
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
2.12B
| node_id
stringlengths 18
32
| number
int64 1
6.65k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| milestone
dict | comments
int64 0
70
| created_at
timestamp[ns, tz=UTC] | updated_at
timestamp[ns, tz=UTC] | closed_at
timestamp[ns, tz=UTC] | author_association
stringclasses 3
values | active_lock_reason
float64 | draft
float64 0
1
⌀ | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
float64 | state_reason
stringclasses 3
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3671/comments | https://api.github.com/repos/huggingface/datasets/issues/3671/events | https://github.com/huggingface/datasets/issues/3671 | 1,122,864,253 | I_kwDODunzps5C7Yx9 | 3,671 | Give an estimate of the dataset size in DatasetInfo | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 0 | 2022-02-03T09:47:10Z | 2022-02-03T09:47:10Z | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently, only part of the datasets provide `dataset_size`, `download_size`, `size_in_bytes` (and `num_bytes` and `num_examples` inside `splits`). I would want to get this information, or an estimation, for all the datasets.
**Describe the solution you'd like**
- get access to the git information for the dataset files hosted on the hub
- look at the [`Content-Length`](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Length) for the files served by HTTP
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3671/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3671/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3670/comments | https://api.github.com/repos/huggingface/datasets/issues/3670/events | https://github.com/huggingface/datasets/pull/3670 | 1,122,439,827 | PR_kwDODunzps4x_kBx | 3,670 | feat: 🎸 generate info if dataset_infos.json does not exist | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [] | closed | false | null | [] | null | 3 | 2022-02-02T22:11:56Z | 2022-02-21T15:57:11Z | 2022-02-21T15:57:10Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3670.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3670",
"merged_at": "2022-02-21T15:57:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3670.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3670"
} | in get_dataset_infos(). Also: add the `use_auth_token` parameter, and create get_dataset_config_info()
✅ Closes: #3013 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3670/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3670/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3669/comments | https://api.github.com/repos/huggingface/datasets/issues/3669/events | https://github.com/huggingface/datasets/pull/3669 | 1,122,335,622 | PR_kwDODunzps4x_OTI | 3,669 | Common voice validated partition | {
"avatar_url": "https://avatars.githubusercontent.com/u/98762373?v=4",
"events_url": "https://api.github.com/users/shalymin-amzn/events{/privacy}",
"followers_url": "https://api.github.com/users/shalymin-amzn/followers",
"following_url": "https://api.github.com/users/shalymin-amzn/following{/other_user}",
"gists_url": "https://api.github.com/users/shalymin-amzn/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shalymin-amzn",
"id": 98762373,
"login": "shalymin-amzn",
"node_id": "U_kgDOBeL-hQ",
"organizations_url": "https://api.github.com/users/shalymin-amzn/orgs",
"received_events_url": "https://api.github.com/users/shalymin-amzn/received_events",
"repos_url": "https://api.github.com/users/shalymin-amzn/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shalymin-amzn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shalymin-amzn/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shalymin-amzn"
} | [] | closed | false | null | [] | null | 7 | 2022-02-02T20:04:43Z | 2022-02-08T17:26:52Z | 2022-02-08T17:23:12Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3669.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3669",
"merged_at": "2022-02-08T17:23:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3669.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3669"
} | This patch adds access to the 'validated' partitions of CommonVoice datasets (provided by the dataset creators but not available in the HuggingFace interface yet).
As 'validated' contains significantly more data than 'train' (although it contains both test and validation, so one needs to be careful there), it can be useful to train better models where no strict comparison with the previous work is intended. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3669/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3669/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3668 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3668/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3668/comments | https://api.github.com/repos/huggingface/datasets/issues/3668/events | https://github.com/huggingface/datasets/issues/3668 | 1,122,261,736 | I_kwDODunzps5C5Fro | 3,668 | Couldn't cast array of type string error with cast_column | {
"avatar_url": "https://avatars.githubusercontent.com/u/25264037?v=4",
"events_url": "https://api.github.com/users/R4ZZ3/events{/privacy}",
"followers_url": "https://api.github.com/users/R4ZZ3/followers",
"following_url": "https://api.github.com/users/R4ZZ3/following{/other_user}",
"gists_url": "https://api.github.com/users/R4ZZ3/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/R4ZZ3",
"id": 25264037,
"login": "R4ZZ3",
"node_id": "MDQ6VXNlcjI1MjY0MDM3",
"organizations_url": "https://api.github.com/users/R4ZZ3/orgs",
"received_events_url": "https://api.github.com/users/R4ZZ3/received_events",
"repos_url": "https://api.github.com/users/R4ZZ3/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/R4ZZ3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/R4ZZ3/subscriptions",
"type": "User",
"url": "https://api.github.com/users/R4ZZ3"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 5 | 2022-02-02T18:33:29Z | 2022-07-19T13:36:24Z | 2022-07-19T13:36:24Z | NONE | null | null | null | ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method
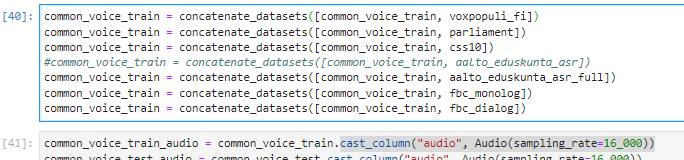
but get error:
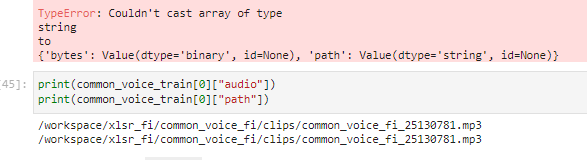
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)
- Python version: 3.8.8
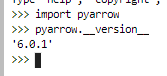
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3668/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3668/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3667/comments | https://api.github.com/repos/huggingface/datasets/issues/3667/events | https://github.com/huggingface/datasets/pull/3667 | 1,122,060,630 | PR_kwDODunzps4x-Ujt | 3,667 | Process .opus files with torchaudio | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
}
] | null | 4 | 2022-02-02T15:23:14Z | 2022-02-04T15:29:38Z | 2022-02-04T15:29:38Z | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3667.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3667",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3667.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3667"
} | @anton-l suggested to proccess .opus files with `torchaudio` instead of `soundfile` as it's faster:

(moreover, I didn't manage to load .opus files with `soundfile` / `librosa` locally on any my machine anyway for some reason, even with `ffmpeg` installed).
For now my current changes work with locally stored file:
```python
# download sample opus file (from MultilingualSpokenWords dataset)
!wget https://huggingface.co/datasets/polinaeterna/test_opus/resolve/main/common_voice_tt_17737010.opus
from datasets import Dataset, Audio
audio_path = "common_voice_tt_17737010.opus"
dataset = Dataset.from_dict({"audio": [audio_path]}).cast_column("audio", Audio(48000))
dataset[0]
# {'audio': {'path': 'common_voice_tt_17737010.opus',
# 'array': array([ 0.0000000e+00, 0.0000000e+00, 3.0517578e-05, ...,
# -6.1035156e-05, 6.1035156e-05, 0.0000000e+00], dtype=float32),
# 'sampling_rate': 48000}}
```
But it doesn't work when loading inside s dataset from bytes (I checked on [MultilingualSpokenWords](https://github.com/huggingface/datasets/pull/3666), the PR is a draft now, maybe the bug is somewhere there )
```python
import torchaudio
with open(audio_path, "rb") as b:
print(torchaudio.load(b))
# RuntimeError: Error loading audio file: failed to open file <in memory buffer>
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3667/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3667/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3666/comments | https://api.github.com/repos/huggingface/datasets/issues/3666/events | https://github.com/huggingface/datasets/pull/3666 | 1,122,058,894 | PR_kwDODunzps4x-ULz | 3,666 | process .opus files (for Multilingual Spoken Words) | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [] | closed | false | null | [] | null | 3 | 2022-02-02T15:21:48Z | 2022-02-22T10:04:03Z | 2022-02-22T10:03:53Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3666.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3666",
"merged_at": "2022-02-22T10:03:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3666.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3666"
} | Opus files requires `libsndfile>=1.0.30`. Add check for this version and tests.
**outdated:**
Add [Multillingual Spoken Words dataset](https://mlcommons.org/en/multilingual-spoken-words/)
You can specify multiple languages for downloading 😌:
```python
ds = load_dataset("datasets/ml_spoken_words", languages=["ar", "tt"])
```
1. I didn't take into account that each time you pass a set of languages the data for a specific language is downloaded even if it was downloaded before (since these are custom configs like `ar+tt` and `ar+tt+br`. Maybe that wasn't a good idea?
2. The script will have to be slightly changed after merge of https://github.com/huggingface/datasets/pull/3664
2. Just can't figure out what wrong with dummy files... 😞 Maybe we should get rid of them at some point 😁 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3666/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3666/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3665/comments | https://api.github.com/repos/huggingface/datasets/issues/3665/events | https://github.com/huggingface/datasets/pull/3665 | 1,121,753,385 | PR_kwDODunzps4x9TnU | 3,665 | Fix MP3 resampling when a dataset's audio files have different sampling rates | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | 2022-02-02T10:31:45Z | 2022-02-02T10:52:26Z | 2022-02-02T10:52:26Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3665.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3665",
"merged_at": "2022-02-02T10:52:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3665.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3665"
} | The resampler needs to be updated if the `orig_freq` doesn't match the audio file sampling rate
Fix https://github.com/huggingface/datasets/issues/3662 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3665/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3665/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3664 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3664/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3664/comments | https://api.github.com/repos/huggingface/datasets/issues/3664/events | https://github.com/huggingface/datasets/pull/3664 | 1,121,233,301 | PR_kwDODunzps4x7mg_ | 3,664 | [WIP] Return local paths to Common Voice | {
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/anton-l",
"id": 26864830,
"login": "anton-l",
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"repos_url": "https://api.github.com/users/anton-l/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"type": "User",
"url": "https://api.github.com/users/anton-l"
} | [] | closed | false | null | [] | null | 19 | 2022-02-01T21:48:27Z | 2022-02-22T09:14:06Z | 2022-02-22T09:14:06Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3664.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3664",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3664.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3664"
} | Fixes https://github.com/huggingface/datasets/issues/3663
This is a proposed way of returning the old local file-based generator while keeping the new streaming generator intact.
TODO:
- [ ] brainstorm a bit more on https://github.com/huggingface/datasets/issues/3663 to see if we can do better
- [ ] refactor the heck out of this PR to avoid completely copying the logic between the two generators | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3664/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3664/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3663/comments | https://api.github.com/repos/huggingface/datasets/issues/3663/events | https://github.com/huggingface/datasets/issues/3663 | 1,121,067,647 | I_kwDODunzps5C0iJ_ | 3,663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
},
{
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/anton-l",
"id": 26864830,
"login": "anton-l",
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"repos_url": "https://api.github.com/users/anton-l/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"type": "User",
"url": "https://api.github.com/users/anton-l"
},
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | 19 | 2022-02-01T18:40:10Z | 2022-09-21T15:03:09Z | 2022-09-21T14:56:22Z | MEMBER | null | null | null | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3663/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3663/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3662/comments | https://api.github.com/repos/huggingface/datasets/issues/3662/events | https://github.com/huggingface/datasets/issues/3662 | 1,121,024,403 | I_kwDODunzps5C0XmT | 3,662 | [Audio] MP3 resampling is incorrect when dataset's audio files have different sampling rates | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 6 | 2022-02-01T17:55:04Z | 2022-02-02T10:52:25Z | 2022-02-02T10:52:25Z | MEMBER | null | null | null | The Audio feature resampler for MP3 gets stuck with the first original frequencies it meets, which leads to subsequent decoding to be incorrect.
Here is a code to reproduce the issue:
Let's first consider two audio files with different sampling rates 32000 and 16000:
```python
# first download a mp3 file with sampling_rate=32000
!wget https://file-examples-com.github.io/uploads/2017/11/file_example_MP3_700KB.mp3
import torchaudio
audio_path = "file_example_MP3_700KB.mp3"
audio_path2 = audio_path.replace(".mp3", "_resampled.mp3")
resample = torchaudio.transforms.Resample(32000, 16000) # create a new file with sampling_rate=16000
torchaudio.save(audio_path2, resample(torchaudio.load(audio_path)[0]), 16000)
```
Then we can see an issue here when decoding:
```python
from datasets import Dataset, Audio
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[0] # decode the first audio file sets the resampler orig_freq to 32000
print(dataset .features["audio"]._resampler.orig_freq)
# 32000
print(dataset[0]["audio"]["array"].shape) # here decoding is fine
# (1308096,)
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[1] # decode the second audio file sets the resampler orig_freq to 16000
print(dataset .features["audio"]._resampler.orig_freq)
# 16000
print(dataset[0]["audio"]["array"].shape) # here decoding uses orig_freq=16000 instead of 32000
# (2616192,)
```
The value of `orig_freq` doesn't change no matter what file needs to be decoded
cc @patrickvonplaten @anton-l @cahya-wirawan @albertvillanova
The issue seems to be here in `Audio.decode_mp3`:
https://github.com/huggingface/datasets/blob/4c417d52def6e20359ca16c6723e0a2855e5c3fd/src/datasets/features/audio.py#L176-L180 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3662/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3662/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3661 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3661/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3661/comments | https://api.github.com/repos/huggingface/datasets/issues/3661/events | https://github.com/huggingface/datasets/pull/3661 | 1,121,000,251 | PR_kwDODunzps4x61ad | 3,661 | Remove unnecessary 'r' arg in | {
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bryant1410",
"id": 3905501,
"login": "bryant1410",
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bryant1410"
} | [] | closed | false | null | [] | null | 1 | 2022-02-01T17:29:27Z | 2022-02-07T16:57:27Z | 2022-02-07T16:02:42Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3661.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3661",
"merged_at": "2022-02-07T16:02:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3661.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3661"
} | Originally from #3489 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3661/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3661/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3660 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3660/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3660/comments | https://api.github.com/repos/huggingface/datasets/issues/3660/events | https://github.com/huggingface/datasets/pull/3660 | 1,120,982,671 | PR_kwDODunzps4x6xr8 | 3,660 | Change HTTP links to HTTPS | {
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bryant1410",
"id": 3905501,
"login": "bryant1410",
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bryant1410"
} | [] | open | false | null | [] | null | 0 | 2022-02-01T17:12:51Z | 2022-09-21T15:16:32Z | null | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3660.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3660",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3660.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3660"
} | I tested the links. I also fixed some typos.
Originally from #3489 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3660/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3660/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3659/comments | https://api.github.com/repos/huggingface/datasets/issues/3659/events | https://github.com/huggingface/datasets/issues/3659 | 1,120,913,672 | I_kwDODunzps5Cz8kI | 3,659 | push_to_hub but preview not working | {
"avatar_url": "https://avatars.githubusercontent.com/u/66082334?v=4",
"events_url": "https://api.github.com/users/thomas-happify/events{/privacy}",
"followers_url": "https://api.github.com/users/thomas-happify/followers",
"following_url": "https://api.github.com/users/thomas-happify/following{/other_user}",
"gists_url": "https://api.github.com/users/thomas-happify/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomas-happify",
"id": 66082334,
"login": "thomas-happify",
"node_id": "MDQ6VXNlcjY2MDgyMzM0",
"organizations_url": "https://api.github.com/users/thomas-happify/orgs",
"received_events_url": "https://api.github.com/users/thomas-happify/received_events",
"repos_url": "https://api.github.com/users/thomas-happify/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomas-happify/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomas-happify/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomas-happify"
} | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 1 | 2022-02-01T16:23:57Z | 2022-02-09T08:00:37Z | 2022-02-09T08:00:37Z | NONE | null | null | null | ## Dataset viewer issue for '*happifyhealth/twitter_pnn*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/happifyhealth/twitter_pnn)*
I used
```
dataset.push_to_hub("happifyhealth/twitter_pnn")
```
but the preview is not working.
Am I the one who added this dataset ? Yes
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3659/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3659/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3658/comments | https://api.github.com/repos/huggingface/datasets/issues/3658/events | https://github.com/huggingface/datasets/issues/3658 | 1,120,880,395 | I_kwDODunzps5Cz0cL | 3,658 | Dataset viewer issue for *P3* | {
"avatar_url": "https://avatars.githubusercontent.com/u/22351555?v=4",
"events_url": "https://api.github.com/users/jeffistyping/events{/privacy}",
"followers_url": "https://api.github.com/users/jeffistyping/followers",
"following_url": "https://api.github.com/users/jeffistyping/following{/other_user}",
"gists_url": "https://api.github.com/users/jeffistyping/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jeffistyping",
"id": 22351555,
"login": "jeffistyping",
"node_id": "MDQ6VXNlcjIyMzUxNTU1",
"organizations_url": "https://api.github.com/users/jeffistyping/orgs",
"received_events_url": "https://api.github.com/users/jeffistyping/received_events",
"repos_url": "https://api.github.com/users/jeffistyping/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jeffistyping/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeffistyping/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jeffistyping"
} | [] | closed | false | null | [] | null | 4 | 2022-02-01T15:57:56Z | 2023-09-25T12:16:21Z | 2023-09-25T12:16:21Z | NONE | null | null | null | ## Dataset viewer issue for '*P3*'
**Link: https://huggingface.co/datasets/bigscience/P3**
```
Status code: 400
Exception: SplitsNotFoundError
Message: The split names could not be parsed from the dataset config.
```
Am I the one who added this dataset ? No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3658/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3658/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3657/comments | https://api.github.com/repos/huggingface/datasets/issues/3657/events | https://github.com/huggingface/datasets/pull/3657 | 1,120,602,620 | PR_kwDODunzps4x5f1I | 3,657 | Extend dataset builder for streaming in `get_dataset_split_names` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 4 | 2022-02-01T12:21:24Z | 2022-02-03T22:49:06Z | 2022-02-02T11:22:01Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3657.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3657",
"merged_at": "2022-02-02T11:22:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3657.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3657"
} | Currently, `get_dataset_split_names` doesn't extend a builder module to support streaming, even though it uses `StreamingDownloadManager` to download data. This PR fixes that.
To test the change, run the following:
```bash
pip install git+https://github.com/huggingface/datasets.git@fix-get_dataset_split_names-streaming
python -c "from datasets import get_dataset_split_names; print(get_dataset_split_names('facebook/multilingual_librispeech', 'german', download_mode='force_redownload', revision='137923f945552c6afdd8b60e4a7b43e3088972c1'))"
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3657/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3657/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3656/comments | https://api.github.com/repos/huggingface/datasets/issues/3656/events | https://github.com/huggingface/datasets/issues/3656 | 1,120,510,823 | I_kwDODunzps5CyaNn | 3,656 | checksum error subjqa dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/9828683?v=4",
"events_url": "https://api.github.com/users/RensDimmendaal/events{/privacy}",
"followers_url": "https://api.github.com/users/RensDimmendaal/followers",
"following_url": "https://api.github.com/users/RensDimmendaal/following{/other_user}",
"gists_url": "https://api.github.com/users/RensDimmendaal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/RensDimmendaal",
"id": 9828683,
"login": "RensDimmendaal",
"node_id": "MDQ6VXNlcjk4Mjg2ODM=",
"organizations_url": "https://api.github.com/users/RensDimmendaal/orgs",
"received_events_url": "https://api.github.com/users/RensDimmendaal/received_events",
"repos_url": "https://api.github.com/users/RensDimmendaal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/RensDimmendaal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RensDimmendaal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/RensDimmendaal"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 2 | 2022-02-01T10:53:33Z | 2022-02-10T10:56:59Z | 2022-02-10T10:56:38Z | NONE | null | null | null | ## Describe the bug
I get a checksum error when loading the `subjqa` dataset (used in the transformers book).
## Steps to reproduce the bug
```python
from datasets import load_dataset
subjqa = load_dataset("subjqa","electronics")
```
## Expected results
Loading the dataset
## Actual results
```
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
<ipython-input-2-d2857d460155> in <module>()
2 from datasets import load_dataset
3
----> 4 subjqa = load_dataset("subjqa","electronics")
3 frames
/usr/local/lib/python3.7/dist-packages/datasets/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums, verification_name)
38 if len(bad_urls) > 0:
39 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 40 raise NonMatchingChecksumError(error_msg + str(bad_urls))
41 logger.info("All the checksums matched successfully" + for_verification_name)
42
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://github.com/lewtun/SubjQA/archive/refs/heads/master.zip']
```
## Environment info
Google colab
- `datasets` version: 1.18.2
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 3.0.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3656/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3656/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3655/comments | https://api.github.com/repos/huggingface/datasets/issues/3655/events | https://github.com/huggingface/datasets/issues/3655 | 1,119,801,077 | I_kwDODunzps5Cvs71 | 3,655 | Pubmed dataset not reachable | {
"avatar_url": "https://avatars.githubusercontent.com/u/77638579?v=4",
"events_url": "https://api.github.com/users/abhi-mosaic/events{/privacy}",
"followers_url": "https://api.github.com/users/abhi-mosaic/followers",
"following_url": "https://api.github.com/users/abhi-mosaic/following{/other_user}",
"gists_url": "https://api.github.com/users/abhi-mosaic/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhi-mosaic",
"id": 77638579,
"login": "abhi-mosaic",
"node_id": "MDQ6VXNlcjc3NjM4NTc5",
"organizations_url": "https://api.github.com/users/abhi-mosaic/orgs",
"received_events_url": "https://api.github.com/users/abhi-mosaic/received_events",
"repos_url": "https://api.github.com/users/abhi-mosaic/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhi-mosaic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhi-mosaic/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhi-mosaic"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 6 | 2022-01-31T18:45:47Z | 2022-12-19T19:18:10Z | 2022-02-14T14:15:41Z | CONTRIBUTOR | null | null | null | ## Describe the bug
Trying to use the `pubmed` dataset fails to reach / download the source files.
## Steps to reproduce the bug
```python
pubmed_train = datasets.load_dataset('pubmed', split='train')
```
## Expected results
Should begin downloading the pubmed dataset.
## Actual results
```
ConnectionError: Couldn't reach ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0865.xml.gz (InvalidSchema("No connection adapters were found for 'ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0865.xml.gz'"))
```
## Environment info
- `datasets` version: 1.18.2
- Platform: macOS-11.4-x86_64-i386-64bit
- Python version: 3.8.2
- PyArrow version: 6.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3655/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3655/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3654/comments | https://api.github.com/repos/huggingface/datasets/issues/3654/events | https://github.com/huggingface/datasets/pull/3654 | 1,119,717,475 | PR_kwDODunzps4x2kiX | 3,654 | Better TQDM output | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 1 | 2022-01-31T17:22:43Z | 2022-02-03T15:55:34Z | 2022-02-03T15:55:33Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3654.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3654",
"merged_at": "2022-02-03T15:55:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3654.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3654"
} | This PR does the following:
* if `dataset_infos.json` exists for a dataset, uses `num_examples` to print the total number of examples that needs to be generated (in `builder.py`)
* fixes `tqdm` + multiprocessing in Jupyter Notebook/Colab (the issue stems from this commit in the `tqdm` repo: https://github.com/tqdm/tqdm/commit/f7722edecc3010cb35cc1c923ac4850a76336f82)
* adds the missing `drop_last_batch` and `with_ranks` params to `DatasetDict.map`
* correctly computes the number of iterations in `map` and the CSV/JSON loader when `batched=True` to fix `tqdm` progress bars
* removes the `bool(logging.get_verbosity() == logging.NOTSET)` (or simplifies `bool(logging.get_verbosity() == logging.NOTSET) or not utils.is_progress_bar_enabled()` to `not utils.is_progress_bar_enabled()`) condition and uses `utils.is_progress_bar_enabled` to check if `tqdm` output is enabled (this comment from @stas00 explains why the `bool(logging.get_verbosity() == logging.NOTSET)` check is problematic: https://github.com/huggingface/transformers/issues/14889#issue-1087318463)
Fix #2630 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3654/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3654/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3653/comments | https://api.github.com/repos/huggingface/datasets/issues/3653/events | https://github.com/huggingface/datasets/issues/3653 | 1,119,186,952 | I_kwDODunzps5CtXAI | 3,653 | `to_json` in multiprocessing fashion sometimes deadlock | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomasw21",
"id": 24695242,
"login": "thomasw21",
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomasw21"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | 0 | 2022-01-31T09:35:07Z | 2022-01-31T09:35:07Z | null | CONTRIBUTOR | null | null | null | ## Describe the bug
`to_json` in multiprocessing fashion sometimes deadlock, instead of raising exceptions. Temporary solution is to see that it deadlocks, and then reduce the number of processes or batch size in order to reduce the memory footprint.
