
text1 stringlengths 2 269k | text2 stringlengths 2 242k | label int64 0 1 |
|---|---|---|
### Feature request
Whisper speech recognition without conditioning on previous text.
As in
https://github.com/openai/whisper/blob/7858aa9c08d98f75575035ecd6481f462d66ca27/whisper/transcribe.py#L278
### Motivation
Whisper implementation is great however conditioning the decoding on previous
text can cause significant hallucination and repetitive text, e.g.:
> "Do you have malpractice? Do you have malpractice? Do you have malpractice?
> Do you have malpractice? Do you have malpractice? Do you have malpractice?
> Do you have malpractice? Do you have malpractice? Do you have malpractice?
> Do you have malpractice? Do you have malpractice? Do you have malpractice?
> Do you have malpractice? Do you have malpractice? Do you have malpractice?
> Do you have malpractice?"
Running openai's model with `--condition_on_previous_text False` drastically
reduces hallucination
@ArthurZucker
|
Hello,
I tried to import this:
`from transformers import AdamW, get_linear_schedule_with_warmup`
but got error : model not found
but when i did this, it worked:
from transformers import AdamW
from transformers import WarmupLinearSchedule as get_linear_schedule_with_warmup
however when I set the scheduler like this :
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total)
I got this error :
__init__() got an unexpected keyword argument 'num_warmup_steps'
| 0 |
### Bug summary
I put a `torch.Tensor` in `matplotlib.pyplot.hist()` , but it draw a wrong
graphic and take a long time.
Although transform to numpy, the function work well. But all the others
function I used are work well on tensor. So I think its a bug.
### Code for reproduction
import matplotlib.pyplot as plt
import torch
plt.hist(torch.randn(20))
plt.show()
### Actual outcome

### Expected outcome

### Additional information
_No response_
### Operating system
Windows
### Matplotlib Version
3.5.1
### Matplotlib Backend
module://ipykernel.pylab.backend_inline
### Python version
3.7.13
### Jupyter version
6.4.8
### Installation
conda
|
### Bug report
**Bug summary**
Generating `np.random.randn(1000)` values, visualizing them with `plt.hist()`.
Works fine with Numpy.
When I replace Numpy with tensorflow.experimental.numpy, Matplotlib 3.3.4
fails to display the histogram correctly. Matplotlib 3.2.2 works fine.
**Code for reproduction**
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
# bad image
labels1 = 15 + 2 * tnp.random.randn(1000)
_ = plt.hist(labels1)
# good image
labels2 = 15 + 2 * np.random.randn(1000)
_ = plt.hist(labels2)
**Actual outcome**

**Expected outcome**

**Matplotlib version**
* Operating system: Windows 10
* Matplotlib version (`import matplotlib; print(matplotlib.__version__)`): 3.3.4
* Matplotlib backend (`print(matplotlib.get_backend())`): module://ipykernel.pylab.backend_inline
* Python version: 3.8.7
* Jupyter version (if applicable): see below
* Other libraries: see below
TensorFlow 2.4.1
jupyter --version
jupyter core : 4.7.0
jupyter-notebook : 6.1.6
qtconsole : 5.0.1
ipython : 7.20.0
ipykernel : 5.4.2
jupyter client : 6.1.7
jupyter lab : not installed
nbconvert : 6.0.7
ipywidgets : 7.6.3
nbformat : 5.0.8
traitlets : 5.0.5
Python installed from python.org as an exe installer. Everything else is `pip
install --user`
Bug opened with TensorFlow on this same issue:
tensorflow/tensorflow#46274
| 1 |
### System info
* Playwright Version: [v1.31.2]
* Operating System: [Windows VM]
* Browser: [ONLY in Chromium]
* Other info: It used to work fine until updated to v1.31 and now even if I revert back to previous versions still getting the same error (the error only happens in the Windows VM , not in my local machine, but I do not have access to that VM Windows machine)
**Error LOG**
2023-03-07T09:27:22.6036536Z �[31m 1) [testing Login Setup] › tests\login-setup.ts:6:5 › Login Setup �[2m────────────────────────────────�[22m�[39m
2023-03-07T09:27:22.6037617Z
2023-03-07T09:27:22.6038162Z browserType.launch: Browser closed.
2023-03-07T09:27:22.6038793Z ==================== Browser output: ====================
2023-03-07T09:27:22.6044850Z <launching> C:\devops-agents\agent\_work\r65\a\Project.Web.Test.Automation\Output\node_modules\playwright-core\.local-browsers\chromium_win64_special-1050\chrome-win\chrome.exe --disable-field-trial-config --disable-background-networking --enable-features=NetworkService,NetworkServiceInProcess --disable-background-timer-throttling --disable-backgrounding-occluded-windows --disable-back-forward-cache --disable-breakpad --disable-client-side-phishing-detection --disable-component-extensions-with-background-pages --disable-component-update --no-default-browser-check --disable-default-apps --disable-dev-shm-usage --disable-extensions --disable-features=ImprovedCookieControls,LazyFrameLoading,GlobalMediaControls,DestroyProfileOnBrowserClose,MediaRouter,DialMediaRouteProvider,AcceptCHFrame,AutoExpandDetailsElement,CertificateTransparencyComponentUpdater,AvoidUnnecessaryBeforeUnloadCheckSync,Translate --allow-pre-commit-input --disable-hang-monitor --disable-ipc-flooding-protection --disable-popup-blocking --disable-prompt-on-repost --disable-renderer-backgrounding --disable-sync --force-color-profile=srgb --metrics-recording-only --no-first-run --enable-automation --password-store=basic --use-mock-keychain --no-service-autorun --export-tagged-pdf --headless --hide-scrollbars --mute-audio --blink-settings=primaryHoverType=2,availableHoverTypes=2,primaryPointerType=4,availablePointerTypes=4 --no-sandbox --user-data-dir=C:\Users\SVC_TE~1\AppData\Local\Temp\playwright_chromiumdev_profile-uvQwhV --remote-debugging-pipe --no-startup-window
2023-03-07T09:27:22.6052457Z <launched> pid=9100
2023-03-07T09:27:22.6054202Z [pid=9100][err] [0307/092645.718:ERROR:main_dll_loader_win.cc(109)] Failed to load Chrome DLL from C:\devops-agents\agent\_work\r65\a\Project.Web.Test.Automation\Output\node_modules\playwright-core\.local-browsers\chromium_win64_special-1050\chrome-win\chrome.dll: The specified procedure could not be found. (0x7F)
2023-03-07T09:27:22.6056487Z =========================== logs ===========================
2023-03-07T09:27:22.6062693Z <launching> C:\devops-agents\agent\_work\r65\a\Project.Web.Test.Automation\Output\node_modules\playwright-core\.local-browsers\chromium_win64_special-1050\chrome-win\chrome.exe --disable-field-trial-config --disable-background-networking --enable-features=NetworkService,NetworkServiceInProcess --disable-background-timer-throttling --disable-backgrounding-occluded-windows --disable-back-forward-cache --disable-breakpad --disable-client-side-phishing-detection --disable-component-extensions-with-background-pages --disable-component-update --no-default-browser-check --disable-default-apps --disable-dev-shm-usage --disable-extensions --disable-features=ImprovedCookieControls,LazyFrameLoading,GlobalMediaControls,DestroyProfileOnBrowserClose,MediaRouter,DialMediaRouteProvider,AcceptCHFrame,AutoExpandDetailsElement,CertificateTransparencyComponentUpdater,AvoidUnnecessaryBeforeUnloadCheckSync,Translate --allow-pre-commit-input --disable-hang-monitor --disable-ipc-flooding-protection --disable-popup-blocking --disable-prompt-on-repost --disable-renderer-backgrounding --disable-sync --force-color-profile=srgb --metrics-recording-only --no-first-run --enable-automation --password-store=basic --use-mock-keychain --no-service-autorun --export-tagged-pdf --headless --hide-scrollbars --mute-audio --blink-settings=primaryHoverType=2,availableHoverTypes=2,primaryPointerType=4,availablePointerTypes=4 --no-sandbox --user-data-dir=C:\Users\SVC_TE~1\AppData\Local\Temp\playwright_chromiumdev_profile-uvQwhV --remote-debugging-pipe --no-startup-window
2023-03-07T09:27:22.6068578Z <launched> pid=9100
2023-03-07T09:27:22.6070213Z [pid=9100][err] [0307/092645.718:ERROR:main_dll_loader_win.cc(109)] Failed to load Chrome DLL from C:\devops-agents\agent\_work\r65\a\Project.Web.Test.Automation\Output\node_modules\playwright-core\.local-browsers\chromium_win64_special-1050\chrome-win\chrome.dll: The specified procedure could not be found. (0x7F)
2023-03-07T09:27:22.6071990Z ============================================================
**Test file**
import { test as setup } from '@playwright/test';
setup('Login Setup', async ({ page }) => {
await this.page.goto('URL');
});
**Steps**
* run: "npm set PLAYWRIGHT_BROWSERS_PATH=0&& playwright install"
* runL "npm set PLAYWRIGHT_BROWSERS_PATH=0&& playwright test"
**Expected**
It used to work fine until updated to v1.31 and now even if I revert back to
previous versions still getting the same error (the error only happens in the
Windows VM , not in my local machine, but I do not have access to that VM
Windows machine)
**Actual**
As you can see in the LOG error, the browser cannot even be executed now.
|
### System info
* Playwright Version: v1.32.2
* Operating System: Windows 11
* Browser: All
* Node.js 18.12.0
* PowerShell 7.3.3
### Source code
* I provided exact source code that allows reproducing the issue locally.
**Link to the GitHub repository with the repro**
https://github.com/tadashi-aikawa/nuxt2-vuetify2-playwright-sandbox.git
**Steps**
#### 1\. Clone the repository and run the application
git clone https://github.com/tadashi-aikawa/nuxt2-vuetify2-playwright-sandbox.git
cd nuxt2-vuetify2-playwright-sandbox
git checkout 413de5f02e7affb8f301396929ca383dc967696e
npm install
npm run dev
#### 2\. Open the playwright GUI mode in another shell process
cd nuxt2-vuetify2-playwright-sandbox
npx playwright test --ui
#### 3\. Run all tests

**Expected**
Success all tests.
**Actual**
Some tests fail as follows.

The terminal that runs "npm run dev" shows errors.
node:events:491
throw er; // Unhandled 'error' event
^
Error: EPERM: operation not permitted, stat 'C:\Users\syoum\tmp\nuxt2-vuetify2-playwright-sandbox\test-results\.playwright-artifacts-1\1a98587cb1640f43c20527b24baacb89.zip'
Emitted 'error' event on FSWatcher instance at:
at FSWatcher.emitWithAll (C:\Users\syoum\tmp\nuxt2-vuetify2-playwright-sandbox\node_modules\chokidar\index.js:540:8)
at awfEmit (C:\Users\syoum\tmp\nuxt2-vuetify2-playwright-sandbox\node_modules\chokidar\index.js:599:14)
at C:\Users\syoum\tmp\nuxt2-vuetify2-playwright-sandbox\node_modules\chokidar\index.js:714:43
at FSReqCallback.oncomplete (node:fs:207:21) {
errno: -4048,
code: 'EPERM',
syscall: 'stat',
path: 'C:\\Users\\syoum\\tmp\\nuxt2-vuetify2-playwright-sandbox\\test-results\\.playwright-artifacts-1\\1a98587cb1640f43c20527b24baacb89.zip'
}
Node.js v18.12.0
### Remarks
* Without UI mode, it is always a success (`npx playwright test`)
* It occurs even if set `1` to `workers`
* I confirmed that I could create `C:\Users\syoum\tmp\nuxt2-vuetify2-playwright-sandbox\test-results\.playwright-artifacts-1\1a98587cb1640f43c20527b24baacb89.zip` manually
* It occurs even if I run them as an administrator
* It occurs even if I select firefox or webkit instead of chromium
Please let me know if any information is missing.
Best regards.
P.S. The new feature, UI mode, is very awesome!! It looks like as a cool IDE
to e2e test! 😄
| 0 |
ERROR: type should be string, got "\n\nhttps://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/container_bridge.go#L122-L143 \ncontainer_bridge.go assumes that the virtual IP of services & pods will be in\nthe `10.` space. \nI propose there is no reason to make this assumption.\n\nAs outlined in #15932, cluster admins may need to deploy to hosts in which\n`10.` is reserved for the nodes. In such a case, Kubelets must support an\nalternative range.\n\n" |
Today kubelet sets up an iptables MASQUERADE rule for any traffic destined for
anything except 10.0.0.0/8. This is close, but not even correct on GCE, and
certainly not right elsewhere.
First GCE. We probably want something like:
iptables -t nat -N KUBE-IPMASQ
iptables -t nat -A KUBE-IPMASQ -d 10.0.0.0/8 -j RETURN
iptables -t nat -A KUBE-IPMASQ -d 172.16.0.0/12 -j RETURN
iptables -t nat -A KUBE-IPMASQ -d 192.168.0.0/16 -j RETURN
iptables -t nat -A KUBE-IPMASQ -j MASQUERADE
iptables -t nat -I POSTROUTING -j KUBE-IPMASQ
This catches all traffic to RFC1918 ranges and masquerades it. We can probably
optimize with CONNMARK or something so we only consider packets from
containers. This is probably still imperfect, but better, for lack of project-
wide NAT for egress.
For other environments, we really have no idea what the correct policy for
this is. It is closer to "your nodes must handle this" than "we can handle
this for you". It's debatable whether we should even try.
Either:
a) We teach kubelet a lot more and let people pass flags to nearly=arbitrarily
configure this
b) We tell people to configure this as part of their node setup
This popped up when I realized GKE allows users to set up 172.* clusters - any
traffic between containers in one of these will get masqueraded - not correct
behavior!! This is not a huge deal right now because kube-proxy has the same
effect when traversing services. As we fix kube-proxy in the wake of 1.0,
masquerade will be a bigger deal, especially for micro-segmenting.
Additional considerations: VPNs have bizarre and very custom needs. Every such
thing has an as yet unmeasured perf implication. This also pops up in our GCE
firewall thing that @ArtfulCoder is working on.
@dchen1107 @alex-mohr
| 1 |
.valid would apply the normal ("successful") input/textarea/select styles when
applied to those input types while within a .control-group.error.
The use case for this is a .control-group section with a "multi-part" input
(ex: time entry with hour and minute fields). If minutes was valid, but hour
was not the .control-group should still have .error applied.
This would give users a more obvious indication of what was left to fix--since
only input/textarea/select's without the .valid class would be marked in the
.error styles.
.valid could inherit direction form the default input/textarea/select styles.
|
It would be useful to provide column push and pull classes for all three
different grids.
This means that `.col-push-*` and `.col-pull-*` only affect the mobile grid
and are joined by `.col-push-sm-*`, `.col-pull-sm-*` and `.col-push-lg-*`,
`.col-pull-lg-*` to control the column order differently depending on the grid
in use.
Summary: Allow for different column reordering in different grids.
| 0 |
### Is there an existing issue for this?
* I have searched the existing issues
### This issue exists in the latest npm version
* I am using the latest npm
### Current Behavior
Currently, my package.json specifies `"typescript": "^5.0.2"`. When I change
it to say `"typescript": "^5.0.3"`, npm 9 spins for 4:28 before deciding it
doesn't exist. For comparison, npm 8 installs it with no problem in 0:44.
Ironically, I can't upgrade npm to 9.6 due to this issue: npm 9.5.1 times out
when I run `npm i -g npm`.
### Expected Behavior
npm 9 should be able to locate and download these versions with similar
performance to npm 8.
### Steps To Reproduce
1. Have a project with a v2 lockfile and TypeScript 5.0.2
2. Install node 18.16.0 with npm 9.5.1
3. Update the package.json to request TypeScript 5.0.3 or newer
4. Run `npm i`
### Environment
* npm: 9.5.1
* Node.js: 18.16.0
* OS Name: Windows 10
* System Model Name: Maingear Vector 2
* npm config:
; "user" config from C:\Users\bbrk2\.npmrc
//registry.npmjs.org/:_authToken = (protected)
; node bin location = C:\Users\bbrk2\.nvm\versions\node\v18.16.0\bin\node.exe
; node version = v18.16.0
; npm local prefix = C:\Users\bbrk2\[REDACTED]
; npm version = 9.5.1
; cwd = C:\Users\bbrk2\[REDACTED]
; HOME = C:\Users\bbrk2
; Run `npm config ls -l` to show all defaults.
|
### Is there an existing issue for this?
* I have searched the existing issues
### This issue exists in the latest npm version
* I am using the latest npm
### Current Behavior
When running `npm install` it will sometimes hang at a random point. When it
does this, it is stuck forever. CTRL+C will do nothing the first time that
combination is pressed when this has occurred. Pressing that key combination
the second time will make the current line (the one showing the little
progress bar) disappear but that's it. No further responses to that key
combination are observed.
The CMD (or Powershell) window cannot be closed regardless. The process cannot
be killed by Task Manager either (Access Denied, although I'm an Administrator
user so I'd assume the real reason is something non-permissions related). The
only way I have found to close it is to reboot the machine.
My suspicion is it's some sort of deadlock, but this is a guess and I have no
idea how to further investigate this. I've tried using Process Explorer to
check for handles to files in the project directory from other processes but
there are none. There are handles held by the Node process npm is using, and
one for the CMD window hosting it, but that's it.
Even running with `log-level silly` yields no useful information. When it
freezes there are no warnings or errors, it just sits on the line it was on.
This is some log output from one of the times when it got stuck (I should
again emphasise that the point where it gets stuck seems to be random, so the
last line shown here isn't always the one it freezes on):
npm timing auditReport:init Completed in 49242ms
npm timing reify:audit Completed in 55729ms
npm timing reifyNode:node_modules/selenium-webdriver Completed in 54728ms
npm timing reifyNode:node_modules/regenerate-unicode-properties Completed in 55637ms
npm timing reifyNode:node_modules/ajv-formats/node_modules/ajv Completed in 56497ms
npm timing reifyNode:node_modules/@angular-devkit/schematics/node_modules/ajv Completed in 56472ms
[##################] \ reify:ajv: timing reifyNode:node_modules/@angular-devkit/schematics/node_modules/ajv Completed in 564
The only thing that I can think of right now is that Bit Defender (the only
other application running) is interfering somehow, however it's the one
application I can't turn off.
I've seen this issue occur on different projects, on different network and
internet connections, and on different machines. Does anyone have any advice
on how to investigate this, or at the very least a way to kill the process
when it hangs like this without having to reboot the machine? Being forced to
reboot when this issue occurs is perhaps the most frustrating thing in all of
this.
### Expected Behavior
`npm install` should either succeed or show an error. If it gets stuck it
should either time-out or be closable by the user.
### Steps To Reproduce
1. Clear down the `node_modules` folder (ie with something like `rmdir /q /s`)
2. Run. `npm install`
3. Watch and wait.
4. If it succeeds, repeat the above steps until the freeze is observed.
### Environment
* npm: 8.1.3
* Node: v16.13.0
* OS: Windows 10 Version 21H1 (OS Build 19043.1288)
* platform: Lenovo ThinkPad
* npm config:
; "builtin" config from C:\Users\<REDACTED>\AppData\Roaming\npm\node_modules\npm\npmrc
prefix = "C:\\Users\\<REDACTED>\\AppData\\Roaming\\npm"
; "user" config from C:\Users\<REDACTED>\.npmrc
//pkgs.dev.azure.com/<REDACTED>/_packaging/<REDACTED>/npm/registry/:_authToken = (protected)
; node bin location = C:\Program Files\nodejs\node.exe
; cwd = C:\Users\<REDACTED>
; HOME = C:\Users\<REDACTED>
; Run `npm config ls -l` to show all defaults.
| 1 |
I love the Acrylic effect in the new terminal. Really gives it a modern feel.
But at the moment, whenever you focus on a different program, i.e click away
from the terminal, it loses the Acrylic effect and goes to a solid color. I
have two monitors so most of the time, I have my terminal visible on the
second monitor while working in the first and most of the time the terminal is
just a solid black color. Would it be possible to make it so that it keeps the
Acrylic effect or is that a limitation of the UI toolkit?
|
Using Windows Store version 0.5.2762.0
Zipped DMP file attached.
conhost.exe.21732.dmp.zip
| 0 |
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
### Environment
* Dubbo version: 2.7.0
* Operating System version: Mac OS
* Java version: 1.8
### Steps to reproduce this issue
#2031 have fixed the writePlace stackOverflow issue. The code have been merged
into hessian-lite, but not in dubbo.
Right now, the issue still there in dubbo 2.7.0. But we are not able to embed
hessian-lite, as we are not able to remove hessian from dubbo(conflicts as
below).
Found in:
org.apache.dubbo:dubbo:jar:2.7.0:compile
com.alibaba:hessian-lite:jar:3.2.5:compile
Duplicate classes:
com/alibaba/com/caucho/hessian/io/HessianDebugState$DateState.class
com/alibaba/com/caucho/hessian/io/ThrowableSerializer.class
1. Define a class with a writeReplace method return this
public class WriteReplaceReturningItself implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
WriteReplaceReturningItself(String name) {
this.name = name;
}
public String getName() {
return name;
}
/**
* Some object may return itself for wrapReplace, e.g.
* https://github.com/FasterXML/jackson-databind/blob/master/src/main/java/com/fasterxml/jackson/databind/JsonMappingException.java#L173
*/
Object writeReplace() {
//do some extra things
return this;
}
}
2. Use Hessian2Output to serialize it
ByteArrayOutputStream bout = new ByteArrayOutputStream();
Hessian2Output out = new Hessian2Output(bout);
out.writeObject(data);
out.flush();
3. Error occurs
java.lang.StackOverflowError
at com.alibaba.com.caucho.hessian.io.SerializerFactory.getSerializer(SerializerFactory.java:302)
at com.alibaba.com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:381)
at com.alibaba.com.caucho.hessian.io.JavaSerializer.writeObject(JavaSerializer.java:226)
at com.alibaba.com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:383)
at com.alibaba.com.caucho.hessian.io.JavaSerializer.writeObject(JavaSerializer.java:226)
Pls. provide [GitHub address] to reproduce this issue.
### Expected Result
The serialization process should complete with no exception or error.
### Actual Result
java.lang.StackOverflowError
at com.alibaba.com.caucho.hessian.io.SerializerFactory.getSerializer(SerializerFactory.java:302)
at com.alibaba.com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:381)
at com.alibaba.com.caucho.hessian.io.JavaSerializer.writeObject(JavaSerializer.java:226)
at com.alibaba.com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:383)
at com.alibaba.com.caucho.hessian.io.JavaSerializer.writeObject(JavaSerializer.java:226)
|
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
https://github.com/apache/incubator-
dubbo/blob/6e4ff91dfca4395a8d1b180f40f632e97acf779d/dubbo-monitor/dubbo-
monitor-
api/src/main/java/org/apache/dubbo/monitor/support/MetricsFilter.java#L44-L47
The way to calculate the invocation time can be improved by using
`java.lang.System#nanoTime`
| 0 |
I hope this is not a dupe, I was really surprised by this bug because - being
so simple in nature - it appears it should have been caught by your tests (or
at least stumbled upon by other people), hence there is a slight probability
that I misunderstood something or that the compiler isn't capable to do the
necessary work (at which point I'd be doubly disappointed).
Anyway, the example is artificial because it's extracted from a larger code
base.
Imagine a simple project, let's start with `tsconfig.json`
{
"compilerOptions": {
"target" : "ES5",
"noImplicitAny": true,
"out": "badout.js"
}
}
In the same folder, add a single file `c.ts` which is just `class C {}`
Add a subfolder called `sub` and put the following two files inside:
// file a.ts
class A extends B {
method1(p1:number, p2:string):void {}
}
// file b.ts
class B {
method1(p1:number, p2:string):void {}
}
Then simply run tsc in the project folder (the one containing `tsconfig.json`
and `c.ts`)
The output will be:
var C = (function () {
function C() {
}
return C;
})();
var __extends = this.__extends || function (d, b) {
for (var p in b) if (b.hasOwnProperty(p)) d[p] = b[p];
function __() { this.constructor = d; }
__.prototype = b.prototype;
d.prototype = new __();
};
var A = (function (_super) {
__extends(A, _super);
function A() {
_super.apply(this, arguments);
}
A.prototype.method1 = function (p1, p2) { };
return A;
})(B);
var B = (function () {
function B() {
}
B.prototype.method1 = function (p1, p2) { };
return B;
})();
The problem is obvious - we're trying to use `B` before it is defined.
If this has been noted and fixed, please forgive the noise.
If not, please try to look into fixing this before 1.5 is "done".
|
The compiler should issue an error when code uses values before they could
possibly be initialized.
// Error, 'Derived' declaration must be after 'Base'
class Derived extends Base { }
class Base { }
| 1 |
_Original tickethttp://projects.scipy.org/numpy/ticket/1044 on 2009-03-09 by
@pv, assigned to unknown._
\--- Continuation of #1440.
Ufuncs return array scalars for 0D array input:
>>> import numpy as np
>>> type(np.conjugate(np.array(1+2j)))
<type 'numpy.complex128'>
>>> type(np.sum(np.array(3.), np.array(5.)))
<type 'numpy.float64'>
Should they return 0D arrays instead?
|
I have a unit test failing on `np.divide.accumulate` with numpy 1.15.0
compiled with the Intel compiler. The same code is fine with a local build of
GCC.
Perhaps this is related to ENH: umath: don't make temporary copies for in-
place accumulation (#10665) where @juliantaylor fixed
`numpy/core/src/umath/loops.c.src` for GCC's `ivdep` pragma. That was reviewed
by @eric-wieser .
### Reproducing code example
Source code was 1.15.0 compiled with the Intel compiler 2018.1.163. where
np.divide.accumulate fails in the numpy unit tests.
I can reproduce with this Python 2.7 test case for `float64` dtype. It runs
correctly for `float32` and `float128` on the Intel compiler. It also runs
correctly for `float64` using GCC instead of Intel.
$ python -c "import numpy as np; acc = np.divide.accumulate;
a = np.ones(8, dtype=np.float64);
print acc(a, out=2*np.ones_like(a)); print acc(a); print acc(a); print acc(a);
print acc(a, out=2*np.ones_like(a))"
[1. 1. 2. 2. 2. 2. 2. 2.]
[1. 1. 1. 1. 2. 2. 2. 2.]
[1. 1. 1. 1. 1. 1. 2. 2.]
[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 2. 2. 2. 2. 2. 2.]
Notice how only the next two elements are set each time `np.divide.accumulate`
runs. That suggests the `float64`s are being processed in pairs. Then in the
final line, specifying the output array again returns to the first line's
incorrect behavior.
### Numpy/Python version information:
numpy 1.15.0 build with ICC 2018.1.163.
python 2.7.11 built with GCC 4.9.3.
| 0 |
With this issue I would like to track the efforts in integrating the
cudnn library within tensorflow.
As of June 17th 2016 doing a manual grep on the repository gives these
functions as being mapped from cudnn to the stream executor,
From chapter 4 of the cudnn User Guide version 5.0 (April 2016):
* cudnnGetVersion
* cudnnGetErrorString
* cudnnCreate
* cudnnDestroy
* cudnnSetStream
* cudnnGetStream
* cudnnCreateTensorDescriptor
* cudnnSetTensor4dDescriptor
* cudnnSetTensor4dDescriptorEx
* cudnnGetTensor4dDescriptor
* cudnnSetTensorNdDescriptor
* cudnnDestroyTensorDescriptor
* cudnnTransformTensor
* cudnnAddTensor
* cudnnOpTensor
* cudnnSetTensor
* cudnnScaleTensor
* cudnnCreateFilterDescriptor
* cudnnSetFilter4dDescriptor
* cudnnGetFilter4dDescriptor
* cudnnSetFilter4dDescriptor_v3 (versioned)
* cudnnGetFilter4dDescriptor_v3 (versioned)
* cudnnSetFilter4dDescriptor_v4 (versioned)
* cudnnGetFilter4dDescriptor_v4 (versioned)
* cudnnSetFilterNdDescriptor
* cudnnGetFilterNdDescriptor
* cudnnGetFilterNdDescriptor_v3 (versioned)
* cudnnGetFilterNdDescriptor_v3 (versioned)
* cudnnGetFilterNdDescriptor_v4 (versioned)
* cudnnGetFilterNdDescriptor_v4 (versioned)
* cudnnDestroyFilterDescriptor
* cudnnCreateConvolutionDescriptor
* cudnnSetConvolution2dDescriptor
* cudnnGetConvolution2dDescriptor
* cudnnGetConvolution2dForwardOutputDim
* cudnnSetConvolutionNdDescriptor
* cudnnGetConvolutionNdDescriptor
* cudnnGetConvolutionNdForwardOutputDim
* cudnnDestroyConvolutionDescriptor
* cudnnFindConvolutionForwardAlgorithm
* cudnnFindConvolutionForwardAlgorithmEx
* cudnnGetConvolutionForwardAlgorithm
* cudnnGetConvolutionForwardWorkspaceSize
* cudnnConvolutionForward
* cudnnConvolutionBackwardBias
* cudnnFindConvolutionBackwardFilterAlgorithm
* cudnnFindConvolutionBackwardFilterAlgorithmEx
* cudnnGetConvolutionBackwardFilterAlgorithm
* cudnnGetConvolutionBackwardFilterWorkspaceSize
* cudnnConvolutionBackwardFilter
* cudnnFindConvolutionBackwardDataAlgorithm
* cudnnFindConvolutionBackwardDataAlgorithmEx
* cudnnGetConvolutionBackwardDataAlgorithm
* cudnnGetConvolutionBackwardDataWorkspaceSize
* cudnnConvolutionBackwardData
* cudnnSoftmaxForward
* cudnnSoftmaxBackward
* cudnnCreatePoolingDescriptor
* cudnnSetPooling2dDescriptor
* cudnnGetPooling2dDescriptor
* cudnnSetPoolingNdDescriptor
* cudnnGetPoolingNdDescriptor
* cudnnSetPooling2dDescriptor_v3 (versioned)
* cudnnGetPooling2dDescriptor_v3 (versioned)
* cudnnSetPoolingNdDescriptor_v3 (versioned)
* cudnnGetPoolingNdDescriptor_v3 (versioned)
* cudnnSetPooling2dDescriptor_v4 (versioned)
* cudnnGetPooling2dDescriptor_v4 (versioned)
* cudnnSetPoolingNdDescriptor_v4 (versioned)
* cudnnGetPoolingNdDescriptor_v4 (versioned)
* cudnnDestroyPoolingDescriptor
* cudnnGetPooling2dForwardOutputDim
* cudnnGetPoolingNdForwardOutputDim
* cudnnPoolingForward
* cudnnPoolingBackward
* cudnnActivationForward
* cudnnActivationBackward
* cudnnCreateActivationDescriptor
* cudnnSetActivationDescriptor
* cudnnGetActivationDescriptor
* cudnnDestroyActivationDescriptor
* cudnnActivationForward_v3 (versioned)
* cudnnActivationBackward_v3 (versioned)
* cudnnActivationForward_v4 (versioned)
* cudnnActivationBackward_v4 (versioned)
* cudnnCreateLRNDescriptor
* cudnnSetLRNDescriptor
* cudnnGetLRNDescriptor
* cudnnDestroyLRNDescriptor
* cudnnLRNCrossChannelForward
* cudnnLRNCrossChannelBackward
* cudnnDivisiveNormalizationForward
* cudnnDivisiveNormalizationBackward
* cudnnBatchNormalizationForwardInference
* cudnnBatchNormalizationForwardTraining
* cudnnBatchNormalizationBackward
* cudnnDeriveBNTensorDescriptor
* cudnnCreateRNNDescriptor
* cudnnDestroyRNNDescriptor
* cudnnSetRNNDescriptor
* cudnnGetRNNWorkspaceSize
* cudnnGetRNNTrainingReserveSize
* cudnnGetRNNParamsSize
* cudnnGetRNNLinLayerMatrixParams
* cudnnGetRNNLinLayerBiasParams
* cudnnRNNForwardInference
* cudnnRNNForwardTraining
* cudnnRNNBackwardData
* cudnnRNNBackwardWeights
* cudnnCreateDropoutDescriptor
* cudnnDestroyDropoutDescriptor
* cudnnDropoutGetStatesSize
* cudnnDropoutGetReserveSpaceSize
* cudnnSetDropoutDescriptor
* cudnnDropoutForward
* cudnnDropoutBackward
* cudnnCreateSpatialTransformerDescriptor
* cudnnDestroySpatialTransformerDescriptor
* cudnnSetSpatialTransformerNdDescriptor
* cudnnSpatialTfGridGeneratorForward
* cudnnSpatialTfGridGeneratorBackward
* cudnnSpatialTfSamplerForward
* cudnnSpatialTfSamplerBackward
### Batch Normalization
Seems @lukemetz was working on it but has stalled for a bit #1759
### What is the plan for the RNN ?
I know @wchan was working on a cpu version. I was trying to get a stub at
using the cudnn version but from the comments in that thread seemed like
@zheng-xq was working on it internally.
Can anyone comment on the status of these ops?
### Other Questions
1. Any reasons why the Softmax functions are not being used ?
2. Would make sense to split the above list in chunks and create issues with contribution welcome, so external contributors can tackle them without duplicating internal work, or mark what google will be working on internally ?
I hope this helps in organizing the work around the cudnn and inspire the
community to contribute. I will try to keep this issue up to date.
| 1 | |
### Bug report
**Bug summary**
If there are multiple curves with the same label in a figure/subplot, only the
last one of them can be selected in the _Figure options_ window under the
_Curves_ tab. In the legend however, they appear as they should.
**Code for reproduction**
import matplotlib.pyplot as plt
plt.plot([0,1],[0,1],label="line")
plt.plot([0,1],[1,0],label="line")
plt.legend()
plt.show()
**Actual outcome**
See description above and the image below.
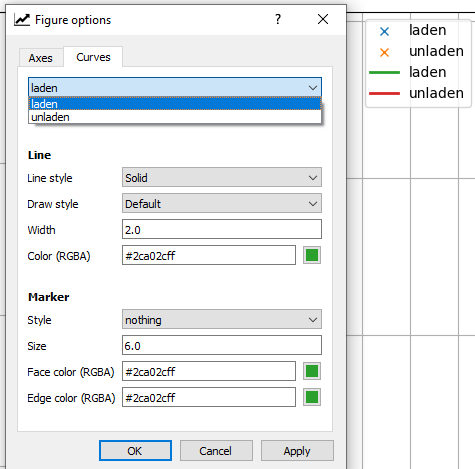
**Expected outcome**
All curves should be listed in the _Figure options_ window, even if they have
the same label.
**Matplotlib version**
* Operating system: Windows 10
* Matplotlib version (`import matplotlib; print(matplotlib.__version__)`): 3.3.4
* Matplotlib backend (`print(matplotlib.get_backend())`): Qt5Agg
* Python version: 3.8.5
* Jupyter version (if applicable): -
* Other libraries: -
Matplotlib has been installed with pip.
|
### Bug report
**Bug summary**
**Code for reproduction**
# Paste your code here
#
#
**Actual outcome**
# If applicable, paste the console output here
#
#
**Expected outcome**
**Matplotlib version**
* Operating system:
* Matplotlib version:
* Matplotlib backend (`print(matplotlib.get_backend())`):
* Python version:
* Jupyter version (if applicable):
* Other libraries:
| 0 |
##### ISSUE TYPE
* Bug Report
##### COMPONENT NAME
Templating
##### ANSIBLE VERSION
1.8.2
##### CONFIGURATION
##### OS / ENVIRONMENT
N/A (but rhel7)
##### SUMMARY
When entering passwords for login/sudo, they are parsed by the templater
instead of being used literally. This creates unexpected behaviour - for
example, with a password that contains a '{':
$ ansible -i "testhost1," all -k -m ping
SSH password:
testhost1 | FAILED => template error while templating string: unexpected token 'eof'
$
If the substring in the password were valud template syntax we'd just get
'invalid password' errors, which would be even more confusing.
There is potential for destructive behaviour and - while very minor -
potential security concerns by use of a malicious password (I don't have a
specific example, but in places with esoteric security implementations one
could see this being exploitable).
##### STEPS TO REPRODUCE
* Set password on remote host '123abc{'
* Attempt ansible run with -k
##### EXPECTED RESULTS
Successfully authenticates against remote host and runs my command
##### ACTUAL RESULTS
Connecting to host host fails with 'error while templating string'
SSH password:
testhost1 | FAILED => template error while templating string: unexpected token 'eof'
|
##### ISSUE TYPE
* Documentation Report
##### COMPONENT NAME
https://docs.ansible.com/ansible/latest/dev_guide/developing_modules_documenting.html#return-
block
##### ANSIBLE VERSION
N/A since it's web documentation
##### CONFIGURATION
N/A
##### OS / ENVIRONMENT
N/A
##### SUMMARY
Documentation has the description for`returned` as "When this value is
returned, such as always, on success, always". First, always is repeated.
Second, it should list all the options for returned and not just 3.
##### STEPS TO REPRODUCE
N/A
##### EXPECTED RESULTS
I'd expect this to be more thorough with a bulleted list of values and what
they mean. Such as...
always - Returned on every request
success - Returned only when request was successful
##### ACTUAL RESULTS
See webpage.
| 0 |
It would be great if Bootstraps javascripts would be compatible with Zepto. As
Zepto is almost API compatible with jquery this shouldn't be that hard.
| 0 | |
please add 'raw' to modules allowed to have duplicate parameters.
ansible/lib/ansible/runner/__init__.py
Line 444 in be4dbe7
| is_shell_module = self.module_name in ('command', 'shell')
---|---
- is_shell_module = self.module_name in ('command', 'shell')
+ is_shell_module = self.module_name in ('command', 'shell', 'raw')
thank you.
|
##### Issue Type:
Feature Idea
##### Ansible Version:
1.6.6
##### Environment:
N/A
##### Summary:
I developed a lookup plugin which is for pulling secret keys from the cloud
server. However, when I use `with_secret` statement like this
- name: foo
bar: secret={{ item }}
with_secret: eggs/spam/secret.txt
and you will see something like this on the screen when you run ansible
ok: [default] => (item="MY_SUPER_SECRET_KEY_HERE")
I really don't like how this works, it displays your secret key on screen. If
you redirect logging for ansible to a file or what, then all your secret keys
are in the file now.
And in other situations, like with_file, you may see something like
ok: [default] => (item="
thousand lines here
thousand lines here
thousand lines here
thousand lines here
thousand lines here
....
I think this is really bad for ansible to print literately everything it got
from a lookup. So, I propose, for a lookup class, if a `sanitize` method is
defined, ansible should then call the method for each item before printing it
on the screen. So that for my secret getting lookup I can write something like
this
def sanitize(self, item):
return '*' * 8
And for huge file and other things, people can write something like
def sanitize(self, item):
return 'File {} ({} bytes)'.format(item._filename, item._size)
def run(self, terms, inject=None, **kwargs):
result = 'a long long long long file content'
result._filename = terms
result._size = len(result)
return [result]
##### Steps To Reproduce:
N/A
##### Expected Results:
N/A
##### Actual Results:
N/A
| 0 |
* Electron Version: 3.0 Beta 4
* Operating System (Platform and Version): Windows10, 8 (x86 and x64)
* Last known working Electron version: 2.x
**Expected Behavior**
PDF should be displayed.
**Actual behavior**
"Save As.." dialog for download appears and pdf will not be displayed, even
when downloaded.
**To Reproduce**
Create a BrowserWindow and load an URL with a pdf or iframes with pdfs.
const win = new BrowserWindow({
width: 800,
height: 600,
webPreferences: {
plugins: true
}
});
win.webContents.loadURL(URL_TO_PDF);
|
* Electron version: 0.36.7
* Operating system: OS X
My electron app needs to make an HTTP request to a service that returns
malformed headers:
$ curl -IS 'http://192.168.0.1/getdeviceinfo/info.bin'
HTTP/1.1 200 OK
Date: Wed, 02 Dec 2015 16:42:45 GMT
Server: nostradamus 1.9.5
Connection: close
Etag: Aug 28 2015, 07:57:20
Transfer-Encoding: chunked
HTTP/1.0 200 OK
Content-Type: text/html
Notice the duplicate `200 OK` header? Yeah, so does the native Node.js parser
and it chokes. In a standalone test script, I've found that I can use the
`http-parser-js` library to make the same request and it handles the bad
headers gracefully.
Now I need to make that work within the Electron app that needs to actually
make the call and retrieve the data and it's failing with the same
`HPE_INVALID_HEADER_TOKEN` I've been getting all along. I assume, for that
reason, that the native HTTP parser is not getting overridden the way that it
does in the test script.
In my electron app's main process, I have the same code I used in my test
script:
process.binding('http_parser').HTTPParser = require('http-parser-js').HTTPParser;
var http = require('http');
var req = http.request( ... )
Is there an alternate process binding syntax I can use within Electron? Or
some other means of making an HTTP request without taxing the Node parser?
| 0 |
Fixing issue #9691 revealed a deeper problem with the QuadPrefixTree's memory
usage. At 1m precision the example shape in
https://gist.github.com/nknize/abbcb87f091b891f85e1 consumes more than 1GB of
memory. This is initially alleviated by using 2 bit encoded quads (instead of
1byte) but only delays the problem. Moreover, as new complex shapes are added
duplicate quadcells are created - thus introducing unnecessary redundant
memory consumption (an inverted index approach makes mosts sense - its
Lucene!).
For now, if a QuadTree is used for complex shapes great care must be taken and
precision must be sacrificed (something that's automatically done with the
distance_error_pct without the user knowing - which is a TERRIBLE approach).
An alternative improvement could be to apply a Hilbert R-Tree - which will be
explored as a separate issue. Or to restrict the accuracy to a lower level of
precision (something that's undergoing experimentation).
|
**Elasticsearch version** :
2.3.4
**JVM version** :
1.8
# some gc log
[monitor.jvm ] [Powerpax] [gc][young][132059][21130] duration [756ms],
collections [1]/[1.4s], total [756ms]/[10.3m], memory
[26.7gb]->[24.1gb]/[29.6gb
], all_pools {[young] [2.7gb]->[3.2mb]/[2.7gb]}{[survivor]
[20.6mb]->[240.8mb]/[357.7mb]}{[old] [23.9gb]->[23.9gb]/[26.5gb]}
# doubt
I use bulk to index. 30 billion doc very day. But some node alway out of
cluster because long time full gc after some days.
I dump bin log and find taskManager object cost most of memory(18GB), I doubt
why taskManager cost cost many memory ? It cache large number of task(request)
? some body can explain the situation? thanks

