553) | 0.640090 / 4.805227 (-4.165138) | 0.117637 / 6.500664 (-6.383027) | 0.042318 / 0.075469 (-0.033151) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.964051 / 1.841788 (-0.877736) | 11.706259 / 8.074308 (3.631951) | 10.752311 / 10.191392 (0.560919) | 0.128117 / 0.680424 (-0.552307) | 0.014001 / 0.534201 (-0.520200) | 0.286255 / 0.579283 (-0.293028) | 0.263810 / 0.434364 (-0.170554) | 0.329347 / 0.540337 (-0.210991) | 0.437349 / 1.386936 (-0.949587) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005303 / 0.011353 (-0.006050) | 0.003586 / 0.011008 (-0.007422) | 0.049339 / 0.038508 (0.010831) | 0.051287 / 0.023109 (0.028178) | 0.274397 / 0.275898 (-0.001501) | 0.292977 / 0.323480 (-0.030503) | 0.004029 / 0.007986 (-0.003957) | 0.002727 / 0.004328 (-0.001602) | 0.048779 / 0.004250 (0.044528) | 0.040075 / 0.037052 (0.003022) | 0.277676 / 0.258489 (0.019187) | 0.301963 / 0.293841 (0.008122) | 0.029340 / 0.128546 (-0.099206) | 0.010714 / 0.075646 (-0.064932) | 0.057253 / 0.419271 (-0.362018) | 0.033426 / 0.043533 (-0.010107) | 0.276673 / 0.255139 (0.021534) | 0.291053 / 0.283200 (0.007854) | 0.017660 / 0.141683 (-0.124023) | 1.122354 / 1.452155 (-0.329800) | 1.180381 / 1.492716 (-0.312335) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091903 / 0.018006 (0.073897) | 0.300720 / 0.000490 (0.300231) | 0.000288 / 0.000200 (0.000088) | 0.000044 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021521 / 0.037411 (-0.015890) | 0.068233 / 0.014526 (0.053707) | 0.081245 / 0.176557 (-0.095312) | 0.119996 / 0.737135 (-0.617139) | 0.082483 / 0.296338 (-0.213856) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.302776 / 0.215209 (0.087567) | 2.950776 / 2.077655 (0.873122) | 1.631032 / 1.504120 (0.126912) | 1.502021 / 1.541195 (-0.039174) | 1.514213 / 1.468490 (0.045723) | 0.578246 / 4.584777 (-4.006531) | 2.443768 / 3.745712 (-1.301944) | 2.827811 / 5.269862 (-2.442051) | 1.771529 / 4.565676 (-2.794148) | 0.064479 / 0.424275 (-0.359797) | 0.005061 / 0.007607 (-0.002546) | 0.350966 / 0.226044 (0.124922) | 3.458616 / 2.268929 (1.189687) | 1.967917 / 55.444624 (-53.476707) | 1.704661 / 6.876477 (-5.171815) | 1.698895 / 2.142072 (-0.443178) | 0.663259 / 4.805227 (-4.141968) | 0.122140 / 6.500664 (-6.378525) | 0.041099 / 0.075469 (-0.034371) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.972080 / 1.841788 (-0.869708) | 12.123286 / 8.074308 (4.048978) | 10.819854 / 10.191392 (0.628462) | 0.131486 / 0.680424 (-0.548938) | 0.015785 / 0.534201 (-0.518416) | 0.290048 / 0.579283 (-0.289235) | 0.277822 / 0.434364 (-0.156542) | 0.325949 / 0.540337 (-0.214388) | 0.577681 / 1.386936 (-0.809255) |\n\n</details>\n</details>\n\n\n"
] |
Fallback on dataset script if user wants to load default config
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6498/reactions"
}
|
PR_kwDODunzps5iBcFj
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6498.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6498",
"merged_at": "2023-12-15T13:10:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6498.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6498"
}
|
2023-12-14T16:46:01Z
|
https://api.github.com/repos/huggingface/datasets/issues/6498/comments
|
Right now this code is failing on `main`:
```python
load_dataset("openbookqa")
```
This is because it tries to load the dataset from the Parquet export but the dataset has multiple configurations and the Parquet export doesn't know which one is the default one.