As @lhoestq pointed out, this might be related to https://bugs.python.org/issue22393#msg315684 where `multiprocessing` fails to raise the OOM exception. One suggested alternative is not use `concurrent.futures` instead.
## Steps to reproduce the bug
## Expected results
Script fails when one worker hits OOM, and raise appropriate error.
## Actual results
Deadlock
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.1
- Platform: Linux
- Python version: 3.8
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3653/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3653/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3652/comments | https://api.github.com/repos/huggingface/datasets/issues/3652/events | https://github.com/huggingface/datasets/pull/3652 | 1,118,808,738 | PR_kwDODunzps4xzinr | 3,652 | sp. Columbia => Colombia | {
"avatar_url": "https://avatars.githubusercontent.com/u/3781280?v=4",
"events_url": "https://api.github.com/users/serapio/events{/privacy}",
"followers_url": "https://api.github.com/users/serapio/followers",
"following_url": "https://api.github.com/users/serapio/following{/other_user}",
"gists_url": "https://api.github.com/users/serapio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/serapio",
"id": 3781280,
"login": "serapio",
"node_id": "MDQ6VXNlcjM3ODEyODA=",
"organizations_url": "https://api.github.com/users/serapio/orgs",
"received_events_url": "https://api.github.com/users/serapio/received_events",
"repos_url": "https://api.github.com/users/serapio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/serapio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/serapio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/serapio"
} | [] | closed | false | null | [] | null | 2 | 2022-01-31T00:41:03Z | 2022-02-09T16:55:25Z | 2022-01-31T08:29:07Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3652.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3652",
"merged_at": "2022-01-31T08:29:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3652.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3652"
} | "Columbia" is various places in North America. The country is "Colombia". | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3652/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3652/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3651/comments | https://api.github.com/repos/huggingface/datasets/issues/3651/events | https://github.com/huggingface/datasets/pull/3651 | 1,118,597,647 | PR_kwDODunzps4xy3De | 3,651 | Update link in wiki_bio dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12"
} | [] | closed | false | null | [] | null | 2 | 2022-01-30T16:28:54Z | 2022-01-31T14:50:48Z | 2022-01-31T08:38:09Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3651.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3651",
"merged_at": "2022-01-31T08:38:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3651.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3651"
} | Fixes #3580 and makes the wiki_bio dataset work again. I changed the link and some documentation, and all the tests pass. Thanks @lhoestq for uploading the dataset to the HuggingFace data bucket.
@lhoestq -- all the tests pass, but I'm still not able to import the dataset, as the old Google Drive link is cached somewhere:
```python
>>> from datasets import load_dataset
load_dataset("wiki_bio>>> load_dataset("wiki_bio")
Using custom data configuration default
Downloading and preparing dataset wiki_bio/default (download: 318.53 MiB, generated: 736.94 MiB, post-processed: Unknown size, total: 1.03 GiB) to /home/jxm3/.cache/huggingface/datasets/wiki_bio/default/1.1.0/5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9...
Traceback (most recent call last):
...
File "/home/jxm3/random/datasets/src/datasets/utils/file_utils.py", line 612, in get_from_cache
raise FileNotFoundError(f"Couldn't find file at {url}")
FileNotFoundError: Couldn't find file at https://drive.google.com/uc?export=download&id=1L7aoUXzHPzyzQ0ns4ApBbYepsjFOtXil
```
what do I have to do to invalidate the cache and actually import the dataset? It's clearly set up correctly, since the data is downloaded and processed by the tests.
As an aside, this caching-loading-scripts behavior makes for a really bad developer experience. I just wasted an hour trying to figure out where the caching was happening and how to disable it, and I don't know. All I wanted to do was update the link and submit a pull request! I recommend that you all either change this behavior (i.e. updating the link to a dataset should "just work") or document it, since I couldn't find any information about this in the contributing.md or readme or anywhere else! Thanks! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3651/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3651/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3650/comments | https://api.github.com/repos/huggingface/datasets/issues/3650/events | https://github.com/huggingface/datasets/pull/3650 | 1,118,537,429 | PR_kwDODunzps4xyr2o | 3,650 | Allow 'to_json' to run in unordered fashion in order to lower memory footprint | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomasw21",
"id": 24695242,
"login": "thomasw21",
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomasw21"
} | [] | closed | false | null | [] | null | 6 | 2022-01-30T13:23:19Z | 2023-09-25T06:28:51Z | 2023-09-24T16:45:48Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3650.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3650",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3650.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3650"
} | I'm using `to_json(..., num_proc=num_proc, compressiong='gzip')` with `num_proc>1`. I'm having an issue where things seem to deadlock at some point. Eventually I see OOM. I'm guessing it's an issue where one process starts to take a long time for a specific batch, and so other process keep accumulating their results in memory.
In order to flush memory, I propose we use optional `imap_unordered`. This will prevent one process to block the other ones. The logical thinking is that index are rarily relevant, and in one wants to keep an index, one can still create another column and reconstruct from there. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3650/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3650/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3649/comments | https://api.github.com/repos/huggingface/datasets/issues/3649/events | https://github.com/huggingface/datasets/issues/3649 | 1,117,502,250 | I_kwDODunzps5Cm7sq | 3,649 | Add IGLUE dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "19E633",
"default": false,
"description": "Multimodal datasets",
"id": 3608944167,
"name": "multimodal",
"node_id": "LA_kwDODunzps7XHB4n",
"url": "https://api.github.com/repos/huggingface/datasets/labels/multimodal"
}
] | open | false | null | [] | null | 0 | 2022-01-28T14:59:41Z | 2022-01-28T15:02:35Z | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** IGLUE
- **Description:** IGLUE brings together 4 vision-and-language tasks across 20 languages (Twitter [thread](https://twitter.com/ebugliarello/status/1487045497583976455?s=20&t=SB4LZGDhhkUW83ugcX_m5w))
- **Paper:** https://arxiv.org/abs/2201.11732
- **Data:** https://github.com/e-bug/iglue
- **Motivation:** This dataset would provide a nice example of combining the text and image features of `datasets` together for multimodal applications.
Note: the data / code are not yet visible on the GitHub repo, so I've pinged the authors for more information.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3649/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3649/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3648/comments | https://api.github.com/repos/huggingface/datasets/issues/3648/events | https://github.com/huggingface/datasets/pull/3648 | 1,117,465,505 | PR_kwDODunzps4xvXig | 3,648 | Fix Windows CI: bump python to 3.7 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | 2022-01-28T14:24:54Z | 2022-01-28T14:40:39Z | 2022-01-28T14:40:39Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3648.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3648",
"merged_at": "2022-01-28T14:40:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3648.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3648"
} | Python>=3.7 is needed to install `tokenizers` 0.11 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3648/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3648/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3647/comments | https://api.github.com/repos/huggingface/datasets/issues/3647/events | https://github.com/huggingface/datasets/pull/3647 | 1,117,383,675 | PR_kwDODunzps4xvGDQ | 3,647 | Fix `add_column` on datasets with indices mapping | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 2 | 2022-01-28T13:06:29Z | 2022-01-28T15:35:58Z | 2022-01-28T15:35:58Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3647.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3647",
"merged_at": "2022-01-28T15:35:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3647.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3647"
} | My initial idea was to avoid the `flatten_indices` call and reorder a new column instead, but in the end I decided to follow `concatenate_datasets` and use `flatten_indices` to avoid padding when `dataset._indices.num_rows != dataset._data.num_rows`.
Fix #3599 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3647/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3647/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3646/comments | https://api.github.com/repos/huggingface/datasets/issues/3646/events | https://github.com/huggingface/datasets/pull/3646 | 1,116,544,627 | PR_kwDODunzps4xsX66 | 3,646 | Fix streaming datasets that are not reset correctly | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 1 | 2022-01-27T17:21:02Z | 2022-01-28T16:34:29Z | 2022-01-28T16:34:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3646.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3646",
"merged_at": "2022-01-28T16:34:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3646.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3646"
} | Streaming datasets that use `StreamingDownloadManager.iter_archive` and `StreamingDownloadManager.iter_files` had some issues. Indeed if you try to iterate over such dataset twice, then the second time it will be empty.
This is because the two methods above are generator functions. I fixed this by making them return iterables that are reset properly instead.
Close https://github.com/huggingface/datasets/issues/3645
cc @anton-l | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3646/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3646/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3645/comments | https://api.github.com/repos/huggingface/datasets/issues/3645/events | https://github.com/huggingface/datasets/issues/3645 | 1,116,541,298 | I_kwDODunzps5CjRFy | 3,645 | Streaming dataset based on dl_manager.iter_archive/iter_files are not reset correctly | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | 0 | 2022-01-27T17:17:41Z | 2022-01-28T16:34:28Z | 2022-01-28T16:34:28Z | MEMBER | null | null | null | Hi ! When iterating over a streaming dataset once, it's not reset correctly because of some issues with `dl_manager.iter_archive` and `dl_manager.iter_files`. Indeed they are generator functions (so the iterator that is returned can be exhausted). They should be iterables instead, and be reset if we do a for loop again:
```python
from datasets import load_dataset
d = load_dataset("common_voice", "ab", split="test", streaming=True)
i = 0
for i, _ in enumerate(d):
pass
print(i) # 8
# let's do it again
i = 0
for i, _ in enumerate(d):
pass
print(i) # 0
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3645/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3645/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3644/comments | https://api.github.com/repos/huggingface/datasets/issues/3644/events | https://github.com/huggingface/datasets/issues/3644 | 1,116,519,670 | I_kwDODunzps5CjLz2 | 3,644 | Add a GROUP BY operator | {
"avatar_url": "https://avatars.githubusercontent.com/u/208336?v=4",
"events_url": "https://api.github.com/users/felix-schneider/events{/privacy}",
"followers_url": "https://api.github.com/users/felix-schneider/followers",
"following_url": "https://api.github.com/users/felix-schneider/following{/other_user}",
"gists_url": "https://api.github.com/users/felix-schneider/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/felix-schneider",
"id": 208336,
"login": "felix-schneider",
"node_id": "MDQ6VXNlcjIwODMzNg==",
"organizations_url": "https://api.github.com/users/felix-schneider/orgs",
"received_events_url": "https://api.github.com/users/felix-schneider/received_events",
"repos_url": "https://api.github.com/users/felix-schneider/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/felix-schneider/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/felix-schneider/subscriptions",
"type": "User",
"url": "https://api.github.com/users/felix-schneider"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 9 | 2022-01-27T16:57:54Z | 2023-03-14T14:45:59Z | null | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
Using batch mapping, we can easily split examples. However, we lack an appropriate option for merging them back together by some key. Consider this example:
```python
# features:
# {
# "example_id": datasets.Value("int32"),
# "text": datasets.Value("string")
# }
ds = datasets.Dataset()
def split(examples):
sentences = [text.split(".") for text in examples["text"]]
return {
"example_id": [
example_id
for example_id, sents in zip(examples["example_id"], sentences)
for _ in sents
],
"sentence": [sent for sents in sentences for sent in sents],
"sentence_id": [i for sents in sentences for i in range(len(sents))],
}
split_ds = ds.map(split, batched=True)
def process(examples):
outputs = some_neural_network_that_works_on_sentences(examples["sentence"])
return {"outputs": outputs}
split_ds = split_ds.map(process, batched=True)
```
I have a dataset consisting of texts that I would like to process sentence by sentence in a batched way. Afterwards, I would like to put it back together as it was, merging the outputs together.
**Describe the solution you'd like**
Ideally, it would look something like this:
```python
def join(examples):
order = np.argsort(examples["sentence_id"])
text = ".".join(examples["text"][i] for i in order)
outputs = [examples["outputs"][i] for i in order]
return {"text": text, "outputs": outputs}
ds = split_ds.group_by("example_id", join)
```
**Describe alternatives you've considered**
Right now, we can do this:
```python
def merge(example):
meeting_id = example["example_id"]
parts = split_ds.filter(lambda x: x["example_id"] == meeting_id).sort("segment_no")
return {"outputs": list(parts["outputs"])}
ds = ds.map(merge)
```
Of course, we could process the dataset like this:
```python
def process(example):
outputs = some_neural_network_that_works_on_sentences(example["text"].split("."))
return {"outputs": outputs}
ds = ds.map(process, batched=True)
```
However, that does not allow using an arbitrary batch size and may lead to very inefficient use of resources if the batch size is much larger than the number of sentences in one example.
I would very much appreciate some kind of group by operator to merge examples based on the value of one column.
| {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3644/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3644/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3643/comments | https://api.github.com/repos/huggingface/datasets/issues/3643/events | https://github.com/huggingface/datasets/pull/3643 | 1,116,417,428 | PR_kwDODunzps4xr8mX | 3,643 | Fix sem_eval_2018_task_1 download location | {
"avatar_url": "https://avatars.githubusercontent.com/u/31095360?v=4",
"events_url": "https://api.github.com/users/maxpel/events{/privacy}",
"followers_url": "https://api.github.com/users/maxpel/followers",
"following_url": "https://api.github.com/users/maxpel/following{/other_user}",
"gists_url": "https://api.github.com/users/maxpel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/maxpel",
"id": 31095360,
"login": "maxpel",
"node_id": "MDQ6VXNlcjMxMDk1MzYw",
"organizations_url": "https://api.github.com/users/maxpel/orgs",
"received_events_url": "https://api.github.com/users/maxpel/received_events",
"repos_url": "https://api.github.com/users/maxpel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/maxpel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maxpel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/maxpel"
} | [] | closed | false | null | [] | null | 1 | 2022-01-27T15:45:00Z | 2022-02-04T15:15:26Z | 2022-02-04T15:15:26Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3643.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3643",
"merged_at": "2022-02-04T15:15:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3643.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3643"
} | As discussed with @lhoestq in https://github.com/huggingface/datasets/issues/3549#issuecomment-1020176931_ this is the new pull request to fix the download location. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3643/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3643/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3642 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3642/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3642/comments | https://api.github.com/repos/huggingface/datasets/issues/3642/events | https://github.com/huggingface/datasets/pull/3642 | 1,116,306,986 | PR_kwDODunzps4xrj2S | 3,642 | Fix dataset slicing with negative bounds when indices mapping is not `None` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 0 | 2022-01-27T14:45:53Z | 2022-01-27T18:16:23Z | 2022-01-27T18:16:22Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3642.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3642",
"merged_at": "2022-01-27T18:16:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3642.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3642"
} | Fix #3611 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3642/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3642/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3641/comments | https://api.github.com/repos/huggingface/datasets/issues/3641/events | https://github.com/huggingface/datasets/pull/3641 | 1,116,284,268 | PR_kwDODunzps4xre7C | 3,641 | Fix numpy rngs when seed is None | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 0 | 2022-01-27T14:29:09Z | 2022-01-27T18:16:08Z | 2022-01-27T18:16:07Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3641.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3641",
"merged_at": "2022-01-27T18:16:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3641.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3641"
} | Fixes the NumPy RNG when `seed` is `None`.
The problem becomes obvious after reading the NumPy notes on RNG (returned by `np.random.get_state()`):
> The MT19937 state vector consists of a 624-element array of 32-bit unsigned integers plus a single integer value between 0 and 624 that indexes the current position within the main array.
`The MT19937 state vector`: the seed which we currently index, but this value stays the same for multiple rounds.
`plus a single integer value`: the `pos` value in this PR (is 624 if `seed` is set to a fixed value with `np.random.seed`, so we take the first value in the `seed` array returned by `np.random.get_state()`: https://stackoverflow.com/questions/32172054/how-can-i-retrieve-the-current-seed-of-numpys-random-number-generator)
NumPy notes: https://numpy.org/doc/stable/reference/random/bit_generators/mt19937.html
Fix #3634 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3641/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3641/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3640/comments | https://api.github.com/repos/huggingface/datasets/issues/3640/events | https://github.com/huggingface/datasets/issues/3640 | 1,116,133,769 | I_kwDODunzps5ChtmJ | 3,640 | Issues with custom dataset in Wav2Vec2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/9079808?v=4",
"events_url": "https://api.github.com/users/peregilk/events{/privacy}",
"followers_url": "https://api.github.com/users/peregilk/followers",
"following_url": "https://api.github.com/users/peregilk/following{/other_user}",
"gists_url": "https://api.github.com/users/peregilk/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/peregilk",
"id": 9079808,
"login": "peregilk",
"node_id": "MDQ6VXNlcjkwNzk4MDg=",
"organizations_url": "https://api.github.com/users/peregilk/orgs",
"received_events_url": "https://api.github.com/users/peregilk/received_events",
"repos_url": "https://api.github.com/users/peregilk/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/peregilk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/peregilk/subscriptions",
"type": "User",
"url": "https://api.github.com/users/peregilk"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 1 | 2022-01-27T12:09:05Z | 2022-01-27T12:29:48Z | 2022-01-27T12:29:48Z | NONE | null | null | null | We are training Vav2Vec using the run_speech_recognition_ctc_bnb.py-script.
This is working fine with Common Voice, however using our custom dataset and data loader at [NbAiLab/NPSC]( https://huggingface.co/datasets/NbAiLab/NPSC) it crashes after roughly 1 epoch with the following stack trace:

We are able to work around the issue, for instance by adding this check in line#222 in transformers/models/wav2vec2/modeling_wav2vec2.py:
```python
if input_length - (mask_length - 1) < num_masked_span:
num_masked_span = input_length - (mask_length - 1)
```
Interestingly, these are the variable values before the adjustment:
```
input_length=10
mask_length=10
num_masked_span=2
````
After adjusting num_masked_spin to 1, the training script runs. The issue is also fixed by setting “replace=True” in the same function.
Do you have any idea what is causing this, and how to fix this error permanently? If you do not think this is an Datasets issue, feel free to move the issue.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3640/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3640/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3639/comments | https://api.github.com/repos/huggingface/datasets/issues/3639/events | https://github.com/huggingface/datasets/issues/3639 | 1,116,021,420 | I_kwDODunzps5ChSKs | 3,639 | same value of precision, recall, f1 score at each epoch for classification task. | {
"avatar_url": "https://avatars.githubusercontent.com/u/10828657?v=4",
"events_url": "https://api.github.com/users/Dhanachandra/events{/privacy}",
"followers_url": "https://api.github.com/users/Dhanachandra/followers",
"following_url": "https://api.github.com/users/Dhanachandra/following{/other_user}",
"gists_url": "https://api.github.com/users/Dhanachandra/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Dhanachandra",
"id": 10828657,
"login": "Dhanachandra",
"node_id": "MDQ6VXNlcjEwODI4NjU3",
"organizations_url": "https://api.github.com/users/Dhanachandra/orgs",
"received_events_url": "https://api.github.com/users/Dhanachandra/received_events",
"repos_url": "https://api.github.com/users/Dhanachandra/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Dhanachandra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dhanachandra/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Dhanachandra"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 1 | 2022-01-27T10:14:16Z | 2022-02-24T09:02:18Z | 2022-02-24T09:02:17Z | NONE | null | null | null | **1st Epoch:**
1/27/2022 09:30:48 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/f1/default/default_experiment-1-0.arrow.59it/s]
01/27/2022 09:30:48 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/precision/default/default_experiment-1-0.arrow
01/27/2022 09:30:49 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/recall/default/default_experiment-1-0.arrow
PRECISION: {'precision': 0.7612903225806451}
RECALL: {'recall': 0.7612903225806451}
F1: {'f1': 0.7612903225806451}
{'eval_loss': 1.4658324718475342, 'eval_accuracy': 0.7612903118133545, 'eval_runtime': 30.0054, 'eval_samples_per_second': 46.492, 'eval_steps_per_second': 46.492, 'epoch': 3.0}
**4th Epoch:**
1/27/2022 09:56:55 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/f1/default/default_experiment-1-0.arrow.92it/s]
01/27/2022 09:56:56 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/precision/default/default_experiment-1-0.arrow
01/27/2022 09:56:56 - INFO - datasets.metric - Removing /home/ubuntu/.cache/huggingface/metrics/recall/default/default_experiment-1-0.arrow
PRECISION: {'precision': 0.7698924731182796}
RECALL: {'recall': 0.7698924731182796}
F1: {'f1': 0.7698924731182796}
## Environment info
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
!pip install -r /content/transformers/examples/pytorch/token-classification/requirements.txt
!pip install datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3639/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3639/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3638/comments | https://api.github.com/repos/huggingface/datasets/issues/3638/events | https://github.com/huggingface/datasets/issues/3638 | 1,115,725,703 | I_kwDODunzps5CgJ-H | 3,638 | AutoTokenizer hash value got change after datasets.map | {
"avatar_url": "https://avatars.githubusercontent.com/u/13161779?v=4",
"events_url": "https://api.github.com/users/tshu-w/events{/privacy}",
"followers_url": "https://api.github.com/users/tshu-w/followers",
"following_url": "https://api.github.com/users/tshu-w/following{/other_user}",
"gists_url": "https://api.github.com/users/tshu-w/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tshu-w",
"id": 13161779,
"login": "tshu-w",
"node_id": "MDQ6VXNlcjEzMTYxNzc5",
"organizations_url": "https://api.github.com/users/tshu-w/orgs",
"received_events_url": "https://api.github.com/users/tshu-w/received_events",
"repos_url": "https://api.github.com/users/tshu-w/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tshu-w/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tshu-w/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tshu-w"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | 11 | 2022-01-27T03:19:03Z | 2022-08-26T07:47:56Z | null | NONE | null | null | null | ## Describe the bug
AutoTokenizer hash value got change after datasets.map
## Steps to reproduce the bug
1. trash huggingface datasets cache
2. run the following code:
```python
from transformers import AutoTokenizer, BertTokenizer
from datasets import load_dataset
from datasets.fingerprint import Hasher
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
raw_datasets = load_dataset("glue", "mrpc")
print(Hasher.hash(tokenize_function))
print(Hasher.hash(tokenizer))
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
print(Hasher.hash(tokenize_function))
print(Hasher.hash(tokenizer))
```
got
```
Reusing dataset glue (/home1/wts/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1112.35it/s]
f4976bb4694ebc51
3fca35a1fd4a1251
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 6.96ba/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 15.25ba/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 5.81ba/s]
d32837619b7d7d01
5fd925c82edd62b6
```
3. run raw_datasets.map(tokenize_function, batched=True) again and see some dataset are not using cache.
## Expected results
`AutoTokenizer` work like specific Tokenizer (The hash value don't change after map):
```python
from transformers import AutoTokenizer, BertTokenizer
from datasets import load_dataset
from datasets.fingerprint import Hasher
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
raw_datasets = load_dataset("glue", "mrpc")
print(Hasher.hash(tokenize_function))
print(Hasher.hash(tokenizer))
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
print(Hasher.hash(tokenize_function))
print(Hasher.hash(tokenizer))
```
```
Reusing dataset glue (/home1/wts/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1091.22it/s]
46d4b31f54153fc7
5b8771afd8d43888
Loading cached processed dataset at /home1/wts/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-6b07ff82ae9d5c51.arrow
Loading cached processed dataset at /home1/wts/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-af738a6d84f3864b.arrow
Loading cached processed dataset at /home1/wts/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-531d2a603ba713c1.arrow
46d4b31f54153fc7
5b8771afd8d43888
```
## Environment info
- `datasets` version: 1.18.0
- Platform: Linux-5.4.0-91-generic-x86_64-with-glibc2.27
- Python version: 3.9.7
- PyArrow version: 6.0.1
| {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3638/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3638/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3637/comments | https://api.github.com/repos/huggingface/datasets/issues/3637/events | https://github.com/huggingface/datasets/issues/3637 | 1,115,526,438 | I_kwDODunzps5CfZUm | 3,637 | [TypeError: Couldn't cast array of type] Cannot load dataset in v1.18 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 3 | 2022-01-26T21:38:02Z | 2022-02-09T16:15:53Z | 2022-02-09T16:15:53Z | MEMBER | null | null | null | ## Describe the bug
I am trying to load the [`GEM/RiSAWOZ` dataset](https://huggingface.co/datasets/GEM/RiSAWOZ) in `datasets` v1.18.1 and am running into a type error when casting the features. The strange thing is that I can load the dataset with v1.17.0. Note that the error is also present if I install from `master` too.