| 0 |
Apparently there isn't any narrative documentations for some non-clustering
metrics as it was pointed in #1507.
|
There is no user guide on the classification / regression metrics....
| 1 |
## The Problem
VSCode can nicely handle comments in JSON files. However, the JSON
specification does **not** allow comments in JSON files. Therefore most JSON
parsers fail when JSON files contain comments. E.g. `package.json` fails, and
even the typescript compiler fails on tsconfig.json files that include
comments.
Another problem is that syntax highlighting does not work on github. For
example, the file `extensions/xml/xml.configuration.json` ist not legal JSON.
This is symptomatic for repositories that are managed with VSCode:
* @dbaeumer in `eslint/.vscode/tasks.json`
* @weinand in `vscode-node-debug/.vscode/launch.json`
* @egamma in `vscode-go/blame/master/.vscode/launch.json`
## Proposal: create a new file type, e.g. `.tson`
Instead of misleading people about the syntax of JSON by providing support for
comments in JSON files, VSCode should rather use a new format like `TSON`,
that would be an extension of JSON that allows for comments. There could be a
simpler pre-processor for TSON (like JSON.minify) that converts TSON into JSON
by stripping away the comments.
With such a new file type, VSCode could happily use them without compromising
the integrity of existing `.json` files.
In addition, it would be cool to use typescript ambient definitions for
`.tson` files. I really like the typescript schema for `tasks.json`.
|
I'm running VSCode in a corporate network (Active Directory), when I install
VSCode I'm asked for an admin password, after the installation normal users
sessions don't have the VSCode context menu options, only the admin account
has that menu.
How can I add the context menu for all users?
| 0 |
In order to have nice looking paths without hash or bang, I am using history
mode:
var router = new VueRouter({
routes: routes,
mode: 'history'
})
However, when I refresh a page, I get a 404 error. If I remove mode:
'history', I can go directly to urls at a path and refresh pages in my
browser.
Can I remove hash and bang (#!) from my urls and be able to refresh pages and
use direct urls to a path?
|
### Vue.js version
2.0.2
### Reproduction Link
When I deployment my vue app to IIS, refresh page in SPA component, I go 404
error
| 1 |
#### Challenge Name
https://www.freecodecamp.com/challenges/target-the-children-of-an-element-
using-
jquery#?solution=%0Afccss%0A%20%20%24(document).ready(function()%20%7B%0A%20%20%20%20%24(%22%23target1%22).css(%22color%22%2C%20%22red%22)%3B%0A%20%20%20%20%24(%22%23target1%22).prop(%22disabled%22%2C%20true)%3B%0A%20%20%20%20%24(%22%23target4%22).remove()%3B%0A%20%20%20%20%24(%22%23target2%22).appendTo(%22%23right-
well%22)%3B%0A%20%20%20%20%24(%22%23target5%22).clone().appendTo(%22%23left-
well%22)%3B%0A%20%20%20%20%24(%22%23target1%22).parent().css(%22background-
color%22%2C%20%22red%22)%3B%0A%20%20%20%20%24(%22%23right-
well%22).children().css(%22color%22%2C%20%22orange%22)%0A%20%20%7D)%3B%0Afcces%0A%0A%3C!--%20Only%20change%20code%20above%20this%20line.%20--%3E%0A%0A%3Cdiv%20class%3D%22container-
fluid%22%3E%0A%20%20%3Ch3%20class%3D%22text-primary%20text-
center%22%3EjQuery%20Playground%3C%2Fh3%3E%0A%20%20%3Cdiv%20class%3D%22row%22%3E%0A%20%20%20%20%3Cdiv%20class%3D%22col-
xs-6%22%3E%0A%20%20%20%20%20%20%3Ch4%3E%23left-
well%3C%2Fh4%3E%0A%20%20%20%20%20%20%3Cdiv%20class%3D%22well%22%20id%3D%22left-
well%22%3E%0A%20%20%20%20%20%20%20%20%3Cbutton%20class%3D%22btn%20btn-
default%20target%22%20id%3D%22target1%22%3E%23target1%3C%2Fbutton%3E%0A%20%20%20%20%20%20%20%20%3Cbutton%20class%3D%22btn%20btn-
default%20target%22%20id%3D%22target2%22%3E%23target2%3C%2Fbutton%3E%0A%20%20%20%20%20%20%20%20%3Cbutton%20class%3D%22btn%20btn-
default%20target%22%20id%3D%22target3%22%3E%23target3%3C%2Fbutton%3E%0A%20%20%20%20%20%20%3C%2Fdiv%3E%0A%20%20%20%20%3C%2Fdiv%3E%0A%20%20%20%20%3Cdiv%20class%3D%22col-
xs-6%22%3E%0A%20%20%20%20%20%20%3Ch4%3E%23right-
well%3C%2Fh4%3E%0A%20%20%20%20%20%20%3Cdiv%20class%3D%22well%22%20id%3D%22right-
well%22%3E%0A%20%20%20%20%20%20%20%20%3Cbutton%20class%3D%22btn%20btn-
default%20target%22%20id%3D%22target4%22%3E%23target4%3C%2Fbutton%3E%0A%20%20%20%20%20%20%20%20%3Cbutton%20class%3D%22btn%20btn-
default%20target%22%20id%3D%22target5%22%3E%23target5%3C%2Fbutton%3E%0A%20%20%20%20%20%20%20%20%3Cbutton%20class%3D%22btn%20btn-
default%20target%22%20id%3D%22target6%22%3E%23target6%3C%2Fbutton%3E%0A%20%20%20%20%20%20%3C%2Fdiv%3E%0A%20%20%20%20%3C%2Fdiv%3E%0A%20%20%3C%2Fdiv%3E%0A%3C%2Fdiv%3E%0A
#### Issue Description
This page was buggy for me on a new iMac. I know this because it didn't work
with my code, and then I tried other things that didn't work, and when I
returned it to my first code (no small errors btw), it functioned fine.
Also, there has been a bug with this code:
$("#target5").clone().appendTo("#left-well");
Apparently, it seems to place two clones at times (most often when I click
CTRL+RTN to test).
Hopefully this helps!
#### Browser Information
* Browser Name, Version: CHROME 54.0.2840.71
* Operating System: OSX El Capitan 10.11.6
* Mobile, Desktop, or Tablet: DESKTOP
#### Your Code
<script> $(document).ready(function() { $("#target1").css("color", "red");
$("#target1").prop("disabled", true); $("#target4").remove();
$("#target2").appendTo("#right-well"); $("#target5").clone().appendTo("#left-
well"); $("#target1").parent().css("background-color", "red"); $("#right-
well").children().css("color", "orange") }); </script>
### jQuery Playground
#### #left-well
#target1 #target2 #target3
#### #right-well
#target4 #target5 #target6
#### Screenshot

|
Challenge Waypoint: Clone an Element Using jQuery has an issue.
User Agent is: `Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.73 Safari/537.36`.
Please describe how to reproduce this issue, and include links to screenshots
if possible.
## Issue
I believe I've found bug in the phone simulation in **Waypoint: Clone an
Element Using jQuery** :
I entered the code to clone `target5` and append it to `left-well`, and now I
see three **target5** buttons in the phone simulator. FCC says my code is
correct and advances me to the next challenge. The following challenges also
show three target5 buttons:
* Waypoint: Target the Parent of an Element Using jQuery
* Waypoint: Target the Children of an Element Using jQuery
@qualitymanifest confirms this issue on his **Linux** box.

## My code:
<script>
$(document).ready(function() {
$("#target1").css("color", "red");
$("#target1").prop("disabled", true);
$("#target4").remove();
$("#target2").appendTo("#right-well");
$("#target5").clone().appendTo("#left-well");
});
</script>
<!-- Only change code above this line. -->
<div class="container-fluid">
<h3 class="text-primary text-center">jQuery Playground</h3>
<div class="row">
<div class="col-xs-6">
<h4>#left-well</h4>
<div class="well" id="left-well">
<button class="btn btn-default target" id="target1">#target1</button>
<button class="btn btn-default target" id="target2">#target2</button>
<button class="btn btn-default target" id="target3">#target3</button>
</div>
</div>
<div class="col-xs-6">
<h4>#right-well</h4>
<div class="well" id="right-well">
<button class="btn btn-default target" id="target4">#target4</button>
<button class="btn btn-default target" id="target5">#target5</button>
<button class="btn btn-default target" id="target6">#target6</button>
</div>
</div>
</div>
</div>
| 1 |
> Issue originally made by @dfilatov
### Bug information
* **Babel version:** 6.3.13
* **Node version:** 4.2.1
* **npm version:** 2.14.7
### Options
--presets es2015
### Input code
export * from './client/mounter';
### Description
Given input code will be transformed to:
var _mounter = require('./client/mounter');
for (var _key in _mounter) {
if (_key === "default") continue;
Object.defineProperty(exports, _key, {
enumerable: true,
get: function get() {
return _mounter[_key];
}
});
}
In result all reexported stuff will reference to the same `_mounter[_key]`,
where `_key` is a last key from `_mounter`.
|
flow v0.32.0:
> New syntax for exact object types: use {| and |} instead of { and }. Where
> {x: string} contains at least the property x, {| x: string |} contains ONLY
> the property x.
| 0 |
I have a form some fields are not validated based on the validation groups.
The validation works as expected but the error message is always added to the
wrong field. It seems to just use which ever property is last in the
validation.yml file.
I believe my use case is valid. It worked fine in 2.4 but when testing 2.5
BETA2 there were test failures. Also seems to be an issue with the master
branch.
I found it easiest to reproduce the issue using a system test. This can be
found in the following repository: https://github.com/tompedals/symfony-form-
test
Model: https://github.com/tompedals/symfony-form-
test/blob/master/src/Test/FormTestBundle/Model/Attachment.php
Form: https://github.com/tompedals/symfony-form-
test/blob/master/src/Test/FormTestBundle/Form/AttachmentType.php
Validation mapping: https://github.com/tompedals/symfony-form-
test/blob/master/src/Test/FormTestBundle/Resources/config/validation.yml
Test: https://github.com/tompedals/symfony-form-
test/blob/master/src/Test/FormTestBundle/Tests/Form/AttachmentTypeTest.php
Use `phpunit -c app` to run the tests.
|
Hello,
When using Validator 2.5 to validate an array of scalars, the `propertyPath`
of the returned violations has really strange values.
Consider the following script:
<?php
require 'vendor/autoload.php';
use Symfony\Component\Validator\Constraints;
use Symfony\Component\Validator\Validation;
$constraints = array(
'foo' => array(
new Constraints\NotBlank(),
new Constraints\Date()
),
'bar' => new Constraints\NotBlank()
);
$collectionConstraint = new Constraints\Collection(array('fields' => $constraints));
$validator = Validation::createValidatorBuilder()
->setApiVersion(Validation::API_VERSION_2_5)
->getValidator();
$value = array(
'foo' => 'bar'
);
$violations = $validator->validate($value, $collectionConstraint);
foreach ($violations as $violation) {
var_dump($violation->getPropertyPath());
}
Output:
string(11) "[foo].[foo]"
string(17) "[foo].[foo].[bar]"
If I set `Validation::API_VERSION_2_4` and call the old `validateValue`
method, it outputs:
string(5) "[foo]"
string(5) "[bar]"
Is this something expected ?
| 1 |
NMF in scikit-learn overview :
**Current implementation (code):**
\- loss = squared (aka Frobenius norm)
\- method = projected gradient
\- regularization = trick to enforce sparseness or low error with beta / eta
**#1348 (or in gist):**
\- loss = (generalized) Kullback-Leibler divergence (aka I-divergence)
\- method = multiplicative update
\- regularization = None
**#2540 [WIP]:**
\- loss = squared (aka Frobenius norm)
\- method = multiplicative update
\- regularization = None
**#896 (or in gist):**
\- loss = squared (aka Frobenius norm)
\- method = coordinate descent, no greedy selection
\- regularization = L1 or L2
**Papers describing the methods:**
\- Multiplicative update
\- Projected gradient
\- Coordinate descent with greedy selection
* * *
**About the uniqueness of the results**
The problem is non-convex, and there is no unique minimum:
Different losses, different initializations, and/or different optimization
methods generally give different results !
**About the methods**
* The multiplicative update (MU) is the most widely used because of it's simplicity. It is very easy to adapt it to squared loss, (generalized) Kullback-Leibler divergence or Itakura–Saito divergence, which are 3 specific cases of the so-called beta-divergence. All three losses seem used in practice. A regularization L1 or L2 can easily be added.
* The Projected gradient (PG) seems very efficient for the squared loss, but does not scale well (w.r.t X size) for the (generalized) KL divergence. A L1 or L2 regularization could possibly be added in the gradient step. I don't know where the sparseness enforcement trick in current code comes from.
* The Coordinate Descent (CD) seems even more efficient for squared loss, and we can add easily L1 or L2 regularization. It can be further speeded up by a greedy selection of coordinate. The adaptation for KL divergence is possible with a Newton method for solving subproblem (slower), but without greedy selection. This adaptation is supposed to be faster than MU-NMF with (generalized) KL divergence.
**About the initialization**
Different schemes exist, and can change significantly both result and speed.
They can be used independantly for each NMF method.
**About the stopping condition**
Actual stopping condition in PG-NMF is bugged (#2557), and leads to poor
minima when the tolerance is not low enough, especially in the random
initialization scheme. It is also completely different from stopping condition
in MU-NMF, which is very difficult to set. Talking with audio scientists (who
use a lot MU-NMF for source seperation) reveals that they just set a number of
iteration.
* * *
As far as I understand NMF, as there is no unique minimum, there is no perfect
loss/method/initialization/regularization. A good choice for some dataset can
be terrible for another one. I don't know how many methods we want to maintain
in scikit-learn, and how much we want to guide users with few possibilities,
but several methods seems more useful than only one.
I have tested MU-NMF, PG-NMF and CD-NMF from scikit-learn code, #2540 and
#896, with squared loss and no regularization, on a subsample of 20news
dataset, and performances are already very different depending on the
initialization (see below).
**Which methods do we want in scikit-learn?**
Why do we have stopped #1348 or #896 ?
Do we want to continue #2540 ?
I can work on it as soon as we have decided.
* * *
NNDSVD (similar curves than NNDSVRAR)

NNDSVDA

Random run 1

Random run 2

Random run 3

|
We should fix the remaining sphinx warnings here:
https://circleci.com/gh/scikit-learn/scikit-learn/1629
and then make circle IO error if there are any warnings (grep'ing for
`WARNINGS` I guess?).
This way we immediately see if someone broke anything in the docs.
| 0 |
**Christian Nelson** opened **SPR-6118** and commented
Spring JDBC 3.0.0.M4 maven pom includes derby and derby.client - these should
be optional dependencies.
Here is the relevant output from mvn dependency:tree...
[INFO] +- org.springframework:spring-orm:jar:3.0.0.M4:compile
[INFO] | +- org.slf4j:slf4j-jdk14:jar:1.5.2:compile
[INFO] | +- org.springframework:spring-beans:jar:3.0.0.M4:compile
[INFO] | +- org.springframework:spring-core:jar:3.0.0.M4:compile
[INFO] | | - org.springframework:spring-asm:jar:3.0.0.M4:compile
[INFO] | +- org.springframework:spring-jdbc:jar:3.0.0.M4:compile
**[INFO] | | +-
org.apache.derby:com.springsource.org.apache.derby:jar:10.5.1000001.764942:compile**
**[INFO] | | -
org.apache.derby:com.springsource.org.apache.derby.client:jar:10.5.1000001.764942:compile**
[INFO] | - org.springframework:spring-tx:jar:3.0.0.M4:compile
[INFO] | +- aopalliance:aopalliance:jar:1.0:compile
[INFO] | +- org.springframework:spring-aop:jar:3.0.0.M4:compile
[INFO] | - org.springframework:spring-context:jar:3.0.0.M4:compile
[INFO] | - org.springframework:spring-expression:jar:3.0.0.M4:compile
These dependencies should be configured as <optional>true</optional> since
they're not required for regular usage of spring-jdbc.
* * *
**Affects:** 3.0 M4
**Issue Links:**
* #10777 Spring JDBC POM should declare derby dependency is optional ( _ **"duplicates"**_ )
|
**Keith Garry Boyce** opened **SPR-1412** and commented
I have a situation when I need access to the portlet name in the controller to
then in turn look up data related to that data in db. I don't want a separate
controller config for each portlet s it would seem if framework detected that
I implement and interface requiring that then it would do the right thing and
give me access to read it. What do you think?
* * *
**Affects:** 2.0 M1
| 0 |
In Polish language exists letter 'ś', written by pressing rightAlt+s. In atom
this combination brings up the 'Spec suite' window.
Worth noticing is fact, that in settings shortcut responsible for this is
**ctrl** -alt-s, yet rightAlt+s alone brings up the window too.
I tried adding
'body':
'ralt-s': ''
'ctrl-alt-s' : ''
to the keymap, but it didn't fix my problem.
Expected change:
* chaning default shortcut to a non-colliding one
or
* making only ctrl-alt-s as hotkey and not rightAlt-s,
|
Original issue: atom/atom#1625
* * *
Use https://atom.io/packages/keyboard-localization until this issue gets fixed
(should be in the Blink upstream).
| 1 |
**I'm submitting a ...** (check one with "x")
[x] bug report => search github for a similar issue or PR before submitting
[ ] feature request
[ ] support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
**Current behavior**
When using Angular 2.3.0 with Safari 9, the application does not start up at
all. Instead the console shows the following error message:
Error: (SystemJS) Strict mode does not allow function declarations in a lexically nested statement.
eval@[native code]
invoke@http://localhost:8000/lib/zone.js:229:31
run@http://localhost:8000/lib/zone.js:113:49
http://localhost:8000/lib/zone.js:509:60
invokeTask@http://localhost:8000/lib/zone.js:262:40
runTask@http://localhost:8000/lib/zone.js:151:57
drainMicroTaskQueue@http://localhost:8000/lib/zone.js:405:42
run@http://localhost:8000/lib/shim.js:4005:30
http://localhost:8000/lib/shim.js:4018:32
flush@http://localhost:8000/lib/shim.js:4373:12
Evaluating http://localhost:8000/lib/@angular/compiler/bundles/compiler.umd.js
Error loading http://localhost:8000/lib/@angular/compiler/bundles/compiler.umd.js as "@angular/compiler" from http://localhost:8000/lib/@angular/platform-browser-dynamic/bundles/platform-browser-dynamic.umd.js — zone.js:672
**Expected behavior**
Expected it, that the application works and starts up according to the
supported browser matrix.
The same plunkr - as shown below - works as expected in Safari 10.
**Minimal reproduction of the problem with instructions**
To reproduce you can use the template offered when creating a new issue:
http://plnkr.co/edit/tpl:AvJOMERrnz94ekVua0u5
Fire it up in Safari 9 and take a look into the console.
**Please tell us about your environment:**
macOS El Capitan 10.11.6
* **Angular version:** 2.3.0
* **Browser:** Safari 9.1.2
Error may be related to #13301
| 0 | |
* VSCode Version: 1.1.0
* OS Version: OS X 10.11.4
Steps to Reproduce:
1. Create a new text file `test.js`
2. Set the content to the following:
let x = true ? '' : `${1}`
console.log('still part of the template!')
VS Code fails to parse the opening `of the template string at the end of the
ternary operator correctly. It therefore sees the final` as an opening tick,
and interprets the rest of the file as a template string:

As a workaround you can wrap the failure case in parenthesis:
let x = true ? '' : (`${1}`)
console.log('still part of the template!')

|
_From@garthk on April 8, 2016 4:30_
* VSCode Version: `Version 0.10.10 (0.10.10)` or `Version 0.10.14-insider (0.10.14-insider) 17fa1cbb49e3c5edd5868f304a64115fcc7c9c2c`
* OS Version: OS X `10.11.4 (15E65)`
* `javascript.validate.enable` set either `true` or `false`
Steps to Reproduce:
1. Open a new Code – Insiders window
2. Paste in the following JavaScript
3. Observe
function test1(x) {
const defaultValue = `${x}`;
const value = x ? x : y;
console.log('so far, so good');
}
function test2(x) {
const value = !x ? `${x}` : x;
console.log('so far, so good');
}
function test3(x) {
const value = x ? x : `${x}`; // this comment is coloured as if it's part of the template literal
console.log('this entire line, too');
} // and this one
If I'm getting this right:
* `test1` shows `code` knows when a template literal ends, usually
* `test2` shows `code` still knows when a template literal ends if it's the first _AssignmentExpression_ in a ternary
* `test3` shows `code` somehow misses the end of a template literal as the second _AssignmentExpression_ in a ternary, highlighting from then on as a string
_Copied from original issue:microsoft/vscode#5090_
| 1 |
ECMAScript 2018 was finalized, what do we need to enable these features by
default for `preset-env`?
SyntaxError: /path/to/file.js:
Support for the experimental syntax 'objectRestSpread' isn't currently enabled (11:9):
10 | {
> 11 | ...example,
| ^
12 | key: 'value',
13 | },
The `proposal` keyword was removed from `@babel/plugin-syntax-object-rest-
spread` package name but `babel-preset-env/data/plugins.json` still have:
babel/packages/babel-preset-env/data/plugins.json
Line 232 in 6f3be3a
| "proposal-object-rest-spread": {
---|---
|
Hi there,
a simple module just reexport a module fails.
export * from './some-module';
My .babelrc looks like this:
{
"presets": ["es2015", "stage-1"],
"plugins": ["transform-async-to-generator"]
}
This should contain the required export-extensions transform.
The error message looks like this:
$ ./node_modules/.bin/babel test.js
Error: test.js: Invariant Violation: To get a node path the parent needs to exist
at Object.invariant [as default] (/home/markusw/source/ankara/node_modules/babel-cli/node_modules/babel-core/node_modules/babel-traverse/node_modules/invariant/invariant.js:44:15)
at Function.get (/home/markusw/source/ankara/node_modules/babel-cli/node_modules/babel-core/node_modules/babel-traverse/lib/path/index.js:82:27)
at TraversalContext.create (/home/markusw/source/ankara/node_modules/babel-cli/node_modules/babel-core/node_modules/babel-traverse/lib/context.js:73:30)
at NodePath._containerInsert (/home/markusw/source/ankara/node_modules/babel-cli/node_modules/babel-core/node_modules/babel-traverse/lib/path/modification.js:80:32)
at NodePath._containerInsertBefore (/home/markusw/source/ankara/node_modules/babel-cli/node_modules/babel-core/node_modules/babel-traverse/lib/path/modification.js:138:15)
at NodePath.insertBefore (/home/markusw/source/ankara/node_modules/babel-cli/node_modules/babel-core/node_modules/babel-traverse/lib/path/modification.js:57:19)
at BlockScoping.wrapClosure (/home/markusw/source/ankara/node_modules/babel-preset-es2015/node_modules/babel-plugin-transform-es2015-block-scoping/lib/index.js:485:21)
at BlockScoping.run (/home/markusw/source/ankara/node_modules/babel-preset-es2015/node_modules/babel-plugin-transform-es2015-block-scoping/lib/index.js:385:12)
at PluginPass.Loop (/home/markusw/source/ankara/node_modules/babel-preset-es2015/node_modules/babel-plugin-transform-es2015-block-scoping/lib/index.js:89:36)
at /home/markusw/source/ankara/node_modules/babel-cli/node_modules/babel-core/node_modules/babel-traverse/lib/visitors.js:271:19
Any hint on this?
| 0 |
# coding: utf-8
import pandas as pd
import numpy as np
frame = pd.read_csv("table.csv", engine="python", parse_dates=['since'])
print frame
d = pd.pivot_table(frame, index=pd.TimeGrouper(key='since', freq='1d'), values=["value"], columns=['id'], aggfunc=np.sum, fill_value=0)
print d
print "^that is not what I expected"
frame = pd.read_csv("table2.csv", engine="python", parse_dates=['since']) # add some values to a day
print frame
d = pd.pivot_table(frame, index=pd.TimeGrouper(key='since', freq='1d'), values=["value"], columns=['id'], aggfunc=np.sum, fill_value=0)
print d
The following data is the contents of `table.csv`
"id","since","value"
"81","2015-01-31 07:00:00+00:00","2200.0000"
"81","2015-02-01 07:00:00+00:00","2200.0000"
This is `table2.csv`:
"id","since","value"
"81","2015-01-31 07:00:00+00:00","2200.0000"
"81","2015-01-31 08:00:00+00:00","2200.0000"
"81","2015-01-31 09:00:00+00:00","2200.0000"
"81","2015-02-01 07:00:00+00:00","2200.0000"
The output of print after pivoting `table.csv`
id value
<pandas.tseries.resample.TimeGrouper object at 0x7fc595f96c10> 81 2200
id 81 2200
I would expect something like this:
value
id 81
since
2015-01-31 2200
2015-02-01 2200
I can trace the problem to here:
https://github.com/pydata/pandas/blob/62529cca28e9c8652ddf7cca3aa6d41d4e30bc0e/pandas/tools/pivot.py#L114
the index created by groupby already has the object there.
I can't figure anything else. What is the problem, any fixes?
Thanks.
|
The following code seems to raise an error, since the result object does not
make sense (well, at least to me):
In [61]: import datetime
In [62]: import pandas as pd
In [63]: df = pd.DataFrame.from_records ( [[datetime.datetime(2014,9,10),1234,"start"],
[datetime.datetime(2013,10,10),1234,"start"]], columns = ["date", "change", "event"] )
In [64]: df
Out[64]:
date change event
0 2014-09-10 1234 start
1 2013-10-10 1234 start
In [65]: ts = df.set_index('date')
In [66]: ts
Out[66]:
change event
date
2014-09-10 1234 start
2013-10-10 1234 start
In [67]: byperiod = ts.groupby([pd.TimeGrouper(freq="M"), "event"], as_index=False)
In [68]: byperiod.groups
Out[68]:
{<pandas.tseries.resample.TimeGrouper at 0xab6bcaec>: [Timestamp('2014-09-10 00:00:00')],
'event': [Timestamp('2013-10-10 00:00:00')]}
I would expect, for Out[68], two groups, one for each (date, event) pair.
Am I wring, or this is a bug?
| 1 |
* **Electron Version:**
* v5.0.0-beta.5
* **Operating System:**
* Windows 10 Pro.
* **Last Known Working Electron version:** :
* 4.x (latest)
### Expected Behavior
When I perfrom a GET-request using `http` or `https` built-in library, I
expect the app to keep running after the request completes.
### Actual Behavior
When performing a GET request to an arbitrary host, the app crashes after **a
few seconds after completing the request**. Usually ranges between 5 and 20
seconds.
### To Reproduce
https://github.com/haroldiedema/electron-5x-http-crash
$ git clone https://github.com/haroldiedema/electron-5x-http-crash
$ npm install
$ node_modules/.bin/electron .
Sit back and wait for a few seconds for the app to crash with exit code 127.
(or exit code 1 if started from npm or yarn).
### Screenshots
N/A
### Additional Information
I think this might have something to do with either:
A) Electron not handling the closing of sockets correctly anymore, or
B) The garbage collector kicking in and cleaning up the socket resource which
makes electron crash.
Then again, that is purely speculation on my end.
|
* **Electron Version** :
* 5.0.0-beta (all)
* **Operating System** :
* Ubuntu 18.10, Linux 4.18, x64
* **Last known working Electron version** (if applicable):
* 4.0.5
### Expected Behavior
Google API should work as it they are meant to.
### Actual behavior
Any Google API calls may crash renderer process (even if they are run on
Worker thread).
The request may be done and the answer given, but immediately or after several
seconds the renderer process may crash.
### To Reproduce
$ git clone https://github.com/ruslang02/youtube-electron-crash-example
$ npm install electron@beta
$ npm start || electron .
Version 5 will randomly crash, version 4: doesn't
### Additional Information
May be a Node.JS bug, but not sure
| 1 |
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
### Environment
* Dubbo version: 2.6.1
* Operating System version: Linux version 3.10.0-693.el7.x86_64 (builder@kbuilder.dev.centos.org) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-16) (GCC) )
* Java version: 1.8.0_171
* zk & zk client version: 3.4.11
* curator version: 4.0.1
### 不定时出现zookeeper session timeout,重连后消费端引用@reference 为空,日志如下
### 消费端jvm日志
04:22:37,427 WARN [main-SendThread(hostname:2181)][zookeeper.ClientCnxn:1111] - Client session timed out, have not heard from server in 33959ms for sessionid 0x10000018d38000b
04:23:07,081 INFO [main-SendThread(hostname:2181)][zookeeper.ClientCnxn:1159] - Client session timed out, have not heard from server in 33959ms for sessionid 0x10000018d38000b, closing socket connection and attempting reconnect
04:23:09,992 INFO [main-EventThread][state.ConnectionStateManager:237] - State change: SUSPENDED
04:23:10,186 INFO [main-SendThread(hostname:2181)][zookeeper.ClientCnxn:1035] - Opening socket connection to server hostname/172.16.10.121:2181. Will not attempt to authenticate using SASL (unknown error)
04:23:10,804 INFO [main-SendThread(hostname:2181)][zookeeper.ClientCnxn:877] - Socket connection established to hostname/172.16.10.121:2181, initiating session
04:23:10,998 WARN [main-SendThread(hostname:2181)][zookeeper.ClientCnxn:1288] - Unable to reconnect to ZooKeeper service, session 0x10000018d38000b has expired
04:23:11,066 INFO [main-SendThread(hostname:2181)][zookeeper.ClientCnxn:1157] - Unable to reconnect to ZooKeeper service, session 0x10000018d38000b has expired, closing socket connection
04:23:11,164 WARN [main-EventThread][curator.ConnectionState:372] - Session expired event received
04:23:12,502 INFO [main-EventThread][zookeeper.ZooKeeper:441] - Initiating client connection, connectString=hostname:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@67f639d3
04:23:13,599 INFO [main-SendThread(hostname:2181)][zookeeper.ClientCnxn:1035] - Opening socket connection to server hostname/172.16.10.121:2181. Will not attempt to authenticate using SASL (unknown error)
04:23:13,671 INFO [main-SendThread(hostname:2181)][zookeeper.ClientCnxn:877] - Socket connection established to hostname/172.16.10.121:2181, initiating session
04:23:13,771 INFO [main-SendThread(hostname:2181)][zookeeper.ClientCnxn:1302] - Session establishment complete on server hostname/172.16.10.121:2181, sessionid = 0x10000018d38002b, negotiated timeout = 40000
04:23:13,672 INFO [main-EventThread][state.ConnectionStateManager:237] - State change: LOST
04:23:13,960 INFO [main-EventThread][state.ConnectionStateManager:237] - State change: RECONNECTED
04:23:14,708 INFO [main-EventThread][zookeeper.ClientCnxn:520] - EventThread shut down for session: 0x10000018d38000b
### zookeeper服务器日志
2018-09-12 02:36:05,355 [myid:] - INFO [SessionTracker:ZooKeeperServer@354] - Expiring session 0x10000018dc20000, timeout of 40000ms exceeded
2018-09-12 02:36:05,356 [myid:] - INFO [SessionTracker:ZooKeeperServer@354] - Expiring session 0x10000018dc20002, timeout of 40000ms exceeded
2018-09-12 02:36:05,356 [myid:] - INFO [SessionTracker:ZooKeeperServer@354] - Expiring session 0x10000018dc20003, timeout of 40000ms exceeded
2018-09-12 02:36:05,356 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@487] - Processed session termination for sessionid: 0x10000018dc20000
2018-09-12 02:36:05,356 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@487] - Processed session termination for sessionid: 0x10000018dc20002
2018-09-12 02:36:05,357 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@487] - Processed session termination for sessionid: 0x10000018dc20003
2018-09-12 02:39:41,884 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@215] - Accepted socket connection from /172.16.10.123:33164
2018-09-12 02:39:41,888 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@938] - Client attempting to establish new session at /172.16.10.123:33164
2018-09-12 02:39:41,996 [myid:] - INFO [SyncThread:0:ZooKeeperServer@683] - Established session 0x10000018d380001 with negotiated timeout 40000 for client /172.16.10.123:33164
|
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
### Environment
* Dubbo version: 2.7.4.1
* Java version: 1.8
### Actual Result
dubbo/dubbo-
common/src/main/java/org/apache/dubbo/rpc/model/ApplicationModel.java
Line 80 in 839d2a6
| public static void iniFrameworkExts() {
---|---
### Expected Result
initFrameworkExts
| 0 |
**Bruno Hansen** opened **SPR-9334** and commented
New support for Jackson 2.X because of changing of packages:
Jackson reference:
http://wiki.fasterxml.com/JacksonRelease20#Changing_Java_packages
Spring forum reference:
http://forum.springsource.org/showthread.php?125213-Support-for-
Jackson-2-0&p=408474#post408474
* * *
**Affects:** 3.2 M1, 3.2 M2
**Reference URL:**
http://forum.springsource.org/showthread.php?125213-Support-for-
Jackson-2-0&p=408474#post408474
**Issue Links:**
* #13940 Use Jackson 2.0 for Jackson based json processing such as MappingJacksonJsonView ( _ **"duplicates"**_ )
|
**Xun Wang** opened **SPR-9302** and commented
Due to recent release of Jackson 2.0, hope it is on the road map to give
Spring user the option to use Jackson 2.0 for Jackson related json functions.
Jackson 2.x has different package name for its classes to let code with 1.x be
able to coexist. Maybe a new set of the Spring classes need to be created for
the same reason for those who like to use the 2.x while others can remain on
1.x. For example MappingJacksonJsonView remains but with
MappingJacksonJsonView2 for the 2.x Jackson. I believe someone has better idea
how to get it done.
* * *
**Affects:** 3.0.5
**Attachments:**
* MappingJacksonHttpMessageConverter.patch ( _1.65 kB_ )
**Sub-tasks:**
* #14141 Backport "Use Jackson 2.0 for Jackson based json processing such as MappingJacksonJsonView"
**Issue Links:**
* #13972 Support for Jackson 2.X ( _ **"is duplicated by"**_ )
* #14589 Add support for jackson 2.0 message converters MappingJacksonHttpMessageConverter refers to the older ObjectMapper package and methods ( _ **"is duplicated by"**_ )
9 votes, 10 watchers
| 1 |
All of the below testing was done with Fiddler. User and password proxy auth
in Fiddler was enabled the default way by doing Rules->Require Proxy
Authentication which requires user be '1' and password be '1'. The code below
does not contain the https section of the proxy as it's largely identical.
If a proxy is set on the session without user and password and Fiddler auth is
off, Fiddler is used correctly:
`session.proxies['http'] = 'http://127.0.0.1:8888'.format(proxy_string)
session.request(....)`
If a proxy is set on the session with user and password, Fiddler returns proxy
auth failures:
`session.proxies['http'] = 'http://1:1@127.0.0.1:8888'.format(proxy_string)
session.request(....)`
If I do exactly the same thing but send the proxy with the request directly,
both cases work.
`proxies = {} proxies['http'] =
'http://1:1@127.0.0.1:8888'.format(proxy_string) session.request(....,
proxies=proxies)`
|
When subscribing to a Server Sent Events endpoint, I notice an error given the
processing of a heartbeat. Heartbeats in SSE can be sent as an empty line.
Consider the following SSE reply for chunked transfer encoding:
00000000 48 54 54 50 2f 31 2e 31 20 32 30 30 20 4f 4b 0d HTTP/1.1 200 OK.
00000010 0a 53 65 72 76 65 72 3a 20 6f 70 65 6e 72 65 73 .Server: openres
00000020 74 79 2f 31 2e 39 2e 31 35 2e 31 0d 0a 44 61 74 ty/1.9.1 5.1..Dat
00000030 65 3a 20 46 72 69 2c 20 32 38 20 4f 63 74 20 32 e: Fri, 28 Oct 2
00000040 30 31 36 20 30 32 3a 33 39 3a 35 34 20 47 4d 54 016 02:3 9:54 GMT
00000050 0d 0a 43 6f 6e 74 65 6e 74 2d 54 79 70 65 3a 20 ..Conten t-Type:
00000060 74 65 78 74 2f 65 76 65 6e 74 2d 73 74 72 65 61 text/eve nt-strea
00000070 6d 0d 0a 54 72 61 6e 73 66 65 72 2d 45 6e 63 6f m..Trans fer-Enco
00000080 64 69 6e 67 3a 20 63 68 75 6e 6b 65 64 0d 0a 43 ding: ch unked..C
00000090 6f 6e 6e 65 63 74 69 6f 6e 3a 20 6b 65 65 70 2d onnectio n: keep-
000000A0 61 6c 69 76 65 0d 0a 0d 0a alive... .
000000A9 31 0d 0a 0a 0d 0a 1.....
With the last line, the `31` indicates that there is just one byte to receive
(ASCII `1`). The chunked size is then followed by a CRLF and then the empty
line (`LF`), followed again by a CRLF.
This appears to cause the following stacktrace:
...
File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/requests/utils.py", line 377, in stream_decode_response_unicode
for chunk in iterator:
File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/requests/models.py", line 676, in generate
for chunk in self.raw.stream(chunk_size, decode_content=True):
File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/requests/packages/urllib3/response.py", line 353, in stream
for line in self.read_chunked(amt, decode_content=decode_content):
File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/requests/packages/urllib3/response.py", line 502, in read_chunked
self._update_chunk_length()
File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/requests/packages/urllib3/response.py", line 448, in _update_chunk_length
line = self._fp.fp.readline()
AttributeError: 'NoneType' object has no attribute 'readline'
What I'm left wondering is whether chunked responses that only contain a
newline cause the requests library a problem.
I'm using requests 2.11.1.
| 0 |
I've created the `_app.js` file exactly as the example in the documentation,
and tried to build it, but i got a big error.
This is my _app.js
import App, { Container } from "next/app";
import React from "react";
import { CSSTransition, TransitionGroup } from "react-transition-group";
import Layout from "../components/App";
export default class MyApp extends App {
static async getInitialProps({ Component, router, ctx }) {
let pageProps = {};
if (Component.getInitialProps) {
pageProps = await Component.getInitialProps(ctx);
}
console.log(ctx, "rendering!");
return { pageProps };
}
render() {
const { Component, pageProps } = this.props;
return (
<Container>
<Layout>
<TransitionGroup>
<CSSTransition
key={this.props.router.route}
classNames="fade"
timeout={2000}>
<Component {...pageProps} />
</CSSTransition>
</TransitionGroup>
</Layout>
<style jsx global>{`...`}</style>
</Container>
);
}
}
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
Project built up to run `yarn start`
## Current Behavior
yarn run v1.5.1
$ next build
> Using external babel configuration
> Location: "/Users/facundogordillo/OneDrive/clinical-web-next/.babelrc"
> Failed to build
{ Error: (client) ./pages/_app.js
Module not found: Error: Can't resolve 'next/app' in '/Users/facundogordillo/OneDrive/clinical-web-next/pages'
resolve 'next/app' in '/Users/facundogordillo/OneDrive/clinical-web-next/pages'
Parsed request is a module
using description file: /Users/facundogordillo/OneDrive/clinical-web-next/package.json (relative path: ./pages)
aliased with mapping 'next': '/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next' to '/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app'
using description file: /Users/facundogordillo/OneDrive/clinical-web-next/package.json (relative path: ./pages)
Field 'browser' doesn't contain a valid alias configuration
after using description file: /Users/facundogordillo/OneDrive/clinical-web-next/package.json (relative path: ./pages)
using description file: /Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/package.json (relative path: ./app)
no extension
Field 'browser' doesn't contain a valid alias configuration
/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app doesn't exist
.js
Field 'browser' doesn't contain a valid alias configuration
/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app.js doesn't exist
.jsx
Field 'browser' doesn't contain a valid alias configuration
/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app.jsx doesn't exist
.json
Field 'browser' doesn't contain a valid alias configuration
/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app.json doesn't exist
as directory
/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app doesn't exist
[/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app]
[/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app.js]
[/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app.jsx]
[/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app.json]
[/Users/facundogordillo/OneDrive/clinical-web-next/node_modules/next/app]
## Context
.babelrc
{
"presets": ["next/babel"],
"plugins": ["import-static-files"]
}
I don't have a next.config.js file.
## Your Environment
Tech | Version
---|---
next | 5.1.0
node | 9.11.1
OS | MacOS High Sierra
browser | Firefox Developer Edition
|
I'm trying to integrate Flow with my current next project I notice there is a
issue with
getInitialProps method. Flow complains:

I'm a little bit confused do I have to specify
`static getInitialProps: (ctx: {pathname: string, query: any, req?: any, res?:
any, jsonPageRes?: any, err?: any}) => Promise<any>; `
for every page or it could be done with next.js.flow file?
I see there is definition within the file
declare module "next/document" {
declare export var Head: Class<React$Component<any, any>>;
declare export var Main: Class<React$Component<any, any>>;
declare export var NextScript: Class<React$Component<any, any>>;
declare export default Class<React$Component<any, any>> & {
getInitialProps: (ctx: {pathname: string, query: any, req?: any, res?: any, jsonPageRes?: any, err?: any}) => Promise<any>;
renderPage(cb: Function): void;
};
}
But it seems this definition already have some problems. Please note I tried
with flow-bin version specified in the example, but I also tried with newest
flow-bin and it seems the same.
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
I think this has to work automatically if it's well defined within the
next.js.flow file
## Steps to Reproduce (for bugs)
1. Take with-flow example
2. Change index.js page to be statefull component and add getInitialProps to it
3. run yarn flow
## Your Environment
Tech | Version
---|---
next | latest
node | 8.7.0
OS | OSX
| 0 |

Anytime I click inside the code editor, a "copy / paste" popup appears,
obscuring the code.
How do I get rid of it?
|
Hey guys,
I just noticed a new feature in the code editor today. Its great to have for
copying and pasting code to ask questions, but it can get in the way if I am
just doing regular copy and pasting.
Would a better solution to this be to hold down shift + highlight the section
as a way to access the menu?
What do you guys think?
| 1 |
_From@alexanderby on November 19, 2015 9:35_
When formatting JavaScript or TypeScript, comments placed between parts of
multi-line expressions are placed wrong.
Expected to look like
doStuff()
.then()
// Comment
.then();
but actually is
doStuff()
.then()
// Comment
.then();
_Copied from original issue:microsoft/vscode#184_
|
To reproduce:
declare var _: any;
function chainer() {
_.chain()
// something here
.then()
// something here
.then()
// something here
.then();
}
Format the code. You get
declare var _: any;
function chainer() {
_.chain()
// something here
.then()
// something here
.then()
// something here
.then();
}
Observe the unindented comments.
| 1 |
`<input type='number' defaultValue={someValue}/>` does not work correctly in
Chrome. When user type in a decimal point `.`, the point will disappear and
the caret will be be reset to the beginning of the input. If you keep typing
in `.` twice, the value of input will disappear. However, if a input has no
defaultValue, it seems to work fine.
I've put together a fiddle page to demo the bug:
https://jsfiddle.net/sc3wpujs/2/
I think it has something to do with the internal state management of an
uncontrolled component. When the first `.` is typed, it does not get to
`target.value` (chrome may have trimmed the "unnecessary" `.` from the value
because it's type is `number`). React pushing `target.value` back to input
causing the `.` to disappear and caret position reset. Now if two `.` are
typed in, the value is no longer a valid number and Chrome may return `''` for
`target.value`, causing the input to be reset.
|
This appears to have been introduced in a new Chrome version, but I can't find
any reference to where.
Affected/Tested Browsers (OS X):
* Chrome 51.0.2704.106 (64-bit)
* Opera 39.0.2256.15
Unaffected Browsers:
* Safari 9.1
* Firefox 49
Backspacing in an input element with `value` or `defaultValue` set causes some
very odd behavior. Once a decimal point is gone, it can't easily be re-added.
Example:

In this example, I simply backspaced twice. On the second backspace, when I
expect `3.` to be showing, the input instead reads `3` and the cursor has
moved to the beginning. The next two jumps are my attempts to add another
decimal point.
Fiddle: https://jsfiddle.net/kmqz6kw8/
Tested with React 15.2.
Notes: This only occurs when `value` or `defaultValue` is set. If neither is
set, the input behaves properly. We are currently working around this issue by
(unfortunately) setting the input value on `componentDidMount` via a ref.
| 1 |
##### System information (version)
* OpenCV => 4.1.0
* Operating System / Platform => Mac OS Mojave 10.14
* Compiler => n/a python 3.7
##### Detailed description
https://docs.opencv.org/4.1.0/dd/dd7/tutorial_morph_lines_detection.html
python version of tutorial throws the following error:
File "ExtractHorzVert.py", line 104, in
main()
File "ExtractHorzVert.py", line 53, in main
horizontalStructure = cv.getStructuringElement(cv.MORPH_RECT,
(horizontal_size, 1))
TypeError: integer argument expected, got float
##### Steps to reproduce
horizontal_size = cols / 30
horizontalStructure = cv.getStructuringElement(cv.MORPH_RECT, (horizontal_size, 1))
|
##### System information (version)
* OpenCV => :3.4
* Operating System / Platform => :Windows 64 Bit / python
* Compiler => :(python 3.6)
##### Detailed description
OpenCV writes a hdr file with header starting with "#?RGBE". But many programs
suppose "#?RADIANCE" and don't work on files with "#?RGBE". Would you change
this header line to "#?RADIANCE"?
| 0 |
I've been messing with it all night to see if I can isolate the problem.
What I've come up with is it seems to fire partially, but the function call
doesn't bubble up to any of the Table components.
In `table-row.js` the following code runs when I click a TableRowColumn:
(lines 179 to 183)
_onCellClick: function _onCellClick(e, columnIndex) {
if (this.props.selectable && this.props.onCellClick) this.props.onCellClick(e, this.props.rowNumber, columnIndex);
e.ctrlKey = true;
this._onRowClick(e);
},
This does then call `_onRowClick` in `table-row.js`:
(lines 166 to 169)
_onRowClick: function _onRowClick(e) {
console.log("table-row") //Ignore this. My test logging.
if (this.props.onRowClick) this.props.onRowClick(e, this.props.rowNumber);
},
My component code looks like this:
<Table
fixedHeader={this.state.fixedHeader}
selectable={this.state.selectable}
onRowClick={this._handleClick.bind(this)}
>
<TableHeader
enableSelectAll={this.state.enableSelectAll}
displaySelectAll={this.state.displaySelectAll}
adjustForCheckbox={this.state.adjustForCheckbox}>
<TableRow
displayRowCheckbox={this.state.displayRowCheckbox}
selectable={false}>
<TableHeaderColumn>Filename</TableHeaderColumn>
<TableHeaderColumn>Experiment</TableHeaderColumn>
<TableHeaderColumn>Date created</TableHeaderColumn>
</TableRow>
</TableHeader>
<TableBody
showRowHover={this.state.showRowHover}
displayRowCheckbox={this.state.displayRowCheckbox}>
{this.props.rows.map(function(row) {
return (
<TableRow
selectable={this.state.selectable}
key={row.name}>
<TableRowColumn>{row.name}</TableRowColumn>
<TableRowColumn>{row.experiment}</TableRowColumn>
<TableRowColumn>{row.created}</TableRowColumn>
</TableRow>
);
}, this)} // you can pass an arg to define 'this' in the callback!
</TableBody>
</Table>
I'm able to get onCellClick to work just fine, but onRowClick doesn't work if
I place it on the `<Table/>, <TableBody/> or <TableRow/>`
One of the things I've noticed is that `table.js` doesn't make any mention of
onRowClick. `table-body.js` makes some mention of `onRowClick`, but it has
different intentions than the similar `onCellClick` code in the same file.
In `table-body.js` lines 194 to 203:
_onRowClick(e, rowNumber) {
console.log("poop")
e.stopPropagation();
if (this.props.selectable) {
// Prevent text selection while selecting rows.
window.getSelection().removeAllRanges();
this._processRowSelection(e, rowNumber);
}
},
(lines 293 to 296):
_onCellClick(e, rowNumber, columnNumber) {
e.stopPropagation();
if (this.props.onCellClick) this.props.onCellClick(rowNumber, this._getColumnId(columnNumber));
},
I've tried messing with material-ul source a bit, but haven't yet found a fix.
I'm missing something, but I don't know what I'm missing.
|
I'm working on implementing sorting functionality and cannot for the life of
me get `onClick` to fire for `<TableHeaderColumn>`. I see that there is an
onClick prop in the docs, but no luck.
<Table
fixedHeader={true}
>
<TableHeader adjustForCheckbox={false} displaySelectAll={false}>
<TableRow>
<TableHeaderColumn style={{width: '7%'}}></TableHeaderColumn>
<TableHeaderColumn style={{width: '12%'}} tooltip="Click to sort">Name</TableHeaderColumn>
<TableHeaderColumn onClick={(row, col) => console.log(col)} style={{width: '17%'}} tooltip="Click to sort">Email</TableHeaderColumn>
<TableHeaderColumn style={{width: '7%'}} tooltip="Click to sort">Role</TableHeaderColumn>
<TableHeaderColumn style={{width: '10%'}} tooltip="Click to sort">Status</TableHeaderColumn>
<TableHeaderColumn style={{width: '2%'}}></TableHeaderColumn>
</TableRow>
</TableHeader>
<TableBody selectable={true} showRowHover={true} displayRowCheckbox={false} style={{overflow: 'visible'}}>
{rows}
</TableBody>
</Table>
This was just for testing purposes, but the third `<TableHeaderColumn>` does
nothing when clicked. It also doesn't fire when passed a `this.handleClick` or
other callback. onCellClick being passed to `<Table>` works when clicked on
anything other than the header cells. This is using React 0.13.2 and Material-
UI 0.11.0.
| 1 |
#### Code Sample, a copy-pastable example if possible
import pandas as pd
import numpy as np
idx0 = range(2)
idx1 = np.repeat(range(2), 2)
midx = pd.MultiIndex(
levels=[idx0, idx1],
labels=[
np.repeat(range(len(idx0)), len(idx1)),
np.tile(range(len(idx1)), len(idx0))
],
names=['idx0', 'idx1']
)
df = pd.DataFrame(
[
[i**2/float(j), 'example{}'.format(i), i**3/float(j)]
for j in range(1, len(idx0) + 1)
for i in range(1, len(idx1) + 1)
],
columns=['col0', 'col1', 'col2'],
index=midx
)
example = df.loc[[(0, 1)]]
For display
In [13]: example
Out[13]:
col0 col1 col2
idx0 idx1
0 1 16.0 example4 64.0
#### Problem description
Taken from this StackOverflow post:
* https://stackoverflow.com/q/46098097/4013571
Given the following dataframe
col0 col1 col2
idx0 idx1
0 0 1.0 example1 1.0
0 4.0 example2 8.0
1 9.0 example3 27.0
1 16.0 example4 64.0
1 0 0.5 example1 0.5
0 2.0 example2 4.0
1 4.5 example3 13.5
1 8.0 example4 32.0
the `.xs` operation will select
In [121]: df.xs((0,1), level=[0,1])
Out[121]:
col0 col1 col2
idx0 idx1
0 1 9.0 example3 27.0
1 16.0 example4 64.0
whilst the `.loc` operation will select
In [125]: df.loc[[(0,1)]]
Out[125]:
col0 col1 col2
idx0 idx1
0 1 16.0 example4 64.0
This is highlighted even further by the following
In [149]: df.loc[pd.IndexSlice[:, 1], :]
Out[149]:
col0 col1 col2
idx0 idx1
0 1 9.0 example3 27.0
1 16.0 example4 64.0
In [150]: df.loc[pd.IndexSlice[0, 1], :]
Out[150]:
col0 16
col1 example4
col2 64
Name: (0, 1), dtype: object
#### Expected Output
Note that this only works for this minimal example because there is only one
label in level 0 index axis
In [8]: df.loc[pd.IndexSlice[:, 1], :]
Out[8]:
col0 col1 col2
idx0 idx1
0 1 9.0 example3 27.0
1 16.0 example4 64.0
#### Output of `pd.show_versions()`
## INSTALLED VERSIONS
commit: None
python: 2.7.13.final.0
python-bits: 64
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 79 Stepping 1, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
LOCALE: None.None
pandas: 0.20.3
pytest: 3.0.7
pip: 9.0.1
setuptools: 36.2.7
Cython: 0.25.2
numpy: 1.13.1
scipy: 0.19.0
xarray: None
IPython: 5.3.0
sphinx: 1.5.6
patsy: 0.4.1
dateutil: 2.6.1
pytz: 2017.2
blosc: None
bottleneck: 1.2.1
tables: 3.2.2
numexpr: 2.6.2
feather: None
matplotlib: 2.0.2
openpyxl: 2.4.7
xlrd: 1.0.0
xlwt: 1.2.0
xlsxwriter: 0.9.6
lxml: 3.7.3
bs4: 4.6.0
html5lib: 0.999
sqlalchemy: 1.1.9
pymysql: None
psycopg2: None
jinja2: 2.9.6
s3fs: None
pandas_gbq: None
pandas_datareader: 0.5.0
|
I have an odd issue where if I specify the axis in concat it throws the
following error:
InvalidIndexError: Reindexing only valid with uniquely valued Index objects
Pandas version: 0.16.0
OS: Ubuntu 14.04 LTS x64
Here's the pickle of the data structure causing this (it's rather large, ~60
megs, but it's my real use case which caused this error)
https://www.dropbox.com/s/02dn99dbi6p14um/pandas_error.pickle?dl=0
import pickle
import pandas as pd
l = pickle.load(open('pandas_error.pickle'))
scan_query = '(index >= 624.306193 & index <= 624.326171) | (index >= 624.807981 & index <= 624.826795) | (index >= 625.309633 & index <= 625.32635) | (index >= 628.315655 & index <= 628.331508) | (index >= 628.815043 & index <= 628.83164)'
# works
pd.concat([i.dropna().to_frame().query(scan_query) for i in l])
# breaks
#pd.concat([i.dropna().to_frame().query(scan_query) for i in l], axis=1)
| 0 |
When using `Deno.listen()` without passing in the parameter `hostname`, it
should listen to both ipv6 and ipv4 by default.
I found that currently it only listens on ipv4.
Deno 1.21.1
|
After upgrading to version 1.14 this error happened when using `deno bundle`
Example test.ts code:
import { Application } from "https://deno.land/x/oak@v9.0.0/mod.ts";
const app = new Application();
app.use((ctx) => {
ctx.response.body = "Hello World!";
});
await app.listen({ port: 8000 });
Commads:
deno bundle test.ts out.js
deno run -A out.js
Error:
error: Uncaught ReferenceError: Cannot access 'Response' before initialization
const DomResponse = Response;
^
Deno version
deno 1.14.0 (release, x86_64-apple-darwin)
v8 9.4.146.15
typescript 4.4.2
| 0 |
* Electron version: 0.37.2 + 0.36.12
* Operating system: OS X 10.11.4 (15E65)
The process doesn't seem to exit like `node` does. I've reduced it to
something `babel-register` is doing. I'm not sure if this is a bug within
babel or electron, so feel free to close this if it's a bug with babel. It's
the same behavior on both 0.37.2 and 0.36.12.
# works properly, does nothing and exits
node -e "require('babel-register')"
# hangs forever until you ctrl+c
ELECTRON_RUN_AS_NODE=true node_modules/.bin/electron -e "require('babel-register')"
A complete test:
mkdir electron-node-hang
cd electron-node-hang
npm init -y
npm install electron-prebuilt babel-register --save
ELECTRON_RUN_AS_NODE=true node_modules/.bin/electron -e "require('babel-register')"
|
## Description
Our project is using `child_process#fork()` to run npm commands, but it turns
out taking much longer time than normal.
I haven't tested if this problem occurs when running other scripts, but as
shown in the test below, running the same code in pure `node` behaves
normally.
## Reproduction
1. In a new folder, clone an empty app: `git clone https://github.com/atom/electron-quick-start`
2. `cd` into that directory and install npm locally: `npm i npm`
3. Open this app: `electron .`
4. In the console, run the following code
var npmpath=require('path').join(__dirname,'node_modules','.bin','npm');
var startTime=new Date().getTime();
var cp=require('child_process');
var child = cp.fork(npmpath,['dist-tag','ls','npm'],{stdio:'pipe',silent:true});
child.stdout.on('data', function(data) {
console.log('stdout: ' + data);
});
child.stderr.on('data', function(data) {
console.log('stdout: ' + data);
});
child.on('close', function(code) {
console.log('closing code: ' + code);
console.log('time: ' + (new Date().getTime()-startTime));
});
On my computer it takes about 36 seconds,

On the other hand, to test it in pure node,
1. Save the script above in the root directory of the same app as `run.js`
2. `node run.js`
On my computer it takes about 1.2 seconds, which is about the same as directly
running this command in command line.

## Platform
* node 5.1.1
* Chrome 47.0.2526.110
* Electron 0.36.5
* OS X 10.11.3
| 1 |
Long pages such as in regex have many examples but it's difficult to know at a
glance what the documentation contains without scanning the entire document.
Having a table of contents would help a lot with this.
Here is a list of links to different TOC styles from various places for ways
it could be done:
* Python 2.7 has one in the sidebar. Stays with you as you scroll.
* Python 3.5 seems to be slightly cleaner but similar. Doesn't stay with you.
* mozilla javascript docs: is nicely in the sidebar. Follows you down the page (requires the window to be wide enough).
* wikipedia: in the middle of the page. Doesn't scroll with you.
* gitbook: stays with you. provides scrolling.
* perl: looks like it's formatted like a man page.
I looked for some more but didn't find other good examples.
Of these, I like the mozilla, python 2, and gitbook TOCs best with the mozilla
probably the best among them (probably because it's small and clean). However,
I think the gitbook style is probably the most appropriate fit to the std libs
style.
I've also provided a mockups of what a TOC could look like in that style which
is similar to a different thread. Clearly, something would need to be done
with the current sidebar to use this format.
Mockup:

|
Here's a minimal code example that reproduces the error:
#![crate_name = "test"]
#![crate_type = "dylib"]
use std::ops::Div;
pub struct Test
{
pub test:i32,
}
impl Div<Test,Test> for Test { fn div( &self, v:&Test ) -> Test { Test{ test:self.test / v.test } } }
And part of the error:
note: D:\#dev\#compilers\Rust\bin\rustlib\i686-pc-windows-gnu\lib\libcore-4e7c5e5c.rlib(core-4e7c5e5c.o):(.text+0x6b9b): undefined reference to `rust_begin_unwind'
Version:
rustc 0.13.0-nightly (45cbdec41 2014-11-07 00:02:18 +0000)
binary: rustc
commit-hash: 45cbdec4174778bf915f17561ef971c068a7fcbc
commit-date: 2014-11-07 00:02:18 +0000
host: i686-pc-windows-gnu
release: 0.13.0-nightly
This also happens on the x86_64 nightly
| 0 |
### System info
* Playwright Version: 1.31.2
* Operating System: Ubuntu 22.04
* Browser: WebKit
### Source code
import { test } from '@playwright/test';
test('getByRole behaviour', async ({ page }) => {
await page.setContent(`
<html>
<body>
<my-dialog>
<button>dont click me</button>
</my-dialog>
<button>click me instead</button>
<script type="module">
class MyDialog extends HTMLElement {
connectedCallback() {
this.attachShadow({mode: 'open'});
this.shadowRoot.innerHTML = 'we dont add a slot here so the light dom is not visible'
}
}
customElements.define('my-dialog', MyDialog);
</script>
</body>
</html>
`);
// chrome finds 1 element, because only one is actually available to the user
// webkit finds 2 elements, so strict validation fails only in webkit
await page.getByRole('button').click();
// finds 2 elements, because there are two elements in the dom
// strict validation fails in all browsers, as expected
// await page.locator('button').click();
});
Config file is the default npm init playwright@latest, strict mode enabled.
**Steps**
* Run the test in chrome and firefox, it works
* Run the test in webkit and the click fails strict validation
**Expected**
All browsers behave the same, ideally the test should pass for all browsers.
**Actual**
WebKit seems to keep light-dom elements in the accessibility tree, even if
they have no slot in the corresponding shadow-root. This causes getByRole to
find more than one element to click on the page.
I am really not sure if this is a playwright issue, a playwright-webkit
issues, or a webkit issue. I'd be perfectly happy with filing the issue
somewhere else if we find this to be the wrong place.
Edit: Whoops, my copy pasta had an accidential display: none on the button, I
removed that with an edit
|
### System info
* Playwright Version: [v1.XX]
* Operating System: [All, Windows 11, Ubuntu 20, macOS 13.2, etc.]
* Browser: [All, Chromium, Firefox, WebKit]
* Other info:
### Source code
* I provided exact source code that allows reproducing the issue locally.
**Link to the GitHub repository with the repro**
[https://github.com/your_profile/playwright_issue_title]
or
**Config file**
// playwright.config.ts
import { defineConfig, devices } from '@playwright/test';
export default defineConfig({
projects: [
{
name: 'chromium',
use: { ...devices['Desktop Chrome'], },
},
});
**Test file (self-contained)**
it('should check the box using setChecked', async ({ page }) => {
await page.setContent(`<input id='checkbox' type='checkbox'></input>`);
await page.getByRole('checkbox').check();
await expect(page.getByRole('checkbox')).toBeChecked();
});
**Steps**
* [Run the test]
* [...]
**Expected**
[Describe expected behavior]
**Actual**
[Describe actual behavior]
| 0 |
The C function `malloc()` returns NULL (i.e. 0) if it fails to allocate
memory. The return value of a `malloc()` call must be checked for this value
before attempting to use the result. Here are places in the scipy code where
this check is not made. If any of these calls fails, the result is likely to
be a segmentation fault.
**Cython**
* `cluster`
In the file `_optimal_leaf_ordering.pyx`, in the function `identify_swaps`
* `interpolate`
In the file `_ppoly.pyx`, in the functions `real_roots`, `croots_poly1` and
`_croots_poly1`
* `spatial`
In `setlist.pxd`, in the function `init`, in the statement `setlists.sets[j] =
...`
* `sparse.csgraph`
File `_shortest_path.pyx`, in the code that creates `nodes` in the functions
`_dijkstra_directed`, `_dijkstra_directed_multi`, `_dijkstra_undirected`,
`_dijkstra_undirected_multi`
* `_lib`
In the file `_ccallback_c.pyx`, the result of `strdup` is used without
checking for NULL. `strdup` can fail to allocate memory for the duplicated
string. In that case, it returns NULL. (Note: this might be harmless. I
haven't checked to see if the pointer is ever dereferenced while the capsule
is in use.)
**C**
* `fftpack`
In the file `fftpack.h`, the macro `GEN_CACHE` is defined. It is used in the
files `convolve.c`, `drfft.c`, `zfft.c`,`zfftnd.c`
* `ndimage`
In the file `src/ni_morphology.c`, at line 624 (at the time of this writing):
`temp->coordinates = malloc(...)`
* `signal`
File `sigtoolsmodule.c`, lines 914--927 (8 unchecked calls to malloc) and line
1096
* * *
We have vendored code in `sparse` and `spatial` that use `malloc`:
* The SuperLU code in `linalg/dsolve/SuperLU/SRC` has its own memory management code. I didn't spend time trying to figure out the memory management here. The file `cmemory.c` is the most relevant, and there appear to be calls to `intMalloc()` and `user_malloc()` that do not check for failure, but I didn't dig deeper to see if those functions check for failure before returning.
* `spatial` provides a wrapper for QHull. I didn't look very deeply into how the qhull code manages memory. It looks like the function `qh_memalloc()` in `mem_r.c` will print an error and exit if it fails.
We should be aware of these vendored packages using malloc, but I think a
thorough review of their memory management is not required. Someone can do a
deep dive into either of these libraries in the future if there is ever a
suspicion that they are leaking memory.
|
My issue is about the error LinAlgError: Schur form not found. Possibly ill-
conditioned raised when I use the following code. The problem is that it only
happens in the first execution of the script, then it disappears. It also
happens when I try to use `scipy.linalg.expm` and `scipy.linalg.logm` as it
has to do with the Schur decomposition.
#### Reproducing code example:
""" Obtains the fidelity for the QFT for n=3 for Qiskit noise model """
import numpy as np
def fidelity(a,b):
''' Computes the fidelity of two density matrices
Args:
a (array): density matrix
b (array): density matrix
Returns:
float: fidelity of a and b
'''
return (np.matrix.trace(scipy.linalg.sqrtm(np.matmul(scipy.linalg.sqrtm(a),np.matmul(b,scipy.linalg.sqrtm(a))))))**2
rho0=np.array([[0.23394436+0.j , 0.11036513+0.07068888j,
0.03302341+0.1088189j , 0.02706909+0.0881958j ,
0.05815633-0.01072523j, 0.02037557-0.02607218j,
0.1016744 +0.00529989j, 0.12719727+0.00524902j],
[0.11036513-0.07068888j, 0.13571167+0.j ,
0.05817668+0.06459554j, 0.05001153+0.03409153j,
0.01467896-0.03614299j, 0.02297974-0.02354262j,
0.05975342-0.05200195j, 0.07036336-0.04786174j],
[0.03302341-0.1088189j , 0.05817668-0.06459554j,
0.14170668+0.j , 0.09006076-0.00379435j,
0.0081075 -0.02009074j, 0.00140381-0.01287842j,
0.01685588-0.05481296j, 0.02995809-0.0568339j ],
[0.02706909-0.0881958j , 0.05001153-0.03409153j,
0.09006076+0.00379435j, 0.1104499 +0.j ,
0.0189209 -0.01251221j, 0.00768026-0.02039591j,
0.03121948-0.0254008j , 0.03673299-0.03857761j],
[0.05815633+0.01072523j, 0.01467896+0.03614299j,
0.0081075 +0.02009074j, 0.0189209 +0.01251221j,
0.0863071 +0.j , 0.04125298+0.00418091j,
0.01762221-0.00102403j, 0.03347778+0.00219727j],
[0.02037557+0.02607218j, 0.02297974+0.02354262j,
0.00140381+0.01287842j, 0.00768026+0.02039591j,
0.04125298-0.00418091j, 0.06473456+0.j ,
0.0410258 +0.00813802j, 0.01971775+0.01372613j],
[0.1016744 -0.00529989j, 0.05975342+0.05200195j,
0.01685588+0.05481296j, 0.03121948+0.0254008j ,
0.01762221+0.00102403j, 0.0410258 -0.00813802j,
0.11333211+0.j , 0.06110975+0.02015177j],
[0.12719727-0.00524902j, 0.07036336+0.04786174j,
0.02995809+0.0568339j , 0.03673299+0.03857761j,
0.03347778-0.00219727j, 0.01971775-0.01372613j,
0.06110975-0.02015177j, 0.11381361+0.j ]])
rho=np.array([[ 0.17706638+0.j , 0.06659953+0.01608955j,
0.0297682 +0.01830716j, 0.00812785+0.01222738j,
0.00753445-0.00309584j, 0.00878906-0.01509603j,
0.02885946-0.0179952j , 0.04318237-0.01519775j],
[ 0.06659953-0.01608955j, 0.13491143+0.j ,
0.03180949+0.01096598j, 0.01931085+0.01529609j,
0.00876872-0.00343831j, 0.00969103-0.01005385j,
0.01644897-0.02258301j, 0.02629598-0.01775106j],
[ 0.0297682 -0.01830716j, 0.03180949-0.01096598j,
0.12190416+0.j , 0.03262329+0.01110501j,
0.0140686 -0.00460815j, 0.00094604-0.01165771j,
0.00431993-0.02871026j, 0.01617432-0.02577718j],
[ 0.00812785-0.01222738j, 0.01931085-0.01529609j,
0.03262329-0.01110501j, 0.10249498+0.j ,
0.00314331-0.00964355j, 0.00564575+0.00064087j,
-0.00264486-0.00935872j, 0.00440131-0.01796807j],
[ 0.00753445+0.00309584j, 0.00876872+0.00343831j,
0.0140686 +0.00460815j, 0.00314331+0.00964355j,
0.10799493+0.j , 0.02676392+0.0035163j ,
0.01410251+0.00034248j, 0.00727336+0.00429281j],
[ 0.00878906+0.01509603j, 0.00969103+0.01005385j,
0.00094604+0.01165771j, 0.00564575-0.00064087j,
0.02676392-0.0035163j , 0.10673353+0.j ,
0.01838175+0.00315348j, 0.02171156+0.01295641j],
[ 0.02885946+0.0179952j , 0.01644897+0.02258301j,
0.00431993+0.02871026j, -0.00264486+0.00935872j,
0.01410251-0.00034248j, 0.01838175-0.00315348j,
0.12371487+0.j , 0.0449117 +0.01037259j],
[ 0.04318237+0.01519775j, 0.02629598+0.01775106j,
0.01617432+0.02577718j, 0.00440131+0.01796807j,
0.00727336-0.00429281j, 0.02171156-0.01295641j,
0.0449117 -0.01037259j, 0.12517971+0.j ]])
fidelity=DAQC.fidelity(rho0,rho)
#### Error message:
File "C:\Users\Paula\Dropbox\Master thesis\FinalCode\ibmq_estimation\DAQC.py", line 37, in fidelity
return (np.matrix.trace(scipy.linalg.sqrtm(np.matmul(scipy.linalg.sqrtm(a),np.matmul(b,scipy.linalg.sqrtm(a))))))**2
File "C:\Users\Paula\Anaconda3\envs\test_env\lib\site-packages\scipy\linalg\_matfuncs_sqrtm.py", line 172, in sqrtm
T, Z = schur(A, output='complex')
File "C:\Users\Paula\Anaconda3\envs\test_env\lib\site-packages\scipy\linalg\decomp_schur.py", line 170, in schur
raise LinAlgError("Schur form not found. Possibly ill-conditioned.")
LinAlgError: Schur form not found. Possibly ill-conditioned.
...
#### Scipy/Numpy/Python version information:
import sys, scipy, numpy; print(scipy.__version__, numpy.__version__, sys.version_info)
1.5.2 1.18.5 sys.version_info(major=3, minor=7, micro=7, releaselevel='final', serial=0)
| 0 |
##### System information (version)
* OpenCV => 4.1.0-dev
* Operating System / Platform => Ubuntu x64 bionic 18.04.1
* Compiler => gcc 8.0.1
**Hello, There is a bug with dot product`dot (InputArray m) const` when used
in c++ implementation, But strangely this bug is not present in python
implementation.**
##### Detailed description
Check following python code:
Python 3.6.8 (default, Jan 14 2019, 11:02:34)
[GCC 8.0.1 20180414 (experimental) [trunk revision 259383]] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import numpy as np
>>> a = np.zeros((5, 5),np.float32)
>>> b = np.ones((5,1),np.float32)
>>> a.dot(b)
array([[0.],
[0.],
[0.],
[0.],
[0.]], dtype=float32)
which works as expected.
But when I tried to implement the same code in C++, it throws the following
error everytime regardless of the case:
abhishek@abhishek-HP-Pavilion-Notebook:~/testing$ ./test
terminate called after throwing an instance of 'cv::Exception'
what(): OpenCV(4.0.1-dev) /home/abhishek/Downloads/opencv-master/modules/core/src/matmul.cpp:3274: error: (-215:Assertion failed) mat.size == size in function 'dot'
Aborted (core dumped)
##### Steps to reproduce
The code I'm using for c++ is as below:
#include <opencv2/opencv.hpp>
#include <iostream>
#include <cassert>
#include <fstream>
int main(){
cv::Mat a = cv::Mat::ones(5,5, CV_32F);
cv::Mat b = cv::Mat::ones(5,1, CV_32F);
cout << a.dot(b) << endl ;
return 0;
}
|
##### System information (version)
* OpenCV => 4.0.1, master branch `e2dbf05`
* Operating System / Platform => Windows 64 Bit
* Compiler => Visual Studio 2017
##### Detailed description
The compilation of the DNN module fails with several error C2398, e.g. due to
the narrowing at line 106 in op_inf_engine.cpp
netBuilder.connect(inpId, {layerId, i});
possible fix
netBuilder.connect(inpId, { static_castInferenceEngine::idx_t(layerId),
static_castInferenceEngine::idx_t(i)});
Affected files are
* convolution_layer.cpp
* pooling_layer.cpp
* op_inf_engine.cpp
| 0 |
From the master, whenever I try to open a shell into a pod running on a remote
node, kubectl would completely hang.
Below a verbose trace.
Can someone point me to where else I can look?
I know kubectl --> master --> proxy --> pod/container.
Where would this error come from.
This has always worked prior to upgrading to kubernetes 1.1.7 and docker 1.10.
I'm going to downgrade one at a time to see which upgrade broke it.
kubectl exec --v=9 kibana-ndeps bash -it
I0209 03:16:35.628245 1 debugging.go:102] curl -k -v -XGET -H "User-Agent: kubectl/v1.1.7 (linux/amd64) kubernetes/e4e6878" http://minux:8080/api
I0209 03:16:35.639050 1 debugging.go:121] GET http://minux:8080/api 200 OK in 10 milliseconds
I0209 03:16:35.639064 1 debugging.go:127] Response Headers:
I0209 03:16:35.639069 1 debugging.go:130] Content-Type: application/json
I0209 03:16:35.639074 1 debugging.go:130] Date: Tue, 09 Feb 2016 03:16:35 GMT
I0209 03:16:35.639079 1 debugging.go:130] Content-Length: 57
I0209 03:16:35.639093 1 request.go:746] Response Body: {
"kind": "APIVersions",
"versions": [
"v1"
]
}
I0209 03:16:35.639218 1 debugging.go:102] curl -k -v -XGET -H "User-Agent: kubectl/v1.1.7 (linux/amd64) kubernetes/e4e6878" http://minux:8080/api/v1/namespaces/default/pods/kibana-ndeps
I0209 03:16:35.640083 1 debugging.go:121] GET http://minux:8080/api/v1/namespaces/default/pods/kibana-ndeps 200 OK in 0 milliseconds
I0209 03:16:35.640096 1 debugging.go:127] Response Headers:
I0209 03:16:35.640101 1 debugging.go:130] Content-Type: application/json
I0209 03:16:35.640106 1 debugging.go:130] Date: Tue, 09 Feb 2016 03:16:35 GMT
I0209 03:16:35.640130 1 request.go:746] Response Body: {"kind":"Pod","apiVersion":"v1","metadata":{"name":"kibana-ndeps","generateName":"kibana-","namespace":"default","selfLink":"/api/v1/namespaces/default/pods/kibana-ndeps","uid":"a4649aad-ced8-11e5-80b6-7824afc0a170","resourceVersion":"13142485","creationTimestamp":"2016-02-09T02:55:57Z","labels":{"name":"kibana"},"annotations":{"kubernetes.io/created-by":"{\"kind\":\"SerializedReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"ReplicationController\",\"namespace\":\"default\",\"name\":\"kibana\",\"uid\":\"4a4de2fe-c888-11e5-b7f7-7824afc0a170\",\"apiVersion\":\"v1\",\"resourceVersion\":\"12885522\"}}\n"}},"spec":{"volumes":[{"name":"log","emptyDir":{}}],"containers":[{"name":"kibana","image":"minux:5000/kibana:latest","env":[{"name":"ELASTICSEARCH_HOST","value":"elasticsearch"}],"resources":{},"volumeMounts":[{"name":"log","mountPath":"/var/log"}],"readinessProbe":{"httpGet":{"path":"/","port":5601,"scheme":"HTTP"},"initialDelaySeconds":30,"timeoutSeconds":1},"terminationMessagePath":"/dev/termination-log","imagePullPolicy":"Always"},{"name":"fluentd-kafka","image":"minux:5000/fluentd-kafka:latest","env":[{"name":"ZOOKEEPER","value":"zookeeper:2181"},{"name":"LABEL","value":"KIBANA"}],"resources":{},"volumeMounts":[{"name":"log","mountPath":"/var/log"}],"terminationMessagePath":"/dev/termination-log","imagePullPolicy":"Always"}],"restartPolicy":"Always","terminationGracePeriodSeconds":30,"dnsPolicy":"ClusterFirst","nodeSelector":{"zone":"green"},"nodeName":"192.168.1.176"},"status":{"phase":"Running","conditions":[{"type":"Ready","status":"True","lastProbeTime":null,"lastTransitionTime":null}],"hostIP":"192.168.1.176","podIP":"10.244.176.4","startTime":"2016-02-09T02:55:59Z","containerStatuses":[{"name":"fluentd-kafka","state":{"running":{"startedAt":"2016-02-09T02:58:38Z"}},"lastState":{},"ready":true,"restartCount":0,"image":"minux:5000/fluentd-kafka:latest","imageID":"docker://sha256:0948b0085872577fa50fc415feda363178bba8361834adae79952aee7431492f","containerID":"docker://e1f509c8fe3f6004c81b26f42c2cfd0c389afef459ac67797ed60f162e30d960"},{"name":"kibana","state":{"running":{"startedAt":"2016-02-09T02:58:38Z"}},"lastState":{},"ready":true,"restartCount":0,"image":"minux:5000/kibana:latest","imageID":"docker://sha256:8b09cbc206d53a799211a4d96ff5e06d19f216be258a8a4dec7204d5911bc18d","containerID":"docker://d7c6bc51d4f70074c89ca21fdc65d075acb322f66fd52c2b7bf5a5cce479c823"}]}}
I0209 03:16:35.640649 1 exec.go:179] defaulting container name to kibana
I0209 03:16:35.640722 1 debugging.go:102] curl -k -v -XPOST -H "X-Stream-Protocol-Version: v2.channel.k8s.io" -H "X-Stream-Protocol-Version: channel.k8s.io" http://minux:8080/api/v1/namespaces/default/pods/kibana-ndeps/exec?command=bash&container=kibana&container=kibana&stderr=true&stdin=true&stdout=true&tty=true
I0209 03:16:35.668922 1 debugging.go:121] POST http://minux:8080/api/v1/namespaces/default/pods/kibana-ndeps/exec?command=bash&container=kibana&container=kibana&stderr=true&stdin=true&stdout=true&tty=true 101 Switching Protocols in 28 milliseconds
I0209 03:16:35.668936 1 debugging.go:127] Response Headers:
I0209 03:16:35.668941 1 debugging.go:130] Connection: Upgrade
I0209 03:16:35.668947 1 debugging.go:130] Upgrade: SPDY/3.1
I0209 03:16:35.668955 1 debugging.go:130] X-Stream-Protocol-Version: v2.channel.k8s.io
I0209 03:16:35.668962 1 debugging.go:130] Date: Tue, 09 Feb 2016 03:16:37 GMT
Content-Type specified (plain/text) must be 'application/json'
|
I have a setup using .AttachToContainer. After upgrading to Docker 1.10-rc2
I'm getting an error `Content-Type specified (plain/text) must be
'application/json'`.
Why am I getting this?
Any help would be great!
/beetree
| 1 |
Looking at core.ops. _comp_method_SERIES and whether we can have the datetime
and timedelta cases defer to Index subclass implementations, a couple
questions come up:
https://github.com/pandas-dev/pandas/blob/master/pandas/core/ops.py#L744
def na_op(x, y):
# dispatch to the categorical if we have a categorical
# in either operand
if is_categorical_dtype(x):
return op(x, y)
elif is_categorical_dtype(y) and not is_scalar(y):
return op(y, x)
This `return op(y, x)` looks weird. Should it be a reverse-op? e.g if op is
operator.ge, should this become `return operator.le(y, x)`? Maybe this is
irrelevant if categorical comparisons are only defined for `__eq__` and
`__ne__`? If that is the explanation, there should be a comment.
Special casing for PeriodIndex:
if isinstance(other, ABCPeriodIndex):
# temp workaround until fixing GH 13637
# tested in test_nat_comparisons
# (pandas.tests.series.test_operators.TestSeriesOperators)
return self._constructor(na_op(self.values,
other.astype(object).values),
index=self.index)
I couldn't tell from #13637 what the connection was. Commenting this out did
not appear to break anything in the tests. Anyone know if this is still
relevant?
**Update** I forgot to mention the question mentioned in the Issue title. Most
cases return `self._constructor(res, index=self.index, name=whatever)`, but
one case returns `self._constructor(na_op(self.values, np.asarray(other)),
index=self.index).__finalize__(self)`. Why is `__finalize__` called in this
case but not others?
|
#!/bin/env python
"""
Example bug in derived Pandas Series.
__finalized__ is not called in arithmetic binary operators, but it is in in some booleans cases.
>>> m = MySeries([1, 2, 3], name='test')
>>> m.x = 42
>>> n=m[:2]
>>> n
0 1
1 2
dtype: int64
>>> n.x
42
>>> o=n+1
>>> o
0 2
1 3
dtype: int64
>>> o.x
Traceback (most recent call last):
...
AttributeError: 'MySeries' object has no attribute 'x'
>>> m = MySeries([True, False, True], name='test2')
>>> m.x = 42
>>> n=m[:2]
>>> n
0 True
1 False
dtype: bool
>>> n.x
42
>>> o=n ^ True
>>> o
0 False
1 True
dtype: bool
>>> o.x
42
>>> p = n ^ o
>>> p
0 True
1 True
dtype: bool
>>> p.x
42
"""
import pandas as pd
class MySeries(pd.Series):
_metadata = ['x']
@property
def _constructor(self):
return MySeries
if __name__ == "__main__":
import doctest
doctest.testmod()
#### Expected Output
In all cases, the metadata 'x' should be transferred from the passed values
when applying binary operators.
When the right-hand value is a constant, the left-hand value metadata should
be used in **finalize** for arithmetic operators, just like it is for Boolean
binary operators.
When two series are used in binary operators, some resolution should be
possible in **finalize**.
I would pass the second (right-hand) value by calling **finalize** (self,
other=other), leaving the resolution to the derived class implementer, but
there might be a smarter approach.
#### output of `pd.show_versions()`
pd.show_versions()
## INSTALLED VERSIONS
commit: None
python: 2.7.6.final.0
python-bits: 64
OS: Linux
OS-release: 3.19.0-59-generic
machine: x86_64
processor: x86_64
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
pandas: 0.18.1
nose: 1.3.7
pip: None
setuptools: 20.2.2
Cython: 0.24
numpy: 1.11.0
scipy: 0.17.0
statsmodels: 0.6.1
xarray: None
IPython: 4.0.1
sphinx: 1.3.1
patsy: 0.4.0
dateutil: 2.4.2
pytz: 2015.7
blosc: None
bottleneck: 1.0.0
tables: 3.2.2
numexpr: 2.5.2
matplotlib: 1.5.0
openpyxl: 2.2.6
xlrd: 0.9.4
xlwt: 1.0.0
xlsxwriter: 0.7.7
lxml: 3.4.4
bs4: 4.4.1
html5lib: 0.9999999
httplib2: None
apiclient: None
sqlalchemy: 1.0.9
pymysql: None
psycopg2: None
jinja2: 2.8
boto: 2.38.0
pandas_datareader: None
| 1 |
Night Light got crashed too.
|
currently to add / remove items in shell, we have to kick explorer. After this
happens, PT can then enable / disable for them showing up.
We should see how we can do some alternative methods
| 1 |
_Original tickethttp://projects.scipy.org/numpy/ticket/859 on 2008-07-24 by
@cournape, assigned to @cournape._
Detected under valgrind, and looking at the code, it looks like there is a
problem, but I don't know enough about that code to solve it quickly:
Tests compress2d==5148==
==5148== Conditional jump or move depends on uninitialised value(s)
==5148== at 0x4636A27: PyArray_MapIterReset (arrayobject.c:10242)
==5148== by 0x466B511: array_subscript (arrayobject.c:2549)
==5148== by 0x466C07B: array_subscript_nice (arrayobject.c:3173)
==5148== by 0x80C7235: PyEval_EvalFrameEx (ceval.c:1193)
==5148== by 0x80CB0D6: PyEval_EvalCodeEx (ceval.c:2836)
==5148== by 0x80C92DD: PyEval_EvalFrameEx (ceval.c:3669)
==5148== by 0x80C95C4: PyEval_EvalFrameEx (ceval.c:3659)
==5148== by 0x80CB0D6: PyEval_EvalCodeEx (ceval.c:2836)
==5148== by 0x81133BA: function_call (funcobject.c:517)
==5148== by 0x805CB36: PyObject_Call (abstract.c:1861)
==5148== by 0x80C7CE3: PyEval_EvalFrameEx (ceval.c:3853)
==5148== by 0x80CB0D6: PyEval_EvalCodeEx (ceval.c:2836)
The problem is inside the macro PyArrayIter_GOTO: some items of the argument
destination are accessed without having been set previously (when they are
swapped with the copyswap function).
|
_Original tickethttp://projects.scipy.org/numpy/ticket/333 on 2006-10-11 by
@FrancescAlted, assigned to unknown._
The next exposes the problem:
In [142]:dt1=numpy.dtype('i4')
In [143]:numpy.array(0, dtype=dt1.type)
Out[143]:array(0)
# good, but
In [144]:dt2=numpy.dtype(('i4',(2,)))
In [145]:numpy.array(0, dtype=dt2.type)
---------------------------------------------------------------------------
exceptions.MemoryError Traceback (most recent call last)
/home/faltet/python.nobackup/numpy/<ipython console>
MemoryError:
Moreover:
In [147]:numpy.array([0], dtype=dt1.type)
Out[147]:array([0])
# good, but
In [148]:numpy.array([0], dtype=dt2.type)
---------------------------------------------------------------------------
exceptions.TypeError Traceback (most recent call last)
/home/faltet/python.nobackup/numpy/<ipython console>
TypeError: expected a readable buffer object
I'd say that the .type is an scalar type that should be independent of the
shape of the base dtype.
| 1 |
### Bug report
Something now breaks this code that used to work. Now, I have to call
plt.subplots first and use stackplot on an axis object.
TypeError: stackplot() got multiple values for argument 'x'
from matplotlib import pyplot as plt
plt.stackplot([1,2,3], [1,2,3])
Should be equivalent to
fig, ax = plt.subplots()
ax.stackplot([1,2,3], [1,2,3])
**Matplotlib version**
* Operating system:
* Matplotlib version: 3.0.0
* Matplotlib backend (`print(matplotlib.get_backend())`): 'module://ipykernel.pylab.backend_inline'
* Python version: 3.6.6
* Jupyter version (if applicable): 4.4.0
* Other libraries:
Installed matplotlib using conda with default channel.
| 1 | |
Again from the paypal/bootstrap-accessibility-plugin, these changes should be
added to the documentation and the JS plugin.
### Tab Panel
1. ~~Add ARIA roles like tablist, presentation, and tab for tabs UL, LI.~~
2. Add tabIndex, ~~aria-expanded~~ , aria-selected, ~~aria-controls~~ for tab.
3. Add ARIA roles of ~~tabpanel~~ , tabIndex, aria-hidden, and aria-labelledBy for tabPanel.
4. Add keydown event listener for the tab to work with keyboard.
5. Dynamically flip tabIndex, aria-selected, and ~~aria-expanded~~ for tab when it is activated and add aria-hidden to hide the previously visible tab.
|
Please see following demo image, when text is too short, popover's arrow
should be correctly adjusted to point to the center of the label.
* image
http://cl.ly/image/0W38012y3K1H
I've created a simple fix for that, but it's doing from outside of the plugin,
would be great if it's integrated into the plugin itself, please see it here:
* sample code
https://gist.github.com/coodoo/5667953
| 0 |
When trying to run the test-suite on a fresh installation it breaks.
Long story short, doctests require `PIL` and `test_lda_predict` fails as well.
This has been done in a Linux machine. @martinagvilas can you replicate in
mac? thx.
cc: @lesteve
Here is what we did:
$ conda remove --name test-sklearn --all
$ conda create --name test-sklearn -y
$ conda activate test-sklearn
$ conda install -c conda-forge scikit-learn cython pytest
$ cd ~
$ python -c "import sklearn; print(sklearn.__version__)" # 0.21.3
$ conda remove --name test-sklearn scikit-learn --force-remove # keep dependencies
$ conda list | grep sklearn
$ cd ~/code/scikit-learn
$ pip install -e .
$ pytest sklearn
Here is the full pytest output
========================= test session starts ==========================
platform linux -- Python 3.7.3, pytest-5.1.2, py-1.8.0, pluggy-0.12.0
rootdir: /home/sik/code/scikit-learn, inifile: setup.cfg
collected 13419 items / 2 skipped / 13417 selected
sklearn/_config.py . [ 0%]
sklearn/discriminant_analysis.py .. [ 0%]
sklearn/exceptions.py .. [ 0%]
sklearn/isotonic.py . [ 0%]
sklearn/kernel_approximation.py .... [ 0%]
sklearn/kernel_ridge.py . [ 0%]
sklearn/naive_bayes.py .... [ 0%]
sklearn/pipeline.py .... [ 0%]
sklearn/random_projection.py ... [ 0%]
sklearn/cluster/affinity_propagation_.py . [ 0%]
sklearn/cluster/bicluster.py .. [ 0%]
sklearn/cluster/birch.py . [ 0%]
sklearn/cluster/dbscan_.py . [ 0%]
sklearn/cluster/hierarchical.py .. [ 0%]
sklearn/cluster/k_means_.py .. [ 0%]
sklearn/cluster/mean_shift_.py . [ 0%]
sklearn/cluster/spectral.py . [ 0%]
sklearn/cluster/tests/test_affinity_propagation.py ......... [ 0%]
sklearn/cluster/tests/test_bicluster.py ........s......... [ 0%]
sklearn/cluster/tests/test_birch.py ....... [ 0%]
sklearn/cluster/tests/test_dbscan.py ........................... [ 0%]
[ 0%]
sklearn/cluster/tests/test_feature_agglomeration.py . [ 0%]
sklearn/cluster/tests/test_hierarchical.py ..................... [ 0%]
................. [ 0%]
sklearn/cluster/tests/test_k_means.py .......................... [ 1%]
................................................................ [ 1%]
.................................. [ 1%]
sklearn/cluster/tests/test_mean_shift.py ............ [ 2%]
sklearn/cluster/tests/test_optics.py ........................... [ 2%]
............. [ 2%]
sklearn/cluster/tests/test_spectral.py .............. [ 2%]
sklearn/compose/_column_transformer.py .. [ 2%]
sklearn/compose/_target.py . [ 2%]
sklearn/compose/tests/test_column_transformer.py .ss.s........s. [ 2%]
...s............sssssssss.........................s.sss.. [ 2%]
sklearn/compose/tests/test_target.py ............. [ 3%]
sklearn/covariance/elliptic_envelope.py . [ 3%]
sklearn/covariance/empirical_covariance_.py . [ 3%]
sklearn/covariance/graph_lasso_.py .. [ 3%]
sklearn/covariance/robust_covariance.py . [ 3%]
sklearn/covariance/shrunk_covariance_.py .. [ 3%]
sklearn/covariance/tests/test_covariance.py ...... [ 3%]
sklearn/covariance/tests/test_elliptic_envelope.py .. [ 3%]
sklearn/covariance/tests/test_graphical_lasso.py ..... [ 3%]
sklearn/covariance/tests/test_robust_covariance.py ....... [ 3%]
sklearn/cross_decomposition/cca_.py . [ 3%]
sklearn/cross_decomposition/pls_.py ... [ 3%]
sklearn/cross_decomposition/tests/test_pls.py ........ [ 3%]
sklearn/datasets/base.py ....... [ 3%]
sklearn/datasets/samples_generator.py . [ 3%]
sklearn/datasets/tests/test_20news.py sss [ 3%]
sklearn/datasets/tests/test_base.py .................... [ 3%]
sklearn/datasets/tests/test_california_housing.py . [ 3%]
sklearn/datasets/tests/test_covtype.py s [ 3%]
sklearn/datasets/tests/test_kddcup99.py ss [ 3%]
sklearn/datasets/tests/test_lfw.py sssss [ 3%]
sklearn/datasets/tests/test_olivetti_faces.py s [ 3%]
sklearn/datasets/tests/test_openml.py ...........sssss.ssssss... [ 3%]
.................................................... [ 4%]
sklearn/datasets/tests/test_rcv1.py s [ 4%]
sklearn/datasets/tests/test_samples_generator.py ............... [ 4%]
............. [ 4%]
sklearn/datasets/tests/test_svmlight_format.py ...........s..... [ 4%]
...................................... [ 4%]
sklearn/decomposition/base.py . [ 4%]
sklearn/decomposition/factor_analysis.py . [ 4%]
sklearn/decomposition/fastica_.py . [ 4%]
sklearn/decomposition/incremental_pca.py .. [ 4%]
sklearn/decomposition/kernel_pca.py . [ 4%]
sklearn/decomposition/nmf.py .. [ 4%]
sklearn/decomposition/online_lda.py . [ 4%]
sklearn/decomposition/pca.py . [ 4%]
sklearn/decomposition/sparse_pca.py .. [ 4%]
sklearn/decomposition/truncated_svd.py . [ 4%]
sklearn/decomposition/tests/test_dict_learning.py .............. [ 5%]
..................................................... [ 5%]
sklearn/decomposition/tests/test_factor_analysis.py . [ 5%]
sklearn/decomposition/tests/test_fastica.py ......... [ 5%]
sklearn/decomposition/tests/test_incremental_pca.py ............ [ 5%]
........ [ 5%]
sklearn/decomposition/tests/test_kernel_pca.py .............. [ 5%]
sklearn/decomposition/tests/test_nmf.py ........................ [ 5%]
[ 5%]
sklearn/decomposition/tests/test_online_lda.py ................. [ 6%]
.............. [ 6%]
sklearn/decomposition/tests/test_pca.py ........................ [ 6%]
................................................................ [ 6%]
...................... [ 7%]
sklearn/decomposition/tests/test_sparse_pca.py .......s...... [ 7%]
sklearn/decomposition/tests/test_truncated_svd.py .............. [ 7%]
.................. [ 7%]
sklearn/ensemble/forest.py .. [ 7%]
sklearn/ensemble/partial_dependence.py .. [ 7%]
sklearn/ensemble/voting.py .. [ 7%]
sklearn/ensemble/weight_boosting.py .. [ 7%]
sklearn/ensemble/_hist_gradient_boosting/gradient_boosting.py .. [ 7%]
[ 7%]
sklearn/ensemble/_hist_gradient_boosting/tests/test_binning.py . [ 7%]
............................................. [ 7%]
sklearn/ensemble/_hist_gradient_boosting/tests/test_gradient_boosting.py . [ 7%]
................................................................ [ 8%]
............... [ 8%]
sklearn/ensemble/_hist_gradient_boosting/tests/test_grower.py .. [ 8%]
...................... [ 8%]
sklearn/ensemble/_hist_gradient_boosting/tests/test_histogram.py . [ 8%]
...... [ 8%]
sklearn/ensemble/_hist_gradient_boosting/tests/test_loss.py .... [ 8%]
....... [ 8%]
sklearn/ensemble/_hist_gradient_boosting/tests/test_predictor.py . [ 8%]
...... [ 8%]
sklearn/ensemble/_hist_gradient_boosting/tests/test_splitting.py . [ 8%]
............... [ 8%]
sklearn/ensemble/_hist_gradient_boosting/tests/test_warm_start.py . [ 8%]
............... [ 8%]
sklearn/ensemble/tests/test_bagging.py ......................... [ 9%]
...... [ 9%]
sklearn/ensemble/tests/test_base.py .... [ 9%]
sklearn/ensemble/tests/test_forest.py .......................... [ 9%]
................................................................ [ 9%]
................................................................ [ 10%]
............. [ 10%]
sklearn/ensemble/tests/test_gradient_boosting.py ............... [ 10%]
................................................................ [ 11%]
............................................... [ 11%]
sklearn/ensemble/tests/test_gradient_boosting_loss_functions.py . [ 11%]
.............. [ 11%]
sklearn/ensemble/tests/test_iforest.py .................... [ 11%]
sklearn/ensemble/tests/test_partial_dependence.py .....sssss [ 11%]
sklearn/ensemble/tests/test_voting.py ......................... [ 11%]
sklearn/ensemble/tests/test_weight_boosting.py ................. [ 12%]
.... [ 12%]
sklearn/experimental/enable_hist_gradient_boosting.py . [ 12%]
sklearn/experimental/enable_iterative_imputer.py . [ 12%]
sklearn/experimental/tests/test_enable_hist_gradient_boosting.py . [ 12%]
[ 12%]
sklearn/experimental/tests/test_enable_iterative_imputer.py . [ 12%]
sklearn/feature_extraction/dict_vectorizer.py .. [ 12%]
sklearn/feature_extraction/hashing.py . [ 12%]
sklearn/feature_extraction/image.py FF [ 12%]
sklearn/feature_extraction/text.py ... [ 12%]
sklearn/feature_extraction/tests/test_dict_vectorizer.py ....... [ 12%]
..................... [ 12%]
sklearn/feature_extraction/tests/test_feature_hasher.py ........ [ 12%]
.. [ 12%]
sklearn/feature_extraction/tests/test_image.py ................. [ 12%]
... [ 12%]
sklearn/feature_extraction/tests/test_text.py .................. [ 12%]
..............................................x.........x..x.... [ 13%]
..........x.................. [ 13%]
sklearn/feature_selection/rfe.py .. [ 13%]
sklearn/feature_selection/univariate_selection.py ...... [ 13%]
sklearn/feature_selection/variance_threshold.py . [ 13%]
sklearn/feature_selection/tests/test_base.py ..... [ 13%]
sklearn/feature_selection/tests/test_chi2.py ..... [ 13%]
sklearn/feature_selection/tests/test_feature_select.py ......... [ 13%]
................................ [ 13%]
sklearn/feature_selection/tests/test_from_model.py ............. [ 13%]
........ [ 14%]
sklearn/feature_selection/tests/test_mutual_info.py ........ [ 14%]
sklearn/feature_selection/tests/test_rfe.py ............ [ 14%]
sklearn/feature_selection/tests/test_variance_threshold.py ... [ 14%]
sklearn/gaussian_process/gpc.py . [ 14%]
sklearn/gaussian_process/gpr.py . [ 14%]
sklearn/gaussian_process/tests/test_gpc.py ..................... [ 14%]
............. [ 14%]
sklearn/gaussian_process/tests/test_gpr.py ..................... [ 14%]
................................................................ [ 15%]
. [ 15%]
sklearn/gaussian_process/tests/test_kernels.py ................. [ 15%]
................................................................ [ 15%]
................................................................ [ 16%]
................................................................ [ 16%]
............................................. [ 17%]
sklearn/impute/_base.py .. [ 17%]
sklearn/impute/_iterative.py . [ 17%]
sklearn/impute/_knn.py . [ 17%]
sklearn/impute/tests/test_impute.py ............................ [ 17%]
......ss..........ss............................................ [ 17%]
................................................................ [ 18%]
.. [ 18%]
sklearn/impute/tests/test_knn.py ............................... [ 18%]
........ [ 18%]
sklearn/inspection/partial_dependence.py .. [ 18%]
sklearn/inspection/tests/test_partial_dependence.py ............ [ 18%]
................................................................ [ 19%]
..................................................ssssssssssssss [ 19%]
[ 19%]
sklearn/inspection/tests/test_permutation_importance.py ..ss.s. [ 19%]
sklearn/linear_model/base.py . [ 19%]
sklearn/linear_model/bayes.py .. [ 19%]
sklearn/linear_model/coordinate_descent.py ......... [ 19%]
sklearn/linear_model/huber.py . [ 19%]
sklearn/linear_model/least_angle.py ..... [ 19%]
sklearn/linear_model/logistic.py .. [ 19%]
sklearn/linear_model/omp.py .. [ 19%]
sklearn/linear_model/passive_aggressive.py .. [ 19%]
sklearn/linear_model/perceptron.py . [ 19%]
sklearn/linear_model/ransac.py . [ 19%]
sklearn/linear_model/ridge.py .... [ 19%]
sklearn/linear_model/sag.py . [ 19%]
sklearn/linear_model/stochastic_gradient.py .. [ 19%]
sklearn/linear_model/theil_sen.py . [ 19%]
sklearn/linear_model/tests/test_base.py ....................... [ 20%]
sklearn/linear_model/tests/test_bayes.py ............. [ 20%]
sklearn/linear_model/tests/test_coordinate_descent.py .......... [ 20%]
........................................ [ 20%]
sklearn/linear_model/tests/test_huber.py .......... [ 20%]
sklearn/linear_model/tests/test_least_angle.py ................. [ 20%]
...................... [ 20%]
sklearn/linear_model/tests/test_logistic.py .................... [ 21%]
................................................................ [ 21%]
............s.....s............................................. [ 21%]
................................... [ 22%]
sklearn/linear_model/tests/test_omp.py .................. [ 22%]
sklearn/linear_model/tests/test_passive_aggressive.py .......... [ 22%]
...... [ 22%]
sklearn/linear_model/tests/test_perceptron.py ... [ 22%]
sklearn/linear_model/tests/test_ransac.py ...................... [ 22%]
. [ 22%]
sklearn/linear_model/tests/test_ridge.py ....................... [ 22%]
................................................................ [ 23%]
................................................................ [ 23%]
................................................................ [ 24%]
................................................................ [ 24%]
................ [ 24%]
sklearn/linear_model/tests/test_sag.py .................. [ 25%]
sklearn/linear_model/tests/test_sgd.py ......................... [ 25%]
................................................................ [ 25%]
................................................................ [ 26%]
........................................................... [ 26%]
sklearn/linear_model/tests/test_sparse_coordinate_descent.py ... [ 26%]
......... [ 26%]
sklearn/linear_model/tests/test_theil_sen.py ................. [ 26%]
sklearn/manifold/isomap.py . [ 26%]
sklearn/manifold/locally_linear.py . [ 26%]
sklearn/manifold/mds.py . [ 26%]
sklearn/manifold/spectral_embedding_.py . [ 26%]
sklearn/manifold/t_sne.py . [ 26%]
sklearn/manifold/tests/test_isomap.py ...... [ 26%]
sklearn/manifold/tests/test_locally_linear.py ....... [ 26%]
sklearn/manifold/tests/test_mds.py ... [ 26%]
sklearn/manifold/tests/test_spectral_embedding.py ....ss....... [ 27%]
sklearn/manifold/tests/test_t_sne.py ........................... [ 27%]
....................... [ 27%]
sklearn/metrics/classification.py ................. [ 27%]
sklearn/metrics/pairwise.py ...... [ 27%]
sklearn/metrics/ranking.py ........ [ 27%]
sklearn/metrics/regression.py .......... [ 27%]
sklearn/metrics/scorer.py . [ 27%]
sklearn/metrics/_plot/tests/test_plot_roc_curve.py sssssssssssss [ 27%]
[ 27%]
sklearn/metrics/cluster/supervised.py ....... [ 27%]
sklearn/metrics/cluster/tests/test_bicluster.py ... [ 27%]
sklearn/metrics/cluster/tests/test_common.py ................... [ 28%]
..................... [ 28%]
sklearn/metrics/cluster/tests/test_supervised.py ............... [ 28%]
.... [ 28%]
sklearn/metrics/cluster/tests/test_unsupervised.py ........... [ 28%]
sklearn/metrics/tests/test_classification.py ................... [ 28%]
........................................................... [ 29%]
sklearn/metrics/tests/test_common.py ........................... [ 29%]
................................................................ [ 29%]
................................................................ [ 30%]
................................................................ [ 30%]
................................................................ [ 31%]
................................................................ [ 31%]
................................................................ [ 32%]
................................................................ [ 32%]
................................................................ [ 33%]
................................................................ [ 33%]
.................... [ 33%]
sklearn/metrics/tests/test_pairwise.py ......................... [ 33%]
................................................................ [ 34%]
...........................x.x.................................. [ 34%]
.................................. [ 35%]
sklearn/metrics/tests/test_ranking.py .......................... [ 35%]
................................................................ [ 35%]
.... [ 35%]
sklearn/metrics/tests/test_regression.py ......... [ 35%]
sklearn/metrics/tests/test_score_objects.py .................... [ 36%]
........................................ [ 36%]
sklearn/mixture/tests/test_bayesian_mixture.py ................. [ 36%]
.. [ 36%]
sklearn/mixture/tests/test_gaussian_mixture.py ................. [ 36%]
.................... [ 36%]
sklearn/mixture/tests/test_mixture.py .. [ 36%]
sklearn/model_selection/_search.py .... [ 36%]
sklearn/model_selection/_split.py .............. [ 36%]
sklearn/model_selection/_validation.py s... [ 36%]
sklearn/model_selection/tests/test_search.py ................... [ 37%]
................................................. [ 37%]
sklearn/model_selection/tests/test_split.py .................... [ 37%]
................................................................ [ 38%]
..................... [ 38%]
sklearn/model_selection/tests/test_validation.py ............... [ 38%]
.......................................... [ 38%]
sklearn/neighbors/base.py .... [ 38%]
sklearn/neighbors/classification.py .. [ 38%]
sklearn/neighbors/graph.py .. [ 38%]
sklearn/neighbors/nca.py . [ 38%]
sklearn/neighbors/nearest_centroid.py . [ 38%]
sklearn/neighbors/regression.py .. [ 38%]
sklearn/neighbors/unsupervised.py . [ 38%]
sklearn/neighbors/tests/test_ball_tree.py ...................... [ 38%]
................................................................ [ 39%]
................................................................ [ 39%]
................................................................ [ 40%]
.................................. [ 40%]
sklearn/neighbors/tests/test_dist_metrics.py ................... [ 40%]
....................................... [ 40%]
sklearn/neighbors/tests/test_kd_tree.py ........................ [ 41%]
..................................................... [ 41%]
sklearn/neighbors/tests/test_kde.py ............................ [ 41%]
............ [ 41%]
sklearn/neighbors/tests/test_lof.py ............ [ 41%]
sklearn/neighbors/tests/test_nca.py ............................ [ 42%]
................................................................ [ 42%]
................................................................ [ 43%]
........................................................... [ 43%]
sklearn/neighbors/tests/test_nearest_centroid.py ......... [ 43%]
sklearn/neighbors/tests/test_neighbors.py ...................... [ 43%]
..................................................... [ 44%]
sklearn/neighbors/tests/test_quad_tree.py ........... [ 44%]
sklearn/neural_network/rbm.py . [ 44%]
sklearn/neural_network/tests/test_mlp.py ....................... [ 44%]
........ [ 44%]
sklearn/neural_network/tests/test_rbm.py ............ [ 44%]
sklearn/neural_network/tests/test_stochastic_optimizers.py ..... [ 44%]
. [ 44%]
sklearn/preprocessing/_discretization.py . [ 44%]
sklearn/preprocessing/_encoders.py .. [ 44%]
sklearn/preprocessing/data.py ............. [ 44%]
sklearn/preprocessing/label.py .... [ 44%]
sklearn/preprocessing/tests/test_common.py ......... [ 44%]
sklearn/preprocessing/tests/test_data.py ....................... [ 45%]
.............................................s.s.s.s...........s [ 45%]
.s.............................................................. [ 45%]
.......................................... [ 46%]
sklearn/preprocessing/tests/test_discretization.py ............. [ 46%]
............................... [ 46%]
sklearn/preprocessing/tests/test_encoders.py ..............sss.. [ 46%]
..........ss.........s......ss..ss...........s.............. [ 47%]
sklearn/preprocessing/tests/test_function_transformer.py ....... [ 47%]
s [ 47%]
sklearn/preprocessing/tests/test_label.py ...................... [ 47%]
............ [ 47%]
sklearn/semi_supervised/label_propagation.py ... [ 47%]
sklearn/semi_supervised/tests/test_label_propagation.py ........ [ 47%]
. [ 47%]
sklearn/svm/classes.py ....... [ 47%]
sklearn/svm/tests/test_bounds.py ................... [ 47%]
sklearn/svm/tests/test_sparse.py ............................... [ 48%]
[ 48%]
sklearn/svm/tests/test_svm.py .................................. [ 48%]
...................... [ 48%]
sklearn/tests/test_base.py .......................... [ 48%]
sklearn/tests/test_calibration.py ........... [ 48%]
sklearn/tests/test_check_build.py . [ 48%]
sklearn/tests/test_common.py ...................s............... [ 48%]
......s...........s............................................. [ 49%]
.......................................s.............s.......... [ 49%]
.........s..............ss...................................... [ 50%]
.............s.....................................s............ [ 50%]
................................................................ [ 51%]
...................................................s............ [ 51%]
.........................s...................................... [ 52%]
.......................s...................................s.... [ 52%]
....................................................s........... [ 53%]
................................................................ [ 53%]
................s........................s...................... [ 54%]
...............s......................................s......... [ 54%]
.....................s......................................s... [ 55%]
...............................................................s [ 55%]
...................s...........s................................ [ 56%]
................................................................ [ 56%]
...............................................................s [ 57%]
......................................s......................... [ 57%]
..........s......................................s.............. [ 58%]
................................................................ [ 58%]
................................................................ [ 59%]
.......................................s........................ [ 59%]
................................................................ [ 59%]
................................................................ [ 60%]
....................s.....................................s..... [ 60%]
................................................................ [ 61%]
................................................................ [ 61%]
..........................s..................................... [ 62%]
.............................s.................................. [ 62%]
................................................................ [ 63%]
.......................s........................................ [ 63%]
................................................................ [ 64%]
................................................................ [ 64%]
...s.......................................................s.... [ 65%]
................................................................ [ 65%]
................................................................ [ 66%]
................................................................ [ 66%]
................................................................ [ 67%]
................................................................ [ 67%]
................................................................ [ 68%]
................................................................ [ 68%]
............s...................................s............... [ 69%]
........................s....................................... [ 69%]
.....................................................s.......... [ 69%]
.............................s.................................. [ 70%]
................................................................ [ 70%]
................................................................ [ 71%]
................................................................ [ 71%]
.............................................................s.. [ 72%]
....................................................s........... [ 72%]
..............................s................................. [ 73%]
................................................................ [ 73%]
................................................................ [ 74%]
..................s............................................. [ 74%]
................................................................ [ 75%]
................................................................ [ 75%]
......................s......................s...s...........s.. [ 76%]
................................................................ [ 76%]
.........................................................s...... [ 77%]
................................................................ [ 77%]
................................................................ [ 78%]
................................................................ [ 78%]
...............................................................s [ 79%]
.......................................s........................ [ 79%]
................................................................ [ 79%]
............................................s................... [ 80%]
................................................................ [ 80%]
................................................................ [ 81%]
.....................s.......................................... [ 81%]
................................................................ [ 82%]
................................................................ [ 82%]
........................................................s....... [ 83%]
...............................s................................ [ 83%]
...s............................................................ [ 84%]
......s...................................s..................... [ 84%]
..............s......................................s.......... [ 85%]
..........................................................s..... [ 85%]
..................................s............................. [ 86%]
.......s......................................s................. [ 86%]
................................................................ [ 87%]
................................................................ [ 87%]
................................................................ [ 88%]
................................................................ [ 88%]
......................................................s......... [ 89%]
................................................................ [ 89%]
................................................................ [ 90%]
......................................................s......... [ 90%]
................................................................ [ 90%]
............................. [ 91%]
sklearn/tests/test_config.py ... [ 91%]
sklearn/tests/test_discriminant_analysis.py F................... [ 91%]
.......... [ 91%]
sklearn/tests/test_docstring_parameters.py ss [ 91%]
sklearn/tests/test_dummy.py .................................... [ 91%]
.................. [ 91%]
sklearn/tests/test_init.py . [ 91%]
sklearn/tests/test_isotonic.py ................................ [ 92%]
sklearn/tests/test_kernel_approximation.py .......... [ 92%]
sklearn/tests/test_kernel_ridge.py ........ [ 92%]
sklearn/tests/test_metaestimators.py . [ 92%]
sklearn/tests/test_multiclass.py ............................... [ 92%]
........ [ 92%]
sklearn/tests/test_multioutput.py ........................... [ 92%]
sklearn/tests/test_naive_bayes.py .............................. [ 92%]
................ [ 93%]
sklearn/tests/test_pipeline.py ................................. [ 93%]
........................... [ 93%]
sklearn/tests/test_random_projection.py ................ [ 93%]
sklearn/tests/test_site_joblib.py . [ 93%]
sklearn/tree/export.py ... [ 93%]
sklearn/tree/tree.py .. [ 93%]
sklearn/tree/tests/test_export.py ......ss [ 93%]
sklearn/tree/tests/test_reingold_tilford.py .. [ 93%]
sklearn/tree/tests/test_tree.py ................................ [ 93%]
................................................................ [ 94%]
................................................................ [ 94%]
................................................................ [ 95%]
......................................................... [ 95%]
sklearn/utils/__init__.py ........ [ 95%]
sklearn/utils/deprecation.py . [ 95%]
sklearn/utils/extmath.py .. [ 95%]
sklearn/utils/graph.py . [ 95%]
sklearn/utils/multiclass.py ... [ 95%]
sklearn/utils/testing.py . [ 95%]
sklearn/utils/validation.py . [ 95%]
sklearn/utils/tests/test_class_weight.py ........... [ 96%]
sklearn/utils/tests/test_cython_blas.py ........................ [ 96%]
.................... [ 96%]
sklearn/utils/tests/test_deprecation.py ... [ 96%]
sklearn/utils/tests/test_estimator_checks.py .......... [ 96%]
sklearn/utils/tests/test_extmath.py ........................... [ 96%]
sklearn/utils/tests/test_fast_dict.py .. [ 96%]
sklearn/utils/tests/test_fixes.py ...... [ 96%]
sklearn/utils/tests/test_linear_assignment.py . [ 96%]
sklearn/utils/tests/test_metaestimators.py .. [ 96%]
sklearn/utils/tests/test_multiclass.py ......s... [ 96%]
sklearn/utils/tests/test_murmurhash.py ...... [ 96%]
sklearn/utils/tests/test_optimize.py . [ 96%]
sklearn/utils/tests/test_pprint.py ......... [ 96%]
sklearn/utils/tests/test_random.py ..... [ 96%]
sklearn/utils/tests/test_seq_dataset.py ......... [ 97%]
sklearn/utils/tests/test_shortest_path.py .... [ 97%]
sklearn/utils/tests/test_show_versions.py ... [ 97%]
sklearn/utils/tests/test_sparsefuncs.py ........................ [ 97%]
......................................... [ 97%]
sklearn/utils/tests/test_testing.py ...........s.......... [ 97%]
sklearn/utils/tests/test_utils.py .............................. [ 97%]
.s...sssss...s..s..ssss..s..s..ssss..s..s..ssss..s........ssssss [ 98%]
ssssssssss........ssssssssssssssss..s..ssss..s..ssss..s..ssss... [ 98%]
s..s..s..s...s...s.ss........................................... [ 99%]
... [ 99%]
sklearn/utils/tests/test_validation.py ......................... [ 99%]
....................s.ss........................... [100%]
=============================== FAILURES ===============================
______ [doctest] sklearn.feature_extraction.image.PatchExtractor _______
459 deterministic.
460 See :term:`Glossary <random_state>`.
461
462
463 Examples
464 --------
465 >>> from sklearn.datasets import load_sample_images
466 >>> from sklearn.feature_extraction import image
467 >>> # Use the array data from the second image in this dataset:
468 >>> X = load_sample_images().images[1]
UNEXPECTED EXCEPTION: ImportError('The Python Imaging Library (PIL) is required to load data from jpeg files. Please refer to https://pillow.readthedocs.io/en/stable/installation.html for installing PIL.')
Traceback (most recent call last):
File "/home/sik/miniconda3/envs/test-sklearn/lib/python3.7/doctest.py", line 1329, in __run
compileflags, 1), test.globs)
File "<doctest sklearn.feature_extraction.image.PatchExtractor[2]>", line 1, in <module>
File "/home/sik/code/scikit-learn/sklearn/datasets/base.py", line 801, in load_sample_images
images = [imread(filename) for filename in filenames]
File "/home/sik/code/scikit-learn/sklearn/datasets/base.py", line 801, in <listcomp>
images = [imread(filename) for filename in filenames]
File "/home/sik/code/scikit-learn/sklearn/externals/_pilutil.py", line 204, in imread
raise ImportError(PILLOW_ERROR_MESSAGE)
ImportError: The Python Imaging Library (PIL) is required to load data from jpeg files. Please refer to https://pillow.readthedocs.io/en/stable/installation.html for installing PIL.
/home/sik/code/scikit-learn/sklearn/feature_extraction/image.py:468: UnexpectedException
____ [doctest] sklearn.feature_extraction.image.extract_patches_2d _____
334 The collection of patches extracted from the image, where `n_patches`
335 is either `max_patches` or the total number of patches that can be
336 extracted.
337
338 Examples
339 --------
340 >>> from sklearn.datasets import load_sample_image
341 >>> from sklearn.feature_extraction import image
342 >>> # Use the array data from the first image in this dataset:
343 >>> one_image = load_sample_image("china.jpg")
UNEXPECTED EXCEPTION: ImportError('The Python Imaging Library (PIL) is required to load data from jpeg files. Please refer to https://pillow.readthedocs.io/en/stable/installation.html for installing PIL.')
Traceback (most recent call last):
File "/home/sik/miniconda3/envs/test-sklearn/lib/python3.7/doctest.py", line 1329, in __run
compileflags, 1), test.globs)
File "<doctest sklearn.feature_extraction.image.extract_patches_2d[2]>", line 1, in <module>
File "/home/sik/code/scikit-learn/sklearn/datasets/base.py", line 838, in load_sample_image
images = load_sample_images()
File "/home/sik/code/scikit-learn/sklearn/datasets/base.py", line 801, in load_sample_images
images = [imread(filename) for filename in filenames]
File "/home/sik/code/scikit-learn/sklearn/datasets/base.py", line 801, in <listcomp>
images = [imread(filename) for filename in filenames]
File "/home/sik/code/scikit-learn/sklearn/externals/_pilutil.py", line 204, in imread
raise ImportError(PILLOW_ERROR_MESSAGE)
ImportError: The Python Imaging Library (PIL) is required to load data from jpeg files. Please refer to https://pillow.readthedocs.io/en/stable/installation.html for installing PIL.
/home/sik/code/scikit-learn/sklearn/feature_extraction/image.py:343: UnexpectedException
___________________________ test_lda_predict ___________________________
def test_lda_predict():
# Test LDA classification.
# This checks that LDA implements fit and predict and returns correct
# values for simple toy data.
for test_case in solver_shrinkage:
solver, shrinkage = test_case
clf = LinearDiscriminantAnalysis(solver=solver, shrinkage=shrinkage)
y_pred = clf.fit(X, y).predict(X)
assert_array_equal(y_pred, y, 'solver %s' % solver)
# Assert that it works with 1D data
y_pred1 = clf.fit(X1, y).predict(X1)
assert_array_equal(y_pred1, y, 'solver %s' % solver)
# Test probability estimates
y_proba_pred1 = clf.predict_proba(X1)
assert_array_equal((y_proba_pred1[:, 1] > 0.5) + 1, y,
'solver %s' % solver)
y_log_proba_pred1 = clf.predict_log_proba(X1)
assert_array_almost_equal(np.exp(y_log_proba_pred1), y_proba_pred1,
> 8, 'solver %s' % solver)
E AssertionError:
E Arrays are not almost equal to 8 decimals
E solver svd
E Mismatch: 16.7%
E Max absolute difference: 5.9604645e-08
E Max relative difference: 4.7683716e-07
E x: array([[9.9999994e-01, 1.1253517e-07],
E [9.9966466e-01, 3.3535002e-04],
E [9.9966466e-01, 3.3535002e-04],...
E y: array([[9.99999881e-01, 1.12535155e-07],
E [9.99664664e-01, 3.35350138e-04],
E [9.99664664e-01, 3.35350138e-04],...
sklearn/tests/test_discriminant_analysis.py:80: AssertionError
======================= short test summary info ========================
SKIPPED [3] /home/sik/code/scikit-learn/sklearn/ensemble/_hist_gradient_boosting/tests/test_compare_lightgbm.py:17: could not import 'lightgbm': No module named 'lightgbm'
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: This test is failing on the buildbot, but cannot reproduce. Temporarily disabling it until it can be reproduced and fixed.
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/compose/tests/test_column_transformer.py:132: could not import 'pandas': No module named 'pandas'
SKIPPED [2] /home/sik/code/scikit-learn/sklearn/compose/tests/test_column_transformer.py:263: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/compose/tests/test_column_transformer.py:467: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/compose/tests/test_column_transformer.py:538: could not import 'pandas': No module named 'pandas'
SKIPPED [9] /home/sik/code/scikit-learn/sklearn/compose/tests/test_column_transformer.py:812: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/compose/tests/test_column_transformer.py:1054: could not import 'pandas': No module named 'pandas'
SKIPPED [2] /home/sik/code/scikit-learn/sklearn/compose/tests/test_column_transformer.py:1091: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/compose/tests/test_column_transformer.py:1125: could not import 'pandas': No module named 'pandas'
SKIPPED [3] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Download 20 newsgroups to run this test
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Covertype dataset can not be loaded.
SKIPPED [2] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: kddcup99 dataset can not be loaded.
SKIPPED [5] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: PIL not installed.
SKIPPED [1] sklearn/datasets/tests/test_olivetti_faces.py:20: Download Olivetti faces dataset to run this test
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:289: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:329: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:348: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:389: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:426: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:478: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:490: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:518: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:557: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:595: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/datasets/tests/test_openml.py:633: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Download RCV1 dataset to run this test.
SKIPPED [1] sklearn/datasets/tests/test_svmlight_format.py:188: testing the overflow of 32 bit sparse indexing requires a large amount of memory
SKIPPED [1] sklearn/decomposition/tests/test_sparse_pca.py:134: skipping mini_batch_fit_transform.
SKIPPED [34] /home/sik/code/scikit-learn/sklearn/conftest.py:18: could not import 'matplotlib': No module named 'matplotlib'
SKIPPED [2] /home/sik/code/scikit-learn/sklearn/impute/tests/test_impute.py:315: could not import 'pandas': No module named 'pandas'
SKIPPED [2] /home/sik/code/scikit-learn/sklearn/impute/tests/test_impute.py:428: could not import 'pandas': No module named 'pandas'
SKIPPED [2] /home/sik/code/scikit-learn/sklearn/inspection/tests/test_permutation_importance.py:52: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/inspection/tests/test_permutation_importance.py:114: could not import 'pandas': No module named 'pandas'
SKIPPED [2] /home/sik/code/scikit-learn/sklearn/linear_model/tests/test_logistic.py:1306: liblinear does not support multinomial logistic
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/manifold/tests/test_spectral_embedding.py:166: could not import 'pyamg': No module named 'pyamg'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/manifold/tests/test_spectral_embedding.py:196: could not import 'pyamg': No module named 'pyamg'
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/doctest.py:351: all tests skipped by +SKIP option
SKIPPED [4] /home/sik/code/scikit-learn/sklearn/preprocessing/tests/test_data.py:866: 'with_mean=True' cannot be used with sparse matrix.
SKIPPED [2] /home/sik/code/scikit-learn/sklearn/preprocessing/tests/test_data.py:1077: RobustScaler cannot center sparse matrix
SKIPPED [3] /home/sik/code/scikit-learn/sklearn/preprocessing/tests/test_encoders.py:127: could not import 'pandas': No module named 'pandas'
SKIPPED [2] /home/sik/code/scikit-learn/sklearn/preprocessing/tests/test_encoders.py:283: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/preprocessing/tests/test_encoders.py:378: could not import 'pandas': No module named 'pandas'
SKIPPED [4] /home/sik/code/scikit-learn/sklearn/preprocessing/tests/test_encoders.py:450: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/preprocessing/tests/test_encoders.py:584: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/preprocessing/tests/test_function_transformer.py:157: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Can't instantiate estimator ColumnTransformer which requires parameters ['transformers']
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Can't instantiate estimator FeatureUnion which requires parameters ['transformer_list']
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Can't instantiate estimator GridSearchCV which requires parameters ['estimator', 'param_grid']
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Can't instantiate estimator Pipeline which requires parameters ['steps']
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Can't instantiate estimator RandomizedSearchCV which requires parameters ['estimator', 'param_distributions']
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Can't instantiate estimator SparseCoder which requires parameters ['dictionary']
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Can't instantiate estimator VotingClassifier which requires parameters ['estimators']
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Can't instantiate estimator VotingRegressor which requires parameters ['estimators']
SKIPPED [50] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: pandas is not installed: not testing for input of type pandas.Series to class weight.
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: score_samples of BernoulliRBM is not invariant when applied to a subset.
SKIPPED [3] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Skipping check_estimators_data_not_an_array for cross decomposition module as estimators are not deterministic.
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: predict of DummyClassifier is not invariant when applied to a subset.
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: transform of MiniBatchSparsePCA is not invariant when applied to a subset.
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Not testing NuSVC class weight as it is ignored.
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: decision_function of NuSVC is not invariant when applied to a subset.
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: transform of SparsePCA is not invariant when applied to a subset.
SKIPPED [2] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: numpydoc is required to test the docstrings
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/utils/tests/test_multiclass.py:299: could not import 'pandas': No module named 'pandas'
SKIPPED [37] /home/sik/code/scikit-learn/sklearn/utils/tests/test_utils.py:239: could not import 'pandas': No module named 'pandas'
SKIPPED [39] /home/sik/code/scikit-learn/sklearn/utils/tests/test_utils.py:242: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/utils/tests/test_utils.py:423: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/utils/tests/test_utils.py:444: could not import 'pandas': No module named 'pandas'
SKIPPED [2] /home/sik/code/scikit-learn/sklearn/utils/tests/test_utils.py:466: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/miniconda3/envs/test-sklearn/lib/python3.7/site-packages/_pytest/unittest.py:238: Pandas not found
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/utils/tests/test_validation.py:719: could not import 'pandas': No module named 'pandas'
SKIPPED [1] /home/sik/code/scikit-learn/sklearn/utils/tests/test_validation.py:732: could not import 'pandas': No module named 'pandas'
= 3 failed, 13147 passed, 265 skipped, 6 xfailed, 1572 warnings in 409.77s (0:06:49) =
This problem is unconstrained.
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 3 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 1.38629D+02 |proj g|= 6.27865D+01
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
3 1 2 1 0 0 2.422D+01 9.713D+01
F = 97.133816163368223
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT
Cauchy time 0.000E+00 seconds.
Subspace minimization time 0.000E+00 seconds.
Line search time 0.000E+00 seconds.
Total User time 0.000E+00 seconds.
Here is the output of `conda list`
# packages in environment at /home/sik/miniconda3/envs/test-sklearn:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
atomicwrites 1.3.0 py_0 conda-forge
attrs 19.1.0 py_0 conda-forge
bzip2 1.0.8 h516909a_0 conda-forge
ca-certificates 2019.6.16 hecc5488_0 conda-forge
certifi 2019.6.16 py37_1 conda-forge
cython 0.29.13 py37he1b5a44_0 conda-forge
importlib_metadata 0.20 py37_0 conda-forge
joblib 0.13.2 pypi_0 pypi
libblas 3.8.0 12_openblas conda-forge
libcblas 3.8.0 12_openblas conda-forge
libffi 3.2.1 he1b5a44_1006 conda-forge
libgcc-ng 9.1.0 hdf63c60_0
libgfortran-ng 7.3.0 hdf63c60_0
liblapack 3.8.0 12_openblas conda-forge
libopenblas 0.3.7 h6e990d7_1 conda-forge
libstdcxx-ng 9.1.0 hdf63c60_0
more-itertools 7.2.0 py_0 conda-forge
ncurses 6.1 hf484d3e_1002 conda-forge
numpy 1.17.1 py37h95a1406_0 conda-forge
openssl 1.1.1c h516909a_0 conda-forge
packaging 19.0 py_0 conda-forge
pip 19.2.3 py37_0 conda-forge
pluggy 0.12.0 py_0 conda-forge
py 1.8.0 py_0 conda-forge
pyparsing 2.4.2 py_0 conda-forge
pytest 5.1.2 py37_0 conda-forge
python 3.7.3 h33d41f4_1 conda-forge
readline 8.0 hf8c457e_0 conda-forge
scikit-learn 0.22.dev0 dev_0 <develop>
scipy 1.3.1 py37h921218d_2 conda-forge
setuptools 41.2.0 py37_0 conda-forge
six 1.12.0 py37_1000 conda-forge
sqlite 3.29.0 hcee41ef_1 conda-forge
tk 8.6.9 hed695b0_1002 conda-forge
wcwidth 0.1.7 py_1 conda-forge
wheel 0.33.6 py37_0 conda-forge
xz 5.2.4 h14c3975_1001 conda-forge
zipp 0.6.0 py_0 conda-forge
zlib 1.2.11 h516909a_1005 conda-forge
|
I haven't followed the openmp building in detail but it looks like on OS X and
windows building are now failing by default?
That's pretty annoying for sprinting with a bigger group and also can raise
the frustration level of new contributors who are likely to be on these OSs
| 1 |
# Environment
Microsoft Windows [Version 10.0.18362.418]
# Steps to reproduce
Open windows terminal and move it with cursor to a new screen in a dual screen
setup. Specifically from a 4k to 1080p monitor.
# Expected behavior
The windows terminal window should move to the other screen.
# Actual behavior
The window when moved to the other screen freezes and then crashes.
Note: It works if the windows terminal window starts and is maximised on the
first monitor and then is win+shift+arrowed to the other monitor. No crash but
if it is not maximized and either moved by way of win+shift+arrows OR cursor
drag then it crashes.
|
# Environment
Windows build number: Microsoft Windows [Version 10.0.18362.418]
Windows Terminal version (if applicable): 0.6.2951.0
# Steps to reproduce
1. Open Windows Terminal with "only one tab open"
2. Drag to another monitor with a lower resolution (from 2160p to 1080p)
# Expected behavior
Terminal is dragged onto another monitor
# Actual behavior
It crashes.
Funny thing: The terminal doesn't crash when I have more than one tab open.
| 1 |
**TypeScript Version:**
1.8.9
React.__spread has been deprecated for a while, and has been removed in 15.0.
(facebook/react@`a142fd2`)
When upgrading a typescript project to React 0.15, an error is shown that
`React.__spread is not defined` when using spread props.
It looks like it'll be turned into a warning instead
soon(facebook/react@`fc1cfb6`), but it's advisable to migrate tsx
transformations from using `React.__spread` to using `Object.assign`
|
**TypeScript Version:**
1.8.10
Node version :v4.2.2
OS: OSX
**Code**
**Main.ts**
/// <reference path="./typings/node/node.d.ts"/>
import * as http from 'http';
namespace Scratch
{
export class ServerWrapper {
public constructor() {
this.server = http.createServer();
}
public Start(handler :(request :http.ClientRequest, response :http.ClientResponse)=>void) :void {
this.server.listen(handler);
}
private server : http.Server;
}
var s = new Scratch.ServerWrapper();
s.Start((req,res)=>{});
}
Compile with
tsc ./Main.ts --outFile /dev/stdout
**Expected behavior:** (what is emitted as Main.js when --outFile is not
specified)
"use strict";
var http = require('http');
var Scratch;
(function (Scratch) {
var ServerWrapper = (function () {
function ServerWrapper() {
this.server = http.createServer();
}
ServerWrapper.prototype.Start = function (handler) {
this.server.listen(handler);
};
return ServerWrapper;
}());
Scratch.ServerWrapper = ServerWrapper;
var s = new Scratch.ServerWrapper();
s.Start(function (req, res) { });
})(Scratch || (Scratch = {}));
**Actual behavior:**
/// <reference path="./typings/node/node.d.ts"/>
| 0 |
**I'm submitting a ...** (check one with "x")
[X] bug report => search github for a similar issue or PR before submitting
[ ] feature request
[ ] support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
**Current behavior**
A plain element attribute (no syntax sugar) containing a number value is being
bound to the component as a string value.
**Expected behavior**
The attribute would be converted to the data type of the input variable it's
being bound to... or at the very least the compiler would warn me of the data-
type mismatch.
**Reproduction of the problem**
Create a component with the following property that uses the Input decorator:
`@Input('maxlength') public maxLength: number;`
Use the custom component somewhere like so:
`<custom-component maxlength="250"></custom-component>`
Note that the "maxLength" property in the JavaScript code contains a string
value despite being defined as a number data type.
**What is the motivation / use case for changing the behavior?**
I want to be able to use a strict equals (===) to compare "maxLength" to
"length", but that doesn't work if "maxLength" is a string and "length" is a
number.
**Please tell us about your environment:**
Windows 8.1, Visual Studio 2015, npm, IIS Express 10
* **Angular version:** 2.0.0
* **Browser:** Chrome 52.0.2743.116
* **Language:** TypeScript 1.8.10
* **Node (for AoT issues):** `node --version` = using JIT, not AoT
|
When building reusable components, using boolean properties, such as
`checked`, `disabled`, `readonly`, etc., is extremely common. This ends up
looking like this:
class CoolCheckbox {
private _checked: boolean;
@Input()
get checked() {
return this._checked;
}
set checked(v: boolean) {
// Is "checked" if *any* value is present other than `false` or `"false"`.
this._checked = value != null && `${value}` !== 'false';
}
}
This is a _lot_ of boilerplate to create a simple boolean bound property, and
something that needs to be done for _every_ boolean `@Input`. The same problem
also applies to `number` inputs.
A simple approach for TypeScript users might be to create their own decorator,
something like
@Input() @BooleanField() checked: boolean;
Unfortunately, this is incompatible with using the offline-compiler, as the
presence of user-defined decorators prevents tree-shaking. As such, this seems
to be something that should really be built into the framework itself. This
could look something like:
class CoolCheckbox {
@BooleanInput() checked: boolean;
}
@pkozlowski-opensource has encountered the same friction for ngBootstrap.
cc @tbosch @mhevery
| 1 |
Original report at SourceForge, opened Fri Feb 11 22:02:28 2011
One of the annoying things about axes.hist is that with histtype='step' the
automatic legend style is an empty box, instead of a line, as I would expect.
This behaviour doesn't seem to make sense, because it seems a line would be
much more appropriate for this case. Example code to demonstrate this:
import matplotlib.pyplot as plt
plt.hist([0,1,1,2,2,2], [0,1,2,3], histtype='step', label="histtype='step'")
plt.legend()
plt.show()
With the current uncustomisability of legend styles one can get around this by
using proxy Line2D objects in building the legend, but this can be a common
operation and becomes messy and annoying.
The cause of this is the fact that in axes.py::7799 (current SVN head), in
axes.hist, patch objects are always created, even for the line-based step
style. I searched the tracker, and couldn't find this mentioned before.
Attached is a patch that makes the very simple change of swapping out the call
to .fill for .plot (only the function is changed here, not yet the
documentation), and it appears to work but I haven't tested exhaustively.
* Is this intended behaviour, that I am just not understanding the requirement for?
* This will cause the return signature to possibly include Line2D's, instead of just patches. Will this break anything?
Thoughts?
### SourceForge History
* On Fri Feb 11 22:02:28 2011, by ndevenish: File Added: 401440: histtype_plot.patch
|
### Bug report
**Bug summary**
**Code for reproduction**
# Paste your code here
#
#
**Actual outcome**
# If applicable, paste the console output here
#
#
**Expected outcome**
**Matplotlib version**
* Operating system:
* Matplotlib version:
* Matplotlib backend (`print(matplotlib.get_backend())`):
* Python version:
* Jupyter version (if applicable):
* Other libraries:
| 0 |
I have a general question about project structures / modules.
It's a project with 3 types of code:
* client: classes used for the client web-app, built into a single js file (with --out).
* server: code running on node
* shared: classes used by both client and server, typically model classes with functions like validation, etc
My aim is this:
* use 1 file per 1 class at the source level
* deploy the client app into a single output file (for performance reasons: better start up time), the server can be deployed as many files (or if possible and makes sense from a perf. point of view it can be a single file too). These can be 2 separate compilations, the client with --out and the server with commonjs.
* reuse the shared model classes (without duplication) in the client and the server
* be able to use circular dependencies (although shared code will not depend on client/node code, only the other way around, circular dependencies can only occur in within the client code)
I can't seem to achieve these goals. The problem is this:
* if I structure the shared code so that I only use the ///<reference.../> tags (like I do in the client) that won't be usable when compiling the server with common.js
* if I use common.js style requires in the shared code then that won't work for the client's single file --out compilation
These are the options I think I have:
* switch to using require js (amd) in the client as opposed to references and the single file output, and maybe use some post compile script to concatenate the modules to a single file. However circular dependencies may occur sometimes and that's a big issue I have with require.js
* switch to using es6 style module syntax and use it on the client and in node with some polyfills/loaders until natively supported
* switch to using commonjs style modules and load them with browserify on the client
* do a pre-compilation step and transform the shared code to be eligible once for the client side single output compilation and once for the node.js side common.js compilation. However this can have many caveats and sounds like a hack.
What I think I'm really looking for is a way for each TypeScript class/file to
be able to "say" what is the class it exports, but not specify how it will be
consumed, ie. via commonjs or as a single file output. Probably that's not
possible though in a simple way?
|
I have a general question about project structures / modules.
It's a project with 3 types of code:
* client: classes used for the client web-app, built into a single js file (with --out).
* server: code running on node
* shared: classes used by both client and server, typically model classes with functions like validation, etc
My aim is this:
* use 1 file per 1 class at the source level
* deploy the client app into a single output file (for performance reasons: better start up time), the server can be deployed as many files (or if possible and makes sense from a perf. point of view it can be a single file too). These can be 2 separate compilations, the client with --out and the server with commonjs.
* reuse the shared model classes (without duplication) in the client and the server
* be able to use circular dependencies (although shared code will not depend on client/node code, only the other way around, circular dependencies can only occur in within the client code)
I can't seem to achieve these goals. The problem is this:
* if I structure the shared code so that I only use the ///<reference.../> tags (like I do in the client) that won't be usable when compiling the server with common.js
* if I use common.js style requires in the shared code then that won't work for the client's single file --out compilation
These are the options I think I have:
* switch to using require js (amd) in the client as opposed to references and the single file output, and maybe use some post compile script to concatenate the modules to a single file. However circular dependencies may occur sometimes and that's a big issue I have with require.js
* switch to using es6 style module syntax and use it on the client and in node with some polyfills/loaders until natively supported
* switch to using commonjs style modules and load them with browserify on the client
* do a pre-compilation step and transform the shared code to be eligible once for the client side single output compilation and once for the node.js side common.js compilation. However this can have many caveats and sounds like a hack.
What I'm really looking for is a way for each TypeScript class/file to be able
to "say" what is the class it exports, but not specify how it will be
consumed, ie. via commonjs or as a single file output. Probably that's not
possible though in a simple way?
| 1 |
The generated code for
type NameOrNameArray = string | string[];
function createName(name) {
if (typeof name === "string") {
return name;
} else if (typeof name == 'number') {
return name.toString();
} else {
return name.join(" ");
}
}
var greetingMessage = `Greetings, ${createName(3213) }`;
alert(greetingMessage);
is
function createName(name) {
if (typeof name === "string") {
return name;
}
else if (typeof name == 'number') {
return name.toString();
}
else {
return name.join(" ");
}
}
the else after } should not newline.
|
I know many users of TypeScript are from a C# background and expect to write
conditionals like in that language. However, for JavaScript developers the
standard for formatting conditionals is different. When TypeScript converts
conditionals to JavaScript, it outputs the `else` and `else if` statements
like so:
}
else if(whatever) {
}
else {
}
The normal JavaScript format is:
} else if (whatever) {
} else {
}
Most teams have coding rules and code review mechanisms in place to make sure
these conventions are followed. For a reference on standard JavaScript
formatting conventions, please consult Douglas Crockford's guide:
http://javascript.crockford.com/code.html. About half way down you'll find the
convention for conditionals.
At very least it would be nice to have a flag that we could set to get the
expected formatting instead of the C/C# style you are currently producing.
| 1 |
does not validate with swagger-tools CLI tool:
https://github.com/apigee-127/swagger-tools/blob/master/docs/CLI.md#validate
|
After #18126 fixed by #18170, I run density test again.
Now the hot spot on the critical path is an inefficient cache
access(https://github.com/kubernetes/kubernetes/blob/master/pkg/client/cache/store.go#L75)
when listing nodes that uses reflection. Reflection causes a lot of
allocations.
A simple fix would be
func NodeKeyFunc(obj interface{}) (string, error) {
key, ok := obj.(*api.Node)
if !ok {
return "", fmt.Errorf("not *api.Node type")
}
meta := key.ObjectMeta
if len(meta.Namespace) > 0 {
return meta.Namespace + "/" + meta.Name, nil
}
return meta.Name, nil
}
The simple fix improves the throughput of scheduler by 15%-20% on 1000 nodes
case.
@lavalamp What do you think about this issue?
/cc @hongchaodeng @wojtek-t @gmarek @davidopp
| 0 |
#### Describe the workflow you want to enable
Current score_func for feature selection methods does not consider
multicollinearity between features.
#### Describe your proposed solution
Introduce mRMR (Minimum Redundancy and Maximum Relevance) score as score_func
for feature selection methods.
Variant of mRMR scores in a nutshell:
* MID: Mutual Information to target - Mutual Information between features
* MIQ: Mutual Information to target / Mutual Information between features
* FCD: F Statistic to target - Correlation between features
* FCQ: F Statistic to target / Correlation between features
From what I understand Mutual Information and F Statistic already implemented
as score_func in scikit-learn, so these mRmR scores are somewhat an extension
of it.
|
Speaking with @jorisvandenbossche IRL, we come to discuss about the mRMR
feature selection among other methods.
#5372 intended at first to implement the mRMR with mutual information as a
metric. However, it has been merged such that mutual information could be used
in the `SelectKBest` class. It was also discuss that the mRMR mechanism could
be implemented in a separate PR with the possibility to plug any metric.
Therefore, I was wondering if scikit-learn will be interested to have this
transformer to perform feature selection.
I would be interested to know the different opinions
@agramfort @MechCoder @jnothman @GaelVaroquaux @amueller @jorisvandenbossche
| 1 |
Now that TypeScript does control flow based type analysis, and there is a
`never` type in the works, is it possible to consider providing better type
checking around `assert(...)` function calls that assert that a variable has a
certain type at runtime?
**TL;DR: some`assert` functions are really just type guards that signal via
`return`/`throw` rather than `true`/`false`.** Example:
assert(typeof s === "string"); // throws if s is not a string
s.length; // s is narrowed to string here...
### Problem
Asserts are common in contract-based programming, but I've also been coming
across this scenario regularly whilst traversing JavaScript ASTs based on the
Parser API (I'm using babel to produce/traverse ASTs).
For example, consider the `MemberExpression`:

Note we can assume `property` is an `Identifier` if `computed===false`. This
is what I'd like to write:
function foo(expr: MemberExprssion) {
if (expr.computed) {
// handle computed case
}
else {
// since computed===false, we know property must be an Identifier
assert(isIdentifier(expr.property));
let name = expr.property.name; // ERROR: name doesn't exist on Identifier|Expression
}
}
Unfortunately that doesn't compile, because `expr.property` does not get
narrowed after the `assert(...)` call.
To get the full benefit of control flow analysis currently, you have to expand
the assert call inline:
...
else {
if (!isIdentifier(expr.property)) {
throw new AssertionError(`Expected property to be an Identifier`);
}
let name = expr.property.name; // OK
}
...
While preparing the typings for `babel-core`, `babel-types` and friends, I
noticed that using asserts this way is the norm. `babel-types` actually
provides an `assertXXX` method for every `isXXX` method. These `assertXXX`
functions are really just type guards that signal via `return`/`throw` rather
than `true`/`false`.
### Possible Solutions?
Not sure if it's feasible at all! But the new work on `never` in #8652
suggests a few possibilities.
#### Specific assertions: assertIsT(...)
// normal type guard
function isIdentifier(n: Node): n is Identifier {
return n.type === 'Identifier';
}
// PROPOSED SYNTAX: assert type guard
function assertIdentifier(n: Node): n is Identifier | never {
if (n.type !== 'Identifier') {
throw new AssertionError(`Expected an Identifier`);
}
}
The compiler would reason that if this assert call returns at all, then it can
safely narrow the variable type in following code.
#### General assertions used with type guards: assert(isT(...))
The more general `assert(cond: boolean)` function would need a different
approach and might not be feasible, but here's an idea:
// General case
declare function assert(cond: boolean): void;
// PROPOSED SYNTAX: Special overload for expressions of the form assert(isT(x))
declare function assert<T>(guard: guard is T): void | never;
For that second `assert` overload to work, the compiler on seeing
`assert(isT(x))` would have to somehow forward the `x is T` narrowing from the
`isT(x)` expression to the `assert(...)` expression at compile-time.
Would be great if it also detected/handled things like `assert(typeof x ==
'string')`.
Not sure if any of this would meet the cost/benefit bar, but it's just an
idea.
|
When writing a node software that should create a batch or symbolic link, we
need to put the folowing line at the begining of the .js file:
#!/bin/node
So npm knows it is a node executable script and creates a batch file with all
the necessary stuff in it.
If we put it at a typescript file to be transpiled to javascript, it works,
but gives annoying compilation error.
I purpose that lines started with `#!` shoud be treated as a special case of
commentary line that should always go to the transpiled file.
| 0 |
Became important when you extend, for example, `DefaultValueAccessor` to work
with `ng-model`
and see a list of errors:
ERROR in ./rating/rating.ts
(50,5): Supplied parameters do not match any signature of call target. (2346)
ERROR in ./timepicker/timepicker.ts
(151,5): Supplied parameters do not match any signature of call target. (2346)
...
I was trying to do it my self but, but constructor type parameters are come as
string, not parsed, to dgeni templates
|
Dgeni should output public constructors in our .d.ts files
| 1 |
### Environment info
Operating System: Ubuntu 14.04 LTS 64-bit
Installed version of CUDA and cuDNN: none (not using GPU)
### Steps to reproduce
Note: TensorFlow was installed previously.
1. Install Bazel as instructed here: http://www.bazel.io/docs/install.html#install-on-ubuntu
2. Install Android Studio (which includes the SDK).
3. Install Android NDK through the Android Studio SDK Manager.
4. Download and unzip the TensorFlow graph as instructed here: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/android/README.md
5. Uncomment the Android entries in the WORKSPACE file and add in paths to the SDK and NDK (in my case, these were `/home/me/Android/Sdk` and `/home/me/android-studio/android-studio/plugins/android-ndk`)
6. Run `$ bazel build //tensorflow/examples/android:tensorflow_demo`
### What have you tried?
1. I've looked around, and my understanding is that the RELEASE.TXT file is not included in the most recent version of the Android NDK. Since the NDK installed via Android Studio is a .jar file, I wasn't sure what to do with that, so I went to the path indicated by the terminal log and created a blank RELEASE.TXT file. This made no difference.
2. According to #1468, it can be resolved by downgrading to an earlier version of the NDK which contains RELEASE.TXT. I downloaded the version of Bazel (for Linux) from the links given, but the downloaded file is a .bin, which is unusable to me. As such, I found this solution to be a dead end.
3. Commenting out the NDK entry is said to resolve the issue, but I haven't tried this yet, since I don't know if it'll cause more complications down the road.
### Logs or other output that would be helpful
ERROR: no such package '@androidndk//': Could not read RELEASE.TXT in Android NDK: /home/me/.cache/bazel/_bazel_me/f3471be34d1e62bf21975aa777cedaa3/external/androidndk/ndk/RELEASE.TXT (No such file or directory).
ERROR: no such package '@androidndk//': Could not read RELEASE.TXT in Android NDK: /home/me/.cache/bazel/_bazel_me/f3471be34d1e62bf21975aa777cedaa3/external/androidndk/ndk/RELEASE.TXT (No such file or directory).
Is there another way to resolve this issue without downgrading or commenting
out the NDK entry? If not, how can I install a previous version of Android
NDK? Thanks in advance.
|
GitHub issues are for bugs / installation problems / feature requests.
For general support from the community, see StackOverflow.
To make bugs and feature requests more easy to find and organize, we close
issues that are deemed
out of scope for GitHub Issues and point people to StackOverflow.
For bugs or installation issues, please provide the following information.
The more information you provide, the more easily we will be able to offer
help and advice.
### Environment info
Operating System:
OS X EI Capitan version 10.11.3
If installed from sources, provide the commit hash:
`13ea3ca`
### Steps to reproduce
1. Build TensorFlow without uncommenting the Android SDK and NDK parts successfully.
2. We can
import tensorflow
in python environment after step 1 and following installation steps.
4\. Download SDK and NDK from what
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/android/README.md
suggested.
3\. Uncomment the Android SDK and NDK repository in WORKSPACE and change the
path.
4\. Rebuild using
$ bazel build -c opt //tensorflow/tools/pip_package:build_pip_package
the console returns the error,
ERROR: .../tensorflow/WORKSPACE:10:1: no such package '@androidndk//': Could not read RELEASE.TXT in Android NDK: /private/var/tmp/.../49fff0428.../external/androidndk/ndk/RELEASE.TXT (No such file or directory) and referenced by '//external:android/crosstool'.
### What have you tried?
1. Commenting NDK repository and leave the SDK in TensorFlow WORKSPACE, build using
$ bazel build -c opt //tensorflow/tools/pip_package:build_pip_package
passed and without error.
2.Finding that Downloaded NDK and NDK in
/private/var/tmp/.../49fff0428.../external/androidndk/ndk are the same. And
there are no RELEASE.TXT in in directory.
### Logs or other output that would be helpful
(If logs are large, please upload as attachment).
ERROR: .../tensorflow/WORKSPACE:10:1: no such package '@androidndk//': Could not read RELEASE.TXT in Android NDK: /private/var/tmp/.../49fff0428.../external/androidndk/ndk/RELEASE.TXT (No such file or directory) and referenced by '//external:android/crosstool'.
Is this error due to the codes or my building processes?
| 1 |
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
### Environment
* Dubbo version: >= 2.7.0
* Operating System version: xxx
* Java version: xxx
### Steps to reproduce this issue
Pls. provide [GitHub address] to reproduce this issue.
issue: #5480
### Expected Result
What do you expected from the above steps?
用户从dubbo 2.6.x升级到apache dubbo
2.7.x时,会存在一些兼容依赖缺失,比如AbstractRegistry、LoggerXxx和其他扩展点兼容问题,导致一些扩展dubbo的一些组件无法良好工作。
期望&建议:
* dubbo 2.7.x 中compatible的模块剥离成独立repository, 形成复用依赖
* 对独立的compatible repository做扩展点梳理和依赖增强(支持更完善)
* 用户dubbo 2.6.x升级上来时,一些扩展能力和基础组件(比如sdk),添加对应 compatible依赖都可以良好工作,提升用户使用体验
### Actual Result
What actually happens?
If there is an exception, please attach the exception trace:
Just put your stack trace here!
|
* I have searched the issues of this repository and believe that this is not a duplicate.
* I have checked the FAQ of this repository and believe that this is not a duplicate.
### Environment
* Dubbo version: 2.7.3(with maven groupId: org.apache.dubbo) (upgrade from 2.6.5 with groupId: com.alibaba)
* Operating System version: CentOS Linux release 7.3.1611 (Core)
* Java version: Oracle JDK 1.8
### Steps to reproduce this issue
1. (Dubbo 2.6.5) Provider-side program with `provider.xml` (Spring-Context-Configuration), which without `metadata-report` configuration. And accesslog enabled:
<dubbo:protocol name="dubbo" port="21881" server="netty" register="true" accesslog="logs/access.log"/>
<!-- 接口的位置 -->
<dubbo:service interface="xxx.xxx.xxxService"
ref="xxxService" timeout="10000" retries="3"
executes="100" loadbalance="leastactive"
accesslog="logs/access-xxx.log" register="true"
owner="jk" group="gp" version="1.0" />
2. Launching the program, and accesslog print exactly.
3. (Upgrade to 2.7.3) Enable metadata-report (I'm not sure whether this affects. Then I tried without metadata-report configuration, and it still not works.), with configuration:
<dubbo:metadata-report address="zookeeper://zk1.registry.gp.org:2181" cycle-report="false" sync-report="true"/>
4. Restart the provider-side program, console got log:
2019-11-05 14:55:28 [DUBBO] You specified the config centre, but there's not even one single config item in it., dubbo version: 2.7.3, current host: 192.168.10.***
2019-11-05 14:55:28 [DUBBO] You specified the config centre, but there's not even one single config item in it., dubbo version: 2.7.3, current host: 192.168.10.***
2019-11-05 14:55:28 [DUBBO] There's no valid monitor config found, if you want to open monitor statistics for Dubbo, please make sure your monitor is configured properly., dubbo version: 2.7.3, current host: 192.168.10.***
and the accesslog file, which specified with path `logs/access-xxx.log` does
NOT print any access log data.
5\. Remove metadata-report configuration, and restart the provider-side
program, the same scene appears in step 4.
6\. I debugged the code, the AccessLogFilter class in dubbo-2.7.3.jar got an
invoker with URL
`dubbo://192.168.10.xxx:20881/xxx.xxx.xxxService?accesslog=logs/access-
xxx.log&anyhost=true&application=platform-xxx-
provider&bean.name=xxx.xxx.xxxService&bind.ip=192.168.10.***&bind.port=20881&deprecated=false&dubbo=2.0.2&dynamic=true&executes=16&generic=false&group=gp&interface=xxx.xxx.xxxService&loadbalance=leastactive&methods=advanced,simple&owner=jk&pid=106617&qos.accept.foreign.ip=false&qos.enable=false&qos.port=33333®ister=true&release=2.7.3&retries=3&revision=1.0.0&server=netty&side=provider&timeout=10000×tamp=1572936930641&version=1.0`
Here we got a parameter named `accesslog` in the URL, but the code retrieved
`dubbo.accesslog` key which assigned by static final variable `ACCESS_LOG_KEY`
in this class, and then got `null` value with accessLogKey variable during the
invoke function below:
@Override
public Result invoke(Invoker<?> invoker, Invocation inv) throws RpcException {
try {
String accessLogKey = invoker.getUrl().getParameter(ACCESS_LOG_KEY);
if (ConfigUtils.isNotEmpty(accessLogKey)) {
AccessLogData logData = buildAccessLogData(invoker, inv);
log(accessLogKey, logData);
}
} catch (Throwable t) {
logger.warn("Exception in AccessLogFilter of service(" + invoker + " -> " + inv + ")", t);
}
return invoker.invoke(inv);
}
AND, I also tried the source code with dubbo-2.6.5 (maven groupId:
com.alibaba), and got different Java implementation source bellow (Notice
that, the `Constants.ACCESS_LOG_KEY` has value `accesslog` assigned, and same
value in 2.7.3 with maven groupId: org.apache.dubbo):
@Override
public Result invoke(Invoker<?> invoker, Invocation inv) throws RpcException {
try {
String accesslog = invoker.getUrl().getParameter(Constants.ACCESS_LOG_KEY);
if (ConfigUtils.isNotEmpty(accesslog)) {
RpcContext context = RpcContext.getContext();
String serviceName = invoker.getInterface().getName();
String version = invoker.getUrl().getParameter(Constants.VERSION_KEY);
String group = invoker.getUrl().getParameter(Constants.GROUP_KEY);
...
####
BTW: The bugfix 4374 shows that this was fixed, but not specified the fixed
version.
### Expected Result
Those accesslog configurations should also work, or some other ways to meet
the accesslog needs.
BTW: It seems that the AccessLogFilter.ACCESS_LOG_KEY used correctly, and
value assigned correctly here. Since it works before metadata-report
configured. But when metadata-report configured, it does not work. Is the URL
value generated correctly?
### Actual Result
I have read the documents of accesslog, but neither the `Logging by logging
framework` part nor the `Logging by specified file path` part works.
If there is an exception, please attach the exception trace:
NO EXCEPTION. CONFIGURATION NOT WORK.
| 0 |
Atom Version: 0.174.0
OS: Windows 7 x64
My Atom Version is 0.174.0, but release note is always 0.158

|
1. Install `linter-jshint`
2. Try doing some javascript
For some reason, these errors aren't occouring in other javascript files in
the same session. Also, this is the same session that I installed linter-
jshint on, through the GUI package installer in `Edit > Preferences`.
**Atom Version** : 0.165.0
**System** : linux 3.13.0-43-generic
**Thrown From** : Atom Core
### Stack Trace
Uncaught Error: Cannot find module './load-config'
At module.js:346
Error: Cannot find module './load-config'
at Module._resolveFilename (module.js:344:15)
at Function.Module._resolveFilename (/usr/share/atom/resources/app/src/module-cache.js:380:52)
at Function.Module._load (module.js:286:25)
at Module.require (module.js:373:17)
at require (module.js:392:17)
at /home/athan/.atom/packages/jshint/node_modules/lazy-req/index.js:6:43
at lint (/home/athan/.atom/packages/jshint/index.js:156:34)
at delayed (/usr/share/atom/resources/app/node_modules/roaster/node_modules/cheerio/node_modules/lodash/dist/lodash.js:5408:27)
### Commands
6x -6:52.9 core:backspace (input.hidden-input)
-6:50.5 core:confirm (input.hidden-input)
-6:44.8 core:undo (atom-workspace.workspace.scrollbars-visible-always.theme-seti-syntax.theme-seti-ui)
13x -6:34.8 core:move-right (input.hidden-input)
6x -6:33.8 core:backspace (input.hidden-input)
-6:32.0 core:confirm (input.hidden-input)
-6:10.6 editor:newline (input.hidden-input)
-5:52.7 core:backspace (input.hidden-input)
-5:44.8 core:save (atom-workspace.workspace.scrollbars-visible-always.theme-seti-syntax.theme-seti-ui)
3x -2:42.2 core:move-down (input.hidden-input)
-1:59.3 core:delete (input.hidden-input)
-1:59.2 core:move-down (input.hidden-input)
-1:56.9 editor:newline (input.hidden-input)
-1:18.3 core:save (input.hidden-input)
-0:59.3 core:confirm (input.hidden-input)
-0:00.0 core:save (input.hidden-input)
### Config
{
"core": {
"themes": [
"seti-ui",
"seti-syntax"
]
},
"editor": {
"showIndentGuide": true,
"showInvisibles": true,
"softWrap": true,
"fontSize": 25,
"invisibles": {},
"softWrapAtPreferredLineLength": true
}
}
### Installed Packages
# User
atom-beautify, v0.21.2
autocomplete-plus, v1.1.0
color-picker, v1.2.6
git-log, v0.2.0
ide-haskell, v0.3.0
javascript-snippets, v1.0.0
jsformat, v0.7.18
language-haml, v0.14.0
language-haskell, v1.0.0
language-javascript-semantic, v0.1.0
linter, v0.9.1
linter-csslint, v0.0.11
linter-erb, v0.0.3
linter-hlint, v0.3.1
linter-htmlhint, v0.0.8
linter-jshint, v0.1.0
linter-jsonlint, v0.1.2
minimap, v3.5.4
script, v2.16.0
seti-syntax, v0.2.1
seti-ui, v0.6.1
travis-ci-status, v0.11.1
# Dev
No dev packages
| 0 |
**Do you want to request a _feature_ or report a _bug_?**
both.
**What is the current behavior?**
There is a existed issue #3926 but it is just one of the problems in some kind
of browsers.
I have uploaded the detail, demo files, test results and temporary solution in
react-compositionevent
The main problem is when users type these words from IME(Chinese, Japanese or
maybe Korean) and do something like search the database or filter out from
some data, sometimes these functions will be unworkable. For example, if users
type "ni" during the composition session, maybe it will be one of "你尼泥腻" in
Chinese or one of "にニ尼煮" in Japanese. But in this moment, the `change` event
also be fired. If the search or filter functions of the application are
designed to be invoked when `change` event occured, there maybe something
wrong logically. These functions should be invoked after users finished the
composition session.
In React, there are three synthetic events - `onCompositionEnd`,
`onCompositionStart` and `onCompositionUpdate`. If the input
components(`<input...>` and `<textarea.../>`) are "uncontrolled", we can use
them to help `onChange` to capture the text correctly. The only different
point is Google Chrome change its events sequence after v53. Check Cinput.js
and Ctextarea.js files.
But if these input components are "controlled", it will be hard to solve the
problem.
Because these the `value` of a controlled component is came from `state`. We
can't modify `state` directly and the only way to update state is using
`this.setState()` to schedule update. But `this.setState()` may be
asynchronous.
After test, i found different OS/browsers could have different results. I have
written some code to solve it. But i thought it isn't a good solution. It uses
the browser detection and two properties of the `state` object. One is for
input, another is for internal functions(search, filter...etc). It can't just
use one property of the `state` object because i can't stop any `change`
events, state need it to update the value of the input element. If i stop some
change events during composition session, i would get nothing after typing
these words from IME.
**If the current behavior is a bug, please provide the steps to reproduce and
if possible a minimal demo of the problem viahttps://jsfiddle.net or similar
(template: https://jsfiddle.net/reactjs/69z2wepo/).**
You can use online test demo: https://eyesofkids.github.io/
or use a normal input component(controlled/uncontrolled) to test.
**What is the expected behavior?**
The input(and textarea) controlled components in React should ensure these
fired "change" and "composition" events is consistent in different browsers. I
found there are 3 different results(events fired sequence) at least.
**Which versions of React, and which browser / OS are affected by this issue?
Did this work in previous versions of React?**
* React 15.4.1
* browsers: chrome, firefox, safari, opera, ie, edge
* OS: macOS, win7, win10
|
### Extra details
* Similar discussion with extra details and reproducing analysis: #8683
* Previous attempt to fix it: #8438 (includes some unit tests, but sufficient to be confident in the fix)
* * *
### Original Issue
When I was trying this example from
https://facebook.github.io/react/blog/2013/11/05/thinking-in-react.html, any
Chinese characters inputted by Chinese pinyin input method would fire too many
renders like:

Actually I would expect those not to fire before I confirm the Chinese
character.
Then I tried another kind of input method - wubi input method, I got this:

It's weird too. So I did a test in jQuery:

Only after I press the space bar to confirm the character, the `keyup` event
would fire.
I know it might be different between the implementation of jQuery `keyup` and
react `onChange` , but I would expect the way how jQuery `keyup` handles
Chinese characters instead of react's `onChange`.
| 1 |
## 🐛 Bug
## To Reproduce
Steps to reproduce the behavior:
[root@ip-172-26-11-98 ~]# python3.9 -m pip install torch==1.7.0+cpu torchvision==0.8.1+cpu torchaudio==0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
Looking in links: https://download.pytorch.org/whl/torch_stable.html
ERROR: Could not find a version that satisfies the requirement torch==1.7.0+cpu (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2)
ERROR: No matching distribution found for torch==1.7.0+cpu
## Expected behavior
Successful installation of torch
## Environment
* PyTorch Version (e.g., 1.0): 1.7
* OS (e.g., Linux): CentOS 7.8
* How you installed PyTorch (`conda`, `pip`, source): pip
* Build command you used (if compiling from source):
* Python version: 3.9
* CUDA/cuDNN version:
* GPU models and configuration:
* Any other relevant information: I had built Python3.9 from source.
## Additional context
I had built Python 3.9 this way:
yum install openssl-devel readline-devel libuuid-devel gdbm-devel sqlite-devel bzip bzip2-devel libffi-devel
wget https://www.python.org/ftp/python/3.9.0/Python-3.9.0.tgz
tar -xzf Python-3.9.0.tgz
rm -rf Python-3.9.0.tgz
cd Python-3.9.0
mkdir build
cd build
../configure --sbindir=/usr/bin/python3.9
make
make install
|
## 🐛 Windows LibTorch C++ Cannot Load CUDA Module
`th.jit.trace()`'ing or `th.jit.script()`'ing even just a Conv2d module will
produce a serialized file that cannot be loaded by the C++ runtime. See the
following two example scripts for a repro:
import torch as th
from torch import nn
d = th.nn.Conv2d(3, 3, 1, 1, 0).cuda()
z = th.zeros(1, 3, 256, 256).cuda()
th.jit.script(d).save("smod.ptj") # Also fails if this is th.jit.trace(d, (z,))
#include <iostream>
#include <torch/script.h>
int main() {
try {
auto mod = torch::jit::load("smod.ptj");
} catch(c10::Error& e) {
std::cerr << e.what() << std::endl;
return 1;
}
return 0;
}
## To Reproduce
Steps to reproduce the behavior:
1. Run the above python script.
2. Compile + run the above C++ program.
The exception text is:
cuda_dispatch_ptr INTERNAL ASSERT FAILED at C:\w\1\s\windows\pytorch\aten\src\ATen/native/DispatchStub.h:70, please report a bug to PyTorch. DispatchStub: missing CUDA kernel (operator () at C:\w\1\s\windows\pytorch\aten\src\ATen/native/DispatchStub.h:70)
(no backtrace available)
and is thrown at `include\ATen\core\TensorMethods.h:249` (the end of an inline
`copy_` method).
Problem persists with latest master builds as well.
I used linux to dump the module since installing pytorch from anaconda
currently results in a pytorch that will not import:
from torch._C import *
ImportError: DLL load failed: The specified procedure could not be found.
## Expected behavior
C++ program returns 0 w/no errors displayed.
## Environment
* PyTorch Version (e.g., 1.0): 1.2 stable (also nightly)
* OS (e.g., Linux): Windows
* How you installed PyTorch (`conda`, `pip`, source): conda (linux), pytorch.org (win binaries)
* Build command you used (if compiling from source):
* Python version: 3.7
* CUDA/cuDNN version: 10.0 / 3.6
* GPU models and configuration: Titan RTX
cc @peterjc123
| 0 |
### Preflight Checklist
* I have read the Contributing Guidelines for this project.
* I agree to follow the Code of Conduct that this project adheres to.
* I have searched the issue tracker for an issue that matches the one I want to file, without success.
### Issue Details
* **Electron Version:**
* 6.0.0-beta3
* **Operating System:**
* macOS 10.13.6 10.14.4 / Windows 7 -->
* **Last Known Working Electron version:** :
* 5.0.1
### Expected Behavior
Clicked button in renderer process, then show file chooser dialog and choose
local files.
### Actual Behavior
Clicked button in renderer process, then crash electron app.
### To Reproduce
1. Clone and start sample app
$ git clone https://github.com/agata/crash-electron-with-file-picker-dialog.git
$ cd ./crash-electron-with-file-picker-dialog
$ npm install
$ npm start
3. Click a button in the app -> Crash electron app
### Screenshots
#### Electron 5.0.1
#### Electron 6.0.0-beta.3
Screencast: Electron-6.0.0-beta.3.mov.zip
### Additional Information
|
* Electron version: 1.8.2-beta1
* Operating system: Mac 10.12.6
### Expected behavior
Not crash
### Actual behavior
crash
### How to reproduce
It seems like use auto-updater.check() may be crash. Not 100% occur
the crash report
perating system: Mac OS X
10.12.5 16F73
CPU: amd64
family 6 model 70 stepping 1
8 CPUs
GPU: UNKNOWN
Crash reason: EXC_BAD_ACCESS / EXC_I386_GPFLT
Crash address: 0x1046326e3
Process uptime: 6447 seconds
Thread 14 (crashed)
0 Electron Framework!<name omitted> [transport_security_state.cc : 865 + 0x3]
rax = 0xbadda3319a85bead rdx = 0x00007f962ff47030
rcx = 0x00007f962fe25a20 rbx = 0x00007f962fe25a20
rsi = 0x00007f962fe25b00 rdi = 0x0000600000628a20
rbp = 0x000070000e2b2150 rsp = 0x000070000e2b20d0
r8 = 0x000070000e2b2120 r9 = 0x000070000e2b2008
r10 = 0x0000000000000000 r11 = 0x0000000000000000
r12 = 0x0000000000000000 r13 = 0x00007f962fe25a68
r14 = 0x00007f962ff47030 r15 = 0x0000000000000000
rip = 0x00000001046326e3
Found by: given as instruction pointer in context
1 Electron Framework!net::SSLClientSocketImpl::VerifyCT() [ssl_client_socket_impl.cc : 1557 + 0x5]
rbp = 0x000070000e2b21d0 rsp = 0x000070000e2b2160
rip = 0x000000010461e70a
Found by: previous frame's frame pointer
2 Electron Framework!net::SSLClientSocketImpl::DoVerifyCertComplete(int) [ssl_client_socket_impl.cc : 1231 + 0x8]
rbp = 0x000070000e2b22a0 rsp = 0x000070000e2b21e0
rip = 0x000000010461e4ab
Found by: previous frame's frame pointer
3 Electron Framework!net::SSLClientSocketImpl::DoHandshakeLoop(int) [ssl_client_socket_impl.cc : 1325 + 0xb]
rbp = 0x000070000e2b2300 rsp = 0x000070000e2b22b0
rip = 0x000000010461c08d
Found by: previous frame's frame pointer
4 Electron Framework!net::SSLClientSocketImpl::OnHandshakeIOComplete(int) [ssl_client_socket_impl.cc : 1288 + 0x5]
rbp = 0x000070000e2b2340 rsp = 0x000070000e2b2310
rip = 0x000000010461dbe5
Found by: previous frame's frame pointer
5 Electron Framework!net::CachingCertVerifier::OnRequestFinished(net::CertVerifier::RequestParams const&, base::Time, base::Callback<void (int), (base::internal::CopyMode)1, (base::internal::RepeatMode)1> const&, net::CertVerifyResult*, int) [callback.h : 80 + 0x3]
rbp = 0x000070000e2b2370 rsp = 0x000070000e2b2350
rip = 0x0000000104443699
Found by: previous frame's frame pointer
6 Electron Framework!net::CertVerifierJob::OnJobCompleted(std::__1::unique_ptr<net::(anonymous namespace)::ResultHelper, std::__1::default_delete<net::(anonymous namespace)::ResultHelper> >) [callback.h : 91 + 0x7]
rbp = 0x000070000e2b2400 rsp = 0x000070000e2b2380
rip = 0x0000000104530317
Found by: previous frame's frame pointer
7 Electron Framework!base::internal::Invoker<base::internal::BindState<void (net::CertVerifierJob::*)(std::__1::unique_ptr<net::(anonymous namespace)::ResultHelper, std::__1::default_delete<net::(anonymous namespace)::ResultHelper> >), base::WeakPtr<net::CertVerifierJob>, base::internal::PassedWrapper<std::__1::unique_ptr<net::(anonymous namespace)::ResultHelper, std::__1::default_delete<net::(anonymous namespace)::ResultHelper> > > >, void ()>::Run(base::internal::BindStateBase*) [bind_internal.h : 214 + 0x3]
rbp = 0x000070000e2b2560 rsp = 0x000070000e2b2410
rip = 0x00000001045307ca
Found by: previous frame's frame pointer
8 Electron Framework!base::(anonymous namespace)::PostTaskAndReplyRelay::RunReplyAndSelfDestruct() [callback.h : 91 + 0x3]
rbp = 0x000070000e2b2590 rsp = 0x000070000e2b2570
rip = 0x0000000102d264a7
Found by: previous frame's frame pointer
9 Electron Framework!<name omitted> [callback.h : 91 + 0x3]
rbp = 0x000070000e2b26d0 rsp = 0x000070000e2b25a0
rip = 0x0000000102d4f721
Found by: previous frame's frame pointer
10 Electron Framework!<name omitted> [message_loop.cc : 423 + 0xf]
rbp = 0x000070000e2b27a0 rsp = 0x000070000e2b26e0
rip = 0x0000000102d17adb
Found by: previous frame's frame pointer
11 Electron Framework!<name omitted> [message_loop.cc : 434 + 0xb]
rbp = 0x000070000e2b27c0 rsp = 0x000070000e2b27b0
rip = 0x0000000102d17e2c
Found by: previous frame's frame pointer
12 Electron Framework!<name omitted> [message_loop.cc : 527 + 0xb]
rbp = 0x000070000e2b2950 rsp = 0x000070000e2b27d0
rip = 0x0000000102d181e3
Found by: previous frame's frame pointer
13 Electron Framework!<name omitted> [message_pump_libevent.cc : 219 + 0x9]
rbp = 0x000070000e2b29c0 rsp = 0x000070000e2b2960
rip = 0x0000000102d1aa05
Found by: previous frame's frame pointer
14 Electron Framework!<name omitted> [message_loop.cc : 387 + 0x9]
rbp = 0x000070000e2b2b10 rsp = 0x000070000e2b29d0
rip = 0x0000000102d177ae
Found by: previous frame's frame pointer
15 Electron Framework!base::RunLoop::Run() [run_loop.cc : 37 + 0x5]
rbp = 0x000070000e2b2ba0 rsp = 0x000070000e2b2b20
rip = 0x0000000102d308e3
Found by: previous frame's frame pointer
16 Electron Framework!<name omitted> [browser_thread_impl.cc : 278 + 0x5]
rbp = 0x000070000e2b2cf0 rsp = 0x000070000e2b2bb0
rip = 0x0000000102fa7ce8
Found by: previous frame's frame pointer
17 Electron Framework!<name omitted> [browser_thread_impl.cc : 313 + 0xb]
rbp = 0x000070000e2b2e50 rsp = 0x000070000e2b2d00
rip = 0x0000000102fa7e76
Found by: previous frame's frame pointer
18 Electron Framework!<name omitted> [thread.cc : 333 + 0xd]
rbp = 0x000070000e2b2ec0 rsp = 0x000070000e2b2e60
rip = 0x0000000102d52789
Found by: previous frame's frame pointer
19 Electron Framework!base::(anonymous namespace)::ThreadFunc(void*) [platform_thread_posix.cc : 71 + 0x8]
rbp = 0x000070000e2b2ef0 rsp = 0x000070000e2b2ed0
rip = 0x0000000102d257b7
Found by: previous frame's frame pointer
20 libsystem_pthread.dylib + 0x393b
rbp = 0x000070000e2b2f10 rsp = 0x000070000e2b2f00
rip = 0x00007fffb828b93b
Found by: previous frame's frame pointer
21 libsystem_pthread.dylib + 0x3887
rbp = 0x000070000e2b2f50 rsp = 0x000070000e2b2f20
rip = 0x00007fffb828b887
Found by: previous frame's frame pointer
22 libsystem_pthread.dylib + 0x308d
rbp = 0x000070000e2b2f78 rsp = 0x000070000e2b2f60
rip = 0x00007fffb828b08d
Found by: previous frame's frame pointer
23 Electron Framework + 0x25f760
rsp = 0x000070000e2b3028 rip = 0x0000000102d25760
Found by: stack scanning
| 0 |
## 🐛 Bug
I am trying to have a generator load objects in the background, as in the
following example. It hangs when trying to call `torch.zeros` in
`split_loader_creator`, but if I remove the seemingly irrelevant line
`torch.zeros(152*4, 168*4).float()` near the end, it seemingly can make
progress. It also seems fine if I change `152*4` and `168*4` to much smaller
numbers. This is on PyTorch 1.5.1, and I do not encounter the issue on 1.4.0.
Am I somehow doing this multiprocessing incorrectly?
## To Reproduce
Run the following code:
import torch
import multiprocessing
import atexit
def split_loader_creator():
for i in range(20):
yield torch.zeros(10, 170, 70)
def background_generator_helper(gen_creator):
def _bg_gen(gen_creator, conn):
gen = gen_creator()
while conn.recv():
try:
conn.send(next(gen))
except StopIteration:
conn.send(StopIteration)
return
except Exception:
import traceback
traceback.print_exc()
parent_conn, child_conn = multiprocessing.Pipe()
p = multiprocessing.Process(target=_bg_gen, args=(gen_creator, child_conn))
p.start()
atexit.register(p.terminate)
parent_conn.send(True)
while True:
parent_conn.send(True)
x = parent_conn.recv()
if x is StopIteration:
return
else:
yield x
def background_generator(gen_creator): # get several processes in the background fetching batches in parallel to keep up with gpu
generator = background_generator_helper(gen_creator)
while True:
batch = next(generator)
if batch is StopIteration:
return
yield batch
torch.zeros(152*4, 168*4).float()
data_loader = background_generator(split_loader_creator)
for i, batch in enumerate(data_loader):
print(i)
## Expected behavior
I expect this script to print the first few integers, but it just hangs at
`torch.zeros` in `split_loader_creator`.
## Environment
* PyTorch Version (e.g., 1.0): 1.5.1
* OS (e.g., Linux): Linux
* How you installed PyTorch (`conda`, `pip`, source): conda
* Build command you used (if compiling from source): n/a
* Python version: 3.6.10
* CUDA/cuDNN version: 10.2 (though I think I got the issue on 10.1 as well)
* GPU models and configuration: Quadro RTX 6000 though the same bug happened for me on other GPUs as well
* Any other relevant information: I suspect it's related to PyTorch, since as mentioned before I didn't encounter the issue on PyTorch 1.4.0. The issue also occurs on 1.5.0.
## Additional context
Someone else also confirmed they could reproduce the issue:
https://discuss.pytorch.org/t/pytorch-hangs-in-thread-after-large-torch-zeros-
call-in-main-process/88484/3
cc @ezyang @gchanan @zou3519
|
## 🐛 Bug
The following program never terminates.
import torch
import torch.multiprocessing as mp
def foo():
x = torch.ones((2, 50, 10))
return torch.einsum('ijl,ikl->ijk', x, x)
if __name__ == '__main__':
foo()
p = mp.Process(target=foo)
p.start()
p.join()
The behavior persists if one changes the `einsum` inside `foo` with an
equivalent operation (e.g., `bmm(y, y.transpose(1,2))`, or `(y.unsqueeze(2) *
y.unsqueeze(1)).sum(3)`.
It doesn't reproduce, however, if one doesn't call `foo` inside the main
block.
## Environment
PyTorch version: 1.0.1.post2
Is debug build: No
CUDA used to build PyTorch: 9.0.176
OS: Arch Linux
GCC version: (GCC) 8.2.1 20181127
CMake version: version 3.13.4
Python version: 3.7
Is CUDA available: No
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
## Additional context
Perhaps related to #2245.
| 1 |
As shown in the example below, when passing in two series with the same name
to `concat` you end up with duplicates of the last series passed in.
In [42]: pd.__version__
Out[42]: '0.10.1'
In [43]: dates = pd.date_range('01-Jan-2013','01-Dec-2013', freq='MS')
...: L = pd.TimeSeries('L', dates, name='LeftRight')
...: R = pd.TimeSeries('R', dates, name='LeftRight')
...:
In [44]: L
Out[44]:
2013-01-01 L
2013-02-01 L
2013-03-01 L
2013-04-01 L
2013-05-01 L
2013-06-01 L
2013-07-01 L
2013-08-01 L
2013-09-01 L
2013-10-01 L
2013-11-01 L
2013-12-01 L
Freq: MS, Name: LeftRight
In [45]: R
Out[45]:
2013-01-01 R
2013-02-01 R
2013-03-01 R
2013-04-01 R
2013-05-01 R
2013-06-01 R
2013-07-01 R
2013-08-01 R
2013-09-01 R
2013-10-01 R
2013-11-01 R
2013-12-01 R
Freq: MS, Name: LeftRight
In [46]: pd.concat([L,R], axis=1)
Out[46]:
LeftRight LeftRight
2013-01-01 R R
2013-02-01 R R
2013-03-01 R R
2013-04-01 R R
2013-05-01 R R
2013-06-01 R R
2013-07-01 R R
2013-08-01 R R
2013-09-01 R R
2013-10-01 R R
2013-11-01 R R
2013-12-01 R R
In [47]: pd.concat([L,R], axis=1, keys=['Left','Right'])
Out[47]:
Left Right
2013-01-01 L R
2013-02-01 L R
2013-03-01 L R
2013-04-01 L R
2013-05-01 L R
2013-06-01 L R
2013-07-01 L R
2013-08-01 L R
2013-09-01 L R
2013-10-01 L R
2013-11-01 L R
2013-12-01 L R
|
Motivating from SO
This is the inverse of `pd.get_dummies`. So maybe `invert_dummies` is better?
I think this name makes more sense though.
This seems a reasonable way to do it. Am I missing anything?
In [46]: s = Series(list('aaabbbccddefgh')).astype('category')
In [47]: s
Out[47]:
0 a
1 a
2 a
3 b
4 b
5 b
6 c
7 c
8 d
9 d
10 e
11 f
12 g
13 h
dtype: category
Categories (8, object): [a < b < c < d < e < f < g < h]
In [48]: df = pd.get_dummies(s)
In [49]: df
Out[49]:
a b c d e f g h
0 1 0 0 0 0 0 0 0
1 1 0 0 0 0 0 0 0
2 1 0 0 0 0 0 0 0
3 0 1 0 0 0 0 0 0
4 0 1 0 0 0 0 0 0
5 0 1 0 0 0 0 0 0
6 0 0 1 0 0 0 0 0
7 0 0 1 0 0 0 0 0
8 0 0 0 1 0 0 0 0
9 0 0 0 1 0 0 0 0
10 0 0 0 0 1 0 0 0
11 0 0 0 0 0 1 0 0
12 0 0 0 0 0 0 1 0
13 0 0 0 0 0 0 0 1
In [50]: x = df.stack()
# I don't think you actually need to specify ALL of the categories here, as by definition
# they are in the dummy matrix to start (and hence the column index)
In [51]: Series(pd.Categorical(x[x!=0].index.get_level_values(1)))
Out[51]:
0 a
1 a
2 a
3 b
4 b
5 b
6 c
7 c
8 d
9 d
10 e
11 f
12 g
13 h
Name: level_1, dtype: category
Categories (8, object): [a < b < c < d < e < f < g < h]
NB. this is buggy ATM.
In [51]: Series(pd.Categorical(x[x!=0].index.get_level_values(1)),categories=df.categories)
| 0 |
When calling `self.replace()` with a signature reconstructed from a serialized
dictionary (e.g. after having been passed through a backend), if that
signature is (or contains) a group which itself contains a chord, celery
explodes after attempting to treat deeply nested dictionaries as signature
objects. See below for a minimal repro I got together today.
My gut feel is that instantiating a signature from a dictionary may not be
recursing down through the structure far enough and it leaves some of the
encapsulated tasks as dicts. I've also noticed that groups containing a group
also break in the same way, but I think that's because there's an internal
promotion to a chord happening somewhere.
# Checklist
* I have verified that the issue exists against the `master` branch of Celery.
* This has already been asked to the discussion group first.
* I have read the relevant section in the
contribution guide
on reporting bugs.
* I have checked the issues list
for similar or identical bug reports.
* I have checked the pull requests list
for existing proposed fixes.
* I have checked the commit log
to find out if the bug was already fixed in the master branch.
* I have included all related issues and possible duplicate issues
in this issue (If there are none, check this box anyway).
## Mandatory Debugging Information
* I have included the output of `celery -A proj report` in the issue.
(if you are not able to do this, then at least specify the Celery
version affected).
* I have verified that the issue exists against the `master` branch of Celery.
* I have included the contents of `pip freeze` in the issue.
* I have included all the versions of all the external dependencies required
to reproduce this bug.
## Optional Debugging Information
* I have tried reproducing the issue on more than one Python version
and/or implementation.
* I have tried reproducing the issue on more than one message broker and/or
result backend.
* I have tried reproducing the issue on more than one version of the message
broker and/or result backend.
* I have tried reproducing the issue on more than one operating system.
* I have tried reproducing the issue on more than one workers pool.
* I have tried reproducing the issue with autoscaling, retries,
ETA/Countdown & rate limits disabled.
* I have tried reproducing the issue after downgrading
and/or upgrading Celery and its dependencies.
## Related Issues and Possible Duplicates
#### Related Issues
* #4015
#### Possible Duplicates
* None
## Environment & Settings
**Celery version** :
**`celery report` Output:**
# Steps to Reproduce
## Required Dependencies
* **Minimal Python Version** : N/A or Unknown
* **Minimal Celery Version** : N/A or Unknown
* **Minimal Kombu Version** : N/A or Unknown
* **Minimal Broker Version** : N/A or Unknown
* **Minimal Result Backend Version** : N/A or Unknown
* **Minimal OS and/or Kernel Version** : N/A or Unknown
* **Minimal Broker Client Version** : N/A or Unknown
* **Minimal Result Backend Client Version** : N/A or Unknown
### Python Packages
**`pip freeze` Output:**
amqp==5.0.1
billiard==3.6.3.0
# Editable install with no version control (celery==5.0.0rc3)
-e /home/maybe/tmp/capp/venv/lib/python3.8/site-packages
click==7.1.2
click-didyoumean==0.0.3
click-repl==0.1.6
future==0.18.2
kombu==5.0.2
prompt-toolkit==3.0.7
pytz==2020.1
redis==3.5.3
six==1.15.0
vine==5.0.0
wcwidth==0.2.5
### Other Dependencies
N/A
## Minimally Reproducible Test Case
import celery
app = celery.Celery("app", backend="redis://")
@app.task
def foo(*_):
return 42
@app.task(bind=True)
def replace_with(self, sig):
assert isinstance(sig, dict)
sig = celery.Signature.from_dict(sig)
raise self.replace(sig)
if __name__ == "__main__":
sig = celery.group(
celery.group(foo.s()),
)
res = sig.delay()
print(res.get())
sig.freeze()
res = replace_with.delay(sig)
print(res.get())
# Expected Behavior
It shouldn't explode. Presumably tasks within the group/chord should be
signatures rather than dicts.
# Actual Behavior
Stack trace in the worker output:
[2020-09-08 12:44:05,453: DEBUG/MainProcess] Task accepted: app.replace_with[dcea02fd-23a3-404a-9fdd-b213eb51c0d1] pid:453431
[2020-09-08 12:44:05,457: ERROR/ForkPoolWorker-8] Task app.replace_with[dcea02fd-23a3-404a-9fdd-b213eb51c0d1] raised unexpected: AttributeError("'dict' object has no attribute '_app'")
Traceback (most recent call last):
File "/home/maybe/tmp/capp/venv/lib64/python3.8/site-packages/kombu/utils/objects.py", line 41, in __get__
return obj.__dict__[self.__name__]
KeyError: 'app'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/maybe/tmp/capp/venv/lib64/python3.8/site-packages/celery/app/trace.py", line 409, in trace_task
R = retval = fun(*args, **kwargs)
File "/home/maybe/tmp/capp/venv/lib64/python3.8/site-packages/celery/app/trace.py", line 701, in __protected_call__
return self.run(*args, **kwargs)
File "/home/maybe/tmp/capp/app.py", line 13, in replace_with
raise self.replace(sig)
File "/home/maybe/tmp/capp/venv/lib64/python3.8/site-packages/celery/app/task.py", line 894, in replace
sig.freeze(self.request.id)
File "/home/maybe/tmp/capp/venv/lib64/python3.8/site-packages/celery/canvas.py", line 1302, in freeze
self.tasks = group(self.tasks, app=self.app)
File "/home/maybe/tmp/capp/venv/lib64/python3.8/site-packages/kombu/utils/objects.py", line 43, in __get__
value = obj.__dict__[self.__name__] = self.__get(obj)
File "/home/maybe/tmp/capp/venv/lib64/python3.8/site-packages/celery/canvas.py", line 1456, in app
return self._get_app(self.body)
File "/home/maybe/tmp/capp/venv/lib64/python3.8/site-packages/celery/canvas.py", line 1466, in _get_app
app = tasks[0]._app
AttributeError: 'dict' object has no attribute '_app'
|
# Checklist
* I have verified that the issue exists against the `master` branch of Celery.
* This has already been asked to the discussion group first.
* I have read the relevant section in the
contribution guide
on reporting bugs.
* I have checked the issues list
for similar or identical bug reports.
* I have checked the pull requests list
for existing proposed fixes.
* I have checked the commit log
to find out if the bug was already fixed in the master branch.
* I have included all related issues and possible duplicate issues
in this issue (If there are none, check this box anyway).
## Mandatory Debugging Information
* I have included the output of `celery -A proj report` in the issue.
(if you are not able to do this, then at least specify the Celery
version affected).
* I have verified that the issue exists against the `master` branch of Celery.
* I have included the contents of `pip freeze` in the issue.
* I have included all the versions of all the external dependencies required
to reproduce this bug.
## Optional Debugging Information
* I have tried reproducing the issue on more than one Python version
and/or implementation.
* I have tried reproducing the issue on more than one message broker and/or
result backend.
* I have tried reproducing the issue on more than one version of the message
broker and/or result backend.
* I have tried reproducing the issue on more than one operating system.
* I have tried reproducing the issue on more than one workers pool.
* I have tried reproducing the issue with autoscaling, retries,
ETA/Countdown & rate limits disabled.
* I have tried reproducing the issue after downgrading
and/or upgrading Celery and its dependencies.
## Related Issues and Possible Duplicates
#### Related Issues
* None
#### Possible Duplicates
* None
## Environment & Settings
5.0.5 (singularity):
**`celery report` Output:**
software -> celery:5.0.5 (singularity) kombu:5.0.2 py:3.8.5
billiard:3.6.4.0 py-amqp:5.0.6
platform -> system:Linux arch:64bit, ELF
kernel version:5.8.0-48-generic imp:CPython
loader -> celery.loaders.app.AppLoader
settings -> transport:pyamqp results:redis://localhost/
broker_url: 'amqp://guest:********@localhost:5672//'
result_backend: 'redis://localhost/'
deprecated_settings: None
# Steps to Reproduce
## Required Dependencies
* **Minimal Python Version** : N/A or Unknown
* **Minimal Celery Version** : N/A or Unknown
* **Minimal Kombu Version** : N/A or Unknown
* **Minimal Broker Version** : N/A or Unknown
* **Minimal Result Backend Version** : N/A or Unknown
* **Minimal OS and/or Kernel Version** : N/A or Unknown
* **Minimal Broker Client Version** : N/A or Unknown
* **Minimal Result Backend Client Version** : N/A or Unknown
### Python Packages
**`pip freeze` Output:**
aiohttp==3.7.4.post0
aiohttp-cors==0.7.0
aioredis==1.3.1
amqp==5.0.6
anykeystore==0.2
apex==0.9.10.dev0
argh==0.26.2
argon2-cffi==20.1.0
astroid==2.4.2
async-generator==1.10
async-timeout==3.0.1
attrs==20.2.0
axial-positional-embedding==0.2.1
backcall==0.2.0
billiard==3.6.4.0
bleach==3.2.1
blessings==1.7
cachetools==4.2.1
celery==5.0.5
certifi==2020.6.20
cffi==1.14.3
chardet==3.0.4
click==7.1.2
click-default-group==1.2.2
click-didyoumean==0.0.3
click-plugins==1.1.1
click-repl==0.1.6
cloudpickle==1.6.0
colorama==0.4.4
colorful==0.5.4
contrastive-learner==0.1.0
cryptacular==1.5.5
cycler==0.10.0
dask==2021.4.0
db-to-sqlite==1.3
decorator==4.4.2
defusedxml==0.6.0
dlib==19.21.0
dnspython==1.16.0
entrypoints==0.3
eventlet==0.30.2
face-recognition==1.3.0
face-recognition-models==0.3.0
filelock==3.0.12
fire==0.3.1
Flask==1.1.2
Flask-Resize==2.0.4
fsspec==0.9.0
future==0.18.2
gevent==21.1.2
google-api-core==1.26.3
google-auth==1.29.0
google-images-download==2.8.0
googleapis-common-protos==1.53.0
gpustat==0.6.0
greenlet==1.0.0
grpcio==1.37.0
hiredis==2.0.0
hupper==1.10.2
idna==2.10
imageio==2.9.0
imutils==0.5.3
ipdb==0.13.4
ipykernel==5.3.4
ipython==7.18.1
ipython-genutils==0.2.0
ipywidgets==7.5.1
isort==5.6.4
itsdangerous==1.1.0
jedi==0.17.2
Jinja2==2.11.2
json5==0.9.5
jsonschema==3.2.0
jupyter-client==6.1.7
jupyter-core==4.6.3
jupyterlab==2.2.8
jupyterlab-pygments==0.1.2
jupyterlab-server==1.2.0
kiwisolver==1.2.0
kombu==5.0.2
kornia==0.4.1
lazy-object-proxy==1.4.3
linear-attention-transformer==0.14.1
linformer==0.2.0
local-attention==1.0.2
locket==0.2.1
lxml==4.6.2
MarkupSafe==1.1.1
matplotlib==3.3.2
mccabe==0.6.1
mistune==0.8.4
modin==0.9.1
msgpack==1.0.2
multidict==5.1.0
nbclient==0.5.0
nbconvert==6.0.7
nbformat==5.0.7
nest-asyncio==1.4.1
networkx==2.5
notebook==6.1.4
numpy==1.19.2
nvidia-ml-py3==7.352.0
oauthlib==3.1.0
opencensus==0.7.12
opencensus-context==0.1.2
opencv-python==4.4.0.46
packaging==20.4
pandas==1.1.3
pandocfilters==1.4.2
parso==0.7.1
partd==1.2.0
PasteDeploy==2.1.1
pbkdf2==1.3
pexpect==4.8.0
pickleshare==0.7.5
pika==1.2.0
pilkit==2.0
Pillow==7.2.0
plaster==1.0
plaster-pastedeploy==0.7
product-key-memory==0.1.10
prometheus-client==0.8.0
prompt-toolkit==3.0.8
protobuf==3.15.8
psutil==5.8.0
psycopg2==2.8.6
ptyprocess==0.6.0
py==1.9.0
py-spy==0.3.5
pyarrow==1.0.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
pycparser==2.20
Pygments==2.7.1
pylint==2.6.0
pyparsing==2.4.7
pyramid==1.10.4
pyramid-mailer==0.15.1
pyrsistent==0.17.3
python-dateutil==2.8.1
python3-openid==3.2.0
pytorch-fid==0.1.1
pytz==2020.1
PyWavelets==1.1.1
pywikibot==5.6.0
PyYAML==5.4.1
pyzmq==19.0.2
ray==1.1.0
redis==3.5.3
repoze.sendmail==4.4.1
requests==2.24.0
requests-oauthlib==1.3.0
retry==0.9.2
rsa==4.7.2
scikit-image==0.18.1
scipy==1.5.3
selenium==3.141.0
Send2Trash==1.5.0
six==1.15.0
SQLAlchemy==1.3.20
sqlite-fts4==1.0.1
sqlite-utils==3.6
swifter==1.0.7
tabulate==0.8.9
termcolor==1.1.0
terminado==0.9.1
testpath==0.4.4
tifffile==2021.3.5
toml==0.10.1
toolz==0.11.1
torch==1.6.0
torchvision==0.7.0
tornado==6.0.4
tqdm==4.50.2
traitlets==5.0.4
transaction==3.0.0
translationstring==1.4
typing-extensions==3.7.4.3
urllib3==1.25.10
vector-quantize-pytorch==0.1.0
velruse==1.1.1
venusian==3.0.0
vine==5.0.0
wcwidth==0.2.5
webencodings==0.5.1
WebOb==1.8.6
Werkzeug==1.0.1
widgetsnbextension==3.5.1
wrapt==1.12.1
WTForms==2.3.3
wtforms-recaptcha==0.3.2
yarl==1.6.3
zope.deprecation==4.4.0
zope.event==4.5.0
zope.interface==5.1.2
zope.sqlalchemy==1.3
### Other Dependencies
N/A
## Minimally Reproducible Test Case
from celery import Celery
from celery.execute import send_task
#random_name = Celery('tasks', backend='redis://localhost', broker='pyamqp://')
r1 = send_task('tasks.add',(1,1))
print(r1.get())
# Expected Behavior
2 printed to the screen without uncommenting the line #random_name
(it makes no sense for this line to have any effect on the program)
# Actual Behavior
"No result backend" Exception, unless the only commented out line is
uncommented.
Accompanying file:
tasks.py
from celery import Celery
app = Celery('tasks', backend='redis://localhost', broker='pyamqp://')
@app.task
def add(x, y):
return x + y
``
| 0 |
Just cloned the rust0.6 from today.
And build it on Ubuntu 12.10 x86_64
when I run rusti and enter 1+1 ,it happens Segmentation fault .
Here som gdb log:
GNU gdb (GDB) 7.5-ubuntu
Copyright (C) 2012 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later http://gnu.org/licenses/gpl.html
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
For bug reporting instructions, please see:
http://www.gnu.org/software/gdb/bugs/...
Reading symbols from /usr/local/bin/rusti...(no debugging symbols
found)...done.
[New LWP 5883]
[New LWP 5884]
[New LWP 5881]
[New LWP 5880]
[New LWP 5882]
warning: Can't read pathname for load map: 输入/输出错误.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Core was generated by `rusti'.
Program terminated with signal 11, Segmentation fault.
#0 0x00007f9d32f69018 in ?? () from /lib64/ld-linux-x86-64.so.2
(gdb) bt full
#0 0x00007f9d32f69018 in ?? () from /lib64/ld-linux-x86-64.so.2
No symbol table info available.
#1 0x00007f9d32f6b63d in ?? () from /lib64/ld-linux-x86-64.so.2
No symbol table info available.
#2 0x00007f9d32f7685b in ?? () from /lib64/ld-linux-x86-64.so.2
No symbol table info available.
#3 0x00007f9d32f72186 in ?? () from /lib64/ld-linux-x86-64.so.2
No symbol table info available.
#4 0x00007f9d32f7632a in ?? () from /lib64/ld-linux-x86-64.so.2
No symbol table info available.
#5 0x00007f9d30710f26 in ?? () from /lib/x86_64-linux-gnu/libdl.so.2
No symbol table info available.
#6 0x00007f9d32f72186 in ?? () from /lib64/ld-linux-x86-64.so.2
No symbol table info available.
#7 0x00007f9d3071152f in ?? () from /lib/x86_64-linux-gnu/libdl.so.2
No symbol table info available.
#8 0x00007f9d30710fc1 in dlopen () from /lib/x86_64-linux-gnu/libdl.so.2
No symbol table info available.
#9 0x00007f9d2fc8cd1a in llvm::sys::DynamicLibrary::getPermanentLibrary(char
const_, std::string_) () from /usr/local/bin/../lib/./librustllvm.so
No symbol table info available.
#10 0x00007f9d2f233d0c in RustMCJITMemoryManager::loadCrate (
this=0x7f9d205a3020, file=<optimized out>, err=err@entry=0x7f9d201008a0)
\---Type to continue, or q to quit---
at /usr/local/src/rust/src/rustllvm/RustWrapper.cpp:197
crate = {static Invalid = 0 '\000', Data = 0x7f9d2f0a7878}
#11 0x00007f9d2f234587 in LLVMRustLoadCrate (mem=,
crate=<optimized out>)
at /usr/local/src/rust/src/rustllvm/RustWrapper.cpp:328
manager = <optimized out>
Err = {static npos = <optimized out>,
_M_dataplus = {<std::allocator<char>> = {<__gnu_cxx::new_allocator<char>> = {<No data fields>}, <No data fields>}, _M_p = 0x7f9d2ee404d8 ""}}
__PRETTY_FUNCTION__ = "bool LLVMRustLoadCrate(void*, const char*)"
#12 0x00007f9d31e223ca in LLVMRustLoadCrate__c_stack_shim ()
from /usr/local/bin/../lib/librustc-c84825241471686d-0.6.so
No symbol table info available.
#13 0x00007f9d31218ab9 in __morestack ()
from /usr/local/bin/../lib/librustrt.so
No symbol table info available.
#14 0x00007f9d31207174 in call_on_c_stack (
fn_ptr=0x7f9d31e22390 <LLVMRustLoadCrate__c_stack_shim>,
args=0x7f9d201035f0, this=0x7f9d28108a10)
at /usr/local/src/rust/src/rt/rust_task.h:491
prev_rust_sp = 0
borrowed_a_c_stack = true
sp = <optimized out>
\---Type to continue, or q to quit---
#15 upcall_call_shim_on_c_stack (args=0x7f9d201035f0,
fn_ptr=0x7f9d31e22390 <LLVMRustLoadCrate__c_stack_shim>)
at /usr/local/src/rust/src/rt/rust_upcall.cpp:60
task = 0x7f9d28108a10
__PRETTY_FUNCTION__ = "void upcall_call_shim_on_c_stack(void*, void*)"
#16 0x00007f9d31d8beb4 in back:🔗:jit::exec::anon::anon::expr_fn_76891 ()
from /usr/local/bin/../lib/librustc-c84825241471686d-0.6.so
No symbol table info available.
#17 0x00007f9d318d2158 in str::as_c_str_28724::_b760a7dcc0e4db::_06 ()
from /usr/local/bin/../lib/librustc-c84825241471686d-0.6.so
No symbol table info available.
#18 0x00007f9d31d8b949 in back:🔗:jit::exec::_c3905cfecb8b69e9::_06 ()
from /usr/local/bin/../lib/librustc-c84825241471686d-0.6.so
No symbol table info available.
#19 0x00007f9d31464d65 in run::_ee4d29fb4c6e65c::_06 ()
from /usr/local/bin/../lib/librusti-5047c7f210c7cac8-0.6.so
No symbol table info available.
#20 0x00007f9d31496aa8 in __morestack ()
from /usr/local/bin/../lib/librusti-5047c7f210c7cac8-0.6.so
No symbol table info available.
#21 0x00007f9d31495a60 in run_line::anon::expr_fn_13894 ()
from /usr/local/bin/../lib/librusti-5047c7f210c7cac8-0.6.so
No symbol table info available.
\---Type to continue, or q to quit---
#22 0x00007f9d31495235 in task:: **extensions**
::try_13791::anon::expr_fn_13846
() from /usr/local/bin/../lib/librusti-5047c7f210c7cac8-0.6.so
No symbol table info available.
#23 0x00007f9d32bf814f in
task::spawn::spawn_raw::make_child_wrapper::anon::expr_fn_10036 () from
/usr/local/bin/../lib/libcore-c3ca5d77d81b46c1-0.6.so
No symbol table info available.
#24 0x00007f9d32c2f520 in __morestack ()
from /usr/local/bin/../lib/libcore-c3ca5d77d81b46c1-0.6.so
No symbol table info available.
#25 0x00007f9d312057f4 in task_start_wrapper (a=0x7f9d28109810)
at /usr/local/src/rust/src/rt/rust_task.cpp:160
__PRETTY_FUNCTION__ = "void task_start_wrapper(spawn_args*)"
env = <optimized out>
ca = {spargs = 0x0, threw_exception = false}
task = 0x7f9d28108a10
threw_exception = false
#26 0x0000000000000000 in ?? ()
No symbol table info available.
(gdb) quit
|
rustc v0.6:
$ rusti
rusti> fn foo() { for 5.times { io::println("hi"); } }
[1] 11363 segmentation fault (core dumped) rusti
$ rusti
rusti> let x = 1;
<anon>:35:4: 35:7 warning: unused variable: `x`
<anon>:35 let x = 1;
^~~
[1] 11937 segmentation fault (core dumped) rusti
I was able to reproduce this today by using `ctrl+c` to exit `rusti`.
Subsequent `rusti` runs segfaulted regardless of the statement.
| 1 |
* [x ] I have searched the issues of this repository and believe that this is not a duplicate.
No errors in development, but when I minify the bundle and hit ssr url, I
receive this error:
https://reactjs.org/docs/error-
decoder.html?invariant=149&args[]=iconMenuContainer
Tech | Version
---|---
Material-UI | 0.19.2
React | 16
browser |
etc |
|
I'm using the `onClick` property for the DatePicker component and it works
fine, the only issue is that my VSC typescript linter is indicating that it is
not a part of the type definition for this component.
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
No type errors would be fantastic - and this is the only one I've run into so
far!
## Current Behavior
This is the error I'm getting:
`Property 'onClick' does not exist on type 'IntrinsicAttributes &
IntrinsicClassAttributes<DatePicker> & Readonly<{ children?: ReactNode; }>
...'.`
## Steps to Reproduce (for bugs)
1. Have typescript setup in a react environment
2. Use `import DatePicker from 'material-ui/DatePicker' ` to import the DatePicker. Right now, I'm getting around this error by using `const DatePicker: any = require('material-ui/DatePicker')`. Lame.
3. Add an `onClick` property to your DatePicker. Eg:
`... onClick={ () => console.log('opening the datepicker') } ...`
4. See annoying red stuff in your editor.
## Context
Annoying typescript issue making me ask my boss annoying typescript questions.
This is more an issue with typescript than you guys, but you've done a really
awesome job so far, this is just a way to make it a little bit better.
## Your Environment
We're running a react/redux/typescript app in Visual Studio Code. I installed
the `@types/material-ui` file and it mostly works great, thanks for putting in
all that work!
Tech | Version
---|---
Material-UI | 0.20.0
React | 16.2.0
browser |
Visual Studio Code | 1.19.1
`@types/material-ui` | 0.20.1
| 0 |
See the attachment. With ansible 1.7.2 this works as expected:
% ansible-playbook --version
ansible-playbook 1.7.2
% ansible-playbook -i hosts/localhost a.yml --tags b
PLAY [localhost]
* * *
GATHERING FACTS
* * *
ok: [localhost]
TASK: [debug msg="b"]
* * *
ok: [localhost] => {
"msg": "b"
}
PLAY RECAP
* * *
localhost : ok=2 changed=0 unreachable=0
failed=0
With 1.9.1 it's broken:
% ansible-playbook --version
ansible-playbook 1.9.1
% ansible-playbook -i hosts/localhost a.yml --tags b
ERROR: tag(s) not found in playbook: b. possible values:
|
##### Issue Type:
Bug Report
##### Ansible Version:
1.8.1-1.el6
##### Environment:
CentOS release 6.6 (Final)
##### Summary:
Tags from includes are being ignored
Tags from within a playbook are working just fine.
After a downgrade to Ansible 1.7.2-2.el6 this is working
##### Steps To Reproduce:
include: someotherplaybook.yml tags=test_tag
ansible-playbook someplaybook.yml -e "target=somehost" -t test_tag
##### Expected Results:
Tags should not be ignored
##### Actual Results:
ERROR: tag(s) not found in playbook: test_tag. possible values:
| 1 |
### Description
Due to the complexity of our DAG, we only use the Graph view to manage it. It
would be great if we could get the task group options (specifically clearing a
task group - (see #26658, #28003).
### Use case/motivation
_No response_
### Related issues
_No response_
### Are you willing to submit a PR?
* Yes I am willing to submit a PR!
### Code of Conduct
* I agree to follow this project's Code of Conduct
|
**Apache Airflow version** : 2.0.0
**Kubernetes version (if you are using kubernetes)** (use `kubectl version`):
1.18.10
**Environment** :
* **Cloud provider or hardware configuration** : Azure AKS
* **OS** (e.g. from /etc/os-release): Linux
* **Kernel** (e.g. `uname -a`): Linux
* **Install tools** : All
**What happened** :
While injecting execution date and previous execution date success as
environment variables using macros the values are not rendered in the pod
**What you expected to happen** :
Values are correctly rendered in the pod so that I can use that in my task.
**How to reproduce it** :
1. Define Kubernetes environment variable like this
` k8s_env_variable = k8s.V1EnvVar( name='execution_date_1', value='{{ ts }}'
)`
2. Inject it in the operator
KubernetesPodOperator(
namespace='airflow',
name=name,
task_id=name,
image="Use your dag image id",
env_vars=[k8s_env_variable],
image_pull_policy='Always',
get_logs=True,
log_events_on_failure=True,
resources=resources,
is_delete_operator_pod=True,
node_selector={'agentpool': 'airflowtasks'},
termination_grace_period=60
)
3. Print execution date in your dag
import os
print(os.getenv('execution_date'))
4. It should have printed the correct execution date instead of nothing.
If you are using kubernetes, please attempt to recreate the issue using
minikube or kind.
## Install minikube/kind
* Minikube https://minikube.sigs.k8s.io/docs/start/
* Kind https://kind.sigs.k8s.io/docs/user/quick-start/
| 0 |
### Bug summary
When the figure has two columns with different numbers of rows, rows on the
same side will have different heights under `constrained` layout.
### Code for reproduction
import matplotlib.pyplot as plt
panels = [
['a', 'c'],
['a', 'c'],
['b', 'c'],
['b', 'c'],
]
fig, axes = plt.subplot_mosaic(
panels, layout = 'constrained')
fig.suptitle('Different height')
fig.canvas.draw()
print("Hieght of 'a':", axes['a'].bbox.bounds[3])
print("Hieght of 'b':", axes['b'].bbox.bounds[3])
plt.savefig('test.png')
### Actual outcome
Hieght of 'a': 180.94277777777785
Hieght of 'b': 189.27677777777777