I fixed this by simply falling back on using the dataset script (which tells the user to pass `trust_remote_code=True`):
```python
load_dataset("openbookqa", trust_remote_code=True)
```
Note that if the user happened to specify a config name I don't fall back on the script since we can use the Parquet export in this case (no need to know which config is the default)
```python
load_dataset("openbookqa", "main")
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6498/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6498/timeline
|
closed
| false | 6,498 | null |
2023-12-15T13:10:48Z
| null | true |
2,041,994,274 |
https://api.github.com/repos/huggingface/datasets/issues/6497
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6497/events
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | null |
2023-12-18T11:50:04Z
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] |
https://github.com/huggingface/datasets/issues/6497
|
MEMBER
|
completed
| null | null |
[] |
Support setting a default config name in push_to_hub
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6497/reactions"
}
|
I_kwDODunzps55tlwi
| null |
2023-12-14T15:59:03Z
|
https://api.github.com/repos/huggingface/datasets/issues/6497/comments
|
In order to convert script-datasets to no-script datasets, we need to support setting a default config name for those scripts that set one.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6497/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6497/timeline
|
closed
| false | 6,497 | null |
2023-12-18T11:50:04Z
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
| false |
2,041,589,386 |
https://api.github.com/repos/huggingface/datasets/issues/6496
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6496/events
|
[] | null |
2023-12-14T12:22:21Z
|
[] |
https://github.com/huggingface/datasets/issues/6496
|
NONE
| null | null | null |
[
"I transferred from datasets-server, since the issue is more about `datasets` and the integration with `huggingface_hub`."
] |
Error when writing a dataset to HF Hub: A commit has happened since. Please refresh and try again.
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6496/reactions"
}
|
I_kwDODunzps55sC6K
| null |
2023-12-14T11:24:54Z
|
https://api.github.com/repos/huggingface/datasets/issues/6496/comments
|
**Describe the bug**
Getting a `412 Client Error: Precondition Failed` when trying to write a dataset to the HF hub.
```
huggingface_hub.utils._errors.HfHubHTTPError: 412 Client Error: Precondition Failed for url: https://huggingface.co/api/datasets/GLorr/test-dask/commit/main (Request ID: Root=1-657ae26f-3bd92bf861bb254b2cc0826c;50a09ab7-9347-406a-ba49-69f98abee9cc)
A commit has happened since. Please refresh and try again.
```
**Steps to reproduce the bug**
This is a minimal reproducer:
```
import dask.dataframe as dd
import pandas as pd
import random
import os
import huggingface_hub
import datasets
huggingface_hub.login(token=os.getenv("HF_TOKEN"))
data = {"number": [random.randint(0,10) for _ in range(1000)]}
df = pd.DataFrame.from_dict(data)
dataframe = dd.from_pandas(df, npartitions=1)
dataframe = dataframe.repartition(npartitions=3)
schema = datasets.Features({"number": datasets.Value("int64")}).arrow_schema
repo_id = "GLorr/test-dask"
repo_path = f"hf://datasets/{repo_id}"
huggingface_hub.create_repo(repo_id=repo_id, repo_type="dataset", exist_ok=True)
dd.to_parquet(dataframe, path=f"{repo_path}/data", schema=schema)
```
**Expected behavior**
Would expect to write to the hub without any problem.
**Environment info**
```
datasets==2.15.0
huggingface-hub==0.19.4
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35808396?v=4",
"events_url": "https://api.github.com/users/GeorgesLorre/events{/privacy}",
"followers_url": "https://api.github.com/users/GeorgesLorre/followers",
"following_url": "https://api.github.com/users/GeorgesLorre/following{/other_user}",
"gists_url": "https://api.github.com/users/GeorgesLorre/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/GeorgesLorre",
"id": 35808396,
"login": "GeorgesLorre",
"node_id": "MDQ6VXNlcjM1ODA4Mzk2",
"organizations_url": "https://api.github.com/users/GeorgesLorre/orgs",
"received_events_url": "https://api.github.com/users/GeorgesLorre/received_events",
"repos_url": "https://api.github.com/users/GeorgesLorre/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/GeorgesLorre/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GeorgesLorre/subscriptions",
"type": "User",
"url": "https://api.github.com/users/GeorgesLorre"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6496/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6496/timeline
|
open
| false | 6,496 | null | null | null | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.