As far as I can tell, the dataset loading script is correct and the problematic features [here](https://huggingface.co/datasets/GEM/RiSAWOZ/blob/main/RiSAWOZ.py#L237) also look fine to me.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dset = load_dataset("GEM/RiSAWOZ")
```
## Expected results
I can load the dataset without error.
## Actual results
<details><summary>Traceback</summary>
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in _prepare_split(self, split_generator)
1083 example = self.info.features.encode_example(record)
-> 1084 writer.write(example, key)
1085 finally:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write(self, example, key, writer_batch_size)
445
--> 446 self.write_examples_on_file()
447
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_examples_on_file(self)
403 batch_examples[col] = [row[0][col] for row in self.current_examples]
--> 404 self.write_batch(batch_examples=batch_examples)
405 self.current_examples = []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)
496 typed_sequence = OptimizedTypedSequence(batch_examples[col], type=col_type, try_type=col_try_type, col=col)
--> 497 arrays.append(pa.array(typed_sequence))
498 inferred_features[col] = typed_sequence.get_inferred_type()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib.array()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib._handle_arrow_array_protocol()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in __arrow_array__(self, type)
204 # We only do it if trying_type is False - since this is what the user asks for.
--> 205 out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
206 return out
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1064 if isinstance(feature, list):
-> 1065 return pa.ListArray.from_arrays(array.offsets, _c(array.values, feature[0]))
1066 elif isinstance(feature, Sequence):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1086 return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
-> 1087 raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
1088
TypeError: Couldn't cast array of type
struct<医院-3.0T MRI: string, 医院-CT: string, 医院-DSA: string, 医院-公交线路: string, 医院-区域: string, 医院-名称: string, 医院-地址: string, 医院-地铁可达: string, 医院-地铁线路: string, 医院-性质: string, 医院-挂号时间: string, 医院-电话: string, 医院-等级: string, 医院-类别: string, 医院-重点科室: string, 医院-门诊时间: string, 天气-城市: string, 天气-天气: string, 天气-日期: string, 天气-温度: string, 天气-紫外线强度: string, 天气-风力风向: string, 旅游景点-区域: string, 旅游景点-名称: string, 旅游景点-地址: string, 旅游景点-开放时间: string, 旅游景点-是否地铁直达: string, 旅游景点-景点类型: string, 旅游景点-最适合人群: string, 旅游景点-消费: string, 旅游景点-特点: string, 旅游景点-电话号码: string, 旅游景点-评分: string, 旅游景点-门票价格: string, 汽车-价格(万元): string, 汽车-倒车影像: string, 汽车-动力水平: string, 汽车-厂商: string, 汽车-发动机排量(L): string, 汽车-发动机马力(Ps): string, 汽车-名称: string, 汽车-定速巡航: string, 汽车-巡航系统: string, 汽车-座位数: string, 汽车-座椅加热: string, 汽车-座椅通风: string, 汽车-所属价格区间: string, 汽车-油耗水平: string, 汽车-环保标准: string, 汽车-级别: string, 汽车-综合油耗(L/100km): string, 汽车-能源类型: string, 汽车-车型: string, 汽车-车系: string, 汽车-车身尺寸(mm): string, 汽车-驱动方式: string, 汽车-驾驶辅助影像: string, 火车-出发地: string, 火车-出发时间: string, 火车-到达时间: string, 火车-坐席: string, 火车-日期: string, 火车-时长: string, 火车-目的地: string, 火车-票价: string, 火车-舱位档次: string, 火车-车型: string, 火车-车次信息: string, 电影-主演: string, 电影-主演名单: string, 电影-具体上映时间: string, 电影-制片国家/地区: string, 电影-导演: string, 电影-年代: string, 电影-片名: string, 电影-片长: string, 电影-类型: string, 电影-豆瓣评分: string, 电脑-CPU: string, 电脑-CPU型号: string, 电脑-产品类别: string, 电脑-价格: string, 电脑-价格区间: string, 电脑-内存容量: string, 电脑-分类: string, 电脑-品牌: string, 电脑-商品名称: string, 电脑-屏幕尺寸: string, 电脑-待机时长: string, 电脑-显卡型号: string, 电脑-显卡类别: string, 电脑-游戏性能: string, 电脑-特性: string, 电脑-硬盘容量: string, 电脑-系列: string, 电脑-系统: string, 电脑-色系: string, 电脑-裸机重量: string, 电视剧-主演: string, 电视剧-主演名单: string, 电视剧-制片国家/地区: string, 电视剧-单集片长: string, 电视剧-导演: string, 电视剧-年代: string, 电视剧-片名: string, 电视剧-类型: string, 电视剧-豆瓣评分: string, 电视剧-集数: string, 电视剧-首播时间: string, 辅导班-上课方式: string, 辅导班-上课时间: string, 辅导班-下课时间: string, 辅导班-价格: string, 辅导班-区域: string, 辅导班-年级: string, 辅导班-开始日期: string, 辅导班-教室地点: string, 辅导班-教师: string, 辅导班-教师网址: string, 辅导班-时段: string, 辅导班-校区: string, 辅导班-每周: string, 辅导班-班号: string, 辅导班-科目: string, 辅导班-结束日期: string, 辅导班-课时: string, 辅导班-课次: string, 辅导班-课程网址: string, 辅导班-难度: string, 通用-产品类别: string, 通用-价格区间: string, 通用-品牌: string, 通用-系列: string, 酒店-价位: string, 酒店-停车场: string, 酒店-区域: string, 酒店-名称: string, 酒店-地址: string, 酒店-房型: string, 酒店-房费: string, 酒店-星级: string, 酒店-电话号码: string, 酒店-评分: string, 酒店-酒店类型: string, 飞机-准点率: string, 飞机-出发地: string, 飞机-到达时间: string, 飞机-日期: string, 飞机-目的地: string, 飞机-票价: string, 飞机-航班信息: string, 飞机-舱位档次: string, 飞机-起飞时间: string, 餐厅-人均消费: string, 餐厅-价位: string, 餐厅-区域: string, 餐厅-名称: string, 餐厅-地址: string, 餐厅-推荐菜: string, 餐厅-是否地铁直达: string, 餐厅-电话号码: string, 餐厅-菜系: string, 餐厅-营业时间: string, 餐厅-评分: string>
to
{'旅游景点-名称': Value(dtype='string', id=None), '旅游景点-区域': Value(dtype='string', id=None), '旅游景点-景点类型': Value(dtype='string', id=None), '旅游景点-最适合人群': Value(dtype='string', id=None), '旅游景点-消费': Value(dtype='string', id=None), '旅游景点-是否地铁直达': Value(dtype='string', id=None), '旅游景点-门票价格': Value(dtype='string', id=None), '旅游景点-电话号码': Value(dtype='string', id=None), '旅游景点-地址': Value(dtype='string', id=None), '旅游景点-评分': Value(dtype='string', id=None), '旅游景点-开放时间': Value(dtype='string', id=None), '旅游景点-特点': Value(dtype='string', id=None), '餐厅-名称': Value(dtype='string', id=None), '餐厅-区域': Value(dtype='string', id=None), '餐厅-菜系': Value(dtype='string', id=None), '餐厅-价位': Value(dtype='string', id=None), '餐厅-是否地铁直达': Value(dtype='string', id=None), '餐厅-人均消费': Value(dtype='string', id=None), '餐厅-地址': Value(dtype='string', id=None), '餐厅-电话号码': Value(dtype='string', id=None), '餐厅-评分': Value(dtype='string', id=None), '餐厅-营业时间': Value(dtype='string', id=None), '餐厅-推荐菜': Value(dtype='string', id=None), '酒店-名称': Value(dtype='string', id=None), '酒店-区域': Value(dtype='string', id=None), '酒店-星级': Value(dtype='string', id=None), '酒店-价位': Value(dtype='string', id=None), '酒店-酒店类型': Value(dtype='string', id=None), '酒店-房型': Value(dtype='string', id=None), '酒店-停车场': Value(dtype='string', id=None), '酒店-房费': Value(dtype='string', id=None), '酒店-地址': Value(dtype='string', id=None), '酒店-电话号码': Value(dtype='string', id=None), '酒店-评分': Value(dtype='string', id=None), '电脑-品牌': Value(dtype='string', id=None), '电脑-产品类别': Value(dtype='string', id=None), '电脑-分类': Value(dtype='string', id=None), '电脑-内存容量': Value(dtype='string', id=None), '电脑-屏幕尺寸': Value(dtype='string', id=None), '电脑-CPU': Value(dtype='string', id=None), '电脑-价格区间': Value(dtype='string', id=None), '电脑-系列': Value(dtype='string', id=None), '电脑-商品名称': Value(dtype='string', id=None), '电脑-系统': Value(dtype='string', id=None), '电脑-游戏性能': Value(dtype='string', id=None), '电脑-CPU型号': Value(dtype='string', id=None), '电脑-裸机重量': Value(dtype='string', id=None), '电脑-显卡类别': Value(dtype='string', id=None), '电脑-显卡型号': Value(dtype='string', id=None), '电脑-特性': Value(dtype='string', id=None), '电脑-色系': Value(dtype='string', id=None), '电脑-待机时长': Value(dtype='string', id=None), '电脑-硬盘容量': Value(dtype='string', id=None), '电脑-价格': Value(dtype='string', id=None), '火车-出发地': Value(dtype='string', id=None), '火车-目的地': Value(dtype='string', id=None), '火车-日期': Value(dtype='string', id=None), '火车-车型': Value(dtype='string', id=None), '火车-坐席': Value(dtype='string', id=None), '火车-车次信息': Value(dtype='string', id=None), '火车-时长': Value(dtype='string', id=None), '火车-出发时间': Value(dtype='string', id=None), '火车-到达时间': Value(dtype='string', id=None), '火车-票价': Value(dtype='string', id=None), '飞机-出发地': Value(dtype='string', id=None), '飞机-目的地': Value(dtype='string', id=None), '飞机-日期': Value(dtype='string', id=None), '飞机-舱位档次': Value(dtype='string', id=None), '飞机-航班信息': Value(dtype='string', id=None), '飞机-起飞时间': Value(dtype='string', id=None), '飞机-到达时间': Value(dtype='string', id=None), '飞机-票价': Value(dtype='string', id=None), '飞机-准点率': Value(dtype='string', id=None), '天气-城市': Value(dtype='string', id=None), '天气-日期': Value(dtype='string', id=None), '天气-天气': Value(dtype='string', id=None), '天气-温度': Value(dtype='string', id=None), '天气-风力风向': Value(dtype='string', id=None), '天气-紫外线强度': Value(dtype='string', id=None), '电影-制片国家/地区': Value(dtype='string', id=None), '电影-类型': Value(dtype='string', id=None), '电影-年代': Value(dtype='string', id=None), '电影-主演': Value(dtype='string', id=None), '电影-导演': Value(dtype='string', id=None), '电影-片名': Value(dtype='string', id=None), '电影-主演名单': Value(dtype='string', id=None), '电影-具体上映时间': Value(dtype='string', id=None), '电影-片长': Value(dtype='string', id=None), '电影-豆瓣评分': Value(dtype='string', id=None), '电视剧-制片国家/地区': Value(dtype='string', id=None), '电视剧-类型': Value(dtype='string', id=None), '电视剧-年代': Value(dtype='string', id=None), '电视剧-主演': Value(dtype='string', id=None), '电视剧-导演': Value(dtype='string', id=None), '电视剧-片名': Value(dtype='string', id=None), '电视剧-主演名单': Value(dtype='string', id=None), '电视剧-首播时间': Value(dtype='string', id=None), '电视剧-集数': Value(dtype='string', id=None), '电视剧-单集片长': Value(dtype='string', id=None), '电视剧-豆瓣评分': Value(dtype='string', id=None), '辅导班-班号': Value(dtype='string', id=None), '辅导班-难度': Value(dtype='string', id=None), '辅导班-科目': Value(dtype='string', id=None), '辅导班-年级': Value(dtype='string', id=None), '辅导班-区域': Value(dtype='string', id=None), '辅导班-校区': Value(dtype='string', id=None), '辅导班-上课方式': Value(dtype='string', id=None), '辅导班-开始日期': Value(dtype='string', id=None), '辅导班-结束日期': Value(dtype='string', id=None), '辅导班-每周': Value(dtype='string', id=None), '辅导班-上课时间': Value(dtype='string', id=None), '辅导班-下课时间': Value(dtype='string', id=None), '辅导班-时段': Value(dtype='string', id=None), '辅导班-课次': Value(dtype='string', id=None), '辅导班-课时': Value(dtype='string', id=None), '辅导班-教室地点': Value(dtype='string', id=None), '辅导班-教师': Value(dtype='string', id=None), '辅导班-价格': Value(dtype='string', id=None), '辅导班-课程网址': Value(dtype='string', id=None), '辅导班-教师网址': Value(dtype='string', id=None), '汽车-名称': Value(dtype='string', id=None), '汽车-车型': Value(dtype='string', id=None), '汽车-级别': Value(dtype='string', id=None), '汽车-座位数': Value(dtype='string', id=None), '汽车-车身尺寸(mm)': Value(dtype='string', id=None), '汽车-厂商': Value(dtype='string', id=None), '汽车-能源类型': Value(dtype='string', id=None), '汽车-发动机排量(L)': Value(dtype='string', id=None), '汽车-发动机马力(Ps)': Value(dtype='string', id=None), '汽车-驱动方式': Value(dtype='string', id=None), '汽车-综合油耗(L/100km)': Value(dtype='string', id=None), '汽车-环保标准': Value(dtype='string', id=None), '汽车-驾驶辅助影像': Value(dtype='string', id=None), '汽车-巡航系统': Value(dtype='string', id=None), '汽车-价格(万元)': Value(dtype='string', id=None), '汽车-车系': Value(dtype='string', id=None), '汽车-动力水平': Value(dtype='string', id=None), '汽车-油耗水平': Value(dtype='string', id=None), '汽车-倒车影像': Value(dtype='string', id=None), '汽车-定速巡航': Value(dtype='string', id=None), '汽车-座椅加热': Value(dtype='string', id=None), '汽车-座椅通风': Value(dtype='string', id=None), '汽车-所属价格区间': Value(dtype='string', id=None), '医院-名称': Value(dtype='string', id=None), '医院-等级': Value(dtype='string', id=None), '医院-类别': Value(dtype='string', id=None), '医院-性质': Value(dtype='string', id=None), '医院-区域': Value(dtype='string', id=None), '医院-地址': Value(dtype='string', id=None), '医院-电话': Value(dtype='string', id=None), '医院-挂号时间': Value(dtype='string', id=None), '医院-门诊时间': Value(dtype='string', id=None), '医院-公交线路': Value(dtype='string', id=None), '医院-地铁可达': Value(dtype='string', id=None), '医院-地铁线路': Value(dtype='string', id=None), '医院-重点科室': Value(dtype='string', id=None), '医院-CT': Value(dtype='string', id=None), '医院-3.0T MRI': Value(dtype='string', id=None), '医院-DSA': Value(dtype='string', id=None)}
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_44306/2896005239.py in <module>
----> 1 dset = load_dataset("GEM/RiSAWOZ")
2 dset
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, script_version, **config_kwargs)
1692
1693 # Download and prepare data
-> 1694 builder_instance.download_and_prepare(
1695 download_config=download_config,
1696 download_mode=download_mode,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
593 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
594 if not downloaded_from_gcs:
--> 595 self._download_and_prepare(
596 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
597 )
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
682 try:
683 # Prepare split will record examples associated to the split
--> 684 self._prepare_split(split_generator, **prepare_split_kwargs)
685 except OSError as e:
686 raise OSError(
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in _prepare_split(self, split_generator)
1084 writer.write(example, key)
1085 finally:
-> 1086 num_examples, num_bytes = writer.finalize()
1087
1088 split_generator.split_info.num_examples = num_examples
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in finalize(self, close_stream)
525 # Re-intializing to empty list for next batch
526 self.hkey_record = []
--> 527 self.write_examples_on_file()
528 if self.pa_writer is None:
529 if self.schema:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_examples_on_file(self)
402 # Since current_examples contains (example, key) tuples
403 batch_examples[col] = [row[0][col] for row in self.current_examples]
--> 404 self.write_batch(batch_examples=batch_examples)
405 self.current_examples = []
406
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)
495 col_try_type = try_features[col] if try_features is not None and col in try_features else None
496 typed_sequence = OptimizedTypedSequence(batch_examples[col], type=col_type, try_type=col_try_type, col=col)
--> 497 arrays.append(pa.array(typed_sequence))
498 inferred_features[col] = typed_sequence.get_inferred_type()
499 schema = inferred_features.arrow_schema if self.pa_writer is None else self.schema
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib.array()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib._handle_arrow_array_protocol()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in __arrow_array__(self, type)
203 # Also, when trying type "string", we don't want to convert integers or floats to "string".
204 # We only do it if trying_type is False - since this is what the user asks for.