### Expected outcome
Same height for 'a' and 'b'.
### Additional information
No bug when axes are generated using `plt.subplot` or when the numbers of rows
are the same for both columns. Same bug for `compressed` layout too.
### Operating system
Ubuntu 22.04
### Matplotlib Version
3.7.1
### Matplotlib Backend
QtAgg
### Python version
Python 3.10.6
### Jupyter version
_No response_
### Installation
pip
|
### Bug report
**Bug summary**
When following the documentation on plotting categorical variables the plots
do not render. Instead various errors are thrown about converting strings to
floats.
**Code for reproduction**
import matplotlib.pyplot as plt
data = {'apples': 10, 'oranges': 15, 'lemons': 5, 'limes': 20}
names = list(data.keys())
values = list(data.values())
fig, axs = plt.subplots(1, 3, figsize=(9, 3), sharey=True)
axs[0].bar(names, values)
axs[1].scatter(names, values)
axs[2].plot(names, values)
fig.suptitle('Categorical Plotting')
**Actual outcome**
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-32-c50911b594df> in <module>()
4
5 fig, axs = plt.subplots(1, 3, figsize=(9, 3), sharey=True)
----> 6 axs[0].bar(names, values)
7 axs[1].scatter(names, values)
8 axs[2].plot(names, values)
/Users/kevin.thompson/venv3/lib/python3.6/site-packages/matplotlib/__init__.py in inner(ax, *args, **kwargs)
1896 warnings.warn(msg % (label_namer, func.__name__),
1897 RuntimeWarning, stacklevel=2)
-> 1898 return func(ax, *args, **kwargs)
1899 pre_doc = inner.__doc__
1900 if pre_doc is None:
/Users/kevin.thompson/venv3/lib/python3.6/site-packages/matplotlib/axes/_axes.py in bar(self, left, height, width, bottom, **kwargs)
2103 if align == 'center':
2104 if orientation == 'vertical':
-> 2105 left = [left[i] - width[i] / 2. for i in xrange(len(left))]
2106 elif orientation == 'horizontal':
2107 bottom = [bottom[i] - height[i] / 2.
/Users/kevin.thompson/venv3/lib/python3.6/site-packages/matplotlib/axes/_axes.py in <listcomp>(.0)
2103 if align == 'center':
2104 if orientation == 'vertical':
-> 2105 left = [left[i] - width[i] / 2. for i in xrange(len(left))]
2106 elif orientation == 'horizontal':
2107 bottom = [bottom[i] - height[i] / 2.
TypeError: unsupported operand type(s) for -: 'str' and 'float'
**Expected outcome**
I expected it to render the pretty pictures found in the documentation I was
trying to duplicate
**Matplotlib version**
* Operating System: OSX 10.11.6 (El Capitan)
* Matplotlib Version: 2.0.2
* Python Version: 3.6.0
* Jupyter Version (if applicable): 4.3.0
Installed via pip in a virtualenv
| 0 |
I'm not sure if this is a bug or corruption experienced during the upgrade but
as of 1.2.0, we're now experiencing duplicate results in all queries:
{
took: 0
timed_out: false
_shards: {
total: 5
successful: 5
failed: 0
}
hits: {
total: 2
max_score: 13.58639
hits: [
{
_index: media6
_type: Media
_id: 534918829017389526_260014085,
_score: 13.58639,
_source: {}
},
{
_index: media6
_type: Media
_id: 534918829017389526_260014085,
_score: 12.815866,
_source: {}
}]
}}
There have been no changes to indexes, types, or other mappings. My
understanding was that a unique ID really depends on index/type/id/routing.
The routing, by
default, is derived from the ID. No parent-child relationships are in use
here.
Cross-posted but unrelated to sort as initially suspected:
http://elasticsearch-users.115913.n3.nabble.com/Duplicate-Results-Following-
Upgrade-to-1-2-0-amp-SortScript-td4056672.html
|
Many people have some challenges when using Git/GitHub to contribute to the
project.
It would be nice to have a GitHub.CHEATSHEET similar to GRADLE.CHEATSHEET.
| 0 |
As for now, there is no way to disable code splitting feature with some
option.
Build & rebuild time is more with code splitting, so, it is useful from
developer experience point of view to disable it in development mode.
https://www.npmjs.com/package/babel-plugin-remove-webpack could handle some of
cases, excluding modern `import()` signature.
|
## Current Problems & Scenarios
Users get fast webpack builds on large code bases by running continuous
processes that watch the file system with webpack-dev-server or webpack's
watch option. Starting those continuous processes can take a lot of time to
build all the modules for the code base anew to fill the memory cache webpack
has to make rebuilds fast. Some webpack uses remove the benefit from running a
continuous process like running tests on a Continuous Integration instance
that will be stopped after it runs, or making a production build for staging
or release which is needed less frequently than development builds. The
production build will just use more resources while the development build
completes faster from not using optimization plugins.
Community solutions and workarounds help remedy this with cache-loader,
DllReferencePlugin, auto-dll-plugin, thread-loader, happypack, and hard-
source-webpack-plugin. Many workarounds also include option tweaks that trade
small loses in file size or feature power for larger improvement to build
time. All of these involve a lot of knowledge about webpack and the community
or finding really good articles on what others have already figured out.
webpack itself does not have some simpler option to turn on or have on by
default.
With the module memory cache there is a second important cache in webpack for
build performance, the resolver's **unsafe cache**. The unsafe cache is memory
only too, and an example of a performance workaround that is on by default in
webpack's core. It trades resolving accuracy for fast repeated resolutions.
That trade means continuous webpack processes need to be restarted to pick up
changes to file resolutions. Or that the option can be disabled but for the
number of resolutions that will change like that restarting will save more
time overall than having the option regularly be off.
### Proposed Solution
**Freeze all modules in a build at needed stages during compilation and write
them to disk.** Later iterative builds, the first build of a continuous
process using an existing on disk module cache, read the cache, validate the
modules, and thaw them during the build. The graph relations between modules
are not explicitly cached. The module relations need to also be validated.
Validating the relations is equivalent to rebuilding the relations through
webpack's normal dependency tracing behaviour.
The resolver's cache can also be frozen and validated with saved missing
paths. The validated resolver's "safe" cache allows retracing dependencies to
execute quickly. Any resolutions that were invalidated will be run through the
resolver normally allowing file path changes to be discovered in iterative and
rebuilds.
Plain json data is easiest to write to and read from disk as well as provide a
state the module's data can be in during validation. Fully thawing that data
into their original shape will require a Compilation to be running so the
Module, Dependency's and other webpack types can be created according to how
that Compilation is configured to create a copy of the past Module
indistinguishable from the last build.
Creating this data will like involve two sets of APIs. One creates the
duplicates and constructing thawed Instances from the disk read duplicate. The
second uses the first to handle the variation in subclassed types in webpack.
As an example the webpack 3 has 49 Dependency subclasses that can be used by
the core of webpack and core plugins. The first API duplicating a NormalModule
doesn't handle the Dependency instances in the module's dependencies list, it
calls to the second API to create duplicates of those values. The second API
uses the first to create those duplicates. To keep this from running in a
circular cycle, uses of the first API are responsible for not duplicating
cyclical references and for creating them while thawing using passed state
information like webpack's Parser uses.
The first data API will likely be a library used to implement a schema of a
Module or Dependency. The second data API may use webpack's
dependencyFactories strategy or Tapable hooks. A Tapable or similar approach
may present opportunities to let plugin authors cache plugin information that
is not tracked by default.
A file system API is needed to write and read the duplicates. This API
organizes them and uses systems and libraries to operate efficiently or to
provide an important point for debugging to loader authors, plugin authors,
and core maintainers. This API may also act as a layer that may separate some
information in a common shape to change its strategy. Asset objects may be
treated this way if they are found to best be stored and loaded with a
different mechanism then the rest of the module data.
This must be a safe cache. Any cached information must be able to be
validated.
Modules validate their build and rendered source through timestamps and
hashes. Timestamps cannot always be validated. Either a file changed in a way
that didn't change its timestamp or the timestamp decreased in cases like a
file being deleted in a context dependency or a file be renamed to the path of
the old file. Hashes of the content, like the rendered source and chunk source
use can be validated. All timestamp checks in modules and elsewhere must be
replaced with hash or other content representative comparisons instead of
filesystem metadata comparisons. File dependency timestamps can be replaced
with hashes of their original content. Context dependency timestamps can be
replaced with hashes of all the sorted relative paths deeply nested under
them.
The cached resolver information needs to validate the filesystem shape and can
do that by `stat()`ing the resolved path and all tested missing paths. A
missing resolved path invalidates the resolution. An existing missing path
invalidates the resolution.
Two larger "validations" also need to be performed.
The webpack's build configuration needs to be the same as the previous build.
Instead of invalidating in case of a different build configuration though, a
separate cache stored adjacent to the other cached modules under other
configurations. Webpack configurations can frequently switch like in cases of
using `webpack` or `webpack-dev-server` which turns on hot module replacement.
Hot module replacement means the configuration is different and needs a
separate cache as the module's will have a different output due to the
additional plugin. One way to compare this is a hash of the configuration. The
configuration can be stringified including any passed function's source and
then hashed. An iterative build will check the new hash to choose its cache.
Smarter configuration hashes could be developed to account for options that
will not modify the already built modules.
The second larger validation is ensuring that dependencies stored in folders
like node_modules have not changed. yarn and npm 5 can help here by trusting
them to do this check and hashing their content. A back up can hash the
combined content of all package.json files under the first depth of
directories under node_modules. webpack will track the content of built
modules, but it does not track the source of loaders, plugins, and
dependencies used by those and webpack. A change to those may have an effect
on how a built module looks. Any changes to these not-tracked-by-webpack files
currently will mean the entire cache is no longer valid. A sibling cache could
be created but if that can be determined to be regularly useful to keep the
old cache.
### User Stories (That speak in solving spirit of these problem areas)
Priority Story
1 As a plugin or loader author, I can use a strategy or provided tools to test
with the cache. In addition I have a strategy or means to have the cache
invalidate entirely or specific modules as I am editing a loader or plugin.
1 As a user, I can rely on the cache to speed up iterative builds and notify
me when an uncached build is starting. I can also turn off the notifications
if I desire. I should never need to personally delete the cache for some
performance trade off. The cache should reset itself as necessary without my
input. I understood I may need to do this for bugs. Best such bugs be squashed
quickly.
1 As a user, I should be able to use loaders and plugins that don't work with
the cache. Modules with uncacheable loaders will not be cached. Modules with
nested objects that cannot be duplicated or thawed from containing values that
are not registered in the second data API will produce a warning about their
cacheability status and allowed to be built in the normal uncached fashion.
1 As a core maintainer, I can test and debug other webpack core features and
core plugins in use with the cache to make sure it can validate and verify
itself for use.
### Non-Goals
This RFC will not look into using a cache built with different node_modules
dependencies than those last installed. This would be a large effort on its
own likely involving trade offs and may best be its own RFC.
This cache will be portable. Reusable on different CI instances or in
different repo clones on the same or different computers. This RFC will not
figure out the specifics of sharing a cache between multiple systems and
leaves this to users to best figure out.
This spec can be bridged into other proposed new features with its module
caching behaviour. This document and issue does not intend to make those
leaps.
### Requirements
A api or library to create duplicates of specific webpack types and later
those back into the specific types with some given helper state like the
compilation and related module, etc. Uses of this api must handle not
duplicating cyclical references, like a dependency to its owning module, and
thawing the reference given the helper state.
A data relation API that either has duplication/thaw handles registered by
some predicate, or like dependencyFactories, or through tapable hooks.
A (disk) cache organization API that either creates objects to handle writing
to and reading from disk kind of like the FileSystem types. This API is for
reading and writing the duplicate objects. Its API shape needs to support
writing only changed objects. This might be done in a batch database like
operation, letting the cache system send a list of changed items to write so
the cache organization API doesn't need to redo work to discover what did and
did not change. It will likely need to read all of the cached objects from
disk during an iterative build. Core implementations of this API will likely
need to be one, a debug implementation, and two, a space and time efficient
implementation.
JSON is at least the starting resting format written to disk. The organization
API might be used to wrap the actual disk implementation. The wrapping
implemetation will turn the JSON objects into strings or buffers and back for
the wrapped implmentation. That can be JSON.stringify and parse or some other
means to do this work quickly as this step is a lot of work. Beating
JSON.parse performance is pretty tricky.
Either in watchpack or another module, timestamps either need to be replaced
with hashes for file and context dependencies or they can be added to the
callback arguments. With a disk cache, timestamps will not be a useful
comparison for considering if needs to be redone. The timestamps are not
guaranteed to represent changes to file or directory content.
Use file and context dependency hashes in needRebuild instead of timestamps.
Hash a representative value of the environment, dependencies in node_modules
and like. A different value from the last time a cache was used means no items
in the cache can be used and they must be destroyed and replaced by freshly
built items.
Hash webpack's compiler configuration and use it as a cache id so multiple
adjacent caches are stored. The right cache needs to selected early on at some
point of plugins being applied to the compiler after defaults are set and
configuration changes are made by tools like webpack-dev-server.
These adjacent caches should be automatically cleaned up by default to keep
the cache from running away in size by each one adding to a larger sum. This
might happen automatically say if there are more than 5 caches including the
one in use, cumulatively they use more than 500 MB. The oldest ones are
deleted first until the cumulative size comes under the 500 MB threshold.
Alternative to the cumulative size a if there are more than 5 caches and some
are older than 2 weeks, caches older than 2 weeks are deleted.
Replace the resolver's **unsafe cache** with a safe cache that validates a
resolution by stating every resolved file and every originally attempted
check. Doing this in bulk skips the logic flow the resolver normally executes.
Very little time is spent doing this as it doesn't rely on js logic to build
the paths. The paths are already built. The resolver's cached items may be
stored with their respective module, consolidating all of the data for a
cached module into one object for debugging and cleanup. If a module is no
longer used in builds, removing it also removes the resolutions that would
lead to it, and less information will need to be read from disk.
### Questions
* How are loaders that load an external configuration (babel-loader, postcss-loader) treated in regards to the cache configuration hash/id? Any method to do this needs to be done before a Compilation starts.
* What enhanced-resolve cases exist that may not be recorded in the missing set?
* How do loader and plugin authors work on their code and test it with the cache?
* JSON is a good resting format. Should we look at others? Beating JSON.parse performance is pretty tricky. protobufjs implementations improve on it in many cases because they store the keys as integers in the output. The protobuf schema defines the key to integer relationship explicitly so its easy to go back and forth.
* Are the version of node or operating system values that should be included in the environment (node_modules and other third party dependencies) comparison? Should they be part of the configuration hash?
### Fundementals
#### 0CJS
* The disk cache should be on by default.
* Each build with a different webpack configuration should store a unique copy of its cache versus another webpack configuration. E.g. A development build and a production build must have distinct caches due to them having different options set.
* After N caches using M MBs total exist any caches older than W weeks past N caches and M MBs total should be deleted.
* Some disk cache information should be in webpack stats. E.g. Root compilation cache id, disk space used by cache, disk space used by all caches, ...
* Any change to node_modules dependencies or other third-party dependency directories must invalidate a saved cache.
* The cache must be portable, reusable by CI, or between members of a project team as long as no node_modules or other third-party dependency directories change.
* Use a efficient and flexible resting format and disk organization implementation.
#### Speed
Iterative builds, builds with a saved cache, should complete significantly
faster than an uncached build. An uncached build saving a cache will be a
small margin slower than one not writing a cache, as writing the cache is an
additional task webpack does not yet perform. A rebuild, a build in the same
process that ran an uncached or iterative build, should be a hard to measure
amount slower, saving only the changed cache state and not the whole cache.
#### Build Size
No change.
#### Security
Similar security as to how third party dependencies are fetched for a project.
### Success Metric
* webpack iterative builds, builds with a cache, should be significantly faster that uncached builds.
* Rebuilds performance should be minimally impacted.
* Iterative build output should match an uncached build given no changes to the sources.
* Cache sharing: a cache should be usable in the next CI run in a different CI instance, or a common updated cache could be pulled from some arbitrary store by team members and used instead of needing to run an uncached build first. (Given that the configuration is not different than the stored caches and that node_modules contains the same dependencies and versions.)
| 0 |
# Bug report
## Describe the bug
A clear and concise description of what the bug is.
## To Reproduce
Steps to reproduce the behavior, please provide code snippets or a repository:
1. Clone https://github.com/tenjojeremy/test-nextjs-simple.git
2. run `yarn`
3. run `yarn start`
4. open localhost
5. you should see 3 posters