--> 205 out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
206 return out
207 except (TypeError, pa.lib.ArrowInvalid) as e: # handle type errors and overflows
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1063 # feature must be either [subfeature] or Sequence(subfeature)
1064 if isinstance(feature, list):
-> 1065 return pa.ListArray.from_arrays(array.offsets, _c(array.values, feature[0]))
1066 elif isinstance(feature, Sequence):
1067 if feature.length > -1:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1085 elif not isinstance(feature, (Sequence, dict, list, tuple)):
1086 return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
-> 1087 raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
1088
1089
TypeError: Couldn't cast array of type
struct<医院-3.0T MRI: string, 医院-CT: string, 医院-DSA: string, 医院-公交线路: string, 医院-区域: string, 医院-名称: string, 医院-地址: string, 医院-地铁可达: string, 医院-地铁线路: string, 医院-性质: string, 医院-挂号时间: string, 医院-电话: string, 医院-等级: string, 医院-类别: string, 医院-重点科室: string, 医院-门诊时间: string, 天气-城市: string, 天气-天气: string, 天气-日期: string, 天气-温度: string, 天气-紫外线强度: string, 天气-风力风向: string, 旅游景点-区域: string, 旅游景点-名称: string, 旅游景点-地址: string, 旅游景点-开放时间: string, 旅游景点-是否地铁直达: string, 旅游景点-景点类型: string, 旅游景点-最适合人群: string, 旅游景点-消费: string, 旅游景点-特点: string, 旅游景点-电话号码: string, 旅游景点-评分: string, 旅游景点-门票价格: string, 汽车-价格(万元): string, 汽车-倒车影像: string, 汽车-动力水平: string, 汽车-厂商: string, 汽车-发动机排量(L): string, 汽车-发动机马力(Ps): string, 汽车-名称: string, 汽车-定速巡航: string, 汽车-巡航系统: string, 汽车-座位数: string, 汽车-座椅加热: string, 汽车-座椅通风: string, 汽车-所属价格区间: string, 汽车-油耗水平: string, 汽车-环保标准: string, 汽车-级别: string, 汽车-综合油耗(L/100km): string, 汽车-能源类型: string, 汽车-车型: string, 汽车-车系: string, 汽车-车身尺寸(mm): string, 汽车-驱动方式: string, 汽车-驾驶辅助影像: string, 火车-出发地: string, 火车-出发时间: string, 火车-到达时间: string, 火车-坐席: string, 火车-日期: string, 火车-时长: string, 火车-目的地: string, 火车-票价: string, 火车-舱位档次: string, 火车-车型: string, 火车-车次信息: string, 电影-主演: string, 电影-主演名单: string, 电影-具体上映时间: string, 电影-制片国家/地区: string, 电影-导演: string, 电影-年代: string, 电影-片名: string, 电影-片长: string, 电影-类型: string, 电影-豆瓣评分: string, 电脑-CPU: string, 电脑-CPU型号: string, 电脑-产品类别: string, 电脑-价格: string, 电脑-价格区间: string, 电脑-内存容量: string, 电脑-分类: string, 电脑-品牌: string, 电脑-商品名称: string, 电脑-屏幕尺寸: string, 电脑-待机时长: string, 电脑-显卡型号: string, 电脑-显卡类别: string, 电脑-游戏性能: string, 电脑-特性: string, 电脑-硬盘容量: string, 电脑-系列: string, 电脑-系统: string, 电脑-色系: string, 电脑-裸机重量: string, 电视剧-主演: string, 电视剧-主演名单: string, 电视剧-制片国家/地区: string, 电视剧-单集片长: string, 电视剧-导演: string, 电视剧-年代: string, 电视剧-片名: string, 电视剧-类型: string, 电视剧-豆瓣评分: string, 电视剧-集数: string, 电视剧-首播时间: string, 辅导班-上课方式: string, 辅导班-上课时间: string, 辅导班-下课时间: string, 辅导班-价格: string, 辅导班-区域: string, 辅导班-年级: string, 辅导班-开始日期: string, 辅导班-教室地点: string, 辅导班-教师: string, 辅导班-教师网址: string, 辅导班-时段: string, 辅导班-校区: string, 辅导班-每周: string, 辅导班-班号: string, 辅导班-科目: string, 辅导班-结束日期: string, 辅导班-课时: string, 辅导班-课次: string, 辅导班-课程网址: string, 辅导班-难度: string, 通用-产品类别: string, 通用-价格区间: string, 通用-品牌: string, 通用-系列: string, 酒店-价位: string, 酒店-停车场: string, 酒店-区域: string, 酒店-名称: string, 酒店-地址: string, 酒店-房型: string, 酒店-房费: string, 酒店-星级: string, 酒店-电话号码: string, 酒店-评分: string, 酒店-酒店类型: string, 飞机-准点率: string, 飞机-出发地: string, 飞机-到达时间: string, 飞机-日期: string, 飞机-目的地: string, 飞机-票价: string, 飞机-航班信息: string, 飞机-舱位档次: string, 飞机-起飞时间: string, 餐厅-人均消费: string, 餐厅-价位: string, 餐厅-区域: string, 餐厅-名称: string, 餐厅-地址: string, 餐厅-推荐菜: string, 餐厅-是否地铁直达: string, 餐厅-电话号码: string, 餐厅-菜系: string, 餐厅-营业时间: string, 餐厅-评分: string>
to
{'旅游景点-名称': Value(dtype='string', id=None), '旅游景点-区域': Value(dtype='string', id=None), '旅游景点-景点类型': Value(dtype='string', id=None), '旅游景点-最适合人群': Value(dtype='string', id=None), '旅游景点-消费': Value(dtype='string', id=None), '旅游景点-是否地铁直达': Value(dtype='string', id=None), '旅游景点-门票价格': Value(dtype='string', id=None), '旅游景点-电话号码': Value(dtype='string', id=None), '旅游景点-地址': Value(dtype='string', id=None), '旅游景点-评分': Value(dtype='string', id=None), '旅游景点-开放时间': Value(dtype='string', id=None), '旅游景点-特点': Value(dtype='string', id=None), '餐厅-名称': Value(dtype='string', id=None), '餐厅-区域': Value(dtype='string', id=None), '餐厅-菜系': Value(dtype='string', id=None), '餐厅-价位': Value(dtype='string', id=None), '餐厅-是否地铁直达': Value(dtype='string', id=None), '餐厅-人均消费': Value(dtype='string', id=None), '餐厅-地址': Value(dtype='string', id=None), '餐厅-电话号码': Value(dtype='string', id=None), '餐厅-评分': Value(dtype='string', id=None), '餐厅-营业时间': Value(dtype='string', id=None), '餐厅-推荐菜': Value(dtype='string', id=None), '酒店-名称': Value(dtype='string', id=None), '酒店-区域': Value(dtype='string', id=None), '酒店-星级': Value(dtype='string', id=None), '酒店-价位': Value(dtype='string', id=None), '酒店-酒店类型': Value(dtype='string', id=None), '酒店-房型': Value(dtype='string', id=None), '酒店-停车场': Value(dtype='string', id=None), '酒店-房费': Value(dtype='string', id=None), '酒店-地址': Value(dtype='string', id=None), '酒店-电话号码': Value(dtype='string', id=None), '酒店-评分': Value(dtype='string', id=None), '电脑-品牌': Value(dtype='string', id=None), '电脑-产品类别': Value(dtype='string', id=None), '电脑-分类': Value(dtype='string', id=None), '电脑-内存容量': Value(dtype='string', id=None), '电脑-屏幕尺寸': Value(dtype='string', id=None), '电脑-CPU': Value(dtype='string', id=None), '电脑-价格区间': Value(dtype='string', id=None), '电脑-系列': Value(dtype='string', id=None), '电脑-商品名称': Value(dtype='string', id=None), '电脑-系统': Value(dtype='string', id=None), '电脑-游戏性能': Value(dtype='string', id=None), '电脑-CPU型号': Value(dtype='string', id=None), '电脑-裸机重量': Value(dtype='string', id=None), '电脑-显卡类别': Value(dtype='string', id=None), '电脑-显卡型号': Value(dtype='string', id=None), '电脑-特性': Value(dtype='string', id=None), '电脑-色系': Value(dtype='string', id=None), '电脑-待机时长': Value(dtype='string', id=None), '电脑-硬盘容量': Value(dtype='string', id=None), '电脑-价格': Value(dtype='string', id=None), '火车-出发地': Value(dtype='string', id=None), '火车-目的地': Value(dtype='string', id=None), '火车-日期': Value(dtype='string', id=None), '火车-车型': Value(dtype='string', id=None), '火车-坐席': Value(dtype='string', id=None), '火车-车次信息': Value(dtype='string', id=None), '火车-时长': Value(dtype='string', id=None), '火车-出发时间': Value(dtype='string', id=None), '火车-到达时间': Value(dtype='string', id=None), '火车-票价': Value(dtype='string', id=None), '飞机-出发地': Value(dtype='string', id=None), '飞机-目的地': Value(dtype='string', id=None), '飞机-日期': Value(dtype='string', id=None), '飞机-舱位档次': Value(dtype='string', id=None), '飞机-航班信息': Value(dtype='string', id=None), '飞机-起飞时间': Value(dtype='string', id=None), '飞机-到达时间': Value(dtype='string', id=None), '飞机-票价': Value(dtype='string', id=None), '飞机-准点率': Value(dtype='string', id=None), '天气-城市': Value(dtype='string', id=None), '天气-日期': Value(dtype='string', id=None), '天气-天气': Value(dtype='string', id=None), '天气-温度': Value(dtype='string', id=None), '天气-风力风向': Value(dtype='string', id=None), '天气-紫外线强度': Value(dtype='string', id=None), '电影-制片国家/地区': Value(dtype='string', id=None), '电影-类型': Value(dtype='string', id=None), '电影-年代': Value(dtype='string', id=None), '电影-主演': Value(dtype='string', id=None), '电影-导演': Value(dtype='string', id=None), '电影-片名': Value(dtype='string', id=None), '电影-主演名单': Value(dtype='string', id=None), '电影-具体上映时间': Value(dtype='string', id=None), '电影-片长': Value(dtype='string', id=None), '电影-豆瓣评分': Value(dtype='string', id=None), '电视剧-制片国家/地区': Value(dtype='string', id=None), '电视剧-类型': Value(dtype='string', id=None), '电视剧-年代': Value(dtype='string', id=None), '电视剧-主演': Value(dtype='string', id=None), '电视剧-导演': Value(dtype='string', id=None), '电视剧-片名': Value(dtype='string', id=None), '电视剧-主演名单': Value(dtype='string', id=None), '电视剧-首播时间': Value(dtype='string', id=None), '电视剧-集数': Value(dtype='string', id=None), '电视剧-单集片长': Value(dtype='string', id=None), '电视剧-豆瓣评分': Value(dtype='string', id=None), '辅导班-班号': Value(dtype='string', id=None), '辅导班-难度': Value(dtype='string', id=None), '辅导班-科目': Value(dtype='string', id=None), '辅导班-年级': Value(dtype='string', id=None), '辅导班-区域': Value(dtype='string', id=None), '辅导班-校区': Value(dtype='string', id=None), '辅导班-上课方式': Value(dtype='string', id=None), '辅导班-开始日期': Value(dtype='string', id=None), '辅导班-结束日期': Value(dtype='string', id=None), '辅导班-每周': Value(dtype='string', id=None), '辅导班-上课时间': Value(dtype='string', id=None), '辅导班-下课时间': Value(dtype='string', id=None), '辅导班-时段': Value(dtype='string', id=None), '辅导班-课次': Value(dtype='string', id=None), '辅导班-课时': Value(dtype='string', id=None), '辅导班-教室地点': Value(dtype='string', id=None), '辅导班-教师': Value(dtype='string', id=None), '辅导班-价格': Value(dtype='string', id=None), '辅导班-课程网址': Value(dtype='string', id=None), '辅导班-教师网址': Value(dtype='string', id=None), '汽车-名称': Value(dtype='string', id=None), '汽车-车型': Value(dtype='string', id=None), '汽车-级别': Value(dtype='string', id=None), '汽车-座位数': Value(dtype='string', id=None), '汽车-车身尺寸(mm)': Value(dtype='string', id=None), '汽车-厂商': Value(dtype='string', id=None), '汽车-能源类型': Value(dtype='string', id=None), '汽车-发动机排量(L)': Value(dtype='string', id=None), '汽车-发动机马力(Ps)': Value(dtype='string', id=None), '汽车-驱动方式': Value(dtype='string', id=None), '汽车-综合油耗(L/100km)': Value(dtype='string', id=None), '汽车-环保标准': Value(dtype='string', id=None), '汽车-驾驶辅助影像': Value(dtype='string', id=None), '汽车-巡航系统': Value(dtype='string', id=None), '汽车-价格(万元)': Value(dtype='string', id=None), '汽车-车系': Value(dtype='string', id=None), '汽车-动力水平': Value(dtype='string', id=None), '汽车-油耗水平': Value(dtype='string', id=None), '汽车-倒车影像': Value(dtype='string', id=None), '汽车-定速巡航': Value(dtype='string', id=None), '汽车-座椅加热': Value(dtype='string', id=None), '汽车-座椅通风': Value(dtype='string', id=None), '汽车-所属价格区间': Value(dtype='string', id=None), '医院-名称': Value(dtype='string', id=None), '医院-等级': Value(dtype='string', id=None), '医院-类别': Value(dtype='string', id=None), '医院-性质': Value(dtype='string', id=None), '医院-区域': Value(dtype='string', id=None), '医院-地址': Value(dtype='string', id=None), '医院-电话': Value(dtype='string', id=None), '医院-挂号时间': Value(dtype='string', id=None), '医院-门诊时间': Value(dtype='string', id=None), '医院-公交线路': Value(dtype='string', id=None), '医院-地铁可达': Value(dtype='string', id=None), '医院-地铁线路': Value(dtype='string', id=None), '医院-重点科室': Value(dtype='string', id=None), '医院-CT': Value(dtype='string', id=None), '医院-3.0T MRI': Value(dtype='string', id=None), '医院-DSA': Value(dtype='string', id=None)}
```
</details>
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.10
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3637/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3637/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3636/comments | https://api.github.com/repos/huggingface/datasets/issues/3636/events | https://github.com/huggingface/datasets/pull/3636 | 1,115,362,702 | PR_kwDODunzps4xohMB | 3,636 | Update index.rst | {
"avatar_url": "https://avatars.githubusercontent.com/u/95622912?v=4",
"events_url": "https://api.github.com/users/VioletteLepercq/events{/privacy}",
"followers_url": "https://api.github.com/users/VioletteLepercq/followers",
"following_url": "https://api.github.com/users/VioletteLepercq/following{/other_user}",
"gists_url": "https://api.github.com/users/VioletteLepercq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/VioletteLepercq",
"id": 95622912,
"login": "VioletteLepercq",
"node_id": "U_kgDOBbMXAA",
"organizations_url": "https://api.github.com/users/VioletteLepercq/orgs",
"received_events_url": "https://api.github.com/users/VioletteLepercq/received_events",
"repos_url": "https://api.github.com/users/VioletteLepercq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/VioletteLepercq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VioletteLepercq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/VioletteLepercq"
} | [] | closed | false | null | [] | null | 0 | 2022-01-26T18:43:09Z | 2022-01-26T18:44:55Z | 2022-01-26T18:44:54Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3636.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3636",
"merged_at": "2022-01-26T18:44:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3636.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3636"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3636/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3636/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3635/comments | https://api.github.com/repos/huggingface/datasets/issues/3635/events | https://github.com/huggingface/datasets/pull/3635 | 1,115,333,219 | PR_kwDODunzps4xobAe | 3,635 | Make `ted_talks_iwslt` dataset streamable | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | 3 | 2022-01-26T18:07:56Z | 2022-10-04T09:36:23Z | 2022-10-03T09:44:47Z | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3635.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3635",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3635.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3635"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3635/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3635/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3634/comments | https://api.github.com/repos/huggingface/datasets/issues/3634/events | https://github.com/huggingface/datasets/issues/3634 | 1,115,133,279 | I_kwDODunzps5Cd5Vf | 3,634 | Dataset.shuffle(seed=None) gives fixed row permutation | {
"avatar_url": "https://avatars.githubusercontent.com/u/18127060?v=4",
"events_url": "https://api.github.com/users/elisno/events{/privacy}",
"followers_url": "https://api.github.com/users/elisno/followers",
"following_url": "https://api.github.com/users/elisno/following{/other_user}",
"gists_url": "https://api.github.com/users/elisno/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/elisno",
"id": 18127060,
"login": "elisno",
"node_id": "MDQ6VXNlcjE4MTI3MDYw",
"organizations_url": "https://api.github.com/users/elisno/orgs",
"received_events_url": "https://api.github.com/users/elisno/received_events",
"repos_url": "https://api.github.com/users/elisno/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/elisno/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/elisno/subscriptions",
"type": "User",
"url": "https://api.github.com/users/elisno"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | 2 | 2022-01-26T15:13:08Z | 2022-01-27T18:16:07Z | 2022-01-27T18:16:07Z | NONE | null | null | null | ## Describe the bug
Repeated attempts to `shuffle` a dataset without specifying a seed give the same results.
## Steps to reproduce the bug
```python
import datasets
# Some toy example
data = datasets.Dataset.from_dict(
{"feature": [1, 2, 3, 4, 5], "label": ["a", "b", "c", "d", "e"]}
)
# Doesn't work as expected
print("Shuffle dataset")
for _ in range(3):
print(data.shuffle(seed=None)[:])
# This seems to work with pandas
print("\nShuffle via pandas")
for _ in range(3):
df = data.to_pandas().sample(frac=1.0)
print(datasets.Dataset.from_pandas(df, preserve_index=False)[:])
```
## Expected results
I assumed that the default setting would initialize a new/random state of a `np.random.BitGenerator` (see [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=shuffle#datasets.Dataset.shuffle)).
Wouldn't that reshuffle the rows each time I call `data.shuffle()`?
## Actual results
```bash
Shuffle dataset
{'feature': [5, 1, 3, 2, 4], 'label': ['e', 'a', 'c', 'b', 'd']}
{'feature': [5, 1, 3, 2, 4], 'label': ['e', 'a', 'c', 'b', 'd']}
{'feature': [5, 1, 3, 2, 4], 'label': ['e', 'a', 'c', 'b', 'd']}
Shuffle via pandas
{'feature': [4, 2, 3, 1, 5], 'label': ['d', 'b', 'c', 'a', 'e']}
{'feature': [2, 5, 3, 4, 1], 'label': ['b', 'e', 'c', 'd', 'a']}
{'feature': [5, 2, 3, 1, 4], 'label': ['e', 'b', 'c', 'a', 'd']}
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.0
- Platform: Linux-5.13.0-27-generic-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3634/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3634/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3633/comments | https://api.github.com/repos/huggingface/datasets/issues/3633/events | https://github.com/huggingface/datasets/pull/3633 | 1,115,040,174 | PR_kwDODunzps4xng6E | 3,633 | Mirror canonical datasets in prod | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | 2022-01-26T13:49:37Z | 2022-01-26T13:56:21Z | 2022-01-26T13:56:21Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3633.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3633",
"merged_at": "2022-01-26T13:56:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3633.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3633"
} | Push the datasets changes to the Hub in production by setting `HF_USE_PROD=1`
I also added a fix that makes the script ignore the json, csv, text, parquet and pandas dataset builders.
cc @SBrandeis | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3633/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3633/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3632/comments | https://api.github.com/repos/huggingface/datasets/issues/3632/events | https://github.com/huggingface/datasets/issues/3632 | 1,115,027,185 | I_kwDODunzps5Cdfbx | 3,632 | Adding CC-100: Monolingual Datasets from Web Crawl Data (Datasets links are invalid) | {
"avatar_url": "https://avatars.githubusercontent.com/u/55232459?v=4",
"events_url": "https://api.github.com/users/AnzorGozalishvili/events{/privacy}",
"followers_url": "https://api.github.com/users/AnzorGozalishvili/followers",
"following_url": "https://api.github.com/users/AnzorGozalishvili/following{/other_user}",
"gists_url": "https://api.github.com/users/AnzorGozalishvili/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AnzorGozalishvili",
"id": 55232459,
"login": "AnzorGozalishvili",
"node_id": "MDQ6VXNlcjU1MjMyNDU5",
"organizations_url": "https://api.github.com/users/AnzorGozalishvili/orgs",
"received_events_url": "https://api.github.com/users/AnzorGozalishvili/received_events",
"repos_url": "https://api.github.com/users/AnzorGozalishvili/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AnzorGozalishvili/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AnzorGozalishvili/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AnzorGozalishvili"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 2 | 2022-01-26T13:35:37Z | 2022-02-10T06:58:11Z | 2022-02-10T06:58:11Z | CONTRIBUTOR | null | null | null | ## Describe the bug
The dataset links are no longer valid for CC-100. It seems that the website which was keeping these files are no longer accessible and therefore this dataset became unusable.
Check out the dataset [homepage](http://data.statmt.org/cc-100/) which isn't accessible.
Also the URLs for dataset file per language isn't accessible: http://data.statmt.org/cc-100/<language code here>.txt.xz (language codes: am, sr, ka, etc.)
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("cc100", "ka")
```
It throws 503 error.
## Expected results
It should successfully download and load dataset but it throws an exception because the dataset files are no longer accessible.
## Environment info
Run from google colab. Just installed the library using pip:
```!pip install -U datasets```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3632/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3632/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3631/comments | https://api.github.com/repos/huggingface/datasets/issues/3631/events | https://github.com/huggingface/datasets/issues/3631 | 1,114,833,662 | I_kwDODunzps5CcwL- | 3,631 | Labels conflict when loading a local CSV file. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8571301?v=4",
"events_url": "https://api.github.com/users/pichljan/events{/privacy}",
"followers_url": "https://api.github.com/users/pichljan/followers",
"following_url": "https://api.github.com/users/pichljan/following{/other_user}",
"gists_url": "https://api.github.com/users/pichljan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pichljan",
"id": 8571301,
"login": "pichljan",
"node_id": "MDQ6VXNlcjg1NzEzMDE=",
"organizations_url": "https://api.github.com/users/pichljan/orgs",
"received_events_url": "https://api.github.com/users/pichljan/received_events",
"repos_url": "https://api.github.com/users/pichljan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pichljan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pichljan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pichljan"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 1 | 2022-01-26T10:00:33Z | 2022-02-11T23:02:31Z | 2022-02-11T23:02:31Z | NONE | null | null | null | ## Describe the bug
I am trying to load a local CSV file with a separate file containing label names. It is successfully loaded for the first time, but when I try to load it again, there is a conflict between provided labels and the cached dataset info. Disabling caching globally and/or using `download_mode="force_redownload"` did not help.
## Steps to reproduce the bug
```python
load_dataset('csv', data_files='data/my_data.csv',
features=Features(text=Value(dtype='string'),
label=ClassLabel(names_file='data/my_data_labels.txt')))
```
`my_data.csv` file has the following structure:
```
text,label
"example1",0
"example2",1
...
```
and the `my_data_labels.txt` looks like this:
```
label1
label2
...
```
## Expected results
Successfully loaded dataset.
## Actual results
```python
File "/usr/local/lib/python3.8/site-packages/datasets/load.py", line 1706, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)
File "/usr/local/lib/python3.8/site-packages/datasets/builder.py", line 766, in as_dataset
datasets = utils.map_nested(
File "/usr/local/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 261, in map_nested
mapped = [
File "/usr/local/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 262, in <listcomp>
_single_map_nested((function, obj, types, None, True))
File "/usr/local/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 197, in _single_map_nested
return function(data_struct)
File "/usr/local/lib/python3.8/site-packages/datasets/builder.py", line 797, in _build_single_dataset
ds = self._as_dataset(
File "/usr/local/lib/python3.8/site-packages/datasets/builder.py", line 872, in _as_dataset
return Dataset(fingerprint=fingerprint, **dataset_kwargs)
File "/usr/local/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 638, in __init__
inferred_features = Features.from_arrow_schema(arrow_table.schema)
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1242, in from_arrow_schema
return Features.from_dict(metadata["info"]["features"])
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1271, in from_dict
obj = generate_from_dict(dic)
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1076, in generate_from_dict
return {key: generate_from_dict(value) for key, value in obj.items()}
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1076, in <dictcomp>
return {key: generate_from_dict(value) for key, value in obj.items()}
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1083, in generate_from_dict
return class_type(**{k: v for k, v in obj.items() if k in field_names})
File "<string>", line 7, in __init__
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 776, in __post_init__
raise ValueError("Please provide either names or names_file but not both.")
ValueError: Please provide either names or names_file but not both.
```
## Environment info
- `datasets` version: 1.18.0
- Python version: 3.8.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3631/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3631/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3630/comments | https://api.github.com/repos/huggingface/datasets/issues/3630/events | https://github.com/huggingface/datasets/issues/3630 | 1,114,578,625 | I_kwDODunzps5Cbx7B | 3,630 | DuplicatedKeysError of NewsQA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/37647985?v=4",
"events_url": "https://api.github.com/users/StevenTang1998/events{/privacy}",
"followers_url": "https://api.github.com/users/StevenTang1998/followers",
"following_url": "https://api.github.com/users/StevenTang1998/following{/other_user}",
"gists_url": "https://api.github.com/users/StevenTang1998/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/StevenTang1998",
"id": 37647985,
"login": "StevenTang1998",
"node_id": "MDQ6VXNlcjM3NjQ3OTg1",
"organizations_url": "https://api.github.com/users/StevenTang1998/orgs",
"received_events_url": "https://api.github.com/users/StevenTang1998/received_events",
"repos_url": "https://api.github.com/users/StevenTang1998/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/StevenTang1998/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/StevenTang1998/subscriptions",
"type": "User",
"url": "https://api.github.com/users/StevenTang1998"
} | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 1 | 2022-01-26T03:05:49Z | 2022-02-14T08:37:19Z | 2022-02-14T08:37:19Z | NONE | null | null | null | After processing the dataset following official [NewsQA](https://github.com/Maluuba/newsqa), I used datasets to load it:
```
a = load_dataset('newsqa', data_dir='news')
```
and the following error occurred:
```
Using custom data configuration default-data_dir=news
Downloading and preparing dataset newsqa/default to /root/.cache/huggingface/datasets/newsqa/default-data_dir=news/1.0.0/b0b23e22d94a3d352ad9d75aff2b71375264a122fae301463079ee8595e05ab9...
Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 1084, in _prepare_split
writer.write(example, key)
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 442, in write
self.check_duplicate_keys()
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 453, in check_duplicate_keys
raise DuplicatedKeysError(key)
datasets.keyhash.DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: ./cnn/stories/6a0f9c8a5d0c6e8949b37924163c92923fe5770d.story
Keys should be unique and deterministic in nature
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/datasets/load.py", line 1694, in load_dataset
builder_instance.download_and_prepare(
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 595, in download_and_prepare
self._download_and_prepare(
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 684, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 1086, in _prepare_split
num_examples, num_bytes = writer.finalize()
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 524, in finalize
self.check_duplicate_keys()
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 453, in check_duplicate_keys
raise DuplicatedKeysError(key)
datasets.keyhash.DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: ./cnn/stories/6a0f9c8a5d0c6e8949b37924163c92923fe5770d.story
Keys should be unique and deterministic in nature
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3630/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3630/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3629/comments | https://api.github.com/repos/huggingface/datasets/issues/3629/events | https://github.com/huggingface/datasets/pull/3629 | 1,113,971,575 | PR_kwDODunzps4xkCZA | 3,629 | Fix Hub repos update when there's a new release | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | 2022-01-25T14:39:45Z | 2022-01-25T14:55:46Z | 2022-01-25T14:55:46Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3629.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3629",
"merged_at": "2022-01-25T14:55:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3629.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3629"
} | It was not listing the full list of datasets correctly
cc @SBrandeis this is why it failed for 1.18.0
We should be good now ! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3629/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3629/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3628/comments | https://api.github.com/repos/huggingface/datasets/issues/3628/events | https://github.com/huggingface/datasets/issues/3628 | 1,113,930,644 | I_kwDODunzps5CZTuU | 3,628 | Dataset Card Creator drops information for "Additional Information" Section | {
"avatar_url": "https://avatars.githubusercontent.com/u/26013491?v=4",
"events_url": "https://api.github.com/users/dennlinger/events{/privacy}",
"followers_url": "https://api.github.com/users/dennlinger/followers",
"following_url": "https://api.github.com/users/dennlinger/following{/other_user}",
"gists_url": "https://api.github.com/users/dennlinger/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dennlinger",
"id": 26013491,
"login": "dennlinger",
"node_id": "MDQ6VXNlcjI2MDEzNDkx",
"organizations_url": "https://api.github.com/users/dennlinger/orgs",
"received_events_url": "https://api.github.com/users/dennlinger/received_events",
"repos_url": "https://api.github.com/users/dennlinger/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dennlinger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dennlinger/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dennlinger"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | 0 | 2022-01-25T14:06:17Z | 2022-01-25T14:09:01Z | null | NONE | null | null | null | First of all, the card creator is a great addition and really helpful for streamlining dataset cards!
## Describe the bug
I encountered an inconvenient bug when entering "Additional Information" in the react app, which drops already entered text when switching to a previous section, and then back again to "Additional Information". I was able to reproduce the issue in both Firefox and Chrome, so I suspect a problem with the React logic that doesn't expect users to switch back in the final section.
Edit: I'm also not sure whether this is the right place to open the bug report on, since it's not clear to me which particular project it belongs to, or where I could find associated source code.
## Steps to reproduce the bug
1. Navigate to the Section "Additional Information" in the [dataset card creator](https://huggingface.co/datasets/card-creator/)
2. Enter text in an arbitrary field, e.g., "Dataset Curators".
3. Switch back to a previous section, like "Dataset Creation".
4. When switching back again to "Additional Information", the text has been deleted.
Notably, this behavior can be reproduced again and again, it's not just problematic for the first "switch-back" from Additional Information.
## Expected results
For step 4, the previously entered information should still be present in the boxes, similar to the behavior to all other sections (switching back there works as expected)
## Actual results
The text boxes are empty again, and previously entered text got deleted.
## Environment info
- `datasets` version: N/A
- Platform: Firefox 96.0 / Chrome 97.0
- Python version: N/A
- PyArrow version: N/A
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3628/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3628/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3627/comments | https://api.github.com/repos/huggingface/datasets/issues/3627/events | https://github.com/huggingface/datasets/pull/3627 | 1,113,556,837 | PR_kwDODunzps4xitGe | 3,627 | Fix host URL in The Pile datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | 4 | 2022-01-25T08:11:28Z | 2022-07-20T20:54:42Z | 2022-02-14T08:40:58Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3627.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3627",
"merged_at": "2022-02-14T08:40:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3627.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3627"
} | This PR fixes the host URL in The Pile datasets, once they have mirrored their data in another server.
Fix #3626. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3627/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3627/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3626/comments | https://api.github.com/repos/huggingface/datasets/issues/3626/events | https://github.com/huggingface/datasets/issues/3626 | 1,113,534,436 | I_kwDODunzps5CXy_k | 3,626 | The Pile cannot connect to host | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 0 | 2022-01-25T07:43:33Z | 2022-02-14T08:40:58Z | 2022-02-14T08:40:58Z | MEMBER | null | null | null | ## Describe the bug
The Pile had issues with their previous host server and have mirrored its content to another server.
The new URL server should be updated.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3626/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3626/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3625/comments | https://api.github.com/repos/huggingface/datasets/issues/3625/events | https://github.com/huggingface/datasets/issues/3625 | 1,113,017,522 | I_kwDODunzps5CV0yy | 3,625 | Add a metadata field for when source data was produced | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_url": "https://api.github.com/users/davanstrien/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/davanstrien",
"id": 8995957,
"login": "davanstrien",
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"organizations_url": "https://api.github.com/users/davanstrien/orgs",
"received_events_url": "https://api.github.com/users/davanstrien/received_events",
"repos_url": "https://api.github.com/users/davanstrien/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/davanstrien/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davanstrien/subscriptions",
"type": "User",
"url": "https://api.github.com/users/davanstrien"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 5 | 2022-01-24T18:52:39Z | 2022-06-28T13:54:49Z | null | MEMBER | null | null | null | **Is your feature request related to a problem? Please describe.**
The current problem is that information about when source data was produced is not easily visible. Though there are a variety of metadata fields available in the dataset viewer, time period information is not included. This feature request suggests making metadata relating to the time that the underlying *source* data was produced more prominent and outlines why this specific information is of particular importance, both in domain-specific historic research and more broadly.
**Describe the solution you'd like**
There are a variety of metadata fields exposed in the dataset viewer (license, task categories, etc.) These fields make this metadata more prominent both for human users and as potentially machine-actionable information (for example, through the API). I would propose to add a metadata field that says when some underlying data was produced. For example, a dataset would be labelled as being produced between `1800-1900`.
**Describe alternatives you've considered**
This information is sometimes available in the Datacard or a paper describing the dataset. However, it's often not that easy to identify or extract this information, particularly if you want to use this field as a filter to identify relevant datasets.
**Additional context**
I believe this feature is relevant for a number of reasons:
- Increasingly, there is an interest in using historical data for training language models (for example, https://huggingface.co/dbmdz/bert-base-historic-dutch-cased), and datasets to support this task (for example, https://huggingface.co/datasets/bnl_newspapers). For these datasets, indicating the time periods covered is particularly relevant.
- More broadly, time is likely a common source of domain drift. Datasets of movie reviews from the 90s may not work well for recent movie reviews. As the documentation and long-term management of ML data become more of a priority, quickly understanding the time when the underlying text (or other data types) is arguably more important.
- time-series data: datasets are adding more support for time series data. Again, the periods covered might be particularly relevant here.
**open questions**
- I think some of my points above apply not only to the underlying data but also to annotations. As a result, there could also be an argument for encoding this information somewhere. However, I would argue (but could be persuaded otherwise) that this is probably less important for filtering. This type of context is already addressed in the datasheets template and often requires more narrative to discuss.
- what level of granularity would make sense for this? e.g. assigning a decade, century or year?
- how to encode this information? What formatting makes sense
- what specific time to encode; a data range? (mean, modal, min, max value?)
This is a slightly amorphous feature request - I would be happy to discuss further/try and propose a more concrete solution if this seems like something that could be worth considering. I realise this might also touch on other parts of the 🤗 hubs ecosystem. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3625/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3625/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3623/comments | https://api.github.com/repos/huggingface/datasets/issues/3623/events | https://github.com/huggingface/datasets/pull/3623 | 1,112,835,239 | PR_kwDODunzps4xgWig | 3,623 | Extend support for streaming datasets that use os.path.relpath | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | 0 | 2022-01-24T16:00:52Z | 2022-02-04T14:03:55Z | 2022-02-04T14:03:54Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3623.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3623",
"merged_at": "2022-02-04T14:03:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3623.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3623"
} | This PR extends the support in streaming mode for datasets that use `os.path.relpath`, by patching that function.
This feature will also be useful to yield the relative path of audio or image files, within an archive or parent dir.
Close #3622. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3623/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3623/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3622/comments | https://api.github.com/repos/huggingface/datasets/issues/3622/events | https://github.com/huggingface/datasets/issues/3622 | 1,112,831,661 | I_kwDODunzps5CVHat | 3,622 | Extend support for streaming datasets that use os.path.relpath | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 0 | 2022-01-24T15:58:23Z | 2022-02-04T14:03:54Z | 2022-02-04T14:03:54Z | MEMBER | null | null | null | Extend support for streaming datasets that use `os.path.relpath`.
This feature will also be useful to yield the relative path of audio or image files.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3622/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3622/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3621/comments | https://api.github.com/repos/huggingface/datasets/issues/3621/events | https://github.com/huggingface/datasets/issues/3621 | 1,112,720,434 | I_kwDODunzps5CUsQy | 3,621 | Consider adding `ipywidgets` as a dependency. | {
"avatar_url": "https://avatars.githubusercontent.com/u/1019791?v=4",
"events_url": "https://api.github.com/users/koaning/events{/privacy}",
"followers_url": "https://api.github.com/users/koaning/followers",
"following_url": "https://api.github.com/users/koaning/following{/other_user}",
"gists_url": "https://api.github.com/users/koaning/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/koaning",
"id": 1019791,
"login": "koaning",
"node_id": "MDQ6VXNlcjEwMTk3OTE=",
"organizations_url": "https://api.github.com/users/koaning/orgs",
"received_events_url": "https://api.github.com/users/koaning/received_events",
"repos_url": "https://api.github.com/users/koaning/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/koaning/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/koaning/subscriptions",
"type": "User",
"url": "https://api.github.com/users/koaning"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 4 | 2022-01-24T14:27:11Z | 2022-02-24T09:04:36Z | 2022-02-24T09:04:36Z | NONE | null | null | null | When I install `datasets` in a fresh virtualenv with jupyterlab I always see this error.
```
ImportError: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
```
It's a bit of a nuisance, because I need to run shut down the jupyterlab server in order to install the required dependency. Might it be an option to just include it as a dependency here? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3621/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3621/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3620/comments | https://api.github.com/repos/huggingface/datasets/issues/3620/events | https://github.com/huggingface/datasets/pull/3620 | 1,112,677,252 | PR_kwDODunzps4xf1J3 | 3,620 | Add Fon language tag | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | 0 | 2022-01-24T13:52:26Z | 2022-02-04T14:04:36Z | 2022-02-04T14:04:35Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3620.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3620",
"merged_at": "2022-02-04T14:04:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3620.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3620"
} | Add Fon language tag to resources. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3620/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3620/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3619/comments | https://api.github.com/repos/huggingface/datasets/issues/3619/events | https://github.com/huggingface/datasets/pull/3619 | 1,112,611,415 | PR_kwDODunzps4xfnCQ | 3,619 | fix meta in mls | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [] | closed | false | null | [] | null | 1 | 2022-01-24T12:54:38Z | 2022-01-24T20:53:22Z | 2022-01-24T20:53:22Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3619.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3619",
"merged_at": "2022-01-24T20:53:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3619.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3619"
} | `monolingual` value of `m ultilinguality` param in yaml meta was changed to `multilingual` :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3619/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3619/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3618/comments | https://api.github.com/repos/huggingface/datasets/issues/3618/events | https://github.com/huggingface/datasets/issues/3618 | 1,112,123,365 | I_kwDODunzps5CSafl | 3,618 | TIMIT Dataset not working with GPU | {
"avatar_url": "https://avatars.githubusercontent.com/u/3227869?v=4",
"events_url": "https://api.github.com/users/TheSeamau5/events{/privacy}",
"followers_url": "https://api.github.com/users/TheSeamau5/followers",
"following_url": "https://api.github.com/users/TheSeamau5/following{/other_user}",
"gists_url": "https://api.github.com/users/TheSeamau5/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/TheSeamau5",
"id": 3227869,
"login": "TheSeamau5",
"node_id": "MDQ6VXNlcjMyMjc4Njk=",
"organizations_url": "https://api.github.com/users/TheSeamau5/orgs",
"received_events_url": "https://api.github.com/users/TheSeamau5/received_events",
"repos_url": "https://api.github.com/users/TheSeamau5/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/TheSeamau5/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TheSeamau5/subscriptions",
"type": "User",
"url": "https://api.github.com/users/TheSeamau5"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 3 | 2022-01-24T03:26:03Z | 2023-07-25T15:20:20Z | 2023-07-25T15:20:20Z | NONE | null | null | null | ## Describe the bug
I am working trying to use the TIMIT dataset in order to fine-tune Wav2Vec2 model and I am unable to load the "audio" column from the dataset when working with a GPU.
I am working on Amazon Sagemaker Studio, on the Python 3 (PyTorch 1.8 Python 3.6 GPU Optimized) environment, with a single ml.g4dn.xlarge instance (corresponds to a Tesla T4 GPU).
I don't know if the issue is GPU related or Python environment related because everything works when I work off of the CPU Optimized environment with a non-GPU instance. My code also works on Google Colab with a GPU instance.
This issue is blocking because I cannot get the 'audio' column in any way due to this error, which means that I can't pass it to any functions. I later use the dataset.map function and that is where I originally noticed this error.
## Steps to reproduce the bug
```python
from datasets import load_dataset
timit_train = load_dataset('timit_asr', split='train')
print(timit_train['audio'])
```
## Expected results
Expected to see inside the 'audio' column, which contains an 'array' nested field with the array data I actually need.
## Actual results
Traceback
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-6-ceeac555e921> in <module>
----> 1 timit_train['audio']
/opt/conda/lib/python3.6/site-packages/datasets/arrow_dataset.py in __getitem__(self, key)
1917 """Can be used to index columns (by string names) or rows (by integer index or iterable of indices or bools)."""
1918 return self._getitem(
-> 1919 key,
1920 )
1921
/opt/conda/lib/python3.6/site-packages/datasets/arrow_dataset.py in _getitem(self, key, decoded, **kwargs)
1902 pa_subtable = query_table(self._data, key, indices=self._indices if self._indices is not None else None)
1903 formatted_output = format_table(
-> 1904 pa_subtable, key, formatter=formatter, format_columns=format_columns, output_all_columns=output_all_columns
1905 )
1906 return formatted_output
/opt/conda/lib/python3.6/site-packages/datasets/formatting/formatting.py in format_table(table, key, formatter, format_columns, output_all_columns)
529 python_formatter = PythonFormatter(features=None)
530 if format_columns is None:
--> 531 return formatter(pa_table, query_type=query_type)
532 elif query_type == "column":
533 if key in format_columns:
/opt/conda/lib/python3.6/site-packages/datasets/formatting/formatting.py in __call__(self, pa_table, query_type)
280 return self.format_row(pa_table)
281 elif query_type == "column":
--> 282 return self.format_column(pa_table)
283 elif query_type == "batch":
284 return self.format_batch(pa_table)
/opt/conda/lib/python3.6/site-packages/datasets/formatting/formatting.py in format_column(self, pa_table)
315 column = self.python_arrow_extractor().extract_column(pa_table)
316 if self.decoded:
--> 317 column = self.python_features_decoder.decode_column(column, pa_table.column_names[0])
318 return column
319
/opt/conda/lib/python3.6/site-packages/datasets/formatting/formatting.py in decode_column(self, column, column_name)
221
222 def decode_column(self, column: list, column_name: str) -> list:
--> 223 return self.features.decode_column(column, column_name) if self.features else column
224
225 def decode_batch(self, batch: dict) -> dict:
/opt/conda/lib/python3.6/site-packages/datasets/features/features.py in decode_column(self, column, column_name)
1337 return (
1338 [self[column_name].decode_example(value) if value is not None else None for value in column]
-> 1339 if self._column_requires_decoding[column_name]
1340 else column
1341 )
/opt/conda/lib/python3.6/site-packages/datasets/features/features.py in <listcomp>(.0)
1336 """
1337 return (
-> 1338 [self[column_name].decode_example(value) if value is not None else None for value in column]
1339 if self._column_requires_decoding[column_name]
1340 else column
/opt/conda/lib/python3.6/site-packages/datasets/features/audio.py in decode_example(self, value)
85 dict
86 """
---> 87 path, file = (value["path"], BytesIO(value["bytes"])) if value["bytes"] is not None else (value["path"], None)
88 if path is None and file is None:
89 raise ValueError(f"An audio sample should have one of 'path' or 'bytes' but both are None in {value}.")
TypeError: string indices must be integers
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.0
- Platform: Linux-4.14.256-197.484.amzn2.x86_64-x86_64-with-debian-buster-sid
- Python version: 3.6.13
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3618/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3618/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3617/comments | https://api.github.com/repos/huggingface/datasets/issues/3617/events | https://github.com/huggingface/datasets/pull/3617 | 1,111,938,691 | PR_kwDODunzps4xdb8K | 3,617 | PR for the CFPB Consumer Complaints dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42403093?v=4",
"events_url": "https://api.github.com/users/kayvane1/events{/privacy}",
"followers_url": "https://api.github.com/users/kayvane1/followers",
"following_url": "https://api.github.com/users/kayvane1/following{/other_user}",
"gists_url": "https://api.github.com/users/kayvane1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kayvane1",
"id": 42403093,
"login": "kayvane1",
"node_id": "MDQ6VXNlcjQyNDAzMDkz",
"organizations_url": "https://api.github.com/users/kayvane1/orgs",
"received_events_url": "https://api.github.com/users/kayvane1/received_events",
"repos_url": "https://api.github.com/users/kayvane1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kayvane1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kayvane1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kayvane1"
} | [] | closed | false | null | [] | null | 8 | 2022-01-23T17:47:12Z | 2022-02-07T21:08:31Z | 2022-02-07T21:08:31Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3617.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3617",
"merged_at": "2022-02-07T21:08:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3617.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3617"
} | Think I followed all the steps but please let me know if anything needs changing or any improvements I can make to the code quality | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3617/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3617/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3616/comments | https://api.github.com/repos/huggingface/datasets/issues/3616/events | https://github.com/huggingface/datasets/pull/3616 | 1,111,587,861 | PR_kwDODunzps4xcZMD | 3,616 | Make streamable the BnL Historical Newspapers dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | 0 | 2022-01-22T14:52:36Z | 2022-02-04T14:05:23Z | 2022-02-04T14:05:21Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3616.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3616",
"merged_at": "2022-02-04T14:05:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3616.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3616"
} | I've refactored the code in order to make the dataset streamable and to avoid it takes too long:
- I've used `iter_files`
Close #3615 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3616/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3616/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3615/comments | https://api.github.com/repos/huggingface/datasets/issues/3615/events | https://github.com/huggingface/datasets/issues/3615 | 1,111,576,876 | I_kwDODunzps5CQVEs | 3,615 | Dataset BnL Historical Newspapers does not work in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 3 | 2022-01-22T14:12:59Z | 2022-02-04T14:05:21Z | 2022-02-04T14:05:21Z | MEMBER | null | null | null | ## Describe the bug
When trying to load in streaming mode, it "hangs"...
## Steps to reproduce the bug
```python
ds = load_dataset("bnl_newspapers", split="train", streaming=True)
```
## Expected results
The code should be optimized, so that it works fast in streaming mode.
CC: @davanstrien
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3615/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3614/comments | https://api.github.com/repos/huggingface/datasets/issues/3614/events | https://github.com/huggingface/datasets/pull/3614 | 1,110,736,657 | PR_kwDODunzps4xZdCe | 3,614 | Minor fixes | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 0 | 2022-01-21T17:48:44Z | 2022-01-24T12:45:49Z | 2022-01-24T12:45:49Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3614.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3614",
"merged_at": "2022-01-24T12:45:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3614.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3614"
} | This PR:
* adds "desc" to the `ignore_kwargs` list in `Dataset.filter`
* fixes the default value of `id` in `DatasetDict.prepare_for_task` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3614/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3614/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3613/comments | https://api.github.com/repos/huggingface/datasets/issues/3613/events | https://github.com/huggingface/datasets/issues/3613 | 1,110,684,015 | I_kwDODunzps5CM7Fv | 3,613 | Files not updating in dataset viewer | {
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "https://api.github.com/users/abidlabs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abidlabs",
"id": 1778297,
"login": "abidlabs",
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"organizations_url": "https://api.github.com/users/abidlabs/orgs",
"received_events_url": "https://api.github.com/users/abidlabs/received_events",
"repos_url": "https://api.github.com/users/abidlabs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abidlabs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abidlabs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abidlabs"
} | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | 2 | 2022-01-21T16:47:20Z | 2022-01-22T08:13:13Z | 2022-01-22T08:13:13Z | MEMBER | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:**
Some examples:
* https://huggingface.co/datasets/abidlabs/crowdsourced-speech4
* https://huggingface.co/datasets/abidlabs/test-audio-13
*short description of the issue*
It seems that the dataset viewer is reading a cached version of the dataset and it is not updating to reflect new files that are added to the dataset. I get this error:
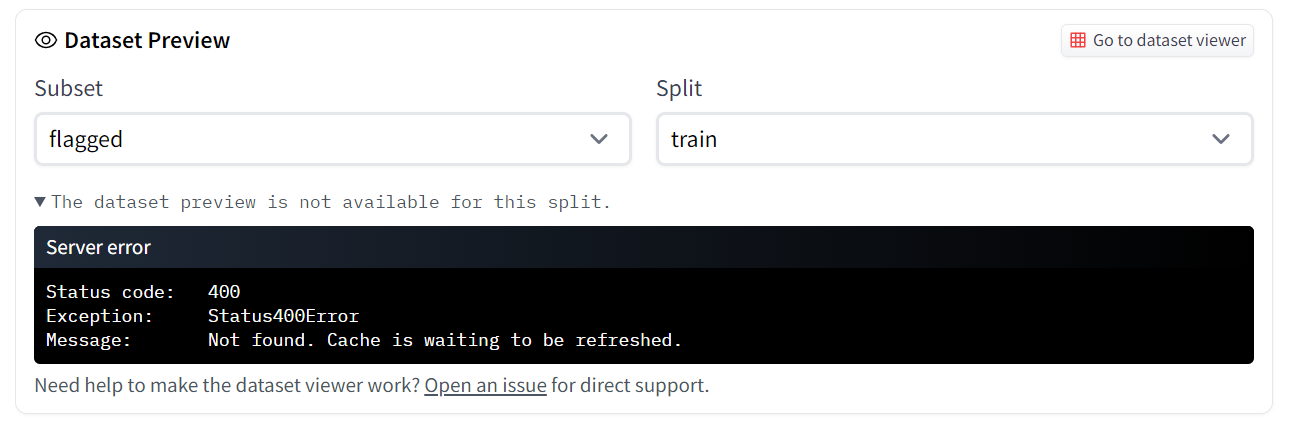
Am I the one who added this dataset? Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3613/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3613/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3612/comments | https://api.github.com/repos/huggingface/datasets/issues/3612/events | https://github.com/huggingface/datasets/pull/3612 | 1,110,506,466 | PR_kwDODunzps4xYsvS | 3,612 | wikifix | {
"avatar_url": "https://avatars.githubusercontent.com/u/68908804?v=4",
"events_url": "https://api.github.com/users/apergo-ai/events{/privacy}",
"followers_url": "https://api.github.com/users/apergo-ai/followers",
"following_url": "https://api.github.com/users/apergo-ai/following{/other_user}",
"gists_url": "https://api.github.com/users/apergo-ai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/apergo-ai",
"id": 68908804,
"login": "apergo-ai",
"node_id": "MDQ6VXNlcjY4OTA4ODA0",
"organizations_url": "https://api.github.com/users/apergo-ai/orgs",
"received_events_url": "https://api.github.com/users/apergo-ai/received_events",
"repos_url": "https://api.github.com/users/apergo-ai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/apergo-ai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/apergo-ai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/apergo-ai"
} | [] | closed | false | null | [] | null | 4 | 2022-01-21T14:05:11Z | 2022-02-03T17:58:16Z | 2022-02-03T17:58:16Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3612.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3612",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3612.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3612"
} | This should get the wikipedia dataloading script back up and running - at least I hope so (tested with language ff and ii) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3612/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3612/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3611/comments | https://api.github.com/repos/huggingface/datasets/issues/3611/events | https://github.com/huggingface/datasets/issues/3611 | 1,110,399,096 | I_kwDODunzps5CL1h4 | 3,611 | Indexing bug after dataset.select() | {
"avatar_url": "https://avatars.githubusercontent.com/u/17096858?v=4",
"events_url": "https://api.github.com/users/kamalkraj/events{/privacy}",
"followers_url": "https://api.github.com/users/kamalkraj/followers",
"following_url": "https://api.github.com/users/kamalkraj/following{/other_user}",
"gists_url": "https://api.github.com/users/kamalkraj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kamalkraj",
"id": 17096858,
"login": "kamalkraj",
"node_id": "MDQ6VXNlcjE3MDk2ODU4",
"organizations_url": "https://api.github.com/users/kamalkraj/orgs",
"received_events_url": "https://api.github.com/users/kamalkraj/received_events",
"repos_url": "https://api.github.com/users/kamalkraj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kamalkraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kamalkraj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kamalkraj"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | 1 | 2022-01-21T12:09:30Z | 2022-01-27T18:16:22Z | 2022-01-27T18:16:22Z | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
Dataset indexing is not working as expected after `dataset.select(range(100))`
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
import datasets
task_to_keys = {
"cola": ("sentence", None),
"mnli": ("premise", "hypothesis"),
"mrpc": ("sentence1", "sentence2"),
"qnli": ("question", "sentence"),
"qqp": ("question1", "question2"),
"rte": ("sentence1", "sentence2"),
"sst2": ("sentence", None),
"stsb": ("sentence1", "sentence2"),
"wnli": ("sentence1", "sentence2"),
}
task_name = "sst2"
raw_datasets = datasets.load_dataset("glue", task_name)
train_dataset = raw_datasets["train"]
print("before select: ",train_dataset[-2:])
# before select: {'sentence': ['a patient viewer ', 'this new jangle of noise , mayhem and stupidity must be a serious contender for the title . '], 'label': [1, 0], 'idx': [67347, 67348]}
train_dataset = train_dataset.select(range(100))
print("after select: ",train_dataset[-2:])
# after select: {'sentence': [], 'label': [], 'idx': []}
```
link to colab: https://colab.research.google.com/drive/1LngeRC9f0jE7eSQ4Kh1cIeb411lRXQD-?usp=sharing
## Expected results
A clear and concise description of the expected results.
showing 98, 99 index data
## Actual results
Specify the actual results or traceback.
empty
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3611/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3611/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3610/comments | https://api.github.com/repos/huggingface/datasets/issues/3610/events | https://github.com/huggingface/datasets/issues/3610 | 1,109,777,314 | I_kwDODunzps5CJdui | 3,610 | Checksum error when trying to load amazon_review dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/32415171?v=4",
"events_url": "https://api.github.com/users/rifoag/events{/privacy}",
"followers_url": "https://api.github.com/users/rifoag/followers",
"following_url": "https://api.github.com/users/rifoag/following{/other_user}",
"gists_url": "https://api.github.com/users/rifoag/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rifoag",
"id": 32415171,
"login": "rifoag",
"node_id": "MDQ6VXNlcjMyNDE1MTcx",
"organizations_url": "https://api.github.com/users/rifoag/orgs",
"received_events_url": "https://api.github.com/users/rifoag/received_events",
"repos_url": "https://api.github.com/users/rifoag/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rifoag/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rifoag/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rifoag"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 1 | 2022-01-20T21:20:32Z | 2022-01-21T13:22:31Z | 2022-01-21T13:22:31Z | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
I am getting the issue when trying to load dataset using
```
dataset = load_dataset("amazon_polarity")
```
## Expected results
dataset loaded
## Actual results
```
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
<ipython-input-3-b4758ba980ae> in <module>()
----> 1 dataset = load_dataset("amazon_polarity")
2 dataset.set_format(type='pandas')
3 content_series = dataset['train']['content']
4 label_series = dataset['train']['label']
5 df = pd.concat([content_series, label_series], axis=1)
3 frames
/usr/local/lib/python3.7/dist-packages/datasets/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums, verification_name)
38 if len(bad_urls) > 0:
39 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 40 raise NonMatchingChecksumError(error_msg + str(bad_urls))
41 logger.info("All the checksums matched successfully" + for_verification_name)
42
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/u/0/uc?id=0Bz8a_Dbh9QhbaW12WVVZS2drcnM&export=download']
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: Google colab
- Python version: 3.7.12 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3610/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3609/comments | https://api.github.com/repos/huggingface/datasets/issues/3609/events | https://github.com/huggingface/datasets/pull/3609 | 1,109,579,112 | PR_kwDODunzps4xVrsG | 3,609 | Fixes to pubmed dataset download function | {
"avatar_url": "https://avatars.githubusercontent.com/u/3886120?v=4",
"events_url": "https://api.github.com/users/spacemanidol/events{/privacy}",
"followers_url": "https://api.github.com/users/spacemanidol/followers",
"following_url": "https://api.github.com/users/spacemanidol/following{/other_user}",
"gists_url": "https://api.github.com/users/spacemanidol/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/spacemanidol",
"id": 3886120,
"login": "spacemanidol",
"node_id": "MDQ6VXNlcjM4ODYxMjA=",
"organizations_url": "https://api.github.com/users/spacemanidol/orgs",
"received_events_url": "https://api.github.com/users/spacemanidol/received_events",
"repos_url": "https://api.github.com/users/spacemanidol/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/spacemanidol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spacemanidol/subscriptions",
"type": "User",
"url": "https://api.github.com/users/spacemanidol"
} | [] | closed | false | null | [] | null | 3 | 2022-01-20T17:31:35Z | 2022-03-03T16:18:52Z | 2022-03-03T14:23:35Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3609.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3609",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3609.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3609"
} | Pubmed has updated its settings for 2022 and thus existing download script does not work. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3609/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3608/comments | https://api.github.com/repos/huggingface/datasets/issues/3608/events | https://github.com/huggingface/datasets/issues/3608 | 1,109,310,981 | I_kwDODunzps5CHr4F | 3,608 | Add support for continuous metrics (RMSE, MAE) | {
"avatar_url": "https://avatars.githubusercontent.com/u/50770?v=4",
"events_url": "https://api.github.com/users/ck37/events{/privacy}",
"followers_url": "https://api.github.com/users/ck37/followers",
"following_url": "https://api.github.com/users/ck37/following{/other_user}",
"gists_url": "https://api.github.com/users/ck37/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ck37",
"id": 50770,
"login": "ck37",
"node_id": "MDQ6VXNlcjUwNzcw",
"organizations_url": "https://api.github.com/users/ck37/orgs",
"received_events_url": "https://api.github.com/users/ck37/received_events",
"repos_url": "https://api.github.com/users/ck37/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ck37/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ck37/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ck37"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | 3 | 2022-01-20T13:35:36Z | 2022-03-09T17:18:20Z | 2022-03-09T17:18:20Z | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
I am uploading our dataset and models for the "Constructing interval measures" method we've developed, which uses item response theory to convert multiple discrete labels into a continuous spectrum for hate speech. Once we have this outcome our NLP models conduct regression rather than classification, so binary metrics are not relevant. The only continuous metrics available at https://huggingface.co/metrics are pearson & spearman correlation, which don't ensure that the prediction is on the same scale as the outcome.