6. run `now`
7. open production site
8. you will see a 500 error

9. open runtime logs in your dashboard
10. see

## Expected behavior
Should display 3 movie posters in production not a 500 error
|
# Feature request
## Is your feature request related to a problem? Please describe.
It's currently not possible to read files from API routes or pages.
## Describe the solution you'd like
I want to be able to call `fs.readFile` with a `__dirname` path and have it
"just work".
This should work in Development and Production mode.
## Describe alternatives you've considered
This may need to integrate with `@zeit/webpack-asset-relocator-loader` in some
capacity. This plugin handles these types of requires.
However, it's not a necessity. I'd be OK with something that _only_ works with
`__dirname` and `__filename` (no relative or cwd-based paths).
## Additional context
Example:
// pages/api/test.js
import fs from 'fs'
import path from 'path'
export default (req, res) => {
const fileContent = fs.readFileSync(
path.join(__dirname, '..', '..', 'package.json'),
'utf8'
)
// ...
}
> Note: I know you can cheat the above example ☝️ with `require`, but that's
> not the point. 😄
| 1 |
**Daigo Kobayashi** opened **SPR-2657** and commented
There is no way to display success message(s) like struts' ActionMessage.
Spring should provide Messages inteface in a similar way of Errors and related
tag libraries.
* * *
**Issue Links:**
* #11130 Flash Scope for Spring MVC (Without Spring Web Flow) ( _ **"duplicates"**_ )
12 votes, 12 watchers
|
**Andy Wilkinson** opened **SPR-9255** and commented
I've been bitten in the past by an intermittent
`BeanCurrentlyInCreationException` when I've `@Autowired` a `FactoryBean`
implementation. I believe that this is considered to be a no-no, but
occassionally I forget and lose hours to diagnosing the problem until the
penny drops. An example can be seen in
https://issuetracker.springsource.com/browse/VMS-604. Today, I've been bitten
by a variation of this same problem.
This time, rather than having an `@Autowired` `FactoryBean` I've got an
`@Autowired` class that's a dependency of the `FactoryBean`. I believe this
means that to avoid a possible `BeanCurrentlyInCreationException` I need to
avoid using `@Autowired` on a `FactoryBean` and also on anything in the
`FactoryBean`'s dependency graph.
The main problem here is the intermittent nature of the failure. There appears
to be something non-deterministic in the code that finds all of the candidates
for a dependency. This, I'm guessing, is what makes the failure intermittent
which, in turn, makes it harder to diagnose. I'm also wondering how Spring
guarantees that there's only one possible candidate for the dependency if it,
apparently, doesn't always need to initialise the `FactoryBean` to satisfy the
dependency. Is there a risk that it might miss the fact that there are
multiple candidates, or is there something about one ordering which means that
it can successfully initialise the `FactoryBean` to check the type that it
will produce without also triggering a `BeanCurrentlyInCreationException`?
Ideally, dependency resolution would be deterministic so that this problem
happen none of the time or all of the time. Right now it's dangerous as the
problem can be lurking for days or weeks until it occurs. If deterministic
dependency resolution isn't possible, I'd love to see some improved
diagnostics for this problem. Something that pointed out the dangerous use of
`@Autowired` on a `FactoryBean` or one of its dependencies would be a big
help.
* * *
**Affects:** 3.1 GA
**Issue Links:**
* #13346 Doc: `@Autowired` properties not reliably set in FactoryBean before getObject ( _ **"duplicates"**_ )
**Referenced from:** commits spring-attic/spring-framework-issues@`6fa97fa`,
spring-attic/spring-framework-issues@`189ba5b`
2 votes, 4 watchers
| 0 |
Hello,
My issue is about lowpass generated in sos form
>>> print(signal.butter(2, 1, 'low', analog=True, output = "sos"))
>>> print(signal.butter(2, 1, 'high', analog=True, output = "sos"))
[[1. 0. 0. 1. 1.41421356 1. ]]
[[1. 0. 0. 1. 1.41421356 1. ]]
As you can see generating a lowpass and a highpass gives the same
coefficients.
Same issue with the cheby1 filter type.
Like the sos configuration doesn't like to see b2 = 0
Cheers,
|
Hello,
I have realized about an issue with sparse matrixes and loadmat function.
I have a set of sparse matrixes for storing very sparse values. Sometimes they
are so sparse that some of the matrixes are never used, so they keep on zeros.
When I try to save them in a matlab file and load them again I always find the
same problem, invalid shape. I know that the sparse matrixes should have at
leas 1 element, and 2 dimensions, but the content of the matrixes is data-
driven.
My point is that is not real the sparse has no shape, it is just there is no
active elements in that moment. Is this a known feature? it is a new bug?
Thabks for your help and sorry if it is duplicated, but I didn't find any
other issue with a similar description.
| 0 |
Hello everybody.
It looks like i found a bundle of bugs in last version of julia. I run an
application which uses many Tasks in it. It also uses generated julia code,
which is run inside these tasks all the time. I obtain these crashes after
~3-20 minutes of running in some random order. I used both debug and release
julia versions for tests...
julia> versioninfo()
Julia Version 0.4.3
Commit a2f713d (2016-01-12 21:37 UTC)
Platform Info:
System: Windows (x86_64-w64-mingw32)
CPU: Intel(R) Core(TM) i7-4700HQ CPU @ 2.40GHz
WORD_SIZE: 64
BLAS: libopenblas (USE64BITINT DYNAMIC_ARCH NO_AFFINITY Haswell)
LAPACK: libopenblas64_
LIBM: libopenlibm
LLVM: libLLVM-3.3
This is first error message:
A s s e r t i o n f a i l e d !
P r o g r a m : c : \ U s e r s \ U s e r \ A p p D a t a \ L o c a l \ J u l i a - 0 . 4 . 3 \ b i n \ j u l i a - d e b u g . e x e
F i l e : t o p l e v e l . c , L i n e 8 3 9
E x p r e s s i o n : j l _ i s _ f u n c t i o n ( f )
This application has requested the Runtime to terminate it in an unusual way.
Please contact the application's support team for more information.
Second error message looks like this:
Please submit a bug report with steps to reproduce this fault, and any error messages that follow (in their entirety). Thanks.
Exception: EXCEPTION_ACCESS_VIOLATION at 0x70116290 -- utf8proc_NFKC at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
utf8proc_NFKC at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
jl_static_eval at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
jl_static_eval at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
jl_static_eval at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
jl_static_eval at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
julia_type_to_llvm at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
jl_compile at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
jl_trampoline_compile_function at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
jl_trampoline at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
anonymous at G:\my\projects\jevo\src\Creature.jl:247
jl_get_system_hooks at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
jl_get_system_hooks at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia-debug.dll (unknown line)
Another one:
Please submit a bug report with steps to reproduce this fault, and any error messages that follow (in their entirety). Thanks.
Exception: EXCEPTION_ACCESS_VIOLATION at 0x64f417e8 -- jl_write_malloc_log at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
jl_write_malloc_log at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
jl_extern_c at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
jl_extern_c at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
jl_load_and_lookup at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
jl_compile at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
jl_trampoline at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
anonymous at g:\my\projects\jevo\src\Creature.jl:247
jl_unprotect_stack at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
The last one:
Please submit a bug report with steps to reproduce this fault, and any error messages that follow (in their entirety). Thanks.
Exception: EXCEPTION_ACCESS_VIOLATION at 0x64f1732d -- jl_add_method at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
jl_add_method at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
jl_method_def at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
anonymous at no file:0
anonymous at g:\my\projects\jevo\src\Creature.jl:247
jl_unprotect_stack at c:\Users\User\AppData\Local\Julia-0.4.3\bin\libjulia.dll (unknown line)
It's hard to provide buggy code sample, because application is big and so many
processes are involved. But, i may provide a high level code:
module Test
type Organism
code::Expr
codeFn::Function
end
type OrganismTask
task::Task
organism::Organism
end
tasks = OrganismTask[]
function born(o::Organism)
return function ()
while true
produce()
try
o.codeFn(o)
end
end
end
end
function run()
for i=1:500
# in real app organism's function is more complicated
org = Organism(:(function (o) return 1 end), function (o) return 1 end)
task = Task(born(org))
push!(tasks, OrganismTask(task, org))
end
while true
for i=1:500
consume(tasks[i].task)
# here is a code, which modify tasks[i].organism.code
tasks[i].organism.codeFn = eval(tasks[i].organism.code)
end
# here is a code, which remove and add tasks from/to tasks variable
end
end
end
If it's hard to find these errors using my sample, you may run my project on
your machine to obtain the same errors. It doesn't require some special
environment fo run. I may provide you exact steps to reproduce it.
Thanks a lot. Julia is a great language ;)
|
Hello,
I am seeing memory corruption when repeatedly using `@eval`. Here is some
example code to reproduce it. I have it failing on both Julia 0.3 and 0.4 at
around 33000 iterations, where the eval'ed function hits corruption.
Thanks!
function to_function(code::Expr)
@eval f() = $code
return f
end
function get_code()
r1 = rand()
r2 = rand()
Expr(:comparison, r1, :<, r2)
end
using Debug
@debug function script1()
srand(0)
for i = 1:100000
code = "nothing"
try
code = get_code()
f = to_function(code)
f()
catch e
println(e)
@bp
end
println("$i: code=$(string(code))")
end
end
| 1 |
* I tried using the `@types/express-sessions` package and had problems.
* I tried using the next stable version of tsc "typescript": "3.8.3"
I am tryng to use express-sessions in my app, but have next error after **yarn
add @types/express-sessions**
Can anybodt help me? ts version: 3.8.3, express version: 4.17.1
* Authors: @TheHandsomeCoder, @donnut, @mdekrey, @mrdziuban, @sbking, @afharo, @teves-castro, @1M0reBug, @hojberg, @samsonkeung, @angeloocana, @raynerd, @moshensky, @ethanresnick, @deftomat, @blimusiek, @biern, @rayhaneh, @rgm, @drewwyatt, @jottenlips, @minitesh, @Krantisinh, @pirix-gh, @brekk, @Nemo108, @jituanlin, @Philippe-mills, @Saul-Mirone
If you do not mention the authors the issue will be ignored.
|
Hi! Have next dep in my package.json file: "express": "4.17.1",
"@types/express": "4.17.3", "express-session": "1.17.1".
Now I'm trying to add "@types/express-session": "1.17.0" but have the next
errors in console.
Can anybody help me?
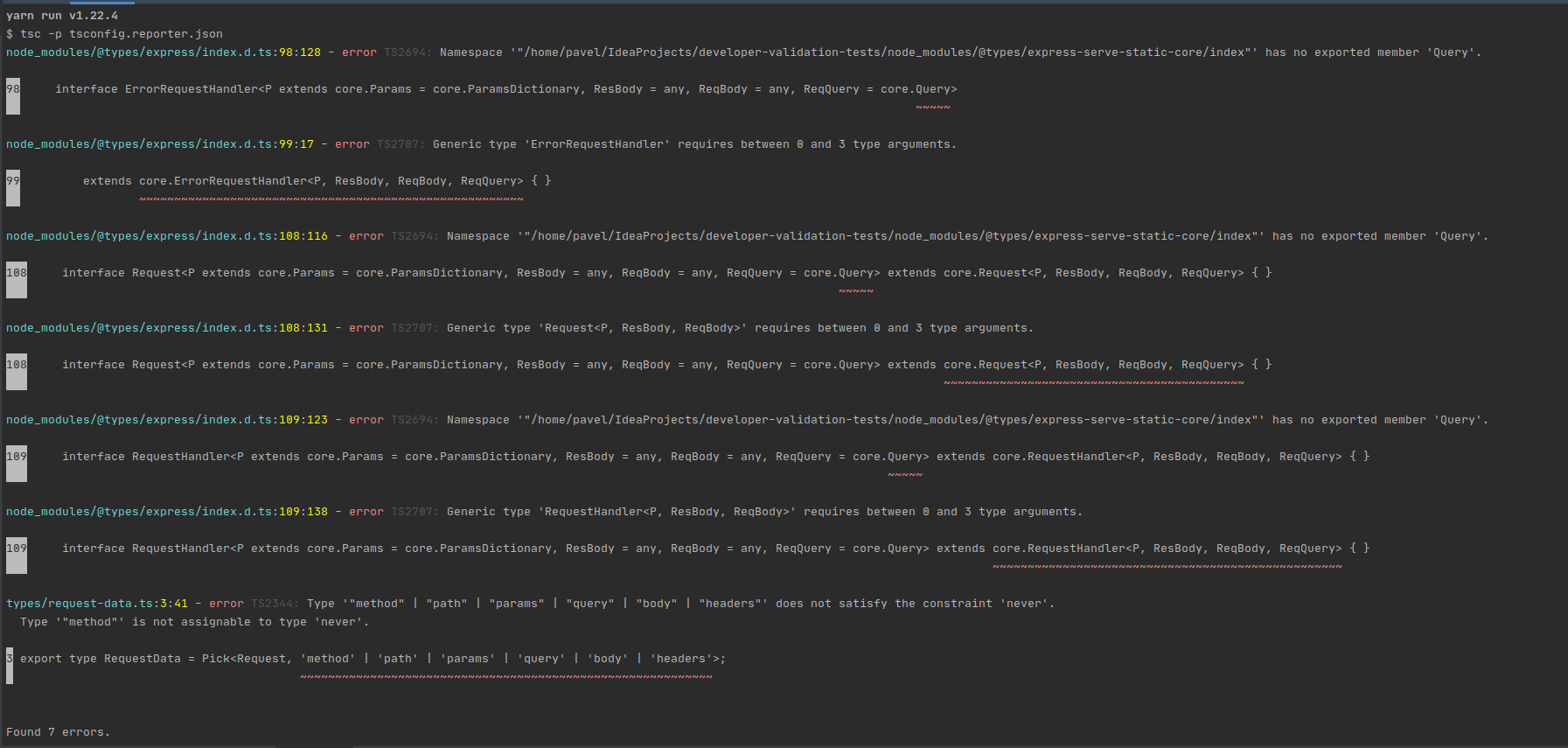
* Authors: @TheHandsomeCoder, @donnut, @mdekrey, @mrdziuban, @sbking, @afharo, @teves-castro, @1M0reBug, @hojberg, @samsonkeung, @angeloocana, @raynerd, @moshensky, @ethanresnick, @deftomat, @blimusiek, @biern, @rayhaneh, @rgm, @drewwyatt, @jottenlips, @minitesh, @Krantisinh, @pirix-gh, @brekk, @Nemo108, @jituanlin, @Philippe-mills, @Saul-Mirone
| 1 |
It is required to obtain Lagrangian multipliers while optimizing a linear
programming problem. Kindly help.
Best regards,
Bharat
|
I have a huge linprog problem of almost 1k variables and restrictions. I can
calculate the solution with scipy.optimize.linprog(method='simplex') but I
need shadow prices (or opportunity costs / duals) of ~100 inequalities.
I'm able to calculate them by adding 1 to the right side of the inequality and
then solving that problem. Then I get the shadow price substracting the
objective functions values for both solutions: shadow_price_i = f_max_original
- f_max_i. Then repeat 100 times. This method works but it's painfully slow
(1h). Note: I could also pose the dual problem and solve it
It's a shame that scipy does not return duals, so I'm opening a feature
request. I'm new contributing to open projects, but I'm a CS graduate and have
experience with both python and the simplex method, so I may be able to do so
with some guidance.
| 1 |
### Bug report
**Bug summary**
Can't use qt4agg, error reported below.
Downgrade to matplotlib 3.1.3 solves the problem.
**Code for reproduction**
import matplotlib as mpl
mpl.use('qt4agg')
Or, set it to Qt4Agg in `matplotlibrc` file.
**Actual outcome**
ImportError: cannot import name '_isdeleted'
Failed to enable GUI event loop integration for 'qt5'
**Matplotlib version**
* Operating system: win 10 LTSC 2019
* Matplotlib version: 3.2.1
* Matplotlib backend (`print(matplotlib.get_backend())`): can only use TkAgg
* Python version: 3.6
|
### Bug report
After updating to latest version (3.2.1) I started getting this error:
# Paste your code here
from matplotlib.backends.backend_qt4agg import FigureCanvasQTAgg as FigureCanvas
>>>from matplotlib.backends.backend_qt4agg import FigureCanvasQTAgg as FigureCanvas
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
from matplotlib.backends.backend_qt4agg import FigureCanvasQTAgg as FigureCanvas
File "C:\Python37-32\lib\site-packages\matplotlib\backends\backend_qt4agg.py", line 5, in <module>
from .backend_qt5agg import (
File "C:\Python37-32\lib\site-packages\matplotlib\backends\backend_qt5agg.py", line 11, in <module>
from .backend_qt5 import (
File "C:\Python37-32\lib\site-packages\matplotlib\backends\backend_qt5.py", line 19, in <module>
from .qt_compat import (
ImportError: cannot import name '_isdeleted' from 'matplotlib.backends.qt_compat' (C:\Python37-32\lib\site-packages\matplotlib\backends\qt_compat.py)
**Matplotlib version**
* Operating system: Windows 10
* Matplotlib version: 3.2.1
* Matplotlib backend (`print(matplotlib.get_backend())`):TkAgg
* Python version:3.7.6 (32Bit)
* Jupyter version (if applicable):
* Other libraries:
altgraph 0.17
astroid 2.3.3
colorama 0.4.3
cx-Freeze 6.1
cycler 0.10.0
future 0.18.2
isort 4.3.21
joblib 0.14.1
kiwisolver 1.1.0
lazy-object-proxy 1.4.3
matplotlib 3.2.1
mccabe 0.6.1
mpmath 1.1.0
numpy 1.18.2+mkl
pandas 1.0.3
pefile 2019.4.18
pip 20.0.2
psutil 5.7.0
PyInstaller 4.0.dev0+d08a42c612
pylint 2.4.4
pyparsing 2.4.6
PyQt4 4.11.4
PyQt5-sip 12.7.1
python-dateutil 2.8.1
pytz 2019.3
pywin32-ctypes 0.2.0
scikit-learn 0.22.2.post1
scipy 1.4.1
setuptools 46.0.0
six 1.14.0
tailer 0.4.1
typed-ast 1.4.1
wrapt 1.12.1
xlrd 1.2.0
XlsxWriter 1.2.8
| 1 |
Hi,
First of all, thank you very much for an awesome library.
I switched from Picasso to Glide, and I like Glide more than Picasso. However,
I've noticed that Glide would load the old image (deleted) instead of the new
image.
For example,
I have the following images on my listview:
Image1
Image2
Image3
etc.
I deleted Image1, and renamed Image2 to Image1.
Glide would display the old picture of Image1 which was deleted instead of
Image2 picture.
I went online and searched for the solution, they said that I can clear the
caches with the following:
public void Clear_GlideCaches() {
new Handler().postDelayed(new Runnable() {
@Override
public void run() {
Glide.get(MainActivity.this).clearMemory();
}}, 0);
AsyncTask.execute(new Runnable() {
@Override
public void run() {
Glide.get(MainActivity.this).clearDiskCache();
}
});
}
This solution didn't seem to work for my situation as Glide still loads the
old deleted images.
Here is my listview adapter:
@Override public View getView(int position, View recycledView, ViewGroup container) {
ViewHolder viewHolder = new ViewHolder();
LayoutInflater inflater = (LayoutInflater) mContext.getSystemService(Context.LAYOUT_INFLATER_SERVICE);
if (recycledView == null) {
recycledView = inflater.inflate(R.layout.listview_layout, container, false);
viewHolder.layout = (RelativeLayout)recycledView.findViewById(R.id.ListViewLayout);
viewHolder.imageView = (ImageView)recycledView.findViewById(R.id.ListViewImage);
recycledView.setTag(viewHolder);
} else {
viewHolder = (ViewHolder)recycledView.getTag();
}
Glide
.with(mContext)
.load(getItem(position).getImageUri())
.centerCrop()
.placeholder(R.color.black)
.crossFade()
.into(viewHolder.imageView);
return recycledView;
}
class ViewHolder {
RelativeLayout layout;
ImageView imageView;
}
On Picasso,
I was able to clear the image cache for specific image without any issues.
Here is the code:
public class ClearPicassoCaches {
public static void clearCache (Picasso p) {
p.cache.clear();
}
}
In ListView Adapter:
public void RefreshPicassoCache(String path) {
Picasso.with(mContext).invalidate("file:///" + path);
}
In MainActivity:
listViewAdapter.RefreshPicassoCache(NewPath); //to refresh the specific image cache.
My questions are:
1)is there a way to refresh (reset) the cache for specific image?
2) is there anyway I can clear the Glide caches, so that it won't display the
old deleted images when the deleted and the new images have the same name.?
I am testing my app on Android 5.1.1 (Lollittlepoop), GN4
**Glide Version** : 3.7.0
I hope someone can help me,
Thank you very much
|
Hi,
How can I clear Glide's cache in case.
* Clear all cache
* Clear cache of an URL.
| 1 |
These aren't documented anywhere and it's unclear how they're different from
`torch::save`
|
These APIs aren't going anywhere as far as I know, but they have no
descriptions or usage instructions
They have some documentation here but that's nowhere on the website:
https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/serialization/pickle.h
And some usages are in the tests but aren't very user-discoverable:
* https://github.com/pytorch/pytorch/blob/master/test/cpp/api/jit.cpp#L120
* https://github.com/pytorch/pytorch/blob/master/test/cpp/jit/test_save_load.cpp#L121
* https://github.com/pytorch/pytorch/blob/master/test/cpp/jit/torch_python_test.cpp#L44-L54
Tagging the JIT team to see if there are any plans for these APIs
cc @gmagogsfm
| 1 |
**Giovanni Dall'Oglio Risso** opened **SPR-8716** and commented
The number comparison can be more accurate with BigDecimals (possibly also
BigIntegers) and other number types:
This test fail, becouse the BigDecimal is converted to Integer, truncating the
value to zero:
@Test
public void testGT() throws Exception
{
ExpressionParser ep = new SpelExpressionParser();
Expression expression = ep.parseExpression("new java.math.BigDecimal('0.1') > 0");
Boolean value = expression.getValue(Boolean.class);
Assert.assertTrue(value);
}
The responsible is the class org.springframework.expression.spel.ast. **OpGT**
(but all the similar classes has the same imprinting)
@Override
public BooleanTypedValue getValueInternal(ExpressionState state) throws EvaluationException {
Object left = getLeftOperand().getValueInternal(state).getValue();
Object right = getRightOperand().getValueInternal(state).getValue();
if (left instanceof Number && right instanceof Number) {
Number leftNumber = (Number) left;
Number rightNumber = (Number) right;
if (leftNumber instanceof Double || rightNumber instanceof Double) {
return BooleanTypedValue.forValue(leftNumber.doubleValue() > rightNumber.doubleValue());
} else if (leftNumber instanceof Long || rightNumber instanceof Long) {
return BooleanTypedValue.forValue(leftNumber.longValue() > rightNumber.longValue());
} else {
return BooleanTypedValue.forValue(leftNumber.intValue() > rightNumber.intValue());
}
}
return BooleanTypedValue.forValue(state.getTypeComparator().compare(left, right) > 0);
}
In order you:
* check if is a Double
* check if is a Long
* treat it as an Integer
I attach my modest suggestion
* * *
**Affects:** 3.0.5
**Attachments:**
* OpGT.java ( _3.08 kB_ )
**Issue Links:**
* #13802 Support BigDecimals with SpEL ( _ **"duplicates"**_ )
|
**Oliver Becker** opened **SPR-9164** and commented
When doing number arithmetic in SpEL the result type is apparently one of
double, long or int.
This has the unwanted effect that for example float or BigDecimal values will
be changed to int.
new java.math.BigDecimal("12.34")
evaluates to 12.34
-(new java.math.BigDecimal("12.34"))
evaluates to -12
see org.springframework.expression.spel.ast
OpPlus, OpMinus, OpMultiply, OpDivide
* * *
**Affects:** 3.1.1
**Reference URL:** #80
**Attachments:**
* SpELFloatLiteralTest.java ( _1.24 kB_ )
**Issue Links:**
* #13358 Expression language not compare BigDecimals with integers ( _ **"is duplicated by"**_ )
* #13832 SpEL: OpEQ should use equals()
* #15943 Downgrade accidental use of Java 1.7 APIs
* #14121 Add SpEL support for float literals
* #14546 SpEL's arithmetic operations should explicitly detect BigInteger/Short/Byte and fall back to double handling for unknown Number subtypes
1 votes, 7 watchers
| 1 |
### System information
* **Have I written custom code (as opposed to using a stock example script provided in TensorFlow)** : No
* **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)** : macOS High Sierra 10.13.2
* **TensorFlow installed from (source or binary)** : source
* **TensorFlow version (use command below)** : tf 1.4
* **Python version** : 3.6.3
* **Bazel version (if compiling from source)** : 0.9.0
* **GCC/Compiler version (if compiling from source)** : Apple LLVM version 9.0.0 (clang-900.0.39.2)
* **Exact command to reproduce** : bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=- msse4.1 --copt=-msse4.2 --config=opt -k //tensorflow/tools/pip_package:build_pip_package
### Describe the problem
I'm unable to compile tensorflow from source. I get too many errors as shown
below in the logs:
### Source code / logs
Rakshiths-MacBook-Pro:tensorflow rakshithgb$ ./configure
WARNING: Running Bazel server needs to be killed, because the startup options are different.
You have bazel 0.9.0-homebrew installed.
Please specify the location of python. [Default is /Users/rakshithgb/miniconda3/bin/python]:
Found possible Python library paths:
/Users/rakshithgb/miniconda3/lib/python3.6/site-packages
Please input the desired Python library path to use. Default is [/Users/rakshithgb/miniconda3/lib/python3.6/site-packages]
Do you wish to build TensorFlow with Google Cloud Platform support? [Y/n]: n
No Google Cloud Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Hadoop File System support? [Y/n]: n
No Hadoop File System support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Amazon S3 File System support? [Y/n]: n
No Amazon S3 File System support will be enabled for TensorFlow.
Do you wish to build TensorFlow with XLA JIT support? [y/N]: n
No XLA JIT support will be enabled for TensorFlow.
Do you wish to build TensorFlow with GDR support? [y/N]: n
No GDR support will be enabled for TensorFlow.
Do you wish to build TensorFlow with VERBS support? [y/N]: n
No VERBS support will be enabled for TensorFlow.
Do you wish to build TensorFlow with OpenCL support? [y/N]: n
No OpenCL support will be enabled for TensorFlow.
Do you wish to build TensorFlow with CUDA support? [y/N]: n
No CUDA support will be enabled for TensorFlow.
Do you wish to build TensorFlow with MPI support? [y/N]: n
No MPI support will be enabled for TensorFlow.
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native]:
Add "--config=mkl" to your bazel command to build with MKL support.
Please note that MKL on MacOS or windows is still not supported.
If you would like to use a local MKL instead of downloading, please set the environment variable "TF_MKL_ROOT" every time before build.
Configuration finished
Rakshiths-MacBook-Pro:tensorflow rakshithgb$ bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=- msse4.1 --copt=-msse4.2 --config=opt -k //tensorflow/tools/pip_package:build_pip_package
..............
ERROR: Skipping 'msse4.1': no such target '//:msse4.1': target 'msse4.1' not declared in package '' defined by /Users/rakshithgb/Documents/Tensorflow/tensorflow/BUILD
WARNING: Target pattern parsing failed.
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/local_config_sycl/sycl/BUILD:4:1: First argument of 'load' must be a label and start with either '//', ':', or '@'. Use --incompatible_load_argument_is_label=false to temporarily disable this check.
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/local_config_sycl/sycl/BUILD:6:1: First argument of 'load' must be a label and start with either '//', ':', or '@'. Use --incompatible_load_argument_is_label=false to temporarily disable this check.
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/local_config_sycl/sycl/BUILD:30:9: Traceback (most recent call last):
File "/private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/local_config_sycl/sycl/BUILD", line 27
cc_library(name = "syclrt", srcs = [sycl_libr...")], <3 more arguments>)
File "/private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/local_config_sycl/sycl/BUILD", line 30, in cc_library
sycl_library_path
name 'sycl_library_path' is not defined
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/local_config_sycl/sycl/BUILD:39:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '@local_config_sycl//sycl:sycl'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:96:1: First argument of 'load' must be a label and start with either '//', ':', or '@'. Use --incompatible_load_argument_is_label=false to temporarily disable this check.
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:98:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:100:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:102:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:104:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:106:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:108:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:110:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:112:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:114:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:116:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:118:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:120:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:122:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:124:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:126:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:131:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:136:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:141:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:146:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:151:1: name 're2_test' is not defined (did you mean 'ios_test'?)
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/bitmap256.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/bitstate.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/compile.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/dfa.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/filtered_re2.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/mimics_pcre.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/nfa.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/onepass.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/parse.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/perl_groups.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/prefilter.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/prefilter.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/prefilter_tree.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/prefilter_tree.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/prog.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/prog.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/re2.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/regexp.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/regexp.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/set.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/simplify.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/stringpiece.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/tostring.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/unicode_casefold.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/unicode_casefold.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/unicode_groups.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/unicode_groups.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/walker-inl.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/flags.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/logging.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/mix.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/mutex.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/rune.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/sparse_array.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/sparse_set.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/strutil.cc' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/strutil.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/utf.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:util/util.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/filtered_re2.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/re2.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/set.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /private/var/tmp/_bazel_rakshithgb/fde7bc60972656b0c2db4fd0b79e24fb/external/com_googlesource_code_re2/BUILD:11:1: Target '@com_googlesource_code_re2//:re2/stringpiece.h' contains an error and its package is in error and referenced by '@com_googlesource_code_re2//:re2'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/platform/default/build_config/BUILD:115:1: Target '@com_googlesource_code_re2//:re2' contains an error and its package is in error and referenced by '//tensorflow/core/platform/default/build_config:platformlib'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/third_party/eigen3/BUILD:20:1: Target '@local_config_sycl//sycl:sycl' contains an error and its package is in error and referenced by '//third_party/eigen3:eigen3'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:3169:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:pooling_ops'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:3798:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:variable_ops'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:717:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:compare_and_bitpack_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:3776:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:scatter_nd_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:3764:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:dense_update_ops'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:643:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:gather_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:607:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:bitcast_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:619:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:constant_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:625:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:diag_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:631:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:edit_distance_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:687:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:mirror_pad_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:711:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:quantize_and_dequantize_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:787:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:split_v_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:774:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:slice_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:3770:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:scatter_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:3758:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:count_up_to_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/BUILD:2215:1: Target '@local_config_sycl//sycl:sycl' contains an error and its package is in error and referenced by '//tensorflow/core:sycl_runtime'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:780:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:split_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:681:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:matrix_set_diag_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:601:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:bcast_ops'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:756:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:reverse_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:699:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:pack_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:813:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:transpose_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:705:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:pad_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:693:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:one_hot_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:649:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:identity_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:661:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:listdiff_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:533:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:immutable_constant_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:655:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:identity_n_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:613:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:concat_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:675:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:matrix_diag_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:839:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:where_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:762:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:reverse_sequence_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:794:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:inplace_ops'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:827:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:unique_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:768:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:shape_ops'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:667:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:matrix_band_part_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:637:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:gather_nd_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:750:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:reshape_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:800:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:tile_ops'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:833:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:unpack_op'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/core/kernels/BUILD:550:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '//tensorflow/core/kernels:debug_ops'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/tools/pip_package/BUILD:101:1: Target '@com_googlesource_code_re2//:LICENSE' contains an error and its package is in error and referenced by '//tensorflow/tools/pip_package:licenses'
ERROR: /Users/rakshithgb/Documents/Tensorflow/tensorflow/tensorflow/tools/pip_package/BUILD:101:1: Target '@local_config_sycl//sycl:LICENSE.text' contains an error and its package is in error and referenced by '//tensorflow/tools/pip_package:licenses'
WARNING: errors encountered while analyzing target '//tensorflow/tools/pip_package:build_pip_package': it will not be built
INFO: Analysed target //tensorflow/tools/pip_package:build_pip_package (204 packages loaded).
INFO: Found 0 targets...
ERROR: command succeeded, but there were errors parsing the target pattern
INFO: Elapsed time: 51.902s, Critical Path: 0.02s
FAILED: Build did NOT complete successfully
|
### System information
Linux ubuntu 16.04
Bazel 0.9.0
CUDA 9.1
cuDNN 7
TF Branch r1.4
I am getting the following errors / warnings using the set-up above, whilst
trying to build the python packages.
francesco@franny:~/Repositories/tensorflow$ git checkout r1.4
Branch 'r1.4' set up to track remote branch 'r1.4' from 'origin'.
Switched to a new branch 'r1.4'
francesco@franny:~/Repositories/tensorflow$ ./configure
Extracting Bazel installation...
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by com.google.protobuf.UnsafeUtil (file:/home/francesco/.cache/bazel/_bazel_francesco/install/754ae0b065b3dfe883541ff567ae8b5e/_embedded_binaries/A-server.jar) to field java.nio.Buffer.address
WARNING: Please consider reporting this to the maintainers of com.google.protobuf.UnsafeUtil
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
You have bazel 0.9.0 installed.
Please specify the location of python. [Default is /usr/bin/python]:
Found possible Python library paths:
/usr/local/lib/python2.7/dist-packages
/usr/lib/python2.7/dist-packages
Please input the desired Python library path to use. Default is [/usr/local/lib/python2.7/dist-packages]
Do you wish to build TensorFlow with jemalloc as malloc support? [Y/n]: n
No jemalloc as malloc support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Google Cloud Platform support? [Y/n]: n
No Google Cloud Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Hadoop File System support? [Y/n]: n
No Hadoop File System support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Amazon S3 File System support? [Y/n]: n
No Amazon S3 File System support will be enabled for TensorFlow.
Do you wish to build TensorFlow with XLA JIT support? [y/N]: n
No XLA JIT support will be enabled for TensorFlow.
Do you wish to build TensorFlow with GDR support? [y/N]: n
No GDR support will be enabled for TensorFlow.
Do you wish to build TensorFlow with VERBS support? [y/N]: n
No VERBS support will be enabled for TensorFlow.
Do you wish to build TensorFlow with OpenCL support? [y/N]: n
No OpenCL support will be enabled for TensorFlow.
Do you wish to build TensorFlow with CUDA support? [y/N]: y
CUDA support will be enabled for TensorFlow.
Please specify the CUDA SDK version you want to use, e.g. 7.0. [Leave empty to default to CUDA 8.0]: 9.1
Please specify the location where CUDA 9.1 toolkit is installed. Refer to README.md for more details. [Default is /usr/local/cuda]:
Please specify the cuDNN version you want to use. [Leave empty to default to cuDNN 6.0]: 7
Please specify the location where cuDNN 7 library is installed. Refer to README.md for more details. [Default is /usr/local/cuda]:
Please specify a list of comma-separated Cuda compute capabilities you want to build with.
You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus.
Please note that each additional compute capability significantly increases your build time and binary size. [Default is: 3.5,5.2]5.2
Do you want to use clang as CUDA compiler? [y/N]: n
nvcc will be used as CUDA compiler.
Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]:
Do you wish to build TensorFlow with MPI support? [y/N]: n
No MPI support will be enabled for TensorFlow.
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native]:
Add "--config=mkl" to your bazel command to build with MKL support.
Please note that MKL on MacOS or windows is still not supported.
If you would like to use a local MKL instead of downloading, please set the environment variable "TF_MKL_ROOT" every time before build.
Configuration finished
francesco@franny:~/Repositories/tensorflow$
francesco@franny:~/Repositories/tensorflow$ bazel build --config=opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
.........
ERROR: /home/francesco/.cache/bazel/_bazel_francesco/4ce2bc3731d0d87739dc505f1772132b/external/local_config_sycl/sycl/BUILD:4:1: First argument of 'load' must be a label and start with either '//', ':', or '@'. Use --incompatible_load_argument_is_label=false to temporarily disable this check.
ERROR: /home/francesco/.cache/bazel/_bazel_francesco/4ce2bc3731d0d87739dc505f1772132b/external/local_config_sycl/sycl/BUILD:6:1: First argument of 'load' must be a label and start with either '//', ':', or '@'. Use --incompatible_load_argument_is_label=false to temporarily disable this check.
ERROR: /home/francesco/.cache/bazel/_bazel_francesco/4ce2bc3731d0d87739dc505f1772132b/external/local_config_sycl/sycl/BUILD:30:9: Traceback (most recent call last):
File "/home/francesco/.cache/bazel/_bazel_francesco/4ce2bc3731d0d87739dc505f1772132b/external/local_config_sycl/sycl/BUILD", line 27
cc_library(name = "syclrt", srcs = [sycl_libr...")], <3 more arguments>)
File "/home/francesco/.cache/bazel/_bazel_francesco/4ce2bc3731d0d87739dc505f1772132b/external/local_config_sycl/sycl/BUILD", line 30, in cc_library
sycl_library_path
name 'sycl_library_path' is not defined
ERROR: /home/francesco/.cache/bazel/_bazel_francesco/4ce2bc3731d0d87739dc505f1772132b/external/local_config_sycl/sycl/BUILD:39:1: Target '@local_config_sycl//sycl:using_sycl' contains an error and its package is in error and referenced by '@local_config_sycl//sycl:sycl'
ERROR: /home/francesco/Repositories/tensorflow/third_party/eigen3/BUILD:20:1: Target '@local_config_sycl//sycl:sycl' contains an error and its package is in error and referenced by '//third_party/eigen3:eigen3'
ERROR: Analysis of target '//tensorflow/tools/pip_package:build_pip_package' failed; build aborted: Loading failed
INFO: Elapsed time: 13.322s
FAILED: Build did NOT complete successfully (93 packages loaded)
currently loading: tensorflow/core/kernels ... (2 packages)
Any help?
| 1 |
I'm using reactstrap (bootstrap) together with react-responsive for my site's
responsive layout.
There is no problem when I'm using reactstrap alone.
However, when I mix react-responsive into the pages to show certain components
only at certain screen breakpoints, I'm getting the following error in the
browser console:
> `main.js:4530 Warning: Expected server HTML to contain a matching <div> in
> <div>.`
* I have searched the issues of this repository and believe that this is not a duplicate.
## Expected Behavior
The error should not be showing up in the browser console.
## Current Behavior
An error `main.js:4530 Warning: Expected server HTML to contain a matching
<div> in <div>.` will appear in the console when ever a page is refreshed.
## Steps to Reproduce (for bugs)
1. Use react-responsive to render a component when a smaller screen size is matched.
2. Refresh page
3. Error should will show up in console.
4. The page however appears to still work normally.
## Context
I'm using reactstrap (bootstrap) together with react-responsive for my site's
responsive layout.
There is no problem when I'm using reactstrap alone.
However, when I mix react-responsive into the pages to show certain components
only at certain screen breakpoints, I'm getting the following error in the
browser's console:
> `main.js:4530 Warning: Expected server HTML to contain a matching <div> in
> <div>.`
Removing the responsive component will get rid of this error message too.
Although I'm not certainly sure what's the cause, I'm suspecting this has to
do with the server side rendering. The mobile component was probably rendered
dynamically on client but not on server side.
Is there anything I can do to fix this error? Any impact if the error is left
unresolved?
## Your Environment
Tech | Version
---|---
next | 5.0.0
node | 6.9.1
OS | Win 10
browser | Chrome
etc |
|
**Describe the bug**
I am having a problem when using packages that have module caching and keep
track of internal state in server rendering. An example of such packages is
redux-act where module caching is used to keep track of an id used to
serialize action types. The bug happens when importing my `store.js` file with
all the actions, reducers and the store in `_app`, and importing it in other
pages as well. This causes my `store.js` file to be bundled with both `_app`
and any other page I am rendering like `index`. This causes the `createAction`
to be called twice to the same action which causes the internal `redux-act`
ids to be out of sync and thus the reducer never handles the add action
**To Reproduce**
this reproduce code is passed on the `with-redux-wrapper` example.
1. clone https://github.com/Ilaiwi/next-_app-bug-example
2. run `npm run dev`
3. go to localhost:3000
**Expected behavior**
the `AddCount` should be 1 because an `add` action was dispatched in
`getInitialProps`
**System information**
* OS: [Windows 10 and osx]
* Version of Next.js: [e.g. 6.0.3]
**Additional context**
what I did in the example is I just added `redux-act` and replaced the actions
with `redux-act` actions and deleted the thunk `AddCount action`.
| 0 |
Using Kubernetes 1.1.2 with Vagrant provider, running two pods:
./cluster/kubectl.sh get po
NAME READY STATUS RESTARTS AGE
mysql-pod 1/1 Running 0 21s
wildfly-rc-l2cto 1/1 Running 0 21s
One of the pods was deleted:
./cluster/kubectl.sh delete po wildfly-rc-l2cto
pod "wildfly-rc-l2cto" deleted
Watching the status of pods are shown as:
./cluster/kubectl.sh get -w po
NAME READY STATUS RESTARTS AGE
mysql-pod 1/1 Running 0 1m
wildfly-rc-2o8vd 1/1 Running 0 13s
wildfly-rc-l2cto 1/1 Terminating 0 1m
NAME READY STATUS RESTARTS AGE
wildfly-rc-l2cto 0/1 Terminating 0 1m
wildfly-rc-l2cto 0/1 Terminating 0 1m
wildfly-rc-l2cto 0/1 Terminating 0 1m
Two issues:
* Refreshed status shows the only for the changed pod and shows it three times
* Even after waiting for 5 minutes, the status does not refresh to Terminated
Just checking the status as `kubectl.sh get po` shows that the pod has been
terminated. But its confusing that with `-w` the status never updates to
Terminated or something intuitive.
|
A Replication Controller is started using https://github.com/arun-
gupta/kubernetes-java-sample/blob/master/wildfly-rc.yaml and shows:
./cluster/kubectl.sh create -f ~/workspaces/kubernetes-java-sample/wildfly-rc.yaml replicationcontrollers/wildfly-rc
Pods are shown correctly as:
./cluster/kubectl.sh get -w po
NAME READY STATUS RESTARTS AGE
wildfly-rc-k6pk2 1/1 Running 0 47s
wildfly-rc-wez29 1/1 Running 0 47s
Scaled up by 1 (config file has 2) as:
./cluster/kubectl.sh scale --replicas=3 rc wildfly-rc
and the output is updated correctly:
NAME READY STATUS RESTARTS AGE
wildfly-rc-aqaqn 0/1 Pending 0 0s
wildfly-rc-aqaqn 0/1 Pending 0 0s
wildfly-rc-aqaqn 0/1 Pending 0 0s
wildfly-rc-aqaqn 0/1 Running 0 2s
wildfly-rc-aqaqn 1/1 Running 0 11s
Replicas are then reduced to 1:
./cluster/kubectl.sh scale --replicas=1 rc wildfly-rc
and the output shows:
wildfly-rc-wez29 1/1 Running 0 1m
wildfly-rc-aqaqn 1/1 Running 0 36s
Ctrl+C and view the list of pods running shows:
./cluster/kubectl.sh get -w po
NAME READY STATUS RESTARTS AGE
wildfly-rc-k6pk2 1/1 Running 0 2m
Seems like the previous two pods were killed but their status was still
updated to Running. This is inconsistent with the current state of Pods
running.
| 1 |
Challenge Use a CSS Class to Style an Element has an issue.
User Agent is: `Mozilla/5.0 (Windows NT 6.0) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/49.0.2623.112 Safari/537.36`.
Please describe how to reproduce this issue, and include links to screenshots
if possible.
My code:
<style>
.red-text {
color: red;
}
</style>
<h2 class="red-text">CatPhotoApp</h2>
<p>Kitty ipsum dolor sit amet, shed everywhere shed everywhere stretching attack your ankles chase the red dot, hairball run catnip eat the grass sniff.</p>
|
Challenge Use a CSS Class to Style an Element has an issue.
User Agent is: `Mozilla/5.0 (Linux; Android 4.4.2; SM-T231 Build/KOT49H)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.105 Safari/537.36`.
Please describe how to reproduce this issue, and include links to screenshots
if possible.
My code:
<style>
.red-text {
color: red;
}
</style>
<h2 class="red-text">CatPhotoApp</h2>
<p>Kitty ipsum dolor sit amet, shed everywhere shed everywhere stretching attack your ankles chase the red dot, hairball run catnip eat the grass sniff.</p>
| 1 |
Describe what you were doing when the bug occurred:
1. Using Profiler tab
2. Clicked on a commit
3. It threw this error
* * *
## Please do not remove the text below this line
DevTools version: 4.6.0-6cceaeb67
Call stack: at j (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:162825)
at N (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:161772)
at e.getCommitTree (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:164582)
at ec (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:339280)
at ci (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:59620)
at nl (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:69923)
at Ll (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:110996)
at qc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:102381)
at Hc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:102306)
at Vc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:102171)
Component stack: in ec
in div
in div
in div
in So
in Unknown
in n
in Unknown
in div
in div
in rl
in Ze
in fn
in Ga
in _s
|
Describe what you were doing when the bug occurred:
1. Profiling a slow component
In a component that rendered 5000 pre tags with single lines of text in them,
that has an unrelated controlled text box is the same component that was typed
into while profiling. App hung a while and, when it rendered again the error
was in the profiler.
* * *
## Please do not remove the text below this line
DevTools version: 4.6.0-6cceaeb67
Call stack: at j (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:162825)
at N (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:161628)
at e.getCommitTree (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:164582)
at ec (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:40:339280)
at ci (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:59620)
at Ll (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:109960)
at qc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:102381)
at Hc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:102306)
at Vc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:102171)
at Tc (chrome-
extension://fmkadmapgofadopljbjfkapdkoienihi/build/main.js:32:98781)
Component stack: in ec
in div
in div
in div
in So
in Unknown
in n
in Unknown
in div
in div
in rl
in Ze
in fn
in Ga
in _s
| 1 |
### Version 2.6.7 on my computer, not sure about the version used in jsfiddle
### Reproduction link
https://jsfiddle.net/cicsolutions/qkzjp520/6/
### Steps to reproduce
Create three named slots: (1) with no dash in the slot name, like 'header' or
'footer', as in the docs. (2) with a dash in the name, like 'card-header' and
(3) with a camelCased slot name.
Console log the slot contents at the created and mounted hooks (other
lifecycle hooks not tested) of the component.
### What is expected?
I would expect the slot contents for all slot name syntaxes to be available at
in the lifecycle hooks and rendered in component. (unsure if hyphenated or
camelCasing is preferred for compound names)
I would 100% expect that if the contents of the slot can be logged to the
console during created/mounted hooks, that it could be rendered via the render
function (which appears to not be true for camelCased slot names)
### What is actually happening?
The slot content for a slot where the name contains a dash is undefined at the
created hook, whereas the slot content where the name does not have a dash is
defined as expected with the slot node object.
Most strange ... content for the slot with a camelCased name is logged to the
console properly, but not rendered in the component.
* * *
Please let me know if this type of report is unhelpful. I really don't have
the time to first search the forums and such, and I'm still learning Vue, so
I'm unsure if for some reason this would be intended behavior.
I do not see anything in the docs that gives notes about the syntax for the
slot names that may be compound phrases/names. However I thought I read
somewhere in the docs that camelCase is not valid HTML, so i first figured the
hyphenated version of the slot name would be correct.
It does make sense to me that the value that follows the colon in the
directive declaration becomes the $slots object key, and the value is not
rendered as a DOM element attribute, so I thought perhaps using camelCase is
the proper way to have compound slot names. But when using camelCase slot
names, the slot content does appear in the console, but is not rendered via
the render function. So ... that's even stranger!?
It would be great if the docs could touch on the proper naming convention for
slot names, as compound slot names seem like they would be a pretty common
approach to slot naming.
Note: I did not test other lifecycle hooks.
Perhaps I'm not understanding slots properly, but it seems strange to me that
a slot named with a dash will render properly but show as undefined for in the
created/mounted hooks. And the opposite: having a camelCase slot name does
show a correct node value in the hooks, however does not actually render the
slotted content.
Hope this helps! Thanks so much for all you do! Vue is simply the best
framework I've ever used!
|
### Version
2.5.13
### Reproduction link
https://codesandbox.io/s/6yk5o1x573
### Steps to reproduce
In parent component, apply a scoped class to a div. In the child, name the
class the same and make sure it's scoped, but use different CSS properties so
there's no overwriting.
### What is expected?
I would expect scoped classes to actually be scoped.
### What is actually happening?
Scoped styles are leaking into the children. The divs are sharing 'data-v'
attributes which is very bad.
| 0 |
# Environment
Windows build number: 10.0.18999.0
Windows Terminal version: 0.5.2762.0
# Steps to reproduce
1. Open a new PowerShell tab. PowerShell version does not matter.
2. Paste and run the following code in the PowerShell tab:
Register-EngineEvent -SourceIdentifier Powershell.Exiting -Action { Set-Content -Value "Hello there." -Path "$env:TEMP\General Kenobi.txt" }
4. Close the PowerShell tab by clicking the x button or by the `exit` command. Or close the Terminal window.
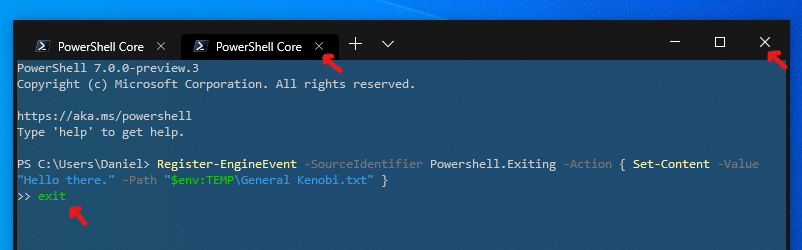
# Expected behavior
The PowerShell tab should trigger the Powershell.Exiting event and a file
`%temp%\General Kenobi.txt` should be created.
# Actual behavior
The event does not trigger and no file is created.
Note: If you reproduce this in the native PowerShell 5 or 7-preview.3 console
(not the Terminal app) you'll find that the event triggers correctly only when
using the `exit` command. Clicking the close button also does not trigger the
event. Although I also reported that at PowerShell/PowerShell#8000, I believe
that with Terminal it's an independent issue.
|
# Description of the new feature/enhancement
Sometimes i need to open many panes in a tab with
splitHorizontal/splitVertical hotkeys. And then broadcast input to all the
panes in current tab, or all tabs.
Is it possible to support broadcast input, like iterm2?

| 0 |
I think Angular 2 is missing a way to retrieve innerHTML of the original
element
<foo>SOME TEXT HERE</foo>
I know I can render the original content with `<ng-content>`
@Component({
selector: 'foo',
template: '<ng-content></ng-content>'
})
However there is no way I can retrieve the original content in constructor, or
anywhere in the code.
The `@Input` is only able to access attribute, but not inner HTML.
And the `ElementRef` in constructor is a already modified element.
May I know what is the proper way to get inner HTML of the element?
|
Use case:
Angular Material has a directive called `md-icon` that lets the user embed SVG
content via URL:
<md-icon svg-src="../img/puppy.svg">
We need to be able to build a directive in angular 2 that directly embeds
content in this way. Using a binding on innerHTML is possible, but susceptible
to XSS and would require ugly string manipulation of DOM-like content.
| 0 |
_dbscan_inner.cpp
c:\users\prasanth chettri\appdata\local\programs\python\python37\lib\site-
packages\numpy\core\include\numpy\npy_1_7_deprecated_api.h(12) : Warning Msg:
Using deprecated NumPy API, disable it by #defining NPY_NO_DEPRECATED_API
NPY_1_7_API_VERSION
sklearn\cluster_dbscan_inner.cpp(5960): error C2039: 'exc_type': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(5961): error C2039: 'exc_value': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(5962): error C2039: 'exc_traceback': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(5969): error C2039: 'exc_type': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(5970): error C2039: 'exc_value': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(5971): error C2039: 'exc_traceback': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(5972): error C2039: 'exc_type': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(5973): error C2039: 'exc_value': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(5974): error C2039: 'exc_traceback': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(6029): error C2039: 'exc_type': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(6030): error C2039: 'exc_value': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(6031): error C2039: 'exc_traceback': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(6032): error C2039: 'exc_type': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(6033): error C2039: 'exc_value': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
sklearn\cluster_dbscan_inner.cpp(6034): error C2039: 'exc_traceback': is not a
member of '_ts'
c:\users\prasanth
chettri\appdata\local\programs\python\python37\include\pystate.h(209): note:
see declaration of '_ts'
----------------------------------------
Command ""c:\users\prasanth
chettri\appdata\local\programs\python\python37\python.exe" -u -c "import
setuptools, tokenize; **file** ='C:\Users\PRASAN ~~1\AppData\Local\Temp\pip-
install-sxdgy2gx\scikit-learn\setup.py';f=getattr(tokenize, 'open', open)(
**file** );code=f.read().replace('\r\n', '\n');f.close();exec(compile(code,
**file** , 'exec'))" install --record
C:\Users\PRASAN~~1\AppData\Local\Temp\pip-record-dheiq8_j\install-record.txt
--single-version-externally-managed --compile" failed with error code 1 in
C:\Users\PRASAN~1\AppData\Local\Temp\pip-install-sxdgy2gx\scikit-learn\
|
#### Description
Unable to `pip install`(compile error: `PyThreadState` has no member ...) with
Python 3.7rc1.
My apologies if this has been reported, but I couldn't find it in the issues
(closed/open) nor any pull request for it.
There have been similar issues with pyyaml (yaml/pyyaml#126), numpy
(numpy/numpy#10500), cython (cython/cython#1978), and pygame
(pygame/pygame#382).
#### Steps/Code to Reproduce
Install Python 3.7rc1.
`pip install scikit-learn`
#### Expected Results
`pip` succeeds.
#### Actual Results
Compilation errors:
...
sklearn/cluster/_dbscan_inner.cpp: In function ‘int
__Pyx__GetException(PyThreadState*, PyObject**, PyObject**, PyObject**)’:
sklearn/cluster/_dbscan_inner.cpp:6029:24: error: ‘PyThreadState’ has no member named ‘exc_type’
tmp_type = tstate->exc_type;
^
sklearn/cluster/_dbscan_inner.cpp:6030:25: error: ‘PyThreadState’ has no member named ‘exc_value’
tmp_value = tstate->exc_value;
^
sklearn/cluster/_dbscan_inner.cpp:6031:22: error: ‘PyThreadState’ has no member named ‘exc_traceback’
tmp_tb = tstate->exc_traceback;
^
sklearn/cluster/_dbscan_inner.cpp:6032:13: error: ‘PyThreadState’ has no member named ‘exc_type’
tstate->exc_type = local_type;
^
sklearn/cluster/_dbscan_inner.cpp:6033:13: error: ‘PyThreadState’ has no member named ‘exc_value’
tstate->exc_value = local_value;
^
sklearn/cluster/_dbscan_inner.cpp:6034:13: error: ‘PyThreadState’ has no member named ‘exc_traceback’
tstate->exc_traceback = local_tb;
^
error: Command "g++ -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g
-fwrapv -O3 -Wall -fPIC
-I/data/install/lib/python3.7/site-packages/numpy/core/include
-I/data/install/lib/python3.7/site-packages/numpy/core/include
-I/data/install/include/python3.7m -c sklearn/cluster/_dbscan_inner.cpp -o
build/temp.linux-x86_64-3.7/sklearn/cluster/_dbscan_inner.o -MMD -MF
build/temp.linux-x86_64-3.7/sklearn/cluster/_dbscan_inner.o.d" failed with exit
status 1
#### Versions
Linux-3.10.0-862.el7.x86_64-x86_64-with-redhat-7.5-Maipo
Python 3.7.0rc1 (default, Jun 19 2018, 10:54:58)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)]
NumPy 1.14.5
SciPy 1.1.0
| 1 |
I think yesterday they were running in under 40 minutes.
I did kubernetes-retired/contrib#1022 because the submit queue is timing out
before merging after running tests. I will try to push it live tonight. But we
need to figure out what caused this.
|
**Is this a request for help?** (If yes, you should use our troubleshooting
guide and community support channels, see
http://kubernetes.io/docs/troubleshooting/.): No
**What keywords did you search in Kubernetes issues before filing this one?**
(If you have found any duplicates, you should instead reply there.): vsphere,
lsilogic-sas
* * *
**Is this a BUG REPORT or FEATURE REQUEST?** (choose one): Bug Report
**Kubernetes version** (use `kubectl version`): Server Version:
version.Info{Major:"1", Minor:"4", GitVersion:"v1.4.5+coreos.0",
GitCommit:"f70c2e5b2944cb5d622621a706bdec3d8a5a9c5e", GitTreeState:"clean",
BuildDate:"2016-10-31T19:16:47Z", GoVersion:"go1.6.3", Compiler:"gc",
Platform:"linux/amd64"}
**Environment** :
* **Cloud provider or hardware configuration** : vSphere (vCenter: 6.5.0, ESXi: 6.0.0)
* **OS** (e.g. from /etc/os-release): CoreOS 1185.3.0 (MoreOS)
* **Kernel** (e.g. `uname -a`): Linux 4.7.3-coreos-r2 #1 SMP Tue Nov 1 01:38:43 UTC 2016 x86_64
* **Install tools** :
* **Others** :
**What happened** :
During pod provisioning, kube-controller-manager logged the following messages
whilst attempting to attach a vSphere volume to the pod;
2016-11-27T14:15:01.636686228Z I1127 14:15:01.636561 1 reconciler.go:168] Started AttachVolume for volume "kubernetes.io/vsphere-volume/[DATASTORE] volumes/VOLUME" to node "NODE"
2016-11-27T14:15:02.085465901Z E1127 14:15:02.085346 1 vsphere.go:667] error creating new SCSI controller: unknown SCSI controller type 'lsiLogic-sas'
2016-11-27T14:15:02.102770470Z E1127 14:15:02.102592 1 attacher.go:79] Error attaching volume "[DATASTORE] volumes/VOLUME": unknown SCSI controller type 'lsiLogic-sas'
2016-11-27T14:15:02.102790243Z E1127 14:15:02.102691 1 nestedpendingoperations.go:253] Operation for "\"kubernetes.io/vsphere-volume/[DATASTORE] volumes/VOLUME\"" failed. No retries permitted until 2016-11-27 14:15:06.102667758 +0000 UTC (durationBeforeRetry 4s). Error: Failed to attach volume "VOLUME" on node "NODE" with: unknown SCSI controller type 'lsiLogic-sas'
2016-11-27T14:15:02.102908054Z I1127 14:15:02.102838 1 event.go:217] Event(api.ObjectReference{Kind:"Pod", Namespace:"default", Name:"mayan-deployment-2304867309-f4tgb", UID:"df9106ba-b4ab-11e6-b3bc-005056892975", APIVersion:"v1", ResourceVersion:"4951433", FieldPath:""}): type: 'Warning' reason: 'FailedMount' Failed to attach volume "VOLUME" on node "NODE" with: unknown SCSI controller type 'lsiLogic-sas'
The operation is attempted again and continues to fail. The pod becomes stuck
in the ContainerCreating state.
**What you expected to happen** :
The volume should be mounted to the host and attached to the pod.
**How to reproduce it** (as minimally and precisely as possible):
1. Create a VMDK using the following command;
vmkfstools -c 2G /vmfs/volumes/DATASTORE/volumes/VOLUME.vmdk
2. Attach a vSphere volume to a pod using the following spec;
volumes:
- name: VOLUME
vsphereVolume:
volumePath: "[DATASTORE] volumes/VOLUME"
fsType: ext4
**Anything else do we need to know** :
This happens both with attaching an existing vSphere volume (as documented
here) and with the vSphere StorageClass provisioner (as documented here). For
the purposes of documenting this issue, I followed the former rather than the
latter, but the error is the same.
Volume/datastore/host names have been substituted from their actual values.
The Kubernetes worker node's VM hardware is as follows;

| 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.