**Describe the solution you'd like**
I would like to be able to tag our models on the Hub with the following metrics:
- RMSE
- MAE
**Describe alternatives you've considered**
I don't know if there are any alternatives.
**Additional context**
Our preprint is available here: https://arxiv.org/abs/2009.10277 . We are making it available for use in Jigsaw's Toxic Severity Rating Kaggle competition: https://www.kaggle.com/c/jigsaw-toxic-severity-rating/overview . I have our first model uploaded to the Hub at https://huggingface.co/ucberkeley-dlab/hate-measure-roberta-large
Thanks,
Chris
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3608/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3608/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3607/comments | https://api.github.com/repos/huggingface/datasets/issues/3607/events | https://github.com/huggingface/datasets/pull/3607 | 1,109,218,370 | PR_kwDODunzps4xUgrR | 3,607 | Add MIT Scene Parsing Benchmark | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 0 | 2022-01-20T12:03:07Z | 2022-02-18T12:51:01Z | 2022-02-18T12:51:00Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3607.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3607",
"merged_at": "2022-02-18T12:51:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3607.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3607"
} | Add MIT Scene Parsing Benchmark (a subset of ADE20k).
TODOs:
* [x] add dummy data
* [x] add dataset card
* [x] generate `dataset_info.json`
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3607/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3607/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3606/comments | https://api.github.com/repos/huggingface/datasets/issues/3606/events | https://github.com/huggingface/datasets/issues/3606 | 1,108,918,701 | I_kwDODunzps5CGMGt | 3,606 | audio column not saved correctly after resampling | {
"avatar_url": "https://avatars.githubusercontent.com/u/24724502?v=4",
"events_url": "https://api.github.com/users/laphang/events{/privacy}",
"followers_url": "https://api.github.com/users/laphang/followers",
"following_url": "https://api.github.com/users/laphang/following{/other_user}",
"gists_url": "https://api.github.com/users/laphang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/laphang",
"id": 24724502,
"login": "laphang",
"node_id": "MDQ6VXNlcjI0NzI0NTAy",
"organizations_url": "https://api.github.com/users/laphang/orgs",
"received_events_url": "https://api.github.com/users/laphang/received_events",
"repos_url": "https://api.github.com/users/laphang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/laphang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/laphang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/laphang"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 3 | 2022-01-20T06:37:10Z | 2022-01-23T01:41:01Z | 2022-01-23T01:24:14Z | NONE | null | null | null | ## Describe the bug
After resampling the audio column, saving with save_to_disk doesn't seem to save with the correct type.
## Steps to reproduce the bug
- load a subset of common voice dataset (48Khz)
- resample audio column to 16Khz
- save with save_to_disk()
- load with load_from_disk()
## Expected results
I expected that after saving the data, and then loading it back in, the audio column has the correct dataset.Audio type (i.e. same as before saving it)
{'accent': Value(dtype='string', id=None),
'age': Value(dtype='string', id=None),
'audio': Audio(sampling_rate=16000, mono=True, _storage_dtype='string', id=None),
'client_id': Value(dtype='string', id=None),
'down_votes': Value(dtype='int64', id=None),
'gender': Value(dtype='string', id=None),
'locale': Value(dtype='string', id=None),
'path': Value(dtype='string', id=None),
'segment': Value(dtype='string', id=None),
'sentence': Value(dtype='string', id=None),
'up_votes': Value(dtype='int64', id=None)}
## Actual results
Audio column does not have the right type
{'accent': Value(dtype='string', id=None),
'age': Value(dtype='string', id=None),
'audio': {'bytes': Value(dtype='binary', id=None),
'path': Value(dtype='string', id=None)},
'client_id': Value(dtype='string', id=None),
'down_votes': Value(dtype='int64', id=None),
'gender': Value(dtype='string', id=None),
'locale': Value(dtype='string', id=None),
'path': Value(dtype='string', id=None),
'segment': Value(dtype='string', id=None),
'sentence': Value(dtype='string', id=None),
'up_votes': Value(dtype='int64', id=None)}
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: linux
- Python version:
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3606/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3606/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3605/comments | https://api.github.com/repos/huggingface/datasets/issues/3605/events | https://github.com/huggingface/datasets/pull/3605 | 1,108,738,561 | PR_kwDODunzps4xS9rX | 3,605 | Adding Turkic X-WMT evaluation set for machine translation | {
"avatar_url": "https://avatars.githubusercontent.com/u/26018417?v=4",
"events_url": "https://api.github.com/users/mirzakhalov/events{/privacy}",
"followers_url": "https://api.github.com/users/mirzakhalov/followers",
"following_url": "https://api.github.com/users/mirzakhalov/following{/other_user}",
"gists_url": "https://api.github.com/users/mirzakhalov/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mirzakhalov",
"id": 26018417,
"login": "mirzakhalov",
"node_id": "MDQ6VXNlcjI2MDE4NDE3",
"organizations_url": "https://api.github.com/users/mirzakhalov/orgs",
"received_events_url": "https://api.github.com/users/mirzakhalov/received_events",
"repos_url": "https://api.github.com/users/mirzakhalov/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mirzakhalov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mirzakhalov/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mirzakhalov"
} | [] | closed | false | null | [] | null | 5 | 2022-01-20T01:40:29Z | 2022-01-31T09:50:57Z | 2022-01-31T09:50:57Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3605.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3605",
"merged_at": "2022-01-31T09:50:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3605.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3605"
} | This dataset is a human-translated evaluation set for MT crowdsourced and provided by the [Turkic Interlingua ](turkic-interlingua.org) community. It contains eval sets for 8 Turkic languages covering 88 language directions. Languages being covered are:
Azerbaijani (az)
Bashkir (ba)
English (en)
Karakalpak (kaa)
Kazakh (kk)
Kirghiz (ky)
Russian (ru)
Turkish (tr)
Sakha (sah)
Uzbek (uz)
More info about the corpus is here: [https://github.com/turkic-interlingua/til-mt/tree/master/xwmt](https://github.com/turkic-interlingua/til-mt/tree/master/xwmt)
A paper describing the test set is here: [https://arxiv.org/abs/2109.04593](https://arxiv.org/abs/2109.04593)
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3605/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3605/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3604/comments | https://api.github.com/repos/huggingface/datasets/issues/3604/events | https://github.com/huggingface/datasets/issues/3604 | 1,108,477,316 | I_kwDODunzps5CEgWE | 3,604 | Dataset Viewer not showing Previews for Private Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "https://api.github.com/users/abidlabs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abidlabs",
"id": 1778297,
"login": "abidlabs",
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"organizations_url": "https://api.github.com/users/abidlabs/orgs",
"received_events_url": "https://api.github.com/users/abidlabs/received_events",
"repos_url": "https://api.github.com/users/abidlabs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abidlabs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abidlabs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abidlabs"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
}
] | null | 2 | 2022-01-19T19:29:26Z | 2022-09-26T08:04:43Z | 2022-09-26T08:04:43Z | MEMBER | null | null | null | ## Dataset viewer issue for 'abidlabs/test-audio-13'
It seems that the dataset viewer does not show previews for `private` datasets, even for the user who's private dataset it is. See [1] for example. If I change the visibility to public, then it does show, but it would be useful to have the viewer even for private datasets.
**Link:**
[1] https://huggingface.co/datasets/abidlabs/test-audio-13
**Am I the one who added this dataset?**
Yes
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3604/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3604/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3603 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3603/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3603/comments | https://api.github.com/repos/huggingface/datasets/issues/3603/events | https://github.com/huggingface/datasets/pull/3603 | 1,108,392,141 | PR_kwDODunzps4xR1ih | 3,603 | Add British Library books dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_url": "https://api.github.com/users/davanstrien/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/davanstrien",
"id": 8995957,
"login": "davanstrien",
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"organizations_url": "https://api.github.com/users/davanstrien/orgs",
"received_events_url": "https://api.github.com/users/davanstrien/received_events",
"repos_url": "https://api.github.com/users/davanstrien/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/davanstrien/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davanstrien/subscriptions",
"type": "User",
"url": "https://api.github.com/users/davanstrien"
} | [] | closed | false | null | [] | null | 4 | 2022-01-19T17:53:05Z | 2022-01-31T17:22:51Z | 2022-01-31T17:01:49Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3603.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3603",
"merged_at": "2022-01-31T17:01:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3603.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3603"
} | This pull request adds a dataset of text from digitised (primarily 19th Century) books from the British Library. This collection has previously been used for training language models, e.g. https://github.com/dbmdz/clef-hipe/blob/main/hlms.md. It would be nice to make this dataset more accessible for others to use through datasets.
This is still a WIP but I wanted to get some initial feedback in particular; I wanted to check:
- I am handling the use of `iter_archive` correctly - I intend to ensure that `dl_manager.download` gets the complete list of URLs to download upfront, so the progress bar knows how much is left to download and then to pass through the `gen_kwargs` a list of downloaded zip archives wrapped in `iter_archive`. I am unsure if there is a more elegant approach for this?
- the number of configs: I have aimed to keep this limited - there are a lot of URLs covering the entire dataset, but I have tried to base the configs on what I believe the majority of people will want to they are not presented with too many options - I am happy to hear suggestions for changing this
If there are other glaring omissions or mistakes, I'd be happy to hear them. If this approach seems sensible in general, I will finish all the remaining TODOs, generate dummy_data, etc.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3603/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3603/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3602/comments | https://api.github.com/repos/huggingface/datasets/issues/3602/events | https://github.com/huggingface/datasets/pull/3602 | 1,108,247,870 | PR_kwDODunzps4xRXVm | 3,602 | Update url for conll2003 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 2 | 2022-01-19T15:35:04Z | 2022-01-20T16:23:03Z | 2022-01-19T15:43:53Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3602.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3602",
"merged_at": "2022-01-19T15:43:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3602.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3602"
} | Following https://github.com/huggingface/datasets/issues/3582 I'm changing the download URL of the conll2003 data files, since the previous host doesn't have the authorization to redistribute the data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3602/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3602/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3601/comments | https://api.github.com/repos/huggingface/datasets/issues/3601/events | https://github.com/huggingface/datasets/pull/3601 | 1,108,207,131 | PR_kwDODunzps4xROtF | 3,601 | Add conll2003 licensing | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | 2022-01-19T15:00:41Z | 2022-01-19T17:17:28Z | 2022-01-19T17:17:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3601.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3601",
"merged_at": "2022-01-19T17:17:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3601.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3601"
} | Following https://github.com/huggingface/datasets/issues/3582, this PR updates the licensing section of the CoNLL2003 dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3601/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3601/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3600/comments | https://api.github.com/repos/huggingface/datasets/issues/3600/events | https://github.com/huggingface/datasets/pull/3600 | 1,108,131,878 | PR_kwDODunzps4xQ-vt | 3,600 | Use old url for conll2003 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | 2022-01-19T13:56:49Z | 2022-01-19T14:16:28Z | 2022-01-19T14:16:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3600.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3600",
"merged_at": "2022-01-19T14:16:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3600.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3600"
} | As reported in https://github.com/huggingface/datasets/issues/3582 the CoNLL2003 data files are not available in the master branch of the repo that used to host them.
For now we can use the URL from an older commit to access the data files | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3600/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3600/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3599/comments | https://api.github.com/repos/huggingface/datasets/issues/3599/events | https://github.com/huggingface/datasets/issues/3599 | 1,108,111,607 | I_kwDODunzps5CDHD3 | 3,599 | The `add_column()` method does not work if used on dataset sliced with `select()` | {
"avatar_url": "https://avatars.githubusercontent.com/u/59422506?v=4",
"events_url": "https://api.github.com/users/ThGouzias/events{/privacy}",
"followers_url": "https://api.github.com/users/ThGouzias/followers",
"following_url": "https://api.github.com/users/ThGouzias/following{/other_user}",
"gists_url": "https://api.github.com/users/ThGouzias/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ThGouzias",
"id": 59422506,
"login": "ThGouzias",
"node_id": "MDQ6VXNlcjU5NDIyNTA2",
"organizations_url": "https://api.github.com/users/ThGouzias/orgs",
"received_events_url": "https://api.github.com/users/ThGouzias/received_events",
"repos_url": "https://api.github.com/users/ThGouzias/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ThGouzias/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ThGouzias/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ThGouzias"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | 1 | 2022-01-19T13:36:50Z | 2022-01-28T15:35:57Z | 2022-01-28T15:35:57Z | NONE | null | null | null | Hello, I posted this as a question on the forums ([here](https://discuss.huggingface.co/t/add-column-does-not-work-if-used-on-dataset-sliced-with-select/13893)):
I have a dataset with 2000 entries
> dataset = Dataset.from_dict({'colA': list(range(2000))})
and from which I want to extract the first one thousand rows, create a new dataset with these and also add a new column to it:
> dataset2 = dataset.select(list(range(1000)))
> final_dataset = dataset2.add_column('colB', list(range(1000)))
This gives an error
>ArrowInvalid: Added column's length must match table's length. Expected length 2000 but got length 1000
So it looks like even though it is a dataset with 1000 rows, it "remembers" the shape of the one it was sliced from.
## Actual results
```
ArrowInvalid Traceback (most recent call last)
<ipython-input-138-e806860f3ce3> in <module>
----> 1 final_dataset = dataset2.add_column('colB', list(range(1000)))
~/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
468 }
469 # apply actual function
--> 470 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
471 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
472 # re-apply format to the output
~/.local/lib/python3.8/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
404 # Call actual function
405
--> 406 out = func(self, *args, **kwargs)
407
408 # Update fingerprint of in-place transforms + update in-place history of transforms
~/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py in add_column(self, name, column, new_fingerprint)
3343 column_table = InMemoryTable.from_pydict({name: column})
3344 # Concatenate tables horizontally
-> 3345 table = ConcatenationTable.from_tables([self._data, column_table], axis=1)
3346 # Update features
3347 info = self.info.copy()
~/.local/lib/python3.8/site-packages/datasets/table.py in from_tables(cls, tables, axis)
729 table_blocks = to_blocks(table)
730 blocks = _extend_blocks(blocks, table_blocks, axis=axis)
--> 731 return cls.from_blocks(blocks)
732
733 @property
~/.local/lib/python3.8/site-packages/datasets/table.py in from_blocks(cls, blocks)
668 @classmethod
669 def from_blocks(cls, blocks: TableBlockContainer) -> "ConcatenationTable":
--> 670 blocks = cls._consolidate_blocks(blocks)
671 if isinstance(blocks, TableBlock):
672 table = blocks
~/.local/lib/python3.8/site-packages/datasets/table.py in _consolidate_blocks(cls, blocks)
664 return cls._merge_blocks(blocks, axis=0)
665 else:
--> 666 return cls._merge_blocks(blocks)
667
668 @classmethod
~/.local/lib/python3.8/site-packages/datasets/table.py in _merge_blocks(cls, blocks, axis)
650 merged_blocks += list(block_group)
651 else: # both
--> 652 merged_blocks = [cls._merge_blocks(row_block, axis=1) for row_block in blocks]
653 if all(len(row_block) == 1 for row_block in merged_blocks):
654 merged_blocks = cls._merge_blocks(
~/.local/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
650 merged_blocks += list(block_group)
651 else: # both
--> 652 merged_blocks = [cls._merge_blocks(row_block, axis=1) for row_block in blocks]
653 if all(len(row_block) == 1 for row_block in merged_blocks):
654 merged_blocks = cls._merge_blocks(
~/.local/lib/python3.8/site-packages/datasets/table.py in _merge_blocks(cls, blocks, axis)
647 for is_in_memory, block_group in groupby(blocks, key=lambda x: isinstance(x, InMemoryTable)):
648 if is_in_memory:
--> 649 block_group = [InMemoryTable(cls._concat_blocks(list(block_group), axis=axis))]
650 merged_blocks += list(block_group)
651 else: # both
~/.local/lib/python3.8/site-packages/datasets/table.py in _concat_blocks(blocks, axis)
626 else:
627 for name, col in zip(table.column_names, table.columns):
--> 628 pa_table = pa_table.append_column(name, col)
629 return pa_table
630 else:
~/.local/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.append_column()
~/.local/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.add_column()
~/.local/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
~/.local/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Added column's length must match table's length. Expected length 2000 but got length 1000
```
A solution provided by @mariosasko is to use `dataset2.flatten_indices()` after the `select()` and before attempting to add the new column:
> dataset = Dataset.from_dict({'colA': list(range(2000))})
> dataset2 = dataset.select(list(range(1000)))
> dataset2 = dataset2.flatten_indices()
> final_dataset = dataset2.add_column('colB', list(range(1000)))
which works.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.13.2 (note: also checked with version 1.17.0, still the same error)
- Platform: Ubuntu 20.04.3
- Python version: 3.8.10
- PyArrow version: 6.0.0
| {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3599/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3599/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3598/comments | https://api.github.com/repos/huggingface/datasets/issues/3598/events | https://github.com/huggingface/datasets/issues/3598 | 1,108,107,199 | I_kwDODunzps5CDF-_ | 3,598 | Readme info not being parsed to show on Dataset card page | {
"avatar_url": "https://avatars.githubusercontent.com/u/79796807?v=4",
"events_url": "https://api.github.com/users/davidcanovas/events{/privacy}",
"followers_url": "https://api.github.com/users/davidcanovas/followers",
"following_url": "https://api.github.com/users/davidcanovas/following{/other_user}",
"gists_url": "https://api.github.com/users/davidcanovas/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/davidcanovas",
"id": 79796807,
"login": "davidcanovas",
"node_id": "MDQ6VXNlcjc5Nzk2ODA3",
"organizations_url": "https://api.github.com/users/davidcanovas/orgs",
"received_events_url": "https://api.github.com/users/davidcanovas/received_events",
"repos_url": "https://api.github.com/users/davidcanovas/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/davidcanovas/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davidcanovas/subscriptions",
"type": "User",
"url": "https://api.github.com/users/davidcanovas"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 4 | 2022-01-19T13:32:29Z | 2022-01-21T10:20:01Z | 2022-01-21T10:20:01Z | NONE | null | null | null | ## Describe the bug
The info contained in the README.md file is not being shown in the dataset main page. Basic info and table of contents are properly formatted in the README.
## Steps to reproduce the bug
# Sample code to reproduce the bug
The README file is this one: https://huggingface.co/datasets/softcatala/Tilde-MODEL-Catalan/blob/main/README.md
## Expected results
README info should appear in the Dataset card page.
## Actual results
Nothing is shown. However, labels are parsed and shown successfully.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3598/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3598/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3597/comments | https://api.github.com/repos/huggingface/datasets/issues/3597/events | https://github.com/huggingface/datasets/issues/3597 | 1,108,092,864 | I_kwDODunzps5CDCfA | 3,597 | ERROR: File "setup.py" or "setup.cfg" not found. Directory cannot be installed in editable mode: /content | {
"avatar_url": "https://avatars.githubusercontent.com/u/49492030?v=4",
"events_url": "https://api.github.com/users/amitkml/events{/privacy}",
"followers_url": "https://api.github.com/users/amitkml/followers",
"following_url": "https://api.github.com/users/amitkml/following{/other_user}",
"gists_url": "https://api.github.com/users/amitkml/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/amitkml",
"id": 49492030,
"login": "amitkml",
"node_id": "MDQ6VXNlcjQ5NDkyMDMw",
"organizations_url": "https://api.github.com/users/amitkml/orgs",
"received_events_url": "https://api.github.com/users/amitkml/received_events",
"repos_url": "https://api.github.com/users/amitkml/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/amitkml/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amitkml/subscriptions",
"type": "User",
"url": "https://api.github.com/users/amitkml"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 2 | 2022-01-19T13:19:28Z | 2022-08-05T12:35:51Z | 2022-02-14T08:46:34Z | NONE | null | null | null | ## Bug
The install of streaming dataset is giving following error.
## Steps to reproduce the bug
```python
! git clone https://github.com/huggingface/datasets.git
! cd datasets
! pip install -e ".[streaming]"
```
## Actual results
Cloning into 'datasets'...
remote: Enumerating objects: 50816, done.
remote: Counting objects: 100% (2356/2356), done.
remote: Compressing objects: 100% (1606/1606), done.
remote: Total 50816 (delta 834), reused 1741 (delta 525), pack-reused 48460
Receiving objects: 100% (50816/50816), 72.47 MiB | 27.68 MiB/s, done.
Resolving deltas: 100% (22541/22541), done.
Checking out files: 100% (6722/6722), done.
ERROR: File "setup.py" or "setup.cfg" not found. Directory cannot be installed in editable mode: /content
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3597/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3596/comments | https://api.github.com/repos/huggingface/datasets/issues/3596/events | https://github.com/huggingface/datasets/issues/3596 | 1,107,345,338 | I_kwDODunzps5CAL-6 | 3,596 | Loss of cast `Image` feature on certain dataset method | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_url": "https://api.github.com/users/davanstrien/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/davanstrien",
"id": 8995957,
"login": "davanstrien",
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"organizations_url": "https://api.github.com/users/davanstrien/orgs",
"received_events_url": "https://api.github.com/users/davanstrien/received_events",
"repos_url": "https://api.github.com/users/davanstrien/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/davanstrien/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davanstrien/subscriptions",
"type": "User",
"url": "https://api.github.com/users/davanstrien"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 7 | 2022-01-18T20:44:01Z | 2022-01-21T18:07:28Z | 2022-01-21T18:07:28Z | MEMBER | null | null | null | ## Describe the bug
When an a column is cast to an `Image` feature, the cast type appears to be lost during certain operations. I first noticed this when using the `push_to_hub` method on a dataset that contained urls pointing to images which had been cast to an `image`. This also happens when using select on a dataset which has had a column cast to an `Image`.
I suspect this might be related to https://github.com/huggingface/datasets/pull/3556 but I don't believe that pull request fixes this issue.
## Steps to reproduce the bug
An example of casting a url to an image followed by using the `select` method:
```python
from datasets import Dataset
from datasets import features
url = "https://cf.ltkcdn.net/cats/images/std-lg/246866-1200x816-grey-white-kitten.webp"
data_dict = {"url": [url]*2}
dataset = Dataset.from_dict(data_dict)
dataset = dataset.cast_column('url',features.Image())
sample = dataset.select([1])
```
[example notebook](https://gist.github.com/davanstrien/06e53f4383c28ae77ce1b30d0eaf0d70#file-potential_casting_bug-ipynb)
## Expected results
The cast value is maintained when further methods are applied to the dataset.
## Actual results
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-12-47f393bc2d0d> in <module>()
----> 1 sample = dataset.select([1])
4 frames
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
487 }
488 # apply actual function
--> 489 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
490 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
491 # re-apply format to the output
/usr/local/lib/python3.7/dist-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
409 # Call actual function
410
--> 411 out = func(self, *args, **kwargs)
412
413 # Update fingerprint of in-place transforms + update in-place history of transforms
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in select(self, indices, keep_in_memory, indices_cache_file_name, writer_batch_size, new_fingerprint)
2772 )
2773 else:
-> 2774 return self._new_dataset_with_indices(indices_buffer=buf_writer.getvalue(), fingerprint=new_fingerprint)
2775
2776 @transmit_format
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in _new_dataset_with_indices(self, indices_cache_file_name, indices_buffer, fingerprint)
2688 split=self.split,
2689 indices_table=indices_table,
-> 2690 fingerprint=fingerprint,
2691 )
2692
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in __init__(self, arrow_table, info, split, indices_table, fingerprint)
664 if self.info.features.type != inferred_features.type:
665 raise ValueError(
--> 666 f"External features info don't match the dataset:\nGot\n{self.info.features}\nwith type\n{self.info.features.type}\n\nbut expected something like\n{inferred_features}\nwith type\n{inferred_features.type}"
667 )
668
ValueError: External features info don't match the dataset:
Got
{'url': Image(id=None)}
with type
struct<url: extension<arrow.py_extension_type<ImageExtensionType>>>
but expected something like
{'url': Value(dtype='string', id=None)}
with type
struct<url: string>
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.1.dev0
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 3.0.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3596/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3596/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3595/comments | https://api.github.com/repos/huggingface/datasets/issues/3595/events | https://github.com/huggingface/datasets/pull/3595 | 1,107,260,527 | PR_kwDODunzps4xOIxH | 3,595 | Add ImageNet toy datasets from fastai | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | 1 | 2022-01-18T19:03:35Z | 2023-09-24T09:39:07Z | 2022-09-30T14:39:35Z | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3595.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3595",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3595.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3595"
} | Adds the ImageNet toy datasets from FastAI: Imagenette, Imagewoof and Imagewang.
TODOs:
* [ ] add dummy data
* [ ] add dataset card
* [ ] generate `dataset_info.json` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3595/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3595/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3594/comments | https://api.github.com/repos/huggingface/datasets/issues/3594/events | https://github.com/huggingface/datasets/pull/3594 | 1,107,174,619 | PR_kwDODunzps4xN3Kk | 3,594 | fix multiple language downloading in mC4 | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [] | closed | false | null | [] | null | 1 | 2022-01-18T17:25:19Z | 2022-01-19T11:22:57Z | 2022-01-18T19:10:22Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3594.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3594",
"merged_at": "2022-01-18T19:10:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3594.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3594"
} | If we try to access multiple languages of the [mC4 dataset](https://github.com/huggingface/datasets/tree/master/datasets/mc4), it will throw an error. For example, if we do
```python
mc4_subset_two_langs = load_dataset("mc4", languages=["st", "su"])
```
we got
```
FileNotFoundError: Couldn't find file at https://huggingface.co/datasets/allenai/c4/resolve/1ddc917116b730e1859edef32896ec5c16be51d0/multilingual/c4-st+su.tfrecord-00000-of-00002.json.gz
```
Now it should work. Check it (from the root dir of a project):
```python
mc4_subset_two_langs = load_dataset("./datasets/mc4/", languages=["st", "su"])
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3594/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3593 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3593/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3593/comments | https://api.github.com/repos/huggingface/datasets/issues/3593/events | https://github.com/huggingface/datasets/pull/3593 | 1,107,070,852 | PR_kwDODunzps4xNhTu | 3,593 | Update README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"events_url": "https://api.github.com/users/borgr/events{/privacy}",
"followers_url": "https://api.github.com/users/borgr/followers",
"following_url": "https://api.github.com/users/borgr/following{/other_user}",
"gists_url": "https://api.github.com/users/borgr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/borgr",
"id": 6416600,
"login": "borgr",
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"organizations_url": "https://api.github.com/users/borgr/orgs",
"received_events_url": "https://api.github.com/users/borgr/received_events",
"repos_url": "https://api.github.com/users/borgr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/borgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/borgr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/borgr"
} | [] | closed | false | null | [] | null | 0 | 2022-01-18T15:52:16Z | 2022-01-20T17:14:53Z | 2022-01-20T17:14:53Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3593.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3593",
"merged_at": "2022-01-20T17:14:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3593.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3593"
} | Towards license of Tweet Eval parts | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3593/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3593/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3592/comments | https://api.github.com/repos/huggingface/datasets/issues/3592/events | https://github.com/huggingface/datasets/pull/3592 | 1,107,026,723 | PR_kwDODunzps4xNYIW | 3,592 | Add QuickDraw dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 1 | 2022-01-18T15:13:39Z | 2022-06-09T10:04:54Z | 2022-06-09T09:56:13Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3592.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3592",
"merged_at": "2022-06-09T09:56:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3592.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3592"
} | Add the QuickDraw dataset.
TODOs:
* [x] add dummy data
* [x] add dataset card
* [x] generate `dataset_info.json` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3592/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3592/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3591/comments | https://api.github.com/repos/huggingface/datasets/issues/3591/events | https://github.com/huggingface/datasets/pull/3591 | 1,106,928,613 | PR_kwDODunzps4xNDoB | 3,591 | Add support for time, date, duration, and decimal dtypes | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 2 | 2022-01-18T13:46:05Z | 2022-01-31T18:29:34Z | 2022-01-20T17:37:33Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3591.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3591",
"merged_at": "2022-01-20T17:37:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3591.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3591"
} | Add support for the pyarrow time (maps to `datetime.time` in python), date (maps to `datetime.time` in python), duration (maps to `datetime.timedelta` in python), and decimal (maps to `decimal.decimal` in python) dtypes. This should be helpful when writing scripts for time-series datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3591/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3591/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3590/comments | https://api.github.com/repos/huggingface/datasets/issues/3590/events | https://github.com/huggingface/datasets/pull/3590 | 1,106,784,860 | PR_kwDODunzps4xMlGg | 3,590 | Update ANLI README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"events_url": "https://api.github.com/users/borgr/events{/privacy}",
"followers_url": "https://api.github.com/users/borgr/followers",
"following_url": "https://api.github.com/users/borgr/following{/other_user}",
"gists_url": "https://api.github.com/users/borgr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/borgr",
"id": 6416600,
"login": "borgr",
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"organizations_url": "https://api.github.com/users/borgr/orgs",
"received_events_url": "https://api.github.com/users/borgr/received_events",
"repos_url": "https://api.github.com/users/borgr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/borgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/borgr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/borgr"
} | [] | closed | false | null | [] | null | 0 | 2022-01-18T11:22:53Z | 2022-01-20T16:58:41Z | 2022-01-20T16:58:41Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3590.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3590",
"merged_at": "2022-01-20T16:58:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3590.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3590"
} | Update license and little things concerning ANLI | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3590/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3590/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3589/comments | https://api.github.com/repos/huggingface/datasets/issues/3589/events | https://github.com/huggingface/datasets/pull/3589 | 1,106,766,114 | PR_kwDODunzps4xMhGp | 3,589 | Pin torchmetrics to fix the COMET test | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | 2022-01-18T11:03:49Z | 2022-01-18T11:04:56Z | 2022-01-18T11:04:55Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3589.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3589",
"merged_at": "2022-01-18T11:04:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3589.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3589"
} | Torchmetrics 0.7.0 got released and has issues with `transformers` (see https://github.com/PyTorchLightning/metrics/issues/770)
I'm pinning it to 0.6.0 in the CI, since 0.7.0 makes the COMET metric test fail. COMET requires torchmetrics==0.6.0 anyway. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3589/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3589/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3588 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3588/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3588/comments | https://api.github.com/repos/huggingface/datasets/issues/3588/events | https://github.com/huggingface/datasets/pull/3588 | 1,106,749,000 | PR_kwDODunzps4xMdiC | 3,588 | Update HellaSwag README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"events_url": "https://api.github.com/users/borgr/events{/privacy}",
"followers_url": "https://api.github.com/users/borgr/followers",
"following_url": "https://api.github.com/users/borgr/following{/other_user}",
"gists_url": "https://api.github.com/users/borgr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/borgr",
"id": 6416600,
"login": "borgr",
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"organizations_url": "https://api.github.com/users/borgr/orgs",
"received_events_url": "https://api.github.com/users/borgr/received_events",
"repos_url": "https://api.github.com/users/borgr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/borgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/borgr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/borgr"
} | [] | closed | false | null | [] | null | 0 | 2022-01-18T10:46:15Z | 2022-01-20T16:57:43Z | 2022-01-20T16:57:43Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3588.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3588",
"merged_at": "2022-01-20T16:57:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3588.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3588"
} | Adding information from the git repo and paper that were missing | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3588/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3588/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3587/comments | https://api.github.com/repos/huggingface/datasets/issues/3587/events | https://github.com/huggingface/datasets/issues/3587 | 1,106,719,182 | I_kwDODunzps5B9zHO | 3,587 | No module named 'fsspec.archive' | {
"avatar_url": "https://avatars.githubusercontent.com/u/13246825?v=4",
"events_url": "https://api.github.com/users/shuuchen/events{/privacy}",
"followers_url": "https://api.github.com/users/shuuchen/followers",
"following_url": "https://api.github.com/users/shuuchen/following{/other_user}",
"gists_url": "https://api.github.com/users/shuuchen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shuuchen",
"id": 13246825,
"login": "shuuchen",
"node_id": "MDQ6VXNlcjEzMjQ2ODI1",
"organizations_url": "https://api.github.com/users/shuuchen/orgs",
"received_events_url": "https://api.github.com/users/shuuchen/received_events",
"repos_url": "https://api.github.com/users/shuuchen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shuuchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shuuchen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shuuchen"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 0 | 2022-01-18T10:17:01Z | 2022-08-11T09:57:54Z | 2022-01-18T10:33:10Z | NONE | null | null | null | ## Describe the bug
Cannot import datasets after installation.
## Steps to reproduce the bug
```shell
$ python
Python 3.9.7 (default, Sep 16 2021, 13:09:58)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import datasets
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/__init__.py", line 34, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 61, in <module>
from .arrow_writer import ArrowWriter, OptimizedTypedSequence
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/arrow_writer.py", line 28, in <module>
from .features import (
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/features/__init__.py", line 2, in <module>
from .audio import Audio
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/features/audio.py", line 7, in <module>
from ..utils.streaming_download_manager import xopen
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 18, in <module>
from ..filesystems import COMPRESSION_FILESYSTEMS
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/filesystems/__init__.py", line 6, in <module>
from . import compression
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/filesystems/compression.py", line 5, in <module>
from fsspec.archive import AbstractArchiveFileSystem
ModuleNotFoundError: No module named 'fsspec.archive'
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3587/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3587/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3586/comments | https://api.github.com/repos/huggingface/datasets/issues/3586/events | https://github.com/huggingface/datasets/issues/3586 | 1,106,455,672 | I_kwDODunzps5B8yx4 | 3,586 | Revisit `enable/disable_` toggle function prefix | {
"avatar_url": "https://avatars.githubusercontent.com/u/25360440?v=4",
"events_url": "https://api.github.com/users/jaketae/events{/privacy}",
"followers_url": "https://api.github.com/users/jaketae/followers",
"following_url": "https://api.github.com/users/jaketae/following{/other_user}",
"gists_url": "https://api.github.com/users/jaketae/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jaketae",
"id": 25360440,
"login": "jaketae",
"node_id": "MDQ6VXNlcjI1MzYwNDQw",
"organizations_url": "https://api.github.com/users/jaketae/orgs",
"received_events_url": "https://api.github.com/users/jaketae/received_events",
"repos_url": "https://api.github.com/users/jaketae/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jaketae/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jaketae/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jaketae"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | 0 | 2022-01-18T04:09:55Z | 2022-03-14T15:01:08Z | 2022-03-14T15:01:08Z | CONTRIBUTOR | null | null | null | As discussed in https://github.com/huggingface/transformers/pull/15167, we should revisit the `enable/disable_` toggle function prefix, potentially in favor of `set_enabled_`. Concretely, this translates to
- De-deprecating `disable_progress_bar()`
- Adding `enable_progress_bar()`
- On the caching side, adding `enable_caching` and `disable_caching`
Additional decisions have to be made with regards to the existing `set_enabled_X` functions; that is, whether to keep them as is or deprecate them in favor of the aforementioned functions.
cc @mariosasko @lhoestq | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3586/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3586/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3585/comments | https://api.github.com/repos/huggingface/datasets/issues/3585/events | https://github.com/huggingface/datasets/issues/3585 | 1,105,821,470 | I_kwDODunzps5B6X8e | 3,585 | Datasets streaming + map doesn't work for `Audio` | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | 1 | 2022-01-17T12:55:42Z | 2022-01-20T13:28:00Z | 2022-01-20T13:28:00Z | MEMBER | null | null | null | ## Describe the bug
When using audio datasets in streaming mode, applying a `map(...)` before iterating leads to an error as the key `array` does not exist anymore.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "en", streaming=True, split="train")
def map_fn(batch):
print("audio keys", batch["audio"].keys())
batch["audio"] = batch["audio"]["array"][:100]
return batch
ds = ds.map(map_fn)
sample = next(iter(ds))
```
I think the audio is somehow decoded before `.map(...)` is actually called.
## Expected results
IMO, the above code snippet should work.
## Actual results
```bash
audio keys dict_keys(['path', 'bytes'])
Traceback (most recent call last):
File "./run_audio.py", line 15, in <module>
sample = next(iter(ds))
File "/home/patrick/python_bin/datasets/iterable_dataset.py", line 341, in __iter__
for key, example in self._iter():
File "/home/patrick/python_bin/datasets/iterable_dataset.py", line 338, in _iter
yield from ex_iterable
File "/home/patrick/python_bin/datasets/iterable_dataset.py", line 192, in __iter__
yield key, self.function(example)
File "./run_audio.py", line 9, in map_fn
batch["input"] = batch["audio"]["array"][:100]
KeyError: 'array'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.1.dev0
- Platform: Linux-5.3.0-64-generic-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3585/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3585/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3584/comments | https://api.github.com/repos/huggingface/datasets/issues/3584/events | https://github.com/huggingface/datasets/issues/3584 | 1,105,231,768 | I_kwDODunzps5B4H-Y | 3,584 | https://huggingface.co/datasets/huggingface/transformers-metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/37082592?v=4",
"events_url": "https://api.github.com/users/ecankirkic/events{/privacy}",
"followers_url": "https://api.github.com/users/ecankirkic/followers",
"following_url": "https://api.github.com/users/ecankirkic/following{/other_user}",
"gists_url": "https://api.github.com/users/ecankirkic/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ecankirkic",
"id": 37082592,
"login": "ecankirkic",
"node_id": "MDQ6VXNlcjM3MDgyNTky",
"organizations_url": "https://api.github.com/users/ecankirkic/orgs",
"received_events_url": "https://api.github.com/users/ecankirkic/received_events",
"repos_url": "https://api.github.com/users/ecankirkic/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ecankirkic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ecankirkic/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ecankirkic"
} | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
},
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | 0 | 2022-01-17T00:18:14Z | 2022-02-14T08:51:27Z | 2022-02-14T08:51:27Z | NONE | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3584/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3584/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3583/comments | https://api.github.com/repos/huggingface/datasets/issues/3583/events | https://github.com/huggingface/datasets/issues/3583 | 1,105,195,144 | I_kwDODunzps5B3_CI | 3,583 | Add The Medical Segmentation Decathlon Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_url": "https://api.github.com/users/omarespejel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/omarespejel",
"id": 4755430,
"login": "omarespejel",
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"organizations_url": "https://api.github.com/users/omarespejel/orgs",
"received_events_url": "https://api.github.com/users/omarespejel/received_events",
"repos_url": "https://api.github.com/users/omarespejel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/omarespejel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omarespejel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/omarespejel"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",
"default": false,
"description": "Vision datasets",
"id": 3608941089,
"name": "vision",
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/64613009?v=4",
"events_url": "https://api.github.com/users/pri1311/events{/privacy}",
"followers_url": "https://api.github.com/users/pri1311/followers",
"following_url": "https://api.github.com/users/pri1311/following{/other_user}",
"gists_url": "https://api.github.com/users/pri1311/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pri1311",
"id": 64613009,
"login": "pri1311",
"node_id": "MDQ6VXNlcjY0NjEzMDA5",
"organizations_url": "https://api.github.com/users/pri1311/orgs",
"received_events_url": "https://api.github.com/users/pri1311/received_events",
"repos_url": "https://api.github.com/users/pri1311/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pri1311/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pri1311/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pri1311"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/64613009?v=4",
"events_url": "https://api.github.com/users/pri1311/events{/privacy}",
"followers_url": "https://api.github.com/users/pri1311/followers",
"following_url": "https://api.github.com/users/pri1311/following{/other_user}",
"gists_url": "https://api.github.com/users/pri1311/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pri1311",
"id": 64613009,
"login": "pri1311",
"node_id": "MDQ6VXNlcjY0NjEzMDA5",
"organizations_url": "https://api.github.com/users/pri1311/orgs",
"received_events_url": "https://api.github.com/users/pri1311/received_events",
"repos_url": "https://api.github.com/users/pri1311/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pri1311/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pri1311/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pri1311"
}
] | null | 5 | 2022-01-16T21:42:25Z | 2022-03-18T10:44:42Z | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** *The Medical Segmentation Decathlon Dataset*
- **Description:** The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data, and small objects.
- **Paper:** [link to the dataset paper if available](https://arxiv.org/abs/2106.05735)
- **Data:** http://medicaldecathlon.com/
- **Motivation:** Hugging Face seeks to democratize ML for society. One of the growing niches within ML is the ML + Medicine community. Key data sets will help increase the supply of HF resources for starting an initial community.
(cc @osanseviero @abidlabs )
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3583/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3582/comments | https://api.github.com/repos/huggingface/datasets/issues/3582/events | https://github.com/huggingface/datasets/issues/3582 | 1,104,877,303 | I_kwDODunzps5B2xb3 | 3,582 | conll 2003 dataset source url is no longer valid | {
"avatar_url": "https://avatars.githubusercontent.com/u/303900?v=4",
"events_url": "https://api.github.com/users/rcanand/events{/privacy}",
"followers_url": "https://api.github.com/users/rcanand/followers",
"following_url": "https://api.github.com/users/rcanand/following{/other_user}",
"gists_url": "https://api.github.com/users/rcanand/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rcanand",
"id": 303900,
"login": "rcanand",
"node_id": "MDQ6VXNlcjMwMzkwMA==",
"organizations_url": "https://api.github.com/users/rcanand/orgs",
"received_events_url": "https://api.github.com/users/rcanand/received_events",
"repos_url": "https://api.github.com/users/rcanand/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rcanand/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rcanand/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rcanand"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | 9 | 2022-01-15T23:04:17Z | 2022-07-20T13:06:40Z | 2022-01-21T16:57:32Z | NONE | null | null | null | ## Describe the bug
Loading `conll2003` dataset fails because it was removed (just yesterday 1/14/2022) from the location it is looking for.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("conll2003")
```
## Expected results
The dataset should load.
## Actual results
It is looking for the dataset at `https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/train.txt` but it was removed from there yesterday (see [commit](https://github.com/davidsbatista/NER-datasets/commit/9d8f45cc7331569af8eb3422bbe1c97cbebd5690) that removed the file and related [issue](https://github.com/davidsbatista/NER-datasets/issues/8)).
- We should replace this with an alternate valid location.
- this is being referenced in the huggingface course chapter 7 [colab notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/chapter7/section2_pt.ipynb), which is also broken.
```python
FileNotFoundError Traceback (most recent call last)
<ipython-input-4-27c956bec93c> in <module>()
1 from datasets import load_dataset
2
----> 3 raw_datasets = load_dataset("conll2003")
11 frames
/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag, max_retries, use_auth_token, ignore_url_params)
610 )
611 elif response is not None and response.status_code == 404:
--> 612 raise FileNotFoundError(f"Couldn't find file at {url}")
613 _raise_if_offline_mode_is_enabled(f"Tried to reach {url}")
614 if head_error is not None:
FileNotFoundError: Couldn't find file at https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/train.txt
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform:
- Python version:
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 5,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3582/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3582/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3581/comments | https://api.github.com/repos/huggingface/datasets/issues/3581/events | https://github.com/huggingface/datasets/issues/3581 | 1,104,857,822 | I_kwDODunzps5B2sre | 3,581 | Unable to create a dataset from a parquet file in S3 | {
"avatar_url": "https://avatars.githubusercontent.com/u/18012903?v=4",
"events_url": "https://api.github.com/users/regCode/events{/privacy}",
"followers_url": "https://api.github.com/users/regCode/followers",
"following_url": "https://api.github.com/users/regCode/following{/other_user}",
"gists_url": "https://api.github.com/users/regCode/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/regCode",
"id": 18012903,
"login": "regCode",
"node_id": "MDQ6VXNlcjE4MDEyOTAz",
"organizations_url": "https://api.github.com/users/regCode/orgs",
"received_events_url": "https://api.github.com/users/regCode/received_events",
"repos_url": "https://api.github.com/users/regCode/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/regCode/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/regCode/subscriptions",
"type": "User",
"url": "https://api.github.com/users/regCode"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | 1 | 2022-01-15T21:34:16Z | 2022-02-14T08:52:57Z | null | NONE | null | null | null | ## Describe the bug
Trying to create a dataset from a parquet file in S3.
## Steps to reproduce the bug
```python
import s3fs
from datasets import Dataset
s3 = s3fs.S3FileSystem(anon=False)
with s3.open(PATH_LTR_TOY_CLEAN_DATASET, 'rb') as s3file:
dataset = Dataset.from_parquet(s3file)
```
## Expected results
A new Dataset object
## Actual results
```AttributeError: 'S3File' object has no attribute 'decode'```
```
AttributeError Traceback (most recent call last)
<command-2452877612515691> in <module>
5
6 with s3.open(PATH_LTR_TOY_CLEAN_DATASET, 'rb') as s3file:
----> 7 dataset = Dataset.from_parquet(s3file)
/databricks/python/lib/python3.8/site-packages/datasets/arrow_dataset.py in from_parquet(path_or_paths, split, features, cache_dir, keep_in_memory, columns, **kwargs)
907 from .io.parquet import ParquetDatasetReader
908
--> 909 return ParquetDatasetReader(
910 path_or_paths,
911 split=split,
/databricks/python/lib/python3.8/site-packages/datasets/io/parquet.py in __init__(self, path_or_paths, split, features, cache_dir, keep_in_memory, **kwargs)
28 path_or_paths = path_or_paths if isinstance(path_or_paths, dict) else {self.split: path_or_paths}
29 hash = _PACKAGED_DATASETS_MODULES["parquet"][1]
---> 30 self.builder = Parquet(
31 cache_dir=cache_dir,
32 data_files=path_or_paths,
/databricks/python/lib/python3.8/site-packages/datasets/builder.py in __init__(self, cache_dir, name, hash, base_path, info, features, use_auth_token, namespace, data_files, data_dir, **config_kwargs)
246
247 if data_files is not None and not isinstance(data_files, DataFilesDict):
--> 248 data_files = DataFilesDict.from_local_or_remote(
249 sanitize_patterns(data_files), base_path=base_path, use_auth_token=use_auth_token
250 )
/databricks/python/lib/python3.8/site-packages/datasets/data_files.py in from_local_or_remote(cls, patterns, base_path, allowed_extensions, use_auth_token)
576 for key, patterns_for_key in patterns.items():
577 out[key] = (
--> 578 DataFilesList.from_local_or_remote(
579 patterns_for_key,
580 base_path=base_path,
/databricks/python/lib/python3.8/site-packages/datasets/data_files.py in from_local_or_remote(cls, patterns, base_path, allowed_extensions, use_auth_token)
544 ) -> "DataFilesList":
545 base_path = base_path if base_path is not None else str(Path().resolve())
--> 546 data_files = resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)
547 origin_metadata = _get_origin_metadata_locally_or_by_urls(data_files, use_auth_token=use_auth_token)
548 return cls(data_files, origin_metadata)
/databricks/python/lib/python3.8/site-packages/datasets/data_files.py in resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)
191 data_files = []
192 for pattern in patterns:
--> 193 if is_remote_url(pattern):
194 data_files.append(Url(pattern))
195 else:
/databricks/python/lib/python3.8/site-packages/datasets/utils/file_utils.py in is_remote_url(url_or_filename)
115
116 def is_remote_url(url_or_filename: str) -> bool:
--> 117 parsed = urlparse(url_or_filename)
118 return parsed.scheme in ("http", "https", "s3", "gs", "hdfs", "ftp")
119
/usr/lib/python3.8/urllib/parse.py in urlparse(url, scheme, allow_fragments)
370 Note that we don't break the components up in smaller bits
371 (e.g. netloc is a single string) and we don't expand % escapes."""
--> 372 url, scheme, _coerce_result = _coerce_args(url, scheme)
373 splitresult = urlsplit(url, scheme, allow_fragments)
374 scheme, netloc, url, query, fragment = splitresult
/usr/lib/python3.8/urllib/parse.py in _coerce_args(*args)
122 if str_input:
123 return args + (_noop,)
--> 124 return _decode_args(args) + (_encode_result,)
125
126 # Result objects are more helpful than simple tuples
/usr/lib/python3.8/urllib/parse.py in _decode_args(args, encoding, errors)
106 def _decode_args(args, encoding=_implicit_encoding,
107 errors=_implicit_errors):
--> 108 return tuple(x.decode(encoding, errors) if x else '' for x in args)
109
110 def _coerce_args(*args):
/usr/lib/python3.8/urllib/parse.py in <genexpr>(.0)
106 def _decode_args(args, encoding=_implicit_encoding,
107 errors=_implicit_errors):
--> 108 return tuple(x.decode(encoding, errors) if x else '' for x in args)
109
110 def _coerce_args(*args):
AttributeError: 'S3File' object has no attribute 'decode'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: Ubuntu 20.04.3 LTS
- Python version: 3.8.10
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3581/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3581/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3580/comments | https://api.github.com/repos/huggingface/datasets/issues/3580/events | https://github.com/huggingface/datasets/issues/3580 | 1,104,663,242 | I_kwDODunzps5B19LK | 3,580 | Bug in wiki bio load | {
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"events_url": "https://api.github.com/users/tuhinjubcse/events{/privacy}",
"followers_url": "https://api.github.com/users/tuhinjubcse/followers",
"following_url": "https://api.github.com/users/tuhinjubcse/following{/other_user}",
"gists_url": "https://api.github.com/users/tuhinjubcse/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tuhinjubcse",
"id": 3104771,
"login": "tuhinjubcse",
"node_id": "MDQ6VXNlcjMxMDQ3NzE=",
"organizations_url": "https://api.github.com/users/tuhinjubcse/orgs",
"received_events_url": "https://api.github.com/users/tuhinjubcse/received_events",
"repos_url": "https://api.github.com/users/tuhinjubcse/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tuhinjubcse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuhinjubcse/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tuhinjubcse"
} | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | 4 | 2022-01-15T10:04:33Z | 2022-01-31T08:38:09Z | 2022-01-31T08:38:09Z | NONE | null | null | null |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
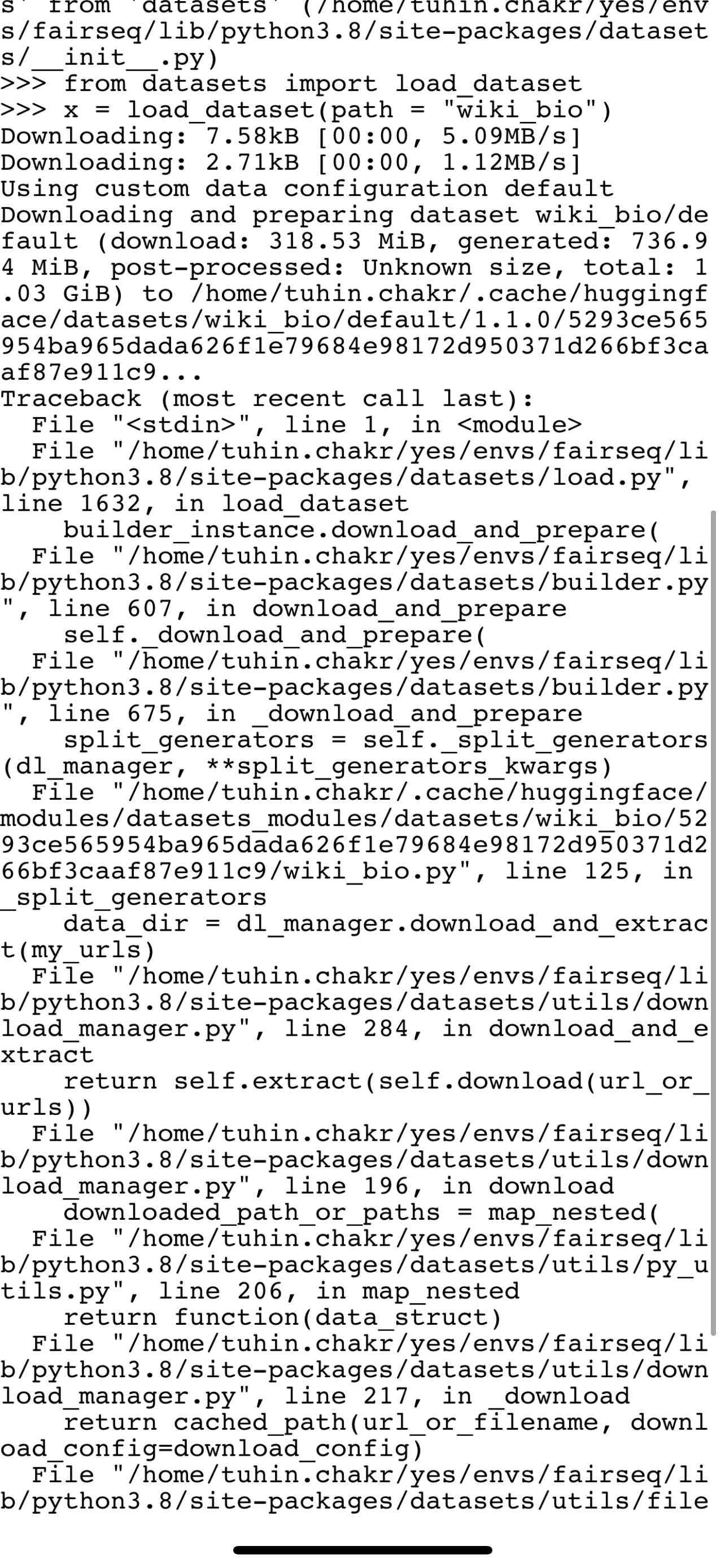
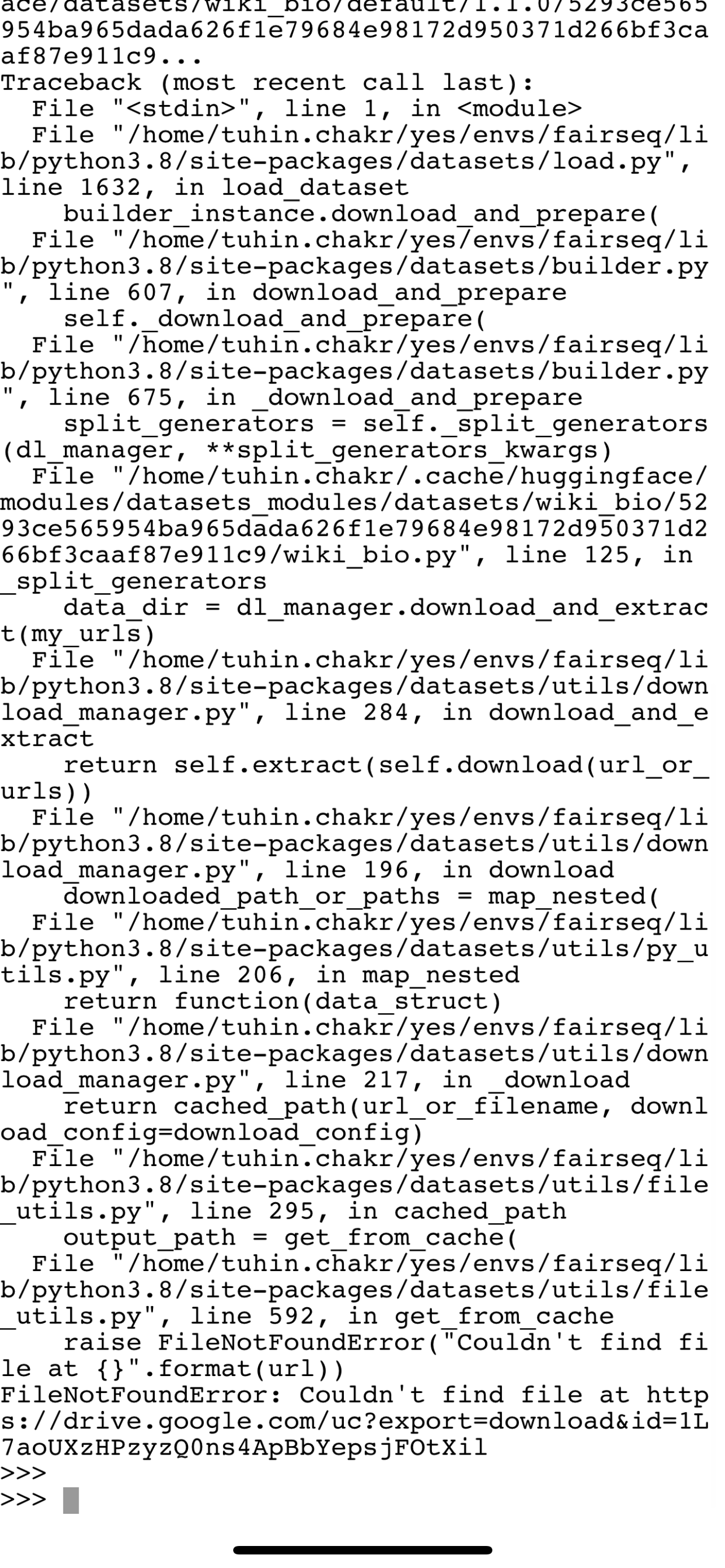
a | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3580/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3580/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3579 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3579/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3579/comments | https://api.github.com/repos/huggingface/datasets/issues/3579/events | https://github.com/huggingface/datasets/pull/3579 | 1,103,451,118 | PR_kwDODunzps4xBmY4 | 3,579 | Add Text2log Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/68908804?v=4",
"events_url": "https://api.github.com/users/apergo-ai/events{/privacy}",
"followers_url": "https://api.github.com/users/apergo-ai/followers",
"following_url": "https://api.github.com/users/apergo-ai/following{/other_user}",
"gists_url": "https://api.github.com/users/apergo-ai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/apergo-ai",
"id": 68908804,
"login": "apergo-ai",
"node_id": "MDQ6VXNlcjY4OTA4ODA0",
"organizations_url": "https://api.github.com/users/apergo-ai/orgs",
"received_events_url": "https://api.github.com/users/apergo-ai/received_events",
"repos_url": "https://api.github.com/users/apergo-ai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/apergo-ai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/apergo-ai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/apergo-ai"
} | [] | closed | false | null | [] | null | 1 | 2022-01-14T10:45:01Z | 2022-01-20T17:09:44Z | 2022-01-20T17:09:44Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3579.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3579",
"merged_at": "2022-01-20T17:09:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3579.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3579"
} | Adding the text2log dataset used for training FOL sentence translating models | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3579/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3579/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3578/comments | https://api.github.com/repos/huggingface/datasets/issues/3578/events | https://github.com/huggingface/datasets/issues/3578 | 1,103,403,287 | I_kwDODunzps5BxJkX | 3,578 | label information get lost after parquet serialization | {
"avatar_url": "https://avatars.githubusercontent.com/u/56633664?v=4",
"events_url": "https://api.github.com/users/Tudyx/events{/privacy}",
"followers_url": "https://api.github.com/users/Tudyx/followers",
"following_url": "https://api.github.com/users/Tudyx/following{/other_user}",
"gists_url": "https://api.github.com/users/Tudyx/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Tudyx",
"id": 56633664,
"login": "Tudyx",
"node_id": "MDQ6VXNlcjU2NjMzNjY0",
"organizations_url": "https://api.github.com/users/Tudyx/orgs",
"received_events_url": "https://api.github.com/users/Tudyx/received_events",
"repos_url": "https://api.github.com/users/Tudyx/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Tudyx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tudyx/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Tudyx"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | 2 | 2022-01-14T10:10:38Z | 2023-07-25T15:44:53Z | 2023-07-25T15:44:53Z | NONE | null | null | null | ## Describe the bug
In *dataset_info.json* file, information about the label get lost after the dataset serialization.
## Steps to reproduce the bug
```python
from datasets import load_dataset
# normal save
dataset = load_dataset('glue', 'sst2', split='train')
dataset.save_to_disk("normal_save")
# save after parquet serialization
dataset.to_parquet("glue-sst2-train.parquet")
dataset = load_dataset("parquet", data_files='glue-sst2-train.parquet')
dataset.save_to_disk("save_after_parquet")
```
## Expected results
I expected to keep label information in *dataset_info.json* file even after parquet serialization
## Actual results
In the normal serialization i got
```json
"label": {
"num_classes": 2,
"names": [
"negative",
"positive"
],
"names_file": null,
"id": null,
"_type": "ClassLabel"
},
```
And after parquet serialization i got
```json
"label": {
"dtype": "int64",
"id": null,
"_type": "Value"
},
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.0
- Platform: ubuntu 20.04
- Python version: 3.8.10
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3578/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3577 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3577/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3577/comments | https://api.github.com/repos/huggingface/datasets/issues/3577/events | https://github.com/huggingface/datasets/issues/3577 | 1,102,598,241 | I_kwDODunzps5BuFBh | 3,577 | Add The Mexican Emotional Speech Database (MESD) | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_url": "https://api.github.com/users/omarespejel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/omarespejel",
"id": 4755430,
"login": "omarespejel",
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"organizations_url": "https://api.github.com/users/omarespejel/orgs",
"received_events_url": "https://api.github.com/users/omarespejel/received_events",
"repos_url": "https://api.github.com/users/omarespejel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/omarespejel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omarespejel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/omarespejel"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] | open | false | null | [] | null | 0 | 2022-01-13T23:49:36Z | 2022-01-27T14:14:38Z | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** *The Mexican Emotional Speech Database (MESD)*
- **Description:** *Contains 864 voice recordings with six different prosodies: anger, disgust, fear, happiness, neutral, and sadness. Furthermore, three voice categories are included: female adult, male adult, and child. *
- **Paper:** *[Paper](https://ieeexplore.ieee.org/abstract/document/9629934/authors#authors)*
- **Data:** *[link to the Github repository or current dataset location](https://data.mendeley.com/datasets/cy34mh68j9/3)*
- **Motivation:** *Would add Spanish speech data to the HF datasets :) *
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3577/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3577/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3576/comments | https://api.github.com/repos/huggingface/datasets/issues/3576/events | https://github.com/huggingface/datasets/pull/3576 | 1,102,059,651 | PR_kwDODunzps4w8sUm | 3,576 | Add PASS dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 0 | 2022-01-13T17:16:07Z | 2022-01-20T16:50:48Z | 2022-01-20T16:50:47Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3576.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3576",
"merged_at": "2022-01-20T16:50:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3576.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3576"
} | This PR adds the PASS dataset.
Closes #3043 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3576/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3576/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3575 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3575/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3575/comments | https://api.github.com/repos/huggingface/datasets/issues/3575/events | https://github.com/huggingface/datasets/pull/3575 | 1,101,947,955 | PR_kwDODunzps4w8Usm | 3,575 | Add Arrow type casting to struct for Image and Audio + Support nested casting | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 9 | 2022-01-13T15:36:59Z | 2022-11-29T11:14:16Z | 2022-01-21T13:22:27Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3575.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3575",
"merged_at": "2022-01-21T13:22:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3575.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3575"
} | ## Intro
1. Currently, it's not possible to have nested features containing Audio or Image.
2. Moreover one can keep an Arrow array as a StringArray to store paths to images, but such arrays can't be directly concatenated to another image array if it's stored an another Arrow type (typically, a StructType).
3. Allowing several Arrow types for a single HF feature type also leads to bugs like this one #3497
4. Issues like #3247 are quite frequent and happen when Arrow fails to reorder StructArrays.
5. Casting Audio feature type is blocking preparation for the ASR task template: https://github.com/huggingface/datasets/pull/3364
All those issues are linked together by the fact that:
- we are limited by the Arrow type casting which is lacking features for nested types.
- and especially for Audio and Image: they are not robust enough for concatenation and feature inference.
## Proposed solution
To fix 1 and 4 I implemented nested array type casting (which is missing in PyArrow).
To fix 2, 3 and 5 while having a simple implementation for nested array type casting, I changed the storage type of Audio and Image to always be a StructType. Also casting from StringType is directly implemented via a new function `cast_storage` that is defined individually for Audio and Image. I also added nested decoding.
## Implementation details
### I. Better Arrow data type casting for nested data structures
I implemented new functions `array_cast` and `table_cast` that do the exact same as `pyarrow.Array.cast` or `pyarrow.Table.cast` but support nested struct casting and array re-ordering.
These functions can be used on PyArrow objects, and are already integrated in our own `datasets.table.Table.cast` functions. So one can do `my_dataset.data.cast(pyarrow_schema_with_custom_hf_types)` directly.
### II. New image and audio extension types with custom casting
I used PyArrow extension types to be able to define what casting is allowed or not. For example both StringType->ImageExtensionType and StructType->ImageExtensionType are allowed, via the `cast_storage` method.
I factorized all the PyArrow + Pandas extension stuff in the `base_extension.py` file. This aims at separating the front-facing API code of `datasets` from the Arrow back-end which requires advanced knowledge.
### III. Nested feature decoding
I added a new function `decode_nested_example` to decode image and audio data in nested data structures. For optimization's sake, this function is only called if a column has at least one feature that requires decoding.
## Alternative considered
The casting to struct type could have been done directly with python objects using some Audio and Image methods, but bringing arrow data to python objects is expensive. The Audio and Image types could also have been able to convert the arrow data directly, but this is not convenient to use when casting a full Arrow Table with nested fields. Therefore I decided to keep the Arrow data casting logic in Arrow extension types.
## Future work
This work can be used to allow the ArrayND feature types to be nested too (see issue #887)
## TODO
- [x] fix current tests
- [x] add new tests
- [x] docstrings/comments | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3575/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3575/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3574/comments | https://api.github.com/repos/huggingface/datasets/issues/3574/events | https://github.com/huggingface/datasets/pull/3574 | 1,101,781,401 | PR_kwDODunzps4w7vu6 | 3,574 | Fix qa4mre tags | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | 2022-01-13T13:56:59Z | 2022-01-13T14:03:02Z | 2022-01-13T14:03:01Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3574.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3574",
"merged_at": "2022-01-13T14:03:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3574.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3574"
} | The YAML tags were invalid. I also fixed the dataset mirroring logging that failed because of this issue [here](https://github.com/huggingface/datasets/actions/runs/1690109581) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3574/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3574/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3573 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3573/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3573/comments | https://api.github.com/repos/huggingface/datasets/issues/3573/events | https://github.com/huggingface/datasets/pull/3573 | 1,101,157,676 | PR_kwDODunzps4w5oE_ | 3,573 | Add Mauve metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/2321244?v=4",
"events_url": "https://api.github.com/users/jthickstun/events{/privacy}",
"followers_url": "https://api.github.com/users/jthickstun/followers",
"following_url": "https://api.github.com/users/jthickstun/following{/other_user}",
"gists_url": "https://api.github.com/users/jthickstun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jthickstun",
"id": 2321244,
"login": "jthickstun",
"node_id": "MDQ6VXNlcjIzMjEyNDQ=",
"organizations_url": "https://api.github.com/users/jthickstun/orgs",
"received_events_url": "https://api.github.com/users/jthickstun/received_events",
"repos_url": "https://api.github.com/users/jthickstun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jthickstun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jthickstun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jthickstun"
} | [] | closed | false | null | [] | null | 1 | 2022-01-13T03:52:48Z | 2022-01-20T15:00:08Z | 2022-01-20T15:00:08Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3573.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3573",
"merged_at": "2022-01-20T15:00:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3573.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3573"
} | Add support for the [Mauve](https://github.com/krishnap25/mauve) metric introduced in this [paper](https://arxiv.org/pdf/2102.01454.pdf) (Neurips, 2021). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3573/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3573/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3572/comments | https://api.github.com/repos/huggingface/datasets/issues/3572/events | https://github.com/huggingface/datasets/issues/3572 | 1,100,634,244 | I_kwDODunzps5BmliE | 3,572 | ConnectionError in IndicGLUE dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/79107194?v=4",
"events_url": "https://api.github.com/users/sahoodib/events{/privacy}",
"followers_url": "https://api.github.com/users/sahoodib/followers",
"following_url": "https://api.github.com/users/sahoodib/following{/other_user}",
"gists_url": "https://api.github.com/users/sahoodib/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sahoodib",
"id": 79107194,
"login": "sahoodib",
"node_id": "MDQ6VXNlcjc5MTA3MTk0",
"organizations_url": "https://api.github.com/users/sahoodib/orgs",
"received_events_url": "https://api.github.com/users/sahoodib/received_events",
"repos_url": "https://api.github.com/users/sahoodib/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sahoodib/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sahoodib/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sahoodib"
} | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | 3 | 2022-01-12T17:59:36Z | 2022-09-15T21:57:34Z | 2022-09-15T21:57:34Z | NONE | null | null | null | While I am trying to load IndicGLUE dataset (https://huggingface.co/datasets/indic_glue) it is giving me with the error:
```
ConnectionError: Couldn't reach https://storage.googleapis.com/ai4bharat-public-indic-nlp-corpora/evaluations/wikiann-ner.tar.gz (error 403) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3572/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3572/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3571 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3571/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3571/comments | https://api.github.com/repos/huggingface/datasets/issues/3571/events | https://github.com/huggingface/datasets/pull/3571 | 1,100,519,604 | PR_kwDODunzps4w3fVQ | 3,571 | Add missing tasks to MuchoCine dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | 0 | 2022-01-12T16:07:32Z | 2022-01-20T16:51:08Z | 2022-01-20T16:51:07Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3571.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3571",
"merged_at": "2022-01-20T16:51:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3571.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3571"
} | Addresses the 2nd bullet point in #2520.
I'm also removing the licensing information, because I couldn't verify that it is correct. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3571/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3571/timeline | null | null | true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.